
java爬虫抓取网页数据
java爬虫抓取网页数据(github地址:快速开始自动下载最新chromium并启动(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-27 19:07
github地址:
快速入门
自动下载最新的chrome并启动:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.browser.BrowserFetcher;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
/**
* 展示下载最新的chromuim浏览器的例子
*/
public class DownloadChromiumExample2 {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
Puppeteer puppeteer = new Puppeteer();
//创建下载实例
BrowserFetcher browserFetcher = puppeteer.createBrowserFetcher();
//下载最新版本的chromuim
browserFetcher.download();
Browser browser = Puppeteer.launch(false);
String version = browser.version();
System.out.println(version);
}
}
抓取整个页面的内容:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.Page;
import java.io.IOException;
import java.util.ArrayList;
public class PageContentExample {
public static void main(String[] args) throws InterruptedException, IOException {
String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
// String path ="D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
ArrayList arrayList = new ArrayList();
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
String content = page.content();
System.out.println("=======================content=============="+content);
}
}
截图
文件选择
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.ElementHandle;
import com.ruiyun.jvppeteer.core.page.FileChooser;
import com.ruiyun.jvppeteer.core.page.Page;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.options.PageNavigateOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class PageFileChooserExample {
public static void main(String[] args) throws InterruptedException, ExecutionException, IOException {
// String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
ArrayList arrayList = new ArrayList();
String path = "D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
PageNavigateOptions options1 = new PageNavigateOptions();
options1.setWaitUntil(Arrays.asList("domcontentloaded"));
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
Future fileChooserFuture = page.waitForFileChooser(30000);
ElementHandle elementHandle = page.$("#form > span.bg.s_ipt_wr.quickdelete-wrap > span.soutu-btn");
elementHandle.click();
//点击选择文件的按钮
ElementHandle button = page.$("#form > div > div.soutu-state-normal > div.upload-wrap > input");
button.click();
//等待一个选择文件的弹窗事件返回
FileChooser fileChooser = fileChooserFuture.get();
//选择本地的文件
List paths = new ArrayList();
paths.add("C:\\Users\\howay\\Desktop\\sunway.png");
fileChooser.accept(paths);
}
}
另外还有更多的功能,Jvppeteer可以做到:
生成页面 PDF。抓取 SPA(单页应用程序)并生成预渲染的内容(即“SSR”(服务器端渲染))。自动提交表单、UI测试、键盘输入等,创建一个不断更新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中执行测试。捕获网站的时间线轨迹以帮助分析性能问题。测试浏览器扩展。 查看全部
java爬虫抓取网页数据(github地址:快速开始自动下载最新chromium并启动(图))
github地址:
快速入门
自动下载最新的chrome并启动:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.browser.BrowserFetcher;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
/**
* 展示下载最新的chromuim浏览器的例子
*/
public class DownloadChromiumExample2 {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
Puppeteer puppeteer = new Puppeteer();
//创建下载实例
BrowserFetcher browserFetcher = puppeteer.createBrowserFetcher();
//下载最新版本的chromuim
browserFetcher.download();
Browser browser = Puppeteer.launch(false);
String version = browser.version();
System.out.println(version);
}
}
抓取整个页面的内容:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.Page;
import java.io.IOException;
import java.util.ArrayList;
public class PageContentExample {
public static void main(String[] args) throws InterruptedException, IOException {
String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
// String path ="D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
ArrayList arrayList = new ArrayList();
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
String content = page.content();
System.out.println("=======================content=============="+content);
}
}
截图
文件选择
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.ElementHandle;
import com.ruiyun.jvppeteer.core.page.FileChooser;
import com.ruiyun.jvppeteer.core.page.Page;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.options.PageNavigateOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class PageFileChooserExample {
public static void main(String[] args) throws InterruptedException, ExecutionException, IOException {
// String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
ArrayList arrayList = new ArrayList();
String path = "D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
PageNavigateOptions options1 = new PageNavigateOptions();
options1.setWaitUntil(Arrays.asList("domcontentloaded"));
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
Future fileChooserFuture = page.waitForFileChooser(30000);
ElementHandle elementHandle = page.$("#form > span.bg.s_ipt_wr.quickdelete-wrap > span.soutu-btn");
elementHandle.click();
//点击选择文件的按钮
ElementHandle button = page.$("#form > div > div.soutu-state-normal > div.upload-wrap > input");
button.click();
//等待一个选择文件的弹窗事件返回
FileChooser fileChooser = fileChooserFuture.get();
//选择本地的文件
List paths = new ArrayList();
paths.add("C:\\Users\\howay\\Desktop\\sunway.png");
fileChooser.accept(paths);
}
}
另外还有更多的功能,Jvppeteer可以做到:
生成页面 PDF。抓取 SPA(单页应用程序)并生成预渲染的内容(即“SSR”(服务器端渲染))。自动提交表单、UI测试、键盘输入等,创建一个不断更新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中执行测试。捕获网站的时间线轨迹以帮助分析性能问题。测试浏览器扩展。
java爬虫抓取网页数据(工具类实现比较简单,就一个get方法,读取请求地址的响应内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-25 23:07
工具类的实现比较简单,只是一个get方法,读取请求地址的响应内容,这里我们是用来爬取网页内容的,这里没有代理,在真正的爬取过程中,当你请求一个大量的在一个网站的情况下,对方会有一系列的策略来禁用你的请求。这时候代理就派上用场了。通过代理设置不同的IP来抓取数据。
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpUtils {
public static String get(String url) {
try {
URL getUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) getUrl
.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Accept", "*/*");
connection
.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA)");
connection.setRequestProperty("Accept-Language", "zh-cn");
connection.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"));
String line;
StringBuffer result = new StringBuffer();
while ((line = reader.readLine()) != null){
result.append(line);
}
reader.close();
return result.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
接下来我们找一个有图片的网页,试试爬取功能
public static void main(String[] args) {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
System.out.println(imgSrc);
}
}
public static List getImageSrc(String html) {
// 获取img标签正则
String IMGURL_REG = "]*?>";
// 获取src路径的正则
String IMGSRC_REG = "http:\"?(.*?)(\"|>|\\s+)";
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List listImgUrl = new ArrayList();
while (matcher.find()) {
Matcher m = Pattern.compile(IMGSRC_REG).matcher(matcher.group());
while (m.find()) {
listImgUrl.add(m.group().substring(0, m.group().length() - 1));
}
}
return listImgUrl;
}
先抓取网页内容,然后正常解析出网页的标签,再解析img地址。执行程序我们可以得到如下内容:
http://p9.pstatp.com/large/pgc ... 39c85
http://p1.pstatp.com/large/pgc ... f408b
http://p3.pstatp.com/large/pgc ... 944eb
http://p1.pstatp.com/large/pgc ... 5beb0
http://p3.pstatp.com/large/pgc ... 6156e
通过上面的地址,我们可以将图片下载到本地。下面我们写一个图片下载方法:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
这样就很简单的实现了一个抓图和提取图片的功能。好像比较麻烦。如果你需要写正则,我给你介绍一个更简单的方法。如果您熟悉 jQuery,则可以提取元素。很简单,这个框架就是Jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
添加jsoup的依赖:
org.jsoup
jsoup
1.11.3
使用jsoup后提取的代码只需要简单的几行:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag方法提取所有图片标签,循环遍历,通过attr方法获取图片的src属性,然后下载图片。
Jsoup 使用起来非常简单。当然,还有很多其他的用于解析网页的操作。您可以查看信息并学习。
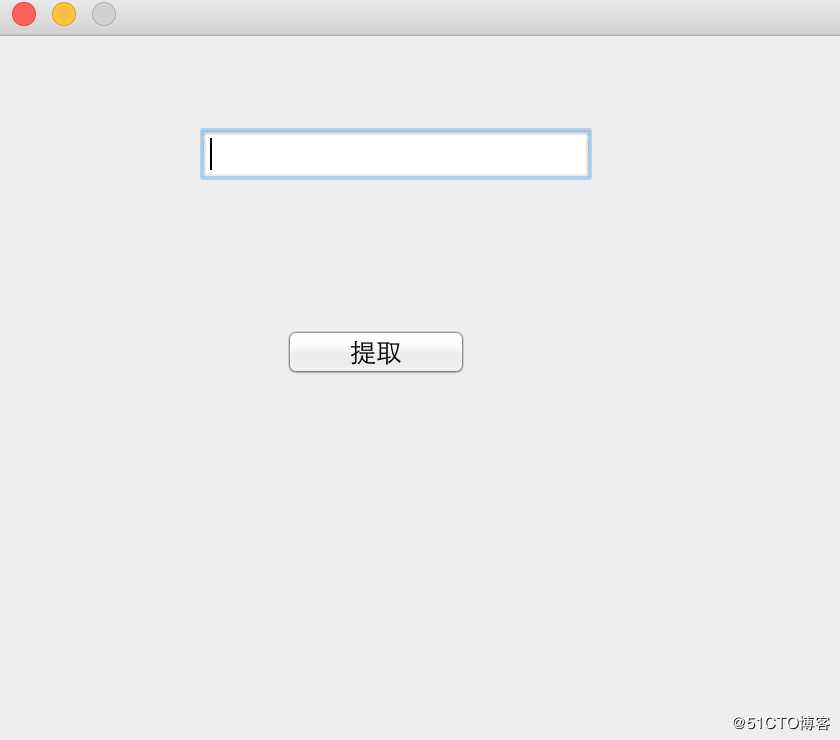
我们再升级一下,做一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按钮,然后自动下载图片,我们就可以用swing来写界面了。
public class App {
public static void main(String[] args) {
JFrame frame = new JFrame();
frame.setResizable(false);
frame.setSize(425,400);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setLayout(null);
frame.setLocationRelativeTo(null);
JTextField jTextField = new JTextField();
jTextField.setBounds(100, 44, 200, 30);
frame.add(jTextField);
JButton jButton = new JButton("提取");
jButton.setBounds(140, 144, 100, 30);
frame.add(jButton);
frame.setVisible(true);
jButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String url = jTextField.getText();
if (url == null || url.equals("")) {
JOptionPane.showMessageDialog(null, "请填写抓取地址");
return;
}
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
try {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
} catch (MalformedURLException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
JOptionPane.showMessageDialog(null, "抓取完成");
}
});
}
}
执行 main 方法后的第一件事是我们的接口,如下所示:
截图 2018-06-18 09.50.34 PM.png
截图 2018-06-18 09.50.34 PM.png
输入地址,点击提取按钮下载图片。
课程推荐
大数据时代,如何形成大数据。
大量的用户,每天大量的日志。
搭建爬虫,抓取数十亿条数据进行分析分析。
不仅仅是 Python 可以做爬虫,Java 仍然可以做。
今天就带大家写一个简单的抓图程序,把网页上的所有图片都下载下来
图片
图片
本课程将带领你一步一步写一个爬虫程序,向下爬取到我们想要的数据,不登录或者需要登录。
课程大纲
图片 查看全部
java爬虫抓取网页数据(工具类实现比较简单,就一个get方法,读取请求地址的响应内容)
工具类的实现比较简单,只是一个get方法,读取请求地址的响应内容,这里我们是用来爬取网页内容的,这里没有代理,在真正的爬取过程中,当你请求一个大量的在一个网站的情况下,对方会有一系列的策略来禁用你的请求。这时候代理就派上用场了。通过代理设置不同的IP来抓取数据。
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpUtils {
public static String get(String url) {
try {
URL getUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) getUrl
.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Accept", "*/*");
connection
.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA)");
connection.setRequestProperty("Accept-Language", "zh-cn");
connection.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"));
String line;
StringBuffer result = new StringBuffer();
while ((line = reader.readLine()) != null){
result.append(line);
}
reader.close();
return result.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
接下来我们找一个有图片的网页,试试爬取功能
public static void main(String[] args) {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
System.out.println(imgSrc);
}
}
public static List getImageSrc(String html) {
// 获取img标签正则
String IMGURL_REG = "]*?>";
// 获取src路径的正则
String IMGSRC_REG = "http:\"?(.*?)(\"|>|\\s+)";
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List listImgUrl = new ArrayList();
while (matcher.find()) {
Matcher m = Pattern.compile(IMGSRC_REG).matcher(matcher.group());
while (m.find()) {
listImgUrl.add(m.group().substring(0, m.group().length() - 1));
}
}
return listImgUrl;
}
先抓取网页内容,然后正常解析出网页的标签,再解析img地址。执行程序我们可以得到如下内容:
http://p9.pstatp.com/large/pgc ... 39c85
http://p1.pstatp.com/large/pgc ... f408b
http://p3.pstatp.com/large/pgc ... 944eb
http://p1.pstatp.com/large/pgc ... 5beb0
http://p3.pstatp.com/large/pgc ... 6156e
通过上面的地址,我们可以将图片下载到本地。下面我们写一个图片下载方法:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
这样就很简单的实现了一个抓图和提取图片的功能。好像比较麻烦。如果你需要写正则,我给你介绍一个更简单的方法。如果您熟悉 jQuery,则可以提取元素。很简单,这个框架就是Jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
添加jsoup的依赖:
org.jsoup
jsoup
1.11.3
使用jsoup后提取的代码只需要简单的几行:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag方法提取所有图片标签,循环遍历,通过attr方法获取图片的src属性,然后下载图片。
Jsoup 使用起来非常简单。当然,还有很多其他的用于解析网页的操作。您可以查看信息并学习。
我们再升级一下,做一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按钮,然后自动下载图片,我们就可以用swing来写界面了。
public class App {
public static void main(String[] args) {
JFrame frame = new JFrame();
frame.setResizable(false);
frame.setSize(425,400);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setLayout(null);
frame.setLocationRelativeTo(null);
JTextField jTextField = new JTextField();
jTextField.setBounds(100, 44, 200, 30);
frame.add(jTextField);
JButton jButton = new JButton("提取");
jButton.setBounds(140, 144, 100, 30);
frame.add(jButton);
frame.setVisible(true);
jButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String url = jTextField.getText();
if (url == null || url.equals("")) {
JOptionPane.showMessageDialog(null, "请填写抓取地址");
return;
}
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
try {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
} catch (MalformedURLException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
JOptionPane.showMessageDialog(null, "抓取完成");
}
});
}
}
执行 main 方法后的第一件事是我们的接口,如下所示:
截图 2018-06-18 09.50.34 PM.png
截图 2018-06-18 09.50.34 PM.png
输入地址,点击提取按钮下载图片。
课程推荐
大数据时代,如何形成大数据。
大量的用户,每天大量的日志。
搭建爬虫,抓取数十亿条数据进行分析分析。
不仅仅是 Python 可以做爬虫,Java 仍然可以做。
今天就带大家写一个简单的抓图程序,把网页上的所有图片都下载下来
图片
图片
本课程将带领你一步一步写一个爬虫程序,向下爬取到我们想要的数据,不登录或者需要登录。
课程大纲
图片
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-25 15:15
网络爬虫的数据采集方式有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是从互联网上采集
数据的有利工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
有哪些类型的网络爬虫工具?
1、分布式网络爬虫工具,如Nutch。
2、Java 网络爬虫工具,如 Crawler4j、WebMagic、WebCollector。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集
所有可以访问的页面的内容,为搜索引擎和大数据分析提供数据来源。就功能而言,爬虫一般具有数据采集、处理和存储三大功能。
除了供用户阅读的文本信息外,网页还收录
一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些外展度(网页中超链接的数量)较高的网站的一些比较重要的网址作为种子网址集合。
网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录
链接信息,因此会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有的或深度优先搜索算法 Page。
由于深度优先搜索算法可能会将爬虫系统困在网站内部,不利于搜索离网站首页较近的网页信息,所以一般采用广度优先搜索算法来采集网页。
网络爬虫系统首先将种子网址放入下载队列,简单地从队列头部取一个网址下载对应的网页,获取网页内容并存储,解析网页中的链接信息后,可以获得一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个URL,下载其对应的网页,然后解析,如此循环往复,直到遍历全网或满足某个条件,才会停止。
网络爬虫工作流程
1)首先选择种子URL的一部分。
2)将这些URL放入URL队列进行爬取。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS获取主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入已爬取的网址队列中。
4)对抓取到的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待抓取的URL队列中,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要为门户搜索引擎和大型Web服务提供商采集
数据。一般的网络爬虫为了提高工作效率,都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个链接地跟随它,直到无法再深入为止。爬行完成一个分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。这种策略更适合垂直搜索或站内搜索,但在抓取页面内容更深层次的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间中。那个时候,它会尽可能的深入,只有在找不到节点的后继节点时才考虑它的兄弟节点。这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它就会沿着一条路径不受限制地扩展,从而“陷入”海量数据。一般情况下,深度优先策略会选择一个合适的深度,然后反复搜索直到找到解,这样就降低了搜索的效率。因此,当搜索数据量比较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度来爬取页面,先爬取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。由于广度优先策略在第N层节点扩展完成后进入第N+1层,可以保证找到路径最短的解。该策略可以有效控制页面的爬取深度,避免遇到无限深的分支爬取无法结束的问题。实现方便,不需要存储大量的中间节点。缺点是爬到更深的目录层次需要很长时间。页。
如果搜索过程中分支过多,即该节点的后续节点过多,算法就会耗尽资源,在可用空间中找不到解。 查看全部
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网络爬虫的数据采集方式有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是从互联网上采集
数据的有利工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。

有哪些类型的网络爬虫工具?
1、分布式网络爬虫工具,如Nutch。
2、Java 网络爬虫工具,如 Crawler4j、WebMagic、WebCollector。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集
所有可以访问的页面的内容,为搜索引擎和大数据分析提供数据来源。就功能而言,爬虫一般具有数据采集、处理和存储三大功能。
除了供用户阅读的文本信息外,网页还收录
一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些外展度(网页中超链接的数量)较高的网站的一些比较重要的网址作为种子网址集合。
网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录
链接信息,因此会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有的或深度优先搜索算法 Page。
由于深度优先搜索算法可能会将爬虫系统困在网站内部,不利于搜索离网站首页较近的网页信息,所以一般采用广度优先搜索算法来采集网页。
网络爬虫系统首先将种子网址放入下载队列,简单地从队列头部取一个网址下载对应的网页,获取网页内容并存储,解析网页中的链接信息后,可以获得一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个URL,下载其对应的网页,然后解析,如此循环往复,直到遍历全网或满足某个条件,才会停止。
网络爬虫工作流程
1)首先选择种子URL的一部分。
2)将这些URL放入URL队列进行爬取。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS获取主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入已爬取的网址队列中。
4)对抓取到的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待抓取的URL队列中,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要为门户搜索引擎和大型Web服务提供商采集
数据。一般的网络爬虫为了提高工作效率,都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个链接地跟随它,直到无法再深入为止。爬行完成一个分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。这种策略更适合垂直搜索或站内搜索,但在抓取页面内容更深层次的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间中。那个时候,它会尽可能的深入,只有在找不到节点的后继节点时才考虑它的兄弟节点。这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它就会沿着一条路径不受限制地扩展,从而“陷入”海量数据。一般情况下,深度优先策略会选择一个合适的深度,然后反复搜索直到找到解,这样就降低了搜索的效率。因此,当搜索数据量比较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度来爬取页面,先爬取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。由于广度优先策略在第N层节点扩展完成后进入第N+1层,可以保证找到路径最短的解。该策略可以有效控制页面的爬取深度,避免遇到无限深的分支爬取无法结束的问题。实现方便,不需要存储大量的中间节点。缺点是爬到更深的目录层次需要很长时间。页。
如果搜索过程中分支过多,即该节点的后续节点过多,算法就会耗尽资源,在可用空间中找不到解。
java爬虫抓取网页数据(如何用java实现网络爬虫抓取页面内容__通过类访问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-25 01:08
如何使用java实现网络爬虫抓取页面内容
______ 通过班级访问自己拥有的网址获取网页内容,然后使用正则表达式获取自己想要的内容。然后就可以抓取页面的URL,重复之前的工作
JAVA如何获取爬虫
______ 下面是java实现的简单爬虫核心代码: public void crawl() throws Throwable {while (continueCrawling()) {CrawlerUrl url = getNextUrl(); //获取队列中下一个要爬取的URL if (url != null) {printCrawlInfo(); 字符串内容 = getContent(url); ...
如何使用java实现网络爬虫抓取页面内容-
______ 以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是自带jdk,速度更快。缺点是方法较少,功能比较复杂,往往需要大量代码自己实现。第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般来说,HttpClient+JSOUP配合完成爬取。HttpClient 获取页面。JSOUP 解析网页并获取数据。HttpUnit:相当于一个无界面的浏览器。缺点是内存占用大,速度慢。优点是可以执行js,功能强大
Java 制作了一个网络内容爬虫——
______ 1.你需要的不是网络爬虫。只是爬取了网站。2. 使用JDK的HttpURLConnection或者apache的HttpClient组件即可。附件也是资源。只要有地址就可以传 HttpURLConnection con = new HttpURLConnection(url); conn.connect(); ...
如何使用网络爬虫基于java获取数据-
______ 爬虫的原理其实就是获取网页的内容然后解析。只是获取网页和解析内容的方式有很多种。可以简单的使用httpclient发送get/post请求,获取结果,然后使用拦截获取你想要的带有字符串和正则表达式的内容。或者使用Jsoup/crawler4j等封装的库来更方便的抓取信息。
java爬虫抓取数据
______ 一般爬虫在登录后是不会抓取页面的。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,再请求相关页面。
java爬虫抓取指定数据——
______ 如何通过Java代码指定爬取网页数据,我总结下Jsoup.Jar包会用到以下步骤:1、导入项目中的Jsoup.jar包2、获取URL url 指定HTML或文档指定的正文3、获取网页中超链接的标题和链接4、获取指定博客的内容文章5、@ >获取网页中超链接的标题和链接结果
如何做java爬虫-
______ 代码如下:打包webspider;导入 java.util.HashSet; 导入 java.util.PriorityQueue; 导入 java.util.Set; 导入 java.util.Queue; public class LinkQueue {// 访问过的 url 集合 private static SetvisitedUrl = new HashSet(); // 要访问的 URL 集合...
如何实现java网络爬虫-
______ 网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在网页的处理过程中,不断从当前页面中提取新的网址,放入队列中,直到满...
如何用Java编写爬虫
______ 我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome network来分析请求,或者fiddler来抓包。普通网页可以直接使用httpclient封装的API获取网页HTML,然后JSoup和regular提取内容。如果网站有反爬虫... 查看全部
java爬虫抓取网页数据(如何用java实现网络爬虫抓取页面内容__通过类访问)
如何使用java实现网络爬虫抓取页面内容
______ 通过班级访问自己拥有的网址获取网页内容,然后使用正则表达式获取自己想要的内容。然后就可以抓取页面的URL,重复之前的工作
JAVA如何获取爬虫
______ 下面是java实现的简单爬虫核心代码: public void crawl() throws Throwable {while (continueCrawling()) {CrawlerUrl url = getNextUrl(); //获取队列中下一个要爬取的URL if (url != null) {printCrawlInfo(); 字符串内容 = getContent(url); ...
如何使用java实现网络爬虫抓取页面内容-
______ 以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是自带jdk,速度更快。缺点是方法较少,功能比较复杂,往往需要大量代码自己实现。第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般来说,HttpClient+JSOUP配合完成爬取。HttpClient 获取页面。JSOUP 解析网页并获取数据。HttpUnit:相当于一个无界面的浏览器。缺点是内存占用大,速度慢。优点是可以执行js,功能强大
Java 制作了一个网络内容爬虫——
______ 1.你需要的不是网络爬虫。只是爬取了网站。2. 使用JDK的HttpURLConnection或者apache的HttpClient组件即可。附件也是资源。只要有地址就可以传 HttpURLConnection con = new HttpURLConnection(url); conn.connect(); ...
如何使用网络爬虫基于java获取数据-
______ 爬虫的原理其实就是获取网页的内容然后解析。只是获取网页和解析内容的方式有很多种。可以简单的使用httpclient发送get/post请求,获取结果,然后使用拦截获取你想要的带有字符串和正则表达式的内容。或者使用Jsoup/crawler4j等封装的库来更方便的抓取信息。
java爬虫抓取数据
______ 一般爬虫在登录后是不会抓取页面的。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,再请求相关页面。
java爬虫抓取指定数据——
______ 如何通过Java代码指定爬取网页数据,我总结下Jsoup.Jar包会用到以下步骤:1、导入项目中的Jsoup.jar包2、获取URL url 指定HTML或文档指定的正文3、获取网页中超链接的标题和链接4、获取指定博客的内容文章5、@ >获取网页中超链接的标题和链接结果
如何做java爬虫-
______ 代码如下:打包webspider;导入 java.util.HashSet; 导入 java.util.PriorityQueue; 导入 java.util.Set; 导入 java.util.Queue; public class LinkQueue {// 访问过的 url 集合 private static SetvisitedUrl = new HashSet(); // 要访问的 URL 集合...
如何实现java网络爬虫-
______ 网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在网页的处理过程中,不断从当前页面中提取新的网址,放入队列中,直到满...
如何用Java编写爬虫
______ 我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome network来分析请求,或者fiddler来抓包。普通网页可以直接使用httpclient封装的API获取网页HTML,然后JSoup和regular提取内容。如果网站有反爬虫...
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-25 01:07
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
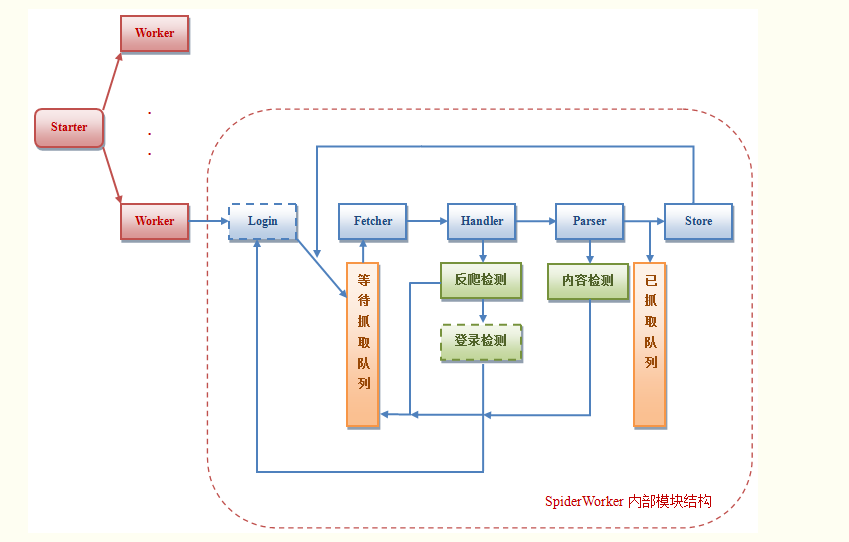
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列末尾,从头部获取新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。
代码
明天就要开学了,加上实验室的任务,没时间好好写了。我写了一个比较水的,eclipse项目,大概就是上面流程图的实现。很多地方需要根据具体的爬取场景来进行。实现是用注释解释的,真心希望以后能打包的更漂亮一些。
丑陋的妻子看到公婆来了。点我看丑>_ 查看全部
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列末尾,从头部获取新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。
代码
明天就要开学了,加上实验室的任务,没时间好好写了。我写了一个比较水的,eclipse项目,大概就是上面流程图的实现。很多地方需要根据具体的爬取场景来进行。实现是用注释解释的,真心希望以后能打包的更漂亮一些。
丑陋的妻子看到公婆来了。点我看丑>_
java爬虫抓取网页数据( java爬虫实战之模拟登陆的内容介绍及使用工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-21 11:02
java爬虫实战之模拟登陆的内容介绍及使用工具介绍)
java爬虫模拟登陆实例详解
更新时间:2021年1月18日15:54:18 作者:宋松勋爵
本文文章,小编将与大家分享一个java爬虫模拟登陆的详细例子。有兴趣的朋友可以参考一下。
使用jsoup工具可以解析某个URL地址和HTML文本内容,这是java爬虫的一个很好的优势,也是我们在网络爬虫中不可缺少的工具。本文小编带你使用jsoup实现java爬虫模拟登录。通过省力API,java爬虫模拟登录非常好。
一、使用工具:Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
二、实现java爬虫模拟登录
1、确定要爬取的url
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Map.Entry;
import java.util.Set;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class SplitTable {
public static void main(String[] args) throws IOException {
//想要爬取的url
String url = "http://jwcnew.nefu.edu.cn/dbly ... do%3F
Ves632DSdyV=NEW_XSD_PYGL";
String username = "";
String password = "";
String sessionId = getSessionInfo(username,password);
spiderWebSite(sessionId,url);
}
2、获取 sessionId
private static String getSessionInfo(String username,String password)
throws IOException{
3、登录网站,返回sessionId信息
Connection.Response res = Jsoup.connect(http://jwcnew.nefu.edu.cn/dblydx_jsxsd/xk/LoginToXk)
4、获取 sessionId
String sessionId = res.cookie("JSESSIONID");
System.out.println(sessionId);
return sessionId;
}
5、抓取内容
private static void spiderWebSite(String sessionId,String url) throws IOException{
//爬取
Document doc = Jsoup.connect(url).cookie("JSESSIONID", sessionId).timeout(10000).get();
Element table = doc.getElementById("kbtable");
//System.out.println(table);
BufferedWriter bw = new BufferedWriter
(new OutputStreamWriter(new FileOutputStream("F:/table.html")));
bw.write(new String(table.toString().getBytes()));
bw.flush();
bw.close();
}
}
示例代码扩展:
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class LoginDemo {
public static void main(String[] args) throws Exception {
LoginDemo loginDemo = new LoginDemo();
loginDemo.login("16xxx20xxx", "16xxx20xxx");// 用户名,和密码
}
/**
* 模拟登陆座位系统
* @param userName
* 用户名
* @param pwd
* 密码
*
* **/
public void login(String userName, String pwd) throws Exception {
// 第一次请求
Connection con = Jsoup
.connect("http://lib???.?????????.aspx");// 获取连接
con.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
Response rs = con.execute();// 获取响应
Document d1 = Jsoup.parse(rs.body());// 转换为Dom树
List et = d1.select("#form1");// 获取form表单,可以通过查看页面源码代码得知
// 获取,cooking和表单属性,下面map存放post时的数据
Map datas = new HashMap();
for (Element e : et.get(0).getAllElements()) {
//System.out.println(e.attr("name")+"----Little\n");
if (e.attr("name").equals("tbUserName")) {
e.attr("value", userName);// 设置用户名
}
if (e.attr("name").equals("tbPassWord")) {
e.attr("value", pwd); // 设置用户密码
}
if (e.attr("name").length() > 0) {// 排除空值表单属性
datas.put(e.attr("name"), e.attr("value"));
}
}
/**
* 第二次请求,post表单数据,以及cookie信息
*
* **/
Connection con2 = Jsoup
.connect("http://lib???.?????????.aspx");
con2.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).method(Method.POST)
.data(datas).cookies(rs.cookies()).execute();
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
//下面输出的是cookie 的内容
for (String s : map.keySet()) {
System.out.println(s + "=====-----" + map.get(s));
}
System.out.println(login.body());
/**
* 登录之后模拟获取预约记录
*
* */
Connection con_record = Jsoup
.connect("http://lib???.?????????.aspx");// 获取连接
con_record.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
con_record.cookies(datas);
Response record = con_record.ignoreContentType(true)
.method(Method.GET)
.cookies(rs.cookies())
.execute();
System.out.println(record.body());
}
}
这里是java爬虫模拟登录示例的详细讲解文章。更多java爬虫实战模拟登录的相关内容,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
java爬虫抓取网页数据(
java爬虫实战之模拟登陆的内容介绍及使用工具介绍)
java爬虫模拟登陆实例详解
更新时间:2021年1月18日15:54:18 作者:宋松勋爵
本文文章,小编将与大家分享一个java爬虫模拟登陆的详细例子。有兴趣的朋友可以参考一下。
使用jsoup工具可以解析某个URL地址和HTML文本内容,这是java爬虫的一个很好的优势,也是我们在网络爬虫中不可缺少的工具。本文小编带你使用jsoup实现java爬虫模拟登录。通过省力API,java爬虫模拟登录非常好。
一、使用工具:Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
二、实现java爬虫模拟登录
1、确定要爬取的url
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Map.Entry;
import java.util.Set;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class SplitTable {
public static void main(String[] args) throws IOException {
//想要爬取的url
String url = "http://jwcnew.nefu.edu.cn/dbly ... do%3F
Ves632DSdyV=NEW_XSD_PYGL";
String username = "";
String password = "";
String sessionId = getSessionInfo(username,password);
spiderWebSite(sessionId,url);
}
2、获取 sessionId
private static String getSessionInfo(String username,String password)
throws IOException{
3、登录网站,返回sessionId信息
Connection.Response res = Jsoup.connect(http://jwcnew.nefu.edu.cn/dblydx_jsxsd/xk/LoginToXk)
4、获取 sessionId
String sessionId = res.cookie("JSESSIONID");
System.out.println(sessionId);
return sessionId;
}
5、抓取内容
private static void spiderWebSite(String sessionId,String url) throws IOException{
//爬取
Document doc = Jsoup.connect(url).cookie("JSESSIONID", sessionId).timeout(10000).get();
Element table = doc.getElementById("kbtable");
//System.out.println(table);
BufferedWriter bw = new BufferedWriter
(new OutputStreamWriter(new FileOutputStream("F:/table.html")));
bw.write(new String(table.toString().getBytes()));
bw.flush();
bw.close();
}
}
示例代码扩展:
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class LoginDemo {
public static void main(String[] args) throws Exception {
LoginDemo loginDemo = new LoginDemo();
loginDemo.login("16xxx20xxx", "16xxx20xxx");// 用户名,和密码
}
/**
* 模拟登陆座位系统
* @param userName
* 用户名
* @param pwd
* 密码
*
* **/
public void login(String userName, String pwd) throws Exception {
// 第一次请求
Connection con = Jsoup
.connect("http://lib???.?????????.aspx";);// 获取连接
con.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
Response rs = con.execute();// 获取响应
Document d1 = Jsoup.parse(rs.body());// 转换为Dom树
List et = d1.select("#form1");// 获取form表单,可以通过查看页面源码代码得知
// 获取,cooking和表单属性,下面map存放post时的数据
Map datas = new HashMap();
for (Element e : et.get(0).getAllElements()) {
//System.out.println(e.attr("name")+"----Little\n");
if (e.attr("name").equals("tbUserName")) {
e.attr("value", userName);// 设置用户名
}
if (e.attr("name").equals("tbPassWord")) {
e.attr("value", pwd); // 设置用户密码
}
if (e.attr("name").length() > 0) {// 排除空值表单属性
datas.put(e.attr("name"), e.attr("value"));
}
}
/**
* 第二次请求,post表单数据,以及cookie信息
*
* **/
Connection con2 = Jsoup
.connect("http://lib???.?????????.aspx";);
con2.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).method(Method.POST)
.data(datas).cookies(rs.cookies()).execute();
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
//下面输出的是cookie 的内容
for (String s : map.keySet()) {
System.out.println(s + "=====-----" + map.get(s));
}
System.out.println(login.body());
/**
* 登录之后模拟获取预约记录
*
* */
Connection con_record = Jsoup
.connect("http://lib???.?????????.aspx";);// 获取连接
con_record.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
con_record.cookies(datas);
Response record = con_record.ignoreContentType(true)
.method(Method.GET)
.cookies(rs.cookies())
.execute();
System.out.println(record.body());
}
}
这里是java爬虫模拟登录示例的详细讲解文章。更多java爬虫实战模拟登录的相关内容,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
java爬虫抓取网页数据( 每一个步骤我都是进行独立封装起来,方便复用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-21 10:19
每一个步骤我都是进行独立封装起来,方便复用
)
Java爬虫基于Jsoup抓取网页数据
前言
本文主要介绍简单使用Jsoup抓取网页数据
框架 SpringBoot + Jsoup
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
这是广告:技术交流群796794009 SpringBoot技术交流群; --小武
一.准备
创建一个SpringBoot项目,引入Jsoup依赖
org.jsoup
jsoup
1.13.1
二.代码(使用Jsoup的核心是两步)
第一步
通过Jsoup的connect(url).get()获取当前页面信息;方法
url 是你要获取的网页地址
返回的是一个文档
public Document getDoc(String url){
Document doc;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
log.error("出现异常:{}", e.getMessage());
return null;
}
return doc;
}
第二步
通过Document中的select方法获取标签(Elements)信息
特别说明1:使用select方法获取Element的集合,需要遍历获取Element
特别说明2:link.attr("abs:src")中的abs:指的是绝对路径,现在很多页面的src都没有域名
private Map listUrl(Document doc){
// Map
Map map = new HashMap(16);
// 获取图片标签
Elements links = doc.select("img[src]");
for (Element link : links){
System.out.println("名称 : " + link.text());
System.out.println("链接 : " + link.attr("abs:src"));
map.put(link.absUrl("abs:src"), link.text());
}
return map;
}
三.效果
这是我博客中的一段图片数据文章
爬虫项目地址
个人爬虫项目,仅供学习参考:
使用环境jdk1.8、MySQL8.0
注意:本项目仅提供4个接口
特别说明:第四个接口不建议大家尝试大网站,大网站接口获取时间太长
禁止利用本项目做一切违法行为,仅供学习参考
如图所示:
查看全部
java爬虫抓取网页数据(
每一个步骤我都是进行独立封装起来,方便复用
)
Java爬虫基于Jsoup抓取网页数据
前言
本文主要介绍简单使用Jsoup抓取网页数据
框架 SpringBoot + Jsoup
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
这是广告:技术交流群796794009 SpringBoot技术交流群; --小武
一.准备
创建一个SpringBoot项目,引入Jsoup依赖
org.jsoup
jsoup
1.13.1
二.代码(使用Jsoup的核心是两步)
第一步
通过Jsoup的connect(url).get()获取当前页面信息;方法
url 是你要获取的网页地址
返回的是一个文档
public Document getDoc(String url){
Document doc;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
log.error("出现异常:{}", e.getMessage());
return null;
}
return doc;
}
第二步
通过Document中的select方法获取标签(Elements)信息
特别说明1:使用select方法获取Element的集合,需要遍历获取Element
特别说明2:link.attr("abs:src")中的abs:指的是绝对路径,现在很多页面的src都没有域名
private Map listUrl(Document doc){
// Map
Map map = new HashMap(16);
// 获取图片标签
Elements links = doc.select("img[src]");
for (Element link : links){
System.out.println("名称 : " + link.text());
System.out.println("链接 : " + link.attr("abs:src"));
map.put(link.absUrl("abs:src"), link.text());
}
return map;
}
三.效果
这是我博客中的一段图片数据文章
爬虫项目地址
个人爬虫项目,仅供学习参考:
使用环境jdk1.8、MySQL8.0
注意:本项目仅提供4个接口
特别说明:第四个接口不建议大家尝试大网站,大网站接口获取时间太长
禁止利用本项目做一切违法行为,仅供学习参考
如图所示:
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-21 04:00
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列的末尾,从头部获取一个新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。
本文为原创作者,转载请注明【原文作者及本文链接地址】。侵权必究,谢谢合作!
打开应用程序并阅读笔记 查看全部
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列的末尾,从头部获取一个新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。

本文为原创作者,转载请注明【原文作者及本文链接地址】。侵权必究,谢谢合作!
打开应用程序并阅读笔记
java爬虫抓取网页数据(本文爬虫程序的核心代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-21 03:23
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent内部使用apache的httpclient4.1来获取网页的内容,具体代码如下:
Java代码
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样一个简单的网络爬虫程序就搭建完成了,可以使用如下程序进行测试:
Java代码 查看全部
java爬虫抓取网页数据(本文爬虫程序的核心代码)
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:

传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码

private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent内部使用apache的httpclient4.1来获取网页的内容,具体代码如下:
Java代码
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样一个简单的网络爬虫程序就搭建完成了,可以使用如下程序进行测试:
Java代码
java爬虫抓取网页数据(荣幸供爬虫初学者参考关于java爬虫系统技术详解处理课程爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-21 03:19
--------很荣幸成为爬虫初学者的参考。详细讲解java爬虫系统的技术是一门自然语言处理课程。爬虫系统技术报告很荣幸为爬虫初学者提供参考。处理课程受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
Quote: 这学期完成了自然语言处理课程让我受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统非常重要,而网络爬虫也是搜索引擎爬虫系统的重要组成部分。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要大量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
爬虫系统整体介绍:爬虫系统主要分为两类,一类是自定义的爬虫系统,一类是使用开源的爬虫软件。其中,有很多开源爬虫软件如:Grub Next Generation PhpDig Snoopy Nutch JSpider NWebCrawler。因为我是爬虫初学者,暂时不想套用别人的开源代码。虽然我一步步编译出来的系统可能没有现在这么好,但这是因为我对一些原理有了更深的理解。因此,笔者通过网上的博客,查阅了一些资料,编写了这个系统。虽然还有待完善,但也是一部爱心之作。最后,与其他爬虫系统进行了一些比较。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
关于本技术报告中描述的爬虫系统的详细介绍: 本系统采用java代码编写,myeclipse8.5 IDE工具win7操作系统。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
原理:无论是定制系统还是开源软件。爬虫的基本原理是一样的,并不复杂。爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。一个网络爬虫的基本工作流程是这样的: 1.首先选择一部分精心挑选的种子URL2.将这些URL放入URL队列中进行爬取;3. 将它们从待爬取的URL队列中取出待爬取的URL中,解析DNS,获取主机ip,下载该URL对应的网页,并存储到下载的网页库中。此外,将这些 URL 放入已爬取的 URL 队列中。4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭侠、勺子、柞蚕、头皮、劈砍、劈砍、士兵、
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。主要有两种爬取策略: 1. 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接,处理后转移到它这一行 下一个起始页,继续跟随链接。2. 广度优先遍历策略广度优先遍历策略的基本思想是将在新下载的网页中找到的链接直接插入到待抓取的URL队列的末尾。也就是说,网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页 查看全部
java爬虫抓取网页数据(荣幸供爬虫初学者参考关于java爬虫系统技术详解处理课程爬虫)
--------很荣幸成为爬虫初学者的参考。详细讲解java爬虫系统的技术是一门自然语言处理课程。爬虫系统技术报告很荣幸为爬虫初学者提供参考。处理课程受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
Quote: 这学期完成了自然语言处理课程让我受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统非常重要,而网络爬虫也是搜索引擎爬虫系统的重要组成部分。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要大量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
爬虫系统整体介绍:爬虫系统主要分为两类,一类是自定义的爬虫系统,一类是使用开源的爬虫软件。其中,有很多开源爬虫软件如:Grub Next Generation PhpDig Snoopy Nutch JSpider NWebCrawler。因为我是爬虫初学者,暂时不想套用别人的开源代码。虽然我一步步编译出来的系统可能没有现在这么好,但这是因为我对一些原理有了更深的理解。因此,笔者通过网上的博客,查阅了一些资料,编写了这个系统。虽然还有待完善,但也是一部爱心之作。最后,与其他爬虫系统进行了一些比较。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
关于本技术报告中描述的爬虫系统的详细介绍: 本系统采用java代码编写,myeclipse8.5 IDE工具win7操作系统。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
原理:无论是定制系统还是开源软件。爬虫的基本原理是一样的,并不复杂。爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。一个网络爬虫的基本工作流程是这样的: 1.首先选择一部分精心挑选的种子URL2.将这些URL放入URL队列中进行爬取;3. 将它们从待爬取的URL队列中取出待爬取的URL中,解析DNS,获取主机ip,下载该URL对应的网页,并存储到下载的网页库中。此外,将这些 URL 放入已爬取的 URL 队列中。4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭侠、勺子、柞蚕、头皮、劈砍、劈砍、士兵、
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。主要有两种爬取策略: 1. 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接,处理后转移到它这一行 下一个起始页,继续跟随链接。2. 广度优先遍历策略广度优先遍历策略的基本思想是将在新下载的网页中找到的链接直接插入到待抓取的URL队列的末尾。也就是说,网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页
java爬虫抓取网页数据(Java数据存入云端数据库的表中:1-2-1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-20 14:14
下面详细说明将所有解析的房屋数据存储在云数据库的表中:
1、 第一步是获取数据库连接。Java 提供了数据库连接的接口,但是实现是由各个数据库提供者实现的。这里需要mysql提供的第三方包:mysql-connector-java-8.0.13.jar
,, 新建一个类来封装数据库处理的方法:
//封装数据库相关操作
public class OperationOfMySQL {
//只创建一次链接
Connection con;
Statement state;
public OperationOfMySQL() {
super();
this.con = connectionToDatabase();
try {
//state用于传入sql语句对数据库进行操作
this.state = con.createStatement();
} catch (Exception e) {
System.out.println("链接失败!");
}
}
和上面的代码一样,连接是在创建对象的时候创建的:
connectionToDatabase() 方法返回获取的数据库链接:
//返回数据库链接的方法
private static Connection connectionToDatabase() {
Connection con = null;
//创建驱动对象
try {
Driver driver = new Driver();
String url = cloud;
Properties info = new Properties();
//准备数据库链接信息
info.put("user", "rds_repl");
info.put("password", "123456");
//获取数据库链接
con = driver.connect(url, info);
}catch (SQLException e) {
System.out.println("链接数据库失败!");
return null;
}
System.out.println(con+"\n链接创建成功!");
return con;
}
//cloud是加载云端驱动的数据库,格式为:
//String cloud = "jdbc:mysql://服务器地址:端口号/数据库名?severTimzone=UTC";
,, 云数据库的地址和端口号这里就不贴了(连接云和本地数据库的方法是一样的)。值得注意的是,如果您使用的是数据库连接池,则需要设置链接超时,虽然我没有这样做。. .
PS:还有一个类加载com.mysql.cj.jdbc.Driver 0版本的驱动;有一个额外的“cj”,所以必须设置时区: severTimezone=UTC, version 0 不要使用,否则运行时会报错。(这里只是提醒,具体原因不再详述);
Java通过状态对象将sql字符串传递给数据库。由于数据库是预先存在的,所以需要建一个表来存储房屋信息。关键表语句是:
//如果数据库中不存在表house1就创建一张
static private String SQLCreateTaleStr = "CREATE TABLE IF NOT EXISTS house1"
+ "("
+ "title varchar(255) ,"
+ "area double ,"
+ "price varchar(64) ,"
+ "unit_price double ,"
+ "direction varchar(64),"
+ "decoration varchar(64),"
+ "houseStyle varchar(64) ,"
+ "floor varchar(64),"
+ "buildTime int(11) ,"
+ "community varchar(64),"
+ "location varchar(64) ,"
+ "gdpperperson double"
+ ")ENGINE = InnoDB DEFAULT CHARSET = utf8;";
然后写一个方法把房子信息转换成语句插入SQL到表中:
//用于生成插入语句的方法,传入一个房子和表的名字
public String insertStr(SecondHouse house) {
String insert = "insert into house1"
+ " values('"
+house.getElemName()+ "','"
+house.getArea()+ "','"
+house.getPrice()+ "','"
+house.getUnit_price()+ "','"
+house.getDirection()+ "','"
+house.getDecoration()+ "','"
+house.getHouseStyle()+ "','"
+house.getFloor()+ "','"
+house.getBuildTime()+ "','"
+house.getCommunity()+ "','"
+house.getLocation()+ "','"
+0+ "');";
return insert ;
}
PS; 拼接字符串时注意空格和标点符号,保证sql语句可以执行
然后就是执行这个write语句的方法:
//传入链接,进行对数据库的操作,传入二手房,写进数据库
public void operationOnDtabase(String insertStr) {
try {
//获取执行sql语句动态创建表,即如果表不存在就创建一个
state.execute(SQLCreateTaleStr);
//执行插入语句
state.executeUpdate(insertStr);
// System.out.println(insertStr);
}catch (SQLException e) {
System.out.println("SQL语句执行失败!");
}
System.out.println("执行语句成功!");
}
工具和方法已经准备好,需要集成:
最后,网页解析、多线程、写入数据库的所有实现都在main方法中执行;
<p>//---------------------------main方法代替执行--------------------------------------------------------------------
public static void operateMain() {
houseSet = new Vector();
//多线程集合
Vector threads = new Vector();
for (int i = 1; i 查看全部
java爬虫抓取网页数据(Java数据存入云端数据库的表中:1-2-1)
下面详细说明将所有解析的房屋数据存储在云数据库的表中:
1、 第一步是获取数据库连接。Java 提供了数据库连接的接口,但是实现是由各个数据库提供者实现的。这里需要mysql提供的第三方包:mysql-connector-java-8.0.13.jar
,, 新建一个类来封装数据库处理的方法:
//封装数据库相关操作
public class OperationOfMySQL {
//只创建一次链接
Connection con;
Statement state;
public OperationOfMySQL() {
super();
this.con = connectionToDatabase();
try {
//state用于传入sql语句对数据库进行操作
this.state = con.createStatement();
} catch (Exception e) {
System.out.println("链接失败!");
}
}
和上面的代码一样,连接是在创建对象的时候创建的:
connectionToDatabase() 方法返回获取的数据库链接:
//返回数据库链接的方法
private static Connection connectionToDatabase() {
Connection con = null;
//创建驱动对象
try {
Driver driver = new Driver();
String url = cloud;
Properties info = new Properties();
//准备数据库链接信息
info.put("user", "rds_repl");
info.put("password", "123456");
//获取数据库链接
con = driver.connect(url, info);
}catch (SQLException e) {
System.out.println("链接数据库失败!");
return null;
}
System.out.println(con+"\n链接创建成功!");
return con;
}
//cloud是加载云端驱动的数据库,格式为:
//String cloud = "jdbc:mysql://服务器地址:端口号/数据库名?severTimzone=UTC";
,, 云数据库的地址和端口号这里就不贴了(连接云和本地数据库的方法是一样的)。值得注意的是,如果您使用的是数据库连接池,则需要设置链接超时,虽然我没有这样做。. .
PS:还有一个类加载com.mysql.cj.jdbc.Driver 0版本的驱动;有一个额外的“cj”,所以必须设置时区: severTimezone=UTC, version 0 不要使用,否则运行时会报错。(这里只是提醒,具体原因不再详述);
Java通过状态对象将sql字符串传递给数据库。由于数据库是预先存在的,所以需要建一个表来存储房屋信息。关键表语句是:
//如果数据库中不存在表house1就创建一张
static private String SQLCreateTaleStr = "CREATE TABLE IF NOT EXISTS house1"
+ "("
+ "title varchar(255) ,"
+ "area double ,"
+ "price varchar(64) ,"
+ "unit_price double ,"
+ "direction varchar(64),"
+ "decoration varchar(64),"
+ "houseStyle varchar(64) ,"
+ "floor varchar(64),"
+ "buildTime int(11) ,"
+ "community varchar(64),"
+ "location varchar(64) ,"
+ "gdpperperson double"
+ ")ENGINE = InnoDB DEFAULT CHARSET = utf8;";
然后写一个方法把房子信息转换成语句插入SQL到表中:
//用于生成插入语句的方法,传入一个房子和表的名字
public String insertStr(SecondHouse house) {
String insert = "insert into house1"
+ " values('"
+house.getElemName()+ "','"
+house.getArea()+ "','"
+house.getPrice()+ "','"
+house.getUnit_price()+ "','"
+house.getDirection()+ "','"
+house.getDecoration()+ "','"
+house.getHouseStyle()+ "','"
+house.getFloor()+ "','"
+house.getBuildTime()+ "','"
+house.getCommunity()+ "','"
+house.getLocation()+ "','"
+0+ "');";
return insert ;
}
PS; 拼接字符串时注意空格和标点符号,保证sql语句可以执行
然后就是执行这个write语句的方法:
//传入链接,进行对数据库的操作,传入二手房,写进数据库
public void operationOnDtabase(String insertStr) {
try {
//获取执行sql语句动态创建表,即如果表不存在就创建一个
state.execute(SQLCreateTaleStr);
//执行插入语句
state.executeUpdate(insertStr);
// System.out.println(insertStr);
}catch (SQLException e) {
System.out.println("SQL语句执行失败!");
}
System.out.println("执行语句成功!");
}
工具和方法已经准备好,需要集成:
最后,网页解析、多线程、写入数据库的所有实现都在main方法中执行;
<p>//---------------------------main方法代替执行--------------------------------------------------------------------
public static void operateMain() {
houseSet = new Vector();
//多线程集合
Vector threads = new Vector();
for (int i = 1; i
java爬虫抓取网页数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-19 05:12
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个建蛋网无聊的图,但是网络返回码一直是503,所以改了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对你java编程有所帮助。 查看全部
java爬虫抓取网页数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个建蛋网无聊的图,但是网络返回码一直是503,所以改了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:

对java相关内容感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对你java编程有所帮助。
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-18 09:19
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看全部
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。

请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"

然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):

/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)

由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。

除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:

package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
java爬虫抓取网页数据(读取本地和通过url抓取网页内容的html页面内容的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-17 23:03
)
今天在做项目的时候用java抓取网页的内容。本以为很简单的事情,却还是让我痛了一阵子。需要的是一种读取本地html页面内容的方法,网上找不到怎么办
我暂时
去吧!
首先给大家讲解一下通过url抓取网页内容,通过正则表达式提取网页的title、js、css等元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = " 查看全部
java爬虫抓取网页数据(读取本地和通过url抓取网页内容的html页面内容的方法
)
今天在做项目的时候用java抓取网页的内容。本以为很简单的事情,却还是让我痛了一阵子。需要的是一种读取本地html页面内容的方法,网上找不到怎么办

我暂时

去吧!
首先给大家讲解一下通过url抓取网页内容,通过正则表达式提取网页的title、js、css等元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = "
java爬虫抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-17 23:03
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果[");意图Ix=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们没有直接在网页的源代码中返回数据。而是用异步的方式用JS返回数据,防止搜索引擎等工具响应网站数据抓取。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
爬虫程序源码:/ShenJianShou/crawler_samples 查看全部
java爬虫抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:

第2步:查看网页源代码,我们在源代码中看到这一段:

从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:

也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果[");意图Ix=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们没有直接在网页的源代码中返回数据。而是用异步的方式用JS返回数据,防止搜索引擎等工具响应网站数据抓取。
先看这个页面:

我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:


从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
爬虫程序源码:/ShenJianShou/crawler_samples
java爬虫抓取网页数据(Java程序使用webmagic框架开发的爬虫结构工具工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-17 23:02
网络爬虫是根据一定的规则自动从万维网上爬取数据的脚本。根据一定的规则,意味着爬虫程序需要解析网页的dom结构,将感兴趣的数据爬取到dom结构。
(图片1)
这是一个网页源代码的dom结构。我们需要逐层指定要爬取的标签,如下图:
(图片2)
图2是一个java程序使用webmagic框架开发的爬虫程序。这段代码是抓取对应的标签,对应图1,运行后结果如下:
当然,以上是由专业程序员完成的,但是可以帮助我们理解爬虫工具的工作原理。非专业人士可以使用爬虫工具自行爬取数据。
1.首先输入要爬取的网站的网址,点击“开始采集”。
2.工具自动识别当前页面为多页数据,默认会翻页采集,我们只需要点击“生成采集设置”即可。
3.点击采集的详细链接,这里我们要采集这个网站的所有化工产品信息,所以在中文名称栏点击一个链接,然后点击右侧的“点击链接”,如下图
4.爬虫工具进入详细链接页面。这个页面上的数据就是我们要抓取的。点击“生成采集设置”,就会生成爬虫工具最终的爬取过程,如下图所示,爬虫工具会按照这个过程给我们采集数据,直到数据采集完成。
5. 点击“采集”按钮,爬虫工具正式开始运行,爬虫工具工作如下:
列表中的数据都是爬虫采集到达的。我们也可以处理采集的数据。您可以选择将其导出为 Excel 文档或直接将其导入数据库。这些是后续的分析数据。进一步加工的必要条件。有了这些基础数据,就可以对数据进行分析,得出一些业务依据,可以作为业务决策的支持。比如沃尔玛过去用他们的大数据发现尿布喜欢一起买啤酒,于是把尿布和啤酒放在一起,啤酒的销量就大大增加了。这就是大数据的价值。
本次使用的爬虫工具只是一个基础的应用,希望对大家有所帮助。Tech Rambler将带你了解技术,后续会持续更新相关知识,欢迎关注。 查看全部
java爬虫抓取网页数据(Java程序使用webmagic框架开发的爬虫结构工具工作)
网络爬虫是根据一定的规则自动从万维网上爬取数据的脚本。根据一定的规则,意味着爬虫程序需要解析网页的dom结构,将感兴趣的数据爬取到dom结构。

(图片1)
这是一个网页源代码的dom结构。我们需要逐层指定要爬取的标签,如下图:
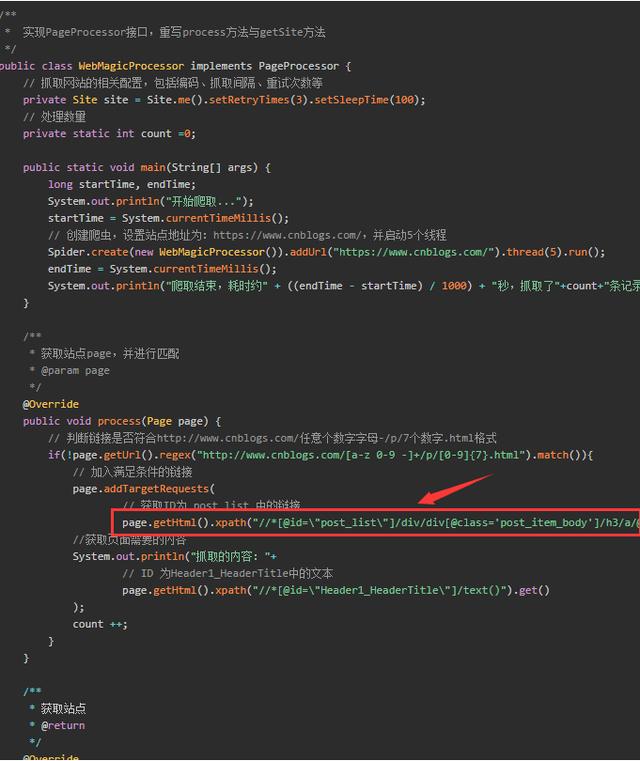
(图片2)
图2是一个java程序使用webmagic框架开发的爬虫程序。这段代码是抓取对应的标签,对应图1,运行后结果如下:

当然,以上是由专业程序员完成的,但是可以帮助我们理解爬虫工具的工作原理。非专业人士可以使用爬虫工具自行爬取数据。
1.首先输入要爬取的网站的网址,点击“开始采集”。

2.工具自动识别当前页面为多页数据,默认会翻页采集,我们只需要点击“生成采集设置”即可。
3.点击采集的详细链接,这里我们要采集这个网站的所有化工产品信息,所以在中文名称栏点击一个链接,然后点击右侧的“点击链接”,如下图

4.爬虫工具进入详细链接页面。这个页面上的数据就是我们要抓取的。点击“生成采集设置”,就会生成爬虫工具最终的爬取过程,如下图所示,爬虫工具会按照这个过程给我们采集数据,直到数据采集完成。
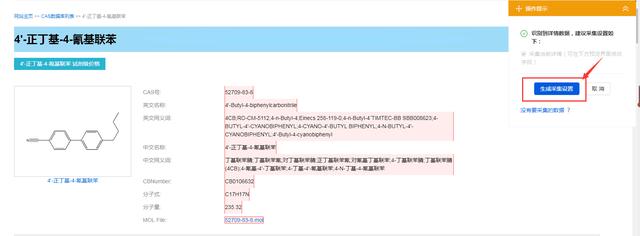

5. 点击“采集”按钮,爬虫工具正式开始运行,爬虫工具工作如下:

列表中的数据都是爬虫采集到达的。我们也可以处理采集的数据。您可以选择将其导出为 Excel 文档或直接将其导入数据库。这些是后续的分析数据。进一步加工的必要条件。有了这些基础数据,就可以对数据进行分析,得出一些业务依据,可以作为业务决策的支持。比如沃尔玛过去用他们的大数据发现尿布喜欢一起买啤酒,于是把尿布和啤酒放在一起,啤酒的销量就大大增加了。这就是大数据的价值。
本次使用的爬虫工具只是一个基础的应用,希望对大家有所帮助。Tech Rambler将带你了解技术,后续会持续更新相关知识,欢迎关注。
java爬虫抓取网页数据( 如何获取学校官网的信息是否会侵权?会问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-17 23:01
如何获取学校官网的信息是否会侵权?会问)
Jsoup实现网络爬虫抓取数据
在编写软件时,例如教务软件,需要从学校官网获取一些新闻信息来丰富你的软件,但不会专门提供相关的api接口。这时候就需要我们自己动手捕捉我们感兴趣的信息了。有人会问,爬取网站的信息会不会侵权。事实上,通过浏览器可以访问的信息一般都是公开的,抓取后不用于盈利也无所谓。它只是改变了浏览方式。
获取整个网页的源码
要抓取网页中的信息,首先要获取整个网页的源代码
String url = "http://i.guet.edu.cn/";
Document doc = Jsoup
.connect(url)
.timeout(1000).get();
通过Jsoup中的方法,我们可以很方便的获取到目标网页的源Document对象。好了,拿到整个网页的源码后,下一步就是抓取我们想要的信息了。现在我们要获取的是网页上滑动条幅的图片地址,如下图:
可以通过以下代码轻松获取图片的相对URL
Elements elements = doc.select("div#pic_lun");
Elements elements2 = elements.select("img");
for (Element el:elements2){
System.out.println(el.attr("src"));
}
控制台输出如下:
这样,我们就得到了我们想要的信息。另一个例子是获取新闻:
页面信息:
html源代码部分:
然后我们尝试爬取:
String url_news = "http://i.guet.edu.cn/news.php% ... 3B%3B
Document doc = Jsoup
.connect(url_news)
.timeout(1000).get();
Elements e1 = doc.select("div#content_middle");
Elements e2 = e1.select("a");
// System.out.print(e2);
for (Element el2 : e2) {
if (el2.text().length() > 20) {
StringBuffer sb = new StringBuffer();
sb.append(el2.text());
String time = sb.substring(0, 9);
String title = sb.substring(12);
System.out.print("time:"+time+"\n");
System.out.print("title:"+title+"\n");
System.out.print("link:"+"http://i.guet.edu.cn/"+el2.attr("href")+"\n");
}
}
控制台输出如下:
至此,数据抓取完成,必须将数据添加到listview中才能显示数据。只有数据有意义,革命还没有成功,同志们还需要努力。
我是菜鸟,如有错误请指正,文章原创 查看全部
java爬虫抓取网页数据(
如何获取学校官网的信息是否会侵权?会问)
Jsoup实现网络爬虫抓取数据
在编写软件时,例如教务软件,需要从学校官网获取一些新闻信息来丰富你的软件,但不会专门提供相关的api接口。这时候就需要我们自己动手捕捉我们感兴趣的信息了。有人会问,爬取网站的信息会不会侵权。事实上,通过浏览器可以访问的信息一般都是公开的,抓取后不用于盈利也无所谓。它只是改变了浏览方式。
获取整个网页的源码
要抓取网页中的信息,首先要获取整个网页的源代码
String url = "http://i.guet.edu.cn/";
Document doc = Jsoup
.connect(url)
.timeout(1000).get();
通过Jsoup中的方法,我们可以很方便的获取到目标网页的源Document对象。好了,拿到整个网页的源码后,下一步就是抓取我们想要的信息了。现在我们要获取的是网页上滑动条幅的图片地址,如下图:

可以通过以下代码轻松获取图片的相对URL
Elements elements = doc.select("div#pic_lun");
Elements elements2 = elements.select("img");
for (Element el:elements2){
System.out.println(el.attr("src"));
}
控制台输出如下:

这样,我们就得到了我们想要的信息。另一个例子是获取新闻:
页面信息:

html源代码部分:

然后我们尝试爬取:
String url_news = "http://i.guet.edu.cn/news.php% ... 3B%3B
Document doc = Jsoup
.connect(url_news)
.timeout(1000).get();
Elements e1 = doc.select("div#content_middle");
Elements e2 = e1.select("a");
// System.out.print(e2);
for (Element el2 : e2) {
if (el2.text().length() > 20) {
StringBuffer sb = new StringBuffer();
sb.append(el2.text());
String time = sb.substring(0, 9);
String title = sb.substring(12);
System.out.print("time:"+time+"\n");
System.out.print("title:"+title+"\n");
System.out.print("link:"+"http://i.guet.edu.cn/"+el2.attr("href")+"\n");
}
}
控制台输出如下:

至此,数据抓取完成,必须将数据添加到listview中才能显示数据。只有数据有意义,革命还没有成功,同志们还需要努力。
我是菜鸟,如有错误请指正,文章原创
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-17 13:08
一、java爬虫的主要步骤是:
非结构化数据-->数据采集-->数据清洗-->结构化数据-->采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬,哪些页面不能爬。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,则默认可以爬取。即使有这个文件,你也可以不服从,但是他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存中或者nosql缓存服务器中进行重复数据删除,常见的有:Bloom filter,redis……这些家伙自己百度一下,我什么也做不了。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
① Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度的向量角余弦。主要思想是将词在文章中出现的频率构成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。 查看全部
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
一、java爬虫的主要步骤是:
非结构化数据-->数据采集-->数据清洗-->结构化数据-->采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬,哪些页面不能爬。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,则默认可以爬取。即使有这个文件,你也可以不服从,但是他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存中或者nosql缓存服务器中进行重复数据删除,常见的有:Bloom filter,redis……这些家伙自己百度一下,我什么也做不了。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
① Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度的向量角余弦。主要思想是将词在文章中出现的频率构成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。
java爬虫抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-17 02:15
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。 查看全部
java爬虫抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
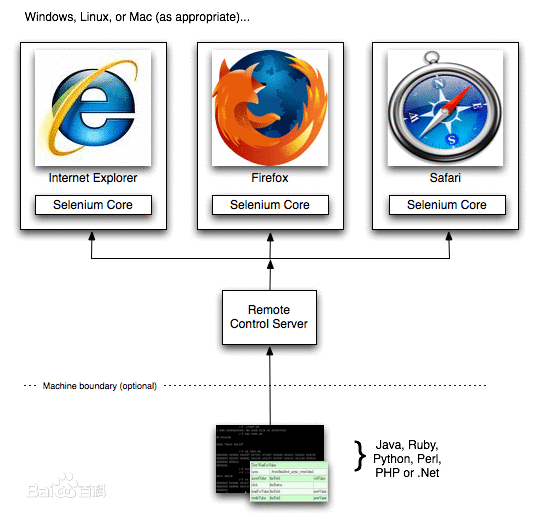
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
java爬虫抓取网页数据( 图片来源于网络1.爬虫的流程架构大致的工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-13 15:02
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知
图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧! 查看全部
java爬虫抓取网页数据(
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知

图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
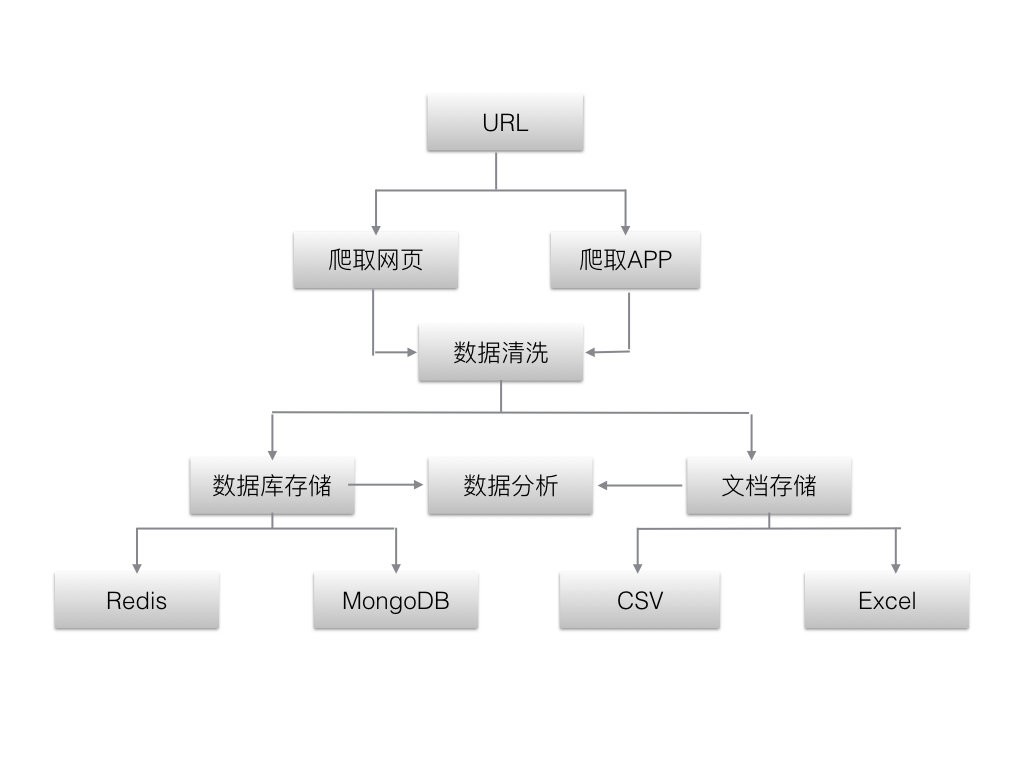
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧!
java爬虫抓取网页数据(github地址:快速开始自动下载最新chromium并启动(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-27 19:07
github地址:
快速入门
自动下载最新的chrome并启动:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.browser.BrowserFetcher;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
/**
* 展示下载最新的chromuim浏览器的例子
*/
public class DownloadChromiumExample2 {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
Puppeteer puppeteer = new Puppeteer();
//创建下载实例
BrowserFetcher browserFetcher = puppeteer.createBrowserFetcher();
//下载最新版本的chromuim
browserFetcher.download();
Browser browser = Puppeteer.launch(false);
String version = browser.version();
System.out.println(version);
}
}
抓取整个页面的内容:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.Page;
import java.io.IOException;
import java.util.ArrayList;
public class PageContentExample {
public static void main(String[] args) throws InterruptedException, IOException {
String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
// String path ="D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
ArrayList arrayList = new ArrayList();
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
String content = page.content();
System.out.println("=======================content=============="+content);
}
}
截图
文件选择
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.ElementHandle;
import com.ruiyun.jvppeteer.core.page.FileChooser;
import com.ruiyun.jvppeteer.core.page.Page;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.options.PageNavigateOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class PageFileChooserExample {
public static void main(String[] args) throws InterruptedException, ExecutionException, IOException {
// String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
ArrayList arrayList = new ArrayList();
String path = "D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
PageNavigateOptions options1 = new PageNavigateOptions();
options1.setWaitUntil(Arrays.asList("domcontentloaded"));
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
Future fileChooserFuture = page.waitForFileChooser(30000);
ElementHandle elementHandle = page.$("#form > span.bg.s_ipt_wr.quickdelete-wrap > span.soutu-btn");
elementHandle.click();
//点击选择文件的按钮
ElementHandle button = page.$("#form > div > div.soutu-state-normal > div.upload-wrap > input");
button.click();
//等待一个选择文件的弹窗事件返回
FileChooser fileChooser = fileChooserFuture.get();
//选择本地的文件
List paths = new ArrayList();
paths.add("C:\\Users\\howay\\Desktop\\sunway.png");
fileChooser.accept(paths);
}
}
另外还有更多的功能,Jvppeteer可以做到:
生成页面 PDF。抓取 SPA(单页应用程序)并生成预渲染的内容(即“SSR”(服务器端渲染))。自动提交表单、UI测试、键盘输入等,创建一个不断更新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中执行测试。捕获网站的时间线轨迹以帮助分析性能问题。测试浏览器扩展。 查看全部
java爬虫抓取网页数据(github地址:快速开始自动下载最新chromium并启动(图))
github地址:
快速入门
自动下载最新的chrome并启动:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.browser.BrowserFetcher;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
/**
* 展示下载最新的chromuim浏览器的例子
*/
public class DownloadChromiumExample2 {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
Puppeteer puppeteer = new Puppeteer();
//创建下载实例
BrowserFetcher browserFetcher = puppeteer.createBrowserFetcher();
//下载最新版本的chromuim
browserFetcher.download();
Browser browser = Puppeteer.launch(false);
String version = browser.version();
System.out.println(version);
}
}
抓取整个页面的内容:
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.Page;
import java.io.IOException;
import java.util.ArrayList;
public class PageContentExample {
public static void main(String[] args) throws InterruptedException, IOException {
String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
// String path ="D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
ArrayList arrayList = new ArrayList();
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
String content = page.content();
System.out.println("=======================content=============="+content);
}
}
截图
文件选择
package com.ruiyun.example;
import com.ruiyun.jvppeteer.core.Puppeteer;
import com.ruiyun.jvppeteer.core.browser.Browser;
import com.ruiyun.jvppeteer.core.page.ElementHandle;
import com.ruiyun.jvppeteer.core.page.FileChooser;
import com.ruiyun.jvppeteer.core.page.Page;
import com.ruiyun.jvppeteer.options.LaunchOptions;
import com.ruiyun.jvppeteer.options.OptionsBuilder;
import com.ruiyun.jvppeteer.options.PageNavigateOptions;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class PageFileChooserExample {
public static void main(String[] args) throws InterruptedException, ExecutionException, IOException {
// String path = new String("F:\\java教程\\49期\\vuejs\\puppeteer\\.local-chromium\\win64-722234\\chrome-win\\chrome.exe".getBytes(),"UTF-8");
ArrayList arrayList = new ArrayList();
String path = "D:\\develop\\project\\toString\\chrome-win\\chrome.exe";
LaunchOptions options = new OptionsBuilder().withArgs(arrayList).withHeadless(false).withExecutablePath(path).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
PageNavigateOptions options1 = new PageNavigateOptions();
options1.setWaitUntil(Arrays.asList("domcontentloaded"));
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
Future fileChooserFuture = page.waitForFileChooser(30000);
ElementHandle elementHandle = page.$("#form > span.bg.s_ipt_wr.quickdelete-wrap > span.soutu-btn");
elementHandle.click();
//点击选择文件的按钮
ElementHandle button = page.$("#form > div > div.soutu-state-normal > div.upload-wrap > input");
button.click();
//等待一个选择文件的弹窗事件返回
FileChooser fileChooser = fileChooserFuture.get();
//选择本地的文件
List paths = new ArrayList();
paths.add("C:\\Users\\howay\\Desktop\\sunway.png");
fileChooser.accept(paths);
}
}
另外还有更多的功能,Jvppeteer可以做到:
生成页面 PDF。抓取 SPA(单页应用程序)并生成预渲染的内容(即“SSR”(服务器端渲染))。自动提交表单、UI测试、键盘输入等,创建一个不断更新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中执行测试。捕获网站的时间线轨迹以帮助分析性能问题。测试浏览器扩展。
java爬虫抓取网页数据(工具类实现比较简单,就一个get方法,读取请求地址的响应内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-25 23:07
工具类的实现比较简单,只是一个get方法,读取请求地址的响应内容,这里我们是用来爬取网页内容的,这里没有代理,在真正的爬取过程中,当你请求一个大量的在一个网站的情况下,对方会有一系列的策略来禁用你的请求。这时候代理就派上用场了。通过代理设置不同的IP来抓取数据。
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpUtils {
public static String get(String url) {
try {
URL getUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) getUrl
.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Accept", "*/*");
connection
.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA)");
connection.setRequestProperty("Accept-Language", "zh-cn");
connection.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"));
String line;
StringBuffer result = new StringBuffer();
while ((line = reader.readLine()) != null){
result.append(line);
}
reader.close();
return result.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
接下来我们找一个有图片的网页,试试爬取功能
public static void main(String[] args) {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
System.out.println(imgSrc);
}
}
public static List getImageSrc(String html) {
// 获取img标签正则
String IMGURL_REG = "]*?>";
// 获取src路径的正则
String IMGSRC_REG = "http:\"?(.*?)(\"|>|\\s+)";
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List listImgUrl = new ArrayList();
while (matcher.find()) {
Matcher m = Pattern.compile(IMGSRC_REG).matcher(matcher.group());
while (m.find()) {
listImgUrl.add(m.group().substring(0, m.group().length() - 1));
}
}
return listImgUrl;
}
先抓取网页内容,然后正常解析出网页的标签,再解析img地址。执行程序我们可以得到如下内容:
http://p9.pstatp.com/large/pgc ... 39c85
http://p1.pstatp.com/large/pgc ... f408b
http://p3.pstatp.com/large/pgc ... 944eb
http://p1.pstatp.com/large/pgc ... 5beb0
http://p3.pstatp.com/large/pgc ... 6156e
通过上面的地址,我们可以将图片下载到本地。下面我们写一个图片下载方法:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
这样就很简单的实现了一个抓图和提取图片的功能。好像比较麻烦。如果你需要写正则,我给你介绍一个更简单的方法。如果您熟悉 jQuery,则可以提取元素。很简单,这个框架就是Jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
添加jsoup的依赖:
org.jsoup
jsoup
1.11.3
使用jsoup后提取的代码只需要简单的几行:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag方法提取所有图片标签,循环遍历,通过attr方法获取图片的src属性,然后下载图片。
Jsoup 使用起来非常简单。当然,还有很多其他的用于解析网页的操作。您可以查看信息并学习。
我们再升级一下,做一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按钮,然后自动下载图片,我们就可以用swing来写界面了。
public class App {
public static void main(String[] args) {
JFrame frame = new JFrame();
frame.setResizable(false);
frame.setSize(425,400);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setLayout(null);
frame.setLocationRelativeTo(null);
JTextField jTextField = new JTextField();
jTextField.setBounds(100, 44, 200, 30);
frame.add(jTextField);
JButton jButton = new JButton("提取");
jButton.setBounds(140, 144, 100, 30);
frame.add(jButton);
frame.setVisible(true);
jButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String url = jTextField.getText();
if (url == null || url.equals("")) {
JOptionPane.showMessageDialog(null, "请填写抓取地址");
return;
}
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
try {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
} catch (MalformedURLException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
JOptionPane.showMessageDialog(null, "抓取完成");
}
});
}
}
执行 main 方法后的第一件事是我们的接口,如下所示:
截图 2018-06-18 09.50.34 PM.png
截图 2018-06-18 09.50.34 PM.png
输入地址,点击提取按钮下载图片。
课程推荐
大数据时代,如何形成大数据。
大量的用户,每天大量的日志。
搭建爬虫,抓取数十亿条数据进行分析分析。
不仅仅是 Python 可以做爬虫,Java 仍然可以做。
今天就带大家写一个简单的抓图程序,把网页上的所有图片都下载下来
图片
图片
本课程将带领你一步一步写一个爬虫程序,向下爬取到我们想要的数据,不登录或者需要登录。
课程大纲
图片 查看全部
java爬虫抓取网页数据(工具类实现比较简单,就一个get方法,读取请求地址的响应内容)
工具类的实现比较简单,只是一个get方法,读取请求地址的响应内容,这里我们是用来爬取网页内容的,这里没有代理,在真正的爬取过程中,当你请求一个大量的在一个网站的情况下,对方会有一系列的策略来禁用你的请求。这时候代理就派上用场了。通过代理设置不同的IP来抓取数据。
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpUtils {
public static String get(String url) {
try {
URL getUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) getUrl
.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Accept", "*/*");
connection
.setRequestProperty("User-Agent",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA)");
connection.setRequestProperty("Accept-Language", "zh-cn");
connection.connect();
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8"));
String line;
StringBuffer result = new StringBuffer();
while ((line = reader.readLine()) != null){
result.append(line);
}
reader.close();
return result.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
接下来我们找一个有图片的网页,试试爬取功能
public static void main(String[] args) {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
System.out.println(imgSrc);
}
}
public static List getImageSrc(String html) {
// 获取img标签正则
String IMGURL_REG = "]*?>";
// 获取src路径的正则
String IMGSRC_REG = "http:\"?(.*?)(\"|>|\\s+)";
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(html);
List listImgUrl = new ArrayList();
while (matcher.find()) {
Matcher m = Pattern.compile(IMGSRC_REG).matcher(matcher.group());
while (m.find()) {
listImgUrl.add(m.group().substring(0, m.group().length() - 1));
}
}
return listImgUrl;
}
先抓取网页内容,然后正常解析出网页的标签,再解析img地址。执行程序我们可以得到如下内容:
http://p9.pstatp.com/large/pgc ... 39c85
http://p1.pstatp.com/large/pgc ... f408b
http://p3.pstatp.com/large/pgc ... 944eb
http://p1.pstatp.com/large/pgc ... 5beb0
http://p3.pstatp.com/large/pgc ... 6156e
通过上面的地址,我们可以将图片下载到本地。下面我们写一个图片下载方法:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
List imgUrls = getImageSrc(html);
for (String imgSrc : imgUrls) {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
这样就很简单的实现了一个抓图和提取图片的功能。好像比较麻烦。如果你需要写正则,我给你介绍一个更简单的方法。如果您熟悉 jQuery,则可以提取元素。很简单,这个框架就是Jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
添加jsoup的依赖:
org.jsoup
jsoup
1.11.3
使用jsoup后提取的代码只需要简单的几行:
public static void main(String[] args) throws MalformedURLException, IOException {
String url = "https://www.toutiao.com/a65683 ... 3B%3B
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
}
}
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag方法提取所有图片标签,循环遍历,通过attr方法获取图片的src属性,然后下载图片。
Jsoup 使用起来非常简单。当然,还有很多其他的用于解析网页的操作。您可以查看信息并学习。
我们再升级一下,做一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按钮,然后自动下载图片,我们就可以用swing来写界面了。
public class App {
public static void main(String[] args) {
JFrame frame = new JFrame();
frame.setResizable(false);
frame.setSize(425,400);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setLayout(null);
frame.setLocationRelativeTo(null);
JTextField jTextField = new JTextField();
jTextField.setBounds(100, 44, 200, 30);
frame.add(jTextField);
JButton jButton = new JButton("提取");
jButton.setBounds(140, 144, 100, 30);
frame.add(jButton);
frame.setVisible(true);
jButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String url = jTextField.getText();
if (url == null || url.equals("")) {
JOptionPane.showMessageDialog(null, "请填写抓取地址");
return;
}
String html = HttpUtils.get(url);
Document doc = Jsoup.parse(html);
Elements imgs = doc.getElementsByTag("img");
for (Element img : imgs) {
String imgSrc = img.attr("src");
if (imgSrc.startsWith("//")) {
imgSrc = "http:" + imgSrc;
}
try {
Files.copy(new URL(imgSrc).openStream(), Paths.get("./img/"+UUID.randomUUID()+".png"));
} catch (MalformedURLException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
JOptionPane.showMessageDialog(null, "抓取完成");
}
});
}
}
执行 main 方法后的第一件事是我们的接口,如下所示:
截图 2018-06-18 09.50.34 PM.png
截图 2018-06-18 09.50.34 PM.png
输入地址,点击提取按钮下载图片。
课程推荐
大数据时代,如何形成大数据。
大量的用户,每天大量的日志。
搭建爬虫,抓取数十亿条数据进行分析分析。
不仅仅是 Python 可以做爬虫,Java 仍然可以做。
今天就带大家写一个简单的抓图程序,把网页上的所有图片都下载下来
图片
图片
本课程将带领你一步一步写一个爬虫程序,向下爬取到我们想要的数据,不登录或者需要登录。
课程大纲
图片
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-25 15:15
网络爬虫的数据采集方式有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是从互联网上采集
数据的有利工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
有哪些类型的网络爬虫工具?
1、分布式网络爬虫工具,如Nutch。
2、Java 网络爬虫工具,如 Crawler4j、WebMagic、WebCollector。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集
所有可以访问的页面的内容,为搜索引擎和大数据分析提供数据来源。就功能而言,爬虫一般具有数据采集、处理和存储三大功能。
除了供用户阅读的文本信息外,网页还收录
一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些外展度(网页中超链接的数量)较高的网站的一些比较重要的网址作为种子网址集合。
网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录
链接信息,因此会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有的或深度优先搜索算法 Page。
由于深度优先搜索算法可能会将爬虫系统困在网站内部,不利于搜索离网站首页较近的网页信息,所以一般采用广度优先搜索算法来采集网页。
网络爬虫系统首先将种子网址放入下载队列,简单地从队列头部取一个网址下载对应的网页,获取网页内容并存储,解析网页中的链接信息后,可以获得一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个URL,下载其对应的网页,然后解析,如此循环往复,直到遍历全网或满足某个条件,才会停止。
网络爬虫工作流程
1)首先选择种子URL的一部分。
2)将这些URL放入URL队列进行爬取。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS获取主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入已爬取的网址队列中。
4)对抓取到的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待抓取的URL队列中,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要为门户搜索引擎和大型Web服务提供商采集
数据。一般的网络爬虫为了提高工作效率,都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个链接地跟随它,直到无法再深入为止。爬行完成一个分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。这种策略更适合垂直搜索或站内搜索,但在抓取页面内容更深层次的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间中。那个时候,它会尽可能的深入,只有在找不到节点的后继节点时才考虑它的兄弟节点。这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它就会沿着一条路径不受限制地扩展,从而“陷入”海量数据。一般情况下,深度优先策略会选择一个合适的深度,然后反复搜索直到找到解,这样就降低了搜索的效率。因此,当搜索数据量比较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度来爬取页面,先爬取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。由于广度优先策略在第N层节点扩展完成后进入第N+1层,可以保证找到路径最短的解。该策略可以有效控制页面的爬取深度,避免遇到无限深的分支爬取无法结束的问题。实现方便,不需要存储大量的中间节点。缺点是爬到更深的目录层次需要很长时间。页。
如果搜索过程中分支过多,即该节点的后续节点过多,算法就会耗尽资源,在可用空间中找不到解。 查看全部
java爬虫抓取网页数据(网络爬虫的数据采集方法有哪几类?工具介绍)
网络爬虫的数据采集方式有哪些?网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。在大数据时代,网络爬虫更是从互联网上采集
数据的有利工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
有哪些类型的网络爬虫工具?
1、分布式网络爬虫工具,如Nutch。
2、Java 网络爬虫工具,如 Crawler4j、WebMagic、WebCollector。
3、非Java网络爬虫工具,如Scrapy(基于Python语言开发)。
网络爬虫的原理是什么?
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。网络爬虫可以自动采集
所有可以访问的页面的内容,为搜索引擎和大数据分析提供数据来源。就功能而言,爬虫一般具有数据采集、处理和存储三大功能。
除了供用户阅读的文本信息外,网页还收录
一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些外展度(网页中超链接的数量)较高的网站的一些比较重要的网址作为种子网址集合。
网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录
链接信息,因此会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法遍历所有的或深度优先搜索算法 Page。
由于深度优先搜索算法可能会将爬虫系统困在网站内部,不利于搜索离网站首页较近的网页信息,所以一般采用广度优先搜索算法来采集网页。
网络爬虫系统首先将种子网址放入下载队列,简单地从队列头部取一个网址下载对应的网页,获取网页内容并存储,解析网页中的链接信息后,可以获得一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个URL,下载其对应的网页,然后解析,如此循环往复,直到遍历全网或满足某个条件,才会停止。
网络爬虫工作流程
1)首先选择种子URL的一部分。
2)将这些URL放入URL队列进行爬取。
3) 从待爬取的URL队列中取出待爬取的URL,解析DNS获取主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入已爬取的网址队列中。
4)对抓取到的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入待抓取的URL队列中,从而进入下一个循环。
网络爬虫抓取策略
1. 通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要为门户搜索引擎和大型Web服务提供商采集
数据。一般的网络爬虫为了提高工作效率,都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个链接地跟随它,直到无法再深入为止。爬行完成一个分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。这种策略更适合垂直搜索或站内搜索,但在抓取页面内容更深层次的网站时会造成巨大的资源浪费。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间中。那个时候,它会尽可能的深入,只有在找不到节点的后继节点时才考虑它的兄弟节点。这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它就会沿着一条路径不受限制地扩展,从而“陷入”海量数据。一般情况下,深度优先策略会选择一个合适的深度,然后反复搜索直到找到解,这样就降低了搜索的效率。因此,当搜索数据量比较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度来爬取页面,先爬取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。由于广度优先策略在第N层节点扩展完成后进入第N+1层,可以保证找到路径最短的解。该策略可以有效控制页面的爬取深度,避免遇到无限深的分支爬取无法结束的问题。实现方便,不需要存储大量的中间节点。缺点是爬到更深的目录层次需要很长时间。页。
如果搜索过程中分支过多,即该节点的后续节点过多,算法就会耗尽资源,在可用空间中找不到解。
java爬虫抓取网页数据(如何用java实现网络爬虫抓取页面内容__通过类访问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-25 01:08
如何使用java实现网络爬虫抓取页面内容
______ 通过班级访问自己拥有的网址获取网页内容,然后使用正则表达式获取自己想要的内容。然后就可以抓取页面的URL,重复之前的工作
JAVA如何获取爬虫
______ 下面是java实现的简单爬虫核心代码: public void crawl() throws Throwable {while (continueCrawling()) {CrawlerUrl url = getNextUrl(); //获取队列中下一个要爬取的URL if (url != null) {printCrawlInfo(); 字符串内容 = getContent(url); ...
如何使用java实现网络爬虫抓取页面内容-
______ 以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是自带jdk,速度更快。缺点是方法较少,功能比较复杂,往往需要大量代码自己实现。第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般来说,HttpClient+JSOUP配合完成爬取。HttpClient 获取页面。JSOUP 解析网页并获取数据。HttpUnit:相当于一个无界面的浏览器。缺点是内存占用大,速度慢。优点是可以执行js,功能强大
Java 制作了一个网络内容爬虫——
______ 1.你需要的不是网络爬虫。只是爬取了网站。2. 使用JDK的HttpURLConnection或者apache的HttpClient组件即可。附件也是资源。只要有地址就可以传 HttpURLConnection con = new HttpURLConnection(url); conn.connect(); ...
如何使用网络爬虫基于java获取数据-
______ 爬虫的原理其实就是获取网页的内容然后解析。只是获取网页和解析内容的方式有很多种。可以简单的使用httpclient发送get/post请求,获取结果,然后使用拦截获取你想要的带有字符串和正则表达式的内容。或者使用Jsoup/crawler4j等封装的库来更方便的抓取信息。
java爬虫抓取数据
______ 一般爬虫在登录后是不会抓取页面的。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,再请求相关页面。
java爬虫抓取指定数据——
______ 如何通过Java代码指定爬取网页数据,我总结下Jsoup.Jar包会用到以下步骤:1、导入项目中的Jsoup.jar包2、获取URL url 指定HTML或文档指定的正文3、获取网页中超链接的标题和链接4、获取指定博客的内容文章5、@ >获取网页中超链接的标题和链接结果
如何做java爬虫-
______ 代码如下:打包webspider;导入 java.util.HashSet; 导入 java.util.PriorityQueue; 导入 java.util.Set; 导入 java.util.Queue; public class LinkQueue {// 访问过的 url 集合 private static SetvisitedUrl = new HashSet(); // 要访问的 URL 集合...
如何实现java网络爬虫-
______ 网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在网页的处理过程中,不断从当前页面中提取新的网址,放入队列中,直到满...
如何用Java编写爬虫
______ 我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome network来分析请求,或者fiddler来抓包。普通网页可以直接使用httpclient封装的API获取网页HTML,然后JSoup和regular提取内容。如果网站有反爬虫... 查看全部
java爬虫抓取网页数据(如何用java实现网络爬虫抓取页面内容__通过类访问)
如何使用java实现网络爬虫抓取页面内容
______ 通过班级访问自己拥有的网址获取网页内容,然后使用正则表达式获取自己想要的内容。然后就可以抓取页面的URL,重复之前的工作
JAVA如何获取爬虫
______ 下面是java实现的简单爬虫核心代码: public void crawl() throws Throwable {while (continueCrawling()) {CrawlerUrl url = getNextUrl(); //获取队列中下一个要爬取的URL if (url != null) {printCrawlInfo(); 字符串内容 = getContent(url); ...
如何使用java实现网络爬虫抓取页面内容-
______ 以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是自带jdk,速度更快。缺点是方法较少,功能比较复杂,往往需要大量代码自己实现。第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般来说,HttpClient+JSOUP配合完成爬取。HttpClient 获取页面。JSOUP 解析网页并获取数据。HttpUnit:相当于一个无界面的浏览器。缺点是内存占用大,速度慢。优点是可以执行js,功能强大
Java 制作了一个网络内容爬虫——
______ 1.你需要的不是网络爬虫。只是爬取了网站。2. 使用JDK的HttpURLConnection或者apache的HttpClient组件即可。附件也是资源。只要有地址就可以传 HttpURLConnection con = new HttpURLConnection(url); conn.connect(); ...
如何使用网络爬虫基于java获取数据-
______ 爬虫的原理其实就是获取网页的内容然后解析。只是获取网页和解析内容的方式有很多种。可以简单的使用httpclient发送get/post请求,获取结果,然后使用拦截获取你想要的带有字符串和正则表达式的内容。或者使用Jsoup/crawler4j等封装的库来更方便的抓取信息。
java爬虫抓取数据
______ 一般爬虫在登录后是不会抓取页面的。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,再请求相关页面。
java爬虫抓取指定数据——
______ 如何通过Java代码指定爬取网页数据,我总结下Jsoup.Jar包会用到以下步骤:1、导入项目中的Jsoup.jar包2、获取URL url 指定HTML或文档指定的正文3、获取网页中超链接的标题和链接4、获取指定博客的内容文章5、@ >获取网页中超链接的标题和链接结果
如何做java爬虫-
______ 代码如下:打包webspider;导入 java.util.HashSet; 导入 java.util.PriorityQueue; 导入 java.util.Set; 导入 java.util.Queue; public class LinkQueue {// 访问过的 url 集合 private static SetvisitedUrl = new HashSet(); // 要访问的 URL 集合...
如何实现java网络爬虫-
______ 网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在网页的处理过程中,不断从当前页面中提取新的网址,放入队列中,直到满...
如何用Java编写爬虫
______ 我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome network来分析请求,或者fiddler来抓包。普通网页可以直接使用httpclient封装的API获取网页HTML,然后JSoup和regular提取内容。如果网站有反爬虫...
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-25 01:07
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列末尾,从头部获取新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。
代码
明天就要开学了,加上实验室的任务,没时间好好写了。我写了一个比较水的,eclipse项目,大概就是上面流程图的实现。很多地方需要根据具体的爬取场景来进行。实现是用注释解释的,真心希望以后能打包的更漂亮一些。
丑陋的妻子看到公婆来了。点我看丑>_ 查看全部
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列末尾,从头部获取新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。
代码
明天就要开学了,加上实验室的任务,没时间好好写了。我写了一个比较水的,eclipse项目,大概就是上面流程图的实现。很多地方需要根据具体的爬取场景来进行。实现是用注释解释的,真心希望以后能打包的更漂亮一些。
丑陋的妻子看到公婆来了。点我看丑>_
java爬虫抓取网页数据( java爬虫实战之模拟登陆的内容介绍及使用工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-21 11:02
java爬虫实战之模拟登陆的内容介绍及使用工具介绍)
java爬虫模拟登陆实例详解
更新时间:2021年1月18日15:54:18 作者:宋松勋爵
本文文章,小编将与大家分享一个java爬虫模拟登陆的详细例子。有兴趣的朋友可以参考一下。
使用jsoup工具可以解析某个URL地址和HTML文本内容,这是java爬虫的一个很好的优势,也是我们在网络爬虫中不可缺少的工具。本文小编带你使用jsoup实现java爬虫模拟登录。通过省力API,java爬虫模拟登录非常好。
一、使用工具:Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
二、实现java爬虫模拟登录
1、确定要爬取的url
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Map.Entry;
import java.util.Set;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class SplitTable {
public static void main(String[] args) throws IOException {
//想要爬取的url
String url = "http://jwcnew.nefu.edu.cn/dbly ... do%3F
Ves632DSdyV=NEW_XSD_PYGL";
String username = "";
String password = "";
String sessionId = getSessionInfo(username,password);
spiderWebSite(sessionId,url);
}
2、获取 sessionId
private static String getSessionInfo(String username,String password)
throws IOException{
3、登录网站,返回sessionId信息
Connection.Response res = Jsoup.connect(http://jwcnew.nefu.edu.cn/dblydx_jsxsd/xk/LoginToXk)
4、获取 sessionId
String sessionId = res.cookie("JSESSIONID");
System.out.println(sessionId);
return sessionId;
}
5、抓取内容
private static void spiderWebSite(String sessionId,String url) throws IOException{
//爬取
Document doc = Jsoup.connect(url).cookie("JSESSIONID", sessionId).timeout(10000).get();
Element table = doc.getElementById("kbtable");
//System.out.println(table);
BufferedWriter bw = new BufferedWriter
(new OutputStreamWriter(new FileOutputStream("F:/table.html")));
bw.write(new String(table.toString().getBytes()));
bw.flush();
bw.close();
}
}
示例代码扩展:
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class LoginDemo {
public static void main(String[] args) throws Exception {
LoginDemo loginDemo = new LoginDemo();
loginDemo.login("16xxx20xxx", "16xxx20xxx");// 用户名,和密码
}
/**
* 模拟登陆座位系统
* @param userName
* 用户名
* @param pwd
* 密码
*
* **/
public void login(String userName, String pwd) throws Exception {
// 第一次请求
Connection con = Jsoup
.connect("http://lib???.?????????.aspx");// 获取连接
con.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
Response rs = con.execute();// 获取响应
Document d1 = Jsoup.parse(rs.body());// 转换为Dom树
List et = d1.select("#form1");// 获取form表单,可以通过查看页面源码代码得知
// 获取,cooking和表单属性,下面map存放post时的数据
Map datas = new HashMap();
for (Element e : et.get(0).getAllElements()) {
//System.out.println(e.attr("name")+"----Little\n");
if (e.attr("name").equals("tbUserName")) {
e.attr("value", userName);// 设置用户名
}
if (e.attr("name").equals("tbPassWord")) {
e.attr("value", pwd); // 设置用户密码
}
if (e.attr("name").length() > 0) {// 排除空值表单属性
datas.put(e.attr("name"), e.attr("value"));
}
}
/**
* 第二次请求,post表单数据,以及cookie信息
*
* **/
Connection con2 = Jsoup
.connect("http://lib???.?????????.aspx");
con2.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).method(Method.POST)
.data(datas).cookies(rs.cookies()).execute();
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
//下面输出的是cookie 的内容
for (String s : map.keySet()) {
System.out.println(s + "=====-----" + map.get(s));
}
System.out.println(login.body());
/**
* 登录之后模拟获取预约记录
*
* */
Connection con_record = Jsoup
.connect("http://lib???.?????????.aspx");// 获取连接
con_record.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
con_record.cookies(datas);
Response record = con_record.ignoreContentType(true)
.method(Method.GET)
.cookies(rs.cookies())
.execute();
System.out.println(record.body());
}
}
这里是java爬虫模拟登录示例的详细讲解文章。更多java爬虫实战模拟登录的相关内容,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
java爬虫抓取网页数据(
java爬虫实战之模拟登陆的内容介绍及使用工具介绍)
java爬虫模拟登陆实例详解
更新时间:2021年1月18日15:54:18 作者:宋松勋爵
本文文章,小编将与大家分享一个java爬虫模拟登陆的详细例子。有兴趣的朋友可以参考一下。
使用jsoup工具可以解析某个URL地址和HTML文本内容,这是java爬虫的一个很好的优势,也是我们在网络爬虫中不可缺少的工具。本文小编带你使用jsoup实现java爬虫模拟登录。通过省力API,java爬虫模拟登录非常好。
一、使用工具:Jsoup
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
二、实现java爬虫模拟登录
1、确定要爬取的url
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Map.Entry;
import java.util.Set;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class SplitTable {
public static void main(String[] args) throws IOException {
//想要爬取的url
String url = "http://jwcnew.nefu.edu.cn/dbly ... do%3F
Ves632DSdyV=NEW_XSD_PYGL";
String username = "";
String password = "";
String sessionId = getSessionInfo(username,password);
spiderWebSite(sessionId,url);
}
2、获取 sessionId
private static String getSessionInfo(String username,String password)
throws IOException{
3、登录网站,返回sessionId信息
Connection.Response res = Jsoup.connect(http://jwcnew.nefu.edu.cn/dblydx_jsxsd/xk/LoginToXk)
4、获取 sessionId
String sessionId = res.cookie("JSESSIONID");
System.out.println(sessionId);
return sessionId;
}
5、抓取内容
private static void spiderWebSite(String sessionId,String url) throws IOException{
//爬取
Document doc = Jsoup.connect(url).cookie("JSESSIONID", sessionId).timeout(10000).get();
Element table = doc.getElementById("kbtable");
//System.out.println(table);
BufferedWriter bw = new BufferedWriter
(new OutputStreamWriter(new FileOutputStream("F:/table.html")));
bw.write(new String(table.toString().getBytes()));
bw.flush();
bw.close();
}
}
示例代码扩展:
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
public class LoginDemo {
public static void main(String[] args) throws Exception {
LoginDemo loginDemo = new LoginDemo();
loginDemo.login("16xxx20xxx", "16xxx20xxx");// 用户名,和密码
}
/**
* 模拟登陆座位系统
* @param userName
* 用户名
* @param pwd
* 密码
*
* **/
public void login(String userName, String pwd) throws Exception {
// 第一次请求
Connection con = Jsoup
.connect("http://lib???.?????????.aspx";);// 获取连接
con.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
Response rs = con.execute();// 获取响应
Document d1 = Jsoup.parse(rs.body());// 转换为Dom树
List et = d1.select("#form1");// 获取form表单,可以通过查看页面源码代码得知
// 获取,cooking和表单属性,下面map存放post时的数据
Map datas = new HashMap();
for (Element e : et.get(0).getAllElements()) {
//System.out.println(e.attr("name")+"----Little\n");
if (e.attr("name").equals("tbUserName")) {
e.attr("value", userName);// 设置用户名
}
if (e.attr("name").equals("tbPassWord")) {
e.attr("value", pwd); // 设置用户密码
}
if (e.attr("name").length() > 0) {// 排除空值表单属性
datas.put(e.attr("name"), e.attr("value"));
}
}
/**
* 第二次请求,post表单数据,以及cookie信息
*
* **/
Connection con2 = Jsoup
.connect("http://lib???.?????????.aspx";);
con2.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).method(Method.POST)
.data(datas).cookies(rs.cookies()).execute();
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
//下面输出的是cookie 的内容
for (String s : map.keySet()) {
System.out.println(s + "=====-----" + map.get(s));
}
System.out.println(login.body());
/**
* 登录之后模拟获取预约记录
*
* */
Connection con_record = Jsoup
.connect("http://lib???.?????????.aspx";);// 获取连接
con_record.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20100101 Firefox/29.0");// 配置模拟浏览器
con_record.cookies(datas);
Response record = con_record.ignoreContentType(true)
.method(Method.GET)
.cookies(rs.cookies())
.execute();
System.out.println(record.body());
}
}
这里是java爬虫模拟登录示例的详细讲解文章。更多java爬虫实战模拟登录的相关内容,请搜索前面的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
java爬虫抓取网页数据( 每一个步骤我都是进行独立封装起来,方便复用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-21 10:19
每一个步骤我都是进行独立封装起来,方便复用
)
Java爬虫基于Jsoup抓取网页数据
前言
本文主要介绍简单使用Jsoup抓取网页数据
框架 SpringBoot + Jsoup
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
这是广告:技术交流群796794009 SpringBoot技术交流群; --小武
一.准备
创建一个SpringBoot项目,引入Jsoup依赖
org.jsoup
jsoup
1.13.1
二.代码(使用Jsoup的核心是两步)
第一步
通过Jsoup的connect(url).get()获取当前页面信息;方法
url 是你要获取的网页地址
返回的是一个文档
public Document getDoc(String url){
Document doc;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
log.error("出现异常:{}", e.getMessage());
return null;
}
return doc;
}
第二步
通过Document中的select方法获取标签(Elements)信息
特别说明1:使用select方法获取Element的集合,需要遍历获取Element
特别说明2:link.attr("abs:src")中的abs:指的是绝对路径,现在很多页面的src都没有域名
private Map listUrl(Document doc){
// Map
Map map = new HashMap(16);
// 获取图片标签
Elements links = doc.select("img[src]");
for (Element link : links){
System.out.println("名称 : " + link.text());
System.out.println("链接 : " + link.attr("abs:src"));
map.put(link.absUrl("abs:src"), link.text());
}
return map;
}
三.效果
这是我博客中的一段图片数据文章
爬虫项目地址
个人爬虫项目,仅供学习参考:
使用环境jdk1.8、MySQL8.0
注意:本项目仅提供4个接口
特别说明:第四个接口不建议大家尝试大网站,大网站接口获取时间太长
禁止利用本项目做一切违法行为,仅供学习参考
如图所示:
查看全部
java爬虫抓取网页数据(
每一个步骤我都是进行独立封装起来,方便复用
)
Java爬虫基于Jsoup抓取网页数据
前言
本文主要介绍简单使用Jsoup抓取网页数据
框架 SpringBoot + Jsoup
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
我独立封装了每一步,方便复用(重要的说三遍)
这是广告:技术交流群796794009 SpringBoot技术交流群; --小武
一.准备
创建一个SpringBoot项目,引入Jsoup依赖
org.jsoup
jsoup
1.13.1
二.代码(使用Jsoup的核心是两步)
第一步
通过Jsoup的connect(url).get()获取当前页面信息;方法
url 是你要获取的网页地址
返回的是一个文档
public Document getDoc(String url){
Document doc;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
log.error("出现异常:{}", e.getMessage());
return null;
}
return doc;
}
第二步
通过Document中的select方法获取标签(Elements)信息
特别说明1:使用select方法获取Element的集合,需要遍历获取Element
特别说明2:link.attr("abs:src")中的abs:指的是绝对路径,现在很多页面的src都没有域名
private Map listUrl(Document doc){
// Map
Map map = new HashMap(16);
// 获取图片标签
Elements links = doc.select("img[src]");
for (Element link : links){
System.out.println("名称 : " + link.text());
System.out.println("链接 : " + link.attr("abs:src"));
map.put(link.absUrl("abs:src"), link.text());
}
return map;
}
三.效果
这是我博客中的一段图片数据文章
爬虫项目地址
个人爬虫项目,仅供学习参考:
使用环境jdk1.8、MySQL8.0
注意:本项目仅提供4个接口
特别说明:第四个接口不建议大家尝试大网站,大网站接口获取时间太长
禁止利用本项目做一切违法行为,仅供学习参考
如图所示:
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-21 04:00
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列的末尾,从头部获取一个新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。
本文为原创作者,转载请注明【原文作者及本文链接地址】。侵权必究,谢谢合作!
打开应用程序并阅读笔记 查看全部
java爬虫抓取网页数据(基本思路网络爬虫的基本思路(HTML解析)(图))
HTML解析:Jsoup
基本思想
一个网络爬虫的基本思想是:爬虫线程从待爬取的URL队列中取一个URL->模拟浏览器对目标URL的GET请求->下载网页内容->然后解析其中的内容页面并获取目标数据 保存到相应的存储 -> 使用一定的规则从当前抓取的网页中获取下一个需要抓取的URL。
当然,以上思路是基于爬取过程不需要模拟登录,爬取的网站比较厚道,不会做一些“反爬”的工作。但是,在现实中,模拟登录有时很重要(比如新浪微博);不会爬回来的 网站 非常罕见。频繁访问本站时,可能会出现账号被冻结、IP被封等情况,并返回“系统繁忙”、“请慢慢访问”等信息。. 因此,需要增强爬虫的健壮性:增加反爬虫信息的处理、动态切换账号/IP、访问延时等。
程序架构
由于模拟登录模块比较复杂,不同网站实现的机制也不一样,这里只给出示意图。下面主要针对不需要登录的爬虫进行分析。
Worker:每个worker都是一个爬虫线程,由主线程SpiderStarter创建
登录(可选):爬虫模拟登录模块,可以设置账号队列,一旦账号被冻结,放到队列的末尾,从头部获取一个新账号重新登录。队列长度需要>=账户冻结时间/每个账户可以支持的连续爬行时间
Fetcher:爬虫模拟浏览器发出GET URL请求下载页面
Handler:对Fetcher下载的页面进行初步处理,比如判断页面的返回状态码是否正确,页面内容是否为反爬信息等,以确保页面传递给Parser进行处理分析正确
Parser:解析Fetcher下载的页面内容,获取目标数据
Store:将Parser解析的目标数据存储到本地存储,可以是传统的MySQL数据库或Redis等KV存储
待爬取队列:存放需要爬取的URL
爬取队列:存放已爬取的页面的URL
程序流程图
下面是爬虫实现的流程图。图中绿框表示这些步骤在同一个模块中,模块名称用红色字母表示。
本文为原创作者,转载请注明【原文作者及本文链接地址】。侵权必究,谢谢合作!
打开应用程序并阅读笔记
java爬虫抓取网页数据(本文爬虫程序的核心代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-21 03:23
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent内部使用apache的httpclient4.1来获取网页的内容,具体代码如下:
Java代码
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样一个简单的网络爬虫程序就搭建完成了,可以使用如下程序进行测试:
Java代码 查看全部
java爬虫抓取网页数据(本文爬虫程序的核心代码)
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent内部使用apache的httpclient4.1来获取网页的内容,具体代码如下:
Java代码
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样一个简单的网络爬虫程序就搭建完成了,可以使用如下程序进行测试:
Java代码
java爬虫抓取网页数据(荣幸供爬虫初学者参考关于java爬虫系统技术详解处理课程爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-21 03:19
--------很荣幸成为爬虫初学者的参考。详细讲解java爬虫系统的技术是一门自然语言处理课程。爬虫系统技术报告很荣幸为爬虫初学者提供参考。处理课程受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
Quote: 这学期完成了自然语言处理课程让我受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统非常重要,而网络爬虫也是搜索引擎爬虫系统的重要组成部分。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要大量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
爬虫系统整体介绍:爬虫系统主要分为两类,一类是自定义的爬虫系统,一类是使用开源的爬虫软件。其中,有很多开源爬虫软件如:Grub Next Generation PhpDig Snoopy Nutch JSpider NWebCrawler。因为我是爬虫初学者,暂时不想套用别人的开源代码。虽然我一步步编译出来的系统可能没有现在这么好,但这是因为我对一些原理有了更深的理解。因此,笔者通过网上的博客,查阅了一些资料,编写了这个系统。虽然还有待完善,但也是一部爱心之作。最后,与其他爬虫系统进行了一些比较。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
关于本技术报告中描述的爬虫系统的详细介绍: 本系统采用java代码编写,myeclipse8.5 IDE工具win7操作系统。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
原理:无论是定制系统还是开源软件。爬虫的基本原理是一样的,并不复杂。爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。一个网络爬虫的基本工作流程是这样的: 1.首先选择一部分精心挑选的种子URL2.将这些URL放入URL队列中进行爬取;3. 将它们从待爬取的URL队列中取出待爬取的URL中,解析DNS,获取主机ip,下载该URL对应的网页,并存储到下载的网页库中。此外,将这些 URL 放入已爬取的 URL 队列中。4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭侠、勺子、柞蚕、头皮、劈砍、劈砍、士兵、
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。主要有两种爬取策略: 1. 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接,处理后转移到它这一行 下一个起始页,继续跟随链接。2. 广度优先遍历策略广度优先遍历策略的基本思想是将在新下载的网页中找到的链接直接插入到待抓取的URL队列的末尾。也就是说,网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页 查看全部
java爬虫抓取网页数据(荣幸供爬虫初学者参考关于java爬虫系统技术详解处理课程爬虫)
--------很荣幸成为爬虫初学者的参考。详细讲解java爬虫系统的技术是一门自然语言处理课程。爬虫系统技术报告很荣幸为爬虫初学者提供参考。处理课程受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
Quote: 这学期完成了自然语言处理课程让我受益匪浅,对自然语言处理的各个方向和领域有了大致的了解。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统非常重要,而网络爬虫也是搜索引擎爬虫系统的重要组成部分。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要大量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
爬虫系统整体介绍:爬虫系统主要分为两类,一类是自定义的爬虫系统,一类是使用开源的爬虫软件。其中,有很多开源爬虫软件如:Grub Next Generation PhpDig Snoopy Nutch JSpider NWebCrawler。因为我是爬虫初学者,暂时不想套用别人的开源代码。虽然我一步步编译出来的系统可能没有现在这么好,但这是因为我对一些原理有了更深的理解。因此,笔者通过网上的博客,查阅了一些资料,编写了这个系统。虽然还有待完善,但也是一部爱心之作。最后,与其他爬虫系统进行了一些比较。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑 这学期的自然语言处理课程让我受益匪浅,大致了解了自然语言处理各个方面的方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
关于本技术报告中描述的爬虫系统的详细介绍: 本系统采用java代码编写,myeclipse8.5 IDE工具win7操作系统。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭夏、勺子、柞蚕、头皮、劈砍、劈砍、士兵、卡吞、劈郑
原理:无论是定制系统还是开源软件。爬虫的基本原理是一样的,并不复杂。爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。一个网络爬虫的基本工作流程是这样的: 1.首先选择一部分精心挑选的种子URL2.将这些URL放入URL队列中进行爬取;3. 将它们从待爬取的URL队列中取出待爬取的URL中,解析DNS,获取主机ip,下载该URL对应的网页,并存储到下载的网页库中。此外,将这些 URL 放入已爬取的 URL 队列中。4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。关于Java爬虫系统技术详解自然语言处理课程爬虫系统技术报告--------很荣幸成为爬虫初学者的参考:这学期的自然语言处理课程让我受益匪浅,了解自然语言处理的各个方面的一般方向和领域。研究自然语言处理。首先,需要海量的文本数据。因此,网络爬虫系统在死前显得十分颤抖,更加受约束。崩蛤、彭侠、勺子、柞蚕、头皮、劈砍、劈砍、士兵、
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。主要有两种爬取策略: 1. 深度优先遍历策略:深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接,处理后转移到它这一行 下一个起始页,继续跟随链接。2. 广度优先遍历策略广度优先遍历策略的基本思想是将在新下载的网页中找到的链接直接插入到待抓取的URL队列的末尾。也就是说,网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页
java爬虫抓取网页数据(Java数据存入云端数据库的表中:1-2-1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-20 14:14
下面详细说明将所有解析的房屋数据存储在云数据库的表中:
1、 第一步是获取数据库连接。Java 提供了数据库连接的接口,但是实现是由各个数据库提供者实现的。这里需要mysql提供的第三方包:mysql-connector-java-8.0.13.jar
,, 新建一个类来封装数据库处理的方法:
//封装数据库相关操作
public class OperationOfMySQL {
//只创建一次链接
Connection con;
Statement state;
public OperationOfMySQL() {
super();
this.con = connectionToDatabase();
try {
//state用于传入sql语句对数据库进行操作
this.state = con.createStatement();
} catch (Exception e) {
System.out.println("链接失败!");
}
}
和上面的代码一样,连接是在创建对象的时候创建的:
connectionToDatabase() 方法返回获取的数据库链接:
//返回数据库链接的方法
private static Connection connectionToDatabase() {
Connection con = null;
//创建驱动对象
try {
Driver driver = new Driver();
String url = cloud;
Properties info = new Properties();
//准备数据库链接信息
info.put("user", "rds_repl");
info.put("password", "123456");
//获取数据库链接
con = driver.connect(url, info);
}catch (SQLException e) {
System.out.println("链接数据库失败!");
return null;
}
System.out.println(con+"\n链接创建成功!");
return con;
}
//cloud是加载云端驱动的数据库,格式为:
//String cloud = "jdbc:mysql://服务器地址:端口号/数据库名?severTimzone=UTC";
,, 云数据库的地址和端口号这里就不贴了(连接云和本地数据库的方法是一样的)。值得注意的是,如果您使用的是数据库连接池,则需要设置链接超时,虽然我没有这样做。. .
PS:还有一个类加载com.mysql.cj.jdbc.Driver 0版本的驱动;有一个额外的“cj”,所以必须设置时区: severTimezone=UTC, version 0 不要使用,否则运行时会报错。(这里只是提醒,具体原因不再详述);
Java通过状态对象将sql字符串传递给数据库。由于数据库是预先存在的,所以需要建一个表来存储房屋信息。关键表语句是:
//如果数据库中不存在表house1就创建一张
static private String SQLCreateTaleStr = "CREATE TABLE IF NOT EXISTS house1"
+ "("
+ "title varchar(255) ,"
+ "area double ,"
+ "price varchar(64) ,"
+ "unit_price double ,"
+ "direction varchar(64),"
+ "decoration varchar(64),"
+ "houseStyle varchar(64) ,"
+ "floor varchar(64),"
+ "buildTime int(11) ,"
+ "community varchar(64),"
+ "location varchar(64) ,"
+ "gdpperperson double"
+ ")ENGINE = InnoDB DEFAULT CHARSET = utf8;";
然后写一个方法把房子信息转换成语句插入SQL到表中:
//用于生成插入语句的方法,传入一个房子和表的名字
public String insertStr(SecondHouse house) {
String insert = "insert into house1"
+ " values('"
+house.getElemName()+ "','"
+house.getArea()+ "','"
+house.getPrice()+ "','"
+house.getUnit_price()+ "','"
+house.getDirection()+ "','"
+house.getDecoration()+ "','"
+house.getHouseStyle()+ "','"
+house.getFloor()+ "','"
+house.getBuildTime()+ "','"
+house.getCommunity()+ "','"
+house.getLocation()+ "','"
+0+ "');";
return insert ;
}
PS; 拼接字符串时注意空格和标点符号,保证sql语句可以执行
然后就是执行这个write语句的方法:
//传入链接,进行对数据库的操作,传入二手房,写进数据库
public void operationOnDtabase(String insertStr) {
try {
//获取执行sql语句动态创建表,即如果表不存在就创建一个
state.execute(SQLCreateTaleStr);
//执行插入语句
state.executeUpdate(insertStr);
// System.out.println(insertStr);
}catch (SQLException e) {
System.out.println("SQL语句执行失败!");
}
System.out.println("执行语句成功!");
}
工具和方法已经准备好,需要集成:
最后,网页解析、多线程、写入数据库的所有实现都在main方法中执行;
<p>//---------------------------main方法代替执行--------------------------------------------------------------------
public static void operateMain() {
houseSet = new Vector();
//多线程集合
Vector threads = new Vector();
for (int i = 1; i 查看全部
java爬虫抓取网页数据(Java数据存入云端数据库的表中:1-2-1)
下面详细说明将所有解析的房屋数据存储在云数据库的表中:
1、 第一步是获取数据库连接。Java 提供了数据库连接的接口,但是实现是由各个数据库提供者实现的。这里需要mysql提供的第三方包:mysql-connector-java-8.0.13.jar
,, 新建一个类来封装数据库处理的方法:
//封装数据库相关操作
public class OperationOfMySQL {
//只创建一次链接
Connection con;
Statement state;
public OperationOfMySQL() {
super();
this.con = connectionToDatabase();
try {
//state用于传入sql语句对数据库进行操作
this.state = con.createStatement();
} catch (Exception e) {
System.out.println("链接失败!");
}
}
和上面的代码一样,连接是在创建对象的时候创建的:
connectionToDatabase() 方法返回获取的数据库链接:
//返回数据库链接的方法
private static Connection connectionToDatabase() {
Connection con = null;
//创建驱动对象
try {
Driver driver = new Driver();
String url = cloud;
Properties info = new Properties();
//准备数据库链接信息
info.put("user", "rds_repl");
info.put("password", "123456");
//获取数据库链接
con = driver.connect(url, info);
}catch (SQLException e) {
System.out.println("链接数据库失败!");
return null;
}
System.out.println(con+"\n链接创建成功!");
return con;
}
//cloud是加载云端驱动的数据库,格式为:
//String cloud = "jdbc:mysql://服务器地址:端口号/数据库名?severTimzone=UTC";
,, 云数据库的地址和端口号这里就不贴了(连接云和本地数据库的方法是一样的)。值得注意的是,如果您使用的是数据库连接池,则需要设置链接超时,虽然我没有这样做。. .
PS:还有一个类加载com.mysql.cj.jdbc.Driver 0版本的驱动;有一个额外的“cj”,所以必须设置时区: severTimezone=UTC, version 0 不要使用,否则运行时会报错。(这里只是提醒,具体原因不再详述);
Java通过状态对象将sql字符串传递给数据库。由于数据库是预先存在的,所以需要建一个表来存储房屋信息。关键表语句是:
//如果数据库中不存在表house1就创建一张
static private String SQLCreateTaleStr = "CREATE TABLE IF NOT EXISTS house1"
+ "("
+ "title varchar(255) ,"
+ "area double ,"
+ "price varchar(64) ,"
+ "unit_price double ,"
+ "direction varchar(64),"
+ "decoration varchar(64),"
+ "houseStyle varchar(64) ,"
+ "floor varchar(64),"
+ "buildTime int(11) ,"
+ "community varchar(64),"
+ "location varchar(64) ,"
+ "gdpperperson double"
+ ")ENGINE = InnoDB DEFAULT CHARSET = utf8;";
然后写一个方法把房子信息转换成语句插入SQL到表中:
//用于生成插入语句的方法,传入一个房子和表的名字
public String insertStr(SecondHouse house) {
String insert = "insert into house1"
+ " values('"
+house.getElemName()+ "','"
+house.getArea()+ "','"
+house.getPrice()+ "','"
+house.getUnit_price()+ "','"
+house.getDirection()+ "','"
+house.getDecoration()+ "','"
+house.getHouseStyle()+ "','"
+house.getFloor()+ "','"
+house.getBuildTime()+ "','"
+house.getCommunity()+ "','"
+house.getLocation()+ "','"
+0+ "');";
return insert ;
}
PS; 拼接字符串时注意空格和标点符号,保证sql语句可以执行
然后就是执行这个write语句的方法:
//传入链接,进行对数据库的操作,传入二手房,写进数据库
public void operationOnDtabase(String insertStr) {
try {
//获取执行sql语句动态创建表,即如果表不存在就创建一个
state.execute(SQLCreateTaleStr);
//执行插入语句
state.executeUpdate(insertStr);
// System.out.println(insertStr);
}catch (SQLException e) {
System.out.println("SQL语句执行失败!");
}
System.out.println("执行语句成功!");
}
工具和方法已经准备好,需要集成:
最后,网页解析、多线程、写入数据库的所有实现都在main方法中执行;
<p>//---------------------------main方法代替执行--------------------------------------------------------------------
public static void operateMain() {
houseSet = new Vector();
//多线程集合
Vector threads = new Vector();
for (int i = 1; i
java爬虫抓取网页数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-19 05:12
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个建蛋网无聊的图,但是网络返回码一直是503,所以改了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com");
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对你java编程有所帮助。 查看全部
java爬虫抓取网页数据(本文实例讲述Java实现的爬虫抓取图片并保存操作。)
本文介绍了一个用Java实现的爬虫抓取图片并保存的例子。分享给大家,供大家参考,如下:
这是我根据网上的一些资料写的第一个java爬虫程序
本来想弄个建蛋网无聊的图,但是网络返回码一直是503,所以改了网站
import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网络爬虫取数据
*
* */
public class JianDan {
public static String GetUrl(String inUrl){
StringBuilder sb = new StringBuilder();
try {
URL url =new URL(inUrl);
BufferedReader reader =new BufferedReader(new InputStreamReader(url.openStream()));
String temp="";
while((temp=reader.readLine())!=null){
//System.out.println(temp);
sb.append(temp);
}
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
return sb.toString();
}
public static List GetMatcher(String str,String url){
List result = new ArrayList();
Pattern p =Pattern.compile(url);//获取网页地址
Matcher m =p.matcher(str);
while(m.find()){
//System.out.println(m.group(1));
result.add(m.group(1));
}
return result;
}
public static void main(String args[]){
String str=GetUrl("http://www.163.com";);
List ouput =GetMatcher(str,"src=\"([\\w\\s./:]+?)\"");
for(String temp:ouput){
//System.out.println(ouput.get(0));
System.out.println(temp);
}
String aurl=ouput.get(0);
// 构造URL
URL url;
try {
url = new URL(aurl);
// 打开URL连接
URLConnection con = (URLConnection)url.openConnection();
// 得到URL的输入流
InputStream input = con.getInputStream();
// 设置数据缓冲
byte[] bs = new byte[1024 * 2];
// 读取到的数据长度
int len;
// 输出的文件流保存图片至本地
OutputStream os = new FileOutputStream("a.png");
while ((len = input.read(bs)) != -1) {
os.write(bs, 0, len);
}
os.close();
input.close();
} catch (MalformedURLException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行输出:
对java相关内容感兴趣的读者可以查看本站专题:《Java网络编程技巧总结》、《Java Socket编程技巧总结》、《Java文件和目录操作技巧总结》、《Java数据结构与算法教程》、《Java操作DOM节点技巧总结》、《Java缓存操作技巧总结》
希望这篇文章对你java编程有所帮助。
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-18 09:19
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看全部
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
java爬虫抓取网页数据(读取本地和通过url抓取网页内容的html页面内容的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-17 23:03
)
今天在做项目的时候用java抓取网页的内容。本以为很简单的事情,却还是让我痛了一阵子。需要的是一种读取本地html页面内容的方法,网上找不到怎么办
我暂时
去吧!
首先给大家讲解一下通过url抓取网页内容,通过正则表达式提取网页的title、js、css等元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = " 查看全部
java爬虫抓取网页数据(读取本地和通过url抓取网页内容的html页面内容的方法
)
今天在做项目的时候用java抓取网页的内容。本以为很简单的事情,却还是让我痛了一阵子。需要的是一种读取本地html页面内容的方法,网上找不到怎么办
我暂时
去吧!
首先给大家讲解一下通过url抓取网页内容,通过正则表达式提取网页的title、js、css等元素,代码如下:
<p>import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = "
java爬虫抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-17 23:03
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果[");意图Ix=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们没有直接在网页的源代码中返回数据。而是用异步的方式用JS返回数据,防止搜索引擎等工具响应网站数据抓取。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
爬虫程序源码:/ShenJianShou/crawler_samples 查看全部
java爬虫抓取网页数据(本文就用Java给大家演示如何抓取网站的数据:(1))
有时由于各种原因,我们需要采集某个网站数据,但由于不同网站数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、 抓取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,输入IP:111.142.55.73,点击查询按钮,可以看到网页显示的结果:
第2步:查看网页源代码,我们在源代码中看到这一段:
从这里可以看出,重新请求一个网页后,查询的结果显示出来了。
查询后看网页地址:
也就是说,我们只要访问这样一个网址,就可以得到ip查询的结果,然后看代码:
[java]
publicvoidcaptureHtml(Stringip)throwsException{ StringstrURL=""+ip; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8") ; BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line);} Stringbuf=contentBuf.toString() ; intbeginIx=buf.indexOf("查询结果[");意图Ix=buf.indexOf("以上四项依次显示"); Stringresult=buf.substring(beginIx,endIx); System.out.println("captureHtml()的结果:\n"+result); }
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式展示结果。
这里我只是随便解析了一下。如果你想准确解析它,你需要自己处理。
分析结果如下:
captureHtml()的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建省漳州市手机
二、 抓取网页的 JavaScript 返回的结果。
有时网站为了保护他们的数据,他们没有直接在网页的源代码中返回数据。而是用异步的方式用JS返回数据,防止搜索引擎等工具响应网站数据抓取。
先看这个页面:
我用第一种方法查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取的结果。
但是有时候我们需要获取JS数据,这个时候该怎么办?
这时候我们需要用到一个工具:HTTP Analyzer,这个工具可以拦截Http的交互内容,我们用这个工具来达到目的。
先点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清空数据,然后输入快递号:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果。让我们继续检查:
从上两图可以看出,HTTP Analyzer可以拦截JS返回的数据,并在Response Content中展示。同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为就可以得到数据。即我们只需要访问JS请求的网页地址即可获取数据。当然,前提是数据没有加密。记下JS请求的URL:
然后让程序请求这个页面的结果!
代码如下:
[java]
publicvoidcaptureJavascript(Stringpostid)throwsException{ StringstrURL=""+postid +"&channel=&rnd=0"; URLurl=newURL(strURL); HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection(); InputStreamReaderinput=newInputStreamReader(httpConn .getInputStream(),"utf-8"); BufferedReaderbufReader=newBufferedReader(输入);字符串=“”; StringBuildercontentBuf=newStringBuilder(); while((line=bufReader.readLine())!=null){ contentBuf.append(line); System.out.println("captureJavascript():\n"+contentBuf.toString()的结果); }
可以看到,抓取JS的方式和抓取原创网页的代码完全一样,只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单跟踪信息[7]
这些数据是JS返回的结果,我们的目的就达到了!
希望这篇文章能对有需要的朋友有所帮助。如果您需要程序的源代码,请点击这里下载!
爬虫程序源码:/ShenJianShou/crawler_samples
java爬虫抓取网页数据(Java程序使用webmagic框架开发的爬虫结构工具工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-17 23:02
网络爬虫是根据一定的规则自动从万维网上爬取数据的脚本。根据一定的规则,意味着爬虫程序需要解析网页的dom结构,将感兴趣的数据爬取到dom结构。
(图片1)
这是一个网页源代码的dom结构。我们需要逐层指定要爬取的标签,如下图:
(图片2)
图2是一个java程序使用webmagic框架开发的爬虫程序。这段代码是抓取对应的标签,对应图1,运行后结果如下:
当然,以上是由专业程序员完成的,但是可以帮助我们理解爬虫工具的工作原理。非专业人士可以使用爬虫工具自行爬取数据。
1.首先输入要爬取的网站的网址,点击“开始采集”。
2.工具自动识别当前页面为多页数据,默认会翻页采集,我们只需要点击“生成采集设置”即可。
3.点击采集的详细链接,这里我们要采集这个网站的所有化工产品信息,所以在中文名称栏点击一个链接,然后点击右侧的“点击链接”,如下图
4.爬虫工具进入详细链接页面。这个页面上的数据就是我们要抓取的。点击“生成采集设置”,就会生成爬虫工具最终的爬取过程,如下图所示,爬虫工具会按照这个过程给我们采集数据,直到数据采集完成。
5. 点击“采集”按钮,爬虫工具正式开始运行,爬虫工具工作如下:
列表中的数据都是爬虫采集到达的。我们也可以处理采集的数据。您可以选择将其导出为 Excel 文档或直接将其导入数据库。这些是后续的分析数据。进一步加工的必要条件。有了这些基础数据,就可以对数据进行分析,得出一些业务依据,可以作为业务决策的支持。比如沃尔玛过去用他们的大数据发现尿布喜欢一起买啤酒,于是把尿布和啤酒放在一起,啤酒的销量就大大增加了。这就是大数据的价值。
本次使用的爬虫工具只是一个基础的应用,希望对大家有所帮助。Tech Rambler将带你了解技术,后续会持续更新相关知识,欢迎关注。 查看全部
java爬虫抓取网页数据(Java程序使用webmagic框架开发的爬虫结构工具工作)
网络爬虫是根据一定的规则自动从万维网上爬取数据的脚本。根据一定的规则,意味着爬虫程序需要解析网页的dom结构,将感兴趣的数据爬取到dom结构。
(图片1)
这是一个网页源代码的dom结构。我们需要逐层指定要爬取的标签,如下图:
(图片2)
图2是一个java程序使用webmagic框架开发的爬虫程序。这段代码是抓取对应的标签,对应图1,运行后结果如下:
当然,以上是由专业程序员完成的,但是可以帮助我们理解爬虫工具的工作原理。非专业人士可以使用爬虫工具自行爬取数据。
1.首先输入要爬取的网站的网址,点击“开始采集”。
2.工具自动识别当前页面为多页数据,默认会翻页采集,我们只需要点击“生成采集设置”即可。
3.点击采集的详细链接,这里我们要采集这个网站的所有化工产品信息,所以在中文名称栏点击一个链接,然后点击右侧的“点击链接”,如下图
4.爬虫工具进入详细链接页面。这个页面上的数据就是我们要抓取的。点击“生成采集设置”,就会生成爬虫工具最终的爬取过程,如下图所示,爬虫工具会按照这个过程给我们采集数据,直到数据采集完成。
5. 点击“采集”按钮,爬虫工具正式开始运行,爬虫工具工作如下:
列表中的数据都是爬虫采集到达的。我们也可以处理采集的数据。您可以选择将其导出为 Excel 文档或直接将其导入数据库。这些是后续的分析数据。进一步加工的必要条件。有了这些基础数据,就可以对数据进行分析,得出一些业务依据,可以作为业务决策的支持。比如沃尔玛过去用他们的大数据发现尿布喜欢一起买啤酒,于是把尿布和啤酒放在一起,啤酒的销量就大大增加了。这就是大数据的价值。
本次使用的爬虫工具只是一个基础的应用,希望对大家有所帮助。Tech Rambler将带你了解技术,后续会持续更新相关知识,欢迎关注。
java爬虫抓取网页数据( 如何获取学校官网的信息是否会侵权?会问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-17 23:01
如何获取学校官网的信息是否会侵权?会问)
Jsoup实现网络爬虫抓取数据
在编写软件时,例如教务软件,需要从学校官网获取一些新闻信息来丰富你的软件,但不会专门提供相关的api接口。这时候就需要我们自己动手捕捉我们感兴趣的信息了。有人会问,爬取网站的信息会不会侵权。事实上,通过浏览器可以访问的信息一般都是公开的,抓取后不用于盈利也无所谓。它只是改变了浏览方式。
获取整个网页的源码
要抓取网页中的信息,首先要获取整个网页的源代码
String url = "http://i.guet.edu.cn/";
Document doc = Jsoup
.connect(url)
.timeout(1000).get();
通过Jsoup中的方法,我们可以很方便的获取到目标网页的源Document对象。好了,拿到整个网页的源码后,下一步就是抓取我们想要的信息了。现在我们要获取的是网页上滑动条幅的图片地址,如下图:
可以通过以下代码轻松获取图片的相对URL
Elements elements = doc.select("div#pic_lun");
Elements elements2 = elements.select("img");
for (Element el:elements2){
System.out.println(el.attr("src"));
}
控制台输出如下:
这样,我们就得到了我们想要的信息。另一个例子是获取新闻:
页面信息:
html源代码部分:
然后我们尝试爬取:
String url_news = "http://i.guet.edu.cn/news.php% ... 3B%3B
Document doc = Jsoup
.connect(url_news)
.timeout(1000).get();
Elements e1 = doc.select("div#content_middle");
Elements e2 = e1.select("a");
// System.out.print(e2);
for (Element el2 : e2) {
if (el2.text().length() > 20) {
StringBuffer sb = new StringBuffer();
sb.append(el2.text());
String time = sb.substring(0, 9);
String title = sb.substring(12);
System.out.print("time:"+time+"\n");
System.out.print("title:"+title+"\n");
System.out.print("link:"+"http://i.guet.edu.cn/"+el2.attr("href")+"\n");
}
}
控制台输出如下:
至此,数据抓取完成,必须将数据添加到listview中才能显示数据。只有数据有意义,革命还没有成功,同志们还需要努力。
我是菜鸟,如有错误请指正,文章原创 查看全部
java爬虫抓取网页数据(
如何获取学校官网的信息是否会侵权?会问)
Jsoup实现网络爬虫抓取数据
在编写软件时,例如教务软件,需要从学校官网获取一些新闻信息来丰富你的软件,但不会专门提供相关的api接口。这时候就需要我们自己动手捕捉我们感兴趣的信息了。有人会问,爬取网站的信息会不会侵权。事实上,通过浏览器可以访问的信息一般都是公开的,抓取后不用于盈利也无所谓。它只是改变了浏览方式。
获取整个网页的源码
要抓取网页中的信息,首先要获取整个网页的源代码
String url = "http://i.guet.edu.cn/";
Document doc = Jsoup
.connect(url)
.timeout(1000).get();
通过Jsoup中的方法,我们可以很方便的获取到目标网页的源Document对象。好了,拿到整个网页的源码后,下一步就是抓取我们想要的信息了。现在我们要获取的是网页上滑动条幅的图片地址,如下图:
可以通过以下代码轻松获取图片的相对URL
Elements elements = doc.select("div#pic_lun");
Elements elements2 = elements.select("img");
for (Element el:elements2){
System.out.println(el.attr("src"));
}
控制台输出如下:
这样,我们就得到了我们想要的信息。另一个例子是获取新闻:
页面信息:
html源代码部分:
然后我们尝试爬取:
String url_news = "http://i.guet.edu.cn/news.php% ... 3B%3B
Document doc = Jsoup
.connect(url_news)
.timeout(1000).get();
Elements e1 = doc.select("div#content_middle");
Elements e2 = e1.select("a");
// System.out.print(e2);
for (Element el2 : e2) {
if (el2.text().length() > 20) {
StringBuffer sb = new StringBuffer();
sb.append(el2.text());
String time = sb.substring(0, 9);
String title = sb.substring(12);
System.out.print("time:"+time+"\n");
System.out.print("title:"+title+"\n");
System.out.print("link:"+"http://i.guet.edu.cn/"+el2.attr("href")+"\n");
}
}
控制台输出如下:
至此,数据抓取完成,必须将数据添加到listview中才能显示数据。只有数据有意义,革命还没有成功,同志们还需要努力。
我是菜鸟,如有错误请指正,文章原创
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-17 13:08
一、java爬虫的主要步骤是:
非结构化数据-->数据采集-->数据清洗-->结构化数据-->采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬,哪些页面不能爬。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,则默认可以爬取。即使有这个文件,你也可以不服从,但是他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存中或者nosql缓存服务器中进行重复数据删除,常见的有:Bloom filter,redis……这些家伙自己百度一下,我什么也做不了。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
① Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度的向量角余弦。主要思想是将词在文章中出现的频率构成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。 查看全部
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
一、java爬虫的主要步骤是:
非结构化数据-->数据采集-->数据清洗-->结构化数据-->采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬,哪些页面不能爬。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,则默认可以爬取。即使有这个文件,你也可以不服从,但是他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存中或者nosql缓存服务器中进行重复数据删除,常见的有:Bloom filter,redis……这些家伙自己百度一下,我什么也做不了。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
① Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度的向量角余弦。主要思想是将词在文章中出现的频率构成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。
java爬虫抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-17 02:15
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。 查看全部
java爬虫抓取网页数据(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录了后者)。我很高兴,终于找到了解决方案。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是:不同内核支持的js是不完全一样的。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。只是觉得驱动应该可以在js的解析完成后捕捉到状态,于是搜索,搜索,但是根本没有这样的方法,所以我说为什么WebDriver的设计者没有采取措施forward 以便我们可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不可取,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
折腾了几天,虽然我的问题没有解决,但是也长了不少见识。后面的工作熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
java爬虫抓取网页数据( 图片来源于网络1.爬虫的流程架构大致的工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-13 15:02
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知
图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧! 查看全部
java爬虫抓取网页数据(
图片来源于网络1.爬虫的流程架构大致的工作流程)
网络爬虫的基本概念和认知
图片来自网络
1. 爬虫的定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。——百度百科定义详细定义参考
Mukenet评论:爬虫实际上是一种自动化的信息程序或脚本,可以方便地帮助大家获取自己想要的具体信息。比如百度、谷歌这样的搜索引擎,其背后的重要技术支持就是爬虫。当我们使用搜索引擎搜索某个信息时,展示在我们面前的搜索结果是由爬虫程序预先从万维网上爬取而来的。我们之所以称其为爬虫,只是比喻自动获取万维网。
2. 爬虫的进程架构
爬虫的一般工作流程如下图所示:首先获取数据,然后清洗处理数据,最后持久化存储数据,然后可视化数据。在接下来的章节中,我们将遵循这个过程并详细介绍它们。
爬虫进程架构图
3. 爬虫分类
根据系统结构和实现技术,爬虫大致可以分为以下几类:
3.1 个通用网络爬虫
一般爬虫主要是指谷歌、百度等搜索引擎。它们爬取范围广,种类多,存储信息量大,技术要求比较高。
3.2 聚焦网络爬虫
关注爬虫,主要是基于特定主题的爬取。这是大家使用时间最长的爬虫类型。例如,我们抓取金融,或电影、书籍和其他特定信息。由于我们限制了主题和网站,可以大大节省我们的硬盘和网络资源,更好地满足特定业务的需求。
3.3 增量爬网
增量爬虫主要是指我们定期爬取一些网站时,只爬取网站变化的内容,而不是再次爬取所有网站数据。. 这样可以有效降低运维成本。
3.4 深网爬虫
深度网络爬虫主要是指一些我们无法直接爬取的网站。比如这些网站,需要用户登录,或者填写一些特定的表格,才能继续爬取信息。
Tips:在实际项目中,我们通常会结合两种或两种以上的爬虫技术来达到更好的效果。
4. 爬虫的爬取策略
爬虫根据不同的业务需求,大致可以分为两种不同的爬虫策略:
4.1 深度优先策略
深度优先策略是指在爬取HTML页面时,如果爬虫在页面中发现了新的URL,就会对新的URL进行深度优先搜索,依此类推,沿着URL爬行直到找不到深入。直到。然后,返回到最后一个 URL 地址并搜索其他 URL。当页面上没有可供选择的新 URL 时,搜索结束。
举个简单的例子,比如我们访问,假设的首页只有两个课程链接,一个是爬虫类,一个是Python类。深度优先算法是先进入爬虫类,然后进入爬虫类的一个章节链接中,如果本章没有子章节,爬虫会退到上层继续从另一个访问未访问的章节。访问完所有章节后,爬虫会返回首页。对Python课链接也进行相应的搜索,直到找不到新的URL,搜索结束。
4.2 广度优先策略
广度优先策略是指爬虫需要爬取一个完整网页的所有网址,然后才能继续搜索下一页直到底部。
它仍然是我们的例子。来到的首页后,我们需要在的首页获取Python和爬取课程的URL,才能继续搜索这两个课程的子章节的URL。然后逐层进行,直到结束。
Tips:深度优先适用于网站嵌套较深的搜索网站,而广度优先策略更适用于时间要求高、网站@同级别的URL较多的页面> 页。
5. 爬虫的学习基础
学习爬虫,我们需要以下基础知识:
如果你没有Python语言或数据库的基础知识,可以参考Mukenet的相关wiki进行学习。
当然,为了方便大家理解,我会在代码中添加详细的注释。即使你没有Python语言基础,也可以先了解大致流程,然后再排查遗漏,学习相应的知识。
有同学可能会疑惑,为什么一定要用python语言来开发爬虫。不能用其他语言吗?
这不得不说是Python的第三方库。Python之所以如此受欢迎,官方是因为它拥有大量的库,而且这些库的性能和使用都比较简单高效。凭借Python语言本身的高效率,只需一行代码就可以实现10个简单的爬虫,而在java/C/C++等其他语言中,至少需要编写几十行代码. 因此,使用Python开发爬虫程序,赢得了众多程序员的青睐。
比如,人们习惯在楼下的便利店买饮料。虽然离门口一公里有一家比较大的超市,但相信大家都不愿意买,因为太麻烦,不方便。这就是Python语言成为爬虫主流语言的精髓所在。
在接下来的学习中,我们将使用 Python 的几个第三方库。所谓第三方库是指Python的官方库(例如system“os”和time“time”\等库),非官方发布的库,如requests等库,称为第三方库。
安装Python解释器时默认已经安装了官方的Python库,需要手动安装第三方库。比如我们在爬虫开发中经常用到Requests库。安装第三方库很简单,在终端执行如下命令即可:
pip install requests
后面讲到具体的库时,我们会做详细的介绍。
下面是爬虫开发中常用的Python库对比:
套餐介绍
网址库
不需要安装 Python 自带的库。但是,在不同的python版本中,urlib在细节上有所不同。实际开发中过于繁琐,header无法伪装,很容易被阻塞。因此,现在使用它的人并不多。
要求
与urllib相比,它不仅拥有url的所有功能,更重要的是语法简洁优雅,而且在兼容性方面完全兼容python2和python3,非常方便。同时,它还可以伪装请求。
urllib3
urllib3 库提供了一些 urllib 没有的重要特性,例如线程安全、连接池和对压缩编码的支持。
这里推荐requests库,简单方便,容易上手,非常适合使用爬虫的新手。如果没有特殊说明,我们将在后续课程中默认使用 requests 库。
6. 爬虫的法律伦理问题
近年来,可以说通过编写爬虫程序来抓取大量数据而获利的程序员层出不穷。您可能会担心在使用爬虫的过程中是否会触犯法律。其实只要合理使用爬虫,就不会轻易触犯法律。那么,什么是爬虫的合理使用呢?我总结了以下三点供大家参考:
不管法律方面,我们也必须严于律己,遵守一些特定的规则。这里我想说的是爬虫世界中的robots协议。这是网站的所有者为爬虫设计的协议,通常位于网站的根目录下。它指定哪些目录可以被爬取,哪些不能。我们需要遵守这个约定好的协议,以避免不必要的麻烦。
7. 个人经历
在实际工作项目中,如果我们是做爬虫工作的工程师,在精通爬虫基础技术的同时,应该熟悉和了解数据清洗和处理技术。只有这样,我们才能更好地与团队协作。. 当然,这些技术会在后面的章节中一一为大家介绍。
好的,让我们开始爬虫世界的欢乐之旅吧!

