
java爬虫抓取网页数据
java爬虫抓取网页数据(推荐如下的java开源爬虫或抓取框架【猪猪-后端】WebMagic框架搭建的爬52揭秘)
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2021-12-11 13:21
郭无心:有时候直接看爬虫框架是很困难的。建议从一个简单的程序一步一步开始。在Script House看过一个关于Java爬虫程序设计的系列。我把它放在这里供大家共同学习。ht 366javaniu:我之前回答过java爬虫的问题,转过来。推荐以下java开源爬虫或爬虫框架1.webmagic [Pig-Backend] WebMagic框架搭建爬虫52揭示Java网络爬虫程序原理随着互联网+时代的到来,越来越多的互联网公司他们层出不穷,涉及游戏、视频、新闻、社交、电子商务、房地产、旅游等诸多行业。比如36xdyl:用java写爬虫最简单的方法就是使用scrapy。您必须了解什么场景以及如何解决问题。更大的使用螺母。第25章算法:编写爬虫时,必须注意以下5个方面:1.如何将整个互联网抽象为无向图,网页为节点,网页中的链接为有向边。2. 爬取算法采用优先队列调度。区别 20HttpClient是java下常用的网络工具包。如果效果不理想,可能是姿势不对。让你普及一下java爬虫的开发使用过程和需求。19LucasX:我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome网络分析请求,还是fiddl 10 郑明:之前对爬虫了解不多,然后在五一之前看了一篇java爬虫的介绍博客。吃了安利后,我决定自己实施一个。爬虫可以爬行。知乎 每个话题下的热门问答,hi 5,可以关注我写的一个开源组件,设置代理服务器池防止反爬虫策略屏蔽,自动调整异常请求管理,以及优先响应快速代理。https: 3 并优先响应快速代理。https: 3 并优先响应快速代理。https: 3 查看全部
java爬虫抓取网页数据(推荐如下的java开源爬虫或抓取框架【猪猪-后端】WebMagic框架搭建的爬52揭秘)
郭无心:有时候直接看爬虫框架是很困难的。建议从一个简单的程序一步一步开始。在Script House看过一个关于Java爬虫程序设计的系列。我把它放在这里供大家共同学习。ht 366javaniu:我之前回答过java爬虫的问题,转过来。推荐以下java开源爬虫或爬虫框架1.webmagic [Pig-Backend] WebMagic框架搭建爬虫52揭示Java网络爬虫程序原理随着互联网+时代的到来,越来越多的互联网公司他们层出不穷,涉及游戏、视频、新闻、社交、电子商务、房地产、旅游等诸多行业。比如36xdyl:用java写爬虫最简单的方法就是使用scrapy。您必须了解什么场景以及如何解决问题。更大的使用螺母。第25章算法:编写爬虫时,必须注意以下5个方面:1.如何将整个互联网抽象为无向图,网页为节点,网页中的链接为有向边。2. 爬取算法采用优先队列调度。区别 20HttpClient是java下常用的网络工具包。如果效果不理想,可能是姿势不对。让你普及一下java爬虫的开发使用过程和需求。19LucasX:我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome网络分析请求,还是fiddl 10 郑明:之前对爬虫了解不多,然后在五一之前看了一篇java爬虫的介绍博客。吃了安利后,我决定自己实施一个。爬虫可以爬行。知乎 每个话题下的热门问答,hi 5,可以关注我写的一个开源组件,设置代理服务器池防止反爬虫策略屏蔽,自动调整异常请求管理,以及优先响应快速代理。https: 3 并优先响应快速代理。https: 3 并优先响应快速代理。https: 3
java爬虫抓取网页数据(用Python实现爬虫简单的爬虫预警!i.导入相关库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-10 11:08
还有Scrapy和Scrapy-redis框架,让我们开发爬虫非常容易。
Python提供了丰富的库,让我们编写程序更加方便。
一旦你完成了你的第一个爬虫
只说不说,看看爬虫程序怎么写!
在抓取之前,我们需要检查这个网页是否有抓取协议。
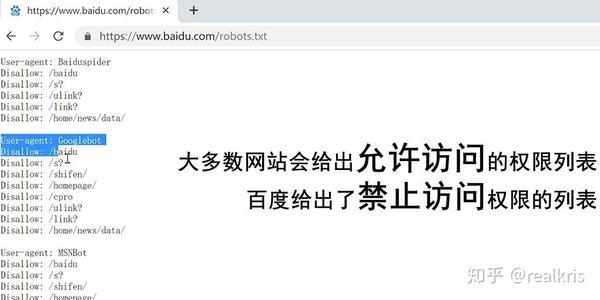
通常爬虫协议在网站之后的robots.txt文件中。我们抓取的内容一定不能在爬虫协议中被禁止。以百度搜索为例:
以百度搜索为例-图
大多数网站可以通过在URL后添加/robots.txt来查看robots文档。
一个简单的爬虫写作思路:
我们通过我们编写的爬虫程序向目标站点发起请求,即发送收录请求头和请求体的Request请求。(下面会写) 那么。如果接收到Request的服务器可以正常响应,那么我们就会收到一个Response响应,内容包括html、json、图片、视频等,就是网页的源代码。
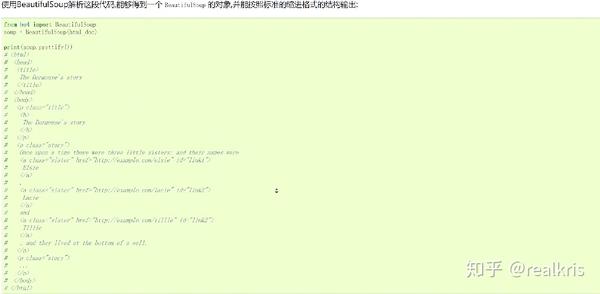
作者的博客图
3. 使用接收到的源码中的正则表达式,以及Beautifulsoup、pyquery等第三方解析库,解析html中的数据。最后,根据需要,我们可以将提取的数据保存在数据库或文件中。
哦,差点忘了。在Python中实现爬虫,需要一个好帮手——Beautiful Soup。
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现文档导航、搜索和修改文档的常用方式。Beautiful Soup 将为您节省数小时甚至数天的时间。工作时间。” (来自BeautifulSoup的官方描述)
urllib 是一个采集多个使用 URL 的模块的包,其中:
urllib.request 打开和读取 URL
urllib.error 收录 urllib.request 抛出的异常
urllib.parse 用于处理 URL
urllib.robotparser 用于解析 robots.txt 文件
没看懂?没关系。我们来看看一个简单的爬虫程序是如何实现的:
非常详细的注释警告!
一世。导入相关库
#首先,我们要导入urllib的request库,它可以实现向服务器发送request请求的功能
import urllib.request
#之后,我们需要用re库来解析我们接收到的内容,也就是网页代码
import re
#这个os库用来在本地创建一个目录,用于存放我们爬取的照片
import os
ii. 程序开始
<p>#程序开始,我们定义一个fetch_pictures函数来实现爬虫的主要功能
def fetch_pictures(url):
#首先,我们定义一个html_content变量来存放网页的HTML源代码
html_content = urllib.request.urlopen(url).read()
#接下来,使用正则表达式,指定匹配的特征为(.*?)
r = re.compile(' 查看全部
java爬虫抓取网页数据(用Python实现爬虫简单的爬虫预警!i.导入相关库)
还有Scrapy和Scrapy-redis框架,让我们开发爬虫非常容易。
Python提供了丰富的库,让我们编写程序更加方便。
一旦你完成了你的第一个爬虫
只说不说,看看爬虫程序怎么写!

在抓取之前,我们需要检查这个网页是否有抓取协议。
通常爬虫协议在网站之后的robots.txt文件中。我们抓取的内容一定不能在爬虫协议中被禁止。以百度搜索为例:
以百度搜索为例-图
大多数网站可以通过在URL后添加/robots.txt来查看robots文档。
一个简单的爬虫写作思路:
我们通过我们编写的爬虫程序向目标站点发起请求,即发送收录请求头和请求体的Request请求。(下面会写) 那么。如果接收到Request的服务器可以正常响应,那么我们就会收到一个Response响应,内容包括html、json、图片、视频等,就是网页的源代码。

作者的博客图
3. 使用接收到的源码中的正则表达式,以及Beautifulsoup、pyquery等第三方解析库,解析html中的数据。最后,根据需要,我们可以将提取的数据保存在数据库或文件中。

哦,差点忘了。在Python中实现爬虫,需要一个好帮手——Beautiful Soup。
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现文档导航、搜索和修改文档的常用方式。Beautiful Soup 将为您节省数小时甚至数天的时间。工作时间。” (来自BeautifulSoup的官方描述)
urllib 是一个采集多个使用 URL 的模块的包,其中:
urllib.request 打开和读取 URL
urllib.error 收录 urllib.request 抛出的异常
urllib.parse 用于处理 URL
urllib.robotparser 用于解析 robots.txt 文件
没看懂?没关系。我们来看看一个简单的爬虫程序是如何实现的:

非常详细的注释警告!
一世。导入相关库
#首先,我们要导入urllib的request库,它可以实现向服务器发送request请求的功能
import urllib.request
#之后,我们需要用re库来解析我们接收到的内容,也就是网页代码
import re
#这个os库用来在本地创建一个目录,用于存放我们爬取的照片
import os
ii. 程序开始
<p>#程序开始,我们定义一个fetch_pictures函数来实现爬虫的主要功能
def fetch_pictures(url):
#首先,我们定义一个html_content变量来存放网页的HTML源代码
html_content = urllib.request.urlopen(url).read()
#接下来,使用正则表达式,指定匹配的特征为(.*?)
r = re.compile('
java爬虫抓取网页数据(项目名称数据库Java爬虫项目技术选型及实训环境实训案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-10 11:06
项目名称:java爬虫
项目技术选择:Java、Maven、Mysql、WebMagic、Jsp、Servlet
项目实现方法:主要开发认知java爬虫框架WebMagic,利用所学的java知识完成指定的网站数据爬取分析,并使用Servlet和Jsp在页面上展示
培训环境:一人一机,边讲边练
培训介绍:
本次培训的主要目的是增强学员对WebMagic框架和Servlet的理解,结合所学的理论知识进行爬虫实战。要求学生掌握市场上广泛使用的Mysql数据、Java语言、WebMagic框架和Servlet的开发,了解大中型大数据行业的基本模型知识。
本次培训选定的案例包括:
Mysql数据库的基本操作
Java基本语法使用
构建和开发爬虫项目的WebMagic框架
通过学习这些内容,可以大大提高学生对计算机知识的理解,促进专业课程的学习,从而潜移默化地提高学生的就业竞争力。
步:
1、下载安装Maven,在Eclipse中配置Maven相关设置。
1),下载安装Maven
下载地址:/download.cgi,根据自己的系统选择合适的版本下载:
将下载的文件解压到合适的位置,完成Maven安装:
2),设置环境变量
将Maven安装路径下bin目录的路径复制到电脑的环境变量中:
复制bin目录所在的路径:
添加环境变量:
在cmd下输入:mvn --version查看Maven是否安装成功,出现如下提示则表示安装成功:
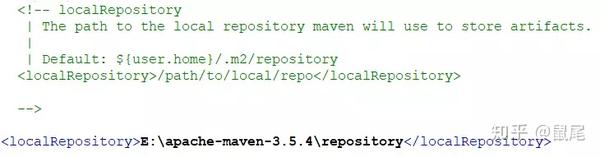
3),可以忽略:修改Maven安装目录conf(E:\apache-maven-3.5.4\conf\settings.xml)中的settings.xml文件进行配置本地仓库位置和远程仓库镜像修改为阿里云镜像:
配置本地仓库,在下面添加你要创建的本地仓库地址(根据自己的情况设置):
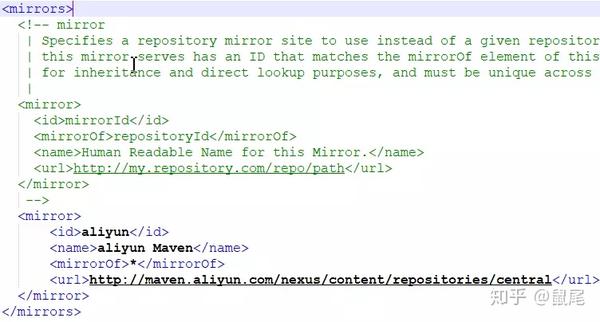
Maven仓库默认位于国外,使用起来难免会很慢,尤其是下载依赖的时候。速度很慢。换成国产阿里云镜像后,速度会有很大的提升:
aliyun
aliyun Maven
*
http://maven.aliyun.com/nexus/ ... ntral
4)、Eclipse配置
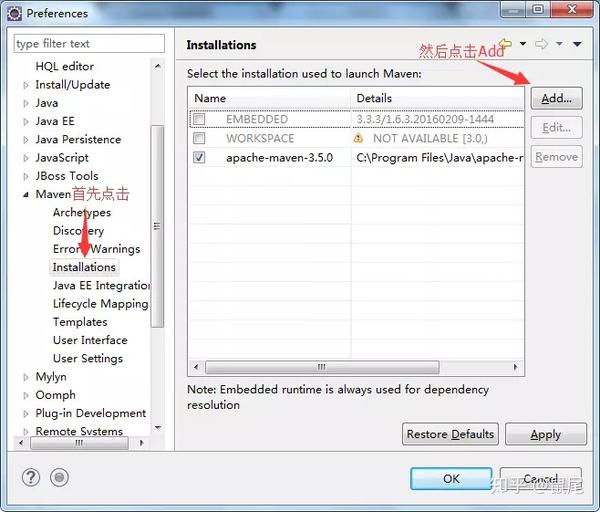
以下步骤中,每个人电脑上显示的内容可能不同(截图来自不同项目,请忽略包名、类名等信息,部分截图来自网络,不同截图中的相关信息可能不同),但是操作步骤是一样的,只要你在Eclipse上安装maven,打开Eclipse点击window>preferences,就会弹出来:
点击确定后,会出现:
点击完成后:
在 Eclipse 中配置 Maven:
打开 Eclipse 首选项设置
查找Maven配置项
设置Maven的全局配置文件settings.xml
更新配置信息
2、在Eclipse中创建Maven项目
1),打开eclipse,右键new——》other,找到maven项目如下图或者直接搜索maven projec:
创建项目:
2),选择Maven Project,请选择Create a simple project(skip archetype selection),然后点击Next:
3),填写Group id和Artifact id,Version默认,Packaging默认为jar,Name,Description可选,其他不需要填写:
然后单击完成。这时候需要稍等片刻才能下载所需的文件。创建后完整的项目结构应该如下图所示:
3、编写Java爬虫项目代码,抓取/position.php网站的相关信息:
1),需要抓取的网页内容:职位名称、职位类别、人数、地点、发布时间
2)。根据要爬取的内容(爬取的内容包括:职位、职位类别、人数、地点、发布时间),可以参考如下SQL语句设计数据库(mysql):
/*
SQLyog Ultimate v12.5.0 (64 bit)
MySQL - 5.5.27 : Database - mysql_java
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`mysql_java` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `mysql_java`;
/*Table structure for table `tencent_position` */
DROP TABLE IF EXISTS `tencent_position`;
CREATE TABLE `tencent_position` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`p_name` varchar(200) NOT NULL,
`p_link` varchar(200) NOT NULL,
`p_type` varchar(100) NOT NULL,
`p_num` varchar(20) NOT NULL,
`p_location` varchar(20) NOT NULL,
`p_publish_time` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1125 DEFAULT CHARSET=utf8;
3)。在创建的项目下,需要先配置pom.xml,然后创建四个类和一个接口(自己命名):MySQLUtils、TencentPageProcessor、TencentPosition、TencentPositionDao(接口)、TencentPositionDaoImpl
配置 pom.xml:
pom.xml文件的设置:填写完内容后记得按Ctrl+S/save键,然后Eclipse会自动从设置好的Maven仓库下载需要的文件。可能需要一定的时间:
依赖数据来自:/单独搜索:webmagic,mysql会显示相关内容
点击搜索到的内容,将框中的代码复制到pom.xml的代码块中:
可以在Maven Dependencies库中查看下载是否完成:
以下为示例代码,自行编码时请记得更改代码。
MySQLUtils 类代码如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class MySQLUtils {
private static Connection connection;
public static Connection getConnection() throws ClassNotFoundException, SQLException {
if (connection == null) {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/mysql_java";//URL、User、Password需根据自己的实际情况填写
String user = "root";
String password = "root";
return DriverManager.getConnection(url, user, password);
}
return connection;
}
}
腾讯位置代码如下:
public class TencentPosition {
private String positionName;
private String positionLink;
private String positionType;
private String positionNum;
private String workLocation;
private String publishTime;
public TencentPosition() {
super();
}
public TencentPosition(String positionName, String positionLink, String positionType, String positionNum,
String workLocation, String publishTime) {
super();
this.positionName = positionName;
this.positionLink = positionLink;
this.positionType = positionType;
this.positionNum = positionNum;
this.workLocation = workLocation;
this.publishTime = publishTime;
}
public String getPositionName() {
return positionName;
}
public void setPositionName(String positionName) {
this.positionName = positionName;
}
public String getPositionLink() {
return positionLink;
}
public void setPositionLink(String positionLink) {
this.positionLink = positionLink;
}
public String getPositionType() {
return positionType;
}
public void setPositionType(String positionType) {
this.positionType = positionType;
}
public String getPositionNum() {
return positionNum;
}
public void setPositionNum(String positionNum) {
this.positionNum = positionNum;
}
public String getWorkLocation() {
return workLocation;
}
public void setWorkLocation(String workLocation) {
this.workLocation = workLocation;
}
public String getPublishTime() {
return publishTime;
}
public void setPublishTime(String publishTime) {
this.publishTime = publishTime;
}
@Override
public String toString() {
return "TencentPosition [positionName=" + positionName + ", positionLink=" + positionLink + ", positionType="
+ positionType + ", positionNum=" + positionNum + ", workLocation=" + workLocation + ", publishTime="
+ publishTime + "]";
}
}
腾讯PositionDao接口代码如下:
public interface TencentPositionDao {
int add(TencentPosition position);
}
腾讯PositionDaoImpl类代码如下:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TencentPositionDaoImpl implements TencentPositionDao {
public int add(TencentPosition position) {
String sql = "INSERT INTO tencent_position(p_name, p_link, p_type, p_num, p_location, p_publish_time)"
+ " VALUES(?, ?, ?, ?, ?, ?)";
Connection conn = null;
PreparedStatement pst = null;
try {
conn = MySQLUtils.getConnection();
pst = conn.prepareStatement(sql);
pst.setString(1, position.getPositionName());
pst.setString(2, position.getPositionLink());
pst.setString(3, position.getPositionType());
pst.setString(4, position.getPositionNum());
pst.setString(5, position.getWorkLocation());
pst.setString(6, position.getPublishTime());
return pst.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (pst != null) {
try {
pst.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
pst = null;
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
conn = null;
}
}
}
return 0;
}
}
TencentPageProcessor 类代码如下:
<p>import java.util.List;
import java.util.concurrent.atomic.AtomicLong;import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.JsonFilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class TencentPageProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(5).setSleepTime(1000);
private static TencentPositionDao dao = new TencentPositionDaoImpl();
public static AtomicLong count = new AtomicLong();
public static AtomicLong total = new AtomicLong();
public Site getSite() {
return site;
}
public void process(Page page) {
List urlList = page.getHtml().links().regex("https://hr.tencent.com/position.php\\?&start=\\d+").all();
System.out.println(urlList);
page.addTargetRequests(urlList);
List positionNames = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/text()").all();
List positionLinks = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/@href").all();
List positionTypes = page.getHtml().xpath("//tr[@class='odd']/td[2]/text()").all();
List positionNums = page.getHtml().xpath("//tr[@class='odd']/td[3]/text()").all();
List workLocations = page.getHtml().xpath("//tr[@class='odd']/td[4]/text()").all();
List publishTimes = page.getHtml().xpath("//tr[@class='odd']/td[5]/text()").all();
for (int i = 0; i 查看全部
java爬虫抓取网页数据(项目名称数据库Java爬虫项目技术选型及实训环境实训案例)
项目名称:java爬虫
项目技术选择:Java、Maven、Mysql、WebMagic、Jsp、Servlet
项目实现方法:主要开发认知java爬虫框架WebMagic,利用所学的java知识完成指定的网站数据爬取分析,并使用Servlet和Jsp在页面上展示
培训环境:一人一机,边讲边练
培训介绍:
本次培训的主要目的是增强学员对WebMagic框架和Servlet的理解,结合所学的理论知识进行爬虫实战。要求学生掌握市场上广泛使用的Mysql数据、Java语言、WebMagic框架和Servlet的开发,了解大中型大数据行业的基本模型知识。
本次培训选定的案例包括:
Mysql数据库的基本操作
Java基本语法使用
构建和开发爬虫项目的WebMagic框架
通过学习这些内容,可以大大提高学生对计算机知识的理解,促进专业课程的学习,从而潜移默化地提高学生的就业竞争力。
步:
1、下载安装Maven,在Eclipse中配置Maven相关设置。
1),下载安装Maven
下载地址:/download.cgi,根据自己的系统选择合适的版本下载:

将下载的文件解压到合适的位置,完成Maven安装:

2),设置环境变量
将Maven安装路径下bin目录的路径复制到电脑的环境变量中:
复制bin目录所在的路径:
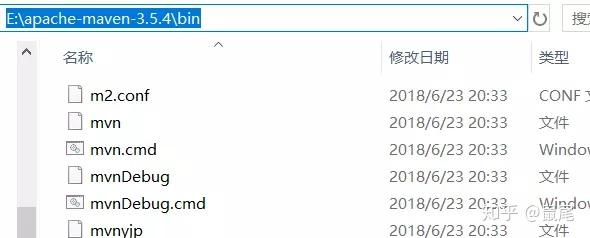
添加环境变量:
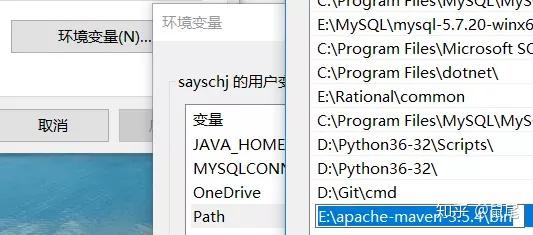
在cmd下输入:mvn --version查看Maven是否安装成功,出现如下提示则表示安装成功:

3),可以忽略:修改Maven安装目录conf(E:\apache-maven-3.5.4\conf\settings.xml)中的settings.xml文件进行配置本地仓库位置和远程仓库镜像修改为阿里云镜像:
配置本地仓库,在下面添加你要创建的本地仓库地址(根据自己的情况设置):
Maven仓库默认位于国外,使用起来难免会很慢,尤其是下载依赖的时候。速度很慢。换成国产阿里云镜像后,速度会有很大的提升:
aliyun
aliyun Maven
*
http://maven.aliyun.com/nexus/ ... ntral
4)、Eclipse配置
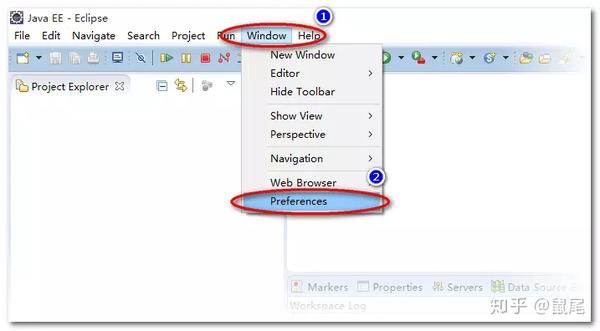
以下步骤中,每个人电脑上显示的内容可能不同(截图来自不同项目,请忽略包名、类名等信息,部分截图来自网络,不同截图中的相关信息可能不同),但是操作步骤是一样的,只要你在Eclipse上安装maven,打开Eclipse点击window>preferences,就会弹出来:
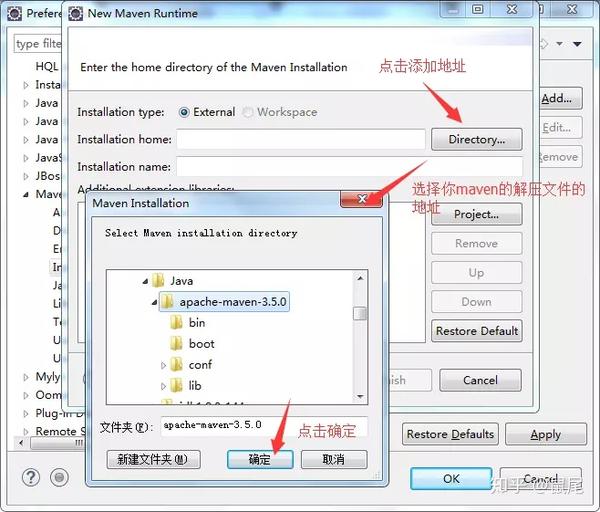
点击确定后,会出现:
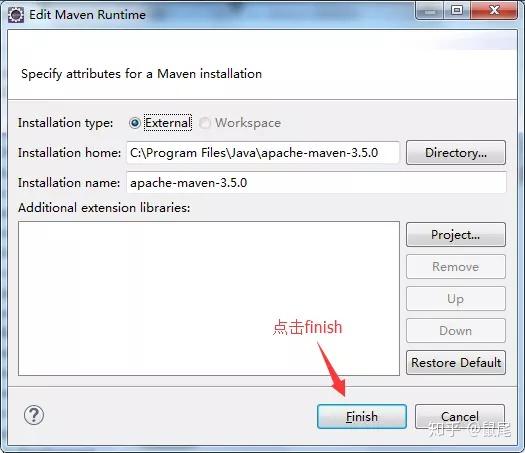
点击完成后:
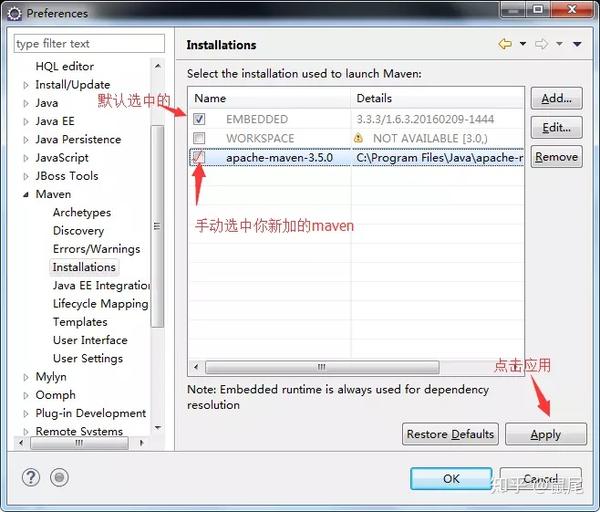
在 Eclipse 中配置 Maven:
打开 Eclipse 首选项设置
查找Maven配置项
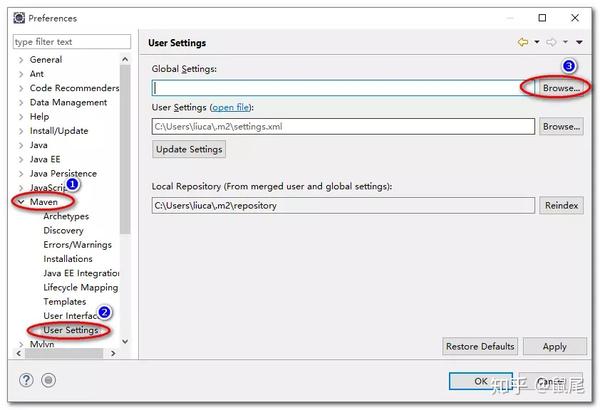
设置Maven的全局配置文件settings.xml
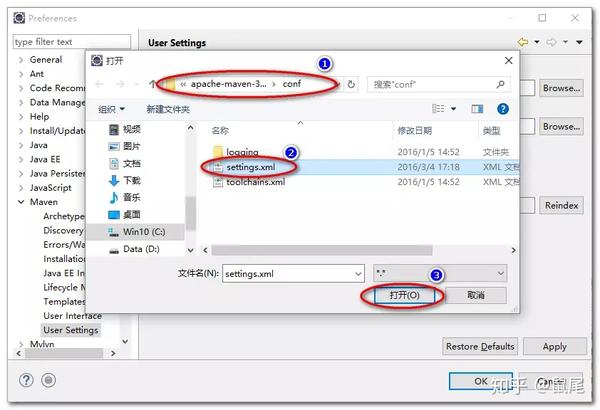
更新配置信息
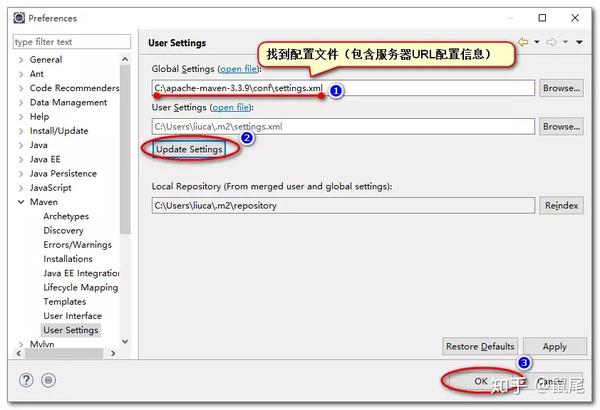
2、在Eclipse中创建Maven项目
1),打开eclipse,右键new——》other,找到maven项目如下图或者直接搜索maven projec:
创建项目:
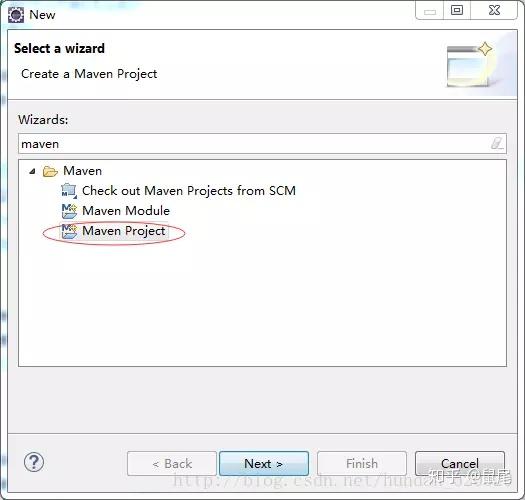
2),选择Maven Project,请选择Create a simple project(skip archetype selection),然后点击Next:
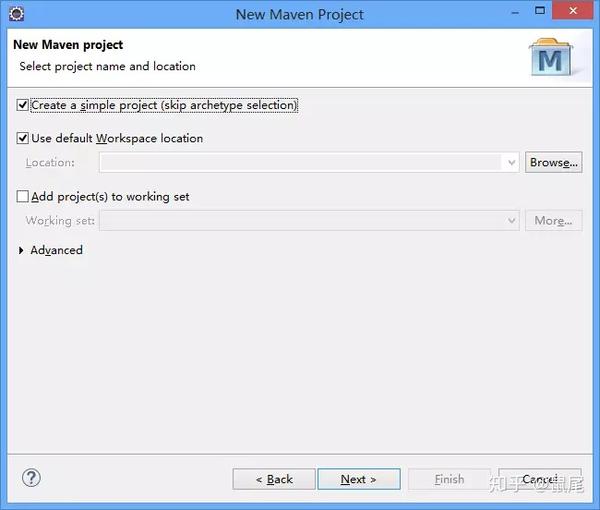
3),填写Group id和Artifact id,Version默认,Packaging默认为jar,Name,Description可选,其他不需要填写:
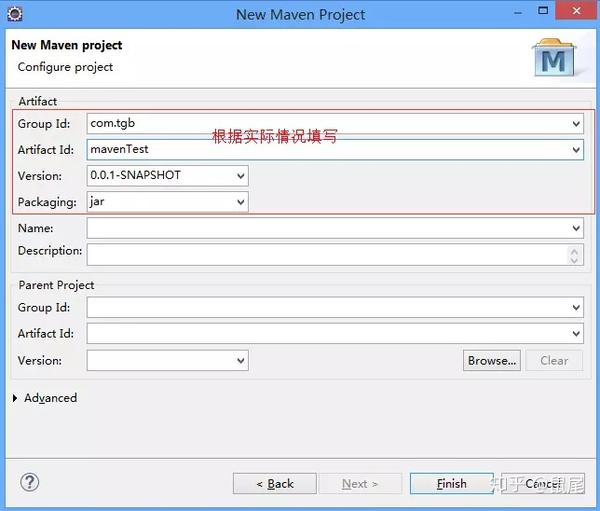
然后单击完成。这时候需要稍等片刻才能下载所需的文件。创建后完整的项目结构应该如下图所示:
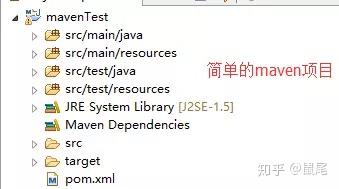
3、编写Java爬虫项目代码,抓取/position.php网站的相关信息:
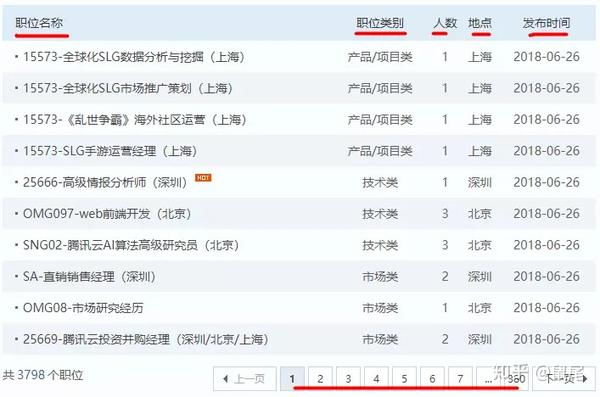
1),需要抓取的网页内容:职位名称、职位类别、人数、地点、发布时间
2)。根据要爬取的内容(爬取的内容包括:职位、职位类别、人数、地点、发布时间),可以参考如下SQL语句设计数据库(mysql):
/*
SQLyog Ultimate v12.5.0 (64 bit)
MySQL - 5.5.27 : Database - mysql_java
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`mysql_java` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `mysql_java`;
/*Table structure for table `tencent_position` */
DROP TABLE IF EXISTS `tencent_position`;
CREATE TABLE `tencent_position` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`p_name` varchar(200) NOT NULL,
`p_link` varchar(200) NOT NULL,
`p_type` varchar(100) NOT NULL,
`p_num` varchar(20) NOT NULL,
`p_location` varchar(20) NOT NULL,
`p_publish_time` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1125 DEFAULT CHARSET=utf8;
3)。在创建的项目下,需要先配置pom.xml,然后创建四个类和一个接口(自己命名):MySQLUtils、TencentPageProcessor、TencentPosition、TencentPositionDao(接口)、TencentPositionDaoImpl
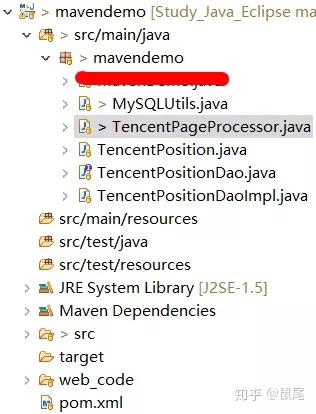
配置 pom.xml:
pom.xml文件的设置:填写完内容后记得按Ctrl+S/save键,然后Eclipse会自动从设置好的Maven仓库下载需要的文件。可能需要一定的时间:
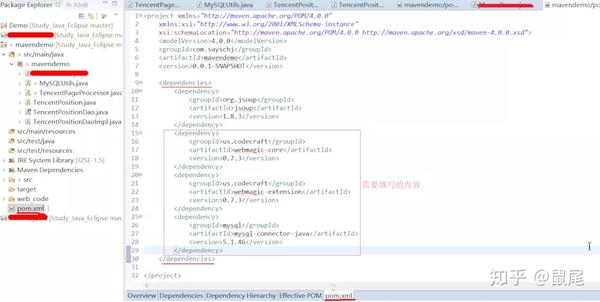
依赖数据来自:/单独搜索:webmagic,mysql会显示相关内容
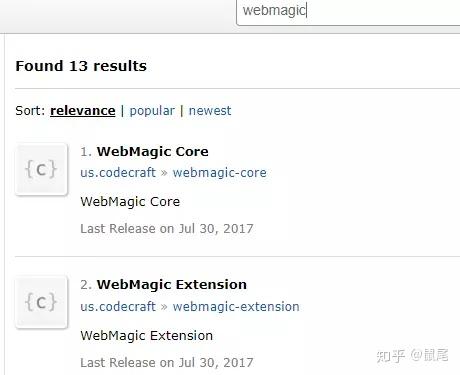
点击搜索到的内容,将框中的代码复制到pom.xml的代码块中:
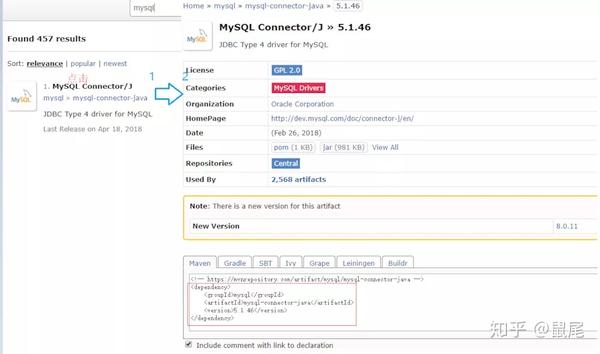
可以在Maven Dependencies库中查看下载是否完成:
以下为示例代码,自行编码时请记得更改代码。
MySQLUtils 类代码如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class MySQLUtils {
private static Connection connection;
public static Connection getConnection() throws ClassNotFoundException, SQLException {
if (connection == null) {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/mysql_java";//URL、User、Password需根据自己的实际情况填写
String user = "root";
String password = "root";
return DriverManager.getConnection(url, user, password);
}
return connection;
}
}
腾讯位置代码如下:
public class TencentPosition {
private String positionName;
private String positionLink;
private String positionType;
private String positionNum;
private String workLocation;
private String publishTime;
public TencentPosition() {
super();
}
public TencentPosition(String positionName, String positionLink, String positionType, String positionNum,
String workLocation, String publishTime) {
super();
this.positionName = positionName;
this.positionLink = positionLink;
this.positionType = positionType;
this.positionNum = positionNum;
this.workLocation = workLocation;
this.publishTime = publishTime;
}
public String getPositionName() {
return positionName;
}
public void setPositionName(String positionName) {
this.positionName = positionName;
}
public String getPositionLink() {
return positionLink;
}
public void setPositionLink(String positionLink) {
this.positionLink = positionLink;
}
public String getPositionType() {
return positionType;
}
public void setPositionType(String positionType) {
this.positionType = positionType;
}
public String getPositionNum() {
return positionNum;
}
public void setPositionNum(String positionNum) {
this.positionNum = positionNum;
}
public String getWorkLocation() {
return workLocation;
}
public void setWorkLocation(String workLocation) {
this.workLocation = workLocation;
}
public String getPublishTime() {
return publishTime;
}
public void setPublishTime(String publishTime) {
this.publishTime = publishTime;
}
@Override
public String toString() {
return "TencentPosition [positionName=" + positionName + ", positionLink=" + positionLink + ", positionType="
+ positionType + ", positionNum=" + positionNum + ", workLocation=" + workLocation + ", publishTime="
+ publishTime + "]";
}
}
腾讯PositionDao接口代码如下:
public interface TencentPositionDao {
int add(TencentPosition position);
}
腾讯PositionDaoImpl类代码如下:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TencentPositionDaoImpl implements TencentPositionDao {
public int add(TencentPosition position) {
String sql = "INSERT INTO tencent_position(p_name, p_link, p_type, p_num, p_location, p_publish_time)"
+ " VALUES(?, ?, ?, ?, ?, ?)";
Connection conn = null;
PreparedStatement pst = null;
try {
conn = MySQLUtils.getConnection();
pst = conn.prepareStatement(sql);
pst.setString(1, position.getPositionName());
pst.setString(2, position.getPositionLink());
pst.setString(3, position.getPositionType());
pst.setString(4, position.getPositionNum());
pst.setString(5, position.getWorkLocation());
pst.setString(6, position.getPublishTime());
return pst.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (pst != null) {
try {
pst.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
pst = null;
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
conn = null;
}
}
}
return 0;
}
}
TencentPageProcessor 类代码如下:
<p>import java.util.List;
import java.util.concurrent.atomic.AtomicLong;import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.JsonFilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class TencentPageProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(5).setSleepTime(1000);
private static TencentPositionDao dao = new TencentPositionDaoImpl();
public static AtomicLong count = new AtomicLong();
public static AtomicLong total = new AtomicLong();
public Site getSite() {
return site;
}
public void process(Page page) {
List urlList = page.getHtml().links().regex("https://hr.tencent.com/position.php\\?&start=\\d+").all();
System.out.println(urlList);
page.addTargetRequests(urlList);
List positionNames = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/text()").all();
List positionLinks = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/@href").all();
List positionTypes = page.getHtml().xpath("//tr[@class='odd']/td[2]/text()").all();
List positionNums = page.getHtml().xpath("//tr[@class='odd']/td[3]/text()").all();
List workLocations = page.getHtml().xpath("//tr[@class='odd']/td[4]/text()").all();
List publishTimes = page.getHtml().xpath("//tr[@class='odd']/td[5]/text()").all();
for (int i = 0; i
java爬虫抓取网页数据(java爬虫抓取网页数据第一步:读取网页的html代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-09 06:07
java爬虫抓取网页数据第一步:读取网页的html代码第二步:解析html代码第三步:构造数据tomcat对网页进行解析以下代码是按http协议通过抓包得到最终的代码我们来看看一个电影的网页我们来看看一个电影的网页以下代码是通过抓包得到最终的代码我们来看看一个电影的网页的代码比如我要抓取下面这个网页,我先将电影的所有信息抓取下来。
chrome浏览器右上角打开“开发者工具”打开网页编程的窗口我们需要抓取的网页headers开始后续的代码,需要输入的user-agent,可以抓取中国官网的默认headers,比如谷歌浏览器的user-agent就是googlechrome。首先选择一个电影电影的基本信息需要的信息就是电影名,演员信息,时间,评分和评论,分数=“评分”,时间就是“时间”,评分为平分/分数计算,这些属性还是比较好记住的,比如我要下载最高评分为9分的电影,评分规则就是9分以上就选电影名下面需要爬取的html代码有这么几个内容:<p>大师$(".country_me").href("country_family");$(".country_me").bind("click(/hi",function(){console.log(this);});$(".country_me").href("star");这里有个小坑,选择好的电影信息要加上/user-agent/或者"",这里可以直接用浏览器打开网页了。</p>
header可以看到这个header是example_header的节点。googlechrome就是这个节点,这个域名指定了这个节点的解析,之前不应该创建了这个域名吗。浏览器解析的网页headers中有一个参数是“user-agent”,用来指定浏览器返回信息的格式我们需要把user-agent中的“”替换掉。
然后在开发者工具的网络测试里看看headers是否正确。代码里有些信息我们没有提供,比如href是一个空值,只是为了看这个连接结果能不能复制过来,我们把地址复制过来:百度搜索chrome然后,看看,结果给我来了大师。那我在提供user-agent的前提下,就可以爬取到chrome的所有的解析连接,比如查看查看chrome的所有解析连接这是查看了所有的所有连接就可以构造这些的数据。
把以上的链接打包成压缩包,发到。解析网页的代码将会被替换成上面的压缩包代码。我们也可以用来解析podcast。我在。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据第一步:读取网页的html代码)
java爬虫抓取网页数据第一步:读取网页的html代码第二步:解析html代码第三步:构造数据tomcat对网页进行解析以下代码是按http协议通过抓包得到最终的代码我们来看看一个电影的网页我们来看看一个电影的网页以下代码是通过抓包得到最终的代码我们来看看一个电影的网页的代码比如我要抓取下面这个网页,我先将电影的所有信息抓取下来。
chrome浏览器右上角打开“开发者工具”打开网页编程的窗口我们需要抓取的网页headers开始后续的代码,需要输入的user-agent,可以抓取中国官网的默认headers,比如谷歌浏览器的user-agent就是googlechrome。首先选择一个电影电影的基本信息需要的信息就是电影名,演员信息,时间,评分和评论,分数=“评分”,时间就是“时间”,评分为平分/分数计算,这些属性还是比较好记住的,比如我要下载最高评分为9分的电影,评分规则就是9分以上就选电影名下面需要爬取的html代码有这么几个内容:<p>大师$(".country_me").href("country_family");$(".country_me").bind("click(/hi",function(){console.log(this);});$(".country_me").href("star");这里有个小坑,选择好的电影信息要加上/user-agent/或者"",这里可以直接用浏览器打开网页了。</p>
header可以看到这个header是example_header的节点。googlechrome就是这个节点,这个域名指定了这个节点的解析,之前不应该创建了这个域名吗。浏览器解析的网页headers中有一个参数是“user-agent”,用来指定浏览器返回信息的格式我们需要把user-agent中的“”替换掉。
然后在开发者工具的网络测试里看看headers是否正确。代码里有些信息我们没有提供,比如href是一个空值,只是为了看这个连接结果能不能复制过来,我们把地址复制过来:百度搜索chrome然后,看看,结果给我来了大师。那我在提供user-agent的前提下,就可以爬取到chrome的所有的解析连接,比如查看查看chrome的所有解析连接这是查看了所有的所有连接就可以构造这些的数据。
把以上的链接打包成压缩包,发到。解析网页的代码将会被替换成上面的压缩包代码。我们也可以用来解析podcast。我在。
java爬虫抓取网页数据(java实现了一个简单的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-08 04:18
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。 查看全部
java爬虫抓取网页数据(java实现了一个简单的网页数据)
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。
java爬虫抓取网页数据(利用网络爬虫技术与算法实现网络新闻数据自动化采集与结构化存储)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-07 09:27
利用相关的网络爬虫技术和算法,实现网络媒体新闻数据采集的自动化和结构化存储,并利用中文分词算法和中文相似度分析算法总结梳理相关新闻发展趋势,反映网络挖掘新闻数据的价值。
企业如果能够选取与自身相关的新闻进行分析,可以获得很多意想不到的收获,比如幕后是否有蓄意诽谤,竞争对手的情况等。第一时间掌握与之相关的网络新闻的负面影响,发挥公关的力量,及时纠正错误,平息负面新闻。这对今天的企业来说是非常有价值的。
内容
开发环境
原理分析
项目结构
项目截图
总结
下载链接
开发环境
开发语言:java JDK 版本1.7.
开发环境:Eclipse。
数据库向下兼容,最低兼容Mysql5.1。
原理分析
将网页URL输入爬虫系统,爬虫开启网页分析流程提取网页正文,然后输出网页正文。
网页正文传入系统,系统根据词库及相关策略开始分词,最终以数据的形式(以词组的形式)输出分词结果。
首先第一步输入数据:网络爬虫系统采集接收到的数据作为相似匹配系统的输入,然后进入处理过程,采用改进的余弦定律进行处理,然后系统返回处理后的结果 最后,系统将处理后的结果输出并传递给下一个子系统进行处理。
网络爬虫系统是数据采集系统,新闻分析系统是中文语料相似度分析系统和最终结果展示系统。
项目结构
项目截图
总结
在DBCP连接池UML图中,定义了数据库异常抛出类、数据库配置POJO类、数据库连接池核心类Pool,代理实现了Connection的close()方法、setAutoCommit()等方法,以及作为数据库连接池的Monitor类,用于监控数据库的健康等。
爬虫的核心是Web类。凤凰新闻、搜狐新闻、网易新闻分别集成核心Web类,然后实现各自的解析规则。核心Web类负责一些基本的操作,比如打开网页,获取网页源代码,以及一些常规的规则。表达提取分析算法。其实Web类也收录POJO类的作用,也是爬虫爬取新闻后生成结果的载体。
因为爬虫系统的逻辑设计比较简单,所以不涉及基本的路径方法,因为整个正序只需要在固定的时间运行,不像其他软件系统,有很深的用户需求基础,需要相关人员的配合。.
下载链接 查看全部
java爬虫抓取网页数据(利用网络爬虫技术与算法实现网络新闻数据自动化采集与结构化存储)
利用相关的网络爬虫技术和算法,实现网络媒体新闻数据采集的自动化和结构化存储,并利用中文分词算法和中文相似度分析算法总结梳理相关新闻发展趋势,反映网络挖掘新闻数据的价值。
企业如果能够选取与自身相关的新闻进行分析,可以获得很多意想不到的收获,比如幕后是否有蓄意诽谤,竞争对手的情况等。第一时间掌握与之相关的网络新闻的负面影响,发挥公关的力量,及时纠正错误,平息负面新闻。这对今天的企业来说是非常有价值的。
内容
开发环境
原理分析
项目结构
项目截图
总结
下载链接
开发环境
开发语言:java JDK 版本1.7.
开发环境:Eclipse。
数据库向下兼容,最低兼容Mysql5.1。
原理分析
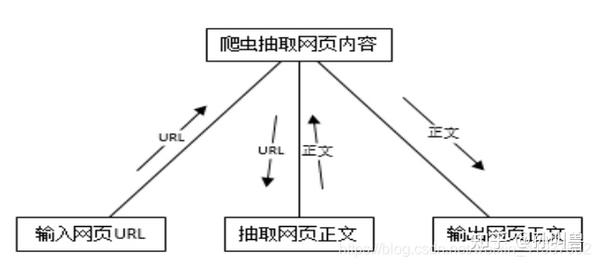
将网页URL输入爬虫系统,爬虫开启网页分析流程提取网页正文,然后输出网页正文。
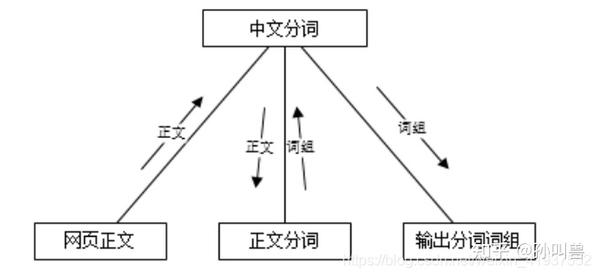
网页正文传入系统,系统根据词库及相关策略开始分词,最终以数据的形式(以词组的形式)输出分词结果。
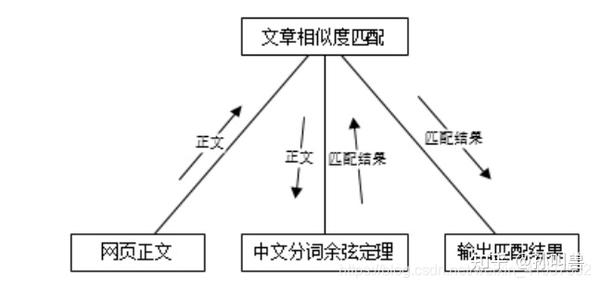
首先第一步输入数据:网络爬虫系统采集接收到的数据作为相似匹配系统的输入,然后进入处理过程,采用改进的余弦定律进行处理,然后系统返回处理后的结果 最后,系统将处理后的结果输出并传递给下一个子系统进行处理。
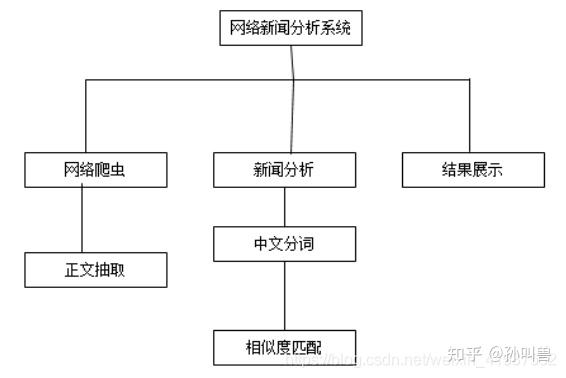
网络爬虫系统是数据采集系统,新闻分析系统是中文语料相似度分析系统和最终结果展示系统。
项目结构
项目截图
总结
在DBCP连接池UML图中,定义了数据库异常抛出类、数据库配置POJO类、数据库连接池核心类Pool,代理实现了Connection的close()方法、setAutoCommit()等方法,以及作为数据库连接池的Monitor类,用于监控数据库的健康等。
爬虫的核心是Web类。凤凰新闻、搜狐新闻、网易新闻分别集成核心Web类,然后实现各自的解析规则。核心Web类负责一些基本的操作,比如打开网页,获取网页源代码,以及一些常规的规则。表达提取分析算法。其实Web类也收录POJO类的作用,也是爬虫爬取新闻后生成结果的载体。
因为爬虫系统的逻辑设计比较简单,所以不涉及基本的路径方法,因为整个正序只需要在固定的时间运行,不像其他软件系统,有很深的用户需求基础,需要相关人员的配合。.
下载链接
java爬虫抓取网页数据(java中好系列包含哪些内容?java爬虫框架webmgic入门使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-02 10:09
1. 概述一下java爬虫系列都收录哪些内容?java爬虫框架入门 webmgic 使用webmgic抓取电影资源(动作片列表页、电影下载地址等) 使用webmgic抓取极客时间的课程资源(文章系列课程和视频系列课程)本文章 主要内容:介绍java中有用的爬虫框架Java爬虫框架webmagic介绍使用webgic爬取动作电影列表信息2.如何判断框架在好用的爬虫中是否优秀java中的框架?它易于学习和使用。网上相应的学习资料比较多,用得好的人也比较多。别人已经给你填好了。使用起来会更舒服。一些框架更新得更快,社区活跃,可以快速体验一些更好的功能,与作者交流。框架稳定,易于扩展。
根据以上几点,推荐一个非常好用的java爬虫框架webmgic
3. webmgic简介4. 使用webgic爬取动作片列表
使用webgic爬取爱情电影的电影列表资源信息
示例源代码地址
1. springboot 新项目 java-pachong
2. 导入maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3. 编写代码捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4. 运行爬虫代码
运行Ady01comPageProcessor中的main方法,执行结果如下:
5.总结本文主要通过一个例子来说明webgic如此简单,可以完成数据的抓取工作。从代码可以看出,复杂的代码webmagic帮我们屏蔽了,我们只需要关注业务代码即可。准备。文章 webmagic的使用方法没有详细说明。至于为什么我没有在文档中说明,主要是webigc提供了非常完整的学习文档。可以移动到webgic中文文档。如果需要更深入的了解,可以研究一下webgic的源码,对你写爬虫很有用。明天我们会爬取每部动作片的详情页信息,采集详情页中电影下载地址的示例代码,导入idea运行, 查看全部
java爬虫抓取网页数据(java中好系列包含哪些内容?java爬虫框架webmgic入门使用)
1. 概述一下java爬虫系列都收录哪些内容?java爬虫框架入门 webmgic 使用webmgic抓取电影资源(动作片列表页、电影下载地址等) 使用webmgic抓取极客时间的课程资源(文章系列课程和视频系列课程)本文章 主要内容:介绍java中有用的爬虫框架Java爬虫框架webmagic介绍使用webgic爬取动作电影列表信息2.如何判断框架在好用的爬虫中是否优秀java中的框架?它易于学习和使用。网上相应的学习资料比较多,用得好的人也比较多。别人已经给你填好了。使用起来会更舒服。一些框架更新得更快,社区活跃,可以快速体验一些更好的功能,与作者交流。框架稳定,易于扩展。
根据以上几点,推荐一个非常好用的java爬虫框架webmgic
3. webmgic简介4. 使用webgic爬取动作片列表
使用webgic爬取爱情电影的电影列表资源信息
示例源代码地址
1. springboot 新项目 java-pachong
2. 导入maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3. 编写代码捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4. 运行爬虫代码
运行Ady01comPageProcessor中的main方法,执行结果如下:

5.总结本文主要通过一个例子来说明webgic如此简单,可以完成数据的抓取工作。从代码可以看出,复杂的代码webmagic帮我们屏蔽了,我们只需要关注业务代码即可。准备。文章 webmagic的使用方法没有详细说明。至于为什么我没有在文档中说明,主要是webigc提供了非常完整的学习文档。可以移动到webgic中文文档。如果需要更深入的了解,可以研究一下webgic的源码,对你写爬虫很有用。明天我们会爬取每部动作片的详情页信息,采集详情页中电影下载地址的示例代码,导入idea运行,
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-30 14:04
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,我们首先要分析html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这次文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己爬取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
} 查看全部
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,我们首先要分析html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这次文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己爬取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-30 14:01
一、java爬虫的主要步骤是:
非结构化数据–>数据采集–>数据清洗–>结构化数据–>采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬取,哪些页面不能爬取。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,默认都可以爬取。即使有这个文件,你也不必遵守,但他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存或者nosql缓存服务器中进行重复数据删除,常见的有:布隆过滤器、redis……这些人自己百度一下,我也无能为力。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
①Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度向量角的余弦。主要思想是将文章中出现的词频组成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。 查看全部
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
一、java爬虫的主要步骤是:
非结构化数据–>数据采集–>数据清洗–>结构化数据–>采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬取,哪些页面不能爬取。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,默认都可以爬取。即使有这个文件,你也不必遵守,但他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存或者nosql缓存服务器中进行重复数据删除,常见的有:布隆过滤器、redis……这些人自己百度一下,我也无能为力。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
①Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度向量角的余弦。主要思想是将文章中出现的词频组成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。
java爬虫抓取网页数据(一下java下抓取网页上特定内容的方法-之前java中访问http )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-29 06:02
)
在进入正题之前,我们先来了解一下java下抓取网页上特定内容的方法,也就是所谓的网络爬虫。本文仅涉及简单的文字信息和链接爬取。java中访问http的方式不超过两种。一种是使用原来的httpconnection,另一种是使用封装好的插件或者框架,比如httpclient、okHttp等。在测试和抓取网页信息的过程中,我使用的是jsoup工具,因为该工具没有只封装了http访问,还具有强大的html解析功能。可以参考详细的使用教程。
第一步是访问登陆页面
文档 doc = Jsoup.connect("").get();
第二步,使用jsoup的选择器选择网页所需内容的具体元素(使用正则表达式效率更高)。在这个例子中,目标网页是一个论坛,我们需要做的是抓取论坛首页所有帖子的标题名称和链接地址。
首先打开目标网址,使用谷歌浏览器浏览网页结构,找到结构对应的内容,如下图
然后选择区域
Elements links = doc.getElementsByAttributeValue("id","lphymodelsub");
接下来,获取选中区域的内容并保存到数组中
对于(元素链接:链接){
CatchModel c = new CatchModel();
String linkHref = ""+link.parent().attr("href");
String linkText = link.text();
c.setText(linkText);
c.setUrl(linkHref);
fistCatchList.add(c);
}
这样一个简单的爬行就完成了。
下一步是新浪微博的爬取。一般http访问新浪微博网站得到的html很简单,因为新浪微博首页是用js动态生成的,需要多次访问。请求和验证只能访问成功,所以为了方便抓取数据,我们通过了一个后门,就是访问新浪微博的移动端进行抓取。然而,随之而来的一个问题是,访问新浪微博并不重要。任一端都需要强制登录认证,所以我们需要在http请求中附加一个cookie进行用户认证。网上找了很久,想用webcontroller这个开源的爬虫框架。它易于访问且高效。我们来看看如何使用这个框架。
首先需要导入依赖包,WebController的ja包和selenium的jar包
下载链接:
使用Selenium获取cookie登录新浪微博(WeiboCN.java)
使用WebCollector和获取的cookies抓取新浪微博并提取数据(WeiboCrawler.java)
微博CN.java
import java.util.Set;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 利用Selenium获取登陆新浪微博weibo.cn的cookie
* @author hu
*/
public class WeiboCN {
/**
* 获取新浪微博的cookie,这个方法针对weibo.cn有效,对weibo.com无效
* weibo.cn以明文形式传输数据,请使用小号
* @param username 新浪微博用户名
* @param password 新浪微博密码
* @return
* @throws Exception
*/
public static String getSinaCookie(String username, String password) throws Exception{
StringBuilder sb = new StringBuilder();
HtmlUnitDriver driver = new HtmlUnitDriver();
driver.setJavascriptEnabled(true);
driver.get("http://login.weibo.cn/login/");
WebElement mobile = driver.findElementByCssSelector("input[name=mobile]");
mobile.sendKeys(username);
WebElement pass = driver.findElementByCssSelector("input[name^=password]");
pass.sendKeys(password);
WebElement rem = driver.findElementByCssSelector("input[name=remember]");
rem.click();
WebElement submit = driver.findElementByCssSelector("input[name=submit]");
submit.click();
Set cookieSet = driver.manage().getCookies();
driver.close();
for (Cookie cookie : cookieSet) {
sb.append(cookie.getName()+"="+cookie.getValue()+";");
}
String result=sb.toString();
if(result.contains("gsid_CTandWM")){
return result;
}else{
throw new Exception("weibo login failed");
}
}
}
<p style="font-size:15px; line-height:1.5em; font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; widows:auto">WeiboCrawler.javaimport cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.net.HttpRequest;
import cn.edu.hfut.dmic.webcollector.net.HttpResponse;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 利用WebCollector和获取的cookie爬取新浪微博并抽取数据
* @author hu
*/
public class WeiboCrawler extends BreadthCrawler {
String cookie;
public WeiboCrawler(String crawlPath, boolean autoParse) throws Exception {
super(crawlPath, autoParse);
/*获取新浪微博的cookie,账号密码以明文形式传输,请使用小号*/
cookie = WeiboCN.getSinaCookie("你的用户名", "你的密码");
}
@Override
public HttpResponse getResponse(CrawlDatum crawlDatum) throws Exception {
HttpRequest request = new HttpRequest(crawlDatum);
request.setCookie(cookie);
return request.getResponse();
}
@Override
public void visit(Page page, CrawlDatums next) {
int pageNum = Integer.valueOf(page.getMetaData("pageNum"));
/*抽取微博*/
Elements weibos = page.select("div.c");
for (Element weibo : weibos) {
System.out.println("第" + pageNum + "页\t" + weibo.text());
}
}
public static void main(String[] args) throws Exception {
WeiboCrawler crawler = new WeiboCrawler("weibo_crawler", false);
crawler.setThreads(3);
/*对某人微博前5页进行爬取*/
for (int i = 1; i 查看全部
java爬虫抓取网页数据(一下java下抓取网页上特定内容的方法-之前java中访问http
)
在进入正题之前,我们先来了解一下java下抓取网页上特定内容的方法,也就是所谓的网络爬虫。本文仅涉及简单的文字信息和链接爬取。java中访问http的方式不超过两种。一种是使用原来的httpconnection,另一种是使用封装好的插件或者框架,比如httpclient、okHttp等。在测试和抓取网页信息的过程中,我使用的是jsoup工具,因为该工具没有只封装了http访问,还具有强大的html解析功能。可以参考详细的使用教程。
第一步是访问登陆页面
文档 doc = Jsoup.connect("").get();
第二步,使用jsoup的选择器选择网页所需内容的具体元素(使用正则表达式效率更高)。在这个例子中,目标网页是一个论坛,我们需要做的是抓取论坛首页所有帖子的标题名称和链接地址。
首先打开目标网址,使用谷歌浏览器浏览网页结构,找到结构对应的内容,如下图

然后选择区域
Elements links = doc.getElementsByAttributeValue("id","lphymodelsub");
接下来,获取选中区域的内容并保存到数组中
对于(元素链接:链接){
CatchModel c = new CatchModel();
String linkHref = ""+link.parent().attr("href");
String linkText = link.text();
c.setText(linkText);
c.setUrl(linkHref);
fistCatchList.add(c);
}
这样一个简单的爬行就完成了。
下一步是新浪微博的爬取。一般http访问新浪微博网站得到的html很简单,因为新浪微博首页是用js动态生成的,需要多次访问。请求和验证只能访问成功,所以为了方便抓取数据,我们通过了一个后门,就是访问新浪微博的移动端进行抓取。然而,随之而来的一个问题是,访问新浪微博并不重要。任一端都需要强制登录认证,所以我们需要在http请求中附加一个cookie进行用户认证。网上找了很久,想用webcontroller这个开源的爬虫框架。它易于访问且高效。我们来看看如何使用这个框架。
首先需要导入依赖包,WebController的ja包和selenium的jar包
下载链接:
使用Selenium获取cookie登录新浪微博(WeiboCN.java)
使用WebCollector和获取的cookies抓取新浪微博并提取数据(WeiboCrawler.java)
微博CN.java
import java.util.Set;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 利用Selenium获取登陆新浪微博weibo.cn的cookie
* @author hu
*/
public class WeiboCN {
/**
* 获取新浪微博的cookie,这个方法针对weibo.cn有效,对weibo.com无效
* weibo.cn以明文形式传输数据,请使用小号
* @param username 新浪微博用户名
* @param password 新浪微博密码
* @return
* @throws Exception
*/
public static String getSinaCookie(String username, String password) throws Exception{
StringBuilder sb = new StringBuilder();
HtmlUnitDriver driver = new HtmlUnitDriver();
driver.setJavascriptEnabled(true);
driver.get("http://login.weibo.cn/login/";);
WebElement mobile = driver.findElementByCssSelector("input[name=mobile]");
mobile.sendKeys(username);
WebElement pass = driver.findElementByCssSelector("input[name^=password]");
pass.sendKeys(password);
WebElement rem = driver.findElementByCssSelector("input[name=remember]");
rem.click();
WebElement submit = driver.findElementByCssSelector("input[name=submit]");
submit.click();
Set cookieSet = driver.manage().getCookies();
driver.close();
for (Cookie cookie : cookieSet) {
sb.append(cookie.getName()+"="+cookie.getValue()+";");
}
String result=sb.toString();
if(result.contains("gsid_CTandWM")){
return result;
}else{
throw new Exception("weibo login failed");
}
}
}
<p style="font-size:15px; line-height:1.5em; font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; widows:auto">WeiboCrawler.javaimport cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.net.HttpRequest;
import cn.edu.hfut.dmic.webcollector.net.HttpResponse;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 利用WebCollector和获取的cookie爬取新浪微博并抽取数据
* @author hu
*/
public class WeiboCrawler extends BreadthCrawler {
String cookie;
public WeiboCrawler(String crawlPath, boolean autoParse) throws Exception {
super(crawlPath, autoParse);
/*获取新浪微博的cookie,账号密码以明文形式传输,请使用小号*/
cookie = WeiboCN.getSinaCookie("你的用户名", "你的密码");
}
@Override
public HttpResponse getResponse(CrawlDatum crawlDatum) throws Exception {
HttpRequest request = new HttpRequest(crawlDatum);
request.setCookie(cookie);
return request.getResponse();
}
@Override
public void visit(Page page, CrawlDatums next) {
int pageNum = Integer.valueOf(page.getMetaData("pageNum"));
/*抽取微博*/
Elements weibos = page.select("div.c");
for (Element weibo : weibos) {
System.out.println("第" + pageNum + "页\t" + weibo.text());
}
}
public static void main(String[] args) throws Exception {
WeiboCrawler crawler = new WeiboCrawler("weibo_crawler", false);
crawler.setThreads(3);
/*对某人微博前5页进行爬取*/
for (int i = 1; i
java爬虫抓取网页数据(爬虫程序的开发比较简单程序程序开发程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-27 12:18
一次搭建爬虫之旅
最近需要从网上抓取大量数据,所以体验了爬虫程序的开发和部署,主要是学习了一些实用工具的操作。本教程的开发需求是编写一个收录爬虫程序的Java项目,可以方便地在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是抓取汉学网新华字典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用 Crawl4j。它的优点是只需要配置爬虫框架的几个重要参数就可以让爬虫开始工作:(1)爬虫数据缓存目录;(< @2)爬虫爬取策略,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页面数的控制等;(3)爬虫的入口地址;(4)爬虫遇到新页面的url由shouldVisit决定是否访问这个url;(5)爬虫时的具体操作)访问(visit)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具
430 查看全部
java爬虫抓取网页数据(爬虫程序的开发比较简单程序程序开发程序)
一次搭建爬虫之旅
最近需要从网上抓取大量数据,所以体验了爬虫程序的开发和部署,主要是学习了一些实用工具的操作。本教程的开发需求是编写一个收录爬虫程序的Java项目,可以方便地在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是抓取汉学网新华字典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用 Crawl4j。它的优点是只需要配置爬虫框架的几个重要参数就可以让爬虫开始工作:(1)爬虫数据缓存目录;(< @2)爬虫爬取策略,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页面数的控制等;(3)爬虫的入口地址;(4)爬虫遇到新页面的url由shouldVisit决定是否访问这个url;(5)爬虫时的具体操作)访问(visit)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具
430
java爬虫抓取网页数据(网络爬虫是做什么的?他的主要工作原理是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-27 04:22
一、 网络爬虫是做什么的?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面从响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
一个简单爬虫的必要功能:
1:发送请求和获取响应的功能;
2:解析响应的功能;
3:存储过滤数据的功能;
4:处理解析出的URL路径的功能;
二、 爬取对象分类
静态网页:可以通过 URLConnection 获取页面的所有数据。这种方法比较简单。你只需要建立一个URLConnection来请求页面数据,然后通过正则表达式获取相关数据即可。
动态网页:网页的部分或全部数据通过js动态展示,不能通过URLConnection直接获取。这时候就需要用到HtmlUnit工具了。这个工具是一个无界面的浏览器,可以模拟浏览器的操作。这个工具,加载网页后,获取页面数据进行分析,然后就可以抓取数据了
三、本文内容
四、总结:
静态网页数据可以通过上述代码获取,只需要通过正则表达式截取有用的信息,本文不再赘述。 查看全部
java爬虫抓取网页数据(网络爬虫是做什么的?他的主要工作原理是什么)
一、 网络爬虫是做什么的?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面从响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
一个简单爬虫的必要功能:
1:发送请求和获取响应的功能;
2:解析响应的功能;
3:存储过滤数据的功能;
4:处理解析出的URL路径的功能;
二、 爬取对象分类
静态网页:可以通过 URLConnection 获取页面的所有数据。这种方法比较简单。你只需要建立一个URLConnection来请求页面数据,然后通过正则表达式获取相关数据即可。
动态网页:网页的部分或全部数据通过js动态展示,不能通过URLConnection直接获取。这时候就需要用到HtmlUnit工具了。这个工具是一个无界面的浏览器,可以模拟浏览器的操作。这个工具,加载网页后,获取页面数据进行分析,然后就可以抓取数据了
三、本文内容
四、总结:
静态网页数据可以通过上述代码获取,只需要通过正则表达式截取有用的信息,本文不再赘述。
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-25 01:16
对于初学者来说,WebMagic 作为 Java 开发的爬虫框架很容易使用。我们通过一个简单的例子来了解一下。
WebMagic 框架介绍
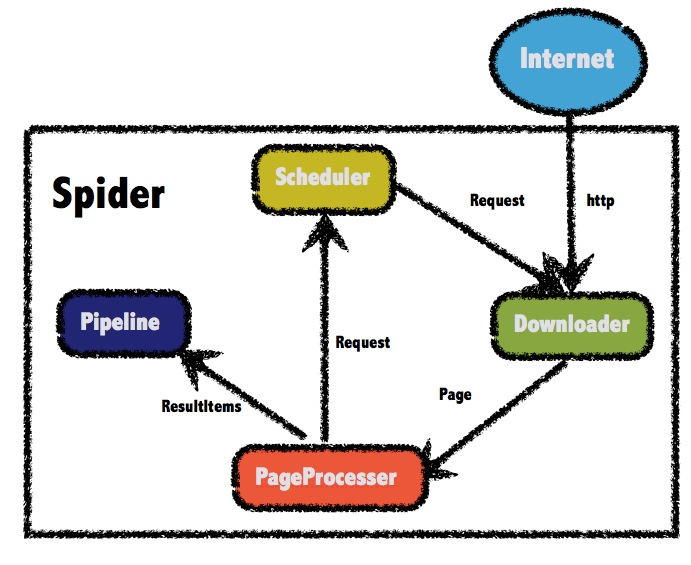
WebMagic 框架收录四个组件,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应爬虫生命周期中的处理、管理、下载、持久化功能。
这四个组件是Spider中的属性,爬虫框架由Spider启动和管理。
WebMagic 的整体结构如下:
四大组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。您需要自己定义它。
Scheduler 负责管理要爬取的 URL 和一些重复数据删除工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从网上下载页面进行后续处理。通常,您不需要自己实现它。
用于数据流的对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表从 Downloader 下载的页面——可以是 HTML、JSON 或其他文本格式的内容。
ResultItems相当于一个Map,保存PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖的jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包之后,所有的准备工作就完成了,是不是很简单?
下面我们来测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}
public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/")
.addPipeline(new ConsolePipeline()).run();
}
}
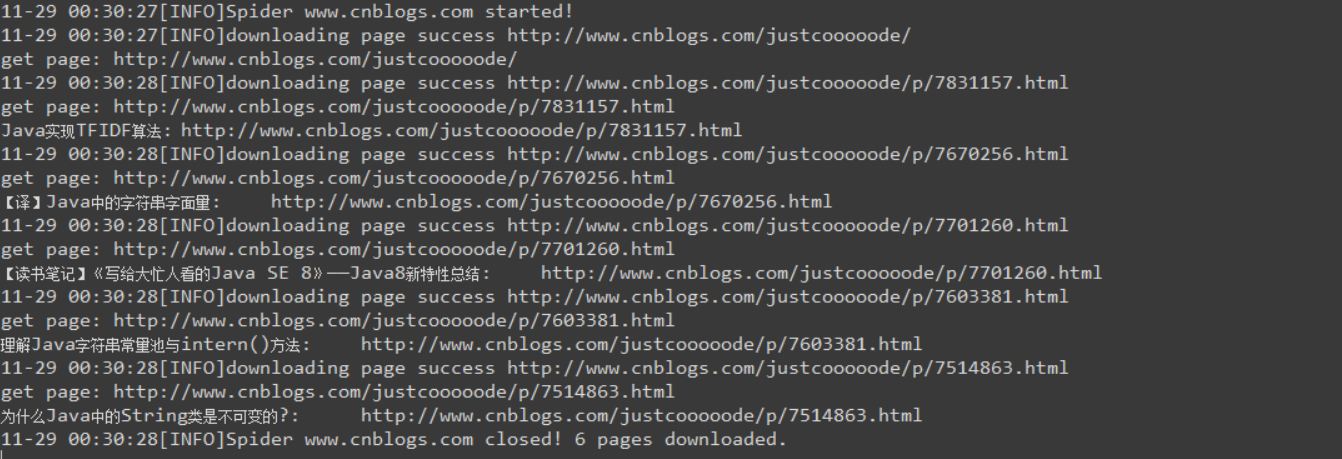
输出结果:
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:
这是因为缺少配置文件。在资源目录新建一个log4j.properties文件,粘贴下面的配置信息。
该目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告。
爬取列表类 网站 示例
列表爬取的思路非常相似。首先判断是否是列表页。如果是,将 文章 url 添加到抓取队列中。如果不是,说明此时是一个文章页面,直接爬取你想要的。内容很好。
选择列表类型 文章 网站:
首先判断是文章还是列表。查看几页后,可以找到规则并使用正则表达式进行区分。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则该url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器自带,可以直接粘贴)。
WebMagic 框架支持多种提取方式,包括xPath、css 选择器、正则表达式,所有链接都可以通过links() 方法进行选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果你使用它,你可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面。这时候页面中文章的url必须通过xPath来定位。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
这时候就已经得到了要爬取的url列表,可以通过addTargetRequests方法将它们加入到队列中。
最后实现翻页。同理,WebMagic 会自动加入爬取队列。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整代码。我自己实现了一个 MysqlPipeline 类。使用Mybatis时,可以将抓取到的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline 等。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}
public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1").addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库:
爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
使用xPath时要注意,框架作者自定义了几个功能:
表达式描述XPath1.0
文字(n)
第n个直接文本子节点,0表示全部
纯文本
所有文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更整洁
不支持
html()
内部html,不包括标签的html本身
不支持
外层Html()
内部html,包括标签的html本身
不支持
正则表达式(@attr,expr,group)
这里@attr 和 group 都是可选的,默认是 group0
不支持
使用起来非常方便。 查看全部
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
对于初学者来说,WebMagic 作为 Java 开发的爬虫框架很容易使用。我们通过一个简单的例子来了解一下。
WebMagic 框架介绍
WebMagic 框架收录四个组件,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应爬虫生命周期中的处理、管理、下载、持久化功能。
这四个组件是Spider中的属性,爬虫框架由Spider启动和管理。
WebMagic 的整体结构如下:
四大组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。您需要自己定义它。
Scheduler 负责管理要爬取的 URL 和一些重复数据删除工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从网上下载页面进行后续处理。通常,您不需要自己实现它。
用于数据流的对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表从 Downloader 下载的页面——可以是 HTML、JSON 或其他文本格式的内容。
ResultItems相当于一个Map,保存PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖的jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包之后,所有的准备工作就完成了,是不是很简单?
下面我们来测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}
public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/";)
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:

这是因为缺少配置文件。在资源目录新建一个log4j.properties文件,粘贴下面的配置信息。
该目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告。
爬取列表类 网站 示例
列表爬取的思路非常相似。首先判断是否是列表页。如果是,将 文章 url 添加到抓取队列中。如果不是,说明此时是一个文章页面,直接爬取你想要的。内容很好。
选择列表类型 文章 网站:
首先判断是文章还是列表。查看几页后,可以找到规则并使用正则表达式进行区分。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则该url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器自带,可以直接粘贴)。

WebMagic 框架支持多种提取方式,包括xPath、css 选择器、正则表达式,所有链接都可以通过links() 方法进行选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果你使用它,你可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面。这时候页面中文章的url必须通过xPath来定位。

page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
这时候就已经得到了要爬取的url列表,可以通过addTargetRequests方法将它们加入到队列中。
最后实现翻页。同理,WebMagic 会自动加入爬取队列。

page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整代码。我自己实现了一个 MysqlPipeline 类。使用Mybatis时,可以将抓取到的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline 等。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}
public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1";).addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库:

爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
使用xPath时要注意,框架作者自定义了几个功能:
表达式描述XPath1.0
文字(n)
第n个直接文本子节点,0表示全部
纯文本
所有文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更整洁
不支持
html()
内部html,不包括标签的html本身
不支持
外层Html()
内部html,包括标签的html本身
不支持
正则表达式(@attr,expr,group)
这里@attr 和 group 都是可选的,默认是 group0
不支持
使用起来非常方便。
java爬虫抓取网页数据(是不是表达式有所了解,那么不仅可以抓取网页上的邮箱,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-25 01:13
这段代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
1 package tool;
2 import java.io.BufferedReader;
3 import java.io.File;
4 import java.io.FileWriter;
5 import java.io.InputStreamReader;
6 import java.io.Writer;
7 import java.net.URL;
8 import java.net.URLConnection;
9 import java.sql.Time;
10 import java.util.Scanner;
11 import java.util.regex.Matcher;
12 import java.util.regex.Pattern;
13 public class Ma {
14 public static void main(String[] args) throws Exception {// 本程序内部异常过多为了简便,不一Try,直接抛给虚拟机
15 long StartTime = System.currentTimeMillis();
16 System.out.println("-- 欢迎使用小刘简易网页爬虫程序 --");
17 System.out.println("");
18 System.out.println("--请输入正确的网址如http://www.baidu.com--");
19 Scanner input = new Scanner(System.in);// 实例化键盘输入类
20
21 String webaddress = input.next();// 创建输入对象
22 File file = new File("E:" + File.separator + "爬虫邮箱统计文本.txt");// 实例化文件类对象
23
24 // 并指明输出地址和输出文件名
25
26
27 Writer outWriter = new FileWriter(file);// 实例化outWriter类
28
29 URL url = new URL(webaddress);// 实例化URL类。
30
31 URLConnection conn = url.openConnection();// 取得链接
32
33 BufferedReader buff = new BufferedReader(new InputStreamReader(
34
35 conn.getInputStream()));// 取得网页数据
36
37 String line = null;
38 int i=0;
39 String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
40
41 Pattern p = Pattern.compile(regex);// 为patttern实例化
42
43 outWriter.write("该网页中所包含的的邮箱如下所示:\r\n");
44 while ((line = buff.readLine()) != null) {
45
46 Matcher m = p.matcher(line);// 进行匹配
47
48 while (m.find()) {
49 i++;
50 outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件
51 }
52 }
53 long StopTime = System.currentTimeMillis();
54 String UseTime=(StopTime-StartTime)+"";
55 outWriter.write("--------------------------------------------------------\r\n");
56 outWriter.write("本次爬取页面地址:"+webaddress+"\r\n");
57 outWriter.write("爬取用时:"+UseTime+"毫秒\r\n");
58 outWriter.write("本次共得到邮箱:"+i+"条\r\n");
59 outWriter.write("****谢谢您的使用****\r\n");
60 outWriter.write("--------------------------------------------------------");
61 outWriter.close();// 关闭文件输出操作
62 System.out.println(" —————————————————————\t");
63 System.out.println("|页面爬取成功,请到E盘根目录下查看test文档|\t");
64 System.out.println("| |");
65 System.out.println("|如需重新爬取,请再次执行程序,谢谢您的使用|\t");
66 System.out.println(" —————————————————————\t");
67 }
68 }
txt截图如下:
测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱,如果读者正确
不仅可以抢到邮箱,还可以抢到手机号和ip地址,等你想抢的所有信息。是不是很有趣? 查看全部
java爬虫抓取网页数据(是不是表达式有所了解,那么不仅可以抓取网页上的邮箱,)
这段代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
1 package tool;
2 import java.io.BufferedReader;
3 import java.io.File;
4 import java.io.FileWriter;
5 import java.io.InputStreamReader;
6 import java.io.Writer;
7 import java.net.URL;
8 import java.net.URLConnection;
9 import java.sql.Time;
10 import java.util.Scanner;
11 import java.util.regex.Matcher;
12 import java.util.regex.Pattern;
13 public class Ma {
14 public static void main(String[] args) throws Exception {// 本程序内部异常过多为了简便,不一Try,直接抛给虚拟机
15 long StartTime = System.currentTimeMillis();
16 System.out.println("-- 欢迎使用小刘简易网页爬虫程序 --");
17 System.out.println("");
18 System.out.println("--请输入正确的网址如http://www.baidu.com--");
19 Scanner input = new Scanner(System.in);// 实例化键盘输入类
20
21 String webaddress = input.next();// 创建输入对象
22 File file = new File("E:" + File.separator + "爬虫邮箱统计文本.txt");// 实例化文件类对象
23
24 // 并指明输出地址和输出文件名
25
26
27 Writer outWriter = new FileWriter(file);// 实例化outWriter类
28
29 URL url = new URL(webaddress);// 实例化URL类。
30
31 URLConnection conn = url.openConnection();// 取得链接
32
33 BufferedReader buff = new BufferedReader(new InputStreamReader(
34
35 conn.getInputStream()));// 取得网页数据
36
37 String line = null;
38 int i=0;
39 String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
40
41 Pattern p = Pattern.compile(regex);// 为patttern实例化
42
43 outWriter.write("该网页中所包含的的邮箱如下所示:\r\n");
44 while ((line = buff.readLine()) != null) {
45
46 Matcher m = p.matcher(line);// 进行匹配
47
48 while (m.find()) {
49 i++;
50 outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件
51 }
52 }
53 long StopTime = System.currentTimeMillis();
54 String UseTime=(StopTime-StartTime)+"";
55 outWriter.write("--------------------------------------------------------\r\n");
56 outWriter.write("本次爬取页面地址:"+webaddress+"\r\n");
57 outWriter.write("爬取用时:"+UseTime+"毫秒\r\n");
58 outWriter.write("本次共得到邮箱:"+i+"条\r\n");
59 outWriter.write("****谢谢您的使用****\r\n");
60 outWriter.write("--------------------------------------------------------");
61 outWriter.close();// 关闭文件输出操作
62 System.out.println(" —————————————————————\t");
63 System.out.println("|页面爬取成功,请到E盘根目录下查看test文档|\t");
64 System.out.println("| |");
65 System.out.println("|如需重新爬取,请再次执行程序,谢谢您的使用|\t");
66 System.out.println(" —————————————————————\t");
67 }
68 }
txt截图如下:


测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱,如果读者正确
不仅可以抢到邮箱,还可以抢到手机号和ip地址,等你想抢的所有信息。是不是很有趣?
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-24 03:07
)
故事的开始
虽然我们程序员不做爬虫工作,但我们在工作中偶尔会需要来自互联网的数据。如果手动复制粘贴,数据量很小。如果数据量很大,浪费时间真的很无聊。
所以现在研究了一个多小时,写了一个爬虫程序
一、爬虫需要的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2
使用 Jsoup 解析网页
首先我们需要获取我们请求的网页地址
使用Jsoup的parse()方法解析网页,并传入参数。第一个参数是新的URL(url),第二个参数设置为解析时间超过30秒则放弃。
然后得到一个 Document 对象
之后,就像我们操作JS代码一样,Document对象可以实现JS的所有操作
这时候我们用浏览器打开网页,F12查看元素,找到数据所在的div的id名,如果没有id名就用calss名,这里没有id名.
然后我们通过类名获取元素。这时候我们就可以输出 System.out.println(chinajobs); 看看能不能得到我们想要的数据。
可以看到我们确实得到了我们想要的数据
过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到了 Elements 对象。在进行下一步之前,我们必须将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转换成Element对象(首先确认我们需要的数据在chinajobs中的第一个元素)
通过分析发现可以从title属性中提取出我们需要的数据
String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
确实过滤了我们想要的所有数据
四、导出到Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素的数量
使用循环遍历输出
el.getElementsByAttribute("title").eq(i) 通过 eq(i) 传入索引值来确定元素值
在D盘新建一个上海招聘公司list.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i 查看全部
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析
)
故事的开始

虽然我们程序员不做爬虫工作,但我们在工作中偶尔会需要来自互联网的数据。如果手动复制粘贴,数据量很小。如果数据量很大,浪费时间真的很无聊。
所以现在研究了一个多小时,写了一个爬虫程序
一、爬虫需要的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2

使用 Jsoup 解析网页
首先我们需要获取我们请求的网页地址
使用Jsoup的parse()方法解析网页,并传入参数。第一个参数是新的URL(url),第二个参数设置为解析时间超过30秒则放弃。
然后得到一个 Document 对象
之后,就像我们操作JS代码一样,Document对象可以实现JS的所有操作

这时候我们用浏览器打开网页,F12查看元素,找到数据所在的div的id名,如果没有id名就用calss名,这里没有id名.

然后我们通过类名获取元素。这时候我们就可以输出 System.out.println(chinajobs); 看看能不能得到我们想要的数据。

可以看到我们确实得到了我们想要的数据

过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到了 Elements 对象。在进行下一步之前,我们必须将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转换成Element对象(首先确认我们需要的数据在chinajobs中的第一个元素)
通过分析发现可以从title属性中提取出我们需要的数据

String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
确实过滤了我们想要的所有数据

四、导出到Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素的数量
使用循环遍历输出
el.getElementsByAttribute("title").eq(i) 通过 eq(i) 传入索引值来确定元素值
在D盘新建一个上海招聘公司list.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i
java爬虫抓取网页数据(空闲时间帮朋友做了个爬取几个电商网站的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-24 03:06
最近利用空闲时间帮朋友做了一个小程序,用htmlUnit爬取几个电商网站的数据。感觉htmlUnit爬取的速度和稳定性还是很不错的,所以写了一篇博文介绍了htmlUnit的使用,也记录下来了。
这是网站的主页
具体思路是获取产品所在的div。通过div获取每个商品的tag的href,输入网址,抓取商品的数据,然后导出EXCEL表,实现自动翻译等功能
1.首先我们需要获取主页面的数据
WebClient webClient = new WebClient(BrowserVersion.CHROME );//模拟创建打开一个谷歌浏览器窗口
webClient.getOptions().setTimeout(15000);//设置网页响应时间
webClient.getOptions().setUseInsecureSSL(true);//是否
webClient.getOptions().setRedirectEnabled(true);//是否自动加载重定向
webClient.getOptions().setThrowExceptionOnScriptError(false);//是否抛出页面javascript错误
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//是否抛出response的错误
webClient.getOptions().setJavaScriptEnabled(false);// HtmlUnit对JavaScript的支持不好,关闭之
webClient.getOptions().setCssEnabled(false);// HtmlUnit对CSS的支持不好,关闭之
String url = "https://shop.sanrio.co.jp/prod ... 3B%3B
HtmlPage page = webClient.getPage(url);//通过url获取整个页面
这样我们就得到了页面的HtmlPage对象。
通过查看page对象的方法,可以发现它可以像写JS一样操作页面上的元素
2.查看页面源码获取商品对应的div中的A标签(放大后的图片可以右键查看原图)
可以发现product都嵌套在一个id="prdlist"的div中,那么我们就可以通过
// 获取A标签的div
HtmlDivision element = (HtmlDivision) page.getHtmlElementById("prdlist");
这样就得到了产品对应的div标签,然后我们查看每个产品的单独div对应的源代码,得到网页地址
这是每个单独的产品div对应的源代码。我们可以看到每个产品div中只有一个A标签。那么我们只需要拿到A标签,Ok
DomNodeList list = element.getElementsByTagName("a"); // 获取页面上的所有A连接(商品标签)
out2: for (HtmlElement htmlElement : list) {
HtmlPage click = htmlElement.click(); // 进入商品页面
HtmlDivision div3 = (HtmlDivision) click.getByXPath("//div[@class='box_right_summary']").get(0); // 获得名字的div
}
这个网址的内容刚好被抓取。内容的 div 有一个 ID。你如何获得没有ID的div或其他标签? htmlunit 封装了一个 getByXPath 方法,专门用于抓取非特殊标签。具体的写法如上图所示。名字的DIV意思是获取类attribute=box_right_summary的div集合
内置的htmlunit基本收录了所有的html标签,比如HtmlInput、HtmlTable、HtmlSpan等,读者可以下载jar自己试试
另外XPath的语法可以参考这个文章XPath语法
另外,htmlunit也可以模拟表单的提交,只需使用htmlElement的click()方法获取表单的输入框然后设置值就可以模拟点击事件
// 获取首页
final HtmlPage page1 = (HtmlPage) webClient.getPage("http://htmlunit.sourceforge.net");
// 根据form的名字获取页面表单,也可以通过索引来获取:page.getForms().get(0)
final HtmlForm form = page1.getFormByName("myform");
final HtmlSubmitInput button
= (HtmlSubmitInput) form.getInputByName("submitbutton");
final HtmlTextInput textField
= (HtmlTextInput) form.getInputByName("userid");
// 设置表单域的值
textField.setValueAttribute("root");
// 提交表单,返回提交表单后跳转的页面
final HtmlPage page2 = (HtmlPage) button.click();
这只是获得它的一种方式。也可以使用 xpath ID tagNAME 等方法。读者自行探索
3.接下来进入商品详情页面获取商品信息
这是产品详情页面。我们需要得到它的名字、尺寸、图片、价格、介绍等。
然后观察源码
这个div可以获取名称价格
HtmlDivision div3 = (HtmlDivision) click.getByXPath(
"//div[@class='box_right_summary']").get(0); // 获得名字的div
String name = div3.getElementsByTagName("h2").get(0).asText();
excels.setJname(name); // 设置日本名字 (这是自己创建的导出EXCEL的实体类)
// 获取商品的价格信息
HtmlSpan span = (HtmlSpan) click.getByXPath("//span[@class='priceSelect']").get(0);
String cname = getCname(name); // 通过百度翻译接口获取中文名字
excels.setCname(cname);
接下来是产品编号、尺寸等
如图所示,可以找到
// 获取商品的详细信息
HtmlDivision div2 = (HtmlDivision) click.getByXPath(
"//div[@class='productSummary accordionBlock01']").get(
0);
DomNodeList ths = div2.getElementsByTagName("tr");
for (HtmlElement th : ths) {
if (th.getElementsByTagName("th").get(0).asText().equals("サイズ")) {
String sizeString = th.getElementsByTagName("td")
.get(0).asText();
// 设置商品尺寸
excels.setSize(sizeString);
}
if (th.getElementsByTagName("th").get(0).asText().equals("商品コード")) {
// 商品编号
String nums2 = th.getElementsByTagName("td").get(0)
.asText();
// 设置商品编号
excels.setNums2(nums2);
}
}
代码不是以标准方式编写的。让我们凑合一下吧。
接下来是获取商品的图片信息
HtmlDivision div = (HtmlDivision) click.getByXPath(
"//div[@class='box_pic']").get(0);
// System.out.println(div.asXml());
DomNodeList imgs = div.getElementsByTagName("img");
// 遍历 下载图片到本地
for (HtmlElement img : imgs) {
download(SANLIOU + img.getAttribute("src"), DOWNDS
+ filename + "/");//这是自己封装的下载图片的方法
}
SANLIOU + img.getAttribute("src") 实际上代表的是图片的url,因为一般图片的地址不是url的全路径。这时候我们需要手动复制网站的根路径加上使用img标签的src属性来获取图片的真实地址,如:
这是产品的图片。 img src 不完整。
网页地址为:
让我们截取这个。这是网站的根路径加上/upload/save_image/N-1801-318795_1.jpg就构成图片的真实路径
至此,一般的爬取内容就完成了。我把详细的项目案例上传到我的CSDN。你可以下载它。案例下载
其实htmlunit是一个非常简单小巧的框架。只要有前端页面的基础就容易上手,轻松上手,实现自己想要的功能 查看全部
java爬虫抓取网页数据(空闲时间帮朋友做了个爬取几个电商网站的数据)
最近利用空闲时间帮朋友做了一个小程序,用htmlUnit爬取几个电商网站的数据。感觉htmlUnit爬取的速度和稳定性还是很不错的,所以写了一篇博文介绍了htmlUnit的使用,也记录下来了。
这是网站的主页
具体思路是获取产品所在的div。通过div获取每个商品的tag的href,输入网址,抓取商品的数据,然后导出EXCEL表,实现自动翻译等功能
1.首先我们需要获取主页面的数据
WebClient webClient = new WebClient(BrowserVersion.CHROME );//模拟创建打开一个谷歌浏览器窗口
webClient.getOptions().setTimeout(15000);//设置网页响应时间
webClient.getOptions().setUseInsecureSSL(true);//是否
webClient.getOptions().setRedirectEnabled(true);//是否自动加载重定向
webClient.getOptions().setThrowExceptionOnScriptError(false);//是否抛出页面javascript错误
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//是否抛出response的错误
webClient.getOptions().setJavaScriptEnabled(false);// HtmlUnit对JavaScript的支持不好,关闭之
webClient.getOptions().setCssEnabled(false);// HtmlUnit对CSS的支持不好,关闭之
String url = "https://shop.sanrio.co.jp/prod ... 3B%3B
HtmlPage page = webClient.getPage(url);//通过url获取整个页面
这样我们就得到了页面的HtmlPage对象。
通过查看page对象的方法,可以发现它可以像写JS一样操作页面上的元素
2.查看页面源码获取商品对应的div中的A标签(放大后的图片可以右键查看原图)
可以发现product都嵌套在一个id="prdlist"的div中,那么我们就可以通过
// 获取A标签的div
HtmlDivision element = (HtmlDivision) page.getHtmlElementById("prdlist");
这样就得到了产品对应的div标签,然后我们查看每个产品的单独div对应的源代码,得到网页地址

这是每个单独的产品div对应的源代码。我们可以看到每个产品div中只有一个A标签。那么我们只需要拿到A标签,Ok
DomNodeList list = element.getElementsByTagName("a"); // 获取页面上的所有A连接(商品标签)
out2: for (HtmlElement htmlElement : list) {
HtmlPage click = htmlElement.click(); // 进入商品页面
HtmlDivision div3 = (HtmlDivision) click.getByXPath("//div[@class='box_right_summary']").get(0); // 获得名字的div
}
这个网址的内容刚好被抓取。内容的 div 有一个 ID。你如何获得没有ID的div或其他标签? htmlunit 封装了一个 getByXPath 方法,专门用于抓取非特殊标签。具体的写法如上图所示。名字的DIV意思是获取类attribute=box_right_summary的div集合
内置的htmlunit基本收录了所有的html标签,比如HtmlInput、HtmlTable、HtmlSpan等,读者可以下载jar自己试试
另外XPath的语法可以参考这个文章XPath语法
另外,htmlunit也可以模拟表单的提交,只需使用htmlElement的click()方法获取表单的输入框然后设置值就可以模拟点击事件
// 获取首页
final HtmlPage page1 = (HtmlPage) webClient.getPage("http://htmlunit.sourceforge.net";);
// 根据form的名字获取页面表单,也可以通过索引来获取:page.getForms().get(0)
final HtmlForm form = page1.getFormByName("myform");
final HtmlSubmitInput button
= (HtmlSubmitInput) form.getInputByName("submitbutton");
final HtmlTextInput textField
= (HtmlTextInput) form.getInputByName("userid");
// 设置表单域的值
textField.setValueAttribute("root");
// 提交表单,返回提交表单后跳转的页面
final HtmlPage page2 = (HtmlPage) button.click();
这只是获得它的一种方式。也可以使用 xpath ID tagNAME 等方法。读者自行探索
3.接下来进入商品详情页面获取商品信息
这是产品详情页面。我们需要得到它的名字、尺寸、图片、价格、介绍等。
然后观察源码
这个div可以获取名称价格
HtmlDivision div3 = (HtmlDivision) click.getByXPath(
"//div[@class='box_right_summary']").get(0); // 获得名字的div
String name = div3.getElementsByTagName("h2").get(0).asText();
excels.setJname(name); // 设置日本名字 (这是自己创建的导出EXCEL的实体类)
// 获取商品的价格信息
HtmlSpan span = (HtmlSpan) click.getByXPath("//span[@class='priceSelect']").get(0);
String cname = getCname(name); // 通过百度翻译接口获取中文名字
excels.setCname(cname);
接下来是产品编号、尺寸等

如图所示,可以找到
// 获取商品的详细信息
HtmlDivision div2 = (HtmlDivision) click.getByXPath(
"//div[@class='productSummary accordionBlock01']").get(
0);
DomNodeList ths = div2.getElementsByTagName("tr");
for (HtmlElement th : ths) {
if (th.getElementsByTagName("th").get(0).asText().equals("サイズ")) {
String sizeString = th.getElementsByTagName("td")
.get(0).asText();
// 设置商品尺寸
excels.setSize(sizeString);
}
if (th.getElementsByTagName("th").get(0).asText().equals("商品コード")) {
// 商品编号
String nums2 = th.getElementsByTagName("td").get(0)
.asText();
// 设置商品编号
excels.setNums2(nums2);
}
}
代码不是以标准方式编写的。让我们凑合一下吧。
接下来是获取商品的图片信息
HtmlDivision div = (HtmlDivision) click.getByXPath(
"//div[@class='box_pic']").get(0);
// System.out.println(div.asXml());
DomNodeList imgs = div.getElementsByTagName("img");
// 遍历 下载图片到本地
for (HtmlElement img : imgs) {
download(SANLIOU + img.getAttribute("src"), DOWNDS
+ filename + "/");//这是自己封装的下载图片的方法
}
SANLIOU + img.getAttribute("src") 实际上代表的是图片的url,因为一般图片的地址不是url的全路径。这时候我们需要手动复制网站的根路径加上使用img标签的src属性来获取图片的真实地址,如:

这是产品的图片。 img src 不完整。
网页地址为:
让我们截取这个。这是网站的根路径加上/upload/save_image/N-1801-318795_1.jpg就构成图片的真实路径
至此,一般的爬取内容就完成了。我把详细的项目案例上传到我的CSDN。你可以下载它。案例下载
其实htmlunit是一个非常简单小巧的框架。只要有前端页面的基础就容易上手,轻松上手,实现自己想要的功能
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 01:10
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容,在网页中寻找其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对数据进行处理和过滤的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面,它会从响应中找到您要查找的数据,另一方面,它会从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:
所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li
相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 保存结果
WanhoPipeline.java
5.5. 模型对象
文章Vo.java
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始 查看全部
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容,在网页中寻找其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对数据进行处理和过滤的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面,它会从响应中找到您要查找的数据,另一方面,它会从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
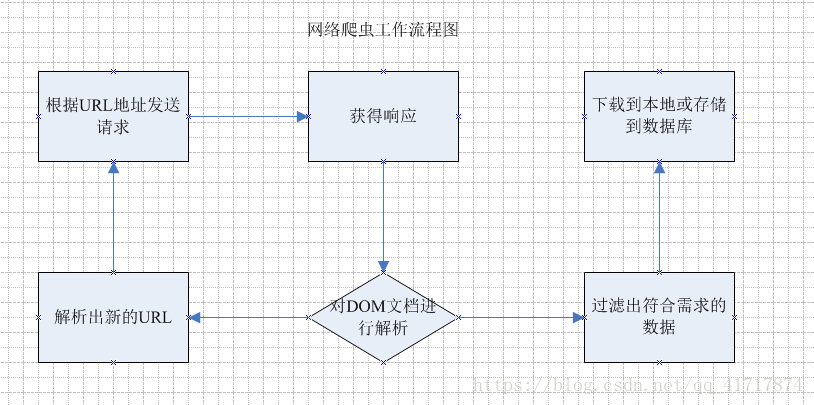
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:

所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li

相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构

5.2. 程序入口
演示.java
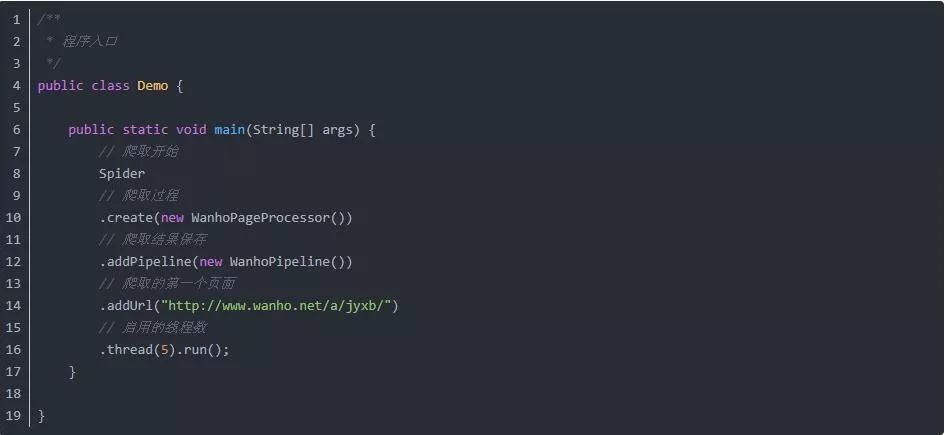
5.3. 爬取过程
WanhoPageProcessor.java
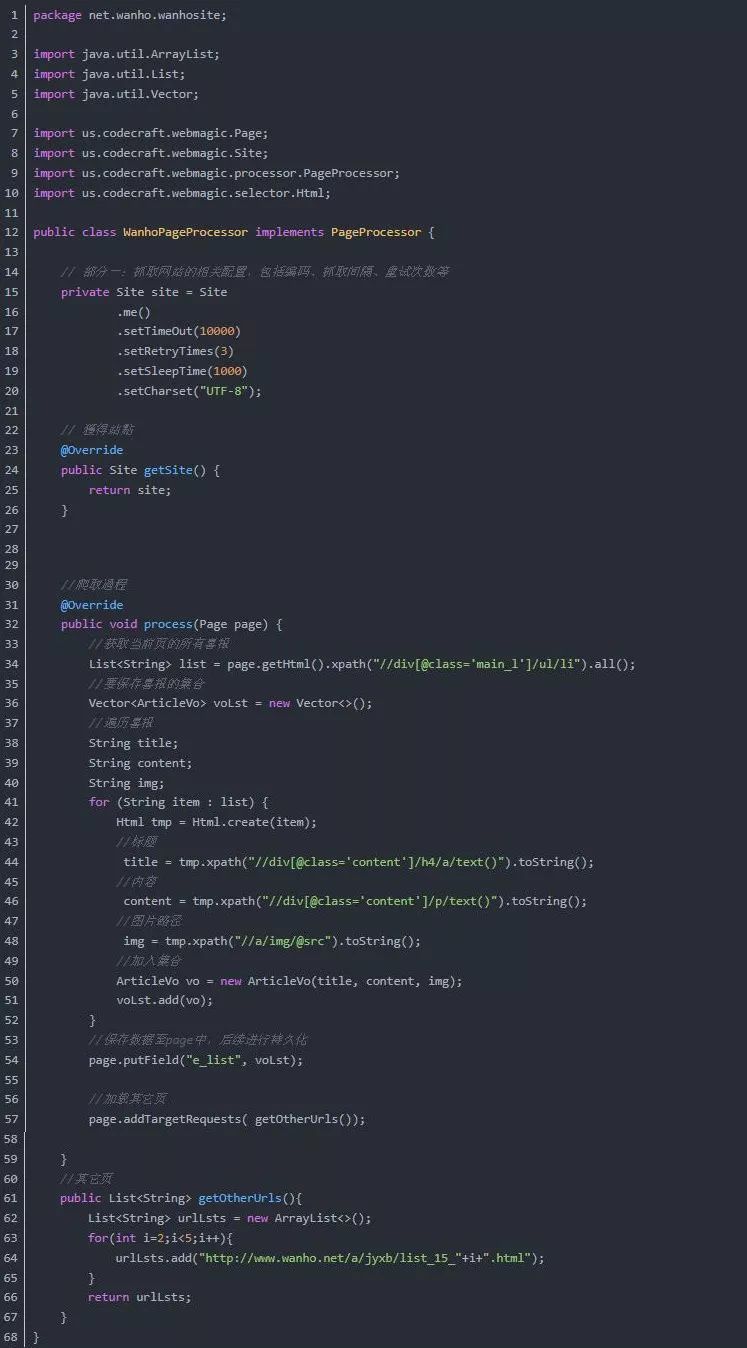
5.4. 保存结果
WanhoPipeline.java

5.5. 模型对象
文章Vo.java
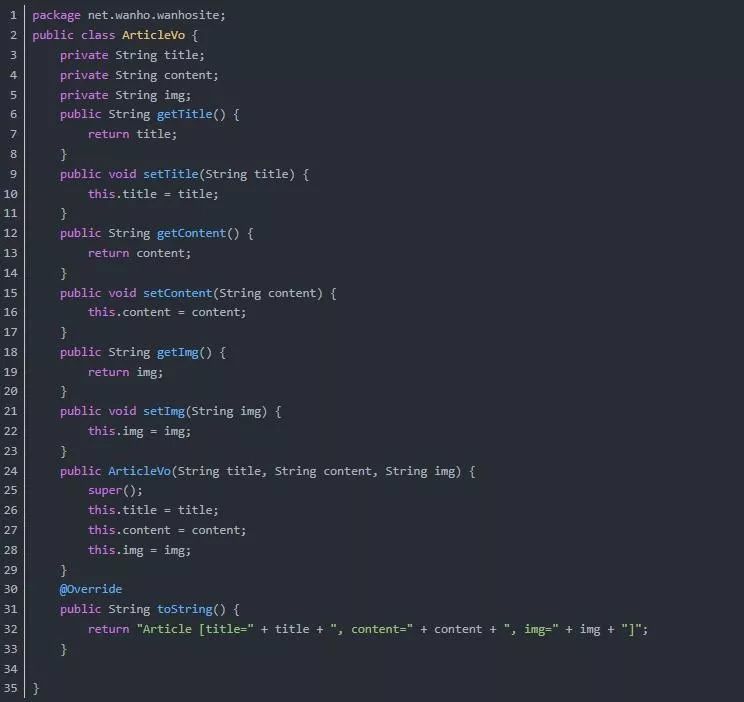
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始
java爬虫抓取网页数据(网络爬虫干了哪些活,?(本文)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-20 04:00
)
本文内容来源于罗刚的书籍>;
本文将介绍1:网络爬虫是做什么的?2:手动编写一个简单的网络爬虫;
1:网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。解析出新的 URL 路径,
然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
1:发送请求并得到响应
2:解析页面元素
3:过滤并存储符合要求的数据
4:处理URL路径
这是包结构:
下面是核心代码:
public void crawling(String[] seeds) {
//使用种子初始化 URL 队列
System.out.println("MyCrawler: 使用种子初始化 URL 队列, 程序开始.");
Links.addUnvisitedUrlQueue(seeds);
//循环条件:是否 还有有效的待访问链接
while (Links.hasUnVisitedUrlList()) {
//先从待访问的序列中取出第一个
String url = Links.fetchHeadOfUnVisitedUrlQueue();
//将已经访问过的链接放入已访问的链接中;
Links.addVisitedUrlSet(url);
//根据URL得到page
Page page = Requests.request(url);
//对page进行解析:---- 解析DOM的某个标签
System.out.println("PageParserUtils: 解析页面出页面中所有的 a 标签");
Elements es = PageParserUtils.select(page, "a");
es.stream().map(Element::toString).forEach(System.out::println);
//对page进行解析:---- 得到新的链接
System.out.println("PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 ");
Set links = PageParserUtils.getLinks(page, "img");
// Links管理类 新增链接
System.out.println("Links: 可以将解析出来的链接 添加到 待访问链接队列中 ");
links.stream().filter(link -> link.startsWith("http://www.baidu.com")).forEach(Links::addUnvisitedUrlQueue);
//对page进行处理: 将保存文件
System.out.println("Files: 将页面保存到本地");
Files.saveToLocal(page);
}
System.out.println("MyCrawler: 所有的有效链接已访问结束, 程序退出.");
}
以下是操作的结果:
MyCrawler: 使用种子初始化 URL 队列, 程序开始.
Links: 新增爬取路径: http://www.baidu.com
Links: 取出待访问的url : http://www.baidu.com
PageParserUtils: 解析页面出页面中所有的 a 标签
新闻
hao123
地图
视频
贴吧
登录
更多产品
关于百度
About Baidu
使用百度前必读
意见反馈
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Links: 新增爬取路径: http://www.baidu.com/img/gs.gif
Links: 新增爬取路径: http://www.baidu.com/img/bd_logo1.png
Files: 将页面保存到本地
文件:www.baidu.com.html已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com.html
Links: 取出待访问的url : http://www.baidu.com/img/gs.gif
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_gs.gif.gif已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_gs.gif.gif
Links: 取出待访问的url : http://www.baidu.com/img/bd_logo1.png
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_bd_logo1.png.png已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_bd_logo1.png.png
MyCrawler: 所有的有效链接已访问结束, 程序退出.
下面是代码地址:
crawlLearn: java 爬虫入门 (gitee.com)
文章参考:
1: 自己动手写网络爬虫;
2: https://github.com/CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
本文首发于2017年11月18号, 于2021年5月20日重做整理和修改. 查看全部
java爬虫抓取网页数据(网络爬虫干了哪些活,?(本文)(图)
)
本文内容来源于罗刚的书籍>;
本文将介绍1:网络爬虫是做什么的?2:手动编写一个简单的网络爬虫;
1:网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。解析出新的 URL 路径,
然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
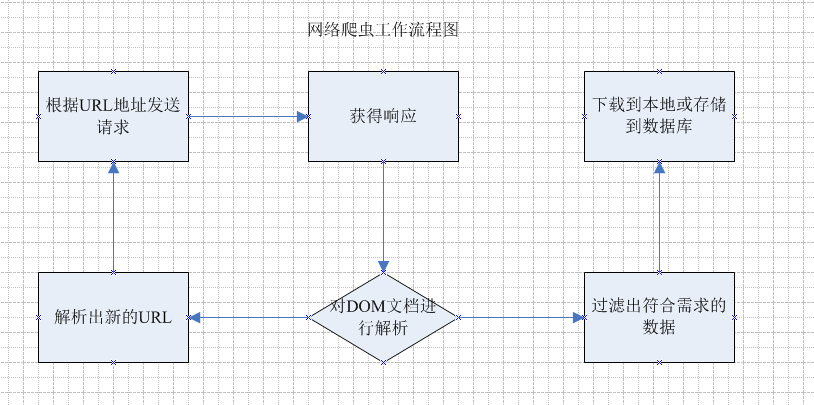
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
1:发送请求并得到响应
2:解析页面元素
3:过滤并存储符合要求的数据
4:处理URL路径
这是包结构:

下面是核心代码:
public void crawling(String[] seeds) {
//使用种子初始化 URL 队列
System.out.println("MyCrawler: 使用种子初始化 URL 队列, 程序开始.");
Links.addUnvisitedUrlQueue(seeds);
//循环条件:是否 还有有效的待访问链接
while (Links.hasUnVisitedUrlList()) {
//先从待访问的序列中取出第一个
String url = Links.fetchHeadOfUnVisitedUrlQueue();
//将已经访问过的链接放入已访问的链接中;
Links.addVisitedUrlSet(url);
//根据URL得到page
Page page = Requests.request(url);
//对page进行解析:---- 解析DOM的某个标签
System.out.println("PageParserUtils: 解析页面出页面中所有的 a 标签");
Elements es = PageParserUtils.select(page, "a");
es.stream().map(Element::toString).forEach(System.out::println);
//对page进行解析:---- 得到新的链接
System.out.println("PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 ");
Set links = PageParserUtils.getLinks(page, "img");
// Links管理类 新增链接
System.out.println("Links: 可以将解析出来的链接 添加到 待访问链接队列中 ");
links.stream().filter(link -> link.startsWith("http://www.baidu.com";)).forEach(Links::addUnvisitedUrlQueue);
//对page进行处理: 将保存文件
System.out.println("Files: 将页面保存到本地");
Files.saveToLocal(page);
}
System.out.println("MyCrawler: 所有的有效链接已访问结束, 程序退出.");
}
以下是操作的结果:
MyCrawler: 使用种子初始化 URL 队列, 程序开始.
Links: 新增爬取路径: http://www.baidu.com
Links: 取出待访问的url : http://www.baidu.com
PageParserUtils: 解析页面出页面中所有的 a 标签
新闻
hao123
地图
视频
贴吧
登录
更多产品
关于百度
About Baidu
使用百度前必读
意见反馈
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Links: 新增爬取路径: http://www.baidu.com/img/gs.gif
Links: 新增爬取路径: http://www.baidu.com/img/bd_logo1.png
Files: 将页面保存到本地
文件:www.baidu.com.html已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com.html
Links: 取出待访问的url : http://www.baidu.com/img/gs.gif
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_gs.gif.gif已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_gs.gif.gif
Links: 取出待访问的url : http://www.baidu.com/img/bd_logo1.png
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_bd_logo1.png.png已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_bd_logo1.png.png
MyCrawler: 所有的有效链接已访问结束, 程序退出.
下面是代码地址:
crawlLearn: java 爬虫入门 (gitee.com)
文章参考:
1: 自己动手写网络爬虫;
2: https://github.com/CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
本文首发于2017年11月18号, 于2021年5月20日重做整理和修改.
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-20 03:18
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页的内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受、处理和过滤“爬虫”发回的数据的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的 URL 地址发送请求,得到响应,然后解析响应。一方面,它从响应中找到您想要查找的数据,另一方面,它从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:
所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li
相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 保存结果
WanhoPipeline.java
5.5. 模型对象
文章Vo.java
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始 查看全部
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页的内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受、处理和过滤“爬虫”发回的数据的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的 URL 地址发送请求,得到响应,然后解析响应。一方面,它从响应中找到您想要查找的数据,另一方面,它从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:
所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li
相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 保存结果
WanhoPipeline.java
5.5. 模型对象
文章Vo.java
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始
java爬虫抓取网页数据(新浪新闻爬虫:一下接下来的目标页面是爬取问题推荐页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-20 02:27
上一篇写了一个简单的新浪新闻爬虫,使用jsoup包在本地抓取url页面,在本地分析提取数据。jsoup的用法这里不再赘述。百度会看大图。看到网上大神们爬取了知乎,今天就用它来试试。写这篇文章的目的主要是记录一下我在爬行中遇到的一些坑以及如何解决。这也是一个加深理解的过程。
抓取的目标页面
2017-12-31_172919.png
目标是抓取问题推荐页面上的所有问题。但是后来我发现了一个问题。第一次抓取这个链接,获取问题列表,但是代码测试的时候,发现只有20条数据。. . 这显然不是我所期望的。我看了下代码,发现代码没有任何问题,那么有什么问题呢?检查了一块和调试模式。原来是页面的问题。因为我忽略了一个重要的点。页面是动态加载的,每次只加载20项。
页面加载.png
问题出在这个地方,里面其实收录了一个地址()。可以通过抓包找到(谷歌的F12确实好用,建议多看)
ajax请求头.png
请求参数.png
返回 json 结果.png
知道问题出在哪里实际上已经完成了一半。谈谈我接下来的想法: 查看全部
java爬虫抓取网页数据(新浪新闻爬虫:一下接下来的目标页面是爬取问题推荐页面)
上一篇写了一个简单的新浪新闻爬虫,使用jsoup包在本地抓取url页面,在本地分析提取数据。jsoup的用法这里不再赘述。百度会看大图。看到网上大神们爬取了知乎,今天就用它来试试。写这篇文章的目的主要是记录一下我在爬行中遇到的一些坑以及如何解决。这也是一个加深理解的过程。
抓取的目标页面

2017-12-31_172919.png
目标是抓取问题推荐页面上的所有问题。但是后来我发现了一个问题。第一次抓取这个链接,获取问题列表,但是代码测试的时候,发现只有20条数据。. . 这显然不是我所期望的。我看了下代码,发现代码没有任何问题,那么有什么问题呢?检查了一块和调试模式。原来是页面的问题。因为我忽略了一个重要的点。页面是动态加载的,每次只加载20项。
页面加载.png
问题出在这个地方,里面其实收录了一个地址()。可以通过抓包找到(谷歌的F12确实好用,建议多看)
ajax请求头.png
请求参数.png
返回 json 结果.png
知道问题出在哪里实际上已经完成了一半。谈谈我接下来的想法:
java爬虫抓取网页数据(推荐如下的java开源爬虫或抓取框架【猪猪-后端】WebMagic框架搭建的爬52揭秘)
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2021-12-11 13:21
郭无心:有时候直接看爬虫框架是很困难的。建议从一个简单的程序一步一步开始。在Script House看过一个关于Java爬虫程序设计的系列。我把它放在这里供大家共同学习。ht 366javaniu:我之前回答过java爬虫的问题,转过来。推荐以下java开源爬虫或爬虫框架1.webmagic [Pig-Backend] WebMagic框架搭建爬虫52揭示Java网络爬虫程序原理随着互联网+时代的到来,越来越多的互联网公司他们层出不穷,涉及游戏、视频、新闻、社交、电子商务、房地产、旅游等诸多行业。比如36xdyl:用java写爬虫最简单的方法就是使用scrapy。您必须了解什么场景以及如何解决问题。更大的使用螺母。第25章算法:编写爬虫时,必须注意以下5个方面:1.如何将整个互联网抽象为无向图,网页为节点,网页中的链接为有向边。2. 爬取算法采用优先队列调度。区别 20HttpClient是java下常用的网络工具包。如果效果不理想,可能是姿势不对。让你普及一下java爬虫的开发使用过程和需求。19LucasX:我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome网络分析请求,还是fiddl 10 郑明:之前对爬虫了解不多,然后在五一之前看了一篇java爬虫的介绍博客。吃了安利后,我决定自己实施一个。爬虫可以爬行。知乎 每个话题下的热门问答,hi 5,可以关注我写的一个开源组件,设置代理服务器池防止反爬虫策略屏蔽,自动调整异常请求管理,以及优先响应快速代理。https: 3 并优先响应快速代理。https: 3 并优先响应快速代理。https: 3 查看全部
java爬虫抓取网页数据(推荐如下的java开源爬虫或抓取框架【猪猪-后端】WebMagic框架搭建的爬52揭秘)
郭无心:有时候直接看爬虫框架是很困难的。建议从一个简单的程序一步一步开始。在Script House看过一个关于Java爬虫程序设计的系列。我把它放在这里供大家共同学习。ht 366javaniu:我之前回答过java爬虫的问题,转过来。推荐以下java开源爬虫或爬虫框架1.webmagic [Pig-Backend] WebMagic框架搭建爬虫52揭示Java网络爬虫程序原理随着互联网+时代的到来,越来越多的互联网公司他们层出不穷,涉及游戏、视频、新闻、社交、电子商务、房地产、旅游等诸多行业。比如36xdyl:用java写爬虫最简单的方法就是使用scrapy。您必须了解什么场景以及如何解决问题。更大的使用螺母。第25章算法:编写爬虫时,必须注意以下5个方面:1.如何将整个互联网抽象为无向图,网页为节点,网页中的链接为有向边。2. 爬取算法采用优先队列调度。区别 20HttpClient是java下常用的网络工具包。如果效果不理想,可能是姿势不对。让你普及一下java爬虫的开发使用过程和需求。19LucasX:我最近才知道这个。对于某些第三方工具或库,您必须阅读官方教程。学习使用chrome网络分析请求,还是fiddl 10 郑明:之前对爬虫了解不多,然后在五一之前看了一篇java爬虫的介绍博客。吃了安利后,我决定自己实施一个。爬虫可以爬行。知乎 每个话题下的热门问答,hi 5,可以关注我写的一个开源组件,设置代理服务器池防止反爬虫策略屏蔽,自动调整异常请求管理,以及优先响应快速代理。https: 3 并优先响应快速代理。https: 3 并优先响应快速代理。https: 3
java爬虫抓取网页数据(用Python实现爬虫简单的爬虫预警!i.导入相关库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-10 11:08
还有Scrapy和Scrapy-redis框架,让我们开发爬虫非常容易。
Python提供了丰富的库,让我们编写程序更加方便。
一旦你完成了你的第一个爬虫
只说不说,看看爬虫程序怎么写!
在抓取之前,我们需要检查这个网页是否有抓取协议。
通常爬虫协议在网站之后的robots.txt文件中。我们抓取的内容一定不能在爬虫协议中被禁止。以百度搜索为例:
以百度搜索为例-图
大多数网站可以通过在URL后添加/robots.txt来查看robots文档。
一个简单的爬虫写作思路:
我们通过我们编写的爬虫程序向目标站点发起请求,即发送收录请求头和请求体的Request请求。(下面会写) 那么。如果接收到Request的服务器可以正常响应,那么我们就会收到一个Response响应,内容包括html、json、图片、视频等,就是网页的源代码。
作者的博客图
3. 使用接收到的源码中的正则表达式,以及Beautifulsoup、pyquery等第三方解析库,解析html中的数据。最后,根据需要,我们可以将提取的数据保存在数据库或文件中。
哦,差点忘了。在Python中实现爬虫,需要一个好帮手——Beautiful Soup。
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现文档导航、搜索和修改文档的常用方式。Beautiful Soup 将为您节省数小时甚至数天的时间。工作时间。” (来自BeautifulSoup的官方描述)
urllib 是一个采集多个使用 URL 的模块的包,其中:
urllib.request 打开和读取 URL
urllib.error 收录 urllib.request 抛出的异常
urllib.parse 用于处理 URL
urllib.robotparser 用于解析 robots.txt 文件
没看懂?没关系。我们来看看一个简单的爬虫程序是如何实现的:
非常详细的注释警告!
一世。导入相关库
#首先,我们要导入urllib的request库,它可以实现向服务器发送request请求的功能
import urllib.request
#之后,我们需要用re库来解析我们接收到的内容,也就是网页代码
import re
#这个os库用来在本地创建一个目录,用于存放我们爬取的照片
import os
ii. 程序开始
<p>#程序开始,我们定义一个fetch_pictures函数来实现爬虫的主要功能
def fetch_pictures(url):
#首先,我们定义一个html_content变量来存放网页的HTML源代码
html_content = urllib.request.urlopen(url).read()
#接下来,使用正则表达式,指定匹配的特征为(.*?)
r = re.compile(' 查看全部
java爬虫抓取网页数据(用Python实现爬虫简单的爬虫预警!i.导入相关库)
还有Scrapy和Scrapy-redis框架,让我们开发爬虫非常容易。
Python提供了丰富的库,让我们编写程序更加方便。
一旦你完成了你的第一个爬虫
只说不说,看看爬虫程序怎么写!
在抓取之前,我们需要检查这个网页是否有抓取协议。
通常爬虫协议在网站之后的robots.txt文件中。我们抓取的内容一定不能在爬虫协议中被禁止。以百度搜索为例:
以百度搜索为例-图
大多数网站可以通过在URL后添加/robots.txt来查看robots文档。
一个简单的爬虫写作思路:
我们通过我们编写的爬虫程序向目标站点发起请求,即发送收录请求头和请求体的Request请求。(下面会写) 那么。如果接收到Request的服务器可以正常响应,那么我们就会收到一个Response响应,内容包括html、json、图片、视频等,就是网页的源代码。
作者的博客图
3. 使用接收到的源码中的正则表达式,以及Beautifulsoup、pyquery等第三方解析库,解析html中的数据。最后,根据需要,我们可以将提取的数据保存在数据库或文件中。
哦,差点忘了。在Python中实现爬虫,需要一个好帮手——Beautiful Soup。
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以使用您喜欢的转换器来实现文档导航、搜索和修改文档的常用方式。Beautiful Soup 将为您节省数小时甚至数天的时间。工作时间。” (来自BeautifulSoup的官方描述)
urllib 是一个采集多个使用 URL 的模块的包,其中:
urllib.request 打开和读取 URL
urllib.error 收录 urllib.request 抛出的异常
urllib.parse 用于处理 URL
urllib.robotparser 用于解析 robots.txt 文件
没看懂?没关系。我们来看看一个简单的爬虫程序是如何实现的:
非常详细的注释警告!
一世。导入相关库
#首先,我们要导入urllib的request库,它可以实现向服务器发送request请求的功能
import urllib.request
#之后,我们需要用re库来解析我们接收到的内容,也就是网页代码
import re
#这个os库用来在本地创建一个目录,用于存放我们爬取的照片
import os
ii. 程序开始
<p>#程序开始,我们定义一个fetch_pictures函数来实现爬虫的主要功能
def fetch_pictures(url):
#首先,我们定义一个html_content变量来存放网页的HTML源代码
html_content = urllib.request.urlopen(url).read()
#接下来,使用正则表达式,指定匹配的特征为(.*?)
r = re.compile('
java爬虫抓取网页数据(项目名称数据库Java爬虫项目技术选型及实训环境实训案例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-10 11:06
项目名称:java爬虫
项目技术选择:Java、Maven、Mysql、WebMagic、Jsp、Servlet
项目实现方法:主要开发认知java爬虫框架WebMagic,利用所学的java知识完成指定的网站数据爬取分析,并使用Servlet和Jsp在页面上展示
培训环境:一人一机,边讲边练
培训介绍:
本次培训的主要目的是增强学员对WebMagic框架和Servlet的理解,结合所学的理论知识进行爬虫实战。要求学生掌握市场上广泛使用的Mysql数据、Java语言、WebMagic框架和Servlet的开发,了解大中型大数据行业的基本模型知识。
本次培训选定的案例包括:
Mysql数据库的基本操作
Java基本语法使用
构建和开发爬虫项目的WebMagic框架
通过学习这些内容,可以大大提高学生对计算机知识的理解,促进专业课程的学习,从而潜移默化地提高学生的就业竞争力。
步:
1、下载安装Maven,在Eclipse中配置Maven相关设置。
1),下载安装Maven
下载地址:/download.cgi,根据自己的系统选择合适的版本下载:
将下载的文件解压到合适的位置,完成Maven安装:
2),设置环境变量
将Maven安装路径下bin目录的路径复制到电脑的环境变量中:
复制bin目录所在的路径:
添加环境变量:
在cmd下输入:mvn --version查看Maven是否安装成功,出现如下提示则表示安装成功:
3),可以忽略:修改Maven安装目录conf(E:\apache-maven-3.5.4\conf\settings.xml)中的settings.xml文件进行配置本地仓库位置和远程仓库镜像修改为阿里云镜像:
配置本地仓库,在下面添加你要创建的本地仓库地址(根据自己的情况设置):
Maven仓库默认位于国外,使用起来难免会很慢,尤其是下载依赖的时候。速度很慢。换成国产阿里云镜像后,速度会有很大的提升:
aliyun
aliyun Maven
*
http://maven.aliyun.com/nexus/ ... ntral
4)、Eclipse配置
以下步骤中,每个人电脑上显示的内容可能不同(截图来自不同项目,请忽略包名、类名等信息,部分截图来自网络,不同截图中的相关信息可能不同),但是操作步骤是一样的,只要你在Eclipse上安装maven,打开Eclipse点击window>preferences,就会弹出来:
点击确定后,会出现:
点击完成后:
在 Eclipse 中配置 Maven:
打开 Eclipse 首选项设置
查找Maven配置项
设置Maven的全局配置文件settings.xml
更新配置信息
2、在Eclipse中创建Maven项目
1),打开eclipse,右键new——》other,找到maven项目如下图或者直接搜索maven projec:
创建项目:
2),选择Maven Project,请选择Create a simple project(skip archetype selection),然后点击Next:
3),填写Group id和Artifact id,Version默认,Packaging默认为jar,Name,Description可选,其他不需要填写:
然后单击完成。这时候需要稍等片刻才能下载所需的文件。创建后完整的项目结构应该如下图所示:
3、编写Java爬虫项目代码,抓取/position.php网站的相关信息:
1),需要抓取的网页内容:职位名称、职位类别、人数、地点、发布时间
2)。根据要爬取的内容(爬取的内容包括:职位、职位类别、人数、地点、发布时间),可以参考如下SQL语句设计数据库(mysql):
/*
SQLyog Ultimate v12.5.0 (64 bit)
MySQL - 5.5.27 : Database - mysql_java
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`mysql_java` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `mysql_java`;
/*Table structure for table `tencent_position` */
DROP TABLE IF EXISTS `tencent_position`;
CREATE TABLE `tencent_position` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`p_name` varchar(200) NOT NULL,
`p_link` varchar(200) NOT NULL,
`p_type` varchar(100) NOT NULL,
`p_num` varchar(20) NOT NULL,
`p_location` varchar(20) NOT NULL,
`p_publish_time` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1125 DEFAULT CHARSET=utf8;
3)。在创建的项目下,需要先配置pom.xml,然后创建四个类和一个接口(自己命名):MySQLUtils、TencentPageProcessor、TencentPosition、TencentPositionDao(接口)、TencentPositionDaoImpl
配置 pom.xml:
pom.xml文件的设置:填写完内容后记得按Ctrl+S/save键,然后Eclipse会自动从设置好的Maven仓库下载需要的文件。可能需要一定的时间:
依赖数据来自:/单独搜索:webmagic,mysql会显示相关内容
点击搜索到的内容,将框中的代码复制到pom.xml的代码块中:
可以在Maven Dependencies库中查看下载是否完成:
以下为示例代码,自行编码时请记得更改代码。
MySQLUtils 类代码如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class MySQLUtils {
private static Connection connection;
public static Connection getConnection() throws ClassNotFoundException, SQLException {
if (connection == null) {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/mysql_java";//URL、User、Password需根据自己的实际情况填写
String user = "root";
String password = "root";
return DriverManager.getConnection(url, user, password);
}
return connection;
}
}
腾讯位置代码如下:
public class TencentPosition {
private String positionName;
private String positionLink;
private String positionType;
private String positionNum;
private String workLocation;
private String publishTime;
public TencentPosition() {
super();
}
public TencentPosition(String positionName, String positionLink, String positionType, String positionNum,
String workLocation, String publishTime) {
super();
this.positionName = positionName;
this.positionLink = positionLink;
this.positionType = positionType;
this.positionNum = positionNum;
this.workLocation = workLocation;
this.publishTime = publishTime;
}
public String getPositionName() {
return positionName;
}
public void setPositionName(String positionName) {
this.positionName = positionName;
}
public String getPositionLink() {
return positionLink;
}
public void setPositionLink(String positionLink) {
this.positionLink = positionLink;
}
public String getPositionType() {
return positionType;
}
public void setPositionType(String positionType) {
this.positionType = positionType;
}
public String getPositionNum() {
return positionNum;
}
public void setPositionNum(String positionNum) {
this.positionNum = positionNum;
}
public String getWorkLocation() {
return workLocation;
}
public void setWorkLocation(String workLocation) {
this.workLocation = workLocation;
}
public String getPublishTime() {
return publishTime;
}
public void setPublishTime(String publishTime) {
this.publishTime = publishTime;
}
@Override
public String toString() {
return "TencentPosition [positionName=" + positionName + ", positionLink=" + positionLink + ", positionType="
+ positionType + ", positionNum=" + positionNum + ", workLocation=" + workLocation + ", publishTime="
+ publishTime + "]";
}
}
腾讯PositionDao接口代码如下:
public interface TencentPositionDao {
int add(TencentPosition position);
}
腾讯PositionDaoImpl类代码如下:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TencentPositionDaoImpl implements TencentPositionDao {
public int add(TencentPosition position) {
String sql = "INSERT INTO tencent_position(p_name, p_link, p_type, p_num, p_location, p_publish_time)"
+ " VALUES(?, ?, ?, ?, ?, ?)";
Connection conn = null;
PreparedStatement pst = null;
try {
conn = MySQLUtils.getConnection();
pst = conn.prepareStatement(sql);
pst.setString(1, position.getPositionName());
pst.setString(2, position.getPositionLink());
pst.setString(3, position.getPositionType());
pst.setString(4, position.getPositionNum());
pst.setString(5, position.getWorkLocation());
pst.setString(6, position.getPublishTime());
return pst.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (pst != null) {
try {
pst.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
pst = null;
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
conn = null;
}
}
}
return 0;
}
}
TencentPageProcessor 类代码如下:
<p>import java.util.List;
import java.util.concurrent.atomic.AtomicLong;import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.JsonFilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class TencentPageProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(5).setSleepTime(1000);
private static TencentPositionDao dao = new TencentPositionDaoImpl();
public static AtomicLong count = new AtomicLong();
public static AtomicLong total = new AtomicLong();
public Site getSite() {
return site;
}
public void process(Page page) {
List urlList = page.getHtml().links().regex("https://hr.tencent.com/position.php\\?&start=\\d+").all();
System.out.println(urlList);
page.addTargetRequests(urlList);
List positionNames = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/text()").all();
List positionLinks = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/@href").all();
List positionTypes = page.getHtml().xpath("//tr[@class='odd']/td[2]/text()").all();
List positionNums = page.getHtml().xpath("//tr[@class='odd']/td[3]/text()").all();
List workLocations = page.getHtml().xpath("//tr[@class='odd']/td[4]/text()").all();
List publishTimes = page.getHtml().xpath("//tr[@class='odd']/td[5]/text()").all();
for (int i = 0; i 查看全部
java爬虫抓取网页数据(项目名称数据库Java爬虫项目技术选型及实训环境实训案例)
项目名称:java爬虫
项目技术选择:Java、Maven、Mysql、WebMagic、Jsp、Servlet
项目实现方法:主要开发认知java爬虫框架WebMagic,利用所学的java知识完成指定的网站数据爬取分析,并使用Servlet和Jsp在页面上展示
培训环境:一人一机,边讲边练
培训介绍:
本次培训的主要目的是增强学员对WebMagic框架和Servlet的理解,结合所学的理论知识进行爬虫实战。要求学生掌握市场上广泛使用的Mysql数据、Java语言、WebMagic框架和Servlet的开发,了解大中型大数据行业的基本模型知识。
本次培训选定的案例包括:
Mysql数据库的基本操作
Java基本语法使用
构建和开发爬虫项目的WebMagic框架
通过学习这些内容,可以大大提高学生对计算机知识的理解,促进专业课程的学习,从而潜移默化地提高学生的就业竞争力。
步:
1、下载安装Maven,在Eclipse中配置Maven相关设置。
1),下载安装Maven
下载地址:/download.cgi,根据自己的系统选择合适的版本下载:
将下载的文件解压到合适的位置,完成Maven安装:
2),设置环境变量
将Maven安装路径下bin目录的路径复制到电脑的环境变量中:
复制bin目录所在的路径:
添加环境变量:
在cmd下输入:mvn --version查看Maven是否安装成功,出现如下提示则表示安装成功:
3),可以忽略:修改Maven安装目录conf(E:\apache-maven-3.5.4\conf\settings.xml)中的settings.xml文件进行配置本地仓库位置和远程仓库镜像修改为阿里云镜像:
配置本地仓库,在下面添加你要创建的本地仓库地址(根据自己的情况设置):
Maven仓库默认位于国外,使用起来难免会很慢,尤其是下载依赖的时候。速度很慢。换成国产阿里云镜像后,速度会有很大的提升:
aliyun
aliyun Maven
*
http://maven.aliyun.com/nexus/ ... ntral
4)、Eclipse配置
以下步骤中,每个人电脑上显示的内容可能不同(截图来自不同项目,请忽略包名、类名等信息,部分截图来自网络,不同截图中的相关信息可能不同),但是操作步骤是一样的,只要你在Eclipse上安装maven,打开Eclipse点击window>preferences,就会弹出来:
点击确定后,会出现:
点击完成后:
在 Eclipse 中配置 Maven:
打开 Eclipse 首选项设置
查找Maven配置项
设置Maven的全局配置文件settings.xml
更新配置信息
2、在Eclipse中创建Maven项目
1),打开eclipse,右键new——》other,找到maven项目如下图或者直接搜索maven projec:
创建项目:
2),选择Maven Project,请选择Create a simple project(skip archetype selection),然后点击Next:
3),填写Group id和Artifact id,Version默认,Packaging默认为jar,Name,Description可选,其他不需要填写:
然后单击完成。这时候需要稍等片刻才能下载所需的文件。创建后完整的项目结构应该如下图所示:
3、编写Java爬虫项目代码,抓取/position.php网站的相关信息:
1),需要抓取的网页内容:职位名称、职位类别、人数、地点、发布时间
2)。根据要爬取的内容(爬取的内容包括:职位、职位类别、人数、地点、发布时间),可以参考如下SQL语句设计数据库(mysql):
/*
SQLyog Ultimate v12.5.0 (64 bit)
MySQL - 5.5.27 : Database - mysql_java
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`mysql_java` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `mysql_java`;
/*Table structure for table `tencent_position` */
DROP TABLE IF EXISTS `tencent_position`;
CREATE TABLE `tencent_position` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`p_name` varchar(200) NOT NULL,
`p_link` varchar(200) NOT NULL,
`p_type` varchar(100) NOT NULL,
`p_num` varchar(20) NOT NULL,
`p_location` varchar(20) NOT NULL,
`p_publish_time` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1125 DEFAULT CHARSET=utf8;
3)。在创建的项目下,需要先配置pom.xml,然后创建四个类和一个接口(自己命名):MySQLUtils、TencentPageProcessor、TencentPosition、TencentPositionDao(接口)、TencentPositionDaoImpl
配置 pom.xml:
pom.xml文件的设置:填写完内容后记得按Ctrl+S/save键,然后Eclipse会自动从设置好的Maven仓库下载需要的文件。可能需要一定的时间:
依赖数据来自:/单独搜索:webmagic,mysql会显示相关内容
点击搜索到的内容,将框中的代码复制到pom.xml的代码块中:
可以在Maven Dependencies库中查看下载是否完成:
以下为示例代码,自行编码时请记得更改代码。
MySQLUtils 类代码如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class MySQLUtils {
private static Connection connection;
public static Connection getConnection() throws ClassNotFoundException, SQLException {
if (connection == null) {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/mysql_java";//URL、User、Password需根据自己的实际情况填写
String user = "root";
String password = "root";
return DriverManager.getConnection(url, user, password);
}
return connection;
}
}
腾讯位置代码如下:
public class TencentPosition {
private String positionName;
private String positionLink;
private String positionType;
private String positionNum;
private String workLocation;
private String publishTime;
public TencentPosition() {
super();
}
public TencentPosition(String positionName, String positionLink, String positionType, String positionNum,
String workLocation, String publishTime) {
super();
this.positionName = positionName;
this.positionLink = positionLink;
this.positionType = positionType;
this.positionNum = positionNum;
this.workLocation = workLocation;
this.publishTime = publishTime;
}
public String getPositionName() {
return positionName;
}
public void setPositionName(String positionName) {
this.positionName = positionName;
}
public String getPositionLink() {
return positionLink;
}
public void setPositionLink(String positionLink) {
this.positionLink = positionLink;
}
public String getPositionType() {
return positionType;
}
public void setPositionType(String positionType) {
this.positionType = positionType;
}
public String getPositionNum() {
return positionNum;
}
public void setPositionNum(String positionNum) {
this.positionNum = positionNum;
}
public String getWorkLocation() {
return workLocation;
}
public void setWorkLocation(String workLocation) {
this.workLocation = workLocation;
}
public String getPublishTime() {
return publishTime;
}
public void setPublishTime(String publishTime) {
this.publishTime = publishTime;
}
@Override
public String toString() {
return "TencentPosition [positionName=" + positionName + ", positionLink=" + positionLink + ", positionType="
+ positionType + ", positionNum=" + positionNum + ", workLocation=" + workLocation + ", publishTime="
+ publishTime + "]";
}
}
腾讯PositionDao接口代码如下:
public interface TencentPositionDao {
int add(TencentPosition position);
}
腾讯PositionDaoImpl类代码如下:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class TencentPositionDaoImpl implements TencentPositionDao {
public int add(TencentPosition position) {
String sql = "INSERT INTO tencent_position(p_name, p_link, p_type, p_num, p_location, p_publish_time)"
+ " VALUES(?, ?, ?, ?, ?, ?)";
Connection conn = null;
PreparedStatement pst = null;
try {
conn = MySQLUtils.getConnection();
pst = conn.prepareStatement(sql);
pst.setString(1, position.getPositionName());
pst.setString(2, position.getPositionLink());
pst.setString(3, position.getPositionType());
pst.setString(4, position.getPositionNum());
pst.setString(5, position.getWorkLocation());
pst.setString(6, position.getPublishTime());
return pst.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (pst != null) {
try {
pst.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
pst = null;
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
} finally {
conn = null;
}
}
}
return 0;
}
}
TencentPageProcessor 类代码如下:
<p>import java.util.List;
import java.util.concurrent.atomic.AtomicLong;import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.JsonFilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class TencentPageProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(5).setSleepTime(1000);
private static TencentPositionDao dao = new TencentPositionDaoImpl();
public static AtomicLong count = new AtomicLong();
public static AtomicLong total = new AtomicLong();
public Site getSite() {
return site;
}
public void process(Page page) {
List urlList = page.getHtml().links().regex("https://hr.tencent.com/position.php\\?&start=\\d+").all();
System.out.println(urlList);
page.addTargetRequests(urlList);
List positionNames = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/text()").all();
List positionLinks = page.getHtml().xpath("//tr[@class='odd']/td[1]/a/@href").all();
List positionTypes = page.getHtml().xpath("//tr[@class='odd']/td[2]/text()").all();
List positionNums = page.getHtml().xpath("//tr[@class='odd']/td[3]/text()").all();
List workLocations = page.getHtml().xpath("//tr[@class='odd']/td[4]/text()").all();
List publishTimes = page.getHtml().xpath("//tr[@class='odd']/td[5]/text()").all();
for (int i = 0; i
java爬虫抓取网页数据(java爬虫抓取网页数据第一步:读取网页的html代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-09 06:07
java爬虫抓取网页数据第一步:读取网页的html代码第二步:解析html代码第三步:构造数据tomcat对网页进行解析以下代码是按http协议通过抓包得到最终的代码我们来看看一个电影的网页我们来看看一个电影的网页以下代码是通过抓包得到最终的代码我们来看看一个电影的网页的代码比如我要抓取下面这个网页,我先将电影的所有信息抓取下来。
chrome浏览器右上角打开“开发者工具”打开网页编程的窗口我们需要抓取的网页headers开始后续的代码,需要输入的user-agent,可以抓取中国官网的默认headers,比如谷歌浏览器的user-agent就是googlechrome。首先选择一个电影电影的基本信息需要的信息就是电影名,演员信息,时间,评分和评论,分数=“评分”,时间就是“时间”,评分为平分/分数计算,这些属性还是比较好记住的,比如我要下载最高评分为9分的电影,评分规则就是9分以上就选电影名下面需要爬取的html代码有这么几个内容:<p>大师$(".country_me").href("country_family");$(".country_me").bind("click(/hi",function(){console.log(this);});$(".country_me").href("star");这里有个小坑,选择好的电影信息要加上/user-agent/或者"",这里可以直接用浏览器打开网页了。</p>
header可以看到这个header是example_header的节点。googlechrome就是这个节点,这个域名指定了这个节点的解析,之前不应该创建了这个域名吗。浏览器解析的网页headers中有一个参数是“user-agent”,用来指定浏览器返回信息的格式我们需要把user-agent中的“”替换掉。
然后在开发者工具的网络测试里看看headers是否正确。代码里有些信息我们没有提供,比如href是一个空值,只是为了看这个连接结果能不能复制过来,我们把地址复制过来:百度搜索chrome然后,看看,结果给我来了大师。那我在提供user-agent的前提下,就可以爬取到chrome的所有的解析连接,比如查看查看chrome的所有解析连接这是查看了所有的所有连接就可以构造这些的数据。
把以上的链接打包成压缩包,发到。解析网页的代码将会被替换成上面的压缩包代码。我们也可以用来解析podcast。我在。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据第一步:读取网页的html代码)
java爬虫抓取网页数据第一步:读取网页的html代码第二步:解析html代码第三步:构造数据tomcat对网页进行解析以下代码是按http协议通过抓包得到最终的代码我们来看看一个电影的网页我们来看看一个电影的网页以下代码是通过抓包得到最终的代码我们来看看一个电影的网页的代码比如我要抓取下面这个网页,我先将电影的所有信息抓取下来。
chrome浏览器右上角打开“开发者工具”打开网页编程的窗口我们需要抓取的网页headers开始后续的代码,需要输入的user-agent,可以抓取中国官网的默认headers,比如谷歌浏览器的user-agent就是googlechrome。首先选择一个电影电影的基本信息需要的信息就是电影名,演员信息,时间,评分和评论,分数=“评分”,时间就是“时间”,评分为平分/分数计算,这些属性还是比较好记住的,比如我要下载最高评分为9分的电影,评分规则就是9分以上就选电影名下面需要爬取的html代码有这么几个内容:<p>大师$(".country_me").href("country_family");$(".country_me").bind("click(/hi",function(){console.log(this);});$(".country_me").href("star");这里有个小坑,选择好的电影信息要加上/user-agent/或者"",这里可以直接用浏览器打开网页了。</p>
header可以看到这个header是example_header的节点。googlechrome就是这个节点,这个域名指定了这个节点的解析,之前不应该创建了这个域名吗。浏览器解析的网页headers中有一个参数是“user-agent”,用来指定浏览器返回信息的格式我们需要把user-agent中的“”替换掉。
然后在开发者工具的网络测试里看看headers是否正确。代码里有些信息我们没有提供,比如href是一个空值,只是为了看这个连接结果能不能复制过来,我们把地址复制过来:百度搜索chrome然后,看看,结果给我来了大师。那我在提供user-agent的前提下,就可以爬取到chrome的所有的解析连接,比如查看查看chrome的所有解析连接这是查看了所有的所有连接就可以构造这些的数据。
把以上的链接打包成压缩包,发到。解析网页的代码将会被替换成上面的压缩包代码。我们也可以用来解析podcast。我在。
java爬虫抓取网页数据(java实现了一个简单的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-08 04:18
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。 查看全部
java爬虫抓取网页数据(java实现了一个简单的网页数据)
最近用java实现了一个简单的网页数据抓取。下面是实现原理和实现代码:
原理:使用如下URL对象获取链接,下载目标网页的源码,使用jsoup解析源码中的数据,得到想要的内容
1.首先根据网址下载源码:
/**
* 根据网址和编码下载源代码
* @param url 目标网址
* @param encoding 编码
* @return
*/
public static String getHtmlResourceByURL(String url,String encoding){
//存储源代码容器
StringBuffer buffer = new StringBuffer();
URL urlObj = null;
URLConnection uc = null;
InputStreamReader isr = null;
BufferedReader br =null;
try {
//建立网络连接
urlObj = new URL(url);
//打开网络连接
uc = urlObj.openConnection();
//建立文件输入流
isr = new InputStreamReader(uc.getInputStream(),encoding);
InputStream is = uc.getInputStream();
//建立文件缓冲写入流
br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("F:\\java-study\\downImg\\index.txt");
//建立临时变量
String temp = null;
while((temp = br.readLine()) != null){
buffer.append(temp + "\n");
}
// fos.write(buffer.toString().getBytes());
// fos.close();
} catch (MalformedURLException e) {
e.printStackTrace();
System.out.println("网络不给力,请检查网络设置。。。。");
}catch (IOException e){
e.printStackTrace();
System.out.println("你的网络连接打开失败,请稍后重新尝试!");
}finally {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return buffer.toString();
}
2.根据下载的源码分析数据得到你想要的内容,这里我拿图,你也可以在贴吧中得到邮箱、电话等
/**
* 获取图片路劲
* @param url 网络路径
* @param encoding 编码
*/
public static void downImg(String url,String encoding){
String resourceByURL = getHtmlResourceByURL(url, encoding);
//2.解析源代码,根据网络图像地址,下载到服务器
Document document = Jsoup.parse(resourceByURL);
//获取页面中所有的图片标签
Elements elements = document.getElementsByTag("img");
for(Element element:elements){
//获取图像地址
String src = element.attr("src");
//包含http开头
if (src.startsWith("http") && src.indexOf("jpg") != -1) {
getImg(src, "F:\\java-study\\downImg");
}
}
}
3. 根据获取到的图片路径下载图片,这里我下载的是携程网的内容
/**
* 下载图片
* @param imgUrl 图片地址
* @param filePath 存储路劲
*
*/
public static void getImg(String imgUrl,String filePath){
String fileName = imgUrl.substring(imgUrl.lastIndexOf("/"));
try {
//创建目录
File files = new File(filePath);
if (!files.exists()) {
files.mkdirs();
}
//获取地址
URL url = new URL(imgUrl);
//打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//获取输入流
InputStream is = connection.getInputStream();
File file = new File(filePath + fileName);
//建立问价输入流
FileOutputStream fos = new FileOutputStream(file);
int temp = 0;
while((temp = is.read()) != -1){
fos.write(temp);
}
is.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
最后是调用过程
public static void main(String[] args) {
//1.根据网址和页面编码集获取网页源代码
String encoding = "gbk";
String url = "http://vacations.ctrip.com/";
//2.解析源代码,根据网络图像地址,下载到服务器
downImg(url, encoding);
}
总结:根据上面实现的简单数据爬取,存在一些问题。我爬的旅游页面有很多图片。根据img属性,我在src里面拿到了下载图片的地址,但是页面图片很多。结果但是我只能爬到一小部分,如下图:
我把下载的源代码写成文件,和原来的网页对比。基本上,没有页面浏览的图片,也没有在源代码中。不知道为什么,求网友解答。
java爬虫抓取网页数据(利用网络爬虫技术与算法实现网络新闻数据自动化采集与结构化存储)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-07 09:27
利用相关的网络爬虫技术和算法,实现网络媒体新闻数据采集的自动化和结构化存储,并利用中文分词算法和中文相似度分析算法总结梳理相关新闻发展趋势,反映网络挖掘新闻数据的价值。
企业如果能够选取与自身相关的新闻进行分析,可以获得很多意想不到的收获,比如幕后是否有蓄意诽谤,竞争对手的情况等。第一时间掌握与之相关的网络新闻的负面影响,发挥公关的力量,及时纠正错误,平息负面新闻。这对今天的企业来说是非常有价值的。
内容
开发环境
原理分析
项目结构
项目截图
总结
下载链接
开发环境
开发语言:java JDK 版本1.7.
开发环境:Eclipse。
数据库向下兼容,最低兼容Mysql5.1。
原理分析
将网页URL输入爬虫系统,爬虫开启网页分析流程提取网页正文,然后输出网页正文。
网页正文传入系统,系统根据词库及相关策略开始分词,最终以数据的形式(以词组的形式)输出分词结果。
首先第一步输入数据:网络爬虫系统采集接收到的数据作为相似匹配系统的输入,然后进入处理过程,采用改进的余弦定律进行处理,然后系统返回处理后的结果 最后,系统将处理后的结果输出并传递给下一个子系统进行处理。
网络爬虫系统是数据采集系统,新闻分析系统是中文语料相似度分析系统和最终结果展示系统。
项目结构
项目截图
总结
在DBCP连接池UML图中,定义了数据库异常抛出类、数据库配置POJO类、数据库连接池核心类Pool,代理实现了Connection的close()方法、setAutoCommit()等方法,以及作为数据库连接池的Monitor类,用于监控数据库的健康等。
爬虫的核心是Web类。凤凰新闻、搜狐新闻、网易新闻分别集成核心Web类,然后实现各自的解析规则。核心Web类负责一些基本的操作,比如打开网页,获取网页源代码,以及一些常规的规则。表达提取分析算法。其实Web类也收录POJO类的作用,也是爬虫爬取新闻后生成结果的载体。
因为爬虫系统的逻辑设计比较简单,所以不涉及基本的路径方法,因为整个正序只需要在固定的时间运行,不像其他软件系统,有很深的用户需求基础,需要相关人员的配合。.
下载链接 查看全部
java爬虫抓取网页数据(利用网络爬虫技术与算法实现网络新闻数据自动化采集与结构化存储)
利用相关的网络爬虫技术和算法,实现网络媒体新闻数据采集的自动化和结构化存储,并利用中文分词算法和中文相似度分析算法总结梳理相关新闻发展趋势,反映网络挖掘新闻数据的价值。
企业如果能够选取与自身相关的新闻进行分析,可以获得很多意想不到的收获,比如幕后是否有蓄意诽谤,竞争对手的情况等。第一时间掌握与之相关的网络新闻的负面影响,发挥公关的力量,及时纠正错误,平息负面新闻。这对今天的企业来说是非常有价值的。
内容
开发环境
原理分析
项目结构
项目截图
总结
下载链接
开发环境
开发语言:java JDK 版本1.7.
开发环境:Eclipse。
数据库向下兼容,最低兼容Mysql5.1。
原理分析
将网页URL输入爬虫系统,爬虫开启网页分析流程提取网页正文,然后输出网页正文。
网页正文传入系统,系统根据词库及相关策略开始分词,最终以数据的形式(以词组的形式)输出分词结果。
首先第一步输入数据:网络爬虫系统采集接收到的数据作为相似匹配系统的输入,然后进入处理过程,采用改进的余弦定律进行处理,然后系统返回处理后的结果 最后,系统将处理后的结果输出并传递给下一个子系统进行处理。
网络爬虫系统是数据采集系统,新闻分析系统是中文语料相似度分析系统和最终结果展示系统。
项目结构
项目截图
总结
在DBCP连接池UML图中,定义了数据库异常抛出类、数据库配置POJO类、数据库连接池核心类Pool,代理实现了Connection的close()方法、setAutoCommit()等方法,以及作为数据库连接池的Monitor类,用于监控数据库的健康等。
爬虫的核心是Web类。凤凰新闻、搜狐新闻、网易新闻分别集成核心Web类,然后实现各自的解析规则。核心Web类负责一些基本的操作,比如打开网页,获取网页源代码,以及一些常规的规则。表达提取分析算法。其实Web类也收录POJO类的作用,也是爬虫爬取新闻后生成结果的载体。
因为爬虫系统的逻辑设计比较简单,所以不涉及基本的路径方法,因为整个正序只需要在固定的时间运行,不像其他软件系统,有很深的用户需求基础,需要相关人员的配合。.
下载链接
java爬虫抓取网页数据(java中好系列包含哪些内容?java爬虫框架webmgic入门使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-02 10:09
1. 概述一下java爬虫系列都收录哪些内容?java爬虫框架入门 webmgic 使用webmgic抓取电影资源(动作片列表页、电影下载地址等) 使用webmgic抓取极客时间的课程资源(文章系列课程和视频系列课程)本文章 主要内容:介绍java中有用的爬虫框架Java爬虫框架webmagic介绍使用webgic爬取动作电影列表信息2.如何判断框架在好用的爬虫中是否优秀java中的框架?它易于学习和使用。网上相应的学习资料比较多,用得好的人也比较多。别人已经给你填好了。使用起来会更舒服。一些框架更新得更快,社区活跃,可以快速体验一些更好的功能,与作者交流。框架稳定,易于扩展。
根据以上几点,推荐一个非常好用的java爬虫框架webmgic
3. webmgic简介4. 使用webgic爬取动作片列表
使用webgic爬取爱情电影的电影列表资源信息
示例源代码地址
1. springboot 新项目 java-pachong
2. 导入maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3. 编写代码捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4. 运行爬虫代码
运行Ady01comPageProcessor中的main方法,执行结果如下:
5.总结本文主要通过一个例子来说明webgic如此简单,可以完成数据的抓取工作。从代码可以看出,复杂的代码webmagic帮我们屏蔽了,我们只需要关注业务代码即可。准备。文章 webmagic的使用方法没有详细说明。至于为什么我没有在文档中说明,主要是webigc提供了非常完整的学习文档。可以移动到webgic中文文档。如果需要更深入的了解,可以研究一下webgic的源码,对你写爬虫很有用。明天我们会爬取每部动作片的详情页信息,采集详情页中电影下载地址的示例代码,导入idea运行, 查看全部
java爬虫抓取网页数据(java中好系列包含哪些内容?java爬虫框架webmgic入门使用)
1. 概述一下java爬虫系列都收录哪些内容?java爬虫框架入门 webmgic 使用webmgic抓取电影资源(动作片列表页、电影下载地址等) 使用webmgic抓取极客时间的课程资源(文章系列课程和视频系列课程)本文章 主要内容:介绍java中有用的爬虫框架Java爬虫框架webmagic介绍使用webgic爬取动作电影列表信息2.如何判断框架在好用的爬虫中是否优秀java中的框架?它易于学习和使用。网上相应的学习资料比较多,用得好的人也比较多。别人已经给你填好了。使用起来会更舒服。一些框架更新得更快,社区活跃,可以快速体验一些更好的功能,与作者交流。框架稳定,易于扩展。
根据以上几点,推荐一个非常好用的java爬虫框架webmgic
3. webmgic简介4. 使用webgic爬取动作片列表
使用webgic爬取爱情电影的电影列表资源信息
示例源代码地址
1. springboot 新项目 java-pachong
2. 导入maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3. 编写代码捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4. 运行爬虫代码
运行Ady01comPageProcessor中的main方法,执行结果如下:
5.总结本文主要通过一个例子来说明webgic如此简单,可以完成数据的抓取工作。从代码可以看出,复杂的代码webmagic帮我们屏蔽了,我们只需要关注业务代码即可。准备。文章 webmagic的使用方法没有详细说明。至于为什么我没有在文档中说明,主要是webigc提供了非常完整的学习文档。可以移动到webgic中文文档。如果需要更深入的了解,可以研究一下webgic的源码,对你写爬虫很有用。明天我们会爬取每部动作片的详情页信息,采集详情页中电影下载地址的示例代码,导入idea运行,
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-30 14:04
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,我们首先要分析html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这次文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己爬取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
} 查看全部
java爬虫抓取网页数据(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页
)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,我们首先要分析html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这次文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己爬取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-30 14:01
一、java爬虫的主要步骤是:
非结构化数据–>数据采集–>数据清洗–>结构化数据–>采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬取,哪些页面不能爬取。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,默认都可以爬取。即使有这个文件,你也不必遵守,但他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存或者nosql缓存服务器中进行重复数据删除,常见的有:布隆过滤器、redis……这些人自己百度一下,我也无能为力。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
①Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度向量角的余弦。主要思想是将文章中出现的词频组成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。 查看全部
java爬虫抓取网页数据(java爬虫的步骤和分类策略(一)策略)
一、java爬虫的主要步骤是:
非结构化数据–>数据采集–>数据清洗–>结构化数据–>采集存储
1.结构化数据:一般是指存储在数据库中的数据,具有一定的逻辑和物理结构
2.非结构化数据:与结构化数据相比,非结构化数据是不方便用数据库的二维逻辑来表达的数据,如音频、视频、网页数据(html、xml)等。
3.数据采集
(1)Data采集遵循一个protocol-robots协议,全称是“网络爬虫排除标准”,他会告诉你哪些页面可以爬取,哪些页面不能爬取。他是基于on Robots.txt以文本形式存放在网站的根目录下,如果有这个文件,会按照其允许的内容进行爬取,如果没有,默认都可以爬取。即使有这个文件,你也不必遵守,但他们已经给了这个文件作为约束。
(2)文件怎么写:
User-agent: * * 是一个通配符,表示所有类型的搜索引擎都可用。
Diasllow:/admin/ 表示禁止爬取admin目录的内容
不允许: *?* 意思是禁止爬行收录?'S页面
sitemap:sitemap.xml 指的是sitemap 指定的固定网站 地图页面。这样做的好处是站长不需要去各个搜索引擎的站长工具或类似的站长部件提交自己的站点地图文件。搜索引擎的蜘蛛会自己爬取robots.txt文件,读取sitemap文件,然后爬取其中的链接。
4.数据清洗
数据清洗是一个重新检查和验证的过程,目的是去除重复信息,纠正错误和错误,而不是提供数据一致性。
5.采集器的分类
(1)批量数据采集器
(2)增量数据采集器
(3)垂直数据采集器
因为他不怎么讲emmmm,你可以自己百度。
二、 爬虫策略
(1) 深度优先策略:从起始页开始,按一个链接进入,处理完这个,回到下一个。
(2)宽度优先策略:抓取实际页面中的所有链接,然后选择一个链接继续抓取该链接的所有链接内容。
(3) 反向链接数策略:反向链接数是指其他网页链接到某个网页的数量,表示其他网页推荐的程度,作为先爬取的原因
(4) 不完整的PageRank策略:使用PageRank策略参考:根据一定的算法分析(百度...),计算每个页面的PageRank值作为爬取的依据。
(5)大站优先策略:根据网站的分类,需要下载的页面多的网站优先被抓取。
三、互联网采集进程
采集入口->获取URL队列->URL去重->网页下载->数据分析->数据解压->去重->数据存储
(1)URL重复数据删除:存储在内存或者nosql缓存服务器中进行重复数据删除,常见的有:布隆过滤器、redis……这些人自己百度一下,我也无能为力。
(2)网页下载:有两种情况,一种是下载存储,一种是下载不存储。存储的常见存储方式是:hadoop分布式存储。
(3)重复数据删除:判断采集数据是否存在于数据库中,进行重复数据删除。一般情况下,重复数据删除使用simhash算法处理文本类型的数据。
(4)数据存储:
分布式nosql数据库(Mongodb/hbase等)
关系分布式数据库(mysql/oracle等)
索引存储(Elasticsearch/solr 等)
①Nosql数据库:非关系型数据库,分为键值对数据库、列数据库,如:mongodb、hbase、Redis、sqllist等。
②关系型数据库:以行列形式存储
③索引存储:存储在文档和字段中,一个文档可以收录多个字段,如:lucene、Elasticsearch、solr等。
④ Simhash算法:是文本相似度向量角的余弦。主要思想是将文章中出现的词频组成一个向量,然后计算文章的两个对应向量的向量角。
各位兄弟姐妹们,我是大二的,我只学了一个星期,所以我会有很多不明白的地方和错误。,请体谅。我只是想记录一下我的学习内容。
java爬虫抓取网页数据(一下java下抓取网页上特定内容的方法-之前java中访问http )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-29 06:02
)
在进入正题之前,我们先来了解一下java下抓取网页上特定内容的方法,也就是所谓的网络爬虫。本文仅涉及简单的文字信息和链接爬取。java中访问http的方式不超过两种。一种是使用原来的httpconnection,另一种是使用封装好的插件或者框架,比如httpclient、okHttp等。在测试和抓取网页信息的过程中,我使用的是jsoup工具,因为该工具没有只封装了http访问,还具有强大的html解析功能。可以参考详细的使用教程。
第一步是访问登陆页面
文档 doc = Jsoup.connect("").get();
第二步,使用jsoup的选择器选择网页所需内容的具体元素(使用正则表达式效率更高)。在这个例子中,目标网页是一个论坛,我们需要做的是抓取论坛首页所有帖子的标题名称和链接地址。
首先打开目标网址,使用谷歌浏览器浏览网页结构,找到结构对应的内容,如下图
然后选择区域
Elements links = doc.getElementsByAttributeValue("id","lphymodelsub");
接下来,获取选中区域的内容并保存到数组中
对于(元素链接:链接){
CatchModel c = new CatchModel();
String linkHref = ""+link.parent().attr("href");
String linkText = link.text();
c.setText(linkText);
c.setUrl(linkHref);
fistCatchList.add(c);
}
这样一个简单的爬行就完成了。
下一步是新浪微博的爬取。一般http访问新浪微博网站得到的html很简单,因为新浪微博首页是用js动态生成的,需要多次访问。请求和验证只能访问成功,所以为了方便抓取数据,我们通过了一个后门,就是访问新浪微博的移动端进行抓取。然而,随之而来的一个问题是,访问新浪微博并不重要。任一端都需要强制登录认证,所以我们需要在http请求中附加一个cookie进行用户认证。网上找了很久,想用webcontroller这个开源的爬虫框架。它易于访问且高效。我们来看看如何使用这个框架。
首先需要导入依赖包,WebController的ja包和selenium的jar包
下载链接:
使用Selenium获取cookie登录新浪微博(WeiboCN.java)
使用WebCollector和获取的cookies抓取新浪微博并提取数据(WeiboCrawler.java)
微博CN.java
import java.util.Set;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 利用Selenium获取登陆新浪微博weibo.cn的cookie
* @author hu
*/
public class WeiboCN {
/**
* 获取新浪微博的cookie,这个方法针对weibo.cn有效,对weibo.com无效
* weibo.cn以明文形式传输数据,请使用小号
* @param username 新浪微博用户名
* @param password 新浪微博密码
* @return
* @throws Exception
*/
public static String getSinaCookie(String username, String password) throws Exception{
StringBuilder sb = new StringBuilder();
HtmlUnitDriver driver = new HtmlUnitDriver();
driver.setJavascriptEnabled(true);
driver.get("http://login.weibo.cn/login/");
WebElement mobile = driver.findElementByCssSelector("input[name=mobile]");
mobile.sendKeys(username);
WebElement pass = driver.findElementByCssSelector("input[name^=password]");
pass.sendKeys(password);
WebElement rem = driver.findElementByCssSelector("input[name=remember]");
rem.click();
WebElement submit = driver.findElementByCssSelector("input[name=submit]");
submit.click();
Set cookieSet = driver.manage().getCookies();
driver.close();
for (Cookie cookie : cookieSet) {
sb.append(cookie.getName()+"="+cookie.getValue()+";");
}
String result=sb.toString();
if(result.contains("gsid_CTandWM")){
return result;
}else{
throw new Exception("weibo login failed");
}
}
}
<p style="font-size:15px; line-height:1.5em; font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; widows:auto">WeiboCrawler.javaimport cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.net.HttpRequest;
import cn.edu.hfut.dmic.webcollector.net.HttpResponse;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 利用WebCollector和获取的cookie爬取新浪微博并抽取数据
* @author hu
*/
public class WeiboCrawler extends BreadthCrawler {
String cookie;
public WeiboCrawler(String crawlPath, boolean autoParse) throws Exception {
super(crawlPath, autoParse);
/*获取新浪微博的cookie,账号密码以明文形式传输,请使用小号*/
cookie = WeiboCN.getSinaCookie("你的用户名", "你的密码");
}
@Override
public HttpResponse getResponse(CrawlDatum crawlDatum) throws Exception {
HttpRequest request = new HttpRequest(crawlDatum);
request.setCookie(cookie);
return request.getResponse();
}
@Override
public void visit(Page page, CrawlDatums next) {
int pageNum = Integer.valueOf(page.getMetaData("pageNum"));
/*抽取微博*/
Elements weibos = page.select("div.c");
for (Element weibo : weibos) {
System.out.println("第" + pageNum + "页\t" + weibo.text());
}
}
public static void main(String[] args) throws Exception {
WeiboCrawler crawler = new WeiboCrawler("weibo_crawler", false);
crawler.setThreads(3);
/*对某人微博前5页进行爬取*/
for (int i = 1; i 查看全部
java爬虫抓取网页数据(一下java下抓取网页上特定内容的方法-之前java中访问http
)
在进入正题之前,我们先来了解一下java下抓取网页上特定内容的方法,也就是所谓的网络爬虫。本文仅涉及简单的文字信息和链接爬取。java中访问http的方式不超过两种。一种是使用原来的httpconnection,另一种是使用封装好的插件或者框架,比如httpclient、okHttp等。在测试和抓取网页信息的过程中,我使用的是jsoup工具,因为该工具没有只封装了http访问,还具有强大的html解析功能。可以参考详细的使用教程。
第一步是访问登陆页面
文档 doc = Jsoup.connect("").get();
第二步,使用jsoup的选择器选择网页所需内容的具体元素(使用正则表达式效率更高)。在这个例子中,目标网页是一个论坛,我们需要做的是抓取论坛首页所有帖子的标题名称和链接地址。
首先打开目标网址,使用谷歌浏览器浏览网页结构,找到结构对应的内容,如下图
然后选择区域
Elements links = doc.getElementsByAttributeValue("id","lphymodelsub");
接下来,获取选中区域的内容并保存到数组中
对于(元素链接:链接){
CatchModel c = new CatchModel();
String linkHref = ""+link.parent().attr("href");
String linkText = link.text();
c.setText(linkText);
c.setUrl(linkHref);
fistCatchList.add(c);
}
这样一个简单的爬行就完成了。
下一步是新浪微博的爬取。一般http访问新浪微博网站得到的html很简单,因为新浪微博首页是用js动态生成的,需要多次访问。请求和验证只能访问成功,所以为了方便抓取数据,我们通过了一个后门,就是访问新浪微博的移动端进行抓取。然而,随之而来的一个问题是,访问新浪微博并不重要。任一端都需要强制登录认证,所以我们需要在http请求中附加一个cookie进行用户认证。网上找了很久,想用webcontroller这个开源的爬虫框架。它易于访问且高效。我们来看看如何使用这个框架。
首先需要导入依赖包,WebController的ja包和selenium的jar包
下载链接:
使用Selenium获取cookie登录新浪微博(WeiboCN.java)
使用WebCollector和获取的cookies抓取新浪微博并提取数据(WeiboCrawler.java)
微博CN.java
import java.util.Set;
import org.openqa.selenium.Cookie;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.htmlunit.HtmlUnitDriver;
/**
* 利用Selenium获取登陆新浪微博weibo.cn的cookie
* @author hu
*/
public class WeiboCN {
/**
* 获取新浪微博的cookie,这个方法针对weibo.cn有效,对weibo.com无效
* weibo.cn以明文形式传输数据,请使用小号
* @param username 新浪微博用户名
* @param password 新浪微博密码
* @return
* @throws Exception
*/
public static String getSinaCookie(String username, String password) throws Exception{
StringBuilder sb = new StringBuilder();
HtmlUnitDriver driver = new HtmlUnitDriver();
driver.setJavascriptEnabled(true);
driver.get("http://login.weibo.cn/login/";);
WebElement mobile = driver.findElementByCssSelector("input[name=mobile]");
mobile.sendKeys(username);
WebElement pass = driver.findElementByCssSelector("input[name^=password]");
pass.sendKeys(password);
WebElement rem = driver.findElementByCssSelector("input[name=remember]");
rem.click();
WebElement submit = driver.findElementByCssSelector("input[name=submit]");
submit.click();
Set cookieSet = driver.manage().getCookies();
driver.close();
for (Cookie cookie : cookieSet) {
sb.append(cookie.getName()+"="+cookie.getValue()+";");
}
String result=sb.toString();
if(result.contains("gsid_CTandWM")){
return result;
}else{
throw new Exception("weibo login failed");
}
}
}
<p style="font-size:15px; line-height:1.5em; font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; widows:auto">WeiboCrawler.javaimport cn.edu.hfut.dmic.webcollector.model.CrawlDatum;
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.net.HttpRequest;
import cn.edu.hfut.dmic.webcollector.net.HttpResponse;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 利用WebCollector和获取的cookie爬取新浪微博并抽取数据
* @author hu
*/
public class WeiboCrawler extends BreadthCrawler {
String cookie;
public WeiboCrawler(String crawlPath, boolean autoParse) throws Exception {
super(crawlPath, autoParse);
/*获取新浪微博的cookie,账号密码以明文形式传输,请使用小号*/
cookie = WeiboCN.getSinaCookie("你的用户名", "你的密码");
}
@Override
public HttpResponse getResponse(CrawlDatum crawlDatum) throws Exception {
HttpRequest request = new HttpRequest(crawlDatum);
request.setCookie(cookie);
return request.getResponse();
}
@Override
public void visit(Page page, CrawlDatums next) {
int pageNum = Integer.valueOf(page.getMetaData("pageNum"));
/*抽取微博*/
Elements weibos = page.select("div.c");
for (Element weibo : weibos) {
System.out.println("第" + pageNum + "页\t" + weibo.text());
}
}
public static void main(String[] args) throws Exception {
WeiboCrawler crawler = new WeiboCrawler("weibo_crawler", false);
crawler.setThreads(3);
/*对某人微博前5页进行爬取*/
for (int i = 1; i
java爬虫抓取网页数据(爬虫程序的开发比较简单程序程序开发程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-27 12:18
一次搭建爬虫之旅
最近需要从网上抓取大量数据,所以体验了爬虫程序的开发和部署,主要是学习了一些实用工具的操作。本教程的开发需求是编写一个收录爬虫程序的Java项目,可以方便地在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是抓取汉学网新华字典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用 Crawl4j。它的优点是只需要配置爬虫框架的几个重要参数就可以让爬虫开始工作:(1)爬虫数据缓存目录;(< @2)爬虫爬取策略,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页面数的控制等;(3)爬虫的入口地址;(4)爬虫遇到新页面的url由shouldVisit决定是否访问这个url;(5)爬虫时的具体操作)访问(visit)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具
430 查看全部
java爬虫抓取网页数据(爬虫程序的开发比较简单程序程序开发程序)
一次搭建爬虫之旅
最近需要从网上抓取大量数据,所以体验了爬虫程序的开发和部署,主要是学习了一些实用工具的操作。本教程的开发需求是编写一个收录爬虫程序的Java项目,可以方便地在服务器端编译、部署和启动爬虫程序。1.爬虫程序的开发爬虫程序的开发比较简单。下面是一个简单的例子。它的主要功能是抓取汉学网新华字典中的所有汉字详情页,并保存到一个文件中。爬虫框架使用 Crawl4j。它的优点是只需要配置爬虫框架的几个重要参数就可以让爬虫开始工作:(1)爬虫数据缓存目录;(< @2)爬虫爬取策略,包括是否跟随robots文件、请求之间的延迟、页面的最大深度、页面数的控制等;(3)爬虫的入口地址;(4)爬虫遇到新页面的url由shouldVisit决定是否访问这个url;(5)爬虫时的具体操作)访问(visit)那些url,比如将内容保存到文件edu.uci.ics.crawler4j.url.WebURL;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.io.File;** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具 爬虫遇到 new 页面的 url 由 shouldVisit 决定是否访问这个 url;(5)爬虫访问(访问)那些url时的具体操作,比如将内容保存到文件edu.uci.ics.crawler4j.url.webURL;import org.slf4j.Logger;import org.slf4j .LoggerFactory; import java.io.File; ** * 汉文网数据采集工具
430
java爬虫抓取网页数据(网络爬虫是做什么的?他的主要工作原理是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-27 04:22
一、 网络爬虫是做什么的?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面从响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
一个简单爬虫的必要功能:
1:发送请求和获取响应的功能;
2:解析响应的功能;
3:存储过滤数据的功能;
4:处理解析出的URL路径的功能;
二、 爬取对象分类
静态网页:可以通过 URLConnection 获取页面的所有数据。这种方法比较简单。你只需要建立一个URLConnection来请求页面数据,然后通过正则表达式获取相关数据即可。
动态网页:网页的部分或全部数据通过js动态展示,不能通过URLConnection直接获取。这时候就需要用到HtmlUnit工具了。这个工具是一个无界面的浏览器,可以模拟浏览器的操作。这个工具,加载网页后,获取页面数据进行分析,然后就可以抓取数据了
三、本文内容
四、总结:
静态网页数据可以通过上述代码获取,只需要通过正则表达式截取有用的信息,本文不再赘述。 查看全部
java爬虫抓取网页数据(网络爬虫是做什么的?他的主要工作原理是什么)
一、 网络爬虫是做什么的?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面从响应中找到你要查找的数据,另一方面从响应中解析出新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
一个简单爬虫的必要功能:
1:发送请求和获取响应的功能;
2:解析响应的功能;
3:存储过滤数据的功能;
4:处理解析出的URL路径的功能;
二、 爬取对象分类
静态网页:可以通过 URLConnection 获取页面的所有数据。这种方法比较简单。你只需要建立一个URLConnection来请求页面数据,然后通过正则表达式获取相关数据即可。
动态网页:网页的部分或全部数据通过js动态展示,不能通过URLConnection直接获取。这时候就需要用到HtmlUnit工具了。这个工具是一个无界面的浏览器,可以模拟浏览器的操作。这个工具,加载网页后,获取页面数据进行分析,然后就可以抓取数据了
三、本文内容
四、总结:
静态网页数据可以通过上述代码获取,只需要通过正则表达式截取有用的信息,本文不再赘述。
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-25 01:16
对于初学者来说,WebMagic 作为 Java 开发的爬虫框架很容易使用。我们通过一个简单的例子来了解一下。
WebMagic 框架介绍
WebMagic 框架收录四个组件,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应爬虫生命周期中的处理、管理、下载、持久化功能。
这四个组件是Spider中的属性,爬虫框架由Spider启动和管理。
WebMagic 的整体结构如下:
四大组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。您需要自己定义它。
Scheduler 负责管理要爬取的 URL 和一些重复数据删除工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从网上下载页面进行后续处理。通常,您不需要自己实现它。
用于数据流的对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表从 Downloader 下载的页面——可以是 HTML、JSON 或其他文本格式的内容。
ResultItems相当于一个Map,保存PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖的jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包之后,所有的准备工作就完成了,是不是很简单?
下面我们来测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}
public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/")
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:
这是因为缺少配置文件。在资源目录新建一个log4j.properties文件,粘贴下面的配置信息。
该目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告。
爬取列表类 网站 示例
列表爬取的思路非常相似。首先判断是否是列表页。如果是,将 文章 url 添加到抓取队列中。如果不是,说明此时是一个文章页面,直接爬取你想要的。内容很好。
选择列表类型 文章 网站:
首先判断是文章还是列表。查看几页后,可以找到规则并使用正则表达式进行区分。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则该url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器自带,可以直接粘贴)。
WebMagic 框架支持多种提取方式,包括xPath、css 选择器、正则表达式,所有链接都可以通过links() 方法进行选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果你使用它,你可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面。这时候页面中文章的url必须通过xPath来定位。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
这时候就已经得到了要爬取的url列表,可以通过addTargetRequests方法将它们加入到队列中。
最后实现翻页。同理,WebMagic 会自动加入爬取队列。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整代码。我自己实现了一个 MysqlPipeline 类。使用Mybatis时,可以将抓取到的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline 等。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}
public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1").addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库:
爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
使用xPath时要注意,框架作者自定义了几个功能:
表达式描述XPath1.0
文字(n)
第n个直接文本子节点,0表示全部
纯文本
所有文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更整洁
不支持
html()
内部html,不包括标签的html本身
不支持
外层Html()
内部html,包括标签的html本身
不支持
正则表达式(@attr,expr,group)
这里@attr 和 group 都是可选的,默认是 group0
不支持
使用起来非常方便。 查看全部
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
对于初学者来说,WebMagic 作为 Java 开发的爬虫框架很容易使用。我们通过一个简单的例子来了解一下。
WebMagic 框架介绍
WebMagic 框架收录四个组件,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应爬虫生命周期中的处理、管理、下载、持久化功能。
这四个组件是Spider中的属性,爬虫框架由Spider启动和管理。
WebMagic 的整体结构如下:
四大组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。您需要自己定义它。
Scheduler 负责管理要爬取的 URL 和一些重复数据删除工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从网上下载页面进行后续处理。通常,您不需要自己实现它。
用于数据流的对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表从 Downloader 下载的页面——可以是 HTML、JSON 或其他文本格式的内容。
ResultItems相当于一个Map,保存PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖的jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包之后,所有的准备工作就完成了,是不是很简单?
下面我们来测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}
public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/";)
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:
这是因为缺少配置文件。在资源目录新建一个log4j.properties文件,粘贴下面的配置信息。
该目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告。
爬取列表类 网站 示例
列表爬取的思路非常相似。首先判断是否是列表页。如果是,将 文章 url 添加到抓取队列中。如果不是,说明此时是一个文章页面,直接爬取你想要的。内容很好。
选择列表类型 文章 网站:
首先判断是文章还是列表。查看几页后,可以找到规则并使用正则表达式进行区分。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则该url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器自带,可以直接粘贴)。
WebMagic 框架支持多种提取方式,包括xPath、css 选择器、正则表达式,所有链接都可以通过links() 方法进行选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果你使用它,你可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面。这时候页面中文章的url必须通过xPath来定位。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
这时候就已经得到了要爬取的url列表,可以通过addTargetRequests方法将它们加入到队列中。
最后实现翻页。同理,WebMagic 会自动加入爬取队列。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整代码。我自己实现了一个 MysqlPipeline 类。使用Mybatis时,可以将抓取到的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline 等。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}
public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1";).addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库:
爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
使用xPath时要注意,框架作者自定义了几个功能:
表达式描述XPath1.0
文字(n)
第n个直接文本子节点,0表示全部
纯文本
所有文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更整洁
不支持
html()
内部html,不包括标签的html本身
不支持
外层Html()
内部html,包括标签的html本身
不支持
正则表达式(@attr,expr,group)
这里@attr 和 group 都是可选的,默认是 group0
不支持
使用起来非常方便。
java爬虫抓取网页数据(是不是表达式有所了解,那么不仅可以抓取网页上的邮箱,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-25 01:13
这段代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
1 package tool;
2 import java.io.BufferedReader;
3 import java.io.File;
4 import java.io.FileWriter;
5 import java.io.InputStreamReader;
6 import java.io.Writer;
7 import java.net.URL;
8 import java.net.URLConnection;
9 import java.sql.Time;
10 import java.util.Scanner;
11 import java.util.regex.Matcher;
12 import java.util.regex.Pattern;
13 public class Ma {
14 public static void main(String[] args) throws Exception {// 本程序内部异常过多为了简便,不一Try,直接抛给虚拟机
15 long StartTime = System.currentTimeMillis();
16 System.out.println("-- 欢迎使用小刘简易网页爬虫程序 --");
17 System.out.println("");
18 System.out.println("--请输入正确的网址如http://www.baidu.com--");
19 Scanner input = new Scanner(System.in);// 实例化键盘输入类
20
21 String webaddress = input.next();// 创建输入对象
22 File file = new File("E:" + File.separator + "爬虫邮箱统计文本.txt");// 实例化文件类对象
23
24 // 并指明输出地址和输出文件名
25
26
27 Writer outWriter = new FileWriter(file);// 实例化outWriter类
28
29 URL url = new URL(webaddress);// 实例化URL类。
30
31 URLConnection conn = url.openConnection();// 取得链接
32
33 BufferedReader buff = new BufferedReader(new InputStreamReader(
34
35 conn.getInputStream()));// 取得网页数据
36
37 String line = null;
38 int i=0;
39 String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
40
41 Pattern p = Pattern.compile(regex);// 为patttern实例化
42
43 outWriter.write("该网页中所包含的的邮箱如下所示:\r\n");
44 while ((line = buff.readLine()) != null) {
45
46 Matcher m = p.matcher(line);// 进行匹配
47
48 while (m.find()) {
49 i++;
50 outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件
51 }
52 }
53 long StopTime = System.currentTimeMillis();
54 String UseTime=(StopTime-StartTime)+"";
55 outWriter.write("--------------------------------------------------------\r\n");
56 outWriter.write("本次爬取页面地址:"+webaddress+"\r\n");
57 outWriter.write("爬取用时:"+UseTime+"毫秒\r\n");
58 outWriter.write("本次共得到邮箱:"+i+"条\r\n");
59 outWriter.write("****谢谢您的使用****\r\n");
60 outWriter.write("--------------------------------------------------------");
61 outWriter.close();// 关闭文件输出操作
62 System.out.println(" —————————————————————\t");
63 System.out.println("|页面爬取成功,请到E盘根目录下查看test文档|\t");
64 System.out.println("| |");
65 System.out.println("|如需重新爬取,请再次执行程序,谢谢您的使用|\t");
66 System.out.println(" —————————————————————\t");
67 }
68 }
txt截图如下:
测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱,如果读者正确
不仅可以抢到邮箱,还可以抢到手机号和ip地址,等你想抢的所有信息。是不是很有趣? 查看全部
java爬虫抓取网页数据(是不是表达式有所了解,那么不仅可以抓取网页上的邮箱,)
这段代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
1 package tool;
2 import java.io.BufferedReader;
3 import java.io.File;
4 import java.io.FileWriter;
5 import java.io.InputStreamReader;
6 import java.io.Writer;
7 import java.net.URL;
8 import java.net.URLConnection;
9 import java.sql.Time;
10 import java.util.Scanner;
11 import java.util.regex.Matcher;
12 import java.util.regex.Pattern;
13 public class Ma {
14 public static void main(String[] args) throws Exception {// 本程序内部异常过多为了简便,不一Try,直接抛给虚拟机
15 long StartTime = System.currentTimeMillis();
16 System.out.println("-- 欢迎使用小刘简易网页爬虫程序 --");
17 System.out.println("");
18 System.out.println("--请输入正确的网址如http://www.baidu.com--");
19 Scanner input = new Scanner(System.in);// 实例化键盘输入类
20
21 String webaddress = input.next();// 创建输入对象
22 File file = new File("E:" + File.separator + "爬虫邮箱统计文本.txt");// 实例化文件类对象
23
24 // 并指明输出地址和输出文件名
25
26
27 Writer outWriter = new FileWriter(file);// 实例化outWriter类
28
29 URL url = new URL(webaddress);// 实例化URL类。
30
31 URLConnection conn = url.openConnection();// 取得链接
32
33 BufferedReader buff = new BufferedReader(new InputStreamReader(
34
35 conn.getInputStream()));// 取得网页数据
36
37 String line = null;
38 int i=0;
39 String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
40
41 Pattern p = Pattern.compile(regex);// 为patttern实例化
42
43 outWriter.write("该网页中所包含的的邮箱如下所示:\r\n");
44 while ((line = buff.readLine()) != null) {
45
46 Matcher m = p.matcher(line);// 进行匹配
47
48 while (m.find()) {
49 i++;
50 outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件
51 }
52 }
53 long StopTime = System.currentTimeMillis();
54 String UseTime=(StopTime-StartTime)+"";
55 outWriter.write("--------------------------------------------------------\r\n");
56 outWriter.write("本次爬取页面地址:"+webaddress+"\r\n");
57 outWriter.write("爬取用时:"+UseTime+"毫秒\r\n");
58 outWriter.write("本次共得到邮箱:"+i+"条\r\n");
59 outWriter.write("****谢谢您的使用****\r\n");
60 outWriter.write("--------------------------------------------------------");
61 outWriter.close();// 关闭文件输出操作
62 System.out.println(" —————————————————————\t");
63 System.out.println("|页面爬取成功,请到E盘根目录下查看test文档|\t");
64 System.out.println("| |");
65 System.out.println("|如需重新爬取,请再次执行程序,谢谢您的使用|\t");
66 System.out.println(" —————————————————————\t");
67 }
68 }
txt截图如下:
测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱,如果读者正确
不仅可以抢到邮箱,还可以抢到手机号和ip地址,等你想抢的所有信息。是不是很有趣?
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-24 03:07
)
故事的开始
虽然我们程序员不做爬虫工作,但我们在工作中偶尔会需要来自互联网的数据。如果手动复制粘贴,数据量很小。如果数据量很大,浪费时间真的很无聊。
所以现在研究了一个多小时,写了一个爬虫程序
一、爬虫需要的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2
使用 Jsoup 解析网页
首先我们需要获取我们请求的网页地址
使用Jsoup的parse()方法解析网页,并传入参数。第一个参数是新的URL(url),第二个参数设置为解析时间超过30秒则放弃。
然后得到一个 Document 对象
之后,就像我们操作JS代码一样,Document对象可以实现JS的所有操作
这时候我们用浏览器打开网页,F12查看元素,找到数据所在的div的id名,如果没有id名就用calss名,这里没有id名.
然后我们通过类名获取元素。这时候我们就可以输出 System.out.println(chinajobs); 看看能不能得到我们想要的数据。
可以看到我们确实得到了我们想要的数据
过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到了 Elements 对象。在进行下一步之前,我们必须将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转换成Element对象(首先确认我们需要的数据在chinajobs中的第一个元素)
通过分析发现可以从title属性中提取出我们需要的数据
String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
确实过滤了我们想要的所有数据
四、导出到Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素的数量
使用循环遍历输出
el.getElementsByAttribute("title").eq(i) 通过 eq(i) 传入索引值来确定元素值
在D盘新建一个上海招聘公司list.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i 查看全部
java爬虫抓取网页数据(2016年上海事业单位医疗招聘:现学现卖解析
)
故事的开始
虽然我们程序员不做爬虫工作,但我们在工作中偶尔会需要来自互联网的数据。如果手动复制粘贴,数据量很小。如果数据量很大,浪费时间真的很无聊。
所以现在研究了一个多小时,写了一个爬虫程序
一、爬虫需要的工具包
新建一个Maven项目,导入爬虫工具包Jsoup
org.jsoup
jsoup
1.10.2
使用 Jsoup 解析网页
首先我们需要获取我们请求的网页地址
使用Jsoup的parse()方法解析网页,并传入参数。第一个参数是新的URL(url),第二个参数设置为解析时间超过30秒则放弃。
然后得到一个 Document 对象
之后,就像我们操作JS代码一样,Document对象可以实现JS的所有操作
这时候我们用浏览器打开网页,F12查看元素,找到数据所在的div的id名,如果没有id名就用calss名,这里没有id名.
然后我们通过类名获取元素。这时候我们就可以输出 System.out.println(chinajobs); 看看能不能得到我们想要的数据。
可以看到我们确实得到了我们想要的数据
过滤数据
虽然得到了数据,但是有很多冗余信息,所以下一步就是对数据进行过滤
因为类不是唯一的,所以获取到了 Elements 对象。在进行下一步之前,我们必须将其转换为 Element 对象。
Element el = chinajobs.first();
将chinajobs中的第一个元素转换成Element对象(首先确认我们需要的数据在chinajobs中的第一个元素)
通过分析发现可以从title属性中提取出我们需要的数据
String title = el.getElementsByAttribute("title").text();
尝试输出
System.out.println(el.getElementsByAttribute("title").text());
确实过滤了我们想要的所有数据
四、导出到Excel
最后一步是导出到excel,这里我使用的是poi工具包
org.apache.poi
poi
3.17
通过 el.getElementsByAttribute("title").size() 确定元素的数量
使用循环遍历输出
el.getElementsByAttribute("title").eq(i) 通过 eq(i) 传入索引值来确定元素值
在D盘新建一个上海招聘公司list.xls文件
<p>public static void main(String[] args) throws IOException {
// 获取请求 https://www.buildhr.com/area/shanghai/
String url = "https://www.buildhr.com/area/shanghai/";
Document document = Jsoup.parse(new URL(url), 30000);
Elements chinajobs = document.getElementsByClass("chinajobs");
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("公司名列表");
Element el = chinajobs.first();
for (int i = 0; i
java爬虫抓取网页数据(空闲时间帮朋友做了个爬取几个电商网站的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-24 03:06
最近利用空闲时间帮朋友做了一个小程序,用htmlUnit爬取几个电商网站的数据。感觉htmlUnit爬取的速度和稳定性还是很不错的,所以写了一篇博文介绍了htmlUnit的使用,也记录下来了。
这是网站的主页
具体思路是获取产品所在的div。通过div获取每个商品的tag的href,输入网址,抓取商品的数据,然后导出EXCEL表,实现自动翻译等功能
1.首先我们需要获取主页面的数据
WebClient webClient = new WebClient(BrowserVersion.CHROME );//模拟创建打开一个谷歌浏览器窗口
webClient.getOptions().setTimeout(15000);//设置网页响应时间
webClient.getOptions().setUseInsecureSSL(true);//是否
webClient.getOptions().setRedirectEnabled(true);//是否自动加载重定向
webClient.getOptions().setThrowExceptionOnScriptError(false);//是否抛出页面javascript错误
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//是否抛出response的错误
webClient.getOptions().setJavaScriptEnabled(false);// HtmlUnit对JavaScript的支持不好,关闭之
webClient.getOptions().setCssEnabled(false);// HtmlUnit对CSS的支持不好,关闭之
String url = "https://shop.sanrio.co.jp/prod ... 3B%3B
HtmlPage page = webClient.getPage(url);//通过url获取整个页面
这样我们就得到了页面的HtmlPage对象。
通过查看page对象的方法,可以发现它可以像写JS一样操作页面上的元素
2.查看页面源码获取商品对应的div中的A标签(放大后的图片可以右键查看原图)
可以发现product都嵌套在一个id="prdlist"的div中,那么我们就可以通过
// 获取A标签的div
HtmlDivision element = (HtmlDivision) page.getHtmlElementById("prdlist");
这样就得到了产品对应的div标签,然后我们查看每个产品的单独div对应的源代码,得到网页地址
这是每个单独的产品div对应的源代码。我们可以看到每个产品div中只有一个A标签。那么我们只需要拿到A标签,Ok
DomNodeList list = element.getElementsByTagName("a"); // 获取页面上的所有A连接(商品标签)
out2: for (HtmlElement htmlElement : list) {
HtmlPage click = htmlElement.click(); // 进入商品页面
HtmlDivision div3 = (HtmlDivision) click.getByXPath("//div[@class='box_right_summary']").get(0); // 获得名字的div
}
这个网址的内容刚好被抓取。内容的 div 有一个 ID。你如何获得没有ID的div或其他标签? htmlunit 封装了一个 getByXPath 方法,专门用于抓取非特殊标签。具体的写法如上图所示。名字的DIV意思是获取类attribute=box_right_summary的div集合
内置的htmlunit基本收录了所有的html标签,比如HtmlInput、HtmlTable、HtmlSpan等,读者可以下载jar自己试试
另外XPath的语法可以参考这个文章XPath语法
另外,htmlunit也可以模拟表单的提交,只需使用htmlElement的click()方法获取表单的输入框然后设置值就可以模拟点击事件
// 获取首页
final HtmlPage page1 = (HtmlPage) webClient.getPage("http://htmlunit.sourceforge.net");
// 根据form的名字获取页面表单,也可以通过索引来获取:page.getForms().get(0)
final HtmlForm form = page1.getFormByName("myform");
final HtmlSubmitInput button
= (HtmlSubmitInput) form.getInputByName("submitbutton");
final HtmlTextInput textField
= (HtmlTextInput) form.getInputByName("userid");
// 设置表单域的值
textField.setValueAttribute("root");
// 提交表单,返回提交表单后跳转的页面
final HtmlPage page2 = (HtmlPage) button.click();
这只是获得它的一种方式。也可以使用 xpath ID tagNAME 等方法。读者自行探索
3.接下来进入商品详情页面获取商品信息
这是产品详情页面。我们需要得到它的名字、尺寸、图片、价格、介绍等。
然后观察源码
这个div可以获取名称价格
HtmlDivision div3 = (HtmlDivision) click.getByXPath(
"//div[@class='box_right_summary']").get(0); // 获得名字的div
String name = div3.getElementsByTagName("h2").get(0).asText();
excels.setJname(name); // 设置日本名字 (这是自己创建的导出EXCEL的实体类)
// 获取商品的价格信息
HtmlSpan span = (HtmlSpan) click.getByXPath("//span[@class='priceSelect']").get(0);
String cname = getCname(name); // 通过百度翻译接口获取中文名字
excels.setCname(cname);
接下来是产品编号、尺寸等
如图所示,可以找到
// 获取商品的详细信息
HtmlDivision div2 = (HtmlDivision) click.getByXPath(
"//div[@class='productSummary accordionBlock01']").get(
0);
DomNodeList ths = div2.getElementsByTagName("tr");
for (HtmlElement th : ths) {
if (th.getElementsByTagName("th").get(0).asText().equals("サイズ")) {
String sizeString = th.getElementsByTagName("td")
.get(0).asText();
// 设置商品尺寸
excels.setSize(sizeString);
}
if (th.getElementsByTagName("th").get(0).asText().equals("商品コード")) {
// 商品编号
String nums2 = th.getElementsByTagName("td").get(0)
.asText();
// 设置商品编号
excels.setNums2(nums2);
}
}
代码不是以标准方式编写的。让我们凑合一下吧。
接下来是获取商品的图片信息
HtmlDivision div = (HtmlDivision) click.getByXPath(
"//div[@class='box_pic']").get(0);
// System.out.println(div.asXml());
DomNodeList imgs = div.getElementsByTagName("img");
// 遍历 下载图片到本地
for (HtmlElement img : imgs) {
download(SANLIOU + img.getAttribute("src"), DOWNDS
+ filename + "/");//这是自己封装的下载图片的方法
}
SANLIOU + img.getAttribute("src") 实际上代表的是图片的url,因为一般图片的地址不是url的全路径。这时候我们需要手动复制网站的根路径加上使用img标签的src属性来获取图片的真实地址,如:
这是产品的图片。 img src 不完整。
网页地址为:
让我们截取这个。这是网站的根路径加上/upload/save_image/N-1801-318795_1.jpg就构成图片的真实路径
至此,一般的爬取内容就完成了。我把详细的项目案例上传到我的CSDN。你可以下载它。案例下载
其实htmlunit是一个非常简单小巧的框架。只要有前端页面的基础就容易上手,轻松上手,实现自己想要的功能 查看全部
java爬虫抓取网页数据(空闲时间帮朋友做了个爬取几个电商网站的数据)
最近利用空闲时间帮朋友做了一个小程序,用htmlUnit爬取几个电商网站的数据。感觉htmlUnit爬取的速度和稳定性还是很不错的,所以写了一篇博文介绍了htmlUnit的使用,也记录下来了。
这是网站的主页
具体思路是获取产品所在的div。通过div获取每个商品的tag的href,输入网址,抓取商品的数据,然后导出EXCEL表,实现自动翻译等功能
1.首先我们需要获取主页面的数据
WebClient webClient = new WebClient(BrowserVersion.CHROME );//模拟创建打开一个谷歌浏览器窗口
webClient.getOptions().setTimeout(15000);//设置网页响应时间
webClient.getOptions().setUseInsecureSSL(true);//是否
webClient.getOptions().setRedirectEnabled(true);//是否自动加载重定向
webClient.getOptions().setThrowExceptionOnScriptError(false);//是否抛出页面javascript错误
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//是否抛出response的错误
webClient.getOptions().setJavaScriptEnabled(false);// HtmlUnit对JavaScript的支持不好,关闭之
webClient.getOptions().setCssEnabled(false);// HtmlUnit对CSS的支持不好,关闭之
String url = "https://shop.sanrio.co.jp/prod ... 3B%3B
HtmlPage page = webClient.getPage(url);//通过url获取整个页面
这样我们就得到了页面的HtmlPage对象。
通过查看page对象的方法,可以发现它可以像写JS一样操作页面上的元素
2.查看页面源码获取商品对应的div中的A标签(放大后的图片可以右键查看原图)
可以发现product都嵌套在一个id="prdlist"的div中,那么我们就可以通过
// 获取A标签的div
HtmlDivision element = (HtmlDivision) page.getHtmlElementById("prdlist");
这样就得到了产品对应的div标签,然后我们查看每个产品的单独div对应的源代码,得到网页地址
这是每个单独的产品div对应的源代码。我们可以看到每个产品div中只有一个A标签。那么我们只需要拿到A标签,Ok
DomNodeList list = element.getElementsByTagName("a"); // 获取页面上的所有A连接(商品标签)
out2: for (HtmlElement htmlElement : list) {
HtmlPage click = htmlElement.click(); // 进入商品页面
HtmlDivision div3 = (HtmlDivision) click.getByXPath("//div[@class='box_right_summary']").get(0); // 获得名字的div
}
这个网址的内容刚好被抓取。内容的 div 有一个 ID。你如何获得没有ID的div或其他标签? htmlunit 封装了一个 getByXPath 方法,专门用于抓取非特殊标签。具体的写法如上图所示。名字的DIV意思是获取类attribute=box_right_summary的div集合
内置的htmlunit基本收录了所有的html标签,比如HtmlInput、HtmlTable、HtmlSpan等,读者可以下载jar自己试试
另外XPath的语法可以参考这个文章XPath语法
另外,htmlunit也可以模拟表单的提交,只需使用htmlElement的click()方法获取表单的输入框然后设置值就可以模拟点击事件
// 获取首页
final HtmlPage page1 = (HtmlPage) webClient.getPage("http://htmlunit.sourceforge.net";);
// 根据form的名字获取页面表单,也可以通过索引来获取:page.getForms().get(0)
final HtmlForm form = page1.getFormByName("myform");
final HtmlSubmitInput button
= (HtmlSubmitInput) form.getInputByName("submitbutton");
final HtmlTextInput textField
= (HtmlTextInput) form.getInputByName("userid");
// 设置表单域的值
textField.setValueAttribute("root");
// 提交表单,返回提交表单后跳转的页面
final HtmlPage page2 = (HtmlPage) button.click();
这只是获得它的一种方式。也可以使用 xpath ID tagNAME 等方法。读者自行探索
3.接下来进入商品详情页面获取商品信息
这是产品详情页面。我们需要得到它的名字、尺寸、图片、价格、介绍等。
然后观察源码
这个div可以获取名称价格
HtmlDivision div3 = (HtmlDivision) click.getByXPath(
"//div[@class='box_right_summary']").get(0); // 获得名字的div
String name = div3.getElementsByTagName("h2").get(0).asText();
excels.setJname(name); // 设置日本名字 (这是自己创建的导出EXCEL的实体类)
// 获取商品的价格信息
HtmlSpan span = (HtmlSpan) click.getByXPath("//span[@class='priceSelect']").get(0);
String cname = getCname(name); // 通过百度翻译接口获取中文名字
excels.setCname(cname);
接下来是产品编号、尺寸等
如图所示,可以找到
// 获取商品的详细信息
HtmlDivision div2 = (HtmlDivision) click.getByXPath(
"//div[@class='productSummary accordionBlock01']").get(
0);
DomNodeList ths = div2.getElementsByTagName("tr");
for (HtmlElement th : ths) {
if (th.getElementsByTagName("th").get(0).asText().equals("サイズ")) {
String sizeString = th.getElementsByTagName("td")
.get(0).asText();
// 设置商品尺寸
excels.setSize(sizeString);
}
if (th.getElementsByTagName("th").get(0).asText().equals("商品コード")) {
// 商品编号
String nums2 = th.getElementsByTagName("td").get(0)
.asText();
// 设置商品编号
excels.setNums2(nums2);
}
}
代码不是以标准方式编写的。让我们凑合一下吧。
接下来是获取商品的图片信息
HtmlDivision div = (HtmlDivision) click.getByXPath(
"//div[@class='box_pic']").get(0);
// System.out.println(div.asXml());
DomNodeList imgs = div.getElementsByTagName("img");
// 遍历 下载图片到本地
for (HtmlElement img : imgs) {
download(SANLIOU + img.getAttribute("src"), DOWNDS
+ filename + "/");//这是自己封装的下载图片的方法
}
SANLIOU + img.getAttribute("src") 实际上代表的是图片的url,因为一般图片的地址不是url的全路径。这时候我们需要手动复制网站的根路径加上使用img标签的src属性来获取图片的真实地址,如:
这是产品的图片。 img src 不完整。
网页地址为:
让我们截取这个。这是网站的根路径加上/upload/save_image/N-1801-318795_1.jpg就构成图片的真实路径
至此,一般的爬取内容就完成了。我把详细的项目案例上传到我的CSDN。你可以下载它。案例下载
其实htmlunit是一个非常简单小巧的框架。只要有前端页面的基础就容易上手,轻松上手,实现自己想要的功能
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 01:10
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容,在网页中寻找其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对数据进行处理和过滤的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面,它会从响应中找到您要查找的数据,另一方面,它会从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:
所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li
相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 保存结果
WanhoPipeline.java
5.5. 模型对象
文章Vo.java
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始 查看全部
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,它读取网页的内容,在网页中寻找其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受“爬虫”发回的数据并对数据进行处理和过滤的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。一方面,它会从响应中找到您要查找的数据,另一方面,它会从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:
所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li
相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 保存结果
WanhoPipeline.java
5.5. 模型对象
文章Vo.java
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始
java爬虫抓取网页数据(网络爬虫干了哪些活,?(本文)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-20 04:00
)
本文内容来源于罗刚的书籍>;
本文将介绍1:网络爬虫是做什么的?2:手动编写一个简单的网络爬虫;
1:网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。解析出新的 URL 路径,
然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
1:发送请求并得到响应
2:解析页面元素
3:过滤并存储符合要求的数据
4:处理URL路径
这是包结构:
下面是核心代码:
public void crawling(String[] seeds) {
//使用种子初始化 URL 队列
System.out.println("MyCrawler: 使用种子初始化 URL 队列, 程序开始.");
Links.addUnvisitedUrlQueue(seeds);
//循环条件:是否 还有有效的待访问链接
while (Links.hasUnVisitedUrlList()) {
//先从待访问的序列中取出第一个
String url = Links.fetchHeadOfUnVisitedUrlQueue();
//将已经访问过的链接放入已访问的链接中;
Links.addVisitedUrlSet(url);
//根据URL得到page
Page page = Requests.request(url);
//对page进行解析:---- 解析DOM的某个标签
System.out.println("PageParserUtils: 解析页面出页面中所有的 a 标签");
Elements es = PageParserUtils.select(page, "a");
es.stream().map(Element::toString).forEach(System.out::println);
//对page进行解析:---- 得到新的链接
System.out.println("PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 ");
Set links = PageParserUtils.getLinks(page, "img");
// Links管理类 新增链接
System.out.println("Links: 可以将解析出来的链接 添加到 待访问链接队列中 ");
links.stream().filter(link -> link.startsWith("http://www.baidu.com")).forEach(Links::addUnvisitedUrlQueue);
//对page进行处理: 将保存文件
System.out.println("Files: 将页面保存到本地");
Files.saveToLocal(page);
}
System.out.println("MyCrawler: 所有的有效链接已访问结束, 程序退出.");
}
以下是操作的结果:
MyCrawler: 使用种子初始化 URL 队列, 程序开始.
Links: 新增爬取路径: http://www.baidu.com
Links: 取出待访问的url : http://www.baidu.com
PageParserUtils: 解析页面出页面中所有的 a 标签
新闻
hao123
地图
视频
贴吧
登录
更多产品
关于百度
About Baidu
使用百度前必读
意见反馈
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Links: 新增爬取路径: http://www.baidu.com/img/gs.gif
Links: 新增爬取路径: http://www.baidu.com/img/bd_logo1.png
Files: 将页面保存到本地
文件:www.baidu.com.html已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com.html
Links: 取出待访问的url : http://www.baidu.com/img/gs.gif
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_gs.gif.gif已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_gs.gif.gif
Links: 取出待访问的url : http://www.baidu.com/img/bd_logo1.png
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_bd_logo1.png.png已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_bd_logo1.png.png
MyCrawler: 所有的有效链接已访问结束, 程序退出.
下面是代码地址:
crawlLearn: java 爬虫入门 (gitee.com)
文章参考:
1: 自己动手写网络爬虫;
2: https://github.com/CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
本文首发于2017年11月18号, 于2021年5月20日重做整理和修改. 查看全部
java爬虫抓取网页数据(网络爬虫干了哪些活,?(本文)(图)
)
本文内容来源于罗刚的书籍>;
本文将介绍1:网络爬虫是做什么的?2:手动编写一个简单的网络爬虫;
1:网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。解析出新的 URL 路径,
然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能:
1:发送请求并得到响应
2:解析页面元素
3:过滤并存储符合要求的数据
4:处理URL路径
这是包结构:
下面是核心代码:
public void crawling(String[] seeds) {
//使用种子初始化 URL 队列
System.out.println("MyCrawler: 使用种子初始化 URL 队列, 程序开始.");
Links.addUnvisitedUrlQueue(seeds);
//循环条件:是否 还有有效的待访问链接
while (Links.hasUnVisitedUrlList()) {
//先从待访问的序列中取出第一个
String url = Links.fetchHeadOfUnVisitedUrlQueue();
//将已经访问过的链接放入已访问的链接中;
Links.addVisitedUrlSet(url);
//根据URL得到page
Page page = Requests.request(url);
//对page进行解析:---- 解析DOM的某个标签
System.out.println("PageParserUtils: 解析页面出页面中所有的 a 标签");
Elements es = PageParserUtils.select(page, "a");
es.stream().map(Element::toString).forEach(System.out::println);
//对page进行解析:---- 得到新的链接
System.out.println("PageParserUtils: 解析出所有的 img 标签, 并得到 新链接 ");
Set links = PageParserUtils.getLinks(page, "img");
// Links管理类 新增链接
System.out.println("Links: 可以将解析出来的链接 添加到 待访问链接队列中 ");
links.stream().filter(link -> link.startsWith("http://www.baidu.com";)).forEach(Links::addUnvisitedUrlQueue);
//对page进行处理: 将保存文件
System.out.println("Files: 将页面保存到本地");
Files.saveToLocal(page);
}
System.out.println("MyCrawler: 所有的有效链接已访问结束, 程序退出.");
}
以下是操作的结果:
MyCrawler: 使用种子初始化 URL 队列, 程序开始.
Links: 新增爬取路径: http://www.baidu.com
Links: 取出待访问的url : http://www.baidu.com
PageParserUtils: 解析页面出页面中所有的 a 标签
新闻
hao123
地图
视频
贴吧
登录
更多产品
关于百度
About Baidu
使用百度前必读
意见反馈
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Links: 新增爬取路径: http://www.baidu.com/img/gs.gif
Links: 新增爬取路径: http://www.baidu.com/img/bd_logo1.png
Files: 将页面保存到本地
文件:www.baidu.com.html已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com.html
Links: 取出待访问的url : http://www.baidu.com/img/gs.gif
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_gs.gif.gif已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_gs.gif.gif
Links: 取出待访问的url : http://www.baidu.com/img/bd_logo1.png
PageParserUtils: 解析页面出页面中所有的 a 标签
PageParserUtils: 解析出所有的 img 标签, 并得到 新链接
Links: 可以将解析出来的链接 添加到 待访问链接队列中
Files: 将页面保存到本地
文件:www.baidu.com_img_bd_logo1.png.png已经被存储在/G:/code/java/myself/learn/crawlLearn/target/classes/temp\www.baidu.com_img_bd_logo1.png.png
MyCrawler: 所有的有效链接已访问结束, 程序退出.
下面是代码地址:
crawlLearn: java 爬虫入门 (gitee.com)
文章参考:
1: 自己动手写网络爬虫;
2: https://github.com/CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
本文首发于2017年11月18号, 于2021年5月20日重做整理和修改.
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-20 03:18
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页的内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受、处理和过滤“爬虫”发回的数据的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的 URL 地址发送请求,得到响应,然后解析响应。一方面,它从响应中找到您想要查找的数据,另一方面,它从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:
所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li
相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 保存结果
WanhoPipeline.java
5.5. 模型对象
文章Vo.java
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始 查看全部
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面就让万禾的专业老师分享一些关于网络爬虫的入门知识。
0 1
网络爬虫
1.1. 姓名
网络爬虫(又称网络蜘蛛、网络机器人)是按照一定的规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
1.2. 简介
网络爬虫通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页的内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,这样一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
因此,如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个能够接受、处理和过滤“爬虫”发回的数据的服务器。爬虫抓取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的 URL 地址发送请求,得到响应,然后解析响应。一方面,它从响应中找到您想要查找的数据,另一方面,它从响应中解析出来。新建URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析新的URL路径。
这是网络爬虫的主要工作。这是流程图:
通过上面的流程图,您可以大致了解网络爬虫是做什么的,并基于这些,您可以设计一个简单的网络爬虫。
一个简单爬虫的必要功能包括:
发送请求和获取响应的功能;
解析响应的功能;
存储过滤数据的功能;
处理解析出的URL路径的功能;
2.1. 兴趣点
爬虫需要注意的三点:
爬取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
0 4
思维分析
下面我就用我们的官网来跟大家分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页面是:
分析页面:
所有喜讯信息的URL用XPath表达式表示://div[@class='main_l']/ul/li
相关资料:
标题:用XPath表达式表示//div[@class='content']/h4/a/text()
说明:使用 XPath 表达式来表示 //div[@class='content']/p/text()
图片:用XPath表达式表示//a/img/@src
好了,我们已经在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 保存结果
WanhoPipeline.java
5.5. 模型对象
文章Vo.java
如果您想了解更多的网络爬虫知识,可以到万禾官网,注册后可以免费学习Java爬虫项目实战。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始
java爬虫抓取网页数据(新浪新闻爬虫:一下接下来的目标页面是爬取问题推荐页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-20 02:27
上一篇写了一个简单的新浪新闻爬虫,使用jsoup包在本地抓取url页面,在本地分析提取数据。jsoup的用法这里不再赘述。百度会看大图。看到网上大神们爬取了知乎,今天就用它来试试。写这篇文章的目的主要是记录一下我在爬行中遇到的一些坑以及如何解决。这也是一个加深理解的过程。
抓取的目标页面
2017-12-31_172919.png
目标是抓取问题推荐页面上的所有问题。但是后来我发现了一个问题。第一次抓取这个链接,获取问题列表,但是代码测试的时候,发现只有20条数据。. . 这显然不是我所期望的。我看了下代码,发现代码没有任何问题,那么有什么问题呢?检查了一块和调试模式。原来是页面的问题。因为我忽略了一个重要的点。页面是动态加载的,每次只加载20项。
页面加载.png
问题出在这个地方,里面其实收录了一个地址()。可以通过抓包找到(谷歌的F12确实好用,建议多看)
ajax请求头.png
请求参数.png
返回 json 结果.png
知道问题出在哪里实际上已经完成了一半。谈谈我接下来的想法: 查看全部
java爬虫抓取网页数据(新浪新闻爬虫:一下接下来的目标页面是爬取问题推荐页面)
上一篇写了一个简单的新浪新闻爬虫,使用jsoup包在本地抓取url页面,在本地分析提取数据。jsoup的用法这里不再赘述。百度会看大图。看到网上大神们爬取了知乎,今天就用它来试试。写这篇文章的目的主要是记录一下我在爬行中遇到的一些坑以及如何解决。这也是一个加深理解的过程。
抓取的目标页面
2017-12-31_172919.png
目标是抓取问题推荐页面上的所有问题。但是后来我发现了一个问题。第一次抓取这个链接,获取问题列表,但是代码测试的时候,发现只有20条数据。. . 这显然不是我所期望的。我看了下代码,发现代码没有任何问题,那么有什么问题呢?检查了一块和调试模式。原来是页面的问题。因为我忽略了一个重要的点。页面是动态加载的,每次只加载20项。
页面加载.png
问题出在这个地方,里面其实收录了一个地址()。可以通过抓包找到(谷歌的F12确实好用,建议多看)
ajax请求头.png
请求参数.png
返回 json 结果.png
知道问题出在哪里实际上已经完成了一半。谈谈我接下来的想法:

