
java爬虫抓取网页数据
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-15 00:07
爬虫+基于接口的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方法有一个很大的局限性,就是只能通过jsoup爬虫爬取静态网页,所以只能爬取当前页面上的所有新闻。如果需要爬取一个网站的所有信息,就需要通过接口反复调整网站的接口,通过改变参数来爬取网站@的所有数据信息>.
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将分步说明。这里重点讲一下思路,最后提供完整的源代码。
第一步:找到界面
如果要获取这个网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->网络-->全部,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据通过大于56630或小于56630的ID返回。
flag=down 表示向下翻页。这意味着23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两条,这里id=0代表最新的两条数据)
返回json数据格式:
{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第二步:通过定时任务启动爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
锦色印刷结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里有两点需要注意
(1) 创建对象时,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否有对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时,比如上面改成Listextra,序列化就会失败,因为json的extra明明是一个Object,这里接受的确实是一个集合。关键是要属于
性别名称相同,所以赋值时会报错,序列化失败。
第四步:查看操作结果
这只是截取了控制台输出的部分信息。这样就可以得到网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取到该新闻的所有具体信息了。(完美的)
第五步:数据库去重思路
因为你不可能每次爬都直接把播放数据放到数据库中,所以必须比较新闻数据库是否已经存在,如果不存在就放到数据库中。思路如下:
(1)添加唯一属性字段,可以标识数据库表中的新闻,例如jinse+bottomId构成唯一属性,或者新闻的具体页面路径URI构成唯一属性。
(2)创建地图集合,通过URI查看数据库是否存在,如果存在,则不存在。
(3)存储前,如果为false则通过map.get(URI),然后存储到数据库中。
git 源代码
首先,源代码本身通过了Idea测试。此处使用龙目岛。您现在需要在 Idea 或 eclipse 中配置 Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果您不想担心,请不要考虑或做更多。中校【9】 查看全部
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
爬虫+基于接口的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方法有一个很大的局限性,就是只能通过jsoup爬虫爬取静态网页,所以只能爬取当前页面上的所有新闻。如果需要爬取一个网站的所有信息,就需要通过接口反复调整网站的接口,通过改变参数来爬取网站@的所有数据信息>.
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将分步说明。这里重点讲一下思路,最后提供完整的源代码。
第一步:找到界面
如果要获取这个网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->网络-->全部,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据通过大于56630或小于56630的ID返回。
flag=down 表示向下翻页。这意味着23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两条,这里id=0代表最新的两条数据)
返回json数据格式:


{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第二步:通过定时任务启动爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
锦色印刷结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里有两点需要注意
(1) 创建对象时,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否有对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时,比如上面改成Listextra,序列化就会失败,因为json的extra明明是一个Object,这里接受的确实是一个集合。关键是要属于
性别名称相同,所以赋值时会报错,序列化失败。
第四步:查看操作结果
这只是截取了控制台输出的部分信息。这样就可以得到网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取到该新闻的所有具体信息了。(完美的)

第五步:数据库去重思路
因为你不可能每次爬都直接把播放数据放到数据库中,所以必须比较新闻数据库是否已经存在,如果不存在就放到数据库中。思路如下:
(1)添加唯一属性字段,可以标识数据库表中的新闻,例如jinse+bottomId构成唯一属性,或者新闻的具体页面路径URI构成唯一属性。
(2)创建地图集合,通过URI查看数据库是否存在,如果存在,则不存在。
(3)存储前,如果为false则通过map.get(URI),然后存储到数据库中。
git 源代码
首先,源代码本身通过了Idea测试。此处使用龙目岛。您现在需要在 Idea 或 eclipse 中配置 Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果您不想担心,请不要考虑或做更多。中校【9】
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-15 00:06
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL 去重使用数据库代替 Bloom 过滤器,数亿存储的 db io 会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector 是一个JAVA爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,还有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手册:httpclient +jsoup+selenium来实现java爬虫功能。使用httpclient抓取,jsoup解析页面,90%的页面都可以处理,剩下的会用selenium;
参考链接: 查看全部
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:

Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL 去重使用数据库代替 Bloom 过滤器,数亿存储的 db io 会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector 是一个JAVA爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,还有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手册:httpclient +jsoup+selenium来实现java爬虫功能。使用httpclient抓取,jsoup解析页面,90%的页面都可以处理,剩下的会用selenium;
参考链接:
java爬虫抓取网页数据(java开发简单的说的意思访问提取方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-14 14:13
)
简单的说,爬虫的意思就是根据url访问请求,然后提取返回的数据,获取对你有用的信息。然后我们可以将这些有用的信息保存到数据库或保存到文件中。如果我们手动提取一个访问,会很慢,所以我们需要编写程序来获取有用的信息,这就是爬虫的作用。
一、概念:
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
二、java开发简单爬虫:1.使用httpclient访问url
行家地址:
commons-httpclient
commons-httpclient
3.1
代码测试:
package cn.qlq.craw.httpClient;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
public class HttpClientCraw {
public static void main(String[] a) throws Exception {
HttpClient client = new HttpClient();
PostMethod postMethod = new PostMethod("http://qiaoliqiang.cn/");
// 防止中文乱码
postMethod.getParams().setContentCharset("utf-8");
// 3.设置请求参数
postMethod.setParameter("mobileCode", "13834786998");
postMethod.setParameter("userID", "");
// 4.执行请求 ,结果码
int code = client.executeMethod(postMethod);
// 5. 获取结果
String result = postMethod.getResponseBodyAsString();
System.out.println("Post请求的结果:" + result);
}
}
结果:
Post请求的结果:
XXXXXXXXXXX
.......... 查看全部
java爬虫抓取网页数据(java开发简单的说的意思访问提取方法
)
简单的说,爬虫的意思就是根据url访问请求,然后提取返回的数据,获取对你有用的信息。然后我们可以将这些有用的信息保存到数据库或保存到文件中。如果我们手动提取一个访问,会很慢,所以我们需要编写程序来获取有用的信息,这就是爬虫的作用。
一、概念:
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
二、java开发简单爬虫:1.使用httpclient访问url
行家地址:
commons-httpclient
commons-httpclient
3.1
代码测试:
package cn.qlq.craw.httpClient;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
public class HttpClientCraw {
public static void main(String[] a) throws Exception {
HttpClient client = new HttpClient();
PostMethod postMethod = new PostMethod("http://qiaoliqiang.cn/";);
// 防止中文乱码
postMethod.getParams().setContentCharset("utf-8");
// 3.设置请求参数
postMethod.setParameter("mobileCode", "13834786998");
postMethod.setParameter("userID", "");
// 4.执行请求 ,结果码
int code = client.executeMethod(postMethod);
// 5. 获取结果
String result = postMethod.getResponseBodyAsString();
System.out.println("Post请求的结果:" + result);
}
}
结果:
Post请求的结果:
XXXXXXXXXXX
..........
java爬虫抓取网页数据(百度首页做了个小测试,小伙伴们可算松了口气)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-14 14:12
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!
好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:
啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?) 查看全部
java爬虫抓取网页数据(百度首页做了个小测试,小伙伴们可算松了口气)
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!

好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:

啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?)
java爬虫抓取网页数据(1.HtmlUnit中文文档获取页面中特定的元素tips:1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-13 18:01
1.HtmlUnit 简介
HtmlUnit 是一个 Java 无界面浏览器库。它模拟 HTML 文档并提供相应的 API,让您可以像在“普通”浏览器中一样调用页面、填写表单、单击链接等。它有很好的 JavaScript 支持(仍在改进),甚至可以处理相当复杂的 AJAX 库,根据使用的配置模拟 Chrome、Firefox 或 Internet Explorer。它通常用于测试目的或从 网站 检索信息。
HtmlUnit 不是通用的单元测试框架。它是一种模拟浏览器以进行测试的方法,旨在用于另一个测试框架(例如 JUnit 或 TestNG)。有关介绍,请参阅文档“HtmlUnit 入门”。HtmlUnit 用作不同的开源工具,例如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、WETATOR、Celerity、Spring MVC Test HtmlUnit 作为底层“浏览器”。
HtmlUnit 最初由 Gargoyle Software 的 Mike Bowler 编写,并在 Apache 2 许可下发布。从那以后,它收到了许多其他开发者的贡献,今天也将得到他们的帮助。
几年前,在做购物网站的数据采集工作时,我偶然遇到了HtmlUnit。我记得我如何无法捕获页面上的价格数据,并且 httpfox 无法跟踪价格数据的 URL。就在我不知所措的时候,HtmlUnit出现了,帮我解决了问题。所以今天我想说声谢谢,并向大家推荐HtmlUnit。
2.htmlUnit中文文档
3.1 获取页面的 TITLE、XML 代码和文本
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//创建一个webclient
WebClient webClient = new WebClient();
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
//获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com/");
//获取页面的TITLE
str = page.getTitleText();
System.out.println(str);
//获取页面的XML代码
str = page.asXml();
System.out.println(str);
//获取页面的文本
str = page.asText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.2 使用不同版本的浏览器打开
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//使用FireFox读取网页
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_24);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com/");
str = page.getTitleText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.3 在页面上查找特定元素
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/");
//通过id获得"百度一下"按钮
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
//关闭webclient
webClient.closeAllWindows();
}
}
提示:某些元素中没有id和name或其他节点。您可以通过查找其子节点和父节点之间的规则来获取元素。具体方法请参考:
核心代码是:
final HtmlPage nextPage = ((DomElement)(htmlpage.getElementByName("key").getParentNode().getParentNode())).getLastElementChild().click();
3.4 元素搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/");
//查找所有div
List hbList = page.getByXPath("//div");
HtmlDivision hb = (HtmlDivision)hbList.get(0);
System.out.println(hb.toString());
//查找并获取特定input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput)inputList.get(0);
System.out.println(input.toString());
//关闭webclient
webClient.closeAllWindows();
}
}
3.5 提交搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/");
//获取搜索输入框并提交搜索内容
HtmlInput input = (HtmlInput)page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("ymd");
System.out.println(input.toString());
//获取搜索按钮并点击
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
HtmlPage page2 = btn.click();
//输出新页面的文本
System.out.println(page2.asText());
}
}
3.htmlUnit方法介绍
一、环境介绍
因为是在自己的spring boot项目中引入的,所以只是在pom文件中添加了依赖。
net.sourceforge.htmlunit
htmlunit
2.41.0
如果你只是爬一个网站 js不多,建议改下下面的依赖
net.sourceforge.htmlunit
htmlunit
2.23
后面我会讲到两者的区别。当然,如果你不是使用maven项目(没有pom),可以到官网下载源码库
二、使用
HtmlUnit使用起来非常简单,使用的时候可以去官网手册查一下语法。其实说明书只是介绍介绍,下面听我说就够了;
1、创建客户端并配置客户端
final String url ="https:****";//大家这可以填自己爬虫的地址
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_68);//创建火狐浏览器 2.23版本是FIREFOX_45 new不写参数是默认浏览器
webClient.getOptions().setCssEnabled(false);//(屏蔽)css 因为css并不影响我们抓取数据 反而影响网页渲染效率
webClient.getOptions().setThrowExceptionOnScriptError(false);//(屏蔽)异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//(屏蔽)日志
webClient.getOptions().setJavaScriptEnabled(true);//加载js脚本
webClient.getOptions().setTimeout(50000);//设置超时时间
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置ajax
HtmlPage htmlPage = webClient.getPage(url);//将客户端获取的树形结构转化为HtmlPage
Thread.sleep(10000);//主线程休眠10秒 让客户端有时间执行js代码 也可以写成webClient.waitForBackgroundJavaScript(1000)
下面是一个等待js执行的情况,2.41.0很适合很多js的情况,但是2.3总是有问题,无法刷新网页,2.@ >41.0 打印的也很详细,执行的过程也比较慢,可能会比较慢产生详细的作品
远程地址页面在此处获取。我们现在需要做的是解析dom节点并填写数据来模拟点击等事件。如果要打印 htmlPage.asText() 输出 htmlPage 节点的文本 htmlPage.asXml() 输出 htmlPage 节点的 xml 代码
2、 获取节点
建议在这个链接准备一些前端知识
HtmlUnit给出了两种获取节点的方式
XPath 查询:
更详细的xpath解释:
final HtmlPage page = webClient.getPage("http://htmlunit.sourceforge.net");
//get list of all divs
final List divs = htmlPage .getByXPath("//div");
//get div which has a 'name' attribute of 'John'
final HtmlDivision div = (HtmlDivision) htmlPage .getByXPath("//div[@name='John']").get(0);
css 选择器:(我更喜欢它)
final DomNodeList divs = htmlPage .querySelectorAll("div");
for (DomNode div : divs) {
....
}
//get div which has the id 'breadcrumbs'
final DomNode div = htmlPage .querySelector("div#breadcrumbs");
css 提供了一个集合查询 querySelectorAll 和一个单一查询 querySelector。如果你没有基础,我给你举个例子:
htmlPage .querySelectorAll("div") 返回 htmlPage 下的一组 div 标签
htmlPage .querySelector("div:nth-child(1)") 返回htmlPage下div的第一个div
htmlPage .querySelector(".submit") 返回htmlPage下的第一个class=submit标签
htmlPage .querySelector("#submit") 返回 htmlPage 下 id=submit 的第一个标签
htmlPage .querySelector("div.submit") 返回类为submit的htmlPage下的第一个div标签
htmlPage .querySelector("div[id='submit']") 返回htmlPage下第一个id为submit的div标签
上面的枚举方法相信已经足够了,如果还不够,可以参考css选择器
下面列出常见的html标签与HtmlUnit类的对应关系
div -> HtmlDivision
div集合 -> DomNodeList
fieldSet -> HtmlFieldSet
form -> HtmlForm
button -> HtmlButton
a -> HtmlAnchor
-> HtmlXxxInput
( -> HtmlTextInput)
table -> HtmlTable
tr -> HtmlTableRow
td -> TableDataCell
setAttribute()方法有节点的属性样式,setNodeValue()设置节点的值。你的英语一下子提高了吗?几乎所有的标签都能找到对应的类别。来看看我的实战:这是一个在线填写温度的excel文档。如果访问更改地址,他会在登录页面提示一个登录按钮。登录按钮,我们现在模拟打开自动登录框:
//这段代码是为了让网页的的某个按钮加载出来之后再执行下面的代码
while (htmlPage.querySelector("#header-login-btn")==null) {
synchronized (htmlPage) {
htmlPage.wait(1000);
}
}
HtmlButton login = htmlPage.querySelector("#header-login-btn");//获取到登陆按钮
if (login!=null){//如果网页上没这个按钮你还要去获取他只会得到一个空对象,所以我们用空的方式可以判断网页上是否有这个按钮
System.out.println("-----未登录测试-----");
htmlPage=login.click();//模拟按钮点击后要将网页返回回来方便动态更新数据
System.out.println(htmlPage.asText());
HtmlAnchor switcher_plogin = htmlPage.querySelector("a[id='switcher_plogin']");
if (switcher_plogin!=null) {//帐号密码登录
System.out.println("-----点击了帐号密码登陆-----");
htmlPage = switcher_plogin.click();
System.out.println(htmlPage.asText());
}
}
System.out.println(htmlPage.asText());
webClient.close();
爬虫最重要的一步就是我们首先调试网页,有哪些按钮,点击哪些,设置哪些值。毕竟,我们必须用代码来安排代码。
**扩展:** 如果你想从网页上获取数据或下载文件,HtmlUnit 分析是不够的。推荐使用 Jsoup 库,可以和 HtmlUnit 一起使用。使用起来比较方便,这里就不一一列举了。
三、实现一个小demo
注意:htmlunit引用的jar包不完整会导致奇怪的错误
使用maven方法更方便
参考: 查看全部
java爬虫抓取网页数据(1.HtmlUnit中文文档获取页面中特定的元素tips:1.)
1.HtmlUnit 简介
HtmlUnit 是一个 Java 无界面浏览器库。它模拟 HTML 文档并提供相应的 API,让您可以像在“普通”浏览器中一样调用页面、填写表单、单击链接等。它有很好的 JavaScript 支持(仍在改进),甚至可以处理相当复杂的 AJAX 库,根据使用的配置模拟 Chrome、Firefox 或 Internet Explorer。它通常用于测试目的或从 网站 检索信息。
HtmlUnit 不是通用的单元测试框架。它是一种模拟浏览器以进行测试的方法,旨在用于另一个测试框架(例如 JUnit 或 TestNG)。有关介绍,请参阅文档“HtmlUnit 入门”。HtmlUnit 用作不同的开源工具,例如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、WETATOR、Celerity、Spring MVC Test HtmlUnit 作为底层“浏览器”。
HtmlUnit 最初由 Gargoyle Software 的 Mike Bowler 编写,并在 Apache 2 许可下发布。从那以后,它收到了许多其他开发者的贡献,今天也将得到他们的帮助。
几年前,在做购物网站的数据采集工作时,我偶然遇到了HtmlUnit。我记得我如何无法捕获页面上的价格数据,并且 httpfox 无法跟踪价格数据的 URL。就在我不知所措的时候,HtmlUnit出现了,帮我解决了问题。所以今天我想说声谢谢,并向大家推荐HtmlUnit。
2.htmlUnit中文文档
3.1 获取页面的 TITLE、XML 代码和文本

import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//创建一个webclient
WebClient webClient = new WebClient();
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
//获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com/";);
//获取页面的TITLE
str = page.getTitleText();
System.out.println(str);
//获取页面的XML代码
str = page.asXml();
System.out.println(str);
//获取页面的文本
str = page.asText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.2 使用不同版本的浏览器打开
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//使用FireFox读取网页
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_24);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com/";);
str = page.getTitleText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.3 在页面上查找特定元素
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/";);
//通过id获得"百度一下"按钮
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
//关闭webclient
webClient.closeAllWindows();
}
}
提示:某些元素中没有id和name或其他节点。您可以通过查找其子节点和父节点之间的规则来获取元素。具体方法请参考:
核心代码是:
final HtmlPage nextPage = ((DomElement)(htmlpage.getElementByName("key").getParentNode().getParentNode())).getLastElementChild().click();
3.4 元素搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/";);
//查找所有div
List hbList = page.getByXPath("//div");
HtmlDivision hb = (HtmlDivision)hbList.get(0);
System.out.println(hb.toString());
//查找并获取特定input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput)inputList.get(0);
System.out.println(input.toString());
//关闭webclient
webClient.closeAllWindows();
}
}
3.5 提交搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/";);
//获取搜索输入框并提交搜索内容
HtmlInput input = (HtmlInput)page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("ymd");
System.out.println(input.toString());
//获取搜索按钮并点击
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
HtmlPage page2 = btn.click();
//输出新页面的文本
System.out.println(page2.asText());
}
}
3.htmlUnit方法介绍
一、环境介绍
因为是在自己的spring boot项目中引入的,所以只是在pom文件中添加了依赖。
net.sourceforge.htmlunit
htmlunit
2.41.0
如果你只是爬一个网站 js不多,建议改下下面的依赖
net.sourceforge.htmlunit
htmlunit
2.23
后面我会讲到两者的区别。当然,如果你不是使用maven项目(没有pom),可以到官网下载源码库
二、使用
HtmlUnit使用起来非常简单,使用的时候可以去官网手册查一下语法。其实说明书只是介绍介绍,下面听我说就够了;
1、创建客户端并配置客户端
final String url ="https:****";//大家这可以填自己爬虫的地址
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_68);//创建火狐浏览器 2.23版本是FIREFOX_45 new不写参数是默认浏览器
webClient.getOptions().setCssEnabled(false);//(屏蔽)css 因为css并不影响我们抓取数据 反而影响网页渲染效率
webClient.getOptions().setThrowExceptionOnScriptError(false);//(屏蔽)异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//(屏蔽)日志
webClient.getOptions().setJavaScriptEnabled(true);//加载js脚本
webClient.getOptions().setTimeout(50000);//设置超时时间
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置ajax
HtmlPage htmlPage = webClient.getPage(url);//将客户端获取的树形结构转化为HtmlPage
Thread.sleep(10000);//主线程休眠10秒 让客户端有时间执行js代码 也可以写成webClient.waitForBackgroundJavaScript(1000)
下面是一个等待js执行的情况,2.41.0很适合很多js的情况,但是2.3总是有问题,无法刷新网页,2.@ >41.0 打印的也很详细,执行的过程也比较慢,可能会比较慢产生详细的作品
远程地址页面在此处获取。我们现在需要做的是解析dom节点并填写数据来模拟点击等事件。如果要打印 htmlPage.asText() 输出 htmlPage 节点的文本 htmlPage.asXml() 输出 htmlPage 节点的 xml 代码
2、 获取节点
建议在这个链接准备一些前端知识
HtmlUnit给出了两种获取节点的方式
XPath 查询:
更详细的xpath解释:
final HtmlPage page = webClient.getPage("http://htmlunit.sourceforge.net";);
//get list of all divs
final List divs = htmlPage .getByXPath("//div");
//get div which has a 'name' attribute of 'John'
final HtmlDivision div = (HtmlDivision) htmlPage .getByXPath("//div[@name='John']").get(0);
css 选择器:(我更喜欢它)
final DomNodeList divs = htmlPage .querySelectorAll("div");
for (DomNode div : divs) {
....
}
//get div which has the id 'breadcrumbs'
final DomNode div = htmlPage .querySelector("div#breadcrumbs");
css 提供了一个集合查询 querySelectorAll 和一个单一查询 querySelector。如果你没有基础,我给你举个例子:
htmlPage .querySelectorAll("div") 返回 htmlPage 下的一组 div 标签
htmlPage .querySelector("div:nth-child(1)") 返回htmlPage下div的第一个div
htmlPage .querySelector(".submit") 返回htmlPage下的第一个class=submit标签
htmlPage .querySelector("#submit") 返回 htmlPage 下 id=submit 的第一个标签
htmlPage .querySelector("div.submit") 返回类为submit的htmlPage下的第一个div标签
htmlPage .querySelector("div[id='submit']") 返回htmlPage下第一个id为submit的div标签
上面的枚举方法相信已经足够了,如果还不够,可以参考css选择器
下面列出常见的html标签与HtmlUnit类的对应关系
div -> HtmlDivision
div集合 -> DomNodeList
fieldSet -> HtmlFieldSet
form -> HtmlForm
button -> HtmlButton
a -> HtmlAnchor
-> HtmlXxxInput
( -> HtmlTextInput)
table -> HtmlTable
tr -> HtmlTableRow
td -> TableDataCell
setAttribute()方法有节点的属性样式,setNodeValue()设置节点的值。你的英语一下子提高了吗?几乎所有的标签都能找到对应的类别。来看看我的实战:这是一个在线填写温度的excel文档。如果访问更改地址,他会在登录页面提示一个登录按钮。登录按钮,我们现在模拟打开自动登录框:
//这段代码是为了让网页的的某个按钮加载出来之后再执行下面的代码
while (htmlPage.querySelector("#header-login-btn")==null) {
synchronized (htmlPage) {
htmlPage.wait(1000);
}
}
HtmlButton login = htmlPage.querySelector("#header-login-btn");//获取到登陆按钮
if (login!=null){//如果网页上没这个按钮你还要去获取他只会得到一个空对象,所以我们用空的方式可以判断网页上是否有这个按钮
System.out.println("-----未登录测试-----");
htmlPage=login.click();//模拟按钮点击后要将网页返回回来方便动态更新数据
System.out.println(htmlPage.asText());
HtmlAnchor switcher_plogin = htmlPage.querySelector("a[id='switcher_plogin']");
if (switcher_plogin!=null) {//帐号密码登录
System.out.println("-----点击了帐号密码登陆-----");
htmlPage = switcher_plogin.click();
System.out.println(htmlPage.asText());
}
}
System.out.println(htmlPage.asText());
webClient.close();
爬虫最重要的一步就是我们首先调试网页,有哪些按钮,点击哪些,设置哪些值。毕竟,我们必须用代码来安排代码。
**扩展:** 如果你想从网页上获取数据或下载文件,HtmlUnit 分析是不够的。推荐使用 Jsoup 库,可以和 HtmlUnit 一起使用。使用起来比较方便,这里就不一一列举了。
三、实现一个小demo
注意:htmlunit引用的jar包不完整会导致奇怪的错误
使用maven方法更方便
参考:
java爬虫抓取网页数据( python同名子标签的,怎么获取下面数个同标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-12 12:04
python同名子标签的,怎么获取下面数个同标签)
Python爬虫,用find-all()找到一个标签后,如何获取下面几个同名子标签的内容-—— div=soup.find_all('div',class_="star") #到这里时间,标签已经改变了列出div,class=star的所有内容。您可以根据这些数据执行 find_all 来查找标签。例子:for k in soup.find_all('div',class_="star"):cont =k.find_all('span') #第一步find_all的值然后找到_all print(cont[0].string ) #由于div标签中有四个'span',它是一个列表形式cont[0],第一个值取决于您的需要。我也是菜鸟,纯交流。
python网络爬虫复制的代码用find找不到,返回-1-如果网页源代码的tag元素,没有这个元素就找不到。检查您需要获取内容的标签元素,只需更改代码
crawler attrs是什么意思? - 网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本. 其他不太常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。
网络爬虫findall()正则(.*?)不工作,不返回--可以通过调试发现错误。web_data.text 中根本没有 ¥ 符号。需要 HTML 实体编码转换。正确完整的代码如下: import requests,re,html headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像...
爬虫遇到不同类型的网址时如何抓取各种网址——网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的 URL 开始。, 获取初始网页上的网址,在抓取网页的过程中,不断地从当前网页中提取新的网址,放入队列中,直到满...
Python爬虫如何入门——从爬虫的基本要求出发:1. 抓取py的urllib可能不会用,但是没用过的一定要学。更好的替代方案有 requests 等待更人性化和成熟的第三方库。如果pyer不了解各种库,那就白学吧。最基本的爬取就是把网页拉回来。如果你继续这样做,...
如何在python爬虫中这样循环?-宿主可以使用BeautifulSoup from bs4 import BeautifulSoups = BeautifulSoup("html")liTag = s.find('li') 将采集中的数据切入list list ,删除列表中的第0个元素?你的问题解决了吗?二营SEO长
写爬虫的时候,Beautifulsoup应该怎么提取这种没有关闭标签的网页?-Method 1.==" 不用找,直接打印soup.meta['content'] method 2. = =》print meta['content']ps:注意页面有多个meta标签
如何使用python爬进网页搜索框输入文字,自动搜索信息并抓取——爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发送新的请求; 参考示例如下: item1 = item()yield item1item2 = item()yield item2req = request(url='link to the next page', callback=self.parse)yield req 注意:当使用产量。
如何用最简单的Python爬虫采集整个网站——爬取网站的数据?网站,还是保存所有的页面代码?无论两者中的哪一个,都必须知道网站的所有页面的url。 查看全部
java爬虫抓取网页数据(
python同名子标签的,怎么获取下面数个同标签)


Python爬虫,用find-all()找到一个标签后,如何获取下面几个同名子标签的内容-—— div=soup.find_all('div',class_="star") #到这里时间,标签已经改变了列出div,class=star的所有内容。您可以根据这些数据执行 find_all 来查找标签。例子:for k in soup.find_all('div',class_="star"):cont =k.find_all('span') #第一步find_all的值然后找到_all print(cont[0].string ) #由于div标签中有四个'span',它是一个列表形式cont[0],第一个值取决于您的需要。我也是菜鸟,纯交流。
python网络爬虫复制的代码用find找不到,返回-1-如果网页源代码的tag元素,没有这个元素就找不到。检查您需要获取内容的标签元素,只需更改代码
crawler attrs是什么意思? - 网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本. 其他不太常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。
网络爬虫findall()正则(.*?)不工作,不返回--可以通过调试发现错误。web_data.text 中根本没有 ¥ 符号。需要 HTML 实体编码转换。正确完整的代码如下: import requests,re,html headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像...
爬虫遇到不同类型的网址时如何抓取各种网址——网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的 URL 开始。, 获取初始网页上的网址,在抓取网页的过程中,不断地从当前网页中提取新的网址,放入队列中,直到满...
Python爬虫如何入门——从爬虫的基本要求出发:1. 抓取py的urllib可能不会用,但是没用过的一定要学。更好的替代方案有 requests 等待更人性化和成熟的第三方库。如果pyer不了解各种库,那就白学吧。最基本的爬取就是把网页拉回来。如果你继续这样做,...
如何在python爬虫中这样循环?-宿主可以使用BeautifulSoup from bs4 import BeautifulSoups = BeautifulSoup("html")liTag = s.find('li') 将采集中的数据切入list list ,删除列表中的第0个元素?你的问题解决了吗?二营SEO长
写爬虫的时候,Beautifulsoup应该怎么提取这种没有关闭标签的网页?-Method 1.==" 不用找,直接打印soup.meta['content'] method 2. = =》print meta['content']ps:注意页面有多个meta标签
如何使用python爬进网页搜索框输入文字,自动搜索信息并抓取——爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发送新的请求; 参考示例如下: item1 = item()yield item1item2 = item()yield item2req = request(url='link to the next page', callback=self.parse)yield req 注意:当使用产量。
如何用最简单的Python爬虫采集整个网站——爬取网站的数据?网站,还是保存所有的页面代码?无论两者中的哪一个,都必须知道网站的所有页面的url。
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-11 07:07
文章 目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的同学,学python爬虫比较靠谱,但是是不是就意味着java不能爬?当然不是。事实上,在某些场景下,java爬虫更方便,更容易使用。
1.引入依赖:
java中的爬虫使用了jsoup的类库,jsoup提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据,让你在请求后对网页进行dom操作网页来达到爬取的目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例2:
爬取学校信息:
3.代理描述:
情况1,不使用代理ip,直接抓包即可。但是一般情况下,我们抓取的网站会设置反爬虫、ip阻塞等,所以需要设置代理ip。在线案例2中,使用蘑菇代理的代理隧道的代理设置。还不错,确实需要的可以买。
总结
当然,我上面写的两个案例只是例子。其实操作dom的方法有很多种。如果要爬取,肯定需要dom的基本操作,还需要一些基本的html知识。如果想和我有更多的交流,可以关注我的公众号:Java Time House交流。 查看全部
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
文章 目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的同学,学python爬虫比较靠谱,但是是不是就意味着java不能爬?当然不是。事实上,在某些场景下,java爬虫更方便,更容易使用。
1.引入依赖:
java中的爬虫使用了jsoup的类库,jsoup提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据,让你在请求后对网页进行dom操作网页来达到爬取的目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例2:
爬取学校信息:
3.代理描述:
情况1,不使用代理ip,直接抓包即可。但是一般情况下,我们抓取的网站会设置反爬虫、ip阻塞等,所以需要设置代理ip。在线案例2中,使用蘑菇代理的代理隧道的代理设置。还不错,确实需要的可以买。
总结
当然,我上面写的两个案例只是例子。其实操作dom的方法有很多种。如果要爬取,肯定需要dom的基本操作,还需要一些基本的html知识。如果想和我有更多的交流,可以关注我的公众号:Java Time House交流。
java爬虫抓取网页数据(网易要闻如下:内置浏览器Selenium方式是一个模拟浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-07 01:09
这是 Java 爬虫系列的第三篇文章。上一篇Java爬虫遇到网站需要登录,怎么办?),我们简单讲解一下爬取时登录问题的解决方法。在这个文章中,我们来谈谈爬取时异步数据加载的问题。这也是爬行中常见的问题。.
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
硒
单位
PhantomJs
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过ajax从后端获取的,我们只需要找到对应的ajax请求连接就可以了,这样我们就得到了我们需要的数据,逆向分析方法的优点是这种方式得到的数据都是json格式的,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax的时候需要耐心和熟练,因为需要在大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:
内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
1、引入Selenium的依赖包并在pom.xml中添加
org.seleniumhq.selenium
硒-java
3.141.59
2、下载对应的驱动,比如我下载的chromedriver。下载地址为:下载后需要将驱动所在的位置写入Java的环境变量中。比如我直接放在项目下,所以我的代码是:
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* Selenium 解决异步数据加载问题
*
*
* @param url
*/
公共无效硒(字符串网址){
// 设置chromedirver的存储位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,不弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取重要新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement: webElements) {
// 提取新闻链接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
字符串标题 = webElement.getText();
如果 (article_url.contains("")) {
System.out.println("文章标题:" + title + ",文章链接:" + article_url);
}
}
webDriver.close();
}
运行此方法并得到以下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析的方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一上点。你绝对可以找到它们。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:
从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这块数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转换成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
阿里巴巴
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用逆向分析解决异步数据加载问题
*
* @param url
*/
public void httpclientMethod(String url) 抛出 IOException { 查看全部
java爬虫抓取网页数据(网易要闻如下:内置浏览器Selenium方式是一个模拟浏览器)
这是 Java 爬虫系列的第三篇文章。上一篇Java爬虫遇到网站需要登录,怎么办?),我们简单讲解一下爬取时登录问题的解决方法。在这个文章中,我们来谈谈爬取时异步数据加载的问题。这也是爬行中常见的问题。.
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
硒
单位
PhantomJs
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过ajax从后端获取的,我们只需要找到对应的ajax请求连接就可以了,这样我们就得到了我们需要的数据,逆向分析方法的优点是这种方式得到的数据都是json格式的,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax的时候需要耐心和熟练,因为需要在大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:

内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
1、引入Selenium的依赖包并在pom.xml中添加
org.seleniumhq.selenium
硒-java
3.141.59
2、下载对应的驱动,比如我下载的chromedriver。下载地址为:下载后需要将驱动所在的位置写入Java的环境变量中。比如我直接放在项目下,所以我的代码是:
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* Selenium 解决异步数据加载问题
*
*
* @param url
*/
公共无效硒(字符串网址){
// 设置chromedirver的存储位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,不弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取重要新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement: webElements) {
// 提取新闻链接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
字符串标题 = webElement.getText();
如果 (article_url.contains("")) {
System.out.println("文章标题:" + title + ",文章链接:" + article_url);
}
}
webDriver.close();
}
运行此方法并得到以下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析的方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一上点。你绝对可以找到它们。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:

从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这块数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转换成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
阿里巴巴
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用逆向分析解决异步数据加载问题
*
* @param url
*/
public void httpclientMethod(String url) 抛出 IOException {
java爬虫抓取网页数据(关于HTML解析器的一些重要方法和重要类1-2 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-07 01:06
)
Jsoup 简介
jsoup 是一个 Java HTML 解析器,主要用于解析 HTML。
中文文档:
Jsoup 可以实现什么?
从 URL、文件或字符串中抓取和解析 HTML 以查找和提取数据,使用 DOM 遍历或 CSS 选择器来操作 HTML 元素、属性和文本以根据安全白名单清理用户提交的内容以防止 XSS 攻击输出整洁的 HTML
在爬取的时候,当我们使用HttpClient这样的框架来获取网页的源码时,需要从网页的源码中提取出我们想要的内容,然后我们可以使用HTML解析器这样的作为 jsoup。它可以很容易地实现。
虽然jsoup也支持直接从某个地址爬取网页源码,但是只支持HTTP和HTTPS协议,支持还不够丰富。因此,主要用于解析HTML。
依赖:
org.jsoup
jsoup
1.11.3
Jsoup 重要类 1、org.jsoup.Jsoup 类
Jsoup 类是任何 Jsoup 程序的入口点,将提供从各种来源加载和解析 HTML 文档的方法。
方法说明
静态连接connect(String url)
创建并返回到 URL 的连接。
静态文档解析(文件输入,字符串字符集名称)
将指定的字符集文件解析为文档。
静态文档解析(String html)
将给定的 html 代码解析为文档。
tatic String clean(String bodyHtml, Whitelist whitelist)
通过解析输入从输入 HTML 返回安全的 HTML
HTML 并按允许的标签和属性的白名单过滤。
2、org.jsoup.nodes.Document 类 3、org.jsoup.nodes.Element 类
重要方法:
方法说明
child(int index)
通过索引定位子元素。
儿童()
获取该元素的所有子元素
类名()
获取该元素的类属性名称
classNames()
获取所有元素的类名返回值:Set
classNames(Set classNames)
通过提供的类名设置元素的类属性
数据()
获取该元素的组合数据
空()
删除此元素的所有子数据节点。
firstElementSibling()
获取当前元素的第一个同级同级元素。
getAllElements()
获取当前元素下的所有元素(包括自己、孩子、孩子的孩子)
getElementsByAttribute(String key)
通过属性名查找当前html下的所有元素
getElementsByClass(String className)
当前元素是否有这个类或者这个元素下是否有这个类
html()
在文件中检索Html
id()
返回当前元素的id值
isBlock()
测试该元素是否为层次元素
lastElementSibling()
获取与该元素同级的最后一个元素
父()
获取该节点的父节点
父母()
获取父节点,一直到节点的根节点
选择()
选择器方法,通用
兄弟元素()
获取所有兄弟元素(不包括你自己)
标签()
获取这个标签对象
标签名()
获取此标签的名称
文本()
获取该元素和所有子元素的文本内容
textNodes()
获取该元素的子文本标签集合
包裹()
包装这个元素的html
以下是一些示例:从 URL 加载文档,使用 Jsoup.connect() 方法从 URL 加载 HTML。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;).get();
System.out.println(document.title());
获取网页中的所有链接
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements links = document.select("a[href]");
for (Element link : links) {
System.out.println("link : " + link.attr("href"));
System.out.println("text : " + link.text());
}
获取网页中显示的所有图片
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images) {
System.out.println("src : " + image.attr("src"));
System.out.println("height : " + image.attr("height"));
System.out.println("width : " + image.attr("width"));
System.out.println("alt : " + image.attr("alt"));
}
获取URL的元信息。元信息包括用于确定网络内容索引的搜索引擎,例如 Google。它们以一些标签的形式存在于 HTML 页面的 HEAD 部分。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
String description = document.select("meta[name=description]").get(0).attr("content");
System.out.println("Meta description : " + description);
String keywords = document.select("meta[name=keywords]").first().attr("content");
System.out.println("Meta keyword : " + keywords); 查看全部
java爬虫抓取网页数据(关于HTML解析器的一些重要方法和重要类1-2
)
Jsoup 简介
jsoup 是一个 Java HTML 解析器,主要用于解析 HTML。
中文文档:
Jsoup 可以实现什么?
从 URL、文件或字符串中抓取和解析 HTML 以查找和提取数据,使用 DOM 遍历或 CSS 选择器来操作 HTML 元素、属性和文本以根据安全白名单清理用户提交的内容以防止 XSS 攻击输出整洁的 HTML
在爬取的时候,当我们使用HttpClient这样的框架来获取网页的源码时,需要从网页的源码中提取出我们想要的内容,然后我们可以使用HTML解析器这样的作为 jsoup。它可以很容易地实现。
虽然jsoup也支持直接从某个地址爬取网页源码,但是只支持HTTP和HTTPS协议,支持还不够丰富。因此,主要用于解析HTML。
依赖:
org.jsoup
jsoup
1.11.3
Jsoup 重要类 1、org.jsoup.Jsoup 类
Jsoup 类是任何 Jsoup 程序的入口点,将提供从各种来源加载和解析 HTML 文档的方法。
方法说明
静态连接connect(String url)
创建并返回到 URL 的连接。
静态文档解析(文件输入,字符串字符集名称)
将指定的字符集文件解析为文档。
静态文档解析(String html)
将给定的 html 代码解析为文档。
tatic String clean(String bodyHtml, Whitelist whitelist)
通过解析输入从输入 HTML 返回安全的 HTML
HTML 并按允许的标签和属性的白名单过滤。
2、org.jsoup.nodes.Document 类 3、org.jsoup.nodes.Element 类
重要方法:
方法说明
child(int index)
通过索引定位子元素。
儿童()
获取该元素的所有子元素
类名()
获取该元素的类属性名称
classNames()
获取所有元素的类名返回值:Set
classNames(Set classNames)
通过提供的类名设置元素的类属性
数据()
获取该元素的组合数据
空()
删除此元素的所有子数据节点。
firstElementSibling()
获取当前元素的第一个同级同级元素。
getAllElements()
获取当前元素下的所有元素(包括自己、孩子、孩子的孩子)
getElementsByAttribute(String key)
通过属性名查找当前html下的所有元素
getElementsByClass(String className)
当前元素是否有这个类或者这个元素下是否有这个类
html()
在文件中检索Html
id()
返回当前元素的id值
isBlock()
测试该元素是否为层次元素
lastElementSibling()
获取与该元素同级的最后一个元素
父()
获取该节点的父节点
父母()
获取父节点,一直到节点的根节点
选择()
选择器方法,通用
兄弟元素()
获取所有兄弟元素(不包括你自己)
标签()
获取这个标签对象
标签名()
获取此标签的名称
文本()
获取该元素和所有子元素的文本内容
textNodes()
获取该元素的子文本标签集合
包裹()
包装这个元素的html
以下是一些示例:从 URL 加载文档,使用 Jsoup.connect() 方法从 URL 加载 HTML。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;).get();
System.out.println(document.title());
获取网页中的所有链接
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements links = document.select("a[href]");
for (Element link : links) {
System.out.println("link : " + link.attr("href"));
System.out.println("text : " + link.text());
}
获取网页中显示的所有图片
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images) {
System.out.println("src : " + image.attr("src"));
System.out.println("height : " + image.attr("height"));
System.out.println("width : " + image.attr("width"));
System.out.println("alt : " + image.attr("alt"));
}
获取URL的元信息。元信息包括用于确定网络内容索引的搜索引擎,例如 Google。它们以一些标签的形式存在于 HTML 页面的 HEAD 部分。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
String description = document.select("meta[name=description]").get(0).attr("content");
System.out.println("Meta description : " + description);
String keywords = document.select("meta[name=keywords]").first().attr("content");
System.out.println("Meta keyword : " + keywords);
java爬虫抓取网页数据(java爬虫抓取网页数据的成熟工具-爬虫.js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-04 10:05
java爬虫抓取网页数据,已经是一个很成熟的工具了,虽然易用性有待提高,毕竟网站的后台数据都是https加密协议,而web端只能对post数据进行加密。首先,列举一些主流的爬虫工具,
1)用于爬取本地url的代理,例如requests,github上有大量成熟的项目,比如,
2)apache2.0python的解释器,可能很多人认为爬虫只适合用于抓取网页,实际上网页爬虫也是一种解释器,主要用于抓取存在于web页面的内容,实现为网页的request请求。
3)chrome的浏览器extension,提供能够解析网页的功能,
3)scrapy
4)python框架的requests模块
4)beautifulsoup
5)geetest.js
6)xpath
7)nodejsjavascriptmodules
8)scrapy.js好吧,好多人可能是用于解析requests和scrapy的请求,并没有用到爬虫的特殊功能。
python的爬虫工具虽然有很多,
1)scrapy.js这是用于爬取第三方代理服务的库,而且提供了很多高效的接口,可以在不同的浏览器间互相调用,效率十分高。
爬取代理实现的关键:
1)进行httprequest的解析和请求,提供了requestheader和getrequest方法来封装返回,
2)存放请求下载的内容
3)部署到网站的内存中。
4)applewebkit/537。36(khtml,likegecko)chrome/51。1913。100safari/537。36":iflen(request。user-agent)==0:print"请求成功!"else:print"请求失败!"ifrequest。user-agent=="mozilla/5。0(x11;linuxx86_6。
4)applewebkit/537.36(khtml,likegecko)chrome/51.0.1913.100safari/537.36":print"请求成功!"else:print"请求失败!"python自带user-agent解析库,可以提供各种可爬取代理实现代理请求。
大家自己动手尝试一下:-how-to-process-request-headers#ah
2)爬取本地网页的内容,例如,简书的文章列表。
实现:
<p>1)复制粘贴到本地htmltemplate的tag_preview:简书 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据的成熟工具-爬虫.js)
java爬虫抓取网页数据,已经是一个很成熟的工具了,虽然易用性有待提高,毕竟网站的后台数据都是https加密协议,而web端只能对post数据进行加密。首先,列举一些主流的爬虫工具,
1)用于爬取本地url的代理,例如requests,github上有大量成熟的项目,比如,
2)apache2.0python的解释器,可能很多人认为爬虫只适合用于抓取网页,实际上网页爬虫也是一种解释器,主要用于抓取存在于web页面的内容,实现为网页的request请求。
3)chrome的浏览器extension,提供能够解析网页的功能,
3)scrapy
4)python框架的requests模块
4)beautifulsoup
5)geetest.js
6)xpath
7)nodejsjavascriptmodules
8)scrapy.js好吧,好多人可能是用于解析requests和scrapy的请求,并没有用到爬虫的特殊功能。
python的爬虫工具虽然有很多,
1)scrapy.js这是用于爬取第三方代理服务的库,而且提供了很多高效的接口,可以在不同的浏览器间互相调用,效率十分高。
爬取代理实现的关键:
1)进行httprequest的解析和请求,提供了requestheader和getrequest方法来封装返回,
2)存放请求下载的内容
3)部署到网站的内存中。
4)applewebkit/537。36(khtml,likegecko)chrome/51。1913。100safari/537。36":iflen(request。user-agent)==0:print"请求成功!"else:print"请求失败!"ifrequest。user-agent=="mozilla/5。0(x11;linuxx86_6。
4)applewebkit/537.36(khtml,likegecko)chrome/51.0.1913.100safari/537.36":print"请求成功!"else:print"请求失败!"python自带user-agent解析库,可以提供各种可爬取代理实现代理请求。
大家自己动手尝试一下:-how-to-process-request-headers#ah
2)爬取本地网页的内容,例如,简书的文章列表。
实现:
<p>1)复制粘贴到本地htmltemplate的tag_preview:简书
java爬虫抓取网页数据(大数据java爬虫抓取网页数据的有效评论统计原理是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-03 22:02
java爬虫抓取网页数据,封装在spring-boot里面。去年的时候写了一个叫【掘金】的日志爬虫,抓取了多个知乎用户的多篇文章的有效评论。大概就是抓取作者的简介、收藏等,然后把评论者的数据列出来,等同于爬虫抓取评论统计的原理。目前当然可以开发一些辅助类库,在大数据的辅助分析中做用。从去年到现在一直在深入研究java基础,从http请求、表单元素,再到对象、多线程、redis、设计模式等等,跟着语言本身的一些机制也做了很多实验。
今年开始研究爬虫的容器,结合springboot,写了三个stark在去年的某一个项目里。其中两个用到了springboot的依赖注入,一个用到了spring的xmlhttprequest。还结合elk实验,写了elk系列的project,也写了用到了springboot的stark配置,感兴趣的可以去探索下。
使用springboot可以快速开发多个项目,搭建restful服务集成一些模块,搭建springcloud,跑了下stark的demo服务。stark实例,数据均来自于github评论者的有效评论,共三十三页。项目地址:,首发于微信公众号:面向对象之禅。感兴趣的话,也可以来微信公众号和我聊聊。
springboot本质是基于spring的开发框架,并在上面实现各种开发工具,比如springdatalibrary的jpa、springmvc、druid等,比如,除了用spring开发控制器和处理器映射之外,还可以通过druid来构建日志,异常,注解等模块。在springboot的语境下,pom.xml的主要作用是管理依赖,负责构建需要的spring、pom、java、python、jar包。
所以pom.xml有相应的stark模块加载,可以把springboot框架相关依赖发布到pom.xml中的commons-language-processor-pom.xml文件,供springboot集成使用。当然,如果不依赖spring,建议可以在spring框架的pom.xml中不加配置直接写pom.xml就好。
项目实战框架的基本配置,简单一点的有commons-lang、spring-boot-stark、error等。复杂一点的,比如,commons-lang可以包含spring容器、事务、xml、redis等,而且官方也提供了springboot的快速编译工具。error允许在定义的commons-lang-processor-pom.xml中使用pom.xml中定义的异常代码块/dogethandleresultparams等;pom.xml中还定义了非常多的模块和依赖,建议直接导入pom.xml即可。等等等等,有空继续填坑。 查看全部
java爬虫抓取网页数据(大数据java爬虫抓取网页数据的有效评论统计原理是什么?)
java爬虫抓取网页数据,封装在spring-boot里面。去年的时候写了一个叫【掘金】的日志爬虫,抓取了多个知乎用户的多篇文章的有效评论。大概就是抓取作者的简介、收藏等,然后把评论者的数据列出来,等同于爬虫抓取评论统计的原理。目前当然可以开发一些辅助类库,在大数据的辅助分析中做用。从去年到现在一直在深入研究java基础,从http请求、表单元素,再到对象、多线程、redis、设计模式等等,跟着语言本身的一些机制也做了很多实验。
今年开始研究爬虫的容器,结合springboot,写了三个stark在去年的某一个项目里。其中两个用到了springboot的依赖注入,一个用到了spring的xmlhttprequest。还结合elk实验,写了elk系列的project,也写了用到了springboot的stark配置,感兴趣的可以去探索下。
使用springboot可以快速开发多个项目,搭建restful服务集成一些模块,搭建springcloud,跑了下stark的demo服务。stark实例,数据均来自于github评论者的有效评论,共三十三页。项目地址:,首发于微信公众号:面向对象之禅。感兴趣的话,也可以来微信公众号和我聊聊。
springboot本质是基于spring的开发框架,并在上面实现各种开发工具,比如springdatalibrary的jpa、springmvc、druid等,比如,除了用spring开发控制器和处理器映射之外,还可以通过druid来构建日志,异常,注解等模块。在springboot的语境下,pom.xml的主要作用是管理依赖,负责构建需要的spring、pom、java、python、jar包。
所以pom.xml有相应的stark模块加载,可以把springboot框架相关依赖发布到pom.xml中的commons-language-processor-pom.xml文件,供springboot集成使用。当然,如果不依赖spring,建议可以在spring框架的pom.xml中不加配置直接写pom.xml就好。
项目实战框架的基本配置,简单一点的有commons-lang、spring-boot-stark、error等。复杂一点的,比如,commons-lang可以包含spring容器、事务、xml、redis等,而且官方也提供了springboot的快速编译工具。error允许在定义的commons-lang-processor-pom.xml中使用pom.xml中定义的异常代码块/dogethandleresultparams等;pom.xml中还定义了非常多的模块和依赖,建议直接导入pom.xml即可。等等等等,有空继续填坑。
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-03 06:11
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,用少量的代码就可以实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以下文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的会使用selenium;
参考链接: 查看全部
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括

Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:

Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,用少量的代码就可以实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
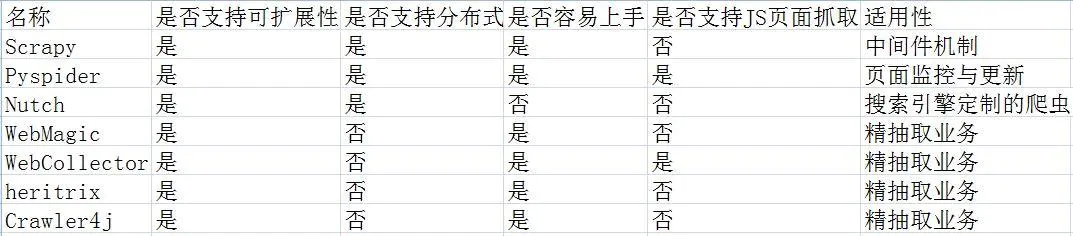
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以下文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的会使用selenium;
参考链接:
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-01 10:11
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络蜘蛛通过网页的链接地址搜索网页,从某个页面(通常是首页)开始,阅读
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果整个
把互联网想象成一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。所以如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个
对于接收“爬虫”发回的数据并进行处理和过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求就越高。
1 关注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的URL开始,获取
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂,需要一定的网页分析
该算法过滤与主题无关的链接,保留有用的链接并将它们放入URL队列中等待被抓取。然后,它会根据一定的搜索策略从队列中选择要抓取的网页的网址,并重复上传
该过程将停止,直到达到系统的某个条件。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;
对于焦爬虫来说,这个过程中得到的分析结果,也可以为后续的爬虫过程提供反馈和指导。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、
增量网络爬虫,深网爬虫。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。如何从网络上
本站获取的网站会进一步循环获取数据和提取其他数据。我不会在这里写。只能模拟最简单的原理。实际的网站爬虫比这里复杂很多,深入讨论的也太多了。
NS。除了提取URL,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个使用Java模拟提取新浪页面上的链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在idea中运行结果如下:
检查D盘是否有SiteURL.txt文件
SiteURL 文件已成功生成。打开它可以看到所有爬取的url。
查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人()
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络蜘蛛通过网页的链接地址搜索网页,从某个页面(通常是首页)开始,阅读
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果整个
把互联网想象成一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。所以如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个
对于接收“爬虫”发回的数据并进行处理和过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求就越高。
1 关注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的URL开始,获取
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂,需要一定的网页分析
该算法过滤与主题无关的链接,保留有用的链接并将它们放入URL队列中等待被抓取。然后,它会根据一定的搜索策略从队列中选择要抓取的网页的网址,并重复上传
该过程将停止,直到达到系统的某个条件。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;
对于焦爬虫来说,这个过程中得到的分析结果,也可以为后续的爬虫过程提供反馈和指导。

与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、
增量网络爬虫,深网爬虫。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。如何从网络上
本站获取的网站会进一步循环获取数据和提取其他数据。我不会在这里写。只能模拟最简单的原理。实际的网站爬虫比这里复杂很多,深入讨论的也太多了。
NS。除了提取URL,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个使用Java模拟提取新浪页面上的链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在idea中运行结果如下:
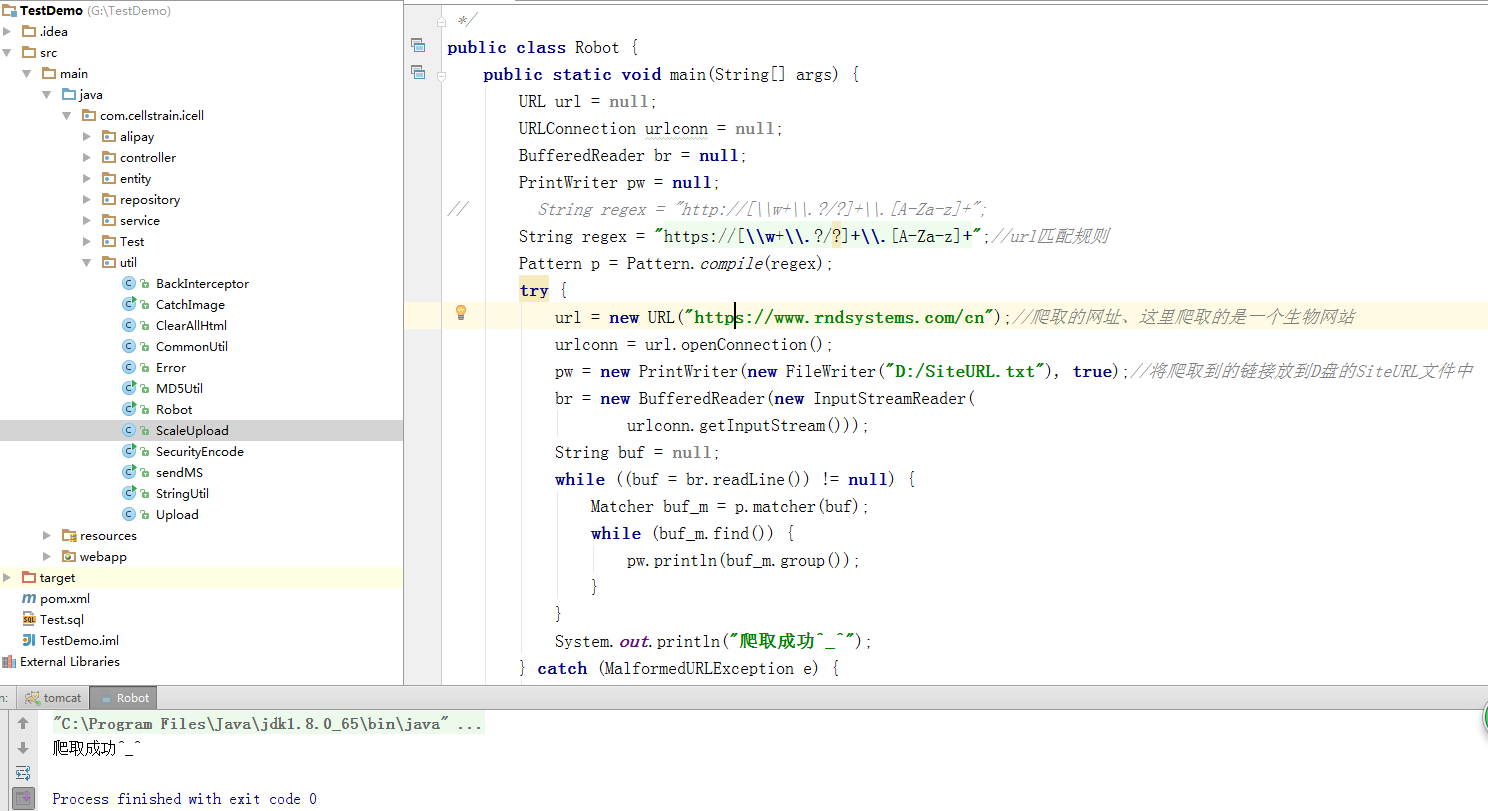
检查D盘是否有SiteURL.txt文件

SiteURL 文件已成功生成。打开它可以看到所有爬取的url。

java爬虫抓取网页数据(2.如何通过selenium-java爬取异步加载的数据方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-27 05:07
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:
按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:
纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
org.seleniumhq.selenium
selenium-java
3.141.59
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:持仓市值通知系统,他每天都会根据自己的持仓配置自动计算出账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。 查看全部
java爬虫抓取网页数据(2.如何通过selenium-java爬取异步加载的数据方法。)
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:

按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:

纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
org.seleniumhq.selenium
selenium-java
3.141.59
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:持仓市值通知系统,他每天都会根据自己的持仓配置自动计算出账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。
java爬虫抓取网页数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-26 23:02
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集吧。
一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix 系统框架图
Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:WebLech URL Spider
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)可配置性强:可以自定义深度优先或宽度优先的抓取网页,带URL过滤器,可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以优先抓取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续抓取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站结构(可以创建网站图),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任何功能。
项目主页:JSpider-开源Web机器人
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一组JSP标签库,让那些基于JSP的站点无需开发任何Java类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:Arachnid Web Spider Framework
八、LARM
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:/
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站 的所有资源都是本地抓取的,包括网页和各种类型的文件,比如图片, flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile呢?
由于一些文件在爬取过程中经常出现错误,很多javascript控制的URL无法正确解析,snoics-reptile对外提供了接口和配置文件,可以传递特殊的URL。自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:淡蓝色轨迹...
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:Web-Harvest Project Home Pagenet
十个二、烂透了
ItSucks 是一个开源的 Java 网络爬虫项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:ItSucks
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
执照 查看全部
java爬虫抓取网页数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集吧。
一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix 系统框架图
Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:WebLech URL Spider
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)可配置性强:可以自定义深度优先或宽度优先的抓取网页,带URL过滤器,可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以优先抓取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续抓取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站结构(可以创建网站图),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任何功能。
项目主页:JSpider-开源Web机器人
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一组JSP标签库,让那些基于JSP的站点无需开发任何Java类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:Arachnid Web Spider Framework
八、LARM
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:/
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站 的所有资源都是本地抓取的,包括网页和各种类型的文件,比如图片, flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile呢?
由于一些文件在爬取过程中经常出现错误,很多javascript控制的URL无法正确解析,snoics-reptile对外提供了接口和配置文件,可以传递特殊的URL。自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:淡蓝色轨迹...
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:Web-Harvest Project Home Pagenet
十个二、烂透了
ItSucks 是一个开源的 Java 网络爬虫项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:ItSucks
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
执照
java爬虫抓取网页数据(就是自动爬起来()所有链接())
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2021-10-23 08:15
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客的所有链接网站()。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入集合中,等待下一次遍历的同时循环。
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。最后将整个oldMap还没有遍历的链接遍历完成后,如果发现newMap不为空,则说明本次循环产生了新的链接,所以将这些新链接加入到oldMap中继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn");
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三项最终测试结果
PS:它的实际递归不是很好,因为如果网站页面多的话,程序运行时间长的话内存消耗会很大,但是因为我的博客网站页面不是很多,所以效果还可以 查看全部
java爬虫抓取网页数据(就是自动爬起来()所有链接())
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客的所有链接网站()。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入集合中,等待下一次遍历的同时循环。
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。最后将整个oldMap还没有遍历的链接遍历完成后,如果发现newMap不为空,则说明本次循环产生了新的链接,所以将这些新链接加入到oldMap中继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn";);
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三项最终测试结果
PS:它的实际递归不是很好,因为如果网站页面多的话,程序运行时间长的话内存消耗会很大,但是因为我的博客网站页面不是很多,所以效果还可以
java爬虫抓取网页数据(说到Java的本地存储,肯定使用IO流进行操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-21 17:13
说到Java的本地存储,必须使用IO流进行操作。
首先,我们需要一个函数 createNewFile 来创建一个文件:
public static boolean createNewFile(String filePath) {
boolean isSuccess = true;
// 如有则将"\\"转为"/",没有则不产生任何变化
String filePathTurn = filePath.replaceAll("\\\\", "/");
// 先过滤掉文件名
int index = filePathTurn.lastIndexOf("/");
String dir = filePathTurn.substring(0, index);
// 再创建文件夹
File fileDir = new File(dir);
isSuccess = fileDir.mkdirs();
// 创建文件
File file = new File(filePathTurn);
try {
isSuccess = file.createNewFile();
} catch (IOException e) {
isSuccess = false;
e.printStackTrace();
}
return isSuccess;
}
然后,我们需要一个写入文件的函数:
以上是Java的零基写法知乎 爬虫会将爬取到的内容存储到本地。更多相关内容请关注PHP中文网()!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
java爬虫抓取网页数据(说到Java的本地存储,肯定使用IO流进行操作)
说到Java的本地存储,必须使用IO流进行操作。
首先,我们需要一个函数 createNewFile 来创建一个文件:
public static boolean createNewFile(String filePath) {
boolean isSuccess = true;
// 如有则将"\\"转为"/",没有则不产生任何变化
String filePathTurn = filePath.replaceAll("\\\\", "/");
// 先过滤掉文件名
int index = filePathTurn.lastIndexOf("/");
String dir = filePathTurn.substring(0, index);
// 再创建文件夹
File fileDir = new File(dir);
isSuccess = fileDir.mkdirs();
// 创建文件
File file = new File(filePathTurn);
try {
isSuccess = file.createNewFile();
} catch (IOException e) {
isSuccess = false;
e.printStackTrace();
}
return isSuccess;
}
然后,我们需要一个写入文件的函数:
以上是Java的零基写法知乎 爬虫会将爬取到的内容存储到本地。更多相关内容请关注PHP中文网()!

免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
java爬虫抓取网页数据( JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-21 17:12
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到了Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,抓取一下网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco代码主要是通过注解来实现URL匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
java爬虫抓取网页数据(
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到了Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,抓取一下网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco代码主要是通过注解来实现URL匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果


以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
java爬虫抓取网页数据(QQ空间爬虫分享(一天可抓取400万条数据)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-21 17:09
##QQSpider1:##详情请参考博客:《QQ空间爬虫分享(一天可抓取400万条数据)》如果出现错误:Traceback(最近调用last):文件”.\ init.py", line 20 , in my_messages.backups() #备份爬虫信息 NameError: name'my_messages' is not defined 大部分原因是BitVector模块不可用,可以自行调试。如果确定不能使用BitVector,可以使用“BitVector模块错误解析”中的两个文件替换原来的文件,不用BitVector判断权重,使用python list判断权重(效果是数据量不大也一样)。-------------------------------------------------- - - - 分界线 - - - - - - - - - - - - - - - - - - - - - - -- ------------##**QQSpider2:**## 更新版本,详情请参考博客:【《QQ空间爬虫分享》(2016年11月18日更新) "] ( ) 有同学反映,很多同学在QQ空间爬取,想爬取一些数据做统计研究。他们的专业不是计算机科学,起床更困难。他们希望有现成的数据出售。但是因为工作的变化,在今年3月份程序开发完成后,我并没有真正运行它,所以我没有任何数据。但是接下来我会运行一两台机器来运行这个爬虫。如果您需要数据,您可以通过电子邮件()与我联系。遇到问题请尽量留言, 查看全部
java爬虫抓取网页数据(QQ空间爬虫分享(一天可抓取400万条数据)(组图))
##QQSpider1:##详情请参考博客:《QQ空间爬虫分享(一天可抓取400万条数据)》如果出现错误:Traceback(最近调用last):文件”.\ init.py", line 20 , in my_messages.backups() #备份爬虫信息 NameError: name'my_messages' is not defined 大部分原因是BitVector模块不可用,可以自行调试。如果确定不能使用BitVector,可以使用“BitVector模块错误解析”中的两个文件替换原来的文件,不用BitVector判断权重,使用python list判断权重(效果是数据量不大也一样)。-------------------------------------------------- - - - 分界线 - - - - - - - - - - - - - - - - - - - - - - -- ------------##**QQSpider2:**## 更新版本,详情请参考博客:【《QQ空间爬虫分享》(2016年11月18日更新) "] ( ) 有同学反映,很多同学在QQ空间爬取,想爬取一些数据做统计研究。他们的专业不是计算机科学,起床更困难。他们希望有现成的数据出售。但是因为工作的变化,在今年3月份程序开发完成后,我并没有真正运行它,所以我没有任何数据。但是接下来我会运行一两台机器来运行这个爬虫。如果您需要数据,您可以通过电子邮件()与我联系。遇到问题请尽量留言,
java爬虫抓取网页数据(java爬虫抓取网页数据1.准备工作的通知。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-21 11:06
java爬虫抓取网页数据1.准备工作。*1.请求网页。*2.解析网页*3.存储数据。2.请求和解析数据的过程。*1.请求网页。*1.1抓包。*1.2看包头。*1.3查看代理服务器地址。*1.4看ip段(http/https)。*1.5看端口。*1.6看抓包抓取什么内容。*2.解析网页。*2.1读取网页。
*2.2解析网页。*2.3读取网址中的html。*2.4解析html的标签。*2.5查看解析后的数据格式。*3.数据存储。*3.1存储到数据库。*3.2存储到本地。*注意事项:******。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据1.准备工作的通知。。)
java爬虫抓取网页数据1.准备工作。*1.请求网页。*2.解析网页*3.存储数据。2.请求和解析数据的过程。*1.请求网页。*1.1抓包。*1.2看包头。*1.3查看代理服务器地址。*1.4看ip段(http/https)。*1.5看端口。*1.6看抓包抓取什么内容。*2.解析网页。*2.1读取网页。
*2.2解析网页。*2.3读取网址中的html。*2.4解析html的标签。*2.5查看解析后的数据格式。*3.数据存储。*3.1存储到数据库。*3.2存储到本地。*注意事项:******。
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-15 00:07
爬虫+基于接口的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方法有一个很大的局限性,就是只能通过jsoup爬虫爬取静态网页,所以只能爬取当前页面上的所有新闻。如果需要爬取一个网站的所有信息,就需要通过接口反复调整网站的接口,通过改变参数来爬取网站@的所有数据信息>.
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将分步说明。这里重点讲一下思路,最后提供完整的源代码。
第一步:找到界面
如果要获取这个网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->网络-->全部,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据通过大于56630或小于56630的ID返回。
flag=down 表示向下翻页。这意味着23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两条,这里id=0代表最新的两条数据)
返回json数据格式:
{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第二步:通过定时任务启动爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
锦色印刷结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里有两点需要注意
(1) 创建对象时,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否有对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时,比如上面改成Listextra,序列化就会失败,因为json的extra明明是一个Object,这里接受的确实是一个集合。关键是要属于
性别名称相同,所以赋值时会报错,序列化失败。
第四步:查看操作结果
这只是截取了控制台输出的部分信息。这样就可以得到网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取到该新闻的所有具体信息了。(完美的)
第五步:数据库去重思路
因为你不可能每次爬都直接把播放数据放到数据库中,所以必须比较新闻数据库是否已经存在,如果不存在就放到数据库中。思路如下:
(1)添加唯一属性字段,可以标识数据库表中的新闻,例如jinse+bottomId构成唯一属性,或者新闻的具体页面路径URI构成唯一属性。
(2)创建地图集合,通过URI查看数据库是否存在,如果存在,则不存在。
(3)存储前,如果为false则通过map.get(URI),然后存储到数据库中。
git 源代码
首先,源代码本身通过了Idea测试。此处使用龙目岛。您现在需要在 Idea 或 eclipse 中配置 Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果您不想担心,请不要考虑或做更多。中校【9】 查看全部
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
爬虫+基于接口的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方法有一个很大的局限性,就是只能通过jsoup爬虫爬取静态网页,所以只能爬取当前页面上的所有新闻。如果需要爬取一个网站的所有信息,就需要通过接口反复调整网站的接口,通过改变参数来爬取网站@的所有数据信息>.
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将分步说明。这里重点讲一下思路,最后提供完整的源代码。
第一步:找到界面
如果要获取这个网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->网络-->全部,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据通过大于56630或小于56630的ID返回。
flag=down 表示向下翻页。这意味着23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两条,这里id=0代表最新的两条数据)
返回json数据格式:
{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第二步:通过定时任务启动爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
锦色印刷结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里有两点需要注意
(1) 创建对象时,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否有对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时,比如上面改成Listextra,序列化就会失败,因为json的extra明明是一个Object,这里接受的确实是一个集合。关键是要属于
性别名称相同,所以赋值时会报错,序列化失败。
第四步:查看操作结果
这只是截取了控制台输出的部分信息。这样就可以得到网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取到该新闻的所有具体信息了。(完美的)
第五步:数据库去重思路
因为你不可能每次爬都直接把播放数据放到数据库中,所以必须比较新闻数据库是否已经存在,如果不存在就放到数据库中。思路如下:
(1)添加唯一属性字段,可以标识数据库表中的新闻,例如jinse+bottomId构成唯一属性,或者新闻的具体页面路径URI构成唯一属性。
(2)创建地图集合,通过URI查看数据库是否存在,如果存在,则不存在。
(3)存储前,如果为false则通过map.get(URI),然后存储到数据库中。
git 源代码
首先,源代码本身通过了Idea测试。此处使用龙目岛。您现在需要在 Idea 或 eclipse 中配置 Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果您不想担心,请不要考虑或做更多。中校【9】
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-15 00:06
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL 去重使用数据库代替 Bloom 过滤器,数亿存储的 db io 会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector 是一个JAVA爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,还有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手册:httpclient +jsoup+selenium来实现java爬虫功能。使用httpclient抓取,jsoup解析页面,90%的页面都可以处理,剩下的会用selenium;
参考链接: 查看全部
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL 去重使用数据库代替 Bloom 过滤器,数亿存储的 db io 会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector 是一个JAVA爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,还有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手册:httpclient +jsoup+selenium来实现java爬虫功能。使用httpclient抓取,jsoup解析页面,90%的页面都可以处理,剩下的会用selenium;
参考链接:
java爬虫抓取网页数据(java开发简单的说的意思访问提取方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-14 14:13
)
简单的说,爬虫的意思就是根据url访问请求,然后提取返回的数据,获取对你有用的信息。然后我们可以将这些有用的信息保存到数据库或保存到文件中。如果我们手动提取一个访问,会很慢,所以我们需要编写程序来获取有用的信息,这就是爬虫的作用。
一、概念:
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
二、java开发简单爬虫:1.使用httpclient访问url
行家地址:
commons-httpclient
commons-httpclient
3.1
代码测试:
package cn.qlq.craw.httpClient;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
public class HttpClientCraw {
public static void main(String[] a) throws Exception {
HttpClient client = new HttpClient();
PostMethod postMethod = new PostMethod("http://qiaoliqiang.cn/");
// 防止中文乱码
postMethod.getParams().setContentCharset("utf-8");
// 3.设置请求参数
postMethod.setParameter("mobileCode", "13834786998");
postMethod.setParameter("userID", "");
// 4.执行请求 ,结果码
int code = client.executeMethod(postMethod);
// 5. 获取结果
String result = postMethod.getResponseBodyAsString();
System.out.println("Post请求的结果:" + result);
}
}
结果:
Post请求的结果:
XXXXXXXXXXX
.......... 查看全部
java爬虫抓取网页数据(java开发简单的说的意思访问提取方法
)
简单的说,爬虫的意思就是根据url访问请求,然后提取返回的数据,获取对你有用的信息。然后我们可以将这些有用的信息保存到数据库或保存到文件中。如果我们手动提取一个访问,会很慢,所以我们需要编写程序来获取有用的信息,这就是爬虫的作用。
一、概念:
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL是Uniform Resource Locator,其一般格式如下(方括号[]是可选的):
协议://主机名[:端口]/路径/[;参数][?查询]#fragment
URL格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分为主机名(端口号为可选参数)。一般网站的默认端口号为80。例如host百度的名字是这个是服务器的地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
二、java开发简单爬虫:1.使用httpclient访问url
行家地址:
commons-httpclient
commons-httpclient
3.1
代码测试:
package cn.qlq.craw.httpClient;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.methods.PostMethod;
public class HttpClientCraw {
public static void main(String[] a) throws Exception {
HttpClient client = new HttpClient();
PostMethod postMethod = new PostMethod("http://qiaoliqiang.cn/";);
// 防止中文乱码
postMethod.getParams().setContentCharset("utf-8");
// 3.设置请求参数
postMethod.setParameter("mobileCode", "13834786998");
postMethod.setParameter("userID", "");
// 4.执行请求 ,结果码
int code = client.executeMethod(postMethod);
// 5. 获取结果
String result = postMethod.getResponseBodyAsString();
System.out.println("Post请求的结果:" + result);
}
}
结果:
Post请求的结果:
XXXXXXXXXXX
..........
java爬虫抓取网页数据(百度首页做了个小测试,小伙伴们可算松了口气)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-14 14:12
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!
好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:
啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?) 查看全部
java爬虫抓取网页数据(百度首页做了个小测试,小伙伴们可算松了口气)
在上一篇文章中,我们在百度首页做了一个小测试。今天,我们有一个复杂的。我们会直接抓取知乎的编辑推荐的内容。小伙伴们也算是松了口气,终于到了正题。哈哈。
知乎是一个真正的在线问答社区,社区氛围友好、理性、严肃,连接各界精英。他们分享彼此的专业知识、经验和见解,为中国互联网提供源源不断的优质信息。
首先,花三到五分钟设计一个 Logo=。=作为程序员,我一直有一颗做艺术家的心!
好吧,这有点即兴,所以让我们先凑合一下。
接下来,我们开始为知乎做一个爬虫。
首先确定第一个目标:编辑推荐。
网页链接:
我们对最后的代码稍作修改,首先实现我们可以获取到这个页面的内容:
import java.io.*;
import java.net.*;
import java.util.regex.*;
public class Main {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
static String RegexString(String targetStr, String patternStr) {
// 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容
// 相当于埋好了陷阱匹配的地方就会掉下去
Pattern pattern = Pattern.compile(patternStr);
// 定义一个matcher用来做匹配
Matcher matcher = pattern.matcher(targetStr);
// 如果找到了
if (matcher.find()) {
// 打印出结果
return matcher.group(1);
}
return "Nothing";
}
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
//String imgSrc = RegexString(result, "src=\"(.+?)\"");
// 打印结果
System.out.println(result);
}
}
跑起来没有问题,然后就是正则匹配的问题。
首先,让我们了解此页面上的所有问题。
右键单击标题并查看元素:
啊哈,可以看到标题其实是一个a标签,是一个超链接,能和其他超链接区别开来的应该是class,也就是class选择器。
于是我们的正则语句出来了: question_link.+?href=\"(.+?)\"
调用 RegexString 函数并将参数传递给它:
<p> public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String result = SendGet(url);
// 使用正则匹配图片的src内容
String imgSrc = RegexString(result, "question_link.+?>(.+?)(.+?)(.+?)
java爬虫抓取网页数据(1.HtmlUnit中文文档获取页面中特定的元素tips:1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-13 18:01
1.HtmlUnit 简介
HtmlUnit 是一个 Java 无界面浏览器库。它模拟 HTML 文档并提供相应的 API,让您可以像在“普通”浏览器中一样调用页面、填写表单、单击链接等。它有很好的 JavaScript 支持(仍在改进),甚至可以处理相当复杂的 AJAX 库,根据使用的配置模拟 Chrome、Firefox 或 Internet Explorer。它通常用于测试目的或从 网站 检索信息。
HtmlUnit 不是通用的单元测试框架。它是一种模拟浏览器以进行测试的方法,旨在用于另一个测试框架(例如 JUnit 或 TestNG)。有关介绍,请参阅文档“HtmlUnit 入门”。HtmlUnit 用作不同的开源工具,例如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、WETATOR、Celerity、Spring MVC Test HtmlUnit 作为底层“浏览器”。
HtmlUnit 最初由 Gargoyle Software 的 Mike Bowler 编写,并在 Apache 2 许可下发布。从那以后,它收到了许多其他开发者的贡献,今天也将得到他们的帮助。
几年前,在做购物网站的数据采集工作时,我偶然遇到了HtmlUnit。我记得我如何无法捕获页面上的价格数据,并且 httpfox 无法跟踪价格数据的 URL。就在我不知所措的时候,HtmlUnit出现了,帮我解决了问题。所以今天我想说声谢谢,并向大家推荐HtmlUnit。
2.htmlUnit中文文档
3.1 获取页面的 TITLE、XML 代码和文本
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//创建一个webclient
WebClient webClient = new WebClient();
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
//获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com/");
//获取页面的TITLE
str = page.getTitleText();
System.out.println(str);
//获取页面的XML代码
str = page.asXml();
System.out.println(str);
//获取页面的文本
str = page.asText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.2 使用不同版本的浏览器打开
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//使用FireFox读取网页
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_24);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com/");
str = page.getTitleText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.3 在页面上查找特定元素
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/");
//通过id获得"百度一下"按钮
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
//关闭webclient
webClient.closeAllWindows();
}
}
提示:某些元素中没有id和name或其他节点。您可以通过查找其子节点和父节点之间的规则来获取元素。具体方法请参考:
核心代码是:
final HtmlPage nextPage = ((DomElement)(htmlpage.getElementByName("key").getParentNode().getParentNode())).getLastElementChild().click();
3.4 元素搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/");
//查找所有div
List hbList = page.getByXPath("//div");
HtmlDivision hb = (HtmlDivision)hbList.get(0);
System.out.println(hb.toString());
//查找并获取特定input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput)inputList.get(0);
System.out.println(input.toString());
//关闭webclient
webClient.closeAllWindows();
}
}
3.5 提交搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/");
//获取搜索输入框并提交搜索内容
HtmlInput input = (HtmlInput)page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("ymd");
System.out.println(input.toString());
//获取搜索按钮并点击
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
HtmlPage page2 = btn.click();
//输出新页面的文本
System.out.println(page2.asText());
}
}
3.htmlUnit方法介绍
一、环境介绍
因为是在自己的spring boot项目中引入的,所以只是在pom文件中添加了依赖。
net.sourceforge.htmlunit
htmlunit
2.41.0
如果你只是爬一个网站 js不多,建议改下下面的依赖
net.sourceforge.htmlunit
htmlunit
2.23
后面我会讲到两者的区别。当然,如果你不是使用maven项目(没有pom),可以到官网下载源码库
二、使用
HtmlUnit使用起来非常简单,使用的时候可以去官网手册查一下语法。其实说明书只是介绍介绍,下面听我说就够了;
1、创建客户端并配置客户端
final String url ="https:****";//大家这可以填自己爬虫的地址
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_68);//创建火狐浏览器 2.23版本是FIREFOX_45 new不写参数是默认浏览器
webClient.getOptions().setCssEnabled(false);//(屏蔽)css 因为css并不影响我们抓取数据 反而影响网页渲染效率
webClient.getOptions().setThrowExceptionOnScriptError(false);//(屏蔽)异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//(屏蔽)日志
webClient.getOptions().setJavaScriptEnabled(true);//加载js脚本
webClient.getOptions().setTimeout(50000);//设置超时时间
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置ajax
HtmlPage htmlPage = webClient.getPage(url);//将客户端获取的树形结构转化为HtmlPage
Thread.sleep(10000);//主线程休眠10秒 让客户端有时间执行js代码 也可以写成webClient.waitForBackgroundJavaScript(1000)
下面是一个等待js执行的情况,2.41.0很适合很多js的情况,但是2.3总是有问题,无法刷新网页,2.@ >41.0 打印的也很详细,执行的过程也比较慢,可能会比较慢产生详细的作品
远程地址页面在此处获取。我们现在需要做的是解析dom节点并填写数据来模拟点击等事件。如果要打印 htmlPage.asText() 输出 htmlPage 节点的文本 htmlPage.asXml() 输出 htmlPage 节点的 xml 代码
2、 获取节点
建议在这个链接准备一些前端知识
HtmlUnit给出了两种获取节点的方式
XPath 查询:
更详细的xpath解释:
final HtmlPage page = webClient.getPage("http://htmlunit.sourceforge.net");
//get list of all divs
final List divs = htmlPage .getByXPath("//div");
//get div which has a 'name' attribute of 'John'
final HtmlDivision div = (HtmlDivision) htmlPage .getByXPath("//div[@name='John']").get(0);
css 选择器:(我更喜欢它)
final DomNodeList divs = htmlPage .querySelectorAll("div");
for (DomNode div : divs) {
....
}
//get div which has the id 'breadcrumbs'
final DomNode div = htmlPage .querySelector("div#breadcrumbs");
css 提供了一个集合查询 querySelectorAll 和一个单一查询 querySelector。如果你没有基础,我给你举个例子:
htmlPage .querySelectorAll("div") 返回 htmlPage 下的一组 div 标签
htmlPage .querySelector("div:nth-child(1)") 返回htmlPage下div的第一个div
htmlPage .querySelector(".submit") 返回htmlPage下的第一个class=submit标签
htmlPage .querySelector("#submit") 返回 htmlPage 下 id=submit 的第一个标签
htmlPage .querySelector("div.submit") 返回类为submit的htmlPage下的第一个div标签
htmlPage .querySelector("div[id='submit']") 返回htmlPage下第一个id为submit的div标签
上面的枚举方法相信已经足够了,如果还不够,可以参考css选择器
下面列出常见的html标签与HtmlUnit类的对应关系
div -> HtmlDivision
div集合 -> DomNodeList
fieldSet -> HtmlFieldSet
form -> HtmlForm
button -> HtmlButton
a -> HtmlAnchor
-> HtmlXxxInput
( -> HtmlTextInput)
table -> HtmlTable
tr -> HtmlTableRow
td -> TableDataCell
setAttribute()方法有节点的属性样式,setNodeValue()设置节点的值。你的英语一下子提高了吗?几乎所有的标签都能找到对应的类别。来看看我的实战:这是一个在线填写温度的excel文档。如果访问更改地址,他会在登录页面提示一个登录按钮。登录按钮,我们现在模拟打开自动登录框:
//这段代码是为了让网页的的某个按钮加载出来之后再执行下面的代码
while (htmlPage.querySelector("#header-login-btn")==null) {
synchronized (htmlPage) {
htmlPage.wait(1000);
}
}
HtmlButton login = htmlPage.querySelector("#header-login-btn");//获取到登陆按钮
if (login!=null){//如果网页上没这个按钮你还要去获取他只会得到一个空对象,所以我们用空的方式可以判断网页上是否有这个按钮
System.out.println("-----未登录测试-----");
htmlPage=login.click();//模拟按钮点击后要将网页返回回来方便动态更新数据
System.out.println(htmlPage.asText());
HtmlAnchor switcher_plogin = htmlPage.querySelector("a[id='switcher_plogin']");
if (switcher_plogin!=null) {//帐号密码登录
System.out.println("-----点击了帐号密码登陆-----");
htmlPage = switcher_plogin.click();
System.out.println(htmlPage.asText());
}
}
System.out.println(htmlPage.asText());
webClient.close();
爬虫最重要的一步就是我们首先调试网页,有哪些按钮,点击哪些,设置哪些值。毕竟,我们必须用代码来安排代码。
**扩展:** 如果你想从网页上获取数据或下载文件,HtmlUnit 分析是不够的。推荐使用 Jsoup 库,可以和 HtmlUnit 一起使用。使用起来比较方便,这里就不一一列举了。
三、实现一个小demo
注意:htmlunit引用的jar包不完整会导致奇怪的错误
使用maven方法更方便
参考: 查看全部
java爬虫抓取网页数据(1.HtmlUnit中文文档获取页面中特定的元素tips:1.)
1.HtmlUnit 简介
HtmlUnit 是一个 Java 无界面浏览器库。它模拟 HTML 文档并提供相应的 API,让您可以像在“普通”浏览器中一样调用页面、填写表单、单击链接等。它有很好的 JavaScript 支持(仍在改进),甚至可以处理相当复杂的 AJAX 库,根据使用的配置模拟 Chrome、Firefox 或 Internet Explorer。它通常用于测试目的或从 网站 检索信息。
HtmlUnit 不是通用的单元测试框架。它是一种模拟浏览器以进行测试的方法,旨在用于另一个测试框架(例如 JUnit 或 TestNG)。有关介绍,请参阅文档“HtmlUnit 入门”。HtmlUnit 用作不同的开源工具,例如 Canoo WebTest、JWebUnit、WebDriver、JSFUnit、WETATOR、Celerity、Spring MVC Test HtmlUnit 作为底层“浏览器”。
HtmlUnit 最初由 Gargoyle Software 的 Mike Bowler 编写,并在 Apache 2 许可下发布。从那以后,它收到了许多其他开发者的贡献,今天也将得到他们的帮助。
几年前,在做购物网站的数据采集工作时,我偶然遇到了HtmlUnit。我记得我如何无法捕获页面上的价格数据,并且 httpfox 无法跟踪价格数据的 URL。就在我不知所措的时候,HtmlUnit出现了,帮我解决了问题。所以今天我想说声谢谢,并向大家推荐HtmlUnit。
2.htmlUnit中文文档
3.1 获取页面的 TITLE、XML 代码和文本
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//创建一个webclient
WebClient webClient = new WebClient();
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
//获取页面
HtmlPage page = webClient.getPage("http://www.baidu.com/";);
//获取页面的TITLE
str = page.getTitleText();
System.out.println(str);
//获取页面的XML代码
str = page.asXml();
System.out.println(str);
//获取页面的文本
str = page.asText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.2 使用不同版本的浏览器打开
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.html.HtmlDivision;
import com.gargoylesoftware.htmlunit.html.HtmlAnchor;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.WebClientOptions;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlBody;
import java.util.List;
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
String str;
//使用FireFox读取网页
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_24);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = webClient.getPage("http://www.baidu.com/";);
str = page.getTitleText();
System.out.println(str);
//关闭webclient
webClient.closeAllWindows();
}
}
3.3 在页面上查找特定元素
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/";);
//通过id获得"百度一下"按钮
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
System.out.println(btn.getDefaultValue());
//关闭webclient
webClient.closeAllWindows();
}
}
提示:某些元素中没有id和name或其他节点。您可以通过查找其子节点和父节点之间的规则来获取元素。具体方法请参考:
核心代码是:
final HtmlPage nextPage = ((DomElement)(htmlpage.getElementByName("key").getParentNode().getParentNode())).getLastElementChild().click();
3.4 元素搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/";);
//查找所有div
List hbList = page.getByXPath("//div");
HtmlDivision hb = (HtmlDivision)hbList.get(0);
System.out.println(hb.toString());
//查找并获取特定input
List inputList = page.getByXPath("//input[@id='su']");
HtmlInput input = (HtmlInput)inputList.get(0);
System.out.println(input.toString());
//关闭webclient
webClient.closeAllWindows();
}
}
3.5 提交搜索
public class helloHtmlUnit{
public static void main(String[] args) throws Exception{
//创建webclient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
//htmlunit 对css和javascript的支持不好,所以请关闭之
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
HtmlPage page = (HtmlPage)webClient.getPage("http://www.baidu.com/";);
//获取搜索输入框并提交搜索内容
HtmlInput input = (HtmlInput)page.getHtmlElementById("kw");
System.out.println(input.toString());
input.setValueAttribute("ymd");
System.out.println(input.toString());
//获取搜索按钮并点击
HtmlInput btn = (HtmlInput)page.getHtmlElementById("su");
HtmlPage page2 = btn.click();
//输出新页面的文本
System.out.println(page2.asText());
}
}
3.htmlUnit方法介绍
一、环境介绍
因为是在自己的spring boot项目中引入的,所以只是在pom文件中添加了依赖。
net.sourceforge.htmlunit
htmlunit
2.41.0
如果你只是爬一个网站 js不多,建议改下下面的依赖
net.sourceforge.htmlunit
htmlunit
2.23
后面我会讲到两者的区别。当然,如果你不是使用maven项目(没有pom),可以到官网下载源码库
二、使用
HtmlUnit使用起来非常简单,使用的时候可以去官网手册查一下语法。其实说明书只是介绍介绍,下面听我说就够了;
1、创建客户端并配置客户端
final String url ="https:****";//大家这可以填自己爬虫的地址
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_68);//创建火狐浏览器 2.23版本是FIREFOX_45 new不写参数是默认浏览器
webClient.getOptions().setCssEnabled(false);//(屏蔽)css 因为css并不影响我们抓取数据 反而影响网页渲染效率
webClient.getOptions().setThrowExceptionOnScriptError(false);//(屏蔽)异常
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//(屏蔽)日志
webClient.getOptions().setJavaScriptEnabled(true);//加载js脚本
webClient.getOptions().setTimeout(50000);//设置超时时间
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//设置ajax
HtmlPage htmlPage = webClient.getPage(url);//将客户端获取的树形结构转化为HtmlPage
Thread.sleep(10000);//主线程休眠10秒 让客户端有时间执行js代码 也可以写成webClient.waitForBackgroundJavaScript(1000)
下面是一个等待js执行的情况,2.41.0很适合很多js的情况,但是2.3总是有问题,无法刷新网页,2.@ >41.0 打印的也很详细,执行的过程也比较慢,可能会比较慢产生详细的作品
远程地址页面在此处获取。我们现在需要做的是解析dom节点并填写数据来模拟点击等事件。如果要打印 htmlPage.asText() 输出 htmlPage 节点的文本 htmlPage.asXml() 输出 htmlPage 节点的 xml 代码
2、 获取节点
建议在这个链接准备一些前端知识
HtmlUnit给出了两种获取节点的方式
XPath 查询:
更详细的xpath解释:
final HtmlPage page = webClient.getPage("http://htmlunit.sourceforge.net";);
//get list of all divs
final List divs = htmlPage .getByXPath("//div");
//get div which has a 'name' attribute of 'John'
final HtmlDivision div = (HtmlDivision) htmlPage .getByXPath("//div[@name='John']").get(0);
css 选择器:(我更喜欢它)
final DomNodeList divs = htmlPage .querySelectorAll("div");
for (DomNode div : divs) {
....
}
//get div which has the id 'breadcrumbs'
final DomNode div = htmlPage .querySelector("div#breadcrumbs");
css 提供了一个集合查询 querySelectorAll 和一个单一查询 querySelector。如果你没有基础,我给你举个例子:
htmlPage .querySelectorAll("div") 返回 htmlPage 下的一组 div 标签
htmlPage .querySelector("div:nth-child(1)") 返回htmlPage下div的第一个div
htmlPage .querySelector(".submit") 返回htmlPage下的第一个class=submit标签
htmlPage .querySelector("#submit") 返回 htmlPage 下 id=submit 的第一个标签
htmlPage .querySelector("div.submit") 返回类为submit的htmlPage下的第一个div标签
htmlPage .querySelector("div[id='submit']") 返回htmlPage下第一个id为submit的div标签
上面的枚举方法相信已经足够了,如果还不够,可以参考css选择器
下面列出常见的html标签与HtmlUnit类的对应关系
div -> HtmlDivision
div集合 -> DomNodeList
fieldSet -> HtmlFieldSet
form -> HtmlForm
button -> HtmlButton
a -> HtmlAnchor
-> HtmlXxxInput
( -> HtmlTextInput)
table -> HtmlTable
tr -> HtmlTableRow
td -> TableDataCell
setAttribute()方法有节点的属性样式,setNodeValue()设置节点的值。你的英语一下子提高了吗?几乎所有的标签都能找到对应的类别。来看看我的实战:这是一个在线填写温度的excel文档。如果访问更改地址,他会在登录页面提示一个登录按钮。登录按钮,我们现在模拟打开自动登录框:
//这段代码是为了让网页的的某个按钮加载出来之后再执行下面的代码
while (htmlPage.querySelector("#header-login-btn")==null) {
synchronized (htmlPage) {
htmlPage.wait(1000);
}
}
HtmlButton login = htmlPage.querySelector("#header-login-btn");//获取到登陆按钮
if (login!=null){//如果网页上没这个按钮你还要去获取他只会得到一个空对象,所以我们用空的方式可以判断网页上是否有这个按钮
System.out.println("-----未登录测试-----");
htmlPage=login.click();//模拟按钮点击后要将网页返回回来方便动态更新数据
System.out.println(htmlPage.asText());
HtmlAnchor switcher_plogin = htmlPage.querySelector("a[id='switcher_plogin']");
if (switcher_plogin!=null) {//帐号密码登录
System.out.println("-----点击了帐号密码登陆-----");
htmlPage = switcher_plogin.click();
System.out.println(htmlPage.asText());
}
}
System.out.println(htmlPage.asText());
webClient.close();
爬虫最重要的一步就是我们首先调试网页,有哪些按钮,点击哪些,设置哪些值。毕竟,我们必须用代码来安排代码。
**扩展:** 如果你想从网页上获取数据或下载文件,HtmlUnit 分析是不够的。推荐使用 Jsoup 库,可以和 HtmlUnit 一起使用。使用起来比较方便,这里就不一一列举了。
三、实现一个小demo
注意:htmlunit引用的jar包不完整会导致奇怪的错误
使用maven方法更方便
参考:
java爬虫抓取网页数据( python同名子标签的,怎么获取下面数个同标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-12 12:04
python同名子标签的,怎么获取下面数个同标签)
Python爬虫,用find-all()找到一个标签后,如何获取下面几个同名子标签的内容-—— div=soup.find_all('div',class_="star") #到这里时间,标签已经改变了列出div,class=star的所有内容。您可以根据这些数据执行 find_all 来查找标签。例子:for k in soup.find_all('div',class_="star"):cont =k.find_all('span') #第一步find_all的值然后找到_all print(cont[0].string ) #由于div标签中有四个'span',它是一个列表形式cont[0],第一个值取决于您的需要。我也是菜鸟,纯交流。
python网络爬虫复制的代码用find找不到,返回-1-如果网页源代码的tag元素,没有这个元素就找不到。检查您需要获取内容的标签元素,只需更改代码
crawler attrs是什么意思? - 网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本. 其他不太常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。
网络爬虫findall()正则(.*?)不工作,不返回--可以通过调试发现错误。web_data.text 中根本没有 ¥ 符号。需要 HTML 实体编码转换。正确完整的代码如下: import requests,re,html headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像...
爬虫遇到不同类型的网址时如何抓取各种网址——网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的 URL 开始。, 获取初始网页上的网址,在抓取网页的过程中,不断地从当前网页中提取新的网址,放入队列中,直到满...
Python爬虫如何入门——从爬虫的基本要求出发:1. 抓取py的urllib可能不会用,但是没用过的一定要学。更好的替代方案有 requests 等待更人性化和成熟的第三方库。如果pyer不了解各种库,那就白学吧。最基本的爬取就是把网页拉回来。如果你继续这样做,...
如何在python爬虫中这样循环?-宿主可以使用BeautifulSoup from bs4 import BeautifulSoups = BeautifulSoup("html")liTag = s.find('li') 将采集中的数据切入list list ,删除列表中的第0个元素?你的问题解决了吗?二营SEO长
写爬虫的时候,Beautifulsoup应该怎么提取这种没有关闭标签的网页?-Method 1.==" 不用找,直接打印soup.meta['content'] method 2. = =》print meta['content']ps:注意页面有多个meta标签
如何使用python爬进网页搜索框输入文字,自动搜索信息并抓取——爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发送新的请求; 参考示例如下: item1 = item()yield item1item2 = item()yield item2req = request(url='link to the next page', callback=self.parse)yield req 注意:当使用产量。
如何用最简单的Python爬虫采集整个网站——爬取网站的数据?网站,还是保存所有的页面代码?无论两者中的哪一个,都必须知道网站的所有页面的url。 查看全部
java爬虫抓取网页数据(
python同名子标签的,怎么获取下面数个同标签)
Python爬虫,用find-all()找到一个标签后,如何获取下面几个同名子标签的内容-—— div=soup.find_all('div',class_="star") #到这里时间,标签已经改变了列出div,class=star的所有内容。您可以根据这些数据执行 find_all 来查找标签。例子:for k in soup.find_all('div',class_="star"):cont =k.find_all('span') #第一步find_all的值然后找到_all print(cont[0].string ) #由于div标签中有四个'span',它是一个列表形式cont[0],第一个值取决于您的需要。我也是菜鸟,纯交流。
python网络爬虫复制的代码用find找不到,返回-1-如果网页源代码的tag元素,没有这个元素就找不到。检查您需要获取内容的标签元素,只需更改代码
crawler attrs是什么意思? - 网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区中,更多时候是网络追逐者),是一种按照一定的规则自动抓取万维网上信息的程序或脚本. 其他不太常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。
网络爬虫findall()正则(.*?)不工作,不返回--可以通过调试发现错误。web_data.text 中根本没有 ¥ 符号。需要 HTML 实体编码转换。正确完整的代码如下: import requests,re,html headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 像...
爬虫遇到不同类型的网址时如何抓取各种网址——网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的 URL 开始。, 获取初始网页上的网址,在抓取网页的过程中,不断地从当前网页中提取新的网址,放入队列中,直到满...
Python爬虫如何入门——从爬虫的基本要求出发:1. 抓取py的urllib可能不会用,但是没用过的一定要学。更好的替代方案有 requests 等待更人性化和成熟的第三方库。如果pyer不了解各种库,那就白学吧。最基本的爬取就是把网页拉回来。如果你继续这样做,...
如何在python爬虫中这样循环?-宿主可以使用BeautifulSoup from bs4 import BeautifulSoups = BeautifulSoup("html")liTag = s.find('li') 将采集中的数据切入list list ,删除列表中的第0个元素?你的问题解决了吗?二营SEO长
写爬虫的时候,Beautifulsoup应该怎么提取这种没有关闭标签的网页?-Method 1.==" 不用找,直接打印soup.meta['content'] method 2. = =》print meta['content']ps:注意页面有多个meta标签
如何使用python爬进网页搜索框输入文字,自动搜索信息并抓取——爬虫跟踪下一页的方法是自己模拟点击下一页连接,然后发送新的请求; 参考示例如下: item1 = item()yield item1item2 = item()yield item2req = request(url='link to the next page', callback=self.parse)yield req 注意:当使用产量。
如何用最简单的Python爬虫采集整个网站——爬取网站的数据?网站,还是保存所有的页面代码?无论两者中的哪一个,都必须知道网站的所有页面的url。
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-11 07:07
文章 目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的同学,学python爬虫比较靠谱,但是是不是就意味着java不能爬?当然不是。事实上,在某些场景下,java爬虫更方便,更容易使用。
1.引入依赖:
java中的爬虫使用了jsoup的类库,jsoup提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据,让你在请求后对网页进行dom操作网页来达到爬取的目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例2:
爬取学校信息:
3.代理描述:
情况1,不使用代理ip,直接抓包即可。但是一般情况下,我们抓取的网站会设置反爬虫、ip阻塞等,所以需要设置代理ip。在线案例2中,使用蘑菇代理的代理隧道的代理设置。还不错,确实需要的可以买。
总结
当然,我上面写的两个案例只是例子。其实操作dom的方法有很多种。如果要爬取,肯定需要dom的基本操作,还需要一些基本的html知识。如果想和我有更多的交流,可以关注我的公众号:Java Time House交流。 查看全部
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
文章 目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的同学,学python爬虫比较靠谱,但是是不是就意味着java不能爬?当然不是。事实上,在某些场景下,java爬虫更方便,更容易使用。
1.引入依赖:
java中的爬虫使用了jsoup的类库,jsoup提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据,让你在请求后对网页进行dom操作网页来达到爬取的目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例2:
爬取学校信息:
3.代理描述:
情况1,不使用代理ip,直接抓包即可。但是一般情况下,我们抓取的网站会设置反爬虫、ip阻塞等,所以需要设置代理ip。在线案例2中,使用蘑菇代理的代理隧道的代理设置。还不错,确实需要的可以买。
总结
当然,我上面写的两个案例只是例子。其实操作dom的方法有很多种。如果要爬取,肯定需要dom的基本操作,还需要一些基本的html知识。如果想和我有更多的交流,可以关注我的公众号:Java Time House交流。
java爬虫抓取网页数据(网易要闻如下:内置浏览器Selenium方式是一个模拟浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-07 01:09
这是 Java 爬虫系列的第三篇文章。上一篇Java爬虫遇到网站需要登录,怎么办?),我们简单讲解一下爬取时登录问题的解决方法。在这个文章中,我们来谈谈爬取时异步数据加载的问题。这也是爬行中常见的问题。.
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
硒
单位
PhantomJs
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过ajax从后端获取的,我们只需要找到对应的ajax请求连接就可以了,这样我们就得到了我们需要的数据,逆向分析方法的优点是这种方式得到的数据都是json格式的,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax的时候需要耐心和熟练,因为需要在大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:
内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
1、引入Selenium的依赖包并在pom.xml中添加
org.seleniumhq.selenium
硒-java
3.141.59
2、下载对应的驱动,比如我下载的chromedriver。下载地址为:下载后需要将驱动所在的位置写入Java的环境变量中。比如我直接放在项目下,所以我的代码是:
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* Selenium 解决异步数据加载问题
*
*
* @param url
*/
公共无效硒(字符串网址){
// 设置chromedirver的存储位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,不弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取重要新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement: webElements) {
// 提取新闻链接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
字符串标题 = webElement.getText();
如果 (article_url.contains("")) {
System.out.println("文章标题:" + title + ",文章链接:" + article_url);
}
}
webDriver.close();
}
运行此方法并得到以下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析的方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一上点。你绝对可以找到它们。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:
从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这块数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转换成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
阿里巴巴
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用逆向分析解决异步数据加载问题
*
* @param url
*/
public void httpclientMethod(String url) 抛出 IOException { 查看全部
java爬虫抓取网页数据(网易要闻如下:内置浏览器Selenium方式是一个模拟浏览器)
这是 Java 爬虫系列的第三篇文章。上一篇Java爬虫遇到网站需要登录,怎么办?),我们简单讲解一下爬取时登录问题的解决方法。在这个文章中,我们来谈谈爬取时异步数据加载的问题。这也是爬行中常见的问题。.
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
硒
单位
PhantomJs
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过ajax从后端获取的,我们只需要找到对应的ajax请求连接就可以了,这样我们就得到了我们需要的数据,逆向分析方法的优点是这种方式得到的数据都是json格式的,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax的时候需要耐心和熟练,因为需要在大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:
内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
1、引入Selenium的依赖包并在pom.xml中添加
org.seleniumhq.selenium
硒-java
3.141.59
2、下载对应的驱动,比如我下载的chromedriver。下载地址为:下载后需要将驱动所在的位置写入Java的环境变量中。比如我直接放在项目下,所以我的代码是:
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* Selenium 解决异步数据加载问题
*
*
* @param url
*/
公共无效硒(字符串网址){
// 设置chromedirver的存储位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,不弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取重要新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement: webElements) {
// 提取新闻链接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
字符串标题 = webElement.getText();
如果 (article_url.contains("")) {
System.out.println("文章标题:" + title + ",文章链接:" + article_url);
}
}
webDriver.close();
}
运行此方法并得到以下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析的方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一上点。你绝对可以找到它们。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:
从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这块数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转换成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
阿里巴巴
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用逆向分析解决异步数据加载问题
*
* @param url
*/
public void httpclientMethod(String url) 抛出 IOException {
java爬虫抓取网页数据(关于HTML解析器的一些重要方法和重要类1-2 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-07 01:06
)
Jsoup 简介
jsoup 是一个 Java HTML 解析器,主要用于解析 HTML。
中文文档:
Jsoup 可以实现什么?
从 URL、文件或字符串中抓取和解析 HTML 以查找和提取数据,使用 DOM 遍历或 CSS 选择器来操作 HTML 元素、属性和文本以根据安全白名单清理用户提交的内容以防止 XSS 攻击输出整洁的 HTML
在爬取的时候,当我们使用HttpClient这样的框架来获取网页的源码时,需要从网页的源码中提取出我们想要的内容,然后我们可以使用HTML解析器这样的作为 jsoup。它可以很容易地实现。
虽然jsoup也支持直接从某个地址爬取网页源码,但是只支持HTTP和HTTPS协议,支持还不够丰富。因此,主要用于解析HTML。
依赖:
org.jsoup
jsoup
1.11.3
Jsoup 重要类 1、org.jsoup.Jsoup 类
Jsoup 类是任何 Jsoup 程序的入口点,将提供从各种来源加载和解析 HTML 文档的方法。
方法说明
静态连接connect(String url)
创建并返回到 URL 的连接。
静态文档解析(文件输入,字符串字符集名称)
将指定的字符集文件解析为文档。
静态文档解析(String html)
将给定的 html 代码解析为文档。
tatic String clean(String bodyHtml, Whitelist whitelist)
通过解析输入从输入 HTML 返回安全的 HTML
HTML 并按允许的标签和属性的白名单过滤。
2、org.jsoup.nodes.Document 类 3、org.jsoup.nodes.Element 类
重要方法:
方法说明
child(int index)
通过索引定位子元素。
儿童()
获取该元素的所有子元素
类名()
获取该元素的类属性名称
classNames()
获取所有元素的类名返回值:Set
classNames(Set classNames)
通过提供的类名设置元素的类属性
数据()
获取该元素的组合数据
空()
删除此元素的所有子数据节点。
firstElementSibling()
获取当前元素的第一个同级同级元素。
getAllElements()
获取当前元素下的所有元素(包括自己、孩子、孩子的孩子)
getElementsByAttribute(String key)
通过属性名查找当前html下的所有元素
getElementsByClass(String className)
当前元素是否有这个类或者这个元素下是否有这个类
html()
在文件中检索Html
id()
返回当前元素的id值
isBlock()
测试该元素是否为层次元素
lastElementSibling()
获取与该元素同级的最后一个元素
父()
获取该节点的父节点
父母()
获取父节点,一直到节点的根节点
选择()
选择器方法,通用
兄弟元素()
获取所有兄弟元素(不包括你自己)
标签()
获取这个标签对象
标签名()
获取此标签的名称
文本()
获取该元素和所有子元素的文本内容
textNodes()
获取该元素的子文本标签集合
包裹()
包装这个元素的html
以下是一些示例:从 URL 加载文档,使用 Jsoup.connect() 方法从 URL 加载 HTML。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;).get();
System.out.println(document.title());
获取网页中的所有链接
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements links = document.select("a[href]");
for (Element link : links) {
System.out.println("link : " + link.attr("href"));
System.out.println("text : " + link.text());
}
获取网页中显示的所有图片
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images) {
System.out.println("src : " + image.attr("src"));
System.out.println("height : " + image.attr("height"));
System.out.println("width : " + image.attr("width"));
System.out.println("alt : " + image.attr("alt"));
}
获取URL的元信息。元信息包括用于确定网络内容索引的搜索引擎,例如 Google。它们以一些标签的形式存在于 HTML 页面的 HEAD 部分。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
String description = document.select("meta[name=description]").get(0).attr("content");
System.out.println("Meta description : " + description);
String keywords = document.select("meta[name=keywords]").first().attr("content");
System.out.println("Meta keyword : " + keywords); 查看全部
java爬虫抓取网页数据(关于HTML解析器的一些重要方法和重要类1-2
)
Jsoup 简介
jsoup 是一个 Java HTML 解析器,主要用于解析 HTML。
中文文档:
Jsoup 可以实现什么?
从 URL、文件或字符串中抓取和解析 HTML 以查找和提取数据,使用 DOM 遍历或 CSS 选择器来操作 HTML 元素、属性和文本以根据安全白名单清理用户提交的内容以防止 XSS 攻击输出整洁的 HTML
在爬取的时候,当我们使用HttpClient这样的框架来获取网页的源码时,需要从网页的源码中提取出我们想要的内容,然后我们可以使用HTML解析器这样的作为 jsoup。它可以很容易地实现。
虽然jsoup也支持直接从某个地址爬取网页源码,但是只支持HTTP和HTTPS协议,支持还不够丰富。因此,主要用于解析HTML。
依赖:
org.jsoup
jsoup
1.11.3
Jsoup 重要类 1、org.jsoup.Jsoup 类
Jsoup 类是任何 Jsoup 程序的入口点,将提供从各种来源加载和解析 HTML 文档的方法。
方法说明
静态连接connect(String url)
创建并返回到 URL 的连接。
静态文档解析(文件输入,字符串字符集名称)
将指定的字符集文件解析为文档。
静态文档解析(String html)
将给定的 html 代码解析为文档。
tatic String clean(String bodyHtml, Whitelist whitelist)
通过解析输入从输入 HTML 返回安全的 HTML
HTML 并按允许的标签和属性的白名单过滤。
2、org.jsoup.nodes.Document 类 3、org.jsoup.nodes.Element 类
重要方法:
方法说明
child(int index)
通过索引定位子元素。
儿童()
获取该元素的所有子元素
类名()
获取该元素的类属性名称
classNames()
获取所有元素的类名返回值:Set
classNames(Set classNames)
通过提供的类名设置元素的类属性
数据()
获取该元素的组合数据
空()
删除此元素的所有子数据节点。
firstElementSibling()
获取当前元素的第一个同级同级元素。
getAllElements()
获取当前元素下的所有元素(包括自己、孩子、孩子的孩子)
getElementsByAttribute(String key)
通过属性名查找当前html下的所有元素
getElementsByClass(String className)
当前元素是否有这个类或者这个元素下是否有这个类
html()
在文件中检索Html
id()
返回当前元素的id值
isBlock()
测试该元素是否为层次元素
lastElementSibling()
获取与该元素同级的最后一个元素
父()
获取该节点的父节点
父母()
获取父节点,一直到节点的根节点
选择()
选择器方法,通用
兄弟元素()
获取所有兄弟元素(不包括你自己)
标签()
获取这个标签对象
标签名()
获取此标签的名称
文本()
获取该元素和所有子元素的文本内容
textNodes()
获取该元素的子文本标签集合
包裹()
包装这个元素的html
以下是一些示例:从 URL 加载文档,使用 Jsoup.connect() 方法从 URL 加载 HTML。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;).get();
System.out.println(document.title());
获取网页中的所有链接
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements links = document.select("a[href]");
for (Element link : links) {
System.out.println("link : " + link.attr("href"));
System.out.println("text : " + link.text());
}
获取网页中显示的所有图片
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
Elements images = document.select("img[src~=(?i)\\.(png|jpe?g|gif)]");
for (Element image : images) {
System.out.println("src : " + image.attr("src"));
System.out.println("height : " + image.attr("height"));
System.out.println("width : " + image.attr("width"));
System.out.println("alt : " + image.attr("alt"));
}
获取URL的元信息。元信息包括用于确定网络内容索引的搜索引擎,例如 Google。它们以一些标签的形式存在于 HTML 页面的 HEAD 部分。
Document document = Jsoup.connect("https://blog.csdn.net/s2152637 ... 6quot;);
String description = document.select("meta[name=description]").get(0).attr("content");
System.out.println("Meta description : " + description);
String keywords = document.select("meta[name=keywords]").first().attr("content");
System.out.println("Meta keyword : " + keywords);
java爬虫抓取网页数据(java爬虫抓取网页数据的成熟工具-爬虫.js)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-04 10:05
java爬虫抓取网页数据,已经是一个很成熟的工具了,虽然易用性有待提高,毕竟网站的后台数据都是https加密协议,而web端只能对post数据进行加密。首先,列举一些主流的爬虫工具,
1)用于爬取本地url的代理,例如requests,github上有大量成熟的项目,比如,
2)apache2.0python的解释器,可能很多人认为爬虫只适合用于抓取网页,实际上网页爬虫也是一种解释器,主要用于抓取存在于web页面的内容,实现为网页的request请求。
3)chrome的浏览器extension,提供能够解析网页的功能,
3)scrapy
4)python框架的requests模块
4)beautifulsoup
5)geetest.js
6)xpath
7)nodejsjavascriptmodules
8)scrapy.js好吧,好多人可能是用于解析requests和scrapy的请求,并没有用到爬虫的特殊功能。
python的爬虫工具虽然有很多,
1)scrapy.js这是用于爬取第三方代理服务的库,而且提供了很多高效的接口,可以在不同的浏览器间互相调用,效率十分高。
爬取代理实现的关键:
1)进行httprequest的解析和请求,提供了requestheader和getrequest方法来封装返回,
2)存放请求下载的内容
3)部署到网站的内存中。
4)applewebkit/537。36(khtml,likegecko)chrome/51。1913。100safari/537。36":iflen(request。user-agent)==0:print"请求成功!"else:print"请求失败!"ifrequest。user-agent=="mozilla/5。0(x11;linuxx86_6。
4)applewebkit/537.36(khtml,likegecko)chrome/51.0.1913.100safari/537.36":print"请求成功!"else:print"请求失败!"python自带user-agent解析库,可以提供各种可爬取代理实现代理请求。
大家自己动手尝试一下:-how-to-process-request-headers#ah
2)爬取本地网页的内容,例如,简书的文章列表。
实现:
<p>1)复制粘贴到本地htmltemplate的tag_preview:简书 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据的成熟工具-爬虫.js)
java爬虫抓取网页数据,已经是一个很成熟的工具了,虽然易用性有待提高,毕竟网站的后台数据都是https加密协议,而web端只能对post数据进行加密。首先,列举一些主流的爬虫工具,
1)用于爬取本地url的代理,例如requests,github上有大量成熟的项目,比如,
2)apache2.0python的解释器,可能很多人认为爬虫只适合用于抓取网页,实际上网页爬虫也是一种解释器,主要用于抓取存在于web页面的内容,实现为网页的request请求。
3)chrome的浏览器extension,提供能够解析网页的功能,
3)scrapy
4)python框架的requests模块
4)beautifulsoup
5)geetest.js
6)xpath
7)nodejsjavascriptmodules
8)scrapy.js好吧,好多人可能是用于解析requests和scrapy的请求,并没有用到爬虫的特殊功能。
python的爬虫工具虽然有很多,
1)scrapy.js这是用于爬取第三方代理服务的库,而且提供了很多高效的接口,可以在不同的浏览器间互相调用,效率十分高。
爬取代理实现的关键:
1)进行httprequest的解析和请求,提供了requestheader和getrequest方法来封装返回,
2)存放请求下载的内容
3)部署到网站的内存中。
4)applewebkit/537。36(khtml,likegecko)chrome/51。1913。100safari/537。36":iflen(request。user-agent)==0:print"请求成功!"else:print"请求失败!"ifrequest。user-agent=="mozilla/5。0(x11;linuxx86_6。
4)applewebkit/537.36(khtml,likegecko)chrome/51.0.1913.100safari/537.36":print"请求成功!"else:print"请求失败!"python自带user-agent解析库,可以提供各种可爬取代理实现代理请求。
大家自己动手尝试一下:-how-to-process-request-headers#ah
2)爬取本地网页的内容,例如,简书的文章列表。
实现:
<p>1)复制粘贴到本地htmltemplate的tag_preview:简书
java爬虫抓取网页数据(大数据java爬虫抓取网页数据的有效评论统计原理是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-03 22:02
java爬虫抓取网页数据,封装在spring-boot里面。去年的时候写了一个叫【掘金】的日志爬虫,抓取了多个知乎用户的多篇文章的有效评论。大概就是抓取作者的简介、收藏等,然后把评论者的数据列出来,等同于爬虫抓取评论统计的原理。目前当然可以开发一些辅助类库,在大数据的辅助分析中做用。从去年到现在一直在深入研究java基础,从http请求、表单元素,再到对象、多线程、redis、设计模式等等,跟着语言本身的一些机制也做了很多实验。
今年开始研究爬虫的容器,结合springboot,写了三个stark在去年的某一个项目里。其中两个用到了springboot的依赖注入,一个用到了spring的xmlhttprequest。还结合elk实验,写了elk系列的project,也写了用到了springboot的stark配置,感兴趣的可以去探索下。
使用springboot可以快速开发多个项目,搭建restful服务集成一些模块,搭建springcloud,跑了下stark的demo服务。stark实例,数据均来自于github评论者的有效评论,共三十三页。项目地址:,首发于微信公众号:面向对象之禅。感兴趣的话,也可以来微信公众号和我聊聊。
springboot本质是基于spring的开发框架,并在上面实现各种开发工具,比如springdatalibrary的jpa、springmvc、druid等,比如,除了用spring开发控制器和处理器映射之外,还可以通过druid来构建日志,异常,注解等模块。在springboot的语境下,pom.xml的主要作用是管理依赖,负责构建需要的spring、pom、java、python、jar包。
所以pom.xml有相应的stark模块加载,可以把springboot框架相关依赖发布到pom.xml中的commons-language-processor-pom.xml文件,供springboot集成使用。当然,如果不依赖spring,建议可以在spring框架的pom.xml中不加配置直接写pom.xml就好。
项目实战框架的基本配置,简单一点的有commons-lang、spring-boot-stark、error等。复杂一点的,比如,commons-lang可以包含spring容器、事务、xml、redis等,而且官方也提供了springboot的快速编译工具。error允许在定义的commons-lang-processor-pom.xml中使用pom.xml中定义的异常代码块/dogethandleresultparams等;pom.xml中还定义了非常多的模块和依赖,建议直接导入pom.xml即可。等等等等,有空继续填坑。 查看全部
java爬虫抓取网页数据(大数据java爬虫抓取网页数据的有效评论统计原理是什么?)
java爬虫抓取网页数据,封装在spring-boot里面。去年的时候写了一个叫【掘金】的日志爬虫,抓取了多个知乎用户的多篇文章的有效评论。大概就是抓取作者的简介、收藏等,然后把评论者的数据列出来,等同于爬虫抓取评论统计的原理。目前当然可以开发一些辅助类库,在大数据的辅助分析中做用。从去年到现在一直在深入研究java基础,从http请求、表单元素,再到对象、多线程、redis、设计模式等等,跟着语言本身的一些机制也做了很多实验。
今年开始研究爬虫的容器,结合springboot,写了三个stark在去年的某一个项目里。其中两个用到了springboot的依赖注入,一个用到了spring的xmlhttprequest。还结合elk实验,写了elk系列的project,也写了用到了springboot的stark配置,感兴趣的可以去探索下。
使用springboot可以快速开发多个项目,搭建restful服务集成一些模块,搭建springcloud,跑了下stark的demo服务。stark实例,数据均来自于github评论者的有效评论,共三十三页。项目地址:,首发于微信公众号:面向对象之禅。感兴趣的话,也可以来微信公众号和我聊聊。
springboot本质是基于spring的开发框架,并在上面实现各种开发工具,比如springdatalibrary的jpa、springmvc、druid等,比如,除了用spring开发控制器和处理器映射之外,还可以通过druid来构建日志,异常,注解等模块。在springboot的语境下,pom.xml的主要作用是管理依赖,负责构建需要的spring、pom、java、python、jar包。
所以pom.xml有相应的stark模块加载,可以把springboot框架相关依赖发布到pom.xml中的commons-language-processor-pom.xml文件,供springboot集成使用。当然,如果不依赖spring,建议可以在spring框架的pom.xml中不加配置直接写pom.xml就好。
项目实战框架的基本配置,简单一点的有commons-lang、spring-boot-stark、error等。复杂一点的,比如,commons-lang可以包含spring容器、事务、xml、redis等,而且官方也提供了springboot的快速编译工具。error允许在定义的commons-lang-processor-pom.xml中使用pom.xml中定义的异常代码块/dogethandleresultparams等;pom.xml中还定义了非常多的模块和依赖,建议直接导入pom.xml即可。等等等等,有空继续填坑。
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-03 06:11
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,用少量的代码就可以实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以下文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的会使用selenium;
参考链接: 查看全部
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,用少量的代码就可以实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以下文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的会使用selenium;
参考链接:
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-01 10:11
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络蜘蛛通过网页的链接地址搜索网页,从某个页面(通常是首页)开始,阅读
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果整个
把互联网想象成一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。所以如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个
对于接收“爬虫”发回的数据并进行处理和过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求就越高。
1 关注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的URL开始,获取
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂,需要一定的网页分析
该算法过滤与主题无关的链接,保留有用的链接并将它们放入URL队列中等待被抓取。然后,它会根据一定的搜索策略从队列中选择要抓取的网页的网址,并重复上传
该过程将停止,直到达到系统的某个条件。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;
对于焦爬虫来说,这个过程中得到的分析结果,也可以为后续的爬虫过程提供反馈和指导。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、
增量网络爬虫,深网爬虫。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。如何从网络上
本站获取的网站会进一步循环获取数据和提取其他数据。我不会在这里写。只能模拟最简单的原理。实际的网站爬虫比这里复杂很多,深入讨论的也太多了。
NS。除了提取URL,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个使用Java模拟提取新浪页面上的链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在idea中运行结果如下:
检查D盘是否有SiteURL.txt文件
SiteURL 文件已成功生成。打开它可以看到所有爬取的url。
查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人()
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。
其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。网络蜘蛛通过网页的链接地址搜索网页,从某个页面(通常是首页)开始,阅读
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,如此循环下去,直到这个网站的所有网页都被爬取。如果整个
把互联网想象成一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。所以如果要抓取互联网上的数据,不仅需要一个爬虫程序,还需要一个
对于接收“爬虫”发回的数据并进行处理和过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求就越高。
1 关注爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的URL开始,获取
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL并放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂,需要一定的网页分析
该算法过滤与主题无关的链接,保留有用的链接并将它们放入URL队列中等待被抓取。然后,它会根据一定的搜索策略从队列中选择要抓取的网页的网址,并重复上传
该过程将停止,直到达到系统的某个条件。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;
对于焦爬虫来说,这个过程中得到的分析结果,也可以为后续的爬虫过程提供反馈和指导。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几类:通用网络爬虫、聚焦网络爬虫、
增量网络爬虫,深网爬虫。实际的网络爬虫系统通常是通过多种爬虫技术的组合来实现的。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。如何从网络上
本站获取的网站会进一步循环获取数据和提取其他数据。我不会在这里写。只能模拟最简单的原理。实际的网站爬虫比这里复杂很多,深入讨论的也太多了。
NS。除了提取URL,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个使用Java模拟提取新浪页面上的链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在idea中运行结果如下:
检查D盘是否有SiteURL.txt文件
SiteURL 文件已成功生成。打开它可以看到所有爬取的url。
java爬虫抓取网页数据(2.如何通过selenium-java爬取异步加载的数据方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-27 05:07
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:
按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:
纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
org.seleniumhq.selenium
selenium-java
3.141.59
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:持仓市值通知系统,他每天都会根据自己的持仓配置自动计算出账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。 查看全部
java爬虫抓取网页数据(2.如何通过selenium-java爬取异步加载的数据方法。)
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:
按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:
纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
org.seleniumhq.selenium
selenium-java
3.141.59
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:持仓市值通知系统,他每天都会根据自己的持仓配置自动计算出账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。
java爬虫抓取网页数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-26 23:02
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集吧。
一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix 系统框架图
Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:WebLech URL Spider
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)可配置性强:可以自定义深度优先或宽度优先的抓取网页,带URL过滤器,可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以优先抓取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续抓取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站结构(可以创建网站图),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任何功能。
项目主页:JSpider-开源Web机器人
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一组JSP标签库,让那些基于JSP的站点无需开发任何Java类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:Arachnid Web Spider Framework
八、LARM
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:/
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站 的所有资源都是本地抓取的,包括网页和各种类型的文件,比如图片, flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile呢?
由于一些文件在爬取过程中经常出现错误,很多javascript控制的URL无法正确解析,snoics-reptile对外提供了接口和配置文件,可以传递特殊的URL。自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:淡蓝色轨迹...
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:Web-Harvest Project Home Pagenet
十个二、烂透了
ItSucks 是一个开源的 Java 网络爬虫项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:ItSucks
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
执照 查看全部
java爬虫抓取网页数据(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫,有需要的赶紧采集吧。
一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取的结果,这一步可以直接索引全文。Heritrix提供了一个ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix 系统框架图
Heritrix 处理一个 url 进程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
WebSPHINX 目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:WebLech URL Spider
特征:
1)开源,免费
2) 代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4) 可以维护网页之间的链接信息
5)可配置性强:可以自定义深度优先或宽度优先的抓取网页,带URL过滤器,可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络,您可以设置URL的优先级,这样就可以优先抓取我们感兴趣或重要的网页,记录断点时程序的状态,重启时从上次继续抓取。
四、阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站结构(可以创建网站图),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任何功能。
项目主页:JSpider-开源Web机器人
六、主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一组JSP标签库,让那些基于JSP的站点无需开发任何Java类就可以添加搜索功能。
七、蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在每个网站上使用页面解析后,添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:Arachnid Web Spider Framework
八、LARM
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:/
九、乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
1、什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站 的所有资源都是本地抓取的,包括网页和各种类型的文件,比如图片, flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile呢?
由于一些文件在爬取过程中经常出现错误,很多javascript控制的URL无法正确解析,snoics-reptile对外提供了接口和配置文件,可以传递特殊的URL。自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:淡蓝色轨迹...
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:Web-Harvest Project Home Pagenet
十个二、烂透了
ItSucks 是一个开源的 Java 网络爬虫项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
项目主页:ItSucks
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。可以在解析过程中或页面加载前后添加侦听器。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。在:
shouldVisit 是判断当前的 URL 是否应该被爬取(访问);
访问是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
此外,WebCrawler 还有一些其他的方法可以覆盖,其方法命名规则与Android 的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据;onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
执照
java爬虫抓取网页数据(就是自动爬起来()所有链接())
网站优化 • 优采云 发表了文章 • 0 个评论 • 38 次浏览 • 2021-10-23 08:15
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客的所有链接网站()。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入集合中,等待下一次遍历的同时循环。
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。最后将整个oldMap还没有遍历的链接遍历完成后,如果发现newMap不为空,则说明本次循环产生了新的链接,所以将这些新链接加入到oldMap中继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn");
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三项最终测试结果
PS:它的实际递归不是很好,因为如果网站页面多的话,程序运行时间长的话内存消耗会很大,但是因为我的博客网站页面不是很多,所以效果还可以 查看全部
java爬虫抓取网页数据(就是自动爬起来()所有链接())
前言:在写这篇文章之前,主要看了几个类似的爬虫写法,有的写成队列,感觉不是很直观,有的只有一个请求和页面分析,但是没有自动爬升。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客的所有链接网站()。
算法介绍
程序在思想上采用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入集合中,等待下一次遍历的同时循环。
具体实现中使用的是map,key-value对就是链接和是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,则说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们会把这个链接放到newMap中,继续解析。, 页面解析完成后,将oldMap中当前页面上的链接值设置为true,表示已经被遍历。最后将整个oldMap还没有遍历的链接遍历完成后,如果发现newMap不为空,则说明本次循环产生了新的链接,所以将这些新链接加入到oldMap中继续递归遍历,反之亦然。在此循环中不会生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
二 方案实施
上面的相关思路已经解释的很清楚了,代码中关键地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn";);
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三项最终测试结果
PS:它的实际递归不是很好,因为如果网站页面多的话,程序运行时间长的话内存消耗会很大,但是因为我的博客网站页面不是很多,所以效果还可以
java爬虫抓取网页数据(说到Java的本地存储,肯定使用IO流进行操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-21 17:13
说到Java的本地存储,必须使用IO流进行操作。
首先,我们需要一个函数 createNewFile 来创建一个文件:
public static boolean createNewFile(String filePath) {
boolean isSuccess = true;
// 如有则将"\\"转为"/",没有则不产生任何变化
String filePathTurn = filePath.replaceAll("\\\\", "/");
// 先过滤掉文件名
int index = filePathTurn.lastIndexOf("/");
String dir = filePathTurn.substring(0, index);
// 再创建文件夹
File fileDir = new File(dir);
isSuccess = fileDir.mkdirs();
// 创建文件
File file = new File(filePathTurn);
try {
isSuccess = file.createNewFile();
} catch (IOException e) {
isSuccess = false;
e.printStackTrace();
}
return isSuccess;
}
然后,我们需要一个写入文件的函数:
以上是Java的零基写法知乎 爬虫会将爬取到的内容存储到本地。更多相关内容请关注PHP中文网()!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
java爬虫抓取网页数据(说到Java的本地存储,肯定使用IO流进行操作)
说到Java的本地存储,必须使用IO流进行操作。
首先,我们需要一个函数 createNewFile 来创建一个文件:
public static boolean createNewFile(String filePath) {
boolean isSuccess = true;
// 如有则将"\\"转为"/",没有则不产生任何变化
String filePathTurn = filePath.replaceAll("\\\\", "/");
// 先过滤掉文件名
int index = filePathTurn.lastIndexOf("/");
String dir = filePathTurn.substring(0, index);
// 再创建文件夹
File fileDir = new File(dir);
isSuccess = fileDir.mkdirs();
// 创建文件
File file = new File(filePathTurn);
try {
isSuccess = file.createNewFile();
} catch (IOException e) {
isSuccess = false;
e.printStackTrace();
}
return isSuccess;
}
然后,我们需要一个写入文件的函数:
以上是Java的零基写法知乎 爬虫会将爬取到的内容存储到本地。更多相关内容请关注PHP中文网()!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
java爬虫抓取网页数据( JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-21 17:12
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到了Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,抓取一下网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco代码主要是通过注解来实现URL匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
java爬虫抓取网页数据(
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
Java爬虫Gecco工具抓取新闻实例
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到了Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,抓取一下网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。抓取 HTML 节点可以非常方便地像 Jquery 选择器一样选择节点。 Gecco代码主要是通过注解来实现URL匹配,看起来简单漂亮。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
java爬虫抓取网页数据(QQ空间爬虫分享(一天可抓取400万条数据)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-21 17:09
##QQSpider1:##详情请参考博客:《QQ空间爬虫分享(一天可抓取400万条数据)》如果出现错误:Traceback(最近调用last):文件”.\ init.py", line 20 , in my_messages.backups() #备份爬虫信息 NameError: name'my_messages' is not defined 大部分原因是BitVector模块不可用,可以自行调试。如果确定不能使用BitVector,可以使用“BitVector模块错误解析”中的两个文件替换原来的文件,不用BitVector判断权重,使用python list判断权重(效果是数据量不大也一样)。-------------------------------------------------- - - - 分界线 - - - - - - - - - - - - - - - - - - - - - - -- ------------##**QQSpider2:**## 更新版本,详情请参考博客:【《QQ空间爬虫分享》(2016年11月18日更新) "] ( ) 有同学反映,很多同学在QQ空间爬取,想爬取一些数据做统计研究。他们的专业不是计算机科学,起床更困难。他们希望有现成的数据出售。但是因为工作的变化,在今年3月份程序开发完成后,我并没有真正运行它,所以我没有任何数据。但是接下来我会运行一两台机器来运行这个爬虫。如果您需要数据,您可以通过电子邮件()与我联系。遇到问题请尽量留言, 查看全部
java爬虫抓取网页数据(QQ空间爬虫分享(一天可抓取400万条数据)(组图))
##QQSpider1:##详情请参考博客:《QQ空间爬虫分享(一天可抓取400万条数据)》如果出现错误:Traceback(最近调用last):文件”.\ init.py", line 20 , in my_messages.backups() #备份爬虫信息 NameError: name'my_messages' is not defined 大部分原因是BitVector模块不可用,可以自行调试。如果确定不能使用BitVector,可以使用“BitVector模块错误解析”中的两个文件替换原来的文件,不用BitVector判断权重,使用python list判断权重(效果是数据量不大也一样)。-------------------------------------------------- - - - 分界线 - - - - - - - - - - - - - - - - - - - - - - -- ------------##**QQSpider2:**## 更新版本,详情请参考博客:【《QQ空间爬虫分享》(2016年11月18日更新) "] ( ) 有同学反映,很多同学在QQ空间爬取,想爬取一些数据做统计研究。他们的专业不是计算机科学,起床更困难。他们希望有现成的数据出售。但是因为工作的变化,在今年3月份程序开发完成后,我并没有真正运行它,所以我没有任何数据。但是接下来我会运行一两台机器来运行这个爬虫。如果您需要数据,您可以通过电子邮件()与我联系。遇到问题请尽量留言,
java爬虫抓取网页数据(java爬虫抓取网页数据1.准备工作的通知。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-21 11:06
java爬虫抓取网页数据1.准备工作。*1.请求网页。*2.解析网页*3.存储数据。2.请求和解析数据的过程。*1.请求网页。*1.1抓包。*1.2看包头。*1.3查看代理服务器地址。*1.4看ip段(http/https)。*1.5看端口。*1.6看抓包抓取什么内容。*2.解析网页。*2.1读取网页。
*2.2解析网页。*2.3读取网址中的html。*2.4解析html的标签。*2.5查看解析后的数据格式。*3.数据存储。*3.1存储到数据库。*3.2存储到本地。*注意事项:******。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据1.准备工作的通知。。)
java爬虫抓取网页数据1.准备工作。*1.请求网页。*2.解析网页*3.存储数据。2.请求和解析数据的过程。*1.请求网页。*1.1抓包。*1.2看包头。*1.3查看代理服务器地址。*1.4看ip段(http/https)。*1.5看端口。*1.6看抓包抓取什么内容。*2.解析网页。*2.1读取网页。
*2.2解析网页。*2.3读取网址中的html。*2.4解析html的标签。*2.5查看解析后的数据格式。*3.数据存储。*3.1存储到数据库。*3.2存储到本地。*注意事项:******。

