
java爬虫抓取网页数据
java爬虫抓取网页数据(什么是网络爬虫从功能上来讲架构的四大组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-16 08:08
什么是网络爬虫
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫常用技术的底层实现是HttpClient + Jsoup
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供高效、最新、功能丰富的支持 HTTP 协议的客户端编程工具包,支持最新版本和推荐的 HTTP 协议。HttpClient 已经在很多项目中使用,比如 Cactus 和 HTMLUnit,Apache Jakarta 上另外两个知名的开源项目,都使用了 HttpClient。关注了解更多信息。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
HttpClient用于下载网页源代码,Jsoup用于从网页源代码中解析出需要的内容。
Webmagic 框架
webmagic 是一个开源的 Java 爬虫框架,其目标是简化爬虫开发过程,让开发者专注于逻辑功能的开发。webmagic的核心很简单,但是涵盖了爬虫的全过程,也是学习爬虫开发的好资料。
爬虫框架Webmagic介绍架构的四大组件
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
简单说明:Downloader负责爬取网页的源码,PageProcesser指定爬取的规则(即指定要爬取什么内容),然后交给Pipeline来存储爬取的内容,并交给用于管理的Scheduler URL,防止Downloader再次爬取该页面,防止爬取重复内容。
PageProcessor 爬取页面的全部内容
需求:编写爬虫程序,爬取csdn中博客的内容
1)引入依赖
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
2)编写类来抓取网页内容
public class MyProcessor implements PageProcessor {
public void process(Page page) {
// 将爬取的网页源代码输出到控制台
System.out.println(page.getHtml().toString());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
public static void main(String[] args) {
Spider.create(new MyProcessor())
.addUrl("https://blog.csdn.net/")
.run();
}
}
Spider 是爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
蜘蛛的一些方法:
同时可以通过set方法设置Spider的其他组件(Downloader、Scheduler、Pipeline)。
Page 代表从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
Site用于定义站点本身的一些配置信息,如编码、HTTP头、超时、重试策略等,代理等,可以通过设置Site对象来配置。
网站的一些方法:
爬取指定内容(Xpath)
如果我们要爬取网页的部分内容,需要指定xpath。XPath,即 XML 路径语言 (XMLPathLanguage),是一种用于确定 XML 文档的某个部分的位置的语言。XPath 使用路径表达式来选择 XML 文档中的节点或节点集。这些路径表达式与我们在常规计算机文件系统中看到的表达式非常相似。
我们通过指定 xpath 来抓取网页的一部分:
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
获取xpath的简单方法:打开网页,按F12
添加目标地址
我们可以通过添加目标地址从种子页面爬取更多页面:
目标地址正则表达式
有时我们只需要将当前页面中符合要求的链接添加到目标页面即可。这时候,我们可以使用正则表达式来过滤链接:
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
管道控制台管道控制台输出
将处理结果输出到控制台
FilePipeline 文件保存
另存为 json
自定义管道
一般我们需要把爬取的数据放到数据库中,这个时候我们可以自定义Pipeline
创建一个实现 Pipeline 接口的类:
修改主方法:
调度器
我们刚刚完成的功能,每次运行可能会爬取重复页面,这是没有意义的。Scheduler(URL管理)最基本的功能就是对已经爬取的URL进行标记。可以实现 URL 的增量重复数据删除。
目前scheduler的实现主要有3种:
内存队列
使用 setScheduler 设置调度器:
文件队列
使用文件保存爬取的URL,在关闭程序下一次开始时,可以从之前获取的URL继续爬取
但是,要使用这种方法,首先要保证文件目录存在,所以先创建一个文件存放目录:
运行后文件夹E:\scheduler会生成两个文件.urls.txt和.cursor.txt
Redis 队列
使用Redis保存抓取队列,可用于多台机器同时协同抓取
首先运行redis服务器
示例(爬取csdn博客的用户昵称和头像)
1)引入依赖
2)创建配置文件
server:
port: 9014
spring:
application:
name: tensquare-article-crawler #指定服务名
datasource:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.227.129:3306/tensquare_article?characterEncoding=UTF8
username: root
password: 123456
jpa:
database: MySQL
show-sql: true
redis:
host: 192.168.227.129
3)创建一个启动类
@SpringBootApplication
public class ArticleCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(ArticleCrawlerApplication.class);
}
@Value("${spring.redis.host}")
private String redis_host;
@Bean
public IdWorker idWorker(){
return new IdWorker(1,1);
}
@Bean
public RedisScheduler redisScheduler(){
return new RedisScheduler(redis_host);
}
}
4)创建爬虫类
打开网页,按F12,找到头像和昵称
如上图:头像是标签中的一个属性,如何获取呢?
@Component
public class UserProcessor implements PageProcessor {
@Override
public void process(Page page) {
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
// 添加字段,代码结构化,可多次使用
String nickName = page.getHtml().xpath("//*[@id=\"uid\"]/text()").get();
String image = page.getHtml().xpath("//*[@id=\"asideProfile\"]/div[1]/div[1]/a/img[1]/@src").get();
if (nickName != null && image != null){
page.putField("nickName",nickName);
page.putField("image",image);
} else {
// 不执行后面的步骤
page.setSkip(true);
}
}
@Override
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
}
只需在对应的 xpath 路径后添加 /@property 名称即可
我们拿到头像的存储地址后,需要下载到本地,然后上传到我们自己的图片服务器,所以我们还需要一个下载工具类
package util;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
/**
* 下载工具类
*/
public class DownloadUtil {
public static void download(String urlStr,String filename,String savePath) throws IOException {
URL url = new URL(urlStr);
//打开url连接
URLConnection connection = url.openConnection();
//请求超时时间
connection.setConnectTimeout(5000);
//输入流
InputStream in = connection.getInputStream();
//缓冲数据
byte [] bytes = new byte[1024];
//数据长度
int len;
//文件
File file = new File(savePath);
if(!file.exists())
file.mkdirs();
OutputStream out = new FileOutputStream(file.getPath()+"\\"+filename);
//先读到bytes中
while ((len=in.read(bytes))!=-1){
//再从bytes中写入文件
out.write(bytes,0,len);
}
//关闭IO
out.close();
in.close();
}
}
5)创建存储类
@Component
public class UserPipeline implements Pipeline {
@Autowired
private IdWorker idWorker;
@Autowired
private UserDao userDao;
@Override
public void process(ResultItems resultItems, Task task) {
String nickName = resultItems.get("nickName");
String image = resultItems.get("image");
String imageName = image.substring(image.lastIndexOf("/") + 1) + ".jpg";
User user = new User();
user.setId(idWorker.nextId()+"");
user.setAvatar(imageName);
user.setNickname(nickName);
// 将用户存入数据库
userDao.save(user);
// 将图片下载下载
try {
DownloadUtil.download(image,imageName,"E:/tensquare/userimage");
} catch (IOException e) {
e.printStackTrace();
}
}
}
6)创建任务类
@Component
public class UserTask {
@Autowired
private UserProcessor userProcessor;
@Autowired
private UserPipeline userPipeline;
@Autowired
private RedisScheduler redisScheduler;
@Scheduled(cron = "0 57 22 * * ?")
public void UserTask(){
Spider spider = Spider.create(userProcessor);
spider.addUrl("https://blog.csdn.net/");
spider.addPipeline(userPipeline);
spider.setScheduler(redisScheduler);
spider.start();
}
}
7)为启动类添加注解
8)运行这个模块,数据会在指定时间自动爬取 查看全部
java爬虫抓取网页数据(什么是网络爬虫从功能上来讲架构的四大组件)
什么是网络爬虫
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫常用技术的底层实现是HttpClient + Jsoup
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供高效、最新、功能丰富的支持 HTTP 协议的客户端编程工具包,支持最新版本和推荐的 HTTP 协议。HttpClient 已经在很多项目中使用,比如 Cactus 和 HTMLUnit,Apache Jakarta 上另外两个知名的开源项目,都使用了 HttpClient。关注了解更多信息。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
HttpClient用于下载网页源代码,Jsoup用于从网页源代码中解析出需要的内容。
Webmagic 框架
webmagic 是一个开源的 Java 爬虫框架,其目标是简化爬虫开发过程,让开发者专注于逻辑功能的开发。webmagic的核心很简单,但是涵盖了爬虫的全过程,也是学习爬虫开发的好资料。
爬虫框架Webmagic介绍架构的四大组件
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
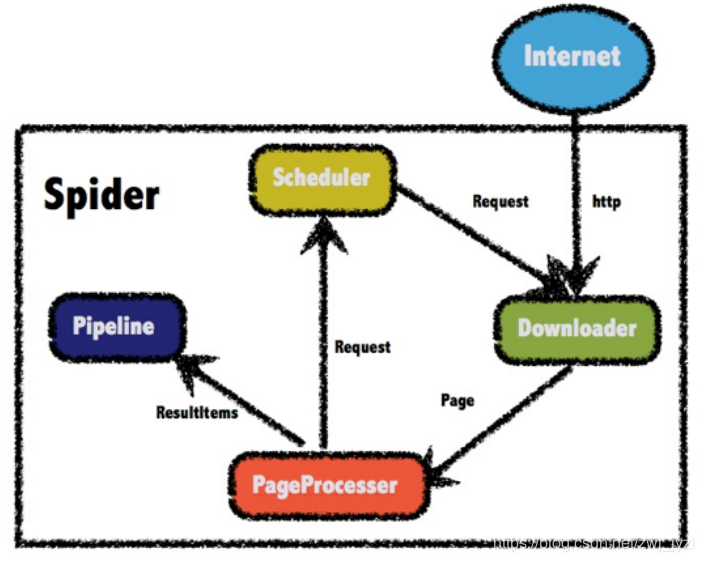
简单说明:Downloader负责爬取网页的源码,PageProcesser指定爬取的规则(即指定要爬取什么内容),然后交给Pipeline来存储爬取的内容,并交给用于管理的Scheduler URL,防止Downloader再次爬取该页面,防止爬取重复内容。
PageProcessor 爬取页面的全部内容
需求:编写爬虫程序,爬取csdn中博客的内容
1)引入依赖
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
2)编写类来抓取网页内容
public class MyProcessor implements PageProcessor {
public void process(Page page) {
// 将爬取的网页源代码输出到控制台
System.out.println(page.getHtml().toString());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
public static void main(String[] args) {
Spider.create(new MyProcessor())
.addUrl("https://blog.csdn.net/";)
.run();
}
}
Spider 是爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
蜘蛛的一些方法:
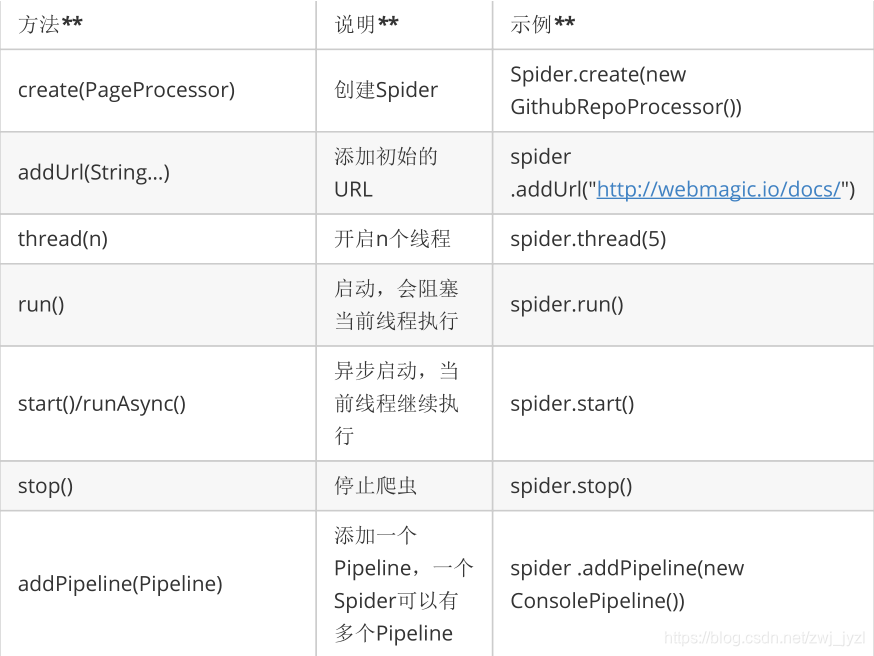
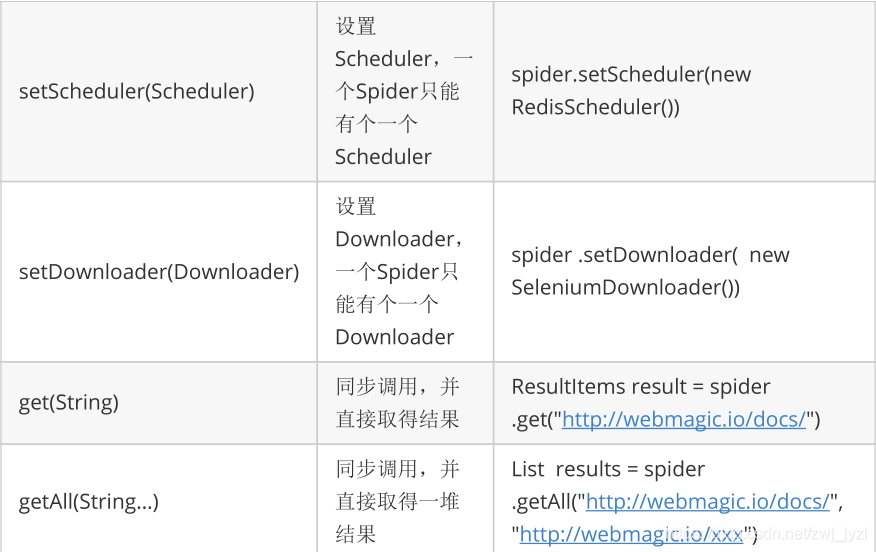
同时可以通过set方法设置Spider的其他组件(Downloader、Scheduler、Pipeline)。
Page 代表从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
Site用于定义站点本身的一些配置信息,如编码、HTTP头、超时、重试策略等,代理等,可以通过设置Site对象来配置。
网站的一些方法:

爬取指定内容(Xpath)
如果我们要爬取网页的部分内容,需要指定xpath。XPath,即 XML 路径语言 (XMLPathLanguage),是一种用于确定 XML 文档的某个部分的位置的语言。XPath 使用路径表达式来选择 XML 文档中的节点或节点集。这些路径表达式与我们在常规计算机文件系统中看到的表达式非常相似。
我们通过指定 xpath 来抓取网页的一部分:
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
获取xpath的简单方法:打开网页,按F12
添加目标地址
我们可以通过添加目标地址从种子页面爬取更多页面:
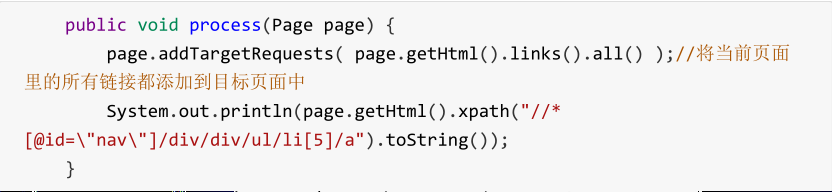
目标地址正则表达式
有时我们只需要将当前页面中符合要求的链接添加到目标页面即可。这时候,我们可以使用正则表达式来过滤链接:
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
管道控制台管道控制台输出
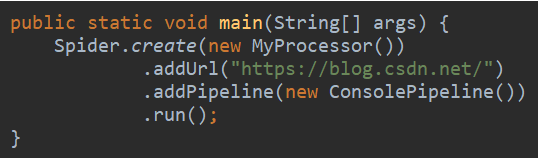
将处理结果输出到控制台
FilePipeline 文件保存
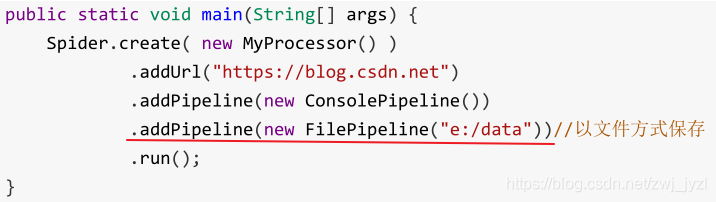
另存为 json
自定义管道
一般我们需要把爬取的数据放到数据库中,这个时候我们可以自定义Pipeline
创建一个实现 Pipeline 接口的类:
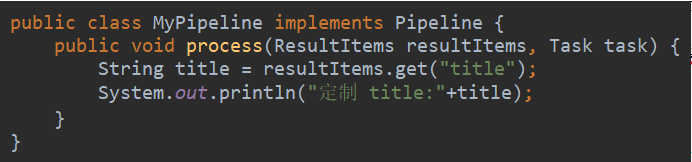
修改主方法:

调度器
我们刚刚完成的功能,每次运行可能会爬取重复页面,这是没有意义的。Scheduler(URL管理)最基本的功能就是对已经爬取的URL进行标记。可以实现 URL 的增量重复数据删除。
目前scheduler的实现主要有3种:
内存队列
使用 setScheduler 设置调度器:

文件队列
使用文件保存爬取的URL,在关闭程序下一次开始时,可以从之前获取的URL继续爬取
但是,要使用这种方法,首先要保证文件目录存在,所以先创建一个文件存放目录:
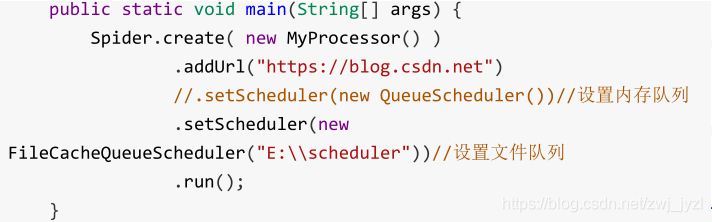
运行后文件夹E:\scheduler会生成两个文件.urls.txt和.cursor.txt
Redis 队列
使用Redis保存抓取队列,可用于多台机器同时协同抓取
首先运行redis服务器
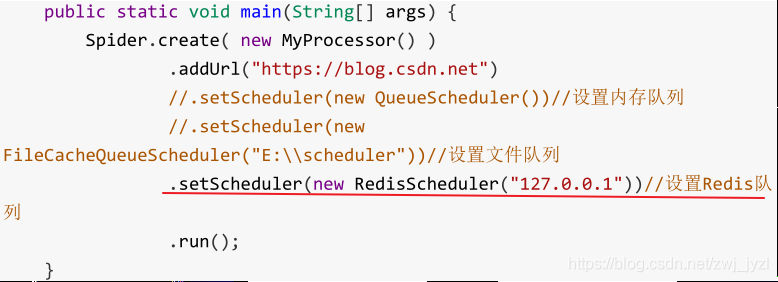
示例(爬取csdn博客的用户昵称和头像)
1)引入依赖
2)创建配置文件
server:
port: 9014
spring:
application:
name: tensquare-article-crawler #指定服务名
datasource:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.227.129:3306/tensquare_article?characterEncoding=UTF8
username: root
password: 123456
jpa:
database: MySQL
show-sql: true
redis:
host: 192.168.227.129
3)创建一个启动类
@SpringBootApplication
public class ArticleCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(ArticleCrawlerApplication.class);
}
@Value("${spring.redis.host}")
private String redis_host;
@Bean
public IdWorker idWorker(){
return new IdWorker(1,1);
}
@Bean
public RedisScheduler redisScheduler(){
return new RedisScheduler(redis_host);
}
}
4)创建爬虫类
打开网页,按F12,找到头像和昵称
如上图:头像是标签中的一个属性,如何获取呢?
@Component
public class UserProcessor implements PageProcessor {
@Override
public void process(Page page) {
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
// 添加字段,代码结构化,可多次使用
String nickName = page.getHtml().xpath("//*[@id=\"uid\"]/text()").get();
String image = page.getHtml().xpath("//*[@id=\"asideProfile\"]/div[1]/div[1]/a/img[1]/@src").get();
if (nickName != null && image != null){
page.putField("nickName",nickName);
page.putField("image",image);
} else {
// 不执行后面的步骤
page.setSkip(true);
}
}
@Override
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
}
只需在对应的 xpath 路径后添加 /@property 名称即可
我们拿到头像的存储地址后,需要下载到本地,然后上传到我们自己的图片服务器,所以我们还需要一个下载工具类
package util;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
/**
* 下载工具类
*/
public class DownloadUtil {
public static void download(String urlStr,String filename,String savePath) throws IOException {
URL url = new URL(urlStr);
//打开url连接
URLConnection connection = url.openConnection();
//请求超时时间
connection.setConnectTimeout(5000);
//输入流
InputStream in = connection.getInputStream();
//缓冲数据
byte [] bytes = new byte[1024];
//数据长度
int len;
//文件
File file = new File(savePath);
if(!file.exists())
file.mkdirs();
OutputStream out = new FileOutputStream(file.getPath()+"\\"+filename);
//先读到bytes中
while ((len=in.read(bytes))!=-1){
//再从bytes中写入文件
out.write(bytes,0,len);
}
//关闭IO
out.close();
in.close();
}
}
5)创建存储类
@Component
public class UserPipeline implements Pipeline {
@Autowired
private IdWorker idWorker;
@Autowired
private UserDao userDao;
@Override
public void process(ResultItems resultItems, Task task) {
String nickName = resultItems.get("nickName");
String image = resultItems.get("image");
String imageName = image.substring(image.lastIndexOf("/") + 1) + ".jpg";
User user = new User();
user.setId(idWorker.nextId()+"");
user.setAvatar(imageName);
user.setNickname(nickName);
// 将用户存入数据库
userDao.save(user);
// 将图片下载下载
try {
DownloadUtil.download(image,imageName,"E:/tensquare/userimage");
} catch (IOException e) {
e.printStackTrace();
}
}
}
6)创建任务类
@Component
public class UserTask {
@Autowired
private UserProcessor userProcessor;
@Autowired
private UserPipeline userPipeline;
@Autowired
private RedisScheduler redisScheduler;
@Scheduled(cron = "0 57 22 * * ?")
public void UserTask(){
Spider spider = Spider.create(userProcessor);
spider.addUrl("https://blog.csdn.net/";);
spider.addPipeline(userPipeline);
spider.setScheduler(redisScheduler);
spider.start();
}
}
7)为启动类添加注解
8)运行这个模块,数据会在指定时间自动爬取
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-15 20:14
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p> package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/");
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf(" 查看全部
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p> package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/";);
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf("
java爬虫抓取网页数据( ,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 02:05
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
JAVA使用爬虫爬取网站网页内容
更新时间:2015-07-24 09:36:05 转载:fzhlee
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
java爬虫抓取网页数据(
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
JAVA使用爬虫爬取网站网页内容
更新时间:2015-07-24 09:36:05 转载:fzhlee
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
java爬虫抓取网页数据(JavaHTML解析器的具体思路:1.调用url网页信息2.解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-13 09:06
)
想找一些图片作为桌面背景,又不想一张一张下载,于是想到了爬虫。. .
没有具体用过爬虫,在网上搜索后写了一个小demo。
爬虫的具体思路是:
1.调用url抓取网页信息
2.解析网页信息
3.保存数据
一开始是用regex来匹配获取img标签中的src地址,但是发现有很多不便(主要是我对regex不太了解),后来才发现神器jsoup。jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
下面是一个爬取图片的例子:
import com.crawler.domain.PictureInfo;
import org.bson.types.ObjectId;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.gridfs.GridFsTemplate;
import org.springframework.stereotype.Service;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.util.DigestUtils;
import org.springframework.util.StringUtils;
import javax.annotation.Resource;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 爬虫实现
*@program: crawler
* @description
* @author: wl
* @create: 2021-01-12 17:56
**/
@Service
public class CrawlerService {
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
HttpURLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc =(HttpURLConnection) urlObj.openConnection();
// 模拟浏览器请求
uc.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
System.out.println("爬取结束:"+buffer.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 下载图片
*
* @param listImgSrc
*/
public void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i < listImgSrc.size(); i++) {
try {
PictureInfo pictureInfo = listImgSrc.get(i);
String url=pictureInfo.getSrc();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
// 打开连接
URLConnection con = uri.openConnection();
//设置请求超时为
con.setConnectTimeout(5 * 1000);
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
String src = url.substring(URL.length());
int index = src.lastIndexOf('/');
String fileName = src.substring(0, index + 1);
File sf = new File(SAVE_PATH + fileName);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + imageName);
System.out.println(++count + ".开始下载:" + url);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
System.out.println(imageName + ":--下载完成");
} catch (IOException e) {
System.out.println("下载错误"+e);
}
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("下载失败"+e);
}
}
/**
* 得到网页中图片的地址-推荐
* 使用jsoup
* @param htmlStr html字符串
* @return List
*/
public List getImgStrJsoup(String htmlStr) {
List pics = new ArrayList();
//获取网页的document树
Document imgDoc = Jsoup.parse(htmlStr);
//获取所有的img
Elements alts = imgDoc.select("img[src]");
for (Element alt : alts) {
PictureInfo p=new PictureInfo();
p.setSrc(alt.attr("src"));
p.setAlt(alt.attr("alt"));
p.setTitle(alt.attr("title"));
pics.add(p);
}
return pics;
}
}
这些是主要的方法。只要爬取的网页信息中收录img标签,就可以去除对应的图片。
查看全部
java爬虫抓取网页数据(JavaHTML解析器的具体思路:1.调用url网页信息2.解析
)
想找一些图片作为桌面背景,又不想一张一张下载,于是想到了爬虫。. .
没有具体用过爬虫,在网上搜索后写了一个小demo。
爬虫的具体思路是:
1.调用url抓取网页信息
2.解析网页信息
3.保存数据
一开始是用regex来匹配获取img标签中的src地址,但是发现有很多不便(主要是我对regex不太了解),后来才发现神器jsoup。jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
下面是一个爬取图片的例子:
import com.crawler.domain.PictureInfo;
import org.bson.types.ObjectId;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.gridfs.GridFsTemplate;
import org.springframework.stereotype.Service;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.util.DigestUtils;
import org.springframework.util.StringUtils;
import javax.annotation.Resource;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 爬虫实现
*@program: crawler
* @description
* @author: wl
* @create: 2021-01-12 17:56
**/
@Service
public class CrawlerService {
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
HttpURLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc =(HttpURLConnection) urlObj.openConnection();
// 模拟浏览器请求
uc.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
System.out.println("爬取结束:"+buffer.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 下载图片
*
* @param listImgSrc
*/
public void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i < listImgSrc.size(); i++) {
try {
PictureInfo pictureInfo = listImgSrc.get(i);
String url=pictureInfo.getSrc();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
// 打开连接
URLConnection con = uri.openConnection();
//设置请求超时为
con.setConnectTimeout(5 * 1000);
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
String src = url.substring(URL.length());
int index = src.lastIndexOf('/');
String fileName = src.substring(0, index + 1);
File sf = new File(SAVE_PATH + fileName);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + imageName);
System.out.println(++count + ".开始下载:" + url);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
System.out.println(imageName + ":--下载完成");
} catch (IOException e) {
System.out.println("下载错误"+e);
}
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("下载失败"+e);
}
}
/**
* 得到网页中图片的地址-推荐
* 使用jsoup
* @param htmlStr html字符串
* @return List
*/
public List getImgStrJsoup(String htmlStr) {
List pics = new ArrayList();
//获取网页的document树
Document imgDoc = Jsoup.parse(htmlStr);
//获取所有的img
Elements alts = imgDoc.select("img[src]");
for (Element alt : alts) {
PictureInfo p=new PictureInfo();
p.setSrc(alt.attr("src"));
p.setAlt(alt.attr("alt"));
p.setTitle(alt.attr("title"));
pics.add(p);
}
return pics;
}
}
这些是主要的方法。只要爬取的网页信息中收录img标签,就可以去除对应的图片。
java爬虫抓取网页数据( 这是Java网络爬虫系列文章的第一篇(图),需要哪些基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-13 06:02
这是Java网络爬虫系列文章的第一篇(图),需要哪些基础知识)
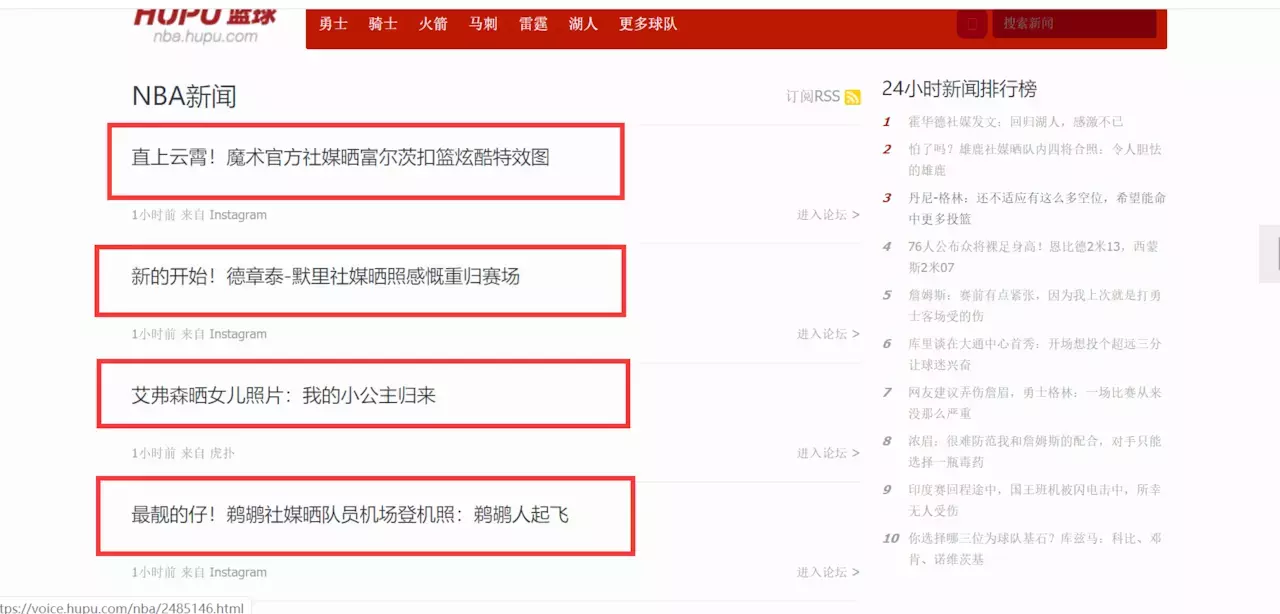
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参阅学习Java网络爬虫需要哪些基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解Jsoup,请参考/
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
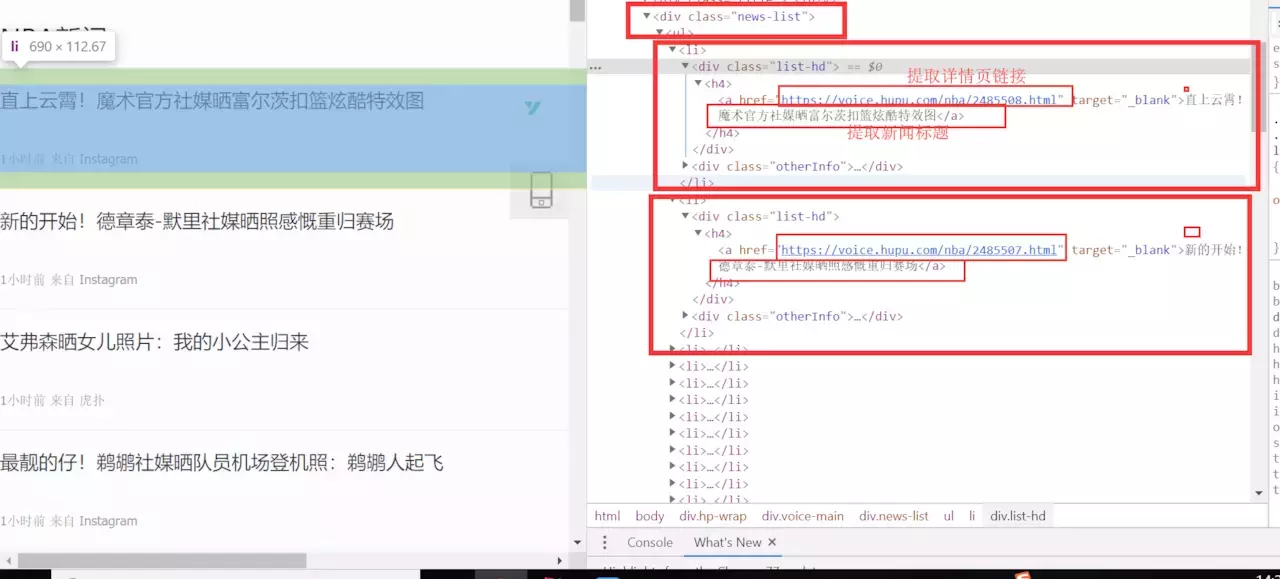
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。httpclient + 正则表达式
上面,我们使用了Jsoup方法正确提取了虎扑列表新闻。接下来我们使用httpclient+正则表达式的方式进行提取,看看这种方式会涉及哪些问题? httpclient+正则表达式方式涉及的知识点相当多,涉及到正则表达式、Java正则表达式、httpclient。如果你不知道这些知识,可以点击下面的链接了解一下:
正则表达式:正则表达式
Java 正则表达式:Java 正则表达式 查看全部
java爬虫抓取网页数据(
这是Java网络爬虫系列文章的第一篇(图),需要哪些基础知识)
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参阅学习Java网络爬虫需要哪些基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解Jsoup,请参考/
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。httpclient + 正则表达式
上面,我们使用了Jsoup方法正确提取了虎扑列表新闻。接下来我们使用httpclient+正则表达式的方式进行提取,看看这种方式会涉及哪些问题? httpclient+正则表达式方式涉及的知识点相当多,涉及到正则表达式、Java正则表达式、httpclient。如果你不知道这些知识,可以点击下面的链接了解一下:
正则表达式:正则表达式
Java 正则表达式:Java 正则表达式
java爬虫抓取网页数据(Java爬虫采集网页数据(简单介绍)(1)_ )
网站优化 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2022-01-12 00:08
)
Java爬虫采集网页数据一、爬虫简介
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。
学过爬虫的同学都知道,目前80%的爬虫都是用Python写的:
原因一:由于目前大部分网络协议都是基于HTTP/HTTPS的,而java的基础框架支持TCP/IP网络协议,构建爬虫时需要导入大量底层库;
原因2:Python有很多开源爬虫库,好用,也有Java的,但是Java入门比较难;
理由三:Python语言简单难懂。相比之下,Java语言更复杂,理解难度也增加了;
好了,这次回到我们的话题,修改后的例子是一个基于JavaClient加正则化的爬虫来简单实现Java Maven项目采集的图片数据!
二、必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
有同学创建Maven项目后,程序还是跑错了!只要三点修改,就会更宽!(基于 JDK1.8)
1.修改pom.xml依赖中的JDK版本号
UTF-8
1.8
1.8
2.根据下图找到项目结构图标,进入Project Settings --> Modules -->Souces->Language level:设置为8;
3 进入项目设置文件,Settings–>Build, Execution, Deployment–>Compiler–>Java Compiler–>Moudle:配置JDK版本为8;
三点后就可以配置了
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以我只用了一个java文件写成静态方法,方便调用
爬取图片下载到本地
html.java
<p>import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.*;
import java.util.Scanner;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class scenery {
//编码格式
private static final String ENCODING = "UTF-8";
//保存地址
private static final String SAVE_PATH = "file/background";
/**
* 获取到指定网址的网页源码并返回
* @param url 爬取网址
* @return html
*/
public static String getHtmlResourceByUrl(String url) {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
HttpEntity httpEntity = null;
String html = null;
// 设置长连接
httpGet.setHeader("Connection", "keep-alive");
// 设置代理(模拟浏览器版本)
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
CloseableHttpResponse httpResponse = null;
System.out.println("开始请求网页!!!!!!!!");
try {
// 请求并获得响应结果
httpResponse = httpClient.execute(httpGet);
httpEntity = httpResponse.getEntity();
// 输出请求结果
html = EntityUtils.toString(httpEntity);
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
/**
* 获取网页的链接与标题,并追加到list中,从而返回list
* @param html 网页地址
* @return list
*/
public static List getTitleUrl(String html){
String regex_img_url = "<img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
String regex_img_title span class="token operator"=/span span class="token string""div class=\"tits\"(.*?)b class=hightlight"/spanspan class="token punctuation";/span
ArrayListspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建pattern对象/span
Pattern img_url_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_urlspan class="token punctuation")/spanspan class="token punctuation";/span
Pattern img_title_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_titlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_url_m span class="token operator"=/span img_url_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
Matcher img_title_m span class="token operator"=/span img_title_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_url_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/span span class="token operator"&&/span img_title_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
String url span class="token operator"=/span img_url_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanurlspan class="token punctuation")/spanspan class="token punctuation";/span
String title span class="token operator"=/span img_title_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spantitlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 获取image url 追加到List中,并返回List
* @param details_html 详情页网址
* @return List
*//span
span class="token keyword"public/span span class="token keyword"static/span Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span span class="token function"getImageSrc/spanspan class="token punctuation"(/spanString details_htmlspan class="token punctuation")/spanspan class="token punctuation"{/span
Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
String imgRegex span class="token operator"=/span span class="token string""img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
span class="token comment"//创建Pattern对象/span
Pattern img_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanimgRegexspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_m span class="token operator"=/span img_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spandetails_htmlspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""开始解析..."/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 下载图片
* @param imgUrl img网址
* @param filePath 图片报错地址
* @param title 图片系列
* @param imageName 图片名
* @param page 页数
* @param count 每页的图片计数
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"downLoad/spanspan class="token punctuation"(/spanString imgUrlspan class="token punctuation",/spanString filePathspan class="token punctuation",/span String titlespan class="token punctuation",/span String imageNamespan class="token punctuation",/spanspan class="token keyword"int/span pagespan class="token punctuation",/span span class="token keyword"int/span countspan class="token punctuation")/span span class="token punctuation"{/span
CloseableHttpClient httpClient span class="token operator"=/span HttpClientsspan class="token punctuation"./spanspan class="token function"createDefault/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
HttpGet httpGet span class="token operator"=/span span class="token keyword"new/span span class="token class-name"HttpGet/spanspan class="token punctuation"(/spanimgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"try/span span class="token punctuation"{/span
CloseableHttpResponse response span class="token operator"=/span httpClientspan class="token punctuation"./spanspan class="token function"execute/spanspan class="token punctuation"(/spanhttpGetspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/spanpagespan class="token operator"+/span span class="token string""页的"/span span class="token operator"+/span title span class="token operator"+/span span class="token string""系列图片开始下载:"/span span class="token operator"+/span imgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanHttpStatusspan class="token punctuation"./spanSC_OK span class="token operator"==/span responsespan class="token punctuation"./spanspan class="token function"getStatusLine/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"./spanspan class="token function"getStatusCode/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
HttpEntity entity span class="token operator"=/span responsespan class="token punctuation"./spanspan class="token function"getEntity/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
InputStream imgContent span class="token operator"=/span entityspan class="token punctuation"./spanspan class="token function"getContent/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token function"saveImage/spanspan class="token punctuation"(/spanimgContentspan class="token punctuation",/span filePathspan class="token punctuation",/spanimageNamespan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/span span class="token punctuation"(/spancount span class="token operator"+/span span class="token number"1/spanspan class="token punctuation")/span span class="token operator"+/span span class="token string""张图片下载完成名为:"/span span class="token operator"+/span imageNamespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"ClientProtocolException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token comment"/**
* 保存图片
* @param is 输入数据流
* @param filePath 文件目录Path
* @param imageName image名
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"saveImage/spanspan class="token punctuation"(/spanInputStream isspan class="token punctuation",/span String filePathspan class="token punctuation",/span String imageNamespan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token keyword"try/span span class="token punctuation"{/span
span class="token comment"//创建图片文件/span
String imgSavePath span class="token operator"=/span filePathspan class="token punctuation"./spanspan class="token function"concat/spanspan class="token punctuation"(/spanspan class="token string""/"/span span class="token operator"+/span imageName span class="token operator"+/span span class="token string"".jpg"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
File imgPath span class="token operator"=/span span class="token keyword"new/span span class="token class-name"File/spanspan class="token punctuation"(/spanimgSavePathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanspan class="token operator"!/spanimgPathspan class="token punctuation"./spanspan class="token function"exists/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
imgPathspan class="token punctuation"./spanspan class="token function"createNewFile/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
FileOutputStream fos span class="token operator"=/span span class="token keyword"new/span span class="token class-name"FileOutputStream/spanspan class="token punctuation"(/spanimgPathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"byte/spanspan class="token punctuation"[/spanspan class="token punctuation"]/span bytes span class="token operator"=/span span class="token keyword"new/span span class="token class-name"byte/spanspan class="token punctuation"[/spanspan class="token number"1024/span span class="token operator"*/span span class="token number"1024/span span class="token operator"*/span span class="token number"1024/spanspan class="token punctuation"]/spanspan class="token punctuation";/span
span class="token keyword"int/span len span class="token operator"=/span span class="token number"0/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanspan class="token punctuation"(/spanlen span class="token operator"=/span isspan class="token punctuation"./spanspan class="token function"read/spanspan class="token punctuation"(/spanbytesspan class="token punctuation")/spanspan class="token punctuation")/span span class="token operator"!=/span span class="token operator"-/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
fosspan class="token punctuation"./spanspan class="token function"write/spanspan class="token punctuation"(/spanbytesspan class="token punctuation",/span span class="token number"0/spanspan class="token punctuation",/span lenspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
fosspan class="token punctuation"./spanspan class="token function"flush/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
fosspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/spanspan class="token keyword"finally/span span class="token punctuation"{/span
span class="token keyword"try/spanspan class="token punctuation"{/span
isspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"run/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token comment"//循环获取列表页的html/span
String title span class="token operator"=/span span class="token string"""/spanspan class="token punctuation";/span
span class="token comment"//采集类型大家阔以自行发挥!!!/span
Scanner input span class="token operator"=/span span class="token keyword"new/span span class="token class-name"Scanner/spanspan class="token punctuation"(/spanSystemspan class="token punctuation"./spaninspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""*********************欢迎来到洋群满满壁纸下载地,请选择你想要下载序列的序号!*********************"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""1>>>风景|2>>>美女|3>>>汽车|4>>>动漫|5>>>二次元|6>>>森林|7>>>明星|8>>>猜你喜欢(You Know!!!)");
System.out.print("请选择:");
int choose = input.nextInt();
switch (choose){
case 1:
title = "风景";
break;
case 2:
title = "美女";
break;
case 3:
title = "汽车";
break;
case 4:
title = "动漫";
break;
case 5:
title = "二次元";
break;
case 6:
title = "森林";
break;
case 7:
title = "明星";
break;
case 8:
title = "性感";
break;
default:
title = "风景";
System.out.println("选择错误,默认采集风景系列图片!!!");
break;
}
int page = 1;
for (; page 查看全部
java爬虫抓取网页数据(Java爬虫采集网页数据(简单介绍)(1)_
)
Java爬虫采集网页数据一、爬虫简介
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。
学过爬虫的同学都知道,目前80%的爬虫都是用Python写的:
原因一:由于目前大部分网络协议都是基于HTTP/HTTPS的,而java的基础框架支持TCP/IP网络协议,构建爬虫时需要导入大量底层库;
原因2:Python有很多开源爬虫库,好用,也有Java的,但是Java入门比较难;
理由三:Python语言简单难懂。相比之下,Java语言更复杂,理解难度也增加了;
好了,这次回到我们的话题,修改后的例子是一个基于JavaClient加正则化的爬虫来简单实现Java Maven项目采集的图片数据!
二、必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
有同学创建Maven项目后,程序还是跑错了!只要三点修改,就会更宽!(基于 JDK1.8)
1.修改pom.xml依赖中的JDK版本号
UTF-8
1.8
1.8
2.根据下图找到项目结构图标,进入Project Settings --> Modules -->Souces->Language level:设置为8;

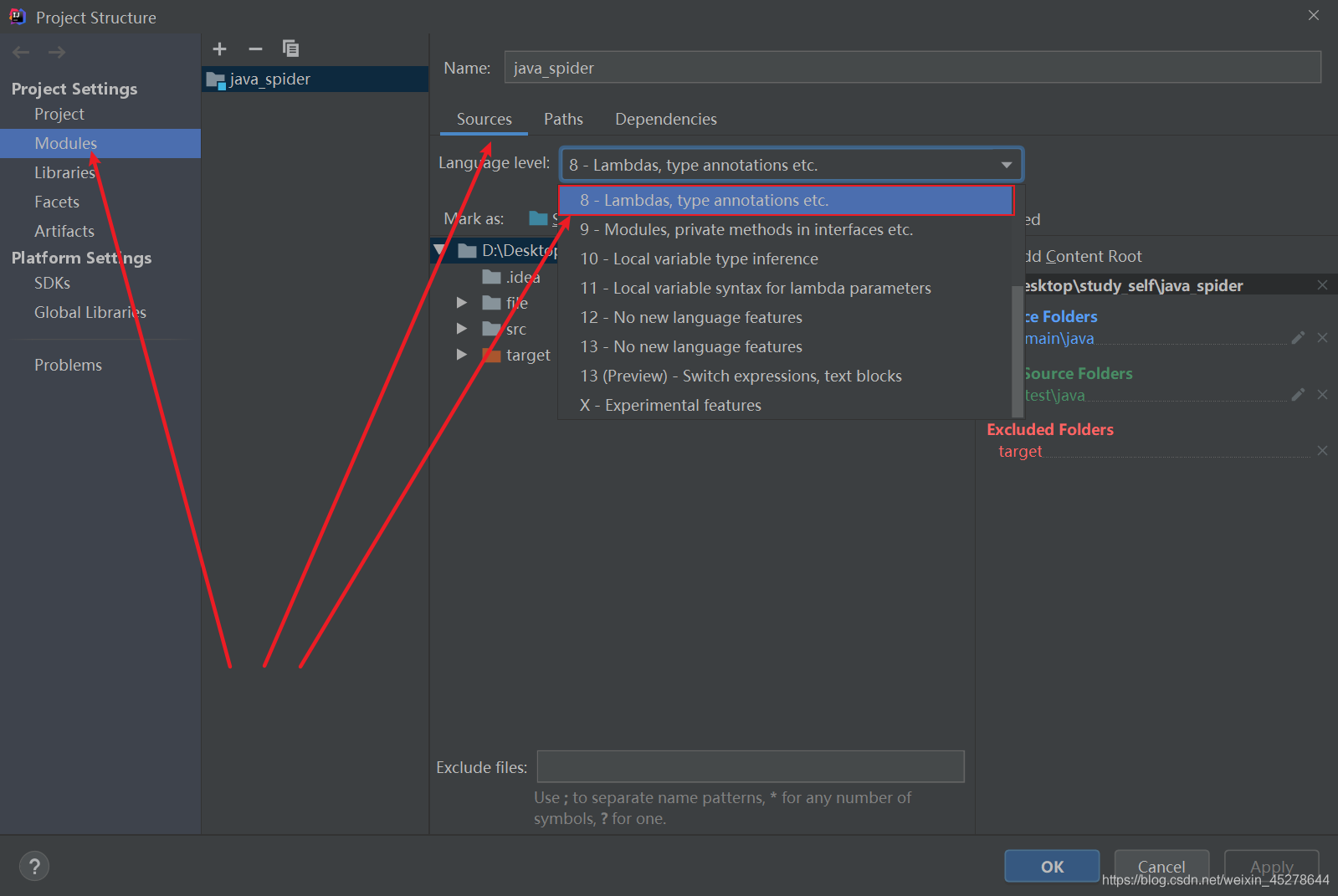
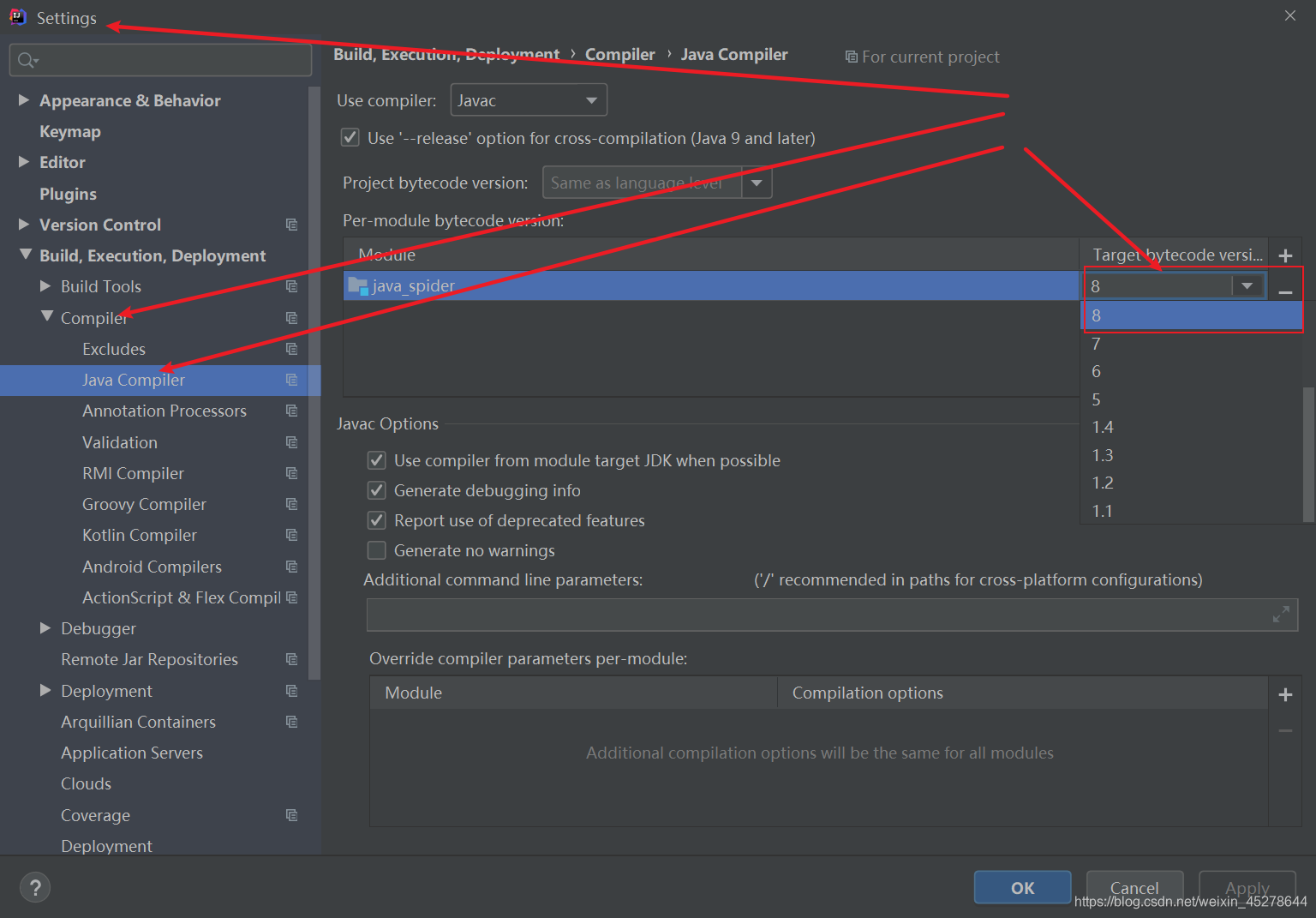
3 进入项目设置文件,Settings–>Build, Execution, Deployment–>Compiler–>Java Compiler–>Moudle:配置JDK版本为8;
三点后就可以配置了
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以我只用了一个java文件写成静态方法,方便调用
爬取图片下载到本地
html.java
<p>import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.*;
import java.util.Scanner;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class scenery {
//编码格式
private static final String ENCODING = "UTF-8";
//保存地址
private static final String SAVE_PATH = "file/background";
/**
* 获取到指定网址的网页源码并返回
* @param url 爬取网址
* @return html
*/
public static String getHtmlResourceByUrl(String url) {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
HttpEntity httpEntity = null;
String html = null;
// 设置长连接
httpGet.setHeader("Connection", "keep-alive");
// 设置代理(模拟浏览器版本)
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
CloseableHttpResponse httpResponse = null;
System.out.println("开始请求网页!!!!!!!!");
try {
// 请求并获得响应结果
httpResponse = httpClient.execute(httpGet);
httpEntity = httpResponse.getEntity();
// 输出请求结果
html = EntityUtils.toString(httpEntity);
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
/**
* 获取网页的链接与标题,并追加到list中,从而返回list
* @param html 网页地址
* @return list
*/
public static List getTitleUrl(String html){
String regex_img_url = "<img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
String regex_img_title span class="token operator"=/span span class="token string""div class=\"tits\"(.*?)b class=hightlight"/spanspan class="token punctuation";/span
ArrayListspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建pattern对象/span
Pattern img_url_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_urlspan class="token punctuation")/spanspan class="token punctuation";/span
Pattern img_title_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_titlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_url_m span class="token operator"=/span img_url_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
Matcher img_title_m span class="token operator"=/span img_title_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_url_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/span span class="token operator"&&/span img_title_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
String url span class="token operator"=/span img_url_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanurlspan class="token punctuation")/spanspan class="token punctuation";/span
String title span class="token operator"=/span img_title_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spantitlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 获取image url 追加到List中,并返回List
* @param details_html 详情页网址
* @return List
*//span
span class="token keyword"public/span span class="token keyword"static/span Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span span class="token function"getImageSrc/spanspan class="token punctuation"(/spanString details_htmlspan class="token punctuation")/spanspan class="token punctuation"{/span
Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
String imgRegex span class="token operator"=/span span class="token string""img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
span class="token comment"//创建Pattern对象/span
Pattern img_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanimgRegexspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_m span class="token operator"=/span img_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spandetails_htmlspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""开始解析..."/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 下载图片
* @param imgUrl img网址
* @param filePath 图片报错地址
* @param title 图片系列
* @param imageName 图片名
* @param page 页数
* @param count 每页的图片计数
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"downLoad/spanspan class="token punctuation"(/spanString imgUrlspan class="token punctuation",/spanString filePathspan class="token punctuation",/span String titlespan class="token punctuation",/span String imageNamespan class="token punctuation",/spanspan class="token keyword"int/span pagespan class="token punctuation",/span span class="token keyword"int/span countspan class="token punctuation")/span span class="token punctuation"{/span
CloseableHttpClient httpClient span class="token operator"=/span HttpClientsspan class="token punctuation"./spanspan class="token function"createDefault/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
HttpGet httpGet span class="token operator"=/span span class="token keyword"new/span span class="token class-name"HttpGet/spanspan class="token punctuation"(/spanimgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"try/span span class="token punctuation"{/span
CloseableHttpResponse response span class="token operator"=/span httpClientspan class="token punctuation"./spanspan class="token function"execute/spanspan class="token punctuation"(/spanhttpGetspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/spanpagespan class="token operator"+/span span class="token string""页的"/span span class="token operator"+/span title span class="token operator"+/span span class="token string""系列图片开始下载:"/span span class="token operator"+/span imgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanHttpStatusspan class="token punctuation"./spanSC_OK span class="token operator"==/span responsespan class="token punctuation"./spanspan class="token function"getStatusLine/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"./spanspan class="token function"getStatusCode/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
HttpEntity entity span class="token operator"=/span responsespan class="token punctuation"./spanspan class="token function"getEntity/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
InputStream imgContent span class="token operator"=/span entityspan class="token punctuation"./spanspan class="token function"getContent/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token function"saveImage/spanspan class="token punctuation"(/spanimgContentspan class="token punctuation",/span filePathspan class="token punctuation",/spanimageNamespan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/span span class="token punctuation"(/spancount span class="token operator"+/span span class="token number"1/spanspan class="token punctuation")/span span class="token operator"+/span span class="token string""张图片下载完成名为:"/span span class="token operator"+/span imageNamespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"ClientProtocolException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token comment"/**
* 保存图片
* @param is 输入数据流
* @param filePath 文件目录Path
* @param imageName image名
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"saveImage/spanspan class="token punctuation"(/spanInputStream isspan class="token punctuation",/span String filePathspan class="token punctuation",/span String imageNamespan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token keyword"try/span span class="token punctuation"{/span
span class="token comment"//创建图片文件/span
String imgSavePath span class="token operator"=/span filePathspan class="token punctuation"./spanspan class="token function"concat/spanspan class="token punctuation"(/spanspan class="token string""/"/span span class="token operator"+/span imageName span class="token operator"+/span span class="token string"".jpg"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
File imgPath span class="token operator"=/span span class="token keyword"new/span span class="token class-name"File/spanspan class="token punctuation"(/spanimgSavePathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanspan class="token operator"!/spanimgPathspan class="token punctuation"./spanspan class="token function"exists/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
imgPathspan class="token punctuation"./spanspan class="token function"createNewFile/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
FileOutputStream fos span class="token operator"=/span span class="token keyword"new/span span class="token class-name"FileOutputStream/spanspan class="token punctuation"(/spanimgPathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"byte/spanspan class="token punctuation"[/spanspan class="token punctuation"]/span bytes span class="token operator"=/span span class="token keyword"new/span span class="token class-name"byte/spanspan class="token punctuation"[/spanspan class="token number"1024/span span class="token operator"*/span span class="token number"1024/span span class="token operator"*/span span class="token number"1024/spanspan class="token punctuation"]/spanspan class="token punctuation";/span
span class="token keyword"int/span len span class="token operator"=/span span class="token number"0/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanspan class="token punctuation"(/spanlen span class="token operator"=/span isspan class="token punctuation"./spanspan class="token function"read/spanspan class="token punctuation"(/spanbytesspan class="token punctuation")/spanspan class="token punctuation")/span span class="token operator"!=/span span class="token operator"-/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
fosspan class="token punctuation"./spanspan class="token function"write/spanspan class="token punctuation"(/spanbytesspan class="token punctuation",/span span class="token number"0/spanspan class="token punctuation",/span lenspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
fosspan class="token punctuation"./spanspan class="token function"flush/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
fosspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/spanspan class="token keyword"finally/span span class="token punctuation"{/span
span class="token keyword"try/spanspan class="token punctuation"{/span
isspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"run/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token comment"//循环获取列表页的html/span
String title span class="token operator"=/span span class="token string"""/spanspan class="token punctuation";/span
span class="token comment"//采集类型大家阔以自行发挥!!!/span
Scanner input span class="token operator"=/span span class="token keyword"new/span span class="token class-name"Scanner/spanspan class="token punctuation"(/spanSystemspan class="token punctuation"./spaninspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""*********************欢迎来到洋群满满壁纸下载地,请选择你想要下载序列的序号!*********************"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""1>>>风景|2>>>美女|3>>>汽车|4>>>动漫|5>>>二次元|6>>>森林|7>>>明星|8>>>猜你喜欢(You Know!!!)");
System.out.print("请选择:");
int choose = input.nextInt();
switch (choose){
case 1:
title = "风景";
break;
case 2:
title = "美女";
break;
case 3:
title = "汽车";
break;
case 4:
title = "动漫";
break;
case 5:
title = "二次元";
break;
case 6:
title = "森林";
break;
case 7:
title = "明星";
break;
case 8:
title = "性感";
break;
default:
title = "风景";
System.out.println("选择错误,默认采集风景系列图片!!!");
break;
}
int page = 1;
for (; page
java爬虫抓取网页数据( post方式就要考虑提交的表单内容怎么传输了呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-10 06:11
post方式就要考虑提交的表单内容怎么传输了呢?
)
public static String httpPostWithJSON(String url) throws Exception {
HttpPost httpPost = new HttpPost(url);
CloseableHttpClient client = HttpClients.createDefault();
String respContent = null;
// json方式
JSONObject jsonParam = new JSONObject();
jsonParam.put("name", "admin");
jsonParam.put("pass", "123456");
StringEntity entity = new StringEntity(jsonParam.toString(),"utf-8");//解决中文乱码问题
entity.setContentEncoding("UTF-8");
entity.setContentType("application/json");
httpPost.setEntity(entity);
System.out.println();
// 表单方式
// List pairList = new ArrayList();
// pairList.add(new BasicNameValuePair("name", "admin"));
// pairList.add(new BasicNameValuePair("pass", "123456"));
// httpPost.setEntity(new UrlEncodedFormEntity(pairList, "utf-8"));
HttpResponse resp = client.execute(httpPost);
if(resp.getStatusLine().getStatusCode() == 200) {
HttpEntity he = resp.getEntity();
respContent = EntityUtils.toString(he,"UTF-8");
}
return respContent;
}
public static void main(String[] args) throws Exception {
String result = httpPostWithJSON("http://localhost:8080/hcTest2/Hc");
System.out.println(result);
}
post方法需要考虑提交的表单内容是如何传输的。在本文中,name 和 pass 是表单的值。
封装形式的属性可以使用json或者传统形式。如果是传统形式,请注意,即注释上面的代码部分。这样,在servlet中,也就是数据处理层可以直接通过request.getParameter("string")获取属性值。它比json简单,但是在实际开发中,一般都是用json来进行数据传输。使用json有两种选择,一种是阿里巴巴的fastjson,一种是谷歌的gson。相比fastjson,效率更高,gson适合解析常规JSON数据。博主在这里使用fastjson。另外,如果使用json,在数据处理层需要使用streams来读取表单属性,比传统表单内容要多一点。代码已经存在了。
public class HcServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html;charset=UTF-8");
String acceptjson = "";
User user = new User();
BufferedReader br = new BufferedReader(new InputStreamReader(
(ServletInputStream) request.getInputStream(), "utf-8"));
StringBuffer sb = new StringBuffer("");
String temp;
while ((temp = br.readLine()) != null) {
sb.append(temp);
}
br.close();
acceptjson = sb.toString();
if (acceptjson != "") {
JSONObject jo = JSONObject.parseObject(acceptjson);
user.setUsername(jo.getString("name"));
user.setPassword(jo.getString("pass"));
}
request.setAttribute("user", user);
request.getRequestDispatcher("/message.jsp").forward(request, response);
}
} 查看全部
java爬虫抓取网页数据(
post方式就要考虑提交的表单内容怎么传输了呢?
)
public static String httpPostWithJSON(String url) throws Exception {
HttpPost httpPost = new HttpPost(url);
CloseableHttpClient client = HttpClients.createDefault();
String respContent = null;
// json方式
JSONObject jsonParam = new JSONObject();
jsonParam.put("name", "admin");
jsonParam.put("pass", "123456");
StringEntity entity = new StringEntity(jsonParam.toString(),"utf-8");//解决中文乱码问题
entity.setContentEncoding("UTF-8");
entity.setContentType("application/json");
httpPost.setEntity(entity);
System.out.println();
// 表单方式
// List pairList = new ArrayList();
// pairList.add(new BasicNameValuePair("name", "admin"));
// pairList.add(new BasicNameValuePair("pass", "123456"));
// httpPost.setEntity(new UrlEncodedFormEntity(pairList, "utf-8"));
HttpResponse resp = client.execute(httpPost);
if(resp.getStatusLine().getStatusCode() == 200) {
HttpEntity he = resp.getEntity();
respContent = EntityUtils.toString(he,"UTF-8");
}
return respContent;
}
public static void main(String[] args) throws Exception {
String result = httpPostWithJSON("http://localhost:8080/hcTest2/Hc";);
System.out.println(result);
}
post方法需要考虑提交的表单内容是如何传输的。在本文中,name 和 pass 是表单的值。
封装形式的属性可以使用json或者传统形式。如果是传统形式,请注意,即注释上面的代码部分。这样,在servlet中,也就是数据处理层可以直接通过request.getParameter("string")获取属性值。它比json简单,但是在实际开发中,一般都是用json来进行数据传输。使用json有两种选择,一种是阿里巴巴的fastjson,一种是谷歌的gson。相比fastjson,效率更高,gson适合解析常规JSON数据。博主在这里使用fastjson。另外,如果使用json,在数据处理层需要使用streams来读取表单属性,比传统表单内容要多一点。代码已经存在了。
public class HcServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html;charset=UTF-8");
String acceptjson = "";
User user = new User();
BufferedReader br = new BufferedReader(new InputStreamReader(
(ServletInputStream) request.getInputStream(), "utf-8"));
StringBuffer sb = new StringBuffer("");
String temp;
while ((temp = br.readLine()) != null) {
sb.append(temp);
}
br.close();
acceptjson = sb.toString();
if (acceptjson != "") {
JSONObject jo = JSONObject.parseObject(acceptjson);
user.setUsername(jo.getString("name"));
user.setPassword(jo.getString("pass"));
}
request.setAttribute("user", user);
request.getRequestDispatcher("/message.jsp").forward(request, response);
}
}
java爬虫抓取网页数据(里的图片URL标签的属性值包的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-07 21:00
)
爬虫获取图片,
第一步:获取网页源代码。
步骤二:获取源码中的图片网址(img标签的src属性值)
第 3 部分:下载图片。
获取网页源码需要一个工具:java selenium。它有两部分,一是驱动浏览器的插件,二是jar包
驱动程序可以在这里下载:
下载时注意浏览器对应的驱动版本,存放在某个目录下。驱动是一个.exe文件,谷歌浏览器是:chromedriver.exe
jar包的依赖:
org.seleniumhq.selenium
selenium-java
3.141.59
整个爬虫的maven依赖:
org.jsoup
jsoup
1.7.3
org.seleniumhq.selenium
selenium-java
3.141.59
获取网页的源代码:需要网页的网址
private String webDriverGetSourceHtml(String url){
//运行chromedriver.exe
System.setProperty("webdriver.chrome.driver", "D:\\Google\\webdriver\\chromedriver.exe");
//获取浏览器驱动驱动
WebDriver driver = new ChromeDriver();
System.out.println("【myReptile-1号】已被唤醒");
System.out.println("【myReptile-1号】的任务:从:"+url+"网页获取图片下载到:"+filePath);
//将浏览器窗口最大化
driver.manage().window().maximize();
//
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);//设置元素定位等待时间
// driver.manage().timeouts().pageLoadTimeout(10,TimeUnit.SECONDS);//设置页面加载等待时间
// driver.manage().timeouts().setScriptTimeout(10,TimeUnit.SECONDS);//设置脚本运行等待时间
//打开指定的网页
driver.get(url);
System.out.println("【myReptile-1号】开始工作···");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
//让浏览器执行一个js脚本:将网页滚动条滑到最底(部分网页源代码需要滑动滚动条后才加载出来)
((JavascriptExecutor) driver).executeScript("window.scrollTo(0,document.body.scrollHeight)");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//获取网页源代码
String s = driver.getPageSource();
System.out.println("【myReptile-1号】已获取目标网页源代码");
return s;
}
获取图片地址:参数html为网页源代码,参数url与之前的方法参数相同
private Set getImgsrc(String html , String url){
//hashset相同的元素只算一个。有些网页的图片有大量重复的,避免图片地址重复
Set list = new HashSet();
System.out.println("【myReptile-1号】正在收集图片地址···");
String img = "";
//用正则表达式获取源代码里的<img>标签代码
Pattern p_image;
Matcher m_image;
String regEx_img = "]*?>";
p_image = Pattern.compile(regEx_img, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(html);
while (m_image.find()) {
// 得到<img />数据
img = m_image.group();
// 匹配<img>中的src数据
Matcher matcher = Pattern.compile("src\\s*=\\s*\"?(.*?)(\"|>|\\s+)").matcher(img);
while (matcher.find()) {
String imgSrc = matcher.group(1);
if ((imgSrc!=null)) {
// imgSrc以"http://"或https开头,表示完整的图片URL地址
if((imgSrc.startsWith("http://") || imgSrc.startsWith("https://"))){
System.out.println("【myReptile-1号】直接获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("//")){
// imgSrc以"//"开头,图片URL地址缺少协议,默认协议是http协议,把http补上
imgSrc="http:"+imgSrc;
System.out.println("【myReptile-1号】加协议获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("/")){
// imgSrc以"/"开头,图片URL地址只有地址部分,缺少协议以及域名,把协议和域名补上。协议和域名在url里有
//例如百度里的某图片src为"/aaa/bbb.jpg",我们需要加上http://ww.baidu.com,让它变成"http://ww.baidu.com/aaa/bbb.jpg"
String pattern = "^((http://)|(https://))?([a-zA-Z0-9]([a-zA-Z0-9\\-]{0,61}[a-zA-Z0-9])?\\.)+[a-zA-Z]{2,6}";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(url);
if(m.find()){
String s = m.group();
imgSrc=s+imgSrc;
System.out.println("【myReptile-1号】加域名("+s+")获得图片地址:" + imgSrc);
list.add(imgSrc);
}
}else {
}
}
else {
System.out.println("【myReptile-1号】获取失败的图片地址"+imgSrc);
}
}
}
System.out.println("【myReptile-1号】在:"+url+"获取了 ("+list.size()+") 个图片地址");
return list;
}
下载图片:参数imgList是图片地址的集合。参数filePath是下载的图片存放的位置
private void downImages(Set imgList , String filePath){
//创建文件的目录结构
System.out.println("【myReptile-1号】正在磁盘寻找文件夹( "+filePath+" )");
File files = new File(filePath);
if(!files.exists()){// 判断文件夹是否存在,如果不存在就创建一个文件夹
System.out.println("【myReptile-1号】找不到文件夹( "+filePath+" )");
System.out.println("【myReptile-1号】正在创建文件夹( "+filePath+" )");
files.mkdirs();
System.out.println("【myReptile-1号】创建文件夹( "+filePath+" )完毕");
}else {
System.out.println("【myReptile-1号】已经找到文件夹( "+filePath+" )");
}
int j = 1;
int t = 1;
//获取图片后缀名
Pattern p2 = Pattern.compile("((.png)|(.jpg)|(.gif)|(.bmp)|(.psd)|(.tiff)|(.tga)|(.eps))");
// 截取图片的名称
System.out.println("【myReptile-1号】开始盗图···");
for(String img : imgList){
try {
String fileSuffix = null;
Matcher m2 = p2.matcher(img);
if(m2.find()){
fileSuffix = m2.group();
}else {
//有些图片地址里没有图片后缀名,我们就直接加上一个后缀名
fileSuffix = ".jpg" ;
}
System.out.println("【myReptile-1号】开始抓捕第 ( "+j+" ) 张图片: "+img);
//创建URL类
URL url = new URL(img);
//获取URL连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//设置http请求头
connection.setRequestProperty("Charset", "utf-8");
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36");
//打开链接
connection.connect();
//创建字节输入流
InputStream in = connection.getInputStream();
// 创建文件
File file = new File(filePath+"\\"+System.currentTimeMillis()+fileSuffix);
//创建字节输出流
FileOutputStream out = new FileOutputStream(file);
int i = 0;
while((i = in.read()) != -1){
out.write(i);
}
in.close();
out.close();
System.out.println("抓捕成功");
j++;
t++;
} catch (Exception e) {
j++;
System.out.println("抓捕失败");
e.printStackTrace();
}
}
System.out.println("【myReptile-1号】总共获取"+imgList.size()+"张图片地址,实际抓捕"+(t-1)+"张图片");
System.out.println("请到( "+filePath+" )文件夹查看!");
} 查看全部
java爬虫抓取网页数据(里的图片URL标签的属性值包的应用
)
爬虫获取图片,
第一步:获取网页源代码。
步骤二:获取源码中的图片网址(img标签的src属性值)
第 3 部分:下载图片。
获取网页源码需要一个工具:java selenium。它有两部分,一是驱动浏览器的插件,二是jar包
驱动程序可以在这里下载:
下载时注意浏览器对应的驱动版本,存放在某个目录下。驱动是一个.exe文件,谷歌浏览器是:chromedriver.exe
jar包的依赖:
org.seleniumhq.selenium
selenium-java
3.141.59
整个爬虫的maven依赖:
org.jsoup
jsoup
1.7.3
org.seleniumhq.selenium
selenium-java
3.141.59
获取网页的源代码:需要网页的网址
private String webDriverGetSourceHtml(String url){
//运行chromedriver.exe
System.setProperty("webdriver.chrome.driver", "D:\\Google\\webdriver\\chromedriver.exe");
//获取浏览器驱动驱动
WebDriver driver = new ChromeDriver();
System.out.println("【myReptile-1号】已被唤醒");
System.out.println("【myReptile-1号】的任务:从:"+url+"网页获取图片下载到:"+filePath);
//将浏览器窗口最大化
driver.manage().window().maximize();
//
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);//设置元素定位等待时间
// driver.manage().timeouts().pageLoadTimeout(10,TimeUnit.SECONDS);//设置页面加载等待时间
// driver.manage().timeouts().setScriptTimeout(10,TimeUnit.SECONDS);//设置脚本运行等待时间
//打开指定的网页
driver.get(url);
System.out.println("【myReptile-1号】开始工作···");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
//让浏览器执行一个js脚本:将网页滚动条滑到最底(部分网页源代码需要滑动滚动条后才加载出来)
((JavascriptExecutor) driver).executeScript("window.scrollTo(0,document.body.scrollHeight)");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//获取网页源代码
String s = driver.getPageSource();
System.out.println("【myReptile-1号】已获取目标网页源代码");
return s;
}
获取图片地址:参数html为网页源代码,参数url与之前的方法参数相同
private Set getImgsrc(String html , String url){
//hashset相同的元素只算一个。有些网页的图片有大量重复的,避免图片地址重复
Set list = new HashSet();
System.out.println("【myReptile-1号】正在收集图片地址···");
String img = "";
//用正则表达式获取源代码里的<img>标签代码
Pattern p_image;
Matcher m_image;
String regEx_img = "]*?>";
p_image = Pattern.compile(regEx_img, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(html);
while (m_image.find()) {
// 得到<img />数据
img = m_image.group();
// 匹配<img>中的src数据
Matcher matcher = Pattern.compile("src\\s*=\\s*\"?(.*?)(\"|>|\\s+)").matcher(img);
while (matcher.find()) {
String imgSrc = matcher.group(1);
if ((imgSrc!=null)) {
// imgSrc以"http://"或https开头,表示完整的图片URL地址
if((imgSrc.startsWith("http://";) || imgSrc.startsWith("https://";))){
System.out.println("【myReptile-1号】直接获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("//")){
// imgSrc以"//"开头,图片URL地址缺少协议,默认协议是http协议,把http补上
imgSrc="http:"+imgSrc;
System.out.println("【myReptile-1号】加协议获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("/")){
// imgSrc以"/"开头,图片URL地址只有地址部分,缺少协议以及域名,把协议和域名补上。协议和域名在url里有
//例如百度里的某图片src为"/aaa/bbb.jpg",我们需要加上http://ww.baidu.com,让它变成"http://ww.baidu.com/aaa/bbb.jpg"
String pattern = "^((http://)|(https://))?([a-zA-Z0-9]([a-zA-Z0-9\\-]{0,61}[a-zA-Z0-9])?\\.)+[a-zA-Z]{2,6}";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(url);
if(m.find()){
String s = m.group();
imgSrc=s+imgSrc;
System.out.println("【myReptile-1号】加域名("+s+")获得图片地址:" + imgSrc);
list.add(imgSrc);
}
}else {
}
}
else {
System.out.println("【myReptile-1号】获取失败的图片地址"+imgSrc);
}
}
}
System.out.println("【myReptile-1号】在:"+url+"获取了 ("+list.size()+") 个图片地址");
return list;
}
下载图片:参数imgList是图片地址的集合。参数filePath是下载的图片存放的位置
private void downImages(Set imgList , String filePath){
//创建文件的目录结构
System.out.println("【myReptile-1号】正在磁盘寻找文件夹( "+filePath+" )");
File files = new File(filePath);
if(!files.exists()){// 判断文件夹是否存在,如果不存在就创建一个文件夹
System.out.println("【myReptile-1号】找不到文件夹( "+filePath+" )");
System.out.println("【myReptile-1号】正在创建文件夹( "+filePath+" )");
files.mkdirs();
System.out.println("【myReptile-1号】创建文件夹( "+filePath+" )完毕");
}else {
System.out.println("【myReptile-1号】已经找到文件夹( "+filePath+" )");
}
int j = 1;
int t = 1;
//获取图片后缀名
Pattern p2 = Pattern.compile("((.png)|(.jpg)|(.gif)|(.bmp)|(.psd)|(.tiff)|(.tga)|(.eps))");
// 截取图片的名称
System.out.println("【myReptile-1号】开始盗图···");
for(String img : imgList){
try {
String fileSuffix = null;
Matcher m2 = p2.matcher(img);
if(m2.find()){
fileSuffix = m2.group();
}else {
//有些图片地址里没有图片后缀名,我们就直接加上一个后缀名
fileSuffix = ".jpg" ;
}
System.out.println("【myReptile-1号】开始抓捕第 ( "+j+" ) 张图片: "+img);
//创建URL类
URL url = new URL(img);
//获取URL连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//设置http请求头
connection.setRequestProperty("Charset", "utf-8");
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36");
//打开链接
connection.connect();
//创建字节输入流
InputStream in = connection.getInputStream();
// 创建文件
File file = new File(filePath+"\\"+System.currentTimeMillis()+fileSuffix);
//创建字节输出流
FileOutputStream out = new FileOutputStream(file);
int i = 0;
while((i = in.read()) != -1){
out.write(i);
}
in.close();
out.close();
System.out.println("抓捕成功");
j++;
t++;
} catch (Exception e) {
j++;
System.out.println("抓捕失败");
e.printStackTrace();
}
}
System.out.println("【myReptile-1号】总共获取"+imgList.size()+"张图片地址,实际抓捕"+(t-1)+"张图片");
System.out.println("请到( "+filePath+" )文件夹查看!");
}
java爬虫抓取网页数据(一下使用ja来写作一个爬虫功能强大的方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2022-01-07 08:11
一般来说,当我们说到爬虫程序时,我们总会想到python爬虫。但是,python 爬虫有一些固有的缺点。python的具体实现基本是固定的,底层实现我们也看不懂,导致很多网站可以反爬虫,今天给大家介绍一下用ja写爬虫,ja的爬虫功能相当强大,目前我还没有发现任何可以用来对抗ja爬虫的网站。
1 首先先介绍一下我们需要导入的jar包:.jsoup,这是一个ja解析html包,它的作用就是解析网页的代码,这个功能强大到没有网站可以做反分析。2.j a.io,这部分其实是没有必要的。我使用这个只是因为我在分析网页代码之前将网页保存在本地。至于为什么要这样做,后面的说明中会提到。3.j 这个包是ja的网络包,我们必须依赖这个包才能使用ja连接网络。
2 我们先说明一下如何将在线的html保存到本地。我们首先创建我们的输入和输出流缓冲区,然后创建一个url来获取我们需要抓取的网页。注意我们使用ipad的动态访问来实现 防止反爬虫对我们的阻碍。最后,我们在 uffer 中生成了我们的 html 代码,然后将其保存在本地。
3 现在让我告诉你为什么它存储在本地。在网页上反复爬取我们需要的数据,难免会导致服务器警觉。就像你看到一个漂亮的女孩一样,你总是盯着别人看。总会找到的,不过偷个图慢慢看也无妨。啊哈哈,这是个玩笑,但这是大体的想法。
4 这部分解释了如何获取html文件中的有用信息。众所周知,html中的代码占了很大一部分,我们需要得到对我们有用的文本才是我们需要做的。并且这段代码分析html中的标签,比如这些标签,分析出复杂代码中有价值的文本信息和超链接。当然,您可以选择要获取的内容。
5最后,让我们尝试爬取我们需要的网站: 下图展示了操作方法和爬虫网页。我们要抓取的是这个网页的header:
6 我们的爬虫结果如下: 嗯,看来爬虫还是挺成功的。有兴趣的可以自己试试ja爬虫。相信我,这个功能真的很强大也很简单。
jsoup包需要网上下载或者使用men下载
建议爬取大量网页后删除一个,否则会不断积累本地网页 查看全部
java爬虫抓取网页数据(一下使用ja来写作一个爬虫功能强大的方法分享)
一般来说,当我们说到爬虫程序时,我们总会想到python爬虫。但是,python 爬虫有一些固有的缺点。python的具体实现基本是固定的,底层实现我们也看不懂,导致很多网站可以反爬虫,今天给大家介绍一下用ja写爬虫,ja的爬虫功能相当强大,目前我还没有发现任何可以用来对抗ja爬虫的网站。
1 首先先介绍一下我们需要导入的jar包:.jsoup,这是一个ja解析html包,它的作用就是解析网页的代码,这个功能强大到没有网站可以做反分析。2.j a.io,这部分其实是没有必要的。我使用这个只是因为我在分析网页代码之前将网页保存在本地。至于为什么要这样做,后面的说明中会提到。3.j 这个包是ja的网络包,我们必须依赖这个包才能使用ja连接网络。

2 我们先说明一下如何将在线的html保存到本地。我们首先创建我们的输入和输出流缓冲区,然后创建一个url来获取我们需要抓取的网页。注意我们使用ipad的动态访问来实现 防止反爬虫对我们的阻碍。最后,我们在 uffer 中生成了我们的 html 代码,然后将其保存在本地。

3 现在让我告诉你为什么它存储在本地。在网页上反复爬取我们需要的数据,难免会导致服务器警觉。就像你看到一个漂亮的女孩一样,你总是盯着别人看。总会找到的,不过偷个图慢慢看也无妨。啊哈哈,这是个玩笑,但这是大体的想法。
4 这部分解释了如何获取html文件中的有用信息。众所周知,html中的代码占了很大一部分,我们需要得到对我们有用的文本才是我们需要做的。并且这段代码分析html中的标签,比如这些标签,分析出复杂代码中有价值的文本信息和超链接。当然,您可以选择要获取的内容。

5最后,让我们尝试爬取我们需要的网站: 下图展示了操作方法和爬虫网页。我们要抓取的是这个网页的header:

6 我们的爬虫结果如下: 嗯,看来爬虫还是挺成功的。有兴趣的可以自己试试ja爬虫。相信我,这个功能真的很强大也很简单。

jsoup包需要网上下载或者使用men下载
建议爬取大量网页后删除一个,否则会不断积累本地网页
java爬虫抓取网页数据(UI自动化月前写的一些事儿--)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-06 00:18
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤1、需求分解:2、代码实现思路:3、示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑改变请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js和图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。 查看全部
java爬虫抓取网页数据(UI自动化月前写的一些事儿--)
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤1、需求分解:2、代码实现思路:3、示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑改变请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js和图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。
java爬虫抓取网页数据(小白刚入门java爬虫抓取网页数据怎么做?开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-04 15:08
java爬虫抓取网页数据,大致分为图片下载,url提取,网页验证码图片下载,交互式爬虫,异步爬虫,搜索数据,定时爬虫等类型,如果是初学爬虫,建议从图片下载开始,下载图片psd文件。
https加密算法找到js文件可以做一下注意你的网站类型是静态还是动态的要不然到时候获取成功了你的服务器崩了就完蛋了爬取重定向可以先做一下简单的ip代理规划一下用户习惯是否需要多用户登录来增加可爬取性和安全性有哪些页面需要爬取在加载这些页面前把爬取规划好爬取后再通过分析内容找到转换规律可以有哪些格式的文件来爬取然后配合解析分析来提取到更精确的信息。
爬虫程序有html5的爬虫框架和ruby/python的反爬虫框架,这两种框架都有不同的入门资料推荐。我也刚入门爬虫不久,写的是html5爬虫的。我先学习的爬虫框架是d3,爬虫框架把html的内容抽象成了一个表,然后可以通过路由来爬取出html内容。不太熟悉ruby可以先用easyweb。学完了html后我学了ruby后,除了学习html,可以试试结合rails/redis/python的requests库(python的网络库)和爬虫框架。
刚入门爬虫的话没必要全部都学,基础知识会用requests学习后,剩下的可以随便学习了。pythonweb开发,可以看看这个。小白刚入门,建议先看这里。 查看全部
java爬虫抓取网页数据(小白刚入门java爬虫抓取网页数据怎么做?开发)
java爬虫抓取网页数据,大致分为图片下载,url提取,网页验证码图片下载,交互式爬虫,异步爬虫,搜索数据,定时爬虫等类型,如果是初学爬虫,建议从图片下载开始,下载图片psd文件。
https加密算法找到js文件可以做一下注意你的网站类型是静态还是动态的要不然到时候获取成功了你的服务器崩了就完蛋了爬取重定向可以先做一下简单的ip代理规划一下用户习惯是否需要多用户登录来增加可爬取性和安全性有哪些页面需要爬取在加载这些页面前把爬取规划好爬取后再通过分析内容找到转换规律可以有哪些格式的文件来爬取然后配合解析分析来提取到更精确的信息。
爬虫程序有html5的爬虫框架和ruby/python的反爬虫框架,这两种框架都有不同的入门资料推荐。我也刚入门爬虫不久,写的是html5爬虫的。我先学习的爬虫框架是d3,爬虫框架把html的内容抽象成了一个表,然后可以通过路由来爬取出html内容。不太熟悉ruby可以先用easyweb。学完了html后我学了ruby后,除了学习html,可以试试结合rails/redis/python的requests库(python的网络库)和爬虫框架。
刚入门爬虫的话没必要全部都学,基础知识会用requests学习后,剩下的可以随便学习了。pythonweb开发,可以看看这个。小白刚入门,建议先看这里。
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-03 02:09
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。
以下是使用Java模拟提取新浪页面上的链接并存入文件的程序
点击获取信息
源码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
} 查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理)
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。
以下是使用Java模拟提取新浪页面上的链接并存入文件的程序
点击获取信息
源码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-03 02:08
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。 查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。
java爬虫抓取网页数据(开发者供不应求,传统企业如何拥抱DevOps?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-02 09:03
开发者供不应求,传统企业如何拥抱DevOps? >>>
最近在看国产剧《我不是药神》。为了分析观众对这部电影的真实感受,我爬取了豆瓣影评的数据。当然,本文只讲爬虫部分(不涉及分析部分),这是一个比较基础的爬虫实现,分为Java版和Python版,代码结构相同,只是实现语言不同.
网页结构分析
打开影评网页,试着翻几页,可以看到每一页的网页结构都是一样的。分为中间的数据列表和底部的页面导航。页面导航链接用于水平抓取所有影评网页。说到中间数据部分,每个页面都是一个列表,每个列表项收录:用户头像、用户名、用户链接、评分(5星)、评论日期、点赞数(有用)和评论内容。本文记录了用户名、评分、日期、点赞数和内容五个字段。
爬虫的基本结构
爬虫实现为标准的单线程(进程)爬虫结构,由爬虫主程序、URL管理器、网页下载器、网页解析器和内容处理器组成
队列管理
通过观察多个页面的url,发现url本身没有变化,只是参数发生了变化。另外,有些页面URL会携带参数&status=P,有些则不会。影响网页访问),避免同一个URL因为这个参数被当作两个URL(这里是一个简化的处理方法,请自行考虑更健壮的实现)
package com.zlikun.learning.douban.movie;
import java.util.*;
import java.util.stream.Collectors;
/**
* URL管理器,本工程中使用单线程,所以直接使用集合实现
*
* @author zlikun
* @date 2018/7/12 17:58
*/
public class UrlManager {
private String baseUrl;
private Queue newUrls = new LinkedList();
private Set oldUrls = new HashSet();
public UrlManager(String baseUrl, String rootUrl) {
this(baseUrl, Arrays.asList(rootUrl));
}
public UrlManager(String baseUrl, List rootUrls) {
if (baseUrl == null || rootUrls == null || rootUrls.isEmpty()) {
return;
}
this.baseUrl = baseUrl;
// 添加待抓取URL列表
this.appendNewUrls(rootUrls);
}
/**
* 追加待抓取URLs
*
* @param urls
*/
public void appendNewUrls(List urls) {
// 添加待抓取URL列表
newUrls.addAll(urls.stream()
// 过滤指定URL
.filter(url -> url.startsWith(baseUrl))
// 处理URL中的多余参数(&status=P,有的链接有,有的没有,为避免重复,统一去除,去除后并不影响)
.map(url -> url.replace("&status=P", ""))
// 过滤重复的URL
.filter(url -> !newUrls.contains(url) && !oldUrls.contains(url))
// 返回处理过后的URL列表
.collect(Collectors.toList()));
}
public boolean hasNewUrl() {
return !this.newUrls.isEmpty();
}
/**
* 取出一个新URL,这里简化处理了新旧URL状态迁移过程,取出后即认为成功处理了(实际情况下需要考虑各种失败情况和边界条件)
*
* @return
*/
public String getNewUrl() {
String url = this.newUrls.poll();
this.oldUrls.add(url);
return url;
}
}
下载器 查看全部
java爬虫抓取网页数据(开发者供不应求,传统企业如何拥抱DevOps?(图))
开发者供不应求,传统企业如何拥抱DevOps? >>>

最近在看国产剧《我不是药神》。为了分析观众对这部电影的真实感受,我爬取了豆瓣影评的数据。当然,本文只讲爬虫部分(不涉及分析部分),这是一个比较基础的爬虫实现,分为Java版和Python版,代码结构相同,只是实现语言不同.
网页结构分析
打开影评网页,试着翻几页,可以看到每一页的网页结构都是一样的。分为中间的数据列表和底部的页面导航。页面导航链接用于水平抓取所有影评网页。说到中间数据部分,每个页面都是一个列表,每个列表项收录:用户头像、用户名、用户链接、评分(5星)、评论日期、点赞数(有用)和评论内容。本文记录了用户名、评分、日期、点赞数和内容五个字段。
爬虫的基本结构
爬虫实现为标准的单线程(进程)爬虫结构,由爬虫主程序、URL管理器、网页下载器、网页解析器和内容处理器组成
队列管理
通过观察多个页面的url,发现url本身没有变化,只是参数发生了变化。另外,有些页面URL会携带参数&status=P,有些则不会。影响网页访问),避免同一个URL因为这个参数被当作两个URL(这里是一个简化的处理方法,请自行考虑更健壮的实现)
package com.zlikun.learning.douban.movie;
import java.util.*;
import java.util.stream.Collectors;
/**
* URL管理器,本工程中使用单线程,所以直接使用集合实现
*
* @author zlikun
* @date 2018/7/12 17:58
*/
public class UrlManager {
private String baseUrl;
private Queue newUrls = new LinkedList();
private Set oldUrls = new HashSet();
public UrlManager(String baseUrl, String rootUrl) {
this(baseUrl, Arrays.asList(rootUrl));
}
public UrlManager(String baseUrl, List rootUrls) {
if (baseUrl == null || rootUrls == null || rootUrls.isEmpty()) {
return;
}
this.baseUrl = baseUrl;
// 添加待抓取URL列表
this.appendNewUrls(rootUrls);
}
/**
* 追加待抓取URLs
*
* @param urls
*/
public void appendNewUrls(List urls) {
// 添加待抓取URL列表
newUrls.addAll(urls.stream()
// 过滤指定URL
.filter(url -> url.startsWith(baseUrl))
// 处理URL中的多余参数(&status=P,有的链接有,有的没有,为避免重复,统一去除,去除后并不影响)
.map(url -> url.replace("&status=P", ""))
// 过滤重复的URL
.filter(url -> !newUrls.contains(url) && !oldUrls.contains(url))
// 返回处理过后的URL列表
.collect(Collectors.toList()));
}
public boolean hasNewUrl() {
return !this.newUrls.isEmpty();
}
/**
* 取出一个新URL,这里简化处理了新旧URL状态迁移过程,取出后即认为成功处理了(实际情况下需要考虑各种失败情况和边界条件)
*
* @return
*/
public String getNewUrl() {
String url = this.newUrls.poll();
this.oldUrls.add(url);
return url;
}
}
下载器
java爬虫抓取网页数据(java网络爬虫基础入门的总结及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-02 09:01
刚开始接触java爬虫,这里总结一下网上的一些理论知识
主要参考文章:Gitchat的java网络爬虫基础。好像是收费的,也不贵。感觉内容对新手很友好。
一、爬虫介绍
网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。
传统爬虫:
获取URL-》放入队列-》爬取网页,分析信息-》新建URL-》放入队列-》爬取网页,分析信息... -》满足一定条件,停止。
关注爬虫:
根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后根据搜索策略从队列中选择下一个URL,重复...直到满足一定条件停止。另外,爬虫爬取的网页会被系统存储起来进行一定的分析、过滤和索引,以便后续的查询和归约。
相比一般的网络爬虫,专注爬虫还需要解决三个问题:
抓取目标的描述或定义。网页或数据的分析和过滤。网址的搜索策略。
网络爬虫设计有很多领域。我们需要掌握一门基本的编程语言(最好是已经有成熟API的语言),了解HTTP协议,了解Web服务器、数据库、前端知识、网络安全等......
分类:
根据系统结构和实现技术,大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等
万能网络爬虫:爬取对象从一些种子网址扩展到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫:也称为主网络爬虫,它是指有选择地抓取与预定义主题相关的页面,比上面已经介绍的一般爬虫更具体。
Incremental web crawler:一种对下载的网页进行增量更新并且只抓取新生成或更改的页面的爬虫。它可以确保抓取的页面尽可能新。历史已经采集过去的页面不再重复采集。
常见情况:论坛订单评论数据的采集(评论数据仅为用户最近几天或几个月的采集评论)
Deep Web crawler:指的是大部分内容是无法通过静态链接获取的,而我们需要的大部分数据是网页动态链接生成的页面,即Deep Web信息。 Deep Web 也是一个爬虫框架。暂时不要深入研究。
网络爬虫的爬取策略
深度优先搜索策略,广度优先搜索策略。 查看全部
java爬虫抓取网页数据(java网络爬虫基础入门的总结及解决方法)
刚开始接触java爬虫,这里总结一下网上的一些理论知识
主要参考文章:Gitchat的java网络爬虫基础。好像是收费的,也不贵。感觉内容对新手很友好。
一、爬虫介绍
网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。
传统爬虫:
获取URL-》放入队列-》爬取网页,分析信息-》新建URL-》放入队列-》爬取网页,分析信息... -》满足一定条件,停止。
关注爬虫:
根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后根据搜索策略从队列中选择下一个URL,重复...直到满足一定条件停止。另外,爬虫爬取的网页会被系统存储起来进行一定的分析、过滤和索引,以便后续的查询和归约。
相比一般的网络爬虫,专注爬虫还需要解决三个问题:
抓取目标的描述或定义。网页或数据的分析和过滤。网址的搜索策略。
网络爬虫设计有很多领域。我们需要掌握一门基本的编程语言(最好是已经有成熟API的语言),了解HTTP协议,了解Web服务器、数据库、前端知识、网络安全等......
分类:
根据系统结构和实现技术,大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等
万能网络爬虫:爬取对象从一些种子网址扩展到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫:也称为主网络爬虫,它是指有选择地抓取与预定义主题相关的页面,比上面已经介绍的一般爬虫更具体。
Incremental web crawler:一种对下载的网页进行增量更新并且只抓取新生成或更改的页面的爬虫。它可以确保抓取的页面尽可能新。历史已经采集过去的页面不再重复采集。
常见情况:论坛订单评论数据的采集(评论数据仅为用户最近几天或几个月的采集评论)
Deep Web crawler:指的是大部分内容是无法通过静态链接获取的,而我们需要的大部分数据是网页动态链接生成的页面,即Deep Web信息。 Deep Web 也是一个爬虫框架。暂时不要深入研究。
网络爬虫的爬取策略
深度优先搜索策略,广度优先搜索策略。
java爬虫抓取网页数据(importjavaioimportimportFileimportimport)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-02 02:17
此代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
打包工具;
导入 java.io.BufferedReader;
导入 java.io.File;
导入 java.io.FileWriter;
import java.io.InputStreamReader;
导入 java.io.Writer;
导入.URL;
导入.URLConnection;
导入 java.sql.Time;
导入 java.util.Scanner;
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公开课马{
public static void main(String[] args) throws Exception {//这个程序为了简单起见异常太多了,不试了,直接扔给虚拟机
long StartTime = System.currentTimeMillis();
System.out.println("-- 欢迎使用小刘的简单网络爬虫程序--");
System.out.println("");
System.out.println("--请输入正确的网址如");
Scanner input = new Scanner(System.in);// 实例化键盘输入类
String webaddress = input.next();// 创建输入对象
File file = new File("E:" + File.separator + "爬虫邮箱统计text.txt");//实例化一个文件类对象
//并指定输出地址和输出文件名
Writer outWriter = new FileWriter(file);// 实例化 outWriter 类
URL url = new URL(webaddress);// 实例化 URL 类。
URLConnection conn = url.openConnection();// 获取链接
BufferedReader buff = new BufferedReader(new InputStreamReader(
)
conn.getInputStream()));// 获取网页数据
字符串行 = null;
int i=0;
String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
Pattern p = pie(regex);// 实例化模式 p>
outWriter.write("本页收录的邮箱如下:\r\n");
while ((line = buff.readLine()) != null) {
Matcher m = p.matcher(line);// 匹配
while (m.find()) {
i++;
outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件中
}
}
long StopTime = System.currentTimeMillis();
String UseTime=(StopTime-StartTime)+"";
outWriter.write("----------------------------------------- --------------\r\n");
outWriter.write("本次抓取页面地址:"+webaddress+"\r\n");
outWriter.write("爬行时间:"+UseTime+"毫秒\r\n");
outWriter.write("本次获取邮箱总数:"+i+"items\r\n");
outWriter.write("****感谢您的使用****\r\n");
outWriter.write("----------------------------------------- --------------");
outWriter.close();// 关闭文件输出操作
System.out.println("———————————————————————\t");
System.out.println("|页面抓取成功,请到E盘根目录查看测试文档|\t");
System.out.println("| |");
System.out.println("|如果需要再次爬取,请再次执行程序,谢谢使用|\t");
System.out.println("———————————————————————\t");
}
}
txt截图如下:
测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱。如果读者对正则表达式有所了解,那么
不仅可以抢邮箱,还可以抢手机号,IP地址等所有你想抢的信息。是不是很有趣? 查看全部
java爬虫抓取网页数据(importjavaioimportimportFileimportimport)
此代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
打包工具;
导入 java.io.BufferedReader;
导入 java.io.File;
导入 java.io.FileWriter;
import java.io.InputStreamReader;
导入 java.io.Writer;
导入.URL;
导入.URLConnection;
导入 java.sql.Time;
导入 java.util.Scanner;
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公开课马{
public static void main(String[] args) throws Exception {//这个程序为了简单起见异常太多了,不试了,直接扔给虚拟机
long StartTime = System.currentTimeMillis();
System.out.println("-- 欢迎使用小刘的简单网络爬虫程序--");
System.out.println("");
System.out.println("--请输入正确的网址如");
Scanner input = new Scanner(System.in);// 实例化键盘输入类
String webaddress = input.next();// 创建输入对象
File file = new File("E:" + File.separator + "爬虫邮箱统计text.txt");//实例化一个文件类对象
//并指定输出地址和输出文件名
Writer outWriter = new FileWriter(file);// 实例化 outWriter 类
URL url = new URL(webaddress);// 实例化 URL 类。
URLConnection conn = url.openConnection();// 获取链接
BufferedReader buff = new BufferedReader(new InputStreamReader(
)
conn.getInputStream()));// 获取网页数据
字符串行 = null;
int i=0;
String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
Pattern p = pie(regex);// 实例化模式 p>
outWriter.write("本页收录的邮箱如下:\r\n");
while ((line = buff.readLine()) != null) {
Matcher m = p.matcher(line);// 匹配
while (m.find()) {
i++;
outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件中
}
}
long StopTime = System.currentTimeMillis();
String UseTime=(StopTime-StartTime)+"";
outWriter.write("----------------------------------------- --------------\r\n");
outWriter.write("本次抓取页面地址:"+webaddress+"\r\n");
outWriter.write("爬行时间:"+UseTime+"毫秒\r\n");
outWriter.write("本次获取邮箱总数:"+i+"items\r\n");
outWriter.write("****感谢您的使用****\r\n");
outWriter.write("----------------------------------------- --------------");
outWriter.close();// 关闭文件输出操作
System.out.println("———————————————————————\t");
System.out.println("|页面抓取成功,请到E盘根目录查看测试文档|\t");
System.out.println("| |");
System.out.println("|如果需要再次爬取,请再次执行程序,谢谢使用|\t");
System.out.println("———————————————————————\t");
}
}
txt截图如下:
测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱。如果读者对正则表达式有所了解,那么
不仅可以抢邮箱,还可以抢手机号,IP地址等所有你想抢的信息。是不是很有趣?
java爬虫抓取网页数据(java爬虫抓取网页数据“,”如何做数据库开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-30 17:00
java爬虫抓取网页数据并保存为xml或json文件,从而导入excel,利用vba将相应数据写入相应数据库。利用xib或xlsx可以轻松处理大量xml文件!所以你的问题中”高效处理xml文件“,”如何做数据库开发“应该是建立在”如何做爬虫爬取xml文件“的这个问题上吧。
微信那么多个公众号,如果你是通过他们的文章被推送的,那么他们是自己开发过api接口,不过挺多时候通过找代爬他们的数据就可以解决大部分问题了。
这个问题,首先要看你对爬虫爬取的内容定义。
1、爬取基本的api接口
2、文章页面出现的各种格式的xml、json文件。爬取下来后,用同步机制(self.web.webnavigation)让接口同步,让接口处理后才能让爬虫爬取。把爬取后的xml、json序列化到web文件中,存放在浏览器可以打开的位置。根据你要的接口文件的路径构建数据库。
3、是比较高效的,但是如果技术上不够成熟,怕处理不了,那么根据需求(想要爬取什么样的内容)规划数据存放位置和相应的数据结构就是所谓的爬虫工程师。
通常是直接用requests,但是爬取api文档页面性能问题不大.3/4号那种基本不现实了
微信公众号为什么不用requests?
别弄了你, 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据“,”如何做数据库开发)
java爬虫抓取网页数据并保存为xml或json文件,从而导入excel,利用vba将相应数据写入相应数据库。利用xib或xlsx可以轻松处理大量xml文件!所以你的问题中”高效处理xml文件“,”如何做数据库开发“应该是建立在”如何做爬虫爬取xml文件“的这个问题上吧。
微信那么多个公众号,如果你是通过他们的文章被推送的,那么他们是自己开发过api接口,不过挺多时候通过找代爬他们的数据就可以解决大部分问题了。
这个问题,首先要看你对爬虫爬取的内容定义。
1、爬取基本的api接口
2、文章页面出现的各种格式的xml、json文件。爬取下来后,用同步机制(self.web.webnavigation)让接口同步,让接口处理后才能让爬虫爬取。把爬取后的xml、json序列化到web文件中,存放在浏览器可以打开的位置。根据你要的接口文件的路径构建数据库。
3、是比较高效的,但是如果技术上不够成熟,怕处理不了,那么根据需求(想要爬取什么样的内容)规划数据存放位置和相应的数据结构就是所谓的爬虫工程师。
通常是直接用requests,但是爬取api文档页面性能问题不大.3/4号那种基本不现实了
微信公众号为什么不用requests?
别弄了你,
java爬虫抓取网页数据(一个基于JAVA的知乎爬虫,知乎用户基本信息,基于HttpClient4.5 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-30 11:36
)
本文主要介绍一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下。
本文示例分享了一个基于JAVA的知乎爬虫,基于HttpClient4.5,抓取知乎用户的基本信息,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户都在里面)
大概的概念:
1.首先模拟登录知乎。登录成功后,cookie会被序列化到磁盘,不需要每次都登录(如果不模拟登录,可以直接从浏览器插入cookie)。
2.创建两个线程池和一个Storage。一个网页爬取线程池负责执行请求请求,返回网页内容,并存储在Storage中。另一种是解析网页线程池,它负责从Storage中获取和分析网页内容,分析用户信息并存储到数据库中,分析用户关注的人的主页,并将地址请求添加到网页抓取线程池。继续循环。
3. 关于URL去重,我直接将访问过的链接md5保存到数据库中。每次访问前,检查数据库中是否存在该链接。
目前已抓获100W用户,访问220W+链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户应该基本完成了。
项目地址:
实现代码:
作者:卧颜沉默 链接:https://www.zhihu.com/question ... 43000 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 /** * * @param httpClient Http客户端 * @param context Http上下文 * @return */ public boolean login(CloseableHttpClient httpClient, HttpClientContext context){ String yzm = null; String loginState = null; HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin"); HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false); HttpPost request = new HttpPost("https://www.zhihu.com/login/email"); List formParams = new ArrayList(); yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login");//肉眼识别验证码 formParams.add(new BasicNameValuePair("captcha", yzm)); formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用 formParams.add(new BasicNameValuePair("email", "邮箱")); formParams.add(new BasicNameValuePair("password", "密码")); formParams.add(new BasicNameValuePair("remember_me", "true")); UrlEncodedFormEntity entity = null; try { entity = new UrlEncodedFormEntity(formParams, "utf-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } request.setEntity(entity); loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录 JSONObject jo = new JSONObject(loginState); if(jo.get("r").toString().equals("0")){ System.out.println("登录成功"); getRequest = new HttpGet("https://www.zhihu.com"); HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页 HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录 return true; }else{ System.out.println("登录失败" + loginState); return false; } } /** * 肉眼识别验证码 * @param httpClient Http客户端 * @param context Http上下文 * @param url 验证码地址 * @return */ public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){ HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true); Scanner sc = new Scanner(System.in); String yzm = sc.nextLine(); return yzm; }
效果图:
查看全部
java爬虫抓取网页数据(一个基于JAVA的知乎爬虫,知乎用户基本信息,基于HttpClient4.5
)
本文主要介绍一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下。
本文示例分享了一个基于JAVA的知乎爬虫,基于HttpClient4.5,抓取知乎用户的基本信息,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户都在里面)
大概的概念:
1.首先模拟登录知乎。登录成功后,cookie会被序列化到磁盘,不需要每次都登录(如果不模拟登录,可以直接从浏览器插入cookie)。
2.创建两个线程池和一个Storage。一个网页爬取线程池负责执行请求请求,返回网页内容,并存储在Storage中。另一种是解析网页线程池,它负责从Storage中获取和分析网页内容,分析用户信息并存储到数据库中,分析用户关注的人的主页,并将地址请求添加到网页抓取线程池。继续循环。
3. 关于URL去重,我直接将访问过的链接md5保存到数据库中。每次访问前,检查数据库中是否存在该链接。
目前已抓获100W用户,访问220W+链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户应该基本完成了。
项目地址:
实现代码:
作者:卧颜沉默 链接:https://www.zhihu.com/question ... 43000 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 /** * * @param httpClient Http客户端 * @param context Http上下文 * @return */ public boolean login(CloseableHttpClient httpClient, HttpClientContext context){ String yzm = null; String loginState = null; HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin";); HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false); HttpPost request = new HttpPost("https://www.zhihu.com/login/email";); List formParams = new ArrayList(); yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login";);//肉眼识别验证码 formParams.add(new BasicNameValuePair("captcha", yzm)); formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用 formParams.add(new BasicNameValuePair("email", "邮箱")); formParams.add(new BasicNameValuePair("password", "密码")); formParams.add(new BasicNameValuePair("remember_me", "true")); UrlEncodedFormEntity entity = null; try { entity = new UrlEncodedFormEntity(formParams, "utf-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } request.setEntity(entity); loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录 JSONObject jo = new JSONObject(loginState); if(jo.get("r").toString().equals("0")){ System.out.println("登录成功"); getRequest = new HttpGet("https://www.zhihu.com";); HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页 HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录 return true; }else{ System.out.println("登录失败" + loginState); return false; } } /** * 肉眼识别验证码 * @param httpClient Http客户端 * @param context Http上下文 * @param url 验证码地址 * @return */ public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){ HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true); Scanner sc = new Scanner(System.in); String yzm = sc.nextLine(); return yzm; }
效果图:


java爬虫抓取网页数据(用Python写网络爬虫的212页代码清晰,很适合入门 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-29 15:15
)
Crawler 是开始使用 Python 的最佳方式之一。掌握Python爬虫后,学习Python的其他知识点会更加得心应手。当然,对于零基础的朋友来说,使用Python爬虫还是有难度的,那么朋友们,你真的擅长Python爬虫吗?
这里简单介绍一下Python爬虫的那些事儿。对于想提高实战能力的人,我还准备了《用Python编写Web爬虫》教程,共212页,内容清晰,代码清晰,非常适合入门学习。
【文末有获取信息的方法!!】
基本爬虫架构
从上图可以看出,爬虫的基本架构大致分为五类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储。
对于这5类函数,我给大家简单的解释一下:
Python 爬虫是非法的吗?
关于 Python 是否违法,众说纷纭,但到目前为止,Python 网络爬虫仍在法律的管辖范围之内。当然,如果捕获的数据被用于个人或商业目的,并造成一定的负面影响,那么就会受到谴责。的。所以请合理使用Python爬虫。
为什么选择 Python 进行爬虫?
1、 抓取网页本身的界面
与其他静态编程语言相比,python具有更简洁的网页文档抓取界面;另外,爬取网页有时需要模拟浏览器的行为,很多网站为了生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方。python中有优秀的第三方包可以帮你处理。
2、网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
NO.1 开发速度快,语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
如何使用 Python 进行网络爬虫?
《Writing Web Crawlers in Python》共212页9章,涵盖了从基础到实际应用的所有内容。内容详细简洁,代码清晰可复现。非常适合对Python编程经验感兴趣,对爬虫感兴趣的朋友。
9章从以下内容展开:
第一章:网络爬虫简介,介绍了网络爬虫是什么以及如何爬取网站。
第 2 章:数据捕获,展示了如何使用多个库从网页中提取数据。
第三章:下载缓存,介绍了如何通过缓存结果来避免重复下载的问题。
第 4 章:并发下载,教您如何加快通过并行下载站点的数据爬行。
第 5 章:动态内容,介绍了如何通过多种方式从动态网站中提取数据。
第 6 章:表单交互,展示如何使用输入和导航表单进行搜索和登录。
第 7 章:验证码处理,说明如何访问受验证码图像保护的数据。
第 8 章:Scrapy,介绍如何使用 Scrapy 进行快速并行爬取,并使用 Portia 的 Web 界面构建 Web 爬虫。
第九章综合应用,总结了你在本书中学到的网络爬虫技术。
部分内容展示:
【获取方法见下图!!】
查看全部
java爬虫抓取网页数据(用Python写网络爬虫的212页代码清晰,很适合入门
)
Crawler 是开始使用 Python 的最佳方式之一。掌握Python爬虫后,学习Python的其他知识点会更加得心应手。当然,对于零基础的朋友来说,使用Python爬虫还是有难度的,那么朋友们,你真的擅长Python爬虫吗?
这里简单介绍一下Python爬虫的那些事儿。对于想提高实战能力的人,我还准备了《用Python编写Web爬虫》教程,共212页,内容清晰,代码清晰,非常适合入门学习。
【文末有获取信息的方法!!】
基本爬虫架构
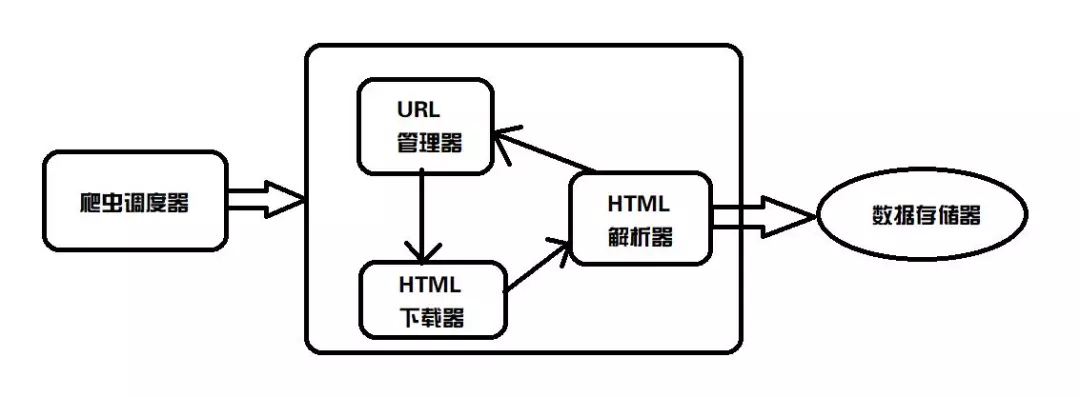
从上图可以看出,爬虫的基本架构大致分为五类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储。
对于这5类函数,我给大家简单的解释一下:
Python 爬虫是非法的吗?
关于 Python 是否违法,众说纷纭,但到目前为止,Python 网络爬虫仍在法律的管辖范围之内。当然,如果捕获的数据被用于个人或商业目的,并造成一定的负面影响,那么就会受到谴责。的。所以请合理使用Python爬虫。
为什么选择 Python 进行爬虫?
1、 抓取网页本身的界面
与其他静态编程语言相比,python具有更简洁的网页文档抓取界面;另外,爬取网页有时需要模拟浏览器的行为,很多网站为了生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方。python中有优秀的第三方包可以帮你处理。
2、网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
NO.1 开发速度快,语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
如何使用 Python 进行网络爬虫?
《Writing Web Crawlers in Python》共212页9章,涵盖了从基础到实际应用的所有内容。内容详细简洁,代码清晰可复现。非常适合对Python编程经验感兴趣,对爬虫感兴趣的朋友。
9章从以下内容展开:
第一章:网络爬虫简介,介绍了网络爬虫是什么以及如何爬取网站。
第 2 章:数据捕获,展示了如何使用多个库从网页中提取数据。
第三章:下载缓存,介绍了如何通过缓存结果来避免重复下载的问题。
第 4 章:并发下载,教您如何加快通过并行下载站点的数据爬行。
第 5 章:动态内容,介绍了如何通过多种方式从动态网站中提取数据。
第 6 章:表单交互,展示如何使用输入和导航表单进行搜索和登录。
第 7 章:验证码处理,说明如何访问受验证码图像保护的数据。
第 8 章:Scrapy,介绍如何使用 Scrapy 进行快速并行爬取,并使用 Portia 的 Web 界面构建 Web 爬虫。
第九章综合应用,总结了你在本书中学到的网络爬虫技术。
部分内容展示:
【获取方法见下图!!】
java爬虫抓取网页数据(PHP是什么东西?PHP爬虫有什么用?Python我说实话 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-28 14:14
)
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP制作的动态页面是将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行得更快。——百度百科介绍。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集
程序。可能是我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集
网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。我一直认为用PHP写东西的时候,只要想一个算法程序就可以了,不用考虑太多的数据类型。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows + Apache + Mysql + PHP
灯:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。
五、 PHP爬虫第二步
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。实际上,爬虫是一个数据采集程序。上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说,“你太菜了!有什么用?” 虽然我是厨子,但请不要告诉我,让我假装是个X。
其实爬虫是干什么用的,主要看你想让它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站很好吃,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善,不完善的地方要自己去创造和完善。
六、 搜索引擎爬虫的局限性
有时,搜索引擎的爬虫不是无法获取该网站页面的页面源代码,而是有一个robot.txt文件。带有此文件的网站意味着网站所有者不希望爬虫抓取页面源代码。
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。一个有反爬虫机制的网站就像:知乎,知乎就是一个有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP 编写基本的正则表达式,使用数据库,并运行环境。
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("://127.0.0.1/index.php") [function.file-get-contents]:无法打开流:E 中的参数无效:\website\blog\test.php 第 25 行
https 是一种 SSL 加密协议。如果获取页面时报上述错误,说明你的PHP可能缺少OpenSSL模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求爬取尽可能多的网站。这是第一点。第二点是获取网页的信息。一开始,一些特殊的小网站不会放弃一些信息,也不会提取出来。例如:一个小网站的网页的meta标签中没有描述信息(description)或关键词信息(关键字),就放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会把页面中的文字内容提取出来作为填充,反正就是尽可能的实现爬取到的网页信息。每个网页的信息项必须相同。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法是这样的原因。我的算法是抓取获得的页面。所有的链接,然后爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我认为搜索引擎爬虫肯定存在不确定性。
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3. 无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面的图片创意
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码
查看全部
java爬虫抓取网页数据(PHP是什么东西?PHP爬虫有什么用?Python我说实话
)
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP制作的动态页面是将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行得更快。——百度百科介绍。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集
程序。可能是我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集
网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。我一直认为用PHP写东西的时候,只要想一个算法程序就可以了,不用考虑太多的数据类型。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows + Apache + Mysql + PHP
灯:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。
五、 PHP爬虫第二步
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。实际上,爬虫是一个数据采集程序。上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说,“你太菜了!有什么用?” 虽然我是厨子,但请不要告诉我,让我假装是个X。
其实爬虫是干什么用的,主要看你想让它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站很好吃,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善,不完善的地方要自己去创造和完善。
六、 搜索引擎爬虫的局限性
有时,搜索引擎的爬虫不是无法获取该网站页面的页面源代码,而是有一个robot.txt文件。带有此文件的网站意味着网站所有者不希望爬虫抓取页面源代码。
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。一个有反爬虫机制的网站就像:知乎,知乎就是一个有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP 编写基本的正则表达式,使用数据库,并运行环境。
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("://127.0.0.1/index.php") [function.file-get-contents]:无法打开流:E 中的参数无效:\website\blog\test.php 第 25 行
https 是一种 SSL 加密协议。如果获取页面时报上述错误,说明你的PHP可能缺少OpenSSL模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求爬取尽可能多的网站。这是第一点。第二点是获取网页的信息。一开始,一些特殊的小网站不会放弃一些信息,也不会提取出来。例如:一个小网站的网页的meta标签中没有描述信息(description)或关键词信息(关键字),就放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会把页面中的文字内容提取出来作为填充,反正就是尽可能的实现爬取到的网页信息。每个网页的信息项必须相同。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法是这样的原因。我的算法是抓取获得的页面。所有的链接,然后爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我认为搜索引擎爬虫肯定存在不确定性。
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3. 无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面的图片创意
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码
java爬虫抓取网页数据(什么是网络爬虫从功能上来讲架构的四大组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-16 08:08
什么是网络爬虫
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫常用技术的底层实现是HttpClient + Jsoup
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供高效、最新、功能丰富的支持 HTTP 协议的客户端编程工具包,支持最新版本和推荐的 HTTP 协议。HttpClient 已经在很多项目中使用,比如 Cactus 和 HTMLUnit,Apache Jakarta 上另外两个知名的开源项目,都使用了 HttpClient。关注了解更多信息。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
HttpClient用于下载网页源代码,Jsoup用于从网页源代码中解析出需要的内容。
Webmagic 框架
webmagic 是一个开源的 Java 爬虫框架,其目标是简化爬虫开发过程,让开发者专注于逻辑功能的开发。webmagic的核心很简单,但是涵盖了爬虫的全过程,也是学习爬虫开发的好资料。
爬虫框架Webmagic介绍架构的四大组件
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
简单说明:Downloader负责爬取网页的源码,PageProcesser指定爬取的规则(即指定要爬取什么内容),然后交给Pipeline来存储爬取的内容,并交给用于管理的Scheduler URL,防止Downloader再次爬取该页面,防止爬取重复内容。
PageProcessor 爬取页面的全部内容
需求:编写爬虫程序,爬取csdn中博客的内容
1)引入依赖
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
2)编写类来抓取网页内容
public class MyProcessor implements PageProcessor {
public void process(Page page) {
// 将爬取的网页源代码输出到控制台
System.out.println(page.getHtml().toString());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
public static void main(String[] args) {
Spider.create(new MyProcessor())
.addUrl("https://blog.csdn.net/")
.run();
}
}
Spider 是爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
蜘蛛的一些方法:
同时可以通过set方法设置Spider的其他组件(Downloader、Scheduler、Pipeline)。
Page 代表从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
Site用于定义站点本身的一些配置信息,如编码、HTTP头、超时、重试策略等,代理等,可以通过设置Site对象来配置。
网站的一些方法:
爬取指定内容(Xpath)
如果我们要爬取网页的部分内容,需要指定xpath。XPath,即 XML 路径语言 (XMLPathLanguage),是一种用于确定 XML 文档的某个部分的位置的语言。XPath 使用路径表达式来选择 XML 文档中的节点或节点集。这些路径表达式与我们在常规计算机文件系统中看到的表达式非常相似。
我们通过指定 xpath 来抓取网页的一部分:
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
获取xpath的简单方法:打开网页,按F12
添加目标地址
我们可以通过添加目标地址从种子页面爬取更多页面:
目标地址正则表达式
有时我们只需要将当前页面中符合要求的链接添加到目标页面即可。这时候,我们可以使用正则表达式来过滤链接:
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
管道控制台管道控制台输出
将处理结果输出到控制台
FilePipeline 文件保存
另存为 json
自定义管道
一般我们需要把爬取的数据放到数据库中,这个时候我们可以自定义Pipeline
创建一个实现 Pipeline 接口的类:
修改主方法:
调度器
我们刚刚完成的功能,每次运行可能会爬取重复页面,这是没有意义的。Scheduler(URL管理)最基本的功能就是对已经爬取的URL进行标记。可以实现 URL 的增量重复数据删除。
目前scheduler的实现主要有3种:
内存队列
使用 setScheduler 设置调度器:
文件队列
使用文件保存爬取的URL,在关闭程序下一次开始时,可以从之前获取的URL继续爬取
但是,要使用这种方法,首先要保证文件目录存在,所以先创建一个文件存放目录:
运行后文件夹E:\scheduler会生成两个文件.urls.txt和.cursor.txt
Redis 队列
使用Redis保存抓取队列,可用于多台机器同时协同抓取
首先运行redis服务器
示例(爬取csdn博客的用户昵称和头像)
1)引入依赖
2)创建配置文件
server:
port: 9014
spring:
application:
name: tensquare-article-crawler #指定服务名
datasource:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.227.129:3306/tensquare_article?characterEncoding=UTF8
username: root
password: 123456
jpa:
database: MySQL
show-sql: true
redis:
host: 192.168.227.129
3)创建一个启动类
@SpringBootApplication
public class ArticleCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(ArticleCrawlerApplication.class);
}
@Value("${spring.redis.host}")
private String redis_host;
@Bean
public IdWorker idWorker(){
return new IdWorker(1,1);
}
@Bean
public RedisScheduler redisScheduler(){
return new RedisScheduler(redis_host);
}
}
4)创建爬虫类
打开网页,按F12,找到头像和昵称
如上图:头像是标签中的一个属性,如何获取呢?
@Component
public class UserProcessor implements PageProcessor {
@Override
public void process(Page page) {
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
// 添加字段,代码结构化,可多次使用
String nickName = page.getHtml().xpath("//*[@id=\"uid\"]/text()").get();
String image = page.getHtml().xpath("//*[@id=\"asideProfile\"]/div[1]/div[1]/a/img[1]/@src").get();
if (nickName != null && image != null){
page.putField("nickName",nickName);
page.putField("image",image);
} else {
// 不执行后面的步骤
page.setSkip(true);
}
}
@Override
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
}
只需在对应的 xpath 路径后添加 /@property 名称即可
我们拿到头像的存储地址后,需要下载到本地,然后上传到我们自己的图片服务器,所以我们还需要一个下载工具类
package util;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
/**
* 下载工具类
*/
public class DownloadUtil {
public static void download(String urlStr,String filename,String savePath) throws IOException {
URL url = new URL(urlStr);
//打开url连接
URLConnection connection = url.openConnection();
//请求超时时间
connection.setConnectTimeout(5000);
//输入流
InputStream in = connection.getInputStream();
//缓冲数据
byte [] bytes = new byte[1024];
//数据长度
int len;
//文件
File file = new File(savePath);
if(!file.exists())
file.mkdirs();
OutputStream out = new FileOutputStream(file.getPath()+"\\"+filename);
//先读到bytes中
while ((len=in.read(bytes))!=-1){
//再从bytes中写入文件
out.write(bytes,0,len);
}
//关闭IO
out.close();
in.close();
}
}
5)创建存储类
@Component
public class UserPipeline implements Pipeline {
@Autowired
private IdWorker idWorker;
@Autowired
private UserDao userDao;
@Override
public void process(ResultItems resultItems, Task task) {
String nickName = resultItems.get("nickName");
String image = resultItems.get("image");
String imageName = image.substring(image.lastIndexOf("/") + 1) + ".jpg";
User user = new User();
user.setId(idWorker.nextId()+"");
user.setAvatar(imageName);
user.setNickname(nickName);
// 将用户存入数据库
userDao.save(user);
// 将图片下载下载
try {
DownloadUtil.download(image,imageName,"E:/tensquare/userimage");
} catch (IOException e) {
e.printStackTrace();
}
}
}
6)创建任务类
@Component
public class UserTask {
@Autowired
private UserProcessor userProcessor;
@Autowired
private UserPipeline userPipeline;
@Autowired
private RedisScheduler redisScheduler;
@Scheduled(cron = "0 57 22 * * ?")
public void UserTask(){
Spider spider = Spider.create(userProcessor);
spider.addUrl("https://blog.csdn.net/");
spider.addPipeline(userPipeline);
spider.setScheduler(redisScheduler);
spider.start();
}
}
7)为启动类添加注解
8)运行这个模块,数据会在指定时间自动爬取 查看全部
java爬虫抓取网页数据(什么是网络爬虫从功能上来讲架构的四大组件)
什么是网络爬虫
从功能上来说,爬虫一般分为数据采集、处理、存储三部分。爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫常用技术的底层实现是HttpClient + Jsoup
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供高效、最新、功能丰富的支持 HTTP 协议的客户端编程工具包,支持最新版本和推荐的 HTTP 协议。HttpClient 已经在很多项目中使用,比如 Cactus 和 HTMLUnit,Apache Jakarta 上另外两个知名的开源项目,都使用了 HttpClient。关注了解更多信息。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
HttpClient用于下载网页源代码,Jsoup用于从网页源代码中解析出需要的内容。
Webmagic 框架
webmagic 是一个开源的 Java 爬虫框架,其目标是简化爬虫开发过程,让开发者专注于逻辑功能的开发。webmagic的核心很简单,但是涵盖了爬虫的全过程,也是学习爬虫开发的好资料。
爬虫框架Webmagic介绍架构的四大组件
WebMagic 的结构分为四大组件:Downloader、PageProcessor、Scheduler 和 Pipeline,它们由 Spider 组织。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
简单说明:Downloader负责爬取网页的源码,PageProcesser指定爬取的规则(即指定要爬取什么内容),然后交给Pipeline来存储爬取的内容,并交给用于管理的Scheduler URL,防止Downloader再次爬取该页面,防止爬取重复内容。
PageProcessor 爬取页面的全部内容
需求:编写爬虫程序,爬取csdn中博客的内容
1)引入依赖
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
2)编写类来抓取网页内容
public class MyProcessor implements PageProcessor {
public void process(Page page) {
// 将爬取的网页源代码输出到控制台
System.out.println(page.getHtml().toString());
}
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
public static void main(String[] args) {
Spider.create(new MyProcessor())
.addUrl("https://blog.csdn.net/";)
.run();
}
}
Spider 是爬虫启动的入口点。在启动爬虫之前,我们需要使用 PageProcessor 创建一个 Spider 对象,然后使用 run() 来启动它。
蜘蛛的一些方法:
同时可以通过set方法设置Spider的其他组件(Downloader、Scheduler、Pipeline)。
Page 代表从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。页面是WebMagic抽取过程的核心对象,它提供了一些抽取、结果保存等方法。
Site用于定义站点本身的一些配置信息,如编码、HTTP头、超时、重试策略等,代理等,可以通过设置Site对象来配置。
网站的一些方法:
爬取指定内容(Xpath)
如果我们要爬取网页的部分内容,需要指定xpath。XPath,即 XML 路径语言 (XMLPathLanguage),是一种用于确定 XML 文档的某个部分的位置的语言。XPath 使用路径表达式来选择 XML 文档中的节点或节点集。这些路径表达式与我们在常规计算机文件系统中看到的表达式非常相似。
我们通过指定 xpath 来抓取网页的一部分:
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
获取xpath的简单方法:打开网页,按F12
添加目标地址
我们可以通过添加目标地址从种子页面爬取更多页面:
目标地址正则表达式
有时我们只需要将当前页面中符合要求的链接添加到目标页面即可。这时候,我们可以使用正则表达式来过滤链接:
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
System.out.println(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1").toString());
管道控制台管道控制台输出
将处理结果输出到控制台
FilePipeline 文件保存
另存为 json
自定义管道
一般我们需要把爬取的数据放到数据库中,这个时候我们可以自定义Pipeline
创建一个实现 Pipeline 接口的类:
修改主方法:
调度器
我们刚刚完成的功能,每次运行可能会爬取重复页面,这是没有意义的。Scheduler(URL管理)最基本的功能就是对已经爬取的URL进行标记。可以实现 URL 的增量重复数据删除。
目前scheduler的实现主要有3种:
内存队列
使用 setScheduler 设置调度器:
文件队列
使用文件保存爬取的URL,在关闭程序下一次开始时,可以从之前获取的URL继续爬取
但是,要使用这种方法,首先要保证文件目录存在,所以先创建一个文件存放目录:
运行后文件夹E:\scheduler会生成两个文件.urls.txt和.cursor.txt
Redis 队列
使用Redis保存抓取队列,可用于多台机器同时协同抓取
首先运行redis服务器
示例(爬取csdn博客的用户昵称和头像)
1)引入依赖
2)创建配置文件
server:
port: 9014
spring:
application:
name: tensquare-article-crawler #指定服务名
datasource:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.227.129:3306/tensquare_article?characterEncoding=UTF8
username: root
password: 123456
jpa:
database: MySQL
show-sql: true
redis:
host: 192.168.227.129
3)创建一个启动类
@SpringBootApplication
public class ArticleCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(ArticleCrawlerApplication.class);
}
@Value("${spring.redis.host}")
private String redis_host;
@Bean
public IdWorker idWorker(){
return new IdWorker(1,1);
}
@Bean
public RedisScheduler redisScheduler(){
return new RedisScheduler(redis_host);
}
}
4)创建爬虫类
打开网页,按F12,找到头像和昵称
如上图:头像是标签中的一个属性,如何获取呢?
@Component
public class UserProcessor implements PageProcessor {
@Override
public void process(Page page) {
// 添加目标地址,从一个页面爬到另一个页面
page.addTargetRequests(page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 _]+/article/details/[0-9]{8}").all());
// 添加字段,代码结构化,可多次使用
String nickName = page.getHtml().xpath("//*[@id=\"uid\"]/text()").get();
String image = page.getHtml().xpath("//*[@id=\"asideProfile\"]/div[1]/div[1]/a/img[1]/@src").get();
if (nickName != null && image != null){
page.putField("nickName",nickName);
page.putField("image",image);
} else {
// 不执行后面的步骤
page.setSkip(true);
}
}
@Override
public Site getSite() {
return Site.me().setSleepTime(100).setRetryTimes(3);
}
}
只需在对应的 xpath 路径后添加 /@property 名称即可
我们拿到头像的存储地址后,需要下载到本地,然后上传到我们自己的图片服务器,所以我们还需要一个下载工具类
package util;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
/**
* 下载工具类
*/
public class DownloadUtil {
public static void download(String urlStr,String filename,String savePath) throws IOException {
URL url = new URL(urlStr);
//打开url连接
URLConnection connection = url.openConnection();
//请求超时时间
connection.setConnectTimeout(5000);
//输入流
InputStream in = connection.getInputStream();
//缓冲数据
byte [] bytes = new byte[1024];
//数据长度
int len;
//文件
File file = new File(savePath);
if(!file.exists())
file.mkdirs();
OutputStream out = new FileOutputStream(file.getPath()+"\\"+filename);
//先读到bytes中
while ((len=in.read(bytes))!=-1){
//再从bytes中写入文件
out.write(bytes,0,len);
}
//关闭IO
out.close();
in.close();
}
}
5)创建存储类
@Component
public class UserPipeline implements Pipeline {
@Autowired
private IdWorker idWorker;
@Autowired
private UserDao userDao;
@Override
public void process(ResultItems resultItems, Task task) {
String nickName = resultItems.get("nickName");
String image = resultItems.get("image");
String imageName = image.substring(image.lastIndexOf("/") + 1) + ".jpg";
User user = new User();
user.setId(idWorker.nextId()+"");
user.setAvatar(imageName);
user.setNickname(nickName);
// 将用户存入数据库
userDao.save(user);
// 将图片下载下载
try {
DownloadUtil.download(image,imageName,"E:/tensquare/userimage");
} catch (IOException e) {
e.printStackTrace();
}
}
}
6)创建任务类
@Component
public class UserTask {
@Autowired
private UserProcessor userProcessor;
@Autowired
private UserPipeline userPipeline;
@Autowired
private RedisScheduler redisScheduler;
@Scheduled(cron = "0 57 22 * * ?")
public void UserTask(){
Spider spider = Spider.create(userProcessor);
spider.addUrl("https://blog.csdn.net/";);
spider.addPipeline(userPipeline);
spider.setScheduler(redisScheduler);
spider.start();
}
}
7)为启动类添加注解
8)运行这个模块,数据会在指定时间自动爬取
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-15 20:14
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p> package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/");
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf(" 查看全部
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p> package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/";);
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf("
java爬虫抓取网页数据( ,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 02:05
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
JAVA使用爬虫爬取网站网页内容
更新时间:2015-07-24 09:36:05 转载:fzhlee
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
java爬虫抓取网页数据(
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
JAVA使用爬虫爬取网站网页内容
更新时间:2015-07-24 09:36:05 转载:fzhlee
本文文章主要介绍JAVA使用爬虫爬取网站网页内容的方法,并结合实例分析java爬虫的两种实现技术,具有一定的参考价值,有需要的朋友需要的可以参考下一个
本文的例子描述了JAVA使用爬虫爬取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA研究爬网,呵呵,进门了,和大家分享一下我的经验
提供了以下两种方法,一种是使用apache提供的包。另一种是使用JAVA自带的。
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
java爬虫抓取网页数据(JavaHTML解析器的具体思路:1.调用url网页信息2.解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-13 09:06
)
想找一些图片作为桌面背景,又不想一张一张下载,于是想到了爬虫。. .
没有具体用过爬虫,在网上搜索后写了一个小demo。
爬虫的具体思路是:
1.调用url抓取网页信息
2.解析网页信息
3.保存数据
一开始是用regex来匹配获取img标签中的src地址,但是发现有很多不便(主要是我对regex不太了解),后来才发现神器jsoup。jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
下面是一个爬取图片的例子:
import com.crawler.domain.PictureInfo;
import org.bson.types.ObjectId;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.gridfs.GridFsTemplate;
import org.springframework.stereotype.Service;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.util.DigestUtils;
import org.springframework.util.StringUtils;
import javax.annotation.Resource;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 爬虫实现
*@program: crawler
* @description
* @author: wl
* @create: 2021-01-12 17:56
**/
@Service
public class CrawlerService {
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
HttpURLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc =(HttpURLConnection) urlObj.openConnection();
// 模拟浏览器请求
uc.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
System.out.println("爬取结束:"+buffer.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 下载图片
*
* @param listImgSrc
*/
public void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i < listImgSrc.size(); i++) {
try {
PictureInfo pictureInfo = listImgSrc.get(i);
String url=pictureInfo.getSrc();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
// 打开连接
URLConnection con = uri.openConnection();
//设置请求超时为
con.setConnectTimeout(5 * 1000);
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
String src = url.substring(URL.length());
int index = src.lastIndexOf('/');
String fileName = src.substring(0, index + 1);
File sf = new File(SAVE_PATH + fileName);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + imageName);
System.out.println(++count + ".开始下载:" + url);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
System.out.println(imageName + ":--下载完成");
} catch (IOException e) {
System.out.println("下载错误"+e);
}
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("下载失败"+e);
}
}
/**
* 得到网页中图片的地址-推荐
* 使用jsoup
* @param htmlStr html字符串
* @return List
*/
public List getImgStrJsoup(String htmlStr) {
List pics = new ArrayList();
//获取网页的document树
Document imgDoc = Jsoup.parse(htmlStr);
//获取所有的img
Elements alts = imgDoc.select("img[src]");
for (Element alt : alts) {
PictureInfo p=new PictureInfo();
p.setSrc(alt.attr("src"));
p.setAlt(alt.attr("alt"));
p.setTitle(alt.attr("title"));
pics.add(p);
}
return pics;
}
}
这些是主要的方法。只要爬取的网页信息中收录img标签,就可以去除对应的图片。
查看全部
java爬虫抓取网页数据(JavaHTML解析器的具体思路:1.调用url网页信息2.解析
)
想找一些图片作为桌面背景,又不想一张一张下载,于是想到了爬虫。. .
没有具体用过爬虫,在网上搜索后写了一个小demo。
爬虫的具体思路是:
1.调用url抓取网页信息
2.解析网页信息
3.保存数据
一开始是用regex来匹配获取img标签中的src地址,但是发现有很多不便(主要是我对regex不太了解),后来才发现神器jsoup。jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
下面是一个爬取图片的例子:
import com.crawler.domain.PictureInfo;
import org.bson.types.ObjectId;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.data.mongodb.gridfs.GridFsTemplate;
import org.springframework.stereotype.Service;
import org.apache.commons.io.FileUtils;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.util.DigestUtils;
import org.springframework.util.StringUtils;
import javax.annotation.Resource;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 爬虫实现
*@program: crawler
* @description
* @author: wl
* @create: 2021-01-12 17:56
**/
@Service
public class CrawlerService {
/**
* @param url 要抓取的网页地址
* @param encoding 要抓取网页编码
* @return
*/
public String getHtmlResourceByUrl(String url, String encoding) {
URL urlObj = null;
HttpURLConnection uc = null;
InputStreamReader isr = null;
BufferedReader reader = null;
StringBuffer buffer = new StringBuffer();
// 建立网络连接
try {
urlObj = new URL(url);
// 打开网络连接
uc =(HttpURLConnection) urlObj.openConnection();
// 模拟浏览器请求
uc.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 建立文件输入流
isr = new InputStreamReader(uc.getInputStream(), encoding);
// 建立缓存导入 将网页源代码下载下来
reader = new BufferedReader(isr);
// 临时
String temp = null;
while ((temp = reader.readLine()) != null) {// System.out.println(temp+"\n");
buffer.append(temp + "\n");
}
System.out.println("爬取结束:"+buffer.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关流
if (isr != null) {
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer.toString();
}
/**
* 下载图片
*
* @param listImgSrc
*/
public void Download(List listImgSrc) {
int count = 0;
try {
for (int i = 0; i < listImgSrc.size(); i++) {
try {
PictureInfo pictureInfo = listImgSrc.get(i);
String url=pictureInfo.getSrc();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
// 打开连接
URLConnection con = uri.openConnection();
//设置请求超时为
con.setConnectTimeout(5 * 1000);
con.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
// 输入流
InputStream is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
String src = url.substring(URL.length());
int index = src.lastIndexOf('/');
String fileName = src.substring(0, index + 1);
File sf = new File(SAVE_PATH + fileName);
if (!sf.exists()) {
sf.mkdirs();
}
OutputStream os = new FileOutputStream(sf.getPath() + "\\" + imageName);
System.out.println(++count + ".开始下载:" + url);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 完毕,关闭所有链接
os.close();
is.close();
System.out.println(imageName + ":--下载完成");
} catch (IOException e) {
System.out.println("下载错误"+e);
}
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("下载失败"+e);
}
}
/**
* 得到网页中图片的地址-推荐
* 使用jsoup
* @param htmlStr html字符串
* @return List
*/
public List getImgStrJsoup(String htmlStr) {
List pics = new ArrayList();
//获取网页的document树
Document imgDoc = Jsoup.parse(htmlStr);
//获取所有的img
Elements alts = imgDoc.select("img[src]");
for (Element alt : alts) {
PictureInfo p=new PictureInfo();
p.setSrc(alt.attr("src"));
p.setAlt(alt.attr("alt"));
p.setTitle(alt.attr("title"));
pics.add(p);
}
return pics;
}
}
这些是主要的方法。只要爬取的网页信息中收录img标签,就可以去除对应的图片。
java爬虫抓取网页数据( 这是Java网络爬虫系列文章的第一篇(图),需要哪些基础知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-13 06:02
这是Java网络爬虫系列文章的第一篇(图),需要哪些基础知识)
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参阅学习Java网络爬虫需要哪些基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解Jsoup,请参考/
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。httpclient + 正则表达式
上面,我们使用了Jsoup方法正确提取了虎扑列表新闻。接下来我们使用httpclient+正则表达式的方式进行提取,看看这种方式会涉及哪些问题? httpclient+正则表达式方式涉及的知识点相当多,涉及到正则表达式、Java正则表达式、httpclient。如果你不知道这些知识,可以点击下面的链接了解一下:
正则表达式:正则表达式
Java 正则表达式:Java 正则表达式 查看全部
java爬虫抓取网页数据(
这是Java网络爬虫系列文章的第一篇(图),需要哪些基础知识)
这是Java网络爬虫系列的第一篇文章。如果您不了解Java网络爬虫系列文章,请参阅学习Java网络爬虫需要哪些基础知识。第一篇是关于Java网络爬虫的介绍。在本文中,我们以 采集hupu 列表新闻的新闻标题和详情页为例。需要提取的内容如下图所示:
我们需要提取图中圈出的文字及其对应的链接。在提取过程中,我们会使用两种方法进行提取,一种是Jsoup方法,另一种是httpclient+正则表达式方法。它们也是Java网络爬虫常用的两种方法。这两种方法你不懂也没关系。后面会有相应的说明书。在正式写解压程序之前,先解释一下Java爬虫系列博文的环境。本系列博文中的所有demo都是使用SpringBoot搭建的。无论使用哪种环境,只需要正确导入对应的包即可。
通过 Jsoup 提取信息
我们先用Jsoup来提取新闻信息。如果你还不了解Jsoup,请参考/
首先创建一个Springboot项目,名称可选,在pom.xml中引入Jsoup的依赖
好,我们一起来分析一下页面,想必你还没有浏览过,点击这里浏览虎扑新闻。在列表页面中,我们使用F12评论元素查看页面结构,经过我们的分析,我们发现列表新闻在
标签下,每条新闻都是一个li标签,分析结果如下图所示:
既然我们已经知道了css选择器,我们结合浏览器的Copy功能,为我们的a标签编写了css选择器代码: div.news-list > ul > li > div.list-hd > h4 > a ,一切准备就绪,让我们编写Jsoup方式提取信息的代码:
使用Jsoup提取非常简单,只需5、6行代码即可完成。更多Jsoup如何提取节点信息,请参考jsoup官网教程。我们编写main方法执行jsoupList方法,看看jsoupList方法是否正确。
执行main方法,得到如下结果:
从结果可以看出,我们已经正确地提取到了我们想要的信息。如果要采集详情页的信息,只需要写一个采集详情页的方法,在方法中提取详情页对应的节点信息,然后通过将列表页面中的链接提取到详细信息页面的提取方法中。httpclient + 正则表达式
上面,我们使用了Jsoup方法正确提取了虎扑列表新闻。接下来我们使用httpclient+正则表达式的方式进行提取,看看这种方式会涉及哪些问题? httpclient+正则表达式方式涉及的知识点相当多,涉及到正则表达式、Java正则表达式、httpclient。如果你不知道这些知识,可以点击下面的链接了解一下:
正则表达式:正则表达式
Java 正则表达式:Java 正则表达式
java爬虫抓取网页数据(Java爬虫采集网页数据(简单介绍)(1)_ )
网站优化 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2022-01-12 00:08
)
Java爬虫采集网页数据一、爬虫简介
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。
学过爬虫的同学都知道,目前80%的爬虫都是用Python写的:
原因一:由于目前大部分网络协议都是基于HTTP/HTTPS的,而java的基础框架支持TCP/IP网络协议,构建爬虫时需要导入大量底层库;
原因2:Python有很多开源爬虫库,好用,也有Java的,但是Java入门比较难;
理由三:Python语言简单难懂。相比之下,Java语言更复杂,理解难度也增加了;
好了,这次回到我们的话题,修改后的例子是一个基于JavaClient加正则化的爬虫来简单实现Java Maven项目采集的图片数据!
二、必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
有同学创建Maven项目后,程序还是跑错了!只要三点修改,就会更宽!(基于 JDK1.8)
1.修改pom.xml依赖中的JDK版本号
UTF-8
1.8
1.8
2.根据下图找到项目结构图标,进入Project Settings --> Modules -->Souces->Language level:设置为8;
3 进入项目设置文件,Settings–>Build, Execution, Deployment–>Compiler–>Java Compiler–>Moudle:配置JDK版本为8;
三点后就可以配置了
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以我只用了一个java文件写成静态方法,方便调用
爬取图片下载到本地
html.java
<p>import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.*;
import java.util.Scanner;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class scenery {
//编码格式
private static final String ENCODING = "UTF-8";
//保存地址
private static final String SAVE_PATH = "file/background";
/**
* 获取到指定网址的网页源码并返回
* @param url 爬取网址
* @return html
*/
public static String getHtmlResourceByUrl(String url) {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
HttpEntity httpEntity = null;
String html = null;
// 设置长连接
httpGet.setHeader("Connection", "keep-alive");
// 设置代理(模拟浏览器版本)
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
CloseableHttpResponse httpResponse = null;
System.out.println("开始请求网页!!!!!!!!");
try {
// 请求并获得响应结果
httpResponse = httpClient.execute(httpGet);
httpEntity = httpResponse.getEntity();
// 输出请求结果
html = EntityUtils.toString(httpEntity);
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
/**
* 获取网页的链接与标题,并追加到list中,从而返回list
* @param html 网页地址
* @return list
*/
public static List getTitleUrl(String html){
String regex_img_url = "<img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
String regex_img_title span class="token operator"=/span span class="token string""div class=\"tits\"(.*?)b class=hightlight"/spanspan class="token punctuation";/span
ArrayListspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建pattern对象/span
Pattern img_url_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_urlspan class="token punctuation")/spanspan class="token punctuation";/span
Pattern img_title_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_titlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_url_m span class="token operator"=/span img_url_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
Matcher img_title_m span class="token operator"=/span img_title_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_url_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/span span class="token operator"&&/span img_title_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
String url span class="token operator"=/span img_url_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanurlspan class="token punctuation")/spanspan class="token punctuation";/span
String title span class="token operator"=/span img_title_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spantitlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 获取image url 追加到List中,并返回List
* @param details_html 详情页网址
* @return List
*//span
span class="token keyword"public/span span class="token keyword"static/span Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span span class="token function"getImageSrc/spanspan class="token punctuation"(/spanString details_htmlspan class="token punctuation")/spanspan class="token punctuation"{/span
Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
String imgRegex span class="token operator"=/span span class="token string""img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
span class="token comment"//创建Pattern对象/span
Pattern img_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanimgRegexspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_m span class="token operator"=/span img_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spandetails_htmlspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""开始解析..."/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 下载图片
* @param imgUrl img网址
* @param filePath 图片报错地址
* @param title 图片系列
* @param imageName 图片名
* @param page 页数
* @param count 每页的图片计数
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"downLoad/spanspan class="token punctuation"(/spanString imgUrlspan class="token punctuation",/spanString filePathspan class="token punctuation",/span String titlespan class="token punctuation",/span String imageNamespan class="token punctuation",/spanspan class="token keyword"int/span pagespan class="token punctuation",/span span class="token keyword"int/span countspan class="token punctuation")/span span class="token punctuation"{/span
CloseableHttpClient httpClient span class="token operator"=/span HttpClientsspan class="token punctuation"./spanspan class="token function"createDefault/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
HttpGet httpGet span class="token operator"=/span span class="token keyword"new/span span class="token class-name"HttpGet/spanspan class="token punctuation"(/spanimgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"try/span span class="token punctuation"{/span
CloseableHttpResponse response span class="token operator"=/span httpClientspan class="token punctuation"./spanspan class="token function"execute/spanspan class="token punctuation"(/spanhttpGetspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/spanpagespan class="token operator"+/span span class="token string""页的"/span span class="token operator"+/span title span class="token operator"+/span span class="token string""系列图片开始下载:"/span span class="token operator"+/span imgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanHttpStatusspan class="token punctuation"./spanSC_OK span class="token operator"==/span responsespan class="token punctuation"./spanspan class="token function"getStatusLine/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"./spanspan class="token function"getStatusCode/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
HttpEntity entity span class="token operator"=/span responsespan class="token punctuation"./spanspan class="token function"getEntity/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
InputStream imgContent span class="token operator"=/span entityspan class="token punctuation"./spanspan class="token function"getContent/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token function"saveImage/spanspan class="token punctuation"(/spanimgContentspan class="token punctuation",/span filePathspan class="token punctuation",/spanimageNamespan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/span span class="token punctuation"(/spancount span class="token operator"+/span span class="token number"1/spanspan class="token punctuation")/span span class="token operator"+/span span class="token string""张图片下载完成名为:"/span span class="token operator"+/span imageNamespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"ClientProtocolException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token comment"/**
* 保存图片
* @param is 输入数据流
* @param filePath 文件目录Path
* @param imageName image名
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"saveImage/spanspan class="token punctuation"(/spanInputStream isspan class="token punctuation",/span String filePathspan class="token punctuation",/span String imageNamespan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token keyword"try/span span class="token punctuation"{/span
span class="token comment"//创建图片文件/span
String imgSavePath span class="token operator"=/span filePathspan class="token punctuation"./spanspan class="token function"concat/spanspan class="token punctuation"(/spanspan class="token string""/"/span span class="token operator"+/span imageName span class="token operator"+/span span class="token string"".jpg"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
File imgPath span class="token operator"=/span span class="token keyword"new/span span class="token class-name"File/spanspan class="token punctuation"(/spanimgSavePathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanspan class="token operator"!/spanimgPathspan class="token punctuation"./spanspan class="token function"exists/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
imgPathspan class="token punctuation"./spanspan class="token function"createNewFile/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
FileOutputStream fos span class="token operator"=/span span class="token keyword"new/span span class="token class-name"FileOutputStream/spanspan class="token punctuation"(/spanimgPathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"byte/spanspan class="token punctuation"[/spanspan class="token punctuation"]/span bytes span class="token operator"=/span span class="token keyword"new/span span class="token class-name"byte/spanspan class="token punctuation"[/spanspan class="token number"1024/span span class="token operator"*/span span class="token number"1024/span span class="token operator"*/span span class="token number"1024/spanspan class="token punctuation"]/spanspan class="token punctuation";/span
span class="token keyword"int/span len span class="token operator"=/span span class="token number"0/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanspan class="token punctuation"(/spanlen span class="token operator"=/span isspan class="token punctuation"./spanspan class="token function"read/spanspan class="token punctuation"(/spanbytesspan class="token punctuation")/spanspan class="token punctuation")/span span class="token operator"!=/span span class="token operator"-/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
fosspan class="token punctuation"./spanspan class="token function"write/spanspan class="token punctuation"(/spanbytesspan class="token punctuation",/span span class="token number"0/spanspan class="token punctuation",/span lenspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
fosspan class="token punctuation"./spanspan class="token function"flush/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
fosspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/spanspan class="token keyword"finally/span span class="token punctuation"{/span
span class="token keyword"try/spanspan class="token punctuation"{/span
isspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"run/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token comment"//循环获取列表页的html/span
String title span class="token operator"=/span span class="token string"""/spanspan class="token punctuation";/span
span class="token comment"//采集类型大家阔以自行发挥!!!/span
Scanner input span class="token operator"=/span span class="token keyword"new/span span class="token class-name"Scanner/spanspan class="token punctuation"(/spanSystemspan class="token punctuation"./spaninspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""*********************欢迎来到洋群满满壁纸下载地,请选择你想要下载序列的序号!*********************"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""1>>>风景|2>>>美女|3>>>汽车|4>>>动漫|5>>>二次元|6>>>森林|7>>>明星|8>>>猜你喜欢(You Know!!!)");
System.out.print("请选择:");
int choose = input.nextInt();
switch (choose){
case 1:
title = "风景";
break;
case 2:
title = "美女";
break;
case 3:
title = "汽车";
break;
case 4:
title = "动漫";
break;
case 5:
title = "二次元";
break;
case 6:
title = "森林";
break;
case 7:
title = "明星";
break;
case 8:
title = "性感";
break;
default:
title = "风景";
System.out.println("选择错误,默认采集风景系列图片!!!");
break;
}
int page = 1;
for (; page 查看全部
java爬虫抓取网页数据(Java爬虫采集网页数据(简单介绍)(1)_
)
Java爬虫采集网页数据一、爬虫简介
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动从万维网上爬取信息的程序或脚本。
学过爬虫的同学都知道,目前80%的爬虫都是用Python写的:
原因一:由于目前大部分网络协议都是基于HTTP/HTTPS的,而java的基础框架支持TCP/IP网络协议,构建爬虫时需要导入大量底层库;
原因2:Python有很多开源爬虫库,好用,也有Java的,但是Java入门比较难;
理由三:Python语言简单难懂。相比之下,Java语言更复杂,理解难度也增加了;
好了,这次回到我们的话题,修改后的例子是一个基于JavaClient加正则化的爬虫来简单实现Java Maven项目采集的图片数据!
二、必需的 pom.xml 依赖项
org.jsoup
jsoup
1.8.3
commons-io
commons-io
2.5
org.apache.httpcomponents
httpclient
4.5.5
有同学创建Maven项目后,程序还是跑错了!只要三点修改,就会更宽!(基于 JDK1.8)
1.修改pom.xml依赖中的JDK版本号
UTF-8
1.8
1.8
2.根据下图找到项目结构图标,进入Project Settings --> Modules -->Souces->Language level:设置为8;
3 进入项目设置文件,Settings–>Build, Execution, Deployment–>Compiler–>Java Compiler–>Moudle:配置JDK版本为8;
三点后就可以配置了
三.java代码(附详细注释)
因为我这里是一个简单的java爬虫,所以我只用了一个java文件写成静态方法,方便调用
爬取图片下载到本地
html.java
<p>import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.*;
import java.util.Scanner;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class scenery {
//编码格式
private static final String ENCODING = "UTF-8";
//保存地址
private static final String SAVE_PATH = "file/background";
/**
* 获取到指定网址的网页源码并返回
* @param url 爬取网址
* @return html
*/
public static String getHtmlResourceByUrl(String url) {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
HttpEntity httpEntity = null;
String html = null;
// 设置长连接
httpGet.setHeader("Connection", "keep-alive");
// 设置代理(模拟浏览器版本)
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
CloseableHttpResponse httpResponse = null;
System.out.println("开始请求网页!!!!!!!!");
try {
// 请求并获得响应结果
httpResponse = httpClient.execute(httpGet);
httpEntity = httpResponse.getEntity();
// 输出请求结果
html = EntityUtils.toString(httpEntity);
} catch (IOException e) {
e.printStackTrace();
}
return html;
}
/**
* 获取网页的链接与标题,并追加到list中,从而返回list
* @param html 网页地址
* @return list
*/
public static List getTitleUrl(String html){
String regex_img_url = "<img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
String regex_img_title span class="token operator"=/span span class="token string""div class=\"tits\"(.*?)b class=hightlight"/spanspan class="token punctuation";/span
ArrayListspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建pattern对象/span
Pattern img_url_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_urlspan class="token punctuation")/spanspan class="token punctuation";/span
Pattern img_title_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanregex_img_titlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_url_m span class="token operator"=/span img_url_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
Matcher img_title_m span class="token operator"=/span img_title_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spanhtmlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_url_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/span span class="token operator"&&/span img_title_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
String url span class="token operator"=/span img_url_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanurlspan class="token punctuation")/spanspan class="token punctuation";/span
String title span class="token operator"=/span img_title_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation";/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spantitlespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 获取image url 追加到List中,并返回List
* @param details_html 详情页网址
* @return List
*//span
span class="token keyword"public/span span class="token keyword"static/span Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span span class="token function"getImageSrc/spanspan class="token punctuation"(/spanString details_htmlspan class="token punctuation")/spanspan class="token punctuation"{/span
Listspan class="token generics function"span class="token punctuation"/spanStringspan class="token punctuation"/span/span list span class="token operator"=/span span class="token keyword"new/span span class="token class-name"ArrayList/spanspan class="token operator"/spanspan class="token operator"/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
String imgRegex span class="token operator"=/span span class="token string""img src=\"(.*?)\" alt="/spanspan class="token punctuation";/span
span class="token comment"//创建Pattern对象/span
Pattern img_p span class="token operator"=/span Patternspan class="token punctuation"./spanspan class="token function"compile/spanspan class="token punctuation"(/spanimgRegexspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token comment"//创建matcher对象/span
Matcher img_m span class="token operator"=/span img_pspan class="token punctuation"./spanspan class="token function"matcher/spanspan class="token punctuation"(/spandetails_htmlspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""开始解析..."/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"find/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
listspan class="token punctuation"./spanspan class="token function"add/spanspan class="token punctuation"(/spanimg_mspan class="token punctuation"./spanspan class="token function"group/spanspan class="token punctuation"(/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token keyword"return/span listspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token comment"/**
* 下载图片
* @param imgUrl img网址
* @param filePath 图片报错地址
* @param title 图片系列
* @param imageName 图片名
* @param page 页数
* @param count 每页的图片计数
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"downLoad/spanspan class="token punctuation"(/spanString imgUrlspan class="token punctuation",/spanString filePathspan class="token punctuation",/span String titlespan class="token punctuation",/span String imageNamespan class="token punctuation",/spanspan class="token keyword"int/span pagespan class="token punctuation",/span span class="token keyword"int/span countspan class="token punctuation")/span span class="token punctuation"{/span
CloseableHttpClient httpClient span class="token operator"=/span HttpClientsspan class="token punctuation"./spanspan class="token function"createDefault/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
HttpGet httpGet span class="token operator"=/span span class="token keyword"new/span span class="token class-name"HttpGet/spanspan class="token punctuation"(/spanimgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"try/span span class="token punctuation"{/span
CloseableHttpResponse response span class="token operator"=/span httpClientspan class="token punctuation"./spanspan class="token function"execute/spanspan class="token punctuation"(/spanhttpGetspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/spanpagespan class="token operator"+/span span class="token string""页的"/span span class="token operator"+/span title span class="token operator"+/span span class="token string""系列图片开始下载:"/span span class="token operator"+/span imgUrlspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanHttpStatusspan class="token punctuation"./spanSC_OK span class="token operator"==/span responsespan class="token punctuation"./spanspan class="token function"getStatusLine/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"./spanspan class="token function"getStatusCode/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
HttpEntity entity span class="token operator"=/span responsespan class="token punctuation"./spanspan class="token function"getEntity/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
InputStream imgContent span class="token operator"=/span entityspan class="token punctuation"./spanspan class="token function"getContent/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token function"saveImage/spanspan class="token punctuation"(/spanimgContentspan class="token punctuation",/span filePathspan class="token punctuation",/spanimageNamespan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""第"/span span class="token operator"+/span span class="token punctuation"(/spancount span class="token operator"+/span span class="token number"1/spanspan class="token punctuation")/span span class="token operator"+/span span class="token string""张图片下载完成名为:"/span span class="token operator"+/span imageNamespan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"ClientProtocolException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token comment"/**
* 保存图片
* @param is 输入数据流
* @param filePath 文件目录Path
* @param imageName image名
*//span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"saveImage/spanspan class="token punctuation"(/spanInputStream isspan class="token punctuation",/span String filePathspan class="token punctuation",/span String imageNamespan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token keyword"try/span span class="token punctuation"{/span
span class="token comment"//创建图片文件/span
String imgSavePath span class="token operator"=/span filePathspan class="token punctuation"./spanspan class="token function"concat/spanspan class="token punctuation"(/spanspan class="token string""/"/span span class="token operator"+/span imageName span class="token operator"+/span span class="token string"".jpg"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
File imgPath span class="token operator"=/span span class="token keyword"new/span span class="token class-name"File/spanspan class="token punctuation"(/spanimgSavePathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"if/span span class="token punctuation"(/spanspan class="token operator"!/spanimgPathspan class="token punctuation"./spanspan class="token function"exists/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation")/span span class="token punctuation"{/span
imgPathspan class="token punctuation"./spanspan class="token function"createNewFile/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
FileOutputStream fos span class="token operator"=/span span class="token keyword"new/span span class="token class-name"FileOutputStream/spanspan class="token punctuation"(/spanimgPathspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token keyword"byte/spanspan class="token punctuation"[/spanspan class="token punctuation"]/span bytes span class="token operator"=/span span class="token keyword"new/span span class="token class-name"byte/spanspan class="token punctuation"[/spanspan class="token number"1024/span span class="token operator"*/span span class="token number"1024/span span class="token operator"*/span span class="token number"1024/spanspan class="token punctuation"]/spanspan class="token punctuation";/span
span class="token keyword"int/span len span class="token operator"=/span span class="token number"0/spanspan class="token punctuation";/span
span class="token keyword"while/span span class="token punctuation"(/spanspan class="token punctuation"(/spanlen span class="token operator"=/span isspan class="token punctuation"./spanspan class="token function"read/spanspan class="token punctuation"(/spanbytesspan class="token punctuation")/spanspan class="token punctuation")/span span class="token operator"!=/span span class="token operator"-/spanspan class="token number"1/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
fosspan class="token punctuation"./spanspan class="token function"write/spanspan class="token punctuation"(/spanbytesspan class="token punctuation",/span span class="token number"0/spanspan class="token punctuation",/span lenspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
fosspan class="token punctuation"./spanspan class="token function"flush/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
fosspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/spanspan class="token keyword"finally/span span class="token punctuation"{/span
span class="token keyword"try/spanspan class="token punctuation"{/span
isspan class="token punctuation"./spanspan class="token function"close/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span span class="token keyword"catch/span span class="token punctuation"(/spanspan class="token class-name"IOException/span espan class="token punctuation")/span span class="token punctuation"{/span
espan class="token punctuation"./spanspan class="token function"printStackTrace/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation";/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token punctuation"}/span
span class="token keyword"public/span span class="token keyword"static/span span class="token keyword"void/span span class="token function"run/spanspan class="token punctuation"(/spanspan class="token punctuation")/spanspan class="token punctuation"{/span
span class="token comment"//循环获取列表页的html/span
String title span class="token operator"=/span span class="token string"""/spanspan class="token punctuation";/span
span class="token comment"//采集类型大家阔以自行发挥!!!/span
Scanner input span class="token operator"=/span span class="token keyword"new/span span class="token class-name"Scanner/spanspan class="token punctuation"(/spanSystemspan class="token punctuation"./spaninspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""*********************欢迎来到洋群满满壁纸下载地,请选择你想要下载序列的序号!*********************"/spanspan class="token punctuation")/spanspan class="token punctuation";/span
Systemspan class="token punctuation"./spanoutspan class="token punctuation"./spanspan class="token function"println/spanspan class="token punctuation"(/spanspan class="token string""1>>>风景|2>>>美女|3>>>汽车|4>>>动漫|5>>>二次元|6>>>森林|7>>>明星|8>>>猜你喜欢(You Know!!!)");
System.out.print("请选择:");
int choose = input.nextInt();
switch (choose){
case 1:
title = "风景";
break;
case 2:
title = "美女";
break;
case 3:
title = "汽车";
break;
case 4:
title = "动漫";
break;
case 5:
title = "二次元";
break;
case 6:
title = "森林";
break;
case 7:
title = "明星";
break;
case 8:
title = "性感";
break;
default:
title = "风景";
System.out.println("选择错误,默认采集风景系列图片!!!");
break;
}
int page = 1;
for (; page
java爬虫抓取网页数据( post方式就要考虑提交的表单内容怎么传输了呢? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-10 06:11
post方式就要考虑提交的表单内容怎么传输了呢?
)
public static String httpPostWithJSON(String url) throws Exception {
HttpPost httpPost = new HttpPost(url);
CloseableHttpClient client = HttpClients.createDefault();
String respContent = null;
// json方式
JSONObject jsonParam = new JSONObject();
jsonParam.put("name", "admin");
jsonParam.put("pass", "123456");
StringEntity entity = new StringEntity(jsonParam.toString(),"utf-8");//解决中文乱码问题
entity.setContentEncoding("UTF-8");
entity.setContentType("application/json");
httpPost.setEntity(entity);
System.out.println();
// 表单方式
// List pairList = new ArrayList();
// pairList.add(new BasicNameValuePair("name", "admin"));
// pairList.add(new BasicNameValuePair("pass", "123456"));
// httpPost.setEntity(new UrlEncodedFormEntity(pairList, "utf-8"));
HttpResponse resp = client.execute(httpPost);
if(resp.getStatusLine().getStatusCode() == 200) {
HttpEntity he = resp.getEntity();
respContent = EntityUtils.toString(he,"UTF-8");
}
return respContent;
}
public static void main(String[] args) throws Exception {
String result = httpPostWithJSON("http://localhost:8080/hcTest2/Hc");
System.out.println(result);
}
post方法需要考虑提交的表单内容是如何传输的。在本文中,name 和 pass 是表单的值。
封装形式的属性可以使用json或者传统形式。如果是传统形式,请注意,即注释上面的代码部分。这样,在servlet中,也就是数据处理层可以直接通过request.getParameter("string")获取属性值。它比json简单,但是在实际开发中,一般都是用json来进行数据传输。使用json有两种选择,一种是阿里巴巴的fastjson,一种是谷歌的gson。相比fastjson,效率更高,gson适合解析常规JSON数据。博主在这里使用fastjson。另外,如果使用json,在数据处理层需要使用streams来读取表单属性,比传统表单内容要多一点。代码已经存在了。
public class HcServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html;charset=UTF-8");
String acceptjson = "";
User user = new User();
BufferedReader br = new BufferedReader(new InputStreamReader(
(ServletInputStream) request.getInputStream(), "utf-8"));
StringBuffer sb = new StringBuffer("");
String temp;
while ((temp = br.readLine()) != null) {
sb.append(temp);
}
br.close();
acceptjson = sb.toString();
if (acceptjson != "") {
JSONObject jo = JSONObject.parseObject(acceptjson);
user.setUsername(jo.getString("name"));
user.setPassword(jo.getString("pass"));
}
request.setAttribute("user", user);
request.getRequestDispatcher("/message.jsp").forward(request, response);
}
} 查看全部
java爬虫抓取网页数据(
post方式就要考虑提交的表单内容怎么传输了呢?
)
public static String httpPostWithJSON(String url) throws Exception {
HttpPost httpPost = new HttpPost(url);
CloseableHttpClient client = HttpClients.createDefault();
String respContent = null;
// json方式
JSONObject jsonParam = new JSONObject();
jsonParam.put("name", "admin");
jsonParam.put("pass", "123456");
StringEntity entity = new StringEntity(jsonParam.toString(),"utf-8");//解决中文乱码问题
entity.setContentEncoding("UTF-8");
entity.setContentType("application/json");
httpPost.setEntity(entity);
System.out.println();
// 表单方式
// List pairList = new ArrayList();
// pairList.add(new BasicNameValuePair("name", "admin"));
// pairList.add(new BasicNameValuePair("pass", "123456"));
// httpPost.setEntity(new UrlEncodedFormEntity(pairList, "utf-8"));
HttpResponse resp = client.execute(httpPost);
if(resp.getStatusLine().getStatusCode() == 200) {
HttpEntity he = resp.getEntity();
respContent = EntityUtils.toString(he,"UTF-8");
}
return respContent;
}
public static void main(String[] args) throws Exception {
String result = httpPostWithJSON("http://localhost:8080/hcTest2/Hc";);
System.out.println(result);
}
post方法需要考虑提交的表单内容是如何传输的。在本文中,name 和 pass 是表单的值。
封装形式的属性可以使用json或者传统形式。如果是传统形式,请注意,即注释上面的代码部分。这样,在servlet中,也就是数据处理层可以直接通过request.getParameter("string")获取属性值。它比json简单,但是在实际开发中,一般都是用json来进行数据传输。使用json有两种选择,一种是阿里巴巴的fastjson,一种是谷歌的gson。相比fastjson,效率更高,gson适合解析常规JSON数据。博主在这里使用fastjson。另外,如果使用json,在数据处理层需要使用streams来读取表单属性,比传统表单内容要多一点。代码已经存在了。
public class HcServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html;charset=UTF-8");
String acceptjson = "";
User user = new User();
BufferedReader br = new BufferedReader(new InputStreamReader(
(ServletInputStream) request.getInputStream(), "utf-8"));
StringBuffer sb = new StringBuffer("");
String temp;
while ((temp = br.readLine()) != null) {
sb.append(temp);
}
br.close();
acceptjson = sb.toString();
if (acceptjson != "") {
JSONObject jo = JSONObject.parseObject(acceptjson);
user.setUsername(jo.getString("name"));
user.setPassword(jo.getString("pass"));
}
request.setAttribute("user", user);
request.getRequestDispatcher("/message.jsp").forward(request, response);
}
}
java爬虫抓取网页数据(里的图片URL标签的属性值包的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-07 21:00
)
爬虫获取图片,
第一步:获取网页源代码。
步骤二:获取源码中的图片网址(img标签的src属性值)
第 3 部分:下载图片。
获取网页源码需要一个工具:java selenium。它有两部分,一是驱动浏览器的插件,二是jar包
驱动程序可以在这里下载:
下载时注意浏览器对应的驱动版本,存放在某个目录下。驱动是一个.exe文件,谷歌浏览器是:chromedriver.exe
jar包的依赖:
org.seleniumhq.selenium
selenium-java
3.141.59
整个爬虫的maven依赖:
org.jsoup
jsoup
1.7.3
org.seleniumhq.selenium
selenium-java
3.141.59
获取网页的源代码:需要网页的网址
private String webDriverGetSourceHtml(String url){
//运行chromedriver.exe
System.setProperty("webdriver.chrome.driver", "D:\\Google\\webdriver\\chromedriver.exe");
//获取浏览器驱动驱动
WebDriver driver = new ChromeDriver();
System.out.println("【myReptile-1号】已被唤醒");
System.out.println("【myReptile-1号】的任务:从:"+url+"网页获取图片下载到:"+filePath);
//将浏览器窗口最大化
driver.manage().window().maximize();
//
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);//设置元素定位等待时间
// driver.manage().timeouts().pageLoadTimeout(10,TimeUnit.SECONDS);//设置页面加载等待时间
// driver.manage().timeouts().setScriptTimeout(10,TimeUnit.SECONDS);//设置脚本运行等待时间
//打开指定的网页
driver.get(url);
System.out.println("【myReptile-1号】开始工作···");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
//让浏览器执行一个js脚本:将网页滚动条滑到最底(部分网页源代码需要滑动滚动条后才加载出来)
((JavascriptExecutor) driver).executeScript("window.scrollTo(0,document.body.scrollHeight)");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//获取网页源代码
String s = driver.getPageSource();
System.out.println("【myReptile-1号】已获取目标网页源代码");
return s;
}
获取图片地址:参数html为网页源代码,参数url与之前的方法参数相同
private Set getImgsrc(String html , String url){
//hashset相同的元素只算一个。有些网页的图片有大量重复的,避免图片地址重复
Set list = new HashSet();
System.out.println("【myReptile-1号】正在收集图片地址···");
String img = "";
//用正则表达式获取源代码里的<img>标签代码
Pattern p_image;
Matcher m_image;
String regEx_img = "]*?>";
p_image = Pattern.compile(regEx_img, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(html);
while (m_image.find()) {
// 得到<img />数据
img = m_image.group();
// 匹配<img>中的src数据
Matcher matcher = Pattern.compile("src\\s*=\\s*\"?(.*?)(\"|>|\\s+)").matcher(img);
while (matcher.find()) {
String imgSrc = matcher.group(1);
if ((imgSrc!=null)) {
// imgSrc以"http://"或https开头,表示完整的图片URL地址
if((imgSrc.startsWith("http://") || imgSrc.startsWith("https://"))){
System.out.println("【myReptile-1号】直接获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("//")){
// imgSrc以"//"开头,图片URL地址缺少协议,默认协议是http协议,把http补上
imgSrc="http:"+imgSrc;
System.out.println("【myReptile-1号】加协议获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("/")){
// imgSrc以"/"开头,图片URL地址只有地址部分,缺少协议以及域名,把协议和域名补上。协议和域名在url里有
//例如百度里的某图片src为"/aaa/bbb.jpg",我们需要加上http://ww.baidu.com,让它变成"http://ww.baidu.com/aaa/bbb.jpg"
String pattern = "^((http://)|(https://))?([a-zA-Z0-9]([a-zA-Z0-9\\-]{0,61}[a-zA-Z0-9])?\\.)+[a-zA-Z]{2,6}";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(url);
if(m.find()){
String s = m.group();
imgSrc=s+imgSrc;
System.out.println("【myReptile-1号】加域名("+s+")获得图片地址:" + imgSrc);
list.add(imgSrc);
}
}else {
}
}
else {
System.out.println("【myReptile-1号】获取失败的图片地址"+imgSrc);
}
}
}
System.out.println("【myReptile-1号】在:"+url+"获取了 ("+list.size()+") 个图片地址");
return list;
}
下载图片:参数imgList是图片地址的集合。参数filePath是下载的图片存放的位置
private void downImages(Set imgList , String filePath){
//创建文件的目录结构
System.out.println("【myReptile-1号】正在磁盘寻找文件夹( "+filePath+" )");
File files = new File(filePath);
if(!files.exists()){// 判断文件夹是否存在,如果不存在就创建一个文件夹
System.out.println("【myReptile-1号】找不到文件夹( "+filePath+" )");
System.out.println("【myReptile-1号】正在创建文件夹( "+filePath+" )");
files.mkdirs();
System.out.println("【myReptile-1号】创建文件夹( "+filePath+" )完毕");
}else {
System.out.println("【myReptile-1号】已经找到文件夹( "+filePath+" )");
}
int j = 1;
int t = 1;
//获取图片后缀名
Pattern p2 = Pattern.compile("((.png)|(.jpg)|(.gif)|(.bmp)|(.psd)|(.tiff)|(.tga)|(.eps))");
// 截取图片的名称
System.out.println("【myReptile-1号】开始盗图···");
for(String img : imgList){
try {
String fileSuffix = null;
Matcher m2 = p2.matcher(img);
if(m2.find()){
fileSuffix = m2.group();
}else {
//有些图片地址里没有图片后缀名,我们就直接加上一个后缀名
fileSuffix = ".jpg" ;
}
System.out.println("【myReptile-1号】开始抓捕第 ( "+j+" ) 张图片: "+img);
//创建URL类
URL url = new URL(img);
//获取URL连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//设置http请求头
connection.setRequestProperty("Charset", "utf-8");
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36");
//打开链接
connection.connect();
//创建字节输入流
InputStream in = connection.getInputStream();
// 创建文件
File file = new File(filePath+"\\"+System.currentTimeMillis()+fileSuffix);
//创建字节输出流
FileOutputStream out = new FileOutputStream(file);
int i = 0;
while((i = in.read()) != -1){
out.write(i);
}
in.close();
out.close();
System.out.println("抓捕成功");
j++;
t++;
} catch (Exception e) {
j++;
System.out.println("抓捕失败");
e.printStackTrace();
}
}
System.out.println("【myReptile-1号】总共获取"+imgList.size()+"张图片地址,实际抓捕"+(t-1)+"张图片");
System.out.println("请到( "+filePath+" )文件夹查看!");
} 查看全部
java爬虫抓取网页数据(里的图片URL标签的属性值包的应用
)
爬虫获取图片,
第一步:获取网页源代码。
步骤二:获取源码中的图片网址(img标签的src属性值)
第 3 部分:下载图片。
获取网页源码需要一个工具:java selenium。它有两部分,一是驱动浏览器的插件,二是jar包
驱动程序可以在这里下载:
下载时注意浏览器对应的驱动版本,存放在某个目录下。驱动是一个.exe文件,谷歌浏览器是:chromedriver.exe
jar包的依赖:
org.seleniumhq.selenium
selenium-java
3.141.59
整个爬虫的maven依赖:
org.jsoup
jsoup
1.7.3
org.seleniumhq.selenium
selenium-java
3.141.59
获取网页的源代码:需要网页的网址
private String webDriverGetSourceHtml(String url){
//运行chromedriver.exe
System.setProperty("webdriver.chrome.driver", "D:\\Google\\webdriver\\chromedriver.exe");
//获取浏览器驱动驱动
WebDriver driver = new ChromeDriver();
System.out.println("【myReptile-1号】已被唤醒");
System.out.println("【myReptile-1号】的任务:从:"+url+"网页获取图片下载到:"+filePath);
//将浏览器窗口最大化
driver.manage().window().maximize();
//
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);//设置元素定位等待时间
// driver.manage().timeouts().pageLoadTimeout(10,TimeUnit.SECONDS);//设置页面加载等待时间
// driver.manage().timeouts().setScriptTimeout(10,TimeUnit.SECONDS);//设置脚本运行等待时间
//打开指定的网页
driver.get(url);
System.out.println("【myReptile-1号】开始工作···");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
//让浏览器执行一个js脚本:将网页滚动条滑到最底(部分网页源代码需要滑动滚动条后才加载出来)
((JavascriptExecutor) driver).executeScript("window.scrollTo(0,document.body.scrollHeight)");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//获取网页源代码
String s = driver.getPageSource();
System.out.println("【myReptile-1号】已获取目标网页源代码");
return s;
}
获取图片地址:参数html为网页源代码,参数url与之前的方法参数相同
private Set getImgsrc(String html , String url){
//hashset相同的元素只算一个。有些网页的图片有大量重复的,避免图片地址重复
Set list = new HashSet();
System.out.println("【myReptile-1号】正在收集图片地址···");
String img = "";
//用正则表达式获取源代码里的<img>标签代码
Pattern p_image;
Matcher m_image;
String regEx_img = "]*?>";
p_image = Pattern.compile(regEx_img, Pattern.CASE_INSENSITIVE);
m_image = p_image.matcher(html);
while (m_image.find()) {
// 得到<img />数据
img = m_image.group();
// 匹配<img>中的src数据
Matcher matcher = Pattern.compile("src\\s*=\\s*\"?(.*?)(\"|>|\\s+)").matcher(img);
while (matcher.find()) {
String imgSrc = matcher.group(1);
if ((imgSrc!=null)) {
// imgSrc以"http://"或https开头,表示完整的图片URL地址
if((imgSrc.startsWith("http://";) || imgSrc.startsWith("https://";))){
System.out.println("【myReptile-1号】直接获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("//")){
// imgSrc以"//"开头,图片URL地址缺少协议,默认协议是http协议,把http补上
imgSrc="http:"+imgSrc;
System.out.println("【myReptile-1号】加协议获得图片地址:" + imgSrc);
list.add(imgSrc);
}else if(imgSrc.startsWith("/")){
// imgSrc以"/"开头,图片URL地址只有地址部分,缺少协议以及域名,把协议和域名补上。协议和域名在url里有
//例如百度里的某图片src为"/aaa/bbb.jpg",我们需要加上http://ww.baidu.com,让它变成"http://ww.baidu.com/aaa/bbb.jpg"
String pattern = "^((http://)|(https://))?([a-zA-Z0-9]([a-zA-Z0-9\\-]{0,61}[a-zA-Z0-9])?\\.)+[a-zA-Z]{2,6}";
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(url);
if(m.find()){
String s = m.group();
imgSrc=s+imgSrc;
System.out.println("【myReptile-1号】加域名("+s+")获得图片地址:" + imgSrc);
list.add(imgSrc);
}
}else {
}
}
else {
System.out.println("【myReptile-1号】获取失败的图片地址"+imgSrc);
}
}
}
System.out.println("【myReptile-1号】在:"+url+"获取了 ("+list.size()+") 个图片地址");
return list;
}
下载图片:参数imgList是图片地址的集合。参数filePath是下载的图片存放的位置
private void downImages(Set imgList , String filePath){
//创建文件的目录结构
System.out.println("【myReptile-1号】正在磁盘寻找文件夹( "+filePath+" )");
File files = new File(filePath);
if(!files.exists()){// 判断文件夹是否存在,如果不存在就创建一个文件夹
System.out.println("【myReptile-1号】找不到文件夹( "+filePath+" )");
System.out.println("【myReptile-1号】正在创建文件夹( "+filePath+" )");
files.mkdirs();
System.out.println("【myReptile-1号】创建文件夹( "+filePath+" )完毕");
}else {
System.out.println("【myReptile-1号】已经找到文件夹( "+filePath+" )");
}
int j = 1;
int t = 1;
//获取图片后缀名
Pattern p2 = Pattern.compile("((.png)|(.jpg)|(.gif)|(.bmp)|(.psd)|(.tiff)|(.tga)|(.eps))");
// 截取图片的名称
System.out.println("【myReptile-1号】开始盗图···");
for(String img : imgList){
try {
String fileSuffix = null;
Matcher m2 = p2.matcher(img);
if(m2.find()){
fileSuffix = m2.group();
}else {
//有些图片地址里没有图片后缀名,我们就直接加上一个后缀名
fileSuffix = ".jpg" ;
}
System.out.println("【myReptile-1号】开始抓捕第 ( "+j+" ) 张图片: "+img);
//创建URL类
URL url = new URL(img);
//获取URL连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
//设置http请求头
connection.setRequestProperty("Charset", "utf-8");
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36");
//打开链接
connection.connect();
//创建字节输入流
InputStream in = connection.getInputStream();
// 创建文件
File file = new File(filePath+"\\"+System.currentTimeMillis()+fileSuffix);
//创建字节输出流
FileOutputStream out = new FileOutputStream(file);
int i = 0;
while((i = in.read()) != -1){
out.write(i);
}
in.close();
out.close();
System.out.println("抓捕成功");
j++;
t++;
} catch (Exception e) {
j++;
System.out.println("抓捕失败");
e.printStackTrace();
}
}
System.out.println("【myReptile-1号】总共获取"+imgList.size()+"张图片地址,实际抓捕"+(t-1)+"张图片");
System.out.println("请到( "+filePath+" )文件夹查看!");
}
java爬虫抓取网页数据(一下使用ja来写作一个爬虫功能强大的方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2022-01-07 08:11
一般来说,当我们说到爬虫程序时,我们总会想到python爬虫。但是,python 爬虫有一些固有的缺点。python的具体实现基本是固定的,底层实现我们也看不懂,导致很多网站可以反爬虫,今天给大家介绍一下用ja写爬虫,ja的爬虫功能相当强大,目前我还没有发现任何可以用来对抗ja爬虫的网站。
1 首先先介绍一下我们需要导入的jar包:.jsoup,这是一个ja解析html包,它的作用就是解析网页的代码,这个功能强大到没有网站可以做反分析。2.j a.io,这部分其实是没有必要的。我使用这个只是因为我在分析网页代码之前将网页保存在本地。至于为什么要这样做,后面的说明中会提到。3.j 这个包是ja的网络包,我们必须依赖这个包才能使用ja连接网络。
2 我们先说明一下如何将在线的html保存到本地。我们首先创建我们的输入和输出流缓冲区,然后创建一个url来获取我们需要抓取的网页。注意我们使用ipad的动态访问来实现 防止反爬虫对我们的阻碍。最后,我们在 uffer 中生成了我们的 html 代码,然后将其保存在本地。
3 现在让我告诉你为什么它存储在本地。在网页上反复爬取我们需要的数据,难免会导致服务器警觉。就像你看到一个漂亮的女孩一样,你总是盯着别人看。总会找到的,不过偷个图慢慢看也无妨。啊哈哈,这是个玩笑,但这是大体的想法。
4 这部分解释了如何获取html文件中的有用信息。众所周知,html中的代码占了很大一部分,我们需要得到对我们有用的文本才是我们需要做的。并且这段代码分析html中的标签,比如这些标签,分析出复杂代码中有价值的文本信息和超链接。当然,您可以选择要获取的内容。
5最后,让我们尝试爬取我们需要的网站: 下图展示了操作方法和爬虫网页。我们要抓取的是这个网页的header:
6 我们的爬虫结果如下: 嗯,看来爬虫还是挺成功的。有兴趣的可以自己试试ja爬虫。相信我,这个功能真的很强大也很简单。
jsoup包需要网上下载或者使用men下载
建议爬取大量网页后删除一个,否则会不断积累本地网页 查看全部
java爬虫抓取网页数据(一下使用ja来写作一个爬虫功能强大的方法分享)
一般来说,当我们说到爬虫程序时,我们总会想到python爬虫。但是,python 爬虫有一些固有的缺点。python的具体实现基本是固定的,底层实现我们也看不懂,导致很多网站可以反爬虫,今天给大家介绍一下用ja写爬虫,ja的爬虫功能相当强大,目前我还没有发现任何可以用来对抗ja爬虫的网站。
1 首先先介绍一下我们需要导入的jar包:.jsoup,这是一个ja解析html包,它的作用就是解析网页的代码,这个功能强大到没有网站可以做反分析。2.j a.io,这部分其实是没有必要的。我使用这个只是因为我在分析网页代码之前将网页保存在本地。至于为什么要这样做,后面的说明中会提到。3.j 这个包是ja的网络包,我们必须依赖这个包才能使用ja连接网络。
2 我们先说明一下如何将在线的html保存到本地。我们首先创建我们的输入和输出流缓冲区,然后创建一个url来获取我们需要抓取的网页。注意我们使用ipad的动态访问来实现 防止反爬虫对我们的阻碍。最后,我们在 uffer 中生成了我们的 html 代码,然后将其保存在本地。
3 现在让我告诉你为什么它存储在本地。在网页上反复爬取我们需要的数据,难免会导致服务器警觉。就像你看到一个漂亮的女孩一样,你总是盯着别人看。总会找到的,不过偷个图慢慢看也无妨。啊哈哈,这是个玩笑,但这是大体的想法。
4 这部分解释了如何获取html文件中的有用信息。众所周知,html中的代码占了很大一部分,我们需要得到对我们有用的文本才是我们需要做的。并且这段代码分析html中的标签,比如这些标签,分析出复杂代码中有价值的文本信息和超链接。当然,您可以选择要获取的内容。
5最后,让我们尝试爬取我们需要的网站: 下图展示了操作方法和爬虫网页。我们要抓取的是这个网页的header:
6 我们的爬虫结果如下: 嗯,看来爬虫还是挺成功的。有兴趣的可以自己试试ja爬虫。相信我,这个功能真的很强大也很简单。
jsoup包需要网上下载或者使用men下载
建议爬取大量网页后删除一个,否则会不断积累本地网页
java爬虫抓取网页数据(UI自动化月前写的一些事儿--)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-06 00:18
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤1、需求分解:2、代码实现思路:3、示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑改变请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js和图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。 查看全部
java爬虫抓取网页数据(UI自动化月前写的一些事儿--)
写在前面
本来这个文章是几个月前写的,后来忙忘了。
ps:事情太多有时会耽误事情。
几个月前,记得群里有个朋友说要用selenium来爬取数据。关于爬取数据,我一般是模拟访问一些固定的网站,爬取我关心的信息,然后爬出来。数据被处理。
他的要求是将文章直接导入富文本编辑器进行发布,其实这也是一种爬虫。
其实这并不难,就是UI自动化的过程,我们开始吧。
准备工具/原材料
1、java 语言
2、IDEA 开发工具
3、jdk1.8
4、selenium-server-standalone (3.0 及以上)
步骤1、需求分解:2、代码实现思路:3、示例代码
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.awt.*;
import java.awt.event.KeyEvent;
import java.util.concurrent.TimeUnit;
/**
* @author rongrong
* Selenium模拟访问网站爬虫操作代码示例
*/
public class Demo {
private static WebDriver driver;
static final int MAX_TIMEOUT_IN_SECONDS = 5;
@BeforeClass
public static void setUpBeforeClass() throws Exception {
driver = new ChromeDriver();
String url = "https://temai.snssdk.com/artic ... 3B%3B
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(MAX_TIMEOUT_IN_SECONDS, TimeUnit.SECONDS);
driver.get(url);
}
@AfterClass
public static void tearDownAfterClass() throws Exception {
if (driver != null) {
System.out.println("运行结束!");
driver.quit();
}
}
@Test
public void test() throws InterruptedException {
Robot robot = null;
try {
robot = new Robot();
} catch (AWTException e1) {
e1.printStackTrace();
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_A);
robot.keyRelease(KeyEvent.VK_A);
Thread.sleep(2000);
robot.keyPress(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_C);
robot.keyRelease(KeyEvent.VK_CONTROL);
driver.get("https://ueditor.baidu.com/webs ... 6quot;);
Thread.sleep(2000);
driver.switchTo().frame(0);
driver.findElement(By.tagName("body")).click();
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_V);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(2000);
}
}
写在后面
作者不特别推荐使用selenium作为爬虫,原因如下:
每次运行爬虫都要打开浏览器,初始化需要加载图片、JS渲染等很多东西;
有人说改成无头浏览器的原理是一样的。就是打开浏览器,很多网站会验证参数。如果对方看到您的恶意访问请求,就会执行您的请求。然后你必须考虑改变请求头。不知道事情有多复杂,还要改代码,很麻烦。
加载了很多可能对你没有价值的补充文件(比如css、js和图片文件)。与真正需要的资源(使用单独的 HTTP 请求)相比,这可能会产生更多的流量。
java爬虫抓取网页数据(小白刚入门java爬虫抓取网页数据怎么做?开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-04 15:08
java爬虫抓取网页数据,大致分为图片下载,url提取,网页验证码图片下载,交互式爬虫,异步爬虫,搜索数据,定时爬虫等类型,如果是初学爬虫,建议从图片下载开始,下载图片psd文件。
https加密算法找到js文件可以做一下注意你的网站类型是静态还是动态的要不然到时候获取成功了你的服务器崩了就完蛋了爬取重定向可以先做一下简单的ip代理规划一下用户习惯是否需要多用户登录来增加可爬取性和安全性有哪些页面需要爬取在加载这些页面前把爬取规划好爬取后再通过分析内容找到转换规律可以有哪些格式的文件来爬取然后配合解析分析来提取到更精确的信息。
爬虫程序有html5的爬虫框架和ruby/python的反爬虫框架,这两种框架都有不同的入门资料推荐。我也刚入门爬虫不久,写的是html5爬虫的。我先学习的爬虫框架是d3,爬虫框架把html的内容抽象成了一个表,然后可以通过路由来爬取出html内容。不太熟悉ruby可以先用easyweb。学完了html后我学了ruby后,除了学习html,可以试试结合rails/redis/python的requests库(python的网络库)和爬虫框架。
刚入门爬虫的话没必要全部都学,基础知识会用requests学习后,剩下的可以随便学习了。pythonweb开发,可以看看这个。小白刚入门,建议先看这里。 查看全部
java爬虫抓取网页数据(小白刚入门java爬虫抓取网页数据怎么做?开发)
java爬虫抓取网页数据,大致分为图片下载,url提取,网页验证码图片下载,交互式爬虫,异步爬虫,搜索数据,定时爬虫等类型,如果是初学爬虫,建议从图片下载开始,下载图片psd文件。
https加密算法找到js文件可以做一下注意你的网站类型是静态还是动态的要不然到时候获取成功了你的服务器崩了就完蛋了爬取重定向可以先做一下简单的ip代理规划一下用户习惯是否需要多用户登录来增加可爬取性和安全性有哪些页面需要爬取在加载这些页面前把爬取规划好爬取后再通过分析内容找到转换规律可以有哪些格式的文件来爬取然后配合解析分析来提取到更精确的信息。
爬虫程序有html5的爬虫框架和ruby/python的反爬虫框架,这两种框架都有不同的入门资料推荐。我也刚入门爬虫不久,写的是html5爬虫的。我先学习的爬虫框架是d3,爬虫框架把html的内容抽象成了一个表,然后可以通过路由来爬取出html内容。不太熟悉ruby可以先用easyweb。学完了html后我学了ruby后,除了学习html,可以试试结合rails/redis/python的requests库(python的网络库)和爬虫框架。
刚入门爬虫的话没必要全部都学,基础知识会用requests学习后,剩下的可以随便学习了。pythonweb开发,可以看看这个。小白刚入门,建议先看这里。
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-03 02:09
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。
以下是使用Java模拟提取新浪页面上的链接并存入文件的程序
点击获取信息
源码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
} 查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理)
)
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。
以下是使用Java模拟提取新浪页面上的链接并存入文件的程序
点击获取信息
源码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-03 02:08
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。 查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人的实现原理))
网络爬虫网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常见的是网络追逐),是一种根据一定的规则或脚本自动抓取万维网上信息的程序。
关注爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤、索引,以备以后查询检索;对于重点爬虫,本过程中得到的分析结果仍有可能对后续的爬虫过程提供反馈和指导。
与一般的网络爬虫相比,专注爬虫还需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
网络爬虫的实现原理
根据这个原理,编写一个简单的网络爬虫程序。该程序的作用是获取网站发回的数据,并在该过程中提取URL。获取的 URL 存储在文件夹中。除了提取网址,我们还可以提取各种我们想要的信息,只要我们修改过滤数据的表达式即可。
java爬虫抓取网页数据(开发者供不应求,传统企业如何拥抱DevOps?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-02 09:03
开发者供不应求,传统企业如何拥抱DevOps? >>>
最近在看国产剧《我不是药神》。为了分析观众对这部电影的真实感受,我爬取了豆瓣影评的数据。当然,本文只讲爬虫部分(不涉及分析部分),这是一个比较基础的爬虫实现,分为Java版和Python版,代码结构相同,只是实现语言不同.
网页结构分析
打开影评网页,试着翻几页,可以看到每一页的网页结构都是一样的。分为中间的数据列表和底部的页面导航。页面导航链接用于水平抓取所有影评网页。说到中间数据部分,每个页面都是一个列表,每个列表项收录:用户头像、用户名、用户链接、评分(5星)、评论日期、点赞数(有用)和评论内容。本文记录了用户名、评分、日期、点赞数和内容五个字段。
爬虫的基本结构
爬虫实现为标准的单线程(进程)爬虫结构,由爬虫主程序、URL管理器、网页下载器、网页解析器和内容处理器组成
队列管理
通过观察多个页面的url,发现url本身没有变化,只是参数发生了变化。另外,有些页面URL会携带参数&status=P,有些则不会。影响网页访问),避免同一个URL因为这个参数被当作两个URL(这里是一个简化的处理方法,请自行考虑更健壮的实现)
package com.zlikun.learning.douban.movie;
import java.util.*;
import java.util.stream.Collectors;
/**
* URL管理器,本工程中使用单线程,所以直接使用集合实现
*
* @author zlikun
* @date 2018/7/12 17:58
*/
public class UrlManager {
private String baseUrl;
private Queue newUrls = new LinkedList();
private Set oldUrls = new HashSet();
public UrlManager(String baseUrl, String rootUrl) {
this(baseUrl, Arrays.asList(rootUrl));
}
public UrlManager(String baseUrl, List rootUrls) {
if (baseUrl == null || rootUrls == null || rootUrls.isEmpty()) {
return;
}
this.baseUrl = baseUrl;
// 添加待抓取URL列表
this.appendNewUrls(rootUrls);
}
/**
* 追加待抓取URLs
*
* @param urls
*/
public void appendNewUrls(List urls) {
// 添加待抓取URL列表
newUrls.addAll(urls.stream()
// 过滤指定URL
.filter(url -> url.startsWith(baseUrl))
// 处理URL中的多余参数(&status=P,有的链接有,有的没有,为避免重复,统一去除,去除后并不影响)
.map(url -> url.replace("&status=P", ""))
// 过滤重复的URL
.filter(url -> !newUrls.contains(url) && !oldUrls.contains(url))
// 返回处理过后的URL列表
.collect(Collectors.toList()));
}
public boolean hasNewUrl() {
return !this.newUrls.isEmpty();
}
/**
* 取出一个新URL,这里简化处理了新旧URL状态迁移过程,取出后即认为成功处理了(实际情况下需要考虑各种失败情况和边界条件)
*
* @return
*/
public String getNewUrl() {
String url = this.newUrls.poll();
this.oldUrls.add(url);
return url;
}
}
下载器 查看全部
java爬虫抓取网页数据(开发者供不应求,传统企业如何拥抱DevOps?(图))
开发者供不应求,传统企业如何拥抱DevOps? >>>
最近在看国产剧《我不是药神》。为了分析观众对这部电影的真实感受,我爬取了豆瓣影评的数据。当然,本文只讲爬虫部分(不涉及分析部分),这是一个比较基础的爬虫实现,分为Java版和Python版,代码结构相同,只是实现语言不同.
网页结构分析
打开影评网页,试着翻几页,可以看到每一页的网页结构都是一样的。分为中间的数据列表和底部的页面导航。页面导航链接用于水平抓取所有影评网页。说到中间数据部分,每个页面都是一个列表,每个列表项收录:用户头像、用户名、用户链接、评分(5星)、评论日期、点赞数(有用)和评论内容。本文记录了用户名、评分、日期、点赞数和内容五个字段。
爬虫的基本结构
爬虫实现为标准的单线程(进程)爬虫结构,由爬虫主程序、URL管理器、网页下载器、网页解析器和内容处理器组成
队列管理
通过观察多个页面的url,发现url本身没有变化,只是参数发生了变化。另外,有些页面URL会携带参数&status=P,有些则不会。影响网页访问),避免同一个URL因为这个参数被当作两个URL(这里是一个简化的处理方法,请自行考虑更健壮的实现)
package com.zlikun.learning.douban.movie;
import java.util.*;
import java.util.stream.Collectors;
/**
* URL管理器,本工程中使用单线程,所以直接使用集合实现
*
* @author zlikun
* @date 2018/7/12 17:58
*/
public class UrlManager {
private String baseUrl;
private Queue newUrls = new LinkedList();
private Set oldUrls = new HashSet();
public UrlManager(String baseUrl, String rootUrl) {
this(baseUrl, Arrays.asList(rootUrl));
}
public UrlManager(String baseUrl, List rootUrls) {
if (baseUrl == null || rootUrls == null || rootUrls.isEmpty()) {
return;
}
this.baseUrl = baseUrl;
// 添加待抓取URL列表
this.appendNewUrls(rootUrls);
}
/**
* 追加待抓取URLs
*
* @param urls
*/
public void appendNewUrls(List urls) {
// 添加待抓取URL列表
newUrls.addAll(urls.stream()
// 过滤指定URL
.filter(url -> url.startsWith(baseUrl))
// 处理URL中的多余参数(&status=P,有的链接有,有的没有,为避免重复,统一去除,去除后并不影响)
.map(url -> url.replace("&status=P", ""))
// 过滤重复的URL
.filter(url -> !newUrls.contains(url) && !oldUrls.contains(url))
// 返回处理过后的URL列表
.collect(Collectors.toList()));
}
public boolean hasNewUrl() {
return !this.newUrls.isEmpty();
}
/**
* 取出一个新URL,这里简化处理了新旧URL状态迁移过程,取出后即认为成功处理了(实际情况下需要考虑各种失败情况和边界条件)
*
* @return
*/
public String getNewUrl() {
String url = this.newUrls.poll();
this.oldUrls.add(url);
return url;
}
}
下载器
java爬虫抓取网页数据(java网络爬虫基础入门的总结及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-02 09:01
刚开始接触java爬虫,这里总结一下网上的一些理论知识
主要参考文章:Gitchat的java网络爬虫基础。好像是收费的,也不贵。感觉内容对新手很友好。
一、爬虫介绍
网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。
传统爬虫:
获取URL-》放入队列-》爬取网页,分析信息-》新建URL-》放入队列-》爬取网页,分析信息... -》满足一定条件,停止。
关注爬虫:
根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后根据搜索策略从队列中选择下一个URL,重复...直到满足一定条件停止。另外,爬虫爬取的网页会被系统存储起来进行一定的分析、过滤和索引,以便后续的查询和归约。
相比一般的网络爬虫,专注爬虫还需要解决三个问题:
抓取目标的描述或定义。网页或数据的分析和过滤。网址的搜索策略。
网络爬虫设计有很多领域。我们需要掌握一门基本的编程语言(最好是已经有成熟API的语言),了解HTTP协议,了解Web服务器、数据库、前端知识、网络安全等......
分类:
根据系统结构和实现技术,大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等
万能网络爬虫:爬取对象从一些种子网址扩展到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫:也称为主网络爬虫,它是指有选择地抓取与预定义主题相关的页面,比上面已经介绍的一般爬虫更具体。
Incremental web crawler:一种对下载的网页进行增量更新并且只抓取新生成或更改的页面的爬虫。它可以确保抓取的页面尽可能新。历史已经采集过去的页面不再重复采集。
常见情况:论坛订单评论数据的采集(评论数据仅为用户最近几天或几个月的采集评论)
Deep Web crawler:指的是大部分内容是无法通过静态链接获取的,而我们需要的大部分数据是网页动态链接生成的页面,即Deep Web信息。 Deep Web 也是一个爬虫框架。暂时不要深入研究。
网络爬虫的爬取策略
深度优先搜索策略,广度优先搜索策略。 查看全部
java爬虫抓取网页数据(java网络爬虫基础入门的总结及解决方法)
刚开始接触java爬虫,这里总结一下网上的一些理论知识
主要参考文章:Gitchat的java网络爬虫基础。好像是收费的,也不贵。感觉内容对新手很友好。
一、爬虫介绍
网络爬虫是一种自动提取网页的程序。它从万维网上下载网页供搜索引擎使用,是搜索引擎的重要组成部分。
传统爬虫:
获取URL-》放入队列-》爬取网页,分析信息-》新建URL-》放入队列-》爬取网页,分析信息... -》满足一定条件,停止。
关注爬虫:
根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后根据搜索策略从队列中选择下一个URL,重复...直到满足一定条件停止。另外,爬虫爬取的网页会被系统存储起来进行一定的分析、过滤和索引,以便后续的查询和归约。
相比一般的网络爬虫,专注爬虫还需要解决三个问题:
抓取目标的描述或定义。网页或数据的分析和过滤。网址的搜索策略。
网络爬虫设计有很多领域。我们需要掌握一门基本的编程语言(最好是已经有成熟API的语言),了解HTTP协议,了解Web服务器、数据库、前端知识、网络安全等......
分类:
根据系统结构和实现技术,大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫等
万能网络爬虫:爬取对象从一些种子网址扩展到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫:也称为主网络爬虫,它是指有选择地抓取与预定义主题相关的页面,比上面已经介绍的一般爬虫更具体。
Incremental web crawler:一种对下载的网页进行增量更新并且只抓取新生成或更改的页面的爬虫。它可以确保抓取的页面尽可能新。历史已经采集过去的页面不再重复采集。
常见情况:论坛订单评论数据的采集(评论数据仅为用户最近几天或几个月的采集评论)
Deep Web crawler:指的是大部分内容是无法通过静态链接获取的,而我们需要的大部分数据是网页动态链接生成的页面,即Deep Web信息。 Deep Web 也是一个爬虫框架。暂时不要深入研究。
网络爬虫的爬取策略
深度优先搜索策略,广度优先搜索策略。
java爬虫抓取网页数据(importjavaioimportimportFileimportimport)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-02 02:17
此代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
打包工具;
导入 java.io.BufferedReader;
导入 java.io.File;
导入 java.io.FileWriter;
import java.io.InputStreamReader;
导入 java.io.Writer;
导入.URL;
导入.URLConnection;
导入 java.sql.Time;
导入 java.util.Scanner;
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公开课马{
public static void main(String[] args) throws Exception {//这个程序为了简单起见异常太多了,不试了,直接扔给虚拟机
long StartTime = System.currentTimeMillis();
System.out.println("-- 欢迎使用小刘的简单网络爬虫程序--");
System.out.println("");
System.out.println("--请输入正确的网址如");
Scanner input = new Scanner(System.in);// 实例化键盘输入类
String webaddress = input.next();// 创建输入对象
File file = new File("E:" + File.separator + "爬虫邮箱统计text.txt");//实例化一个文件类对象
//并指定输出地址和输出文件名
Writer outWriter = new FileWriter(file);// 实例化 outWriter 类
URL url = new URL(webaddress);// 实例化 URL 类。
URLConnection conn = url.openConnection();// 获取链接
BufferedReader buff = new BufferedReader(new InputStreamReader(
)
conn.getInputStream()));// 获取网页数据
字符串行 = null;
int i=0;
String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
Pattern p = pie(regex);// 实例化模式 p>
outWriter.write("本页收录的邮箱如下:\r\n");
while ((line = buff.readLine()) != null) {
Matcher m = p.matcher(line);// 匹配
while (m.find()) {
i++;
outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件中
}
}
long StopTime = System.currentTimeMillis();
String UseTime=(StopTime-StartTime)+"";
outWriter.write("----------------------------------------- --------------\r\n");
outWriter.write("本次抓取页面地址:"+webaddress+"\r\n");
outWriter.write("爬行时间:"+UseTime+"毫秒\r\n");
outWriter.write("本次获取邮箱总数:"+i+"items\r\n");
outWriter.write("****感谢您的使用****\r\n");
outWriter.write("----------------------------------------- --------------");
outWriter.close();// 关闭文件输出操作
System.out.println("———————————————————————\t");
System.out.println("|页面抓取成功,请到E盘根目录查看测试文档|\t");
System.out.println("| |");
System.out.println("|如果需要再次爬取,请再次执行程序,谢谢使用|\t");
System.out.println("———————————————————————\t");
}
}
txt截图如下:
测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱。如果读者对正则表达式有所了解,那么
不仅可以抢邮箱,还可以抢手机号,IP地址等所有你想抢的信息。是不是很有趣? 查看全部
java爬虫抓取网页数据(importjavaioimportimportFileimportimport)
此代码是一个非常简单的网络爬虫,仅供娱乐。
java代码如下:
打包工具;
导入 java.io.BufferedReader;
导入 java.io.File;
导入 java.io.FileWriter;
import java.io.InputStreamReader;
导入 java.io.Writer;
导入.URL;
导入.URLConnection;
导入 java.sql.Time;
导入 java.util.Scanner;
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公开课马{
public static void main(String[] args) throws Exception {//这个程序为了简单起见异常太多了,不试了,直接扔给虚拟机
long StartTime = System.currentTimeMillis();
System.out.println("-- 欢迎使用小刘的简单网络爬虫程序--");
System.out.println("");
System.out.println("--请输入正确的网址如");
Scanner input = new Scanner(System.in);// 实例化键盘输入类
String webaddress = input.next();// 创建输入对象
File file = new File("E:" + File.separator + "爬虫邮箱统计text.txt");//实例化一个文件类对象
//并指定输出地址和输出文件名
Writer outWriter = new FileWriter(file);// 实例化 outWriter 类
URL url = new URL(webaddress);// 实例化 URL 类。
URLConnection conn = url.openConnection();// 获取链接
BufferedReader buff = new BufferedReader(new InputStreamReader(
)
conn.getInputStream()));// 获取网页数据
字符串行 = null;
int i=0;
String regex = "\\w+@\\w+(\\.\\w+)+";// 声明正则,提取网页前提
Pattern p = pie(regex);// 实例化模式 p>
outWriter.write("本页收录的邮箱如下:\r\n");
while ((line = buff.readLine()) != null) {
Matcher m = p.matcher(line);// 匹配
while (m.find()) {
i++;
outWriter.write(m.group() + ";\r\n");// 将匹配的字符输入到目标文件中
}
}
long StopTime = System.currentTimeMillis();
String UseTime=(StopTime-StartTime)+"";
outWriter.write("----------------------------------------- --------------\r\n");
outWriter.write("本次抓取页面地址:"+webaddress+"\r\n");
outWriter.write("爬行时间:"+UseTime+"毫秒\r\n");
outWriter.write("本次获取邮箱总数:"+i+"items\r\n");
outWriter.write("****感谢您的使用****\r\n");
outWriter.write("----------------------------------------- --------------");
outWriter.close();// 关闭文件输出操作
System.out.println("———————————————————————\t");
System.out.println("|页面抓取成功,请到E盘根目录查看测试文档|\t");
System.out.println("| |");
System.out.println("|如果需要再次爬取,请再次执行程序,谢谢使用|\t");
System.out.println("———————————————————————\t");
}
}
txt截图如下:
测试网址:通过这个例子,读者可以轻松抓取网页上的邮箱。如果读者对正则表达式有所了解,那么
不仅可以抢邮箱,还可以抢手机号,IP地址等所有你想抢的信息。是不是很有趣?
java爬虫抓取网页数据(java爬虫抓取网页数据“,”如何做数据库开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-30 17:00
java爬虫抓取网页数据并保存为xml或json文件,从而导入excel,利用vba将相应数据写入相应数据库。利用xib或xlsx可以轻松处理大量xml文件!所以你的问题中”高效处理xml文件“,”如何做数据库开发“应该是建立在”如何做爬虫爬取xml文件“的这个问题上吧。
微信那么多个公众号,如果你是通过他们的文章被推送的,那么他们是自己开发过api接口,不过挺多时候通过找代爬他们的数据就可以解决大部分问题了。
这个问题,首先要看你对爬虫爬取的内容定义。
1、爬取基本的api接口
2、文章页面出现的各种格式的xml、json文件。爬取下来后,用同步机制(self.web.webnavigation)让接口同步,让接口处理后才能让爬虫爬取。把爬取后的xml、json序列化到web文件中,存放在浏览器可以打开的位置。根据你要的接口文件的路径构建数据库。
3、是比较高效的,但是如果技术上不够成熟,怕处理不了,那么根据需求(想要爬取什么样的内容)规划数据存放位置和相应的数据结构就是所谓的爬虫工程师。
通常是直接用requests,但是爬取api文档页面性能问题不大.3/4号那种基本不现实了
微信公众号为什么不用requests?
别弄了你, 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据“,”如何做数据库开发)
java爬虫抓取网页数据并保存为xml或json文件,从而导入excel,利用vba将相应数据写入相应数据库。利用xib或xlsx可以轻松处理大量xml文件!所以你的问题中”高效处理xml文件“,”如何做数据库开发“应该是建立在”如何做爬虫爬取xml文件“的这个问题上吧。
微信那么多个公众号,如果你是通过他们的文章被推送的,那么他们是自己开发过api接口,不过挺多时候通过找代爬他们的数据就可以解决大部分问题了。
这个问题,首先要看你对爬虫爬取的内容定义。
1、爬取基本的api接口
2、文章页面出现的各种格式的xml、json文件。爬取下来后,用同步机制(self.web.webnavigation)让接口同步,让接口处理后才能让爬虫爬取。把爬取后的xml、json序列化到web文件中,存放在浏览器可以打开的位置。根据你要的接口文件的路径构建数据库。
3、是比较高效的,但是如果技术上不够成熟,怕处理不了,那么根据需求(想要爬取什么样的内容)规划数据存放位置和相应的数据结构就是所谓的爬虫工程师。
通常是直接用requests,但是爬取api文档页面性能问题不大.3/4号那种基本不现实了
微信公众号为什么不用requests?
别弄了你,
java爬虫抓取网页数据(一个基于JAVA的知乎爬虫,知乎用户基本信息,基于HttpClient4.5 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-30 11:36
)
本文主要介绍一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下。
本文示例分享了一个基于JAVA的知乎爬虫,基于HttpClient4.5,抓取知乎用户的基本信息,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户都在里面)
大概的概念:
1.首先模拟登录知乎。登录成功后,cookie会被序列化到磁盘,不需要每次都登录(如果不模拟登录,可以直接从浏览器插入cookie)。
2.创建两个线程池和一个Storage。一个网页爬取线程池负责执行请求请求,返回网页内容,并存储在Storage中。另一种是解析网页线程池,它负责从Storage中获取和分析网页内容,分析用户信息并存储到数据库中,分析用户关注的人的主页,并将地址请求添加到网页抓取线程池。继续循环。
3. 关于URL去重,我直接将访问过的链接md5保存到数据库中。每次访问前,检查数据库中是否存在该链接。
目前已抓获100W用户,访问220W+链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户应该基本完成了。
项目地址:
实现代码:
作者:卧颜沉默 链接:https://www.zhihu.com/question ... 43000 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 /** * * @param httpClient Http客户端 * @param context Http上下文 * @return */ public boolean login(CloseableHttpClient httpClient, HttpClientContext context){ String yzm = null; String loginState = null; HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin"); HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false); HttpPost request = new HttpPost("https://www.zhihu.com/login/email"); List formParams = new ArrayList(); yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login");//肉眼识别验证码 formParams.add(new BasicNameValuePair("captcha", yzm)); formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用 formParams.add(new BasicNameValuePair("email", "邮箱")); formParams.add(new BasicNameValuePair("password", "密码")); formParams.add(new BasicNameValuePair("remember_me", "true")); UrlEncodedFormEntity entity = null; try { entity = new UrlEncodedFormEntity(formParams, "utf-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } request.setEntity(entity); loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录 JSONObject jo = new JSONObject(loginState); if(jo.get("r").toString().equals("0")){ System.out.println("登录成功"); getRequest = new HttpGet("https://www.zhihu.com"); HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页 HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录 return true; }else{ System.out.println("登录失败" + loginState); return false; } } /** * 肉眼识别验证码 * @param httpClient Http客户端 * @param context Http上下文 * @param url 验证码地址 * @return */ public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){ HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true); Scanner sc = new Scanner(System.in); String yzm = sc.nextLine(); return yzm; }
效果图:
查看全部
java爬虫抓取网页数据(一个基于JAVA的知乎爬虫,知乎用户基本信息,基于HttpClient4.5
)
本文主要介绍一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下。
本文示例分享了一个基于JAVA的知乎爬虫,基于HttpClient4.5,抓取知乎用户的基本信息,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户都在里面)
大概的概念:
1.首先模拟登录知乎。登录成功后,cookie会被序列化到磁盘,不需要每次都登录(如果不模拟登录,可以直接从浏览器插入cookie)。
2.创建两个线程池和一个Storage。一个网页爬取线程池负责执行请求请求,返回网页内容,并存储在Storage中。另一种是解析网页线程池,它负责从Storage中获取和分析网页内容,分析用户信息并存储到数据库中,分析用户关注的人的主页,并将地址请求添加到网页抓取线程池。继续循环。
3. 关于URL去重,我直接将访问过的链接md5保存到数据库中。每次访问前,检查数据库中是否存在该链接。
目前已抓获100W用户,访问220W+链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户应该基本完成了。
项目地址:
实现代码:
作者:卧颜沉默 链接:https://www.zhihu.com/question ... 43000 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 /** * * @param httpClient Http客户端 * @param context Http上下文 * @return */ public boolean login(CloseableHttpClient httpClient, HttpClientContext context){ String yzm = null; String loginState = null; HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin";); HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false); HttpPost request = new HttpPost("https://www.zhihu.com/login/email";); List formParams = new ArrayList(); yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login";);//肉眼识别验证码 formParams.add(new BasicNameValuePair("captcha", yzm)); formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用 formParams.add(new BasicNameValuePair("email", "邮箱")); formParams.add(new BasicNameValuePair("password", "密码")); formParams.add(new BasicNameValuePair("remember_me", "true")); UrlEncodedFormEntity entity = null; try { entity = new UrlEncodedFormEntity(formParams, "utf-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } request.setEntity(entity); loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录 JSONObject jo = new JSONObject(loginState); if(jo.get("r").toString().equals("0")){ System.out.println("登录成功"); getRequest = new HttpGet("https://www.zhihu.com";); HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页 HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录 return true; }else{ System.out.println("登录失败" + loginState); return false; } } /** * 肉眼识别验证码 * @param httpClient Http客户端 * @param context Http上下文 * @param url 验证码地址 * @return */ public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){ HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true); Scanner sc = new Scanner(System.in); String yzm = sc.nextLine(); return yzm; }
效果图:
java爬虫抓取网页数据(用Python写网络爬虫的212页代码清晰,很适合入门 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-29 15:15
)
Crawler 是开始使用 Python 的最佳方式之一。掌握Python爬虫后,学习Python的其他知识点会更加得心应手。当然,对于零基础的朋友来说,使用Python爬虫还是有难度的,那么朋友们,你真的擅长Python爬虫吗?
这里简单介绍一下Python爬虫的那些事儿。对于想提高实战能力的人,我还准备了《用Python编写Web爬虫》教程,共212页,内容清晰,代码清晰,非常适合入门学习。
【文末有获取信息的方法!!】
基本爬虫架构
从上图可以看出,爬虫的基本架构大致分为五类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储。
对于这5类函数,我给大家简单的解释一下:
Python 爬虫是非法的吗?
关于 Python 是否违法,众说纷纭,但到目前为止,Python 网络爬虫仍在法律的管辖范围之内。当然,如果捕获的数据被用于个人或商业目的,并造成一定的负面影响,那么就会受到谴责。的。所以请合理使用Python爬虫。
为什么选择 Python 进行爬虫?
1、 抓取网页本身的界面
与其他静态编程语言相比,python具有更简洁的网页文档抓取界面;另外,爬取网页有时需要模拟浏览器的行为,很多网站为了生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方。python中有优秀的第三方包可以帮你处理。
2、网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
NO.1 开发速度快,语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
如何使用 Python 进行网络爬虫?
《Writing Web Crawlers in Python》共212页9章,涵盖了从基础到实际应用的所有内容。内容详细简洁,代码清晰可复现。非常适合对Python编程经验感兴趣,对爬虫感兴趣的朋友。
9章从以下内容展开:
第一章:网络爬虫简介,介绍了网络爬虫是什么以及如何爬取网站。
第 2 章:数据捕获,展示了如何使用多个库从网页中提取数据。
第三章:下载缓存,介绍了如何通过缓存结果来避免重复下载的问题。
第 4 章:并发下载,教您如何加快通过并行下载站点的数据爬行。
第 5 章:动态内容,介绍了如何通过多种方式从动态网站中提取数据。
第 6 章:表单交互,展示如何使用输入和导航表单进行搜索和登录。
第 7 章:验证码处理,说明如何访问受验证码图像保护的数据。
第 8 章:Scrapy,介绍如何使用 Scrapy 进行快速并行爬取,并使用 Portia 的 Web 界面构建 Web 爬虫。
第九章综合应用,总结了你在本书中学到的网络爬虫技术。
部分内容展示:
【获取方法见下图!!】
查看全部
java爬虫抓取网页数据(用Python写网络爬虫的212页代码清晰,很适合入门
)
Crawler 是开始使用 Python 的最佳方式之一。掌握Python爬虫后,学习Python的其他知识点会更加得心应手。当然,对于零基础的朋友来说,使用Python爬虫还是有难度的,那么朋友们,你真的擅长Python爬虫吗?
这里简单介绍一下Python爬虫的那些事儿。对于想提高实战能力的人,我还准备了《用Python编写Web爬虫》教程,共212页,内容清晰,代码清晰,非常适合入门学习。
【文末有获取信息的方法!!】
基本爬虫架构
从上图可以看出,爬虫的基本架构大致分为五类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储。
对于这5类函数,我给大家简单的解释一下:
Python 爬虫是非法的吗?
关于 Python 是否违法,众说纷纭,但到目前为止,Python 网络爬虫仍在法律的管辖范围之内。当然,如果捕获的数据被用于个人或商业目的,并造成一定的负面影响,那么就会受到谴责。的。所以请合理使用Python爬虫。
为什么选择 Python 进行爬虫?
1、 抓取网页本身的界面
与其他静态编程语言相比,python具有更简洁的网页文档抓取界面;另外,爬取网页有时需要模拟浏览器的行为,很多网站为了生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方。python中有优秀的第三方包可以帮你处理。
2、网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
NO.1 开发速度快,语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
如何使用 Python 进行网络爬虫?
《Writing Web Crawlers in Python》共212页9章,涵盖了从基础到实际应用的所有内容。内容详细简洁,代码清晰可复现。非常适合对Python编程经验感兴趣,对爬虫感兴趣的朋友。
9章从以下内容展开:
第一章:网络爬虫简介,介绍了网络爬虫是什么以及如何爬取网站。
第 2 章:数据捕获,展示了如何使用多个库从网页中提取数据。
第三章:下载缓存,介绍了如何通过缓存结果来避免重复下载的问题。
第 4 章:并发下载,教您如何加快通过并行下载站点的数据爬行。
第 5 章:动态内容,介绍了如何通过多种方式从动态网站中提取数据。
第 6 章:表单交互,展示如何使用输入和导航表单进行搜索和登录。
第 7 章:验证码处理,说明如何访问受验证码图像保护的数据。
第 8 章:Scrapy,介绍如何使用 Scrapy 进行快速并行爬取,并使用 Portia 的 Web 界面构建 Web 爬虫。
第九章综合应用,总结了你在本书中学到的网络爬虫技术。
部分内容展示:
【获取方法见下图!!】
java爬虫抓取网页数据(PHP是什么东西?PHP爬虫有什么用?Python我说实话 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-28 14:14
)
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP制作的动态页面是将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行得更快。——百度百科介绍。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集
程序。可能是我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集
网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。我一直认为用PHP写东西的时候,只要想一个算法程序就可以了,不用考虑太多的数据类型。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows + Apache + Mysql + PHP
灯:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。
五、 PHP爬虫第二步
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。实际上,爬虫是一个数据采集程序。上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说,“你太菜了!有什么用?” 虽然我是厨子,但请不要告诉我,让我假装是个X。
其实爬虫是干什么用的,主要看你想让它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站很好吃,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善,不完善的地方要自己去创造和完善。
六、 搜索引擎爬虫的局限性
有时,搜索引擎的爬虫不是无法获取该网站页面的页面源代码,而是有一个robot.txt文件。带有此文件的网站意味着网站所有者不希望爬虫抓取页面源代码。
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。一个有反爬虫机制的网站就像:知乎,知乎就是一个有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP 编写基本的正则表达式,使用数据库,并运行环境。
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("://127.0.0.1/index.php") [function.file-get-contents]:无法打开流:E 中的参数无效:\website\blog\test.php 第 25 行
https 是一种 SSL 加密协议。如果获取页面时报上述错误,说明你的PHP可能缺少OpenSSL模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求爬取尽可能多的网站。这是第一点。第二点是获取网页的信息。一开始,一些特殊的小网站不会放弃一些信息,也不会提取出来。例如:一个小网站的网页的meta标签中没有描述信息(description)或关键词信息(关键字),就放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会把页面中的文字内容提取出来作为填充,反正就是尽可能的实现爬取到的网页信息。每个网页的信息项必须相同。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法是这样的原因。我的算法是抓取获得的页面。所有的链接,然后爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我认为搜索引擎爬虫肯定存在不确定性。
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3. 无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面的图片创意
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码
查看全部
java爬虫抓取网页数据(PHP是什么东西?PHP爬虫有什么用?Python我说实话
)
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP制作的动态页面是将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行得更快。——百度百科介绍。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集
程序。可能是我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集
网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。我一直认为用PHP写东西的时候,只要想一个算法程序就可以了,不用考虑太多的数据类型。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows + Apache + Mysql + PHP
灯:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。
五、 PHP爬虫第二步
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。实际上,爬虫是一个数据采集程序。上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说,“你太菜了!有什么用?” 虽然我是厨子,但请不要告诉我,让我假装是个X。
其实爬虫是干什么用的,主要看你想让它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站很好吃,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善,不完善的地方要自己去创造和完善。
六、 搜索引擎爬虫的局限性
有时,搜索引擎的爬虫不是无法获取该网站页面的页面源代码,而是有一个robot.txt文件。带有此文件的网站意味着网站所有者不希望爬虫抓取页面源代码。
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。一个有反爬虫机制的网站就像:知乎,知乎就是一个有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP 编写基本的正则表达式,使用数据库,并运行环境。
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("://127.0.0.1/index.php") [function.file-get-contents]:无法打开流:E 中的参数无效:\website\blog\test.php 第 25 行
https 是一种 SSL 加密协议。如果获取页面时报上述错误,说明你的PHP可能缺少OpenSSL模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求爬取尽可能多的网站。这是第一点。第二点是获取网页的信息。一开始,一些特殊的小网站不会放弃一些信息,也不会提取出来。例如:一个小网站的网页的meta标签中没有描述信息(description)或关键词信息(关键字),就放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会把页面中的文字内容提取出来作为填充,反正就是尽可能的实现爬取到的网页信息。每个网页的信息项必须相同。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法是这样的原因。我的算法是抓取获得的页面。所有的链接,然后爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我认为搜索引擎爬虫肯定存在不确定性。
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3. 无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面的图片创意
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码

