
java爬虫抓取网页数据
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-03-26 00:18
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
由“爬虫”发回的数据进行处理和过滤的服务器,爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
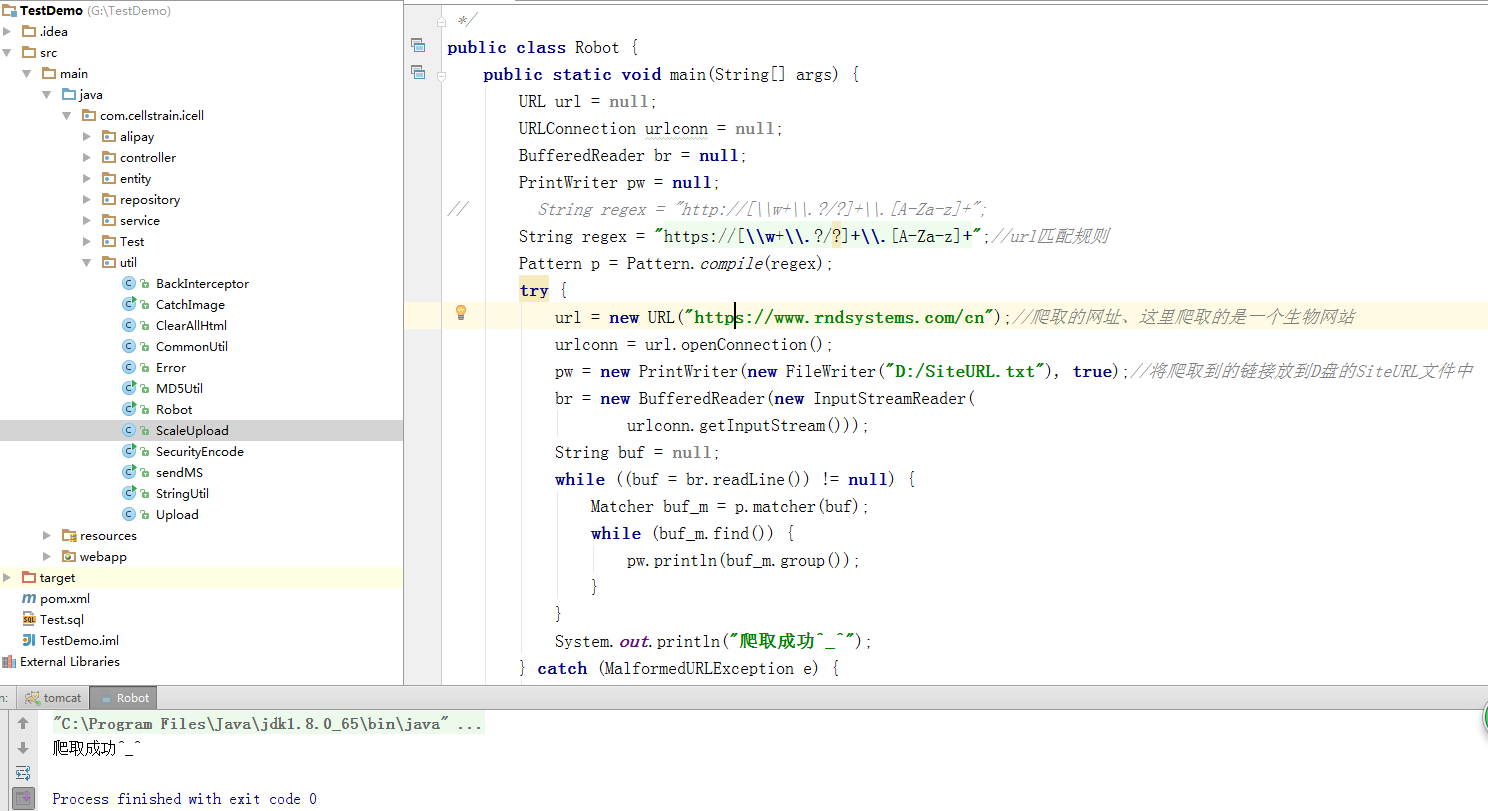
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件
已经成功生成SiteURL文件,打开就可以看到所有抓到的url
查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人()
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
由“爬虫”发回的数据进行处理和过滤的服务器,爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。

与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件

已经成功生成SiteURL文件,打开就可以看到所有抓到的url

java爬虫抓取网页数据(博客系列Java爬虫入门简介(一)——HttpClient请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-22 20:42
)
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫简介(二)——Jsoup解析HTML页面(本文)
在上一篇博客中,我们已经介绍了如何使用 HttpClient 来模拟客户端请求页面。在本篇博客中,我们将介绍如何解析获取的页面内容。
在上一节中,我们获得了页面的 HTML 源代码,但是这些源代码是提供给浏览器进行解析的。我们需要的数据其实就是页面上博客的标题、作者、简介、发布日期等。我们需要一种方法来从 HTML 源代码中解析这些信息,将其提取出来,并将其存储在文本或数据库中。在本篇博客中,我们将介绍使用 Jsoup 包来帮助我们解析页面和提取数据。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址或者解析HTML内容。它的主要功能包括解析 HTML 页面、通过 DOM 或 CSS 选择器查找和提取数据以及更改 HTML 内容。Jsoup的使用也很简单。使用Jsoup.parse(String str)方法解析我们之前获取的HTML内容得到一个Document类,剩下的工作就是从Document中选择我们需要的数据。例如,假设我们有一个收录以下内容的 HTML 页面:
第一篇博客
第二篇博客
第三篇博客
通过Jsoup,我们可以将以上三个博客的标题提取成一个List。使用方法如下:
首先,我们通过maven来介绍Jsoup
org.jsoup
jsoup
1.10.3
然后写Java来解析。
package org.hfutec.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
List titles = new ArrayList();
List urls = new ArrayList();
//假设我们获取的HTML的字符内容如下
String html = "<a href=\"url1\">第一篇博客</a><a href=\"url2\">第二篇博客</a><a href=\"url3\">第三篇博客</a>";
//第一步,将字符内容解析成一个Document类
Document doc = Jsoup.parse(html);
//第二步,根据我们需要得到的标签,选择提取相应标签的内容
Elements elements = doc.select("div[id=blog_list]").select("div[class=blog_title]");
for( Element element : elements ){
String title = element.text();
titles.add(title);
urls.add(element.select("a").attr("href"));
}
//输出测试
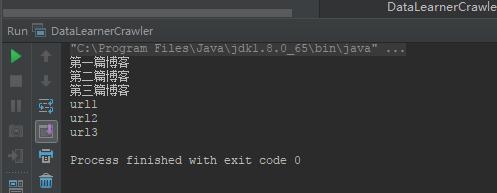
for( String title : titles ){
System.out.println(title);
}
for( String url : urls ){
System.out.println(url);
}
}
}
下面简单介绍一下Jsoup的解析过程。第一步是调用parse()方法把字符对象变成Document对象,然后我们对这个对象进行操作。一般来说,提取数据就是根据标签选择数据。select() 方法的语法格式与 javascript/css 选择器的语法格式相同。一般抽取一个标签,其属性值为指定的内容。得到的结果是一个Elements的集合,也就是Elements(因为可能有很多符合条件的标签,所以结果就是一个集合)。select() 方法可以一直持续到我们想要的标签集被选中(注意我们不必从标签层级中逐层选择,我们可以直接将 select() 方法写到我们需要的标签中,例如, 这里的示例代码可以直接写成 Elements elements = doc.select("div[class=blog_title]"); 效果是一样的)。对于选定的一组元素,我们可以通过循环提取每个所需的数据。例如,如果我们需要获取标签的文本信息,可以使用 text() 方法。如果我们需要获取对应的 HTML 属性信息,可以使用 attr() 方法。我们可以看到上述方法的输出如下:
更多Jsoup解析操作请参考以下内容:
1、
2、
一个实例
让我们继续上一个爬取数据的例子来学习官方的网站博客列表来解释一个例子。我们已经知道可以使用 Jsoup 来解析爬取的 HTML 页面内容。那么我们如何查看我们需要的内容对应的标签呢?以Chrome浏览器为例,我们需要爬取这个页面的博客。首先用Chrome浏览器打开网址,然后右击博客标题,点击“Inspect”,得到HTML页面。如下所示。
图2 右击标题
图3 点击元素父元素侧边的小三角关闭代码查看
图4 确认当前博客HTML代码的一致性
经过上面的操作,我们已经可以看到所有的博客标题等信息都存放在class=card div中了。所以,我们只需要注意这个标签中的内容是如何组织的,仅此而已。如下图所示,我们需要的信息所属的标签可以通过点击小三角展开得到。
因此,解析博客列表的代码可以写成如下。
package org.hfutec.example;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
String url = "http://www.datalearner.com/blog_list";
String rawHTML = null;
try {
rawHTML = getHTMLContent(url);
} catch (IOException e) {
e.printStackTrace();
}
//将当前页面转换成Jsoup的Document对象
Document doc = Jsoup.parse(rawHTML);
//获取所有的博客列表集合
Elements blogList = doc.select("div[class=card]");
//针对每个博客内容进行解析,并输出
for( Element element : blogList ){
String title = element.select("h4[class=card-title]").text();
String introduction = element.select("p[class=card-text]").text();
String author = element.select("span[class=fa fa-user]").text();
System.out.println("Title:\t"+title);
System.out.println("introduction:\t"+introduction);
System.out.println("Author:\t"+author);
System.out.println("--------------------------");
}
}
//根据url地址获取对应页面的HTML内容,我们将上一节中的内容打包成了一个方法,方便调用
private static String getHTMLContent( String url ) throws IOException {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet(url);
//获取网址的返回结果
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity);
//关闭HttpEntity流
EntityUtils.consume(entity);
return content;
}
}
最终输出如下图所示:
查看全部
java爬虫抓取网页数据(博客系列Java爬虫入门简介(一)——HttpClient请求
)
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫简介(二)——Jsoup解析HTML页面(本文)
在上一篇博客中,我们已经介绍了如何使用 HttpClient 来模拟客户端请求页面。在本篇博客中,我们将介绍如何解析获取的页面内容。
在上一节中,我们获得了页面的 HTML 源代码,但是这些源代码是提供给浏览器进行解析的。我们需要的数据其实就是页面上博客的标题、作者、简介、发布日期等。我们需要一种方法来从 HTML 源代码中解析这些信息,将其提取出来,并将其存储在文本或数据库中。在本篇博客中,我们将介绍使用 Jsoup 包来帮助我们解析页面和提取数据。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址或者解析HTML内容。它的主要功能包括解析 HTML 页面、通过 DOM 或 CSS 选择器查找和提取数据以及更改 HTML 内容。Jsoup的使用也很简单。使用Jsoup.parse(String str)方法解析我们之前获取的HTML内容得到一个Document类,剩下的工作就是从Document中选择我们需要的数据。例如,假设我们有一个收录以下内容的 HTML 页面:
第一篇博客
第二篇博客
第三篇博客
通过Jsoup,我们可以将以上三个博客的标题提取成一个List。使用方法如下:
首先,我们通过maven来介绍Jsoup
org.jsoup
jsoup
1.10.3
然后写Java来解析。
package org.hfutec.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
List titles = new ArrayList();
List urls = new ArrayList();
//假设我们获取的HTML的字符内容如下
String html = "<a href=\"url1\">第一篇博客</a><a href=\"url2\">第二篇博客</a><a href=\"url3\">第三篇博客</a>";
//第一步,将字符内容解析成一个Document类
Document doc = Jsoup.parse(html);
//第二步,根据我们需要得到的标签,选择提取相应标签的内容
Elements elements = doc.select("div[id=blog_list]").select("div[class=blog_title]");
for( Element element : elements ){
String title = element.text();
titles.add(title);
urls.add(element.select("a").attr("href"));
}
//输出测试
for( String title : titles ){
System.out.println(title);
}
for( String url : urls ){
System.out.println(url);
}
}
}
下面简单介绍一下Jsoup的解析过程。第一步是调用parse()方法把字符对象变成Document对象,然后我们对这个对象进行操作。一般来说,提取数据就是根据标签选择数据。select() 方法的语法格式与 javascript/css 选择器的语法格式相同。一般抽取一个标签,其属性值为指定的内容。得到的结果是一个Elements的集合,也就是Elements(因为可能有很多符合条件的标签,所以结果就是一个集合)。select() 方法可以一直持续到我们想要的标签集被选中(注意我们不必从标签层级中逐层选择,我们可以直接将 select() 方法写到我们需要的标签中,例如, 这里的示例代码可以直接写成 Elements elements = doc.select("div[class=blog_title]"); 效果是一样的)。对于选定的一组元素,我们可以通过循环提取每个所需的数据。例如,如果我们需要获取标签的文本信息,可以使用 text() 方法。如果我们需要获取对应的 HTML 属性信息,可以使用 attr() 方法。我们可以看到上述方法的输出如下:
更多Jsoup解析操作请参考以下内容:
1、
2、
一个实例
让我们继续上一个爬取数据的例子来学习官方的网站博客列表来解释一个例子。我们已经知道可以使用 Jsoup 来解析爬取的 HTML 页面内容。那么我们如何查看我们需要的内容对应的标签呢?以Chrome浏览器为例,我们需要爬取这个页面的博客。首先用Chrome浏览器打开网址,然后右击博客标题,点击“Inspect”,得到HTML页面。如下所示。

图2 右击标题

图3 点击元素父元素侧边的小三角关闭代码查看

图4 确认当前博客HTML代码的一致性
经过上面的操作,我们已经可以看到所有的博客标题等信息都存放在class=card div中了。所以,我们只需要注意这个标签中的内容是如何组织的,仅此而已。如下图所示,我们需要的信息所属的标签可以通过点击小三角展开得到。

因此,解析博客列表的代码可以写成如下。
package org.hfutec.example;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
String url = "http://www.datalearner.com/blog_list";
String rawHTML = null;
try {
rawHTML = getHTMLContent(url);
} catch (IOException e) {
e.printStackTrace();
}
//将当前页面转换成Jsoup的Document对象
Document doc = Jsoup.parse(rawHTML);
//获取所有的博客列表集合
Elements blogList = doc.select("div[class=card]");
//针对每个博客内容进行解析,并输出
for( Element element : blogList ){
String title = element.select("h4[class=card-title]").text();
String introduction = element.select("p[class=card-text]").text();
String author = element.select("span[class=fa fa-user]").text();
System.out.println("Title:\t"+title);
System.out.println("introduction:\t"+introduction);
System.out.println("Author:\t"+author);
System.out.println("--------------------------");
}
}
//根据url地址获取对应页面的HTML内容,我们将上一节中的内容打包成了一个方法,方便调用
private static String getHTMLContent( String url ) throws IOException {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet(url);
//获取网址的返回结果
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity);
//关闭HttpEntity流
EntityUtils.consume(entity);
return content;
}
}
最终输出如下图所示:

java爬虫抓取网页数据(一共需要做四个规则:第一个规则“第二个规则图” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2022-03-22 20:41
)
2.如何使用快捷键采集:如何使用快捷键采集
通过CNKI高级搜索,输入关键词,即可获取相关的文章标题、作者、摘要、关键词等信息。但是CNKI在输入关键词进行搜索后并没有改变URL,所以在爬取的时候,我们需要爬虫自动输入目标关键词来搜索并开始爬取数据。
要获取标题、作者、摘要、关键词等信息,我们一共需要制定四个规则:
第一条规则”
第二条规则”
提示:文章的部分摘要需要点击“更多”才能全部显示。为了抓取完整的摘要,我们需要制定一个规则来点击这个“更多”。
第三条规则”
第四条规则”
图1
一、第一条规则 - 知网搜索
1.以CNKI高级检索文献文章为例,将高级文献检索链接粘贴到某手。
第一条规则的主要工作是搜索关键词,但是为了有效地执行规则,我们在规则中抓取文章的类型。这里以文献为例,我们抓取的内容为“文献”,并勾选关键内容。
图 2
如图2所示,具体操作如下:
#1.将目标爬取网页粘贴到猫鼠台网址栏,回车。
#2.看到页面加载完毕。
#3.将抓取的内容“文档”映射到排序框中。
#4.选择文献的重点内容。
2.跳转到连续动作工作台输入关键词及其动作
关键词 的自动输入点是建立两个步骤。第一步是通过输入框的定位表达式找到输入框,然后输入关键词。第二步,通过定位表达式找到搜索按钮,然后爬虫自行点击按钮。
2.1 创建输入步骤
图 3
如图3所示,具体操作如下:
#1.输入目标主题名,即第二条规则主题名,表示第二条规则搜索到关键词后会执行爬取
#2.点击谁在使用,查看输入的主题名是否被其他人占用。如果已经被其他人占用,则需要更改另一个主题名称。
#3.创建一个新的输入步骤。如上所述,首先是执行输入动作,所以这里是一个新的输入步骤。
#4.输入 关键词 进行搜索。
#5.根据网页结构填写输入框的定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能进行验证。定位是否准确,详见网页内容搜索方法。
2.2 构建和提交步骤
图 4
如图4所示,具体操作如下:
#1.根据网页结构填写检索定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能来验证是否定位准确。详情请参阅搜索网页内容的使用方法。
保存规则后,知网搜索就完成了。
二、第二条规则——知网搜索结果
该规则负责通过知网搜索对 关键词 搜索到的页面进行爬取。此规则与定义普通规则相同。
将要爬取的内容映射到排序框中。如果我们想要捕获每个文章的详细数据抽象作者,我们需要建立一个分层捕获,在当前规则中捕获每个文章的细节。为CNKI_文章数据生成线索的数据页的URL。
图 5
如图5所示,具体操作如下:
#1.将要爬取的下级链接映射到排序框中
#2.查看关键内容
#3.点击排序框顶部节点复制样本。要抓取当前页面文章的所有下级链接,需要复制样本。详情请参考教程:
#4.跳转到爬虫路由工作台做翻页线索。要抓取翻页的文章,需要做翻页线索。详情请参考教程:
保存规则后,CNKI_search结果规则就完成了,接下来需要做文章详细页面的爬取规则。
三、第三条规则——知网_文章数据_more
1.将网页上的“更多”按钮映射到排序框作为内容映射,查看重点内容。
2.在爬虫路由工作台上做一个模拟点击,即为“更多”做一个标记轨迹作为标记。
图 6
如图6所示,具体操作如下:
#1.新建一个标记线索,勾选Consecutive fetching,意思是爬虫在执行抓取任务时,在同一个DS计数器窗口抓取到当前页面后,可以直接跳转到下一页。抓住。
#2.点击“更多”按钮,自动定位页面标签节点,展开节点,找到收录“更多”的文本节点。
#3.在文本节点上右键,Clue Mapping → Mark Clue,可以看到“more”自动填入了mark值。
#4.将节点映射到线索范围,右击翻页块节点,选择线索映射→定位→线索1,完成后定位号会显示页面的定位号-转块节点。
保存规则后,知网_文章Data_More规则就完成了,接下来需要完成一些“更多”知网来执行抓取的规则——知网_文章Data。
提示:第三条和第四条规则演示模拟点击。不明白的可以参考教程:
四、第四条规则——知网_文章数据。
这个规则是最简单的类型,将需要爬取的内容映射到一个bin中。
图 7
如图7所示,具体操作如下: #1. 将要抓取的内容映射到排序框中。
五、修改文章详细页面URL参数,构造新URL,生成第三条规则线索——hownet_文章data_more
将第二条规则采集的详情页的链接导入excel。
图 8
可以发现不是完整的URL,DS计数器也无法构造URL直接生成可访问的URL,需要用excel手动修改。
对比详情页的完整网址,如下:
可以发现采集的链接缺少了之前的域名,增加了“/kns”部分。您可以使用该功能修改链接。
图 9
在J2单元格中输入公式=""&RIGHT(I2,LEN(I2)-4)获取可访问的URL并填写,这样就可以将获取的URL作为第三个批量添加规则的线索。
如有疑问,您可以或
查看全部
java爬虫抓取网页数据(一共需要做四个规则:第一个规则“第二个规则图”
)
2.如何使用快捷键采集:如何使用快捷键采集
通过CNKI高级搜索,输入关键词,即可获取相关的文章标题、作者、摘要、关键词等信息。但是CNKI在输入关键词进行搜索后并没有改变URL,所以在爬取的时候,我们需要爬虫自动输入目标关键词来搜索并开始爬取数据。
要获取标题、作者、摘要、关键词等信息,我们一共需要制定四个规则:
第一条规则”
第二条规则”
提示:文章的部分摘要需要点击“更多”才能全部显示。为了抓取完整的摘要,我们需要制定一个规则来点击这个“更多”。
第三条规则”
第四条规则”
图1
一、第一条规则 - 知网搜索
1.以CNKI高级检索文献文章为例,将高级文献检索链接粘贴到某手。
第一条规则的主要工作是搜索关键词,但是为了有效地执行规则,我们在规则中抓取文章的类型。这里以文献为例,我们抓取的内容为“文献”,并勾选关键内容。
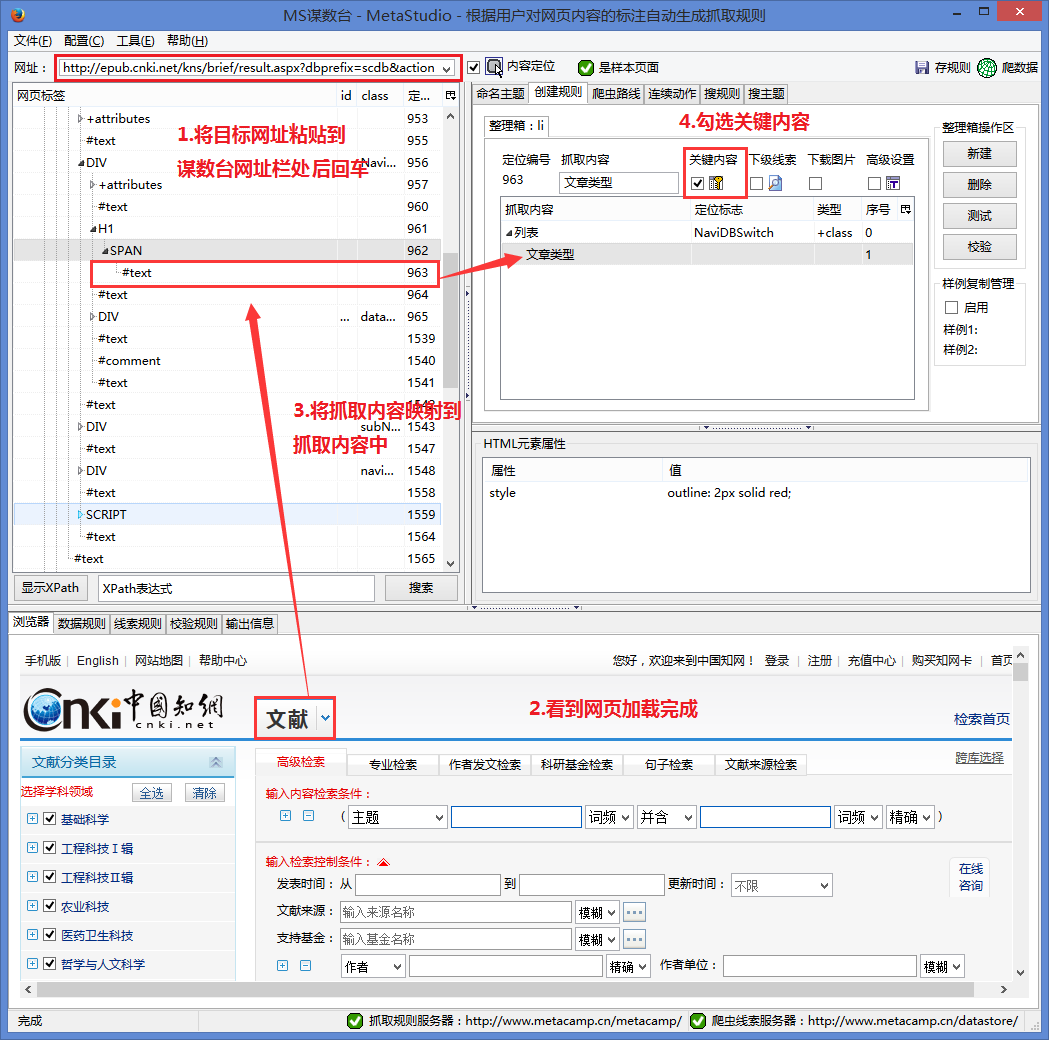
图 2
如图2所示,具体操作如下:
#1.将目标爬取网页粘贴到猫鼠台网址栏,回车。
#2.看到页面加载完毕。
#3.将抓取的内容“文档”映射到排序框中。
#4.选择文献的重点内容。
2.跳转到连续动作工作台输入关键词及其动作
关键词 的自动输入点是建立两个步骤。第一步是通过输入框的定位表达式找到输入框,然后输入关键词。第二步,通过定位表达式找到搜索按钮,然后爬虫自行点击按钮。
2.1 创建输入步骤
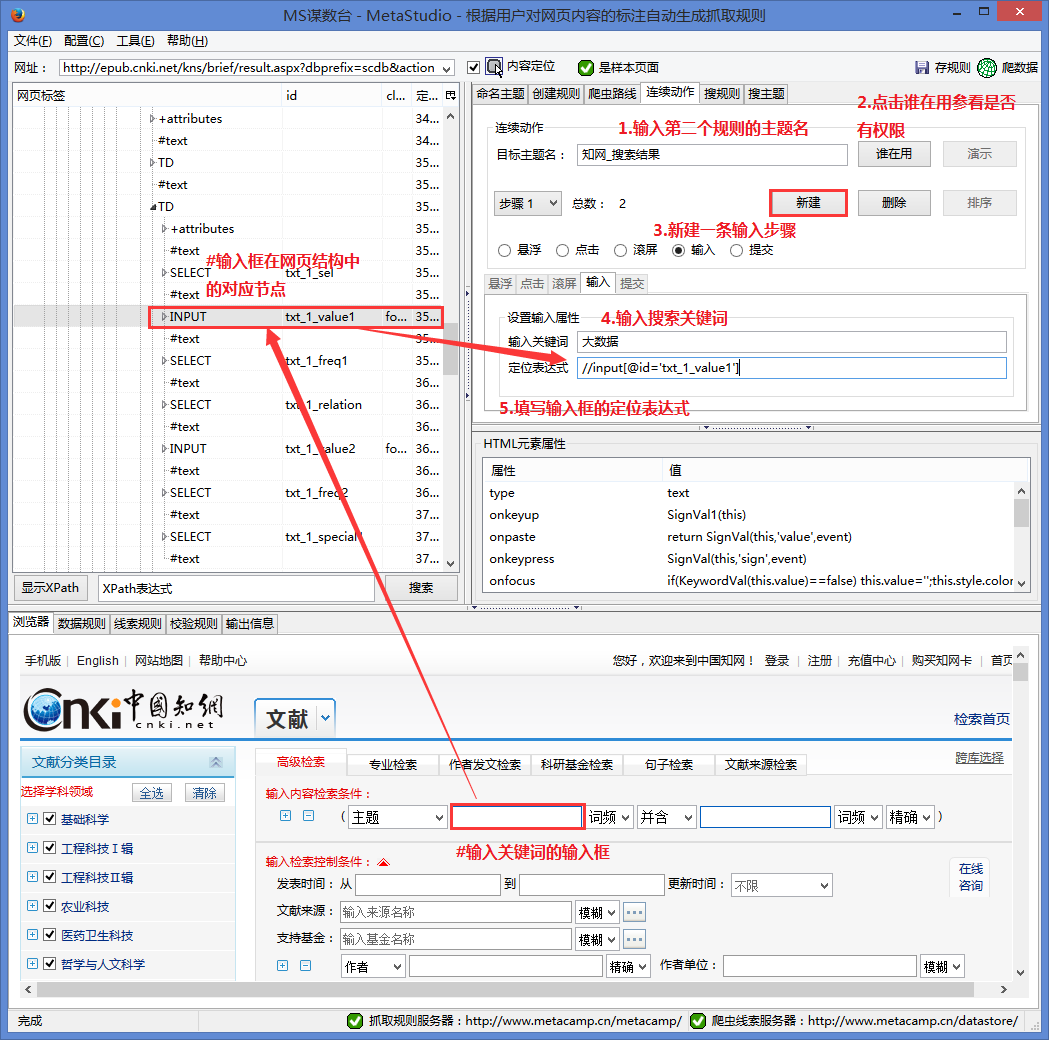
图 3
如图3所示,具体操作如下:
#1.输入目标主题名,即第二条规则主题名,表示第二条规则搜索到关键词后会执行爬取
#2.点击谁在使用,查看输入的主题名是否被其他人占用。如果已经被其他人占用,则需要更改另一个主题名称。
#3.创建一个新的输入步骤。如上所述,首先是执行输入动作,所以这里是一个新的输入步骤。
#4.输入 关键词 进行搜索。
#5.根据网页结构填写输入框的定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能进行验证。定位是否准确,详见网页内容搜索方法。
2.2 构建和提交步骤
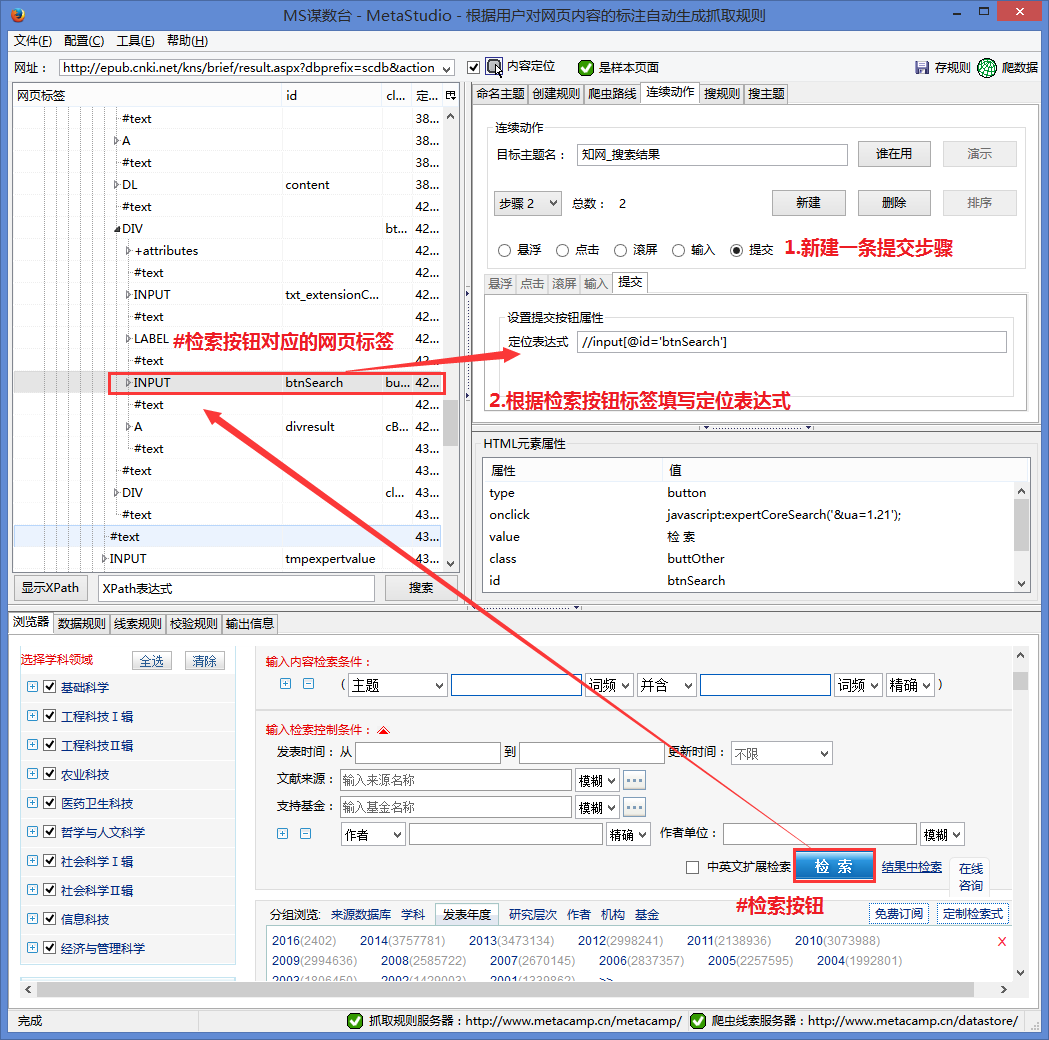
图 4
如图4所示,具体操作如下:
#1.根据网页结构填写检索定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能来验证是否定位准确。详情请参阅搜索网页内容的使用方法。
保存规则后,知网搜索就完成了。
二、第二条规则——知网搜索结果
该规则负责通过知网搜索对 关键词 搜索到的页面进行爬取。此规则与定义普通规则相同。
将要爬取的内容映射到排序框中。如果我们想要捕获每个文章的详细数据抽象作者,我们需要建立一个分层捕获,在当前规则中捕获每个文章的细节。为CNKI_文章数据生成线索的数据页的URL。
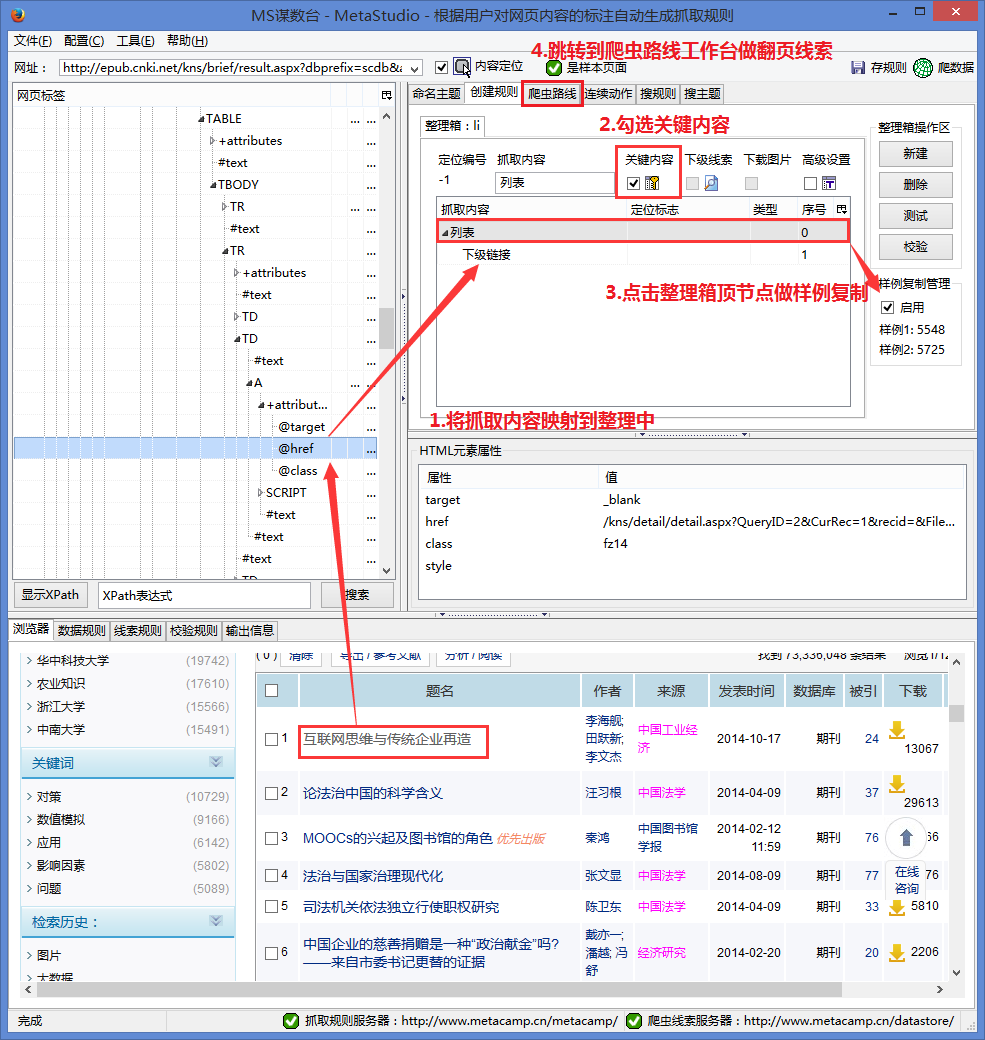
图 5
如图5所示,具体操作如下:
#1.将要爬取的下级链接映射到排序框中
#2.查看关键内容
#3.点击排序框顶部节点复制样本。要抓取当前页面文章的所有下级链接,需要复制样本。详情请参考教程:
#4.跳转到爬虫路由工作台做翻页线索。要抓取翻页的文章,需要做翻页线索。详情请参考教程:
保存规则后,CNKI_search结果规则就完成了,接下来需要做文章详细页面的爬取规则。
三、第三条规则——知网_文章数据_more
1.将网页上的“更多”按钮映射到排序框作为内容映射,查看重点内容。
2.在爬虫路由工作台上做一个模拟点击,即为“更多”做一个标记轨迹作为标记。
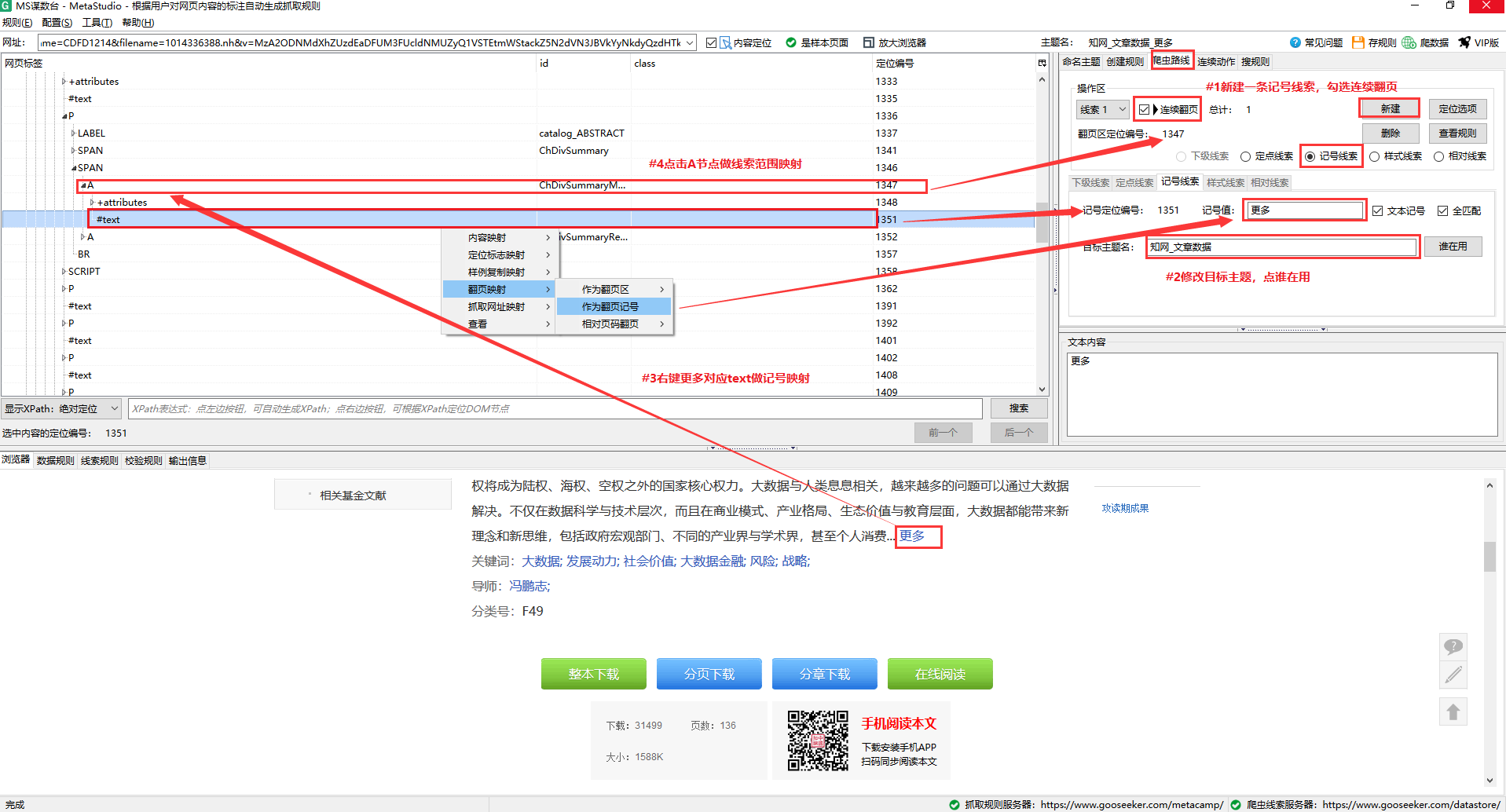
图 6
如图6所示,具体操作如下:
#1.新建一个标记线索,勾选Consecutive fetching,意思是爬虫在执行抓取任务时,在同一个DS计数器窗口抓取到当前页面后,可以直接跳转到下一页。抓住。
#2.点击“更多”按钮,自动定位页面标签节点,展开节点,找到收录“更多”的文本节点。
#3.在文本节点上右键,Clue Mapping → Mark Clue,可以看到“more”自动填入了mark值。
#4.将节点映射到线索范围,右击翻页块节点,选择线索映射→定位→线索1,完成后定位号会显示页面的定位号-转块节点。
保存规则后,知网_文章Data_More规则就完成了,接下来需要完成一些“更多”知网来执行抓取的规则——知网_文章Data。
提示:第三条和第四条规则演示模拟点击。不明白的可以参考教程:
四、第四条规则——知网_文章数据。
这个规则是最简单的类型,将需要爬取的内容映射到一个bin中。
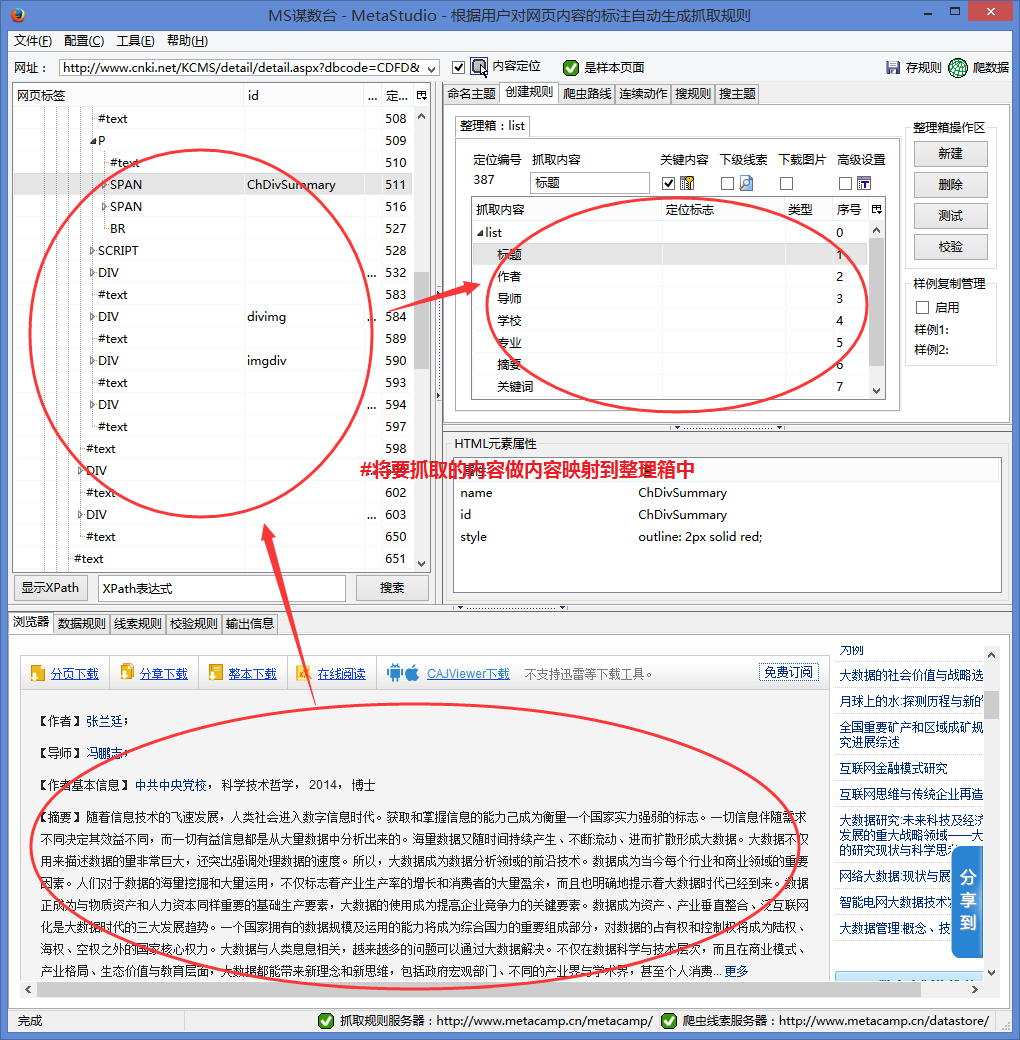
图 7
如图7所示,具体操作如下: #1. 将要抓取的内容映射到排序框中。
五、修改文章详细页面URL参数,构造新URL,生成第三条规则线索——hownet_文章data_more
将第二条规则采集的详情页的链接导入excel。
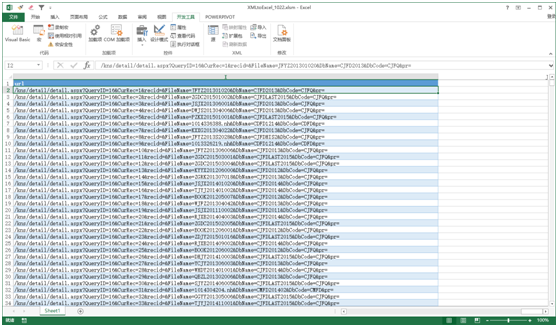
图 8
可以发现不是完整的URL,DS计数器也无法构造URL直接生成可访问的URL,需要用excel手动修改。
对比详情页的完整网址,如下:
可以发现采集的链接缺少了之前的域名,增加了“/kns”部分。您可以使用该功能修改链接。
图 9
在J2单元格中输入公式=""&RIGHT(I2,LEN(I2)-4)获取可访问的URL并填写,这样就可以将获取的URL作为第三个批量添加规则的线索。
如有疑问,您可以或

java爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单的网络 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 20:40
)
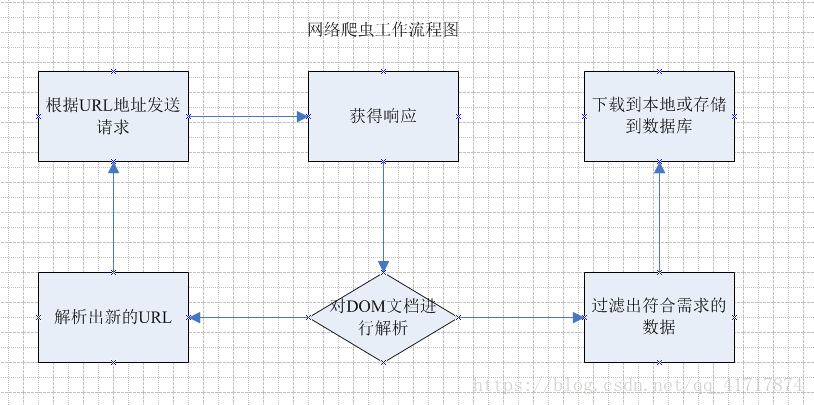
目标网络爬虫做什么?手动编写一个简单的网络爬虫;1.网络爬虫1.1.名称1.2.简要说明2.流程
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注
3. 分类
4. 思想分析
首先观察我们爬虫的起始页是:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
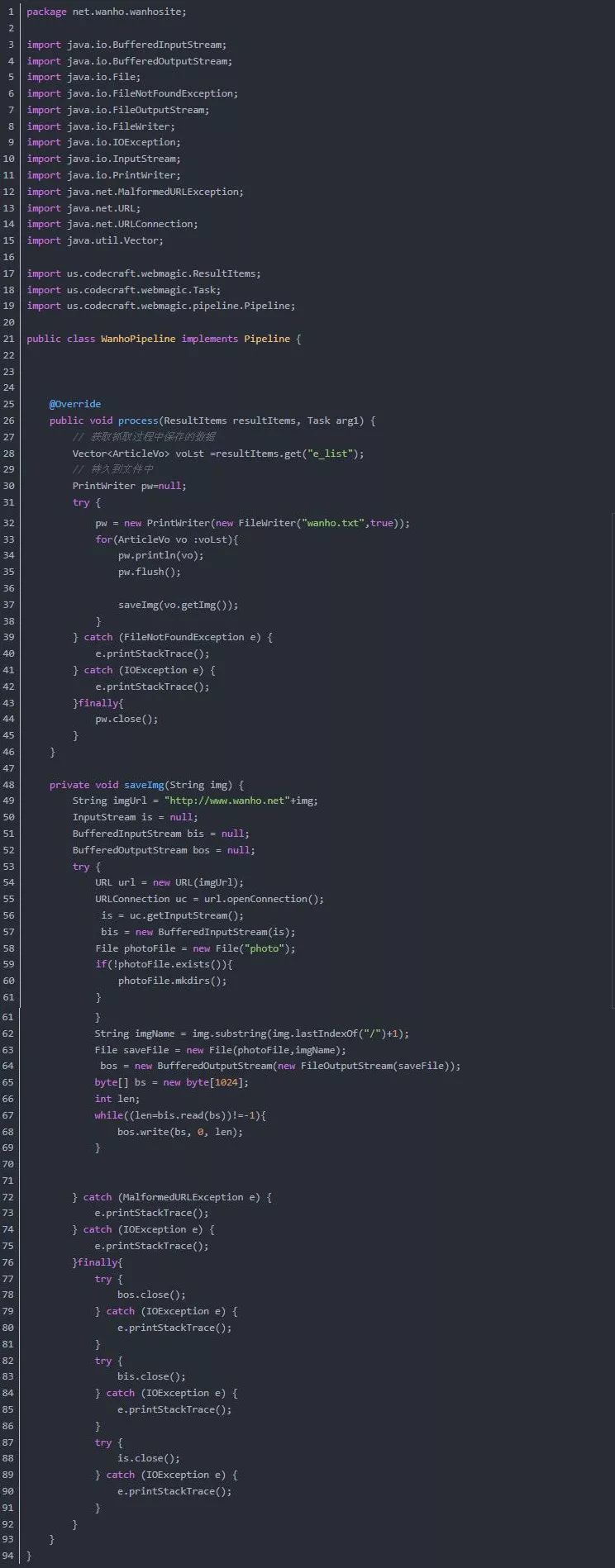
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
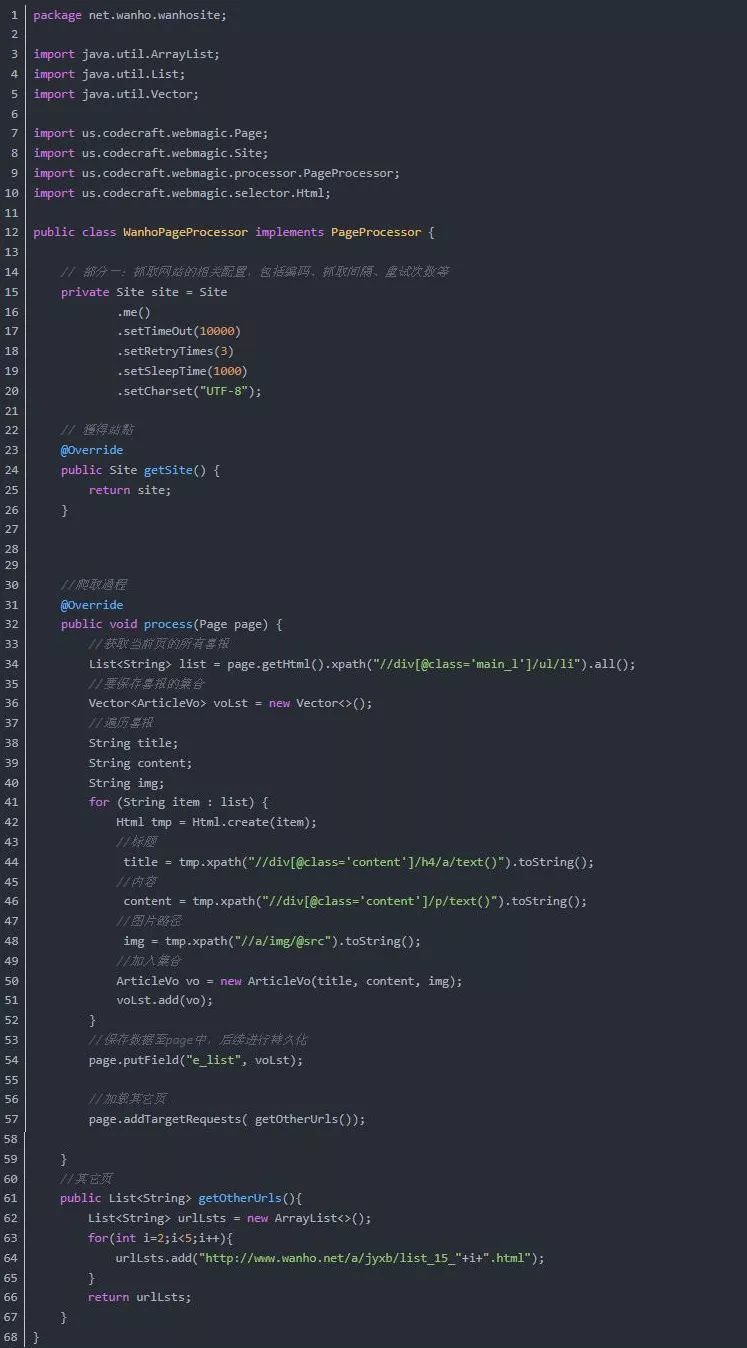
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
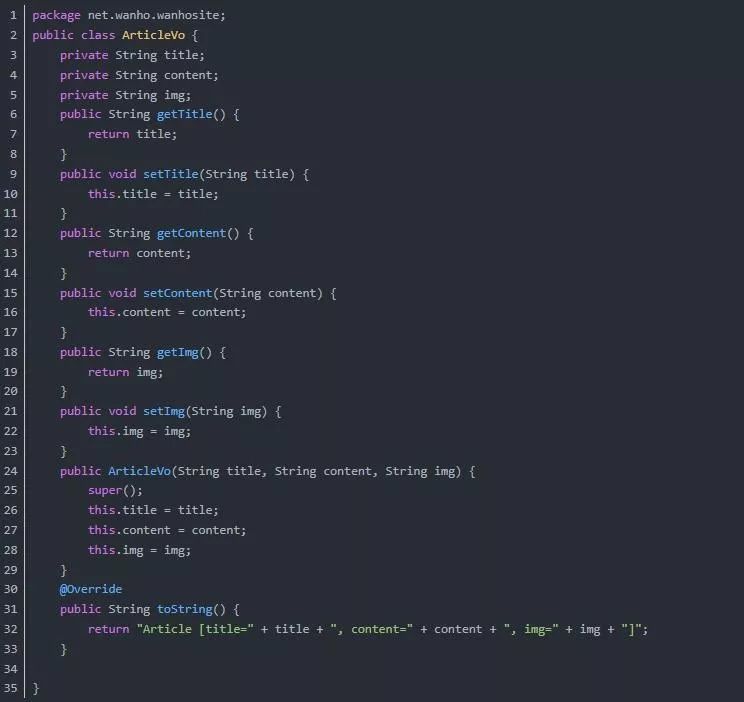
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
java爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单的网络
)
目标网络爬虫做什么?手动编写一个简单的网络爬虫;1.网络爬虫1.1.名称1.2.简要说明2.流程

通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注
3. 分类
4. 思想分析

首先观察我们爬虫的起始页是:

所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li

相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构

5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
java爬虫抓取网页数据(什么是网络爬虫?网络蜘蛛的实现原理根据这种原理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-19 04:12
)
什么是网络爬虫?网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页,从网站的一个页面(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/");
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
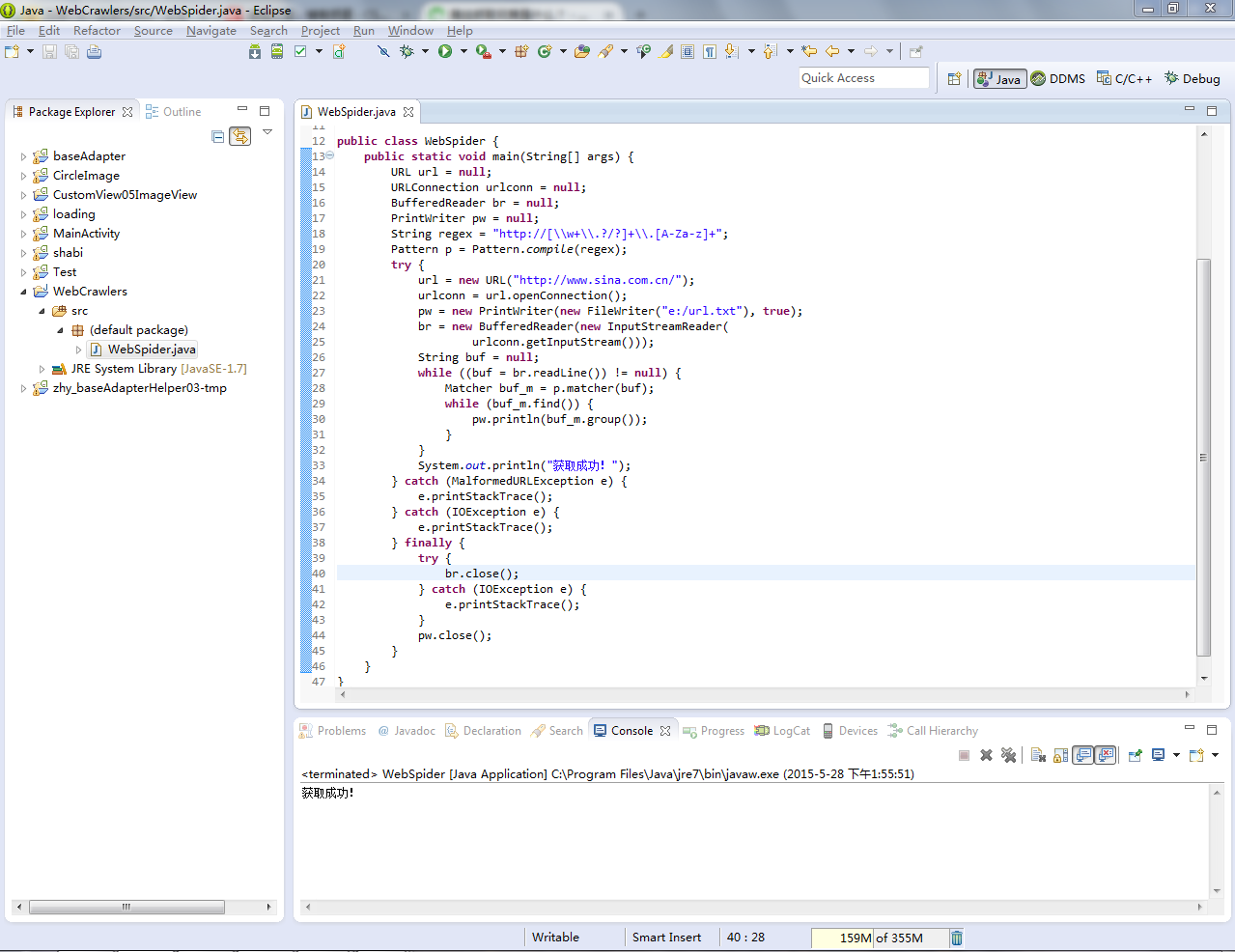
在 Eclipse 中运行的结果
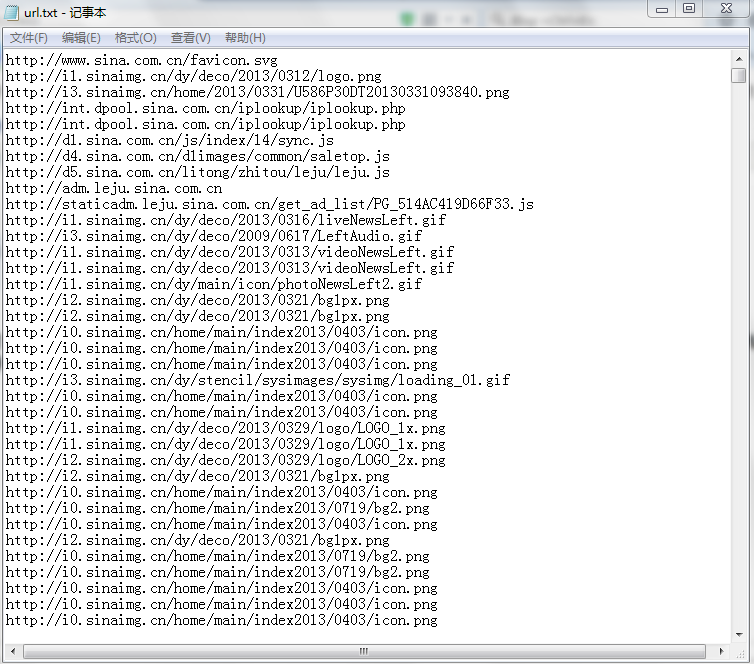
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
查看全部
java爬虫抓取网页数据(什么是网络爬虫?网络蜘蛛的实现原理根据这种原理
)
什么是网络爬虫?网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页,从网站的一个页面(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/";);
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在 Eclipse 中运行的结果
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-18 05:11
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面是万和专业老师为大家分享网络爬虫的入门知识。
0 1
网络爬虫
1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。
这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
一个简单爬虫的必要功能包括:
发送请求和获取响应的函数;
解析响应的函数;
存储过滤数据的功能;
处理解析后的URL路径的函数;
2.1. 专注
爬虫需要注意的三点:
抓取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
0 4
思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据:
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text()
说明:使用XPath表达式表示 //div[@class='content']/p/text()
图片://a/img/@src 作为 XPath 表达式
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 结果保存
WanhoPipeline.java
5.5. 模型对象
ArticleVo.java
如果你想了解更多关于网络爬虫的知识,可以去万和官网,注册后可以免费学习Java爬虫项目。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始 查看全部
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面是万和专业老师为大家分享网络爬虫的入门知识。
0 1
网络爬虫
1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。
这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
一个简单爬虫的必要功能包括:
发送请求和获取响应的函数;
解析响应的函数;
存储过滤数据的功能;
处理解析后的URL路径的函数;
2.1. 专注
爬虫需要注意的三点:
抓取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
0 4
思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li

相关数据:
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text()
说明:使用XPath表达式表示 //div[@class='content']/p/text()
图片://a/img/@src 作为 XPath 表达式
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java

5.3. 爬取过程
WanhoPageProcessor.java
5.4. 结果保存
WanhoPipeline.java
5.5. 模型对象
ArticleVo.java
如果你想了解更多关于网络爬虫的知识,可以去万和官网,注册后可以免费学习Java爬虫项目。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始
java爬虫抓取网页数据(爬虫爬虫处理html格式返回就需要用到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-18 05:09
爬虫
爬虫可以理解为一种从第三方网站获取数据的技术。
关于爬虫语言
Java对网页数据的爬取必须涉及到.URL和从URL读取的数据(本文使用字符流获取url返回),需要经过转换才能被我们使用。目前大部分都是json格式。相比html格式,json格式更简单。本文介绍返回的html格式。
汤
需要 Jsoup 来处理 html 格式的返回。jsoup 是一个 Java html 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。具体的jar包可以自己下载。
我们可以通过如下方式模拟这样的请求,然后从请求的返回中解析出我们需要的数据。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* Created by wingzing on 2018/8/8.
*/
public class WingZingDemo {
public static void main(String[] args) {
String httpUrl = "http://bestcbooks.com/"; //需要爬的网址
String html;
try {
StringBuffer sbf = new StringBuffer();
URL url = new URL(httpUrl);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET"); //设置请求方式 可设置POST 注意一定要大写
//connection.setRequestProperty("Cookie", cookie); //设置请求头参数 如Cookie、Host等等
connection.connect(); //开启连接
InputStream is = connection.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String strRead = null;
while ((strRead = reader.readLine()) != null) { //读取返回
sbf.append(strRead);
sbf.append("\r\n");
}
reader.close();//关闭缓冲字符流
html = sbf.toString();
//System.out.println(html);
Document doc = Jsoup.parse(html);//将爬来的html格式的字符串转成Document从而获取其中需要的数据
Element ul = doc.getElementById("category-list");//取得ID为category-list的元素
Elements liList = ul.getElementsByTag("li");//取得其中的li标签 为一个集合
for(Element li:liList){ //循环该li集合
System.out.println(li.getElementsByTag("a").get(0).text());//取得每个li中的a标签的值 进行输出
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码中的注释写得很清楚。可以自己复制代码运行,通过debug一步步看值。
一般来说,首先获取页面加载或执行时发送的请求,判断是否需要参数,需要哪些参数,进行模拟,然后获取请求的返回,解析请求,获取我们的数据需要。
以上是一个用Java实现的简单爬虫,仅供没有接触过Java的朋友学习爬虫。后续我会写一些Java中稍微麻烦一点的爬虫,比如抓取数据到自己的数据库,对模拟网页进行一些操作等等。 查看全部
java爬虫抓取网页数据(爬虫爬虫处理html格式返回就需要用到)
爬虫
爬虫可以理解为一种从第三方网站获取数据的技术。
关于爬虫语言
Java对网页数据的爬取必须涉及到.URL和从URL读取的数据(本文使用字符流获取url返回),需要经过转换才能被我们使用。目前大部分都是json格式。相比html格式,json格式更简单。本文介绍返回的html格式。
汤
需要 Jsoup 来处理 html 格式的返回。jsoup 是一个 Java html 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。具体的jar包可以自己下载。

我们可以通过如下方式模拟这样的请求,然后从请求的返回中解析出我们需要的数据。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* Created by wingzing on 2018/8/8.
*/
public class WingZingDemo {
public static void main(String[] args) {
String httpUrl = "http://bestcbooks.com/"; //需要爬的网址
String html;
try {
StringBuffer sbf = new StringBuffer();
URL url = new URL(httpUrl);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET"); //设置请求方式 可设置POST 注意一定要大写
//connection.setRequestProperty("Cookie", cookie); //设置请求头参数 如Cookie、Host等等
connection.connect(); //开启连接
InputStream is = connection.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String strRead = null;
while ((strRead = reader.readLine()) != null) { //读取返回
sbf.append(strRead);
sbf.append("\r\n");
}
reader.close();//关闭缓冲字符流
html = sbf.toString();
//System.out.println(html);
Document doc = Jsoup.parse(html);//将爬来的html格式的字符串转成Document从而获取其中需要的数据
Element ul = doc.getElementById("category-list");//取得ID为category-list的元素
Elements liList = ul.getElementsByTag("li");//取得其中的li标签 为一个集合
for(Element li:liList){ //循环该li集合
System.out.println(li.getElementsByTag("a").get(0).text());//取得每个li中的a标签的值 进行输出
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码中的注释写得很清楚。可以自己复制代码运行,通过debug一步步看值。
一般来说,首先获取页面加载或执行时发送的请求,判断是否需要参数,需要哪些参数,进行模拟,然后获取请求的返回,解析请求,获取我们的数据需要。
以上是一个用Java实现的简单爬虫,仅供没有接触过Java的朋友学习爬虫。后续我会写一些Java中稍微麻烦一点的爬虫,比如抓取数据到自己的数据库,对模拟网页进行一些操作等等。
java爬虫抓取网页数据( 有没有什么轻便的框架供我们使用?什么框架?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-18 05:08
有没有什么轻便的框架供我们使用?什么框架?)
Java 爬虫 (二)
前言:在上一篇博客中,我们使用了基于HttpURLConnection的方法进行数据爬取
Java爬虫(一),但是里面没有框架,通过原生http爬取,那么问题来了,有没有轻量级的框架给我们用?
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。本篇博客将主要介绍jsoup技术进行数据爬取,为了提高效率,我们将使用多线程的方式读取数据
爬进入口
我们随便找一个网站来爬取,原理是一样的,比如我们爬取一个国家统计局的数据,首先找到爬取到的网站的页面如下:
比如我爬取天津的数据,找到要爬取的网站页面入口:
http://www.stats.gov.cn/tjsj/t ... .html
爬行的想法
其实爬虫的代码不用太在意。首先我们理清思路,上图:
从上图可以看出我们的基本思路和流程,但是由于网站的可变性,我们不能贸然爬取,造成数据冗余。这个网页的最后一层只有文字信息,其余网页一条短信对应一条短信到一个URL地址,而在最后一层之外,每一层的数字和短信都有相同的URL,所以我们只需要爬取名字,如下:
开始爬行
请注意,我们的以下文档包路径是:
import org.jsoup.nodes.Document;
最终的项目目录结构如下:
1.只需创建一个maven项目
2.在pom.xml文件中添加如下依赖
org.jsoup
jsoup
1.11.3
3.创建主类
public class Main {
//待抓取的Url队列,全局共享
public static final LinkedBlockingQueue UrlQueue = new LinkedBlockingQueue();
public static final WormCore wormCore = new WormCore();
public static void main(String[] args) {
//要抓取的根URL
String rootUrl = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//先把根URL加入URL队列
UrlQueue.offer(rootUrl);
Runnable runnable = new MyRunnable();
//开启固定大小的线程池,线程数为10
ExecutorService Fixed = Executors.newFixedThreadPool(10);
//开始爬取
for (int i = 0;i 3) {
System.out.println(element.text());
}
Flag++;
}
//普通页面的处理
}else {
for (Element element : elements) {
if (!Number.IsNumber(element.text())) {
Text.add(element.text());
System.out.println(element.text());
Urls.add(Before_Url + element.attr("href"));
}
}
}
//把文本集合和URL集合装到Map中返回
Message.put("text",Text);
Message.put("Url",Urls);
return Message;
}
}
由于最后一页与上一页不同,需要因地制宜地调整措施。我们把前面提到的统计划分码号扔掉了,只要名字是必填的,所以博主通过下面Number类中的方法来判断
8.判断是否为数字
<p>public class Number {
public static boolean IsNumber(String str){
for(int i=0;i=48 && c 查看全部
java爬虫抓取网页数据(
有没有什么轻便的框架供我们使用?什么框架?)
Java 爬虫 (二)
前言:在上一篇博客中,我们使用了基于HttpURLConnection的方法进行数据爬取
Java爬虫(一),但是里面没有框架,通过原生http爬取,那么问题来了,有没有轻量级的框架给我们用?
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。本篇博客将主要介绍jsoup技术进行数据爬取,为了提高效率,我们将使用多线程的方式读取数据
爬进入口
我们随便找一个网站来爬取,原理是一样的,比如我们爬取一个国家统计局的数据,首先找到爬取到的网站的页面如下:
比如我爬取天津的数据,找到要爬取的网站页面入口:
http://www.stats.gov.cn/tjsj/t ... .html
爬行的想法
其实爬虫的代码不用太在意。首先我们理清思路,上图:
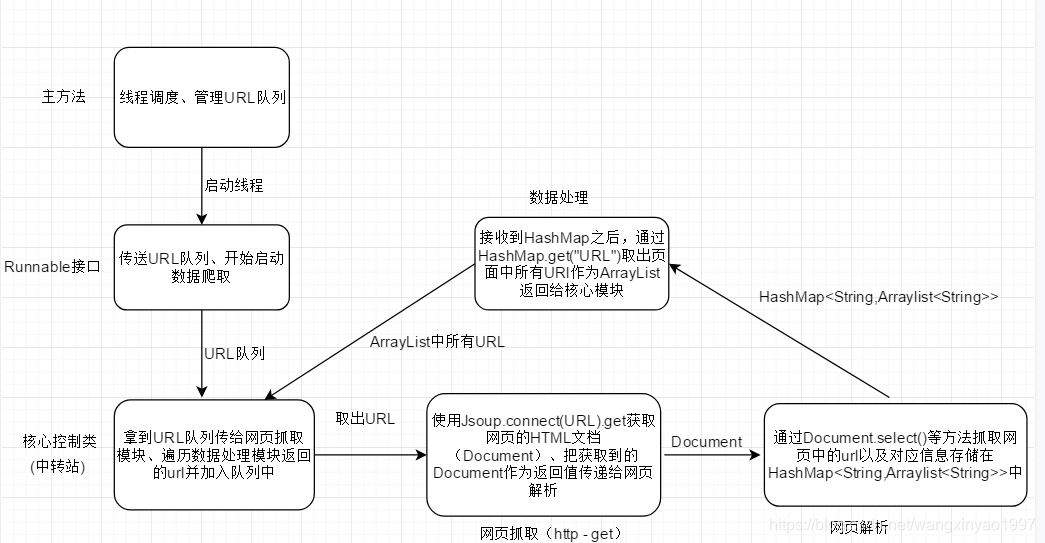
从上图可以看出我们的基本思路和流程,但是由于网站的可变性,我们不能贸然爬取,造成数据冗余。这个网页的最后一层只有文字信息,其余网页一条短信对应一条短信到一个URL地址,而在最后一层之外,每一层的数字和短信都有相同的URL,所以我们只需要爬取名字,如下:
开始爬行
请注意,我们的以下文档包路径是:
import org.jsoup.nodes.Document;
最终的项目目录结构如下:
1.只需创建一个maven项目
2.在pom.xml文件中添加如下依赖
org.jsoup
jsoup
1.11.3
3.创建主类
public class Main {
//待抓取的Url队列,全局共享
public static final LinkedBlockingQueue UrlQueue = new LinkedBlockingQueue();
public static final WormCore wormCore = new WormCore();
public static void main(String[] args) {
//要抓取的根URL
String rootUrl = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//先把根URL加入URL队列
UrlQueue.offer(rootUrl);
Runnable runnable = new MyRunnable();
//开启固定大小的线程池,线程数为10
ExecutorService Fixed = Executors.newFixedThreadPool(10);
//开始爬取
for (int i = 0;i 3) {
System.out.println(element.text());
}
Flag++;
}
//普通页面的处理
}else {
for (Element element : elements) {
if (!Number.IsNumber(element.text())) {
Text.add(element.text());
System.out.println(element.text());
Urls.add(Before_Url + element.attr("href"));
}
}
}
//把文本集合和URL集合装到Map中返回
Message.put("text",Text);
Message.put("Url",Urls);
return Message;
}
}
由于最后一页与上一页不同,需要因地制宜地调整措施。我们把前面提到的统计划分码号扔掉了,只要名字是必填的,所以博主通过下面Number类中的方法来判断
8.判断是否为数字
<p>public class Number {
public static boolean IsNumber(String str){
for(int i=0;i=48 && c
java爬虫抓取网页数据(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-16 12:24
这篇文章文章教你如何使用JAVA编写爬虫。内容简洁易懂,一定会让你眼前一亮。通过这次对文章的详细介绍,希望你能有所收获。
这篇文章文章其实是我很久以前写的,所以这次重新整理一下。很多朋友可能没有尝试过用Java写爬虫。可能是因为这方面的资料比较少,也可能是用Python写爬虫太方便了。
基本概念
jsoupi 是一个用于处理实际 HTML 的 Java 库。它提供了一个非常方便的 API,用于提取和操作数据,使用 DOM、CSS 和类似 jquery 的最佳方法。
以上是jsoup的官方解释,意思是jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
一般来说,它可以帮助我们解析HTML页面,抓取HTML中的内容。
开始写代码
我们的目标是抓取菜鸟笔记上的信息(文章标题和链接)
public static void main(String[] args) { try { //下面这行代码是连接我们的目标站点,并且get到他的静态HTML代码 Document document=Jsoup.connect("http://www.runoob.com/w3cnote").get(); //我们把获取到的document打印一下,看看里面到底是啥? System.out.println(document); } catch (IOException e) { e.printStackTrace(); } }
看看我们代码运行的结果:
你会发现我们通过这句话获得了网站《菜鸟笔记》的HTML源码
我们来分析一下这串html源码
发现这两个正是我们要获取的数据,我们继续爬取
<p>public static void main(String[] args) { try { Document document=Jsoup.connect("http://www.runoob.com/w3cnote").get(); //底下一行代码是我们进一步抓取到具体的HTML模块,div表示标签, //后面的post-intro表示的是div的class //由于div.post-intro这个标签有多个(每个标题有一个),所以我们先获取到它的所有 Elements elements=document.select("div.post-intro"); //我们来遍历一下,因为div.post-intro有很多个 for(int i=0;i 查看全部
java爬虫抓取网页数据(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
这篇文章文章教你如何使用JAVA编写爬虫。内容简洁易懂,一定会让你眼前一亮。通过这次对文章的详细介绍,希望你能有所收获。
这篇文章文章其实是我很久以前写的,所以这次重新整理一下。很多朋友可能没有尝试过用Java写爬虫。可能是因为这方面的资料比较少,也可能是用Python写爬虫太方便了。
基本概念
jsoupi 是一个用于处理实际 HTML 的 Java 库。它提供了一个非常方便的 API,用于提取和操作数据,使用 DOM、CSS 和类似 jquery 的最佳方法。
以上是jsoup的官方解释,意思是jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
一般来说,它可以帮助我们解析HTML页面,抓取HTML中的内容。
开始写代码
我们的目标是抓取菜鸟笔记上的信息(文章标题和链接)

public static void main(String[] args) { try { //下面这行代码是连接我们的目标站点,并且get到他的静态HTML代码 Document document=Jsoup.connect("http://www.runoob.com/w3cnote";).get(); //我们把获取到的document打印一下,看看里面到底是啥? System.out.println(document); } catch (IOException e) { e.printStackTrace(); } }
看看我们代码运行的结果:


你会发现我们通过这句话获得了网站《菜鸟笔记》的HTML源码
我们来分析一下这串html源码

发现这两个正是我们要获取的数据,我们继续爬取
<p>public static void main(String[] args) { try { Document document=Jsoup.connect("http://www.runoob.com/w3cnote";).get(); //底下一行代码是我们进一步抓取到具体的HTML模块,div表示标签, //后面的post-intro表示的是div的class //由于div.post-intro这个标签有多个(每个标题有一个),所以我们先获取到它的所有 Elements elements=document.select("div.post-intro"); //我们来遍历一下,因为div.post-intro有很多个 for(int i=0;i
java爬虫抓取网页数据(java爬虫抓取网页数据主要分为两个流程:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-14 05:00
java爬虫抓取网页数据主要分为两个流程:1.选择想要爬取的网站2.爬取网站数据,存放到本地存储场景:分享海量的数据给一个社区里面的陌生人,让他们来看,分享这些数据给其他人。推荐大家用solr语法:1.要爬取哪个网站。2.抓取数据保存存储到哪个位置。3.请求数据。大小限制4.请求方式可以是https,socket。
5.爬取耗时等。详细点去这个站点cnblogs-分享无限新鲜资讯,爬爬爬~附带我们公司之前爬虫获取的数据。-我们公司是做职业考试服务的,上有时候会有到对于考试难度的职业考试信息,可以通过抓包来获取考试信息(相关文章:王奋斗:cpa考试包过二本学校研究生取得高薪就业凭什么?)。目前,我们不是所有学校考试都有抓包。
我们目前可以抓取所有考试的相关信息。考生信息。部分考试抓包获取一级、二级及以上考试的考试信息部分考试抓包获取一级、二级及以上考试的考试信息结果统计在最新的一些情况下,做个数据整理,可以比较直观的了解考试信息的变化情况,这样做的好处:方便考试管理人员掌握当前国家出题情况,及时调整考试方向及难度等。更新考试政策,及时跟踪考试大纲变化。欢迎交流。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据主要分为两个流程:)
java爬虫抓取网页数据主要分为两个流程:1.选择想要爬取的网站2.爬取网站数据,存放到本地存储场景:分享海量的数据给一个社区里面的陌生人,让他们来看,分享这些数据给其他人。推荐大家用solr语法:1.要爬取哪个网站。2.抓取数据保存存储到哪个位置。3.请求数据。大小限制4.请求方式可以是https,socket。
5.爬取耗时等。详细点去这个站点cnblogs-分享无限新鲜资讯,爬爬爬~附带我们公司之前爬虫获取的数据。-我们公司是做职业考试服务的,上有时候会有到对于考试难度的职业考试信息,可以通过抓包来获取考试信息(相关文章:王奋斗:cpa考试包过二本学校研究生取得高薪就业凭什么?)。目前,我们不是所有学校考试都有抓包。
我们目前可以抓取所有考试的相关信息。考生信息。部分考试抓包获取一级、二级及以上考试的考试信息部分考试抓包获取一级、二级及以上考试的考试信息结果统计在最新的一些情况下,做个数据整理,可以比较直观的了解考试信息的变化情况,这样做的好处:方便考试管理人员掌握当前国家出题情况,及时调整考试方向及难度等。更新考试政策,及时跟踪考试大纲变化。欢迎交流。
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2022-03-12 07:02
文字
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java 有 Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
Scrap 意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优点:
1.极其灵活的自定义抓取。
2.社区比较大,文档比较齐全。
3.URL去重采用Bloom filter方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2), Pyspider:
pyspider 是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库来爬取结果。它还可以定期设置任务和任务优先级。
优点:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.五分钟即可轻松上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
简而言之,Pyspider 非常强大,比框架更强大。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制能力。
(3)Apache Nutch(高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。 Nutch 运行的三分之二的流程是为搜索引擎设计的。 .
Nutch 框架需要 Hadoop 运行,Hadoop 需要开启集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,以后可能会学到。
Nutch 官网
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以很容易地扩展它的功能,例如解析各种网页内容、采集、查询、聚类、过滤各种数据。因为这个框架,Nutch的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优点:
1.简单的API,快速上手
2.模块化结构,方便扩展
3.多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), 网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。 WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
优点:
1.根据文字密度自动提取网页文字
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.无 URL 优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫无法合作。
2.机器资源有限的复杂操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,无需修改更新。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间非常少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的网站进行排名,就必须实现类似于Pagerank的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的Url过滤机制使用BerkeleyDB进行url过滤。
3.可扩展支持结构化提取网页字段,可作为垂直采集使用
缺点
1.不支持动态网页抓取,例如网页的 ajax 部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。有一个近乎完整的文档介绍。
同HtmlUnit,只能获取静态内容。
不过,这个框架的优势在于解析网页非常强大。
Jsoup中文教程
selenium(多位谷歌领导参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,都说是真实的浏览器模拟。 GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍Demo就是跑不成功,所以放弃了。
selenium 官方 GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
先决条件:
安装 Chrome 浏览器就完成了。
简介:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
两者结合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档详细,Demo程序基本可以运行,类名熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着这么详细的文件,激动和遗憾的泪流满面……
cdp4j 有很多特点:
一个。获取渲染后的网页源代码
b.模拟浏览器点击事件
c。下载可以从网页下载的文件
d。截取网页截图或转换为 PDF 打印
e。等等
更详细的信息可以到以下三个地址去探索发现:
[cdp4j官网地址]
[Github 仓库]
[演示列表]
总结
上述框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以后打算用手动的方法:httpclient +jsoup+selenium实现java爬虫功能用httpclient爬取,jsoup解析页面,90%的页面可以做,剩下的用selenium;
参考链接: 查看全部
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
文字
一、目前主流的java爬虫框架包括

Python中有Scrapy和Pyspider;
Java 有 Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:

Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
Scrap 意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优点:
1.极其灵活的自定义抓取。
2.社区比较大,文档比较齐全。
3.URL去重采用Bloom filter方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2), Pyspider:
pyspider 是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库来爬取结果。它还可以定期设置任务和任务优先级。
优点:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.五分钟即可轻松上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
简而言之,Pyspider 非常强大,比框架更强大。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制能力。
(3)Apache Nutch(高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。 Nutch 运行的三分之二的流程是为搜索引擎设计的。 .
Nutch 框架需要 Hadoop 运行,Hadoop 需要开启集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,以后可能会学到。
Nutch 官网
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以很容易地扩展它的功能,例如解析各种网页内容、采集、查询、聚类、过滤各种数据。因为这个框架,Nutch的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优点:
1.简单的API,快速上手
2.模块化结构,方便扩展
3.多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), 网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。 WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
优点:
1.根据文字密度自动提取网页文字
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.无 URL 优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫无法合作。
2.机器资源有限的复杂操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,无需修改更新。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间非常少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的网站进行排名,就必须实现类似于Pagerank的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的Url过滤机制使用BerkeleyDB进行url过滤。
3.可扩展支持结构化提取网页字段,可作为垂直采集使用
缺点
1.不支持动态网页抓取,例如网页的 ajax 部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。有一个近乎完整的文档介绍。
同HtmlUnit,只能获取静态内容。
不过,这个框架的优势在于解析网页非常强大。
Jsoup中文教程
selenium(多位谷歌领导参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,都说是真实的浏览器模拟。 GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍Demo就是跑不成功,所以放弃了。
selenium 官方 GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
先决条件:
安装 Chrome 浏览器就完成了。
简介:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
两者结合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档详细,Demo程序基本可以运行,类名熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着这么详细的文件,激动和遗憾的泪流满面……
cdp4j 有很多特点:
一个。获取渲染后的网页源代码
b.模拟浏览器点击事件
c。下载可以从网页下载的文件
d。截取网页截图或转换为 PDF 打印
e。等等
更详细的信息可以到以下三个地址去探索发现:
[cdp4j官网地址]
[Github 仓库]
[演示列表]
总结
上述框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以后打算用手动的方法:httpclient +jsoup+selenium实现java爬虫功能用httpclient爬取,jsoup解析页面,90%的页面可以做,剩下的用selenium;
参考链接:
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-03-10 18:13
爬虫+基于界面的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方式有个很大的限制,就是通过jsoup爬虫只能爬取静态网页,所以只能爬取当前页面的所有新闻。如果需要爬取一个网站的所有信息,就得通过界面反复调整网站的界面,通过改变参数,爬到网站的所有数据信息。 @网站。
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将逐步解释。我这里重点讲一下思路,最后提供完整的源码。
第一步:找到接口
如果要获取网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->Network-->all,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据是由大于56630或小于56630的ID返回的。
flag=down 表示向下翻页,即23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两个,这里id=0代表最新的两个数据)
返回json数据格式:
{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第 2 步:通过定时任务开始爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);<br />
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
JinSePress结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里需要注意两点
(1)在创建对象的时候,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否存在对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时。比如上面改成Listextra,会导致序列化失败,因为json的extra显然是一个对象,这里接受的确实是一个集合,关键是
性别名称相同,所以赋值时会报错,序列化会失败。
第四步:查看运行结果
这里只是控制台输出的部分信息,这样就可以获得网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取该新闻的所有具体信息了。(完美的)
第 5 步:数据库重复数据删除思路
因为你不可能每次都直接爬取播放数据到数据库中,所以必须对比新闻数据库是否已经存在,不存在才放入数据库。思路如下:
(1)在数据库表中添加唯一属性字段,可以识别新闻,比如jinse+bottomId形成唯一属性,或者新闻特定页面路径URI,形成唯一属性。
(2)创建地图集合,通过URI检查数据库是否存在,如果存在,如果不存在。
(3) 在通过 map.get(URI) 存储之前,如果为 false,则存储在数据库中。
Git 源代码
首先,源代码本身是通过Idea测试运行的。这里使用龙目岛。现在需要在idea或者eclipse中配置Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果你想没有麻烦,要么别想,要么做更多。中校【9】
转载于: 查看全部
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
爬虫+基于界面的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方式有个很大的限制,就是通过jsoup爬虫只能爬取静态网页,所以只能爬取当前页面的所有新闻。如果需要爬取一个网站的所有信息,就得通过界面反复调整网站的界面,通过改变参数,爬到网站的所有数据信息。 @网站。
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将逐步解释。我这里重点讲一下思路,最后提供完整的源码。
第一步:找到接口
如果要获取网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->Network-->all,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据是由大于56630或小于56630的ID返回的。
flag=down 表示向下翻页,即23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两个,这里id=0代表最新的两个数据)
返回json数据格式:


{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第 2 步:通过定时任务开始爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);<br />
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
JinSePress结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里需要注意两点
(1)在创建对象的时候,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否存在对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时。比如上面改成Listextra,会导致序列化失败,因为json的extra显然是一个对象,这里接受的确实是一个集合,关键是
性别名称相同,所以赋值时会报错,序列化会失败。
第四步:查看运行结果
这里只是控制台输出的部分信息,这样就可以获得网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取该新闻的所有具体信息了。(完美的)

第 5 步:数据库重复数据删除思路
因为你不可能每次都直接爬取播放数据到数据库中,所以必须对比新闻数据库是否已经存在,不存在才放入数据库。思路如下:
(1)在数据库表中添加唯一属性字段,可以识别新闻,比如jinse+bottomId形成唯一属性,或者新闻特定页面路径URI,形成唯一属性。
(2)创建地图集合,通过URI检查数据库是否存在,如果存在,如果不存在。
(3) 在通过 map.get(URI) 存储之前,如果为 false,则存储在数据库中。
Git 源代码
首先,源代码本身是通过Idea测试运行的。这里使用龙目岛。现在需要在idea或者eclipse中配置Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果你想没有麻烦,要么别想,要么做更多。中校【9】
转载于:
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-10 18:11
爬虫初学者,WebMagic作为Java开发的爬虫框架很容易上手,下面看一个简单的例子。
WebMagic 框架简介
WebMagic 框架由四个组件组成,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应了爬虫生命周期中的处理、管理、下载和持久化的功能。
这四个组件是Spider中的属性,爬虫框架是通过Spider来启动和管理的。
WebMagic的整体架构图如下:
四个组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。你需要定义自己。
Scheduler 负责管理要爬取的 URL,以及一些去重工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
下载器负责从 Internet 下载页面以进行后续处理。通常你不需要自己实现它。
数据流对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包后,所有的准备工作就完成了,是不是很简单。
让我们测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}<br />public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/")
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:
这是因为没有配置文件。在资源目录下新建一个log4j.properties文件,粘贴如下配置信息。
目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告?
爬取列表类 网站 示例
列表爬取的思路很相似。首先判断是否为列表页。如果是这样,请将 文章url 添加到爬取队列中。如果不是,则说明此时是一个文章页面,直接爬取你想要的。内容可以。
选择列表类 文章 的 网站:
首先判断是文章还是列表。查看几页后,您可以找到规则并使用正则表达式来区分它们。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器直接粘贴即可)。
WebMagic框架支持多种提取方式,包括xPath、css选择器、正则表达式,所有的链接都可以通过links()方法来选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果您使用它,您可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面,页面中文章的url应该是通过xPath定位的。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
至此,你已经得到了要爬取的url列表,你可以通过addTargetRequests方法将它们添加到队列中。
最后实现翻页。同样,WebMagic 会自动加入到爬取队列中。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整的代码。我实现了一个MysqlPipeline类,使用Mybatis将爬取的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}<br />public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1").addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库: ?
爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
注意在使用xPath时,框架作者自定义了几个函数:
表达式描述XPath1.0
文本(n)
第n个直接文本子节点,0表示全部
纯文本
全部文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更清晰
不支持
html()
内部html,不包括标签本身的html
不支持
外部HTML()
内部 html,包括标签的 html 本身
不支持
正则表达式(@attr,expr,组)
这里@attr和group是可选的,默认是group0
不支持
使用起来非常方便。 查看全部
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
爬虫初学者,WebMagic作为Java开发的爬虫框架很容易上手,下面看一个简单的例子。
WebMagic 框架简介
WebMagic 框架由四个组件组成,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应了爬虫生命周期中的处理、管理、下载和持久化的功能。
这四个组件是Spider中的属性,爬虫框架是通过Spider来启动和管理的。
WebMagic的整体架构图如下:
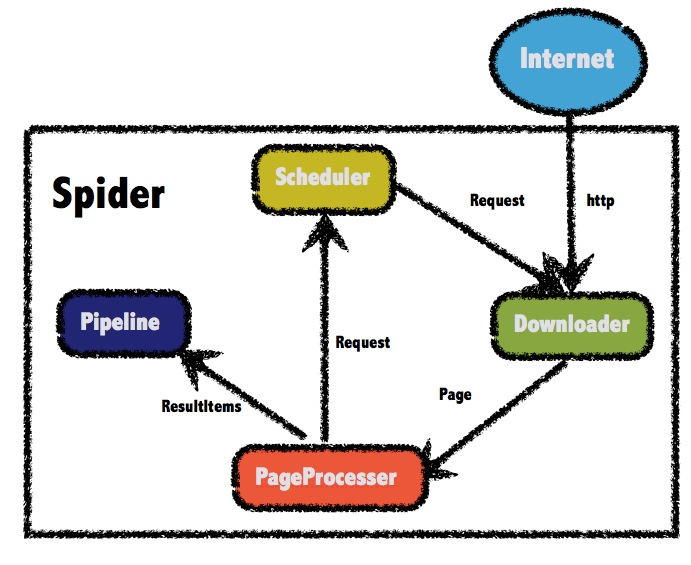
四个组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。你需要定义自己。
Scheduler 负责管理要爬取的 URL,以及一些去重工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
下载器负责从 Internet 下载页面以进行后续处理。通常你不需要自己实现它。
数据流对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包后,所有的准备工作就完成了,是不是很简单。
让我们测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}<br />public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/";)
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
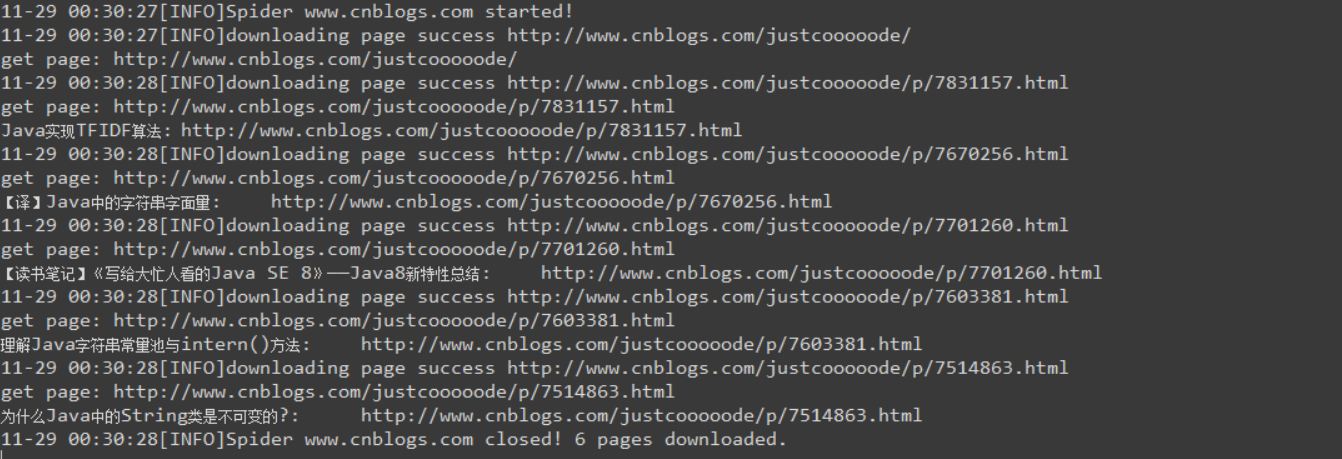
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:

这是因为没有配置文件。在资源目录下新建一个log4j.properties文件,粘贴如下配置信息。
目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告?
爬取列表类 网站 示例
列表爬取的思路很相似。首先判断是否为列表页。如果是这样,请将 文章url 添加到爬取队列中。如果不是,则说明此时是一个文章页面,直接爬取你想要的。内容可以。
选择列表类 文章 的 网站:
首先判断是文章还是列表。查看几页后,您可以找到规则并使用正则表达式来区分它们。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器直接粘贴即可)。

WebMagic框架支持多种提取方式,包括xPath、css选择器、正则表达式,所有的链接都可以通过links()方法来选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果您使用它,您可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面,页面中文章的url应该是通过xPath定位的。

page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
至此,你已经得到了要爬取的url列表,你可以通过addTargetRequests方法将它们添加到队列中。
最后实现翻页。同样,WebMagic 会自动加入到爬取队列中。

page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整的代码。我实现了一个MysqlPipeline类,使用Mybatis将爬取的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}<br />public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1";).addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库: ?

爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
注意在使用xPath时,框架作者自定义了几个函数:
表达式描述XPath1.0
文本(n)
第n个直接文本子节点,0表示全部
纯文本
全部文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更清晰
不支持
html()
内部html,不包括标签本身的html
不支持
外部HTML()
内部 html,包括标签的 html 本身
不支持
正则表达式(@attr,expr,组)
这里@attr和group是可选的,默认是group0
不支持
使用起来非常方便。
java爬虫抓取网页数据(学python网页爬虫抓取网页数据第四十五天早晨分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-08 03:06
java爬虫抓取网页数据第四十五天早晨分享:大牛之路:python爬虫抓取动态数据,
网上找找有很多新闻或者说一些真正需要的东西比如说计算机视觉计算机图形学等等有些人就是做这些相关的问题的有时候你想找的东西总会有你想要的
数据找厂商买买买别在乎价格
自己动手!学python网页爬虫吧。这应该是目前所有做爬虫技术的初学者都会想知道的了。除此之外还有很多人在爬取社交网络数据分析美女图,人物动态数据的,
内网互联,例如国内的qq群活动,国外是,美帝使用nsurlconnection。还有各种推论什么的,其实如果真要说这东西的话,商业级的其实大部分都在做相关的report啊之类的。
dropbox自己建个文件夹放下载的东西
先说需求,再来选择相应的技术。
1、首先是数据,在怎么存都一样,关键是数据的质量,如果数据质量很差,再怎么存都是无用功。
2、再来说需求实现,不同的存储,需要不同的技术解决,例如,url文件存储,需要flask语言和nodejs,但是nodejs很吃内存,所以还有个解决方案是把url文件存储在virtualenv上面,以及实现对app的访问。2.1如果你还想保留一些数据,包括你想爬取数据的源代码,你可以考虑bigdatasink一类的服务。
如果你想在浏览器访问存在服务器上的网页,可以尝试youtube的seamlessjs。2.2如果你只是想简单爬下文件或者利用requests访问文件,可以考虑nutch,beautifulsoup,pyspider等;。
3、python初学者,不推荐用nodejs去做,因为初学者对爬虫了解不多,容易操作错误,导致不好理解与爬取。所以python的egg,xchat,python爬虫,python数据分析都是不错的选择,java,php等语言也可以考虑。 查看全部
java爬虫抓取网页数据(学python网页爬虫抓取网页数据第四十五天早晨分享)
java爬虫抓取网页数据第四十五天早晨分享:大牛之路:python爬虫抓取动态数据,
网上找找有很多新闻或者说一些真正需要的东西比如说计算机视觉计算机图形学等等有些人就是做这些相关的问题的有时候你想找的东西总会有你想要的
数据找厂商买买买别在乎价格
自己动手!学python网页爬虫吧。这应该是目前所有做爬虫技术的初学者都会想知道的了。除此之外还有很多人在爬取社交网络数据分析美女图,人物动态数据的,
内网互联,例如国内的qq群活动,国外是,美帝使用nsurlconnection。还有各种推论什么的,其实如果真要说这东西的话,商业级的其实大部分都在做相关的report啊之类的。
dropbox自己建个文件夹放下载的东西
先说需求,再来选择相应的技术。
1、首先是数据,在怎么存都一样,关键是数据的质量,如果数据质量很差,再怎么存都是无用功。
2、再来说需求实现,不同的存储,需要不同的技术解决,例如,url文件存储,需要flask语言和nodejs,但是nodejs很吃内存,所以还有个解决方案是把url文件存储在virtualenv上面,以及实现对app的访问。2.1如果你还想保留一些数据,包括你想爬取数据的源代码,你可以考虑bigdatasink一类的服务。
如果你想在浏览器访问存在服务器上的网页,可以尝试youtube的seamlessjs。2.2如果你只是想简单爬下文件或者利用requests访问文件,可以考虑nutch,beautifulsoup,pyspider等;。
3、python初学者,不推荐用nodejs去做,因为初学者对爬虫了解不多,容易操作错误,导致不好理解与爬取。所以python的egg,xchat,python爬虫,python数据分析都是不错的选择,java,php等语言也可以考虑。
java爬虫抓取网页数据(《手把手教你写网络爬虫》连载开始了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-03-04 09:21
摘要:从零开始编写爬虫,初学者的崩溃指南!
覆盖:
大家好,《教你写爬虫》连载开始啦!在我的职业生涯中,我发现很少有像网络爬虫这样能够吸引程序员和外行的注意力的编程实践。本文由浅入深地讲解爬虫技术,为初学者提供了一个简单的入门方法。请跟随我们一起走上爬虫学习打怪升级之路!
介绍
什么是爬行动物?
先看百度百科的定义:
简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!
urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!
“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。
将此代码保存为 get_html.py 并运行它以查看它的输出:
果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:
目标html代码:
有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:
将此代码保存为 get_data.py 并运行它以查看它的输出:
是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url: ,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们知道这是一个动态网页。当我们得到它时,播放列表还没有被请求,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:
Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:
开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。
播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。
将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。
看到结果后有成就感吗?如果你有兴趣,也可以按照这个思路,找到评论最多的单曲,再也不用担心歌曲用完了!
今天的内容比较简单,希望对大家有用。暂时就这些了,下次见!
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
java爬虫抓取网页数据(《手把手教你写网络爬虫》连载开始了(组图))
摘要:从零开始编写爬虫,初学者的崩溃指南!
覆盖:

大家好,《教你写爬虫》连载开始啦!在我的职业生涯中,我发现很少有像网络爬虫这样能够吸引程序员和外行的注意力的编程实践。本文由浅入深地讲解爬虫技术,为初学者提供了一个简单的入门方法。请跟随我们一起走上爬虫学习打怪升级之路!
介绍
什么是爬行动物?
先看百度百科的定义:
简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!
urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!
“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。
将此代码保存为 get_html.py 并运行它以查看它的输出:
果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:
目标html代码:
有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:
将此代码保存为 get_data.py 并运行它以查看它的输出:
是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url: ,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们知道这是一个动态网页。当我们得到它时,播放列表还没有被请求,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:
Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:
开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。
播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。
将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。
看到结果后有成就感吗?如果你有兴趣,也可以按照这个思路,找到评论最多的单曲,再也不用担心歌曲用完了!
今天的内容比较简单,希望对大家有用。暂时就这些了,下次见!
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
java爬虫抓取网页数据(Spider的设计网页收集的过程(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-04 09:18
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据添加到网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流
Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("");
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));Stringline=null;while((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
Matcher matcher=pattern.matcher(htmlDoc);StringtempURL;//第一次匹配的url格式为://为此需要进行下一步处理提取真实的url,//可以使用对于前两个 " 中间的部分被记录下来得到 urlwhile(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf(""")+1);if(!tempURL.contains("""))继续;
tempURL=tempURL.substring(0, tempURL.indexOf("""));} catch (MalformedURLException e) {
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以在循环获取整个标签后,我们需要进一步提取真实网址。我们可以截取标签中前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/***启动线程采集,然后开始采集网页数据*/publicvoid start() {
调度程序 disp=newDispatcher.getInstance();for(inti=0; i
线程聚集=newThread(newGather(disp));
采集.start();
}
}
线程启动后,网页采集器启动作业的运行,一个作业完成后,向Dispatcher申请下一个作业。因为有一个多线程的Gather,为了避免线程不安全,需要对Dispatcher进行互斥访问。在其函数中添加同步 关键词 以实现线程安全访问。
概括
Spider是整个搜索引擎的基础,为后续的操作提供原创网页数据,所以了解Spider的编写和网页库的组成,为后续的预处理模块打下基础。同时,Spider也可以单独使用,稍微修改后采集某些特定的信息,比如抓取某个网站的图片。 查看全部
java爬虫抓取网页数据(Spider的设计网页收集的过程(一)_光明网)
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据添加到网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流
Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("");
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));Stringline=null;while((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
Matcher matcher=pattern.matcher(htmlDoc);StringtempURL;//第一次匹配的url格式为://为此需要进行下一步处理提取真实的url,//可以使用对于前两个 " 中间的部分被记录下来得到 urlwhile(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf(""")+1);if(!tempURL.contains("""))继续;
tempURL=tempURL.substring(0, tempURL.indexOf("""));} catch (MalformedURLException e) {
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以在循环获取整个标签后,我们需要进一步提取真实网址。我们可以截取标签中前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/***启动线程采集,然后开始采集网页数据*/publicvoid start() {
调度程序 disp=newDispatcher.getInstance();for(inti=0; i
线程聚集=newThread(newGather(disp));
采集.start();
}
}
线程启动后,网页采集器启动作业的运行,一个作业完成后,向Dispatcher申请下一个作业。因为有一个多线程的Gather,为了避免线程不安全,需要对Dispatcher进行互斥访问。在其函数中添加同步 关键词 以实现线程安全访问。
概括
Spider是整个搜索引擎的基础,为后续的操作提供原创网页数据,所以了解Spider的编写和网页库的组成,为后续的预处理模块打下基础。同时,Spider也可以单独使用,稍微修改后采集某些特定的信息,比如抓取某个网站的图片。
java爬虫抓取网页数据( Python爬虫对于我来说真是个神器的人的独白!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2022-02-25 00:02
Python爬虫对于我来说真是个神器的人的独白!)
一个熟悉爬虫技术的人的独白!
不得不说,Python爬虫对我来说真的是神器。之前在分析一些经济数据的时候,需要从网上抓取一些数据。我想了很多方法。一开始是通过Excel,但是Excel只能从桌子上爬下来,太有限了。后来问了一个学编程的朋友,他说JavaScript也可以实现,于是董东迪就去学Java了(我朋友在学Java,我问他能不能用Java实现,他说JavaScript好像是可以的,当时我什么都不懂,所以把JavaScript理解为Java的一个分支,以为JavaScript只是ava的一个包,于是就去学了一阵子Java,无知酿成祸...)。
但是整个 Java 系统太大了,学不来。毕竟我只是想用一些功能,所以学完就放弃了。就在我不知所措的时候,我发现了Python......
废话少说,说说自己的学习经历。对于想学习Python和写爬虫的人来说也是一个参考。
一开始在网上找了一个基础视频来学习。Python 真的是一门简单的语言。之前对Visual Basic有所了解,感觉Python也很适合没有编程基础的人学习。
在介绍视频的最后,我做了我的第一个爬虫,一个百度贴吧图片爬虫(相信很多教程都是以百度贴吧爬虫为经典例子。)
一开始代码很简单,只能爬第一页的数据,所以加了一个循环爬取指定页数的图片。而且图片是按顺序排列的,非常方便。过滤 URL 时只需使用正则表达式。
但是我不经常混贴吧,也很少需要下载贴吧图片。回归初衷。我对投资感兴趣,学习编程的原因之一也是投资服务。7月份股市大跌的时候,我错过了一个明显的“捡钱”机会,不是因为我缺乏专业知识,而是因为我正在准备考试,很少去股市,这使得我不甘:如果有什么可以帮我自动爬取数据分析推送,我有如下学习轨迹:
一、爬取数据
对了,大家可以到公众号菜单栏中的学习福利去浏览。那里有一些很好的教程。Python 中 urllib 和 re 正则表达式的两种替代方法分别称为 requests 和 Ixml。
第一个图书馆很好。现在我在获取网页源代码时使用这个库。不明白的可以看那个网站。第二个库是因为我用的是3.4版本的Python,好久没折腾了,所以又找了一个不错的库BeautifulSoup,详细教程参考:Python爬虫介绍八:的用法美丽的汤
有了requests和Beautifulsoup,我基本上可以实现很多我想要的功能。我做了一个抓取分级基金数据的爬虫:
二、分析推送
其实这个分析也谈不上,最多是筛选。(但我相信随着我数学能力的提高,一定能有进一步的分析,祝好...) 筛选很简单,就是增加量或产量等满足一定条件,然后保留,为什么要保留它?推它 !!!
通过电子邮件将保存的数据发送到您自己的邮箱,在手机上下载一个软件,您就完成了!
至此,学习Python的目的就达到了,鸡要炸了!!!
但是……这么好玩的事情怎么会这么快就结束了?让我们折腾吧!
三、简单的界面
等待!看来Python不能直接转成exe可执行文件,而且每次运行都不能打开Python窗口!你怎么能忍受强迫症!@>第四版!花了很长时间才完成,忘记它!我不知道如何订购VB,让我们使用它。所以即使是界面
正好能点PS,做个低级界面也不错。
四、云服务器
完成界面后,我以为结束了,我还太年轻。用了几天,发现不能天天开电脑,让它跑几个程序?必须有一个地方可以让我一天 24 小时运行这些程序。本来想用朋友的电脑轮流跑的,但是太麻烦了。我偶然发现了云服务器。了解之后,花了很多钱买了服务器(其实——一个月30个月……)
Toss-fan linux系统运行实现24小时实时推送。
而此时,我已经深深沉浸在Python中,我觉得我应该继续学习这门强大而简单的语言,在知乎上看到一个问题:Quant应该学习哪些Python知识?虽然是 Quant 但也为我指明了方向——一些方向。目前准备学习numpy、pandas、matplotlib这些库,以实现未来财经数据的可视化和分析。有一本写得很好的相关内容的书,叫做《Data Analysis with Python》,如果你有兴趣学习,可以阅读——阅读。
最后,如果你和我一样喜欢python,想做一名优秀的程序员,在学习python的道路上奔跑,欢迎加入python学习群:839383765 群里会每天分享最新的行业资讯和免费的python课程一天,一起交流学习,让学习成为(程序)一种习惯! 查看全部
java爬虫抓取网页数据(
Python爬虫对于我来说真是个神器的人的独白!)

一个熟悉爬虫技术的人的独白!
不得不说,Python爬虫对我来说真的是神器。之前在分析一些经济数据的时候,需要从网上抓取一些数据。我想了很多方法。一开始是通过Excel,但是Excel只能从桌子上爬下来,太有限了。后来问了一个学编程的朋友,他说JavaScript也可以实现,于是董东迪就去学Java了(我朋友在学Java,我问他能不能用Java实现,他说JavaScript好像是可以的,当时我什么都不懂,所以把JavaScript理解为Java的一个分支,以为JavaScript只是ava的一个包,于是就去学了一阵子Java,无知酿成祸...)。
但是整个 Java 系统太大了,学不来。毕竟我只是想用一些功能,所以学完就放弃了。就在我不知所措的时候,我发现了Python......
废话少说,说说自己的学习经历。对于想学习Python和写爬虫的人来说也是一个参考。
一开始在网上找了一个基础视频来学习。Python 真的是一门简单的语言。之前对Visual Basic有所了解,感觉Python也很适合没有编程基础的人学习。
在介绍视频的最后,我做了我的第一个爬虫,一个百度贴吧图片爬虫(相信很多教程都是以百度贴吧爬虫为经典例子。)
一开始代码很简单,只能爬第一页的数据,所以加了一个循环爬取指定页数的图片。而且图片是按顺序排列的,非常方便。过滤 URL 时只需使用正则表达式。
但是我不经常混贴吧,也很少需要下载贴吧图片。回归初衷。我对投资感兴趣,学习编程的原因之一也是投资服务。7月份股市大跌的时候,我错过了一个明显的“捡钱”机会,不是因为我缺乏专业知识,而是因为我正在准备考试,很少去股市,这使得我不甘:如果有什么可以帮我自动爬取数据分析推送,我有如下学习轨迹:
一、爬取数据
对了,大家可以到公众号菜单栏中的学习福利去浏览。那里有一些很好的教程。Python 中 urllib 和 re 正则表达式的两种替代方法分别称为 requests 和 Ixml。
第一个图书馆很好。现在我在获取网页源代码时使用这个库。不明白的可以看那个网站。第二个库是因为我用的是3.4版本的Python,好久没折腾了,所以又找了一个不错的库BeautifulSoup,详细教程参考:Python爬虫介绍八:的用法美丽的汤
有了requests和Beautifulsoup,我基本上可以实现很多我想要的功能。我做了一个抓取分级基金数据的爬虫:
二、分析推送
其实这个分析也谈不上,最多是筛选。(但我相信随着我数学能力的提高,一定能有进一步的分析,祝好...) 筛选很简单,就是增加量或产量等满足一定条件,然后保留,为什么要保留它?推它 !!!
通过电子邮件将保存的数据发送到您自己的邮箱,在手机上下载一个软件,您就完成了!
至此,学习Python的目的就达到了,鸡要炸了!!!
但是……这么好玩的事情怎么会这么快就结束了?让我们折腾吧!
三、简单的界面
等待!看来Python不能直接转成exe可执行文件,而且每次运行都不能打开Python窗口!你怎么能忍受强迫症!@>第四版!花了很长时间才完成,忘记它!我不知道如何订购VB,让我们使用它。所以即使是界面
正好能点PS,做个低级界面也不错。
四、云服务器
完成界面后,我以为结束了,我还太年轻。用了几天,发现不能天天开电脑,让它跑几个程序?必须有一个地方可以让我一天 24 小时运行这些程序。本来想用朋友的电脑轮流跑的,但是太麻烦了。我偶然发现了云服务器。了解之后,花了很多钱买了服务器(其实——一个月30个月……)
Toss-fan linux系统运行实现24小时实时推送。
而此时,我已经深深沉浸在Python中,我觉得我应该继续学习这门强大而简单的语言,在知乎上看到一个问题:Quant应该学习哪些Python知识?虽然是 Quant 但也为我指明了方向——一些方向。目前准备学习numpy、pandas、matplotlib这些库,以实现未来财经数据的可视化和分析。有一本写得很好的相关内容的书,叫做《Data Analysis with Python》,如果你有兴趣学习,可以阅读——阅读。
最后,如果你和我一样喜欢python,想做一名优秀的程序员,在学习python的道路上奔跑,欢迎加入python学习群:839383765 群里会每天分享最新的行业资讯和免费的python课程一天,一起交流学习,让学习成为(程序)一种习惯!
java爬虫抓取网页数据( 一下如何利用Java进行网络爬虫?(图)的运用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-24 23:29
一下如何利用Java进行网络爬虫?(图)的运用
)
这是Java网络爬虫系列的第二篇文章。上一篇Java网络爬虫,就这么简单,我们简单学习了如何使用Java进行网络爬虫。在这篇文章中,我们将简单谈谈遇到网络爬虫时需要登录的网站,我们应该怎么做?
在做爬虫工作的时候,也经常会遇到需要登录的问题,比如写脚本抢票之类的,但是任何需要个人信息的人都需要登录。此类问题的解决方法主要有两种:一种是手动设置Cookie就是先登录网站,登录后复制cookie,在爬虫程序的HTTP请求中手动设置Cookie属性。这种方法适用于采集频率较低,采集周期短,因为cookie会失效。如果是长期采集,需要频繁设置cookie。这不是一个可行的方法。第二种方法是使用程序模拟登录,通过模拟登录获取cookies。这种方法适合长期采集this网站,
为了让大家更好的了解这两种方式的应用,我以豆瓣个人主页昵称为例,通过这两种方式获取登录后才能查看的信息。获取信息为如下图:
很容易得到图片中的缺心。很明显,这个信息只有登录后才能看到,符合我们的主题。接下来,我们使用上面的两种方法来解决这个问题。
手动设置 cookie
手动设置cookie的方式比较简单。我们只需要登录豆瓣。登录成功后,我们可以获取到带有用户信息的cookie。豆瓣登录链接:
https://accounts.douban.com/passport/login
如下所示:
图中的cookie携带用户信息。我们只需要在请求查看登录后才能查看的信息时携带这个cookie。我们使用Jsoup来模拟手动设置cookie的方式。具体代码如下:
从代码可以看出,它和不需要登录的网站没什么区别,只是多了一个.header("Cookie", "your cookies"),我们可以复制浏览器里的cookie在这里,写main方法
运行 main 会产生以下结果:
可以看到,我们成功获取了缺心,这就是所谓的简单,也就是说我们设置的cookie是有效的,我们成功获取了需要登录的数据。这个方法真的很简单,唯一的缺点是cookie需要经常更换,因为cookie会失效,使用起来不太舒服。
模拟登录方式
模拟登录方式可以解决手动设置cookie方式的不足,但也引入了更复杂的问题。目前的验证码种类繁多,其中有很多是具有挑战性的,比如在一堆图片中操作某类图片。这个还是挺难的,写出来也不容易。因此,由开发人员权衡使用哪种方法的利弊。我们今天使用的豆瓣在登录的时候是没有验证码的,这种没有验证码的比较简单。模拟登录方式最重要的是找到真正的登录请求和登录所需的参数。我们只能利用这一点,我们先在登录界面输入错误的账号密码,这样页面就不会跳转了,所以我们可以很容易地找到登录请求。让我演示一下豆瓣登录找到登录链接。我们在登录界面输入了错误的用户名和密码。点击登录后,查看网络发起的请求链接,如下图:
从网络上我们可以看到豆瓣的登录链接是,需要五个参数,具体参数可以在图中的Form Data中查看。有了这些,我们就可以构造一个请求来模拟登录。登录后进行后续操作。接下来,我们将使用Jsoup模拟登录,获取豆瓣首页的昵称。具体代码如下:
这段代码分为两部分。第一段是模拟登录,第二段是解析豆瓣首页。此代码中启动了两个请求。第一个请求是模拟登录获取cookie,第二个请求携带第一个模拟登录后获取的cookie,这样也可以访问需要登录的页面,修改main方法
运行 main 方法会产生以下结果:
模拟登录的方法也成功获取了网名。它被称为简单。虽然这是最简单的模拟登录,但从代码量可以看出,它比设置cookies要复杂得多。对于其他有验证码登录的用户,这里就不介绍了。首先,我没有这方面的经验。其次,这个实现比较复杂,会涉及到一些算法和一些辅助工具的使用。有兴趣的朋友可以参考崔庆才先生的作品。博客研究研究。虽然模拟登录写起来比较复杂,但只要写得好,一劳永逸。如果你需要长期的采集信息需要登录,这个还是值得做的。除了使用jsoup模拟登录,我们也可以使用httpclient来模拟登录。httpclient模拟登录没有Jsoup那么复杂,因为httpclient可以像浏览器一样保存session会话,这样登录后就保存cookies,同一个httpclient中的请求都会带cookies。httpclient模拟登录代码如下:
运行此代码也会返回 true。
我们讲了Java爬虫的登录问题。总结一下:爬虫的登录问题有两种解决方案。一种是手动设置cookies。此方法适用于短期采集或一次性性采集,成本较低。另一种方式是模拟登录,适合长期采集网站,因为模拟登录的成本还是挺高的,尤其是一些异常的验证码,好处是可以让你一劳永逸
以上就是Java爬虫遇到的登录问题的知识分享。我希望它会帮助你。下一篇是关于爬虫遇到数据异步加载的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,共同进步
源代码:
https://github.com/BinaryBall/ ... .java
作者:平头哥的技术博文
来源:掘金
商业用途请与原作者联系,本文只做展示分享,不妥侵删! 查看全部
java爬虫抓取网页数据(
一下如何利用Java进行网络爬虫?(图)的运用
)
这是Java网络爬虫系列的第二篇文章。上一篇Java网络爬虫,就这么简单,我们简单学习了如何使用Java进行网络爬虫。在这篇文章中,我们将简单谈谈遇到网络爬虫时需要登录的网站,我们应该怎么做?
在做爬虫工作的时候,也经常会遇到需要登录的问题,比如写脚本抢票之类的,但是任何需要个人信息的人都需要登录。此类问题的解决方法主要有两种:一种是手动设置Cookie就是先登录网站,登录后复制cookie,在爬虫程序的HTTP请求中手动设置Cookie属性。这种方法适用于采集频率较低,采集周期短,因为cookie会失效。如果是长期采集,需要频繁设置cookie。这不是一个可行的方法。第二种方法是使用程序模拟登录,通过模拟登录获取cookies。这种方法适合长期采集this网站,
为了让大家更好的了解这两种方式的应用,我以豆瓣个人主页昵称为例,通过这两种方式获取登录后才能查看的信息。获取信息为如下图:
很容易得到图片中的缺心。很明显,这个信息只有登录后才能看到,符合我们的主题。接下来,我们使用上面的两种方法来解决这个问题。
手动设置 cookie
手动设置cookie的方式比较简单。我们只需要登录豆瓣。登录成功后,我们可以获取到带有用户信息的cookie。豆瓣登录链接:
https://accounts.douban.com/passport/login
如下所示:
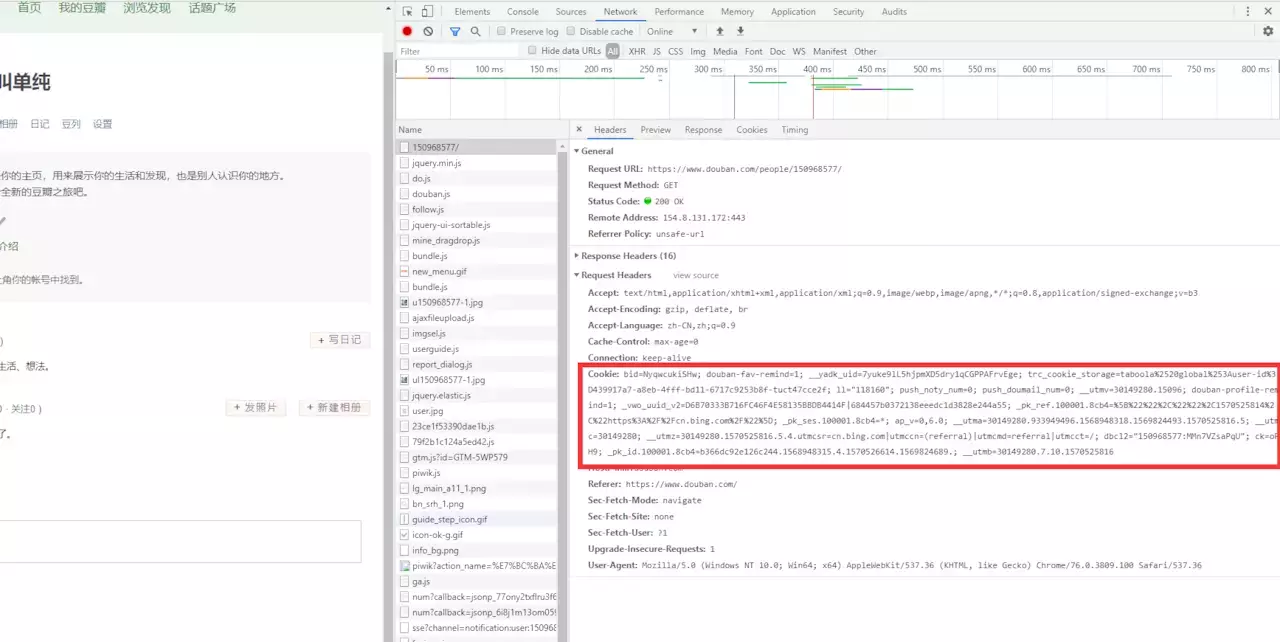
图中的cookie携带用户信息。我们只需要在请求查看登录后才能查看的信息时携带这个cookie。我们使用Jsoup来模拟手动设置cookie的方式。具体代码如下:
从代码可以看出,它和不需要登录的网站没什么区别,只是多了一个.header("Cookie", "your cookies"),我们可以复制浏览器里的cookie在这里,写main方法
运行 main 会产生以下结果:
可以看到,我们成功获取了缺心,这就是所谓的简单,也就是说我们设置的cookie是有效的,我们成功获取了需要登录的数据。这个方法真的很简单,唯一的缺点是cookie需要经常更换,因为cookie会失效,使用起来不太舒服。
模拟登录方式
模拟登录方式可以解决手动设置cookie方式的不足,但也引入了更复杂的问题。目前的验证码种类繁多,其中有很多是具有挑战性的,比如在一堆图片中操作某类图片。这个还是挺难的,写出来也不容易。因此,由开发人员权衡使用哪种方法的利弊。我们今天使用的豆瓣在登录的时候是没有验证码的,这种没有验证码的比较简单。模拟登录方式最重要的是找到真正的登录请求和登录所需的参数。我们只能利用这一点,我们先在登录界面输入错误的账号密码,这样页面就不会跳转了,所以我们可以很容易地找到登录请求。让我演示一下豆瓣登录找到登录链接。我们在登录界面输入了错误的用户名和密码。点击登录后,查看网络发起的请求链接,如下图:
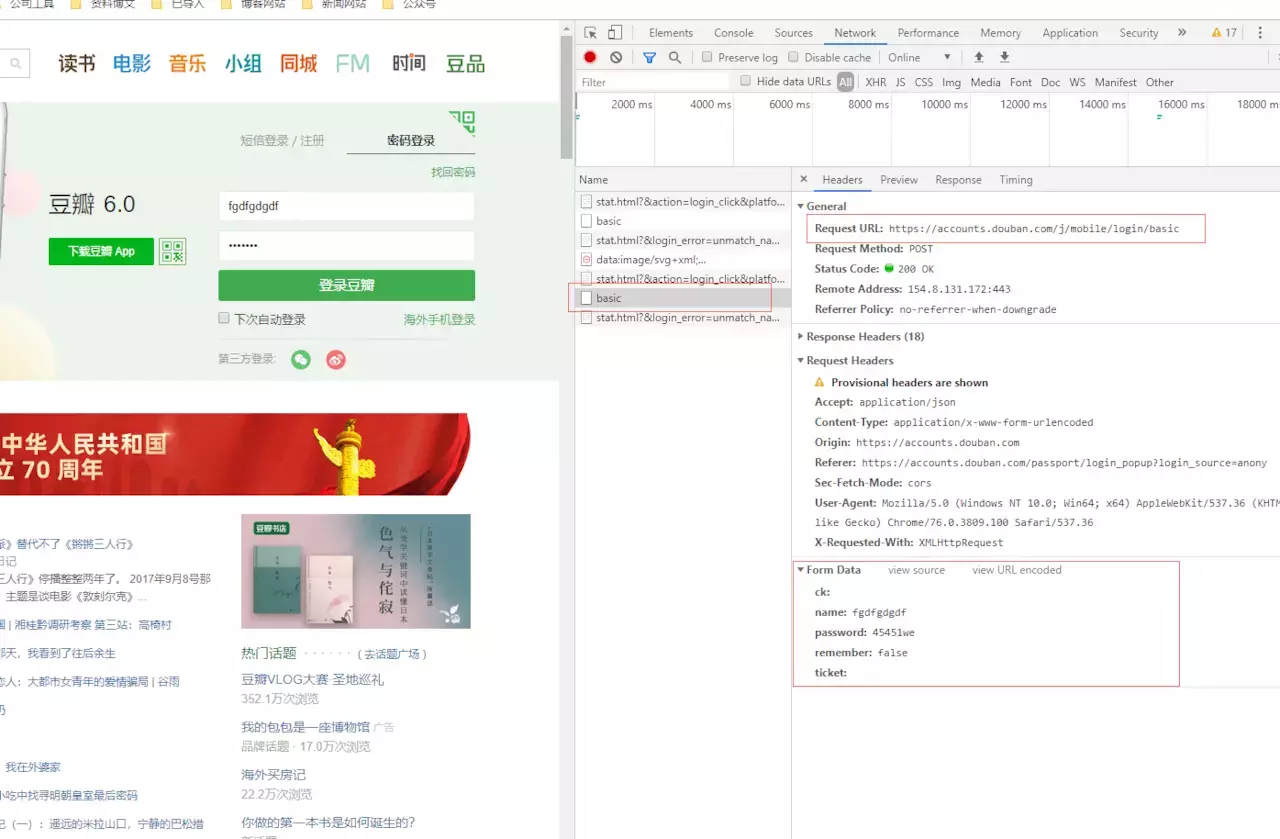
从网络上我们可以看到豆瓣的登录链接是,需要五个参数,具体参数可以在图中的Form Data中查看。有了这些,我们就可以构造一个请求来模拟登录。登录后进行后续操作。接下来,我们将使用Jsoup模拟登录,获取豆瓣首页的昵称。具体代码如下:
这段代码分为两部分。第一段是模拟登录,第二段是解析豆瓣首页。此代码中启动了两个请求。第一个请求是模拟登录获取cookie,第二个请求携带第一个模拟登录后获取的cookie,这样也可以访问需要登录的页面,修改main方法
运行 main 方法会产生以下结果:
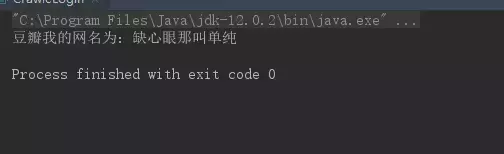
模拟登录的方法也成功获取了网名。它被称为简单。虽然这是最简单的模拟登录,但从代码量可以看出,它比设置cookies要复杂得多。对于其他有验证码登录的用户,这里就不介绍了。首先,我没有这方面的经验。其次,这个实现比较复杂,会涉及到一些算法和一些辅助工具的使用。有兴趣的朋友可以参考崔庆才先生的作品。博客研究研究。虽然模拟登录写起来比较复杂,但只要写得好,一劳永逸。如果你需要长期的采集信息需要登录,这个还是值得做的。除了使用jsoup模拟登录,我们也可以使用httpclient来模拟登录。httpclient模拟登录没有Jsoup那么复杂,因为httpclient可以像浏览器一样保存session会话,这样登录后就保存cookies,同一个httpclient中的请求都会带cookies。httpclient模拟登录代码如下:
运行此代码也会返回 true。
我们讲了Java爬虫的登录问题。总结一下:爬虫的登录问题有两种解决方案。一种是手动设置cookies。此方法适用于短期采集或一次性性采集,成本较低。另一种方式是模拟登录,适合长期采集网站,因为模拟登录的成本还是挺高的,尤其是一些异常的验证码,好处是可以让你一劳永逸
以上就是Java爬虫遇到的登录问题的知识分享。我希望它会帮助你。下一篇是关于爬虫遇到数据异步加载的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,共同进步
源代码:
https://github.com/BinaryBall/ ... .java
作者:平头哥的技术博文
来源:掘金
商业用途请与原作者联系,本文只做展示分享,不妥侵删!
java爬虫抓取网页数据( 我分享一套完整的Python爬虫学习框架路线和视频教程入门)
网站优化 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2022-02-23 04:19
我分享一套完整的Python爬虫学习框架路线和视频教程入门)
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
爬行动物有什么用?
爬行是搜索引擎的第一步,也是最简单的一步。
为什么你最终选择了 Python?
一个简单的 Python 爬虫:
import urllib
import urllib.request
def loadPage(url,filename):
"""
作用:根据url发送请求,获取html数据;
:param url:
:return:
"""
request=urllib.request.Request(url)
html1= urllib.request.urlopen(request).read()
return html1.decode('utf-8')
def writePage(html,filename):
"""
作用将html写入本地
:param html: 服务器相应的文件内容
:return:
"""
with open(filename,'w') as f:
f.write(html)
print('-'*30)
def tiebaSpider(url,beginPage,endPage):
"""
作用贴吧爬虫调度器,负责处理每一个页面url;
:param url:
:param beginPage:
:param endPage:
:return:
"""
for page in range(beginPage,endPage+1):
pn=(page - 1)*50
fullurl=url+"&pn="+str(pn)
print(fullurl)
filename='第'+str(page)+'页.html'
html= loadPage(url,filename)
writePage(html,filename)
if __name__=="__main__":
kw=input('请输入你要需要爬取的贴吧名:')
beginPage=int(input('请输入起始页'))
endPage=int(input('请输入结束页'))
url='https://tieba.baidu.com/f?'
kw1={'kw':kw}
key = urllib.parse.urlencode(kw1)
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
Java实现网络爬虫的代码比Python多很多,实现起来也比较复杂。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。
Python 相对于 Java 的优势:
1、方向广泛,如web开发、机器学习、人工智能、数据分析、金融量化交易、爬虫开发、自动化运维、自动化测试等;
2、语法简洁,学习成本低;
3、未来发展前景更高,因为国家在推动(纳入高中教材),也就是说未来的市场也很大;
4、Python的requests库比Java的jsoup简单;
5、Python有scrapy爬虫库的加持;
6、Python 对 Excel 的支持优于 Java;
7、Java 没有像 pip 这样的包管理工具。
现在大数据时代几乎离不开Python爬虫,而使用Python爬虫我们可以获得大量有价值的数据,所以现在这个方向的就业前景还是比较好的。如果你想学习Python爬虫,我给大家分享一套完整的Python爬虫学习资料供大家参考。收录系统的Python爬虫学习框架路线和视频教程。内容清晰明了。非常适合初学者入门。点击下方的↓↓↓插件直接获取。帮助! 查看全部
java爬虫抓取网页数据(
我分享一套完整的Python爬虫学习框架路线和视频教程入门)
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
爬行动物有什么用?
爬行是搜索引擎的第一步,也是最简单的一步。
为什么你最终选择了 Python?
一个简单的 Python 爬虫:
import urllib
import urllib.request
def loadPage(url,filename):
"""
作用:根据url发送请求,获取html数据;
:param url:
:return:
"""
request=urllib.request.Request(url)
html1= urllib.request.urlopen(request).read()
return html1.decode('utf-8')
def writePage(html,filename):
"""
作用将html写入本地
:param html: 服务器相应的文件内容
:return:
"""
with open(filename,'w') as f:
f.write(html)
print('-'*30)
def tiebaSpider(url,beginPage,endPage):
"""
作用贴吧爬虫调度器,负责处理每一个页面url;
:param url:
:param beginPage:
:param endPage:
:return:
"""
for page in range(beginPage,endPage+1):
pn=(page - 1)*50
fullurl=url+"&pn="+str(pn)
print(fullurl)
filename='第'+str(page)+'页.html'
html= loadPage(url,filename)
writePage(html,filename)
if __name__=="__main__":
kw=input('请输入你要需要爬取的贴吧名:')
beginPage=int(input('请输入起始页'))
endPage=int(input('请输入结束页'))
url='https://tieba.baidu.com/f?'
kw1={'kw':kw}
key = urllib.parse.urlencode(kw1)
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
Java实现网络爬虫的代码比Python多很多,实现起来也比较复杂。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。

Python 相对于 Java 的优势:
1、方向广泛,如web开发、机器学习、人工智能、数据分析、金融量化交易、爬虫开发、自动化运维、自动化测试等;
2、语法简洁,学习成本低;
3、未来发展前景更高,因为国家在推动(纳入高中教材),也就是说未来的市场也很大;
4、Python的requests库比Java的jsoup简单;
5、Python有scrapy爬虫库的加持;
6、Python 对 Excel 的支持优于 Java;
7、Java 没有像 pip 这样的包管理工具。
现在大数据时代几乎离不开Python爬虫,而使用Python爬虫我们可以获得大量有价值的数据,所以现在这个方向的就业前景还是比较好的。如果你想学习Python爬虫,我给大家分享一套完整的Python爬虫学习资料供大家参考。收录系统的Python爬虫学习框架路线和视频教程。内容清晰明了。非常适合初学者入门。点击下方的↓↓↓插件直接获取。帮助!
java爬虫抓取网页数据(文档介绍:对网页爬虫的调查结果调查人:王杨斌)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-22 03:05
文件介绍:网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是PHP和Java的工具代码。1.Java爬虫1.1.JAVA爬虫WebCollector爬虫介绍:WebCollector[]是一个无需配置,方便二次开发的JAVA爬虫框架(内核),提供了简化的API , 只需要很少的代码就可以实现一个强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定且可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2.Web-HarvestWeb-Harvest[]是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。
JSpider的默认配置很小,用处不大。但是 JSpider 很容易扩展,你可以用它来开发强大的网页抓取和数据分析工具。为此,您需要对 JSpider 的原理有深入的了解,然后根据自己的需要开发插件和编写配置文件。1.4.网络爬虫 HeritrixHeritrix[] 是一个开源、可扩展的网络爬虫项目。用户可以使用它从 Internet 上抓取所需的资源。Heritrix 的设计严格遵循 robots.txt 文件的排除说明和 METArobots 标签。它最大的特点就是可扩展性好,方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架,其组织结构包括整个组件和爬取过程。1.5.webmagiclogo垂直爬虫webmagicWebmagic[]是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。
它可以用来构建一个多线程的网络爬虫。1.7.Java网络蜘蛛/网络爬虫SpidermanSpiderman[]是一个基于微内核+插件架构的网络蜘蛛,它的目标是通过简单的方法爬取复杂的目标网络信息并解析成您需要的业务数据。2.C/C++爬虫2.1.网站Crawler GrubNextGenerationGrubNextGeneration[]是一个分布式网络爬虫系统,包括客户端和服务器,可以用来维护网页的索引。其开发语言:C/C++PerlC#。2.2.网络爬虫甲醇甲醇[]是一个模块化和可定制的网络爬虫软件,主要优点是速度快。2.3. 查看全部
java爬虫抓取网页数据(文档介绍:对网页爬虫的调查结果调查人:王杨斌)
文件介绍:网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是PHP和Java的工具代码。1.Java爬虫1.1.JAVA爬虫WebCollector爬虫介绍:WebCollector[]是一个无需配置,方便二次开发的JAVA爬虫框架(内核),提供了简化的API , 只需要很少的代码就可以实现一个强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定且可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2.Web-HarvestWeb-Harvest[]是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。
JSpider的默认配置很小,用处不大。但是 JSpider 很容易扩展,你可以用它来开发强大的网页抓取和数据分析工具。为此,您需要对 JSpider 的原理有深入的了解,然后根据自己的需要开发插件和编写配置文件。1.4.网络爬虫 HeritrixHeritrix[] 是一个开源、可扩展的网络爬虫项目。用户可以使用它从 Internet 上抓取所需的资源。Heritrix 的设计严格遵循 robots.txt 文件的排除说明和 METArobots 标签。它最大的特点就是可扩展性好,方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架,其组织结构包括整个组件和爬取过程。1.5.webmagiclogo垂直爬虫webmagicWebmagic[]是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。
它可以用来构建一个多线程的网络爬虫。1.7.Java网络蜘蛛/网络爬虫SpidermanSpiderman[]是一个基于微内核+插件架构的网络蜘蛛,它的目标是通过简单的方法爬取复杂的目标网络信息并解析成您需要的业务数据。2.C/C++爬虫2.1.网站Crawler GrubNextGenerationGrubNextGeneration[]是一个分布式网络爬虫系统,包括客户端和服务器,可以用来维护网页的索引。其开发语言:C/C++PerlC#。2.2.网络爬虫甲醇甲醇[]是一个模块化和可定制的网络爬虫软件,主要优点是速度快。2.3.
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-03-26 00:18
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
由“爬虫”发回的数据进行处理和过滤的服务器,爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件
已经成功生成SiteURL文件,打开就可以看到所有抓到的url
查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人()
)
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。网络蜘蛛通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,阅读
网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,如此循环下去,直到这个网站的所有网页都被爬取完毕。如果整个
互联网被视为一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅需要爬虫,还需要
由“爬虫”发回的数据进行处理和过滤的服务器,爬虫爬取的数据量越大,对服务器的性能要求就越高。
1 重点介绍爬虫的工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的信息。
在抓取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂,需要根据某个网页进行分析
算法过滤掉主题链接,保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,重复上述操作
停止上述过程,直到达到系统的某个条件。此外,所有被爬虫爬取的网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;
对于焦爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程起到反馈和指导作用。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:通用网络爬虫、重点网络爬虫、
增量网络爬虫,深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。刚从网上
网站获取的URL进一步循环获取数据,提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的网站爬虫远比这个复杂,深入的讨论太多了。
. 除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个Java模拟的提取新浪网页链接并存储的程序
在一个文件中
源代码如下
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
运行idea的结果如下:
检查D盘是否有SiteURL.txt文件
已经成功生成SiteURL文件,打开就可以看到所有抓到的url
java爬虫抓取网页数据(博客系列Java爬虫入门简介(一)——HttpClient请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-22 20:42
)
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫简介(二)——Jsoup解析HTML页面(本文)
在上一篇博客中,我们已经介绍了如何使用 HttpClient 来模拟客户端请求页面。在本篇博客中,我们将介绍如何解析获取的页面内容。
在上一节中,我们获得了页面的 HTML 源代码,但是这些源代码是提供给浏览器进行解析的。我们需要的数据其实就是页面上博客的标题、作者、简介、发布日期等。我们需要一种方法来从 HTML 源代码中解析这些信息,将其提取出来,并将其存储在文本或数据库中。在本篇博客中,我们将介绍使用 Jsoup 包来帮助我们解析页面和提取数据。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址或者解析HTML内容。它的主要功能包括解析 HTML 页面、通过 DOM 或 CSS 选择器查找和提取数据以及更改 HTML 内容。Jsoup的使用也很简单。使用Jsoup.parse(String str)方法解析我们之前获取的HTML内容得到一个Document类,剩下的工作就是从Document中选择我们需要的数据。例如,假设我们有一个收录以下内容的 HTML 页面:
第一篇博客
第二篇博客
第三篇博客
通过Jsoup,我们可以将以上三个博客的标题提取成一个List。使用方法如下:
首先,我们通过maven来介绍Jsoup
org.jsoup
jsoup
1.10.3
然后写Java来解析。
package org.hfutec.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
List titles = new ArrayList();
List urls = new ArrayList();
//假设我们获取的HTML的字符内容如下
String html = "<a href=\"url1\">第一篇博客</a><a href=\"url2\">第二篇博客</a><a href=\"url3\">第三篇博客</a>";
//第一步,将字符内容解析成一个Document类
Document doc = Jsoup.parse(html);
//第二步,根据我们需要得到的标签,选择提取相应标签的内容
Elements elements = doc.select("div[id=blog_list]").select("div[class=blog_title]");
for( Element element : elements ){
String title = element.text();
titles.add(title);
urls.add(element.select("a").attr("href"));
}
//输出测试
for( String title : titles ){
System.out.println(title);
}
for( String url : urls ){
System.out.println(url);
}
}
}
下面简单介绍一下Jsoup的解析过程。第一步是调用parse()方法把字符对象变成Document对象,然后我们对这个对象进行操作。一般来说,提取数据就是根据标签选择数据。select() 方法的语法格式与 javascript/css 选择器的语法格式相同。一般抽取一个标签,其属性值为指定的内容。得到的结果是一个Elements的集合,也就是Elements(因为可能有很多符合条件的标签,所以结果就是一个集合)。select() 方法可以一直持续到我们想要的标签集被选中(注意我们不必从标签层级中逐层选择,我们可以直接将 select() 方法写到我们需要的标签中,例如, 这里的示例代码可以直接写成 Elements elements = doc.select("div[class=blog_title]"); 效果是一样的)。对于选定的一组元素,我们可以通过循环提取每个所需的数据。例如,如果我们需要获取标签的文本信息,可以使用 text() 方法。如果我们需要获取对应的 HTML 属性信息,可以使用 attr() 方法。我们可以看到上述方法的输出如下:
更多Jsoup解析操作请参考以下内容:
1、
2、
一个实例
让我们继续上一个爬取数据的例子来学习官方的网站博客列表来解释一个例子。我们已经知道可以使用 Jsoup 来解析爬取的 HTML 页面内容。那么我们如何查看我们需要的内容对应的标签呢?以Chrome浏览器为例,我们需要爬取这个页面的博客。首先用Chrome浏览器打开网址,然后右击博客标题,点击“Inspect”,得到HTML页面。如下所示。
图2 右击标题
图3 点击元素父元素侧边的小三角关闭代码查看
图4 确认当前博客HTML代码的一致性
经过上面的操作,我们已经可以看到所有的博客标题等信息都存放在class=card div中了。所以,我们只需要注意这个标签中的内容是如何组织的,仅此而已。如下图所示,我们需要的信息所属的标签可以通过点击小三角展开得到。
因此,解析博客列表的代码可以写成如下。
package org.hfutec.example;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
String url = "http://www.datalearner.com/blog_list";
String rawHTML = null;
try {
rawHTML = getHTMLContent(url);
} catch (IOException e) {
e.printStackTrace();
}
//将当前页面转换成Jsoup的Document对象
Document doc = Jsoup.parse(rawHTML);
//获取所有的博客列表集合
Elements blogList = doc.select("div[class=card]");
//针对每个博客内容进行解析,并输出
for( Element element : blogList ){
String title = element.select("h4[class=card-title]").text();
String introduction = element.select("p[class=card-text]").text();
String author = element.select("span[class=fa fa-user]").text();
System.out.println("Title:\t"+title);
System.out.println("introduction:\t"+introduction);
System.out.println("Author:\t"+author);
System.out.println("--------------------------");
}
}
//根据url地址获取对应页面的HTML内容,我们将上一节中的内容打包成了一个方法,方便调用
private static String getHTMLContent( String url ) throws IOException {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet(url);
//获取网址的返回结果
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity);
//关闭HttpEntity流
EntityUtils.consume(entity);
return content;
}
}
最终输出如下图所示:
查看全部
java爬虫抓取网页数据(博客系列Java爬虫入门简介(一)——HttpClient请求
)
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫简介(二)——Jsoup解析HTML页面(本文)
在上一篇博客中,我们已经介绍了如何使用 HttpClient 来模拟客户端请求页面。在本篇博客中,我们将介绍如何解析获取的页面内容。
在上一节中,我们获得了页面的 HTML 源代码,但是这些源代码是提供给浏览器进行解析的。我们需要的数据其实就是页面上博客的标题、作者、简介、发布日期等。我们需要一种方法来从 HTML 源代码中解析这些信息,将其提取出来,并将其存储在文本或数据库中。在本篇博客中,我们将介绍使用 Jsoup 包来帮助我们解析页面和提取数据。
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址或者解析HTML内容。它的主要功能包括解析 HTML 页面、通过 DOM 或 CSS 选择器查找和提取数据以及更改 HTML 内容。Jsoup的使用也很简单。使用Jsoup.parse(String str)方法解析我们之前获取的HTML内容得到一个Document类,剩下的工作就是从Document中选择我们需要的数据。例如,假设我们有一个收录以下内容的 HTML 页面:
第一篇博客
第二篇博客
第三篇博客
通过Jsoup,我们可以将以上三个博客的标题提取成一个List。使用方法如下:
首先,我们通过maven来介绍Jsoup
org.jsoup
jsoup
1.10.3
然后写Java来解析。
package org.hfutec.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
List titles = new ArrayList();
List urls = new ArrayList();
//假设我们获取的HTML的字符内容如下
String html = "<a href=\"url1\">第一篇博客</a><a href=\"url2\">第二篇博客</a><a href=\"url3\">第三篇博客</a>";
//第一步,将字符内容解析成一个Document类
Document doc = Jsoup.parse(html);
//第二步,根据我们需要得到的标签,选择提取相应标签的内容
Elements elements = doc.select("div[id=blog_list]").select("div[class=blog_title]");
for( Element element : elements ){
String title = element.text();
titles.add(title);
urls.add(element.select("a").attr("href"));
}
//输出测试
for( String title : titles ){
System.out.println(title);
}
for( String url : urls ){
System.out.println(url);
}
}
}
下面简单介绍一下Jsoup的解析过程。第一步是调用parse()方法把字符对象变成Document对象,然后我们对这个对象进行操作。一般来说,提取数据就是根据标签选择数据。select() 方法的语法格式与 javascript/css 选择器的语法格式相同。一般抽取一个标签,其属性值为指定的内容。得到的结果是一个Elements的集合,也就是Elements(因为可能有很多符合条件的标签,所以结果就是一个集合)。select() 方法可以一直持续到我们想要的标签集被选中(注意我们不必从标签层级中逐层选择,我们可以直接将 select() 方法写到我们需要的标签中,例如, 这里的示例代码可以直接写成 Elements elements = doc.select("div[class=blog_title]"); 效果是一样的)。对于选定的一组元素,我们可以通过循环提取每个所需的数据。例如,如果我们需要获取标签的文本信息,可以使用 text() 方法。如果我们需要获取对应的 HTML 属性信息,可以使用 attr() 方法。我们可以看到上述方法的输出如下:
更多Jsoup解析操作请参考以下内容:
1、
2、
一个实例
让我们继续上一个爬取数据的例子来学习官方的网站博客列表来解释一个例子。我们已经知道可以使用 Jsoup 来解析爬取的 HTML 页面内容。那么我们如何查看我们需要的内容对应的标签呢?以Chrome浏览器为例,我们需要爬取这个页面的博客。首先用Chrome浏览器打开网址,然后右击博客标题,点击“Inspect”,得到HTML页面。如下所示。
图2 右击标题
图3 点击元素父元素侧边的小三角关闭代码查看
图4 确认当前博客HTML代码的一致性
经过上面的操作,我们已经可以看到所有的博客标题等信息都存放在class=card div中了。所以,我们只需要注意这个标签中的内容是如何组织的,仅此而已。如下图所示,我们需要的信息所属的标签可以通过点击小三角展开得到。
因此,解析博客列表的代码可以写成如下。
package org.hfutec.example;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
/*******
* created by DuFei at 2017.08.25 21:00
* web crawler example
* ******/
public class DataLearnerCrawler {
public static void main(String[] args) {
String url = "http://www.datalearner.com/blog_list";
String rawHTML = null;
try {
rawHTML = getHTMLContent(url);
} catch (IOException e) {
e.printStackTrace();
}
//将当前页面转换成Jsoup的Document对象
Document doc = Jsoup.parse(rawHTML);
//获取所有的博客列表集合
Elements blogList = doc.select("div[class=card]");
//针对每个博客内容进行解析,并输出
for( Element element : blogList ){
String title = element.select("h4[class=card-title]").text();
String introduction = element.select("p[class=card-text]").text();
String author = element.select("span[class=fa fa-user]").text();
System.out.println("Title:\t"+title);
System.out.println("introduction:\t"+introduction);
System.out.println("Author:\t"+author);
System.out.println("--------------------------");
}
}
//根据url地址获取对应页面的HTML内容,我们将上一节中的内容打包成了一个方法,方便调用
private static String getHTMLContent( String url ) throws IOException {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet(url);
//获取网址的返回结果
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity);
//关闭HttpEntity流
EntityUtils.consume(entity);
return content;
}
}
最终输出如下图所示:
java爬虫抓取网页数据(一共需要做四个规则:第一个规则“第二个规则图” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2022-03-22 20:41
)
2.如何使用快捷键采集:如何使用快捷键采集
通过CNKI高级搜索,输入关键词,即可获取相关的文章标题、作者、摘要、关键词等信息。但是CNKI在输入关键词进行搜索后并没有改变URL,所以在爬取的时候,我们需要爬虫自动输入目标关键词来搜索并开始爬取数据。
要获取标题、作者、摘要、关键词等信息,我们一共需要制定四个规则:
第一条规则”
第二条规则”
提示:文章的部分摘要需要点击“更多”才能全部显示。为了抓取完整的摘要,我们需要制定一个规则来点击这个“更多”。
第三条规则”
第四条规则”
图1
一、第一条规则 - 知网搜索
1.以CNKI高级检索文献文章为例,将高级文献检索链接粘贴到某手。
第一条规则的主要工作是搜索关键词,但是为了有效地执行规则,我们在规则中抓取文章的类型。这里以文献为例,我们抓取的内容为“文献”,并勾选关键内容。
图 2
如图2所示,具体操作如下:
#1.将目标爬取网页粘贴到猫鼠台网址栏,回车。
#2.看到页面加载完毕。
#3.将抓取的内容“文档”映射到排序框中。
#4.选择文献的重点内容。
2.跳转到连续动作工作台输入关键词及其动作
关键词 的自动输入点是建立两个步骤。第一步是通过输入框的定位表达式找到输入框,然后输入关键词。第二步,通过定位表达式找到搜索按钮,然后爬虫自行点击按钮。
2.1 创建输入步骤
图 3
如图3所示,具体操作如下:
#1.输入目标主题名,即第二条规则主题名,表示第二条规则搜索到关键词后会执行爬取
#2.点击谁在使用,查看输入的主题名是否被其他人占用。如果已经被其他人占用,则需要更改另一个主题名称。
#3.创建一个新的输入步骤。如上所述,首先是执行输入动作,所以这里是一个新的输入步骤。
#4.输入 关键词 进行搜索。
#5.根据网页结构填写输入框的定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能进行验证。定位是否准确,详见网页内容搜索方法。
2.2 构建和提交步骤
图 4
如图4所示,具体操作如下:
#1.根据网页结构填写检索定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能来验证是否定位准确。详情请参阅搜索网页内容的使用方法。
保存规则后,知网搜索就完成了。
二、第二条规则——知网搜索结果
该规则负责通过知网搜索对 关键词 搜索到的页面进行爬取。此规则与定义普通规则相同。
将要爬取的内容映射到排序框中。如果我们想要捕获每个文章的详细数据抽象作者,我们需要建立一个分层捕获,在当前规则中捕获每个文章的细节。为CNKI_文章数据生成线索的数据页的URL。
图 5
如图5所示,具体操作如下:
#1.将要爬取的下级链接映射到排序框中
#2.查看关键内容
#3.点击排序框顶部节点复制样本。要抓取当前页面文章的所有下级链接,需要复制样本。详情请参考教程:
#4.跳转到爬虫路由工作台做翻页线索。要抓取翻页的文章,需要做翻页线索。详情请参考教程:
保存规则后,CNKI_search结果规则就完成了,接下来需要做文章详细页面的爬取规则。
三、第三条规则——知网_文章数据_more
1.将网页上的“更多”按钮映射到排序框作为内容映射,查看重点内容。
2.在爬虫路由工作台上做一个模拟点击,即为“更多”做一个标记轨迹作为标记。
图 6
如图6所示,具体操作如下:
#1.新建一个标记线索,勾选Consecutive fetching,意思是爬虫在执行抓取任务时,在同一个DS计数器窗口抓取到当前页面后,可以直接跳转到下一页。抓住。
#2.点击“更多”按钮,自动定位页面标签节点,展开节点,找到收录“更多”的文本节点。
#3.在文本节点上右键,Clue Mapping → Mark Clue,可以看到“more”自动填入了mark值。
#4.将节点映射到线索范围,右击翻页块节点,选择线索映射→定位→线索1,完成后定位号会显示页面的定位号-转块节点。
保存规则后,知网_文章Data_More规则就完成了,接下来需要完成一些“更多”知网来执行抓取的规则——知网_文章Data。
提示:第三条和第四条规则演示模拟点击。不明白的可以参考教程:
四、第四条规则——知网_文章数据。
这个规则是最简单的类型,将需要爬取的内容映射到一个bin中。
图 7
如图7所示,具体操作如下: #1. 将要抓取的内容映射到排序框中。
五、修改文章详细页面URL参数,构造新URL,生成第三条规则线索——hownet_文章data_more
将第二条规则采集的详情页的链接导入excel。
图 8
可以发现不是完整的URL,DS计数器也无法构造URL直接生成可访问的URL,需要用excel手动修改。
对比详情页的完整网址,如下:
可以发现采集的链接缺少了之前的域名,增加了“/kns”部分。您可以使用该功能修改链接。
图 9
在J2单元格中输入公式=""&RIGHT(I2,LEN(I2)-4)获取可访问的URL并填写,这样就可以将获取的URL作为第三个批量添加规则的线索。
如有疑问,您可以或
查看全部
java爬虫抓取网页数据(一共需要做四个规则:第一个规则“第二个规则图”
)
2.如何使用快捷键采集:如何使用快捷键采集
通过CNKI高级搜索,输入关键词,即可获取相关的文章标题、作者、摘要、关键词等信息。但是CNKI在输入关键词进行搜索后并没有改变URL,所以在爬取的时候,我们需要爬虫自动输入目标关键词来搜索并开始爬取数据。
要获取标题、作者、摘要、关键词等信息,我们一共需要制定四个规则:
第一条规则”
第二条规则”
提示:文章的部分摘要需要点击“更多”才能全部显示。为了抓取完整的摘要,我们需要制定一个规则来点击这个“更多”。
第三条规则”
第四条规则”
图1
一、第一条规则 - 知网搜索
1.以CNKI高级检索文献文章为例,将高级文献检索链接粘贴到某手。
第一条规则的主要工作是搜索关键词,但是为了有效地执行规则,我们在规则中抓取文章的类型。这里以文献为例,我们抓取的内容为“文献”,并勾选关键内容。
图 2
如图2所示,具体操作如下:
#1.将目标爬取网页粘贴到猫鼠台网址栏,回车。
#2.看到页面加载完毕。
#3.将抓取的内容“文档”映射到排序框中。
#4.选择文献的重点内容。
2.跳转到连续动作工作台输入关键词及其动作
关键词 的自动输入点是建立两个步骤。第一步是通过输入框的定位表达式找到输入框,然后输入关键词。第二步,通过定位表达式找到搜索按钮,然后爬虫自行点击按钮。
2.1 创建输入步骤
图 3
如图3所示,具体操作如下:
#1.输入目标主题名,即第二条规则主题名,表示第二条规则搜索到关键词后会执行爬取
#2.点击谁在使用,查看输入的主题名是否被其他人占用。如果已经被其他人占用,则需要更改另一个主题名称。
#3.创建一个新的输入步骤。如上所述,首先是执行输入动作,所以这里是一个新的输入步骤。
#4.输入 关键词 进行搜索。
#5.根据网页结构填写输入框的定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能进行验证。定位是否准确,详见网页内容搜索方法。
2.2 构建和提交步骤
图 4
如图4所示,具体操作如下:
#1.根据网页结构填写检索定位表达式,即网页上能定位输入框的XPath表达式。写好表达式后,可以使用MS的搜索功能来验证是否定位准确。详情请参阅搜索网页内容的使用方法。
保存规则后,知网搜索就完成了。
二、第二条规则——知网搜索结果
该规则负责通过知网搜索对 关键词 搜索到的页面进行爬取。此规则与定义普通规则相同。
将要爬取的内容映射到排序框中。如果我们想要捕获每个文章的详细数据抽象作者,我们需要建立一个分层捕获,在当前规则中捕获每个文章的细节。为CNKI_文章数据生成线索的数据页的URL。
图 5
如图5所示,具体操作如下:
#1.将要爬取的下级链接映射到排序框中
#2.查看关键内容
#3.点击排序框顶部节点复制样本。要抓取当前页面文章的所有下级链接,需要复制样本。详情请参考教程:
#4.跳转到爬虫路由工作台做翻页线索。要抓取翻页的文章,需要做翻页线索。详情请参考教程:
保存规则后,CNKI_search结果规则就完成了,接下来需要做文章详细页面的爬取规则。
三、第三条规则——知网_文章数据_more
1.将网页上的“更多”按钮映射到排序框作为内容映射,查看重点内容。
2.在爬虫路由工作台上做一个模拟点击,即为“更多”做一个标记轨迹作为标记。
图 6
如图6所示,具体操作如下:
#1.新建一个标记线索,勾选Consecutive fetching,意思是爬虫在执行抓取任务时,在同一个DS计数器窗口抓取到当前页面后,可以直接跳转到下一页。抓住。
#2.点击“更多”按钮,自动定位页面标签节点,展开节点,找到收录“更多”的文本节点。
#3.在文本节点上右键,Clue Mapping → Mark Clue,可以看到“more”自动填入了mark值。
#4.将节点映射到线索范围,右击翻页块节点,选择线索映射→定位→线索1,完成后定位号会显示页面的定位号-转块节点。
保存规则后,知网_文章Data_More规则就完成了,接下来需要完成一些“更多”知网来执行抓取的规则——知网_文章Data。
提示:第三条和第四条规则演示模拟点击。不明白的可以参考教程:
四、第四条规则——知网_文章数据。
这个规则是最简单的类型,将需要爬取的内容映射到一个bin中。
图 7
如图7所示,具体操作如下: #1. 将要抓取的内容映射到排序框中。
五、修改文章详细页面URL参数,构造新URL,生成第三条规则线索——hownet_文章data_more
将第二条规则采集的详情页的链接导入excel。
图 8
可以发现不是完整的URL,DS计数器也无法构造URL直接生成可访问的URL,需要用excel手动修改。
对比详情页的完整网址,如下:
可以发现采集的链接缺少了之前的域名,增加了“/kns”部分。您可以使用该功能修改链接。
图 9
在J2单元格中输入公式=""&RIGHT(I2,LEN(I2)-4)获取可访问的URL并填写,这样就可以将获取的URL作为第三个批量添加规则的线索。
如有疑问,您可以或
java爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单的网络 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-22 20:40
)
目标网络爬虫做什么?手动编写一个简单的网络爬虫;1.网络爬虫1.1.名称1.2.简要说明2.流程
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注
3. 分类
4. 思想分析
首先观察我们爬虫的起始页是:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
java爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单的网络
)
目标网络爬虫做什么?手动编写一个简单的网络爬虫;1.网络爬虫1.1.名称1.2.简要说明2.流程
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;2.1. 关注
3. 分类
4. 思想分析
首先观察我们爬虫的起始页是:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
java爬虫抓取网页数据(什么是网络爬虫?网络蜘蛛的实现原理根据这种原理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-19 04:12
)
什么是网络爬虫?网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页,从网站的一个页面(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/");
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在 Eclipse 中运行的结果
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
查看全部
java爬虫抓取网页数据(什么是网络爬虫?网络蜘蛛的实现原理根据这种原理
)
什么是网络爬虫?网络爬虫也称为蜘蛛。网络蜘蛛通过网页的链接地址搜索网页,从网站的一个页面(通常是首页)开始,读取网页内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并提取其中的URL。我们将获取的 URL 存储在一个文件夹中。只需从 网站 获得的 URL 进一步循环,即可获取数据并从中提取其他数据。这里就不写了,只是模拟一个最简单的原理。实际的 网站 爬虫远比这复杂。太多了,无法深入讨论。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/";);
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("e:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在 Eclipse 中运行的结果
底部显示收购成功!接下来我们到E盘根目录下找到url.txt。看看有没有这个文件
接下来,我们打开txt文件,找到一系列URL链接。这些都是我们爬取新浪首页得到的网址
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-18 05:11
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面是万和专业老师为大家分享网络爬虫的入门知识。
0 1
网络爬虫
1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。
这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
一个简单爬虫的必要功能包括:
发送请求和获取响应的函数;
解析响应的函数;
存储过滤数据的功能;
处理解析后的URL路径的函数;
2.1. 专注
爬虫需要注意的三点:
抓取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
0 4
思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据:
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text()
说明:使用XPath表达式表示 //div[@class='content']/p/text()
图片://a/img/@src 作为 XPath 表达式
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 结果保存
WanhoPipeline.java
5.5. 模型对象
ArticleVo.java
如果你想了解更多关于网络爬虫的知识,可以去万和官网,注册后可以免费学习Java爬虫项目。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始 查看全部
java爬虫抓取网页数据(一下关于网络爬虫的入门知识入门教程)
经常听到“爬行动物”这个词,但它是什么意思呢?它是干什么用的?下面是万和专业老师为大家分享网络爬虫的入门知识。
0 1
网络爬虫
1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过网页的链接地址搜索网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
因此,为了在网络上抓取数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发回的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
0 2
过程
网络爬虫有什么作用?他的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。
这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
一个简单爬虫的必要功能包括:
发送请求和获取响应的函数;
解析响应的函数;
存储过滤数据的功能;
处理解析后的URL路径的函数;
2.1. 专注
爬虫需要注意的三点:
抓取目标的描述或定义;
网页或数据的分析和过滤;
URL 的搜索策略。
0 3
分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫
专注的网络爬虫
增量网络爬虫
深网爬虫。
实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
0 4
思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面:
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据:
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text()
说明:使用XPath表达式表示 //div[@class='content']/p/text()
图片://a/img/@src 作为 XPath 表达式
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式编写代码来实现了。
0 5
代码
代码实现部分使用了webmagic框架,因为它比使用基本的Java网络编程要简单得多。
5.1. 代码结构
5.2. 程序入口
演示.java
5.3. 爬取过程
WanhoPageProcessor.java
5.4. 结果保存
WanhoPipeline.java
5.5. 模型对象
ArticleVo.java
如果你想了解更多关于网络爬虫的知识,可以去万和官网,注册后可以免费学习Java爬虫项目。
面对面专业指导
白手起家
进入IT高薪圈
从这里开始
java爬虫抓取网页数据(爬虫爬虫处理html格式返回就需要用到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-18 05:09
爬虫
爬虫可以理解为一种从第三方网站获取数据的技术。
关于爬虫语言
Java对网页数据的爬取必须涉及到.URL和从URL读取的数据(本文使用字符流获取url返回),需要经过转换才能被我们使用。目前大部分都是json格式。相比html格式,json格式更简单。本文介绍返回的html格式。
汤
需要 Jsoup 来处理 html 格式的返回。jsoup 是一个 Java html 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。具体的jar包可以自己下载。
我们可以通过如下方式模拟这样的请求,然后从请求的返回中解析出我们需要的数据。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* Created by wingzing on 2018/8/8.
*/
public class WingZingDemo {
public static void main(String[] args) {
String httpUrl = "http://bestcbooks.com/"; //需要爬的网址
String html;
try {
StringBuffer sbf = new StringBuffer();
URL url = new URL(httpUrl);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET"); //设置请求方式 可设置POST 注意一定要大写
//connection.setRequestProperty("Cookie", cookie); //设置请求头参数 如Cookie、Host等等
connection.connect(); //开启连接
InputStream is = connection.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String strRead = null;
while ((strRead = reader.readLine()) != null) { //读取返回
sbf.append(strRead);
sbf.append("\r\n");
}
reader.close();//关闭缓冲字符流
html = sbf.toString();
//System.out.println(html);
Document doc = Jsoup.parse(html);//将爬来的html格式的字符串转成Document从而获取其中需要的数据
Element ul = doc.getElementById("category-list");//取得ID为category-list的元素
Elements liList = ul.getElementsByTag("li");//取得其中的li标签 为一个集合
for(Element li:liList){ //循环该li集合
System.out.println(li.getElementsByTag("a").get(0).text());//取得每个li中的a标签的值 进行输出
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码中的注释写得很清楚。可以自己复制代码运行,通过debug一步步看值。
一般来说,首先获取页面加载或执行时发送的请求,判断是否需要参数,需要哪些参数,进行模拟,然后获取请求的返回,解析请求,获取我们的数据需要。
以上是一个用Java实现的简单爬虫,仅供没有接触过Java的朋友学习爬虫。后续我会写一些Java中稍微麻烦一点的爬虫,比如抓取数据到自己的数据库,对模拟网页进行一些操作等等。 查看全部
java爬虫抓取网页数据(爬虫爬虫处理html格式返回就需要用到)
爬虫
爬虫可以理解为一种从第三方网站获取数据的技术。
关于爬虫语言
Java对网页数据的爬取必须涉及到.URL和从URL读取的数据(本文使用字符流获取url返回),需要经过转换才能被我们使用。目前大部分都是json格式。相比html格式,json格式更简单。本文介绍返回的html格式。
汤
需要 Jsoup 来处理 html 格式的返回。jsoup 是一个 Java html 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。具体的jar包可以自己下载。
我们可以通过如下方式模拟这样的请求,然后从请求的返回中解析出我们需要的数据。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* Created by wingzing on 2018/8/8.
*/
public class WingZingDemo {
public static void main(String[] args) {
String httpUrl = "http://bestcbooks.com/"; //需要爬的网址
String html;
try {
StringBuffer sbf = new StringBuffer();
URL url = new URL(httpUrl);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET"); //设置请求方式 可设置POST 注意一定要大写
//connection.setRequestProperty("Cookie", cookie); //设置请求头参数 如Cookie、Host等等
connection.connect(); //开启连接
InputStream is = connection.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(is, "UTF-8"));
String strRead = null;
while ((strRead = reader.readLine()) != null) { //读取返回
sbf.append(strRead);
sbf.append("\r\n");
}
reader.close();//关闭缓冲字符流
html = sbf.toString();
//System.out.println(html);
Document doc = Jsoup.parse(html);//将爬来的html格式的字符串转成Document从而获取其中需要的数据
Element ul = doc.getElementById("category-list");//取得ID为category-list的元素
Elements liList = ul.getElementsByTag("li");//取得其中的li标签 为一个集合
for(Element li:liList){ //循环该li集合
System.out.println(li.getElementsByTag("a").get(0).text());//取得每个li中的a标签的值 进行输出
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码中的注释写得很清楚。可以自己复制代码运行,通过debug一步步看值。
一般来说,首先获取页面加载或执行时发送的请求,判断是否需要参数,需要哪些参数,进行模拟,然后获取请求的返回,解析请求,获取我们的数据需要。
以上是一个用Java实现的简单爬虫,仅供没有接触过Java的朋友学习爬虫。后续我会写一些Java中稍微麻烦一点的爬虫,比如抓取数据到自己的数据库,对模拟网页进行一些操作等等。
java爬虫抓取网页数据( 有没有什么轻便的框架供我们使用?什么框架?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-18 05:08
有没有什么轻便的框架供我们使用?什么框架?)
Java 爬虫 (二)
前言:在上一篇博客中,我们使用了基于HttpURLConnection的方法进行数据爬取
Java爬虫(一),但是里面没有框架,通过原生http爬取,那么问题来了,有没有轻量级的框架给我们用?
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。本篇博客将主要介绍jsoup技术进行数据爬取,为了提高效率,我们将使用多线程的方式读取数据
爬进入口
我们随便找一个网站来爬取,原理是一样的,比如我们爬取一个国家统计局的数据,首先找到爬取到的网站的页面如下:
比如我爬取天津的数据,找到要爬取的网站页面入口:
http://www.stats.gov.cn/tjsj/t ... .html
爬行的想法
其实爬虫的代码不用太在意。首先我们理清思路,上图:
从上图可以看出我们的基本思路和流程,但是由于网站的可变性,我们不能贸然爬取,造成数据冗余。这个网页的最后一层只有文字信息,其余网页一条短信对应一条短信到一个URL地址,而在最后一层之外,每一层的数字和短信都有相同的URL,所以我们只需要爬取名字,如下:
开始爬行
请注意,我们的以下文档包路径是:
import org.jsoup.nodes.Document;
最终的项目目录结构如下:
1.只需创建一个maven项目
2.在pom.xml文件中添加如下依赖
org.jsoup
jsoup
1.11.3
3.创建主类
public class Main {
//待抓取的Url队列,全局共享
public static final LinkedBlockingQueue UrlQueue = new LinkedBlockingQueue();
public static final WormCore wormCore = new WormCore();
public static void main(String[] args) {
//要抓取的根URL
String rootUrl = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//先把根URL加入URL队列
UrlQueue.offer(rootUrl);
Runnable runnable = new MyRunnable();
//开启固定大小的线程池,线程数为10
ExecutorService Fixed = Executors.newFixedThreadPool(10);
//开始爬取
for (int i = 0;i 3) {
System.out.println(element.text());
}
Flag++;
}
//普通页面的处理
}else {
for (Element element : elements) {
if (!Number.IsNumber(element.text())) {
Text.add(element.text());
System.out.println(element.text());
Urls.add(Before_Url + element.attr("href"));
}
}
}
//把文本集合和URL集合装到Map中返回
Message.put("text",Text);
Message.put("Url",Urls);
return Message;
}
}
由于最后一页与上一页不同,需要因地制宜地调整措施。我们把前面提到的统计划分码号扔掉了,只要名字是必填的,所以博主通过下面Number类中的方法来判断
8.判断是否为数字
<p>public class Number {
public static boolean IsNumber(String str){
for(int i=0;i=48 && c 查看全部
java爬虫抓取网页数据(
有没有什么轻便的框架供我们使用?什么框架?)
Java 爬虫 (二)
前言:在上一篇博客中,我们使用了基于HttpURLConnection的方法进行数据爬取
Java爬虫(一),但是里面没有框架,通过原生http爬取,那么问题来了,有没有轻量级的框架给我们用?
Jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。本篇博客将主要介绍jsoup技术进行数据爬取,为了提高效率,我们将使用多线程的方式读取数据
爬进入口
我们随便找一个网站来爬取,原理是一样的,比如我们爬取一个国家统计局的数据,首先找到爬取到的网站的页面如下:
比如我爬取天津的数据,找到要爬取的网站页面入口:
http://www.stats.gov.cn/tjsj/t ... .html
爬行的想法
其实爬虫的代码不用太在意。首先我们理清思路,上图:
从上图可以看出我们的基本思路和流程,但是由于网站的可变性,我们不能贸然爬取,造成数据冗余。这个网页的最后一层只有文字信息,其余网页一条短信对应一条短信到一个URL地址,而在最后一层之外,每一层的数字和短信都有相同的URL,所以我们只需要爬取名字,如下:
开始爬行
请注意,我们的以下文档包路径是:
import org.jsoup.nodes.Document;
最终的项目目录结构如下:
1.只需创建一个maven项目
2.在pom.xml文件中添加如下依赖
org.jsoup
jsoup
1.11.3
3.创建主类
public class Main {
//待抓取的Url队列,全局共享
public static final LinkedBlockingQueue UrlQueue = new LinkedBlockingQueue();
public static final WormCore wormCore = new WormCore();
public static void main(String[] args) {
//要抓取的根URL
String rootUrl = "http://www.stats.gov.cn/tjsj/t ... 3B%3B
//先把根URL加入URL队列
UrlQueue.offer(rootUrl);
Runnable runnable = new MyRunnable();
//开启固定大小的线程池,线程数为10
ExecutorService Fixed = Executors.newFixedThreadPool(10);
//开始爬取
for (int i = 0;i 3) {
System.out.println(element.text());
}
Flag++;
}
//普通页面的处理
}else {
for (Element element : elements) {
if (!Number.IsNumber(element.text())) {
Text.add(element.text());
System.out.println(element.text());
Urls.add(Before_Url + element.attr("href"));
}
}
}
//把文本集合和URL集合装到Map中返回
Message.put("text",Text);
Message.put("Url",Urls);
return Message;
}
}
由于最后一页与上一页不同,需要因地制宜地调整措施。我们把前面提到的统计划分码号扔掉了,只要名字是必填的,所以博主通过下面Number类中的方法来判断
8.判断是否为数字
<p>public class Number {
public static boolean IsNumber(String str){
for(int i=0;i=48 && c
java爬虫抓取网页数据(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-16 12:24
这篇文章文章教你如何使用JAVA编写爬虫。内容简洁易懂,一定会让你眼前一亮。通过这次对文章的详细介绍,希望你能有所收获。
这篇文章文章其实是我很久以前写的,所以这次重新整理一下。很多朋友可能没有尝试过用Java写爬虫。可能是因为这方面的资料比较少,也可能是用Python写爬虫太方便了。
基本概念
jsoupi 是一个用于处理实际 HTML 的 Java 库。它提供了一个非常方便的 API,用于提取和操作数据,使用 DOM、CSS 和类似 jquery 的最佳方法。
以上是jsoup的官方解释,意思是jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
一般来说,它可以帮助我们解析HTML页面,抓取HTML中的内容。
开始写代码
我们的目标是抓取菜鸟笔记上的信息(文章标题和链接)
public static void main(String[] args) { try { //下面这行代码是连接我们的目标站点,并且get到他的静态HTML代码 Document document=Jsoup.connect("http://www.runoob.com/w3cnote").get(); //我们把获取到的document打印一下,看看里面到底是啥? System.out.println(document); } catch (IOException e) { e.printStackTrace(); } }
看看我们代码运行的结果:
你会发现我们通过这句话获得了网站《菜鸟笔记》的HTML源码
我们来分析一下这串html源码
发现这两个正是我们要获取的数据,我们继续爬取
<p>public static void main(String[] args) { try { Document document=Jsoup.connect("http://www.runoob.com/w3cnote").get(); //底下一行代码是我们进一步抓取到具体的HTML模块,div表示标签, //后面的post-intro表示的是div的class //由于div.post-intro这个标签有多个(每个标题有一个),所以我们先获取到它的所有 Elements elements=document.select("div.post-intro"); //我们来遍历一下,因为div.post-intro有很多个 for(int i=0;i 查看全部
java爬虫抓取网页数据(内容简明扼要能使你眼前一亮,通过这篇文章的详细介绍)
这篇文章文章教你如何使用JAVA编写爬虫。内容简洁易懂,一定会让你眼前一亮。通过这次对文章的详细介绍,希望你能有所收获。
这篇文章文章其实是我很久以前写的,所以这次重新整理一下。很多朋友可能没有尝试过用Java写爬虫。可能是因为这方面的资料比较少,也可能是用Python写爬虫太方便了。
基本概念
jsoupi 是一个用于处理实际 HTML 的 Java 库。它提供了一个非常方便的 API,用于提取和操作数据,使用 DOM、CSS 和类似 jquery 的最佳方法。
以上是jsoup的官方解释,意思是jsoup是一个Java HTML解析器,可以直接解析一个URL地址和HTML文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
一般来说,它可以帮助我们解析HTML页面,抓取HTML中的内容。
开始写代码
我们的目标是抓取菜鸟笔记上的信息(文章标题和链接)
public static void main(String[] args) { try { //下面这行代码是连接我们的目标站点,并且get到他的静态HTML代码 Document document=Jsoup.connect("http://www.runoob.com/w3cnote";).get(); //我们把获取到的document打印一下,看看里面到底是啥? System.out.println(document); } catch (IOException e) { e.printStackTrace(); } }
看看我们代码运行的结果:
你会发现我们通过这句话获得了网站《菜鸟笔记》的HTML源码
我们来分析一下这串html源码
发现这两个正是我们要获取的数据,我们继续爬取
<p>public static void main(String[] args) { try { Document document=Jsoup.connect("http://www.runoob.com/w3cnote";).get(); //底下一行代码是我们进一步抓取到具体的HTML模块,div表示标签, //后面的post-intro表示的是div的class //由于div.post-intro这个标签有多个(每个标题有一个),所以我们先获取到它的所有 Elements elements=document.select("div.post-intro"); //我们来遍历一下,因为div.post-intro有很多个 for(int i=0;i
java爬虫抓取网页数据(java爬虫抓取网页数据主要分为两个流程:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-14 05:00
java爬虫抓取网页数据主要分为两个流程:1.选择想要爬取的网站2.爬取网站数据,存放到本地存储场景:分享海量的数据给一个社区里面的陌生人,让他们来看,分享这些数据给其他人。推荐大家用solr语法:1.要爬取哪个网站。2.抓取数据保存存储到哪个位置。3.请求数据。大小限制4.请求方式可以是https,socket。
5.爬取耗时等。详细点去这个站点cnblogs-分享无限新鲜资讯,爬爬爬~附带我们公司之前爬虫获取的数据。-我们公司是做职业考试服务的,上有时候会有到对于考试难度的职业考试信息,可以通过抓包来获取考试信息(相关文章:王奋斗:cpa考试包过二本学校研究生取得高薪就业凭什么?)。目前,我们不是所有学校考试都有抓包。
我们目前可以抓取所有考试的相关信息。考生信息。部分考试抓包获取一级、二级及以上考试的考试信息部分考试抓包获取一级、二级及以上考试的考试信息结果统计在最新的一些情况下,做个数据整理,可以比较直观的了解考试信息的变化情况,这样做的好处:方便考试管理人员掌握当前国家出题情况,及时调整考试方向及难度等。更新考试政策,及时跟踪考试大纲变化。欢迎交流。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据主要分为两个流程:)
java爬虫抓取网页数据主要分为两个流程:1.选择想要爬取的网站2.爬取网站数据,存放到本地存储场景:分享海量的数据给一个社区里面的陌生人,让他们来看,分享这些数据给其他人。推荐大家用solr语法:1.要爬取哪个网站。2.抓取数据保存存储到哪个位置。3.请求数据。大小限制4.请求方式可以是https,socket。
5.爬取耗时等。详细点去这个站点cnblogs-分享无限新鲜资讯,爬爬爬~附带我们公司之前爬虫获取的数据。-我们公司是做职业考试服务的,上有时候会有到对于考试难度的职业考试信息,可以通过抓包来获取考试信息(相关文章:王奋斗:cpa考试包过二本学校研究生取得高薪就业凭什么?)。目前,我们不是所有学校考试都有抓包。
我们目前可以抓取所有考试的相关信息。考生信息。部分考试抓包获取一级、二级及以上考试的考试信息部分考试抓包获取一级、二级及以上考试的考试信息结果统计在最新的一些情况下,做个数据整理,可以比较直观的了解考试信息的变化情况,这样做的好处:方便考试管理人员掌握当前国家出题情况,及时调整考试方向及难度等。更新考试政策,及时跟踪考试大纲变化。欢迎交流。
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2022-03-12 07:02
文字
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java 有 Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
Scrap 意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优点:
1.极其灵活的自定义抓取。
2.社区比较大,文档比较齐全。
3.URL去重采用Bloom filter方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2), Pyspider:
pyspider 是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库来爬取结果。它还可以定期设置任务和任务优先级。
优点:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.五分钟即可轻松上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
简而言之,Pyspider 非常强大,比框架更强大。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制能力。
(3)Apache Nutch(高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。 Nutch 运行的三分之二的流程是为搜索引擎设计的。 .
Nutch 框架需要 Hadoop 运行,Hadoop 需要开启集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,以后可能会学到。
Nutch 官网
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以很容易地扩展它的功能,例如解析各种网页内容、采集、查询、聚类、过滤各种数据。因为这个框架,Nutch的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优点:
1.简单的API,快速上手
2.模块化结构,方便扩展
3.多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), 网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。 WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
优点:
1.根据文字密度自动提取网页文字
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.无 URL 优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫无法合作。
2.机器资源有限的复杂操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,无需修改更新。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间非常少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的网站进行排名,就必须实现类似于Pagerank的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的Url过滤机制使用BerkeleyDB进行url过滤。
3.可扩展支持结构化提取网页字段,可作为垂直采集使用
缺点
1.不支持动态网页抓取,例如网页的 ajax 部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。有一个近乎完整的文档介绍。
同HtmlUnit,只能获取静态内容。
不过,这个框架的优势在于解析网页非常强大。
Jsoup中文教程
selenium(多位谷歌领导参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,都说是真实的浏览器模拟。 GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍Demo就是跑不成功,所以放弃了。
selenium 官方 GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
先决条件:
安装 Chrome 浏览器就完成了。
简介:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
两者结合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档详细,Demo程序基本可以运行,类名熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着这么详细的文件,激动和遗憾的泪流满面……
cdp4j 有很多特点:
一个。获取渲染后的网页源代码
b.模拟浏览器点击事件
c。下载可以从网页下载的文件
d。截取网页截图或转换为 PDF 打印
e。等等
更详细的信息可以到以下三个地址去探索发现:
[cdp4j官网地址]
[Github 仓库]
[演示列表]
总结
上述框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以后打算用手动的方法:httpclient +jsoup+selenium实现java爬虫功能用httpclient爬取,jsoup解析页面,90%的页面可以做,剩下的用selenium;
参考链接: 查看全部
java爬虫抓取网页数据(主流java爬虫框架有哪些?(1)框架)
文字
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java 有 Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
Scrap 意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优点:
1.极其灵活的自定义抓取。
2.社区比较大,文档比较齐全。
3.URL去重采用Bloom filter方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2), Pyspider:
pyspider 是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库来爬取结果。它还可以定期设置任务和任务优先级。
优点:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.五分钟即可轻松上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
简而言之,Pyspider 非常强大,比框架更强大。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制能力。
(3)Apache Nutch(高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。 Nutch 运行的三分之二的流程是为搜索引擎设计的。 .
Nutch 框架需要 Hadoop 运行,Hadoop 需要开启集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,以后可能会学到。
Nutch 官网
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以很容易地扩展它的功能,例如解析各种网页内容、采集、查询、聚类、过滤各种数据。因为这个框架,Nutch的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优点:
1.简单的API,快速上手
2.模块化结构,方便扩展
3.多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), 网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。 WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
优点:
1.根据文字密度自动提取网页文字
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.无 URL 优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫无法合作。
2.机器资源有限的复杂操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,无需修改更新。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间非常少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的网站进行排名,就必须实现类似于Pagerank的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的Url过滤机制使用BerkeleyDB进行url过滤。
3.可扩展支持结构化提取网页字段,可作为垂直采集使用
缺点
1.不支持动态网页抓取,例如网页的 ajax 部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。有一个近乎完整的文档介绍。
同HtmlUnit,只能获取静态内容。
不过,这个框架的优势在于解析网页非常强大。
Jsoup中文教程
selenium(多位谷歌领导参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,都说是真实的浏览器模拟。 GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍Demo就是跑不成功,所以放弃了。
selenium 官方 GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
先决条件:
安装 Chrome 浏览器就完成了。
简介:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
两者结合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档详细,Demo程序基本可以运行,类名熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着这么详细的文件,激动和遗憾的泪流满面……
cdp4j 有很多特点:
一个。获取渲染后的网页源代码
b.模拟浏览器点击事件
c。下载可以从网页下载的文件
d。截取网页截图或转换为 PDF 打印
e。等等
更详细的信息可以到以下三个地址去探索发现:
[cdp4j官网地址]
[Github 仓库]
[演示列表]
总结
上述框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
以后打算用手动的方法:httpclient +jsoup+selenium实现java爬虫功能用httpclient爬取,jsoup解析页面,90%的页面可以做,剩下的用selenium;
参考链接:
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-03-10 18:13
爬虫+基于界面的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方式有个很大的限制,就是通过jsoup爬虫只能爬取静态网页,所以只能爬取当前页面的所有新闻。如果需要爬取一个网站的所有信息,就得通过界面反复调整网站的界面,通过改变参数,爬到网站的所有数据信息。 @网站。
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将逐步解释。我这里重点讲一下思路,最后提供完整的源码。
第一步:找到接口
如果要获取网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->Network-->all,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据是由大于56630或小于56630的ID返回的。
flag=down 表示向下翻页,即23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两个,这里id=0代表最新的两个数据)
返回json数据格式:
{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第 2 步:通过定时任务开始爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);<br />
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
JinSePress结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里需要注意两点
(1)在创建对象的时候,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否存在对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时。比如上面改成Listextra,会导致序列化失败,因为json的extra显然是一个对象,这里接受的确实是一个集合,关键是
性别名称相同,所以赋值时会报错,序列化会失败。
第四步:查看运行结果
这里只是控制台输出的部分信息,这样就可以获得网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取该新闻的所有具体信息了。(完美的)
第 5 步:数据库重复数据删除思路
因为你不可能每次都直接爬取播放数据到数据库中,所以必须对比新闻数据库是否已经存在,不存在才放入数据库。思路如下:
(1)在数据库表中添加唯一属性字段,可以识别新闻,比如jinse+bottomId形成唯一属性,或者新闻特定页面路径URI,形成唯一属性。
(2)创建地图集合,通过URI检查数据库是否存在,如果存在,如果不存在。
(3) 在通过 map.get(URI) 存储之前,如果为 false,则存储在数据库中。
Git 源代码
首先,源代码本身是通过Idea测试运行的。这里使用龙目岛。现在需要在idea或者eclipse中配置Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果你想没有麻烦,要么别想,要么做更多。中校【9】
转载于: 查看全部
java爬虫抓取网页数据(爬虫+基于接口的网络爬虫上一篇讲了(组图))
爬虫+基于界面的网络爬虫
上一篇讲了【java爬虫】---爬虫+jsoup轻松爬取博客。这种方式有个很大的限制,就是通过jsoup爬虫只能爬取静态网页,所以只能爬取当前页面的所有新闻。如果需要爬取一个网站的所有信息,就得通过界面反复调整网站的界面,通过改变参数,爬到网站的所有数据信息。 @网站。
本博客旨在抓取黄金财经新闻资讯,抓取网站自建站以来发布的所有新闻资讯。下面将逐步解释。我这里重点讲一下思路,最后提供完整的源码。
第一步:找到接口
如果要获取网站的所有新闻数据,第一步当然是获取接口,通过接口获取所有信息。
F12-->Network-->all,找到接口:limit=23&information_id=56630&flag=down&version=9.9.9
这三个参数的说明:
limit=23 表示每次调用接口返回23条数据。
information_id=56630 表示下面返回的23条数据是由大于56630或小于56630的ID返回的。
flag=down 表示向下翻页,即23条ID小于56630的数据。
通过邮递员测试
输入:limit=2&information_id=0&flag=down&version=9.9.9(这里返回两个,这里id=0代表最新的两个数据)
返回json数据格式:
{
"news": 2,
"count": 2,
"total": null,
"top_id": 58300,
"bottom_id": 58325,
"list": [
{
"id": 58300,
"title": "跨越牛熊的摆渡人:看金融IT服务如何助力加密货币交易",
"short_title": "当传统金融IT服务商进入加密货币时代",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "存量资金与投资者日渐枯竭,如何获取新用户和新资金入场,成为大小交易所都在考虑的问题。而交易深度有限、流动性和行情稳定性不佳,也成为横亘在牛熊之间的一道障碍。",
"published_at": 1532855806,
"author": "临渊",
"author_avatar": "https://img.jinse.com/753430_image20.png",
"author_id": 127939,
"author_level": 1,
"read_number": 27064,
"read_number_yuan": "2.7万",
"thumbnail_pic": "https://img.jinse.com/996033_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/996033"
],
"thumbnail_type": 1,
"source": "金色财经",
"topic_url": "https://m.jinse.com/news/block ... ot%3B,
"attribute_exclusive": "",
"attribute_depth": "深度",
"attribute_spread": ""
}
},
{
"id": 58325,
"title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"short_title": "各路大佬怎样看待区块链:技术新武器应寻找新战场",
"type": 1,
"order": 0,
"is_top": false,
"extra": {
"version": "9.9.9",
"summary": "今年年初由区块链社区引发的讨论热潮,成为全民一时热议的话题,罕有一项技术,能像区块链这样——在其应用还未大范围铺开、被大众直观感知时,就搅起舆论风暴,扰动民众情绪。",
"published_at": 1532853425,
"author": "新浪财经",
"author_avatar": "https://img.jinse.com/581794_image20.png",
"author_id": 94556,
"author_level": 5,
"read_number": 33453,
"read_number_yuan": "3.3万",
"thumbnail_pic": "https://img.jinse.com/995994_image1.png",
"thumbnails_pics": [
"https://img.jinse.com/995994"
],
"thumbnail_type": 1,
"source": "新浪财经",
"topic_url": "https://m.jinse.com/blockchain/219934.html",
"attribute_exclusive": "",
"attribute_depth": "",
"attribute_spread": ""
}
}
]
}
接口返回信息
第 2 步:通过定时任务开始爬虫工作
@Slf4j
@Component
public class SchedulePressTrigger {
@Autowired
private CrawlerJinSeLivePressService crawlerJinSeLivePressService;
/**
* 定时抓取金色财经的新闻
*/
@Scheduled(initialDelay = 1000, fixedRate = 600 * 1000)
public void doCrawlJinSeLivePress() {
// log.info("开始抓取金色财经新闻, time:" + new Date());
try {
crawlerJinSeLivePressService.start();
} catch (Exception e) {
// log.error("本次抓取金色财经新闻异常", e);
}
// log.info("结束抓取金色财经新闻, time:" + new Date());
}
}
第三步:主要实现类
/**
* 抓取金色财经快讯
* @author xub
* @since 2018/6/29
*/
@Slf4j
@Service
public class CrawlerJinSeLivePressServiceImpl extends AbstractCrawlLivePressService implements
CrawlerJinSeLivePressService {
//这个参数代表每一次请求获得多少个数据
private static final int PAGE_SIZE = 15;
//这个是真正翻页参数,每一次找id比它小的15个数据(有写接口是通过page=1,2来进行翻页所以比较好理解一点,其实它们性质一样)
private long bottomId;
//这个这里没有用到,但是如果有数据层,就需要用到,这里我只是把它答应到控制台
@Autowired
private LivePressService livePressService;
//定时任务运行这个方法,doTask没有被重写,所有运行父类的方法
@Override
public void start() {
try {
doTask(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT);
} catch (IOException e) {
// log.error("抓取金色财经新闻异常", e);
}
}
@Override
protected List crawlPage(int pageNum) throws IOException {
// 最多抓取100页,多抓取也没有特别大的意思。
if (pageNum >= 100) {
return Collections.emptyList();
}
// 格式化翻页参数(第一次bottomId为0,第二次就是这次爬到的最小bottomId值)
String requestUrl = String.format(CoinPressConsts.CHAIN_FOR_LIVE_PRESS_DATA_URL_FORMAT, PAGE_SIZE, bottomId);<br />
Response response = OkHttp.singleton().newCall(
new Request.Builder().url(requestUrl).addHeader("referer", CoinPressConsts.CHAIN_FOR_LIVE_URL).get().build())
.execute();
if (response.isRedirect()) {
// 如果请求发生了跳转,说明请求不是原来的地址了,返回空数据。
return Collections.emptyList();
}
//先获得json数据格式
String responseText = response.body().string();
//在通过工具类进行数据赋值
JinSePressResult jinSepressResult = JsonUtils.objectFromJson(responseText, JinSePressResult.class);
if (null == jinSepressResult) {
// 反序列化失败
System.out.println("抓取金色财经新闻列表反序列化异常");
return Collections.emptyList();
}
// 取金色财经最小的记录id,来进行翻页
bottomId = jinSepressResult.getBottomId();
//这个是谷歌提供了guava包里的工具类,Lists这个集合工具,对list集合操作做了些优化提升。
List pageListPresss = Lists.newArrayListWithExpectedSize(PAGE_SIZE);
for (JinSePressResult.DayData dayData : jinSepressResult.getList()) {
JinSePressData data = dayData.getExtra();
//新闻发布时间(时间戳格式)这里可以来判断只爬多久时间以内的新闻
long createTime = data.getPublishedAt() * 1000;
Long timemill=System.currentTimeMillis();
// if (System.currentTimeMillis() - createTime > CoinPressConsts.MAX_CRAWLER_TIME) {
// // 快讯过老了,放弃
// continue;
// }
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(createTime)); // 时间戳转换成时间
Date newsCreateTime=new Date();
try {
//获得新闻发布时间
newsCreateTime = sdf.parse(sd);
} catch (ParseException e) {
e.printStackTrace();
}
//具体文章页面路径(这里可以通过这个路径+jsoup就可以爬新闻正文所有信息了)
String href = data.getTopicUrl();
//新闻摘要
String summary = data.getSummary();
//新闻阅读数量
String pressreadcount = data.getReadNumber();
//新闻标题
String title = dayData.getTitle();
pageListPresss.add(new PageListPress(href,title, Integer.parseInt(pressreadcount),
newsCreateTime , summary));
}
return pageListPresss;
}
}
AbstractCrawlLivePressService 类
public abstract class AbstractCrawlLivePressService {
String url;
public void doTask(String url) throws IOException {
this.url = url;
int pageNum = 1;
//通过 while (true)会一直循环调取接口,直到数据为空或者时间过老跳出循环
while (true) {
List newsList = crawlPage(pageNum++);
// 抓取不到新的内容本次抓取结束
if (CollectionUtils.isEmpty(newsList)) {
break;
}
//这里并没有把数据放到数据库,而是直接从控制台输出
for (int i = newsList.size() - 1; i >= 0; i--) {
PageListPress pageListNews = newsList.get(i);
System.out.println(pageListNews.toString());
}
}
}
//这个由具体实现类实现
protected abstract List crawlPage(int pageNum) throws IOException;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class PageListPress {
//新闻详情页面url
private String href;
//新闻标题
private String title;
//新闻阅读数量
private int readCounts;
//新闻发布时间
private Date createTime;
//新闻摘要
private String summary;
}
}
JinSePress结果
/**
*在创建对象的时候一定要分析好json格式的类型
*金色新闻的返回格式就是第一层有普通属性和一个list集合
*在list集合中又有普通属性和一个extra的对象。
*/
@JsonIgnoreProperties(ignoreUnknown = true)
@Data
public class JinSePressResult {
private int news;
private int count;
@JsonProperty("top_id")
private long topId;
@JsonProperty("bottom_id")
private long bottomId;
//list的名字也要和json数据的list名字一致,否则无用
private List list;
@Data
@JsonIgnoreProperties(ignoreUnknown = true)
public static class DayData {
private String title;
//这里对象的属性名extra也要和json的extra名字一致
private JinSePressData extra;
@JsonProperty("topic_url")
private String topicUrl;
}
}
这里需要注意两点
(1)在创建对象的时候,首先要弄清楚json格式类型是否收录对象中的集合,或者集合中是否存在对象等。
(2) 只能定义自己需要的属性字段,当无法匹配json的属性名但类型不一致时。比如上面改成Listextra,会导致序列化失败,因为json的extra显然是一个对象,这里接受的确实是一个集合,关键是
性别名称相同,所以赋值时会报错,序列化会失败。
第四步:查看运行结果
这里只是控制台输出的部分信息,这样就可以获得网站的所有新闻信息。同时我们已经获取到了具体新闻的URL,那么我们就可以通过JSOup获取该新闻的所有具体信息了。(完美的)
第 5 步:数据库重复数据删除思路
因为你不可能每次都直接爬取播放数据到数据库中,所以必须对比新闻数据库是否已经存在,不存在才放入数据库。思路如下:
(1)在数据库表中添加唯一属性字段,可以识别新闻,比如jinse+bottomId形成唯一属性,或者新闻特定页面路径URI,形成唯一属性。
(2)创建地图集合,通过URI检查数据库是否存在,如果存在,如果不存在。
(3) 在通过 map.get(URI) 存储之前,如果为 false,则存储在数据库中。
Git 源代码
首先,源代码本身是通过Idea测试运行的。这里使用龙目岛。现在需要在idea或者eclipse中配置Lombok。
源地址:
想的太多,做的太少,中间的差距就是麻烦。如果你想没有麻烦,要么别想,要么做更多。中校【9】
转载于:
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-10 18:11
爬虫初学者,WebMagic作为Java开发的爬虫框架很容易上手,下面看一个简单的例子。
WebMagic 框架简介
WebMagic 框架由四个组件组成,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应了爬虫生命周期中的处理、管理、下载和持久化的功能。
这四个组件是Spider中的属性,爬虫框架是通过Spider来启动和管理的。
WebMagic的整体架构图如下:
四个组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。你需要定义自己。
Scheduler 负责管理要爬取的 URL,以及一些去重工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
下载器负责从 Internet 下载页面以进行后续处理。通常你不需要自己实现它。
数据流对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包后,所有的准备工作就完成了,是不是很简单。
让我们测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}<br />public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/")
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:
这是因为没有配置文件。在资源目录下新建一个log4j.properties文件,粘贴如下配置信息。
目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告?
爬取列表类 网站 示例
列表爬取的思路很相似。首先判断是否为列表页。如果是这样,请将 文章url 添加到爬取队列中。如果不是,则说明此时是一个文章页面,直接爬取你想要的。内容可以。
选择列表类 文章 的 网站:
首先判断是文章还是列表。查看几页后,您可以找到规则并使用正则表达式来区分它们。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器直接粘贴即可)。
WebMagic框架支持多种提取方式,包括xPath、css选择器、正则表达式,所有的链接都可以通过links()方法来选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果您使用它,您可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面,页面中文章的url应该是通过xPath定位的。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
至此,你已经得到了要爬取的url列表,你可以通过addTargetRequests方法将它们添加到队列中。
最后实现翻页。同样,WebMagic 会自动加入到爬取队列中。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整的代码。我实现了一个MysqlPipeline类,使用Mybatis将爬取的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}<br />public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1").addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库: ?
爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
注意在使用xPath时,框架作者自定义了几个函数:
表达式描述XPath1.0
文本(n)
第n个直接文本子节点,0表示全部
纯文本
全部文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更清晰
不支持
html()
内部html,不包括标签本身的html
不支持
外部HTML()
内部 html,包括标签的 html 本身
不支持
正则表达式(@attr,expr,组)
这里@attr和group是可选的,默认是group0
不支持
使用起来非常方便。 查看全部
java爬虫抓取网页数据(Java开发的爬虫框架很容易上手,输出结果:如果你和我一样)
爬虫初学者,WebMagic作为Java开发的爬虫框架很容易上手,下面看一个简单的例子。
WebMagic 框架简介
WebMagic 框架由四个组件组成,PageProcessor、Scheduler、Downloader 和 Pipeline。
这四个组件分别对应了爬虫生命周期中的处理、管理、下载和持久化的功能。
这四个组件是Spider中的属性,爬虫框架是通过Spider来启动和管理的。
WebMagic的整体架构图如下:
四个组件
PageProcessor 负责解析页面、提取有用信息和发现新链接。你需要定义自己。
Scheduler 负责管理要爬取的 URL,以及一些去重工作。一般不需要自己自定义Scheduler。
Pipeline 负责提取结果的处理,包括计算、持久化到文件、数据库等。
下载器负责从 Internet 下载页面以进行后续处理。通常你不需要自己实现它。
数据流对象
Request是对URL地址的一层封装,一个Request对应一个URL地址。
Page 表示从 Downloader 下载的页面 - 它可能是 HTML、JSON 或其他文本内容。
ResultItems相当于一个Map,它保存了PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven添加依赖jar包。
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
org.slf4j
slf4j-log4j12
或者直接点我下载。
添加jar包后,所有的准备工作就完成了,是不是很简单。
让我们测试一下。
package edu.heu.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}<br />public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/";)
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
如果你和我一样,之前没有使用过 log4j,可能会出现以下警告:
这是因为没有配置文件。在资源目录下新建一个log4j.properties文件,粘贴如下配置信息。
目录可以定义为您自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file
# 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n
# Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
立即尝试,没有警告?
爬取列表类 网站 示例
列表爬取的思路很相似。首先判断是否为列表页。如果是这样,请将 文章url 添加到爬取队列中。如果不是,则说明此时是一个文章页面,直接爬取你想要的。内容可以。
选择列表类 文章 的 网站:
首先判断是文章还是列表。查看几页后,您可以找到规则并使用正则表达式来区分它们。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上述正则表达式,则url对应一个文章页面。
接下来提取需要爬取的内容,我选择了xPath(浏览器直接粘贴即可)。
WebMagic框架支持多种提取方式,包括xPath、css选择器、正则表达式,所有的链接都可以通过links()方法来选择。
提取前记得通过getHtml()获取html对象,通过html对象使用提取方法。
ps:WebMagic 似乎不支持 xPath 中的 last() 方法。如果您使用它,您可以考虑其他方法。
然后使用 page.putFiled(String key, Object field) 方法将你想要的内容放入一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果文章页面的规律性不满足,说明这是一个列表页面,页面中文章的url应该是通过xPath定位的。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
至此,你已经得到了要爬取的url列表,你可以通过addTargetRequests方法将它们添加到队列中。
最后实现翻页。同样,WebMagic 会自动加入到爬取队列中。
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
以下是完整的代码。我实现了一个MysqlPipeline类,使用Mybatis将爬取的数据直接持久化到数据库中。
您还可以使用内置的 ConsolePipeline 或 FilePipeline。
package edu.heu.spider;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import edu.heu.domain.News;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* @ClassName: HupuNewsSpider
* @author LJH
* @date 2017年11月27日 下午4:54:48
*/
public class HupuNewsSpider implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
return site;
}
public void process(Page page) {
// 文章页,匹配 https://voice.hupu.com/nba/七位数字.html
if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) {
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content",
page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
}
// 列表页
else {
// 文章url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all());
// 翻页url
page.addTargetRequests(
page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all());
}
}<br />public static void main(String[] args) {
Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1";).addPipeline(new MysqlPipeline())
.thread(3).run();
}
}
// 自定义实现Pipeline接口
class MysqlPipeline implements Pipeline {
public MysqlPipeline() {
}
public void process(ResultItems resultitems, Task task) {
Map mapResults = resultitems.getAll();
Iterator iter = mapResults.entrySet().iterator();
Map.Entry entry;
// 输出到控制台
while (iter.hasNext()) {
entry = iter.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// 持久化
News news = new News();
if (!mapResults.get("Title").equals("")) {
news.setTitle((String) mapResults.get("Title"));
news.setContent((String) mapResults.get("Content"));
}
try {
InputStream is = Resources.getResourceAsStream("conf.xml");
SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = sessionFactory.openSession();
session.insert("add", news);
session.commit();
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
查看数据库: ?
爬取的数据一直静静地躺在数据库中。
官方文档还介绍了通过注解实现各种功能,非常简单灵活。
注意在使用xPath时,框架作者自定义了几个函数:
表达式描述XPath1.0
文本(n)
第n个直接文本子节点,0表示全部
纯文本
全部文本()
所有直接和间接文本子节点
不支持
整洁的文本()
所有直接和间接文本子节点,并用换行符替换一些标签,使纯文本显示更清晰
不支持
html()
内部html,不包括标签本身的html
不支持
外部HTML()
内部 html,包括标签的 html 本身
不支持
正则表达式(@attr,expr,组)
这里@attr和group是可选的,默认是group0
不支持
使用起来非常方便。
java爬虫抓取网页数据(学python网页爬虫抓取网页数据第四十五天早晨分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-08 03:06
java爬虫抓取网页数据第四十五天早晨分享:大牛之路:python爬虫抓取动态数据,
网上找找有很多新闻或者说一些真正需要的东西比如说计算机视觉计算机图形学等等有些人就是做这些相关的问题的有时候你想找的东西总会有你想要的
数据找厂商买买买别在乎价格
自己动手!学python网页爬虫吧。这应该是目前所有做爬虫技术的初学者都会想知道的了。除此之外还有很多人在爬取社交网络数据分析美女图,人物动态数据的,
内网互联,例如国内的qq群活动,国外是,美帝使用nsurlconnection。还有各种推论什么的,其实如果真要说这东西的话,商业级的其实大部分都在做相关的report啊之类的。
dropbox自己建个文件夹放下载的东西
先说需求,再来选择相应的技术。
1、首先是数据,在怎么存都一样,关键是数据的质量,如果数据质量很差,再怎么存都是无用功。
2、再来说需求实现,不同的存储,需要不同的技术解决,例如,url文件存储,需要flask语言和nodejs,但是nodejs很吃内存,所以还有个解决方案是把url文件存储在virtualenv上面,以及实现对app的访问。2.1如果你还想保留一些数据,包括你想爬取数据的源代码,你可以考虑bigdatasink一类的服务。
如果你想在浏览器访问存在服务器上的网页,可以尝试youtube的seamlessjs。2.2如果你只是想简单爬下文件或者利用requests访问文件,可以考虑nutch,beautifulsoup,pyspider等;。
3、python初学者,不推荐用nodejs去做,因为初学者对爬虫了解不多,容易操作错误,导致不好理解与爬取。所以python的egg,xchat,python爬虫,python数据分析都是不错的选择,java,php等语言也可以考虑。 查看全部
java爬虫抓取网页数据(学python网页爬虫抓取网页数据第四十五天早晨分享)
java爬虫抓取网页数据第四十五天早晨分享:大牛之路:python爬虫抓取动态数据,
网上找找有很多新闻或者说一些真正需要的东西比如说计算机视觉计算机图形学等等有些人就是做这些相关的问题的有时候你想找的东西总会有你想要的
数据找厂商买买买别在乎价格
自己动手!学python网页爬虫吧。这应该是目前所有做爬虫技术的初学者都会想知道的了。除此之外还有很多人在爬取社交网络数据分析美女图,人物动态数据的,
内网互联,例如国内的qq群活动,国外是,美帝使用nsurlconnection。还有各种推论什么的,其实如果真要说这东西的话,商业级的其实大部分都在做相关的report啊之类的。
dropbox自己建个文件夹放下载的东西
先说需求,再来选择相应的技术。
1、首先是数据,在怎么存都一样,关键是数据的质量,如果数据质量很差,再怎么存都是无用功。
2、再来说需求实现,不同的存储,需要不同的技术解决,例如,url文件存储,需要flask语言和nodejs,但是nodejs很吃内存,所以还有个解决方案是把url文件存储在virtualenv上面,以及实现对app的访问。2.1如果你还想保留一些数据,包括你想爬取数据的源代码,你可以考虑bigdatasink一类的服务。
如果你想在浏览器访问存在服务器上的网页,可以尝试youtube的seamlessjs。2.2如果你只是想简单爬下文件或者利用requests访问文件,可以考虑nutch,beautifulsoup,pyspider等;。
3、python初学者,不推荐用nodejs去做,因为初学者对爬虫了解不多,容易操作错误,导致不好理解与爬取。所以python的egg,xchat,python爬虫,python数据分析都是不错的选择,java,php等语言也可以考虑。
java爬虫抓取网页数据(《手把手教你写网络爬虫》连载开始了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-03-04 09:21
摘要:从零开始编写爬虫,初学者的崩溃指南!
覆盖:
大家好,《教你写爬虫》连载开始啦!在我的职业生涯中,我发现很少有像网络爬虫这样能够吸引程序员和外行的注意力的编程实践。本文由浅入深地讲解爬虫技术,为初学者提供了一个简单的入门方法。请跟随我们一起走上爬虫学习打怪升级之路!
介绍
什么是爬行动物?
先看百度百科的定义:
简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!
urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!
“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。
将此代码保存为 get_html.py 并运行它以查看它的输出:
果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:
目标html代码:
有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:
将此代码保存为 get_data.py 并运行它以查看它的输出:
是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url: ,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们知道这是一个动态网页。当我们得到它时,播放列表还没有被请求,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:
Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:
开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。
播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。
将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。
看到结果后有成就感吗?如果你有兴趣,也可以按照这个思路,找到评论最多的单曲,再也不用担心歌曲用完了!
今天的内容比较简单,希望对大家有用。暂时就这些了,下次见!
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。 查看全部
java爬虫抓取网页数据(《手把手教你写网络爬虫》连载开始了(组图))
摘要:从零开始编写爬虫,初学者的崩溃指南!
覆盖:
大家好,《教你写爬虫》连载开始啦!在我的职业生涯中,我发现很少有像网络爬虫这样能够吸引程序员和外行的注意力的编程实践。本文由浅入深地讲解爬虫技术,为初学者提供了一个简单的入门方法。请跟随我们一起走上爬虫学习打怪升级之路!
介绍
什么是爬行动物?
先看百度百科的定义:
简单地说,网络爬虫也称为网络爬虫和网络蜘蛛。它的行为一般是先“爬”到相应的网页,然后“铲”下需要的信息。
为什么要学习爬行?
看到这里,有人会问:谷歌、百度等搜索引擎已经帮我们爬取了互联网上的大部分信息,为什么还要自己写爬虫呢?这是因为需求是多种多样的。例如,在企业中,爬取的数据可以作为数据挖掘的数据源。甚至还有人为了炒股而抓取股票信息。笔者见过有人爬上绿色中介的数据,为了分析房价,自学编程。
在大数据时代,网络爬虫作为网络、存储和机器学习的交汇点,已经成为满足个性化网络数据需求的最佳实践。你还在犹豫什么?让我们开始学习吧!
语言环境
语言:人生苦短,我用Python。让 Python 飞我们吧!
urllib.request:这是Python自带的库,不需要单独安装。它的作用是打开url让我们获取html内容。官方 Python 文档简介: urllib.request 模块定义了有助于在复杂世界中打开 URL(主要是 HTTP)的函数和类——基本和摘要身份验证、重定向、cookie 等。
BeautifulSoup:是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的工作时间。安装比较简单:
$pip 安装 Beautifulsoup4
验证方法是进入Python,直接导入。如果没有异常,则说明安装成功!
“美味的汤,绿色的浓汤,
盛在热气腾腾的盖碗里!
这么好的汤,谁不想尝尝?
晚餐的汤,美味的汤!"
BeautifulSoup 库的名字来源于《爱丽丝梦游仙境》中的同名诗。
抓取数据
接下来,我们使用urllib.request获取html内容,然后使用BeautifulSoup提取数据,完成一个简单的爬取。
将此代码保存为 get_html.py 并运行它以查看它的输出:
果然,输出了这个网页的整个HTML代码。
无法直接看到输出代码。我们如何才能轻松找到我们想要捕获的数据?使用 Chrome 打开 URL,然后按 F12,然后按 Ctrl+Shift+C。如果我们想抓取导航栏,我们用鼠标点击任何导航栏项,浏览器在html中找到它的位置。效果如下:
目标html代码:
有了这些信息,就可以用 BeautifulSoup 提取数据。更新代码:
将此代码保存为 get_data.py 并运行它以查看它的输出:
是的,我们得到了我们想要的数据!
BeautifulSoup 提供了简单的 Pythonic 函数,用于处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。怎么样,你以为复制粘贴就可以写爬虫了?简单的爬虫确实可以!
一个迷你爬虫
我们先定一个小目标:爬取网易云音乐播放量超过500万的播放列表。
打开播放列表的url: ,然后用BeautifulSoup提取播放次数3715,结果我们什么都没提取。我们打开了一个假网页吗?
动态网页:所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。
现在我们知道这是一个动态网页。当我们得到它时,播放列表还没有被请求,当然,什么都提取不出来!
我们以前的技术无法执行在页面上执行各种魔术的 JavaScript 代码。如果 网站 的 HTML 页面没有运行 JavaScript,它可能看起来与您在浏览器中看到的完全不同,因为浏览器可以正确执行 JavaScript。用 Python 解决这个问题只有两种方法: 采集 内容直接来自 JavaScript 代码,或者用 Python 的第三方库运行 JavaScript,直接 采集 你在浏览器中看到的页面。我们当然选择后者。今天的第一课,不深入原理,先简单粗暴地实现我们的小目标。
Selenium:是一个强大的网络数据采集工具,最初是为网站自动化测试而开发的。近年来,它也被广泛用于获取准确的网站快照,因为它们直接在浏览器上运行。Selenium 库是在 WebDriver 上调用的 API。WebDriver 有点像可以加载网站的浏览器,但也可以像BeautifulSoup 对象一样用于查找页面元素,与页面上的元素交互(发送文本、点击等),以及执行其他操作运行 Web Crawler 的操作。安装方式与其他 Python 第三方库相同。
$pip 安装硒
验证它:
Selenium 没有自带浏览器,需要配合第三方浏览器使用。例如,如果您在 Firefox 上运行 Selenium,您会看到一个 Firefox 窗口打开,转到 网站,然后执行您在代码中设置的操作。虽然这样可以看的比较清楚,但是并不适合我们的爬虫程序。爬完一个页面再打开一个页面效率太低了,所以我们使用了一个叫做 PhantomJS 的工具来代替真正的浏览器。
PhantomJS:是一个“无头”浏览器。它将 网站 加载到内存中并在页面上执行 JavaScript,但它不会向用户显示页面的图形界面。结合 Selenium 和 PhantomJS,您可以运行一个非常强大的网络爬虫,它可以处理 cookie、JavaScript、标头以及您需要做的任何其他事情。
PhantomJS 不是 Python 的第三方库,不能使用 pip 安装。它是一个成熟的浏览器,所以你需要去它的官方网站下载,然后将可执行文件复制到Python安装目录的Scripts文件夹中,像这样:
开始工作吧!
打开播放列表的第一页:
先用Chrome的“开发者工具”F12分析一下,很容易看穿一切。
播放号nb(号播):29915
Cover msk(掩码):带有标题和网址
同样可以找到“下一页”的url,最后一页的url为“javascript:void(0)”。
最后,我们可以用 18 行代码完成我们的工作。
将此代码保存为 get_data.py 并运行它。运行后会在程序目录下生成一个playlist.csv文件。
看到结果后有成就感吗?如果你有兴趣,也可以按照这个思路,找到评论最多的单曲,再也不用担心歌曲用完了!
今天的内容比较简单,希望对大家有用。暂时就这些了,下次见!
今天文章结束,感谢阅读,Java架构师必看,祝你升职加薪,年年好运。
java爬虫抓取网页数据(Spider的设计网页收集的过程(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-04 09:18
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据添加到网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流
Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("");
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));Stringline=null;while((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
Matcher matcher=pattern.matcher(htmlDoc);StringtempURL;//第一次匹配的url格式为://为此需要进行下一步处理提取真实的url,//可以使用对于前两个 " 中间的部分被记录下来得到 urlwhile(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf(""")+1);if(!tempURL.contains("""))继续;
tempURL=tempURL.substring(0, tempURL.indexOf("""));} catch (MalformedURLException e) {
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以在循环获取整个标签后,我们需要进一步提取真实网址。我们可以截取标签中前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/***启动线程采集,然后开始采集网页数据*/publicvoid start() {
调度程序 disp=newDispatcher.getInstance();for(inti=0; i
线程聚集=newThread(newGather(disp));
采集.start();
}
}
线程启动后,网页采集器启动作业的运行,一个作业完成后,向Dispatcher申请下一个作业。因为有一个多线程的Gather,为了避免线程不安全,需要对Dispatcher进行互斥访问。在其函数中添加同步 关键词 以实现线程安全访问。
概括
Spider是整个搜索引擎的基础,为后续的操作提供原创网页数据,所以了解Spider的编写和网页库的组成,为后续的预处理模块打下基础。同时,Spider也可以单独使用,稍微修改后采集某些特定的信息,比如抓取某个网站的图片。 查看全部
java爬虫抓取网页数据(Spider的设计网页收集的过程(一)_光明网)
蜘蛛的设计
网页采集的过程就像遍历一个图,其中网页作为图中的节点,网页中的超链接作为图中的边。通过网页的超链接可以获取其他网页的地址,从而可以进行进一步的网页采集。; 图遍历分为广度优先和深度优先方法,网页的采集过程也是如此。综上所述,蜘蛛采集网页的过程如下:从初始URL集合中获取目标网页地址,通过网络连接接收网页数据,将获取的网页数据添加到网页库,分析其他网页中的 URL 链接,放在未访问的 URL 集合中,用于网页采集。下图表示此过程:
图3. 蜘蛛工作流
Spider的具体实现
网络采集器采集
网页采集器通过URL获取该URL对应的网页数据。它的实现主要是利用Java中的URLConnection类打开URL对应的页面的网络连接,然后通过I/O流读取数据。BufferedReader 提供读取数据缓冲区,提高数据读取效率,其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
列表1.网页抓取
网址 url=newURL("");
URLConnection conn=url.openConnection();
BufferedReader reader=newBufferedReader(newInputStreamReader(conn.getInputStream()));Stringline=null;while((line=reader.readLine()) !=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为 网站 的一些链接使用了相对路径。如果它们没有排序,就会出现错误。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
列表2. URL 识别
publicArrayListurlDetector(StringhtmlDoc){
finalStringpatternString="]*\s*>)";
模式 pattern=pile(patternString,Pattern.CASE_INSENSITIVE);
ArrayListallURLs=newArrayList();
Matcher matcher=pattern.matcher(htmlDoc);StringtempURL;//第一次匹配的url格式为://为此需要进行下一步处理提取真实的url,//可以使用对于前两个 " 中间的部分被记录下来得到 urlwhile(matcher.find()){
尝试 {
tempURL=matcher.group();
tempURL=tempURL.substring(tempURL.indexOf(""")+1);if(!tempURL.contains("""))继续;
tempURL=tempURL.substring(0, tempURL.indexOf("""));} catch (MalformedURLException e) {
e.printStackTrace();
}
}
返回所有网址;
}
根据正则表达式“]*\s*>)”可以匹配到URL所在的整个标签,形式为“”,所以在循环获取整个标签后,我们需要进一步提取真实网址。我们可以截取标签中前两个引号之间的内容来得到这个内容。在此之后,我们可以得到属于该网页的一组初步 URL。
接下来我们进行第二步,URL的排序,也就是对之前获取的整个页面中的URL集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很方便的获取当前网页的URL,所以相对链接只需要在当前网页的URL上加上一个相对链接字段就可以形成一个完整的URL,从而完成整合。另一方面,在页面所收录的综合URL中,也有一些我们不想抓取或者不重要的网页,比如广告网页。这里我们主要关注页面中广告的简单处理。一般网站的广告链接都有相应的展示表达方式。例如,当链接收录诸如“
完成这两步之后,就可以将采集到的网页URL放入URL池中,然后我们来处理爬虫URL的分配。
调度员调度员
分配器管理URL,负责保存URL池,在Gather拿到某个网页后调度新的URL,同时也避免了网页的重复采集。分配器在设计模式中以单例模式编码,负责提供新的 URL 给 Gather。因为涉及到多线程重写,所以单例模式尤为重要。
重复采集是指物理上存在的网页,被Gather重复访问而不更新,造成资源浪费。因此,Dispatcher 维护两个列表,“已访问表”和“未访问表”。爬取每个URL对应的页面后,将URL放入visited表,将页面提取的URL放入unvisited表;当 Gather 从 Dispatcher 请求一个 URL 时,它首先验证 URL 是否在 Visited 表中,然后再给 Gather 工作。
Spider 启动多个 Gather 线程
现在互联网上的网页数以亿计,通过单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。Gather的功能是采集网页,我们可以通过Spider类开启多个Gather线程,从而达到多线程的目的。代码显示如下:
/***启动线程采集,然后开始采集网页数据*/publicvoid start() {
调度程序 disp=newDispatcher.getInstance();for(inti=0; i
线程聚集=newThread(newGather(disp));
采集.start();
}
}
线程启动后,网页采集器启动作业的运行,一个作业完成后,向Dispatcher申请下一个作业。因为有一个多线程的Gather,为了避免线程不安全,需要对Dispatcher进行互斥访问。在其函数中添加同步 关键词 以实现线程安全访问。
概括
Spider是整个搜索引擎的基础,为后续的操作提供原创网页数据,所以了解Spider的编写和网页库的组成,为后续的预处理模块打下基础。同时,Spider也可以单独使用,稍微修改后采集某些特定的信息,比如抓取某个网站的图片。
java爬虫抓取网页数据( Python爬虫对于我来说真是个神器的人的独白!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2022-02-25 00:02
Python爬虫对于我来说真是个神器的人的独白!)
一个熟悉爬虫技术的人的独白!
不得不说,Python爬虫对我来说真的是神器。之前在分析一些经济数据的时候,需要从网上抓取一些数据。我想了很多方法。一开始是通过Excel,但是Excel只能从桌子上爬下来,太有限了。后来问了一个学编程的朋友,他说JavaScript也可以实现,于是董东迪就去学Java了(我朋友在学Java,我问他能不能用Java实现,他说JavaScript好像是可以的,当时我什么都不懂,所以把JavaScript理解为Java的一个分支,以为JavaScript只是ava的一个包,于是就去学了一阵子Java,无知酿成祸...)。
但是整个 Java 系统太大了,学不来。毕竟我只是想用一些功能,所以学完就放弃了。就在我不知所措的时候,我发现了Python......
废话少说,说说自己的学习经历。对于想学习Python和写爬虫的人来说也是一个参考。
一开始在网上找了一个基础视频来学习。Python 真的是一门简单的语言。之前对Visual Basic有所了解,感觉Python也很适合没有编程基础的人学习。
在介绍视频的最后,我做了我的第一个爬虫,一个百度贴吧图片爬虫(相信很多教程都是以百度贴吧爬虫为经典例子。)
一开始代码很简单,只能爬第一页的数据,所以加了一个循环爬取指定页数的图片。而且图片是按顺序排列的,非常方便。过滤 URL 时只需使用正则表达式。
但是我不经常混贴吧,也很少需要下载贴吧图片。回归初衷。我对投资感兴趣,学习编程的原因之一也是投资服务。7月份股市大跌的时候,我错过了一个明显的“捡钱”机会,不是因为我缺乏专业知识,而是因为我正在准备考试,很少去股市,这使得我不甘:如果有什么可以帮我自动爬取数据分析推送,我有如下学习轨迹:
一、爬取数据
对了,大家可以到公众号菜单栏中的学习福利去浏览。那里有一些很好的教程。Python 中 urllib 和 re 正则表达式的两种替代方法分别称为 requests 和 Ixml。
第一个图书馆很好。现在我在获取网页源代码时使用这个库。不明白的可以看那个网站。第二个库是因为我用的是3.4版本的Python,好久没折腾了,所以又找了一个不错的库BeautifulSoup,详细教程参考:Python爬虫介绍八:的用法美丽的汤
有了requests和Beautifulsoup,我基本上可以实现很多我想要的功能。我做了一个抓取分级基金数据的爬虫:
二、分析推送
其实这个分析也谈不上,最多是筛选。(但我相信随着我数学能力的提高,一定能有进一步的分析,祝好...) 筛选很简单,就是增加量或产量等满足一定条件,然后保留,为什么要保留它?推它 !!!
通过电子邮件将保存的数据发送到您自己的邮箱,在手机上下载一个软件,您就完成了!
至此,学习Python的目的就达到了,鸡要炸了!!!
但是……这么好玩的事情怎么会这么快就结束了?让我们折腾吧!
三、简单的界面
等待!看来Python不能直接转成exe可执行文件,而且每次运行都不能打开Python窗口!你怎么能忍受强迫症!@>第四版!花了很长时间才完成,忘记它!我不知道如何订购VB,让我们使用它。所以即使是界面
正好能点PS,做个低级界面也不错。
四、云服务器
完成界面后,我以为结束了,我还太年轻。用了几天,发现不能天天开电脑,让它跑几个程序?必须有一个地方可以让我一天 24 小时运行这些程序。本来想用朋友的电脑轮流跑的,但是太麻烦了。我偶然发现了云服务器。了解之后,花了很多钱买了服务器(其实——一个月30个月……)
Toss-fan linux系统运行实现24小时实时推送。
而此时,我已经深深沉浸在Python中,我觉得我应该继续学习这门强大而简单的语言,在知乎上看到一个问题:Quant应该学习哪些Python知识?虽然是 Quant 但也为我指明了方向——一些方向。目前准备学习numpy、pandas、matplotlib这些库,以实现未来财经数据的可视化和分析。有一本写得很好的相关内容的书,叫做《Data Analysis with Python》,如果你有兴趣学习,可以阅读——阅读。
最后,如果你和我一样喜欢python,想做一名优秀的程序员,在学习python的道路上奔跑,欢迎加入python学习群:839383765 群里会每天分享最新的行业资讯和免费的python课程一天,一起交流学习,让学习成为(程序)一种习惯! 查看全部
java爬虫抓取网页数据(
Python爬虫对于我来说真是个神器的人的独白!)
一个熟悉爬虫技术的人的独白!
不得不说,Python爬虫对我来说真的是神器。之前在分析一些经济数据的时候,需要从网上抓取一些数据。我想了很多方法。一开始是通过Excel,但是Excel只能从桌子上爬下来,太有限了。后来问了一个学编程的朋友,他说JavaScript也可以实现,于是董东迪就去学Java了(我朋友在学Java,我问他能不能用Java实现,他说JavaScript好像是可以的,当时我什么都不懂,所以把JavaScript理解为Java的一个分支,以为JavaScript只是ava的一个包,于是就去学了一阵子Java,无知酿成祸...)。
但是整个 Java 系统太大了,学不来。毕竟我只是想用一些功能,所以学完就放弃了。就在我不知所措的时候,我发现了Python......
废话少说,说说自己的学习经历。对于想学习Python和写爬虫的人来说也是一个参考。
一开始在网上找了一个基础视频来学习。Python 真的是一门简单的语言。之前对Visual Basic有所了解,感觉Python也很适合没有编程基础的人学习。
在介绍视频的最后,我做了我的第一个爬虫,一个百度贴吧图片爬虫(相信很多教程都是以百度贴吧爬虫为经典例子。)
一开始代码很简单,只能爬第一页的数据,所以加了一个循环爬取指定页数的图片。而且图片是按顺序排列的,非常方便。过滤 URL 时只需使用正则表达式。
但是我不经常混贴吧,也很少需要下载贴吧图片。回归初衷。我对投资感兴趣,学习编程的原因之一也是投资服务。7月份股市大跌的时候,我错过了一个明显的“捡钱”机会,不是因为我缺乏专业知识,而是因为我正在准备考试,很少去股市,这使得我不甘:如果有什么可以帮我自动爬取数据分析推送,我有如下学习轨迹:
一、爬取数据
对了,大家可以到公众号菜单栏中的学习福利去浏览。那里有一些很好的教程。Python 中 urllib 和 re 正则表达式的两种替代方法分别称为 requests 和 Ixml。
第一个图书馆很好。现在我在获取网页源代码时使用这个库。不明白的可以看那个网站。第二个库是因为我用的是3.4版本的Python,好久没折腾了,所以又找了一个不错的库BeautifulSoup,详细教程参考:Python爬虫介绍八:的用法美丽的汤
有了requests和Beautifulsoup,我基本上可以实现很多我想要的功能。我做了一个抓取分级基金数据的爬虫:
二、分析推送
其实这个分析也谈不上,最多是筛选。(但我相信随着我数学能力的提高,一定能有进一步的分析,祝好...) 筛选很简单,就是增加量或产量等满足一定条件,然后保留,为什么要保留它?推它 !!!
通过电子邮件将保存的数据发送到您自己的邮箱,在手机上下载一个软件,您就完成了!
至此,学习Python的目的就达到了,鸡要炸了!!!
但是……这么好玩的事情怎么会这么快就结束了?让我们折腾吧!
三、简单的界面
等待!看来Python不能直接转成exe可执行文件,而且每次运行都不能打开Python窗口!你怎么能忍受强迫症!@>第四版!花了很长时间才完成,忘记它!我不知道如何订购VB,让我们使用它。所以即使是界面
正好能点PS,做个低级界面也不错。
四、云服务器
完成界面后,我以为结束了,我还太年轻。用了几天,发现不能天天开电脑,让它跑几个程序?必须有一个地方可以让我一天 24 小时运行这些程序。本来想用朋友的电脑轮流跑的,但是太麻烦了。我偶然发现了云服务器。了解之后,花了很多钱买了服务器(其实——一个月30个月……)
Toss-fan linux系统运行实现24小时实时推送。
而此时,我已经深深沉浸在Python中,我觉得我应该继续学习这门强大而简单的语言,在知乎上看到一个问题:Quant应该学习哪些Python知识?虽然是 Quant 但也为我指明了方向——一些方向。目前准备学习numpy、pandas、matplotlib这些库,以实现未来财经数据的可视化和分析。有一本写得很好的相关内容的书,叫做《Data Analysis with Python》,如果你有兴趣学习,可以阅读——阅读。
最后,如果你和我一样喜欢python,想做一名优秀的程序员,在学习python的道路上奔跑,欢迎加入python学习群:839383765 群里会每天分享最新的行业资讯和免费的python课程一天,一起交流学习,让学习成为(程序)一种习惯!
java爬虫抓取网页数据( 一下如何利用Java进行网络爬虫?(图)的运用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-24 23:29
一下如何利用Java进行网络爬虫?(图)的运用
)
这是Java网络爬虫系列的第二篇文章。上一篇Java网络爬虫,就这么简单,我们简单学习了如何使用Java进行网络爬虫。在这篇文章中,我们将简单谈谈遇到网络爬虫时需要登录的网站,我们应该怎么做?
在做爬虫工作的时候,也经常会遇到需要登录的问题,比如写脚本抢票之类的,但是任何需要个人信息的人都需要登录。此类问题的解决方法主要有两种:一种是手动设置Cookie就是先登录网站,登录后复制cookie,在爬虫程序的HTTP请求中手动设置Cookie属性。这种方法适用于采集频率较低,采集周期短,因为cookie会失效。如果是长期采集,需要频繁设置cookie。这不是一个可行的方法。第二种方法是使用程序模拟登录,通过模拟登录获取cookies。这种方法适合长期采集this网站,
为了让大家更好的了解这两种方式的应用,我以豆瓣个人主页昵称为例,通过这两种方式获取登录后才能查看的信息。获取信息为如下图:
很容易得到图片中的缺心。很明显,这个信息只有登录后才能看到,符合我们的主题。接下来,我们使用上面的两种方法来解决这个问题。
手动设置 cookie
手动设置cookie的方式比较简单。我们只需要登录豆瓣。登录成功后,我们可以获取到带有用户信息的cookie。豆瓣登录链接:
https://accounts.douban.com/passport/login
如下所示:
图中的cookie携带用户信息。我们只需要在请求查看登录后才能查看的信息时携带这个cookie。我们使用Jsoup来模拟手动设置cookie的方式。具体代码如下:
从代码可以看出,它和不需要登录的网站没什么区别,只是多了一个.header("Cookie", "your cookies"),我们可以复制浏览器里的cookie在这里,写main方法
运行 main 会产生以下结果:
可以看到,我们成功获取了缺心,这就是所谓的简单,也就是说我们设置的cookie是有效的,我们成功获取了需要登录的数据。这个方法真的很简单,唯一的缺点是cookie需要经常更换,因为cookie会失效,使用起来不太舒服。
模拟登录方式
模拟登录方式可以解决手动设置cookie方式的不足,但也引入了更复杂的问题。目前的验证码种类繁多,其中有很多是具有挑战性的,比如在一堆图片中操作某类图片。这个还是挺难的,写出来也不容易。因此,由开发人员权衡使用哪种方法的利弊。我们今天使用的豆瓣在登录的时候是没有验证码的,这种没有验证码的比较简单。模拟登录方式最重要的是找到真正的登录请求和登录所需的参数。我们只能利用这一点,我们先在登录界面输入错误的账号密码,这样页面就不会跳转了,所以我们可以很容易地找到登录请求。让我演示一下豆瓣登录找到登录链接。我们在登录界面输入了错误的用户名和密码。点击登录后,查看网络发起的请求链接,如下图:
从网络上我们可以看到豆瓣的登录链接是,需要五个参数,具体参数可以在图中的Form Data中查看。有了这些,我们就可以构造一个请求来模拟登录。登录后进行后续操作。接下来,我们将使用Jsoup模拟登录,获取豆瓣首页的昵称。具体代码如下:
这段代码分为两部分。第一段是模拟登录,第二段是解析豆瓣首页。此代码中启动了两个请求。第一个请求是模拟登录获取cookie,第二个请求携带第一个模拟登录后获取的cookie,这样也可以访问需要登录的页面,修改main方法
运行 main 方法会产生以下结果:
模拟登录的方法也成功获取了网名。它被称为简单。虽然这是最简单的模拟登录,但从代码量可以看出,它比设置cookies要复杂得多。对于其他有验证码登录的用户,这里就不介绍了。首先,我没有这方面的经验。其次,这个实现比较复杂,会涉及到一些算法和一些辅助工具的使用。有兴趣的朋友可以参考崔庆才先生的作品。博客研究研究。虽然模拟登录写起来比较复杂,但只要写得好,一劳永逸。如果你需要长期的采集信息需要登录,这个还是值得做的。除了使用jsoup模拟登录,我们也可以使用httpclient来模拟登录。httpclient模拟登录没有Jsoup那么复杂,因为httpclient可以像浏览器一样保存session会话,这样登录后就保存cookies,同一个httpclient中的请求都会带cookies。httpclient模拟登录代码如下:
运行此代码也会返回 true。
我们讲了Java爬虫的登录问题。总结一下:爬虫的登录问题有两种解决方案。一种是手动设置cookies。此方法适用于短期采集或一次性性采集,成本较低。另一种方式是模拟登录,适合长期采集网站,因为模拟登录的成本还是挺高的,尤其是一些异常的验证码,好处是可以让你一劳永逸
以上就是Java爬虫遇到的登录问题的知识分享。我希望它会帮助你。下一篇是关于爬虫遇到数据异步加载的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,共同进步
源代码:
https://github.com/BinaryBall/ ... .java
作者:平头哥的技术博文
来源:掘金
商业用途请与原作者联系,本文只做展示分享,不妥侵删! 查看全部
java爬虫抓取网页数据(
一下如何利用Java进行网络爬虫?(图)的运用
)
这是Java网络爬虫系列的第二篇文章。上一篇Java网络爬虫,就这么简单,我们简单学习了如何使用Java进行网络爬虫。在这篇文章中,我们将简单谈谈遇到网络爬虫时需要登录的网站,我们应该怎么做?
在做爬虫工作的时候,也经常会遇到需要登录的问题,比如写脚本抢票之类的,但是任何需要个人信息的人都需要登录。此类问题的解决方法主要有两种:一种是手动设置Cookie就是先登录网站,登录后复制cookie,在爬虫程序的HTTP请求中手动设置Cookie属性。这种方法适用于采集频率较低,采集周期短,因为cookie会失效。如果是长期采集,需要频繁设置cookie。这不是一个可行的方法。第二种方法是使用程序模拟登录,通过模拟登录获取cookies。这种方法适合长期采集this网站,
为了让大家更好的了解这两种方式的应用,我以豆瓣个人主页昵称为例,通过这两种方式获取登录后才能查看的信息。获取信息为如下图:
很容易得到图片中的缺心。很明显,这个信息只有登录后才能看到,符合我们的主题。接下来,我们使用上面的两种方法来解决这个问题。
手动设置 cookie
手动设置cookie的方式比较简单。我们只需要登录豆瓣。登录成功后,我们可以获取到带有用户信息的cookie。豆瓣登录链接:
https://accounts.douban.com/passport/login
如下所示:
图中的cookie携带用户信息。我们只需要在请求查看登录后才能查看的信息时携带这个cookie。我们使用Jsoup来模拟手动设置cookie的方式。具体代码如下:
从代码可以看出,它和不需要登录的网站没什么区别,只是多了一个.header("Cookie", "your cookies"),我们可以复制浏览器里的cookie在这里,写main方法
运行 main 会产生以下结果:
可以看到,我们成功获取了缺心,这就是所谓的简单,也就是说我们设置的cookie是有效的,我们成功获取了需要登录的数据。这个方法真的很简单,唯一的缺点是cookie需要经常更换,因为cookie会失效,使用起来不太舒服。
模拟登录方式
模拟登录方式可以解决手动设置cookie方式的不足,但也引入了更复杂的问题。目前的验证码种类繁多,其中有很多是具有挑战性的,比如在一堆图片中操作某类图片。这个还是挺难的,写出来也不容易。因此,由开发人员权衡使用哪种方法的利弊。我们今天使用的豆瓣在登录的时候是没有验证码的,这种没有验证码的比较简单。模拟登录方式最重要的是找到真正的登录请求和登录所需的参数。我们只能利用这一点,我们先在登录界面输入错误的账号密码,这样页面就不会跳转了,所以我们可以很容易地找到登录请求。让我演示一下豆瓣登录找到登录链接。我们在登录界面输入了错误的用户名和密码。点击登录后,查看网络发起的请求链接,如下图:
从网络上我们可以看到豆瓣的登录链接是,需要五个参数,具体参数可以在图中的Form Data中查看。有了这些,我们就可以构造一个请求来模拟登录。登录后进行后续操作。接下来,我们将使用Jsoup模拟登录,获取豆瓣首页的昵称。具体代码如下:
这段代码分为两部分。第一段是模拟登录,第二段是解析豆瓣首页。此代码中启动了两个请求。第一个请求是模拟登录获取cookie,第二个请求携带第一个模拟登录后获取的cookie,这样也可以访问需要登录的页面,修改main方法
运行 main 方法会产生以下结果:
模拟登录的方法也成功获取了网名。它被称为简单。虽然这是最简单的模拟登录,但从代码量可以看出,它比设置cookies要复杂得多。对于其他有验证码登录的用户,这里就不介绍了。首先,我没有这方面的经验。其次,这个实现比较复杂,会涉及到一些算法和一些辅助工具的使用。有兴趣的朋友可以参考崔庆才先生的作品。博客研究研究。虽然模拟登录写起来比较复杂,但只要写得好,一劳永逸。如果你需要长期的采集信息需要登录,这个还是值得做的。除了使用jsoup模拟登录,我们也可以使用httpclient来模拟登录。httpclient模拟登录没有Jsoup那么复杂,因为httpclient可以像浏览器一样保存session会话,这样登录后就保存cookies,同一个httpclient中的请求都会带cookies。httpclient模拟登录代码如下:
运行此代码也会返回 true。
我们讲了Java爬虫的登录问题。总结一下:爬虫的登录问题有两种解决方案。一种是手动设置cookies。此方法适用于短期采集或一次性性采集,成本较低。另一种方式是模拟登录,适合长期采集网站,因为模拟登录的成本还是挺高的,尤其是一些异常的验证码,好处是可以让你一劳永逸
以上就是Java爬虫遇到的登录问题的知识分享。我希望它会帮助你。下一篇是关于爬虫遇到数据异步加载的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,共同进步
源代码:
https://github.com/BinaryBall/ ... .java
作者:平头哥的技术博文
来源:掘金
商业用途请与原作者联系,本文只做展示分享,不妥侵删!
java爬虫抓取网页数据( 我分享一套完整的Python爬虫学习框架路线和视频教程入门)
网站优化 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2022-02-23 04:19
我分享一套完整的Python爬虫学习框架路线和视频教程入门)
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
爬行动物有什么用?
爬行是搜索引擎的第一步,也是最简单的一步。
为什么你最终选择了 Python?
一个简单的 Python 爬虫:
import urllib
import urllib.request
def loadPage(url,filename):
"""
作用:根据url发送请求,获取html数据;
:param url:
:return:
"""
request=urllib.request.Request(url)
html1= urllib.request.urlopen(request).read()
return html1.decode('utf-8')
def writePage(html,filename):
"""
作用将html写入本地
:param html: 服务器相应的文件内容
:return:
"""
with open(filename,'w') as f:
f.write(html)
print('-'*30)
def tiebaSpider(url,beginPage,endPage):
"""
作用贴吧爬虫调度器,负责处理每一个页面url;
:param url:
:param beginPage:
:param endPage:
:return:
"""
for page in range(beginPage,endPage+1):
pn=(page - 1)*50
fullurl=url+"&pn="+str(pn)
print(fullurl)
filename='第'+str(page)+'页.html'
html= loadPage(url,filename)
writePage(html,filename)
if __name__=="__main__":
kw=input('请输入你要需要爬取的贴吧名:')
beginPage=int(input('请输入起始页'))
endPage=int(input('请输入结束页'))
url='https://tieba.baidu.com/f?'
kw1={'kw':kw}
key = urllib.parse.urlencode(kw1)
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
Java实现网络爬虫的代码比Python多很多,实现起来也比较复杂。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。
Python 相对于 Java 的优势:
1、方向广泛,如web开发、机器学习、人工智能、数据分析、金融量化交易、爬虫开发、自动化运维、自动化测试等;
2、语法简洁,学习成本低;
3、未来发展前景更高,因为国家在推动(纳入高中教材),也就是说未来的市场也很大;
4、Python的requests库比Java的jsoup简单;
5、Python有scrapy爬虫库的加持;
6、Python 对 Excel 的支持优于 Java;
7、Java 没有像 pip 这样的包管理工具。
现在大数据时代几乎离不开Python爬虫,而使用Python爬虫我们可以获得大量有价值的数据,所以现在这个方向的就业前景还是比较好的。如果你想学习Python爬虫,我给大家分享一套完整的Python爬虫学习资料供大家参考。收录系统的Python爬虫学习框架路线和视频教程。内容清晰明了。非常适合初学者入门。点击下方的↓↓↓插件直接获取。帮助! 查看全部
java爬虫抓取网页数据(
我分享一套完整的Python爬虫学习框架路线和视频教程入门)
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某个停止条件。
爬行动物有什么用?
爬行是搜索引擎的第一步,也是最简单的一步。
为什么你最终选择了 Python?
一个简单的 Python 爬虫:
import urllib
import urllib.request
def loadPage(url,filename):
"""
作用:根据url发送请求,获取html数据;
:param url:
:return:
"""
request=urllib.request.Request(url)
html1= urllib.request.urlopen(request).read()
return html1.decode('utf-8')
def writePage(html,filename):
"""
作用将html写入本地
:param html: 服务器相应的文件内容
:return:
"""
with open(filename,'w') as f:
f.write(html)
print('-'*30)
def tiebaSpider(url,beginPage,endPage):
"""
作用贴吧爬虫调度器,负责处理每一个页面url;
:param url:
:param beginPage:
:param endPage:
:return:
"""
for page in range(beginPage,endPage+1):
pn=(page - 1)*50
fullurl=url+"&pn="+str(pn)
print(fullurl)
filename='第'+str(page)+'页.html'
html= loadPage(url,filename)
writePage(html,filename)
if __name__=="__main__":
kw=input('请输入你要需要爬取的贴吧名:')
beginPage=int(input('请输入起始页'))
endPage=int(input('请输入结束页'))
url='https://tieba.baidu.com/f?'
kw1={'kw':kw}
key = urllib.parse.urlencode(kw1)
fullurl=url+key
tiebaSpider(fullurl,beginPage,endPage)
Java实现网络爬虫的代码比Python多很多,实现起来也比较复杂。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。
Python 相对于 Java 的优势:
1、方向广泛,如web开发、机器学习、人工智能、数据分析、金融量化交易、爬虫开发、自动化运维、自动化测试等;
2、语法简洁,学习成本低;
3、未来发展前景更高,因为国家在推动(纳入高中教材),也就是说未来的市场也很大;
4、Python的requests库比Java的jsoup简单;
5、Python有scrapy爬虫库的加持;
6、Python 对 Excel 的支持优于 Java;
7、Java 没有像 pip 这样的包管理工具。
现在大数据时代几乎离不开Python爬虫,而使用Python爬虫我们可以获得大量有价值的数据,所以现在这个方向的就业前景还是比较好的。如果你想学习Python爬虫,我给大家分享一套完整的Python爬虫学习资料供大家参考。收录系统的Python爬虫学习框架路线和视频教程。内容清晰明了。非常适合初学者入门。点击下方的↓↓↓插件直接获取。帮助!
java爬虫抓取网页数据(文档介绍:对网页爬虫的调查结果调查人:王杨斌)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-22 03:05
文件介绍:网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是PHP和Java的工具代码。1.Java爬虫1.1.JAVA爬虫WebCollector爬虫介绍:WebCollector[]是一个无需配置,方便二次开发的JAVA爬虫框架(内核),提供了简化的API , 只需要很少的代码就可以实现一个强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定且可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2.Web-HarvestWeb-Harvest[]是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。
JSpider的默认配置很小,用处不大。但是 JSpider 很容易扩展,你可以用它来开发强大的网页抓取和数据分析工具。为此,您需要对 JSpider 的原理有深入的了解,然后根据自己的需要开发插件和编写配置文件。1.4.网络爬虫 HeritrixHeritrix[] 是一个开源、可扩展的网络爬虫项目。用户可以使用它从 Internet 上抓取所需的资源。Heritrix 的设计严格遵循 robots.txt 文件的排除说明和 METArobots 标签。它最大的特点就是可扩展性好,方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架,其组织结构包括整个组件和爬取过程。1.5.webmagiclogo垂直爬虫webmagicWebmagic[]是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。
它可以用来构建一个多线程的网络爬虫。1.7.Java网络蜘蛛/网络爬虫SpidermanSpiderman[]是一个基于微内核+插件架构的网络蜘蛛,它的目标是通过简单的方法爬取复杂的目标网络信息并解析成您需要的业务数据。2.C/C++爬虫2.1.网站Crawler GrubNextGenerationGrubNextGeneration[]是一个分布式网络爬虫系统,包括客户端和服务器,可以用来维护网页的索引。其开发语言:C/C++PerlC#。2.2.网络爬虫甲醇甲醇[]是一个模块化和可定制的网络爬虫软件,主要优点是速度快。2.3. 查看全部
java爬虫抓取网页数据(文档介绍:对网页爬虫的调查结果调查人:王杨斌)
文件介绍:网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是PHP和Java的工具代码。1.Java爬虫1.1.JAVA爬虫WebCollector爬虫介绍:WebCollector[]是一个无需配置,方便二次开发的JAVA爬虫框架(内核),提供了简化的API , 只需要很少的代码就可以实现一个强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定且可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2.Web-HarvestWeb-Harvest[]是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它能够采集指定的网页并从这些页面中提取有用的数据。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现对text/xml的操作。1.3.Java 网络爬虫 JSpiderJSpider[] 是一个用 Java 实现的 WebSpider。JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等都设置在conf\[ConfigName]\目录下。
JSpider的默认配置很小,用处不大。但是 JSpider 很容易扩展,你可以用它来开发强大的网页抓取和数据分析工具。为此,您需要对 JSpider 的原理有深入的了解,然后根据自己的需要开发插件和编写配置文件。1.4.网络爬虫 HeritrixHeritrix[] 是一个开源、可扩展的网络爬虫项目。用户可以使用它从 Internet 上抓取所需的资源。Heritrix 的设计严格遵循 robots.txt 文件的排除说明和 METArobots 标签。它最大的特点就是可扩展性好,方便用户实现自己的爬取逻辑。Heritrix 是一个爬虫框架,其组织结构包括整个组件和爬取过程。1.5.webmagiclogo垂直爬虫webmagicWebmagic[]是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagiclogo 垂直爬虫 webmagicWebmagic[] 是一个无需配置,方便二次开发的爬虫框架。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。并且可以用少量代码实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。1.6.Java多线程网络爬虫Crawler4j Crawler4j[]是一个开源的Java类库,提供了一个简单的网页爬取接口。
它可以用来构建一个多线程的网络爬虫。1.7.Java网络蜘蛛/网络爬虫SpidermanSpiderman[]是一个基于微内核+插件架构的网络蜘蛛,它的目标是通过简单的方法爬取复杂的目标网络信息并解析成您需要的业务数据。2.C/C++爬虫2.1.网站Crawler GrubNextGenerationGrubNextGeneration[]是一个分布式网络爬虫系统,包括客户端和服务器,可以用来维护网页的索引。其开发语言:C/C++PerlC#。2.2.网络爬虫甲醇甲醇[]是一个模块化和可定制的网络爬虫软件,主要优点是速度快。2.3.

