
java爬虫抓取网页数据
java爬虫抓取网页数据(java爬虫抓取网页数据,可以用echarts,我常用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-18 10:02
java爬虫抓取网页数据,可以用echarts,我常用echarts来作为analyticitem类型的参数传入到basedata分析数据。创建实例之后,查看vara={aid:1,ac:[1,-2,-3],ad:[3,-5,-4],ag:[3,5,-1,-2],code:[0,1,-2,-3],sex:[2,1,0,2],index:[1,2,-3,-4],location:[]};就可以分析了。
chrome下chromeextensionexplorer|你值得拥有补充一下楼上用dom实现的那个图,属于数据反爬虫,
selenium+beautifulsoup
不评价书籍,不评价特定的网站及方法。我要说的是方法论,并不是要列举实例。之所以要简单地描述这个问题是因为它没有那么复杂。其一,大部分方法并不需要爬取特定类型的数据(无论如何都是一样),其二,有用的数据可能存在可以解析的问题(估计比较费事),其三,数据可能很复杂,采集、清洗、保存要麻烦,其四,如果只是单纯地看数据的话可能不需要最终返回productdata。具体的可参看我之前的回答,要是有时间可以自己琢磨一下,相信有兴趣能解决你的问题。
自动化的一般步骤:清理过滤数据获取数据存储数据查询数据采集数据设计分析实际上,所有的数据抓取,都可以简单分为三步:预处理——>清洗过滤数据——>数据存储——>数据查询这三步大致可以被分为两步:1。抓取第一步:先将抓取的数据爬虫变为urls,之后将数据根据urls存储;2。抓取第二步:自己设计数据存储的方式,并爬取或者数据导出。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据,可以用echarts,我常用)
java爬虫抓取网页数据,可以用echarts,我常用echarts来作为analyticitem类型的参数传入到basedata分析数据。创建实例之后,查看vara={aid:1,ac:[1,-2,-3],ad:[3,-5,-4],ag:[3,5,-1,-2],code:[0,1,-2,-3],sex:[2,1,0,2],index:[1,2,-3,-4],location:[]};就可以分析了。
chrome下chromeextensionexplorer|你值得拥有补充一下楼上用dom实现的那个图,属于数据反爬虫,
selenium+beautifulsoup
不评价书籍,不评价特定的网站及方法。我要说的是方法论,并不是要列举实例。之所以要简单地描述这个问题是因为它没有那么复杂。其一,大部分方法并不需要爬取特定类型的数据(无论如何都是一样),其二,有用的数据可能存在可以解析的问题(估计比较费事),其三,数据可能很复杂,采集、清洗、保存要麻烦,其四,如果只是单纯地看数据的话可能不需要最终返回productdata。具体的可参看我之前的回答,要是有时间可以自己琢磨一下,相信有兴趣能解决你的问题。
自动化的一般步骤:清理过滤数据获取数据存储数据查询数据采集数据设计分析实际上,所有的数据抓取,都可以简单分为三步:预处理——>清洗过滤数据——>数据存储——>数据查询这三步大致可以被分为两步:1。抓取第一步:先将抓取的数据爬虫变为urls,之后将数据根据urls存储;2。抓取第二步:自己设计数据存储的方式,并爬取或者数据导出。
java爬虫抓取网页数据(java爬虫抓取网页数据的原理最简单的方法是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-09 14:01
java爬虫抓取网页数据的原理最简单的方法就是模拟浏览器从服务器获取数据。自己动手制作一个爬虫的话,可以用到很多东西,从分析请求,到动态解析,再到模拟鼠标键盘行为,然后根据不同需求定制不同的爬虫。主要的爬虫类库有python3.4版本的flask,2.8版本的httplib2。有了这些工具之后,可以自己构造规则,用自定义规则再次让爬虫爬取,或者手动写个简单的爬虫接口。
httplib2爬虫思路手写爬虫框架思路主要是构造请求和解析请求。这里我只要讲如何构造。爬虫结构如下,其中scrapy的代码和源码等是对应middleware版本的爬虫。如果你想构造详细的可执行爬虫,可以用apicallback接口获取最新的爬虫代码和api文档等。python3.4flask爬虫代码apicallbackx5方法做整理,以后爬虫的编程规范。
代码架构如下,为了让爬虫结构尽量清晰,后续的代码不会复杂到二次代码的结构,有改动可以通过配置apicallback执行。globalapicallbackscomputerimportrequests#扫描所有请求importre#给代码注册证书token=requests.get("/").content.contenttoken=pile("")#给爬虫加约束条件score=re.findall(r'score\n',token)#检查爬虫是否符合约束条件attr=re.findall(r'<a>',token)#定义请求路径response=python3.4文档方法异步/同步请求pipeline调用循环none_url=requests.get("/")none_url.split("/")withopen("/'xxxx'/'file_name'",'w')asf:f.write(none_url)这里主要解决url重复的问题。
cookie爬虫中会保存上次抓取到的cookie值,也是后续判断爬虫抓取结果是否一致的重要信息,因此后续编写爬虫的时候需要注意使用cookie。python3.4flask爬虫实现代码首先定义一个请求函数request,目的是获取页面地址,flask中根据url地址来获取文件。再定义循环for循环,循环请求地址,返回结果,获取到响应头信息,然后根据响应头信息解析response.cookie。
其中flask的文档方法很多,建议直接看代码。然后就可以用这个构造简单的爬虫,例如从百度搜索获取得分。最终定义爬虫的apicallback函数globalapicallbackflask.app.urlhandler{'xxxx':'','score':0,'c':1,'result':none}这个函数就是urlhandler接收请求地址和响应结果返回响应头,然后解析cookie完成get请求,最后就是根据请求结果返回。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据的原理最简单的方法是什么)
java爬虫抓取网页数据的原理最简单的方法就是模拟浏览器从服务器获取数据。自己动手制作一个爬虫的话,可以用到很多东西,从分析请求,到动态解析,再到模拟鼠标键盘行为,然后根据不同需求定制不同的爬虫。主要的爬虫类库有python3.4版本的flask,2.8版本的httplib2。有了这些工具之后,可以自己构造规则,用自定义规则再次让爬虫爬取,或者手动写个简单的爬虫接口。
httplib2爬虫思路手写爬虫框架思路主要是构造请求和解析请求。这里我只要讲如何构造。爬虫结构如下,其中scrapy的代码和源码等是对应middleware版本的爬虫。如果你想构造详细的可执行爬虫,可以用apicallback接口获取最新的爬虫代码和api文档等。python3.4flask爬虫代码apicallbackx5方法做整理,以后爬虫的编程规范。
代码架构如下,为了让爬虫结构尽量清晰,后续的代码不会复杂到二次代码的结构,有改动可以通过配置apicallback执行。globalapicallbackscomputerimportrequests#扫描所有请求importre#给代码注册证书token=requests.get("/").content.contenttoken=pile("")#给爬虫加约束条件score=re.findall(r'score\n',token)#检查爬虫是否符合约束条件attr=re.findall(r'<a>',token)#定义请求路径response=python3.4文档方法异步/同步请求pipeline调用循环none_url=requests.get("/")none_url.split("/")withopen("/'xxxx'/'file_name'",'w')asf:f.write(none_url)这里主要解决url重复的问题。
cookie爬虫中会保存上次抓取到的cookie值,也是后续判断爬虫抓取结果是否一致的重要信息,因此后续编写爬虫的时候需要注意使用cookie。python3.4flask爬虫实现代码首先定义一个请求函数request,目的是获取页面地址,flask中根据url地址来获取文件。再定义循环for循环,循环请求地址,返回结果,获取到响应头信息,然后根据响应头信息解析response.cookie。
其中flask的文档方法很多,建议直接看代码。然后就可以用这个构造简单的爬虫,例如从百度搜索获取得分。最终定义爬虫的apicallback函数globalapicallbackflask.app.urlhandler{'xxxx':'','score':0,'c':1,'result':none}这个函数就是urlhandler接收请求地址和响应结果返回响应头,然后解析cookie完成get请求,最后就是根据请求结果返回。
java爬虫抓取网页数据(阿里巴巴如何开始学习java爬虫(没错就是我自己))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-06 17:03
java爬虫抓取网页数据的文章并不少见,但是实际中,更多是通过爬虫获取网页爬虫可以说是一个工具,一个提高工作效率的工具,看似简单,但是却要稍加学习才能理解,最近也想借此机会,开始学习java爬虫(没错就是我自己)。在开始之前,我们得明确的一点是:想要理解“爬虫”并不仅仅需要学习编程语言和编程规范,同时也要知道python语言的语法等,才能把爬虫发挥到最大。
先抛结论:爬虫是一种互联网网络技术,通过网络采集信息,然后再推送到互联网上。这里我们需要认识一下爬虫的概念,举个简单的例子:阿里巴巴是中国最大的b2b电商网站,用户可以通过上面的搜索框搜索商品或服务,阿里巴巴会从阿里巴巴的各个站点上抓取商品并发给客户。如果不使用“爬虫”功能,那么所抓取的数据都是下载下来的,不能发布在搜索框中。
那么我们看一下阿里巴巴如何抓取每一个客户的商品信息的:马云,姓马的我都知道了。马云创立了阿里巴巴,把一部分的商品信息推送给商家,商家在阿里上面拍下某个商品,然后在其他的站点上面购买该商品,阿里收集这些商品信息再发给商家。这样,通过阿里巴巴爬虫来采集数据,进行商品发布给用户。简单来说,阿里巴巴这个例子就是一个爬虫抓取商品信息的例子,那么如何开始学习java爬虫呢?我想了好几天,终于决定用nodejs开始学习(目前只接触到了nodejs)。
(后面会有关于nodejs的小黄文哦~)下面我先给一些实用的学习资料和使用工具:@night夜色、@c5game、@vscode、@seozoom、@v2ex之前一直用python,所以学习比较顺利;sqlite不知道从哪儿开始入手,又买了一本pythonmysql教程,为了熟悉数据库,还买了《pythonsql语言详解》来学习;并且安装了windows和linux系统,准备简单了解一下命令行相关操作;python的super是最近找的视频,和教程;学习过程也是比较坎坷,后面继续努力吧;目前学习中涉及到的知识点:爬虫、web模式与数据库表连接(mysql)、读取html文件、xpath、相关语言工具等;。 查看全部
java爬虫抓取网页数据(阿里巴巴如何开始学习java爬虫(没错就是我自己))
java爬虫抓取网页数据的文章并不少见,但是实际中,更多是通过爬虫获取网页爬虫可以说是一个工具,一个提高工作效率的工具,看似简单,但是却要稍加学习才能理解,最近也想借此机会,开始学习java爬虫(没错就是我自己)。在开始之前,我们得明确的一点是:想要理解“爬虫”并不仅仅需要学习编程语言和编程规范,同时也要知道python语言的语法等,才能把爬虫发挥到最大。
先抛结论:爬虫是一种互联网网络技术,通过网络采集信息,然后再推送到互联网上。这里我们需要认识一下爬虫的概念,举个简单的例子:阿里巴巴是中国最大的b2b电商网站,用户可以通过上面的搜索框搜索商品或服务,阿里巴巴会从阿里巴巴的各个站点上抓取商品并发给客户。如果不使用“爬虫”功能,那么所抓取的数据都是下载下来的,不能发布在搜索框中。
那么我们看一下阿里巴巴如何抓取每一个客户的商品信息的:马云,姓马的我都知道了。马云创立了阿里巴巴,把一部分的商品信息推送给商家,商家在阿里上面拍下某个商品,然后在其他的站点上面购买该商品,阿里收集这些商品信息再发给商家。这样,通过阿里巴巴爬虫来采集数据,进行商品发布给用户。简单来说,阿里巴巴这个例子就是一个爬虫抓取商品信息的例子,那么如何开始学习java爬虫呢?我想了好几天,终于决定用nodejs开始学习(目前只接触到了nodejs)。
(后面会有关于nodejs的小黄文哦~)下面我先给一些实用的学习资料和使用工具:@night夜色、@c5game、@vscode、@seozoom、@v2ex之前一直用python,所以学习比较顺利;sqlite不知道从哪儿开始入手,又买了一本pythonmysql教程,为了熟悉数据库,还买了《pythonsql语言详解》来学习;并且安装了windows和linux系统,准备简单了解一下命令行相关操作;python的super是最近找的视频,和教程;学习过程也是比较坎坷,后面继续努力吧;目前学习中涉及到的知识点:爬虫、web模式与数据库表连接(mysql)、读取html文件、xpath、相关语言工具等;。
java爬虫抓取网页数据(本文并不是讲解爬虫的相关技术实现的,而是..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-05 18:04
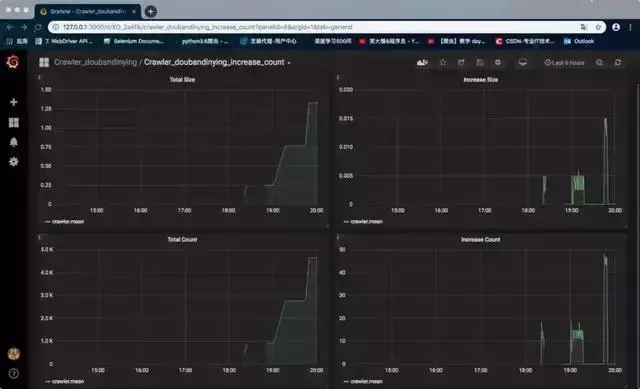
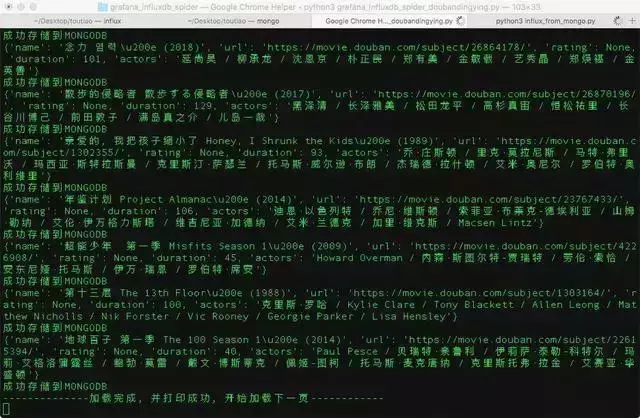
本文不讲解爬虫相关技术的实现,而是从实际的角度出发,将MongoDB抓取并存储的数据用InfluxDB处理,再通过Grafana抓取爬虫的数据。显示图形界面。
开始之前先简单介绍一下Grafana和InfluxDB:
最终效果如下:
请注意,以下操作均在 Mac 下实现。但原理类似,你可以在自己的电脑上进行实验。
2. 安装和配置 InfluxDB
安装 InfluxDB
修改配置文件/usr/local/etc/influxdb.conf。如果原文件中没有对应的配置项,需要自己添加。
3. 安装 Grafana
安装 Grafana
并修改Grafana配置文件/usr/local/etc/grafana/grafana.ini如下:
4.爬虫代码
因为这里主要介绍Grafana和InfluxDB如何与爬虫结合,而不是爬虫的原理,而且代码比较多,影响可读性,所以就不贴爬虫代码了。
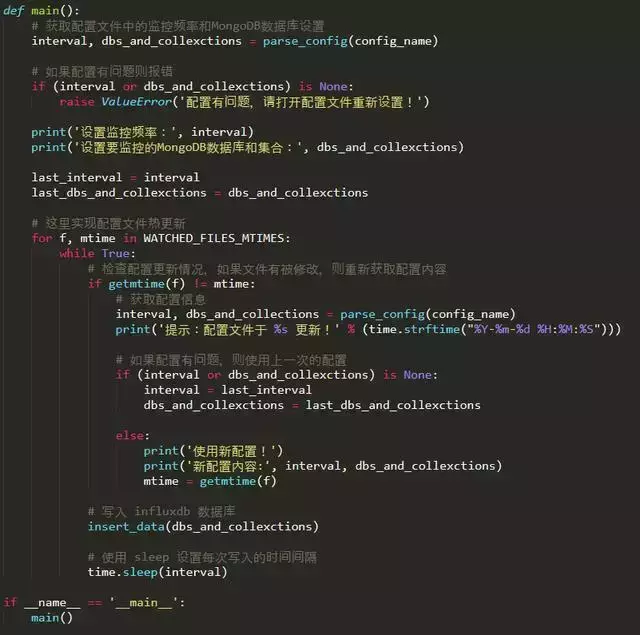
5.监控脚本
考虑到可能会加入爬虫监控,这里使用热更新来动态配置监控。
配置文件influx_settings.conf主要用于热更新相关设置。
如何动态读取这个配置文件的设置?需要写一个脚本来监控。代码如下:
我们来试试吧
python3 influx_monitor.py
运行,得到如下内容,说明监控脚本运行成功。
再创建一个窗口,修改配置文件influx_settings.conf
# 修改间隔时间为8秒
interval = 8
第一次切换到运行influxDB的窗口,会提示配置更新,说明配置热更新生效。
6. 配置 Grafana
首先打开Chrome浏览器,输入:3000登录grafana页面。
连接本地influxDB数据库,如下图。
在红框中选择Type为InfluxDB,并输入URL::8086
在红框中输入influxDB数据库名称
新仪表板
新的图表类型仪表板
修改仪表板设置
点击红框修改设置
修改仪表板配置
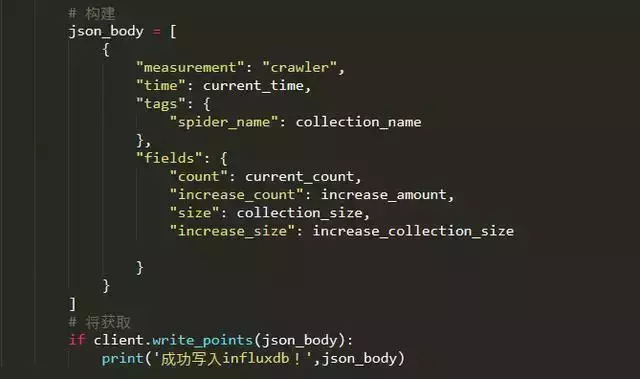
设置监控数据对象
监控脚本中,写入influxDB的代码如下,其中“measurement”对应表名,“fields”对应写入的字段;
7.运行爬虫文件
启动 MongoDB 数据库服务。
brew services mongodb start
新建一个终端窗口并运行爬虫文件。
爬虫文件运行成功
我们可以在刚刚打开的控制台中查看效果展示:
怎么样?你学会了吗?如果你和我一样喜欢python,也在学习python的道路上奔跑,欢迎加入python学习群:839383 765 群里会分享最新的行业资讯,企业项目案例,分享免费的python课程,一起交流学习每天,让学习把(编辑)变成(处理)一种习惯! 查看全部
java爬虫抓取网页数据(本文并不是讲解爬虫的相关技术实现的,而是..)
本文不讲解爬虫相关技术的实现,而是从实际的角度出发,将MongoDB抓取并存储的数据用InfluxDB处理,再通过Grafana抓取爬虫的数据。显示图形界面。
开始之前先简单介绍一下Grafana和InfluxDB:
最终效果如下:
请注意,以下操作均在 Mac 下实现。但原理类似,你可以在自己的电脑上进行实验。
2. 安装和配置 InfluxDB
安装 InfluxDB

修改配置文件/usr/local/etc/influxdb.conf。如果原文件中没有对应的配置项,需要自己添加。
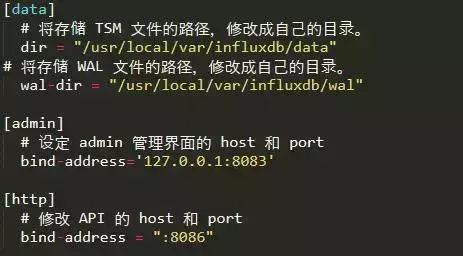
3. 安装 Grafana
安装 Grafana

并修改Grafana配置文件/usr/local/etc/grafana/grafana.ini如下:
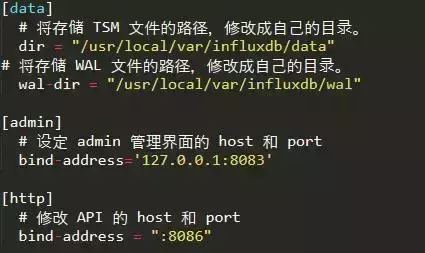
4.爬虫代码
因为这里主要介绍Grafana和InfluxDB如何与爬虫结合,而不是爬虫的原理,而且代码比较多,影响可读性,所以就不贴爬虫代码了。
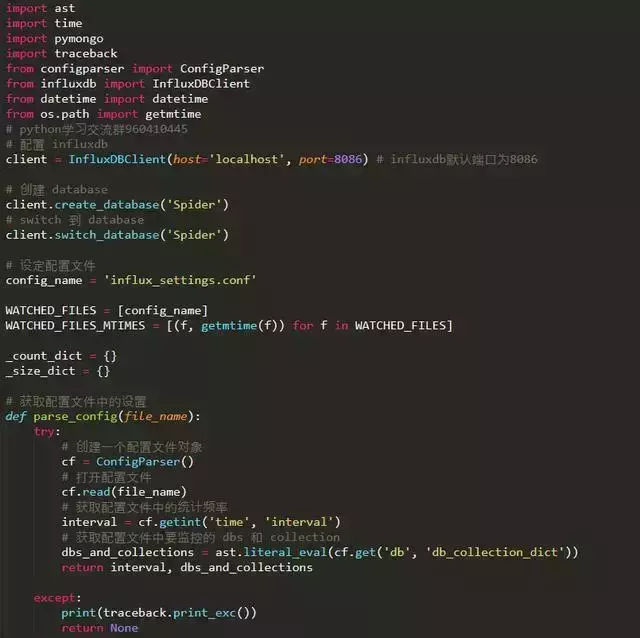
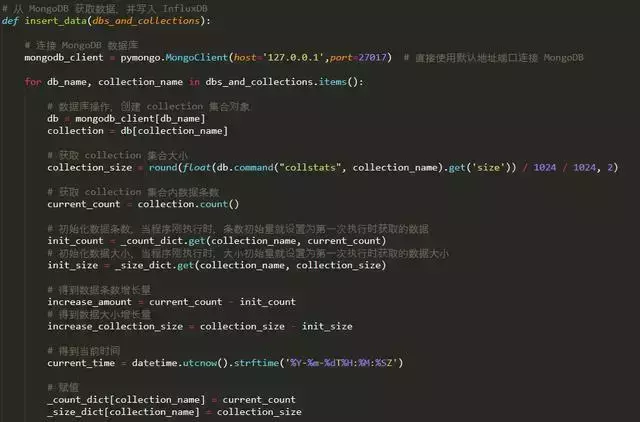
5.监控脚本
考虑到可能会加入爬虫监控,这里使用热更新来动态配置监控。
配置文件influx_settings.conf主要用于热更新相关设置。
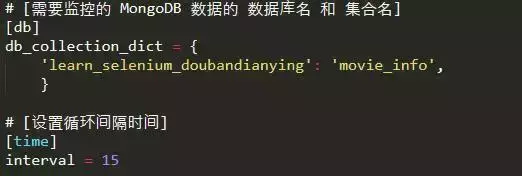
如何动态读取这个配置文件的设置?需要写一个脚本来监控。代码如下:
我们来试试吧
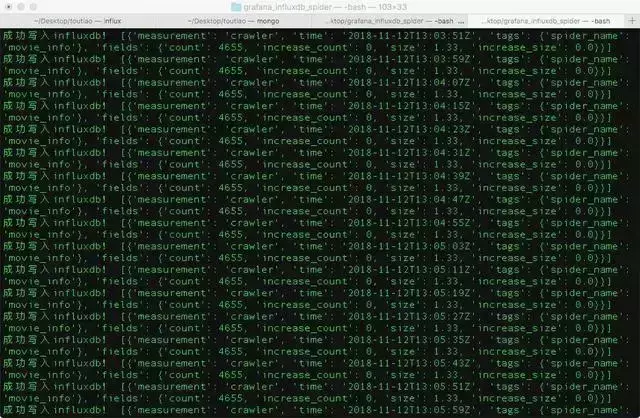
python3 influx_monitor.py
运行,得到如下内容,说明监控脚本运行成功。
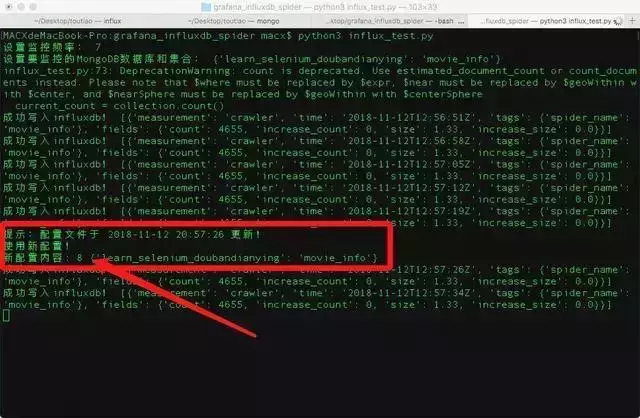
再创建一个窗口,修改配置文件influx_settings.conf
# 修改间隔时间为8秒
interval = 8
第一次切换到运行influxDB的窗口,会提示配置更新,说明配置热更新生效。
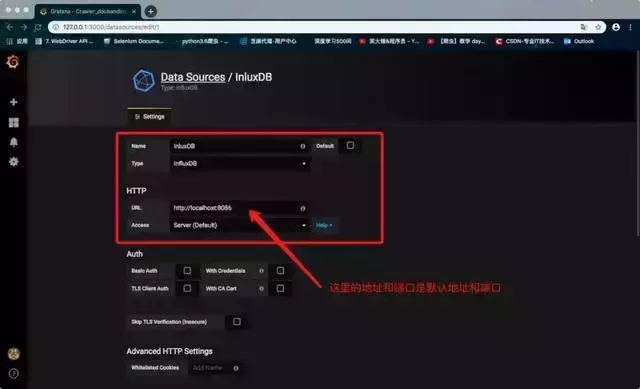
6. 配置 Grafana
首先打开Chrome浏览器,输入:3000登录grafana页面。
连接本地influxDB数据库,如下图。
在红框中选择Type为InfluxDB,并输入URL::8086
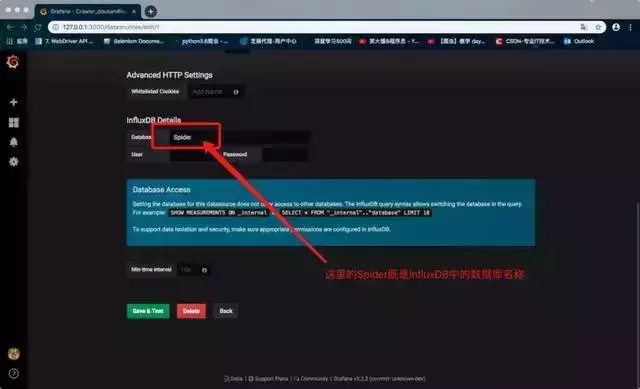
在红框中输入influxDB数据库名称
新仪表板
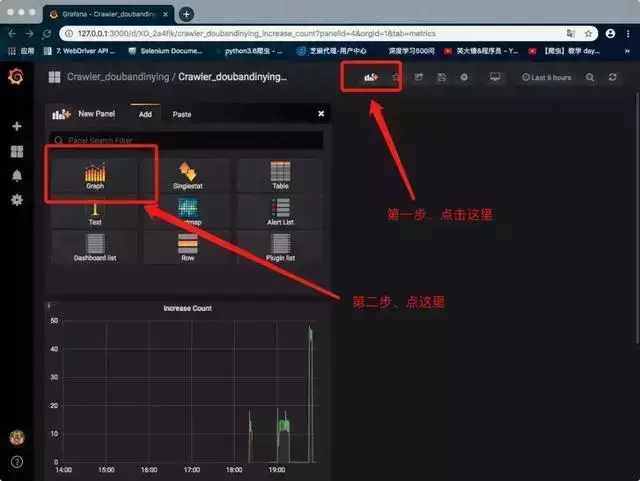
新的图表类型仪表板
修改仪表板设置
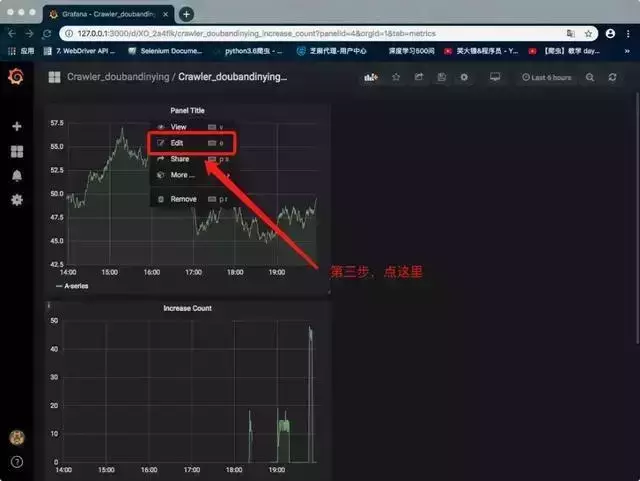
点击红框修改设置
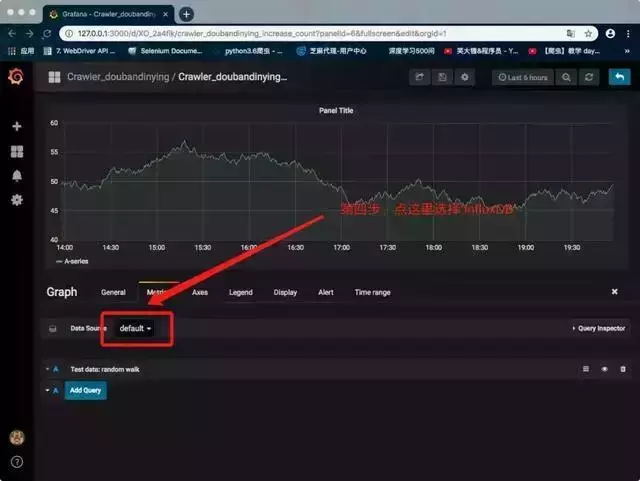
修改仪表板配置
设置监控数据对象
监控脚本中,写入influxDB的代码如下,其中“measurement”对应表名,“fields”对应写入的字段;
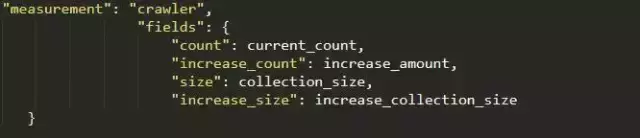
7.运行爬虫文件
启动 MongoDB 数据库服务。
brew services mongodb start
新建一个终端窗口并运行爬虫文件。
爬虫文件运行成功
我们可以在刚刚打开的控制台中查看效果展示:
怎么样?你学会了吗?如果你和我一样喜欢python,也在学习python的道路上奔跑,欢迎加入python学习群:839383 765 群里会分享最新的行业资讯,企业项目案例,分享免费的python课程,一起交流学习每天,让学习把(编辑)变成(处理)一种习惯!
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2022-02-03 08:10
文章目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的话,学python爬虫比较靠谱,但是那是不是说java不会爬呢?当然不是。事实上,在某些场景下,java爬虫更加方便易用。
1.引入依赖:
java中的爬虫使用jsoup类库。jsoup提供了一个非常省力的API,可以通过DOM、CSS以及类似jQuery的操作方式来检索和操作数据,这样就可以在请求网页后对网页进行dom操作。达到爬虫目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例二:
获取学校信息:
3.代理说明:
情况1,不使用代理ip,直接抓取即可。但是通常情况下,我们抓取的网站会设置反爬虫、拦截ip等,所以我们需要设置代理ip。网上案例2,使用的是蘑菇代理的代理隧道的代理设置。还不错,如果真的需要,可以买。
总结
当然,我上面写的两个案例只是例子。事实上,操作 DOM 的方法有很多种。如果要爬,肯定需要DOM的基本操作,还需要一些基本的html知识。如果你想和我有更多的交流,可以关注我的公众号:Java Time House进行交流。 查看全部
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
文章目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的话,学python爬虫比较靠谱,但是那是不是说java不会爬呢?当然不是。事实上,在某些场景下,java爬虫更加方便易用。
1.引入依赖:
java中的爬虫使用jsoup类库。jsoup提供了一个非常省力的API,可以通过DOM、CSS以及类似jQuery的操作方式来检索和操作数据,这样就可以在请求网页后对网页进行dom操作。达到爬虫目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例二:
获取学校信息:
3.代理说明:
情况1,不使用代理ip,直接抓取即可。但是通常情况下,我们抓取的网站会设置反爬虫、拦截ip等,所以我们需要设置代理ip。网上案例2,使用的是蘑菇代理的代理隧道的代理设置。还不错,如果真的需要,可以买。
总结
当然,我上面写的两个案例只是例子。事实上,操作 DOM 的方法有很多种。如果要爬,肯定需要DOM的基本操作,还需要一些基本的html知识。如果你想和我有更多的交流,可以关注我的公众号:Java Time House进行交流。
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-03 08:09
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p>package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/");
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf(" 查看全部
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p>package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/";);
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf("
java爬虫抓取网页数据(Jsoup需要的jar包:链接Jsoup不支持xpath的东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-03 08:07
二、Jsoup
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页、加载更多等等。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome
1、HeadlessChrome与PhantomJS的对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
使用 Python 做 HeadlessChrome 更简单更简单。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/");
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i 查看全部
java爬虫抓取网页数据(Jsoup需要的jar包:链接Jsoup不支持xpath的东西)
二、Jsoup
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页、加载更多等等。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome
1、HeadlessChrome与PhantomJS的对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
使用 Python 做 HeadlessChrome 更简单更简单。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/";);
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i
java爬虫抓取网页数据(2.网络爬虫(英语:webcrawler)抓取测试类4.测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-02 13:05
1. 网络爬虫
网络爬虫,也称为网络蜘蛛,是一种用于自动浏览万维网的网络机器人。它的目的通常是编译一个网络索引。简单来说就是获取被请求页面的源码,然后通过正则表达式获取你需要的内容。实现大致分为以下几个步骤:
(1)爬取网页源码
(2)用正则截取你需要的内容(我这里截取问题,下面回答)
2.爬取网页源码
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class Spider {
/**
* @auther: Ragty
* @describe: 爬虫爬取网页源码
* @param: [url]
* @return: java.lang.String
* @date: 2019/1/23
*/
public static String getSource (String url) {
BufferedReader reader = null;
String result = "";
try {
URL realurl = new URL(url);
URLConnection conn = realurl.openConnection(); //连接外部url
reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = "";
while ( (line = reader.readLine()) != null ) {
result += line;
}
if (reader != null) {
reader.close();
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
3.爬取规则和实体类
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import JavaSpider.spider.Spider;
public class Imooc {
public String question;
public String quesUrl;
public String quesDescription;
public Map answers;
public String nextUrl;
/**
* @auther: Ragty
* @describe: 爬取慕课问答界面的问题及回答
* @param: [url]
* @return:
* @date: 2019/1/23
*/
public Imooc(String url) {
question="";
quesUrl=url;
quesDescription="";
answers = new HashMap();
nextUrl="";
//获取单个问题页面源码
String codeSource = Spider.getSource(url);
//正则获取question
Pattern pattern=Pattern.compile("js-qa-wenda-title.+?>(.+?)");
Matcher matcher=pattern.matcher(codeSource);
if(matcher.find()){
question = matcher.group(1);
}
//正则表达式获取问题描述
pattern=Pattern.compile("js-qa-wenda.+?rich-text\">(.+?)");
matcher=pattern.matcher(codeSource);
if(matcher.find()){
quesDescription = matcher.group(1).replace("<p>", "").replace("", "");
}
//正则表达式获取答案列表
pattern=Pattern.compile("nickname.+?>(.+?)</a>.+?answer-desc rich-text aimgPreview.+?>(.+?)");
matcher=pattern.matcher(codeSource);
while(matcher.find()){
String answer = matcher.group(2).replace("
", "");
answer = answer.replace("", "");
answer = answer.replace("<br />", "");
String name = matcher.group(1);
answers.put(name.trim(), answer.trim());
}
//正则表达式获取下一个url 爬取获取相关问题的url
pattern=Pattern.compile("class=\"r relwenda\".+?href=\"(.+?)\".+?</a>");//获取回答者name
matcher=pattern.matcher(codeSource);
while(matcher.find()){
nextUrl="http://www.imooc.com"+matcher.group(1);
//只取第一个推荐
if(!nextUrl.equals(quesUrl)){
break;
}
}
}
@Override
public String toString() {
return "问题为:"+ question +"\n问题地址为:"+quesUrl+
"\n问题的表述为:"+quesDescription+"\n"
+ "回答的内容为:"+answers+"\n指向下一个链接地址为:"+nextUrl+"\n";
}
}
</p>
3.抢试课
<p>package JavaSpider.main;
import JavaSpider.bean.Imooc;
public class Main {
public static void main(String[] args) {
String url = "http://www.imooc.com/wenda/detail/351144";
Imooc imooc;
for(int i=0; i 查看全部
java爬虫抓取网页数据(2.网络爬虫(英语:webcrawler)抓取测试类4.测试)
1. 网络爬虫
网络爬虫,也称为网络蜘蛛,是一种用于自动浏览万维网的网络机器人。它的目的通常是编译一个网络索引。简单来说就是获取被请求页面的源码,然后通过正则表达式获取你需要的内容。实现大致分为以下几个步骤:
(1)爬取网页源码
(2)用正则截取你需要的内容(我这里截取问题,下面回答)
2.爬取网页源码
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class Spider {
/**
* @auther: Ragty
* @describe: 爬虫爬取网页源码
* @param: [url]
* @return: java.lang.String
* @date: 2019/1/23
*/
public static String getSource (String url) {
BufferedReader reader = null;
String result = "";
try {
URL realurl = new URL(url);
URLConnection conn = realurl.openConnection(); //连接外部url
reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = "";
while ( (line = reader.readLine()) != null ) {
result += line;
}
if (reader != null) {
reader.close();
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
3.爬取规则和实体类
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import JavaSpider.spider.Spider;
public class Imooc {
public String question;
public String quesUrl;
public String quesDescription;
public Map answers;
public String nextUrl;
/**
* @auther: Ragty
* @describe: 爬取慕课问答界面的问题及回答
* @param: [url]
* @return:
* @date: 2019/1/23
*/
public Imooc(String url) {
question="";
quesUrl=url;
quesDescription="";
answers = new HashMap();
nextUrl="";
//获取单个问题页面源码
String codeSource = Spider.getSource(url);
//正则获取question
Pattern pattern=Pattern.compile("js-qa-wenda-title.+?>(.+?)");
Matcher matcher=pattern.matcher(codeSource);
if(matcher.find()){
question = matcher.group(1);
}
//正则表达式获取问题描述
pattern=Pattern.compile("js-qa-wenda.+?rich-text\">(.+?)");
matcher=pattern.matcher(codeSource);
if(matcher.find()){
quesDescription = matcher.group(1).replace("<p>", "").replace("", "");
}
//正则表达式获取答案列表
pattern=Pattern.compile("nickname.+?>(.+?)</a>.+?answer-desc rich-text aimgPreview.+?>(.+?)");
matcher=pattern.matcher(codeSource);
while(matcher.find()){
String answer = matcher.group(2).replace("
", "");
answer = answer.replace("", "");
answer = answer.replace("<br />", "");
String name = matcher.group(1);
answers.put(name.trim(), answer.trim());
}
//正则表达式获取下一个url 爬取获取相关问题的url
pattern=Pattern.compile("class=\"r relwenda\".+?href=\"(.+?)\".+?</a>");//获取回答者name
matcher=pattern.matcher(codeSource);
while(matcher.find()){
nextUrl="http://www.imooc.com"+matcher.group(1);
//只取第一个推荐
if(!nextUrl.equals(quesUrl)){
break;
}
}
}
@Override
public String toString() {
return "问题为:"+ question +"\n问题地址为:"+quesUrl+
"\n问题的表述为:"+quesDescription+"\n"
+ "回答的内容为:"+answers+"\n指向下一个链接地址为:"+nextUrl+"\n";
}
}
</p>
3.抢试课
<p>package JavaSpider.main;
import JavaSpider.bean.Imooc;
public class Main {
public static void main(String[] args) {
String url = "http://www.imooc.com/wenda/detail/351144";
Imooc imooc;
for(int i=0; i
java爬虫抓取网页数据(最快捷,最方便的图片上传和管理系统·采用MVC架构,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-02 02:04
·最快最方便的图片上传和管理系统·MVC架构,详细标注,方便二次开发和扩展·UTF-8编码,便于在国外主机安装·支持批量上传,远程抓图·自动外部图片保存在本地· 自动控制上传图片和本地化图片的大小 · 自动为上传和本地化的图片添加水印 · 自动提取第一张图片为缩略图 · 自动生成任意大小的缩略图 · 幻灯片模式图片展示页面 · 支持静态缓存,全站生成 HTML。内置采集器,快速抓取网络图文。自由分类,自动生成导航和内容调用。模板分离设计,模板设计简单。 查看全部
java爬虫抓取网页数据(最快捷,最方便的图片上传和管理系统·采用MVC架构,)
·最快最方便的图片上传和管理系统·MVC架构,详细标注,方便二次开发和扩展·UTF-8编码,便于在国外主机安装·支持批量上传,远程抓图·自动外部图片保存在本地· 自动控制上传图片和本地化图片的大小 · 自动为上传和本地化的图片添加水印 · 自动提取第一张图片为缩略图 · 自动生成任意大小的缩略图 · 幻灯片模式图片展示页面 · 支持静态缓存,全站生成 HTML。内置采集器,快速抓取网络图文。自由分类,自动生成导航和内容调用。模板分离设计,模板设计简单。
java爬虫抓取网页数据(一下NetDiscovery爬虫爬虫框架里的downloader对象对象1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-01 08:12
大家好,本文文章介绍NetDiscovery爬虫框架中的downloader对象
1) 前言
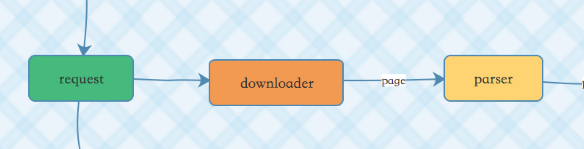
面向对象设计仍然是当前编程的核心思想。从下面的截图可以了解爬虫框架的主要对象:
程序在本地组织好一个请求后,交给下载器从网络抓取数据到本地,然后解析器对本地数据进行处理,最终生成可用信息。
2) 下载器介绍
下载器也称为下载器。它的主要功能是访问网络并成功获取我们想要的数据:如html网页、json/xml数据、二进制流(图片、办公文档等)
NetDiscovery 目前支持的下载器实现有:
面向接口的编程是该框架的重要设计思想之一。
下面介绍一些下载器代码。这些代码的共同点是实现Downloader接口。
作为程序开发人员,您还可以实现接口 discovery.core.downloader.Downloader 来创建自己的下载器类。
//1、构建一个URL对象
url = new URL(request.getUrl());
//2、获取一个HttpURLConnection对象
conn = url.openConnection();
//3、一堆设置
conn .setDoOutput(true);
conn .setDoInput(true);
conn .setRequestMethod("POST");
......
//4、访问网络服务
conn.connect();
//5、执行成功的话,获取结果
conn.getResponseCode();
conn.getInputStream();
//1、获取一个HttpManager对象(框架自己封装的)
HttpManager httpManager = HttpManager.get();
//2、然后把request扔进去,等结果就可以了.request也是框架封装的
httpManager.getResponse(request)
//3、等来结果后,进行处理
@Override
public Response apply(CloseableHttpResponse closeableHttpResponse) throws Exception {
String charset = null;
if (Preconditions.isNotBlank(request.getCharset())) {
charset = request.getCharset(); //针对一些还是GB2312编码的网页
} else {
charset = "UTF-8";
}
String html = EntityUtils.toString(closeableHttpResponse.getEntity(), charset);
Response response = new Response();
response.setContent(html.getBytes());
response.setStatusCode(closeableHttpResponse.getStatusLine().getStatusCode());
if (closeableHttpResponse.containsHeader("Content-Type")) {
response.setContentType(closeableHttpResponse.getFirstHeader("Content-Type").getValue());
}
return response;
}
3) 总结
总之,爬虫程序本质上是一个网络程序,而网络程序的核心模块离不开对网络数据的处理。建议学习爬虫的小伙伴,如果想看源码,可以从框架中的下载器相关代码入手。我相信会有收获。 查看全部
java爬虫抓取网页数据(一下NetDiscovery爬虫爬虫框架里的downloader对象对象1))
大家好,本文文章介绍NetDiscovery爬虫框架中的downloader对象
1) 前言
面向对象设计仍然是当前编程的核心思想。从下面的截图可以了解爬虫框架的主要对象:
程序在本地组织好一个请求后,交给下载器从网络抓取数据到本地,然后解析器对本地数据进行处理,最终生成可用信息。
2) 下载器介绍
下载器也称为下载器。它的主要功能是访问网络并成功获取我们想要的数据:如html网页、json/xml数据、二进制流(图片、办公文档等)
NetDiscovery 目前支持的下载器实现有:

面向接口的编程是该框架的重要设计思想之一。
下面介绍一些下载器代码。这些代码的共同点是实现Downloader接口。
作为程序开发人员,您还可以实现接口 discovery.core.downloader.Downloader 来创建自己的下载器类。
//1、构建一个URL对象
url = new URL(request.getUrl());
//2、获取一个HttpURLConnection对象
conn = url.openConnection();
//3、一堆设置
conn .setDoOutput(true);
conn .setDoInput(true);
conn .setRequestMethod("POST");
......
//4、访问网络服务
conn.connect();
//5、执行成功的话,获取结果
conn.getResponseCode();
conn.getInputStream();
//1、获取一个HttpManager对象(框架自己封装的)
HttpManager httpManager = HttpManager.get();
//2、然后把request扔进去,等结果就可以了.request也是框架封装的
httpManager.getResponse(request)
//3、等来结果后,进行处理
@Override
public Response apply(CloseableHttpResponse closeableHttpResponse) throws Exception {
String charset = null;
if (Preconditions.isNotBlank(request.getCharset())) {
charset = request.getCharset(); //针对一些还是GB2312编码的网页
} else {
charset = "UTF-8";
}
String html = EntityUtils.toString(closeableHttpResponse.getEntity(), charset);
Response response = new Response();
response.setContent(html.getBytes());
response.setStatusCode(closeableHttpResponse.getStatusLine().getStatusCode());
if (closeableHttpResponse.containsHeader("Content-Type")) {
response.setContentType(closeableHttpResponse.getFirstHeader("Content-Type").getValue());
}
return response;
}
3) 总结
总之,爬虫程序本质上是一个网络程序,而网络程序的核心模块离不开对网络数据的处理。建议学习爬虫的小伙伴,如果想看源码,可以从框架中的下载器相关代码入手。我相信会有收获。
java爬虫抓取网页数据(讲解爬虫基础在本文中我将写一个爬虫网的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-01 04:04
解释爬虫的基础 在这篇文章中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。必备知识:了解java语言语法、Html语法。输入主题:一、明确要抓取的信息。比如我想在这个webapp中抓取的信息是:职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别1、创建一个Struts2 web项目导入需要的架子包2、
讲解爬虫基础
在本文中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。
必备知识:了解java语言语法、Html语法。
重点:
一、指定要抓取的信息。
比如我想在这个webapp中抓取的信息是:
职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别
1、创建一个Struts2 web项目并导入所需的shelf包
2、搭建基本框架
3、建立连接
使用方法获取连接
文档 doc = Jsoup.connect("");
Document对象是网页解析后的对象类型,加载后可以输出。
输出的时候发现无法得到想要的内容,于是输出了整个网页,看到结果是这样的
此时,分析可能的原因。一般来说,网站采用了反爬虫机制。第一个尝试是写浏览器的头文件。
文档 doc = Jsoup.connect("").userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/ 30.0").get();
然后再运行一次就可以得到你想要的了
3、分析网页
建议您使用谷歌浏览器,F12 分析源码。
您可以清楚地看到它的结构,因此无需借用其他工具。
元素元素 = doc.select("ul[class=item_con_list]").select("li[class=con_list_item default_list]");
使用选择器选择此页面上的所有职业信息。Elements 是元素的集合,然后一步一步抓取需要的信息。
输出所需信息
这样的数据,输出是这样的,我们可以添加到数据库中。
这些都没有了。
原文地址:~all~es_rank~default-11-79052808.pc_search_all_es&utm_term=java%E7%88%AC%E8%99%AB
这个 文章 网址:
类似推荐 查看全部
java爬虫抓取网页数据(讲解爬虫基础在本文中我将写一个爬虫网的信息)
解释爬虫的基础 在这篇文章中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。必备知识:了解java语言语法、Html语法。输入主题:一、明确要抓取的信息。比如我想在这个webapp中抓取的信息是:职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别1、创建一个Struts2 web项目导入需要的架子包2、
讲解爬虫基础
在本文中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。
必备知识:了解java语言语法、Html语法。
重点:
一、指定要抓取的信息。
比如我想在这个webapp中抓取的信息是:
职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别
1、创建一个Struts2 web项目并导入所需的shelf包
2、搭建基本框架
3、建立连接
使用方法获取连接
文档 doc = Jsoup.connect("");
Document对象是网页解析后的对象类型,加载后可以输出。
输出的时候发现无法得到想要的内容,于是输出了整个网页,看到结果是这样的

此时,分析可能的原因。一般来说,网站采用了反爬虫机制。第一个尝试是写浏览器的头文件。
文档 doc = Jsoup.connect("").userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/ 30.0").get();
然后再运行一次就可以得到你想要的了
3、分析网页
建议您使用谷歌浏览器,F12 分析源码。
您可以清楚地看到它的结构,因此无需借用其他工具。
元素元素 = doc.select("ul[class=item_con_list]").select("li[class=con_list_item default_list]");
使用选择器选择此页面上的所有职业信息。Elements 是元素的集合,然后一步一步抓取需要的信息。
输出所需信息

这样的数据,输出是这样的,我们可以添加到数据库中。
这些都没有了。
原文地址:~all~es_rank~default-11-79052808.pc_search_all_es&utm_term=java%E7%88%AC%E8%99%AB
这个 文章 网址:
类似推荐
java爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-30 01:21
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以把数据持久化到avro文件、hbase、mysql等,其实很多人都搞错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。 查看全部
java爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。

2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。

2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。

网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。


2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD

2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以把数据持久化到avro文件、hbase、mysql等,其实很多人都搞错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。

分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。

上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
java爬虫抓取网页数据( Java也可以做爬虫,一键爬取文章内容并保存入库! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-27 13:19
Java也可以做爬虫,一键爬取文章内容并保存入库!
)
简介其实Java也可以是爬虫。虽然没有Python强大,但基本功能没有问题。本文将介绍一键抓取文章内容并存入库。一键爬取配置文件介绍:
<br /><br />com.kotcrab.remark<br />remark<br />1.2.0<br />
创建爬虫基础配置表,匹配相关博客元素:
CREATE TABLE `app_blog_crawl` (<br />`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',<br />`type` VARCHAR(255) NOT NULL COMMENT '类型',<br />`url` VARCHAR(255) NOT NULL COMMENT '网址',<br />`title` VARCHAR(255) NOT NULL COMMENT '标题元素',<br />`content` VARCHAR(255) NOT NULL COMMENT '内容元素',<br />`gmt_create` DATETIME NOT NULL COMMENT '创建时间',<br />`gmt_modified` DATETIME NOT NULL COMMENT '修改时间',<br /> PRIMARY KEY (`id`)<br /> ) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
背景抓取并将富文本转换为 MD 格式:
/**<br /> * 爬取-爪哇笔记<br /> * 1)获取数据库配置<br /> * 2)根据数据库配置读取文章相关元素<br /> * 3)富文本转MD,并返回前端实体内容<br /> * 源码:https://gitee.com/52itstyle/SPTools<br /> * @param url<br /> * @return<br /> */<br />@RequestMapping("crawl")<br />public Result crawl(String url) {<br />try {<br />String domain = JsoupUtils.getDomain(url);<br />String nativeSql = "SELECT * FROM app_blog_crawl WHERE url = ?";<br /> AppBlogCrawl crawl =<br /> dynamicQuery.nativeQuerySingleResult(AppBlogCrawl.class,nativeSql,new Object[]{domain});<br />if(crawl!=null){<br /> Document document = JsoupUtils.getDocument(url);<br />String title = document.select(crawl.getTitle()).text();<br />String content = document.select(crawl.getContent()).html();<br /> Remark remark = new Remark();<br />String markdown = remark.convertFragment(content);<br /> AppBlog blog = new AppBlog();<br /> blog.setTitle(title);<br /> blog.setContent(markdown);<br /> blog.setUrl(url);<br />return Result.ok(blog);<br /> }else{<br />return Result.error("目前暂不支持此网站抓取");<br /> }<br /> } catch (Exception e) {<br />return Result.error("抓取异常");<br /> }<br />}
工具:
/**<br /> * 工具类<br /> */<br />public classJsoupUtils{<br /><br />/**<br /> * 获取 document<br /> * @param url<br /> * @return<br /> * @throws IOException<br /> */<br />publicstatic Document getDocument(String url)throws IOException {<br /> Document document = Jsoup.connect(url)<br /> .timeout(100000)<br /> .ignoreContentType(true)<br /> .userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36")<br /> .get();<br />return document;<br /> }<br /><br />/**<br /> * 获取域名<br /> * @param url<br /> * @return<br /> */<br />publicstatic String getDomain(String url){<br />return url.split("/")[0]+"//"+url.split("/")[2];<br /> }<br />}
预览
总结其实目前很多社区都有个人博客或者微信公众号的同步功能,比如腾讯云社区、云栖社区、开源中国,国内最大的社区。如果觉得不好玩,还可以实现更有趣的功能,比如定时抓取指定日期的博文,指定关键词。
<strong style="color:rgb(39,39,39);">— 【 THE END 】—</strong>本公众号全部博文已整理成一个目录,请在公众号里回复「m」获取!
3T技术资源出炉!包括但不限于:Java、C/C++、Linux、Python、大数据、人工智能等,在公众号回复“1024”即可免费领取!!
查看全部
java爬虫抓取网页数据(
Java也可以做爬虫,一键爬取文章内容并保存入库!
)

简介其实Java也可以是爬虫。虽然没有Python强大,但基本功能没有问题。本文将介绍一键抓取文章内容并存入库。一键爬取配置文件介绍:
<br /><br />com.kotcrab.remark<br />remark<br />1.2.0<br />
创建爬虫基础配置表,匹配相关博客元素:
CREATE TABLE `app_blog_crawl` (<br />`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',<br />`type` VARCHAR(255) NOT NULL COMMENT '类型',<br />`url` VARCHAR(255) NOT NULL COMMENT '网址',<br />`title` VARCHAR(255) NOT NULL COMMENT '标题元素',<br />`content` VARCHAR(255) NOT NULL COMMENT '内容元素',<br />`gmt_create` DATETIME NOT NULL COMMENT '创建时间',<br />`gmt_modified` DATETIME NOT NULL COMMENT '修改时间',<br /> PRIMARY KEY (`id`)<br /> ) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
背景抓取并将富文本转换为 MD 格式:
/**<br /> * 爬取-爪哇笔记<br /> * 1)获取数据库配置<br /> * 2)根据数据库配置读取文章相关元素<br /> * 3)富文本转MD,并返回前端实体内容<br /> * 源码:https://gitee.com/52itstyle/SPTools<br /> * @param url<br /> * @return<br /> */<br />@RequestMapping("crawl")<br />public Result crawl(String url) {<br />try {<br />String domain = JsoupUtils.getDomain(url);<br />String nativeSql = "SELECT * FROM app_blog_crawl WHERE url = ?";<br /> AppBlogCrawl crawl =<br /> dynamicQuery.nativeQuerySingleResult(AppBlogCrawl.class,nativeSql,new Object[]{domain});<br />if(crawl!=null){<br /> Document document = JsoupUtils.getDocument(url);<br />String title = document.select(crawl.getTitle()).text();<br />String content = document.select(crawl.getContent()).html();<br /> Remark remark = new Remark();<br />String markdown = remark.convertFragment(content);<br /> AppBlog blog = new AppBlog();<br /> blog.setTitle(title);<br /> blog.setContent(markdown);<br /> blog.setUrl(url);<br />return Result.ok(blog);<br /> }else{<br />return Result.error("目前暂不支持此网站抓取");<br /> }<br /> } catch (Exception e) {<br />return Result.error("抓取异常");<br /> }<br />}
工具:
/**<br /> * 工具类<br /> */<br />public classJsoupUtils{<br /><br />/**<br /> * 获取 document<br /> * @param url<br /> * @return<br /> * @throws IOException<br /> */<br />publicstatic Document getDocument(String url)throws IOException {<br /> Document document = Jsoup.connect(url)<br /> .timeout(100000)<br /> .ignoreContentType(true)<br /> .userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36")<br /> .get();<br />return document;<br /> }<br /><br />/**<br /> * 获取域名<br /> * @param url<br /> * @return<br /> */<br />publicstatic String getDomain(String url){<br />return url.split("/")[0]+"//"+url.split("/")[2];<br /> }<br />}
预览
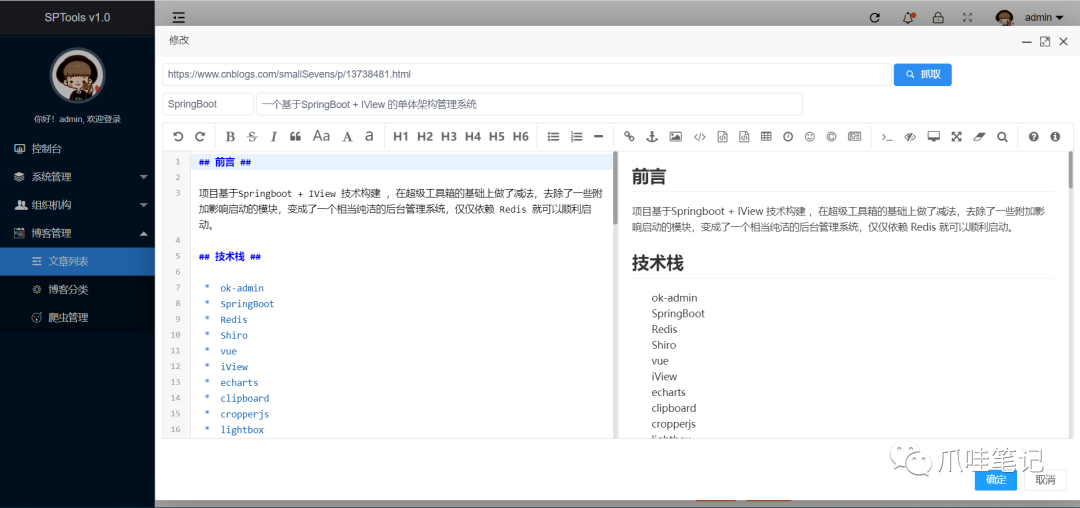
总结其实目前很多社区都有个人博客或者微信公众号的同步功能,比如腾讯云社区、云栖社区、开源中国,国内最大的社区。如果觉得不好玩,还可以实现更有趣的功能,比如定时抓取指定日期的博文,指定关键词。
<strong style="color:rgb(39,39,39);">— 【 THE END 】—</strong>本公众号全部博文已整理成一个目录,请在公众号里回复「m」获取!
3T技术资源出炉!包括但不限于:Java、C/C++、Linux、Python、大数据、人工智能等,在公众号回复“1024”即可免费领取!!

java爬虫抓取网页数据(一种网页数据收集日期的原因及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-27 13:15
列表1.网页抓取
URLurl=newURL("");
URLConnectionconn=url.openConnection();
BufferedReaderreader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
while((line=reader.readLine())!=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为一些网站链接使用了相对路径,如果没有排序就会出错。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下: 查看全部
java爬虫抓取网页数据(一种网页数据收集日期的原因及解决办法(一))
列表1.网页抓取
URLurl=newURL("");
URLConnectionconn=url.openConnection();
BufferedReaderreader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
while((line=reader.readLine())!=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为一些网站链接使用了相对路径,如果没有排序就会出错。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
java爬虫抓取网页数据(小崔以ja语言来演示一下如何实现网络爬虫,源代码会附在最后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-27 13:13
很多时候我们需要一些数据或信息,而这些信息可能是收费的,不是公开的,或者信息量可能比较大。如果我们简单地手动做,可能会浪费时间,所以我们需要编写一个网络爬虫,高效地抓取你需要的信息。这里小崔使用ja语言来演示如何实现一个网络爬虫。最后附上源代码。
1 首先,在开始写代码之前,首先要搞清楚爬虫爬取网页需要具备哪些功能,爬虫需要用什么数据结构来实现呢?可以控制爬虫自动重启吗?
2 考虑到以上问题,我们需要确定要写多少个类来实现这些功能,所以我们只好用一张图来表示爬虫的几个类的功能。这里小崔只实现了基本的功能,所以画图比较简单,不过明白了这一点,就可以添加自己需要的具体功能了。
3 接下来,我们将根据我们要解决的问题,一一设计我们的各个类。我们的主要问题是: 1.如何下载网页 2.如何从网页中提取 URL 3.如何构建 URL 队列 4.如何使爬虫工作
4 第一个问题,解决如何下载网页
5 这里我们使用第三方开源包来完成这个功能,因为ja自带的实现这个功能的包不好用,请百度下载这个包。包的名称是 HttpClient。
6.很多朋友可能不知道这个包怎么用。为了减少大家的麻烦,节省大家的时间,小翠在这里给大家介绍一下这款包的使用方法。(1)通过get获取Re e对象。(2)获取Re e对象的Entity。(3)通过Entity获取I utStream对象,然后做线处理。
7 可能很多新手只是对我说这句话,并不能深入理解其中的内涵。我将在下面以代码的形式展示它。
8 下面是获取Re e对象的Entity的代码示例
9 通过Entity获取I utStream对象,然后处理返回的内容
10 好了,第一个问题我们已经解决了,我们来解决第二个问题,如何从网页中提取URL
11 提取URL,这里我们还是使用第三方开源的jar包,Jsoup是Ja的HTML解析器,可以直接解析一个URL地址和HTML文本内容,提供了非常省力的API,可以取回数据并通过 DOM、CSS 和类似于 JQuery 的操作方法进行操作。
12使用JSOUP从文件加载网页 File i ut = new File("D:/test.html");Document doc = Jsoup.parse(i ut,"UTF-8","URL/"); 请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定网址(虽然不能指定,比如第一种方法?方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数名为baseURL的意思是当HTML文档使用相对路径的方式引用外部文件时,jsoup会自动为这些 URL 添加前缀,即 baseURL。例如,将开源软件转换为开源软件。
13 下面是解析提取HTML元素的示例代码
14 我们来解决第三个问题,如何建立一个URL队列
15 构建URL队列,首先需要分析爬虫中的队列。爬虫中的队列分析如下: ① 初始种子队列 ② 爬虫从哪里开始 ③ 只使用一次 ④ ArrayList ⾜sufficient 创建新的URL时,需要判断该URL是否已经存在于爬取的队列中(查找) ,如果没有,将URL添加到待爬取队列中 Hashta e
16 解决这些问题后,一个简单的爬虫就完成了。现在你可以开始你的爬虫工作了。如果需要一些具体的功能,可以自己在类中实现相应的功能。
下载jar包,不同版本没有效果
本次经验是小崔原创,如果觉得对你有帮助,记得投上一票哦! 查看全部
java爬虫抓取网页数据(小崔以ja语言来演示一下如何实现网络爬虫,源代码会附在最后)
很多时候我们需要一些数据或信息,而这些信息可能是收费的,不是公开的,或者信息量可能比较大。如果我们简单地手动做,可能会浪费时间,所以我们需要编写一个网络爬虫,高效地抓取你需要的信息。这里小崔使用ja语言来演示如何实现一个网络爬虫。最后附上源代码。
1 首先,在开始写代码之前,首先要搞清楚爬虫爬取网页需要具备哪些功能,爬虫需要用什么数据结构来实现呢?可以控制爬虫自动重启吗?

2 考虑到以上问题,我们需要确定要写多少个类来实现这些功能,所以我们只好用一张图来表示爬虫的几个类的功能。这里小崔只实现了基本的功能,所以画图比较简单,不过明白了这一点,就可以添加自己需要的具体功能了。

3 接下来,我们将根据我们要解决的问题,一一设计我们的各个类。我们的主要问题是: 1.如何下载网页 2.如何从网页中提取 URL 3.如何构建 URL 队列 4.如何使爬虫工作

4 第一个问题,解决如何下载网页

5 这里我们使用第三方开源包来完成这个功能,因为ja自带的实现这个功能的包不好用,请百度下载这个包。包的名称是 HttpClient。

6.很多朋友可能不知道这个包怎么用。为了减少大家的麻烦,节省大家的时间,小翠在这里给大家介绍一下这款包的使用方法。(1)通过get获取Re e对象。(2)获取Re e对象的Entity。(3)通过Entity获取I utStream对象,然后做线处理。

7 可能很多新手只是对我说这句话,并不能深入理解其中的内涵。我将在下面以代码的形式展示它。

8 下面是获取Re e对象的Entity的代码示例

9 通过Entity获取I utStream对象,然后处理返回的内容

10 好了,第一个问题我们已经解决了,我们来解决第二个问题,如何从网页中提取URL

11 提取URL,这里我们还是使用第三方开源的jar包,Jsoup是Ja的HTML解析器,可以直接解析一个URL地址和HTML文本内容,提供了非常省力的API,可以取回数据并通过 DOM、CSS 和类似于 JQuery 的操作方法进行操作。

12使用JSOUP从文件加载网页 File i ut = new File("D:/test.html");Document doc = Jsoup.parse(i ut,"UTF-8","URL/"); 请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定网址(虽然不能指定,比如第一种方法?方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数名为baseURL的意思是当HTML文档使用相对路径的方式引用外部文件时,jsoup会自动为这些 URL 添加前缀,即 baseURL。例如,将开源软件转换为开源软件。

13 下面是解析提取HTML元素的示例代码

14 我们来解决第三个问题,如何建立一个URL队列

15 构建URL队列,首先需要分析爬虫中的队列。爬虫中的队列分析如下: ① 初始种子队列 ② 爬虫从哪里开始 ③ 只使用一次 ④ ArrayList ⾜sufficient 创建新的URL时,需要判断该URL是否已经存在于爬取的队列中(查找) ,如果没有,将URL添加到待爬取队列中 Hashta e

16 解决这些问题后,一个简单的爬虫就完成了。现在你可以开始你的爬虫工作了。如果需要一些具体的功能,可以自己在类中实现相应的功能。

下载jar包,不同版本没有效果
本次经验是小崔原创,如果觉得对你有帮助,记得投上一票哦!
java爬虫抓取网页数据(初识爬虫的几种分类及注意事项!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-22 22:10
第一次认识爬行动物
一、爬虫介绍
模拟浏览器,发送请求,获取响应
网络爬虫,英文名Spider,又称网络蜘蛛、网络机器人,在数据分析应用中,更多的爬虫称为数据采集程序,是一种按照一定规则自动爬取网络信息的程序或脚本.
l 原则上只要是客户端(浏览器)能做的,爬虫都能做
l 爬虫只能获取客户端(浏览器)显示的数据
网络中的数据可以通过Web服务器【Nginx/Apache】、数据库服务【MySQL/Redis/MongoDB】、索引库、大数据、视频/图片库、云存储【阿里巴巴云OSS】等提供。重要的是源是Web服务器
不过大家一定要注意,可以爬取的数据必须是公开的,非盈利的,比如:如果你入侵别人的非公网,他们会通过ip定位你,这是违法的。或者,一些财务管理网站,如果爬取数据,肯定是不允许的。如果你的朋友不听话硬要爬,那没人能保护你,狗头救你一命~~~
爬虫类著名案例:“乔达科技”被一锅抓,“马车来了”涉嫌盗窃数据被警方立案等。
二、爬虫分类
万能爬虫:
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息决定了整个引擎系统的内容是否丰富,信息是否及时,所以它的性能直接影响搜索的效果引擎
每个人都应该注意。一般的爬虫虽然简单方便,但缺点也很明显。小助手为大家罗列了几点,大家可以理解:
l 一般搜索引擎返回的结果都是网页,大多数情况下,网页中90%的内容对用户来说是无用的。
l 不同领域、不同背景的用户往往有不同的检索目的和需求,搜索引擎无法为特定用户提供搜索结果。
l 随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频、多媒体等不同的数据,一般的搜索引擎对这些文件是无能为力的,它们不能很好地被发现和获得。
l 通用搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询,无法准确理解用户的具体需求。
专注于爬虫:
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的不同之处在于:专注爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息,如12306抢票,或抢某(某类)网站data
根据目的是否为获取数据,可分为:
l 功能爬虫,投票点赞你喜欢的明星
l 数据增量爬虫,如招聘信息
2. 根据url地址和对应的页面内容是否发生变化,增量数据爬虫可以分为:
l 基于url地址变化和内容变化的数据增量爬虫
lurl地址不变,内容变化的数据增量爬虫
看到这里,有没有发现通用爬虫简单,但不实用,专注爬虫应用广泛,实用,但实现起来比较困难,不过没关系,借助小助手,我们都可以学习吧,哦福利!!!
三、爬虫的作用
爬虫在互联网世界有很多功能,比如:
1. 数据采集,例如: 查看全部
java爬虫抓取网页数据(初识爬虫的几种分类及注意事项!(一))
第一次认识爬行动物
一、爬虫介绍
模拟浏览器,发送请求,获取响应
网络爬虫,英文名Spider,又称网络蜘蛛、网络机器人,在数据分析应用中,更多的爬虫称为数据采集程序,是一种按照一定规则自动爬取网络信息的程序或脚本.
l 原则上只要是客户端(浏览器)能做的,爬虫都能做
l 爬虫只能获取客户端(浏览器)显示的数据
网络中的数据可以通过Web服务器【Nginx/Apache】、数据库服务【MySQL/Redis/MongoDB】、索引库、大数据、视频/图片库、云存储【阿里巴巴云OSS】等提供。重要的是源是Web服务器
不过大家一定要注意,可以爬取的数据必须是公开的,非盈利的,比如:如果你入侵别人的非公网,他们会通过ip定位你,这是违法的。或者,一些财务管理网站,如果爬取数据,肯定是不允许的。如果你的朋友不听话硬要爬,那没人能保护你,狗头救你一命~~~
爬虫类著名案例:“乔达科技”被一锅抓,“马车来了”涉嫌盗窃数据被警方立案等。

二、爬虫分类
万能爬虫:
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息决定了整个引擎系统的内容是否丰富,信息是否及时,所以它的性能直接影响搜索的效果引擎
每个人都应该注意。一般的爬虫虽然简单方便,但缺点也很明显。小助手为大家罗列了几点,大家可以理解:
l 一般搜索引擎返回的结果都是网页,大多数情况下,网页中90%的内容对用户来说是无用的。
l 不同领域、不同背景的用户往往有不同的检索目的和需求,搜索引擎无法为特定用户提供搜索结果。
l 随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频、多媒体等不同的数据,一般的搜索引擎对这些文件是无能为力的,它们不能很好地被发现和获得。
l 通用搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询,无法准确理解用户的具体需求。
专注于爬虫:
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的不同之处在于:专注爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息,如12306抢票,或抢某(某类)网站data
根据目的是否为获取数据,可分为:
l 功能爬虫,投票点赞你喜欢的明星
l 数据增量爬虫,如招聘信息
2. 根据url地址和对应的页面内容是否发生变化,增量数据爬虫可以分为:
l 基于url地址变化和内容变化的数据增量爬虫
lurl地址不变,内容变化的数据增量爬虫
看到这里,有没有发现通用爬虫简单,但不实用,专注爬虫应用广泛,实用,但实现起来比较困难,不过没关系,借助小助手,我们都可以学习吧,哦福利!!!
三、爬虫的作用
爬虫在互联网世界有很多功能,比如:
1. 数据采集,例如:
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛)蜘蛛,聚焦爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-21 09:03
小编将与大家分享如何用java编写网络爬虫。相信大部分人都不太了解,所以分享一下这个文章,供大家参考。希望大家看完这篇文章收获会喜欢,一起来了解一下吧!
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
聚焦爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并将其中的url提取出来,我们将获取到的url存放在一个文件夹中。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。
下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
以上就是如何用java编写网络爬虫的全部内容,感谢阅读!相信大家都有一定的了解。希望分享的内容对大家有所帮助。想了解更多知识,请关注易宿云行业资讯频道! 查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛)蜘蛛,聚焦爬虫)
小编将与大家分享如何用java编写网络爬虫。相信大部分人都不太了解,所以分享一下这个文章,供大家参考。希望大家看完这篇文章收获会喜欢,一起来了解一下吧!
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。

聚焦爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并将其中的url提取出来,我们将获取到的url存放在一个文件夹中。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。
下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
以上就是如何用java编写网络爬虫的全部内容,感谢阅读!相信大家都有一定的了解。希望分享的内容对大家有所帮助。想了解更多知识,请关注易宿云行业资讯频道!
java爬虫抓取网页数据(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-21 09:02
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻的例子,有一定的参考价值,感兴趣的朋友可以参考一下。
最近看到Gecoo爬虫工具,感觉还是比较简单好用的。都写个DEMO测试,抓起来。网站
,主要是抓取新闻的标题和发布时间作为抓取的测试对象。通过选择像 Jquery 选择器这样的节点来抓取 HTML 节点非常方便。 Gecco代码主要使用注解来实现URL匹配,看起来更加简洁美观。
添加 Maven 依赖
com.geccocrawler
gecco
1.0.8
编写爬取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
写爬吉祥页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持PHPERZ。 查看全部
java爬虫抓取网页数据(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻的例子,有一定的参考价值,感兴趣的朋友可以参考一下。
最近看到Gecoo爬虫工具,感觉还是比较简单好用的。都写个DEMO测试,抓起来。网站
,主要是抓取新闻的标题和发布时间作为抓取的测试对象。通过选择像 Jquery 选择器这样的节点来抓取 HTML 节点非常方便。 Gecco代码主要使用注解来实现URL匹配,看起来更加简洁美观。
添加 Maven 依赖
com.geccocrawler
gecco
1.0.8
编写爬取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
写爬吉祥页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持PHPERZ。
java爬虫抓取网页数据(想了解Python爬虫模拟登陆知乎的相关内容吗(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-18 13:14
想知道Python爬虫模拟登录知乎的相关内容吗?本文将为大家讲解python模拟登录知乎的相关知识以及一些代码示例。欢迎阅读和指正。重点:python,模拟登录知乎,python,爬虫,模拟登录,python,爬虫,知乎一起学习。
之前写过一篇用python爬虫爬取电影天堂资源文章的文章,重点是如何解析页面,提高爬虫效率。由于电影天堂中资源的访问权限对每个人都是一样的,所以无需登录验证操作。写完那个文章,又抽时间研究了网上的python模拟登陆。有很多关于这部分的信息。demos全部登录知乎的原因是知乎的登录比较简单,只需要post几个参数就可以保存cookie了。而且它还没有加密。很适合教学。我也是新手,经过一点点探索,终于成功登陆知乎。
首先说一下爬虫模拟登录的基本原理。我也刚刚开始接触一些深层次的东西。首先,一个重要的概念是cookie。我们都知道HTTP是一种无状态协议,也就是说当浏览器客户端向服务器提交请求,服务器响应响应时,它们之间的连接就会中断。结果,当客户端向服务器发送请求时,服务器无法判断这两个客户端是否相同。这绝对是不可能的。这就是cookies发挥作用的地方。当客户端向服务器发送请求时,服务器会为其分配一个标识符(cookie)并将其保存到客户端本地。当客户端再次发送请求时,会连同cookie一起发送到服务器。当服务器看到cookie时,原来是你,这是你的,拿去吧。所以爬虫模拟登录就是模拟浏览器客户端的行为。首先,将您的基本登录信息发送到指定的 url 服务器。验证成功后,会返回一个cookie。我们可以使用此 cookie 进行后续的爬取工作。.
我这里用chrome的开发者工具抓包,不过你也可以用fiddler、firebug等,不过作为前端er,你对chrome有特殊的爱好。准备好工具接下来打开知乎的登录页面,勾选#signin我们可以很容易的看到发送的请求就是登录信息。当然,我是用手机登录,用邮箱登录。最后一个是电子邮件。
所以我们只需要将数据发布到这个地址
phone_num 登录名
密码密码
captcha_type 验证码类型(这个参数在这里没有实际作用)
rember_me 记住密码
_xsrf是一个隐藏的表单元素知乎,用来防御CSRF(对于CSRF,请在此处打开)我发现这个值是固定的,所以就写在这里了。有兴趣的可以写个正则表达式把这部分值提取出来,这样比较严谨。
当您看到服务器返回此信息时,表示您已成功登录
{"r":0,
"msg": "\u767b\u5f55\u6210\u529f"
}#翻译过来就是 “登陆成功” 四个大字
然后就可以用这个身份去爬知乎上的页面了
page=opener.open("https://www.zhihu.com/people/yu-yi-56-70")
content = page.read().decode('utf-8')
print(content)
这段代码通过实例化一个opener对象来保存登录成功后的cookie信息,然后通过opener带着cookie访问服务器上关于身份的完整页面。比较复杂的,比如微博登录,把请求的数据加密,然后写出来,有时间分享给大家。
相关文章 查看全部
java爬虫抓取网页数据(想了解Python爬虫模拟登陆知乎的相关内容吗(组图))
想知道Python爬虫模拟登录知乎的相关内容吗?本文将为大家讲解python模拟登录知乎的相关知识以及一些代码示例。欢迎阅读和指正。重点:python,模拟登录知乎,python,爬虫,模拟登录,python,爬虫,知乎一起学习。
之前写过一篇用python爬虫爬取电影天堂资源文章的文章,重点是如何解析页面,提高爬虫效率。由于电影天堂中资源的访问权限对每个人都是一样的,所以无需登录验证操作。写完那个文章,又抽时间研究了网上的python模拟登陆。有很多关于这部分的信息。demos全部登录知乎的原因是知乎的登录比较简单,只需要post几个参数就可以保存cookie了。而且它还没有加密。很适合教学。我也是新手,经过一点点探索,终于成功登陆知乎。
首先说一下爬虫模拟登录的基本原理。我也刚刚开始接触一些深层次的东西。首先,一个重要的概念是cookie。我们都知道HTTP是一种无状态协议,也就是说当浏览器客户端向服务器提交请求,服务器响应响应时,它们之间的连接就会中断。结果,当客户端向服务器发送请求时,服务器无法判断这两个客户端是否相同。这绝对是不可能的。这就是cookies发挥作用的地方。当客户端向服务器发送请求时,服务器会为其分配一个标识符(cookie)并将其保存到客户端本地。当客户端再次发送请求时,会连同cookie一起发送到服务器。当服务器看到cookie时,原来是你,这是你的,拿去吧。所以爬虫模拟登录就是模拟浏览器客户端的行为。首先,将您的基本登录信息发送到指定的 url 服务器。验证成功后,会返回一个cookie。我们可以使用此 cookie 进行后续的爬取工作。.
我这里用chrome的开发者工具抓包,不过你也可以用fiddler、firebug等,不过作为前端er,你对chrome有特殊的爱好。准备好工具接下来打开知乎的登录页面,勾选#signin我们可以很容易的看到发送的请求就是登录信息。当然,我是用手机登录,用邮箱登录。最后一个是电子邮件。

所以我们只需要将数据发布到这个地址

phone_num 登录名
密码密码
captcha_type 验证码类型(这个参数在这里没有实际作用)
rember_me 记住密码
_xsrf是一个隐藏的表单元素知乎,用来防御CSRF(对于CSRF,请在此处打开)我发现这个值是固定的,所以就写在这里了。有兴趣的可以写个正则表达式把这部分值提取出来,这样比较严谨。
当您看到服务器返回此信息时,表示您已成功登录
{"r":0,
"msg": "\u767b\u5f55\u6210\u529f"
}#翻译过来就是 “登陆成功” 四个大字
然后就可以用这个身份去爬知乎上的页面了
page=opener.open("https://www.zhihu.com/people/yu-yi-56-70";)
content = page.read().decode('utf-8')
print(content)
这段代码通过实例化一个opener对象来保存登录成功后的cookie信息,然后通过opener带着cookie访问服务器上关于身份的完整页面。比较复杂的,比如微博登录,把请求的数据加密,然后写出来,有时间分享给大家。
相关文章
java爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-18 09:12
说起网络爬虫,相信大家都不陌生。爬虫可以捕获 网站 或应用程序的内容以提取有用的有价值信息。爬虫可以用很多编程语言来实现,但是Python是最常用的,你知道为什么吗?一起来看看神龙IP吧~
与C相比,Python和C Python的语言虽然是从C发展而来的,但是在使用上,Python的库是完整的和方便的,而C的语言就麻烦很多了。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但是,在运行速度方面,C语言更好。
与Java相比,Java的解析器多,对网页解析的支持非常好。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。如果需要处理复杂的网页、解析网页内容生成结构化数据或精细解析网页内容,java 更适合。
Python与其他语言没有本质区别,比Python语法简洁明了,开发效率高。此外,python语言的流行还有几个原因:
1.网页抓取界面简洁;
与其他动态脚本语言相比,Python 提供了更完善的访问 Web 文档的 API;与其他静态编程语言相比,Python 爬取网页文档的界面更加简洁。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。 查看全部
java爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
说起网络爬虫,相信大家都不陌生。爬虫可以捕获 网站 或应用程序的内容以提取有用的有价值信息。爬虫可以用很多编程语言来实现,但是Python是最常用的,你知道为什么吗?一起来看看神龙IP吧~
与C相比,Python和C Python的语言虽然是从C发展而来的,但是在使用上,Python的库是完整的和方便的,而C的语言就麻烦很多了。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但是,在运行速度方面,C语言更好。
与Java相比,Java的解析器多,对网页解析的支持非常好。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。如果需要处理复杂的网页、解析网页内容生成结构化数据或精细解析网页内容,java 更适合。
Python与其他语言没有本质区别,比Python语法简洁明了,开发效率高。此外,python语言的流行还有几个原因:
1.网页抓取界面简洁;
与其他动态脚本语言相比,Python 提供了更完善的访问 Web 文档的 API;与其他静态编程语言相比,Python 爬取网页文档的界面更加简洁。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。
java爬虫抓取网页数据(java爬虫抓取网页数据,可以用echarts,我常用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-18 10:02
java爬虫抓取网页数据,可以用echarts,我常用echarts来作为analyticitem类型的参数传入到basedata分析数据。创建实例之后,查看vara={aid:1,ac:[1,-2,-3],ad:[3,-5,-4],ag:[3,5,-1,-2],code:[0,1,-2,-3],sex:[2,1,0,2],index:[1,2,-3,-4],location:[]};就可以分析了。
chrome下chromeextensionexplorer|你值得拥有补充一下楼上用dom实现的那个图,属于数据反爬虫,
selenium+beautifulsoup
不评价书籍,不评价特定的网站及方法。我要说的是方法论,并不是要列举实例。之所以要简单地描述这个问题是因为它没有那么复杂。其一,大部分方法并不需要爬取特定类型的数据(无论如何都是一样),其二,有用的数据可能存在可以解析的问题(估计比较费事),其三,数据可能很复杂,采集、清洗、保存要麻烦,其四,如果只是单纯地看数据的话可能不需要最终返回productdata。具体的可参看我之前的回答,要是有时间可以自己琢磨一下,相信有兴趣能解决你的问题。
自动化的一般步骤:清理过滤数据获取数据存储数据查询数据采集数据设计分析实际上,所有的数据抓取,都可以简单分为三步:预处理——>清洗过滤数据——>数据存储——>数据查询这三步大致可以被分为两步:1。抓取第一步:先将抓取的数据爬虫变为urls,之后将数据根据urls存储;2。抓取第二步:自己设计数据存储的方式,并爬取或者数据导出。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据,可以用echarts,我常用)
java爬虫抓取网页数据,可以用echarts,我常用echarts来作为analyticitem类型的参数传入到basedata分析数据。创建实例之后,查看vara={aid:1,ac:[1,-2,-3],ad:[3,-5,-4],ag:[3,5,-1,-2],code:[0,1,-2,-3],sex:[2,1,0,2],index:[1,2,-3,-4],location:[]};就可以分析了。
chrome下chromeextensionexplorer|你值得拥有补充一下楼上用dom实现的那个图,属于数据反爬虫,
selenium+beautifulsoup
不评价书籍,不评价特定的网站及方法。我要说的是方法论,并不是要列举实例。之所以要简单地描述这个问题是因为它没有那么复杂。其一,大部分方法并不需要爬取特定类型的数据(无论如何都是一样),其二,有用的数据可能存在可以解析的问题(估计比较费事),其三,数据可能很复杂,采集、清洗、保存要麻烦,其四,如果只是单纯地看数据的话可能不需要最终返回productdata。具体的可参看我之前的回答,要是有时间可以自己琢磨一下,相信有兴趣能解决你的问题。
自动化的一般步骤:清理过滤数据获取数据存储数据查询数据采集数据设计分析实际上,所有的数据抓取,都可以简单分为三步:预处理——>清洗过滤数据——>数据存储——>数据查询这三步大致可以被分为两步:1。抓取第一步:先将抓取的数据爬虫变为urls,之后将数据根据urls存储;2。抓取第二步:自己设计数据存储的方式,并爬取或者数据导出。
java爬虫抓取网页数据(java爬虫抓取网页数据的原理最简单的方法是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-09 14:01
java爬虫抓取网页数据的原理最简单的方法就是模拟浏览器从服务器获取数据。自己动手制作一个爬虫的话,可以用到很多东西,从分析请求,到动态解析,再到模拟鼠标键盘行为,然后根据不同需求定制不同的爬虫。主要的爬虫类库有python3.4版本的flask,2.8版本的httplib2。有了这些工具之后,可以自己构造规则,用自定义规则再次让爬虫爬取,或者手动写个简单的爬虫接口。
httplib2爬虫思路手写爬虫框架思路主要是构造请求和解析请求。这里我只要讲如何构造。爬虫结构如下,其中scrapy的代码和源码等是对应middleware版本的爬虫。如果你想构造详细的可执行爬虫,可以用apicallback接口获取最新的爬虫代码和api文档等。python3.4flask爬虫代码apicallbackx5方法做整理,以后爬虫的编程规范。
代码架构如下,为了让爬虫结构尽量清晰,后续的代码不会复杂到二次代码的结构,有改动可以通过配置apicallback执行。globalapicallbackscomputerimportrequests#扫描所有请求importre#给代码注册证书token=requests.get("/").content.contenttoken=pile("")#给爬虫加约束条件score=re.findall(r'score\n',token)#检查爬虫是否符合约束条件attr=re.findall(r'<a>',token)#定义请求路径response=python3.4文档方法异步/同步请求pipeline调用循环none_url=requests.get("/")none_url.split("/")withopen("/'xxxx'/'file_name'",'w')asf:f.write(none_url)这里主要解决url重复的问题。
cookie爬虫中会保存上次抓取到的cookie值,也是后续判断爬虫抓取结果是否一致的重要信息,因此后续编写爬虫的时候需要注意使用cookie。python3.4flask爬虫实现代码首先定义一个请求函数request,目的是获取页面地址,flask中根据url地址来获取文件。再定义循环for循环,循环请求地址,返回结果,获取到响应头信息,然后根据响应头信息解析response.cookie。
其中flask的文档方法很多,建议直接看代码。然后就可以用这个构造简单的爬虫,例如从百度搜索获取得分。最终定义爬虫的apicallback函数globalapicallbackflask.app.urlhandler{'xxxx':'','score':0,'c':1,'result':none}这个函数就是urlhandler接收请求地址和响应结果返回响应头,然后解析cookie完成get请求,最后就是根据请求结果返回。 查看全部
java爬虫抓取网页数据(java爬虫抓取网页数据的原理最简单的方法是什么)
java爬虫抓取网页数据的原理最简单的方法就是模拟浏览器从服务器获取数据。自己动手制作一个爬虫的话,可以用到很多东西,从分析请求,到动态解析,再到模拟鼠标键盘行为,然后根据不同需求定制不同的爬虫。主要的爬虫类库有python3.4版本的flask,2.8版本的httplib2。有了这些工具之后,可以自己构造规则,用自定义规则再次让爬虫爬取,或者手动写个简单的爬虫接口。
httplib2爬虫思路手写爬虫框架思路主要是构造请求和解析请求。这里我只要讲如何构造。爬虫结构如下,其中scrapy的代码和源码等是对应middleware版本的爬虫。如果你想构造详细的可执行爬虫,可以用apicallback接口获取最新的爬虫代码和api文档等。python3.4flask爬虫代码apicallbackx5方法做整理,以后爬虫的编程规范。
代码架构如下,为了让爬虫结构尽量清晰,后续的代码不会复杂到二次代码的结构,有改动可以通过配置apicallback执行。globalapicallbackscomputerimportrequests#扫描所有请求importre#给代码注册证书token=requests.get("/").content.contenttoken=pile("")#给爬虫加约束条件score=re.findall(r'score\n',token)#检查爬虫是否符合约束条件attr=re.findall(r'<a>',token)#定义请求路径response=python3.4文档方法异步/同步请求pipeline调用循环none_url=requests.get("/")none_url.split("/")withopen("/'xxxx'/'file_name'",'w')asf:f.write(none_url)这里主要解决url重复的问题。
cookie爬虫中会保存上次抓取到的cookie值,也是后续判断爬虫抓取结果是否一致的重要信息,因此后续编写爬虫的时候需要注意使用cookie。python3.4flask爬虫实现代码首先定义一个请求函数request,目的是获取页面地址,flask中根据url地址来获取文件。再定义循环for循环,循环请求地址,返回结果,获取到响应头信息,然后根据响应头信息解析response.cookie。
其中flask的文档方法很多,建议直接看代码。然后就可以用这个构造简单的爬虫,例如从百度搜索获取得分。最终定义爬虫的apicallback函数globalapicallbackflask.app.urlhandler{'xxxx':'','score':0,'c':1,'result':none}这个函数就是urlhandler接收请求地址和响应结果返回响应头,然后解析cookie完成get请求,最后就是根据请求结果返回。
java爬虫抓取网页数据(阿里巴巴如何开始学习java爬虫(没错就是我自己))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-06 17:03
java爬虫抓取网页数据的文章并不少见,但是实际中,更多是通过爬虫获取网页爬虫可以说是一个工具,一个提高工作效率的工具,看似简单,但是却要稍加学习才能理解,最近也想借此机会,开始学习java爬虫(没错就是我自己)。在开始之前,我们得明确的一点是:想要理解“爬虫”并不仅仅需要学习编程语言和编程规范,同时也要知道python语言的语法等,才能把爬虫发挥到最大。
先抛结论:爬虫是一种互联网网络技术,通过网络采集信息,然后再推送到互联网上。这里我们需要认识一下爬虫的概念,举个简单的例子:阿里巴巴是中国最大的b2b电商网站,用户可以通过上面的搜索框搜索商品或服务,阿里巴巴会从阿里巴巴的各个站点上抓取商品并发给客户。如果不使用“爬虫”功能,那么所抓取的数据都是下载下来的,不能发布在搜索框中。
那么我们看一下阿里巴巴如何抓取每一个客户的商品信息的:马云,姓马的我都知道了。马云创立了阿里巴巴,把一部分的商品信息推送给商家,商家在阿里上面拍下某个商品,然后在其他的站点上面购买该商品,阿里收集这些商品信息再发给商家。这样,通过阿里巴巴爬虫来采集数据,进行商品发布给用户。简单来说,阿里巴巴这个例子就是一个爬虫抓取商品信息的例子,那么如何开始学习java爬虫呢?我想了好几天,终于决定用nodejs开始学习(目前只接触到了nodejs)。
(后面会有关于nodejs的小黄文哦~)下面我先给一些实用的学习资料和使用工具:@night夜色、@c5game、@vscode、@seozoom、@v2ex之前一直用python,所以学习比较顺利;sqlite不知道从哪儿开始入手,又买了一本pythonmysql教程,为了熟悉数据库,还买了《pythonsql语言详解》来学习;并且安装了windows和linux系统,准备简单了解一下命令行相关操作;python的super是最近找的视频,和教程;学习过程也是比较坎坷,后面继续努力吧;目前学习中涉及到的知识点:爬虫、web模式与数据库表连接(mysql)、读取html文件、xpath、相关语言工具等;。 查看全部
java爬虫抓取网页数据(阿里巴巴如何开始学习java爬虫(没错就是我自己))
java爬虫抓取网页数据的文章并不少见,但是实际中,更多是通过爬虫获取网页爬虫可以说是一个工具,一个提高工作效率的工具,看似简单,但是却要稍加学习才能理解,最近也想借此机会,开始学习java爬虫(没错就是我自己)。在开始之前,我们得明确的一点是:想要理解“爬虫”并不仅仅需要学习编程语言和编程规范,同时也要知道python语言的语法等,才能把爬虫发挥到最大。
先抛结论:爬虫是一种互联网网络技术,通过网络采集信息,然后再推送到互联网上。这里我们需要认识一下爬虫的概念,举个简单的例子:阿里巴巴是中国最大的b2b电商网站,用户可以通过上面的搜索框搜索商品或服务,阿里巴巴会从阿里巴巴的各个站点上抓取商品并发给客户。如果不使用“爬虫”功能,那么所抓取的数据都是下载下来的,不能发布在搜索框中。
那么我们看一下阿里巴巴如何抓取每一个客户的商品信息的:马云,姓马的我都知道了。马云创立了阿里巴巴,把一部分的商品信息推送给商家,商家在阿里上面拍下某个商品,然后在其他的站点上面购买该商品,阿里收集这些商品信息再发给商家。这样,通过阿里巴巴爬虫来采集数据,进行商品发布给用户。简单来说,阿里巴巴这个例子就是一个爬虫抓取商品信息的例子,那么如何开始学习java爬虫呢?我想了好几天,终于决定用nodejs开始学习(目前只接触到了nodejs)。
(后面会有关于nodejs的小黄文哦~)下面我先给一些实用的学习资料和使用工具:@night夜色、@c5game、@vscode、@seozoom、@v2ex之前一直用python,所以学习比较顺利;sqlite不知道从哪儿开始入手,又买了一本pythonmysql教程,为了熟悉数据库,还买了《pythonsql语言详解》来学习;并且安装了windows和linux系统,准备简单了解一下命令行相关操作;python的super是最近找的视频,和教程;学习过程也是比较坎坷,后面继续努力吧;目前学习中涉及到的知识点:爬虫、web模式与数据库表连接(mysql)、读取html文件、xpath、相关语言工具等;。
java爬虫抓取网页数据(本文并不是讲解爬虫的相关技术实现的,而是..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-05 18:04
本文不讲解爬虫相关技术的实现,而是从实际的角度出发,将MongoDB抓取并存储的数据用InfluxDB处理,再通过Grafana抓取爬虫的数据。显示图形界面。
开始之前先简单介绍一下Grafana和InfluxDB:
最终效果如下:
请注意,以下操作均在 Mac 下实现。但原理类似,你可以在自己的电脑上进行实验。
2. 安装和配置 InfluxDB
安装 InfluxDB
修改配置文件/usr/local/etc/influxdb.conf。如果原文件中没有对应的配置项,需要自己添加。
3. 安装 Grafana
安装 Grafana
并修改Grafana配置文件/usr/local/etc/grafana/grafana.ini如下:
4.爬虫代码
因为这里主要介绍Grafana和InfluxDB如何与爬虫结合,而不是爬虫的原理,而且代码比较多,影响可读性,所以就不贴爬虫代码了。
5.监控脚本
考虑到可能会加入爬虫监控,这里使用热更新来动态配置监控。
配置文件influx_settings.conf主要用于热更新相关设置。
如何动态读取这个配置文件的设置?需要写一个脚本来监控。代码如下:
我们来试试吧
python3 influx_monitor.py
运行,得到如下内容,说明监控脚本运行成功。
再创建一个窗口,修改配置文件influx_settings.conf
# 修改间隔时间为8秒
interval = 8
第一次切换到运行influxDB的窗口,会提示配置更新,说明配置热更新生效。
6. 配置 Grafana
首先打开Chrome浏览器,输入:3000登录grafana页面。
连接本地influxDB数据库,如下图。
在红框中选择Type为InfluxDB,并输入URL::8086
在红框中输入influxDB数据库名称
新仪表板
新的图表类型仪表板
修改仪表板设置
点击红框修改设置
修改仪表板配置
设置监控数据对象
监控脚本中,写入influxDB的代码如下,其中“measurement”对应表名,“fields”对应写入的字段;
7.运行爬虫文件
启动 MongoDB 数据库服务。
brew services mongodb start
新建一个终端窗口并运行爬虫文件。
爬虫文件运行成功
我们可以在刚刚打开的控制台中查看效果展示:
怎么样?你学会了吗?如果你和我一样喜欢python,也在学习python的道路上奔跑,欢迎加入python学习群:839383 765 群里会分享最新的行业资讯,企业项目案例,分享免费的python课程,一起交流学习每天,让学习把(编辑)变成(处理)一种习惯! 查看全部
java爬虫抓取网页数据(本文并不是讲解爬虫的相关技术实现的,而是..)
本文不讲解爬虫相关技术的实现,而是从实际的角度出发,将MongoDB抓取并存储的数据用InfluxDB处理,再通过Grafana抓取爬虫的数据。显示图形界面。
开始之前先简单介绍一下Grafana和InfluxDB:
最终效果如下:
请注意,以下操作均在 Mac 下实现。但原理类似,你可以在自己的电脑上进行实验。
2. 安装和配置 InfluxDB
安装 InfluxDB
修改配置文件/usr/local/etc/influxdb.conf。如果原文件中没有对应的配置项,需要自己添加。
3. 安装 Grafana
安装 Grafana
并修改Grafana配置文件/usr/local/etc/grafana/grafana.ini如下:
4.爬虫代码
因为这里主要介绍Grafana和InfluxDB如何与爬虫结合,而不是爬虫的原理,而且代码比较多,影响可读性,所以就不贴爬虫代码了。
5.监控脚本
考虑到可能会加入爬虫监控,这里使用热更新来动态配置监控。
配置文件influx_settings.conf主要用于热更新相关设置。
如何动态读取这个配置文件的设置?需要写一个脚本来监控。代码如下:
我们来试试吧
python3 influx_monitor.py
运行,得到如下内容,说明监控脚本运行成功。
再创建一个窗口,修改配置文件influx_settings.conf
# 修改间隔时间为8秒
interval = 8
第一次切换到运行influxDB的窗口,会提示配置更新,说明配置热更新生效。
6. 配置 Grafana
首先打开Chrome浏览器,输入:3000登录grafana页面。
连接本地influxDB数据库,如下图。
在红框中选择Type为InfluxDB,并输入URL::8086
在红框中输入influxDB数据库名称
新仪表板
新的图表类型仪表板
修改仪表板设置
点击红框修改设置
修改仪表板配置
设置监控数据对象
监控脚本中,写入influxDB的代码如下,其中“measurement”对应表名,“fields”对应写入的字段;
7.运行爬虫文件
启动 MongoDB 数据库服务。
brew services mongodb start
新建一个终端窗口并运行爬虫文件。
爬虫文件运行成功
我们可以在刚刚打开的控制台中查看效果展示:
怎么样?你学会了吗?如果你和我一样喜欢python,也在学习python的道路上奔跑,欢迎加入python学习群:839383 765 群里会分享最新的行业资讯,企业项目案例,分享免费的python课程,一起交流学习每天,让学习把(编辑)变成(处理)一种习惯!
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2022-02-03 08:10
文章目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的话,学python爬虫比较靠谱,但是那是不是说java不会爬呢?当然不是。事实上,在某些场景下,java爬虫更加方便易用。
1.引入依赖:
java中的爬虫使用jsoup类库。jsoup提供了一个非常省力的API,可以通过DOM、CSS以及类似jQuery的操作方式来检索和操作数据,这样就可以在请求网页后对网页进行dom操作。达到爬虫目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例二:
获取学校信息:
3.代理说明:
情况1,不使用代理ip,直接抓取即可。但是通常情况下,我们抓取的网站会设置反爬虫、拦截ip等,所以我们需要设置代理ip。网上案例2,使用的是蘑菇代理的代理隧道的代理设置。还不错,如果真的需要,可以买。
总结
当然,我上面写的两个案例只是例子。事实上,操作 DOM 的方法有很多种。如果要爬,肯定需要DOM的基本操作,还需要一些基本的html知识。如果你想和我有更多的交流,可以关注我的公众号:Java Time House进行交流。 查看全部
java爬虫抓取网页数据(是不是代表java就不能爬虫呢?案例分析案例总结!)
文章目录摘要前言
现在提到爬虫都是python,类库比较丰富。不懂java的话,学python爬虫比较靠谱,但是那是不是说java不会爬呢?当然不是。事实上,在某些场景下,java爬虫更加方便易用。
1.引入依赖:
java中的爬虫使用jsoup类库。jsoup提供了一个非常省力的API,可以通过DOM、CSS以及类似jQuery的操作方式来检索和操作数据,这样就可以在请求网页后对网页进行dom操作。达到爬虫目的。
org.jsoup
jsoup
1.10.3
2.代码实战:
案例一:
履带股分析结果:
StockShow stockShow = new StockShow();
String doUrl = String.format("url", stockCode);
Document doc = null;
try {
doc = Jsoup.connect(doUrl).get();
Elements stockName = doc.select("div[class=stockname]");
Elements stockTotal = doc.select("div[class=stocktotal]");
Elements shortStr = doc.select("li[class=short]");
Elements midStr = doc.select("li[class=mid]");
Elements longStr = doc.select("li[class=long]");
Elements stockType = doc.select("div[class=value_bar]").select("span[class=cur]");
stockShow.setStockName(stockName.get(0).text());
stockShow.setStockTotal(stockTotal.get(0).text().split(":")[1]);
stockShow.setShortStr(shortStr.get(0).text().split(":")[1]);
stockShow.setMidStr(midStr.get(0).text().split(":")[1]);
stockShow.setLongStr(longStr.get(0).text().split(":")[1]);
stockShow.setStockType(stockType.get(0).text());
} catch (IOException e) {
log.error("findStockAnalysisByStockCode,{}",e.getMessage());
}
案例二:
获取学校信息:
3.代理说明:
情况1,不使用代理ip,直接抓取即可。但是通常情况下,我们抓取的网站会设置反爬虫、拦截ip等,所以我们需要设置代理ip。网上案例2,使用的是蘑菇代理的代理隧道的代理设置。还不错,如果真的需要,可以买。
总结
当然,我上面写的两个案例只是例子。事实上,操作 DOM 的方法有很多种。如果要爬,肯定需要DOM的基本操作,还需要一些基本的html知识。如果你想和我有更多的交流,可以关注我的公众号:Java Time House进行交流。
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-03 08:09
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p>package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/");
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf(" 查看全部
java爬虫抓取网页数据(自动在工程下创建Pictures文件夹)
为达到效果,在项目下自动创建Pictures文件夹,根据网站URL爬取图片,逐层获取。图片下的分层URL为网站的文件夹命名,用于安装该层URL下的图片。同时将文件名、路径、URL插入数据库,方便索引。
第一步是创建持久层类来存储文件名、路径和URL。
package org.amuxia.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class JDBCHelper {
private static final String driver = "com.mysql.jdbc.Driver";
private static final String DBurl = "jdbc:mysql://127.0.0.1:3306/edupic";
private static final String user = "root";
private static final String password = "root";
private PreparedStatement pstmt = null;
private Connection spiderconn = null;
public void insertFilePath(String fileName, String filepath, String url) {
try {
Class.forName(driver);
spiderconn = DriverManager.getConnection(DBurl, user, password);
String sql = "insert into FilePath (filename,filepath,url) values (?,?,?)";
pstmt = spiderconn.prepareStatement(sql);
pstmt.setString(1, fileName);
pstmt.setString(2, filepath);
pstmt.setString(3, url);
pstmt.executeUpdate();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
pstmt.close();
spiderconn.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
第二步,创建一个解析URL并爬取的类
<p>package org.amuxia.demo;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetWeb {
private int webDepth = 5; // 爬虫深度
private int intThreadNum = 1; // 线程数
private String strHomePage = ""; // 主页地址
private String myDomain; // 域名
private String fPath = "CSDN"; // 储存网页文件的目录名
private ArrayList arrUrls = new ArrayList(); // 存储未处理URL
private ArrayList arrUrl = new ArrayList(); // 存储所有URL供建立索引
private Hashtable allUrls = new Hashtable(); // 存储所有URL的网页号
private Hashtable deepUrls = new Hashtable(); // 存储所有URL深度
private int intWebIndex = 0; // 网页对应文件下标,从0开始
private long startTime;
private int webSuccessed = 0;
private int webFailed = 0;
public static void main(String[] args) {
GetWeb gw = new GetWeb("http://www.csdn.net/";);
gw.getWebByHomePage();
}
public GetWeb(String s) {
this.strHomePage = s;
}
public GetWeb(String s, int i) {
this.strHomePage = s;
this.webDepth = i;
}
public synchronized void addWebSuccessed() {
webSuccessed++;
}
public synchronized void addWebFailed() {
webFailed++;
}
public synchronized String getAUrl() {
String tmpAUrl = arrUrls.get(0);
arrUrls.remove(0);
return tmpAUrl;
}
public synchronized String getUrl() {
String tmpUrl = arrUrl.get(0);
arrUrl.remove(0);
return tmpUrl;
}
public synchronized Integer getIntWebIndex() {
intWebIndex++;
return intWebIndex;
}
/**
* 由用户提供的域名站点开始,对所有链接页面进行抓取
*/
public void getWebByHomePage() {
startTime = System.currentTimeMillis();
this.myDomain = getDomain();
if (myDomain == null) {
System.out.println("Wrong input!");
return;
}
System.out.println("Homepage = " + strHomePage);
System.out.println("Domain = " + myDomain);
arrUrls.add(strHomePage);
arrUrl.add(strHomePage);
allUrls.put(strHomePage, 0);
deepUrls.put(strHomePage, 1);
File fDir = new File(fPath);
if (!fDir.exists()) {
fDir.mkdir();
}
System.out.println("开始工作");
String tmp = getAUrl(); // 取出新的URL
this.getWebByUrl(tmp, allUrls.get(tmp) + ""); // 对新URL所对应的网页进行抓取
int i = 0;
for (i = 0; i < intThreadNum; i++) {
new Thread(new Processer(this)).start();
}
while (true) {
if (arrUrls.isEmpty() && Thread.activeCount() == 1) {
long finishTime = System.currentTimeMillis();
long costTime = finishTime - startTime;
System.out.println("\n\n\n\n\n完成");
System.out.println(
"开始时间 = " + startTime + " " + "结束时间 = " + finishTime + " " + "爬取总时间= " + costTime + "ms");
System.out.println("爬取的URL总数 = " + (webSuccessed + webFailed) + " 成功的URL总数: " + webSuccessed
+ " 失败的URL总数: " + webFailed);
String strIndex = "";
String tmpUrl = "";
while (!arrUrl.isEmpty()) {
tmpUrl = getUrl();
strIndex += "Web depth:" + deepUrls.get(tmpUrl) + " Filepath: " + fPath + "/web"
+ allUrls.get(tmpUrl) + ".htm" + "url:" + tmpUrl + "\n\n";
}
System.out.println(strIndex);
try {
PrintWriter pwIndex = new PrintWriter(new FileOutputStream("fileindex.txt"));
pwIndex.println(strIndex);
pwIndex.close();
} catch (Exception e) {
System.out.println("生成索引文件失败!");
}
break;
}
}
}
/**
* 对后续解析的网站进行爬取
*
* @param strUrl
* @param fileIndex
*/
public void getWebByUrl(String strUrl, String fileIndex) {
try {
System.out.println("通过URL得到网站: " + strUrl);
URL url = new URL(strUrl);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
InputStream is = null;
is = url.openStream();
String filename = strUrl.replaceAll("/", "_");
filename = filename.replace(":", ".");
if (filename.indexOf("*") > 0) {
filename = filename.replaceAll("*", ".");
}
if (filename.indexOf("?") > 0) {
filename = filename.replaceAll("?", ".");
}
if (filename.indexOf("\"") > 0) {
filename = filename.replaceAll("\"", ".");
}
if (filename.indexOf(">") > 0) {
filename = filename.replaceAll(">", ".");
}
if (filename.indexOf("
java爬虫抓取网页数据(Jsoup需要的jar包:链接Jsoup不支持xpath的东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-03 08:07
二、Jsoup
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页、加载更多等等。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome
1、HeadlessChrome与PhantomJS的对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
使用 Python 做 HeadlessChrome 更简单更简单。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/");
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i 查看全部
java爬虫抓取网页数据(Jsoup需要的jar包:链接Jsoup不支持xpath的东西)
二、Jsoup
需要的jar包:
1
2 org.jsoup
3 jsoup
4 1.10.3
5
代码如下:
1 // 请求超时时间,30秒
2 public static final int TIME_OUT = 30*1000;
3 // 模拟浏览器请求头信息
4 public static Map headers = new HashMap();
5 static{
6 headers.put("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0");
7 headers.put("Accept", "text/html");
8 headers.put("Accept-Language", "zh-CN,zh");
9 }
10
11 //根据url获取html文档
12 protected Document getDoc(String url) throws IOException{
13 if(logger.isDebugEnabled())
14 logger.debug(url);
15 //新建一个连接
16 Connection conn = Jsoup.connect(url).timeout(TIME_OUT);
17 conn = conn.headers(headers);
18 conn = conn.proxy(Proxy.NO_PROXY);
19 Document doc = conn.get();
20
21 if(logger.isTraceEnabled()){
22 logger.trace("["+url+"]\n"+doc);
23 }
24 return doc;
25 }
1 public static final String CHINAZ_ICP_URL = "http://icp.chinaz.com/?type=host&s=%s";
2 public List doHandler(String domain) {
3 List results = new ArrayList();
4 String url = String.format(CHINAZ_ICP_URL, domain);
5 Document doc;
6 try {
7 doc = this.getDoc(url);
8 // 获取当前页ICP信息所在标签
9 Elements eles = doc.select("ul.IcpMain01>li:lt(7)>p");
10
11 if(null == eles || eles.isEmpty()){
12 return results;
13 }
14 //获取ICP信息
15 for (Element element : eles) {
16 //当前元素为认证信息时,跳过
17 if("safe".equals(element.attr("id"))){
18 continue;
19 }
20 Node firstNode = element.childNode(0);
21 if(firstNode.childNodeSize() > 0){
22 results.add(element.child(0).text());
23 }else{
24 results.add(((TextNode)firstNode).text());
25 }
26 }
27 } catch (IOException e) {
28 logger.error("get Chinaz ICP message error :",e);
29 }
30 doc = null;
31 return results;
32 }
参考Jsoup的文档:链接
Jsoup不支持xpath解析,很蛋疼,不过有人要弄个支持xpath的东西---JsoupXpath,链接,有兴趣的网友可以自己试试!
三、htmlunit
支持Xpath解析,可以模拟浏览器动作,比如点击下一页、加载更多等等。文档链接:
需要的jar包
1
2 net.sourceforge.htmlunit
3 htmlunit
4 2.18
5
代码如下:
1 import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
2 import com.gargoylesoftware.htmlunit.TopLevelWindow;
3 import com.gargoylesoftware.htmlunit.WebClient;
4 import com.gargoylesoftware.htmlunit.html.HtmlPage;
5 import com.gargoylesoftware.htmlunit.html.HtmlTableRow;
6
7 import java.io.IOException;
8 import java.util.ArrayList;
9 import java.util.List;
10
11
12 public class UrlTest {
13
14 public static void main(String[] args) {
15 BaseCollector baseCollector = new BaseCollector();
16 WebClient webClient = baseCollector.getWebClient();
17 String url="http://htmlunit.sourceforge.net/";
18 HtmlPage homePage= null;
19 try {
20 homePage = webClient.getPage(url);
21 if (homePage != null && homePage instanceof HtmlPage) {
22 homePage.getEnclosingWindow().setName("IpHomePage");
23 System.out.println("打开 IPHomePage ");
24 System.out.println("内容是: "+homePage.getBody().getTextContent());
25
26 List htmlTableRows = (List) homePage.getByXPath("/html/body/pre");
27 if (htmlTableRows != null && htmlTableRows.size() > 0) {
28 for (int i = 0; i < htmlTableRows.size(); i++) {
29 HtmlTableRow htmlTableRow = htmlTableRows.get(i);
30 //日期
31 String firstTime = htmlTableRow.getCell(0).getTextContent().trim();
32 System.out.println(firstTime);
33 }
34
35 }
36 closeWindowByName(webClient, "IPHomePage");
37 System.out.println("关闭 IPHomePage ");
38 }
39 webClient.close();
40
41 } catch (IOException e) {
42 System.out.println(e.getMessage()+" ===="+e);
43 }catch (FailingHttpStatusCodeException e){
44 System.out.println(e.getMessage()+" ===="+e);
45 }
46 System.out.println("内容是: "+homePage.getBody().getTextContent());
47 }
48
49 public static void closeWindowByName(WebClient webClient, String name){
50 List list = webClient.getTopLevelWindows();
51 List windowNames = new ArrayList();
52 for (int j = 0; j < list.size(); j++) {
53 if(list.get(j).getName().equals(name)){
54 list.get(j).close();
55 }
56 windowNames.add(list.get(j).getName());
57 }
58 System.out.println("当前窗口 : {}"+list.toString());
59 }
60 }
61
62
四、HeadlessChrome
1、HeadlessChrome与PhantomJS的对比
在 Chrome 不提供原生无头模式之前,Web 开发者可以使用 PhantomJS 等第三方无头浏览器。现在 Headless 已经正式准备就绪,PhantomJS 的维护者 VitalySlobodin 在邮件列表中宣布了他的辞职。另一个流行的浏览器 Firefox 也准备提供 Headless 模式。
2、什么是HeadlessChrome
HeadlessChrome 是一种无界面形式的 Chrome 浏览器。您可以使用 Chrome 支持的所有功能运行您的程序,而无需打开浏览器。与现代浏览器相比,HeadlessChrome更方便测试web应用、获取网站的截图、爬取信息等。
3、环境配置
您需要先下载 chrome-driver。不同版本的 Chrome 对应不同的 Chrome 驱动程序。您可以通过此链接下载相应的Chrome驱动程序
支持各种元素的获取,List elements = driver.findElements(By.xpath("//*[@id=\"body\"]/ul[2]/li"));
可以模拟浏览器的各种动作,driver.findElement(By.linkText("Next")).click();
使用 Python 做 HeadlessChrome 更简单更简单。 . . . 链接:
你可以参考一下
需要的jar包:
1
2 org.seleniumhq.selenium
3 selenium-chrome-driver
4 3.11.0
5
代码如下:
<p> 1 import org.jsoup.Jsoup;
2 import org.jsoup.nodes.Document;
3 import org.openqa.selenium.By;
4 import org.openqa.selenium.WebDriver;
5 import org.openqa.selenium.WebElement;
6 import org.openqa.selenium.chrome.ChromeDriver;
7 import org.openqa.selenium.chrome.ChromeOptions;
8
9 import java.util.List;
10 import java.util.concurrent.TimeUnit;
11
12 /**
13 * Created by sqy on 2018/5/2.
14 */
15 public class HeadlessChromeTest {
16
17 public static void main(String args[]) {
18
19
20
21 //G:\chromedriver
22 System.setProperty("webdriver.chrome.driver","G:\\chromedriver\\chromedriver.exe");
23 ChromeOptions chromeOptions = new ChromeOptions();
24 // 设置为 headless 模式 (必须)
25 chromeOptions.addArguments("--headless");
26 // 设置浏览器窗口打开大小 (非必须)
27 chromeOptions.addArguments("--window-size=1920,1080");
28 WebDriver driver = new ChromeDriver(chromeOptions);
29 driver.get("https://lvyou.baidu.com/scene/s-feb/";);
30
31 System.out.println("url: "+driver.getCurrentUrl());
32
33 for(int i=0;i
java爬虫抓取网页数据(2.网络爬虫(英语:webcrawler)抓取测试类4.测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-02 13:05
1. 网络爬虫
网络爬虫,也称为网络蜘蛛,是一种用于自动浏览万维网的网络机器人。它的目的通常是编译一个网络索引。简单来说就是获取被请求页面的源码,然后通过正则表达式获取你需要的内容。实现大致分为以下几个步骤:
(1)爬取网页源码
(2)用正则截取你需要的内容(我这里截取问题,下面回答)
2.爬取网页源码
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class Spider {
/**
* @auther: Ragty
* @describe: 爬虫爬取网页源码
* @param: [url]
* @return: java.lang.String
* @date: 2019/1/23
*/
public static String getSource (String url) {
BufferedReader reader = null;
String result = "";
try {
URL realurl = new URL(url);
URLConnection conn = realurl.openConnection(); //连接外部url
reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = "";
while ( (line = reader.readLine()) != null ) {
result += line;
}
if (reader != null) {
reader.close();
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
3.爬取规则和实体类
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import JavaSpider.spider.Spider;
public class Imooc {
public String question;
public String quesUrl;
public String quesDescription;
public Map answers;
public String nextUrl;
/**
* @auther: Ragty
* @describe: 爬取慕课问答界面的问题及回答
* @param: [url]
* @return:
* @date: 2019/1/23
*/
public Imooc(String url) {
question="";
quesUrl=url;
quesDescription="";
answers = new HashMap();
nextUrl="";
//获取单个问题页面源码
String codeSource = Spider.getSource(url);
//正则获取question
Pattern pattern=Pattern.compile("js-qa-wenda-title.+?>(.+?)");
Matcher matcher=pattern.matcher(codeSource);
if(matcher.find()){
question = matcher.group(1);
}
//正则表达式获取问题描述
pattern=Pattern.compile("js-qa-wenda.+?rich-text\">(.+?)");
matcher=pattern.matcher(codeSource);
if(matcher.find()){
quesDescription = matcher.group(1).replace("<p>", "").replace("", "");
}
//正则表达式获取答案列表
pattern=Pattern.compile("nickname.+?>(.+?)</a>.+?answer-desc rich-text aimgPreview.+?>(.+?)");
matcher=pattern.matcher(codeSource);
while(matcher.find()){
String answer = matcher.group(2).replace("
", "");
answer = answer.replace("", "");
answer = answer.replace("<br />", "");
String name = matcher.group(1);
answers.put(name.trim(), answer.trim());
}
//正则表达式获取下一个url 爬取获取相关问题的url
pattern=Pattern.compile("class=\"r relwenda\".+?href=\"(.+?)\".+?</a>");//获取回答者name
matcher=pattern.matcher(codeSource);
while(matcher.find()){
nextUrl="http://www.imooc.com"+matcher.group(1);
//只取第一个推荐
if(!nextUrl.equals(quesUrl)){
break;
}
}
}
@Override
public String toString() {
return "问题为:"+ question +"\n问题地址为:"+quesUrl+
"\n问题的表述为:"+quesDescription+"\n"
+ "回答的内容为:"+answers+"\n指向下一个链接地址为:"+nextUrl+"\n";
}
}
</p>
3.抢试课
<p>package JavaSpider.main;
import JavaSpider.bean.Imooc;
public class Main {
public static void main(String[] args) {
String url = "http://www.imooc.com/wenda/detail/351144";
Imooc imooc;
for(int i=0; i 查看全部
java爬虫抓取网页数据(2.网络爬虫(英语:webcrawler)抓取测试类4.测试)
1. 网络爬虫
网络爬虫,也称为网络蜘蛛,是一种用于自动浏览万维网的网络机器人。它的目的通常是编译一个网络索引。简单来说就是获取被请求页面的源码,然后通过正则表达式获取你需要的内容。实现大致分为以下几个步骤:
(1)爬取网页源码
(2)用正则截取你需要的内容(我这里截取问题,下面回答)
2.爬取网页源码
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
public class Spider {
/**
* @auther: Ragty
* @describe: 爬虫爬取网页源码
* @param: [url]
* @return: java.lang.String
* @date: 2019/1/23
*/
public static String getSource (String url) {
BufferedReader reader = null;
String result = "";
try {
URL realurl = new URL(url);
URLConnection conn = realurl.openConnection(); //连接外部url
reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = "";
while ( (line = reader.readLine()) != null ) {
result += line;
}
if (reader != null) {
reader.close();
}
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
3.爬取规则和实体类
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import JavaSpider.spider.Spider;
public class Imooc {
public String question;
public String quesUrl;
public String quesDescription;
public Map answers;
public String nextUrl;
/**
* @auther: Ragty
* @describe: 爬取慕课问答界面的问题及回答
* @param: [url]
* @return:
* @date: 2019/1/23
*/
public Imooc(String url) {
question="";
quesUrl=url;
quesDescription="";
answers = new HashMap();
nextUrl="";
//获取单个问题页面源码
String codeSource = Spider.getSource(url);
//正则获取question
Pattern pattern=Pattern.compile("js-qa-wenda-title.+?>(.+?)");
Matcher matcher=pattern.matcher(codeSource);
if(matcher.find()){
question = matcher.group(1);
}
//正则表达式获取问题描述
pattern=Pattern.compile("js-qa-wenda.+?rich-text\">(.+?)");
matcher=pattern.matcher(codeSource);
if(matcher.find()){
quesDescription = matcher.group(1).replace("<p>", "").replace("", "");
}
//正则表达式获取答案列表
pattern=Pattern.compile("nickname.+?>(.+?)</a>.+?answer-desc rich-text aimgPreview.+?>(.+?)");
matcher=pattern.matcher(codeSource);
while(matcher.find()){
String answer = matcher.group(2).replace("
", "");
answer = answer.replace("", "");
answer = answer.replace("<br />", "");
String name = matcher.group(1);
answers.put(name.trim(), answer.trim());
}
//正则表达式获取下一个url 爬取获取相关问题的url
pattern=Pattern.compile("class=\"r relwenda\".+?href=\"(.+?)\".+?</a>");//获取回答者name
matcher=pattern.matcher(codeSource);
while(matcher.find()){
nextUrl="http://www.imooc.com"+matcher.group(1);
//只取第一个推荐
if(!nextUrl.equals(quesUrl)){
break;
}
}
}
@Override
public String toString() {
return "问题为:"+ question +"\n问题地址为:"+quesUrl+
"\n问题的表述为:"+quesDescription+"\n"
+ "回答的内容为:"+answers+"\n指向下一个链接地址为:"+nextUrl+"\n";
}
}
</p>
3.抢试课
<p>package JavaSpider.main;
import JavaSpider.bean.Imooc;
public class Main {
public static void main(String[] args) {
String url = "http://www.imooc.com/wenda/detail/351144";
Imooc imooc;
for(int i=0; i
java爬虫抓取网页数据(最快捷,最方便的图片上传和管理系统·采用MVC架构,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-02 02:04
·最快最方便的图片上传和管理系统·MVC架构,详细标注,方便二次开发和扩展·UTF-8编码,便于在国外主机安装·支持批量上传,远程抓图·自动外部图片保存在本地· 自动控制上传图片和本地化图片的大小 · 自动为上传和本地化的图片添加水印 · 自动提取第一张图片为缩略图 · 自动生成任意大小的缩略图 · 幻灯片模式图片展示页面 · 支持静态缓存,全站生成 HTML。内置采集器,快速抓取网络图文。自由分类,自动生成导航和内容调用。模板分离设计,模板设计简单。 查看全部
java爬虫抓取网页数据(最快捷,最方便的图片上传和管理系统·采用MVC架构,)
·最快最方便的图片上传和管理系统·MVC架构,详细标注,方便二次开发和扩展·UTF-8编码,便于在国外主机安装·支持批量上传,远程抓图·自动外部图片保存在本地· 自动控制上传图片和本地化图片的大小 · 自动为上传和本地化的图片添加水印 · 自动提取第一张图片为缩略图 · 自动生成任意大小的缩略图 · 幻灯片模式图片展示页面 · 支持静态缓存,全站生成 HTML。内置采集器,快速抓取网络图文。自由分类,自动生成导航和内容调用。模板分离设计,模板设计简单。
java爬虫抓取网页数据(一下NetDiscovery爬虫爬虫框架里的downloader对象对象1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-01 08:12
大家好,本文文章介绍NetDiscovery爬虫框架中的downloader对象
1) 前言
面向对象设计仍然是当前编程的核心思想。从下面的截图可以了解爬虫框架的主要对象:
程序在本地组织好一个请求后,交给下载器从网络抓取数据到本地,然后解析器对本地数据进行处理,最终生成可用信息。
2) 下载器介绍
下载器也称为下载器。它的主要功能是访问网络并成功获取我们想要的数据:如html网页、json/xml数据、二进制流(图片、办公文档等)
NetDiscovery 目前支持的下载器实现有:
面向接口的编程是该框架的重要设计思想之一。
下面介绍一些下载器代码。这些代码的共同点是实现Downloader接口。
作为程序开发人员,您还可以实现接口 discovery.core.downloader.Downloader 来创建自己的下载器类。
//1、构建一个URL对象
url = new URL(request.getUrl());
//2、获取一个HttpURLConnection对象
conn = url.openConnection();
//3、一堆设置
conn .setDoOutput(true);
conn .setDoInput(true);
conn .setRequestMethod("POST");
......
//4、访问网络服务
conn.connect();
//5、执行成功的话,获取结果
conn.getResponseCode();
conn.getInputStream();
//1、获取一个HttpManager对象(框架自己封装的)
HttpManager httpManager = HttpManager.get();
//2、然后把request扔进去,等结果就可以了.request也是框架封装的
httpManager.getResponse(request)
//3、等来结果后,进行处理
@Override
public Response apply(CloseableHttpResponse closeableHttpResponse) throws Exception {
String charset = null;
if (Preconditions.isNotBlank(request.getCharset())) {
charset = request.getCharset(); //针对一些还是GB2312编码的网页
} else {
charset = "UTF-8";
}
String html = EntityUtils.toString(closeableHttpResponse.getEntity(), charset);
Response response = new Response();
response.setContent(html.getBytes());
response.setStatusCode(closeableHttpResponse.getStatusLine().getStatusCode());
if (closeableHttpResponse.containsHeader("Content-Type")) {
response.setContentType(closeableHttpResponse.getFirstHeader("Content-Type").getValue());
}
return response;
}
3) 总结
总之,爬虫程序本质上是一个网络程序,而网络程序的核心模块离不开对网络数据的处理。建议学习爬虫的小伙伴,如果想看源码,可以从框架中的下载器相关代码入手。我相信会有收获。 查看全部
java爬虫抓取网页数据(一下NetDiscovery爬虫爬虫框架里的downloader对象对象1))
大家好,本文文章介绍NetDiscovery爬虫框架中的downloader对象
1) 前言
面向对象设计仍然是当前编程的核心思想。从下面的截图可以了解爬虫框架的主要对象:
程序在本地组织好一个请求后,交给下载器从网络抓取数据到本地,然后解析器对本地数据进行处理,最终生成可用信息。
2) 下载器介绍
下载器也称为下载器。它的主要功能是访问网络并成功获取我们想要的数据:如html网页、json/xml数据、二进制流(图片、办公文档等)
NetDiscovery 目前支持的下载器实现有:
面向接口的编程是该框架的重要设计思想之一。
下面介绍一些下载器代码。这些代码的共同点是实现Downloader接口。
作为程序开发人员,您还可以实现接口 discovery.core.downloader.Downloader 来创建自己的下载器类。
//1、构建一个URL对象
url = new URL(request.getUrl());
//2、获取一个HttpURLConnection对象
conn = url.openConnection();
//3、一堆设置
conn .setDoOutput(true);
conn .setDoInput(true);
conn .setRequestMethod("POST");
......
//4、访问网络服务
conn.connect();
//5、执行成功的话,获取结果
conn.getResponseCode();
conn.getInputStream();
//1、获取一个HttpManager对象(框架自己封装的)
HttpManager httpManager = HttpManager.get();
//2、然后把request扔进去,等结果就可以了.request也是框架封装的
httpManager.getResponse(request)
//3、等来结果后,进行处理
@Override
public Response apply(CloseableHttpResponse closeableHttpResponse) throws Exception {
String charset = null;
if (Preconditions.isNotBlank(request.getCharset())) {
charset = request.getCharset(); //针对一些还是GB2312编码的网页
} else {
charset = "UTF-8";
}
String html = EntityUtils.toString(closeableHttpResponse.getEntity(), charset);
Response response = new Response();
response.setContent(html.getBytes());
response.setStatusCode(closeableHttpResponse.getStatusLine().getStatusCode());
if (closeableHttpResponse.containsHeader("Content-Type")) {
response.setContentType(closeableHttpResponse.getFirstHeader("Content-Type").getValue());
}
return response;
}
3) 总结
总之,爬虫程序本质上是一个网络程序,而网络程序的核心模块离不开对网络数据的处理。建议学习爬虫的小伙伴,如果想看源码,可以从框架中的下载器相关代码入手。我相信会有收获。
java爬虫抓取网页数据(讲解爬虫基础在本文中我将写一个爬虫网的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-01 04:04
解释爬虫的基础 在这篇文章中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。必备知识:了解java语言语法、Html语法。输入主题:一、明确要抓取的信息。比如我想在这个webapp中抓取的信息是:职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别1、创建一个Struts2 web项目导入需要的架子包2、
讲解爬虫基础
在本文中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。
必备知识:了解java语言语法、Html语法。
重点:
一、指定要抓取的信息。
比如我想在这个webapp中抓取的信息是:
职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别
1、创建一个Struts2 web项目并导入所需的shelf包
2、搭建基本框架
3、建立连接
使用方法获取连接
文档 doc = Jsoup.connect("");
Document对象是网页解析后的对象类型,加载后可以输出。
输出的时候发现无法得到想要的内容,于是输出了整个网页,看到结果是这样的
此时,分析可能的原因。一般来说,网站采用了反爬虫机制。第一个尝试是写浏览器的头文件。
文档 doc = Jsoup.connect("").userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/ 30.0").get();
然后再运行一次就可以得到你想要的了
3、分析网页
建议您使用谷歌浏览器,F12 分析源码。
您可以清楚地看到它的结构,因此无需借用其他工具。
元素元素 = doc.select("ul[class=item_con_list]").select("li[class=con_list_item default_list]");
使用选择器选择此页面上的所有职业信息。Elements 是元素的集合,然后一步一步抓取需要的信息。
输出所需信息
这样的数据,输出是这样的,我们可以添加到数据库中。
这些都没有了。
原文地址:~all~es_rank~default-11-79052808.pc_search_all_es&utm_term=java%E7%88%AC%E8%99%AB
这个 文章 网址:
类似推荐 查看全部
java爬虫抓取网页数据(讲解爬虫基础在本文中我将写一个爬虫网的信息)
解释爬虫的基础 在这篇文章中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。必备知识:了解java语言语法、Html语法。输入主题:一、明确要抓取的信息。比如我想在这个webapp中抓取的信息是:职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别1、创建一个Struts2 web项目导入需要的架子包2、
讲解爬虫基础
在本文中,我将编写一个爬虫来爬取钩网的信息并将其存储在数据库中。使用 Struts2 框架。
必备知识:了解java语言语法、Html语法。
重点:
一、指定要抓取的信息。
比如我想在这个webapp中抓取的信息是:
职位名称、公司名称、公司网站、福利、月薪、发布日期、工作地点、工作性质、最低学历、工作类别
1、创建一个Struts2 web项目并导入所需的shelf包
2、搭建基本框架
3、建立连接
使用方法获取连接
文档 doc = Jsoup.connect("");
Document对象是网页解析后的对象类型,加载后可以输出。
输出的时候发现无法得到想要的内容,于是输出了整个网页,看到结果是这样的
此时,分析可能的原因。一般来说,网站采用了反爬虫机制。第一个尝试是写浏览器的头文件。
文档 doc = Jsoup.connect("").userAgent("Mozilla/5.0 (Windows NT 6.1; rv:30.0) Gecko/20100101 Firefox/ 30.0").get();
然后再运行一次就可以得到你想要的了
3、分析网页
建议您使用谷歌浏览器,F12 分析源码。
您可以清楚地看到它的结构,因此无需借用其他工具。
元素元素 = doc.select("ul[class=item_con_list]").select("li[class=con_list_item default_list]");
使用选择器选择此页面上的所有职业信息。Elements 是元素的集合,然后一步一步抓取需要的信息。
输出所需信息
这样的数据,输出是这样的,我们可以添加到数据库中。
这些都没有了。
原文地址:~all~es_rank~default-11-79052808.pc_search_all_es&utm_term=java%E7%88%AC%E8%99%AB
这个 文章 网址:
类似推荐
java爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-30 01:21
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以把数据持久化到avro文件、hbase、mysql等,其实很多人都搞错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。 查看全部
java爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以把数据持久化到avro文件、hbase、mysql等,其实很多人都搞错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。这个Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人已经解决了困难和复杂的问题(如DOM树解析定位、字符集检测、海量URL去重等),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,就可以使用上面的方法,直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
java爬虫抓取网页数据( Java也可以做爬虫,一键爬取文章内容并保存入库! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-27 13:19
Java也可以做爬虫,一键爬取文章内容并保存入库!
)
简介其实Java也可以是爬虫。虽然没有Python强大,但基本功能没有问题。本文将介绍一键抓取文章内容并存入库。一键爬取配置文件介绍:
<br /><br />com.kotcrab.remark<br />remark<br />1.2.0<br />
创建爬虫基础配置表,匹配相关博客元素:
CREATE TABLE `app_blog_crawl` (<br />`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',<br />`type` VARCHAR(255) NOT NULL COMMENT '类型',<br />`url` VARCHAR(255) NOT NULL COMMENT '网址',<br />`title` VARCHAR(255) NOT NULL COMMENT '标题元素',<br />`content` VARCHAR(255) NOT NULL COMMENT '内容元素',<br />`gmt_create` DATETIME NOT NULL COMMENT '创建时间',<br />`gmt_modified` DATETIME NOT NULL COMMENT '修改时间',<br /> PRIMARY KEY (`id`)<br /> ) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
背景抓取并将富文本转换为 MD 格式:
/**<br /> * 爬取-爪哇笔记<br /> * 1)获取数据库配置<br /> * 2)根据数据库配置读取文章相关元素<br /> * 3)富文本转MD,并返回前端实体内容<br /> * 源码:https://gitee.com/52itstyle/SPTools<br /> * @param url<br /> * @return<br /> */<br />@RequestMapping("crawl")<br />public Result crawl(String url) {<br />try {<br />String domain = JsoupUtils.getDomain(url);<br />String nativeSql = "SELECT * FROM app_blog_crawl WHERE url = ?";<br /> AppBlogCrawl crawl =<br /> dynamicQuery.nativeQuerySingleResult(AppBlogCrawl.class,nativeSql,new Object[]{domain});<br />if(crawl!=null){<br /> Document document = JsoupUtils.getDocument(url);<br />String title = document.select(crawl.getTitle()).text();<br />String content = document.select(crawl.getContent()).html();<br /> Remark remark = new Remark();<br />String markdown = remark.convertFragment(content);<br /> AppBlog blog = new AppBlog();<br /> blog.setTitle(title);<br /> blog.setContent(markdown);<br /> blog.setUrl(url);<br />return Result.ok(blog);<br /> }else{<br />return Result.error("目前暂不支持此网站抓取");<br /> }<br /> } catch (Exception e) {<br />return Result.error("抓取异常");<br /> }<br />}
工具:
/**<br /> * 工具类<br /> */<br />public classJsoupUtils{<br /><br />/**<br /> * 获取 document<br /> * @param url<br /> * @return<br /> * @throws IOException<br /> */<br />publicstatic Document getDocument(String url)throws IOException {<br /> Document document = Jsoup.connect(url)<br /> .timeout(100000)<br /> .ignoreContentType(true)<br /> .userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36")<br /> .get();<br />return document;<br /> }<br /><br />/**<br /> * 获取域名<br /> * @param url<br /> * @return<br /> */<br />publicstatic String getDomain(String url){<br />return url.split("/")[0]+"//"+url.split("/")[2];<br /> }<br />}
预览
总结其实目前很多社区都有个人博客或者微信公众号的同步功能,比如腾讯云社区、云栖社区、开源中国,国内最大的社区。如果觉得不好玩,还可以实现更有趣的功能,比如定时抓取指定日期的博文,指定关键词。
<strong style="color:rgb(39,39,39);">— 【 THE END 】—</strong>本公众号全部博文已整理成一个目录,请在公众号里回复「m」获取!
3T技术资源出炉!包括但不限于:Java、C/C++、Linux、Python、大数据、人工智能等,在公众号回复“1024”即可免费领取!!
查看全部
java爬虫抓取网页数据(
Java也可以做爬虫,一键爬取文章内容并保存入库!
)
简介其实Java也可以是爬虫。虽然没有Python强大,但基本功能没有问题。本文将介绍一键抓取文章内容并存入库。一键爬取配置文件介绍:
<br /><br />com.kotcrab.remark<br />remark<br />1.2.0<br />
创建爬虫基础配置表,匹配相关博客元素:
CREATE TABLE `app_blog_crawl` (<br />`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',<br />`type` VARCHAR(255) NOT NULL COMMENT '类型',<br />`url` VARCHAR(255) NOT NULL COMMENT '网址',<br />`title` VARCHAR(255) NOT NULL COMMENT '标题元素',<br />`content` VARCHAR(255) NOT NULL COMMENT '内容元素',<br />`gmt_create` DATETIME NOT NULL COMMENT '创建时间',<br />`gmt_modified` DATETIME NOT NULL COMMENT '修改时间',<br /> PRIMARY KEY (`id`)<br /> ) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8
背景抓取并将富文本转换为 MD 格式:
/**<br /> * 爬取-爪哇笔记<br /> * 1)获取数据库配置<br /> * 2)根据数据库配置读取文章相关元素<br /> * 3)富文本转MD,并返回前端实体内容<br /> * 源码:https://gitee.com/52itstyle/SPTools<br /> * @param url<br /> * @return<br /> */<br />@RequestMapping("crawl")<br />public Result crawl(String url) {<br />try {<br />String domain = JsoupUtils.getDomain(url);<br />String nativeSql = "SELECT * FROM app_blog_crawl WHERE url = ?";<br /> AppBlogCrawl crawl =<br /> dynamicQuery.nativeQuerySingleResult(AppBlogCrawl.class,nativeSql,new Object[]{domain});<br />if(crawl!=null){<br /> Document document = JsoupUtils.getDocument(url);<br />String title = document.select(crawl.getTitle()).text();<br />String content = document.select(crawl.getContent()).html();<br /> Remark remark = new Remark();<br />String markdown = remark.convertFragment(content);<br /> AppBlog blog = new AppBlog();<br /> blog.setTitle(title);<br /> blog.setContent(markdown);<br /> blog.setUrl(url);<br />return Result.ok(blog);<br /> }else{<br />return Result.error("目前暂不支持此网站抓取");<br /> }<br /> } catch (Exception e) {<br />return Result.error("抓取异常");<br /> }<br />}
工具:
/**<br /> * 工具类<br /> */<br />public classJsoupUtils{<br /><br />/**<br /> * 获取 document<br /> * @param url<br /> * @return<br /> * @throws IOException<br /> */<br />publicstatic Document getDocument(String url)throws IOException {<br /> Document document = Jsoup.connect(url)<br /> .timeout(100000)<br /> .ignoreContentType(true)<br /> .userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36")<br /> .get();<br />return document;<br /> }<br /><br />/**<br /> * 获取域名<br /> * @param url<br /> * @return<br /> */<br />publicstatic String getDomain(String url){<br />return url.split("/")[0]+"//"+url.split("/")[2];<br /> }<br />}
预览
总结其实目前很多社区都有个人博客或者微信公众号的同步功能,比如腾讯云社区、云栖社区、开源中国,国内最大的社区。如果觉得不好玩,还可以实现更有趣的功能,比如定时抓取指定日期的博文,指定关键词。
<strong style="color:rgb(39,39,39);">— 【 THE END 】—</strong>本公众号全部博文已整理成一个目录,请在公众号里回复「m」获取!
3T技术资源出炉!包括但不限于:Java、C/C++、Linux、Python、大数据、人工智能等,在公众号回复“1024”即可免费领取!!
java爬虫抓取网页数据(一种网页数据收集日期的原因及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-27 13:15
列表1.网页抓取
URLurl=newURL("");
URLConnectionconn=url.openConnection();
BufferedReaderreader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
while((line=reader.readLine())!=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为一些网站链接使用了相对路径,如果没有排序就会出错。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下: 查看全部
java爬虫抓取网页数据(一种网页数据收集日期的原因及解决办法(一))
列表1.网页抓取
URLurl=newURL("");
URLConnectionconn=url.openConnection();
BufferedReaderreader=newBufferedReader(newInputStreamReader(conn.getInputStream()));
字符串=空;
while((line=reader.readLine())!=null)
document.append(line+"\n");
使用Java语言的好处是不需要自己去处理底层的连接操作。喜欢或精通Java网络编程的读者,不用上述方法也能实现URL类及相关操作,也是一个很好的练习。
网页处理
采集到的单个网页需要以两种不同的方式进行处理。一是将其作为原创数据放入网页库中进行后续处理;另一种是解析后提取URL连接,放入URL池等待对应的网页。采集。
网页需要以一定的格式保存,以便以后可以批量处理数据。这里是一种存储数据格式,是从北大天网的存储格式简化而来的:
网页库由多条记录组成,每条记录收录一条网页数据信息,记录存储以便添加;
一条记录由数据头、数据和空行组成,顺序为:表头+空行+数据+空行;
头部由几个属性组成,包括:版本号、日期、IP地址、数据长度,以属性名和属性值的方式排列,中间加一个冒号,每个属性占一行;
数据是网页数据。
需要注意的是,之所以加上数据采集日期,是因为很多网站的内容是动态变化的,比如一些大型门户网站的首页内容网站,也就是说如果不爬取同日 对于网页数据,很可能会出现数据过期的问题,所以需要添加日期信息来识别。
URL的提取分为两步。第一步是识别URL,第二步是组织URL。这两个步骤主要是因为一些网站链接使用了相对路径,如果没有排序就会出错。. URL的标识主要是通过正则表达式来匹配的。该过程首先将一个字符串设置为匹配字符串模式,然后在Pattern中编译后使用Matcher类匹配对应的字符串。实现代码如下:
java爬虫抓取网页数据(小崔以ja语言来演示一下如何实现网络爬虫,源代码会附在最后)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-27 13:13
很多时候我们需要一些数据或信息,而这些信息可能是收费的,不是公开的,或者信息量可能比较大。如果我们简单地手动做,可能会浪费时间,所以我们需要编写一个网络爬虫,高效地抓取你需要的信息。这里小崔使用ja语言来演示如何实现一个网络爬虫。最后附上源代码。
1 首先,在开始写代码之前,首先要搞清楚爬虫爬取网页需要具备哪些功能,爬虫需要用什么数据结构来实现呢?可以控制爬虫自动重启吗?
2 考虑到以上问题,我们需要确定要写多少个类来实现这些功能,所以我们只好用一张图来表示爬虫的几个类的功能。这里小崔只实现了基本的功能,所以画图比较简单,不过明白了这一点,就可以添加自己需要的具体功能了。
3 接下来,我们将根据我们要解决的问题,一一设计我们的各个类。我们的主要问题是: 1.如何下载网页 2.如何从网页中提取 URL 3.如何构建 URL 队列 4.如何使爬虫工作
4 第一个问题,解决如何下载网页
5 这里我们使用第三方开源包来完成这个功能,因为ja自带的实现这个功能的包不好用,请百度下载这个包。包的名称是 HttpClient。
6.很多朋友可能不知道这个包怎么用。为了减少大家的麻烦,节省大家的时间,小翠在这里给大家介绍一下这款包的使用方法。(1)通过get获取Re e对象。(2)获取Re e对象的Entity。(3)通过Entity获取I utStream对象,然后做线处理。
7 可能很多新手只是对我说这句话,并不能深入理解其中的内涵。我将在下面以代码的形式展示它。
8 下面是获取Re e对象的Entity的代码示例
9 通过Entity获取I utStream对象,然后处理返回的内容
10 好了,第一个问题我们已经解决了,我们来解决第二个问题,如何从网页中提取URL
11 提取URL,这里我们还是使用第三方开源的jar包,Jsoup是Ja的HTML解析器,可以直接解析一个URL地址和HTML文本内容,提供了非常省力的API,可以取回数据并通过 DOM、CSS 和类似于 JQuery 的操作方法进行操作。
12使用JSOUP从文件加载网页 File i ut = new File("D:/test.html");Document doc = Jsoup.parse(i ut,"UTF-8","URL/"); 请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定网址(虽然不能指定,比如第一种方法?方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数名为baseURL的意思是当HTML文档使用相对路径的方式引用外部文件时,jsoup会自动为这些 URL 添加前缀,即 baseURL。例如,将开源软件转换为开源软件。
13 下面是解析提取HTML元素的示例代码
14 我们来解决第三个问题,如何建立一个URL队列
15 构建URL队列,首先需要分析爬虫中的队列。爬虫中的队列分析如下: ① 初始种子队列 ② 爬虫从哪里开始 ③ 只使用一次 ④ ArrayList ⾜sufficient 创建新的URL时,需要判断该URL是否已经存在于爬取的队列中(查找) ,如果没有,将URL添加到待爬取队列中 Hashta e
16 解决这些问题后,一个简单的爬虫就完成了。现在你可以开始你的爬虫工作了。如果需要一些具体的功能,可以自己在类中实现相应的功能。
下载jar包,不同版本没有效果
本次经验是小崔原创,如果觉得对你有帮助,记得投上一票哦! 查看全部
java爬虫抓取网页数据(小崔以ja语言来演示一下如何实现网络爬虫,源代码会附在最后)
很多时候我们需要一些数据或信息,而这些信息可能是收费的,不是公开的,或者信息量可能比较大。如果我们简单地手动做,可能会浪费时间,所以我们需要编写一个网络爬虫,高效地抓取你需要的信息。这里小崔使用ja语言来演示如何实现一个网络爬虫。最后附上源代码。
1 首先,在开始写代码之前,首先要搞清楚爬虫爬取网页需要具备哪些功能,爬虫需要用什么数据结构来实现呢?可以控制爬虫自动重启吗?
2 考虑到以上问题,我们需要确定要写多少个类来实现这些功能,所以我们只好用一张图来表示爬虫的几个类的功能。这里小崔只实现了基本的功能,所以画图比较简单,不过明白了这一点,就可以添加自己需要的具体功能了。
3 接下来,我们将根据我们要解决的问题,一一设计我们的各个类。我们的主要问题是: 1.如何下载网页 2.如何从网页中提取 URL 3.如何构建 URL 队列 4.如何使爬虫工作
4 第一个问题,解决如何下载网页
5 这里我们使用第三方开源包来完成这个功能,因为ja自带的实现这个功能的包不好用,请百度下载这个包。包的名称是 HttpClient。
6.很多朋友可能不知道这个包怎么用。为了减少大家的麻烦,节省大家的时间,小翠在这里给大家介绍一下这款包的使用方法。(1)通过get获取Re e对象。(2)获取Re e对象的Entity。(3)通过Entity获取I utStream对象,然后做线处理。
7 可能很多新手只是对我说这句话,并不能深入理解其中的内涵。我将在下面以代码的形式展示它。
8 下面是获取Re e对象的Entity的代码示例
9 通过Entity获取I utStream对象,然后处理返回的内容
10 好了,第一个问题我们已经解决了,我们来解决第二个问题,如何从网页中提取URL
11 提取URL,这里我们还是使用第三方开源的jar包,Jsoup是Ja的HTML解析器,可以直接解析一个URL地址和HTML文本内容,提供了非常省力的API,可以取回数据并通过 DOM、CSS 和类似于 JQuery 的操作方法进行操作。
12使用JSOUP从文件加载网页 File i ut = new File("D:/test.html");Document doc = Jsoup.parse(i ut,"UTF-8","URL/"); 请注意最后一个HTML文档输入法中parse的第三个参数。为什么这里需要指定网址(虽然不能指定,比如第一种方法?方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数名为baseURL的意思是当HTML文档使用相对路径的方式引用外部文件时,jsoup会自动为这些 URL 添加前缀,即 baseURL。例如,将开源软件转换为开源软件。
13 下面是解析提取HTML元素的示例代码
14 我们来解决第三个问题,如何建立一个URL队列
15 构建URL队列,首先需要分析爬虫中的队列。爬虫中的队列分析如下: ① 初始种子队列 ② 爬虫从哪里开始 ③ 只使用一次 ④ ArrayList ⾜sufficient 创建新的URL时,需要判断该URL是否已经存在于爬取的队列中(查找) ,如果没有,将URL添加到待爬取队列中 Hashta e
16 解决这些问题后,一个简单的爬虫就完成了。现在你可以开始你的爬虫工作了。如果需要一些具体的功能,可以自己在类中实现相应的功能。
下载jar包,不同版本没有效果
本次经验是小崔原创,如果觉得对你有帮助,记得投上一票哦!
java爬虫抓取网页数据(初识爬虫的几种分类及注意事项!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-22 22:10
第一次认识爬行动物
一、爬虫介绍
模拟浏览器,发送请求,获取响应
网络爬虫,英文名Spider,又称网络蜘蛛、网络机器人,在数据分析应用中,更多的爬虫称为数据采集程序,是一种按照一定规则自动爬取网络信息的程序或脚本.
l 原则上只要是客户端(浏览器)能做的,爬虫都能做
l 爬虫只能获取客户端(浏览器)显示的数据
网络中的数据可以通过Web服务器【Nginx/Apache】、数据库服务【MySQL/Redis/MongoDB】、索引库、大数据、视频/图片库、云存储【阿里巴巴云OSS】等提供。重要的是源是Web服务器
不过大家一定要注意,可以爬取的数据必须是公开的,非盈利的,比如:如果你入侵别人的非公网,他们会通过ip定位你,这是违法的。或者,一些财务管理网站,如果爬取数据,肯定是不允许的。如果你的朋友不听话硬要爬,那没人能保护你,狗头救你一命~~~
爬虫类著名案例:“乔达科技”被一锅抓,“马车来了”涉嫌盗窃数据被警方立案等。
二、爬虫分类
万能爬虫:
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息决定了整个引擎系统的内容是否丰富,信息是否及时,所以它的性能直接影响搜索的效果引擎
每个人都应该注意。一般的爬虫虽然简单方便,但缺点也很明显。小助手为大家罗列了几点,大家可以理解:
l 一般搜索引擎返回的结果都是网页,大多数情况下,网页中90%的内容对用户来说是无用的。
l 不同领域、不同背景的用户往往有不同的检索目的和需求,搜索引擎无法为特定用户提供搜索结果。
l 随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频、多媒体等不同的数据,一般的搜索引擎对这些文件是无能为力的,它们不能很好地被发现和获得。
l 通用搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询,无法准确理解用户的具体需求。
专注于爬虫:
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的不同之处在于:专注爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息,如12306抢票,或抢某(某类)网站data
根据目的是否为获取数据,可分为:
l 功能爬虫,投票点赞你喜欢的明星
l 数据增量爬虫,如招聘信息
2. 根据url地址和对应的页面内容是否发生变化,增量数据爬虫可以分为:
l 基于url地址变化和内容变化的数据增量爬虫
lurl地址不变,内容变化的数据增量爬虫
看到这里,有没有发现通用爬虫简单,但不实用,专注爬虫应用广泛,实用,但实现起来比较困难,不过没关系,借助小助手,我们都可以学习吧,哦福利!!!
三、爬虫的作用
爬虫在互联网世界有很多功能,比如:
1. 数据采集,例如: 查看全部
java爬虫抓取网页数据(初识爬虫的几种分类及注意事项!(一))
第一次认识爬行动物
一、爬虫介绍
模拟浏览器,发送请求,获取响应
网络爬虫,英文名Spider,又称网络蜘蛛、网络机器人,在数据分析应用中,更多的爬虫称为数据采集程序,是一种按照一定规则自动爬取网络信息的程序或脚本.
l 原则上只要是客户端(浏览器)能做的,爬虫都能做
l 爬虫只能获取客户端(浏览器)显示的数据
网络中的数据可以通过Web服务器【Nginx/Apache】、数据库服务【MySQL/Redis/MongoDB】、索引库、大数据、视频/图片库、云存储【阿里巴巴云OSS】等提供。重要的是源是Web服务器
不过大家一定要注意,可以爬取的数据必须是公开的,非盈利的,比如:如果你入侵别人的非公网,他们会通过ip定位你,这是违法的。或者,一些财务管理网站,如果爬取数据,肯定是不允许的。如果你的朋友不听话硬要爬,那没人能保护你,狗头救你一命~~~
爬虫类著名案例:“乔达科技”被一锅抓,“马车来了”涉嫌盗窃数据被警方立案等。
二、爬虫分类
万能爬虫:
一般的网络爬虫从互联网上采集网页,采集信息,这些网页信息决定了整个引擎系统的内容是否丰富,信息是否及时,所以它的性能直接影响搜索的效果引擎
每个人都应该注意。一般的爬虫虽然简单方便,但缺点也很明显。小助手为大家罗列了几点,大家可以理解:
l 一般搜索引擎返回的结果都是网页,大多数情况下,网页中90%的内容对用户来说是无用的。
l 不同领域、不同背景的用户往往有不同的检索目的和需求,搜索引擎无法为特定用户提供搜索结果。
l 随着万维网上数据形式的丰富和网络技术的不断发展,出现了大量的图片、数据库、音频、视频、多媒体等不同的数据,一般的搜索引擎对这些文件是无能为力的,它们不能很好地被发现和获得。
l 通用搜索引擎大多提供基于关键词的检索,难以支持基于语义信息的查询,无法准确理解用户的具体需求。
专注于爬虫:
聚焦爬虫是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的不同之处在于:专注爬虫在实现网页爬取时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息,如12306抢票,或抢某(某类)网站data
根据目的是否为获取数据,可分为:
l 功能爬虫,投票点赞你喜欢的明星
l 数据增量爬虫,如招聘信息
2. 根据url地址和对应的页面内容是否发生变化,增量数据爬虫可以分为:
l 基于url地址变化和内容变化的数据增量爬虫
lurl地址不变,内容变化的数据增量爬虫
看到这里,有没有发现通用爬虫简单,但不实用,专注爬虫应用广泛,实用,但实现起来比较困难,不过没关系,借助小助手,我们都可以学习吧,哦福利!!!
三、爬虫的作用
爬虫在互联网世界有很多功能,比如:
1. 数据采集,例如:
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛)蜘蛛,聚焦爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-21 09:03
小编将与大家分享如何用java编写网络爬虫。相信大部分人都不太了解,所以分享一下这个文章,供大家参考。希望大家看完这篇文章收获会喜欢,一起来了解一下吧!
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
聚焦爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并将其中的url提取出来,我们将获取到的url存放在一个文件夹中。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。
下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
以上就是如何用java编写网络爬虫的全部内容,感谢阅读!相信大家都有一定的了解。希望分享的内容对大家有所帮助。想了解更多知识,请关注易宿云行业资讯频道! 查看全部
java爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛)蜘蛛,聚焦爬虫)
小编将与大家分享如何用java编写网络爬虫。相信大部分人都不太了解,所以分享一下这个文章,供大家参考。希望大家看完这篇文章收获会喜欢,一起来了解一下吧!
网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
聚焦爬虫工作原理及关键技术概述
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
网络爬虫实现原理
根据这个原理,编写一个简单的网络爬虫程序,这个程序的作用是获取网站发回的数据,并将其中的url提取出来,我们将获取到的url存放在一个文件夹中。除了提取URL之外,我们还可以提取我们想要的各种其他信息,只要我们修改过滤数据的表达式即可。
下面是一个用Java模拟的程序,用来提取新浪网页上的链接,并保存在一个文件中
源代码如下:
package com.cellstrain.icell.util;
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn";);//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
以上就是如何用java编写网络爬虫的全部内容,感谢阅读!相信大家都有一定的了解。希望分享的内容对大家有所帮助。想了解更多知识,请关注易宿云行业资讯频道!
java爬虫抓取网页数据(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-21 09:02
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻的例子,有一定的参考价值,感兴趣的朋友可以参考一下。
最近看到Gecoo爬虫工具,感觉还是比较简单好用的。都写个DEMO测试,抓起来。网站
,主要是抓取新闻的标题和发布时间作为抓取的测试对象。通过选择像 Jquery 选择器这样的节点来抓取 HTML 节点非常方便。 Gecco代码主要使用注解来实现URL匹配,看起来更加简洁美观。
添加 Maven 依赖
com.geccocrawler
gecco
1.0.8
编写爬取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
写爬吉祥页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持PHPERZ。 查看全部
java爬虫抓取网页数据(这里有新鲜出炉的Java函数式编程,程序狗速度看过来!)
新鲜出炉的Java函数式编程来了,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。 ),JavaSE(j2se)的总称。
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻的例子,有一定的参考价值,感兴趣的朋友可以参考一下。
最近看到Gecoo爬虫工具,感觉还是比较简单好用的。都写个DEMO测试,抓起来。网站
,主要是抓取新闻的标题和发布时间作为抓取的测试对象。通过选择像 Jquery 选择器这样的节点来抓取 HTML 节点非常方便。 Gecco代码主要使用注解来实现URL匹配,看起来更加简洁美观。
添加 Maven 依赖
com.geccocrawler
gecco
1.0.8
编写爬取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
写爬吉祥页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持PHPERZ。
java爬虫抓取网页数据(想了解Python爬虫模拟登陆知乎的相关内容吗(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-18 13:14
想知道Python爬虫模拟登录知乎的相关内容吗?本文将为大家讲解python模拟登录知乎的相关知识以及一些代码示例。欢迎阅读和指正。重点:python,模拟登录知乎,python,爬虫,模拟登录,python,爬虫,知乎一起学习。
之前写过一篇用python爬虫爬取电影天堂资源文章的文章,重点是如何解析页面,提高爬虫效率。由于电影天堂中资源的访问权限对每个人都是一样的,所以无需登录验证操作。写完那个文章,又抽时间研究了网上的python模拟登陆。有很多关于这部分的信息。demos全部登录知乎的原因是知乎的登录比较简单,只需要post几个参数就可以保存cookie了。而且它还没有加密。很适合教学。我也是新手,经过一点点探索,终于成功登陆知乎。
首先说一下爬虫模拟登录的基本原理。我也刚刚开始接触一些深层次的东西。首先,一个重要的概念是cookie。我们都知道HTTP是一种无状态协议,也就是说当浏览器客户端向服务器提交请求,服务器响应响应时,它们之间的连接就会中断。结果,当客户端向服务器发送请求时,服务器无法判断这两个客户端是否相同。这绝对是不可能的。这就是cookies发挥作用的地方。当客户端向服务器发送请求时,服务器会为其分配一个标识符(cookie)并将其保存到客户端本地。当客户端再次发送请求时,会连同cookie一起发送到服务器。当服务器看到cookie时,原来是你,这是你的,拿去吧。所以爬虫模拟登录就是模拟浏览器客户端的行为。首先,将您的基本登录信息发送到指定的 url 服务器。验证成功后,会返回一个cookie。我们可以使用此 cookie 进行后续的爬取工作。.
我这里用chrome的开发者工具抓包,不过你也可以用fiddler、firebug等,不过作为前端er,你对chrome有特殊的爱好。准备好工具接下来打开知乎的登录页面,勾选#signin我们可以很容易的看到发送的请求就是登录信息。当然,我是用手机登录,用邮箱登录。最后一个是电子邮件。
所以我们只需要将数据发布到这个地址
phone_num 登录名
密码密码
captcha_type 验证码类型(这个参数在这里没有实际作用)
rember_me 记住密码
_xsrf是一个隐藏的表单元素知乎,用来防御CSRF(对于CSRF,请在此处打开)我发现这个值是固定的,所以就写在这里了。有兴趣的可以写个正则表达式把这部分值提取出来,这样比较严谨。
当您看到服务器返回此信息时,表示您已成功登录
{"r":0,
"msg": "\u767b\u5f55\u6210\u529f"
}#翻译过来就是 “登陆成功” 四个大字
然后就可以用这个身份去爬知乎上的页面了
page=opener.open("https://www.zhihu.com/people/yu-yi-56-70")
content = page.read().decode('utf-8')
print(content)
这段代码通过实例化一个opener对象来保存登录成功后的cookie信息,然后通过opener带着cookie访问服务器上关于身份的完整页面。比较复杂的,比如微博登录,把请求的数据加密,然后写出来,有时间分享给大家。
相关文章 查看全部
java爬虫抓取网页数据(想了解Python爬虫模拟登陆知乎的相关内容吗(组图))
想知道Python爬虫模拟登录知乎的相关内容吗?本文将为大家讲解python模拟登录知乎的相关知识以及一些代码示例。欢迎阅读和指正。重点:python,模拟登录知乎,python,爬虫,模拟登录,python,爬虫,知乎一起学习。
之前写过一篇用python爬虫爬取电影天堂资源文章的文章,重点是如何解析页面,提高爬虫效率。由于电影天堂中资源的访问权限对每个人都是一样的,所以无需登录验证操作。写完那个文章,又抽时间研究了网上的python模拟登陆。有很多关于这部分的信息。demos全部登录知乎的原因是知乎的登录比较简单,只需要post几个参数就可以保存cookie了。而且它还没有加密。很适合教学。我也是新手,经过一点点探索,终于成功登陆知乎。
首先说一下爬虫模拟登录的基本原理。我也刚刚开始接触一些深层次的东西。首先,一个重要的概念是cookie。我们都知道HTTP是一种无状态协议,也就是说当浏览器客户端向服务器提交请求,服务器响应响应时,它们之间的连接就会中断。结果,当客户端向服务器发送请求时,服务器无法判断这两个客户端是否相同。这绝对是不可能的。这就是cookies发挥作用的地方。当客户端向服务器发送请求时,服务器会为其分配一个标识符(cookie)并将其保存到客户端本地。当客户端再次发送请求时,会连同cookie一起发送到服务器。当服务器看到cookie时,原来是你,这是你的,拿去吧。所以爬虫模拟登录就是模拟浏览器客户端的行为。首先,将您的基本登录信息发送到指定的 url 服务器。验证成功后,会返回一个cookie。我们可以使用此 cookie 进行后续的爬取工作。.
我这里用chrome的开发者工具抓包,不过你也可以用fiddler、firebug等,不过作为前端er,你对chrome有特殊的爱好。准备好工具接下来打开知乎的登录页面,勾选#signin我们可以很容易的看到发送的请求就是登录信息。当然,我是用手机登录,用邮箱登录。最后一个是电子邮件。
所以我们只需要将数据发布到这个地址
phone_num 登录名
密码密码
captcha_type 验证码类型(这个参数在这里没有实际作用)
rember_me 记住密码
_xsrf是一个隐藏的表单元素知乎,用来防御CSRF(对于CSRF,请在此处打开)我发现这个值是固定的,所以就写在这里了。有兴趣的可以写个正则表达式把这部分值提取出来,这样比较严谨。
当您看到服务器返回此信息时,表示您已成功登录
{"r":0,
"msg": "\u767b\u5f55\u6210\u529f"
}#翻译过来就是 “登陆成功” 四个大字
然后就可以用这个身份去爬知乎上的页面了
page=opener.open("https://www.zhihu.com/people/yu-yi-56-70";)
content = page.read().decode('utf-8')
print(content)
这段代码通过实例化一个opener对象来保存登录成功后的cookie信息,然后通过opener带着cookie访问服务器上关于身份的完整页面。比较复杂的,比如微博登录,把请求的数据加密,然后写出来,有时间分享给大家。
相关文章
java爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-18 09:12
说起网络爬虫,相信大家都不陌生。爬虫可以捕获 网站 或应用程序的内容以提取有用的有价值信息。爬虫可以用很多编程语言来实现,但是Python是最常用的,你知道为什么吗?一起来看看神龙IP吧~
与C相比,Python和C Python的语言虽然是从C发展而来的,但是在使用上,Python的库是完整的和方便的,而C的语言就麻烦很多了。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但是,在运行速度方面,C语言更好。
与Java相比,Java的解析器多,对网页解析的支持非常好。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。如果需要处理复杂的网页、解析网页内容生成结构化数据或精细解析网页内容,java 更适合。
Python与其他语言没有本质区别,比Python语法简洁明了,开发效率高。此外,python语言的流行还有几个原因:
1.网页抓取界面简洁;
与其他动态脚本语言相比,Python 提供了更完善的访问 Web 文档的 API;与其他静态编程语言相比,Python 爬取网页文档的界面更加简洁。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。 查看全部
java爬虫抓取网页数据(Python却是最常用的,你知道为什么吗?和神龙IP)
说起网络爬虫,相信大家都不陌生。爬虫可以捕获 网站 或应用程序的内容以提取有用的有价值信息。爬虫可以用很多编程语言来实现,但是Python是最常用的,你知道为什么吗?一起来看看神龙IP吧~
与C相比,Python和C Python的语言虽然是从C发展而来的,但是在使用上,Python的库是完整的和方便的,而C的语言就麻烦很多了。要实现同样的功能,Python 只需要 10 行代码,而 C 语言可能需要 100 行甚至更多。但是,在运行速度方面,C语言更好。
与Java相比,Java的解析器多,对网页解析的支持非常好。Java也有爬虫的相关库,但没有Python多。但是,就爬虫的效果而言,Java和Python都可以做到,只是工程量不同,实现方式也不同。如果需要处理复杂的网页、解析网页内容生成结构化数据或精细解析网页内容,java 更适合。
Python与其他语言没有本质区别,比Python语法简洁明了,开发效率高。此外,python语言的流行还有几个原因:
1.网页抓取界面简洁;
与其他动态脚本语言相比,Python 提供了更完善的访问 Web 文档的 API;与其他静态编程语言相比,Python 爬取网页文档的界面更加简洁。
2.强大的第三方库
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这时候我们就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有一些优秀的第三方包可以为你做这件事,例如 Requests 或 Mechanize。
3.数据处理快捷方便
抓取的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python的Beautiful Soup提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。其实很多语言和工具都可以做到以上功能,但是Python可以做到最快最干净。

