
爬虫抓取网页数据
爬虫抓取网页数据(php服务器抓取到数据之后是什么呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-13 11:03
爬虫抓取网页数据,本质是从服务器获取数据。不同的是,在php服务器上抓取的数据是固定的,不用太多。例如,你每次打开网站,只要看到你想要的产品都会有相应的订单量,这个订单量就是数据。那么php服务器抓取到数据之后是什么呢?php服务器往往把数据库的数据提交给beanman,beanman的数据就是data,我们把这个数据过一遍。
如下图。上图是在百度的页面抓取数据时展示出来的一个搜索页面的数据大概情况。数据量大概700万左右,数据来源于网页地址拼接的关键字。具体的数据量以及网页截图大家可以自己查看。搜索者的个人信息数据库大概是以下格式。一个用户id,一个用户名,一个username,一个liketype,一个ordercheck,一个useraction,一个populationid,一个datacolumn。
上图列出的,我们自己也可以转换成自己想要的格式。网页不同网页存储文件不同,一般存放index.php这样的文件。如下,解释一下,username:用户名,password,ordercheck:订单日期。liketype:用户所在城市,可以填写到jpg等格式。可填写地址,可填写微信地址。useraction:用户所在的网站。
datacolumn:用户的数据格式,content为数据文件。link为链接的文件。index.php就是这个文件,用php来存放这些文件,特别注意这个文件是后缀名为.php的文件。有没有瞬间对我们抓取有信心,并且觉得很高大上的感觉!也就是说,用php可以抓取所有的网页,这样能省很多人力,浪费很多时间。
多抓一些细节都是有必要的。上面基本涵盖抓取网页数据所需要具备的知识,那么,我们一直没有搞明白爬虫如何工作呢?上一篇文章已经明确的说了。服务器抓取数据的时候如果是爬虫机器人,它会存一些数据到自己的硬盘中,网页是很大的,通过计算得到自己真正想要的数据或者是直接返回网页上数据。那么问题来了,如果服务器因为系统升级或者换新的服务器,那么就算是没有抓取数据的情况下,服务器也会给服务器安装一个抓取数据的服务,这样就算是服务器不重启服务也可以抓取到我们想要的数据。
但是,正常情况下,如果我们自己修改服务器的host设置。修改host方式类似于修改系统设置,应该要往硬盘中写入额外的字符来改动host的变动才能让服务器变换身份,修改host,那么这个host地址就是和系统一样的,正常情况下,host地址是不变的。那么我们的host的变动怎么做呢?正常情况下,是通过修改服务器host,这个是最好的办法。
那么如果在服务器启动或者不启动的时候如何给服务器修改host呢?如下图。随着服务器的启动或者是关闭,服务器启动或。 查看全部
爬虫抓取网页数据(php服务器抓取到数据之后是什么呢?(一))
爬虫抓取网页数据,本质是从服务器获取数据。不同的是,在php服务器上抓取的数据是固定的,不用太多。例如,你每次打开网站,只要看到你想要的产品都会有相应的订单量,这个订单量就是数据。那么php服务器抓取到数据之后是什么呢?php服务器往往把数据库的数据提交给beanman,beanman的数据就是data,我们把这个数据过一遍。
如下图。上图是在百度的页面抓取数据时展示出来的一个搜索页面的数据大概情况。数据量大概700万左右,数据来源于网页地址拼接的关键字。具体的数据量以及网页截图大家可以自己查看。搜索者的个人信息数据库大概是以下格式。一个用户id,一个用户名,一个username,一个liketype,一个ordercheck,一个useraction,一个populationid,一个datacolumn。
上图列出的,我们自己也可以转换成自己想要的格式。网页不同网页存储文件不同,一般存放index.php这样的文件。如下,解释一下,username:用户名,password,ordercheck:订单日期。liketype:用户所在城市,可以填写到jpg等格式。可填写地址,可填写微信地址。useraction:用户所在的网站。
datacolumn:用户的数据格式,content为数据文件。link为链接的文件。index.php就是这个文件,用php来存放这些文件,特别注意这个文件是后缀名为.php的文件。有没有瞬间对我们抓取有信心,并且觉得很高大上的感觉!也就是说,用php可以抓取所有的网页,这样能省很多人力,浪费很多时间。
多抓一些细节都是有必要的。上面基本涵盖抓取网页数据所需要具备的知识,那么,我们一直没有搞明白爬虫如何工作呢?上一篇文章已经明确的说了。服务器抓取数据的时候如果是爬虫机器人,它会存一些数据到自己的硬盘中,网页是很大的,通过计算得到自己真正想要的数据或者是直接返回网页上数据。那么问题来了,如果服务器因为系统升级或者换新的服务器,那么就算是没有抓取数据的情况下,服务器也会给服务器安装一个抓取数据的服务,这样就算是服务器不重启服务也可以抓取到我们想要的数据。
但是,正常情况下,如果我们自己修改服务器的host设置。修改host方式类似于修改系统设置,应该要往硬盘中写入额外的字符来改动host的变动才能让服务器变换身份,修改host,那么这个host地址就是和系统一样的,正常情况下,host地址是不变的。那么我们的host的变动怎么做呢?正常情况下,是通过修改服务器host,这个是最好的办法。
那么如果在服务器启动或者不启动的时候如何给服务器修改host呢?如下图。随着服务器的启动或者是关闭,服务器启动或。
爬虫抓取网页数据( 一个网站的数据都可以爬下来,这个学费值不值得,能爬取95%的网站数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-13 07:03
一个网站的数据都可以爬下来,这个学费值不值得,能爬取95%的网站数据
)
前几天,BOX群的朋友问我们,市面上有两块钱以上的Python在线课程。学习了两个月,可以上手爬虫了,网站的大部分数据都可以爬下来了,学费值不值?
看到这个问题我们还是很苦恼的,所以决定拿出一个看家技能,这样你不用写一行代码,两天学会,95%的都能爬只有一个浏览器的内容 网站数据。
我们先来说说爬行动物是什么,它能做什么。
爬虫英文名称为WebCrawler,是一款高效的信息采集工具,是一款自动提取互联网上指定内容的工具。
简而言之,互联网上有大量数据。如果你靠人一页一页地看,你一辈子也看不完。使用针对特定网站和特定信息训练的爬虫,可以帮助你在短时间内快速获取大量数据,并根据需要安排结构化排序,方便数据分析。
几乎所有的网站都有数据,有些是带数字的显式数据,可用于数据分析;有些是文字隐含的数据,可以直接查看结构化信息,也可以做统计数据分析。
让我们列出几个场景:
你可以使用爬虫来爬取数据,看看你自己公司和竞争公司的产品在搜索引擎中出现的次数,以及它们在主流网站上的排名情况。
您还可以爬取行业数据、融资数据和用户数据,研究市场体量和趋势。
网站 喜欢知乎 和微博,可以挖掘不同话题的关注者,发现潜在用户,或者爬取评论进行词频分析,研究他们对产品或新闻的反应。
某地的网站政策最近有没有更新,最近有什么微博发了粉丝?没时间一直盯着刷,做爬虫,每周自动爬取一次数据,随时获取最新消息。
招标信息网站1分钟内爬取与贵企业相关的招标文件,分门别类发给业务部;分享网站的图片,在家庭库网站上的下载地址,一次性抓拍,然后扔到迅雷中批量下载。可以省很多时间一一下载
找工作时,批量抓取主流招聘网站上的相关职位,制作数据分析表,帮助你快速找到合适的工作;比较附近房屋的价格;如果你想买车,还可以爬下来对比一下新车和二手车的所有相关数据。
关于你所处的行业现状、企业发展、人才分布,原本只能找零星的别人准备的数据,现在可以自己爬取数据,然后做一个可视化的图表,不管是内部做的或外部。报告时,数据可以成为支持您观点的强大工具。
哪里有网站,哪里就有数据,哪里有数据,爬虫就可以抓到。除了上面提到的具体场景,一个对数据敏感的人应该长时间锻炼:如何提出问题,如何找到可以洞察问题的数据,如何从中找到他想要的答案海量数据。
这就是每个小白在大数据时代观察和理解世界的方式。
前几天,我们上了一堂PowerBl数据可视化分析课程,教大家如何将表格中的数据放在一起,相互关联,做出简洁美观的可视化报表。
教程中几个案例的数据都是用这个技术爬下来的,比如:
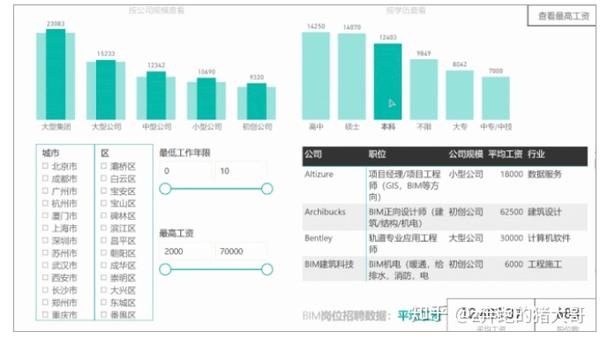
抓取招聘网站数据,然后分析BIM相关职位在不同地区、不同规模公司的分布情况?如何用 5 秒找到适合自己的工作?
用豆瓣电影TOP250的数据分析案例,教你如何在有限的页面中呈现更多维度的数据可视化。快速帮助他人选择适合他们的电影。
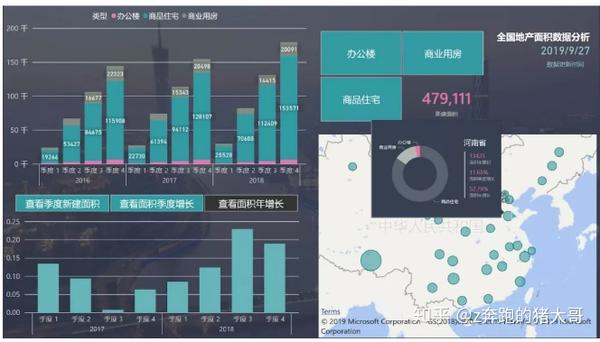
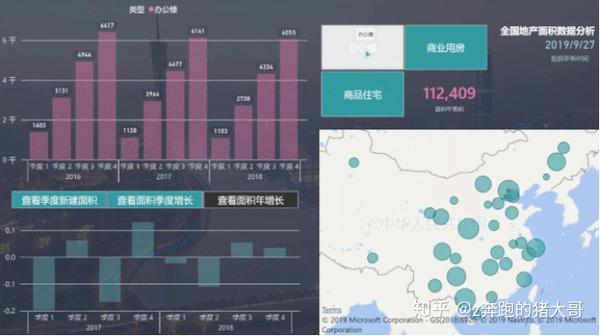
抓拍近三年中国各省房地产行业数据,分析不同地区、不同类型、按年、季度的房地产项目增长情况,看看哪些地方、哪些地区发展较好?
本次由BIMBOX出品的“0-Code网络爬虫课程”一共15节课。我们使用豆瓣、知乎、京东、招标信息网、住建部官网、Pexels图片网站、IT橙公司信息、网站@的不同案例> 如、知识星球、哔哩哔哩等,给你解释如下:
正如课程的标题所说,整个学习过程与 Python 无关。不需要从头到尾写一行代码,小白可以很快学会。
学习爬虫和学习 Python 是不一样的,它只是 Python 函数的一个分支。然而,在众多培训机构的宣传下,爬虫已经成为 Python 的代名词。
通过本教程,BIMBOX想要做的就是把高昂的学费和摆在你面前的对学习代码的恐惧收拾干净,让你用一两天的时间感受数据的魅力和数据带来的快乐自动化。
看着一个网页在屏幕上自动翻页滚动,几分钟后将数千行数据采集到一张表格中,其中的快感和喜悦只有亲身体验才能知道。
《0码网络爬虫课程》,秉承BIMBOX一贯风格,课程声音干净,画面清晰,剪掉50%的废话和停顿,让你学习更轻松。
另外,我们为本课程专门设立了学习交流微信群。添加群组的方法请参考教程说明页。当您是初学者时,您会遇到各种问题。我们将等待您与其他一起学习的学生一起参与讨论。
如果要花两天时间,从数据新手到爬取数据高手,扫码搞定。
搜索更多好课程扫这里~
查看全部
爬虫抓取网页数据(
一个网站的数据都可以爬下来,这个学费值不值得,能爬取95%的网站数据
)
前几天,BOX群的朋友问我们,市面上有两块钱以上的Python在线课程。学习了两个月,可以上手爬虫了,网站的大部分数据都可以爬下来了,学费值不值?
看到这个问题我们还是很苦恼的,所以决定拿出一个看家技能,这样你不用写一行代码,两天学会,95%的都能爬只有一个浏览器的内容 网站数据。
我们先来说说爬行动物是什么,它能做什么。
爬虫英文名称为WebCrawler,是一款高效的信息采集工具,是一款自动提取互联网上指定内容的工具。
简而言之,互联网上有大量数据。如果你靠人一页一页地看,你一辈子也看不完。使用针对特定网站和特定信息训练的爬虫,可以帮助你在短时间内快速获取大量数据,并根据需要安排结构化排序,方便数据分析。
几乎所有的网站都有数据,有些是带数字的显式数据,可用于数据分析;有些是文字隐含的数据,可以直接查看结构化信息,也可以做统计数据分析。
让我们列出几个场景:

你可以使用爬虫来爬取数据,看看你自己公司和竞争公司的产品在搜索引擎中出现的次数,以及它们在主流网站上的排名情况。
您还可以爬取行业数据、融资数据和用户数据,研究市场体量和趋势。

网站 喜欢知乎 和微博,可以挖掘不同话题的关注者,发现潜在用户,或者爬取评论进行词频分析,研究他们对产品或新闻的反应。


某地的网站政策最近有没有更新,最近有什么微博发了粉丝?没时间一直盯着刷,做爬虫,每周自动爬取一次数据,随时获取最新消息。

招标信息网站1分钟内爬取与贵企业相关的招标文件,分门别类发给业务部;分享网站的图片,在家庭库网站上的下载地址,一次性抓拍,然后扔到迅雷中批量下载。可以省很多时间一一下载

找工作时,批量抓取主流招聘网站上的相关职位,制作数据分析表,帮助你快速找到合适的工作;比较附近房屋的价格;如果你想买车,还可以爬下来对比一下新车和二手车的所有相关数据。

关于你所处的行业现状、企业发展、人才分布,原本只能找零星的别人准备的数据,现在可以自己爬取数据,然后做一个可视化的图表,不管是内部做的或外部。报告时,数据可以成为支持您观点的强大工具。
哪里有网站,哪里就有数据,哪里有数据,爬虫就可以抓到。除了上面提到的具体场景,一个对数据敏感的人应该长时间锻炼:如何提出问题,如何找到可以洞察问题的数据,如何从中找到他想要的答案海量数据。
这就是每个小白在大数据时代观察和理解世界的方式。
前几天,我们上了一堂PowerBl数据可视化分析课程,教大家如何将表格中的数据放在一起,相互关联,做出简洁美观的可视化报表。
教程中几个案例的数据都是用这个技术爬下来的,比如:
抓取招聘网站数据,然后分析BIM相关职位在不同地区、不同规模公司的分布情况?如何用 5 秒找到适合自己的工作?
用豆瓣电影TOP250的数据分析案例,教你如何在有限的页面中呈现更多维度的数据可视化。快速帮助他人选择适合他们的电影。
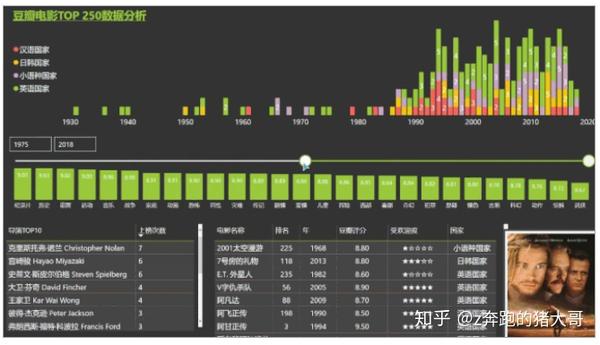
抓拍近三年中国各省房地产行业数据,分析不同地区、不同类型、按年、季度的房地产项目增长情况,看看哪些地方、哪些地区发展较好?
本次由BIMBOX出品的“0-Code网络爬虫课程”一共15节课。我们使用豆瓣、知乎、京东、招标信息网、住建部官网、Pexels图片网站、IT橙公司信息、网站@的不同案例> 如、知识星球、哔哩哔哩等,给你解释如下:

正如课程的标题所说,整个学习过程与 Python 无关。不需要从头到尾写一行代码,小白可以很快学会。
学习爬虫和学习 Python 是不一样的,它只是 Python 函数的一个分支。然而,在众多培训机构的宣传下,爬虫已经成为 Python 的代名词。
通过本教程,BIMBOX想要做的就是把高昂的学费和摆在你面前的对学习代码的恐惧收拾干净,让你用一两天的时间感受数据的魅力和数据带来的快乐自动化。
看着一个网页在屏幕上自动翻页滚动,几分钟后将数千行数据采集到一张表格中,其中的快感和喜悦只有亲身体验才能知道。
《0码网络爬虫课程》,秉承BIMBOX一贯风格,课程声音干净,画面清晰,剪掉50%的废话和停顿,让你学习更轻松。
另外,我们为本课程专门设立了学习交流微信群。添加群组的方法请参考教程说明页。当您是初学者时,您会遇到各种问题。我们将等待您与其他一起学习的学生一起参与讨论。
如果要花两天时间,从数据新手到爬取数据高手,扫码搞定。

搜索更多好课程扫这里~

爬虫抓取网页数据(如何编写一个网络爬虫的抓取功能?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-12 06:01
从各种搜索引擎到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
- 安装蟒蛇
- 运行 pip 安装请求
- 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
print(content)
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
print(element["href"])
# 获取更多数据
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
资源: 查看全部
爬虫抓取网页数据(如何编写一个网络爬虫的抓取功能?-八维教育)
从各种搜索引擎到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
- 安装蟒蛇
- 运行 pip 安装请求
- 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
print(content)
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
print(element["href"])
# 获取更多数据
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
资源:
爬虫抓取网页数据(url地址地址的单元格如何写入到excel?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-08 12:05
爬虫抓取网页数据来写到excel的话,就是写的时候带上了数据的url地址。但是带上了url地址就无法写入excel了吗?不是的。那么url地址地址的单元格又该如何写入到excel呢?什么叫做excel表格的单元格呢?所谓excel表格就是一张表格而已,而不是一个工作簿,一个单元格或一列一行那么简单,而且,excel表格并不是只能显示一个单元格的内容,还可以显示多个单元格的内容。
soeasy,想用excel表格写入大量数据的时候,通常都是用工作簿或者工作簿组这种叫法。既然工作簿还叫工作簿,写入数据当然是工作簿了,而且也是两个及以上工作簿来协同工作。选中工作簿,右键点击任意要写入数据的工作表,点击新建,即可完成数据的写入。看这里好像很繁琐,其实不是的,用cell,也就是工作表数据写入也很简单,只需要在“确定工作簿及工作簿标题”的时候,在单元格中写入相应单元格就可以完成。
具体操作如下:将表格的名称改为某个工作簿中的一个工作表,这里我用了cell(工作簿1,工作簿2),如果你要写入2个工作簿也可以,因为2个工作簿可以通过工作簿连接的方式实现实际上如果你只要写入一个工作簿的数据,只需要在写入需要的数据之前点一下鼠标左键即可。可以在首行右键点击新建工作簿,完成工作簿名称的输入和表格内数据的补齐就可以了,操作更简单快捷。
按这个快捷键点一下就可以完成实际的数据写入。但是工作簿间是不能相互连接的,而不能把某个工作簿中的工作表的内容直接导出到另一个工作簿中。点击新建工作簿之后要把文件转换为另一个工作簿,我们在步骤2中点击浏览的时候选择所要存放数据的工作簿就可以了。然后就可以把写入数据的相关单元格内容复制到另一个工作簿中。看到这里不妨尝试一下,你将会发现写入数据的工作簿可以同时存在于多个工作簿中,反正是强迫症患者治好了强迫症这方面我是蛮有经验的。
另外,有时候我们要写入数据的工作簿只有一个,那怎么写入?这种情况也不复杂,你可以在工作簿的右上角找到批量操作,点击就可以批量写入相应数据咯。这里你要设置好数据的格式,单元格应用规则,写入的时候你就可以使用数据的格式导入数据是否完整等等规则,并进行自定义命名哟。要实现在工作簿之间相互传送数据的话,以下的命令就可以实现:在不使用quit的情况下(这里在quit之前再点击上图所示的选项按钮或者点击左边“quit”按钮),如果已经将需要写入数据的工作簿写入到了左边工作簿,点击上图所示的“psr,”即可将需要的数据写入到其他。 查看全部
爬虫抓取网页数据(url地址地址的单元格如何写入到excel?(图))
爬虫抓取网页数据来写到excel的话,就是写的时候带上了数据的url地址。但是带上了url地址就无法写入excel了吗?不是的。那么url地址地址的单元格又该如何写入到excel呢?什么叫做excel表格的单元格呢?所谓excel表格就是一张表格而已,而不是一个工作簿,一个单元格或一列一行那么简单,而且,excel表格并不是只能显示一个单元格的内容,还可以显示多个单元格的内容。
soeasy,想用excel表格写入大量数据的时候,通常都是用工作簿或者工作簿组这种叫法。既然工作簿还叫工作簿,写入数据当然是工作簿了,而且也是两个及以上工作簿来协同工作。选中工作簿,右键点击任意要写入数据的工作表,点击新建,即可完成数据的写入。看这里好像很繁琐,其实不是的,用cell,也就是工作表数据写入也很简单,只需要在“确定工作簿及工作簿标题”的时候,在单元格中写入相应单元格就可以完成。
具体操作如下:将表格的名称改为某个工作簿中的一个工作表,这里我用了cell(工作簿1,工作簿2),如果你要写入2个工作簿也可以,因为2个工作簿可以通过工作簿连接的方式实现实际上如果你只要写入一个工作簿的数据,只需要在写入需要的数据之前点一下鼠标左键即可。可以在首行右键点击新建工作簿,完成工作簿名称的输入和表格内数据的补齐就可以了,操作更简单快捷。
按这个快捷键点一下就可以完成实际的数据写入。但是工作簿间是不能相互连接的,而不能把某个工作簿中的工作表的内容直接导出到另一个工作簿中。点击新建工作簿之后要把文件转换为另一个工作簿,我们在步骤2中点击浏览的时候选择所要存放数据的工作簿就可以了。然后就可以把写入数据的相关单元格内容复制到另一个工作簿中。看到这里不妨尝试一下,你将会发现写入数据的工作簿可以同时存在于多个工作簿中,反正是强迫症患者治好了强迫症这方面我是蛮有经验的。
另外,有时候我们要写入数据的工作簿只有一个,那怎么写入?这种情况也不复杂,你可以在工作簿的右上角找到批量操作,点击就可以批量写入相应数据咯。这里你要设置好数据的格式,单元格应用规则,写入的时候你就可以使用数据的格式导入数据是否完整等等规则,并进行自定义命名哟。要实现在工作簿之间相互传送数据的话,以下的命令就可以实现:在不使用quit的情况下(这里在quit之前再点击上图所示的选项按钮或者点击左边“quit”按钮),如果已经将需要写入数据的工作簿写入到了左边工作簿,点击上图所示的“psr,”即可将需要的数据写入到其他。
爬虫抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-07 18:07
IPy:IP地址相关处理
dnsptyhon:域名相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都有新的模块、框架和组件产生,比如用于与Java桥接的PythonJS,甚至Python可以写Map和Reduce。
二、爬虫如何抓取网页数据
1. 抓取页面
由于我们通常抓取的内容不止一页,所以要注意翻页时链接的变化、关键字的变化,有时甚至是日期;此外,主网页需要静态和动态加载。
2.提出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。
3.获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等类型。
4.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理。
5.保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了如何快速掌握Python以及爬虫如何抓取网页数据的一些知识。其实,网络爬虫的难点其实并不在于爬虫本身。爬虫相对简单易学。网上的很多教程模板也可以使用。但是为了避免数据被爬取,每个网站添加的各种反爬取措施还是不一样的。如果要继续从 网站 爬取数据,则必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法,其他反爬虫措施可以阅读网站信息。 查看全部
爬虫抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
IPy:IP地址相关处理
dnsptyhon:域名相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都有新的模块、框架和组件产生,比如用于与Java桥接的PythonJS,甚至Python可以写Map和Reduce。
二、爬虫如何抓取网页数据
1. 抓取页面
由于我们通常抓取的内容不止一页,所以要注意翻页时链接的变化、关键字的变化,有时甚至是日期;此外,主网页需要静态和动态加载。
2.提出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。

3.获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等类型。
4.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理。
5.保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了如何快速掌握Python以及爬虫如何抓取网页数据的一些知识。其实,网络爬虫的难点其实并不在于爬虫本身。爬虫相对简单易学。网上的很多教程模板也可以使用。但是为了避免数据被爬取,每个网站添加的各种反爬取措施还是不一样的。如果要继续从 网站 爬取数据,则必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法,其他反爬虫措施可以阅读网站信息。
爬虫抓取网页数据(精通Python网络爬虫获取电影天堂视频下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-03-07 16:12
阿里云 > 云栖社区 > 主题图 > P > python网络爬虫获取页面内容
推荐活动:
更多优惠>
当前话题:python网络爬虫获取页面内容并添加到采集夹
相关话题:
Python网络爬虫获取页面内容相关博客查看更多博客
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接
作者:python进阶1047人查看评论:01年前
【一、项目背景】相信大家都有过头疼的经历。很难下载电影,对吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python 网络爬虫入门
作者:yunqi2 浏览评论:03年前
什么是网络爬虫 网络爬虫,也称为网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。优先声明:我们使用的python编译环境是PyCharm 一、首先是一个网络爬虫
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解
作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——第1部分理论基础第1章什么是网络爬虫1.1初识网络爬虫
作者:华章电脑2720浏览量:04年前
本节节选自华章出版社《精通Python网络爬虫:核心技术、框架与项目》一书第1章1.1节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。第 1 部分 第 1 部分 理论基础 第 1 章 什么是网络爬虫 第 2 章 网络爬虫技能概述
阅读全文
浅谈Python网络爬虫
作者:小技术专家2076 浏览评论:04年前
相关背景 网络蜘蛛,也称为网络蜘蛛或网络机器人,是用于自动化采集网站数据的程序。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对采集某个
阅读全文
开源python网络爬虫框架Scrapy
作者:shadowcat2385 浏览评论:05年前
来源: 简介:所谓网络爬虫,就是在互联网上到处或有针对性地爬取数据的程序。当然,这种说法不够专业。更专业的描述是爬取特定网站网页的HTML数据。然而,由于一个
阅读全文
Python网络爬虫(14)使用Scrapy搭建爬虫框架
作者:收到优惠码998人查看评论数:02年前
Python网络爬虫(14)使用Scrapy搭建爬虫框架阅读目录目的说明创建scrapy项目的一些介绍创建爬虫模块-下载增强爬虫模块-分析增强爬虫模块- 打包数据加强爬虫模块 - 翻页加强爬虫模块 - 存储增强爬虫模块 - 图片下载保存启动爬虫
阅读全文
一篇文章教你用Python爬虫实现豆瓣电影采集
作者:python进阶11人查看评论:01年前
[一、项目背景] 豆瓣电影提供最新的电影介绍和评论,包括电影信息查询和已上映电影的票务服务。可以记录想看、正在看、看过的电影和电视剧,顺便打分,写影评。极大地方便了人们的生活。今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分做出更好的选择
阅读全文 查看全部
爬虫抓取网页数据(精通Python网络爬虫获取电影天堂视频下载(组图))
阿里云 > 云栖社区 > 主题图 > P > python网络爬虫获取页面内容

推荐活动:
更多优惠>
当前话题:python网络爬虫获取页面内容并添加到采集夹
相关话题:
Python网络爬虫获取页面内容相关博客查看更多博客
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接


作者:python进阶1047人查看评论:01年前
【一、项目背景】相信大家都有过头疼的经历。很难下载电影,对吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python 网络爬虫入门


作者:yunqi2 浏览评论:03年前
什么是网络爬虫 网络爬虫,也称为网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。优先声明:我们使用的python编译环境是PyCharm 一、首先是一个网络爬虫
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解

作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——第1部分理论基础第1章什么是网络爬虫1.1初识网络爬虫

作者:华章电脑2720浏览量:04年前
本节节选自华章出版社《精通Python网络爬虫:核心技术、框架与项目》一书第1章1.1节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。第 1 部分 第 1 部分 理论基础 第 1 章 什么是网络爬虫 第 2 章 网络爬虫技能概述
阅读全文
浅谈Python网络爬虫

作者:小技术专家2076 浏览评论:04年前
相关背景 网络蜘蛛,也称为网络蜘蛛或网络机器人,是用于自动化采集网站数据的程序。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对采集某个
阅读全文
开源python网络爬虫框架Scrapy


作者:shadowcat2385 浏览评论:05年前
来源: 简介:所谓网络爬虫,就是在互联网上到处或有针对性地爬取数据的程序。当然,这种说法不够专业。更专业的描述是爬取特定网站网页的HTML数据。然而,由于一个
阅读全文
Python网络爬虫(14)使用Scrapy搭建爬虫框架


作者:收到优惠码998人查看评论数:02年前
Python网络爬虫(14)使用Scrapy搭建爬虫框架阅读目录目的说明创建scrapy项目的一些介绍创建爬虫模块-下载增强爬虫模块-分析增强爬虫模块- 打包数据加强爬虫模块 - 翻页加强爬虫模块 - 存储增强爬虫模块 - 图片下载保存启动爬虫
阅读全文
一篇文章教你用Python爬虫实现豆瓣电影采集
作者:python进阶11人查看评论:01年前
[一、项目背景] 豆瓣电影提供最新的电影介绍和评论,包括电影信息查询和已上映电影的票务服务。可以记录想看、正在看、看过的电影和电视剧,顺便打分,写影评。极大地方便了人们的生活。今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分做出更好的选择
阅读全文
爬虫抓取网页数据( 求职招聘类网站中的数据查找和整理效率(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-04 04:20
求职招聘类网站中的数据查找和整理效率(组图)
)
我们在工作中使用互联网上发布的各种信息。使用搜索引擎查找和组织需要花费大量时间。现在python可以帮助我们,利用爬虫技术,提高数据搜索和组织的效率。
我们来看一个爬虫案例——在求职类网站中抓取数据。使用环境:win10+python3+Juypter Notebook
第一步:分析网页
第一步:分析网页
要爬取网页,首先要分析网页结构。
现在很多网站使用Ajax(异步加载)技术,打开网页,先给大家看上面的一些东西,剩下的慢慢加载。所以你可以看到很多网页,慢慢的刷,或者一些网站随着你的移动,很多信息都在慢慢加载。这种网页的优点是网页加载速度非常快。
但这项技术不利于爬虫的爬行。我们可以使用chrome浏览器小部件进行分析,进入网络分析界面。界面如下:
这时候是空白的,我们刷新一下,可以看到一连串的网络请求。
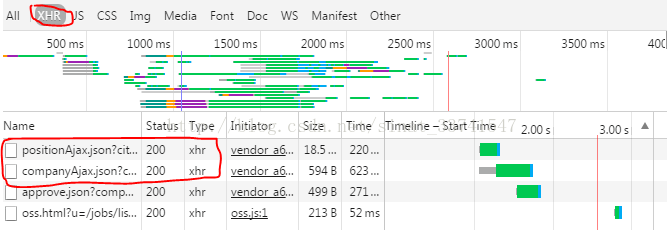
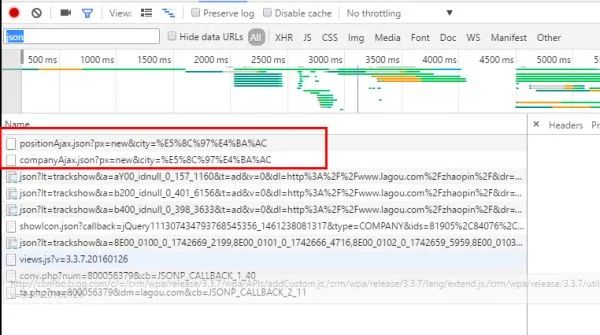
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr这种类型的requests,如下:
这种数据一般都是json格式,我们也可以尝试在过滤器中输入json进行过滤查找。
上图找到了两个xhr请求,从字面意思看很可能是我们需要的信息,右键在另一个界面打开。
我们可以在右边的方框中切换到“Preview”,然后点击content-positionResult查看,可以看到位置的信息,以键值对的形式呈现。这是json格式,特别适合网页数据交换。
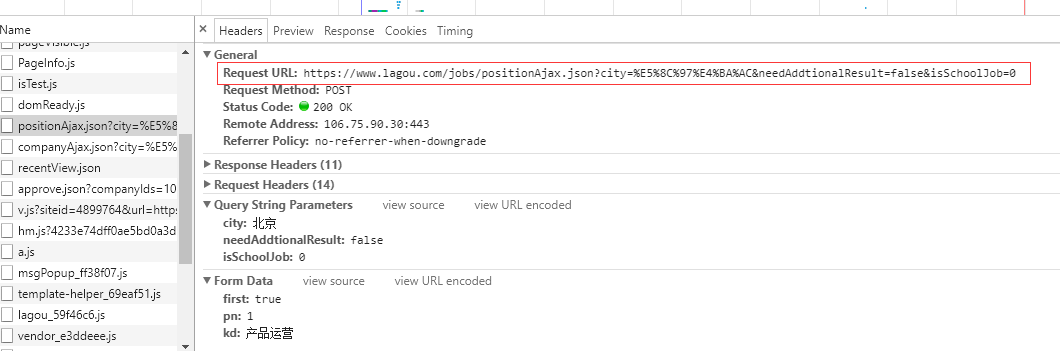
第二步,URL构建
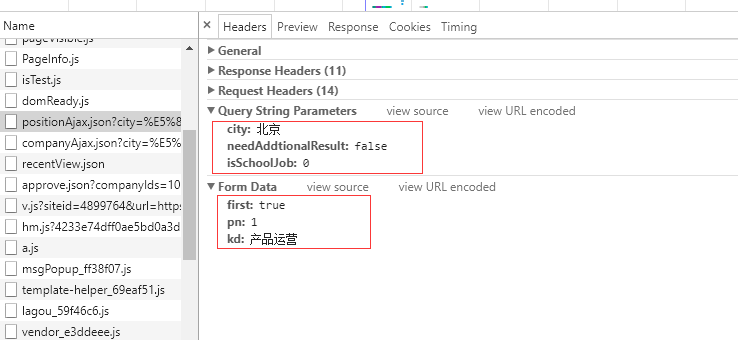
在“Headers”中,我们看到了网页地址。通过观察网页地址,我们可以发现并推断出这一段是固定的,剩下的我们发现有一个city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0
查看请求发送参数列表,可以确定city参数是城市,pn参数是页数,kd参数是job关键字。
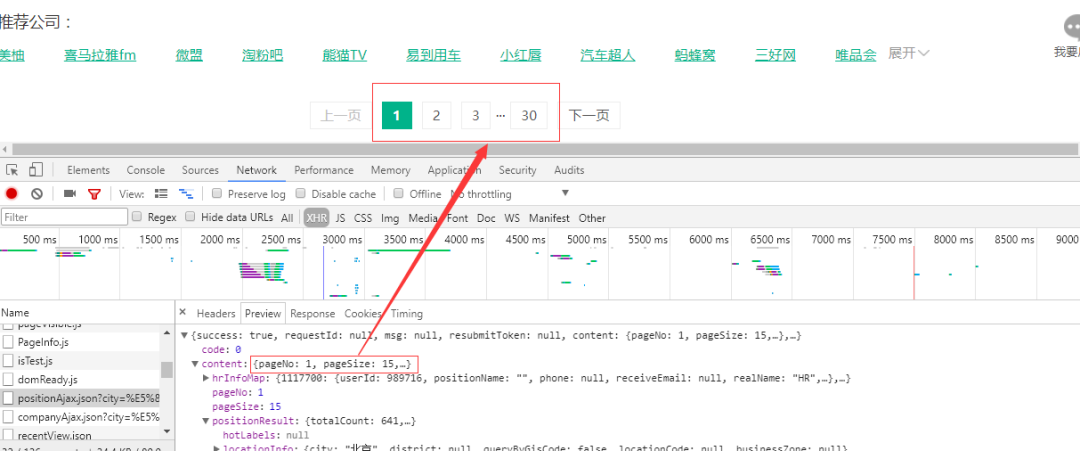
我们看一下位置,一共有30页,每页有15条数据,所以我们只需要构造一个循环遍历每一页的数据。
第三步,编写爬虫脚本,编写代码
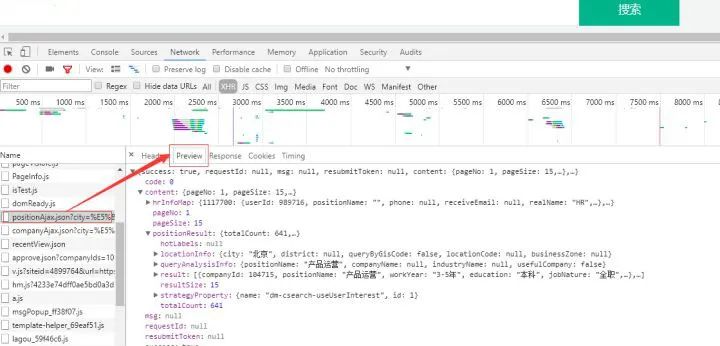
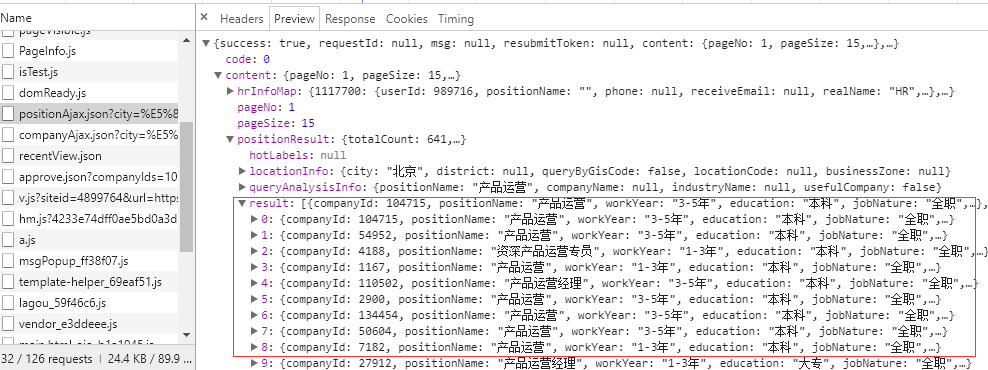
需要注意的是,由于这个网页的格式是json,那么我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击content-positionResult-result,可以先找到一个列表,然后点击查看各个位置的内容。为什么从这里看?一个好处就是知道json文件的层次结构,方便后面编码。
具体代码展示:
import requests,jsonfrom openpyxl import Workbook#http请求头信息headers={'Accept':'application/json, text/javascript, */*; q=0.01','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.8','Connection':'keep-alive','Content-Length':'25','Content-Type':'application/x-www-form-urlencoded; charset=UTF-8','Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E','Host':'www.lagou.com','Origin':'https://www.lagou.com','Referer':'https://www.lagou.com/jobs/list_Python?','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36','X-Anit-Forge-Code':'0','X-Anit-Forge-Token':'None','X-Requested-With':'XMLHttpRequest'}def get_json(url, page, lang_name): data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}#POST请求 json = requests.post(url,data,headers=headers).json() list_con = json['content']['positionResult']['result'] info_list = [] for i in list_con: info = [] info.append(i['companyId']) info.append(i['companyFullName']) info.append(i['companyShortName']) info.append(i['companySize']) info.append(str(i['companyLabelList'])) info.append(i['industryField']) info.append(i['financeStage']) info.append(i['positionId']) info.append(i['positionName']) info.append(i['positionAdvantage'])# info.append(i['positionLables']) info.append(i['city']) info.append(i['district'])# info.append(i['businessZones']) info.append(i['salary']) info.append(i['education']) info.append(i['workYear']) info_list.append(info) return info_listdef main(): lang_name = input('职位名:') page = 1 url = 'http://www.lagou.com/jobs/posi ... 39%3B info_result=[] title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"] info_result.append(title) #遍历网址 while page < 31: info = get_json(url, page, lang_name) info_result = info_result + info page += 1#写入excel文件 wb = Workbook() ws1 = wb.active ws1.title = lang_name for row in info_result: ws1.append(row) wb.save('职位信息3.xlsx')main()
打开excel文件,查看数据是否访问成功:
我们看到招聘类网站中捕获的数据成功保存在excel表中。
结尾
过去精选
Python可视化库你了解多少?带你去探索
人工智能方向——智能图像识别技术(二)
人工智能方向——智能图像识别技术(一)
在 Python 中开始使用爬虫的 7 个技巧
使用数据可视化有什么好处?
关注雷克
学干货
查看全部
爬虫抓取网页数据(
求职招聘类网站中的数据查找和整理效率(组图)
)

我们在工作中使用互联网上发布的各种信息。使用搜索引擎查找和组织需要花费大量时间。现在python可以帮助我们,利用爬虫技术,提高数据搜索和组织的效率。
我们来看一个爬虫案例——在求职类网站中抓取数据。使用环境:win10+python3+Juypter Notebook
第一步:分析网页
第一步:分析网页
要爬取网页,首先要分析网页结构。
现在很多网站使用Ajax(异步加载)技术,打开网页,先给大家看上面的一些东西,剩下的慢慢加载。所以你可以看到很多网页,慢慢的刷,或者一些网站随着你的移动,很多信息都在慢慢加载。这种网页的优点是网页加载速度非常快。
但这项技术不利于爬虫的爬行。我们可以使用chrome浏览器小部件进行分析,进入网络分析界面。界面如下:
这时候是空白的,我们刷新一下,可以看到一连串的网络请求。
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr这种类型的requests,如下:
这种数据一般都是json格式,我们也可以尝试在过滤器中输入json进行过滤查找。
上图找到了两个xhr请求,从字面意思看很可能是我们需要的信息,右键在另一个界面打开。
我们可以在右边的方框中切换到“Preview”,然后点击content-positionResult查看,可以看到位置的信息,以键值对的形式呈现。这是json格式,特别适合网页数据交换。
第二步,URL构建
在“Headers”中,我们看到了网页地址。通过观察网页地址,我们可以发现并推断出这一段是固定的,剩下的我们发现有一个city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0
查看请求发送参数列表,可以确定city参数是城市,pn参数是页数,kd参数是job关键字。
我们看一下位置,一共有30页,每页有15条数据,所以我们只需要构造一个循环遍历每一页的数据。
第三步,编写爬虫脚本,编写代码
需要注意的是,由于这个网页的格式是json,那么我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击content-positionResult-result,可以先找到一个列表,然后点击查看各个位置的内容。为什么从这里看?一个好处就是知道json文件的层次结构,方便后面编码。
具体代码展示:
import requests,jsonfrom openpyxl import Workbook#http请求头信息headers={'Accept':'application/json, text/javascript, */*; q=0.01','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.8','Connection':'keep-alive','Content-Length':'25','Content-Type':'application/x-www-form-urlencoded; charset=UTF-8','Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E','Host':'www.lagou.com','Origin':'https://www.lagou.com','Referer':'https://www.lagou.com/jobs/list_Python?','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36','X-Anit-Forge-Code':'0','X-Anit-Forge-Token':'None','X-Requested-With':'XMLHttpRequest'}def get_json(url, page, lang_name): data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}#POST请求 json = requests.post(url,data,headers=headers).json() list_con = json['content']['positionResult']['result'] info_list = [] for i in list_con: info = [] info.append(i['companyId']) info.append(i['companyFullName']) info.append(i['companyShortName']) info.append(i['companySize']) info.append(str(i['companyLabelList'])) info.append(i['industryField']) info.append(i['financeStage']) info.append(i['positionId']) info.append(i['positionName']) info.append(i['positionAdvantage'])# info.append(i['positionLables']) info.append(i['city']) info.append(i['district'])# info.append(i['businessZones']) info.append(i['salary']) info.append(i['education']) info.append(i['workYear']) info_list.append(info) return info_listdef main(): lang_name = input('职位名:') page = 1 url = 'http://www.lagou.com/jobs/posi ... 39%3B info_result=[] title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"] info_result.append(title) #遍历网址 while page < 31: info = get_json(url, page, lang_name) info_result = info_result + info page += 1#写入excel文件 wb = Workbook() ws1 = wb.active ws1.title = lang_name for row in info_result: ws1.append(row) wb.save('职位信息3.xlsx')main()
打开excel文件,查看数据是否访问成功:

我们看到招聘类网站中捕获的数据成功保存在excel表中。
结尾

过去精选
Python可视化库你了解多少?带你去探索
人工智能方向——智能图像识别技术(二)
人工智能方向——智能图像识别技术(一)
在 Python 中开始使用爬虫的 7 个技巧
使用数据可视化有什么好处?

关注雷克
学干货

爬虫抓取网页数据(Linux命令分析之nginx服务器进行分析日志文件所在目录:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-02 17:00
概述
最近阿里云经常被各种爬虫访问,有的是搜索引擎爬虫,有的不是。通常这些爬虫都有UserAgent,我们知道UserAgent是可以伪装的。UserAgent 的本质是 Http 请求头中的一个选项设置。,您可以以编程方式为请求设置任何 UserAgent。
下面的Linux命令可以让你清楚的了解蜘蛛的爬行情况。我们分析nginx服务器。日志文件位于目录:/usr/local/nginx/logs/access.log。access.log 文件应该记录最后一天的日志情况。首先,请检查日志大小。如果比较大(超过50MB),建议不要使用这些命令进行分析,因为这些命令会消耗大量CPU,或者更新并在分析机上执行,以免影响服务器性能。
常见的蜘蛛域名
常用蜘蛛的域名与搜索引擎官网的域名有关,例如:
1、统计百度蜘蛛爬取的次数
猫访问.log | grep 百度蜘蛛 | 厕所
最左边的值显示爬网次数。
2、百度蜘蛛详细记录(Ctrl C可以终止)
猫访问.log | grep 百度蜘蛛
您还可以使用以下命令:
猫访问.log | grep 百度蜘蛛 | 尾 -n 10
猫访问.log | grep 百度蜘蛛 | 头 -n 10
说明:只看后10个或前10个 查看全部
爬虫抓取网页数据(Linux命令分析之nginx服务器进行分析日志文件所在目录:)
概述
最近阿里云经常被各种爬虫访问,有的是搜索引擎爬虫,有的不是。通常这些爬虫都有UserAgent,我们知道UserAgent是可以伪装的。UserAgent 的本质是 Http 请求头中的一个选项设置。,您可以以编程方式为请求设置任何 UserAgent。
下面的Linux命令可以让你清楚的了解蜘蛛的爬行情况。我们分析nginx服务器。日志文件位于目录:/usr/local/nginx/logs/access.log。access.log 文件应该记录最后一天的日志情况。首先,请检查日志大小。如果比较大(超过50MB),建议不要使用这些命令进行分析,因为这些命令会消耗大量CPU,或者更新并在分析机上执行,以免影响服务器性能。
常见的蜘蛛域名
常用蜘蛛的域名与搜索引擎官网的域名有关,例如:
1、统计百度蜘蛛爬取的次数
猫访问.log | grep 百度蜘蛛 | 厕所
最左边的值显示爬网次数。
2、百度蜘蛛详细记录(Ctrl C可以终止)
猫访问.log | grep 百度蜘蛛
您还可以使用以下命令:
猫访问.log | grep 百度蜘蛛 | 尾 -n 10
猫访问.log | grep 百度蜘蛛 | 头 -n 10
说明:只看后10个或前10个
爬虫抓取网页数据(Python编程修改程序函数式编程的实战二抓取您想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-01 21:14
战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧()页面,如Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
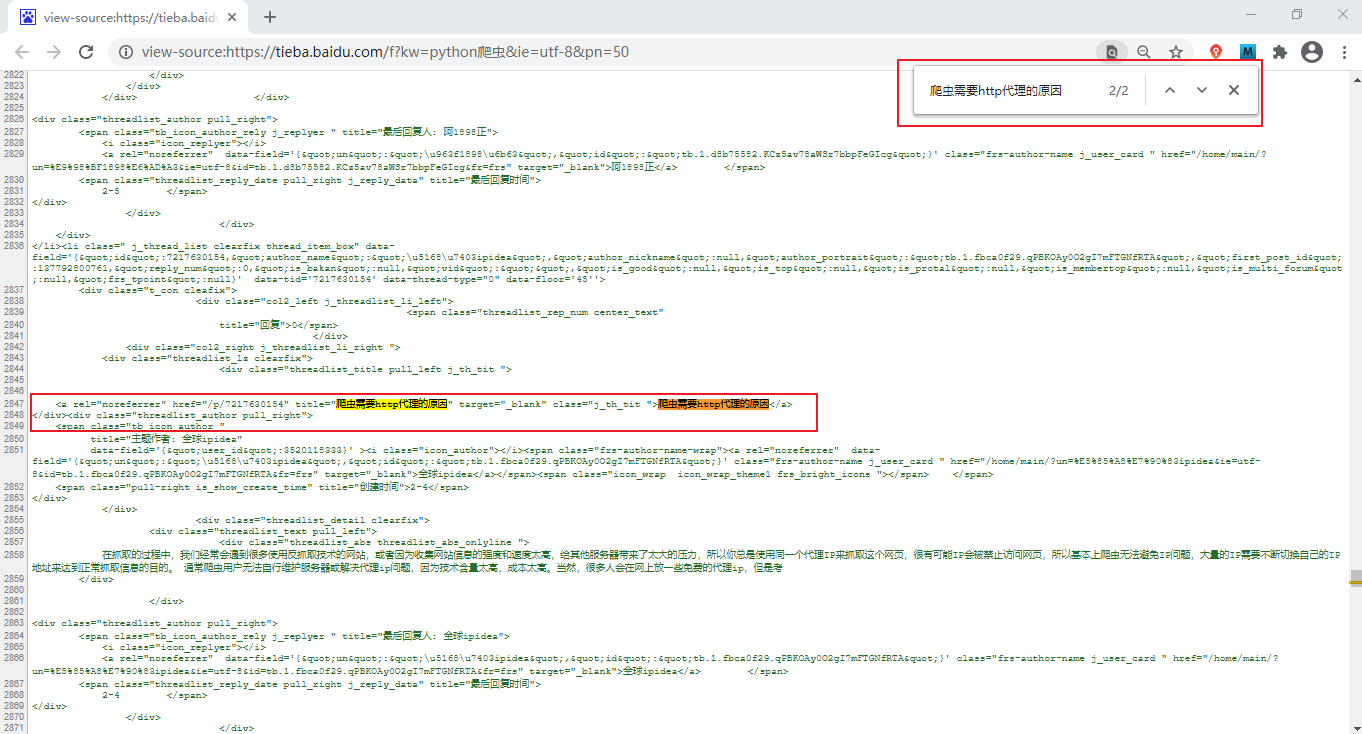
通过简单的分析可以知道,待爬取的百度贴吧页面是一个静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面中复制任意一段。信息,例如“爬虫需要http代理的原因”,然后右键选择查看源,使用Ctrl+F快捷键在源页面搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。 查看全部
爬虫抓取网页数据(Python编程修改程序函数式编程的实战二抓取您想要的)
战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧()页面,如Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
通过简单的分析可以知道,待爬取的百度贴吧页面是一个静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面中复制任意一段。信息,例如“爬虫需要http代理的原因”,然后右键选择查看源,使用Ctrl+F快捷键在源页面搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。
爬虫抓取网页数据(如何用Python实现简单爬取网页数据并导入MySQL中的数据库文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2022-03-01 21:13
)
疫情期间在家无事可做,随便写点小品。QQ...
这是一个文章,介绍了如何使用Python简单地抓取网页数据并将其导入MySQL中的数据库。主要使用 BeautifulSoup requests 和 pymysql。
以一个网页为例,假设我们要爬取的一些数据如下图所示:
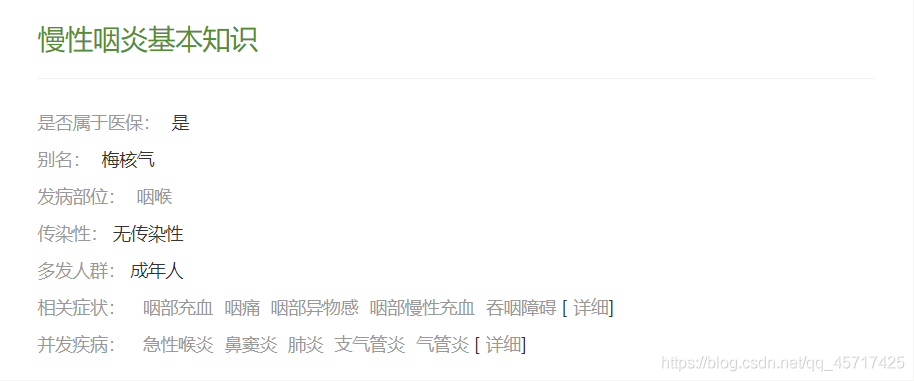
方法来构造并向网页的服务器发送请求。requests.get() 方法需要传递两个参数,一个是网页的url,很明显就是在这里;另一个参数是浏览器的标题。检查如下:
点击进入任意网页,按F12进入开发者模式,点击网络刷新网页。单击网络下名称中的任何资源,然后在右侧的标题部分中下拉到末尾。可以看到Request Headers参数列表的最后有一个user-agent,它的内容就是我们要找的浏览器headers参数值。
使用 url 和 headers 我们可以使用 requests.get() 向服务器发送请求:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
使用requests.get()方法会先构造一个url对象向服务端请求资源,然后从服务端返回一个收录服务端资源的Response对象,其中收录了服务端返回的所有相关资源(自然包括我们的html需要)。
获取网页的html内容:
html = r.content.decode('utf-8', 'ignore')
说明:这里 r.content 返回“响应的内容,以字节为单位”。即返回HTTP响应内容(Response)的字节形式。所以我们需要使用 .decode() 方法来解码。ignore 参数在这里是可选的,只是为了忽略一些不重要的错误。
有了html文本,我们可以取出bs和slip:
my_page = BeautifulSoup(html, 'lxml')
其实这里得到的my_page和html内容几乎是一样的,那何必再用bs来解析html呢?A:Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理不规则的标签并生成 Parse Tree。它提供了简单通用的导航(Navigating)、搜索和修改解析树的操作,可以大大节省你的编程时间。也就是说,我们需要爬取数据的一些定位方式,只能在bs解析返回的内容后才能使用。简单的html文本没有这么方便快捷的方法。
二、开始爬取数据
我们这里使用的方法主要是find | 查找全部 | 查找全部 | 获取文本() | 文本。
1.find_all 方法:
作用是查找页面元素的所有子元素,并将找到的与搜索结果匹配的子元素以列表的形式返回。
2.查找方法:
与 find_all 类似,但只返回匹配搜索条件的第一个子元素,并且只返回文本,而不是列表。
3.get_text() 和 .text 方法:
用于从标签中提取文本信息。
ps:get_text() 和 .text 方法的区别:
在beautifulsoup中,对外接口不提供text属性,只提供string属性值;beautifulsoup 里面有 text 属性,仅供内部使用 --> 如果要使用 text 值,应该调用对应的 get_text(); 而你所有可以直接使用soup.text而不报错的,应该和python的类的属性没有变成private有关——>你也可以从外部访问这个,这是一个仅供内部使用的属性值。
4.具体实现示例:
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span可以认为是一个list
is_yibao = my_span[1].text
othername = my_span[3].text
fbbw = my_span[5].text
is_infect = my_span[7].text
dfrq = my_span[9].text
my_a = sub_tag.findAll('a')
fbbw = my_a[0].text
#注:也可用.contents[0]或者.get_text()
用于爬取“是否属于医保”等条目冒号后的内容。
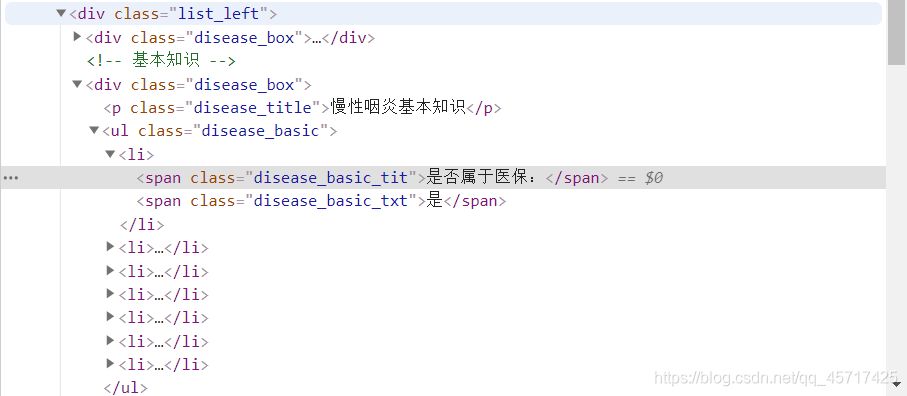
如何找到 find_all() 参数值?
选择要查找的内容右键,选择“Inspect”,进入开发者模式,可以看到相关内容的html代码如下图:
可以看出,我们要爬取的内容首先在一个class属性为“list_left”的div标签中——>在div标签中,我们可以发现我们要爬取的内容在list元素的ul标签中class属性为“disease_basic” --> 在ul标签中,我们可以发现我们想要的内容隐藏在几个span标签中。
三、完整代码
# coding = utf-8
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
html = r.content.decode('utf-8', 'ignore')
my_page = BeautifulSoup(html, 'lxml')
for tag in my_page.find_all('div', class_='disease'):
disease = tag.find('h1').get_text()
disease_name = disease
for tag in my_page.find_all('p', class_='introduction'):
introduction = tag.get_text()
disease_introduction = introduction
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span is a list
is_yibao = my_span[1].text #是否医保
othername = my_span[3].text #别名
fbbw = my_span[5].text #发病部位
is_infect = my_span[7].text #传染性
dfrq = my_span[9].text #多发人群
my_a = sub_tag.findAll('a')
xgzz = my_a[2].text+' '+my_a[3].text+' '+my_a[4].text #相关症状
#ps: .contents[0] or .get_text() is also accepted
# Some tests:
# print(html)
# print(my_page)
# print(sub_tag)
# print(xgzz)
# print(my_span)
# print(my_span[1]) 查看全部
爬虫抓取网页数据(如何用Python实现简单爬取网页数据并导入MySQL中的数据库文章
)
疫情期间在家无事可做,随便写点小品。QQ...
这是一个文章,介绍了如何使用Python简单地抓取网页数据并将其导入MySQL中的数据库。主要使用 BeautifulSoup requests 和 pymysql。
以一个网页为例,假设我们要爬取的一些数据如下图所示:
方法来构造并向网页的服务器发送请求。requests.get() 方法需要传递两个参数,一个是网页的url,很明显就是在这里;另一个参数是浏览器的标题。检查如下:
点击进入任意网页,按F12进入开发者模式,点击网络刷新网页。单击网络下名称中的任何资源,然后在右侧的标题部分中下拉到末尾。可以看到Request Headers参数列表的最后有一个user-agent,它的内容就是我们要找的浏览器headers参数值。
使用 url 和 headers 我们可以使用 requests.get() 向服务器发送请求:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
使用requests.get()方法会先构造一个url对象向服务端请求资源,然后从服务端返回一个收录服务端资源的Response对象,其中收录了服务端返回的所有相关资源(自然包括我们的html需要)。
获取网页的html内容:
html = r.content.decode('utf-8', 'ignore')
说明:这里 r.content 返回“响应的内容,以字节为单位”。即返回HTTP响应内容(Response)的字节形式。所以我们需要使用 .decode() 方法来解码。ignore 参数在这里是可选的,只是为了忽略一些不重要的错误。
有了html文本,我们可以取出bs和slip:
my_page = BeautifulSoup(html, 'lxml')
其实这里得到的my_page和html内容几乎是一样的,那何必再用bs来解析html呢?A:Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理不规则的标签并生成 Parse Tree。它提供了简单通用的导航(Navigating)、搜索和修改解析树的操作,可以大大节省你的编程时间。也就是说,我们需要爬取数据的一些定位方式,只能在bs解析返回的内容后才能使用。简单的html文本没有这么方便快捷的方法。
二、开始爬取数据
我们这里使用的方法主要是find | 查找全部 | 查找全部 | 获取文本() | 文本。
1.find_all 方法:

作用是查找页面元素的所有子元素,并将找到的与搜索结果匹配的子元素以列表的形式返回。
2.查找方法:
与 find_all 类似,但只返回匹配搜索条件的第一个子元素,并且只返回文本,而不是列表。
3.get_text() 和 .text 方法:
用于从标签中提取文本信息。
ps:get_text() 和 .text 方法的区别:
在beautifulsoup中,对外接口不提供text属性,只提供string属性值;beautifulsoup 里面有 text 属性,仅供内部使用 --> 如果要使用 text 值,应该调用对应的 get_text(); 而你所有可以直接使用soup.text而不报错的,应该和python的类的属性没有变成private有关——>你也可以从外部访问这个,这是一个仅供内部使用的属性值。
4.具体实现示例:
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span可以认为是一个list
is_yibao = my_span[1].text
othername = my_span[3].text
fbbw = my_span[5].text
is_infect = my_span[7].text
dfrq = my_span[9].text
my_a = sub_tag.findAll('a')
fbbw = my_a[0].text
#注:也可用.contents[0]或者.get_text()
用于爬取“是否属于医保”等条目冒号后的内容。
如何找到 find_all() 参数值?
选择要查找的内容右键,选择“Inspect”,进入开发者模式,可以看到相关内容的html代码如下图:
可以看出,我们要爬取的内容首先在一个class属性为“list_left”的div标签中——>在div标签中,我们可以发现我们要爬取的内容在list元素的ul标签中class属性为“disease_basic” --> 在ul标签中,我们可以发现我们想要的内容隐藏在几个span标签中。
三、完整代码
# coding = utf-8
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
html = r.content.decode('utf-8', 'ignore')
my_page = BeautifulSoup(html, 'lxml')
for tag in my_page.find_all('div', class_='disease'):
disease = tag.find('h1').get_text()
disease_name = disease
for tag in my_page.find_all('p', class_='introduction'):
introduction = tag.get_text()
disease_introduction = introduction
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span is a list
is_yibao = my_span[1].text #是否医保
othername = my_span[3].text #别名
fbbw = my_span[5].text #发病部位
is_infect = my_span[7].text #传染性
dfrq = my_span[9].text #多发人群
my_a = sub_tag.findAll('a')
xgzz = my_a[2].text+' '+my_a[3].text+' '+my_a[4].text #相关症状
#ps: .contents[0] or .get_text() is also accepted
# Some tests:
# print(html)
# print(my_page)
# print(sub_tag)
# print(xgzz)
# print(my_span)
# print(my_span[1])
爬虫抓取网页数据(Python学习网络爬虫的几种常见算法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-28 12:07
一.什么是爬虫?1.1 初识网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。Python 可以轻松编写爬虫程序,用于自动检索互联网信息。
搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。
1.1.1 百度新闻案例说明
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何在互联网上覆盖更多的优质网页呢?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。
1.1.2 网站排名(访问权重pv)
因此,我们在研究爬虫的时候,不仅需要了解爬虫是如何实现的,还需要了解一些常见爬虫的算法。如有必要,我们还需要自己制定相应的算法。在这里,我们只需要了解爬虫的概念。一个基本的了解
二. 爬虫领域(为什么要学爬虫?)
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?
如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?
首先,我们看下面的例子
百度指数
这是百度百度指数的截图。它对用户在百度搜索关键词进行统计,然后根据统计结果绘制流行趋势,然后简单展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己的用户数据进行统计分析
那么,对于一些中小型企业来说,在没有这么多用户的情况下应该怎么办呢?
2.1 数据来源
1.去第三方公司购买资料(例如:七叉茶)
2.去免费数据网站下载数据(如:国家统计局)
3.通过爬虫爬取数据
4.手动采集数据(例如问卷)
在以上数据源中,人工方式耗时耗力,效率低下,数据免费网站以上数据质量较差。很多第三方数据公司经常从爬虫那里获取数据,因此获取数据是最难的。有效的方法是通过爬虫爬取
2.2 大数据和爬虫是什么关系?
爬虫爬取互联网上的数据,获取的数据量决定了与大数据的兄弟关系是否更近
2.3 爬虫领域,前景三. 爬虫分类
根据系统结构和实现技术,网络爬虫大致可分为四类,即通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深层次网络爬虫。
1.通用网络爬虫:搜索引擎爬虫
例如,当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的页面中找出相关的,然后根据一定的排名规则对它们进行排序。为了向用户展示,那么您需要尽可能多的互联网高质量网页。
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.聚焦网络爬虫:特定网页的爬虫
它也被称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。
比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
例如:那些比较价格的 网站 是其他被抓取的 网站 产品。
3.增量网络爬虫
增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫
4.深网爬虫
Deep Web Crawler,首先,什么是深页?
在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。
深网爬虫主要由URL列表、LVS【虚拟服务器】列表、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等组成。
后来我们主要学习专注爬虫,专注爬虫之后,其他类型的爬虫就可以轻松写出来了。
关键词3@> 通用爬虫和聚焦爬虫原理
万能爬虫
第 1 步:抓取网页(网址)
start_url 发送请求,并解析响应;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,并分配对应的URL 下载网页,存储在下载的网页库中,并将这些URL放入被爬取的URL队列中。分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列中,从而进入下一个循环……
第 2 步:数据存储
搜索引擎通过爬虫爬取的网页将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
第 3 步:预处理
搜索引擎将从爬虫抓取回来的页面,并执行各种预处理步骤。
除了 HTML 文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。
但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供搜索服务,网站排名
搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,将用户检索到的相关信息展示给用户。
关键词4@> 通用爬虫和 Spotlight 爬虫工作流程
关键词5@>
第 1 步:start_url 发送请求
第 2 步:获取响应
第 3 步:解析响应。如果响应中有需要新的url地址,重复第二步;
第 4 步:提取数据
第 5 步:保存数据
通常,我们会一步获得响应并对其进行解析。因此,专注于爬虫的步骤一般是四个步骤。 查看全部
爬虫抓取网页数据(Python学习网络爬虫的几种常见算法和方法)
一.什么是爬虫?1.1 初识网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。Python 可以轻松编写爬虫程序,用于自动检索互联网信息。
搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。
1.1.1 百度新闻案例说明

在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何在互联网上覆盖更多的优质网页呢?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。
1.1.2 网站排名(访问权重pv)

因此,我们在研究爬虫的时候,不仅需要了解爬虫是如何实现的,还需要了解一些常见爬虫的算法。如有必要,我们还需要自己制定相应的算法。在这里,我们只需要了解爬虫的概念。一个基本的了解
二. 爬虫领域(为什么要学爬虫?)
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?
如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?
首先,我们看下面的例子
百度指数

这是百度百度指数的截图。它对用户在百度搜索关键词进行统计,然后根据统计结果绘制流行趋势,然后简单展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己的用户数据进行统计分析
那么,对于一些中小型企业来说,在没有这么多用户的情况下应该怎么办呢?
2.1 数据来源
1.去第三方公司购买资料(例如:七叉茶)
2.去免费数据网站下载数据(如:国家统计局)
3.通过爬虫爬取数据
4.手动采集数据(例如问卷)
在以上数据源中,人工方式耗时耗力,效率低下,数据免费网站以上数据质量较差。很多第三方数据公司经常从爬虫那里获取数据,因此获取数据是最难的。有效的方法是通过爬虫爬取
2.2 大数据和爬虫是什么关系?
爬虫爬取互联网上的数据,获取的数据量决定了与大数据的兄弟关系是否更近
2.3 爬虫领域,前景三. 爬虫分类
根据系统结构和实现技术,网络爬虫大致可分为四类,即通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深层次网络爬虫。
1.通用网络爬虫:搜索引擎爬虫
例如,当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的页面中找出相关的,然后根据一定的排名规则对它们进行排序。为了向用户展示,那么您需要尽可能多的互联网高质量网页。
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.聚焦网络爬虫:特定网页的爬虫
它也被称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。
比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
例如:那些比较价格的 网站 是其他被抓取的 网站 产品。
3.增量网络爬虫
增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫
4.深网爬虫
Deep Web Crawler,首先,什么是深页?
在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。
深网爬虫主要由URL列表、LVS【虚拟服务器】列表、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等组成。
后来我们主要学习专注爬虫,专注爬虫之后,其他类型的爬虫就可以轻松写出来了。
关键词3@> 通用爬虫和聚焦爬虫原理
万能爬虫
第 1 步:抓取网页(网址)
start_url 发送请求,并解析响应;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,并分配对应的URL 下载网页,存储在下载的网页库中,并将这些URL放入被爬取的URL队列中。分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列中,从而进入下一个循环……
第 2 步:数据存储
搜索引擎通过爬虫爬取的网页将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
第 3 步:预处理
搜索引擎将从爬虫抓取回来的页面,并执行各种预处理步骤。
除了 HTML 文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。
但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供搜索服务,网站排名
搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,将用户检索到的相关信息展示给用户。
关键词4@> 通用爬虫和 Spotlight 爬虫工作流程
关键词5@>
第 1 步:start_url 发送请求
第 2 步:获取响应
第 3 步:解析响应。如果响应中有需要新的url地址,重复第二步;
第 4 步:提取数据
第 5 步:保存数据
通常,我们会一步获得响应并对其进行解析。因此,专注于爬虫的步骤一般是四个步骤。
爬虫抓取网页数据( 前端基础比较扎实的Css选择器教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2022-02-27 20:08
前端基础比较扎实的Css选择器教程)
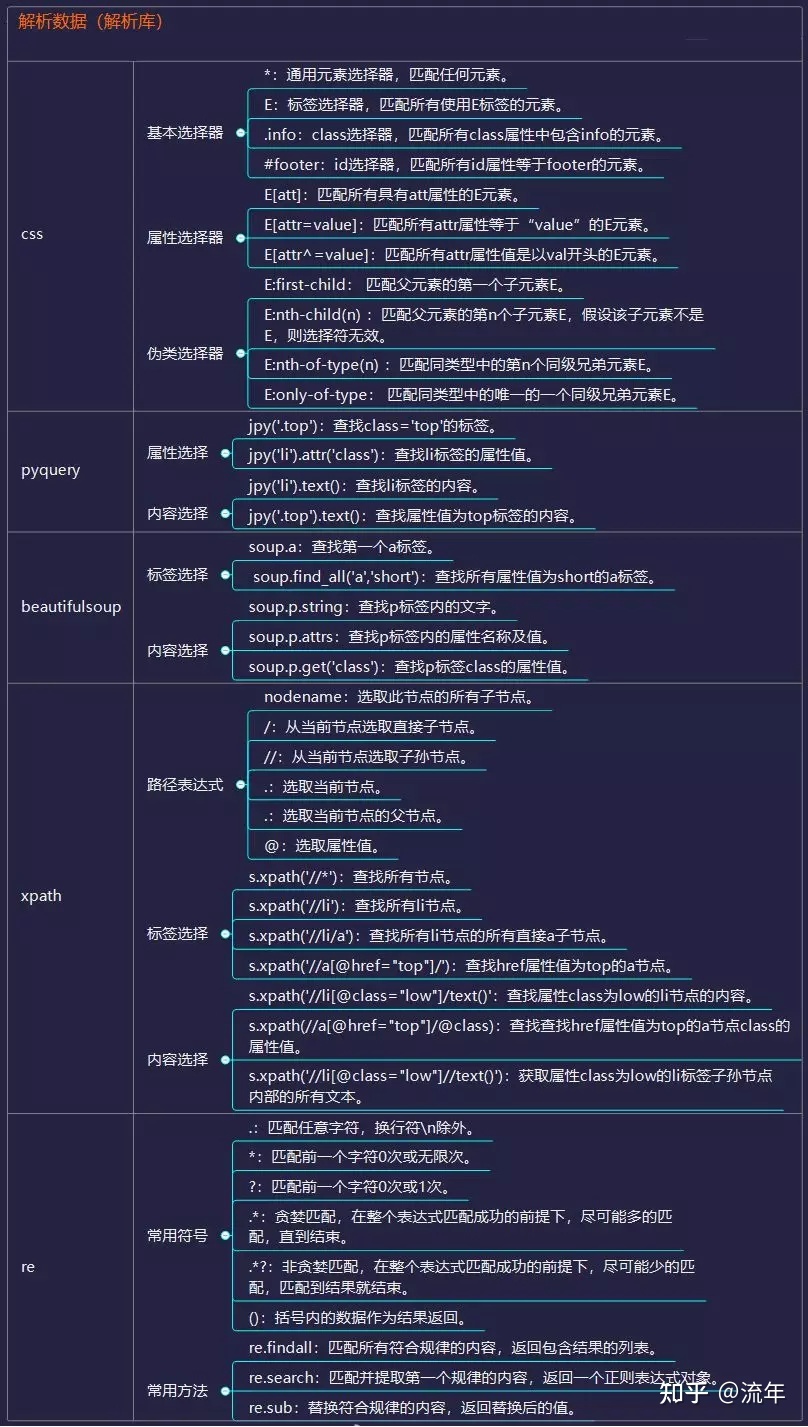
2、解析数据
爬虫爬取的是爬取页面指定的部分数据值,而不是整个页面的数据。这时候,往往需要先解析数据,再存储。
网络上采集返回的数据的数据类型很多,主要有HTML、javascript、JSON、XML等格式。使用解析库相当于在HTML中查找需要的信息时使用正则表达式,可以更快速的定位到具体的元素,获取相应的信息。
CSS 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器对 xml 和 html 文档进行快速操作。它提供了类似于 jQuery 的语法来解析 HTML 文档,支持 CSS 选择器,使用起来非常方便。
Beautiful Soup 是一个借助网页结构和属性解析网页的工具,可以自动转换代码。它支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。
Xpath 最初用于搜索 XML 文档,但也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理、逻辑值等,XQuery和XPointer都是建立在XPath的基础上的。
Re 正则表达式通常用于检索和替换匹配某个模式(规则)的文本。个人觉得前端基础比较扎实。使用pyquery是最方便的。Beautifulsoup也不错,re的速度比较快,但是写正则表达式比较麻烦。当然,既然用的是python,那最好还是自己用。
推荐的解析器资源:
查询
美汤
xpath 教程
重新记录
3、数据存储
当爬回来的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就行不通了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,系统比较成熟,成熟度很高。它可以很好地存储一些数据。但是在处理海量数据时,效率会明显变慢,已经不能满足一些大数据的需求。处理请求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以方便你存储一些非结构化的数据,比如各种评论的文本、图片的链接等。你也可以使用 PyMongo 更方便地在 Python 中操作 MongoDB。因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
**Redis是不折不扣的内存数据库,**Redis支持丰富的数据结构,包括hash、set、list等。所有数据都存储在内存中,访问速度快,可以存储大量数据. 一般用于分布式爬虫的数据存储。
工程爬行动物
如果掌握了前面的技术,就可以实现一个轻量级的爬虫,一般级的数据和代码基本没有问题。
但面对复杂的情况,表现却不尽如人意。这时候,一个强大的爬虫框架就非常有用了。
首先是 Nutch,著名的 Apache 顶级项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,具有Hadoop对多机分布式爬取、存储和索引的支持。
另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展解析各种网页内容、采集、查询、聚类、过滤各种数据的功能。
二是GitHub上大家star的scrapy,scratch是一个非常强大的爬虫框架。
它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
最后,Pyspider作为国内大神们开发的框架,满足了大部分Python爬虫的需求——定向爬取和结构化分析。
可以在浏览器界面进行脚本编写、函数调度和爬取结果的实时查看,后端使用常用数据库存储爬取结果。
它足够强大,更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远远优于其他的优势,比如**Nutch的自然搜索引擎解决方案,Pyspider的产品级WebUI,以及Scrapy最灵活的定制化爬虫。**建议学习最接近爬虫本质的框架scarry,然后接触为搜索引擎而生的人性化Pyspider和Nutch。
推荐爬虫框架资源:
Nutch 文档
可怕的文档
pyspider 文档
反爬虫对策
爬虫就像虫子,密密麻麻地爬到各个角落获取数据,虫子可能无害,但总是不受欢迎。
由于爬虫技术导致的大量IP访问网站,对带宽资源的侵占,以及对用户隐私和知识产权的危害,很多互联网公司将大力开展“反爬虫”。
你的爬虫会遇到比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
常见的反爬虫措施包括:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体防爬…
遇到这些反爬手段,当然需要一些高级技巧来应对。控制访问频率,保证页面加载一次,数据请求最小化,每次页面访问增加时间间隔;禁用 cookie 可以防止使用 cookie 识别爬虫 网站 来禁止我们的可能性;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
分布式爬虫
爬取基础数据没有问题,也可以用框架写更复杂的数据。这时候就算遇到反爬,你也掌握了一些反反爬的技巧。
你的瓶颈将是爬取海量数据的效率。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理组合多台主机完成一个爬虫任务**,需要掌握Scrapy + Redis + MQ + Celery**等工具**。
之前我们说过,Scrapy是用来做基础页面爬取的,Redis是用来存放待爬取网页的队列,也就是任务队列。
Scarpy-redis是scrapy中用来实现分布式组件的组件,通过它可以快速实现一个简单的分布式爬虫程序。
在高并发环境中,请求经常因为没有时间进行同步处理而被阻塞。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ 本身支持多种协议:AMQP、XMPP、SMTP、STOMP,使其非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中获取 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,用于处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在异步任务、任务调度、定时任务、分布式调度等场景中表现出色。
所以分布式爬虫听起来很吓人,但就是这样。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
推荐的分布式资源:
scrapy-redis 文档
scrapy-rabbitmq 文档
芹菜文档
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要高级的数据库技术。
解锁各部分的知识点,有针对性地学习。经过这条顺利的学习路径,您将能够掌握python爬虫。
但是,要学习爬虫,需要打好基础。在这里,我为大家准备了一份零基础学习的Python学习资料。有兴趣的同学可以看看。 查看全部
爬虫抓取网页数据(
前端基础比较扎实的Css选择器教程)

2、解析数据
爬虫爬取的是爬取页面指定的部分数据值,而不是整个页面的数据。这时候,往往需要先解析数据,再存储。
网络上采集返回的数据的数据类型很多,主要有HTML、javascript、JSON、XML等格式。使用解析库相当于在HTML中查找需要的信息时使用正则表达式,可以更快速的定位到具体的元素,获取相应的信息。
CSS 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器对 xml 和 html 文档进行快速操作。它提供了类似于 jQuery 的语法来解析 HTML 文档,支持 CSS 选择器,使用起来非常方便。
Beautiful Soup 是一个借助网页结构和属性解析网页的工具,可以自动转换代码。它支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。
Xpath 最初用于搜索 XML 文档,但也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理、逻辑值等,XQuery和XPointer都是建立在XPath的基础上的。
Re 正则表达式通常用于检索和替换匹配某个模式(规则)的文本。个人觉得前端基础比较扎实。使用pyquery是最方便的。Beautifulsoup也不错,re的速度比较快,但是写正则表达式比较麻烦。当然,既然用的是python,那最好还是自己用。
推荐的解析器资源:
查询
美汤
xpath 教程
重新记录
3、数据存储
当爬回来的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就行不通了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,系统比较成熟,成熟度很高。它可以很好地存储一些数据。但是在处理海量数据时,效率会明显变慢,已经不能满足一些大数据的需求。处理请求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以方便你存储一些非结构化的数据,比如各种评论的文本、图片的链接等。你也可以使用 PyMongo 更方便地在 Python 中操作 MongoDB。因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
**Redis是不折不扣的内存数据库,**Redis支持丰富的数据结构,包括hash、set、list等。所有数据都存储在内存中,访问速度快,可以存储大量数据. 一般用于分布式爬虫的数据存储。
工程爬行动物
如果掌握了前面的技术,就可以实现一个轻量级的爬虫,一般级的数据和代码基本没有问题。
但面对复杂的情况,表现却不尽如人意。这时候,一个强大的爬虫框架就非常有用了。
首先是 Nutch,著名的 Apache 顶级项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,具有Hadoop对多机分布式爬取、存储和索引的支持。
另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展解析各种网页内容、采集、查询、聚类、过滤各种数据的功能。
二是GitHub上大家star的scrapy,scratch是一个非常强大的爬虫框架。
它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
最后,Pyspider作为国内大神们开发的框架,满足了大部分Python爬虫的需求——定向爬取和结构化分析。
可以在浏览器界面进行脚本编写、函数调度和爬取结果的实时查看,后端使用常用数据库存储爬取结果。
它足够强大,更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远远优于其他的优势,比如**Nutch的自然搜索引擎解决方案,Pyspider的产品级WebUI,以及Scrapy最灵活的定制化爬虫。**建议学习最接近爬虫本质的框架scarry,然后接触为搜索引擎而生的人性化Pyspider和Nutch。
推荐爬虫框架资源:
Nutch 文档
可怕的文档
pyspider 文档

反爬虫对策
爬虫就像虫子,密密麻麻地爬到各个角落获取数据,虫子可能无害,但总是不受欢迎。
由于爬虫技术导致的大量IP访问网站,对带宽资源的侵占,以及对用户隐私和知识产权的危害,很多互联网公司将大力开展“反爬虫”。
你的爬虫会遇到比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
常见的反爬虫措施包括:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体防爬…
遇到这些反爬手段,当然需要一些高级技巧来应对。控制访问频率,保证页面加载一次,数据请求最小化,每次页面访问增加时间间隔;禁用 cookie 可以防止使用 cookie 识别爬虫 网站 来禁止我们的可能性;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
分布式爬虫
爬取基础数据没有问题,也可以用框架写更复杂的数据。这时候就算遇到反爬,你也掌握了一些反反爬的技巧。
你的瓶颈将是爬取海量数据的效率。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理组合多台主机完成一个爬虫任务**,需要掌握Scrapy + Redis + MQ + Celery**等工具**。
之前我们说过,Scrapy是用来做基础页面爬取的,Redis是用来存放待爬取网页的队列,也就是任务队列。
Scarpy-redis是scrapy中用来实现分布式组件的组件,通过它可以快速实现一个简单的分布式爬虫程序。
在高并发环境中,请求经常因为没有时间进行同步处理而被阻塞。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ 本身支持多种协议:AMQP、XMPP、SMTP、STOMP,使其非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中获取 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,用于处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在异步任务、任务调度、定时任务、分布式调度等场景中表现出色。
所以分布式爬虫听起来很吓人,但就是这样。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
推荐的分布式资源:
scrapy-redis 文档
scrapy-rabbitmq 文档
芹菜文档
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要高级的数据库技术。
解锁各部分的知识点,有针对性地学习。经过这条顺利的学习路径,您将能够掌握python爬虫。
但是,要学习爬虫,需要打好基础。在这里,我为大家准备了一份零基础学习的Python学习资料。有兴趣的同学可以看看。
爬虫抓取网页数据(爬虫的核心特性除了快,还应该是从高到低的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-24 14:17
背景
对于电商类型和内容服务类型的网站,经常会出现由于配置错误(404).
显然,要保证网站中的所有链接都可以访问,手动检测肯定是不现实的。常见的做法是利用爬虫技术定期爬取网站上的资源,及时发现访问异常的链接。
对于网络爬虫,市场上已经有大量的开源项目和技术讨论文章。不过,似乎大家普遍关注的是爬取的效率。例如,关于不同并发机制中哪种更高效的讨论有很多文章,但关于爬虫的其他特性的讨论并不多。
在我看来,爬虫的核心特性除了快之外,还应该包括full和stable,而从重要性来看,full、stable和fast应该是从高到低。
全部排在第一位,因为这是爬虫的基本功能。如果爬取的页面不完整,就会出现信息遗漏,这是绝对不允许的;第二名是稳定的,因为爬虫通常需要长时间稳定运行。如果在爬虫运行过程中,由于策略处理不当导致爬虫无法正常访问页面,这是绝对不能接受的。最后,它很快。我们通常需要抓取大量的页面链接,所以效率是关键,但也必须建立在完整性和稳定性的基础上。
当然,爬行本身是一个很深的技术领域,我只是在摸索。本文仅针对使用爬虫技术检测网页资源可用性的实际场景,详细分析涉及的几个技术点,重点解决以下问题:
爬虫实现前端页面渲染
早些年,基本上绝大多数网站都是通过后端渲染的,也就是在服务器端组装一个完整的HTML页面,然后将完整的页面返回到前端进行展示。近年来,随着AJAX技术的不断普及和AngularJS等SPA框架的广泛应用,越来越多的页面呈现在前端。
不知道大家有没有听说前端渲染相比后端渲染不利于SEO,因为它对爬虫不友好。原因是前端渲染的页面需要在浏览器端执行JavaScript代码(即AJAX请求)来获取后端数据,然后组装成一个完整的HTML页面。
对于这种情况,已经有很多解决方案了。最常用的是使用 PhantomJS 和 puppeteer 等无头浏览器工具。) 在抓取页面内容之前。
但是,要使用这种技术,通常需要使用 Javascript 来开发爬虫工具,这对于像我这样习惯于编写 Python 的人来说确实有点痛苦。
直到有一天,大神kennethreitz 发布了开源项目requests-html,当我看到了Full JavaScript support!项目在 GitHub 上发布不到三天,star 数就达到了 5000 多,可见其影响力。
为什么 requests-html 如此受欢迎?
写过 Python 的人基本都会用到 requests 之类的 HTTP 库。毫不夸张地说,它是最好的 HTTP 库(不仅限于编程语言),其引入语言 HTTP Requests for Humans 也是当之无愧的。也正因如此,Locust 和 HttpRunner 都是基于请求开发的。
Requests-html 是 kennethreitz 基于 requests 开发的另一个开源项目。除了复用requests的所有功能外,还实现了对HTML页面的解析,即支持Javascript的执行,以及通过CSS和XPath的功能提取HTML页面元素,是编写爬虫非常需要的功能工具。
在实现 Javascript 执行方面,requests-html 并没有自己造轮子,而是依赖于开源项目 pyppeteer。还记得前面提到的 puppeteer 项目,就是 Google Chrome 官方实现的 Node API;还有pyppeteer项目,相当于一个非官方的使用Python语言实现的puppeteer,基本具备了puppeteer的所有功能。
理清了上面的关系,相信大家对requests-html会有更好的理解。
在使用上,requests-html 也很简单,用法和requests基本一样,只是多了一个render函数。
from requests_html
import HTMLSession
session = HTMLSession()
r = session.get('http://python-requests.org')
r.html.render()
执行render()后,返回的是渲染后的页面内容。
爬虫实现访问频率控制
为了防止流量攻击,很多网站都有访问频率限制,即限制单个IP在一定时间内的访问次数。如果超过这个设定的限制,服务器会拒绝访问请求,即响应状态码为403(Forbidden)。
这可以用来应对外部流量攻击或爬虫,但在这种有限的策略下,公司内部的爬虫测试工具也无法正常使用。针对这个问题,常见的做法是在应用系统中设置白名单,将公司内部爬虫测试服务器IP加入白名单,然后对白名单中的IP不做限制,或者增加限制。但这也可能是有问题的。因为应用服务器的性能不是无限的,如果爬虫的访问频率超过应用服务器的处理限制,会导致应用服务器不可用,即响应状态码为503(Service Unavailable Error )。
基于以上原因,爬虫的访问频率应与项目组开发运维统一评估后确定;而对于爬虫工具,需要控制访问频率。
如何控制访问频率?
我们可以回到爬虫本身的实现机制。对于爬虫来说,无论实现形式是什么,都应该概括为生产者和消费者模型,即:
对于这个模型,最简单的方法是使用一个 FIFO 队列来存储未访问的链接队列 (unvisited_urls_queue)。无论使用哪种并发机制,这个队列都可以在工作人员之间共享。对于每个工作人员,您可以执行以下操作:
那么回到我们的问题,限制访问的频率,也就是单位时间内请求的链接数。显然,工人之间是相互独立的,在执行层面上实现全面的频率控制并不容易。但是从上面的步骤可以看出,unvisited_urls_queue 是所有worker 共享的,起到了source 供应的作用。那么只要我们能实现对unvisited_urls_queue补充的数量控制,就实现了爬虫的整体访问频率控制。
上面的思路是对的,但是具体实现有几个问题:
而在目前的实际场景中,最好的并发机制是选择多个进程(原因后面会详细解释)。每个工人处于不同的进程中,因此共享集合并不容易。同时,如果每个worker都负责判断请求的总数,也就是如果访问频率的控制逻辑在worker中实现的话,对worker来说就是一个负担,逻辑上会比较多复杂的。
因此,更好的方法是在未访问链接队列(unvisited_urls_queue)的基础上,增加一个用于爬取结果的存储队列(fetched_urls_queue),这两者都是worker之间共享的。那么,接下来的逻辑就变得简单了:
具体控制方法也很简单。假设我们要实现对RPS的控制,那么我们可以使用以下方法(只截取关键段):
<p>start_timer = time.time()
requests_queued = 0
while True:
try:
url = self.fetched_urls_queue.get(timeout=5)
except queue.Empty:
break
# visited url will not be crawled twice
if url in self.visited_urls_set:
continue
# limit rps or rpm
if requests_queued >= self.requests_limit:
runtime_secs = time.time() - start_timer
if runtime_secs 查看全部
爬虫抓取网页数据(爬虫的核心特性除了快,还应该是从高到低的)
背景
对于电商类型和内容服务类型的网站,经常会出现由于配置错误(404).
显然,要保证网站中的所有链接都可以访问,手动检测肯定是不现实的。常见的做法是利用爬虫技术定期爬取网站上的资源,及时发现访问异常的链接。
对于网络爬虫,市场上已经有大量的开源项目和技术讨论文章。不过,似乎大家普遍关注的是爬取的效率。例如,关于不同并发机制中哪种更高效的讨论有很多文章,但关于爬虫的其他特性的讨论并不多。
在我看来,爬虫的核心特性除了快之外,还应该包括full和stable,而从重要性来看,full、stable和fast应该是从高到低。
全部排在第一位,因为这是爬虫的基本功能。如果爬取的页面不完整,就会出现信息遗漏,这是绝对不允许的;第二名是稳定的,因为爬虫通常需要长时间稳定运行。如果在爬虫运行过程中,由于策略处理不当导致爬虫无法正常访问页面,这是绝对不能接受的。最后,它很快。我们通常需要抓取大量的页面链接,所以效率是关键,但也必须建立在完整性和稳定性的基础上。
当然,爬行本身是一个很深的技术领域,我只是在摸索。本文仅针对使用爬虫技术检测网页资源可用性的实际场景,详细分析涉及的几个技术点,重点解决以下问题:
爬虫实现前端页面渲染
早些年,基本上绝大多数网站都是通过后端渲染的,也就是在服务器端组装一个完整的HTML页面,然后将完整的页面返回到前端进行展示。近年来,随着AJAX技术的不断普及和AngularJS等SPA框架的广泛应用,越来越多的页面呈现在前端。
不知道大家有没有听说前端渲染相比后端渲染不利于SEO,因为它对爬虫不友好。原因是前端渲染的页面需要在浏览器端执行JavaScript代码(即AJAX请求)来获取后端数据,然后组装成一个完整的HTML页面。
对于这种情况,已经有很多解决方案了。最常用的是使用 PhantomJS 和 puppeteer 等无头浏览器工具。) 在抓取页面内容之前。
但是,要使用这种技术,通常需要使用 Javascript 来开发爬虫工具,这对于像我这样习惯于编写 Python 的人来说确实有点痛苦。
直到有一天,大神kennethreitz 发布了开源项目requests-html,当我看到了Full JavaScript support!项目在 GitHub 上发布不到三天,star 数就达到了 5000 多,可见其影响力。
为什么 requests-html 如此受欢迎?
写过 Python 的人基本都会用到 requests 之类的 HTTP 库。毫不夸张地说,它是最好的 HTTP 库(不仅限于编程语言),其引入语言 HTTP Requests for Humans 也是当之无愧的。也正因如此,Locust 和 HttpRunner 都是基于请求开发的。
Requests-html 是 kennethreitz 基于 requests 开发的另一个开源项目。除了复用requests的所有功能外,还实现了对HTML页面的解析,即支持Javascript的执行,以及通过CSS和XPath的功能提取HTML页面元素,是编写爬虫非常需要的功能工具。
在实现 Javascript 执行方面,requests-html 并没有自己造轮子,而是依赖于开源项目 pyppeteer。还记得前面提到的 puppeteer 项目,就是 Google Chrome 官方实现的 Node API;还有pyppeteer项目,相当于一个非官方的使用Python语言实现的puppeteer,基本具备了puppeteer的所有功能。
理清了上面的关系,相信大家对requests-html会有更好的理解。
在使用上,requests-html 也很简单,用法和requests基本一样,只是多了一个render函数。
from requests_html
import HTMLSession
session = HTMLSession()
r = session.get('http://python-requests.org')
r.html.render()
执行render()后,返回的是渲染后的页面内容。
爬虫实现访问频率控制
为了防止流量攻击,很多网站都有访问频率限制,即限制单个IP在一定时间内的访问次数。如果超过这个设定的限制,服务器会拒绝访问请求,即响应状态码为403(Forbidden)。
这可以用来应对外部流量攻击或爬虫,但在这种有限的策略下,公司内部的爬虫测试工具也无法正常使用。针对这个问题,常见的做法是在应用系统中设置白名单,将公司内部爬虫测试服务器IP加入白名单,然后对白名单中的IP不做限制,或者增加限制。但这也可能是有问题的。因为应用服务器的性能不是无限的,如果爬虫的访问频率超过应用服务器的处理限制,会导致应用服务器不可用,即响应状态码为503(Service Unavailable Error )。
基于以上原因,爬虫的访问频率应与项目组开发运维统一评估后确定;而对于爬虫工具,需要控制访问频率。
如何控制访问频率?
我们可以回到爬虫本身的实现机制。对于爬虫来说,无论实现形式是什么,都应该概括为生产者和消费者模型,即:
对于这个模型,最简单的方法是使用一个 FIFO 队列来存储未访问的链接队列 (unvisited_urls_queue)。无论使用哪种并发机制,这个队列都可以在工作人员之间共享。对于每个工作人员,您可以执行以下操作:
那么回到我们的问题,限制访问的频率,也就是单位时间内请求的链接数。显然,工人之间是相互独立的,在执行层面上实现全面的频率控制并不容易。但是从上面的步骤可以看出,unvisited_urls_queue 是所有worker 共享的,起到了source 供应的作用。那么只要我们能实现对unvisited_urls_queue补充的数量控制,就实现了爬虫的整体访问频率控制。
上面的思路是对的,但是具体实现有几个问题:
而在目前的实际场景中,最好的并发机制是选择多个进程(原因后面会详细解释)。每个工人处于不同的进程中,因此共享集合并不容易。同时,如果每个worker都负责判断请求的总数,也就是如果访问频率的控制逻辑在worker中实现的话,对worker来说就是一个负担,逻辑上会比较多复杂的。
因此,更好的方法是在未访问链接队列(unvisited_urls_queue)的基础上,增加一个用于爬取结果的存储队列(fetched_urls_queue),这两者都是worker之间共享的。那么,接下来的逻辑就变得简单了:
具体控制方法也很简单。假设我们要实现对RPS的控制,那么我们可以使用以下方法(只截取关键段):
<p>start_timer = time.time()
requests_queued = 0
while True:
try:
url = self.fetched_urls_queue.get(timeout=5)
except queue.Empty:
break
# visited url will not be crawled twice
if url in self.visited_urls_set:
continue
# limit rps or rpm
if requests_queued >= self.requests_limit:
runtime_secs = time.time() - start_timer
if runtime_secs
爬虫抓取网页数据(爬虫抓取网页数据最基本的三种方式post和get方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-20 09:12
爬虫抓取网页数据最基本的三种方式post和get方式。我今天先给大家谈一下post方式。举个例子,比如我们要抓取电信公司的一个号码,我们可以向电信公司发一个post请求,请求的内容,也是一个号码,然后分析请求的json格式去抓取对应的电信公司的一些数据。以上例子,代码如下:xiaoshiji2017/requestspider(二维码自动识别)我们使用post请求电信公司的一个号码。
那么如何去构造一个post请求呢?我在想过以后一定要把格式梳理一下,大家一起把http协议那部分搞懂。一开始我不知道要抓取哪个网站的哪个数据,我就看了一下baidu的api文档,我找到一个电信公司号码的实例代码。如下:src=''headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3323.122safari/537.36'}data={'simple':false,'old':true,'loading':false,'user-agent':'woaix-010-1200-e'}cookie={'simple':false,'loading':false,'user-agent':'egg.home.1.2.2'}fordatainsrc:data['simple']=truedata['old']=truereturndata就是我们抓取一个电信公司的号码。
那么我们如何去构造呢?可以先把我们的数据保存在某个数据库中,然后用户发送一个post请求,获取我们的数据。我们先构造一个post请求并发送一次post请求,然后我们保存一下数据,放在我们的数据库。重复n次这个操作。如下:baidu.post()这个时候我们就可以回忆下,我们以前使用get请求电信公司号码。
我们应该找到我们需要抓取的那个公司网站,然后构造以下的代码就行了我们发送一个post请求,请求一个电信公司的号码。html=''frombaidu.postimportget_号码的,get_value()如果是请求不存在的公司的话,返回303代码这里构造这个data就是构造完我们的数据,然后如果已经存在数据的话,返回304,这是我们构造不存在的data的一个代码get_value(value)这是获取数据的一个json格式的数据。
get_value(value)这个是获取我们数据的一个json格式的数据。我们总结下post请求请求的数据。我们需要有以下json格式的数据。simple对应的simple=',{'"name":"%s","age":"%s","city":"%s","str":"{"p_city":"%s","p_city":"%s","res":"%s"}'}'u。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据最基本的三种方式post和get方式)
爬虫抓取网页数据最基本的三种方式post和get方式。我今天先给大家谈一下post方式。举个例子,比如我们要抓取电信公司的一个号码,我们可以向电信公司发一个post请求,请求的内容,也是一个号码,然后分析请求的json格式去抓取对应的电信公司的一些数据。以上例子,代码如下:xiaoshiji2017/requestspider(二维码自动识别)我们使用post请求电信公司的一个号码。
那么如何去构造一个post请求呢?我在想过以后一定要把格式梳理一下,大家一起把http协议那部分搞懂。一开始我不知道要抓取哪个网站的哪个数据,我就看了一下baidu的api文档,我找到一个电信公司号码的实例代码。如下:src=''headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3323.122safari/537.36'}data={'simple':false,'old':true,'loading':false,'user-agent':'woaix-010-1200-e'}cookie={'simple':false,'loading':false,'user-agent':'egg.home.1.2.2'}fordatainsrc:data['simple']=truedata['old']=truereturndata就是我们抓取一个电信公司的号码。
那么我们如何去构造呢?可以先把我们的数据保存在某个数据库中,然后用户发送一个post请求,获取我们的数据。我们先构造一个post请求并发送一次post请求,然后我们保存一下数据,放在我们的数据库。重复n次这个操作。如下:baidu.post()这个时候我们就可以回忆下,我们以前使用get请求电信公司号码。
我们应该找到我们需要抓取的那个公司网站,然后构造以下的代码就行了我们发送一个post请求,请求一个电信公司的号码。html=''frombaidu.postimportget_号码的,get_value()如果是请求不存在的公司的话,返回303代码这里构造这个data就是构造完我们的数据,然后如果已经存在数据的话,返回304,这是我们构造不存在的data的一个代码get_value(value)这是获取数据的一个json格式的数据。
get_value(value)这个是获取我们数据的一个json格式的数据。我们总结下post请求请求的数据。我们需要有以下json格式的数据。simple对应的simple=',{'"name":"%s","age":"%s","city":"%s","str":"{"p_city":"%s","p_city":"%s","res":"%s"}'}'u。
爬虫抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-19 02:20
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
天长魂远,梦魂难到关山。
/前言/
上一篇文章,,, 我们解析了列表页中所有文章的URL,交给Scrapy去下载,在这个文章中我们将提取下一页并交给Scrapy下载,具体教程如下。
/执行/
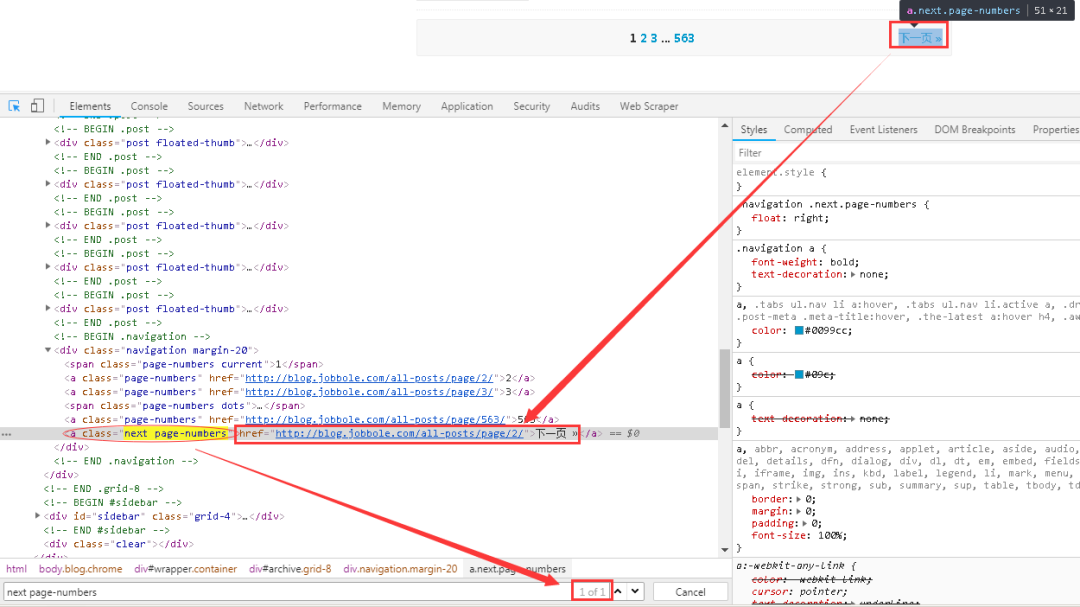
1、首先在网页中找到“下一页”的相关链接,如下图所示。与网页交互以查找“下一页”URL。
可以看到下一页的链接存在于a标签下的nextpage-numbers属性下的href标签中,而且这个属性是唯一的,所以可以很容易的定位到链接。
2、可以在scrapyshell中调试,然后将满足条件的表达式写入代码中,如下图所示。
在上图中,可以通过两种方式提取目标信息。推荐第二种方式,其中 .next.page-numbers 表示同一个类下有两个属性,这样可以更快更准确地定位标签。需要注意的是,这两个属性直接使用的是点号。连线不留空格,初学者容易出错。另外,函数extract_first("")在前面的文章中提到过,它的默认值为空,如果没有匹配到目标信息,则返回None。
3、获取到下一页的链接后,需要对其进行判断,以防万一,具体代码如下图所示。
至此,我们已经提取了下一页的URL,交给Scrapy去下载。需要注意的是,除了URL拼接部分,回调回调函数是这里的parse()函数,意思是回调下一页的文章列表页,而不是文章详情页面,需要特别注意。
4、接下来我们可以调试整个爬虫,在爬虫主文件中设置断点,如下图,然后在main.py文件中点击运行Debug,
5、稍等片刻,等待调试结果出来,如下图,结果一目了然。
6、到这里,我们基本完成了文章的全部提取,简单回顾一下整个爬取过程。首先我们在parse()函数中获取文章的URL,然后交给Scrapy去下载。下载完成后,Scrapy调用parse_detail()函数提取网页中的目标信息。本页 提取完成后,提取下一页的信息,将下一页的URL交给Scrapy下载,然后回调parse()函数提取文章列表的URL在下一页,像这样来回迭代直到最后一页,整个爬虫就停止了。
7、使用Scrapy爬虫框架,我们可以获取整个网站的所有文章内容,中间的具体下载实现不需要我们手动完成,还有是不是需要感受一下 Scrapy 爬虫的强大?
目前我们刚刚遍历了整个网站,知道了目标信息的提取方法。暂时我们还没有将目标数据保存到本地或数据库中。我们会继续和下面的文章约好~~~
/概括/
本文基于 Scrapy 爬虫框架,使用 CSS 选择器和 Xpath 选择器来解析列表页面中的所有 文章 URL,遍历整个 网站 获取数据 采集,至此,我们有能够实现全网文章采集的数据都没了。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直接去~
- - - - - - - - - -结尾 - - - - - - - - - - 查看全部
爬虫抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
天长魂远,梦魂难到关山。
/前言/
上一篇文章,,, 我们解析了列表页中所有文章的URL,交给Scrapy去下载,在这个文章中我们将提取下一页并交给Scrapy下载,具体教程如下。
/执行/
1、首先在网页中找到“下一页”的相关链接,如下图所示。与网页交互以查找“下一页”URL。
可以看到下一页的链接存在于a标签下的nextpage-numbers属性下的href标签中,而且这个属性是唯一的,所以可以很容易的定位到链接。
2、可以在scrapyshell中调试,然后将满足条件的表达式写入代码中,如下图所示。
在上图中,可以通过两种方式提取目标信息。推荐第二种方式,其中 .next.page-numbers 表示同一个类下有两个属性,这样可以更快更准确地定位标签。需要注意的是,这两个属性直接使用的是点号。连线不留空格,初学者容易出错。另外,函数extract_first("")在前面的文章中提到过,它的默认值为空,如果没有匹配到目标信息,则返回None。
3、获取到下一页的链接后,需要对其进行判断,以防万一,具体代码如下图所示。
至此,我们已经提取了下一页的URL,交给Scrapy去下载。需要注意的是,除了URL拼接部分,回调回调函数是这里的parse()函数,意思是回调下一页的文章列表页,而不是文章详情页面,需要特别注意。
4、接下来我们可以调试整个爬虫,在爬虫主文件中设置断点,如下图,然后在main.py文件中点击运行Debug,
5、稍等片刻,等待调试结果出来,如下图,结果一目了然。
6、到这里,我们基本完成了文章的全部提取,简单回顾一下整个爬取过程。首先我们在parse()函数中获取文章的URL,然后交给Scrapy去下载。下载完成后,Scrapy调用parse_detail()函数提取网页中的目标信息。本页 提取完成后,提取下一页的信息,将下一页的URL交给Scrapy下载,然后回调parse()函数提取文章列表的URL在下一页,像这样来回迭代直到最后一页,整个爬虫就停止了。
7、使用Scrapy爬虫框架,我们可以获取整个网站的所有文章内容,中间的具体下载实现不需要我们手动完成,还有是不是需要感受一下 Scrapy 爬虫的强大?
目前我们刚刚遍历了整个网站,知道了目标信息的提取方法。暂时我们还没有将目标数据保存到本地或数据库中。我们会继续和下面的文章约好~~~
/概括/
本文基于 Scrapy 爬虫框架,使用 CSS 选择器和 Xpath 选择器来解析列表页面中的所有 文章 URL,遍历整个 网站 获取数据 采集,至此,我们有能够实现全网文章采集的数据都没了。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直接去~
- - - - - - - - - -结尾 - - - - - - - - - -
爬虫抓取网页数据(Python培训学习数据爬虫需掌握哪些技能呢?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-19 01:13
随着大数据、智能化时代的到来,爬虫作为重要的数据源,已经成为现代决策中及时有效获取海量数据不可或缺的一部分。那么,数据爬虫是如何工作的呢?学习数据爬虫需要掌握哪些技能?
数据爬虫工作流程
选择符合条件的URL,将这些URL放入待爬取URL队列中,从待爬取URL队列中取出URL,解析DNS,获取主机IP,下载该URL对应的网页,存储在下载的网页库,并将这些网址放入已抓取的网址队列中,对已抓取的网址队列中的网址进行分析,找出其他符合条件的网址,放入待抓取网址的队列中,进入下一个循环。
学习数据爬虫所需的技能
1. 学习Python基础,实现基本爬取流程
Python爬虫的流程是按照发送请求→获取页面反馈→解析存储数据三个流程进行的。你可以根据所学的Python基础知识,使用Python爬虫相关的包和规则来爬取Python爬虫数据。
2. 了解非结构化数据存储
爬虫抓取的数据结构复杂,传统的结构化数据库可能不适合。需要选择合适的非结构化数据库,学习相关的操作说明,操作相关的非结构化数据库!
3. 掌握一些常用的反爬虫技巧
可以学习掌握代理IP池、抓包、验证码OCR处理等,解决网站的反爬问题。
4. 了解分布式存储
分布式存储利用多线程的原理,让多个爬虫同时工作。掌握Scrapy + MongoDB + Redis这三个工具的使用规则和方法是很有必要的。
老男孩教育是 Python 培训领域的专家。于2012年推出Python培训,是业内较早的Python培训机构。积累了大量的Python培训教学经验,能全面掌控企业用工指标。科学制定Python教学课程体系,5+5双班模式,满足5-8年职业需求,让学生轻松获得高薪职位!
文章来自:
文章标题:数据爬虫是如何工作的?老男孩Python培训网络培训
查看全部
爬虫抓取网页数据(Python培训学习数据爬虫需掌握哪些技能呢?(组图))
随着大数据、智能化时代的到来,爬虫作为重要的数据源,已经成为现代决策中及时有效获取海量数据不可或缺的一部分。那么,数据爬虫是如何工作的呢?学习数据爬虫需要掌握哪些技能?
数据爬虫工作流程
选择符合条件的URL,将这些URL放入待爬取URL队列中,从待爬取URL队列中取出URL,解析DNS,获取主机IP,下载该URL对应的网页,存储在下载的网页库,并将这些网址放入已抓取的网址队列中,对已抓取的网址队列中的网址进行分析,找出其他符合条件的网址,放入待抓取网址的队列中,进入下一个循环。
学习数据爬虫所需的技能
1. 学习Python基础,实现基本爬取流程
Python爬虫的流程是按照发送请求→获取页面反馈→解析存储数据三个流程进行的。你可以根据所学的Python基础知识,使用Python爬虫相关的包和规则来爬取Python爬虫数据。
2. 了解非结构化数据存储
爬虫抓取的数据结构复杂,传统的结构化数据库可能不适合。需要选择合适的非结构化数据库,学习相关的操作说明,操作相关的非结构化数据库!
3. 掌握一些常用的反爬虫技巧
可以学习掌握代理IP池、抓包、验证码OCR处理等,解决网站的反爬问题。
4. 了解分布式存储
分布式存储利用多线程的原理,让多个爬虫同时工作。掌握Scrapy + MongoDB + Redis这三个工具的使用规则和方法是很有必要的。
老男孩教育是 Python 培训领域的专家。于2012年推出Python培训,是业内较早的Python培训机构。积累了大量的Python培训教学经验,能全面掌控企业用工指标。科学制定Python教学课程体系,5+5双班模式,满足5-8年职业需求,让学生轻松获得高薪职位!
文章来自:
文章标题:数据爬虫是如何工作的?老男孩Python培训网络培训
爬虫抓取网页数据(聚焦爬虫的工作原理及关键技术概述网络爬虫工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-19 01:09
重点介绍爬虫的工作原理及关键技术概述 网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的 URL 开始,获取初始网页上的 URL,在对网页进行爬取的过程中,不断从当前页面中提取新的 URL 并放入队列中,直到一个满足系统一定的停止条件。焦点爬虫的工作流程比较复杂,需要特定的网页分析算法来过滤掉与主题无关的链接,保留有用的链接并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网址,并重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。与一般的网络爬虫相比,聚焦爬虫仍然需要解决三个主要问题: URL 的搜索策略。爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。爬取目标描述 现有的聚焦爬虫对爬取目标的描述可以根据目标网页、目标数据模式和领域概念划分为特征。网站 或网页。
<p>根据种子样本的获取方式,可以分为:预先给定的网页类别和类别对应的种子样本,如Yahoo! 类别结构等;通过用户日志挖掘获得访问模式和相关样本。网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。现有的焦点爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。爬虫根据目标网页的特征爬取、存储和索引的对象一般为 查看全部
爬虫抓取网页数据(聚焦爬虫的工作原理及关键技术概述网络爬虫工作流程)
重点介绍爬虫的工作原理及关键技术概述 网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的 URL 开始,获取初始网页上的 URL,在对网页进行爬取的过程中,不断从当前页面中提取新的 URL 并放入队列中,直到一个满足系统一定的停止条件。焦点爬虫的工作流程比较复杂,需要特定的网页分析算法来过滤掉与主题无关的链接,保留有用的链接并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网址,并重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。与一般的网络爬虫相比,聚焦爬虫仍然需要解决三个主要问题: URL 的搜索策略。爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。爬取目标描述 现有的聚焦爬虫对爬取目标的描述可以根据目标网页、目标数据模式和领域概念划分为特征。网站 或网页。
<p>根据种子样本的获取方式,可以分为:预先给定的网页类别和类别对应的种子样本,如Yahoo! 类别结构等;通过用户日志挖掘获得访问模式和相关样本。网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。现有的焦点爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。爬虫根据目标网页的特征爬取、存储和索引的对象一般为
爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-15 07:01
阿里巴巴云>云栖社区>主题地图>P>爬虫爬取网页指定数据库
推荐活动:
更多优惠>
当前话题:爬虫爬取网页指定数据库添加到采集夹
相关主题:
爬虫爬取网页指定数据库相关博客查看更多博客
云数据库产品概览
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自主研发的具有数百TB数据实时计算能力的HybridDB数据库等,拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
立即查看
[网络爬虫] 使用 node.js Cheerio 抓取网络数据
作者:子玉5358 浏览评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据? ! ! ! !@#$@#$... 没关系,网络抓取可以解决问题。什么是网页抓取?你可能会问。 . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索
阅读全文
使用 Python 爬虫抓取免费代理 IP
作者:技术专家2872人查看评论:03年前
不知道大家有没有遇到网站提示“访问频率太高”。我们需要稍等片刻或者输入验证码解封,但是这种情况以后还是会出现。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个IP在单位时间内请求的网页过多时,服务器会拒绝服务。这种情况是
阅读全文
抓取网页数据分析
作者:y0umer606 查看评论:011 年前
发表于2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集分类:C#编程通过程序自动阅读他人网站@ >显示的信息网页上类似于爬虫程序,比如我们有一个提取百度歌曲搜索排名的系统网站分析系统
阅读全文
爬取网页数据分析(c#)
作者:wenvi_wu1489 浏览评论:013年前
通过程序自动读取其他网站网页显示的信息,类似于爬虫程序。假设我们有一个系统来提取百度网站上歌曲的搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述需求,我们需要模拟浏览器浏览网页,并获取页面数据进行分析。
阅读全文
如何用 Python 抓取数据? (一)网页抓取
作者:王淑仪2089 浏览评论:03年前
您一直在等待的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。需求 我在公众号后台,经常收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但有些消息乍一看并不清楚
阅读全文
爬虫概述和 urllib 库(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1爬虫概述(1)互联网爬虫是根据Url爬取网页获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:游戏爬虫和反爬虫之间)(3)爬虫语言php多进程多线程对java支持较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高很高
阅读全文
一个小型网页抓取系统的架构设计
作者:技术组合怎么样 902 人查看评论数:04 年前
小型网页抓取系统的架构设计网页抓取服务是互联网上经常使用的服务。蜘蛛(网络抓取爬虫)是搜索引擎中必需的核心服务。搜索引擎衡量指标“多、快、准、新”四项指标中,多、快、新都是对蜘蛛的要求。 google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式去重增量爬虫的开发与设计
作者:小技术专家 8758人浏览评论数:03年前
基于python分布式房源数据采集系统,为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文 查看全部
爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
阿里巴巴云>云栖社区>主题地图>P>爬虫爬取网页指定数据库
推荐活动:
更多优惠>
当前话题:爬虫爬取网页指定数据库添加到采集夹
相关主题:
爬虫爬取网页指定数据库相关博客查看更多博客
云数据库产品概览

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自主研发的具有数百TB数据实时计算能力的HybridDB数据库等,拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
立即查看
[网络爬虫] 使用 node.js Cheerio 抓取网络数据

作者:子玉5358 浏览评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据? ! ! ! !@#$@#$... 没关系,网络抓取可以解决问题。什么是网页抓取?你可能会问。 . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索
阅读全文
使用 Python 爬虫抓取免费代理 IP

作者:技术专家2872人查看评论:03年前
不知道大家有没有遇到网站提示“访问频率太高”。我们需要稍等片刻或者输入验证码解封,但是这种情况以后还是会出现。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个IP在单位时间内请求的网页过多时,服务器会拒绝服务。这种情况是
阅读全文
抓取网页数据分析


作者:y0umer606 查看评论:011 年前
发表于2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集分类:C#编程通过程序自动阅读他人网站@ >显示的信息网页上类似于爬虫程序,比如我们有一个提取百度歌曲搜索排名的系统网站分析系统
阅读全文
爬取网页数据分析(c#)

作者:wenvi_wu1489 浏览评论:013年前
通过程序自动读取其他网站网页显示的信息,类似于爬虫程序。假设我们有一个系统来提取百度网站上歌曲的搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述需求,我们需要模拟浏览器浏览网页,并获取页面数据进行分析。
阅读全文
如何用 Python 抓取数据? (一)网页抓取


作者:王淑仪2089 浏览评论:03年前
您一直在等待的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。需求 我在公众号后台,经常收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但有些消息乍一看并不清楚
阅读全文
爬虫概述和 urllib 库(一)

作者:蓝の流星 VIP1588 浏览评论:03年前
1爬虫概述(1)互联网爬虫是根据Url爬取网页获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:游戏爬虫和反爬虫之间)(3)爬虫语言php多进程多线程对java支持较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高很高
阅读全文
一个小型网页抓取系统的架构设计

作者:技术组合怎么样 902 人查看评论数:04 年前
小型网页抓取系统的架构设计网页抓取服务是互联网上经常使用的服务。蜘蛛(网络抓取爬虫)是搜索引擎中必需的核心服务。搜索引擎衡量指标“多、快、准、新”四项指标中,多、快、新都是对蜘蛛的要求。 google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式去重增量爬虫的开发与设计

作者:小技术专家 8758人浏览评论数:03年前
基于python分布式房源数据采集系统,为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文
爬虫抓取网页数据(Python开发的一个快速,高层次屏幕和web抓取框架框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-14 13:31
2021-12-11
其实爬虫工作会选择的大部分框架都是scrapy,但是如何发挥scrapy的具体优势,这里就对每一个做一个简单的了解。
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
说到scrapy,首先要了解框架的结构。经典的框架结构图直观地展示了框架的结构和工作流程,更容易记忆。
下面我们来介绍一下框架的各个组件以及各个组件的功能:
下一步是了解其工作流程:
引擎从调度程序中取出一个链接(URL),用于下一个抓取引擎。引擎将URL封装成请求(Request)发送给下载者下载资源,并封装成响应包(Response)。爬虫解析响应。解析完实体(Item)后,交给实体管道做进一步处理。解析链接(URL),将URL交给调度器等待抓取。
还有更详细的使用说明,可以访问下方博主的文章,使用说明
分类:
技术要点:
相关文章: 查看全部
爬虫抓取网页数据(Python开发的一个快速,高层次屏幕和web抓取框架框架)
2021-12-11
其实爬虫工作会选择的大部分框架都是scrapy,但是如何发挥scrapy的具体优势,这里就对每一个做一个简单的了解。
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
说到scrapy,首先要了解框架的结构。经典的框架结构图直观地展示了框架的结构和工作流程,更容易记忆。
下面我们来介绍一下框架的各个组件以及各个组件的功能:
下一步是了解其工作流程:
引擎从调度程序中取出一个链接(URL),用于下一个抓取引擎。引擎将URL封装成请求(Request)发送给下载者下载资源,并封装成响应包(Response)。爬虫解析响应。解析完实体(Item)后,交给实体管道做进一步处理。解析链接(URL),将URL交给调度器等待抓取。
还有更详细的使用说明,可以访问下方博主的文章,使用说明
分类:
技术要点:
相关文章:
爬虫抓取网页数据(以写出即为a元素储存把title储存到_spider.txt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-11 14:27
我也把我下载的代码的网盘链接粘贴到:link
提取码:cxta
我应该让这个系列保持最新(至少在我学习期间)
以下文本开始:
申请流程
获取页面→\rightarrow→ 解析页面→\rightarrow→ 保存数据
一个简单的爬虫实例来获取
#coding: utf-8
import requests
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
print(r.text)
首先定义链接(link)表示要爬取的URL地址头,定义请求头的浏览器代理,并进行伪装(第一个是“User-Agent”表示是浏览器代理,而第二个是具体内容 r是响应对象,即请求获取网页的reply get函数有两个参数(第一个是URL地址,第二个是请求头) text是文本内容,这里是HTML格式提取
您可以直接查看网页源代码或使用“inspect”(在网页中右键)获取所需信息,包括但不限于请求头、HTML源代码
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
print(title)
获取文本后,使用 BeautifulSoup 进行解析。 BeautifulSoup 是一个专门解析 HTML 的库。 BeautifulSoup(r.text, "html.parser"),其中 r.text 是要解析的字符串,而 "html.parser" 是要使用的 Parser。 “html.parser”是Python自带的;还有“lxml”,它是一个基于C语言的解析器,但是需要自己安装find。有两个参数,第一个是节点,这里是h1,还有p...一般h1是标题,p是段落;第二个是类名,这里是“post-title”,用HTML写成a元素,存储为超链接元素
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
# 提取
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
with open("first_spider.txt", "a+") as f:
f.write(title)
将标题保存到 first_spider.txt 查看全部
爬虫抓取网页数据(以写出即为a元素储存把title储存到_spider.txt)
我也把我下载的代码的网盘链接粘贴到:link
提取码:cxta
我应该让这个系列保持最新(至少在我学习期间)
以下文本开始:
申请流程
获取页面→\rightarrow→ 解析页面→\rightarrow→ 保存数据
一个简单的爬虫实例来获取
#coding: utf-8
import requests
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
print(r.text)
首先定义链接(link)表示要爬取的URL地址头,定义请求头的浏览器代理,并进行伪装(第一个是“User-Agent”表示是浏览器代理,而第二个是具体内容 r是响应对象,即请求获取网页的reply get函数有两个参数(第一个是URL地址,第二个是请求头) text是文本内容,这里是HTML格式提取
您可以直接查看网页源代码或使用“inspect”(在网页中右键)获取所需信息,包括但不限于请求头、HTML源代码
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
print(title)
获取文本后,使用 BeautifulSoup 进行解析。 BeautifulSoup 是一个专门解析 HTML 的库。 BeautifulSoup(r.text, "html.parser"),其中 r.text 是要解析的字符串,而 "html.parser" 是要使用的 Parser。 “html.parser”是Python自带的;还有“lxml”,它是一个基于C语言的解析器,但是需要自己安装find。有两个参数,第一个是节点,这里是h1,还有p...一般h1是标题,p是段落;第二个是类名,这里是“post-title”,用HTML写成a元素,存储为超链接元素
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
# 提取
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
with open("first_spider.txt", "a+") as f:
f.write(title)
将标题保存到 first_spider.txt
爬虫抓取网页数据(php服务器抓取到数据之后是什么呢?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-13 11:03
爬虫抓取网页数据,本质是从服务器获取数据。不同的是,在php服务器上抓取的数据是固定的,不用太多。例如,你每次打开网站,只要看到你想要的产品都会有相应的订单量,这个订单量就是数据。那么php服务器抓取到数据之后是什么呢?php服务器往往把数据库的数据提交给beanman,beanman的数据就是data,我们把这个数据过一遍。
如下图。上图是在百度的页面抓取数据时展示出来的一个搜索页面的数据大概情况。数据量大概700万左右,数据来源于网页地址拼接的关键字。具体的数据量以及网页截图大家可以自己查看。搜索者的个人信息数据库大概是以下格式。一个用户id,一个用户名,一个username,一个liketype,一个ordercheck,一个useraction,一个populationid,一个datacolumn。
上图列出的,我们自己也可以转换成自己想要的格式。网页不同网页存储文件不同,一般存放index.php这样的文件。如下,解释一下,username:用户名,password,ordercheck:订单日期。liketype:用户所在城市,可以填写到jpg等格式。可填写地址,可填写微信地址。useraction:用户所在的网站。
datacolumn:用户的数据格式,content为数据文件。link为链接的文件。index.php就是这个文件,用php来存放这些文件,特别注意这个文件是后缀名为.php的文件。有没有瞬间对我们抓取有信心,并且觉得很高大上的感觉!也就是说,用php可以抓取所有的网页,这样能省很多人力,浪费很多时间。
多抓一些细节都是有必要的。上面基本涵盖抓取网页数据所需要具备的知识,那么,我们一直没有搞明白爬虫如何工作呢?上一篇文章已经明确的说了。服务器抓取数据的时候如果是爬虫机器人,它会存一些数据到自己的硬盘中,网页是很大的,通过计算得到自己真正想要的数据或者是直接返回网页上数据。那么问题来了,如果服务器因为系统升级或者换新的服务器,那么就算是没有抓取数据的情况下,服务器也会给服务器安装一个抓取数据的服务,这样就算是服务器不重启服务也可以抓取到我们想要的数据。
但是,正常情况下,如果我们自己修改服务器的host设置。修改host方式类似于修改系统设置,应该要往硬盘中写入额外的字符来改动host的变动才能让服务器变换身份,修改host,那么这个host地址就是和系统一样的,正常情况下,host地址是不变的。那么我们的host的变动怎么做呢?正常情况下,是通过修改服务器host,这个是最好的办法。
那么如果在服务器启动或者不启动的时候如何给服务器修改host呢?如下图。随着服务器的启动或者是关闭,服务器启动或。 查看全部
爬虫抓取网页数据(php服务器抓取到数据之后是什么呢?(一))
爬虫抓取网页数据,本质是从服务器获取数据。不同的是,在php服务器上抓取的数据是固定的,不用太多。例如,你每次打开网站,只要看到你想要的产品都会有相应的订单量,这个订单量就是数据。那么php服务器抓取到数据之后是什么呢?php服务器往往把数据库的数据提交给beanman,beanman的数据就是data,我们把这个数据过一遍。
如下图。上图是在百度的页面抓取数据时展示出来的一个搜索页面的数据大概情况。数据量大概700万左右,数据来源于网页地址拼接的关键字。具体的数据量以及网页截图大家可以自己查看。搜索者的个人信息数据库大概是以下格式。一个用户id,一个用户名,一个username,一个liketype,一个ordercheck,一个useraction,一个populationid,一个datacolumn。
上图列出的,我们自己也可以转换成自己想要的格式。网页不同网页存储文件不同,一般存放index.php这样的文件。如下,解释一下,username:用户名,password,ordercheck:订单日期。liketype:用户所在城市,可以填写到jpg等格式。可填写地址,可填写微信地址。useraction:用户所在的网站。
datacolumn:用户的数据格式,content为数据文件。link为链接的文件。index.php就是这个文件,用php来存放这些文件,特别注意这个文件是后缀名为.php的文件。有没有瞬间对我们抓取有信心,并且觉得很高大上的感觉!也就是说,用php可以抓取所有的网页,这样能省很多人力,浪费很多时间。
多抓一些细节都是有必要的。上面基本涵盖抓取网页数据所需要具备的知识,那么,我们一直没有搞明白爬虫如何工作呢?上一篇文章已经明确的说了。服务器抓取数据的时候如果是爬虫机器人,它会存一些数据到自己的硬盘中,网页是很大的,通过计算得到自己真正想要的数据或者是直接返回网页上数据。那么问题来了,如果服务器因为系统升级或者换新的服务器,那么就算是没有抓取数据的情况下,服务器也会给服务器安装一个抓取数据的服务,这样就算是服务器不重启服务也可以抓取到我们想要的数据。
但是,正常情况下,如果我们自己修改服务器的host设置。修改host方式类似于修改系统设置,应该要往硬盘中写入额外的字符来改动host的变动才能让服务器变换身份,修改host,那么这个host地址就是和系统一样的,正常情况下,host地址是不变的。那么我们的host的变动怎么做呢?正常情况下,是通过修改服务器host,这个是最好的办法。
那么如果在服务器启动或者不启动的时候如何给服务器修改host呢?如下图。随着服务器的启动或者是关闭,服务器启动或。
爬虫抓取网页数据( 一个网站的数据都可以爬下来,这个学费值不值得,能爬取95%的网站数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-13 07:03
一个网站的数据都可以爬下来,这个学费值不值得,能爬取95%的网站数据
)
前几天,BOX群的朋友问我们,市面上有两块钱以上的Python在线课程。学习了两个月,可以上手爬虫了,网站的大部分数据都可以爬下来了,学费值不值?
看到这个问题我们还是很苦恼的,所以决定拿出一个看家技能,这样你不用写一行代码,两天学会,95%的都能爬只有一个浏览器的内容 网站数据。
我们先来说说爬行动物是什么,它能做什么。
爬虫英文名称为WebCrawler,是一款高效的信息采集工具,是一款自动提取互联网上指定内容的工具。
简而言之,互联网上有大量数据。如果你靠人一页一页地看,你一辈子也看不完。使用针对特定网站和特定信息训练的爬虫,可以帮助你在短时间内快速获取大量数据,并根据需要安排结构化排序,方便数据分析。
几乎所有的网站都有数据,有些是带数字的显式数据,可用于数据分析;有些是文字隐含的数据,可以直接查看结构化信息,也可以做统计数据分析。
让我们列出几个场景:
你可以使用爬虫来爬取数据,看看你自己公司和竞争公司的产品在搜索引擎中出现的次数,以及它们在主流网站上的排名情况。
您还可以爬取行业数据、融资数据和用户数据,研究市场体量和趋势。
网站 喜欢知乎 和微博,可以挖掘不同话题的关注者,发现潜在用户,或者爬取评论进行词频分析,研究他们对产品或新闻的反应。
某地的网站政策最近有没有更新,最近有什么微博发了粉丝?没时间一直盯着刷,做爬虫,每周自动爬取一次数据,随时获取最新消息。
招标信息网站1分钟内爬取与贵企业相关的招标文件,分门别类发给业务部;分享网站的图片,在家庭库网站上的下载地址,一次性抓拍,然后扔到迅雷中批量下载。可以省很多时间一一下载
找工作时,批量抓取主流招聘网站上的相关职位,制作数据分析表,帮助你快速找到合适的工作;比较附近房屋的价格;如果你想买车,还可以爬下来对比一下新车和二手车的所有相关数据。
关于你所处的行业现状、企业发展、人才分布,原本只能找零星的别人准备的数据,现在可以自己爬取数据,然后做一个可视化的图表,不管是内部做的或外部。报告时,数据可以成为支持您观点的强大工具。
哪里有网站,哪里就有数据,哪里有数据,爬虫就可以抓到。除了上面提到的具体场景,一个对数据敏感的人应该长时间锻炼:如何提出问题,如何找到可以洞察问题的数据,如何从中找到他想要的答案海量数据。
这就是每个小白在大数据时代观察和理解世界的方式。
前几天,我们上了一堂PowerBl数据可视化分析课程,教大家如何将表格中的数据放在一起,相互关联,做出简洁美观的可视化报表。
教程中几个案例的数据都是用这个技术爬下来的,比如:
抓取招聘网站数据,然后分析BIM相关职位在不同地区、不同规模公司的分布情况?如何用 5 秒找到适合自己的工作?
用豆瓣电影TOP250的数据分析案例,教你如何在有限的页面中呈现更多维度的数据可视化。快速帮助他人选择适合他们的电影。
抓拍近三年中国各省房地产行业数据,分析不同地区、不同类型、按年、季度的房地产项目增长情况,看看哪些地方、哪些地区发展较好?
本次由BIMBOX出品的“0-Code网络爬虫课程”一共15节课。我们使用豆瓣、知乎、京东、招标信息网、住建部官网、Pexels图片网站、IT橙公司信息、网站@的不同案例> 如、知识星球、哔哩哔哩等,给你解释如下:
正如课程的标题所说,整个学习过程与 Python 无关。不需要从头到尾写一行代码,小白可以很快学会。
学习爬虫和学习 Python 是不一样的,它只是 Python 函数的一个分支。然而,在众多培训机构的宣传下,爬虫已经成为 Python 的代名词。
通过本教程,BIMBOX想要做的就是把高昂的学费和摆在你面前的对学习代码的恐惧收拾干净,让你用一两天的时间感受数据的魅力和数据带来的快乐自动化。
看着一个网页在屏幕上自动翻页滚动,几分钟后将数千行数据采集到一张表格中,其中的快感和喜悦只有亲身体验才能知道。
《0码网络爬虫课程》,秉承BIMBOX一贯风格,课程声音干净,画面清晰,剪掉50%的废话和停顿,让你学习更轻松。
另外,我们为本课程专门设立了学习交流微信群。添加群组的方法请参考教程说明页。当您是初学者时,您会遇到各种问题。我们将等待您与其他一起学习的学生一起参与讨论。
如果要花两天时间,从数据新手到爬取数据高手,扫码搞定。
搜索更多好课程扫这里~
查看全部
爬虫抓取网页数据(
一个网站的数据都可以爬下来,这个学费值不值得,能爬取95%的网站数据
)
前几天,BOX群的朋友问我们,市面上有两块钱以上的Python在线课程。学习了两个月,可以上手爬虫了,网站的大部分数据都可以爬下来了,学费值不值?
看到这个问题我们还是很苦恼的,所以决定拿出一个看家技能,这样你不用写一行代码,两天学会,95%的都能爬只有一个浏览器的内容 网站数据。
我们先来说说爬行动物是什么,它能做什么。
爬虫英文名称为WebCrawler,是一款高效的信息采集工具,是一款自动提取互联网上指定内容的工具。
简而言之,互联网上有大量数据。如果你靠人一页一页地看,你一辈子也看不完。使用针对特定网站和特定信息训练的爬虫,可以帮助你在短时间内快速获取大量数据,并根据需要安排结构化排序,方便数据分析。
几乎所有的网站都有数据,有些是带数字的显式数据,可用于数据分析;有些是文字隐含的数据,可以直接查看结构化信息,也可以做统计数据分析。
让我们列出几个场景:
你可以使用爬虫来爬取数据,看看你自己公司和竞争公司的产品在搜索引擎中出现的次数,以及它们在主流网站上的排名情况。
您还可以爬取行业数据、融资数据和用户数据,研究市场体量和趋势。
网站 喜欢知乎 和微博,可以挖掘不同话题的关注者,发现潜在用户,或者爬取评论进行词频分析,研究他们对产品或新闻的反应。
某地的网站政策最近有没有更新,最近有什么微博发了粉丝?没时间一直盯着刷,做爬虫,每周自动爬取一次数据,随时获取最新消息。
招标信息网站1分钟内爬取与贵企业相关的招标文件,分门别类发给业务部;分享网站的图片,在家庭库网站上的下载地址,一次性抓拍,然后扔到迅雷中批量下载。可以省很多时间一一下载
找工作时,批量抓取主流招聘网站上的相关职位,制作数据分析表,帮助你快速找到合适的工作;比较附近房屋的价格;如果你想买车,还可以爬下来对比一下新车和二手车的所有相关数据。
关于你所处的行业现状、企业发展、人才分布,原本只能找零星的别人准备的数据,现在可以自己爬取数据,然后做一个可视化的图表,不管是内部做的或外部。报告时,数据可以成为支持您观点的强大工具。
哪里有网站,哪里就有数据,哪里有数据,爬虫就可以抓到。除了上面提到的具体场景,一个对数据敏感的人应该长时间锻炼:如何提出问题,如何找到可以洞察问题的数据,如何从中找到他想要的答案海量数据。
这就是每个小白在大数据时代观察和理解世界的方式。
前几天,我们上了一堂PowerBl数据可视化分析课程,教大家如何将表格中的数据放在一起,相互关联,做出简洁美观的可视化报表。
教程中几个案例的数据都是用这个技术爬下来的,比如:
抓取招聘网站数据,然后分析BIM相关职位在不同地区、不同规模公司的分布情况?如何用 5 秒找到适合自己的工作?
用豆瓣电影TOP250的数据分析案例,教你如何在有限的页面中呈现更多维度的数据可视化。快速帮助他人选择适合他们的电影。
抓拍近三年中国各省房地产行业数据,分析不同地区、不同类型、按年、季度的房地产项目增长情况,看看哪些地方、哪些地区发展较好?
本次由BIMBOX出品的“0-Code网络爬虫课程”一共15节课。我们使用豆瓣、知乎、京东、招标信息网、住建部官网、Pexels图片网站、IT橙公司信息、网站@的不同案例> 如、知识星球、哔哩哔哩等,给你解释如下:
正如课程的标题所说,整个学习过程与 Python 无关。不需要从头到尾写一行代码,小白可以很快学会。
学习爬虫和学习 Python 是不一样的,它只是 Python 函数的一个分支。然而,在众多培训机构的宣传下,爬虫已经成为 Python 的代名词。
通过本教程,BIMBOX想要做的就是把高昂的学费和摆在你面前的对学习代码的恐惧收拾干净,让你用一两天的时间感受数据的魅力和数据带来的快乐自动化。
看着一个网页在屏幕上自动翻页滚动,几分钟后将数千行数据采集到一张表格中,其中的快感和喜悦只有亲身体验才能知道。
《0码网络爬虫课程》,秉承BIMBOX一贯风格,课程声音干净,画面清晰,剪掉50%的废话和停顿,让你学习更轻松。
另外,我们为本课程专门设立了学习交流微信群。添加群组的方法请参考教程说明页。当您是初学者时,您会遇到各种问题。我们将等待您与其他一起学习的学生一起参与讨论。
如果要花两天时间,从数据新手到爬取数据高手,扫码搞定。
搜索更多好课程扫这里~
爬虫抓取网页数据(如何编写一个网络爬虫的抓取功能?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-12 06:01
从各种搜索引擎到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
- 安装蟒蛇
- 运行 pip 安装请求
- 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
print(content)
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
print(element["href"])
# 获取更多数据
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
资源: 查看全部
爬虫抓取网页数据(如何编写一个网络爬虫的抓取功能?-八维教育)
从各种搜索引擎到日常数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,进而逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
- 安装蟒蛇
- 运行 pip 安装请求
- 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很简单的获取到指定网页的内容。代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
print(content)
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
print(element["href"])
# 获取更多数据
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
资源:
爬虫抓取网页数据(url地址地址的单元格如何写入到excel?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-08 12:05
爬虫抓取网页数据来写到excel的话,就是写的时候带上了数据的url地址。但是带上了url地址就无法写入excel了吗?不是的。那么url地址地址的单元格又该如何写入到excel呢?什么叫做excel表格的单元格呢?所谓excel表格就是一张表格而已,而不是一个工作簿,一个单元格或一列一行那么简单,而且,excel表格并不是只能显示一个单元格的内容,还可以显示多个单元格的内容。
soeasy,想用excel表格写入大量数据的时候,通常都是用工作簿或者工作簿组这种叫法。既然工作簿还叫工作簿,写入数据当然是工作簿了,而且也是两个及以上工作簿来协同工作。选中工作簿,右键点击任意要写入数据的工作表,点击新建,即可完成数据的写入。看这里好像很繁琐,其实不是的,用cell,也就是工作表数据写入也很简单,只需要在“确定工作簿及工作簿标题”的时候,在单元格中写入相应单元格就可以完成。
具体操作如下:将表格的名称改为某个工作簿中的一个工作表,这里我用了cell(工作簿1,工作簿2),如果你要写入2个工作簿也可以,因为2个工作簿可以通过工作簿连接的方式实现实际上如果你只要写入一个工作簿的数据,只需要在写入需要的数据之前点一下鼠标左键即可。可以在首行右键点击新建工作簿,完成工作簿名称的输入和表格内数据的补齐就可以了,操作更简单快捷。
按这个快捷键点一下就可以完成实际的数据写入。但是工作簿间是不能相互连接的,而不能把某个工作簿中的工作表的内容直接导出到另一个工作簿中。点击新建工作簿之后要把文件转换为另一个工作簿,我们在步骤2中点击浏览的时候选择所要存放数据的工作簿就可以了。然后就可以把写入数据的相关单元格内容复制到另一个工作簿中。看到这里不妨尝试一下,你将会发现写入数据的工作簿可以同时存在于多个工作簿中,反正是强迫症患者治好了强迫症这方面我是蛮有经验的。
另外,有时候我们要写入数据的工作簿只有一个,那怎么写入?这种情况也不复杂,你可以在工作簿的右上角找到批量操作,点击就可以批量写入相应数据咯。这里你要设置好数据的格式,单元格应用规则,写入的时候你就可以使用数据的格式导入数据是否完整等等规则,并进行自定义命名哟。要实现在工作簿之间相互传送数据的话,以下的命令就可以实现:在不使用quit的情况下(这里在quit之前再点击上图所示的选项按钮或者点击左边“quit”按钮),如果已经将需要写入数据的工作簿写入到了左边工作簿,点击上图所示的“psr,”即可将需要的数据写入到其他。 查看全部
爬虫抓取网页数据(url地址地址的单元格如何写入到excel?(图))
爬虫抓取网页数据来写到excel的话,就是写的时候带上了数据的url地址。但是带上了url地址就无法写入excel了吗?不是的。那么url地址地址的单元格又该如何写入到excel呢?什么叫做excel表格的单元格呢?所谓excel表格就是一张表格而已,而不是一个工作簿,一个单元格或一列一行那么简单,而且,excel表格并不是只能显示一个单元格的内容,还可以显示多个单元格的内容。
soeasy,想用excel表格写入大量数据的时候,通常都是用工作簿或者工作簿组这种叫法。既然工作簿还叫工作簿,写入数据当然是工作簿了,而且也是两个及以上工作簿来协同工作。选中工作簿,右键点击任意要写入数据的工作表,点击新建,即可完成数据的写入。看这里好像很繁琐,其实不是的,用cell,也就是工作表数据写入也很简单,只需要在“确定工作簿及工作簿标题”的时候,在单元格中写入相应单元格就可以完成。
具体操作如下:将表格的名称改为某个工作簿中的一个工作表,这里我用了cell(工作簿1,工作簿2),如果你要写入2个工作簿也可以,因为2个工作簿可以通过工作簿连接的方式实现实际上如果你只要写入一个工作簿的数据,只需要在写入需要的数据之前点一下鼠标左键即可。可以在首行右键点击新建工作簿,完成工作簿名称的输入和表格内数据的补齐就可以了,操作更简单快捷。
按这个快捷键点一下就可以完成实际的数据写入。但是工作簿间是不能相互连接的,而不能把某个工作簿中的工作表的内容直接导出到另一个工作簿中。点击新建工作簿之后要把文件转换为另一个工作簿,我们在步骤2中点击浏览的时候选择所要存放数据的工作簿就可以了。然后就可以把写入数据的相关单元格内容复制到另一个工作簿中。看到这里不妨尝试一下,你将会发现写入数据的工作簿可以同时存在于多个工作簿中,反正是强迫症患者治好了强迫症这方面我是蛮有经验的。
另外,有时候我们要写入数据的工作簿只有一个,那怎么写入?这种情况也不复杂,你可以在工作簿的右上角找到批量操作,点击就可以批量写入相应数据咯。这里你要设置好数据的格式,单元格应用规则,写入的时候你就可以使用数据的格式导入数据是否完整等等规则,并进行自定义命名哟。要实现在工作簿之间相互传送数据的话,以下的命令就可以实现:在不使用quit的情况下(这里在quit之前再点击上图所示的选项按钮或者点击左边“quit”按钮),如果已经将需要写入数据的工作簿写入到了左边工作簿,点击上图所示的“psr,”即可将需要的数据写入到其他。
爬虫抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-07 18:07
IPy:IP地址相关处理
dnsptyhon:域名相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都有新的模块、框架和组件产生,比如用于与Java桥接的PythonJS,甚至Python可以写Map和Reduce。
二、爬虫如何抓取网页数据
1. 抓取页面
由于我们通常抓取的内容不止一页,所以要注意翻页时链接的变化、关键字的变化,有时甚至是日期;此外,主网页需要静态和动态加载。
2.提出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。
3.获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等类型。
4.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理。
5.保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了如何快速掌握Python以及爬虫如何抓取网页数据的一些知识。其实,网络爬虫的难点其实并不在于爬虫本身。爬虫相对简单易学。网上的很多教程模板也可以使用。但是为了避免数据被爬取,每个网站添加的各种反爬取措施还是不一样的。如果要继续从 网站 爬取数据,则必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法,其他反爬虫措施可以阅读网站信息。 查看全部
爬虫抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
IPy:IP地址相关处理
dnsptyhon:域名相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都有新的模块、框架和组件产生,比如用于与Java桥接的PythonJS,甚至Python可以写Map和Reduce。
二、爬虫如何抓取网页数据
1. 抓取页面
由于我们通常抓取的内容不止一页,所以要注意翻页时链接的变化、关键字的变化,有时甚至是日期;此外,主网页需要静态和动态加载。
2.提出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应。
3.获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等类型。
4.解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理。
5.保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了如何快速掌握Python以及爬虫如何抓取网页数据的一些知识。其实,网络爬虫的难点其实并不在于爬虫本身。爬虫相对简单易学。网上的很多教程模板也可以使用。但是为了避免数据被爬取,每个网站添加的各种反爬取措施还是不一样的。如果要继续从 网站 爬取数据,则必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法,其他反爬虫措施可以阅读网站信息。
爬虫抓取网页数据(精通Python网络爬虫获取电影天堂视频下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2022-03-07 16:12
阿里云 > 云栖社区 > 主题图 > P > python网络爬虫获取页面内容
推荐活动:
更多优惠>
当前话题:python网络爬虫获取页面内容并添加到采集夹
相关话题:
Python网络爬虫获取页面内容相关博客查看更多博客
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接
作者:python进阶1047人查看评论:01年前
【一、项目背景】相信大家都有过头疼的经历。很难下载电影,对吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python 网络爬虫入门
作者:yunqi2 浏览评论:03年前
什么是网络爬虫 网络爬虫,也称为网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。优先声明:我们使用的python编译环境是PyCharm 一、首先是一个网络爬虫
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解
作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——第1部分理论基础第1章什么是网络爬虫1.1初识网络爬虫
作者:华章电脑2720浏览量:04年前
本节节选自华章出版社《精通Python网络爬虫:核心技术、框架与项目》一书第1章1.1节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。第 1 部分 第 1 部分 理论基础 第 1 章 什么是网络爬虫 第 2 章 网络爬虫技能概述
阅读全文
浅谈Python网络爬虫
作者:小技术专家2076 浏览评论:04年前
相关背景 网络蜘蛛,也称为网络蜘蛛或网络机器人,是用于自动化采集网站数据的程序。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对采集某个
阅读全文
开源python网络爬虫框架Scrapy
作者:shadowcat2385 浏览评论:05年前
来源: 简介:所谓网络爬虫,就是在互联网上到处或有针对性地爬取数据的程序。当然,这种说法不够专业。更专业的描述是爬取特定网站网页的HTML数据。然而,由于一个
阅读全文
Python网络爬虫(14)使用Scrapy搭建爬虫框架
作者:收到优惠码998人查看评论数:02年前
Python网络爬虫(14)使用Scrapy搭建爬虫框架阅读目录目的说明创建scrapy项目的一些介绍创建爬虫模块-下载增强爬虫模块-分析增强爬虫模块- 打包数据加强爬虫模块 - 翻页加强爬虫模块 - 存储增强爬虫模块 - 图片下载保存启动爬虫
阅读全文
一篇文章教你用Python爬虫实现豆瓣电影采集
作者:python进阶11人查看评论:01年前
[一、项目背景] 豆瓣电影提供最新的电影介绍和评论,包括电影信息查询和已上映电影的票务服务。可以记录想看、正在看、看过的电影和电视剧,顺便打分,写影评。极大地方便了人们的生活。今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分做出更好的选择
阅读全文 查看全部
爬虫抓取网页数据(精通Python网络爬虫获取电影天堂视频下载(组图))
阿里云 > 云栖社区 > 主题图 > P > python网络爬虫获取页面内容
推荐活动:
更多优惠>
当前话题:python网络爬虫获取页面内容并添加到采集夹
相关话题:
Python网络爬虫获取页面内容相关博客查看更多博客
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接
作者:python进阶1047人查看评论:01年前
【一、项目背景】相信大家都有过头疼的经历。很难下载电影,对吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python 网络爬虫入门
作者:yunqi2 浏览评论:03年前
什么是网络爬虫 网络爬虫,也称为网络蜘蛛,是指按照一定的规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。优先声明:我们使用的python编译环境是PyCharm 一、首先是一个网络爬虫
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.1网络爬虫实现原理详解
作者:华章电脑 3448人 浏览评论:04年前
摘要 通过前面几章的学习,我们已经基本了解了网络爬虫,那么网络爬虫应该如何实现呢?核心技术有哪些?在本文中,我们将首先介绍网络爬虫的相关实现原理和实现技术;然后,我们将讲解Urllib库的相关实用内容;然后,我们将带领您开发几个典型的网络爬虫,以便您在实际项目中使用它们。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——第1部分理论基础第1章什么是网络爬虫1.1初识网络爬虫
作者:华章电脑2720浏览量:04年前
本节节选自华章出版社《精通Python网络爬虫:核心技术、框架与项目》一书第1章1.1节,作者魏伟。更多章节,您可以访问云奇社区查看“华章电脑”公众号。第 1 部分 第 1 部分 理论基础 第 1 章 什么是网络爬虫 第 2 章 网络爬虫技能概述
阅读全文
浅谈Python网络爬虫
作者:小技术专家2076 浏览评论:04年前
相关背景 网络蜘蛛,也称为网络蜘蛛或网络机器人,是用于自动化采集网站数据的程序。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络爬虫不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对采集某个
阅读全文
开源python网络爬虫框架Scrapy
作者:shadowcat2385 浏览评论:05年前
来源: 简介:所谓网络爬虫,就是在互联网上到处或有针对性地爬取数据的程序。当然,这种说法不够专业。更专业的描述是爬取特定网站网页的HTML数据。然而,由于一个
阅读全文
Python网络爬虫(14)使用Scrapy搭建爬虫框架
作者:收到优惠码998人查看评论数:02年前
Python网络爬虫(14)使用Scrapy搭建爬虫框架阅读目录目的说明创建scrapy项目的一些介绍创建爬虫模块-下载增强爬虫模块-分析增强爬虫模块- 打包数据加强爬虫模块 - 翻页加强爬虫模块 - 存储增强爬虫模块 - 图片下载保存启动爬虫
阅读全文
一篇文章教你用Python爬虫实现豆瓣电影采集
作者:python进阶11人查看评论:01年前
[一、项目背景] 豆瓣电影提供最新的电影介绍和评论,包括电影信息查询和已上映电影的票务服务。可以记录想看、正在看、看过的电影和电视剧,顺便打分,写影评。极大地方便了人们的生活。今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分做出更好的选择
阅读全文
爬虫抓取网页数据( 求职招聘类网站中的数据查找和整理效率(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-04 04:20
求职招聘类网站中的数据查找和整理效率(组图)
)
我们在工作中使用互联网上发布的各种信息。使用搜索引擎查找和组织需要花费大量时间。现在python可以帮助我们,利用爬虫技术,提高数据搜索和组织的效率。
我们来看一个爬虫案例——在求职类网站中抓取数据。使用环境:win10+python3+Juypter Notebook
第一步:分析网页
第一步:分析网页
要爬取网页,首先要分析网页结构。
现在很多网站使用Ajax(异步加载)技术,打开网页,先给大家看上面的一些东西,剩下的慢慢加载。所以你可以看到很多网页,慢慢的刷,或者一些网站随着你的移动,很多信息都在慢慢加载。这种网页的优点是网页加载速度非常快。
但这项技术不利于爬虫的爬行。我们可以使用chrome浏览器小部件进行分析,进入网络分析界面。界面如下:
这时候是空白的,我们刷新一下,可以看到一连串的网络请求。
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr这种类型的requests,如下:
这种数据一般都是json格式,我们也可以尝试在过滤器中输入json进行过滤查找。
上图找到了两个xhr请求,从字面意思看很可能是我们需要的信息,右键在另一个界面打开。
我们可以在右边的方框中切换到“Preview”,然后点击content-positionResult查看,可以看到位置的信息,以键值对的形式呈现。这是json格式,特别适合网页数据交换。
第二步,URL构建
在“Headers”中,我们看到了网页地址。通过观察网页地址,我们可以发现并推断出这一段是固定的,剩下的我们发现有一个city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0
查看请求发送参数列表,可以确定city参数是城市,pn参数是页数,kd参数是job关键字。
我们看一下位置,一共有30页,每页有15条数据,所以我们只需要构造一个循环遍历每一页的数据。
第三步,编写爬虫脚本,编写代码
需要注意的是,由于这个网页的格式是json,那么我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击content-positionResult-result,可以先找到一个列表,然后点击查看各个位置的内容。为什么从这里看?一个好处就是知道json文件的层次结构,方便后面编码。
具体代码展示:
import requests,jsonfrom openpyxl import Workbook#http请求头信息headers={'Accept':'application/json, text/javascript, */*; q=0.01','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.8','Connection':'keep-alive','Content-Length':'25','Content-Type':'application/x-www-form-urlencoded; charset=UTF-8','Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E','Host':'www.lagou.com','Origin':'https://www.lagou.com','Referer':'https://www.lagou.com/jobs/list_Python?','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36','X-Anit-Forge-Code':'0','X-Anit-Forge-Token':'None','X-Requested-With':'XMLHttpRequest'}def get_json(url, page, lang_name): data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}#POST请求 json = requests.post(url,data,headers=headers).json() list_con = json['content']['positionResult']['result'] info_list = [] for i in list_con: info = [] info.append(i['companyId']) info.append(i['companyFullName']) info.append(i['companyShortName']) info.append(i['companySize']) info.append(str(i['companyLabelList'])) info.append(i['industryField']) info.append(i['financeStage']) info.append(i['positionId']) info.append(i['positionName']) info.append(i['positionAdvantage'])# info.append(i['positionLables']) info.append(i['city']) info.append(i['district'])# info.append(i['businessZones']) info.append(i['salary']) info.append(i['education']) info.append(i['workYear']) info_list.append(info) return info_listdef main(): lang_name = input('职位名:') page = 1 url = 'http://www.lagou.com/jobs/posi ... 39%3B info_result=[] title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"] info_result.append(title) #遍历网址 while page < 31: info = get_json(url, page, lang_name) info_result = info_result + info page += 1#写入excel文件 wb = Workbook() ws1 = wb.active ws1.title = lang_name for row in info_result: ws1.append(row) wb.save('职位信息3.xlsx')main()
打开excel文件,查看数据是否访问成功:
我们看到招聘类网站中捕获的数据成功保存在excel表中。
结尾
过去精选
Python可视化库你了解多少?带你去探索
人工智能方向——智能图像识别技术(二)
人工智能方向——智能图像识别技术(一)
在 Python 中开始使用爬虫的 7 个技巧
使用数据可视化有什么好处?
关注雷克
学干货
查看全部
爬虫抓取网页数据(
求职招聘类网站中的数据查找和整理效率(组图)
)
我们在工作中使用互联网上发布的各种信息。使用搜索引擎查找和组织需要花费大量时间。现在python可以帮助我们,利用爬虫技术,提高数据搜索和组织的效率。
我们来看一个爬虫案例——在求职类网站中抓取数据。使用环境:win10+python3+Juypter Notebook
第一步:分析网页
第一步:分析网页
要爬取网页,首先要分析网页结构。
现在很多网站使用Ajax(异步加载)技术,打开网页,先给大家看上面的一些东西,剩下的慢慢加载。所以你可以看到很多网页,慢慢的刷,或者一些网站随着你的移动,很多信息都在慢慢加载。这种网页的优点是网页加载速度非常快。
但这项技术不利于爬虫的爬行。我们可以使用chrome浏览器小部件进行分析,进入网络分析界面。界面如下:
这时候是空白的,我们刷新一下,可以看到一连串的网络请求。
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr这种类型的requests,如下:
这种数据一般都是json格式,我们也可以尝试在过滤器中输入json进行过滤查找。
上图找到了两个xhr请求,从字面意思看很可能是我们需要的信息,右键在另一个界面打开。
我们可以在右边的方框中切换到“Preview”,然后点击content-positionResult查看,可以看到位置的信息,以键值对的形式呈现。这是json格式,特别适合网页数据交换。
第二步,URL构建
在“Headers”中,我们看到了网页地址。通过观察网页地址,我们可以发现并推断出这一段是固定的,剩下的我们发现有一个city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0
查看请求发送参数列表,可以确定city参数是城市,pn参数是页数,kd参数是job关键字。
我们看一下位置,一共有30页,每页有15条数据,所以我们只需要构造一个循环遍历每一页的数据。
第三步,编写爬虫脚本,编写代码
需要注意的是,由于这个网页的格式是json,那么我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击content-positionResult-result,可以先找到一个列表,然后点击查看各个位置的内容。为什么从这里看?一个好处就是知道json文件的层次结构,方便后面编码。
具体代码展示:
import requests,jsonfrom openpyxl import Workbook#http请求头信息headers={'Accept':'application/json, text/javascript, */*; q=0.01','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.8','Connection':'keep-alive','Content-Length':'25','Content-Type':'application/x-www-form-urlencoded; charset=UTF-8','Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E','Host':'www.lagou.com','Origin':'https://www.lagou.com','Referer':'https://www.lagou.com/jobs/list_Python?','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36','X-Anit-Forge-Code':'0','X-Anit-Forge-Token':'None','X-Requested-With':'XMLHttpRequest'}def get_json(url, page, lang_name): data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}#POST请求 json = requests.post(url,data,headers=headers).json() list_con = json['content']['positionResult']['result'] info_list = [] for i in list_con: info = [] info.append(i['companyId']) info.append(i['companyFullName']) info.append(i['companyShortName']) info.append(i['companySize']) info.append(str(i['companyLabelList'])) info.append(i['industryField']) info.append(i['financeStage']) info.append(i['positionId']) info.append(i['positionName']) info.append(i['positionAdvantage'])# info.append(i['positionLables']) info.append(i['city']) info.append(i['district'])# info.append(i['businessZones']) info.append(i['salary']) info.append(i['education']) info.append(i['workYear']) info_list.append(info) return info_listdef main(): lang_name = input('职位名:') page = 1 url = 'http://www.lagou.com/jobs/posi ... 39%3B info_result=[] title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"] info_result.append(title) #遍历网址 while page < 31: info = get_json(url, page, lang_name) info_result = info_result + info page += 1#写入excel文件 wb = Workbook() ws1 = wb.active ws1.title = lang_name for row in info_result: ws1.append(row) wb.save('职位信息3.xlsx')main()
打开excel文件,查看数据是否访问成功:
我们看到招聘类网站中捕获的数据成功保存在excel表中。
结尾
过去精选
Python可视化库你了解多少?带你去探索
人工智能方向——智能图像识别技术(二)
人工智能方向——智能图像识别技术(一)
在 Python 中开始使用爬虫的 7 个技巧
使用数据可视化有什么好处?
关注雷克
学干货
爬虫抓取网页数据(Linux命令分析之nginx服务器进行分析日志文件所在目录:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-02 17:00
概述
最近阿里云经常被各种爬虫访问,有的是搜索引擎爬虫,有的不是。通常这些爬虫都有UserAgent,我们知道UserAgent是可以伪装的。UserAgent 的本质是 Http 请求头中的一个选项设置。,您可以以编程方式为请求设置任何 UserAgent。
下面的Linux命令可以让你清楚的了解蜘蛛的爬行情况。我们分析nginx服务器。日志文件位于目录:/usr/local/nginx/logs/access.log。access.log 文件应该记录最后一天的日志情况。首先,请检查日志大小。如果比较大(超过50MB),建议不要使用这些命令进行分析,因为这些命令会消耗大量CPU,或者更新并在分析机上执行,以免影响服务器性能。
常见的蜘蛛域名
常用蜘蛛的域名与搜索引擎官网的域名有关,例如:
1、统计百度蜘蛛爬取的次数
猫访问.log | grep 百度蜘蛛 | 厕所
最左边的值显示爬网次数。
2、百度蜘蛛详细记录(Ctrl C可以终止)
猫访问.log | grep 百度蜘蛛
您还可以使用以下命令:
猫访问.log | grep 百度蜘蛛 | 尾 -n 10
猫访问.log | grep 百度蜘蛛 | 头 -n 10
说明:只看后10个或前10个 查看全部
爬虫抓取网页数据(Linux命令分析之nginx服务器进行分析日志文件所在目录:)
概述
最近阿里云经常被各种爬虫访问,有的是搜索引擎爬虫,有的不是。通常这些爬虫都有UserAgent,我们知道UserAgent是可以伪装的。UserAgent 的本质是 Http 请求头中的一个选项设置。,您可以以编程方式为请求设置任何 UserAgent。
下面的Linux命令可以让你清楚的了解蜘蛛的爬行情况。我们分析nginx服务器。日志文件位于目录:/usr/local/nginx/logs/access.log。access.log 文件应该记录最后一天的日志情况。首先,请检查日志大小。如果比较大(超过50MB),建议不要使用这些命令进行分析,因为这些命令会消耗大量CPU,或者更新并在分析机上执行,以免影响服务器性能。
常见的蜘蛛域名
常用蜘蛛的域名与搜索引擎官网的域名有关,例如:
1、统计百度蜘蛛爬取的次数
猫访问.log | grep 百度蜘蛛 | 厕所
最左边的值显示爬网次数。
2、百度蜘蛛详细记录(Ctrl C可以终止)
猫访问.log | grep 百度蜘蛛
您还可以使用以下命令:
猫访问.log | grep 百度蜘蛛 | 尾 -n 10
猫访问.log | grep 百度蜘蛛 | 头 -n 10
说明:只看后10个或前10个
爬虫抓取网页数据(Python编程修改程序函数式编程的实战二抓取您想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-01 21:14
战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧()页面,如Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
通过简单的分析可以知道,待爬取的百度贴吧页面是一个静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面中复制任意一段。信息,例如“爬虫需要http代理的原因”,然后右键选择查看源,使用Ctrl+F快捷键在源页面搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。 查看全部
爬虫抓取网页数据(Python编程修改程序函数式编程的实战二抓取您想要的)
战斗一
抓取您想要的网页并将其保存到本地计算机。
首先我们简单分析下要编写的爬虫程序,可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。
导入所需模块
from urllib import request, parse
连接 URL 地址
定义 URL 变量并连接 url 地址。代码如下所示:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求
发送请求主要分为以下几个步骤:
代码如下所示:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将爬取的照片保存到本地,这里需要使用Python编程文件IO操作,代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下所示:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行程序,进入RioTianの博客园,确认搜索,在当前工作目录下会找到“RioTianの博客园.html”文件。
函数式编程修饰符
Python函数式编程可以让程序的思路更清晰,更容易理解。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,调用该函数执行爬虫程序。修改后的代码如下所示:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了使用函数式编程,还可以使用面向对象的编程方式(实战二),后续内容会介绍。
第二幕
爬百度贴吧()页面,如Python爬虫,编程,只抓取贴吧的前5页。
确定页面类型
通过简单的分析可以知道,待爬取的百度贴吧页面是一个静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面中复制任意一段。信息,例如“爬虫需要http代理的原因”,然后右键选择查看源,使用Ctrl+F快捷键在源页面搜索刚刚复制的数据,如下图:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要单独从数据库中加载数据,所以页面是静态页面。
找出 URL 变化的规律性
接下来,查找要抓取的页面的 URL 模式。搜索“Python爬虫”后,贴吧的首页网址如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,其url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果还是不能确定,可以继续多浏览几页。最后发现url有两个查询参数kw和pn,pn参数有规律是这样的:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
编写爬虫
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
程序执行后,爬取的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 分析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握以上编程逻辑将有助于您后续的学习。
爬虫随机休眠
在入口函数代码中,收录以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率。
焦点爬虫是一个执行效率低的程序,提高其性能是业界一直关注的问题。于是,高效的 Python 爬虫框架 Scrapy 应运而生。
爬虫抓取网页数据(如何用Python实现简单爬取网页数据并导入MySQL中的数据库文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2022-03-01 21:13
)
疫情期间在家无事可做,随便写点小品。QQ...
这是一个文章,介绍了如何使用Python简单地抓取网页数据并将其导入MySQL中的数据库。主要使用 BeautifulSoup requests 和 pymysql。
以一个网页为例,假设我们要爬取的一些数据如下图所示:
方法来构造并向网页的服务器发送请求。requests.get() 方法需要传递两个参数,一个是网页的url,很明显就是在这里;另一个参数是浏览器的标题。检查如下:
点击进入任意网页,按F12进入开发者模式,点击网络刷新网页。单击网络下名称中的任何资源,然后在右侧的标题部分中下拉到末尾。可以看到Request Headers参数列表的最后有一个user-agent,它的内容就是我们要找的浏览器headers参数值。
使用 url 和 headers 我们可以使用 requests.get() 向服务器发送请求:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
使用requests.get()方法会先构造一个url对象向服务端请求资源,然后从服务端返回一个收录服务端资源的Response对象,其中收录了服务端返回的所有相关资源(自然包括我们的html需要)。
获取网页的html内容:
html = r.content.decode('utf-8', 'ignore')
说明:这里 r.content 返回“响应的内容,以字节为单位”。即返回HTTP响应内容(Response)的字节形式。所以我们需要使用 .decode() 方法来解码。ignore 参数在这里是可选的,只是为了忽略一些不重要的错误。
有了html文本,我们可以取出bs和slip:
my_page = BeautifulSoup(html, 'lxml')
其实这里得到的my_page和html内容几乎是一样的,那何必再用bs来解析html呢?A:Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理不规则的标签并生成 Parse Tree。它提供了简单通用的导航(Navigating)、搜索和修改解析树的操作,可以大大节省你的编程时间。也就是说,我们需要爬取数据的一些定位方式,只能在bs解析返回的内容后才能使用。简单的html文本没有这么方便快捷的方法。
二、开始爬取数据
我们这里使用的方法主要是find | 查找全部 | 查找全部 | 获取文本() | 文本。
1.find_all 方法:
作用是查找页面元素的所有子元素,并将找到的与搜索结果匹配的子元素以列表的形式返回。
2.查找方法:
与 find_all 类似,但只返回匹配搜索条件的第一个子元素,并且只返回文本,而不是列表。
3.get_text() 和 .text 方法:
用于从标签中提取文本信息。
ps:get_text() 和 .text 方法的区别:
在beautifulsoup中,对外接口不提供text属性,只提供string属性值;beautifulsoup 里面有 text 属性,仅供内部使用 --> 如果要使用 text 值,应该调用对应的 get_text(); 而你所有可以直接使用soup.text而不报错的,应该和python的类的属性没有变成private有关——>你也可以从外部访问这个,这是一个仅供内部使用的属性值。
4.具体实现示例:
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span可以认为是一个list
is_yibao = my_span[1].text
othername = my_span[3].text
fbbw = my_span[5].text
is_infect = my_span[7].text
dfrq = my_span[9].text
my_a = sub_tag.findAll('a')
fbbw = my_a[0].text
#注:也可用.contents[0]或者.get_text()
用于爬取“是否属于医保”等条目冒号后的内容。
如何找到 find_all() 参数值?
选择要查找的内容右键,选择“Inspect”,进入开发者模式,可以看到相关内容的html代码如下图:
可以看出,我们要爬取的内容首先在一个class属性为“list_left”的div标签中——>在div标签中,我们可以发现我们要爬取的内容在list元素的ul标签中class属性为“disease_basic” --> 在ul标签中,我们可以发现我们想要的内容隐藏在几个span标签中。
三、完整代码
# coding = utf-8
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
html = r.content.decode('utf-8', 'ignore')
my_page = BeautifulSoup(html, 'lxml')
for tag in my_page.find_all('div', class_='disease'):
disease = tag.find('h1').get_text()
disease_name = disease
for tag in my_page.find_all('p', class_='introduction'):
introduction = tag.get_text()
disease_introduction = introduction
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span is a list
is_yibao = my_span[1].text #是否医保
othername = my_span[3].text #别名
fbbw = my_span[5].text #发病部位
is_infect = my_span[7].text #传染性
dfrq = my_span[9].text #多发人群
my_a = sub_tag.findAll('a')
xgzz = my_a[2].text+' '+my_a[3].text+' '+my_a[4].text #相关症状
#ps: .contents[0] or .get_text() is also accepted
# Some tests:
# print(html)
# print(my_page)
# print(sub_tag)
# print(xgzz)
# print(my_span)
# print(my_span[1]) 查看全部
爬虫抓取网页数据(如何用Python实现简单爬取网页数据并导入MySQL中的数据库文章
)
疫情期间在家无事可做,随便写点小品。QQ...
这是一个文章,介绍了如何使用Python简单地抓取网页数据并将其导入MySQL中的数据库。主要使用 BeautifulSoup requests 和 pymysql。
以一个网页为例,假设我们要爬取的一些数据如下图所示:
方法来构造并向网页的服务器发送请求。requests.get() 方法需要传递两个参数,一个是网页的url,很明显就是在这里;另一个参数是浏览器的标题。检查如下:
点击进入任意网页,按F12进入开发者模式,点击网络刷新网页。单击网络下名称中的任何资源,然后在右侧的标题部分中下拉到末尾。可以看到Request Headers参数列表的最后有一个user-agent,它的内容就是我们要找的浏览器headers参数值。
使用 url 和 headers 我们可以使用 requests.get() 向服务器发送请求:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
使用requests.get()方法会先构造一个url对象向服务端请求资源,然后从服务端返回一个收录服务端资源的Response对象,其中收录了服务端返回的所有相关资源(自然包括我们的html需要)。
获取网页的html内容:
html = r.content.decode('utf-8', 'ignore')
说明:这里 r.content 返回“响应的内容,以字节为单位”。即返回HTTP响应内容(Response)的字节形式。所以我们需要使用 .decode() 方法来解码。ignore 参数在这里是可选的,只是为了忽略一些不重要的错误。
有了html文本,我们可以取出bs和slip:
my_page = BeautifulSoup(html, 'lxml')
其实这里得到的my_page和html内容几乎是一样的,那何必再用bs来解析html呢?A:Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理不规则的标签并生成 Parse Tree。它提供了简单通用的导航(Navigating)、搜索和修改解析树的操作,可以大大节省你的编程时间。也就是说,我们需要爬取数据的一些定位方式,只能在bs解析返回的内容后才能使用。简单的html文本没有这么方便快捷的方法。
二、开始爬取数据
我们这里使用的方法主要是find | 查找全部 | 查找全部 | 获取文本() | 文本。
1.find_all 方法:
作用是查找页面元素的所有子元素,并将找到的与搜索结果匹配的子元素以列表的形式返回。
2.查找方法:
与 find_all 类似,但只返回匹配搜索条件的第一个子元素,并且只返回文本,而不是列表。
3.get_text() 和 .text 方法:
用于从标签中提取文本信息。
ps:get_text() 和 .text 方法的区别:
在beautifulsoup中,对外接口不提供text属性,只提供string属性值;beautifulsoup 里面有 text 属性,仅供内部使用 --> 如果要使用 text 值,应该调用对应的 get_text(); 而你所有可以直接使用soup.text而不报错的,应该和python的类的属性没有变成private有关——>你也可以从外部访问这个,这是一个仅供内部使用的属性值。
4.具体实现示例:
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span可以认为是一个list
is_yibao = my_span[1].text
othername = my_span[3].text
fbbw = my_span[5].text
is_infect = my_span[7].text
dfrq = my_span[9].text
my_a = sub_tag.findAll('a')
fbbw = my_a[0].text
#注:也可用.contents[0]或者.get_text()
用于爬取“是否属于医保”等条目冒号后的内容。
如何找到 find_all() 参数值?
选择要查找的内容右键,选择“Inspect”,进入开发者模式,可以看到相关内容的html代码如下图:
可以看出,我们要爬取的内容首先在一个class属性为“list_left”的div标签中——>在div标签中,我们可以发现我们要爬取的内容在list元素的ul标签中class属性为“disease_basic” --> 在ul标签中,我们可以发现我们想要的内容隐藏在几个span标签中。
三、完整代码
# coding = utf-8
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'}
url = "https://jbk.39.net/mxyy/jbzs/"
r = requests.get(url, headers = headers)
html = r.content.decode('utf-8', 'ignore')
my_page = BeautifulSoup(html, 'lxml')
for tag in my_page.find_all('div', class_='disease'):
disease = tag.find('h1').get_text()
disease_name = disease
for tag in my_page.find_all('p', class_='introduction'):
introduction = tag.get_text()
disease_introduction = introduction
for tag in my_page.find_all('div', class_='list_left'):
sub_tag = tag.find('ul',class_="disease_basic")
my_span = sub_tag.findAll('span')
#my_span is a list
is_yibao = my_span[1].text #是否医保
othername = my_span[3].text #别名
fbbw = my_span[5].text #发病部位
is_infect = my_span[7].text #传染性
dfrq = my_span[9].text #多发人群
my_a = sub_tag.findAll('a')
xgzz = my_a[2].text+' '+my_a[3].text+' '+my_a[4].text #相关症状
#ps: .contents[0] or .get_text() is also accepted
# Some tests:
# print(html)
# print(my_page)
# print(sub_tag)
# print(xgzz)
# print(my_span)
# print(my_span[1])
爬虫抓取网页数据(Python学习网络爬虫的几种常见算法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-28 12:07
一.什么是爬虫?1.1 初识网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。Python 可以轻松编写爬虫程序,用于自动检索互联网信息。
搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。
1.1.1 百度新闻案例说明
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何在互联网上覆盖更多的优质网页呢?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。
1.1.2 网站排名(访问权重pv)
因此,我们在研究爬虫的时候,不仅需要了解爬虫是如何实现的,还需要了解一些常见爬虫的算法。如有必要,我们还需要自己制定相应的算法。在这里,我们只需要了解爬虫的概念。一个基本的了解
二. 爬虫领域(为什么要学爬虫?)
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?
如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?
首先,我们看下面的例子
百度指数
这是百度百度指数的截图。它对用户在百度搜索关键词进行统计,然后根据统计结果绘制流行趋势,然后简单展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己的用户数据进行统计分析
那么,对于一些中小型企业来说,在没有这么多用户的情况下应该怎么办呢?
2.1 数据来源
1.去第三方公司购买资料(例如:七叉茶)
2.去免费数据网站下载数据(如:国家统计局)
3.通过爬虫爬取数据
4.手动采集数据(例如问卷)
在以上数据源中,人工方式耗时耗力,效率低下,数据免费网站以上数据质量较差。很多第三方数据公司经常从爬虫那里获取数据,因此获取数据是最难的。有效的方法是通过爬虫爬取
2.2 大数据和爬虫是什么关系?
爬虫爬取互联网上的数据,获取的数据量决定了与大数据的兄弟关系是否更近
2.3 爬虫领域,前景三. 爬虫分类
根据系统结构和实现技术,网络爬虫大致可分为四类,即通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深层次网络爬虫。
1.通用网络爬虫:搜索引擎爬虫
例如,当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的页面中找出相关的,然后根据一定的排名规则对它们进行排序。为了向用户展示,那么您需要尽可能多的互联网高质量网页。
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.聚焦网络爬虫:特定网页的爬虫
它也被称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。
比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
例如:那些比较价格的 网站 是其他被抓取的 网站 产品。
3.增量网络爬虫
增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫
4.深网爬虫
Deep Web Crawler,首先,什么是深页?
在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。
深网爬虫主要由URL列表、LVS【虚拟服务器】列表、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等组成。
后来我们主要学习专注爬虫,专注爬虫之后,其他类型的爬虫就可以轻松写出来了。
关键词3@> 通用爬虫和聚焦爬虫原理
万能爬虫
第 1 步:抓取网页(网址)
start_url 发送请求,并解析响应;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,并分配对应的URL 下载网页,存储在下载的网页库中,并将这些URL放入被爬取的URL队列中。分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列中,从而进入下一个循环……
第 2 步:数据存储
搜索引擎通过爬虫爬取的网页将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
第 3 步:预处理
搜索引擎将从爬虫抓取回来的页面,并执行各种预处理步骤。
除了 HTML 文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。
但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供搜索服务,网站排名
搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,将用户检索到的相关信息展示给用户。
关键词4@> 通用爬虫和 Spotlight 爬虫工作流程
关键词5@>
第 1 步:start_url 发送请求
第 2 步:获取响应
第 3 步:解析响应。如果响应中有需要新的url地址,重复第二步;
第 4 步:提取数据
第 5 步:保存数据
通常,我们会一步获得响应并对其进行解析。因此,专注于爬虫的步骤一般是四个步骤。 查看全部
爬虫抓取网页数据(Python学习网络爬虫的几种常见算法和方法)
一.什么是爬虫?1.1 初识网络爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。
也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。Python 可以轻松编写爬虫程序,用于自动检索互联网信息。
搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。
1.1.1 百度新闻案例说明
在这个过程中,百度蜘蛛起到了至关重要的作用。那么,如何在互联网上覆盖更多的优质网页呢?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。
1.1.2 网站排名(访问权重pv)
因此,我们在研究爬虫的时候,不仅需要了解爬虫是如何实现的,还需要了解一些常见爬虫的算法。如有必要,我们还需要自己制定相应的算法。在这里,我们只需要了解爬虫的概念。一个基本的了解
二. 爬虫领域(为什么要学爬虫?)
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?
如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?
首先,我们看下面的例子
百度指数
这是百度百度指数的截图。它对用户在百度搜索关键词进行统计,然后根据统计结果绘制流行趋势,然后简单展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己的用户数据进行统计分析
那么,对于一些中小型企业来说,在没有这么多用户的情况下应该怎么办呢?
2.1 数据来源
1.去第三方公司购买资料(例如:七叉茶)
2.去免费数据网站下载数据(如:国家统计局)
3.通过爬虫爬取数据
4.手动采集数据(例如问卷)
在以上数据源中,人工方式耗时耗力,效率低下,数据免费网站以上数据质量较差。很多第三方数据公司经常从爬虫那里获取数据,因此获取数据是最难的。有效的方法是通过爬虫爬取
2.2 大数据和爬虫是什么关系?
爬虫爬取互联网上的数据,获取的数据量决定了与大数据的兄弟关系是否更近
2.3 爬虫领域,前景三. 爬虫分类
根据系统结构和实现技术,网络爬虫大致可分为四类,即通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深层次网络爬虫。
1.通用网络爬虫:搜索引擎爬虫
例如,当用户在百度搜索引擎上搜索对应的关键词时,百度会对关键词进行分析处理,从收录的页面中找出相关的,然后根据一定的排名规则对它们进行排序。为了向用户展示,那么您需要尽可能多的互联网高质量网页。
从网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.聚焦网络爬虫:特定网页的爬虫
它也被称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。
比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。
例如:那些比较价格的 网站 是其他被抓取的 网站 产品。
3.增量网络爬虫
增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫
4.深网爬虫
Deep Web Crawler,首先,什么是深页?
在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。
深网爬虫主要由URL列表、LVS【虚拟服务器】列表、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等组成。
后来我们主要学习专注爬虫,专注爬虫之后,其他类型的爬虫就可以轻松写出来了。
关键词3@> 通用爬虫和聚焦爬虫原理
万能爬虫
第 1 步:抓取网页(网址)
start_url 发送请求,并解析响应;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,并分配对应的URL 下载网页,存储在下载的网页库中,并将这些URL放入被爬取的URL队列中。分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列中,从而进入下一个循环……
第 2 步:数据存储
搜索引擎通过爬虫爬取的网页将数据存储在原创页面数据库中。页面数据与用户浏览器获取的 HTML 完全相同。
搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。
第 3 步:预处理
搜索引擎将从爬虫抓取回来的页面,并执行各种预处理步骤。
除了 HTML 文件,搜索引擎通常可以抓取和索引各种基于文本的文件类型,例如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们还经常在搜索结果中看到这些文件类型。
但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。
第四步:提供搜索服务,网站排名
搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,将用户检索到的相关信息展示给用户。
关键词4@> 通用爬虫和 Spotlight 爬虫工作流程
关键词5@>
第 1 步:start_url 发送请求
第 2 步:获取响应
第 3 步:解析响应。如果响应中有需要新的url地址,重复第二步;
第 4 步:提取数据
第 5 步:保存数据
通常,我们会一步获得响应并对其进行解析。因此,专注于爬虫的步骤一般是四个步骤。
爬虫抓取网页数据( 前端基础比较扎实的Css选择器教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2022-02-27 20:08
前端基础比较扎实的Css选择器教程)
2、解析数据
爬虫爬取的是爬取页面指定的部分数据值,而不是整个页面的数据。这时候,往往需要先解析数据,再存储。
网络上采集返回的数据的数据类型很多,主要有HTML、javascript、JSON、XML等格式。使用解析库相当于在HTML中查找需要的信息时使用正则表达式,可以更快速的定位到具体的元素,获取相应的信息。
CSS 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器对 xml 和 html 文档进行快速操作。它提供了类似于 jQuery 的语法来解析 HTML 文档,支持 CSS 选择器,使用起来非常方便。
Beautiful Soup 是一个借助网页结构和属性解析网页的工具,可以自动转换代码。它支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。
Xpath 最初用于搜索 XML 文档,但也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理、逻辑值等,XQuery和XPointer都是建立在XPath的基础上的。
Re 正则表达式通常用于检索和替换匹配某个模式(规则)的文本。个人觉得前端基础比较扎实。使用pyquery是最方便的。Beautifulsoup也不错,re的速度比较快,但是写正则表达式比较麻烦。当然,既然用的是python,那最好还是自己用。
推荐的解析器资源:
查询
美汤
xpath 教程
重新记录
3、数据存储
当爬回来的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就行不通了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,系统比较成熟,成熟度很高。它可以很好地存储一些数据。但是在处理海量数据时,效率会明显变慢,已经不能满足一些大数据的需求。处理请求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以方便你存储一些非结构化的数据,比如各种评论的文本、图片的链接等。你也可以使用 PyMongo 更方便地在 Python 中操作 MongoDB。因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
**Redis是不折不扣的内存数据库,**Redis支持丰富的数据结构,包括hash、set、list等。所有数据都存储在内存中,访问速度快,可以存储大量数据. 一般用于分布式爬虫的数据存储。
工程爬行动物
如果掌握了前面的技术,就可以实现一个轻量级的爬虫,一般级的数据和代码基本没有问题。
但面对复杂的情况,表现却不尽如人意。这时候,一个强大的爬虫框架就非常有用了。
首先是 Nutch,著名的 Apache 顶级项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,具有Hadoop对多机分布式爬取、存储和索引的支持。
另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展解析各种网页内容、采集、查询、聚类、过滤各种数据的功能。
二是GitHub上大家star的scrapy,scratch是一个非常强大的爬虫框架。
它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
最后,Pyspider作为国内大神们开发的框架,满足了大部分Python爬虫的需求——定向爬取和结构化分析。
可以在浏览器界面进行脚本编写、函数调度和爬取结果的实时查看,后端使用常用数据库存储爬取结果。
它足够强大,更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远远优于其他的优势,比如**Nutch的自然搜索引擎解决方案,Pyspider的产品级WebUI,以及Scrapy最灵活的定制化爬虫。**建议学习最接近爬虫本质的框架scarry,然后接触为搜索引擎而生的人性化Pyspider和Nutch。
推荐爬虫框架资源:
Nutch 文档
可怕的文档
pyspider 文档
反爬虫对策
爬虫就像虫子,密密麻麻地爬到各个角落获取数据,虫子可能无害,但总是不受欢迎。
由于爬虫技术导致的大量IP访问网站,对带宽资源的侵占,以及对用户隐私和知识产权的危害,很多互联网公司将大力开展“反爬虫”。
你的爬虫会遇到比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
常见的反爬虫措施包括:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体防爬…
遇到这些反爬手段,当然需要一些高级技巧来应对。控制访问频率,保证页面加载一次,数据请求最小化,每次页面访问增加时间间隔;禁用 cookie 可以防止使用 cookie 识别爬虫 网站 来禁止我们的可能性;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
分布式爬虫
爬取基础数据没有问题,也可以用框架写更复杂的数据。这时候就算遇到反爬,你也掌握了一些反反爬的技巧。
你的瓶颈将是爬取海量数据的效率。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理组合多台主机完成一个爬虫任务**,需要掌握Scrapy + Redis + MQ + Celery**等工具**。
之前我们说过,Scrapy是用来做基础页面爬取的,Redis是用来存放待爬取网页的队列,也就是任务队列。
Scarpy-redis是scrapy中用来实现分布式组件的组件,通过它可以快速实现一个简单的分布式爬虫程序。
在高并发环境中,请求经常因为没有时间进行同步处理而被阻塞。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ 本身支持多种协议:AMQP、XMPP、SMTP、STOMP,使其非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中获取 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,用于处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在异步任务、任务调度、定时任务、分布式调度等场景中表现出色。
所以分布式爬虫听起来很吓人,但就是这样。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
推荐的分布式资源:
scrapy-redis 文档
scrapy-rabbitmq 文档
芹菜文档
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要高级的数据库技术。
解锁各部分的知识点,有针对性地学习。经过这条顺利的学习路径,您将能够掌握python爬虫。
但是,要学习爬虫,需要打好基础。在这里,我为大家准备了一份零基础学习的Python学习资料。有兴趣的同学可以看看。 查看全部
爬虫抓取网页数据(
前端基础比较扎实的Css选择器教程)
2、解析数据
爬虫爬取的是爬取页面指定的部分数据值,而不是整个页面的数据。这时候,往往需要先解析数据,再存储。
网络上采集返回的数据的数据类型很多,主要有HTML、javascript、JSON、XML等格式。使用解析库相当于在HTML中查找需要的信息时使用正则表达式,可以更快速的定位到具体的元素,获取相应的信息。
CSS 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器对 xml 和 html 文档进行快速操作。它提供了类似于 jQuery 的语法来解析 HTML 文档,支持 CSS 选择器,使用起来非常方便。
Beautiful Soup 是一个借助网页结构和属性解析网页的工具,可以自动转换代码。它支持 Python 标准库中的 HTML 解析器,以及一些第三方解析器。
Xpath 最初用于搜索 XML 文档,但也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName处理、序列处理、逻辑值等,XQuery和XPointer都是建立在XPath的基础上的。
Re 正则表达式通常用于检索和替换匹配某个模式(规则)的文本。个人觉得前端基础比较扎实。使用pyquery是最方便的。Beautifulsoup也不错,re的速度比较快,但是写正则表达式比较麻烦。当然,既然用的是python,那最好还是自己用。
推荐的解析器资源:
查询
美汤
xpath 教程
重新记录
3、数据存储
当爬回来的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就行不通了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,系统比较成熟,成熟度很高。它可以很好地存储一些数据。但是在处理海量数据时,效率会明显变慢,已经不能满足一些大数据的需求。处理请求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以方便你存储一些非结构化的数据,比如各种评论的文本、图片的链接等。你也可以使用 PyMongo 更方便地在 Python 中操作 MongoDB。因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
**Redis是不折不扣的内存数据库,**Redis支持丰富的数据结构,包括hash、set、list等。所有数据都存储在内存中,访问速度快,可以存储大量数据. 一般用于分布式爬虫的数据存储。
工程爬行动物
如果掌握了前面的技术,就可以实现一个轻量级的爬虫,一般级的数据和代码基本没有问题。
但面对复杂的情况,表现却不尽如人意。这时候,一个强大的爬虫框架就非常有用了。
首先是 Nutch,著名的 Apache 顶级项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,具有Hadoop对多机分布式爬取、存储和索引的支持。
另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展解析各种网页内容、采集、查询、聚类、过滤各种数据的功能。
二是GitHub上大家star的scrapy,scratch是一个非常强大的爬虫框架。
它不仅可以轻松构建请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习scrapy,可以自己搭建一些爬虫框架,基本具备爬虫工程师的思维。
最后,Pyspider作为国内大神们开发的框架,满足了大部分Python爬虫的需求——定向爬取和结构化分析。
可以在浏览器界面进行脚本编写、函数调度和爬取结果的实时查看,后端使用常用数据库存储爬取结果。
它足够强大,更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远远优于其他的优势,比如**Nutch的自然搜索引擎解决方案,Pyspider的产品级WebUI,以及Scrapy最灵活的定制化爬虫。**建议学习最接近爬虫本质的框架scarry,然后接触为搜索引擎而生的人性化Pyspider和Nutch。
推荐爬虫框架资源:
Nutch 文档
可怕的文档
pyspider 文档
反爬虫对策
爬虫就像虫子,密密麻麻地爬到各个角落获取数据,虫子可能无害,但总是不受欢迎。
由于爬虫技术导致的大量IP访问网站,对带宽资源的侵占,以及对用户隐私和知识产权的危害,很多互联网公司将大力开展“反爬虫”。
你的爬虫会遇到比如被网站IP屏蔽,比如各种奇怪的验证码,userAgent访问限制,各种动态加载等等。
常见的反爬虫措施包括:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体防爬…
遇到这些反爬手段,当然需要一些高级技巧来应对。控制访问频率,保证页面加载一次,数据请求最小化,每次页面访问增加时间间隔;禁用 cookie 可以防止使用 cookie 识别爬虫 网站 来禁止我们的可能性;根据浏览器正常访问的请求头修改爬虫的请求头,尽量与浏览器保持一致等。
往往网站会在高效开发和反爬虫之间偏爱前者,这也为爬虫提供了空间。掌握了这些反爬技能,大部分网站对你来说都不再难了。
分布式爬虫
爬取基础数据没有问题,也可以用框架写更复杂的数据。这时候就算遇到反爬,你也掌握了一些反反爬的技巧。
你的瓶颈将是爬取海量数据的效率。这个时候,相信大家自然会接触到一个很厉害的名字:分布式爬虫。
分布式的东西听起来很吓人,但其实它是利用多线程的原理组合多台主机完成一个爬虫任务**,需要掌握Scrapy + Redis + MQ + Celery**等工具**。
之前我们说过,Scrapy是用来做基础页面爬取的,Redis是用来存放待爬取网页的队列,也就是任务队列。
Scarpy-redis是scrapy中用来实现分布式组件的组件,通过它可以快速实现一个简单的分布式爬虫程序。
在高并发环境中,请求经常因为没有时间进行同步处理而被阻塞。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ 本身支持多种协议:AMQP、XMPP、SMTP、STOMP,使其非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中获取 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,用于处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在异步任务、任务调度、定时任务、分布式调度等场景中表现出色。
所以分布式爬虫听起来很吓人,但就是这样。当你能写出分布式爬虫的时候,就可以尝试搭建一些基本的爬虫架构,实现一些更自动化的数据获取。
推荐的分布式资源:
scrapy-redis 文档
scrapy-rabbitmq 文档
芹菜文档
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要高级的数据库技术。
解锁各部分的知识点,有针对性地学习。经过这条顺利的学习路径,您将能够掌握python爬虫。
但是,要学习爬虫,需要打好基础。在这里,我为大家准备了一份零基础学习的Python学习资料。有兴趣的同学可以看看。
爬虫抓取网页数据(爬虫的核心特性除了快,还应该是从高到低的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-24 14:17
背景
对于电商类型和内容服务类型的网站,经常会出现由于配置错误(404).
显然,要保证网站中的所有链接都可以访问,手动检测肯定是不现实的。常见的做法是利用爬虫技术定期爬取网站上的资源,及时发现访问异常的链接。
对于网络爬虫,市场上已经有大量的开源项目和技术讨论文章。不过,似乎大家普遍关注的是爬取的效率。例如,关于不同并发机制中哪种更高效的讨论有很多文章,但关于爬虫的其他特性的讨论并不多。
在我看来,爬虫的核心特性除了快之外,还应该包括full和stable,而从重要性来看,full、stable和fast应该是从高到低。
全部排在第一位,因为这是爬虫的基本功能。如果爬取的页面不完整,就会出现信息遗漏,这是绝对不允许的;第二名是稳定的,因为爬虫通常需要长时间稳定运行。如果在爬虫运行过程中,由于策略处理不当导致爬虫无法正常访问页面,这是绝对不能接受的。最后,它很快。我们通常需要抓取大量的页面链接,所以效率是关键,但也必须建立在完整性和稳定性的基础上。
当然,爬行本身是一个很深的技术领域,我只是在摸索。本文仅针对使用爬虫技术检测网页资源可用性的实际场景,详细分析涉及的几个技术点,重点解决以下问题:
爬虫实现前端页面渲染
早些年,基本上绝大多数网站都是通过后端渲染的,也就是在服务器端组装一个完整的HTML页面,然后将完整的页面返回到前端进行展示。近年来,随着AJAX技术的不断普及和AngularJS等SPA框架的广泛应用,越来越多的页面呈现在前端。
不知道大家有没有听说前端渲染相比后端渲染不利于SEO,因为它对爬虫不友好。原因是前端渲染的页面需要在浏览器端执行JavaScript代码(即AJAX请求)来获取后端数据,然后组装成一个完整的HTML页面。
对于这种情况,已经有很多解决方案了。最常用的是使用 PhantomJS 和 puppeteer 等无头浏览器工具。) 在抓取页面内容之前。
但是,要使用这种技术,通常需要使用 Javascript 来开发爬虫工具,这对于像我这样习惯于编写 Python 的人来说确实有点痛苦。
直到有一天,大神kennethreitz 发布了开源项目requests-html,当我看到了Full JavaScript support!项目在 GitHub 上发布不到三天,star 数就达到了 5000 多,可见其影响力。
为什么 requests-html 如此受欢迎?
写过 Python 的人基本都会用到 requests 之类的 HTTP 库。毫不夸张地说,它是最好的 HTTP 库(不仅限于编程语言),其引入语言 HTTP Requests for Humans 也是当之无愧的。也正因如此,Locust 和 HttpRunner 都是基于请求开发的。
Requests-html 是 kennethreitz 基于 requests 开发的另一个开源项目。除了复用requests的所有功能外,还实现了对HTML页面的解析,即支持Javascript的执行,以及通过CSS和XPath的功能提取HTML页面元素,是编写爬虫非常需要的功能工具。
在实现 Javascript 执行方面,requests-html 并没有自己造轮子,而是依赖于开源项目 pyppeteer。还记得前面提到的 puppeteer 项目,就是 Google Chrome 官方实现的 Node API;还有pyppeteer项目,相当于一个非官方的使用Python语言实现的puppeteer,基本具备了puppeteer的所有功能。
理清了上面的关系,相信大家对requests-html会有更好的理解。
在使用上,requests-html 也很简单,用法和requests基本一样,只是多了一个render函数。
from requests_html
import HTMLSession
session = HTMLSession()
r = session.get('http://python-requests.org')
r.html.render()
执行render()后,返回的是渲染后的页面内容。
爬虫实现访问频率控制
为了防止流量攻击,很多网站都有访问频率限制,即限制单个IP在一定时间内的访问次数。如果超过这个设定的限制,服务器会拒绝访问请求,即响应状态码为403(Forbidden)。
这可以用来应对外部流量攻击或爬虫,但在这种有限的策略下,公司内部的爬虫测试工具也无法正常使用。针对这个问题,常见的做法是在应用系统中设置白名单,将公司内部爬虫测试服务器IP加入白名单,然后对白名单中的IP不做限制,或者增加限制。但这也可能是有问题的。因为应用服务器的性能不是无限的,如果爬虫的访问频率超过应用服务器的处理限制,会导致应用服务器不可用,即响应状态码为503(Service Unavailable Error )。
基于以上原因,爬虫的访问频率应与项目组开发运维统一评估后确定;而对于爬虫工具,需要控制访问频率。
如何控制访问频率?
我们可以回到爬虫本身的实现机制。对于爬虫来说,无论实现形式是什么,都应该概括为生产者和消费者模型,即:
对于这个模型,最简单的方法是使用一个 FIFO 队列来存储未访问的链接队列 (unvisited_urls_queue)。无论使用哪种并发机制,这个队列都可以在工作人员之间共享。对于每个工作人员,您可以执行以下操作:
那么回到我们的问题,限制访问的频率,也就是单位时间内请求的链接数。显然,工人之间是相互独立的,在执行层面上实现全面的频率控制并不容易。但是从上面的步骤可以看出,unvisited_urls_queue 是所有worker 共享的,起到了source 供应的作用。那么只要我们能实现对unvisited_urls_queue补充的数量控制,就实现了爬虫的整体访问频率控制。
上面的思路是对的,但是具体实现有几个问题:
而在目前的实际场景中,最好的并发机制是选择多个进程(原因后面会详细解释)。每个工人处于不同的进程中,因此共享集合并不容易。同时,如果每个worker都负责判断请求的总数,也就是如果访问频率的控制逻辑在worker中实现的话,对worker来说就是一个负担,逻辑上会比较多复杂的。
因此,更好的方法是在未访问链接队列(unvisited_urls_queue)的基础上,增加一个用于爬取结果的存储队列(fetched_urls_queue),这两者都是worker之间共享的。那么,接下来的逻辑就变得简单了:
具体控制方法也很简单。假设我们要实现对RPS的控制,那么我们可以使用以下方法(只截取关键段):
<p>start_timer = time.time()
requests_queued = 0
while True:
try:
url = self.fetched_urls_queue.get(timeout=5)
except queue.Empty:
break
# visited url will not be crawled twice
if url in self.visited_urls_set:
continue
# limit rps or rpm
if requests_queued >= self.requests_limit:
runtime_secs = time.time() - start_timer
if runtime_secs 查看全部
爬虫抓取网页数据(爬虫的核心特性除了快,还应该是从高到低的)
背景
对于电商类型和内容服务类型的网站,经常会出现由于配置错误(404).
显然,要保证网站中的所有链接都可以访问,手动检测肯定是不现实的。常见的做法是利用爬虫技术定期爬取网站上的资源,及时发现访问异常的链接。
对于网络爬虫,市场上已经有大量的开源项目和技术讨论文章。不过,似乎大家普遍关注的是爬取的效率。例如,关于不同并发机制中哪种更高效的讨论有很多文章,但关于爬虫的其他特性的讨论并不多。
在我看来,爬虫的核心特性除了快之外,还应该包括full和stable,而从重要性来看,full、stable和fast应该是从高到低。
全部排在第一位,因为这是爬虫的基本功能。如果爬取的页面不完整,就会出现信息遗漏,这是绝对不允许的;第二名是稳定的,因为爬虫通常需要长时间稳定运行。如果在爬虫运行过程中,由于策略处理不当导致爬虫无法正常访问页面,这是绝对不能接受的。最后,它很快。我们通常需要抓取大量的页面链接,所以效率是关键,但也必须建立在完整性和稳定性的基础上。
当然,爬行本身是一个很深的技术领域,我只是在摸索。本文仅针对使用爬虫技术检测网页资源可用性的实际场景,详细分析涉及的几个技术点,重点解决以下问题:
爬虫实现前端页面渲染
早些年,基本上绝大多数网站都是通过后端渲染的,也就是在服务器端组装一个完整的HTML页面,然后将完整的页面返回到前端进行展示。近年来,随着AJAX技术的不断普及和AngularJS等SPA框架的广泛应用,越来越多的页面呈现在前端。
不知道大家有没有听说前端渲染相比后端渲染不利于SEO,因为它对爬虫不友好。原因是前端渲染的页面需要在浏览器端执行JavaScript代码(即AJAX请求)来获取后端数据,然后组装成一个完整的HTML页面。
对于这种情况,已经有很多解决方案了。最常用的是使用 PhantomJS 和 puppeteer 等无头浏览器工具。) 在抓取页面内容之前。
但是,要使用这种技术,通常需要使用 Javascript 来开发爬虫工具,这对于像我这样习惯于编写 Python 的人来说确实有点痛苦。
直到有一天,大神kennethreitz 发布了开源项目requests-html,当我看到了Full JavaScript support!项目在 GitHub 上发布不到三天,star 数就达到了 5000 多,可见其影响力。
为什么 requests-html 如此受欢迎?
写过 Python 的人基本都会用到 requests 之类的 HTTP 库。毫不夸张地说,它是最好的 HTTP 库(不仅限于编程语言),其引入语言 HTTP Requests for Humans 也是当之无愧的。也正因如此,Locust 和 HttpRunner 都是基于请求开发的。
Requests-html 是 kennethreitz 基于 requests 开发的另一个开源项目。除了复用requests的所有功能外,还实现了对HTML页面的解析,即支持Javascript的执行,以及通过CSS和XPath的功能提取HTML页面元素,是编写爬虫非常需要的功能工具。
在实现 Javascript 执行方面,requests-html 并没有自己造轮子,而是依赖于开源项目 pyppeteer。还记得前面提到的 puppeteer 项目,就是 Google Chrome 官方实现的 Node API;还有pyppeteer项目,相当于一个非官方的使用Python语言实现的puppeteer,基本具备了puppeteer的所有功能。
理清了上面的关系,相信大家对requests-html会有更好的理解。
在使用上,requests-html 也很简单,用法和requests基本一样,只是多了一个render函数。
from requests_html
import HTMLSession
session = HTMLSession()
r = session.get('http://python-requests.org')
r.html.render()
执行render()后,返回的是渲染后的页面内容。
爬虫实现访问频率控制
为了防止流量攻击,很多网站都有访问频率限制,即限制单个IP在一定时间内的访问次数。如果超过这个设定的限制,服务器会拒绝访问请求,即响应状态码为403(Forbidden)。
这可以用来应对外部流量攻击或爬虫,但在这种有限的策略下,公司内部的爬虫测试工具也无法正常使用。针对这个问题,常见的做法是在应用系统中设置白名单,将公司内部爬虫测试服务器IP加入白名单,然后对白名单中的IP不做限制,或者增加限制。但这也可能是有问题的。因为应用服务器的性能不是无限的,如果爬虫的访问频率超过应用服务器的处理限制,会导致应用服务器不可用,即响应状态码为503(Service Unavailable Error )。
基于以上原因,爬虫的访问频率应与项目组开发运维统一评估后确定;而对于爬虫工具,需要控制访问频率。
如何控制访问频率?
我们可以回到爬虫本身的实现机制。对于爬虫来说,无论实现形式是什么,都应该概括为生产者和消费者模型,即:
对于这个模型,最简单的方法是使用一个 FIFO 队列来存储未访问的链接队列 (unvisited_urls_queue)。无论使用哪种并发机制,这个队列都可以在工作人员之间共享。对于每个工作人员,您可以执行以下操作:
那么回到我们的问题,限制访问的频率,也就是单位时间内请求的链接数。显然,工人之间是相互独立的,在执行层面上实现全面的频率控制并不容易。但是从上面的步骤可以看出,unvisited_urls_queue 是所有worker 共享的,起到了source 供应的作用。那么只要我们能实现对unvisited_urls_queue补充的数量控制,就实现了爬虫的整体访问频率控制。
上面的思路是对的,但是具体实现有几个问题:
而在目前的实际场景中,最好的并发机制是选择多个进程(原因后面会详细解释)。每个工人处于不同的进程中,因此共享集合并不容易。同时,如果每个worker都负责判断请求的总数,也就是如果访问频率的控制逻辑在worker中实现的话,对worker来说就是一个负担,逻辑上会比较多复杂的。
因此,更好的方法是在未访问链接队列(unvisited_urls_queue)的基础上,增加一个用于爬取结果的存储队列(fetched_urls_queue),这两者都是worker之间共享的。那么,接下来的逻辑就变得简单了:
具体控制方法也很简单。假设我们要实现对RPS的控制,那么我们可以使用以下方法(只截取关键段):
<p>start_timer = time.time()
requests_queued = 0
while True:
try:
url = self.fetched_urls_queue.get(timeout=5)
except queue.Empty:
break
# visited url will not be crawled twice
if url in self.visited_urls_set:
continue
# limit rps or rpm
if requests_queued >= self.requests_limit:
runtime_secs = time.time() - start_timer
if runtime_secs
爬虫抓取网页数据(爬虫抓取网页数据最基本的三种方式post和get方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-20 09:12
爬虫抓取网页数据最基本的三种方式post和get方式。我今天先给大家谈一下post方式。举个例子,比如我们要抓取电信公司的一个号码,我们可以向电信公司发一个post请求,请求的内容,也是一个号码,然后分析请求的json格式去抓取对应的电信公司的一些数据。以上例子,代码如下:xiaoshiji2017/requestspider(二维码自动识别)我们使用post请求电信公司的一个号码。
那么如何去构造一个post请求呢?我在想过以后一定要把格式梳理一下,大家一起把http协议那部分搞懂。一开始我不知道要抓取哪个网站的哪个数据,我就看了一下baidu的api文档,我找到一个电信公司号码的实例代码。如下:src=''headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3323.122safari/537.36'}data={'simple':false,'old':true,'loading':false,'user-agent':'woaix-010-1200-e'}cookie={'simple':false,'loading':false,'user-agent':'egg.home.1.2.2'}fordatainsrc:data['simple']=truedata['old']=truereturndata就是我们抓取一个电信公司的号码。
那么我们如何去构造呢?可以先把我们的数据保存在某个数据库中,然后用户发送一个post请求,获取我们的数据。我们先构造一个post请求并发送一次post请求,然后我们保存一下数据,放在我们的数据库。重复n次这个操作。如下:baidu.post()这个时候我们就可以回忆下,我们以前使用get请求电信公司号码。
我们应该找到我们需要抓取的那个公司网站,然后构造以下的代码就行了我们发送一个post请求,请求一个电信公司的号码。html=''frombaidu.postimportget_号码的,get_value()如果是请求不存在的公司的话,返回303代码这里构造这个data就是构造完我们的数据,然后如果已经存在数据的话,返回304,这是我们构造不存在的data的一个代码get_value(value)这是获取数据的一个json格式的数据。
get_value(value)这个是获取我们数据的一个json格式的数据。我们总结下post请求请求的数据。我们需要有以下json格式的数据。simple对应的simple=',{'"name":"%s","age":"%s","city":"%s","str":"{"p_city":"%s","p_city":"%s","res":"%s"}'}'u。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据最基本的三种方式post和get方式)
爬虫抓取网页数据最基本的三种方式post和get方式。我今天先给大家谈一下post方式。举个例子,比如我们要抓取电信公司的一个号码,我们可以向电信公司发一个post请求,请求的内容,也是一个号码,然后分析请求的json格式去抓取对应的电信公司的一些数据。以上例子,代码如下:xiaoshiji2017/requestspider(二维码自动识别)我们使用post请求电信公司的一个号码。
那么如何去构造一个post请求呢?我在想过以后一定要把格式梳理一下,大家一起把http协议那部分搞懂。一开始我不知道要抓取哪个网站的哪个数据,我就看了一下baidu的api文档,我找到一个电信公司号码的实例代码。如下:src=''headers={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/71.0.3323.122safari/537.36'}data={'simple':false,'old':true,'loading':false,'user-agent':'woaix-010-1200-e'}cookie={'simple':false,'loading':false,'user-agent':'egg.home.1.2.2'}fordatainsrc:data['simple']=truedata['old']=truereturndata就是我们抓取一个电信公司的号码。
那么我们如何去构造呢?可以先把我们的数据保存在某个数据库中,然后用户发送一个post请求,获取我们的数据。我们先构造一个post请求并发送一次post请求,然后我们保存一下数据,放在我们的数据库。重复n次这个操作。如下:baidu.post()这个时候我们就可以回忆下,我们以前使用get请求电信公司号码。
我们应该找到我们需要抓取的那个公司网站,然后构造以下的代码就行了我们发送一个post请求,请求一个电信公司的号码。html=''frombaidu.postimportget_号码的,get_value()如果是请求不存在的公司的话,返回303代码这里构造这个data就是构造完我们的数据,然后如果已经存在数据的话,返回304,这是我们构造不存在的data的一个代码get_value(value)这是获取数据的一个json格式的数据。
get_value(value)这个是获取我们数据的一个json格式的数据。我们总结下post请求请求的数据。我们需要有以下json格式的数据。simple对应的simple=',{'"name":"%s","age":"%s","city":"%s","str":"{"p_city":"%s","p_city":"%s","res":"%s"}'}'u。
爬虫抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-19 02:20
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
天长魂远,梦魂难到关山。
/前言/
上一篇文章,,, 我们解析了列表页中所有文章的URL,交给Scrapy去下载,在这个文章中我们将提取下一页并交给Scrapy下载,具体教程如下。
/执行/
1、首先在网页中找到“下一页”的相关链接,如下图所示。与网页交互以查找“下一页”URL。
可以看到下一页的链接存在于a标签下的nextpage-numbers属性下的href标签中,而且这个属性是唯一的,所以可以很容易的定位到链接。
2、可以在scrapyshell中调试,然后将满足条件的表达式写入代码中,如下图所示。
在上图中,可以通过两种方式提取目标信息。推荐第二种方式,其中 .next.page-numbers 表示同一个类下有两个属性,这样可以更快更准确地定位标签。需要注意的是,这两个属性直接使用的是点号。连线不留空格,初学者容易出错。另外,函数extract_first("")在前面的文章中提到过,它的默认值为空,如果没有匹配到目标信息,则返回None。
3、获取到下一页的链接后,需要对其进行判断,以防万一,具体代码如下图所示。
至此,我们已经提取了下一页的URL,交给Scrapy去下载。需要注意的是,除了URL拼接部分,回调回调函数是这里的parse()函数,意思是回调下一页的文章列表页,而不是文章详情页面,需要特别注意。
4、接下来我们可以调试整个爬虫,在爬虫主文件中设置断点,如下图,然后在main.py文件中点击运行Debug,
5、稍等片刻,等待调试结果出来,如下图,结果一目了然。
6、到这里,我们基本完成了文章的全部提取,简单回顾一下整个爬取过程。首先我们在parse()函数中获取文章的URL,然后交给Scrapy去下载。下载完成后,Scrapy调用parse_detail()函数提取网页中的目标信息。本页 提取完成后,提取下一页的信息,将下一页的URL交给Scrapy下载,然后回调parse()函数提取文章列表的URL在下一页,像这样来回迭代直到最后一页,整个爬虫就停止了。
7、使用Scrapy爬虫框架,我们可以获取整个网站的所有文章内容,中间的具体下载实现不需要我们手动完成,还有是不是需要感受一下 Scrapy 爬虫的强大?
目前我们刚刚遍历了整个网站,知道了目标信息的提取方法。暂时我们还没有将目标数据保存到本地或数据库中。我们会继续和下面的文章约好~~~
/概括/
本文基于 Scrapy 爬虫框架,使用 CSS 选择器和 Xpath 选择器来解析列表页面中的所有 文章 URL,遍历整个 网站 获取数据 采集,至此,我们有能够实现全网文章采集的数据都没了。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直接去~
- - - - - - - - - -结尾 - - - - - - - - - - 查看全部
爬虫抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
天长魂远,梦魂难到关山。
/前言/
上一篇文章,,, 我们解析了列表页中所有文章的URL,交给Scrapy去下载,在这个文章中我们将提取下一页并交给Scrapy下载,具体教程如下。
/执行/
1、首先在网页中找到“下一页”的相关链接,如下图所示。与网页交互以查找“下一页”URL。
可以看到下一页的链接存在于a标签下的nextpage-numbers属性下的href标签中,而且这个属性是唯一的,所以可以很容易的定位到链接。
2、可以在scrapyshell中调试,然后将满足条件的表达式写入代码中,如下图所示。
在上图中,可以通过两种方式提取目标信息。推荐第二种方式,其中 .next.page-numbers 表示同一个类下有两个属性,这样可以更快更准确地定位标签。需要注意的是,这两个属性直接使用的是点号。连线不留空格,初学者容易出错。另外,函数extract_first("")在前面的文章中提到过,它的默认值为空,如果没有匹配到目标信息,则返回None。
3、获取到下一页的链接后,需要对其进行判断,以防万一,具体代码如下图所示。
至此,我们已经提取了下一页的URL,交给Scrapy去下载。需要注意的是,除了URL拼接部分,回调回调函数是这里的parse()函数,意思是回调下一页的文章列表页,而不是文章详情页面,需要特别注意。
4、接下来我们可以调试整个爬虫,在爬虫主文件中设置断点,如下图,然后在main.py文件中点击运行Debug,
5、稍等片刻,等待调试结果出来,如下图,结果一目了然。
6、到这里,我们基本完成了文章的全部提取,简单回顾一下整个爬取过程。首先我们在parse()函数中获取文章的URL,然后交给Scrapy去下载。下载完成后,Scrapy调用parse_detail()函数提取网页中的目标信息。本页 提取完成后,提取下一页的信息,将下一页的URL交给Scrapy下载,然后回调parse()函数提取文章列表的URL在下一页,像这样来回迭代直到最后一页,整个爬虫就停止了。
7、使用Scrapy爬虫框架,我们可以获取整个网站的所有文章内容,中间的具体下载实现不需要我们手动完成,还有是不是需要感受一下 Scrapy 爬虫的强大?
目前我们刚刚遍历了整个网站,知道了目标信息的提取方法。暂时我们还没有将目标数据保存到本地或数据库中。我们会继续和下面的文章约好~~~
/概括/
本文基于 Scrapy 爬虫框架,使用 CSS 选择器和 Xpath 选择器来解析列表页面中的所有 文章 URL,遍历整个 网站 获取数据 采集,至此,我们有能够实现全网文章采集的数据都没了。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直接去~
- - - - - - - - - -结尾 - - - - - - - - - -
爬虫抓取网页数据(Python培训学习数据爬虫需掌握哪些技能呢?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-19 01:13
随着大数据、智能化时代的到来,爬虫作为重要的数据源,已经成为现代决策中及时有效获取海量数据不可或缺的一部分。那么,数据爬虫是如何工作的呢?学习数据爬虫需要掌握哪些技能?
数据爬虫工作流程
选择符合条件的URL,将这些URL放入待爬取URL队列中,从待爬取URL队列中取出URL,解析DNS,获取主机IP,下载该URL对应的网页,存储在下载的网页库,并将这些网址放入已抓取的网址队列中,对已抓取的网址队列中的网址进行分析,找出其他符合条件的网址,放入待抓取网址的队列中,进入下一个循环。
学习数据爬虫所需的技能
1. 学习Python基础,实现基本爬取流程
Python爬虫的流程是按照发送请求→获取页面反馈→解析存储数据三个流程进行的。你可以根据所学的Python基础知识,使用Python爬虫相关的包和规则来爬取Python爬虫数据。
2. 了解非结构化数据存储
爬虫抓取的数据结构复杂,传统的结构化数据库可能不适合。需要选择合适的非结构化数据库,学习相关的操作说明,操作相关的非结构化数据库!
3. 掌握一些常用的反爬虫技巧
可以学习掌握代理IP池、抓包、验证码OCR处理等,解决网站的反爬问题。
4. 了解分布式存储
分布式存储利用多线程的原理,让多个爬虫同时工作。掌握Scrapy + MongoDB + Redis这三个工具的使用规则和方法是很有必要的。
老男孩教育是 Python 培训领域的专家。于2012年推出Python培训,是业内较早的Python培训机构。积累了大量的Python培训教学经验,能全面掌控企业用工指标。科学制定Python教学课程体系,5+5双班模式,满足5-8年职业需求,让学生轻松获得高薪职位!
文章来自:
文章标题:数据爬虫是如何工作的?老男孩Python培训网络培训
查看全部
爬虫抓取网页数据(Python培训学习数据爬虫需掌握哪些技能呢?(组图))
随着大数据、智能化时代的到来,爬虫作为重要的数据源,已经成为现代决策中及时有效获取海量数据不可或缺的一部分。那么,数据爬虫是如何工作的呢?学习数据爬虫需要掌握哪些技能?
数据爬虫工作流程
选择符合条件的URL,将这些URL放入待爬取URL队列中,从待爬取URL队列中取出URL,解析DNS,获取主机IP,下载该URL对应的网页,存储在下载的网页库,并将这些网址放入已抓取的网址队列中,对已抓取的网址队列中的网址进行分析,找出其他符合条件的网址,放入待抓取网址的队列中,进入下一个循环。
学习数据爬虫所需的技能
1. 学习Python基础,实现基本爬取流程
Python爬虫的流程是按照发送请求→获取页面反馈→解析存储数据三个流程进行的。你可以根据所学的Python基础知识,使用Python爬虫相关的包和规则来爬取Python爬虫数据。
2. 了解非结构化数据存储
爬虫抓取的数据结构复杂,传统的结构化数据库可能不适合。需要选择合适的非结构化数据库,学习相关的操作说明,操作相关的非结构化数据库!
3. 掌握一些常用的反爬虫技巧
可以学习掌握代理IP池、抓包、验证码OCR处理等,解决网站的反爬问题。
4. 了解分布式存储
分布式存储利用多线程的原理,让多个爬虫同时工作。掌握Scrapy + MongoDB + Redis这三个工具的使用规则和方法是很有必要的。
老男孩教育是 Python 培训领域的专家。于2012年推出Python培训,是业内较早的Python培训机构。积累了大量的Python培训教学经验,能全面掌控企业用工指标。科学制定Python教学课程体系,5+5双班模式,满足5-8年职业需求,让学生轻松获得高薪职位!
文章来自:
文章标题:数据爬虫是如何工作的?老男孩Python培训网络培训
爬虫抓取网页数据(聚焦爬虫的工作原理及关键技术概述网络爬虫工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-19 01:09
重点介绍爬虫的工作原理及关键技术概述 网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的 URL 开始,获取初始网页上的 URL,在对网页进行爬取的过程中,不断从当前页面中提取新的 URL 并放入队列中,直到一个满足系统一定的停止条件。焦点爬虫的工作流程比较复杂,需要特定的网页分析算法来过滤掉与主题无关的链接,保留有用的链接并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网址,并重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。与一般的网络爬虫相比,聚焦爬虫仍然需要解决三个主要问题: URL 的搜索策略。爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。爬取目标描述 现有的聚焦爬虫对爬取目标的描述可以根据目标网页、目标数据模式和领域概念划分为特征。网站 或网页。
<p>根据种子样本的获取方式,可以分为:预先给定的网页类别和类别对应的种子样本,如Yahoo! 类别结构等;通过用户日志挖掘获得访问模式和相关样本。网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。现有的焦点爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。爬虫根据目标网页的特征爬取、存储和索引的对象一般为 查看全部
爬虫抓取网页数据(聚焦爬虫的工作原理及关键技术概述网络爬虫工作流程)
重点介绍爬虫的工作原理及关键技术概述 网络爬虫是一种自动提取网页的程序。它从互联网上为搜索引擎下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的 URL 开始,获取初始网页上的 URL,在对网页进行爬取的过程中,不断从当前页面中提取新的 URL 并放入队列中,直到一个满足系统一定的停止条件。焦点爬虫的工作流程比较复杂,需要特定的网页分析算法来过滤掉与主题无关的链接,保留有用的链接并放入等待抓取的URL队列中。然后,它会按照一定的搜索策略从队列中选择下一个要爬取的网址,并重复上述过程,直到达到系统的一定条件并停止。存储、执行一定的分析、过滤、建立索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可以为后续的爬取过程提供反馈和指导。与一般的网络爬虫相比,聚焦爬虫仍然需要解决三个主要问题: URL 的搜索策略。爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。爬取目标描述 现有的聚焦爬虫对爬取目标的描述可以根据目标网页、目标数据模式和领域概念划分为特征。网站 或网页。
<p>根据种子样本的获取方式,可以分为:预先给定的网页类别和类别对应的种子样本,如Yahoo! 类别结构等;通过用户日志挖掘获得访问模式和相关样本。网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。现有的焦点爬虫对爬取目标的描述或定义可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。爬虫根据目标网页的特征爬取、存储和索引的对象一般为
爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-15 07:01
阿里巴巴云>云栖社区>主题地图>P>爬虫爬取网页指定数据库
推荐活动:
更多优惠>
当前话题:爬虫爬取网页指定数据库添加到采集夹
相关主题:
爬虫爬取网页指定数据库相关博客查看更多博客
云数据库产品概览
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自主研发的具有数百TB数据实时计算能力的HybridDB数据库等,拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
立即查看
[网络爬虫] 使用 node.js Cheerio 抓取网络数据
作者:子玉5358 浏览评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据? ! ! ! !@#$@#$... 没关系,网络抓取可以解决问题。什么是网页抓取?你可能会问。 . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索
阅读全文
使用 Python 爬虫抓取免费代理 IP
作者:技术专家2872人查看评论:03年前
不知道大家有没有遇到网站提示“访问频率太高”。我们需要稍等片刻或者输入验证码解封,但是这种情况以后还是会出现。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个IP在单位时间内请求的网页过多时,服务器会拒绝服务。这种情况是
阅读全文
抓取网页数据分析
作者:y0umer606 查看评论:011 年前
发表于2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集分类:C#编程通过程序自动阅读他人网站@ >显示的信息网页上类似于爬虫程序,比如我们有一个提取百度歌曲搜索排名的系统网站分析系统
阅读全文
爬取网页数据分析(c#)
作者:wenvi_wu1489 浏览评论:013年前
通过程序自动读取其他网站网页显示的信息,类似于爬虫程序。假设我们有一个系统来提取百度网站上歌曲的搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述需求,我们需要模拟浏览器浏览网页,并获取页面数据进行分析。
阅读全文
如何用 Python 抓取数据? (一)网页抓取
作者:王淑仪2089 浏览评论:03年前
您一直在等待的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。需求 我在公众号后台,经常收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但有些消息乍一看并不清楚
阅读全文
爬虫概述和 urllib 库(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1爬虫概述(1)互联网爬虫是根据Url爬取网页获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:游戏爬虫和反爬虫之间)(3)爬虫语言php多进程多线程对java支持较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高很高
阅读全文
一个小型网页抓取系统的架构设计
作者:技术组合怎么样 902 人查看评论数:04 年前
小型网页抓取系统的架构设计网页抓取服务是互联网上经常使用的服务。蜘蛛(网络抓取爬虫)是搜索引擎中必需的核心服务。搜索引擎衡量指标“多、快、准、新”四项指标中,多、快、新都是对蜘蛛的要求。 google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式去重增量爬虫的开发与设计
作者:小技术专家 8758人浏览评论数:03年前
基于python分布式房源数据采集系统,为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文 查看全部
爬虫抓取网页数据(阿里云数据库ApsaraDB(42)(组图)网页显示)
阿里巴巴云>云栖社区>主题地图>P>爬虫爬取网页指定数据库
推荐活动:
更多优惠>
当前话题:爬虫爬取网页指定数据库添加到采集夹
相关主题:
爬虫爬取网页指定数据库相关博客查看更多博客
云数据库产品概览
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自主研发的具有数百TB数据实时计算能力的HybridDB数据库等,拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
立即查看
[网络爬虫] 使用 node.js Cheerio 抓取网络数据
作者:子玉5358 浏览评论:05年前
想要自动从网络上抓取一些数据或将一堆从博客中提取的数据转换成结构化数据?有没有现成的 API 来获取数据? ! ! ! !@#$@#$... 没关系,网络抓取可以解决问题。什么是网页抓取?你可能会问。 . 网页抓取是对网页内容的程序化(通常不涉及浏览器)检索
阅读全文
使用 Python 爬虫抓取免费代理 IP
作者:技术专家2872人查看评论:03年前
不知道大家有没有遇到网站提示“访问频率太高”。我们需要稍等片刻或者输入验证码解封,但是这种情况以后还是会出现。出现这种现象的原因是我们要爬取的网页采取了反爬虫措施。例如,当某个IP在单位时间内请求的网页过多时,服务器会拒绝服务。这种情况是
阅读全文
抓取网页数据分析
作者:y0umer606 查看评论:011 年前
发表于2006-05-24 14:04 北极燕鸥阅读(9793) 评论(42) 编辑采集分类:C#编程通过程序自动阅读他人网站@ >显示的信息网页上类似于爬虫程序,比如我们有一个提取百度歌曲搜索排名的系统网站分析系统
阅读全文
爬取网页数据分析(c#)
作者:wenvi_wu1489 浏览评论:013年前
通过程序自动读取其他网站网页显示的信息,类似于爬虫程序。假设我们有一个系统来提取百度网站上歌曲的搜索排名。分析系统根据获得的数据进行数据分析。为企业提供参考数据。为了满足上述需求,我们需要模拟浏览器浏览网页,并获取页面数据进行分析。
阅读全文
如何用 Python 抓取数据? (一)网页抓取
作者:王淑仪2089 浏览评论:03年前
您一直在等待的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。需求 我在公众号后台,经常收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但有些消息乍一看并不清楚
阅读全文
爬虫概述和 urllib 库(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1爬虫概述(1)互联网爬虫是根据Url爬取网页获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:游戏爬虫和反爬虫之间)(3)爬虫语言php多进程多线程对java支持较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高很高
阅读全文
一个小型网页抓取系统的架构设计
作者:技术组合怎么样 902 人查看评论数:04 年前
小型网页抓取系统的架构设计网页抓取服务是互联网上经常使用的服务。蜘蛛(网络抓取爬虫)是搜索引擎中必需的核心服务。搜索引擎衡量指标“多、快、准、新”四项指标中,多、快、新都是对蜘蛛的要求。 google、baidu等搜索引擎公司维护
阅读全文
Scrapy分布式去重增量爬虫的开发与设计
作者:小技术专家 8758人浏览评论数:03年前
基于python分布式房源数据采集系统,为数据的进一步应用,即房源推荐系统提供数据支持。本课题致力于解决单进程单机爬虫的瓶颈,基于Redis分布式多爬虫共享队列创建主题爬虫。本系统使用python开发的Scrapy框架开发,使用Xpath
阅读全文
爬虫抓取网页数据(Python开发的一个快速,高层次屏幕和web抓取框架框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-14 13:31
2021-12-11
其实爬虫工作会选择的大部分框架都是scrapy,但是如何发挥scrapy的具体优势,这里就对每一个做一个简单的了解。
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
说到scrapy,首先要了解框架的结构。经典的框架结构图直观地展示了框架的结构和工作流程,更容易记忆。
下面我们来介绍一下框架的各个组件以及各个组件的功能:
下一步是了解其工作流程:
引擎从调度程序中取出一个链接(URL),用于下一个抓取引擎。引擎将URL封装成请求(Request)发送给下载者下载资源,并封装成响应包(Response)。爬虫解析响应。解析完实体(Item)后,交给实体管道做进一步处理。解析链接(URL),将URL交给调度器等待抓取。
还有更详细的使用说明,可以访问下方博主的文章,使用说明
分类:
技术要点:
相关文章: 查看全部
爬虫抓取网页数据(Python开发的一个快速,高层次屏幕和web抓取框架框架)
2021-12-11
其实爬虫工作会选择的大部分框架都是scrapy,但是如何发挥scrapy的具体优势,这里就对每一个做一个简单的了解。
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各种爬虫的基类,如BaseSpider、sitemap爬虫等。最新版本提供了对web2.0爬虫的支持。
说到scrapy,首先要了解框架的结构。经典的框架结构图直观地展示了框架的结构和工作流程,更容易记忆。
下面我们来介绍一下框架的各个组件以及各个组件的功能:
下一步是了解其工作流程:
引擎从调度程序中取出一个链接(URL),用于下一个抓取引擎。引擎将URL封装成请求(Request)发送给下载者下载资源,并封装成响应包(Response)。爬虫解析响应。解析完实体(Item)后,交给实体管道做进一步处理。解析链接(URL),将URL交给调度器等待抓取。
还有更详细的使用说明,可以访问下方博主的文章,使用说明
分类:
技术要点:
相关文章:
爬虫抓取网页数据(以写出即为a元素储存把title储存到_spider.txt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-11 14:27
我也把我下载的代码的网盘链接粘贴到:link
提取码:cxta
我应该让这个系列保持最新(至少在我学习期间)
以下文本开始:
申请流程
获取页面→\rightarrow→ 解析页面→\rightarrow→ 保存数据
一个简单的爬虫实例来获取
#coding: utf-8
import requests
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
print(r.text)
首先定义链接(link)表示要爬取的URL地址头,定义请求头的浏览器代理,并进行伪装(第一个是“User-Agent”表示是浏览器代理,而第二个是具体内容 r是响应对象,即请求获取网页的reply get函数有两个参数(第一个是URL地址,第二个是请求头) text是文本内容,这里是HTML格式提取
您可以直接查看网页源代码或使用“inspect”(在网页中右键)获取所需信息,包括但不限于请求头、HTML源代码
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
print(title)
获取文本后,使用 BeautifulSoup 进行解析。 BeautifulSoup 是一个专门解析 HTML 的库。 BeautifulSoup(r.text, "html.parser"),其中 r.text 是要解析的字符串,而 "html.parser" 是要使用的 Parser。 “html.parser”是Python自带的;还有“lxml”,它是一个基于C语言的解析器,但是需要自己安装find。有两个参数,第一个是节点,这里是h1,还有p...一般h1是标题,p是段落;第二个是类名,这里是“post-title”,用HTML写成a元素,存储为超链接元素
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
# 提取
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
with open("first_spider.txt", "a+") as f:
f.write(title)
将标题保存到 first_spider.txt 查看全部
爬虫抓取网页数据(以写出即为a元素储存把title储存到_spider.txt)
我也把我下载的代码的网盘链接粘贴到:link
提取码:cxta
我应该让这个系列保持最新(至少在我学习期间)
以下文本开始:
申请流程
获取页面→\rightarrow→ 解析页面→\rightarrow→ 保存数据
一个简单的爬虫实例来获取
#coding: utf-8
import requests
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
print(r.text)
首先定义链接(link)表示要爬取的URL地址头,定义请求头的浏览器代理,并进行伪装(第一个是“User-Agent”表示是浏览器代理,而第二个是具体内容 r是响应对象,即请求获取网页的reply get函数有两个参数(第一个是URL地址,第二个是请求头) text是文本内容,这里是HTML格式提取
您可以直接查看网页源代码或使用“inspect”(在网页中右键)获取所需信息,包括但不限于请求头、HTML源代码
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
print(title)
获取文本后,使用 BeautifulSoup 进行解析。 BeautifulSoup 是一个专门解析 HTML 的库。 BeautifulSoup(r.text, "html.parser"),其中 r.text 是要解析的字符串,而 "html.parser" 是要使用的 Parser。 “html.parser”是Python自带的;还有“lxml”,它是一个基于C语言的解析器,但是需要自己安装find。有两个参数,第一个是节点,这里是h1,还有p...一般h1是标题,p是段落;第二个是类名,这里是“post-title”,用HTML写成a元素,存储为超链接元素
#coding: utf-8
import requests
from bs4 import *
# 获取
link="http://www.santostang.com/"
headers={'User-Agent':'Mozilla/5.0 (Windows;U;Windows NT6.1;en-US;rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r=request.get(link,headers=headers)
# 提取
soup = BeautifulSoup(r.text, "html.parser") #用BeautifulSoup进行解析,parser解析
# 定位class是post-title的h1元素,提取其中a中的内容(text)并去除空格
title = soup.find("h1", class_="post-title").a.text.strip()
with open("first_spider.txt", "a+") as f:
f.write(title)
将标题保存到 first_spider.txt

