
爬虫抓取网页数据
爬虫抓取网页数据(Bit-Map,增量抓取技术最主要的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-14 14:13
爬虫抓取网页数据(Bit-Map,增量抓取技术最主要的方法(组图))
本文讨论了网络数据采集的发展历程、核心技术和发展趋势:
开发过程
当然,您可以使用爬虫框架进行数据捕获。
核心技术
1.增量爬取技术
增量爬取技术的主要方法是去除重复,包括方法
内存重复数据删除、关系/非关系数据库重复数据删除和缓存数据库重复数据删除。
该策略包括:
直接方法,MD5/SHA-1生成信息汇总,Bit-Map,BloomFiter。
来自期刊文章
2.分布式设计
多线程/多进程提高爬虫效率,可搭建Hadoop集群/Spark集群进行分布式爬虫:
来自论文
3.IP代理池设计
目前有许多免费代理可用。最好构建一个IP代理池,打包成API供程序使用。比如一个开源代理池的结构如下:
本框架使用Flask接受用户请求,并调用Schedule对代理进行强制刷新或定时刷新
开源IP池框架的未来发展:
1.智能:
对于URL队列生成和网页结构抓取,利用机器学习方法自动生成URL队列模型和网页结构模型,减少对人工干预和网页规则的依赖。
2. 聚类:
当捕获到的数据发送到各个系统时,需要考虑各个系统的对接问题。效率很重要,解决效率的关键是各个系统之间的分配问题。
3.图形化:
面对大量的数据采集任务,傻瓜式的图形表示对于非专业人士或专业人士来说已经足够了。未来,只是网络上的一点点数据采集任务。
对于业余爱好者和非专业人士,比如我:简单的爬虫技巧就够了,因为数据量不大,要求不高,而对于专业爬虫做产品,没必要懂一年半了。 查看全部
本文讨论了网络数据采集的发展历程、核心技术和发展趋势:
开发过程
当然,您可以使用爬虫框架进行数据捕获。
核心技术
1.增量爬取技术
增量爬取技术的主要方法是去除重复,包括方法
内存重复数据删除、关系/非关系数据库重复数据删除和缓存数据库重复数据删除。
该策略包括:
直接方法,MD5/SHA-1生成信息汇总,Bit-Map,BloomFiter。
来自期刊文章
2.分布式设计
多线程/多进程提高爬虫效率,可搭建Hadoop集群/Spark集群进行分布式爬虫:
来自论文
3.IP代理池设计
目前有许多免费代理可用。最好构建一个IP代理池,打包成API供程序使用。比如一个开源代理池的结构如下:
本框架使用Flask接受用户请求,并调用Schedule对代理进行强制刷新或定时刷新
开源IP池框架的未来发展:
1.智能:
对于URL队列生成和网页结构抓取,利用机器学习方法自动生成URL队列模型和网页结构模型,减少对人工干预和网页规则的依赖。
2. 聚类:
当捕获到的数据发送到各个系统时,需要考虑各个系统的对接问题。效率很重要,解决效率的关键是各个系统之间的分配问题。
3.图形化:
面对大量的数据采集任务,傻瓜式的图形表示对于非专业人士或专业人士来说已经足够了。未来,只是网络上的一点点数据采集任务。
对于业余爱好者和非专业人士,比如我:简单的爬虫技巧就够了,因为数据量不大,要求不高,而对于专业爬虫做产品,没必要懂一年半了。 查看全部
爬虫抓取网页数据(Bit-Map,增量抓取技术最主要的方法(组图))
本文讨论了网络数据采集的发展历程、核心技术和发展趋势:
开发过程
当然,您可以使用爬虫框架进行数据捕获。
核心技术
1.增量爬取技术
增量爬取技术的主要方法是去除重复,包括方法
内存重复数据删除、关系/非关系数据库重复数据删除和缓存数据库重复数据删除。
该策略包括:
直接方法,MD5/SHA-1生成信息汇总,Bit-Map,BloomFiter。

来自期刊文章
2.分布式设计
多线程/多进程提高爬虫效率,可搭建Hadoop集群/Spark集群进行分布式爬虫:
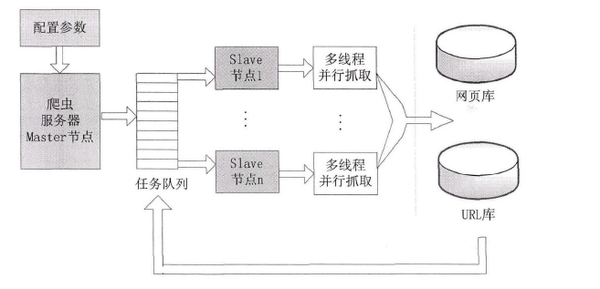
来自论文
3.IP代理池设计
目前有许多免费代理可用。最好构建一个IP代理池,打包成API供程序使用。比如一个开源代理池的结构如下:
本框架使用Flask接受用户请求,并调用Schedule对代理进行强制刷新或定时刷新
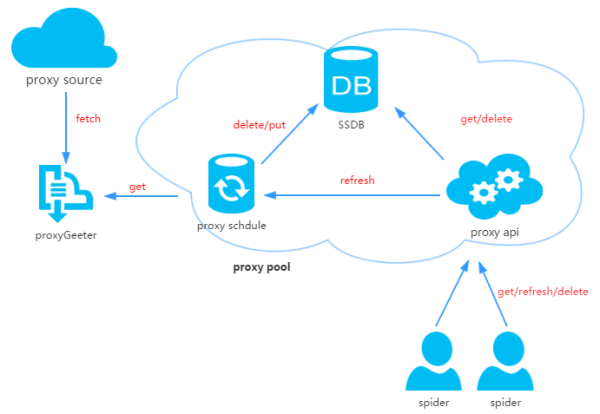
开源IP池框架的未来发展:
1.智能:
对于URL队列生成和网页结构抓取,利用机器学习方法自动生成URL队列模型和网页结构模型,减少对人工干预和网页规则的依赖。
2. 聚类:
当捕获到的数据发送到各个系统时,需要考虑各个系统的对接问题。效率很重要,解决效率的关键是各个系统之间的分配问题。
3.图形化:
面对大量的数据采集任务,傻瓜式的图形表示对于非专业人士或专业人士来说已经足够了。未来,只是网络上的一点点数据采集任务。
对于业余爱好者和非专业人士,比如我:简单的爬虫技巧就够了,因为数据量不大,要求不高,而对于专业爬虫做产品,没必要懂一年半了。
爬虫抓取网页数据(廖雪峰Python3开发环境搭建预备知识教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-09-12 22:00
爬虫抓取网页数据(廖雪峰Python3开发环境搭建预备知识教程)
一、prep 知识
1.Python3.x 基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3)鱼C工作室Python教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境搭建:
Sublime text3搭建Pyhthon IDE查看博客:
网址:
网址:
二、网络爬虫定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL 是 Uniform Resource Locator,其一般格式如下(方括号 [] 是可选的):
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL 的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(端口号是可选参数),一般网站默认端口号是80,比如百度的主机名,这个是服务器地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、 简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。 urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用urllib.request.urlopen()接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
了解了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后展示给我们。
回到正题,虽然我们成功获取了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以使用一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(也以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就可以知道网页使用的是哪种编码。如下:
这样我们就知道了网站的编码方式,但这需要我们每次都打开浏览器找到编码方式。显然,这需要很多麻烦。用几行代码解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页编码的方式有很多种,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,这是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以写一个小程序来判断网页的编码方式,新建的文件名是chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
一、prep 知识
1.Python3.x 基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3)鱼C工作室Python教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境搭建:
Sublime text3搭建Pyhthon IDE查看博客:
网址:
网址:
二、网络爬虫定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL 是 Uniform Resource Locator,其一般格式如下(方括号 [] 是可选的):
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL 的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(端口号是可选参数),一般网站默认端口号是80,比如百度的主机名,这个是服务器地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、 简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。 urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用urllib.request.urlopen()接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
了解了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后展示给我们。
回到正题,虽然我们成功获取了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以使用一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(也以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就可以知道网页使用的是哪种编码。如下:
这样我们就知道了网站的编码方式,但这需要我们每次都打开浏览器找到编码方式。显然,这需要很多麻烦。用几行代码解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页编码的方式有很多种,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,这是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以写一个小程序来判断网页的编码方式,新建的文件名是chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
爬虫抓取网页数据(廖雪峰Python3开发环境搭建预备知识教程)
一、prep 知识
1.Python3.x 基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3)鱼C工作室Python教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境搭建:
Sublime text3搭建Pyhthon IDE查看博客:
网址:
网址:
二、网络爬虫定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL 是 Uniform Resource Locator,其一般格式如下(方括号 [] 是可选的):
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL 的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(端口号是可选参数),一般网站默认端口号是80,比如百度的主机名,这个是服务器地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、 简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。 urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:

1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用urllib.request.urlopen()接口函数轻松打开一个网站,读取和打印信息。

urlopen 有一些可选参数。具体信息请参考Python自带的文档。
了解了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:

您也可以在cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:

其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:

如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:

我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后展示给我们。
回到正题,虽然我们成功获取了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以使用一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(也以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
这样我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:

当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就可以知道网页使用的是哪种编码。如下:

这样我们就知道了网站的编码方式,但这需要我们每次都打开浏览器找到编码方式。显然,这需要很多麻烦。用几行代码解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页编码的方式有很多种,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,这是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet

安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以写一个小程序来判断网页的编码方式,新建的文件名是chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:

看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址:
爬虫抓取网页数据(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-12 21:12
爬虫抓取网页数据(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是 Ajax:
Ajax(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装 Selenium 和 chromedriver:
安装Selenium:Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后放在一个不需要权限的纯英文目录。
快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
鼠标相关的操作较多。
Cookie 操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页使用 Ajax 技术,因此程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。 查看全部
什么是 Ajax:
Ajax(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装 Selenium 和 chromedriver:
安装Selenium:Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后放在一个不需要权限的纯英文目录。
快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
鼠标相关的操作较多。
Cookie 操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页使用 Ajax 技术,因此程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。 查看全部
爬虫抓取网页数据(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是 Ajax:
Ajax(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装 Selenium 和 chromedriver:
安装Selenium:Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后放在一个不需要权限的纯英文目录。
快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
鼠标相关的操作较多。
Cookie 操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页使用 Ajax 技术,因此程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。
爬虫抓取网页数据(Bit-Map,增量抓取技术最主要的方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-14 14:13
爬虫抓取网页数据(Bit-Map,增量抓取技术最主要的方法(组图))
本文讨论了网络数据采集的发展历程、核心技术和发展趋势:
开发过程
当然,您可以使用爬虫框架进行数据捕获。
核心技术
1.增量爬取技术
增量爬取技术的主要方法是去除重复,包括方法
内存重复数据删除、关系/非关系数据库重复数据删除和缓存数据库重复数据删除。
该策略包括:
直接方法,MD5/SHA-1生成信息汇总,Bit-Map,BloomFiter。
来自期刊文章
2.分布式设计
多线程/多进程提高爬虫效率,可搭建Hadoop集群/Spark集群进行分布式爬虫:
来自论文
3.IP代理池设计
目前有许多免费代理可用。最好构建一个IP代理池,打包成API供程序使用。比如一个开源代理池的结构如下:
本框架使用Flask接受用户请求,并调用Schedule对代理进行强制刷新或定时刷新
开源IP池框架的未来发展:
1.智能:
对于URL队列生成和网页结构抓取,利用机器学习方法自动生成URL队列模型和网页结构模型,减少对人工干预和网页规则的依赖。
2. 聚类:
当捕获到的数据发送到各个系统时,需要考虑各个系统的对接问题。效率很重要,解决效率的关键是各个系统之间的分配问题。
3.图形化:
面对大量的数据采集任务,傻瓜式的图形表示对于非专业人士或专业人士来说已经足够了。未来,只是网络上的一点点数据采集任务。
对于业余爱好者和非专业人士,比如我:简单的爬虫技巧就够了,因为数据量不大,要求不高,而对于专业爬虫做产品,没必要懂一年半了。 查看全部
本文讨论了网络数据采集的发展历程、核心技术和发展趋势:
开发过程
当然,您可以使用爬虫框架进行数据捕获。
核心技术
1.增量爬取技术
增量爬取技术的主要方法是去除重复,包括方法
内存重复数据删除、关系/非关系数据库重复数据删除和缓存数据库重复数据删除。
该策略包括:
直接方法,MD5/SHA-1生成信息汇总,Bit-Map,BloomFiter。
来自期刊文章
2.分布式设计
多线程/多进程提高爬虫效率,可搭建Hadoop集群/Spark集群进行分布式爬虫:
来自论文
3.IP代理池设计
目前有许多免费代理可用。最好构建一个IP代理池,打包成API供程序使用。比如一个开源代理池的结构如下:
本框架使用Flask接受用户请求,并调用Schedule对代理进行强制刷新或定时刷新
开源IP池框架的未来发展:
1.智能:
对于URL队列生成和网页结构抓取,利用机器学习方法自动生成URL队列模型和网页结构模型,减少对人工干预和网页规则的依赖。
2. 聚类:
当捕获到的数据发送到各个系统时,需要考虑各个系统的对接问题。效率很重要,解决效率的关键是各个系统之间的分配问题。
3.图形化:
面对大量的数据采集任务,傻瓜式的图形表示对于非专业人士或专业人士来说已经足够了。未来,只是网络上的一点点数据采集任务。
对于业余爱好者和非专业人士,比如我:简单的爬虫技巧就够了,因为数据量不大,要求不高,而对于专业爬虫做产品,没必要懂一年半了。 查看全部
爬虫抓取网页数据(Bit-Map,增量抓取技术最主要的方法(组图))
本文讨论了网络数据采集的发展历程、核心技术和发展趋势:
开发过程
当然,您可以使用爬虫框架进行数据捕获。
核心技术
1.增量爬取技术
增量爬取技术的主要方法是去除重复,包括方法
内存重复数据删除、关系/非关系数据库重复数据删除和缓存数据库重复数据删除。
该策略包括:
直接方法,MD5/SHA-1生成信息汇总,Bit-Map,BloomFiter。
来自期刊文章
2.分布式设计
多线程/多进程提高爬虫效率,可搭建Hadoop集群/Spark集群进行分布式爬虫:
来自论文
3.IP代理池设计
目前有许多免费代理可用。最好构建一个IP代理池,打包成API供程序使用。比如一个开源代理池的结构如下:
本框架使用Flask接受用户请求,并调用Schedule对代理进行强制刷新或定时刷新
开源IP池框架的未来发展:
1.智能:
对于URL队列生成和网页结构抓取,利用机器学习方法自动生成URL队列模型和网页结构模型,减少对人工干预和网页规则的依赖。
2. 聚类:
当捕获到的数据发送到各个系统时,需要考虑各个系统的对接问题。效率很重要,解决效率的关键是各个系统之间的分配问题。
3.图形化:
面对大量的数据采集任务,傻瓜式的图形表示对于非专业人士或专业人士来说已经足够了。未来,只是网络上的一点点数据采集任务。
对于业余爱好者和非专业人士,比如我:简单的爬虫技巧就够了,因为数据量不大,要求不高,而对于专业爬虫做产品,没必要懂一年半了。
爬虫抓取网页数据(廖雪峰Python3开发环境搭建预备知识教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-09-12 22:00
爬虫抓取网页数据(廖雪峰Python3开发环境搭建预备知识教程)
一、prep 知识
1.Python3.x 基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3)鱼C工作室Python教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境搭建:
Sublime text3搭建Pyhthon IDE查看博客:
网址:
网址:
二、网络爬虫定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL 是 Uniform Resource Locator,其一般格式如下(方括号 [] 是可选的):
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL 的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(端口号是可选参数),一般网站默认端口号是80,比如百度的主机名,这个是服务器地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、 简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。 urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用urllib.request.urlopen()接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
了解了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后展示给我们。
回到正题,虽然我们成功获取了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以使用一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(也以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就可以知道网页使用的是哪种编码。如下:
这样我们就知道了网站的编码方式,但这需要我们每次都打开浏览器找到编码方式。显然,这需要很多麻烦。用几行代码解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页编码的方式有很多种,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,这是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以写一个小程序来判断网页的编码方式,新建的文件名是chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
一、prep 知识
1.Python3.x 基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3)鱼C工作室Python教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境搭建:
Sublime text3搭建Pyhthon IDE查看博客:
网址:
网址:
二、网络爬虫定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL 是 Uniform Resource Locator,其一般格式如下(方括号 [] 是可选的):
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL 的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(端口号是可选参数),一般网站默认端口号是80,比如百度的主机名,这个是服务器地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、 简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。 urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用urllib.request.urlopen()接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
了解了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com")
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后展示给我们。
回到正题,虽然我们成功获取了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以使用一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(也以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
这样我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就可以知道网页使用的是哪种编码。如下:
这样我们就知道了网站的编码方式,但这需要我们每次都打开浏览器找到编码方式。显然,这需要很多麻烦。用几行代码解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页编码的方式有很多种,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,这是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以写一个小程序来判断网页的编码方式,新建的文件名是chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址: 查看全部
爬虫抓取网页数据(廖雪峰Python3开发环境搭建预备知识教程)
一、prep 知识
1.Python3.x 基础知识学习:
您可以通过以下方式学习:
(1)廖雪峰Python3教程(文档):
网址:
(2)菜鸟教程Python3教程(文档):
网址:
(3)鱼C工作室Python教程(视频):
小龟老师人很好,讲课风格幽默诙谐。如果时间充裕,可以考虑看视频。
网址:
2.开发环境搭建:
Sublime text3搭建Pyhthon IDE查看博客:
网址:
网址:
二、网络爬虫定义
网络爬虫也称为网络蜘蛛。如果将 Internet 比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。网络爬虫根据网页的地址,即 URL 搜索网页。举个简单的例子,我们在浏览器地址栏中输入的字符串就是URL,例如:
URL 是 Uniform Resource Locator,其一般格式如下(方括号 [] 是可选的):
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL 的格式由三部分组成:
(1)protocol:第一部分是协议,比如百度使用的是https协议;
(2)hostname[:port]:第二部分是主机名(端口号是可选参数),一般网站默认端口号是80,比如百度的主机名,这个是服务器地址;
(3)path:第三部分是宿主机资源的具体地址,如目录、文件名等。
网络爬虫根据这个 URL 获取网页信息。
三、 简单爬虫示例
在 Python3.x 中,我们可以使用 urlib 组件来抓取网页。 urllib 是一个 URL 处理包。这个包收录一些处理 URL 的模块,如下:
1.urllib.request 模块用于打开和读取 URL;
2.urllib.error 模块中收录了 urllib.request 产生的一些错误,可以通过 try 捕获和处理;
3.urllib.parse 模块收录一些解析 URL 的方法;
4.urllib.robotparser 模块用于解析 robots.txt 文本文件。它提供了一个单独的RobotFileParser类,通过该类提供的can_fetch()方法来测试爬虫是否可以下载一个页面。
我们使用urllib.request.urlopen()接口函数轻松打开一个网站,读取和打印信息。
urlopen 有一些可选参数。具体信息请参考Python自带的文档。
了解了这些,我们就可以写出最简单的程序了,文件名是urllib_test01.py,感受一下一个urllib库的魅力:
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com";)
html = response.read()
print(html)
urllib 使用 request.urlopen() 打开和读取 URLs 信息,返回的对象 response 就像一个文本对象,我们可以调用 read() 来读取它。然后通过print(),将读取到的信息打印出来。
运行程序ctrl+b,可以在Sublime中查看结果,如下:
您也可以在cmd(控制台)中输入命令:
python urllib_test01.py
运行py文件,输出信息相同,如下:
其实这是浏览器接收到的信息,但是我们在使用浏览器的时候,浏览器已经把这些信息转换成界面信息供我们浏览了。当然,我们也可以从浏览器中查看这些代码。比如使用谷歌浏览器,在任意界面右击选择Check,即勾选元素(不是所有页面都可以勾选元素,比如起点中文网站的付费版块。)。以百度界面为例。截图如下:
如您所见,我们的审核结果在右侧。我们可以在本地更改元素,即浏览器(客户端),但这不会上传到服务器。例如,我可以修改我的支付宝余额并安装一个包,例如:
我真的有钱吗?显然,如果我被迫这样做,我就没有钱了。我刚刚修改了review元素的信息。
有些偏差,但事实是浏览器作为客户端从服务器获取信息,然后解析信息,然后展示给我们。
回到正题,虽然我们成功获取了信息,但很明显,都是二进制乱码,看起来很不方便。我们该怎么办?
我们可以使用一个简单的decode()命令来解码网页的信息并显示出来。我们新建一个文件,命名为urllib_test02.py,编写如下代码(也以百度翻译网站为例):
# -*- coding: UTF-8 -*-
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/";)
html = response.read()
html = html.decode("utf-8")
print(html)
这样我们就可以得到这个结果。显然,解码后的信息看起来更整洁、更舒服:
当然,前提是我们已经知道这个网页是utf-8编码的,如何查看网页的编码呢?需要人工操作,一个很简单的方法就是使用浏览器查看元素。只需要找到head标签开头的chareset就可以知道网页使用的是哪种编码。如下:
这样我们就知道了网站的编码方式,但这需要我们每次都打开浏览器找到编码方式。显然,这需要很多麻烦。用几行代码解决,更省事,更爽。
四、自动获取网页编码方式的方法
获取网页编码的方式有很多种,我更喜欢使用第三方库。
首先我们需要安装第三方库chardet,这是一个用来判断编码的模块。安装方法如下图所示。只需输入命令:
pip install chardet
安装后,我们可以使用chardet.detect()方法来判断网页的编码。此时,我们可以写一个小程序来判断网页的编码方式,新建的文件名是chardet_test01.py:
# -*- coding: UTF-8 -*-
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://fanyi.baidu.com/";)
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,查看输出结果如下:
看,返回的是字典,所以我们知道了网页的编码方式,我们可以根据得到的信息使用不同的解码方式。
PS:关于编码方式的内容,可以自行百度,或者阅读这篇博客:
网址:
爬虫抓取网页数据(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-12 21:12
爬虫抓取网页数据(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是 Ajax:
Ajax(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装 Selenium 和 chromedriver:
安装Selenium:Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后放在一个不需要权限的纯英文目录。
快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
鼠标相关的操作较多。
Cookie 操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页使用 Ajax 技术,因此程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。 查看全部
什么是 Ajax:
Ajax(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装 Selenium 和 chromedriver:
安装Selenium:Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后放在一个不需要权限的纯英文目录。
快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
鼠标相关的操作较多。
Cookie 操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页使用 Ajax 技术,因此程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。 查看全部
爬虫抓取网页数据(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和XML)
什么是 Ajax:
Ajax(Asynchronouse JavaScript And XML)异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。该方法的优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
分析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
大量代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:安装 Selenium 和 chromedriver:
安装Selenium:Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后放在一个不需要权限的纯英文目录。
快速入门:
现在以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。 driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
注意 find_element 是获取第一个满足条件的元素。 find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框中的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,可以在网页上用鼠标点击。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
Select select:不能直接点击select元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方法有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,那么这次可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
鼠标相关的操作较多。
Cookie 操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的网页使用 Ajax 技术,因此程序无法确定某个元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。 Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有些网页有时会被频繁抓取。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。下面以Chrome浏览器为例进行说明:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。 screentshot:获取当前页面的截图。此方法只能在驱动上使用。
driver 的对象类也是继承自 WebElement。
更多内容请阅读相关源码。

