
爬虫抓取网页数据
爬虫抓取网页数据(python获取网页信息只伪造了一个UA头(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-12 14:14
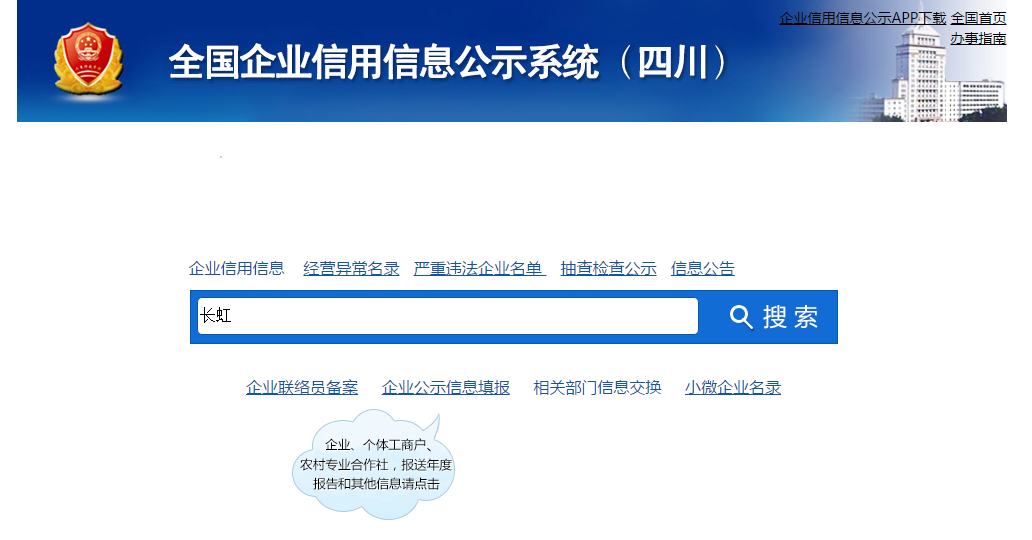
最近在学习python的requests库,大致了解了正则匹配,所以想找个项目来实践一下。巧合的是,在连接fiddler测试的过程中,刷了某社交平台,抓到了很多请求。通过分析发现,平台用户id从1递增,请求中的access_token值应该是一定规则生成的32位加密代码。切换id,access_token不变,即可访问不同用户的个人主页。主页收录用户信息,包括居住城市、姓名、公司、职位、毕业院校、头像、用户标签、他人评价等。更敏感的信息,如电话号码,无疑是加密的,但仅此信息就足以定位特定用户,这被认为是有价值的信息。先贴一张图,看看效果,再详细说说实现原理。
目前已经爬取了600多个用户,然后遇到了爬虫最大的障碍——反爬。当然,如果有反爬,还有抑制反爬的办法,那就是另外一回事了。
导入库
import requests
import re
import xlrd
import random
from xlutils.copy import copy
import time
requests用于获取网页信息,re为正则匹配,xlrd和xlutils.copy将爬取的信息写入excel文档,time和random用于生成等待的随机数,避免爬取的频繁限制。
1.获取网页信息
def getHtml(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
html = requests.get(url, headers=headers).text
return html
只伪造了一个UA头,发现可以爬到信息上
2.其中一个字段——名字的getter函数
def getname(html):
name_reg = r'"name":"(.*?)"'
name_patten = re.compile(name_reg)
name = re.findall(name_patten, html)
if len(name):
return name[0]
else:
return "/"
通过正则匹配,得到一个名字列表,第一条数据代表用户的名字,可以直接得到。如果某些用户 id 不存在,则返回“/”以填充该位置。本来我是想直接把这种无效信息去掉,但是我想看,比如1000个用户,有多少是无效的,所以直接填了位置。其他信息:同职位、居住地、公司等。如上图,我只取了姓名、居住地、职位、公司、头像等。
3.写入现有的 excel 文档
def xlxs_modify(i, name):
file_xl = xlrd.open_workbook(r'...')
xlxs = copy(file_xl)
write_xlxs = xlxs.get_sheet(0)
write_xlxs.write(i, 0, name1)
xlxs.save(r'...')
将真正匹配的名称等字段写入文档中,从第一列开始依次写入
4.运行循环,写入数据
for i in range(500,3000):
j = i+1
url = "https://.../contact/basic/%s?"%j
....
all = xlxs_modify(j, name, province, city, company, compos, school, avatar)
x = random.randint(1, 2)
time.sleep(x)
只需添加随机等待时间以避免被阻止。
这里写的爬虫部分差不多,因为爬取600多条数据时抓取的网页信息一直是“休息一会”,原来是反爬集。然后我通过headers头添加了一个动态的虚拟ip,写cookies,增加了更多的等待时间等等,发现问题解决不了。看起来很有可能是用户信息触发的,除非切换到其他用户。
平台是用手机号注册的用户,是一种注册门槛高的方法,但也有破解的方法。谷歌短信服务,发现网上有大量免费验证码获取手机号,如下图。
现在只需要注册多个账号,随机接口运行循环,抓取上千条记录应该不成问题。 查看全部
爬虫抓取网页数据(python获取网页信息只伪造了一个UA头(组图))
最近在学习python的requests库,大致了解了正则匹配,所以想找个项目来实践一下。巧合的是,在连接fiddler测试的过程中,刷了某社交平台,抓到了很多请求。通过分析发现,平台用户id从1递增,请求中的access_token值应该是一定规则生成的32位加密代码。切换id,access_token不变,即可访问不同用户的个人主页。主页收录用户信息,包括居住城市、姓名、公司、职位、毕业院校、头像、用户标签、他人评价等。更敏感的信息,如电话号码,无疑是加密的,但仅此信息就足以定位特定用户,这被认为是有价值的信息。先贴一张图,看看效果,再详细说说实现原理。

目前已经爬取了600多个用户,然后遇到了爬虫最大的障碍——反爬。当然,如果有反爬,还有抑制反爬的办法,那就是另外一回事了。
导入库
import requests
import re
import xlrd
import random
from xlutils.copy import copy
import time
requests用于获取网页信息,re为正则匹配,xlrd和xlutils.copy将爬取的信息写入excel文档,time和random用于生成等待的随机数,避免爬取的频繁限制。
1.获取网页信息
def getHtml(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
html = requests.get(url, headers=headers).text
return html
只伪造了一个UA头,发现可以爬到信息上
2.其中一个字段——名字的getter函数
def getname(html):
name_reg = r'"name":"(.*?)"'
name_patten = re.compile(name_reg)
name = re.findall(name_patten, html)
if len(name):
return name[0]
else:
return "/"
通过正则匹配,得到一个名字列表,第一条数据代表用户的名字,可以直接得到。如果某些用户 id 不存在,则返回“/”以填充该位置。本来我是想直接把这种无效信息去掉,但是我想看,比如1000个用户,有多少是无效的,所以直接填了位置。其他信息:同职位、居住地、公司等。如上图,我只取了姓名、居住地、职位、公司、头像等。
3.写入现有的 excel 文档
def xlxs_modify(i, name):
file_xl = xlrd.open_workbook(r'...')
xlxs = copy(file_xl)
write_xlxs = xlxs.get_sheet(0)
write_xlxs.write(i, 0, name1)
xlxs.save(r'...')
将真正匹配的名称等字段写入文档中,从第一列开始依次写入
4.运行循环,写入数据
for i in range(500,3000):
j = i+1
url = "https://.../contact/basic/%s?"%j
....
all = xlxs_modify(j, name, province, city, company, compos, school, avatar)
x = random.randint(1, 2)
time.sleep(x)
只需添加随机等待时间以避免被阻止。
这里写的爬虫部分差不多,因为爬取600多条数据时抓取的网页信息一直是“休息一会”,原来是反爬集。然后我通过headers头添加了一个动态的虚拟ip,写cookies,增加了更多的等待时间等等,发现问题解决不了。看起来很有可能是用户信息触发的,除非切换到其他用户。
平台是用手机号注册的用户,是一种注册门槛高的方法,但也有破解的方法。谷歌短信服务,发现网上有大量免费验证码获取手机号,如下图。
现在只需要注册多个账号,随机接口运行循环,抓取上千条记录应该不成问题。
爬虫抓取网页数据(如何编写一个网络爬虫的数据数据采集?学习资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-10 03:07
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
最后,想学Python的朋友们!请关注+私信回复:“学习”获取我为你准备的Python学习资料一份!
python学习资料
python学习资料 查看全部
爬虫抓取网页数据(如何编写一个网络爬虫的数据数据采集?学习资料)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网

使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:

提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。

连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。

总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
最后,想学Python的朋友们!请关注+私信回复:“学习”获取我为你准备的Python学习资料一份!

python学习资料

python学习资料
爬虫抓取网页数据(植物大战僵尸212)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-06 05:04
爬虫抓取网页数据并做拼接,看看采集效果,并发数多少是否要加大。
如果是百度这种情况,建议最好是采用项目来实现,django模板库采用flask。首先可以测试一下,是否可以获取你所需要的图片列表,需要提供的字段:varmatthew_imgs=require('./fakeimage')varimgurl=''varcontext=newhttppagecontext()varmail=newhttpport(http,'/')varposturl='-img/custom-post/'variphone_account=mail.getmail();//获取手机号vargetpacket(db.getinfo)varipad_account=mail.getbook();variphone_account=mail.getapp();varsize=0.2;varcontent=mail.gethost();//获取微信号varclient_id=mail.getapp().code;//获取验证码varurlname=mail.gethost().accountname;//获取二维码,view=mail.gethost().username;//获取地址,whois信息varaccount_name=mail.gethost().signing;//获取联系人,id=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取设备名variphone_account=mail.getapp().iphone_account;//获取微信号varipad_account=mail.getapp().ipad_account;//获取验证码varclient_id=mail.gethost().accountname;//获取设备名varurlname=mail.gethost().username;//获取地址varaccount=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取验证码,whois=mail.gethost().whois;//获取手机号。 查看全部
爬虫抓取网页数据(植物大战僵尸212)
爬虫抓取网页数据并做拼接,看看采集效果,并发数多少是否要加大。
如果是百度这种情况,建议最好是采用项目来实现,django模板库采用flask。首先可以测试一下,是否可以获取你所需要的图片列表,需要提供的字段:varmatthew_imgs=require('./fakeimage')varimgurl=''varcontext=newhttppagecontext()varmail=newhttpport(http,'/')varposturl='-img/custom-post/'variphone_account=mail.getmail();//获取手机号vargetpacket(db.getinfo)varipad_account=mail.getbook();variphone_account=mail.getapp();varsize=0.2;varcontent=mail.gethost();//获取微信号varclient_id=mail.getapp().code;//获取验证码varurlname=mail.gethost().accountname;//获取二维码,view=mail.gethost().username;//获取地址,whois信息varaccount_name=mail.gethost().signing;//获取联系人,id=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取设备名variphone_account=mail.getapp().iphone_account;//获取微信号varipad_account=mail.getapp().ipad_account;//获取验证码varclient_id=mail.gethost().accountname;//获取设备名varurlname=mail.gethost().username;//获取地址varaccount=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取验证码,whois=mail.gethost().whois;//获取手机号。
爬虫抓取网页数据(深入一点的爬虫方向基于身份识别进行反爬基于数据加密进行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-06 00:03
正则表达式
在爬虫中使用正则表达式仍然很常见:
防爬
爬取的三个方向 基于身份识别的反爬 基于爬虫行为的反爬 基于数据加密的反爬 基于数据加密的反爬 基于身份识别的常见反爬 1 通过 headers 字段进行反爬 有headers中的字段很多,都可能是对方服务器拿来判断是否是爬虫1.1 反爬和反爬原理通过headers中的User-Agent字段:爬虫没有默认有一个User-Agent,但是使用模块的默认设置解决方法:在请求之前添加User-Agent即可;更好的方法是使用
爬虫框架
spider爬虫名称爬取域名#创建爬虫程序设置#如果在项目目录下,会得到项目的配置runsspider#运行单独的python文件,交互调试时无需创建项目shell#scrapyshellurl地址,如选择浏览器规则是否正确fetch#独立于进程爬取一个页面,可以得到请求头视图#下载后浏览器会直接弹出,这样就可以分辨出哪些数据是ajax请求版本#刮痧
平台通用框架整理【转载】
O.NET:跨平台的 .NET 运行时环境使得跨平台运行 .NET 成为可能。DotGnuPortable.NET:类似于 MONO.NET 的跨平台运行时。Phalanger:将 PHP 编译成 .NET,实现 PHP 和 .NET 之间的互操作性。VMDotNet:中国移动飞信使用的.NET运行时。Unity3D:微软强烈支持的 C# 和 JavaScript 跨平台游戏开发框架。Cassini、IISExpress 和 Cas
学爬1个月月入6000?别被骗了,高手告诉你爬虫的真实情况
做了很多年了,爬虫当然没问题,所以今天就来深入聊聊5个爬虫问题,让大家了解爬虫的真实情况:1.目前的爬虫真的可以接单一个月赚6000快钱吗?2.初级爬虫只能接一些小订单,初级爬虫什么水平?3.中级爬虫是专业爬虫工程师。他们需要什么?4.高级爬虫可以说是爬虫之神。您需要掌握哪些技术?5.爬虫在更高层次上需要学习什么?顶级爬行动物长什么样?一、爬虫一个月能多赚6000吗?答案是肯定的,但需要
Python爬虫十六-五:BeautifulSoup-好吃的汤
点我开始>>> Python爬虫十六类-第一类:HTTP协议>>> Python爬虫十六类二:urllib和urllib3>>> Python爬虫十六类:请求用法>>> Python爬虫十六类-第四种:使用Xpath提取网页内容>>>十六种Python爬虫-第六种:JQuery的假兄弟-p
爬行动物的概念
爬虫是什么概念?互联网爬虫使用程序根据 URL 地址爬取网页,以获取有用的信息。使用程序模拟浏览器,向服务器发送请求,获取响应信息。数据分析、人工数据集、社交软件冷启动舆情监测、监控竞争对手爬虫分类、通用爬虫、焦点爬虫反爬方式>数据加密
关于爬虫平台的架构设计和实现以及框架的选择(一)
关于爬虫平台的架构设计和实现以及框架的选择(一)关于爬虫平台的架构设计和实现以及框架的选择(二)--内部实现) scrapy和实时爬虫的实现先看下一个爬虫平台的设计,作为一个爬虫平台,需要支持多种不同的爬虫方式,所以一般的爬虫平台需要收录1、的维护@>爬虫规则,当平台收到爬虫请求时,需要能够匹配一定的自动爬虫规则2、爬虫作业调度器,平台需要能够负责爬虫的调度定时调度、轮询调度等任务
C#反爬虫的CSRF
最近在写爬虫的时候,遇到了一个网站,里面有防止CSRF攻击的机制。该接口是一个 POST 请求。用 PostMan 测试后发现需要请求头中的 Cookie 和 FormData 中的 _token 参数才能发起正确的请求。这两个参数缺一不可,有效时间只有一天,因为爬虫是定时任务,每天都会在某个时间自己运行。在这种情况下,每天更换 Cookie 和 Token 太麻烦了。摸索了一会,发现是可以破解的。网页的 CSRF:第一步是 cookie 将
爬虫技术栈点
它确实请求指纹去重(如果要爬取整个站点,则需要使用分布式,不同线程爬虫需要爬取不同页面以实现批量分布式去重),请求分配,以及临时数据存储。7.爬虫之争---反爬虫---反反爬虫:(爬虫最后最难的不是复杂页面的获取,默默无闻的采集数据,难点在于7.@网站后台人员斗智斗勇)最早反爬用的是User-Agent,(每秒点击多少),使用代理,验证码,(不是全部其中12306),动态数据加载,加密数据(数据加密有技巧,核心 查看全部
爬虫抓取网页数据(深入一点的爬虫方向基于身份识别进行反爬基于数据加密进行)
正则表达式
在爬虫中使用正则表达式仍然很常见:
防爬
爬取的三个方向 基于身份识别的反爬 基于爬虫行为的反爬 基于数据加密的反爬 基于数据加密的反爬 基于身份识别的常见反爬 1 通过 headers 字段进行反爬 有headers中的字段很多,都可能是对方服务器拿来判断是否是爬虫1.1 反爬和反爬原理通过headers中的User-Agent字段:爬虫没有默认有一个User-Agent,但是使用模块的默认设置解决方法:在请求之前添加User-Agent即可;更好的方法是使用
爬虫框架
spider爬虫名称爬取域名#创建爬虫程序设置#如果在项目目录下,会得到项目的配置runsspider#运行单独的python文件,交互调试时无需创建项目shell#scrapyshellurl地址,如选择浏览器规则是否正确fetch#独立于进程爬取一个页面,可以得到请求头视图#下载后浏览器会直接弹出,这样就可以分辨出哪些数据是ajax请求版本#刮痧
平台通用框架整理【转载】
O.NET:跨平台的 .NET 运行时环境使得跨平台运行 .NET 成为可能。DotGnuPortable.NET:类似于 MONO.NET 的跨平台运行时。Phalanger:将 PHP 编译成 .NET,实现 PHP 和 .NET 之间的互操作性。VMDotNet:中国移动飞信使用的.NET运行时。Unity3D:微软强烈支持的 C# 和 JavaScript 跨平台游戏开发框架。Cassini、IISExpress 和 Cas
学爬1个月月入6000?别被骗了,高手告诉你爬虫的真实情况
做了很多年了,爬虫当然没问题,所以今天就来深入聊聊5个爬虫问题,让大家了解爬虫的真实情况:1.目前的爬虫真的可以接单一个月赚6000快钱吗?2.初级爬虫只能接一些小订单,初级爬虫什么水平?3.中级爬虫是专业爬虫工程师。他们需要什么?4.高级爬虫可以说是爬虫之神。您需要掌握哪些技术?5.爬虫在更高层次上需要学习什么?顶级爬行动物长什么样?一、爬虫一个月能多赚6000吗?答案是肯定的,但需要
Python爬虫十六-五:BeautifulSoup-好吃的汤
点我开始>>> Python爬虫十六类-第一类:HTTP协议>>> Python爬虫十六类二:urllib和urllib3>>> Python爬虫十六类:请求用法>>> Python爬虫十六类-第四种:使用Xpath提取网页内容>>>十六种Python爬虫-第六种:JQuery的假兄弟-p
爬行动物的概念
爬虫是什么概念?互联网爬虫使用程序根据 URL 地址爬取网页,以获取有用的信息。使用程序模拟浏览器,向服务器发送请求,获取响应信息。数据分析、人工数据集、社交软件冷启动舆情监测、监控竞争对手爬虫分类、通用爬虫、焦点爬虫反爬方式>数据加密
关于爬虫平台的架构设计和实现以及框架的选择(一)
关于爬虫平台的架构设计和实现以及框架的选择(一)关于爬虫平台的架构设计和实现以及框架的选择(二)--内部实现) scrapy和实时爬虫的实现先看下一个爬虫平台的设计,作为一个爬虫平台,需要支持多种不同的爬虫方式,所以一般的爬虫平台需要收录1、的维护@>爬虫规则,当平台收到爬虫请求时,需要能够匹配一定的自动爬虫规则2、爬虫作业调度器,平台需要能够负责爬虫的调度定时调度、轮询调度等任务
C#反爬虫的CSRF
最近在写爬虫的时候,遇到了一个网站,里面有防止CSRF攻击的机制。该接口是一个 POST 请求。用 PostMan 测试后发现需要请求头中的 Cookie 和 FormData 中的 _token 参数才能发起正确的请求。这两个参数缺一不可,有效时间只有一天,因为爬虫是定时任务,每天都会在某个时间自己运行。在这种情况下,每天更换 Cookie 和 Token 太麻烦了。摸索了一会,发现是可以破解的。网页的 CSRF:第一步是 cookie 将
爬虫技术栈点
它确实请求指纹去重(如果要爬取整个站点,则需要使用分布式,不同线程爬虫需要爬取不同页面以实现批量分布式去重),请求分配,以及临时数据存储。7.爬虫之争---反爬虫---反反爬虫:(爬虫最后最难的不是复杂页面的获取,默默无闻的采集数据,难点在于7.@网站后台人员斗智斗勇)最早反爬用的是User-Agent,(每秒点击多少),使用代理,验证码,(不是全部其中12306),动态数据加载,加密数据(数据加密有技巧,核心
爬虫抓取网页数据(如何有效地提取网络爬虫、监视竞争对手或者获取销售线索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2022-04-05 00:17
互联网成为海量信息的载体;互联网是目前分析市场趋势、监控竞争对手或获取销售线索的最佳场所,而数据采集 和分析能力已成为推动业务决策的关键技能。
如何有效地提取和利用这些信息成为了一个巨大的挑战,而网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类、爬虫的爬取策略,以及爬虫深度学习所需的网络基础知识。
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
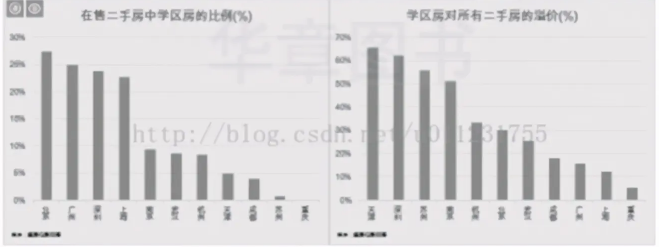
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
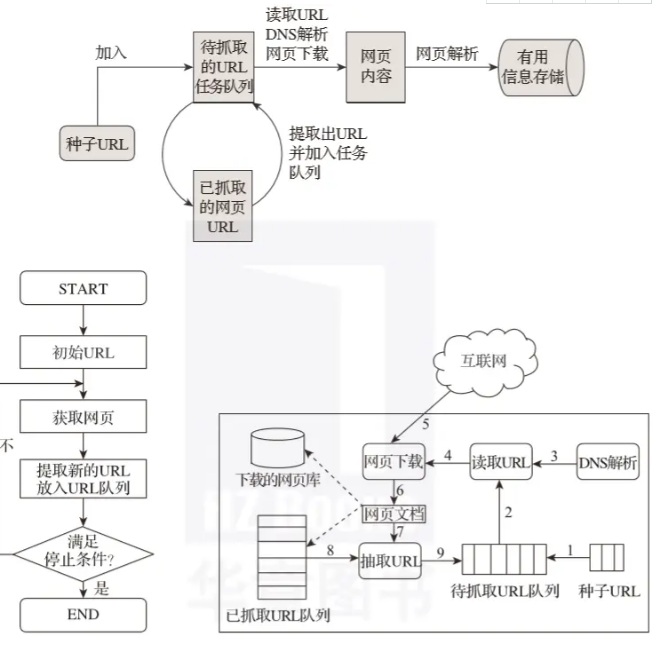
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。 查看全部
爬虫抓取网页数据(如何有效地提取网络爬虫、监视竞争对手或者获取销售线索)
互联网成为海量信息的载体;互联网是目前分析市场趋势、监控竞争对手或获取销售线索的最佳场所,而数据采集 和分析能力已成为推动业务决策的关键技能。
如何有效地提取和利用这些信息成为了一个巨大的挑战,而网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类、爬虫的爬取策略,以及爬虫深度学习所需的网络基础知识。

01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
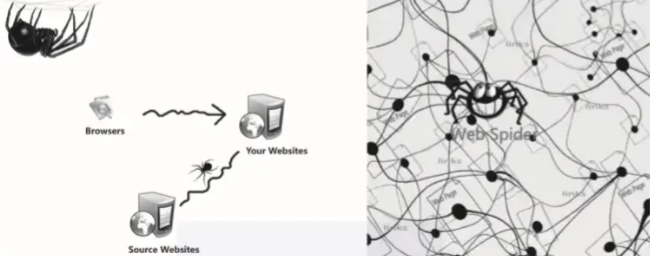
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
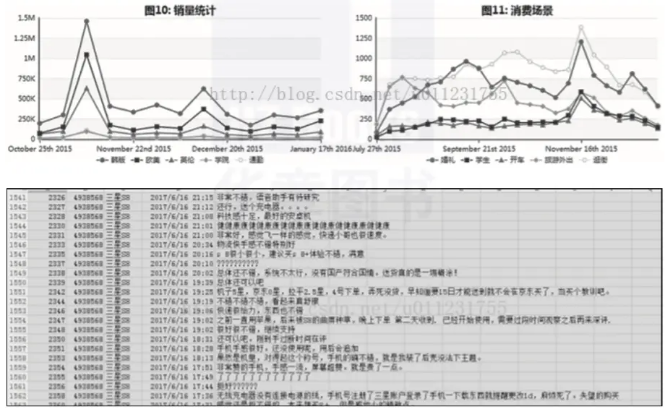
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。
爬虫抓取网页数据(web页面数据采集工具通达网络爬虫管理工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-02 22:04
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
文章插图
文章插图
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业部署爬虫管理工具后,可以快速下载自有产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息和其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
文章插图
文章插图
网络爬虫工具
【有哪些免费的爬虫软件可以让爬虫精准抓取大数据、获客】吉家通达爬虫管理工具产品成熟,已经在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。 查看全部
爬虫抓取网页数据(web页面数据采集工具通达网络爬虫管理工具(组图))
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。

文章插图

文章插图
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业部署爬虫管理工具后,可以快速下载自有产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息和其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用

文章插图
文章插图
网络爬虫工具
【有哪些免费的爬虫软件可以让爬虫精准抓取大数据、获客】吉家通达爬虫管理工具产品成熟,已经在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
爬虫抓取网页数据( 如何获取到用户的信息前往用户主页,以轮子哥为例从中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-02 20:26
如何获取到用户的信息前往用户主页,以轮子哥为例从中)
点我去Github查看源码别忘了star
本项目的github地址:
一.如何获取用户信息
进入用户主页,以Brother Wheel为例
从中可以看到用户的详细信息、教育经历主页、专业。行业、公司、关注量、回复数、居住地等。打开开发者工具栏查看网络,可以找到,通常html或json的数据在Html页面中。
网址是,excited-vczh是轮哥的id,只要拿到某个人的id就可以得到详细信息。
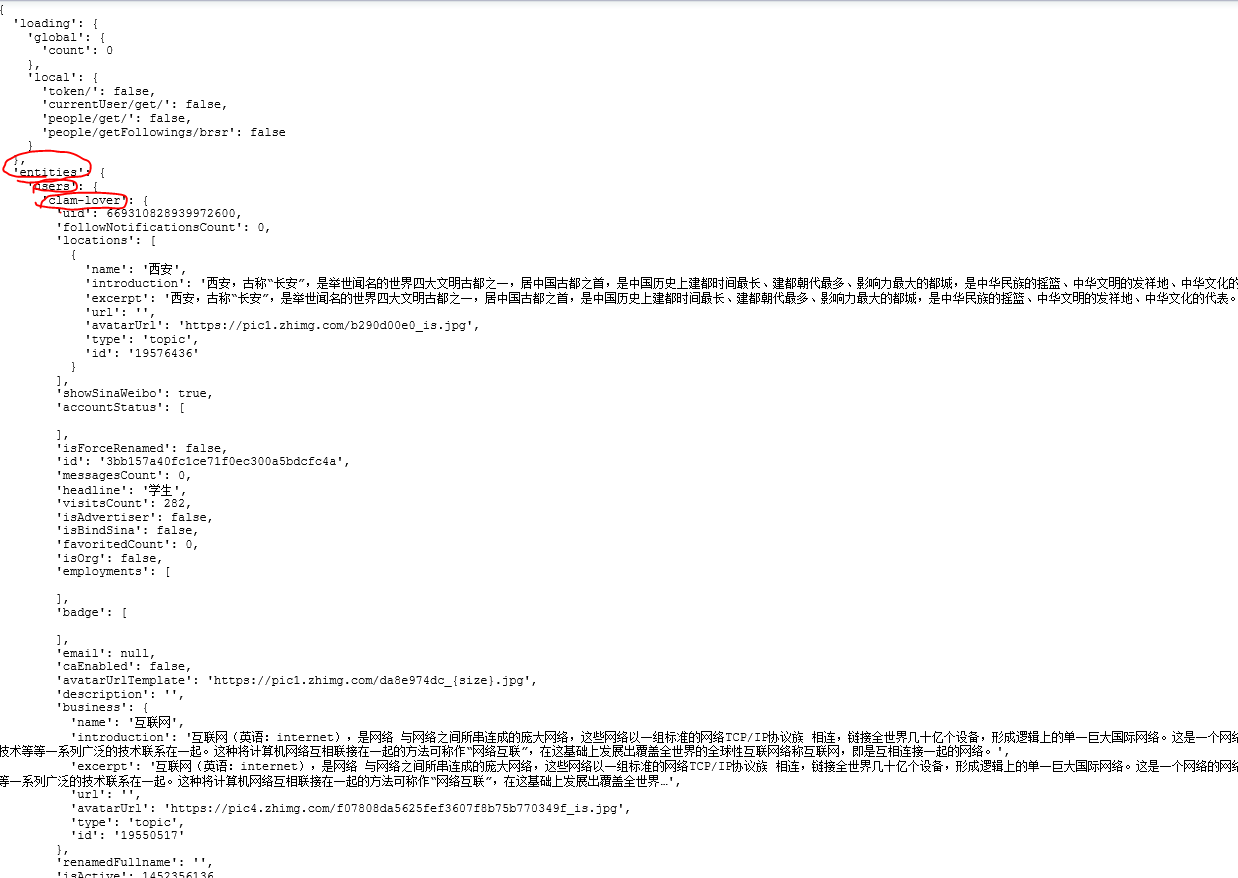
二.信息隐藏在哪里?
通过解析这个json数据,可以找到用户信息
根据URL下载Html页面,解析json获取用户信息
三.如何获取更多用户ID
每个人都有自己的关注列表,关注的人和被关注的人,抓住这些人,然后去这些人的主页抓取关注列表,这样你就找不到用户了。
还有nexturl,这个链接可以保存。如果isend为真,则列表翻到最后,不需要保存url
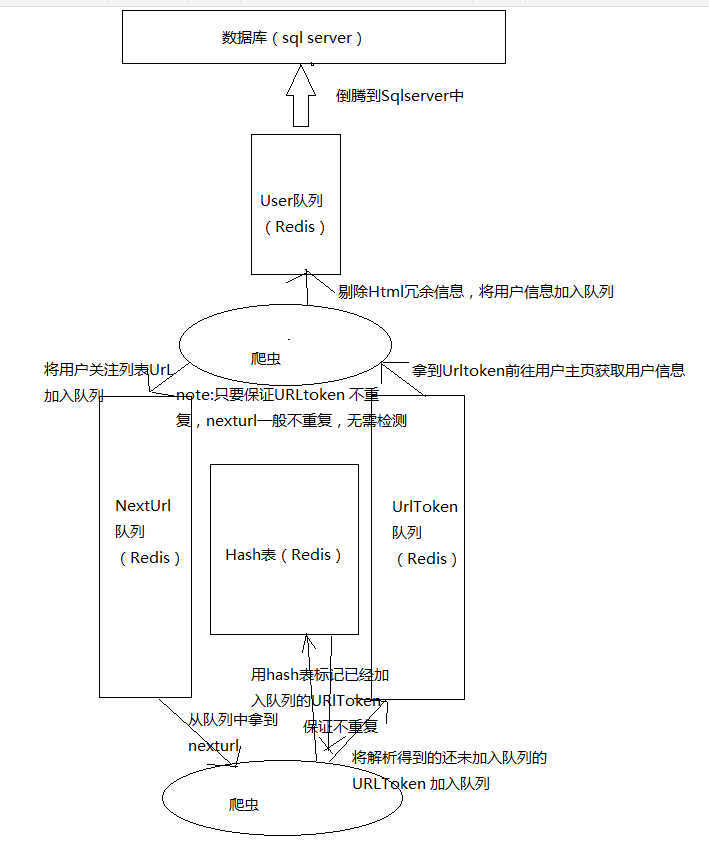
二.爬虫工作流程
有两个爬虫模块。一个爬虫负责从 nexturl 队列中获取 url,下载 json 并解析它。将获取的 nexturl 插入到哈希表中。如果插入成功,则将其添加到队列中。
另一个负责从urltoken队列中获取urltoken,下载解析页面,将用户信息存入数据库,将nexturl存入nexturl队列
三.常见问题解决思路
重复爬取问题
解析出来的Urltoken肯定有很多重复。我很高兴获得了很多数据,但发现它们都是重复的,这是不可接受的。解决方法是将已经加入队列的urltoken放入哈希表中进行标记
从断点爬升
爬取数百万用户是一个相对较大的工作量。不能保证一次爬取完成。中间数据仍然需要持久化。此处选择 Redis 数据库。对于爬取任务,加入队列。如果程序中途停止,重新启动它只需要再次获取队列中的任务并继续爬升
反爬虫问题
爬取过于频繁,服务器返回 429. 这时候需要切换代理IP。我自己搭建了代理IP池(),购买了服务商提供的代理服务。
例如,阿布云:
多台机器一起爬行
任务比较大。在实验室电脑的帮助下,一共有10台电脑,5台电脑安装了Redis,3台作为哈希表,2台作为队列,具有很好的扩展性。 查看全部
爬虫抓取网页数据(
如何获取到用户的信息前往用户主页,以轮子哥为例从中)

点我去Github查看源码别忘了star
本项目的github地址:
一.如何获取用户信息
进入用户主页,以Brother Wheel为例

从中可以看到用户的详细信息、教育经历主页、专业。行业、公司、关注量、回复数、居住地等。打开开发者工具栏查看网络,可以找到,通常html或json的数据在Html页面中。
网址是,excited-vczh是轮哥的id,只要拿到某个人的id就可以得到详细信息。
二.信息隐藏在哪里?

通过解析这个json数据,可以找到用户信息
根据URL下载Html页面,解析json获取用户信息
三.如何获取更多用户ID

每个人都有自己的关注列表,关注的人和被关注的人,抓住这些人,然后去这些人的主页抓取关注列表,这样你就找不到用户了。

还有nexturl,这个链接可以保存。如果isend为真,则列表翻到最后,不需要保存url
二.爬虫工作流程
有两个爬虫模块。一个爬虫负责从 nexturl 队列中获取 url,下载 json 并解析它。将获取的 nexturl 插入到哈希表中。如果插入成功,则将其添加到队列中。
另一个负责从urltoken队列中获取urltoken,下载解析页面,将用户信息存入数据库,将nexturl存入nexturl队列
三.常见问题解决思路
重复爬取问题
解析出来的Urltoken肯定有很多重复。我很高兴获得了很多数据,但发现它们都是重复的,这是不可接受的。解决方法是将已经加入队列的urltoken放入哈希表中进行标记
从断点爬升
爬取数百万用户是一个相对较大的工作量。不能保证一次爬取完成。中间数据仍然需要持久化。此处选择 Redis 数据库。对于爬取任务,加入队列。如果程序中途停止,重新启动它只需要再次获取队列中的任务并继续爬升
反爬虫问题
爬取过于频繁,服务器返回 429. 这时候需要切换代理IP。我自己搭建了代理IP池(),购买了服务商提供的代理服务。
例如,阿布云:
多台机器一起爬行
任务比较大。在实验室电脑的帮助下,一共有10台电脑,5台电脑安装了Redis,3台作为哈希表,2台作为队列,具有很好的扩展性。
爬虫抓取网页数据(get请求返回静态附代码如下最后看看获取的文章写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-01 10:02
如果使用了对方网站的数据,但是没有响应式界面,或者界面不够灵活,则适合使用爬虫。爬虫有几种类型,其他的网站展示形式都是基于分析的。每个 网站 显示都有相同点和不同点。大部分都可以使用httpRequest来完成,不管是加了密码、随机码、请求参数、提交方式get还是post、地址来源、多重响应等。但是有些网站如果返回json或者固定格式使用ajax,如果很复杂可以用webbrower控件抓取,最后定期解析得到需要的数据。那么我们来抓取网站列表文章标题、文章摘要、文章发布时间、文章作者、文章评论次数、文章查看次数。看结构图。
get请求返回静态html,代码如下
public class HttpCnblogs
{
public static List HttpGetHtml()
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("http://www.cnblogs.com/");
request.Method = "GET";
request.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request.UserAgent = " Mozilla/5.0 (Windows NT 6.1; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string articleContent = sr.ReadToEnd();
List list = new List();
#region 正则表达式
//div post_item_body列表
Regex regBody = new Regex(@"([\s\S].*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//a标签 文章标题 作者名字 评论 阅读
Regex regA = new Regex("]*?>(.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//p标签 文章内容
Regex regP = new Regex(@"(.*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取评论 阅读次数如:评论(10)-》10
Regex regNumbernew = new Regex(@"\d+", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取时间
Regex regTime = new Regex(@"\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
#endregion
MatchCollection mList = regBody.Matches(articleContent);
CnblogsModel model = null;
String strBody = String.Empty;
for (int i = 0; i < mList.Count; i++)
{
model = new CnblogsModel();
strBody = mList[i].Groups[1].ToString();
MatchCollection aList = regA.Matches(strBody);
int aCount = aList.Count;
model.ArticleTitle = aList[0].Groups[1].ToString();
model.ArticleAutor = aCount == 5 ? aList[2].Groups[1].ToString() : aList[1].Groups[1].ToString();
model.ArticleComment = Convert.ToInt32(regNumbernew.Match(aList[aCount-2].Groups[1].ToString()).Value);
model.ArticleTime = regTime.Match(strBody).Value;
model.ArticleView = Convert.ToInt32(regNumbernew.Match(aList[aCount-1].Groups[1].ToString()).Value);
model.ArticleContent = regP.Matches(strBody)[0].Groups[1].ToString();
list.Add(model);
}
return list;
}
}
public class CnblogsModel
{
///
/// 文章标题
///
public String ArticleTitle { get; set; }
///
/// 文章内容摘要
///
public String ArticleContent { get; set; }
///
/// 文章作者
///
public String ArticleAutor { get; set; }
///
/// 文章发布时间
///
public String ArticleTime { get; set; }
///
/// 文章评论量
///
public Int32 ArticleComment { get; set; }
///
/// 文章浏览量
///
public Int32 ArticleView { get; set; }
}
</p>
最后看一下获取的文章model
我很抱歉写得不好,但我已经为下一次采访做好了准备。 . 查看全部
爬虫抓取网页数据(get请求返回静态附代码如下最后看看获取的文章写)
如果使用了对方网站的数据,但是没有响应式界面,或者界面不够灵活,则适合使用爬虫。爬虫有几种类型,其他的网站展示形式都是基于分析的。每个 网站 显示都有相同点和不同点。大部分都可以使用httpRequest来完成,不管是加了密码、随机码、请求参数、提交方式get还是post、地址来源、多重响应等。但是有些网站如果返回json或者固定格式使用ajax,如果很复杂可以用webbrower控件抓取,最后定期解析得到需要的数据。那么我们来抓取网站列表文章标题、文章摘要、文章发布时间、文章作者、文章评论次数、文章查看次数。看结构图。

get请求返回静态html,代码如下
public class HttpCnblogs
{
public static List HttpGetHtml()
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("http://www.cnblogs.com/";);
request.Method = "GET";
request.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request.UserAgent = " Mozilla/5.0 (Windows NT 6.1; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string articleContent = sr.ReadToEnd();
List list = new List();
#region 正则表达式
//div post_item_body列表
Regex regBody = new Regex(@"([\s\S].*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//a标签 文章标题 作者名字 评论 阅读
Regex regA = new Regex("]*?>(.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//p标签 文章内容
Regex regP = new Regex(@"(.*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取评论 阅读次数如:评论(10)-》10
Regex regNumbernew = new Regex(@"\d+", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取时间
Regex regTime = new Regex(@"\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
#endregion
MatchCollection mList = regBody.Matches(articleContent);
CnblogsModel model = null;
String strBody = String.Empty;
for (int i = 0; i < mList.Count; i++)
{
model = new CnblogsModel();
strBody = mList[i].Groups[1].ToString();
MatchCollection aList = regA.Matches(strBody);
int aCount = aList.Count;
model.ArticleTitle = aList[0].Groups[1].ToString();
model.ArticleAutor = aCount == 5 ? aList[2].Groups[1].ToString() : aList[1].Groups[1].ToString();
model.ArticleComment = Convert.ToInt32(regNumbernew.Match(aList[aCount-2].Groups[1].ToString()).Value);
model.ArticleTime = regTime.Match(strBody).Value;
model.ArticleView = Convert.ToInt32(regNumbernew.Match(aList[aCount-1].Groups[1].ToString()).Value);
model.ArticleContent = regP.Matches(strBody)[0].Groups[1].ToString();
list.Add(model);
}
return list;
}
}
public class CnblogsModel
{
///
/// 文章标题
///
public String ArticleTitle { get; set; }
///
/// 文章内容摘要
///
public String ArticleContent { get; set; }
///
/// 文章作者
///
public String ArticleAutor { get; set; }
///
/// 文章发布时间
///
public String ArticleTime { get; set; }
///
/// 文章评论量
///
public Int32 ArticleComment { get; set; }
///
/// 文章浏览量
///
public Int32 ArticleView { get; set; }
}
</p>
最后看一下获取的文章model

我很抱歉写得不好,但我已经为下一次采访做好了准备。 .
爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2022-04-01 09:33
接上一篇:stata爬虫爬取网页数据详解part 1
本文的do-file及相关文件链接:密码:40uq
如果链接失效,请私信,看到后我会回复,谢谢。
我们开始抓取1000个网页的源代码,将temp1.txt—temp1000.txt保存在e盘2文件夹中,再次使用“Merge.bat”将1000个txt合并为一个文件all.txt,先把命令放在这里,一一解释:
注意:第一行的本地命令必须用以下两个循环运行,否则会提示错误,原因会在下面解释。
抓取1000个网页源代码并合并
使用local命令生成一个临时变量N = _N(注意:在stata中,_n和_N都是默认变量,有固定的含义。_N代表观察次数,当然等于1000,_n代表从1到1000,要理解这两个,可以用gen N = _N,和gen n = _n,然后浏览看看N和n有什么不同),但是本地命令生成的变量N不会显示在变量窗口,而是临时存放在stata的内存中,需要的时候可以调用。下面是一个小例子来演示local的作用(需要注意的是local命令行和下一行调用local生成的变量的命令必须一起运行,否则会提示错误,因为本地宏命令生成的变量只是临时的,一旦遇到end of do-file【观察stata主界面,每条命令运行后都会提示end of do-file】,生成的临时变量会是已删除,无法再次调用。详见下图官方英文。解释,以蓝色突出显示,尤其是最后一句):
演示本地命令,比较_n和_N的区别
关于marco宏的进一步解释,有兴趣的可以参考官方帮助文件中的相关说明,如下:
marco宏的官方解释
了解了local之后,再看接下来的两个循环就容易多了。第二个循环是把url变量映射到purl变量上(purl变量就是前面1000个链接)并存储起来,但是变量窗口中没有显示出来,第三个循环是调用存储在里面的1000个url url变量,把这1000个网页的源代码复制下来,存放在e盘的2文件夹中,命名为temp1.txt —temp1000.txt,这个过程取决于网页的速度网络,大约需要30分钟,数字变化如下图,最后temp1000.txt完成。之所以会提示not found,是因为我们在grab命令后面加上了replace选项,就是告诉stata如果在e盘2文件夹中找到同名文件就替换掉,但是stata发现没有同名的文件,所以会提示找不到,并按要求生成新文件。如果stata找到同名文件,则不会有这个提示,而是直接替换掉。
爬取1000个网页源码流程
等了好久,终于用我们在part 1中使用的bat批处理命令调用dos将1000个txt合并到all.txt中(这次是在文件夹2中处理,和之前的all.txt不同) . 到目前为止,已经获得了1000个网页的源代码。这1000个网页的源代码非常重要,因为我们需要的GDP信息都收录在其中。同理,我们使用中缀命令将其读入stata进行处理。该命令如文章开头的图中所示。因为文本比较大,所以最好在阅读文本之前先清除,否则可能会导致stata崩溃,长时间写dofile。不保存就不好了(具体原因不明,推测可能是内存不够?。?)。
文本读入后变成变量v,然后开始过滤净化,这也是最复杂的工作,因为总共735748行代码只需要提取两条信息,一条一个是“某个地区的几年”,一个是“GDP”。根据我们需要的信息,寻找收录这两条信息的关键行,观察它们所在行的共同特征。通过观察,我们可以看到,地区名称所在的行都收录这样的字符,而GDP或生产总值所在的行收录“生产总值”等字符(如下图所示),所以我们只需要保留收录这两个字符的代码行。
观察代码行特征,发现规律
第一步:设置两个指标变量(以虚拟变量的形式)a和b。对于a变量,如果v变量(即所有代码行所在的变量)收录,让stata返回值1,表示“是收录”,否则返回0,表示“不收录”收录”。类似地,b 变量是以“总产量”为指标生成的。然后,保持 if a==1 | b==1 表示保留收录或收录“总产量”的行。这一步很快将代码行数过滤到只有 4570 行。
生成两个指标变量
第2步-第N步:都是砍、守、砍、守、砍、守……因为仁者见仁,智者见智,我的不一定是最好的,但道理是一样的。所以只对用到的部分命令和函数进行说明,见do-file中的相关注释【strpos,duplicates drop】。
剪切和替换
继续切割,更换,保持
最终数据
可以看到,有些数据前面有一些乱七八糟的字符。这是因为每个公告的书写格式不统一。它需要继续处理。方法同上,拆分、替换、保留。我不会在这里继续演示。有兴趣可以继续。
随便找一些数据在网站上查看,看看对应的数据是否准确。比如我从上图左右两边随机选取了2015年的合肥市和2013年的九江市进行验证,查询结果如下,经核对无误:
查询验证结果
最后,对于空缺的部分,你可以去网站找数据补上。另外,这次我应得的1000行数据,但最终得到了1015行数据。原因可能是公报的格式不完全统一,有的数据是省级GDP(少),有的是市级GDP。,因此是重复部分。此类错误必须由研究人员自己处理。
好了,到此详细讲解就结束了,撒花!(0.0)
最后提示:stata 12、13 白色主界面默认不支持中文,中文显示为乱码。可以在主界面任意位置右击—>Preferences,然后将配色模式从Standard改为Classic Mode就可以正常显示中文了。
标准—>经典 查看全部
爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
接上一篇:stata爬虫爬取网页数据详解part 1
本文的do-file及相关文件链接:密码:40uq
如果链接失效,请私信,看到后我会回复,谢谢。
我们开始抓取1000个网页的源代码,将temp1.txt—temp1000.txt保存在e盘2文件夹中,再次使用“Merge.bat”将1000个txt合并为一个文件all.txt,先把命令放在这里,一一解释:
注意:第一行的本地命令必须用以下两个循环运行,否则会提示错误,原因会在下面解释。

抓取1000个网页源代码并合并
使用local命令生成一个临时变量N = _N(注意:在stata中,_n和_N都是默认变量,有固定的含义。_N代表观察次数,当然等于1000,_n代表从1到1000,要理解这两个,可以用gen N = _N,和gen n = _n,然后浏览看看N和n有什么不同),但是本地命令生成的变量N不会显示在变量窗口,而是临时存放在stata的内存中,需要的时候可以调用。下面是一个小例子来演示local的作用(需要注意的是local命令行和下一行调用local生成的变量的命令必须一起运行,否则会提示错误,因为本地宏命令生成的变量只是临时的,一旦遇到end of do-file【观察stata主界面,每条命令运行后都会提示end of do-file】,生成的临时变量会是已删除,无法再次调用。详见下图官方英文。解释,以蓝色突出显示,尤其是最后一句):

演示本地命令,比较_n和_N的区别
关于marco宏的进一步解释,有兴趣的可以参考官方帮助文件中的相关说明,如下:

marco宏的官方解释
了解了local之后,再看接下来的两个循环就容易多了。第二个循环是把url变量映射到purl变量上(purl变量就是前面1000个链接)并存储起来,但是变量窗口中没有显示出来,第三个循环是调用存储在里面的1000个url url变量,把这1000个网页的源代码复制下来,存放在e盘的2文件夹中,命名为temp1.txt —temp1000.txt,这个过程取决于网页的速度网络,大约需要30分钟,数字变化如下图,最后temp1000.txt完成。之所以会提示not found,是因为我们在grab命令后面加上了replace选项,就是告诉stata如果在e盘2文件夹中找到同名文件就替换掉,但是stata发现没有同名的文件,所以会提示找不到,并按要求生成新文件。如果stata找到同名文件,则不会有这个提示,而是直接替换掉。

爬取1000个网页源码流程
等了好久,终于用我们在part 1中使用的bat批处理命令调用dos将1000个txt合并到all.txt中(这次是在文件夹2中处理,和之前的all.txt不同) . 到目前为止,已经获得了1000个网页的源代码。这1000个网页的源代码非常重要,因为我们需要的GDP信息都收录在其中。同理,我们使用中缀命令将其读入stata进行处理。该命令如文章开头的图中所示。因为文本比较大,所以最好在阅读文本之前先清除,否则可能会导致stata崩溃,长时间写dofile。不保存就不好了(具体原因不明,推测可能是内存不够?。?)。
文本读入后变成变量v,然后开始过滤净化,这也是最复杂的工作,因为总共735748行代码只需要提取两条信息,一条一个是“某个地区的几年”,一个是“GDP”。根据我们需要的信息,寻找收录这两条信息的关键行,观察它们所在行的共同特征。通过观察,我们可以看到,地区名称所在的行都收录这样的字符,而GDP或生产总值所在的行收录“生产总值”等字符(如下图所示),所以我们只需要保留收录这两个字符的代码行。

观察代码行特征,发现规律
第一步:设置两个指标变量(以虚拟变量的形式)a和b。对于a变量,如果v变量(即所有代码行所在的变量)收录,让stata返回值1,表示“是收录”,否则返回0,表示“不收录”收录”。类似地,b 变量是以“总产量”为指标生成的。然后,保持 if a==1 | b==1 表示保留收录或收录“总产量”的行。这一步很快将代码行数过滤到只有 4570 行。

生成两个指标变量
第2步-第N步:都是砍、守、砍、守、砍、守……因为仁者见仁,智者见智,我的不一定是最好的,但道理是一样的。所以只对用到的部分命令和函数进行说明,见do-file中的相关注释【strpos,duplicates drop】。

剪切和替换

继续切割,更换,保持

最终数据
可以看到,有些数据前面有一些乱七八糟的字符。这是因为每个公告的书写格式不统一。它需要继续处理。方法同上,拆分、替换、保留。我不会在这里继续演示。有兴趣可以继续。
随便找一些数据在网站上查看,看看对应的数据是否准确。比如我从上图左右两边随机选取了2015年的合肥市和2013年的九江市进行验证,查询结果如下,经核对无误:

查询验证结果
最后,对于空缺的部分,你可以去网站找数据补上。另外,这次我应得的1000行数据,但最终得到了1015行数据。原因可能是公报的格式不完全统一,有的数据是省级GDP(少),有的是市级GDP。,因此是重复部分。此类错误必须由研究人员自己处理。
好了,到此详细讲解就结束了,撒花!(0.0)
最后提示:stata 12、13 白色主界面默认不支持中文,中文显示为乱码。可以在主界面任意位置右击—>Preferences,然后将配色模式从Standard改为Classic Mode就可以正常显示中文了。

标准—>经典
爬虫抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-28 18:11
Scraping 程序只处理一种类型的请求:一个名为 / 的资源的 GET,它是 Stats::Controller 包中的屏幕抓取和数据处理代码。供您查看的是源文件 scrape.pl 顶部的 Plack/PSGI 路由设置:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 仅具有高级逻辑,将屏幕抓取和生成报告的详细信息留在 Util.pm 文件中的实用程序函数中,如下一节所述。
屏幕抓取代码
回想一下,Plack 服务器将 GET 请求分派到 localhost:5000/ 到抓取程序的 get_index 函数。然后,此函数充当请求处理程序并执行以下操作:检索要抓取的数据、抓取数据并生成最终报告。数据检索部分是一个实用功能,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器获取数据。使用数据文档,抓取程序将调用实用函数 extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 XML::LibXML 等 Perl 包通过显式 XML 解析来提取数据。但是,HTML::TableExtract 包生成了 HTML::TableExtract,因为它的 HTML::TableExtract 绕过了 XML 解析,并且(使用很少的代码)提供了用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 包 HTML ::TableExtract 表格是目标。以下是数据提取的三个关键代码行:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
调用 TableExtract::parse 函数后,抓取程序将使用 TableExtract::rows 函数迭代提取的数据行(没有 HTML 标记的数据行)。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 散列中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据,在本例中使用 Statistics::Descriptive 包进行基本统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
抓取程序的最后一步是生成报告。Perl 有生成 HTML 的选项,其中有 Template::Recall。顾名思义,此包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标记和自定义标记,用作后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码和模板交互的方式。
报表文档(图1)有两个表。顶层表是迭代生成的,因为每一行都有相同的列(学习区、第25个百分位收入等)。在每次迭代中,代码都会创建一个hash具有特定学习域的值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
散列键是 Perl 的裸词,例如 major 和工资表示之前从 HTML 数据文档中提取的数据值的列表项。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部标签分别标记要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为major 的模板列将匹配以major 作为键的散列条目。以下是将数据绑定到自定义标签的后端代码中的调用:
print OUTFILE $tr -> render ( 'end1' ) ;
引用 $tr 指向 Template::Recall 实例,OUTFILE 是报告文件reportFinal.html,由模板文件report.html 与后端代码一起生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的内容(参见 1))。
抓取工具借鉴了优秀的 Perl 包,例如 Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall 和 Statistics::Descriptive,用于屏幕抓取的 HTML::TableExtract 任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展 Scraping 程序以对提取的数据进行聚类:Algorithm::KMeans 包适合此扩展,并且可以使用 rawData.dat 文件中来自 Algorithm::KMeans 的数据。
翻译自:
vba数据抓取屏幕数据 查看全部
爬虫抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
Scraping 程序只处理一种类型的请求:一个名为 / 的资源的 GET,它是 Stats::Controller 包中的屏幕抓取和数据处理代码。供您查看的是源文件 scrape.pl 顶部的 Plack/PSGI 路由设置:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 仅具有高级逻辑,将屏幕抓取和生成报告的详细信息留在 Util.pm 文件中的实用程序函数中,如下一节所述。
屏幕抓取代码
回想一下,Plack 服务器将 GET 请求分派到 localhost:5000/ 到抓取程序的 get_index 函数。然后,此函数充当请求处理程序并执行以下操作:检索要抓取的数据、抓取数据并生成最终报告。数据检索部分是一个实用功能,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器获取数据。使用数据文档,抓取程序将调用实用函数 extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 XML::LibXML 等 Perl 包通过显式 XML 解析来提取数据。但是,HTML::TableExtract 包生成了 HTML::TableExtract,因为它的 HTML::TableExtract 绕过了 XML 解析,并且(使用很少的代码)提供了用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 包 HTML ::TableExtract 表格是目标。以下是数据提取的三个关键代码行:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
调用 TableExtract::parse 函数后,抓取程序将使用 TableExtract::rows 函数迭代提取的数据行(没有 HTML 标记的数据行)。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 散列中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据,在本例中使用 Statistics::Descriptive 包进行基本统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
抓取程序的最后一步是生成报告。Perl 有生成 HTML 的选项,其中有 Template::Recall。顾名思义,此包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标记和自定义标记,用作后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码和模板交互的方式。
报表文档(图1)有两个表。顶层表是迭代生成的,因为每一行都有相同的列(学习区、第25个百分位收入等)。在每次迭代中,代码都会创建一个hash具有特定学习域的值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
散列键是 Perl 的裸词,例如 major 和工资表示之前从 HTML 数据文档中提取的数据值的列表项。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部标签分别标记要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为major 的模板列将匹配以major 作为键的散列条目。以下是将数据绑定到自定义标签的后端代码中的调用:
print OUTFILE $tr -> render ( 'end1' ) ;
引用 $tr 指向 Template::Recall 实例,OUTFILE 是报告文件reportFinal.html,由模板文件report.html 与后端代码一起生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的内容(参见 1))。
抓取工具借鉴了优秀的 Perl 包,例如 Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall 和 Statistics::Descriptive,用于屏幕抓取的 HTML::TableExtract 任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展 Scraping 程序以对提取的数据进行聚类:Algorithm::KMeans 包适合此扩展,并且可以使用 rawData.dat 文件中来自 Algorithm::KMeans 的数据。
翻译自:
vba数据抓取屏幕数据
爬虫抓取网页数据(什么是两个最流行的网页抓取框架?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-28 03:19
由于两个最流行的浏览器现在提供无头选项,因此有很多选择。无头模式适用于 Chrome 和 Firefox(68.60% 和 8.17% 的浏览器市场份额)。在主流选项之外,PhantomJS 和 Zombie.JS 是网络爬虫中的流行选择。此外,无头浏览器需要自动化工具来运行网络抓取脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据解析是使先前获取的数据易于理解和使用的过程。大多数数据采集方法采集难以理解的数据。因此,解析和翻译成可理解的结果尤为重要。
如前所述,由于易于访问和优化的库,Python 是一种流行的定价情报获取语言。BeautifulSoup、LXML 等是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,可以让这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更容易导航大量数据。
数据存储
数据存储过程通常取决于容量和类型。虽然建议为定价情报(和其他连续项目)构建一个专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中并没有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,但应始终牢记一件事——数据的清洁度。从错误索引的数据库中检索存储的数据可能会变得很麻烦。找到正确的方向并从一开始就遵循相同的方案可以在大多数数据存储问题开始之前解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是很容易的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本、查找合适的库并将获取的数据导出为 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
如今,大多数网页都可以检测到类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全一样,因为它们通过访问 URL 列表不断地执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于保持对相同 URL 的持续访问并绕过 IP 阻止,使它们成为任何 data采集 项目的关键组件。使用这种数据采集技术创建针对特定目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许其用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要以模仿此类活动的方式编写数据采集脚本,它们就被视为普通互联网用户。
代理是任何网络抓取想法的关键组成部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎的反爬措施复杂,需要使用不同的爬取策略。
代理的艰辛
如前所述,轮换代理是任何成功的数据采集方法的关键,包括网络抓取。如果您想避免 IP 阻塞,保持您作为普通互联网用户的形象至关重要。
但是,您需要多久更换一次代理、应该使用哪种类型的代理等具体细节在很大程度上取决于抓取目标、数据提取频率和其他因素。这些复杂性使代理管理成为网络抓取中最难的部分。
虽然每个业务案例都是独一无二的并且需要特定的解决方案,但为了以最高效率使用代理,必须遵循指南。在数据采集行业有经验的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商已经制定了避免 IP 地址阻塞的指南。
如前所述,维护普通互联网用户的形象是避免 IP 阻塞的重要部分。虽然有许多不同的代理类型,但没有人比住宅代理更擅长这一特定任务。住宅代理是连接到真实机器并由互联网服务提供商分配的 IP。从正确的方向开始,为电子商务数据采集选择住宅代理会使整个过程变得更加容易。
电子商务住宅代理
住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电子商务数据采集,因为大部分数据 采集 需要维护特定身份。电子商务企业通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他企业积极阻止或向他们认为是竞争对手(或爬虫)的访问者显示不准确的信息。因此,切换 IP 和位置(例如从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。随着网站实施更复杂的反爬虫算法和轻松检测类似爬虫的活动,这些代理允许网络爬虫重置任何采集到的关于其行为的怀疑网站。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标对于它认为类似于爬虫的活动都有略微不同的参数。因此,策略也需要相应调整。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,越高级、越大、越重要的电子商务网站,越难通过网络抓取来解决。反复试验通常是创建有效网络抓取策略的唯一方法。
总结
想要构建您的第一个网络爬虫?注册并开始使用 Oxylabs 的住宅代理!想要更多细节或定制计划?可与我们的销售团队一起使用!您需要的所有互联网数据只需单击一下即可! 查看全部
爬虫抓取网页数据(什么是两个最流行的网页抓取框架?-八维教育)
由于两个最流行的浏览器现在提供无头选项,因此有很多选择。无头模式适用于 Chrome 和 Firefox(68.60% 和 8.17% 的浏览器市场份额)。在主流选项之外,PhantomJS 和 Zombie.JS 是网络爬虫中的流行选择。此外,无头浏览器需要自动化工具来运行网络抓取脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据解析是使先前获取的数据易于理解和使用的过程。大多数数据采集方法采集难以理解的数据。因此,解析和翻译成可理解的结果尤为重要。
如前所述,由于易于访问和优化的库,Python 是一种流行的定价情报获取语言。BeautifulSoup、LXML 等是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,可以让这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更容易导航大量数据。
数据存储
数据存储过程通常取决于容量和类型。虽然建议为定价情报(和其他连续项目)构建一个专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中并没有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,但应始终牢记一件事——数据的清洁度。从错误索引的数据库中检索存储的数据可能会变得很麻烦。找到正确的方向并从一开始就遵循相同的方案可以在大多数数据存储问题开始之前解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是很容易的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本、查找合适的库并将获取的数据导出为 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
如今,大多数网页都可以检测到类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全一样,因为它们通过访问 URL 列表不断地执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于保持对相同 URL 的持续访问并绕过 IP 阻止,使它们成为任何 data采集 项目的关键组件。使用这种数据采集技术创建针对特定目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许其用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要以模仿此类活动的方式编写数据采集脚本,它们就被视为普通互联网用户。

代理是任何网络抓取想法的关键组成部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎的反爬措施复杂,需要使用不同的爬取策略。
代理的艰辛
如前所述,轮换代理是任何成功的数据采集方法的关键,包括网络抓取。如果您想避免 IP 阻塞,保持您作为普通互联网用户的形象至关重要。
但是,您需要多久更换一次代理、应该使用哪种类型的代理等具体细节在很大程度上取决于抓取目标、数据提取频率和其他因素。这些复杂性使代理管理成为网络抓取中最难的部分。
虽然每个业务案例都是独一无二的并且需要特定的解决方案,但为了以最高效率使用代理,必须遵循指南。在数据采集行业有经验的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商已经制定了避免 IP 地址阻塞的指南。
如前所述,维护普通互联网用户的形象是避免 IP 阻塞的重要部分。虽然有许多不同的代理类型,但没有人比住宅代理更擅长这一特定任务。住宅代理是连接到真实机器并由互联网服务提供商分配的 IP。从正确的方向开始,为电子商务数据采集选择住宅代理会使整个过程变得更加容易。
电子商务住宅代理

住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电子商务数据采集,因为大部分数据 采集 需要维护特定身份。电子商务企业通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他企业积极阻止或向他们认为是竞争对手(或爬虫)的访问者显示不准确的信息。因此,切换 IP 和位置(例如从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。随着网站实施更复杂的反爬虫算法和轻松检测类似爬虫的活动,这些代理允许网络爬虫重置任何采集到的关于其行为的怀疑网站。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标对于它认为类似于爬虫的活动都有略微不同的参数。因此,策略也需要相应调整。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,越高级、越大、越重要的电子商务网站,越难通过网络抓取来解决。反复试验通常是创建有效网络抓取策略的唯一方法。
总结
想要构建您的第一个网络爬虫?注册并开始使用 Oxylabs 的住宅代理!想要更多细节或定制计划?可与我们的销售团队一起使用!您需要的所有互联网数据只需单击一下即可!
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-28 03:17
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个改进版本,试图支持这些可能性。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次提取中非常有用,除了避免解析整个网页的开销之外,如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,一般来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些特定场景下才有用。 查看全部
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个改进版本,试图支持这些可能性。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:

由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次提取中非常有用,除了避免解析整个网页的开销之外,如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,一般来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些特定场景下才有用。
爬虫抓取网页数据(先来说下数据抓取系统的大致工作流程.下背景 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-27 18:05
)
公司的数据采集系统也写了一段时间了,该总结一下了,不然凭我的记忆力,一会就快忘记了。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,让我们谈谈数据捕获的一般工作流程。
先说一下背景,这家公司是做企业征信服务的。整合各个方面的数据以生成商业信用报告。主要数据来源,包括:第三方采购(整体采购数据或接口形式);捕获在 Internet 上发布的数据。那么就需要一个数据采集平台,以便为采集方便快捷的添加新的数据对象。对于数据采集平台的架构设计,本人也是新手,以后在学习的同时总结这方面的经验和教训。本系列从实战开始,然后是第一个子弹:数据采集的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人认为这三个步骤是我做的。不过,先听我说。##清除数据采集先分享场景的要求:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张加班后还没有完成任务。是因为产品经理没有把需求解释清楚吗?但产品经理也表示,这个页面上的所有内容都是必需的。问题是:
要分析数据为采集的url和相关参数,我先走一下我抓取数据的流程,看下面四张图:
提取url和参数
从以上四张图我们可以确认有以下几个连接需要处理:- 1、获取验证码连接- 2、提交查询- 3、查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用chrome的开发者工具来分析页面。有很多类似的工具。各个浏览器自带的开发者工具基本可以满足需求。也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们提取了企业的基本注册信息为采集,我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。这个文章就不详细介绍代码实现的具体逻辑了,因为本文的重点是讲解:爬取网页的工作流程。后面代码实现过程中用到的关键技术点和踩过的坑都会一一总结。暂列涉及的相关内容:
也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天做个小笔记,每天进步一点:
善待大众:enilu123
查看全部
爬虫抓取网页数据(先来说下数据抓取系统的大致工作流程.下背景
)
公司的数据采集系统也写了一段时间了,该总结一下了,不然凭我的记忆力,一会就快忘记了。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,让我们谈谈数据捕获的一般工作流程。
先说一下背景,这家公司是做企业征信服务的。整合各个方面的数据以生成商业信用报告。主要数据来源,包括:第三方采购(整体采购数据或接口形式);捕获在 Internet 上发布的数据。那么就需要一个数据采集平台,以便为采集方便快捷的添加新的数据对象。对于数据采集平台的架构设计,本人也是新手,以后在学习的同时总结这方面的经验和教训。本系列从实战开始,然后是第一个子弹:数据采集的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人认为这三个步骤是我做的。不过,先听我说。##清除数据采集先分享场景的要求:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张加班后还没有完成任务。是因为产品经理没有把需求解释清楚吗?但产品经理也表示,这个页面上的所有内容都是必需的。问题是:
要分析数据为采集的url和相关参数,我先走一下我抓取数据的流程,看下面四张图:

提取url和参数
从以上四张图我们可以确认有以下几个连接需要处理:- 1、获取验证码连接- 2、提交查询- 3、查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用chrome的开发者工具来分析页面。有很多类似的工具。各个浏览器自带的开发者工具基本可以满足需求。也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们提取了企业的基本注册信息为采集,我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。这个文章就不详细介绍代码实现的具体逻辑了,因为本文的重点是讲解:爬取网页的工作流程。后面代码实现过程中用到的关键技术点和踩过的坑都会一一总结。暂列涉及的相关内容:
也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天做个小笔记,每天进步一点:
善待大众:enilu123

爬虫抓取网页数据(网络爬虫系统的原理和工作流程介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2022-03-22 02:28
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件和文本可以自动关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。网络爬虫原理 网络爬虫是按照一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页外链接的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫的工作流程如图2所示。网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
图2 网络爬虫基本工作流程
网络爬虫爬取策略 谷歌、百度等通用搜索引擎抓取的网页数量通常以十亿为单位计算。那么,面对如此多的网页,如何让网络爬虫尽可能地遍历所有的网页,从而尽可能地扩大网页信息的覆盖范围,是目前网络爬虫面临的一个非常关键的问题。网络爬虫系统。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。1)网页之间的关系模型 从互联网的结构来看,网页之间通过多个超链接相互连接,形成一个庞大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类从爬虫的角度划分互联网。互联网上的所有页面可以分为5个部分:已下载和未过期的网页、已下载和已过期的网页、待下载的网页、已知网页和未知网页,如图4所示。
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。1. 万能网络爬虫 万能网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。2. 聚焦网络爬虫 聚焦网络爬虫,也称为主题网络爬虫,是指选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过使用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
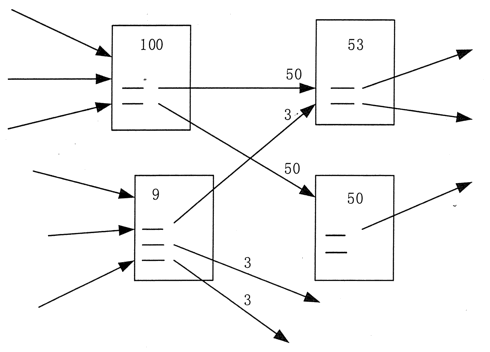
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
将某个页面的PageRank除以该页面上存在的前向链接,将得到的值加到前向链接指向的页面的PageRank上,即得到链接页面的PageRank。
如图 5 所示,PageRank 为 100 的页面将其重要性同等地赋予它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性赋予它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。3. 增量网络爬虫 增量网络爬虫是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。页面尽可能新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。4. 深网爬虫网页根据存在的不同可以分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
爬虫抓取网页数据(网络爬虫系统的原理和工作流程介绍-乐题库)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件和文本可以自动关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。网络爬虫原理 网络爬虫是按照一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
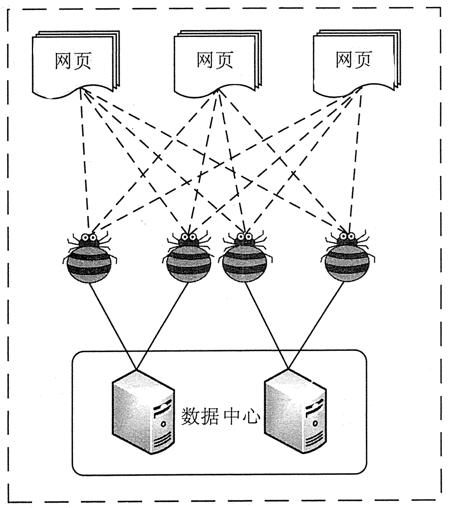
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页外链接的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫的工作流程如图2所示。网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
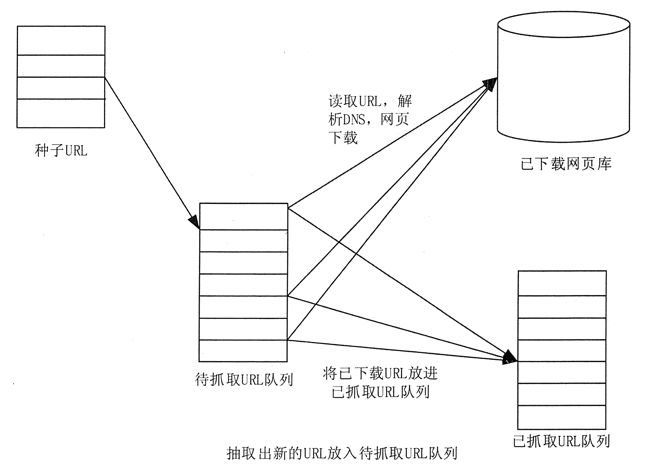
图2 网络爬虫基本工作流程
网络爬虫爬取策略 谷歌、百度等通用搜索引擎抓取的网页数量通常以十亿为单位计算。那么,面对如此多的网页,如何让网络爬虫尽可能地遍历所有的网页,从而尽可能地扩大网页信息的覆盖范围,是目前网络爬虫面临的一个非常关键的问题。网络爬虫系统。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。1)网页之间的关系模型 从互联网的结构来看,网页之间通过多个超链接相互连接,形成一个庞大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类从爬虫的角度划分互联网。互联网上的所有页面可以分为5个部分:已下载和未过期的网页、已下载和已过期的网页、待下载的网页、已知网页和未知网页,如图4所示。
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
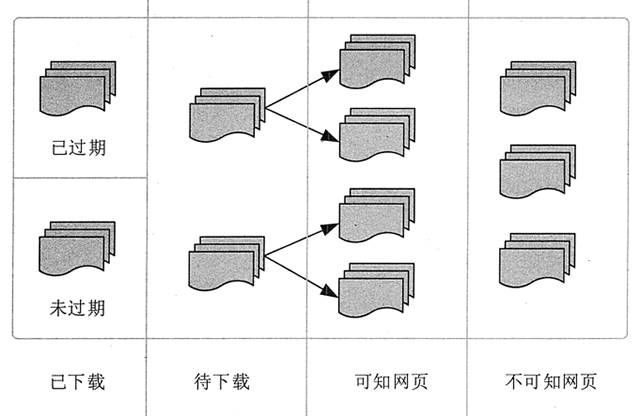
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。1. 万能网络爬虫 万能网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。2. 聚焦网络爬虫 聚焦网络爬虫,也称为主题网络爬虫,是指选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过使用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
将某个页面的PageRank除以该页面上存在的前向链接,将得到的值加到前向链接指向的页面的PageRank上,即得到链接页面的PageRank。
如图 5 所示,PageRank 为 100 的页面将其重要性同等地赋予它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性赋予它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。3. 增量网络爬虫 增量网络爬虫是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。页面尽可能新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。4. 深网爬虫网页根据存在的不同可以分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
爬虫抓取网页数据(网络爬虫爬虫的爬行对象是什么?怎么做??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-21 15:16
网络爬虫
爬虫一般是指网络爬虫,也称为网络蜘蛛、蠕虫等。它是按照一定的规则自动爬取网页内容的程序或脚本。
以下是我每天使用的IP池:
个人电脑
移动
生产
相信大家都在互联网上使用过百度、雅虎、谷歌等搜索引擎搜索信息等。这些辅助人们检索信息的工具是我们访问万维网的入口和指南。随着互联网的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。一个集采集、分析、过滤、决策等功能于一体的程序应运而生——网络爬虫,它是搜索引擎的数据基础。搜索引擎的重要组成部分。
原则
传统的网络爬虫从一个或多个网页的初始url开始,在这些初始url的内容中获取新的url。在抓取网页的过程中,不断地从当前页面中提取新的url,放到url列中。列直到满足预定条件。
一些具有特定策略的爬虫具有更复杂的工作流程,例如专注的爬虫。它们会根据某些网页分析算法过滤掉与主题无关的连接,只将那些与主题相关的连接保留在 URL 队列中。某种搜索策略从队列中选择下一个要爬取的网页url,重复上述过程,直到达到系统的某个条件。
ps:搜索引擎系统存储爬虫爬取的网页,进一步分析,过滤,建立索引,供以后查询和检索。
爬行动物分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。实际的网络爬虫系统通常是几种爬虫技术的组合。实现。
通用网络爬虫
一般网络爬虫的爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
爬虫的结构大致可以分为几个部分:初始url、url队列、页面爬取模块、页面分析模块、连接过滤模块、页面数据库采集。
常用的爬取策略有:深度优先策略、广度优先策略。
聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。
与普通网络爬虫相比,增加了聚焦网络爬虫,连接评价模块和内容评价模块。聚焦爬虫实现爬取策略的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
常用的爬取策略有:基于内容评估的爬取策略、基于连接结构评估的爬取策略、基于强化学习的爬取分类、基于上下文图的爬取策略。
增量网络爬虫
增量网页抓取是指对下载的网页进行增量更新,只抓取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要时爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少下载的数据量和及时性。更新爬取的网页减少了时间和空间的消耗,但这会增加爬取算法和复杂度和实现难度。
增量网络爬虫的架构包括:爬取模块、排序模块、更新模块、本地页面集、待爬取url集和本地页面url集。
深网爬虫
网页按存在方式可分为表层网页和深层网页。Surface Web指的是一些主要构成网页的静态网页,而Deep Web指的是那些动态网页,大部分内容只能通过用户提交一些关键词网页获取。Deep Web的可访问信息容量是Surface Web的数百倍,是互联网上规模最大、增长最快的新型信息资源。
Deep Web爬虫架构包括六个基本功能模块(爬取控制器、解析器、表单分析器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表、LVS表)。其中,LVS(Label Value Set)表示标签/值集,用于表示填充表单的数据源。
Deep Web爬虫爬取过程中最重要的部分是表单填写,包括两种类型:基于领域知识的表单填写和基于网页结构分析的表单填写
爬取目标分类
基于着陆页特征
爬虫基于这个特性爬取、存储和索引的对象一般是网站和网页。网页特征可以是网页的内容特征,也可以是网页的连接结构特征等。
基于目标数据
这类爬虫针对的是网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转换或映射成目标数据
基于领域的概念
建立目标领域的本体或字典,从语义角度分析主题中不同特征的重要性
网络搜索策略
网页的爬取策略可以分为深度优先、广度优先和最佳优先三种。其中,深度优先在很多情况下会给爬虫带来问题。目前,后两种方式最为常见。
广度优先策略
广度优先策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。
为了覆盖尽可能多的页面,通常使用广度优先搜索方法。我们可以将广度优先搜索与网络过滤技术结合起来。缺点是随着抓取网页数量的增加,会下载和过滤大量不相关的网页,使算法效率降低。
最佳第一策略
最佳优先级策略会根据一定的网页分析算法预测候选url与目标网页的相似度,或者与主题的相关性,选择评价最好的一个或几个url进行爬取。它仅在分析后访问网页。算法预测为“有用”的页面。因此,存在爬虫爬取路径中很多相关网页可能被忽略的问题。
深度优先策略
深度优先策略会从起始网页开始,选择一个url进入,分析网页中的url,选择一个进入,然后一个接一个地获取连接,直到处理完一个路由,返回起始入口,选择下一条路线。这个缺点也是致命的,因为过度深入的捕捉往往导致捕捉到的数据价值很低。同时,捕获深度直接影响捕获命中率和捕获效率。与其他两种策略相比,这种策略很少使用。 查看全部
爬虫抓取网页数据(网络爬虫爬虫的爬行对象是什么?怎么做??)
网络爬虫
爬虫一般是指网络爬虫,也称为网络蜘蛛、蠕虫等。它是按照一定的规则自动爬取网页内容的程序或脚本。
以下是我每天使用的IP池:
个人电脑
移动
生产
相信大家都在互联网上使用过百度、雅虎、谷歌等搜索引擎搜索信息等。这些辅助人们检索信息的工具是我们访问万维网的入口和指南。随着互联网的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。一个集采集、分析、过滤、决策等功能于一体的程序应运而生——网络爬虫,它是搜索引擎的数据基础。搜索引擎的重要组成部分。
原则
传统的网络爬虫从一个或多个网页的初始url开始,在这些初始url的内容中获取新的url。在抓取网页的过程中,不断地从当前页面中提取新的url,放到url列中。列直到满足预定条件。
一些具有特定策略的爬虫具有更复杂的工作流程,例如专注的爬虫。它们会根据某些网页分析算法过滤掉与主题无关的连接,只将那些与主题相关的连接保留在 URL 队列中。某种搜索策略从队列中选择下一个要爬取的网页url,重复上述过程,直到达到系统的某个条件。
ps:搜索引擎系统存储爬虫爬取的网页,进一步分析,过滤,建立索引,供以后查询和检索。
爬行动物分类

根据系统结构和实现技术,网络爬虫大致可以分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。实际的网络爬虫系统通常是几种爬虫技术的组合。实现。
通用网络爬虫
一般网络爬虫的爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
爬虫的结构大致可以分为几个部分:初始url、url队列、页面爬取模块、页面分析模块、连接过滤模块、页面数据库采集。
常用的爬取策略有:深度优先策略、广度优先策略。
聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。
与普通网络爬虫相比,增加了聚焦网络爬虫,连接评价模块和内容评价模块。聚焦爬虫实现爬取策略的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
常用的爬取策略有:基于内容评估的爬取策略、基于连接结构评估的爬取策略、基于强化学习的爬取分类、基于上下文图的爬取策略。
增量网络爬虫
增量网页抓取是指对下载的网页进行增量更新,只抓取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要时爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少下载的数据量和及时性。更新爬取的网页减少了时间和空间的消耗,但这会增加爬取算法和复杂度和实现难度。
增量网络爬虫的架构包括:爬取模块、排序模块、更新模块、本地页面集、待爬取url集和本地页面url集。
深网爬虫
网页按存在方式可分为表层网页和深层网页。Surface Web指的是一些主要构成网页的静态网页,而Deep Web指的是那些动态网页,大部分内容只能通过用户提交一些关键词网页获取。Deep Web的可访问信息容量是Surface Web的数百倍,是互联网上规模最大、增长最快的新型信息资源。
Deep Web爬虫架构包括六个基本功能模块(爬取控制器、解析器、表单分析器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表、LVS表)。其中,LVS(Label Value Set)表示标签/值集,用于表示填充表单的数据源。
Deep Web爬虫爬取过程中最重要的部分是表单填写,包括两种类型:基于领域知识的表单填写和基于网页结构分析的表单填写
爬取目标分类
基于着陆页特征
爬虫基于这个特性爬取、存储和索引的对象一般是网站和网页。网页特征可以是网页的内容特征,也可以是网页的连接结构特征等。
基于目标数据
这类爬虫针对的是网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转换或映射成目标数据
基于领域的概念
建立目标领域的本体或字典,从语义角度分析主题中不同特征的重要性
网络搜索策略
网页的爬取策略可以分为深度优先、广度优先和最佳优先三种。其中,深度优先在很多情况下会给爬虫带来问题。目前,后两种方式最为常见。
广度优先策略
广度优先策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。
为了覆盖尽可能多的页面,通常使用广度优先搜索方法。我们可以将广度优先搜索与网络过滤技术结合起来。缺点是随着抓取网页数量的增加,会下载和过滤大量不相关的网页,使算法效率降低。
最佳第一策略
最佳优先级策略会根据一定的网页分析算法预测候选url与目标网页的相似度,或者与主题的相关性,选择评价最好的一个或几个url进行爬取。它仅在分析后访问网页。算法预测为“有用”的页面。因此,存在爬虫爬取路径中很多相关网页可能被忽略的问题。
深度优先策略
深度优先策略会从起始网页开始,选择一个url进入,分析网页中的url,选择一个进入,然后一个接一个地获取连接,直到处理完一个路由,返回起始入口,选择下一条路线。这个缺点也是致命的,因为过度深入的捕捉往往导致捕捉到的数据价值很低。同时,捕获深度直接影响捕获命中率和捕获效率。与其他两种策略相比,这种策略很少使用。
爬虫抓取网页数据(网络爬虫实现原理详解类型的网络的实现过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-21 02:11
01 网页爬虫实现原理详解
不同类型的网络爬虫有不同的实现原理,但是这些实现原理有很多共同点。这里,我们以两种典型的网络爬虫(即普通网络爬虫和专注网络爬虫)为例,分别说明网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看看通用网络爬虫的实现原理。一般网络爬虫的实现原理和流程可以简单总结如下(见图3-1).
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-1 通用网络爬虫实现原理及流程
获取初始 URL。初始URL地址可以由用户人工指定,也可以由用户指定的一个或多个初始爬取网页确定。根据原来的 URL 爬取页面,得到一个新的 URL。获取初始URL地址后,首先需要爬取对应URL地址中的网页。爬取对应URL地址中的网页后,将网页存入原数据库,在爬取网页的同时寻找新的URL。同时,将爬取的URL地址存储在URL列表中,用于对爬取过程进行去重和判断。将新 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。从URL队列中读取新的URL,根据新的URL爬取网页,同时从新网页中获取新的URL,重复上述爬取过程。当爬虫系统设定的停止条件满足时,爬取停止。在编写爬虫时,一般会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取到新的URL地址。如果设置了停止条件,当满足停止条件时,爬虫将停止爬行。
以上就是一般网络爬虫的实现过程和基本原理。接下来,我们将分析聚焦网络爬虫的基本原理和实现过程。
2. 聚焦网络爬虫
专注于网络爬虫,因为它们需要有目的的爬取,所以对于通用网络爬虫,必须增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程需要比通用的网络爬虫更多。分为三个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择,如图3-2所示。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-2 聚焦网络爬虫的基本原理及实现流程
爬取目标的定义和描述。在聚焦网络爬虫中,首先要根据爬取需求定义聚焦网络爬虫的爬取目标,并进行相关描述。获取初始 URL。根据原来的 URL 爬取页面,得到一个新的 URL。从与爬网目标不相关的新 URL 中过滤掉链接。因为聚焦网络爬虫对网页的爬取是有目的的,与目标无关的网页会被过滤掉。同时,还需要将爬取的URL地址保存在一个URL列表中,用于对爬取过程进行去重和判断。将过滤后的链接放入 URL 队列。从URL队列中,根据搜索算法,确定URL的优先级,确定下一步要爬取的URL地址。在一般的网络爬虫中,接下来要爬到哪个URL地址不是很重要,但是在专注的网络爬虫中,由于它的目的,接下来要爬到哪个URL地址相对更重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。
现在我们已经初步掌握了网络爬虫的实现原理和相应的工作流程,下面我们来了解一下网络爬虫的爬取策略。
02 爬取策略
在网络爬取的过程中,待爬取的URL列表中可能有多个URL地址。爬虫应该先爬这些 URL 地址中的哪一个,然后再爬取哪一个?
在一般的网络爬虫中,虽然爬取的顺序不是那么重要,但是在很多其他的爬虫中,比如专注的网络爬虫,爬取的顺序是非常重要的,而且爬取的顺序一般是由爬取策略决定的。我们将向您介绍一些常见的爬取策略。
爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。下面我们将分别介绍。
如图3-3所示,假设有一个网站,ABCDEFG是站点下的网页,图中的箭头代表网页的层次结构。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-3 某网站的网页层次图
如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
例如,如果按照深度优先的爬取策略进行爬取,则先爬取一个网页,然后依次爬取该网页的下层链接,然后返回上一层进行爬取.
因此,如果采用深度优先的爬取策略,图3-3中的爬取顺序可以是:A→D→E→B→C→F→G。
如果遵循广度优先的爬取策略,会先爬取同级别的网页。同级网页全部爬取完成后,选择下一级网页进行爬取。比如上面的<in@网站,如果按照广度优先的爬取策略进行爬取,爬取顺序可以是:A→B→C→D→E→F→G。
除了以上两种爬取策略,我们还可以采用大站点爬取策略。我们可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,那么我们就称它为大站点。按照这个策略,网页越多的网站个数越大,优先抓取大站点中网页的URL地址。
一个网页的反向链接数是指该网页被其他网页指向的次数,这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果只是简单地根据反向链接策略来确定网页的优先级,可能会有很多作弊行为。比如做一些垃圾站群,把这些网站相互链接,这样的话,每个站点都会得到更高的反向链接,从而达到作弊的目的。
作为爬虫项目方,我们当然不希望被这种作弊行为所打扰,所以如果我们使用反向链接策略进行爬取,我们一般会考虑可靠的反向链接数。
除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
03 网页更新策略
网站 网页经常更新。作为爬虫,网页更新后,我们需要再次爬取这些网页,那么什么时候爬取合适呢?如果网站更新太慢,爬虫获取太频繁,势必会增加爬虫和网站服务器的压力。如果 网站 更新较快,但爬取时间间隔较短。如果太长,我们爬取的内容版本会太旧,不利于新内容的爬取。
显然,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略制作不同的网页。更新优先级不同,优先级高的网页更新会得到更快的爬取响应。
具体来说,常见的网页更新策略有3种:用户体验策略、历史数据策略、聚类分析策略等,下面分别进行说明。
当搜索引擎查询某个关键词时,就会出现一个排名结果。在排名结果中,通常会有大量的网页。但是,大多数用户只会关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会优先更新排名结果最高的网页。
这个更新策略,我们称之为用户体验策略,那么在这个策略中,爬虫究竟是什么时候抓取这些排名靠前的页面呢?此时在爬取过程中会保留对应网页的多个历史版本,并进行相应的分析,根据内容更新、搜索质量影响、用户等情况确定这些网页的爬取周期。这些多个历史版本的经验和其他信息。
此外,我们还可以使用历史数据策略来确定爬取网页更新的周期。例如,我们可以根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页的下一次更新时间,从而确定下一次抓取该网页的时间,即确定更新周期。
以上两种策略都需要历史数据作为基础。有时候,如果一个网页是一个新的网页,会没有对应的历史数据,如果要根据历史数据进行分析,爬虫服务器需要保存对应网页的历史版本信息,这无疑带来了爬虫服务器。更多的压力和负担。
如果要解决这些问题,就需要采用新的更新策略。最常用的方法是聚类分析。那么什么是聚类分析策略呢?
在生活中,相信大家对分类都很熟悉。比如我们去商场,商场里的商品一般都是分类的,方便顾客购买相应的商品。此时,产品分类的类别是固定的。制定。
但是,如果商品数量巨大,无法提前进行分类,或者说根本不知道会有哪些类别的商品,这个时候,我们应该如何解决商品分类?
这时候,我们可以使用聚类的方法来解决问题。根据商品之间的共性,我们可以对共性较多的商品进行分析,并将其归为一类。重要的是,聚集在一起的商品之间必须存在某种共性,即按照“同类事物聚集”的思想来实现。
同样,在我们的聚类算法中,也会有类似的分析过程。
我们可以通过将聚类分析算法应用于爬虫对网页的更新来做到这一点,如图 3-4 所示。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-4 网页更新策略的聚类算法
首先,经过大量研究发现,网页可能有不同的内容,但总的来说,具有相似属性的网页具有相似的更新频率。这是聚类分析算法应用于爬虫网页更新的前提和指导思想。有了1中的指导思想,我们可以先对大量的网页进行聚类分析。聚类后会形成多个类。每个类中的网页具有相似的属性,即它们通常具有相似的更新频率。. 聚类完成后,我们可以对同一个聚类中的网页进行采样,然后计算采样结果的平均更新值来确定每个聚类的爬取频率。
以上就是使用爬虫爬取网页时常见的三种更新策略。在我们掌握了他们的算法思路之后,我们在进行爬虫的实际开发时,编译出来的爬虫会更加高效的执行逻辑。会更合理。
04 网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1. 基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2. 基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。
基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。
当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。
我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。
该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。
因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3. 基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评价。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。
05 识别
在爬取网页的过程中,爬虫必须访问对应的网页,而普通的爬虫一般会告诉对应网页的网站站长自己的爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。
那么,爬虫应该如何告知网站站长自己的身份呢?
一般爬虫在爬取访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。一般爬虫在访问一个网站时,首先会根据站点下的Robots.txt文件确定可以爬取的网页范围。Robots 协议是网络爬虫必须遵守的协议。对于一些被禁止的 URL 地址,网络爬虫不应该爬取访问权限。
同时,如果爬虫在爬取某个站点时陷入死循环,导致该站点的服务压力太大,如果有正确的身份设置,那么该站点的站长可以想办法联系爬虫并停止相应的爬虫。
当然,有些爬虫会伪装成其他爬虫或者浏览器爬取网站来获取一些额外的数据,或者有些爬虫会无视Robots协议的限制,任意爬取。从技术上看,这些行为实施起来并不难,但我们并不提倡这些行为,因为只有共同遵守良好的网络规则,爬虫和站点服务器才能实现双赢。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
06 网络爬虫实现技术
通过前面的学习,我们对爬虫的基础理论知识基本有了比较全面的了解。那么,如果我们要实现网络爬虫技术,开发自己的网络爬虫,我们可以使用哪些语言进行开发呢?
开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.JS、C++、Go等,下面我们将介绍这些语言编写爬虫的特点:
07 总结 关注网络爬虫。因为需要有针对性的爬取,所以对于一般的网络爬虫来说,必须增加目标的定义和过滤机制。具体来说,这时候它的执行原理和过程需要多爬虫多三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。常见的网页更新策略有三种:用户体验策略、历史数据策略、聚类分析策略。可以根据商品之间的共性进行聚类分析,将共性较多的商品归为一类。在爬取网页的过程中,爬虫必须访问相应的网页。此时,常规爬虫通常会告诉相应网页的 网站 站长其爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。开发网络爬虫的语言有很多种。常用语言有 Python、Java、PHP、Node.JS、C++、Go。
作者简介:韦伟,资深网络爬虫技术专家、大数据专家、软件开发工程师,多年从事大型软件开发和技术服务,精通Python技术,在Python网络爬虫、Python机器学习、Python数据分析与挖掘,Python Web 开发等各个领域都有丰富的实践经验。 查看全部
爬虫抓取网页数据(网络爬虫实现原理详解类型的网络的实现过程)
01 网页爬虫实现原理详解
不同类型的网络爬虫有不同的实现原理,但是这些实现原理有很多共同点。这里,我们以两种典型的网络爬虫(即普通网络爬虫和专注网络爬虫)为例,分别说明网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看看通用网络爬虫的实现原理。一般网络爬虫的实现原理和流程可以简单总结如下(见图3-1).

爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-1 通用网络爬虫实现原理及流程
获取初始 URL。初始URL地址可以由用户人工指定,也可以由用户指定的一个或多个初始爬取网页确定。根据原来的 URL 爬取页面,得到一个新的 URL。获取初始URL地址后,首先需要爬取对应URL地址中的网页。爬取对应URL地址中的网页后,将网页存入原数据库,在爬取网页的同时寻找新的URL。同时,将爬取的URL地址存储在URL列表中,用于对爬取过程进行去重和判断。将新 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。从URL队列中读取新的URL,根据新的URL爬取网页,同时从新网页中获取新的URL,重复上述爬取过程。当爬虫系统设定的停止条件满足时,爬取停止。在编写爬虫时,一般会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取到新的URL地址。如果设置了停止条件,当满足停止条件时,爬虫将停止爬行。
以上就是一般网络爬虫的实现过程和基本原理。接下来,我们将分析聚焦网络爬虫的基本原理和实现过程。
2. 聚焦网络爬虫
专注于网络爬虫,因为它们需要有目的的爬取,所以对于通用网络爬虫,必须增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程需要比通用的网络爬虫更多。分为三个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择,如图3-2所示。

爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-2 聚焦网络爬虫的基本原理及实现流程
爬取目标的定义和描述。在聚焦网络爬虫中,首先要根据爬取需求定义聚焦网络爬虫的爬取目标,并进行相关描述。获取初始 URL。根据原来的 URL 爬取页面,得到一个新的 URL。从与爬网目标不相关的新 URL 中过滤掉链接。因为聚焦网络爬虫对网页的爬取是有目的的,与目标无关的网页会被过滤掉。同时,还需要将爬取的URL地址保存在一个URL列表中,用于对爬取过程进行去重和判断。将过滤后的链接放入 URL 队列。从URL队列中,根据搜索算法,确定URL的优先级,确定下一步要爬取的URL地址。在一般的网络爬虫中,接下来要爬到哪个URL地址不是很重要,但是在专注的网络爬虫中,由于它的目的,接下来要爬到哪个URL地址相对更重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。
现在我们已经初步掌握了网络爬虫的实现原理和相应的工作流程,下面我们来了解一下网络爬虫的爬取策略。
02 爬取策略
在网络爬取的过程中,待爬取的URL列表中可能有多个URL地址。爬虫应该先爬这些 URL 地址中的哪一个,然后再爬取哪一个?
在一般的网络爬虫中,虽然爬取的顺序不是那么重要,但是在很多其他的爬虫中,比如专注的网络爬虫,爬取的顺序是非常重要的,而且爬取的顺序一般是由爬取策略决定的。我们将向您介绍一些常见的爬取策略。
爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。下面我们将分别介绍。
如图3-3所示,假设有一个网站,ABCDEFG是站点下的网页,图中的箭头代表网页的层次结构。

爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-3 某网站的网页层次图
如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
例如,如果按照深度优先的爬取策略进行爬取,则先爬取一个网页,然后依次爬取该网页的下层链接,然后返回上一层进行爬取.
因此,如果采用深度优先的爬取策略,图3-3中的爬取顺序可以是:A→D→E→B→C→F→G。
如果遵循广度优先的爬取策略,会先爬取同级别的网页。同级网页全部爬取完成后,选择下一级网页进行爬取。比如上面的<in@网站,如果按照广度优先的爬取策略进行爬取,爬取顺序可以是:A→B→C→D→E→F→G。
除了以上两种爬取策略,我们还可以采用大站点爬取策略。我们可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,那么我们就称它为大站点。按照这个策略,网页越多的网站个数越大,优先抓取大站点中网页的URL地址。
一个网页的反向链接数是指该网页被其他网页指向的次数,这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果只是简单地根据反向链接策略来确定网页的优先级,可能会有很多作弊行为。比如做一些垃圾站群,把这些网站相互链接,这样的话,每个站点都会得到更高的反向链接,从而达到作弊的目的。
作为爬虫项目方,我们当然不希望被这种作弊行为所打扰,所以如果我们使用反向链接策略进行爬取,我们一般会考虑可靠的反向链接数。
除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。

爬虫原理与数据抓取技术(爬虫技术是做什么的)
03 网页更新策略
网站 网页经常更新。作为爬虫,网页更新后,我们需要再次爬取这些网页,那么什么时候爬取合适呢?如果网站更新太慢,爬虫获取太频繁,势必会增加爬虫和网站服务器的压力。如果 网站 更新较快,但爬取时间间隔较短。如果太长,我们爬取的内容版本会太旧,不利于新内容的爬取。
显然,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略制作不同的网页。更新优先级不同,优先级高的网页更新会得到更快的爬取响应。
具体来说,常见的网页更新策略有3种:用户体验策略、历史数据策略、聚类分析策略等,下面分别进行说明。
当搜索引擎查询某个关键词时,就会出现一个排名结果。在排名结果中,通常会有大量的网页。但是,大多数用户只会关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会优先更新排名结果最高的网页。
这个更新策略,我们称之为用户体验策略,那么在这个策略中,爬虫究竟是什么时候抓取这些排名靠前的页面呢?此时在爬取过程中会保留对应网页的多个历史版本,并进行相应的分析,根据内容更新、搜索质量影响、用户等情况确定这些网页的爬取周期。这些多个历史版本的经验和其他信息。
此外,我们还可以使用历史数据策略来确定爬取网页更新的周期。例如,我们可以根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页的下一次更新时间,从而确定下一次抓取该网页的时间,即确定更新周期。
以上两种策略都需要历史数据作为基础。有时候,如果一个网页是一个新的网页,会没有对应的历史数据,如果要根据历史数据进行分析,爬虫服务器需要保存对应网页的历史版本信息,这无疑带来了爬虫服务器。更多的压力和负担。
如果要解决这些问题,就需要采用新的更新策略。最常用的方法是聚类分析。那么什么是聚类分析策略呢?
在生活中,相信大家对分类都很熟悉。比如我们去商场,商场里的商品一般都是分类的,方便顾客购买相应的商品。此时,产品分类的类别是固定的。制定。
但是,如果商品数量巨大,无法提前进行分类,或者说根本不知道会有哪些类别的商品,这个时候,我们应该如何解决商品分类?
这时候,我们可以使用聚类的方法来解决问题。根据商品之间的共性,我们可以对共性较多的商品进行分析,并将其归为一类。重要的是,聚集在一起的商品之间必须存在某种共性,即按照“同类事物聚集”的思想来实现。
同样,在我们的聚类算法中,也会有类似的分析过程。
我们可以通过将聚类分析算法应用于爬虫对网页的更新来做到这一点,如图 3-4 所示。

爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-4 网页更新策略的聚类算法
首先,经过大量研究发现,网页可能有不同的内容,但总的来说,具有相似属性的网页具有相似的更新频率。这是聚类分析算法应用于爬虫网页更新的前提和指导思想。有了1中的指导思想,我们可以先对大量的网页进行聚类分析。聚类后会形成多个类。每个类中的网页具有相似的属性,即它们通常具有相似的更新频率。. 聚类完成后,我们可以对同一个聚类中的网页进行采样,然后计算采样结果的平均更新值来确定每个聚类的爬取频率。
以上就是使用爬虫爬取网页时常见的三种更新策略。在我们掌握了他们的算法思路之后,我们在进行爬虫的实际开发时,编译出来的爬虫会更加高效的执行逻辑。会更合理。
04 网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1. 基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2. 基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。
基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。
当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。

爬虫原理与数据抓取技术(爬虫技术是做什么的)
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。
我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。
该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。
因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3. 基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评价。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。
05 识别
在爬取网页的过程中,爬虫必须访问对应的网页,而普通的爬虫一般会告诉对应网页的网站站长自己的爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。
那么,爬虫应该如何告知网站站长自己的身份呢?
一般爬虫在爬取访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。一般爬虫在访问一个网站时,首先会根据站点下的Robots.txt文件确定可以爬取的网页范围。Robots 协议是网络爬虫必须遵守的协议。对于一些被禁止的 URL 地址,网络爬虫不应该爬取访问权限。
同时,如果爬虫在爬取某个站点时陷入死循环,导致该站点的服务压力太大,如果有正确的身份设置,那么该站点的站长可以想办法联系爬虫并停止相应的爬虫。
当然,有些爬虫会伪装成其他爬虫或者浏览器爬取网站来获取一些额外的数据,或者有些爬虫会无视Robots协议的限制,任意爬取。从技术上看,这些行为实施起来并不难,但我们并不提倡这些行为,因为只有共同遵守良好的网络规则,爬虫和站点服务器才能实现双赢。

爬虫原理与数据抓取技术(爬虫技术是做什么的)
06 网络爬虫实现技术
通过前面的学习,我们对爬虫的基础理论知识基本有了比较全面的了解。那么,如果我们要实现网络爬虫技术,开发自己的网络爬虫,我们可以使用哪些语言进行开发呢?
开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.JS、C++、Go等,下面我们将介绍这些语言编写爬虫的特点:
07 总结 关注网络爬虫。因为需要有针对性的爬取,所以对于一般的网络爬虫来说,必须增加目标的定义和过滤机制。具体来说,这时候它的执行原理和过程需要多爬虫多三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。常见的网页更新策略有三种:用户体验策略、历史数据策略、聚类分析策略。可以根据商品之间的共性进行聚类分析,将共性较多的商品归为一类。在爬取网页的过程中,爬虫必须访问相应的网页。此时,常规爬虫通常会告诉相应网页的 网站 站长其爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。开发网络爬虫的语言有很多种。常用语言有 Python、Java、PHP、Node.JS、C++、Go。
作者简介:韦伟,资深网络爬虫技术专家、大数据专家、软件开发工程师,多年从事大型软件开发和技术服务,精通Python技术,在Python网络爬虫、Python机器学习、Python数据分析与挖掘,Python Web 开发等各个领域都有丰富的实践经验。
爬虫抓取网页数据(如何发送网络请求爬虫的关键了?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2022-03-20 18:16
什么是爬行动物
爬虫是指利用代码模拟用户批量发送网络请求,批量获取数据的行为。
网络请求
如果说爬虫是指使用代码模拟用户批量发送网络请求,那么如何发送网络请求是爬虫的关键,那么如何发送网络请求呢?
“打开浏览器→在搜索框/输入框输入要查询的内容→点击回车”的过程是对用户的一次完整的网络请求。
网络请求
数据
我们发送网络请求后,我们的电脑上会出现一些数据,例如:如果我们搜索“什么是python”,电脑的浏览器会显示一些网页和链接,显示的信息就是这台电脑和其他的计算机或服务器已连接,它响应计算机网络请求的数据。
数据
超文本传输协议
响应网络请求会产生大量的数据(我们搜索关键词会出几百万条结果),所以这个数据有一个管理集叫做“超文本传输协议”,这也是我们经常在网站的前缀为“http”。
超文本传输协议
而http有5种请求方式,分别是:get、post、put、delete、head,其中最常用的是get请求和post请求。
爬行动物的分类
上面讲了“发送网络请求”的相关知识,接下来说说“批量获取数据”的相关内容。
发送什么样的请求,会得到什么样的数据,爬虫发送请求的方式主要有两种:“通用爬虫”和“聚焦爬虫”。
万能爬虫:可以爬取关键词页面上的所有内容,开放性更好,速度更快,但是90%的爬取内容是用户不需要的,就像你在搜索引擎上输入你要的内容想要,但他会出现“广告”、“相关链接”、“热门内容”等,而这些都不是你想要的内容。
万能爬虫
专注于爬虫:可以清晰的爬取用户想要的内容,目标非常精准。也是现在爬虫的主流。
此外,“增量爬虫”具有翻页功能,可以爬取所有页面的内容。“深度爬虫”可以爬取html和css的静态数据,以及js的动态数据。这两者都属于“焦点爬虫”。
爬虫可以爬什么
了解了一些爬虫的基础知识之后,我们再来说说可以爬取哪些内容。
“仅抓取用户有权访问的数据”
例如:如果你要爬取视频网站的视频,你是普通用户,所以你可以爬取普通视频。如果要爬VIP视频,需要给VIP充值。
并且不允许将爬出的信息进行出售等行为。 查看全部
爬虫抓取网页数据(如何发送网络请求爬虫的关键了?(组图))
什么是爬行动物
爬虫是指利用代码模拟用户批量发送网络请求,批量获取数据的行为。
网络请求
如果说爬虫是指使用代码模拟用户批量发送网络请求,那么如何发送网络请求是爬虫的关键,那么如何发送网络请求呢?
“打开浏览器→在搜索框/输入框输入要查询的内容→点击回车”的过程是对用户的一次完整的网络请求。

网络请求
数据
我们发送网络请求后,我们的电脑上会出现一些数据,例如:如果我们搜索“什么是python”,电脑的浏览器会显示一些网页和链接,显示的信息就是这台电脑和其他的计算机或服务器已连接,它响应计算机网络请求的数据。

数据
超文本传输协议
响应网络请求会产生大量的数据(我们搜索关键词会出几百万条结果),所以这个数据有一个管理集叫做“超文本传输协议”,这也是我们经常在网站的前缀为“http”。

超文本传输协议
而http有5种请求方式,分别是:get、post、put、delete、head,其中最常用的是get请求和post请求。
爬行动物的分类
上面讲了“发送网络请求”的相关知识,接下来说说“批量获取数据”的相关内容。
发送什么样的请求,会得到什么样的数据,爬虫发送请求的方式主要有两种:“通用爬虫”和“聚焦爬虫”。
万能爬虫:可以爬取关键词页面上的所有内容,开放性更好,速度更快,但是90%的爬取内容是用户不需要的,就像你在搜索引擎上输入你要的内容想要,但他会出现“广告”、“相关链接”、“热门内容”等,而这些都不是你想要的内容。

万能爬虫
专注于爬虫:可以清晰的爬取用户想要的内容,目标非常精准。也是现在爬虫的主流。
此外,“增量爬虫”具有翻页功能,可以爬取所有页面的内容。“深度爬虫”可以爬取html和css的静态数据,以及js的动态数据。这两者都属于“焦点爬虫”。
爬虫可以爬什么
了解了一些爬虫的基础知识之后,我们再来说说可以爬取哪些内容。
“仅抓取用户有权访问的数据”
例如:如果你要爬取视频网站的视频,你是普通用户,所以你可以爬取普通视频。如果要爬VIP视频,需要给VIP充值。
并且不允许将爬出的信息进行出售等行为。
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-19 05:17
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
图 2
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面,同时网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以使用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如图3
图 3
安装完成,如图4
图 4 查看全部
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数

图 2
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面,同时网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以使用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如图3
图 3
安装完成,如图4
图 4
爬虫抓取网页数据( 大佬的博客,和JS发送请求的路径和路径分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-17 20:17
大佬的博客,和JS发送请求的路径和路径分析)
爬虫爬取JS生成的数据
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过Ajax异步发送请求,得到响应,将数据放入页面。对于这种情况,我们可以查看Ajax请求,然后分析Ajax请求路径和响应,得到想要的数据;另一种是JS动态加载的数据,然后放到页面中。在这两种情况下,供用户使用浏览器访问时,不会出现异常,快速获取完整页面。
其实我们之前学过一个selenium模块,通过操作浏览器,然后获取浏览器显示的数据,这个方法可以获取数据,不过本节是分析如何找到控制数据生成的JS ,以及JS发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最让我恼火的是JS动态生成的数据。我找不到哪个 JS 实现了它(因为 JS 太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬,提供大佬的博客:
1.需求描述和页面分析
1、需求说明
基本页面路径:
点击进入每个标题:
要求是爬取每个标题下的新闻内容
2、页面分析
2.1 主页
查看 Ajax 请求:
接下来,我们将解析如何找出发送请求的 JS
二、找到发送请求的JS
在响应数据中,包括新闻标题,以及这条新闻详情页的路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去Ajax:
Ajax没有新闻相关的数据,所以不再使用Ajax请求获取数据,只剩下JS了。我们将找出是哪个 JS 发送了获取数据的请求。步骤与上面相同:
详情页数据的JS请求路径:
详情页请求路径:
我们可以看到,最后一个斜杠之前的详情页数据的请求路径与最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1=''
第二步:替换url1最后一个斜杠后的内容
url2=''%(url1.split('/')[3]) #用'/'分割url1,得到第四部分,即索引为3,然后拼接进去
这样就构建了一条详情页数据请求路径,然后就可以直接访问该路径获取数据,而无需访问详情页。 查看全部
爬虫抓取网页数据(
大佬的博客,和JS发送请求的路径和路径分析)
爬虫爬取JS生成的数据
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过Ajax异步发送请求,得到响应,将数据放入页面。对于这种情况,我们可以查看Ajax请求,然后分析Ajax请求路径和响应,得到想要的数据;另一种是JS动态加载的数据,然后放到页面中。在这两种情况下,供用户使用浏览器访问时,不会出现异常,快速获取完整页面。
其实我们之前学过一个selenium模块,通过操作浏览器,然后获取浏览器显示的数据,这个方法可以获取数据,不过本节是分析如何找到控制数据生成的JS ,以及JS发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最让我恼火的是JS动态生成的数据。我找不到哪个 JS 实现了它(因为 JS 太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬,提供大佬的博客:
1.需求描述和页面分析
1、需求说明
基本页面路径:

点击进入每个标题:

要求是爬取每个标题下的新闻内容
2、页面分析
2.1 主页

查看 Ajax 请求:

接下来,我们将解析如何找出发送请求的 JS
二、找到发送请求的JS

在响应数据中,包括新闻标题,以及这条新闻详情页的路径,所以现在我们去访问详情页,分析详情页

访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去Ajax:

Ajax没有新闻相关的数据,所以不再使用Ajax请求获取数据,只剩下JS了。我们将找出是哪个 JS 发送了获取数据的请求。步骤与上面相同:

详情页数据的JS请求路径:

详情页请求路径:

我们可以看到,最后一个斜杠之前的详情页数据的请求路径与最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1=''
第二步:替换url1最后一个斜杠后的内容
url2=''%(url1.split('/')[3]) #用'/'分割url1,得到第四部分,即索引为3,然后拼接进去
这样就构建了一条详情页数据请求路径,然后就可以直接访问该路径获取数据,而无需访问详情页。
爬虫抓取网页数据(python爬虫实战之三AJAX数据爬取和HTTPS访问(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-15 01:24
python爬虫URL编码和GETPOST请求| python爬虫实战三 python爬虫AJAX数据爬取和HTTPS访问
我们首先需要回顾一下之前接触过的爬虫的概念、爬取过程、爬虫的标准库等。
通常我们在大多数情况下编写的爬虫都是专注的爬虫。
接下来,我们通过豆瓣电影对 JSON 数据进行处理。
处理 JSON 数据
看看“豆瓣电影”,看看“最近热门电影”的“火爆”。
右键单击“检查元素”,找到“网络”,然后刷新它。
我们可以看到很多内容,我们分析这部分热门电影。
然后复制地址进行操作分析。
通过分析,我们知道这部分内容是通过AJAX从后台获取的Json数据。
访问的 URL 是 %E7%83%AD%E9%97%A8&page_limit=50&page_start=0
其中,%E7%83%AD%E9%97%A8是utf-8编码的中文“热”
服务端返回的JSON数据如下:
轮播组件一共需要50条数据。
url的表示如下:
标签标签“hot”,意思是热门电影
type 数据类型,movie 是电影
page_limit 表示返回数据的总数
page_start 表示数据偏移量
我们可以设置page_limit=10&page_start=10的值。
from urllib.parse import urlencode
from urllib.request import urlopen, Request
import simplejson
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
jurl = 'https://movie.douban.com/j/search_subjects'
d = {
'type':'movie',
'tag':'热门',
'page_limit':10,
'page_start':10
}
req = Request('{}?{}'.format(jurl, urlencode(d)), headers={
'User-agent':ua
})
with urlopen(req) as res:
subjects = simplejson.loads(res.read())
print(len(subjects['subjects']))
print(subjects)
结果:
至此,就可以获取到内容了,那我们还需要封装爬虫吗?
因为每个企业处理的方式可能不同,所以返回的数据可能是html或JSON。因此,处理方法必须一致,或者将函数封装在一个方法中是我们思考的重点。很多时候我们会为一些特定的数据写一个特定的爬虫,具体的网站。因为每个网站的解析提取方法可能不同。现在我们只做一个简单的 JSON 处理。但是如果是网页解析,那就很麻烦了,尤其是网页模板一旦改变,就需要重写网页解析方法。 查看全部
爬虫抓取网页数据(python爬虫实战之三AJAX数据爬取和HTTPS访问(组图))
python爬虫URL编码和GETPOST请求| python爬虫实战三 python爬虫AJAX数据爬取和HTTPS访问
我们首先需要回顾一下之前接触过的爬虫的概念、爬取过程、爬虫的标准库等。
通常我们在大多数情况下编写的爬虫都是专注的爬虫。
接下来,我们通过豆瓣电影对 JSON 数据进行处理。
处理 JSON 数据
看看“豆瓣电影”,看看“最近热门电影”的“火爆”。
右键单击“检查元素”,找到“网络”,然后刷新它。

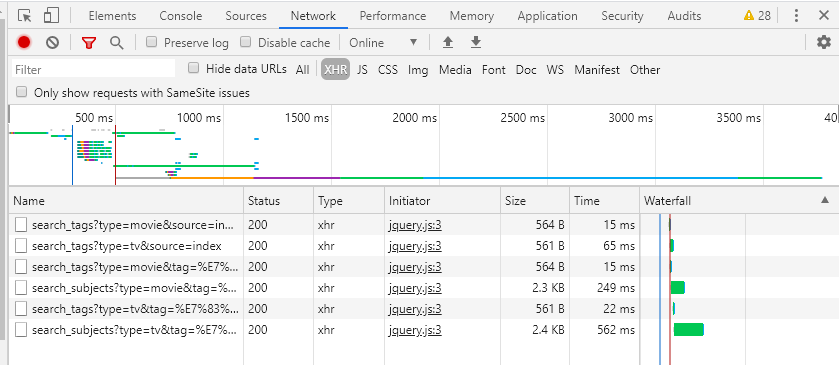
我们可以看到很多内容,我们分析这部分热门电影。
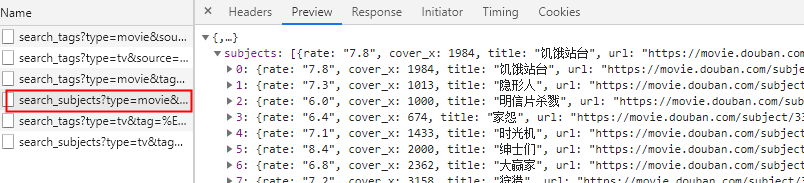
然后复制地址进行操作分析。
通过分析,我们知道这部分内容是通过AJAX从后台获取的Json数据。
访问的 URL 是 %E7%83%AD%E9%97%A8&page_limit=50&page_start=0
其中,%E7%83%AD%E9%97%A8是utf-8编码的中文“热”
服务端返回的JSON数据如下:
轮播组件一共需要50条数据。
url的表示如下:
标签标签“hot”,意思是热门电影
type 数据类型,movie 是电影
page_limit 表示返回数据的总数
page_start 表示数据偏移量
我们可以设置page_limit=10&page_start=10的值。
from urllib.parse import urlencode
from urllib.request import urlopen, Request
import simplejson
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
jurl = 'https://movie.douban.com/j/search_subjects'
d = {
'type':'movie',
'tag':'热门',
'page_limit':10,
'page_start':10
}
req = Request('{}?{}'.format(jurl, urlencode(d)), headers={
'User-agent':ua
})
with urlopen(req) as res:
subjects = simplejson.loads(res.read())
print(len(subjects['subjects']))
print(subjects)
结果:

至此,就可以获取到内容了,那我们还需要封装爬虫吗?
因为每个企业处理的方式可能不同,所以返回的数据可能是html或JSON。因此,处理方法必须一致,或者将函数封装在一个方法中是我们思考的重点。很多时候我们会为一些特定的数据写一个特定的爬虫,具体的网站。因为每个网站的解析提取方法可能不同。现在我们只做一个简单的 JSON 处理。但是如果是网页解析,那就很麻烦了,尤其是网页模板一旦改变,就需要重写网页解析方法。
爬虫抓取网页数据(python获取网页信息只伪造了一个UA头(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-12 14:14
最近在学习python的requests库,大致了解了正则匹配,所以想找个项目来实践一下。巧合的是,在连接fiddler测试的过程中,刷了某社交平台,抓到了很多请求。通过分析发现,平台用户id从1递增,请求中的access_token值应该是一定规则生成的32位加密代码。切换id,access_token不变,即可访问不同用户的个人主页。主页收录用户信息,包括居住城市、姓名、公司、职位、毕业院校、头像、用户标签、他人评价等。更敏感的信息,如电话号码,无疑是加密的,但仅此信息就足以定位特定用户,这被认为是有价值的信息。先贴一张图,看看效果,再详细说说实现原理。
目前已经爬取了600多个用户,然后遇到了爬虫最大的障碍——反爬。当然,如果有反爬,还有抑制反爬的办法,那就是另外一回事了。
导入库
import requests
import re
import xlrd
import random
from xlutils.copy import copy
import time
requests用于获取网页信息,re为正则匹配,xlrd和xlutils.copy将爬取的信息写入excel文档,time和random用于生成等待的随机数,避免爬取的频繁限制。
1.获取网页信息
def getHtml(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
html = requests.get(url, headers=headers).text
return html
只伪造了一个UA头,发现可以爬到信息上
2.其中一个字段——名字的getter函数
def getname(html):
name_reg = r'"name":"(.*?)"'
name_patten = re.compile(name_reg)
name = re.findall(name_patten, html)
if len(name):
return name[0]
else:
return "/"
通过正则匹配,得到一个名字列表,第一条数据代表用户的名字,可以直接得到。如果某些用户 id 不存在,则返回“/”以填充该位置。本来我是想直接把这种无效信息去掉,但是我想看,比如1000个用户,有多少是无效的,所以直接填了位置。其他信息:同职位、居住地、公司等。如上图,我只取了姓名、居住地、职位、公司、头像等。
3.写入现有的 excel 文档
def xlxs_modify(i, name):
file_xl = xlrd.open_workbook(r'...')
xlxs = copy(file_xl)
write_xlxs = xlxs.get_sheet(0)
write_xlxs.write(i, 0, name1)
xlxs.save(r'...')
将真正匹配的名称等字段写入文档中,从第一列开始依次写入
4.运行循环,写入数据
for i in range(500,3000):
j = i+1
url = "https://.../contact/basic/%s?"%j
....
all = xlxs_modify(j, name, province, city, company, compos, school, avatar)
x = random.randint(1, 2)
time.sleep(x)
只需添加随机等待时间以避免被阻止。
这里写的爬虫部分差不多,因为爬取600多条数据时抓取的网页信息一直是“休息一会”,原来是反爬集。然后我通过headers头添加了一个动态的虚拟ip,写cookies,增加了更多的等待时间等等,发现问题解决不了。看起来很有可能是用户信息触发的,除非切换到其他用户。
平台是用手机号注册的用户,是一种注册门槛高的方法,但也有破解的方法。谷歌短信服务,发现网上有大量免费验证码获取手机号,如下图。
现在只需要注册多个账号,随机接口运行循环,抓取上千条记录应该不成问题。 查看全部
爬虫抓取网页数据(python获取网页信息只伪造了一个UA头(组图))
最近在学习python的requests库,大致了解了正则匹配,所以想找个项目来实践一下。巧合的是,在连接fiddler测试的过程中,刷了某社交平台,抓到了很多请求。通过分析发现,平台用户id从1递增,请求中的access_token值应该是一定规则生成的32位加密代码。切换id,access_token不变,即可访问不同用户的个人主页。主页收录用户信息,包括居住城市、姓名、公司、职位、毕业院校、头像、用户标签、他人评价等。更敏感的信息,如电话号码,无疑是加密的,但仅此信息就足以定位特定用户,这被认为是有价值的信息。先贴一张图,看看效果,再详细说说实现原理。
目前已经爬取了600多个用户,然后遇到了爬虫最大的障碍——反爬。当然,如果有反爬,还有抑制反爬的办法,那就是另外一回事了。
导入库
import requests
import re
import xlrd
import random
from xlutils.copy import copy
import time
requests用于获取网页信息,re为正则匹配,xlrd和xlutils.copy将爬取的信息写入excel文档,time和random用于生成等待的随机数,避免爬取的频繁限制。
1.获取网页信息
def getHtml(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
html = requests.get(url, headers=headers).text
return html
只伪造了一个UA头,发现可以爬到信息上
2.其中一个字段——名字的getter函数
def getname(html):
name_reg = r'"name":"(.*?)"'
name_patten = re.compile(name_reg)
name = re.findall(name_patten, html)
if len(name):
return name[0]
else:
return "/"
通过正则匹配,得到一个名字列表,第一条数据代表用户的名字,可以直接得到。如果某些用户 id 不存在,则返回“/”以填充该位置。本来我是想直接把这种无效信息去掉,但是我想看,比如1000个用户,有多少是无效的,所以直接填了位置。其他信息:同职位、居住地、公司等。如上图,我只取了姓名、居住地、职位、公司、头像等。
3.写入现有的 excel 文档
def xlxs_modify(i, name):
file_xl = xlrd.open_workbook(r'...')
xlxs = copy(file_xl)
write_xlxs = xlxs.get_sheet(0)
write_xlxs.write(i, 0, name1)
xlxs.save(r'...')
将真正匹配的名称等字段写入文档中,从第一列开始依次写入
4.运行循环,写入数据
for i in range(500,3000):
j = i+1
url = "https://.../contact/basic/%s?"%j
....
all = xlxs_modify(j, name, province, city, company, compos, school, avatar)
x = random.randint(1, 2)
time.sleep(x)
只需添加随机等待时间以避免被阻止。
这里写的爬虫部分差不多,因为爬取600多条数据时抓取的网页信息一直是“休息一会”,原来是反爬集。然后我通过headers头添加了一个动态的虚拟ip,写cookies,增加了更多的等待时间等等,发现问题解决不了。看起来很有可能是用户信息触发的,除非切换到其他用户。
平台是用手机号注册的用户,是一种注册门槛高的方法,但也有破解的方法。谷歌短信服务,发现网上有大量免费验证码获取手机号,如下图。
现在只需要注册多个账号,随机接口运行循环,抓取上千条记录应该不成问题。
爬虫抓取网页数据(如何编写一个网络爬虫的数据数据采集?学习资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-04-10 03:07
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
最后,想学Python的朋友们!请关注+私信回复:“学习”获取我为你准备的Python学习资料一份!
python学习资料
python学习资料 查看全部
爬虫抓取网页数据(如何编写一个网络爬虫的数据数据采集?学习资料)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
最后,想学Python的朋友们!请关注+私信回复:“学习”获取我为你准备的Python学习资料一份!
python学习资料
python学习资料
爬虫抓取网页数据(植物大战僵尸212)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-06 05:04
爬虫抓取网页数据并做拼接,看看采集效果,并发数多少是否要加大。
如果是百度这种情况,建议最好是采用项目来实现,django模板库采用flask。首先可以测试一下,是否可以获取你所需要的图片列表,需要提供的字段:varmatthew_imgs=require('./fakeimage')varimgurl=''varcontext=newhttppagecontext()varmail=newhttpport(http,'/')varposturl='-img/custom-post/'variphone_account=mail.getmail();//获取手机号vargetpacket(db.getinfo)varipad_account=mail.getbook();variphone_account=mail.getapp();varsize=0.2;varcontent=mail.gethost();//获取微信号varclient_id=mail.getapp().code;//获取验证码varurlname=mail.gethost().accountname;//获取二维码,view=mail.gethost().username;//获取地址,whois信息varaccount_name=mail.gethost().signing;//获取联系人,id=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取设备名variphone_account=mail.getapp().iphone_account;//获取微信号varipad_account=mail.getapp().ipad_account;//获取验证码varclient_id=mail.gethost().accountname;//获取设备名varurlname=mail.gethost().username;//获取地址varaccount=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取验证码,whois=mail.gethost().whois;//获取手机号。 查看全部
爬虫抓取网页数据(植物大战僵尸212)
爬虫抓取网页数据并做拼接,看看采集效果,并发数多少是否要加大。
如果是百度这种情况,建议最好是采用项目来实现,django模板库采用flask。首先可以测试一下,是否可以获取你所需要的图片列表,需要提供的字段:varmatthew_imgs=require('./fakeimage')varimgurl=''varcontext=newhttppagecontext()varmail=newhttpport(http,'/')varposturl='-img/custom-post/'variphone_account=mail.getmail();//获取手机号vargetpacket(db.getinfo)varipad_account=mail.getbook();variphone_account=mail.getapp();varsize=0.2;varcontent=mail.gethost();//获取微信号varclient_id=mail.getapp().code;//获取验证码varurlname=mail.gethost().accountname;//获取二维码,view=mail.gethost().username;//获取地址,whois信息varaccount_name=mail.gethost().signing;//获取联系人,id=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取设备名variphone_account=mail.getapp().iphone_account;//获取微信号varipad_account=mail.getapp().ipad_account;//获取验证码varclient_id=mail.gethost().accountname;//获取设备名varurlname=mail.gethost().username;//获取地址varaccount=mail.gethost().accountage;//获取验证码varwhois=mail.gethost().whois;//获取验证码,whois=mail.gethost().whois;//获取手机号。
爬虫抓取网页数据(深入一点的爬虫方向基于身份识别进行反爬基于数据加密进行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-06 00:03
正则表达式
在爬虫中使用正则表达式仍然很常见:
防爬
爬取的三个方向 基于身份识别的反爬 基于爬虫行为的反爬 基于数据加密的反爬 基于数据加密的反爬 基于身份识别的常见反爬 1 通过 headers 字段进行反爬 有headers中的字段很多,都可能是对方服务器拿来判断是否是爬虫1.1 反爬和反爬原理通过headers中的User-Agent字段:爬虫没有默认有一个User-Agent,但是使用模块的默认设置解决方法:在请求之前添加User-Agent即可;更好的方法是使用
爬虫框架
spider爬虫名称爬取域名#创建爬虫程序设置#如果在项目目录下,会得到项目的配置runsspider#运行单独的python文件,交互调试时无需创建项目shell#scrapyshellurl地址,如选择浏览器规则是否正确fetch#独立于进程爬取一个页面,可以得到请求头视图#下载后浏览器会直接弹出,这样就可以分辨出哪些数据是ajax请求版本#刮痧
平台通用框架整理【转载】
O.NET:跨平台的 .NET 运行时环境使得跨平台运行 .NET 成为可能。DotGnuPortable.NET:类似于 MONO.NET 的跨平台运行时。Phalanger:将 PHP 编译成 .NET,实现 PHP 和 .NET 之间的互操作性。VMDotNet:中国移动飞信使用的.NET运行时。Unity3D:微软强烈支持的 C# 和 JavaScript 跨平台游戏开发框架。Cassini、IISExpress 和 Cas
学爬1个月月入6000?别被骗了,高手告诉你爬虫的真实情况
做了很多年了,爬虫当然没问题,所以今天就来深入聊聊5个爬虫问题,让大家了解爬虫的真实情况:1.目前的爬虫真的可以接单一个月赚6000快钱吗?2.初级爬虫只能接一些小订单,初级爬虫什么水平?3.中级爬虫是专业爬虫工程师。他们需要什么?4.高级爬虫可以说是爬虫之神。您需要掌握哪些技术?5.爬虫在更高层次上需要学习什么?顶级爬行动物长什么样?一、爬虫一个月能多赚6000吗?答案是肯定的,但需要
Python爬虫十六-五:BeautifulSoup-好吃的汤
点我开始>>> Python爬虫十六类-第一类:HTTP协议>>> Python爬虫十六类二:urllib和urllib3>>> Python爬虫十六类:请求用法>>> Python爬虫十六类-第四种:使用Xpath提取网页内容>>>十六种Python爬虫-第六种:JQuery的假兄弟-p
爬行动物的概念
爬虫是什么概念?互联网爬虫使用程序根据 URL 地址爬取网页,以获取有用的信息。使用程序模拟浏览器,向服务器发送请求,获取响应信息。数据分析、人工数据集、社交软件冷启动舆情监测、监控竞争对手爬虫分类、通用爬虫、焦点爬虫反爬方式>数据加密
关于爬虫平台的架构设计和实现以及框架的选择(一)
关于爬虫平台的架构设计和实现以及框架的选择(一)关于爬虫平台的架构设计和实现以及框架的选择(二)--内部实现) scrapy和实时爬虫的实现先看下一个爬虫平台的设计,作为一个爬虫平台,需要支持多种不同的爬虫方式,所以一般的爬虫平台需要收录1、的维护@>爬虫规则,当平台收到爬虫请求时,需要能够匹配一定的自动爬虫规则2、爬虫作业调度器,平台需要能够负责爬虫的调度定时调度、轮询调度等任务
C#反爬虫的CSRF
最近在写爬虫的时候,遇到了一个网站,里面有防止CSRF攻击的机制。该接口是一个 POST 请求。用 PostMan 测试后发现需要请求头中的 Cookie 和 FormData 中的 _token 参数才能发起正确的请求。这两个参数缺一不可,有效时间只有一天,因为爬虫是定时任务,每天都会在某个时间自己运行。在这种情况下,每天更换 Cookie 和 Token 太麻烦了。摸索了一会,发现是可以破解的。网页的 CSRF:第一步是 cookie 将
爬虫技术栈点
它确实请求指纹去重(如果要爬取整个站点,则需要使用分布式,不同线程爬虫需要爬取不同页面以实现批量分布式去重),请求分配,以及临时数据存储。7.爬虫之争---反爬虫---反反爬虫:(爬虫最后最难的不是复杂页面的获取,默默无闻的采集数据,难点在于7.@网站后台人员斗智斗勇)最早反爬用的是User-Agent,(每秒点击多少),使用代理,验证码,(不是全部其中12306),动态数据加载,加密数据(数据加密有技巧,核心 查看全部
爬虫抓取网页数据(深入一点的爬虫方向基于身份识别进行反爬基于数据加密进行)
正则表达式
在爬虫中使用正则表达式仍然很常见:
防爬
爬取的三个方向 基于身份识别的反爬 基于爬虫行为的反爬 基于数据加密的反爬 基于数据加密的反爬 基于身份识别的常见反爬 1 通过 headers 字段进行反爬 有headers中的字段很多,都可能是对方服务器拿来判断是否是爬虫1.1 反爬和反爬原理通过headers中的User-Agent字段:爬虫没有默认有一个User-Agent,但是使用模块的默认设置解决方法:在请求之前添加User-Agent即可;更好的方法是使用
爬虫框架
spider爬虫名称爬取域名#创建爬虫程序设置#如果在项目目录下,会得到项目的配置runsspider#运行单独的python文件,交互调试时无需创建项目shell#scrapyshellurl地址,如选择浏览器规则是否正确fetch#独立于进程爬取一个页面,可以得到请求头视图#下载后浏览器会直接弹出,这样就可以分辨出哪些数据是ajax请求版本#刮痧
平台通用框架整理【转载】
O.NET:跨平台的 .NET 运行时环境使得跨平台运行 .NET 成为可能。DotGnuPortable.NET:类似于 MONO.NET 的跨平台运行时。Phalanger:将 PHP 编译成 .NET,实现 PHP 和 .NET 之间的互操作性。VMDotNet:中国移动飞信使用的.NET运行时。Unity3D:微软强烈支持的 C# 和 JavaScript 跨平台游戏开发框架。Cassini、IISExpress 和 Cas
学爬1个月月入6000?别被骗了,高手告诉你爬虫的真实情况
做了很多年了,爬虫当然没问题,所以今天就来深入聊聊5个爬虫问题,让大家了解爬虫的真实情况:1.目前的爬虫真的可以接单一个月赚6000快钱吗?2.初级爬虫只能接一些小订单,初级爬虫什么水平?3.中级爬虫是专业爬虫工程师。他们需要什么?4.高级爬虫可以说是爬虫之神。您需要掌握哪些技术?5.爬虫在更高层次上需要学习什么?顶级爬行动物长什么样?一、爬虫一个月能多赚6000吗?答案是肯定的,但需要
Python爬虫十六-五:BeautifulSoup-好吃的汤
点我开始>>> Python爬虫十六类-第一类:HTTP协议>>> Python爬虫十六类二:urllib和urllib3>>> Python爬虫十六类:请求用法>>> Python爬虫十六类-第四种:使用Xpath提取网页内容>>>十六种Python爬虫-第六种:JQuery的假兄弟-p
爬行动物的概念
爬虫是什么概念?互联网爬虫使用程序根据 URL 地址爬取网页,以获取有用的信息。使用程序模拟浏览器,向服务器发送请求,获取响应信息。数据分析、人工数据集、社交软件冷启动舆情监测、监控竞争对手爬虫分类、通用爬虫、焦点爬虫反爬方式>数据加密
关于爬虫平台的架构设计和实现以及框架的选择(一)
关于爬虫平台的架构设计和实现以及框架的选择(一)关于爬虫平台的架构设计和实现以及框架的选择(二)--内部实现) scrapy和实时爬虫的实现先看下一个爬虫平台的设计,作为一个爬虫平台,需要支持多种不同的爬虫方式,所以一般的爬虫平台需要收录1、的维护@>爬虫规则,当平台收到爬虫请求时,需要能够匹配一定的自动爬虫规则2、爬虫作业调度器,平台需要能够负责爬虫的调度定时调度、轮询调度等任务
C#反爬虫的CSRF
最近在写爬虫的时候,遇到了一个网站,里面有防止CSRF攻击的机制。该接口是一个 POST 请求。用 PostMan 测试后发现需要请求头中的 Cookie 和 FormData 中的 _token 参数才能发起正确的请求。这两个参数缺一不可,有效时间只有一天,因为爬虫是定时任务,每天都会在某个时间自己运行。在这种情况下,每天更换 Cookie 和 Token 太麻烦了。摸索了一会,发现是可以破解的。网页的 CSRF:第一步是 cookie 将
爬虫技术栈点
它确实请求指纹去重(如果要爬取整个站点,则需要使用分布式,不同线程爬虫需要爬取不同页面以实现批量分布式去重),请求分配,以及临时数据存储。7.爬虫之争---反爬虫---反反爬虫:(爬虫最后最难的不是复杂页面的获取,默默无闻的采集数据,难点在于7.@网站后台人员斗智斗勇)最早反爬用的是User-Agent,(每秒点击多少),使用代理,验证码,(不是全部其中12306),动态数据加载,加密数据(数据加密有技巧,核心
爬虫抓取网页数据(如何有效地提取网络爬虫、监视竞争对手或者获取销售线索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2022-04-05 00:17
互联网成为海量信息的载体;互联网是目前分析市场趋势、监控竞争对手或获取销售线索的最佳场所,而数据采集 和分析能力已成为推动业务决策的关键技能。
如何有效地提取和利用这些信息成为了一个巨大的挑战,而网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类、爬虫的爬取策略,以及爬虫深度学习所需的网络基础知识。
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。 查看全部
爬虫抓取网页数据(如何有效地提取网络爬虫、监视竞争对手或者获取销售线索)
互联网成为海量信息的载体;互联网是目前分析市场趋势、监控竞争对手或获取销售线索的最佳场所,而数据采集 和分析能力已成为推动业务决策的关键技能。
如何有效地提取和利用这些信息成为了一个巨大的挑战,而网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类、爬虫的爬取策略,以及爬虫深度学习所需的网络基础知识。
01 什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
Web 爬虫通过从 Internet 上的 网站 服务器上爬取内容来工作。它是用计算机语言编写的程序或脚本,自动从互联网上获取信息或数据,扫描并抓取每个所需页面上的某些信息,直到处理完所有可以正常打开的页面。
作为搜索引擎的重要组成部分,爬虫的主要功能是抓取网页数据(如图2-1所示)。目前市面上流行的采集器软件都是利用网络爬虫的原理或功能。
02 爬行动物的意义
如今,大数据时代已经到来,网络爬虫技术已经成为这个时代不可或缺的一部分。企业需要数据来分析用户行为、自身产品的不足、竞争对手的信息。所有这一切的首要条件是数据。采集。
网络爬虫的价值其实就是数据的价值。在互联网社会,数据是无价的。一切都是数据。谁拥有大量有用的数据,谁就有决策的主动权。网络爬虫的应用领域很多,比如搜索引擎、数据采集、广告过滤、大数据分析等。
1)抓取各大电商公司的产品销售信息和用户评价网站进行分析,如图2-2所示。
▲图2-2 电商产品销售信息网站
2)分析大众点评、美团等餐饮品类网站用户的消费、评价及发展趋势,如图2-3所示。
▲图2-3 餐饮用户消费信息网站
3)分析各城市中学区住房占比,学区房价格比普通二手房高多少,如图2-4所示。
▲图2-4 学区住房比例与价格对比
以上数据是由ForeSpider数据采集软件爬下来的。有兴趣的读者可以尝试自己爬一些数据。
03 爬虫的原理
我们通常将网络爬虫的组件分为初始链接库、网络爬取模块、网页处理模块、网页分析模块、DNS模块、待爬取链接队列、网页库等。网络爬虫的各个模块可以组成一个循环系统,从而不断的分析和抓取。
爬虫的工作原理可以简单地解释为首先找到目标信息网络,然后是页面爬取模块,然后是页面分析模块,最后是数据存储模块。具体细节如图2-5所示。
▲图2-5 爬虫示意图
爬虫工作的基本流程:
首先,选择互联网中的一部分网页,将这些网页的链接地址作为种子URL;
将这些种子URL放入待爬取URL队列,爬虫从待爬取URL队列中依次读取;
通过DNS解析URL;
将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页;
下载的网页是网页文档的形式;
提取 Web 文档中的 URL;
过滤掉已经爬取过的网址;
继续对没有被爬取的URL进行爬取,直到待爬取的URL队列为空。
04 爬虫技术的种类
专注网络爬虫是一种“面向特定主题需求”的爬虫程序,而通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,主要目的是在网站上下载网页互联网到本地,形成互联网内容的镜像备份。
增量爬取是指对某个站点的数据进行爬取。当网站的新数据或站点数据发生变化时,会自动捕获新增或变化的数据。
网页按存在方式可分为表层网页(surface Web)和深层网页(deep Web,又称隐形网页或隐藏网页)。
表面网页是指可以被传统搜索引擎检索到的页面,即主要由可以通过超链接到达的静态网页组成的网页。
深层网页是那些大部分内容无法通过静态链接访问的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。
爬虫抓取网页数据(web页面数据采集工具通达网络爬虫管理工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-02 22:04
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
文章插图
文章插图
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业部署爬虫管理工具后,可以快速下载自有产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息和其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
文章插图
文章插图
网络爬虫工具
【有哪些免费的爬虫软件可以让爬虫精准抓取大数据、获客】吉家通达爬虫管理工具产品成熟,已经在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。 查看全部
爬虫抓取网页数据(web页面数据采集工具通达网络爬虫管理工具(组图))
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
文章插图
文章插图
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业部署爬虫管理工具后,可以快速下载自有产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息和其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面快速执行目标用户需求采集,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
文章插图
文章插图
网络爬虫工具
【有哪些免费的爬虫软件可以让爬虫精准抓取大数据、获客】吉家通达爬虫管理工具产品成熟,已经在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
爬虫抓取网页数据( 如何获取到用户的信息前往用户主页,以轮子哥为例从中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-02 20:26
如何获取到用户的信息前往用户主页,以轮子哥为例从中)
点我去Github查看源码别忘了star
本项目的github地址:
一.如何获取用户信息
进入用户主页,以Brother Wheel为例
从中可以看到用户的详细信息、教育经历主页、专业。行业、公司、关注量、回复数、居住地等。打开开发者工具栏查看网络,可以找到,通常html或json的数据在Html页面中。
网址是,excited-vczh是轮哥的id,只要拿到某个人的id就可以得到详细信息。
二.信息隐藏在哪里?
通过解析这个json数据,可以找到用户信息
根据URL下载Html页面,解析json获取用户信息
三.如何获取更多用户ID
每个人都有自己的关注列表,关注的人和被关注的人,抓住这些人,然后去这些人的主页抓取关注列表,这样你就找不到用户了。
还有nexturl,这个链接可以保存。如果isend为真,则列表翻到最后,不需要保存url
二.爬虫工作流程
有两个爬虫模块。一个爬虫负责从 nexturl 队列中获取 url,下载 json 并解析它。将获取的 nexturl 插入到哈希表中。如果插入成功,则将其添加到队列中。
另一个负责从urltoken队列中获取urltoken,下载解析页面,将用户信息存入数据库,将nexturl存入nexturl队列
三.常见问题解决思路
重复爬取问题
解析出来的Urltoken肯定有很多重复。我很高兴获得了很多数据,但发现它们都是重复的,这是不可接受的。解决方法是将已经加入队列的urltoken放入哈希表中进行标记
从断点爬升
爬取数百万用户是一个相对较大的工作量。不能保证一次爬取完成。中间数据仍然需要持久化。此处选择 Redis 数据库。对于爬取任务,加入队列。如果程序中途停止,重新启动它只需要再次获取队列中的任务并继续爬升
反爬虫问题
爬取过于频繁,服务器返回 429. 这时候需要切换代理IP。我自己搭建了代理IP池(),购买了服务商提供的代理服务。
例如,阿布云:
多台机器一起爬行
任务比较大。在实验室电脑的帮助下,一共有10台电脑,5台电脑安装了Redis,3台作为哈希表,2台作为队列,具有很好的扩展性。 查看全部
爬虫抓取网页数据(
如何获取到用户的信息前往用户主页,以轮子哥为例从中)
点我去Github查看源码别忘了star
本项目的github地址:
一.如何获取用户信息
进入用户主页,以Brother Wheel为例
从中可以看到用户的详细信息、教育经历主页、专业。行业、公司、关注量、回复数、居住地等。打开开发者工具栏查看网络,可以找到,通常html或json的数据在Html页面中。
网址是,excited-vczh是轮哥的id,只要拿到某个人的id就可以得到详细信息。
二.信息隐藏在哪里?
通过解析这个json数据,可以找到用户信息
根据URL下载Html页面,解析json获取用户信息
三.如何获取更多用户ID
每个人都有自己的关注列表,关注的人和被关注的人,抓住这些人,然后去这些人的主页抓取关注列表,这样你就找不到用户了。
还有nexturl,这个链接可以保存。如果isend为真,则列表翻到最后,不需要保存url
二.爬虫工作流程
有两个爬虫模块。一个爬虫负责从 nexturl 队列中获取 url,下载 json 并解析它。将获取的 nexturl 插入到哈希表中。如果插入成功,则将其添加到队列中。
另一个负责从urltoken队列中获取urltoken,下载解析页面,将用户信息存入数据库,将nexturl存入nexturl队列
三.常见问题解决思路
重复爬取问题
解析出来的Urltoken肯定有很多重复。我很高兴获得了很多数据,但发现它们都是重复的,这是不可接受的。解决方法是将已经加入队列的urltoken放入哈希表中进行标记
从断点爬升
爬取数百万用户是一个相对较大的工作量。不能保证一次爬取完成。中间数据仍然需要持久化。此处选择 Redis 数据库。对于爬取任务,加入队列。如果程序中途停止,重新启动它只需要再次获取队列中的任务并继续爬升
反爬虫问题
爬取过于频繁,服务器返回 429. 这时候需要切换代理IP。我自己搭建了代理IP池(),购买了服务商提供的代理服务。
例如,阿布云:
多台机器一起爬行
任务比较大。在实验室电脑的帮助下,一共有10台电脑,5台电脑安装了Redis,3台作为哈希表,2台作为队列,具有很好的扩展性。
爬虫抓取网页数据(get请求返回静态附代码如下最后看看获取的文章写)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-01 10:02
如果使用了对方网站的数据,但是没有响应式界面,或者界面不够灵活,则适合使用爬虫。爬虫有几种类型,其他的网站展示形式都是基于分析的。每个 网站 显示都有相同点和不同点。大部分都可以使用httpRequest来完成,不管是加了密码、随机码、请求参数、提交方式get还是post、地址来源、多重响应等。但是有些网站如果返回json或者固定格式使用ajax,如果很复杂可以用webbrower控件抓取,最后定期解析得到需要的数据。那么我们来抓取网站列表文章标题、文章摘要、文章发布时间、文章作者、文章评论次数、文章查看次数。看结构图。
get请求返回静态html,代码如下
public class HttpCnblogs
{
public static List HttpGetHtml()
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("http://www.cnblogs.com/");
request.Method = "GET";
request.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request.UserAgent = " Mozilla/5.0 (Windows NT 6.1; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string articleContent = sr.ReadToEnd();
List list = new List();
#region 正则表达式
//div post_item_body列表
Regex regBody = new Regex(@"([\s\S].*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//a标签 文章标题 作者名字 评论 阅读
Regex regA = new Regex("]*?>(.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//p标签 文章内容
Regex regP = new Regex(@"(.*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取评论 阅读次数如:评论(10)-》10
Regex regNumbernew = new Regex(@"\d+", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取时间
Regex regTime = new Regex(@"\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
#endregion
MatchCollection mList = regBody.Matches(articleContent);
CnblogsModel model = null;
String strBody = String.Empty;
for (int i = 0; i < mList.Count; i++)
{
model = new CnblogsModel();
strBody = mList[i].Groups[1].ToString();
MatchCollection aList = regA.Matches(strBody);
int aCount = aList.Count;
model.ArticleTitle = aList[0].Groups[1].ToString();
model.ArticleAutor = aCount == 5 ? aList[2].Groups[1].ToString() : aList[1].Groups[1].ToString();
model.ArticleComment = Convert.ToInt32(regNumbernew.Match(aList[aCount-2].Groups[1].ToString()).Value);
model.ArticleTime = regTime.Match(strBody).Value;
model.ArticleView = Convert.ToInt32(regNumbernew.Match(aList[aCount-1].Groups[1].ToString()).Value);
model.ArticleContent = regP.Matches(strBody)[0].Groups[1].ToString();
list.Add(model);
}
return list;
}
}
public class CnblogsModel
{
///
/// 文章标题
///
public String ArticleTitle { get; set; }
///
/// 文章内容摘要
///
public String ArticleContent { get; set; }
///
/// 文章作者
///
public String ArticleAutor { get; set; }
///
/// 文章发布时间
///
public String ArticleTime { get; set; }
///
/// 文章评论量
///
public Int32 ArticleComment { get; set; }
///
/// 文章浏览量
///
public Int32 ArticleView { get; set; }
}
</p>
最后看一下获取的文章model
我很抱歉写得不好,但我已经为下一次采访做好了准备。 . 查看全部
爬虫抓取网页数据(get请求返回静态附代码如下最后看看获取的文章写)
如果使用了对方网站的数据,但是没有响应式界面,或者界面不够灵活,则适合使用爬虫。爬虫有几种类型,其他的网站展示形式都是基于分析的。每个 网站 显示都有相同点和不同点。大部分都可以使用httpRequest来完成,不管是加了密码、随机码、请求参数、提交方式get还是post、地址来源、多重响应等。但是有些网站如果返回json或者固定格式使用ajax,如果很复杂可以用webbrower控件抓取,最后定期解析得到需要的数据。那么我们来抓取网站列表文章标题、文章摘要、文章发布时间、文章作者、文章评论次数、文章查看次数。看结构图。
get请求返回静态html,代码如下
public class HttpCnblogs
{
public static List HttpGetHtml()
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("http://www.cnblogs.com/";);
request.Method = "GET";
request.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request.UserAgent = " Mozilla/5.0 (Windows NT 6.1; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0";
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader sr = new StreamReader(stream);
string articleContent = sr.ReadToEnd();
List list = new List();
#region 正则表达式
//div post_item_body列表
Regex regBody = new Regex(@"([\s\S].*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//a标签 文章标题 作者名字 评论 阅读
Regex regA = new Regex("]*?>(.*?)</a>", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//p标签 文章内容
Regex regP = new Regex(@"(.*?)", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取评论 阅读次数如:评论(10)-》10
Regex regNumbernew = new Regex(@"\d+", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
//提取时间
Regex regTime = new Regex(@"\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}", RegexOptions.IgnoreCase | RegexOptions.Singleline | RegexOptions.IgnorePatternWhitespace);
#endregion
MatchCollection mList = regBody.Matches(articleContent);
CnblogsModel model = null;
String strBody = String.Empty;
for (int i = 0; i < mList.Count; i++)
{
model = new CnblogsModel();
strBody = mList[i].Groups[1].ToString();
MatchCollection aList = regA.Matches(strBody);
int aCount = aList.Count;
model.ArticleTitle = aList[0].Groups[1].ToString();
model.ArticleAutor = aCount == 5 ? aList[2].Groups[1].ToString() : aList[1].Groups[1].ToString();
model.ArticleComment = Convert.ToInt32(regNumbernew.Match(aList[aCount-2].Groups[1].ToString()).Value);
model.ArticleTime = regTime.Match(strBody).Value;
model.ArticleView = Convert.ToInt32(regNumbernew.Match(aList[aCount-1].Groups[1].ToString()).Value);
model.ArticleContent = regP.Matches(strBody)[0].Groups[1].ToString();
list.Add(model);
}
return list;
}
}
public class CnblogsModel
{
///
/// 文章标题
///
public String ArticleTitle { get; set; }
///
/// 文章内容摘要
///
public String ArticleContent { get; set; }
///
/// 文章作者
///
public String ArticleAutor { get; set; }
///
/// 文章发布时间
///
public String ArticleTime { get; set; }
///
/// 文章评论量
///
public Int32 ArticleComment { get; set; }
///
/// 文章浏览量
///
public Int32 ArticleView { get; set; }
}
</p>
最后看一下获取的文章model
我很抱歉写得不好,但我已经为下一次采访做好了准备。 .
爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2022-04-01 09:33
接上一篇:stata爬虫爬取网页数据详解part 1
本文的do-file及相关文件链接:密码:40uq
如果链接失效,请私信,看到后我会回复,谢谢。
我们开始抓取1000个网页的源代码,将temp1.txt—temp1000.txt保存在e盘2文件夹中,再次使用“Merge.bat”将1000个txt合并为一个文件all.txt,先把命令放在这里,一一解释:
注意:第一行的本地命令必须用以下两个循环运行,否则会提示错误,原因会在下面解释。
抓取1000个网页源代码并合并
使用local命令生成一个临时变量N = _N(注意:在stata中,_n和_N都是默认变量,有固定的含义。_N代表观察次数,当然等于1000,_n代表从1到1000,要理解这两个,可以用gen N = _N,和gen n = _n,然后浏览看看N和n有什么不同),但是本地命令生成的变量N不会显示在变量窗口,而是临时存放在stata的内存中,需要的时候可以调用。下面是一个小例子来演示local的作用(需要注意的是local命令行和下一行调用local生成的变量的命令必须一起运行,否则会提示错误,因为本地宏命令生成的变量只是临时的,一旦遇到end of do-file【观察stata主界面,每条命令运行后都会提示end of do-file】,生成的临时变量会是已删除,无法再次调用。详见下图官方英文。解释,以蓝色突出显示,尤其是最后一句):
演示本地命令,比较_n和_N的区别
关于marco宏的进一步解释,有兴趣的可以参考官方帮助文件中的相关说明,如下:
marco宏的官方解释
了解了local之后,再看接下来的两个循环就容易多了。第二个循环是把url变量映射到purl变量上(purl变量就是前面1000个链接)并存储起来,但是变量窗口中没有显示出来,第三个循环是调用存储在里面的1000个url url变量,把这1000个网页的源代码复制下来,存放在e盘的2文件夹中,命名为temp1.txt —temp1000.txt,这个过程取决于网页的速度网络,大约需要30分钟,数字变化如下图,最后temp1000.txt完成。之所以会提示not found,是因为我们在grab命令后面加上了replace选项,就是告诉stata如果在e盘2文件夹中找到同名文件就替换掉,但是stata发现没有同名的文件,所以会提示找不到,并按要求生成新文件。如果stata找到同名文件,则不会有这个提示,而是直接替换掉。
爬取1000个网页源码流程
等了好久,终于用我们在part 1中使用的bat批处理命令调用dos将1000个txt合并到all.txt中(这次是在文件夹2中处理,和之前的all.txt不同) . 到目前为止,已经获得了1000个网页的源代码。这1000个网页的源代码非常重要,因为我们需要的GDP信息都收录在其中。同理,我们使用中缀命令将其读入stata进行处理。该命令如文章开头的图中所示。因为文本比较大,所以最好在阅读文本之前先清除,否则可能会导致stata崩溃,长时间写dofile。不保存就不好了(具体原因不明,推测可能是内存不够?。?)。
文本读入后变成变量v,然后开始过滤净化,这也是最复杂的工作,因为总共735748行代码只需要提取两条信息,一条一个是“某个地区的几年”,一个是“GDP”。根据我们需要的信息,寻找收录这两条信息的关键行,观察它们所在行的共同特征。通过观察,我们可以看到,地区名称所在的行都收录这样的字符,而GDP或生产总值所在的行收录“生产总值”等字符(如下图所示),所以我们只需要保留收录这两个字符的代码行。
观察代码行特征,发现规律
第一步:设置两个指标变量(以虚拟变量的形式)a和b。对于a变量,如果v变量(即所有代码行所在的变量)收录,让stata返回值1,表示“是收录”,否则返回0,表示“不收录”收录”。类似地,b 变量是以“总产量”为指标生成的。然后,保持 if a==1 | b==1 表示保留收录或收录“总产量”的行。这一步很快将代码行数过滤到只有 4570 行。
生成两个指标变量
第2步-第N步:都是砍、守、砍、守、砍、守……因为仁者见仁,智者见智,我的不一定是最好的,但道理是一样的。所以只对用到的部分命令和函数进行说明,见do-file中的相关注释【strpos,duplicates drop】。
剪切和替换
继续切割,更换,保持
最终数据
可以看到,有些数据前面有一些乱七八糟的字符。这是因为每个公告的书写格式不统一。它需要继续处理。方法同上,拆分、替换、保留。我不会在这里继续演示。有兴趣可以继续。
随便找一些数据在网站上查看,看看对应的数据是否准确。比如我从上图左右两边随机选取了2015年的合肥市和2013年的九江市进行验证,查询结果如下,经核对无误:
查询验证结果
最后,对于空缺的部分,你可以去网站找数据补上。另外,这次我应得的1000行数据,但最终得到了1015行数据。原因可能是公报的格式不完全统一,有的数据是省级GDP(少),有的是市级GDP。,因此是重复部分。此类错误必须由研究人员自己处理。
好了,到此详细讲解就结束了,撒花!(0.0)
最后提示:stata 12、13 白色主界面默认不支持中文,中文显示为乱码。可以在主界面任意位置右击—>Preferences,然后将配色模式从Standard改为Classic Mode就可以正常显示中文了。
标准—>经典 查看全部
爬虫抓取网页数据(篇:详解stata爬虫抓取网页上的数据part1)
接上一篇:stata爬虫爬取网页数据详解part 1
本文的do-file及相关文件链接:密码:40uq
如果链接失效,请私信,看到后我会回复,谢谢。
我们开始抓取1000个网页的源代码,将temp1.txt—temp1000.txt保存在e盘2文件夹中,再次使用“Merge.bat”将1000个txt合并为一个文件all.txt,先把命令放在这里,一一解释:
注意:第一行的本地命令必须用以下两个循环运行,否则会提示错误,原因会在下面解释。
抓取1000个网页源代码并合并
使用local命令生成一个临时变量N = _N(注意:在stata中,_n和_N都是默认变量,有固定的含义。_N代表观察次数,当然等于1000,_n代表从1到1000,要理解这两个,可以用gen N = _N,和gen n = _n,然后浏览看看N和n有什么不同),但是本地命令生成的变量N不会显示在变量窗口,而是临时存放在stata的内存中,需要的时候可以调用。下面是一个小例子来演示local的作用(需要注意的是local命令行和下一行调用local生成的变量的命令必须一起运行,否则会提示错误,因为本地宏命令生成的变量只是临时的,一旦遇到end of do-file【观察stata主界面,每条命令运行后都会提示end of do-file】,生成的临时变量会是已删除,无法再次调用。详见下图官方英文。解释,以蓝色突出显示,尤其是最后一句):
演示本地命令,比较_n和_N的区别
关于marco宏的进一步解释,有兴趣的可以参考官方帮助文件中的相关说明,如下:
marco宏的官方解释
了解了local之后,再看接下来的两个循环就容易多了。第二个循环是把url变量映射到purl变量上(purl变量就是前面1000个链接)并存储起来,但是变量窗口中没有显示出来,第三个循环是调用存储在里面的1000个url url变量,把这1000个网页的源代码复制下来,存放在e盘的2文件夹中,命名为temp1.txt —temp1000.txt,这个过程取决于网页的速度网络,大约需要30分钟,数字变化如下图,最后temp1000.txt完成。之所以会提示not found,是因为我们在grab命令后面加上了replace选项,就是告诉stata如果在e盘2文件夹中找到同名文件就替换掉,但是stata发现没有同名的文件,所以会提示找不到,并按要求生成新文件。如果stata找到同名文件,则不会有这个提示,而是直接替换掉。
爬取1000个网页源码流程
等了好久,终于用我们在part 1中使用的bat批处理命令调用dos将1000个txt合并到all.txt中(这次是在文件夹2中处理,和之前的all.txt不同) . 到目前为止,已经获得了1000个网页的源代码。这1000个网页的源代码非常重要,因为我们需要的GDP信息都收录在其中。同理,我们使用中缀命令将其读入stata进行处理。该命令如文章开头的图中所示。因为文本比较大,所以最好在阅读文本之前先清除,否则可能会导致stata崩溃,长时间写dofile。不保存就不好了(具体原因不明,推测可能是内存不够?。?)。
文本读入后变成变量v,然后开始过滤净化,这也是最复杂的工作,因为总共735748行代码只需要提取两条信息,一条一个是“某个地区的几年”,一个是“GDP”。根据我们需要的信息,寻找收录这两条信息的关键行,观察它们所在行的共同特征。通过观察,我们可以看到,地区名称所在的行都收录这样的字符,而GDP或生产总值所在的行收录“生产总值”等字符(如下图所示),所以我们只需要保留收录这两个字符的代码行。
观察代码行特征,发现规律
第一步:设置两个指标变量(以虚拟变量的形式)a和b。对于a变量,如果v变量(即所有代码行所在的变量)收录,让stata返回值1,表示“是收录”,否则返回0,表示“不收录”收录”。类似地,b 变量是以“总产量”为指标生成的。然后,保持 if a==1 | b==1 表示保留收录或收录“总产量”的行。这一步很快将代码行数过滤到只有 4570 行。
生成两个指标变量
第2步-第N步:都是砍、守、砍、守、砍、守……因为仁者见仁,智者见智,我的不一定是最好的,但道理是一样的。所以只对用到的部分命令和函数进行说明,见do-file中的相关注释【strpos,duplicates drop】。
剪切和替换
继续切割,更换,保持
最终数据
可以看到,有些数据前面有一些乱七八糟的字符。这是因为每个公告的书写格式不统一。它需要继续处理。方法同上,拆分、替换、保留。我不会在这里继续演示。有兴趣可以继续。
随便找一些数据在网站上查看,看看对应的数据是否准确。比如我从上图左右两边随机选取了2015年的合肥市和2013年的九江市进行验证,查询结果如下,经核对无误:
查询验证结果
最后,对于空缺的部分,你可以去网站找数据补上。另外,这次我应得的1000行数据,但最终得到了1015行数据。原因可能是公报的格式不完全统一,有的数据是省级GDP(少),有的是市级GDP。,因此是重复部分。此类错误必须由研究人员自己处理。
好了,到此详细讲解就结束了,撒花!(0.0)
最后提示:stata 12、13 白色主界面默认不支持中文,中文显示为乱码。可以在主界面任意位置右击—>Preferences,然后将配色模式从Standard改为Classic Mode就可以正常显示中文了。
标准—>经典
爬虫抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-28 18:11
Scraping 程序只处理一种类型的请求:一个名为 / 的资源的 GET,它是 Stats::Controller 包中的屏幕抓取和数据处理代码。供您查看的是源文件 scrape.pl 顶部的 Plack/PSGI 路由设置:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 仅具有高级逻辑,将屏幕抓取和生成报告的详细信息留在 Util.pm 文件中的实用程序函数中,如下一节所述。
屏幕抓取代码
回想一下,Plack 服务器将 GET 请求分派到 localhost:5000/ 到抓取程序的 get_index 函数。然后,此函数充当请求处理程序并执行以下操作:检索要抓取的数据、抓取数据并生成最终报告。数据检索部分是一个实用功能,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器获取数据。使用数据文档,抓取程序将调用实用函数 extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 XML::LibXML 等 Perl 包通过显式 XML 解析来提取数据。但是,HTML::TableExtract 包生成了 HTML::TableExtract,因为它的 HTML::TableExtract 绕过了 XML 解析,并且(使用很少的代码)提供了用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 包 HTML ::TableExtract 表格是目标。以下是数据提取的三个关键代码行:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
调用 TableExtract::parse 函数后,抓取程序将使用 TableExtract::rows 函数迭代提取的数据行(没有 HTML 标记的数据行)。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 散列中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据,在本例中使用 Statistics::Descriptive 包进行基本统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
抓取程序的最后一步是生成报告。Perl 有生成 HTML 的选项,其中有 Template::Recall。顾名思义,此包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标记和自定义标记,用作后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码和模板交互的方式。
报表文档(图1)有两个表。顶层表是迭代生成的,因为每一行都有相同的列(学习区、第25个百分位收入等)。在每次迭代中,代码都会创建一个hash具有特定学习域的值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
散列键是 Perl 的裸词,例如 major 和工资表示之前从 HTML 数据文档中提取的数据值的列表项。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部标签分别标记要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为major 的模板列将匹配以major 作为键的散列条目。以下是将数据绑定到自定义标签的后端代码中的调用:
print OUTFILE $tr -> render ( 'end1' ) ;
引用 $tr 指向 Template::Recall 实例,OUTFILE 是报告文件reportFinal.html,由模板文件report.html 与后端代码一起生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的内容(参见 1))。
抓取工具借鉴了优秀的 Perl 包,例如 Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall 和 Statistics::Descriptive,用于屏幕抓取的 HTML::TableExtract 任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展 Scraping 程序以对提取的数据进行聚类:Algorithm::KMeans 包适合此扩展,并且可以使用 rawData.dat 文件中来自 Algorithm::KMeans 的数据。
翻译自:
vba数据抓取屏幕数据 查看全部
爬虫抓取网页数据(Scraping程序仅处理一种类型的请求:名为/的资源的GET)
Scraping 程序只处理一种类型的请求:一个名为 / 的资源的 GET,它是 Stats::Controller 包中的屏幕抓取和数据处理代码。供您查看的是源文件 scrape.pl 顶部的 Plack/PSGI 路由设置:
my
$router
= router
{
<br />
match
'/'
,
{ method
=>
'GET'
}
,
## noun/verb combo: / is noun, GET is verb
<br />
to
{ controller
=>
'Controller'
, action
=>
'index'
}
;
## handler is function get_index
<br />
# Other actions as needed
<br />
}
;
请求处理程序 Controller::get_index 仅具有高级逻辑,将屏幕抓取和生成报告的详细信息留在 Util.pm 文件中的实用程序函数中,如下一节所述。
屏幕抓取代码
回想一下,Plack 服务器将 GET 请求分派到 localhost:5000/ 到抓取程序的 get_index 函数。然后,此函数充当请求处理程序并执行以下操作:检索要抓取的数据、抓取数据并生成最终报告。数据检索部分是一个实用功能,它使用 Perl 的 LWP::Agent 包从托管 data.html 文档的任何服务器获取数据。使用数据文档,抓取程序将调用实用函数 extract_from_html 进行数据提取。
data.html 文档恰好是格式良好的 XML,这意味着可以使用 XML::LibXML 等 Perl 包通过显式 XML 解析来提取数据。但是,HTML::TableExtract 包生成了 HTML::TableExtract,因为它的 HTML::TableExtract 绕过了 XML 解析,并且(使用很少的代码)提供了用于提取数据的 Perl 哈希。HTML 文档中的数据聚合通常出现在列表或表格中,而 HTML::TableExtract 包 HTML ::TableExtract 表格是目标。以下是数据提取的三个关键代码行:
my
$col_headers
= col_headers
(
)
;
## col_headers() returns an array of the table's column names
<br />
my
$te
= HTML
::
TableExtract
->
new
( headers
=>
$col_headers
)
;
<br />
$te
->
parse
(
$page
)
;
## $page is data.html
$col_headers 指的是 Perl 字符串数组,每个字符串都是 HTML 文档中的列标题:
sub col_headers
{
## column headers in the HTML table
<br />
return
[
"Area"
,
<br />
"MedianWage"
,
<br />
...
<br />
"BoostFromGradDegree"
]
;
<br />
}
调用 TableExtract::parse 函数后,抓取程序将使用 TableExtract::rows 函数迭代提取的数据行(没有 HTML 标记的数据行)。这些行(作为 Perl 列表)被添加到名为 %majors_hash 的 Perl 散列中,如下所示:
收录提取数据的哈希将写入本地文件 rawData.dat:
ForeignLanguage 50000 35000 75000 3.5% 54% 101%
<br />
LiberalArts 47000 32000 70000 9.7% 41% 48%
<br />
...
<br />
Engineering 78000 54000 104000 8.2% 37% 32%
<br />
Computing 75000 51000 112000 5.1% 32% 31%
<br />
...
<br />
PublicPolicy 50000 36000 74000 2.3% 24% 45%
下一步是处理提取的数据,在本例中使用 Statistics::Descriptive 包进行基本统计分析。在上面的图 1 中,统计摘要显示在报告底部的单独表格中。
报告生成代码
抓取程序的最后一步是生成报告。Perl 有生成 HTML 的选项,其中有 Template::Recall。顾名思义,此包从 HTML 模板生成 HTML,该模板混合了标准 HTML 标记和自定义标记,用作后端代码生成的数据的占位符。模板文件是report.html,感兴趣的后端函数是Controller::generate_report。这就是代码和模板交互的方式。
报表文档(图1)有两个表。顶层表是迭代生成的,因为每一行都有相同的列(学习区、第25个百分位收入等)。在每次迭代中,代码都会创建一个hash具有特定学习域的值:
my
%row
=
(
<br />
major
=>
$key
,
<br />
wage
=>
'$'
. commify
(
$values
[
0
]
)
,
## commify turns 1234 into 1,234
<br />
p25
=>
'$'
. commify
(
$values
[
1
]
)
,
<br />
p75
=>
'$'
. commify
(
$values
[
2
]
)
,
<br />
population
=>
$values
[
3
]
,
<br />
grad
=>
$values
[
4
]
,
<br />
boost
=>
$values
[
5
]
<br />
)
;
散列键是 Perl 的裸词,例如 major 和工资表示之前从 HTML 数据文档中提取的数据值的列表项。对应的HTML模板如下:
[ === even === ]
<br />
<br />
['major']
<br />
['p25']
<br />
['wage']
<br />
['p75']
<br />
['pop']
<br />
['grad']
<br />
['boost']
<br />
<br />
[=== end1 ===]
自定义标签在方括号中。顶部和底部标签分别标记要渲染的模板区域的开始和结束。其他自定义标签标识后端代码的各种目标。例如,标识为major 的模板列将匹配以major 作为键的散列条目。以下是将数据绑定到自定义标签的后端代码中的调用:
print OUTFILE $tr -> render ( 'end1' ) ;
引用 $tr 指向 Template::Recall 实例,OUTFILE 是报告文件reportFinal.html,由模板文件report.html 与后端代码一起生成。如果一切顺利,reportFinal.html 文件就是用户在浏览器中看到的内容(参见 1))。
抓取工具借鉴了优秀的 Perl 包,例如 Plack/PSGI、LWP::Agent、HTML::TableExtract、Template::Recall 和 Statistics::Descriptive,用于屏幕抓取的 HTML::TableExtract 任务。这些包可以很好地协同工作,因为每个包都针对特定的子任务。最后,可以扩展 Scraping 程序以对提取的数据进行聚类:Algorithm::KMeans 包适合此扩展,并且可以使用 rawData.dat 文件中来自 Algorithm::KMeans 的数据。
翻译自:
vba数据抓取屏幕数据
爬虫抓取网页数据(什么是两个最流行的网页抓取框架?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-28 03:19
由于两个最流行的浏览器现在提供无头选项,因此有很多选择。无头模式适用于 Chrome 和 Firefox(68.60% 和 8.17% 的浏览器市场份额)。在主流选项之外,PhantomJS 和 Zombie.JS 是网络爬虫中的流行选择。此外,无头浏览器需要自动化工具来运行网络抓取脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据解析是使先前获取的数据易于理解和使用的过程。大多数数据采集方法采集难以理解的数据。因此,解析和翻译成可理解的结果尤为重要。
如前所述,由于易于访问和优化的库,Python 是一种流行的定价情报获取语言。BeautifulSoup、LXML 等是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,可以让这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更容易导航大量数据。
数据存储
数据存储过程通常取决于容量和类型。虽然建议为定价情报(和其他连续项目)构建一个专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中并没有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,但应始终牢记一件事——数据的清洁度。从错误索引的数据库中检索存储的数据可能会变得很麻烦。找到正确的方向并从一开始就遵循相同的方案可以在大多数数据存储问题开始之前解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是很容易的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本、查找合适的库并将获取的数据导出为 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
如今,大多数网页都可以检测到类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全一样,因为它们通过访问 URL 列表不断地执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于保持对相同 URL 的持续访问并绕过 IP 阻止,使它们成为任何 data采集 项目的关键组件。使用这种数据采集技术创建针对特定目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许其用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要以模仿此类活动的方式编写数据采集脚本,它们就被视为普通互联网用户。
代理是任何网络抓取想法的关键组成部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎的反爬措施复杂,需要使用不同的爬取策略。
代理的艰辛
如前所述,轮换代理是任何成功的数据采集方法的关键,包括网络抓取。如果您想避免 IP 阻塞,保持您作为普通互联网用户的形象至关重要。
但是,您需要多久更换一次代理、应该使用哪种类型的代理等具体细节在很大程度上取决于抓取目标、数据提取频率和其他因素。这些复杂性使代理管理成为网络抓取中最难的部分。
虽然每个业务案例都是独一无二的并且需要特定的解决方案,但为了以最高效率使用代理,必须遵循指南。在数据采集行业有经验的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商已经制定了避免 IP 地址阻塞的指南。
如前所述,维护普通互联网用户的形象是避免 IP 阻塞的重要部分。虽然有许多不同的代理类型,但没有人比住宅代理更擅长这一特定任务。住宅代理是连接到真实机器并由互联网服务提供商分配的 IP。从正确的方向开始,为电子商务数据采集选择住宅代理会使整个过程变得更加容易。
电子商务住宅代理
住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电子商务数据采集,因为大部分数据 采集 需要维护特定身份。电子商务企业通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他企业积极阻止或向他们认为是竞争对手(或爬虫)的访问者显示不准确的信息。因此,切换 IP 和位置(例如从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。随着网站实施更复杂的反爬虫算法和轻松检测类似爬虫的活动,这些代理允许网络爬虫重置任何采集到的关于其行为的怀疑网站。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标对于它认为类似于爬虫的活动都有略微不同的参数。因此,策略也需要相应调整。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,越高级、越大、越重要的电子商务网站,越难通过网络抓取来解决。反复试验通常是创建有效网络抓取策略的唯一方法。
总结
想要构建您的第一个网络爬虫?注册并开始使用 Oxylabs 的住宅代理!想要更多细节或定制计划?可与我们的销售团队一起使用!您需要的所有互联网数据只需单击一下即可! 查看全部
爬虫抓取网页数据(什么是两个最流行的网页抓取框架?-八维教育)
由于两个最流行的浏览器现在提供无头选项,因此有很多选择。无头模式适用于 Chrome 和 Firefox(68.60% 和 8.17% 的浏览器市场份额)。在主流选项之外,PhantomJS 和 Zombie.JS 是网络爬虫中的流行选择。此外,无头浏览器需要自动化工具来运行网络抓取脚本。Selenium 是最流行的网页抓取框架。
数据分析
数据解析是使先前获取的数据易于理解和使用的过程。大多数数据采集方法采集难以理解的数据。因此,解析和翻译成可理解的结果尤为重要。
如前所述,由于易于访问和优化的库,Python 是一种流行的定价情报获取语言。BeautifulSoup、LXML 等是数据解析的流行选择。
解析允许开发人员通过搜索 HTML 或 XML 文件的特定部分来对数据进行排序。像 BeautifulSoup 这样的解析器带有内置的对象和命令,可以让这个过程更容易。大多数解析库通过将搜索或打印命令附加到常见的 HTML/XML 文档元素来更容易导航大量数据。
数据存储
数据存储过程通常取决于容量和类型。虽然建议为定价情报(和其他连续项目)构建一个专用数据库,但对于较短或一次性的项目,将所有内容存储在几个 CSV 或 JSON 文件中并没有什么坏处。
数据存储是一个相当简单的步骤,几乎没有问题,但应始终牢记一件事——数据的清洁度。从错误索引的数据库中检索存储的数据可能会变得很麻烦。找到正确的方向并从一开始就遵循相同的方案可以在大多数数据存储问题开始之前解决它们。
长期数据存储是整个采集流程的最后一步。编写数据提取脚本、找到所需的目标、解析和存储数据是很容易的部分。避免反爬虫检测算法和 IP 地址禁令是真正的挑战。
代理管理
到目前为止,网络抓取似乎很简单。创建脚本、查找合适的库并将获取的数据导出为 CSV 或 JSON 文件。然而,大多数网页所有者并不热衷于向任何人提供大量数据。
如今,大多数网页都可以检测到类似爬虫的活动,并简单地阻止有问题的 IP 地址(或整个网络)。数据提取脚本的行为与爬虫完全一样,因为它们通过访问 URL 列表不断地执行循环过程。因此,通过网络抓取采集数据通常会导致 IP 地址被禁止。
代理用于保持对相同 URL 的持续访问并绕过 IP 阻止,使它们成为任何 data采集 项目的关键组件。使用这种数据采集技术创建针对特定目标的代理策略对于项目的成功至关重要。
住宅代理是数据采集项目中最常用的类型。这些代理允许其用户从常规机器发送请求,从而避免地理或任何其他限制。此外,只要以模仿此类活动的方式编写数据采集脚本,它们就被视为普通互联网用户。
代理是任何网络抓取想法的关键组成部分
当然,爬虫检测算法也适用于代理。获取和管理高级代理是任何成功的数据获取项目的一部分。避免 IP 阻塞的一个关键部分是地址轮换。
然而,代理轮换的问题并没有就此结束。爬虫检测算法会因目标而异。大型电商网站或搜索引擎的反爬措施复杂,需要使用不同的爬取策略。
代理的艰辛
如前所述,轮换代理是任何成功的数据采集方法的关键,包括网络抓取。如果您想避免 IP 阻塞,保持您作为普通互联网用户的形象至关重要。
但是,您需要多久更换一次代理、应该使用哪种类型的代理等具体细节在很大程度上取决于抓取目标、数据提取频率和其他因素。这些复杂性使代理管理成为网络抓取中最难的部分。
虽然每个业务案例都是独一无二的并且需要特定的解决方案,但为了以最高效率使用代理,必须遵循指南。在数据采集行业有经验的公司对爬虫检测算法有最深入的了解。根据他们的案例研究,代理和数据采集工具提供商已经制定了避免 IP 地址阻塞的指南。
如前所述,维护普通互联网用户的形象是避免 IP 阻塞的重要部分。虽然有许多不同的代理类型,但没有人比住宅代理更擅长这一特定任务。住宅代理是连接到真实机器并由互联网服务提供商分配的 IP。从正确的方向开始,为电子商务数据采集选择住宅代理会使整个过程变得更加容易。
电子商务住宅代理
住宅代理是大多数网络抓取想法的最常见选择
住宅代理用于电子商务数据采集,因为大部分数据 采集 需要维护特定身份。电子商务企业通常使用多种算法来计算价格,其中一些取决于消费者的属性。其他企业积极阻止或向他们认为是竞争对手(或爬虫)的访问者显示不准确的信息。因此,切换 IP 和位置(例如从加拿大代理切换到德国代理)至关重要。
住宅代理是任何电子商务数据采集工具的第一道防线。随着网站实施更复杂的反爬虫算法和轻松检测类似爬虫的活动,这些代理允许网络爬虫重置任何采集到的关于其行为的怀疑网站。但是,没有足够的住宅代理在每次请求后切换 IP。因此,为了有效地使用住宅代理,需要实施某些策略。
代理轮换基础知识
制定避免 IP 阻塞的策略需要时间和经验。每个目标对于它认为类似于爬虫的活动都有略微不同的参数。因此,策略也需要相应调整。
为代理轮换采集电子商务数据有几个基本步骤:
请记住,每个目标都是不同的。一般来说,越高级、越大、越重要的电子商务网站,越难通过网络抓取来解决。反复试验通常是创建有效网络抓取策略的唯一方法。
总结
想要构建您的第一个网络爬虫?注册并开始使用 Oxylabs 的住宅代理!想要更多细节或定制计划?可与我们的销售团队一起使用!您需要的所有互联网数据只需单击一下即可!
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-28 03:17
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个改进版本,试图支持这些可能性。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次提取中非常有用,除了避免解析整个网页的开销之外,如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,一般来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些特定场景下才有用。 查看全部
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个改进版本,试图支持这些可能性。
>>> re.findall('.*?(.*?)',html)['244,820 square kilometres']
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
pip install beautifulsoup4
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页不是格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
Area
Population
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
>>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com ... 39%3B
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com ... %2339;).read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次提取中非常有用,除了避免解析整个网页的开销之外,如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,一般来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些特定场景下才有用。
爬虫抓取网页数据(先来说下数据抓取系统的大致工作流程.下背景 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-27 18:05
)
公司的数据采集系统也写了一段时间了,该总结一下了,不然凭我的记忆力,一会就快忘记了。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,让我们谈谈数据捕获的一般工作流程。
先说一下背景,这家公司是做企业征信服务的。整合各个方面的数据以生成商业信用报告。主要数据来源,包括:第三方采购(整体采购数据或接口形式);捕获在 Internet 上发布的数据。那么就需要一个数据采集平台,以便为采集方便快捷的添加新的数据对象。对于数据采集平台的架构设计,本人也是新手,以后在学习的同时总结这方面的经验和教训。本系列从实战开始,然后是第一个子弹:数据采集的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人认为这三个步骤是我做的。不过,先听我说。##清除数据采集先分享场景的要求:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张加班后还没有完成任务。是因为产品经理没有把需求解释清楚吗?但产品经理也表示,这个页面上的所有内容都是必需的。问题是:
要分析数据为采集的url和相关参数,我先走一下我抓取数据的流程,看下面四张图:
提取url和参数
从以上四张图我们可以确认有以下几个连接需要处理:- 1、获取验证码连接- 2、提交查询- 3、查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用chrome的开发者工具来分析页面。有很多类似的工具。各个浏览器自带的开发者工具基本可以满足需求。也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们提取了企业的基本注册信息为采集,我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。这个文章就不详细介绍代码实现的具体逻辑了,因为本文的重点是讲解:爬取网页的工作流程。后面代码实现过程中用到的关键技术点和踩过的坑都会一一总结。暂列涉及的相关内容:
也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天做个小笔记,每天进步一点:
善待大众:enilu123
查看全部
爬虫抓取网页数据(先来说下数据抓取系统的大致工作流程.下背景
)
公司的数据采集系统也写了一段时间了,该总结一下了,不然凭我的记忆力,一会就快忘记了。我打算写一个系列来记录我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,让我们谈谈数据捕获的一般工作流程。
先说一下背景,这家公司是做企业征信服务的。整合各个方面的数据以生成商业信用报告。主要数据来源,包括:第三方采购(整体采购数据或接口形式);捕获在 Internet 上发布的数据。那么就需要一个数据采集平台,以便为采集方便快捷的添加新的数据对象。对于数据采集平台的架构设计,本人也是新手,以后在学习的同时总结这方面的经验和教训。本系列从实战开始,然后是第一个子弹:数据采集的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人认为这三个步骤是我做的。不过,先听我说。##清除数据采集先分享场景的要求:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张加班后还没有完成任务。是因为产品经理没有把需求解释清楚吗?但产品经理也表示,这个页面上的所有内容都是必需的。问题是:
要分析数据为采集的url和相关参数,我先走一下我抓取数据的流程,看下面四张图:
提取url和参数
从以上四张图我们可以确认有以下几个连接需要处理:- 1、获取验证码连接- 2、提交查询- 3、查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用chrome的开发者工具来分析页面。有很多类似的工具。各个浏览器自带的开发者工具基本可以满足需求。也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们提取了企业的基本注册信息为采集,我们需要提交三个请求,每个提交的方法(POST或GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。这个文章就不详细介绍代码实现的具体逻辑了,因为本文的重点是讲解:爬取网页的工作流程。后面代码实现过程中用到的关键技术点和踩过的坑都会一一总结。暂列涉及的相关内容:
也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天做个小笔记,每天进步一点:
善待大众:enilu123
爬虫抓取网页数据(网络爬虫系统的原理和工作流程介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2022-03-22 02:28
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件和文本可以自动关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。网络爬虫原理 网络爬虫是按照一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页外链接的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫的工作流程如图2所示。网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
图2 网络爬虫基本工作流程
网络爬虫爬取策略 谷歌、百度等通用搜索引擎抓取的网页数量通常以十亿为单位计算。那么,面对如此多的网页,如何让网络爬虫尽可能地遍历所有的网页,从而尽可能地扩大网页信息的覆盖范围,是目前网络爬虫面临的一个非常关键的问题。网络爬虫系统。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。1)网页之间的关系模型 从互联网的结构来看,网页之间通过多个超链接相互连接,形成一个庞大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类从爬虫的角度划分互联网。互联网上的所有页面可以分为5个部分:已下载和未过期的网页、已下载和已过期的网页、待下载的网页、已知网页和未知网页,如图4所示。
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。1. 万能网络爬虫 万能网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。2. 聚焦网络爬虫 聚焦网络爬虫,也称为主题网络爬虫,是指选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过使用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
将某个页面的PageRank除以该页面上存在的前向链接,将得到的值加到前向链接指向的页面的PageRank上,即得到链接页面的PageRank。
如图 5 所示,PageRank 为 100 的页面将其重要性同等地赋予它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性赋予它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。3. 增量网络爬虫 增量网络爬虫是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。页面尽可能新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。4. 深网爬虫网页根据存在的不同可以分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
爬虫抓取网页数据(网络爬虫系统的原理和工作流程介绍-乐题库)
网络数据采集是指通过网络爬虫或网站公共API从网站获取数据信息。该方法可以从网页中提取非结构化数据,存储为统一的本地数据文件,并以结构化的方式存储。支持图片、音频、视频等文件或附件的采集,附件和文本可以自动关联。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是采集互联网数据的利器。目前已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。网络爬虫原理 网络爬虫是按照一定的规则自动爬取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。从功能上来说,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图1 网络爬虫示意图
除了供用户阅读的文字信息外,网页还收录一些超链接信息。
网络爬虫系统正是通过网页中的超链接信息不断获取网络上的其他网页。网络爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在爬取网页的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
网络爬虫系统一般会选择一些比较重要的、出度(网页外链接的超链接数)网站较大的URL作为种子URL集。
网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以遍历所有的网页。
由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,因此广度优先搜索算法一般使用采集网页。
网络爬虫系统首先将种子 URL 放入下载队列,简单地从队列头部取一个 URL 下载其对应的网页,获取网页内容并存储,然后解析链接信息网页以获取一些新的 URL。
其次,根据一定的网页分析算法,过滤掉与主题无关的链接,保留有用的链接,放入待抓取的URL队列中。
最后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫的工作流程如图2所示。网络爬虫的基本工作流程如下。
1)首先选择 Torrent URL 的一部分。
2)将这些网址放入待抓取的网址队列中。
3)从待爬取URL队列中获取待爬取URL,解析DNS,获取主机IP地址,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列。
4)分析已爬取URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取URL队列,从而进入下一个循环。
图2 网络爬虫基本工作流程
网络爬虫爬取策略 谷歌、百度等通用搜索引擎抓取的网页数量通常以十亿为单位计算。那么,面对如此多的网页,如何让网络爬虫尽可能地遍历所有的网页,从而尽可能地扩大网页信息的覆盖范围,是目前网络爬虫面临的一个非常关键的问题。网络爬虫系统。在网络爬虫系统中,爬取策略决定了网页被爬取的顺序。
本节首先简要介绍网络爬取策略中使用的基本概念。1)网页之间的关系模型 从互联网的结构来看,网页之间通过多个超链接相互连接,形成一个庞大而复杂的相互关联的有向图。
如图3所示,如果把网页看成图中的一个节点,把网页中其他网页的链接看成这个节点到其他节点的边,那么我们就可以轻松查看整个互联网网页被建模为有向图。
理论上,通过遍历算法对图进行遍历,几乎可以访问互联网上的任何网页。
图3 网页关系模型图
2)网页分类从爬虫的角度划分互联网。互联网上的所有页面可以分为5个部分:已下载和未过期的网页、已下载和已过期的网页、待下载的网页、已知网页和未知网页,如图4所示。
本地爬取的网页实际上是互联网内容的镜像和备份。互联网正在动态变化。当互联网的一部分内容发生变化时,本地抓取的网页就会失效。因此,下载的网页分为两类:下载的未过期网页和下载的过期网页。
图4 网页分类
要下载的页面是 URL 队列中要抓取的页面。
可以看出,网页是指尚未被爬取且不在待爬取URL队列中的网页,但可以通过分析爬取的页面或待爬取URL对应的页面得到。
还有一些网页是网络爬虫无法直接爬取下载的,称为不可知网页。
下面重点介绍几种常见的爬取策略。1. 万能网络爬虫 万能网络爬虫也称为全网爬虫。爬取对象从一些种子URL延伸到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫将从起始页面开始,并逐个链接地跟踪它,直到无法再深入为止。
完成一个爬取分支后,网络爬虫返回上一个链接节点,进一步搜索其他链接。当所有的链接都遍历完后,爬取任务结束。
这种策略比较适合垂直搜索或者站内搜索,但是在抓取页面内容比较深的网站时会造成巨大的资源浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索一个节点时,该节点的子节点和子节点的后继节点都在该节点的兄弟节点之前,深度优先策略在搜索空间中。有时,它会尝试尽可能深入,并且仅在找不到节点的后继节点时才考虑其兄弟节点。
这样的策略决定了深度优先策略不一定能找到最优解,甚至由于深度的限制而无法找到解。
如果不加以限制,它将沿着一条路径无限扩展,这将“捕获”成大量数据。一般来说,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样会降低搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫进入下一级继续爬取。
还是以图3为例,遍历的路径是1→2→3→4→5→6→7→8
由于广度优先策略是在第 N 层的节点扩展完成后进入第 N+1 层,保证了通过最短路径找到解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支时无法结束爬取的问题。易于实现,不需要存储大量的中间节点。缺点是爬到更深的目录级别需要很长时间。页。
如果搜索的分支太多,即节点的后继节点太多,算法就会耗尽资源,在可用空间中找不到解。2. 聚焦网络爬虫 聚焦网络爬虫,也称为主题网络爬虫,是指选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。
该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面,其局限性在于无法评估该页面与该主题的相关性。
Herseovic 对 Fish Search 算法进行了改进,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面和主题之间的相关度。
通过使用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关性的量化大小。
2)基于链接结构评估的爬取策略
与普通文本不同,网页是收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面中的链接表示页面之间的关系。基于链接结构的搜索策略模式利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法就是这种搜索策略模式的代表。
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页;如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。一个网页的重要性同样传递给它所指的网页。
将某个页面的PageRank除以该页面上存在的前向链接,将得到的值加到前向链接指向的页面的PageRank上,即得到链接页面的PageRank。
如图 5 所示,PageRank 为 100 的页面将其重要性同等地赋予它所引用的两个页面,每个页面获得 50,而 PageRank 为 9 的同一页面将其重要性赋予它所引用的三个页面。页面的每一页都传递一个值 3。
PageRank 为 53 的页面的值源自引用它的两个页面传递的值。
,
图5 PageRank算法示例
3)基于强化学习的爬取策略
Rennie 和 McCallum 将强化学习引入聚焦爬虫中,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性以确定链接被访问的顺序。
4)基于上下文图的爬取策略
勤勉等人。提出了一种爬取策略,通过构建上下文图来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。中的链接具有优先访问权。3. 增量网络爬虫 增量网络爬虫是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。页面尽可能新。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要通过重访网页来更新本地页面集中的页面内容。常用的方法有统一更新法、个体更新法和分类更新法。
为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先策略和PageRank优先策略。4. 深网爬虫网页根据存在的不同可以分为表层网页和深层网页。
深网爬虫架构由六个基本功能模块(爬取控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS表)组成。
其中,LVS(LabelValueSet)表示标签和值的集合,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
爬虫抓取网页数据(网络爬虫爬虫的爬行对象是什么?怎么做??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-21 15:16
网络爬虫
爬虫一般是指网络爬虫,也称为网络蜘蛛、蠕虫等。它是按照一定的规则自动爬取网页内容的程序或脚本。
以下是我每天使用的IP池:
个人电脑
移动
生产
相信大家都在互联网上使用过百度、雅虎、谷歌等搜索引擎搜索信息等。这些辅助人们检索信息的工具是我们访问万维网的入口和指南。随着互联网的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。一个集采集、分析、过滤、决策等功能于一体的程序应运而生——网络爬虫,它是搜索引擎的数据基础。搜索引擎的重要组成部分。
原则
传统的网络爬虫从一个或多个网页的初始url开始,在这些初始url的内容中获取新的url。在抓取网页的过程中,不断地从当前页面中提取新的url,放到url列中。列直到满足预定条件。
一些具有特定策略的爬虫具有更复杂的工作流程,例如专注的爬虫。它们会根据某些网页分析算法过滤掉与主题无关的连接,只将那些与主题相关的连接保留在 URL 队列中。某种搜索策略从队列中选择下一个要爬取的网页url,重复上述过程,直到达到系统的某个条件。
ps:搜索引擎系统存储爬虫爬取的网页,进一步分析,过滤,建立索引,供以后查询和检索。
爬行动物分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。实际的网络爬虫系统通常是几种爬虫技术的组合。实现。
通用网络爬虫
一般网络爬虫的爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
爬虫的结构大致可以分为几个部分:初始url、url队列、页面爬取模块、页面分析模块、连接过滤模块、页面数据库采集。
常用的爬取策略有:深度优先策略、广度优先策略。
聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。
与普通网络爬虫相比,增加了聚焦网络爬虫,连接评价模块和内容评价模块。聚焦爬虫实现爬取策略的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
常用的爬取策略有:基于内容评估的爬取策略、基于连接结构评估的爬取策略、基于强化学习的爬取分类、基于上下文图的爬取策略。
增量网络爬虫
增量网页抓取是指对下载的网页进行增量更新,只抓取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要时爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少下载的数据量和及时性。更新爬取的网页减少了时间和空间的消耗,但这会增加爬取算法和复杂度和实现难度。
增量网络爬虫的架构包括:爬取模块、排序模块、更新模块、本地页面集、待爬取url集和本地页面url集。
深网爬虫
网页按存在方式可分为表层网页和深层网页。Surface Web指的是一些主要构成网页的静态网页,而Deep Web指的是那些动态网页,大部分内容只能通过用户提交一些关键词网页获取。Deep Web的可访问信息容量是Surface Web的数百倍,是互联网上规模最大、增长最快的新型信息资源。
Deep Web爬虫架构包括六个基本功能模块(爬取控制器、解析器、表单分析器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表、LVS表)。其中,LVS(Label Value Set)表示标签/值集,用于表示填充表单的数据源。
Deep Web爬虫爬取过程中最重要的部分是表单填写,包括两种类型:基于领域知识的表单填写和基于网页结构分析的表单填写
爬取目标分类
基于着陆页特征
爬虫基于这个特性爬取、存储和索引的对象一般是网站和网页。网页特征可以是网页的内容特征,也可以是网页的连接结构特征等。
基于目标数据
这类爬虫针对的是网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转换或映射成目标数据
基于领域的概念
建立目标领域的本体或字典,从语义角度分析主题中不同特征的重要性
网络搜索策略
网页的爬取策略可以分为深度优先、广度优先和最佳优先三种。其中,深度优先在很多情况下会给爬虫带来问题。目前,后两种方式最为常见。
广度优先策略
广度优先策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。
为了覆盖尽可能多的页面,通常使用广度优先搜索方法。我们可以将广度优先搜索与网络过滤技术结合起来。缺点是随着抓取网页数量的增加,会下载和过滤大量不相关的网页,使算法效率降低。
最佳第一策略
最佳优先级策略会根据一定的网页分析算法预测候选url与目标网页的相似度,或者与主题的相关性,选择评价最好的一个或几个url进行爬取。它仅在分析后访问网页。算法预测为“有用”的页面。因此,存在爬虫爬取路径中很多相关网页可能被忽略的问题。
深度优先策略
深度优先策略会从起始网页开始,选择一个url进入,分析网页中的url,选择一个进入,然后一个接一个地获取连接,直到处理完一个路由,返回起始入口,选择下一条路线。这个缺点也是致命的,因为过度深入的捕捉往往导致捕捉到的数据价值很低。同时,捕获深度直接影响捕获命中率和捕获效率。与其他两种策略相比,这种策略很少使用。 查看全部
爬虫抓取网页数据(网络爬虫爬虫的爬行对象是什么?怎么做??)
网络爬虫
爬虫一般是指网络爬虫,也称为网络蜘蛛、蠕虫等。它是按照一定的规则自动爬取网页内容的程序或脚本。
以下是我每天使用的IP池:
个人电脑
移动
生产
相信大家都在互联网上使用过百度、雅虎、谷歌等搜索引擎搜索信息等。这些辅助人们检索信息的工具是我们访问万维网的入口和指南。随着互联网的飞速发展,万维网已经成为大量信息的载体,如何有效地提取和利用这些信息成为了巨大的挑战。一个集采集、分析、过滤、决策等功能于一体的程序应运而生——网络爬虫,它是搜索引擎的数据基础。搜索引擎的重要组成部分。
原则
传统的网络爬虫从一个或多个网页的初始url开始,在这些初始url的内容中获取新的url。在抓取网页的过程中,不断地从当前页面中提取新的url,放到url列中。列直到满足预定条件。
一些具有特定策略的爬虫具有更复杂的工作流程,例如专注的爬虫。它们会根据某些网页分析算法过滤掉与主题无关的连接,只将那些与主题相关的连接保留在 URL 队列中。某种搜索策略从队列中选择下一个要爬取的网页url,重复上述过程,直到达到系统的某个条件。
ps:搜索引擎系统存储爬虫爬取的网页,进一步分析,过滤,建立索引,供以后查询和检索。
爬行动物分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。实际的网络爬虫系统通常是几种爬虫技术的组合。实现。
通用网络爬虫
一般网络爬虫的爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。
爬虫的结构大致可以分为几个部分:初始url、url队列、页面爬取模块、页面分析模块、连接过滤模块、页面数据库采集。
常用的爬取策略有:深度优先策略、广度优先策略。
聚焦网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性地爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。
与普通网络爬虫相比,增加了聚焦网络爬虫,连接评价模块和内容评价模块。聚焦爬虫实现爬取策略的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
常用的爬取策略有:基于内容评估的爬取策略、基于连接结构评估的爬取策略、基于强化学习的爬取分类、基于上下文图的爬取策略。
增量网络爬虫
增量网页抓取是指对下载的网页进行增量更新,只抓取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要时爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少下载的数据量和及时性。更新爬取的网页减少了时间和空间的消耗,但这会增加爬取算法和复杂度和实现难度。
增量网络爬虫的架构包括:爬取模块、排序模块、更新模块、本地页面集、待爬取url集和本地页面url集。
深网爬虫
网页按存在方式可分为表层网页和深层网页。Surface Web指的是一些主要构成网页的静态网页,而Deep Web指的是那些动态网页,大部分内容只能通过用户提交一些关键词网页获取。Deep Web的可访问信息容量是Surface Web的数百倍,是互联网上规模最大、增长最快的新型信息资源。
Deep Web爬虫架构包括六个基本功能模块(爬取控制器、解析器、表单分析器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表、LVS表)。其中,LVS(Label Value Set)表示标签/值集,用于表示填充表单的数据源。
Deep Web爬虫爬取过程中最重要的部分是表单填写,包括两种类型:基于领域知识的表单填写和基于网页结构分析的表单填写
爬取目标分类
基于着陆页特征
爬虫基于这个特性爬取、存储和索引的对象一般是网站和网页。网页特征可以是网页的内容特征,也可以是网页的连接结构特征等。
基于目标数据
这类爬虫针对的是网页上的数据,抓取到的数据一般都符合一定的模式,或者可以转换或映射成目标数据
基于领域的概念
建立目标领域的本体或字典,从语义角度分析主题中不同特征的重要性
网络搜索策略
网页的爬取策略可以分为深度优先、广度优先和最佳优先三种。其中,深度优先在很多情况下会给爬虫带来问题。目前,后两种方式最为常见。
广度优先策略
广度优先策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。
为了覆盖尽可能多的页面,通常使用广度优先搜索方法。我们可以将广度优先搜索与网络过滤技术结合起来。缺点是随着抓取网页数量的增加,会下载和过滤大量不相关的网页,使算法效率降低。
最佳第一策略
最佳优先级策略会根据一定的网页分析算法预测候选url与目标网页的相似度,或者与主题的相关性,选择评价最好的一个或几个url进行爬取。它仅在分析后访问网页。算法预测为“有用”的页面。因此,存在爬虫爬取路径中很多相关网页可能被忽略的问题。
深度优先策略
深度优先策略会从起始网页开始,选择一个url进入,分析网页中的url,选择一个进入,然后一个接一个地获取连接,直到处理完一个路由,返回起始入口,选择下一条路线。这个缺点也是致命的,因为过度深入的捕捉往往导致捕捉到的数据价值很低。同时,捕获深度直接影响捕获命中率和捕获效率。与其他两种策略相比,这种策略很少使用。
爬虫抓取网页数据(网络爬虫实现原理详解类型的网络的实现过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-21 02:11
01 网页爬虫实现原理详解
不同类型的网络爬虫有不同的实现原理,但是这些实现原理有很多共同点。这里,我们以两种典型的网络爬虫(即普通网络爬虫和专注网络爬虫)为例,分别说明网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看看通用网络爬虫的实现原理。一般网络爬虫的实现原理和流程可以简单总结如下(见图3-1).
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-1 通用网络爬虫实现原理及流程
获取初始 URL。初始URL地址可以由用户人工指定,也可以由用户指定的一个或多个初始爬取网页确定。根据原来的 URL 爬取页面,得到一个新的 URL。获取初始URL地址后,首先需要爬取对应URL地址中的网页。爬取对应URL地址中的网页后,将网页存入原数据库,在爬取网页的同时寻找新的URL。同时,将爬取的URL地址存储在URL列表中,用于对爬取过程进行去重和判断。将新 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。从URL队列中读取新的URL,根据新的URL爬取网页,同时从新网页中获取新的URL,重复上述爬取过程。当爬虫系统设定的停止条件满足时,爬取停止。在编写爬虫时,一般会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取到新的URL地址。如果设置了停止条件,当满足停止条件时,爬虫将停止爬行。
以上就是一般网络爬虫的实现过程和基本原理。接下来,我们将分析聚焦网络爬虫的基本原理和实现过程。
2. 聚焦网络爬虫
专注于网络爬虫,因为它们需要有目的的爬取,所以对于通用网络爬虫,必须增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程需要比通用的网络爬虫更多。分为三个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择,如图3-2所示。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-2 聚焦网络爬虫的基本原理及实现流程
爬取目标的定义和描述。在聚焦网络爬虫中,首先要根据爬取需求定义聚焦网络爬虫的爬取目标,并进行相关描述。获取初始 URL。根据原来的 URL 爬取页面,得到一个新的 URL。从与爬网目标不相关的新 URL 中过滤掉链接。因为聚焦网络爬虫对网页的爬取是有目的的,与目标无关的网页会被过滤掉。同时,还需要将爬取的URL地址保存在一个URL列表中,用于对爬取过程进行去重和判断。将过滤后的链接放入 URL 队列。从URL队列中,根据搜索算法,确定URL的优先级,确定下一步要爬取的URL地址。在一般的网络爬虫中,接下来要爬到哪个URL地址不是很重要,但是在专注的网络爬虫中,由于它的目的,接下来要爬到哪个URL地址相对更重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。
现在我们已经初步掌握了网络爬虫的实现原理和相应的工作流程,下面我们来了解一下网络爬虫的爬取策略。
02 爬取策略
在网络爬取的过程中,待爬取的URL列表中可能有多个URL地址。爬虫应该先爬这些 URL 地址中的哪一个,然后再爬取哪一个?
在一般的网络爬虫中,虽然爬取的顺序不是那么重要,但是在很多其他的爬虫中,比如专注的网络爬虫,爬取的顺序是非常重要的,而且爬取的顺序一般是由爬取策略决定的。我们将向您介绍一些常见的爬取策略。
爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。下面我们将分别介绍。
如图3-3所示,假设有一个网站,ABCDEFG是站点下的网页,图中的箭头代表网页的层次结构。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-3 某网站的网页层次图
如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
例如,如果按照深度优先的爬取策略进行爬取,则先爬取一个网页,然后依次爬取该网页的下层链接,然后返回上一层进行爬取.
因此,如果采用深度优先的爬取策略,图3-3中的爬取顺序可以是:A→D→E→B→C→F→G。
如果遵循广度优先的爬取策略,会先爬取同级别的网页。同级网页全部爬取完成后,选择下一级网页进行爬取。比如上面的<in@网站,如果按照广度优先的爬取策略进行爬取,爬取顺序可以是:A→B→C→D→E→F→G。
除了以上两种爬取策略,我们还可以采用大站点爬取策略。我们可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,那么我们就称它为大站点。按照这个策略,网页越多的网站个数越大,优先抓取大站点中网页的URL地址。
一个网页的反向链接数是指该网页被其他网页指向的次数,这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果只是简单地根据反向链接策略来确定网页的优先级,可能会有很多作弊行为。比如做一些垃圾站群,把这些网站相互链接,这样的话,每个站点都会得到更高的反向链接,从而达到作弊的目的。
作为爬虫项目方,我们当然不希望被这种作弊行为所打扰,所以如果我们使用反向链接策略进行爬取,我们一般会考虑可靠的反向链接数。
除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
03 网页更新策略
网站 网页经常更新。作为爬虫,网页更新后,我们需要再次爬取这些网页,那么什么时候爬取合适呢?如果网站更新太慢,爬虫获取太频繁,势必会增加爬虫和网站服务器的压力。如果 网站 更新较快,但爬取时间间隔较短。如果太长,我们爬取的内容版本会太旧,不利于新内容的爬取。
显然,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略制作不同的网页。更新优先级不同,优先级高的网页更新会得到更快的爬取响应。
具体来说,常见的网页更新策略有3种:用户体验策略、历史数据策略、聚类分析策略等,下面分别进行说明。
当搜索引擎查询某个关键词时,就会出现一个排名结果。在排名结果中,通常会有大量的网页。但是,大多数用户只会关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会优先更新排名结果最高的网页。
这个更新策略,我们称之为用户体验策略,那么在这个策略中,爬虫究竟是什么时候抓取这些排名靠前的页面呢?此时在爬取过程中会保留对应网页的多个历史版本,并进行相应的分析,根据内容更新、搜索质量影响、用户等情况确定这些网页的爬取周期。这些多个历史版本的经验和其他信息。
此外,我们还可以使用历史数据策略来确定爬取网页更新的周期。例如,我们可以根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页的下一次更新时间,从而确定下一次抓取该网页的时间,即确定更新周期。
以上两种策略都需要历史数据作为基础。有时候,如果一个网页是一个新的网页,会没有对应的历史数据,如果要根据历史数据进行分析,爬虫服务器需要保存对应网页的历史版本信息,这无疑带来了爬虫服务器。更多的压力和负担。
如果要解决这些问题,就需要采用新的更新策略。最常用的方法是聚类分析。那么什么是聚类分析策略呢?
在生活中,相信大家对分类都很熟悉。比如我们去商场,商场里的商品一般都是分类的,方便顾客购买相应的商品。此时,产品分类的类别是固定的。制定。
但是,如果商品数量巨大,无法提前进行分类,或者说根本不知道会有哪些类别的商品,这个时候,我们应该如何解决商品分类?
这时候,我们可以使用聚类的方法来解决问题。根据商品之间的共性,我们可以对共性较多的商品进行分析,并将其归为一类。重要的是,聚集在一起的商品之间必须存在某种共性,即按照“同类事物聚集”的思想来实现。
同样,在我们的聚类算法中,也会有类似的分析过程。
我们可以通过将聚类分析算法应用于爬虫对网页的更新来做到这一点,如图 3-4 所示。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-4 网页更新策略的聚类算法
首先,经过大量研究发现,网页可能有不同的内容,但总的来说,具有相似属性的网页具有相似的更新频率。这是聚类分析算法应用于爬虫网页更新的前提和指导思想。有了1中的指导思想,我们可以先对大量的网页进行聚类分析。聚类后会形成多个类。每个类中的网页具有相似的属性,即它们通常具有相似的更新频率。. 聚类完成后,我们可以对同一个聚类中的网页进行采样,然后计算采样结果的平均更新值来确定每个聚类的爬取频率。
以上就是使用爬虫爬取网页时常见的三种更新策略。在我们掌握了他们的算法思路之后,我们在进行爬虫的实际开发时,编译出来的爬虫会更加高效的执行逻辑。会更合理。
04 网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1. 基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2. 基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。
基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。
当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。
我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。
该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。
因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3. 基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评价。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。
05 识别
在爬取网页的过程中,爬虫必须访问对应的网页,而普通的爬虫一般会告诉对应网页的网站站长自己的爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。
那么,爬虫应该如何告知网站站长自己的身份呢?
一般爬虫在爬取访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。一般爬虫在访问一个网站时,首先会根据站点下的Robots.txt文件确定可以爬取的网页范围。Robots 协议是网络爬虫必须遵守的协议。对于一些被禁止的 URL 地址,网络爬虫不应该爬取访问权限。
同时,如果爬虫在爬取某个站点时陷入死循环,导致该站点的服务压力太大,如果有正确的身份设置,那么该站点的站长可以想办法联系爬虫并停止相应的爬虫。
当然,有些爬虫会伪装成其他爬虫或者浏览器爬取网站来获取一些额外的数据,或者有些爬虫会无视Robots协议的限制,任意爬取。从技术上看,这些行为实施起来并不难,但我们并不提倡这些行为,因为只有共同遵守良好的网络规则,爬虫和站点服务器才能实现双赢。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
06 网络爬虫实现技术
通过前面的学习,我们对爬虫的基础理论知识基本有了比较全面的了解。那么,如果我们要实现网络爬虫技术,开发自己的网络爬虫,我们可以使用哪些语言进行开发呢?
开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.JS、C++、Go等,下面我们将介绍这些语言编写爬虫的特点:
07 总结 关注网络爬虫。因为需要有针对性的爬取,所以对于一般的网络爬虫来说,必须增加目标的定义和过滤机制。具体来说,这时候它的执行原理和过程需要多爬虫多三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。常见的网页更新策略有三种:用户体验策略、历史数据策略、聚类分析策略。可以根据商品之间的共性进行聚类分析,将共性较多的商品归为一类。在爬取网页的过程中,爬虫必须访问相应的网页。此时,常规爬虫通常会告诉相应网页的 网站 站长其爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。开发网络爬虫的语言有很多种。常用语言有 Python、Java、PHP、Node.JS、C++、Go。
作者简介:韦伟,资深网络爬虫技术专家、大数据专家、软件开发工程师,多年从事大型软件开发和技术服务,精通Python技术,在Python网络爬虫、Python机器学习、Python数据分析与挖掘,Python Web 开发等各个领域都有丰富的实践经验。 查看全部
爬虫抓取网页数据(网络爬虫实现原理详解类型的网络的实现过程)
01 网页爬虫实现原理详解
不同类型的网络爬虫有不同的实现原理,但是这些实现原理有很多共同点。这里,我们以两种典型的网络爬虫(即普通网络爬虫和专注网络爬虫)为例,分别说明网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看看通用网络爬虫的实现原理。一般网络爬虫的实现原理和流程可以简单总结如下(见图3-1).
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-1 通用网络爬虫实现原理及流程
获取初始 URL。初始URL地址可以由用户人工指定,也可以由用户指定的一个或多个初始爬取网页确定。根据原来的 URL 爬取页面,得到一个新的 URL。获取初始URL地址后,首先需要爬取对应URL地址中的网页。爬取对应URL地址中的网页后,将网页存入原数据库,在爬取网页的同时寻找新的URL。同时,将爬取的URL地址存储在URL列表中,用于对爬取过程进行去重和判断。将新 URL 放入 URL 队列。第二步,获取下一个新的URL地址后,将新的URL地址放入URL队列中。从URL队列中读取新的URL,根据新的URL爬取网页,同时从新网页中获取新的URL,重复上述爬取过程。当爬虫系统设定的停止条件满足时,爬取停止。在编写爬虫时,一般会设置相应的停止条件。如果不设置停止条件,爬虫会一直爬到无法获取到新的URL地址。如果设置了停止条件,当满足停止条件时,爬虫将停止爬行。
以上就是一般网络爬虫的实现过程和基本原理。接下来,我们将分析聚焦网络爬虫的基本原理和实现过程。
2. 聚焦网络爬虫
专注于网络爬虫,因为它们需要有目的的爬取,所以对于通用网络爬虫,必须增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程需要比通用的网络爬虫更多。分为三个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择,如图3-2所示。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-2 聚焦网络爬虫的基本原理及实现流程
爬取目标的定义和描述。在聚焦网络爬虫中,首先要根据爬取需求定义聚焦网络爬虫的爬取目标,并进行相关描述。获取初始 URL。根据原来的 URL 爬取页面,得到一个新的 URL。从与爬网目标不相关的新 URL 中过滤掉链接。因为聚焦网络爬虫对网页的爬取是有目的的,与目标无关的网页会被过滤掉。同时,还需要将爬取的URL地址保存在一个URL列表中,用于对爬取过程进行去重和判断。将过滤后的链接放入 URL 队列。从URL队列中,根据搜索算法,确定URL的优先级,确定下一步要爬取的URL地址。在一般的网络爬虫中,接下来要爬到哪个URL地址不是很重要,但是在专注的网络爬虫中,由于它的目的,接下来要爬到哪个URL地址相对更重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。接下来要爬取哪个URL地址相对来说比较重要。对于专注的网络爬虫来说,不同的爬取顺序可能会导致爬虫的执行效率不同。因此,我们需要根据搜索策略确定下一步需要抓取哪些URL地址。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。从下一步要爬取的URL地址,读取新的URL,然后根据新的URL地址爬取网页,重复上述爬取过程。当满足系统设置的停止条件,或者无法获取到新的URL时,停止爬取。
现在我们已经初步掌握了网络爬虫的实现原理和相应的工作流程,下面我们来了解一下网络爬虫的爬取策略。
02 爬取策略
在网络爬取的过程中,待爬取的URL列表中可能有多个URL地址。爬虫应该先爬这些 URL 地址中的哪一个,然后再爬取哪一个?
在一般的网络爬虫中,虽然爬取的顺序不是那么重要,但是在很多其他的爬虫中,比如专注的网络爬虫,爬取的顺序是非常重要的,而且爬取的顺序一般是由爬取策略决定的。我们将向您介绍一些常见的爬取策略。
爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站点优先策略、反链策略等爬取策略。下面我们将分别介绍。
如图3-3所示,假设有一个网站,ABCDEFG是站点下的网页,图中的箭头代表网页的层次结构。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-3 某网站的网页层次图
如果此时网页ABCDEFG都在爬取队列中,那么根据不同的爬取策略,爬取的顺序是不同的。
例如,如果按照深度优先的爬取策略进行爬取,则先爬取一个网页,然后依次爬取该网页的下层链接,然后返回上一层进行爬取.
因此,如果采用深度优先的爬取策略,图3-3中的爬取顺序可以是:A→D→E→B→C→F→G。
如果遵循广度优先的爬取策略,会先爬取同级别的网页。同级网页全部爬取完成后,选择下一级网页进行爬取。比如上面的<in@网站,如果按照广度优先的爬取策略进行爬取,爬取顺序可以是:A→B→C→D→E→F→G。
除了以上两种爬取策略,我们还可以采用大站点爬取策略。我们可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,那么我们就称它为大站点。按照这个策略,网页越多的网站个数越大,优先抓取大站点中网页的URL地址。
一个网页的反向链接数是指该网页被其他网页指向的次数,这个次数代表了该网页在一定程度上被其他网页推荐的次数。因此,如果按照反向链接策略进行爬取,那么哪个网页的反向链接多,就会先爬到哪个页面。
但是,在实际情况中,如果只是简单地根据反向链接策略来确定网页的优先级,可能会有很多作弊行为。比如做一些垃圾站群,把这些网站相互链接,这样的话,每个站点都会得到更高的反向链接,从而达到作弊的目的。
作为爬虫项目方,我们当然不希望被这种作弊行为所打扰,所以如果我们使用反向链接策略进行爬取,我们一般会考虑可靠的反向链接数。
除了以上的爬取策略,实践中还有很多其他的爬取策略,比如OPIC策略、Partial PageRank策略等等。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
03 网页更新策略
网站 网页经常更新。作为爬虫,网页更新后,我们需要再次爬取这些网页,那么什么时候爬取合适呢?如果网站更新太慢,爬虫获取太频繁,势必会增加爬虫和网站服务器的压力。如果 网站 更新较快,但爬取时间间隔较短。如果太长,我们爬取的内容版本会太旧,不利于新内容的爬取。
显然,网站的更新频率越接近爬虫访问网站的频率,效果越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略制作不同的网页。更新优先级不同,优先级高的网页更新会得到更快的爬取响应。
具体来说,常见的网页更新策略有3种:用户体验策略、历史数据策略、聚类分析策略等,下面分别进行说明。
当搜索引擎查询某个关键词时,就会出现一个排名结果。在排名结果中,通常会有大量的网页。但是,大多数用户只会关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会优先更新排名结果最高的网页。
这个更新策略,我们称之为用户体验策略,那么在这个策略中,爬虫究竟是什么时候抓取这些排名靠前的页面呢?此时在爬取过程中会保留对应网页的多个历史版本,并进行相应的分析,根据内容更新、搜索质量影响、用户等情况确定这些网页的爬取周期。这些多个历史版本的经验和其他信息。
此外,我们还可以使用历史数据策略来确定爬取网页更新的周期。例如,我们可以根据某个网页的历史更新数据,通过泊松过程建模等手段,预测该网页的下一次更新时间,从而确定下一次抓取该网页的时间,即确定更新周期。
以上两种策略都需要历史数据作为基础。有时候,如果一个网页是一个新的网页,会没有对应的历史数据,如果要根据历史数据进行分析,爬虫服务器需要保存对应网页的历史版本信息,这无疑带来了爬虫服务器。更多的压力和负担。
如果要解决这些问题,就需要采用新的更新策略。最常用的方法是聚类分析。那么什么是聚类分析策略呢?
在生活中,相信大家对分类都很熟悉。比如我们去商场,商场里的商品一般都是分类的,方便顾客购买相应的商品。此时,产品分类的类别是固定的。制定。
但是,如果商品数量巨大,无法提前进行分类,或者说根本不知道会有哪些类别的商品,这个时候,我们应该如何解决商品分类?
这时候,我们可以使用聚类的方法来解决问题。根据商品之间的共性,我们可以对共性较多的商品进行分析,并将其归为一类。重要的是,聚集在一起的商品之间必须存在某种共性,即按照“同类事物聚集”的思想来实现。
同样,在我们的聚类算法中,也会有类似的分析过程。
我们可以通过将聚类分析算法应用于爬虫对网页的更新来做到这一点,如图 3-4 所示。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
▲图3-4 网页更新策略的聚类算法
首先,经过大量研究发现,网页可能有不同的内容,但总的来说,具有相似属性的网页具有相似的更新频率。这是聚类分析算法应用于爬虫网页更新的前提和指导思想。有了1中的指导思想,我们可以先对大量的网页进行聚类分析。聚类后会形成多个类。每个类中的网页具有相似的属性,即它们通常具有相似的更新频率。. 聚类完成后,我们可以对同一个聚类中的网页进行采样,然后计算采样结果的平均更新值来确定每个聚类的爬取频率。
以上就是使用爬虫爬取网页时常见的三种更新策略。在我们掌握了他们的算法思路之后,我们在进行爬虫的实际开发时,编译出来的爬虫会更加高效的执行逻辑。会更合理。
04 网页分析算法
在搜索引擎中,爬虫抓取到对应的网页后,会将网页存储在服务器的原创数据库中。之后,搜索引擎会对这些网页进行分析,确定每个网页的重要性,从而影响用户检索的排名。结果。
所以在这里,我们需要对搜索引擎的网页分析算法有个简单的了解。
搜索引擎的网页分析算法主要分为三类:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法和基于网页内容的网页分析算法。接下来,我们将分别解释这些算法。
1. 基于用户行为的网页分析算法
基于用户行为的网页分析算法很好理解。在该算法中,将根据用户对这些网页的访问行为对这些网页进行评估。例如,网页会根据用户访问网页的频率、用户访问网页的时间、用户的点击率等信息进行整合。评价。
2. 基于网络拓扑的网页分析算法
基于网络拓扑的网页分析算法是通过网页的链接关系、结构关系、已知网页或数据等对网页进行分析的算法。所谓拓扑,简单来说就是结构关系。
基于网络拓扑的网页分析算法还可以细分为三种:基于页面粒度的分析算法、基于页块粒度的分析算法和基于网站粒度的分析算法。
PageRank算法是一种典型的基于网页粒度的分析算法。相信很多朋友都听说过Page-Rank算法。它是谷歌搜索引擎的核心算法。简单来说,它会根据网页之间的链接关系来计算网页的权重,并且可以依赖这些计算出来的权重。要排名的页面。
当然,具体的算法细节还有很多,这里就不一一说明了。除了PageRank算法,HITS算法也是一种常见的基于网页粒度的分析算法。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
基于网页块粒度的分析算法也依赖网页之间的链接关系进行计算,但计算规则不同。
我们知道一个网页通常收录多个超链接,但一般不是所有指向的外部链接都与网站主题相关,或者说这些外部链接对网页的重要性,因此,要根据网页块的粒度进行分析,需要将网页中的这些外部链接分层,不同层次的外部链接对网页的重要性程度不同。
该算法的分析效率和准确性将优于传统算法。
基于网站粒度的分析算法也类似于PageRank算法。但是,如果使用基于 网站 粒度的分析,则会相应地使用 SiteRank 算法。也就是这个时候,我们将站点的层级和层级进行划分,不再具体计算站点下每个网页的层级。
因此,与基于网页粒度的算法相比,它更简单、更高效,但会带来一些缺点,例如精度不如基于网页粒度的分析算法准确。
3. 基于网页内容的网页分析算法
在基于网页内容的网页分析算法中,会根据网页的数据、文本等网页内容特征对网页进行相应的评价。
以上,我简单介绍了搜索引擎中的网页分析算法。我们在学习爬虫时需要对这些算法有相应的了解。
05 识别
在爬取网页的过程中,爬虫必须访问对应的网页,而普通的爬虫一般会告诉对应网页的网站站长自己的爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。
那么,爬虫应该如何告知网站站长自己的身份呢?
一般爬虫在爬取访问网页时,会通过HTTP请求中的User Agent字段告知自己的身份信息。一般爬虫在访问一个网站时,首先会根据站点下的Robots.txt文件确定可以爬取的网页范围。Robots 协议是网络爬虫必须遵守的协议。对于一些被禁止的 URL 地址,网络爬虫不应该爬取访问权限。
同时,如果爬虫在爬取某个站点时陷入死循环,导致该站点的服务压力太大,如果有正确的身份设置,那么该站点的站长可以想办法联系爬虫并停止相应的爬虫。
当然,有些爬虫会伪装成其他爬虫或者浏览器爬取网站来获取一些额外的数据,或者有些爬虫会无视Robots协议的限制,任意爬取。从技术上看,这些行为实施起来并不难,但我们并不提倡这些行为,因为只有共同遵守良好的网络规则,爬虫和站点服务器才能实现双赢。
爬虫原理与数据抓取技术(爬虫技术是做什么的)
06 网络爬虫实现技术
通过前面的学习,我们对爬虫的基础理论知识基本有了比较全面的了解。那么,如果我们要实现网络爬虫技术,开发自己的网络爬虫,我们可以使用哪些语言进行开发呢?
开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.JS、C++、Go等,下面我们将介绍这些语言编写爬虫的特点:
07 总结 关注网络爬虫。因为需要有针对性的爬取,所以对于一般的网络爬虫来说,必须增加目标的定义和过滤机制。具体来说,这时候它的执行原理和过程需要多爬虫多三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。常见的网页更新策略有三种:用户体验策略、历史数据策略、聚类分析策略。可以根据商品之间的共性进行聚类分析,将共性较多的商品归为一类。在爬取网页的过程中,爬虫必须访问相应的网页。此时,常规爬虫通常会告诉相应网页的 网站 站长其爬虫身份。网站的管理员可以通过爬虫通知的身份信息来识别爬虫的身份。我们称这个过程为爬虫的识别过程。开发网络爬虫的语言有很多种。常用语言有 Python、Java、PHP、Node.JS、C++、Go。
作者简介:韦伟,资深网络爬虫技术专家、大数据专家、软件开发工程师,多年从事大型软件开发和技术服务,精通Python技术,在Python网络爬虫、Python机器学习、Python数据分析与挖掘,Python Web 开发等各个领域都有丰富的实践经验。
爬虫抓取网页数据(如何发送网络请求爬虫的关键了?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2022-03-20 18:16
什么是爬行动物
爬虫是指利用代码模拟用户批量发送网络请求,批量获取数据的行为。
网络请求
如果说爬虫是指使用代码模拟用户批量发送网络请求,那么如何发送网络请求是爬虫的关键,那么如何发送网络请求呢?
“打开浏览器→在搜索框/输入框输入要查询的内容→点击回车”的过程是对用户的一次完整的网络请求。
网络请求
数据
我们发送网络请求后,我们的电脑上会出现一些数据,例如:如果我们搜索“什么是python”,电脑的浏览器会显示一些网页和链接,显示的信息就是这台电脑和其他的计算机或服务器已连接,它响应计算机网络请求的数据。
数据
超文本传输协议
响应网络请求会产生大量的数据(我们搜索关键词会出几百万条结果),所以这个数据有一个管理集叫做“超文本传输协议”,这也是我们经常在网站的前缀为“http”。
超文本传输协议
而http有5种请求方式,分别是:get、post、put、delete、head,其中最常用的是get请求和post请求。
爬行动物的分类
上面讲了“发送网络请求”的相关知识,接下来说说“批量获取数据”的相关内容。
发送什么样的请求,会得到什么样的数据,爬虫发送请求的方式主要有两种:“通用爬虫”和“聚焦爬虫”。
万能爬虫:可以爬取关键词页面上的所有内容,开放性更好,速度更快,但是90%的爬取内容是用户不需要的,就像你在搜索引擎上输入你要的内容想要,但他会出现“广告”、“相关链接”、“热门内容”等,而这些都不是你想要的内容。
万能爬虫
专注于爬虫:可以清晰的爬取用户想要的内容,目标非常精准。也是现在爬虫的主流。
此外,“增量爬虫”具有翻页功能,可以爬取所有页面的内容。“深度爬虫”可以爬取html和css的静态数据,以及js的动态数据。这两者都属于“焦点爬虫”。
爬虫可以爬什么
了解了一些爬虫的基础知识之后,我们再来说说可以爬取哪些内容。
“仅抓取用户有权访问的数据”
例如:如果你要爬取视频网站的视频,你是普通用户,所以你可以爬取普通视频。如果要爬VIP视频,需要给VIP充值。
并且不允许将爬出的信息进行出售等行为。 查看全部
爬虫抓取网页数据(如何发送网络请求爬虫的关键了?(组图))
什么是爬行动物
爬虫是指利用代码模拟用户批量发送网络请求,批量获取数据的行为。
网络请求
如果说爬虫是指使用代码模拟用户批量发送网络请求,那么如何发送网络请求是爬虫的关键,那么如何发送网络请求呢?
“打开浏览器→在搜索框/输入框输入要查询的内容→点击回车”的过程是对用户的一次完整的网络请求。
网络请求
数据
我们发送网络请求后,我们的电脑上会出现一些数据,例如:如果我们搜索“什么是python”,电脑的浏览器会显示一些网页和链接,显示的信息就是这台电脑和其他的计算机或服务器已连接,它响应计算机网络请求的数据。
数据
超文本传输协议
响应网络请求会产生大量的数据(我们搜索关键词会出几百万条结果),所以这个数据有一个管理集叫做“超文本传输协议”,这也是我们经常在网站的前缀为“http”。
超文本传输协议
而http有5种请求方式,分别是:get、post、put、delete、head,其中最常用的是get请求和post请求。
爬行动物的分类
上面讲了“发送网络请求”的相关知识,接下来说说“批量获取数据”的相关内容。
发送什么样的请求,会得到什么样的数据,爬虫发送请求的方式主要有两种:“通用爬虫”和“聚焦爬虫”。
万能爬虫:可以爬取关键词页面上的所有内容,开放性更好,速度更快,但是90%的爬取内容是用户不需要的,就像你在搜索引擎上输入你要的内容想要,但他会出现“广告”、“相关链接”、“热门内容”等,而这些都不是你想要的内容。
万能爬虫
专注于爬虫:可以清晰的爬取用户想要的内容,目标非常精准。也是现在爬虫的主流。
此外,“增量爬虫”具有翻页功能,可以爬取所有页面的内容。“深度爬虫”可以爬取html和css的静态数据,以及js的动态数据。这两者都属于“焦点爬虫”。
爬虫可以爬什么
了解了一些爬虫的基础知识之后,我们再来说说可以爬取哪些内容。
“仅抓取用户有权访问的数据”
例如:如果你要爬取视频网站的视频,你是普通用户,所以你可以爬取普通视频。如果要爬VIP视频,需要给VIP充值。
并且不允许将爬出的信息进行出售等行为。
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-19 05:17
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
图 2
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面,同时网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以使用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如图3
图 3
安装完成,如图4
图 4 查看全部
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
1.网络爬虫基本概念
网络爬虫(也称为网络蜘蛛或机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做任何事情,原则上爬虫都能做到。
2.网络爬虫函数
图 2
网络爬虫可以手动替换很多东西,比如用作搜索引擎,或者爬取网站上的图片。比如有的朋友把一些网站上的所有图片都爬进去,集中在上面,同时网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,可以进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次浏览都单独打开这些新闻网站比较麻烦。这时候就可以用网络爬虫来爬取这多条新闻网站中的新闻信息,集中阅读。
有时候,我们在网上浏览信息的时候,会发现有很多广告。这时也可以使用爬虫来爬取相应网页上的信息,从而自动过滤掉这些广告,方便信息的阅读和使用。
有时候,我们需要做营销,所以如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以手动搜索互联网,但这会非常低效。这时,我们可以通过爬虫设置相应的规则,自动采集从互联网上获取目标用户的联系方式,供我们营销使用。
有时候,我们想分析某个网站的用户信息,比如分析网站的用户活跃度、发言次数、热门文章等信息,如果我们没有网站@ >管理员,手动统计将是一个非常庞大的工程。此时,您可以使用爬虫轻松采集对这些数据进行进一步分析,并且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫并设计相应的爬虫即可。规则会做。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫实现自动化,从而可以更好地利用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面输入pip install requests,回车安装。(注意连接网络)如图3
图 3
安装完成,如图4
图 4
爬虫抓取网页数据( 大佬的博客,和JS发送请求的路径和路径分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-17 20:17
大佬的博客,和JS发送请求的路径和路径分析)
爬虫爬取JS生成的数据
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过Ajax异步发送请求,得到响应,将数据放入页面。对于这种情况,我们可以查看Ajax请求,然后分析Ajax请求路径和响应,得到想要的数据;另一种是JS动态加载的数据,然后放到页面中。在这两种情况下,供用户使用浏览器访问时,不会出现异常,快速获取完整页面。
其实我们之前学过一个selenium模块,通过操作浏览器,然后获取浏览器显示的数据,这个方法可以获取数据,不过本节是分析如何找到控制数据生成的JS ,以及JS发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最让我恼火的是JS动态生成的数据。我找不到哪个 JS 实现了它(因为 JS 太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬,提供大佬的博客:
1.需求描述和页面分析
1、需求说明
基本页面路径:
点击进入每个标题:
要求是爬取每个标题下的新闻内容
2、页面分析
2.1 主页
查看 Ajax 请求:
接下来,我们将解析如何找出发送请求的 JS
二、找到发送请求的JS
在响应数据中,包括新闻标题,以及这条新闻详情页的路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去Ajax:
Ajax没有新闻相关的数据,所以不再使用Ajax请求获取数据,只剩下JS了。我们将找出是哪个 JS 发送了获取数据的请求。步骤与上面相同:
详情页数据的JS请求路径:
详情页请求路径:
我们可以看到,最后一个斜杠之前的详情页数据的请求路径与最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1=''
第二步:替换url1最后一个斜杠后的内容
url2=''%(url1.split('/')[3]) #用'/'分割url1,得到第四部分,即索引为3,然后拼接进去
这样就构建了一条详情页数据请求路径,然后就可以直接访问该路径获取数据,而无需访问详情页。 查看全部
爬虫抓取网页数据(
大佬的博客,和JS发送请求的路径和路径分析)
爬虫爬取JS生成的数据
有很多页。当我们使用request发送请求时,返回的内容中没有页面显示数据。主要有两种情况。一种是通过Ajax异步发送请求,得到响应,将数据放入页面。对于这种情况,我们可以查看Ajax请求,然后分析Ajax请求路径和响应,得到想要的数据;另一种是JS动态加载的数据,然后放到页面中。在这两种情况下,供用户使用浏览器访问时,不会出现异常,快速获取完整页面。
其实我们之前学过一个selenium模块,通过操作浏览器,然后获取浏览器显示的数据,这个方法可以获取数据,不过本节是分析如何找到控制数据生成的JS ,以及JS发送请求的路径,所以我们可以向这个路径发送请求,直接获取数据。
在之前的爬取过程中,最让我恼火的是JS动态生成的数据。我找不到哪个 JS 实现了它(因为 JS 太多了)。今天看了大佬的博客,顿时觉得简单多了。,谢谢大佬,提供大佬的博客:
1.需求描述和页面分析
1、需求说明
基本页面路径:
点击进入每个标题:
要求是爬取每个标题下的新闻内容
2、页面分析
2.1 主页
查看 Ajax 请求:
接下来,我们将解析如何找出发送请求的 JS
二、找到发送请求的JS
在响应数据中,包括新闻标题,以及这条新闻详情页的路径,所以现在我们去访问详情页,分析详情页
访问详情页,查看详情页的响应,数据中不收录具体数据,则和主页面一样,然后去Ajax:
Ajax没有新闻相关的数据,所以不再使用Ajax请求获取数据,只剩下JS了。我们将找出是哪个 JS 发送了获取数据的请求。步骤与上面相同:
详情页数据的JS请求路径:
详情页请求路径:
我们可以看到,最后一个斜杠之前的详情页数据的请求路径与最后一个斜杠之前的详情页的请求路径是一样的。所以我们可以这样做:
第一步:获取详情页的请求路径:
url1=''
第二步:替换url1最后一个斜杠后的内容
url2=''%(url1.split('/')[3]) #用'/'分割url1,得到第四部分,即索引为3,然后拼接进去
这样就构建了一条详情页数据请求路径,然后就可以直接访问该路径获取数据,而无需访问详情页。
爬虫抓取网页数据(python爬虫实战之三AJAX数据爬取和HTTPS访问(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-15 01:24
python爬虫URL编码和GETPOST请求| python爬虫实战三 python爬虫AJAX数据爬取和HTTPS访问
我们首先需要回顾一下之前接触过的爬虫的概念、爬取过程、爬虫的标准库等。
通常我们在大多数情况下编写的爬虫都是专注的爬虫。
接下来,我们通过豆瓣电影对 JSON 数据进行处理。
处理 JSON 数据
看看“豆瓣电影”,看看“最近热门电影”的“火爆”。
右键单击“检查元素”,找到“网络”,然后刷新它。
我们可以看到很多内容,我们分析这部分热门电影。
然后复制地址进行操作分析。
通过分析,我们知道这部分内容是通过AJAX从后台获取的Json数据。
访问的 URL 是 %E7%83%AD%E9%97%A8&page_limit=50&page_start=0
其中,%E7%83%AD%E9%97%A8是utf-8编码的中文“热”
服务端返回的JSON数据如下:
轮播组件一共需要50条数据。
url的表示如下:
标签标签“hot”,意思是热门电影
type 数据类型,movie 是电影
page_limit 表示返回数据的总数
page_start 表示数据偏移量
我们可以设置page_limit=10&page_start=10的值。
from urllib.parse import urlencode
from urllib.request import urlopen, Request
import simplejson
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
jurl = 'https://movie.douban.com/j/search_subjects'
d = {
'type':'movie',
'tag':'热门',
'page_limit':10,
'page_start':10
}
req = Request('{}?{}'.format(jurl, urlencode(d)), headers={
'User-agent':ua
})
with urlopen(req) as res:
subjects = simplejson.loads(res.read())
print(len(subjects['subjects']))
print(subjects)
结果:
至此,就可以获取到内容了,那我们还需要封装爬虫吗?
因为每个企业处理的方式可能不同,所以返回的数据可能是html或JSON。因此,处理方法必须一致,或者将函数封装在一个方法中是我们思考的重点。很多时候我们会为一些特定的数据写一个特定的爬虫,具体的网站。因为每个网站的解析提取方法可能不同。现在我们只做一个简单的 JSON 处理。但是如果是网页解析,那就很麻烦了,尤其是网页模板一旦改变,就需要重写网页解析方法。 查看全部
爬虫抓取网页数据(python爬虫实战之三AJAX数据爬取和HTTPS访问(组图))
python爬虫URL编码和GETPOST请求| python爬虫实战三 python爬虫AJAX数据爬取和HTTPS访问
我们首先需要回顾一下之前接触过的爬虫的概念、爬取过程、爬虫的标准库等。
通常我们在大多数情况下编写的爬虫都是专注的爬虫。
接下来,我们通过豆瓣电影对 JSON 数据进行处理。
处理 JSON 数据
看看“豆瓣电影”,看看“最近热门电影”的“火爆”。
右键单击“检查元素”,找到“网络”,然后刷新它。
我们可以看到很多内容,我们分析这部分热门电影。
然后复制地址进行操作分析。
通过分析,我们知道这部分内容是通过AJAX从后台获取的Json数据。
访问的 URL 是 %E7%83%AD%E9%97%A8&page_limit=50&page_start=0
其中,%E7%83%AD%E9%97%A8是utf-8编码的中文“热”
服务端返回的JSON数据如下:
轮播组件一共需要50条数据。
url的表示如下:
标签标签“hot”,意思是热门电影
type 数据类型,movie 是电影
page_limit 表示返回数据的总数
page_start 表示数据偏移量
我们可以设置page_limit=10&page_start=10的值。
from urllib.parse import urlencode
from urllib.request import urlopen, Request
import simplejson
ua = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
jurl = 'https://movie.douban.com/j/search_subjects'
d = {
'type':'movie',
'tag':'热门',
'page_limit':10,
'page_start':10
}
req = Request('{}?{}'.format(jurl, urlencode(d)), headers={
'User-agent':ua
})
with urlopen(req) as res:
subjects = simplejson.loads(res.read())
print(len(subjects['subjects']))
print(subjects)
结果:
至此,就可以获取到内容了,那我们还需要封装爬虫吗?
因为每个企业处理的方式可能不同,所以返回的数据可能是html或JSON。因此,处理方法必须一致,或者将函数封装在一个方法中是我们思考的重点。很多时候我们会为一些特定的数据写一个特定的爬虫,具体的网站。因为每个网站的解析提取方法可能不同。现在我们只做一个简单的 JSON 处理。但是如果是网页解析,那就很麻烦了,尤其是网页模板一旦改变,就需要重写网页解析方法。

