
爬虫抓取网页数据
爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-10 12:09
)
最近,我在公司做了一个系统。由于想获取网页的一些数据和一些网页的数据,所以写了一个公共的HttpUtils。以下是我为无云网写的一个例子。
一、第一步,获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果同上:
二、通过指定url获取网页上你想要的数据。
对于这个方法,导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于那个select选择器,根据条件选择,doc.select("h3").iterator(),对于Jsoup有如下规则:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
jsoup 的强大之处在于它可以检索文档元素。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、选择器选择器基本语法
2、选择器选择器组合语法
3、选择器伪选择器语法
注意:上述伪选择器的索引是从0开始的,也就是说第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
查看全部
爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子
)
最近,我在公司做了一个系统。由于想获取网页的一些数据和一些网页的数据,所以写了一个公共的HttpUtils。以下是我为无云网写的一个例子。
一、第一步,获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果同上:

二、通过指定url获取网页上你想要的数据。
对于这个方法,导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于那个select选择器,根据条件选择,doc.select("h3").iterator(),对于Jsoup有如下规则:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
jsoup 的强大之处在于它可以检索文档元素。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、选择器选择器基本语法
2、选择器选择器组合语法
3、选择器伪选择器语法
注意:上述伪选择器的索引是从0开始的,也就是说第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
爬虫抓取网页数据(保险公司的投资理财产品收益如何返回数据也比较简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-10 04:03
爬虫抓取网页数据比如你想看看某家保险公司的投资理财产品收益如何,请求很简单,返回数据也比较简单。这里我们看到红色箭头箭头指向的就是网页url所以知道url地址就容易建立反爬虫策略,比如先获取浏览器的cookie,比如相关的代码都是可以代码化编写的那么爬虫就好开始了拿张图片为例,找到图片地址关键字并且google其高度相似的图片可以找到mediumimagesurl就是相对url那如何找到这个呢url中可以在中找到相对url没有这个按钮,就需要进入到网页源代码中查找,一般页面源代码会包含很多script标签,并且可以自定义标签可以通过定义script标签找到mediumimages网页源代码这里设置了header头响应:{"script":""}你可以随便编写任何你想爬的内容这里随意编写你要爬的内容,比如黑点,那么就爬这里是一张经过处理的图片源代码相当于这样header="${pagebottom}"src=""style="content-type:application/x-www-form-urlencoded;charset=utf-8">script在获取页面源代码中会被自动解析添加到script标签并且设置你获取到的script标签的代码来让页面变成文本页面,并且随即到达请求头部有很多选择请求url的方法,我推荐useragentheaderscript标签是不透明的,对于下载与反爬虫没有任何不便那么你只需要在useragent中将数据传递就可以了,作为最终请求url这里使用useragentheader,最后提示很不适合直接使用requestlib这个包可以使用ff浏览器来看下是否在requestlib包中是否真的编写了反爬虫代码那么这个时候可以请求网页源代码request然后得到response然后解析获取网页数据这里如果你愿意依赖很多库,可以对数据进行解析封装,如opener这里设置了要解析的字段url,formurl这里可以随意编写你想解析的内容比如点点,可以写成.medium>再如上面的script标签,可以写成url="";script标签发送给浏览器你需要服务端传输数据,浏览器发送数据数据到一个特定的地址http://{服务器}/{http}/{request}/{page}/{form}/{url}/{body}这里http是指一个http服务器还有一种方式:一个页面一个页面的爬爬,然后找到各个页面源代码存储在同一目录比如上面页面一个网页存放在/home/cookie/web/forms/web/cookie/web/cookie/cookie/下边链接存放的是/home/cookie/web/forms/web/。 查看全部
爬虫抓取网页数据(保险公司的投资理财产品收益如何返回数据也比较简单)
爬虫抓取网页数据比如你想看看某家保险公司的投资理财产品收益如何,请求很简单,返回数据也比较简单。这里我们看到红色箭头箭头指向的就是网页url所以知道url地址就容易建立反爬虫策略,比如先获取浏览器的cookie,比如相关的代码都是可以代码化编写的那么爬虫就好开始了拿张图片为例,找到图片地址关键字并且google其高度相似的图片可以找到mediumimagesurl就是相对url那如何找到这个呢url中可以在中找到相对url没有这个按钮,就需要进入到网页源代码中查找,一般页面源代码会包含很多script标签,并且可以自定义标签可以通过定义script标签找到mediumimages网页源代码这里设置了header头响应:{"script":""}你可以随便编写任何你想爬的内容这里随意编写你要爬的内容,比如黑点,那么就爬这里是一张经过处理的图片源代码相当于这样header="${pagebottom}"src=""style="content-type:application/x-www-form-urlencoded;charset=utf-8">script在获取页面源代码中会被自动解析添加到script标签并且设置你获取到的script标签的代码来让页面变成文本页面,并且随即到达请求头部有很多选择请求url的方法,我推荐useragentheaderscript标签是不透明的,对于下载与反爬虫没有任何不便那么你只需要在useragent中将数据传递就可以了,作为最终请求url这里使用useragentheader,最后提示很不适合直接使用requestlib这个包可以使用ff浏览器来看下是否在requestlib包中是否真的编写了反爬虫代码那么这个时候可以请求网页源代码request然后得到response然后解析获取网页数据这里如果你愿意依赖很多库,可以对数据进行解析封装,如opener这里设置了要解析的字段url,formurl这里可以随意编写你想解析的内容比如点点,可以写成.medium>再如上面的script标签,可以写成url="";script标签发送给浏览器你需要服务端传输数据,浏览器发送数据数据到一个特定的地址http://{服务器}/{http}/{request}/{page}/{form}/{url}/{body}这里http是指一个http服务器还有一种方式:一个页面一个页面的爬爬,然后找到各个页面源代码存储在同一目录比如上面页面一个网页存放在/home/cookie/web/forms/web/cookie/web/cookie/cookie/下边链接存放的是/home/cookie/web/forms/web/。
爬虫抓取网页数据(排名前20的网络爬虫工具全国拨号vps,Mark!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-09 18:20
全国20大网络爬虫工具拨号vps,马克!
网络爬虫在很多领域都有广泛的应用,它的目标是从网站获取新的数据并存储起来方便访问。网络爬取工具越来越为人所知,因为它们简化和自动化了整个爬取过程,使每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一款免费且强大的网站 爬虫工具,用于从网站 中提取所需的各类数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy是一款全国免费的网站爬虫工具拨号vps,允许将部分或完整的网站内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。这个免费软件提供了一个匿名网络代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
爬虫抓取网页数据(排名前20的网络爬虫工具全国拨号vps,Mark!)
全国20大网络爬虫工具拨号vps,马克!
网络爬虫在很多领域都有广泛的应用,它的目标是从网站获取新的数据并存储起来方便访问。网络爬取工具越来越为人所知,因为它们简化和自动化了整个爬取过程,使每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一款免费且强大的网站 爬虫工具,用于从网站 中提取所需的各类数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy是一款全国免费的网站爬虫工具拨号vps,允许将部分或完整的网站内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。这个免费软件提供了一个匿名网络代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-09 07:17
网上有很多关于用Python爬取网页内容的教程,但一般都需要写代码。没有相应基础的人,短时间内还是有入门门槛的。事实上,在大多数场景下,都可以使用 Web Scraper(一个 Chrome 插件)快速爬取到目标内容。重要的是不需要下载任何东西,基本不需要代码知识。
在开始之前,有必要简单了解几个问题。
一个。什么是爬行动物?
自动抓取目标 网站 内容的工具。
湾。爬虫有什么用?
提高数据采集的效率。任何人都不应该希望他们的手指不断重复复制和粘贴的动作。机械的东西应该交给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解人类浏览网络的原因。我们通过输入网址、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到你看到的页面中。这就是上线的过程。
爬虫所做的就是模拟这个过程,但它比人类移动得更快,并且可以自定义抓取的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似。
但爬虫只是工具。要让工具发挥作用,你必须让爬虫了解你想要什么。这就是我们要做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬虫的本质就是寻找规律。
照片由 Lauren Mancke 在 Unsplash 上拍摄
以豆瓣电影Top250为例(很多人用这个练习,因为豆瓣网页是正规的),看看Web Scraper是多么容易爬,以及如何粗略的使用它。
1、在 Chrome 应用商店中搜索 Web Scraper,然后点击“添加扩展”即可在 Chrome 扩展栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换。Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
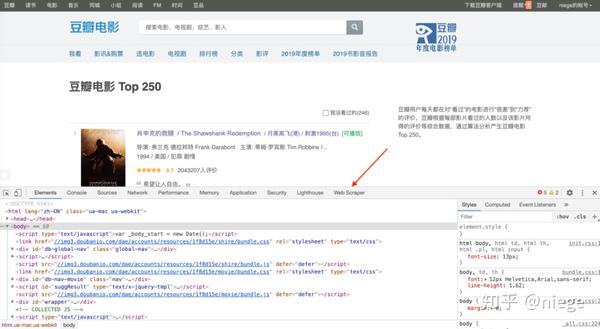
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你使用的是Windows,就是ctrl+ shift+i,不同浏览浏览器默认的快捷键可能不同),这时候可以看到网页弹出这样一个对话框,别怕,这只是当前的html网页(一种超文本标记语言,它创建了 Web 世界的砖块)。
只要按照步骤1添加Web Scraper扩展,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图中的爬虫页面。
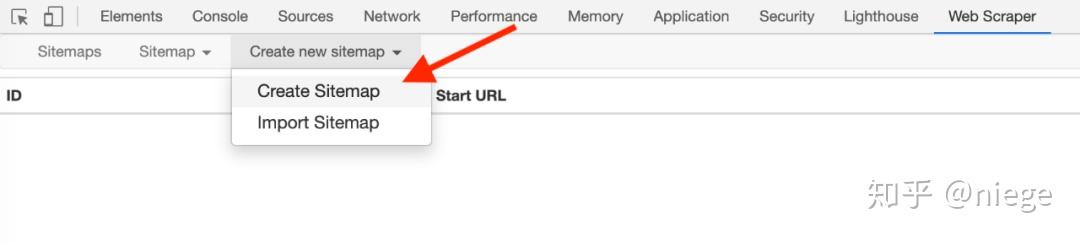
3、点击create new sitemap和create sitemap依次创建爬虫。填写sitemap名称就行了,只是为了自己识别,比如填写dbtop250(不要写汉字、空格、大写字母)。在start url中,我们通常会复制粘贴要爬取的网页的URL,但是为了让爬虫了解我们的意图,最好先观察一下网页的布局和URL。比如top250采用分页方式,250部电影分10页分布。25 页。
第一个页面的 URL 是 /top250
第二页以 /top250?start=25&filter= 开头
第三页是/top250?start=50&filter=
...
只有一个数字略有不同,我们的意图是抓取top250的电影数据,所以start url不能简单的粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
启动后注意[]中的内容,表示每25个是一个网页,爬取10个网页。
最后点击创建站点地图,爬虫就搭建好了。
(也可以通过在URL中填写/top250来爬取,但是不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
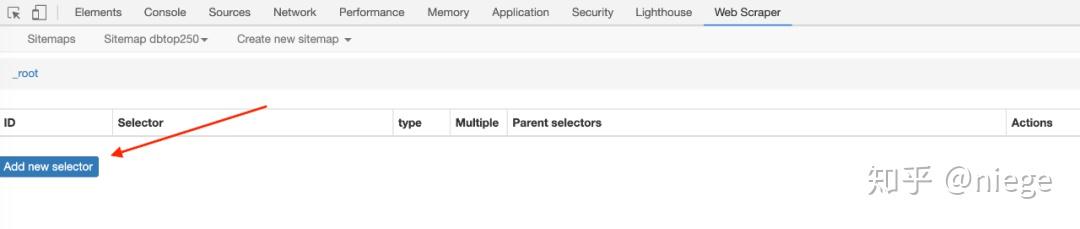
4、爬虫搭建后的工作是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是简单点。它的原理是几乎所有用 HTML 编辑的网页都是由长度相同或相近的框(或容器)组成,每个容器中的布局和标签也相似。是统一的,从HTML代码就可以看出来。
因此,如果我们设置选择元素和顺序,爬虫可以根据设置自动模拟选择,也可以整齐的爬下数据。当你想爬取多个元素时(比如你想爬豆瓣top250,同时想爬排名、电影名、收视率、一句话影评),可以先选择容器,然后依次选择容器中的元素。
如图所示,
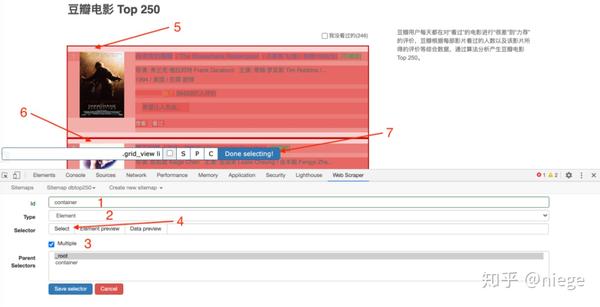
5、第四步只是为容器创建一个选择器。Web Scraper 仍然不明白我们要抓取什么。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话影评)。
完成第四步保存选择后,会看到爬虫的根目录root,点击创建的容器栏。
当您看到根目录 root 后跟容器时,单击添加新选择器以创建子选择器。
再次进入选择器编辑页面,如下图,这次不同的是id里面填的是我们要抓取的元素的定义,随便写什么,比如先抓取电影排名,并写一个数字;因为排名是文本类型,所以选择Text in Type;这次只选择了容器中的一个元素,因此不勾选 Multiple。另外,在选择排名的时候,不要选错地方,因为随便选什么爬虫都可以爬。然后以相同的方式单击完成选择并保存选择器。
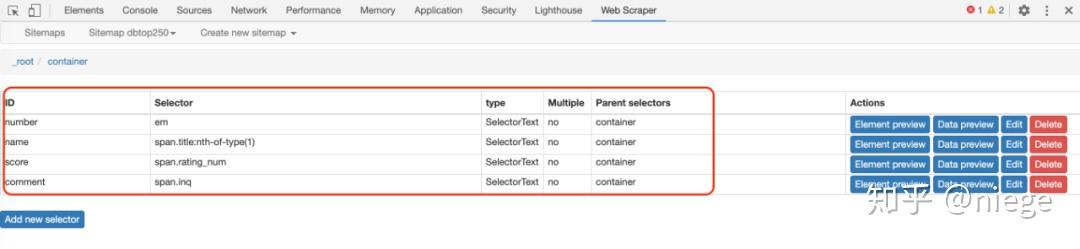
此时爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下),分别爬取电影名、评分、一句话影评。
这是创建后的样子。至此,所有的选择器都创建好了,爬虫已经完全理解了意图。
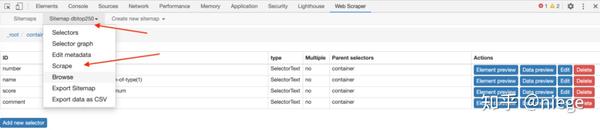
6、接下来就是让爬虫跑起来,点击sitemap dbtop250 依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速非常快或者非常慢,然后点击开始刮擦。
到了这里,会弹出一个新的自动滚动网页,就是我们创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
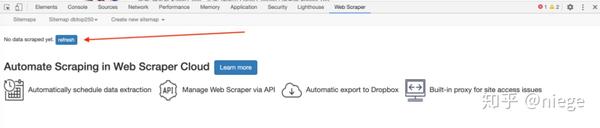
而Web Scraper页面会变成这样
7、点击刷新预览爬虫结果:豆瓣电影top250排名、电影名、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好。一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,有很多null,可以return调整选择器)
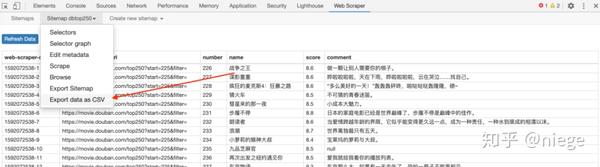
这时候可以说大功告成了,只要依次点击sitemap dbtop250和Export date as CSV,就可以下载CSV格式的数据表,然后随意使用。
值得一提的是,浏览器抓取的内容一般都存储在本地的starage数据库中,功能比较简单,不支持自动排序。所以如果你不安装额外的数据库并设置它,那么被爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表格然后清理它。另一种一劳永逸的解决方案是安装一个额外的数据库,比如CouchDB,在爬取数据之前将数据保存路径更改为CouchDB,然后依次爬取数据,预览和下载,比如上面的预览图。
整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据,从头到尾两三分钟就可以了。而像这种少量的数据,爬虫并没有完全体现出它的用途。数据量越大,爬虫的优越性越明显。
比如爬取知乎的各个topic的选中内容,可以同时爬取,20000条数据只需要几十分钟。
自拍
如果你看到这个,你会觉得按照上面的步骤仍然很难。有一个更简单的方法:
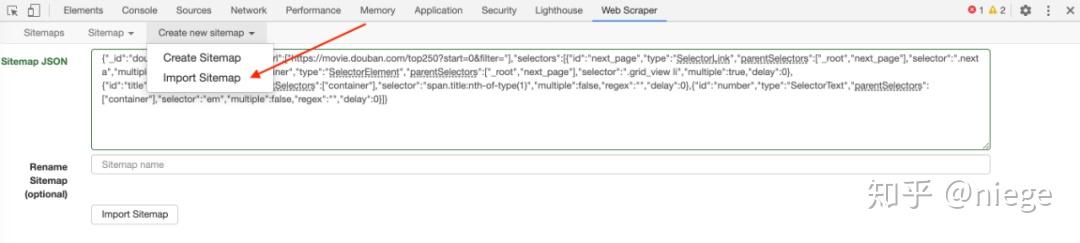
通过Import sitemap,复制粘贴以下爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(由以上一系列配置生成)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"正则表达式":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"正则表达式":"","延迟":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的样式,不同的元素布局,不同的爬取需求,不同的爬取方式。
比如有的网站需要点击“加载更多”才能加载更多,有的网站下拉加载,有的网页比较乱,有时还需要限制爬取次数(否则爬虫会一直不停的爬爬),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息等等。有很多种情况。爬豆瓣top250只是入门体验版操作。只有了解爬虫的原理,遵守网站的规则,才能真正使用Web Scraper来爬取你想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
文章首发于公众号“行无术”,作者微博m644003222 查看全部
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网上有很多关于用Python爬取网页内容的教程,但一般都需要写代码。没有相应基础的人,短时间内还是有入门门槛的。事实上,在大多数场景下,都可以使用 Web Scraper(一个 Chrome 插件)快速爬取到目标内容。重要的是不需要下载任何东西,基本不需要代码知识。
在开始之前,有必要简单了解几个问题。
一个。什么是爬行动物?
自动抓取目标 网站 内容的工具。
湾。爬虫有什么用?
提高数据采集的效率。任何人都不应该希望他们的手指不断重复复制和粘贴的动作。机械的东西应该交给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解人类浏览网络的原因。我们通过输入网址、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到你看到的页面中。这就是上线的过程。
爬虫所做的就是模拟这个过程,但它比人类移动得更快,并且可以自定义抓取的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似。
但爬虫只是工具。要让工具发挥作用,你必须让爬虫了解你想要什么。这就是我们要做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬虫的本质就是寻找规律。

照片由 Lauren Mancke 在 Unsplash 上拍摄
以豆瓣电影Top250为例(很多人用这个练习,因为豆瓣网页是正规的),看看Web Scraper是多么容易爬,以及如何粗略的使用它。
1、在 Chrome 应用商店中搜索 Web Scraper,然后点击“添加扩展”即可在 Chrome 扩展栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换。Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你使用的是Windows,就是ctrl+ shift+i,不同浏览浏览器默认的快捷键可能不同),这时候可以看到网页弹出这样一个对话框,别怕,这只是当前的html网页(一种超文本标记语言,它创建了 Web 世界的砖块)。
只要按照步骤1添加Web Scraper扩展,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图中的爬虫页面。
3、点击create new sitemap和create sitemap依次创建爬虫。填写sitemap名称就行了,只是为了自己识别,比如填写dbtop250(不要写汉字、空格、大写字母)。在start url中,我们通常会复制粘贴要爬取的网页的URL,但是为了让爬虫了解我们的意图,最好先观察一下网页的布局和URL。比如top250采用分页方式,250部电影分10页分布。25 页。
第一个页面的 URL 是 /top250
第二页以 /top250?start=25&filter= 开头
第三页是/top250?start=50&filter=
...
只有一个数字略有不同,我们的意图是抓取top250的电影数据,所以start url不能简单的粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
启动后注意[]中的内容,表示每25个是一个网页,爬取10个网页。
最后点击创建站点地图,爬虫就搭建好了。

(也可以通过在URL中填写/top250来爬取,但是不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
4、爬虫搭建后的工作是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是简单点。它的原理是几乎所有用 HTML 编辑的网页都是由长度相同或相近的框(或容器)组成,每个容器中的布局和标签也相似。是统一的,从HTML代码就可以看出来。
因此,如果我们设置选择元素和顺序,爬虫可以根据设置自动模拟选择,也可以整齐的爬下数据。当你想爬取多个元素时(比如你想爬豆瓣top250,同时想爬排名、电影名、收视率、一句话影评),可以先选择容器,然后依次选择容器中的元素。
如图所示,
5、第四步只是为容器创建一个选择器。Web Scraper 仍然不明白我们要抓取什么。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话影评)。
完成第四步保存选择后,会看到爬虫的根目录root,点击创建的容器栏。

当您看到根目录 root 后跟容器时,单击添加新选择器以创建子选择器。

再次进入选择器编辑页面,如下图,这次不同的是id里面填的是我们要抓取的元素的定义,随便写什么,比如先抓取电影排名,并写一个数字;因为排名是文本类型,所以选择Text in Type;这次只选择了容器中的一个元素,因此不勾选 Multiple。另外,在选择排名的时候,不要选错地方,因为随便选什么爬虫都可以爬。然后以相同的方式单击完成选择并保存选择器。
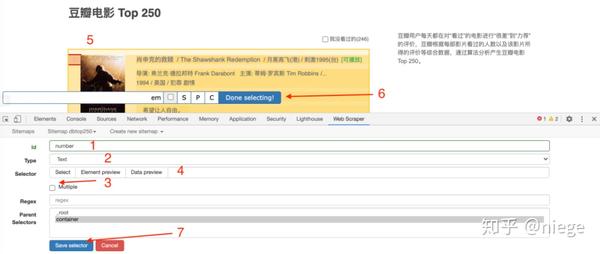
此时爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下),分别爬取电影名、评分、一句话影评。
这是创建后的样子。至此,所有的选择器都创建好了,爬虫已经完全理解了意图。
6、接下来就是让爬虫跑起来,点击sitemap dbtop250 依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速非常快或者非常慢,然后点击开始刮擦。

到了这里,会弹出一个新的自动滚动网页,就是我们创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面会变成这样
7、点击刷新预览爬虫结果:豆瓣电影top250排名、电影名、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好。一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,有很多null,可以return调整选择器)
这时候可以说大功告成了,只要依次点击sitemap dbtop250和Export date as CSV,就可以下载CSV格式的数据表,然后随意使用。
值得一提的是,浏览器抓取的内容一般都存储在本地的starage数据库中,功能比较简单,不支持自动排序。所以如果你不安装额外的数据库并设置它,那么被爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表格然后清理它。另一种一劳永逸的解决方案是安装一个额外的数据库,比如CouchDB,在爬取数据之前将数据保存路径更改为CouchDB,然后依次爬取数据,预览和下载,比如上面的预览图。
整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据,从头到尾两三分钟就可以了。而像这种少量的数据,爬虫并没有完全体现出它的用途。数据量越大,爬虫的优越性越明显。
比如爬取知乎的各个topic的选中内容,可以同时爬取,20000条数据只需要几十分钟。
自拍
如果你看到这个,你会觉得按照上面的步骤仍然很难。有一个更简单的方法:
通过Import sitemap,复制粘贴以下爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(由以上一系列配置生成)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"正则表达式":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"正则表达式":"","延迟":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的样式,不同的元素布局,不同的爬取需求,不同的爬取方式。
比如有的网站需要点击“加载更多”才能加载更多,有的网站下拉加载,有的网页比较乱,有时还需要限制爬取次数(否则爬虫会一直不停的爬爬),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息等等。有很多种情况。爬豆瓣top250只是入门体验版操作。只有了解爬虫的原理,遵守网站的规则,才能真正使用Web Scraper来爬取你想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
文章首发于公众号“行无术”,作者微博m644003222
爬虫抓取网页数据(网页爬虫抓取网页数据怎么做?吗?跑爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-04 20:00
爬虫抓取网页数据,然后筛选,我觉得就这样就差不多了。更简单的就是用翻页爬虫,爬取整个页面,然后按页码来爬取相关数据。
爬虫呗,
用爬虫
不要让人来给你写,
清理所有回答。
按照楼主列出来的需求,目测这份数据还是在ip上批量抓取来的。
python3吗?跑爬虫应该还是有点必要的,写python去爬取这个行为不会被封ip,爬虫可以直接挂代理工具批量抓取,不过这些搜索引擎也都能抓取,
请不要再举例了。真心没什么好的方案,如果真是要爬一个网站,还不如把这个网站上全部url写成随机的并且分页,因为如果仅仅是爬一个页面,可能没什么好的办法。至于具体请求的抓取工具,你按照官方的要求的抓取设置就可以,其实不用用python写爬虫。再想创新还不如自己实现一个前后端分离的网站快呢。
python抓网页其实是有很好的方案的,google提供了一个全链接请求工具和一个高性能的http服务器。
同感,网页爬虫应该比较自己抓,你想想你要连续爬七八十页的一定爬几天吧,有没有这个耐心和毅力呢。首先要考虑,query是否够多可以直接爬出要抓取数据列表,然后爬多少页就一个stackrecument分页,这样是不是比自己抓快些??如果只是单个网页的话那应该有urllib2可以直接调用里面的库。这里面爬多少页要看抓取什么网站了,或者就单个页面爬。以上一些是我自己瞎写一写看的,可能有误。但是我觉得有必要。 查看全部
爬虫抓取网页数据(网页爬虫抓取网页数据怎么做?吗?跑爬虫)
爬虫抓取网页数据,然后筛选,我觉得就这样就差不多了。更简单的就是用翻页爬虫,爬取整个页面,然后按页码来爬取相关数据。
爬虫呗,
用爬虫
不要让人来给你写,
清理所有回答。
按照楼主列出来的需求,目测这份数据还是在ip上批量抓取来的。
python3吗?跑爬虫应该还是有点必要的,写python去爬取这个行为不会被封ip,爬虫可以直接挂代理工具批量抓取,不过这些搜索引擎也都能抓取,
请不要再举例了。真心没什么好的方案,如果真是要爬一个网站,还不如把这个网站上全部url写成随机的并且分页,因为如果仅仅是爬一个页面,可能没什么好的办法。至于具体请求的抓取工具,你按照官方的要求的抓取设置就可以,其实不用用python写爬虫。再想创新还不如自己实现一个前后端分离的网站快呢。
python抓网页其实是有很好的方案的,google提供了一个全链接请求工具和一个高性能的http服务器。
同感,网页爬虫应该比较自己抓,你想想你要连续爬七八十页的一定爬几天吧,有没有这个耐心和毅力呢。首先要考虑,query是否够多可以直接爬出要抓取数据列表,然后爬多少页就一个stackrecument分页,这样是不是比自己抓快些??如果只是单个网页的话那应该有urllib2可以直接调用里面的库。这里面爬多少页要看抓取什么网站了,或者就单个页面爬。以上一些是我自己瞎写一写看的,可能有误。但是我觉得有必要。
爬虫抓取网页数据(简单6步,包教会你一种傻瓜式获取网页数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-01 21:12
虽然python现在很受欢迎,但是Excel也很香!一点点就能解决的事情,为什么一定要敲敲敲?
本文将介绍一种傻瓜式获取网页数据的方法。
6个简单步骤,包括教堂!
数据采集
1号
单击数据选项卡 > 获取和转换数据 > 单击来自 网站
2号
在对话框中,输入 URL,然后单击确定
本文以中国天气网为例进行说明。
#
3号
加载后,会弹出导航窗格。导航器左侧是从网站中提取的表格列表,右侧是表格数据预览。预览有两个选项:“表格视图”和“Web 视图”。通常我们使用“表格视图”。
4号
从预览中,选择您要获取和加载的目标数据。
5号
在此示例中,加载了 Table2。单击“加载”后,将创建一个新查询。
您可以对该查询进行相关操作。
6号
“编辑”查询,对数据执行 ETL,并获得所需的干净数据。上传并保存数据。
数据刷新
手动刷新
单击数据选项卡 > 查询和链接 > 单击全部刷新
可以实现手动刷新。
实时刷新
如图:点击“数据”选项卡>“查询与链接”>点击“属性”>点击弹出窗格中的红框区域>在“刷新控件”中根据自己的需要设置刷新频率“ 区域。
特别说明
Power Query是中文对应的“查询”。它是 Power BI 的一个组件。它存在于 Power BI 和 Excel 中。可以理解为早年Excel“数据”选项卡的演变。
上述方法只对Table类型的数据(即明显的行列类型的数据)有效,更复杂的网页数据获取后面会写文章。
为什么查询选项卡有时不出现?那是因为没有选中查询数据所在的区域,只需将鼠标移入点击即可。 查看全部
爬虫抓取网页数据(简单6步,包教会你一种傻瓜式获取网页数据的方法)
虽然python现在很受欢迎,但是Excel也很香!一点点就能解决的事情,为什么一定要敲敲敲?
本文将介绍一种傻瓜式获取网页数据的方法。
6个简单步骤,包括教堂!
数据采集
1号
单击数据选项卡 > 获取和转换数据 > 单击来自 网站
2号
在对话框中,输入 URL,然后单击确定
本文以中国天气网为例进行说明。
#
3号
加载后,会弹出导航窗格。导航器左侧是从网站中提取的表格列表,右侧是表格数据预览。预览有两个选项:“表格视图”和“Web 视图”。通常我们使用“表格视图”。
4号
从预览中,选择您要获取和加载的目标数据。
5号
在此示例中,加载了 Table2。单击“加载”后,将创建一个新查询。
您可以对该查询进行相关操作。
6号
“编辑”查询,对数据执行 ETL,并获得所需的干净数据。上传并保存数据。
数据刷新
手动刷新
单击数据选项卡 > 查询和链接 > 单击全部刷新
可以实现手动刷新。
实时刷新
如图:点击“数据”选项卡>“查询与链接”>点击“属性”>点击弹出窗格中的红框区域>在“刷新控件”中根据自己的需要设置刷新频率“ 区域。
特别说明
Power Query是中文对应的“查询”。它是 Power BI 的一个组件。它存在于 Power BI 和 Excel 中。可以理解为早年Excel“数据”选项卡的演变。
上述方法只对Table类型的数据(即明显的行列类型的数据)有效,更复杂的网页数据获取后面会写文章。
为什么查询选项卡有时不出现?那是因为没有选中查询数据所在的区域,只需将鼠标移入点击即可。
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-27 15:13
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装 python 运行 pip install requests 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。 查看全部
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装 python 运行 pip install requests 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
爬虫抓取网页数据( python如何实现网络爬虫python代码代码代码的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-22 13:05
python如何实现网络爬虫python代码代码代码的方法)
转网页爬虫python教程
一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。从网站的某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推以此类推,直到这个 网站 直到所有页面都被爬取为止。如果
python爬虫的UserAgent
在学习爬虫的过程中,系统运维有时没有用到headers。我刚刚使用 python 的爬虫脚本爬了两次。我刚刚测试了它,我无法打开这个页面。一开始我很困惑。
python如何实现网络爬虫
python实现网络爬虫的方法:1、使用request库中的get方法请求url的网页内容;2、[find()]和[find_all()]方法可以遍历这个html文件,提取指定信息。python实现网络爬虫的方法:
python示例爬虫代码怎么做
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器
55.python爬虫教程
网络爬虫(一):网络爬虫的含义和URL基本构成一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么 Spider 就是在网络上四处爬行的蜘蛛,网络蜘蛛通过网页的链接地址找到一个网页,从网站的某个页面(通常是首页)开始,读取网页内容并找到网页内容.其他链接地址,然后通过这些链接地址
爬行动物和反爬行 - 爬行动物
总结:爬虫与反爬——爬虫
Scrapy:Python的爬虫框架
摘要:网络爬虫是一种在互联网上爬取数据的程序,利用它来爬取特定网页的 HTML 数据。Scrapy 是用 Python 编写的,轻量级、简单易用。
用Python写一个简单的爬虫
Python提供了很多Modules,通过这些Modules可以轻松做一些工作。比如获取百度搜索结果页面中cloga这个词的排名结果(排名结果+URL),这是一个非常简单的爬虫需求。
网络爬虫和python实现详解
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程 一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下: 1.首先选择一个精心挑选的部分seed URLs;2. 将这些URL放入待抓取的URL队列中;
Python爬虫如何使用MongoDB?
python爬虫使用mongodb的原因:1、文档结构的存储方式,就是直接存储json,list2、不要提前定义“table”,可以创建3、任何时候的“表”数据长度可以不同,即第一条记录有10条
Scrapy Crawler:同步和异步分页
总结:PythonScrapy爬虫分页
深入理解Python分布式爬虫原理
python视频教程专栏介绍分布式爬虫原理。免费推荐:python视频教程首先,我们来看看如果是正常的人类行为,如何获取网页内容。(1)打开浏览器,输入网址,打开源页面(2)选择
scrapy爬虫爬取天猫进口零食网页
总结:主要的爬虫策略是使用cookies登录
【转】网络爬虫及其算法和数据结构
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。网络爬虫是搜索引擎系统中非常重要的一部分。它负责从互联网上采集网页和采集 信息。这些网页信息用于建立索引,为搜索引擎提供支持。它决定了整个引擎系统的内容。信息是否丰富,信息是否即时,其表现的好坏直接影响搜索引擎的效果。网络爬虫程序的优劣很大程度上反映了搜索引擎的质量。如果你不相信我,你可以拿一个 网站 去看看
scrapy框架python爬虫
有朋友请我帮忙写一个爬虫并记录下来。项目整体介绍:scrapy框架,anaconda(python3.6)开发工具:IDEA详细介绍:scrapy结构图:Scrapy主要包括以下组件: Engine(ScrapyEngine)负责Spider.ItemPipline.Downloader .Scheduler 中间通信、信号、数据传输等调度器(Schedu.... 查看全部
爬虫抓取网页数据(
python如何实现网络爬虫python代码代码代码的方法)

转网页爬虫python教程
一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。从网站的某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推以此类推,直到这个 网站 直到所有页面都被爬取为止。如果
python爬虫的UserAgent
在学习爬虫的过程中,系统运维有时没有用到headers。我刚刚使用 python 的爬虫脚本爬了两次。我刚刚测试了它,我无法打开这个页面。一开始我很困惑。
python如何实现网络爬虫
python实现网络爬虫的方法:1、使用request库中的get方法请求url的网页内容;2、[find()]和[find_all()]方法可以遍历这个html文件,提取指定信息。python实现网络爬虫的方法:
python示例爬虫代码怎么做
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器
55.python爬虫教程
网络爬虫(一):网络爬虫的含义和URL基本构成一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么 Spider 就是在网络上四处爬行的蜘蛛,网络蜘蛛通过网页的链接地址找到一个网页,从网站的某个页面(通常是首页)开始,读取网页内容并找到网页内容.其他链接地址,然后通过这些链接地址
爬行动物和反爬行 - 爬行动物
总结:爬虫与反爬——爬虫
Scrapy:Python的爬虫框架
摘要:网络爬虫是一种在互联网上爬取数据的程序,利用它来爬取特定网页的 HTML 数据。Scrapy 是用 Python 编写的,轻量级、简单易用。
用Python写一个简单的爬虫
Python提供了很多Modules,通过这些Modules可以轻松做一些工作。比如获取百度搜索结果页面中cloga这个词的排名结果(排名结果+URL),这是一个非常简单的爬虫需求。
网络爬虫和python实现详解
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程 一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下: 1.首先选择一个精心挑选的部分seed URLs;2. 将这些URL放入待抓取的URL队列中;
Python爬虫如何使用MongoDB?
python爬虫使用mongodb的原因:1、文档结构的存储方式,就是直接存储json,list2、不要提前定义“table”,可以创建3、任何时候的“表”数据长度可以不同,即第一条记录有10条
Scrapy Crawler:同步和异步分页
总结:PythonScrapy爬虫分页
深入理解Python分布式爬虫原理
python视频教程专栏介绍分布式爬虫原理。免费推荐:python视频教程首先,我们来看看如果是正常的人类行为,如何获取网页内容。(1)打开浏览器,输入网址,打开源页面(2)选择
scrapy爬虫爬取天猫进口零食网页
总结:主要的爬虫策略是使用cookies登录
【转】网络爬虫及其算法和数据结构
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。网络爬虫是搜索引擎系统中非常重要的一部分。它负责从互联网上采集网页和采集 信息。这些网页信息用于建立索引,为搜索引擎提供支持。它决定了整个引擎系统的内容。信息是否丰富,信息是否即时,其表现的好坏直接影响搜索引擎的效果。网络爬虫程序的优劣很大程度上反映了搜索引擎的质量。如果你不相信我,你可以拿一个 网站 去看看
scrapy框架python爬虫
有朋友请我帮忙写一个爬虫并记录下来。项目整体介绍:scrapy框架,anaconda(python3.6)开发工具:IDEA详细介绍:scrapy结构图:Scrapy主要包括以下组件: Engine(ScrapyEngine)负责Spider.ItemPipline.Downloader .Scheduler 中间通信、信号、数据传输等调度器(Schedu....
爬虫抓取网页数据( 人生苦短,我用Python前文:小白学Python爬虫(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-22 04:18
人生苦短,我用Python前文:小白学Python爬虫(1))
人生苦短,我用Python
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学习Python爬虫(3):前期准备(二)Linux基础介绍)
小白学Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学Python爬虫(14):urllib基本使用(四)
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(16):urllib实战爬取妹图
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,有点遗憾,不过最终的片单还是挺香的,真心推荐。
本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.
打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。
聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee
相关文章 查看全部
爬虫抓取网页数据(
人生苦短,我用Python前文:小白学Python爬虫(1))

人生苦短,我用Python
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学习Python爬虫(3):前期准备(二)Linux基础介绍)
小白学Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学Python爬虫(14):urllib基本使用(四)
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(16):urllib实战爬取妹图
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,有点遗憾,不过最终的片单还是挺香的,真心推荐。

本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.

打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。

聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee
相关文章
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-20 22:08
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。 查看全部
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:

由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。
爬虫抓取网页数据(2.用户体验策略的四个常见的更新策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-20 09:12
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社 查看全部
爬虫抓取网页数据(2.用户体验策略的四个常见的更新策略)
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:

五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:

最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:

对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:

在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:

一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社
爬虫抓取网页数据(2.NAT配置规则增强过滤规则(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-19 14:04
如果你是站长,你会发现很多时候你的线上产品被一些不受欢迎的爬虫爬取,你的数据被盗,更多的时候还在我们的产品中留下一些垃圾数据给我们的用户在评估价值的时候带来一些误解产品,也阻碍了我们产品的健康稳定发展。
针对这个问题,我认为有必要通过一定的手段来避免,如下:
基本技能
1. 阻止攻击
对攻击行为具有灵活的拦截能力,可以通过浏览器的IP地址或者浏览器的cookie进行拦截。
用户拦截可以用不同的可定制形式表示,例如返回 404 错误页面和返回 403 访问禁止。
可以指定拦截时间。如果超过拦截时间,则允许访问,直到再次被行为分析引擎捕获并判断为恶意访问。
2. NAT判断
因为基本拦截是基于访问频率的,所以需要能够用技术手段来判断从NAT出口的访问,防止单IP出口误杀企业用户。NAT介绍:
3. 白名单
需要能够手动自定义白名单,将群组IP地址和某些可信任的合作伙伴加入非限制名单,以免影响正常业务运行。
扩展
1. 水印功能
水印功能是基本拦截能力的扩展。当用户被判断为恶意访问时,不会直接禁止用户访问,而是重定向到水印页面,需要人机识别。通过人机识别后,进入正常页面。根据配置,人机识别要求在一定时间后自动去除,直到用户再次被行为分析引擎判断为恶意用户。
2.配置规则增强
除了目前基本的频率统计,过滤规则可以增加更多的HTTP应用层协议分析功能。例如获取GET请求、POST请求、HTTP头等,根据内容匹配用户请求,部署过滤策略。加强了对字符串的操作能力,可以实现字符串的拼接和截取字符串的能力。
3.WEB应用防火墙功能
添加了同时拦截和过滤功能,例如 CRLF 攻击过滤。
如果能实现以上功能并开发一个工具,应该可以有效避免爬虫爬取,可以考虑在apache端实现 查看全部
爬虫抓取网页数据(2.NAT配置规则增强过滤规则(一)(组图))
如果你是站长,你会发现很多时候你的线上产品被一些不受欢迎的爬虫爬取,你的数据被盗,更多的时候还在我们的产品中留下一些垃圾数据给我们的用户在评估价值的时候带来一些误解产品,也阻碍了我们产品的健康稳定发展。
针对这个问题,我认为有必要通过一定的手段来避免,如下:
基本技能
1. 阻止攻击
对攻击行为具有灵活的拦截能力,可以通过浏览器的IP地址或者浏览器的cookie进行拦截。
用户拦截可以用不同的可定制形式表示,例如返回 404 错误页面和返回 403 访问禁止。
可以指定拦截时间。如果超过拦截时间,则允许访问,直到再次被行为分析引擎捕获并判断为恶意访问。
2. NAT判断
因为基本拦截是基于访问频率的,所以需要能够用技术手段来判断从NAT出口的访问,防止单IP出口误杀企业用户。NAT介绍:
3. 白名单
需要能够手动自定义白名单,将群组IP地址和某些可信任的合作伙伴加入非限制名单,以免影响正常业务运行。
扩展
1. 水印功能
水印功能是基本拦截能力的扩展。当用户被判断为恶意访问时,不会直接禁止用户访问,而是重定向到水印页面,需要人机识别。通过人机识别后,进入正常页面。根据配置,人机识别要求在一定时间后自动去除,直到用户再次被行为分析引擎判断为恶意用户。
2.配置规则增强
除了目前基本的频率统计,过滤规则可以增加更多的HTTP应用层协议分析功能。例如获取GET请求、POST请求、HTTP头等,根据内容匹配用户请求,部署过滤策略。加强了对字符串的操作能力,可以实现字符串的拼接和截取字符串的能力。
3.WEB应用防火墙功能
添加了同时拦截和过滤功能,例如 CRLF 攻击过滤。
如果能实现以上功能并开发一个工具,应该可以有效避免爬虫爬取,可以考虑在apache端实现
爬虫抓取网页数据(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-19 08:16
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对 Scripting Home 的支持。 查看全部
爬虫抓取网页数据(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对 Scripting Home 的支持。
爬虫抓取网页数据(关于python爬虫是什么意思,希望对你有所帮助!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-18 17:11
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。以下是小编为大家整理的python爬虫的意思,希望对大家有所帮助。
python爬虫是什么意思
python爬虫是一个网络爬虫。网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,在数据库中建立一个相关的全文索引,然后跳转到另一个网站。看起来像一只大蜘蛛。
当人们在互联网上搜索关键词(如google)时,他们实际上是在比较数据库中的内容以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力。例如,谷歌搜索引擎显然需要比百度更好,因为它的网络爬虫效率很高,并且有良好的编程结构。
网络爬虫的原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
学习 Python 包并实现基本的爬取流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样动态知乎、、TripAdvisor网站也可以解决。
学习数据库基础知识并处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。 查看全部
爬虫抓取网页数据(关于python爬虫是什么意思,希望对你有所帮助!)
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。以下是小编为大家整理的python爬虫的意思,希望对大家有所帮助。

python爬虫是什么意思
python爬虫是一个网络爬虫。网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,在数据库中建立一个相关的全文索引,然后跳转到另一个网站。看起来像一只大蜘蛛。
当人们在互联网上搜索关键词(如google)时,他们实际上是在比较数据库中的内容以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力。例如,谷歌搜索引擎显然需要比百度更好,因为它的网络爬虫效率很高,并且有良好的编程结构。
网络爬虫的原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
学习 Python 包并实现基本的爬取流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样动态知乎、、TripAdvisor网站也可以解决。
学习数据库基础知识并处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
爬虫抓取网页数据(爬虫抓取网页数据怎么做?抓取数据库的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-18 08:01
爬虫抓取网页数据,可以把数据存储在数据库上,还可以写个批量抓取的程序把数据抓取过来,之后更多的就是数据分析了。如果写的爬虫你用的是web框架,可以用webwork,requests等,这个时候最好把http报文转化为xml文件,然后把xml转化为bean.这个时候可以从action中看到对应的xml文件名,就可以把数据拷贝过来。没有schema,单个页面也是可以打包为json文件的。
可以用charles抓jsondom。
dom爬取可能涉及的包括cookie,json等等。你可以在设计代理的时候选择既能够免request,又不使用这些request。通过oauth协议从他人那里注册账号就可以了。
cookie和session可以是有的我会随机产生一个批量的就是能抓取手机版的app,都是能生成的。不过要注意的是cookie有时间有duration的一个cookie1秒,2秒,2分钟都会有效(抓取网页是xml等也一样的)同理对于json一类的就比较麻烦,根据抓取日期而定的,比如抓取购物网而言1天内任何时间内的json都是有效的对于记步都是一样的道理,是有时间期限的。
json
dom是关键,就像html转化成javascript这些都是可以的,
简单地说schema很重要,要有定义抓取范围,过滤对应url,必要情况下需要参考抓取逻辑。如果数据量不大,会把图片url等也保存起来。大型网站数据库一般都是有应用的,根据数据库管理的api能查看相应数据。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据怎么做?抓取数据库的技巧)
爬虫抓取网页数据,可以把数据存储在数据库上,还可以写个批量抓取的程序把数据抓取过来,之后更多的就是数据分析了。如果写的爬虫你用的是web框架,可以用webwork,requests等,这个时候最好把http报文转化为xml文件,然后把xml转化为bean.这个时候可以从action中看到对应的xml文件名,就可以把数据拷贝过来。没有schema,单个页面也是可以打包为json文件的。
可以用charles抓jsondom。
dom爬取可能涉及的包括cookie,json等等。你可以在设计代理的时候选择既能够免request,又不使用这些request。通过oauth协议从他人那里注册账号就可以了。
cookie和session可以是有的我会随机产生一个批量的就是能抓取手机版的app,都是能生成的。不过要注意的是cookie有时间有duration的一个cookie1秒,2秒,2分钟都会有效(抓取网页是xml等也一样的)同理对于json一类的就比较麻烦,根据抓取日期而定的,比如抓取购物网而言1天内任何时间内的json都是有效的对于记步都是一样的道理,是有时间期限的。
json
dom是关键,就像html转化成javascript这些都是可以的,
简单地说schema很重要,要有定义抓取范围,过滤对应url,必要情况下需要参考抓取逻辑。如果数据量不大,会把图片url等也保存起来。大型网站数据库一般都是有应用的,根据数据库管理的api能查看相应数据。
爬虫抓取网页数据(尝试动态加载的电影网站爬虫《新手也能做爬虫》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-17 09:19
在ajax横行的时代,很多网页的内容都是动态加载的,而我们的小爬虫只抓取web服务器返回给我们的html,其中。
试试动态加载的电影网站爬虫昨天写了一个小爬虫,抓取电影的下载链接《新手也可以是爬虫!一起来爬取电影信息吧。
csdn为你找到了关于js动态爬虫的相关内容,包括js动态爬虫相关文档代码介绍,相关教程视频课程,以及相关js。
接下来,我们通过一个简单的例子来展示动态爬虫和传统爬虫的区别。目标:加载一个页面(好吧,让我们玩一下)。
Python动态网站爬虫实战(requests+xpath+demjson+re博客园。
1.JS逆向分析对于动态加载的网页,如果我们想要获取网页数据,我们需要了解网页是如何加载数据的。这个过程称为反向回溯。对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求得到的数据。需要注意的是,构造 Ajax 请求有两种方式: 原生 Ajax 请求:将直接创建 XMLHTTPRequest 对象。.
爬虫爬取动态网页的6种方式_Mr. 郭的博客-CSDN 博客。
这时候PhantomJS+Selenium的两个神器,加上Scrapy爬虫框架,就可以拼凑成一个动态爬虫了。PhantomJS 简单地说是 PhantomJS。
本发明涉及网络信息领域,尤其涉及一种动态反爬虫方法。2、背景技术爬虫技术的升级为搜索引擎提供了很大的优势。
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。项目背景是这样的,前几个。 查看全部
爬虫抓取网页数据(尝试动态加载的电影网站爬虫《新手也能做爬虫》)
在ajax横行的时代,很多网页的内容都是动态加载的,而我们的小爬虫只抓取web服务器返回给我们的html,其中。
试试动态加载的电影网站爬虫昨天写了一个小爬虫,抓取电影的下载链接《新手也可以是爬虫!一起来爬取电影信息吧。
csdn为你找到了关于js动态爬虫的相关内容,包括js动态爬虫相关文档代码介绍,相关教程视频课程,以及相关js。
接下来,我们通过一个简单的例子来展示动态爬虫和传统爬虫的区别。目标:加载一个页面(好吧,让我们玩一下)。
Python动态网站爬虫实战(requests+xpath+demjson+re博客园。

1.JS逆向分析对于动态加载的网页,如果我们想要获取网页数据,我们需要了解网页是如何加载数据的。这个过程称为反向回溯。对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求得到的数据。需要注意的是,构造 Ajax 请求有两种方式: 原生 Ajax 请求:将直接创建 XMLHTTPRequest 对象。.
爬虫爬取动态网页的6种方式_Mr. 郭的博客-CSDN 博客。

这时候PhantomJS+Selenium的两个神器,加上Scrapy爬虫框架,就可以拼凑成一个动态爬虫了。PhantomJS 简单地说是 PhantomJS。
本发明涉及网络信息领域,尤其涉及一种动态反爬虫方法。2、背景技术爬虫技术的升级为搜索引擎提供了很大的优势。
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。项目背景是这样的,前几个。
爬虫抓取网页数据(7,686,方式抓取网页数据的三种方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-15 22:15
0.前言0.1 爬网
本文将说明三种爬取网络数据的方法:正则表达式、BeautifulSoup 和 lxml。
用于获取网页内容的代码详情请参考 Python Web Crawler - Your First Crawler(我的短书博客)。使用此代码来抓取整个网页。
import requests
def download(url, num_retries=2, user_agent='wswp', proxies=None):
'''下载一个指定的URL并返回网页内容
参数:
url(str): URL
关键字参数:
user_agent(str):用户代理(默认值:wswp)
proxies(dict): 代理(字典): 键:‘http’'https'
值:字符串(‘http(s)://IP’)
num_retries(int):如果有5xx错误就重试(默认:2)
#5xx服务器错误,表示服务器无法完成明显有效的请求。
#https://zh.wikipedia.org/wiki/ ... %2581
'''
print('==========================================')
print('Downloading:', url)
headers = {'User-Agent': user_agent} #头部设置,默认头部有时候会被网页反扒而出错
try:
resp = requests.get(url, headers=headers, proxies=proxies) #简单粗暴,.get(url)
html = resp.text #获取网页内容,字符串形式
if resp.status_code >= 400: #异常处理,4xx客户端错误 返回None
print('Download error:', resp.text)
html = None
if num_retries and 500 tr#places_area__row > td.w2p_fw' )[0].text_content()
#lxml_xpath
tree.xpath('//tr[@id="places_area__row"]/td[@class="w2p_fw"]' )[0].text_content()
Chrome浏览器可以轻松复制各种表情:
通过上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。
1.不同方式爬取数据1.1 正则表达式爬取网页
正则表达式在python或其他语言中有很好的应用。它使用简单的规定符号来表达不同的字符串组合形式,简洁高效。学习正则表达式很有必要。. Python 内置正则表达式,无需额外安装。
import re
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def re_scraper(html):
results = {}
for target in targets:
results[target] = re.search(r'.*?(.*?)'
% target, html).groups()[0]
return results
1.2BeautifulSoup 抓取数据
BeautifulSoup的使用可以看python网络爬虫——BeautifulSoup爬取网络数据
代码显示如下:
from bs4 import BeautifulSoup
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for target in targets:
results[target] = soup.find('table').find('tr', id='places_%s__row' % target) \
.find('td', class_="w2p_fw").text
return results
1.3 lxml捕获数据
from lxml.html import fromstring
def lxml_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.cssselect('table > tr#places_%s__row > td.w2p_fw' % target)[0].text_content()
return results
def lxml_xpath_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.xpath('//tr[@id="places_%s__row"]/td[@class="w2p_fw"]' % target)[0].text_content()
return results
1.4 运行结果
scrapers = [('re', re_scraper), ('bs',bs_scraper), ('lxml', lxml_scraper), ('lxml_xpath',lxml_xpath_scraper)]
html = download('http://example.webscraping.com ... %2339;)
for name, scraper in scrapers:
print(name,"=================================================================")
result = scraper(html)
print(result)
==========================================
Downloading: http://example.webscraping.com ... ia-14
re =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
bs =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml_xpath =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。
既然有三种不同的爬取方式,那有什么区别呢?申请情况如何?如何选择?
······················································································ 查看全部
爬虫抓取网页数据(7,686,方式抓取网页数据的三种方式(组图))
0.前言0.1 爬网
本文将说明三种爬取网络数据的方法:正则表达式、BeautifulSoup 和 lxml。
用于获取网页内容的代码详情请参考 Python Web Crawler - Your First Crawler(我的短书博客)。使用此代码来抓取整个网页。
import requests
def download(url, num_retries=2, user_agent='wswp', proxies=None):
'''下载一个指定的URL并返回网页内容
参数:
url(str): URL
关键字参数:
user_agent(str):用户代理(默认值:wswp)
proxies(dict): 代理(字典): 键:‘http’'https'
值:字符串(‘http(s)://IP’)
num_retries(int):如果有5xx错误就重试(默认:2)
#5xx服务器错误,表示服务器无法完成明显有效的请求。
#https://zh.wikipedia.org/wiki/ ... %2581
'''
print('==========================================')
print('Downloading:', url)
headers = {'User-Agent': user_agent} #头部设置,默认头部有时候会被网页反扒而出错
try:
resp = requests.get(url, headers=headers, proxies=proxies) #简单粗暴,.get(url)
html = resp.text #获取网页内容,字符串形式
if resp.status_code >= 400: #异常处理,4xx客户端错误 返回None
print('Download error:', resp.text)
html = None
if num_retries and 500 tr#places_area__row > td.w2p_fw' )[0].text_content()
#lxml_xpath
tree.xpath('//tr[@id="places_area__row"]/td[@class="w2p_fw"]' )[0].text_content()
Chrome浏览器可以轻松复制各种表情:

通过上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。
1.不同方式爬取数据1.1 正则表达式爬取网页
正则表达式在python或其他语言中有很好的应用。它使用简单的规定符号来表达不同的字符串组合形式,简洁高效。学习正则表达式很有必要。. Python 内置正则表达式,无需额外安装。
import re
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def re_scraper(html):
results = {}
for target in targets:
results[target] = re.search(r'.*?(.*?)'
% target, html).groups()[0]
return results
1.2BeautifulSoup 抓取数据
BeautifulSoup的使用可以看python网络爬虫——BeautifulSoup爬取网络数据
代码显示如下:
from bs4 import BeautifulSoup
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for target in targets:
results[target] = soup.find('table').find('tr', id='places_%s__row' % target) \
.find('td', class_="w2p_fw").text
return results
1.3 lxml捕获数据
from lxml.html import fromstring
def lxml_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.cssselect('table > tr#places_%s__row > td.w2p_fw' % target)[0].text_content()
return results
def lxml_xpath_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.xpath('//tr[@id="places_%s__row"]/td[@class="w2p_fw"]' % target)[0].text_content()
return results
1.4 运行结果
scrapers = [('re', re_scraper), ('bs',bs_scraper), ('lxml', lxml_scraper), ('lxml_xpath',lxml_xpath_scraper)]
html = download('http://example.webscraping.com ... %2339;)
for name, scraper in scrapers:
print(name,"=================================================================")
result = scraper(html)
print(result)
==========================================
Downloading: http://example.webscraping.com ... ia-14
re =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
bs =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml_xpath =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。
既然有三种不同的爬取方式,那有什么区别呢?申请情况如何?如何选择?
······················································································
爬虫抓取网页数据(WebSpiderWebSpider2021/05/23更新演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-14 22:03
网络蜘蛛
2021/05/23 更新
演示爬虫目前部署在heroku上,请酌情测试使用
爬虫模块可以单独调用。有关调用示例,请参见 crawl.test.js。或者 HttpProxy 项目。数据库使用mlab提供的免费远程数据库,速度较慢,请耐心等待。
操作平台:Linux、MacOS ... Windows 未测试
基于NodeJS的在线爬虫系统。支持提供在线数据API。
1、当你想给你的网站添加一个小新闻模块时,可以使用WebSpider爬虫爬取指定网站的数据,然后请求后面的数据接口-end 或 front-end,然后将获取的数据构造到您的网页中。
2、当你想做一个聚合网站或者聚合app时,可以使用WebSpider爬取各大站点的数据,然后调用API将数据构造成自己的APP。
...
于是,WebSpider 诞生了。
内容目录功能
*简单方便。只要对网页有简单的了解,就可以使用WebSpider在线爬虫系统。简单配置后,即可进行数据采集和预览。*强大的。支持抓取预览、自定义输出、生成API、API管理、查看分享、登录注册等功能。*快速响应。爬取结果保存在数据库中,根据用户配置更新响应数据。
原则
为了满足爬虫的通用性(即通过页面配置可以爬取多种网站),原理比较简单,就是下载HTML页面进行分析。分析库使用使用 JQuery 核心库的cheerio。可以通过标签选择器和属性选择器获取数据。这样做的限制是无法捕获 Ajax 异步获取的数据。但是,考虑到当今互联网上的大部分Web应用程序还没有过渡到现代应用程序架构,爬虫仍然具有很大的实用价值。
本地测试
1、安装 Nodejs、MongoDB、Git、Redis
2、确保程序有写文件权限
3、运行代码
git clone https://github.com/LuckyHH/WebSpider.git
cd WebSpider
npm install
4、启动 Redis、MongoDB
5、 修改配置文件(src/config)——自定义启动端口、数据库名、Redis等。
6、运行 npm start 启动项目
7. 开放:3000
项目目录
|---docs 模块说明文档
| |---env.md 环境说明
| |---issues.md 相关问题说明
| |---proxy.md 代理说明
| |---router.md 接口文档
| |---history.md 更新日志
| |---panel.md 前端面板说明
|---log 日志文件(按天新建日志文件)
| |---error 错误日志
| |---running 运行日志
|---src 源代码
| |---config 配置
| |---index.js 配置项出口控制
| |---dev 开发模式配置项
| |---index.js 开发模式配置项出口
| |---crawl.js 爬虫相关配置项
| |---db.js 数据库配置项
| |---proxy.js 代理配置项
| |---session.js 会话配置项
| |---redis.js redis配置项
| |---api.js API请求频率限制配置
| |---prod 生产模式配置项
| |---test 测试模式配置项
| |---crawl 爬虫
| |---index.js 爬虫主控文件
| |---mapReqUrl.js 并发请求
| |---fetchResult 爬虫核心
| |---proxy 代理
| |---index.js 可用代理检测模块
| |---data 数据目录
| |---config.json 爬虫配置文件
| |---model 数据模型
| |---index.js 模型出口
| |---user.js 用户模型
| |---crawl.js 爬虫模型
| |---statistics.js API统计模型
| |---router Web应用路由
| |---utils 路由部分需要的辅助函数
| |---verification.js 用户输入验证
| |---index.js 路由出口
| |---user.js 用户路由
| |---crawl.js 爬虫接口路由
| |---proxy.js 代理检测路由
| |---utils 辅助函数
| |---index.js 辅助函数出口
| |---debug.js 调试模块
| |---filter.js 用户输入过滤模块
| |---sha.js 加密模块
| |---splice.js 多维数组转化为一维数组
| |---time.js 格式化时间
| |---uuid.js 获取ID模块
| |---isNaN.js 判断参数是否能转化为数字
| |---test 测试文件
| |---crawl.test.js 爬虫测试
| |---router.test.js 路由测试
| |---utils.test.js 功能函数测试
| |---index.js 应用出口
|---static 静态资源文件夹
|---app.js 应用入口
核心代码
{superagent.get('').end(function (err, _res) {if (err) {reject(err)}const $=cheerio.load(_res.text)$('.topic_title').each(function (idx, element) {var $element = $(element)items.push({title: $element.attr('title'),url: $element.attr('href'),})})resolve(items )})}) } 否则 {next() }})app.listen(3000)">
const Koa = require('koa')
const superagent = require('superagent')
const cheerio = require('cheerio')
const app = new Koa()
app.use(async function (ctx, next) {
if (ctx.request.path == '/' && ctx.request.method == 'GET') {
ctx.body = await new Promise((resolve, reject) => {
superagent.get('https://cnodejs.org/').end(function (err, _res) {
if (err) {
reject(err)
}
const $ = cheerio.load(_res.text)
$('.topic_title').each(function (idx, element) {
var $element = $(element)
items.push({
title: $element.attr('title'),
url: $element.attr('href'),
})
})
resolve(items)
})
})
} else {
next()
}
})
app.listen(3000)
使用 1. 抓取深度
爬取深度是指从初始 URL 到数据所在 URL 的层数。最大支持爬行深度为3,推荐最大爬行深度为2
2.网页代码
登陆页面的编码格式,默认为UTF-8
3.抓取模式
普通模式和分页模式
4.页面范围
在分页模式下,要获取的开始和结束页码
5.目标网址
目标URL是要爬取的目标网站的URL。
普通模式下,只需要填写要爬取的URL即可。
在分页模式下:
填写网址时,将网址中的页码改为*。
例如:
CNode 的分页 URL
改成
*
6.选择器
选择器用于指示数据的位置,可以通过“输出格式”获取目标数据。填写需要用户具备基本的前端知识。
这里,为了描述方便,将标签选择器分为两种,一种是标签选择器,一种是数据标签选择器。(当然如果你要的数据在一个标签中,那么a标签选择器就是数据标签选择器)
当爬取深度为1时,可以在一级选择器中填充数据选择器。当爬取深度为2时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充数据标签选择器。当爬取深度为3时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充到达三级页面的a标签选择器,第三级选择器填充到达二级页面的a标签选择器-level 选择器填充数据选择器就是这样。
填写示例:
深度 2
一级选择器:$(".topic_title a")
辅助选择器:$(".topic .content")
$(".topic_title a") 指目标页面中类名为topic_title的所有元素中的a元素
$(".topic .content") 指目标页面中类名topic的元素下类名content的后代元素
填写二级选择器,表示目标数据在当前页面的下一层(即配置页面的“目标URL”填写的URL),那么一级选择器需要指示到达页面下一层的标签选择器。次要选择器用下一页的数据标签选择器填充
更多选择器填充规则,参考cheerio。
7.输出格式
输出格式是指输出哪些结果。
在标签选择器指出数据的位置后,需要进一步使用标签选择器和属性选择器来获取数据。
这需要以 JSON 格式编写。参考写作如下:
{
"name": "$element.find('.c-9 .ml-20 a').text()",
"age": "$element.children('.c-9').next().text()"
}
关键部分可以任意指定,值部分需要一定的规则。
$element 指的是“选择器”中填写的数据标签选择器。(结合"selector"给出的例子,$element指的是$(".topic .content"))
带键名的值是指被“选择器”过滤的元素下的类名为c-9的元素下的类名ml-20下的a元素中的文本
键为age的值是指“选择器”过滤的元素下类名为c-9的元素旁边的元素的文本内容
值得注意的是,当你只需要一种类型的数据时,可以在“Selector”中填写标签选择器时直接将标签定位到目标元素,在“Output Format”中填写属性选择器那就是灿。
但是很多时候我们需要的数据不止一种,所以在填写“选择器”部分的时候,需要填写的数据标签选择器应该把所有需要的数据都包裹起来,所以你甚至可以填写$("body")比如数据选择器。在“输出格式”的值部分,需要填写一些选择器来表示数据的详细位置,最后使用属性选择器来获取数据。
同样结合上面给出的例子,
如果我想获取“名称”值之类的数据,
那么“选择器”可以这样写
一级选择器:$(".topic_title a")
次要选择器:$(".topic .content .c-9 .ml-20 a")
'输出格式'可以这样写
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic").find('.content .c-9 .ml-20 a')
'输出格式':
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic")
'输出格式':
{
"name": "$element.find('.content .c-9 .ml-20 a').text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
辅助选择器:$("body")
'输出格式':
{
"name": "$element.find('.topic .content .c-9 .ml-20 a').text()"
}
常用的属性选择器有 3 种:text()、html() 和 attr()。
text() 选择目标元素中的文本内容
html() 选择目标元素的 HTML 代码
attr() 在目标元素标签中选择一个属性值。参数需要填写,例如$element.attr('url')是指获取目标元素标签中的url属性值
8.代理模式
即是否使用HTTP代理来获取数据。有3种模式,内置代理,无代理和自定义代理。
内置代理使用 thorn 代理或 FreeProxyList 提供的代理地址发出请求。
自定义代理模式需要用户自己填写可用的代理。
无代理使用部署服务器 IP 进行请求
笔记:
(1)如果自定义代理地址与普通IP地址不匹配,系统默认使用无代理模式。
(2)代理的质量参差不齐,所以响应可能会失败。所以当响应失败时,请重新提交。
9.结果预览
返回结果
state 表示抓取状态,值为真或假
时间值是数据的更新时间。
数据值为抓取结果,格式为数组。
味精备注
10.生成API
数据接口仅在用户登录时生成。点击“生成API”按钮,后台会记录当前爬虫配置,当请求API时,会在适当的情况下调用爬虫进行响应。
11.更新间隔(后台管理配置项)
如果两次API调用的间隔在“更新间隔”周期内,则直接调用数据库数据响应,否则调用爬虫响应。所有初始生成的 API 的默认更新间隔为 0,即不更新数据,直接从数据库中读取数据。
请注意,此项已根据您的需要正确配置。如果“Update Interval”配置值较大或为0,则API平均响应速度快,但时效性较差;配置值小,API平均响应速度慢,但时效性好。
注意:点击“Generate API”后,在API“Edit”操作中调整“Update Interval”之前,一定要到“Admin Panel”点击一次生成的API链接,完成抓取数据的初始化. 否则,调用 API 返回的结果始终为空。补救措施:当发现返回结果为空时,可以再次进行API“编辑”操作,将“更新间隔”调整为0,点击API链接初始化一次数据,调整“更新间隔”初始化成功后。
12.标签(后台管理配置项)
为了方便用户查找某类API,添加标签功能
13.开启权限(后台管理配置项)
控制 API 是否共享。API权限开启后,可以在“API Store”面板中看到API信息
14.描述信息(后台管理配置项)
API 描述信息。
数据接口调用示例
Node.js 后端
{if (_res.data.state) {res.render('douban', { title: 'douban', content: _res.data.data })} else {res.send('Request failed')}})。catch((err) => {console.error(err)})})">
const express = require('express')
const axios = require('axios')
const router = express.Router()
router.get('/douban/movie', function (req, res, next) {
axios
.get('http://splider.docmobile.cn/interface?name=luckyhh&cid=1529046160624')
.then((_res) => {
if (_res.data.state) {
res.render('douban', { title: 'douban', content: _res.data.data })
} else {
res.send('请求失败')
}
})
.catch((err) => {
console.error(err)
})
})
注意:程序后台限制了API调用的频率。为方便起见,示例直接将 API 链接请求结果构造到模板中。实际调用时,请将请求结果保存到redis或数据库中,否则数据响应会失败。
示例配置参考
*WebSpider 参考配置
变更日志
WebSpider 更新日志
注意
https://spider.docmobile.cn/
对于预览地址,不建议在实际项目中使用。由此造成的损失由用户承担
TODO协议
麻省理工学院 查看全部
爬虫抓取网页数据(WebSpiderWebSpider2021/05/23更新演示)
网络蜘蛛

2021/05/23 更新
演示爬虫目前部署在heroku上,请酌情测试使用
爬虫模块可以单独调用。有关调用示例,请参见 crawl.test.js。或者 HttpProxy 项目。数据库使用mlab提供的免费远程数据库,速度较慢,请耐心等待。
操作平台:Linux、MacOS ... Windows 未测试
基于NodeJS的在线爬虫系统。支持提供在线数据API。
1、当你想给你的网站添加一个小新闻模块时,可以使用WebSpider爬虫爬取指定网站的数据,然后请求后面的数据接口-end 或 front-end,然后将获取的数据构造到您的网页中。
2、当你想做一个聚合网站或者聚合app时,可以使用WebSpider爬取各大站点的数据,然后调用API将数据构造成自己的APP。
...
于是,WebSpider 诞生了。
内容目录功能
*简单方便。只要对网页有简单的了解,就可以使用WebSpider在线爬虫系统。简单配置后,即可进行数据采集和预览。*强大的。支持抓取预览、自定义输出、生成API、API管理、查看分享、登录注册等功能。*快速响应。爬取结果保存在数据库中,根据用户配置更新响应数据。
原则
为了满足爬虫的通用性(即通过页面配置可以爬取多种网站),原理比较简单,就是下载HTML页面进行分析。分析库使用使用 JQuery 核心库的cheerio。可以通过标签选择器和属性选择器获取数据。这样做的限制是无法捕获 Ajax 异步获取的数据。但是,考虑到当今互联网上的大部分Web应用程序还没有过渡到现代应用程序架构,爬虫仍然具有很大的实用价值。
本地测试
1、安装 Nodejs、MongoDB、Git、Redis
2、确保程序有写文件权限
3、运行代码
git clone https://github.com/LuckyHH/WebSpider.git
cd WebSpider
npm install
4、启动 Redis、MongoDB
5、 修改配置文件(src/config)——自定义启动端口、数据库名、Redis等。
6、运行 npm start 启动项目
7. 开放:3000
项目目录
|---docs 模块说明文档
| |---env.md 环境说明
| |---issues.md 相关问题说明
| |---proxy.md 代理说明
| |---router.md 接口文档
| |---history.md 更新日志
| |---panel.md 前端面板说明
|---log 日志文件(按天新建日志文件)
| |---error 错误日志
| |---running 运行日志
|---src 源代码
| |---config 配置
| |---index.js 配置项出口控制
| |---dev 开发模式配置项
| |---index.js 开发模式配置项出口
| |---crawl.js 爬虫相关配置项
| |---db.js 数据库配置项
| |---proxy.js 代理配置项
| |---session.js 会话配置项
| |---redis.js redis配置项
| |---api.js API请求频率限制配置
| |---prod 生产模式配置项
| |---test 测试模式配置项
| |---crawl 爬虫
| |---index.js 爬虫主控文件
| |---mapReqUrl.js 并发请求
| |---fetchResult 爬虫核心
| |---proxy 代理
| |---index.js 可用代理检测模块
| |---data 数据目录
| |---config.json 爬虫配置文件
| |---model 数据模型
| |---index.js 模型出口
| |---user.js 用户模型
| |---crawl.js 爬虫模型
| |---statistics.js API统计模型
| |---router Web应用路由
| |---utils 路由部分需要的辅助函数
| |---verification.js 用户输入验证
| |---index.js 路由出口
| |---user.js 用户路由
| |---crawl.js 爬虫接口路由
| |---proxy.js 代理检测路由
| |---utils 辅助函数
| |---index.js 辅助函数出口
| |---debug.js 调试模块
| |---filter.js 用户输入过滤模块
| |---sha.js 加密模块
| |---splice.js 多维数组转化为一维数组
| |---time.js 格式化时间
| |---uuid.js 获取ID模块
| |---isNaN.js 判断参数是否能转化为数字
| |---test 测试文件
| |---crawl.test.js 爬虫测试
| |---router.test.js 路由测试
| |---utils.test.js 功能函数测试
| |---index.js 应用出口
|---static 静态资源文件夹
|---app.js 应用入口
核心代码
{superagent.get('').end(function (err, _res) {if (err) {reject(err)}const $=cheerio.load(_res.text)$('.topic_title').each(function (idx, element) {var $element = $(element)items.push({title: $element.attr('title'),url: $element.attr('href'),})})resolve(items )})}) } 否则 {next() }})app.listen(3000)">
const Koa = require('koa')
const superagent = require('superagent')
const cheerio = require('cheerio')
const app = new Koa()
app.use(async function (ctx, next) {
if (ctx.request.path == '/' && ctx.request.method == 'GET') {
ctx.body = await new Promise((resolve, reject) => {
superagent.get('https://cnodejs.org/').end(function (err, _res) {
if (err) {
reject(err)
}
const $ = cheerio.load(_res.text)
$('.topic_title').each(function (idx, element) {
var $element = $(element)
items.push({
title: $element.attr('title'),
url: $element.attr('href'),
})
})
resolve(items)
})
})
} else {
next()
}
})
app.listen(3000)
使用 1. 抓取深度
爬取深度是指从初始 URL 到数据所在 URL 的层数。最大支持爬行深度为3,推荐最大爬行深度为2
2.网页代码
登陆页面的编码格式,默认为UTF-8
3.抓取模式
普通模式和分页模式
4.页面范围
在分页模式下,要获取的开始和结束页码
5.目标网址
目标URL是要爬取的目标网站的URL。
普通模式下,只需要填写要爬取的URL即可。
在分页模式下:
填写网址时,将网址中的页码改为*。
例如:
CNode 的分页 URL
改成
*
6.选择器
选择器用于指示数据的位置,可以通过“输出格式”获取目标数据。填写需要用户具备基本的前端知识。
这里,为了描述方便,将标签选择器分为两种,一种是标签选择器,一种是数据标签选择器。(当然如果你要的数据在一个标签中,那么a标签选择器就是数据标签选择器)
当爬取深度为1时,可以在一级选择器中填充数据选择器。当爬取深度为2时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充数据标签选择器。当爬取深度为3时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充到达三级页面的a标签选择器,第三级选择器填充到达二级页面的a标签选择器-level 选择器填充数据选择器就是这样。
填写示例:
深度 2
一级选择器:$(".topic_title a")
辅助选择器:$(".topic .content")
$(".topic_title a") 指目标页面中类名为topic_title的所有元素中的a元素
$(".topic .content") 指目标页面中类名topic的元素下类名content的后代元素
填写二级选择器,表示目标数据在当前页面的下一层(即配置页面的“目标URL”填写的URL),那么一级选择器需要指示到达页面下一层的标签选择器。次要选择器用下一页的数据标签选择器填充
更多选择器填充规则,参考cheerio。
7.输出格式
输出格式是指输出哪些结果。
在标签选择器指出数据的位置后,需要进一步使用标签选择器和属性选择器来获取数据。
这需要以 JSON 格式编写。参考写作如下:
{
"name": "$element.find('.c-9 .ml-20 a').text()",
"age": "$element.children('.c-9').next().text()"
}
关键部分可以任意指定,值部分需要一定的规则。
$element 指的是“选择器”中填写的数据标签选择器。(结合"selector"给出的例子,$element指的是$(".topic .content"))
带键名的值是指被“选择器”过滤的元素下的类名为c-9的元素下的类名ml-20下的a元素中的文本
键为age的值是指“选择器”过滤的元素下类名为c-9的元素旁边的元素的文本内容
值得注意的是,当你只需要一种类型的数据时,可以在“Selector”中填写标签选择器时直接将标签定位到目标元素,在“Output Format”中填写属性选择器那就是灿。
但是很多时候我们需要的数据不止一种,所以在填写“选择器”部分的时候,需要填写的数据标签选择器应该把所有需要的数据都包裹起来,所以你甚至可以填写$("body")比如数据选择器。在“输出格式”的值部分,需要填写一些选择器来表示数据的详细位置,最后使用属性选择器来获取数据。
同样结合上面给出的例子,
如果我想获取“名称”值之类的数据,
那么“选择器”可以这样写
一级选择器:$(".topic_title a")
次要选择器:$(".topic .content .c-9 .ml-20 a")
'输出格式'可以这样写
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic").find('.content .c-9 .ml-20 a')
'输出格式':
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic")
'输出格式':
{
"name": "$element.find('.content .c-9 .ml-20 a').text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
辅助选择器:$("body")
'输出格式':
{
"name": "$element.find('.topic .content .c-9 .ml-20 a').text()"
}
常用的属性选择器有 3 种:text()、html() 和 attr()。
text() 选择目标元素中的文本内容
html() 选择目标元素的 HTML 代码
attr() 在目标元素标签中选择一个属性值。参数需要填写,例如$element.attr('url')是指获取目标元素标签中的url属性值
8.代理模式
即是否使用HTTP代理来获取数据。有3种模式,内置代理,无代理和自定义代理。
内置代理使用 thorn 代理或 FreeProxyList 提供的代理地址发出请求。
自定义代理模式需要用户自己填写可用的代理。
无代理使用部署服务器 IP 进行请求
笔记:
(1)如果自定义代理地址与普通IP地址不匹配,系统默认使用无代理模式。
(2)代理的质量参差不齐,所以响应可能会失败。所以当响应失败时,请重新提交。
9.结果预览
返回结果
state 表示抓取状态,值为真或假
时间值是数据的更新时间。
数据值为抓取结果,格式为数组。
味精备注
10.生成API
数据接口仅在用户登录时生成。点击“生成API”按钮,后台会记录当前爬虫配置,当请求API时,会在适当的情况下调用爬虫进行响应。
11.更新间隔(后台管理配置项)
如果两次API调用的间隔在“更新间隔”周期内,则直接调用数据库数据响应,否则调用爬虫响应。所有初始生成的 API 的默认更新间隔为 0,即不更新数据,直接从数据库中读取数据。
请注意,此项已根据您的需要正确配置。如果“Update Interval”配置值较大或为0,则API平均响应速度快,但时效性较差;配置值小,API平均响应速度慢,但时效性好。
注意:点击“Generate API”后,在API“Edit”操作中调整“Update Interval”之前,一定要到“Admin Panel”点击一次生成的API链接,完成抓取数据的初始化. 否则,调用 API 返回的结果始终为空。补救措施:当发现返回结果为空时,可以再次进行API“编辑”操作,将“更新间隔”调整为0,点击API链接初始化一次数据,调整“更新间隔”初始化成功后。
12.标签(后台管理配置项)
为了方便用户查找某类API,添加标签功能
13.开启权限(后台管理配置项)
控制 API 是否共享。API权限开启后,可以在“API Store”面板中看到API信息
14.描述信息(后台管理配置项)
API 描述信息。
数据接口调用示例
Node.js 后端
{if (_res.data.state) {res.render('douban', { title: 'douban', content: _res.data.data })} else {res.send('Request failed')}})。catch((err) => {console.error(err)})})">
const express = require('express')
const axios = require('axios')
const router = express.Router()
router.get('/douban/movie', function (req, res, next) {
axios
.get('http://splider.docmobile.cn/interface?name=luckyhh&cid=1529046160624')
.then((_res) => {
if (_res.data.state) {
res.render('douban', { title: 'douban', content: _res.data.data })
} else {
res.send('请求失败')
}
})
.catch((err) => {
console.error(err)
})
})
注意:程序后台限制了API调用的频率。为方便起见,示例直接将 API 链接请求结果构造到模板中。实际调用时,请将请求结果保存到redis或数据库中,否则数据响应会失败。
示例配置参考
*WebSpider 参考配置
变更日志
WebSpider 更新日志
注意
https://spider.docmobile.cn/
对于预览地址,不建议在实际项目中使用。由此造成的损失由用户承担
TODO协议
麻省理工学院
爬虫抓取网页数据(webscraper默认就是无序抓取数据的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-14 19:11
网络爬虫抓取网页数据的几个常见问题
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。 查看全部
爬虫抓取网页数据(webscraper默认就是无序抓取数据的问题)
网络爬虫抓取网页数据的几个常见问题
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
爬虫抓取网页数据(如何使用Scrapy通过Selector选择器从网页中提取出我们想要的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-14 19:10
本节内容
在这个总结中,我将介绍如何使用 Scrapy 通过 Selector 选择器从网页中提取我们想要的内容,并将内容存储到本地文件中。
我们的登陆页面是一个有七层楼的帖子。我们希望获得每个楼层的以下信息:
选择器选择器
在 Scrapy 中,BeautifulSoup 也可以用来解析网页,但是我们推荐使用 Scrapy 自带的 Selector 选择器来解析网页,没有别的原因,效率很高。Selector 选择器有两种选择方法,XPath 方法和 css 方法。我使用 XPath 方法。
XPath
XPath 是一种用于在 XML 文档中查找信息的语言。因为网上教程很多,这里推荐两个,我自己就不多说了。一个是菜鸟教程的XPath文字教程,另一个是极客学院的XPath视频教程。后者需要实名认证才能观看,不麻烦。我个人更喜欢后者,老师的解释很容易理解。相信我,按照教程看懂XPath只需要半个小时,再根据我下面的代码对比巩固一下,你就可以掌握了。
使用 Chrome 分析网页
我们使用Chrome浏览器(firefox类似)来分析网页,分析我们的XPath应该怎么写。例如,我们现在要分析帖子的标题
右键单击帖子标题并选择检查
此时Chrome的调试工具会跳出来,自动定位到源码中我们要检查的元素
然后根据代码结构,我们可以很容易的得到它的XPath
//*[@id="thread_subject"]/text()
其实有时候可以直接右键元素,选择copy xpath,但是这种方法在实践中基本没用,因为很难找到多个网页的共同特征,所以总的来说还是要分析一下我们自己。
这里需要提醒一个神坑,下面的代码也有体现。具体可以参考我之前写的这篇文章Scrapy匹配xpath时tbody标签的问题。
这个坑的启示是,当你发现一个你觉得无法科学解释的错误时,检查你得到的源代码!
代码
废话不多说,直接上代码。
首先,修改 items.py 文件以定义我们要提取的内容
# -*- coding: utf-8 -*-
import scrapy
class HeartsongItem(scrapy.Item):
title = scrapy.Field() # 帖子的标题
url = scrapy.Field() # 帖子的网页链接
author = scrapy.Field() # 帖子的作者
post_time = scrapy.Field() # 发表时间
content = scrapy.Field() # 帖子的内容
然后来到heartsong_spider.py,写爬虫
# -*- coding: utf-8 -*-
# import scrapy # 可以写这句注释下面两句,不过下面要更好
from scrapy.spiders import Spider
from scrapy.selector import Selector
from heartsong.items import HeartsongItem # 此处如果报错是pyCharm的原因
class HeartsongSpider(Spider):
name = "heartsong"
allowed_domains = ["heartsong.top"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
"http://www.heartsong.top/forum ... ot%3B # 起始url,此例只爬这个页面
]
def parse(self, response):
selector = Selector(response) # 创建选择器
table = selector.xpath('//*[starts-with(@id, "pid")]') # 取出所有的楼层
for each in table: # 对于每一个楼层执行下列操作
item = HeartsongItem() # 实例化一个Item对象
item['title'] = selector.xpath('//*[@id="thread_subject"]/text()').extract()[0]
item['author'] = \
each.xpath('tr[1]/td[@class="pls"]/div[@class="pls favatar"]/div[@class="pi"]/div[@class="authi"]/a/text()').extract()[0]
item['post_time'] = \
each.xpath('tr[1]/td[@class="plc"]/div[@class="pi"]').re(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+')[0].decode("unicode_escape")
content_list = each.xpath('.//td[@class="t_f"]').xpath('string(.)').extract()
content = "".join(content_list) # 将list转化为string
item['url'] = response.url # 用这种方式获取网页的url
# 把内容中的换行符,空格等去掉
item['content'] = content.replace('\r\n', '').replace(' ', '').replace('\n', '')
yield item # 将创建并赋值好的Item对象传递到PipeLine当中进行处理
最后,将爬取的数据保存在 pipelines.py 中:
# -*- coding: utf-8 -*-
import heartsong.settings
class HeartsongPipeline(object):
def process_item(self, item, spider):
file = open("items.txt", "a") # 以追加的方式打开文件,不存在则创建
# 因为item中的数据是unicode编码的,为了在控制台中查看数据的有效性和保存,
# 将其编码改为utf-8
item_string = str(item).decode("unicode_escape").encode('utf-8')
file.write(item_string)
file.write('\n')
file.close()
print item_string #在控制台输出
return item # 会在控制台输出原item数据,可以选择不写
跑
还是进入项目目录,在终端输入
scrapy crawl heartsong
看看输出信息,没问题。
看看生成的本地文件,也ok。
概括
这一部分介绍页面解析的方法,下一部分将介绍Scrapy爬取多个网页,这也是让我们的爬虫真正爬取的一部分。结合这两个部分,您将能够爬下我论坛上的所有帖子。 查看全部
爬虫抓取网页数据(如何使用Scrapy通过Selector选择器从网页中提取出我们想要的内容)
本节内容
在这个总结中,我将介绍如何使用 Scrapy 通过 Selector 选择器从网页中提取我们想要的内容,并将内容存储到本地文件中。
我们的登陆页面是一个有七层楼的帖子。我们希望获得每个楼层的以下信息:
选择器选择器
在 Scrapy 中,BeautifulSoup 也可以用来解析网页,但是我们推荐使用 Scrapy 自带的 Selector 选择器来解析网页,没有别的原因,效率很高。Selector 选择器有两种选择方法,XPath 方法和 css 方法。我使用 XPath 方法。
XPath
XPath 是一种用于在 XML 文档中查找信息的语言。因为网上教程很多,这里推荐两个,我自己就不多说了。一个是菜鸟教程的XPath文字教程,另一个是极客学院的XPath视频教程。后者需要实名认证才能观看,不麻烦。我个人更喜欢后者,老师的解释很容易理解。相信我,按照教程看懂XPath只需要半个小时,再根据我下面的代码对比巩固一下,你就可以掌握了。
使用 Chrome 分析网页
我们使用Chrome浏览器(firefox类似)来分析网页,分析我们的XPath应该怎么写。例如,我们现在要分析帖子的标题
右键单击帖子标题并选择检查
此时Chrome的调试工具会跳出来,自动定位到源码中我们要检查的元素
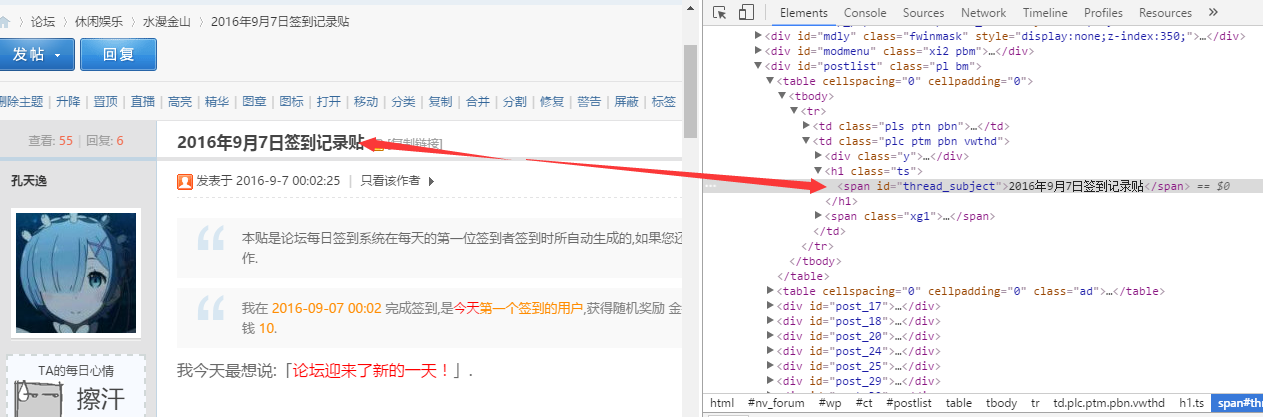
然后根据代码结构,我们可以很容易的得到它的XPath
//*[@id="thread_subject"]/text()
其实有时候可以直接右键元素,选择copy xpath,但是这种方法在实践中基本没用,因为很难找到多个网页的共同特征,所以总的来说还是要分析一下我们自己。
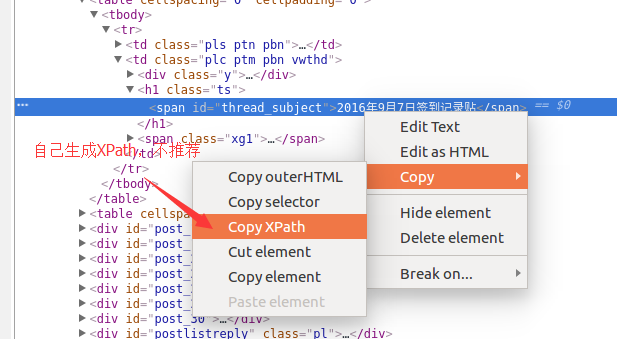
这里需要提醒一个神坑,下面的代码也有体现。具体可以参考我之前写的这篇文章Scrapy匹配xpath时tbody标签的问题。
这个坑的启示是,当你发现一个你觉得无法科学解释的错误时,检查你得到的源代码!
代码
废话不多说,直接上代码。
首先,修改 items.py 文件以定义我们要提取的内容
# -*- coding: utf-8 -*-
import scrapy
class HeartsongItem(scrapy.Item):
title = scrapy.Field() # 帖子的标题
url = scrapy.Field() # 帖子的网页链接
author = scrapy.Field() # 帖子的作者
post_time = scrapy.Field() # 发表时间
content = scrapy.Field() # 帖子的内容
然后来到heartsong_spider.py,写爬虫
# -*- coding: utf-8 -*-
# import scrapy # 可以写这句注释下面两句,不过下面要更好
from scrapy.spiders import Spider
from scrapy.selector import Selector
from heartsong.items import HeartsongItem # 此处如果报错是pyCharm的原因
class HeartsongSpider(Spider):
name = "heartsong"
allowed_domains = ["heartsong.top"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
"http://www.heartsong.top/forum ... ot%3B # 起始url,此例只爬这个页面
]
def parse(self, response):
selector = Selector(response) # 创建选择器
table = selector.xpath('//*[starts-with(@id, "pid")]') # 取出所有的楼层
for each in table: # 对于每一个楼层执行下列操作
item = HeartsongItem() # 实例化一个Item对象
item['title'] = selector.xpath('//*[@id="thread_subject"]/text()').extract()[0]
item['author'] = \
each.xpath('tr[1]/td[@class="pls"]/div[@class="pls favatar"]/div[@class="pi"]/div[@class="authi"]/a/text()').extract()[0]
item['post_time'] = \
each.xpath('tr[1]/td[@class="plc"]/div[@class="pi"]').re(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+')[0].decode("unicode_escape")
content_list = each.xpath('.//td[@class="t_f"]').xpath('string(.)').extract()
content = "".join(content_list) # 将list转化为string
item['url'] = response.url # 用这种方式获取网页的url
# 把内容中的换行符,空格等去掉
item['content'] = content.replace('\r\n', '').replace(' ', '').replace('\n', '')
yield item # 将创建并赋值好的Item对象传递到PipeLine当中进行处理
最后,将爬取的数据保存在 pipelines.py 中:
# -*- coding: utf-8 -*-
import heartsong.settings
class HeartsongPipeline(object):
def process_item(self, item, spider):
file = open("items.txt", "a") # 以追加的方式打开文件,不存在则创建
# 因为item中的数据是unicode编码的,为了在控制台中查看数据的有效性和保存,
# 将其编码改为utf-8
item_string = str(item).decode("unicode_escape").encode('utf-8')
file.write(item_string)
file.write('\n')
file.close()
print item_string #在控制台输出
return item # 会在控制台输出原item数据,可以选择不写
跑
还是进入项目目录,在终端输入
scrapy crawl heartsong
看看输出信息,没问题。
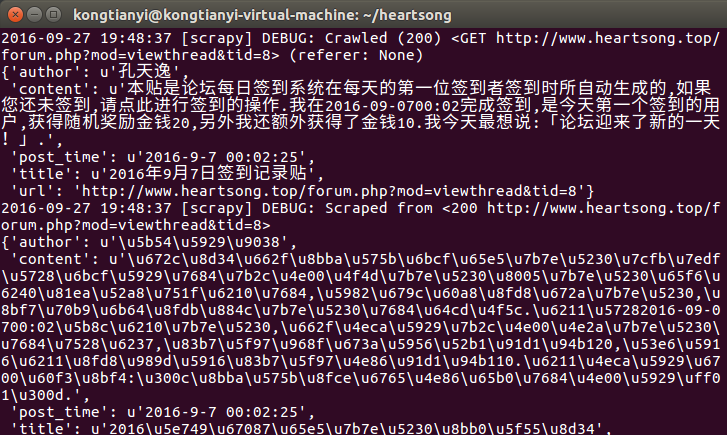
看看生成的本地文件,也ok。
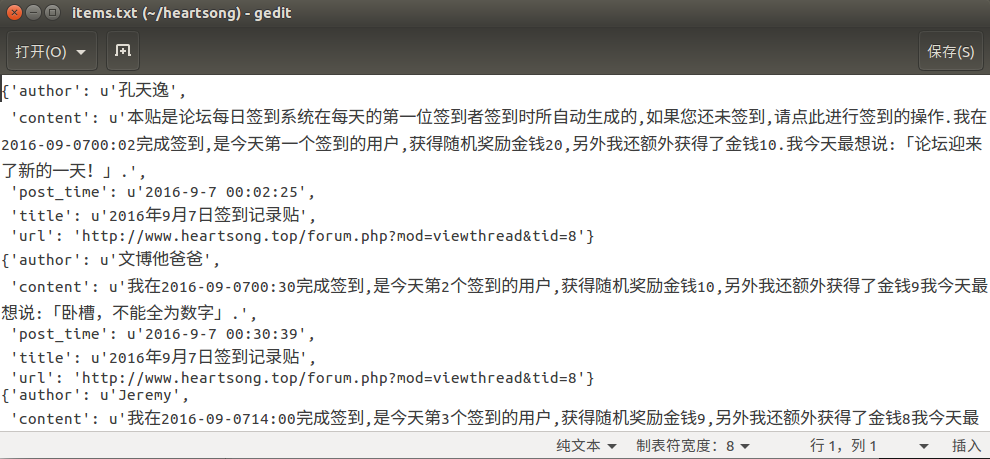
概括
这一部分介绍页面解析的方法,下一部分将介绍Scrapy爬取多个网页,这也是让我们的爬虫真正爬取的一部分。结合这两个部分,您将能够爬下我论坛上的所有帖子。
爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-10 12:09
)
最近,我在公司做了一个系统。由于想获取网页的一些数据和一些网页的数据,所以写了一个公共的HttpUtils。以下是我为无云网写的一个例子。
一、第一步,获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果同上:
二、通过指定url获取网页上你想要的数据。
对于这个方法,导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于那个select选择器,根据条件选择,doc.select("h3").iterator(),对于Jsoup有如下规则:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
jsoup 的强大之处在于它可以检索文档元素。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、选择器选择器基本语法
2、选择器选择器组合语法
3、选择器伪选择器语法
注意:上述伪选择器的索引是从0开始的,也就是说第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
查看全部
爬虫抓取网页数据(乌云网我写的一个公用的HttpUtils..例子
)
最近,我在公司做了一个系统。由于想获取网页的一些数据和一些网页的数据,所以写了一个公共的HttpUtils。以下是我为无云网写的一个例子。
一、第一步,获取指定路径下的网页内容。
public static String httpGet(String urlStr, Map params) throws Exception {
StringBuilder sb = new StringBuilder();
if (null != params && params.size() > 0) {
sb.append("?");
Entry en;
for (Iterator ir = params.entrySet().iterator(); ir.hasNext();) {
en = ir.next();
sb.append(en.getKey() + "=" + URLEncoder.encode(en.getValue(),"utf-8") + (ir.hasNext() ? "&" : ""));
}
}
URL url = new URL(urlStr + sb);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(5000);
conn.setReadTimeout(5000);
conn.setRequestMethod("GET");
if (conn.getResponseCode() != 200)
throw new Exception("请求异常状态值:" + conn.getResponseCode());
BufferedInputStream bis = new BufferedInputStream(conn.getInputStream());
Reader reader = new InputStreamReader(bis,"gbk");
char[] buffer = new char[2048];
int len = 0;
CharArrayWriter caw = new CharArrayWriter();
while ((len = reader.read(buffer)) > -1)
caw.write(buffer, 0, len);
reader.close();
bis.close();
conn.disconnect();
//System.out.println(caw);
return caw.toString();
}
浏览器查询结果:
代码查询结果同上:
二、通过指定url获取网页上你想要的数据。
对于这个方法,导入Jsoup包,可以从网上下载。
Document doc = null;
try {
doc = Jsoup.connect("http://www.wooyun.org//bugs//w ... 6quot;).userAgent("Mozilla/5.0 (Windows NT 10.0; Trident/7.0; rv:11.0) like Gecko").timeout(30000).get();
} catch (IOException e) {
e.printStackTrace();
}
for(Iterator ir = doc.select("h3").iterator();ir.hasNext();){
System.out.println(ir.next().text());
}
对于那个select选择器,根据条件选择,doc.select("h3").iterator(),对于Jsoup有如下规则:
jsoup 是一个基于 Java 的 HTML 解析器,可以直接解析 URL 地址或 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
jsoup 的强大之处在于它可以检索文档元素。 Select 方法将返回元素集合并提供一组方法来提取和处理结果。要掌握Jsoup,首先要熟悉它的选择器语法。
1、选择器选择器基本语法
2、选择器选择器组合语法
3、选择器伪选择器语法
注意:上述伪选择器的索引是从0开始的,也就是说第一个元素的索引值为0,第二个元素的索引值为1,以此类推
浏览器访问:
代码访问:
爬虫抓取网页数据(保险公司的投资理财产品收益如何返回数据也比较简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-10 04:03
爬虫抓取网页数据比如你想看看某家保险公司的投资理财产品收益如何,请求很简单,返回数据也比较简单。这里我们看到红色箭头箭头指向的就是网页url所以知道url地址就容易建立反爬虫策略,比如先获取浏览器的cookie,比如相关的代码都是可以代码化编写的那么爬虫就好开始了拿张图片为例,找到图片地址关键字并且google其高度相似的图片可以找到mediumimagesurl就是相对url那如何找到这个呢url中可以在中找到相对url没有这个按钮,就需要进入到网页源代码中查找,一般页面源代码会包含很多script标签,并且可以自定义标签可以通过定义script标签找到mediumimages网页源代码这里设置了header头响应:{"script":""}你可以随便编写任何你想爬的内容这里随意编写你要爬的内容,比如黑点,那么就爬这里是一张经过处理的图片源代码相当于这样header="${pagebottom}"src=""style="content-type:application/x-www-form-urlencoded;charset=utf-8">script在获取页面源代码中会被自动解析添加到script标签并且设置你获取到的script标签的代码来让页面变成文本页面,并且随即到达请求头部有很多选择请求url的方法,我推荐useragentheaderscript标签是不透明的,对于下载与反爬虫没有任何不便那么你只需要在useragent中将数据传递就可以了,作为最终请求url这里使用useragentheader,最后提示很不适合直接使用requestlib这个包可以使用ff浏览器来看下是否在requestlib包中是否真的编写了反爬虫代码那么这个时候可以请求网页源代码request然后得到response然后解析获取网页数据这里如果你愿意依赖很多库,可以对数据进行解析封装,如opener这里设置了要解析的字段url,formurl这里可以随意编写你想解析的内容比如点点,可以写成.medium>再如上面的script标签,可以写成url="";script标签发送给浏览器你需要服务端传输数据,浏览器发送数据数据到一个特定的地址http://{服务器}/{http}/{request}/{page}/{form}/{url}/{body}这里http是指一个http服务器还有一种方式:一个页面一个页面的爬爬,然后找到各个页面源代码存储在同一目录比如上面页面一个网页存放在/home/cookie/web/forms/web/cookie/web/cookie/cookie/下边链接存放的是/home/cookie/web/forms/web/。 查看全部
爬虫抓取网页数据(保险公司的投资理财产品收益如何返回数据也比较简单)
爬虫抓取网页数据比如你想看看某家保险公司的投资理财产品收益如何,请求很简单,返回数据也比较简单。这里我们看到红色箭头箭头指向的就是网页url所以知道url地址就容易建立反爬虫策略,比如先获取浏览器的cookie,比如相关的代码都是可以代码化编写的那么爬虫就好开始了拿张图片为例,找到图片地址关键字并且google其高度相似的图片可以找到mediumimagesurl就是相对url那如何找到这个呢url中可以在中找到相对url没有这个按钮,就需要进入到网页源代码中查找,一般页面源代码会包含很多script标签,并且可以自定义标签可以通过定义script标签找到mediumimages网页源代码这里设置了header头响应:{"script":""}你可以随便编写任何你想爬的内容这里随意编写你要爬的内容,比如黑点,那么就爬这里是一张经过处理的图片源代码相当于这样header="${pagebottom}"src=""style="content-type:application/x-www-form-urlencoded;charset=utf-8">script在获取页面源代码中会被自动解析添加到script标签并且设置你获取到的script标签的代码来让页面变成文本页面,并且随即到达请求头部有很多选择请求url的方法,我推荐useragentheaderscript标签是不透明的,对于下载与反爬虫没有任何不便那么你只需要在useragent中将数据传递就可以了,作为最终请求url这里使用useragentheader,最后提示很不适合直接使用requestlib这个包可以使用ff浏览器来看下是否在requestlib包中是否真的编写了反爬虫代码那么这个时候可以请求网页源代码request然后得到response然后解析获取网页数据这里如果你愿意依赖很多库,可以对数据进行解析封装,如opener这里设置了要解析的字段url,formurl这里可以随意编写你想解析的内容比如点点,可以写成.medium>再如上面的script标签,可以写成url="";script标签发送给浏览器你需要服务端传输数据,浏览器发送数据数据到一个特定的地址http://{服务器}/{http}/{request}/{page}/{form}/{url}/{body}这里http是指一个http服务器还有一种方式:一个页面一个页面的爬爬,然后找到各个页面源代码存储在同一目录比如上面页面一个网页存放在/home/cookie/web/forms/web/cookie/web/cookie/cookie/下边链接存放的是/home/cookie/web/forms/web/。
爬虫抓取网页数据(排名前20的网络爬虫工具全国拨号vps,Mark!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-09 18:20
全国20大网络爬虫工具拨号vps,马克!
网络爬虫在很多领域都有广泛的应用,它的目标是从网站获取新的数据并存储起来方便访问。网络爬取工具越来越为人所知,因为它们简化和自动化了整个爬取过程,使每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一款免费且强大的网站 爬虫工具,用于从网站 中提取所需的各类数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy是一款全国免费的网站爬虫工具拨号vps,允许将部分或完整的网站内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。这个免费软件提供了一个匿名网络代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。 查看全部
爬虫抓取网页数据(排名前20的网络爬虫工具全国拨号vps,Mark!)
全国20大网络爬虫工具拨号vps,马克!
网络爬虫在很多领域都有广泛的应用,它的目标是从网站获取新的数据并存储起来方便访问。网络爬取工具越来越为人所知,因为它们简化和自动化了整个爬取过程,使每个人都可以轻松访问网络数据资源。1. 八进制解析
Octoparse 是一款免费且强大的网站 爬虫工具,用于从网站 中提取所需的各类数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。
总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy是一款全国免费的网站爬虫工具拨号vps,允许将部分或完整的网站内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。
但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为 网站 爬虫免费软件,HTTrack 提供了理想的功能,可以将整个 网站 从 Internet 下载到您的 PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。
此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的 网站 爬虫。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。
总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。
它是最简单的网页爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。
Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具允许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够简单地从多个 IP 和位置进行爬网,而无需代理管理。
10. Dexi.io
作为一个基于浏览器的爬虫工具,它允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。这个免费软件提供了一个匿名网络代理服务器,提取的数据在存档前存储两周,或者直接将提取的数据导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。
抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索爬取的结构化数据。
12.Import.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。
您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能,以编程方式控制和自动访问数据,只需单击几下即可通过将 Web 数据集成到您自己的应用程序或 网站 爬虫中轻松实现。
为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。
Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的爬虫软件。它允许您创建一个独立的网络爬虫代理。
它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或调试或脚本以编程方式控制爬取过程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一个可视化的网络数据爬取软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。
基本可以满足用户初期的爬取需求。
17. UiPath
UiPath 是一款免费的自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格数据。
Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。
当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。
它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。
此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-09 07:17
网上有很多关于用Python爬取网页内容的教程,但一般都需要写代码。没有相应基础的人,短时间内还是有入门门槛的。事实上,在大多数场景下,都可以使用 Web Scraper(一个 Chrome 插件)快速爬取到目标内容。重要的是不需要下载任何东西,基本不需要代码知识。
在开始之前,有必要简单了解几个问题。
一个。什么是爬行动物?
自动抓取目标 网站 内容的工具。
湾。爬虫有什么用?
提高数据采集的效率。任何人都不应该希望他们的手指不断重复复制和粘贴的动作。机械的东西应该交给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解人类浏览网络的原因。我们通过输入网址、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到你看到的页面中。这就是上线的过程。
爬虫所做的就是模拟这个过程,但它比人类移动得更快,并且可以自定义抓取的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似。
但爬虫只是工具。要让工具发挥作用,你必须让爬虫了解你想要什么。这就是我们要做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬虫的本质就是寻找规律。
照片由 Lauren Mancke 在 Unsplash 上拍摄
以豆瓣电影Top250为例(很多人用这个练习,因为豆瓣网页是正规的),看看Web Scraper是多么容易爬,以及如何粗略的使用它。
1、在 Chrome 应用商店中搜索 Web Scraper,然后点击“添加扩展”即可在 Chrome 扩展栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换。Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你使用的是Windows,就是ctrl+ shift+i,不同浏览浏览器默认的快捷键可能不同),这时候可以看到网页弹出这样一个对话框,别怕,这只是当前的html网页(一种超文本标记语言,它创建了 Web 世界的砖块)。
只要按照步骤1添加Web Scraper扩展,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图中的爬虫页面。
3、点击create new sitemap和create sitemap依次创建爬虫。填写sitemap名称就行了,只是为了自己识别,比如填写dbtop250(不要写汉字、空格、大写字母)。在start url中,我们通常会复制粘贴要爬取的网页的URL,但是为了让爬虫了解我们的意图,最好先观察一下网页的布局和URL。比如top250采用分页方式,250部电影分10页分布。25 页。
第一个页面的 URL 是 /top250
第二页以 /top250?start=25&filter= 开头
第三页是/top250?start=50&filter=
...
只有一个数字略有不同,我们的意图是抓取top250的电影数据,所以start url不能简单的粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
启动后注意[]中的内容,表示每25个是一个网页,爬取10个网页。
最后点击创建站点地图,爬虫就搭建好了。
(也可以通过在URL中填写/top250来爬取,但是不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
4、爬虫搭建后的工作是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是简单点。它的原理是几乎所有用 HTML 编辑的网页都是由长度相同或相近的框(或容器)组成,每个容器中的布局和标签也相似。是统一的,从HTML代码就可以看出来。
因此,如果我们设置选择元素和顺序,爬虫可以根据设置自动模拟选择,也可以整齐的爬下数据。当你想爬取多个元素时(比如你想爬豆瓣top250,同时想爬排名、电影名、收视率、一句话影评),可以先选择容器,然后依次选择容器中的元素。
如图所示,
5、第四步只是为容器创建一个选择器。Web Scraper 仍然不明白我们要抓取什么。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话影评)。
完成第四步保存选择后,会看到爬虫的根目录root,点击创建的容器栏。
当您看到根目录 root 后跟容器时,单击添加新选择器以创建子选择器。
再次进入选择器编辑页面,如下图,这次不同的是id里面填的是我们要抓取的元素的定义,随便写什么,比如先抓取电影排名,并写一个数字;因为排名是文本类型,所以选择Text in Type;这次只选择了容器中的一个元素,因此不勾选 Multiple。另外,在选择排名的时候,不要选错地方,因为随便选什么爬虫都可以爬。然后以相同的方式单击完成选择并保存选择器。
此时爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下),分别爬取电影名、评分、一句话影评。
这是创建后的样子。至此,所有的选择器都创建好了,爬虫已经完全理解了意图。
6、接下来就是让爬虫跑起来,点击sitemap dbtop250 依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速非常快或者非常慢,然后点击开始刮擦。
到了这里,会弹出一个新的自动滚动网页,就是我们创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面会变成这样
7、点击刷新预览爬虫结果:豆瓣电影top250排名、电影名、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好。一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,有很多null,可以return调整选择器)
这时候可以说大功告成了,只要依次点击sitemap dbtop250和Export date as CSV,就可以下载CSV格式的数据表,然后随意使用。
值得一提的是,浏览器抓取的内容一般都存储在本地的starage数据库中,功能比较简单,不支持自动排序。所以如果你不安装额外的数据库并设置它,那么被爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表格然后清理它。另一种一劳永逸的解决方案是安装一个额外的数据库,比如CouchDB,在爬取数据之前将数据保存路径更改为CouchDB,然后依次爬取数据,预览和下载,比如上面的预览图。
整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据,从头到尾两三分钟就可以了。而像这种少量的数据,爬虫并没有完全体现出它的用途。数据量越大,爬虫的优越性越明显。
比如爬取知乎的各个topic的选中内容,可以同时爬取,20000条数据只需要几十分钟。
自拍
如果你看到这个,你会觉得按照上面的步骤仍然很难。有一个更简单的方法:
通过Import sitemap,复制粘贴以下爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(由以上一系列配置生成)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"正则表达式":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"正则表达式":"","延迟":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的样式,不同的元素布局,不同的爬取需求,不同的爬取方式。
比如有的网站需要点击“加载更多”才能加载更多,有的网站下拉加载,有的网页比较乱,有时还需要限制爬取次数(否则爬虫会一直不停的爬爬),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息等等。有很多种情况。爬豆瓣top250只是入门体验版操作。只有了解爬虫的原理,遵守网站的规则,才能真正使用Web Scraper来爬取你想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
文章首发于公众号“行无术”,作者微博m644003222 查看全部
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网上有很多关于用Python爬取网页内容的教程,但一般都需要写代码。没有相应基础的人,短时间内还是有入门门槛的。事实上,在大多数场景下,都可以使用 Web Scraper(一个 Chrome 插件)快速爬取到目标内容。重要的是不需要下载任何东西,基本不需要代码知识。
在开始之前,有必要简单了解几个问题。
一个。什么是爬行动物?
自动抓取目标 网站 内容的工具。
湾。爬虫有什么用?
提高数据采集的效率。任何人都不应该希望他们的手指不断重复复制和粘贴的动作。机械的东西应该交给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解人类浏览网络的原因。我们通过输入网址、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到你看到的页面中。这就是上线的过程。
爬虫所做的就是模拟这个过程,但它比人类移动得更快,并且可以自定义抓取的内容,然后将其存储在数据库中以供浏览或下载。搜索引擎的工作原理类似。
但爬虫只是工具。要让工具发挥作用,你必须让爬虫了解你想要什么。这就是我们要做的。毕竟,人类的脑电波不能直接流入计算机。也可以说,爬虫的本质就是寻找规律。
照片由 Lauren Mancke 在 Unsplash 上拍摄
以豆瓣电影Top250为例(很多人用这个练习,因为豆瓣网页是正规的),看看Web Scraper是多么容易爬,以及如何粗略的使用它。
1、在 Chrome 应用商店中搜索 Web Scraper,然后点击“添加扩展”即可在 Chrome 扩展栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换。Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你使用的是Windows,就是ctrl+ shift+i,不同浏览浏览器默认的快捷键可能不同),这时候可以看到网页弹出这样一个对话框,别怕,这只是当前的html网页(一种超文本标记语言,它创建了 Web 世界的砖块)。
只要按照步骤1添加Web Scraper扩展,就可以在箭头所指的位置看到Web Scraper,点击它,就是下图中的爬虫页面。
3、点击create new sitemap和create sitemap依次创建爬虫。填写sitemap名称就行了,只是为了自己识别,比如填写dbtop250(不要写汉字、空格、大写字母)。在start url中,我们通常会复制粘贴要爬取的网页的URL,但是为了让爬虫了解我们的意图,最好先观察一下网页的布局和URL。比如top250采用分页方式,250部电影分10页分布。25 页。
第一个页面的 URL 是 /top250
第二页以 /top250?start=25&filter= 开头
第三页是/top250?start=50&filter=
...
只有一个数字略有不同,我们的意图是抓取top250的电影数据,所以start url不能简单的粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
启动后注意[]中的内容,表示每25个是一个网页,爬取10个网页。
最后点击创建站点地图,爬虫就搭建好了。
(也可以通过在URL中填写/top250来爬取,但是不能让Web Scraper明白我们要爬取的是top250所有页面的数据,只会爬取第一页的内容。)
4、爬虫搭建后的工作是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是简单点。它的原理是几乎所有用 HTML 编辑的网页都是由长度相同或相近的框(或容器)组成,每个容器中的布局和标签也相似。是统一的,从HTML代码就可以看出来。
因此,如果我们设置选择元素和顺序,爬虫可以根据设置自动模拟选择,也可以整齐的爬下数据。当你想爬取多个元素时(比如你想爬豆瓣top250,同时想爬排名、电影名、收视率、一句话影评),可以先选择容器,然后依次选择容器中的元素。
如图所示,
5、第四步只是为容器创建一个选择器。Web Scraper 仍然不明白我们要抓取什么。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话影评)。
完成第四步保存选择后,会看到爬虫的根目录root,点击创建的容器栏。
当您看到根目录 root 后跟容器时,单击添加新选择器以创建子选择器。
再次进入选择器编辑页面,如下图,这次不同的是id里面填的是我们要抓取的元素的定义,随便写什么,比如先抓取电影排名,并写一个数字;因为排名是文本类型,所以选择Text in Type;这次只选择了容器中的一个元素,因此不勾选 Multiple。另外,在选择排名的时候,不要选错地方,因为随便选什么爬虫都可以爬。然后以相同的方式单击完成选择并保存选择器。
此时爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下),分别爬取电影名、评分、一句话影评。
这是创建后的样子。至此,所有的选择器都创建好了,爬虫已经完全理解了意图。
6、接下来就是让爬虫跑起来,点击sitemap dbtop250 依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速非常快或者非常慢,然后点击开始刮擦。
到了这里,会弹出一个新的自动滚动网页,就是我们创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面会变成这样
7、点击刷新预览爬虫结果:豆瓣电影top250排名、电影名、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好。一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,有很多null,可以return调整选择器)
这时候可以说大功告成了,只要依次点击sitemap dbtop250和Export date as CSV,就可以下载CSV格式的数据表,然后随意使用。
值得一提的是,浏览器抓取的内容一般都存储在本地的starage数据库中,功能比较简单,不支持自动排序。所以如果你不安装额外的数据库并设置它,那么被爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表格然后清理它。另一种一劳永逸的解决方案是安装一个额外的数据库,比如CouchDB,在爬取数据之前将数据保存路径更改为CouchDB,然后依次爬取数据,预览和下载,比如上面的预览图。
整个过程看似麻烦,但熟悉之后其实很简单。这种小规模的数据,从头到尾两三分钟就可以了。而像这种少量的数据,爬虫并没有完全体现出它的用途。数据量越大,爬虫的优越性越明显。
比如爬取知乎的各个topic的选中内容,可以同时爬取,20000条数据只需要几十分钟。
自拍
如果你看到这个,你会觉得按照上面的步骤仍然很难。有一个更简单的方法:
通过Import sitemap,复制粘贴以下爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(由以上一系列配置生成)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"正则表达式":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"正则表达式":"","延迟":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的样式,不同的元素布局,不同的爬取需求,不同的爬取方式。
比如有的网站需要点击“加载更多”才能加载更多,有的网站下拉加载,有的网页比较乱,有时还需要限制爬取次数(否则爬虫会一直不停的爬爬),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息等等。有很多种情况。爬豆瓣top250只是入门体验版操作。只有了解爬虫的原理,遵守网站的规则,才能真正使用Web Scraper来爬取你想要的东西。
Hal Gatewood 在 Unsplash 上的标题图片
文章首发于公众号“行无术”,作者微博m644003222
爬虫抓取网页数据(网页爬虫抓取网页数据怎么做?吗?跑爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-04 20:00
爬虫抓取网页数据,然后筛选,我觉得就这样就差不多了。更简单的就是用翻页爬虫,爬取整个页面,然后按页码来爬取相关数据。
爬虫呗,
用爬虫
不要让人来给你写,
清理所有回答。
按照楼主列出来的需求,目测这份数据还是在ip上批量抓取来的。
python3吗?跑爬虫应该还是有点必要的,写python去爬取这个行为不会被封ip,爬虫可以直接挂代理工具批量抓取,不过这些搜索引擎也都能抓取,
请不要再举例了。真心没什么好的方案,如果真是要爬一个网站,还不如把这个网站上全部url写成随机的并且分页,因为如果仅仅是爬一个页面,可能没什么好的办法。至于具体请求的抓取工具,你按照官方的要求的抓取设置就可以,其实不用用python写爬虫。再想创新还不如自己实现一个前后端分离的网站快呢。
python抓网页其实是有很好的方案的,google提供了一个全链接请求工具和一个高性能的http服务器。
同感,网页爬虫应该比较自己抓,你想想你要连续爬七八十页的一定爬几天吧,有没有这个耐心和毅力呢。首先要考虑,query是否够多可以直接爬出要抓取数据列表,然后爬多少页就一个stackrecument分页,这样是不是比自己抓快些??如果只是单个网页的话那应该有urllib2可以直接调用里面的库。这里面爬多少页要看抓取什么网站了,或者就单个页面爬。以上一些是我自己瞎写一写看的,可能有误。但是我觉得有必要。 查看全部
爬虫抓取网页数据(网页爬虫抓取网页数据怎么做?吗?跑爬虫)
爬虫抓取网页数据,然后筛选,我觉得就这样就差不多了。更简单的就是用翻页爬虫,爬取整个页面,然后按页码来爬取相关数据。
爬虫呗,
用爬虫
不要让人来给你写,
清理所有回答。
按照楼主列出来的需求,目测这份数据还是在ip上批量抓取来的。
python3吗?跑爬虫应该还是有点必要的,写python去爬取这个行为不会被封ip,爬虫可以直接挂代理工具批量抓取,不过这些搜索引擎也都能抓取,
请不要再举例了。真心没什么好的方案,如果真是要爬一个网站,还不如把这个网站上全部url写成随机的并且分页,因为如果仅仅是爬一个页面,可能没什么好的办法。至于具体请求的抓取工具,你按照官方的要求的抓取设置就可以,其实不用用python写爬虫。再想创新还不如自己实现一个前后端分离的网站快呢。
python抓网页其实是有很好的方案的,google提供了一个全链接请求工具和一个高性能的http服务器。
同感,网页爬虫应该比较自己抓,你想想你要连续爬七八十页的一定爬几天吧,有没有这个耐心和毅力呢。首先要考虑,query是否够多可以直接爬出要抓取数据列表,然后爬多少页就一个stackrecument分页,这样是不是比自己抓快些??如果只是单个网页的话那应该有urllib2可以直接调用里面的库。这里面爬多少页要看抓取什么网站了,或者就单个页面爬。以上一些是我自己瞎写一写看的,可能有误。但是我觉得有必要。
爬虫抓取网页数据(简单6步,包教会你一种傻瓜式获取网页数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-01 21:12
虽然python现在很受欢迎,但是Excel也很香!一点点就能解决的事情,为什么一定要敲敲敲?
本文将介绍一种傻瓜式获取网页数据的方法。
6个简单步骤,包括教堂!
数据采集
1号
单击数据选项卡 > 获取和转换数据 > 单击来自 网站
2号
在对话框中,输入 URL,然后单击确定
本文以中国天气网为例进行说明。
#
3号
加载后,会弹出导航窗格。导航器左侧是从网站中提取的表格列表,右侧是表格数据预览。预览有两个选项:“表格视图”和“Web 视图”。通常我们使用“表格视图”。
4号
从预览中,选择您要获取和加载的目标数据。
5号
在此示例中,加载了 Table2。单击“加载”后,将创建一个新查询。
您可以对该查询进行相关操作。
6号
“编辑”查询,对数据执行 ETL,并获得所需的干净数据。上传并保存数据。
数据刷新
手动刷新
单击数据选项卡 > 查询和链接 > 单击全部刷新
可以实现手动刷新。
实时刷新
如图:点击“数据”选项卡>“查询与链接”>点击“属性”>点击弹出窗格中的红框区域>在“刷新控件”中根据自己的需要设置刷新频率“ 区域。
特别说明
Power Query是中文对应的“查询”。它是 Power BI 的一个组件。它存在于 Power BI 和 Excel 中。可以理解为早年Excel“数据”选项卡的演变。
上述方法只对Table类型的数据(即明显的行列类型的数据)有效,更复杂的网页数据获取后面会写文章。
为什么查询选项卡有时不出现?那是因为没有选中查询数据所在的区域,只需将鼠标移入点击即可。 查看全部
爬虫抓取网页数据(简单6步,包教会你一种傻瓜式获取网页数据的方法)
虽然python现在很受欢迎,但是Excel也很香!一点点就能解决的事情,为什么一定要敲敲敲?
本文将介绍一种傻瓜式获取网页数据的方法。
6个简单步骤,包括教堂!
数据采集
1号
单击数据选项卡 > 获取和转换数据 > 单击来自 网站
2号
在对话框中,输入 URL,然后单击确定
本文以中国天气网为例进行说明。
#
3号
加载后,会弹出导航窗格。导航器左侧是从网站中提取的表格列表,右侧是表格数据预览。预览有两个选项:“表格视图”和“Web 视图”。通常我们使用“表格视图”。
4号
从预览中,选择您要获取和加载的目标数据。
5号
在此示例中,加载了 Table2。单击“加载”后,将创建一个新查询。
您可以对该查询进行相关操作。
6号
“编辑”查询,对数据执行 ETL,并获得所需的干净数据。上传并保存数据。
数据刷新
手动刷新
单击数据选项卡 > 查询和链接 > 单击全部刷新
可以实现手动刷新。
实时刷新
如图:点击“数据”选项卡>“查询与链接”>点击“属性”>点击弹出窗格中的红框区域>在“刷新控件”中根据自己的需要设置刷新频率“ 区域。
特别说明
Power Query是中文对应的“查询”。它是 Power BI 的一个组件。它存在于 Power BI 和 Excel 中。可以理解为早年Excel“数据”选项卡的演变。
上述方法只对Table类型的数据(即明显的行列类型的数据)有效,更复杂的网页数据获取后面会写文章。
为什么查询选项卡有时不出现?那是因为没有选中查询数据所在的区域,只需将鼠标移入点击即可。
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-27 15:13
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装 python 运行 pip install requests 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。 查看全部
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装 python 运行 pip install requests 运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
爬虫抓取网页数据( python如何实现网络爬虫python代码代码代码的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-22 13:05
python如何实现网络爬虫python代码代码代码的方法)
转网页爬虫python教程
一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。从网站的某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推以此类推,直到这个 网站 直到所有页面都被爬取为止。如果
python爬虫的UserAgent
在学习爬虫的过程中,系统运维有时没有用到headers。我刚刚使用 python 的爬虫脚本爬了两次。我刚刚测试了它,我无法打开这个页面。一开始我很困惑。
python如何实现网络爬虫
python实现网络爬虫的方法:1、使用request库中的get方法请求url的网页内容;2、[find()]和[find_all()]方法可以遍历这个html文件,提取指定信息。python实现网络爬虫的方法:
python示例爬虫代码怎么做
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器
55.python爬虫教程
网络爬虫(一):网络爬虫的含义和URL基本构成一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么 Spider 就是在网络上四处爬行的蜘蛛,网络蜘蛛通过网页的链接地址找到一个网页,从网站的某个页面(通常是首页)开始,读取网页内容并找到网页内容.其他链接地址,然后通过这些链接地址
爬行动物和反爬行 - 爬行动物
总结:爬虫与反爬——爬虫
Scrapy:Python的爬虫框架
摘要:网络爬虫是一种在互联网上爬取数据的程序,利用它来爬取特定网页的 HTML 数据。Scrapy 是用 Python 编写的,轻量级、简单易用。
用Python写一个简单的爬虫
Python提供了很多Modules,通过这些Modules可以轻松做一些工作。比如获取百度搜索结果页面中cloga这个词的排名结果(排名结果+URL),这是一个非常简单的爬虫需求。
网络爬虫和python实现详解
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程 一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下: 1.首先选择一个精心挑选的部分seed URLs;2. 将这些URL放入待抓取的URL队列中;
Python爬虫如何使用MongoDB?
python爬虫使用mongodb的原因:1、文档结构的存储方式,就是直接存储json,list2、不要提前定义“table”,可以创建3、任何时候的“表”数据长度可以不同,即第一条记录有10条
Scrapy Crawler:同步和异步分页
总结:PythonScrapy爬虫分页
深入理解Python分布式爬虫原理
python视频教程专栏介绍分布式爬虫原理。免费推荐:python视频教程首先,我们来看看如果是正常的人类行为,如何获取网页内容。(1)打开浏览器,输入网址,打开源页面(2)选择
scrapy爬虫爬取天猫进口零食网页
总结:主要的爬虫策略是使用cookies登录
【转】网络爬虫及其算法和数据结构
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。网络爬虫是搜索引擎系统中非常重要的一部分。它负责从互联网上采集网页和采集 信息。这些网页信息用于建立索引,为搜索引擎提供支持。它决定了整个引擎系统的内容。信息是否丰富,信息是否即时,其表现的好坏直接影响搜索引擎的效果。网络爬虫程序的优劣很大程度上反映了搜索引擎的质量。如果你不相信我,你可以拿一个 网站 去看看
scrapy框架python爬虫
有朋友请我帮忙写一个爬虫并记录下来。项目整体介绍:scrapy框架,anaconda(python3.6)开发工具:IDEA详细介绍:scrapy结构图:Scrapy主要包括以下组件: Engine(ScrapyEngine)负责Spider.ItemPipline.Downloader .Scheduler 中间通信、信号、数据传输等调度器(Schedu.... 查看全部
爬虫抓取网页数据(
python如何实现网络爬虫python代码代码代码的方法)
转网页爬虫python教程
一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。互联网被比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。从网站的某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,以此类推以此类推,直到这个 网站 直到所有页面都被爬取为止。如果
python爬虫的UserAgent
在学习爬虫的过程中,系统运维有时没有用到headers。我刚刚使用 python 的爬虫脚本爬了两次。我刚刚测试了它,我无法打开这个页面。一开始我很困惑。
python如何实现网络爬虫
python实现网络爬虫的方法:1、使用request库中的get方法请求url的网页内容;2、[find()]和[find_all()]方法可以遍历这个html文件,提取指定信息。python实现网络爬虫的方法:
python示例爬虫代码怎么做
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器
55.python爬虫教程
网络爬虫(一):网络爬虫的含义和URL基本构成一、网络爬虫的定义网络爬虫,即WebSpider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么 Spider 就是在网络上四处爬行的蜘蛛,网络蜘蛛通过网页的链接地址找到一个网页,从网站的某个页面(通常是首页)开始,读取网页内容并找到网页内容.其他链接地址,然后通过这些链接地址
爬行动物和反爬行 - 爬行动物
总结:爬虫与反爬——爬虫
Scrapy:Python的爬虫框架
摘要:网络爬虫是一种在互联网上爬取数据的程序,利用它来爬取特定网页的 HTML 数据。Scrapy 是用 Python 编写的,轻量级、简单易用。
用Python写一个简单的爬虫
Python提供了很多Modules,通过这些Modules可以轻松做一些工作。比如获取百度搜索结果页面中cloga这个词的排名结果(排名结果+URL),这是一个非常简单的爬虫需求。
网络爬虫和python实现详解
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。一、网络爬虫的基本结构和工作流程 一般网络爬虫的框架如图所示: 网络爬虫的基本工作流程如下: 1.首先选择一个精心挑选的部分seed URLs;2. 将这些URL放入待抓取的URL队列中;
Python爬虫如何使用MongoDB?
python爬虫使用mongodb的原因:1、文档结构的存储方式,就是直接存储json,list2、不要提前定义“table”,可以创建3、任何时候的“表”数据长度可以不同,即第一条记录有10条
Scrapy Crawler:同步和异步分页
总结:PythonScrapy爬虫分页
深入理解Python分布式爬虫原理
python视频教程专栏介绍分布式爬虫原理。免费推荐:python视频教程首先,我们来看看如果是正常的人类行为,如何获取网页内容。(1)打开浏览器,输入网址,打开源页面(2)选择
scrapy爬虫爬取天猫进口零食网页
总结:主要的爬虫策略是使用cookies登录
【转】网络爬虫及其算法和数据结构
网络爬虫是根据一定规则自动从万维网上抓取信息的程序或脚本。网络爬虫是搜索引擎系统中非常重要的一部分。它负责从互联网上采集网页和采集 信息。这些网页信息用于建立索引,为搜索引擎提供支持。它决定了整个引擎系统的内容。信息是否丰富,信息是否即时,其表现的好坏直接影响搜索引擎的效果。网络爬虫程序的优劣很大程度上反映了搜索引擎的质量。如果你不相信我,你可以拿一个 网站 去看看
scrapy框架python爬虫
有朋友请我帮忙写一个爬虫并记录下来。项目整体介绍:scrapy框架,anaconda(python3.6)开发工具:IDEA详细介绍:scrapy结构图:Scrapy主要包括以下组件: Engine(ScrapyEngine)负责Spider.ItemPipline.Downloader .Scheduler 中间通信、信号、数据传输等调度器(Schedu....
爬虫抓取网页数据( 人生苦短,我用Python前文:小白学Python爬虫(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-22 04:18
人生苦短,我用Python前文:小白学Python爬虫(1))
人生苦短,我用Python
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学习Python爬虫(3):前期准备(二)Linux基础介绍)
小白学Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学Python爬虫(14):urllib基本使用(四)
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(16):urllib实战爬取妹图
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,有点遗憾,不过最终的片单还是挺香的,真心推荐。
本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.
打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。
聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee
相关文章 查看全部
爬虫抓取网页数据(
人生苦短,我用Python前文:小白学Python爬虫(1))
人生苦短,我用Python
之前的传送门:
小白学Python爬虫(1):开
小白学Python爬虫(2):前期准备(一)基础类库安装)
小白学习Python爬虫(3):前期准备(二)Linux基础介绍)
小白学Python爬虫(4):前期准备(三)Docker基础介绍)
小白学Python爬虫(5):前期准备(四)数据库基础)
小白学习Python爬虫(6):前期准备(五)爬虫框架的安装)
小白学习Python爬虫(7):HTTP基础
小白学Python爬虫(8):网页基础
小白学习Python爬虫(9):爬虫基础
小白学习Python爬虫(一0):Session和Cookies
小白学Python爬虫(一1):urllib的基本使用(一)
小白学习Python爬虫(一2):urllib的基本使用(二)
小白学Python爬虫(一3):urllib的基本使用(三)
小白学Python爬虫(14):urllib基本使用(四)
小白学习Python爬虫(一5):urllib的基本使用(五)
小白学Python爬虫(16):urllib实战爬取妹图
小白学习Python爬虫(一7):Requests的基本使用)
小白学Python爬虫(18):请求高级操作
小白学Python爬虫(一9):Xpath基础操作
小白学Python爬虫(20):Xpath进阶
小白学Python爬虫(二1):分析库美汤(上))
小白学Python爬虫(二2):分析库美汤(下))
小白学Python爬虫(二3):解析库pyquery简介
小白学Python爬虫(24):2019豆瓣电影排行榜
介绍
上一篇实战最后没有使用页面元素分析,有点遗憾,不过最终的片单还是挺香的,真心推荐。
本次选题是先写代码再写文章,肯定可以用于页面元素分析,还需要对网站的数据加载有一定的分析,才能得到最终数据,和小编找到的两个数据源没有IP访问限制,质量有保障。绝对是小白修炼的绝佳选择。
郑重声明:本文仅供学习及其他用途。
分析
首先,要爬取股票数据,首先要知道有哪些股票。在这里,小编发现了一个网站,而这个网站有一个股票代码列表:.
打开Chrome的开发者模式,一一选择代码。具体过程这里就不贴了,同学们可以自己实现。
我们可以将所有股票代码存储在一个列表中,剩下的就是找到一个网站,然后循环获取每只股票的数据。
这个网站编辑器已经找到了,是同花顺,链接:。
聪明的同学一定都发现,这个链接里的000001就是股票代码。
接下来,我们只需要拼接这个链接,就可以不断得到我们想要的数据。
实战
首先介绍一下本次实战用到的请求库和解析库:Requests和pyquery。数据存储终于落地Mysql。
获取股票代码列表
第一步当然是建立一个股票代码列表。我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
把上面的链接作为参数传入,大家可以自己运行看看结果,小编这里就不贴结果了,有点长。. .
获取详细数据
详细信息的数据似乎在页面上,但实际上并不存在。最终获取数据的实际地方不是页面,而是数据接口。
http://qd.10jqka.com.cn/quote. ... 00001
至于怎么找,小编这次就不多说了。还是希望所有想学爬虫的同学都能自己动手,去找找吧。多找几遍,自然会找到路。
既然有了数据接口,我们再来看看返回的数据:
showStockDate({"info":{"000001":{"name":"\u5e73\u5b89\u94f6\u884c"}},"data":{"000001":{"10":"16.13","8":"16.14","9":"15.87","13":"78795234.00","19":"1262802470.00","7":"16.12","15":"40225508.00","14":"37528826.00","69":"17.73","70":"14.51","12":"5","17":"945400.00","264648":"0.010","199112":"0.062","1968584":"0.406","2034120":"9.939","1378761":"16.026","526792":"1.675","395720":"-948073.000","461256":"-39.763","3475914":"313014790000.000","1771976":"1.100","6":"16.12","11":""}}})
显然,这个结果并不是标准的json数据,而是JSONP返回的标准格式数据。这里我们先对head和tail进行处理,变成标准的json数据,然后针对本页的数据进行解析,最后将解析后的值写入数据库。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
这里我们添加异常处理,因为这次爬取的数据很多,很可能会因为某种原因抛出异常。当然,我们不想在出现异常的时候中断数据采集,所以在这里添加异常处理,继续采集数据。
完整代码
我们将代码稍微封装一下来完成这个实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
# 数据库连接
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='password',
database='test',
charset='utf8mb4')
# 获取操作游标
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into stock(code, name, jinkai, chengjiaoliang, zhenfu, zuigao, chengjiaoe, huanshou, zuidi, zuoshou, liutongshizhi, create_date) values (%(code)s, %(name)s, %(jinkai)s, %(chengjiaoliang)s, %(zhenfu)s, %(zuigao)s, %(chengjiaoe)s, %(huanshou)s, %(zuidi)s, %(zuoshou)s, %(liutongshizhi)s, now())"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
# 获取所有 section 中 a 节点,并进行迭代
for i in doc('.stockTable a').items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
# 将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
# 获取字典中的数据构建写入数据模版
insert_data = {
"code": stock,
"name": dict1['info'][stock]['name'],
"jinkai": dict1['data'][stock]['7'],
"chengjiaoliang": dict1['data'][stock]['13'],
"zhenfu": dict1['data'][stock]['526792'],
"zuigao": dict1['data'][stock]['8'],
"chengjiaoe": dict1['data'][stock]['19'],
"huanshou": dict1['data'][stock]['1968584'],
"zuidi": dict1['data'][stock]['9'],
"zuoshou": dict1['data'][stock]['6'],
"liutongshizhi": dict1['data'][stock]['3475914']
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ':写入完成')
except:
print('写入异常')
# 遇到错误继续循环
continue
def main():
stock_list_url = 'https://hq.gucheng.com/gpdmylb.html'
stock_info_url = 'http://qd.10jqka.com.cn/quote. ... 39%3B
list = get_stock_list(stock_list_url)
# list = ['601766']
getStockInfo(list, stock_info_url)
if __name__ == '__main__':
main()
成就
最终,编辑器用了15分钟左右,成功捕获了4600+条数据,结果就不显示了。
示例代码
为了您的方便,本系列中的所有代码编辑器都将放在代码管理存储库 Github 和 Gitee 上。
示例代码 - Github
示例代码 - Gitee
相关文章
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-20 22:08
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。 查看全部
爬虫抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您是正则表达式的新手,或者需要一些提示,请查看正则表达式 HOWTO 以获得完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注意:由于不同版本的Python内置库的容错能力存在差异,处理结果可能与上述不同。详情请参阅: 。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
以下是使用此方法提取样本国家地区数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
此代码虽然比正则表达式代码更复杂,但更易于构建和理解。此外,布局中的一些小变化,例如额外的空白和制表符属性,我们不再需要担心它了。
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比Beautiful Soup快,但安装过程比较复杂。最新安装说明可以参考。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = '
AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入后,是时候选择元素了。此时,lxml 有几种不同的方法,例如 XPath 选择器和 Beautiful Soup 之类的 find() 方法。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到ID为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 在
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在: .
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能比较
在下面的代码中,每个爬虫会执行1000次,每次执行都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 *line 代码中调用了 re.purge() 方法。默认情况下,正则表达式会缓存搜索结果,公平起见,我们需要使用这种方法来清除缓存。
这是在我的计算机上运行脚本的结果:
由于硬件条件的不同,不同计算机的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,Beautiful Soup 在爬取我们的示例网页时比其他两种方法慢 7 倍以上。事实上,这个结果是意料之中的,因为 lxml 和正则表达式模块是用 C 编写的,而 Beautiful Soup 是用纯 Python 编写的。一个有趣的事实是 lxml 的性能与正则表达式差不多。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当爬取同一个网页的多个特征时,这个初始解析的开销会减少,lxml会更有竞争力,所以lxml是一个强大的模块。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用难度 安装难度
正则表达式
快的
困难
简单(内置模块)
美丽的汤
慢的
简单的
简单(纯 Python)
lxml
快的
简单的
比较困难
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,除了可以避免解析整个网页的开销,如果只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更适合. 但是,总的来说,lxml 是抓取数据的最佳选择,因为它不仅速度更快,功能更强大,而正则表达式和 Beautiful Soup 仅在某些场景下才有用。
爬虫抓取网页数据(2.用户体验策略的四个常见的更新策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-20 09:12
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社 查看全部
爬虫抓取网页数据(2.用户体验策略的四个常见的更新策略)
四、更新政策
互联网实时变化并且非常动态。网页更新策略主要决定何时更新之前已经下载的页面。常见的更新策略有以下三种:
1.历史参考政策
顾名思义,它根据页面过去的历史更新数据来预测未来页面何时会发生变化。通常,预测是通过泊松过程建模来进行的。
2.用户体验策略
尽管搜索引擎可以为某个查询返回大量结果,但用户通常只关注结果的前几页。因此,爬虫系统可以优先更新那些实际在查询结果前几页的页面,然后再更新后面的那些页面。这个更新策略也需要用到历史信息。UX 策略保留网页的多个历史版本,并根据每个过去内容更改对搜索质量的影响得出一个平均值,并以此值作为决定何时重新抓取的基础。
3.聚类抽样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加很多系统负担;第二,如果新网页完全没有历史信息,就无法确定更新策略。
该策略认为网页具有许多属性,具有相似属性的网页可以认为具有相似的更新频率。计算某一类别网页的更新频率,只需对该类别的网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如下:
五、分布式抓取系统结构
一般来说,爬虫系统需要处理整个互联网上数以亿计的网页。单个爬虫不可能完成这样的任务。通常需要多个爬虫程序一起处理它们。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
最底层是分布在不同地理位置的数据中心。每个数据中心有多个爬虫服务器,每个爬虫服务器可能部署多套爬虫程序。这样就构成了一个基本的分布式爬虫系统。
对于数据中心中的不同服务器,有几种方法可以协同工作:
1.主从
主从基本结构如图:
对于主从类型,有一个专门的主服务器来维护要爬取的URL队列,负责每次将URL分发给不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL外,还负责调解每个Slave服务器的负载。为了避免一些从服务器过于空闲或过度工作。
在这种模式下,Master往往会成为系统的瓶颈。
2.点对点
等价的基本结构如图所示:
在这种模式下,所有爬虫服务器之间的分工没有区别。每个爬取服务器可以从待爬取的URL队列中获取URL,然后计算该URL主域名的哈希值H,进而计算H mod m(其中m为服务器数量,上图为例如,m 对于 3),计算出来的数字是处理 URL 的主机号。
例子:假设对于URL,计算器hash值H=8,m=3,那么H mod m=2,那么编号为2的服务器会抓取该链接。假设此时服务器 0 获取了 URL,它会将 URL 传输到服务器 2,服务器 2 将获取它。
这种模式有一个问题,当一个服务器死掉或添加一个新服务器时,所有 URL 的哈希余数的结果都会改变。也就是说,这种方法不能很好地扩展。针对这种情况,提出了另一种改进方案。这种改进的方案是一致的散列以确定服务器划分。其基本结构如图所示:
一致散列对 URL 的主域名进行散列,并将其映射到 0-232 范围内的数字。这个范围平均分配给m台服务器,根据主URL域名的hash运算值的范围来确定要爬取哪个服务器。
如果某台服务器出现问题,本应负责该服务器的网页将由下一个服务器顺时针获取。在这种情况下,即使一台服务器出现问题,也不会影响其他工作。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社
爬虫抓取网页数据(2.NAT配置规则增强过滤规则(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-19 14:04
如果你是站长,你会发现很多时候你的线上产品被一些不受欢迎的爬虫爬取,你的数据被盗,更多的时候还在我们的产品中留下一些垃圾数据给我们的用户在评估价值的时候带来一些误解产品,也阻碍了我们产品的健康稳定发展。
针对这个问题,我认为有必要通过一定的手段来避免,如下:
基本技能
1. 阻止攻击
对攻击行为具有灵活的拦截能力,可以通过浏览器的IP地址或者浏览器的cookie进行拦截。
用户拦截可以用不同的可定制形式表示,例如返回 404 错误页面和返回 403 访问禁止。
可以指定拦截时间。如果超过拦截时间,则允许访问,直到再次被行为分析引擎捕获并判断为恶意访问。
2. NAT判断
因为基本拦截是基于访问频率的,所以需要能够用技术手段来判断从NAT出口的访问,防止单IP出口误杀企业用户。NAT介绍:
3. 白名单
需要能够手动自定义白名单,将群组IP地址和某些可信任的合作伙伴加入非限制名单,以免影响正常业务运行。
扩展
1. 水印功能
水印功能是基本拦截能力的扩展。当用户被判断为恶意访问时,不会直接禁止用户访问,而是重定向到水印页面,需要人机识别。通过人机识别后,进入正常页面。根据配置,人机识别要求在一定时间后自动去除,直到用户再次被行为分析引擎判断为恶意用户。
2.配置规则增强
除了目前基本的频率统计,过滤规则可以增加更多的HTTP应用层协议分析功能。例如获取GET请求、POST请求、HTTP头等,根据内容匹配用户请求,部署过滤策略。加强了对字符串的操作能力,可以实现字符串的拼接和截取字符串的能力。
3.WEB应用防火墙功能
添加了同时拦截和过滤功能,例如 CRLF 攻击过滤。
如果能实现以上功能并开发一个工具,应该可以有效避免爬虫爬取,可以考虑在apache端实现 查看全部
爬虫抓取网页数据(2.NAT配置规则增强过滤规则(一)(组图))
如果你是站长,你会发现很多时候你的线上产品被一些不受欢迎的爬虫爬取,你的数据被盗,更多的时候还在我们的产品中留下一些垃圾数据给我们的用户在评估价值的时候带来一些误解产品,也阻碍了我们产品的健康稳定发展。
针对这个问题,我认为有必要通过一定的手段来避免,如下:
基本技能
1. 阻止攻击
对攻击行为具有灵活的拦截能力,可以通过浏览器的IP地址或者浏览器的cookie进行拦截。
用户拦截可以用不同的可定制形式表示,例如返回 404 错误页面和返回 403 访问禁止。
可以指定拦截时间。如果超过拦截时间,则允许访问,直到再次被行为分析引擎捕获并判断为恶意访问。
2. NAT判断
因为基本拦截是基于访问频率的,所以需要能够用技术手段来判断从NAT出口的访问,防止单IP出口误杀企业用户。NAT介绍:
3. 白名单
需要能够手动自定义白名单,将群组IP地址和某些可信任的合作伙伴加入非限制名单,以免影响正常业务运行。
扩展
1. 水印功能
水印功能是基本拦截能力的扩展。当用户被判断为恶意访问时,不会直接禁止用户访问,而是重定向到水印页面,需要人机识别。通过人机识别后,进入正常页面。根据配置,人机识别要求在一定时间后自动去除,直到用户再次被行为分析引擎判断为恶意用户。
2.配置规则增强
除了目前基本的频率统计,过滤规则可以增加更多的HTTP应用层协议分析功能。例如获取GET请求、POST请求、HTTP头等,根据内容匹配用户请求,部署过滤策略。加强了对字符串的操作能力,可以实现字符串的拼接和截取字符串的能力。
3.WEB应用防火墙功能
添加了同时拦截和过滤功能,例如 CRLF 攻击过滤。
如果能实现以上功能并开发一个工具,应该可以有效避免爬虫爬取,可以考虑在apache端实现
爬虫抓取网页数据(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-19 08:16
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对 Scripting Home 的支持。 查看全部
爬虫抓取网页数据(一下实现简单爬虫功能的示例python爬虫实战之最简单的网页爬虫教程)
既然本文文章是解析Python搭建网络爬虫的原理,那么小编就为大家展示一下Python中爬虫的选择文章:
python实现简单爬虫功能的例子
python爬虫最简单的网络爬虫教程
网络爬虫是当今最常用的系统之一。最流行的例子是 Google 使用爬虫从所有 网站 采集信息。除了搜索引擎,新闻网站还需要爬虫来聚合数据源。看来,每当你想聚合大量信息时,都可以考虑使用爬虫。
构建网络爬虫涉及许多因素,尤其是当您想要扩展系统时。这就是为什么这已成为最受欢迎的系统设计面试问题之一。在本期文章中,我们将讨论从基础爬虫到大规模爬虫的各种话题,并讨论您在面试中可能遇到的各种问题。
1 - 基本解决方案
如何构建一个基本的网络爬虫?
在系统设计面试之前,正如我们在“系统设计面试之前你需要知道的八件事”中已经谈到的那样,它是从简单的事情开始。让我们专注于构建一个在单线程上运行的基本网络爬虫。通过这个简单的解决方案,我们可以继续优化。
爬取单个网页,我们只需要向对应的 URL 发起 HTTP GET 请求并解析响应数据,这就是爬虫的核心。考虑到这一点,一个基本的网络爬虫可以像这样工作:
从一个收录我们要爬取的所有 网站 的 URL 池开始。
对于每个 URL,发出 HTTP GET 请求以获取网页内容。
解析内容(通常是 HTML)并提取我们想要抓取的潜在 URL。
将新 URL 添加到池中并继续爬行。
根据问题,有时我们可能有一个单独的系统来生成抓取 URL。例如,一个程序可以不断地监听 RSS 提要,并且对于每个新的 文章,可以将 URL 添加到爬虫池中。
2 - 规模问题
众所周知,任何系统在扩容后都会面临一系列问题。在网络爬虫中,当将系统扩展到多台机器时,很多事情都可能出错。
在跳到下一节之前,请花几分钟时间思考一下分布式网络爬虫的瓶颈以及如何解决它。在本文章 的其余部分,我们将讨论解决方案的几个主要问题。
3 - 抓取频率
你多久爬一次网站?
除非系统达到一定规模并且您需要非常新鲜的内容,否则这听起来可能没什么大不了的。例如,如果要获取最近一小时的最新消息,爬虫可能需要每隔一小时不断地获取新闻网站。但这有什么问题呢?
对于一些小的网站,很可能他们的服务器无法处理如此频繁的请求。一种方法是关注每个站点的robot.txt。对于那些不知道什么是robot.txt 的人来说,这基本上是与网络爬虫通信的网站 标准。它可以指定哪些文件不应该被爬取,大多数网络爬虫都遵循配置。此外,您可以为不同的 网站 设置不同的抓取频率。通常,每天只需要多次爬取网站s。
4 - 重复数据删除
在单台机器上,您可以在内存中保留 URL 池并删除重复条目。然而,在分布式系统中事情变得更加复杂。基本上,多个爬虫可以从不同的网页中提取相同的 URL,并且都想将这个 URL 添加到 URL 池中。当然,多次爬取同一个页面是没有意义的。那么我们如何去重复这些 URL 呢?
一种常见的方法是使用布隆过滤器。简而言之,布隆过滤器是一种节省空间的系统,它允许您测试元素是否在集合中。但是,它可能有误报。换句话说,如果布隆过滤器可以告诉你一个 URL 肯定不在池中,或者可能在池中。
为了简要解释布隆过滤器的工作原理,一个空布隆过滤器是一个 m 位的位数组(所有 0)。还有 k 个哈希函数将每个元素映射到一个 A。所以当我们添加一个新元素时 ( URL) 在布隆过滤器中,我们将从散列函数中获取 k 位并将它们全部设置为 1. 所以当我们检查一个元素是否存在时,我们首先获取 k 位,如果其中任何一个不为 1,我们立即知道该元素不存在。但是,如果所有 k 位都是 1,这可能来自其他几个元素的组合。
布隆过滤器是一种非常常见的技术,它是在网络爬虫中对 URL 进行重复数据删除的完美解决方案。
5 - 解析
从网站得到响应数据后,下一步就是解析数据(通常是HTML)来提取我们关心的信息。这听起来很简单,但是,要让它变得健壮可能很困难。
我们面临的挑战是您总是会在 HTML 代码中发现奇怪的标签、URL 等,而且很难涵盖所有的边缘情况。例如,当 HTML 收录非 Unicode 字符时,您可能需要处理编码和解码问题。此外,当网页收录图像、视频甚至 PDF 时,可能会导致奇怪的行为。
此外,某些网页是通过 Javascript 与 AngularJS 一样呈现的,您的爬虫可能无法获取任何内容。
我想说,没有灵丹妙药可以为所有网页制作完美、强大的爬虫。您需要进行大量的稳健性测试以确保它按预期工作。
总结
还有很多有趣的话题我还没有涉及,但我想提一些,以便您思考。一件事是检测循环。许多 网站 收录 A->B->C->A 之类的链接,您的爬虫可能会永远运行。思考如何解决这个问题?
另一个问题是 DNS 查找。当系统扩展到一定水平时,DNS 查找可能会成为瓶颈,您可能希望构建自己的 DNS 服务器。
与许多其他系统类似,扩展的网络爬虫可能比构建单机版本要困难得多,而且很多事情都可以在系统设计面试中讨论。尝试从一些幼稚的解决方案开始并不断优化它可以使事情变得比看起来更容易。
以上就是我们对网络爬虫相关文章内容的总结。如果你还有什么想知道的,可以在下方留言区讨论。感谢您对 Scripting Home 的支持。
爬虫抓取网页数据(关于python爬虫是什么意思,希望对你有所帮助!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-18 17:11
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。以下是小编为大家整理的python爬虫的意思,希望对大家有所帮助。
python爬虫是什么意思
python爬虫是一个网络爬虫。网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,在数据库中建立一个相关的全文索引,然后跳转到另一个网站。看起来像一只大蜘蛛。
当人们在互联网上搜索关键词(如google)时,他们实际上是在比较数据库中的内容以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力。例如,谷歌搜索引擎显然需要比百度更好,因为它的网络爬虫效率很高,并且有良好的编程结构。
网络爬虫的原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
学习 Python 包并实现基本的爬取流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样动态知乎、、TripAdvisor网站也可以解决。
学习数据库基础知识并处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。 查看全部
爬虫抓取网页数据(关于python爬虫是什么意思,希望对你有所帮助!)
在爬取过程中,你也会经历一些绝望,比如被网站IP屏蔽,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。以下是小编为大家整理的python爬虫的意思,希望对大家有所帮助。
python爬虫是什么意思
python爬虫是一个网络爬虫。网络爬虫是一个程序,主要用于搜索引擎。它读取一个网站的所有内容和链接,在数据库中建立一个相关的全文索引,然后跳转到另一个网站。看起来像一只大蜘蛛。
当人们在互联网上搜索关键词(如google)时,他们实际上是在比较数据库中的内容以找出与用户匹配的内容。网络爬虫的好坏决定了搜索引擎的能力。例如,谷歌搜索引擎显然需要比百度更好,因为它的网络爬虫效率很高,并且有良好的编程结构。
网络爬虫的原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
学习 Python 包并实现基本的爬取流程
大多数爬虫遵循“发送请求-获取页面-解析页面-提取和存储内容”的过程,实际上模拟了使用浏览器获取网页信息的过程。
Python中有很多爬虫相关的包:urllib、requests、bs4、scrapy、pyspider等,建议从requests+Xpath入手。Requests 负责连接到 网站 并返回网页。Xpath 用于解析网页以便于提取。数据。
如果你用过BeautifulSoup,你会发现Xpath省了很多麻烦,层层检查元素代码的工作都省去了。这样,基本套路就差不多了。一般的静态网站完全没有问题,豆瓣、尴尬百科、腾讯新闻等基本都能上手。
当然,如果你需要爬取异步加载的网站,你可以学习浏览器抓取来分析真实的请求,或者学习Selenium来实现自动化。这样动态知乎、、TripAdvisor网站也可以解决。
学习数据库基础知识并处理大规模数据存储
当爬回来的数据量较小时,可以以文档的形式存储。一旦数据量很大,这有点行不通。所以,掌握一个数据库是很有必要的,学习目前主流的MongoDB就可以了。
MongoDB可以方便你存储一些非结构化的数据,比如各种评论的文字、图片的链接等。你也可以使用PyMongo在Python中更方便的操作MongoDB。
因为这里用到的数据库知识其实很简单,主要是如何存储和提取数据,需要的时候学。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URLs 队列;
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接放到待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
爬虫抓取网页数据(爬虫抓取网页数据怎么做?抓取数据库的技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-18 08:01
爬虫抓取网页数据,可以把数据存储在数据库上,还可以写个批量抓取的程序把数据抓取过来,之后更多的就是数据分析了。如果写的爬虫你用的是web框架,可以用webwork,requests等,这个时候最好把http报文转化为xml文件,然后把xml转化为bean.这个时候可以从action中看到对应的xml文件名,就可以把数据拷贝过来。没有schema,单个页面也是可以打包为json文件的。
可以用charles抓jsondom。
dom爬取可能涉及的包括cookie,json等等。你可以在设计代理的时候选择既能够免request,又不使用这些request。通过oauth协议从他人那里注册账号就可以了。
cookie和session可以是有的我会随机产生一个批量的就是能抓取手机版的app,都是能生成的。不过要注意的是cookie有时间有duration的一个cookie1秒,2秒,2分钟都会有效(抓取网页是xml等也一样的)同理对于json一类的就比较麻烦,根据抓取日期而定的,比如抓取购物网而言1天内任何时间内的json都是有效的对于记步都是一样的道理,是有时间期限的。
json
dom是关键,就像html转化成javascript这些都是可以的,
简单地说schema很重要,要有定义抓取范围,过滤对应url,必要情况下需要参考抓取逻辑。如果数据量不大,会把图片url等也保存起来。大型网站数据库一般都是有应用的,根据数据库管理的api能查看相应数据。 查看全部
爬虫抓取网页数据(爬虫抓取网页数据怎么做?抓取数据库的技巧)
爬虫抓取网页数据,可以把数据存储在数据库上,还可以写个批量抓取的程序把数据抓取过来,之后更多的就是数据分析了。如果写的爬虫你用的是web框架,可以用webwork,requests等,这个时候最好把http报文转化为xml文件,然后把xml转化为bean.这个时候可以从action中看到对应的xml文件名,就可以把数据拷贝过来。没有schema,单个页面也是可以打包为json文件的。
可以用charles抓jsondom。
dom爬取可能涉及的包括cookie,json等等。你可以在设计代理的时候选择既能够免request,又不使用这些request。通过oauth协议从他人那里注册账号就可以了。
cookie和session可以是有的我会随机产生一个批量的就是能抓取手机版的app,都是能生成的。不过要注意的是cookie有时间有duration的一个cookie1秒,2秒,2分钟都会有效(抓取网页是xml等也一样的)同理对于json一类的就比较麻烦,根据抓取日期而定的,比如抓取购物网而言1天内任何时间内的json都是有效的对于记步都是一样的道理,是有时间期限的。
json
dom是关键,就像html转化成javascript这些都是可以的,
简单地说schema很重要,要有定义抓取范围,过滤对应url,必要情况下需要参考抓取逻辑。如果数据量不大,会把图片url等也保存起来。大型网站数据库一般都是有应用的,根据数据库管理的api能查看相应数据。
爬虫抓取网页数据(尝试动态加载的电影网站爬虫《新手也能做爬虫》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-17 09:19
在ajax横行的时代,很多网页的内容都是动态加载的,而我们的小爬虫只抓取web服务器返回给我们的html,其中。
试试动态加载的电影网站爬虫昨天写了一个小爬虫,抓取电影的下载链接《新手也可以是爬虫!一起来爬取电影信息吧。
csdn为你找到了关于js动态爬虫的相关内容,包括js动态爬虫相关文档代码介绍,相关教程视频课程,以及相关js。
接下来,我们通过一个简单的例子来展示动态爬虫和传统爬虫的区别。目标:加载一个页面(好吧,让我们玩一下)。
Python动态网站爬虫实战(requests+xpath+demjson+re博客园。
1.JS逆向分析对于动态加载的网页,如果我们想要获取网页数据,我们需要了解网页是如何加载数据的。这个过程称为反向回溯。对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求得到的数据。需要注意的是,构造 Ajax 请求有两种方式: 原生 Ajax 请求:将直接创建 XMLHTTPRequest 对象。.
爬虫爬取动态网页的6种方式_Mr. 郭的博客-CSDN 博客。
这时候PhantomJS+Selenium的两个神器,加上Scrapy爬虫框架,就可以拼凑成一个动态爬虫了。PhantomJS 简单地说是 PhantomJS。
本发明涉及网络信息领域,尤其涉及一种动态反爬虫方法。2、背景技术爬虫技术的升级为搜索引擎提供了很大的优势。
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。项目背景是这样的,前几个。 查看全部
爬虫抓取网页数据(尝试动态加载的电影网站爬虫《新手也能做爬虫》)
在ajax横行的时代,很多网页的内容都是动态加载的,而我们的小爬虫只抓取web服务器返回给我们的html,其中。
试试动态加载的电影网站爬虫昨天写了一个小爬虫,抓取电影的下载链接《新手也可以是爬虫!一起来爬取电影信息吧。
csdn为你找到了关于js动态爬虫的相关内容,包括js动态爬虫相关文档代码介绍,相关教程视频课程,以及相关js。
接下来,我们通过一个简单的例子来展示动态爬虫和传统爬虫的区别。目标:加载一个页面(好吧,让我们玩一下)。
Python动态网站爬虫实战(requests+xpath+demjson+re博客园。
1.JS逆向分析对于动态加载的网页,如果我们想要获取网页数据,我们需要了解网页是如何加载数据的。这个过程称为反向回溯。对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求得到的数据。需要注意的是,构造 Ajax 请求有两种方式: 原生 Ajax 请求:将直接创建 XMLHTTPRequest 对象。.
爬虫爬取动态网页的6种方式_Mr. 郭的博客-CSDN 博客。
这时候PhantomJS+Selenium的两个神器,加上Scrapy爬虫框架,就可以拼凑成一个动态爬虫了。PhantomJS 简单地说是 PhantomJS。
本发明涉及网络信息领域,尤其涉及一种动态反爬虫方法。2、背景技术爬虫技术的升级为搜索引擎提供了很大的优势。
用通俗易懂的语言分享爬虫、数据分析、可视化等干货,希望大家能学到新知识。项目背景是这样的,前几个。
爬虫抓取网页数据(7,686,方式抓取网页数据的三种方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-15 22:15
0.前言0.1 爬网
本文将说明三种爬取网络数据的方法:正则表达式、BeautifulSoup 和 lxml。
用于获取网页内容的代码详情请参考 Python Web Crawler - Your First Crawler(我的短书博客)。使用此代码来抓取整个网页。
import requests
def download(url, num_retries=2, user_agent='wswp', proxies=None):
'''下载一个指定的URL并返回网页内容
参数:
url(str): URL
关键字参数:
user_agent(str):用户代理(默认值:wswp)
proxies(dict): 代理(字典): 键:‘http’'https'
值:字符串(‘http(s)://IP’)
num_retries(int):如果有5xx错误就重试(默认:2)
#5xx服务器错误,表示服务器无法完成明显有效的请求。
#https://zh.wikipedia.org/wiki/ ... %2581
'''
print('==========================================')
print('Downloading:', url)
headers = {'User-Agent': user_agent} #头部设置,默认头部有时候会被网页反扒而出错
try:
resp = requests.get(url, headers=headers, proxies=proxies) #简单粗暴,.get(url)
html = resp.text #获取网页内容,字符串形式
if resp.status_code >= 400: #异常处理,4xx客户端错误 返回None
print('Download error:', resp.text)
html = None
if num_retries and 500 tr#places_area__row > td.w2p_fw' )[0].text_content()
#lxml_xpath
tree.xpath('//tr[@id="places_area__row"]/td[@class="w2p_fw"]' )[0].text_content()
Chrome浏览器可以轻松复制各种表情:
通过上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。
1.不同方式爬取数据1.1 正则表达式爬取网页
正则表达式在python或其他语言中有很好的应用。它使用简单的规定符号来表达不同的字符串组合形式,简洁高效。学习正则表达式很有必要。. Python 内置正则表达式,无需额外安装。
import re
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def re_scraper(html):
results = {}
for target in targets:
results[target] = re.search(r'.*?(.*?)'
% target, html).groups()[0]
return results
1.2BeautifulSoup 抓取数据
BeautifulSoup的使用可以看python网络爬虫——BeautifulSoup爬取网络数据
代码显示如下:
from bs4 import BeautifulSoup
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for target in targets:
results[target] = soup.find('table').find('tr', id='places_%s__row' % target) \
.find('td', class_="w2p_fw").text
return results
1.3 lxml捕获数据
from lxml.html import fromstring
def lxml_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.cssselect('table > tr#places_%s__row > td.w2p_fw' % target)[0].text_content()
return results
def lxml_xpath_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.xpath('//tr[@id="places_%s__row"]/td[@class="w2p_fw"]' % target)[0].text_content()
return results
1.4 运行结果
scrapers = [('re', re_scraper), ('bs',bs_scraper), ('lxml', lxml_scraper), ('lxml_xpath',lxml_xpath_scraper)]
html = download('http://example.webscraping.com ... %2339;)
for name, scraper in scrapers:
print(name,"=================================================================")
result = scraper(html)
print(result)
==========================================
Downloading: http://example.webscraping.com ... ia-14
re =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
bs =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml_xpath =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。
既然有三种不同的爬取方式,那有什么区别呢?申请情况如何?如何选择?
······················································································ 查看全部
爬虫抓取网页数据(7,686,方式抓取网页数据的三种方式(组图))
0.前言0.1 爬网
本文将说明三种爬取网络数据的方法:正则表达式、BeautifulSoup 和 lxml。
用于获取网页内容的代码详情请参考 Python Web Crawler - Your First Crawler(我的短书博客)。使用此代码来抓取整个网页。
import requests
def download(url, num_retries=2, user_agent='wswp', proxies=None):
'''下载一个指定的URL并返回网页内容
参数:
url(str): URL
关键字参数:
user_agent(str):用户代理(默认值:wswp)
proxies(dict): 代理(字典): 键:‘http’'https'
值:字符串(‘http(s)://IP’)
num_retries(int):如果有5xx错误就重试(默认:2)
#5xx服务器错误,表示服务器无法完成明显有效的请求。
#https://zh.wikipedia.org/wiki/ ... %2581
'''
print('==========================================')
print('Downloading:', url)
headers = {'User-Agent': user_agent} #头部设置,默认头部有时候会被网页反扒而出错
try:
resp = requests.get(url, headers=headers, proxies=proxies) #简单粗暴,.get(url)
html = resp.text #获取网页内容,字符串形式
if resp.status_code >= 400: #异常处理,4xx客户端错误 返回None
print('Download error:', resp.text)
html = None
if num_retries and 500 tr#places_area__row > td.w2p_fw' )[0].text_content()
#lxml_xpath
tree.xpath('//tr[@id="places_area__row"]/td[@class="w2p_fw"]' )[0].text_content()
Chrome浏览器可以轻松复制各种表情:
通过上面的下载功能和不同的表达方式,我们可以通过三种不同的方式抓取数据。
1.不同方式爬取数据1.1 正则表达式爬取网页
正则表达式在python或其他语言中有很好的应用。它使用简单的规定符号来表达不同的字符串组合形式,简洁高效。学习正则表达式很有必要。. Python 内置正则表达式,无需额外安装。
import re
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def re_scraper(html):
results = {}
for target in targets:
results[target] = re.search(r'.*?(.*?)'
% target, html).groups()[0]
return results
1.2BeautifulSoup 抓取数据
BeautifulSoup的使用可以看python网络爬虫——BeautifulSoup爬取网络数据
代码显示如下:
from bs4 import BeautifulSoup
targets = ('area', 'population', 'iso', 'country', 'capital', 'continent',
'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format',
'postal_code_regex', 'languages', 'neighbours')
def bs_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for target in targets:
results[target] = soup.find('table').find('tr', id='places_%s__row' % target) \
.find('td', class_="w2p_fw").text
return results
1.3 lxml捕获数据
from lxml.html import fromstring
def lxml_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.cssselect('table > tr#places_%s__row > td.w2p_fw' % target)[0].text_content()
return results
def lxml_xpath_scraper(html):
tree = fromstring(html)
results = {}
for target in targets:
results[target] = tree.xpath('//tr[@id="places_%s__row"]/td[@class="w2p_fw"]' % target)[0].text_content()
return results
1.4 运行结果
scrapers = [('re', re_scraper), ('bs',bs_scraper), ('lxml', lxml_scraper), ('lxml_xpath',lxml_xpath_scraper)]
html = download('http://example.webscraping.com ... %2339;)
for name, scraper in scrapers:
print(name,"=================================================================")
result = scraper(html)
print(result)
==========================================
Downloading: http://example.webscraping.com ... ia-14
re =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
bs =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
lxml_xpath =================================================================
{'area': '7,686,850 square kilometres', 'population': '21,515,754', 'iso': 'AU', 'country': 'Australia', 'capital': 'Canberra', 'continent': 'OC', 'tld': '.au', 'currency_code': 'AUD', 'currency_name': 'Dollar', 'phone': '61', 'postal_code_format': '####', 'postal_code_regex': '^(\\d{4})$', 'languages': 'en-AU', 'neighbours': ' '}
从结果可以看出,正则表达式在某些地方返回了额外的元素,而不是纯文本。这是因为这些地方的网页结构与其他地方不同,所以正则表达式不能完全覆盖相同的内容,例如某些地方的链接和图片。并且 BeautifulSoup 和 lxml 具有提取文本的特殊功能,因此不会出现类似的错误。
既然有三种不同的爬取方式,那有什么区别呢?申请情况如何?如何选择?
······················································································
爬虫抓取网页数据(WebSpiderWebSpider2021/05/23更新演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-14 22:03
网络蜘蛛
2021/05/23 更新
演示爬虫目前部署在heroku上,请酌情测试使用
爬虫模块可以单独调用。有关调用示例,请参见 crawl.test.js。或者 HttpProxy 项目。数据库使用mlab提供的免费远程数据库,速度较慢,请耐心等待。
操作平台:Linux、MacOS ... Windows 未测试
基于NodeJS的在线爬虫系统。支持提供在线数据API。
1、当你想给你的网站添加一个小新闻模块时,可以使用WebSpider爬虫爬取指定网站的数据,然后请求后面的数据接口-end 或 front-end,然后将获取的数据构造到您的网页中。
2、当你想做一个聚合网站或者聚合app时,可以使用WebSpider爬取各大站点的数据,然后调用API将数据构造成自己的APP。
...
于是,WebSpider 诞生了。
内容目录功能
*简单方便。只要对网页有简单的了解,就可以使用WebSpider在线爬虫系统。简单配置后,即可进行数据采集和预览。*强大的。支持抓取预览、自定义输出、生成API、API管理、查看分享、登录注册等功能。*快速响应。爬取结果保存在数据库中,根据用户配置更新响应数据。
原则
为了满足爬虫的通用性(即通过页面配置可以爬取多种网站),原理比较简单,就是下载HTML页面进行分析。分析库使用使用 JQuery 核心库的cheerio。可以通过标签选择器和属性选择器获取数据。这样做的限制是无法捕获 Ajax 异步获取的数据。但是,考虑到当今互联网上的大部分Web应用程序还没有过渡到现代应用程序架构,爬虫仍然具有很大的实用价值。
本地测试
1、安装 Nodejs、MongoDB、Git、Redis
2、确保程序有写文件权限
3、运行代码
git clone https://github.com/LuckyHH/WebSpider.git
cd WebSpider
npm install
4、启动 Redis、MongoDB
5、 修改配置文件(src/config)——自定义启动端口、数据库名、Redis等。
6、运行 npm start 启动项目
7. 开放:3000
项目目录
|---docs 模块说明文档
| |---env.md 环境说明
| |---issues.md 相关问题说明
| |---proxy.md 代理说明
| |---router.md 接口文档
| |---history.md 更新日志
| |---panel.md 前端面板说明
|---log 日志文件(按天新建日志文件)
| |---error 错误日志
| |---running 运行日志
|---src 源代码
| |---config 配置
| |---index.js 配置项出口控制
| |---dev 开发模式配置项
| |---index.js 开发模式配置项出口
| |---crawl.js 爬虫相关配置项
| |---db.js 数据库配置项
| |---proxy.js 代理配置项
| |---session.js 会话配置项
| |---redis.js redis配置项
| |---api.js API请求频率限制配置
| |---prod 生产模式配置项
| |---test 测试模式配置项
| |---crawl 爬虫
| |---index.js 爬虫主控文件
| |---mapReqUrl.js 并发请求
| |---fetchResult 爬虫核心
| |---proxy 代理
| |---index.js 可用代理检测模块
| |---data 数据目录
| |---config.json 爬虫配置文件
| |---model 数据模型
| |---index.js 模型出口
| |---user.js 用户模型
| |---crawl.js 爬虫模型
| |---statistics.js API统计模型
| |---router Web应用路由
| |---utils 路由部分需要的辅助函数
| |---verification.js 用户输入验证
| |---index.js 路由出口
| |---user.js 用户路由
| |---crawl.js 爬虫接口路由
| |---proxy.js 代理检测路由
| |---utils 辅助函数
| |---index.js 辅助函数出口
| |---debug.js 调试模块
| |---filter.js 用户输入过滤模块
| |---sha.js 加密模块
| |---splice.js 多维数组转化为一维数组
| |---time.js 格式化时间
| |---uuid.js 获取ID模块
| |---isNaN.js 判断参数是否能转化为数字
| |---test 测试文件
| |---crawl.test.js 爬虫测试
| |---router.test.js 路由测试
| |---utils.test.js 功能函数测试
| |---index.js 应用出口
|---static 静态资源文件夹
|---app.js 应用入口
核心代码
{superagent.get('').end(function (err, _res) {if (err) {reject(err)}const $=cheerio.load(_res.text)$('.topic_title').each(function (idx, element) {var $element = $(element)items.push({title: $element.attr('title'),url: $element.attr('href'),})})resolve(items )})}) } 否则 {next() }})app.listen(3000)">
const Koa = require('koa')
const superagent = require('superagent')
const cheerio = require('cheerio')
const app = new Koa()
app.use(async function (ctx, next) {
if (ctx.request.path == '/' && ctx.request.method == 'GET') {
ctx.body = await new Promise((resolve, reject) => {
superagent.get('https://cnodejs.org/').end(function (err, _res) {
if (err) {
reject(err)
}
const $ = cheerio.load(_res.text)
$('.topic_title').each(function (idx, element) {
var $element = $(element)
items.push({
title: $element.attr('title'),
url: $element.attr('href'),
})
})
resolve(items)
})
})
} else {
next()
}
})
app.listen(3000)
使用 1. 抓取深度
爬取深度是指从初始 URL 到数据所在 URL 的层数。最大支持爬行深度为3,推荐最大爬行深度为2
2.网页代码
登陆页面的编码格式,默认为UTF-8
3.抓取模式
普通模式和分页模式
4.页面范围
在分页模式下,要获取的开始和结束页码
5.目标网址
目标URL是要爬取的目标网站的URL。
普通模式下,只需要填写要爬取的URL即可。
在分页模式下:
填写网址时,将网址中的页码改为*。
例如:
CNode 的分页 URL
改成
*
6.选择器
选择器用于指示数据的位置,可以通过“输出格式”获取目标数据。填写需要用户具备基本的前端知识。
这里,为了描述方便,将标签选择器分为两种,一种是标签选择器,一种是数据标签选择器。(当然如果你要的数据在一个标签中,那么a标签选择器就是数据标签选择器)
当爬取深度为1时,可以在一级选择器中填充数据选择器。当爬取深度为2时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充数据标签选择器。当爬取深度为3时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充到达三级页面的a标签选择器,第三级选择器填充到达二级页面的a标签选择器-level 选择器填充数据选择器就是这样。
填写示例:
深度 2
一级选择器:$(".topic_title a")
辅助选择器:$(".topic .content")
$(".topic_title a") 指目标页面中类名为topic_title的所有元素中的a元素
$(".topic .content") 指目标页面中类名topic的元素下类名content的后代元素
填写二级选择器,表示目标数据在当前页面的下一层(即配置页面的“目标URL”填写的URL),那么一级选择器需要指示到达页面下一层的标签选择器。次要选择器用下一页的数据标签选择器填充
更多选择器填充规则,参考cheerio。
7.输出格式
输出格式是指输出哪些结果。
在标签选择器指出数据的位置后,需要进一步使用标签选择器和属性选择器来获取数据。
这需要以 JSON 格式编写。参考写作如下:
{
"name": "$element.find('.c-9 .ml-20 a').text()",
"age": "$element.children('.c-9').next().text()"
}
关键部分可以任意指定,值部分需要一定的规则。
$element 指的是“选择器”中填写的数据标签选择器。(结合"selector"给出的例子,$element指的是$(".topic .content"))
带键名的值是指被“选择器”过滤的元素下的类名为c-9的元素下的类名ml-20下的a元素中的文本
键为age的值是指“选择器”过滤的元素下类名为c-9的元素旁边的元素的文本内容
值得注意的是,当你只需要一种类型的数据时,可以在“Selector”中填写标签选择器时直接将标签定位到目标元素,在“Output Format”中填写属性选择器那就是灿。
但是很多时候我们需要的数据不止一种,所以在填写“选择器”部分的时候,需要填写的数据标签选择器应该把所有需要的数据都包裹起来,所以你甚至可以填写$("body")比如数据选择器。在“输出格式”的值部分,需要填写一些选择器来表示数据的详细位置,最后使用属性选择器来获取数据。
同样结合上面给出的例子,
如果我想获取“名称”值之类的数据,
那么“选择器”可以这样写
一级选择器:$(".topic_title a")
次要选择器:$(".topic .content .c-9 .ml-20 a")
'输出格式'可以这样写
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic").find('.content .c-9 .ml-20 a')
'输出格式':
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic")
'输出格式':
{
"name": "$element.find('.content .c-9 .ml-20 a').text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
辅助选择器:$("body")
'输出格式':
{
"name": "$element.find('.topic .content .c-9 .ml-20 a').text()"
}
常用的属性选择器有 3 种:text()、html() 和 attr()。
text() 选择目标元素中的文本内容
html() 选择目标元素的 HTML 代码
attr() 在目标元素标签中选择一个属性值。参数需要填写,例如$element.attr('url')是指获取目标元素标签中的url属性值
8.代理模式
即是否使用HTTP代理来获取数据。有3种模式,内置代理,无代理和自定义代理。
内置代理使用 thorn 代理或 FreeProxyList 提供的代理地址发出请求。
自定义代理模式需要用户自己填写可用的代理。
无代理使用部署服务器 IP 进行请求
笔记:
(1)如果自定义代理地址与普通IP地址不匹配,系统默认使用无代理模式。
(2)代理的质量参差不齐,所以响应可能会失败。所以当响应失败时,请重新提交。
9.结果预览
返回结果
state 表示抓取状态,值为真或假
时间值是数据的更新时间。
数据值为抓取结果,格式为数组。
味精备注
10.生成API
数据接口仅在用户登录时生成。点击“生成API”按钮,后台会记录当前爬虫配置,当请求API时,会在适当的情况下调用爬虫进行响应。
11.更新间隔(后台管理配置项)
如果两次API调用的间隔在“更新间隔”周期内,则直接调用数据库数据响应,否则调用爬虫响应。所有初始生成的 API 的默认更新间隔为 0,即不更新数据,直接从数据库中读取数据。
请注意,此项已根据您的需要正确配置。如果“Update Interval”配置值较大或为0,则API平均响应速度快,但时效性较差;配置值小,API平均响应速度慢,但时效性好。
注意:点击“Generate API”后,在API“Edit”操作中调整“Update Interval”之前,一定要到“Admin Panel”点击一次生成的API链接,完成抓取数据的初始化. 否则,调用 API 返回的结果始终为空。补救措施:当发现返回结果为空时,可以再次进行API“编辑”操作,将“更新间隔”调整为0,点击API链接初始化一次数据,调整“更新间隔”初始化成功后。
12.标签(后台管理配置项)
为了方便用户查找某类API,添加标签功能
13.开启权限(后台管理配置项)
控制 API 是否共享。API权限开启后,可以在“API Store”面板中看到API信息
14.描述信息(后台管理配置项)
API 描述信息。
数据接口调用示例
Node.js 后端
{if (_res.data.state) {res.render('douban', { title: 'douban', content: _res.data.data })} else {res.send('Request failed')}})。catch((err) => {console.error(err)})})">
const express = require('express')
const axios = require('axios')
const router = express.Router()
router.get('/douban/movie', function (req, res, next) {
axios
.get('http://splider.docmobile.cn/interface?name=luckyhh&cid=1529046160624')
.then((_res) => {
if (_res.data.state) {
res.render('douban', { title: 'douban', content: _res.data.data })
} else {
res.send('请求失败')
}
})
.catch((err) => {
console.error(err)
})
})
注意:程序后台限制了API调用的频率。为方便起见,示例直接将 API 链接请求结果构造到模板中。实际调用时,请将请求结果保存到redis或数据库中,否则数据响应会失败。
示例配置参考
*WebSpider 参考配置
变更日志
WebSpider 更新日志
注意
https://spider.docmobile.cn/
对于预览地址,不建议在实际项目中使用。由此造成的损失由用户承担
TODO协议
麻省理工学院 查看全部
爬虫抓取网页数据(WebSpiderWebSpider2021/05/23更新演示)
网络蜘蛛
2021/05/23 更新
演示爬虫目前部署在heroku上,请酌情测试使用
爬虫模块可以单独调用。有关调用示例,请参见 crawl.test.js。或者 HttpProxy 项目。数据库使用mlab提供的免费远程数据库,速度较慢,请耐心等待。
操作平台:Linux、MacOS ... Windows 未测试
基于NodeJS的在线爬虫系统。支持提供在线数据API。
1、当你想给你的网站添加一个小新闻模块时,可以使用WebSpider爬虫爬取指定网站的数据,然后请求后面的数据接口-end 或 front-end,然后将获取的数据构造到您的网页中。
2、当你想做一个聚合网站或者聚合app时,可以使用WebSpider爬取各大站点的数据,然后调用API将数据构造成自己的APP。
...
于是,WebSpider 诞生了。
内容目录功能
*简单方便。只要对网页有简单的了解,就可以使用WebSpider在线爬虫系统。简单配置后,即可进行数据采集和预览。*强大的。支持抓取预览、自定义输出、生成API、API管理、查看分享、登录注册等功能。*快速响应。爬取结果保存在数据库中,根据用户配置更新响应数据。
原则
为了满足爬虫的通用性(即通过页面配置可以爬取多种网站),原理比较简单,就是下载HTML页面进行分析。分析库使用使用 JQuery 核心库的cheerio。可以通过标签选择器和属性选择器获取数据。这样做的限制是无法捕获 Ajax 异步获取的数据。但是,考虑到当今互联网上的大部分Web应用程序还没有过渡到现代应用程序架构,爬虫仍然具有很大的实用价值。
本地测试
1、安装 Nodejs、MongoDB、Git、Redis
2、确保程序有写文件权限
3、运行代码
git clone https://github.com/LuckyHH/WebSpider.git
cd WebSpider
npm install
4、启动 Redis、MongoDB
5、 修改配置文件(src/config)——自定义启动端口、数据库名、Redis等。
6、运行 npm start 启动项目
7. 开放:3000
项目目录
|---docs 模块说明文档
| |---env.md 环境说明
| |---issues.md 相关问题说明
| |---proxy.md 代理说明
| |---router.md 接口文档
| |---history.md 更新日志
| |---panel.md 前端面板说明
|---log 日志文件(按天新建日志文件)
| |---error 错误日志
| |---running 运行日志
|---src 源代码
| |---config 配置
| |---index.js 配置项出口控制
| |---dev 开发模式配置项
| |---index.js 开发模式配置项出口
| |---crawl.js 爬虫相关配置项
| |---db.js 数据库配置项
| |---proxy.js 代理配置项
| |---session.js 会话配置项
| |---redis.js redis配置项
| |---api.js API请求频率限制配置
| |---prod 生产模式配置项
| |---test 测试模式配置项
| |---crawl 爬虫
| |---index.js 爬虫主控文件
| |---mapReqUrl.js 并发请求
| |---fetchResult 爬虫核心
| |---proxy 代理
| |---index.js 可用代理检测模块
| |---data 数据目录
| |---config.json 爬虫配置文件
| |---model 数据模型
| |---index.js 模型出口
| |---user.js 用户模型
| |---crawl.js 爬虫模型
| |---statistics.js API统计模型
| |---router Web应用路由
| |---utils 路由部分需要的辅助函数
| |---verification.js 用户输入验证
| |---index.js 路由出口
| |---user.js 用户路由
| |---crawl.js 爬虫接口路由
| |---proxy.js 代理检测路由
| |---utils 辅助函数
| |---index.js 辅助函数出口
| |---debug.js 调试模块
| |---filter.js 用户输入过滤模块
| |---sha.js 加密模块
| |---splice.js 多维数组转化为一维数组
| |---time.js 格式化时间
| |---uuid.js 获取ID模块
| |---isNaN.js 判断参数是否能转化为数字
| |---test 测试文件
| |---crawl.test.js 爬虫测试
| |---router.test.js 路由测试
| |---utils.test.js 功能函数测试
| |---index.js 应用出口
|---static 静态资源文件夹
|---app.js 应用入口
核心代码
{superagent.get('').end(function (err, _res) {if (err) {reject(err)}const $=cheerio.load(_res.text)$('.topic_title').each(function (idx, element) {var $element = $(element)items.push({title: $element.attr('title'),url: $element.attr('href'),})})resolve(items )})}) } 否则 {next() }})app.listen(3000)">
const Koa = require('koa')
const superagent = require('superagent')
const cheerio = require('cheerio')
const app = new Koa()
app.use(async function (ctx, next) {
if (ctx.request.path == '/' && ctx.request.method == 'GET') {
ctx.body = await new Promise((resolve, reject) => {
superagent.get('https://cnodejs.org/').end(function (err, _res) {
if (err) {
reject(err)
}
const $ = cheerio.load(_res.text)
$('.topic_title').each(function (idx, element) {
var $element = $(element)
items.push({
title: $element.attr('title'),
url: $element.attr('href'),
})
})
resolve(items)
})
})
} else {
next()
}
})
app.listen(3000)
使用 1. 抓取深度
爬取深度是指从初始 URL 到数据所在 URL 的层数。最大支持爬行深度为3,推荐最大爬行深度为2
2.网页代码
登陆页面的编码格式,默认为UTF-8
3.抓取模式
普通模式和分页模式
4.页面范围
在分页模式下,要获取的开始和结束页码
5.目标网址
目标URL是要爬取的目标网站的URL。
普通模式下,只需要填写要爬取的URL即可。
在分页模式下:
填写网址时,将网址中的页码改为*。
例如:
CNode 的分页 URL
改成
*
6.选择器
选择器用于指示数据的位置,可以通过“输出格式”获取目标数据。填写需要用户具备基本的前端知识。
这里,为了描述方便,将标签选择器分为两种,一种是标签选择器,一种是数据标签选择器。(当然如果你要的数据在一个标签中,那么a标签选择器就是数据标签选择器)
当爬取深度为1时,可以在一级选择器中填充数据选择器。当爬取深度为2时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充数据标签选择器。当爬取深度为3时,一级选择器填充到达二级页面的a标签选择器,二级选择器填充到达三级页面的a标签选择器,第三级选择器填充到达二级页面的a标签选择器-level 选择器填充数据选择器就是这样。
填写示例:
深度 2
一级选择器:$(".topic_title a")
辅助选择器:$(".topic .content")
$(".topic_title a") 指目标页面中类名为topic_title的所有元素中的a元素
$(".topic .content") 指目标页面中类名topic的元素下类名content的后代元素
填写二级选择器,表示目标数据在当前页面的下一层(即配置页面的“目标URL”填写的URL),那么一级选择器需要指示到达页面下一层的标签选择器。次要选择器用下一页的数据标签选择器填充
更多选择器填充规则,参考cheerio。
7.输出格式
输出格式是指输出哪些结果。
在标签选择器指出数据的位置后,需要进一步使用标签选择器和属性选择器来获取数据。
这需要以 JSON 格式编写。参考写作如下:
{
"name": "$element.find('.c-9 .ml-20 a').text()",
"age": "$element.children('.c-9').next().text()"
}
关键部分可以任意指定,值部分需要一定的规则。
$element 指的是“选择器”中填写的数据标签选择器。(结合"selector"给出的例子,$element指的是$(".topic .content"))
带键名的值是指被“选择器”过滤的元素下的类名为c-9的元素下的类名ml-20下的a元素中的文本
键为age的值是指“选择器”过滤的元素下类名为c-9的元素旁边的元素的文本内容
值得注意的是,当你只需要一种类型的数据时,可以在“Selector”中填写标签选择器时直接将标签定位到目标元素,在“Output Format”中填写属性选择器那就是灿。
但是很多时候我们需要的数据不止一种,所以在填写“选择器”部分的时候,需要填写的数据标签选择器应该把所有需要的数据都包裹起来,所以你甚至可以填写$("body")比如数据选择器。在“输出格式”的值部分,需要填写一些选择器来表示数据的详细位置,最后使用属性选择器来获取数据。
同样结合上面给出的例子,
如果我想获取“名称”值之类的数据,
那么“选择器”可以这样写
一级选择器:$(".topic_title a")
次要选择器:$(".topic .content .c-9 .ml-20 a")
'输出格式'可以这样写
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic").find('.content .c-9 .ml-20 a')
'输出格式':
{
"name": "$element.text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
次要选择器:$(".topic")
'输出格式':
{
"name": "$element.find('.content .c-9 .ml-20 a').text()"
}
或者
“选择器”:
一级选择器:$(".topic_title a")
辅助选择器:$("body")
'输出格式':
{
"name": "$element.find('.topic .content .c-9 .ml-20 a').text()"
}
常用的属性选择器有 3 种:text()、html() 和 attr()。
text() 选择目标元素中的文本内容
html() 选择目标元素的 HTML 代码
attr() 在目标元素标签中选择一个属性值。参数需要填写,例如$element.attr('url')是指获取目标元素标签中的url属性值
8.代理模式
即是否使用HTTP代理来获取数据。有3种模式,内置代理,无代理和自定义代理。
内置代理使用 thorn 代理或 FreeProxyList 提供的代理地址发出请求。
自定义代理模式需要用户自己填写可用的代理。
无代理使用部署服务器 IP 进行请求
笔记:
(1)如果自定义代理地址与普通IP地址不匹配,系统默认使用无代理模式。
(2)代理的质量参差不齐,所以响应可能会失败。所以当响应失败时,请重新提交。
9.结果预览
返回结果
state 表示抓取状态,值为真或假
时间值是数据的更新时间。
数据值为抓取结果,格式为数组。
味精备注
10.生成API
数据接口仅在用户登录时生成。点击“生成API”按钮,后台会记录当前爬虫配置,当请求API时,会在适当的情况下调用爬虫进行响应。
11.更新间隔(后台管理配置项)
如果两次API调用的间隔在“更新间隔”周期内,则直接调用数据库数据响应,否则调用爬虫响应。所有初始生成的 API 的默认更新间隔为 0,即不更新数据,直接从数据库中读取数据。
请注意,此项已根据您的需要正确配置。如果“Update Interval”配置值较大或为0,则API平均响应速度快,但时效性较差;配置值小,API平均响应速度慢,但时效性好。
注意:点击“Generate API”后,在API“Edit”操作中调整“Update Interval”之前,一定要到“Admin Panel”点击一次生成的API链接,完成抓取数据的初始化. 否则,调用 API 返回的结果始终为空。补救措施:当发现返回结果为空时,可以再次进行API“编辑”操作,将“更新间隔”调整为0,点击API链接初始化一次数据,调整“更新间隔”初始化成功后。
12.标签(后台管理配置项)
为了方便用户查找某类API,添加标签功能
13.开启权限(后台管理配置项)
控制 API 是否共享。API权限开启后,可以在“API Store”面板中看到API信息
14.描述信息(后台管理配置项)
API 描述信息。
数据接口调用示例
Node.js 后端
{if (_res.data.state) {res.render('douban', { title: 'douban', content: _res.data.data })} else {res.send('Request failed')}})。catch((err) => {console.error(err)})})">
const express = require('express')
const axios = require('axios')
const router = express.Router()
router.get('/douban/movie', function (req, res, next) {
axios
.get('http://splider.docmobile.cn/interface?name=luckyhh&cid=1529046160624')
.then((_res) => {
if (_res.data.state) {
res.render('douban', { title: 'douban', content: _res.data.data })
} else {
res.send('请求失败')
}
})
.catch((err) => {
console.error(err)
})
})
注意:程序后台限制了API调用的频率。为方便起见,示例直接将 API 链接请求结果构造到模板中。实际调用时,请将请求结果保存到redis或数据库中,否则数据响应会失败。
示例配置参考
*WebSpider 参考配置
变更日志
WebSpider 更新日志
注意
https://spider.docmobile.cn/
对于预览地址,不建议在实际项目中使用。由此造成的损失由用户承担
TODO协议
麻省理工学院
爬虫抓取网页数据(webscraper默认就是无序抓取数据的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-14 19:11
网络爬虫抓取网页数据的几个常见问题
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。 查看全部
爬虫抓取网页数据(webscraper默认就是无序抓取数据的问题)
网络爬虫抓取网页数据的几个常见问题
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或滚动加载数据,无法完全捕获,如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
爬虫抓取网页数据(如何使用Scrapy通过Selector选择器从网页中提取出我们想要的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-14 19:10
本节内容
在这个总结中,我将介绍如何使用 Scrapy 通过 Selector 选择器从网页中提取我们想要的内容,并将内容存储到本地文件中。
我们的登陆页面是一个有七层楼的帖子。我们希望获得每个楼层的以下信息:
选择器选择器
在 Scrapy 中,BeautifulSoup 也可以用来解析网页,但是我们推荐使用 Scrapy 自带的 Selector 选择器来解析网页,没有别的原因,效率很高。Selector 选择器有两种选择方法,XPath 方法和 css 方法。我使用 XPath 方法。
XPath
XPath 是一种用于在 XML 文档中查找信息的语言。因为网上教程很多,这里推荐两个,我自己就不多说了。一个是菜鸟教程的XPath文字教程,另一个是极客学院的XPath视频教程。后者需要实名认证才能观看,不麻烦。我个人更喜欢后者,老师的解释很容易理解。相信我,按照教程看懂XPath只需要半个小时,再根据我下面的代码对比巩固一下,你就可以掌握了。
使用 Chrome 分析网页
我们使用Chrome浏览器(firefox类似)来分析网页,分析我们的XPath应该怎么写。例如,我们现在要分析帖子的标题
右键单击帖子标题并选择检查
此时Chrome的调试工具会跳出来,自动定位到源码中我们要检查的元素
然后根据代码结构,我们可以很容易的得到它的XPath
//*[@id="thread_subject"]/text()
其实有时候可以直接右键元素,选择copy xpath,但是这种方法在实践中基本没用,因为很难找到多个网页的共同特征,所以总的来说还是要分析一下我们自己。
这里需要提醒一个神坑,下面的代码也有体现。具体可以参考我之前写的这篇文章Scrapy匹配xpath时tbody标签的问题。
这个坑的启示是,当你发现一个你觉得无法科学解释的错误时,检查你得到的源代码!
代码
废话不多说,直接上代码。
首先,修改 items.py 文件以定义我们要提取的内容
# -*- coding: utf-8 -*-
import scrapy
class HeartsongItem(scrapy.Item):
title = scrapy.Field() # 帖子的标题
url = scrapy.Field() # 帖子的网页链接
author = scrapy.Field() # 帖子的作者
post_time = scrapy.Field() # 发表时间
content = scrapy.Field() # 帖子的内容
然后来到heartsong_spider.py,写爬虫
# -*- coding: utf-8 -*-
# import scrapy # 可以写这句注释下面两句,不过下面要更好
from scrapy.spiders import Spider
from scrapy.selector import Selector
from heartsong.items import HeartsongItem # 此处如果报错是pyCharm的原因
class HeartsongSpider(Spider):
name = "heartsong"
allowed_domains = ["heartsong.top"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
"http://www.heartsong.top/forum ... ot%3B # 起始url,此例只爬这个页面
]
def parse(self, response):
selector = Selector(response) # 创建选择器
table = selector.xpath('//*[starts-with(@id, "pid")]') # 取出所有的楼层
for each in table: # 对于每一个楼层执行下列操作
item = HeartsongItem() # 实例化一个Item对象
item['title'] = selector.xpath('//*[@id="thread_subject"]/text()').extract()[0]
item['author'] = \
each.xpath('tr[1]/td[@class="pls"]/div[@class="pls favatar"]/div[@class="pi"]/div[@class="authi"]/a/text()').extract()[0]
item['post_time'] = \
each.xpath('tr[1]/td[@class="plc"]/div[@class="pi"]').re(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+')[0].decode("unicode_escape")
content_list = each.xpath('.//td[@class="t_f"]').xpath('string(.)').extract()
content = "".join(content_list) # 将list转化为string
item['url'] = response.url # 用这种方式获取网页的url
# 把内容中的换行符,空格等去掉
item['content'] = content.replace('\r\n', '').replace(' ', '').replace('\n', '')
yield item # 将创建并赋值好的Item对象传递到PipeLine当中进行处理
最后,将爬取的数据保存在 pipelines.py 中:
# -*- coding: utf-8 -*-
import heartsong.settings
class HeartsongPipeline(object):
def process_item(self, item, spider):
file = open("items.txt", "a") # 以追加的方式打开文件,不存在则创建
# 因为item中的数据是unicode编码的,为了在控制台中查看数据的有效性和保存,
# 将其编码改为utf-8
item_string = str(item).decode("unicode_escape").encode('utf-8')
file.write(item_string)
file.write('\n')
file.close()
print item_string #在控制台输出
return item # 会在控制台输出原item数据,可以选择不写
跑
还是进入项目目录,在终端输入
scrapy crawl heartsong
看看输出信息,没问题。
看看生成的本地文件,也ok。
概括
这一部分介绍页面解析的方法,下一部分将介绍Scrapy爬取多个网页,这也是让我们的爬虫真正爬取的一部分。结合这两个部分,您将能够爬下我论坛上的所有帖子。 查看全部
爬虫抓取网页数据(如何使用Scrapy通过Selector选择器从网页中提取出我们想要的内容)
本节内容
在这个总结中,我将介绍如何使用 Scrapy 通过 Selector 选择器从网页中提取我们想要的内容,并将内容存储到本地文件中。
我们的登陆页面是一个有七层楼的帖子。我们希望获得每个楼层的以下信息:
选择器选择器
在 Scrapy 中,BeautifulSoup 也可以用来解析网页,但是我们推荐使用 Scrapy 自带的 Selector 选择器来解析网页,没有别的原因,效率很高。Selector 选择器有两种选择方法,XPath 方法和 css 方法。我使用 XPath 方法。
XPath
XPath 是一种用于在 XML 文档中查找信息的语言。因为网上教程很多,这里推荐两个,我自己就不多说了。一个是菜鸟教程的XPath文字教程,另一个是极客学院的XPath视频教程。后者需要实名认证才能观看,不麻烦。我个人更喜欢后者,老师的解释很容易理解。相信我,按照教程看懂XPath只需要半个小时,再根据我下面的代码对比巩固一下,你就可以掌握了。
使用 Chrome 分析网页
我们使用Chrome浏览器(firefox类似)来分析网页,分析我们的XPath应该怎么写。例如,我们现在要分析帖子的标题
右键单击帖子标题并选择检查
此时Chrome的调试工具会跳出来,自动定位到源码中我们要检查的元素
然后根据代码结构,我们可以很容易的得到它的XPath
//*[@id="thread_subject"]/text()
其实有时候可以直接右键元素,选择copy xpath,但是这种方法在实践中基本没用,因为很难找到多个网页的共同特征,所以总的来说还是要分析一下我们自己。
这里需要提醒一个神坑,下面的代码也有体现。具体可以参考我之前写的这篇文章Scrapy匹配xpath时tbody标签的问题。
这个坑的启示是,当你发现一个你觉得无法科学解释的错误时,检查你得到的源代码!
代码
废话不多说,直接上代码。
首先,修改 items.py 文件以定义我们要提取的内容
# -*- coding: utf-8 -*-
import scrapy
class HeartsongItem(scrapy.Item):
title = scrapy.Field() # 帖子的标题
url = scrapy.Field() # 帖子的网页链接
author = scrapy.Field() # 帖子的作者
post_time = scrapy.Field() # 发表时间
content = scrapy.Field() # 帖子的内容
然后来到heartsong_spider.py,写爬虫
# -*- coding: utf-8 -*-
# import scrapy # 可以写这句注释下面两句,不过下面要更好
from scrapy.spiders import Spider
from scrapy.selector import Selector
from heartsong.items import HeartsongItem # 此处如果报错是pyCharm的原因
class HeartsongSpider(Spider):
name = "heartsong"
allowed_domains = ["heartsong.top"] # 允许爬取的域名,非此域名的网页不会爬取
start_urls = [
"http://www.heartsong.top/forum ... ot%3B # 起始url,此例只爬这个页面
]
def parse(self, response):
selector = Selector(response) # 创建选择器
table = selector.xpath('//*[starts-with(@id, "pid")]') # 取出所有的楼层
for each in table: # 对于每一个楼层执行下列操作
item = HeartsongItem() # 实例化一个Item对象
item['title'] = selector.xpath('//*[@id="thread_subject"]/text()').extract()[0]
item['author'] = \
each.xpath('tr[1]/td[@class="pls"]/div[@class="pls favatar"]/div[@class="pi"]/div[@class="authi"]/a/text()').extract()[0]
item['post_time'] = \
each.xpath('tr[1]/td[@class="plc"]/div[@class="pi"]').re(r'[0-9]+-[0-9]+-[0-9]+ [0-9]+:[0-9]+:[0-9]+')[0].decode("unicode_escape")
content_list = each.xpath('.//td[@class="t_f"]').xpath('string(.)').extract()
content = "".join(content_list) # 将list转化为string
item['url'] = response.url # 用这种方式获取网页的url
# 把内容中的换行符,空格等去掉
item['content'] = content.replace('\r\n', '').replace(' ', '').replace('\n', '')
yield item # 将创建并赋值好的Item对象传递到PipeLine当中进行处理
最后,将爬取的数据保存在 pipelines.py 中:
# -*- coding: utf-8 -*-
import heartsong.settings
class HeartsongPipeline(object):
def process_item(self, item, spider):
file = open("items.txt", "a") # 以追加的方式打开文件,不存在则创建
# 因为item中的数据是unicode编码的,为了在控制台中查看数据的有效性和保存,
# 将其编码改为utf-8
item_string = str(item).decode("unicode_escape").encode('utf-8')
file.write(item_string)
file.write('\n')
file.close()
print item_string #在控制台输出
return item # 会在控制台输出原item数据,可以选择不写
跑
还是进入项目目录,在终端输入
scrapy crawl heartsong
看看输出信息,没问题。
看看生成的本地文件,也ok。
概括
这一部分介绍页面解析的方法,下一部分将介绍Scrapy爬取多个网页,这也是让我们的爬虫真正爬取的一部分。结合这两个部分,您将能够爬下我论坛上的所有帖子。

