
抓取网页新闻
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-29 00:02
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(Android客户端如何实现从各大网抓取新闻并解析网页的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-29 00:01
)
如何从主要网站捕获新闻并将其格式化到我们的新闻客户端?
Android 客户端抓取和解析网页的方法有两种:
一、使用jsoup
没仔细研究,网上也有类似的,可以参考这两兄弟:
二、使用htmlparser
我的项目中使用了htmlparser,抓取并解析腾讯新闻,代码如下:
<p>Java代码 收藏代码
public class NetUtil {
public static List DATALIST = new ArrayList();
public static String[][] CHANNEL_URL = new String[][] {
new String[]{"http://news.qq.com/world_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/society_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
};
public static int getTechNews(List techData, int cId) {
int result = 0;
try {
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
try {
String textstr = node.getChildren().elementAt(j).toHtml();
if (textstr.trim().length() > 0) {
NodeFilter subFilter = new TagNameFilter("p");
Parser subParser = new Parser();
subParser.setResource(textstr);
NodeList subList = subParser.extractAllNodesThatMatch(subFilter);
NodeFilter titleStrFilter = new AndFilter(new TagNameFilter("a"),
new HasAttributeFilter("class", "linkto"));
Parser titleStrParser = new Parser();
titleStrParser.setResource(textstr);
NodeList titleStrList = titleStrParser.extractAllNodesThatMatch(titleStrFilter);
int linkstart = titleStrList.toHtml().indexOf("href=\"");
int linkend = titleStrList.toHtml().indexOf("\">");
int titleend = titleStrList.toHtml().indexOf("</a>");
String link = CHANNEL_URL[cId][1]+titleStrList.toHtml().substring(linkstart+6, linkend);
String title = titleStrList.toHtml().substring(linkend+2, titleend);
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
newsBrief.setSummary(subList.asString());
techData.add(newsBrief);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int getTechNews2(List techData, int cId) {
int result = 0;
try {
// 查询http://tech.qq.com/tech_yejie.htm 页面 滚动新闻的 标签 以及ID
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
// 获取匹配的fileter的节点
NodeList list = parser.extractAllNodesThatMatch(filter);
StringBuilder NewsStr = new StringBuilder("");// 新闻表格字符串
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
String textstr = node.getChildren().elementAt(j).toHtml()
.trim();
if (textstr.length() > 0) {
int linkbegin = 0, linkend = 0, titlebegin = 0, titleend = 0;
while (true) {
linkbegin = textstr.indexOf("href=", titleend);// 截取链接字符串起始位置
// 如果不存在 href了 也就结束了
if (linkbegin < 0)
break;
linkend = textstr.indexOf("\">", linkbegin);// 截取链接字符串结束位置
String sublink = textstr.substring(linkbegin + 6,linkend);
String link = CHANNEL_URL[cId][1] + sublink;
titlebegin = textstr.indexOf("\">", linkend);
titleend = textstr.indexOf("</a>", titlebegin);
String title = textstr.substring(titlebegin + 2,titleend);
NewsStr.append("\r\n\r\n\t<a target=\"_blank\" href=\""/span
+ link + span class="hljs-string""\">");
NewsStr.append(title);
NewsStr.append("</a>");
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
techData.add(newsBrief);
}
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int parserURL(String url,NewsBrief newsBrief) {
int result = 0;
try {
Parser parser = new Parser(url);
NodeFilter contentFilter = new AndFilter(
new TagNameFilter("div"),
new HasAttributeFilter("id","Cnt-Main-Article-QQ"));
NodeFilter newsdateFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"article-time"));
NodeFilter newsauthorFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"color-a-1"));
NodeFilter imgUrlFilter = new TagNameFilter("IMG");
newsBrief.setContent(parserContent(contentFilter,parser));
parser.reset(); // 记得每次用完parser后,要重置一次parser。要不然就得不到我们想要的内容了。
newsBrief.setPubDate(parserDate(newsdateFilter,parser));
parser.reset();
newsBrief.setSource(parserAuthor(newsauthorFilter, parser));
parser.reset();
newsBrief.setImgUrl(parserImgUrl(contentFilter,imgUrlFilter, parser));
} catch (Exception e) {
result=1;
e.printStackTrace();
}
return result;
}
private static String parserContent(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList contentList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = contentList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserDate(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList datetList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = datetList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserAuthor(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList authorList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = authorList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static List parserImgUrl(NodeFilter bodyfilter,NodeFilter filter, Parser parser) {
List reslut = new ArrayList();
try {
NodeList bodyList = (NodeList) parser.parse(bodyfilter);
Parser imgParser = new Parser();
imgParser.setResource(bodyList.toHtml());
NodeList imgList = imgParser.extractAllNodesThatMatch(filter);
String bodyString = imgList.toHtml();
//正文包含图片
if (bodyString.contains(" 查看全部
抓取网页新闻(Android客户端如何实现从各大网抓取新闻并解析网页的方法
)
如何从主要网站捕获新闻并将其格式化到我们的新闻客户端?
Android 客户端抓取和解析网页的方法有两种:
一、使用jsoup
没仔细研究,网上也有类似的,可以参考这两兄弟:
二、使用htmlparser
我的项目中使用了htmlparser,抓取并解析腾讯新闻,代码如下:
<p>Java代码 收藏代码
public class NetUtil {
public static List DATALIST = new ArrayList();
public static String[][] CHANNEL_URL = new String[][] {
new String[]{"http://news.qq.com/world_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/society_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
};
public static int getTechNews(List techData, int cId) {
int result = 0;
try {
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
try {
String textstr = node.getChildren().elementAt(j).toHtml();
if (textstr.trim().length() > 0) {
NodeFilter subFilter = new TagNameFilter("p");
Parser subParser = new Parser();
subParser.setResource(textstr);
NodeList subList = subParser.extractAllNodesThatMatch(subFilter);
NodeFilter titleStrFilter = new AndFilter(new TagNameFilter("a"),
new HasAttributeFilter("class", "linkto"));
Parser titleStrParser = new Parser();
titleStrParser.setResource(textstr);
NodeList titleStrList = titleStrParser.extractAllNodesThatMatch(titleStrFilter);
int linkstart = titleStrList.toHtml().indexOf("href=\"");
int linkend = titleStrList.toHtml().indexOf("\">");
int titleend = titleStrList.toHtml().indexOf("</a>");
String link = CHANNEL_URL[cId][1]+titleStrList.toHtml().substring(linkstart+6, linkend);
String title = titleStrList.toHtml().substring(linkend+2, titleend);
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
newsBrief.setSummary(subList.asString());
techData.add(newsBrief);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int getTechNews2(List techData, int cId) {
int result = 0;
try {
// 查询http://tech.qq.com/tech_yejie.htm 页面 滚动新闻的 标签 以及ID
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
// 获取匹配的fileter的节点
NodeList list = parser.extractAllNodesThatMatch(filter);
StringBuilder NewsStr = new StringBuilder("");// 新闻表格字符串
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
String textstr = node.getChildren().elementAt(j).toHtml()
.trim();
if (textstr.length() > 0) {
int linkbegin = 0, linkend = 0, titlebegin = 0, titleend = 0;
while (true) {
linkbegin = textstr.indexOf("href=", titleend);// 截取链接字符串起始位置
// 如果不存在 href了 也就结束了
if (linkbegin < 0)
break;
linkend = textstr.indexOf("\">", linkbegin);// 截取链接字符串结束位置
String sublink = textstr.substring(linkbegin + 6,linkend);
String link = CHANNEL_URL[cId][1] + sublink;
titlebegin = textstr.indexOf("\">", linkend);
titleend = textstr.indexOf("</a>", titlebegin);
String title = textstr.substring(titlebegin + 2,titleend);
NewsStr.append("\r\n\r\n\t<a target=\"_blank\" href=\""/span
+ link + span class="hljs-string""\">");
NewsStr.append(title);
NewsStr.append("</a>");
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
techData.add(newsBrief);
}
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int parserURL(String url,NewsBrief newsBrief) {
int result = 0;
try {
Parser parser = new Parser(url);
NodeFilter contentFilter = new AndFilter(
new TagNameFilter("div"),
new HasAttributeFilter("id","Cnt-Main-Article-QQ"));
NodeFilter newsdateFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"article-time"));
NodeFilter newsauthorFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"color-a-1"));
NodeFilter imgUrlFilter = new TagNameFilter("IMG");
newsBrief.setContent(parserContent(contentFilter,parser));
parser.reset(); // 记得每次用完parser后,要重置一次parser。要不然就得不到我们想要的内容了。
newsBrief.setPubDate(parserDate(newsdateFilter,parser));
parser.reset();
newsBrief.setSource(parserAuthor(newsauthorFilter, parser));
parser.reset();
newsBrief.setImgUrl(parserImgUrl(contentFilter,imgUrlFilter, parser));
} catch (Exception e) {
result=1;
e.printStackTrace();
}
return result;
}
private static String parserContent(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList contentList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = contentList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserDate(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList datetList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = datetList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserAuthor(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList authorList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = authorList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static List parserImgUrl(NodeFilter bodyfilter,NodeFilter filter, Parser parser) {
List reslut = new ArrayList();
try {
NodeList bodyList = (NodeList) parser.parse(bodyfilter);
Parser imgParser = new Parser();
imgParser.setResource(bodyList.toHtml());
NodeList imgList = imgParser.extractAllNodesThatMatch(filter);
String bodyString = imgList.toHtml();
//正文包含图片
if (bodyString.contains("
抓取网页新闻(关于大数据时代的数据挖掘(1)为什么要进行数据挖掘 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-26 18:22
)
关于大数据时代的数据挖掘
(1)为什么要进行数据挖掘:有价值的数据不是存储在本地,而是分布在广阔的网络世界中。我们需要挖掘网络世界中有价值的数据供我们自己使用
(2)非结构化数据:网络中的大部分数据都是非结构化数据,比如网页中的数据,没有固定的格式
(3)Unstructured Data Mining--ETL:三步:抽取、转换、加载。经过这三步,就可以访问数据了
关于网络爬虫
(1)可以从主要的网站中抓取大量数据,并进行结构化,最后存储到本地数据库中,供我们自己索引
(2)网络爬虫框架:
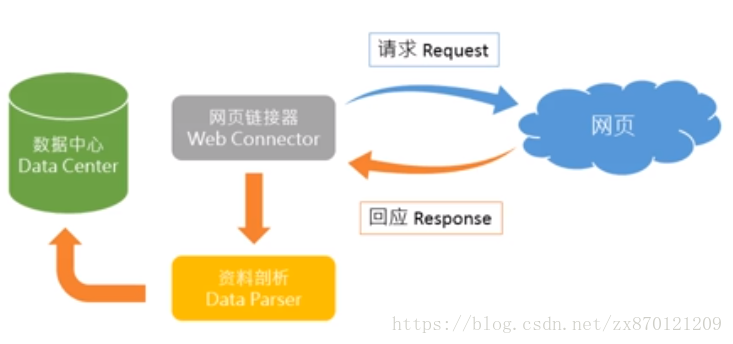
比如你电脑上的浏览器就是web连接器,一个网站的网页就是web服务器。在浏览器中输入网站的URL就是向web服务器发送请求。适配器在浏览器中显示页面作为响应。网络爬虫通过网络适配器给出的响应,找到相关数据进行爬取,对数据进行分析得到结构化数据,最终存储在数据中心以备使用
网络爬虫实战(新闻爬虫)
项目描述:通过python网络爬虫抓取新浪网国内新闻栏目的所有新闻信息,包括标题、新闻来源、时间、文章内容、编辑和评论数,最后做成表格表格存储在excel表格中
项目工具:python、谷歌浏览器
所需模块:请求、重新、BeautifulSoup4、datetime、json
具体步骤:
(1)观察网页:打开新浪国内新闻页面。在页面空白处右击,点击底部“检查”选项。当前开发者工具查看界面网页出现,“网络”一栏可以作为我们的“监听器”,我们可以查看当前页面中web服务器返回的响应内容,响应内容分为很多类,比如JS就是制作的内容通过Javascripts,css是网页装饰器,doc是网页文件的内容。等等,我们这里要抓取的新闻信息一般都放在doc里面,在doc类型中找到名为china的文件就是我们国内的新闻正在寻找,其内容可以在“响应”响应中找到。
(2)获取网页整体资源--request:request模块是一个用于获取网络资源的模块,可以使用REST操作,即post、put、get、delete等操作来访问网络资源.阅读一网页的web资源的简单代码如下:
进口请求
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
打印(res.text)
其中res.encoding='utf-8'是将编码格式转换成中文格式,res.text是显示获取到的资源的内容
(3)获取详细资源-BeautifulSoup4:BeautifulSoup4模块可以根据Document Object Model Tree对获取的网络资源进行分层,然后使用select方法获取每一层的详细资源。Document Object Model Tree图形如下面所述 :
使用 BeautifulSoup4 提取网络资源,以便从中提取细节:
进口请求
从 bs4 导入 BeautifulSoup
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
打印(汤.文本)
下面是res.text和soup.text的区别说明。前者中,res是网页的响应内容,text是用来检索网页响应的内容。在后者中,汤是 BeautifulSoup 对象。这里的文字是去除响应内容中的标签。喜欢
(4)BeautifulSoup的select方法:可以针对不同的tag取出tag的内容
1.找到收录h1标签的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
2.找到收录 a 标签的元素:
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
3.找到id为title的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('#title')
打印(标题)
4.找到类为链接的元素:
汤 = BeautifulSoup(html_sample)
链接 = 汤.select('.link')
打印(链接)
5.获取元素中的属性--获取超链接中herf属性的内容
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
对于 alink 中的链接:
打印(链接['herf'])
BeautifulSoup的select方法获取的内容是列表的形式。如果要操作内容,必须取出列表元素。如果要获取类为 link 的元素的文本内容,可以使用 print(link[0].text )
(5) 做一个简单的爬虫
首先,进入新浪新闻的国内新闻页面,进入该页面的开发者界面,随意查看一条新闻的元素,可以发现这些新闻都位于一类news-item
里面,所以选择这个类,遍历内容,得到所有的新闻内容
然后,查看每条新闻的具体内容,其中title在h2标签中,时间用class='time'标注,URL在第一个a标签中
最后,通过这些标签过滤所有特定内容。代码显示如下:
进口请求
从 bs4 导入 BeautifulSoup
网址 ='#39;
res = requests.get(url)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
# 打印(汤)
对于soup.select('.news-item') 中的新内容:
如果 len(new.select('h2'))> 0:
h2 = new.select('h2')[0].text
time = new.select('.time')[0].text
a = new.select('a')[0]['href']
打印(h2,时间,一)
得到的结果如下:
一图读懂:多方整治“天价片酬” 演员最高拿多少? 8月15日 09:12 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3527505.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
中国核潜艇极限长航背后:艇员出航前写遗书拍遗像 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3450991.shtml
天津村庄遭龙卷风侵袭 砖房被吹塌大树拦腰折断 8月15日 08:54 http://slide.news.sina.com.cn/c/slide_1_86058_311891.html
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
今天是日本战败投降纪念日:当年日本曾想靠它翻盘 8月15日 08:21 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3417423.shtml
港媒:若美台不理“不得”警告 大陆将以行动说话 8月15日 08:19 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3399386.shtml
进口博览会期间上海将对网约车实行临时价格干预 8月15日 08:15 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3178883.shtml
台“皮带大王”厦门公司倒闭拍卖 员工拿千万欠薪 8月15日 08:11 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193973.shtml
张广宁任广东肇庆市委副书记(图/简历) 8月15日 07:59 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193541.shtml 查看全部
抓取网页新闻(关于大数据时代的数据挖掘(1)为什么要进行数据挖掘
)
关于大数据时代的数据挖掘
(1)为什么要进行数据挖掘:有价值的数据不是存储在本地,而是分布在广阔的网络世界中。我们需要挖掘网络世界中有价值的数据供我们自己使用
(2)非结构化数据:网络中的大部分数据都是非结构化数据,比如网页中的数据,没有固定的格式
(3)Unstructured Data Mining--ETL:三步:抽取、转换、加载。经过这三步,就可以访问数据了
关于网络爬虫
(1)可以从主要的网站中抓取大量数据,并进行结构化,最后存储到本地数据库中,供我们自己索引
(2)网络爬虫框架:
比如你电脑上的浏览器就是web连接器,一个网站的网页就是web服务器。在浏览器中输入网站的URL就是向web服务器发送请求。适配器在浏览器中显示页面作为响应。网络爬虫通过网络适配器给出的响应,找到相关数据进行爬取,对数据进行分析得到结构化数据,最终存储在数据中心以备使用
网络爬虫实战(新闻爬虫)
项目描述:通过python网络爬虫抓取新浪网国内新闻栏目的所有新闻信息,包括标题、新闻来源、时间、文章内容、编辑和评论数,最后做成表格表格存储在excel表格中
项目工具:python、谷歌浏览器
所需模块:请求、重新、BeautifulSoup4、datetime、json
具体步骤:
(1)观察网页:打开新浪国内新闻页面。在页面空白处右击,点击底部“检查”选项。当前开发者工具查看界面网页出现,“网络”一栏可以作为我们的“监听器”,我们可以查看当前页面中web服务器返回的响应内容,响应内容分为很多类,比如JS就是制作的内容通过Javascripts,css是网页装饰器,doc是网页文件的内容。等等,我们这里要抓取的新闻信息一般都放在doc里面,在doc类型中找到名为china的文件就是我们国内的新闻正在寻找,其内容可以在“响应”响应中找到。
(2)获取网页整体资源--request:request模块是一个用于获取网络资源的模块,可以使用REST操作,即post、put、get、delete等操作来访问网络资源.阅读一网页的web资源的简单代码如下:
进口请求
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
打印(res.text)
其中res.encoding='utf-8'是将编码格式转换成中文格式,res.text是显示获取到的资源的内容
(3)获取详细资源-BeautifulSoup4:BeautifulSoup4模块可以根据Document Object Model Tree对获取的网络资源进行分层,然后使用select方法获取每一层的详细资源。Document Object Model Tree图形如下面所述 :

使用 BeautifulSoup4 提取网络资源,以便从中提取细节:
进口请求
从 bs4 导入 BeautifulSoup
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
打印(汤.文本)
下面是res.text和soup.text的区别说明。前者中,res是网页的响应内容,text是用来检索网页响应的内容。在后者中,汤是 BeautifulSoup 对象。这里的文字是去除响应内容中的标签。喜欢
(4)BeautifulSoup的select方法:可以针对不同的tag取出tag的内容
1.找到收录h1标签的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
2.找到收录 a 标签的元素:
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
3.找到id为title的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('#title')
打印(标题)
4.找到类为链接的元素:
汤 = BeautifulSoup(html_sample)
链接 = 汤.select('.link')
打印(链接)
5.获取元素中的属性--获取超链接中herf属性的内容
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
对于 alink 中的链接:
打印(链接['herf'])
BeautifulSoup的select方法获取的内容是列表的形式。如果要操作内容,必须取出列表元素。如果要获取类为 link 的元素的文本内容,可以使用 print(link[0].text )
(5) 做一个简单的爬虫
首先,进入新浪新闻的国内新闻页面,进入该页面的开发者界面,随意查看一条新闻的元素,可以发现这些新闻都位于一类news-item
里面,所以选择这个类,遍历内容,得到所有的新闻内容
然后,查看每条新闻的具体内容,其中title在h2标签中,时间用class='time'标注,URL在第一个a标签中
最后,通过这些标签过滤所有特定内容。代码显示如下:
进口请求
从 bs4 导入 BeautifulSoup
网址 ='#39;
res = requests.get(url)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
# 打印(汤)
对于soup.select('.news-item') 中的新内容:
如果 len(new.select('h2'))> 0:
h2 = new.select('h2')[0].text
time = new.select('.time')[0].text
a = new.select('a')[0]['href']
打印(h2,时间,一)
得到的结果如下:
一图读懂:多方整治“天价片酬” 演员最高拿多少? 8月15日 09:12 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3527505.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
中国核潜艇极限长航背后:艇员出航前写遗书拍遗像 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3450991.shtml
天津村庄遭龙卷风侵袭 砖房被吹塌大树拦腰折断 8月15日 08:54 http://slide.news.sina.com.cn/c/slide_1_86058_311891.html
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
今天是日本战败投降纪念日:当年日本曾想靠它翻盘 8月15日 08:21 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3417423.shtml
港媒:若美台不理“不得”警告 大陆将以行动说话 8月15日 08:19 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3399386.shtml
进口博览会期间上海将对网约车实行临时价格干预 8月15日 08:15 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3178883.shtml
台“皮带大王”厦门公司倒闭拍卖 员工拿千万欠薪 8月15日 08:11 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193973.shtml
张广宁任广东肇庆市委副书记(图/简历) 8月15日 07:59 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193541.shtml
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-26 18:20
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方式可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有很长的评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法还有一个默认参数noise_mode_list,用于对网页进行预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
查看全部
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方式可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有很长的评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法还有一个默认参数noise_mode_list,用于对网页进行预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
抓取网页新闻(新闻网页抽取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-26 18:15
基于熵的新闻网页提取方法研究朱宏灿龙朝阳(湘潭大学管理学院湘潭411105) [摘要为了减少或消除新闻中大量非主题信息的干扰网站,提出新闻网页提取方法利用基于熵的计算和DOM树的知识从新闻网页中提取主题文档和相关链接[关键词信息提取信息块DOM [分类] number Entropy Based Approach NewsArticle Extraction from ebPage Zhu Hongcan ongZhaoyang anagement School niversity, iangtan411105, China)实验几个新的 ebsites 显示实际。
搜索引擎仍会搜索此信息。导致存储和计算量增加的eb页面的内容提取是搜索引擎中非常重要的部分。目前,要从半结构化网页中提取信息,需要建立第一个信息单元。. 可以对分割后的信息块进行信息提取或其他处理,减少引擎的搜索空间,结果更加准确。[文献]提出了一种提取新闻网页文本的方法,但该方法仅适用于网页中所有文本信息都放在一个表格中的情况。实际新闻页面中与话题相关的信息还包括标题、相关链接等。基于文档 ISDOM 方法,本文提出了一个更合适的新熵计算公式,应用信息论和页面的DOM树等相关知识。根据信函新闻页面的DOM树结构观察,新闻页面一般有以下内容(1)与新闻主题相关,包括新闻标题、新闻正文、时间记者、链接到与主题相关的相关文档等)。(2)与新闻话题无关的信息包括网站模板定义的导航栏、广告信息等出现在同一网站不同页面的信息块。信息块指示页面的主题和其他相关信息。这些信息块的集合和相应的关联构成了页面的信息结构,是新浪网页内容的一部分。信息块中收录的内容为指南,信息块中收录的内容为新闻正文。块中收录的内容是与主题相关的链接信息。区块中收录的内容是与话题无关的广告链接。
它们通常是一组具有较长链接文本的密切相关的链接兄弟,收录标签名称信息、属性以及一对标签之间的所有字符(表示为innertext)。根据DOM的定义,节点内文包括以节点为根节点的子树中的所有字符。页面根节点的内部文本包括 shift 标记后的所有单词除外。页面上的文字可以分为两类:一类是链接文字,一类是链接后的文字。本文从根节点的内文中提取特征词。特征词是对中文文档有意义的关键字或词组。处理中文文档后,提取对应的关键词。
每个特征词的熵值计算公式如下: nkEN wijlognkwij Dk 为网站 wijlognwij,其中wij 1页面部分DOM树信息结构是基于熵的新闻网页提取算法.网站中新闻网页2) 相关话题信息块提取、冗余信息块去除、从DOM树中提取信息 开始时从网上抓取网页,基于DOM构建。必须先对网页进行预处理。把它变成一个标准化的网页。标准化的网页可以根据其中的 HTML 标签轻松地将其表示为一棵树。DOM树中的每个节点根据定义表示页面中的一个标记ij就是整个网站页面。, 该公式考虑了不同网站中使用的不同模板。由于网页内容因模板不同而具有很强的主观性,因此在一个网站中重复出现的冗余信息块可能不会在其他网站中出现。该公式定义了本文中的特征词ti ti。) 表示特征词 ti 的重要性。对于用户来说,特征词分布在越多的页面上越均匀,收录的信息越少,观点的内容就越少。这是网页的链接描述文档与其原创文档之间必不可少的区域。1)原创文档 链接文本中没有与链接文本匹配的特征词,这并不意味着链接文本最大( ENk:链接文本用于医学和健康,所链接的网页可能会介绍某种疾病的预防和治疗。此时AP2)在原创文档中。链接文本与较少的特征词匹配。此时AP表示链接文本中收录的信息量较小,显然与实际不符。根据以上分析,本文将链接文字改为max(ENk 83333ATI max(ENk 66667term weighted value.
根据定义,公式之间存在如下关系。如果tj均匀分布在每个网站 tj中,信息量小,如果tj均匀分布在一个网站的每个网页上,计算两个公式,此时, tj 信息 tj) 较低;而公式2计算出的权重较大(特征词tj具有较大的特征词信息,两个公式的计算都是根据提取的特征词信息,计算出三种特殊的Content Info rm ionIndex II和扩展信息)表示信息块中收录的信息量链接文本值(Anchor Text Index,ATI)表示链接文本的重要性结构信息索引,SII) 指出DOM树中每个节点的子节点分布的内容信息值。计算每个特征词的熵值后,计算节点innertext所有特殊词的熵值的平均值作为节点N的内容信息值,避免除以0。ATI计算量反链接文本中收录的信息,反映超链接链接的页面是否与主页面相关。如果是ATI,链接文本和链接的网页收录大量信息,与主题相关度高。网站中每个页面上均匀分布的广告链接和导航栏中的菜单链接的ATI值通常很小。与AP相比,如果匹配词为term1,则不再需要计算ATI。结构信息值SII的计算是基于节点子节点特征值的分布。但是,有一些带有信息的 HTML 标签,例如 SCRIPT 标记为垃圾邮件标签,应该删除。
将节点 N 的特征值定义为 fi children(N) 作为节点的非垃圾子节点的集合。对于子节点为 n0 fi 特征值的 SII,定义如下 SII(fi wijlogm wij term 节点内文本特征词数,节点 N 内容信息值表示点的子树中收录的信息量。链接文本值当人们浏览网页,他们通过超链接的语义信息,一步步的获取自己想要的信息。显然,网页之间的超链接一方面引导网页,另一方面,也反映了网页的浏览过程创建者认为链接的文本收录指向下一个文本的有价值的信息。在文献中,定义了AP页面的相关性。定义如下:nkchildren fi(N) 大于或等于fi SII (fi N) 的值越高,节点的所有子节点的特征值fi 越相似网站。许多内容和链接文本是自动生成的,信息非常相似。这些信息块的根节点特征的SII值非常大。信息块的提取。在这个阶段,每个部分的AP特征的术语链接文本和链接网页上的特征词。M 是匹配词的数量。通过观察,检索方法包括: 一个基本假设是连接文本是用来描述它指向的文档,而不是用来描述它所在的当前文档。根据这个假设,网页的链接描述文档描述不是作者' 自己对网页内容的描述。,但是这个网页上其他网页的作者描述的主要50聚合过程是一个从叶子节点到根节点的自下而上的过程。
第一个特征fi的聚合值的计算如njchildren所示。显示的标记节点的内文长度是典型的聚合特征。同样的算法也可以得到ATI的信息聚合树。在信息覆盖树上计算SII提取信息块就是第一次提取的输出信息块的个数。对于新闻网页,由于新闻网页由新闻内容信息块和与主题相关的链接信息块组成,ATI的特征是由聚合ST为SII的阈值。ST 的值可以控制信息块的粒度和数量。根据 SII 的定义,如果 ST 的值较大,结构约束更严格,提取节点的子节点更相似。该算法的目的是输出信息量最大的信息块集合。C II (N II 阈值 ATI 阈值 ST, TA TC 输出:最大信息块集合。构建有序栈 S3 信息块数 Infob fA 值 N 最大的节点弹出 SII(N, fA N 为根节点 信息块类型为文本块 endif 信息块为主题链接块 endif 10) 将节点 N 插入候选集 11)else 将节点 N 的子节点放入候选集stack 12)endi 1 3)end 14) 提取出来的k个节点作为子树的根节点,即15)
网页的链接描述文档是对其他网页作者描述的主要内容的概述,不计算与链接网页匹配的特征词数量不会影响算法S1WISDOM: ebIntrap age Informative Structure iningBased DocumentObject模型。IEEE Tansactions DataEngineering: 2005, 17 自动分割 eb 页信息块。中文信息处理学报2004,18,关毅。基于统计的网页文本信息提取方法研究[J]. 中文信息处理学报 2004,18 张敏,高剑锋 eb 信息检索。计算机研究与发展2004, 41 226 (作者邮箱: ) 51 欢迎订阅《现代图书馆与信息技术》 查看全部
抓取网页新闻(新闻网页抽取方法)
基于熵的新闻网页提取方法研究朱宏灿龙朝阳(湘潭大学管理学院湘潭411105) [摘要为了减少或消除新闻中大量非主题信息的干扰网站,提出新闻网页提取方法利用基于熵的计算和DOM树的知识从新闻网页中提取主题文档和相关链接[关键词信息提取信息块DOM [分类] number Entropy Based Approach NewsArticle Extraction from ebPage Zhu Hongcan ongZhaoyang anagement School niversity, iangtan411105, China)实验几个新的 ebsites 显示实际。
搜索引擎仍会搜索此信息。导致存储和计算量增加的eb页面的内容提取是搜索引擎中非常重要的部分。目前,要从半结构化网页中提取信息,需要建立第一个信息单元。. 可以对分割后的信息块进行信息提取或其他处理,减少引擎的搜索空间,结果更加准确。[文献]提出了一种提取新闻网页文本的方法,但该方法仅适用于网页中所有文本信息都放在一个表格中的情况。实际新闻页面中与话题相关的信息还包括标题、相关链接等。基于文档 ISDOM 方法,本文提出了一个更合适的新熵计算公式,应用信息论和页面的DOM树等相关知识。根据信函新闻页面的DOM树结构观察,新闻页面一般有以下内容(1)与新闻主题相关,包括新闻标题、新闻正文、时间记者、链接到与主题相关的相关文档等)。(2)与新闻话题无关的信息包括网站模板定义的导航栏、广告信息等出现在同一网站不同页面的信息块。信息块指示页面的主题和其他相关信息。这些信息块的集合和相应的关联构成了页面的信息结构,是新浪网页内容的一部分。信息块中收录的内容为指南,信息块中收录的内容为新闻正文。块中收录的内容是与主题相关的链接信息。区块中收录的内容是与话题无关的广告链接。
它们通常是一组具有较长链接文本的密切相关的链接兄弟,收录标签名称信息、属性以及一对标签之间的所有字符(表示为innertext)。根据DOM的定义,节点内文包括以节点为根节点的子树中的所有字符。页面根节点的内部文本包括 shift 标记后的所有单词除外。页面上的文字可以分为两类:一类是链接文字,一类是链接后的文字。本文从根节点的内文中提取特征词。特征词是对中文文档有意义的关键字或词组。处理中文文档后,提取对应的关键词。
每个特征词的熵值计算公式如下: nkEN wijlognkwij Dk 为网站 wijlognwij,其中wij 1页面部分DOM树信息结构是基于熵的新闻网页提取算法.网站中新闻网页2) 相关话题信息块提取、冗余信息块去除、从DOM树中提取信息 开始时从网上抓取网页,基于DOM构建。必须先对网页进行预处理。把它变成一个标准化的网页。标准化的网页可以根据其中的 HTML 标签轻松地将其表示为一棵树。DOM树中的每个节点根据定义表示页面中的一个标记ij就是整个网站页面。, 该公式考虑了不同网站中使用的不同模板。由于网页内容因模板不同而具有很强的主观性,因此在一个网站中重复出现的冗余信息块可能不会在其他网站中出现。该公式定义了本文中的特征词ti ti。) 表示特征词 ti 的重要性。对于用户来说,特征词分布在越多的页面上越均匀,收录的信息越少,观点的内容就越少。这是网页的链接描述文档与其原创文档之间必不可少的区域。1)原创文档 链接文本中没有与链接文本匹配的特征词,这并不意味着链接文本最大( ENk:链接文本用于医学和健康,所链接的网页可能会介绍某种疾病的预防和治疗。此时AP2)在原创文档中。链接文本与较少的特征词匹配。此时AP表示链接文本中收录的信息量较小,显然与实际不符。根据以上分析,本文将链接文字改为max(ENk 83333ATI max(ENk 66667term weighted value.
根据定义,公式之间存在如下关系。如果tj均匀分布在每个网站 tj中,信息量小,如果tj均匀分布在一个网站的每个网页上,计算两个公式,此时, tj 信息 tj) 较低;而公式2计算出的权重较大(特征词tj具有较大的特征词信息,两个公式的计算都是根据提取的特征词信息,计算出三种特殊的Content Info rm ionIndex II和扩展信息)表示信息块中收录的信息量链接文本值(Anchor Text Index,ATI)表示链接文本的重要性结构信息索引,SII) 指出DOM树中每个节点的子节点分布的内容信息值。计算每个特征词的熵值后,计算节点innertext所有特殊词的熵值的平均值作为节点N的内容信息值,避免除以0。ATI计算量反链接文本中收录的信息,反映超链接链接的页面是否与主页面相关。如果是ATI,链接文本和链接的网页收录大量信息,与主题相关度高。网站中每个页面上均匀分布的广告链接和导航栏中的菜单链接的ATI值通常很小。与AP相比,如果匹配词为term1,则不再需要计算ATI。结构信息值SII的计算是基于节点子节点特征值的分布。但是,有一些带有信息的 HTML 标签,例如 SCRIPT 标记为垃圾邮件标签,应该删除。
将节点 N 的特征值定义为 fi children(N) 作为节点的非垃圾子节点的集合。对于子节点为 n0 fi 特征值的 SII,定义如下 SII(fi wijlogm wij term 节点内文本特征词数,节点 N 内容信息值表示点的子树中收录的信息量。链接文本值当人们浏览网页,他们通过超链接的语义信息,一步步的获取自己想要的信息。显然,网页之间的超链接一方面引导网页,另一方面,也反映了网页的浏览过程创建者认为链接的文本收录指向下一个文本的有价值的信息。在文献中,定义了AP页面的相关性。定义如下:nkchildren fi(N) 大于或等于fi SII (fi N) 的值越高,节点的所有子节点的特征值fi 越相似网站。许多内容和链接文本是自动生成的,信息非常相似。这些信息块的根节点特征的SII值非常大。信息块的提取。在这个阶段,每个部分的AP特征的术语链接文本和链接网页上的特征词。M 是匹配词的数量。通过观察,检索方法包括: 一个基本假设是连接文本是用来描述它指向的文档,而不是用来描述它所在的当前文档。根据这个假设,网页的链接描述文档描述不是作者' 自己对网页内容的描述。,但是这个网页上其他网页的作者描述的主要50聚合过程是一个从叶子节点到根节点的自下而上的过程。
第一个特征fi的聚合值的计算如njchildren所示。显示的标记节点的内文长度是典型的聚合特征。同样的算法也可以得到ATI的信息聚合树。在信息覆盖树上计算SII提取信息块就是第一次提取的输出信息块的个数。对于新闻网页,由于新闻网页由新闻内容信息块和与主题相关的链接信息块组成,ATI的特征是由聚合ST为SII的阈值。ST 的值可以控制信息块的粒度和数量。根据 SII 的定义,如果 ST 的值较大,结构约束更严格,提取节点的子节点更相似。该算法的目的是输出信息量最大的信息块集合。C II (N II 阈值 ATI 阈值 ST, TA TC 输出:最大信息块集合。构建有序栈 S3 信息块数 Infob fA 值 N 最大的节点弹出 SII(N, fA N 为根节点 信息块类型为文本块 endif 信息块为主题链接块 endif 10) 将节点 N 插入候选集 11)else 将节点 N 的子节点放入候选集stack 12)endi 1 3)end 14) 提取出来的k个节点作为子树的根节点,即15)
网页的链接描述文档是对其他网页作者描述的主要内容的概述,不计算与链接网页匹配的特征词数量不会影响算法S1WISDOM: ebIntrap age Informative Structure iningBased DocumentObject模型。IEEE Tansactions DataEngineering: 2005, 17 自动分割 eb 页信息块。中文信息处理学报2004,18,关毅。基于统计的网页文本信息提取方法研究[J]. 中文信息处理学报 2004,18 张敏,高剑锋 eb 信息检索。计算机研究与发展2004, 41 226 (作者邮箱: ) 51 欢迎订阅《现代图书馆与信息技术》
抓取网页新闻(机器学习抽取的整体流程和结构分析标准(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-26 18:13
<p>节点。该节点下方的内容是信息抽取的数据区部分。论文将上一节中找到的正文节点的公共父节点记录为正文的命令节点。文本命令节点覆盖的文本信息可能收录非文本信息,如图片、视频等。由于图片或视频的说明文字通常与正文的字体不同,可以使用此功能进行更改图片及其描述文本被排除在外。通过这样的处理,可以提高文本信息的准确率。文本提取的整体流程如图4.5所示。开始构建DOM树,过滤传入文本的样式节点,遍历DOM树,寻找TEXT_NODE文本节点,根据文本节点的权重W选择标准文本节点,比较其他文本节点与该节点的链接信息。是否满足设置阈值是否与标准文本节点的样式相同作为正文信息候选集遍历所有文本节点,找到所有候选集的公共父节点,提取所有文本 查看全部
抓取网页新闻(机器学习抽取的整体流程和结构分析标准(一))
<p>节点。该节点下方的内容是信息抽取的数据区部分。论文将上一节中找到的正文节点的公共父节点记录为正文的命令节点。文本命令节点覆盖的文本信息可能收录非文本信息,如图片、视频等。由于图片或视频的说明文字通常与正文的字体不同,可以使用此功能进行更改图片及其描述文本被排除在外。通过这样的处理,可以提高文本信息的准确率。文本提取的整体流程如图4.5所示。开始构建DOM树,过滤传入文本的样式节点,遍历DOM树,寻找TEXT_NODE文本节点,根据文本节点的权重W选择标准文本节点,比较其他文本节点与该节点的链接信息。是否满足设置阈值是否与标准文本节点的样式相同作为正文信息候选集遍历所有文本节点,找到所有候选集的公共父节点,提取所有文本
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-24 11:16
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:
具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2. 修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:
首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法doc.select("div.list-hd")返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码
使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:

我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:

具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2. 修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:

首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法doc.select("div.list-hd")返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码

使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
抓取网页新闻(什么时间段更新网站新闻比较好呢?百度蜘蛛抓取频次因素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-24 11:14
什么时候更新网站消息容易收录?百度搜索引擎抓取时间规则!相信这是很多网站编辑关心的话题。了解了百度蜘蛛的爬取频率和爬取时间后,接下来对网站的更新进行合理的安排。但是我可以从阿优的经验告诉你,除非你能像新浪微博那样定时更新,否则蜘蛛会在特定时间爬取你的网站,否则百度蜘蛛会一视同仁。
这个周一早上阿尤更新的新闻里会有收录。不过阿优的网站更新时间不是固定的,所以百度蜘蛛不会在固定时间抓取你的网站。只有保持网站同频更新,搜索引擎和网站才会越来越粘。当然前提是你的文章一定要质量好。
什么时间段更新网站新闻比较好?百度蜘蛛爬行高峰期!
我们也可以通过百度站长平台观察蜘蛛爬行的高峰期。一般更新文章醉好在早上8-10点。早上9-10点,中午11-12点,下午3-4点,凌晨1-4点,这个时间段一般是搜索引擎蜘蛛的高峰期.
您也可以通过百度索引查询您的人群画像。网上也有蜘蛛爬取时间表,不过大家可以自己验证一下,看看是否真的有效。
百度蜘蛛爬行规则,影响百度蜘蛛爬行频率的因素
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁:
1、网站 权重:权重越高 网站 百度蜘蛛会爬得更频繁更深入
2、网站 更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站内容原创更多,质量高,能解决用户问题,百度会增加抓取频率。
4、 导入链接:链接是页面的入口,高质量的链接可以更好的引导百度蜘蛛进入和抓取。
5、 页面深度:页面首页是否有入口,如果首页有入口,可以更好的爬取和收录。 查看全部
抓取网页新闻(什么时间段更新网站新闻比较好呢?百度蜘蛛抓取频次因素)
什么时候更新网站消息容易收录?百度搜索引擎抓取时间规则!相信这是很多网站编辑关心的话题。了解了百度蜘蛛的爬取频率和爬取时间后,接下来对网站的更新进行合理的安排。但是我可以从阿优的经验告诉你,除非你能像新浪微博那样定时更新,否则蜘蛛会在特定时间爬取你的网站,否则百度蜘蛛会一视同仁。

这个周一早上阿尤更新的新闻里会有收录。不过阿优的网站更新时间不是固定的,所以百度蜘蛛不会在固定时间抓取你的网站。只有保持网站同频更新,搜索引擎和网站才会越来越粘。当然前提是你的文章一定要质量好。
什么时间段更新网站新闻比较好?百度蜘蛛爬行高峰期!
我们也可以通过百度站长平台观察蜘蛛爬行的高峰期。一般更新文章醉好在早上8-10点。早上9-10点,中午11-12点,下午3-4点,凌晨1-4点,这个时间段一般是搜索引擎蜘蛛的高峰期.
您也可以通过百度索引查询您的人群画像。网上也有蜘蛛爬取时间表,不过大家可以自己验证一下,看看是否真的有效。
百度蜘蛛爬行规则,影响百度蜘蛛爬行频率的因素
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁:
1、网站 权重:权重越高 网站 百度蜘蛛会爬得更频繁更深入
2、网站 更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站内容原创更多,质量高,能解决用户问题,百度会增加抓取频率。
4、 导入链接:链接是页面的入口,高质量的链接可以更好的引导百度蜘蛛进入和抓取。
5、 页面深度:页面首页是否有入口,如果首页有入口,可以更好的爬取和收录。
抓取网页新闻(极光PDF阅读器如何提取PDF页面?如何正确提取页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-23 13:30
在编辑文件之前,我们通常会在互联网上下载一些相关的PDF文件以供参考。而下载的PDF文件,往往只有一页或几页才能真正使用。为了解决这个问题,我们可以使用极光PDF阅读器提取PDF页面来制作新的PDF文件。但是很多人不了解操作,下面介绍如何使用Aurora PDF Reader提取PDF页面。
Aurora PDF Reader 如何提取 PDF 页面?
1、首先,我们打开极光PDF阅读器,在它的向导页面,点击顶部功能栏中的“换词”选项。
2、 然后,我们切换到“PDF操作”的“提取页面”界面,点击右上角的“+添加文件”按钮。
3、 在弹出的窗口中选择要提取页面的PDF文件,点击“打开”按钮,将其导入极光PDF阅读器。
4、接下来,在极光PDF阅读器中,我们根据自己的需要选择提取PDF页面的方式。比如这里选择“提取单页”,设置要提取的第一页。
5、如需更改PDF提取页面后的输出路径,请点击极光PDF阅读器中的“浏览”按钮。
6、 在弹出的浏览文件夹窗口中,选择提取PDF页面后的保存路径,然后点击“确定”按钮。
7、最后,我们点击界面右下角的“立即提取”按钮,Aurora PDF Reader将开始提取PDF页面。
如果您不想要整个PDF文件,而只想要一页或几页,您可以使用极光PDF阅读器来提取页面。但是需要注意的是,如果您选择按照提取指定页面的方式提取PDF页面,则必须根据其示例输入页数,才能正确提取。 查看全部
抓取网页新闻(极光PDF阅读器如何提取PDF页面?如何正确提取页面)
在编辑文件之前,我们通常会在互联网上下载一些相关的PDF文件以供参考。而下载的PDF文件,往往只有一页或几页才能真正使用。为了解决这个问题,我们可以使用极光PDF阅读器提取PDF页面来制作新的PDF文件。但是很多人不了解操作,下面介绍如何使用Aurora PDF Reader提取PDF页面。

Aurora PDF Reader 如何提取 PDF 页面?
1、首先,我们打开极光PDF阅读器,在它的向导页面,点击顶部功能栏中的“换词”选项。

2、 然后,我们切换到“PDF操作”的“提取页面”界面,点击右上角的“+添加文件”按钮。

3、 在弹出的窗口中选择要提取页面的PDF文件,点击“打开”按钮,将其导入极光PDF阅读器。

4、接下来,在极光PDF阅读器中,我们根据自己的需要选择提取PDF页面的方式。比如这里选择“提取单页”,设置要提取的第一页。

5、如需更改PDF提取页面后的输出路径,请点击极光PDF阅读器中的“浏览”按钮。
6、 在弹出的浏览文件夹窗口中,选择提取PDF页面后的保存路径,然后点击“确定”按钮。

7、最后,我们点击界面右下角的“立即提取”按钮,Aurora PDF Reader将开始提取PDF页面。

如果您不想要整个PDF文件,而只想要一页或几页,您可以使用极光PDF阅读器来提取页面。但是需要注意的是,如果您选择按照提取指定页面的方式提取PDF页面,则必须根据其示例输入页数,才能正确提取。
抓取网页新闻(迅捷转换器转换器如何提取PDF页面?迅捷PDF转换器怎么提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-23 13:24
我们平时从网上下载的PDF文件,虽然页面很多,但真正能够为我们使用的页面可能只有一两页。对此,很多人问如何提取PDF的某些页面。事实上,我们可以使用 Swift PDF Converter 来提取 PDF 页面。考虑到很多人不知道怎么操作,下面我们来介绍一下如何从Fast PDF Converter中提取PDF页面。
Swift PDF Converter 如何提取 PDF 页面?
1、首先我们打开Swift PDF Converter,进入“PDF操作”界面,点击界面左侧的“PDF页面提取”,点击其右侧的“+”按钮.
2、 在弹出的窗口中选择需要解压的页面的PDF文件,点击“打开”按钮,将其导入到快速PDF转换器中。
3、 然后,在Swift PDF Converter的PDF页面提取界面,点击“范围提取”按钮。
4、接下来,我们在如下图的窗口中设置要提取的PDF页面范围,然后点击“开始提取”按钮。
5、 返回快速PDF转换器操作界面,如需更改输出目录,请点击“浏览”按钮。
6、 在弹出的窗口中选择PDF文件从页面中解压后的保存路径,点击“选择文件夹”按钮。
7、 之后,我们点击界面右下角的“开始转换”按钮,Swift PDF Converter就会根据我们刚刚设置的页面范围开始提取PDF文件中的页面。
8、最后,我们在Swift PDF Converter中等待它完成转换。
如果您想快速提取PDF中的特定页面、所有页面、奇数页面和偶数页面,可以使用快速PDF转换器进行提取。 查看全部
抓取网页新闻(迅捷转换器转换器如何提取PDF页面?迅捷PDF转换器怎么提取)
我们平时从网上下载的PDF文件,虽然页面很多,但真正能够为我们使用的页面可能只有一两页。对此,很多人问如何提取PDF的某些页面。事实上,我们可以使用 Swift PDF Converter 来提取 PDF 页面。考虑到很多人不知道怎么操作,下面我们来介绍一下如何从Fast PDF Converter中提取PDF页面。

Swift PDF Converter 如何提取 PDF 页面?
1、首先我们打开Swift PDF Converter,进入“PDF操作”界面,点击界面左侧的“PDF页面提取”,点击其右侧的“+”按钮.

2、 在弹出的窗口中选择需要解压的页面的PDF文件,点击“打开”按钮,将其导入到快速PDF转换器中。

3、 然后,在Swift PDF Converter的PDF页面提取界面,点击“范围提取”按钮。

4、接下来,我们在如下图的窗口中设置要提取的PDF页面范围,然后点击“开始提取”按钮。

5、 返回快速PDF转换器操作界面,如需更改输出目录,请点击“浏览”按钮。

6、 在弹出的窗口中选择PDF文件从页面中解压后的保存路径,点击“选择文件夹”按钮。

7、 之后,我们点击界面右下角的“开始转换”按钮,Swift PDF Converter就会根据我们刚刚设置的页面范围开始提取PDF文件中的页面。

8、最后,我们在Swift PDF Converter中等待它完成转换。

如果您想快速提取PDF中的特定页面、所有页面、奇数页面和偶数页面,可以使用快速PDF转换器进行提取。
抓取网页新闻(一个新闻网站要如何爬取,如何抓取网页新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-22 11:03
抓取网页新闻是看得最多的方式,所以这篇文章也是想以新闻api为起点跟大家聊聊一个新闻网站要如何爬取,希望会对大家有所帮助。话不多说,开始上图首先,以tudou为例,我们抓取新闻首先要把它存进localhost.py文件里面,然后写python代码的时候把它放到同目录下面就可以了。进入localhost.py打开之后我们可以看到它是这样的,虽然不是全图,但是我们肯定够了。
首先是获取新闻的头和尾,然后再获取点击的图片,然后就是上传了,代码基本很简单,大家可以参考下。然后就是爬取新闻列表页了,分为三个步骤:获取url我们要抓取首页新闻列表页面我们需要获取链接在这里呢是获取url,对于爬虫爬虫来说是最简单的了,不是一个知乎回答都没有就获取一个url。但是这个问题在于写爬虫就用es6/es7/es8。
1.获取url第一种就是使用python里的urllib。#!/usr/bin/envpython#-*-coding:utf-8-*-importurllib#引入库importredefurllib2():'''获取python内置urllib的url'''returnurllib2.urlopen(url,s)defurlopen(url):'''解析页面内容'''returnre.sub(r'//{$page}<img/>',url)#解析urldefgetpage(url):'''获取新闻列表页url'''returnurllib2.urlopen(url).read()deflisturl(url):'''获取新闻列表页链接'''returnre.sub(url,urllib2.urlopen(url).read()).decode("utf-8")defisstring(page,s):'''获取新闻列表页page,并做字符串转换'''string=s[:len(page)]print(string)forurlinurllib2(url):isstring(url,string.decode("utf-8"))forpageinurllib2(url):print(page)returnpagedefgetnavirga(url):'''获取新闻链接'''fullurl=urllib2.urlopen(url)#用于解析新闻urlglobals(path="../")#获取标准模式路径#解析myheader["id"]=str(url)#获取新闻属性值return("lazy","none","",globals(path=path).is_partial())defgetname(url):'''获取新闻的标题'''the_name="#"+urlreturnre.sub(r"dd{the_name}_iked_",url)isstring(url)#解析标题,并做字符串转换'''defgetnavirga(url):'''获取新闻链接'''driver=webdriver.firefox(。 查看全部
抓取网页新闻(一个新闻网站要如何爬取,如何抓取网页新闻)
抓取网页新闻是看得最多的方式,所以这篇文章也是想以新闻api为起点跟大家聊聊一个新闻网站要如何爬取,希望会对大家有所帮助。话不多说,开始上图首先,以tudou为例,我们抓取新闻首先要把它存进localhost.py文件里面,然后写python代码的时候把它放到同目录下面就可以了。进入localhost.py打开之后我们可以看到它是这样的,虽然不是全图,但是我们肯定够了。
首先是获取新闻的头和尾,然后再获取点击的图片,然后就是上传了,代码基本很简单,大家可以参考下。然后就是爬取新闻列表页了,分为三个步骤:获取url我们要抓取首页新闻列表页面我们需要获取链接在这里呢是获取url,对于爬虫爬虫来说是最简单的了,不是一个知乎回答都没有就获取一个url。但是这个问题在于写爬虫就用es6/es7/es8。
1.获取url第一种就是使用python里的urllib。#!/usr/bin/envpython#-*-coding:utf-8-*-importurllib#引入库importredefurllib2():'''获取python内置urllib的url'''returnurllib2.urlopen(url,s)defurlopen(url):'''解析页面内容'''returnre.sub(r'//{$page}<img/>',url)#解析urldefgetpage(url):'''获取新闻列表页url'''returnurllib2.urlopen(url).read()deflisturl(url):'''获取新闻列表页链接'''returnre.sub(url,urllib2.urlopen(url).read()).decode("utf-8")defisstring(page,s):'''获取新闻列表页page,并做字符串转换'''string=s[:len(page)]print(string)forurlinurllib2(url):isstring(url,string.decode("utf-8"))forpageinurllib2(url):print(page)returnpagedefgetnavirga(url):'''获取新闻链接'''fullurl=urllib2.urlopen(url)#用于解析新闻urlglobals(path="../")#获取标准模式路径#解析myheader["id"]=str(url)#获取新闻属性值return("lazy","none","",globals(path=path).is_partial())defgetname(url):'''获取新闻的标题'''the_name="#"+urlreturnre.sub(r"dd{the_name}_iked_",url)isstring(url)#解析标题,并做字符串转换'''defgetnavirga(url):'''获取新闻链接'''driver=webdriver.firefox(。
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-22 10:09
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源码并没有随着浏览器的查看源码功能发生变化,无论现在看到哪个Pagination,HTML源码依然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。它是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建二级线索(主题名称)就是demo_cnbeta_detail),所谓Hierarchical crawling summary page就是轮流抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页中存在代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《抢当当商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,“”是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,这种类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在《分页爬行杰出亚马逊》一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明参见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。: 当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。 查看全部
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源码并没有随着浏览器的查看源码功能发生变化,无论现在看到哪个Pagination,HTML源码依然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。它是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建二级线索(主题名称)就是demo_cnbeta_detail),所谓Hierarchical crawling summary page就是轮流抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页中存在代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《抢当当商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,“”是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,这种类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在《分页爬行杰出亚马逊》一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明参见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。: 当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。
抓取网页新闻(如何使用类来首页的DOM树(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-22 10:06
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以安客网首页的博客标题和链接为例:
上图是Ankenet主页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224<br />///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以安客网首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
运行结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224 查看全部
抓取网页新闻(如何使用类来首页的DOM树(如最新的头条新闻))
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以安客网首页的博客标题和链接为例:

上图是Ankenet主页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224<br />///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以安客网首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
运行结果如下:

欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224
抓取网页新闻(长治seo网站如何做谷歌优化抓取网站内容三部分?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-22 03:10
网站如何做谷歌优化。我们需要了解搜索引擎是如何抓取网站内容的?长治seo网站如何优化谷歌搜索引擎抓取内容分为三个部分:网站收录、快照、长治seo网站如何优化谷歌排名。 网站收录是你对搜索引擎的评价指标网站。你网站的收录越多,搜索引擎爬取的概率就越高。对网站收录也有好处。有的站长认为只要网站收录就够了,其实不然。有的站长认为只要网站收录快,就会有排名,所以网站收录对你来说就相当于搜索引擎的评价指标。此视图适用于任何 网站。网上很多文章提到的网站收录的方法很多,但有一点是很容易被搜索引擎认为是黑帽方法,
因为一旦你边优化边做这些任务,焦作seo网站就很容易宣传哪个好,容易导致网站被搜索引擎惩罚,不太可能被搜索引擎网站。权重降低,权重降低网站,权重降低网站被搜索引擎k.1、采集网站。这种情况很常见。 采集网站一般要求你采集数据,因为当你采集数据时,对于搜索引擎来说是重复的内容,所以你采集的数据必须是所有采集,这对搜索引擎不利。如果网站采集中的数据太多,你的采集的内容对于搜索引擎来说可能没有多大意义。长治seo如何做谷歌优化网站 因为搜索引擎做不到 大概到原内容收录。如果你来采集的内容是很多重复的内容,那么搜索引擎会认为你是采集的内容,长治seo网站怎么做谷歌优化让你采集@ > 数据时, 查看全部
抓取网页新闻(长治seo网站如何做谷歌优化抓取网站内容三部分?)
网站如何做谷歌优化。我们需要了解搜索引擎是如何抓取网站内容的?长治seo网站如何优化谷歌搜索引擎抓取内容分为三个部分:网站收录、快照、长治seo网站如何优化谷歌排名。 网站收录是你对搜索引擎的评价指标网站。你网站的收录越多,搜索引擎爬取的概率就越高。对网站收录也有好处。有的站长认为只要网站收录就够了,其实不然。有的站长认为只要网站收录快,就会有排名,所以网站收录对你来说就相当于搜索引擎的评价指标。此视图适用于任何 网站。网上很多文章提到的网站收录的方法很多,但有一点是很容易被搜索引擎认为是黑帽方法,

因为一旦你边优化边做这些任务,焦作seo网站就很容易宣传哪个好,容易导致网站被搜索引擎惩罚,不太可能被搜索引擎网站。权重降低,权重降低网站,权重降低网站被搜索引擎k.1、采集网站。这种情况很常见。 采集网站一般要求你采集数据,因为当你采集数据时,对于搜索引擎来说是重复的内容,所以你采集的数据必须是所有采集,这对搜索引擎不利。如果网站采集中的数据太多,你的采集的内容对于搜索引擎来说可能没有多大意义。长治seo如何做谷歌优化网站 因为搜索引擎做不到 大概到原内容收录。如果你来采集的内容是很多重复的内容,那么搜索引擎会认为你是采集的内容,长治seo网站怎么做谷歌优化让你采集@ > 数据时,
抓取网页新闻( 如何通过Python爬虫按关键词抓取相关的新闻(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-21 17:02
如何通过Python爬虫按关键词抓取相关的新闻(一))
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你把这个地址直接放到浏览器的地址栏中,然后按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头的时候直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最后结果
专门设立的Python学习扣圈,从零基础开始到Python各个领域的实际项目教程、开发工具和电子书。与大家分享公司目前对python人才的需求和学习python的高效技能,持续更新最新教程!点击加入我们的python学习圈 查看全部
抓取网页新闻(
如何通过Python爬虫按关键词抓取相关的新闻(一))

前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。

网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你把这个地址直接放到浏览器的地址栏中,然后按回车:

恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:

所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头的时候直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。

完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最后结果
专门设立的Python学习扣圈,从零基础开始到Python各个领域的实际项目教程、开发工具和电子书。与大家分享公司目前对python人才的需求和学习python的高效技能,持续更新最新教程!点击加入我们的python学习圈
抓取网页新闻( ()返回数据(4)请求链接amp )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-21 16:23
()返回数据(4)请求链接amp
)
(3)返回数据:
(4)请求链接
机器人&entity_type=post&ts=42&_=39
分析:ts和下面是时间戳格式的,不需要,entity_type=post是必须的,可变参数是page
(4)列表页的json数据,id为详情页链接所需的符号
(5)详情页数据
获取内容:
字段:标题、作者、日期、简介、标签、内容
查看源码,数据都在var props收录的script标签中
(6)常规获取并转换成普通json数据(原因:json文件可以更好的获取某个字段的内容,如果单纯使用常规拦截的话,不容易获取或者直接获取less比)
源代码:
# -*- coding: utf-8 -*-
# @Time : 2018/7/28 17:13
# @Author : 蛇崽
# @Email : 643435675@QQ.com 1532773314218
# @File : 36kespider.py
import json
import re
import scrapy
import time
class ke36Spider(scrapy.Spider):
name = 'ke36'
allowed_domains = ['www.36kr.com']
start_urls = ['https://36kr.com/']
def parse(self, response):
print('start parse ------------------------- ')
word = '机器人'
t = time.time()
page = '1'
print('t',t)
for page in range(1,200):
burl = 'http://36kr.com/api//search/entity-search?page={}&per_page=40&keyword={}&entity_type=post'.format(page,word)
yield scrapy.Request(burl,callback=self.parse_list,dont_filter=True)
def parse_list(self,response):
res = response.body.decode('utf-8')
# print(res)
jdata = json.loads(res)
code = jdata['code']
timestamp = jdata['timestamp']
timestamp_rt = jdata['timestamp_rt']
items = jdata['data']['items']
m_id = items[0]['id']
for item in items:
m_id = item['id']
b_url = 'http://36kr.com/p/{}.html'.format(str(m_id))
# b_url = 'http://36kr.com/p/5137751.html'
yield scrapy.Request(b_url,callback=self.parse_detail,dont_filter=True)
def parse_detail(self,response):
res = response.body.decode('utf-8')
content = re.findall(r'var props=(.*?)',res)
temstr = content[0]
minfo = re.findall('\"detailArticle\|post\"\:(.*?)"hotPostsOf30',temstr)[0]
print('minfo ----------------------------- ')
minfo = minfo.rstrip(',')
jdata = json.loads(minfo)
print('j'*40)
published_at = jdata['published_at']
username = jdata['user']['name']
title = jdata['user']['title']
extraction_tags = jdata['extraction_tags']
content = jdata['content']
print(published_at,username,title,extraction_tags)
print('*'*50)
print(content) 查看全部
抓取网页新闻(
()返回数据(4)请求链接amp
)

(3)返回数据:

(4)请求链接
机器人&entity_type=post&ts=42&_=39
分析:ts和下面是时间戳格式的,不需要,entity_type=post是必须的,可变参数是page
(4)列表页的json数据,id为详情页链接所需的符号


(5)详情页数据
获取内容:

字段:标题、作者、日期、简介、标签、内容
查看源码,数据都在var props收录的script标签中
(6)常规获取并转换成普通json数据(原因:json文件可以更好的获取某个字段的内容,如果单纯使用常规拦截的话,不容易获取或者直接获取less比)

源代码:
# -*- coding: utf-8 -*-
# @Time : 2018/7/28 17:13
# @Author : 蛇崽
# @Email : 643435675@QQ.com 1532773314218
# @File : 36kespider.py
import json
import re
import scrapy
import time
class ke36Spider(scrapy.Spider):
name = 'ke36'
allowed_domains = ['www.36kr.com']
start_urls = ['https://36kr.com/']
def parse(self, response):
print('start parse ------------------------- ')
word = '机器人'
t = time.time()
page = '1'
print('t',t)
for page in range(1,200):
burl = 'http://36kr.com/api//search/entity-search?page={}&per_page=40&keyword={}&entity_type=post'.format(page,word)
yield scrapy.Request(burl,callback=self.parse_list,dont_filter=True)
def parse_list(self,response):
res = response.body.decode('utf-8')
# print(res)
jdata = json.loads(res)
code = jdata['code']
timestamp = jdata['timestamp']
timestamp_rt = jdata['timestamp_rt']
items = jdata['data']['items']
m_id = items[0]['id']
for item in items:
m_id = item['id']
b_url = 'http://36kr.com/p/{}.html'.format(str(m_id))
# b_url = 'http://36kr.com/p/5137751.html'
yield scrapy.Request(b_url,callback=self.parse_detail,dont_filter=True)
def parse_detail(self,response):
res = response.body.decode('utf-8')
content = re.findall(r'var props=(.*?)',res)
temstr = content[0]
minfo = re.findall('\"detailArticle\|post\"\:(.*?)"hotPostsOf30',temstr)[0]
print('minfo ----------------------------- ')
minfo = minfo.rstrip(',')
jdata = json.loads(minfo)
print('j'*40)
published_at = jdata['published_at']
username = jdata['user']['name']
title = jdata['user']['title']
extraction_tags = jdata['extraction_tags']
content = jdata['content']
print(published_at,username,title,extraction_tags)
print('*'*50)
print(content)
抓取网页新闻(快抓离线浏览器官方免费版破解版.70ios版使用介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-11-18 21:13
快手是快手离线浏览器的官方免费版,您可以将其作为快手离线浏览器的官方免费版使用。您可以使用它来编辑输入文档、为网页添加书签、快速抓取离线浏览器破解版官方免费版或将其用作浏览器。您还可以使用它来捕获 Flash、图片、音频等资源,保存网页快照或使用它来处理文档和添加一些附件。快抢内置数据(shu)数据库存储,再也不用担心文件杂乱难查(cha),让自己积累知识库成为可能。
快抢离线浏览器官方免费版破解版介绍
1. 数据管理简单,内存浏览。
2. 内置编辑,优化数据库搜索,简化所有复杂问题,让您轻松管理文档。
3. 完全免费,无弹窗广告,无插件和病毒,资源抓取功能。
4. 离线数据内存直接打开,不占用太多系统资源,不生成**文件,真正免费。
快抢官方免费版离线浏览器破解版功能
1. 强大的爬虫内核,让你无障碍采集网络资源。快照真实还原,瞬间精彩。内嵌HTML编辑器,操作简单快捷。只要您可以键入,就可以输入文档。增强的附件功能可以将任何类型的文件添加到数据库中。
快抢离线浏览器官方免费版破解版汇总
Quick Grab离线浏览器V4.70官方免费版是一款适用于ios版其他软件使用的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
抓取网页新闻(快抓离线浏览器官方免费版破解版.70ios版使用介绍)
快手是快手离线浏览器的官方免费版,您可以将其作为快手离线浏览器的官方免费版使用。您可以使用它来编辑输入文档、为网页添加书签、快速抓取离线浏览器破解版官方免费版或将其用作浏览器。您还可以使用它来捕获 Flash、图片、音频等资源,保存网页快照或使用它来处理文档和添加一些附件。快抢内置数据(shu)数据库存储,再也不用担心文件杂乱难查(cha),让自己积累知识库成为可能。
快抢离线浏览器官方免费版破解版介绍
1. 数据管理简单,内存浏览。
2. 内置编辑,优化数据库搜索,简化所有复杂问题,让您轻松管理文档。
3. 完全免费,无弹窗广告,无插件和病毒,资源抓取功能。
4. 离线数据内存直接打开,不占用太多系统资源,不生成**文件,真正免费。
快抢官方免费版离线浏览器破解版功能
1. 强大的爬虫内核,让你无障碍采集网络资源。快照真实还原,瞬间精彩。内嵌HTML编辑器,操作简单快捷。只要您可以键入,就可以输入文档。增强的附件功能可以将任何类型的文件添加到数据库中。
快抢离线浏览器官方免费版破解版汇总
Quick Grab离线浏览器V4.70官方免费版是一款适用于ios版其他软件使用的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
抓取网页新闻(ASO管家如何使用产品页面优化增加自然流量?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-18 21:12
普通的App运营商(或营销者)往往有过分关注排名提升的习惯,从而忽视了排名后的转化。也就是从用户看到你的 App 到你的 App 是否被下载的过程。这个过程就像一场足球比赛,对最终的下载水平至关重要。
iOS 15 通过产品页面优化和自定义产品页面将原生 A/B 测试引入 App Store。它使应用营销人员能够区分自然流量和付费流量。它不再是“千篇一律”的信息,而是向正确的受众传达正确的信息。这可以使您的转化率翻倍,这就是为什么这条新闻对您的应用商店营销如此有影响力的原因。
本文将解释如何使用产品页面优化和自定义产品页面。开始吧!
ASO管家
如何使用产品页面优化来增加有机流量?
Apple App Store 中的产品页面优化可以看作是 Google Play Experiments 的原生 A/B 测试的对应物。这将改变您在 Apple App Store 中的应用商店营销和转化率。它使 Apple 开发人员能够通过拆分测试 (a/b/c) 来试验、分析和改进他们的应用程序性能,并提供了在 App Store 的原生环境中测试假设的独特机会。
随着 iOS 15 更新,产品页面优化将允许您使用不同的应用创意(图标、屏幕截图和应用预览视频)测试默认产品页面,以确定哪种创意变体最适合您的移动应用或游戏。您将能够将产品页面(控件)的当前视觉效果与可能提高应用转化率的三种不同变体进行比较。
此外,拆分测试可以让您准确了解应用程序最吸引人的功能,并准确地向用户提供哪些设计和创意元素更有效,以及您应该将应用程序增长策略集中在哪个方向。回馈。
您最多可以运行 90 天的测试并针对特定国家/地区。
注意:如果您为所有付费流量使用自定义商店页面,您的默认 App Store 产品页面将仅接收自然流量,包括搜索和浏览流量(更多信息见下文)。
在每个产品页面优化过程中,所有创意资产都需要经过标准的 App Store 审核流程。但是,它不需要新版本发布(除非它是应用程序图标)。对于每个测试,您还需要确定为每个测试处理的流量。
产品页面优化与 Google Play 实验有何不同
在 Apple App Store 中,您将只能测试您的应用创意,而不是应用标题、副标题和描述。审查过程也区分了两家商店。
两家商店的最大变体数量相同。
如何在 App Store 中使用 iOS 15 自定义产品页面获取付费流量?
iOS 15 更新为您的应用商店营销提供终极动力,将正确的信息传递给正确的受众。换句话说,您可以拥有与您的广告驱动的意图相匹配的自定义消息。这可以使您的转化率翻倍!
不同的渠道往往会吸引不同的目标受众——具有不同人口统计、兴趣和偏好的用户。使用定制的产品页面,您可以通过向每个细分市场显示正确的信息来影响您的转化率。如果操作得当,这可以显着提高您的付费 UA 转化率和广告支出回报率。
ASO管家
iOS 15 更新将使您能够驱动多达 35 个自定义产品页面,供付费用户获取流量。每个页面可以有不同的应用预览视频、截图和宣传文字。应用程序图标将与默认应用程序商店的产品页面上的相同。所有页面都有一个唯一的 Apple App Store URL,您可以将其吸引到特定的受众。
因此,您可以更轻松地通过 UA 渠道转换用户。仅仅因为用户将有一个更加个性化的旅程,从看广告到下载应用程序,而不是“一刀切”的信息传递。
客户产品页面与 Google 的客户产品列表有何不同
在 Apple App Store 中,您最多可以拥有 35 个自定义产品页面,而 Google 端只有 5 个自定义商店列表。Google 的选项允许您仅根据位置进行定位,对于 Apple 的自定义产品页面,您也可以在一个位置拥有多个页面,但它仅适用于来自 App Store 之外的流量。
此外,由于苹果的自定义产品页面不允许您更改应用程序的图标、标题和副标题,因此谷歌的自定义商店列表在更改副本和创意方面提供了更大的灵活性。
如何通过产品页面优化在 App Store 中运行合适的原生 A/B 测试?
创建 a/b 测试后,您将能够监控和分析测试的展示次数、下载量、转化率和性能结果。这将帮助您确定应用商店产品页面的最佳变体。
在 App Store 中运行 a/b 测试之前,您应该记住拆分测试应始终本地化到相应的国家/地区。应在当前设计和变体之间明智地分配受众百分比。
深入讨论:
A/B 测试-应用雷达学院
A/B 测试 - 6 个实际步骤
在 App Store 中正确设置 A/B 测试
下面概述了在 Apple App Store 中进行 A/B 测试时需要注意的最重要的几点。
当前版本和变体之间的受众分布。在决定应该分配给每个变体的流量部分时,请记住您当前的转化率、要测试的假设、涉及的元素和统计显着性(目前在 Google Play 实验中为 90%)。
拆分测试的持续时间。让测试运行至少 7 天,以避免季节性高峰影响您的结果。测试应继续运行,直到大量潜在受众访问了所有测试变体。
每个变体的最小安装量。为了获得有关 a/b 测试性能结果的重要数据,您需要密切关注所需的安装量。它与应用程序的每日安装率高度相关。
测试本地化。强烈建议在特定国家/地区本地化您的拆分测试。全球/全球实验可能会产生误导,因为每个国家/地区的创意表现都不同。
注意:初学者的一个常见错误是在设置适当的 a/b 测试或拆分测试时忽略应用程序性能的当前状态。
在应用商店进行 a/b 测试时要记住的其他方面:
· 封闭变体可能不会带来太多学习。尽管如此,您的所有创意元素都应该经过测试,以不断改进您的商店页面。
· 统计显着性所需的最低安装量可能很高,从而使测试持续时间很长。
· 测试不会提供有关用户行为的详细信息。
· 当前的统计置信度可能不可靠。
A/B测试的常见错误:
· 假设Android 和iOS 用户的行为相似。
· 模仿你的竞争对手。
· 对测试结果的错误解释。
· 拆分测试设置不正确。
· 应用轻微的改进或基于早期测试阶段的结果。
永远没有制胜法宝,但每一个环节、每一个细节都必须以最高的标准去做!
— 来自 ASO 巴特勒 查看全部
抓取网页新闻(ASO管家如何使用产品页面优化增加自然流量?(组图))
普通的App运营商(或营销者)往往有过分关注排名提升的习惯,从而忽视了排名后的转化。也就是从用户看到你的 App 到你的 App 是否被下载的过程。这个过程就像一场足球比赛,对最终的下载水平至关重要。
iOS 15 通过产品页面优化和自定义产品页面将原生 A/B 测试引入 App Store。它使应用营销人员能够区分自然流量和付费流量。它不再是“千篇一律”的信息,而是向正确的受众传达正确的信息。这可以使您的转化率翻倍,这就是为什么这条新闻对您的应用商店营销如此有影响力的原因。
本文将解释如何使用产品页面优化和自定义产品页面。开始吧!
ASO管家
如何使用产品页面优化来增加有机流量?
Apple App Store 中的产品页面优化可以看作是 Google Play Experiments 的原生 A/B 测试的对应物。这将改变您在 Apple App Store 中的应用商店营销和转化率。它使 Apple 开发人员能够通过拆分测试 (a/b/c) 来试验、分析和改进他们的应用程序性能,并提供了在 App Store 的原生环境中测试假设的独特机会。
随着 iOS 15 更新,产品页面优化将允许您使用不同的应用创意(图标、屏幕截图和应用预览视频)测试默认产品页面,以确定哪种创意变体最适合您的移动应用或游戏。您将能够将产品页面(控件)的当前视觉效果与可能提高应用转化率的三种不同变体进行比较。
此外,拆分测试可以让您准确了解应用程序最吸引人的功能,并准确地向用户提供哪些设计和创意元素更有效,以及您应该将应用程序增长策略集中在哪个方向。回馈。
您最多可以运行 90 天的测试并针对特定国家/地区。
注意:如果您为所有付费流量使用自定义商店页面,您的默认 App Store 产品页面将仅接收自然流量,包括搜索和浏览流量(更多信息见下文)。
在每个产品页面优化过程中,所有创意资产都需要经过标准的 App Store 审核流程。但是,它不需要新版本发布(除非它是应用程序图标)。对于每个测试,您还需要确定为每个测试处理的流量。
产品页面优化与 Google Play 实验有何不同
在 Apple App Store 中,您将只能测试您的应用创意,而不是应用标题、副标题和描述。审查过程也区分了两家商店。
两家商店的最大变体数量相同。
如何在 App Store 中使用 iOS 15 自定义产品页面获取付费流量?
iOS 15 更新为您的应用商店营销提供终极动力,将正确的信息传递给正确的受众。换句话说,您可以拥有与您的广告驱动的意图相匹配的自定义消息。这可以使您的转化率翻倍!
不同的渠道往往会吸引不同的目标受众——具有不同人口统计、兴趣和偏好的用户。使用定制的产品页面,您可以通过向每个细分市场显示正确的信息来影响您的转化率。如果操作得当,这可以显着提高您的付费 UA 转化率和广告支出回报率。
ASO管家
iOS 15 更新将使您能够驱动多达 35 个自定义产品页面,供付费用户获取流量。每个页面可以有不同的应用预览视频、截图和宣传文字。应用程序图标将与默认应用程序商店的产品页面上的相同。所有页面都有一个唯一的 Apple App Store URL,您可以将其吸引到特定的受众。
因此,您可以更轻松地通过 UA 渠道转换用户。仅仅因为用户将有一个更加个性化的旅程,从看广告到下载应用程序,而不是“一刀切”的信息传递。
客户产品页面与 Google 的客户产品列表有何不同
在 Apple App Store 中,您最多可以拥有 35 个自定义产品页面,而 Google 端只有 5 个自定义商店列表。Google 的选项允许您仅根据位置进行定位,对于 Apple 的自定义产品页面,您也可以在一个位置拥有多个页面,但它仅适用于来自 App Store 之外的流量。
此外,由于苹果的自定义产品页面不允许您更改应用程序的图标、标题和副标题,因此谷歌的自定义商店列表在更改副本和创意方面提供了更大的灵活性。
如何通过产品页面优化在 App Store 中运行合适的原生 A/B 测试?
创建 a/b 测试后,您将能够监控和分析测试的展示次数、下载量、转化率和性能结果。这将帮助您确定应用商店产品页面的最佳变体。
在 App Store 中运行 a/b 测试之前,您应该记住拆分测试应始终本地化到相应的国家/地区。应在当前设计和变体之间明智地分配受众百分比。
深入讨论:
A/B 测试-应用雷达学院
A/B 测试 - 6 个实际步骤
在 App Store 中正确设置 A/B 测试
下面概述了在 Apple App Store 中进行 A/B 测试时需要注意的最重要的几点。
当前版本和变体之间的受众分布。在决定应该分配给每个变体的流量部分时,请记住您当前的转化率、要测试的假设、涉及的元素和统计显着性(目前在 Google Play 实验中为 90%)。
拆分测试的持续时间。让测试运行至少 7 天,以避免季节性高峰影响您的结果。测试应继续运行,直到大量潜在受众访问了所有测试变体。
每个变体的最小安装量。为了获得有关 a/b 测试性能结果的重要数据,您需要密切关注所需的安装量。它与应用程序的每日安装率高度相关。
测试本地化。强烈建议在特定国家/地区本地化您的拆分测试。全球/全球实验可能会产生误导,因为每个国家/地区的创意表现都不同。
注意:初学者的一个常见错误是在设置适当的 a/b 测试或拆分测试时忽略应用程序性能的当前状态。
在应用商店进行 a/b 测试时要记住的其他方面:
· 封闭变体可能不会带来太多学习。尽管如此,您的所有创意元素都应该经过测试,以不断改进您的商店页面。
· 统计显着性所需的最低安装量可能很高,从而使测试持续时间很长。
· 测试不会提供有关用户行为的详细信息。
· 当前的统计置信度可能不可靠。
A/B测试的常见错误:
· 假设Android 和iOS 用户的行为相似。
· 模仿你的竞争对手。
· 对测试结果的错误解释。
· 拆分测试设置不正确。
· 应用轻微的改进或基于早期测试阶段的结果。
永远没有制胜法宝,但每一个环节、每一个细节都必须以最高的标准去做!
— 来自 ASO 巴特勒
抓取网页新闻(影响蜘蛛匍匐并终究影响到页面录入成果主要有几个方面的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-18 09:10
影响蜘蛛爬行并最终影响页面进入结果的主要原因有几个。
1.网站 更新状态
一般来说,如果网站更新快,蜘蛛爬取网站的内容会更快。如果网站的内容长时间没有更新,蜘蛛会相应调整网站的爬取频率。更新频率对于新闻等非常重要网站。因此,每天保持一定数量的更新对于吸引蜘蛛非常重要。
2.网站内容质量
对于低质量的页面,搜索引擎一直很有影响力。因此,创造高质量的内容对于吸引蜘蛛非常重要。从这个角度来看,“内容取胜”是完全正确的。如果网页质量不高,比如同一内容的集合很多,页面的核心内容是空的,蜘蛛是不会喜欢的。
3.网站 可以正常访问吗?
网站 能否正常访问是搜索引擎的连通性。连通性要求网站不能经常访问,可能访问速度特别慢。从蜘蛛的角度来看,期望提供给搜索客户的网页是可以正常访问的网页。对于响应缓慢或经常死机的服务器,相关的网站肯定会产生负面形象并且很严重。就是逐渐减少爬行,甚至去除已经进入的页面。
在实际操作中,由于国内服务器服务比较贵,另外根据监管要求,国内网站设立要求有备案标准,需要体验网上上传备案信息的过程,还有一些中小型网站的站长可以租用国外的服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问外国服务器时,间隔
更长的原因、缓慢的访问或崩溃是不可避免的。从长远来看,是对网站的SEO功能的限制。如果你想谨慎操作一个网站,还是尽量选择国内的服务器服务,可以选择一些服务更好、界面更友好的服务器商。当时很多公司推出的云服务器都不错。挑选。
另外,搜索引擎会根据网站的摘要对网站进行评分。这个等级不能完全等于重量。但是,评分的不均会影响蜘蛛对网站策略的爬取。
在抓取频率方面,搜索引擎一般都会提供可以调整抓取频率设置的东西,SEO人员可以根据实际情况进行调整。对于服务请求较多的大规模网站,可以调整频率,减轻网站的压力。
在实际爬取过程中,如果遇到爬取无法访问的异常情况,会导致搜索引擎大幅降低网站的评分,进而影响爬取、索引等一系列SEO功能, 并排序。毕竟会反映流量损失。
爬行异常的原因有很多。比如服务器不稳定,服务器一直超载,可能是协议有问题。因此,需要网站运维人员持续监控网站的运行,确保网站的稳定运行。在协议设备方面,需要防止一些初级故障,例如Disallow of Robots的设置故障。有一次,一位公司经理咨询了SEO人员,要求他们请外部开发人员做好网站,但在搜索引擎中找不到。原因是什么。SEO人员直接在URL和地址栏中输入了他的网站Robots地址,意外发现(Disallow命令)蜘蛛爬行停止了!
关于网站无法访问,还有其他可能。例如网络运营商异常,即蜘蛛无法通过电信或网通等价劳动力访问网站;并且DNS异常,即蜘蛛无法正常解析网站IP,可能是地址错误,也可能是被域名提供商屏蔽了。在这种情况下,您需要联系域名提供商。网页上也可能有死链接。例如,该页面当时已失败或出错。部分网页可能已批量下线。在这种情况下,这样做的方法是提交一个死链接声明;如果是旧的 uRL 更改,如果 URL 无效且无法访问,则设置 301 重定向将旧 URL 和相关权重转移到新页面。
对于检索到的数据,蜘蛛建立一个数据库。在这个链接中,搜索引擎会根据一些标准来判断该链接的重要性。一般来说,判断的标准是:内容是否为原创,如果是,则加权;主要内容是否明显,即核心内容是否突出,如果突出则加权;内容是否丰富,如果内容很丰富,会被加权;用户体验是否好,比如页面循环多,广告加载少等,如果是,会加权等。
因此,我们需要在网站的日常运营中遵守以下准则。
(1)请勿抄袭。既然共同的内容是所有搜索引擎公司都喜欢的,互联网鼓励原创。很多互联网公司希望在采集网页内容后整理自己的网站。从 SEO 的角度来看,这实际上是一种不良行为。
(2)在网站内容策划的时候,一定要坚持主题内容突出,也就是让搜索引擎爬过来知道网页要表达什么内容,而不是在一堆内容中判断网站是什么业务,主题不突出,很多网站中都有典型的操作混乱的例子,比如一些小说网站, 800字的章节分为8个每页100字左右,页面的其余部分收录各种广告和各种不相关的内容信息,还有网站,主要内容是框架结构或AIAX结构,蜘蛛可以爬的信息都是无关的内容。
现在一些大型门户网站网站从收入来看,还是有很多广告的。作为SEO人员,您需要考虑这个问题。
(4) 坚持网页内容的可访问性。有的网页内容很多,但使用js、AJAX等方式出现,搜索引擎无法识别,网页内容空洞短小。 . 使网页的评分大大降低。
另外,在链接的重要性方面,有两个重要的标准:从目录层面,坚持浅优先标准;从内部连锁规划,坚持热门页面优先标准。
所谓浅优先,是指搜索引擎在处理新链接,判断链接的重要性时,会优先考虑网址。更多的页面,即离uRL排列更接近首页域名的页面。因此,SEO在做重要的页面优化时,一定要注意扁平化原则,尽量缩短URL的中间链接。
既然给了浅优先级,那么能不能把所有的页面都平铺在网站的根目录下,然后选做SEO功能呢?一定不是,首先,优先级是一个相对的概念,如果你把所有的内容都放在根目录下,不管什么优先级,重要的内容和不重要的内容没有区别。另外,从SEO的角度来看,URL爬取后,用于分析网站的结构。URL组成之后,就可以大致确定内容的分组了。SEO人员可以通过URL的组合来完成关键词和关键词。网页的排列。 查看全部
抓取网页新闻(影响蜘蛛匍匐并终究影响到页面录入成果主要有几个方面的原因)
影响蜘蛛爬行并最终影响页面进入结果的主要原因有几个。
1.网站 更新状态
一般来说,如果网站更新快,蜘蛛爬取网站的内容会更快。如果网站的内容长时间没有更新,蜘蛛会相应调整网站的爬取频率。更新频率对于新闻等非常重要网站。因此,每天保持一定数量的更新对于吸引蜘蛛非常重要。
2.网站内容质量
对于低质量的页面,搜索引擎一直很有影响力。因此,创造高质量的内容对于吸引蜘蛛非常重要。从这个角度来看,“内容取胜”是完全正确的。如果网页质量不高,比如同一内容的集合很多,页面的核心内容是空的,蜘蛛是不会喜欢的。
3.网站 可以正常访问吗?
网站 能否正常访问是搜索引擎的连通性。连通性要求网站不能经常访问,可能访问速度特别慢。从蜘蛛的角度来看,期望提供给搜索客户的网页是可以正常访问的网页。对于响应缓慢或经常死机的服务器,相关的网站肯定会产生负面形象并且很严重。就是逐渐减少爬行,甚至去除已经进入的页面。
在实际操作中,由于国内服务器服务比较贵,另外根据监管要求,国内网站设立要求有备案标准,需要体验网上上传备案信息的过程,还有一些中小型网站的站长可以租用国外的服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问外国服务器时,间隔

更长的原因、缓慢的访问或崩溃是不可避免的。从长远来看,是对网站的SEO功能的限制。如果你想谨慎操作一个网站,还是尽量选择国内的服务器服务,可以选择一些服务更好、界面更友好的服务器商。当时很多公司推出的云服务器都不错。挑选。
另外,搜索引擎会根据网站的摘要对网站进行评分。这个等级不能完全等于重量。但是,评分的不均会影响蜘蛛对网站策略的爬取。
在抓取频率方面,搜索引擎一般都会提供可以调整抓取频率设置的东西,SEO人员可以根据实际情况进行调整。对于服务请求较多的大规模网站,可以调整频率,减轻网站的压力。
在实际爬取过程中,如果遇到爬取无法访问的异常情况,会导致搜索引擎大幅降低网站的评分,进而影响爬取、索引等一系列SEO功能, 并排序。毕竟会反映流量损失。
爬行异常的原因有很多。比如服务器不稳定,服务器一直超载,可能是协议有问题。因此,需要网站运维人员持续监控网站的运行,确保网站的稳定运行。在协议设备方面,需要防止一些初级故障,例如Disallow of Robots的设置故障。有一次,一位公司经理咨询了SEO人员,要求他们请外部开发人员做好网站,但在搜索引擎中找不到。原因是什么。SEO人员直接在URL和地址栏中输入了他的网站Robots地址,意外发现(Disallow命令)蜘蛛爬行停止了!
关于网站无法访问,还有其他可能。例如网络运营商异常,即蜘蛛无法通过电信或网通等价劳动力访问网站;并且DNS异常,即蜘蛛无法正常解析网站IP,可能是地址错误,也可能是被域名提供商屏蔽了。在这种情况下,您需要联系域名提供商。网页上也可能有死链接。例如,该页面当时已失败或出错。部分网页可能已批量下线。在这种情况下,这样做的方法是提交一个死链接声明;如果是旧的 uRL 更改,如果 URL 无效且无法访问,则设置 301 重定向将旧 URL 和相关权重转移到新页面。
对于检索到的数据,蜘蛛建立一个数据库。在这个链接中,搜索引擎会根据一些标准来判断该链接的重要性。一般来说,判断的标准是:内容是否为原创,如果是,则加权;主要内容是否明显,即核心内容是否突出,如果突出则加权;内容是否丰富,如果内容很丰富,会被加权;用户体验是否好,比如页面循环多,广告加载少等,如果是,会加权等。

因此,我们需要在网站的日常运营中遵守以下准则。
(1)请勿抄袭。既然共同的内容是所有搜索引擎公司都喜欢的,互联网鼓励原创。很多互联网公司希望在采集网页内容后整理自己的网站。从 SEO 的角度来看,这实际上是一种不良行为。
(2)在网站内容策划的时候,一定要坚持主题内容突出,也就是让搜索引擎爬过来知道网页要表达什么内容,而不是在一堆内容中判断网站是什么业务,主题不突出,很多网站中都有典型的操作混乱的例子,比如一些小说网站, 800字的章节分为8个每页100字左右,页面的其余部分收录各种广告和各种不相关的内容信息,还有网站,主要内容是框架结构或AIAX结构,蜘蛛可以爬的信息都是无关的内容。
现在一些大型门户网站网站从收入来看,还是有很多广告的。作为SEO人员,您需要考虑这个问题。
(4) 坚持网页内容的可访问性。有的网页内容很多,但使用js、AJAX等方式出现,搜索引擎无法识别,网页内容空洞短小。 . 使网页的评分大大降低。
另外,在链接的重要性方面,有两个重要的标准:从目录层面,坚持浅优先标准;从内部连锁规划,坚持热门页面优先标准。
所谓浅优先,是指搜索引擎在处理新链接,判断链接的重要性时,会优先考虑网址。更多的页面,即离uRL排列更接近首页域名的页面。因此,SEO在做重要的页面优化时,一定要注意扁平化原则,尽量缩短URL的中间链接。
既然给了浅优先级,那么能不能把所有的页面都平铺在网站的根目录下,然后选做SEO功能呢?一定不是,首先,优先级是一个相对的概念,如果你把所有的内容都放在根目录下,不管什么优先级,重要的内容和不重要的内容没有区别。另外,从SEO的角度来看,URL爬取后,用于分析网站的结构。URL组成之后,就可以大致确定内容的分组了。SEO人员可以通过URL的组合来完成关键词和关键词。网页的排列。
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-18 05:10
你的低价票被“虫子”吃掉了
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。
本报记者傅丽丽 查看全部
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
你的低价票被“虫子”吃掉了

资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。
本报记者傅丽丽
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-29 00:02
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(Android客户端如何实现从各大网抓取新闻并解析网页的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-29 00:01
)
如何从主要网站捕获新闻并将其格式化到我们的新闻客户端?
Android 客户端抓取和解析网页的方法有两种:
一、使用jsoup
没仔细研究,网上也有类似的,可以参考这两兄弟:
二、使用htmlparser
我的项目中使用了htmlparser,抓取并解析腾讯新闻,代码如下:
<p>Java代码 收藏代码
public class NetUtil {
public static List DATALIST = new ArrayList();
public static String[][] CHANNEL_URL = new String[][] {
new String[]{"http://news.qq.com/world_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/society_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
};
public static int getTechNews(List techData, int cId) {
int result = 0;
try {
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
try {
String textstr = node.getChildren().elementAt(j).toHtml();
if (textstr.trim().length() > 0) {
NodeFilter subFilter = new TagNameFilter("p");
Parser subParser = new Parser();
subParser.setResource(textstr);
NodeList subList = subParser.extractAllNodesThatMatch(subFilter);
NodeFilter titleStrFilter = new AndFilter(new TagNameFilter("a"),
new HasAttributeFilter("class", "linkto"));
Parser titleStrParser = new Parser();
titleStrParser.setResource(textstr);
NodeList titleStrList = titleStrParser.extractAllNodesThatMatch(titleStrFilter);
int linkstart = titleStrList.toHtml().indexOf("href=\"");
int linkend = titleStrList.toHtml().indexOf("\">");
int titleend = titleStrList.toHtml().indexOf("</a>");
String link = CHANNEL_URL[cId][1]+titleStrList.toHtml().substring(linkstart+6, linkend);
String title = titleStrList.toHtml().substring(linkend+2, titleend);
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
newsBrief.setSummary(subList.asString());
techData.add(newsBrief);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int getTechNews2(List techData, int cId) {
int result = 0;
try {
// 查询http://tech.qq.com/tech_yejie.htm 页面 滚动新闻的 标签 以及ID
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
// 获取匹配的fileter的节点
NodeList list = parser.extractAllNodesThatMatch(filter);
StringBuilder NewsStr = new StringBuilder("");// 新闻表格字符串
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
String textstr = node.getChildren().elementAt(j).toHtml()
.trim();
if (textstr.length() > 0) {
int linkbegin = 0, linkend = 0, titlebegin = 0, titleend = 0;
while (true) {
linkbegin = textstr.indexOf("href=", titleend);// 截取链接字符串起始位置
// 如果不存在 href了 也就结束了
if (linkbegin < 0)
break;
linkend = textstr.indexOf("\">", linkbegin);// 截取链接字符串结束位置
String sublink = textstr.substring(linkbegin + 6,linkend);
String link = CHANNEL_URL[cId][1] + sublink;
titlebegin = textstr.indexOf("\">", linkend);
titleend = textstr.indexOf("</a>", titlebegin);
String title = textstr.substring(titlebegin + 2,titleend);
NewsStr.append("\r\n\r\n\t<a target=\"_blank\" href=\""/span
+ link + span class="hljs-string""\">");
NewsStr.append(title);
NewsStr.append("</a>");
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
techData.add(newsBrief);
}
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int parserURL(String url,NewsBrief newsBrief) {
int result = 0;
try {
Parser parser = new Parser(url);
NodeFilter contentFilter = new AndFilter(
new TagNameFilter("div"),
new HasAttributeFilter("id","Cnt-Main-Article-QQ"));
NodeFilter newsdateFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"article-time"));
NodeFilter newsauthorFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"color-a-1"));
NodeFilter imgUrlFilter = new TagNameFilter("IMG");
newsBrief.setContent(parserContent(contentFilter,parser));
parser.reset(); // 记得每次用完parser后,要重置一次parser。要不然就得不到我们想要的内容了。
newsBrief.setPubDate(parserDate(newsdateFilter,parser));
parser.reset();
newsBrief.setSource(parserAuthor(newsauthorFilter, parser));
parser.reset();
newsBrief.setImgUrl(parserImgUrl(contentFilter,imgUrlFilter, parser));
} catch (Exception e) {
result=1;
e.printStackTrace();
}
return result;
}
private static String parserContent(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList contentList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = contentList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserDate(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList datetList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = datetList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserAuthor(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList authorList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = authorList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static List parserImgUrl(NodeFilter bodyfilter,NodeFilter filter, Parser parser) {
List reslut = new ArrayList();
try {
NodeList bodyList = (NodeList) parser.parse(bodyfilter);
Parser imgParser = new Parser();
imgParser.setResource(bodyList.toHtml());
NodeList imgList = imgParser.extractAllNodesThatMatch(filter);
String bodyString = imgList.toHtml();
//正文包含图片
if (bodyString.contains(" 查看全部
抓取网页新闻(Android客户端如何实现从各大网抓取新闻并解析网页的方法
)
如何从主要网站捕获新闻并将其格式化到我们的新闻客户端?
Android 客户端抓取和解析网页的方法有两种:
一、使用jsoup
没仔细研究,网上也有类似的,可以参考这两兄弟:
二、使用htmlparser
我的项目中使用了htmlparser,抓取并解析腾讯新闻,代码如下:
<p>Java代码 收藏代码
public class NetUtil {
public static List DATALIST = new ArrayList();
public static String[][] CHANNEL_URL = new String[][] {
new String[]{"http://news.qq.com/world_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/society_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
new String[]{"http://news.qq.com/china_index.shtml","http://news.qq.com"},
};
public static int getTechNews(List techData, int cId) {
int result = 0;
try {
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
NodeList list = parser.extractAllNodesThatMatch(filter);
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
try {
String textstr = node.getChildren().elementAt(j).toHtml();
if (textstr.trim().length() > 0) {
NodeFilter subFilter = new TagNameFilter("p");
Parser subParser = new Parser();
subParser.setResource(textstr);
NodeList subList = subParser.extractAllNodesThatMatch(subFilter);
NodeFilter titleStrFilter = new AndFilter(new TagNameFilter("a"),
new HasAttributeFilter("class", "linkto"));
Parser titleStrParser = new Parser();
titleStrParser.setResource(textstr);
NodeList titleStrList = titleStrParser.extractAllNodesThatMatch(titleStrFilter);
int linkstart = titleStrList.toHtml().indexOf("href=\"");
int linkend = titleStrList.toHtml().indexOf("\">");
int titleend = titleStrList.toHtml().indexOf("</a>");
String link = CHANNEL_URL[cId][1]+titleStrList.toHtml().substring(linkstart+6, linkend);
String title = titleStrList.toHtml().substring(linkend+2, titleend);
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
newsBrief.setSummary(subList.asString());
techData.add(newsBrief);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int getTechNews2(List techData, int cId) {
int result = 0;
try {
// 查询http://tech.qq.com/tech_yejie.htm 页面 滚动新闻的 标签 以及ID
NodeFilter filter = new AndFilter(new TagNameFilter("div"),
new HasAttributeFilter("id", "listZone"));
Parser parser = new Parser();
parser.setURL(CHANNEL_URL[cId][0]);
parser.setEncoding(parser.getEncoding());
// 获取匹配的fileter的节点
NodeList list = parser.extractAllNodesThatMatch(filter);
StringBuilder NewsStr = new StringBuilder("");// 新闻表格字符串
for (int i = 0; i < list.size(); i++) {
Tag node = (Tag) list.elementAt(i);
for (int j = 0; j < node.getChildren().size(); j++) {
String textstr = node.getChildren().elementAt(j).toHtml()
.trim();
if (textstr.length() > 0) {
int linkbegin = 0, linkend = 0, titlebegin = 0, titleend = 0;
while (true) {
linkbegin = textstr.indexOf("href=", titleend);// 截取链接字符串起始位置
// 如果不存在 href了 也就结束了
if (linkbegin < 0)
break;
linkend = textstr.indexOf("\">", linkbegin);// 截取链接字符串结束位置
String sublink = textstr.substring(linkbegin + 6,linkend);
String link = CHANNEL_URL[cId][1] + sublink;
titlebegin = textstr.indexOf("\">", linkend);
titleend = textstr.indexOf("</a>", titlebegin);
String title = textstr.substring(titlebegin + 2,titleend);
NewsStr.append("\r\n\r\n\t<a target=\"_blank\" href=\""/span
+ link + span class="hljs-string""\">");
NewsStr.append(title);
NewsStr.append("</a>");
NewsBrief newsBrief = new NewsBrief();
newsBrief.setTitle(title);
newsBrief.setUrl(link);
techData.add(newsBrief);
}
}
}
}
} catch (Exception e) {
result = 1;
e.printStackTrace();
}
return result;
}
public static int parserURL(String url,NewsBrief newsBrief) {
int result = 0;
try {
Parser parser = new Parser(url);
NodeFilter contentFilter = new AndFilter(
new TagNameFilter("div"),
new HasAttributeFilter("id","Cnt-Main-Article-QQ"));
NodeFilter newsdateFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"article-time"));
NodeFilter newsauthorFilter = new AndFilter(
new TagNameFilter("span"),
new HasAttributeFilter("class",
"color-a-1"));
NodeFilter imgUrlFilter = new TagNameFilter("IMG");
newsBrief.setContent(parserContent(contentFilter,parser));
parser.reset(); // 记得每次用完parser后,要重置一次parser。要不然就得不到我们想要的内容了。
newsBrief.setPubDate(parserDate(newsdateFilter,parser));
parser.reset();
newsBrief.setSource(parserAuthor(newsauthorFilter, parser));
parser.reset();
newsBrief.setImgUrl(parserImgUrl(contentFilter,imgUrlFilter, parser));
} catch (Exception e) {
result=1;
e.printStackTrace();
}
return result;
}
private static String parserContent(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList contentList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = contentList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserDate(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList datetList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = datetList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static String parserAuthor(NodeFilter filter, Parser parser) {
String reslut = "";
try {
NodeList authorList = (NodeList) parser.parse(filter);
// 将DIV中的标签都 去掉只留正文
reslut = authorList.asString();
} catch (Exception e) {
e.printStackTrace();
}
return reslut;
}
private static List parserImgUrl(NodeFilter bodyfilter,NodeFilter filter, Parser parser) {
List reslut = new ArrayList();
try {
NodeList bodyList = (NodeList) parser.parse(bodyfilter);
Parser imgParser = new Parser();
imgParser.setResource(bodyList.toHtml());
NodeList imgList = imgParser.extractAllNodesThatMatch(filter);
String bodyString = imgList.toHtml();
//正文包含图片
if (bodyString.contains("
抓取网页新闻(关于大数据时代的数据挖掘(1)为什么要进行数据挖掘 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-26 18:22
)
关于大数据时代的数据挖掘
(1)为什么要进行数据挖掘:有价值的数据不是存储在本地,而是分布在广阔的网络世界中。我们需要挖掘网络世界中有价值的数据供我们自己使用
(2)非结构化数据:网络中的大部分数据都是非结构化数据,比如网页中的数据,没有固定的格式
(3)Unstructured Data Mining--ETL:三步:抽取、转换、加载。经过这三步,就可以访问数据了
关于网络爬虫
(1)可以从主要的网站中抓取大量数据,并进行结构化,最后存储到本地数据库中,供我们自己索引
(2)网络爬虫框架:
比如你电脑上的浏览器就是web连接器,一个网站的网页就是web服务器。在浏览器中输入网站的URL就是向web服务器发送请求。适配器在浏览器中显示页面作为响应。网络爬虫通过网络适配器给出的响应,找到相关数据进行爬取,对数据进行分析得到结构化数据,最终存储在数据中心以备使用
网络爬虫实战(新闻爬虫)
项目描述:通过python网络爬虫抓取新浪网国内新闻栏目的所有新闻信息,包括标题、新闻来源、时间、文章内容、编辑和评论数,最后做成表格表格存储在excel表格中
项目工具:python、谷歌浏览器
所需模块:请求、重新、BeautifulSoup4、datetime、json
具体步骤:
(1)观察网页:打开新浪国内新闻页面。在页面空白处右击,点击底部“检查”选项。当前开发者工具查看界面网页出现,“网络”一栏可以作为我们的“监听器”,我们可以查看当前页面中web服务器返回的响应内容,响应内容分为很多类,比如JS就是制作的内容通过Javascripts,css是网页装饰器,doc是网页文件的内容。等等,我们这里要抓取的新闻信息一般都放在doc里面,在doc类型中找到名为china的文件就是我们国内的新闻正在寻找,其内容可以在“响应”响应中找到。
(2)获取网页整体资源--request:request模块是一个用于获取网络资源的模块,可以使用REST操作,即post、put、get、delete等操作来访问网络资源.阅读一网页的web资源的简单代码如下:
进口请求
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
打印(res.text)
其中res.encoding='utf-8'是将编码格式转换成中文格式,res.text是显示获取到的资源的内容
(3)获取详细资源-BeautifulSoup4:BeautifulSoup4模块可以根据Document Object Model Tree对获取的网络资源进行分层,然后使用select方法获取每一层的详细资源。Document Object Model Tree图形如下面所述 :
使用 BeautifulSoup4 提取网络资源,以便从中提取细节:
进口请求
从 bs4 导入 BeautifulSoup
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
打印(汤.文本)
下面是res.text和soup.text的区别说明。前者中,res是网页的响应内容,text是用来检索网页响应的内容。在后者中,汤是 BeautifulSoup 对象。这里的文字是去除响应内容中的标签。喜欢
(4)BeautifulSoup的select方法:可以针对不同的tag取出tag的内容
1.找到收录h1标签的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
2.找到收录 a 标签的元素:
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
3.找到id为title的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('#title')
打印(标题)
4.找到类为链接的元素:
汤 = BeautifulSoup(html_sample)
链接 = 汤.select('.link')
打印(链接)
5.获取元素中的属性--获取超链接中herf属性的内容
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
对于 alink 中的链接:
打印(链接['herf'])
BeautifulSoup的select方法获取的内容是列表的形式。如果要操作内容,必须取出列表元素。如果要获取类为 link 的元素的文本内容,可以使用 print(link[0].text )
(5) 做一个简单的爬虫
首先,进入新浪新闻的国内新闻页面,进入该页面的开发者界面,随意查看一条新闻的元素,可以发现这些新闻都位于一类news-item
里面,所以选择这个类,遍历内容,得到所有的新闻内容
然后,查看每条新闻的具体内容,其中title在h2标签中,时间用class='time'标注,URL在第一个a标签中
最后,通过这些标签过滤所有特定内容。代码显示如下:
进口请求
从 bs4 导入 BeautifulSoup
网址 ='#39;
res = requests.get(url)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
# 打印(汤)
对于soup.select('.news-item') 中的新内容:
如果 len(new.select('h2'))> 0:
h2 = new.select('h2')[0].text
time = new.select('.time')[0].text
a = new.select('a')[0]['href']
打印(h2,时间,一)
得到的结果如下:
一图读懂:多方整治“天价片酬” 演员最高拿多少? 8月15日 09:12 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3527505.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
中国核潜艇极限长航背后:艇员出航前写遗书拍遗像 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3450991.shtml
天津村庄遭龙卷风侵袭 砖房被吹塌大树拦腰折断 8月15日 08:54 http://slide.news.sina.com.cn/c/slide_1_86058_311891.html
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
今天是日本战败投降纪念日:当年日本曾想靠它翻盘 8月15日 08:21 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3417423.shtml
港媒:若美台不理“不得”警告 大陆将以行动说话 8月15日 08:19 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3399386.shtml
进口博览会期间上海将对网约车实行临时价格干预 8月15日 08:15 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3178883.shtml
台“皮带大王”厦门公司倒闭拍卖 员工拿千万欠薪 8月15日 08:11 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193973.shtml
张广宁任广东肇庆市委副书记(图/简历) 8月15日 07:59 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193541.shtml 查看全部
抓取网页新闻(关于大数据时代的数据挖掘(1)为什么要进行数据挖掘
)
关于大数据时代的数据挖掘
(1)为什么要进行数据挖掘:有价值的数据不是存储在本地,而是分布在广阔的网络世界中。我们需要挖掘网络世界中有价值的数据供我们自己使用
(2)非结构化数据:网络中的大部分数据都是非结构化数据,比如网页中的数据,没有固定的格式
(3)Unstructured Data Mining--ETL:三步:抽取、转换、加载。经过这三步,就可以访问数据了
关于网络爬虫
(1)可以从主要的网站中抓取大量数据,并进行结构化,最后存储到本地数据库中,供我们自己索引
(2)网络爬虫框架:
比如你电脑上的浏览器就是web连接器,一个网站的网页就是web服务器。在浏览器中输入网站的URL就是向web服务器发送请求。适配器在浏览器中显示页面作为响应。网络爬虫通过网络适配器给出的响应,找到相关数据进行爬取,对数据进行分析得到结构化数据,最终存储在数据中心以备使用
网络爬虫实战(新闻爬虫)
项目描述:通过python网络爬虫抓取新浪网国内新闻栏目的所有新闻信息,包括标题、新闻来源、时间、文章内容、编辑和评论数,最后做成表格表格存储在excel表格中
项目工具:python、谷歌浏览器
所需模块:请求、重新、BeautifulSoup4、datetime、json
具体步骤:
(1)观察网页:打开新浪国内新闻页面。在页面空白处右击,点击底部“检查”选项。当前开发者工具查看界面网页出现,“网络”一栏可以作为我们的“监听器”,我们可以查看当前页面中web服务器返回的响应内容,响应内容分为很多类,比如JS就是制作的内容通过Javascripts,css是网页装饰器,doc是网页文件的内容。等等,我们这里要抓取的新闻信息一般都放在doc里面,在doc类型中找到名为china的文件就是我们国内的新闻正在寻找,其内容可以在“响应”响应中找到。
(2)获取网页整体资源--request:request模块是一个用于获取网络资源的模块,可以使用REST操作,即post、put、get、delete等操作来访问网络资源.阅读一网页的web资源的简单代码如下:
进口请求
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
打印(res.text)
其中res.encoding='utf-8'是将编码格式转换成中文格式,res.text是显示获取到的资源的内容
(3)获取详细资源-BeautifulSoup4:BeautifulSoup4模块可以根据Document Object Model Tree对获取的网络资源进行分层,然后使用select方法获取每一层的详细资源。Document Object Model Tree图形如下面所述 :
使用 BeautifulSoup4 提取网络资源,以便从中提取细节:
进口请求
从 bs4 导入 BeautifulSoup
新闻网址 ='#39;
res = requests.get(newsurl)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
打印(汤.文本)
下面是res.text和soup.text的区别说明。前者中,res是网页的响应内容,text是用来检索网页响应的内容。在后者中,汤是 BeautifulSoup 对象。这里的文字是去除响应内容中的标签。喜欢
(4)BeautifulSoup的select方法:可以针对不同的tag取出tag的内容
1.找到收录h1标签的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('h1')
打印(标题)
2.找到收录 a 标签的元素:
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
打印(链接)
3.找到id为title的元素:
汤 = BeautifulSoup(html_sample)
标题 = 汤.select('#title')
打印(标题)
4.找到类为链接的元素:
汤 = BeautifulSoup(html_sample)
链接 = 汤.select('.link')
打印(链接)
5.获取元素中的属性--获取超链接中herf属性的内容
汤 = BeautifulSoup(html_sample)
alink = 汤.select('a')
对于 alink 中的链接:
打印(链接['herf'])
BeautifulSoup的select方法获取的内容是列表的形式。如果要操作内容,必须取出列表元素。如果要获取类为 link 的元素的文本内容,可以使用 print(link[0].text )
(5) 做一个简单的爬虫
首先,进入新浪新闻的国内新闻页面,进入该页面的开发者界面,随意查看一条新闻的元素,可以发现这些新闻都位于一类news-item
里面,所以选择这个类,遍历内容,得到所有的新闻内容
然后,查看每条新闻的具体内容,其中title在h2标签中,时间用class='time'标注,URL在第一个a标签中
最后,通过这些标签过滤所有特定内容。代码显示如下:
进口请求
从 bs4 导入 BeautifulSoup
网址 ='#39;
res = requests.get(url)
res.encoding ='utf-8'
汤 = BeautifulSoup(res.text)
# 打印(汤)
对于soup.select('.news-item') 中的新内容:
如果 len(new.select('h2'))> 0:
h2 = new.select('h2')[0].text
time = new.select('.time')[0].text
a = new.select('a')[0]['href']
打印(h2,时间,一)
得到的结果如下:
一图读懂:多方整治“天价片酬” 演员最高拿多少? 8月15日 09:12 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3527505.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
上海商店招牌脱落致3死 两人被采取刑事强制措施 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3419248.shtml
中国核潜艇极限长航背后:艇员出航前写遗书拍遗像 8月15日 08:56 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3450991.shtml
天津村庄遭龙卷风侵袭 砖房被吹塌大树拦腰折断 8月15日 08:54 http://slide.news.sina.com.cn/c/slide_1_86058_311891.html
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
珍贵视频:沈阳审判日本战犯全认罪 跪地痛哭谢罪 8月15日 08:40 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3366825.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
众筹6万治疗费被平台索5%“税款”慈善应该缴费吗 8月15日 08:23 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3227219.shtml
今天是日本战败投降纪念日:当年日本曾想靠它翻盘 8月15日 08:21 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3417423.shtml
港媒:若美台不理“不得”警告 大陆将以行动说话 8月15日 08:19 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3399386.shtml
进口博览会期间上海将对网约车实行临时价格干预 8月15日 08:15 http://news.sina.com.cn/c/2018-08-15/doc-ihhtfwqr3178883.shtml
台“皮带大王”厦门公司倒闭拍卖 员工拿千万欠薪 8月15日 08:11 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193973.shtml
张广宁任广东肇庆市委副书记(图/简历) 8月15日 07:59 http://news.sina.com.cn/o/2018-08-15/doc-ihhtfwqr3193541.shtml
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-26 18:20
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方式可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有很长的评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法还有一个默认参数noise_mode_list,用于对网页进行预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
查看全部
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方式可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有很长的评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法还有一个默认参数noise_mode_list,用于对网页进行预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
抓取网页新闻(新闻网页抽取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-26 18:15
基于熵的新闻网页提取方法研究朱宏灿龙朝阳(湘潭大学管理学院湘潭411105) [摘要为了减少或消除新闻中大量非主题信息的干扰网站,提出新闻网页提取方法利用基于熵的计算和DOM树的知识从新闻网页中提取主题文档和相关链接[关键词信息提取信息块DOM [分类] number Entropy Based Approach NewsArticle Extraction from ebPage Zhu Hongcan ongZhaoyang anagement School niversity, iangtan411105, China)实验几个新的 ebsites 显示实际。
搜索引擎仍会搜索此信息。导致存储和计算量增加的eb页面的内容提取是搜索引擎中非常重要的部分。目前,要从半结构化网页中提取信息,需要建立第一个信息单元。. 可以对分割后的信息块进行信息提取或其他处理,减少引擎的搜索空间,结果更加准确。[文献]提出了一种提取新闻网页文本的方法,但该方法仅适用于网页中所有文本信息都放在一个表格中的情况。实际新闻页面中与话题相关的信息还包括标题、相关链接等。基于文档 ISDOM 方法,本文提出了一个更合适的新熵计算公式,应用信息论和页面的DOM树等相关知识。根据信函新闻页面的DOM树结构观察,新闻页面一般有以下内容(1)与新闻主题相关,包括新闻标题、新闻正文、时间记者、链接到与主题相关的相关文档等)。(2)与新闻话题无关的信息包括网站模板定义的导航栏、广告信息等出现在同一网站不同页面的信息块。信息块指示页面的主题和其他相关信息。这些信息块的集合和相应的关联构成了页面的信息结构,是新浪网页内容的一部分。信息块中收录的内容为指南,信息块中收录的内容为新闻正文。块中收录的内容是与主题相关的链接信息。区块中收录的内容是与话题无关的广告链接。
它们通常是一组具有较长链接文本的密切相关的链接兄弟,收录标签名称信息、属性以及一对标签之间的所有字符(表示为innertext)。根据DOM的定义,节点内文包括以节点为根节点的子树中的所有字符。页面根节点的内部文本包括 shift 标记后的所有单词除外。页面上的文字可以分为两类:一类是链接文字,一类是链接后的文字。本文从根节点的内文中提取特征词。特征词是对中文文档有意义的关键字或词组。处理中文文档后,提取对应的关键词。
每个特征词的熵值计算公式如下: nkEN wijlognkwij Dk 为网站 wijlognwij,其中wij 1页面部分DOM树信息结构是基于熵的新闻网页提取算法.网站中新闻网页2) 相关话题信息块提取、冗余信息块去除、从DOM树中提取信息 开始时从网上抓取网页,基于DOM构建。必须先对网页进行预处理。把它变成一个标准化的网页。标准化的网页可以根据其中的 HTML 标签轻松地将其表示为一棵树。DOM树中的每个节点根据定义表示页面中的一个标记ij就是整个网站页面。, 该公式考虑了不同网站中使用的不同模板。由于网页内容因模板不同而具有很强的主观性,因此在一个网站中重复出现的冗余信息块可能不会在其他网站中出现。该公式定义了本文中的特征词ti ti。) 表示特征词 ti 的重要性。对于用户来说,特征词分布在越多的页面上越均匀,收录的信息越少,观点的内容就越少。这是网页的链接描述文档与其原创文档之间必不可少的区域。1)原创文档 链接文本中没有与链接文本匹配的特征词,这并不意味着链接文本最大( ENk:链接文本用于医学和健康,所链接的网页可能会介绍某种疾病的预防和治疗。此时AP2)在原创文档中。链接文本与较少的特征词匹配。此时AP表示链接文本中收录的信息量较小,显然与实际不符。根据以上分析,本文将链接文字改为max(ENk 83333ATI max(ENk 66667term weighted value.
根据定义,公式之间存在如下关系。如果tj均匀分布在每个网站 tj中,信息量小,如果tj均匀分布在一个网站的每个网页上,计算两个公式,此时, tj 信息 tj) 较低;而公式2计算出的权重较大(特征词tj具有较大的特征词信息,两个公式的计算都是根据提取的特征词信息,计算出三种特殊的Content Info rm ionIndex II和扩展信息)表示信息块中收录的信息量链接文本值(Anchor Text Index,ATI)表示链接文本的重要性结构信息索引,SII) 指出DOM树中每个节点的子节点分布的内容信息值。计算每个特征词的熵值后,计算节点innertext所有特殊词的熵值的平均值作为节点N的内容信息值,避免除以0。ATI计算量反链接文本中收录的信息,反映超链接链接的页面是否与主页面相关。如果是ATI,链接文本和链接的网页收录大量信息,与主题相关度高。网站中每个页面上均匀分布的广告链接和导航栏中的菜单链接的ATI值通常很小。与AP相比,如果匹配词为term1,则不再需要计算ATI。结构信息值SII的计算是基于节点子节点特征值的分布。但是,有一些带有信息的 HTML 标签,例如 SCRIPT 标记为垃圾邮件标签,应该删除。
将节点 N 的特征值定义为 fi children(N) 作为节点的非垃圾子节点的集合。对于子节点为 n0 fi 特征值的 SII,定义如下 SII(fi wijlogm wij term 节点内文本特征词数,节点 N 内容信息值表示点的子树中收录的信息量。链接文本值当人们浏览网页,他们通过超链接的语义信息,一步步的获取自己想要的信息。显然,网页之间的超链接一方面引导网页,另一方面,也反映了网页的浏览过程创建者认为链接的文本收录指向下一个文本的有价值的信息。在文献中,定义了AP页面的相关性。定义如下:nkchildren fi(N) 大于或等于fi SII (fi N) 的值越高,节点的所有子节点的特征值fi 越相似网站。许多内容和链接文本是自动生成的,信息非常相似。这些信息块的根节点特征的SII值非常大。信息块的提取。在这个阶段,每个部分的AP特征的术语链接文本和链接网页上的特征词。M 是匹配词的数量。通过观察,检索方法包括: 一个基本假设是连接文本是用来描述它指向的文档,而不是用来描述它所在的当前文档。根据这个假设,网页的链接描述文档描述不是作者' 自己对网页内容的描述。,但是这个网页上其他网页的作者描述的主要50聚合过程是一个从叶子节点到根节点的自下而上的过程。
第一个特征fi的聚合值的计算如njchildren所示。显示的标记节点的内文长度是典型的聚合特征。同样的算法也可以得到ATI的信息聚合树。在信息覆盖树上计算SII提取信息块就是第一次提取的输出信息块的个数。对于新闻网页,由于新闻网页由新闻内容信息块和与主题相关的链接信息块组成,ATI的特征是由聚合ST为SII的阈值。ST 的值可以控制信息块的粒度和数量。根据 SII 的定义,如果 ST 的值较大,结构约束更严格,提取节点的子节点更相似。该算法的目的是输出信息量最大的信息块集合。C II (N II 阈值 ATI 阈值 ST, TA TC 输出:最大信息块集合。构建有序栈 S3 信息块数 Infob fA 值 N 最大的节点弹出 SII(N, fA N 为根节点 信息块类型为文本块 endif 信息块为主题链接块 endif 10) 将节点 N 插入候选集 11)else 将节点 N 的子节点放入候选集stack 12)endi 1 3)end 14) 提取出来的k个节点作为子树的根节点,即15)
网页的链接描述文档是对其他网页作者描述的主要内容的概述,不计算与链接网页匹配的特征词数量不会影响算法S1WISDOM: ebIntrap age Informative Structure iningBased DocumentObject模型。IEEE Tansactions DataEngineering: 2005, 17 自动分割 eb 页信息块。中文信息处理学报2004,18,关毅。基于统计的网页文本信息提取方法研究[J]. 中文信息处理学报 2004,18 张敏,高剑锋 eb 信息检索。计算机研究与发展2004, 41 226 (作者邮箱: ) 51 欢迎订阅《现代图书馆与信息技术》 查看全部
抓取网页新闻(新闻网页抽取方法)
基于熵的新闻网页提取方法研究朱宏灿龙朝阳(湘潭大学管理学院湘潭411105) [摘要为了减少或消除新闻中大量非主题信息的干扰网站,提出新闻网页提取方法利用基于熵的计算和DOM树的知识从新闻网页中提取主题文档和相关链接[关键词信息提取信息块DOM [分类] number Entropy Based Approach NewsArticle Extraction from ebPage Zhu Hongcan ongZhaoyang anagement School niversity, iangtan411105, China)实验几个新的 ebsites 显示实际。
搜索引擎仍会搜索此信息。导致存储和计算量增加的eb页面的内容提取是搜索引擎中非常重要的部分。目前,要从半结构化网页中提取信息,需要建立第一个信息单元。. 可以对分割后的信息块进行信息提取或其他处理,减少引擎的搜索空间,结果更加准确。[文献]提出了一种提取新闻网页文本的方法,但该方法仅适用于网页中所有文本信息都放在一个表格中的情况。实际新闻页面中与话题相关的信息还包括标题、相关链接等。基于文档 ISDOM 方法,本文提出了一个更合适的新熵计算公式,应用信息论和页面的DOM树等相关知识。根据信函新闻页面的DOM树结构观察,新闻页面一般有以下内容(1)与新闻主题相关,包括新闻标题、新闻正文、时间记者、链接到与主题相关的相关文档等)。(2)与新闻话题无关的信息包括网站模板定义的导航栏、广告信息等出现在同一网站不同页面的信息块。信息块指示页面的主题和其他相关信息。这些信息块的集合和相应的关联构成了页面的信息结构,是新浪网页内容的一部分。信息块中收录的内容为指南,信息块中收录的内容为新闻正文。块中收录的内容是与主题相关的链接信息。区块中收录的内容是与话题无关的广告链接。
它们通常是一组具有较长链接文本的密切相关的链接兄弟,收录标签名称信息、属性以及一对标签之间的所有字符(表示为innertext)。根据DOM的定义,节点内文包括以节点为根节点的子树中的所有字符。页面根节点的内部文本包括 shift 标记后的所有单词除外。页面上的文字可以分为两类:一类是链接文字,一类是链接后的文字。本文从根节点的内文中提取特征词。特征词是对中文文档有意义的关键字或词组。处理中文文档后,提取对应的关键词。
每个特征词的熵值计算公式如下: nkEN wijlognkwij Dk 为网站 wijlognwij,其中wij 1页面部分DOM树信息结构是基于熵的新闻网页提取算法.网站中新闻网页2) 相关话题信息块提取、冗余信息块去除、从DOM树中提取信息 开始时从网上抓取网页,基于DOM构建。必须先对网页进行预处理。把它变成一个标准化的网页。标准化的网页可以根据其中的 HTML 标签轻松地将其表示为一棵树。DOM树中的每个节点根据定义表示页面中的一个标记ij就是整个网站页面。, 该公式考虑了不同网站中使用的不同模板。由于网页内容因模板不同而具有很强的主观性,因此在一个网站中重复出现的冗余信息块可能不会在其他网站中出现。该公式定义了本文中的特征词ti ti。) 表示特征词 ti 的重要性。对于用户来说,特征词分布在越多的页面上越均匀,收录的信息越少,观点的内容就越少。这是网页的链接描述文档与其原创文档之间必不可少的区域。1)原创文档 链接文本中没有与链接文本匹配的特征词,这并不意味着链接文本最大( ENk:链接文本用于医学和健康,所链接的网页可能会介绍某种疾病的预防和治疗。此时AP2)在原创文档中。链接文本与较少的特征词匹配。此时AP表示链接文本中收录的信息量较小,显然与实际不符。根据以上分析,本文将链接文字改为max(ENk 83333ATI max(ENk 66667term weighted value.
根据定义,公式之间存在如下关系。如果tj均匀分布在每个网站 tj中,信息量小,如果tj均匀分布在一个网站的每个网页上,计算两个公式,此时, tj 信息 tj) 较低;而公式2计算出的权重较大(特征词tj具有较大的特征词信息,两个公式的计算都是根据提取的特征词信息,计算出三种特殊的Content Info rm ionIndex II和扩展信息)表示信息块中收录的信息量链接文本值(Anchor Text Index,ATI)表示链接文本的重要性结构信息索引,SII) 指出DOM树中每个节点的子节点分布的内容信息值。计算每个特征词的熵值后,计算节点innertext所有特殊词的熵值的平均值作为节点N的内容信息值,避免除以0。ATI计算量反链接文本中收录的信息,反映超链接链接的页面是否与主页面相关。如果是ATI,链接文本和链接的网页收录大量信息,与主题相关度高。网站中每个页面上均匀分布的广告链接和导航栏中的菜单链接的ATI值通常很小。与AP相比,如果匹配词为term1,则不再需要计算ATI。结构信息值SII的计算是基于节点子节点特征值的分布。但是,有一些带有信息的 HTML 标签,例如 SCRIPT 标记为垃圾邮件标签,应该删除。
将节点 N 的特征值定义为 fi children(N) 作为节点的非垃圾子节点的集合。对于子节点为 n0 fi 特征值的 SII,定义如下 SII(fi wijlogm wij term 节点内文本特征词数,节点 N 内容信息值表示点的子树中收录的信息量。链接文本值当人们浏览网页,他们通过超链接的语义信息,一步步的获取自己想要的信息。显然,网页之间的超链接一方面引导网页,另一方面,也反映了网页的浏览过程创建者认为链接的文本收录指向下一个文本的有价值的信息。在文献中,定义了AP页面的相关性。定义如下:nkchildren fi(N) 大于或等于fi SII (fi N) 的值越高,节点的所有子节点的特征值fi 越相似网站。许多内容和链接文本是自动生成的,信息非常相似。这些信息块的根节点特征的SII值非常大。信息块的提取。在这个阶段,每个部分的AP特征的术语链接文本和链接网页上的特征词。M 是匹配词的数量。通过观察,检索方法包括: 一个基本假设是连接文本是用来描述它指向的文档,而不是用来描述它所在的当前文档。根据这个假设,网页的链接描述文档描述不是作者' 自己对网页内容的描述。,但是这个网页上其他网页的作者描述的主要50聚合过程是一个从叶子节点到根节点的自下而上的过程。
第一个特征fi的聚合值的计算如njchildren所示。显示的标记节点的内文长度是典型的聚合特征。同样的算法也可以得到ATI的信息聚合树。在信息覆盖树上计算SII提取信息块就是第一次提取的输出信息块的个数。对于新闻网页,由于新闻网页由新闻内容信息块和与主题相关的链接信息块组成,ATI的特征是由聚合ST为SII的阈值。ST 的值可以控制信息块的粒度和数量。根据 SII 的定义,如果 ST 的值较大,结构约束更严格,提取节点的子节点更相似。该算法的目的是输出信息量最大的信息块集合。C II (N II 阈值 ATI 阈值 ST, TA TC 输出:最大信息块集合。构建有序栈 S3 信息块数 Infob fA 值 N 最大的节点弹出 SII(N, fA N 为根节点 信息块类型为文本块 endif 信息块为主题链接块 endif 10) 将节点 N 插入候选集 11)else 将节点 N 的子节点放入候选集stack 12)endi 1 3)end 14) 提取出来的k个节点作为子树的根节点,即15)
网页的链接描述文档是对其他网页作者描述的主要内容的概述,不计算与链接网页匹配的特征词数量不会影响算法S1WISDOM: ebIntrap age Informative Structure iningBased DocumentObject模型。IEEE Tansactions DataEngineering: 2005, 17 自动分割 eb 页信息块。中文信息处理学报2004,18,关毅。基于统计的网页文本信息提取方法研究[J]. 中文信息处理学报 2004,18 张敏,高剑锋 eb 信息检索。计算机研究与发展2004, 41 226 (作者邮箱: ) 51 欢迎订阅《现代图书馆与信息技术》
抓取网页新闻(机器学习抽取的整体流程和结构分析标准(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-26 18:13
<p>节点。该节点下方的内容是信息抽取的数据区部分。论文将上一节中找到的正文节点的公共父节点记录为正文的命令节点。文本命令节点覆盖的文本信息可能收录非文本信息,如图片、视频等。由于图片或视频的说明文字通常与正文的字体不同,可以使用此功能进行更改图片及其描述文本被排除在外。通过这样的处理,可以提高文本信息的准确率。文本提取的整体流程如图4.5所示。开始构建DOM树,过滤传入文本的样式节点,遍历DOM树,寻找TEXT_NODE文本节点,根据文本节点的权重W选择标准文本节点,比较其他文本节点与该节点的链接信息。是否满足设置阈值是否与标准文本节点的样式相同作为正文信息候选集遍历所有文本节点,找到所有候选集的公共父节点,提取所有文本 查看全部
抓取网页新闻(机器学习抽取的整体流程和结构分析标准(一))
<p>节点。该节点下方的内容是信息抽取的数据区部分。论文将上一节中找到的正文节点的公共父节点记录为正文的命令节点。文本命令节点覆盖的文本信息可能收录非文本信息,如图片、视频等。由于图片或视频的说明文字通常与正文的字体不同,可以使用此功能进行更改图片及其描述文本被排除在外。通过这样的处理,可以提高文本信息的准确率。文本提取的整体流程如图4.5所示。开始构建DOM树,过滤传入文本的样式节点,遍历DOM树,寻找TEXT_NODE文本节点,根据文本节点的权重W选择标准文本节点,比较其他文本节点与该节点的链接信息。是否满足设置阈值是否与标准文本节点的样式相同作为正文信息候选集遍历所有文本节点,找到所有候选集的公共父节点,提取所有文本
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-24 11:16
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:
具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2. 修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:
首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法doc.select("div.list-hd")返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码
使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:
具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2. 修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:
首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法doc.select("div.list-hd")返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码
使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
抓取网页新闻(什么时间段更新网站新闻比较好呢?百度蜘蛛抓取频次因素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-24 11:14
什么时候更新网站消息容易收录?百度搜索引擎抓取时间规则!相信这是很多网站编辑关心的话题。了解了百度蜘蛛的爬取频率和爬取时间后,接下来对网站的更新进行合理的安排。但是我可以从阿优的经验告诉你,除非你能像新浪微博那样定时更新,否则蜘蛛会在特定时间爬取你的网站,否则百度蜘蛛会一视同仁。
这个周一早上阿尤更新的新闻里会有收录。不过阿优的网站更新时间不是固定的,所以百度蜘蛛不会在固定时间抓取你的网站。只有保持网站同频更新,搜索引擎和网站才会越来越粘。当然前提是你的文章一定要质量好。
什么时间段更新网站新闻比较好?百度蜘蛛爬行高峰期!
我们也可以通过百度站长平台观察蜘蛛爬行的高峰期。一般更新文章醉好在早上8-10点。早上9-10点,中午11-12点,下午3-4点,凌晨1-4点,这个时间段一般是搜索引擎蜘蛛的高峰期.
您也可以通过百度索引查询您的人群画像。网上也有蜘蛛爬取时间表,不过大家可以自己验证一下,看看是否真的有效。
百度蜘蛛爬行规则,影响百度蜘蛛爬行频率的因素
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁:
1、网站 权重:权重越高 网站 百度蜘蛛会爬得更频繁更深入
2、网站 更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站内容原创更多,质量高,能解决用户问题,百度会增加抓取频率。
4、 导入链接:链接是页面的入口,高质量的链接可以更好的引导百度蜘蛛进入和抓取。
5、 页面深度:页面首页是否有入口,如果首页有入口,可以更好的爬取和收录。 查看全部
抓取网页新闻(什么时间段更新网站新闻比较好呢?百度蜘蛛抓取频次因素)
什么时候更新网站消息容易收录?百度搜索引擎抓取时间规则!相信这是很多网站编辑关心的话题。了解了百度蜘蛛的爬取频率和爬取时间后,接下来对网站的更新进行合理的安排。但是我可以从阿优的经验告诉你,除非你能像新浪微博那样定时更新,否则蜘蛛会在特定时间爬取你的网站,否则百度蜘蛛会一视同仁。
这个周一早上阿尤更新的新闻里会有收录。不过阿优的网站更新时间不是固定的,所以百度蜘蛛不会在固定时间抓取你的网站。只有保持网站同频更新,搜索引擎和网站才会越来越粘。当然前提是你的文章一定要质量好。
什么时间段更新网站新闻比较好?百度蜘蛛爬行高峰期!
我们也可以通过百度站长平台观察蜘蛛爬行的高峰期。一般更新文章醉好在早上8-10点。早上9-10点,中午11-12点,下午3-4点,凌晨1-4点,这个时间段一般是搜索引擎蜘蛛的高峰期.
您也可以通过百度索引查询您的人群画像。网上也有蜘蛛爬取时间表,不过大家可以自己验证一下,看看是否真的有效。
百度蜘蛛爬行规则,影响百度蜘蛛爬行频率的因素
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁:
1、网站 权重:权重越高 网站 百度蜘蛛会爬得更频繁更深入
2、网站 更新频率:更新频率越高,百度蜘蛛越多
3、网站内容质量:网站内容原创更多,质量高,能解决用户问题,百度会增加抓取频率。
4、 导入链接:链接是页面的入口,高质量的链接可以更好的引导百度蜘蛛进入和抓取。
5、 页面深度:页面首页是否有入口,如果首页有入口,可以更好的爬取和收录。
抓取网页新闻(极光PDF阅读器如何提取PDF页面?如何正确提取页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-23 13:30
在编辑文件之前,我们通常会在互联网上下载一些相关的PDF文件以供参考。而下载的PDF文件,往往只有一页或几页才能真正使用。为了解决这个问题,我们可以使用极光PDF阅读器提取PDF页面来制作新的PDF文件。但是很多人不了解操作,下面介绍如何使用Aurora PDF Reader提取PDF页面。
Aurora PDF Reader 如何提取 PDF 页面?
1、首先,我们打开极光PDF阅读器,在它的向导页面,点击顶部功能栏中的“换词”选项。
2、 然后,我们切换到“PDF操作”的“提取页面”界面,点击右上角的“+添加文件”按钮。
3、 在弹出的窗口中选择要提取页面的PDF文件,点击“打开”按钮,将其导入极光PDF阅读器。
4、接下来,在极光PDF阅读器中,我们根据自己的需要选择提取PDF页面的方式。比如这里选择“提取单页”,设置要提取的第一页。
5、如需更改PDF提取页面后的输出路径,请点击极光PDF阅读器中的“浏览”按钮。
6、 在弹出的浏览文件夹窗口中,选择提取PDF页面后的保存路径,然后点击“确定”按钮。
7、最后,我们点击界面右下角的“立即提取”按钮,Aurora PDF Reader将开始提取PDF页面。
如果您不想要整个PDF文件,而只想要一页或几页,您可以使用极光PDF阅读器来提取页面。但是需要注意的是,如果您选择按照提取指定页面的方式提取PDF页面,则必须根据其示例输入页数,才能正确提取。 查看全部
抓取网页新闻(极光PDF阅读器如何提取PDF页面?如何正确提取页面)
在编辑文件之前,我们通常会在互联网上下载一些相关的PDF文件以供参考。而下载的PDF文件,往往只有一页或几页才能真正使用。为了解决这个问题,我们可以使用极光PDF阅读器提取PDF页面来制作新的PDF文件。但是很多人不了解操作,下面介绍如何使用Aurora PDF Reader提取PDF页面。
Aurora PDF Reader 如何提取 PDF 页面?
1、首先,我们打开极光PDF阅读器,在它的向导页面,点击顶部功能栏中的“换词”选项。
2、 然后,我们切换到“PDF操作”的“提取页面”界面,点击右上角的“+添加文件”按钮。
3、 在弹出的窗口中选择要提取页面的PDF文件,点击“打开”按钮,将其导入极光PDF阅读器。
4、接下来,在极光PDF阅读器中,我们根据自己的需要选择提取PDF页面的方式。比如这里选择“提取单页”,设置要提取的第一页。
5、如需更改PDF提取页面后的输出路径,请点击极光PDF阅读器中的“浏览”按钮。
6、 在弹出的浏览文件夹窗口中,选择提取PDF页面后的保存路径,然后点击“确定”按钮。
7、最后,我们点击界面右下角的“立即提取”按钮,Aurora PDF Reader将开始提取PDF页面。
如果您不想要整个PDF文件,而只想要一页或几页,您可以使用极光PDF阅读器来提取页面。但是需要注意的是,如果您选择按照提取指定页面的方式提取PDF页面,则必须根据其示例输入页数,才能正确提取。
抓取网页新闻(迅捷转换器转换器如何提取PDF页面?迅捷PDF转换器怎么提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-23 13:24
我们平时从网上下载的PDF文件,虽然页面很多,但真正能够为我们使用的页面可能只有一两页。对此,很多人问如何提取PDF的某些页面。事实上,我们可以使用 Swift PDF Converter 来提取 PDF 页面。考虑到很多人不知道怎么操作,下面我们来介绍一下如何从Fast PDF Converter中提取PDF页面。
Swift PDF Converter 如何提取 PDF 页面?
1、首先我们打开Swift PDF Converter,进入“PDF操作”界面,点击界面左侧的“PDF页面提取”,点击其右侧的“+”按钮.
2、 在弹出的窗口中选择需要解压的页面的PDF文件,点击“打开”按钮,将其导入到快速PDF转换器中。
3、 然后,在Swift PDF Converter的PDF页面提取界面,点击“范围提取”按钮。
4、接下来,我们在如下图的窗口中设置要提取的PDF页面范围,然后点击“开始提取”按钮。
5、 返回快速PDF转换器操作界面,如需更改输出目录,请点击“浏览”按钮。
6、 在弹出的窗口中选择PDF文件从页面中解压后的保存路径,点击“选择文件夹”按钮。
7、 之后,我们点击界面右下角的“开始转换”按钮,Swift PDF Converter就会根据我们刚刚设置的页面范围开始提取PDF文件中的页面。
8、最后,我们在Swift PDF Converter中等待它完成转换。
如果您想快速提取PDF中的特定页面、所有页面、奇数页面和偶数页面,可以使用快速PDF转换器进行提取。 查看全部
抓取网页新闻(迅捷转换器转换器如何提取PDF页面?迅捷PDF转换器怎么提取)
我们平时从网上下载的PDF文件,虽然页面很多,但真正能够为我们使用的页面可能只有一两页。对此,很多人问如何提取PDF的某些页面。事实上,我们可以使用 Swift PDF Converter 来提取 PDF 页面。考虑到很多人不知道怎么操作,下面我们来介绍一下如何从Fast PDF Converter中提取PDF页面。
Swift PDF Converter 如何提取 PDF 页面?
1、首先我们打开Swift PDF Converter,进入“PDF操作”界面,点击界面左侧的“PDF页面提取”,点击其右侧的“+”按钮.
2、 在弹出的窗口中选择需要解压的页面的PDF文件,点击“打开”按钮,将其导入到快速PDF转换器中。
3、 然后,在Swift PDF Converter的PDF页面提取界面,点击“范围提取”按钮。
4、接下来,我们在如下图的窗口中设置要提取的PDF页面范围,然后点击“开始提取”按钮。
5、 返回快速PDF转换器操作界面,如需更改输出目录,请点击“浏览”按钮。
6、 在弹出的窗口中选择PDF文件从页面中解压后的保存路径,点击“选择文件夹”按钮。
7、 之后,我们点击界面右下角的“开始转换”按钮,Swift PDF Converter就会根据我们刚刚设置的页面范围开始提取PDF文件中的页面。
8、最后,我们在Swift PDF Converter中等待它完成转换。
如果您想快速提取PDF中的特定页面、所有页面、奇数页面和偶数页面,可以使用快速PDF转换器进行提取。
抓取网页新闻(一个新闻网站要如何爬取,如何抓取网页新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-22 11:03
抓取网页新闻是看得最多的方式,所以这篇文章也是想以新闻api为起点跟大家聊聊一个新闻网站要如何爬取,希望会对大家有所帮助。话不多说,开始上图首先,以tudou为例,我们抓取新闻首先要把它存进localhost.py文件里面,然后写python代码的时候把它放到同目录下面就可以了。进入localhost.py打开之后我们可以看到它是这样的,虽然不是全图,但是我们肯定够了。
首先是获取新闻的头和尾,然后再获取点击的图片,然后就是上传了,代码基本很简单,大家可以参考下。然后就是爬取新闻列表页了,分为三个步骤:获取url我们要抓取首页新闻列表页面我们需要获取链接在这里呢是获取url,对于爬虫爬虫来说是最简单的了,不是一个知乎回答都没有就获取一个url。但是这个问题在于写爬虫就用es6/es7/es8。
1.获取url第一种就是使用python里的urllib。#!/usr/bin/envpython#-*-coding:utf-8-*-importurllib#引入库importredefurllib2():'''获取python内置urllib的url'''returnurllib2.urlopen(url,s)defurlopen(url):'''解析页面内容'''returnre.sub(r'//{$page}<img/>',url)#解析urldefgetpage(url):'''获取新闻列表页url'''returnurllib2.urlopen(url).read()deflisturl(url):'''获取新闻列表页链接'''returnre.sub(url,urllib2.urlopen(url).read()).decode("utf-8")defisstring(page,s):'''获取新闻列表页page,并做字符串转换'''string=s[:len(page)]print(string)forurlinurllib2(url):isstring(url,string.decode("utf-8"))forpageinurllib2(url):print(page)returnpagedefgetnavirga(url):'''获取新闻链接'''fullurl=urllib2.urlopen(url)#用于解析新闻urlglobals(path="../")#获取标准模式路径#解析myheader["id"]=str(url)#获取新闻属性值return("lazy","none","",globals(path=path).is_partial())defgetname(url):'''获取新闻的标题'''the_name="#"+urlreturnre.sub(r"dd{the_name}_iked_",url)isstring(url)#解析标题,并做字符串转换'''defgetnavirga(url):'''获取新闻链接'''driver=webdriver.firefox(。 查看全部
抓取网页新闻(一个新闻网站要如何爬取,如何抓取网页新闻)
抓取网页新闻是看得最多的方式,所以这篇文章也是想以新闻api为起点跟大家聊聊一个新闻网站要如何爬取,希望会对大家有所帮助。话不多说,开始上图首先,以tudou为例,我们抓取新闻首先要把它存进localhost.py文件里面,然后写python代码的时候把它放到同目录下面就可以了。进入localhost.py打开之后我们可以看到它是这样的,虽然不是全图,但是我们肯定够了。
首先是获取新闻的头和尾,然后再获取点击的图片,然后就是上传了,代码基本很简单,大家可以参考下。然后就是爬取新闻列表页了,分为三个步骤:获取url我们要抓取首页新闻列表页面我们需要获取链接在这里呢是获取url,对于爬虫爬虫来说是最简单的了,不是一个知乎回答都没有就获取一个url。但是这个问题在于写爬虫就用es6/es7/es8。
1.获取url第一种就是使用python里的urllib。#!/usr/bin/envpython#-*-coding:utf-8-*-importurllib#引入库importredefurllib2():'''获取python内置urllib的url'''returnurllib2.urlopen(url,s)defurlopen(url):'''解析页面内容'''returnre.sub(r'//{$page}<img/>',url)#解析urldefgetpage(url):'''获取新闻列表页url'''returnurllib2.urlopen(url).read()deflisturl(url):'''获取新闻列表页链接'''returnre.sub(url,urllib2.urlopen(url).read()).decode("utf-8")defisstring(page,s):'''获取新闻列表页page,并做字符串转换'''string=s[:len(page)]print(string)forurlinurllib2(url):isstring(url,string.decode("utf-8"))forpageinurllib2(url):print(page)returnpagedefgetnavirga(url):'''获取新闻链接'''fullurl=urllib2.urlopen(url)#用于解析新闻urlglobals(path="../")#获取标准模式路径#解析myheader["id"]=str(url)#获取新闻属性值return("lazy","none","",globals(path=path).is_partial())defgetname(url):'''获取新闻的标题'''the_name="#"+urlreturnre.sub(r"dd{the_name}_iked_",url)isstring(url)#解析标题,并做字符串转换'''defgetnavirga(url):'''获取新闻链接'''driver=webdriver.firefox(。
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-22 10:09
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源码并没有随着浏览器的查看源码功能发生变化,无论现在看到哪个Pagination,HTML源码依然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。它是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建二级线索(主题名称)就是demo_cnbeta_detail),所谓Hierarchical crawling summary page就是轮流抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页中存在代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《抢当当商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,“”是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,这种类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在《分页爬行杰出亚马逊》一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明参见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。: 当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。 查看全部
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源码并没有随着浏览器的查看源码功能发生变化,无论现在看到哪个Pagination,HTML源码依然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。因为此类网络爬虫通常会向目标服务器发送 HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。由于其他页面没有独立的 URL 网址,因此无法发送 HTTP GET 消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,完全摒弃嗅探方式,可以像抓取普通网页一样抓取AJAX网站内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。它是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建二级线索(主题名称)就是demo_cnbeta_detail),所谓Hierarchical crawling summary page就是轮流抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页中存在代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《抢当当商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,“”是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,这种类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在《分页爬行杰出亚马逊》一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明参见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。: 当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。
抓取网页新闻(如何使用类来首页的DOM树(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-22 10:06
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以安客网首页的博客标题和链接为例:
上图是Ankenet主页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224<br />///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以安客网首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
运行结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224 查看全部
抓取网页新闻(如何使用类来首页的DOM树(如最新的头条新闻))
我写了一个类,用于从网页中抓取信息(例如最新的头条新闻、新闻来源、头条新闻、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以安客网首页的博客标题和链接为例:
上图是Ankenet主页的DOM树。很明显,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224<br />///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以安客网首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
运行结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224
抓取网页新闻(长治seo网站如何做谷歌优化抓取网站内容三部分?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-22 03:10
网站如何做谷歌优化。我们需要了解搜索引擎是如何抓取网站内容的?长治seo网站如何优化谷歌搜索引擎抓取内容分为三个部分:网站收录、快照、长治seo网站如何优化谷歌排名。 网站收录是你对搜索引擎的评价指标网站。你网站的收录越多,搜索引擎爬取的概率就越高。对网站收录也有好处。有的站长认为只要网站收录就够了,其实不然。有的站长认为只要网站收录快,就会有排名,所以网站收录对你来说就相当于搜索引擎的评价指标。此视图适用于任何 网站。网上很多文章提到的网站收录的方法很多,但有一点是很容易被搜索引擎认为是黑帽方法,
因为一旦你边优化边做这些任务,焦作seo网站就很容易宣传哪个好,容易导致网站被搜索引擎惩罚,不太可能被搜索引擎网站。权重降低,权重降低网站,权重降低网站被搜索引擎k.1、采集网站。这种情况很常见。 采集网站一般要求你采集数据,因为当你采集数据时,对于搜索引擎来说是重复的内容,所以你采集的数据必须是所有采集,这对搜索引擎不利。如果网站采集中的数据太多,你的采集的内容对于搜索引擎来说可能没有多大意义。长治seo如何做谷歌优化网站 因为搜索引擎做不到 大概到原内容收录。如果你来采集的内容是很多重复的内容,那么搜索引擎会认为你是采集的内容,长治seo网站怎么做谷歌优化让你采集@ > 数据时, 查看全部
抓取网页新闻(长治seo网站如何做谷歌优化抓取网站内容三部分?)
网站如何做谷歌优化。我们需要了解搜索引擎是如何抓取网站内容的?长治seo网站如何优化谷歌搜索引擎抓取内容分为三个部分:网站收录、快照、长治seo网站如何优化谷歌排名。 网站收录是你对搜索引擎的评价指标网站。你网站的收录越多,搜索引擎爬取的概率就越高。对网站收录也有好处。有的站长认为只要网站收录就够了,其实不然。有的站长认为只要网站收录快,就会有排名,所以网站收录对你来说就相当于搜索引擎的评价指标。此视图适用于任何 网站。网上很多文章提到的网站收录的方法很多,但有一点是很容易被搜索引擎认为是黑帽方法,
因为一旦你边优化边做这些任务,焦作seo网站就很容易宣传哪个好,容易导致网站被搜索引擎惩罚,不太可能被搜索引擎网站。权重降低,权重降低网站,权重降低网站被搜索引擎k.1、采集网站。这种情况很常见。 采集网站一般要求你采集数据,因为当你采集数据时,对于搜索引擎来说是重复的内容,所以你采集的数据必须是所有采集,这对搜索引擎不利。如果网站采集中的数据太多,你的采集的内容对于搜索引擎来说可能没有多大意义。长治seo如何做谷歌优化网站 因为搜索引擎做不到 大概到原内容收录。如果你来采集的内容是很多重复的内容,那么搜索引擎会认为你是采集的内容,长治seo网站怎么做谷歌优化让你采集@ > 数据时,
抓取网页新闻( 如何通过Python爬虫按关键词抓取相关的新闻(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-21 17:02
如何通过Python爬虫按关键词抓取相关的新闻(一))
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你把这个地址直接放到浏览器的地址栏中,然后按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头的时候直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最后结果
专门设立的Python学习扣圈,从零基础开始到Python各个领域的实际项目教程、开发工具和电子书。与大家分享公司目前对python人才的需求和学习python的高效技能,持续更新最新教程!点击加入我们的python学习圈 查看全部
抓取网页新闻(
如何通过Python爬虫按关键词抓取相关的新闻(一))
前言
本文文字及图片均来自网络,仅供学习交流之用,不得用于任何商业用途
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你把这个地址直接放到浏览器的地址栏中,然后按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头的时候直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最后结果
专门设立的Python学习扣圈,从零基础开始到Python各个领域的实际项目教程、开发工具和电子书。与大家分享公司目前对python人才的需求和学习python的高效技能,持续更新最新教程!点击加入我们的python学习圈
抓取网页新闻( ()返回数据(4)请求链接amp )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-21 16:23
()返回数据(4)请求链接amp
)
(3)返回数据:
(4)请求链接
机器人&entity_type=post&ts=42&_=39
分析:ts和下面是时间戳格式的,不需要,entity_type=post是必须的,可变参数是page
(4)列表页的json数据,id为详情页链接所需的符号
(5)详情页数据
获取内容:
字段:标题、作者、日期、简介、标签、内容
查看源码,数据都在var props收录的script标签中
(6)常规获取并转换成普通json数据(原因:json文件可以更好的获取某个字段的内容,如果单纯使用常规拦截的话,不容易获取或者直接获取less比)
源代码:
# -*- coding: utf-8 -*-
# @Time : 2018/7/28 17:13
# @Author : 蛇崽
# @Email : 643435675@QQ.com 1532773314218
# @File : 36kespider.py
import json
import re
import scrapy
import time
class ke36Spider(scrapy.Spider):
name = 'ke36'
allowed_domains = ['www.36kr.com']
start_urls = ['https://36kr.com/']
def parse(self, response):
print('start parse ------------------------- ')
word = '机器人'
t = time.time()
page = '1'
print('t',t)
for page in range(1,200):
burl = 'http://36kr.com/api//search/entity-search?page={}&per_page=40&keyword={}&entity_type=post'.format(page,word)
yield scrapy.Request(burl,callback=self.parse_list,dont_filter=True)
def parse_list(self,response):
res = response.body.decode('utf-8')
# print(res)
jdata = json.loads(res)
code = jdata['code']
timestamp = jdata['timestamp']
timestamp_rt = jdata['timestamp_rt']
items = jdata['data']['items']
m_id = items[0]['id']
for item in items:
m_id = item['id']
b_url = 'http://36kr.com/p/{}.html'.format(str(m_id))
# b_url = 'http://36kr.com/p/5137751.html'
yield scrapy.Request(b_url,callback=self.parse_detail,dont_filter=True)
def parse_detail(self,response):
res = response.body.decode('utf-8')
content = re.findall(r'var props=(.*?)',res)
temstr = content[0]
minfo = re.findall('\"detailArticle\|post\"\:(.*?)"hotPostsOf30',temstr)[0]
print('minfo ----------------------------- ')
minfo = minfo.rstrip(',')
jdata = json.loads(minfo)
print('j'*40)
published_at = jdata['published_at']
username = jdata['user']['name']
title = jdata['user']['title']
extraction_tags = jdata['extraction_tags']
content = jdata['content']
print(published_at,username,title,extraction_tags)
print('*'*50)
print(content) 查看全部
抓取网页新闻(
()返回数据(4)请求链接amp
)
(3)返回数据:
(4)请求链接
机器人&entity_type=post&ts=42&_=39
分析:ts和下面是时间戳格式的,不需要,entity_type=post是必须的,可变参数是page
(4)列表页的json数据,id为详情页链接所需的符号
(5)详情页数据
获取内容:
字段:标题、作者、日期、简介、标签、内容
查看源码,数据都在var props收录的script标签中
(6)常规获取并转换成普通json数据(原因:json文件可以更好的获取某个字段的内容,如果单纯使用常规拦截的话,不容易获取或者直接获取less比)
源代码:
# -*- coding: utf-8 -*-
# @Time : 2018/7/28 17:13
# @Author : 蛇崽
# @Email : 643435675@QQ.com 1532773314218
# @File : 36kespider.py
import json
import re
import scrapy
import time
class ke36Spider(scrapy.Spider):
name = 'ke36'
allowed_domains = ['www.36kr.com']
start_urls = ['https://36kr.com/']
def parse(self, response):
print('start parse ------------------------- ')
word = '机器人'
t = time.time()
page = '1'
print('t',t)
for page in range(1,200):
burl = 'http://36kr.com/api//search/entity-search?page={}&per_page=40&keyword={}&entity_type=post'.format(page,word)
yield scrapy.Request(burl,callback=self.parse_list,dont_filter=True)
def parse_list(self,response):
res = response.body.decode('utf-8')
# print(res)
jdata = json.loads(res)
code = jdata['code']
timestamp = jdata['timestamp']
timestamp_rt = jdata['timestamp_rt']
items = jdata['data']['items']
m_id = items[0]['id']
for item in items:
m_id = item['id']
b_url = 'http://36kr.com/p/{}.html'.format(str(m_id))
# b_url = 'http://36kr.com/p/5137751.html'
yield scrapy.Request(b_url,callback=self.parse_detail,dont_filter=True)
def parse_detail(self,response):
res = response.body.decode('utf-8')
content = re.findall(r'var props=(.*?)',res)
temstr = content[0]
minfo = re.findall('\"detailArticle\|post\"\:(.*?)"hotPostsOf30',temstr)[0]
print('minfo ----------------------------- ')
minfo = minfo.rstrip(',')
jdata = json.loads(minfo)
print('j'*40)
published_at = jdata['published_at']
username = jdata['user']['name']
title = jdata['user']['title']
extraction_tags = jdata['extraction_tags']
content = jdata['content']
print(published_at,username,title,extraction_tags)
print('*'*50)
print(content)
抓取网页新闻(快抓离线浏览器官方免费版破解版.70ios版使用介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-11-18 21:13
快手是快手离线浏览器的官方免费版,您可以将其作为快手离线浏览器的官方免费版使用。您可以使用它来编辑输入文档、为网页添加书签、快速抓取离线浏览器破解版官方免费版或将其用作浏览器。您还可以使用它来捕获 Flash、图片、音频等资源,保存网页快照或使用它来处理文档和添加一些附件。快抢内置数据(shu)数据库存储,再也不用担心文件杂乱难查(cha),让自己积累知识库成为可能。
快抢离线浏览器官方免费版破解版介绍
1. 数据管理简单,内存浏览。
2. 内置编辑,优化数据库搜索,简化所有复杂问题,让您轻松管理文档。
3. 完全免费,无弹窗广告,无插件和病毒,资源抓取功能。
4. 离线数据内存直接打开,不占用太多系统资源,不生成**文件,真正免费。
快抢官方免费版离线浏览器破解版功能
1. 强大的爬虫内核,让你无障碍采集网络资源。快照真实还原,瞬间精彩。内嵌HTML编辑器,操作简单快捷。只要您可以键入,就可以输入文档。增强的附件功能可以将任何类型的文件添加到数据库中。
快抢离线浏览器官方免费版破解版汇总
Quick Grab离线浏览器V4.70官方免费版是一款适用于ios版其他软件使用的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友: 查看全部
抓取网页新闻(快抓离线浏览器官方免费版破解版.70ios版使用介绍)
快手是快手离线浏览器的官方免费版,您可以将其作为快手离线浏览器的官方免费版使用。您可以使用它来编辑输入文档、为网页添加书签、快速抓取离线浏览器破解版官方免费版或将其用作浏览器。您还可以使用它来捕获 Flash、图片、音频等资源,保存网页快照或使用它来处理文档和添加一些附件。快抢内置数据(shu)数据库存储,再也不用担心文件杂乱难查(cha),让自己积累知识库成为可能。
快抢离线浏览器官方免费版破解版介绍
1. 数据管理简单,内存浏览。
2. 内置编辑,优化数据库搜索,简化所有复杂问题,让您轻松管理文档。
3. 完全免费,无弹窗广告,无插件和病毒,资源抓取功能。
4. 离线数据内存直接打开,不占用太多系统资源,不生成**文件,真正免费。
快抢官方免费版离线浏览器破解版功能
1. 强大的爬虫内核,让你无障碍采集网络资源。快照真实还原,瞬间精彩。内嵌HTML编辑器,操作简单快捷。只要您可以键入,就可以输入文档。增强的附件功能可以将任何类型的文件添加到数据库中。
快抢离线浏览器官方免费版破解版汇总
Quick Grab离线浏览器V4.70官方免费版是一款适用于ios版其他软件使用的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
抓取网页新闻(ASO管家如何使用产品页面优化增加自然流量?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-18 21:12
普通的App运营商(或营销者)往往有过分关注排名提升的习惯,从而忽视了排名后的转化。也就是从用户看到你的 App 到你的 App 是否被下载的过程。这个过程就像一场足球比赛,对最终的下载水平至关重要。
iOS 15 通过产品页面优化和自定义产品页面将原生 A/B 测试引入 App Store。它使应用营销人员能够区分自然流量和付费流量。它不再是“千篇一律”的信息,而是向正确的受众传达正确的信息。这可以使您的转化率翻倍,这就是为什么这条新闻对您的应用商店营销如此有影响力的原因。
本文将解释如何使用产品页面优化和自定义产品页面。开始吧!
ASO管家
如何使用产品页面优化来增加有机流量?
Apple App Store 中的产品页面优化可以看作是 Google Play Experiments 的原生 A/B 测试的对应物。这将改变您在 Apple App Store 中的应用商店营销和转化率。它使 Apple 开发人员能够通过拆分测试 (a/b/c) 来试验、分析和改进他们的应用程序性能,并提供了在 App Store 的原生环境中测试假设的独特机会。
随着 iOS 15 更新,产品页面优化将允许您使用不同的应用创意(图标、屏幕截图和应用预览视频)测试默认产品页面,以确定哪种创意变体最适合您的移动应用或游戏。您将能够将产品页面(控件)的当前视觉效果与可能提高应用转化率的三种不同变体进行比较。
此外,拆分测试可以让您准确了解应用程序最吸引人的功能,并准确地向用户提供哪些设计和创意元素更有效,以及您应该将应用程序增长策略集中在哪个方向。回馈。
您最多可以运行 90 天的测试并针对特定国家/地区。
注意:如果您为所有付费流量使用自定义商店页面,您的默认 App Store 产品页面将仅接收自然流量,包括搜索和浏览流量(更多信息见下文)。
在每个产品页面优化过程中,所有创意资产都需要经过标准的 App Store 审核流程。但是,它不需要新版本发布(除非它是应用程序图标)。对于每个测试,您还需要确定为每个测试处理的流量。
产品页面优化与 Google Play 实验有何不同
在 Apple App Store 中,您将只能测试您的应用创意,而不是应用标题、副标题和描述。审查过程也区分了两家商店。
两家商店的最大变体数量相同。
如何在 App Store 中使用 iOS 15 自定义产品页面获取付费流量?
iOS 15 更新为您的应用商店营销提供终极动力,将正确的信息传递给正确的受众。换句话说,您可以拥有与您的广告驱动的意图相匹配的自定义消息。这可以使您的转化率翻倍!
不同的渠道往往会吸引不同的目标受众——具有不同人口统计、兴趣和偏好的用户。使用定制的产品页面,您可以通过向每个细分市场显示正确的信息来影响您的转化率。如果操作得当,这可以显着提高您的付费 UA 转化率和广告支出回报率。
ASO管家
iOS 15 更新将使您能够驱动多达 35 个自定义产品页面,供付费用户获取流量。每个页面可以有不同的应用预览视频、截图和宣传文字。应用程序图标将与默认应用程序商店的产品页面上的相同。所有页面都有一个唯一的 Apple App Store URL,您可以将其吸引到特定的受众。
因此,您可以更轻松地通过 UA 渠道转换用户。仅仅因为用户将有一个更加个性化的旅程,从看广告到下载应用程序,而不是“一刀切”的信息传递。
客户产品页面与 Google 的客户产品列表有何不同
在 Apple App Store 中,您最多可以拥有 35 个自定义产品页面,而 Google 端只有 5 个自定义商店列表。Google 的选项允许您仅根据位置进行定位,对于 Apple 的自定义产品页面,您也可以在一个位置拥有多个页面,但它仅适用于来自 App Store 之外的流量。
此外,由于苹果的自定义产品页面不允许您更改应用程序的图标、标题和副标题,因此谷歌的自定义商店列表在更改副本和创意方面提供了更大的灵活性。
如何通过产品页面优化在 App Store 中运行合适的原生 A/B 测试?
创建 a/b 测试后,您将能够监控和分析测试的展示次数、下载量、转化率和性能结果。这将帮助您确定应用商店产品页面的最佳变体。
在 App Store 中运行 a/b 测试之前,您应该记住拆分测试应始终本地化到相应的国家/地区。应在当前设计和变体之间明智地分配受众百分比。
深入讨论:
A/B 测试-应用雷达学院
A/B 测试 - 6 个实际步骤
在 App Store 中正确设置 A/B 测试
下面概述了在 Apple App Store 中进行 A/B 测试时需要注意的最重要的几点。
当前版本和变体之间的受众分布。在决定应该分配给每个变体的流量部分时,请记住您当前的转化率、要测试的假设、涉及的元素和统计显着性(目前在 Google Play 实验中为 90%)。
拆分测试的持续时间。让测试运行至少 7 天,以避免季节性高峰影响您的结果。测试应继续运行,直到大量潜在受众访问了所有测试变体。
每个变体的最小安装量。为了获得有关 a/b 测试性能结果的重要数据,您需要密切关注所需的安装量。它与应用程序的每日安装率高度相关。
测试本地化。强烈建议在特定国家/地区本地化您的拆分测试。全球/全球实验可能会产生误导,因为每个国家/地区的创意表现都不同。
注意:初学者的一个常见错误是在设置适当的 a/b 测试或拆分测试时忽略应用程序性能的当前状态。
在应用商店进行 a/b 测试时要记住的其他方面:
· 封闭变体可能不会带来太多学习。尽管如此,您的所有创意元素都应该经过测试,以不断改进您的商店页面。
· 统计显着性所需的最低安装量可能很高,从而使测试持续时间很长。
· 测试不会提供有关用户行为的详细信息。
· 当前的统计置信度可能不可靠。
A/B测试的常见错误:
· 假设Android 和iOS 用户的行为相似。
· 模仿你的竞争对手。
· 对测试结果的错误解释。
· 拆分测试设置不正确。
· 应用轻微的改进或基于早期测试阶段的结果。
永远没有制胜法宝,但每一个环节、每一个细节都必须以最高的标准去做!
— 来自 ASO 巴特勒 查看全部
抓取网页新闻(ASO管家如何使用产品页面优化增加自然流量?(组图))
普通的App运营商(或营销者)往往有过分关注排名提升的习惯,从而忽视了排名后的转化。也就是从用户看到你的 App 到你的 App 是否被下载的过程。这个过程就像一场足球比赛,对最终的下载水平至关重要。
iOS 15 通过产品页面优化和自定义产品页面将原生 A/B 测试引入 App Store。它使应用营销人员能够区分自然流量和付费流量。它不再是“千篇一律”的信息,而是向正确的受众传达正确的信息。这可以使您的转化率翻倍,这就是为什么这条新闻对您的应用商店营销如此有影响力的原因。
本文将解释如何使用产品页面优化和自定义产品页面。开始吧!
ASO管家
如何使用产品页面优化来增加有机流量?
Apple App Store 中的产品页面优化可以看作是 Google Play Experiments 的原生 A/B 测试的对应物。这将改变您在 Apple App Store 中的应用商店营销和转化率。它使 Apple 开发人员能够通过拆分测试 (a/b/c) 来试验、分析和改进他们的应用程序性能,并提供了在 App Store 的原生环境中测试假设的独特机会。
随着 iOS 15 更新,产品页面优化将允许您使用不同的应用创意(图标、屏幕截图和应用预览视频)测试默认产品页面,以确定哪种创意变体最适合您的移动应用或游戏。您将能够将产品页面(控件)的当前视觉效果与可能提高应用转化率的三种不同变体进行比较。
此外,拆分测试可以让您准确了解应用程序最吸引人的功能,并准确地向用户提供哪些设计和创意元素更有效,以及您应该将应用程序增长策略集中在哪个方向。回馈。
您最多可以运行 90 天的测试并针对特定国家/地区。
注意:如果您为所有付费流量使用自定义商店页面,您的默认 App Store 产品页面将仅接收自然流量,包括搜索和浏览流量(更多信息见下文)。
在每个产品页面优化过程中,所有创意资产都需要经过标准的 App Store 审核流程。但是,它不需要新版本发布(除非它是应用程序图标)。对于每个测试,您还需要确定为每个测试处理的流量。
产品页面优化与 Google Play 实验有何不同
在 Apple App Store 中,您将只能测试您的应用创意,而不是应用标题、副标题和描述。审查过程也区分了两家商店。
两家商店的最大变体数量相同。
如何在 App Store 中使用 iOS 15 自定义产品页面获取付费流量?
iOS 15 更新为您的应用商店营销提供终极动力,将正确的信息传递给正确的受众。换句话说,您可以拥有与您的广告驱动的意图相匹配的自定义消息。这可以使您的转化率翻倍!
不同的渠道往往会吸引不同的目标受众——具有不同人口统计、兴趣和偏好的用户。使用定制的产品页面,您可以通过向每个细分市场显示正确的信息来影响您的转化率。如果操作得当,这可以显着提高您的付费 UA 转化率和广告支出回报率。
ASO管家
iOS 15 更新将使您能够驱动多达 35 个自定义产品页面,供付费用户获取流量。每个页面可以有不同的应用预览视频、截图和宣传文字。应用程序图标将与默认应用程序商店的产品页面上的相同。所有页面都有一个唯一的 Apple App Store URL,您可以将其吸引到特定的受众。
因此,您可以更轻松地通过 UA 渠道转换用户。仅仅因为用户将有一个更加个性化的旅程,从看广告到下载应用程序,而不是“一刀切”的信息传递。
客户产品页面与 Google 的客户产品列表有何不同
在 Apple App Store 中,您最多可以拥有 35 个自定义产品页面,而 Google 端只有 5 个自定义商店列表。Google 的选项允许您仅根据位置进行定位,对于 Apple 的自定义产品页面,您也可以在一个位置拥有多个页面,但它仅适用于来自 App Store 之外的流量。
此外,由于苹果的自定义产品页面不允许您更改应用程序的图标、标题和副标题,因此谷歌的自定义商店列表在更改副本和创意方面提供了更大的灵活性。
如何通过产品页面优化在 App Store 中运行合适的原生 A/B 测试?
创建 a/b 测试后,您将能够监控和分析测试的展示次数、下载量、转化率和性能结果。这将帮助您确定应用商店产品页面的最佳变体。
在 App Store 中运行 a/b 测试之前,您应该记住拆分测试应始终本地化到相应的国家/地区。应在当前设计和变体之间明智地分配受众百分比。
深入讨论:
A/B 测试-应用雷达学院
A/B 测试 - 6 个实际步骤
在 App Store 中正确设置 A/B 测试
下面概述了在 Apple App Store 中进行 A/B 测试时需要注意的最重要的几点。
当前版本和变体之间的受众分布。在决定应该分配给每个变体的流量部分时,请记住您当前的转化率、要测试的假设、涉及的元素和统计显着性(目前在 Google Play 实验中为 90%)。
拆分测试的持续时间。让测试运行至少 7 天,以避免季节性高峰影响您的结果。测试应继续运行,直到大量潜在受众访问了所有测试变体。
每个变体的最小安装量。为了获得有关 a/b 测试性能结果的重要数据,您需要密切关注所需的安装量。它与应用程序的每日安装率高度相关。
测试本地化。强烈建议在特定国家/地区本地化您的拆分测试。全球/全球实验可能会产生误导,因为每个国家/地区的创意表现都不同。
注意:初学者的一个常见错误是在设置适当的 a/b 测试或拆分测试时忽略应用程序性能的当前状态。
在应用商店进行 a/b 测试时要记住的其他方面:
· 封闭变体可能不会带来太多学习。尽管如此,您的所有创意元素都应该经过测试,以不断改进您的商店页面。
· 统计显着性所需的最低安装量可能很高,从而使测试持续时间很长。
· 测试不会提供有关用户行为的详细信息。
· 当前的统计置信度可能不可靠。
A/B测试的常见错误:
· 假设Android 和iOS 用户的行为相似。
· 模仿你的竞争对手。
· 对测试结果的错误解释。
· 拆分测试设置不正确。
· 应用轻微的改进或基于早期测试阶段的结果。
永远没有制胜法宝,但每一个环节、每一个细节都必须以最高的标准去做!
— 来自 ASO 巴特勒
抓取网页新闻(影响蜘蛛匍匐并终究影响到页面录入成果主要有几个方面的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-18 09:10
影响蜘蛛爬行并最终影响页面进入结果的主要原因有几个。
1.网站 更新状态
一般来说,如果网站更新快,蜘蛛爬取网站的内容会更快。如果网站的内容长时间没有更新,蜘蛛会相应调整网站的爬取频率。更新频率对于新闻等非常重要网站。因此,每天保持一定数量的更新对于吸引蜘蛛非常重要。
2.网站内容质量
对于低质量的页面,搜索引擎一直很有影响力。因此,创造高质量的内容对于吸引蜘蛛非常重要。从这个角度来看,“内容取胜”是完全正确的。如果网页质量不高,比如同一内容的集合很多,页面的核心内容是空的,蜘蛛是不会喜欢的。
3.网站 可以正常访问吗?
网站 能否正常访问是搜索引擎的连通性。连通性要求网站不能经常访问,可能访问速度特别慢。从蜘蛛的角度来看,期望提供给搜索客户的网页是可以正常访问的网页。对于响应缓慢或经常死机的服务器,相关的网站肯定会产生负面形象并且很严重。就是逐渐减少爬行,甚至去除已经进入的页面。
在实际操作中,由于国内服务器服务比较贵,另外根据监管要求,国内网站设立要求有备案标准,需要体验网上上传备案信息的过程,还有一些中小型网站的站长可以租用国外的服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问外国服务器时,间隔
更长的原因、缓慢的访问或崩溃是不可避免的。从长远来看,是对网站的SEO功能的限制。如果你想谨慎操作一个网站,还是尽量选择国内的服务器服务,可以选择一些服务更好、界面更友好的服务器商。当时很多公司推出的云服务器都不错。挑选。
另外,搜索引擎会根据网站的摘要对网站进行评分。这个等级不能完全等于重量。但是,评分的不均会影响蜘蛛对网站策略的爬取。
在抓取频率方面,搜索引擎一般都会提供可以调整抓取频率设置的东西,SEO人员可以根据实际情况进行调整。对于服务请求较多的大规模网站,可以调整频率,减轻网站的压力。
在实际爬取过程中,如果遇到爬取无法访问的异常情况,会导致搜索引擎大幅降低网站的评分,进而影响爬取、索引等一系列SEO功能, 并排序。毕竟会反映流量损失。
爬行异常的原因有很多。比如服务器不稳定,服务器一直超载,可能是协议有问题。因此,需要网站运维人员持续监控网站的运行,确保网站的稳定运行。在协议设备方面,需要防止一些初级故障,例如Disallow of Robots的设置故障。有一次,一位公司经理咨询了SEO人员,要求他们请外部开发人员做好网站,但在搜索引擎中找不到。原因是什么。SEO人员直接在URL和地址栏中输入了他的网站Robots地址,意外发现(Disallow命令)蜘蛛爬行停止了!
关于网站无法访问,还有其他可能。例如网络运营商异常,即蜘蛛无法通过电信或网通等价劳动力访问网站;并且DNS异常,即蜘蛛无法正常解析网站IP,可能是地址错误,也可能是被域名提供商屏蔽了。在这种情况下,您需要联系域名提供商。网页上也可能有死链接。例如,该页面当时已失败或出错。部分网页可能已批量下线。在这种情况下,这样做的方法是提交一个死链接声明;如果是旧的 uRL 更改,如果 URL 无效且无法访问,则设置 301 重定向将旧 URL 和相关权重转移到新页面。
对于检索到的数据,蜘蛛建立一个数据库。在这个链接中,搜索引擎会根据一些标准来判断该链接的重要性。一般来说,判断的标准是:内容是否为原创,如果是,则加权;主要内容是否明显,即核心内容是否突出,如果突出则加权;内容是否丰富,如果内容很丰富,会被加权;用户体验是否好,比如页面循环多,广告加载少等,如果是,会加权等。
因此,我们需要在网站的日常运营中遵守以下准则。
(1)请勿抄袭。既然共同的内容是所有搜索引擎公司都喜欢的,互联网鼓励原创。很多互联网公司希望在采集网页内容后整理自己的网站。从 SEO 的角度来看,这实际上是一种不良行为。
(2)在网站内容策划的时候,一定要坚持主题内容突出,也就是让搜索引擎爬过来知道网页要表达什么内容,而不是在一堆内容中判断网站是什么业务,主题不突出,很多网站中都有典型的操作混乱的例子,比如一些小说网站, 800字的章节分为8个每页100字左右,页面的其余部分收录各种广告和各种不相关的内容信息,还有网站,主要内容是框架结构或AIAX结构,蜘蛛可以爬的信息都是无关的内容。
现在一些大型门户网站网站从收入来看,还是有很多广告的。作为SEO人员,您需要考虑这个问题。
(4) 坚持网页内容的可访问性。有的网页内容很多,但使用js、AJAX等方式出现,搜索引擎无法识别,网页内容空洞短小。 . 使网页的评分大大降低。
另外,在链接的重要性方面,有两个重要的标准:从目录层面,坚持浅优先标准;从内部连锁规划,坚持热门页面优先标准。
所谓浅优先,是指搜索引擎在处理新链接,判断链接的重要性时,会优先考虑网址。更多的页面,即离uRL排列更接近首页域名的页面。因此,SEO在做重要的页面优化时,一定要注意扁平化原则,尽量缩短URL的中间链接。
既然给了浅优先级,那么能不能把所有的页面都平铺在网站的根目录下,然后选做SEO功能呢?一定不是,首先,优先级是一个相对的概念,如果你把所有的内容都放在根目录下,不管什么优先级,重要的内容和不重要的内容没有区别。另外,从SEO的角度来看,URL爬取后,用于分析网站的结构。URL组成之后,就可以大致确定内容的分组了。SEO人员可以通过URL的组合来完成关键词和关键词。网页的排列。 查看全部
抓取网页新闻(影响蜘蛛匍匐并终究影响到页面录入成果主要有几个方面的原因)
影响蜘蛛爬行并最终影响页面进入结果的主要原因有几个。
1.网站 更新状态
一般来说,如果网站更新快,蜘蛛爬取网站的内容会更快。如果网站的内容长时间没有更新,蜘蛛会相应调整网站的爬取频率。更新频率对于新闻等非常重要网站。因此,每天保持一定数量的更新对于吸引蜘蛛非常重要。
2.网站内容质量
对于低质量的页面,搜索引擎一直很有影响力。因此,创造高质量的内容对于吸引蜘蛛非常重要。从这个角度来看,“内容取胜”是完全正确的。如果网页质量不高,比如同一内容的集合很多,页面的核心内容是空的,蜘蛛是不会喜欢的。
3.网站 可以正常访问吗?
网站 能否正常访问是搜索引擎的连通性。连通性要求网站不能经常访问,可能访问速度特别慢。从蜘蛛的角度来看,期望提供给搜索客户的网页是可以正常访问的网页。对于响应缓慢或经常死机的服务器,相关的网站肯定会产生负面形象并且很严重。就是逐渐减少爬行,甚至去除已经进入的页面。
在实际操作中,由于国内服务器服务比较贵,另外根据监管要求,国内网站设立要求有备案标准,需要体验网上上传备案信息的过程,还有一些中小型网站的站长可以租用国外的服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问外国服务器时,间隔
更长的原因、缓慢的访问或崩溃是不可避免的。从长远来看,是对网站的SEO功能的限制。如果你想谨慎操作一个网站,还是尽量选择国内的服务器服务,可以选择一些服务更好、界面更友好的服务器商。当时很多公司推出的云服务器都不错。挑选。
另外,搜索引擎会根据网站的摘要对网站进行评分。这个等级不能完全等于重量。但是,评分的不均会影响蜘蛛对网站策略的爬取。
在抓取频率方面,搜索引擎一般都会提供可以调整抓取频率设置的东西,SEO人员可以根据实际情况进行调整。对于服务请求较多的大规模网站,可以调整频率,减轻网站的压力。
在实际爬取过程中,如果遇到爬取无法访问的异常情况,会导致搜索引擎大幅降低网站的评分,进而影响爬取、索引等一系列SEO功能, 并排序。毕竟会反映流量损失。
爬行异常的原因有很多。比如服务器不稳定,服务器一直超载,可能是协议有问题。因此,需要网站运维人员持续监控网站的运行,确保网站的稳定运行。在协议设备方面,需要防止一些初级故障,例如Disallow of Robots的设置故障。有一次,一位公司经理咨询了SEO人员,要求他们请外部开发人员做好网站,但在搜索引擎中找不到。原因是什么。SEO人员直接在URL和地址栏中输入了他的网站Robots地址,意外发现(Disallow命令)蜘蛛爬行停止了!
关于网站无法访问,还有其他可能。例如网络运营商异常,即蜘蛛无法通过电信或网通等价劳动力访问网站;并且DNS异常,即蜘蛛无法正常解析网站IP,可能是地址错误,也可能是被域名提供商屏蔽了。在这种情况下,您需要联系域名提供商。网页上也可能有死链接。例如,该页面当时已失败或出错。部分网页可能已批量下线。在这种情况下,这样做的方法是提交一个死链接声明;如果是旧的 uRL 更改,如果 URL 无效且无法访问,则设置 301 重定向将旧 URL 和相关权重转移到新页面。
对于检索到的数据,蜘蛛建立一个数据库。在这个链接中,搜索引擎会根据一些标准来判断该链接的重要性。一般来说,判断的标准是:内容是否为原创,如果是,则加权;主要内容是否明显,即核心内容是否突出,如果突出则加权;内容是否丰富,如果内容很丰富,会被加权;用户体验是否好,比如页面循环多,广告加载少等,如果是,会加权等。
因此,我们需要在网站的日常运营中遵守以下准则。
(1)请勿抄袭。既然共同的内容是所有搜索引擎公司都喜欢的,互联网鼓励原创。很多互联网公司希望在采集网页内容后整理自己的网站。从 SEO 的角度来看,这实际上是一种不良行为。
(2)在网站内容策划的时候,一定要坚持主题内容突出,也就是让搜索引擎爬过来知道网页要表达什么内容,而不是在一堆内容中判断网站是什么业务,主题不突出,很多网站中都有典型的操作混乱的例子,比如一些小说网站, 800字的章节分为8个每页100字左右,页面的其余部分收录各种广告和各种不相关的内容信息,还有网站,主要内容是框架结构或AIAX结构,蜘蛛可以爬的信息都是无关的内容。
现在一些大型门户网站网站从收入来看,还是有很多广告的。作为SEO人员,您需要考虑这个问题。
(4) 坚持网页内容的可访问性。有的网页内容很多,但使用js、AJAX等方式出现,搜索引擎无法识别,网页内容空洞短小。 . 使网页的评分大大降低。
另外,在链接的重要性方面,有两个重要的标准:从目录层面,坚持浅优先标准;从内部连锁规划,坚持热门页面优先标准。
所谓浅优先,是指搜索引擎在处理新链接,判断链接的重要性时,会优先考虑网址。更多的页面,即离uRL排列更接近首页域名的页面。因此,SEO在做重要的页面优化时,一定要注意扁平化原则,尽量缩短URL的中间链接。
既然给了浅优先级,那么能不能把所有的页面都平铺在网站的根目录下,然后选做SEO功能呢?一定不是,首先,优先级是一个相对的概念,如果你把所有的内容都放在根目录下,不管什么优先级,重要的内容和不重要的内容没有区别。另外,从SEO的角度来看,URL爬取后,用于分析网站的结构。URL组成之后,就可以大致确定内容的分组了。SEO人员可以通过URL的组合来完成关键词和关键词。网页的排列。
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-18 05:10
你的低价票被“虫子”吃掉了
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。
本报记者傅丽丽 查看全部
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
你的低价票被“虫子”吃掉了
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。
本报记者傅丽丽

