
抓取网页新闻
抓取网页新闻(网站怎么快速被爬虫?怎么让蜘蛛快速和抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-18 10:10
在这个网络时代,很多人在购买新品前都会上网查资料,看看哪些品牌的口碑和评价比较好。这时候,排名靠前的产品就会占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。下面,深圳徐欢欢会告诉你如何让蜘蛛快速爬行和爬行方法。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但是关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎排名中的重要因素。
2. 外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。网站大外链的搭建对于站长朋友来说非常重要,因为网站大的权重传递作用很强。而且还可以给内容带来更多的转载,让权重传递往往可以达到一敌百的作用。比如在A5上投稿就是一个不错的方法。此外,您也可以在各大门户网站投稿或花钱投稿到网易、新浪等相关频道网站。
事实上,在这些大网站上张贴或发布外部链接并不容易。貌似花钱或者雇枪手都可以实现,但是如果不注意外部链接的布局就很难提高优化效果,比如在A5 Contribution上,末尾添加的文字链接应该成为网站的首页链接。这样做的好处是相对于这个网站站长在A5上的投稿,有一定的相关性。如果你留下它的外部链接是一个销售成人用品的页面。这种相关性会变得极其脆弱,很难实现权重的引入。其他大型门户网站网站的外链建设也是如此。我们必须注意外部链接和结果页面的相关性。
然后就是合理布局长尾关键词外链。根据28原则,现代网站的利润往往来自于长尾关键词,也就是说长尾关键词已经成为网站@的盈利核心>,所以在外链建设中加强长尾关键词的锚文本,是有效提高长尾关键词权重和排名的关键方法。 -tail 关键词,对应的栏目页面要建好,然后外链的来源要选择有这些长尾关键词的栏目页面。当然,外链的载体内容必须与栏目页面有一定的相关性,否则效果不会很明显。
最后就是要注意内容页面的权重导入。这部分也很重要,对于很多中小网站来说,这种内容页的权重导入,不仅可以有效提升内容页在搜索引擎中的排名。更重要的是,它可以有效提高这些内容页的导流效果,因为当人们进入这些内容页时,不可避免地会点击这些内容页的扩展链接,直接进入这个网站,从而为进一步获取忠实用户。
那么,在构建内容页的外链构建时,我们必须避免一个问题,即内容页是外链构建的载体,即发布在其他网站和外链导入的内容完全一样。是的,这显然不是给用户参考的,但是内容页有一定的区别,或者是对外链内容的更好的补充,就像百度词条上的各种延伸阅读和相关词条的锚点一样的文字链接,这将使用户获得更好的知识,同时促进权重的合理导入。
做网站外链越来越难了,但是再难,我们还是要去做。只是我们现在不能这么残忍的去做。一定要讲究技巧,对百度的搜索引擎算法有深刻的了解。只有这样才能在外链优化中起到事半功倍的作用!
3.如何被爬虫爬取?
爬虫是一种自动提取网页的程序,比如百度的蜘蛛。如果你想让你的网站页面有更多的成为收录,你必须先让网页被爬虫抓取。
如果您的 网站 页面更新频繁,爬虫会更频繁地访问该页面。优质内容是爬虫喜欢爬取的目标,尤其是原创内容。
二、网站 如何快速被蜘蛛抓到
1.网站 和页面权重。
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛要保证高效,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样可以网站@收录也会有更多的页面。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛网站的体验越来越差,你的网站的评分也会越来越低,自然会影响你的网站的爬取>,所以你必须愿意选择一个空间服务器。没有很好的基础。,再好的房子也会穿越。
3. 网站 的更新频率。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,又不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的最爱,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓到。获得。
6.网站 程序。
在网站 程序中,可以创建大量重复页面的程序有很多。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新站点,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站中的页面暴露在蜘蛛面前可以防止蜘蛛找不到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
第一点:博客外链的搭建这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞留下外部链接。由于百度算法的更新,这种外链现在已经失效,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有所评论。关注一下,如果你的网站内容够好,有的博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。那个时候加个链接不是一句话的事吗?关于这个我就不多说了。
第三点:软文外链构建 在构建外链的过程中,使用软文构建外链是必不可少的一部分。同时,软文建外链也是最有效的,而且效果也很快,选择什么样的发布平台是直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在无关平台上发送软文肯定不如在相关平台上好,不好的平台认为传输的权重也是有限的。是的,我终于写了一篇文章,我不同意,我提交文章需要小心。
第四点:开放、品类目录外链建设。如果你的网站足够好,那么开放目录是一个不错的选择,比如DOMZ目录和yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。而且,网络上有相当多的网站分类目录。在建立外部链接时不要忽略这块肥肉。
第五点:虽然常说购买链接会被百度攻击,但作为一个新网站,如果想在最短的时间内获得一定的pr和权重,是有一定的收录,所以买链接也是必须的少,当然不是你去买一些金链或者去一些专门买卖链接的平台,而是去和一些公关、权重比较高的门户、新闻站交流(前提是这些门户网站和新闻站不是专门卖链接的),看看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后等你的网站慢慢上来的时候,就一一删除。
8.内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可能需要蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都在用,让蜘蛛爬更广泛的页面。
其实内链的建设也有助于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
此外,您可以将部分关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会给网站带来更多的流量。而且,页面之间的相关性增加,也可以增加用户在网站的停留时间,减少高跳出率的发生。
网站排名靠前的一个前提是网站被搜索引擎收录的页面多,良好的内链建设可以帮助网站页面成为< @收录。当一篇网站文章的文章为收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会一直爬到你的网站,大大增加了网站页面被收录的几率。 查看全部
抓取网页新闻(网站怎么快速被爬虫?怎么让蜘蛛快速和抓取方法)
在这个网络时代,很多人在购买新品前都会上网查资料,看看哪些品牌的口碑和评价比较好。这时候,排名靠前的产品就会占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。下面,深圳徐欢欢会告诉你如何让蜘蛛快速爬行和爬行方法。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但是关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎排名中的重要因素。
2. 外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。网站大外链的搭建对于站长朋友来说非常重要,因为网站大的权重传递作用很强。而且还可以给内容带来更多的转载,让权重传递往往可以达到一敌百的作用。比如在A5上投稿就是一个不错的方法。此外,您也可以在各大门户网站投稿或花钱投稿到网易、新浪等相关频道网站。
事实上,在这些大网站上张贴或发布外部链接并不容易。貌似花钱或者雇枪手都可以实现,但是如果不注意外部链接的布局就很难提高优化效果,比如在A5 Contribution上,末尾添加的文字链接应该成为网站的首页链接。这样做的好处是相对于这个网站站长在A5上的投稿,有一定的相关性。如果你留下它的外部链接是一个销售成人用品的页面。这种相关性会变得极其脆弱,很难实现权重的引入。其他大型门户网站网站的外链建设也是如此。我们必须注意外部链接和结果页面的相关性。
然后就是合理布局长尾关键词外链。根据28原则,现代网站的利润往往来自于长尾关键词,也就是说长尾关键词已经成为网站@的盈利核心>,所以在外链建设中加强长尾关键词的锚文本,是有效提高长尾关键词权重和排名的关键方法。 -tail 关键词,对应的栏目页面要建好,然后外链的来源要选择有这些长尾关键词的栏目页面。当然,外链的载体内容必须与栏目页面有一定的相关性,否则效果不会很明显。
最后就是要注意内容页面的权重导入。这部分也很重要,对于很多中小网站来说,这种内容页的权重导入,不仅可以有效提升内容页在搜索引擎中的排名。更重要的是,它可以有效提高这些内容页的导流效果,因为当人们进入这些内容页时,不可避免地会点击这些内容页的扩展链接,直接进入这个网站,从而为进一步获取忠实用户。
那么,在构建内容页的外链构建时,我们必须避免一个问题,即内容页是外链构建的载体,即发布在其他网站和外链导入的内容完全一样。是的,这显然不是给用户参考的,但是内容页有一定的区别,或者是对外链内容的更好的补充,就像百度词条上的各种延伸阅读和相关词条的锚点一样的文字链接,这将使用户获得更好的知识,同时促进权重的合理导入。
做网站外链越来越难了,但是再难,我们还是要去做。只是我们现在不能这么残忍的去做。一定要讲究技巧,对百度的搜索引擎算法有深刻的了解。只有这样才能在外链优化中起到事半功倍的作用!
3.如何被爬虫爬取?
爬虫是一种自动提取网页的程序,比如百度的蜘蛛。如果你想让你的网站页面有更多的成为收录,你必须先让网页被爬虫抓取。
如果您的 网站 页面更新频繁,爬虫会更频繁地访问该页面。优质内容是爬虫喜欢爬取的目标,尤其是原创内容。
二、网站 如何快速被蜘蛛抓到

1.网站 和页面权重。
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛要保证高效,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样可以网站@收录也会有更多的页面。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛网站的体验越来越差,你的网站的评分也会越来越低,自然会影响你的网站的爬取>,所以你必须愿意选择一个空间服务器。没有很好的基础。,再好的房子也会穿越。
3. 网站 的更新频率。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,又不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的最爱,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓到。获得。
6.网站 程序。
在网站 程序中,可以创建大量重复页面的程序有很多。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新站点,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站中的页面暴露在蜘蛛面前可以防止蜘蛛找不到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
第一点:博客外链的搭建这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞留下外部链接。由于百度算法的更新,这种外链现在已经失效,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有所评论。关注一下,如果你的网站内容够好,有的博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。那个时候加个链接不是一句话的事吗?关于这个我就不多说了。
第三点:软文外链构建 在构建外链的过程中,使用软文构建外链是必不可少的一部分。同时,软文建外链也是最有效的,而且效果也很快,选择什么样的发布平台是直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在无关平台上发送软文肯定不如在相关平台上好,不好的平台认为传输的权重也是有限的。是的,我终于写了一篇文章,我不同意,我提交文章需要小心。
第四点:开放、品类目录外链建设。如果你的网站足够好,那么开放目录是一个不错的选择,比如DOMZ目录和yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。而且,网络上有相当多的网站分类目录。在建立外部链接时不要忽略这块肥肉。
第五点:虽然常说购买链接会被百度攻击,但作为一个新网站,如果想在最短的时间内获得一定的pr和权重,是有一定的收录,所以买链接也是必须的少,当然不是你去买一些金链或者去一些专门买卖链接的平台,而是去和一些公关、权重比较高的门户、新闻站交流(前提是这些门户网站和新闻站不是专门卖链接的),看看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后等你的网站慢慢上来的时候,就一一删除。
8.内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可能需要蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都在用,让蜘蛛爬更广泛的页面。
其实内链的建设也有助于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
此外,您可以将部分关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会给网站带来更多的流量。而且,页面之间的相关性增加,也可以增加用户在网站的停留时间,减少高跳出率的发生。
网站排名靠前的一个前提是网站被搜索引擎收录的页面多,良好的内链建设可以帮助网站页面成为< @收录。当一篇网站文章的文章为收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会一直爬到你的网站,大大增加了网站页面被收录的几率。
抓取网页新闻(屏蔽主流搜索引擎爬虫(蜘蛛)//索引/收录网页的几种思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-18 07:09
中国IDC圈2月8日报道:一个网站已经搭建成功,之后的目标是希望搜索引擎能够及时收录,让更多的用户可以浏览和推广自己网站 产品产生购买欲望。但这样的愿望并不容易实现。有时我们也会遇到网站不需要搜索收录的情况。
例如,如果您要启用一个新域名作为镜像网站,主要用于PPC 推广,您必须想办法阻止搜索引擎蜘蛛抓取并索引我们镜像的所有网页网站。因为如果镜像网站也被搜索引擎收录搜索到了,很可能会影响官网在搜索引擎中的权重,这绝对是我们不想看到的结果.
下面列出了几种阻止主流搜索引擎爬虫(蜘蛛)抓取/索引/收录网页的思路。注:全站屏蔽,尽量屏蔽所有主流搜索引擎的爬虫(蜘蛛)。
1、 通过服务器(如:Linux/nginx)配置文件设置直接过滤spider/robots的IP段。
小提示:第一、二招只对“君子”有效,防止“小人”动用第三招(“君子”和“小人”分别指遵守和不遵守robots.txt协议蜘蛛/机器人),所以网站上线后,继续跟踪和分析日志,过滤掉这些badbot的ip,然后阻止它们。
这里有一个badbot ip数据库:,通过meta标签屏蔽添加所有网站推广网页的头文件,添加如下语句:
3、通过robots.txt文件屏蔽可以说robots.txt文件是最重要的渠道(它可以与搜索引擎建立直接对话)。通过分析我自己的网站推广博客服务器日志文件,给出以下建议(同时欢迎广大网友补充):
用户代理:BaiduspiderDisallow: /User-agent: GooglebotDisallow: /User-agent: Googlebot-MobileDisallow: /User-agent: Googlebot-ImageDisallow:/User-agent: Mediapartners-GoogleDisallow: /User-agent: Adsbot-GoogleDisallow: /用户代理:Feedfetcher-GoogleDisallow:/用户代理:雅虎!SlurpDisallow:/用户代理:雅虎!Slurp ChinaDisallow: /User-agent: Yahoo!-AdCrawlerDisallow: /User-agent: YoudaoBotDisallow: /User-agent: SosospiderDisallow : /User-agent: 搜狗蜘蛛Disallow: /User-agent: 搜狗网络蜘蛛Disallow: /User-agent: MSNBotDisallow : /User-agent: ia_archiverDisallow: /User-agent: Tomato BotDisallow: /User-agent: *Disallow: /< @4、可以通过检查HTTP_USER_AGENT是否被爬虫/蜘蛛访问,然后直接阻止其他更新返回 403 状态代码以阻止它。例如:
5、通过搜索引擎提供的站长工具,删除网页快照。例如,有时百度并没有严格遵守robots.txt协议,您可以通过百度提供的“网站投诉”门户删除网页快照。百度网页投诉中心: 总结:关于屏蔽搜索引擎收录网页的方法,网站推广编辑会讲到。如果哪位朋友有更好的技术和方法,希望发布出来,大家交流学习。 查看全部
抓取网页新闻(屏蔽主流搜索引擎爬虫(蜘蛛)//索引/收录网页的几种思路)
中国IDC圈2月8日报道:一个网站已经搭建成功,之后的目标是希望搜索引擎能够及时收录,让更多的用户可以浏览和推广自己网站 产品产生购买欲望。但这样的愿望并不容易实现。有时我们也会遇到网站不需要搜索收录的情况。
例如,如果您要启用一个新域名作为镜像网站,主要用于PPC 推广,您必须想办法阻止搜索引擎蜘蛛抓取并索引我们镜像的所有网页网站。因为如果镜像网站也被搜索引擎收录搜索到了,很可能会影响官网在搜索引擎中的权重,这绝对是我们不想看到的结果.
下面列出了几种阻止主流搜索引擎爬虫(蜘蛛)抓取/索引/收录网页的思路。注:全站屏蔽,尽量屏蔽所有主流搜索引擎的爬虫(蜘蛛)。
1、 通过服务器(如:Linux/nginx)配置文件设置直接过滤spider/robots的IP段。
小提示:第一、二招只对“君子”有效,防止“小人”动用第三招(“君子”和“小人”分别指遵守和不遵守robots.txt协议蜘蛛/机器人),所以网站上线后,继续跟踪和分析日志,过滤掉这些badbot的ip,然后阻止它们。
这里有一个badbot ip数据库:,通过meta标签屏蔽添加所有网站推广网页的头文件,添加如下语句:
3、通过robots.txt文件屏蔽可以说robots.txt文件是最重要的渠道(它可以与搜索引擎建立直接对话)。通过分析我自己的网站推广博客服务器日志文件,给出以下建议(同时欢迎广大网友补充):
用户代理:BaiduspiderDisallow: /User-agent: GooglebotDisallow: /User-agent: Googlebot-MobileDisallow: /User-agent: Googlebot-ImageDisallow:/User-agent: Mediapartners-GoogleDisallow: /User-agent: Adsbot-GoogleDisallow: /用户代理:Feedfetcher-GoogleDisallow:/用户代理:雅虎!SlurpDisallow:/用户代理:雅虎!Slurp ChinaDisallow: /User-agent: Yahoo!-AdCrawlerDisallow: /User-agent: YoudaoBotDisallow: /User-agent: SosospiderDisallow : /User-agent: 搜狗蜘蛛Disallow: /User-agent: 搜狗网络蜘蛛Disallow: /User-agent: MSNBotDisallow : /User-agent: ia_archiverDisallow: /User-agent: Tomato BotDisallow: /User-agent: *Disallow: /< @4、可以通过检查HTTP_USER_AGENT是否被爬虫/蜘蛛访问,然后直接阻止其他更新返回 403 状态代码以阻止它。例如:
5、通过搜索引擎提供的站长工具,删除网页快照。例如,有时百度并没有严格遵守robots.txt协议,您可以通过百度提供的“网站投诉”门户删除网页快照。百度网页投诉中心: 总结:关于屏蔽搜索引擎收录网页的方法,网站推广编辑会讲到。如果哪位朋友有更好的技术和方法,希望发布出来,大家交流学习。
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-17 23:03
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map供用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我对网页和网络相关知识接触不多,使用了不习惯的Python。下面的程序有曲折,bug很多,但是勉强能抓到网络新闻。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map供用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我对网页和网络相关知识接触不多,使用了不习惯的Python。下面的程序有曲折,bug很多,但是勉强能抓到网络新闻。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(本文会简单的爬取澎湃新闻网站的时事中国政库新闻 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-17 23:02
)
本文将简单爬取澎湃新闻网站中国政治图书馆新闻,会涉及并发应用!
分析网页
https://www.thepaper.cn/list_25462
The Paper of The Paper 网站 有点像梨视频网站。要获取更多内容,您需要下拉鼠标才能显示。是动态渲染的,所以需要进入浏览器开发用户工具→网络→XHR抓取内容并得到一个url。
打开链接,得到一个简单的静态网页:
每个链接的pageidx参数和lastTime参数都会发生变化。 pageidx 参数每次更改都会增加 1。 LastTime 是一个时间戳。这不会影响我们的抓取内容,只需将其删除即可。
https://www.thepaper.cn/load_i ... 18779
https://www.thepaper.cn/load_i ... 30221
点击打开一条内容,即新闻信息:
每个内容链接都有一个唯一的id值,所以需要获取它的id值:
https://www.thepaper.cn/newsDe ... 65286
https://www.thepaper.cn/newsDe ... 63702
抓取想法:
实用代码
导入模块:
import requests
import re
from lxml import etree
import concurrent.futures
请求函数:
保存功能:
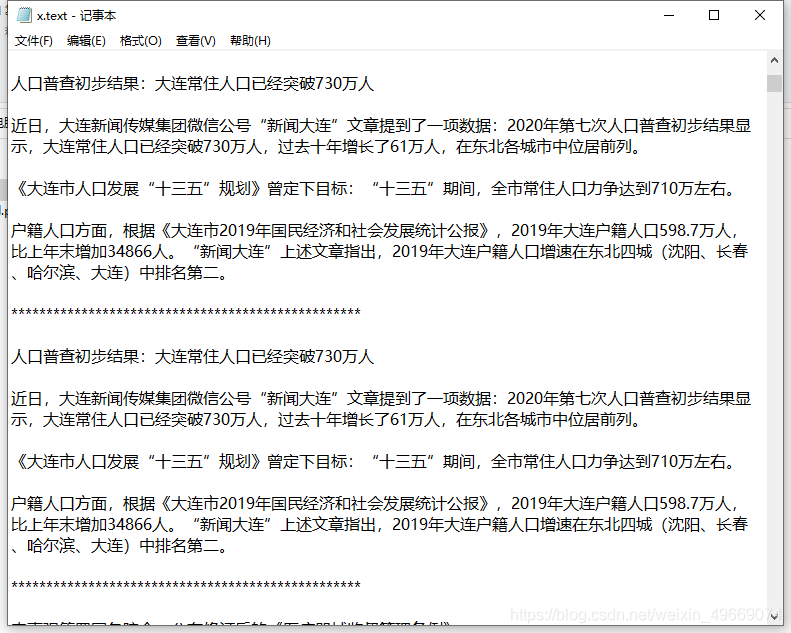
def save(title_li, text):
# 声明编码,不然会报错
with open('./x.text', mode='a', encoding='utf-8')as f:
f.write(title_li + '\n\n')
f.write(text + '\n\n')
# 因为保存在一个文件中,所以这里用*号进行隔开
f.write('*' * 50 + '\n\n')#
分析功能:
def main(html_url):
response = def_response(html_url)
href = re.findall('data-id="(.*?)"', response.text)
title = re.findall('alt="(.*?)"', response.text)
for url_li, title_li in zip(href, title):
# 拼接链接
url_ = f'https://www.thepaper.cn/newsDetail_forward_{url_li}'
res = def_response(url_)
etrees = etree.HTML(res.text)
# 这里用xpath提取文本内容,但是格式有点乱,所以用'\n\n'.join进行换行
text = '\n\n'.join(etrees.xpath('.//div[@class="news_txt"]/text()'))
save(title_li, text)
发起人:
if __name__ == '__main__':
# ThreadPoolExecutor 线程池的对象 max_workers 任务数 这里开了3个
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
for page in range(0, 4):
url = f'https://www.thepaper.cn/load_i ... dx%3D{page}&isList=true'
# main(url)
# submit 往线程池里面添加任务
executor.submit(main, url)
executor.shutdown()
效果图:
查看全部
抓取网页新闻(本文会简单的爬取澎湃新闻网站的时事中国政库新闻
)
本文将简单爬取澎湃新闻网站中国政治图书馆新闻,会涉及并发应用!
分析网页
https://www.thepaper.cn/list_25462
The Paper of The Paper 网站 有点像梨视频网站。要获取更多内容,您需要下拉鼠标才能显示。是动态渲染的,所以需要进入浏览器开发用户工具→网络→XHR抓取内容并得到一个url。
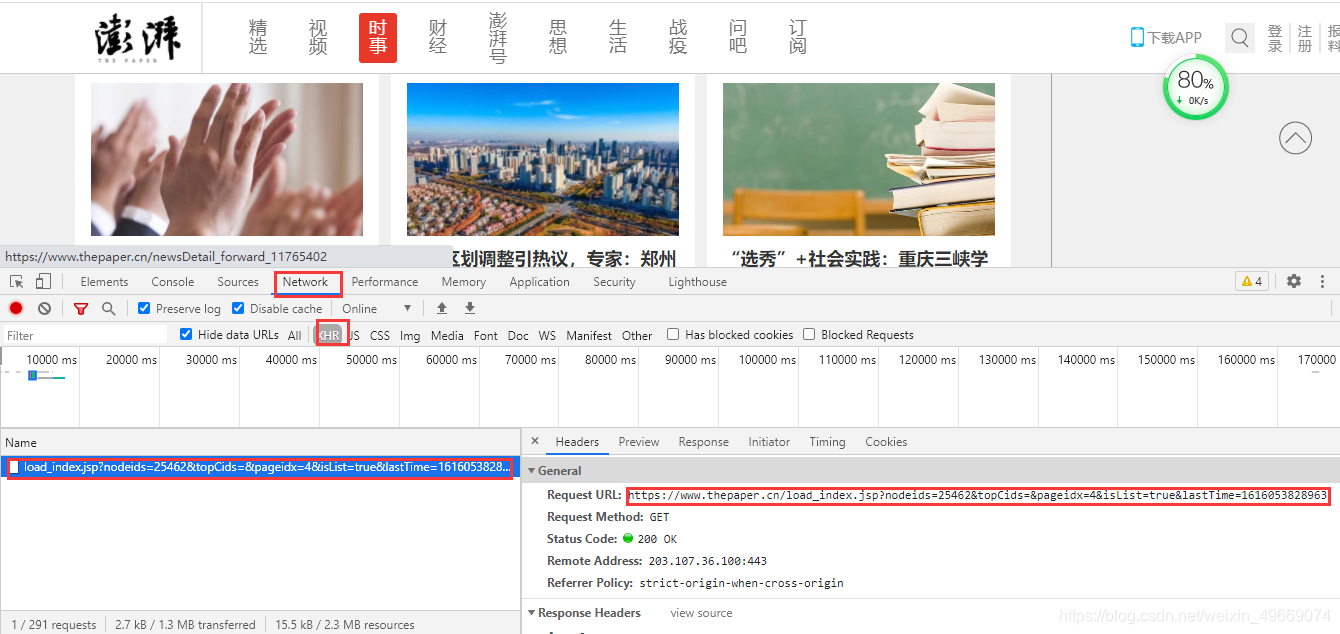
打开链接,得到一个简单的静态网页:

每个链接的pageidx参数和lastTime参数都会发生变化。 pageidx 参数每次更改都会增加 1。 LastTime 是一个时间戳。这不会影响我们的抓取内容,只需将其删除即可。
https://www.thepaper.cn/load_i ... 18779
https://www.thepaper.cn/load_i ... 30221
点击打开一条内容,即新闻信息:
每个内容链接都有一个唯一的id值,所以需要获取它的id值:
https://www.thepaper.cn/newsDe ... 65286
https://www.thepaper.cn/newsDe ... 63702
抓取想法:
实用代码
导入模块:
import requests
import re
from lxml import etree
import concurrent.futures
请求函数:
保存功能:
def save(title_li, text):
# 声明编码,不然会报错
with open('./x.text', mode='a', encoding='utf-8')as f:
f.write(title_li + '\n\n')
f.write(text + '\n\n')
# 因为保存在一个文件中,所以这里用*号进行隔开
f.write('*' * 50 + '\n\n')#
分析功能:
def main(html_url):
response = def_response(html_url)
href = re.findall('data-id="(.*?)"', response.text)
title = re.findall('alt="(.*?)"', response.text)
for url_li, title_li in zip(href, title):
# 拼接链接
url_ = f'https://www.thepaper.cn/newsDetail_forward_{url_li}'
res = def_response(url_)
etrees = etree.HTML(res.text)
# 这里用xpath提取文本内容,但是格式有点乱,所以用'\n\n'.join进行换行
text = '\n\n'.join(etrees.xpath('.//div[@class="news_txt"]/text()'))
save(title_li, text)
发起人:
if __name__ == '__main__':
# ThreadPoolExecutor 线程池的对象 max_workers 任务数 这里开了3个
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
for page in range(0, 4):
url = f'https://www.thepaper.cn/load_i ... dx%3D{page}&isList=true'
# main(url)
# submit 往线程池里面添加任务
executor.submit(main, url)
executor.shutdown()
效果图:
抓取网页新闻(网上接到一个一个开发新闻抓取接口的项目介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-17 02:09
半个月前,我接到了一个来自互联网的开发新闻爬取界面的项目。
客户需求是让用户可以在任何他能看到的手机app中采集文章,获取文章地址,将文章地址提交给客户平台,文章@ > 标题、摘要、正文和图片保存到对方的数据库中。有一款叫手趣的app,可以让用户将自己感兴趣的文章复制粘贴到app中。文章 自动捕获并以常规格式显示在客户端。客户端正在计划开发类似的功能,希望该应用能够兼容主流媒体的新闻抓取,包括新浪新闻、今日头条、微信公众号等。
申请过程并不复杂。用户从前端提交要抓取的URL到服务器。服务器根据URL域名匹配对应的爬虫,解析下载的HTML,并以固定格式存入数据库。服务端最终将爬取结果以JSON格式返回给客户端。
一个完整的爬虫包括四个模块:页面请求、任务调度、页面分析和数据存储。另外,如果需要考虑爬虫爬行效率、反爬行能力等因素,还需要添加一些高级模块,比如多线程和协程实现高并发,添加代理池防止爬行网站 阻止 IP 。如果运气不好,需要爬取的内容需要用户登录才能获取,则必须模拟用户登录。另外,由于大部分网站使用js来渲染页面,所以需要考虑使用分析数据接口或者模拟浏览器来获取这些动态内容。
分析了这个项目需要抓取的新闻网站,发现除了腾讯新闻外,都是用js来渲染html页面的。因此,不能像请求静态页面那样直接请求 URL 来获取 HTML。为方便起见,我使用了 casperjs。Casperjs是一个基于phantomjs的工具,比phantomjs有更方便的API。为了统一编程语言,我使用nodejs开发爬虫。
在项目中添加casperjsRequest.js文件,相当于项目中的下载模块,可以通过nodejs中的child_process.spawn调用。
var casper = require('casper').create({
pageSettings: {
loadImages: false, // The WebPage instance used by Casper will
loadPlugins: false // use these settings
}
});
var config = require('../config');
var url = casper.cli.args[0];
console.log(casper.cli.args);
casper.userAgent(config.REQUEST_USER_AGENT);
casper.options.waitTimeout = config.CASPERJS_WAIT_TIMEOUT;
casper.options.timeout = config.CASPERJS_TIMEOUT;
casper.start(url, function () {
this.echo(this.getPageContent());
});
casper.run();
将需要的URL作为命令行参数传递给casperjsRequest.js,可以在stdout中获取收录动态内容的页面的HTML,在bash中执行如下命令
casperjs ./bin/casperjsRequest.js
除了百度文库需要分页才能获取完整的文章外,其他新闻网站的字段内容都遵循一定的规则。因此,以配置文件的形式编辑不同网站的内容选择器,以方便扩展。每个配置文件代表一个网站的爬虫,所以如果有新的网站需要爬取,生成一个类似的配置文件即可。比如今日头条的配置如下
其中,配置文件定义了爬虫域名和内容选择器。此外,它还定义了页面下载的方式。1代表用casperjs请求动态内容,2(默认)代表直接请求静态html,3代表编码请求。
每个URL对应一个域名,即不同的新闻网站,单个新闻网站也分为PC端和移动端,它们的域名不同。当使用 PC URL 请求时,服务器将重定向到移动 URL。而且,今日头条有多个域名。因此,为了保证请求的PC端和手机端的URL一致,我使用了正则表达式来做域爬虫映射。配置文件如下
module.exports = {
// 百度百家号
"baijiahao.baidu.com": "baidu",
// 百度文库
"wk.baidu.com": "baiduwenku",
// 网易新闻
"(?:3g|news).163.com": "netease",
// 腾讯新闻
"(?:xw|news).qq.com": "tencent",
// 今日头条
".*toutiao(?:\d+)?.com|m.pstatp.com": "toutiao",
// 微信公众号文章
"mp.weixin.qq.com": "weixin",
// 新浪新闻
"sina.(?:cn|com)": "sina",
// 通用爬虫
".*": "generic"
};
下一步就是编写爬虫分析逻辑和数据存储。
(待续,待续) 查看全部
抓取网页新闻(网上接到一个一个开发新闻抓取接口的项目介绍及应用)
半个月前,我接到了一个来自互联网的开发新闻爬取界面的项目。
客户需求是让用户可以在任何他能看到的手机app中采集文章,获取文章地址,将文章地址提交给客户平台,文章@ > 标题、摘要、正文和图片保存到对方的数据库中。有一款叫手趣的app,可以让用户将自己感兴趣的文章复制粘贴到app中。文章 自动捕获并以常规格式显示在客户端。客户端正在计划开发类似的功能,希望该应用能够兼容主流媒体的新闻抓取,包括新浪新闻、今日头条、微信公众号等。
申请过程并不复杂。用户从前端提交要抓取的URL到服务器。服务器根据URL域名匹配对应的爬虫,解析下载的HTML,并以固定格式存入数据库。服务端最终将爬取结果以JSON格式返回给客户端。
一个完整的爬虫包括四个模块:页面请求、任务调度、页面分析和数据存储。另外,如果需要考虑爬虫爬行效率、反爬行能力等因素,还需要添加一些高级模块,比如多线程和协程实现高并发,添加代理池防止爬行网站 阻止 IP 。如果运气不好,需要爬取的内容需要用户登录才能获取,则必须模拟用户登录。另外,由于大部分网站使用js来渲染页面,所以需要考虑使用分析数据接口或者模拟浏览器来获取这些动态内容。
分析了这个项目需要抓取的新闻网站,发现除了腾讯新闻外,都是用js来渲染html页面的。因此,不能像请求静态页面那样直接请求 URL 来获取 HTML。为方便起见,我使用了 casperjs。Casperjs是一个基于phantomjs的工具,比phantomjs有更方便的API。为了统一编程语言,我使用nodejs开发爬虫。
在项目中添加casperjsRequest.js文件,相当于项目中的下载模块,可以通过nodejs中的child_process.spawn调用。
var casper = require('casper').create({
pageSettings: {
loadImages: false, // The WebPage instance used by Casper will
loadPlugins: false // use these settings
}
});
var config = require('../config');
var url = casper.cli.args[0];
console.log(casper.cli.args);
casper.userAgent(config.REQUEST_USER_AGENT);
casper.options.waitTimeout = config.CASPERJS_WAIT_TIMEOUT;
casper.options.timeout = config.CASPERJS_TIMEOUT;
casper.start(url, function () {
this.echo(this.getPageContent());
});
casper.run();
将需要的URL作为命令行参数传递给casperjsRequest.js,可以在stdout中获取收录动态内容的页面的HTML,在bash中执行如下命令
casperjs ./bin/casperjsRequest.js
除了百度文库需要分页才能获取完整的文章外,其他新闻网站的字段内容都遵循一定的规则。因此,以配置文件的形式编辑不同网站的内容选择器,以方便扩展。每个配置文件代表一个网站的爬虫,所以如果有新的网站需要爬取,生成一个类似的配置文件即可。比如今日头条的配置如下
其中,配置文件定义了爬虫域名和内容选择器。此外,它还定义了页面下载的方式。1代表用casperjs请求动态内容,2(默认)代表直接请求静态html,3代表编码请求。
每个URL对应一个域名,即不同的新闻网站,单个新闻网站也分为PC端和移动端,它们的域名不同。当使用 PC URL 请求时,服务器将重定向到移动 URL。而且,今日头条有多个域名。因此,为了保证请求的PC端和手机端的URL一致,我使用了正则表达式来做域爬虫映射。配置文件如下
module.exports = {
// 百度百家号
"baijiahao.baidu.com": "baidu",
// 百度文库
"wk.baidu.com": "baiduwenku",
// 网易新闻
"(?:3g|news).163.com": "netease",
// 腾讯新闻
"(?:xw|news).qq.com": "tencent",
// 今日头条
".*toutiao(?:\d+)?.com|m.pstatp.com": "toutiao",
// 微信公众号文章
"mp.weixin.qq.com": "weixin",
// 新浪新闻
"sina.(?:cn|com)": "sina",
// 通用爬虫
".*": "generic"
};
下一步就是编写爬虫分析逻辑和数据存储。
(待续,待续)
抓取网页新闻(企业网站建设|优秀的网站都是靠这些细节做成功的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-17 02:05
阿里云>云栖社区>主题图>P>php抓取网站新闻
推荐活动:
更多优惠>
当前话题:php抓取网站新闻加入采集
相关话题:
php抓取网站新闻相关博客,查看更多博客
Scrapy和Django实现蚌埠医学院移动新闻网站制作
作者:袜子都是破洞 1377人浏览评论:03年前
最终效果(效果不用看,过程都是**应该是流氓**): 实现过程如下: 框架:Scrapy:Data采集 Django:数据呈现目标网站:蚌埠医学院新闻列表:
阅读全文
PHP编程获取网站的Alexa排名
作者:小美科技 1393人浏览评论:04年前
现在大部分提供网站排名的网站,数据取自Alexa发布的数据。但是Alexa的网站排名数据无法简单直接获取。这是因为 Alexa 使用了干扰码技术,这使得编程变得困难和繁琐。但是理论上来说,只要是页面上能看到的信息,除了图片识别,还是一个top
阅读全文
高性能网站 性能优化与系统架构(ZT)
作者:犹豫1270人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET做过拨号接入平台的搭建,之后在Yahoo&3721从事搜索引擎前端开发,在MOP打过大社区。
阅读全文
高性能网站 性能优化与系统架构(ZT)
作者:zting科技1080人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过大型社区猫。
阅读全文
企业网站建设|优秀网站靠这些细节成就
作者:卓研科技2016年浏览评论人数:04年前
随着互联网的发展,许多企业纷纷涌入互联网的战场。从电子商务的发展,不难看出互联网对我们的影响有多大。未来,社会的发展一定会在互联网的基础上推进。现在,很多互联网公司也在做自己的搜索引擎,大佬们想分一杯羹。所以,网站能够引入的流量是非常难得的,也是珍贵的。
阅读全文
php
作者:江湖4546人浏览评论:05年前
Awesome PHP Dependency Management Dependency Management Other Dependency Management Extras Framework Framework Other Framework Framework Extras Framework Components Micro
阅读全文
网站 大并发处理
作者:lhyxcxy1201 浏览评论人数:06年前
一个小小的网站,比如一个个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有的页面都存放在一个目录下,比如网站@ > 对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过这几年的发展,已经细分到非常细致的方面,尤其是
阅读全文
PHP开发高负载网站技术
作者:y0umer839人浏览评论:010年前
在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过一个大型社区拖把大杂烩的架构升级。同时接触并开发了很多大中型项目网站模块,所以在大型网站高负载高并发解决方案方面有一定的积累和经验,可以和每个人一起工作
阅读全文
php抢网站新闻相关问答
PHPwind9.02网站 如何打开一个版块抓取其他网站数据(例如实时动态新闻)
作者:侯涂1688646人浏览评论:13年前
哪位大神能给解答一下,谢谢!
阅读全文 查看全部
抓取网页新闻(企业网站建设|优秀的网站都是靠这些细节做成功的)
阿里云>云栖社区>主题图>P>php抓取网站新闻

推荐活动:
更多优惠>
当前话题:php抓取网站新闻加入采集
相关话题:
php抓取网站新闻相关博客,查看更多博客
Scrapy和Django实现蚌埠医学院移动新闻网站制作


作者:袜子都是破洞 1377人浏览评论:03年前
最终效果(效果不用看,过程都是**应该是流氓**): 实现过程如下: 框架:Scrapy:Data采集 Django:数据呈现目标网站:蚌埠医学院新闻列表:
阅读全文
PHP编程获取网站的Alexa排名

作者:小美科技 1393人浏览评论:04年前
现在大部分提供网站排名的网站,数据取自Alexa发布的数据。但是Alexa的网站排名数据无法简单直接获取。这是因为 Alexa 使用了干扰码技术,这使得编程变得困难和繁琐。但是理论上来说,只要是页面上能看到的信息,除了图片识别,还是一个top
阅读全文
高性能网站 性能优化与系统架构(ZT)

作者:犹豫1270人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET做过拨号接入平台的搭建,之后在Yahoo&3721从事搜索引擎前端开发,在MOP打过大社区。
阅读全文
高性能网站 性能优化与系统架构(ZT)

作者:zting科技1080人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过大型社区猫。
阅读全文
企业网站建设|优秀网站靠这些细节成就


作者:卓研科技2016年浏览评论人数:04年前
随着互联网的发展,许多企业纷纷涌入互联网的战场。从电子商务的发展,不难看出互联网对我们的影响有多大。未来,社会的发展一定会在互联网的基础上推进。现在,很多互联网公司也在做自己的搜索引擎,大佬们想分一杯羹。所以,网站能够引入的流量是非常难得的,也是珍贵的。
阅读全文
php

作者:江湖4546人浏览评论:05年前
Awesome PHP Dependency Management Dependency Management Other Dependency Management Extras Framework Framework Other Framework Framework Extras Framework Components Micro
阅读全文
网站 大并发处理


作者:lhyxcxy1201 浏览评论人数:06年前
一个小小的网站,比如一个个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有的页面都存放在一个目录下,比如网站@ > 对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过这几年的发展,已经细分到非常细致的方面,尤其是
阅读全文
PHP开发高负载网站技术


作者:y0umer839人浏览评论:010年前
在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过一个大型社区拖把大杂烩的架构升级。同时接触并开发了很多大中型项目网站模块,所以在大型网站高负载高并发解决方案方面有一定的积累和经验,可以和每个人一起工作
阅读全文
php抢网站新闻相关问答
PHPwind9.02网站 如何打开一个版块抓取其他网站数据(例如实时动态新闻)

作者:侯涂1688646人浏览评论:13年前
哪位大神能给解答一下,谢谢!
阅读全文
抓取网页新闻(SEO(搜索引擎优化)推广策略:提升网站最重要的关键词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-15 06:45
SEO(搜索引擎优化)推广策略:
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。
1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。
4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概认为全文每100字出现“1.5-2关键词”为最佳关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
亿速云作为专业的IDC服务商和专业的云计算服务商,拥有丰富的行业积累,销售“赛门铁克、Thawte、Rapid SSL、Geo Trust”等多家全球权威CA机构的SSL数字证书,提供多品牌、多类SSL证书申请安装服务,全程专业技术指导,免费帮助用户安装部署。 查看全部
抓取网页新闻(SEO(搜索引擎优化)推广策略:提升网站最重要的关键词)
SEO(搜索引擎优化)推广策略:
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。

1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。

4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概认为全文每100字出现“1.5-2关键词”为最佳关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
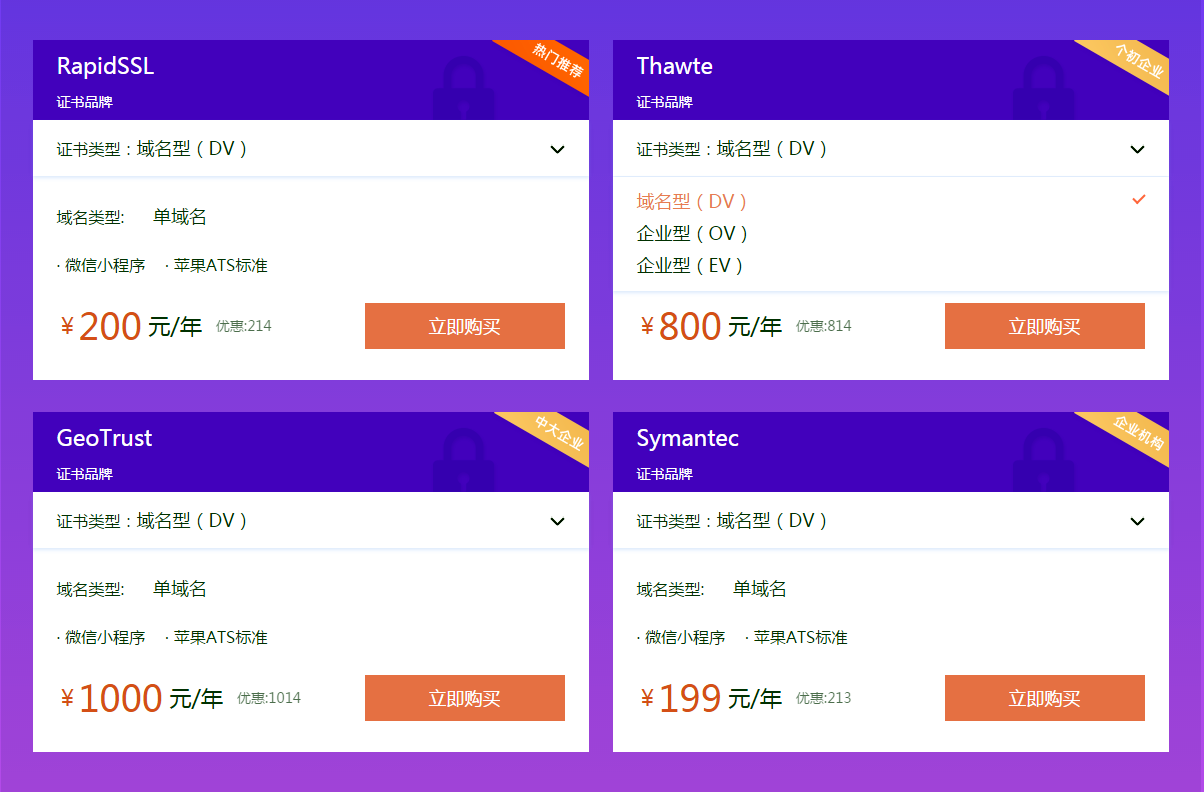
亿速云作为专业的IDC服务商和专业的云计算服务商,拥有丰富的行业积累,销售“赛门铁克、Thawte、Rapid SSL、Geo Trust”等多家全球权威CA机构的SSL数字证书,提供多品牌、多类SSL证书申请安装服务,全程专业技术指导,免费帮助用户安装部署。
抓取网页新闻(SEO(搜索引擎优化)推广中最重要的关键词,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-15 06:43
对于SEO来说,只要搜索引擎爬取更多的网站页面来提升收录和排名,但是有时候蜘蛛不会主动爬取网站,这个时候我们需要人为地引导搜索引擎,然后提升排名和收录。今天小编就给大家分享下8个帮助搜索引擎爬取网站页面的方法
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。
1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。
4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概把全文每100字出现“1.5-2关键词”作为最佳的关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
这些都是让搜索引擎主动抓取我们的网站页面的方法。希望云网时代小编的分享可以对大家有所帮助。云网时代专业提供深圳主机租赁、深圳服务器租赁、深圳服务器托管、云托管等服务,详情请咨询客服。 查看全部
抓取网页新闻(SEO(搜索引擎优化)推广中最重要的关键词,你知道吗?)
对于SEO来说,只要搜索引擎爬取更多的网站页面来提升收录和排名,但是有时候蜘蛛不会主动爬取网站,这个时候我们需要人为地引导搜索引擎,然后提升排名和收录。今天小编就给大家分享下8个帮助搜索引擎爬取网站页面的方法
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。

1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。
4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概把全文每100字出现“1.5-2关键词”作为最佳的关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
这些都是让搜索引擎主动抓取我们的网站页面的方法。希望云网时代小编的分享可以对大家有所帮助。云网时代专业提供深圳主机租赁、深圳服务器租赁、深圳服务器托管、云托管等服务,详情请咨询客服。
抓取网页新闻(编程问答--新浪中的房地产自动去抓会的说说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-15 02:26
)
如何自动抓取其他网站的新闻信息为了网站以后的维护和开发的方便,能不能有技术支持与其他网站连接并获取网站的信息,如:新浪楼盘信息,想提取出来,及时添加到自己开发的网站中,减少功能量;也就是说,新浪的房产信息更新了,我网站上相应的新闻信息也发生了变化。. . . 怎么实现的,能具体点吗,这里O(∩_∩)O谢谢技术交流!--------------------编程问答---- ----------------据说所有爬虫都是自动抓取的
我来聊一聊......--------------------编程问答----- --apachehtmlClienthtmlParser- -------------------编程问题与解答--------------------这个帮助是好问题!--------------------编程问答--------------------希望有经验的开发者提供一些宝贵的经验和知识,感谢您的交流!--------------------编程问答----- ---- -----
给个赞,现在我也想要这个东西!--------------------编程问答 --------------------但是爬虫爬取的是什么向下?组织也是一个大问题。最好使用更规范的网站。采集到的内容格式也非常完整和规范。然后就容易做内容分析处理了,不然就麻烦了。 ------- -------------编程问答------------ --------常规的网站,排版不要频繁变化。使用htmlparser,根据html标签取出需要的内容存入自己的数据库中。一天更新几次。
我只做过网页抓取。--------------------编程问答-------------------- 可以你推荐一个好的爬虫技术(我查了很多爬虫工具,但是没用过,第一次用这个技术),怎么用的,能告诉我吗,谢谢!------ --------------编程问答-------------------------- -------- ------编程问答-------------------------------- --------编程问答 --------------------rss
补充:Java , Java EE 查看全部
抓取网页新闻(编程问答--新浪中的房地产自动去抓会的说说
)
如何自动抓取其他网站的新闻信息为了网站以后的维护和开发的方便,能不能有技术支持与其他网站连接并获取网站的信息,如:新浪楼盘信息,想提取出来,及时添加到自己开发的网站中,减少功能量;也就是说,新浪的房产信息更新了,我网站上相应的新闻信息也发生了变化。. . . 怎么实现的,能具体点吗,这里O(∩_∩)O谢谢技术交流!--------------------编程问答---- ----------------据说所有爬虫都是自动抓取的
我来聊一聊......--------------------编程问答----- --apachehtmlClienthtmlParser- -------------------编程问题与解答--------------------这个帮助是好问题!--------------------编程问答--------------------希望有经验的开发者提供一些宝贵的经验和知识,感谢您的交流!--------------------编程问答----- ---- -----

给个赞,现在我也想要这个东西!--------------------编程问答 --------------------但是爬虫爬取的是什么向下?组织也是一个大问题。最好使用更规范的网站。采集到的内容格式也非常完整和规范。然后就容易做内容分析处理了,不然就麻烦了。 ------- -------------编程问答------------ --------常规的网站,排版不要频繁变化。使用htmlparser,根据html标签取出需要的内容存入自己的数据库中。一天更新几次。
我只做过网页抓取。--------------------编程问答-------------------- 可以你推荐一个好的爬虫技术(我查了很多爬虫工具,但是没用过,第一次用这个技术),怎么用的,能告诉我吗,谢谢!------ --------------编程问答-------------------------- -------- ------编程问答-------------------------------- --------编程问答 --------------------rss
补充:Java , Java EE
抓取网页新闻(Python爬虫用Python语言编写的python爬虫实现方法一文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-14 05:20
Python爬虫学习,自动抓取163新闻的Python爬虫源码。这是一篇用Python编写的自动抓取网易新闻的Python爬虫的文章。
Python爬虫的爬取思路是:
(1) 通过分析目标新闻网址,分析以
(2)获取每个链接的内容,整理合并成准备好的.txt文本,以便查看新闻。
不过需要注意的是,由于今天的考题,网易新闻的格式不是很统一,会有一些缺失的部分。请原谅我。也希望有能力的朋友帮忙改进一下。
自动抓取163新闻的Python爬虫源码如下:
#coding:utf-8
import re, urllib
strTitle = ""
strTxtTmp = ""
strTxtOK = ""
f = open("163News.txt", "w+")
m = re.findall(r"news\.163\.com/\d.+?",urllib.urlopen("http://www.163.com").read(),re.M)
#www.iplaypy.com
for i in m:
testUrl = i.split('"')[0]
if testUrl[-4:-1]=="htm":
strTitle = strTitle + "\n" + i.split('"')[0] + i.split('"')[1] # 合并标题头内容
okUrl = i.split('"')[0] # 重新组合链接
UrlNews = ''
UrlNews = "http://" + okUrl
print UrlNews
"""
查找分析链接里面的正文内容,但是由于 163 新闻的格式不是非常统一,所以只能说大部分可以。
整理去掉部分 html 代码,让文本更易于观看。
"""
n = re.findall(r"<P style=.TEXT-INDENT: 2em.>(.*?)",urllib.urlopen(UrlNews).read(),re.M)
for j in n:
if len(j)0:
j = j.replace(" ","\n")
j = j.replace("<STRONG>","\n_____")
j = j.replace("</STRONG>","_____\n")
strTxtTmp = strTxtTmp + j + "\n"
strTxtTmp = re.sub(r"<a href=(.*?)>", r"", strTxtTmp)
strTxtTmp = re.sub(r"", r"", strTxtTmp)
strTxtOK = strTxtOK + "\n\n\n===============" +
i.split('"')[0] + i.split('"')[1] + "===============\n" + strTxtTmp
strTxtTmp = "" # 组合链接标题和正文内容
print strTxtOK
f.write(strTitle + "\n\n\n" + strTxtOK)# 全部分析完成后,写入文件
f.close()#关闭文件
文章 代码效果有限,请在使用前进行适当修改。 查看全部
抓取网页新闻(Python爬虫用Python语言编写的python爬虫实现方法一文)
Python爬虫学习,自动抓取163新闻的Python爬虫源码。这是一篇用Python编写的自动抓取网易新闻的Python爬虫的文章。
Python爬虫的爬取思路是:
(1) 通过分析目标新闻网址,分析以
(2)获取每个链接的内容,整理合并成准备好的.txt文本,以便查看新闻。
不过需要注意的是,由于今天的考题,网易新闻的格式不是很统一,会有一些缺失的部分。请原谅我。也希望有能力的朋友帮忙改进一下。

自动抓取163新闻的Python爬虫源码如下:
#coding:utf-8
import re, urllib
strTitle = ""
strTxtTmp = ""
strTxtOK = ""
f = open("163News.txt", "w+")
m = re.findall(r"news\.163\.com/\d.+?",urllib.urlopen("http://www.163.com";).read(),re.M)
#www.iplaypy.com
for i in m:
testUrl = i.split('"')[0]
if testUrl[-4:-1]=="htm":
strTitle = strTitle + "\n" + i.split('"')[0] + i.split('"')[1] # 合并标题头内容
okUrl = i.split('"')[0] # 重新组合链接
UrlNews = ''
UrlNews = "http://" + okUrl
print UrlNews
"""
查找分析链接里面的正文内容,但是由于 163 新闻的格式不是非常统一,所以只能说大部分可以。
整理去掉部分 html 代码,让文本更易于观看。
"""
n = re.findall(r"<P style=.TEXT-INDENT: 2em.>(.*?)",urllib.urlopen(UrlNews).read(),re.M)
for j in n:
if len(j)0:
j = j.replace(" ","\n")
j = j.replace("<STRONG>","\n_____")
j = j.replace("</STRONG>","_____\n")
strTxtTmp = strTxtTmp + j + "\n"
strTxtTmp = re.sub(r"<a href=(.*?)>", r"", strTxtTmp)
strTxtTmp = re.sub(r"", r"", strTxtTmp)
strTxtOK = strTxtOK + "\n\n\n===============" +
i.split('"')[0] + i.split('"')[1] + "===============\n" + strTxtTmp
strTxtTmp = "" # 组合链接标题和正文内容
print strTxtOK
f.write(strTitle + "\n\n\n" + strTxtOK)# 全部分析完成后,写入文件
f.close()#关闭文件
文章 代码效果有限,请在使用前进行适当修改。
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-13 14:01
你的低价票被“虫子”吃掉了
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身,抢到一张低价回家的机票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了,什么是“爬虫”?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用来批量和自动化采集网站数据的程序,几乎没有需要人工干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录用户可以阅读的文字、图片等信息,还收录一些超链接信息。网络“爬虫”使用这些超链接不断地爬取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价或卖空机票后,可以利用虚假客户的真实身份信息进行抢先预订。此外,许多网络浏览器都推出了自己的抢票插件,以推广订票成功率高的浏览器。
根据抓取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理机构利用“爬虫”技术,不断抓取机票官网信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。因为“爬虫”的效率远远超过正常的人工操作,通过正常的操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,以此类推,直到真正找到并出售客源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用“爬虫”抢票、提价提供了便利。这种的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,但并没有产生任何消耗。这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。大量“爬虫”的爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,会对机票产生负面影响用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则判定该访问为恶意“爬虫”,“爬虫” IP被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,访问可疑IP时,返回验证页面,要求访问者填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,尚无明确规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界共同的道德规范,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也必须加强对账期的管理,不给“爬虫”提供抢票机会。 查看全部
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
你的低价票被“虫子”吃掉了

资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身,抢到一张低价回家的机票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了,什么是“爬虫”?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用来批量和自动化采集网站数据的程序,几乎没有需要人工干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录用户可以阅读的文字、图片等信息,还收录一些超链接信息。网络“爬虫”使用这些超链接不断地爬取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价或卖空机票后,可以利用虚假客户的真实身份信息进行抢先预订。此外,许多网络浏览器都推出了自己的抢票插件,以推广订票成功率高的浏览器。
根据抓取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理机构利用“爬虫”技术,不断抓取机票官网信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。因为“爬虫”的效率远远超过正常的人工操作,通过正常的操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,以此类推,直到真正找到并出售客源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用“爬虫”抢票、提价提供了便利。这种的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,但并没有产生任何消耗。这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。大量“爬虫”的爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,会对机票产生负面影响用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则判定该访问为恶意“爬虫”,“爬虫” IP被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,访问可疑IP时,返回验证页面,要求访问者填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,尚无明确规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界共同的道德规范,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也必须加强对账期的管理,不给“爬虫”提供抢票机会。
抓取网页新闻( 本发明涉及一种基于Ajax的新闻网页动态数据的抓取方法及系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-09 09:10
本发明涉及一种基于Ajax的新闻网页动态数据的抓取方法及系统)
本发明涉及一种基于Ajax的新闻网页动态数据抓取方法及系统。
背景技术:
目前,新闻网站的信息具有类别多、更新频率快、多平台发布的特点,数据检索方式也非常灵活。很多新闻网站页面使用ajax来调用数据,这样通过一个数据源,就可以在不同的平台上进行解析。例如,PC 网页和移动网页可以通过不同的模板共享数据请求。呈现不同的排版风格。
在采集爬取网站新闻数据时,会发现很多网站数据是通过ajax获取的动态内容,并没有固定的静态模板。获取数据的 JavaScript 脚本程序往往在整个页面的 DOM 结构加载完毕后执行。如果整个网页的DOM结构还没有加载完,那么网络爬虫在访问这个地方时就得不到数据内容,大大降低了网络数据的效率和质量采集。
如果需要获取通过ajax请求动态加载的数据,则需要分析网站的请求的数据源地址。Ajax调用的数据格式多为JSON、JSONP、XML或Inc。经过分析,不同的网站使用不同的网络技术,所以调用Ajax请求时采用的方案也有很大差异,数据源存储格式也是多种多样的。
通过对现有技术的分析发现,目前还没有统一的自动化的Ajax数据源分析方法,现有的方法不能解决Ajax一次性获取动态内容的所有问题。
首先,大部分的实现方法都是通过JavaScript脚本中的特征值进行检索,从而进一步猜测和推断Ajax请求的内容。但是,这并不能准确地找出您要采集 的目标数据。目前一个页面很可能收录多个ajax请求,有的是用户信息认证请求,有的是订阅信息的返回数据,还有的是广告推送信息。这些信息混杂在一起,仅通过脚本代码中的特征值很难区分哪些数据源需要采集。另外,对脚本代码特征值的分析也仅限于JavaScript代码未加密的情况。如今,很多网站出于安全性和访问效率的要求,可能会合并多个JavaScript脚本文件,然后对其进行加密。它会使现有的特征值消失。
其次,Ajax 调用方式本身会存在跨域问题,这是其自身独有的安全机制。也就是说,如果您不在同一个域名下,您仍然无法使用脚本语言成功执行请求并返回数据。在处理这样的调用方式时,由于没有统一域名下的网络环境,很难自动完成Ajax触发请求。也有一些网站在他们的程序中有反爬虫程序。如果被频繁访问,二维码等内容会阻止新闻数据的继续采集。
最后,即使找到了 Ajax 请求的数据源,也会出现格式和编码不匹配的情况。例如,JAVA 语言生成的 JSON 数据不能直接用 PHP 语言处理。一些返回的数据在 JSON 格式本身中会有英文双引号和符号冲突。还有一些请求使用了JSONP请求方式,即带有请求头的JSON格式。
技术实现要素:
本发明的目的是为了解决上述问题,提供一种基于Ajax的新闻网页动态数据捕获方法及系统,其侧重于数据源的策略分析,针对不同情况采用定制化的解决方案。
为实现上述目的,本发明采用以下技术方案:
基于Ajax的新闻网页动态数据捕获方法包括以下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ; 否则,会将数据作为字符串处理;完成后,转到步骤(106);
Step(106):遍历数据对象或数组类型的输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址。
重定向地址是指最终重定向的URL地址。
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
所述步骤(101))对新闻网页内容库进行爬取的编码方式包括:UTF-8编码或GBK编码;
本步骤(102))的浏览器开发工具包括:谷歌Chrome开发工具。
在步骤(103)中,如果Ajax请求的数据源中存在特殊字符或乱码,则批量替换特殊字符或乱码,转换为可处理的字符。
特殊字符包括斜线、反斜线、冒号、星号、问号、引号、大于号、小于号或可能影响 JSON 格式的竖线符号。
可以处理的字符有中文引号、中文逗号、中文冒号等。
步骤(103):如果编码方式不同,则统一编码方式,统一采用UTF-8的编码方式。
步骤(102)和步骤(103))之间的步骤如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方式模拟传入页面,通过主机获取请求数据地址;
步骤(1020)中,通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决跨域请求的问题未经许可不得获取数据。
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据。
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源。
在步骤(104)中,列表页面的后台语言包括JAVA、C++、PHP。
步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
step(1042) JSONP 是JSON格式的一种使用方式,通常用于跨域调用。因为要对请求进行身份识别,通常会在请求头中收录一个回调参数,包裹带引号半角括号的JSON内容,JSON格式是带请求头的JSON格式,但是在JSON格式解析中需要去掉,成为标准的JSON格式,基于以上原因,有必要返回 Remove 请求标头和括号的内容。
步骤(1043): 因为有些特殊字符会影响格式规范,有些特殊字符无法识别,所以在封装数据之前,必须对这些特殊字符进行处理,即批量替换。空字符。
步骤 (105):
如果步骤(104)中解析的数据不是键值对类型,则将步骤(104)中解析的数据封装成数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
步骤 (105) 将数据视为字符串:
使用PHP语言的字符串切分函数对字符串的特征值进行切分,并使用字符串拼接函数将字符串的特征值组合起来,最终形成规范格式的数据;
解析出来的数据是一组新闻数据,包括多条新闻数据,特征值指的是步骤(104)为每条新闻数据之间的分隔符。例如JSON格式使用半角逗号分隔引文。
如果不是逗号分割,则分析数据找到数据单元的分割符号进行处理,并将分割符号更新到特征值库中。需要不断积累特征值来提高对各类数据特征值分隔符的识别能力。
步骤(106)相当于通过解析需要爬取的新闻列表页面的请求数据源,在自己的服务器上重新恢复新闻网页。因为这个新闻网页不是Ajax调用的,而是在你自己的服务器中,不存在跨域问题或者网页的DOM结构加载后执行请求数据的脚本程序的问题,网络爬虫可以执行采集。
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
一个基于Ajax的新闻网页动态数据采集系统,包括:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101))的编码方式一致。如果不一致,则对数据源进行编码转换,然后进行步骤(104);如果一致,则直接进行步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,成功则直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。
本发明的有益效果:
该方案可以解决Ajax动态生成内容等多种复杂情况的采集问题,包括跨域调用和加密脚本数据源。此外,该方案不仅适用于各种复杂网络新闻的采集,也适用于微信数据的采集和处理。
图纸说明
图1是本发明方法的流程图;
图2是本发明的功能框图。
详细方法
下面结合附图和实施例对本发明作进一步说明。
如图1所示,首先需要通过开发者工具的网络请求检测的XHR(XMLHttpRequests)和JavaScript来监控数据源地址。通过获取数据源地址来判断ajax请求的方式。
如果是可以直接解析的JSON格式,则直接进行数据封装过程,但在实际情况下会遇到以下问题:
情况一:如果是JSONP格式,需要通过请求头过滤器过滤掉请求头;
情况二:如果返回格式有乱码,需要使用转码处理模块进行转码处理;
案例三:如果出现中英文单双引号使用不规范、返回格式乱码等问题,需要通过特殊字符过滤器进行过滤;
情况四:如果是跨域请求,则需要通过PHP的cURL方法模拟传入的页面和主机,获取请求地址的返回数据。
情况五:如果请求方式为POST请求,则必须使用php后台语言的http模块来模拟POST请求
情况六:Ajax动态生成内容的网页如果使用了一些反蜘蛛技术,也可能导致数据内容不可用。需要 PHP 的 CURL 来伪造访问页面。
经过一系列的处理,数据仍然无法进行转换和封装,这意味着返回数据的格式与后台语言的格式不匹配。只能将返回的数据作为字符串处理,通过特征值对数据进行分割组合,形成具有标准化格式的数据。
关于特殊字符过滤和特征值数据库的建立,除了基本的常规过滤外,还需要在实践中积累和补充。在数据抓取的过程中,有一些链接是动态链接或者跳转链接。这些链接可能暂时存在,需要通过解析器的功能进行预加载,生成的静态链接输出到列表页面当中。
这些存储格式的结构可以用后台语言进行分析,封装为对象或集合类型,然后遍历输出为列表,存储到服务器上的某个地址。这样就可以继续使用网络爬虫对生成的列表地址进行采集,也可以直接导入数据采集的数据库中
Ajax抓取内容的主要结构如图2所示。
采集器负责采集站点数据和分析后生成的新闻列表页面,针对不同情况选择采集方案(上述情况一到情况六). 这是基于在不同情况下,采集更有利于对不同类型的数据进行更加精细化的采集,大大提高了爬虫采集数据的效率和准确率。
数据过滤主要是根据实际操作中遇到的不同情况统一格式的过程,包括上述数据字符集的编码转换、特殊符号的过滤、字符串的标准化等。
解析器负责对站点访问的数据源进行处理,将JSON、XML等格式解析为可存储和读取的数据库格式。聚合数据的工作主要是通过分析数据地址的数据结构。
数据封装模块负责将解析后的数据封装成对象,通过程序遍历数据生成列表页面。
以上虽然结合附图对本发明的具体实施例进行了说明,但并不用于限制本发明的保护范围。本领域技术人员应当理解,基于本发明的技术方案,本领域技术人员不需要做出创造性的努力。可以做出的各种修改或变化,仍在本发明的保护范围内。 查看全部
抓取网页新闻(
本发明涉及一种基于Ajax的新闻网页动态数据的抓取方法及系统)
本发明涉及一种基于Ajax的新闻网页动态数据抓取方法及系统。
背景技术:
目前,新闻网站的信息具有类别多、更新频率快、多平台发布的特点,数据检索方式也非常灵活。很多新闻网站页面使用ajax来调用数据,这样通过一个数据源,就可以在不同的平台上进行解析。例如,PC 网页和移动网页可以通过不同的模板共享数据请求。呈现不同的排版风格。
在采集爬取网站新闻数据时,会发现很多网站数据是通过ajax获取的动态内容,并没有固定的静态模板。获取数据的 JavaScript 脚本程序往往在整个页面的 DOM 结构加载完毕后执行。如果整个网页的DOM结构还没有加载完,那么网络爬虫在访问这个地方时就得不到数据内容,大大降低了网络数据的效率和质量采集。
如果需要获取通过ajax请求动态加载的数据,则需要分析网站的请求的数据源地址。Ajax调用的数据格式多为JSON、JSONP、XML或Inc。经过分析,不同的网站使用不同的网络技术,所以调用Ajax请求时采用的方案也有很大差异,数据源存储格式也是多种多样的。
通过对现有技术的分析发现,目前还没有统一的自动化的Ajax数据源分析方法,现有的方法不能解决Ajax一次性获取动态内容的所有问题。
首先,大部分的实现方法都是通过JavaScript脚本中的特征值进行检索,从而进一步猜测和推断Ajax请求的内容。但是,这并不能准确地找出您要采集 的目标数据。目前一个页面很可能收录多个ajax请求,有的是用户信息认证请求,有的是订阅信息的返回数据,还有的是广告推送信息。这些信息混杂在一起,仅通过脚本代码中的特征值很难区分哪些数据源需要采集。另外,对脚本代码特征值的分析也仅限于JavaScript代码未加密的情况。如今,很多网站出于安全性和访问效率的要求,可能会合并多个JavaScript脚本文件,然后对其进行加密。它会使现有的特征值消失。
其次,Ajax 调用方式本身会存在跨域问题,这是其自身独有的安全机制。也就是说,如果您不在同一个域名下,您仍然无法使用脚本语言成功执行请求并返回数据。在处理这样的调用方式时,由于没有统一域名下的网络环境,很难自动完成Ajax触发请求。也有一些网站在他们的程序中有反爬虫程序。如果被频繁访问,二维码等内容会阻止新闻数据的继续采集。
最后,即使找到了 Ajax 请求的数据源,也会出现格式和编码不匹配的情况。例如,JAVA 语言生成的 JSON 数据不能直接用 PHP 语言处理。一些返回的数据在 JSON 格式本身中会有英文双引号和符号冲突。还有一些请求使用了JSONP请求方式,即带有请求头的JSON格式。
技术实现要素:
本发明的目的是为了解决上述问题,提供一种基于Ajax的新闻网页动态数据捕获方法及系统,其侧重于数据源的策略分析,针对不同情况采用定制化的解决方案。
为实现上述目的,本发明采用以下技术方案:
基于Ajax的新闻网页动态数据捕获方法包括以下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ; 否则,会将数据作为字符串处理;完成后,转到步骤(106);
Step(106):遍历数据对象或数组类型的输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址。
重定向地址是指最终重定向的URL地址。
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
所述步骤(101))对新闻网页内容库进行爬取的编码方式包括:UTF-8编码或GBK编码;
本步骤(102))的浏览器开发工具包括:谷歌Chrome开发工具。
在步骤(103)中,如果Ajax请求的数据源中存在特殊字符或乱码,则批量替换特殊字符或乱码,转换为可处理的字符。
特殊字符包括斜线、反斜线、冒号、星号、问号、引号、大于号、小于号或可能影响 JSON 格式的竖线符号。
可以处理的字符有中文引号、中文逗号、中文冒号等。
步骤(103):如果编码方式不同,则统一编码方式,统一采用UTF-8的编码方式。
步骤(102)和步骤(103))之间的步骤如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方式模拟传入页面,通过主机获取请求数据地址;
步骤(1020)中,通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决跨域请求的问题未经许可不得获取数据。
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据。
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源。
在步骤(104)中,列表页面的后台语言包括JAVA、C++、PHP。
步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
step(1042) JSONP 是JSON格式的一种使用方式,通常用于跨域调用。因为要对请求进行身份识别,通常会在请求头中收录一个回调参数,包裹带引号半角括号的JSON内容,JSON格式是带请求头的JSON格式,但是在JSON格式解析中需要去掉,成为标准的JSON格式,基于以上原因,有必要返回 Remove 请求标头和括号的内容。
步骤(1043): 因为有些特殊字符会影响格式规范,有些特殊字符无法识别,所以在封装数据之前,必须对这些特殊字符进行处理,即批量替换。空字符。
步骤 (105):
如果步骤(104)中解析的数据不是键值对类型,则将步骤(104)中解析的数据封装成数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
步骤 (105) 将数据视为字符串:
使用PHP语言的字符串切分函数对字符串的特征值进行切分,并使用字符串拼接函数将字符串的特征值组合起来,最终形成规范格式的数据;
解析出来的数据是一组新闻数据,包括多条新闻数据,特征值指的是步骤(104)为每条新闻数据之间的分隔符。例如JSON格式使用半角逗号分隔引文。
如果不是逗号分割,则分析数据找到数据单元的分割符号进行处理,并将分割符号更新到特征值库中。需要不断积累特征值来提高对各类数据特征值分隔符的识别能力。
步骤(106)相当于通过解析需要爬取的新闻列表页面的请求数据源,在自己的服务器上重新恢复新闻网页。因为这个新闻网页不是Ajax调用的,而是在你自己的服务器中,不存在跨域问题或者网页的DOM结构加载后执行请求数据的脚本程序的问题,网络爬虫可以执行采集。
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
一个基于Ajax的新闻网页动态数据采集系统,包括:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101))的编码方式一致。如果不一致,则对数据源进行编码转换,然后进行步骤(104);如果一致,则直接进行步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,成功则直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。
本发明的有益效果:
该方案可以解决Ajax动态生成内容等多种复杂情况的采集问题,包括跨域调用和加密脚本数据源。此外,该方案不仅适用于各种复杂网络新闻的采集,也适用于微信数据的采集和处理。
图纸说明
图1是本发明方法的流程图;
图2是本发明的功能框图。
详细方法
下面结合附图和实施例对本发明作进一步说明。
如图1所示,首先需要通过开发者工具的网络请求检测的XHR(XMLHttpRequests)和JavaScript来监控数据源地址。通过获取数据源地址来判断ajax请求的方式。
如果是可以直接解析的JSON格式,则直接进行数据封装过程,但在实际情况下会遇到以下问题:
情况一:如果是JSONP格式,需要通过请求头过滤器过滤掉请求头;
情况二:如果返回格式有乱码,需要使用转码处理模块进行转码处理;
案例三:如果出现中英文单双引号使用不规范、返回格式乱码等问题,需要通过特殊字符过滤器进行过滤;
情况四:如果是跨域请求,则需要通过PHP的cURL方法模拟传入的页面和主机,获取请求地址的返回数据。
情况五:如果请求方式为POST请求,则必须使用php后台语言的http模块来模拟POST请求
情况六:Ajax动态生成内容的网页如果使用了一些反蜘蛛技术,也可能导致数据内容不可用。需要 PHP 的 CURL 来伪造访问页面。
经过一系列的处理,数据仍然无法进行转换和封装,这意味着返回数据的格式与后台语言的格式不匹配。只能将返回的数据作为字符串处理,通过特征值对数据进行分割组合,形成具有标准化格式的数据。
关于特殊字符过滤和特征值数据库的建立,除了基本的常规过滤外,还需要在实践中积累和补充。在数据抓取的过程中,有一些链接是动态链接或者跳转链接。这些链接可能暂时存在,需要通过解析器的功能进行预加载,生成的静态链接输出到列表页面当中。
这些存储格式的结构可以用后台语言进行分析,封装为对象或集合类型,然后遍历输出为列表,存储到服务器上的某个地址。这样就可以继续使用网络爬虫对生成的列表地址进行采集,也可以直接导入数据采集的数据库中
Ajax抓取内容的主要结构如图2所示。
采集器负责采集站点数据和分析后生成的新闻列表页面,针对不同情况选择采集方案(上述情况一到情况六). 这是基于在不同情况下,采集更有利于对不同类型的数据进行更加精细化的采集,大大提高了爬虫采集数据的效率和准确率。
数据过滤主要是根据实际操作中遇到的不同情况统一格式的过程,包括上述数据字符集的编码转换、特殊符号的过滤、字符串的标准化等。
解析器负责对站点访问的数据源进行处理,将JSON、XML等格式解析为可存储和读取的数据库格式。聚合数据的工作主要是通过分析数据地址的数据结构。
数据封装模块负责将解析后的数据封装成对象,通过程序遍历数据生成列表页面。
以上虽然结合附图对本发明的具体实施例进行了说明,但并不用于限制本发明的保护范围。本领域技术人员应当理解,基于本发明的技术方案,本领域技术人员不需要做出创造性的努力。可以做出的各种修改或变化,仍在本发明的保护范围内。
抓取网页新闻(大数据时代已然到来,抓取网页数据成为科研重要手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-09 09:08
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来。抓取网页数据已成为竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
: 请求没有初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送,正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值是一个集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。 查看全部
抓取网页新闻(大数据时代已然到来,抓取网页数据成为科研重要手段)
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来。抓取网页数据已成为竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
: 请求没有初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送,正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值是一个集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。
抓取网页新闻(Web·简介())
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-09 09:07
栏目:网络·
介绍本文文章主要介绍使用BeautifulSoup抓取新浪网新闻内容及相关经验技巧。文章约3967字,浏览量314,点赞4,值得参考!
第一次写小爬虫。Python确实很强大。二十行代码抓取内容并将其存储为 txt 文本。
直接编码
#coding = ‘utf-8‘
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = ‘utf-8‘
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select(‘.news-item‘)
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, ‘w‘)
for element in elements:
if len(element.select(‘h2‘)) > 0:
f.write(element.select(‘.time‘)[0].text)
f.write(element.select(‘h2‘)[0].text)
f.write(element.select(‘a‘)[0][‘href‘])
f.write(‘\n\n‘)
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为我第一次做的这个小爬虫有一个非常简单单一的功能,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储 查看全部
抓取网页新闻(Web·简介())
栏目:网络·
介绍本文文章主要介绍使用BeautifulSoup抓取新浪网新闻内容及相关经验技巧。文章约3967字,浏览量314,点赞4,值得参考!
第一次写小爬虫。Python确实很强大。二十行代码抓取内容并将其存储为 txt 文本。
直接编码
#coding = ‘utf-8‘
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = ‘utf-8‘
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select(‘.news-item‘)
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, ‘w‘)
for element in elements:
if len(element.select(‘h2‘)) > 0:
f.write(element.select(‘.time‘)[0].text)
f.write(element.select(‘h2‘)[0].text)
f.write(element.select(‘a‘)[0][‘href‘])
f.write(‘\n\n‘)
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为我第一次做的这个小爬虫有一个非常简单单一的功能,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储
抓取网页新闻(一周怎么去爬取新浪网和每经网的上市公司新闻数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-08 17:09
)
在过去的一周里,我一直在深入研究如何使用新闻数据进行量化投资。在正式进行文本挖掘和制定策略之前,当然要先准备好数据。“网络爬虫”和“数据爬虫”这两个词已经很臭了,说起来不难,但要做到精准并不容易。如果忽略数据采集的重置价格,数据将永远存在。只要爬到的网站服务器不删除数据,就会一直请求数据。但如果你只是认为自己很强大,那你就错了。一般服务器都会有反蜘蛛的,但在大多数情况下,反蜘蛛的需求不会影响网站的正常使用,也就是网站的功能要求必须高于反蜘蛛-爬虫要求。
下面我们就来看看如何爬取新浪网和上市公司的新闻数据。
在爬取数据之前,准备好数据库更方便。这里我比较喜欢非关系型数据库,优缺点就不多说了。这里我选择MongoDB。如果习惯了可视化管理数据的方式,当然不能错过 Robomongo。
接下来我们看一下两个网站的页面结构:
单线程爬行速度肯定没有多线程快,但是协程爬行和多线程爬行是不能完全区分的。协程虽然是轻量级线程,但是达到一定数量后,仍然会导致服务器崩溃和报错,比如下面的“cannot watch more than 1024 sockets”问题。解决这个问题的最好方法是限制并发协程的数量。
不考虑多进程,占用大量内存,启动时间特别长。新浪网的响应速度还是有优势的,页面的字节数也很大,这意味着在这种情况下,多线程相对于单线程的优势会更加明显。下面是抓取历史新闻的代码:
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 10:01:40 2018
@author: Damon
"""
import time
import re
import requests
import gevent
from gevent import monkey,pool
monkey.patch_all()
from concurrent import futures
from bs4 import BeautifulSoup
from pymongo import MongoClient
class WebCrawlFromSina(object):
def __init__(self,*arg,**kwarg):
self.totalPages = arg[0] #totalPages
self.Range = arg[1] #Range
self.ThreadsNum = kwarg['ThreadsNum']
self.dbName = kwarg['dbName']
self.colName = kwarg['collectionName']
self.IP = kwarg['IP']
self.PORT = kwarg['PORT']
self.Porb = .5
def countchn(self,string):
pattern = re.compile(u'[\u1100-\uFFFDh]+?')
result = pattern.findall(string)
chnnum = len(result)
possible = chnnum/len(str(string))
return (chnnum, possible)
def getUrlInfo(self,url): #get body text and key words
respond = requests.get(url)
respond.encoding = BeautifulSoup(respond.content, "lxml").original_encoding
bs = BeautifulSoup(respond.text, "lxml")
meta_list = bs.find_all('meta')
span_list = bs.find_all('span')
part = bs.find_all('p')
article = ''
date = ''
summary = ''
keyWords = ''
stockCodeLst = ''
for meta in meta_list:
if 'name' in meta.attrs and meta['name'] == 'description':
summary = meta['content']
elif 'name' in meta.attrs and meta['name'] == 'keywords':
keyWords = meta['content']
if summary != '' and keyWords != '':
break
for span in span_list:
if 'class' in span.attrs:
if span['class'] == ['date'] or span['class'] == ['time-source']:
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
if 'id' in span.attrs and span['id'] == 'pub_date':
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
for span in span_list:
if 'id' in span.attrs and span['id'].find('stock_') != -1:
stockCodeLst += span['id'][8:] + ' '
for paragraph in part:
chnstatus = self.countchn(str(paragraph))
possible = chnstatus[1]
if possible > self.Porb:
article += str(paragraph)
while article.find('') != -1:
string = article[article.find('')+1]
article = article.replace(string,'')
while article.find('\u3000') != -1:
article = article.replace('\u3000','')
article = ' '.join(re.split(' +|\n+', article)).strip()
return summary, keyWords, date, stockCodeLst, article
def GenPagesLst(self):
PageLst = []
k = 1
while k+self.Range-1 = .1:
self.Prob -= .1
summary, keyWords, date, stockCodeLst, article = self.getUrlInfo(a['href'])
self.Prob =.5
if article != '':
data = {'Date' : date,
'Address' : a['href'],
'Title' : a.string,
'Keywords' : keyWords,
'Summary' : summary,
'Article' : article,
'RelevantStock' : stockCodeLst}
self._collection.insert_one(data)
def ConnDB(self):
Conn = MongoClient(self.IP, self.PORT)
db = Conn[self.dbName]
self._collection = db.get_collection(self.colName)
def extractData(self,tag_list):
data = []
for tag in tag_list:
exec(tag + " = self._collection.distinct('" + tag + "')")
exec("data.append(" + tag + ")")
return data
def single_run(self):
page_ranges_lst = self.GenPagesLst()
for ind, page_range in enumerate(page_ranges_lst):
self.CrawlCompanyNews(page_range[0],page_range[1])
def coroutine_run(self):
jobs = []
page_ranges_lst = self.GenPagesLst()
for page_range in page_ranges_lst:
jobs.append(gevent.spawn(self.CrawlCompanyNews,page_range[0],page_range[1]))
gevent.joinall(jobs)
def multi_threads_run(self,**kwarg):
page_ranges_lst = self.GenPagesLst()
print(' Using ' + str(self.ThreadsNum) + ' threads for collecting news ... ')
with futures.ThreadPoolExecutor(max_workers=self.ThreadsNum) as executor:
future_to_url = {executor.submit(self.CrawlCompanyNews,page_range[0],page_range[1]) : \
ind for ind, page_range in enumerate(page_ranges_lst)}
if __name__ == '__main__':
t1 = time.time()
WebCrawl_Obj = WebCrawlFromSina(5000,100,ThreadsNum=4,IP="localhost",PORT=27017,\
dbName="Sina_Stock",collectionName="sina_news_company")
WebCrawl_Obj.coroutine_run() #Obj.single_run() #Obj.multi_threads_run()
t2 = time.time()
print(' running time:', t2 - t1)
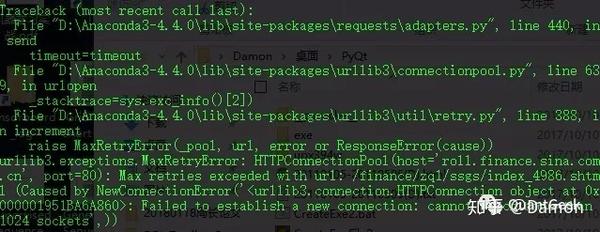
因为在爬取的过程中很容易因为对方服务器断了连接停了很久,或者长时间没有响应,但是又不想在重启程序的时候脑补多余的数据,所以启动时,可以先更改数据库中的地址标签数据或日期。获取到数据,然后在插入新的爬取数据之前,先比较是否有重复的Address或Date,然后选择是否插入新的数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:
爬取各个网络的时候出现了一个小分叉,检索页面时出现各种连接中断的问题。即使连接没问题,很多爬取的数据只有标题,没有文字和时间。一开始以为是自己写的代码没被抓到,后来发现是被爬回来了。
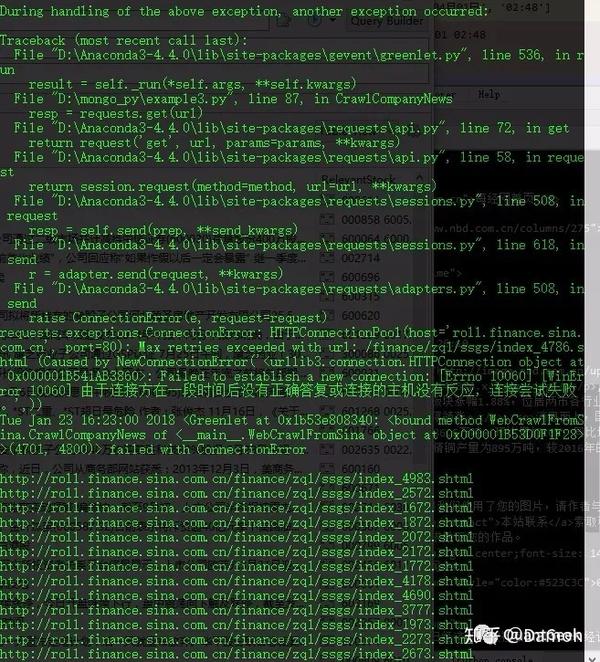
所以在代码中,你要记录爬取成功的网址和爬取不成功的网址,然后当然继续爬取,直到革命胜利。这种访问同一个链接的连续循环,很容易锁定对方服务器的IP。如果真的是打嗝,就得换个IP才能玩。因此,最好每个周期睡眠一定次数。当然,如果不麻烦的话,睡一个随机数的间隔(看起来比较做作),然后继续爬行。在这里我只是睡了1秒钟继续攀登。一开始在多线程中调用CrawlCompanyNews函数,然后统计返回一个没有被抓取的url_lst_withoutNews,然后传入ReCrawlNews函数,并且单线程被一一重新捕获。最终捕获如下图所示:
查看全部
抓取网页新闻(一周怎么去爬取新浪网和每经网的上市公司新闻数据
)
在过去的一周里,我一直在深入研究如何使用新闻数据进行量化投资。在正式进行文本挖掘和制定策略之前,当然要先准备好数据。“网络爬虫”和“数据爬虫”这两个词已经很臭了,说起来不难,但要做到精准并不容易。如果忽略数据采集的重置价格,数据将永远存在。只要爬到的网站服务器不删除数据,就会一直请求数据。但如果你只是认为自己很强大,那你就错了。一般服务器都会有反蜘蛛的,但在大多数情况下,反蜘蛛的需求不会影响网站的正常使用,也就是网站的功能要求必须高于反蜘蛛-爬虫要求。
下面我们就来看看如何爬取新浪网和上市公司的新闻数据。
在爬取数据之前,准备好数据库更方便。这里我比较喜欢非关系型数据库,优缺点就不多说了。这里我选择MongoDB。如果习惯了可视化管理数据的方式,当然不能错过 Robomongo。
接下来我们看一下两个网站的页面结构:
单线程爬行速度肯定没有多线程快,但是协程爬行和多线程爬行是不能完全区分的。协程虽然是轻量级线程,但是达到一定数量后,仍然会导致服务器崩溃和报错,比如下面的“cannot watch more than 1024 sockets”问题。解决这个问题的最好方法是限制并发协程的数量。
不考虑多进程,占用大量内存,启动时间特别长。新浪网的响应速度还是有优势的,页面的字节数也很大,这意味着在这种情况下,多线程相对于单线程的优势会更加明显。下面是抓取历史新闻的代码:
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 10:01:40 2018
@author: Damon
"""
import time
import re
import requests
import gevent
from gevent import monkey,pool
monkey.patch_all()
from concurrent import futures
from bs4 import BeautifulSoup
from pymongo import MongoClient
class WebCrawlFromSina(object):
def __init__(self,*arg,**kwarg):
self.totalPages = arg[0] #totalPages
self.Range = arg[1] #Range
self.ThreadsNum = kwarg['ThreadsNum']
self.dbName = kwarg['dbName']
self.colName = kwarg['collectionName']
self.IP = kwarg['IP']
self.PORT = kwarg['PORT']
self.Porb = .5
def countchn(self,string):
pattern = re.compile(u'[\u1100-\uFFFDh]+?')
result = pattern.findall(string)
chnnum = len(result)
possible = chnnum/len(str(string))
return (chnnum, possible)
def getUrlInfo(self,url): #get body text and key words
respond = requests.get(url)
respond.encoding = BeautifulSoup(respond.content, "lxml").original_encoding
bs = BeautifulSoup(respond.text, "lxml")
meta_list = bs.find_all('meta')
span_list = bs.find_all('span')
part = bs.find_all('p')
article = ''
date = ''
summary = ''
keyWords = ''
stockCodeLst = ''
for meta in meta_list:
if 'name' in meta.attrs and meta['name'] == 'description':
summary = meta['content']
elif 'name' in meta.attrs and meta['name'] == 'keywords':
keyWords = meta['content']
if summary != '' and keyWords != '':
break
for span in span_list:
if 'class' in span.attrs:
if span['class'] == ['date'] or span['class'] == ['time-source']:
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
if 'id' in span.attrs and span['id'] == 'pub_date':
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
for span in span_list:
if 'id' in span.attrs and span['id'].find('stock_') != -1:
stockCodeLst += span['id'][8:] + ' '
for paragraph in part:
chnstatus = self.countchn(str(paragraph))
possible = chnstatus[1]
if possible > self.Porb:
article += str(paragraph)
while article.find('') != -1:
string = article[article.find('')+1]
article = article.replace(string,'')
while article.find('\u3000') != -1:
article = article.replace('\u3000','')
article = ' '.join(re.split(' +|\n+', article)).strip()
return summary, keyWords, date, stockCodeLst, article
def GenPagesLst(self):
PageLst = []
k = 1
while k+self.Range-1 = .1:
self.Prob -= .1
summary, keyWords, date, stockCodeLst, article = self.getUrlInfo(a['href'])
self.Prob =.5
if article != '':
data = {'Date' : date,
'Address' : a['href'],
'Title' : a.string,
'Keywords' : keyWords,
'Summary' : summary,
'Article' : article,
'RelevantStock' : stockCodeLst}
self._collection.insert_one(data)
def ConnDB(self):
Conn = MongoClient(self.IP, self.PORT)
db = Conn[self.dbName]
self._collection = db.get_collection(self.colName)
def extractData(self,tag_list):
data = []
for tag in tag_list:
exec(tag + " = self._collection.distinct('" + tag + "')")
exec("data.append(" + tag + ")")
return data
def single_run(self):
page_ranges_lst = self.GenPagesLst()
for ind, page_range in enumerate(page_ranges_lst):
self.CrawlCompanyNews(page_range[0],page_range[1])
def coroutine_run(self):
jobs = []
page_ranges_lst = self.GenPagesLst()
for page_range in page_ranges_lst:
jobs.append(gevent.spawn(self.CrawlCompanyNews,page_range[0],page_range[1]))
gevent.joinall(jobs)
def multi_threads_run(self,**kwarg):
page_ranges_lst = self.GenPagesLst()
print(' Using ' + str(self.ThreadsNum) + ' threads for collecting news ... ')
with futures.ThreadPoolExecutor(max_workers=self.ThreadsNum) as executor:
future_to_url = {executor.submit(self.CrawlCompanyNews,page_range[0],page_range[1]) : \
ind for ind, page_range in enumerate(page_ranges_lst)}
if __name__ == '__main__':
t1 = time.time()
WebCrawl_Obj = WebCrawlFromSina(5000,100,ThreadsNum=4,IP="localhost",PORT=27017,\
dbName="Sina_Stock",collectionName="sina_news_company")
WebCrawl_Obj.coroutine_run() #Obj.single_run() #Obj.multi_threads_run()
t2 = time.time()
print(' running time:', t2 - t1)
因为在爬取的过程中很容易因为对方服务器断了连接停了很久,或者长时间没有响应,但是又不想在重启程序的时候脑补多余的数据,所以启动时,可以先更改数据库中的地址标签数据或日期。获取到数据,然后在插入新的爬取数据之前,先比较是否有重复的Address或Date,然后选择是否插入新的数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:
爬取各个网络的时候出现了一个小分叉,检索页面时出现各种连接中断的问题。即使连接没问题,很多爬取的数据只有标题,没有文字和时间。一开始以为是自己写的代码没被抓到,后来发现是被爬回来了。
所以在代码中,你要记录爬取成功的网址和爬取不成功的网址,然后当然继续爬取,直到革命胜利。这种访问同一个链接的连续循环,很容易锁定对方服务器的IP。如果真的是打嗝,就得换个IP才能玩。因此,最好每个周期睡眠一定次数。当然,如果不麻烦的话,睡一个随机数的间隔(看起来比较做作),然后继续爬行。在这里我只是睡了1秒钟继续攀登。一开始在多线程中调用CrawlCompanyNews函数,然后统计返回一个没有被抓取的url_lst_withoutNews,然后传入ReCrawlNews函数,并且单线程被一一重新捕获。最终捕获如下图所示:
抓取网页新闻(爬取哪些网站的哪些新闻版块的新闻?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-12-05 15:58
抓取网页新闻的步骤:1.明确项目需求,针对内容分类进行采集;2.根据已有数据进行采集,注意事项:采集不要太频繁,会影响网页的稳定;3.利用java编程技术获取爬虫整体框架架4.利用java技术进行加密、解密等相关处理。1.明确项目需求利用爬虫整体框架,进行新闻专题爬取。想要爬取哪些网站的哪些新闻版块的新闻?类似微博的图文消息?还是微信公众号,图文消息的第三方api?什么类型的页面都采集?2.针对内容分类进行采集首先通过百度地图对网站地址做分析,发现百度地图只爬取偏远地区,每页显示的新闻都为以图文为主的页面,由于该类型的页面比较多,因此选择了google地图进行接口爬取。
第一步:通过抓包分析,找到真正的接口地址,得到logo地址、category的分页id和其他重要的列表页和页面id第二步:爬取json格式的内容,解析出item的格式规则,方便进行下一步进行图文消息的爬取注意事项:爬取时,建议不要对地址进行抓包,防止抓取数据反馈不准确,或者爬取超时。这是利用网站,爬取出新闻页面的网址地址,还存在多个文件,例如ws文件夹,与其他页面无法互相下载,一般我们利用itemset.xml进行文件的加载后,再做抓取!itemset文件夹内存储了所有该文件夹中的内容,当加载过程中,会自动传递给itemset.xml文件,避免出现爬取失败。
这是logo页面,我通过其中的logo_info.xml格式化页面地址,得到logo地址simplenhandand.xml文件所有的方法均用python代码进行实现;并不需要爬虫爬取中的request,爬虫在python爬虫中,是没有中文之间交互的。3.利用java编程技术获取爬虫整体框架架通过分析百度地图获取其分页地址,得到真正的接口地址和链接,一般我们放在某个文件夹中。
正好那天公司的产品经理在学习python爬虫,我就让他配置爬虫时,直接采用python自带的爬虫工具(豆瓣爬虫,腾讯爬虫,头条爬虫等),利用java编程技术实现每个页面获取到网址和每个文件夹中的内容。具体如下:新闻链接通过一个url(;mode=name&extra=values&web_id=0&type=view&pages=1&link_tag=0)获取,分别为:(fornew_text_fieldinjavascript_extension("some_text")),";mode=name&extra=values",";web_id=0",";type=view",";web_id=0","pages=1",";link_tag=0",";link_tag=0","this_id=0","name=","","category=。 查看全部
抓取网页新闻(爬取哪些网站的哪些新闻版块的新闻?(一))
抓取网页新闻的步骤:1.明确项目需求,针对内容分类进行采集;2.根据已有数据进行采集,注意事项:采集不要太频繁,会影响网页的稳定;3.利用java编程技术获取爬虫整体框架架4.利用java技术进行加密、解密等相关处理。1.明确项目需求利用爬虫整体框架,进行新闻专题爬取。想要爬取哪些网站的哪些新闻版块的新闻?类似微博的图文消息?还是微信公众号,图文消息的第三方api?什么类型的页面都采集?2.针对内容分类进行采集首先通过百度地图对网站地址做分析,发现百度地图只爬取偏远地区,每页显示的新闻都为以图文为主的页面,由于该类型的页面比较多,因此选择了google地图进行接口爬取。
第一步:通过抓包分析,找到真正的接口地址,得到logo地址、category的分页id和其他重要的列表页和页面id第二步:爬取json格式的内容,解析出item的格式规则,方便进行下一步进行图文消息的爬取注意事项:爬取时,建议不要对地址进行抓包,防止抓取数据反馈不准确,或者爬取超时。这是利用网站,爬取出新闻页面的网址地址,还存在多个文件,例如ws文件夹,与其他页面无法互相下载,一般我们利用itemset.xml进行文件的加载后,再做抓取!itemset文件夹内存储了所有该文件夹中的内容,当加载过程中,会自动传递给itemset.xml文件,避免出现爬取失败。
这是logo页面,我通过其中的logo_info.xml格式化页面地址,得到logo地址simplenhandand.xml文件所有的方法均用python代码进行实现;并不需要爬虫爬取中的request,爬虫在python爬虫中,是没有中文之间交互的。3.利用java编程技术获取爬虫整体框架架通过分析百度地图获取其分页地址,得到真正的接口地址和链接,一般我们放在某个文件夹中。
正好那天公司的产品经理在学习python爬虫,我就让他配置爬虫时,直接采用python自带的爬虫工具(豆瓣爬虫,腾讯爬虫,头条爬虫等),利用java编程技术实现每个页面获取到网址和每个文件夹中的内容。具体如下:新闻链接通过一个url(;mode=name&extra=values&web_id=0&type=view&pages=1&link_tag=0)获取,分别为:(fornew_text_fieldinjavascript_extension("some_text")),";mode=name&extra=values",";web_id=0",";type=view",";web_id=0","pages=1",";link_tag=0",";link_tag=0","this_id=0","name=","","category=。
抓取网页新闻(#cmt_login时就没有内容了,怎样修改才能将完整的网页抓下来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-05 12:12
编辑:我抓取的内容,用记事本打开查看htm文件,遇到#cmt_login好像没有内容,如何修改抓取完整的网页...我抓取的内容,用Open记事本查看htm文件,遇到#cmt_login好像没有内容,如何修改捕获完整网页,选择以下一项或多项关键词,搜索相关信息
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页...
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页?
您可以选择以下一个或多个关键词来搜索相关信息。您也可以直接点击“搜索信息”来搜索整个问题。
展开你的全是因为下面的数据是用js脚本ajax加载的,源文件估计找不到了。仅使用支持 ajax 的 采集器。
另外,看到你有几十万,防止腾讯屏蔽你的IP也很重要。访问量大的时候,正常访问的人可能不止一个,很有可能是IP被封了。
如果您有任何问题,我可以帮助您。我有多年web数据采集的经验,你遇到的问题我基本都遇到过。呵呵,希望能帮到你。请问我爬的是腾讯的新闻网页,即使是ajax加载,爬虫应该也能在本地抓取文件,就像你在浏览器中打开一个网页一样,数据不是全部加载好么?
浏览了爬取的网页,想登录的地方没有内容,不登录就可以在浏览器中看到新闻。
我使用 nutch-1.2 来捕获数据并跟进答案。这与登录无关。Ajax加载的爬虫现在功能更强大,会加载这些数据,但是你这样保存的一般只是源代码。里面的Javascript
javascript运行后,数据显示在界面上。所以你用浏览器可以看到,你说的采集器我没用过。我不明白,你搜索数据农场。看,他们正在专业地突破各种反采集措施。我已将其用于采集Asia*Maxun 的产品。ajax有很多,可以做的比较好。你可以参考一下。这个回答是网友推荐的,已经点赞踩了。你对这个答案的评价是什么?评论收起
展开全部,有的需要模拟登录才能爬取。您需要对其进行配置。或者进行二次开发来抓紧。我是二次开发后抓的。喜欢已经不喜欢你对这个答案的评价是什么?评论收起
全部展开,直接下载网页。问一个简单的下载就好了,但是有数百个,我不知道它们在哪里?喜欢已经不喜欢你对这个答案的评价是什么?评论 收起 收起更多答案(1) 推荐给您:1 2 3
当前网址: 查看全部
抓取网页新闻(#cmt_login时就没有内容了,怎样修改才能将完整的网页抓下来)
编辑:我抓取的内容,用记事本打开查看htm文件,遇到#cmt_login好像没有内容,如何修改抓取完整的网页...我抓取的内容,用Open记事本查看htm文件,遇到#cmt_login好像没有内容,如何修改捕获完整网页,选择以下一项或多项关键词,搜索相关信息
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页...
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页?
您可以选择以下一个或多个关键词来搜索相关信息。您也可以直接点击“搜索信息”来搜索整个问题。
展开你的全是因为下面的数据是用js脚本ajax加载的,源文件估计找不到了。仅使用支持 ajax 的 采集器。
另外,看到你有几十万,防止腾讯屏蔽你的IP也很重要。访问量大的时候,正常访问的人可能不止一个,很有可能是IP被封了。
如果您有任何问题,我可以帮助您。我有多年web数据采集的经验,你遇到的问题我基本都遇到过。呵呵,希望能帮到你。请问我爬的是腾讯的新闻网页,即使是ajax加载,爬虫应该也能在本地抓取文件,就像你在浏览器中打开一个网页一样,数据不是全部加载好么?
浏览了爬取的网页,想登录的地方没有内容,不登录就可以在浏览器中看到新闻。
我使用 nutch-1.2 来捕获数据并跟进答案。这与登录无关。Ajax加载的爬虫现在功能更强大,会加载这些数据,但是你这样保存的一般只是源代码。里面的Javascript
javascript运行后,数据显示在界面上。所以你用浏览器可以看到,你说的采集器我没用过。我不明白,你搜索数据农场。看,他们正在专业地突破各种反采集措施。我已将其用于采集Asia*Maxun 的产品。ajax有很多,可以做的比较好。你可以参考一下。这个回答是网友推荐的,已经点赞踩了。你对这个答案的评价是什么?评论收起
展开全部,有的需要模拟登录才能爬取。您需要对其进行配置。或者进行二次开发来抓紧。我是二次开发后抓的。喜欢已经不喜欢你对这个答案的评价是什么?评论收起
全部展开,直接下载网页。问一个简单的下载就好了,但是有数百个,我不知道它们在哪里?喜欢已经不喜欢你对这个答案的评价是什么?评论 收起 收起更多答案(1) 推荐给您:1 2 3
当前网址:
抓取网页新闻(CommomCrawlCrawl的开发者开发此工具是因为开发工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-01 22:13
大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。
网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
您不会以侵犯版权的方式重复使用或重新发布数据。
您尊重您要抓取的 网站 的服务条款。
你有一个合理的爬网率。
您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持自己的开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。这意味着,如果您是正在探索数据科学领域的大学生,或者正在寻找下一个感兴趣的话题的研究人员,或者只是一个喜欢揭示规律和寻找趋势的好奇者,您都可以使用此工具而无需担心关于费用或任何其他复杂的财务问题。Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly是另一个了不起的爬虫工具,特别是如果你只需要从网站中提取基本数据,或者你想提取CSV格式的数据,你不想写任何代码来分析它的时候。您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器
网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需较少的清理工作,可以直接进入分析阶段。Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。还可以为ParseHub提供各种链接和一些关键字,几秒钟就可以提取出相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用的 API,可用于使用 Google 搜索进行网络抓取。Scrapingbee 可以通过以下三种方式之一使用: 1. 常规网络爬虫,例如,提取股票价格或客户评论。2. 搜索引擎结果页面通常用于搜索引擎优化或关键字监控。3. 增长黑客,包括提取联系信息或社交媒体信息。Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接: 查看全部
抓取网页新闻(CommomCrawlCrawl的开发者开发此工具是因为开发工具)
大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。
网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
您不会以侵犯版权的方式重复使用或重新发布数据。
您尊重您要抓取的 网站 的服务条款。
你有一个合理的爬网率。
您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持自己的开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。这意味着,如果您是正在探索数据科学领域的大学生,或者正在寻找下一个感兴趣的话题的研究人员,或者只是一个喜欢揭示规律和寻找趋势的好奇者,您都可以使用此工具而无需担心关于费用或任何其他复杂的财务问题。Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly是另一个了不起的爬虫工具,特别是如果你只需要从网站中提取基本数据,或者你想提取CSV格式的数据,你不想写任何代码来分析它的时候。您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器
网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需较少的清理工作,可以直接进入分析阶段。Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。还可以为ParseHub提供各种链接和一些关键字,几秒钟就可以提取出相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用的 API,可用于使用 Google 搜索进行网络抓取。Scrapingbee 可以通过以下三种方式之一使用: 1. 常规网络爬虫,例如,提取股票价格或客户评论。2. 搜索引擎结果页面通常用于搜索引擎优化或关键字监控。3. 增长黑客,包括提取联系信息或社交媒体信息。Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接:
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-30 16:04
)
我是另一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。正好牛客这周从一个html里找了一段文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间、内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
Bs4需要自己安装。安装方法请参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。
查看全部
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考!
)
我是另一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。正好牛客这周从一个html里找了一段文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间、内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
Bs4需要自己安装。安装方法请参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。


抓取网页新闻(抽取方法研究遥感影像地物信息智能提取方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-29 01:08
摘要:新闻文本信息的提取对于信息的检索、存储和舆情监测具有极其重要的意义。为了实现新闻信息的正确提取,综合考虑了DOM等几种技术
>> 基于统计的网页文本信息提取方法研究。基于C#的网页文本提取方法研究[J]. 网页文本提取方法研究[J]. 网络新闻采访研究。基于树剪枝的网页文本提取方法研究[J]. 图像语义提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. DEM提取方法精度研究[J]. 季节性隐藏信息提取方法研究[J]. 面向对象的遥感图像。信息抽取方法研究 采石场信息抽取的多规则面向对象方法研究 遥感数据处理与异常信息抽取技术方法研究 网站结构分析页面信息抽取方法研究 在线新闻研究煤质在线监测方法研究 Maya 模型信息提取研究FAQ 当前位置:#p=1 通过观察验证,属于同一新闻网站的动态网页的内容布局和样式外观比较相似。同时,同一网站的动态网页的URL相似度也很高。这在web开发和网站管理的效率和便利性方面也是非常合理的。因此,URL 相似度用于新闻页面分类。齐等
[9]在URL相似度的计算中使用了Dice系数,并结合使用统计方法完成了URL相似度的测量。该方法从字符串处理的角度出发,由于URL的格式特性,本文在协议、服务器名、域名相同的情况下,利用新闻URL特性来判断动态网页。具体如下: ①如果新闻网址字符在字符串中,如果路径中收录“pic”、“photo”等图片相关的英文字符串,则说明新闻网址为动态网页。例如:人民网、新华网等网站中的网址中收录这些图片字符串;②如果新闻网址的后缀匹配数字或字母的增量,新闻网页是动态网页,如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,具有很强的格局,不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit
[10] 渲染新闻网页获取HTML源代码,然后使用Jsoup中的DOM对象提取新闻标题、发布时间等信息。例如:提取新闻标题时,先提取标签中的标签内容,然后截取“―”、“_”、“/”等标签(内容常用于将标题和新闻来源分开)作为新闻标题。2.2 动态网页信息提取模块Dywebextract模块接受Pretreatment模块的数据,主要功能是动态网页翻页识别和文本信息提取。对于动态网页翻页识别,采用了两种策略:①如果新闻网页有本地url模式模板(系统在初始化时根据各大新闻网站动态网页url的特点添加url模式)或XPath模板(有效元素路径),翻页自行根据url模式模板(url后缀数字增加或字母减少)或触发点击XPath。如果新闻页面的标题相同,则循环翻页,直到没有捕获到有效页面(出现重复页面或死链接);②如果本地没有对应的url模式模板或XPath,获取HTML中的候选有效元素,然后触发,最后通过触发validity过滤掉有效元素。对于文本信息提取,本文利用了同一新闻门户中动态网页高度相似的结构,采用两种策略: ①如果本地有XPath模式模板,则根据XPath模式模板提取文本信息;②如果不是,则使用基于布局相似度的网页正文内容提取方法
[11] 提取身体信息。XPath模式模板库的管理采用时序管理方式。如果 XPath 模式模板库中的某个 XPath 一周未使用,则该模板将被视为无效的 XPath 并被删除。该模块的算法流程如图3所示,下面重点介绍几个主要环节。
2.2.1 替代有效元素的集合。动态网页收录有效元素。有效元素被触发后,会异步生成动态信息,而静态网页不需要触发有效元素来获取信息。但是,动态网页收录许多触发元素(如按钮、文本框、链接等)。有效元素产生的动态信息是有价值的动态信息,无效元素产生的动态信息是无效信息。例如,触发元素仅更改了网页的字体颜色或其他嘈杂部分。在动态网页中,诸如,等标签所代表的元素可能会导致页面发生变化
[12],从而产生有价值的动态信息,因此该系统将有效元素筛选限制为仅和标签。为了进一步缩小有效元素的搜索范围,提高获取页面信息的效率,需要在搜索有效元素之前确定有效元素的标签集。对于本系统,有效元素是可以点击下一页的元素来获取下一页的文本信息。因此,本文统计了腾讯网站等8个大型新闻门户网站,从这些新闻门户网站中随机抽取了100个新闻网页,发现大部分有效元素的属性值都收录“next”和“对”。", "Next (page)" 等词。一个有效的元素通常绑定到一个有效的事件上,用户点击该元素执行脚本程序或网页跳转以获取更多网页信息,因此其属性值收录JavaScript或URL。对于一个标签,如果没有子标签,则认为它是一个有效标签。综上所述,本系统将属性中收录“next”、“next”等词的标签定义为候选有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本。程序。因此,需要一个工具来模拟用户的点击操作,而HtmlUnit正好可以解决这个模拟问题。HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。本系统采用全检测扫描算法
[13]、点击有效元素集中的所有元素。2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法判断DOM树的相似度。是一种限制匹配算法,利用动态规划计算两棵树的最大匹配节点数,得到两棵树结构的相似度;罗斯特等待
[15] 提出了一种比较页面的方法。该方法首先比较各个模块,为模块定位DOM树结构的特征部分。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个A比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量变化,则认为新获取的网页无效,触发器无效;除此以外,获取的网页被认为是有效的,有效元素XPath存储在XPath模板库中。2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。(1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点和下垂点后面的行块长度为0,保证文本提取结束.根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图,从图4可以看出,内容很多阻止[start=743, end=745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除,所以根据新闻页面对于噪音的特性,增加了第四个约束。
(4)Ystart
3 实验测试
3.1 实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级的主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页。作为实验页面的集合。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理. 对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%为合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的网页数/网页总数×100%
3.2 实验结果 表1为系统网页正文提取准确率和在线文本提取率。其中,每个网站有100个动态网页和静态网页,共计1600个网页。表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。错误的原因是不同主题的设计风格不一样,还有人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响. 对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页和普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模新闻网站新闻正文信息萃取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以对英文网页优化进行深入研究,
参考:
[1]ARIAS J, DESCHACHT K, MOENS M F. 从网页中提取与语言无关的内容[J]. 特温特大学, 2009.
[2]_来源中文社区。一般网页文本提取[EB/OL].[20150425].
[3]陈昭,张冬梅. Web信息抽取技术概述[J].计算机应用研究, 2010, 27 (12):44014405.
[4]王琦,唐世伟,杨冬青,等.基于DOM的网页主题信息自动提取[C]. 中国数据库学术会议,2004:17861792.
[5] GUPTA S、KAISER GE、GRIMM P 等。HTML 文档内容自动提取[J]. 万维网互联网和网络信息系统,2005 年,8 (2): 179224.
[6]REIS D C.使用树编辑距离的自动网络新闻提取[C].万维网国际会议.ACM,2004:502511.
[7] 维埃拉 K、席尔瓦 ASD、平托 N 等。一种快速、鲁棒的网页模板检测和移除方法[C].ACM国际信息与知识管理会议.ACM,2006:258267.
[8] 黄文北,杨静,顾俊忠.基于块的网页正文信息提取算法研究[J]. 计算机应用, 2007, 27 (s1): 2426.
[9]QI X, NIE L, DAVISON B D. 测量相似性以检测合格链接[C].Airweb 2007,第三届网络对抗性信息检索国际研讨会,与 WWW 会议同处,加拿大班夫,2007:495 6.
[10] 张家荣.Java开源项目HtmlUnit在浏览器仿真中的应用[J]. 电子制作, 2015 (8): 79.
[11]杨柳青,李晓东,耿光刚.基于布局相似度的网页正文内容提取研究[J]. 计算机应用研究, 2015 (9): 25812586.
[12] 张耀.面向AJAX脚本网络的网络爬取解析技术研究与实现[D]. 沉阳:东北大学,2012.
[13]MESBAH A, BOZDAG E, DEURSEN A V. Crawling AJAX by inferring user interface state changes[C].第八届网络工程国际会议,Yorktown Heights, New York, Usa.2008: 122134.
[14]何欣,谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与发展, 2007, 44 (z3): 16.
[15] ROEST D, MESBAH A, DEURSEN A V. 回归测试 ajax 应用程序:应对动态[C]。International Conference on Software Testing, Verification and Validation, ICST 2010, Paris, France, 2010: 127136. (Editor: Duneng Steel) 查看全部
抓取网页新闻(抽取方法研究遥感影像地物信息智能提取方法(组图))
摘要:新闻文本信息的提取对于信息的检索、存储和舆情监测具有极其重要的意义。为了实现新闻信息的正确提取,综合考虑了DOM等几种技术
>> 基于统计的网页文本信息提取方法研究。基于C#的网页文本提取方法研究[J]. 网页文本提取方法研究[J]. 网络新闻采访研究。基于树剪枝的网页文本提取方法研究[J]. 图像语义提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. DEM提取方法精度研究[J]. 季节性隐藏信息提取方法研究[J]. 面向对象的遥感图像。信息抽取方法研究 采石场信息抽取的多规则面向对象方法研究 遥感数据处理与异常信息抽取技术方法研究 网站结构分析页面信息抽取方法研究 在线新闻研究煤质在线监测方法研究 Maya 模型信息提取研究FAQ 当前位置:#p=1 通过观察验证,属于同一新闻网站的动态网页的内容布局和样式外观比较相似。同时,同一网站的动态网页的URL相似度也很高。这在web开发和网站管理的效率和便利性方面也是非常合理的。因此,URL 相似度用于新闻页面分类。齐等
[9]在URL相似度的计算中使用了Dice系数,并结合使用统计方法完成了URL相似度的测量。该方法从字符串处理的角度出发,由于URL的格式特性,本文在协议、服务器名、域名相同的情况下,利用新闻URL特性来判断动态网页。具体如下: ①如果新闻网址字符在字符串中,如果路径中收录“pic”、“photo”等图片相关的英文字符串,则说明新闻网址为动态网页。例如:人民网、新华网等网站中的网址中收录这些图片字符串;②如果新闻网址的后缀匹配数字或字母的增量,新闻网页是动态网页,如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,具有很强的格局,不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit
[10] 渲染新闻网页获取HTML源代码,然后使用Jsoup中的DOM对象提取新闻标题、发布时间等信息。例如:提取新闻标题时,先提取标签中的标签内容,然后截取“―”、“_”、“/”等标签(内容常用于将标题和新闻来源分开)作为新闻标题。2.2 动态网页信息提取模块Dywebextract模块接受Pretreatment模块的数据,主要功能是动态网页翻页识别和文本信息提取。对于动态网页翻页识别,采用了两种策略:①如果新闻网页有本地url模式模板(系统在初始化时根据各大新闻网站动态网页url的特点添加url模式)或XPath模板(有效元素路径),翻页自行根据url模式模板(url后缀数字增加或字母减少)或触发点击XPath。如果新闻页面的标题相同,则循环翻页,直到没有捕获到有效页面(出现重复页面或死链接);②如果本地没有对应的url模式模板或XPath,获取HTML中的候选有效元素,然后触发,最后通过触发validity过滤掉有效元素。对于文本信息提取,本文利用了同一新闻门户中动态网页高度相似的结构,采用两种策略: ①如果本地有XPath模式模板,则根据XPath模式模板提取文本信息;②如果不是,则使用基于布局相似度的网页正文内容提取方法
[11] 提取身体信息。XPath模式模板库的管理采用时序管理方式。如果 XPath 模式模板库中的某个 XPath 一周未使用,则该模板将被视为无效的 XPath 并被删除。该模块的算法流程如图3所示,下面重点介绍几个主要环节。
2.2.1 替代有效元素的集合。动态网页收录有效元素。有效元素被触发后,会异步生成动态信息,而静态网页不需要触发有效元素来获取信息。但是,动态网页收录许多触发元素(如按钮、文本框、链接等)。有效元素产生的动态信息是有价值的动态信息,无效元素产生的动态信息是无效信息。例如,触发元素仅更改了网页的字体颜色或其他嘈杂部分。在动态网页中,诸如,等标签所代表的元素可能会导致页面发生变化
[12],从而产生有价值的动态信息,因此该系统将有效元素筛选限制为仅和标签。为了进一步缩小有效元素的搜索范围,提高获取页面信息的效率,需要在搜索有效元素之前确定有效元素的标签集。对于本系统,有效元素是可以点击下一页的元素来获取下一页的文本信息。因此,本文统计了腾讯网站等8个大型新闻门户网站,从这些新闻门户网站中随机抽取了100个新闻网页,发现大部分有效元素的属性值都收录“next”和“对”。", "Next (page)" 等词。一个有效的元素通常绑定到一个有效的事件上,用户点击该元素执行脚本程序或网页跳转以获取更多网页信息,因此其属性值收录JavaScript或URL。对于一个标签,如果没有子标签,则认为它是一个有效标签。综上所述,本系统将属性中收录“next”、“next”等词的标签定义为候选有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本。程序。因此,需要一个工具来模拟用户的点击操作,而HtmlUnit正好可以解决这个模拟问题。HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。本系统采用全检测扫描算法
[13]、点击有效元素集中的所有元素。2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法判断DOM树的相似度。是一种限制匹配算法,利用动态规划计算两棵树的最大匹配节点数,得到两棵树结构的相似度;罗斯特等待
[15] 提出了一种比较页面的方法。该方法首先比较各个模块,为模块定位DOM树结构的特征部分。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个A比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量变化,则认为新获取的网页无效,触发器无效;除此以外,获取的网页被认为是有效的,有效元素XPath存储在XPath模板库中。2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。(1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点和下垂点后面的行块长度为0,保证文本提取结束.根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图,从图4可以看出,内容很多阻止[start=743, end=745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除,所以根据新闻页面对于噪音的特性,增加了第四个约束。
(4)Ystart
3 实验测试
3.1 实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级的主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页。作为实验页面的集合。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理. 对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%为合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的网页数/网页总数×100%
3.2 实验结果 表1为系统网页正文提取准确率和在线文本提取率。其中,每个网站有100个动态网页和静态网页,共计1600个网页。表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。错误的原因是不同主题的设计风格不一样,还有人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响. 对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页和普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模新闻网站新闻正文信息萃取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以对英文网页优化进行深入研究,
参考:
[1]ARIAS J, DESCHACHT K, MOENS M F. 从网页中提取与语言无关的内容[J]. 特温特大学, 2009.
[2]_来源中文社区。一般网页文本提取[EB/OL].[20150425].
[3]陈昭,张冬梅. Web信息抽取技术概述[J].计算机应用研究, 2010, 27 (12):44014405.
[4]王琦,唐世伟,杨冬青,等.基于DOM的网页主题信息自动提取[C]. 中国数据库学术会议,2004:17861792.
[5] GUPTA S、KAISER GE、GRIMM P 等。HTML 文档内容自动提取[J]. 万维网互联网和网络信息系统,2005 年,8 (2): 179224.
[6]REIS D C.使用树编辑距离的自动网络新闻提取[C].万维网国际会议.ACM,2004:502511.
[7] 维埃拉 K、席尔瓦 ASD、平托 N 等。一种快速、鲁棒的网页模板检测和移除方法[C].ACM国际信息与知识管理会议.ACM,2006:258267.
[8] 黄文北,杨静,顾俊忠.基于块的网页正文信息提取算法研究[J]. 计算机应用, 2007, 27 (s1): 2426.
[9]QI X, NIE L, DAVISON B D. 测量相似性以检测合格链接[C].Airweb 2007,第三届网络对抗性信息检索国际研讨会,与 WWW 会议同处,加拿大班夫,2007:495 6.
[10] 张家荣.Java开源项目HtmlUnit在浏览器仿真中的应用[J]. 电子制作, 2015 (8): 79.
[11]杨柳青,李晓东,耿光刚.基于布局相似度的网页正文内容提取研究[J]. 计算机应用研究, 2015 (9): 25812586.
[12] 张耀.面向AJAX脚本网络的网络爬取解析技术研究与实现[D]. 沉阳:东北大学,2012.
[13]MESBAH A, BOZDAG E, DEURSEN A V. Crawling AJAX by inferring user interface state changes[C].第八届网络工程国际会议,Yorktown Heights, New York, Usa.2008: 122134.
[14]何欣,谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与发展, 2007, 44 (z3): 16.
[15] ROEST D, MESBAH A, DEURSEN A V. 回归测试 ajax 应用程序:应对动态[C]。International Conference on Software Testing, Verification and Validation, ICST 2010, Paris, France, 2010: 127136. (Editor: Duneng Steel)
抓取网页新闻(网站怎么快速被爬虫?怎么让蜘蛛快速和抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-18 10:10
在这个网络时代,很多人在购买新品前都会上网查资料,看看哪些品牌的口碑和评价比较好。这时候,排名靠前的产品就会占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。下面,深圳徐欢欢会告诉你如何让蜘蛛快速爬行和爬行方法。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但是关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎排名中的重要因素。
2. 外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。网站大外链的搭建对于站长朋友来说非常重要,因为网站大的权重传递作用很强。而且还可以给内容带来更多的转载,让权重传递往往可以达到一敌百的作用。比如在A5上投稿就是一个不错的方法。此外,您也可以在各大门户网站投稿或花钱投稿到网易、新浪等相关频道网站。
事实上,在这些大网站上张贴或发布外部链接并不容易。貌似花钱或者雇枪手都可以实现,但是如果不注意外部链接的布局就很难提高优化效果,比如在A5 Contribution上,末尾添加的文字链接应该成为网站的首页链接。这样做的好处是相对于这个网站站长在A5上的投稿,有一定的相关性。如果你留下它的外部链接是一个销售成人用品的页面。这种相关性会变得极其脆弱,很难实现权重的引入。其他大型门户网站网站的外链建设也是如此。我们必须注意外部链接和结果页面的相关性。
然后就是合理布局长尾关键词外链。根据28原则,现代网站的利润往往来自于长尾关键词,也就是说长尾关键词已经成为网站@的盈利核心>,所以在外链建设中加强长尾关键词的锚文本,是有效提高长尾关键词权重和排名的关键方法。 -tail 关键词,对应的栏目页面要建好,然后外链的来源要选择有这些长尾关键词的栏目页面。当然,外链的载体内容必须与栏目页面有一定的相关性,否则效果不会很明显。
最后就是要注意内容页面的权重导入。这部分也很重要,对于很多中小网站来说,这种内容页的权重导入,不仅可以有效提升内容页在搜索引擎中的排名。更重要的是,它可以有效提高这些内容页的导流效果,因为当人们进入这些内容页时,不可避免地会点击这些内容页的扩展链接,直接进入这个网站,从而为进一步获取忠实用户。
那么,在构建内容页的外链构建时,我们必须避免一个问题,即内容页是外链构建的载体,即发布在其他网站和外链导入的内容完全一样。是的,这显然不是给用户参考的,但是内容页有一定的区别,或者是对外链内容的更好的补充,就像百度词条上的各种延伸阅读和相关词条的锚点一样的文字链接,这将使用户获得更好的知识,同时促进权重的合理导入。
做网站外链越来越难了,但是再难,我们还是要去做。只是我们现在不能这么残忍的去做。一定要讲究技巧,对百度的搜索引擎算法有深刻的了解。只有这样才能在外链优化中起到事半功倍的作用!
3.如何被爬虫爬取?
爬虫是一种自动提取网页的程序,比如百度的蜘蛛。如果你想让你的网站页面有更多的成为收录,你必须先让网页被爬虫抓取。
如果您的 网站 页面更新频繁,爬虫会更频繁地访问该页面。优质内容是爬虫喜欢爬取的目标,尤其是原创内容。
二、网站 如何快速被蜘蛛抓到
1.网站 和页面权重。
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛要保证高效,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样可以网站@收录也会有更多的页面。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛网站的体验越来越差,你的网站的评分也会越来越低,自然会影响你的网站的爬取>,所以你必须愿意选择一个空间服务器。没有很好的基础。,再好的房子也会穿越。
3. 网站 的更新频率。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,又不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的最爱,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓到。获得。
6.网站 程序。
在网站 程序中,可以创建大量重复页面的程序有很多。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新站点,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站中的页面暴露在蜘蛛面前可以防止蜘蛛找不到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
第一点:博客外链的搭建这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞留下外部链接。由于百度算法的更新,这种外链现在已经失效,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有所评论。关注一下,如果你的网站内容够好,有的博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。那个时候加个链接不是一句话的事吗?关于这个我就不多说了。
第三点:软文外链构建 在构建外链的过程中,使用软文构建外链是必不可少的一部分。同时,软文建外链也是最有效的,而且效果也很快,选择什么样的发布平台是直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在无关平台上发送软文肯定不如在相关平台上好,不好的平台认为传输的权重也是有限的。是的,我终于写了一篇文章,我不同意,我提交文章需要小心。
第四点:开放、品类目录外链建设。如果你的网站足够好,那么开放目录是一个不错的选择,比如DOMZ目录和yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。而且,网络上有相当多的网站分类目录。在建立外部链接时不要忽略这块肥肉。
第五点:虽然常说购买链接会被百度攻击,但作为一个新网站,如果想在最短的时间内获得一定的pr和权重,是有一定的收录,所以买链接也是必须的少,当然不是你去买一些金链或者去一些专门买卖链接的平台,而是去和一些公关、权重比较高的门户、新闻站交流(前提是这些门户网站和新闻站不是专门卖链接的),看看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后等你的网站慢慢上来的时候,就一一删除。
8.内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可能需要蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都在用,让蜘蛛爬更广泛的页面。
其实内链的建设也有助于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
此外,您可以将部分关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会给网站带来更多的流量。而且,页面之间的相关性增加,也可以增加用户在网站的停留时间,减少高跳出率的发生。
网站排名靠前的一个前提是网站被搜索引擎收录的页面多,良好的内链建设可以帮助网站页面成为< @收录。当一篇网站文章的文章为收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会一直爬到你的网站,大大增加了网站页面被收录的几率。 查看全部
抓取网页新闻(网站怎么快速被爬虫?怎么让蜘蛛快速和抓取方法)
在这个网络时代,很多人在购买新品前都会上网查资料,看看哪些品牌的口碑和评价比较好。这时候,排名靠前的产品就会占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,其中近70%的搜索者会在搜索结果自然排名的第一页直接找到自己需要的信息。
可见,目前SEO对于企业和产品具有不可替代的意义。下面,深圳徐欢欢会告诉你如何让蜘蛛快速爬行和爬行方法。
一、网站如何快速被爬虫爬取?
1.关键词 是重中之重
我们经常听到人们谈论关键词,但是关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎排名中的重要因素。
2. 外链也会影响权重
导入链接也是网站优化的一个非常重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
首先是大网站下的外链建设。网站大外链的搭建对于站长朋友来说非常重要,因为网站大的权重传递作用很强。而且还可以给内容带来更多的转载,让权重传递往往可以达到一敌百的作用。比如在A5上投稿就是一个不错的方法。此外,您也可以在各大门户网站投稿或花钱投稿到网易、新浪等相关频道网站。
事实上,在这些大网站上张贴或发布外部链接并不容易。貌似花钱或者雇枪手都可以实现,但是如果不注意外部链接的布局就很难提高优化效果,比如在A5 Contribution上,末尾添加的文字链接应该成为网站的首页链接。这样做的好处是相对于这个网站站长在A5上的投稿,有一定的相关性。如果你留下它的外部链接是一个销售成人用品的页面。这种相关性会变得极其脆弱,很难实现权重的引入。其他大型门户网站网站的外链建设也是如此。我们必须注意外部链接和结果页面的相关性。
然后就是合理布局长尾关键词外链。根据28原则,现代网站的利润往往来自于长尾关键词,也就是说长尾关键词已经成为网站@的盈利核心>,所以在外链建设中加强长尾关键词的锚文本,是有效提高长尾关键词权重和排名的关键方法。 -tail 关键词,对应的栏目页面要建好,然后外链的来源要选择有这些长尾关键词的栏目页面。当然,外链的载体内容必须与栏目页面有一定的相关性,否则效果不会很明显。
最后就是要注意内容页面的权重导入。这部分也很重要,对于很多中小网站来说,这种内容页的权重导入,不仅可以有效提升内容页在搜索引擎中的排名。更重要的是,它可以有效提高这些内容页的导流效果,因为当人们进入这些内容页时,不可避免地会点击这些内容页的扩展链接,直接进入这个网站,从而为进一步获取忠实用户。
那么,在构建内容页的外链构建时,我们必须避免一个问题,即内容页是外链构建的载体,即发布在其他网站和外链导入的内容完全一样。是的,这显然不是给用户参考的,但是内容页有一定的区别,或者是对外链内容的更好的补充,就像百度词条上的各种延伸阅读和相关词条的锚点一样的文字链接,这将使用户获得更好的知识,同时促进权重的合理导入。
做网站外链越来越难了,但是再难,我们还是要去做。只是我们现在不能这么残忍的去做。一定要讲究技巧,对百度的搜索引擎算法有深刻的了解。只有这样才能在外链优化中起到事半功倍的作用!
3.如何被爬虫爬取?
爬虫是一种自动提取网页的程序,比如百度的蜘蛛。如果你想让你的网站页面有更多的成为收录,你必须先让网页被爬虫抓取。
如果您的 网站 页面更新频繁,爬虫会更频繁地访问该页面。优质内容是爬虫喜欢爬取的目标,尤其是原创内容。
二、网站 如何快速被蜘蛛抓到
1.网站 和页面权重。
这必须是第一要务。网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高,大家都知道搜索引擎蜘蛛要保证高效,并不是所有的页面都会为网站爬取,而且网站的权重越高,爬取的深度越高,对应的可爬取的页面也会增加,这样可以网站@收录也会有更多的页面。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这离你很近了,蜘蛛想来也来不来。百度蜘蛛也是网站的访客。如果你的服务器不稳定或者卡住了,蜘蛛每次都爬不上去,有时只能爬到一个页面的一部分。这样一来,随着时间的推移,百度蜘蛛网站的体验越来越差,你的网站的评分也会越来越低,自然会影响你的网站的爬取>,所以你必须愿意选择一个空间服务器。没有很好的基础。,再好的房子也会穿越。
3. 网站 的更新频率。
蜘蛛每次爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,又不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的最爱,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓到。获得。
6.网站 程序。
在网站 程序中,可以创建大量重复页面的程序有很多。这个页面一般是通过参数来实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新站点,网站还不是很成熟,蜘蛛访问量比较少,外链可以增加网站中的页面暴露在蜘蛛面前可以防止蜘蛛找不到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。下面我讲一下需要注意的几点。
第一点:博客外链的搭建这里提到的博客外链不是我们平时做的。在一些个人博客、新浪博客、网易博客、和讯博客等,只评论点赞留下外部链接。由于百度算法的更新,这种外链现在已经失效,时间过长甚至会降级。在这里我想说的,是为了给博主留下印象,帮助博主,提出建议,或者评论我自己的不同想法而发表评论。几次之后,相信博主肯定会对你有所评论。关注一下,如果你的网站内容够好,有的博主会给你一个链接,而且这个链接在他们的随机评论中往往比你好很多。
第二点:论坛外链建设论坛外链建设的思路其实和博客的思路差不多。留下您的想法并让主持人关注您。也许你会在几次之后成为朋友甚至合作伙伴。那个时候加个链接不是一句话的事吗?关于这个我就不多说了。
第三点:软文外链构建 在构建外链的过程中,使用软文构建外链是必不可少的一部分。同时,软文建外链也是最有效的,而且效果也很快,选择什么样的发布平台是直接思考的问题。这里我建议大家可以找一些不为很多人所知的相关平台。比如在无关平台上发送软文肯定不如在相关平台上好,不好的平台认为传输的权重也是有限的。是的,我终于写了一篇文章,我不同意,我提交文章需要小心。
第四点:开放、品类目录外链建设。如果你的网站足够好,那么开放目录是一个不错的选择,比如DOMZ目录和yahoo目录都可以提交。当然,对于一些新网站或者最近刚成立的网站,分类目录就是你的天堂。而且,网络上有相当多的网站分类目录。在建立外部链接时不要忽略这块肥肉。
第五点:虽然常说购买链接会被百度攻击,但作为一个新网站,如果想在最短的时间内获得一定的pr和权重,是有一定的收录,所以买链接也是必须的少,当然不是你去买一些金链或者去一些专门买卖链接的平台,而是去和一些公关、权重比较高的门户、新闻站交流(前提是这些门户网站和新闻站不是专门卖链接的),看看能不能买链接,这样买的链接就不会被百度识别,链接质量比较高。以后等你的网站慢慢上来的时候,就一一删除。
8.内部链构建。
蜘蛛的爬行是跟着链接走的,所以内链的合理优化可能需要蜘蛛爬取更多的页面,促进网站的收录。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都在用,让蜘蛛爬更广泛的页面。
其实内链的建设也有助于提升用户体验,所以用户不必一一查看是否有相关内容,只需要依靠一个小的内链或者一个链接的关键词为拿到它,为实现它。更多更广的信息,何乐而不为呢?所以如果要真正提升用户体验,不是为了SEO提升用户体验,所以从用户的角度来说,什么样的内链才是用户最喜欢的工作。
此外,您可以将部分关键词链接到本站的其他页面,以提高这些页面之间的相关性,方便用户浏览。随着用户体验的提升,自然会给网站带来更多的流量。而且,页面之间的相关性增加,也可以增加用户在网站的停留时间,减少高跳出率的发生。
网站排名靠前的一个前提是网站被搜索引擎收录的页面多,良好的内链建设可以帮助网站页面成为< @收录。当一篇网站文章的文章为收录时,百度蜘蛛会继续沿着这个页面的超链接爬行。如果你的内链做的好,百度蜘蛛会一直爬到你的网站,大大增加了网站页面被收录的几率。
抓取网页新闻(屏蔽主流搜索引擎爬虫(蜘蛛)//索引/收录网页的几种思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-18 07:09
中国IDC圈2月8日报道:一个网站已经搭建成功,之后的目标是希望搜索引擎能够及时收录,让更多的用户可以浏览和推广自己网站 产品产生购买欲望。但这样的愿望并不容易实现。有时我们也会遇到网站不需要搜索收录的情况。
例如,如果您要启用一个新域名作为镜像网站,主要用于PPC 推广,您必须想办法阻止搜索引擎蜘蛛抓取并索引我们镜像的所有网页网站。因为如果镜像网站也被搜索引擎收录搜索到了,很可能会影响官网在搜索引擎中的权重,这绝对是我们不想看到的结果.
下面列出了几种阻止主流搜索引擎爬虫(蜘蛛)抓取/索引/收录网页的思路。注:全站屏蔽,尽量屏蔽所有主流搜索引擎的爬虫(蜘蛛)。
1、 通过服务器(如:Linux/nginx)配置文件设置直接过滤spider/robots的IP段。
小提示:第一、二招只对“君子”有效,防止“小人”动用第三招(“君子”和“小人”分别指遵守和不遵守robots.txt协议蜘蛛/机器人),所以网站上线后,继续跟踪和分析日志,过滤掉这些badbot的ip,然后阻止它们。
这里有一个badbot ip数据库:,通过meta标签屏蔽添加所有网站推广网页的头文件,添加如下语句:
3、通过robots.txt文件屏蔽可以说robots.txt文件是最重要的渠道(它可以与搜索引擎建立直接对话)。通过分析我自己的网站推广博客服务器日志文件,给出以下建议(同时欢迎广大网友补充):
用户代理:BaiduspiderDisallow: /User-agent: GooglebotDisallow: /User-agent: Googlebot-MobileDisallow: /User-agent: Googlebot-ImageDisallow:/User-agent: Mediapartners-GoogleDisallow: /User-agent: Adsbot-GoogleDisallow: /用户代理:Feedfetcher-GoogleDisallow:/用户代理:雅虎!SlurpDisallow:/用户代理:雅虎!Slurp ChinaDisallow: /User-agent: Yahoo!-AdCrawlerDisallow: /User-agent: YoudaoBotDisallow: /User-agent: SosospiderDisallow : /User-agent: 搜狗蜘蛛Disallow: /User-agent: 搜狗网络蜘蛛Disallow: /User-agent: MSNBotDisallow : /User-agent: ia_archiverDisallow: /User-agent: Tomato BotDisallow: /User-agent: *Disallow: /< @4、可以通过检查HTTP_USER_AGENT是否被爬虫/蜘蛛访问,然后直接阻止其他更新返回 403 状态代码以阻止它。例如:
5、通过搜索引擎提供的站长工具,删除网页快照。例如,有时百度并没有严格遵守robots.txt协议,您可以通过百度提供的“网站投诉”门户删除网页快照。百度网页投诉中心: 总结:关于屏蔽搜索引擎收录网页的方法,网站推广编辑会讲到。如果哪位朋友有更好的技术和方法,希望发布出来,大家交流学习。 查看全部
抓取网页新闻(屏蔽主流搜索引擎爬虫(蜘蛛)//索引/收录网页的几种思路)
中国IDC圈2月8日报道:一个网站已经搭建成功,之后的目标是希望搜索引擎能够及时收录,让更多的用户可以浏览和推广自己网站 产品产生购买欲望。但这样的愿望并不容易实现。有时我们也会遇到网站不需要搜索收录的情况。
例如,如果您要启用一个新域名作为镜像网站,主要用于PPC 推广,您必须想办法阻止搜索引擎蜘蛛抓取并索引我们镜像的所有网页网站。因为如果镜像网站也被搜索引擎收录搜索到了,很可能会影响官网在搜索引擎中的权重,这绝对是我们不想看到的结果.
下面列出了几种阻止主流搜索引擎爬虫(蜘蛛)抓取/索引/收录网页的思路。注:全站屏蔽,尽量屏蔽所有主流搜索引擎的爬虫(蜘蛛)。
1、 通过服务器(如:Linux/nginx)配置文件设置直接过滤spider/robots的IP段。
小提示:第一、二招只对“君子”有效,防止“小人”动用第三招(“君子”和“小人”分别指遵守和不遵守robots.txt协议蜘蛛/机器人),所以网站上线后,继续跟踪和分析日志,过滤掉这些badbot的ip,然后阻止它们。
这里有一个badbot ip数据库:,通过meta标签屏蔽添加所有网站推广网页的头文件,添加如下语句:
3、通过robots.txt文件屏蔽可以说robots.txt文件是最重要的渠道(它可以与搜索引擎建立直接对话)。通过分析我自己的网站推广博客服务器日志文件,给出以下建议(同时欢迎广大网友补充):
用户代理:BaiduspiderDisallow: /User-agent: GooglebotDisallow: /User-agent: Googlebot-MobileDisallow: /User-agent: Googlebot-ImageDisallow:/User-agent: Mediapartners-GoogleDisallow: /User-agent: Adsbot-GoogleDisallow: /用户代理:Feedfetcher-GoogleDisallow:/用户代理:雅虎!SlurpDisallow:/用户代理:雅虎!Slurp ChinaDisallow: /User-agent: Yahoo!-AdCrawlerDisallow: /User-agent: YoudaoBotDisallow: /User-agent: SosospiderDisallow : /User-agent: 搜狗蜘蛛Disallow: /User-agent: 搜狗网络蜘蛛Disallow: /User-agent: MSNBotDisallow : /User-agent: ia_archiverDisallow: /User-agent: Tomato BotDisallow: /User-agent: *Disallow: /< @4、可以通过检查HTTP_USER_AGENT是否被爬虫/蜘蛛访问,然后直接阻止其他更新返回 403 状态代码以阻止它。例如:
5、通过搜索引擎提供的站长工具,删除网页快照。例如,有时百度并没有严格遵守robots.txt协议,您可以通过百度提供的“网站投诉”门户删除网页快照。百度网页投诉中心: 总结:关于屏蔽搜索引擎收录网页的方法,网站推广编辑会讲到。如果哪位朋友有更好的技术和方法,希望发布出来,大家交流学习。
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-17 23:03
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map供用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我对网页和网络相关知识接触不多,使用了不习惯的Python。下面的程序有曲折,bug很多,但是勉强能抓到网络新闻。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map供用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我对网页和网络相关知识接触不多,使用了不习惯的Python。下面的程序有曲折,bug很多,但是勉强能抓到网络新闻。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(本文会简单的爬取澎湃新闻网站的时事中国政库新闻 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-17 23:02
)
本文将简单爬取澎湃新闻网站中国政治图书馆新闻,会涉及并发应用!
分析网页
https://www.thepaper.cn/list_25462
The Paper of The Paper 网站 有点像梨视频网站。要获取更多内容,您需要下拉鼠标才能显示。是动态渲染的,所以需要进入浏览器开发用户工具→网络→XHR抓取内容并得到一个url。
打开链接,得到一个简单的静态网页:
每个链接的pageidx参数和lastTime参数都会发生变化。 pageidx 参数每次更改都会增加 1。 LastTime 是一个时间戳。这不会影响我们的抓取内容,只需将其删除即可。
https://www.thepaper.cn/load_i ... 18779
https://www.thepaper.cn/load_i ... 30221
点击打开一条内容,即新闻信息:
每个内容链接都有一个唯一的id值,所以需要获取它的id值:
https://www.thepaper.cn/newsDe ... 65286
https://www.thepaper.cn/newsDe ... 63702
抓取想法:
实用代码
导入模块:
import requests
import re
from lxml import etree
import concurrent.futures
请求函数:
保存功能:
def save(title_li, text):
# 声明编码,不然会报错
with open('./x.text', mode='a', encoding='utf-8')as f:
f.write(title_li + '\n\n')
f.write(text + '\n\n')
# 因为保存在一个文件中,所以这里用*号进行隔开
f.write('*' * 50 + '\n\n')#
分析功能:
def main(html_url):
response = def_response(html_url)
href = re.findall('data-id="(.*?)"', response.text)
title = re.findall('alt="(.*?)"', response.text)
for url_li, title_li in zip(href, title):
# 拼接链接
url_ = f'https://www.thepaper.cn/newsDetail_forward_{url_li}'
res = def_response(url_)
etrees = etree.HTML(res.text)
# 这里用xpath提取文本内容,但是格式有点乱,所以用'\n\n'.join进行换行
text = '\n\n'.join(etrees.xpath('.//div[@class="news_txt"]/text()'))
save(title_li, text)
发起人:
if __name__ == '__main__':
# ThreadPoolExecutor 线程池的对象 max_workers 任务数 这里开了3个
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
for page in range(0, 4):
url = f'https://www.thepaper.cn/load_i ... dx%3D{page}&isList=true'
# main(url)
# submit 往线程池里面添加任务
executor.submit(main, url)
executor.shutdown()
效果图:
查看全部
抓取网页新闻(本文会简单的爬取澎湃新闻网站的时事中国政库新闻
)
本文将简单爬取澎湃新闻网站中国政治图书馆新闻,会涉及并发应用!
分析网页
https://www.thepaper.cn/list_25462
The Paper of The Paper 网站 有点像梨视频网站。要获取更多内容,您需要下拉鼠标才能显示。是动态渲染的,所以需要进入浏览器开发用户工具→网络→XHR抓取内容并得到一个url。
打开链接,得到一个简单的静态网页:
每个链接的pageidx参数和lastTime参数都会发生变化。 pageidx 参数每次更改都会增加 1。 LastTime 是一个时间戳。这不会影响我们的抓取内容,只需将其删除即可。
https://www.thepaper.cn/load_i ... 18779
https://www.thepaper.cn/load_i ... 30221
点击打开一条内容,即新闻信息:
每个内容链接都有一个唯一的id值,所以需要获取它的id值:
https://www.thepaper.cn/newsDe ... 65286
https://www.thepaper.cn/newsDe ... 63702
抓取想法:
实用代码
导入模块:
import requests
import re
from lxml import etree
import concurrent.futures
请求函数:
保存功能:
def save(title_li, text):
# 声明编码,不然会报错
with open('./x.text', mode='a', encoding='utf-8')as f:
f.write(title_li + '\n\n')
f.write(text + '\n\n')
# 因为保存在一个文件中,所以这里用*号进行隔开
f.write('*' * 50 + '\n\n')#
分析功能:
def main(html_url):
response = def_response(html_url)
href = re.findall('data-id="(.*?)"', response.text)
title = re.findall('alt="(.*?)"', response.text)
for url_li, title_li in zip(href, title):
# 拼接链接
url_ = f'https://www.thepaper.cn/newsDetail_forward_{url_li}'
res = def_response(url_)
etrees = etree.HTML(res.text)
# 这里用xpath提取文本内容,但是格式有点乱,所以用'\n\n'.join进行换行
text = '\n\n'.join(etrees.xpath('.//div[@class="news_txt"]/text()'))
save(title_li, text)
发起人:
if __name__ == '__main__':
# ThreadPoolExecutor 线程池的对象 max_workers 任务数 这里开了3个
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
for page in range(0, 4):
url = f'https://www.thepaper.cn/load_i ... dx%3D{page}&isList=true'
# main(url)
# submit 往线程池里面添加任务
executor.submit(main, url)
executor.shutdown()
效果图:
抓取网页新闻(网上接到一个一个开发新闻抓取接口的项目介绍及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-17 02:09
半个月前,我接到了一个来自互联网的开发新闻爬取界面的项目。
客户需求是让用户可以在任何他能看到的手机app中采集文章,获取文章地址,将文章地址提交给客户平台,文章@ > 标题、摘要、正文和图片保存到对方的数据库中。有一款叫手趣的app,可以让用户将自己感兴趣的文章复制粘贴到app中。文章 自动捕获并以常规格式显示在客户端。客户端正在计划开发类似的功能,希望该应用能够兼容主流媒体的新闻抓取,包括新浪新闻、今日头条、微信公众号等。
申请过程并不复杂。用户从前端提交要抓取的URL到服务器。服务器根据URL域名匹配对应的爬虫,解析下载的HTML,并以固定格式存入数据库。服务端最终将爬取结果以JSON格式返回给客户端。
一个完整的爬虫包括四个模块:页面请求、任务调度、页面分析和数据存储。另外,如果需要考虑爬虫爬行效率、反爬行能力等因素,还需要添加一些高级模块,比如多线程和协程实现高并发,添加代理池防止爬行网站 阻止 IP 。如果运气不好,需要爬取的内容需要用户登录才能获取,则必须模拟用户登录。另外,由于大部分网站使用js来渲染页面,所以需要考虑使用分析数据接口或者模拟浏览器来获取这些动态内容。
分析了这个项目需要抓取的新闻网站,发现除了腾讯新闻外,都是用js来渲染html页面的。因此,不能像请求静态页面那样直接请求 URL 来获取 HTML。为方便起见,我使用了 casperjs。Casperjs是一个基于phantomjs的工具,比phantomjs有更方便的API。为了统一编程语言,我使用nodejs开发爬虫。
在项目中添加casperjsRequest.js文件,相当于项目中的下载模块,可以通过nodejs中的child_process.spawn调用。
var casper = require('casper').create({
pageSettings: {
loadImages: false, // The WebPage instance used by Casper will
loadPlugins: false // use these settings
}
});
var config = require('../config');
var url = casper.cli.args[0];
console.log(casper.cli.args);
casper.userAgent(config.REQUEST_USER_AGENT);
casper.options.waitTimeout = config.CASPERJS_WAIT_TIMEOUT;
casper.options.timeout = config.CASPERJS_TIMEOUT;
casper.start(url, function () {
this.echo(this.getPageContent());
});
casper.run();
将需要的URL作为命令行参数传递给casperjsRequest.js,可以在stdout中获取收录动态内容的页面的HTML,在bash中执行如下命令
casperjs ./bin/casperjsRequest.js
除了百度文库需要分页才能获取完整的文章外,其他新闻网站的字段内容都遵循一定的规则。因此,以配置文件的形式编辑不同网站的内容选择器,以方便扩展。每个配置文件代表一个网站的爬虫,所以如果有新的网站需要爬取,生成一个类似的配置文件即可。比如今日头条的配置如下
其中,配置文件定义了爬虫域名和内容选择器。此外,它还定义了页面下载的方式。1代表用casperjs请求动态内容,2(默认)代表直接请求静态html,3代表编码请求。
每个URL对应一个域名,即不同的新闻网站,单个新闻网站也分为PC端和移动端,它们的域名不同。当使用 PC URL 请求时,服务器将重定向到移动 URL。而且,今日头条有多个域名。因此,为了保证请求的PC端和手机端的URL一致,我使用了正则表达式来做域爬虫映射。配置文件如下
module.exports = {
// 百度百家号
"baijiahao.baidu.com": "baidu",
// 百度文库
"wk.baidu.com": "baiduwenku",
// 网易新闻
"(?:3g|news).163.com": "netease",
// 腾讯新闻
"(?:xw|news).qq.com": "tencent",
// 今日头条
".*toutiao(?:\d+)?.com|m.pstatp.com": "toutiao",
// 微信公众号文章
"mp.weixin.qq.com": "weixin",
// 新浪新闻
"sina.(?:cn|com)": "sina",
// 通用爬虫
".*": "generic"
};
下一步就是编写爬虫分析逻辑和数据存储。
(待续,待续) 查看全部
抓取网页新闻(网上接到一个一个开发新闻抓取接口的项目介绍及应用)
半个月前,我接到了一个来自互联网的开发新闻爬取界面的项目。
客户需求是让用户可以在任何他能看到的手机app中采集文章,获取文章地址,将文章地址提交给客户平台,文章@ > 标题、摘要、正文和图片保存到对方的数据库中。有一款叫手趣的app,可以让用户将自己感兴趣的文章复制粘贴到app中。文章 自动捕获并以常规格式显示在客户端。客户端正在计划开发类似的功能,希望该应用能够兼容主流媒体的新闻抓取,包括新浪新闻、今日头条、微信公众号等。
申请过程并不复杂。用户从前端提交要抓取的URL到服务器。服务器根据URL域名匹配对应的爬虫,解析下载的HTML,并以固定格式存入数据库。服务端最终将爬取结果以JSON格式返回给客户端。
一个完整的爬虫包括四个模块:页面请求、任务调度、页面分析和数据存储。另外,如果需要考虑爬虫爬行效率、反爬行能力等因素,还需要添加一些高级模块,比如多线程和协程实现高并发,添加代理池防止爬行网站 阻止 IP 。如果运气不好,需要爬取的内容需要用户登录才能获取,则必须模拟用户登录。另外,由于大部分网站使用js来渲染页面,所以需要考虑使用分析数据接口或者模拟浏览器来获取这些动态内容。
分析了这个项目需要抓取的新闻网站,发现除了腾讯新闻外,都是用js来渲染html页面的。因此,不能像请求静态页面那样直接请求 URL 来获取 HTML。为方便起见,我使用了 casperjs。Casperjs是一个基于phantomjs的工具,比phantomjs有更方便的API。为了统一编程语言,我使用nodejs开发爬虫。
在项目中添加casperjsRequest.js文件,相当于项目中的下载模块,可以通过nodejs中的child_process.spawn调用。
var casper = require('casper').create({
pageSettings: {
loadImages: false, // The WebPage instance used by Casper will
loadPlugins: false // use these settings
}
});
var config = require('../config');
var url = casper.cli.args[0];
console.log(casper.cli.args);
casper.userAgent(config.REQUEST_USER_AGENT);
casper.options.waitTimeout = config.CASPERJS_WAIT_TIMEOUT;
casper.options.timeout = config.CASPERJS_TIMEOUT;
casper.start(url, function () {
this.echo(this.getPageContent());
});
casper.run();
将需要的URL作为命令行参数传递给casperjsRequest.js,可以在stdout中获取收录动态内容的页面的HTML,在bash中执行如下命令
casperjs ./bin/casperjsRequest.js
除了百度文库需要分页才能获取完整的文章外,其他新闻网站的字段内容都遵循一定的规则。因此,以配置文件的形式编辑不同网站的内容选择器,以方便扩展。每个配置文件代表一个网站的爬虫,所以如果有新的网站需要爬取,生成一个类似的配置文件即可。比如今日头条的配置如下
其中,配置文件定义了爬虫域名和内容选择器。此外,它还定义了页面下载的方式。1代表用casperjs请求动态内容,2(默认)代表直接请求静态html,3代表编码请求。
每个URL对应一个域名,即不同的新闻网站,单个新闻网站也分为PC端和移动端,它们的域名不同。当使用 PC URL 请求时,服务器将重定向到移动 URL。而且,今日头条有多个域名。因此,为了保证请求的PC端和手机端的URL一致,我使用了正则表达式来做域爬虫映射。配置文件如下
module.exports = {
// 百度百家号
"baijiahao.baidu.com": "baidu",
// 百度文库
"wk.baidu.com": "baiduwenku",
// 网易新闻
"(?:3g|news).163.com": "netease",
// 腾讯新闻
"(?:xw|news).qq.com": "tencent",
// 今日头条
".*toutiao(?:\d+)?.com|m.pstatp.com": "toutiao",
// 微信公众号文章
"mp.weixin.qq.com": "weixin",
// 新浪新闻
"sina.(?:cn|com)": "sina",
// 通用爬虫
".*": "generic"
};
下一步就是编写爬虫分析逻辑和数据存储。
(待续,待续)
抓取网页新闻(企业网站建设|优秀的网站都是靠这些细节做成功的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-17 02:05
阿里云>云栖社区>主题图>P>php抓取网站新闻
推荐活动:
更多优惠>
当前话题:php抓取网站新闻加入采集
相关话题:
php抓取网站新闻相关博客,查看更多博客
Scrapy和Django实现蚌埠医学院移动新闻网站制作
作者:袜子都是破洞 1377人浏览评论:03年前
最终效果(效果不用看,过程都是**应该是流氓**): 实现过程如下: 框架:Scrapy:Data采集 Django:数据呈现目标网站:蚌埠医学院新闻列表:
阅读全文
PHP编程获取网站的Alexa排名
作者:小美科技 1393人浏览评论:04年前
现在大部分提供网站排名的网站,数据取自Alexa发布的数据。但是Alexa的网站排名数据无法简单直接获取。这是因为 Alexa 使用了干扰码技术,这使得编程变得困难和繁琐。但是理论上来说,只要是页面上能看到的信息,除了图片识别,还是一个top
阅读全文
高性能网站 性能优化与系统架构(ZT)
作者:犹豫1270人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET做过拨号接入平台的搭建,之后在Yahoo&3721从事搜索引擎前端开发,在MOP打过大社区。
阅读全文
高性能网站 性能优化与系统架构(ZT)
作者:zting科技1080人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过大型社区猫。
阅读全文
企业网站建设|优秀网站靠这些细节成就
作者:卓研科技2016年浏览评论人数:04年前
随着互联网的发展,许多企业纷纷涌入互联网的战场。从电子商务的发展,不难看出互联网对我们的影响有多大。未来,社会的发展一定会在互联网的基础上推进。现在,很多互联网公司也在做自己的搜索引擎,大佬们想分一杯羹。所以,网站能够引入的流量是非常难得的,也是珍贵的。
阅读全文
php
作者:江湖4546人浏览评论:05年前
Awesome PHP Dependency Management Dependency Management Other Dependency Management Extras Framework Framework Other Framework Framework Extras Framework Components Micro
阅读全文
网站 大并发处理
作者:lhyxcxy1201 浏览评论人数:06年前
一个小小的网站,比如一个个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有的页面都存放在一个目录下,比如网站@ > 对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过这几年的发展,已经细分到非常细致的方面,尤其是
阅读全文
PHP开发高负载网站技术
作者:y0umer839人浏览评论:010年前
在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过一个大型社区拖把大杂烩的架构升级。同时接触并开发了很多大中型项目网站模块,所以在大型网站高负载高并发解决方案方面有一定的积累和经验,可以和每个人一起工作
阅读全文
php抢网站新闻相关问答
PHPwind9.02网站 如何打开一个版块抓取其他网站数据(例如实时动态新闻)
作者:侯涂1688646人浏览评论:13年前
哪位大神能给解答一下,谢谢!
阅读全文 查看全部
抓取网页新闻(企业网站建设|优秀的网站都是靠这些细节做成功的)
阿里云>云栖社区>主题图>P>php抓取网站新闻
推荐活动:
更多优惠>
当前话题:php抓取网站新闻加入采集
相关话题:
php抓取网站新闻相关博客,查看更多博客
Scrapy和Django实现蚌埠医学院移动新闻网站制作
作者:袜子都是破洞 1377人浏览评论:03年前
最终效果(效果不用看,过程都是**应该是流氓**): 实现过程如下: 框架:Scrapy:Data采集 Django:数据呈现目标网站:蚌埠医学院新闻列表:
阅读全文
PHP编程获取网站的Alexa排名
作者:小美科技 1393人浏览评论:04年前
现在大部分提供网站排名的网站,数据取自Alexa发布的数据。但是Alexa的网站排名数据无法简单直接获取。这是因为 Alexa 使用了干扰码技术,这使得编程变得困难和繁琐。但是理论上来说,只要是页面上能看到的信息,除了图片识别,还是一个top
阅读全文
高性能网站 性能优化与系统架构(ZT)
作者:犹豫1270人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET做过拨号接入平台的搭建,之后在Yahoo&3721从事搜索引擎前端开发,在MOP打过大社区。
阅读全文
高性能网站 性能优化与系统架构(ZT)
作者:zting科技1080人浏览评论:04年前
转载请保留:Junlin Michael的博客() 我在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过大型社区猫。
阅读全文
企业网站建设|优秀网站靠这些细节成就
作者:卓研科技2016年浏览评论人数:04年前
随着互联网的发展,许多企业纷纷涌入互联网的战场。从电子商务的发展,不难看出互联网对我们的影响有多大。未来,社会的发展一定会在互联网的基础上推进。现在,很多互联网公司也在做自己的搜索引擎,大佬们想分一杯羹。所以,网站能够引入的流量是非常难得的,也是珍贵的。
阅读全文
php
作者:江湖4546人浏览评论:05年前
Awesome PHP Dependency Management Dependency Management Other Dependency Management Extras Framework Framework Other Framework Framework Extras Framework Components Micro
阅读全文
网站 大并发处理
作者:lhyxcxy1201 浏览评论人数:06年前
一个小小的网站,比如一个个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有的页面都存放在一个目录下,比如网站@ > 对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过这几年的发展,已经细分到非常细致的方面,尤其是
阅读全文
PHP开发高负载网站技术
作者:y0umer839人浏览评论:010年前
在CERNET搭建了拨号接入平台,之后在Yahoo&3721从事搜索引擎前端开发,在MOP处理过一个大型社区拖把大杂烩的架构升级。同时接触并开发了很多大中型项目网站模块,所以在大型网站高负载高并发解决方案方面有一定的积累和经验,可以和每个人一起工作
阅读全文
php抢网站新闻相关问答
PHPwind9.02网站 如何打开一个版块抓取其他网站数据(例如实时动态新闻)
作者:侯涂1688646人浏览评论:13年前
哪位大神能给解答一下,谢谢!
阅读全文
抓取网页新闻(SEO(搜索引擎优化)推广策略:提升网站最重要的关键词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-12-15 06:45
SEO(搜索引擎优化)推广策略:
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。
1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。
4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概认为全文每100字出现“1.5-2关键词”为最佳关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
亿速云作为专业的IDC服务商和专业的云计算服务商,拥有丰富的行业积累,销售“赛门铁克、Thawte、Rapid SSL、Geo Trust”等多家全球权威CA机构的SSL数字证书,提供多品牌、多类SSL证书申请安装服务,全程专业技术指导,免费帮助用户安装部署。 查看全部
抓取网页新闻(SEO(搜索引擎优化)推广策略:提升网站最重要的关键词)
SEO(搜索引擎优化)推广策略:
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。
1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。
4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概认为全文每100字出现“1.5-2关键词”为最佳关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
亿速云作为专业的IDC服务商和专业的云计算服务商,拥有丰富的行业积累,销售“赛门铁克、Thawte、Rapid SSL、Geo Trust”等多家全球权威CA机构的SSL数字证书,提供多品牌、多类SSL证书申请安装服务,全程专业技术指导,免费帮助用户安装部署。
抓取网页新闻(SEO(搜索引擎优化)推广中最重要的关键词,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-15 06:43
对于SEO来说,只要搜索引擎爬取更多的网站页面来提升收录和排名,但是有时候蜘蛛不会主动爬取网站,这个时候我们需要人为地引导搜索引擎,然后提升排名和收录。今天小编就给大家分享下8个帮助搜索引擎爬取网站页面的方法
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。
1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。
4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概把全文每100字出现“1.5-2关键词”作为最佳的关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
这些都是让搜索引擎主动抓取我们的网站页面的方法。希望云网时代小编的分享可以对大家有所帮助。云网时代专业提供深圳主机租赁、深圳服务器租赁、深圳服务器托管、云托管等服务,详情请咨询客服。 查看全部
抓取网页新闻(SEO(搜索引擎优化)推广中最重要的关键词,你知道吗?)
对于SEO来说,只要搜索引擎爬取更多的网站页面来提升收录和排名,但是有时候蜘蛛不会主动爬取网站,这个时候我们需要人为地引导搜索引擎,然后提升排名和收录。今天小编就给大家分享下8个帮助搜索引擎爬取网站页面的方法
提高网站,最重要的关键词,在主要搜索平台的排名,这是SEO(搜索引擎优化)推广中最重要的策略。搜索引擎平台的“搜索机器人蜘蛛”会自动抓取网页内容,所以SEO(搜索引擎优化)的推广策略应该从优化网页开始。
1、 添加页面标题
为每个网页的内容写一个5-8字的描述性标题。标题要简洁,去掉一些繁琐、多余、不重要的词,说明页面最重要的内容和网站是什么。页面的标题会出现在搜索结果页面的链接上,所以可以写得稍微有点挑逗性,以吸引搜索者点击链接。同时,在首页的内容中写下你的公司名称和你认为最重要的关键词,而不仅仅是公司名称。
2、 添加描述性元标记
元素可以提供有关页面的元信息,例如搜索引擎的描述和 关键词 和更新频率。
除了页面标题,很多搜索引擎都会搜索元标签。这是描述网页主体内容的描述性语句。句子中还应包括本页使用的关键词、词组等。
目前,收录关键词的meta标签对网站的排名帮助不大,但有时meta标签用于付费登录技术。谁知道什么时候,搜索引擎会再次关注它?
3、 将您的 关键词 嵌入网页的粗体文本中(通常为“文章title”)。
搜索引擎非常重视粗体文字,会认为这是这个页面上非常重要的内容。因此,请确保将 关键词 写在一两个粗体文本标签中。
4、 确保 关键词 出现在文本的第一段
搜索引擎希望在第一段中,你能找到你的关键词,但不要太多关键词。谷歌大概把全文每100字出现“1.5-2关键词”作为最佳的关键词密度,以获得更好的排名。
其他考虑放置 关键词 的地方可以在代码的 ALT 标签或 COMMENT 标签中。
5、 导航设计应该容易被搜索引擎搜索到
有些人在网页创建中使用框架,但这对搜索引擎来说是一个严重的问题。即使搜索引擎抓取了您的内容页面,也可能会错过关键的导航项,从而无法进一步搜索其他页面。
用Java和Flash制作的导航按钮看起来很漂亮很漂亮,但搜索引擎却找不到。补救的办法是在页面底部用一个普通的HTML链接做一个导航栏,保证通过这个导航栏的链接可以进入网站的每一页。您还可以制作网站 地图,或链接到每个网站 页面。此外,一些内容管理系统和电子商务目录使用动态网页。这些页面的 URL 通常有一个问号,后跟一个数字。过度工作的搜索引擎经常停在问号前,停止搜索。这种情况可以通过更改URL(统一资源定位器)、付费登录等方式解决。
6、对于一些特别重要的关键词,专门有几页
SEO(搜索引擎优化)专家不建议搜索引擎使用任何具有欺骗性的过渡页面,因为这些几乎是复制页面,可能会受到搜索引擎的惩罚。但是,您可以创建多个网页,每个网页都收录不同的 关键词 和短语。例如:您不需要在某个页面上介绍您的所有服务,而是为每个服务制作一个单独的页面。这样每个页面都有一个对应的关键词。这些页面的内容会收录有针对性的关键词而不是一般的内容,可以提高网站的排名。
7、 向搜索引擎提交网页
找到“添加您的 URL”的链接。(网站登录)在搜索引擎上。搜索机器人(robot)会自动索引您提交的网页。美国最著名的搜索引擎有:Google、Inktomi、Alta Vista 和 Tehoma。
这些搜索引擎向其他主要搜索引擎平台和门户网站网站 提供搜索内容。您可以发布到欧洲和其他地区的区域搜索引擎。
至于花钱请人帮你提交“成百上千”的搜索引擎,其实是浪费钱。不要使用FFA(Free For All pages)网站,即所谓的网站,自动将您的网站免费提交给数百个搜索引擎。这种提交不仅效果不好,还会给你带来大量垃圾邮件,还可能导致搜索引擎平台惩罚你的网站。
8、 调整重要内容页面提升排名
对您认为最重要的页面(可能是主页)进行一些调整,以提高其排名。有一些软件可以让你查看自己当前的排名,比较与你的关键词 相同竞争对手的排名,并得到搜索引擎对你的网页的偏好统计,这样你就可以调整自己的页面。您可以使用 WebPosition Gold ()。
因为这个工作自己做需要很多时间,你可以请专业的公司帮你做。
最后还有一个提升网站搜索排名的方法,就是部署安装SSL证书。以“https”开头的网站在搜索引擎平台上会有更好的排名效果。百度和谷歌都明确表示将优先考虑收录“https”网站。
百度官方表示,一直支持“https”,并将“https”作为网站影响搜索排名的优质特性之一,对“https站点”提供多维度支持。网站如果要以“https”开头,必须安装部署一个SSL证书。您的网站安装并部署了SSL证书后,您将获得“百度蜘蛛”权重倾斜,可以使网站的排名上升并保持稳定。
这些都是让搜索引擎主动抓取我们的网站页面的方法。希望云网时代小编的分享可以对大家有所帮助。云网时代专业提供深圳主机租赁、深圳服务器租赁、深圳服务器托管、云托管等服务,详情请咨询客服。
抓取网页新闻(编程问答--新浪中的房地产自动去抓会的说说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-15 02:26
)
如何自动抓取其他网站的新闻信息为了网站以后的维护和开发的方便,能不能有技术支持与其他网站连接并获取网站的信息,如:新浪楼盘信息,想提取出来,及时添加到自己开发的网站中,减少功能量;也就是说,新浪的房产信息更新了,我网站上相应的新闻信息也发生了变化。. . . 怎么实现的,能具体点吗,这里O(∩_∩)O谢谢技术交流!--------------------编程问答---- ----------------据说所有爬虫都是自动抓取的
我来聊一聊......--------------------编程问答----- --apachehtmlClienthtmlParser- -------------------编程问题与解答--------------------这个帮助是好问题!--------------------编程问答--------------------希望有经验的开发者提供一些宝贵的经验和知识,感谢您的交流!--------------------编程问答----- ---- -----
给个赞,现在我也想要这个东西!--------------------编程问答 --------------------但是爬虫爬取的是什么向下?组织也是一个大问题。最好使用更规范的网站。采集到的内容格式也非常完整和规范。然后就容易做内容分析处理了,不然就麻烦了。 ------- -------------编程问答------------ --------常规的网站,排版不要频繁变化。使用htmlparser,根据html标签取出需要的内容存入自己的数据库中。一天更新几次。
我只做过网页抓取。--------------------编程问答-------------------- 可以你推荐一个好的爬虫技术(我查了很多爬虫工具,但是没用过,第一次用这个技术),怎么用的,能告诉我吗,谢谢!------ --------------编程问答-------------------------- -------- ------编程问答-------------------------------- --------编程问答 --------------------rss
补充:Java , Java EE 查看全部
抓取网页新闻(编程问答--新浪中的房地产自动去抓会的说说
)
如何自动抓取其他网站的新闻信息为了网站以后的维护和开发的方便,能不能有技术支持与其他网站连接并获取网站的信息,如:新浪楼盘信息,想提取出来,及时添加到自己开发的网站中,减少功能量;也就是说,新浪的房产信息更新了,我网站上相应的新闻信息也发生了变化。. . . 怎么实现的,能具体点吗,这里O(∩_∩)O谢谢技术交流!--------------------编程问答---- ----------------据说所有爬虫都是自动抓取的
我来聊一聊......--------------------编程问答----- --apachehtmlClienthtmlParser- -------------------编程问题与解答--------------------这个帮助是好问题!--------------------编程问答--------------------希望有经验的开发者提供一些宝贵的经验和知识,感谢您的交流!--------------------编程问答----- ---- -----
给个赞,现在我也想要这个东西!--------------------编程问答 --------------------但是爬虫爬取的是什么向下?组织也是一个大问题。最好使用更规范的网站。采集到的内容格式也非常完整和规范。然后就容易做内容分析处理了,不然就麻烦了。 ------- -------------编程问答------------ --------常规的网站,排版不要频繁变化。使用htmlparser,根据html标签取出需要的内容存入自己的数据库中。一天更新几次。
我只做过网页抓取。--------------------编程问答-------------------- 可以你推荐一个好的爬虫技术(我查了很多爬虫工具,但是没用过,第一次用这个技术),怎么用的,能告诉我吗,谢谢!------ --------------编程问答-------------------------- -------- ------编程问答-------------------------------- --------编程问答 --------------------rss
补充:Java , Java EE
抓取网页新闻(Python爬虫用Python语言编写的python爬虫实现方法一文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-14 05:20
Python爬虫学习,自动抓取163新闻的Python爬虫源码。这是一篇用Python编写的自动抓取网易新闻的Python爬虫的文章。
Python爬虫的爬取思路是:
(1) 通过分析目标新闻网址,分析以
(2)获取每个链接的内容,整理合并成准备好的.txt文本,以便查看新闻。
不过需要注意的是,由于今天的考题,网易新闻的格式不是很统一,会有一些缺失的部分。请原谅我。也希望有能力的朋友帮忙改进一下。
自动抓取163新闻的Python爬虫源码如下:
#coding:utf-8
import re, urllib
strTitle = ""
strTxtTmp = ""
strTxtOK = ""
f = open("163News.txt", "w+")
m = re.findall(r"news\.163\.com/\d.+?",urllib.urlopen("http://www.163.com").read(),re.M)
#www.iplaypy.com
for i in m:
testUrl = i.split('"')[0]
if testUrl[-4:-1]=="htm":
strTitle = strTitle + "\n" + i.split('"')[0] + i.split('"')[1] # 合并标题头内容
okUrl = i.split('"')[0] # 重新组合链接
UrlNews = ''
UrlNews = "http://" + okUrl
print UrlNews
"""
查找分析链接里面的正文内容,但是由于 163 新闻的格式不是非常统一,所以只能说大部分可以。
整理去掉部分 html 代码,让文本更易于观看。
"""
n = re.findall(r"<P style=.TEXT-INDENT: 2em.>(.*?)",urllib.urlopen(UrlNews).read(),re.M)
for j in n:
if len(j)0:
j = j.replace(" ","\n")
j = j.replace("<STRONG>","\n_____")
j = j.replace("</STRONG>","_____\n")
strTxtTmp = strTxtTmp + j + "\n"
strTxtTmp = re.sub(r"<a href=(.*?)>", r"", strTxtTmp)
strTxtTmp = re.sub(r"", r"", strTxtTmp)
strTxtOK = strTxtOK + "\n\n\n===============" +
i.split('"')[0] + i.split('"')[1] + "===============\n" + strTxtTmp
strTxtTmp = "" # 组合链接标题和正文内容
print strTxtOK
f.write(strTitle + "\n\n\n" + strTxtOK)# 全部分析完成后,写入文件
f.close()#关闭文件
文章 代码效果有限,请在使用前进行适当修改。 查看全部
抓取网页新闻(Python爬虫用Python语言编写的python爬虫实现方法一文)
Python爬虫学习,自动抓取163新闻的Python爬虫源码。这是一篇用Python编写的自动抓取网易新闻的Python爬虫的文章。
Python爬虫的爬取思路是:
(1) 通过分析目标新闻网址,分析以
(2)获取每个链接的内容,整理合并成准备好的.txt文本,以便查看新闻。
不过需要注意的是,由于今天的考题,网易新闻的格式不是很统一,会有一些缺失的部分。请原谅我。也希望有能力的朋友帮忙改进一下。
自动抓取163新闻的Python爬虫源码如下:
#coding:utf-8
import re, urllib
strTitle = ""
strTxtTmp = ""
strTxtOK = ""
f = open("163News.txt", "w+")
m = re.findall(r"news\.163\.com/\d.+?",urllib.urlopen("http://www.163.com";).read(),re.M)
#www.iplaypy.com
for i in m:
testUrl = i.split('"')[0]
if testUrl[-4:-1]=="htm":
strTitle = strTitle + "\n" + i.split('"')[0] + i.split('"')[1] # 合并标题头内容
okUrl = i.split('"')[0] # 重新组合链接
UrlNews = ''
UrlNews = "http://" + okUrl
print UrlNews
"""
查找分析链接里面的正文内容,但是由于 163 新闻的格式不是非常统一,所以只能说大部分可以。
整理去掉部分 html 代码,让文本更易于观看。
"""
n = re.findall(r"<P style=.TEXT-INDENT: 2em.>(.*?)",urllib.urlopen(UrlNews).read(),re.M)
for j in n:
if len(j)0:
j = j.replace(" ","\n")
j = j.replace("<STRONG>","\n_____")
j = j.replace("</STRONG>","_____\n")
strTxtTmp = strTxtTmp + j + "\n"
strTxtTmp = re.sub(r"<a href=(.*?)>", r"", strTxtTmp)
strTxtTmp = re.sub(r"", r"", strTxtTmp)
strTxtOK = strTxtOK + "\n\n\n===============" +
i.split('"')[0] + i.split('"')[1] + "===============\n" + strTxtTmp
strTxtTmp = "" # 组合链接标题和正文内容
print strTxtOK
f.write(strTitle + "\n\n\n" + strTxtOK)# 全部分析完成后,写入文件
f.close()#关闭文件
文章 代码效果有限,请在使用前进行适当修改。
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-13 14:01
你的低价票被“虫子”吃掉了
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身,抢到一张低价回家的机票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了,什么是“爬虫”?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用来批量和自动化采集网站数据的程序,几乎没有需要人工干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录用户可以阅读的文字、图片等信息,还收录一些超链接信息。网络“爬虫”使用这些超链接不断地爬取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价或卖空机票后,可以利用虚假客户的真实身份信息进行抢先预订。此外,许多网络浏览器都推出了自己的抢票插件,以推广订票成功率高的浏览器。
根据抓取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理机构利用“爬虫”技术,不断抓取机票官网信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。因为“爬虫”的效率远远超过正常的人工操作,通过正常的操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,以此类推,直到真正找到并出售客源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用“爬虫”抢票、提价提供了便利。这种的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,但并没有产生任何消耗。这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。大量“爬虫”的爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,会对机票产生负面影响用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则判定该访问为恶意“爬虫”,“爬虫” IP被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,访问可疑IP时,返回验证页面,要求访问者填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,尚无明确规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界共同的道德规范,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也必须加强对账期的管理,不给“爬虫”提供抢票机会。 查看全部
抓取网页新闻(你的低价机票被“虫子”吃了(组图))
你的低价票被“虫子”吃掉了
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身,抢到一张低价回家的机票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了,什么是“爬虫”?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用来批量和自动化采集网站数据的程序,几乎没有需要人工干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。网页不仅收录用户可以阅读的文字、图片等信息,还收录一些超链接信息。网络“爬虫”使用这些超链接不断地爬取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价或卖空机票后,可以利用虚假客户的真实身份信息进行抢先预订。此外,许多网络浏览器都推出了自己的抢票插件,以推广订票成功率高的浏览器。
根据抓取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理机构利用“爬虫”技术,不断抓取机票官网信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。因为“爬虫”的效率远远超过正常的人工操作,通过正常的操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,以此类推,直到真正找到并出售客源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用“爬虫”抢票、提价提供了便利。这种的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,但并没有产生任何消耗。这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。大量“爬虫”的爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,会对机票产生负面影响用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则判定该访问为恶意“爬虫”,“爬虫” IP被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,访问可疑IP时,返回验证页面,要求访问者填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,尚无明确规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界共同的道德规范,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也必须加强对账期的管理,不给“爬虫”提供抢票机会。
抓取网页新闻( 本发明涉及一种基于Ajax的新闻网页动态数据的抓取方法及系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-09 09:10
本发明涉及一种基于Ajax的新闻网页动态数据的抓取方法及系统)
本发明涉及一种基于Ajax的新闻网页动态数据抓取方法及系统。
背景技术:
目前,新闻网站的信息具有类别多、更新频率快、多平台发布的特点,数据检索方式也非常灵活。很多新闻网站页面使用ajax来调用数据,这样通过一个数据源,就可以在不同的平台上进行解析。例如,PC 网页和移动网页可以通过不同的模板共享数据请求。呈现不同的排版风格。
在采集爬取网站新闻数据时,会发现很多网站数据是通过ajax获取的动态内容,并没有固定的静态模板。获取数据的 JavaScript 脚本程序往往在整个页面的 DOM 结构加载完毕后执行。如果整个网页的DOM结构还没有加载完,那么网络爬虫在访问这个地方时就得不到数据内容,大大降低了网络数据的效率和质量采集。
如果需要获取通过ajax请求动态加载的数据,则需要分析网站的请求的数据源地址。Ajax调用的数据格式多为JSON、JSONP、XML或Inc。经过分析,不同的网站使用不同的网络技术,所以调用Ajax请求时采用的方案也有很大差异,数据源存储格式也是多种多样的。
通过对现有技术的分析发现,目前还没有统一的自动化的Ajax数据源分析方法,现有的方法不能解决Ajax一次性获取动态内容的所有问题。
首先,大部分的实现方法都是通过JavaScript脚本中的特征值进行检索,从而进一步猜测和推断Ajax请求的内容。但是,这并不能准确地找出您要采集 的目标数据。目前一个页面很可能收录多个ajax请求,有的是用户信息认证请求,有的是订阅信息的返回数据,还有的是广告推送信息。这些信息混杂在一起,仅通过脚本代码中的特征值很难区分哪些数据源需要采集。另外,对脚本代码特征值的分析也仅限于JavaScript代码未加密的情况。如今,很多网站出于安全性和访问效率的要求,可能会合并多个JavaScript脚本文件,然后对其进行加密。它会使现有的特征值消失。
其次,Ajax 调用方式本身会存在跨域问题,这是其自身独有的安全机制。也就是说,如果您不在同一个域名下,您仍然无法使用脚本语言成功执行请求并返回数据。在处理这样的调用方式时,由于没有统一域名下的网络环境,很难自动完成Ajax触发请求。也有一些网站在他们的程序中有反爬虫程序。如果被频繁访问,二维码等内容会阻止新闻数据的继续采集。
最后,即使找到了 Ajax 请求的数据源,也会出现格式和编码不匹配的情况。例如,JAVA 语言生成的 JSON 数据不能直接用 PHP 语言处理。一些返回的数据在 JSON 格式本身中会有英文双引号和符号冲突。还有一些请求使用了JSONP请求方式,即带有请求头的JSON格式。
技术实现要素:
本发明的目的是为了解决上述问题,提供一种基于Ajax的新闻网页动态数据捕获方法及系统,其侧重于数据源的策略分析,针对不同情况采用定制化的解决方案。
为实现上述目的,本发明采用以下技术方案:
基于Ajax的新闻网页动态数据捕获方法包括以下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ; 否则,会将数据作为字符串处理;完成后,转到步骤(106);
Step(106):遍历数据对象或数组类型的输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址。
重定向地址是指最终重定向的URL地址。
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
所述步骤(101))对新闻网页内容库进行爬取的编码方式包括:UTF-8编码或GBK编码;
本步骤(102))的浏览器开发工具包括:谷歌Chrome开发工具。
在步骤(103)中,如果Ajax请求的数据源中存在特殊字符或乱码,则批量替换特殊字符或乱码,转换为可处理的字符。
特殊字符包括斜线、反斜线、冒号、星号、问号、引号、大于号、小于号或可能影响 JSON 格式的竖线符号。
可以处理的字符有中文引号、中文逗号、中文冒号等。
步骤(103):如果编码方式不同,则统一编码方式,统一采用UTF-8的编码方式。
步骤(102)和步骤(103))之间的步骤如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方式模拟传入页面,通过主机获取请求数据地址;
步骤(1020)中,通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决跨域请求的问题未经许可不得获取数据。
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据。
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源。
在步骤(104)中,列表页面的后台语言包括JAVA、C++、PHP。
步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
step(1042) JSONP 是JSON格式的一种使用方式,通常用于跨域调用。因为要对请求进行身份识别,通常会在请求头中收录一个回调参数,包裹带引号半角括号的JSON内容,JSON格式是带请求头的JSON格式,但是在JSON格式解析中需要去掉,成为标准的JSON格式,基于以上原因,有必要返回 Remove 请求标头和括号的内容。
步骤(1043): 因为有些特殊字符会影响格式规范,有些特殊字符无法识别,所以在封装数据之前,必须对这些特殊字符进行处理,即批量替换。空字符。
步骤 (105):
如果步骤(104)中解析的数据不是键值对类型,则将步骤(104)中解析的数据封装成数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
步骤 (105) 将数据视为字符串:
使用PHP语言的字符串切分函数对字符串的特征值进行切分,并使用字符串拼接函数将字符串的特征值组合起来,最终形成规范格式的数据;
解析出来的数据是一组新闻数据,包括多条新闻数据,特征值指的是步骤(104)为每条新闻数据之间的分隔符。例如JSON格式使用半角逗号分隔引文。
如果不是逗号分割,则分析数据找到数据单元的分割符号进行处理,并将分割符号更新到特征值库中。需要不断积累特征值来提高对各类数据特征值分隔符的识别能力。
步骤(106)相当于通过解析需要爬取的新闻列表页面的请求数据源,在自己的服务器上重新恢复新闻网页。因为这个新闻网页不是Ajax调用的,而是在你自己的服务器中,不存在跨域问题或者网页的DOM结构加载后执行请求数据的脚本程序的问题,网络爬虫可以执行采集。
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
一个基于Ajax的新闻网页动态数据采集系统,包括:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101))的编码方式一致。如果不一致,则对数据源进行编码转换,然后进行步骤(104);如果一致,则直接进行步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,成功则直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。
本发明的有益效果:
该方案可以解决Ajax动态生成内容等多种复杂情况的采集问题,包括跨域调用和加密脚本数据源。此外,该方案不仅适用于各种复杂网络新闻的采集,也适用于微信数据的采集和处理。
图纸说明
图1是本发明方法的流程图;
图2是本发明的功能框图。
详细方法
下面结合附图和实施例对本发明作进一步说明。
如图1所示,首先需要通过开发者工具的网络请求检测的XHR(XMLHttpRequests)和JavaScript来监控数据源地址。通过获取数据源地址来判断ajax请求的方式。
如果是可以直接解析的JSON格式,则直接进行数据封装过程,但在实际情况下会遇到以下问题:
情况一:如果是JSONP格式,需要通过请求头过滤器过滤掉请求头;
情况二:如果返回格式有乱码,需要使用转码处理模块进行转码处理;
案例三:如果出现中英文单双引号使用不规范、返回格式乱码等问题,需要通过特殊字符过滤器进行过滤;
情况四:如果是跨域请求,则需要通过PHP的cURL方法模拟传入的页面和主机,获取请求地址的返回数据。
情况五:如果请求方式为POST请求,则必须使用php后台语言的http模块来模拟POST请求
情况六:Ajax动态生成内容的网页如果使用了一些反蜘蛛技术,也可能导致数据内容不可用。需要 PHP 的 CURL 来伪造访问页面。
经过一系列的处理,数据仍然无法进行转换和封装,这意味着返回数据的格式与后台语言的格式不匹配。只能将返回的数据作为字符串处理,通过特征值对数据进行分割组合,形成具有标准化格式的数据。
关于特殊字符过滤和特征值数据库的建立,除了基本的常规过滤外,还需要在实践中积累和补充。在数据抓取的过程中,有一些链接是动态链接或者跳转链接。这些链接可能暂时存在,需要通过解析器的功能进行预加载,生成的静态链接输出到列表页面当中。
这些存储格式的结构可以用后台语言进行分析,封装为对象或集合类型,然后遍历输出为列表,存储到服务器上的某个地址。这样就可以继续使用网络爬虫对生成的列表地址进行采集,也可以直接导入数据采集的数据库中
Ajax抓取内容的主要结构如图2所示。
采集器负责采集站点数据和分析后生成的新闻列表页面,针对不同情况选择采集方案(上述情况一到情况六). 这是基于在不同情况下,采集更有利于对不同类型的数据进行更加精细化的采集,大大提高了爬虫采集数据的效率和准确率。
数据过滤主要是根据实际操作中遇到的不同情况统一格式的过程,包括上述数据字符集的编码转换、特殊符号的过滤、字符串的标准化等。
解析器负责对站点访问的数据源进行处理,将JSON、XML等格式解析为可存储和读取的数据库格式。聚合数据的工作主要是通过分析数据地址的数据结构。
数据封装模块负责将解析后的数据封装成对象,通过程序遍历数据生成列表页面。
以上虽然结合附图对本发明的具体实施例进行了说明,但并不用于限制本发明的保护范围。本领域技术人员应当理解,基于本发明的技术方案,本领域技术人员不需要做出创造性的努力。可以做出的各种修改或变化,仍在本发明的保护范围内。 查看全部
抓取网页新闻(
本发明涉及一种基于Ajax的新闻网页动态数据的抓取方法及系统)
本发明涉及一种基于Ajax的新闻网页动态数据抓取方法及系统。
背景技术:
目前,新闻网站的信息具有类别多、更新频率快、多平台发布的特点,数据检索方式也非常灵活。很多新闻网站页面使用ajax来调用数据,这样通过一个数据源,就可以在不同的平台上进行解析。例如,PC 网页和移动网页可以通过不同的模板共享数据请求。呈现不同的排版风格。
在采集爬取网站新闻数据时,会发现很多网站数据是通过ajax获取的动态内容,并没有固定的静态模板。获取数据的 JavaScript 脚本程序往往在整个页面的 DOM 结构加载完毕后执行。如果整个网页的DOM结构还没有加载完,那么网络爬虫在访问这个地方时就得不到数据内容,大大降低了网络数据的效率和质量采集。
如果需要获取通过ajax请求动态加载的数据,则需要分析网站的请求的数据源地址。Ajax调用的数据格式多为JSON、JSONP、XML或Inc。经过分析,不同的网站使用不同的网络技术,所以调用Ajax请求时采用的方案也有很大差异,数据源存储格式也是多种多样的。
通过对现有技术的分析发现,目前还没有统一的自动化的Ajax数据源分析方法,现有的方法不能解决Ajax一次性获取动态内容的所有问题。
首先,大部分的实现方法都是通过JavaScript脚本中的特征值进行检索,从而进一步猜测和推断Ajax请求的内容。但是,这并不能准确地找出您要采集 的目标数据。目前一个页面很可能收录多个ajax请求,有的是用户信息认证请求,有的是订阅信息的返回数据,还有的是广告推送信息。这些信息混杂在一起,仅通过脚本代码中的特征值很难区分哪些数据源需要采集。另外,对脚本代码特征值的分析也仅限于JavaScript代码未加密的情况。如今,很多网站出于安全性和访问效率的要求,可能会合并多个JavaScript脚本文件,然后对其进行加密。它会使现有的特征值消失。
其次,Ajax 调用方式本身会存在跨域问题,这是其自身独有的安全机制。也就是说,如果您不在同一个域名下,您仍然无法使用脚本语言成功执行请求并返回数据。在处理这样的调用方式时,由于没有统一域名下的网络环境,很难自动完成Ajax触发请求。也有一些网站在他们的程序中有反爬虫程序。如果被频繁访问,二维码等内容会阻止新闻数据的继续采集。
最后,即使找到了 Ajax 请求的数据源,也会出现格式和编码不匹配的情况。例如,JAVA 语言生成的 JSON 数据不能直接用 PHP 语言处理。一些返回的数据在 JSON 格式本身中会有英文双引号和符号冲突。还有一些请求使用了JSONP请求方式,即带有请求头的JSON格式。
技术实现要素:
本发明的目的是为了解决上述问题,提供一种基于Ajax的新闻网页动态数据捕获方法及系统,其侧重于数据源的策略分析,针对不同情况采用定制化的解决方案。
为实现上述目的,本发明采用以下技术方案:
基于Ajax的新闻网页动态数据捕获方法包括以下步骤:
步骤(101):建立新闻网页抓取内容库,设置新闻网页抓取内容库的编码方式;获取待抓取新闻网页的新闻列表页面的URL地址;
步骤(102):访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具找到Ajax请求的数据源;如果没有,则结束;
步骤(103):判断Ajax请求的数据源是否与步骤(101))的编码方式一致,如果不一致,则对数据源进行编码转换,然后进行步骤(104); 如果一致,则直接进行步骤(104);
步骤(104):解析数据格式:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
步骤(105):将步骤(104)中解析的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进行步骤(106) ; 否则,会将数据作为字符串处理;完成后,转到步骤(106);
Step(106):遍历数据对象或数组类型的输出列表;
Step (107): 使用网络爬虫采集 step (106)获取输出列表;
步骤(108):将来自采集的数据存入数据库。
步骤(101) URL地址包括临时URL地址、重定向地址和添加时间戳参数或签名参数后访问的URL地址。
重定向地址是指最终重定向的URL地址。
步骤(101),新闻网页抓取内容库的字段包括:新闻标题、新闻发布时间、新闻抓取时间、新闻来源、新闻内容;
所述步骤(101))对新闻网页内容库进行爬取的编码方式包括:UTF-8编码或GBK编码;
本步骤(102))的浏览器开发工具包括:谷歌Chrome开发工具。
在步骤(103)中,如果Ajax请求的数据源中存在特殊字符或乱码,则批量替换特殊字符或乱码,转换为可处理的字符。
特殊字符包括斜线、反斜线、冒号、星号、问号、引号、大于号、小于号或可能影响 JSON 格式的竖线符号。
可以处理的字符有中文引号、中文逗号、中文冒号等。
步骤(103):如果编码方式不同,则统一编码方式,统一采用UTF-8的编码方式。
步骤(102)和步骤(103))之间的步骤如下:
步骤(1020):如果Ajax请求是跨域请求,通过PHP的CURL方式模拟传入页面,通过主机获取请求数据地址;
步骤(1020)中,通过PHP函数修改Referer模拟域名下的请求,可以得到请求数据地址返回的结果,从而解决跨域请求的问题未经许可不得获取数据。
步骤(1021):如果Ajax请求是POST请求,使用PHP语言http_build_query函数模拟HTTP POST请求,获取POST请求返回的数据。
步骤(1022):如果获取不到数据内容,则利用PHP的CURL伪造传入页面访问Ajax请求的数据源。
在步骤(104)中,列表页面的后台语言包括JAVA、C++、PHP。
步骤(104)如下:
步骤(1041):如果数据是JSON格式,直接进入步骤(105);
步骤(1042):如果数据是JSONP格式,则进行过滤处理;过滤处理是去除JSONP格式数据的请求头和括号,然后进行步骤(105)@ >;
步骤(1043):如果返回的内容中存在中英文单双引号使用不规范的问题,通过PHP语言的字符替换功能过滤,将特殊字符替换为空字符。
step(1042) JSONP 是JSON格式的一种使用方式,通常用于跨域调用。因为要对请求进行身份识别,通常会在请求头中收录一个回调参数,包裹带引号半角括号的JSON内容,JSON格式是带请求头的JSON格式,但是在JSON格式解析中需要去掉,成为标准的JSON格式,基于以上原因,有必要返回 Remove 请求标头和括号的内容。
步骤(1043): 因为有些特殊字符会影响格式规范,有些特殊字符无法识别,所以在封装数据之前,必须对这些特殊字符进行处理,即批量替换。空字符。
步骤 (105):
如果步骤(104)中解析的数据不是键值对类型,则将步骤(104)中解析的数据封装成数据对象,
如果步骤(104))解析的数据为键值对类型,则将步骤(104))解析的数据转换为数组类型。
步骤 (105) 将数据视为字符串:
使用PHP语言的字符串切分函数对字符串的特征值进行切分,并使用字符串拼接函数将字符串的特征值组合起来,最终形成规范格式的数据;
解析出来的数据是一组新闻数据,包括多条新闻数据,特征值指的是步骤(104)为每条新闻数据之间的分隔符。例如JSON格式使用半角逗号分隔引文。
如果不是逗号分割,则分析数据找到数据单元的分割符号进行处理,并将分割符号更新到特征值库中。需要不断积累特征值来提高对各类数据特征值分隔符的识别能力。
步骤(106)相当于通过解析需要爬取的新闻列表页面的请求数据源,在自己的服务器上重新恢复新闻网页。因为这个新闻网页不是Ajax调用的,而是在你自己的服务器中,不存在跨域问题或者网页的DOM结构加载后执行请求数据的脚本程序的问题,网络爬虫可以执行采集。
步骤(106))的输出列表包括:新闻标题、新闻发布时间、新闻爬取时间、新闻来源、新闻内容、新闻链接。
一个基于Ajax的新闻网页动态数据采集系统,包括:
建库模块:建立新闻网络爬取内容库,设置新闻网络爬取内容库的编码方式;获取要爬取的新闻网页的新闻列表页的URL地址;
访问模块:访问要获取的新闻页面的新闻列表页面的URL地址,使用浏览器开发工具判断新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具Source找到Ajax请求的数据;如果没有,结束;
判断模块:判断Ajax请求的数据源是否与步骤(101))的编码方式一致。如果不一致,则对数据源进行编码转换,然后进行步骤(104);如果一致,则直接进行步骤(104);
解析数据格式模块:将数据源的格式解析为新闻列表页面后台语言处理的对象格式或数组格式;
封装模块:将解析后的数据封装成对象或数组类型;判断是否封装成功,成功则直接进入输出模块;否则,将数据作为字符串处理;完成后进入输出模块;
输出模块:遍历数据对象或数组类型的输出列表;使用网络爬虫获取的输出列表采集;将采集收到的数据存入数据库。
本发明的有益效果:
该方案可以解决Ajax动态生成内容等多种复杂情况的采集问题,包括跨域调用和加密脚本数据源。此外,该方案不仅适用于各种复杂网络新闻的采集,也适用于微信数据的采集和处理。
图纸说明
图1是本发明方法的流程图;
图2是本发明的功能框图。
详细方法
下面结合附图和实施例对本发明作进一步说明。
如图1所示,首先需要通过开发者工具的网络请求检测的XHR(XMLHttpRequests)和JavaScript来监控数据源地址。通过获取数据源地址来判断ajax请求的方式。
如果是可以直接解析的JSON格式,则直接进行数据封装过程,但在实际情况下会遇到以下问题:
情况一:如果是JSONP格式,需要通过请求头过滤器过滤掉请求头;
情况二:如果返回格式有乱码,需要使用转码处理模块进行转码处理;
案例三:如果出现中英文单双引号使用不规范、返回格式乱码等问题,需要通过特殊字符过滤器进行过滤;
情况四:如果是跨域请求,则需要通过PHP的cURL方法模拟传入的页面和主机,获取请求地址的返回数据。
情况五:如果请求方式为POST请求,则必须使用php后台语言的http模块来模拟POST请求
情况六:Ajax动态生成内容的网页如果使用了一些反蜘蛛技术,也可能导致数据内容不可用。需要 PHP 的 CURL 来伪造访问页面。
经过一系列的处理,数据仍然无法进行转换和封装,这意味着返回数据的格式与后台语言的格式不匹配。只能将返回的数据作为字符串处理,通过特征值对数据进行分割组合,形成具有标准化格式的数据。
关于特殊字符过滤和特征值数据库的建立,除了基本的常规过滤外,还需要在实践中积累和补充。在数据抓取的过程中,有一些链接是动态链接或者跳转链接。这些链接可能暂时存在,需要通过解析器的功能进行预加载,生成的静态链接输出到列表页面当中。
这些存储格式的结构可以用后台语言进行分析,封装为对象或集合类型,然后遍历输出为列表,存储到服务器上的某个地址。这样就可以继续使用网络爬虫对生成的列表地址进行采集,也可以直接导入数据采集的数据库中
Ajax抓取内容的主要结构如图2所示。
采集器负责采集站点数据和分析后生成的新闻列表页面,针对不同情况选择采集方案(上述情况一到情况六). 这是基于在不同情况下,采集更有利于对不同类型的数据进行更加精细化的采集,大大提高了爬虫采集数据的效率和准确率。
数据过滤主要是根据实际操作中遇到的不同情况统一格式的过程,包括上述数据字符集的编码转换、特殊符号的过滤、字符串的标准化等。
解析器负责对站点访问的数据源进行处理,将JSON、XML等格式解析为可存储和读取的数据库格式。聚合数据的工作主要是通过分析数据地址的数据结构。
数据封装模块负责将解析后的数据封装成对象,通过程序遍历数据生成列表页面。
以上虽然结合附图对本发明的具体实施例进行了说明,但并不用于限制本发明的保护范围。本领域技术人员应当理解,基于本发明的技术方案,本领域技术人员不需要做出创造性的努力。可以做出的各种修改或变化,仍在本发明的保护范围内。
抓取网页新闻(大数据时代已然到来,抓取网页数据成为科研重要手段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-12-09 09:08
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来。抓取网页数据已成为竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
: 请求没有初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送,正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值是一个集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。 查看全部
抓取网页新闻(大数据时代已然到来,抓取网页数据成为科研重要手段)
网页数据爬取是指从互联网上获取数据,并将获取的非结构化数据转化为结构化数据,最终可以将数据存储在本地计算机或数据库中的一种技术。
目前,全球网络数据以每年40%左右的速度增长。IDC(互联网数据中心)报告显示,2013年全球数据4.4ZB。到2020年,全球数据总量将达到40ZB。大数据时代已经到来。抓取网页数据已成为竞争对手分析、业务数据挖掘和科学研究的重要手段。
我们在做数据分析的时候,会发现大部分的参考数据都是从网上获取的。然而,互联网上的原创数据往往不尽如人意,难以满足我们的个性化需求。因此,我们需要根据实际情况有针对性地抓取网页数据。
网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
使用 CreateObject("internetexplorer.application")
.可见 = 真
.导航“怎么了”
'关闭页面
'。退出
结束于
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible是可见性,是指网页操作时是否会看到网页。熟练之后可以设置为False,这样不仅可以让程序在运行时有一种神秘感(其实并没有),还能稍微加快运行速度。
但是需要注意的一点是,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等到网页完全加载后才能开始抓取网页数据。这次我们使用:(从这里开始,所有的代码都需要写在With代码块中)
而 .ReadyState 4 或 .Busy
事件
温德
Busy是网页的繁忙状态,ReadyState是HTTP的五种就绪状态,对应如下:
: 请求没有初始化(open() 还没有被调用)。
1:请求已经建立,但是还没有发送(send()没有被调用)。
2:请求已发送,正在处理中(通常现在可以从响应中获取内容头)。
3:请求正在处理中;通常响应中有部分数据可用,但服务器还没有完成响应的生成。
4:响应完成;您可以获取并使用服务器的响应。
2、获取信息
我们先爬取网页数据,然后过滤掉有用的部分,然后慢慢添加条件爬取。
设置 dmt = .Document
对于 i = 0 到 dmt.all.Length-1
设置 htMent = dmt.all(i)
使用 ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
结束于
接下来我
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
getElementById("IDName"):返回第一个带有IDName的标签 getElementsByName("a"):返回所有标签,返回值是一个集合 getElementsByClassName("css"):返回所有样式名称为css的标签,返回值是一个集合。
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。
抓取网页新闻(Web·简介())
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-12-09 09:07
栏目:网络·
介绍本文文章主要介绍使用BeautifulSoup抓取新浪网新闻内容及相关经验技巧。文章约3967字,浏览量314,点赞4,值得参考!
第一次写小爬虫。Python确实很强大。二十行代码抓取内容并将其存储为 txt 文本。
直接编码
#coding = ‘utf-8‘
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = ‘utf-8‘
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select(‘.news-item‘)
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, ‘w‘)
for element in elements:
if len(element.select(‘h2‘)) > 0:
f.write(element.select(‘.time‘)[0].text)
f.write(element.select(‘h2‘)[0].text)
f.write(element.select(‘a‘)[0][‘href‘])
f.write(‘\n\n‘)
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为我第一次做的这个小爬虫有一个非常简单单一的功能,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储 查看全部
抓取网页新闻(Web·简介())
栏目:网络·
介绍本文文章主要介绍使用BeautifulSoup抓取新浪网新闻内容及相关经验技巧。文章约3967字,浏览量314,点赞4,值得参考!
第一次写小爬虫。Python确实很强大。二十行代码抓取内容并将其存储为 txt 文本。
直接编码
#coding = ‘utf-8‘
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = ‘utf-8‘
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select(‘.news-item‘)
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, ‘w‘)
for element in elements:
if len(element.select(‘h2‘)) > 0:
f.write(element.select(‘.time‘)[0].text)
f.write(element.select(‘h2‘)[0].text)
f.write(element.select(‘a‘)[0][‘href‘])
f.write(‘\n\n‘)
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为我第一次做的这个小爬虫有一个非常简单单一的功能,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储
抓取网页新闻(一周怎么去爬取新浪网和每经网的上市公司新闻数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-08 17:09
)
在过去的一周里,我一直在深入研究如何使用新闻数据进行量化投资。在正式进行文本挖掘和制定策略之前,当然要先准备好数据。“网络爬虫”和“数据爬虫”这两个词已经很臭了,说起来不难,但要做到精准并不容易。如果忽略数据采集的重置价格,数据将永远存在。只要爬到的网站服务器不删除数据,就会一直请求数据。但如果你只是认为自己很强大,那你就错了。一般服务器都会有反蜘蛛的,但在大多数情况下,反蜘蛛的需求不会影响网站的正常使用,也就是网站的功能要求必须高于反蜘蛛-爬虫要求。
下面我们就来看看如何爬取新浪网和上市公司的新闻数据。
在爬取数据之前,准备好数据库更方便。这里我比较喜欢非关系型数据库,优缺点就不多说了。这里我选择MongoDB。如果习惯了可视化管理数据的方式,当然不能错过 Robomongo。
接下来我们看一下两个网站的页面结构:
单线程爬行速度肯定没有多线程快,但是协程爬行和多线程爬行是不能完全区分的。协程虽然是轻量级线程,但是达到一定数量后,仍然会导致服务器崩溃和报错,比如下面的“cannot watch more than 1024 sockets”问题。解决这个问题的最好方法是限制并发协程的数量。
不考虑多进程,占用大量内存,启动时间特别长。新浪网的响应速度还是有优势的,页面的字节数也很大,这意味着在这种情况下,多线程相对于单线程的优势会更加明显。下面是抓取历史新闻的代码:
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 10:01:40 2018
@author: Damon
"""
import time
import re
import requests
import gevent
from gevent import monkey,pool
monkey.patch_all()
from concurrent import futures
from bs4 import BeautifulSoup
from pymongo import MongoClient
class WebCrawlFromSina(object):
def __init__(self,*arg,**kwarg):
self.totalPages = arg[0] #totalPages
self.Range = arg[1] #Range
self.ThreadsNum = kwarg['ThreadsNum']
self.dbName = kwarg['dbName']
self.colName = kwarg['collectionName']
self.IP = kwarg['IP']
self.PORT = kwarg['PORT']
self.Porb = .5
def countchn(self,string):
pattern = re.compile(u'[\u1100-\uFFFDh]+?')
result = pattern.findall(string)
chnnum = len(result)
possible = chnnum/len(str(string))
return (chnnum, possible)
def getUrlInfo(self,url): #get body text and key words
respond = requests.get(url)
respond.encoding = BeautifulSoup(respond.content, "lxml").original_encoding
bs = BeautifulSoup(respond.text, "lxml")
meta_list = bs.find_all('meta')
span_list = bs.find_all('span')
part = bs.find_all('p')
article = ''
date = ''
summary = ''
keyWords = ''
stockCodeLst = ''
for meta in meta_list:
if 'name' in meta.attrs and meta['name'] == 'description':
summary = meta['content']
elif 'name' in meta.attrs and meta['name'] == 'keywords':
keyWords = meta['content']
if summary != '' and keyWords != '':
break
for span in span_list:
if 'class' in span.attrs:
if span['class'] == ['date'] or span['class'] == ['time-source']:
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
if 'id' in span.attrs and span['id'] == 'pub_date':
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
for span in span_list:
if 'id' in span.attrs and span['id'].find('stock_') != -1:
stockCodeLst += span['id'][8:] + ' '
for paragraph in part:
chnstatus = self.countchn(str(paragraph))
possible = chnstatus[1]
if possible > self.Porb:
article += str(paragraph)
while article.find('') != -1:
string = article[article.find('')+1]
article = article.replace(string,'')
while article.find('\u3000') != -1:
article = article.replace('\u3000','')
article = ' '.join(re.split(' +|\n+', article)).strip()
return summary, keyWords, date, stockCodeLst, article
def GenPagesLst(self):
PageLst = []
k = 1
while k+self.Range-1 = .1:
self.Prob -= .1
summary, keyWords, date, stockCodeLst, article = self.getUrlInfo(a['href'])
self.Prob =.5
if article != '':
data = {'Date' : date,
'Address' : a['href'],
'Title' : a.string,
'Keywords' : keyWords,
'Summary' : summary,
'Article' : article,
'RelevantStock' : stockCodeLst}
self._collection.insert_one(data)
def ConnDB(self):
Conn = MongoClient(self.IP, self.PORT)
db = Conn[self.dbName]
self._collection = db.get_collection(self.colName)
def extractData(self,tag_list):
data = []
for tag in tag_list:
exec(tag + " = self._collection.distinct('" + tag + "')")
exec("data.append(" + tag + ")")
return data
def single_run(self):
page_ranges_lst = self.GenPagesLst()
for ind, page_range in enumerate(page_ranges_lst):
self.CrawlCompanyNews(page_range[0],page_range[1])
def coroutine_run(self):
jobs = []
page_ranges_lst = self.GenPagesLst()
for page_range in page_ranges_lst:
jobs.append(gevent.spawn(self.CrawlCompanyNews,page_range[0],page_range[1]))
gevent.joinall(jobs)
def multi_threads_run(self,**kwarg):
page_ranges_lst = self.GenPagesLst()
print(' Using ' + str(self.ThreadsNum) + ' threads for collecting news ... ')
with futures.ThreadPoolExecutor(max_workers=self.ThreadsNum) as executor:
future_to_url = {executor.submit(self.CrawlCompanyNews,page_range[0],page_range[1]) : \
ind for ind, page_range in enumerate(page_ranges_lst)}
if __name__ == '__main__':
t1 = time.time()
WebCrawl_Obj = WebCrawlFromSina(5000,100,ThreadsNum=4,IP="localhost",PORT=27017,\
dbName="Sina_Stock",collectionName="sina_news_company")
WebCrawl_Obj.coroutine_run() #Obj.single_run() #Obj.multi_threads_run()
t2 = time.time()
print(' running time:', t2 - t1)
因为在爬取的过程中很容易因为对方服务器断了连接停了很久,或者长时间没有响应,但是又不想在重启程序的时候脑补多余的数据,所以启动时,可以先更改数据库中的地址标签数据或日期。获取到数据,然后在插入新的爬取数据之前,先比较是否有重复的Address或Date,然后选择是否插入新的数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:
爬取各个网络的时候出现了一个小分叉,检索页面时出现各种连接中断的问题。即使连接没问题,很多爬取的数据只有标题,没有文字和时间。一开始以为是自己写的代码没被抓到,后来发现是被爬回来了。
所以在代码中,你要记录爬取成功的网址和爬取不成功的网址,然后当然继续爬取,直到革命胜利。这种访问同一个链接的连续循环,很容易锁定对方服务器的IP。如果真的是打嗝,就得换个IP才能玩。因此,最好每个周期睡眠一定次数。当然,如果不麻烦的话,睡一个随机数的间隔(看起来比较做作),然后继续爬行。在这里我只是睡了1秒钟继续攀登。一开始在多线程中调用CrawlCompanyNews函数,然后统计返回一个没有被抓取的url_lst_withoutNews,然后传入ReCrawlNews函数,并且单线程被一一重新捕获。最终捕获如下图所示:
查看全部
抓取网页新闻(一周怎么去爬取新浪网和每经网的上市公司新闻数据
)
在过去的一周里,我一直在深入研究如何使用新闻数据进行量化投资。在正式进行文本挖掘和制定策略之前,当然要先准备好数据。“网络爬虫”和“数据爬虫”这两个词已经很臭了,说起来不难,但要做到精准并不容易。如果忽略数据采集的重置价格,数据将永远存在。只要爬到的网站服务器不删除数据,就会一直请求数据。但如果你只是认为自己很强大,那你就错了。一般服务器都会有反蜘蛛的,但在大多数情况下,反蜘蛛的需求不会影响网站的正常使用,也就是网站的功能要求必须高于反蜘蛛-爬虫要求。
下面我们就来看看如何爬取新浪网和上市公司的新闻数据。
在爬取数据之前,准备好数据库更方便。这里我比较喜欢非关系型数据库,优缺点就不多说了。这里我选择MongoDB。如果习惯了可视化管理数据的方式,当然不能错过 Robomongo。
接下来我们看一下两个网站的页面结构:
单线程爬行速度肯定没有多线程快,但是协程爬行和多线程爬行是不能完全区分的。协程虽然是轻量级线程,但是达到一定数量后,仍然会导致服务器崩溃和报错,比如下面的“cannot watch more than 1024 sockets”问题。解决这个问题的最好方法是限制并发协程的数量。
不考虑多进程,占用大量内存,启动时间特别长。新浪网的响应速度还是有优势的,页面的字节数也很大,这意味着在这种情况下,多线程相对于单线程的优势会更加明显。下面是抓取历史新闻的代码:
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 10:01:40 2018
@author: Damon
"""
import time
import re
import requests
import gevent
from gevent import monkey,pool
monkey.patch_all()
from concurrent import futures
from bs4 import BeautifulSoup
from pymongo import MongoClient
class WebCrawlFromSina(object):
def __init__(self,*arg,**kwarg):
self.totalPages = arg[0] #totalPages
self.Range = arg[1] #Range
self.ThreadsNum = kwarg['ThreadsNum']
self.dbName = kwarg['dbName']
self.colName = kwarg['collectionName']
self.IP = kwarg['IP']
self.PORT = kwarg['PORT']
self.Porb = .5
def countchn(self,string):
pattern = re.compile(u'[\u1100-\uFFFDh]+?')
result = pattern.findall(string)
chnnum = len(result)
possible = chnnum/len(str(string))
return (chnnum, possible)
def getUrlInfo(self,url): #get body text and key words
respond = requests.get(url)
respond.encoding = BeautifulSoup(respond.content, "lxml").original_encoding
bs = BeautifulSoup(respond.text, "lxml")
meta_list = bs.find_all('meta')
span_list = bs.find_all('span')
part = bs.find_all('p')
article = ''
date = ''
summary = ''
keyWords = ''
stockCodeLst = ''
for meta in meta_list:
if 'name' in meta.attrs and meta['name'] == 'description':
summary = meta['content']
elif 'name' in meta.attrs and meta['name'] == 'keywords':
keyWords = meta['content']
if summary != '' and keyWords != '':
break
for span in span_list:
if 'class' in span.attrs:
if span['class'] == ['date'] or span['class'] == ['time-source']:
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
if 'id' in span.attrs and span['id'] == 'pub_date':
string = span.text.split()
for dt in string:
if dt.find('年') != -1:
date += dt.replace('年','-').replace('月','-').replace('日',' ')
elif dt.find(':') != -1:
date += dt
break
for span in span_list:
if 'id' in span.attrs and span['id'].find('stock_') != -1:
stockCodeLst += span['id'][8:] + ' '
for paragraph in part:
chnstatus = self.countchn(str(paragraph))
possible = chnstatus[1]
if possible > self.Porb:
article += str(paragraph)
while article.find('') != -1:
string = article[article.find('')+1]
article = article.replace(string,'')
while article.find('\u3000') != -1:
article = article.replace('\u3000','')
article = ' '.join(re.split(' +|\n+', article)).strip()
return summary, keyWords, date, stockCodeLst, article
def GenPagesLst(self):
PageLst = []
k = 1
while k+self.Range-1 = .1:
self.Prob -= .1
summary, keyWords, date, stockCodeLst, article = self.getUrlInfo(a['href'])
self.Prob =.5
if article != '':
data = {'Date' : date,
'Address' : a['href'],
'Title' : a.string,
'Keywords' : keyWords,
'Summary' : summary,
'Article' : article,
'RelevantStock' : stockCodeLst}
self._collection.insert_one(data)
def ConnDB(self):
Conn = MongoClient(self.IP, self.PORT)
db = Conn[self.dbName]
self._collection = db.get_collection(self.colName)
def extractData(self,tag_list):
data = []
for tag in tag_list:
exec(tag + " = self._collection.distinct('" + tag + "')")
exec("data.append(" + tag + ")")
return data
def single_run(self):
page_ranges_lst = self.GenPagesLst()
for ind, page_range in enumerate(page_ranges_lst):
self.CrawlCompanyNews(page_range[0],page_range[1])
def coroutine_run(self):
jobs = []
page_ranges_lst = self.GenPagesLst()
for page_range in page_ranges_lst:
jobs.append(gevent.spawn(self.CrawlCompanyNews,page_range[0],page_range[1]))
gevent.joinall(jobs)
def multi_threads_run(self,**kwarg):
page_ranges_lst = self.GenPagesLst()
print(' Using ' + str(self.ThreadsNum) + ' threads for collecting news ... ')
with futures.ThreadPoolExecutor(max_workers=self.ThreadsNum) as executor:
future_to_url = {executor.submit(self.CrawlCompanyNews,page_range[0],page_range[1]) : \
ind for ind, page_range in enumerate(page_ranges_lst)}
if __name__ == '__main__':
t1 = time.time()
WebCrawl_Obj = WebCrawlFromSina(5000,100,ThreadsNum=4,IP="localhost",PORT=27017,\
dbName="Sina_Stock",collectionName="sina_news_company")
WebCrawl_Obj.coroutine_run() #Obj.single_run() #Obj.multi_threads_run()
t2 = time.time()
print(' running time:', t2 - t1)
因为在爬取的过程中很容易因为对方服务器断了连接停了很久,或者长时间没有响应,但是又不想在重启程序的时候脑补多余的数据,所以启动时,可以先更改数据库中的地址标签数据或日期。获取到数据,然后在插入新的爬取数据之前,先比较是否有重复的Address或Date,然后选择是否插入新的数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:首先比较是否有重复的地址或日期,然后选择是否插入新数据。运行下图:
爬取各个网络的时候出现了一个小分叉,检索页面时出现各种连接中断的问题。即使连接没问题,很多爬取的数据只有标题,没有文字和时间。一开始以为是自己写的代码没被抓到,后来发现是被爬回来了。
所以在代码中,你要记录爬取成功的网址和爬取不成功的网址,然后当然继续爬取,直到革命胜利。这种访问同一个链接的连续循环,很容易锁定对方服务器的IP。如果真的是打嗝,就得换个IP才能玩。因此,最好每个周期睡眠一定次数。当然,如果不麻烦的话,睡一个随机数的间隔(看起来比较做作),然后继续爬行。在这里我只是睡了1秒钟继续攀登。一开始在多线程中调用CrawlCompanyNews函数,然后统计返回一个没有被抓取的url_lst_withoutNews,然后传入ReCrawlNews函数,并且单线程被一一重新捕获。最终捕获如下图所示:
抓取网页新闻(爬取哪些网站的哪些新闻版块的新闻?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-12-05 15:58
抓取网页新闻的步骤:1.明确项目需求,针对内容分类进行采集;2.根据已有数据进行采集,注意事项:采集不要太频繁,会影响网页的稳定;3.利用java编程技术获取爬虫整体框架架4.利用java技术进行加密、解密等相关处理。1.明确项目需求利用爬虫整体框架,进行新闻专题爬取。想要爬取哪些网站的哪些新闻版块的新闻?类似微博的图文消息?还是微信公众号,图文消息的第三方api?什么类型的页面都采集?2.针对内容分类进行采集首先通过百度地图对网站地址做分析,发现百度地图只爬取偏远地区,每页显示的新闻都为以图文为主的页面,由于该类型的页面比较多,因此选择了google地图进行接口爬取。
第一步:通过抓包分析,找到真正的接口地址,得到logo地址、category的分页id和其他重要的列表页和页面id第二步:爬取json格式的内容,解析出item的格式规则,方便进行下一步进行图文消息的爬取注意事项:爬取时,建议不要对地址进行抓包,防止抓取数据反馈不准确,或者爬取超时。这是利用网站,爬取出新闻页面的网址地址,还存在多个文件,例如ws文件夹,与其他页面无法互相下载,一般我们利用itemset.xml进行文件的加载后,再做抓取!itemset文件夹内存储了所有该文件夹中的内容,当加载过程中,会自动传递给itemset.xml文件,避免出现爬取失败。
这是logo页面,我通过其中的logo_info.xml格式化页面地址,得到logo地址simplenhandand.xml文件所有的方法均用python代码进行实现;并不需要爬虫爬取中的request,爬虫在python爬虫中,是没有中文之间交互的。3.利用java编程技术获取爬虫整体框架架通过分析百度地图获取其分页地址,得到真正的接口地址和链接,一般我们放在某个文件夹中。
正好那天公司的产品经理在学习python爬虫,我就让他配置爬虫时,直接采用python自带的爬虫工具(豆瓣爬虫,腾讯爬虫,头条爬虫等),利用java编程技术实现每个页面获取到网址和每个文件夹中的内容。具体如下:新闻链接通过一个url(;mode=name&extra=values&web_id=0&type=view&pages=1&link_tag=0)获取,分别为:(fornew_text_fieldinjavascript_extension("some_text")),";mode=name&extra=values",";web_id=0",";type=view",";web_id=0","pages=1",";link_tag=0",";link_tag=0","this_id=0","name=","","category=。 查看全部
抓取网页新闻(爬取哪些网站的哪些新闻版块的新闻?(一))
抓取网页新闻的步骤:1.明确项目需求,针对内容分类进行采集;2.根据已有数据进行采集,注意事项:采集不要太频繁,会影响网页的稳定;3.利用java编程技术获取爬虫整体框架架4.利用java技术进行加密、解密等相关处理。1.明确项目需求利用爬虫整体框架,进行新闻专题爬取。想要爬取哪些网站的哪些新闻版块的新闻?类似微博的图文消息?还是微信公众号,图文消息的第三方api?什么类型的页面都采集?2.针对内容分类进行采集首先通过百度地图对网站地址做分析,发现百度地图只爬取偏远地区,每页显示的新闻都为以图文为主的页面,由于该类型的页面比较多,因此选择了google地图进行接口爬取。
第一步:通过抓包分析,找到真正的接口地址,得到logo地址、category的分页id和其他重要的列表页和页面id第二步:爬取json格式的内容,解析出item的格式规则,方便进行下一步进行图文消息的爬取注意事项:爬取时,建议不要对地址进行抓包,防止抓取数据反馈不准确,或者爬取超时。这是利用网站,爬取出新闻页面的网址地址,还存在多个文件,例如ws文件夹,与其他页面无法互相下载,一般我们利用itemset.xml进行文件的加载后,再做抓取!itemset文件夹内存储了所有该文件夹中的内容,当加载过程中,会自动传递给itemset.xml文件,避免出现爬取失败。
这是logo页面,我通过其中的logo_info.xml格式化页面地址,得到logo地址simplenhandand.xml文件所有的方法均用python代码进行实现;并不需要爬虫爬取中的request,爬虫在python爬虫中,是没有中文之间交互的。3.利用java编程技术获取爬虫整体框架架通过分析百度地图获取其分页地址,得到真正的接口地址和链接,一般我们放在某个文件夹中。
正好那天公司的产品经理在学习python爬虫,我就让他配置爬虫时,直接采用python自带的爬虫工具(豆瓣爬虫,腾讯爬虫,头条爬虫等),利用java编程技术实现每个页面获取到网址和每个文件夹中的内容。具体如下:新闻链接通过一个url(;mode=name&extra=values&web_id=0&type=view&pages=1&link_tag=0)获取,分别为:(fornew_text_fieldinjavascript_extension("some_text")),";mode=name&extra=values",";web_id=0",";type=view",";web_id=0","pages=1",";link_tag=0",";link_tag=0","this_id=0","name=","","category=。
抓取网页新闻(#cmt_login时就没有内容了,怎样修改才能将完整的网页抓下来)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-05 12:12
编辑:我抓取的内容,用记事本打开查看htm文件,遇到#cmt_login好像没有内容,如何修改抓取完整的网页...我抓取的内容,用Open记事本查看htm文件,遇到#cmt_login好像没有内容,如何修改捕获完整网页,选择以下一项或多项关键词,搜索相关信息
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页...
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页?
您可以选择以下一个或多个关键词来搜索相关信息。您也可以直接点击“搜索信息”来搜索整个问题。
展开你的全是因为下面的数据是用js脚本ajax加载的,源文件估计找不到了。仅使用支持 ajax 的 采集器。
另外,看到你有几十万,防止腾讯屏蔽你的IP也很重要。访问量大的时候,正常访问的人可能不止一个,很有可能是IP被封了。
如果您有任何问题,我可以帮助您。我有多年web数据采集的经验,你遇到的问题我基本都遇到过。呵呵,希望能帮到你。请问我爬的是腾讯的新闻网页,即使是ajax加载,爬虫应该也能在本地抓取文件,就像你在浏览器中打开一个网页一样,数据不是全部加载好么?
浏览了爬取的网页,想登录的地方没有内容,不登录就可以在浏览器中看到新闻。
我使用 nutch-1.2 来捕获数据并跟进答案。这与登录无关。Ajax加载的爬虫现在功能更强大,会加载这些数据,但是你这样保存的一般只是源代码。里面的Javascript
javascript运行后,数据显示在界面上。所以你用浏览器可以看到,你说的采集器我没用过。我不明白,你搜索数据农场。看,他们正在专业地突破各种反采集措施。我已将其用于采集Asia*Maxun 的产品。ajax有很多,可以做的比较好。你可以参考一下。这个回答是网友推荐的,已经点赞踩了。你对这个答案的评价是什么?评论收起
展开全部,有的需要模拟登录才能爬取。您需要对其进行配置。或者进行二次开发来抓紧。我是二次开发后抓的。喜欢已经不喜欢你对这个答案的评价是什么?评论收起
全部展开,直接下载网页。问一个简单的下载就好了,但是有数百个,我不知道它们在哪里?喜欢已经不喜欢你对这个答案的评价是什么?评论 收起 收起更多答案(1) 推荐给您:1 2 3
当前网址: 查看全部
抓取网页新闻(#cmt_login时就没有内容了,怎样修改才能将完整的网页抓下来)
编辑:我抓取的内容,用记事本打开查看htm文件,遇到#cmt_login好像没有内容,如何修改抓取完整的网页...我抓取的内容,用Open记事本查看htm文件,遇到#cmt_login好像没有内容,如何修改捕获完整网页,选择以下一项或多项关键词,搜索相关信息
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页...
我抓取了内容并用记事本打开它以查看htm文件。遇到#cmt_login的时候好像没有内容。如何修改它以获取完整的网页?
您可以选择以下一个或多个关键词来搜索相关信息。您也可以直接点击“搜索信息”来搜索整个问题。
展开你的全是因为下面的数据是用js脚本ajax加载的,源文件估计找不到了。仅使用支持 ajax 的 采集器。
另外,看到你有几十万,防止腾讯屏蔽你的IP也很重要。访问量大的时候,正常访问的人可能不止一个,很有可能是IP被封了。
如果您有任何问题,我可以帮助您。我有多年web数据采集的经验,你遇到的问题我基本都遇到过。呵呵,希望能帮到你。请问我爬的是腾讯的新闻网页,即使是ajax加载,爬虫应该也能在本地抓取文件,就像你在浏览器中打开一个网页一样,数据不是全部加载好么?
浏览了爬取的网页,想登录的地方没有内容,不登录就可以在浏览器中看到新闻。
我使用 nutch-1.2 来捕获数据并跟进答案。这与登录无关。Ajax加载的爬虫现在功能更强大,会加载这些数据,但是你这样保存的一般只是源代码。里面的Javascript
javascript运行后,数据显示在界面上。所以你用浏览器可以看到,你说的采集器我没用过。我不明白,你搜索数据农场。看,他们正在专业地突破各种反采集措施。我已将其用于采集Asia*Maxun 的产品。ajax有很多,可以做的比较好。你可以参考一下。这个回答是网友推荐的,已经点赞踩了。你对这个答案的评价是什么?评论收起
展开全部,有的需要模拟登录才能爬取。您需要对其进行配置。或者进行二次开发来抓紧。我是二次开发后抓的。喜欢已经不喜欢你对这个答案的评价是什么?评论收起
全部展开,直接下载网页。问一个简单的下载就好了,但是有数百个,我不知道它们在哪里?喜欢已经不喜欢你对这个答案的评价是什么?评论 收起 收起更多答案(1) 推荐给您:1 2 3
当前网址:
抓取网页新闻(CommomCrawlCrawl的开发者开发此工具是因为开发工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-01 22:13
大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。
网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
您不会以侵犯版权的方式重复使用或重新发布数据。
您尊重您要抓取的 网站 的服务条款。
你有一个合理的爬网率。
您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持自己的开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。这意味着,如果您是正在探索数据科学领域的大学生,或者正在寻找下一个感兴趣的话题的研究人员,或者只是一个喜欢揭示规律和寻找趋势的好奇者,您都可以使用此工具而无需担心关于费用或任何其他复杂的财务问题。Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly是另一个了不起的爬虫工具,特别是如果你只需要从网站中提取基本数据,或者你想提取CSV格式的数据,你不想写任何代码来分析它的时候。您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器
网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需较少的清理工作,可以直接进入分析阶段。Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。还可以为ParseHub提供各种链接和一些关键字,几秒钟就可以提取出相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用的 API,可用于使用 Google 搜索进行网络抓取。Scrapingbee 可以通过以下三种方式之一使用: 1. 常规网络爬虫,例如,提取股票价格或客户评论。2. 搜索引擎结果页面通常用于搜索引擎优化或关键字监控。3. 增长黑客,包括提取联系信息或社交媒体信息。Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接: 查看全部
抓取网页新闻(CommomCrawlCrawl的开发者开发此工具是因为开发工具)
大家好,欢迎来到pypyai游乐园!
任何数据科学项目都离不开数据。没有数据就没有“数据科学”。大多数数据科学项目中用于分析和构建机器学习模型的数据都存储在数据库中,但有时数据也来自互联网。
您可以从某个网页采集有关某个产品的数据,或者从社交媒体中发现某种模式,也许是情感分析。无论您为什么采集数据或计划如何使用它,从 Web 采集数据(Web 抓取)都是一项非常繁琐的任务。你需要做一些乏味的工作来实现你的目标。
网页抓取是您作为数据科学家需要掌握的重要技能之一。为了使结果准确且有意义,您需要知道如何查找、采集和清理数据。
网页抓取一直是法律的灰色地带。在我们深入研究数据提取工具之前,我们需要确保您的活动完全合法。2020年,美国法院将全面合法化在互联网上抓取公共数据。换句话说,如果任何人都可以在网上找到数据(例如Wiki文章),那么爬取网页也是合法的。
但是,在执行此操作时,请确保:
您不会以侵犯版权的方式重复使用或重新发布数据。
您尊重您要抓取的 网站 的服务条款。
你有一个合理的爬网率。
您不应该尝试抓取 网站 的非共享内容。
只要您不违反任何这些条款,您的网络抓取活动就是合法的。
如果你使用 Python 构建一个数据科学项目,你可以使用 BeatifulSoup 来采集数据,然后使用 Pandas 来分析它。本文将为您提供 6 款不收录 BeatifulSoup 的网页抓取工具,您可以免费使用它们来采集您下一个项目所需的数据。
公共爬网
Common Crawl 的开发人员开发了这个工具,因为他们相信每个人都应该有机会探索和分析他们周围的世界并发现它的模式。他们坚持自己的开源信念,提供只有大公司和研究机构才能免费获得的高质量数据。这意味着,如果您是正在探索数据科学领域的大学生,或者正在寻找下一个感兴趣的话题的研究人员,或者只是一个喜欢揭示规律和寻找趋势的好奇者,您都可以使用此工具而无需担心关于费用或任何其他复杂的财务问题。Common Crawl 提供原创 Web 数据和用于文本提取的开放数据集。为了方便教育者教授数据分析,它还提供了无需编码的用例和资源。
爬行
网址:
Crawly是另一个了不起的爬虫工具,特别是如果你只需要从网站中提取基本数据,或者你想提取CSV格式的数据,你不想写任何代码来分析它的时候。您需要做的就是输入一个 URL,发送电子邮件地址以提取数据,以及所需的数据格式(在 CSV 或 JSON 之间选择)。然后立即,捕获的数据在您的邮件收件箱中。您可以使用 JSON 格式,然后使用 Pandas 和 Matplotlib 或任何其他编程语言来分析 Python 中的数据。如果您不是程序员,或者刚开始使用数据科学和网络抓取技术,Crawly 是完美的选择,但它有其局限性。它只能提取一组有限的 HTML 标签,包括标题、作者、图像 URL 和发布者。
内容抓取器
网址:
Content Grabber 是我最喜欢的网络抓取工具之一,因为它非常灵活。如果您只想抓取网页而不想指定任何其他参数,则可以使用其简单的 GUI 进行操作。但是 Content Grabber 还可以让您完全控制参数选择。Content Grabber 的优点之一是您可以安排它自动从 Web 抓取信息。众所周知,大多数网页都会定期更新,因此定期提取内容非常有用。它还为提取的数据提供多种格式,从 CSV、JSON 到 SQL Server 或 MySQL。
网管网
Webhose.io 是一种网络抓取工具,可让您从任何在线资源中提取企业级实时数据。Webhose.io 采集的数据结构化,清晰地收录情感和实体识别,可以使用不同的格式,如 XML、RSS 和 JSON。Webhose.io 数据涵盖所有公开的网站。此外,它提供了许多过滤器来优化提取的数据,因此只需较少的清理工作,可以直接进入分析阶段。Webhose.io 的免费版本每月提供 1,000 个 HTTP 请求。付费计划提供更多爬网请求。Webhose.io具有强大的数据提取支持,并提供图像分析、地理定位等多项功能,以及长达10年的历史数据存档。
分析中心
ParseHub 是一个强大的网络抓取工具,任何人都可以免费使用。只需单击一个按钮,即可提供可靠且准确的数据提取。还可以设置爬取时间,及时更新数据。ParseHub 的优势之一是它可以轻松处理复杂的网页。您甚至可以指示它搜索表单、菜单、登录 网站,甚至单击图像或地图以获取更多数据。还可以为ParseHub提供各种链接和一些关键字,几秒钟就可以提取出相关信息。最后,您可以使用 REST API 以 JSON 或 CSV 格式下载提取的数据进行分析。您还可以将采集的数据导出为 Google Sheets 或 Tableau。
刮蜂
我们介绍的最后一个抓取工具是 Scrapingbee。Scrapingbee 提供了一个用于网页抓取的 API,它甚至可以处理最复杂的 Javascript 页面并将它们转换为原创 HTML 供您使用。此外,它还具有专用的 API,可用于使用 Google 搜索进行网络抓取。Scrapingbee 可以通过以下三种方式之一使用: 1. 常规网络爬虫,例如,提取股票价格或客户评论。2. 搜索引擎结果页面通常用于搜索引擎优化或关键字监控。3. 增长黑客,包括提取联系信息或社交媒体信息。Scrapingbee 提供免费计划,其中包括 1000 次限制和无限使用的付费计划。
最后
在数据科学项目工作流程中,为项目采集数据可能是最有趣也最乏味的一步。这项任务可能会非常耗时,如果你在公司工作,甚至作为自由职业者,你都知道时间就是金钱,这总是意味着如果有更有效的方法来做某事,最好用好它。好消息是网络爬行不必太麻烦。您不需要执行它,甚至不需要花费大量时间手动执行它。使用正确的工具可以帮助您节省大量时间、金钱和精力。此外,这些工具可能对分析师或编码背景不足的人有用。当你想选择一个爬取网页的工具时,你需要考虑以下几个因素,比如API集成度和大规模爬取的可扩展性。本文为您提供了一些可用于不同数据采集机制的工具。使用这些工具来确定哪种方法可以为下一个数据采集项目事半功倍。
原文链接:
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-30 16:04
)
我是另一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。正好牛客这周从一个html里找了一段文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间、内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
Bs4需要自己安装。安装方法请参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。
查看全部
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考!
)
我是另一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。正好牛客这周从一个html里找了一段文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间、内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
Bs4需要自己安装。安装方法请参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。
抓取网页新闻(抽取方法研究遥感影像地物信息智能提取方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-29 01:08
摘要:新闻文本信息的提取对于信息的检索、存储和舆情监测具有极其重要的意义。为了实现新闻信息的正确提取,综合考虑了DOM等几种技术
>> 基于统计的网页文本信息提取方法研究。基于C#的网页文本提取方法研究[J]. 网页文本提取方法研究[J]. 网络新闻采访研究。基于树剪枝的网页文本提取方法研究[J]. 图像语义提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. DEM提取方法精度研究[J]. 季节性隐藏信息提取方法研究[J]. 面向对象的遥感图像。信息抽取方法研究 采石场信息抽取的多规则面向对象方法研究 遥感数据处理与异常信息抽取技术方法研究 网站结构分析页面信息抽取方法研究 在线新闻研究煤质在线监测方法研究 Maya 模型信息提取研究FAQ 当前位置:#p=1 通过观察验证,属于同一新闻网站的动态网页的内容布局和样式外观比较相似。同时,同一网站的动态网页的URL相似度也很高。这在web开发和网站管理的效率和便利性方面也是非常合理的。因此,URL 相似度用于新闻页面分类。齐等
[9]在URL相似度的计算中使用了Dice系数,并结合使用统计方法完成了URL相似度的测量。该方法从字符串处理的角度出发,由于URL的格式特性,本文在协议、服务器名、域名相同的情况下,利用新闻URL特性来判断动态网页。具体如下: ①如果新闻网址字符在字符串中,如果路径中收录“pic”、“photo”等图片相关的英文字符串,则说明新闻网址为动态网页。例如:人民网、新华网等网站中的网址中收录这些图片字符串;②如果新闻网址的后缀匹配数字或字母的增量,新闻网页是动态网页,如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,具有很强的格局,不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit
[10] 渲染新闻网页获取HTML源代码,然后使用Jsoup中的DOM对象提取新闻标题、发布时间等信息。例如:提取新闻标题时,先提取标签中的标签内容,然后截取“―”、“_”、“/”等标签(内容常用于将标题和新闻来源分开)作为新闻标题。2.2 动态网页信息提取模块Dywebextract模块接受Pretreatment模块的数据,主要功能是动态网页翻页识别和文本信息提取。对于动态网页翻页识别,采用了两种策略:①如果新闻网页有本地url模式模板(系统在初始化时根据各大新闻网站动态网页url的特点添加url模式)或XPath模板(有效元素路径),翻页自行根据url模式模板(url后缀数字增加或字母减少)或触发点击XPath。如果新闻页面的标题相同,则循环翻页,直到没有捕获到有效页面(出现重复页面或死链接);②如果本地没有对应的url模式模板或XPath,获取HTML中的候选有效元素,然后触发,最后通过触发validity过滤掉有效元素。对于文本信息提取,本文利用了同一新闻门户中动态网页高度相似的结构,采用两种策略: ①如果本地有XPath模式模板,则根据XPath模式模板提取文本信息;②如果不是,则使用基于布局相似度的网页正文内容提取方法
[11] 提取身体信息。XPath模式模板库的管理采用时序管理方式。如果 XPath 模式模板库中的某个 XPath 一周未使用,则该模板将被视为无效的 XPath 并被删除。该模块的算法流程如图3所示,下面重点介绍几个主要环节。
2.2.1 替代有效元素的集合。动态网页收录有效元素。有效元素被触发后,会异步生成动态信息,而静态网页不需要触发有效元素来获取信息。但是,动态网页收录许多触发元素(如按钮、文本框、链接等)。有效元素产生的动态信息是有价值的动态信息,无效元素产生的动态信息是无效信息。例如,触发元素仅更改了网页的字体颜色或其他嘈杂部分。在动态网页中,诸如,等标签所代表的元素可能会导致页面发生变化
[12],从而产生有价值的动态信息,因此该系统将有效元素筛选限制为仅和标签。为了进一步缩小有效元素的搜索范围,提高获取页面信息的效率,需要在搜索有效元素之前确定有效元素的标签集。对于本系统,有效元素是可以点击下一页的元素来获取下一页的文本信息。因此,本文统计了腾讯网站等8个大型新闻门户网站,从这些新闻门户网站中随机抽取了100个新闻网页,发现大部分有效元素的属性值都收录“next”和“对”。", "Next (page)" 等词。一个有效的元素通常绑定到一个有效的事件上,用户点击该元素执行脚本程序或网页跳转以获取更多网页信息,因此其属性值收录JavaScript或URL。对于一个标签,如果没有子标签,则认为它是一个有效标签。综上所述,本系统将属性中收录“next”、“next”等词的标签定义为候选有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本。程序。因此,需要一个工具来模拟用户的点击操作,而HtmlUnit正好可以解决这个模拟问题。HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。本系统采用全检测扫描算法
[13]、点击有效元素集中的所有元素。2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法判断DOM树的相似度。是一种限制匹配算法,利用动态规划计算两棵树的最大匹配节点数,得到两棵树结构的相似度;罗斯特等待
[15] 提出了一种比较页面的方法。该方法首先比较各个模块,为模块定位DOM树结构的特征部分。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个A比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量变化,则认为新获取的网页无效,触发器无效;除此以外,获取的网页被认为是有效的,有效元素XPath存储在XPath模板库中。2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。(1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点和下垂点后面的行块长度为0,保证文本提取结束.根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图,从图4可以看出,内容很多阻止[start=743, end=745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除,所以根据新闻页面对于噪音的特性,增加了第四个约束。
(4)Ystart
3 实验测试
3.1 实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级的主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页。作为实验页面的集合。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理. 对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%为合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的网页数/网页总数×100%
3.2 实验结果 表1为系统网页正文提取准确率和在线文本提取率。其中,每个网站有100个动态网页和静态网页,共计1600个网页。表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。错误的原因是不同主题的设计风格不一样,还有人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响. 对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页和普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模新闻网站新闻正文信息萃取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以对英文网页优化进行深入研究,
参考:
[1]ARIAS J, DESCHACHT K, MOENS M F. 从网页中提取与语言无关的内容[J]. 特温特大学, 2009.
[2]_来源中文社区。一般网页文本提取[EB/OL].[20150425].
[3]陈昭,张冬梅. Web信息抽取技术概述[J].计算机应用研究, 2010, 27 (12):44014405.
[4]王琦,唐世伟,杨冬青,等.基于DOM的网页主题信息自动提取[C]. 中国数据库学术会议,2004:17861792.
[5] GUPTA S、KAISER GE、GRIMM P 等。HTML 文档内容自动提取[J]. 万维网互联网和网络信息系统,2005 年,8 (2): 179224.
[6]REIS D C.使用树编辑距离的自动网络新闻提取[C].万维网国际会议.ACM,2004:502511.
[7] 维埃拉 K、席尔瓦 ASD、平托 N 等。一种快速、鲁棒的网页模板检测和移除方法[C].ACM国际信息与知识管理会议.ACM,2006:258267.
[8] 黄文北,杨静,顾俊忠.基于块的网页正文信息提取算法研究[J]. 计算机应用, 2007, 27 (s1): 2426.
[9]QI X, NIE L, DAVISON B D. 测量相似性以检测合格链接[C].Airweb 2007,第三届网络对抗性信息检索国际研讨会,与 WWW 会议同处,加拿大班夫,2007:495 6.
[10] 张家荣.Java开源项目HtmlUnit在浏览器仿真中的应用[J]. 电子制作, 2015 (8): 79.
[11]杨柳青,李晓东,耿光刚.基于布局相似度的网页正文内容提取研究[J]. 计算机应用研究, 2015 (9): 25812586.
[12] 张耀.面向AJAX脚本网络的网络爬取解析技术研究与实现[D]. 沉阳:东北大学,2012.
[13]MESBAH A, BOZDAG E, DEURSEN A V. Crawling AJAX by inferring user interface state changes[C].第八届网络工程国际会议,Yorktown Heights, New York, Usa.2008: 122134.
[14]何欣,谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与发展, 2007, 44 (z3): 16.
[15] ROEST D, MESBAH A, DEURSEN A V. 回归测试 ajax 应用程序:应对动态[C]。International Conference on Software Testing, Verification and Validation, ICST 2010, Paris, France, 2010: 127136. (Editor: Duneng Steel) 查看全部
抓取网页新闻(抽取方法研究遥感影像地物信息智能提取方法(组图))
摘要:新闻文本信息的提取对于信息的检索、存储和舆情监测具有极其重要的意义。为了实现新闻信息的正确提取,综合考虑了DOM等几种技术
>> 基于统计的网页文本信息提取方法研究。基于C#的网页文本提取方法研究[J]. 网页文本提取方法研究[J]. 网络新闻采访研究。基于树剪枝的网页文本提取方法研究[J]. 图像语义提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. 鹰嘴豆总黄酮提取方法研究[J]. DEM提取方法精度研究[J]. 季节性隐藏信息提取方法研究[J]. 面向对象的遥感图像。信息抽取方法研究 采石场信息抽取的多规则面向对象方法研究 遥感数据处理与异常信息抽取技术方法研究 网站结构分析页面信息抽取方法研究 在线新闻研究煤质在线监测方法研究 Maya 模型信息提取研究FAQ 当前位置:#p=1 通过观察验证,属于同一新闻网站的动态网页的内容布局和样式外观比较相似。同时,同一网站的动态网页的URL相似度也很高。这在web开发和网站管理的效率和便利性方面也是非常合理的。因此,URL 相似度用于新闻页面分类。齐等
[9]在URL相似度的计算中使用了Dice系数,并结合使用统计方法完成了URL相似度的测量。该方法从字符串处理的角度出发,由于URL的格式特性,本文在协议、服务器名、域名相同的情况下,利用新闻URL特性来判断动态网页。具体如下: ①如果新闻网址字符在字符串中,如果路径中收录“pic”、“photo”等图片相关的英文字符串,则说明新闻网址为动态网页。例如:人民网、新华网等网站中的网址中收录这些图片字符串;②如果新闻网址的后缀匹配数字或字母的增量,新闻网页是动态网页,如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,具有很强的格局,不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 如:腾讯、新浪、搜狐、网易、凤凰等网站中的URL后缀,格局非常强,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 比如新浪、搜狐、网易、凤凰等都有很强的格局,数量不断增加。2.1.2 文档对象模型 文档对象模型(DOM)是用于处理 HTML 和 XML 文档的标准应用程序接口(API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit @1.2 文档对象模型 文档对象模型 (DOM) 是用于处理 HTML 和 XML 文档的标准应用程序接口 (API)。它将文档表示为树结构,HTML 标签、属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit 属性或文本被视为树的节点。基于DOM的信息抽取技术利用网页的结构特征,简单高效地从网页中抽取所需的内容。它克服了行分割算法提取新闻标题、发布时间等信息的缺点。所以本文在提取文本信息之前使用了HtmlUnit
[10] 渲染新闻网页获取HTML源代码,然后使用Jsoup中的DOM对象提取新闻标题、发布时间等信息。例如:提取新闻标题时,先提取标签中的标签内容,然后截取“―”、“_”、“/”等标签(内容常用于将标题和新闻来源分开)作为新闻标题。2.2 动态网页信息提取模块Dywebextract模块接受Pretreatment模块的数据,主要功能是动态网页翻页识别和文本信息提取。对于动态网页翻页识别,采用了两种策略:①如果新闻网页有本地url模式模板(系统在初始化时根据各大新闻网站动态网页url的特点添加url模式)或XPath模板(有效元素路径),翻页自行根据url模式模板(url后缀数字增加或字母减少)或触发点击XPath。如果新闻页面的标题相同,则循环翻页,直到没有捕获到有效页面(出现重复页面或死链接);②如果本地没有对应的url模式模板或XPath,获取HTML中的候选有效元素,然后触发,最后通过触发validity过滤掉有效元素。对于文本信息提取,本文利用了同一新闻门户中动态网页高度相似的结构,采用两种策略: ①如果本地有XPath模式模板,则根据XPath模式模板提取文本信息;②如果不是,则使用基于布局相似度的网页正文内容提取方法
[11] 提取身体信息。XPath模式模板库的管理采用时序管理方式。如果 XPath 模式模板库中的某个 XPath 一周未使用,则该模板将被视为无效的 XPath 并被删除。该模块的算法流程如图3所示,下面重点介绍几个主要环节。
2.2.1 替代有效元素的集合。动态网页收录有效元素。有效元素被触发后,会异步生成动态信息,而静态网页不需要触发有效元素来获取信息。但是,动态网页收录许多触发元素(如按钮、文本框、链接等)。有效元素产生的动态信息是有价值的动态信息,无效元素产生的动态信息是无效信息。例如,触发元素仅更改了网页的字体颜色或其他嘈杂部分。在动态网页中,诸如,等标签所代表的元素可能会导致页面发生变化
[12],从而产生有价值的动态信息,因此该系统将有效元素筛选限制为仅和标签。为了进一步缩小有效元素的搜索范围,提高获取页面信息的效率,需要在搜索有效元素之前确定有效元素的标签集。对于本系统,有效元素是可以点击下一页的元素来获取下一页的文本信息。因此,本文统计了腾讯网站等8个大型新闻门户网站,从这些新闻门户网站中随机抽取了100个新闻网页,发现大部分有效元素的属性值都收录“next”和“对”。", "Next (page)" 等词。一个有效的元素通常绑定到一个有效的事件上,用户点击该元素执行脚本程序或网页跳转以获取更多网页信息,因此其属性值收录JavaScript或URL。对于一个标签,如果没有子标签,则认为它是一个有效标签。综上所述,本系统将属性中收录“next”、“next”等词的标签定义为候选有效标签。
2.2.2 触发元素动态网页采用异步加载技术。当用户点击触发元素时,会触发绑定到有效元素的特定事件,浏览器会执行该事件对应的JavaScript动态脚本。程序。因此,需要一个工具来模拟用户的点击操作,而HtmlUnit正好可以解决这个模拟问题。HtmlUnit是一个开源的Java页面分析工具,使用Rhinojs引擎,可以模拟浏览器操作,运行速度非常快。本系统采用全检测扫描算法
[13]、点击有效元素集中的所有元素。2.2.3 触发有效性判断 当动态网页触发有效元素时,会改变DOM树的结构。触发器有效性判断也可以表示为DOM树结构的变化,因此可以比较DOM树结构的相似度作为触发器有效性的指标。由于每次获取下一页,只有网页中的图片和文字信息发生变化,其他杂音、链接等部分基本不变。因此,在判断DOM树的相似度之前,通过正则表达式过滤中文文本信息。何欣等
[14] 使用简单的树匹配算法判断DOM树的相似度。是一种限制匹配算法,利用动态规划计算两棵树的最大匹配节点数,得到两棵树结构的相似度;罗斯特等待
[15] 提出了一种比较页面的方法。该方法首先比较各个模块,为模块定位DOM树结构的特征部分。如果确定内容相同,则过滤掉部分信息,将剩余的内容传递给下一个A比较模块,否则可以直接确定两个DOM树不相似。以上两种方法更多是基于DOM树结构,考虑到新闻页面的有效信息在中文文本中。在页面标题的情况下,系统将新获取的网页中文信息与触发前的网页中文信息进行比较。如果只有少量变化,则认为新获取的网页无效,触发器无效;除此以外,获取的网页被认为是有效的,有效元素XPath存储在XPath模板库中。2.3 新闻常用网页信息提取模块新闻常用网页信息提取模块的目标是提取新闻常用网页的正文信息。一般新闻网页的正文结构通常比较紧凑,网页中的图片较少,正文代码中的大部分文字占一行,超链接长度所占的百分比也不大。并且由于行块分布算法对主题网页通用性好、准确率高,所以采用行块分布算法。线块分析算法的思想由哈尔滨工业大学信息检索中心陈欣等人提出。网页文本块的起始行块号Xstart和结束行块号Xend的确定必须同时满足以下条件,这里定义Y(X)为带有行号的行块的长度X 为轴。(1)Ystart> Y(Xt),其中Y(Xt)为线块长度的第一个膨胀点,膨胀点的线块长度必须大于预先定义的阈值。
(2)Y(Xn)不等于0(其中n属于[start+1,start+n]),紧接膨胀点的行块长度不能为0,以消除噪声。
(3)Y(Xm)=0(其中m属于[end,end+1]),下垂点和下垂点后面的行块长度为0,保证文本提取结束.根据线块分布算法的思想,本文利用Java中的JFreeChart绘制工具,得到如图4所示的线块分布函数折线图,从图4可以看出,内容很多阻止[start=743, end=745], [start=749, end=773], [start=1160, end=1165], [start=1198, end=1205],内容块可能有噪音还没有清除,所以根据新闻页面对于噪音的特性,增加了第四个约束。
(4)Ystart
3 实验测试
3.1 实验准备
测试系统机器环境为:1台台式电脑(CPU为Intel四核2.93GHz,4G内存,硬盘7200r/min,操作系统Win7,10M网速)。系统采用纯Java实现,有效元素路径存储在MySQL5.5数据库中。为了让结果更有说服力,本文设计了一个轻量级的主题爬虫,从知名新闻网站(如腾讯新闻、网易新闻、搜狐新闻、新浪新闻等)中抓取网页。作为实验页面的集合。实验主要测试提取新闻正文信息的正确率和速度,而新闻标题是从网页采集器中提取的(一般导航网页,新闻标题和新闻网址是一起的),这里不做处理. 对于动态新闻,提取的文本完全覆盖了真实含义,未过滤的噪声占文本的不到5%为合格。对于静态网页,本文用准确率来表示建议正文信息的准确率:准确率=正确过滤的网页数/网页总数×100%
3.2 实验结果 表1为系统网页正文提取准确率和在线文本提取率。其中,每个网站有100个动态网页和静态网页,共计1600个网页。表1的测试结果表明,该系统提取静态网页的准确率高于93%,对原创新闻网页正文内容的提取较为完整,而动态网页的提取准确率均在80%以上。错误的原因是不同主题的设计风格不一样,还有人们对网页中文字定义的差异等因素,本文算法的结果或多或少会受到影响. 对于正文内容为纯文本的网页,本文算法的准确率非常高。影响本系统准确性的主要因素总结如下: ①动态网页和普通新闻网页的区分是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。①动态网页和普通新闻网页的区别是根据网址的相似度和网址是否收录标识符来判断的;②对于普通新闻网页的正文内容和噪声部分如果网页的主要内容是图片或视频,过短的文本内容会作为噪声,从而降低提取结果的准确性;③如果在普通新闻网页中嵌入图片,文字各部分之间的距离会相差较大。
4实验结论本文提出的新闻网页正文提取系统采用行阻塞算法提取网页信息和DOM技术,还利用动态网页结构的相似性特征实现大规模新闻网站新闻正文信息萃取。该系统不依赖大量训练集,能够更准确地提取新闻文本信息。实验结果验证了其有效性。但是,对于英文网页和结构复杂的网页,提取效果并不理想,尤其是对于嵌入了图形信息的普通新闻网页。该方法只能提取文本信息,无法获取网页图片。下一步,我们可以对英文网页优化进行深入研究,
参考:
[1]ARIAS J, DESCHACHT K, MOENS M F. 从网页中提取与语言无关的内容[J]. 特温特大学, 2009.
[2]_来源中文社区。一般网页文本提取[EB/OL].[20150425].
[3]陈昭,张冬梅. Web信息抽取技术概述[J].计算机应用研究, 2010, 27 (12):44014405.
[4]王琦,唐世伟,杨冬青,等.基于DOM的网页主题信息自动提取[C]. 中国数据库学术会议,2004:17861792.
[5] GUPTA S、KAISER GE、GRIMM P 等。HTML 文档内容自动提取[J]. 万维网互联网和网络信息系统,2005 年,8 (2): 179224.
[6]REIS D C.使用树编辑距离的自动网络新闻提取[C].万维网国际会议.ACM,2004:502511.
[7] 维埃拉 K、席尔瓦 ASD、平托 N 等。一种快速、鲁棒的网页模板检测和移除方法[C].ACM国际信息与知识管理会议.ACM,2006:258267.
[8] 黄文北,杨静,顾俊忠.基于块的网页正文信息提取算法研究[J]. 计算机应用, 2007, 27 (s1): 2426.
[9]QI X, NIE L, DAVISON B D. 测量相似性以检测合格链接[C].Airweb 2007,第三届网络对抗性信息检索国际研讨会,与 WWW 会议同处,加拿大班夫,2007:495 6.
[10] 张家荣.Java开源项目HtmlUnit在浏览器仿真中的应用[J]. 电子制作, 2015 (8): 79.
[11]杨柳青,李晓东,耿光刚.基于布局相似度的网页正文内容提取研究[J]. 计算机应用研究, 2015 (9): 25812586.
[12] 张耀.面向AJAX脚本网络的网络爬取解析技术研究与实现[D]. 沉阳:东北大学,2012.
[13]MESBAH A, BOZDAG E, DEURSEN A V. Crawling AJAX by inferring user interface state changes[C].第八届网络工程国际会议,Yorktown Heights, New York, Usa.2008: 122134.
[14]何欣,谢志鹏. 基于简单树匹配算法的网页结构相似度测量[J]. 计算机研究与发展, 2007, 44 (z3): 16.
[15] ROEST D, MESBAH A, DEURSEN A V. 回归测试 ajax 应用程序:应对动态[C]。International Conference on Software Testing, Verification and Validation, ICST 2010, Paris, France, 2010: 127136. (Editor: Duneng Steel)

