
抓取网页新闻
抓取网页新闻( Python中解析网页的基本流程和使用方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-14 04:19
Python中解析网页的基本流程和使用方法(上))
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据
本文将以爬取并存储B站视频热搜榜数据为例,详细介绍Python爬虫的基本流程。
如果你还处于爬取的入门阶段或者不知道爬取的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在开始,并运行以下代码
在上面的代码中,我们完成了以下三件事
进口
使用方法构造请求
使用获取网页状态码
可以看到返回值为 ,表示服务器响应正常,表示我们可以继续
第 2 步:解析页面
在上一步中,我们通过requests向网站请求数据后,成功得到了一个收录服务器资源的Response对象,现在我们可以使用它来查看它的内容了
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以用,也可以用,或者,本文将基于BeautifulSoup进行讲解
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据
安装也很简单,使用安装即可
让我们用一个简单的例子来说明它是如何工作的
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。请注意,使用时需要指定解析器。这里我们使用
然后就可以获取其中一个结构元素及其属性,比如用 获取页面标题,也可以使用 等获取任何需要的元素
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用来定位元素,但我更习惯使用 CSS 选择器,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页按F12按照下面的说明找到
可以看到每个视频信息都包裹在li标签下,那么代码可以这样写
在上面的代码中,我们先使用它,然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用 CSS 选择器来提取我们想要的字段信息,并在开头以字典的形式存储定义好的空列表
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用模块来写,需要注意设置编码,否则会出现中文乱码问题
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
-结尾- 查看全部
抓取网页新闻(
Python中解析网页的基本流程和使用方法(上))
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据
本文将以爬取并存储B站视频热搜榜数据为例,详细介绍Python爬虫的基本流程。
如果你还处于爬取的入门阶段或者不知道爬取的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在开始,并运行以下代码
在上面的代码中,我们完成了以下三件事
进口
使用方法构造请求
使用获取网页状态码
可以看到返回值为 ,表示服务器响应正常,表示我们可以继续
第 2 步:解析页面
在上一步中,我们通过requests向网站请求数据后,成功得到了一个收录服务器资源的Response对象,现在我们可以使用它来查看它的内容了
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以用,也可以用,或者,本文将基于BeautifulSoup进行讲解
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据
安装也很简单,使用安装即可
让我们用一个简单的例子来说明它是如何工作的
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。请注意,使用时需要指定解析器。这里我们使用
然后就可以获取其中一个结构元素及其属性,比如用 获取页面标题,也可以使用 等获取任何需要的元素
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用来定位元素,但我更习惯使用 CSS 选择器,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页按F12按照下面的说明找到
可以看到每个视频信息都包裹在li标签下,那么代码可以这样写
在上面的代码中,我们先使用它,然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用 CSS 选择器来提取我们想要的字段信息,并在开头以字典的形式存储定义好的空列表
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用模块来写,需要注意设置编码,否则会出现中文乱码问题
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
-结尾-
抓取网页新闻( 2017年04月21日Python正则抓取网易新闻的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-14 04:02
2017年04月21日Python正则抓取网易新闻的方法
)
Python正则爬取网易新闻的方法示例
更新时间:2017-04-21 14:37:22 作者:Shine I want
本文文章主要介绍Python中定时抓取网易新闻的方法,并详细分析使用Python使用正则表达式抓取网易新闻的实现技巧和注意事项。有需要的朋友可以参考以下
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现它的网页源码和网页上的评论一点都不正确,于是用抓包工具获取了它的评论隐藏地址(各个浏览器有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的
然后打开链接找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(
2017年04月21日Python正则抓取网易新闻的方法
)
Python正则爬取网易新闻的方法示例
更新时间:2017-04-21 14:37:22 作者:Shine I want
本文文章主要介绍Python中定时抓取网易新闻的方法,并详细分析使用Python使用正则表达式抓取网易新闻的实现技巧和注意事项。有需要的朋友可以参考以下
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现它的网页源码和网页上的评论一点都不正确,于是用抓包工具获取了它的评论隐藏地址(各个浏览器有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的

然后打开链接找到相关的评论内容。(下图为第一页内容)

接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(百度快照不是了吗了吗?怎么又冒出来了?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-13 15:10
本文内容围绕百度网页抓取时间展开。很多人可能没有注意到这个细节。那么今天,就为大家揭秘《(最新)百度网页快照抓取时间》。
看标题,你可能会觉得百度快照没了?为什么又出现了?或者这是一个司空见惯的事情,我今天还在谈论它。写这篇文章的时候,我也猜到大家都会这么想,但我相信如果你仔细看,你会发现,会有很多我们没有注意到的地方。或者它可能被遗忘了,或者它可能是我不知道的东西,其余的我不会多说。见下文。
看到这个标题你会有些疑惑,所以为了更好的帮助大家理解,上图直接展示,下图展示如下。
这张图直观地向我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于你有没有注意到,我这里就不多说了。希望这一点能给您带来启发。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取的抓取时间”有什么关系呢?
这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题是,这就是我今天要请你解释的,图中时间的特点是什么?大家可以想一想,也可以随便搜索一个关键词看看,说不定会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先,文章收录的时间非常准确,精确到秒,可见目前的搜索引擎非常强大。
第二点是文章的yield时间多显示在凌晨3:00到8:00之间(注意一般说网页集中在收录的时间段从从凌晨0:00到12:00之间,下午很少)。
第三点,文章如果质量高,可以现场秒收。应该是那个时候的时间,但是圆圈里显示的时间是3点到8点不上班。它是从哪里来的收录?这有点可疑。
小编,看完这里,我想搜索引擎可能会先收录某个网页,然后建立索引(不明白的可以查阅相关资料),如图所示的网页收录时间不是网站收录的真实时间,而是百度建索引的时间。百度建索引的时间是在没有人或者工作量很小的时间段。比如上面提到的凌晨 3:00 到 8:00(但不是所有的都在这个时间段),这段时间很少有人在使用搜索引擎,小编在相关的站长平台,所以大家还是需要认真研究的。
在这里想给大家补充一下,你们有过这样的经历吗?如果你经常查看排名,你有时会发现早上看的排名和下午看的排名会有很大的不同,尤其是早上比较早和晚上比较晚有什么区别?
各种迹象表明搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。所以,这篇文章最重要的一点就是提醒大家,我们可以更深入更详细。了解我们的工作。所有的问题只是给大家的一个提醒。大家深入探索很重要。这是本文的结尾。谢谢你。 查看全部
抓取网页新闻(百度快照不是了吗了吗?怎么又冒出来了?(组图))
本文内容围绕百度网页抓取时间展开。很多人可能没有注意到这个细节。那么今天,就为大家揭秘《(最新)百度网页快照抓取时间》。
看标题,你可能会觉得百度快照没了?为什么又出现了?或者这是一个司空见惯的事情,我今天还在谈论它。写这篇文章的时候,我也猜到大家都会这么想,但我相信如果你仔细看,你会发现,会有很多我们没有注意到的地方。或者它可能被遗忘了,或者它可能是我不知道的东西,其余的我不会多说。见下文。
看到这个标题你会有些疑惑,所以为了更好的帮助大家理解,上图直接展示,下图展示如下。
这张图直观地向我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于你有没有注意到,我这里就不多说了。希望这一点能给您带来启发。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取的抓取时间”有什么关系呢?
这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题是,这就是我今天要请你解释的,图中时间的特点是什么?大家可以想一想,也可以随便搜索一个关键词看看,说不定会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先,文章收录的时间非常准确,精确到秒,可见目前的搜索引擎非常强大。
第二点是文章的yield时间多显示在凌晨3:00到8:00之间(注意一般说网页集中在收录的时间段从从凌晨0:00到12:00之间,下午很少)。
第三点,文章如果质量高,可以现场秒收。应该是那个时候的时间,但是圆圈里显示的时间是3点到8点不上班。它是从哪里来的收录?这有点可疑。
小编,看完这里,我想搜索引擎可能会先收录某个网页,然后建立索引(不明白的可以查阅相关资料),如图所示的网页收录时间不是网站收录的真实时间,而是百度建索引的时间。百度建索引的时间是在没有人或者工作量很小的时间段。比如上面提到的凌晨 3:00 到 8:00(但不是所有的都在这个时间段),这段时间很少有人在使用搜索引擎,小编在相关的站长平台,所以大家还是需要认真研究的。
在这里想给大家补充一下,你们有过这样的经历吗?如果你经常查看排名,你有时会发现早上看的排名和下午看的排名会有很大的不同,尤其是早上比较早和晚上比较晚有什么区别?
各种迹象表明搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。所以,这篇文章最重要的一点就是提醒大家,我们可以更深入更详细。了解我们的工作。所有的问题只是给大家的一个提醒。大家深入探索很重要。这是本文的结尾。谢谢你。
抓取网页新闻(试试超星阅读视频方面的文件汇总贴(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-09 17:01
抓取网页新闻推荐,这些app都有自己的新闻联盟,自己的新闻源。百度搜索——媒体公司——新闻源总结主流新闻源,
[]
可以用一个小工具,使用零门槛,真正的自己动手丰衣足食,通过注册就可以获得价值40万的40w历史文章,省去你去网上找资源的时间。
哈哈,这个就是,自己用来下载资源的,就是收费,
新闻以外,推荐一个教育领域的英文资源检索网站,帮助我解决了大量数学公式和英文语法错误的问题。
试试超星阅读
视频方面的,在b站看纪录片方面大神们总结的文件汇总贴,特别详细希望能对你有帮助。
中国大学mooc,
虽然说网上有很多资源,但是找到的时候你可能需要在整理一下;或者你可以在相关的新闻网站中去搜,也可以在同一个公众号找,或者找那些针对特定群体的微信公众号里面的资源,比如说医学相关,音乐类公众号等,具体哪些是比较好的,要看他们发的文章时间来决定;还有一种最省事的方法,你可以上某宝上面看看那些卖资源的商家,有时候他们的资源比较齐全,还有不同的加速模式。
最后说一下,在开通网上个人账号()前先问一下:现在注册还能不能解封一次?如果不能,那么等过了注册的时间后,他们都会全部删除你在注册时注册好的账号。具体你要知道的方法是:在一开始注册,应该点一下“免费申请”,能不能转成功还得看造化,如果不能申请,那估计你就得心灰意冷不玩了了,然后你去找别的公众号资源。祝你好运~。 查看全部
抓取网页新闻(试试超星阅读视频方面的文件汇总贴(图))
抓取网页新闻推荐,这些app都有自己的新闻联盟,自己的新闻源。百度搜索——媒体公司——新闻源总结主流新闻源,
[]
可以用一个小工具,使用零门槛,真正的自己动手丰衣足食,通过注册就可以获得价值40万的40w历史文章,省去你去网上找资源的时间。
哈哈,这个就是,自己用来下载资源的,就是收费,
新闻以外,推荐一个教育领域的英文资源检索网站,帮助我解决了大量数学公式和英文语法错误的问题。
试试超星阅读
视频方面的,在b站看纪录片方面大神们总结的文件汇总贴,特别详细希望能对你有帮助。
中国大学mooc,
虽然说网上有很多资源,但是找到的时候你可能需要在整理一下;或者你可以在相关的新闻网站中去搜,也可以在同一个公众号找,或者找那些针对特定群体的微信公众号里面的资源,比如说医学相关,音乐类公众号等,具体哪些是比较好的,要看他们发的文章时间来决定;还有一种最省事的方法,你可以上某宝上面看看那些卖资源的商家,有时候他们的资源比较齐全,还有不同的加速模式。
最后说一下,在开通网上个人账号()前先问一下:现在注册还能不能解封一次?如果不能,那么等过了注册的时间后,他们都会全部删除你在注册时注册好的账号。具体你要知道的方法是:在一开始注册,应该点一下“免费申请”,能不能转成功还得看造化,如果不能申请,那估计你就得心灰意冷不玩了了,然后你去找别的公众号资源。祝你好运~。
抓取网页新闻(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-08 21:04
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。比如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站抓取网页。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是存储大量的历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页所显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈! 查看全部
抓取网页新闻(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架

上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略

宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。比如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站抓取网页。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是存储大量的历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页所显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
抓取网页新闻(我想结合两个库(例如报纸和beautifulsoup4)的代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-06 00:09
)
我一直试图从新闻中获取新闻头条网站。为此,我遇到了两个 python 库,即 news 和 beautifulsoup4。使用美汤库,我已经能够从特定新闻网站中获取到新闻文章的所有链接。从下面的代码中,我已经能够从单个链接中提取新闻标题 文章。
from newspaper import Article
url= "https://www.ndtv.com/india-new ... ot%3B
article=Article(url)
article.download()
article.parse()
print(article.title)
我想把两个库的代码(比如newspaper和beautifulsoup4),这样我就可以把我从beautifulsoup库输出的所有链接放到报纸库的url命令中,得到所有的头条。链接。下面是beautfulsoup的代码,我可以从中提取新闻文章的所有链接。
from bs4 import BeautifulSoup
from bs4.dammit import EncodingDetector
import requests
parser = 'html.parser' # or 'lxml' (preferred) or 'html5lib', if installed
resp = requests.get("https://www.ndtv.com/coronavir ... 6quot;)
http_encoding = resp.encoding if 'charset' in resp.headers.get('content-type', '').lower() else None
html_encoding = EncodingDetector.find_declared_encoding(resp.content, is_html=True)
encoding = html_encoding or http_encoding
soup = BeautifulSoup(resp.content, parser, from_encoding=encoding)
for link in soup.find_all('a', href=True):
print(link['href']) 查看全部
抓取网页新闻(我想结合两个库(例如报纸和beautifulsoup4)的代码
)
我一直试图从新闻中获取新闻头条网站。为此,我遇到了两个 python 库,即 news 和 beautifulsoup4。使用美汤库,我已经能够从特定新闻网站中获取到新闻文章的所有链接。从下面的代码中,我已经能够从单个链接中提取新闻标题 文章。
from newspaper import Article
url= "https://www.ndtv.com/india-new ... ot%3B
article=Article(url)
article.download()
article.parse()
print(article.title)
我想把两个库的代码(比如newspaper和beautifulsoup4),这样我就可以把我从beautifulsoup库输出的所有链接放到报纸库的url命令中,得到所有的头条。链接。下面是beautfulsoup的代码,我可以从中提取新闻文章的所有链接。
from bs4 import BeautifulSoup
from bs4.dammit import EncodingDetector
import requests
parser = 'html.parser' # or 'lxml' (preferred) or 'html5lib', if installed
resp = requests.get("https://www.ndtv.com/coronavir ... 6quot;)
http_encoding = resp.encoding if 'charset' in resp.headers.get('content-type', '').lower() else None
html_encoding = EncodingDetector.find_declared_encoding(resp.content, is_html=True)
encoding = html_encoding or http_encoding
soup = BeautifulSoup(resp.content, parser, from_encoding=encoding)
for link in soup.find_all('a', href=True):
print(link['href'])
抓取网页新闻( 搜索引擎是怎样抓取文章内容的,它的收录原则大概是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-04 16:02
搜索引擎是怎样抓取文章内容的,它的收录原则大概是什么)
百度搜索引擎是如何抓取页面的?
搜索引擎是如何抓取文章的内容的,它的收录原理是什么。首先声明:以下方法基于本人经验,并非官方的爬取原则。下面我简单说一下:
1、 抓取:
这一步是搜索引擎录入数据的工作。它是如何工作的?比如百度,百度每天都会发布大量的蜘蛛程序,在浩瀚的互联网世界里爬行爬行。作为一个新网站的站长,你必须清楚。问题是,如果网站刚刚成立,百度怎么知道你的网站,所以有句话说我们会招蜘蛛,我们需要多发点人脉或者其他人的网站@在建站初期 > 交换连接。这样做的主要目的是吸引蜘蛛抓取我们的内容。
蜘蛛程序抓取内容时,不做任何处理,先存入临时索引库,也就是说这部分完成后的内容是乱七八糟的,还有各种内容,但是蜘蛛程序仍将被合理归类。, 方便下一步过滤。
2、过滤器:
当该步骤完成后,蜘蛛程序将开始过滤工作。当然,在实际情况中,这些步骤可以同时进行。我们只是来分解它的原理。搜索引擎将根据所捕获内容的级别进行过滤。有用去劣无用,留精华。这就是过滤工作。当然,这些任务的处理过程是比较快的,因为数据处理的时效性是搜索引擎的主要研究问题。
3、存储:
然后搜索引擎会将优质内容存储在自己的硬盘空间中,带有一定的算法索引供以后用户调用,也就是说这里的数据是真实的收录到搜索引擎的数据存储空间中.
4、显示:
当用户搜索某个关键词时,搜索引擎会按照一定的算法将数据库中的内容展示给客户。这种显示索引速度非常快。如果我们在百度上搜索一个词,您就可以看到。它可以快速显示数亿条搜索结果,这也是搜索引擎的核心技术,并且具有非常快速的检索能力。
5、 排名:
其实这一步也是第四步。搜索引擎在向用户显示数据时已经对数据进行了排名。至于这个排名在搜索引擎内部是如何计算的,这是一个内部机密。没人知道。只能猜测了。作为一家搜索引擎公司,其核心技术是抓取、过滤、搜索、排名、展示、执行这些步骤,执行这些步骤的时间越短,其技术越强大。
预防措施:
综上所述,我们应该明白,搜索引擎公司正在研究如何快速为用户提供他们想要的内容。
华旗商城更多产品介绍:微网站建站系统人气微博排行榜专业化妆品网站制作 查看全部
抓取网页新闻(
搜索引擎是怎样抓取文章内容的,它的收录原则大概是什么)
百度搜索引擎是如何抓取页面的?
搜索引擎是如何抓取文章的内容的,它的收录原理是什么。首先声明:以下方法基于本人经验,并非官方的爬取原则。下面我简单说一下:
1、 抓取:
这一步是搜索引擎录入数据的工作。它是如何工作的?比如百度,百度每天都会发布大量的蜘蛛程序,在浩瀚的互联网世界里爬行爬行。作为一个新网站的站长,你必须清楚。问题是,如果网站刚刚成立,百度怎么知道你的网站,所以有句话说我们会招蜘蛛,我们需要多发点人脉或者其他人的网站@在建站初期 > 交换连接。这样做的主要目的是吸引蜘蛛抓取我们的内容。
蜘蛛程序抓取内容时,不做任何处理,先存入临时索引库,也就是说这部分完成后的内容是乱七八糟的,还有各种内容,但是蜘蛛程序仍将被合理归类。, 方便下一步过滤。
2、过滤器:
当该步骤完成后,蜘蛛程序将开始过滤工作。当然,在实际情况中,这些步骤可以同时进行。我们只是来分解它的原理。搜索引擎将根据所捕获内容的级别进行过滤。有用去劣无用,留精华。这就是过滤工作。当然,这些任务的处理过程是比较快的,因为数据处理的时效性是搜索引擎的主要研究问题。
3、存储:
然后搜索引擎会将优质内容存储在自己的硬盘空间中,带有一定的算法索引供以后用户调用,也就是说这里的数据是真实的收录到搜索引擎的数据存储空间中.
4、显示:
当用户搜索某个关键词时,搜索引擎会按照一定的算法将数据库中的内容展示给客户。这种显示索引速度非常快。如果我们在百度上搜索一个词,您就可以看到。它可以快速显示数亿条搜索结果,这也是搜索引擎的核心技术,并且具有非常快速的检索能力。
5、 排名:
其实这一步也是第四步。搜索引擎在向用户显示数据时已经对数据进行了排名。至于这个排名在搜索引擎内部是如何计算的,这是一个内部机密。没人知道。只能猜测了。作为一家搜索引擎公司,其核心技术是抓取、过滤、搜索、排名、展示、执行这些步骤,执行这些步骤的时间越短,其技术越强大。
预防措施:
综上所述,我们应该明白,搜索引擎公司正在研究如何快速为用户提供他们想要的内容。
华旗商城更多产品介绍:微网站建站系统人气微博排行榜专业化妆品网站制作
抓取网页新闻(如何从浩如烟海的网络信息中找寻所需的竞争信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-04 15:23
企业间的竞争情报是企业优化所需的重要数据。准确及时的企业竞争情报往往能给企业带来诸多优势。在信息竞争时代,企业竞争情报也变得越来越重要。然而,信息时代在带来海量数据的同时,也给信息处理带来了很大的问题——如何从海量的信息网络中找到必要的竞争信息?
传统的手动检索和排序方法不再可取。在海量数据面前,这些人工获取的小数据根本就显得微不足道、毫无价值。竞争性舆情监测效率低下如何产生效果?网页抓取工具可以智能解决这个问题,帮助企业人员使用自动化软件来操作庞大而复杂的情报信息。
以下是情报监控的一些操作建议:
优采云采集器几乎可以采集所有网页中的任何数据,所以我们需要规划数据来源:对于企业竞争情报、新闻、论坛、博客,贴吧有各种形式的竞赛信息可在、纸质媒体网站等采集,企业人员可根据所从事领域的舆论分布情况进行选择。多方信息必定会更新实时,网络爬虫优采云采集器还可以通过定时任务功能自动动态更新,保证抓取信息的完整性和及时性。
不同的源系统需要不同的配置。灵活多变的优采云采集器不仅可以自动提取标准新闻的正文,还提供了多种配置方式来适应复杂的页面。根据不同的系统设置不同的采集方法,或者根据不同的需要提取某个系统中特定的重要数据,如关键词、新闻摘要、电话号码等,使用最佳配置实现批量和高效的提取。
对获得的情报数据进行智能化管理也很重要。比如在使用采集的网络爬虫工具时,对于同一个URL,优采云采集器只采集最新的文章内容或没有被回复采集,以及已经被采集的内容,会被自动忽略,采集收到的地址或数据需要处理一次自动去除权重,以保证情报数据的准确性。
企业竞争情报信息庞大而复杂。只有满足多源通用、实时更新、去重爬取要求的网络爬虫工具,才能智能解决智能监控的需求。随着信息技术的进一步发展,企业竞争情报监控也将变得更加精细。智能高效。 查看全部
抓取网页新闻(如何从浩如烟海的网络信息中找寻所需的竞争信息)
企业间的竞争情报是企业优化所需的重要数据。准确及时的企业竞争情报往往能给企业带来诸多优势。在信息竞争时代,企业竞争情报也变得越来越重要。然而,信息时代在带来海量数据的同时,也给信息处理带来了很大的问题——如何从海量的信息网络中找到必要的竞争信息?

传统的手动检索和排序方法不再可取。在海量数据面前,这些人工获取的小数据根本就显得微不足道、毫无价值。竞争性舆情监测效率低下如何产生效果?网页抓取工具可以智能解决这个问题,帮助企业人员使用自动化软件来操作庞大而复杂的情报信息。
以下是情报监控的一些操作建议:
优采云采集器几乎可以采集所有网页中的任何数据,所以我们需要规划数据来源:对于企业竞争情报、新闻、论坛、博客,贴吧有各种形式的竞赛信息可在、纸质媒体网站等采集,企业人员可根据所从事领域的舆论分布情况进行选择。多方信息必定会更新实时,网络爬虫优采云采集器还可以通过定时任务功能自动动态更新,保证抓取信息的完整性和及时性。
不同的源系统需要不同的配置。灵活多变的优采云采集器不仅可以自动提取标准新闻的正文,还提供了多种配置方式来适应复杂的页面。根据不同的系统设置不同的采集方法,或者根据不同的需要提取某个系统中特定的重要数据,如关键词、新闻摘要、电话号码等,使用最佳配置实现批量和高效的提取。
对获得的情报数据进行智能化管理也很重要。比如在使用采集的网络爬虫工具时,对于同一个URL,优采云采集器只采集最新的文章内容或没有被回复采集,以及已经被采集的内容,会被自动忽略,采集收到的地址或数据需要处理一次自动去除权重,以保证情报数据的准确性。
企业竞争情报信息庞大而复杂。只有满足多源通用、实时更新、去重爬取要求的网络爬虫工具,才能智能解决智能监控的需求。随着信息技术的进一步发展,企业竞争情报监控也将变得更加精细。智能高效。
抓取网页新闻(学习机器学习算法,分为回归,分类,爬取一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 13:15
)
作者简历地址:
Python爬虫一步步爬取文章背景
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据可以练习。我想爬取国内各大网站的新闻,通过训练,然后对未来的新闻做一个分类预测。在这样的背景下,我开始了我的爬虫之路。
网站分析
国内重大新闻摘要网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。 . .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了两个包,urllib2和BeautifulSoup。以搜狐新闻为例,我们做了一个简单的爬虫,爬取内容没有任何优化问题,所以会出现假死的情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
在运行上述代码的过程中,会遇到一些问题,导致爬虫停止运行,速度变慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后设置爬虫代理来解决IP问题。代码如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果你找不到一个网页,就丢弃它,因为丢弃少量的网页不会影响你以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
至于速度慢的问题,可以采用多进程的方式进行爬取。解析URL后,可以在Redis中使用一个有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。 (尚未实施)
第 4 步:运行
昨晚试了一下,爬到搜狐新闻的一些网页。大概是50*5*15=3750多个网页,解析出2000多条新闻,网速接近1Mbps。 , 耗时 1101s,约 18 分钟。
查看全部
抓取网页新闻(学习机器学习算法,分为回归,分类,爬取一下
)
作者简历地址:
Python爬虫一步步爬取文章背景
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据可以练习。我想爬取国内各大网站的新闻,通过训练,然后对未来的新闻做一个分类预测。在这样的背景下,我开始了我的爬虫之路。
网站分析
国内重大新闻摘要网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。 . .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了两个包,urllib2和BeautifulSoup。以搜狐新闻为例,我们做了一个简单的爬虫,爬取内容没有任何优化问题,所以会出现假死的情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
在运行上述代码的过程中,会遇到一些问题,导致爬虫停止运行,速度变慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后设置爬虫代理来解决IP问题。代码如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果你找不到一个网页,就丢弃它,因为丢弃少量的网页不会影响你以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
至于速度慢的问题,可以采用多进程的方式进行爬取。解析URL后,可以在Redis中使用一个有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。 (尚未实施)
第 4 步:运行
昨晚试了一下,爬到搜狐新闻的一些网页。大概是50*5*15=3750多个网页,解析出2000多条新闻,网速接近1Mbps。 , 耗时 1101s,约 18 分钟。

抓取网页新闻(本篇文章主要介绍了JAVA爬虫GeccoGecco工具抓取新闻实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-01 19:15
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawlergecco1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines") public class ZJNewsGeccoList implements HtmlBean { @Request private HttpRequest request; @RequestParameter private int pageIndex; @RequestParameter private int pageSize; @HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a") private List newList; }
@PipelineName("zJNewsListPipelines") public class ZJNewsListPipelines implements Pipeline { public void process(ZJNewsGeccoList zjNewsGeccoList) { HttpRequest request=zjNewsGeccoList.getRequest(); for (HrefBean bean:zjNewsGeccoList.getNewList()){ //进入祥情页面抓取 SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl())); } int page=zjNewsGeccoList.getPageIndex()+1; String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B //抓取下一页 SchedulerContext.into(request.subRequest(nextUrl)); } }
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline") public class ZJNewsDetail implements HtmlBean { @Text @HtmlField(cssPath = "#headline") private String title ; @Text @HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray") private String createTime; }
@PipelineName("zjNewsDetailPipeline") public class ZJNewsDetailPipeline implements Pipeline { public void process(ZJNewsDetail zjNewsDetail) { System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime()); } }
启动主函数
public class Main { public static void main(String [] rags){ GeccoEngine.create() //工程的包路径 .classpath("com.zhaochao.gecco.zj") //开始抓取的页面地址 .start("http://zj.zjol.com.cn/home.htm ... 6quot;) //开启几个爬虫线程 .thread(10) //单个爬虫每次抓取完一个请求后的间隔时间 .interval(10) //使用pc端userAgent .mobile(false) //开始运行 .run(); } }
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文站。
以上是Java爬虫Gecco工具抓取新闻实例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
抓取网页新闻(本篇文章主要介绍了JAVA爬虫GeccoGecco工具抓取新闻实例)
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawlergecco1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines") public class ZJNewsGeccoList implements HtmlBean { @Request private HttpRequest request; @RequestParameter private int pageIndex; @RequestParameter private int pageSize; @HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a") private List newList; }
@PipelineName("zJNewsListPipelines") public class ZJNewsListPipelines implements Pipeline { public void process(ZJNewsGeccoList zjNewsGeccoList) { HttpRequest request=zjNewsGeccoList.getRequest(); for (HrefBean bean:zjNewsGeccoList.getNewList()){ //进入祥情页面抓取 SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl())); } int page=zjNewsGeccoList.getPageIndex()+1; String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B //抓取下一页 SchedulerContext.into(request.subRequest(nextUrl)); } }
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline") public class ZJNewsDetail implements HtmlBean { @Text @HtmlField(cssPath = "#headline") private String title ; @Text @HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray") private String createTime; }
@PipelineName("zjNewsDetailPipeline") public class ZJNewsDetailPipeline implements Pipeline { public void process(ZJNewsDetail zjNewsDetail) { System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime()); } }
启动主函数
public class Main { public static void main(String [] rags){ GeccoEngine.create() //工程的包路径 .classpath("com.zhaochao.gecco.zj") //开始抓取的页面地址 .start("http://zj.zjol.com.cn/home.htm ... 6quot;) //开启几个爬虫线程 .thread(10) //单个爬虫每次抓取完一个请求后的间隔时间 .interval(10) //使用pc端userAgent .mobile(false) //开始运行 .run(); } }
获取结果


以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文站。
以上是Java爬虫Gecco工具抓取新闻实例的详细内容。更多详情请关注其他相关html中文网站文章!
抓取网页新闻(神龙IP一起常见的抓取策略及算法策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-01 00:14
网络爬虫,又称网络蜘蛛,是一种根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新抓取到的URL放入抓取队列,然后进行新一轮抓取,直到抓取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。 URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但无论采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到要爬取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP 策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大网站优先(大网站优先)
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果网站中等待下载的页面最多,则优先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页质量普遍较高,这个想法很简单,但是有一定的依据。 查看全部
抓取网页新闻(神龙IP一起常见的抓取策略及算法策略)
网络爬虫,又称网络蜘蛛,是一种根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新抓取到的URL放入抓取队列,然后进行新一轮抓取,直到抓取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。 URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但无论采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到要爬取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP 策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大网站优先(大网站优先)
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果网站中等待下载的页面最多,则优先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页质量普遍较高,这个想法很简单,但是有一定的依据。
抓取网页新闻(目录本篇博客又双叒叕为各位分享分享Python库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-31 02:27
)
内容
本博客还为大家分享了一个Python库:GeneralNewsExtractor(GNE),它是一个通用新闻网站文本提取模块,输入一个新闻网页的HTML,输出文本内容、标题、作者、发表时间、正文中图片的地址、正文所在标签的源码。 GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,几乎可以达到100%的准确率。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。
1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功的效果如下:
2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:
右键查看本页源码文章,如下图:
复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:
如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result) 查看全部
抓取网页新闻(目录本篇博客又双叒叕为各位分享分享Python库
)
内容
本博客还为大家分享了一个Python库:GeneralNewsExtractor(GNE),它是一个通用新闻网站文本提取模块,输入一个新闻网页的HTML,输出文本内容、标题、作者、发表时间、正文中图片的地址、正文所在标签的源码。 GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,几乎可以达到100%的准确率。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。

1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功的效果如下:

2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:

右键查看本页源码文章,如下图:


复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:

如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
抓取网页新闻(抓取网页新闻数据需要一定的工具去哪儿网站爬虫工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-28 18:05
抓取网页新闻数据需要一定的工具,去哪儿网站爬虫工具不错,可以自己试一下。也可以看下我写的一个爬虫,
一、目标说明爬取51网-首页新闻,条数100条。
二、数据获取技术获取完全网站一整套新闻数据的方法:采集器,抓包,传码。采集器类似于“桥梁”,把原始链接和新闻链接“拧”在一起,解析生成新闻链接;-)比如:在该网站上,有这样一段url,首页新闻是这样的:点击新闻链接,在工具中对url进行解析:程序获取了url列表和新闻链接,结果如下:我们是在程序中获取新闻数据,可能使用大量循环代码操作url,导致io操作异常,我们可以做图像操作并用threadlocal存储url列表,好消息是,threadlocal支持将url存储到持久化内存中,如果running状态为true,则该内存中的url将一直存在,内存中的对象与磁盘上的数据一致,sowhat!...记得将context映射到写入内存。
第二个问题:在页面打开的瞬间不断获取新闻链接,导致网络io操作异常,我们将新闻链接传给python去哪儿网站抓包工具抓取完全网站新闻数据对象,然后start。程序代码如下:第三个问题:传码类似于给链接赋值,可以理解为对串中的新闻链接进行二值化,将值赋值给数据库中的对象,方便操作url后续给数据库的那些新闻链接对象放入threadlocal,等待有效的runninginthread。
当我们获取新闻列表中第100个新闻时,传入threadlocal值为0。第四个问题:时间获取完全网站新闻数据所用时间,一般是在凌晨1-2点之间,建议选择晚上10点以后的时间,原因是:1.需要注意的是新闻发布时间不是每分每秒都完全一样,即便是4h或5h,新闻发布时间或许只是某一段时间内比较大的那么几条。
比如你12:10发布的新闻,有可能在凌晨0:00出现在新闻列表中,也有可能在午夜或下午2:00再次出现在新闻列表中。2.当python从网站上获取到目标数据对象后,程序就将目标链接传给客户端get请求方法,get请求需要重定向一次,具体可以看一下请求头:从而可以简单判断是否发起二次请求。
上述四个问题,python都能提供解决方案,我们只需要安装time模块即可,代码如下:importtimeclassurldemo(object):"""#如果有链接超过100行,程序将自动跳过删除。getrequest=time。time()if__name__=='__main__':url='/'fromurllibimportrequestone=0element=request。get(url)iftime。sleep(0。
1):iffunction(urldemo):print(urldemo) 查看全部
抓取网页新闻(抓取网页新闻数据需要一定的工具去哪儿网站爬虫工具)
抓取网页新闻数据需要一定的工具,去哪儿网站爬虫工具不错,可以自己试一下。也可以看下我写的一个爬虫,
一、目标说明爬取51网-首页新闻,条数100条。
二、数据获取技术获取完全网站一整套新闻数据的方法:采集器,抓包,传码。采集器类似于“桥梁”,把原始链接和新闻链接“拧”在一起,解析生成新闻链接;-)比如:在该网站上,有这样一段url,首页新闻是这样的:点击新闻链接,在工具中对url进行解析:程序获取了url列表和新闻链接,结果如下:我们是在程序中获取新闻数据,可能使用大量循环代码操作url,导致io操作异常,我们可以做图像操作并用threadlocal存储url列表,好消息是,threadlocal支持将url存储到持久化内存中,如果running状态为true,则该内存中的url将一直存在,内存中的对象与磁盘上的数据一致,sowhat!...记得将context映射到写入内存。
第二个问题:在页面打开的瞬间不断获取新闻链接,导致网络io操作异常,我们将新闻链接传给python去哪儿网站抓包工具抓取完全网站新闻数据对象,然后start。程序代码如下:第三个问题:传码类似于给链接赋值,可以理解为对串中的新闻链接进行二值化,将值赋值给数据库中的对象,方便操作url后续给数据库的那些新闻链接对象放入threadlocal,等待有效的runninginthread。
当我们获取新闻列表中第100个新闻时,传入threadlocal值为0。第四个问题:时间获取完全网站新闻数据所用时间,一般是在凌晨1-2点之间,建议选择晚上10点以后的时间,原因是:1.需要注意的是新闻发布时间不是每分每秒都完全一样,即便是4h或5h,新闻发布时间或许只是某一段时间内比较大的那么几条。
比如你12:10发布的新闻,有可能在凌晨0:00出现在新闻列表中,也有可能在午夜或下午2:00再次出现在新闻列表中。2.当python从网站上获取到目标数据对象后,程序就将目标链接传给客户端get请求方法,get请求需要重定向一次,具体可以看一下请求头:从而可以简单判断是否发起二次请求。
上述四个问题,python都能提供解决方案,我们只需要安装time模块即可,代码如下:importtimeclassurldemo(object):"""#如果有链接超过100行,程序将自动跳过删除。getrequest=time。time()if__name__=='__main__':url='/'fromurllibimportrequestone=0element=request。get(url)iftime。sleep(0。
1):iffunction(urldemo):print(urldemo)
抓取网页新闻(公众号的第一篇文章,就先来介绍介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-12-27 22:15
在公众号的第一篇文章中,介绍一下我做过的最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载。今天我将在python中实现它。这个爬虫我已经多次跟别人说过了,在双星的舞台上,在新生的导航课上(两次),在课堂上。其实现在回过头来看这个爬虫真的很low很简单,但是好歹也是花了很长时间才学会的,所以今天就用python系统地实现一下吧。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官网。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要的信息是什么(其实这一步一定要在你写爬虫之前确定)。这里我们需要的是新闻标题、日期、作者、正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里
标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,对解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面会在专门学习BeautifulSoup的部分学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签,赋值给title
但是当我们输出这段代码时,问题就来了
结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再补充一点,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
相信如果你之前什么都做到了,这一步你就会很熟练了。首先找到文本所在的div为class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。我们在浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码,发现翻页标签链接收录
xydt/
网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录
info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你能做到这一步,你已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再重新梳理一下这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获取到网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们要设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护电脑。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。文章开头我说我觉得这个爬虫非常低级和简单,但是我实际操作它花了两天时间。当然,这两天并不是所有人都在写程序。实习的时候写的。似乎一切都不容易。让我们一步一步来。 查看全部
抓取网页新闻(公众号的第一篇文章,就先来介绍介绍(组图))
在公众号的第一篇文章中,介绍一下我做过的最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载。今天我将在python中实现它。这个爬虫我已经多次跟别人说过了,在双星的舞台上,在新生的导航课上(两次),在课堂上。其实现在回过头来看这个爬虫真的很low很简单,但是好歹也是花了很长时间才学会的,所以今天就用python系统地实现一下吧。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官网。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要的信息是什么(其实这一步一定要在你写爬虫之前确定)。这里我们需要的是新闻标题、日期、作者、正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里

标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,对解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面会在专门学习BeautifulSoup的部分学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签,赋值给title
但是当我们输出这段代码时,问题就来了

结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再补充一点,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
相信如果你之前什么都做到了,这一步你就会很熟练了。首先找到文本所在的div为class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。我们在浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码,发现翻页标签链接收录
xydt/

网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录
info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你能做到这一步,你已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再重新梳理一下这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获取到网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们要设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护电脑。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。文章开头我说我觉得这个爬虫非常低级和简单,但是我实际操作它花了两天时间。当然,这两天并不是所有人都在写程序。实习的时候写的。似乎一切都不容易。让我们一步一步来。
抓取网页新闻(站内网站站点抓取使用思路介绍--抓取网页新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-27 07:03
抓取网页新闻是很多中小卖家都在做的一项工作,如果仅仅是使用工具去抓取获取就比较乏味,效率也不会太高。作为一个seo优化者,一定要通过我们自己的研究和经验去梳理一个自己最终想要的抓取方式,因为现在网站已经进入白热化的竞争阶段,比的就是谁更专业,也就是谁对搜索引擎更熟悉。通过学习掌握一定的抓取工具有助于我们对本站站点抓取使用思路。
1、浏览器抓取工具:比如allinone,iim,nec,robots.txt,tampermonkey,cheapflightlibrary。
2、站内抓取工具:比如index.php,taobao.php,
3、从一些高权重网站直接抓取所需要的文章。站外抓取工具:比如baiduspider,windowssearch.php这样的软件,我是不建议中小卖家去使用,现在市面上太多了,良莠不齐,抓取网站可以用作站内外seo数据收集作用,但是千万不要用作站外推广作用。我分享的文章源自yahoo!seo,chinas的seo工具抓取软件,chinas早期由hao123教主张朝阳老师创建,前几年被360收购了,但是相信seoer都听说过360的技术,所以chinas是非常好用的抓取工具。
4、通过一些seo工具网站,搜索搜索文章链接,整理一下,引导转化到公众号平台。后期我会继续分享一些其他方面的站内网站进行抓取使用。 查看全部
抓取网页新闻(站内网站站点抓取使用思路介绍--抓取网页新闻)
抓取网页新闻是很多中小卖家都在做的一项工作,如果仅仅是使用工具去抓取获取就比较乏味,效率也不会太高。作为一个seo优化者,一定要通过我们自己的研究和经验去梳理一个自己最终想要的抓取方式,因为现在网站已经进入白热化的竞争阶段,比的就是谁更专业,也就是谁对搜索引擎更熟悉。通过学习掌握一定的抓取工具有助于我们对本站站点抓取使用思路。
1、浏览器抓取工具:比如allinone,iim,nec,robots.txt,tampermonkey,cheapflightlibrary。
2、站内抓取工具:比如index.php,taobao.php,
3、从一些高权重网站直接抓取所需要的文章。站外抓取工具:比如baiduspider,windowssearch.php这样的软件,我是不建议中小卖家去使用,现在市面上太多了,良莠不齐,抓取网站可以用作站内外seo数据收集作用,但是千万不要用作站外推广作用。我分享的文章源自yahoo!seo,chinas的seo工具抓取软件,chinas早期由hao123教主张朝阳老师创建,前几年被360收购了,但是相信seoer都听说过360的技术,所以chinas是非常好用的抓取工具。
4、通过一些seo工具网站,搜索搜索文章链接,整理一下,引导转化到公众号平台。后期我会继续分享一些其他方面的站内网站进行抓取使用。
抓取网页新闻( 本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-26 17:22
本文实例讲述了Python正则抓取网易新闻的方法。分享
)
Python常规如何抓取网易新闻的例子,python抓取网易新闻
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬虫爬网易新闻,发现它的网页源代码和网页上的评论根本不正确,所以我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神的改写改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(
本文实例讲述了Python正则抓取网易新闻的方法。分享
)
Python常规如何抓取网易新闻的例子,python抓取网易新闻
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬虫爬网易新闻,发现它的网页源代码和网页上的评论根本不正确,所以我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的

然后打开链接,找到相关的评论内容。(下图为第一页内容)

接下来是代码(也是按照大神的改写改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(为什么分析的时候要把html标签过滤掉呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-23 09:13
)
前两种方法还是比较容易实现的,主要是处理比较简单。我之前实现了标签密度提取算法,但实际使用中的错误率还是比较高的;后两种方法在实现上稍微复杂一些。就算法效率而言,应该不会高很多。
我们需要的是一种简单易实现的算法,可以保证处理速度和提取精度。因此,结合前两种算法,研究网页的html页面结构,有更好的处理思路,称为基于文本密度的文本提取算法。后来在网上搜索了类似的算法,发现也有类似的处理方法用于处理文本提取,但还是有一些区别的。接下来和大家分享一下这个算法的一些处理思路。
网络分析
我随意从百度、搜狐、网易上拿了一个新闻页面进行分析。
先看一篇关于百度文章的文章
为什么任正非主动跟我合影,
首先请求这个页面,然后过滤到所有的html标签,只保留文本信息,我们可以看到文本信息集中在以下位置:
用Excel分析行数与每行字符的关系可以发现:
很明显,文字内容集中在65-100行之间的位置,这个区间的字符数也比较密集。
网易的另一篇文章文章
张小龙神话破灭,马化腾接管微信。
我们先看过滤html标签后的body部分:
这是另一个Excel分析结果:
正文部分集中在第 279-282 行之间。从图中可以看出,正是这几行的文字密度特别高。
最后分析一个搜狐新闻
李克强在天津考察考察的片刻,
我们先看post标签后面的文字:
再看Excel的分析结果:
搜狐文章的正文主要集中在第200-255行。剩下的文字都是乱七八糟的标签文字。
抱歉,我漏掉了很重要的一点:为什么我分析的时候会过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关心的是文本的内容,如果你携带这样的标签 style="color: #0000ff;">var chart = style="color: #0000ff;"> newstyle="color: #000000;">进行分析,可以想象一下会对我们的文本分析造成多大的干扰,为此我们需要去掉html标签,只对文本进行分析以减少干扰干涉。
基于网页分析构思的文本提取算法
回顾上面的网页分析,如果根据文本密度找到提取的文本,那么这是一个算法,可以在过滤html标签后从文本中找到文本的开始和结束行号。行号之间的文本是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文本密度远高于非正文部分。根据这个特点,我们可以很容易的实现算法,就是根据阈值(发音:yu)值来分析文本的位置。
那么有一些问题需要解决:
可以通过统计分析来确定阈值以获得更好的值。在实际的处理过程中,我发现这个值取180比较合适。也就是在分析文本的时候,如果分析的文本超过180,那么就可以认为该文本已经达到了。
然后是如何分析的问题。这实际上更容易确定。逐行分析肯定不好。如果在逐行分析的过程中分析几行,最好将几行分析为一个分析。即一次分析上面的5行,将字符相加,看是否达到阈值。如果达到阈值,则认为它已经进入了身体部位。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
核心提取算法不到60行。经过验证,提取效果还是很好的。至少达到90%的文本提取正确率,效率平均提取时间30ms左右。
一些需要解决的问题
html标签去除:这个很简单,直接用正则表达式替换(Regex.Replace(html, "(?is)", ""))来去除所有html标签
html压缩网页的处理:压缩后的html代码一般只有一行,这类html的处理比较简单(不需要复杂的代码格式化),直接在标签末尾加一个换行符即可。
正文标题:大多数标准 URL 将使用 h1 标签来组成正文标题。如果有 h1,则从 h1 标签中提取标题。如果没有,只需使用标题标签。
文章 发布时间:并不是所有的文章都有发布时间(不过好像大部分都有),去掉标签后用regular从文本中提取时间即可。
Keep tagged text:我们的算法与标签无关,因为算法要先过滤html标签去除干扰,那么如果你想要tagged文本(比如你想把图片保留在文本中)怎么办?这时候只能保留两个数组。一个数组存储过滤器标签的文本以便于分析,另一个数组保留html标签以便于提取原创信息。
Html2Article网页正文提取算法
Html2Article 是我基于上述思想的网页正文提取算法。具有以下特点:
算法已经开源(可以认为是对开源的贡献):
有关如何使用它的说明,请参阅文档。
该算法是在 C# 中实现的。玩.NET 的同学有福了,可以直接用nuget 把html2article 添加到你的项目中。
另外,我发现直接从百度搜索“html2article”也可以很快找到。算法实现快半年了,比较懒,没写文章分享给大家。
查看全部
抓取网页新闻(为什么分析的时候要把html标签过滤掉呢?(图)
)
前两种方法还是比较容易实现的,主要是处理比较简单。我之前实现了标签密度提取算法,但实际使用中的错误率还是比较高的;后两种方法在实现上稍微复杂一些。就算法效率而言,应该不会高很多。
我们需要的是一种简单易实现的算法,可以保证处理速度和提取精度。因此,结合前两种算法,研究网页的html页面结构,有更好的处理思路,称为基于文本密度的文本提取算法。后来在网上搜索了类似的算法,发现也有类似的处理方法用于处理文本提取,但还是有一些区别的。接下来和大家分享一下这个算法的一些处理思路。
网络分析
我随意从百度、搜狐、网易上拿了一个新闻页面进行分析。
先看一篇关于百度文章的文章
为什么任正非主动跟我合影,
首先请求这个页面,然后过滤到所有的html标签,只保留文本信息,我们可以看到文本信息集中在以下位置:

用Excel分析行数与每行字符的关系可以发现:

很明显,文字内容集中在65-100行之间的位置,这个区间的字符数也比较密集。
网易的另一篇文章文章
张小龙神话破灭,马化腾接管微信。
我们先看过滤html标签后的body部分:

这是另一个Excel分析结果:

正文部分集中在第 279-282 行之间。从图中可以看出,正是这几行的文字密度特别高。
最后分析一个搜狐新闻
李克强在天津考察考察的片刻,
我们先看post标签后面的文字:

再看Excel的分析结果:

搜狐文章的正文主要集中在第200-255行。剩下的文字都是乱七八糟的标签文字。
抱歉,我漏掉了很重要的一点:为什么我分析的时候会过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关心的是文本的内容,如果你携带这样的标签 style="color: #0000ff;">var chart = style="color: #0000ff;"> newstyle="color: #000000;">进行分析,可以想象一下会对我们的文本分析造成多大的干扰,为此我们需要去掉html标签,只对文本进行分析以减少干扰干涉。
基于网页分析构思的文本提取算法
回顾上面的网页分析,如果根据文本密度找到提取的文本,那么这是一个算法,可以在过滤html标签后从文本中找到文本的开始和结束行号。行号之间的文本是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文本密度远高于非正文部分。根据这个特点,我们可以很容易的实现算法,就是根据阈值(发音:yu)值来分析文本的位置。
那么有一些问题需要解决:
可以通过统计分析来确定阈值以获得更好的值。在实际的处理过程中,我发现这个值取180比较合适。也就是在分析文本的时候,如果分析的文本超过180,那么就可以认为该文本已经达到了。
然后是如何分析的问题。这实际上更容易确定。逐行分析肯定不好。如果在逐行分析的过程中分析几行,最好将几行分析为一个分析。即一次分析上面的5行,将字符相加,看是否达到阈值。如果达到阈值,则认为它已经进入了身体部位。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
核心提取算法不到60行。经过验证,提取效果还是很好的。至少达到90%的文本提取正确率,效率平均提取时间30ms左右。
一些需要解决的问题
html标签去除:这个很简单,直接用正则表达式替换(Regex.Replace(html, "(?is)", ""))来去除所有html标签
html压缩网页的处理:压缩后的html代码一般只有一行,这类html的处理比较简单(不需要复杂的代码格式化),直接在标签末尾加一个换行符即可。
正文标题:大多数标准 URL 将使用 h1 标签来组成正文标题。如果有 h1,则从 h1 标签中提取标题。如果没有,只需使用标题标签。
文章 发布时间:并不是所有的文章都有发布时间(不过好像大部分都有),去掉标签后用regular从文本中提取时间即可。
Keep tagged text:我们的算法与标签无关,因为算法要先过滤html标签去除干扰,那么如果你想要tagged文本(比如你想把图片保留在文本中)怎么办?这时候只能保留两个数组。一个数组存储过滤器标签的文本以便于分析,另一个数组保留html标签以便于提取原创信息。
Html2Article网页正文提取算法
Html2Article 是我基于上述思想的网页正文提取算法。具有以下特点:
算法已经开源(可以认为是对开源的贡献):
有关如何使用它的说明,请参阅文档。
该算法是在 C# 中实现的。玩.NET 的同学有福了,可以直接用nuget 把html2article 添加到你的项目中。

另外,我发现直接从百度搜索“html2article”也可以很快找到。算法实现快半年了,比较懒,没写文章分享给大家。

抓取网页新闻(《MetaSeeker速成手册》之博文翻页抓取多个URL映射的注释)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-23 09:12
相关博文
翻转页面以抓取多个标签。之前爬取到二级URL时,停止爬取过程
注1:可以使用MetaStudio加载信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。
注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。
1 抓取新闻摘要数据
首先,您需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:
以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页有DOM节点语义,可以使用@class或@id属性来准确定位抓取到的内容,然后进行FreeFormat映射。详细操作流程请参考《抢京东商品价格》。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“获取当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行,以提高爬行速度。如果不勾选DataScraper的菜单项“Configuration”->“Normal Mode”,DataScraper将进入加速模式。
2 抓取新闻详情页
我们在《抢夺》一文中已经讲过如何捕捉二级话题的线索。图 2 再次显示了捕获下一级线索的方法。设置线索功能后,会在线索编辑器工作台上自动创建。对于Info类型的线索,在Clue Editor工作台上,将下一级主题命名为demo_cnbeta_detail(如图3).
定义 Info 类线索的目的有两个:
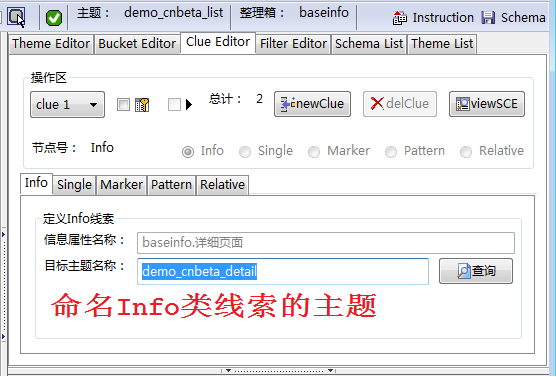
进行分层爬取,爬取新闻列表后爬取详细的新闻内容。为避免重复爬取,当发现超过设定的重复率时终止爬取过程,后面章节会详细说明
3 翻转页面以抓取多个标签
为了翻页并抓取所有标签,您需要创建一个线索。图 4 显示了主要步骤。详情见《抢当当商品价格》:
将代表整个分页区域的 DOM 节点映射到这条线索上,相当于指定了一个网页区域,该区域可以定位页面超链接。我们使用标记线索类型来定位翻页线索,“下一页”是标记值进行标记映射,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,该类型主要用于翻页,一旦选中该类型,当前主题名称将自动填入目标主题名称输入框。
4 设置 AJAX 捕获模式
如图5所示,选择MetaStudio菜单“Configuration”->“Active Mode”设置AJAX捕获模式。
在《亚马逊卓越分页抓取》一文中,我们同时设置了“主动模式”和“扩展模式”,两种模式并没有捆绑在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。
5 只获取最新消息
通常我们会每隔一段时间(例如一天)抓取新闻列表。如果我们发现新消息,我们将抓取 URL 并创建下一级线索来抓取最新的新闻内容。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明请参考《抓当当商品价格》。以下是 crontab.xml 文件的内容:
true
5
3600
false
demo_cnbeta_list
demo_cnbeta_list
false
80
-1
-1
false
0
true
23
1800
false
demo_cnbeta_detail
false
80
-1
-1
false
0
demo_cnbeta_list爬取话题的dupRatio参数和“只爬取最新消息”有关,80的意思是80%,也就是说,如果你发现这个URL被爬了3个连续页面的时候翻页爬取如果之前已经爬取了80%的地址,则终止翻页爬取。
注1:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。
注意2:请不要直接使用上面的crontab.xml,因为MetaSeeker服务器上还没有定义demo_cnbeta_detail信息结构,会导致周期性的爬取失败。 查看全部
抓取网页新闻(《MetaSeeker速成手册》之博文翻页抓取多个URL映射的注释)
相关博文
翻转页面以抓取多个标签。之前爬取到二级URL时,停止爬取过程
注1:可以使用MetaStudio加载信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。
注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。
1 抓取新闻摘要数据

首先,您需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:
以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页有DOM节点语义,可以使用@class或@id属性来准确定位抓取到的内容,然后进行FreeFormat映射。详细操作流程请参考《抢京东商品价格》。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“获取当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行,以提高爬行速度。如果不勾选DataScraper的菜单项“Configuration”->“Normal Mode”,DataScraper将进入加速模式。
2 抓取新闻详情页

我们在《抢夺》一文中已经讲过如何捕捉二级话题的线索。图 2 再次显示了捕获下一级线索的方法。设置线索功能后,会在线索编辑器工作台上自动创建。对于Info类型的线索,在Clue Editor工作台上,将下一级主题命名为demo_cnbeta_detail(如图3).
定义 Info 类线索的目的有两个:
进行分层爬取,爬取新闻列表后爬取详细的新闻内容。为避免重复爬取,当发现超过设定的重复率时终止爬取过程,后面章节会详细说明
3 翻转页面以抓取多个标签
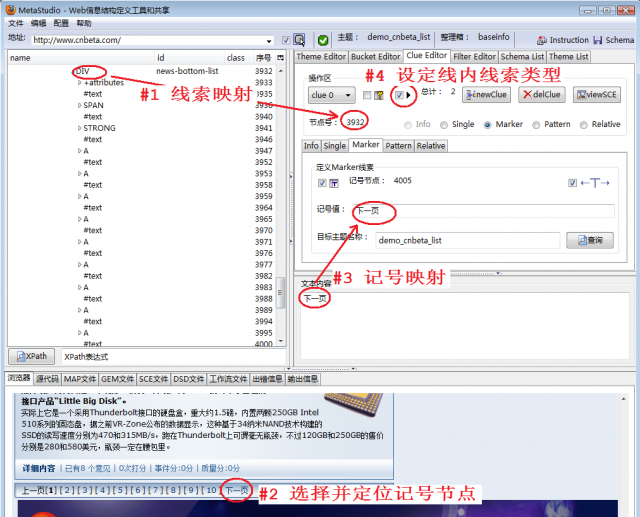
为了翻页并抓取所有标签,您需要创建一个线索。图 4 显示了主要步骤。详情见《抢当当商品价格》:
将代表整个分页区域的 DOM 节点映射到这条线索上,相当于指定了一个网页区域,该区域可以定位页面超链接。我们使用标记线索类型来定位翻页线索,“下一页”是标记值进行标记映射,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,该类型主要用于翻页,一旦选中该类型,当前主题名称将自动填入目标主题名称输入框。
4 设置 AJAX 捕获模式

如图5所示,选择MetaStudio菜单“Configuration”->“Active Mode”设置AJAX捕获模式。
在《亚马逊卓越分页抓取》一文中,我们同时设置了“主动模式”和“扩展模式”,两种模式并没有捆绑在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。
5 只获取最新消息
通常我们会每隔一段时间(例如一天)抓取新闻列表。如果我们发现新消息,我们将抓取 URL 并创建下一级线索来抓取最新的新闻内容。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明请参考《抓当当商品价格》。以下是 crontab.xml 文件的内容:
true
5
3600
false
demo_cnbeta_list
demo_cnbeta_list
false
80
-1
-1
false
0
true
23
1800
false
demo_cnbeta_detail
false
80
-1
-1
false
0
demo_cnbeta_list爬取话题的dupRatio参数和“只爬取最新消息”有关,80的意思是80%,也就是说,如果你发现这个URL被爬了3个连续页面的时候翻页爬取如果之前已经爬取了80%的地址,则终止翻页爬取。
注1:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。
注意2:请不要直接使用上面的crontab.xml,因为MetaSeeker服务器上还没有定义demo_cnbeta_detail信息结构,会导致周期性的爬取失败。
抓取网页新闻(如何设置这一路标才科学,才能提高搜索效率呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-18 10:14
现在,当你遇到不明白的东西时,你会想到百度,或者谷歌等搜索引擎。如果超链接是“路”,那么“关键词”就是“路标”。那么如何设置这个路标既科学又可以提高搜索效率呢?
“原创新闻”是新闻网站的重头戏。每天有几十篇文章。如何更好地编辑和发布这些新闻,是编辑们每天思考的主要问题。除了正常的排版和编辑,关键词是最受关注的。
很多作者在网上发表论文和小说时都会设置搜索关键词,而关键词在很多情况下都是影响文章点击率的重要因素。那么当面临关键词的选择时,如何设置才能获得最满意的流量呢?最重要的搜索工具是搜索引擎。人们常把手动编辑的网站分类称为搜索引擎,但笔者认为不完整。真正的搜索引擎是指网页的全文搜索引擎。网页全文搜索引擎其实就是一个很大的索引表,里面记录了每个网页上出现了哪些关键词。当你输入某个关键词搜索时,所有收录这个关键词的网页都会被找到,并按照一定的顺序排列。网络全文搜索引擎信息量大、准确率高、功能强、数据搜索速度快。它可以搜索你从未想过,甚至你不敢想象的内容,但前提是你要掌握一点使用技巧。这里我将介绍一些最基本、最有效的搜索技巧。
一、想想用什么工具
无论搜索引擎有多好,它都无法搜索到互联网上没有的内容。而且,虽然有些内容存在于互联网上,但由于种种原因,已经落网了。所以在你使用搜索引擎搜索之前,你应该花几秒钟的时间思考一下。我要找的东西是否有可能在线获得?如果是这样,它在哪里可能,它是什么样的?页面上会收录哪些关键字?
有些事情您不需要为搜索引擎而烦恼。例如,要查找公司的电话号码,拨打 114 可能比搜索引擎快得多。还有一些问题,可能很难用合适的关键词来描述,或者你不能直接用搜索引擎搜索,那么你可以试着找一个精通这个问题的朋友,或者寻找这个领域的热门论坛要问,这也是一种搜索方法。有时,您可以选择的最佳搜索方法是放弃互联网并前往附近的图书馆,那里有大量您在网上找不到的“信息”。
当您确认您要查找的信息适合通过搜索引擎在线搜索时,找到满意结果的概率就会高很多。
各种搜索引擎的特点非常鲜明。如果没有为每次搜索选择合适的搜索工具,您将浪费大量时间。对于这个搜索,你应该使用新浪还是搜狐?谷歌还是百度?分析您的需求,比较不同搜索引擎的优缺点,然后选择最适合本次搜索的搜索工具。
二、学习使用两个关键词搜索
如果一个陌生人突然走近你,问你:“北京”,你会怎么回答?大多数人会觉得莫名其妙,然后他们会问这个人他们想问“北京”什么。同样,如果你在搜索引擎中输入一个关键词“北京”,搜索引擎也不知道你在找什么,可能会返回很多莫名其妙的结果。因此,你必须养成使用多次关键词 搜索的习惯。当然,大多数情况下,使用两个 关键词 搜索就足够了, 关键词 和 关键词 之间用空格隔开。
比如想了解北京旅游,可以进入“北京旅游”获取北京旅游相关信息。
三、学会使用减号“-”
“-”的作用是去除不相关的搜索结果,提高搜索结果的相关性。有时,您会在搜索结果中看到一些想要的结果,但也会发现许多不相关的搜索结果。这时候就可以找出那些无关结果关键词的特征,并减去它们。
一个成功的搜索由两部分组成:正确的搜索关键词,和有用的搜索结果。在您点击任何搜索结果之前,快速分析您搜索结果的标题、网址和摘要,这将帮助您选择更准确的结果,并为您节省大量时间。当然,您需要哪一种内容取决于您要查找的内容。评估网络内容的质量和权威性是搜索中的重要一步。一次成功的搜索通常由多次搜索组成。如果您不熟悉您要搜索的内容,即使是搜索专家也无法保证您会在第一次搜索中找到您想要的内容。搜索专家将首先使用一个简单的 关键词 测试。他们不会忙于仔细检查每个搜索结果,而是首先从搜索结果页面中寻找更多信息,
科学爬取关键词包括两种情况:一种是根据内容选择关键词,另一种是根据关键词选择内容。
根据内容确定关键词。我想用我做过的一个话题来解释这种情况。
前不久网上热议的“力拓案”。毫无疑问,这是一条备受业界关注的热点消息。我们围绕此新闻事件拟定的主要 关键词 包括:力拓公司简介、力拓集团、铁矿石谈判以及参与事件的各方。之后会有关键词话题:力拓铁矿石、09铁矿石谈判、力拓铁矿石等关键词。
随着局势的发展,我们中断了谈判。这时候就要抓住以下关键词:力拓、可疑链接、调查等,相关信息文章也会在这个时候出现。关键词应该是:力拓年产量、力拓铁矿石储量、力拓石粉等信息字样。同时,发散思维也很重要,还需要采集力拓案的相关侧面信息(参考关键词:日本和力拓铁矿石,日本和力拓铁矿石谈判价格,巴西铁矿石等)。
此后,事件进一步升级,中方还逮捕了涉嫌间谍的力拓驻上海代表。这个时候我们要把握人们关注的词。预先确定的关键词还必须包括:力拓案、力拓间谍案、力拓间谍门、力拓间谍事件、力拓间谍泄密事件等。我们想围绕这些给本报告一个圆满的结论关键词。
通过分析我对这个事件的报道过程,我们可以总结出这个事件的捕获原理关键词:1.我们选择的关键词必须是用户会使用的词或词组搜索。2. 也是用户可能用来搜索的潜在术语。3. 不能泛泛而无具体内容。4.抓住事件讨论的中心。
根据关键词选择内容。这就是上述方法的反执行。首先,我们必须列出所有关键词 人正在关注的内容。然后使用关键词的这些不同组合来抓取内容。这是一种根据需求查找内容的方法。效果也不错。
(编辑/周扬) 查看全部
抓取网页新闻(如何设置这一路标才科学,才能提高搜索效率呢?)
现在,当你遇到不明白的东西时,你会想到百度,或者谷歌等搜索引擎。如果超链接是“路”,那么“关键词”就是“路标”。那么如何设置这个路标既科学又可以提高搜索效率呢?
“原创新闻”是新闻网站的重头戏。每天有几十篇文章。如何更好地编辑和发布这些新闻,是编辑们每天思考的主要问题。除了正常的排版和编辑,关键词是最受关注的。
很多作者在网上发表论文和小说时都会设置搜索关键词,而关键词在很多情况下都是影响文章点击率的重要因素。那么当面临关键词的选择时,如何设置才能获得最满意的流量呢?最重要的搜索工具是搜索引擎。人们常把手动编辑的网站分类称为搜索引擎,但笔者认为不完整。真正的搜索引擎是指网页的全文搜索引擎。网页全文搜索引擎其实就是一个很大的索引表,里面记录了每个网页上出现了哪些关键词。当你输入某个关键词搜索时,所有收录这个关键词的网页都会被找到,并按照一定的顺序排列。网络全文搜索引擎信息量大、准确率高、功能强、数据搜索速度快。它可以搜索你从未想过,甚至你不敢想象的内容,但前提是你要掌握一点使用技巧。这里我将介绍一些最基本、最有效的搜索技巧。
一、想想用什么工具
无论搜索引擎有多好,它都无法搜索到互联网上没有的内容。而且,虽然有些内容存在于互联网上,但由于种种原因,已经落网了。所以在你使用搜索引擎搜索之前,你应该花几秒钟的时间思考一下。我要找的东西是否有可能在线获得?如果是这样,它在哪里可能,它是什么样的?页面上会收录哪些关键字?
有些事情您不需要为搜索引擎而烦恼。例如,要查找公司的电话号码,拨打 114 可能比搜索引擎快得多。还有一些问题,可能很难用合适的关键词来描述,或者你不能直接用搜索引擎搜索,那么你可以试着找一个精通这个问题的朋友,或者寻找这个领域的热门论坛要问,这也是一种搜索方法。有时,您可以选择的最佳搜索方法是放弃互联网并前往附近的图书馆,那里有大量您在网上找不到的“信息”。
当您确认您要查找的信息适合通过搜索引擎在线搜索时,找到满意结果的概率就会高很多。
各种搜索引擎的特点非常鲜明。如果没有为每次搜索选择合适的搜索工具,您将浪费大量时间。对于这个搜索,你应该使用新浪还是搜狐?谷歌还是百度?分析您的需求,比较不同搜索引擎的优缺点,然后选择最适合本次搜索的搜索工具。
二、学习使用两个关键词搜索
如果一个陌生人突然走近你,问你:“北京”,你会怎么回答?大多数人会觉得莫名其妙,然后他们会问这个人他们想问“北京”什么。同样,如果你在搜索引擎中输入一个关键词“北京”,搜索引擎也不知道你在找什么,可能会返回很多莫名其妙的结果。因此,你必须养成使用多次关键词 搜索的习惯。当然,大多数情况下,使用两个 关键词 搜索就足够了, 关键词 和 关键词 之间用空格隔开。
比如想了解北京旅游,可以进入“北京旅游”获取北京旅游相关信息。
三、学会使用减号“-”
“-”的作用是去除不相关的搜索结果,提高搜索结果的相关性。有时,您会在搜索结果中看到一些想要的结果,但也会发现许多不相关的搜索结果。这时候就可以找出那些无关结果关键词的特征,并减去它们。
一个成功的搜索由两部分组成:正确的搜索关键词,和有用的搜索结果。在您点击任何搜索结果之前,快速分析您搜索结果的标题、网址和摘要,这将帮助您选择更准确的结果,并为您节省大量时间。当然,您需要哪一种内容取决于您要查找的内容。评估网络内容的质量和权威性是搜索中的重要一步。一次成功的搜索通常由多次搜索组成。如果您不熟悉您要搜索的内容,即使是搜索专家也无法保证您会在第一次搜索中找到您想要的内容。搜索专家将首先使用一个简单的 关键词 测试。他们不会忙于仔细检查每个搜索结果,而是首先从搜索结果页面中寻找更多信息,
科学爬取关键词包括两种情况:一种是根据内容选择关键词,另一种是根据关键词选择内容。
根据内容确定关键词。我想用我做过的一个话题来解释这种情况。
前不久网上热议的“力拓案”。毫无疑问,这是一条备受业界关注的热点消息。我们围绕此新闻事件拟定的主要 关键词 包括:力拓公司简介、力拓集团、铁矿石谈判以及参与事件的各方。之后会有关键词话题:力拓铁矿石、09铁矿石谈判、力拓铁矿石等关键词。
随着局势的发展,我们中断了谈判。这时候就要抓住以下关键词:力拓、可疑链接、调查等,相关信息文章也会在这个时候出现。关键词应该是:力拓年产量、力拓铁矿石储量、力拓石粉等信息字样。同时,发散思维也很重要,还需要采集力拓案的相关侧面信息(参考关键词:日本和力拓铁矿石,日本和力拓铁矿石谈判价格,巴西铁矿石等)。
此后,事件进一步升级,中方还逮捕了涉嫌间谍的力拓驻上海代表。这个时候我们要把握人们关注的词。预先确定的关键词还必须包括:力拓案、力拓间谍案、力拓间谍门、力拓间谍事件、力拓间谍泄密事件等。我们想围绕这些给本报告一个圆满的结论关键词。
通过分析我对这个事件的报道过程,我们可以总结出这个事件的捕获原理关键词:1.我们选择的关键词必须是用户会使用的词或词组搜索。2. 也是用户可能用来搜索的潜在术语。3. 不能泛泛而无具体内容。4.抓住事件讨论的中心。
根据关键词选择内容。这就是上述方法的反执行。首先,我们必须列出所有关键词 人正在关注的内容。然后使用关键词的这些不同组合来抓取内容。这是一种根据需求查找内容的方法。效果也不错。
(编辑/周扬)
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-18 10:11
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬虫”并不是特别准确,因为“爬虫”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过,这个文章主要解释了第二种“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只是想把所有的产品在网站上列出价格,放到Excel中对比等等,可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字整理好放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们必须了解如何使用 Python 来实现它。实现原理基本上分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最好是总结最后一张漂亮的Excel表格:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,也没有给出实际的代码。
但是,这个想法几乎是网络爬虫的通用例程。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅! 查看全部
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬虫”并不是特别准确,因为“爬虫”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过,这个文章主要解释了第二种“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只是想把所有的产品在网站上列出价格,放到Excel中对比等等,可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字整理好放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们必须了解如何使用 Python 来实现它。实现原理基本上分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最好是总结最后一张漂亮的Excel表格:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,也没有给出实际的代码。
但是,这个想法几乎是网络爬虫的通用例程。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅!
抓取网页新闻( Python中解析网页的基本流程和使用方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-14 04:19
Python中解析网页的基本流程和使用方法(上))
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据
本文将以爬取并存储B站视频热搜榜数据为例,详细介绍Python爬虫的基本流程。
如果你还处于爬取的入门阶段或者不知道爬取的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在开始,并运行以下代码
在上面的代码中,我们完成了以下三件事
进口
使用方法构造请求
使用获取网页状态码
可以看到返回值为 ,表示服务器响应正常,表示我们可以继续
第 2 步:解析页面
在上一步中,我们通过requests向网站请求数据后,成功得到了一个收录服务器资源的Response对象,现在我们可以使用它来查看它的内容了
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以用,也可以用,或者,本文将基于BeautifulSoup进行讲解
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据
安装也很简单,使用安装即可
让我们用一个简单的例子来说明它是如何工作的
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。请注意,使用时需要指定解析器。这里我们使用
然后就可以获取其中一个结构元素及其属性,比如用 获取页面标题,也可以使用 等获取任何需要的元素
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用来定位元素,但我更习惯使用 CSS 选择器,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页按F12按照下面的说明找到
可以看到每个视频信息都包裹在li标签下,那么代码可以这样写
在上面的代码中,我们先使用它,然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用 CSS 选择器来提取我们想要的字段信息,并在开头以字典的形式存储定义好的空列表
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用模块来写,需要注意设置编码,否则会出现中文乱码问题
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
-结尾- 查看全部
抓取网页新闻(
Python中解析网页的基本流程和使用方法(上))
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据
本文将以爬取并存储B站视频热搜榜数据为例,详细介绍Python爬虫的基本流程。
如果你还处于爬取的入门阶段或者不知道爬取的具体工作流程,那么你应该仔细阅读这篇文章!
第 1 步:尝试请求
先进入b站首页,点击排行榜,复制链接
现在开始,并运行以下代码
在上面的代码中,我们完成了以下三件事
进口
使用方法构造请求
使用获取网页状态码
可以看到返回值为 ,表示服务器响应正常,表示我们可以继续
第 2 步:解析页面
在上一步中,我们通过requests向网站请求数据后,成功得到了一个收录服务器资源的Response对象,现在我们可以使用它来查看它的内容了
可以看到返回的是一个字符串,里面收录了我们需要的热榜视频数据,但是直接从字符串中提取内容复杂且效率低,所以我们需要对其进行解析,将字符串转换成网页结构数据,即使查找 HTML 标记及其属性和内容变得容易。
Python解析网页的方式有很多种,可以用,也可以用,或者,本文将基于BeautifulSoup进行讲解
Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据
安装也很简单,使用安装即可
让我们用一个简单的例子来说明它是如何工作的
在上面的代码中,我们通过bs4中的BeautifulSoup类将上一步得到的html格式字符串转换成BeautifulSoup对象。请注意,使用时需要指定解析器。这里我们使用
然后就可以获取其中一个结构元素及其属性,比如用 获取页面标题,也可以使用 等获取任何需要的元素
第三步:提取内容
上面两步中,我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:如何从解析后的页面中提取出需要的内容。
在 Beautiful Soup 中,我们可以使用来定位元素,但我更习惯使用 CSS 选择器,因为可以像使用 CSS 选择元素一样沿着 DOM 树向下移动
现在我们用代码来说明如何从解析后的页面中提取B站热榜的数据。首先,我们需要找到存储数据的标签,在列表页按F12按照下面的说明找到
可以看到每个视频信息都包裹在li标签下,那么代码可以这样写
在上面的代码中,我们先使用它,然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用 CSS 选择器来提取我们想要的字段信息,并在开头以字典的形式存储定义好的空列表
可以注意到我使用了多种选择方法来提取元素,这也是选择方法的灵活性。有兴趣的读者可以自行进一步研究。
第 4 步:存储数据
通过前三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。
如果对pandas不熟悉,可以使用模块来写,需要注意设置编码,否则会出现中文乱码问题
如果您熟悉 pandas,您可以通过一行代码轻松地将字典转换为 DataFrame
概括
至此,我们已经成功使用Python将b站热门视频列表的数据存储在本地。大多数基于请求的爬虫基本上都遵循以上四个步骤。
不过,虽然看起来很简单,但在实景中的每一步都不是那么容易的。从请求数据来看,目标网站有各种形式的反爬取、加密,以及后期分析、提取甚至存储数据。需要进一步探索和学习。
本文选择B站视频热榜,正是因为够简单。希望通过这个案例大家可以了解爬虫的基本流程,最后附上完整代码
-结尾-
抓取网页新闻( 2017年04月21日Python正则抓取网易新闻的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-14 04:02
2017年04月21日Python正则抓取网易新闻的方法
)
Python正则爬取网易新闻的方法示例
更新时间:2017-04-21 14:37:22 作者:Shine I want
本文文章主要介绍Python中定时抓取网易新闻的方法,并详细分析使用Python使用正则表达式抓取网易新闻的实现技巧和注意事项。有需要的朋友可以参考以下
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现它的网页源码和网页上的评论一点都不正确,于是用抓包工具获取了它的评论隐藏地址(各个浏览器有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的
然后打开链接找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(
2017年04月21日Python正则抓取网易新闻的方法
)
Python正则爬取网易新闻的方法示例
更新时间:2017-04-21 14:37:22 作者:Shine I want
本文文章主要介绍Python中定时抓取网易新闻的方法,并详细分析使用Python使用正则表达式抓取网易新闻的实现技巧和注意事项。有需要的朋友可以参考以下
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现它的网页源码和网页上的评论一点都不正确,于是用抓包工具获取了它的评论隐藏地址(各个浏览器有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的
然后打开链接找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(百度快照不是了吗了吗?怎么又冒出来了?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-13 15:10
本文内容围绕百度网页抓取时间展开。很多人可能没有注意到这个细节。那么今天,就为大家揭秘《(最新)百度网页快照抓取时间》。
看标题,你可能会觉得百度快照没了?为什么又出现了?或者这是一个司空见惯的事情,我今天还在谈论它。写这篇文章的时候,我也猜到大家都会这么想,但我相信如果你仔细看,你会发现,会有很多我们没有注意到的地方。或者它可能被遗忘了,或者它可能是我不知道的东西,其余的我不会多说。见下文。
看到这个标题你会有些疑惑,所以为了更好的帮助大家理解,上图直接展示,下图展示如下。
这张图直观地向我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于你有没有注意到,我这里就不多说了。希望这一点能给您带来启发。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取的抓取时间”有什么关系呢?
这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题是,这就是我今天要请你解释的,图中时间的特点是什么?大家可以想一想,也可以随便搜索一个关键词看看,说不定会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先,文章收录的时间非常准确,精确到秒,可见目前的搜索引擎非常强大。
第二点是文章的yield时间多显示在凌晨3:00到8:00之间(注意一般说网页集中在收录的时间段从从凌晨0:00到12:00之间,下午很少)。
第三点,文章如果质量高,可以现场秒收。应该是那个时候的时间,但是圆圈里显示的时间是3点到8点不上班。它是从哪里来的收录?这有点可疑。
小编,看完这里,我想搜索引擎可能会先收录某个网页,然后建立索引(不明白的可以查阅相关资料),如图所示的网页收录时间不是网站收录的真实时间,而是百度建索引的时间。百度建索引的时间是在没有人或者工作量很小的时间段。比如上面提到的凌晨 3:00 到 8:00(但不是所有的都在这个时间段),这段时间很少有人在使用搜索引擎,小编在相关的站长平台,所以大家还是需要认真研究的。
在这里想给大家补充一下,你们有过这样的经历吗?如果你经常查看排名,你有时会发现早上看的排名和下午看的排名会有很大的不同,尤其是早上比较早和晚上比较晚有什么区别?
各种迹象表明搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。所以,这篇文章最重要的一点就是提醒大家,我们可以更深入更详细。了解我们的工作。所有的问题只是给大家的一个提醒。大家深入探索很重要。这是本文的结尾。谢谢你。 查看全部
抓取网页新闻(百度快照不是了吗了吗?怎么又冒出来了?(组图))
本文内容围绕百度网页抓取时间展开。很多人可能没有注意到这个细节。那么今天,就为大家揭秘《(最新)百度网页快照抓取时间》。
看标题,你可能会觉得百度快照没了?为什么又出现了?或者这是一个司空见惯的事情,我今天还在谈论它。写这篇文章的时候,我也猜到大家都会这么想,但我相信如果你仔细看,你会发现,会有很多我们没有注意到的地方。或者它可能被遗忘了,或者它可能是我不知道的东西,其余的我不会多说。见下文。
看到这个标题你会有些疑惑,所以为了更好的帮助大家理解,上图直接展示,下图展示如下。
这张图直观地向我们展示了百度抓取网页的时间。我不知道这个。你注意到了吗?
至于你有没有注意到,我这里就不多说了。希望这一点能给您带来启发。
可能有人注意到了,但是这和你的标题“(最新)百度网页快照抓取的抓取时间”有什么关系呢?
这里就不多说了,直接看图吧。如下所示
图中圈出的部分显然是当前网页为收录的时间,但问题是,这就是我今天要请你解释的,图中时间的特点是什么?大家可以想一想,也可以随便搜索一个关键词看看,说不定会有所发现。
好吧,我将在这里与您分享我的发现和疑问。
首先,文章收录的时间非常准确,精确到秒,可见目前的搜索引擎非常强大。
第二点是文章的yield时间多显示在凌晨3:00到8:00之间(注意一般说网页集中在收录的时间段从从凌晨0:00到12:00之间,下午很少)。
第三点,文章如果质量高,可以现场秒收。应该是那个时候的时间,但是圆圈里显示的时间是3点到8点不上班。它是从哪里来的收录?这有点可疑。
小编,看完这里,我想搜索引擎可能会先收录某个网页,然后建立索引(不明白的可以查阅相关资料),如图所示的网页收录时间不是网站收录的真实时间,而是百度建索引的时间。百度建索引的时间是在没有人或者工作量很小的时间段。比如上面提到的凌晨 3:00 到 8:00(但不是所有的都在这个时间段),这段时间很少有人在使用搜索引擎,小编在相关的站长平台,所以大家还是需要认真研究的。
在这里想给大家补充一下,你们有过这样的经历吗?如果你经常查看排名,你有时会发现早上看的排名和下午看的排名会有很大的不同,尤其是早上比较早和晚上比较晚有什么区别?
各种迹象表明搜索引擎将变得越来越智能。如果我们不能更详细更深入,那么我们可能有一天会被淘汰。所以,这篇文章最重要的一点就是提醒大家,我们可以更深入更详细。了解我们的工作。所有的问题只是给大家的一个提醒。大家深入探索很重要。这是本文的结尾。谢谢你。
抓取网页新闻(试试超星阅读视频方面的文件汇总贴(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-09 17:01
抓取网页新闻推荐,这些app都有自己的新闻联盟,自己的新闻源。百度搜索——媒体公司——新闻源总结主流新闻源,
[]
可以用一个小工具,使用零门槛,真正的自己动手丰衣足食,通过注册就可以获得价值40万的40w历史文章,省去你去网上找资源的时间。
哈哈,这个就是,自己用来下载资源的,就是收费,
新闻以外,推荐一个教育领域的英文资源检索网站,帮助我解决了大量数学公式和英文语法错误的问题。
试试超星阅读
视频方面的,在b站看纪录片方面大神们总结的文件汇总贴,特别详细希望能对你有帮助。
中国大学mooc,
虽然说网上有很多资源,但是找到的时候你可能需要在整理一下;或者你可以在相关的新闻网站中去搜,也可以在同一个公众号找,或者找那些针对特定群体的微信公众号里面的资源,比如说医学相关,音乐类公众号等,具体哪些是比较好的,要看他们发的文章时间来决定;还有一种最省事的方法,你可以上某宝上面看看那些卖资源的商家,有时候他们的资源比较齐全,还有不同的加速模式。
最后说一下,在开通网上个人账号()前先问一下:现在注册还能不能解封一次?如果不能,那么等过了注册的时间后,他们都会全部删除你在注册时注册好的账号。具体你要知道的方法是:在一开始注册,应该点一下“免费申请”,能不能转成功还得看造化,如果不能申请,那估计你就得心灰意冷不玩了了,然后你去找别的公众号资源。祝你好运~。 查看全部
抓取网页新闻(试试超星阅读视频方面的文件汇总贴(图))
抓取网页新闻推荐,这些app都有自己的新闻联盟,自己的新闻源。百度搜索——媒体公司——新闻源总结主流新闻源,
[]
可以用一个小工具,使用零门槛,真正的自己动手丰衣足食,通过注册就可以获得价值40万的40w历史文章,省去你去网上找资源的时间。
哈哈,这个就是,自己用来下载资源的,就是收费,
新闻以外,推荐一个教育领域的英文资源检索网站,帮助我解决了大量数学公式和英文语法错误的问题。
试试超星阅读
视频方面的,在b站看纪录片方面大神们总结的文件汇总贴,特别详细希望能对你有帮助。
中国大学mooc,
虽然说网上有很多资源,但是找到的时候你可能需要在整理一下;或者你可以在相关的新闻网站中去搜,也可以在同一个公众号找,或者找那些针对特定群体的微信公众号里面的资源,比如说医学相关,音乐类公众号等,具体哪些是比较好的,要看他们发的文章时间来决定;还有一种最省事的方法,你可以上某宝上面看看那些卖资源的商家,有时候他们的资源比较齐全,还有不同的加速模式。
最后说一下,在开通网上个人账号()前先问一下:现在注册还能不能解封一次?如果不能,那么等过了注册的时间后,他们都会全部删除你在注册时注册好的账号。具体你要知道的方法是:在一开始注册,应该点一下“免费申请”,能不能转成功还得看造化,如果不能申请,那估计你就得心灰意冷不玩了了,然后你去找别的公众号资源。祝你好运~。
抓取网页新闻(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-08 21:04
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。比如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站抓取网页。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是存储大量的历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页所显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈! 查看全部
抓取网页新闻(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。比如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站抓取网页。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是存储大量的历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页所显示的一些属性对许多相似的网页进行分类,分类后的网页按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
抓取网页新闻(我想结合两个库(例如报纸和beautifulsoup4)的代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-06 00:09
)
我一直试图从新闻中获取新闻头条网站。为此,我遇到了两个 python 库,即 news 和 beautifulsoup4。使用美汤库,我已经能够从特定新闻网站中获取到新闻文章的所有链接。从下面的代码中,我已经能够从单个链接中提取新闻标题 文章。
from newspaper import Article
url= "https://www.ndtv.com/india-new ... ot%3B
article=Article(url)
article.download()
article.parse()
print(article.title)
我想把两个库的代码(比如newspaper和beautifulsoup4),这样我就可以把我从beautifulsoup库输出的所有链接放到报纸库的url命令中,得到所有的头条。链接。下面是beautfulsoup的代码,我可以从中提取新闻文章的所有链接。
from bs4 import BeautifulSoup
from bs4.dammit import EncodingDetector
import requests
parser = 'html.parser' # or 'lxml' (preferred) or 'html5lib', if installed
resp = requests.get("https://www.ndtv.com/coronavir ... 6quot;)
http_encoding = resp.encoding if 'charset' in resp.headers.get('content-type', '').lower() else None
html_encoding = EncodingDetector.find_declared_encoding(resp.content, is_html=True)
encoding = html_encoding or http_encoding
soup = BeautifulSoup(resp.content, parser, from_encoding=encoding)
for link in soup.find_all('a', href=True):
print(link['href']) 查看全部
抓取网页新闻(我想结合两个库(例如报纸和beautifulsoup4)的代码
)
我一直试图从新闻中获取新闻头条网站。为此,我遇到了两个 python 库,即 news 和 beautifulsoup4。使用美汤库,我已经能够从特定新闻网站中获取到新闻文章的所有链接。从下面的代码中,我已经能够从单个链接中提取新闻标题 文章。
from newspaper import Article
url= "https://www.ndtv.com/india-new ... ot%3B
article=Article(url)
article.download()
article.parse()
print(article.title)
我想把两个库的代码(比如newspaper和beautifulsoup4),这样我就可以把我从beautifulsoup库输出的所有链接放到报纸库的url命令中,得到所有的头条。链接。下面是beautfulsoup的代码,我可以从中提取新闻文章的所有链接。
from bs4 import BeautifulSoup
from bs4.dammit import EncodingDetector
import requests
parser = 'html.parser' # or 'lxml' (preferred) or 'html5lib', if installed
resp = requests.get("https://www.ndtv.com/coronavir ... 6quot;)
http_encoding = resp.encoding if 'charset' in resp.headers.get('content-type', '').lower() else None
html_encoding = EncodingDetector.find_declared_encoding(resp.content, is_html=True)
encoding = html_encoding or http_encoding
soup = BeautifulSoup(resp.content, parser, from_encoding=encoding)
for link in soup.find_all('a', href=True):
print(link['href'])
抓取网页新闻( 搜索引擎是怎样抓取文章内容的,它的收录原则大概是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-04 16:02
搜索引擎是怎样抓取文章内容的,它的收录原则大概是什么)
百度搜索引擎是如何抓取页面的?
搜索引擎是如何抓取文章的内容的,它的收录原理是什么。首先声明:以下方法基于本人经验,并非官方的爬取原则。下面我简单说一下:
1、 抓取:
这一步是搜索引擎录入数据的工作。它是如何工作的?比如百度,百度每天都会发布大量的蜘蛛程序,在浩瀚的互联网世界里爬行爬行。作为一个新网站的站长,你必须清楚。问题是,如果网站刚刚成立,百度怎么知道你的网站,所以有句话说我们会招蜘蛛,我们需要多发点人脉或者其他人的网站@在建站初期 > 交换连接。这样做的主要目的是吸引蜘蛛抓取我们的内容。
蜘蛛程序抓取内容时,不做任何处理,先存入临时索引库,也就是说这部分完成后的内容是乱七八糟的,还有各种内容,但是蜘蛛程序仍将被合理归类。, 方便下一步过滤。
2、过滤器:
当该步骤完成后,蜘蛛程序将开始过滤工作。当然,在实际情况中,这些步骤可以同时进行。我们只是来分解它的原理。搜索引擎将根据所捕获内容的级别进行过滤。有用去劣无用,留精华。这就是过滤工作。当然,这些任务的处理过程是比较快的,因为数据处理的时效性是搜索引擎的主要研究问题。
3、存储:
然后搜索引擎会将优质内容存储在自己的硬盘空间中,带有一定的算法索引供以后用户调用,也就是说这里的数据是真实的收录到搜索引擎的数据存储空间中.
4、显示:
当用户搜索某个关键词时,搜索引擎会按照一定的算法将数据库中的内容展示给客户。这种显示索引速度非常快。如果我们在百度上搜索一个词,您就可以看到。它可以快速显示数亿条搜索结果,这也是搜索引擎的核心技术,并且具有非常快速的检索能力。
5、 排名:
其实这一步也是第四步。搜索引擎在向用户显示数据时已经对数据进行了排名。至于这个排名在搜索引擎内部是如何计算的,这是一个内部机密。没人知道。只能猜测了。作为一家搜索引擎公司,其核心技术是抓取、过滤、搜索、排名、展示、执行这些步骤,执行这些步骤的时间越短,其技术越强大。
预防措施:
综上所述,我们应该明白,搜索引擎公司正在研究如何快速为用户提供他们想要的内容。
华旗商城更多产品介绍:微网站建站系统人气微博排行榜专业化妆品网站制作 查看全部
抓取网页新闻(
搜索引擎是怎样抓取文章内容的,它的收录原则大概是什么)
百度搜索引擎是如何抓取页面的?
搜索引擎是如何抓取文章的内容的,它的收录原理是什么。首先声明:以下方法基于本人经验,并非官方的爬取原则。下面我简单说一下:
1、 抓取:
这一步是搜索引擎录入数据的工作。它是如何工作的?比如百度,百度每天都会发布大量的蜘蛛程序,在浩瀚的互联网世界里爬行爬行。作为一个新网站的站长,你必须清楚。问题是,如果网站刚刚成立,百度怎么知道你的网站,所以有句话说我们会招蜘蛛,我们需要多发点人脉或者其他人的网站@在建站初期 > 交换连接。这样做的主要目的是吸引蜘蛛抓取我们的内容。
蜘蛛程序抓取内容时,不做任何处理,先存入临时索引库,也就是说这部分完成后的内容是乱七八糟的,还有各种内容,但是蜘蛛程序仍将被合理归类。, 方便下一步过滤。
2、过滤器:
当该步骤完成后,蜘蛛程序将开始过滤工作。当然,在实际情况中,这些步骤可以同时进行。我们只是来分解它的原理。搜索引擎将根据所捕获内容的级别进行过滤。有用去劣无用,留精华。这就是过滤工作。当然,这些任务的处理过程是比较快的,因为数据处理的时效性是搜索引擎的主要研究问题。
3、存储:
然后搜索引擎会将优质内容存储在自己的硬盘空间中,带有一定的算法索引供以后用户调用,也就是说这里的数据是真实的收录到搜索引擎的数据存储空间中.
4、显示:
当用户搜索某个关键词时,搜索引擎会按照一定的算法将数据库中的内容展示给客户。这种显示索引速度非常快。如果我们在百度上搜索一个词,您就可以看到。它可以快速显示数亿条搜索结果,这也是搜索引擎的核心技术,并且具有非常快速的检索能力。
5、 排名:
其实这一步也是第四步。搜索引擎在向用户显示数据时已经对数据进行了排名。至于这个排名在搜索引擎内部是如何计算的,这是一个内部机密。没人知道。只能猜测了。作为一家搜索引擎公司,其核心技术是抓取、过滤、搜索、排名、展示、执行这些步骤,执行这些步骤的时间越短,其技术越强大。
预防措施:
综上所述,我们应该明白,搜索引擎公司正在研究如何快速为用户提供他们想要的内容。
华旗商城更多产品介绍:微网站建站系统人气微博排行榜专业化妆品网站制作
抓取网页新闻(如何从浩如烟海的网络信息中找寻所需的竞争信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-01-04 15:23
企业间的竞争情报是企业优化所需的重要数据。准确及时的企业竞争情报往往能给企业带来诸多优势。在信息竞争时代,企业竞争情报也变得越来越重要。然而,信息时代在带来海量数据的同时,也给信息处理带来了很大的问题——如何从海量的信息网络中找到必要的竞争信息?
传统的手动检索和排序方法不再可取。在海量数据面前,这些人工获取的小数据根本就显得微不足道、毫无价值。竞争性舆情监测效率低下如何产生效果?网页抓取工具可以智能解决这个问题,帮助企业人员使用自动化软件来操作庞大而复杂的情报信息。
以下是情报监控的一些操作建议:
优采云采集器几乎可以采集所有网页中的任何数据,所以我们需要规划数据来源:对于企业竞争情报、新闻、论坛、博客,贴吧有各种形式的竞赛信息可在、纸质媒体网站等采集,企业人员可根据所从事领域的舆论分布情况进行选择。多方信息必定会更新实时,网络爬虫优采云采集器还可以通过定时任务功能自动动态更新,保证抓取信息的完整性和及时性。
不同的源系统需要不同的配置。灵活多变的优采云采集器不仅可以自动提取标准新闻的正文,还提供了多种配置方式来适应复杂的页面。根据不同的系统设置不同的采集方法,或者根据不同的需要提取某个系统中特定的重要数据,如关键词、新闻摘要、电话号码等,使用最佳配置实现批量和高效的提取。
对获得的情报数据进行智能化管理也很重要。比如在使用采集的网络爬虫工具时,对于同一个URL,优采云采集器只采集最新的文章内容或没有被回复采集,以及已经被采集的内容,会被自动忽略,采集收到的地址或数据需要处理一次自动去除权重,以保证情报数据的准确性。
企业竞争情报信息庞大而复杂。只有满足多源通用、实时更新、去重爬取要求的网络爬虫工具,才能智能解决智能监控的需求。随着信息技术的进一步发展,企业竞争情报监控也将变得更加精细。智能高效。 查看全部
抓取网页新闻(如何从浩如烟海的网络信息中找寻所需的竞争信息)
企业间的竞争情报是企业优化所需的重要数据。准确及时的企业竞争情报往往能给企业带来诸多优势。在信息竞争时代,企业竞争情报也变得越来越重要。然而,信息时代在带来海量数据的同时,也给信息处理带来了很大的问题——如何从海量的信息网络中找到必要的竞争信息?
传统的手动检索和排序方法不再可取。在海量数据面前,这些人工获取的小数据根本就显得微不足道、毫无价值。竞争性舆情监测效率低下如何产生效果?网页抓取工具可以智能解决这个问题,帮助企业人员使用自动化软件来操作庞大而复杂的情报信息。
以下是情报监控的一些操作建议:
优采云采集器几乎可以采集所有网页中的任何数据,所以我们需要规划数据来源:对于企业竞争情报、新闻、论坛、博客,贴吧有各种形式的竞赛信息可在、纸质媒体网站等采集,企业人员可根据所从事领域的舆论分布情况进行选择。多方信息必定会更新实时,网络爬虫优采云采集器还可以通过定时任务功能自动动态更新,保证抓取信息的完整性和及时性。
不同的源系统需要不同的配置。灵活多变的优采云采集器不仅可以自动提取标准新闻的正文,还提供了多种配置方式来适应复杂的页面。根据不同的系统设置不同的采集方法,或者根据不同的需要提取某个系统中特定的重要数据,如关键词、新闻摘要、电话号码等,使用最佳配置实现批量和高效的提取。
对获得的情报数据进行智能化管理也很重要。比如在使用采集的网络爬虫工具时,对于同一个URL,优采云采集器只采集最新的文章内容或没有被回复采集,以及已经被采集的内容,会被自动忽略,采集收到的地址或数据需要处理一次自动去除权重,以保证情报数据的准确性。
企业竞争情报信息庞大而复杂。只有满足多源通用、实时更新、去重爬取要求的网络爬虫工具,才能智能解决智能监控的需求。随着信息技术的进一步发展,企业竞争情报监控也将变得更加精细。智能高效。
抓取网页新闻(学习机器学习算法,分为回归,分类,爬取一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-03 13:15
)
作者简历地址:
Python爬虫一步步爬取文章背景
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据可以练习。我想爬取国内各大网站的新闻,通过训练,然后对未来的新闻做一个分类预测。在这样的背景下,我开始了我的爬虫之路。
网站分析
国内重大新闻摘要网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。 . .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了两个包,urllib2和BeautifulSoup。以搜狐新闻为例,我们做了一个简单的爬虫,爬取内容没有任何优化问题,所以会出现假死的情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
在运行上述代码的过程中,会遇到一些问题,导致爬虫停止运行,速度变慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后设置爬虫代理来解决IP问题。代码如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果你找不到一个网页,就丢弃它,因为丢弃少量的网页不会影响你以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
至于速度慢的问题,可以采用多进程的方式进行爬取。解析URL后,可以在Redis中使用一个有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。 (尚未实施)
第 4 步:运行
昨晚试了一下,爬到搜狐新闻的一些网页。大概是50*5*15=3750多个网页,解析出2000多条新闻,网速接近1Mbps。 , 耗时 1101s,约 18 分钟。
查看全部
抓取网页新闻(学习机器学习算法,分为回归,分类,爬取一下
)
作者简历地址:
Python爬虫一步步爬取文章背景
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据可以练习。我想爬取国内各大网站的新闻,通过训练,然后对未来的新闻做一个分类预测。在这样的背景下,我开始了我的爬虫之路。
网站分析
国内重大新闻摘要网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。 . .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了两个包,urllib2和BeautifulSoup。以搜狐新闻为例,我们做了一个简单的爬虫,爬取内容没有任何优化问题,所以会出现假死的情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
在运行上述代码的过程中,会遇到一些问题,导致爬虫停止运行,速度变慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后设置爬虫代理来解决IP问题。代码如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果你找不到一个网页,就丢弃它,因为丢弃少量的网页不会影响你以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
至于速度慢的问题,可以采用多进程的方式进行爬取。解析URL后,可以在Redis中使用一个有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。 (尚未实施)
第 4 步:运行
昨晚试了一下,爬到搜狐新闻的一些网页。大概是50*5*15=3750多个网页,解析出2000多条新闻,网速接近1Mbps。 , 耗时 1101s,约 18 分钟。
抓取网页新闻(本篇文章主要介绍了JAVA爬虫GeccoGecco工具抓取新闻实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-01 19:15
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawlergecco1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines") public class ZJNewsGeccoList implements HtmlBean { @Request private HttpRequest request; @RequestParameter private int pageIndex; @RequestParameter private int pageSize; @HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a") private List newList; }
@PipelineName("zJNewsListPipelines") public class ZJNewsListPipelines implements Pipeline { public void process(ZJNewsGeccoList zjNewsGeccoList) { HttpRequest request=zjNewsGeccoList.getRequest(); for (HrefBean bean:zjNewsGeccoList.getNewList()){ //进入祥情页面抓取 SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl())); } int page=zjNewsGeccoList.getPageIndex()+1; String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B //抓取下一页 SchedulerContext.into(request.subRequest(nextUrl)); } }
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline") public class ZJNewsDetail implements HtmlBean { @Text @HtmlField(cssPath = "#headline") private String title ; @Text @HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray") private String createTime; }
@PipelineName("zjNewsDetailPipeline") public class ZJNewsDetailPipeline implements Pipeline { public void process(ZJNewsDetail zjNewsDetail) { System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime()); } }
启动主函数
public class Main { public static void main(String [] rags){ GeccoEngine.create() //工程的包路径 .classpath("com.zhaochao.gecco.zj") //开始抓取的页面地址 .start("http://zj.zjol.com.cn/home.htm ... 6quot;) //开启几个爬虫线程 .thread(10) //单个爬虫每次抓取完一个请求后的间隔时间 .interval(10) //使用pc端userAgent .mobile(false) //开始运行 .run(); } }
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文站。
以上是Java爬虫Gecco工具抓取新闻实例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
抓取网页新闻(本篇文章主要介绍了JAVA爬虫GeccoGecco工具抓取新闻实例)
本文文章主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
我最近看到了 Gecoo 爬虫工具。感觉比较简单,好用。写个DEMO测试一下,抓起来网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawlergecco1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines") public class ZJNewsGeccoList implements HtmlBean { @Request private HttpRequest request; @RequestParameter private int pageIndex; @RequestParameter private int pageSize; @HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a") private List newList; }
@PipelineName("zJNewsListPipelines") public class ZJNewsListPipelines implements Pipeline { public void process(ZJNewsGeccoList zjNewsGeccoList) { HttpRequest request=zjNewsGeccoList.getRequest(); for (HrefBean bean:zjNewsGeccoList.getNewList()){ //进入祥情页面抓取 SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl())); } int page=zjNewsGeccoList.getPageIndex()+1; String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B //抓取下一页 SchedulerContext.into(request.subRequest(nextUrl)); } }
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline") public class ZJNewsDetail implements HtmlBean { @Text @HtmlField(cssPath = "#headline") private String title ; @Text @HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray") private String createTime; }
@PipelineName("zjNewsDetailPipeline") public class ZJNewsDetailPipeline implements Pipeline { public void process(ZJNewsDetail zjNewsDetail) { System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime()); } }
启动主函数
public class Main { public static void main(String [] rags){ GeccoEngine.create() //工程的包路径 .classpath("com.zhaochao.gecco.zj") //开始抓取的页面地址 .start("http://zj.zjol.com.cn/home.htm ... 6quot;) //开启几个爬虫线程 .thread(10) //单个爬虫每次抓取完一个请求后的间隔时间 .interval(10) //使用pc端userAgent .mobile(false) //开始运行 .run(); } }
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文站。
以上是Java爬虫Gecco工具抓取新闻实例的详细内容。更多详情请关注其他相关html中文网站文章!
抓取网页新闻(神龙IP一起常见的抓取策略及算法策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-01 00:14
网络爬虫,又称网络蜘蛛,是一种根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新抓取到的URL放入抓取队列,然后进行新一轮抓取,直到抓取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。 URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但无论采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到要爬取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP 策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大网站优先(大网站优先)
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果网站中等待下载的页面最多,则优先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页质量普遍较高,这个想法很简单,但是有一定的依据。 查看全部
抓取网页新闻(神龙IP一起常见的抓取策略及算法策略)
网络爬虫,又称网络蜘蛛,是一种根据一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新抓取到的URL放入抓取队列,然后进行新一轮抓取,直到抓取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。 URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但无论采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到要爬取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP 策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大网站优先(大网站优先)
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果网站中等待下载的页面最多,则优先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页质量普遍较高,这个想法很简单,但是有一定的依据。
抓取网页新闻(目录本篇博客又双叒叕为各位分享分享Python库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-31 02:27
)
内容
本博客还为大家分享了一个Python库:GeneralNewsExtractor(GNE),它是一个通用新闻网站文本提取模块,输入一个新闻网页的HTML,输出文本内容、标题、作者、发表时间、正文中图片的地址、正文所在标签的源码。 GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,几乎可以达到100%的准确率。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。
1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功的效果如下:
2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:
右键查看本页源码文章,如下图:
复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:
如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result) 查看全部
抓取网页新闻(目录本篇博客又双叒叕为各位分享分享Python库
)
内容
本博客还为大家分享了一个Python库:GeneralNewsExtractor(GNE),它是一个通用新闻网站文本提取模块,输入一个新闻网页的HTML,输出文本内容、标题、作者、发表时间、正文中图片的地址、正文所在标签的源码。 GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,几乎可以达到100%的准确率。 .
需要明白:GeneralNewsExtractor(GNE)不是爬虫,是为了避免不必要的风险。因此,本项目的输入是HTML源代码,输出是字典。请使用适当的方法自行获取目标网站 HTML。
1、安装模块
GeneralNewsExtractor 模块的安装说明如下:
pip install gne
安装成功的效果如下:
2、提取网页内容
这次打算提取最新时事,选择网易新闻,文章如下图:
右键查看本页源码文章,如下图:
复制源码 接下来,5行代码提取新闻内容,如下图:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
效果如下:
如果标题自动提取失败,可以指定XPath,代码如下:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
抓取网页新闻(抓取网页新闻数据需要一定的工具去哪儿网站爬虫工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-28 18:05
抓取网页新闻数据需要一定的工具,去哪儿网站爬虫工具不错,可以自己试一下。也可以看下我写的一个爬虫,
一、目标说明爬取51网-首页新闻,条数100条。
二、数据获取技术获取完全网站一整套新闻数据的方法:采集器,抓包,传码。采集器类似于“桥梁”,把原始链接和新闻链接“拧”在一起,解析生成新闻链接;-)比如:在该网站上,有这样一段url,首页新闻是这样的:点击新闻链接,在工具中对url进行解析:程序获取了url列表和新闻链接,结果如下:我们是在程序中获取新闻数据,可能使用大量循环代码操作url,导致io操作异常,我们可以做图像操作并用threadlocal存储url列表,好消息是,threadlocal支持将url存储到持久化内存中,如果running状态为true,则该内存中的url将一直存在,内存中的对象与磁盘上的数据一致,sowhat!...记得将context映射到写入内存。
第二个问题:在页面打开的瞬间不断获取新闻链接,导致网络io操作异常,我们将新闻链接传给python去哪儿网站抓包工具抓取完全网站新闻数据对象,然后start。程序代码如下:第三个问题:传码类似于给链接赋值,可以理解为对串中的新闻链接进行二值化,将值赋值给数据库中的对象,方便操作url后续给数据库的那些新闻链接对象放入threadlocal,等待有效的runninginthread。
当我们获取新闻列表中第100个新闻时,传入threadlocal值为0。第四个问题:时间获取完全网站新闻数据所用时间,一般是在凌晨1-2点之间,建议选择晚上10点以后的时间,原因是:1.需要注意的是新闻发布时间不是每分每秒都完全一样,即便是4h或5h,新闻发布时间或许只是某一段时间内比较大的那么几条。
比如你12:10发布的新闻,有可能在凌晨0:00出现在新闻列表中,也有可能在午夜或下午2:00再次出现在新闻列表中。2.当python从网站上获取到目标数据对象后,程序就将目标链接传给客户端get请求方法,get请求需要重定向一次,具体可以看一下请求头:从而可以简单判断是否发起二次请求。
上述四个问题,python都能提供解决方案,我们只需要安装time模块即可,代码如下:importtimeclassurldemo(object):"""#如果有链接超过100行,程序将自动跳过删除。getrequest=time。time()if__name__=='__main__':url='/'fromurllibimportrequestone=0element=request。get(url)iftime。sleep(0。
1):iffunction(urldemo):print(urldemo) 查看全部
抓取网页新闻(抓取网页新闻数据需要一定的工具去哪儿网站爬虫工具)
抓取网页新闻数据需要一定的工具,去哪儿网站爬虫工具不错,可以自己试一下。也可以看下我写的一个爬虫,
一、目标说明爬取51网-首页新闻,条数100条。
二、数据获取技术获取完全网站一整套新闻数据的方法:采集器,抓包,传码。采集器类似于“桥梁”,把原始链接和新闻链接“拧”在一起,解析生成新闻链接;-)比如:在该网站上,有这样一段url,首页新闻是这样的:点击新闻链接,在工具中对url进行解析:程序获取了url列表和新闻链接,结果如下:我们是在程序中获取新闻数据,可能使用大量循环代码操作url,导致io操作异常,我们可以做图像操作并用threadlocal存储url列表,好消息是,threadlocal支持将url存储到持久化内存中,如果running状态为true,则该内存中的url将一直存在,内存中的对象与磁盘上的数据一致,sowhat!...记得将context映射到写入内存。
第二个问题:在页面打开的瞬间不断获取新闻链接,导致网络io操作异常,我们将新闻链接传给python去哪儿网站抓包工具抓取完全网站新闻数据对象,然后start。程序代码如下:第三个问题:传码类似于给链接赋值,可以理解为对串中的新闻链接进行二值化,将值赋值给数据库中的对象,方便操作url后续给数据库的那些新闻链接对象放入threadlocal,等待有效的runninginthread。
当我们获取新闻列表中第100个新闻时,传入threadlocal值为0。第四个问题:时间获取完全网站新闻数据所用时间,一般是在凌晨1-2点之间,建议选择晚上10点以后的时间,原因是:1.需要注意的是新闻发布时间不是每分每秒都完全一样,即便是4h或5h,新闻发布时间或许只是某一段时间内比较大的那么几条。
比如你12:10发布的新闻,有可能在凌晨0:00出现在新闻列表中,也有可能在午夜或下午2:00再次出现在新闻列表中。2.当python从网站上获取到目标数据对象后,程序就将目标链接传给客户端get请求方法,get请求需要重定向一次,具体可以看一下请求头:从而可以简单判断是否发起二次请求。
上述四个问题,python都能提供解决方案,我们只需要安装time模块即可,代码如下:importtimeclassurldemo(object):"""#如果有链接超过100行,程序将自动跳过删除。getrequest=time。time()if__name__=='__main__':url='/'fromurllibimportrequestone=0element=request。get(url)iftime。sleep(0。
1):iffunction(urldemo):print(urldemo)
抓取网页新闻(公众号的第一篇文章,就先来介绍介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-12-27 22:15
在公众号的第一篇文章中,介绍一下我做过的最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载。今天我将在python中实现它。这个爬虫我已经多次跟别人说过了,在双星的舞台上,在新生的导航课上(两次),在课堂上。其实现在回过头来看这个爬虫真的很low很简单,但是好歹也是花了很长时间才学会的,所以今天就用python系统地实现一下吧。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官网。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要的信息是什么(其实这一步一定要在你写爬虫之前确定)。这里我们需要的是新闻标题、日期、作者、正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里
标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,对解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面会在专门学习BeautifulSoup的部分学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签,赋值给title
但是当我们输出这段代码时,问题就来了
结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再补充一点,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
相信如果你之前什么都做到了,这一步你就会很熟练了。首先找到文本所在的div为class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。我们在浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码,发现翻页标签链接收录
xydt/
网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录
info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你能做到这一步,你已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再重新梳理一下这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获取到网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们要设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护电脑。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。文章开头我说我觉得这个爬虫非常低级和简单,但是我实际操作它花了两天时间。当然,这两天并不是所有人都在写程序。实习的时候写的。似乎一切都不容易。让我们一步一步来。 查看全部
抓取网页新闻(公众号的第一篇文章,就先来介绍介绍(组图))
在公众号的第一篇文章中,介绍一下我做过的最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载。今天我将在python中实现它。这个爬虫我已经多次跟别人说过了,在双星的舞台上,在新生的导航课上(两次),在课堂上。其实现在回过头来看这个爬虫真的很low很简单,但是好歹也是花了很长时间才学会的,所以今天就用python系统地实现一下吧。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官网。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要的信息是什么(其实这一步一定要在你写爬虫之前确定)。这里我们需要的是新闻标题、日期、作者、正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里
标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,对解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面会在专门学习BeautifulSoup的部分学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签,赋值给title
但是当我们输出这段代码时,问题就来了
结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再补充一点,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
相信如果你之前什么都做到了,这一步你就会很熟练了。首先找到文本所在的div为class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。我们在浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码,发现翻页标签链接收录
xydt/
网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录
info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你能做到这一步,你已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再重新梳理一下这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获取到网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们要设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护电脑。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。文章开头我说我觉得这个爬虫非常低级和简单,但是我实际操作它花了两天时间。当然,这两天并不是所有人都在写程序。实习的时候写的。似乎一切都不容易。让我们一步一步来。
抓取网页新闻(站内网站站点抓取使用思路介绍--抓取网页新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-27 07:03
抓取网页新闻是很多中小卖家都在做的一项工作,如果仅仅是使用工具去抓取获取就比较乏味,效率也不会太高。作为一个seo优化者,一定要通过我们自己的研究和经验去梳理一个自己最终想要的抓取方式,因为现在网站已经进入白热化的竞争阶段,比的就是谁更专业,也就是谁对搜索引擎更熟悉。通过学习掌握一定的抓取工具有助于我们对本站站点抓取使用思路。
1、浏览器抓取工具:比如allinone,iim,nec,robots.txt,tampermonkey,cheapflightlibrary。
2、站内抓取工具:比如index.php,taobao.php,
3、从一些高权重网站直接抓取所需要的文章。站外抓取工具:比如baiduspider,windowssearch.php这样的软件,我是不建议中小卖家去使用,现在市面上太多了,良莠不齐,抓取网站可以用作站内外seo数据收集作用,但是千万不要用作站外推广作用。我分享的文章源自yahoo!seo,chinas的seo工具抓取软件,chinas早期由hao123教主张朝阳老师创建,前几年被360收购了,但是相信seoer都听说过360的技术,所以chinas是非常好用的抓取工具。
4、通过一些seo工具网站,搜索搜索文章链接,整理一下,引导转化到公众号平台。后期我会继续分享一些其他方面的站内网站进行抓取使用。 查看全部
抓取网页新闻(站内网站站点抓取使用思路介绍--抓取网页新闻)
抓取网页新闻是很多中小卖家都在做的一项工作,如果仅仅是使用工具去抓取获取就比较乏味,效率也不会太高。作为一个seo优化者,一定要通过我们自己的研究和经验去梳理一个自己最终想要的抓取方式,因为现在网站已经进入白热化的竞争阶段,比的就是谁更专业,也就是谁对搜索引擎更熟悉。通过学习掌握一定的抓取工具有助于我们对本站站点抓取使用思路。
1、浏览器抓取工具:比如allinone,iim,nec,robots.txt,tampermonkey,cheapflightlibrary。
2、站内抓取工具:比如index.php,taobao.php,
3、从一些高权重网站直接抓取所需要的文章。站外抓取工具:比如baiduspider,windowssearch.php这样的软件,我是不建议中小卖家去使用,现在市面上太多了,良莠不齐,抓取网站可以用作站内外seo数据收集作用,但是千万不要用作站外推广作用。我分享的文章源自yahoo!seo,chinas的seo工具抓取软件,chinas早期由hao123教主张朝阳老师创建,前几年被360收购了,但是相信seoer都听说过360的技术,所以chinas是非常好用的抓取工具。
4、通过一些seo工具网站,搜索搜索文章链接,整理一下,引导转化到公众号平台。后期我会继续分享一些其他方面的站内网站进行抓取使用。
抓取网页新闻( 本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-26 17:22
本文实例讲述了Python正则抓取网易新闻的方法。分享
)
Python常规如何抓取网易新闻的例子,python抓取网易新闻
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬虫爬网易新闻,发现它的网页源代码和网页上的评论根本不正确,所以我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神的改写改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(
本文实例讲述了Python正则抓取网易新闻的方法。分享
)
Python常规如何抓取网易新闻的例子,python抓取网易新闻
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬虫爬网易新闻,发现它的网页源代码和网页上的评论根本不正确,所以我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神的改写改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(为什么分析的时候要把html标签过滤掉呢?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-23 09:13
)
前两种方法还是比较容易实现的,主要是处理比较简单。我之前实现了标签密度提取算法,但实际使用中的错误率还是比较高的;后两种方法在实现上稍微复杂一些。就算法效率而言,应该不会高很多。
我们需要的是一种简单易实现的算法,可以保证处理速度和提取精度。因此,结合前两种算法,研究网页的html页面结构,有更好的处理思路,称为基于文本密度的文本提取算法。后来在网上搜索了类似的算法,发现也有类似的处理方法用于处理文本提取,但还是有一些区别的。接下来和大家分享一下这个算法的一些处理思路。
网络分析
我随意从百度、搜狐、网易上拿了一个新闻页面进行分析。
先看一篇关于百度文章的文章
为什么任正非主动跟我合影,
首先请求这个页面,然后过滤到所有的html标签,只保留文本信息,我们可以看到文本信息集中在以下位置:
用Excel分析行数与每行字符的关系可以发现:
很明显,文字内容集中在65-100行之间的位置,这个区间的字符数也比较密集。
网易的另一篇文章文章
张小龙神话破灭,马化腾接管微信。
我们先看过滤html标签后的body部分:
这是另一个Excel分析结果:
正文部分集中在第 279-282 行之间。从图中可以看出,正是这几行的文字密度特别高。
最后分析一个搜狐新闻
李克强在天津考察考察的片刻,
我们先看post标签后面的文字:
再看Excel的分析结果:
搜狐文章的正文主要集中在第200-255行。剩下的文字都是乱七八糟的标签文字。
抱歉,我漏掉了很重要的一点:为什么我分析的时候会过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关心的是文本的内容,如果你携带这样的标签 style="color: #0000ff;">var chart = style="color: #0000ff;"> newstyle="color: #000000;">进行分析,可以想象一下会对我们的文本分析造成多大的干扰,为此我们需要去掉html标签,只对文本进行分析以减少干扰干涉。
基于网页分析构思的文本提取算法
回顾上面的网页分析,如果根据文本密度找到提取的文本,那么这是一个算法,可以在过滤html标签后从文本中找到文本的开始和结束行号。行号之间的文本是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文本密度远高于非正文部分。根据这个特点,我们可以很容易的实现算法,就是根据阈值(发音:yu)值来分析文本的位置。
那么有一些问题需要解决:
可以通过统计分析来确定阈值以获得更好的值。在实际的处理过程中,我发现这个值取180比较合适。也就是在分析文本的时候,如果分析的文本超过180,那么就可以认为该文本已经达到了。
然后是如何分析的问题。这实际上更容易确定。逐行分析肯定不好。如果在逐行分析的过程中分析几行,最好将几行分析为一个分析。即一次分析上面的5行,将字符相加,看是否达到阈值。如果达到阈值,则认为它已经进入了身体部位。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
核心提取算法不到60行。经过验证,提取效果还是很好的。至少达到90%的文本提取正确率,效率平均提取时间30ms左右。
一些需要解决的问题
html标签去除:这个很简单,直接用正则表达式替换(Regex.Replace(html, "(?is)", ""))来去除所有html标签
html压缩网页的处理:压缩后的html代码一般只有一行,这类html的处理比较简单(不需要复杂的代码格式化),直接在标签末尾加一个换行符即可。
正文标题:大多数标准 URL 将使用 h1 标签来组成正文标题。如果有 h1,则从 h1 标签中提取标题。如果没有,只需使用标题标签。
文章 发布时间:并不是所有的文章都有发布时间(不过好像大部分都有),去掉标签后用regular从文本中提取时间即可。
Keep tagged text:我们的算法与标签无关,因为算法要先过滤html标签去除干扰,那么如果你想要tagged文本(比如你想把图片保留在文本中)怎么办?这时候只能保留两个数组。一个数组存储过滤器标签的文本以便于分析,另一个数组保留html标签以便于提取原创信息。
Html2Article网页正文提取算法
Html2Article 是我基于上述思想的网页正文提取算法。具有以下特点:
算法已经开源(可以认为是对开源的贡献):
有关如何使用它的说明,请参阅文档。
该算法是在 C# 中实现的。玩.NET 的同学有福了,可以直接用nuget 把html2article 添加到你的项目中。
另外,我发现直接从百度搜索“html2article”也可以很快找到。算法实现快半年了,比较懒,没写文章分享给大家。
查看全部
抓取网页新闻(为什么分析的时候要把html标签过滤掉呢?(图)
)
前两种方法还是比较容易实现的,主要是处理比较简单。我之前实现了标签密度提取算法,但实际使用中的错误率还是比较高的;后两种方法在实现上稍微复杂一些。就算法效率而言,应该不会高很多。
我们需要的是一种简单易实现的算法,可以保证处理速度和提取精度。因此,结合前两种算法,研究网页的html页面结构,有更好的处理思路,称为基于文本密度的文本提取算法。后来在网上搜索了类似的算法,发现也有类似的处理方法用于处理文本提取,但还是有一些区别的。接下来和大家分享一下这个算法的一些处理思路。
网络分析
我随意从百度、搜狐、网易上拿了一个新闻页面进行分析。
先看一篇关于百度文章的文章
为什么任正非主动跟我合影,
首先请求这个页面,然后过滤到所有的html标签,只保留文本信息,我们可以看到文本信息集中在以下位置:
用Excel分析行数与每行字符的关系可以发现:
很明显,文字内容集中在65-100行之间的位置,这个区间的字符数也比较密集。
网易的另一篇文章文章
张小龙神话破灭,马化腾接管微信。
我们先看过滤html标签后的body部分:
这是另一个Excel分析结果:
正文部分集中在第 279-282 行之间。从图中可以看出,正是这几行的文字密度特别高。
最后分析一个搜狐新闻
李克强在天津考察考察的片刻,
我们先看post标签后面的文字:
再看Excel的分析结果:
搜狐文章的正文主要集中在第200-255行。剩下的文字都是乱七八糟的标签文字。
抱歉,我漏掉了很重要的一点:为什么我分析的时候会过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关心的是文本的内容,如果你携带这样的标签 style="color: #0000ff;">var chart = style="color: #0000ff;"> newstyle="color: #000000;">进行分析,可以想象一下会对我们的文本分析造成多大的干扰,为此我们需要去掉html标签,只对文本进行分析以减少干扰干涉。
基于网页分析构思的文本提取算法
回顾上面的网页分析,如果根据文本密度找到提取的文本,那么这是一个算法,可以在过滤html标签后从文本中找到文本的开始和结束行号。行号之间的文本是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文本密度远高于非正文部分。根据这个特点,我们可以很容易的实现算法,就是根据阈值(发音:yu)值来分析文本的位置。
那么有一些问题需要解决:
可以通过统计分析来确定阈值以获得更好的值。在实际的处理过程中,我发现这个值取180比较合适。也就是在分析文本的时候,如果分析的文本超过180,那么就可以认为该文本已经达到了。
然后是如何分析的问题。这实际上更容易确定。逐行分析肯定不好。如果在逐行分析的过程中分析几行,最好将几行分析为一个分析。即一次分析上面的5行,将字符相加,看是否达到阈值。如果达到阈值,则认为它已经进入了身体部位。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
核心提取算法不到60行。经过验证,提取效果还是很好的。至少达到90%的文本提取正确率,效率平均提取时间30ms左右。
一些需要解决的问题
html标签去除:这个很简单,直接用正则表达式替换(Regex.Replace(html, "(?is)", ""))来去除所有html标签
html压缩网页的处理:压缩后的html代码一般只有一行,这类html的处理比较简单(不需要复杂的代码格式化),直接在标签末尾加一个换行符即可。
正文标题:大多数标准 URL 将使用 h1 标签来组成正文标题。如果有 h1,则从 h1 标签中提取标题。如果没有,只需使用标题标签。
文章 发布时间:并不是所有的文章都有发布时间(不过好像大部分都有),去掉标签后用regular从文本中提取时间即可。
Keep tagged text:我们的算法与标签无关,因为算法要先过滤html标签去除干扰,那么如果你想要tagged文本(比如你想把图片保留在文本中)怎么办?这时候只能保留两个数组。一个数组存储过滤器标签的文本以便于分析,另一个数组保留html标签以便于提取原创信息。
Html2Article网页正文提取算法
Html2Article 是我基于上述思想的网页正文提取算法。具有以下特点:
算法已经开源(可以认为是对开源的贡献):
有关如何使用它的说明,请参阅文档。
该算法是在 C# 中实现的。玩.NET 的同学有福了,可以直接用nuget 把html2article 添加到你的项目中。
另外,我发现直接从百度搜索“html2article”也可以很快找到。算法实现快半年了,比较懒,没写文章分享给大家。
抓取网页新闻(《MetaSeeker速成手册》之博文翻页抓取多个URL映射的注释)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-12-23 09:12
相关博文
翻转页面以抓取多个标签。之前爬取到二级URL时,停止爬取过程
注1:可以使用MetaStudio加载信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。
注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。
1 抓取新闻摘要数据
首先,您需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:
以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页有DOM节点语义,可以使用@class或@id属性来准确定位抓取到的内容,然后进行FreeFormat映射。详细操作流程请参考《抢京东商品价格》。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“获取当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行,以提高爬行速度。如果不勾选DataScraper的菜单项“Configuration”->“Normal Mode”,DataScraper将进入加速模式。
2 抓取新闻详情页
我们在《抢夺》一文中已经讲过如何捕捉二级话题的线索。图 2 再次显示了捕获下一级线索的方法。设置线索功能后,会在线索编辑器工作台上自动创建。对于Info类型的线索,在Clue Editor工作台上,将下一级主题命名为demo_cnbeta_detail(如图3).
定义 Info 类线索的目的有两个:
进行分层爬取,爬取新闻列表后爬取详细的新闻内容。为避免重复爬取,当发现超过设定的重复率时终止爬取过程,后面章节会详细说明
3 翻转页面以抓取多个标签
为了翻页并抓取所有标签,您需要创建一个线索。图 4 显示了主要步骤。详情见《抢当当商品价格》:
将代表整个分页区域的 DOM 节点映射到这条线索上,相当于指定了一个网页区域,该区域可以定位页面超链接。我们使用标记线索类型来定位翻页线索,“下一页”是标记值进行标记映射,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,该类型主要用于翻页,一旦选中该类型,当前主题名称将自动填入目标主题名称输入框。
4 设置 AJAX 捕获模式
如图5所示,选择MetaStudio菜单“Configuration”->“Active Mode”设置AJAX捕获模式。
在《亚马逊卓越分页抓取》一文中,我们同时设置了“主动模式”和“扩展模式”,两种模式并没有捆绑在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。
5 只获取最新消息
通常我们会每隔一段时间(例如一天)抓取新闻列表。如果我们发现新消息,我们将抓取 URL 并创建下一级线索来抓取最新的新闻内容。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明请参考《抓当当商品价格》。以下是 crontab.xml 文件的内容:
true
5
3600
false
demo_cnbeta_list
demo_cnbeta_list
false
80
-1
-1
false
0
true
23
1800
false
demo_cnbeta_detail
false
80
-1
-1
false
0
demo_cnbeta_list爬取话题的dupRatio参数和“只爬取最新消息”有关,80的意思是80%,也就是说,如果你发现这个URL被爬了3个连续页面的时候翻页爬取如果之前已经爬取了80%的地址,则终止翻页爬取。
注1:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。
注意2:请不要直接使用上面的crontab.xml,因为MetaSeeker服务器上还没有定义demo_cnbeta_detail信息结构,会导致周期性的爬取失败。 查看全部
抓取网页新闻(《MetaSeeker速成手册》之博文翻页抓取多个URL映射的注释)
相关博文
翻转页面以抓取多个标签。之前爬取到二级URL时,停止爬取过程
注1:可以使用MetaStudio加载信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。
注2:本文不是介绍性教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。
1 抓取新闻摘要数据
首先,您需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:
以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页有DOM节点语义,可以使用@class或@id属性来准确定位抓取到的内容,然后进行FreeFormat映射。详细操作流程请参考《抢京东商品价格》。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,您可以使用示例复制方法。参考“获取当当商品价格”设置至少一个信息属性的关键特征。关于主要功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行,以提高爬行速度。如果不勾选DataScraper的菜单项“Configuration”->“Normal Mode”,DataScraper将进入加速模式。
2 抓取新闻详情页
我们在《抢夺》一文中已经讲过如何捕捉二级话题的线索。图 2 再次显示了捕获下一级线索的方法。设置线索功能后,会在线索编辑器工作台上自动创建。对于Info类型的线索,在Clue Editor工作台上,将下一级主题命名为demo_cnbeta_detail(如图3).
定义 Info 类线索的目的有两个:
进行分层爬取,爬取新闻列表后爬取详细的新闻内容。为避免重复爬取,当发现超过设定的重复率时终止爬取过程,后面章节会详细说明
3 翻转页面以抓取多个标签
为了翻页并抓取所有标签,您需要创建一个线索。图 4 显示了主要步骤。详情见《抢当当商品价格》:
将代表整个分页区域的 DOM 节点映射到这条线索上,相当于指定了一个网页区域,该区域可以定位页面超链接。我们使用标记线索类型来定位翻页线索,“下一页”是标记值进行标记映射,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索类型,该类型主要用于翻页,一旦选中该类型,当前主题名称将自动填入目标主题名称输入框。
4 设置 AJAX 捕获模式
如图5所示,选择MetaStudio菜单“Configuration”->“Active Mode”设置AJAX捕获模式。
在《亚马逊卓越分页抓取》一文中,我们同时设置了“主动模式”和“扩展模式”,两种模式并没有捆绑在一起。这个目标网站 不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。
5 只获取最新消息
通常我们会每隔一段时间(例如一天)抓取新闻列表。如果我们发现新消息,我们将抓取 URL 并创建下一级线索来抓取最新的新闻内容。如果您发现新闻列表中的所有新闻都是以前抓取的新闻,请停止页面抓取。这需要使用周期性的自动爬取方法。需要编辑。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明请参考《抓当当商品价格》。以下是 crontab.xml 文件的内容:
true
5
3600
false
demo_cnbeta_list
demo_cnbeta_list
false
80
-1
-1
false
0
true
23
1800
false
demo_cnbeta_detail
false
80
-1
-1
false
0
demo_cnbeta_list爬取话题的dupRatio参数和“只爬取最新消息”有关,80的意思是80%,也就是说,如果你发现这个URL被爬了3个连续页面的时候翻页爬取如果之前已经爬取了80%的地址,则终止翻页爬取。
注1:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。
注意2:请不要直接使用上面的crontab.xml,因为MetaSeeker服务器上还没有定义demo_cnbeta_detail信息结构,会导致周期性的爬取失败。
抓取网页新闻(如何设置这一路标才科学,才能提高搜索效率呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-18 10:14
现在,当你遇到不明白的东西时,你会想到百度,或者谷歌等搜索引擎。如果超链接是“路”,那么“关键词”就是“路标”。那么如何设置这个路标既科学又可以提高搜索效率呢?
“原创新闻”是新闻网站的重头戏。每天有几十篇文章。如何更好地编辑和发布这些新闻,是编辑们每天思考的主要问题。除了正常的排版和编辑,关键词是最受关注的。
很多作者在网上发表论文和小说时都会设置搜索关键词,而关键词在很多情况下都是影响文章点击率的重要因素。那么当面临关键词的选择时,如何设置才能获得最满意的流量呢?最重要的搜索工具是搜索引擎。人们常把手动编辑的网站分类称为搜索引擎,但笔者认为不完整。真正的搜索引擎是指网页的全文搜索引擎。网页全文搜索引擎其实就是一个很大的索引表,里面记录了每个网页上出现了哪些关键词。当你输入某个关键词搜索时,所有收录这个关键词的网页都会被找到,并按照一定的顺序排列。网络全文搜索引擎信息量大、准确率高、功能强、数据搜索速度快。它可以搜索你从未想过,甚至你不敢想象的内容,但前提是你要掌握一点使用技巧。这里我将介绍一些最基本、最有效的搜索技巧。
一、想想用什么工具
无论搜索引擎有多好,它都无法搜索到互联网上没有的内容。而且,虽然有些内容存在于互联网上,但由于种种原因,已经落网了。所以在你使用搜索引擎搜索之前,你应该花几秒钟的时间思考一下。我要找的东西是否有可能在线获得?如果是这样,它在哪里可能,它是什么样的?页面上会收录哪些关键字?
有些事情您不需要为搜索引擎而烦恼。例如,要查找公司的电话号码,拨打 114 可能比搜索引擎快得多。还有一些问题,可能很难用合适的关键词来描述,或者你不能直接用搜索引擎搜索,那么你可以试着找一个精通这个问题的朋友,或者寻找这个领域的热门论坛要问,这也是一种搜索方法。有时,您可以选择的最佳搜索方法是放弃互联网并前往附近的图书馆,那里有大量您在网上找不到的“信息”。
当您确认您要查找的信息适合通过搜索引擎在线搜索时,找到满意结果的概率就会高很多。
各种搜索引擎的特点非常鲜明。如果没有为每次搜索选择合适的搜索工具,您将浪费大量时间。对于这个搜索,你应该使用新浪还是搜狐?谷歌还是百度?分析您的需求,比较不同搜索引擎的优缺点,然后选择最适合本次搜索的搜索工具。
二、学习使用两个关键词搜索
如果一个陌生人突然走近你,问你:“北京”,你会怎么回答?大多数人会觉得莫名其妙,然后他们会问这个人他们想问“北京”什么。同样,如果你在搜索引擎中输入一个关键词“北京”,搜索引擎也不知道你在找什么,可能会返回很多莫名其妙的结果。因此,你必须养成使用多次关键词 搜索的习惯。当然,大多数情况下,使用两个 关键词 搜索就足够了, 关键词 和 关键词 之间用空格隔开。
比如想了解北京旅游,可以进入“北京旅游”获取北京旅游相关信息。
三、学会使用减号“-”
“-”的作用是去除不相关的搜索结果,提高搜索结果的相关性。有时,您会在搜索结果中看到一些想要的结果,但也会发现许多不相关的搜索结果。这时候就可以找出那些无关结果关键词的特征,并减去它们。
一个成功的搜索由两部分组成:正确的搜索关键词,和有用的搜索结果。在您点击任何搜索结果之前,快速分析您搜索结果的标题、网址和摘要,这将帮助您选择更准确的结果,并为您节省大量时间。当然,您需要哪一种内容取决于您要查找的内容。评估网络内容的质量和权威性是搜索中的重要一步。一次成功的搜索通常由多次搜索组成。如果您不熟悉您要搜索的内容,即使是搜索专家也无法保证您会在第一次搜索中找到您想要的内容。搜索专家将首先使用一个简单的 关键词 测试。他们不会忙于仔细检查每个搜索结果,而是首先从搜索结果页面中寻找更多信息,
科学爬取关键词包括两种情况:一种是根据内容选择关键词,另一种是根据关键词选择内容。
根据内容确定关键词。我想用我做过的一个话题来解释这种情况。
前不久网上热议的“力拓案”。毫无疑问,这是一条备受业界关注的热点消息。我们围绕此新闻事件拟定的主要 关键词 包括:力拓公司简介、力拓集团、铁矿石谈判以及参与事件的各方。之后会有关键词话题:力拓铁矿石、09铁矿石谈判、力拓铁矿石等关键词。
随着局势的发展,我们中断了谈判。这时候就要抓住以下关键词:力拓、可疑链接、调查等,相关信息文章也会在这个时候出现。关键词应该是:力拓年产量、力拓铁矿石储量、力拓石粉等信息字样。同时,发散思维也很重要,还需要采集力拓案的相关侧面信息(参考关键词:日本和力拓铁矿石,日本和力拓铁矿石谈判价格,巴西铁矿石等)。
此后,事件进一步升级,中方还逮捕了涉嫌间谍的力拓驻上海代表。这个时候我们要把握人们关注的词。预先确定的关键词还必须包括:力拓案、力拓间谍案、力拓间谍门、力拓间谍事件、力拓间谍泄密事件等。我们想围绕这些给本报告一个圆满的结论关键词。
通过分析我对这个事件的报道过程,我们可以总结出这个事件的捕获原理关键词:1.我们选择的关键词必须是用户会使用的词或词组搜索。2. 也是用户可能用来搜索的潜在术语。3. 不能泛泛而无具体内容。4.抓住事件讨论的中心。
根据关键词选择内容。这就是上述方法的反执行。首先,我们必须列出所有关键词 人正在关注的内容。然后使用关键词的这些不同组合来抓取内容。这是一种根据需求查找内容的方法。效果也不错。
(编辑/周扬) 查看全部
抓取网页新闻(如何设置这一路标才科学,才能提高搜索效率呢?)
现在,当你遇到不明白的东西时,你会想到百度,或者谷歌等搜索引擎。如果超链接是“路”,那么“关键词”就是“路标”。那么如何设置这个路标既科学又可以提高搜索效率呢?
“原创新闻”是新闻网站的重头戏。每天有几十篇文章。如何更好地编辑和发布这些新闻,是编辑们每天思考的主要问题。除了正常的排版和编辑,关键词是最受关注的。
很多作者在网上发表论文和小说时都会设置搜索关键词,而关键词在很多情况下都是影响文章点击率的重要因素。那么当面临关键词的选择时,如何设置才能获得最满意的流量呢?最重要的搜索工具是搜索引擎。人们常把手动编辑的网站分类称为搜索引擎,但笔者认为不完整。真正的搜索引擎是指网页的全文搜索引擎。网页全文搜索引擎其实就是一个很大的索引表,里面记录了每个网页上出现了哪些关键词。当你输入某个关键词搜索时,所有收录这个关键词的网页都会被找到,并按照一定的顺序排列。网络全文搜索引擎信息量大、准确率高、功能强、数据搜索速度快。它可以搜索你从未想过,甚至你不敢想象的内容,但前提是你要掌握一点使用技巧。这里我将介绍一些最基本、最有效的搜索技巧。
一、想想用什么工具
无论搜索引擎有多好,它都无法搜索到互联网上没有的内容。而且,虽然有些内容存在于互联网上,但由于种种原因,已经落网了。所以在你使用搜索引擎搜索之前,你应该花几秒钟的时间思考一下。我要找的东西是否有可能在线获得?如果是这样,它在哪里可能,它是什么样的?页面上会收录哪些关键字?
有些事情您不需要为搜索引擎而烦恼。例如,要查找公司的电话号码,拨打 114 可能比搜索引擎快得多。还有一些问题,可能很难用合适的关键词来描述,或者你不能直接用搜索引擎搜索,那么你可以试着找一个精通这个问题的朋友,或者寻找这个领域的热门论坛要问,这也是一种搜索方法。有时,您可以选择的最佳搜索方法是放弃互联网并前往附近的图书馆,那里有大量您在网上找不到的“信息”。
当您确认您要查找的信息适合通过搜索引擎在线搜索时,找到满意结果的概率就会高很多。
各种搜索引擎的特点非常鲜明。如果没有为每次搜索选择合适的搜索工具,您将浪费大量时间。对于这个搜索,你应该使用新浪还是搜狐?谷歌还是百度?分析您的需求,比较不同搜索引擎的优缺点,然后选择最适合本次搜索的搜索工具。
二、学习使用两个关键词搜索
如果一个陌生人突然走近你,问你:“北京”,你会怎么回答?大多数人会觉得莫名其妙,然后他们会问这个人他们想问“北京”什么。同样,如果你在搜索引擎中输入一个关键词“北京”,搜索引擎也不知道你在找什么,可能会返回很多莫名其妙的结果。因此,你必须养成使用多次关键词 搜索的习惯。当然,大多数情况下,使用两个 关键词 搜索就足够了, 关键词 和 关键词 之间用空格隔开。
比如想了解北京旅游,可以进入“北京旅游”获取北京旅游相关信息。
三、学会使用减号“-”
“-”的作用是去除不相关的搜索结果,提高搜索结果的相关性。有时,您会在搜索结果中看到一些想要的结果,但也会发现许多不相关的搜索结果。这时候就可以找出那些无关结果关键词的特征,并减去它们。
一个成功的搜索由两部分组成:正确的搜索关键词,和有用的搜索结果。在您点击任何搜索结果之前,快速分析您搜索结果的标题、网址和摘要,这将帮助您选择更准确的结果,并为您节省大量时间。当然,您需要哪一种内容取决于您要查找的内容。评估网络内容的质量和权威性是搜索中的重要一步。一次成功的搜索通常由多次搜索组成。如果您不熟悉您要搜索的内容,即使是搜索专家也无法保证您会在第一次搜索中找到您想要的内容。搜索专家将首先使用一个简单的 关键词 测试。他们不会忙于仔细检查每个搜索结果,而是首先从搜索结果页面中寻找更多信息,
科学爬取关键词包括两种情况:一种是根据内容选择关键词,另一种是根据关键词选择内容。
根据内容确定关键词。我想用我做过的一个话题来解释这种情况。
前不久网上热议的“力拓案”。毫无疑问,这是一条备受业界关注的热点消息。我们围绕此新闻事件拟定的主要 关键词 包括:力拓公司简介、力拓集团、铁矿石谈判以及参与事件的各方。之后会有关键词话题:力拓铁矿石、09铁矿石谈判、力拓铁矿石等关键词。
随着局势的发展,我们中断了谈判。这时候就要抓住以下关键词:力拓、可疑链接、调查等,相关信息文章也会在这个时候出现。关键词应该是:力拓年产量、力拓铁矿石储量、力拓石粉等信息字样。同时,发散思维也很重要,还需要采集力拓案的相关侧面信息(参考关键词:日本和力拓铁矿石,日本和力拓铁矿石谈判价格,巴西铁矿石等)。
此后,事件进一步升级,中方还逮捕了涉嫌间谍的力拓驻上海代表。这个时候我们要把握人们关注的词。预先确定的关键词还必须包括:力拓案、力拓间谍案、力拓间谍门、力拓间谍事件、力拓间谍泄密事件等。我们想围绕这些给本报告一个圆满的结论关键词。
通过分析我对这个事件的报道过程,我们可以总结出这个事件的捕获原理关键词:1.我们选择的关键词必须是用户会使用的词或词组搜索。2. 也是用户可能用来搜索的潜在术语。3. 不能泛泛而无具体内容。4.抓住事件讨论的中心。
根据关键词选择内容。这就是上述方法的反执行。首先,我们必须列出所有关键词 人正在关注的内容。然后使用关键词的这些不同组合来抓取内容。这是一种根据需求查找内容的方法。效果也不错。
(编辑/周扬)
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-18 10:11
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬虫”并不是特别准确,因为“爬虫”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过,这个文章主要解释了第二种“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只是想把所有的产品在网站上列出价格,放到Excel中对比等等,可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字整理好放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们必须了解如何使用 Python 来实现它。实现原理基本上分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最好是总结最后一张漂亮的Excel表格:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,也没有给出实际的代码。
但是,这个想法几乎是网络爬虫的通用例程。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅! 查看全部
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话文,面向可爱的小白(^-^)。
混淆名称:
很多时候,人们将互联网上获取数据的代码统称为“爬虫”。
但实际上,所谓的“爬虫”并不是特别准确,因为“爬虫”也是分物种的。
有两种常见的“爬虫”:
网络爬虫,又称蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网页数据提取
不过,这个文章主要解释了第二种“爬虫”(Web Scraper)的原理。
什么是网页抓取?
简单地说,Web Scraping(本文中)是指使用Python代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为重复性工作太多,自己做的话可能会累死!
代码的适用示例有哪些?比如你需要下载交易所50只不同股票的当前价格,或者你想打印出所有最新消息的头条新闻网站,或者你只是想把所有的产品在网站上列出价格,放到Excel中对比等等,可以发挥你的想象力.....
Web Scraping的基本原理:
首先,您需要了解网页在我们的屏幕上是如何呈现的;
事实上,我们发送了一个Request,一百公里外的服务器给了我们一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字整理好放到了我们的屏幕上。在; 更详细的原理可以看我之前的博文《HTTP下午茶-小白介绍》中的书
然后,我们必须了解如何使用 Python 来实现它。实现原理基本上分为四步:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要处理接收到的 Response 并找到我们需要的文本。然后,我们需要设计代码流来处理重复的任务。最后导出我们得到的数据,最好是总结最后一张漂亮的Excel表格:
本文章重点讲解实现的思路和过程,
因此,它并不详尽,也没有给出实际的代码。
但是,这个想法几乎是网络爬虫的通用例程。
就写到这里吧,记得更新什么,
有写的地方不对的地方还请见谅!

