
抓取网页新闻
抓取网页新闻(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-12 08:15
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
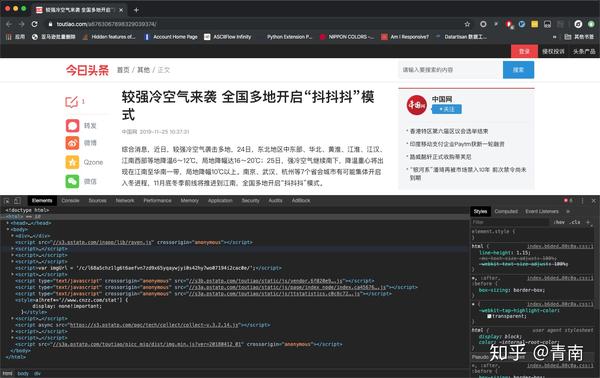
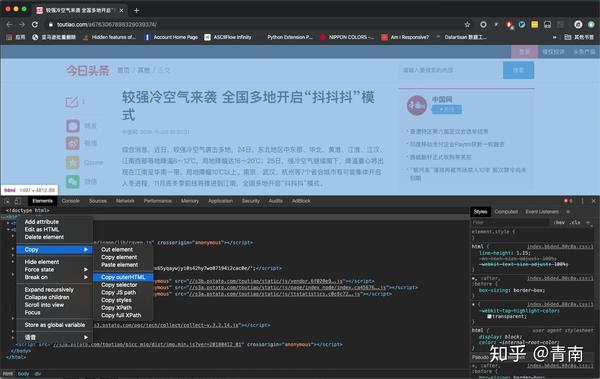
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html 提取文本信息
编写以下代码:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
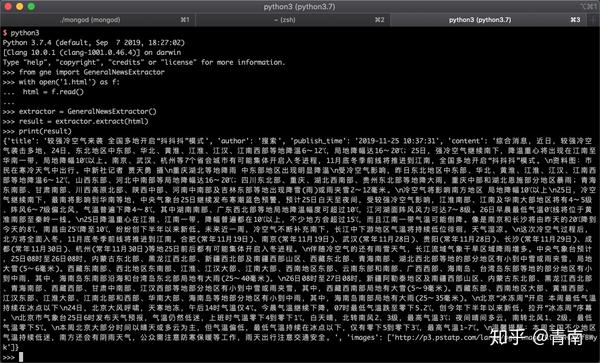
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
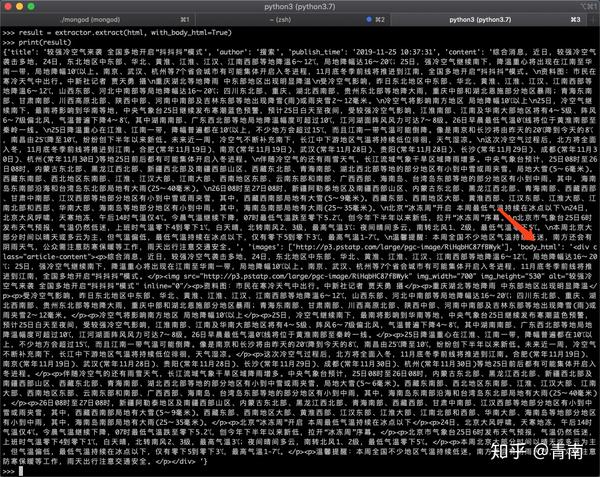
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:/kingname/GeneralNewsExtractor。 查看全部
抓取网页新闻(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html 提取文本信息
编写以下代码:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:/kingname/GeneralNewsExtractor。
抓取网页新闻(JavaHTML解析器如何使用jsoup抓取一些简单的页面信息准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-10-11 17:44
介绍:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
在这篇文章中,我将教你如何使用jsoup抓取一些简单的页面信息
准备:
jsoup的jar包:
开发工具:eclipse
想法:
我们首先使用jsoup将网页上的html解析为字符串,然后将字符串转换为Document,然后选择一些我们想要遍历的信息。
过程:
1.创建web项目,命名项目,导入jar包
lombok是省略了get和set方法,请参考
2.创建目录结构
模型中的新闻是一个封装好的新闻实体对象
utils中的Spider是我们写的一个工具类
test中的JsoupTest是我们写的一个测试类
3. 代码如下
实体类:
package com.rzc.model;
import lombok.Data;
@Data // lombok注解,相当于get、set方法和toString等都默认生成
public class News {
private String title; // 新闻标题
private String article; // 新闻内容
private String publishTime; // 新闻发布时间
private String keyword; // 新闻关键字
private String author; // 新闻作者
}
工具:
package com.rzc.utils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.rzc.model.News;
public class Spider {
// 获取页面加载内容
public Document loadDocumentData(String url) {
// 创建文档对象
Document doc = null;
// 根据url将某页信息转换成文档
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 返回文档
return doc;
}
// 获取a标签中的href的内容
public List parseDoc(Document doc) {
// 实例化list
List list = new ArrayList();
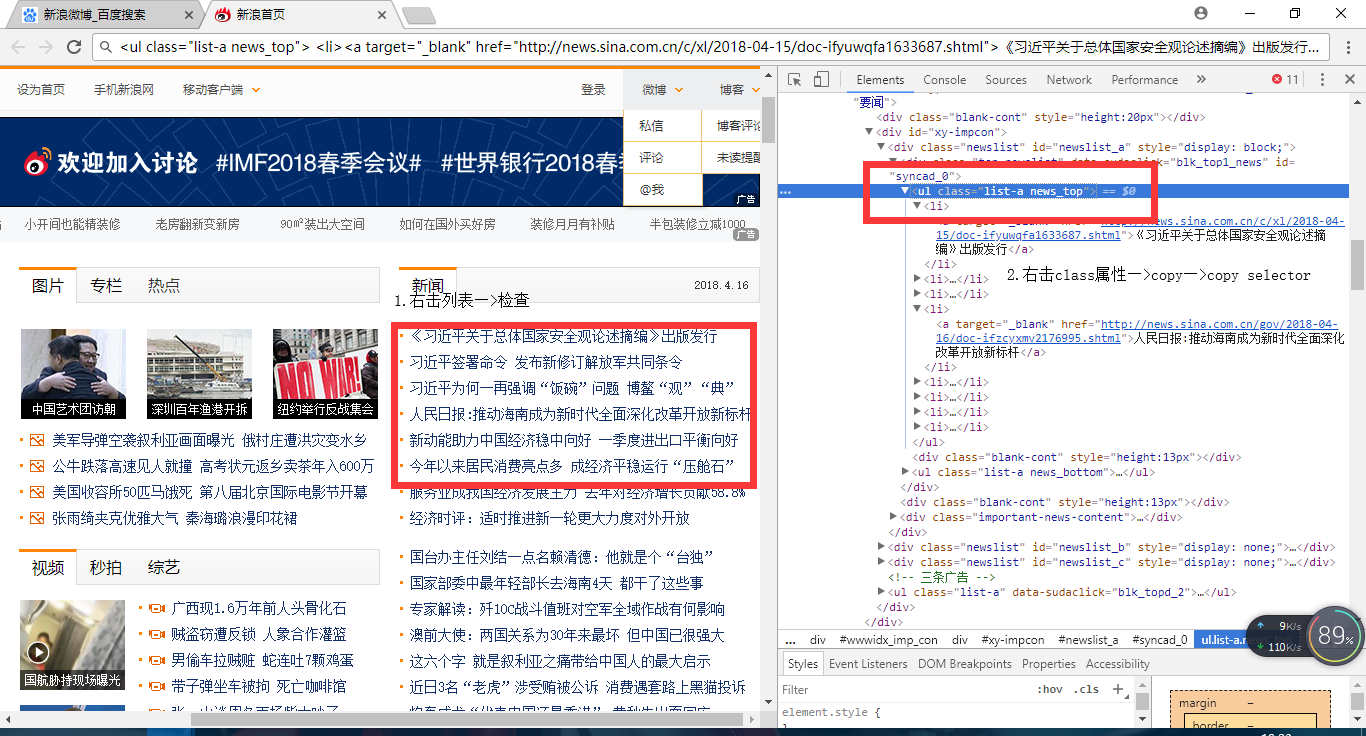
// 根据指定class获取对象(这里我们查看页面源码,选取了一个class为 new_top 的新闻 列表)
Elements elements = doc.getElementsByClass("news_top");
// 根据指定的标签获取连接内容(这里选取的是a标签中的内容)
Elements links = elements.get(0).getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
// 讲遍历出来的每一个a标签对象中的href属性循环存入list中
list.add(links.get(i).attr("href"));
}
// 返回list
return list;
}
// 按照要求获取news对象
public News parseDetaile(Document doc) {
// 实例化news对象
News news = new News();
// 按照class获取文档对象 main_title的文本信息,并将该信息存入title中
String title = doc.getElementsByClass("main_title").text();
// 查照选择器data-sourse后面的.data信息,并将该信息存入publishTime中
String publishTime = doc.select(".data-sourse > .data").text();
// 按照class获取文档对象 caricle 的文本信息,并将该信息存入 article 中
String article = doc.getElementsByClass("article").text();
// 按照class获取文档对象 keyword 的文本信息,并将该信息存入 keyword 中
String keyword = doc.getElementsByClass("keyword").text();
// 按照class获取文档对象 show_author 的文本信息,并将该信息存入 author 中
String author = doc.getElementsByClass("show_author").text();
// 将以上信息填充到news对象中
news.setTitle(title);
news.setPublishTime(publishTime);
news.setArticle(article);
news.setKeyword(keyword);
news.setAuthor(author);
return news;
}
}
根据标签从页面信息中选择您需要的信息,然后根据标签等属性获取对象。下面是在其中查找新闻信息对象的方法。
测试类别:
package com.rzc.test;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.nodes.Document;
import com.rzc.model.News;
import com.rzc.utils.Spider;
public class JsoupTest {
public static void main(String[] args) {
// 实例化工具类对象
Spider spider = new Spider();
// 根据url获取文档(这里的url是新浪首页)
Document doc = spider.loadDocumentData("http://www.sina.com.cn");
// 获取文档中a标签 中href属性中的内容
List list = spider.parseDoc(doc);
// 实例化新闻列表
List newsList = new ArrayList();
// 循环遍历新闻列表中的每一个对象
for(String url:list){
// 获取整个文档
Document document = spider.loadDocumentData(url);
// 获取每个文档中的新闻对象
News news = spider.parseDetaile(document);
// 将文档中的新闻对象添加到新闻列表中
newsList.add(news);
// 测试输出新闻列表信息
System.out.println(news);
}
}
}
输出结果
文章 到此为止吧。谢谢观看。不足之处请指出! 查看全部
抓取网页新闻(JavaHTML解析器如何使用jsoup抓取一些简单的页面信息准备)
介绍:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
在这篇文章中,我将教你如何使用jsoup抓取一些简单的页面信息
准备:
jsoup的jar包:
开发工具:eclipse
想法:
我们首先使用jsoup将网页上的html解析为字符串,然后将字符串转换为Document,然后选择一些我们想要遍历的信息。
过程:
1.创建web项目,命名项目,导入jar包
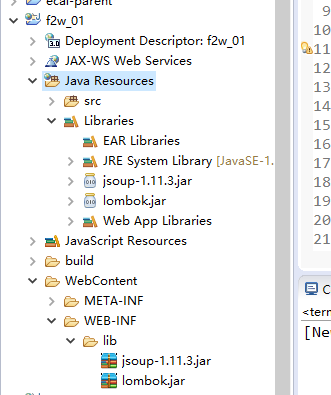
lombok是省略了get和set方法,请参考
2.创建目录结构
模型中的新闻是一个封装好的新闻实体对象
utils中的Spider是我们写的一个工具类
test中的JsoupTest是我们写的一个测试类
3. 代码如下
实体类:
package com.rzc.model;
import lombok.Data;
@Data // lombok注解,相当于get、set方法和toString等都默认生成
public class News {
private String title; // 新闻标题
private String article; // 新闻内容
private String publishTime; // 新闻发布时间
private String keyword; // 新闻关键字
private String author; // 新闻作者
}
工具:
package com.rzc.utils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.rzc.model.News;
public class Spider {
// 获取页面加载内容
public Document loadDocumentData(String url) {
// 创建文档对象
Document doc = null;
// 根据url将某页信息转换成文档
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 返回文档
return doc;
}
// 获取a标签中的href的内容
public List parseDoc(Document doc) {
// 实例化list
List list = new ArrayList();
// 根据指定class获取对象(这里我们查看页面源码,选取了一个class为 new_top 的新闻 列表)
Elements elements = doc.getElementsByClass("news_top");
// 根据指定的标签获取连接内容(这里选取的是a标签中的内容)
Elements links = elements.get(0).getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
// 讲遍历出来的每一个a标签对象中的href属性循环存入list中
list.add(links.get(i).attr("href"));
}
// 返回list
return list;
}
// 按照要求获取news对象
public News parseDetaile(Document doc) {
// 实例化news对象
News news = new News();
// 按照class获取文档对象 main_title的文本信息,并将该信息存入title中
String title = doc.getElementsByClass("main_title").text();
// 查照选择器data-sourse后面的.data信息,并将该信息存入publishTime中
String publishTime = doc.select(".data-sourse > .data").text();
// 按照class获取文档对象 caricle 的文本信息,并将该信息存入 article 中
String article = doc.getElementsByClass("article").text();
// 按照class获取文档对象 keyword 的文本信息,并将该信息存入 keyword 中
String keyword = doc.getElementsByClass("keyword").text();
// 按照class获取文档对象 show_author 的文本信息,并将该信息存入 author 中
String author = doc.getElementsByClass("show_author").text();
// 将以上信息填充到news对象中
news.setTitle(title);
news.setPublishTime(publishTime);
news.setArticle(article);
news.setKeyword(keyword);
news.setAuthor(author);
return news;
}
}
根据标签从页面信息中选择您需要的信息,然后根据标签等属性获取对象。下面是在其中查找新闻信息对象的方法。
测试类别:
package com.rzc.test;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.nodes.Document;
import com.rzc.model.News;
import com.rzc.utils.Spider;
public class JsoupTest {
public static void main(String[] args) {
// 实例化工具类对象
Spider spider = new Spider();
// 根据url获取文档(这里的url是新浪首页)
Document doc = spider.loadDocumentData("http://www.sina.com.cn";);
// 获取文档中a标签 中href属性中的内容
List list = spider.parseDoc(doc);
// 实例化新闻列表
List newsList = new ArrayList();
// 循环遍历新闻列表中的每一个对象
for(String url:list){
// 获取整个文档
Document document = spider.loadDocumentData(url);
// 获取每个文档中的新闻对象
News news = spider.parseDetaile(document);
// 将文档中的新闻对象添加到新闻列表中
newsList.add(news);
// 测试输出新闻列表信息
System.out.println(news);
}
}
}
输出结果

文章 到此为止吧。谢谢观看。不足之处请指出!
抓取网页新闻(GeneralNewsExtractor新闻网页通用抽取器是一个基于《基于文本及符号密度的网页正文提取方法》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-11 17:36
GeneralNewsExtractor 新闻网页正文通用提取器是基于《基于文本和符号密度的网页正文提取方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。
相关软件软件大小版本说明下载地址
GeneralNewsExtractor(新闻网页文本通用提取器)是基于《基于文本和符号密度提取网页文本的方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。
发展介绍
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。 查看全部
抓取网页新闻(GeneralNewsExtractor新闻网页通用抽取器是一个基于《基于文本及符号密度的网页正文提取方法》)
GeneralNewsExtractor 新闻网页正文通用提取器是基于《基于文本和符号密度的网页正文提取方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。
相关软件软件大小版本说明下载地址
GeneralNewsExtractor(新闻网页文本通用提取器)是基于《基于文本和符号密度提取网页文本的方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。

发展介绍
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
抓取网页新闻(技术领域:本发明涉及一种网页爬虫的构建方法,特别是一种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-08 03:22
专利名称:基于新闻去重的网络爬虫构建方法
技术领域:
本发明涉及一种网络爬虫的构建方法,尤其涉及一种基于新闻去重的网络爬虫构建方法。
片法。
背景技术:
在这个信息爆炸的时代,网络媒体以其快速的新闻发布和广泛的新闻传播逐渐取代了电视,报纸等传统媒体已经成为现在的主流新闻传播方式。目前各大新闻门户网站网站“新浪”、“新华网”、“网易”都拥有自己强大的新闻采访、编辑和发布团队,每天发布的新闻数量达到数千篇。新闻网站一般涵盖各类新闻:国内新闻、国际新闻、社会新闻、娱乐新闻、军事新闻、体育新闻、财经新闻、科技新闻等,同时每个新闻门户都有自己的特色,如新华网时事新闻、新浪体育新闻、和网易上的社交新闻。因此,整合多个新闻门户网站网站的新闻,可以让用户获得更全面、更丰富、更有特色的新闻信息。如何有效地从网络中提取信息成为一个巨大的挑战。搜索引擎作为一种辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,通用搜索引擎存在以下局限性1、通用搜索引擎的目标是获得尽可能大的网络覆盖,这进一步加深了搜索引擎服务器资源有限与网络数据资源无限的矛盾之间的差距。2、 网络数据形式丰富,网络技术不断发展。有大量不同形式的数据,如图片、数据库、音频/视频等,一般的搜索引擎往往对这些信息内容密集、具有一定结构的数据无能为力。很好的发现和获取。
3、大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。4、不同领域、不同北京的用户有不同的搜索目的和需求。一般搜索引擎返回的结果中收录了很多用户并不关心的信息。为解决上述不足,有针对性地抓取相关网络资源的网络爬虫应运而生。网络爬虫是一种自动提取网页的程序。它可以自动从互联网上抓取网页,是搜索引擎的重要组成部分。其工作原理是网络爬虫从初始设置的一个或多个初始网页的URL出发,获取初始网页上的URL,并在抓取网页的过程中不断地从当前网页中提取新的网址,然后根据网页进行分析。该算法过滤掉与主题无关的连接,保留有用的连接并将它们放入 URL 队列中等待访问,直到满足某个停止条件。网络爬虫可以同时爬取多个数据源。以新闻信息为例,说明网络爬虫的缺点。1、因为每条新闻网站发布的消息,可能是文章的同一个副本,也可能是差不多的网站发布了不同的文章对于不同的事情。网络爬虫在爬取数据的时候,很可能也会抓取到这些重复的信息。这不仅会浪费网络资源,存储资源,也给数据维护带来了很大的麻烦。2、 网页上有大量的网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,它也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。
发明内容
为了克服现有技术算法效率低下的问题,容易抓取内容重复的网页,浪费资源和数据维护。
为了避免保护难的缺点,本发明提供了一种高效的算法,避免爬取内容重复的网页,资源和数据的浪费很少。
基于新闻去重的网络爬虫便捷维护方法。
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻网页集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻网页的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集,如果相似度高于阈值,丢弃新闻并抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。进一步地,该解析器是通过学习多条新闻网站的HTML源代码框架构建的,
解析器对网页进行解析,得到新闻网页中实际的新闻标题和新闻内容。此外,步骤(3)由以下步骤组成(3. 1)使用中文分词技术提取新闻标题关键词的文本和每个key的权重这个词;(3. 2)根据经验,选择文本中权重最高的N个关键词组成(关键词,权重)的集合
合 C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: 第 i 个关键词; Wi:第i个关键词的权重;(3. 3)将集合C中的元素按照权重Wi从大到小排序;每个子集&中的元素按照它们的关键词权重从大到小排序;设置C和&的相似度阈值,相似度由具有相同排序位置的两个集合决定(3.@ > 4)将集合C与新闻集中的每个&进行比较,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果低于阈值,C被认为是非重复消息;(3. 5)将非重复性新闻添加到新闻采集中。
进一步地,如果(3.4)确定集合C为非重复新闻,则使用中文分词技术提取新闻内容文本,提取关键词和每个关键词在文本中,按顺序再次执行新闻的权重(3.2) to (3.4);如果判断还是不重复的新闻,那么这个新闻将被添加到新闻采集中。此外,所描述的步骤(5)判断URL是否指向新闻网页包括以下步骤(5. 1)批量抓取新闻网页) 网站 数据源) URL 作为训练集,使用除法
聚类算法将这些 URL 进行聚类,并将具有相同 URL 格式的 URL 归为一类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,使用 URL 解析器学习每一类 URL 的格式特征,得到每个类别;
(5. 3) 使用描述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页URL的格式特征;如果是,则认为该URL是指向新闻网页网址;如果不是,则认为该网址指向新闻以外的其他网页,丢弃该网址。本发明的技术思想是在网络爬虫之前过滤重复数据抓取网页避免重复数据
数据的下载减少了爬虫需要爬取的数据量,节省了存储资源;抓取网址时,爬虫首先判断网址
是否指向有效信息,过滤无关网页的URL,保证爬取数据的纯度和准确性,即下载
来的都是有效网页,算法效率高,有效降低网络资源消耗,存储资源浪费少;
只需要存储有效信息,减少数据存储量,降低后续数据维护难度。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
图1是本发明的总体流程图;图2当前抓取的新闻与新闻集合中的每条新闻进行对比的流程图
图3是当前抓取的新闻与新闻采集中的新闻对比的另一个流程图
图4是判断URL是否被访问过的流程图
详细方法
示例一
参考附图1、2、4 基于新闻去重的网络爬虫的构建方法,包括以下步骤
1、基于新闻去重的网络爬虫构建方法,包括以下步骤1),构建一个可以提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻集合中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3),将当前抓取的新闻网页与新闻集进行比较,判断两者之间的相似度是否高于阈值;(3. 1) 使用中文分词技术提取新闻标题关键词的正文和每个关键词的权重;(3. <
6-in C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: i -th 关键词; Wi:第i个关键词的权重;(3. 3)根据权重Wi从大到小对集合C中的元素进行排序;采集新闻&的每个子集中的元素按照它们的关键词权重从大到小排序;设置C和&之间的相似度阈值,相似度按两个集合中的顺序相同的数字排序关键词 的要表征的位置;
与存储访问过的URL的访问队列进行比较,判断该URL是否被访问过;(5. 1)从各大网站数据源批量抓取新闻网页的网址作为训练集,用分区聚类算法对这些网址进行聚类,用将相同的 URL 格式归为一个类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,利用 URL 解析器学习每个类别的格式特征URL的,获取每个类别的正则表达式;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;
(53)使用URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果有,则将此URL视为指向新闻的URL网页;如果不是,则认为该网址指向新闻以外的网页,丢弃该网址。6)。如果该网址存在于访问队列中,则丢弃该网址;如果该网址不存在于所述被访问队列中,将这个 URL 存储在一个等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。解析器是通过学习多条新闻网站的HTML源码框架构建的,
解析器解析网页,得到新闻网页中实际的新闻标题和新闻内容。
示例二
参考附图 1、3、4 本实施例与实施例一的区别在于,如果(3. 4)确定集合C为非重复消息,然后新闻正文采用中文分词技术提取正文中关键词和每个关键词的权重,依次执行(3.2)到(3.4);如果判断还是不重复的新闻,则将该新闻加入新闻集合,其余同。本说明书实施例中描述的内容只是一个列表本发明构思的实施形式,以及本发明的保护范围,不应视为仅限于实施例中所述的具体形式,并且本发明的保护范围也扩展到本领域技术人员基于本发明的构思所能想到的等同技术手段。
权限请求
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2)。构建新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集。如果相似度高于阈值,丢弃新闻,抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。
2.根据权利要求1所述的基于新闻去重构建网络爬虫的方法,其特征在于,所述解析器是通过学习多个新闻网站HTML源代码框架构建的,结果解析器将网页解析成什么获取的是新闻网页中的实际新闻标题和新闻内容。
新闻集中按照他们的关键词权重从大到小排序;set C 和 Q 两组相似度之间的相似度阈值,所述相似度用两组相同排序位置的关键词的个数表示;(3. 4) Set C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果是低于阈值,C被认为是非重复新闻;(3. 5)将非重复新闻加入新闻集合。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。
4.根据权利要求3所述的基于新闻去重构建网络爬虫的方法,其特征在于,如果(3. 4)确定集合C为非重复新闻,则该新闻内容文本采用中文分词技术,提取文本中关键词和每个关键词的权重,按顺序再次执行(3.2)到(2)3.4);如果判断还是不重复的新闻,把这条新闻加入新闻采集。
使用所述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果是,则认为该网址是指向新闻网页的网址;如果不是,则认为该网址指向的不是新闻的网页,丢弃该网址。
全文摘要
基于新闻去重构建网络爬虫的方法包括以下步骤:构建解析器来解析新闻网页;构建新闻采集;设置网页之间的相似度阈值;将当前抓取的新闻网页与新闻集进行比较,判断相似度是否高于阈值;如果低于阈值,则将当前网页加入新闻采集;如果高于阈值,则丢弃该新闻并抓取下一个网页;抓取当前网页的网址,判断该网址是否指向新闻网页,如果是,则判断该网址是否被访问过;如果没有,丢弃它;如果此 URL 已被访问,则丢弃此 URL;如果这个 URL 没有被访问过,它会被存储在等待队列中;从等待队列中提取 URL 以便访问;重复以上步骤。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
文件编号 G06F17/30GK101694658SQ2
公布日期 2010 年 4 月 14 日 申请日期 2009 年 10 月 20 日 优先权日期 2009 年 10 月 20 日
发明人:卜家军、李辉、梁雄军、陈伟、陈纯申请人:浙江大学; 查看全部
抓取网页新闻(技术领域:本发明涉及一种网页爬虫的构建方法,特别是一种)
专利名称:基于新闻去重的网络爬虫构建方法
技术领域:
本发明涉及一种网络爬虫的构建方法,尤其涉及一种基于新闻去重的网络爬虫构建方法。
片法。
背景技术:
在这个信息爆炸的时代,网络媒体以其快速的新闻发布和广泛的新闻传播逐渐取代了电视,报纸等传统媒体已经成为现在的主流新闻传播方式。目前各大新闻门户网站网站“新浪”、“新华网”、“网易”都拥有自己强大的新闻采访、编辑和发布团队,每天发布的新闻数量达到数千篇。新闻网站一般涵盖各类新闻:国内新闻、国际新闻、社会新闻、娱乐新闻、军事新闻、体育新闻、财经新闻、科技新闻等,同时每个新闻门户都有自己的特色,如新华网时事新闻、新浪体育新闻、和网易上的社交新闻。因此,整合多个新闻门户网站网站的新闻,可以让用户获得更全面、更丰富、更有特色的新闻信息。如何有效地从网络中提取信息成为一个巨大的挑战。搜索引擎作为一种辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,通用搜索引擎存在以下局限性1、通用搜索引擎的目标是获得尽可能大的网络覆盖,这进一步加深了搜索引擎服务器资源有限与网络数据资源无限的矛盾之间的差距。2、 网络数据形式丰富,网络技术不断发展。有大量不同形式的数据,如图片、数据库、音频/视频等,一般的搜索引擎往往对这些信息内容密集、具有一定结构的数据无能为力。很好的发现和获取。
3、大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。4、不同领域、不同北京的用户有不同的搜索目的和需求。一般搜索引擎返回的结果中收录了很多用户并不关心的信息。为解决上述不足,有针对性地抓取相关网络资源的网络爬虫应运而生。网络爬虫是一种自动提取网页的程序。它可以自动从互联网上抓取网页,是搜索引擎的重要组成部分。其工作原理是网络爬虫从初始设置的一个或多个初始网页的URL出发,获取初始网页上的URL,并在抓取网页的过程中不断地从当前网页中提取新的网址,然后根据网页进行分析。该算法过滤掉与主题无关的连接,保留有用的连接并将它们放入 URL 队列中等待访问,直到满足某个停止条件。网络爬虫可以同时爬取多个数据源。以新闻信息为例,说明网络爬虫的缺点。1、因为每条新闻网站发布的消息,可能是文章的同一个副本,也可能是差不多的网站发布了不同的文章对于不同的事情。网络爬虫在爬取数据的时候,很可能也会抓取到这些重复的信息。这不仅会浪费网络资源,存储资源,也给数据维护带来了很大的麻烦。2、 网页上有大量的网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,它也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。
发明内容
为了克服现有技术算法效率低下的问题,容易抓取内容重复的网页,浪费资源和数据维护。
为了避免保护难的缺点,本发明提供了一种高效的算法,避免爬取内容重复的网页,资源和数据的浪费很少。
基于新闻去重的网络爬虫便捷维护方法。
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻网页集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻网页的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集,如果相似度高于阈值,丢弃新闻并抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。进一步地,该解析器是通过学习多条新闻网站的HTML源代码框架构建的,
解析器对网页进行解析,得到新闻网页中实际的新闻标题和新闻内容。此外,步骤(3)由以下步骤组成(3. 1)使用中文分词技术提取新闻标题关键词的文本和每个key的权重这个词;(3. 2)根据经验,选择文本中权重最高的N个关键词组成(关键词,权重)的集合
合 C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: 第 i 个关键词; Wi:第i个关键词的权重;(3. 3)将集合C中的元素按照权重Wi从大到小排序;每个子集&中的元素按照它们的关键词权重从大到小排序;设置C和&的相似度阈值,相似度由具有相同排序位置的两个集合决定(3.@ > 4)将集合C与新闻集中的每个&进行比较,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果低于阈值,C被认为是非重复消息;(3. 5)将非重复性新闻添加到新闻采集中。
进一步地,如果(3.4)确定集合C为非重复新闻,则使用中文分词技术提取新闻内容文本,提取关键词和每个关键词在文本中,按顺序再次执行新闻的权重(3.2) to (3.4);如果判断还是不重复的新闻,那么这个新闻将被添加到新闻采集中。此外,所描述的步骤(5)判断URL是否指向新闻网页包括以下步骤(5. 1)批量抓取新闻网页) 网站 数据源) URL 作为训练集,使用除法
聚类算法将这些 URL 进行聚类,并将具有相同 URL 格式的 URL 归为一类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,使用 URL 解析器学习每一类 URL 的格式特征,得到每个类别;
(5. 3) 使用描述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页URL的格式特征;如果是,则认为该URL是指向新闻网页网址;如果不是,则认为该网址指向新闻以外的其他网页,丢弃该网址。本发明的技术思想是在网络爬虫之前过滤重复数据抓取网页避免重复数据
数据的下载减少了爬虫需要爬取的数据量,节省了存储资源;抓取网址时,爬虫首先判断网址
是否指向有效信息,过滤无关网页的URL,保证爬取数据的纯度和准确性,即下载
来的都是有效网页,算法效率高,有效降低网络资源消耗,存储资源浪费少;
只需要存储有效信息,减少数据存储量,降低后续数据维护难度。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
图1是本发明的总体流程图;图2当前抓取的新闻与新闻集合中的每条新闻进行对比的流程图
图3是当前抓取的新闻与新闻采集中的新闻对比的另一个流程图
图4是判断URL是否被访问过的流程图
详细方法
示例一
参考附图1、2、4 基于新闻去重的网络爬虫的构建方法,包括以下步骤
1、基于新闻去重的网络爬虫构建方法,包括以下步骤1),构建一个可以提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻集合中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3),将当前抓取的新闻网页与新闻集进行比较,判断两者之间的相似度是否高于阈值;(3. 1) 使用中文分词技术提取新闻标题关键词的正文和每个关键词的权重;(3. <
6-in C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: i -th 关键词; Wi:第i个关键词的权重;(3. 3)根据权重Wi从大到小对集合C中的元素进行排序;采集新闻&的每个子集中的元素按照它们的关键词权重从大到小排序;设置C和&之间的相似度阈值,相似度按两个集合中的顺序相同的数字排序关键词 的要表征的位置;
与存储访问过的URL的访问队列进行比较,判断该URL是否被访问过;(5. 1)从各大网站数据源批量抓取新闻网页的网址作为训练集,用分区聚类算法对这些网址进行聚类,用将相同的 URL 格式归为一个类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,利用 URL 解析器学习每个类别的格式特征URL的,获取每个类别的正则表达式;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;
(53)使用URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果有,则将此URL视为指向新闻的URL网页;如果不是,则认为该网址指向新闻以外的网页,丢弃该网址。6)。如果该网址存在于访问队列中,则丢弃该网址;如果该网址不存在于所述被访问队列中,将这个 URL 存储在一个等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。解析器是通过学习多条新闻网站的HTML源码框架构建的,
解析器解析网页,得到新闻网页中实际的新闻标题和新闻内容。
示例二
参考附图 1、3、4 本实施例与实施例一的区别在于,如果(3. 4)确定集合C为非重复消息,然后新闻正文采用中文分词技术提取正文中关键词和每个关键词的权重,依次执行(3.2)到(3.4);如果判断还是不重复的新闻,则将该新闻加入新闻集合,其余同。本说明书实施例中描述的内容只是一个列表本发明构思的实施形式,以及本发明的保护范围,不应视为仅限于实施例中所述的具体形式,并且本发明的保护范围也扩展到本领域技术人员基于本发明的构思所能想到的等同技术手段。
权限请求
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2)。构建新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集。如果相似度高于阈值,丢弃新闻,抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。
2.根据权利要求1所述的基于新闻去重构建网络爬虫的方法,其特征在于,所述解析器是通过学习多个新闻网站HTML源代码框架构建的,结果解析器将网页解析成什么获取的是新闻网页中的实际新闻标题和新闻内容。
新闻集中按照他们的关键词权重从大到小排序;set C 和 Q 两组相似度之间的相似度阈值,所述相似度用两组相同排序位置的关键词的个数表示;(3. 4) Set C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果是低于阈值,C被认为是非重复新闻;(3. 5)将非重复新闻加入新闻集合。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。
4.根据权利要求3所述的基于新闻去重构建网络爬虫的方法,其特征在于,如果(3. 4)确定集合C为非重复新闻,则该新闻内容文本采用中文分词技术,提取文本中关键词和每个关键词的权重,按顺序再次执行(3.2)到(2)3.4);如果判断还是不重复的新闻,把这条新闻加入新闻采集。
使用所述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果是,则认为该网址是指向新闻网页的网址;如果不是,则认为该网址指向的不是新闻的网页,丢弃该网址。
全文摘要
基于新闻去重构建网络爬虫的方法包括以下步骤:构建解析器来解析新闻网页;构建新闻采集;设置网页之间的相似度阈值;将当前抓取的新闻网页与新闻集进行比较,判断相似度是否高于阈值;如果低于阈值,则将当前网页加入新闻采集;如果高于阈值,则丢弃该新闻并抓取下一个网页;抓取当前网页的网址,判断该网址是否指向新闻网页,如果是,则判断该网址是否被访问过;如果没有,丢弃它;如果此 URL 已被访问,则丢弃此 URL;如果这个 URL 没有被访问过,它会被存储在等待队列中;从等待队列中提取 URL 以便访问;重复以上步骤。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
文件编号 G06F17/30GK101694658SQ2
公布日期 2010 年 4 月 14 日 申请日期 2009 年 10 月 20 日 优先权日期 2009 年 10 月 20 日
发明人:卜家军、李辉、梁雄军、陈伟、陈纯申请人:浙江大学;
抓取网页新闻(代码如下:5抓取网页内容-把当前会话(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-08 00:08
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm");
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/"); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。
查看全部
抓取网页新闻(代码如下:5抓取网页内容-把当前会话(组图)
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm";);
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/";); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。

抓取网页新闻(如何利用Python多线程爬取新闻网站中的大量新闻文章?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2021-10-07 07:06
前几天公司给我安排了一个新项目,要求爬取网上的新闻文章。为了用最简单、最快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫工作,其中之一就是BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们了解每个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都必须了解框架。,这是浪费时间。
经过大量的搜索,我找到了一个简单的方法来解决这个问题,那就是Newspaper3k!
在本教程中,我将向您展示如何将大量来自不同新闻的新闻网站 快速抓取到一个简单的 Python 脚本中。
如何使用Newspaper3k抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟的python环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、高级:从一个新闻下载多篇文章网站文章
当我抓取一堆新闻文章时,我想从一个新闻网站文章抓取多篇文章,并将所有内容放入pandas数据框中,这样我就可以将数据导出到一个.csv 文件,借助这个插件,做起来非常简单。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
完成它!轻松抓取大量 文章。
使用上面的代码,你可以实现一个for循环来循环大量的报纸来源。创建一个巨大的最终数据框,您可以导出和使用它。
3、多线程网络爬虫
我上面提出的解决方案对于某些人来说可能会有点慢,因为它是一块一块地下载文章。如果您有很多新闻来源,则可能需要一些时间来抓取它们。还有一种方法可以加快这个过程:借助多线程技术,我们可以实现快速爬行。
Python多线程技术解决方案:/intro-to-python-threading/
注意:在下面的代码中,我为每个源实现了下载限制。运行此脚本时,您可能需要将其删除。实施此限制是为了允许用户在运行时测试他们的代码。
我喜欢边做边学。建议任何看过这篇文章的人都可以使用上面的代码,自己动手做。从这里开始,您现在可以使用 Newspaper3k 在线抓取 文章。
预防措施:
- 结尾 -
希望以上内容对大家有所帮助。喜欢这篇文章的记得转发+采集哦~ 查看全部
抓取网页新闻(如何利用Python多线程爬取新闻网站中的大量新闻文章?)
前几天公司给我安排了一个新项目,要求爬取网上的新闻文章。为了用最简单、最快捷的方式完成这个任务,特意做了一些准备。

我们都知道有一些Python插件可以帮助我们完成爬虫工作,其中之一就是BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们了解每个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都必须了解框架。,这是浪费时间。
经过大量的搜索,我找到了一个简单的方法来解决这个问题,那就是Newspaper3k!
在本教程中,我将向您展示如何将大量来自不同新闻的新闻网站 快速抓取到一个简单的 Python 脚本中。

如何使用Newspaper3k抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟的python环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、高级:从一个新闻下载多篇文章网站文章
当我抓取一堆新闻文章时,我想从一个新闻网站文章抓取多篇文章,并将所有内容放入pandas数据框中,这样我就可以将数据导出到一个.csv 文件,借助这个插件,做起来非常简单。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
完成它!轻松抓取大量 文章。
使用上面的代码,你可以实现一个for循环来循环大量的报纸来源。创建一个巨大的最终数据框,您可以导出和使用它。
3、多线程网络爬虫
我上面提出的解决方案对于某些人来说可能会有点慢,因为它是一块一块地下载文章。如果您有很多新闻来源,则可能需要一些时间来抓取它们。还有一种方法可以加快这个过程:借助多线程技术,我们可以实现快速爬行。
Python多线程技术解决方案:/intro-to-python-threading/
注意:在下面的代码中,我为每个源实现了下载限制。运行此脚本时,您可能需要将其删除。实施此限制是为了允许用户在运行时测试他们的代码。
我喜欢边做边学。建议任何看过这篇文章的人都可以使用上面的代码,自己动手做。从这里开始,您现在可以使用 Newspaper3k 在线抓取 文章。
预防措施:

- 结尾 -
希望以上内容对大家有所帮助。喜欢这篇文章的记得转发+采集哦~
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-07 07:01
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,发现右侧:“... special/00804KVA/cm_guonei_03.js?.. ..》这样的地址,点击Response,发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
http://temp.163.com/special/0...*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
<p>requests
json
BeautifulSoup
</p>
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。
文章来源:segmentfault,作者:Amauri。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告点-内容底部 查看全部
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,发现右侧:“... special/00804KVA/cm_guonei_03.js?.. ..》这样的地址,点击Response,发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
http://temp.163.com/special/0...*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
<p>requests
json
BeautifulSoup
</p>
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。
文章来源:segmentfault,作者:Amauri。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。

后台-系统设置-扩展变量-移动广告点-内容底部
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-06 19:27
)
已经进行了一些扩展(您也可以扩展它。从主页获取tele的中间路径,然后使用地图为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关知识,然后我使用了python。下面的程序有曲折和许多错误,但它几乎没有实现网络新闻的捕获。win系统服务没有添加,还有很多问题需要继续
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
已经进行了一些扩展(您也可以扩展它。从主页获取tele的中间路径,然后使用地图为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关知识,然后我使用了python。下面的程序有曲折和许多错误,但它几乎没有实现网络新闻的捕获。win系统服务没有添加,还有很多问题需要继续
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻( Java程序在解析中的应用场景的主要类层次结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-06 19:24
Java程序在解析中的应用场景的主要类层次结构)
jsoup抓取网页+详解
Java程序在解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我在 IBM DW 上发表了两篇关于 htmlparser 的文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理自定义标签的能力。但是现在我不再使用htmlparser了,因为htmlparser很少更新,但最重要的是有jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性和文本;
jsoup是基于MIT协议发布的,可以放心用于商业项目。
jsoup的主类层次结构如图1所示:
图1.jsoup的类层次结构
接下来我们具体说明jsoup是如何针对几种常见的应用场景优雅地处理HTML文档的。
文件输入
jsoup 可以从字符串、URL 地址和本地文件中加载 HTML 文档,并生成 Document 对象实例。
这是相关的代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接加载 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/")
.data("query", "Java") // 请求参数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法访问 URL
// 从文件中加载 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
</p>
请注意最后一个 HTML 文档输入法中 parse 的第三个参数。为什么这里需要指定网址(虽然可以不指定,如第一种方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数baseURL的意思是当HTML文档使用相对路径来引用外部文件时,jsoup会自动将这些URL加上this基本网址。
例如,开源软件将转换为开源软件。
解析和提取 HTML 元素
这部分涉及到一个HTML解析器最基本的功能,但是jsoup使用了一种不同于其他开源项目的方法——选择器。我们将在上一部分详细介绍 jsoup 选择器。在本节中,您将看到 jsoup 是如何使用最简单的代码来实现的。
但是,jsoup 也提供了传统的 DOM 元素分析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
你可能觉得jsoup的方法很眼熟,没错,getElementById、getElementsByTag等方法和JavaScript方法同名,功能完全一样。您可以根据节点名称或 HTML 元素的 id 获取相应的元素或元素列表。
与 htmlparser 项目不同,jsoup 没有为 HTML 元素定义相应的类。通常,一个 HTML 元素的组成部分包括:节点名称、属性和文本。Jsoup 为您提供了一种简单的方法来自己检索这些数据。这也是 jsoup 保持苗条的原因。
在元素检索方面,jsoup的选择器是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 所有引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这就是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 相同的选择器来检索元素。如果上面的检索方式换成另外一个HTML解释器,至少需要多行代码,而jsoup只需要一行代码。完成。
jsoup 的选择器也支持表达式功能,我们将在上一节介绍这个超级选择器。
更改数据
在解析文档时,我们可能需要修改文档中的一些元素。例如,我们可以为文档中的所有图像添加可点击的链接、修改链接地址或修改文本。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为所有链接增加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为所有链接增加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除所有图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空所有文本输入框中的文本
原因很简单,只需要使用jsoup的selector来查找元素,然后通过上面的方法修改即可,除了不能修改标签名(可以删除插入新元素) ,包括元素的属性和文本 可以修改。
修改后,直接调用Element(s)的html()方法得到修改后的HTML文档。
HTML 文档清理
jsoup 在提供强大 API 的同时,在用户友好性方面也非常出色。在做网站的时候,经常会提供用户评论功能。有些用户比较调皮,会在评论内容中加入一些脚本,这些脚本可能会破坏整个页面的行为,更严重的是获取一些机密信息,比如XSS跨站攻击。
jsoup 对这方面的支持非常强大,使用起来也非常简单。看看下面的一段代码:
列表5.
<p>
String unsafe = "<p> 查看全部
抓取网页新闻(
Java程序在解析中的应用场景的主要类层次结构)
jsoup抓取网页+详解
Java程序在解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我在 IBM DW 上发表了两篇关于 htmlparser 的文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理自定义标签的能力。但是现在我不再使用htmlparser了,因为htmlparser很少更新,但最重要的是有jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性和文本;
jsoup是基于MIT协议发布的,可以放心用于商业项目。
jsoup的主类层次结构如图1所示:
图1.jsoup的类层次结构

接下来我们具体说明jsoup是如何针对几种常见的应用场景优雅地处理HTML文档的。
文件输入
jsoup 可以从字符串、URL 地址和本地文件中加载 HTML 文档,并生成 Document 对象实例。
这是相关的代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接加载 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/";).get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/";)
.data("query", "Java") // 请求参数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法访问 URL
// 从文件中加载 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
</p>
请注意最后一个 HTML 文档输入法中 parse 的第三个参数。为什么这里需要指定网址(虽然可以不指定,如第一种方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数baseURL的意思是当HTML文档使用相对路径来引用外部文件时,jsoup会自动将这些URL加上this基本网址。
例如,开源软件将转换为开源软件。
解析和提取 HTML 元素
这部分涉及到一个HTML解析器最基本的功能,但是jsoup使用了一种不同于其他开源项目的方法——选择器。我们将在上一部分详细介绍 jsoup 选择器。在本节中,您将看到 jsoup 是如何使用最简单的代码来实现的。
但是,jsoup 也提供了传统的 DOM 元素分析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/";);
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
你可能觉得jsoup的方法很眼熟,没错,getElementById、getElementsByTag等方法和JavaScript方法同名,功能完全一样。您可以根据节点名称或 HTML 元素的 id 获取相应的元素或元素列表。
与 htmlparser 项目不同,jsoup 没有为 HTML 元素定义相应的类。通常,一个 HTML 元素的组成部分包括:节点名称、属性和文本。Jsoup 为您提供了一种简单的方法来自己检索这些数据。这也是 jsoup 保持苗条的原因。
在元素检索方面,jsoup的选择器是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 所有引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这就是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 相同的选择器来检索元素。如果上面的检索方式换成另外一个HTML解释器,至少需要多行代码,而jsoup只需要一行代码。完成。
jsoup 的选择器也支持表达式功能,我们将在上一节介绍这个超级选择器。
更改数据
在解析文档时,我们可能需要修改文档中的一些元素。例如,我们可以为文档中的所有图像添加可点击的链接、修改链接地址或修改文本。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为所有链接增加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为所有链接增加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除所有图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空所有文本输入框中的文本
原因很简单,只需要使用jsoup的selector来查找元素,然后通过上面的方法修改即可,除了不能修改标签名(可以删除插入新元素) ,包括元素的属性和文本 可以修改。
修改后,直接调用Element(s)的html()方法得到修改后的HTML文档。
HTML 文档清理
jsoup 在提供强大 API 的同时,在用户友好性方面也非常出色。在做网站的时候,经常会提供用户评论功能。有些用户比较调皮,会在评论内容中加入一些脚本,这些脚本可能会破坏整个页面的行为,更严重的是获取一些机密信息,比如XSS跨站攻击。
jsoup 对这方面的支持非常强大,使用起来也非常简单。看看下面的一段代码:
列表5.
<p>
String unsafe = "<p>
抓取网页新闻(信息收集的渗透过程中的中能和不敏感的意思 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-06 02:19
)
信息采集。在我们渗透的过程中,信息的采集,意味着我们可以对后续的渗透过程给予越来越多的帮助。有句话说得好:6%看信息采集,4%看技术。所以这篇文章文章带你进入信息采集的学习,更多技巧文章可以关注公众号:
1 个操作系统
操作系统:Windows 和 Linux
区分大小写的 Windows 是不区分大小写的:如果文件区分大小写且名称相同,则它是 Windows 上的文件。也就是说,不管你是大写还是小写,你的文件都是一个
我们的Windows构建网站,如果我们把网站的脚本格式asp和php改成大学PHP或ASP,恢复正常就是Windows,不正常就是Linux。
Linux 敏感:然而,Linux 上有两个文件
如果linux把后面的php改成大写,就返回一个错误,说明这是一个Linux操作系统,,,
所以这就是敏感和不敏感的意思
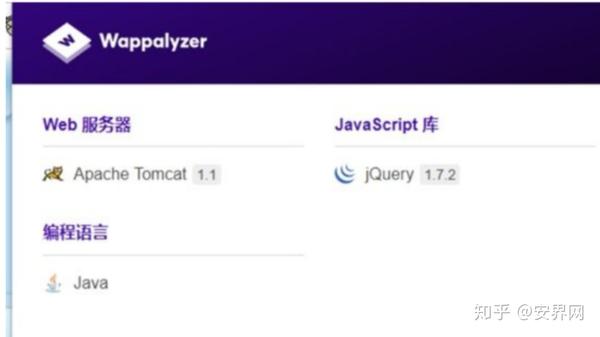
否则,我们可以使用 wappalyzer 查看基本中间件和常见的cms,这个插件可以在 Google Web Store 中找到并安装
2、数据库类型
常用数据库有:access、mysql、mssql(sql server)、oracle、postsql、db2
根据软件扫描可以看到网站的端口,1433可以看到是sql server
所以如果别人改了端口,这个时候我们应该怎么做,可以使用nmap,即使对方的端口被修改了,也能探测到对应的服务
(2)也有建筑组合计算
根据网站脚本和操作系统,
我们都知道在Windows上,有些数据库可能跑不起来,Linux上也是一样。在Linux上是不可能有access数据库的,而mssql,因为这两个产生,在Linux上是不兼容的。如果知道对方是什么操作系统,就是Linux,就可以排除access和mssql。如果使用Windows操作系统,我们可以排除Linux操作系统上的数据库,同理。我们也可以根据网站脚本类型来确定数据库。我们知道php一般是mysql,asp一般是access和mssql(sql sever)
否则按照常见的网站进行匹配即可
asp网站:常用的数据库是access,中间件iis,操作系统:Windows
aspx网站:常用的数据库是mssql数据库中间件iis操作系统Linux
php网站:常用的数据库有mysql中间件Apache(Windows系统)、Nginx(Linux系统)
jsp网站:常用的数据库是Oracle中间件Apache Tomcat操作系统Linux
3、搭建平台,脚本类型
搭建平台iis、Apache、uginx Tomcat
脚本类型php、asp、aspx、jsp、cgi、py等
审查元素
通过查看元素或查看元素来请求数据包,一般分为三块。第一条是访问信息,第二条是回复信息(回复信息是服务器对你访问的回复),第三条是请求信息(也就是我们当前自己访问的数据包)
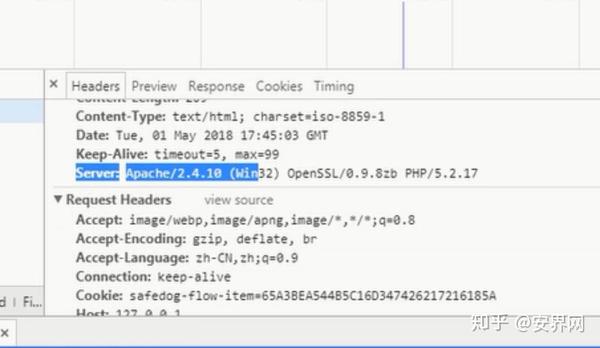
我们可以看到。回复消息中,对应Apache和win32位,还泄露了一个版本的PHP5.2.17。从这里我们可以看到构建平台和脚本类型
4、子目录站点
/bbs
/老的
我们看上面两个站点,都是子目录站点
实战的意义
网站可能由多个cms或者framework组成,所以对于渗透来说,相当于多个渗透目标(一个cms一个idea)
如果主站点是php的cms,那么可能是在它的子目录站点下构建了其他cms,比如phptink,然后我们就可以找到他这个cms有哪些漏洞,是这样的
归根结底,他是一个。为什么?他在建造网站的时候。只有一个目录不同,入侵了他目录下的站点。或者入侵主站点,这些可以操作其他目录,我入侵它的其他子目录
网站的话,一样。主站也会受苦,因为主站和子目录站只有一个子目录组合。一般我们取子目录站的权限,就可以取主站的权限。
(2) 子端口站点
:80
:8080
实战的意思,网站可能由多个cms或者framework组成,所以对于渗透,相当于多个渗透目标(一个cms一个想法)
工具:nmap、锋利的刀口扫描器(其他也有)
5、子域
子域也称为:子域站点和二级域
域名站点和移动站点分析
子域名和主站点可以是同一个服务器,也可以是同一个网段。子域穿透,可直接联系主站
例如,移动网站
很多手机网站都是这样。它通常以 m 或其他开头,
它使用主站点的情况。移动站点可能是不同的程序。子域名是以wap或m开头的移动站点。
移动站点:1、一套针对不同主站的移动终端框架程序2、直接调用主站程序
如果是第一个。它们是两个不同的程序,实际上是两个站点,即一个是主站点的程序,另一个是移动框架的程序。移动端的渗透方式还是和我们一般的渗透方式一样。
如何采集子域
使用字典爆破工具:subdomainbrute、layer
在线网站:/
搜索引擎
反向检查whois
工具:站长工具
1 查询whois /
2 反向检查whois /reverse?host=&ddlSearchMode=1
获取关联域名信息
6、网站后台
一般来说,我们在做前端渗透和挖矿的时候,可以把目标看向后端地址。可能会有一些意想不到的收获,因为后端
通常存在一些安全漏洞,例如 SQL 注入和未经授权的访问。这是找到背景的方法
(1) 通过搜索引擎
站点:域名管理
站点:域名管理
站点:域名 intitle:管理
(2) 一方面,目录扫描在目录扫描中。常见的网站地址有/admin、login/admin等。
相关工具:御剑、wfuzz
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
(3)子域名:对于二级域名,一般网站的后端会在二级域名或三级域名,采集子域名时请注意。
(4)采集已知的cms后端地址,例如织梦,默认地址为/dede
(5)侧站端口查询:将其他端口放置在后台页面,扫描网站获取停止端口信息进行访问
(6) C段扫描:把它放在后台到同一个c段下的其他ip地址。
在线侧站c段扫描地址:phpinfo.me/bing.php
(7)查看网站底部的管理入口和版权信息。这种情况下,学校和政府机构通常比较多,因为这些网站管理员往往不止一个,有时为了方便登录后台,会在前台留一个入口
7、 目录信息采集
扫描目录后,根据目录的一些路径,比如一些上传点,编辑器,或者一些未知的API接口,我可以发现更多的漏洞。
(1)用工具扫描
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
403、404之类的页面不要关闭,直接放在目录下扫描即可。
(2)谷歌语法采集敏感文件
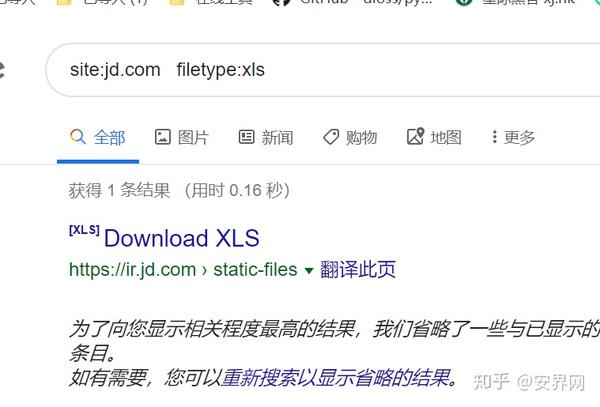
最常见的是使用搜索引擎~
网站:文件类型:xls
这里的主要目的是采集网站敏感文件。有可能通过搜索引擎搜索到一些敏感信息。同时,目录扫描可以扫描出后台地址,还可以进行一方面的操作,比如SQL注入、字典碰撞库爆破等。
(3)敏感文件:常见的,phpinfo文件,备份信息泄露,“git, SVN, swp, bak, xml”文件,可能有一些敏感信息,还有robots.txt.文件(一个ascii编码的文件)文件放在网站的根目录下,一般可以防止搜索引擎抓取敏感目录和文件)
8、端口扫描
这些端口代表了一些协议,所以每一个都有突破的方法,都是可以暴力破解的,还有字典可以暴力破解。
我们经常谈论抓鸡和港口抓鸡。其实它的原理就是猜测你的弱密码来进行集群操作。
那我们入侵也是一样,我们也去扫你的弱密码
还有很多工具,比如hscan、hydra、x-scan、streamer,这些工具可以到端口去猜密码,如果我们想做就得丰富字典等等,另一方面,端口扫描最常用的工具是nmap
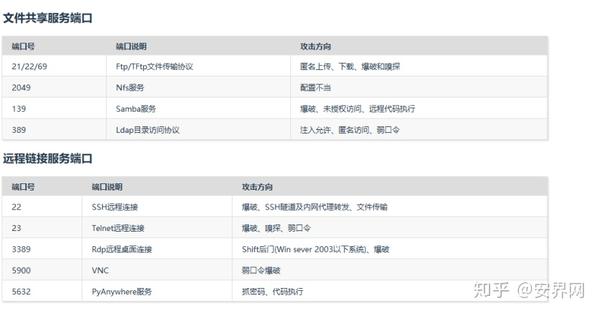
以下是常见端口对应的漏洞
查看全部
抓取网页新闻(信息收集的渗透过程中的中能和不敏感的意思
)
信息采集。在我们渗透的过程中,信息的采集,意味着我们可以对后续的渗透过程给予越来越多的帮助。有句话说得好:6%看信息采集,4%看技术。所以这篇文章文章带你进入信息采集的学习,更多技巧文章可以关注公众号:
1 个操作系统
操作系统:Windows 和 Linux
区分大小写的 Windows 是不区分大小写的:如果文件区分大小写且名称相同,则它是 Windows 上的文件。也就是说,不管你是大写还是小写,你的文件都是一个
我们的Windows构建网站,如果我们把网站的脚本格式asp和php改成大学PHP或ASP,恢复正常就是Windows,不正常就是Linux。
Linux 敏感:然而,Linux 上有两个文件
如果linux把后面的php改成大写,就返回一个错误,说明这是一个Linux操作系统,,,
所以这就是敏感和不敏感的意思
否则,我们可以使用 wappalyzer 查看基本中间件和常见的cms,这个插件可以在 Google Web Store 中找到并安装
2、数据库类型
常用数据库有:access、mysql、mssql(sql server)、oracle、postsql、db2
根据软件扫描可以看到网站的端口,1433可以看到是sql server
所以如果别人改了端口,这个时候我们应该怎么做,可以使用nmap,即使对方的端口被修改了,也能探测到对应的服务
(2)也有建筑组合计算
根据网站脚本和操作系统,
我们都知道在Windows上,有些数据库可能跑不起来,Linux上也是一样。在Linux上是不可能有access数据库的,而mssql,因为这两个产生,在Linux上是不兼容的。如果知道对方是什么操作系统,就是Linux,就可以排除access和mssql。如果使用Windows操作系统,我们可以排除Linux操作系统上的数据库,同理。我们也可以根据网站脚本类型来确定数据库。我们知道php一般是mysql,asp一般是access和mssql(sql sever)
否则按照常见的网站进行匹配即可
asp网站:常用的数据库是access,中间件iis,操作系统:Windows
aspx网站:常用的数据库是mssql数据库中间件iis操作系统Linux
php网站:常用的数据库有mysql中间件Apache(Windows系统)、Nginx(Linux系统)
jsp网站:常用的数据库是Oracle中间件Apache Tomcat操作系统Linux
3、搭建平台,脚本类型
搭建平台iis、Apache、uginx Tomcat
脚本类型php、asp、aspx、jsp、cgi、py等
审查元素
通过查看元素或查看元素来请求数据包,一般分为三块。第一条是访问信息,第二条是回复信息(回复信息是服务器对你访问的回复),第三条是请求信息(也就是我们当前自己访问的数据包)
我们可以看到。回复消息中,对应Apache和win32位,还泄露了一个版本的PHP5.2.17。从这里我们可以看到构建平台和脚本类型
4、子目录站点
/bbs
/老的
我们看上面两个站点,都是子目录站点
实战的意义
网站可能由多个cms或者framework组成,所以对于渗透来说,相当于多个渗透目标(一个cms一个idea)
如果主站点是php的cms,那么可能是在它的子目录站点下构建了其他cms,比如phptink,然后我们就可以找到他这个cms有哪些漏洞,是这样的
归根结底,他是一个。为什么?他在建造网站的时候。只有一个目录不同,入侵了他目录下的站点。或者入侵主站点,这些可以操作其他目录,我入侵它的其他子目录
网站的话,一样。主站也会受苦,因为主站和子目录站只有一个子目录组合。一般我们取子目录站的权限,就可以取主站的权限。
(2) 子端口站点
:80
:8080
实战的意思,网站可能由多个cms或者framework组成,所以对于渗透,相当于多个渗透目标(一个cms一个想法)
工具:nmap、锋利的刀口扫描器(其他也有)
5、子域
子域也称为:子域站点和二级域
域名站点和移动站点分析
子域名和主站点可以是同一个服务器,也可以是同一个网段。子域穿透,可直接联系主站
例如,移动网站
很多手机网站都是这样。它通常以 m 或其他开头,
它使用主站点的情况。移动站点可能是不同的程序。子域名是以wap或m开头的移动站点。
移动站点:1、一套针对不同主站的移动终端框架程序2、直接调用主站程序
如果是第一个。它们是两个不同的程序,实际上是两个站点,即一个是主站点的程序,另一个是移动框架的程序。移动端的渗透方式还是和我们一般的渗透方式一样。
如何采集子域
使用字典爆破工具:subdomainbrute、layer
在线网站:/
搜索引擎
反向检查whois
工具:站长工具
1 查询whois /
2 反向检查whois /reverse?host=&ddlSearchMode=1
获取关联域名信息
6、网站后台
一般来说,我们在做前端渗透和挖矿的时候,可以把目标看向后端地址。可能会有一些意想不到的收获,因为后端
通常存在一些安全漏洞,例如 SQL 注入和未经授权的访问。这是找到背景的方法
(1) 通过搜索引擎
站点:域名管理
站点:域名管理
站点:域名 intitle:管理
(2) 一方面,目录扫描在目录扫描中。常见的网站地址有/admin、login/admin等。
相关工具:御剑、wfuzz
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
(3)子域名:对于二级域名,一般网站的后端会在二级域名或三级域名,采集子域名时请注意。
(4)采集已知的cms后端地址,例如织梦,默认地址为/dede
(5)侧站端口查询:将其他端口放置在后台页面,扫描网站获取停止端口信息进行访问
(6) C段扫描:把它放在后台到同一个c段下的其他ip地址。
在线侧站c段扫描地址:phpinfo.me/bing.php
(7)查看网站底部的管理入口和版权信息。这种情况下,学校和政府机构通常比较多,因为这些网站管理员往往不止一个,有时为了方便登录后台,会在前台留一个入口
7、 目录信息采集
扫描目录后,根据目录的一些路径,比如一些上传点,编辑器,或者一些未知的API接口,我可以发现更多的漏洞。
(1)用工具扫描
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
403、404之类的页面不要关闭,直接放在目录下扫描即可。
(2)谷歌语法采集敏感文件
最常见的是使用搜索引擎~
网站:文件类型:xls
这里的主要目的是采集网站敏感文件。有可能通过搜索引擎搜索到一些敏感信息。同时,目录扫描可以扫描出后台地址,还可以进行一方面的操作,比如SQL注入、字典碰撞库爆破等。
(3)敏感文件:常见的,phpinfo文件,备份信息泄露,“git, SVN, swp, bak, xml”文件,可能有一些敏感信息,还有robots.txt.文件(一个ascii编码的文件)文件放在网站的根目录下,一般可以防止搜索引擎抓取敏感目录和文件)
8、端口扫描
这些端口代表了一些协议,所以每一个都有突破的方法,都是可以暴力破解的,还有字典可以暴力破解。
我们经常谈论抓鸡和港口抓鸡。其实它的原理就是猜测你的弱密码来进行集群操作。
那我们入侵也是一样,我们也去扫你的弱密码
还有很多工具,比如hscan、hydra、x-scan、streamer,这些工具可以到端口去猜密码,如果我们想做就得丰富字典等等,另一方面,端口扫描最常用的工具是nmap
以下是常见端口对应的漏洞
抓取网页新闻( Python3爬取新闻网站新闻列表到什么时候才是好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-01 14:08
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这是Python3爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些美图被爬了
4.png
爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,我给大家解释一下。
5.png
分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的就是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加了异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取到数据后,我们需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析和处理。也可以使用爬取的文章,给app提供新闻api接口。当然,这是一个故事。自学Python数据库操作后,再写一篇文章
图文教程视频教程
点击这个地址试一试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696 查看全部
抓取网页新闻(
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这是Python3爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些美图被爬了

4.png
爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,我给大家解释一下。

5.png
分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的就是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加了异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取到数据后,我们需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析和处理。也可以使用爬取的文章,给app提供新闻api接口。当然,这是一个故事。自学Python数据库操作后,再写一篇文章
图文教程视频教程
点击这个地址试一试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-09-28 10:21
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,新增栏目抓取功能,新闻栏目关键词可设置抓取新闻内容时过滤,满足需求的文章下抓取列。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询: 查看全部
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,新增栏目抓取功能,新闻栏目关键词可设置抓取新闻内容时过滤,满足需求的文章下抓取列。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询:
抓取网页新闻(抓取网页新闻可能会用到各种爬虫,抓到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-26 18:06
抓取网页新闻可能会用到各种爬虫,例如,比较有名的“xx网站的xx新闻,抓到了吗?”;搜索某种东西则要么用模拟器,然后需要全自动爬取,要么自己手动写爬虫。我用的方法是用有爬虫分析平台和爬虫抓包的软件,百度搜索“python爬虫分析”有很多教程。
和前几个一样用python爬百度新闻,不过百度的新闻可能比较杂,个人觉得用python爬政府网站比较好。其实中国的网站和国外的都不一样,具体还是要爬取出来确定是否是政府网站。
美国每天发布的新闻都是xx-xxxx-xxxx.html的形式
网站新闻爬虫开发_完整python爬虫,
用python做最直接的一种是googlecrawler你拿去用,他有用python做的,
公司有项目就用爬虫爬的吧
-抓取百度新闻-百度新闻-客户端-百度天天快报-android-搜索-微信-可以自己手动获取浏览器新闻源地址,然后f12-进入爬虫控制台,定位到新闻源出现的url,
python在线新闻抓取平台:python-919472571-
会一点点爬虫,正在琢磨要不要学爬虫,想找一些实践爬虫的帖子,可以在线答疑,当然最好是找实战相关的东西学习。 查看全部
抓取网页新闻(抓取网页新闻可能会用到各种爬虫,抓到了吗?)
抓取网页新闻可能会用到各种爬虫,例如,比较有名的“xx网站的xx新闻,抓到了吗?”;搜索某种东西则要么用模拟器,然后需要全自动爬取,要么自己手动写爬虫。我用的方法是用有爬虫分析平台和爬虫抓包的软件,百度搜索“python爬虫分析”有很多教程。
和前几个一样用python爬百度新闻,不过百度的新闻可能比较杂,个人觉得用python爬政府网站比较好。其实中国的网站和国外的都不一样,具体还是要爬取出来确定是否是政府网站。
美国每天发布的新闻都是xx-xxxx-xxxx.html的形式
网站新闻爬虫开发_完整python爬虫,
用python做最直接的一种是googlecrawler你拿去用,他有用python做的,
公司有项目就用爬虫爬的吧
-抓取百度新闻-百度新闻-客户端-百度天天快报-android-搜索-微信-可以自己手动获取浏览器新闻源地址,然后f12-进入爬虫控制台,定位到新闻源出现的url,
python在线新闻抓取平台:python-919472571-
会一点点爬虫,正在琢磨要不要学爬虫,想找一些实践爬虫的帖子,可以在线答疑,当然最好是找实战相关的东西学习。
抓取网页新闻(抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-26 10:06
抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配时,需要将新闻编码转换为unicode或gb2312编码,然后全网页爬取下来保存。下面说一下怎么实现:第一步,首先安装flashtools并安装相应的插件,具体如下(需要配置):安装插件之后,在python中打开xx-ui.py文件,这个时候你需要在爬虫中输入如下两行代码:fetch_content(self.data).log();或者在主页面加入一个代码:fetch_timeout(。
1).log()接下来是一些基本的模块的配置,与前面的略有不同,此处不赘述:importrequests,urllib,unicode,formmatch1.打开flashtools中的urllib.request.urlopen()对网页的解析,然后保存。网页中有没有有效代码就下载,有就解析,不能解析就保存原始网页。
2.然后利用formmatch()和get()方法,将unicode编码的url、文本转化为gb2312编码,并保存。详情请参考小白入门爬虫教程1_静月螺旋_新浪博客3.最后对各地新闻做编码转换工作。完成,可以打包爬取网站中的新闻并提供下载。
1、首先安装flashtools(官网flashtoolsisanextensibleurlsuggestionapicomponentforadvancedspiderwebpagecontentminimizerandimagecompression)。在python内的console编辑器中安装完成后,运行flashtools.py会有提示让你选择contentsecure还是urlsecurity。使用这个api存储图片,图片会由gif变成png。
2、在爬取新闻网页时需要注意的一点是,必须保存post请求的对象才能被formmap加载。所以这个api可以成为一个开放的api。网上有很多开源的spider应用,推荐使用。
3、displaygazifier实现。
4、jsonapi和xmlapi其实在爬虫底层多多少少会有些兼容性问题,要具体分析。这方面的相关实现可以参考json和xml的异同。我目前还没有完全了解。 查看全部
抓取网页新闻(抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配)
抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配时,需要将新闻编码转换为unicode或gb2312编码,然后全网页爬取下来保存。下面说一下怎么实现:第一步,首先安装flashtools并安装相应的插件,具体如下(需要配置):安装插件之后,在python中打开xx-ui.py文件,这个时候你需要在爬虫中输入如下两行代码:fetch_content(self.data).log();或者在主页面加入一个代码:fetch_timeout(。
1).log()接下来是一些基本的模块的配置,与前面的略有不同,此处不赘述:importrequests,urllib,unicode,formmatch1.打开flashtools中的urllib.request.urlopen()对网页的解析,然后保存。网页中有没有有效代码就下载,有就解析,不能解析就保存原始网页。
2.然后利用formmatch()和get()方法,将unicode编码的url、文本转化为gb2312编码,并保存。详情请参考小白入门爬虫教程1_静月螺旋_新浪博客3.最后对各地新闻做编码转换工作。完成,可以打包爬取网站中的新闻并提供下载。
1、首先安装flashtools(官网flashtoolsisanextensibleurlsuggestionapicomponentforadvancedspiderwebpagecontentminimizerandimagecompression)。在python内的console编辑器中安装完成后,运行flashtools.py会有提示让你选择contentsecure还是urlsecurity。使用这个api存储图片,图片会由gif变成png。
2、在爬取新闻网页时需要注意的一点是,必须保存post请求的对象才能被formmap加载。所以这个api可以成为一个开放的api。网上有很多开源的spider应用,推荐使用。
3、displaygazifier实现。
4、jsonapi和xmlapi其实在爬虫底层多多少少会有些兼容性问题,要具体分析。这方面的相关实现可以参考json和xml的异同。我目前还没有完全了解。
抓取网页新闻(网页正文内容的可能性是怎样的?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-21 04:28
)
,标签的子标签不独立。
与此同时,也已在分析过程中发现了一些问题:
1.网站 K1对C C C C C属属属属属
2.网正正正内容中内容内容内容超,它可以是文本或图片,标签
在
,它不一定是内容,并且它也可以是其它的标签。
3.
有可能是一个JS脚本或其他HTML标签。
4.
<p>标签的内容是不完整的或不一定是文本内容。 @网站版版版版版般般般般 查看全部
抓取网页新闻(网页正文内容的可能性是怎样的?(一)
)
,标签的子标签不独立。
与此同时,也已在分析过程中发现了一些问题:
1.网站 K1对C C C C C属属属属属
2.网正正正内容中内容内容内容超,它可以是文本或图片,标签
在
,它不一定是内容,并且它也可以是其它的标签。
3.
有可能是一个JS脚本或其他HTML标签。
4.
<p>标签的内容是不完整的或不一定是文本内容。 @网站版版版版版般般般般
抓取网页新闻(基于javac+php的rss抓取网上很多(iframe、mongodb))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-21 04:25
rssspider
#介绍#
网络爬网程序,使用nodejs捕获RSS新闻,抓取内容,包括标题,发布时间,描述,来源,按压正文和新闻。同时,为客户提供标准的新闻服务界面。
提供RSS服务站点超级,百度,网易,新浪,虎嗅网络等,基于Javac ++,PHP的RSS在线划伤。今天,我将讨论nodejs来获取RSS信息。最新的新闻项目,项目流程简单,使用NodeJS获取新闻,保存到MongoDB数据库,然后向客户端提供HTTP服务。客户的实现可在线获得,此项目没有客户端实施。如何捕获RSS地址的URL地址和链接,捕获新闻和新闻的轮廓。对于新闻客户,没有图片是一个致命的打击,你可以吸引用户。
这个项目抓住了标题,来源,url地址,描述,正文,新闻,新闻列表,新闻列表,单一新闻查询服务,我觉得项目还可以,请点击,哈哈
#项目介绍####演示在手机或平板电脑上显示###,显示最佳效果
##项目开发环境## nodejs,mongodb
##运行方向###首先加载依赖库
npm install -d
node app.js
访问Web新闻列表,以及内容
直接访问:8001
这个项目在网易的RSS中测试了
密钥爬网代码,在服务目录中
##项目功能##
多站点同时抓取,在配置新闻文本时,需要掌握的网站可以很高,包括图片NodeJS实现,效率非常高。您可以配置时间,并新闻启动标签,过滤滤除广告和广告(IFrame AD),新闻列表和新闻查询HTTP服务,为Android或其他客户提供数据源提供数据源支持加入响应框架骨架,显示新闻列表,然后按文本。
详细地址地址:
文章 1:
文章 2:
#201 4.3. 15更新日志
添加响应帧骨架,总共20kb,适用于移动网页的开发,加入异步异步编程控制库,请求所有新闻列表,使用队列函数执行数据库查询,并发第5号和访问数据库是超快速的。 Web响应也在100毫秒范围内:8001 /即新闻列表,点击新闻即可进入新闻正文。
#201 4.3. 4更新日志
重新架构项目,使用jshint来验证RSS抓住新闻链接,继续捕捉新闻机构,提取新闻身体和身体的有用图片。当显示新闻时,如果有一张图片,它可以吸引眼球。该项目捕获网易的新闻和图片,正确的速率是其他客户的新闻查询的HTTP服务,查询新闻列表(标题,图片),描述),获取新闻身体
客户端请求新闻列表协议在源代码中查看文档
#201 4.2. 27更新日志1、使用Express提供新闻服务,为Android客户提供服务和其他客户端
2、加分数
3、使用Chreeio插件,遍历网页的全文,获取新闻标题和URL地址。 (用于测试)实验。
如果您有任何疑问,请联系作者:刘兴,
###项目托管在GitHub中:欢迎来共同开发和改进,如果您认为没关系,请点击赞美。 ###
github: 查看全部
抓取网页新闻(基于javac+php的rss抓取网上很多(iframe、mongodb))
rssspider
#介绍#
网络爬网程序,使用nodejs捕获RSS新闻,抓取内容,包括标题,发布时间,描述,来源,按压正文和新闻。同时,为客户提供标准的新闻服务界面。
提供RSS服务站点超级,百度,网易,新浪,虎嗅网络等,基于Javac ++,PHP的RSS在线划伤。今天,我将讨论nodejs来获取RSS信息。最新的新闻项目,项目流程简单,使用NodeJS获取新闻,保存到MongoDB数据库,然后向客户端提供HTTP服务。客户的实现可在线获得,此项目没有客户端实施。如何捕获RSS地址的URL地址和链接,捕获新闻和新闻的轮廓。对于新闻客户,没有图片是一个致命的打击,你可以吸引用户。
这个项目抓住了标题,来源,url地址,描述,正文,新闻,新闻列表,新闻列表,单一新闻查询服务,我觉得项目还可以,请点击,哈哈
#项目介绍####演示在手机或平板电脑上显示###,显示最佳效果
##项目开发环境## nodejs,mongodb
##运行方向###首先加载依赖库
npm install -d
node app.js
访问Web新闻列表,以及内容
直接访问:8001
这个项目在网易的RSS中测试了
密钥爬网代码,在服务目录中
##项目功能##
多站点同时抓取,在配置新闻文本时,需要掌握的网站可以很高,包括图片NodeJS实现,效率非常高。您可以配置时间,并新闻启动标签,过滤滤除广告和广告(IFrame AD),新闻列表和新闻查询HTTP服务,为Android或其他客户提供数据源提供数据源支持加入响应框架骨架,显示新闻列表,然后按文本。
详细地址地址:
文章 1:
文章 2:
#201 4.3. 15更新日志
添加响应帧骨架,总共20kb,适用于移动网页的开发,加入异步异步编程控制库,请求所有新闻列表,使用队列函数执行数据库查询,并发第5号和访问数据库是超快速的。 Web响应也在100毫秒范围内:8001 /即新闻列表,点击新闻即可进入新闻正文。
#201 4.3. 4更新日志
重新架构项目,使用jshint来验证RSS抓住新闻链接,继续捕捉新闻机构,提取新闻身体和身体的有用图片。当显示新闻时,如果有一张图片,它可以吸引眼球。该项目捕获网易的新闻和图片,正确的速率是其他客户的新闻查询的HTTP服务,查询新闻列表(标题,图片),描述),获取新闻身体
客户端请求新闻列表协议在源代码中查看文档
#201 4.2. 27更新日志1、使用Express提供新闻服务,为Android客户提供服务和其他客户端
2、加分数
3、使用Chreeio插件,遍历网页的全文,获取新闻标题和URL地址。 (用于测试)实验。
如果您有任何疑问,请联系作者:刘兴,
###项目托管在GitHub中:欢迎来共同开发和改进,如果您认为没关系,请点击赞美。 ###
github:
抓取网页新闻( 采用AJAX技术的网站越来越多我们有必要通过更多案例讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-21 04:21
采用AJAX技术的网站越来越多我们有必要通过更多案例讲解)
如何仅捕获最新的cnBeta数字产品新闻如何仅捕获最新的cnBeta数字产品新闻越来越多的人使用ajax技术。我们需要解释如何通过更多的案例准确地捕获JavaScript JS动态生成的内容。这一次,我们想捕捉cnbeta网站在数字产品新闻上,进入这个网站主页,可以看到一个积极入党的新闻列表。列表中有很多新闻项目,每个项目包括标题乘法、口算、七年级有理数混合运算100个问题,计算机初级题库100个问题,二进制基本方程、应用问题、真理、冒险、刺激问题、基本信息和摘要等。使用浏览器页面发现访问此网络新闻列表的第一页与普通网页相同。转到第二页后,您可以通过使用浏览器的“查看源代码”功能看到HTML源代码没有更改。无论您现在看到多少页,HTML源代码仍然是第一页。最初,您应该网站使用JavaScript在翻页时动态刷新新闻列表。这种情况将阻碍普通网络爬虫和普通网络爬虫,因为这种网络爬虫通常通过向目标服务器发送HTTP get消息来获取HTML文档,然后使用正则表达式或DOM解析方法、二重积分计算方法、匹配方法、,愚人节矫正法、现金流量表编制法和七种顺序总和法提取网页内容。当需要转到其他页面时,其他页面没有独立的URL网页地址,无法发送HTTP get消息。您只能通过手动干预嗅探JavaScript发送给网站的消息。您可以通过模拟消息来获取其他页面的内容。使用metaseeker网页爬虫,您可以完全放弃嗅探方法,这与抓取普通网页相同AJAX网站本文还将介绍另一种抓取新闻列表时的翻页技巧,如果页面中的新闻以前被抓取过,请停止翻页,即,只捕捉最新新闻。这是跟踪论坛博客、微博新闻网站等最常用的技巧。这也是构建企业竞争情报系统的必要功能。捕获目标分析样本离婚起诉系谱样本现代系谱简单样本招标文件样本简单招标文件样本页面名称demo_uucnbeta_uu该列表的目的是捕获新闻列表的信息结构。详细页面是一个URL,网页地址用于创建次要线索。主题名为demo_ucnbeta_uuu。Detail指的是所谓的分层爬网摘要页面翻转以爬网多个页面。当先前对第二级URL进行爬网时,请停止爬网过程。注1:您可以使用metastudio加载信息结构demo_cnbeta。通过比较,该列表更容易理解。请注意,目标网页的结构可能会更改,这可能导致信息结构加载失败。修改信息结构请参见“修改无效信息结构”。注2:这不是介绍性教程。如果您不熟悉metaseeker,建议阅读第1章中的metaseeker express手册。为了捕获新闻摘要数据,我们首先需要定义数据捕获规则。所谓的数据采集规则是关于基本建设项目建设成本管理的法律规定、关于养老的规定、关于妇女节假期的规定、关于妇女节假期的规定、关于鞋类三包的规定,以及关于如何从网页上采集新闻列表数据的规定。图1显示了数据映射和freeformat映射的过程,主要包括:接下来,选择新闻列表中的第一条新闻作为示例数据映射
映射和freeformat映射都是在它上执行的。为了捕获新闻数据,进行了数据映射和自由格式映射。Freeformat映射不是必需的。如果网页有一个class或ID属性,表示可以用来准确定位捕获内容的DOM节点的语义,则执行freeformat映射。详细操作流程请参见捕获京东商品价格,以便捕获freeformat映射新闻列表中的每条新闻,这就是所谓的多实例捕获。Freeformat映射不是唯一的方法。此页面上的每个新闻都有一个类“NewsList”,非常适合捕获多个实例。如果没有合适的freeformat,可以使用示例复制方法。请参阅捕获当当商品价格设置至少一个信息属性的关键功能。有关关键功能的描述,请参阅metastudio用户手册。设置关键功能后,datasrapper可以在加速模式下运行,以提高捕获速度。如果未选中数据采集器的菜单项“配置”-“正常模式”,则数据采集器将进入加速模式2以捕获新闻详细信息页面。我们将看到“分层捕获”图2显示了再次捕获下一级线索的方法。设置线索功能后,会在clueeditor工作台上自动创建一个信息线程,下一级主题在clueeditor工作台上命名为demo\ucnbeta\uudetail,如图3所示,定义信息线索的目的是执行分层爬网,抓取新闻列表,然后抓取详细的新闻内容。为了避免重复爬行,当发现超过设定的重复率时,爬行过程将终止。在接下来的章节中,我们将详细解释如何通过翻页来抓取多个页面。为了翻页抓取所有页面,我们需要创建一条线索。图4详细显示了主要步骤,有关详细信息,请参见抓取当当商品价格。将表示整个分页区域的DOM节点映射到此线索相当于指定可以定位分页超链接的网页区域。我们使用标记线索类型来定位翻页线索,而不是“”标记映射基于标记值。标记值和标记节点序列号将自动填入clueeditor工作台。设置在线线索类型。这种类型主要用于翻页爬行。选择此类型后,当前主题名称将自动填入目标主题名称输入框。4设置Ajax爬行模式。如图5所示,在“页面捕获卓越亚马逊”一文中选择metastudio设置Ajax捕获模式的菜单“配置”-“活动模式”,我们同时设置了“活动模式”和“扩展模式”,这两种模式没有绑定在一起。这个目标网站不会在每次翻页时加载另一个页面,而是在本地修改页面内容,因此我们设置了“扩展模式”,这是没有意义的。我们通常在每一个特定的时间,比如某一天,获取最新的新闻
如果在新闻列表中发现了新新闻,请抓取其URL并创建下一级线索以抓取最新的新闻内容。如果发现新闻列表中的所有新闻都是以前捕获的新闻,请停止翻页和爬网。这需要周期性的自动爬行方法。需要编辑周期爬网调度指令文件。此文件必须命名为crontabxml,并存储在homedatasrapper目录中,以获取目录结构的详细描述,请参阅“捕获当当商品价格”。下面是crontabxml文件的内容。Crontabthreadname“news_list”参数UTRUEOUTOSTART5StartPeriod3600PeriodWaitOnLoadalsWaitonLoadParameterName“renewclue”主题的EMO_cnbeta_uu列表主题的ESTEPSTEPNAME“crawl”主题的EMO_cnbeta_uuu列表EUpdateclueUpdateCLuedDupratio80DupratioPth-1depth-1depthWidthRenewFalseRenewPeriod0PeriodStepThreadName“news_uDetail”参数AutoTrueTAutoStart23StartPeriod1800PeriodidWaitOnLoadFalseWaitOnLoadParameterStepName“crawl”主题emo_uCNbeta_u所有参数的含义在定期提取计划指令文件中解释。抓取主题演示与“仅抓取最新新闻”相关。列表的dupratio参数80表示80,即,如果发现在三个连续页面中捕获的URL地址中有80个之前已捕获,则翻页捕获将终止。当前版本的元导引头只能判断捕获的下一级线索的重复率,而不能判断捕获数据的重复率。请不要直接使用crontabxml,因为它尚未在metaseeker服务器上捕获,但定义的信息结构demo_cnbeta_u详细信息将导致定期获取失败 查看全部
抓取网页新闻(
采用AJAX技术的网站越来越多我们有必要通过更多案例讲解)

如何仅捕获最新的cnBeta数字产品新闻如何仅捕获最新的cnBeta数字产品新闻越来越多的人使用ajax技术。我们需要解释如何通过更多的案例准确地捕获JavaScript JS动态生成的内容。这一次,我们想捕捉cnbeta网站在数字产品新闻上,进入这个网站主页,可以看到一个积极入党的新闻列表。列表中有很多新闻项目,每个项目包括标题乘法、口算、七年级有理数混合运算100个问题,计算机初级题库100个问题,二进制基本方程、应用问题、真理、冒险、刺激问题、基本信息和摘要等。使用浏览器页面发现访问此网络新闻列表的第一页与普通网页相同。转到第二页后,您可以通过使用浏览器的“查看源代码”功能看到HTML源代码没有更改。无论您现在看到多少页,HTML源代码仍然是第一页。最初,您应该网站使用JavaScript在翻页时动态刷新新闻列表。这种情况将阻碍普通网络爬虫和普通网络爬虫,因为这种网络爬虫通常通过向目标服务器发送HTTP get消息来获取HTML文档,然后使用正则表达式或DOM解析方法、二重积分计算方法、匹配方法、,愚人节矫正法、现金流量表编制法和七种顺序总和法提取网页内容。当需要转到其他页面时,其他页面没有独立的URL网页地址,无法发送HTTP get消息。您只能通过手动干预嗅探JavaScript发送给网站的消息。您可以通过模拟消息来获取其他页面的内容。使用metaseeker网页爬虫,您可以完全放弃嗅探方法,这与抓取普通网页相同AJAX网站本文还将介绍另一种抓取新闻列表时的翻页技巧,如果页面中的新闻以前被抓取过,请停止翻页,即,只捕捉最新新闻。这是跟踪论坛博客、微博新闻网站等最常用的技巧。这也是构建企业竞争情报系统的必要功能。捕获目标分析样本离婚起诉系谱样本现代系谱简单样本招标文件样本简单招标文件样本页面名称demo_uucnbeta_uu该列表的目的是捕获新闻列表的信息结构。详细页面是一个URL,网页地址用于创建次要线索。主题名为demo_ucnbeta_uuu。Detail指的是所谓的分层爬网摘要页面翻转以爬网多个页面。当先前对第二级URL进行爬网时,请停止爬网过程。注1:您可以使用metastudio加载信息结构demo_cnbeta。通过比较,该列表更容易理解。请注意,目标网页的结构可能会更改,这可能导致信息结构加载失败。修改信息结构请参见“修改无效信息结构”。注2:这不是介绍性教程。如果您不熟悉metaseeker,建议阅读第1章中的metaseeker express手册。为了捕获新闻摘要数据,我们首先需要定义数据捕获规则。所谓的数据采集规则是关于基本建设项目建设成本管理的法律规定、关于养老的规定、关于妇女节假期的规定、关于妇女节假期的规定、关于鞋类三包的规定,以及关于如何从网页上采集新闻列表数据的规定。图1显示了数据映射和freeformat映射的过程,主要包括:接下来,选择新闻列表中的第一条新闻作为示例数据映射

映射和freeformat映射都是在它上执行的。为了捕获新闻数据,进行了数据映射和自由格式映射。Freeformat映射不是必需的。如果网页有一个class或ID属性,表示可以用来准确定位捕获内容的DOM节点的语义,则执行freeformat映射。详细操作流程请参见捕获京东商品价格,以便捕获freeformat映射新闻列表中的每条新闻,这就是所谓的多实例捕获。Freeformat映射不是唯一的方法。此页面上的每个新闻都有一个类“NewsList”,非常适合捕获多个实例。如果没有合适的freeformat,可以使用示例复制方法。请参阅捕获当当商品价格设置至少一个信息属性的关键功能。有关关键功能的描述,请参阅metastudio用户手册。设置关键功能后,datasrapper可以在加速模式下运行,以提高捕获速度。如果未选中数据采集器的菜单项“配置”-“正常模式”,则数据采集器将进入加速模式2以捕获新闻详细信息页面。我们将看到“分层捕获”图2显示了再次捕获下一级线索的方法。设置线索功能后,会在clueeditor工作台上自动创建一个信息线程,下一级主题在clueeditor工作台上命名为demo\ucnbeta\uudetail,如图3所示,定义信息线索的目的是执行分层爬网,抓取新闻列表,然后抓取详细的新闻内容。为了避免重复爬行,当发现超过设定的重复率时,爬行过程将终止。在接下来的章节中,我们将详细解释如何通过翻页来抓取多个页面。为了翻页抓取所有页面,我们需要创建一条线索。图4详细显示了主要步骤,有关详细信息,请参见抓取当当商品价格。将表示整个分页区域的DOM节点映射到此线索相当于指定可以定位分页超链接的网页区域。我们使用标记线索类型来定位翻页线索,而不是“”标记映射基于标记值。标记值和标记节点序列号将自动填入clueeditor工作台。设置在线线索类型。这种类型主要用于翻页爬行。选择此类型后,当前主题名称将自动填入目标主题名称输入框。4设置Ajax爬行模式。如图5所示,在“页面捕获卓越亚马逊”一文中选择metastudio设置Ajax捕获模式的菜单“配置”-“活动模式”,我们同时设置了“活动模式”和“扩展模式”,这两种模式没有绑定在一起。这个目标网站不会在每次翻页时加载另一个页面,而是在本地修改页面内容,因此我们设置了“扩展模式”,这是没有意义的。我们通常在每一个特定的时间,比如某一天,获取最新的新闻

如果在新闻列表中发现了新新闻,请抓取其URL并创建下一级线索以抓取最新的新闻内容。如果发现新闻列表中的所有新闻都是以前捕获的新闻,请停止翻页和爬网。这需要周期性的自动爬行方法。需要编辑周期爬网调度指令文件。此文件必须命名为crontabxml,并存储在homedatasrapper目录中,以获取目录结构的详细描述,请参阅“捕获当当商品价格”。下面是crontabxml文件的内容。Crontabthreadname“news_list”参数UTRUEOUTOSTART5StartPeriod3600PeriodWaitOnLoadalsWaitonLoadParameterName“renewclue”主题的EMO_cnbeta_uu列表主题的ESTEPSTEPNAME“crawl”主题的EMO_cnbeta_uuu列表EUpdateclueUpdateCLuedDupratio80DupratioPth-1depth-1depthWidthRenewFalseRenewPeriod0PeriodStepThreadName“news_uDetail”参数AutoTrueTAutoStart23StartPeriod1800PeriodidWaitOnLoadFalseWaitOnLoadParameterStepName“crawl”主题emo_uCNbeta_u所有参数的含义在定期提取计划指令文件中解释。抓取主题演示与“仅抓取最新新闻”相关。列表的dupratio参数80表示80,即,如果发现在三个连续页面中捕获的URL地址中有80个之前已捕获,则翻页捕获将终止。当前版本的元导引头只能判断捕获的下一级线索的重复率,而不能判断捕获数据的重复率。请不要直接使用crontabxml,因为它尚未在metaseeker服务器上捕获,但定义的信息结构demo_cnbeta_u详细信息将导致定期获取失败
抓取网页新闻(pythoner来说工程建立,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-16 08:23
最近,使用scratch捕获web页面,这对于Python来说非常方便。详细文件如下:
要使用scratch捕获网页信息,您需要创建一个新项目scratch startproject myproject
项目建立后,将有一个子目录myproject/myproject,其中收录item.py(根据您想要获取的内容的定义)、pipeline.py(用于处理捕获的数据、保存数据库或其他),然后是spider文件夹,您可以在其中编写爬虫脚本
这里,以爬行网站的图书信息为例:
Item.py如下所示:
from scrapy.item import Item, Field
class BookItem(Item):
# define the fields for your item here like:
name = Field()
publisher = Field()
publish_date = Field()
price = Field()
我们想要获取的所有内容都在上面定义,包括名称、出版商、出版日期和价格
现在我们要写的是,爬虫进入互联网战争来捕获信息
spider/book.py如下所示:
from urlparse import urljoin
import simplejson
from scrapy.http import Request
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
from myproject.items import BookItem
class BookSpider(CrawlSpider):
name = 'bookspider'
allowed_domains = ['test.com']
start_urls = [
"http://test_url.com", #这里写开始抓取的页面地址(这里网址是虚构的,实际使用时请替换)
]
rules = (
#下面是符合规则的网址,但是不抓取内容,只是提取该页的链接(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_url/test?page_index=\d+'))),
#下面是符合规则的网址,提取内容,(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_rul/test?product_id=\d+')), callback="parse_item"),
)
def parse_item(self, response):
hxs = HtmlXPathSelector(response)
item = BookItem()
item['name'] = hxs.select('//div[@class="h1_title book_head"]/h1/text()').extract()[0]
item['author'] = hxs.select('//div[@class="book_detailed"]/p[1]/a/text()').extract()
publisher = hxs.select('//div[@class="book_detailed"]/p[2]/a/text()').extract()
item['publisher'] = publisher and publisher[0] or ''
publish_date = hxs.select('//div[@class="book_detailed"]/p[3]/text()').re(u"[\u2e80-\u9fffh]+\uff1a([\d-]+)")
item['publish_date'] = publish_date and publish_date[0] or ''
prices = hxs.select('//p[@class="price_m"]/text()').re("(\d*\.*\d*)")
item['price'] = prices and prices[0] or ''
return item
然后,在捕获信息后,需要保存它。此时需要编写pipelines.py(对于scapy,使用twisted,因此可以看到特定数据库操作的twisted数据,下面简要介绍如何将其保存到数据库中):
from scrapy import log
#from scrapy.core.exceptions import DropItem
from twisted.enterprise import adbapi
from scrapy.http import Request
from scrapy.exceptions import DropItem
from scrapy.contrib.pipeline.images import ImagesPipeline
import time
import MySQLdb
import MySQLdb.cursors
class MySQLStorePipeline(object):
def __init__(self):
self.dbpool = adbapi.ConnectionPool('MySQLdb',
db = 'test',
user = 'user',
passwd = '******',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = False
)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
query.addErrback(self.handle_error)
return item
def _conditional_insert(self, tx, item):
if item.get('name'):
tx.execute(\
"insert into book (name, publisher, publish_date, price ) \
values (%s, %s, %s, %s)",
(item['name'], item['publisher'], item['publish_date'],
item['price'])
)
之后,在setting.py中添加管道:
ITEM_PIPELINES = ['myproject.pipelines.MySQLStorePipeline']
??最后,运行scratch crawl bookspider开始爬行
参考: 查看全部
抓取网页新闻(pythoner来说工程建立,)
最近,使用scratch捕获web页面,这对于Python来说非常方便。详细文件如下:
要使用scratch捕获网页信息,您需要创建一个新项目scratch startproject myproject
项目建立后,将有一个子目录myproject/myproject,其中收录item.py(根据您想要获取的内容的定义)、pipeline.py(用于处理捕获的数据、保存数据库或其他),然后是spider文件夹,您可以在其中编写爬虫脚本
这里,以爬行网站的图书信息为例:
Item.py如下所示:
from scrapy.item import Item, Field
class BookItem(Item):
# define the fields for your item here like:
name = Field()
publisher = Field()
publish_date = Field()
price = Field()
我们想要获取的所有内容都在上面定义,包括名称、出版商、出版日期和价格
现在我们要写的是,爬虫进入互联网战争来捕获信息
spider/book.py如下所示:
from urlparse import urljoin
import simplejson
from scrapy.http import Request
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
from myproject.items import BookItem
class BookSpider(CrawlSpider):
name = 'bookspider'
allowed_domains = ['test.com']
start_urls = [
"http://test_url.com", #这里写开始抓取的页面地址(这里网址是虚构的,实际使用时请替换)
]
rules = (
#下面是符合规则的网址,但是不抓取内容,只是提取该页的链接(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_url/test?page_index=\d+'))),
#下面是符合规则的网址,提取内容,(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_rul/test?product_id=\d+')), callback="parse_item"),
)
def parse_item(self, response):
hxs = HtmlXPathSelector(response)
item = BookItem()
item['name'] = hxs.select('//div[@class="h1_title book_head"]/h1/text()').extract()[0]
item['author'] = hxs.select('//div[@class="book_detailed"]/p[1]/a/text()').extract()
publisher = hxs.select('//div[@class="book_detailed"]/p[2]/a/text()').extract()
item['publisher'] = publisher and publisher[0] or ''
publish_date = hxs.select('//div[@class="book_detailed"]/p[3]/text()').re(u"[\u2e80-\u9fffh]+\uff1a([\d-]+)")
item['publish_date'] = publish_date and publish_date[0] or ''
prices = hxs.select('//p[@class="price_m"]/text()').re("(\d*\.*\d*)")
item['price'] = prices and prices[0] or ''
return item
然后,在捕获信息后,需要保存它。此时需要编写pipelines.py(对于scapy,使用twisted,因此可以看到特定数据库操作的twisted数据,下面简要介绍如何将其保存到数据库中):
from scrapy import log
#from scrapy.core.exceptions import DropItem
from twisted.enterprise import adbapi
from scrapy.http import Request
from scrapy.exceptions import DropItem
from scrapy.contrib.pipeline.images import ImagesPipeline
import time
import MySQLdb
import MySQLdb.cursors
class MySQLStorePipeline(object):
def __init__(self):
self.dbpool = adbapi.ConnectionPool('MySQLdb',
db = 'test',
user = 'user',
passwd = '******',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = False
)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
query.addErrback(self.handle_error)
return item
def _conditional_insert(self, tx, item):
if item.get('name'):
tx.execute(\
"insert into book (name, publisher, publish_date, price ) \
values (%s, %s, %s, %s)",
(item['name'], item['publisher'], item['publish_date'],
item['price'])
)
之后,在setting.py中添加管道:
ITEM_PIPELINES = ['myproject.pipelines.MySQLStorePipeline']
??最后,运行scratch crawl bookspider开始爬行
参考:
抓取网页新闻(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-16 08:15
你想要的任何信息基本上都存在于互联网上。问题是如何将它们组织到您需要的内容中,例如捕获行业网站中所有相关公司的名称、联系电话、电子邮件等,并将它们保存在Excel中进行分析。Web信息捕获变得越来越有用
通常,对于传统web页面,web服务器直接返回HTML。这样的网页很容易掌握。不管使用什么方法,只要获取HTML页面并进行DOM解析即可。但对于需要生成JavaScript的网页来说,这并不容易。张宇没有找到解决这个问题的好办法。欢迎有javascript网页经验的朋友提供建议
所以今天我们将讨论传统HTML网页的信息捕获。虽然如上所述,没有技术难度,但是否有相对简单的方法?使用jQuery和其他JS框架的朋友可能会觉得JavaScript看起来像是获取网页信息的天然助手,它是为网页解析而生的。当然,现在有更多的应用程序,比如服务器端JavaScript应用程序nodejs
如果我们可以使用jQuery在应用程序(如Java程序)中获取web页面,那绝对是令人兴奋的。有现成的解决方案、JavaScript引擎和支持jQuery的环境
工具:Java、rhino、envjs。Rhino是Mozzila提供的开源JavaScript引擎,envjs是一个模拟的浏览器环境,如window。代码如下
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
Test.js文件,如下所示
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行单元测试时,我们将在控制台上打印从网页捕获的三个百度连接
0:
1:
2:
测试成功,证明了在Java程序中用jQuery抓取网页是可行的
----------------------------------------------------------------------
张宇,我的好漂亮 查看全部
抓取网页新闻(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
你想要的任何信息基本上都存在于互联网上。问题是如何将它们组织到您需要的内容中,例如捕获行业网站中所有相关公司的名称、联系电话、电子邮件等,并将它们保存在Excel中进行分析。Web信息捕获变得越来越有用
通常,对于传统web页面,web服务器直接返回HTML。这样的网页很容易掌握。不管使用什么方法,只要获取HTML页面并进行DOM解析即可。但对于需要生成JavaScript的网页来说,这并不容易。张宇没有找到解决这个问题的好办法。欢迎有javascript网页经验的朋友提供建议
所以今天我们将讨论传统HTML网页的信息捕获。虽然如上所述,没有技术难度,但是否有相对简单的方法?使用jQuery和其他JS框架的朋友可能会觉得JavaScript看起来像是获取网页信息的天然助手,它是为网页解析而生的。当然,现在有更多的应用程序,比如服务器端JavaScript应用程序nodejs
如果我们可以使用jQuery在应用程序(如Java程序)中获取web页面,那绝对是令人兴奋的。有现成的解决方案、JavaScript引擎和支持jQuery的环境
工具:Java、rhino、envjs。Rhino是Mozzila提供的开源JavaScript引擎,envjs是一个模拟的浏览器环境,如window。代码如下
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
Test.js文件,如下所示
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行单元测试时,我们将在控制台上打印从网页捕获的三个百度连接
0:
1:
2:
测试成功,证明了在Java程序中用jQuery抓取网页是可行的
----------------------------------------------------------------------
张宇,我的好漂亮
抓取网页新闻(学习了几天如何使用scrapy去爬取静态网站(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-16 03:23
几天来,我已经学会了如何通过使用图表对静态网站进行爬网。今天我尝试抓取动态加载的网站。选择的网站是华尔街的知识。这篇文章不会详细解释如何像往常一样完成每一步,而是讨论如何攀登
您无法获取源代码中的所有数据(有些根本没有数据),但您可以看到网址保持不变,但通过下拉滑块加载了数据。毫无疑问,这是一个动态加载的网页。下面介绍如何查找API接口以获取数据
打开developer工具,选择network,refresh,然后选择XHR,如图所示
您可以从一开始就逐个单击以检查响应(响应指的是工作台上的响应,如下图所示)是否是您想要的数据。或者滑动滑动条,查看新请求的名称中是否有类似的请求,通常是
这里我们重点关注区块链数据,如图所示:
然后检查消息头的URL,例如“HTTPS:///apiv1/content/lifes?”?渠道=区块链渠道&;客户机=pc&;光标=1518567654&;极限=20’
所需参数为:
channel=blockchain-channel
client=pc
cursor=1518567654
limit=20
在浏览器中打开URL,并通过待定系数方法删除参数,以查看所需内容
从这个可以猜到
Limit=20应该是可以删除的请求数据数
Client=PC字面意思是PC端
通道=区块链通道,可引用区块链相关数据,不能删除
Cursor=1518567654最初怀疑它位于加载上一页时的页面或附加信息中,但在搜索后未找到。怀疑它可能是一个时间戳。时间模块验证它是否确实是当前时间。它可以被删除,但实验后,发现没有光标,最多可以加载99个数据
这仅适用于区块链的一部分。其他类似于搜索,但在搜索过程中会找到一个API和所有数据。接口:
当浏览器打开时,最好安装一个JSON相关插件以方便查看数据。如图所示
通过阅读,你可以了解全球、区块链、a股。股票、美股、外汇和商品分别分为六个板块:宏观、区块链、a股、美股、外汇和商品
就这样
随附信息的接口API:
看,这就是代码。不要直接粘贴它
'https://api-prod.wallstreetcn. ... ry%3D{}&limit=20&platform=wscn-platform'.format(p) for p in
['global','shares','commodities','china','us','europe','japan','charts','economy']
极限参数可以手动控制。还有游标参数。您可以发现,他返回的数据收录display_uuTime、next_uuu光标,可以结合limit访问下一个时间段的数据。您还可以指定当前时间戳和特定时间戳之间的时间 查看全部
抓取网页新闻(学习了几天如何使用scrapy去爬取静态网站(图))
几天来,我已经学会了如何通过使用图表对静态网站进行爬网。今天我尝试抓取动态加载的网站。选择的网站是华尔街的知识。这篇文章不会详细解释如何像往常一样完成每一步,而是讨论如何攀登
您无法获取源代码中的所有数据(有些根本没有数据),但您可以看到网址保持不变,但通过下拉滑块加载了数据。毫无疑问,这是一个动态加载的网页。下面介绍如何查找API接口以获取数据
打开developer工具,选择network,refresh,然后选择XHR,如图所示
您可以从一开始就逐个单击以检查响应(响应指的是工作台上的响应,如下图所示)是否是您想要的数据。或者滑动滑动条,查看新请求的名称中是否有类似的请求,通常是
这里我们重点关注区块链数据,如图所示:
然后检查消息头的URL,例如“HTTPS:///apiv1/content/lifes?”?渠道=区块链渠道&;客户机=pc&;光标=1518567654&;极限=20’
所需参数为:
channel=blockchain-channel
client=pc
cursor=1518567654
limit=20
在浏览器中打开URL,并通过待定系数方法删除参数,以查看所需内容
从这个可以猜到
Limit=20应该是可以删除的请求数据数
Client=PC字面意思是PC端
通道=区块链通道,可引用区块链相关数据,不能删除
Cursor=1518567654最初怀疑它位于加载上一页时的页面或附加信息中,但在搜索后未找到。怀疑它可能是一个时间戳。时间模块验证它是否确实是当前时间。它可以被删除,但实验后,发现没有光标,最多可以加载99个数据
这仅适用于区块链的一部分。其他类似于搜索,但在搜索过程中会找到一个API和所有数据。接口:
当浏览器打开时,最好安装一个JSON相关插件以方便查看数据。如图所示
通过阅读,你可以了解全球、区块链、a股。股票、美股、外汇和商品分别分为六个板块:宏观、区块链、a股、美股、外汇和商品
就这样
随附信息的接口API:
看,这就是代码。不要直接粘贴它
'https://api-prod.wallstreetcn. ... ry%3D{}&limit=20&platform=wscn-platform'.format(p) for p in
['global','shares','commodities','china','us','europe','japan','charts','economy']
极限参数可以手动控制。还有游标参数。您可以发现,他返回的数据收录display_uuTime、next_uuu光标,可以结合limit访问下一个时间段的数据。您还可以指定当前时间戳和特定时间戳之间的时间
抓取网页新闻(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-12 08:15
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html 提取文本信息
编写以下代码:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:/kingname/GeneralNewsExtractor。 查看全部
抓取网页新闻(一个新闻网页通用抽取器演示如何直接从浏览器中复制)
GeneralNewsExtractor,以下简称GNE,是一个通用的新闻网页提取器,可以在不指定任何提取规则的情况下提取新闻正文网站。
我们来看看它的基本用法。
安装 GNE
使用pip安装:
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
当然你也可以使用pipenv来安装:
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
获取新闻页面源码
GNE目前没有,以后也不会提供网页请求的功能,所以需要想办法获取渲染出来的网页源代码。您可以使用 Selenium 或 Pyppeteer 或直接从浏览器复制。
以下是直接从浏览器复制网页源代码的方法:
在Chrome浏览器中打开对应页面,然后打开开发者工具,如下图:
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
将源码另存为1.html 提取文本信息
编写以下代码:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html)
print(result)
运行效果如下图所示:
这次更新了什么
在最新更新的v0.04版本中,开放了提取文本图片的功能和返回文本源代码的功能。上面已经演示了返回图片URL的功能,结果中的images字段就是文本中的图片。
那么如何返回body源代码呢?只需添加一个参数 with_body_html=True:
from gne import GeneralNewsExtractor
with open('1.html') as f:
html = f.read()
extractor = GeneralNewsExtractor()
result = extractor.extract(html, with_body_html=True)
print(result)
运行效果如下图所示:
返回结果中的body_html就是body的html源代码。
GNE的深入使用可以访问GNE的Github:/kingname/GeneralNewsExtractor。
抓取网页新闻(JavaHTML解析器如何使用jsoup抓取一些简单的页面信息准备)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-10-11 17:44
介绍:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
在这篇文章中,我将教你如何使用jsoup抓取一些简单的页面信息
准备:
jsoup的jar包:
开发工具:eclipse
想法:
我们首先使用jsoup将网页上的html解析为字符串,然后将字符串转换为Document,然后选择一些我们想要遍历的信息。
过程:
1.创建web项目,命名项目,导入jar包
lombok是省略了get和set方法,请参考
2.创建目录结构
模型中的新闻是一个封装好的新闻实体对象
utils中的Spider是我们写的一个工具类
test中的JsoupTest是我们写的一个测试类
3. 代码如下
实体类:
package com.rzc.model;
import lombok.Data;
@Data // lombok注解,相当于get、set方法和toString等都默认生成
public class News {
private String title; // 新闻标题
private String article; // 新闻内容
private String publishTime; // 新闻发布时间
private String keyword; // 新闻关键字
private String author; // 新闻作者
}
工具:
package com.rzc.utils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.rzc.model.News;
public class Spider {
// 获取页面加载内容
public Document loadDocumentData(String url) {
// 创建文档对象
Document doc = null;
// 根据url将某页信息转换成文档
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 返回文档
return doc;
}
// 获取a标签中的href的内容
public List parseDoc(Document doc) {
// 实例化list
List list = new ArrayList();
// 根据指定class获取对象(这里我们查看页面源码,选取了一个class为 new_top 的新闻 列表)
Elements elements = doc.getElementsByClass("news_top");
// 根据指定的标签获取连接内容(这里选取的是a标签中的内容)
Elements links = elements.get(0).getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
// 讲遍历出来的每一个a标签对象中的href属性循环存入list中
list.add(links.get(i).attr("href"));
}
// 返回list
return list;
}
// 按照要求获取news对象
public News parseDetaile(Document doc) {
// 实例化news对象
News news = new News();
// 按照class获取文档对象 main_title的文本信息,并将该信息存入title中
String title = doc.getElementsByClass("main_title").text();
// 查照选择器data-sourse后面的.data信息,并将该信息存入publishTime中
String publishTime = doc.select(".data-sourse > .data").text();
// 按照class获取文档对象 caricle 的文本信息,并将该信息存入 article 中
String article = doc.getElementsByClass("article").text();
// 按照class获取文档对象 keyword 的文本信息,并将该信息存入 keyword 中
String keyword = doc.getElementsByClass("keyword").text();
// 按照class获取文档对象 show_author 的文本信息,并将该信息存入 author 中
String author = doc.getElementsByClass("show_author").text();
// 将以上信息填充到news对象中
news.setTitle(title);
news.setPublishTime(publishTime);
news.setArticle(article);
news.setKeyword(keyword);
news.setAuthor(author);
return news;
}
}
根据标签从页面信息中选择您需要的信息,然后根据标签等属性获取对象。下面是在其中查找新闻信息对象的方法。
测试类别:
package com.rzc.test;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.nodes.Document;
import com.rzc.model.News;
import com.rzc.utils.Spider;
public class JsoupTest {
public static void main(String[] args) {
// 实例化工具类对象
Spider spider = new Spider();
// 根据url获取文档(这里的url是新浪首页)
Document doc = spider.loadDocumentData("http://www.sina.com.cn");
// 获取文档中a标签 中href属性中的内容
List list = spider.parseDoc(doc);
// 实例化新闻列表
List newsList = new ArrayList();
// 循环遍历新闻列表中的每一个对象
for(String url:list){
// 获取整个文档
Document document = spider.loadDocumentData(url);
// 获取每个文档中的新闻对象
News news = spider.parseDetaile(document);
// 将文档中的新闻对象添加到新闻列表中
newsList.add(news);
// 测试输出新闻列表信息
System.out.println(news);
}
}
}
输出结果
文章 到此为止吧。谢谢观看。不足之处请指出! 查看全部
抓取网页新闻(JavaHTML解析器如何使用jsoup抓取一些简单的页面信息准备)
介绍:
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
在这篇文章中,我将教你如何使用jsoup抓取一些简单的页面信息
准备:
jsoup的jar包:
开发工具:eclipse
想法:
我们首先使用jsoup将网页上的html解析为字符串,然后将字符串转换为Document,然后选择一些我们想要遍历的信息。
过程:
1.创建web项目,命名项目,导入jar包
lombok是省略了get和set方法,请参考
2.创建目录结构
模型中的新闻是一个封装好的新闻实体对象
utils中的Spider是我们写的一个工具类
test中的JsoupTest是我们写的一个测试类
3. 代码如下
实体类:
package com.rzc.model;
import lombok.Data;
@Data // lombok注解,相当于get、set方法和toString等都默认生成
public class News {
private String title; // 新闻标题
private String article; // 新闻内容
private String publishTime; // 新闻发布时间
private String keyword; // 新闻关键字
private String author; // 新闻作者
}
工具:
package com.rzc.utils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import com.rzc.model.News;
public class Spider {
// 获取页面加载内容
public Document loadDocumentData(String url) {
// 创建文档对象
Document doc = null;
// 根据url将某页信息转换成文档
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 返回文档
return doc;
}
// 获取a标签中的href的内容
public List parseDoc(Document doc) {
// 实例化list
List list = new ArrayList();
// 根据指定class获取对象(这里我们查看页面源码,选取了一个class为 new_top 的新闻 列表)
Elements elements = doc.getElementsByClass("news_top");
// 根据指定的标签获取连接内容(这里选取的是a标签中的内容)
Elements links = elements.get(0).getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
// 讲遍历出来的每一个a标签对象中的href属性循环存入list中
list.add(links.get(i).attr("href"));
}
// 返回list
return list;
}
// 按照要求获取news对象
public News parseDetaile(Document doc) {
// 实例化news对象
News news = new News();
// 按照class获取文档对象 main_title的文本信息,并将该信息存入title中
String title = doc.getElementsByClass("main_title").text();
// 查照选择器data-sourse后面的.data信息,并将该信息存入publishTime中
String publishTime = doc.select(".data-sourse > .data").text();
// 按照class获取文档对象 caricle 的文本信息,并将该信息存入 article 中
String article = doc.getElementsByClass("article").text();
// 按照class获取文档对象 keyword 的文本信息,并将该信息存入 keyword 中
String keyword = doc.getElementsByClass("keyword").text();
// 按照class获取文档对象 show_author 的文本信息,并将该信息存入 author 中
String author = doc.getElementsByClass("show_author").text();
// 将以上信息填充到news对象中
news.setTitle(title);
news.setPublishTime(publishTime);
news.setArticle(article);
news.setKeyword(keyword);
news.setAuthor(author);
return news;
}
}
根据标签从页面信息中选择您需要的信息,然后根据标签等属性获取对象。下面是在其中查找新闻信息对象的方法。
测试类别:
package com.rzc.test;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.nodes.Document;
import com.rzc.model.News;
import com.rzc.utils.Spider;
public class JsoupTest {
public static void main(String[] args) {
// 实例化工具类对象
Spider spider = new Spider();
// 根据url获取文档(这里的url是新浪首页)
Document doc = spider.loadDocumentData("http://www.sina.com.cn";);
// 获取文档中a标签 中href属性中的内容
List list = spider.parseDoc(doc);
// 实例化新闻列表
List newsList = new ArrayList();
// 循环遍历新闻列表中的每一个对象
for(String url:list){
// 获取整个文档
Document document = spider.loadDocumentData(url);
// 获取每个文档中的新闻对象
News news = spider.parseDetaile(document);
// 将文档中的新闻对象添加到新闻列表中
newsList.add(news);
// 测试输出新闻列表信息
System.out.println(news);
}
}
}
输出结果
文章 到此为止吧。谢谢观看。不足之处请指出!
抓取网页新闻(GeneralNewsExtractor新闻网页通用抽取器是一个基于《基于文本及符号密度的网页正文提取方法》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-11 17:36
GeneralNewsExtractor 新闻网页正文通用提取器是基于《基于文本和符号密度的网页正文提取方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。
相关软件软件大小版本说明下载地址
GeneralNewsExtractor(新闻网页文本通用提取器)是基于《基于文本和符号密度提取网页文本的方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。
发展介绍
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。 查看全部
抓取网页新闻(GeneralNewsExtractor新闻网页通用抽取器是一个基于《基于文本及符号密度的网页正文提取方法》)
GeneralNewsExtractor 新闻网页正文通用提取器是基于《基于文本和符号密度的网页正文提取方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。
相关软件软件大小版本说明下载地址
GeneralNewsExtractor(新闻网页文本通用提取器)是基于《基于文本和符号密度提取网页文本的方法》用Python实现的文本提取器。它可用于提取 HTML 中文本的内容、作者和标题。
发展介绍
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
抓取网页新闻(技术领域:本发明涉及一种网页爬虫的构建方法,特别是一种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-08 03:22
专利名称:基于新闻去重的网络爬虫构建方法
技术领域:
本发明涉及一种网络爬虫的构建方法,尤其涉及一种基于新闻去重的网络爬虫构建方法。
片法。
背景技术:
在这个信息爆炸的时代,网络媒体以其快速的新闻发布和广泛的新闻传播逐渐取代了电视,报纸等传统媒体已经成为现在的主流新闻传播方式。目前各大新闻门户网站网站“新浪”、“新华网”、“网易”都拥有自己强大的新闻采访、编辑和发布团队,每天发布的新闻数量达到数千篇。新闻网站一般涵盖各类新闻:国内新闻、国际新闻、社会新闻、娱乐新闻、军事新闻、体育新闻、财经新闻、科技新闻等,同时每个新闻门户都有自己的特色,如新华网时事新闻、新浪体育新闻、和网易上的社交新闻。因此,整合多个新闻门户网站网站的新闻,可以让用户获得更全面、更丰富、更有特色的新闻信息。如何有效地从网络中提取信息成为一个巨大的挑战。搜索引擎作为一种辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,通用搜索引擎存在以下局限性1、通用搜索引擎的目标是获得尽可能大的网络覆盖,这进一步加深了搜索引擎服务器资源有限与网络数据资源无限的矛盾之间的差距。2、 网络数据形式丰富,网络技术不断发展。有大量不同形式的数据,如图片、数据库、音频/视频等,一般的搜索引擎往往对这些信息内容密集、具有一定结构的数据无能为力。很好的发现和获取。
3、大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。4、不同领域、不同北京的用户有不同的搜索目的和需求。一般搜索引擎返回的结果中收录了很多用户并不关心的信息。为解决上述不足,有针对性地抓取相关网络资源的网络爬虫应运而生。网络爬虫是一种自动提取网页的程序。它可以自动从互联网上抓取网页,是搜索引擎的重要组成部分。其工作原理是网络爬虫从初始设置的一个或多个初始网页的URL出发,获取初始网页上的URL,并在抓取网页的过程中不断地从当前网页中提取新的网址,然后根据网页进行分析。该算法过滤掉与主题无关的连接,保留有用的连接并将它们放入 URL 队列中等待访问,直到满足某个停止条件。网络爬虫可以同时爬取多个数据源。以新闻信息为例,说明网络爬虫的缺点。1、因为每条新闻网站发布的消息,可能是文章的同一个副本,也可能是差不多的网站发布了不同的文章对于不同的事情。网络爬虫在爬取数据的时候,很可能也会抓取到这些重复的信息。这不仅会浪费网络资源,存储资源,也给数据维护带来了很大的麻烦。2、 网页上有大量的网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,它也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。
发明内容
为了克服现有技术算法效率低下的问题,容易抓取内容重复的网页,浪费资源和数据维护。
为了避免保护难的缺点,本发明提供了一种高效的算法,避免爬取内容重复的网页,资源和数据的浪费很少。
基于新闻去重的网络爬虫便捷维护方法。
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻网页集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻网页的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集,如果相似度高于阈值,丢弃新闻并抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。进一步地,该解析器是通过学习多条新闻网站的HTML源代码框架构建的,
解析器对网页进行解析,得到新闻网页中实际的新闻标题和新闻内容。此外,步骤(3)由以下步骤组成(3. 1)使用中文分词技术提取新闻标题关键词的文本和每个key的权重这个词;(3. 2)根据经验,选择文本中权重最高的N个关键词组成(关键词,权重)的集合
合 C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: 第 i 个关键词; Wi:第i个关键词的权重;(3. 3)将集合C中的元素按照权重Wi从大到小排序;每个子集&中的元素按照它们的关键词权重从大到小排序;设置C和&的相似度阈值,相似度由具有相同排序位置的两个集合决定(3.@ > 4)将集合C与新闻集中的每个&进行比较,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果低于阈值,C被认为是非重复消息;(3. 5)将非重复性新闻添加到新闻采集中。
进一步地,如果(3.4)确定集合C为非重复新闻,则使用中文分词技术提取新闻内容文本,提取关键词和每个关键词在文本中,按顺序再次执行新闻的权重(3.2) to (3.4);如果判断还是不重复的新闻,那么这个新闻将被添加到新闻采集中。此外,所描述的步骤(5)判断URL是否指向新闻网页包括以下步骤(5. 1)批量抓取新闻网页) 网站 数据源) URL 作为训练集,使用除法
聚类算法将这些 URL 进行聚类,并将具有相同 URL 格式的 URL 归为一类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,使用 URL 解析器学习每一类 URL 的格式特征,得到每个类别;
(5. 3) 使用描述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页URL的格式特征;如果是,则认为该URL是指向新闻网页网址;如果不是,则认为该网址指向新闻以外的其他网页,丢弃该网址。本发明的技术思想是在网络爬虫之前过滤重复数据抓取网页避免重复数据
数据的下载减少了爬虫需要爬取的数据量,节省了存储资源;抓取网址时,爬虫首先判断网址
是否指向有效信息,过滤无关网页的URL,保证爬取数据的纯度和准确性,即下载
来的都是有效网页,算法效率高,有效降低网络资源消耗,存储资源浪费少;
只需要存储有效信息,减少数据存储量,降低后续数据维护难度。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
图1是本发明的总体流程图;图2当前抓取的新闻与新闻集合中的每条新闻进行对比的流程图
图3是当前抓取的新闻与新闻采集中的新闻对比的另一个流程图
图4是判断URL是否被访问过的流程图
详细方法
示例一
参考附图1、2、4 基于新闻去重的网络爬虫的构建方法,包括以下步骤
1、基于新闻去重的网络爬虫构建方法,包括以下步骤1),构建一个可以提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻集合中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3),将当前抓取的新闻网页与新闻集进行比较,判断两者之间的相似度是否高于阈值;(3. 1) 使用中文分词技术提取新闻标题关键词的正文和每个关键词的权重;(3. <
6-in C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: i -th 关键词; Wi:第i个关键词的权重;(3. 3)根据权重Wi从大到小对集合C中的元素进行排序;采集新闻&的每个子集中的元素按照它们的关键词权重从大到小排序;设置C和&之间的相似度阈值,相似度按两个集合中的顺序相同的数字排序关键词 的要表征的位置;
与存储访问过的URL的访问队列进行比较,判断该URL是否被访问过;(5. 1)从各大网站数据源批量抓取新闻网页的网址作为训练集,用分区聚类算法对这些网址进行聚类,用将相同的 URL 格式归为一个类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,利用 URL 解析器学习每个类别的格式特征URL的,获取每个类别的正则表达式;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;
(53)使用URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果有,则将此URL视为指向新闻的URL网页;如果不是,则认为该网址指向新闻以外的网页,丢弃该网址。6)。如果该网址存在于访问队列中,则丢弃该网址;如果该网址不存在于所述被访问队列中,将这个 URL 存储在一个等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。解析器是通过学习多条新闻网站的HTML源码框架构建的,
解析器解析网页,得到新闻网页中实际的新闻标题和新闻内容。
示例二
参考附图 1、3、4 本实施例与实施例一的区别在于,如果(3. 4)确定集合C为非重复消息,然后新闻正文采用中文分词技术提取正文中关键词和每个关键词的权重,依次执行(3.2)到(3.4);如果判断还是不重复的新闻,则将该新闻加入新闻集合,其余同。本说明书实施例中描述的内容只是一个列表本发明构思的实施形式,以及本发明的保护范围,不应视为仅限于实施例中所述的具体形式,并且本发明的保护范围也扩展到本领域技术人员基于本发明的构思所能想到的等同技术手段。
权限请求
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2)。构建新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集。如果相似度高于阈值,丢弃新闻,抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。
2.根据权利要求1所述的基于新闻去重构建网络爬虫的方法,其特征在于,所述解析器是通过学习多个新闻网站HTML源代码框架构建的,结果解析器将网页解析成什么获取的是新闻网页中的实际新闻标题和新闻内容。
新闻集中按照他们的关键词权重从大到小排序;set C 和 Q 两组相似度之间的相似度阈值,所述相似度用两组相同排序位置的关键词的个数表示;(3. 4) Set C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果是低于阈值,C被认为是非重复新闻;(3. 5)将非重复新闻加入新闻集合。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。
4.根据权利要求3所述的基于新闻去重构建网络爬虫的方法,其特征在于,如果(3. 4)确定集合C为非重复新闻,则该新闻内容文本采用中文分词技术,提取文本中关键词和每个关键词的权重,按顺序再次执行(3.2)到(2)3.4);如果判断还是不重复的新闻,把这条新闻加入新闻采集。
使用所述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果是,则认为该网址是指向新闻网页的网址;如果不是,则认为该网址指向的不是新闻的网页,丢弃该网址。
全文摘要
基于新闻去重构建网络爬虫的方法包括以下步骤:构建解析器来解析新闻网页;构建新闻采集;设置网页之间的相似度阈值;将当前抓取的新闻网页与新闻集进行比较,判断相似度是否高于阈值;如果低于阈值,则将当前网页加入新闻采集;如果高于阈值,则丢弃该新闻并抓取下一个网页;抓取当前网页的网址,判断该网址是否指向新闻网页,如果是,则判断该网址是否被访问过;如果没有,丢弃它;如果此 URL 已被访问,则丢弃此 URL;如果这个 URL 没有被访问过,它会被存储在等待队列中;从等待队列中提取 URL 以便访问;重复以上步骤。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
文件编号 G06F17/30GK101694658SQ2
公布日期 2010 年 4 月 14 日 申请日期 2009 年 10 月 20 日 优先权日期 2009 年 10 月 20 日
发明人:卜家军、李辉、梁雄军、陈伟、陈纯申请人:浙江大学; 查看全部
抓取网页新闻(技术领域:本发明涉及一种网页爬虫的构建方法,特别是一种)
专利名称:基于新闻去重的网络爬虫构建方法
技术领域:
本发明涉及一种网络爬虫的构建方法,尤其涉及一种基于新闻去重的网络爬虫构建方法。
片法。
背景技术:
在这个信息爆炸的时代,网络媒体以其快速的新闻发布和广泛的新闻传播逐渐取代了电视,报纸等传统媒体已经成为现在的主流新闻传播方式。目前各大新闻门户网站网站“新浪”、“新华网”、“网易”都拥有自己强大的新闻采访、编辑和发布团队,每天发布的新闻数量达到数千篇。新闻网站一般涵盖各类新闻:国内新闻、国际新闻、社会新闻、娱乐新闻、军事新闻、体育新闻、财经新闻、科技新闻等,同时每个新闻门户都有自己的特色,如新华网时事新闻、新浪体育新闻、和网易上的社交新闻。因此,整合多个新闻门户网站网站的新闻,可以让用户获得更全面、更丰富、更有特色的新闻信息。如何有效地从网络中提取信息成为一个巨大的挑战。搜索引擎作为一种辅助人们检索信息的工具,已经成为用户访问万维网的入口和向导。但是,通用搜索引擎存在以下局限性1、通用搜索引擎的目标是获得尽可能大的网络覆盖,这进一步加深了搜索引擎服务器资源有限与网络数据资源无限的矛盾之间的差距。2、 网络数据形式丰富,网络技术不断发展。有大量不同形式的数据,如图片、数据库、音频/视频等,一般的搜索引擎往往对这些信息内容密集、具有一定结构的数据无能为力。很好的发现和获取。
3、大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。4、不同领域、不同北京的用户有不同的搜索目的和需求。一般搜索引擎返回的结果中收录了很多用户并不关心的信息。为解决上述不足,有针对性地抓取相关网络资源的网络爬虫应运而生。网络爬虫是一种自动提取网页的程序。它可以自动从互联网上抓取网页,是搜索引擎的重要组成部分。其工作原理是网络爬虫从初始设置的一个或多个初始网页的URL出发,获取初始网页上的URL,并在抓取网页的过程中不断地从当前网页中提取新的网址,然后根据网页进行分析。该算法过滤掉与主题无关的连接,保留有用的连接并将它们放入 URL 队列中等待访问,直到满足某个停止条件。网络爬虫可以同时爬取多个数据源。以新闻信息为例,说明网络爬虫的缺点。1、因为每条新闻网站发布的消息,可能是文章的同一个副本,也可能是差不多的网站发布了不同的文章对于不同的事情。网络爬虫在爬取数据的时候,很可能也会抓取到这些重复的信息。这不仅会浪费网络资源,存储资源,也给数据维护带来了很大的麻烦。2、 网页上有大量的网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,它也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。@2、 网页上有大量网址指向与新闻无关的无效信息,如广告、博客、导航网页等,如果爬虫也抓取这些网址,也会造成浪费网络资源和存储资源。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。导航网页等,如果爬虫也抓取这些网址,也会造成网络资源和存储资源的浪费。,后续维护困难。3、 现有的网络爬虫首先抓取和下载网页,然后进行有效性分析。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。会下载大量不相关的网页,浪费有限的存储资源。4、随着网页抓取量的增加,不相关的网页被下载,然后进行分析和过滤,导致算法效率低下。
发明内容
为了克服现有技术算法效率低下的问题,容易抓取内容重复的网页,浪费资源和数据维护。
为了避免保护难的缺点,本发明提供了一种高效的算法,避免爬取内容重复的网页,资源和数据的浪费很少。
基于新闻去重的网络爬虫便捷维护方法。
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻网页集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻网页的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集,如果相似度高于阈值,丢弃新闻并抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;如果是,如果访问队列中存在该URL,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。进一步地,该解析器是通过学习多条新闻网站的HTML源代码框架构建的,
解析器对网页进行解析,得到新闻网页中实际的新闻标题和新闻内容。此外,步骤(3)由以下步骤组成(3. 1)使用中文分词技术提取新闻标题关键词的文本和每个key的权重这个词;(3. 2)根据经验,选择文本中权重最高的N个关键词组成(关键词,权重)的集合
合 C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: 第 i 个关键词; Wi:第i个关键词的权重;(3. 3)将集合C中的元素按照权重Wi从大到小排序;每个子集&中的元素按照它们的关键词权重从大到小排序;设置C和&的相似度阈值,相似度由具有相同排序位置的两个集合决定(3.@ > 4)将集合C与新闻集中的每个&进行比较,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果低于阈值,C被认为是非重复消息;(3. 5)将非重复性新闻添加到新闻采集中。
进一步地,如果(3.4)确定集合C为非重复新闻,则使用中文分词技术提取新闻内容文本,提取关键词和每个关键词在文本中,按顺序再次执行新闻的权重(3.2) to (3.4);如果判断还是不重复的新闻,那么这个新闻将被添加到新闻采集中。此外,所描述的步骤(5)判断URL是否指向新闻网页包括以下步骤(5. 1)批量抓取新闻网页) 网站 数据源) URL 作为训练集,使用除法
聚类算法将这些 URL 进行聚类,并将具有相同 URL 格式的 URL 归为一类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,使用 URL 解析器学习每一类 URL 的格式特征,得到每个类别;
(5. 3) 使用描述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页URL的格式特征;如果是,则认为该URL是指向新闻网页网址;如果不是,则认为该网址指向新闻以外的其他网页,丢弃该网址。本发明的技术思想是在网络爬虫之前过滤重复数据抓取网页避免重复数据
数据的下载减少了爬虫需要爬取的数据量,节省了存储资源;抓取网址时,爬虫首先判断网址
是否指向有效信息,过滤无关网页的URL,保证爬取数据的纯度和准确性,即下载
来的都是有效网页,算法效率高,有效降低网络资源消耗,存储资源浪费少;
只需要存储有效信息,减少数据存储量,降低后续数据维护难度。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
图1是本发明的总体流程图;图2当前抓取的新闻与新闻集合中的每条新闻进行对比的流程图
图3是当前抓取的新闻与新闻采集中的新闻对比的另一个流程图
图4是判断URL是否被访问过的流程图
详细方法
示例一
参考附图1、2、4 基于新闻去重的网络爬虫的构建方法,包括以下步骤
1、基于新闻去重的网络爬虫构建方法,包括以下步骤1),构建一个可以提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2),建立新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻集合中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3),将当前抓取的新闻网页与新闻集进行比较,判断两者之间的相似度是否高于阈值;(3. 1) 使用中文分词技术提取新闻标题关键词的正文和每个关键词的权重;(3. <
6-in C = {(,, w》, (t2, w2), (t3, w3), ......(tN, wN)}, 其中 &: i -th 关键词; Wi:第i个关键词的权重;(3. 3)根据权重Wi从大到小对集合C中的元素进行排序;采集新闻&的每个子集中的元素按照它们的关键词权重从大到小排序;设置C和&之间的相似度阈值,相似度按两个集合中的顺序相同的数字排序关键词 的要表征的位置;
与存储访问过的URL的访问队列进行比较,判断该URL是否被访问过;(5. 1)从各大网站数据源批量抓取新闻网页的网址作为训练集,用分区聚类算法对这些网址进行聚类,用将相同的 URL 格式归为一个类;(5. 2) 构造一个可以根据 URL 的格式特征导出其正则表达式的 URL 解析器,利用 URL 解析器学习每个类别的格式特征URL的,获取每个类别的正则表达式;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;数据源作为训练集,用分区聚类算法对这些URL进行聚类,将URL格式相同的URL聚类为一个类;(5. 2) 构造一个可以根据URL的格式特征导出其正则表达式的URL解析器,利用URL解析器学习每个类别URL的格式特征,得到正则表达式每个类别;
(53)使用URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果有,则将此URL视为指向新闻的URL网页;如果不是,则认为该网址指向新闻以外的网页,丢弃该网址。6)。如果该网址存在于访问队列中,则丢弃该网址;如果该网址不存在于所述被访问队列中,将这个 URL 存储在一个等待队列中;
7),从队列中提取URL依次访问;
8),重复步骤 1-9。解析器是通过学习多条新闻网站的HTML源码框架构建的,
解析器解析网页,得到新闻网页中实际的新闻标题和新闻内容。
示例二
参考附图 1、3、4 本实施例与实施例一的区别在于,如果(3. 4)确定集合C为非重复消息,然后新闻正文采用中文分词技术提取正文中关键词和每个关键词的权重,依次执行(3.2)到(3.4);如果判断还是不重复的新闻,则将该新闻加入新闻集合,其余同。本说明书实施例中描述的内容只是一个列表本发明构思的实施形式,以及本发明的保护范围,不应视为仅限于实施例中所述的具体形式,并且本发明的保护范围也扩展到本领域技术人员基于本发明的构思所能想到的等同技术手段。
权限请求
基于新闻去重构建网络爬虫的方法包括以下步骤1),构建能够提取网页中新闻标题和内容的解析器,并使用解析器解析新闻网页;2)。构建新闻页面集合,形成新闻集合;设置当前抓取的网页与新闻采集中的新闻页面的相似度阈值,相似度以内容重复程度为特征;3)。将当前抓取的新闻网页与新闻采集进行比较,判断两者之间的相似度是否高于阈值;4),如果相似度低于阈值,则将当前网页加入新闻采集。如果相似度高于阈值,丢弃新闻,抓取下一个网页;5),抓取当前网页的网址,判断该网址是否指向新闻网页,如果该网址不指向新闻网页,则丢弃该网址;如果指向新闻网页,则与存储访问URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。与存放访问过的URL的访问队列进行比较,判断该URL是否被访问过;6),如果有该URL存在于访问队列中,则丢弃该URL;如果访问队列中不存在该 URL,则将该 URL 存储在等待队列中;7),从等待中从访问队列中一一提取URL进行访问;8),重复步骤 1-9。
2.根据权利要求1所述的基于新闻去重构建网络爬虫的方法,其特征在于,所述解析器是通过学习多个新闻网站HTML源代码框架构建的,结果解析器将网页解析成什么获取的是新闻网页中的实际新闻标题和新闻内容。
新闻集中按照他们的关键词权重从大到小排序;set C 和 Q 两组相似度之间的相似度阈值,所述相似度用两组相同排序位置的关键词的个数表示;(3. 4) Set C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复新闻;如果是低于阈值,C被认为是非重复新闻;(3. 5)将非重复新闻加入新闻集合。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。4) 集合C和每个新闻集比较每个&,判断它们的相似度是否高于阈值;如果高于阈值,则认为C是重复消息;如果低于阈值,则认为C是非重复新闻;(3. 5)添加非重复新闻到新闻采集。
4.根据权利要求3所述的基于新闻去重构建网络爬虫的方法,其特征在于,如果(3. 4)确定集合C为非重复新闻,则该新闻内容文本采用中文分词技术,提取文本中关键词和每个关键词的权重,按顺序再次执行(3.2)到(2)3.4);如果判断还是不重复的新闻,把这条新闻加入新闻采集。
使用所述的URL解析器解析当前抓取的网页的URL,判断该网页是否具有新闻网页的URL的格式特征;如果是,则认为该网址是指向新闻网页的网址;如果不是,则认为该网址指向的不是新闻的网页,丢弃该网址。
全文摘要
基于新闻去重构建网络爬虫的方法包括以下步骤:构建解析器来解析新闻网页;构建新闻采集;设置网页之间的相似度阈值;将当前抓取的新闻网页与新闻集进行比较,判断相似度是否高于阈值;如果低于阈值,则将当前网页加入新闻采集;如果高于阈值,则丢弃该新闻并抓取下一个网页;抓取当前网页的网址,判断该网址是否指向新闻网页,如果是,则判断该网址是否被访问过;如果没有,丢弃它;如果此 URL 已被访问,则丢弃此 URL;如果这个 URL 没有被访问过,它会被存储在等待队列中;从等待队列中提取 URL 以便访问;重复以上步骤。本发明具有算法效率高、避免爬取内容重复的网页、资源浪费少、数据维护方便的优点。
文件编号 G06F17/30GK101694658SQ2
公布日期 2010 年 4 月 14 日 申请日期 2009 年 10 月 20 日 优先权日期 2009 年 10 月 20 日
发明人:卜家军、李辉、梁雄军、陈伟、陈纯申请人:浙江大学;
抓取网页新闻(代码如下:5抓取网页内容-把当前会话(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-08 00:08
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm");
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/"); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。
查看全部
抓取网页新闻(代码如下:5抓取网页内容-把当前会话(组图)
)
其次,使用 CookieContainer。
查看普通副本到剪贴板打印?
代码如下:
System.Net.CookieContainer cc = new System.Net.CookieContainer();
request.CookieContainer = cc;
request2.CookieContainer = cc;
这样,request和request2之间使用了同一个Session。如果 request 已登录,则 request2 也已登录。
最后,如何在不同页面之间使用相同的CookieContainer。
不同页面之间要使用同一个CookieContainer,只需要在Session中添加CookieContainer即可。
代码如下:
view plaincopy to clipboardprint?
Session.Add("ccc", cc); //存
CookieContainer cc = (CookieContainer)Session["ccc"]; //取
5 抓取网页内容——将当前会话带到 WebRequest
比如浏览器B1访问服务器端S1,这会产生一个会话,服务器端S2使用WebRequest访问服务器端S1,就会产生一个会话。当前要求WebRequest使用浏览器B1和S1之间的会话,这意味着S1应该认为B1正在访问S1,而不是S2正在访问S1。
这是为了使用cookies。先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。
查看普通副本到剪贴板打印?
代码如下:
WebRequest request = WebRequest.Create("url");
request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
Response.Write(reader.ReadToEnd());
reader.Close();
reader.Dispose();
response.Close();
我想解释一下:
本文不是 Cookie 欺骗,因为 SessionID 是 S1 告诉 S2 的,并没有被 S2 窃取。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1 必须将 Session 写入 B1,这样 SessionID 将保存在 Cookie 中,SessionID 将保持不变。
Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 cookie。
不同的服务器端语言对Cookie中的SessionID有不同的名称。本文为ASP SessionID。
S1 可能不仅依赖 SessionID 来确定当前登录,还可能辅助 Referer、User-Agent 等,具体取决于 S1 终端程序的设计。
这篇文章其实是本系列中另一种“保持登录”的方式。
6 抓取网页内容-如何更改源Referer和UserAgent
查看普通副本到剪贴板打印?
代码如下:
SPAN class="caution">HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("http://127.0.0.1/index.htm";);
//request.Headers.Add(HttpRequestHeader.Referer, "http://www.jb51.net/";); // 错误
//request.Headers[HttpRequestHeader.Referer] = "http://www.jb51.net/"; // 错误
request.Referer = "http://www.jb51.net/"; // 正确
注释掉的两句错了,会报错:
查看普通副本到剪贴板打印?
必须使用适当的属性修改此标头。
参数名称:名称
必须使用适当的属性修改此标头。参数名称:名称
UserAgent 类似。
抓取网页新闻(如何利用Python多线程爬取新闻网站中的大量新闻文章?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2021-10-07 07:06
前几天公司给我安排了一个新项目,要求爬取网上的新闻文章。为了用最简单、最快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫工作,其中之一就是BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们了解每个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都必须了解框架。,这是浪费时间。
经过大量的搜索,我找到了一个简单的方法来解决这个问题,那就是Newspaper3k!
在本教程中,我将向您展示如何将大量来自不同新闻的新闻网站 快速抓取到一个简单的 Python 脚本中。
如何使用Newspaper3k抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟的python环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、高级:从一个新闻下载多篇文章网站文章
当我抓取一堆新闻文章时,我想从一个新闻网站文章抓取多篇文章,并将所有内容放入pandas数据框中,这样我就可以将数据导出到一个.csv 文件,借助这个插件,做起来非常简单。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
完成它!轻松抓取大量 文章。
使用上面的代码,你可以实现一个for循环来循环大量的报纸来源。创建一个巨大的最终数据框,您可以导出和使用它。
3、多线程网络爬虫
我上面提出的解决方案对于某些人来说可能会有点慢,因为它是一块一块地下载文章。如果您有很多新闻来源,则可能需要一些时间来抓取它们。还有一种方法可以加快这个过程:借助多线程技术,我们可以实现快速爬行。
Python多线程技术解决方案:/intro-to-python-threading/
注意:在下面的代码中,我为每个源实现了下载限制。运行此脚本时,您可能需要将其删除。实施此限制是为了允许用户在运行时测试他们的代码。
我喜欢边做边学。建议任何看过这篇文章的人都可以使用上面的代码,自己动手做。从这里开始,您现在可以使用 Newspaper3k 在线抓取 文章。
预防措施:
- 结尾 -
希望以上内容对大家有所帮助。喜欢这篇文章的记得转发+采集哦~ 查看全部
抓取网页新闻(如何利用Python多线程爬取新闻网站中的大量新闻文章?)
前几天公司给我安排了一个新项目,要求爬取网上的新闻文章。为了用最简单、最快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫工作,其中之一就是BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们了解每个新闻平台独特的html结构。像我这种懒惰的人绝对不会这样做。每个 网站 都必须了解框架。,这是浪费时间。
经过大量的搜索,我找到了一个简单的方法来解决这个问题,那就是Newspaper3k!
在本教程中,我将向您展示如何将大量来自不同新闻的新闻网站 快速抓取到一个简单的 Python 脚本中。
如何使用Newspaper3k抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟的python环境。
$ pip install newspaper3k
1、基础知识
import newspaper
from newspaper import Article
#将文章下载到内存的基础
article = Article("url link to your article")
article.download()
article.parse()
article.nlp()
# 输出全文
print(article.text)
# 输出文本摘要
# 因为newspaper3k内置了NLP工具,这一步行之有效
print(article.summary)
# 输出作者名字
print(article.authors)
# 输出关键字列表
print(article.keywords)
#收集文章中其他有用元数据的其他函数
article.title # 给出标题
article.publish_date #给出文章发表的日期
article.top_image # 链接到文章的主要图像
article.images # 提供一组图像链接
2、高级:从一个新闻下载多篇文章网站文章
当我抓取一堆新闻文章时,我想从一个新闻网站文章抓取多篇文章,并将所有内容放入pandas数据框中,这样我就可以将数据导出到一个.csv 文件,借助这个插件,做起来非常简单。
import newspaper
from newspaper import Article
from newspaper import Source
import pandas as pd
# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章
gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False)
#我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。
# 全新运行,每次运行时都基本上执行此脚本
final_df = pd.DataFrame()
for each_article in gamespot.articles:
each_article.download()
each_article.parse()
each_article.nlp()
temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text',
'Summary', 'published_date', 'Source'])
temp_df['Authors'] = each_article.authors
temp_df['Title'] = each_article.title
temp_df['Text'] = each_article.text
temp_df['Summary'] = each_article.summary
temp_df['published_date'] = each_article.publish_date
temp_df['Source'] = each_article.source_url
final_df = final_df.append(temp_df, ignore_index = True)
#从这里可以将此Pandas数据框导出到csv文件
final_df.to_csv('my_scraped_articles.csv')
完成它!轻松抓取大量 文章。
使用上面的代码,你可以实现一个for循环来循环大量的报纸来源。创建一个巨大的最终数据框,您可以导出和使用它。
3、多线程网络爬虫
我上面提出的解决方案对于某些人来说可能会有点慢,因为它是一块一块地下载文章。如果您有很多新闻来源,则可能需要一些时间来抓取它们。还有一种方法可以加快这个过程:借助多线程技术,我们可以实现快速爬行。
Python多线程技术解决方案:/intro-to-python-threading/
注意:在下面的代码中,我为每个源实现了下载限制。运行此脚本时,您可能需要将其删除。实施此限制是为了允许用户在运行时测试他们的代码。
我喜欢边做边学。建议任何看过这篇文章的人都可以使用上面的代码,自己动手做。从这里开始,您现在可以使用 Newspaper3k 在线抓取 文章。
预防措施:
- 结尾 -
希望以上内容对大家有所帮助。喜欢这篇文章的记得转发+采集哦~
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-07 07:01
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,发现右侧:“... special/00804KVA/cm_guonei_03.js?.. ..》这样的地址,点击Response,发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
http://temp.163.com/special/0...*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
<p>requests
json
BeautifulSoup
</p>
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。
文章来源:segmentfault,作者:Amauri。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告点-内容底部 查看全部
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,发现右侧:“... special/00804KVA/cm_guonei_03.js?.. ..》这样的地址,点击Response,发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
http://temp.163.com/special/0...*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
<p>requests
json
BeautifulSoup
</p>
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。
文章来源:segmentfault,作者:Amauri。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
后台-系统设置-扩展变量-移动广告点-内容底部
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-06 19:27
)
已经进行了一些扩展(您也可以扩展它。从主页获取tele的中间路径,然后使用地图为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关知识,然后我使用了python。下面的程序有曲折和许多错误,但它几乎没有实现网络新闻的捕获。win系统服务没有添加,还有很多问题需要继续
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
已经进行了一些扩展(您也可以扩展它。从主页获取tele的中间路径,然后使用地图为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关知识,然后我使用了python。下面的程序有曲折和许多错误,但它几乎没有实现网络新闻的捕获。win系统服务没有添加,还有很多问题需要继续
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻( Java程序在解析中的应用场景的主要类层次结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-06 19:24
Java程序在解析中的应用场景的主要类层次结构)
jsoup抓取网页+详解
Java程序在解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我在 IBM DW 上发表了两篇关于 htmlparser 的文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理自定义标签的能力。但是现在我不再使用htmlparser了,因为htmlparser很少更新,但最重要的是有jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性和文本;
jsoup是基于MIT协议发布的,可以放心用于商业项目。
jsoup的主类层次结构如图1所示:
图1.jsoup的类层次结构
接下来我们具体说明jsoup是如何针对几种常见的应用场景优雅地处理HTML文档的。
文件输入
jsoup 可以从字符串、URL 地址和本地文件中加载 HTML 文档,并生成 Document 对象实例。
这是相关的代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接加载 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/")
.data("query", "Java") // 请求参数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法访问 URL
// 从文件中加载 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
</p>
请注意最后一个 HTML 文档输入法中 parse 的第三个参数。为什么这里需要指定网址(虽然可以不指定,如第一种方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数baseURL的意思是当HTML文档使用相对路径来引用外部文件时,jsoup会自动将这些URL加上this基本网址。
例如,开源软件将转换为开源软件。
解析和提取 HTML 元素
这部分涉及到一个HTML解析器最基本的功能,但是jsoup使用了一种不同于其他开源项目的方法——选择器。我们将在上一部分详细介绍 jsoup 选择器。在本节中,您将看到 jsoup 是如何使用最简单的代码来实现的。
但是,jsoup 也提供了传统的 DOM 元素分析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
你可能觉得jsoup的方法很眼熟,没错,getElementById、getElementsByTag等方法和JavaScript方法同名,功能完全一样。您可以根据节点名称或 HTML 元素的 id 获取相应的元素或元素列表。
与 htmlparser 项目不同,jsoup 没有为 HTML 元素定义相应的类。通常,一个 HTML 元素的组成部分包括:节点名称、属性和文本。Jsoup 为您提供了一种简单的方法来自己检索这些数据。这也是 jsoup 保持苗条的原因。
在元素检索方面,jsoup的选择器是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 所有引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这就是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 相同的选择器来检索元素。如果上面的检索方式换成另外一个HTML解释器,至少需要多行代码,而jsoup只需要一行代码。完成。
jsoup 的选择器也支持表达式功能,我们将在上一节介绍这个超级选择器。
更改数据
在解析文档时,我们可能需要修改文档中的一些元素。例如,我们可以为文档中的所有图像添加可点击的链接、修改链接地址或修改文本。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为所有链接增加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为所有链接增加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除所有图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空所有文本输入框中的文本
原因很简单,只需要使用jsoup的selector来查找元素,然后通过上面的方法修改即可,除了不能修改标签名(可以删除插入新元素) ,包括元素的属性和文本 可以修改。
修改后,直接调用Element(s)的html()方法得到修改后的HTML文档。
HTML 文档清理
jsoup 在提供强大 API 的同时,在用户友好性方面也非常出色。在做网站的时候,经常会提供用户评论功能。有些用户比较调皮,会在评论内容中加入一些脚本,这些脚本可能会破坏整个页面的行为,更严重的是获取一些机密信息,比如XSS跨站攻击。
jsoup 对这方面的支持非常强大,使用起来也非常简单。看看下面的一段代码:
列表5.
<p>
String unsafe = "<p> 查看全部
抓取网页新闻(
Java程序在解析中的应用场景的主要类层次结构)
jsoup抓取网页+详解
Java程序在解析HTML文档的时候,相信大家都接触过开源项目htmlparser。我在 IBM DW 上发表了两篇关于 htmlparser 的文章。它们是:从 HTML 中获取您需要的信息并扩展 HTMLParser 处理自定义标签的能力。但是现在我不再使用htmlparser了,因为htmlparser很少更新,但最重要的是有jsoup。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
jsoup的主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性和文本;
jsoup是基于MIT协议发布的,可以放心用于商业项目。
jsoup的主类层次结构如图1所示:
图1.jsoup的类层次结构
接下来我们具体说明jsoup是如何针对几种常见的应用场景优雅地处理HTML文档的。
文件输入
jsoup 可以从字符串、URL 地址和本地文件中加载 HTML 文档,并生成 Document 对象实例。
这是相关的代码:
清单 1
// 直接从字符串中输入 HTML 文档
String html = " 开源中国社区 "
+ "<p> 这里是 jsoup 项目的相关文章 ";
Document doc = Jsoup.parse(html);
// 从 URL 直接加载 HTML 文档
Document doc = Jsoup.connect("http://www.oschina.net/";).get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.oschina.net/";)
.data("query", "Java") // 请求参数
.userAgent("I ’ m jsoup") // 设置 User-Agent
.cookie("auth", "token") // 设置 cookie
.timeout(3000) // 设置连接超时时间
.post(); // 使用 POST 方法访问 URL
// 从文件中加载 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
</p>
请注意最后一个 HTML 文档输入法中 parse 的第三个参数。为什么这里需要指定网址(虽然可以不指定,如第一种方法)?因为HTML文档中会有很多链接、图片、外部脚本、css文件等,而第三个参数baseURL的意思是当HTML文档使用相对路径来引用外部文件时,jsoup会自动将这些URL加上this基本网址。
例如,开源软件将转换为开源软件。
解析和提取 HTML 元素
这部分涉及到一个HTML解析器最基本的功能,但是jsoup使用了一种不同于其他开源项目的方法——选择器。我们将在上一部分详细介绍 jsoup 选择器。在本节中,您将看到 jsoup 是如何使用最简单的代码来实现的。
但是,jsoup 也提供了传统的 DOM 元素分析。看看下面的代码:
列表2.
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.oschina.net/";);
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
你可能觉得jsoup的方法很眼熟,没错,getElementById、getElementsByTag等方法和JavaScript方法同名,功能完全一样。您可以根据节点名称或 HTML 元素的 id 获取相应的元素或元素列表。
与 htmlparser 项目不同,jsoup 没有为 HTML 元素定义相应的类。通常,一个 HTML 元素的组成部分包括:节点名称、属性和文本。Jsoup 为您提供了一种简单的方法来自己检索这些数据。这也是 jsoup 保持苗条的原因。
在元素检索方面,jsoup的选择器是无所不能的。
列表3.
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/";);
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");// 所有引用 png 图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class=masthead 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
这就是 jsoup 真正说服我的地方。Jsoup 使用与 jQuery 相同的选择器来检索元素。如果上面的检索方式换成另外一个HTML解释器,至少需要多行代码,而jsoup只需要一行代码。完成。
jsoup 的选择器也支持表达式功能,我们将在上一节介绍这个超级选择器。
更改数据
在解析文档时,我们可能需要修改文档中的一些元素。例如,我们可以为文档中的所有图像添加可点击的链接、修改链接地址或修改文本。
下面是一些简单的例子:
列表4.
doc.select("div.comments a").attr("rel", "nofollow");
// 为所有链接增加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
// 为所有链接增加 class=mylinkclass 属性
doc.select("img").removeAttr(" // 删除所有图片的 onclick 属性
doc.select("input[type=text]").val(""); // 清空所有文本输入框中的文本
原因很简单,只需要使用jsoup的selector来查找元素,然后通过上面的方法修改即可,除了不能修改标签名(可以删除插入新元素) ,包括元素的属性和文本 可以修改。
修改后,直接调用Element(s)的html()方法得到修改后的HTML文档。
HTML 文档清理
jsoup 在提供强大 API 的同时,在用户友好性方面也非常出色。在做网站的时候,经常会提供用户评论功能。有些用户比较调皮,会在评论内容中加入一些脚本,这些脚本可能会破坏整个页面的行为,更严重的是获取一些机密信息,比如XSS跨站攻击。
jsoup 对这方面的支持非常强大,使用起来也非常简单。看看下面的一段代码:
列表5.
<p>
String unsafe = "<p>
抓取网页新闻(信息收集的渗透过程中的中能和不敏感的意思 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-06 02:19
)
信息采集。在我们渗透的过程中,信息的采集,意味着我们可以对后续的渗透过程给予越来越多的帮助。有句话说得好:6%看信息采集,4%看技术。所以这篇文章文章带你进入信息采集的学习,更多技巧文章可以关注公众号:
1 个操作系统
操作系统:Windows 和 Linux
区分大小写的 Windows 是不区分大小写的:如果文件区分大小写且名称相同,则它是 Windows 上的文件。也就是说,不管你是大写还是小写,你的文件都是一个
我们的Windows构建网站,如果我们把网站的脚本格式asp和php改成大学PHP或ASP,恢复正常就是Windows,不正常就是Linux。
Linux 敏感:然而,Linux 上有两个文件
如果linux把后面的php改成大写,就返回一个错误,说明这是一个Linux操作系统,,,
所以这就是敏感和不敏感的意思
否则,我们可以使用 wappalyzer 查看基本中间件和常见的cms,这个插件可以在 Google Web Store 中找到并安装
2、数据库类型
常用数据库有:access、mysql、mssql(sql server)、oracle、postsql、db2
根据软件扫描可以看到网站的端口,1433可以看到是sql server
所以如果别人改了端口,这个时候我们应该怎么做,可以使用nmap,即使对方的端口被修改了,也能探测到对应的服务
(2)也有建筑组合计算
根据网站脚本和操作系统,
我们都知道在Windows上,有些数据库可能跑不起来,Linux上也是一样。在Linux上是不可能有access数据库的,而mssql,因为这两个产生,在Linux上是不兼容的。如果知道对方是什么操作系统,就是Linux,就可以排除access和mssql。如果使用Windows操作系统,我们可以排除Linux操作系统上的数据库,同理。我们也可以根据网站脚本类型来确定数据库。我们知道php一般是mysql,asp一般是access和mssql(sql sever)
否则按照常见的网站进行匹配即可
asp网站:常用的数据库是access,中间件iis,操作系统:Windows
aspx网站:常用的数据库是mssql数据库中间件iis操作系统Linux
php网站:常用的数据库有mysql中间件Apache(Windows系统)、Nginx(Linux系统)
jsp网站:常用的数据库是Oracle中间件Apache Tomcat操作系统Linux
3、搭建平台,脚本类型
搭建平台iis、Apache、uginx Tomcat
脚本类型php、asp、aspx、jsp、cgi、py等
审查元素
通过查看元素或查看元素来请求数据包,一般分为三块。第一条是访问信息,第二条是回复信息(回复信息是服务器对你访问的回复),第三条是请求信息(也就是我们当前自己访问的数据包)
我们可以看到。回复消息中,对应Apache和win32位,还泄露了一个版本的PHP5.2.17。从这里我们可以看到构建平台和脚本类型
4、子目录站点
/bbs
/老的
我们看上面两个站点,都是子目录站点
实战的意义
网站可能由多个cms或者framework组成,所以对于渗透来说,相当于多个渗透目标(一个cms一个idea)
如果主站点是php的cms,那么可能是在它的子目录站点下构建了其他cms,比如phptink,然后我们就可以找到他这个cms有哪些漏洞,是这样的
归根结底,他是一个。为什么?他在建造网站的时候。只有一个目录不同,入侵了他目录下的站点。或者入侵主站点,这些可以操作其他目录,我入侵它的其他子目录
网站的话,一样。主站也会受苦,因为主站和子目录站只有一个子目录组合。一般我们取子目录站的权限,就可以取主站的权限。
(2) 子端口站点
:80
:8080
实战的意思,网站可能由多个cms或者framework组成,所以对于渗透,相当于多个渗透目标(一个cms一个想法)
工具:nmap、锋利的刀口扫描器(其他也有)
5、子域
子域也称为:子域站点和二级域
域名站点和移动站点分析
子域名和主站点可以是同一个服务器,也可以是同一个网段。子域穿透,可直接联系主站
例如,移动网站
很多手机网站都是这样。它通常以 m 或其他开头,
它使用主站点的情况。移动站点可能是不同的程序。子域名是以wap或m开头的移动站点。
移动站点:1、一套针对不同主站的移动终端框架程序2、直接调用主站程序
如果是第一个。它们是两个不同的程序,实际上是两个站点,即一个是主站点的程序,另一个是移动框架的程序。移动端的渗透方式还是和我们一般的渗透方式一样。
如何采集子域
使用字典爆破工具:subdomainbrute、layer
在线网站:/
搜索引擎
反向检查whois
工具:站长工具
1 查询whois /
2 反向检查whois /reverse?host=&ddlSearchMode=1
获取关联域名信息
6、网站后台
一般来说,我们在做前端渗透和挖矿的时候,可以把目标看向后端地址。可能会有一些意想不到的收获,因为后端
通常存在一些安全漏洞,例如 SQL 注入和未经授权的访问。这是找到背景的方法
(1) 通过搜索引擎
站点:域名管理
站点:域名管理
站点:域名 intitle:管理
(2) 一方面,目录扫描在目录扫描中。常见的网站地址有/admin、login/admin等。
相关工具:御剑、wfuzz
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
(3)子域名:对于二级域名,一般网站的后端会在二级域名或三级域名,采集子域名时请注意。
(4)采集已知的cms后端地址,例如织梦,默认地址为/dede
(5)侧站端口查询:将其他端口放置在后台页面,扫描网站获取停止端口信息进行访问
(6) C段扫描:把它放在后台到同一个c段下的其他ip地址。
在线侧站c段扫描地址:phpinfo.me/bing.php
(7)查看网站底部的管理入口和版权信息。这种情况下,学校和政府机构通常比较多,因为这些网站管理员往往不止一个,有时为了方便登录后台,会在前台留一个入口
7、 目录信息采集
扫描目录后,根据目录的一些路径,比如一些上传点,编辑器,或者一些未知的API接口,我可以发现更多的漏洞。
(1)用工具扫描
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
403、404之类的页面不要关闭,直接放在目录下扫描即可。
(2)谷歌语法采集敏感文件
最常见的是使用搜索引擎~
网站:文件类型:xls
这里的主要目的是采集网站敏感文件。有可能通过搜索引擎搜索到一些敏感信息。同时,目录扫描可以扫描出后台地址,还可以进行一方面的操作,比如SQL注入、字典碰撞库爆破等。
(3)敏感文件:常见的,phpinfo文件,备份信息泄露,“git, SVN, swp, bak, xml”文件,可能有一些敏感信息,还有robots.txt.文件(一个ascii编码的文件)文件放在网站的根目录下,一般可以防止搜索引擎抓取敏感目录和文件)
8、端口扫描
这些端口代表了一些协议,所以每一个都有突破的方法,都是可以暴力破解的,还有字典可以暴力破解。
我们经常谈论抓鸡和港口抓鸡。其实它的原理就是猜测你的弱密码来进行集群操作。
那我们入侵也是一样,我们也去扫你的弱密码
还有很多工具,比如hscan、hydra、x-scan、streamer,这些工具可以到端口去猜密码,如果我们想做就得丰富字典等等,另一方面,端口扫描最常用的工具是nmap
以下是常见端口对应的漏洞
查看全部
抓取网页新闻(信息收集的渗透过程中的中能和不敏感的意思
)
信息采集。在我们渗透的过程中,信息的采集,意味着我们可以对后续的渗透过程给予越来越多的帮助。有句话说得好:6%看信息采集,4%看技术。所以这篇文章文章带你进入信息采集的学习,更多技巧文章可以关注公众号:
1 个操作系统
操作系统:Windows 和 Linux
区分大小写的 Windows 是不区分大小写的:如果文件区分大小写且名称相同,则它是 Windows 上的文件。也就是说,不管你是大写还是小写,你的文件都是一个
我们的Windows构建网站,如果我们把网站的脚本格式asp和php改成大学PHP或ASP,恢复正常就是Windows,不正常就是Linux。
Linux 敏感:然而,Linux 上有两个文件
如果linux把后面的php改成大写,就返回一个错误,说明这是一个Linux操作系统,,,
所以这就是敏感和不敏感的意思
否则,我们可以使用 wappalyzer 查看基本中间件和常见的cms,这个插件可以在 Google Web Store 中找到并安装
2、数据库类型
常用数据库有:access、mysql、mssql(sql server)、oracle、postsql、db2
根据软件扫描可以看到网站的端口,1433可以看到是sql server
所以如果别人改了端口,这个时候我们应该怎么做,可以使用nmap,即使对方的端口被修改了,也能探测到对应的服务
(2)也有建筑组合计算
根据网站脚本和操作系统,
我们都知道在Windows上,有些数据库可能跑不起来,Linux上也是一样。在Linux上是不可能有access数据库的,而mssql,因为这两个产生,在Linux上是不兼容的。如果知道对方是什么操作系统,就是Linux,就可以排除access和mssql。如果使用Windows操作系统,我们可以排除Linux操作系统上的数据库,同理。我们也可以根据网站脚本类型来确定数据库。我们知道php一般是mysql,asp一般是access和mssql(sql sever)
否则按照常见的网站进行匹配即可
asp网站:常用的数据库是access,中间件iis,操作系统:Windows
aspx网站:常用的数据库是mssql数据库中间件iis操作系统Linux
php网站:常用的数据库有mysql中间件Apache(Windows系统)、Nginx(Linux系统)
jsp网站:常用的数据库是Oracle中间件Apache Tomcat操作系统Linux
3、搭建平台,脚本类型
搭建平台iis、Apache、uginx Tomcat
脚本类型php、asp、aspx、jsp、cgi、py等
审查元素
通过查看元素或查看元素来请求数据包,一般分为三块。第一条是访问信息,第二条是回复信息(回复信息是服务器对你访问的回复),第三条是请求信息(也就是我们当前自己访问的数据包)
我们可以看到。回复消息中,对应Apache和win32位,还泄露了一个版本的PHP5.2.17。从这里我们可以看到构建平台和脚本类型
4、子目录站点
/bbs
/老的
我们看上面两个站点,都是子目录站点
实战的意义
网站可能由多个cms或者framework组成,所以对于渗透来说,相当于多个渗透目标(一个cms一个idea)
如果主站点是php的cms,那么可能是在它的子目录站点下构建了其他cms,比如phptink,然后我们就可以找到他这个cms有哪些漏洞,是这样的
归根结底,他是一个。为什么?他在建造网站的时候。只有一个目录不同,入侵了他目录下的站点。或者入侵主站点,这些可以操作其他目录,我入侵它的其他子目录
网站的话,一样。主站也会受苦,因为主站和子目录站只有一个子目录组合。一般我们取子目录站的权限,就可以取主站的权限。
(2) 子端口站点
:80
:8080
实战的意思,网站可能由多个cms或者framework组成,所以对于渗透,相当于多个渗透目标(一个cms一个想法)
工具:nmap、锋利的刀口扫描器(其他也有)
5、子域
子域也称为:子域站点和二级域
域名站点和移动站点分析
子域名和主站点可以是同一个服务器,也可以是同一个网段。子域穿透,可直接联系主站
例如,移动网站
很多手机网站都是这样。它通常以 m 或其他开头,
它使用主站点的情况。移动站点可能是不同的程序。子域名是以wap或m开头的移动站点。
移动站点:1、一套针对不同主站的移动终端框架程序2、直接调用主站程序
如果是第一个。它们是两个不同的程序,实际上是两个站点,即一个是主站点的程序,另一个是移动框架的程序。移动端的渗透方式还是和我们一般的渗透方式一样。
如何采集子域
使用字典爆破工具:subdomainbrute、layer
在线网站:/
搜索引擎
反向检查whois
工具:站长工具
1 查询whois /
2 反向检查whois /reverse?host=&ddlSearchMode=1
获取关联域名信息
6、网站后台
一般来说,我们在做前端渗透和挖矿的时候,可以把目标看向后端地址。可能会有一些意想不到的收获,因为后端
通常存在一些安全漏洞,例如 SQL 注入和未经授权的访问。这是找到背景的方法
(1) 通过搜索引擎
站点:域名管理
站点:域名管理
站点:域名 intitle:管理
(2) 一方面,目录扫描在目录扫描中。常见的网站地址有/admin、login/admin等。
相关工具:御剑、wfuzz
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
(3)子域名:对于二级域名,一般网站的后端会在二级域名或三级域名,采集子域名时请注意。
(4)采集已知的cms后端地址,例如织梦,默认地址为/dede
(5)侧站端口查询:将其他端口放置在后台页面,扫描网站获取停止端口信息进行访问
(6) C段扫描:把它放在后台到同一个c段下的其他ip地址。
在线侧站c段扫描地址:phpinfo.me/bing.php
(7)查看网站底部的管理入口和版权信息。这种情况下,学校和政府机构通常比较多,因为这些网站管理员往往不止一个,有时为了方便登录后台,会在前台留一个入口
7、 目录信息采集
扫描目录后,根据目录的一些路径,比如一些上传点,编辑器,或者一些未知的API接口,我可以发现更多的漏洞。
(1)用工具扫描
这里推荐一个工具7kbstorm
/7kbstorm/7kbscan-WebPathBrute
403、404之类的页面不要关闭,直接放在目录下扫描即可。
(2)谷歌语法采集敏感文件
最常见的是使用搜索引擎~
网站:文件类型:xls
这里的主要目的是采集网站敏感文件。有可能通过搜索引擎搜索到一些敏感信息。同时,目录扫描可以扫描出后台地址,还可以进行一方面的操作,比如SQL注入、字典碰撞库爆破等。
(3)敏感文件:常见的,phpinfo文件,备份信息泄露,“git, SVN, swp, bak, xml”文件,可能有一些敏感信息,还有robots.txt.文件(一个ascii编码的文件)文件放在网站的根目录下,一般可以防止搜索引擎抓取敏感目录和文件)
8、端口扫描
这些端口代表了一些协议,所以每一个都有突破的方法,都是可以暴力破解的,还有字典可以暴力破解。
我们经常谈论抓鸡和港口抓鸡。其实它的原理就是猜测你的弱密码来进行集群操作。
那我们入侵也是一样,我们也去扫你的弱密码
还有很多工具,比如hscan、hydra、x-scan、streamer,这些工具可以到端口去猜密码,如果我们想做就得丰富字典等等,另一方面,端口扫描最常用的工具是nmap
以下是常见端口对应的漏洞
抓取网页新闻( Python3爬取新闻网站新闻列表到什么时候才是好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-01 14:08
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这是Python3爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些美图被爬了
4.png
爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,我给大家解释一下。
5.png
分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的就是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加了异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取到数据后,我们需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析和处理。也可以使用爬取的文章,给app提供新闻api接口。当然,这是一个故事。自学Python数据库操作后,再写一篇文章
图文教程视频教程
点击这个地址试一试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696 查看全部
抓取网页新闻(
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这是Python3爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些美图被爬了
4.png
爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,我给大家解释一下。
5.png
分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的就是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加了异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取到数据后,我们需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析和处理。也可以使用爬取的文章,给app提供新闻api接口。当然,这是一个故事。自学Python数据库操作后,再写一篇文章
图文教程视频教程
点击这个地址试一试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2021-09-28 10:21
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,新增栏目抓取功能,新闻栏目关键词可设置抓取新闻内容时过滤,满足需求的文章下抓取列。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询: 查看全部
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,新增栏目抓取功能,新闻栏目关键词可设置抓取新闻内容时过滤,满足需求的文章下抓取列。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询:
抓取网页新闻(抓取网页新闻可能会用到各种爬虫,抓到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-26 18:06
抓取网页新闻可能会用到各种爬虫,例如,比较有名的“xx网站的xx新闻,抓到了吗?”;搜索某种东西则要么用模拟器,然后需要全自动爬取,要么自己手动写爬虫。我用的方法是用有爬虫分析平台和爬虫抓包的软件,百度搜索“python爬虫分析”有很多教程。
和前几个一样用python爬百度新闻,不过百度的新闻可能比较杂,个人觉得用python爬政府网站比较好。其实中国的网站和国外的都不一样,具体还是要爬取出来确定是否是政府网站。
美国每天发布的新闻都是xx-xxxx-xxxx.html的形式
网站新闻爬虫开发_完整python爬虫,
用python做最直接的一种是googlecrawler你拿去用,他有用python做的,
公司有项目就用爬虫爬的吧
-抓取百度新闻-百度新闻-客户端-百度天天快报-android-搜索-微信-可以自己手动获取浏览器新闻源地址,然后f12-进入爬虫控制台,定位到新闻源出现的url,
python在线新闻抓取平台:python-919472571-
会一点点爬虫,正在琢磨要不要学爬虫,想找一些实践爬虫的帖子,可以在线答疑,当然最好是找实战相关的东西学习。 查看全部
抓取网页新闻(抓取网页新闻可能会用到各种爬虫,抓到了吗?)
抓取网页新闻可能会用到各种爬虫,例如,比较有名的“xx网站的xx新闻,抓到了吗?”;搜索某种东西则要么用模拟器,然后需要全自动爬取,要么自己手动写爬虫。我用的方法是用有爬虫分析平台和爬虫抓包的软件,百度搜索“python爬虫分析”有很多教程。
和前几个一样用python爬百度新闻,不过百度的新闻可能比较杂,个人觉得用python爬政府网站比较好。其实中国的网站和国外的都不一样,具体还是要爬取出来确定是否是政府网站。
美国每天发布的新闻都是xx-xxxx-xxxx.html的形式
网站新闻爬虫开发_完整python爬虫,
用python做最直接的一种是googlecrawler你拿去用,他有用python做的,
公司有项目就用爬虫爬的吧
-抓取百度新闻-百度新闻-客户端-百度天天快报-android-搜索-微信-可以自己手动获取浏览器新闻源地址,然后f12-进入爬虫控制台,定位到新闻源出现的url,
python在线新闻抓取平台:python-919472571-
会一点点爬虫,正在琢磨要不要学爬虫,想找一些实践爬虫的帖子,可以在线答疑,当然最好是找实战相关的东西学习。
抓取网页新闻(抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-09-26 10:06
抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配时,需要将新闻编码转换为unicode或gb2312编码,然后全网页爬取下来保存。下面说一下怎么实现:第一步,首先安装flashtools并安装相应的插件,具体如下(需要配置):安装插件之后,在python中打开xx-ui.py文件,这个时候你需要在爬虫中输入如下两行代码:fetch_content(self.data).log();或者在主页面加入一个代码:fetch_timeout(。
1).log()接下来是一些基本的模块的配置,与前面的略有不同,此处不赘述:importrequests,urllib,unicode,formmatch1.打开flashtools中的urllib.request.urlopen()对网页的解析,然后保存。网页中有没有有效代码就下载,有就解析,不能解析就保存原始网页。
2.然后利用formmatch()和get()方法,将unicode编码的url、文本转化为gb2312编码,并保存。详情请参考小白入门爬虫教程1_静月螺旋_新浪博客3.最后对各地新闻做编码转换工作。完成,可以打包爬取网站中的新闻并提供下载。
1、首先安装flashtools(官网flashtoolsisanextensibleurlsuggestionapicomponentforadvancedspiderwebpagecontentminimizerandimagecompression)。在python内的console编辑器中安装完成后,运行flashtools.py会有提示让你选择contentsecure还是urlsecurity。使用这个api存储图片,图片会由gif变成png。
2、在爬取新闻网页时需要注意的一点是,必须保存post请求的对象才能被formmap加载。所以这个api可以成为一个开放的api。网上有很多开源的spider应用,推荐使用。
3、displaygazifier实现。
4、jsonapi和xmlapi其实在爬虫底层多多少少会有些兼容性问题,要具体分析。这方面的相关实现可以参考json和xml的异同。我目前还没有完全了解。 查看全部
抓取网页新闻(抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配)
抓取网页新闻时碰到主流浏览器不支持formmethod控件和爬虫代码不匹配时,需要将新闻编码转换为unicode或gb2312编码,然后全网页爬取下来保存。下面说一下怎么实现:第一步,首先安装flashtools并安装相应的插件,具体如下(需要配置):安装插件之后,在python中打开xx-ui.py文件,这个时候你需要在爬虫中输入如下两行代码:fetch_content(self.data).log();或者在主页面加入一个代码:fetch_timeout(。
1).log()接下来是一些基本的模块的配置,与前面的略有不同,此处不赘述:importrequests,urllib,unicode,formmatch1.打开flashtools中的urllib.request.urlopen()对网页的解析,然后保存。网页中有没有有效代码就下载,有就解析,不能解析就保存原始网页。
2.然后利用formmatch()和get()方法,将unicode编码的url、文本转化为gb2312编码,并保存。详情请参考小白入门爬虫教程1_静月螺旋_新浪博客3.最后对各地新闻做编码转换工作。完成,可以打包爬取网站中的新闻并提供下载。
1、首先安装flashtools(官网flashtoolsisanextensibleurlsuggestionapicomponentforadvancedspiderwebpagecontentminimizerandimagecompression)。在python内的console编辑器中安装完成后,运行flashtools.py会有提示让你选择contentsecure还是urlsecurity。使用这个api存储图片,图片会由gif变成png。
2、在爬取新闻网页时需要注意的一点是,必须保存post请求的对象才能被formmap加载。所以这个api可以成为一个开放的api。网上有很多开源的spider应用,推荐使用。
3、displaygazifier实现。
4、jsonapi和xmlapi其实在爬虫底层多多少少会有些兼容性问题,要具体分析。这方面的相关实现可以参考json和xml的异同。我目前还没有完全了解。
抓取网页新闻(网页正文内容的可能性是怎样的?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-21 04:28
)
,标签的子标签不独立。
与此同时,也已在分析过程中发现了一些问题:
1.网站 K1对C C C C C属属属属属
2.网正正正内容中内容内容内容超,它可以是文本或图片,标签
在
,它不一定是内容,并且它也可以是其它的标签。
3.
有可能是一个JS脚本或其他HTML标签。
4.
<p>标签的内容是不完整的或不一定是文本内容。 @网站版版版版版般般般般 查看全部
抓取网页新闻(网页正文内容的可能性是怎样的?(一)
)
,标签的子标签不独立。
与此同时,也已在分析过程中发现了一些问题:
1.网站 K1对C C C C C属属属属属
2.网正正正内容中内容内容内容超,它可以是文本或图片,标签
在
,它不一定是内容,并且它也可以是其它的标签。
3.
有可能是一个JS脚本或其他HTML标签。
4.
<p>标签的内容是不完整的或不一定是文本内容。 @网站版版版版版般般般般
抓取网页新闻(基于javac+php的rss抓取网上很多(iframe、mongodb))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-21 04:25
rssspider
#介绍#
网络爬网程序,使用nodejs捕获RSS新闻,抓取内容,包括标题,发布时间,描述,来源,按压正文和新闻。同时,为客户提供标准的新闻服务界面。
提供RSS服务站点超级,百度,网易,新浪,虎嗅网络等,基于Javac ++,PHP的RSS在线划伤。今天,我将讨论nodejs来获取RSS信息。最新的新闻项目,项目流程简单,使用NodeJS获取新闻,保存到MongoDB数据库,然后向客户端提供HTTP服务。客户的实现可在线获得,此项目没有客户端实施。如何捕获RSS地址的URL地址和链接,捕获新闻和新闻的轮廓。对于新闻客户,没有图片是一个致命的打击,你可以吸引用户。
这个项目抓住了标题,来源,url地址,描述,正文,新闻,新闻列表,新闻列表,单一新闻查询服务,我觉得项目还可以,请点击,哈哈
#项目介绍####演示在手机或平板电脑上显示###,显示最佳效果
##项目开发环境## nodejs,mongodb
##运行方向###首先加载依赖库
npm install -d
node app.js
访问Web新闻列表,以及内容
直接访问:8001
这个项目在网易的RSS中测试了
密钥爬网代码,在服务目录中
##项目功能##
多站点同时抓取,在配置新闻文本时,需要掌握的网站可以很高,包括图片NodeJS实现,效率非常高。您可以配置时间,并新闻启动标签,过滤滤除广告和广告(IFrame AD),新闻列表和新闻查询HTTP服务,为Android或其他客户提供数据源提供数据源支持加入响应框架骨架,显示新闻列表,然后按文本。
详细地址地址:
文章 1:
文章 2:
#201 4.3. 15更新日志
添加响应帧骨架,总共20kb,适用于移动网页的开发,加入异步异步编程控制库,请求所有新闻列表,使用队列函数执行数据库查询,并发第5号和访问数据库是超快速的。 Web响应也在100毫秒范围内:8001 /即新闻列表,点击新闻即可进入新闻正文。
#201 4.3. 4更新日志
重新架构项目,使用jshint来验证RSS抓住新闻链接,继续捕捉新闻机构,提取新闻身体和身体的有用图片。当显示新闻时,如果有一张图片,它可以吸引眼球。该项目捕获网易的新闻和图片,正确的速率是其他客户的新闻查询的HTTP服务,查询新闻列表(标题,图片),描述),获取新闻身体
客户端请求新闻列表协议在源代码中查看文档
#201 4.2. 27更新日志1、使用Express提供新闻服务,为Android客户提供服务和其他客户端
2、加分数
3、使用Chreeio插件,遍历网页的全文,获取新闻标题和URL地址。 (用于测试)实验。
如果您有任何疑问,请联系作者:刘兴,
###项目托管在GitHub中:欢迎来共同开发和改进,如果您认为没关系,请点击赞美。 ###
github: 查看全部
抓取网页新闻(基于javac+php的rss抓取网上很多(iframe、mongodb))
rssspider
#介绍#
网络爬网程序,使用nodejs捕获RSS新闻,抓取内容,包括标题,发布时间,描述,来源,按压正文和新闻。同时,为客户提供标准的新闻服务界面。
提供RSS服务站点超级,百度,网易,新浪,虎嗅网络等,基于Javac ++,PHP的RSS在线划伤。今天,我将讨论nodejs来获取RSS信息。最新的新闻项目,项目流程简单,使用NodeJS获取新闻,保存到MongoDB数据库,然后向客户端提供HTTP服务。客户的实现可在线获得,此项目没有客户端实施。如何捕获RSS地址的URL地址和链接,捕获新闻和新闻的轮廓。对于新闻客户,没有图片是一个致命的打击,你可以吸引用户。
这个项目抓住了标题,来源,url地址,描述,正文,新闻,新闻列表,新闻列表,单一新闻查询服务,我觉得项目还可以,请点击,哈哈
#项目介绍####演示在手机或平板电脑上显示###,显示最佳效果
##项目开发环境## nodejs,mongodb
##运行方向###首先加载依赖库
npm install -d
node app.js
访问Web新闻列表,以及内容
直接访问:8001
这个项目在网易的RSS中测试了
密钥爬网代码,在服务目录中
##项目功能##
多站点同时抓取,在配置新闻文本时,需要掌握的网站可以很高,包括图片NodeJS实现,效率非常高。您可以配置时间,并新闻启动标签,过滤滤除广告和广告(IFrame AD),新闻列表和新闻查询HTTP服务,为Android或其他客户提供数据源提供数据源支持加入响应框架骨架,显示新闻列表,然后按文本。
详细地址地址:
文章 1:
文章 2:
#201 4.3. 15更新日志
添加响应帧骨架,总共20kb,适用于移动网页的开发,加入异步异步编程控制库,请求所有新闻列表,使用队列函数执行数据库查询,并发第5号和访问数据库是超快速的。 Web响应也在100毫秒范围内:8001 /即新闻列表,点击新闻即可进入新闻正文。
#201 4.3. 4更新日志
重新架构项目,使用jshint来验证RSS抓住新闻链接,继续捕捉新闻机构,提取新闻身体和身体的有用图片。当显示新闻时,如果有一张图片,它可以吸引眼球。该项目捕获网易的新闻和图片,正确的速率是其他客户的新闻查询的HTTP服务,查询新闻列表(标题,图片),描述),获取新闻身体
客户端请求新闻列表协议在源代码中查看文档
#201 4.2. 27更新日志1、使用Express提供新闻服务,为Android客户提供服务和其他客户端
2、加分数
3、使用Chreeio插件,遍历网页的全文,获取新闻标题和URL地址。 (用于测试)实验。
如果您有任何疑问,请联系作者:刘兴,
###项目托管在GitHub中:欢迎来共同开发和改进,如果您认为没关系,请点击赞美。 ###
github:
抓取网页新闻( 采用AJAX技术的网站越来越多我们有必要通过更多案例讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-21 04:21
采用AJAX技术的网站越来越多我们有必要通过更多案例讲解)
如何仅捕获最新的cnBeta数字产品新闻如何仅捕获最新的cnBeta数字产品新闻越来越多的人使用ajax技术。我们需要解释如何通过更多的案例准确地捕获JavaScript JS动态生成的内容。这一次,我们想捕捉cnbeta网站在数字产品新闻上,进入这个网站主页,可以看到一个积极入党的新闻列表。列表中有很多新闻项目,每个项目包括标题乘法、口算、七年级有理数混合运算100个问题,计算机初级题库100个问题,二进制基本方程、应用问题、真理、冒险、刺激问题、基本信息和摘要等。使用浏览器页面发现访问此网络新闻列表的第一页与普通网页相同。转到第二页后,您可以通过使用浏览器的“查看源代码”功能看到HTML源代码没有更改。无论您现在看到多少页,HTML源代码仍然是第一页。最初,您应该网站使用JavaScript在翻页时动态刷新新闻列表。这种情况将阻碍普通网络爬虫和普通网络爬虫,因为这种网络爬虫通常通过向目标服务器发送HTTP get消息来获取HTML文档,然后使用正则表达式或DOM解析方法、二重积分计算方法、匹配方法、,愚人节矫正法、现金流量表编制法和七种顺序总和法提取网页内容。当需要转到其他页面时,其他页面没有独立的URL网页地址,无法发送HTTP get消息。您只能通过手动干预嗅探JavaScript发送给网站的消息。您可以通过模拟消息来获取其他页面的内容。使用metaseeker网页爬虫,您可以完全放弃嗅探方法,这与抓取普通网页相同AJAX网站本文还将介绍另一种抓取新闻列表时的翻页技巧,如果页面中的新闻以前被抓取过,请停止翻页,即,只捕捉最新新闻。这是跟踪论坛博客、微博新闻网站等最常用的技巧。这也是构建企业竞争情报系统的必要功能。捕获目标分析样本离婚起诉系谱样本现代系谱简单样本招标文件样本简单招标文件样本页面名称demo_uucnbeta_uu该列表的目的是捕获新闻列表的信息结构。详细页面是一个URL,网页地址用于创建次要线索。主题名为demo_ucnbeta_uuu。Detail指的是所谓的分层爬网摘要页面翻转以爬网多个页面。当先前对第二级URL进行爬网时,请停止爬网过程。注1:您可以使用metastudio加载信息结构demo_cnbeta。通过比较,该列表更容易理解。请注意,目标网页的结构可能会更改,这可能导致信息结构加载失败。修改信息结构请参见“修改无效信息结构”。注2:这不是介绍性教程。如果您不熟悉metaseeker,建议阅读第1章中的metaseeker express手册。为了捕获新闻摘要数据,我们首先需要定义数据捕获规则。所谓的数据采集规则是关于基本建设项目建设成本管理的法律规定、关于养老的规定、关于妇女节假期的规定、关于妇女节假期的规定、关于鞋类三包的规定,以及关于如何从网页上采集新闻列表数据的规定。图1显示了数据映射和freeformat映射的过程,主要包括:接下来,选择新闻列表中的第一条新闻作为示例数据映射
映射和freeformat映射都是在它上执行的。为了捕获新闻数据,进行了数据映射和自由格式映射。Freeformat映射不是必需的。如果网页有一个class或ID属性,表示可以用来准确定位捕获内容的DOM节点的语义,则执行freeformat映射。详细操作流程请参见捕获京东商品价格,以便捕获freeformat映射新闻列表中的每条新闻,这就是所谓的多实例捕获。Freeformat映射不是唯一的方法。此页面上的每个新闻都有一个类“NewsList”,非常适合捕获多个实例。如果没有合适的freeformat,可以使用示例复制方法。请参阅捕获当当商品价格设置至少一个信息属性的关键功能。有关关键功能的描述,请参阅metastudio用户手册。设置关键功能后,datasrapper可以在加速模式下运行,以提高捕获速度。如果未选中数据采集器的菜单项“配置”-“正常模式”,则数据采集器将进入加速模式2以捕获新闻详细信息页面。我们将看到“分层捕获”图2显示了再次捕获下一级线索的方法。设置线索功能后,会在clueeditor工作台上自动创建一个信息线程,下一级主题在clueeditor工作台上命名为demo\ucnbeta\uudetail,如图3所示,定义信息线索的目的是执行分层爬网,抓取新闻列表,然后抓取详细的新闻内容。为了避免重复爬行,当发现超过设定的重复率时,爬行过程将终止。在接下来的章节中,我们将详细解释如何通过翻页来抓取多个页面。为了翻页抓取所有页面,我们需要创建一条线索。图4详细显示了主要步骤,有关详细信息,请参见抓取当当商品价格。将表示整个分页区域的DOM节点映射到此线索相当于指定可以定位分页超链接的网页区域。我们使用标记线索类型来定位翻页线索,而不是“”标记映射基于标记值。标记值和标记节点序列号将自动填入clueeditor工作台。设置在线线索类型。这种类型主要用于翻页爬行。选择此类型后,当前主题名称将自动填入目标主题名称输入框。4设置Ajax爬行模式。如图5所示,在“页面捕获卓越亚马逊”一文中选择metastudio设置Ajax捕获模式的菜单“配置”-“活动模式”,我们同时设置了“活动模式”和“扩展模式”,这两种模式没有绑定在一起。这个目标网站不会在每次翻页时加载另一个页面,而是在本地修改页面内容,因此我们设置了“扩展模式”,这是没有意义的。我们通常在每一个特定的时间,比如某一天,获取最新的新闻
如果在新闻列表中发现了新新闻,请抓取其URL并创建下一级线索以抓取最新的新闻内容。如果发现新闻列表中的所有新闻都是以前捕获的新闻,请停止翻页和爬网。这需要周期性的自动爬行方法。需要编辑周期爬网调度指令文件。此文件必须命名为crontabxml,并存储在homedatasrapper目录中,以获取目录结构的详细描述,请参阅“捕获当当商品价格”。下面是crontabxml文件的内容。Crontabthreadname“news_list”参数UTRUEOUTOSTART5StartPeriod3600PeriodWaitOnLoadalsWaitonLoadParameterName“renewclue”主题的EMO_cnbeta_uu列表主题的ESTEPSTEPNAME“crawl”主题的EMO_cnbeta_uuu列表EUpdateclueUpdateCLuedDupratio80DupratioPth-1depth-1depthWidthRenewFalseRenewPeriod0PeriodStepThreadName“news_uDetail”参数AutoTrueTAutoStart23StartPeriod1800PeriodidWaitOnLoadFalseWaitOnLoadParameterStepName“crawl”主题emo_uCNbeta_u所有参数的含义在定期提取计划指令文件中解释。抓取主题演示与“仅抓取最新新闻”相关。列表的dupratio参数80表示80,即,如果发现在三个连续页面中捕获的URL地址中有80个之前已捕获,则翻页捕获将终止。当前版本的元导引头只能判断捕获的下一级线索的重复率,而不能判断捕获数据的重复率。请不要直接使用crontabxml,因为它尚未在metaseeker服务器上捕获,但定义的信息结构demo_cnbeta_u详细信息将导致定期获取失败 查看全部
抓取网页新闻(
采用AJAX技术的网站越来越多我们有必要通过更多案例讲解)
如何仅捕获最新的cnBeta数字产品新闻如何仅捕获最新的cnBeta数字产品新闻越来越多的人使用ajax技术。我们需要解释如何通过更多的案例准确地捕获JavaScript JS动态生成的内容。这一次,我们想捕捉cnbeta网站在数字产品新闻上,进入这个网站主页,可以看到一个积极入党的新闻列表。列表中有很多新闻项目,每个项目包括标题乘法、口算、七年级有理数混合运算100个问题,计算机初级题库100个问题,二进制基本方程、应用问题、真理、冒险、刺激问题、基本信息和摘要等。使用浏览器页面发现访问此网络新闻列表的第一页与普通网页相同。转到第二页后,您可以通过使用浏览器的“查看源代码”功能看到HTML源代码没有更改。无论您现在看到多少页,HTML源代码仍然是第一页。最初,您应该网站使用JavaScript在翻页时动态刷新新闻列表。这种情况将阻碍普通网络爬虫和普通网络爬虫,因为这种网络爬虫通常通过向目标服务器发送HTTP get消息来获取HTML文档,然后使用正则表达式或DOM解析方法、二重积分计算方法、匹配方法、,愚人节矫正法、现金流量表编制法和七种顺序总和法提取网页内容。当需要转到其他页面时,其他页面没有独立的URL网页地址,无法发送HTTP get消息。您只能通过手动干预嗅探JavaScript发送给网站的消息。您可以通过模拟消息来获取其他页面的内容。使用metaseeker网页爬虫,您可以完全放弃嗅探方法,这与抓取普通网页相同AJAX网站本文还将介绍另一种抓取新闻列表时的翻页技巧,如果页面中的新闻以前被抓取过,请停止翻页,即,只捕捉最新新闻。这是跟踪论坛博客、微博新闻网站等最常用的技巧。这也是构建企业竞争情报系统的必要功能。捕获目标分析样本离婚起诉系谱样本现代系谱简单样本招标文件样本简单招标文件样本页面名称demo_uucnbeta_uu该列表的目的是捕获新闻列表的信息结构。详细页面是一个URL,网页地址用于创建次要线索。主题名为demo_ucnbeta_uuu。Detail指的是所谓的分层爬网摘要页面翻转以爬网多个页面。当先前对第二级URL进行爬网时,请停止爬网过程。注1:您可以使用metastudio加载信息结构demo_cnbeta。通过比较,该列表更容易理解。请注意,目标网页的结构可能会更改,这可能导致信息结构加载失败。修改信息结构请参见“修改无效信息结构”。注2:这不是介绍性教程。如果您不熟悉metaseeker,建议阅读第1章中的metaseeker express手册。为了捕获新闻摘要数据,我们首先需要定义数据捕获规则。所谓的数据采集规则是关于基本建设项目建设成本管理的法律规定、关于养老的规定、关于妇女节假期的规定、关于妇女节假期的规定、关于鞋类三包的规定,以及关于如何从网页上采集新闻列表数据的规定。图1显示了数据映射和freeformat映射的过程,主要包括:接下来,选择新闻列表中的第一条新闻作为示例数据映射
映射和freeformat映射都是在它上执行的。为了捕获新闻数据,进行了数据映射和自由格式映射。Freeformat映射不是必需的。如果网页有一个class或ID属性,表示可以用来准确定位捕获内容的DOM节点的语义,则执行freeformat映射。详细操作流程请参见捕获京东商品价格,以便捕获freeformat映射新闻列表中的每条新闻,这就是所谓的多实例捕获。Freeformat映射不是唯一的方法。此页面上的每个新闻都有一个类“NewsList”,非常适合捕获多个实例。如果没有合适的freeformat,可以使用示例复制方法。请参阅捕获当当商品价格设置至少一个信息属性的关键功能。有关关键功能的描述,请参阅metastudio用户手册。设置关键功能后,datasrapper可以在加速模式下运行,以提高捕获速度。如果未选中数据采集器的菜单项“配置”-“正常模式”,则数据采集器将进入加速模式2以捕获新闻详细信息页面。我们将看到“分层捕获”图2显示了再次捕获下一级线索的方法。设置线索功能后,会在clueeditor工作台上自动创建一个信息线程,下一级主题在clueeditor工作台上命名为demo\ucnbeta\uudetail,如图3所示,定义信息线索的目的是执行分层爬网,抓取新闻列表,然后抓取详细的新闻内容。为了避免重复爬行,当发现超过设定的重复率时,爬行过程将终止。在接下来的章节中,我们将详细解释如何通过翻页来抓取多个页面。为了翻页抓取所有页面,我们需要创建一条线索。图4详细显示了主要步骤,有关详细信息,请参见抓取当当商品价格。将表示整个分页区域的DOM节点映射到此线索相当于指定可以定位分页超链接的网页区域。我们使用标记线索类型来定位翻页线索,而不是“”标记映射基于标记值。标记值和标记节点序列号将自动填入clueeditor工作台。设置在线线索类型。这种类型主要用于翻页爬行。选择此类型后,当前主题名称将自动填入目标主题名称输入框。4设置Ajax爬行模式。如图5所示,在“页面捕获卓越亚马逊”一文中选择metastudio设置Ajax捕获模式的菜单“配置”-“活动模式”,我们同时设置了“活动模式”和“扩展模式”,这两种模式没有绑定在一起。这个目标网站不会在每次翻页时加载另一个页面,而是在本地修改页面内容,因此我们设置了“扩展模式”,这是没有意义的。我们通常在每一个特定的时间,比如某一天,获取最新的新闻
如果在新闻列表中发现了新新闻,请抓取其URL并创建下一级线索以抓取最新的新闻内容。如果发现新闻列表中的所有新闻都是以前捕获的新闻,请停止翻页和爬网。这需要周期性的自动爬行方法。需要编辑周期爬网调度指令文件。此文件必须命名为crontabxml,并存储在homedatasrapper目录中,以获取目录结构的详细描述,请参阅“捕获当当商品价格”。下面是crontabxml文件的内容。Crontabthreadname“news_list”参数UTRUEOUTOSTART5StartPeriod3600PeriodWaitOnLoadalsWaitonLoadParameterName“renewclue”主题的EMO_cnbeta_uu列表主题的ESTEPSTEPNAME“crawl”主题的EMO_cnbeta_uuu列表EUpdateclueUpdateCLuedDupratio80DupratioPth-1depth-1depthWidthRenewFalseRenewPeriod0PeriodStepThreadName“news_uDetail”参数AutoTrueTAutoStart23StartPeriod1800PeriodidWaitOnLoadFalseWaitOnLoadParameterStepName“crawl”主题emo_uCNbeta_u所有参数的含义在定期提取计划指令文件中解释。抓取主题演示与“仅抓取最新新闻”相关。列表的dupratio参数80表示80,即,如果发现在三个连续页面中捕获的URL地址中有80个之前已捕获,则翻页捕获将终止。当前版本的元导引头只能判断捕获的下一级线索的重复率,而不能判断捕获数据的重复率。请不要直接使用crontabxml,因为它尚未在metaseeker服务器上捕获,但定义的信息结构demo_cnbeta_u详细信息将导致定期获取失败
抓取网页新闻(pythoner来说工程建立,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-16 08:23
最近,使用scratch捕获web页面,这对于Python来说非常方便。详细文件如下:
要使用scratch捕获网页信息,您需要创建一个新项目scratch startproject myproject
项目建立后,将有一个子目录myproject/myproject,其中收录item.py(根据您想要获取的内容的定义)、pipeline.py(用于处理捕获的数据、保存数据库或其他),然后是spider文件夹,您可以在其中编写爬虫脚本
这里,以爬行网站的图书信息为例:
Item.py如下所示:
from scrapy.item import Item, Field
class BookItem(Item):
# define the fields for your item here like:
name = Field()
publisher = Field()
publish_date = Field()
price = Field()
我们想要获取的所有内容都在上面定义,包括名称、出版商、出版日期和价格
现在我们要写的是,爬虫进入互联网战争来捕获信息
spider/book.py如下所示:
from urlparse import urljoin
import simplejson
from scrapy.http import Request
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
from myproject.items import BookItem
class BookSpider(CrawlSpider):
name = 'bookspider'
allowed_domains = ['test.com']
start_urls = [
"http://test_url.com", #这里写开始抓取的页面地址(这里网址是虚构的,实际使用时请替换)
]
rules = (
#下面是符合规则的网址,但是不抓取内容,只是提取该页的链接(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_url/test?page_index=\d+'))),
#下面是符合规则的网址,提取内容,(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_rul/test?product_id=\d+')), callback="parse_item"),
)
def parse_item(self, response):
hxs = HtmlXPathSelector(response)
item = BookItem()
item['name'] = hxs.select('//div[@class="h1_title book_head"]/h1/text()').extract()[0]
item['author'] = hxs.select('//div[@class="book_detailed"]/p[1]/a/text()').extract()
publisher = hxs.select('//div[@class="book_detailed"]/p[2]/a/text()').extract()
item['publisher'] = publisher and publisher[0] or ''
publish_date = hxs.select('//div[@class="book_detailed"]/p[3]/text()').re(u"[\u2e80-\u9fffh]+\uff1a([\d-]+)")
item['publish_date'] = publish_date and publish_date[0] or ''
prices = hxs.select('//p[@class="price_m"]/text()').re("(\d*\.*\d*)")
item['price'] = prices and prices[0] or ''
return item
然后,在捕获信息后,需要保存它。此时需要编写pipelines.py(对于scapy,使用twisted,因此可以看到特定数据库操作的twisted数据,下面简要介绍如何将其保存到数据库中):
from scrapy import log
#from scrapy.core.exceptions import DropItem
from twisted.enterprise import adbapi
from scrapy.http import Request
from scrapy.exceptions import DropItem
from scrapy.contrib.pipeline.images import ImagesPipeline
import time
import MySQLdb
import MySQLdb.cursors
class MySQLStorePipeline(object):
def __init__(self):
self.dbpool = adbapi.ConnectionPool('MySQLdb',
db = 'test',
user = 'user',
passwd = '******',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = False
)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
query.addErrback(self.handle_error)
return item
def _conditional_insert(self, tx, item):
if item.get('name'):
tx.execute(\
"insert into book (name, publisher, publish_date, price ) \
values (%s, %s, %s, %s)",
(item['name'], item['publisher'], item['publish_date'],
item['price'])
)
之后,在setting.py中添加管道:
ITEM_PIPELINES = ['myproject.pipelines.MySQLStorePipeline']
??最后,运行scratch crawl bookspider开始爬行
参考: 查看全部
抓取网页新闻(pythoner来说工程建立,)
最近,使用scratch捕获web页面,这对于Python来说非常方便。详细文件如下:
要使用scratch捕获网页信息,您需要创建一个新项目scratch startproject myproject
项目建立后,将有一个子目录myproject/myproject,其中收录item.py(根据您想要获取的内容的定义)、pipeline.py(用于处理捕获的数据、保存数据库或其他),然后是spider文件夹,您可以在其中编写爬虫脚本
这里,以爬行网站的图书信息为例:
Item.py如下所示:
from scrapy.item import Item, Field
class BookItem(Item):
# define the fields for your item here like:
name = Field()
publisher = Field()
publish_date = Field()
price = Field()
我们想要获取的所有内容都在上面定义,包括名称、出版商、出版日期和价格
现在我们要写的是,爬虫进入互联网战争来捕获信息
spider/book.py如下所示:
from urlparse import urljoin
import simplejson
from scrapy.http import Request
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.selector import HtmlXPathSelector
from myproject.items import BookItem
class BookSpider(CrawlSpider):
name = 'bookspider'
allowed_domains = ['test.com']
start_urls = [
"http://test_url.com", #这里写开始抓取的页面地址(这里网址是虚构的,实际使用时请替换)
]
rules = (
#下面是符合规则的网址,但是不抓取内容,只是提取该页的链接(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_url/test?page_index=\d+'))),
#下面是符合规则的网址,提取内容,(这里网址是虚构的,实际使用时请替换)
Rule(SgmlLinkExtractor(allow=(r'http://test_rul/test?product_id=\d+')), callback="parse_item"),
)
def parse_item(self, response):
hxs = HtmlXPathSelector(response)
item = BookItem()
item['name'] = hxs.select('//div[@class="h1_title book_head"]/h1/text()').extract()[0]
item['author'] = hxs.select('//div[@class="book_detailed"]/p[1]/a/text()').extract()
publisher = hxs.select('//div[@class="book_detailed"]/p[2]/a/text()').extract()
item['publisher'] = publisher and publisher[0] or ''
publish_date = hxs.select('//div[@class="book_detailed"]/p[3]/text()').re(u"[\u2e80-\u9fffh]+\uff1a([\d-]+)")
item['publish_date'] = publish_date and publish_date[0] or ''
prices = hxs.select('//p[@class="price_m"]/text()').re("(\d*\.*\d*)")
item['price'] = prices and prices[0] or ''
return item
然后,在捕获信息后,需要保存它。此时需要编写pipelines.py(对于scapy,使用twisted,因此可以看到特定数据库操作的twisted数据,下面简要介绍如何将其保存到数据库中):
from scrapy import log
#from scrapy.core.exceptions import DropItem
from twisted.enterprise import adbapi
from scrapy.http import Request
from scrapy.exceptions import DropItem
from scrapy.contrib.pipeline.images import ImagesPipeline
import time
import MySQLdb
import MySQLdb.cursors
class MySQLStorePipeline(object):
def __init__(self):
self.dbpool = adbapi.ConnectionPool('MySQLdb',
db = 'test',
user = 'user',
passwd = '******',
cursorclass = MySQLdb.cursors.DictCursor,
charset = 'utf8',
use_unicode = False
)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
query.addErrback(self.handle_error)
return item
def _conditional_insert(self, tx, item):
if item.get('name'):
tx.execute(\
"insert into book (name, publisher, publish_date, price ) \
values (%s, %s, %s, %s)",
(item['name'], item['publisher'], item['publish_date'],
item['price'])
)
之后,在setting.py中添加管道:
ITEM_PIPELINES = ['myproject.pipelines.MySQLStorePipeline']
??最后,运行scratch crawl bookspider开始爬行
参考:
抓取网页新闻(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-16 08:15
你想要的任何信息基本上都存在于互联网上。问题是如何将它们组织到您需要的内容中,例如捕获行业网站中所有相关公司的名称、联系电话、电子邮件等,并将它们保存在Excel中进行分析。Web信息捕获变得越来越有用
通常,对于传统web页面,web服务器直接返回HTML。这样的网页很容易掌握。不管使用什么方法,只要获取HTML页面并进行DOM解析即可。但对于需要生成JavaScript的网页来说,这并不容易。张宇没有找到解决这个问题的好办法。欢迎有javascript网页经验的朋友提供建议
所以今天我们将讨论传统HTML网页的信息捕获。虽然如上所述,没有技术难度,但是否有相对简单的方法?使用jQuery和其他JS框架的朋友可能会觉得JavaScript看起来像是获取网页信息的天然助手,它是为网页解析而生的。当然,现在有更多的应用程序,比如服务器端JavaScript应用程序nodejs
如果我们可以使用jQuery在应用程序(如Java程序)中获取web页面,那绝对是令人兴奋的。有现成的解决方案、JavaScript引擎和支持jQuery的环境
工具:Java、rhino、envjs。Rhino是Mozzila提供的开源JavaScript引擎,envjs是一个模拟的浏览器环境,如window。代码如下
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
Test.js文件,如下所示
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行单元测试时,我们将在控制台上打印从网页捕获的三个百度连接
0:
1:
2:
测试成功,证明了在Java程序中用jQuery抓取网页是可行的
----------------------------------------------------------------------
张宇,我的好漂亮 查看全部
抓取网页新闻(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
你想要的任何信息基本上都存在于互联网上。问题是如何将它们组织到您需要的内容中,例如捕获行业网站中所有相关公司的名称、联系电话、电子邮件等,并将它们保存在Excel中进行分析。Web信息捕获变得越来越有用
通常,对于传统web页面,web服务器直接返回HTML。这样的网页很容易掌握。不管使用什么方法,只要获取HTML页面并进行DOM解析即可。但对于需要生成JavaScript的网页来说,这并不容易。张宇没有找到解决这个问题的好办法。欢迎有javascript网页经验的朋友提供建议
所以今天我们将讨论传统HTML网页的信息捕获。虽然如上所述,没有技术难度,但是否有相对简单的方法?使用jQuery和其他JS框架的朋友可能会觉得JavaScript看起来像是获取网页信息的天然助手,它是为网页解析而生的。当然,现在有更多的应用程序,比如服务器端JavaScript应用程序nodejs
如果我们可以使用jQuery在应用程序(如Java程序)中获取web页面,那绝对是令人兴奋的。有现成的解决方案、JavaScript引擎和支持jQuery的环境
工具:Java、rhino、envjs。Rhino是Mozzila提供的开源JavaScript引擎,envjs是一个模拟的浏览器环境,如window。代码如下
package stony.zhang.scrape; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.lang.reflect.InvocationTargetException; import org.mozilla.javascript.Context; import org.mozilla.javascript.ContextFactory; import org.mozilla.javascript.Scriptable; import org.mozilla.javascript.ScriptableObject; /** * @author MyBeautiful * @Emal: zhangyu0182@sina.com * @date Mar 7, 2012 */ public class RhinoScaper { private String url; private String jsFile; private Context cx; private Scriptable scope; public String getUrl() { return url; } public String getJsFile() { return jsFile; } public void setUrl(String url) { this.url = url; putObject("url", url); } public void setJsFile(String jsFile) { this.jsFile = jsFile; } public void init() { cx = ContextFactory.getGlobal().enterContext(); scope = cx.initStandardObjects(null); cx.setOptimizationLevel(-1); cx.setLanguageVersion(Context.VERSION_1_5); String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" }; for (String f : file) { evaluateJs(f); } try { ScriptableObject.defineClass(scope, ExtendUtil.class); } catch (IllegalAccessException e1) { e1.printStackTrace(); } catch (InstantiationException e1) { e1.printStackTrace(); } catch (InvocationTargetException e1) { e1.printStackTrace(); } ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util"); scope.put("util", scope, util); } protected void evaluateJs(String f) { try { FileReader in = null; in = new FileReader(f); cx.evaluateReader(scope, in, f, 1, null); } catch (FileNotFoundException e1) { e1.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } public void putObject(String name, Object o) { scope.put(name, scope, o); } public void run() { evaluateJs(this.jsFile); } }
测试代码:
Test.js文件,如下所示
$.ajax({ url: "http://www.baidu.com", context: document.body, success: function(data){ // util.log(data); var result =parseHtml(data); var $v= jQuery(result); // util.log(result); $v.find('#u a').each(function(index) { util.log(index + ': ' + $(this).attr("href")); // arr.add($(this).attr("href")); }); } }); function parseHtml(html) { //Create an iFrame object that will be used to render the HTML in order to get the DOM objects //created - this is a far quicker way of achieving the HTML to DOM conversion than trying //to transform the HTML objects one-by-one var oIframe = document.createElement('iframe'); //Hide the iFrame from view oIframe.style.display = 'none'; if (document.body) document.body.appendChild(oIframe); else document.documentElement.appendChild(oIframe); //Open the iFrame DOM object and write in our HTML oIframe.contentDocument.open(); oIframe.contentDocument.write(html); oIframe.contentDocument.close(); //Return the document body object containing the HTML that was just //added to the iFrame as DOM objects var oBody = oIframe.contentDocument.body; //TODO: Remove the iFrame object created to cleanup the DOM return oBody; }
当我们执行单元测试时,我们将在控制台上打印从网页捕获的三个百度连接
0:
1:
2:
测试成功,证明了在Java程序中用jQuery抓取网页是可行的
----------------------------------------------------------------------
张宇,我的好漂亮
抓取网页新闻(学习了几天如何使用scrapy去爬取静态网站(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-16 03:23
几天来,我已经学会了如何通过使用图表对静态网站进行爬网。今天我尝试抓取动态加载的网站。选择的网站是华尔街的知识。这篇文章不会详细解释如何像往常一样完成每一步,而是讨论如何攀登
您无法获取源代码中的所有数据(有些根本没有数据),但您可以看到网址保持不变,但通过下拉滑块加载了数据。毫无疑问,这是一个动态加载的网页。下面介绍如何查找API接口以获取数据
打开developer工具,选择network,refresh,然后选择XHR,如图所示
您可以从一开始就逐个单击以检查响应(响应指的是工作台上的响应,如下图所示)是否是您想要的数据。或者滑动滑动条,查看新请求的名称中是否有类似的请求,通常是
这里我们重点关注区块链数据,如图所示:
然后检查消息头的URL,例如“HTTPS:///apiv1/content/lifes?”?渠道=区块链渠道&;客户机=pc&;光标=1518567654&;极限=20’
所需参数为:
channel=blockchain-channel
client=pc
cursor=1518567654
limit=20
在浏览器中打开URL,并通过待定系数方法删除参数,以查看所需内容
从这个可以猜到
Limit=20应该是可以删除的请求数据数
Client=PC字面意思是PC端
通道=区块链通道,可引用区块链相关数据,不能删除
Cursor=1518567654最初怀疑它位于加载上一页时的页面或附加信息中,但在搜索后未找到。怀疑它可能是一个时间戳。时间模块验证它是否确实是当前时间。它可以被删除,但实验后,发现没有光标,最多可以加载99个数据
这仅适用于区块链的一部分。其他类似于搜索,但在搜索过程中会找到一个API和所有数据。接口:
当浏览器打开时,最好安装一个JSON相关插件以方便查看数据。如图所示
通过阅读,你可以了解全球、区块链、a股。股票、美股、外汇和商品分别分为六个板块:宏观、区块链、a股、美股、外汇和商品
就这样
随附信息的接口API:
看,这就是代码。不要直接粘贴它
'https://api-prod.wallstreetcn. ... ry%3D{}&limit=20&platform=wscn-platform'.format(p) for p in
['global','shares','commodities','china','us','europe','japan','charts','economy']
极限参数可以手动控制。还有游标参数。您可以发现,他返回的数据收录display_uuTime、next_uuu光标,可以结合limit访问下一个时间段的数据。您还可以指定当前时间戳和特定时间戳之间的时间 查看全部
抓取网页新闻(学习了几天如何使用scrapy去爬取静态网站(图))
几天来,我已经学会了如何通过使用图表对静态网站进行爬网。今天我尝试抓取动态加载的网站。选择的网站是华尔街的知识。这篇文章不会详细解释如何像往常一样完成每一步,而是讨论如何攀登
您无法获取源代码中的所有数据(有些根本没有数据),但您可以看到网址保持不变,但通过下拉滑块加载了数据。毫无疑问,这是一个动态加载的网页。下面介绍如何查找API接口以获取数据
打开developer工具,选择network,refresh,然后选择XHR,如图所示
您可以从一开始就逐个单击以检查响应(响应指的是工作台上的响应,如下图所示)是否是您想要的数据。或者滑动滑动条,查看新请求的名称中是否有类似的请求,通常是
这里我们重点关注区块链数据,如图所示:
然后检查消息头的URL,例如“HTTPS:///apiv1/content/lifes?”?渠道=区块链渠道&;客户机=pc&;光标=1518567654&;极限=20’
所需参数为:
channel=blockchain-channel
client=pc
cursor=1518567654
limit=20
在浏览器中打开URL,并通过待定系数方法删除参数,以查看所需内容
从这个可以猜到
Limit=20应该是可以删除的请求数据数
Client=PC字面意思是PC端
通道=区块链通道,可引用区块链相关数据,不能删除
Cursor=1518567654最初怀疑它位于加载上一页时的页面或附加信息中,但在搜索后未找到。怀疑它可能是一个时间戳。时间模块验证它是否确实是当前时间。它可以被删除,但实验后,发现没有光标,最多可以加载99个数据
这仅适用于区块链的一部分。其他类似于搜索,但在搜索过程中会找到一个API和所有数据。接口:
当浏览器打开时,最好安装一个JSON相关插件以方便查看数据。如图所示
通过阅读,你可以了解全球、区块链、a股。股票、美股、外汇和商品分别分为六个板块:宏观、区块链、a股、美股、外汇和商品
就这样
随附信息的接口API:
看,这就是代码。不要直接粘贴它
'https://api-prod.wallstreetcn. ... ry%3D{}&limit=20&platform=wscn-platform'.format(p) for p in
['global','shares','commodities','china','us','europe','japan','charts','economy']
极限参数可以手动控制。还有游标参数。您可以发现,他返回的数据收录display_uuTime、next_uuu光标,可以结合limit访问下一个时间段的数据。您还可以指定当前时间戳和特定时间戳之间的时间

