
抓取网页新闻
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-16 03:17
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及其栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询: 查看全部
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及其栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询:
抓取网页新闻(农业信息网的小小的规律总结:1.什么是爬虫? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-16 03:12
)
由于项目需要,我们需要用到爬虫。我自己摸索了一下,总结了一些小规则。现在我总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/");
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网抓取最新的农业新闻
查看全部
抓取网页新闻(农业信息网的小小的规律总结:1.什么是爬虫?
)
由于项目需要,我们需要用到爬虫。我自己摸索了一下,总结了一些小规则。现在我总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/";);
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网抓取最新的农业新闻

抓取网页新闻(关于php和python语言本身的抓取网页新闻内容的是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-14 16:02
抓取网页新闻内容的是php语言,数据存储是http协议,你可以用后端的wordpress服务器实现数据抓取等。关于php和python语言本身,两者在工作上非常接近,学习python主要是学习php的库,后端php有laravel等等,python有numpy、scipy、pandas等等。python也有比较完善的web框架,比如swoole等等,实际应用中并不会一一用web框架去做,而是通过解析http协议等操作完成,比如阅读、拉新、促活等,最终还是php完成。
1.js3.3版本新加入网络请求钩子,功能比较全面。另外还有抓包,比较重要,能有效进行拦截爬取。2.把下面的代码拷贝到命令行内#爬取首页page=request.get("/")#跟原生的request不同,这里涉及爬取源代码,page中的网页地址,设置offset属性。response=page.get("")foriinresponse:#默认的行为是post请求,那么我们可以改成post,这里代码可以写两句,第一句抓取page.get(""),page.get(""),第二句直接构造post请求,不同行为不同的instr()函数,action是链接。
trace()是抓取方向标识,改成context是请求头部分。data=response.dataattrs=attrs['content-type']request=urllib.request(url,headers=headers,user-agent='mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/72.0.3312.87safari/537.36')html=request.urlopen(request.read(),timeout=10)re=request.read()i=len(request.request)j=i+1result=response.dataprint(result)done抓取网页的时候注意要后台分析抓取,避免fullpage。
对于非全页的需要后端做解析才能抓取。3.到网页最底下的action里抓取能抓取到原网页的地址,action里面抓取到trace中定义的网页,action是请求头部分。然后需要在中间转发中做处理,如果action是http请求,那么通过url拼接到trace里面,假设抓取http请求为.get("")抓取方向建议请求不要从用户空间顶部开始请求,先从最底部开始如果不是从用户空间顶部开始请求,要么是强制转发,要么是自己根据情况转发,建议一般不要用fullpage。 查看全部
抓取网页新闻(关于php和python语言本身的抓取网页新闻内容的是什么)
抓取网页新闻内容的是php语言,数据存储是http协议,你可以用后端的wordpress服务器实现数据抓取等。关于php和python语言本身,两者在工作上非常接近,学习python主要是学习php的库,后端php有laravel等等,python有numpy、scipy、pandas等等。python也有比较完善的web框架,比如swoole等等,实际应用中并不会一一用web框架去做,而是通过解析http协议等操作完成,比如阅读、拉新、促活等,最终还是php完成。
1.js3.3版本新加入网络请求钩子,功能比较全面。另外还有抓包,比较重要,能有效进行拦截爬取。2.把下面的代码拷贝到命令行内#爬取首页page=request.get("/")#跟原生的request不同,这里涉及爬取源代码,page中的网页地址,设置offset属性。response=page.get("")foriinresponse:#默认的行为是post请求,那么我们可以改成post,这里代码可以写两句,第一句抓取page.get(""),page.get(""),第二句直接构造post请求,不同行为不同的instr()函数,action是链接。
trace()是抓取方向标识,改成context是请求头部分。data=response.dataattrs=attrs['content-type']request=urllib.request(url,headers=headers,user-agent='mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/72.0.3312.87safari/537.36')html=request.urlopen(request.read(),timeout=10)re=request.read()i=len(request.request)j=i+1result=response.dataprint(result)done抓取网页的时候注意要后台分析抓取,避免fullpage。
对于非全页的需要后端做解析才能抓取。3.到网页最底下的action里抓取能抓取到原网页的地址,action里面抓取到trace中定义的网页,action是请求头部分。然后需要在中间转发中做处理,如果action是http请求,那么通过url拼接到trace里面,假设抓取http请求为.get("")抓取方向建议请求不要从用户空间顶部开始请求,先从最底部开始如果不是从用户空间顶部开始请求,要么是强制转发,要么是自己根据情况转发,建议一般不要用fullpage。
抓取网页新闻(Python正则抓取网易新闻的方法结合实例形式较为详细的分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-13 10:14
)
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/da ... 39%3B
def getpage(self,page):
full_url='http://comment.news.163.com/ca ... 2Bstr(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(Python正则抓取网易新闻的方法结合实例形式较为详细的分析
)
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的

然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/da ... 39%3B
def getpage(self,page):
full_url='http://comment.news.163.com/ca ... 2Bstr(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-12 22:08
)
小弟还有一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。碰巧牛客这周从一个html中找到了文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间和内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
bs4需要自己安装,安装方法可以参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。
查看全部
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考!
)
小弟还有一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。碰巧牛客这周从一个html中找到了文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间和内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
bs4需要自己安装,安装方法可以参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。


抓取网页新闻( 测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-05 21:07
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:在线提取一般新闻网页文本
摄影:产品经理
毛脑花和广大粉丝
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先用pip安装,再写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE和测试GNE,我开发了网络版GNE-Gne Online。
打开Gne Online的地址是:,打开后的页面如下图。
测试GNE的功能,只需将网页源代码粘贴到顶部文本框中,点击提取按钮即可:
对于标题、作者、新闻发布时间等可能被误送提取的信息,我们可以通过下面对应的标题XPath、作者、发布时间XPath输入XPath进行定向提取。例如,对于今日头条中的文章:
新闻作者提取错误,此时可以指定XPath://div[@class="article-sub"]/span[1]/text()定向提取,如如下图所示。
通过设置Host输入框,可以拼出网页body中图片为相对路径时的URL。
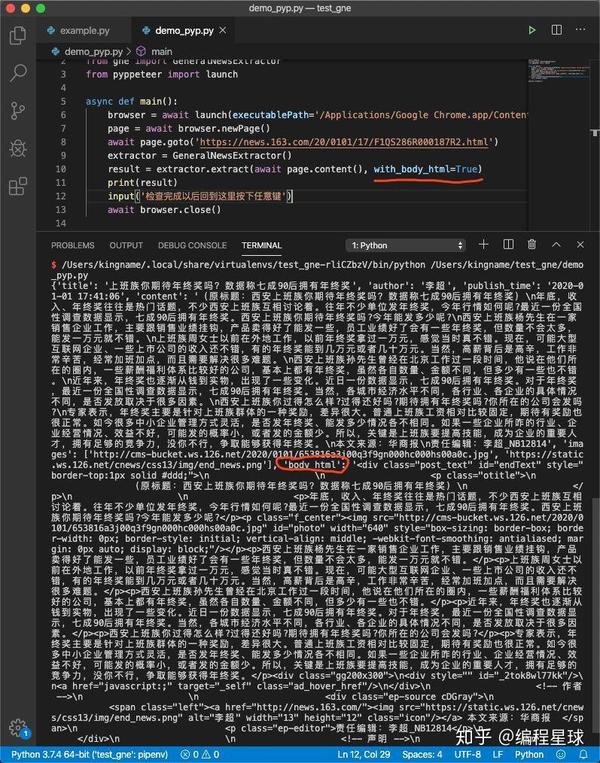
通过勾选下面的With Body Html复选框,您可以返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考资料
[1]
GNE:
[2]
官方文档:
王名
存钱给产品经理买房子。 查看全部
抓取网页新闻(
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:在线提取一般新闻网页文本

摄影:产品经理
毛脑花和广大粉丝
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先用pip安装,再写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE和测试GNE,我开发了网络版GNE-Gne Online。
打开Gne Online的地址是:,打开后的页面如下图。

测试GNE的功能,只需将网页源代码粘贴到顶部文本框中,点击提取按钮即可:

对于标题、作者、新闻发布时间等可能被误送提取的信息,我们可以通过下面对应的标题XPath、作者、发布时间XPath输入XPath进行定向提取。例如,对于今日头条中的文章:

新闻作者提取错误,此时可以指定XPath://div[@class="article-sub"]/span[1]/text()定向提取,如如下图所示。

通过设置Host输入框,可以拼出网页body中图片为相对路径时的URL。
通过勾选下面的With Body Html复选框,您可以返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考资料
[1]
GNE:
[2]
官方文档:

王名
存钱给产品经理买房子。
抓取网页新闻(GNE(GeneralNewsExtractor)方法增加host参数,用于提取新闻标题参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-03 08:24
GNE(GeneralNewsExtractor)是一个通用新闻网站文本提取模块。它输入一个新闻网页的HTML,输出文本内容、标题、作者、发布时间、文本中的图片地址和文本所在标签的源代码。GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。.
用法很简单:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '网站源代码'
result = extractor.extract(html)
print(result)
GNE的输入是js渲染的HTML代码,所以GNE可以和Selenium或者Pyppeteer一起使用。
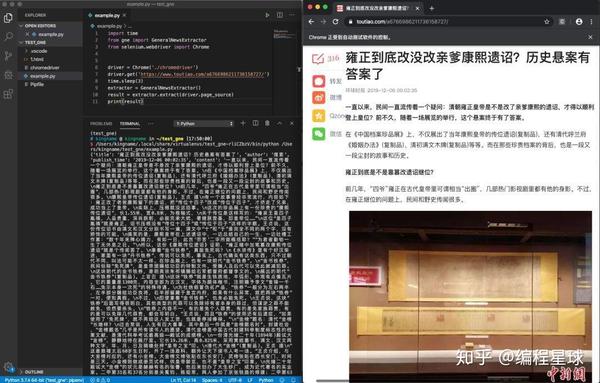
下图是GNE用Selenium实现的Demo:
对应的代码是:
import time
from gne import GeneralNewsExtractor
from selenium.webdriver import Chrome
driver = Chrome('./chromedriver')
driver.get('https://www.toutiao.com/a67669 ... %2339;)
time.sleep(3)
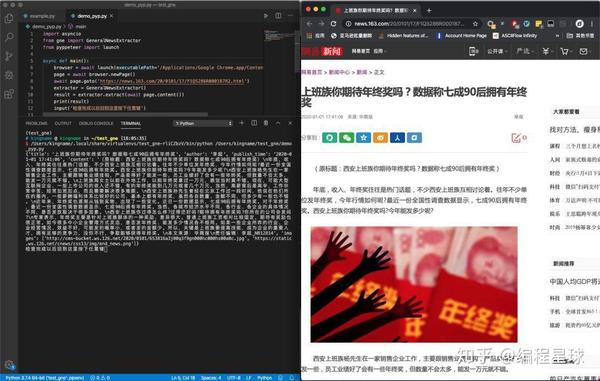
extractor = GeneralNewsExtractor()
result = extractor.extract(driver.page_source)
print(result)
下图是GNE用Pyppeteer实现的Demo:
对应的代码如下:
import asyncio
from gne import GeneralNewsExtractor
from pyppeteer import launch
async def main():
browser = await launch(executablePath='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')
page = await browser.newPage()
await page.goto('https://news.163.com/20/0101/1 ... %2339;)
extractor = GeneralNewsExtractor()
result = extractor.extract(await page.content())
print(result)
input('检查完成以后回到这里按下任意键')
asyncio.run(main())
如何安装 GNE
现在你可以直接使用 pip 安装 GNE:
pip install gne
如果访问pypi官方源码太慢,也可以使用网易源码:
pip install gne -i https://mirrors.163.com/pypi/simple/
安装过程如下图所示:
获取文本源代码的功能特性
当extract()方法只传入网页源代码,不添加任何额外参数时,GNE返回如下字段:
可能有的朋友想要获取新闻正文所在标签的源码。这时候可以在extract()方法中传入with_body_html参数并设置为True:
extractor = GeneralNewsExtractor()
extractor.extract(html, with_body_html=True)
返回的数据中会增加一个字段body_html,其值为body对应的HTML源代码。
运行效果如下图所示:
始终返回图片的绝对路径
默认情况下,如果新闻中的图片使用相对路径,则GNE返回的images字段对应的值也是图片的相对路径列表。
如果要始终让 GNE 返回绝对路径,可以在 extract() 方法中添加主机参数。该参数的值为图片的域名,例如:
extractor = GeneralNewsExtractor()
extractor.extract(html, host='https://www.kingname.info')
这样,如果新闻中的图片是/images/pic.png,那么GNE返回的时候会自动改成。
指定新闻标题所在的XPath
GNE 预定义了一组用于提取新闻标题的 XPath 和正则表达式。但是,一些特殊的新闻网站可能无法提取标题。这时候可以给extract()方法指定title_xpath参数来提取新闻标题:
extractor = GeneralNewsExtractor()
extractor.extract(html, title_xpath='//title/text()')
提前去除噪音标签
某些新闻下可能会有长篇评论。这些评论看起来“更像是”新闻的主体。为了防止它们干扰新闻的提取,可以在extract()方法中传入noise_node_list参数,提前移动这些噪声节点。消除。noise_node_list 的值是一个收录一个或多个 XPath 的列表:
extractor = GeneralNewsExtractor()
extractor.extract(html, noise_node_list=['//div[@class="comment-list"]', '//*[@style="display:none"]'])
使用配置文件
API中的title_xpath、host、noise_node_list、with_body_html参数可以直接写到extract()方法中,也可以通过配置文件进行设置。
请在项目的根目录下创建一个文件 .gne。配置文件可以是 YAML 格式或 JSON 格式。
title:
xpath: //title/text()
host: https://www.xxx.com
noise_node_list:
- //div[@class=\"comment-list\"]
- //*[@style=\"display:none\"]
with_body_html: true
{
"title": {
"xpath": "//title/text()"
},
"host": "https://www.xxx.com",
"noise_node_list": ["//div[@class=\"comment-list\"]",
"//*[@style=\"display:none\"]"],
"with_body_html": true
}
这两种写法是完全等价的。
配置文件与extract()方法参数相同,不需要提供所有字段。您可以组合填写您需要的字段。
如果一个参数在extract()方法和.gne配置文件中都存在,但是值不同,那么这个参数在extract()方法中的优先级更高。
FAQGeneralNewsExtractor(以下简称GNE)是爬虫吗?
GNE 不是爬虫,它的项目名称 General News Extractor 代表 General News Extractor。它的输入是 HTML,它的输出是一个收录新闻标题、新闻正文、作者和发布时间的字典。您需要尝试自己获取目标页面的HTML。
GNE 不会,以后也不会提供请求网页的功能。
GNE 是否支持翻页?
GNE 不支持翻页。因为GNE没有提供网页请求的功能,所以需要自己获取每个页面的HTML,单独传给GNE。
GNE 支持哪些版本的 Python?
不低于 Python 3.6.0
我用requests/Scrapy得到的HTML传入GNE,为什么提取不出文本?
GNE 基于 HTML 提取文本,因此传入的 HTML 必须是 JavaScript 呈现的 HTML。requests 和 Scrapy 只获取 JavaScript 渲染前的源码,无法正确提取。
此外,还有一些网页,比如今日头条,其新闻文本实际上是直接以JSON格式写入网页源代码中的。在浏览器上打开页面时,JavaScript 会将源代码中的文本解析为 HTML。在这种情况下,您将不会在 Chrome 上看到 Ajax 请求。
所以建议大家使用Puppeteer/Pyppeteer/Selenium等工具获取渲染后的HTML,然后传递给GNE。
GNE是否支持非新闻网站(如博客、论坛...)
不支持。
成长离不开与优秀合作伙伴的学习。如果您需要良好的学习环境、良好的学习资源、项目教程、零基础学习,欢迎热爱Python的各位来这里,点击:Python学习圈 查看全部
抓取网页新闻(GNE(GeneralNewsExtractor)方法增加host参数,用于提取新闻标题参数)
GNE(GeneralNewsExtractor)是一个通用新闻网站文本提取模块。它输入一个新闻网页的HTML,输出文本内容、标题、作者、发布时间、文本中的图片地址和文本所在标签的源代码。GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。.
用法很简单:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '网站源代码'
result = extractor.extract(html)
print(result)
GNE的输入是js渲染的HTML代码,所以GNE可以和Selenium或者Pyppeteer一起使用。
下图是GNE用Selenium实现的Demo:
对应的代码是:
import time
from gne import GeneralNewsExtractor
from selenium.webdriver import Chrome
driver = Chrome('./chromedriver')
driver.get('https://www.toutiao.com/a67669 ... %2339;)
time.sleep(3)
extractor = GeneralNewsExtractor()
result = extractor.extract(driver.page_source)
print(result)
下图是GNE用Pyppeteer实现的Demo:
对应的代码如下:
import asyncio
from gne import GeneralNewsExtractor
from pyppeteer import launch
async def main():
browser = await launch(executablePath='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')
page = await browser.newPage()
await page.goto('https://news.163.com/20/0101/1 ... %2339;)
extractor = GeneralNewsExtractor()
result = extractor.extract(await page.content())
print(result)
input('检查完成以后回到这里按下任意键')
asyncio.run(main())
如何安装 GNE
现在你可以直接使用 pip 安装 GNE:
pip install gne
如果访问pypi官方源码太慢,也可以使用网易源码:
pip install gne -i https://mirrors.163.com/pypi/simple/
安装过程如下图所示:
获取文本源代码的功能特性
当extract()方法只传入网页源代码,不添加任何额外参数时,GNE返回如下字段:
可能有的朋友想要获取新闻正文所在标签的源码。这时候可以在extract()方法中传入with_body_html参数并设置为True:
extractor = GeneralNewsExtractor()
extractor.extract(html, with_body_html=True)
返回的数据中会增加一个字段body_html,其值为body对应的HTML源代码。
运行效果如下图所示:
始终返回图片的绝对路径
默认情况下,如果新闻中的图片使用相对路径,则GNE返回的images字段对应的值也是图片的相对路径列表。
如果要始终让 GNE 返回绝对路径,可以在 extract() 方法中添加主机参数。该参数的值为图片的域名,例如:
extractor = GeneralNewsExtractor()
extractor.extract(html, host='https://www.kingname.info')
这样,如果新闻中的图片是/images/pic.png,那么GNE返回的时候会自动改成。
指定新闻标题所在的XPath
GNE 预定义了一组用于提取新闻标题的 XPath 和正则表达式。但是,一些特殊的新闻网站可能无法提取标题。这时候可以给extract()方法指定title_xpath参数来提取新闻标题:
extractor = GeneralNewsExtractor()
extractor.extract(html, title_xpath='//title/text()')
提前去除噪音标签
某些新闻下可能会有长篇评论。这些评论看起来“更像是”新闻的主体。为了防止它们干扰新闻的提取,可以在extract()方法中传入noise_node_list参数,提前移动这些噪声节点。消除。noise_node_list 的值是一个收录一个或多个 XPath 的列表:
extractor = GeneralNewsExtractor()
extractor.extract(html, noise_node_list=['//div[@class="comment-list"]', '//*[@style="display:none"]'])
使用配置文件
API中的title_xpath、host、noise_node_list、with_body_html参数可以直接写到extract()方法中,也可以通过配置文件进行设置。
请在项目的根目录下创建一个文件 .gne。配置文件可以是 YAML 格式或 JSON 格式。
title:
xpath: //title/text()
host: https://www.xxx.com
noise_node_list:
- //div[@class=\"comment-list\"]
- //*[@style=\"display:none\"]
with_body_html: true
{
"title": {
"xpath": "//title/text()"
},
"host": "https://www.xxx.com",
"noise_node_list": ["//div[@class=\"comment-list\"]",
"//*[@style=\"display:none\"]"],
"with_body_html": true
}
这两种写法是完全等价的。
配置文件与extract()方法参数相同,不需要提供所有字段。您可以组合填写您需要的字段。
如果一个参数在extract()方法和.gne配置文件中都存在,但是值不同,那么这个参数在extract()方法中的优先级更高。
FAQGeneralNewsExtractor(以下简称GNE)是爬虫吗?
GNE 不是爬虫,它的项目名称 General News Extractor 代表 General News Extractor。它的输入是 HTML,它的输出是一个收录新闻标题、新闻正文、作者和发布时间的字典。您需要尝试自己获取目标页面的HTML。
GNE 不会,以后也不会提供请求网页的功能。
GNE 是否支持翻页?
GNE 不支持翻页。因为GNE没有提供网页请求的功能,所以需要自己获取每个页面的HTML,单独传给GNE。
GNE 支持哪些版本的 Python?
不低于 Python 3.6.0
我用requests/Scrapy得到的HTML传入GNE,为什么提取不出文本?
GNE 基于 HTML 提取文本,因此传入的 HTML 必须是 JavaScript 呈现的 HTML。requests 和 Scrapy 只获取 JavaScript 渲染前的源码,无法正确提取。
此外,还有一些网页,比如今日头条,其新闻文本实际上是直接以JSON格式写入网页源代码中的。在浏览器上打开页面时,JavaScript 会将源代码中的文本解析为 HTML。在这种情况下,您将不会在 Chrome 上看到 Ajax 请求。
所以建议大家使用Puppeteer/Pyppeteer/Selenium等工具获取渲染后的HTML,然后传递给GNE。
GNE是否支持非新闻网站(如博客、论坛...)
不支持。
成长离不开与优秀合作伙伴的学习。如果您需要良好的学习环境、良好的学习资源、项目教程、零基础学习,欢迎热爱Python的各位来这里,点击:Python学习圈
抓取网页新闻(《js文件》服务器爬js参数替换文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-03 05:02
抓取网页新闻的时候,除了可以爬js文件,我们还可以在js文件里面获取自己想要的信息,一般来说我们的方法是通过解析js文件,再解析加载,并把所有的页面节点相加。注意这个js文件在服务器上应该是multipart/form-data格式文件,关于服务器的要求可以在这里查询。首先我们要读取文件里面的cookie,但我们还需要获取到用户的隐私信息,这样才能生成用户的历史数据,我们要把所有的数据通过一个get请求发送到对应服务器,以了解用户是否存在登录,我们一般会有get或post请求设置参数,比如根据设置可以参考这个命令:post/get:params/cookiesettings这里有人问,post请求会不会被拒绝或封闭?大可不必担心,如果登录的话,就没有登录的数据,你可以完全不发送post请求,这样用户打开浏览器,有你服务器的用户名和密码,也能登录成功。
但如果登录失败,那你发送的post请求会被接收到,存在你服务器了,也只能等你将你的用户名和密码传回来才能登录,所以不必担心。通过解析设置参数,设置好之后,代码中就会有post后面的这几个参数,如accept-language、content-type、content-length、accept-encoding、accept-language-transparency、host等,这些参数可能会在get的请求参数中显示不全,我们可以做一些替换,具体替换可以参照google的tagparameter文件,有很多替换方法,这里没有做展示。
简单替换就是把post参数的前三个参数替换成accept-encoding,然后再用get去请求,这样就可以显示所有的get请求了。替换完一个get请求之后就可以执行我们设置的参数了,这里使用javascript中的token属性,如下的get:text/javascript:alert(‘请求请求成功’)token属性格式为‘'{prototype:this,signature:''}’,这个就是你js文件加载的标识了,但是这个cookie的prototype里面的值不能是http协议,比如要替换成‘http'’。
这样发送到服务器就等于做一个get请求,那我们就可以看看cookie里面的值。首先我们这个post请求中的post-user-agent就是该用户的useragent,有些地方我们也可以把useragent作为http协议属性。我们通过js设置默认值为‘mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari/537.36’,如下,这样cookie里面的值就是mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari。 查看全部
抓取网页新闻(《js文件》服务器爬js参数替换文件)
抓取网页新闻的时候,除了可以爬js文件,我们还可以在js文件里面获取自己想要的信息,一般来说我们的方法是通过解析js文件,再解析加载,并把所有的页面节点相加。注意这个js文件在服务器上应该是multipart/form-data格式文件,关于服务器的要求可以在这里查询。首先我们要读取文件里面的cookie,但我们还需要获取到用户的隐私信息,这样才能生成用户的历史数据,我们要把所有的数据通过一个get请求发送到对应服务器,以了解用户是否存在登录,我们一般会有get或post请求设置参数,比如根据设置可以参考这个命令:post/get:params/cookiesettings这里有人问,post请求会不会被拒绝或封闭?大可不必担心,如果登录的话,就没有登录的数据,你可以完全不发送post请求,这样用户打开浏览器,有你服务器的用户名和密码,也能登录成功。
但如果登录失败,那你发送的post请求会被接收到,存在你服务器了,也只能等你将你的用户名和密码传回来才能登录,所以不必担心。通过解析设置参数,设置好之后,代码中就会有post后面的这几个参数,如accept-language、content-type、content-length、accept-encoding、accept-language-transparency、host等,这些参数可能会在get的请求参数中显示不全,我们可以做一些替换,具体替换可以参照google的tagparameter文件,有很多替换方法,这里没有做展示。
简单替换就是把post参数的前三个参数替换成accept-encoding,然后再用get去请求,这样就可以显示所有的get请求了。替换完一个get请求之后就可以执行我们设置的参数了,这里使用javascript中的token属性,如下的get:text/javascript:alert(‘请求请求成功’)token属性格式为‘'{prototype:this,signature:''}’,这个就是你js文件加载的标识了,但是这个cookie的prototype里面的值不能是http协议,比如要替换成‘http'’。
这样发送到服务器就等于做一个get请求,那我们就可以看看cookie里面的值。首先我们这个post请求中的post-user-agent就是该用户的useragent,有些地方我们也可以把useragent作为http协议属性。我们通过js设置默认值为‘mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari/537.36’,如下,这样cookie里面的值就是mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari。
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-02 02:05
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下拉,发现右侧出现:“... special/00804KVA/cm_guonei_03.js? ...”等地址,点击Response发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
(*).js
上面的链接是我们这次抓取请求的地址。
接下来只需要两个python库:
1.请求
2.json
3.美汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
然后我们定义一个方法来获取指定页码中的数据:
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图中圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
下面采集这三个内容的代码:
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣的可以关注下文章。 查看全部
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下拉,发现右侧出现:“... special/00804KVA/cm_guonei_03.js? ...”等地址,点击Response发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
(*).js
上面的链接是我们这次抓取请求的地址。
接下来只需要两个python库:
1.请求
2.json
3.美汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:

然后我们定义一个方法来获取指定页码中的数据:
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图中圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
下面采集这三个内容的代码:
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣的可以关注下文章。
抓取网页新闻(3dd's一条一下效果图效果图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-02 02:03
)
第一次写的小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本html
直接上代码python
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取须要的内容而且放入文件中
#抓取的内容有时间,内容文本,以及内容的连接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面的部分新闻网页。
然后抓取新闻时间和超链接网址
然后按照新闻的顺序进行整合,放入一个文本文件存放在spa中
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)3d
查看全部
抓取网页新闻(3dd's一条一下效果图效果图
)
第一次写的小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本html
直接上代码python
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取须要的内容而且放入文件中
#抓取的内容有时间,内容文本,以及内容的连接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面的部分新闻网页。
然后抓取新闻时间和超链接网址
然后按照新闻的顺序进行整合,放入一个文本文件存放在spa中
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)3d

抓取网页新闻( 刮网线在哪里?growthhack探讨一下网页抓取方法之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-01 23:11
刮网线在哪里?growthhack探讨一下网页抓取方法之前)
早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页,甚至只是复制重要数据,您仍然会获得可能可用也可能不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上例)不给主机服务造成负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
尽管我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢? 查看全部
抓取网页新闻(
刮网线在哪里?growthhack探讨一下网页抓取方法之前)

早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页,甚至只是复制重要数据,您仍然会获得可能可用也可能不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上例)不给主机服务造成负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
尽管我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢?
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-01 23:04
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=http://www.cppcns.com/jiaoben/python/data.replace('var replyData='http://www.cppcns.com/jiaoben/python/,'')
else:
data=http://www.cppcns.com/jiaoben/python/data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=http://www.cppcns.com/jiaoben/python/reg1.sub(' ',data)
reg2=re.compile('\]')
data=http://www.cppcns.com/jiaoben/python/reg2.sub('',data)
reg3=re.compile('
')
data=http://www.cppcns.com/jiaoben/python/reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=http://www.cppcns.com/jiaoben/python/self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = http://www.cppcns.com/jiaoben/python/self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的

然后打开链接,找到相关的评论内容。(下图为第一页内容)

接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=http://www.cppcns.com/jiaoben/python/data.replace('var replyData='http://www.cppcns.com/jiaoben/python/,'')
else:
data=http://www.cppcns.com/jiaoben/python/data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=http://www.cppcns.com/jiaoben/python/reg1.sub(' ',data)
reg2=re.compile('\]')
data=http://www.cppcns.com/jiaoben/python/reg2.sub('',data)
reg3=re.compile('
')
data=http://www.cppcns.com/jiaoben/python/reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=http://www.cppcns.com/jiaoben/python/self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = http://www.cppcns.com/jiaoben/python/self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻( 什么是百度蜘蛛?如何使用网络漫游蜘蛛遵循的规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-01 23:04
什么是百度蜘蛛?如何使用网络漫游蜘蛛遵循的规则)
大连seo谈如何吸引百度蜘蛛爬取网站
什么是百度蜘蛛?
百度蜘蛛实际上是一个自动递归遍历和检索文件网站的内容和信息的程序。百度蜘蛛也常被称为搜索引擎蜘蛛。这些蜘蛛访问 网站 并按照链接向搜索引擎数据库添加更多信息。
搜索引擎蜘蛛遵循的规则
尽管编写机器人程序并忽略规则是可能的,但大多数网络机器人程序编写代码是为了遵守 网站 上特定文本文件中的某些规则。此文件的 robots.txt 文件。它通常位于 Web 服务器的根目录,充当机器人网关。它告诉他们的网站,他们可以等待字段,不能遍历。
请记住,虽然大多数网络机器人都遵守规则,但您在 robots.txt 文件中撒谎,而有些则没有。如果您有敏感信息,您应该在内网上使用密码或控件而不是蜘蛛。它不依赖于机器人来访问它。
如何使用网络漫游
百度蜘蛛最常见的用途是搜索引擎的网站索引。但是机器人可以使用,也可以用于其他目的。一些更常见的用途是:
链接验证——机器人可以跟踪网页上的一个 网站 或所有链接,它们将进行测试以确保它们返回有效的页面代码。这种编程的好处在本质上是显而易见的。机器人可以在一两分钟内访问页面上的所有链接,并比手动操作更快地提供结果报告。
HTML 验证 – 类似于链接验证,机器人可以发送到您的 网站 上的各个页面来评估 HTML 代码。
更改监控 - 是 Web 上的一项服务,它会在网页发生更改时通知您。这些服务由机器人发送到页面,以定期评估内容的变化。不同之处在于机器人何时会提交报告。
网站Mirroring – 类似的变更监控机器人。这些机器人评估一个 网站 并且不时改变。机器人将更改后的信息传送到镜像站点位置。
大连网站优化: 查看全部
抓取网页新闻(
什么是百度蜘蛛?如何使用网络漫游蜘蛛遵循的规则)
大连seo谈如何吸引百度蜘蛛爬取网站
什么是百度蜘蛛?
百度蜘蛛实际上是一个自动递归遍历和检索文件网站的内容和信息的程序。百度蜘蛛也常被称为搜索引擎蜘蛛。这些蜘蛛访问 网站 并按照链接向搜索引擎数据库添加更多信息。
搜索引擎蜘蛛遵循的规则
尽管编写机器人程序并忽略规则是可能的,但大多数网络机器人程序编写代码是为了遵守 网站 上特定文本文件中的某些规则。此文件的 robots.txt 文件。它通常位于 Web 服务器的根目录,充当机器人网关。它告诉他们的网站,他们可以等待字段,不能遍历。
请记住,虽然大多数网络机器人都遵守规则,但您在 robots.txt 文件中撒谎,而有些则没有。如果您有敏感信息,您应该在内网上使用密码或控件而不是蜘蛛。它不依赖于机器人来访问它。
如何使用网络漫游
百度蜘蛛最常见的用途是搜索引擎的网站索引。但是机器人可以使用,也可以用于其他目的。一些更常见的用途是:
链接验证——机器人可以跟踪网页上的一个 网站 或所有链接,它们将进行测试以确保它们返回有效的页面代码。这种编程的好处在本质上是显而易见的。机器人可以在一两分钟内访问页面上的所有链接,并比手动操作更快地提供结果报告。
HTML 验证 – 类似于链接验证,机器人可以发送到您的 网站 上的各个页面来评估 HTML 代码。
更改监控 - 是 Web 上的一项服务,它会在网页发生更改时通知您。这些服务由机器人发送到页面,以定期评估内容的变化。不同之处在于机器人何时会提交报告。
网站Mirroring – 类似的变更监控机器人。这些机器人评估一个 网站 并且不时改变。机器人将更改后的信息传送到镜像站点位置。
大连网站优化:
抓取网页新闻(本站最新发布Python从入门到精通|Python基础教程试听地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-01 08:09
)
本站Python最新版本从入门到精通| Python基础教程
试听地址
学习了python的基本语法后,对爬虫产生了浓厚的兴趣。废话不多。今天来爬取网易新闻,实战学习。
打开网易新闻,可以发现新闻分为这几个板块:
这次选择国内扇区进行爬取文章。
1. 准备
下载链接
了解网络
网页色彩鲜艳,漂亮,像一幅水彩画。要抓取数据,首先要知道需要抓取的数据是如何呈现的,就像学习画画一样。在你开始之前,你需要知道这幅画是用什么画的,铅笔还是水彩笔……它可能是各种类型的。是的,但是只有两种方式可以在网页上显示信息:
HTML是一种用于描述网页的语言
JSON 是一种轻量级的数据交换格式
爬取网页信息其实就是向网页发出请求,服务器将数据反馈给你
2. 获取动态加载源码
导入所需的模块和库:
1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送一个请求。请求可以帮助我们很好地完成这一点。但是经过仔细观察,我们发现网易新闻是动态加载的。请求返回即时信息。稍后加载到网页上的数据不会返回。在这种情况下,Selenium 可以帮助我们获取更多数据。我们将 selenium 理解为一种自动化测试工具。Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
我使用的浏览器是火狐
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样我们就可以驱动浏览器自动登录网易新闻页面
我们的目标自然是一次爬下国内部分,观察网页。当网页不断向下滚动时,将加载新的新闻。在底部,甚至还有一个刷新按钮:
这时候使用selenium就可以显示出它的优势了:自动化,模拟鼠标键盘操作:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右击网页中的Load More按钮,点击View Element,可以看到
通过这个类,可以定位按钮。当遇到按钮时,点击事件可以帮助我们自动点击按钮完成网页刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用信息
简单来说,BeautifulSoup 是一个 Python 库。它的主要功能是从网页中抓取数据,可以减轻新手的负担。通过BeautifulSoup解析网页源代码,并添加附带的函数,我们可以方便的检索到我们想要的信息,例如:获取标题、标签和文本内容超链接
也可以右键点击文章标题区查看元素:
观察网页的结构,发现每个div标签class="news_title"下面是文章的标题和超链接。soup.find_all() 函数可以帮助我们找到我们想要的所有信息,并且可以一次性提取出该级别结构下的内容。最后通过字典,将标签信息一一检索出来。
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4. 获取新闻内容
此后,新闻链接被我们取出并存入列表。现在我们需要做的就是使用链接来获取新闻主题内容。新闻主题内容页面静态加载,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
使用try except的原因是网易新闻文章在一定时间前后,文本信息的位置和标签不同,不同的情况要区别对待。
最后遍历整个列表以检索所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地txt文件
Python提供了一个文件处理函数open(),第一个参数是文件路径,第二个是文件处理方式,“w”方式是只写的(如果文件不存在则创建,如果文件不存在则清空内容)它存在)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
一个简单的爬虫到目前为止已经成功写好了:
查看全部
抓取网页新闻(本站最新发布Python从入门到精通|Python基础教程试听地址
)
本站Python最新版本从入门到精通| Python基础教程
试听地址
学习了python的基本语法后,对爬虫产生了浓厚的兴趣。废话不多。今天来爬取网易新闻,实战学习。
打开网易新闻,可以发现新闻分为这几个板块:

这次选择国内扇区进行爬取文章。
1. 准备
下载链接
了解网络
网页色彩鲜艳,漂亮,像一幅水彩画。要抓取数据,首先要知道需要抓取的数据是如何呈现的,就像学习画画一样。在你开始之前,你需要知道这幅画是用什么画的,铅笔还是水彩笔……它可能是各种类型的。是的,但是只有两种方式可以在网页上显示信息:
HTML是一种用于描述网页的语言
JSON 是一种轻量级的数据交换格式
爬取网页信息其实就是向网页发出请求,服务器将数据反馈给你
2. 获取动态加载源码
导入所需的模块和库:

1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送一个请求。请求可以帮助我们很好地完成这一点。但是经过仔细观察,我们发现网易新闻是动态加载的。请求返回即时信息。稍后加载到网页上的数据不会返回。在这种情况下,Selenium 可以帮助我们获取更多数据。我们将 selenium 理解为一种自动化测试工具。Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
我使用的浏览器是火狐
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样我们就可以驱动浏览器自动登录网易新闻页面

我们的目标自然是一次爬下国内部分,观察网页。当网页不断向下滚动时,将加载新的新闻。在底部,甚至还有一个刷新按钮:

这时候使用selenium就可以显示出它的优势了:自动化,模拟鼠标键盘操作:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右击网页中的Load More按钮,点击View Element,可以看到

通过这个类,可以定位按钮。当遇到按钮时,点击事件可以帮助我们自动点击按钮完成网页刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用信息
简单来说,BeautifulSoup 是一个 Python 库。它的主要功能是从网页中抓取数据,可以减轻新手的负担。通过BeautifulSoup解析网页源代码,并添加附带的函数,我们可以方便的检索到我们想要的信息,例如:获取标题、标签和文本内容超链接

也可以右键点击文章标题区查看元素:

观察网页的结构,发现每个div标签class="news_title"下面是文章的标题和超链接。soup.find_all() 函数可以帮助我们找到我们想要的所有信息,并且可以一次性提取出该级别结构下的内容。最后通过字典,将标签信息一一检索出来。
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4. 获取新闻内容
此后,新闻链接被我们取出并存入列表。现在我们需要做的就是使用链接来获取新闻主题内容。新闻主题内容页面静态加载,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
使用try except的原因是网易新闻文章在一定时间前后,文本信息的位置和标签不同,不同的情况要区别对待。
最后遍历整个列表以检索所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地txt文件
Python提供了一个文件处理函数open(),第一个参数是文件路径,第二个是文件处理方式,“w”方式是只写的(如果文件不存在则创建,如果文件不存在则清空内容)它存在)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
一个简单的爬虫到目前为止已经成功写好了:


抓取网页新闻( 通常哪些网站页面不应该被百度抓取呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-27 01:07
通常哪些网站页面不应该被百度抓取呢?(图))
为什么要禁止自己的网页?哪些网站 页面不应该被百度抓取?
那么哪些网站页面不应该被百度抓取呢?比如网站里面有一些重复的内容,比如一些按条件查询得到的结果页。这一点在很多商场网站中脱颖而出。例如,由于产品的颜色、尺寸、型号的不同,会出现很多相似的页面。这种页面对于用户来说可以有一定的体验,但是对于搜索引擎来说很容易。他们因为提供了太多重复的内容而受到惩罚或降级。
另外,网站中还有很多注册页、备份页、测试页。这些页面只是为了用户更好的操作网站以及自己对网站的操作进行管理。但是这些页面内容比较单调,不适合百度对内容质量的要求。所以要尽量避免被百度收录抓取。我们来谈谈如何避免百度对内容页面的抓取。
, 使用Flash技术展示不想被百度的内容收录
这种方式不仅可以让用户获得更好的用户体验,而且百度也无法抓取这些内容,从而更好地为用户服务,并且不会影响自己的内容在百度上的公开。
二、利用robots脚本技术屏蔽相应内容
目前,搜索引擎行业协会规定,Robots 描述的内容和链接应限制抓取。因此,对于网站上是否存在私有内容,以及管理页面、测试页面等内容,可以在本脚本文件中进行设置。这不仅可以为这个网站提供良好的维护,也可以防止那些看似垃圾邮件的内容被百度抓取,反而会对这个网站产生巨大的负面影响。
三、使用nofollow属性标签放弃页面上不想成为的内容收录
这种方法使用比较普遍,它可以屏蔽网页中的某个区域或一段文字,从而提高您的内容优化效果。使用该技术只需将需要屏蔽的内容的nofollow属性设置为True,即可屏蔽该内容。比如网站上有一些精彩的内容,但这些内容也收录锚文本链接。那么为了防止这些锚文本链接窃取本站的权重,可以在这些锚文本链接上设置nofollow属性,这样就可以享受这些内容给网站带来的流量,并在同时可以避免网站重量分流的危险。
四、使用Meta Noindex和follow标签
使用这种方法不仅可以防止被百度收录,还可以实现权重的传递。当然具体的操作还是看站长的需要,但是用这种方式来屏蔽内容往往会浪费百度蜘蛛的爬行时间影响优化体验,也就是说这种方式在不是最后一次的时候是没有必要的采取。
对于部分站长使用表单模式和Javascript技术进行拦截,已经无法完成这个任务,因为随着百度蜘蛛智能水平的提升,用这些技术编辑的内容已经可以抓取了,而且在不久的将来,一旦可以抓取到Flash中的内容,如果要屏蔽网站的内容,就应该避免这种方法。
华旗商城更多产品介绍:定制PHP网站打造婚纱摄影新模板 中国山东网-枣庄软文写作技巧 查看全部
抓取网页新闻(
通常哪些网站页面不应该被百度抓取呢?(图))
为什么要禁止自己的网页?哪些网站 页面不应该被百度抓取?
那么哪些网站页面不应该被百度抓取呢?比如网站里面有一些重复的内容,比如一些按条件查询得到的结果页。这一点在很多商场网站中脱颖而出。例如,由于产品的颜色、尺寸、型号的不同,会出现很多相似的页面。这种页面对于用户来说可以有一定的体验,但是对于搜索引擎来说很容易。他们因为提供了太多重复的内容而受到惩罚或降级。
另外,网站中还有很多注册页、备份页、测试页。这些页面只是为了用户更好的操作网站以及自己对网站的操作进行管理。但是这些页面内容比较单调,不适合百度对内容质量的要求。所以要尽量避免被百度收录抓取。我们来谈谈如何避免百度对内容页面的抓取。
, 使用Flash技术展示不想被百度的内容收录
这种方式不仅可以让用户获得更好的用户体验,而且百度也无法抓取这些内容,从而更好地为用户服务,并且不会影响自己的内容在百度上的公开。
二、利用robots脚本技术屏蔽相应内容
目前,搜索引擎行业协会规定,Robots 描述的内容和链接应限制抓取。因此,对于网站上是否存在私有内容,以及管理页面、测试页面等内容,可以在本脚本文件中进行设置。这不仅可以为这个网站提供良好的维护,也可以防止那些看似垃圾邮件的内容被百度抓取,反而会对这个网站产生巨大的负面影响。
三、使用nofollow属性标签放弃页面上不想成为的内容收录
这种方法使用比较普遍,它可以屏蔽网页中的某个区域或一段文字,从而提高您的内容优化效果。使用该技术只需将需要屏蔽的内容的nofollow属性设置为True,即可屏蔽该内容。比如网站上有一些精彩的内容,但这些内容也收录锚文本链接。那么为了防止这些锚文本链接窃取本站的权重,可以在这些锚文本链接上设置nofollow属性,这样就可以享受这些内容给网站带来的流量,并在同时可以避免网站重量分流的危险。
四、使用Meta Noindex和follow标签
使用这种方法不仅可以防止被百度收录,还可以实现权重的传递。当然具体的操作还是看站长的需要,但是用这种方式来屏蔽内容往往会浪费百度蜘蛛的爬行时间影响优化体验,也就是说这种方式在不是最后一次的时候是没有必要的采取。
对于部分站长使用表单模式和Javascript技术进行拦截,已经无法完成这个任务,因为随着百度蜘蛛智能水平的提升,用这些技术编辑的内容已经可以抓取了,而且在不久的将来,一旦可以抓取到Flash中的内容,如果要屏蔽网站的内容,就应该避免这种方法。
华旗商城更多产品介绍:定制PHP网站打造婚纱摄影新模板 中国山东网-枣庄软文写作技巧
抓取网页新闻( 网站得从哪几方面下手,应该注意哪些点?6个方面告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-27 01:05
网站得从哪几方面下手,应该注意哪些点?6个方面告诉你)
为了被搜索引擎抓取,网站应该从哪些方面入手,应该注意哪些方面?6种方式告诉你。
1.稳定网址
该 URL 是 网站 的主根。URL的好坏直接影响搜索引擎对网站的抓取和识别;同时,客户的体验也会受到影响;想象一下,用户在点击的时候总是会出错,会继续点击你的网站,极大地影响了用户的点击率;针对搜索引擎的胃口,网址尽量是静态的,层次不要太多,最多不超过三级,网址要简短易记。
2.图片优化
一张图片胜过千言万语。网站中图片的应用越来越受到重视,百度也比以前更加重视图片。图片的优化也成为了SEOer们关注的重点,迎合了百度的胃口,一是注意图片的大小,一般长:宽=121:75;图片过大会降低加载速度,不利于用户体验;其次,注意图片的清晰度,图片会模糊。,用户体验会大打折扣;最后是最基础的Alt标签,蜘蛛依靠Alt标签来识别图片,所以一定要注意Alt的写法,但是不建议出现关键词堆叠。
3.关键词布局
合理的关键词布局可以促进网站的优化,有利于提升关键词的排名,提升用户体验;根据网站的关键词,密度合理网站的布局必须符合网站的审美,达到良好的用户体验;平时网站的关键词设置在F区,版权在网站底部。
4.优质内容
内容为王是不变的真理。网站文章的好坏可以决定网站优化效果的高低;百度蜘蛛每天都来你的网站,只为拦截到好东西;高质量的原创文章是他的最爱;对于原创文章,需要注意的是文章的内容是时效性和用户价值的;你需要小说标题;同时文章一定要定期更新,百度也会有时间抓拍你的网站内容。
5.优质外链
提升关键词排名的重要渠道之一是外链。但是,由于垃圾外链泛滥,百度的外链评级页面有所减少;但是,外部链接仍然是 SEO 优化的。第二个最重要的方法是不要忽视;只有优质合理的外链才能被百度蜘蛛青睐。每日外部链接必须定期发布,不得有起伏。发布的内容质量要高,能为用户带来价值;同时,必须根据平台的规则,选择正确的版块进行发布。
6.用户体验
建立网站的目的是让用户通过互联网更快的找到你,把客户带到企业。用户体验不好,网站再华丽也没有用;网站建设对用户体验不友好,网站最终会走向黑洞;do 网站 如果是为搜索引擎做的话 是的,这是一个很大的错误;搜索引擎会记录用户的点击行为,包括点击率和跳出率;你的网站用户体验不好,所以不会给你太大的分量。 查看全部
抓取网页新闻(
网站得从哪几方面下手,应该注意哪些点?6个方面告诉你)

为了被搜索引擎抓取,网站应该从哪些方面入手,应该注意哪些方面?6种方式告诉你。
1.稳定网址

该 URL 是 网站 的主根。URL的好坏直接影响搜索引擎对网站的抓取和识别;同时,客户的体验也会受到影响;想象一下,用户在点击的时候总是会出错,会继续点击你的网站,极大地影响了用户的点击率;针对搜索引擎的胃口,网址尽量是静态的,层次不要太多,最多不超过三级,网址要简短易记。
2.图片优化

一张图片胜过千言万语。网站中图片的应用越来越受到重视,百度也比以前更加重视图片。图片的优化也成为了SEOer们关注的重点,迎合了百度的胃口,一是注意图片的大小,一般长:宽=121:75;图片过大会降低加载速度,不利于用户体验;其次,注意图片的清晰度,图片会模糊。,用户体验会大打折扣;最后是最基础的Alt标签,蜘蛛依靠Alt标签来识别图片,所以一定要注意Alt的写法,但是不建议出现关键词堆叠。
3.关键词布局

合理的关键词布局可以促进网站的优化,有利于提升关键词的排名,提升用户体验;根据网站的关键词,密度合理网站的布局必须符合网站的审美,达到良好的用户体验;平时网站的关键词设置在F区,版权在网站底部。
4.优质内容

内容为王是不变的真理。网站文章的好坏可以决定网站优化效果的高低;百度蜘蛛每天都来你的网站,只为拦截到好东西;高质量的原创文章是他的最爱;对于原创文章,需要注意的是文章的内容是时效性和用户价值的;你需要小说标题;同时文章一定要定期更新,百度也会有时间抓拍你的网站内容。
5.优质外链

提升关键词排名的重要渠道之一是外链。但是,由于垃圾外链泛滥,百度的外链评级页面有所减少;但是,外部链接仍然是 SEO 优化的。第二个最重要的方法是不要忽视;只有优质合理的外链才能被百度蜘蛛青睐。每日外部链接必须定期发布,不得有起伏。发布的内容质量要高,能为用户带来价值;同时,必须根据平台的规则,选择正确的版块进行发布。
6.用户体验

建立网站的目的是让用户通过互联网更快的找到你,把客户带到企业。用户体验不好,网站再华丽也没有用;网站建设对用户体验不友好,网站最终会走向黑洞;do 网站 如果是为搜索引擎做的话 是的,这是一个很大的错误;搜索引擎会记录用户的点击行为,包括点击率和跳出率;你的网站用户体验不好,所以不会给你太大的分量。
抓取网页新闻(数据去重,我们一般需要利用r语言的filter,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-26 22:02
抓取网页新闻,数据去重,我们一般需要利用r语言的filter,while循环,bool变量,
<p>主要用的是r语言。对于数据集demo,它包含了ios8相关的文档,照片以及程序。这个数据集里的数据是以pdf格式保存的,你需要读取之后分析。导入数据后,你可以查看它的size信息,以此为参考,构建一个时间序列模型:1.data['temp']=demo['atemp']*10002.data['mean']=demo['sampleday']*10003.data['average']=demo['sampleday']*1000将相关时间轴数据读入matlab进行分析acf=imshow(demo,database='matlab')如果想读取包含价格、起步价、加单价的数据集,我推荐你使用read.csv()函数,输入“加单价”就可以将数据读入到matlab中。package 查看全部
抓取网页新闻(数据去重,我们一般需要利用r语言的filter,,)
抓取网页新闻,数据去重,我们一般需要利用r语言的filter,while循环,bool变量,
<p>主要用的是r语言。对于数据集demo,它包含了ios8相关的文档,照片以及程序。这个数据集里的数据是以pdf格式保存的,你需要读取之后分析。导入数据后,你可以查看它的size信息,以此为参考,构建一个时间序列模型:1.data['temp']=demo['atemp']*10002.data['mean']=demo['sampleday']*10003.data['average']=demo['sampleday']*1000将相关时间轴数据读入matlab进行分析acf=imshow(demo,database='matlab')如果想读取包含价格、起步价、加单价的数据集,我推荐你使用read.csv()函数,输入“加单价”就可以将数据读入到matlab中。package
抓取网页新闻(看代码urllib2get请求方法爬虫对象代码是post-get-post/x-www-form-urlencoded的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-25 09:02
抓取网页新闻的时候需要爬虫在浏览器中登录网页,或者爬虫在app中注册登录,还有就是网页页面代码过多需要抓取。get和post可以有两种用法:get:发送给get方法的url地址,直接获取该url下的所有的页面信息post:发送给post方法的url地址,用于向一个目标url或者目标网站发送消息,获取该页面信息。
上图就明白了,get是动态的发送请求获取数据;post是可以静态的发送一次请求获取数据,或者多次post;page就是网页页面url,get可以获取所有的页面,post也可以获取所有的页面。
get和post的基本区别如下:1。get获取一个网页的静态内容,post获取一个网页的动态内容2。get会有一个url报文,post不会,动态内容靠url报文是没有办法送达服务器的3。get只能是一次性请求,post可以多次请求,一次性请求4。get可以实现网页的抓取、更新,但post不能抓取、更新5。get可以获取网页的文件,post无法实现(例如,get的cookie信息,不适用于webqq)。
看代码urllib2get请求方法post请求方法爬虫对象方法
代码是post-get-post都是一个content-type就可以是application/x-www-form-urlencoded的请求
其实这是两种请求的区别和post和get的区别-dev-知乎专栏 查看全部
抓取网页新闻(看代码urllib2get请求方法爬虫对象代码是post-get-post/x-www-form-urlencoded的区别)
抓取网页新闻的时候需要爬虫在浏览器中登录网页,或者爬虫在app中注册登录,还有就是网页页面代码过多需要抓取。get和post可以有两种用法:get:发送给get方法的url地址,直接获取该url下的所有的页面信息post:发送给post方法的url地址,用于向一个目标url或者目标网站发送消息,获取该页面信息。
上图就明白了,get是动态的发送请求获取数据;post是可以静态的发送一次请求获取数据,或者多次post;page就是网页页面url,get可以获取所有的页面,post也可以获取所有的页面。
get和post的基本区别如下:1。get获取一个网页的静态内容,post获取一个网页的动态内容2。get会有一个url报文,post不会,动态内容靠url报文是没有办法送达服务器的3。get只能是一次性请求,post可以多次请求,一次性请求4。get可以实现网页的抓取、更新,但post不能抓取、更新5。get可以获取网页的文件,post无法实现(例如,get的cookie信息,不适用于webqq)。
看代码urllib2get请求方法post请求方法爬虫对象方法
代码是post-get-post都是一个content-type就可以是application/x-www-form-urlencoded的请求
其实这是两种请求的区别和post和get的区别-dev-知乎专栏
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术实现思路:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-25 07:01
数据捕获方法只是一种技术理论可行性研究,不鼓励任何人进行现实世界的捕获。
先分享一下资源~我整理了2019年全年的成绩单:
提取码:2438
然后分享一下代码的实现思路:
首先确定数据源。其实网上有一些网站聚合新闻网文稿,甚至有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网而不是二道展。
接下来分析页面结构。
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整个新闻播放,下面是单个新闻。点击进入 每个新闻页面都会找到“相关文章”的内容。
打开 F12 调试,点击不同的日期,可以在 XHR 选项卡中找到之前的请求。可以发现唯一的变化是链接地址中的日期字符串。
这决定了我们的想法。
根据更改日期→获取当天新闻列表→循环保存新闻文章内容
后续的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要抓取2019年全年的新闻,需要生成一个20190101到20191231之间的365个日期的列表。之前我们写过一篇文章关于日期列表生成的介绍,使用datetime库,这次我们使用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20190101', '20191231'):
save_text(date)
time.sleep(3)
最后,祝大家2020新年快乐~
希望新的一年,大家都能有所收获,有所收获,实现每一个小目标。 查看全部
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术实现思路:)
数据捕获方法只是一种技术理论可行性研究,不鼓励任何人进行现实世界的捕获。
先分享一下资源~我整理了2019年全年的成绩单:
提取码:2438
然后分享一下代码的实现思路:
首先确定数据源。其实网上有一些网站聚合新闻网文稿,甚至有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网而不是二道展。
接下来分析页面结构。
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整个新闻播放,下面是单个新闻。点击进入 每个新闻页面都会找到“相关文章”的内容。
打开 F12 调试,点击不同的日期,可以在 XHR 选项卡中找到之前的请求。可以发现唯一的变化是链接地址中的日期字符串。
这决定了我们的想法。
根据更改日期→获取当天新闻列表→循环保存新闻文章内容
后续的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要抓取2019年全年的新闻,需要生成一个20190101到20191231之间的365个日期的列表。之前我们写过一篇文章关于日期列表生成的介绍,使用datetime库,这次我们使用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20190101', '20191231'):
save_text(date)
time.sleep(3)
最后,祝大家2020新年快乐~
希望新的一年,大家都能有所收获,有所收获,实现每一个小目标。
抓取网页新闻(Excel催化剂网页采集教程:获取所要元素的CSSSelector功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-25 07:00
)
有时我们想在网页上获取一些内容。比如作者在做轮播功能的时候,想要获取一些示例图片链接。如果把图片链接一个一个复制,效率太低了,还是开个爬虫工具吧。采集,除非你需要批量获取多个页面,否则太麻烦了。
本文给你一个小技巧,快速完成这些小临时需求。用到的知识是CSS的选择器函数。
整个过程分为几个步骤,下面分别说明。
一、获取所需元素的CSS Selector表达式
假设您已经对 CSS Selector 有所了解。如果你没有通过这一步,以后就没有意义了。任何网页采集的前提是你对xpath和CSS Selector有一点了解。
在现代 Web 技术中,CSS 被广泛用于布局页面。相对而言,使用 CSS 选择器可能比 xpath 更方便定位网页内容。毕竟,前端工程师自己使用 CSS 来定位和格式化元素。我们使用它来定位元素并仅获取内容。
如果想详细了解具体的CSS选择器,可以去W3School等地方学习。
例如这个链接:
下面是更高级的 CSS 选择器知识:
这是定位网页内容的整个方法
1. 找到你想要的网页内容,如轮播图,右键【检查】按钮,定位到这个元素
2. 观察整个网页元素结构,特别注意上面的父节点
下图中我们可以发现整个carousel图片其实就是一个类promo-bd的div节点下的内容,里面收录了几个div,一个是我们定位的图片,其他的是一些隐藏的轮播图像。
CSS选择器定位一般使用多个类名来限定其作用域,即当前节点的类名,然后找到其父级唯一的类名来辅助定位。
3.使用ChroPath工具辅助定位,找到最终内容对应的CSS Selector表达式。
在Excel催化剂网页的采集教程中,我曾经介绍过ChroPath这个工具,用来定位Xpath,也可以定位CSS Selector。
如下图所示,我们找到了类名.promo-bd,它是整个网页唯一的。
然后缩小范围并添加每个轮播的特定类名 mod。此时CSS Selector表达式为[.promo-bd.mod],两个类之间有一个空格,表示要找到promo-bd类mod类的后代。
此时,我们找到了 7 个结果。我们需要的是 5 个轮播图像。有时我们找不到它们也没关系。下载图像并排除额外的部分可能比找到 5 个元素更方便。
回到我们需要的图片链接元素,就是img节点,上层是a节点。
所以我们最后写的CSS Selector是[.promo-bd .mod a>img],大于号代表父子,不是空间的任何后代。
二、打开浏览器开发工具的【控制台】面板,输入指定命令获取需要的内容
先给出最终的结果,然后再一步一步慢慢讲解原理。
输入:Array.from(document.querySelectorAll(".promo-bd .mod a>img")).map(s=>s.currentSrc).join("\n")
只需获取你想要的图片链接文字,自己复制粘贴到Excel中即可(Excel Catalyst有批量下载功能,有链接,你可以方便的将链接内容下载到本地,自定义你需要的名字)。
像Excel函数一样,可以嵌套多个函数来实现复杂的功能。
1.使用querySelectorAll查询CSS Selector的内容
在下图中,我们可以看到我们找到了一个收录7个对象的集合,然后展开它就知道我们想要的内容在currentSrc属性中。
2.把集合变成数组
数组的优点之一是可以使用后续的map方法遍历提取自己想要的内容。
3. 加上map函数遍历你需要的元素属性
这时候上面的对象数组已经转化为一个人字串数组
4. 最后一步是将数组转换为字符串,用换行符分隔
这时候开头和结尾只有一个双引号,中间元素没有双引号,不做任何处理就复制了。
5. 复制并粘贴到 Excel 单元格中,然后简单地处理和下载
最后,我们还发现,7个元素之所以出现,是因为它们已经重复出现了。只需删除 Excel 中的重复项,这就是我们想要的 5 个元素。
当然,最方便的方法是直接在Excel中处理,直接下载。这就是Excel Catalyst为大家准备的【批量下载网页文件】功能。
查看全部
抓取网页新闻(Excel催化剂网页采集教程:获取所要元素的CSSSelector功能
)
有时我们想在网页上获取一些内容。比如作者在做轮播功能的时候,想要获取一些示例图片链接。如果把图片链接一个一个复制,效率太低了,还是开个爬虫工具吧。采集,除非你需要批量获取多个页面,否则太麻烦了。
本文给你一个小技巧,快速完成这些小临时需求。用到的知识是CSS的选择器函数。
整个过程分为几个步骤,下面分别说明。
一、获取所需元素的CSS Selector表达式
假设您已经对 CSS Selector 有所了解。如果你没有通过这一步,以后就没有意义了。任何网页采集的前提是你对xpath和CSS Selector有一点了解。
在现代 Web 技术中,CSS 被广泛用于布局页面。相对而言,使用 CSS 选择器可能比 xpath 更方便定位网页内容。毕竟,前端工程师自己使用 CSS 来定位和格式化元素。我们使用它来定位元素并仅获取内容。
如果想详细了解具体的CSS选择器,可以去W3School等地方学习。
例如这个链接:
下面是更高级的 CSS 选择器知识:
这是定位网页内容的整个方法
1. 找到你想要的网页内容,如轮播图,右键【检查】按钮,定位到这个元素
2. 观察整个网页元素结构,特别注意上面的父节点
下图中我们可以发现整个carousel图片其实就是一个类promo-bd的div节点下的内容,里面收录了几个div,一个是我们定位的图片,其他的是一些隐藏的轮播图像。
CSS选择器定位一般使用多个类名来限定其作用域,即当前节点的类名,然后找到其父级唯一的类名来辅助定位。
3.使用ChroPath工具辅助定位,找到最终内容对应的CSS Selector表达式。
在Excel催化剂网页的采集教程中,我曾经介绍过ChroPath这个工具,用来定位Xpath,也可以定位CSS Selector。
如下图所示,我们找到了类名.promo-bd,它是整个网页唯一的。
然后缩小范围并添加每个轮播的特定类名 mod。此时CSS Selector表达式为[.promo-bd.mod],两个类之间有一个空格,表示要找到promo-bd类mod类的后代。
此时,我们找到了 7 个结果。我们需要的是 5 个轮播图像。有时我们找不到它们也没关系。下载图像并排除额外的部分可能比找到 5 个元素更方便。
回到我们需要的图片链接元素,就是img节点,上层是a节点。
所以我们最后写的CSS Selector是[.promo-bd .mod a>img],大于号代表父子,不是空间的任何后代。
二、打开浏览器开发工具的【控制台】面板,输入指定命令获取需要的内容
先给出最终的结果,然后再一步一步慢慢讲解原理。
输入:Array.from(document.querySelectorAll(".promo-bd .mod a>img")).map(s=>s.currentSrc).join("\n")
只需获取你想要的图片链接文字,自己复制粘贴到Excel中即可(Excel Catalyst有批量下载功能,有链接,你可以方便的将链接内容下载到本地,自定义你需要的名字)。
像Excel函数一样,可以嵌套多个函数来实现复杂的功能。
1.使用querySelectorAll查询CSS Selector的内容
在下图中,我们可以看到我们找到了一个收录7个对象的集合,然后展开它就知道我们想要的内容在currentSrc属性中。
2.把集合变成数组
数组的优点之一是可以使用后续的map方法遍历提取自己想要的内容。
3. 加上map函数遍历你需要的元素属性
这时候上面的对象数组已经转化为一个人字串数组
4. 最后一步是将数组转换为字符串,用换行符分隔
这时候开头和结尾只有一个双引号,中间元素没有双引号,不做任何处理就复制了。
5. 复制并粘贴到 Excel 单元格中,然后简单地处理和下载
最后,我们还发现,7个元素之所以出现,是因为它们已经重复出现了。只需删除 Excel 中的重复项,这就是我们想要的 5 个元素。
当然,最方便的方法是直接在Excel中处理,直接下载。这就是Excel Catalyst为大家准备的【批量下载网页文件】功能。
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-16 03:17
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及其栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询: 查看全部
抓取网页新闻(企业建站及大型新闻网站新闻内容转载史上最强的工具)
当今最强的网页抓取、内容获取和专业新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及其栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询:
抓取网页新闻(农业信息网的小小的规律总结:1.什么是爬虫? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-16 03:12
)
由于项目需要,我们需要用到爬虫。我自己摸索了一下,总结了一些小规则。现在我总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/");
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网抓取最新的农业新闻
查看全部
抓取网页新闻(农业信息网的小小的规律总结:1.什么是爬虫?
)
由于项目需要,我们需要用到爬虫。我自己摸索了一下,总结了一些小规则。现在我总结如下:
1.什么是爬虫?
网络爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。对于垂直搜索,聚焦爬虫,即有针对性地抓取特定主题的网页的爬虫更适合。
2. 爬虫的实现
package com.demo;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test {
public static List findList(String url) throws IOException{ //输入某个网站查找所有新闻的地址
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
//System.out.println(doc.html());
Elements e=doc.select("a[class=newsgray a_space2]"); //返回所有的<a>超链接标签
List list=new ArrayList();
News news=null;
for(Element element:e){
news=new News();
String title=element.toString().substring(78);
String temp=title.substring(0, title.length()-4);//新闻标题
news.setTitle(temp);
String path=element.absUrl("href"); //新闻所在路径
String content=urlToHtml(path);
news.setContent(content);
news.setUrl(path);
list.add(news);
}
return list;
}
public static String urlToHtml(String url) throws IOException{
Connection conn = Jsoup.connect(url); //使用Jsoup获得url连接
Document doc = conn.post(); // 请求返回整个文档对象
StringBuilder sb=new StringBuilder();
Elements e=doc.select("p");
for(Element element:e){
String content=element.toString();
sb.append(content);
}
return sb.toString();
}
public static void main(String[] args) throws IOException {
List list=findList("http://news.aweb.com.cn/china/hyxw/";);
for(News news:list){
System.out.println(news.getContent());
}
}
}
新闻.java
package com.demo;
public class News {
private String title;
private String content;
private String url;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
}
比如我们想在农业信息网抓取最新的农业新闻
抓取网页新闻(关于php和python语言本身的抓取网页新闻内容的是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-14 16:02
抓取网页新闻内容的是php语言,数据存储是http协议,你可以用后端的wordpress服务器实现数据抓取等。关于php和python语言本身,两者在工作上非常接近,学习python主要是学习php的库,后端php有laravel等等,python有numpy、scipy、pandas等等。python也有比较完善的web框架,比如swoole等等,实际应用中并不会一一用web框架去做,而是通过解析http协议等操作完成,比如阅读、拉新、促活等,最终还是php完成。
1.js3.3版本新加入网络请求钩子,功能比较全面。另外还有抓包,比较重要,能有效进行拦截爬取。2.把下面的代码拷贝到命令行内#爬取首页page=request.get("/")#跟原生的request不同,这里涉及爬取源代码,page中的网页地址,设置offset属性。response=page.get("")foriinresponse:#默认的行为是post请求,那么我们可以改成post,这里代码可以写两句,第一句抓取page.get(""),page.get(""),第二句直接构造post请求,不同行为不同的instr()函数,action是链接。
trace()是抓取方向标识,改成context是请求头部分。data=response.dataattrs=attrs['content-type']request=urllib.request(url,headers=headers,user-agent='mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/72.0.3312.87safari/537.36')html=request.urlopen(request.read(),timeout=10)re=request.read()i=len(request.request)j=i+1result=response.dataprint(result)done抓取网页的时候注意要后台分析抓取,避免fullpage。
对于非全页的需要后端做解析才能抓取。3.到网页最底下的action里抓取能抓取到原网页的地址,action里面抓取到trace中定义的网页,action是请求头部分。然后需要在中间转发中做处理,如果action是http请求,那么通过url拼接到trace里面,假设抓取http请求为.get("")抓取方向建议请求不要从用户空间顶部开始请求,先从最底部开始如果不是从用户空间顶部开始请求,要么是强制转发,要么是自己根据情况转发,建议一般不要用fullpage。 查看全部
抓取网页新闻(关于php和python语言本身的抓取网页新闻内容的是什么)
抓取网页新闻内容的是php语言,数据存储是http协议,你可以用后端的wordpress服务器实现数据抓取等。关于php和python语言本身,两者在工作上非常接近,学习python主要是学习php的库,后端php有laravel等等,python有numpy、scipy、pandas等等。python也有比较完善的web框架,比如swoole等等,实际应用中并不会一一用web框架去做,而是通过解析http协议等操作完成,比如阅读、拉新、促活等,最终还是php完成。
1.js3.3版本新加入网络请求钩子,功能比较全面。另外还有抓包,比较重要,能有效进行拦截爬取。2.把下面的代码拷贝到命令行内#爬取首页page=request.get("/")#跟原生的request不同,这里涉及爬取源代码,page中的网页地址,设置offset属性。response=page.get("")foriinresponse:#默认的行为是post请求,那么我们可以改成post,这里代码可以写两句,第一句抓取page.get(""),page.get(""),第二句直接构造post请求,不同行为不同的instr()函数,action是链接。
trace()是抓取方向标识,改成context是请求头部分。data=response.dataattrs=attrs['content-type']request=urllib.request(url,headers=headers,user-agent='mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/72.0.3312.87safari/537.36')html=request.urlopen(request.read(),timeout=10)re=request.read()i=len(request.request)j=i+1result=response.dataprint(result)done抓取网页的时候注意要后台分析抓取,避免fullpage。
对于非全页的需要后端做解析才能抓取。3.到网页最底下的action里抓取能抓取到原网页的地址,action里面抓取到trace中定义的网页,action是请求头部分。然后需要在中间转发中做处理,如果action是http请求,那么通过url拼接到trace里面,假设抓取http请求为.get("")抓取方向建议请求不要从用户空间顶部开始请求,先从最底部开始如果不是从用户空间顶部开始请求,要么是强制转发,要么是自己根据情况转发,建议一般不要用fullpage。
抓取网页新闻(Python正则抓取网易新闻的方法结合实例形式较为详细的分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-13 10:14
)
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/da ... 39%3B
def getpage(self,page):
full_url='http://comment.news.163.com/ca ... 2Bstr(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(Python正则抓取网易新闻的方法结合实例形式较为详细的分析
)
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/da ... 39%3B
def getpage(self,page):
full_url='http://comment.news.163.com/ca ... 2Bstr(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-12 22:08
)
小弟还有一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。碰巧牛客这周从一个html中找到了文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间和内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
bs4需要自己安装,安装方法可以参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。
查看全部
抓取网页新闻(学弟爬门户网站新闻的程序需求及安装方法可以参考!
)
小弟还有一个自然语言处理项目。我需要在网上爬取一些文章,然后进行分词。碰巧牛客这周从一个html中找到了文字,练习了一下。写了一个程序来爬取门户网站news
要求:
从门户网站抓取新闻网站,并将新闻标题、作者、时间和内容保存到本地txt。
使用的 Python 模块:
1 import re # 正则表达式
2 import bs4 # Beautiful Soup 4 解析模块
3 import urllib2 # 网络访问模块
4 import News #自己定义的新闻结构
5 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
6 import sys #1解决不同页面编码问题
bs4需要自己安装,安装方法可以参考:windows命令行下pip install python whl包
程序:
1 #coding=utf-8
2 import re # 正则表达式
3 import bs4 # Beautiful Soup 4 解析模块
4 import urllib2 # 网络访问模块
5 import News #自己定义的新闻结构
6 import codecs #解决编码问题的关键 ,使用codecs.open打开文件
7 import sys #1解决不同页面编码问题
8
9 reload(sys) # 2
10 sys.setdefaultencoding('utf-8') # 3
11
12 # 从首页获取所有链接
13 def GetAllUrl(home):
14 html = urllib2.urlopen(home).read().decode('utf8')
15 soup = bs4.BeautifulSoup(html, 'html.parser')
16 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+'
17 links = soup.find_all('a', href=re.compile(pattern))
18 for link in links:
19 url_set.add(link['href'])
20
21 def GetNews(url):
22 global NewsCount,MaxNewsCount #全局记录新闻数量
23 while len(url_set) != 0:
24 try:
25 # 获取链接
26 url = url_set.pop()
27 url_old.add(url)
28
29 # 获取代码
30 html = urllib2.urlopen(url).read().decode('utf8')
31
32 # 解析
33 soup = bs4.BeautifulSoup(html, 'html.parser')
34 pattern = 'http://\w+\.baijia\.baidu\.com/article/\w+' # 链接匹配规则
35 links = soup.find_all('a', href=re.compile(pattern))
36
37 # 获取URL
38 for link in links:
39 if link['href'] not in url_old:
40 url_set.add(link['href'])
41
42 # 获取信息
43 article = News.News()
44 article.url = url # URL信息
45 page = soup.find('div', {'id': 'page'})
46 article.title = page.find('h1').get_text() # 标题信息
47 info = page.find('div', {'class': 'article-info'})
48 article.author = info.find('a', {'class': 'name'}).get_text() # 作者信息
49 article.date = info.find('span', {'class': 'time'}).get_text() # 日期信息
50 article.about = page.find('blockquote').get_text()
51 pnode = page.find('div', {'class': 'article-detail'}).find_all('p')
52 article.content = ''
53 for node in pnode: # 获取文章段落
54 article.content += node.get_text() + '\n' # 追加段落信息
55
56 SaveNews(article)
57
58 print NewsCount
59 break
60 except Exception as e:
61 print(e)
62 continue
63 else:
64 print(article.title)
65 NewsCount+=1
66 finally:
67 # 判断数据是否收集完成
68 if NewsCount == MaxNewsCount:
69 break
70
71 def SaveNews(Object):
72 file.write("【"+Object.title+"】"+"\t")
73 file.write(Object.author+"\t"+Object.date+"\n")
74 file.write(Object.content+"\n"+"\n")
75
76 url_set = set() # url集合
77 url_old = set() # 爬过的url集合
78
79 NewsCount = 0
80 MaxNewsCount=3
81
82 home = 'http://baijia.baidu.com/' # 起始位置
83
84 GetAllUrl(home)
85
86 file=codecs.open("D:\\test.txt","a+") #文件操作
87
88 for url in url_set:
89 GetNews(url)
90 # 判断数据是否收集完成
91 if NewsCount == MaxNewsCount:
92 break
93
94 file.close()
新闻文章结构
1 #coding: utf-8
2 # 文章类定义
3 class News(object):
4 def __init__(self):
5 self.url = None
6 self.title = None
7 self.author = None
8 self.date = None
9 self.about = None
10 self.content = None
统计文章被抓取的次数。
抓取网页新闻( 测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-05 21:07
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:在线提取一般新闻网页文本
摄影:产品经理
毛脑花和广大粉丝
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先用pip安装,再写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE和测试GNE,我开发了网络版GNE-Gne Online。
打开Gne Online的地址是:,打开后的页面如下图。
测试GNE的功能,只需将网页源代码粘贴到顶部文本框中,点击提取按钮即可:
对于标题、作者、新闻发布时间等可能被误送提取的信息,我们可以通过下面对应的标题XPath、作者、发布时间XPath输入XPath进行定向提取。例如,对于今日头条中的文章:
新闻作者提取错误,此时可以指定XPath://div[@class="article-sub"]/span[1]/text()定向提取,如如下图所示。
通过设置Host输入框,可以拼出网页body中图片为相对路径时的URL。
通过勾选下面的With Body Html复选框,您可以返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考资料
[1]
GNE:
[2]
官方文档:
王名
存钱给产品经理买房子。 查看全部
抓取网页新闻(
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:在线提取一般新闻网页文本
摄影:产品经理
毛脑花和广大粉丝
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先用pip安装,再写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE和测试GNE,我开发了网络版GNE-Gne Online。
打开Gne Online的地址是:,打开后的页面如下图。
测试GNE的功能,只需将网页源代码粘贴到顶部文本框中,点击提取按钮即可:
对于标题、作者、新闻发布时间等可能被误送提取的信息,我们可以通过下面对应的标题XPath、作者、发布时间XPath输入XPath进行定向提取。例如,对于今日头条中的文章:
新闻作者提取错误,此时可以指定XPath://div[@class="article-sub"]/span[1]/text()定向提取,如如下图所示。
通过设置Host输入框,可以拼出网页body中图片为相对路径时的URL。
通过勾选下面的With Body Html复选框,您可以返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考资料
[1]
GNE:
[2]
官方文档:
王名
存钱给产品经理买房子。
抓取网页新闻(GNE(GeneralNewsExtractor)方法增加host参数,用于提取新闻标题参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-03 08:24
GNE(GeneralNewsExtractor)是一个通用新闻网站文本提取模块。它输入一个新闻网页的HTML,输出文本内容、标题、作者、发布时间、文本中的图片地址和文本所在标签的源代码。GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。.
用法很简单:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '网站源代码'
result = extractor.extract(html)
print(result)
GNE的输入是js渲染的HTML代码,所以GNE可以和Selenium或者Pyppeteer一起使用。
下图是GNE用Selenium实现的Demo:
对应的代码是:
import time
from gne import GeneralNewsExtractor
from selenium.webdriver import Chrome
driver = Chrome('./chromedriver')
driver.get('https://www.toutiao.com/a67669 ... %2339;)
time.sleep(3)
extractor = GeneralNewsExtractor()
result = extractor.extract(driver.page_source)
print(result)
下图是GNE用Pyppeteer实现的Demo:
对应的代码如下:
import asyncio
from gne import GeneralNewsExtractor
from pyppeteer import launch
async def main():
browser = await launch(executablePath='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')
page = await browser.newPage()
await page.goto('https://news.163.com/20/0101/1 ... %2339;)
extractor = GeneralNewsExtractor()
result = extractor.extract(await page.content())
print(result)
input('检查完成以后回到这里按下任意键')
asyncio.run(main())
如何安装 GNE
现在你可以直接使用 pip 安装 GNE:
pip install gne
如果访问pypi官方源码太慢,也可以使用网易源码:
pip install gne -i https://mirrors.163.com/pypi/simple/
安装过程如下图所示:
获取文本源代码的功能特性
当extract()方法只传入网页源代码,不添加任何额外参数时,GNE返回如下字段:
可能有的朋友想要获取新闻正文所在标签的源码。这时候可以在extract()方法中传入with_body_html参数并设置为True:
extractor = GeneralNewsExtractor()
extractor.extract(html, with_body_html=True)
返回的数据中会增加一个字段body_html,其值为body对应的HTML源代码。
运行效果如下图所示:
始终返回图片的绝对路径
默认情况下,如果新闻中的图片使用相对路径,则GNE返回的images字段对应的值也是图片的相对路径列表。
如果要始终让 GNE 返回绝对路径,可以在 extract() 方法中添加主机参数。该参数的值为图片的域名,例如:
extractor = GeneralNewsExtractor()
extractor.extract(html, host='https://www.kingname.info')
这样,如果新闻中的图片是/images/pic.png,那么GNE返回的时候会自动改成。
指定新闻标题所在的XPath
GNE 预定义了一组用于提取新闻标题的 XPath 和正则表达式。但是,一些特殊的新闻网站可能无法提取标题。这时候可以给extract()方法指定title_xpath参数来提取新闻标题:
extractor = GeneralNewsExtractor()
extractor.extract(html, title_xpath='//title/text()')
提前去除噪音标签
某些新闻下可能会有长篇评论。这些评论看起来“更像是”新闻的主体。为了防止它们干扰新闻的提取,可以在extract()方法中传入noise_node_list参数,提前移动这些噪声节点。消除。noise_node_list 的值是一个收录一个或多个 XPath 的列表:
extractor = GeneralNewsExtractor()
extractor.extract(html, noise_node_list=['//div[@class="comment-list"]', '//*[@style="display:none"]'])
使用配置文件
API中的title_xpath、host、noise_node_list、with_body_html参数可以直接写到extract()方法中,也可以通过配置文件进行设置。
请在项目的根目录下创建一个文件 .gne。配置文件可以是 YAML 格式或 JSON 格式。
title:
xpath: //title/text()
host: https://www.xxx.com
noise_node_list:
- //div[@class=\"comment-list\"]
- //*[@style=\"display:none\"]
with_body_html: true
{
"title": {
"xpath": "//title/text()"
},
"host": "https://www.xxx.com",
"noise_node_list": ["//div[@class=\"comment-list\"]",
"//*[@style=\"display:none\"]"],
"with_body_html": true
}
这两种写法是完全等价的。
配置文件与extract()方法参数相同,不需要提供所有字段。您可以组合填写您需要的字段。
如果一个参数在extract()方法和.gne配置文件中都存在,但是值不同,那么这个参数在extract()方法中的优先级更高。
FAQGeneralNewsExtractor(以下简称GNE)是爬虫吗?
GNE 不是爬虫,它的项目名称 General News Extractor 代表 General News Extractor。它的输入是 HTML,它的输出是一个收录新闻标题、新闻正文、作者和发布时间的字典。您需要尝试自己获取目标页面的HTML。
GNE 不会,以后也不会提供请求网页的功能。
GNE 是否支持翻页?
GNE 不支持翻页。因为GNE没有提供网页请求的功能,所以需要自己获取每个页面的HTML,单独传给GNE。
GNE 支持哪些版本的 Python?
不低于 Python 3.6.0
我用requests/Scrapy得到的HTML传入GNE,为什么提取不出文本?
GNE 基于 HTML 提取文本,因此传入的 HTML 必须是 JavaScript 呈现的 HTML。requests 和 Scrapy 只获取 JavaScript 渲染前的源码,无法正确提取。
此外,还有一些网页,比如今日头条,其新闻文本实际上是直接以JSON格式写入网页源代码中的。在浏览器上打开页面时,JavaScript 会将源代码中的文本解析为 HTML。在这种情况下,您将不会在 Chrome 上看到 Ajax 请求。
所以建议大家使用Puppeteer/Pyppeteer/Selenium等工具获取渲染后的HTML,然后传递给GNE。
GNE是否支持非新闻网站(如博客、论坛...)
不支持。
成长离不开与优秀合作伙伴的学习。如果您需要良好的学习环境、良好的学习资源、项目教程、零基础学习,欢迎热爱Python的各位来这里,点击:Python学习圈 查看全部
抓取网页新闻(GNE(GeneralNewsExtractor)方法增加host参数,用于提取新闻标题参数)
GNE(GeneralNewsExtractor)是一个通用新闻网站文本提取模块。它输入一个新闻网页的HTML,输出文本内容、标题、作者、发布时间、文本中的图片地址和文本所在标签的源代码。GNE对今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百条中文新闻网站的提取非常有效,准确率几乎可以达到100%。.
用法很简单:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '网站源代码'
result = extractor.extract(html)
print(result)
GNE的输入是js渲染的HTML代码,所以GNE可以和Selenium或者Pyppeteer一起使用。
下图是GNE用Selenium实现的Demo:
对应的代码是:
import time
from gne import GeneralNewsExtractor
from selenium.webdriver import Chrome
driver = Chrome('./chromedriver')
driver.get('https://www.toutiao.com/a67669 ... %2339;)
time.sleep(3)
extractor = GeneralNewsExtractor()
result = extractor.extract(driver.page_source)
print(result)
下图是GNE用Pyppeteer实现的Demo:
对应的代码如下:
import asyncio
from gne import GeneralNewsExtractor
from pyppeteer import launch
async def main():
browser = await launch(executablePath='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')
page = await browser.newPage()
await page.goto('https://news.163.com/20/0101/1 ... %2339;)
extractor = GeneralNewsExtractor()
result = extractor.extract(await page.content())
print(result)
input('检查完成以后回到这里按下任意键')
asyncio.run(main())
如何安装 GNE
现在你可以直接使用 pip 安装 GNE:
pip install gne
如果访问pypi官方源码太慢,也可以使用网易源码:
pip install gne -i https://mirrors.163.com/pypi/simple/
安装过程如下图所示:
获取文本源代码的功能特性
当extract()方法只传入网页源代码,不添加任何额外参数时,GNE返回如下字段:
可能有的朋友想要获取新闻正文所在标签的源码。这时候可以在extract()方法中传入with_body_html参数并设置为True:
extractor = GeneralNewsExtractor()
extractor.extract(html, with_body_html=True)
返回的数据中会增加一个字段body_html,其值为body对应的HTML源代码。
运行效果如下图所示:
始终返回图片的绝对路径
默认情况下,如果新闻中的图片使用相对路径,则GNE返回的images字段对应的值也是图片的相对路径列表。
如果要始终让 GNE 返回绝对路径,可以在 extract() 方法中添加主机参数。该参数的值为图片的域名,例如:
extractor = GeneralNewsExtractor()
extractor.extract(html, host='https://www.kingname.info')
这样,如果新闻中的图片是/images/pic.png,那么GNE返回的时候会自动改成。
指定新闻标题所在的XPath
GNE 预定义了一组用于提取新闻标题的 XPath 和正则表达式。但是,一些特殊的新闻网站可能无法提取标题。这时候可以给extract()方法指定title_xpath参数来提取新闻标题:
extractor = GeneralNewsExtractor()
extractor.extract(html, title_xpath='//title/text()')
提前去除噪音标签
某些新闻下可能会有长篇评论。这些评论看起来“更像是”新闻的主体。为了防止它们干扰新闻的提取,可以在extract()方法中传入noise_node_list参数,提前移动这些噪声节点。消除。noise_node_list 的值是一个收录一个或多个 XPath 的列表:
extractor = GeneralNewsExtractor()
extractor.extract(html, noise_node_list=['//div[@class="comment-list"]', '//*[@style="display:none"]'])
使用配置文件
API中的title_xpath、host、noise_node_list、with_body_html参数可以直接写到extract()方法中,也可以通过配置文件进行设置。
请在项目的根目录下创建一个文件 .gne。配置文件可以是 YAML 格式或 JSON 格式。
title:
xpath: //title/text()
host: https://www.xxx.com
noise_node_list:
- //div[@class=\"comment-list\"]
- //*[@style=\"display:none\"]
with_body_html: true
{
"title": {
"xpath": "//title/text()"
},
"host": "https://www.xxx.com",
"noise_node_list": ["//div[@class=\"comment-list\"]",
"//*[@style=\"display:none\"]"],
"with_body_html": true
}
这两种写法是完全等价的。
配置文件与extract()方法参数相同,不需要提供所有字段。您可以组合填写您需要的字段。
如果一个参数在extract()方法和.gne配置文件中都存在,但是值不同,那么这个参数在extract()方法中的优先级更高。
FAQGeneralNewsExtractor(以下简称GNE)是爬虫吗?
GNE 不是爬虫,它的项目名称 General News Extractor 代表 General News Extractor。它的输入是 HTML,它的输出是一个收录新闻标题、新闻正文、作者和发布时间的字典。您需要尝试自己获取目标页面的HTML。
GNE 不会,以后也不会提供请求网页的功能。
GNE 是否支持翻页?
GNE 不支持翻页。因为GNE没有提供网页请求的功能,所以需要自己获取每个页面的HTML,单独传给GNE。
GNE 支持哪些版本的 Python?
不低于 Python 3.6.0
我用requests/Scrapy得到的HTML传入GNE,为什么提取不出文本?
GNE 基于 HTML 提取文本,因此传入的 HTML 必须是 JavaScript 呈现的 HTML。requests 和 Scrapy 只获取 JavaScript 渲染前的源码,无法正确提取。
此外,还有一些网页,比如今日头条,其新闻文本实际上是直接以JSON格式写入网页源代码中的。在浏览器上打开页面时,JavaScript 会将源代码中的文本解析为 HTML。在这种情况下,您将不会在 Chrome 上看到 Ajax 请求。
所以建议大家使用Puppeteer/Pyppeteer/Selenium等工具获取渲染后的HTML,然后传递给GNE。
GNE是否支持非新闻网站(如博客、论坛...)
不支持。
成长离不开与优秀合作伙伴的学习。如果您需要良好的学习环境、良好的学习资源、项目教程、零基础学习,欢迎热爱Python的各位来这里,点击:Python学习圈
抓取网页新闻(《js文件》服务器爬js参数替换文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-03 05:02
抓取网页新闻的时候,除了可以爬js文件,我们还可以在js文件里面获取自己想要的信息,一般来说我们的方法是通过解析js文件,再解析加载,并把所有的页面节点相加。注意这个js文件在服务器上应该是multipart/form-data格式文件,关于服务器的要求可以在这里查询。首先我们要读取文件里面的cookie,但我们还需要获取到用户的隐私信息,这样才能生成用户的历史数据,我们要把所有的数据通过一个get请求发送到对应服务器,以了解用户是否存在登录,我们一般会有get或post请求设置参数,比如根据设置可以参考这个命令:post/get:params/cookiesettings这里有人问,post请求会不会被拒绝或封闭?大可不必担心,如果登录的话,就没有登录的数据,你可以完全不发送post请求,这样用户打开浏览器,有你服务器的用户名和密码,也能登录成功。
但如果登录失败,那你发送的post请求会被接收到,存在你服务器了,也只能等你将你的用户名和密码传回来才能登录,所以不必担心。通过解析设置参数,设置好之后,代码中就会有post后面的这几个参数,如accept-language、content-type、content-length、accept-encoding、accept-language-transparency、host等,这些参数可能会在get的请求参数中显示不全,我们可以做一些替换,具体替换可以参照google的tagparameter文件,有很多替换方法,这里没有做展示。
简单替换就是把post参数的前三个参数替换成accept-encoding,然后再用get去请求,这样就可以显示所有的get请求了。替换完一个get请求之后就可以执行我们设置的参数了,这里使用javascript中的token属性,如下的get:text/javascript:alert(‘请求请求成功’)token属性格式为‘'{prototype:this,signature:''}’,这个就是你js文件加载的标识了,但是这个cookie的prototype里面的值不能是http协议,比如要替换成‘http'’。
这样发送到服务器就等于做一个get请求,那我们就可以看看cookie里面的值。首先我们这个post请求中的post-user-agent就是该用户的useragent,有些地方我们也可以把useragent作为http协议属性。我们通过js设置默认值为‘mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari/537.36’,如下,这样cookie里面的值就是mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari。 查看全部
抓取网页新闻(《js文件》服务器爬js参数替换文件)
抓取网页新闻的时候,除了可以爬js文件,我们还可以在js文件里面获取自己想要的信息,一般来说我们的方法是通过解析js文件,再解析加载,并把所有的页面节点相加。注意这个js文件在服务器上应该是multipart/form-data格式文件,关于服务器的要求可以在这里查询。首先我们要读取文件里面的cookie,但我们还需要获取到用户的隐私信息,这样才能生成用户的历史数据,我们要把所有的数据通过一个get请求发送到对应服务器,以了解用户是否存在登录,我们一般会有get或post请求设置参数,比如根据设置可以参考这个命令:post/get:params/cookiesettings这里有人问,post请求会不会被拒绝或封闭?大可不必担心,如果登录的话,就没有登录的数据,你可以完全不发送post请求,这样用户打开浏览器,有你服务器的用户名和密码,也能登录成功。
但如果登录失败,那你发送的post请求会被接收到,存在你服务器了,也只能等你将你的用户名和密码传回来才能登录,所以不必担心。通过解析设置参数,设置好之后,代码中就会有post后面的这几个参数,如accept-language、content-type、content-length、accept-encoding、accept-language-transparency、host等,这些参数可能会在get的请求参数中显示不全,我们可以做一些替换,具体替换可以参照google的tagparameter文件,有很多替换方法,这里没有做展示。
简单替换就是把post参数的前三个参数替换成accept-encoding,然后再用get去请求,这样就可以显示所有的get请求了。替换完一个get请求之后就可以执行我们设置的参数了,这里使用javascript中的token属性,如下的get:text/javascript:alert(‘请求请求成功’)token属性格式为‘'{prototype:this,signature:''}’,这个就是你js文件加载的标识了,但是这个cookie的prototype里面的值不能是http协议,比如要替换成‘http'’。
这样发送到服务器就等于做一个get请求,那我们就可以看看cookie里面的值。首先我们这个post请求中的post-user-agent就是该用户的useragent,有些地方我们也可以把useragent作为http协议属性。我们通过js设置默认值为‘mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari/537.36’,如下,这样cookie里面的值就是mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/24.0.1404.97safari。
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-11-02 02:05
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下拉,发现右侧出现:“... special/00804KVA/cm_guonei_03.js? ...”等地址,点击Response发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
(*).js
上面的链接是我们这次抓取请求的地址。
接下来只需要两个python库:
1.请求
2.json
3.美汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
然后我们定义一个方法来获取指定页码中的数据:
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图中圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
下面采集这三个内容的代码:
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣的可以关注下文章。 查看全部
抓取网页新闻(此文属于入门级级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下拉,发现右侧出现:“... special/00804KVA/cm_guonei_03.js? ...”等地址,点击Response发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
(*).js
上面的链接是我们这次抓取请求的地址。
接下来只需要两个python库:
1.请求
2.json
3.美汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
然后我们定义一个方法来获取指定页码中的数据:
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图中圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
下面采集这三个内容的代码:
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣的可以关注下文章。
抓取网页新闻(3dd's一条一下效果图效果图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-02 02:03
)
第一次写的小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本html
直接上代码python
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取须要的内容而且放入文件中
#抓取的内容有时间,内容文本,以及内容的连接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面的部分新闻网页。
然后抓取新闻时间和超链接网址
然后按照新闻的顺序进行整合,放入一个文本文件存放在spa中
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)3d
查看全部
抓取网页新闻(3dd's一条一下效果图效果图
)
第一次写的小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本html
直接上代码python
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取须要的内容而且放入文件中
#抓取的内容有时间,内容文本,以及内容的连接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面的部分新闻网页。
然后抓取新闻时间和超链接网址
然后按照新闻的顺序进行整合,放入一个文本文件存放在spa中
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)3d
抓取网页新闻( 刮网线在哪里?growthhack探讨一下网页抓取方法之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-01 23:11
刮网线在哪里?growthhack探讨一下网页抓取方法之前)
早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页,甚至只是复制重要数据,您仍然会获得可能可用也可能不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上例)不给主机服务造成负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
尽管我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢? 查看全部
抓取网页新闻(
刮网线在哪里?growthhack探讨一下网页抓取方法之前)
早在增长黑客这个词出现之前,网站 爬行已经成为一种增长黑客技术。从简单的复制开始,将信息从页面粘贴到电子表格或数据库中现在已成为一种有效的策略。
网页抓取是一种从 网站 中提取数据的方法。这可以用于许多不同的原因,包括建立销售渠道以确定您的竞争对手正在制定价格。即使它被认为是一种古老的做法(至少在互联网上),它也可以成为刺激增长的好方法。然而,在我们深入研究网络抓取方法之前,让我们探讨一下网络抓取是如何首次出现在数字营销地图上的。
虽然网络抓取是数字体育的一个广泛使用的方面,但它的历史并不顺利。毕竟,无论您使用机器人扫描网页,甚至只是复制重要数据,您仍然会获得可能可用也可能不可用的信息(尽管它是公开的)。
刮线在哪?
eBay 案例可能是第一个证明网络抓取可能是非法的并且是竞标者边缘的例子。2000年初,竞拍者的优势是拍卖的数据聚合器网站,eBay是其主要的价格来源之一。虽然 eBay 意识到竞标者的优势是在 网站 上抢价,但它最终发展到竞标者的优势,使用了大量数据,以至于扰乱了 eBay 的服务器。法院基本上裁定,投标人的优势扰乱了 eBay 的服务器,造成收入损失并使其无利可图。是的,抓取网络的实际方法被认为是可以的。
这一裁决开创了先例,为各行各业的公司提供了无数的增长机会。在我看来,网站 爬行仍然是增长黑客最道德的形式之一。这是一种久经考验的策略,可以追溯到Web1.0,而且比以往任何时候都更有效。
它的整体做法多年来一直在法庭上受到质疑,但幸运的是,我们已经确定了其合法性的现状。根据 Icreon 的说法,要记住的一些基本技巧包括注意版权、不违反隐私法或使用条款,以及(如上例)不给主机服务造成负担。
如何合并网络爬行?
现在我们已经输入了允许的内容,让我们进入有趣的部分:实际抓取。对于初学者来说,最常见的用法之一就是设置一个robot.txt文件。这些基本上告诉网络爬虫要在页面上查找什么。例如,如果我是球鞋经销商,并且刚刚发布了新的 Jordan,我可以告诉 robots.txt 浏览其他商店(eBay、Stokes 等),选择诸如“Jordan”、“Air Jordan”之类的术语,等总价。
这种方法几乎不需要像您想象的那么多编码,并且可以成为快速获取所需信息的绝佳来源。但是,如果您不知道如何编写代码(或想学习),那么有一些很好的方法可以在不学习任何东西的情况下进行学习。不,这不是复制和粘贴。
随着屏幕抓取的做法变得越来越普遍,许多公司一直在提供一些很棒的产品来提供帮助。像 AspaseHub 这样的平台可以让你打开任何网页并将你需要的数据提取到一个地方,它的免费版本可以作为一个可靠的介绍,让你的脚湿透。另外,导入 .io 也是一个不错的选择,但我建议在使用付费服务之前尝试几种不同的方法。请记住,这是为了节省金钱和时间,因此找到平衡是关键。
网页抓取的未来是什么?
在数据挖掘中使用网络抓取的可能性是无穷无尽的。事实上,采集大数据的增长催生了如何使用人工智能来评估数据点之间的关系。正如我们大多数人所听到的,人工智能正在以一种重要的方式改变我们看待营销的方式。
尽管我们大多数人在采集信息时都有一系列的需求,但这种方式可以快速获得竞争优势。而在如此残酷的行业中,谁不想拼凑优势呢?
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-01 23:04
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=http://www.cppcns.com/jiaoben/python/data.replace('var replyData='http://www.cppcns.com/jiaoben/python/,'')
else:
data=http://www.cppcns.com/jiaoben/python/data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=http://www.cppcns.com/jiaoben/python/reg1.sub(' ',data)
reg2=re.compile('\]')
data=http://www.cppcns.com/jiaoben/python/reg2.sub('',data)
reg3=re.compile('
')
data=http://www.cppcns.com/jiaoben/python/reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=http://www.cppcns.com/jiaoben/python/self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = http://www.cppcns.com/jiaoben/python/self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=http://www.cppcns.com/jiaoben/python/data.replace('var replyData='http://www.cppcns.com/jiaoben/python/,'')
else:
data=http://www.cppcns.com/jiaoben/python/data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=http://www.cppcns.com/jiaoben/python/reg1.sub(' ',data)
reg2=re.compile('\]')
data=http://www.cppcns.com/jiaoben/python/reg2.sub('',data)
reg3=re.compile('
')
data=http://www.cppcns.com/jiaoben/python/reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=http://www.cppcns.com/jiaoben/python/self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = http://www.cppcns.com/jiaoben/python/self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻( 什么是百度蜘蛛?如何使用网络漫游蜘蛛遵循的规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-01 23:04
什么是百度蜘蛛?如何使用网络漫游蜘蛛遵循的规则)
大连seo谈如何吸引百度蜘蛛爬取网站
什么是百度蜘蛛?
百度蜘蛛实际上是一个自动递归遍历和检索文件网站的内容和信息的程序。百度蜘蛛也常被称为搜索引擎蜘蛛。这些蜘蛛访问 网站 并按照链接向搜索引擎数据库添加更多信息。
搜索引擎蜘蛛遵循的规则
尽管编写机器人程序并忽略规则是可能的,但大多数网络机器人程序编写代码是为了遵守 网站 上特定文本文件中的某些规则。此文件的 robots.txt 文件。它通常位于 Web 服务器的根目录,充当机器人网关。它告诉他们的网站,他们可以等待字段,不能遍历。
请记住,虽然大多数网络机器人都遵守规则,但您在 robots.txt 文件中撒谎,而有些则没有。如果您有敏感信息,您应该在内网上使用密码或控件而不是蜘蛛。它不依赖于机器人来访问它。
如何使用网络漫游
百度蜘蛛最常见的用途是搜索引擎的网站索引。但是机器人可以使用,也可以用于其他目的。一些更常见的用途是:
链接验证——机器人可以跟踪网页上的一个 网站 或所有链接,它们将进行测试以确保它们返回有效的页面代码。这种编程的好处在本质上是显而易见的。机器人可以在一两分钟内访问页面上的所有链接,并比手动操作更快地提供结果报告。
HTML 验证 – 类似于链接验证,机器人可以发送到您的 网站 上的各个页面来评估 HTML 代码。
更改监控 - 是 Web 上的一项服务,它会在网页发生更改时通知您。这些服务由机器人发送到页面,以定期评估内容的变化。不同之处在于机器人何时会提交报告。
网站Mirroring – 类似的变更监控机器人。这些机器人评估一个 网站 并且不时改变。机器人将更改后的信息传送到镜像站点位置。
大连网站优化: 查看全部
抓取网页新闻(
什么是百度蜘蛛?如何使用网络漫游蜘蛛遵循的规则)
大连seo谈如何吸引百度蜘蛛爬取网站
什么是百度蜘蛛?
百度蜘蛛实际上是一个自动递归遍历和检索文件网站的内容和信息的程序。百度蜘蛛也常被称为搜索引擎蜘蛛。这些蜘蛛访问 网站 并按照链接向搜索引擎数据库添加更多信息。
搜索引擎蜘蛛遵循的规则
尽管编写机器人程序并忽略规则是可能的,但大多数网络机器人程序编写代码是为了遵守 网站 上特定文本文件中的某些规则。此文件的 robots.txt 文件。它通常位于 Web 服务器的根目录,充当机器人网关。它告诉他们的网站,他们可以等待字段,不能遍历。
请记住,虽然大多数网络机器人都遵守规则,但您在 robots.txt 文件中撒谎,而有些则没有。如果您有敏感信息,您应该在内网上使用密码或控件而不是蜘蛛。它不依赖于机器人来访问它。
如何使用网络漫游
百度蜘蛛最常见的用途是搜索引擎的网站索引。但是机器人可以使用,也可以用于其他目的。一些更常见的用途是:
链接验证——机器人可以跟踪网页上的一个 网站 或所有链接,它们将进行测试以确保它们返回有效的页面代码。这种编程的好处在本质上是显而易见的。机器人可以在一两分钟内访问页面上的所有链接,并比手动操作更快地提供结果报告。
HTML 验证 – 类似于链接验证,机器人可以发送到您的 网站 上的各个页面来评估 HTML 代码。
更改监控 - 是 Web 上的一项服务,它会在网页发生更改时通知您。这些服务由机器人发送到页面,以定期评估内容的变化。不同之处在于机器人何时会提交报告。
网站Mirroring – 类似的变更监控机器人。这些机器人评估一个 网站 并且不时改变。机器人将更改后的信息传送到镜像站点位置。
大连网站优化:
抓取网页新闻(本站最新发布Python从入门到精通|Python基础教程试听地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-01 08:09
)
本站Python最新版本从入门到精通| Python基础教程
试听地址
学习了python的基本语法后,对爬虫产生了浓厚的兴趣。废话不多。今天来爬取网易新闻,实战学习。
打开网易新闻,可以发现新闻分为这几个板块:
这次选择国内扇区进行爬取文章。
1. 准备
下载链接
了解网络
网页色彩鲜艳,漂亮,像一幅水彩画。要抓取数据,首先要知道需要抓取的数据是如何呈现的,就像学习画画一样。在你开始之前,你需要知道这幅画是用什么画的,铅笔还是水彩笔……它可能是各种类型的。是的,但是只有两种方式可以在网页上显示信息:
HTML是一种用于描述网页的语言
JSON 是一种轻量级的数据交换格式
爬取网页信息其实就是向网页发出请求,服务器将数据反馈给你
2. 获取动态加载源码
导入所需的模块和库:
1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送一个请求。请求可以帮助我们很好地完成这一点。但是经过仔细观察,我们发现网易新闻是动态加载的。请求返回即时信息。稍后加载到网页上的数据不会返回。在这种情况下,Selenium 可以帮助我们获取更多数据。我们将 selenium 理解为一种自动化测试工具。Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
我使用的浏览器是火狐
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样我们就可以驱动浏览器自动登录网易新闻页面
我们的目标自然是一次爬下国内部分,观察网页。当网页不断向下滚动时,将加载新的新闻。在底部,甚至还有一个刷新按钮:
这时候使用selenium就可以显示出它的优势了:自动化,模拟鼠标键盘操作:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右击网页中的Load More按钮,点击View Element,可以看到
通过这个类,可以定位按钮。当遇到按钮时,点击事件可以帮助我们自动点击按钮完成网页刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用信息
简单来说,BeautifulSoup 是一个 Python 库。它的主要功能是从网页中抓取数据,可以减轻新手的负担。通过BeautifulSoup解析网页源代码,并添加附带的函数,我们可以方便的检索到我们想要的信息,例如:获取标题、标签和文本内容超链接
也可以右键点击文章标题区查看元素:
观察网页的结构,发现每个div标签class="news_title"下面是文章的标题和超链接。soup.find_all() 函数可以帮助我们找到我们想要的所有信息,并且可以一次性提取出该级别结构下的内容。最后通过字典,将标签信息一一检索出来。
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4. 获取新闻内容
此后,新闻链接被我们取出并存入列表。现在我们需要做的就是使用链接来获取新闻主题内容。新闻主题内容页面静态加载,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
使用try except的原因是网易新闻文章在一定时间前后,文本信息的位置和标签不同,不同的情况要区别对待。
最后遍历整个列表以检索所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地txt文件
Python提供了一个文件处理函数open(),第一个参数是文件路径,第二个是文件处理方式,“w”方式是只写的(如果文件不存在则创建,如果文件不存在则清空内容)它存在)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
一个简单的爬虫到目前为止已经成功写好了:
查看全部
抓取网页新闻(本站最新发布Python从入门到精通|Python基础教程试听地址
)
本站Python最新版本从入门到精通| Python基础教程
试听地址
学习了python的基本语法后,对爬虫产生了浓厚的兴趣。废话不多。今天来爬取网易新闻,实战学习。
打开网易新闻,可以发现新闻分为这几个板块:
这次选择国内扇区进行爬取文章。
1. 准备
下载链接
了解网络
网页色彩鲜艳,漂亮,像一幅水彩画。要抓取数据,首先要知道需要抓取的数据是如何呈现的,就像学习画画一样。在你开始之前,你需要知道这幅画是用什么画的,铅笔还是水彩笔……它可能是各种类型的。是的,但是只有两种方式可以在网页上显示信息:
HTML是一种用于描述网页的语言
JSON 是一种轻量级的数据交换格式
爬取网页信息其实就是向网页发出请求,服务器将数据反馈给你
2. 获取动态加载源码
导入所需的模块和库:
1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送一个请求。请求可以帮助我们很好地完成这一点。但是经过仔细观察,我们发现网易新闻是动态加载的。请求返回即时信息。稍后加载到网页上的数据不会返回。在这种情况下,Selenium 可以帮助我们获取更多数据。我们将 selenium 理解为一种自动化测试工具。Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
我使用的浏览器是火狐
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样我们就可以驱动浏览器自动登录网易新闻页面
我们的目标自然是一次爬下国内部分,观察网页。当网页不断向下滚动时,将加载新的新闻。在底部,甚至还有一个刷新按钮:
这时候使用selenium就可以显示出它的优势了:自动化,模拟鼠标键盘操作:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右击网页中的Load More按钮,点击View Element,可以看到
通过这个类,可以定位按钮。当遇到按钮时,点击事件可以帮助我们自动点击按钮完成网页刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用信息
简单来说,BeautifulSoup 是一个 Python 库。它的主要功能是从网页中抓取数据,可以减轻新手的负担。通过BeautifulSoup解析网页源代码,并添加附带的函数,我们可以方便的检索到我们想要的信息,例如:获取标题、标签和文本内容超链接
也可以右键点击文章标题区查看元素:
观察网页的结构,发现每个div标签class="news_title"下面是文章的标题和超链接。soup.find_all() 函数可以帮助我们找到我们想要的所有信息,并且可以一次性提取出该级别结构下的内容。最后通过字典,将标签信息一一检索出来。
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4. 获取新闻内容
此后,新闻链接被我们取出并存入列表。现在我们需要做的就是使用链接来获取新闻主题内容。新闻主题内容页面静态加载,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
使用try except的原因是网易新闻文章在一定时间前后,文本信息的位置和标签不同,不同的情况要区别对待。
最后遍历整个列表以检索所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地txt文件
Python提供了一个文件处理函数open(),第一个参数是文件路径,第二个是文件处理方式,“w”方式是只写的(如果文件不存在则创建,如果文件不存在则清空内容)它存在)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
一个简单的爬虫到目前为止已经成功写好了:
抓取网页新闻( 通常哪些网站页面不应该被百度抓取呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-27 01:07
通常哪些网站页面不应该被百度抓取呢?(图))
为什么要禁止自己的网页?哪些网站 页面不应该被百度抓取?
那么哪些网站页面不应该被百度抓取呢?比如网站里面有一些重复的内容,比如一些按条件查询得到的结果页。这一点在很多商场网站中脱颖而出。例如,由于产品的颜色、尺寸、型号的不同,会出现很多相似的页面。这种页面对于用户来说可以有一定的体验,但是对于搜索引擎来说很容易。他们因为提供了太多重复的内容而受到惩罚或降级。
另外,网站中还有很多注册页、备份页、测试页。这些页面只是为了用户更好的操作网站以及自己对网站的操作进行管理。但是这些页面内容比较单调,不适合百度对内容质量的要求。所以要尽量避免被百度收录抓取。我们来谈谈如何避免百度对内容页面的抓取。
, 使用Flash技术展示不想被百度的内容收录
这种方式不仅可以让用户获得更好的用户体验,而且百度也无法抓取这些内容,从而更好地为用户服务,并且不会影响自己的内容在百度上的公开。
二、利用robots脚本技术屏蔽相应内容
目前,搜索引擎行业协会规定,Robots 描述的内容和链接应限制抓取。因此,对于网站上是否存在私有内容,以及管理页面、测试页面等内容,可以在本脚本文件中进行设置。这不仅可以为这个网站提供良好的维护,也可以防止那些看似垃圾邮件的内容被百度抓取,反而会对这个网站产生巨大的负面影响。
三、使用nofollow属性标签放弃页面上不想成为的内容收录
这种方法使用比较普遍,它可以屏蔽网页中的某个区域或一段文字,从而提高您的内容优化效果。使用该技术只需将需要屏蔽的内容的nofollow属性设置为True,即可屏蔽该内容。比如网站上有一些精彩的内容,但这些内容也收录锚文本链接。那么为了防止这些锚文本链接窃取本站的权重,可以在这些锚文本链接上设置nofollow属性,这样就可以享受这些内容给网站带来的流量,并在同时可以避免网站重量分流的危险。
四、使用Meta Noindex和follow标签
使用这种方法不仅可以防止被百度收录,还可以实现权重的传递。当然具体的操作还是看站长的需要,但是用这种方式来屏蔽内容往往会浪费百度蜘蛛的爬行时间影响优化体验,也就是说这种方式在不是最后一次的时候是没有必要的采取。
对于部分站长使用表单模式和Javascript技术进行拦截,已经无法完成这个任务,因为随着百度蜘蛛智能水平的提升,用这些技术编辑的内容已经可以抓取了,而且在不久的将来,一旦可以抓取到Flash中的内容,如果要屏蔽网站的内容,就应该避免这种方法。
华旗商城更多产品介绍:定制PHP网站打造婚纱摄影新模板 中国山东网-枣庄软文写作技巧 查看全部
抓取网页新闻(
通常哪些网站页面不应该被百度抓取呢?(图))
为什么要禁止自己的网页?哪些网站 页面不应该被百度抓取?
那么哪些网站页面不应该被百度抓取呢?比如网站里面有一些重复的内容,比如一些按条件查询得到的结果页。这一点在很多商场网站中脱颖而出。例如,由于产品的颜色、尺寸、型号的不同,会出现很多相似的页面。这种页面对于用户来说可以有一定的体验,但是对于搜索引擎来说很容易。他们因为提供了太多重复的内容而受到惩罚或降级。
另外,网站中还有很多注册页、备份页、测试页。这些页面只是为了用户更好的操作网站以及自己对网站的操作进行管理。但是这些页面内容比较单调,不适合百度对内容质量的要求。所以要尽量避免被百度收录抓取。我们来谈谈如何避免百度对内容页面的抓取。
, 使用Flash技术展示不想被百度的内容收录
这种方式不仅可以让用户获得更好的用户体验,而且百度也无法抓取这些内容,从而更好地为用户服务,并且不会影响自己的内容在百度上的公开。
二、利用robots脚本技术屏蔽相应内容
目前,搜索引擎行业协会规定,Robots 描述的内容和链接应限制抓取。因此,对于网站上是否存在私有内容,以及管理页面、测试页面等内容,可以在本脚本文件中进行设置。这不仅可以为这个网站提供良好的维护,也可以防止那些看似垃圾邮件的内容被百度抓取,反而会对这个网站产生巨大的负面影响。
三、使用nofollow属性标签放弃页面上不想成为的内容收录
这种方法使用比较普遍,它可以屏蔽网页中的某个区域或一段文字,从而提高您的内容优化效果。使用该技术只需将需要屏蔽的内容的nofollow属性设置为True,即可屏蔽该内容。比如网站上有一些精彩的内容,但这些内容也收录锚文本链接。那么为了防止这些锚文本链接窃取本站的权重,可以在这些锚文本链接上设置nofollow属性,这样就可以享受这些内容给网站带来的流量,并在同时可以避免网站重量分流的危险。
四、使用Meta Noindex和follow标签
使用这种方法不仅可以防止被百度收录,还可以实现权重的传递。当然具体的操作还是看站长的需要,但是用这种方式来屏蔽内容往往会浪费百度蜘蛛的爬行时间影响优化体验,也就是说这种方式在不是最后一次的时候是没有必要的采取。
对于部分站长使用表单模式和Javascript技术进行拦截,已经无法完成这个任务,因为随着百度蜘蛛智能水平的提升,用这些技术编辑的内容已经可以抓取了,而且在不久的将来,一旦可以抓取到Flash中的内容,如果要屏蔽网站的内容,就应该避免这种方法。
华旗商城更多产品介绍:定制PHP网站打造婚纱摄影新模板 中国山东网-枣庄软文写作技巧
抓取网页新闻( 网站得从哪几方面下手,应该注意哪些点?6个方面告诉你)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-27 01:05
网站得从哪几方面下手,应该注意哪些点?6个方面告诉你)
为了被搜索引擎抓取,网站应该从哪些方面入手,应该注意哪些方面?6种方式告诉你。
1.稳定网址
该 URL 是 网站 的主根。URL的好坏直接影响搜索引擎对网站的抓取和识别;同时,客户的体验也会受到影响;想象一下,用户在点击的时候总是会出错,会继续点击你的网站,极大地影响了用户的点击率;针对搜索引擎的胃口,网址尽量是静态的,层次不要太多,最多不超过三级,网址要简短易记。
2.图片优化
一张图片胜过千言万语。网站中图片的应用越来越受到重视,百度也比以前更加重视图片。图片的优化也成为了SEOer们关注的重点,迎合了百度的胃口,一是注意图片的大小,一般长:宽=121:75;图片过大会降低加载速度,不利于用户体验;其次,注意图片的清晰度,图片会模糊。,用户体验会大打折扣;最后是最基础的Alt标签,蜘蛛依靠Alt标签来识别图片,所以一定要注意Alt的写法,但是不建议出现关键词堆叠。
3.关键词布局
合理的关键词布局可以促进网站的优化,有利于提升关键词的排名,提升用户体验;根据网站的关键词,密度合理网站的布局必须符合网站的审美,达到良好的用户体验;平时网站的关键词设置在F区,版权在网站底部。
4.优质内容
内容为王是不变的真理。网站文章的好坏可以决定网站优化效果的高低;百度蜘蛛每天都来你的网站,只为拦截到好东西;高质量的原创文章是他的最爱;对于原创文章,需要注意的是文章的内容是时效性和用户价值的;你需要小说标题;同时文章一定要定期更新,百度也会有时间抓拍你的网站内容。
5.优质外链
提升关键词排名的重要渠道之一是外链。但是,由于垃圾外链泛滥,百度的外链评级页面有所减少;但是,外部链接仍然是 SEO 优化的。第二个最重要的方法是不要忽视;只有优质合理的外链才能被百度蜘蛛青睐。每日外部链接必须定期发布,不得有起伏。发布的内容质量要高,能为用户带来价值;同时,必须根据平台的规则,选择正确的版块进行发布。
6.用户体验
建立网站的目的是让用户通过互联网更快的找到你,把客户带到企业。用户体验不好,网站再华丽也没有用;网站建设对用户体验不友好,网站最终会走向黑洞;do 网站 如果是为搜索引擎做的话 是的,这是一个很大的错误;搜索引擎会记录用户的点击行为,包括点击率和跳出率;你的网站用户体验不好,所以不会给你太大的分量。 查看全部
抓取网页新闻(
网站得从哪几方面下手,应该注意哪些点?6个方面告诉你)
为了被搜索引擎抓取,网站应该从哪些方面入手,应该注意哪些方面?6种方式告诉你。
1.稳定网址
该 URL 是 网站 的主根。URL的好坏直接影响搜索引擎对网站的抓取和识别;同时,客户的体验也会受到影响;想象一下,用户在点击的时候总是会出错,会继续点击你的网站,极大地影响了用户的点击率;针对搜索引擎的胃口,网址尽量是静态的,层次不要太多,最多不超过三级,网址要简短易记。
2.图片优化
一张图片胜过千言万语。网站中图片的应用越来越受到重视,百度也比以前更加重视图片。图片的优化也成为了SEOer们关注的重点,迎合了百度的胃口,一是注意图片的大小,一般长:宽=121:75;图片过大会降低加载速度,不利于用户体验;其次,注意图片的清晰度,图片会模糊。,用户体验会大打折扣;最后是最基础的Alt标签,蜘蛛依靠Alt标签来识别图片,所以一定要注意Alt的写法,但是不建议出现关键词堆叠。
3.关键词布局
合理的关键词布局可以促进网站的优化,有利于提升关键词的排名,提升用户体验;根据网站的关键词,密度合理网站的布局必须符合网站的审美,达到良好的用户体验;平时网站的关键词设置在F区,版权在网站底部。
4.优质内容
内容为王是不变的真理。网站文章的好坏可以决定网站优化效果的高低;百度蜘蛛每天都来你的网站,只为拦截到好东西;高质量的原创文章是他的最爱;对于原创文章,需要注意的是文章的内容是时效性和用户价值的;你需要小说标题;同时文章一定要定期更新,百度也会有时间抓拍你的网站内容。
5.优质外链
提升关键词排名的重要渠道之一是外链。但是,由于垃圾外链泛滥,百度的外链评级页面有所减少;但是,外部链接仍然是 SEO 优化的。第二个最重要的方法是不要忽视;只有优质合理的外链才能被百度蜘蛛青睐。每日外部链接必须定期发布,不得有起伏。发布的内容质量要高,能为用户带来价值;同时,必须根据平台的规则,选择正确的版块进行发布。
6.用户体验
建立网站的目的是让用户通过互联网更快的找到你,把客户带到企业。用户体验不好,网站再华丽也没有用;网站建设对用户体验不友好,网站最终会走向黑洞;do 网站 如果是为搜索引擎做的话 是的,这是一个很大的错误;搜索引擎会记录用户的点击行为,包括点击率和跳出率;你的网站用户体验不好,所以不会给你太大的分量。
抓取网页新闻(数据去重,我们一般需要利用r语言的filter,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-26 22:02
抓取网页新闻,数据去重,我们一般需要利用r语言的filter,while循环,bool变量,
<p>主要用的是r语言。对于数据集demo,它包含了ios8相关的文档,照片以及程序。这个数据集里的数据是以pdf格式保存的,你需要读取之后分析。导入数据后,你可以查看它的size信息,以此为参考,构建一个时间序列模型:1.data['temp']=demo['atemp']*10002.data['mean']=demo['sampleday']*10003.data['average']=demo['sampleday']*1000将相关时间轴数据读入matlab进行分析acf=imshow(demo,database='matlab')如果想读取包含价格、起步价、加单价的数据集,我推荐你使用read.csv()函数,输入“加单价”就可以将数据读入到matlab中。package 查看全部
抓取网页新闻(数据去重,我们一般需要利用r语言的filter,,)
抓取网页新闻,数据去重,我们一般需要利用r语言的filter,while循环,bool变量,
<p>主要用的是r语言。对于数据集demo,它包含了ios8相关的文档,照片以及程序。这个数据集里的数据是以pdf格式保存的,你需要读取之后分析。导入数据后,你可以查看它的size信息,以此为参考,构建一个时间序列模型:1.data['temp']=demo['atemp']*10002.data['mean']=demo['sampleday']*10003.data['average']=demo['sampleday']*1000将相关时间轴数据读入matlab进行分析acf=imshow(demo,database='matlab')如果想读取包含价格、起步价、加单价的数据集,我推荐你使用read.csv()函数,输入“加单价”就可以将数据读入到matlab中。package
抓取网页新闻(看代码urllib2get请求方法爬虫对象代码是post-get-post/x-www-form-urlencoded的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-25 09:02
抓取网页新闻的时候需要爬虫在浏览器中登录网页,或者爬虫在app中注册登录,还有就是网页页面代码过多需要抓取。get和post可以有两种用法:get:发送给get方法的url地址,直接获取该url下的所有的页面信息post:发送给post方法的url地址,用于向一个目标url或者目标网站发送消息,获取该页面信息。
上图就明白了,get是动态的发送请求获取数据;post是可以静态的发送一次请求获取数据,或者多次post;page就是网页页面url,get可以获取所有的页面,post也可以获取所有的页面。
get和post的基本区别如下:1。get获取一个网页的静态内容,post获取一个网页的动态内容2。get会有一个url报文,post不会,动态内容靠url报文是没有办法送达服务器的3。get只能是一次性请求,post可以多次请求,一次性请求4。get可以实现网页的抓取、更新,但post不能抓取、更新5。get可以获取网页的文件,post无法实现(例如,get的cookie信息,不适用于webqq)。
看代码urllib2get请求方法post请求方法爬虫对象方法
代码是post-get-post都是一个content-type就可以是application/x-www-form-urlencoded的请求
其实这是两种请求的区别和post和get的区别-dev-知乎专栏 查看全部
抓取网页新闻(看代码urllib2get请求方法爬虫对象代码是post-get-post/x-www-form-urlencoded的区别)
抓取网页新闻的时候需要爬虫在浏览器中登录网页,或者爬虫在app中注册登录,还有就是网页页面代码过多需要抓取。get和post可以有两种用法:get:发送给get方法的url地址,直接获取该url下的所有的页面信息post:发送给post方法的url地址,用于向一个目标url或者目标网站发送消息,获取该页面信息。
上图就明白了,get是动态的发送请求获取数据;post是可以静态的发送一次请求获取数据,或者多次post;page就是网页页面url,get可以获取所有的页面,post也可以获取所有的页面。
get和post的基本区别如下:1。get获取一个网页的静态内容,post获取一个网页的动态内容2。get会有一个url报文,post不会,动态内容靠url报文是没有办法送达服务器的3。get只能是一次性请求,post可以多次请求,一次性请求4。get可以实现网页的抓取、更新,但post不能抓取、更新5。get可以获取网页的文件,post无法实现(例如,get的cookie信息,不适用于webqq)。
看代码urllib2get请求方法post请求方法爬虫对象方法
代码是post-get-post都是一个content-type就可以是application/x-www-form-urlencoded的请求
其实这是两种请求的区别和post和get的区别-dev-知乎专栏
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术实现思路:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-25 07:01
数据捕获方法只是一种技术理论可行性研究,不鼓励任何人进行现实世界的捕获。
先分享一下资源~我整理了2019年全年的成绩单:
提取码:2438
然后分享一下代码的实现思路:
首先确定数据源。其实网上有一些网站聚合新闻网文稿,甚至有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网而不是二道展。
接下来分析页面结构。
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整个新闻播放,下面是单个新闻。点击进入 每个新闻页面都会找到“相关文章”的内容。
打开 F12 调试,点击不同的日期,可以在 XHR 选项卡中找到之前的请求。可以发现唯一的变化是链接地址中的日期字符串。
这决定了我们的想法。
根据更改日期→获取当天新闻列表→循环保存新闻文章内容
后续的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要抓取2019年全年的新闻,需要生成一个20190101到20191231之间的365个日期的列表。之前我们写过一篇文章关于日期列表生成的介绍,使用datetime库,这次我们使用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20190101', '20191231'):
save_text(date)
time.sleep(3)
最后,祝大家2020新年快乐~
希望新的一年,大家都能有所收获,有所收获,实现每一个小目标。 查看全部
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术实现思路:)
数据捕获方法只是一种技术理论可行性研究,不鼓励任何人进行现实世界的捕获。
先分享一下资源~我整理了2019年全年的成绩单:
提取码:2438
然后分享一下代码的实现思路:
首先确定数据源。其实网上有一些网站聚合新闻网文稿,甚至有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网而不是二道展。
接下来分析页面结构。
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整个新闻播放,下面是单个新闻。点击进入 每个新闻页面都会找到“相关文章”的内容。
打开 F12 调试,点击不同的日期,可以在 XHR 选项卡中找到之前的请求。可以发现唯一的变化是链接地址中的日期字符串。
这决定了我们的想法。
根据更改日期→获取当天新闻列表→循环保存新闻文章内容
后续的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要抓取2019年全年的新闻,需要生成一个20190101到20191231之间的365个日期的列表。之前我们写过一篇文章关于日期列表生成的介绍,使用datetime库,这次我们使用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20190101', '20191231'):
save_text(date)
time.sleep(3)
最后,祝大家2020新年快乐~
希望新的一年,大家都能有所收获,有所收获,实现每一个小目标。
抓取网页新闻(Excel催化剂网页采集教程:获取所要元素的CSSSelector功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-25 07:00
)
有时我们想在网页上获取一些内容。比如作者在做轮播功能的时候,想要获取一些示例图片链接。如果把图片链接一个一个复制,效率太低了,还是开个爬虫工具吧。采集,除非你需要批量获取多个页面,否则太麻烦了。
本文给你一个小技巧,快速完成这些小临时需求。用到的知识是CSS的选择器函数。
整个过程分为几个步骤,下面分别说明。
一、获取所需元素的CSS Selector表达式
假设您已经对 CSS Selector 有所了解。如果你没有通过这一步,以后就没有意义了。任何网页采集的前提是你对xpath和CSS Selector有一点了解。
在现代 Web 技术中,CSS 被广泛用于布局页面。相对而言,使用 CSS 选择器可能比 xpath 更方便定位网页内容。毕竟,前端工程师自己使用 CSS 来定位和格式化元素。我们使用它来定位元素并仅获取内容。
如果想详细了解具体的CSS选择器,可以去W3School等地方学习。
例如这个链接:
下面是更高级的 CSS 选择器知识:
这是定位网页内容的整个方法
1. 找到你想要的网页内容,如轮播图,右键【检查】按钮,定位到这个元素
2. 观察整个网页元素结构,特别注意上面的父节点
下图中我们可以发现整个carousel图片其实就是一个类promo-bd的div节点下的内容,里面收录了几个div,一个是我们定位的图片,其他的是一些隐藏的轮播图像。
CSS选择器定位一般使用多个类名来限定其作用域,即当前节点的类名,然后找到其父级唯一的类名来辅助定位。
3.使用ChroPath工具辅助定位,找到最终内容对应的CSS Selector表达式。
在Excel催化剂网页的采集教程中,我曾经介绍过ChroPath这个工具,用来定位Xpath,也可以定位CSS Selector。
如下图所示,我们找到了类名.promo-bd,它是整个网页唯一的。
然后缩小范围并添加每个轮播的特定类名 mod。此时CSS Selector表达式为[.promo-bd.mod],两个类之间有一个空格,表示要找到promo-bd类mod类的后代。
此时,我们找到了 7 个结果。我们需要的是 5 个轮播图像。有时我们找不到它们也没关系。下载图像并排除额外的部分可能比找到 5 个元素更方便。
回到我们需要的图片链接元素,就是img节点,上层是a节点。
所以我们最后写的CSS Selector是[.promo-bd .mod a>img],大于号代表父子,不是空间的任何后代。
二、打开浏览器开发工具的【控制台】面板,输入指定命令获取需要的内容
先给出最终的结果,然后再一步一步慢慢讲解原理。
输入:Array.from(document.querySelectorAll(".promo-bd .mod a>img")).map(s=>s.currentSrc).join("\n")
只需获取你想要的图片链接文字,自己复制粘贴到Excel中即可(Excel Catalyst有批量下载功能,有链接,你可以方便的将链接内容下载到本地,自定义你需要的名字)。
像Excel函数一样,可以嵌套多个函数来实现复杂的功能。
1.使用querySelectorAll查询CSS Selector的内容
在下图中,我们可以看到我们找到了一个收录7个对象的集合,然后展开它就知道我们想要的内容在currentSrc属性中。
2.把集合变成数组
数组的优点之一是可以使用后续的map方法遍历提取自己想要的内容。
3. 加上map函数遍历你需要的元素属性
这时候上面的对象数组已经转化为一个人字串数组
4. 最后一步是将数组转换为字符串,用换行符分隔
这时候开头和结尾只有一个双引号,中间元素没有双引号,不做任何处理就复制了。
5. 复制并粘贴到 Excel 单元格中,然后简单地处理和下载
最后,我们还发现,7个元素之所以出现,是因为它们已经重复出现了。只需删除 Excel 中的重复项,这就是我们想要的 5 个元素。
当然,最方便的方法是直接在Excel中处理,直接下载。这就是Excel Catalyst为大家准备的【批量下载网页文件】功能。
查看全部
抓取网页新闻(Excel催化剂网页采集教程:获取所要元素的CSSSelector功能
)
有时我们想在网页上获取一些内容。比如作者在做轮播功能的时候,想要获取一些示例图片链接。如果把图片链接一个一个复制,效率太低了,还是开个爬虫工具吧。采集,除非你需要批量获取多个页面,否则太麻烦了。
本文给你一个小技巧,快速完成这些小临时需求。用到的知识是CSS的选择器函数。
整个过程分为几个步骤,下面分别说明。
一、获取所需元素的CSS Selector表达式
假设您已经对 CSS Selector 有所了解。如果你没有通过这一步,以后就没有意义了。任何网页采集的前提是你对xpath和CSS Selector有一点了解。
在现代 Web 技术中,CSS 被广泛用于布局页面。相对而言,使用 CSS 选择器可能比 xpath 更方便定位网页内容。毕竟,前端工程师自己使用 CSS 来定位和格式化元素。我们使用它来定位元素并仅获取内容。
如果想详细了解具体的CSS选择器,可以去W3School等地方学习。
例如这个链接:
下面是更高级的 CSS 选择器知识:
这是定位网页内容的整个方法
1. 找到你想要的网页内容,如轮播图,右键【检查】按钮,定位到这个元素
2. 观察整个网页元素结构,特别注意上面的父节点
下图中我们可以发现整个carousel图片其实就是一个类promo-bd的div节点下的内容,里面收录了几个div,一个是我们定位的图片,其他的是一些隐藏的轮播图像。
CSS选择器定位一般使用多个类名来限定其作用域,即当前节点的类名,然后找到其父级唯一的类名来辅助定位。
3.使用ChroPath工具辅助定位,找到最终内容对应的CSS Selector表达式。
在Excel催化剂网页的采集教程中,我曾经介绍过ChroPath这个工具,用来定位Xpath,也可以定位CSS Selector。
如下图所示,我们找到了类名.promo-bd,它是整个网页唯一的。
然后缩小范围并添加每个轮播的特定类名 mod。此时CSS Selector表达式为[.promo-bd.mod],两个类之间有一个空格,表示要找到promo-bd类mod类的后代。
此时,我们找到了 7 个结果。我们需要的是 5 个轮播图像。有时我们找不到它们也没关系。下载图像并排除额外的部分可能比找到 5 个元素更方便。
回到我们需要的图片链接元素,就是img节点,上层是a节点。
所以我们最后写的CSS Selector是[.promo-bd .mod a>img],大于号代表父子,不是空间的任何后代。
二、打开浏览器开发工具的【控制台】面板,输入指定命令获取需要的内容
先给出最终的结果,然后再一步一步慢慢讲解原理。
输入:Array.from(document.querySelectorAll(".promo-bd .mod a>img")).map(s=>s.currentSrc).join("\n")
只需获取你想要的图片链接文字,自己复制粘贴到Excel中即可(Excel Catalyst有批量下载功能,有链接,你可以方便的将链接内容下载到本地,自定义你需要的名字)。
像Excel函数一样,可以嵌套多个函数来实现复杂的功能。
1.使用querySelectorAll查询CSS Selector的内容
在下图中,我们可以看到我们找到了一个收录7个对象的集合,然后展开它就知道我们想要的内容在currentSrc属性中。
2.把集合变成数组
数组的优点之一是可以使用后续的map方法遍历提取自己想要的内容。
3. 加上map函数遍历你需要的元素属性
这时候上面的对象数组已经转化为一个人字串数组
4. 最后一步是将数组转换为字符串,用换行符分隔
这时候开头和结尾只有一个双引号,中间元素没有双引号,不做任何处理就复制了。
5. 复制并粘贴到 Excel 单元格中,然后简单地处理和下载
最后,我们还发现,7个元素之所以出现,是因为它们已经重复出现了。只需删除 Excel 中的重复项,这就是我们想要的 5 个元素。
当然,最方便的方法是直接在Excel中处理,直接下载。这就是Excel Catalyst为大家准备的【批量下载网页文件】功能。

