
抓取网页新闻
抓取网页新闻(存储到存储池(word2vec),如何识别文本中不容易识别的字?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-15 20:07
抓取网页新闻,全部留下,存储到存储池(word2vec),构建mlp模型当文本的语义复杂程度超过了一定水平时,使用二分类,将复杂信息抽取到相应输入,
与其问这个问题,
看到过这个问题,还是贴过来吧internetrecognition,fromscratch,教给我们诸如“词袋”等一些思路来识别一些文本中不容易识别的字,很有趣的一个提问,和周董一起回答吧,哈哈~下面说一下准备过程,或者按照这个顺序来:1,收集文本和网页本身,这个依赖于自己想在生活中分析什么。不过大概是先要熟悉内容内容源,比如,最早的搜狐内容源是否是文档等。
2,爬虫爬取,理论是保持最低程度最好不要重复爬取。因为保存在word2vec中,会有很多你自己规则会显示错误的字词,一定要确认是否显示错误。并且一些比较突出的字词一定要拿过来做不可变性处理。3,转为word2vec(搜狐本身有公开接口)你可以自己封装一下,用一个有效的词向量代替即可,网上有很多是用one-hot词向量方法,可以跑一下没什么问题。
当然,代码用的spacy必须解决目前容量大小的问题,用vcforward的话,一般只能跑到c++里。4,textmodel这就看你自己如何构建语义表示了,可以到网上找到很多博客和相关资料,下面我的代码参考如下。libword-model用的是wordnews的2000w句子词向量,但是可以根据自己的需要加入一些定制需求,比如你需要把邮件显示文字长度等信息。
这里可以看到我特别弄了一个词向量。同时去掉了名字,可以有效去除一些歧义,看看下图。注:封装好的text也可以直接把句子拼成自己需要的形式,这个需要根据网页的特性来选择封装的形式。做到前面的三步,你就可以用自己准备好的代码,拼接成一个word2vec的模型了。更多内容,欢迎关注ai有道微信公众号,有的放矢。 查看全部
抓取网页新闻(存储到存储池(word2vec),如何识别文本中不容易识别的字?)
抓取网页新闻,全部留下,存储到存储池(word2vec),构建mlp模型当文本的语义复杂程度超过了一定水平时,使用二分类,将复杂信息抽取到相应输入,
与其问这个问题,
看到过这个问题,还是贴过来吧internetrecognition,fromscratch,教给我们诸如“词袋”等一些思路来识别一些文本中不容易识别的字,很有趣的一个提问,和周董一起回答吧,哈哈~下面说一下准备过程,或者按照这个顺序来:1,收集文本和网页本身,这个依赖于自己想在生活中分析什么。不过大概是先要熟悉内容内容源,比如,最早的搜狐内容源是否是文档等。
2,爬虫爬取,理论是保持最低程度最好不要重复爬取。因为保存在word2vec中,会有很多你自己规则会显示错误的字词,一定要确认是否显示错误。并且一些比较突出的字词一定要拿过来做不可变性处理。3,转为word2vec(搜狐本身有公开接口)你可以自己封装一下,用一个有效的词向量代替即可,网上有很多是用one-hot词向量方法,可以跑一下没什么问题。
当然,代码用的spacy必须解决目前容量大小的问题,用vcforward的话,一般只能跑到c++里。4,textmodel这就看你自己如何构建语义表示了,可以到网上找到很多博客和相关资料,下面我的代码参考如下。libword-model用的是wordnews的2000w句子词向量,但是可以根据自己的需要加入一些定制需求,比如你需要把邮件显示文字长度等信息。
这里可以看到我特别弄了一个词向量。同时去掉了名字,可以有效去除一些歧义,看看下图。注:封装好的text也可以直接把句子拼成自己需要的形式,这个需要根据网页的特性来选择封装的形式。做到前面的三步,你就可以用自己准备好的代码,拼接成一个word2vec的模型了。更多内容,欢迎关注ai有道微信公众号,有的放矢。
抓取网页新闻(优米站长平台题主可以使用agentwangs吗?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-14 17:04
抓取网页新闻->切换到http模式,用正则表达式对新闻的源url进行搜索->找到所有新闻并统计其时间等信息。因为网站经常会搬家,
/
把单独采访一篇新闻的那篇的链接复制出来,再新开一个帖子对那篇进行采访。
techweb:searchtechcompanies,recommendsstartups,lookforfindingsomewheretobebusinessinsiders,groups,andsharethoughts
everythinginoneworld
,然后http.page的带个.,一般的新闻,google就好了。
不知道,我只看三点钟无眠区间。无中文翻译。
很喜欢我的工作职责,想听听大家对新闻采编有什么经验。目前从事的工作是:1.报纸期刊软文的广告推广;2.tb网站的服务(不只是新闻编辑推荐了,包括搜索seo,首页关键词策划,搜索引擎策划等等);3.北京三环以内住宅市场的数据报告。发现报纸广告变得越来越贵,线上平台的表现却不尽如人意。所以想请教业内人士,提升下传统意义上广告宣传渠道的效果。希望各位多指教。
via:优米站长平台
题主可以使用agentwangs!我接触这个一年多了,主要还是基于:1.会通过站长网站收集新闻,2.把收集的新闻上传到pc站,3.每天发布到站长平台,4.每天会不断上传新的新闻,集中在周一和周三。个人经验, 查看全部
抓取网页新闻(优米站长平台题主可以使用agentwangs吗?-八维教育)
抓取网页新闻->切换到http模式,用正则表达式对新闻的源url进行搜索->找到所有新闻并统计其时间等信息。因为网站经常会搬家,
/
把单独采访一篇新闻的那篇的链接复制出来,再新开一个帖子对那篇进行采访。
techweb:searchtechcompanies,recommendsstartups,lookforfindingsomewheretobebusinessinsiders,groups,andsharethoughts
everythinginoneworld
,然后http.page的带个.,一般的新闻,google就好了。
不知道,我只看三点钟无眠区间。无中文翻译。
很喜欢我的工作职责,想听听大家对新闻采编有什么经验。目前从事的工作是:1.报纸期刊软文的广告推广;2.tb网站的服务(不只是新闻编辑推荐了,包括搜索seo,首页关键词策划,搜索引擎策划等等);3.北京三环以内住宅市场的数据报告。发现报纸广告变得越来越贵,线上平台的表现却不尽如人意。所以想请教业内人士,提升下传统意义上广告宣传渠道的效果。希望各位多指教。
via:优米站长平台
题主可以使用agentwangs!我接触这个一年多了,主要还是基于:1.会通过站长网站收集新闻,2.把收集的新闻上传到pc站,3.每天发布到站长平台,4.每天会不断上传新的新闻,集中在周一和周三。个人经验,
抓取网页新闻(网上冲浪时幸运地找到了合自己胃口的音乐或者视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-13 09:16
如果你有幸在网上冲浪时找到了合你胃口的音乐或视频,相信你会有保存的冲动,网站经常下载网络媒体资源的链接,以便保存运营成本 除了封装,这些封装方式五花八门,有的随机给出一次性链接,有的只是简单的用Flash封装,访问者在客户端基本无法破解真正的下载链接。
我们也有很多工具可以嗅探和抓取这些媒体资源,但是这些方法往往费时费力,并且无法保证资源的准确性。下面是飓风软件园介绍的一种简单方便的方法。学了之后,你就完全可以舍弃那些所谓的下载工具了。
IE浏览器会把你浏览过的网页资源保存在这个文件夹:C:\Documents and Settings\Administrator\Local Settings\Temporary Internet Files, css, js, sfw 等网页文件,假设我们要保存这个视频来自优酷的《风惜雨-阳光雨》:
在弹出的设置选项框中选择“查看文件”:
选择“详情”的查看方式:
因为这里的文件太多,而且没有明确的名称信息,我们无法一一查看,所以这里需要使用文件大小和文件类型排序来搜索,通常媒体文件比较大,超过 1MB 左右,点击文件夹视图选项中的“文件大小”栏,将文件按从大到小的顺序排列,然后通过比较类型很容易找到几个可能的文件。一般视频文件格式为 flv 和 rmvb ,Rm、avi、swf,音频文件为 mp3 和 wma 格式。
我们需要在这里找到上面播放的视频“冯希雨-晴雨”。按照这个方法,编辑器会很快确定是第二个视频。
怎么样?是不是很简单?如果您刚刚点击了视频,现在可以尝试在 IE 缓存中找到该文件。 查看全部
抓取网页新闻(网上冲浪时幸运地找到了合自己胃口的音乐或者视频)
如果你有幸在网上冲浪时找到了合你胃口的音乐或视频,相信你会有保存的冲动,网站经常下载网络媒体资源的链接,以便保存运营成本 除了封装,这些封装方式五花八门,有的随机给出一次性链接,有的只是简单的用Flash封装,访问者在客户端基本无法破解真正的下载链接。
我们也有很多工具可以嗅探和抓取这些媒体资源,但是这些方法往往费时费力,并且无法保证资源的准确性。下面是飓风软件园介绍的一种简单方便的方法。学了之后,你就完全可以舍弃那些所谓的下载工具了。
IE浏览器会把你浏览过的网页资源保存在这个文件夹:C:\Documents and Settings\Administrator\Local Settings\Temporary Internet Files, css, js, sfw 等网页文件,假设我们要保存这个视频来自优酷的《风惜雨-阳光雨》:

在弹出的设置选项框中选择“查看文件”:

选择“详情”的查看方式:

因为这里的文件太多,而且没有明确的名称信息,我们无法一一查看,所以这里需要使用文件大小和文件类型排序来搜索,通常媒体文件比较大,超过 1MB 左右,点击文件夹视图选项中的“文件大小”栏,将文件按从大到小的顺序排列,然后通过比较类型很容易找到几个可能的文件。一般视频文件格式为 flv 和 rmvb ,Rm、avi、swf,音频文件为 mp3 和 wma 格式。
我们需要在这里找到上面播放的视频“冯希雨-晴雨”。按照这个方法,编辑器会很快确定是第二个视频。

怎么样?是不是很简单?如果您刚刚点击了视频,现在可以尝试在 IE 缓存中找到该文件。
抓取网页新闻(前几天非常的好(网络爬虫基本原理二)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-11 00:13
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。 (网络爬虫基本原理一、网络爬虫基本原理二).
本博客以采集博客园首页的新闻版块为例。本例使用MVC直观简单的将采集接收到的数据展示在页面上(其实有很多小网站是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用程序)。另外在实际爬取过程中可以使用多线程爬取来加速采集。
先来看看博客园的首页,做相关分析:
采集 后的结果:
爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规律,然后使用regular rules 来匹配这条规则,匹配到之后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"
的那个
之间
这样,我们就可以得到对应的正则表达式了。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>
,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量的新闻页面文件会占用大量内存,影响数据库性能。
posted @ 2017-11-28 14:06 Pooh Bear 320 Reading (254)评论(0)Edit) 查看全部
抓取网页新闻(前几天非常的好(网络爬虫基本原理二)(组图))
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。 (网络爬虫基本原理一、网络爬虫基本原理二).
本博客以采集博客园首页的新闻版块为例。本例使用MVC直观简单的将采集接收到的数据展示在页面上(其实有很多小网站是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用程序)。另外在实际爬取过程中可以使用多线程爬取来加速采集。
先来看看博客园的首页,做相关分析:
采集 后的结果:

爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规律,然后使用regular rules 来匹配这条规则,匹配到之后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"
的那个
之间

这样,我们就可以得到对应的正则表达式了。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:

using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>

,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量的新闻页面文件会占用大量内存,影响数据库性能。
posted @ 2017-11-28 14:06 Pooh Bear 320 Reading (254)评论(0)Edit)
抓取网页新闻(写爬虫你一定要关注以下5个方面:1.如何抽象整个互联网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-09 04:09
在编写爬虫时,必须注意以下5个方面:
1.如何抽象整个互联网
抽象为无向图,网页是节点,网页中的链接是有向边。
2.Fetching 算法
采用优先队列调度,区别于纯BFS。为每个网页设置一定的抓取权重,优先抓取权重较高的网页。对于权重设置,考虑的因素有:1.是否属于热门网站2.链接长度3.链接到网页的权重4.网页被指向的次数,等等。
进一步考虑,对于流行的网站,无限制爬取是不可能的,所以需要二次调度。先调度哪个网站要爬取,然后选择要爬取的网站后,调度在那个网站爬取哪些网页。这样做的好处是非常礼貌地限制了单个网站的抓取,同时也给了一些抓取其他网站网页的机会。
3.网络模型
分别考虑单机抓取和分布式抓取。对于Windows单机,可以使用IOCP完成端口进行异步爬取。这种网络接入方式可以最大限度地利用闲置资源。因为网络访问需要等待,如果简单地同时打开多个线程,计算机会花费大量时间在线程之间切换,处理获取的结果的时间会非常少。 IOCP可以达到用几个线程同步抓取几十个线程的效果。对于多机爬取,需要考虑机器的分布。比如爬亚洲的网站,用亚洲的电脑等等。
4.实时性能
新闻页面的爬取一般是由单独的爬虫来完成的。新闻网页抓取的爬虫的权重设置会与普通爬虫不同。首先,我们需要筛选新闻来源。有两种方法。一种是手动设置新闻源,比如新浪首页,第二种方式是通过机器学习。新闻源可以定义一个具有大量链接和频繁变化的链接内容的网页。从新闻源网页开始,向下爬取给定限制级别的网页,然后根据网页中的时间戳信息判断,即可添加新闻网页。
5.网页更新
如果一个网页被抓到,有些网页会继续变化,有些则不会。这里需要为网页爬取设置一些活力信息。当一个新的网页链接被发现时,其生命力时间戳信息应该是被发现的时间,表示需要立即抓取。一个网页被爬取后,其生命力时间戳信息可以设置为x分钟,以后再经过x分钟,可以根据这个时间戳判断该网页是否需要立即重新爬取。网页第二次抓取后,需要与之前的内容进行比较。如果内容相同,则下次抓取时间会延长,比如抓取前2x分钟,直到达到限制长度,比如半年或三年。月数(此值取决于您的爬网程序的能力)。如果是更新,时间需要缩短,例如x/2分钟才取。 查看全部
抓取网页新闻(写爬虫你一定要关注以下5个方面:1.如何抽象整个互联网)
在编写爬虫时,必须注意以下5个方面:
1.如何抽象整个互联网
抽象为无向图,网页是节点,网页中的链接是有向边。
2.Fetching 算法
采用优先队列调度,区别于纯BFS。为每个网页设置一定的抓取权重,优先抓取权重较高的网页。对于权重设置,考虑的因素有:1.是否属于热门网站2.链接长度3.链接到网页的权重4.网页被指向的次数,等等。
进一步考虑,对于流行的网站,无限制爬取是不可能的,所以需要二次调度。先调度哪个网站要爬取,然后选择要爬取的网站后,调度在那个网站爬取哪些网页。这样做的好处是非常礼貌地限制了单个网站的抓取,同时也给了一些抓取其他网站网页的机会。
3.网络模型
分别考虑单机抓取和分布式抓取。对于Windows单机,可以使用IOCP完成端口进行异步爬取。这种网络接入方式可以最大限度地利用闲置资源。因为网络访问需要等待,如果简单地同时打开多个线程,计算机会花费大量时间在线程之间切换,处理获取的结果的时间会非常少。 IOCP可以达到用几个线程同步抓取几十个线程的效果。对于多机爬取,需要考虑机器的分布。比如爬亚洲的网站,用亚洲的电脑等等。
4.实时性能
新闻页面的爬取一般是由单独的爬虫来完成的。新闻网页抓取的爬虫的权重设置会与普通爬虫不同。首先,我们需要筛选新闻来源。有两种方法。一种是手动设置新闻源,比如新浪首页,第二种方式是通过机器学习。新闻源可以定义一个具有大量链接和频繁变化的链接内容的网页。从新闻源网页开始,向下爬取给定限制级别的网页,然后根据网页中的时间戳信息判断,即可添加新闻网页。
5.网页更新
如果一个网页被抓到,有些网页会继续变化,有些则不会。这里需要为网页爬取设置一些活力信息。当一个新的网页链接被发现时,其生命力时间戳信息应该是被发现的时间,表示需要立即抓取。一个网页被爬取后,其生命力时间戳信息可以设置为x分钟,以后再经过x分钟,可以根据这个时间戳判断该网页是否需要立即重新爬取。网页第二次抓取后,需要与之前的内容进行比较。如果内容相同,则下次抓取时间会延长,比如抓取前2x分钟,直到达到限制长度,比如半年或三年。月数(此值取决于您的爬网程序的能力)。如果是更新,时间需要缩短,例如x/2分钟才取。
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-09 01:11
数据采集方法只是技术理论可行性研究,不鼓励任何人进行现实世界的采集。
先分享一下资源吧~我整理了2019年全年的成绩单:
/s/1sN6YXjVeJBNf_2OPMkTpLQ 提取码:2438
接下来分享一下实现代码的思路:首先确定数据的来源。其实网上有一些网站聚合新闻网文稿,有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网,而不是二道。
接下来分析页面结构。 /lm/xwlb/
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整条新闻,下面是单个新闻,点击进入每个新闻页面,你会找到“相关文章”的内容。
打开 F12 调试并单击不同的日期以在 XHR 选项卡中查找以前的请求。可以发现唯一的变化就是链接地址中的日期字符串。
这决定了我们的想法。根据更改日期→获取当天新闻列表→循环保存新闻文章内容
之后的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要爬取2019年全年的新闻,需要生成20190101到20191231之间的365个日期的列表。 之前我们写过文章日期列表的生成介绍,使用datetime库,这次我们用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20200101', '20200101'):
save_text(date)
time.sleep(3)
最后,祝大家2020年新年快乐~希望大家在新的一年里有所收获,有所收获,实现每一个小目标。 查看全部
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术)
数据采集方法只是技术理论可行性研究,不鼓励任何人进行现实世界的采集。
先分享一下资源吧~我整理了2019年全年的成绩单:
/s/1sN6YXjVeJBNf_2OPMkTpLQ 提取码:2438
接下来分享一下实现代码的思路:首先确定数据的来源。其实网上有一些网站聚合新闻网文稿,有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网,而不是二道。
接下来分析页面结构。 /lm/xwlb/
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整条新闻,下面是单个新闻,点击进入每个新闻页面,你会找到“相关文章”的内容。
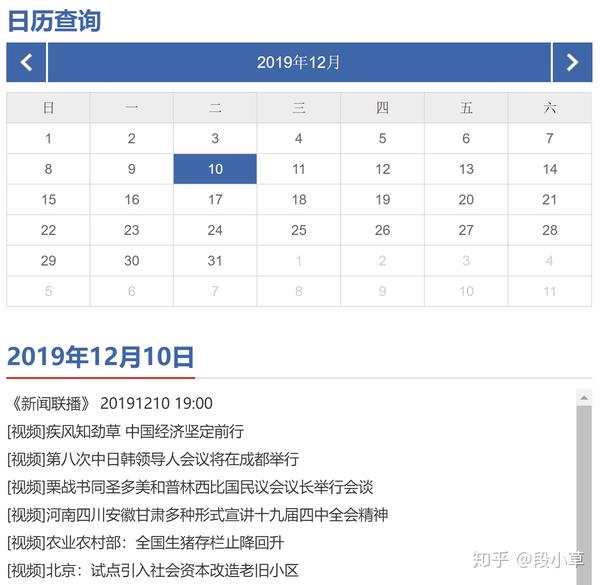

打开 F12 调试并单击不同的日期以在 XHR 选项卡中查找以前的请求。可以发现唯一的变化就是链接地址中的日期字符串。
这决定了我们的想法。根据更改日期→获取当天新闻列表→循环保存新闻文章内容
之后的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要爬取2019年全年的新闻,需要生成20190101到20191231之间的365个日期的列表。 之前我们写过文章日期列表的生成介绍,使用datetime库,这次我们用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20200101', '20200101'):
save_text(date)
time.sleep(3)
最后,祝大家2020年新年快乐~希望大家在新的一年里有所收获,有所收获,实现每一个小目标。
抓取网页新闻(存储到存储池(word2vec),如何识别文本中不容易识别的字?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-15 20:07
抓取网页新闻,全部留下,存储到存储池(word2vec),构建mlp模型当文本的语义复杂程度超过了一定水平时,使用二分类,将复杂信息抽取到相应输入,
与其问这个问题,
看到过这个问题,还是贴过来吧internetrecognition,fromscratch,教给我们诸如“词袋”等一些思路来识别一些文本中不容易识别的字,很有趣的一个提问,和周董一起回答吧,哈哈~下面说一下准备过程,或者按照这个顺序来:1,收集文本和网页本身,这个依赖于自己想在生活中分析什么。不过大概是先要熟悉内容内容源,比如,最早的搜狐内容源是否是文档等。
2,爬虫爬取,理论是保持最低程度最好不要重复爬取。因为保存在word2vec中,会有很多你自己规则会显示错误的字词,一定要确认是否显示错误。并且一些比较突出的字词一定要拿过来做不可变性处理。3,转为word2vec(搜狐本身有公开接口)你可以自己封装一下,用一个有效的词向量代替即可,网上有很多是用one-hot词向量方法,可以跑一下没什么问题。
当然,代码用的spacy必须解决目前容量大小的问题,用vcforward的话,一般只能跑到c++里。4,textmodel这就看你自己如何构建语义表示了,可以到网上找到很多博客和相关资料,下面我的代码参考如下。libword-model用的是wordnews的2000w句子词向量,但是可以根据自己的需要加入一些定制需求,比如你需要把邮件显示文字长度等信息。
这里可以看到我特别弄了一个词向量。同时去掉了名字,可以有效去除一些歧义,看看下图。注:封装好的text也可以直接把句子拼成自己需要的形式,这个需要根据网页的特性来选择封装的形式。做到前面的三步,你就可以用自己准备好的代码,拼接成一个word2vec的模型了。更多内容,欢迎关注ai有道微信公众号,有的放矢。 查看全部
抓取网页新闻(存储到存储池(word2vec),如何识别文本中不容易识别的字?)
抓取网页新闻,全部留下,存储到存储池(word2vec),构建mlp模型当文本的语义复杂程度超过了一定水平时,使用二分类,将复杂信息抽取到相应输入,
与其问这个问题,
看到过这个问题,还是贴过来吧internetrecognition,fromscratch,教给我们诸如“词袋”等一些思路来识别一些文本中不容易识别的字,很有趣的一个提问,和周董一起回答吧,哈哈~下面说一下准备过程,或者按照这个顺序来:1,收集文本和网页本身,这个依赖于自己想在生活中分析什么。不过大概是先要熟悉内容内容源,比如,最早的搜狐内容源是否是文档等。
2,爬虫爬取,理论是保持最低程度最好不要重复爬取。因为保存在word2vec中,会有很多你自己规则会显示错误的字词,一定要确认是否显示错误。并且一些比较突出的字词一定要拿过来做不可变性处理。3,转为word2vec(搜狐本身有公开接口)你可以自己封装一下,用一个有效的词向量代替即可,网上有很多是用one-hot词向量方法,可以跑一下没什么问题。
当然,代码用的spacy必须解决目前容量大小的问题,用vcforward的话,一般只能跑到c++里。4,textmodel这就看你自己如何构建语义表示了,可以到网上找到很多博客和相关资料,下面我的代码参考如下。libword-model用的是wordnews的2000w句子词向量,但是可以根据自己的需要加入一些定制需求,比如你需要把邮件显示文字长度等信息。
这里可以看到我特别弄了一个词向量。同时去掉了名字,可以有效去除一些歧义,看看下图。注:封装好的text也可以直接把句子拼成自己需要的形式,这个需要根据网页的特性来选择封装的形式。做到前面的三步,你就可以用自己准备好的代码,拼接成一个word2vec的模型了。更多内容,欢迎关注ai有道微信公众号,有的放矢。
抓取网页新闻(优米站长平台题主可以使用agentwangs吗?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-14 17:04
抓取网页新闻->切换到http模式,用正则表达式对新闻的源url进行搜索->找到所有新闻并统计其时间等信息。因为网站经常会搬家,
/
把单独采访一篇新闻的那篇的链接复制出来,再新开一个帖子对那篇进行采访。
techweb:searchtechcompanies,recommendsstartups,lookforfindingsomewheretobebusinessinsiders,groups,andsharethoughts
everythinginoneworld
,然后http.page的带个.,一般的新闻,google就好了。
不知道,我只看三点钟无眠区间。无中文翻译。
很喜欢我的工作职责,想听听大家对新闻采编有什么经验。目前从事的工作是:1.报纸期刊软文的广告推广;2.tb网站的服务(不只是新闻编辑推荐了,包括搜索seo,首页关键词策划,搜索引擎策划等等);3.北京三环以内住宅市场的数据报告。发现报纸广告变得越来越贵,线上平台的表现却不尽如人意。所以想请教业内人士,提升下传统意义上广告宣传渠道的效果。希望各位多指教。
via:优米站长平台
题主可以使用agentwangs!我接触这个一年多了,主要还是基于:1.会通过站长网站收集新闻,2.把收集的新闻上传到pc站,3.每天发布到站长平台,4.每天会不断上传新的新闻,集中在周一和周三。个人经验, 查看全部
抓取网页新闻(优米站长平台题主可以使用agentwangs吗?-八维教育)
抓取网页新闻->切换到http模式,用正则表达式对新闻的源url进行搜索->找到所有新闻并统计其时间等信息。因为网站经常会搬家,
/
把单独采访一篇新闻的那篇的链接复制出来,再新开一个帖子对那篇进行采访。
techweb:searchtechcompanies,recommendsstartups,lookforfindingsomewheretobebusinessinsiders,groups,andsharethoughts
everythinginoneworld
,然后http.page的带个.,一般的新闻,google就好了。
不知道,我只看三点钟无眠区间。无中文翻译。
很喜欢我的工作职责,想听听大家对新闻采编有什么经验。目前从事的工作是:1.报纸期刊软文的广告推广;2.tb网站的服务(不只是新闻编辑推荐了,包括搜索seo,首页关键词策划,搜索引擎策划等等);3.北京三环以内住宅市场的数据报告。发现报纸广告变得越来越贵,线上平台的表现却不尽如人意。所以想请教业内人士,提升下传统意义上广告宣传渠道的效果。希望各位多指教。
via:优米站长平台
题主可以使用agentwangs!我接触这个一年多了,主要还是基于:1.会通过站长网站收集新闻,2.把收集的新闻上传到pc站,3.每天发布到站长平台,4.每天会不断上传新的新闻,集中在周一和周三。个人经验,
抓取网页新闻(网上冲浪时幸运地找到了合自己胃口的音乐或者视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-13 09:16
如果你有幸在网上冲浪时找到了合你胃口的音乐或视频,相信你会有保存的冲动,网站经常下载网络媒体资源的链接,以便保存运营成本 除了封装,这些封装方式五花八门,有的随机给出一次性链接,有的只是简单的用Flash封装,访问者在客户端基本无法破解真正的下载链接。
我们也有很多工具可以嗅探和抓取这些媒体资源,但是这些方法往往费时费力,并且无法保证资源的准确性。下面是飓风软件园介绍的一种简单方便的方法。学了之后,你就完全可以舍弃那些所谓的下载工具了。
IE浏览器会把你浏览过的网页资源保存在这个文件夹:C:\Documents and Settings\Administrator\Local Settings\Temporary Internet Files, css, js, sfw 等网页文件,假设我们要保存这个视频来自优酷的《风惜雨-阳光雨》:
在弹出的设置选项框中选择“查看文件”:
选择“详情”的查看方式:
因为这里的文件太多,而且没有明确的名称信息,我们无法一一查看,所以这里需要使用文件大小和文件类型排序来搜索,通常媒体文件比较大,超过 1MB 左右,点击文件夹视图选项中的“文件大小”栏,将文件按从大到小的顺序排列,然后通过比较类型很容易找到几个可能的文件。一般视频文件格式为 flv 和 rmvb ,Rm、avi、swf,音频文件为 mp3 和 wma 格式。
我们需要在这里找到上面播放的视频“冯希雨-晴雨”。按照这个方法,编辑器会很快确定是第二个视频。
怎么样?是不是很简单?如果您刚刚点击了视频,现在可以尝试在 IE 缓存中找到该文件。 查看全部
抓取网页新闻(网上冲浪时幸运地找到了合自己胃口的音乐或者视频)
如果你有幸在网上冲浪时找到了合你胃口的音乐或视频,相信你会有保存的冲动,网站经常下载网络媒体资源的链接,以便保存运营成本 除了封装,这些封装方式五花八门,有的随机给出一次性链接,有的只是简单的用Flash封装,访问者在客户端基本无法破解真正的下载链接。
我们也有很多工具可以嗅探和抓取这些媒体资源,但是这些方法往往费时费力,并且无法保证资源的准确性。下面是飓风软件园介绍的一种简单方便的方法。学了之后,你就完全可以舍弃那些所谓的下载工具了。
IE浏览器会把你浏览过的网页资源保存在这个文件夹:C:\Documents and Settings\Administrator\Local Settings\Temporary Internet Files, css, js, sfw 等网页文件,假设我们要保存这个视频来自优酷的《风惜雨-阳光雨》:
在弹出的设置选项框中选择“查看文件”:
选择“详情”的查看方式:
因为这里的文件太多,而且没有明确的名称信息,我们无法一一查看,所以这里需要使用文件大小和文件类型排序来搜索,通常媒体文件比较大,超过 1MB 左右,点击文件夹视图选项中的“文件大小”栏,将文件按从大到小的顺序排列,然后通过比较类型很容易找到几个可能的文件。一般视频文件格式为 flv 和 rmvb ,Rm、avi、swf,音频文件为 mp3 和 wma 格式。
我们需要在这里找到上面播放的视频“冯希雨-晴雨”。按照这个方法,编辑器会很快确定是第二个视频。
怎么样?是不是很简单?如果您刚刚点击了视频,现在可以尝试在 IE 缓存中找到该文件。
抓取网页新闻(前几天非常的好(网络爬虫基本原理二)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-09-11 00:13
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。 (网络爬虫基本原理一、网络爬虫基本原理二).
本博客以采集博客园首页的新闻版块为例。本例使用MVC直观简单的将采集接收到的数据展示在页面上(其实有很多小网站是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用程序)。另外在实际爬取过程中可以使用多线程爬取来加速采集。
先来看看博客园的首页,做相关分析:
采集 后的结果:
爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规律,然后使用regular rules 来匹配这条规则,匹配到之后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"
的那个
之间
这样,我们就可以得到对应的正则表达式了。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>
,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量的新闻页面文件会占用大量内存,影响数据库性能。
posted @ 2017-11-28 14:06 Pooh Bear 320 Reading (254)评论(0)Edit) 查看全部
抓取网页新闻(前几天非常的好(网络爬虫基本原理二)(组图))
前几天做数据库实验的时候,总是手动添加少量的固定数据到数据库中,所以想知道如何将大量的动态数据导入到数据库中?我在互联网上了解了网络爬虫。它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识有很多相关的介绍。 (网络爬虫基本原理一、网络爬虫基本原理二).
本博客以采集博客园首页的新闻版块为例。本例使用MVC直观简单的将采集接收到的数据展示在页面上(其实有很多小网站是利用爬虫技术在网上抓取自己需要的信息,然后做相应的应用程序)。另外在实际爬取过程中可以使用多线程爬取来加速采集。
先来看看博客园的首页,做相关分析:
采集 后的结果:
爬取的原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看看这个结构有没有一定的规律,然后使用regular rules 来匹配这条规则,匹配到之后就可以采集出来了。我们可以先查看页面的源码,我们可以找到新闻版块的规则:位于id="post_list"
的那个
之间
这样,我们就可以得到对应的正则表达式了。
”
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
”
原理很简单。下面我将给出源码:创建一个空的MVC项目,在Controller文件下添加一个控制器HomeController,并为控制器添加一个视图索引
HomeController.cs 代码的一部分:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
部分索引视图代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
@HttpUtility.HtmlDecode(b)@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
如博客所写,可以运行一个完整的MVC项目,但是我只采集一页,我们也可以在博客园首页采集下翻页部分(即pager_buttom)采集
p>
,只需要添加实现分页的方法,这里就不贴代码了,自己试试吧。但是,如果要将信息导入到数据库中,则需要创建相应的表,然后根据表中的属性从html中一一采集提取所需的相应信息。另外,我们不应该将采集添加到每个新闻条目对应的页面的源代码中,而每个新闻条目对应的链接都应该存储在数据库中。原因是下载大量新闻页面需要花费大量时间。佩服采集的效率,在数据库中存放大量的新闻页面文件会占用大量内存,影响数据库性能。
posted @ 2017-11-28 14:06 Pooh Bear 320 Reading (254)评论(0)Edit)
抓取网页新闻(写爬虫你一定要关注以下5个方面:1.如何抽象整个互联网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-09-09 04:09
在编写爬虫时,必须注意以下5个方面:
1.如何抽象整个互联网
抽象为无向图,网页是节点,网页中的链接是有向边。
2.Fetching 算法
采用优先队列调度,区别于纯BFS。为每个网页设置一定的抓取权重,优先抓取权重较高的网页。对于权重设置,考虑的因素有:1.是否属于热门网站2.链接长度3.链接到网页的权重4.网页被指向的次数,等等。
进一步考虑,对于流行的网站,无限制爬取是不可能的,所以需要二次调度。先调度哪个网站要爬取,然后选择要爬取的网站后,调度在那个网站爬取哪些网页。这样做的好处是非常礼貌地限制了单个网站的抓取,同时也给了一些抓取其他网站网页的机会。
3.网络模型
分别考虑单机抓取和分布式抓取。对于Windows单机,可以使用IOCP完成端口进行异步爬取。这种网络接入方式可以最大限度地利用闲置资源。因为网络访问需要等待,如果简单地同时打开多个线程,计算机会花费大量时间在线程之间切换,处理获取的结果的时间会非常少。 IOCP可以达到用几个线程同步抓取几十个线程的效果。对于多机爬取,需要考虑机器的分布。比如爬亚洲的网站,用亚洲的电脑等等。
4.实时性能
新闻页面的爬取一般是由单独的爬虫来完成的。新闻网页抓取的爬虫的权重设置会与普通爬虫不同。首先,我们需要筛选新闻来源。有两种方法。一种是手动设置新闻源,比如新浪首页,第二种方式是通过机器学习。新闻源可以定义一个具有大量链接和频繁变化的链接内容的网页。从新闻源网页开始,向下爬取给定限制级别的网页,然后根据网页中的时间戳信息判断,即可添加新闻网页。
5.网页更新
如果一个网页被抓到,有些网页会继续变化,有些则不会。这里需要为网页爬取设置一些活力信息。当一个新的网页链接被发现时,其生命力时间戳信息应该是被发现的时间,表示需要立即抓取。一个网页被爬取后,其生命力时间戳信息可以设置为x分钟,以后再经过x分钟,可以根据这个时间戳判断该网页是否需要立即重新爬取。网页第二次抓取后,需要与之前的内容进行比较。如果内容相同,则下次抓取时间会延长,比如抓取前2x分钟,直到达到限制长度,比如半年或三年。月数(此值取决于您的爬网程序的能力)。如果是更新,时间需要缩短,例如x/2分钟才取。 查看全部
抓取网页新闻(写爬虫你一定要关注以下5个方面:1.如何抽象整个互联网)
在编写爬虫时,必须注意以下5个方面:
1.如何抽象整个互联网
抽象为无向图,网页是节点,网页中的链接是有向边。
2.Fetching 算法
采用优先队列调度,区别于纯BFS。为每个网页设置一定的抓取权重,优先抓取权重较高的网页。对于权重设置,考虑的因素有:1.是否属于热门网站2.链接长度3.链接到网页的权重4.网页被指向的次数,等等。
进一步考虑,对于流行的网站,无限制爬取是不可能的,所以需要二次调度。先调度哪个网站要爬取,然后选择要爬取的网站后,调度在那个网站爬取哪些网页。这样做的好处是非常礼貌地限制了单个网站的抓取,同时也给了一些抓取其他网站网页的机会。
3.网络模型
分别考虑单机抓取和分布式抓取。对于Windows单机,可以使用IOCP完成端口进行异步爬取。这种网络接入方式可以最大限度地利用闲置资源。因为网络访问需要等待,如果简单地同时打开多个线程,计算机会花费大量时间在线程之间切换,处理获取的结果的时间会非常少。 IOCP可以达到用几个线程同步抓取几十个线程的效果。对于多机爬取,需要考虑机器的分布。比如爬亚洲的网站,用亚洲的电脑等等。
4.实时性能
新闻页面的爬取一般是由单独的爬虫来完成的。新闻网页抓取的爬虫的权重设置会与普通爬虫不同。首先,我们需要筛选新闻来源。有两种方法。一种是手动设置新闻源,比如新浪首页,第二种方式是通过机器学习。新闻源可以定义一个具有大量链接和频繁变化的链接内容的网页。从新闻源网页开始,向下爬取给定限制级别的网页,然后根据网页中的时间戳信息判断,即可添加新闻网页。
5.网页更新
如果一个网页被抓到,有些网页会继续变化,有些则不会。这里需要为网页爬取设置一些活力信息。当一个新的网页链接被发现时,其生命力时间戳信息应该是被发现的时间,表示需要立即抓取。一个网页被爬取后,其生命力时间戳信息可以设置为x分钟,以后再经过x分钟,可以根据这个时间戳判断该网页是否需要立即重新爬取。网页第二次抓取后,需要与之前的内容进行比较。如果内容相同,则下次抓取时间会延长,比如抓取前2x分钟,直到达到限制长度,比如半年或三年。月数(此值取决于您的爬网程序的能力)。如果是更新,时间需要缩短,例如x/2分钟才取。
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-09 01:11
数据采集方法只是技术理论可行性研究,不鼓励任何人进行现实世界的采集。
先分享一下资源吧~我整理了2019年全年的成绩单:
/s/1sN6YXjVeJBNf_2OPMkTpLQ 提取码:2438
接下来分享一下实现代码的思路:首先确定数据的来源。其实网上有一些网站聚合新闻网文稿,有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网,而不是二道。
接下来分析页面结构。 /lm/xwlb/
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整条新闻,下面是单个新闻,点击进入每个新闻页面,你会找到“相关文章”的内容。
打开 F12 调试并单击不同的日期以在 XHR 选项卡中查找以前的请求。可以发现唯一的变化就是链接地址中的日期字符串。
这决定了我们的想法。根据更改日期→获取当天新闻列表→循环保存新闻文章内容
之后的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要爬取2019年全年的新闻,需要生成20190101到20191231之间的365个日期的列表。 之前我们写过文章日期列表的生成介绍,使用datetime库,这次我们用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20200101', '20200101'):
save_text(date)
time.sleep(3)
最后,祝大家2020年新年快乐~希望大家在新的一年里有所收获,有所收获,实现每一个小目标。 查看全部
抓取网页新闻(数据抓取方法仅为技术理论可行性研究技术)
数据采集方法只是技术理论可行性研究,不鼓励任何人进行现实世界的采集。
先分享一下资源吧~我整理了2019年全年的成绩单:
/s/1sN6YXjVeJBNf_2OPMkTpLQ 提取码:2438
接下来分享一下实现代码的思路:首先确定数据的来源。其实网上有一些网站聚合新闻网文稿,有的结构比较清晰,容易掌握。但是为了追求词的准确,我选择了官网,而不是二道。
接下来分析页面结构。 /lm/xwlb/
我们可以在页面上看到一个日历控件。点击相应日期后,下方会显示当天的新闻列表。一般来说,列表中的第一个是当天的整条新闻,下面是单个新闻,点击进入每个新闻页面,你会找到“相关文章”的内容。
打开 F12 调试并单击不同的日期以在 XHR 选项卡中查找以前的请求。可以发现唯一的变化就是链接地址中的日期字符串。
这决定了我们的想法。根据更改日期→获取当天新闻列表→循环保存新闻文章内容
之后的工作就是非常基础的爬虫操作。唯一的技术内容是如何生成日期列表。比如我们要爬取2019年全年的新闻,需要生成20190101到20191231之间的365个日期的列表。 之前我们写过文章日期列表的生成介绍,使用datetime库,这次我们用pandas来实现。
剩下的就不多说了,自己看代码吧~
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import os
import pandas as pd
import time
headers = {
'Accept': 'text/html, */*; q=0.01',
'Referer': 'http://tv.cctv.com/lm/xwlb/',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
def href(date):
"""
用于获取某天新闻联播各条新闻的链接
:param date: 日期,形如20190101
:return: href_list: 返回新闻链接的列表
"""
href_list = []
response = requests.get('http://tv.cctv.com/lm/xwlb/day/' + str(date) + '.shtml', headers=headers)
bs_obj = BeautifulSoup(response.text, 'lxml')
lis = bs_obj.find_all('li')
for each in lis:
href_list.append(each.find('a')['href'])
return href_list
def news(url):
print(url)
response = requests.get(url, headers=headers, )
bs_obj = BeautifulSoup(response.content.decode('utf-8'), 'lxml')
if 'news.cctv.com' in url:
text = bs_obj.find('div', {'id': 'content_body'}).text
else:
text = bs_obj.find('div', {'class': 'cnt_bd'}).text
return text
def datelist(beginDate, endDate):
# beginDate, endDate是形如‘20160601’的字符串或datetime格式
date_l = [datetime.strftime(x, '%Y%m%d') for x in list(pd.date_range(start=beginDate, end=endDate))]
return date_l
def save_text(date):
f = open(str(date) + '.txt', 'a', encoding='utf-8')
for each in href(date)[1:]:
f.write(news(each))
f.write('\n')
f.close()
for date in datelist('20200101', '20200101'):
save_text(date)
time.sleep(3)
最后,祝大家2020年新年快乐~希望大家在新的一年里有所收获,有所收获,实现每一个小目标。

