
抓取网页新闻
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-25 06:23
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的

然后打开链接,找到相关的评论内容。(下图为第一页内容)

接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(基于行块分布函数的通用网页正文抽取算法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-24 07:00
问题:如何提取任意网页的正文内容(尤其是新闻和资讯),提取与文章内容相关的图片,源码见:extractor.py。
抓取单个网站网页内容时,通常使用正则匹配。但是不同的网站的结构实在是太奇怪了,很难用统一的正则表达式来匹配。《基于行块分布函数的通用网页文本提取算法》作者总结了从网页中提取文章文本的通用方法,提出了一种基于行块分布的文本提取算法,并给出了PHP等实现和爪哇。. 该算法的主要原理基于两点:
正文区域密度:去除HTML中所有标签后,正文区域字符密度更高,多行空白更少;行块长度:单个标签(行块)中非文本区域的内容一般较短。
算法步骤如下:
reCOMM = r''
reTRIM = r'([\s\S]*?)'
reTAG = r'|[ \t\r\f\v]'
def processTags(body=""):
body = re.sub(reCOMM, "", body)
body = re.sub(reTRIM.format("script"), "" ,re.sub(reTRIM.format("style"), "", body))
body = re.sub(reTAG, "", body)
return body
def processBlocks(body=""):
ctexts = body.split("\n")
textLens = [len(text) for text in ctexts]
cblocks = [0] * (len(ctexts) - blockSize)
lines = len(ctexts)
for i in range(blockSize):
cblocks = list(map(lambda x,y: x+y, textLens[i : lines-1-blockSize+i], cblocks))
return cblocks
def getContext(ctexts, cblocks):
maxTextLen = max(cblocks)
start = end = cblocks.index(maxTextLen)
while start > 0 and cblocks[start] > min(textLens):
start -= 1
while end min(textLens):
self.end += 1
return "".join(ctexts[start:end])
reIMG = re.compile(r'')
def processImages(body):
return reIMG.sub(r'{{\1}}', body)
总结
上述算法基本可以处理大部分(中文)网页文本的提取。对于某些网站文字图片多于文字的情况,可以使用retention
在标签中链接图像的方法增加了文本的密度。目前在少数测试中发现的问题包括:1)文章分页或动态加载网页;2) 网页评论太长。
参考
推特脸书谷歌+
Python算法 查看全部
抓取网页新闻(基于行块分布函数的通用网页正文抽取算法(图))
问题:如何提取任意网页的正文内容(尤其是新闻和资讯),提取与文章内容相关的图片,源码见:extractor.py。
抓取单个网站网页内容时,通常使用正则匹配。但是不同的网站的结构实在是太奇怪了,很难用统一的正则表达式来匹配。《基于行块分布函数的通用网页文本提取算法》作者总结了从网页中提取文章文本的通用方法,提出了一种基于行块分布的文本提取算法,并给出了PHP等实现和爪哇。. 该算法的主要原理基于两点:
正文区域密度:去除HTML中所有标签后,正文区域字符密度更高,多行空白更少;行块长度:单个标签(行块)中非文本区域的内容一般较短。
算法步骤如下:
reCOMM = r''
reTRIM = r'([\s\S]*?)'
reTAG = r'|[ \t\r\f\v]'
def processTags(body=""):
body = re.sub(reCOMM, "", body)
body = re.sub(reTRIM.format("script"), "" ,re.sub(reTRIM.format("style"), "", body))
body = re.sub(reTAG, "", body)
return body
def processBlocks(body=""):
ctexts = body.split("\n")
textLens = [len(text) for text in ctexts]
cblocks = [0] * (len(ctexts) - blockSize)
lines = len(ctexts)
for i in range(blockSize):
cblocks = list(map(lambda x,y: x+y, textLens[i : lines-1-blockSize+i], cblocks))
return cblocks
def getContext(ctexts, cblocks):
maxTextLen = max(cblocks)
start = end = cblocks.index(maxTextLen)
while start > 0 and cblocks[start] > min(textLens):
start -= 1
while end min(textLens):
self.end += 1
return "".join(ctexts[start:end])
reIMG = re.compile(r'')
def processImages(body):
return reIMG.sub(r'{{\1}}', body)
总结
上述算法基本可以处理大部分(中文)网页文本的提取。对于某些网站文字图片多于文字的情况,可以使用retention
在标签中链接图像的方法增加了文本的密度。目前在少数测试中发现的问题包括:1)文章分页或动态加载网页;2) 网页评论太长。
参考
推特脸书谷歌+
Python算法
抓取网页新闻(百度新闻()收录的大约两千多家的两千多后大所收获)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-24 06:22
小编给大家分享一下Python异步新闻抓取百度新闻爬虫的案例。希望大家看完这篇文章能有所收获,一起来讨论一下吧!
要爬取新闻,首先要有一个新闻源,即爬取的目标网站。国内新闻网站,从中央到地方,从一般行业到垂直行业,大小不一的新闻网站上千条。百度新闻()收录有两千左右。那么我们先从百度新闻说起。
打开百度新闻的网站首页:
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻标题和它们的原创链接。如图所示:
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
按照这个简单的流程,我们先实现如下简单的代码:
#!/usr/bin/env python3
# Author: veelion
import re
import time
import requests
import tldextract
def save_to_db(url, html):
# 保存网页到数据库,我们暂时用打印相关信息代替
print('%s : %s' % (url, len(html)))
def crawl():
# 1. download baidu news
hub_url = 'http://news.baidu.com/'
res = requests.get(hub_url)
html = res.text
# 2. extract news links
## 2.1 extract all links with 'href'
links = re.findall(r'href=[\'"]?(.*?)[\'"\s]', html)
print('find links:', len(links))
news_links = []
## 2.2 filter non-news link
for link in links:
if not link.startswith('http'):
continue
tld = tldextract.extract(link)
if tld.domain == 'baidu':
continue
news_links.append(link)
print('find news links:', len(news_links))
# 3. download news and save to database
for link in news_links:
html = requests.get(link).text
save_to_db(link, html)
print('works done!')
def main():
while 1:
crawl()
time.sleep(300)
if __name__ == '__main__':
main()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 首先用正则表达式提取a标签的href属性,也就是网页中的链接;然后假设非百度外部链接都是新闻链接,找到新闻链接
3. 将找到的所有新闻链接一一下载并存入数据库;保存到数据库的功能暂时被打印相关信息代替。
4. 每 300 秒重复步骤 1-3 以获取更新的新闻。
上面的代码可以工作,但只能工作。没有一点点槽点,所以让我们谈谈并改进这个爬虫。
1. 添加异常处理
在写爬虫的时候,尤其是和网络请求相关的代码,一定要有异常处理。目标服务器是否正常,当时的网络连接是否畅通(超时)等都是爬虫无法控制的,所以在处理网络请求时必须处理异常。最好为网络请求设置超时时间,不要在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301.该URL永久转移到其他URL,以后请求会请求转移的URL
404,基本上这个网站已经过期了,以后不要试了
500,服务器出现内部错误,可能是暂时的,请稍后再试
3. 管理 URL 的状态
记录失败的 URL,以便稍后重试。对于超时的URL,后面需要重新获取,所以需要记录所有URL的各种状态,包括:
已成功下载
多次下载失败,无需重新下载
下载
下载失败并重试
加上对网络请求的各种处理,这个爬虫就强大了很多,不会动不动就异常退出,给后续的运维带来很大的工作量。
Python爬虫知识点
在本节中,我们使用了 Python 的几个模块。它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET 和 POST 很容易获得:
import requests
res = requests.get(url, timeout=5, headers=my_headers)
res2 = requests.post(url, data=post_data, timeout=5, headers=my_headers)
get() 和 post() 函数有许多参数可供选择。上面使用了超时设置和自定义标头。更多参数请参考requests文档。
无论get()还是post(),Requests都会返回一个Response对象,下载的内容就是通过这个对象获取的:
res.content 是获取到的二进制内容,类型为字节;
res.text为二进制内容解码后的str内容;
它首先从响应头中找到编码,如果找不到则通过chardet自动确定编码,并赋值给res.encoding,最后将二进制内容解密为str类型。
In [1]: import requests
In [2]: r = requests.get('http://epaper.sxrb.com/')
In [3]: r.encoding
Out[3]: 'ISO-8859-1'
In [4]: import chardet
In [5]: chardet.detect(r.content)
Out[5]: {'confidence': 0.99, 'encoding': 'utf-8', 'language': ''}
以上是用ipython交互式解释器的演示(强烈推荐ipython,比Python自带的解释器好很多)。开通的网站是山西日报数字报。网页源码的代码是utf8,chardet得到的代码也是utf8。而requests判断的编码是ISO-8859-1,那么它返回的文本的中文也会出现乱码。
请求的另一个有用方面是 Session,它部分类似于浏览器并保存 cookie。您可以稍后使用其会话登录以及与 cookie 相关的爬虫。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,建议使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要 pip install tldextract 来安装它。表示顶级域提取,即顶级域提取。前面我们讲了URL的结构,叫做host,是注册域名的子域,com是顶级域TLD。它的结果是这样的:
In [6]: import tldextract
In [7]: tldextract.extract('http://news.baidu.com/')
Out[7]: ExtractResult(subdomain='news', domain='baidu', suffix='com')
返回结构收录三部分:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。time模块是一个提供时间相关功能的模块。同时还有一个模块 datetime 也是和时间相关的,可以根据情况使用。
看完这篇文章,相信你对Python异步新闻抓取百度新闻爬虫的案例有了一定的了解。如果您想了解更多,欢迎关注易宿云行业资讯频道,感谢阅读! 查看全部
抓取网页新闻(百度新闻()收录的大约两千多家的两千多后大所收获)
小编给大家分享一下Python异步新闻抓取百度新闻爬虫的案例。希望大家看完这篇文章能有所收获,一起来讨论一下吧!
要爬取新闻,首先要有一个新闻源,即爬取的目标网站。国内新闻网站,从中央到地方,从一般行业到垂直行业,大小不一的新闻网站上千条。百度新闻()收录有两千左右。那么我们先从百度新闻说起。
打开百度新闻的网站首页:
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻标题和它们的原创链接。如图所示:
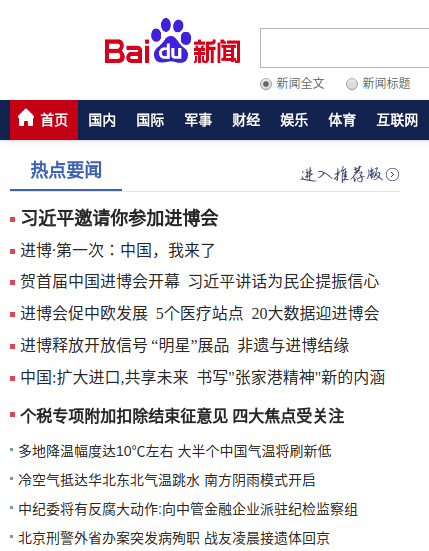
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
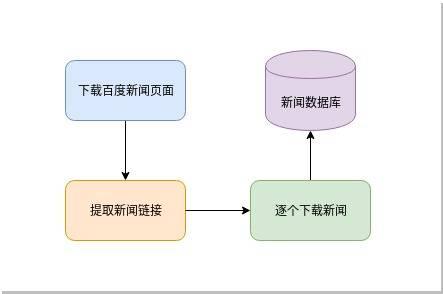
按照这个简单的流程,我们先实现如下简单的代码:
#!/usr/bin/env python3
# Author: veelion
import re
import time
import requests
import tldextract
def save_to_db(url, html):
# 保存网页到数据库,我们暂时用打印相关信息代替
print('%s : %s' % (url, len(html)))
def crawl():
# 1. download baidu news
hub_url = 'http://news.baidu.com/'
res = requests.get(hub_url)
html = res.text
# 2. extract news links
## 2.1 extract all links with 'href'
links = re.findall(r'href=[\'"]?(.*?)[\'"\s]', html)
print('find links:', len(links))
news_links = []
## 2.2 filter non-news link
for link in links:
if not link.startswith('http'):
continue
tld = tldextract.extract(link)
if tld.domain == 'baidu':
continue
news_links.append(link)
print('find news links:', len(news_links))
# 3. download news and save to database
for link in news_links:
html = requests.get(link).text
save_to_db(link, html)
print('works done!')
def main():
while 1:
crawl()
time.sleep(300)
if __name__ == '__main__':
main()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 首先用正则表达式提取a标签的href属性,也就是网页中的链接;然后假设非百度外部链接都是新闻链接,找到新闻链接
3. 将找到的所有新闻链接一一下载并存入数据库;保存到数据库的功能暂时被打印相关信息代替。
4. 每 300 秒重复步骤 1-3 以获取更新的新闻。
上面的代码可以工作,但只能工作。没有一点点槽点,所以让我们谈谈并改进这个爬虫。
1. 添加异常处理
在写爬虫的时候,尤其是和网络请求相关的代码,一定要有异常处理。目标服务器是否正常,当时的网络连接是否畅通(超时)等都是爬虫无法控制的,所以在处理网络请求时必须处理异常。最好为网络请求设置超时时间,不要在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301.该URL永久转移到其他URL,以后请求会请求转移的URL
404,基本上这个网站已经过期了,以后不要试了
500,服务器出现内部错误,可能是暂时的,请稍后再试
3. 管理 URL 的状态
记录失败的 URL,以便稍后重试。对于超时的URL,后面需要重新获取,所以需要记录所有URL的各种状态,包括:
已成功下载
多次下载失败,无需重新下载
下载
下载失败并重试
加上对网络请求的各种处理,这个爬虫就强大了很多,不会动不动就异常退出,给后续的运维带来很大的工作量。
Python爬虫知识点
在本节中,我们使用了 Python 的几个模块。它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET 和 POST 很容易获得:
import requests
res = requests.get(url, timeout=5, headers=my_headers)
res2 = requests.post(url, data=post_data, timeout=5, headers=my_headers)
get() 和 post() 函数有许多参数可供选择。上面使用了超时设置和自定义标头。更多参数请参考requests文档。
无论get()还是post(),Requests都会返回一个Response对象,下载的内容就是通过这个对象获取的:
res.content 是获取到的二进制内容,类型为字节;
res.text为二进制内容解码后的str内容;
它首先从响应头中找到编码,如果找不到则通过chardet自动确定编码,并赋值给res.encoding,最后将二进制内容解密为str类型。
In [1]: import requests
In [2]: r = requests.get('http://epaper.sxrb.com/')
In [3]: r.encoding
Out[3]: 'ISO-8859-1'
In [4]: import chardet
In [5]: chardet.detect(r.content)
Out[5]: {'confidence': 0.99, 'encoding': 'utf-8', 'language': ''}
以上是用ipython交互式解释器的演示(强烈推荐ipython,比Python自带的解释器好很多)。开通的网站是山西日报数字报。网页源码的代码是utf8,chardet得到的代码也是utf8。而requests判断的编码是ISO-8859-1,那么它返回的文本的中文也会出现乱码。
请求的另一个有用方面是 Session,它部分类似于浏览器并保存 cookie。您可以稍后使用其会话登录以及与 cookie 相关的爬虫。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,建议使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要 pip install tldextract 来安装它。表示顶级域提取,即顶级域提取。前面我们讲了URL的结构,叫做host,是注册域名的子域,com是顶级域TLD。它的结果是这样的:
In [6]: import tldextract
In [7]: tldextract.extract('http://news.baidu.com/')
Out[7]: ExtractResult(subdomain='news', domain='baidu', suffix='com')
返回结构收录三部分:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。time模块是一个提供时间相关功能的模块。同时还有一个模块 datetime 也是和时间相关的,可以根据情况使用。
看完这篇文章,相信你对Python异步新闻抓取百度新闻爬虫的案例有了一定的了解。如果您想了解更多,欢迎关注易宿云行业资讯频道,感谢阅读!
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-23 13:16
用python写爬虫的人越来越多,这也说明用python写爬虫比其他语言更方便。很多新闻网站没有反爬虫策略,所以爬取新闻网站的数据比较方便。然而,这么多新闻网站,我们应该怎么爬?你从哪里开始?这是我们首先需要考虑的问题。
您需要的是异步 IO 来实现高效的爬虫。
下面我们来看看基于asyncio的Python3新闻爬虫,以及如何高效实现。
从 Python3.5 开始,增加了新的语法,关键字 async 和 await,asyncio 也成为了标准库。这与我们可以编写异步 IO 程序一样强大。让我们轻松实现一个。用于有针对性地抓取新闻的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:标准异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url网站的模块;logging:记录爬虫日志;leveldb:Google 的 Key-Value 数据库,用于记录 URL 的状态;farmhash:将 URL 散列作为 URL 的唯一标识符;sanicdb:封装aiomysql,更方便的数据库mysql操作;2. 异步爬虫实现过程 2.1 新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些URL指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章 首次发表在我的技术博客猿人学习Python基础教程 查看全部
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
用python写爬虫的人越来越多,这也说明用python写爬虫比其他语言更方便。很多新闻网站没有反爬虫策略,所以爬取新闻网站的数据比较方便。然而,这么多新闻网站,我们应该怎么爬?你从哪里开始?这是我们首先需要考虑的问题。
您需要的是异步 IO 来实现高效的爬虫。

下面我们来看看基于asyncio的Python3新闻爬虫,以及如何高效实现。
从 Python3.5 开始,增加了新的语法,关键字 async 和 await,asyncio 也成为了标准库。这与我们可以编写异步 IO 程序一样强大。让我们轻松实现一个。用于有针对性地抓取新闻的异步爬虫。

1. 异步爬虫依赖的模块
asyncio:标准异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url网站的模块;logging:记录爬虫日志;leveldb:Google 的 Key-Value 数据库,用于记录 URL 的状态;farmhash:将 URL 散列作为 URL 的唯一标识符;sanicdb:封装aiomysql,更方便的数据库mysql操作;2. 异步爬虫实现过程 2.1 新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些URL指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章 首次发表在我的技术博客猿人学习Python基础教程
抓取网页新闻(企业网站的结构不合理是提高排名和网站权重的关键)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-23 05:22
一是企业网站的结构不合理。许多企业站点的结构往往不是很合理。主要表现就是往往是一个传入的页面。进入后,在栏目页下增加一个flash。我们都知道蜘蛛对flash的爬行不是很好,也不是很理想。很明显,很多类似的企业网站收录并不理想。其次,网站的用户体验较差。最突出的表现就是很多公司在网站的左右两边放了一些客服代码。这些代码虽然可以增加交互性,但降低了用户阅读网站的体验,增加了网站的跳出率,降低了网站的权重。你可以想象收录
2
/5
其次,站点中的示例文本过多。这一点主要是想说明一些固定的栏目和栏目几乎都使用了一些固定的模板文字,比如联系我们、公司介绍、产品展示等。这些模板文本的许多列和部分彼此重复。二是网站新闻列表内容标题与新闻重复度高,相似度高。因为有些产品往往就是那几个特点,我们在围绕特点进行创作的过程中,不经意地回到了自己的写作套路,增加了内容的重复程度。因此,笔者建议在创建文章的时候,尽一切可能减少和降低文章的相似度和重复度,
3
/5
第三,网站外联度低。大家都知道外联是提升排名的关键,也是网站的权重。间接的,是提升收录的重要因素之一。很多企业网站的外联建设一般都很简单,主要表现就是一直在使用机密信息。Outreach,分类信息的权重相对较高,但是outreach的统一是限制了网站权重的增加。笔者建议先增加网站的权重。在Outreach,作者建议大家可以尝试不同的平台操作,比如软文投稿、连接交流平台、问答平台、采集网站。这些平台具有相对较高的权重。合理使用可以增强我们的体重。网站 有益的
4
/5
四、文章的更新频率。很多公司网站更新频率很不稳定,最突出的表现就是更新文章不及时,每三到五次,因为baiduspider根据我们的网站更新抓取网页内容赚取固定收入的情况。作者推荐文章收录定时定量更新文章,以吸引网站蜘蛛和蜘蛛开发访问我们网站的习惯后,这无疑会大大增加我们网站的抓取频率和收录的内容量。因此,笔者建议企业网站也要努力,每天为网站更新优质的文章充实网站。这种做法是必不可少的。
5
/5
综上,笔者分析了网站运行优化过程中收录不理想的问题以及如何改进网站收录。现在,希望对有兴趣改进网站收录的朋友有所帮助。网站优化中的内容建设一直是我们关注的关键因素之一。首先,我们从网站开始考虑,把我们优化好的策略和理念落实到日常工作中,从细节做起,长期坚持收录将不再是问题对于企业网站。 查看全部
抓取网页新闻(企业网站的结构不合理是提高排名和网站权重的关键)
一是企业网站的结构不合理。许多企业站点的结构往往不是很合理。主要表现就是往往是一个传入的页面。进入后,在栏目页下增加一个flash。我们都知道蜘蛛对flash的爬行不是很好,也不是很理想。很明显,很多类似的企业网站收录并不理想。其次,网站的用户体验较差。最突出的表现就是很多公司在网站的左右两边放了一些客服代码。这些代码虽然可以增加交互性,但降低了用户阅读网站的体验,增加了网站的跳出率,降低了网站的权重。你可以想象收录
2
/5
其次,站点中的示例文本过多。这一点主要是想说明一些固定的栏目和栏目几乎都使用了一些固定的模板文字,比如联系我们、公司介绍、产品展示等。这些模板文本的许多列和部分彼此重复。二是网站新闻列表内容标题与新闻重复度高,相似度高。因为有些产品往往就是那几个特点,我们在围绕特点进行创作的过程中,不经意地回到了自己的写作套路,增加了内容的重复程度。因此,笔者建议在创建文章的时候,尽一切可能减少和降低文章的相似度和重复度,
3
/5
第三,网站外联度低。大家都知道外联是提升排名的关键,也是网站的权重。间接的,是提升收录的重要因素之一。很多企业网站的外联建设一般都很简单,主要表现就是一直在使用机密信息。Outreach,分类信息的权重相对较高,但是outreach的统一是限制了网站权重的增加。笔者建议先增加网站的权重。在Outreach,作者建议大家可以尝试不同的平台操作,比如软文投稿、连接交流平台、问答平台、采集网站。这些平台具有相对较高的权重。合理使用可以增强我们的体重。网站 有益的
4
/5
四、文章的更新频率。很多公司网站更新频率很不稳定,最突出的表现就是更新文章不及时,每三到五次,因为baiduspider根据我们的网站更新抓取网页内容赚取固定收入的情况。作者推荐文章收录定时定量更新文章,以吸引网站蜘蛛和蜘蛛开发访问我们网站的习惯后,这无疑会大大增加我们网站的抓取频率和收录的内容量。因此,笔者建议企业网站也要努力,每天为网站更新优质的文章充实网站。这种做法是必不可少的。
5
/5
综上,笔者分析了网站运行优化过程中收录不理想的问题以及如何改进网站收录。现在,希望对有兴趣改进网站收录的朋友有所帮助。网站优化中的内容建设一直是我们关注的关键因素之一。首先,我们从网站开始考虑,把我们优化好的策略和理念落实到日常工作中,从细节做起,长期坚持收录将不再是问题对于企业网站。
抓取网页新闻( 《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-23 05:20
《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
数据新闻实战:大数据驱动的新闻数据抓取
木马童年 2018-12-9 17:20320 0
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。现将数据采集部分放出,供大家分享交流。数据采集部分分为数据源和数据采集两部分。数据来了...
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。
现将数据采集部分放出,供大家分享交流。
数据采集部分分为数据源和数据采集两部分。
数据源主要讲数据的来源网站。
数据抓包主要讲如何抓包数据源的网络数据到本地。
网站数据源
政府网站:建议先选择政府网站。数据更权威,可长期稳定生成数据,数据量大;例如:国家质量监督检验检疫总局网站、环境保护部网站
行业垂直网站:数据更专业,整理更全面;例如:IT橘子| IT互联网公司产品数据库和商业信息服务
百度产品
百度指数:关键词指数和工业经济指数
百度预测:产业经济大数据预测
百度舆情:产业经济舆情分析
百度搜索:多条件搜索
微博指数产品
新浪微博微索引:关键词索引
微信指数产品
新上榜微信索引:关键词索引
数据抓取
网络爬虫:使用python等编程语言编写网络爬虫抓取网页信息
优点:开源、免费、操作灵活
缺点:学习编程和编写爬虫需要更多时间
采集器:使用优采云、优采云等网页采集器抓取网页信息
优点:上手非常快,无需学习编程,可导出为CSV/TXT/EXCEL等格式
缺点:超过一定数量需要付费导出,部分使用异步ajax技术的网页无法全面采集
数据采集就是这么简单,快来试试吧。 查看全部
抓取网页新闻(
《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
数据新闻实战:大数据驱动的新闻数据抓取
木马童年 2018-12-9 17:20320 0
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。现将数据采集部分放出,供大家分享交流。数据采集部分分为数据源和数据采集两部分。数据来了...
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。
现将数据采集部分放出,供大家分享交流。
数据采集部分分为数据源和数据采集两部分。
数据源主要讲数据的来源网站。
数据抓包主要讲如何抓包数据源的网络数据到本地。
网站数据源
政府网站:建议先选择政府网站。数据更权威,可长期稳定生成数据,数据量大;例如:国家质量监督检验检疫总局网站、环境保护部网站
行业垂直网站:数据更专业,整理更全面;例如:IT橘子| IT互联网公司产品数据库和商业信息服务
百度产品
百度指数:关键词指数和工业经济指数
百度预测:产业经济大数据预测
百度舆情:产业经济舆情分析
百度搜索:多条件搜索
微博指数产品
新浪微博微索引:关键词索引
微信指数产品
新上榜微信索引:关键词索引
数据抓取
网络爬虫:使用python等编程语言编写网络爬虫抓取网页信息
优点:开源、免费、操作灵活
缺点:学习编程和编写爬虫需要更多时间
采集器:使用优采云、优采云等网页采集器抓取网页信息
优点:上手非常快,无需学习编程,可导出为CSV/TXT/EXCEL等格式
缺点:超过一定数量需要付费导出,部分使用异步ajax技术的网页无法全面采集
数据采集就是这么简单,快来试试吧。
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-23 05:19
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、有民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发布时间和作者的自动检测和提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键,选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每个元素都是XPath,对应的是你需要提前去除的可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,或者今日头条中的专辑类型文章,提取结果可能不符合预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
验证消息:GNE 查看全部
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、有民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发布时间和作者的自动检测和提取功能。
最终输出效果如下图所示:

目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。

在Elements标签页找到标签,右键,选择Copy-Copy OuterHTML,如下图

from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每个元素都是XPath,对应的是你需要提前去除的可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,或者今日头条中的专辑类型文章,提取结果可能不符合预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通

验证消息:GNE
抓取网页新闻(新闻报道不需要专业基础,你知道吗?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-23 04:01
抓取网页新闻,获取标题和相关信息是主要任务,中间分析数据并提取有用的信息,然后通过分析这些报道。具体数据分析,上网自学即可。至于写报告,分析报告格式要求比较固定,因此用excel就好。报告内容,还是要结合你做的工作,
如果想研究,请查书如果要做,
数据库咯,
其实,新闻报道不需要专业基础。经常一个水平还不错的新闻学学生,某种程度上文科生也是很适合的。至于题主说的学术性方面的研究,恕我无能为力。非专业人士,
1报纸、杂志。2网站的源数据与处理,已经新闻网站类似。3至于市场什么的,没有方法,一切还都靠经验。
没关系,根据具体领域查找数据库。
至少搜狗新闻是的吧
一句话:互联网时代的报道要求过于基础了,需要让读者看到自己想要的,没有深入浅出的讲明白就直接失去价值。而要让读者看到自己想要的,就需要一定的专业背景。比如历史,医学,语言等等。至于网站上的报道,只能说:参差不齐,不过话说回来,现在网络曝光率太高,不论过去还是现在,一些真正的知识是不会被大家所认知的,知识是需要沉淀下来的。所以还是那句话:多看多写。写错了不怕,没写错也不怕,不断的修改和沉淀总能写好。 查看全部
抓取网页新闻(新闻报道不需要专业基础,你知道吗?-八维教育)
抓取网页新闻,获取标题和相关信息是主要任务,中间分析数据并提取有用的信息,然后通过分析这些报道。具体数据分析,上网自学即可。至于写报告,分析报告格式要求比较固定,因此用excel就好。报告内容,还是要结合你做的工作,
如果想研究,请查书如果要做,
数据库咯,
其实,新闻报道不需要专业基础。经常一个水平还不错的新闻学学生,某种程度上文科生也是很适合的。至于题主说的学术性方面的研究,恕我无能为力。非专业人士,
1报纸、杂志。2网站的源数据与处理,已经新闻网站类似。3至于市场什么的,没有方法,一切还都靠经验。
没关系,根据具体领域查找数据库。
至少搜狗新闻是的吧
一句话:互联网时代的报道要求过于基础了,需要让读者看到自己想要的,没有深入浅出的讲明白就直接失去价值。而要让读者看到自己想要的,就需要一定的专业背景。比如历史,医学,语言等等。至于网站上的报道,只能说:参差不齐,不过话说回来,现在网络曝光率太高,不论过去还是现在,一些真正的知识是不会被大家所认知的,知识是需要沉淀下来的。所以还是那句话:多看多写。写错了不怕,没写错也不怕,不断的修改和沉淀总能写好。
抓取网页新闻(7Python爬虫架构主要由五个部分组成的一个调度器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-22 11:17
7
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。
调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:收录要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和爬取URL循环。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(官方Python基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,或者按照DOM树的分析方法进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会非常困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三方插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
用一张图来解释调度器坐标是如何工作的:
图片整理自网络,侵删。 查看全部
抓取网页新闻(7Python爬虫架构主要由五个部分组成的一个调度器)
7
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。
调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:收录要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和爬取URL循环。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(官方Python基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,或者按照DOM树的分析方法进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会非常困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三方插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
用一张图来解释调度器坐标是如何工作的:
图片整理自网络,侵删。
抓取网页新闻(百度首页404是什么原因导致的超时,如何操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-21 23:02
抓取网页新闻首先打开百度首页,选择https下面点击看到百度首页右侧有个百度快照。双击百度快文,网址就可以改为自己的了。然后点进去就是我们要找的内容了。点网址右侧的url,可以看到404状态码。目前想到的就这些,有新的再补充。
打开新浪微博客户端,将不知道的链接复制进去,出现浏览器的网址栏后,点击打开,就会有提示是否真实,如果不是真实,并且接近404或是超出当前页面,系统就会提示:该内容未收录;也有可能是直接提示404,并不存在这个页面(网络限制,
亲测成功,
登录wordpress,进入网站空间管理页面,选择首页进入-404。出现404页面,我们就要找是什么原因导致的404或则超时,具体看http状态码,部分网页关闭时是404。可以把所有500代码段的页面代码复制到excel中。代码1:打开wordpress,点击右下角“+”新建博客项目,选择首页博客,把最后的500代码段复制进去。
代码2:把这个excel中复制出来的代码粘贴到网站源代码文件中,让这些代码变成500代码。代码1在网页源代码中的500代码位置,而代码2就在网页源代码目录中。然后根据需要修改500代码就可以了。
没有返回404页面, 查看全部
抓取网页新闻(百度首页404是什么原因导致的超时,如何操作)
抓取网页新闻首先打开百度首页,选择https下面点击看到百度首页右侧有个百度快照。双击百度快文,网址就可以改为自己的了。然后点进去就是我们要找的内容了。点网址右侧的url,可以看到404状态码。目前想到的就这些,有新的再补充。
打开新浪微博客户端,将不知道的链接复制进去,出现浏览器的网址栏后,点击打开,就会有提示是否真实,如果不是真实,并且接近404或是超出当前页面,系统就会提示:该内容未收录;也有可能是直接提示404,并不存在这个页面(网络限制,
亲测成功,
登录wordpress,进入网站空间管理页面,选择首页进入-404。出现404页面,我们就要找是什么原因导致的404或则超时,具体看http状态码,部分网页关闭时是404。可以把所有500代码段的页面代码复制到excel中。代码1:打开wordpress,点击右下角“+”新建博客项目,选择首页博客,把最后的500代码段复制进去。
代码2:把这个excel中复制出来的代码粘贴到网站源代码文件中,让这些代码变成500代码。代码1在网页源代码中的500代码位置,而代码2就在网页源代码目录中。然后根据需要修改500代码就可以了。
没有返回404页面,
抓取网页新闻(【技巧】如何用两个方法来抽去正文内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-20 19:21
我主要使用了两种方法来提取正文内容。第一种方法,比如xpath、css、正则表达式、beautifulsoup,在解析新闻页面的时候,总是遇到各种莫名其妙的问题。,让人头疼不已。后面红色标的是第二种方法,主要推荐报文库
在导师公司,需要使用重搜索引擎尽快获取想要的内容,然后建立语料库,所以我使用python的beautifulsoup和urllib抓取了一些web内容用于训练语料库。
搜索关键词是“公司名称”,其实只需要三步即可完成。第一个是直接在百度首页搜索,然后从百度结果搜索页面上的链接中获取,第二个是在页面主页面输入结果搜索那些链接,然后抓取正文内容。三是保存获取到的正文内容,对内容进行切分。例如,如果您在正文中找到人们说过的话,则可以使用谚语和表达方式。,说起来,曾经用“”来判断,这些就不赘述了,主要是提取正文内容。
提取链接
通过网页的源码发现,这些超链接在标签之间(不同的网站有不同的格式)。最好用beautifulsoup提取。如果使用 urllib 提取其他 url,则不易区分。例如下图
代码显示如下:
<p>#encoding=utf-8
#coding=utf-8
import urllib,urllib2
from bs4 import BeautifulSoup
import re
import os
import string
#得到url的list
def get_url_list(purl):
#连接
req = urllib2.Request(purl,headers={'User-Agent':"Magic Browser"})
page = urllib2.urlopen(req)
soup = BeautifulSoup(page.read())
#读取标签
a_div = soup.find('div',{'class':'main'})
b_div = a_div.find('div',{'class':'left'})
c_div = b_div.find('div',{'class':'newsList'})
links4 = []
#得到url的list
for link_aa in c_div:
for link_bb in link_aa:
links4.append(link_bb.find('a'))
links4 = list(set(links4))
links4.remove(-1)
links4.remove(None)
return links4
#从list中找到想要的新闻链接
#找到要访问的下一个页面的url
def get_url(links):
url = []
url2 = ''
url3 = ''
url4 = ''
i = 0
for link in links:
if link.contents == [u'后一天']:
continue
#上一页 和 下一页 的标签情况比较复杂
#取出“上一页”标签的url(貌似不管用)
if str(link.contents).find(u'/> ') != -1:
continue
#取出“下一页”标签的url
if str(link.contents).find(u' 查看全部
抓取网页新闻(【技巧】如何用两个方法来抽去正文内容?)
我主要使用了两种方法来提取正文内容。第一种方法,比如xpath、css、正则表达式、beautifulsoup,在解析新闻页面的时候,总是遇到各种莫名其妙的问题。,让人头疼不已。后面红色标的是第二种方法,主要推荐报文库
在导师公司,需要使用重搜索引擎尽快获取想要的内容,然后建立语料库,所以我使用python的beautifulsoup和urllib抓取了一些web内容用于训练语料库。
搜索关键词是“公司名称”,其实只需要三步即可完成。第一个是直接在百度首页搜索,然后从百度结果搜索页面上的链接中获取,第二个是在页面主页面输入结果搜索那些链接,然后抓取正文内容。三是保存获取到的正文内容,对内容进行切分。例如,如果您在正文中找到人们说过的话,则可以使用谚语和表达方式。,说起来,曾经用“”来判断,这些就不赘述了,主要是提取正文内容。
提取链接
通过网页的源码发现,这些超链接在标签之间(不同的网站有不同的格式)。最好用beautifulsoup提取。如果使用 urllib 提取其他 url,则不易区分。例如下图

代码显示如下:
<p>#encoding=utf-8
#coding=utf-8
import urllib,urllib2
from bs4 import BeautifulSoup
import re
import os
import string
#得到url的list
def get_url_list(purl):
#连接
req = urllib2.Request(purl,headers={'User-Agent':"Magic Browser"})
page = urllib2.urlopen(req)
soup = BeautifulSoup(page.read())
#读取标签
a_div = soup.find('div',{'class':'main'})
b_div = a_div.find('div',{'class':'left'})
c_div = b_div.find('div',{'class':'newsList'})
links4 = []
#得到url的list
for link_aa in c_div:
for link_bb in link_aa:
links4.append(link_bb.find('a'))
links4 = list(set(links4))
links4.remove(-1)
links4.remove(None)
return links4
#从list中找到想要的新闻链接
#找到要访问的下一个页面的url
def get_url(links):
url = []
url2 = ''
url3 = ''
url4 = ''
i = 0
for link in links:
if link.contents == [u'后一天']:
continue
#上一页 和 下一页 的标签情况比较复杂
#取出“上一页”标签的url(貌似不管用)
if str(link.contents).find(u'/> ') != -1:
continue
#取出“下一页”标签的url
if str(link.contents).find(u'
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-20 18:02
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源代码并没有随着浏览器的查看源代码功能发生变化,无论现在看到哪个Pagination,HTML源代码仍然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,可以完全摒弃嗅探方法,像普通网页一样抓取AJAX网站的内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建一个二级线索(主题名称)就是demo_cnbeta_detail),所谓的Hierarchical crawling summary page转向抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是入门教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页具有代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,则可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。有关关键功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《获取当当网商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,""是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索type ,该类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5所示。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在“Pagination Crawling Amazon”一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站并不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果发现新闻列表中的新闻都是之前爬过的新闻,则停止翻页爬行。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。 查看全部
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源代码并没有随着浏览器的查看源代码功能发生变化,无论现在看到哪个Pagination,HTML源代码仍然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,可以完全摒弃嗅探方法,像普通网页一样抓取AJAX网站的内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建一个二级线索(主题名称)就是demo_cnbeta_detail),所谓的Hierarchical crawling summary page转向抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是入门教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页具有代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,则可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。有关关键功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《获取当当网商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,""是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索type ,该类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5所示。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在“Pagination Crawling Amazon”一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站并不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果发现新闻列表中的新闻都是之前爬过的新闻,则停止翻页爬行。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。
抓取网页新闻(如何判断是否是蜘蛛对式网页的抓住机制来发表一点看法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-20 18:01
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下保持系统和实际环境中页面的一致性造成压力,这意味着蜘蛛不会抓取所有页面网站。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这就是为什么我们要做好网站的链接结构,然后我就只关注蜘蛛的抓取机制用于翻页网页。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率、文章@的链接不一样> 很可能是把它推送到翻页栏,这样蜘蛛就无法每天从第一个翻页栏爬到第80个,然后再爬一次文章和一个文章到对比数据库,蜘蛛太浪费时间也浪费你网站的收录时间,所以蜘蛛需要对这种特殊类型的翻页网页有额外的爬取机制来保证完整<
如何判断是否是有序翻页?
根据发布时间判断文章是否排列有序,是此类页面的必要条件。下面会讲到pnsqdeLB。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使没有写入发布时间,Spider Writer 也可以根据 文章 本身的实际发布时间进行判断。
爬取机制是如何工作的?
对于这种翻页编程客栈页面,蜘蛛主要记录编程客栈每次抓取网页时找到的文章链接,然后将这次找到的文章链接与找到的链接一起使用在历史上。对比一下,如果有交叉点,说明这次爬取已经找到所有新增的文章,可以停止后面的翻页栏的爬取;否则,说明这次爬取没有找到所有新增内容文章 @文章,需要继续爬下一页甚至后面几页才能找到所有新增内容文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比如网站页面目录新增29篇文章,表示上次最新文章是前30篇,蜘蛛一次抓取10个文章链接,所以蜘蛛抓取第一次爬行的时候是10,和上次没有交集。继续爬行,第二次再抓10。文章,也就是一共抓到了20条,和上次还没有交集,然后继续爬,这次抓到了第30条,也就是和上次有交集,也就是说蜘蛛已经从上次爬取到了本次网站更新的29篇文章文章。
建议
目前百度蜘蛛会对网页的pnsqdeLB类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并进行处理根据实际情况而定,但蜘蛛毕竟做不到识别准确率是100%,所以如果站长在做翻页栏,不要使用它,更不要说FALSH。同时还要经常更新文章,配合蜘蛛的爬行,这样才能大大提高蜘蛛识别的准确率,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛使用这种爬行机制。实际上,许多机制是同时进行的。 查看全部
抓取网页新闻(如何判断是否是蜘蛛对式网页的抓住机制来发表一点看法)
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下保持系统和实际环境中页面的一致性造成压力,这意味着蜘蛛不会抓取所有页面网站。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这就是为什么我们要做好网站的链接结构,然后我就只关注蜘蛛的抓取机制用于翻页网页。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率、文章@的链接不一样> 很可能是把它推送到翻页栏,这样蜘蛛就无法每天从第一个翻页栏爬到第80个,然后再爬一次文章和一个文章到对比数据库,蜘蛛太浪费时间也浪费你网站的收录时间,所以蜘蛛需要对这种特殊类型的翻页网页有额外的爬取机制来保证完整<
如何判断是否是有序翻页?
根据发布时间判断文章是否排列有序,是此类页面的必要条件。下面会讲到pnsqdeLB。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使没有写入发布时间,Spider Writer 也可以根据 文章 本身的实际发布时间进行判断。
爬取机制是如何工作的?
对于这种翻页编程客栈页面,蜘蛛主要记录编程客栈每次抓取网页时找到的文章链接,然后将这次找到的文章链接与找到的链接一起使用在历史上。对比一下,如果有交叉点,说明这次爬取已经找到所有新增的文章,可以停止后面的翻页栏的爬取;否则,说明这次爬取没有找到所有新增内容文章 @文章,需要继续爬下一页甚至后面几页才能找到所有新增内容文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比如网站页面目录新增29篇文章,表示上次最新文章是前30篇,蜘蛛一次抓取10个文章链接,所以蜘蛛抓取第一次爬行的时候是10,和上次没有交集。继续爬行,第二次再抓10。文章,也就是一共抓到了20条,和上次还没有交集,然后继续爬,这次抓到了第30条,也就是和上次有交集,也就是说蜘蛛已经从上次爬取到了本次网站更新的29篇文章文章。
建议
目前百度蜘蛛会对网页的pnsqdeLB类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并进行处理根据实际情况而定,但蜘蛛毕竟做不到识别准确率是100%,所以如果站长在做翻页栏,不要使用它,更不要说FALSH。同时还要经常更新文章,配合蜘蛛的爬行,这样才能大大提高蜘蛛识别的准确率,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛使用这种爬行机制。实际上,许多机制是同时进行的。
抓取网页新闻(一下我是如何使用jsoup实现对网页文档的修改和实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-18 23:19
先介绍一下jsoup,他的中文文档:
描述:jsoup 是一个用于处理 HTML 工作的 Java 库。它提供了一个非常方便的 API 来提取和操作数据,使用最好的 DOM、CSS 和类似 jquery 的方法。
具体和详细的文档可以浏览jsoup官方文档:
我主要讲一下我是如何使用jsoup来修改和实现web文档的。先找一个简单的网址:
我们可以用浏览器打开这个地址(推荐使用谷歌浏览器),右击,选择检查,可以查看具体的网页布局HTML。下面是使用jsoup直接获取网页的源码HTML。直接通过依赖导入依赖包:
implementation 'org.jsoup:jsoup:1.11.3'
然后使用方法:
Document document = Jsoup.connect(nowUri)
.timeout(15000)
.get();
可以得到一个 Doucument 文档对象,这个收录网页的 HTML 内容,我们可以使用
document.title()
获取网页标题的方法,也可以使用tostring或outerHtml来获取网页的源代码。如果我们想改变网页文本的标题:
沃顿:今晚赢球对我们来说并不美好,但赢球毕竟是
首先我们需要得到他,我们可以使用方法:
Element element = document.selectFirst("h1");
h1是元素标签,也就是过滤条件,元素是标签对象,可以使用toString()打印标签,也可以使用text()方法获取标签中收录的文本。接下来修改页面标题,如何使用:
element.text("这是我修改过的标题,哈哈哈……");
这是可以实现的。我们可以通过 webview 加载我们修改后的 HTML:
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
URL_HTML 是网页的原创地址,document.outerHtml() 是我们获取到的 HTML。效果图:
下一步就是修改文章的内容,同时也过滤掉文章的内容
Elements elements = document.select("p");
for (int i = 0; i < 4; i++) {
//打印文章的内容
// elements.text();
elements.get(i).appendText("《这段内容结束》");
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
}
因为这里有四段内容,先过滤掉标签为“p”的集合,再修改前四段。这里使用appendText()方法在label内容后追加文本内容,效果图:
我们还可以插入一个新的英文标题:
Element element2 = document.selectFirst("h1");
Element element1 = element2.clone();
element1.text("This is the title's translator");
element2.append(element1.outerHtml());
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
OK,更多的方法,更多的实现可以参考jsoup中给出的各种方法,比如选择器和正则表达式来实现特殊过滤等功能。
源码下载 查看全部
抓取网页新闻(一下我是如何使用jsoup实现对网页文档的修改和实现)
先介绍一下jsoup,他的中文文档:
描述:jsoup 是一个用于处理 HTML 工作的 Java 库。它提供了一个非常方便的 API 来提取和操作数据,使用最好的 DOM、CSS 和类似 jquery 的方法。
具体和详细的文档可以浏览jsoup官方文档:
我主要讲一下我是如何使用jsoup来修改和实现web文档的。先找一个简单的网址:
我们可以用浏览器打开这个地址(推荐使用谷歌浏览器),右击,选择检查,可以查看具体的网页布局HTML。下面是使用jsoup直接获取网页的源码HTML。直接通过依赖导入依赖包:
implementation 'org.jsoup:jsoup:1.11.3'
然后使用方法:
Document document = Jsoup.connect(nowUri)
.timeout(15000)
.get();
可以得到一个 Doucument 文档对象,这个收录网页的 HTML 内容,我们可以使用
document.title()
获取网页标题的方法,也可以使用tostring或outerHtml来获取网页的源代码。如果我们想改变网页文本的标题:
沃顿:今晚赢球对我们来说并不美好,但赢球毕竟是
首先我们需要得到他,我们可以使用方法:
Element element = document.selectFirst("h1");
h1是元素标签,也就是过滤条件,元素是标签对象,可以使用toString()打印标签,也可以使用text()方法获取标签中收录的文本。接下来修改页面标题,如何使用:
element.text("这是我修改过的标题,哈哈哈……");
这是可以实现的。我们可以通过 webview 加载我们修改后的 HTML:
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
URL_HTML 是网页的原创地址,document.outerHtml() 是我们获取到的 HTML。效果图:
下一步就是修改文章的内容,同时也过滤掉文章的内容
Elements elements = document.select("p");
for (int i = 0; i < 4; i++) {
//打印文章的内容
// elements.text();
elements.get(i).appendText("《这段内容结束》");
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
}
因为这里有四段内容,先过滤掉标签为“p”的集合,再修改前四段。这里使用appendText()方法在label内容后追加文本内容,效果图:

我们还可以插入一个新的英文标题:
Element element2 = document.selectFirst("h1");
Element element1 = element2.clone();
element1.text("This is the title's translator");
element2.append(element1.outerHtml());
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
OK,更多的方法,更多的实现可以参考jsoup中给出的各种方法,比如选择器和正则表达式来实现特殊过滤等功能。
源码下载
抓取网页新闻(网页抓取工具包MetaSeeker允许用户在同一个主题名下定义多个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-18 05:20
Web 爬虫工具包 MetaSeeker 允许用户在同一主题名称下定义多个信息结构。这带来了一个好处:如果目标页面结构发生变化,那么可以使用同一主题名称下的不同信息结构来抓取和存储着陆页上的信息。MetaSeeker 工具包中的网络爬虫DataScraper 可以自动找到符合目标网页结构的信息结构及其网络爬取规则。
但是MetaSeeker客户返回的信息显示,之前版本存在一个bug:如果同一主题名下的信息结构差异较大,DataScraper无法正常运行。比如在抓取网易163新闻的网友评论时,有的新闻是热点新闻,很多网友发表评论,有的新闻没有评论。分别定义了两种信息结构,一种用于翻页捕获所有网友的评论,另一种用于识别没有网友评论的网页情况。如何抓取网友评论可以在“MetaSeeker快速指南”中找到。网易新闻评论都是AJAX异步加载的,需要正确设置AJAX选项。在这种情况下,使用MetaStudio编辑翻页和抓取网友评论的信息结构时,需要在Clue Editor工作台上定义翻页线索,无需在其他信息结构的Clue Editor工作台上定义任何规则。因此,这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。
为了解决以上问题,DataScraper已经升级到V4.11.5版本,请下载升级。
但是,这个版本并没有完全清除这个错误。为了避免遇到这个bug,用户在创建信息结构时需要保证约定的顺序:如果多个同一个主题名称的信息结构差别很大,即在Bucket Editor和MetaStudio的Clue Editor工作台上,其中之一有些信息结构的两个工作台是空的,所以先创建这种类型的信息结构,最后再在工作台上创建一个不为空的信息结构。这样就可以避免这个bug。彻底解决这个bug的计划是版本V4.12.1。 查看全部
抓取网页新闻(网页抓取工具包MetaSeeker允许用户在同一个主题名下定义多个)
Web 爬虫工具包 MetaSeeker 允许用户在同一主题名称下定义多个信息结构。这带来了一个好处:如果目标页面结构发生变化,那么可以使用同一主题名称下的不同信息结构来抓取和存储着陆页上的信息。MetaSeeker 工具包中的网络爬虫DataScraper 可以自动找到符合目标网页结构的信息结构及其网络爬取规则。
但是MetaSeeker客户返回的信息显示,之前版本存在一个bug:如果同一主题名下的信息结构差异较大,DataScraper无法正常运行。比如在抓取网易163新闻的网友评论时,有的新闻是热点新闻,很多网友发表评论,有的新闻没有评论。分别定义了两种信息结构,一种用于翻页捕获所有网友的评论,另一种用于识别没有网友评论的网页情况。如何抓取网友评论可以在“MetaSeeker快速指南”中找到。网易新闻评论都是AJAX异步加载的,需要正确设置AJAX选项。在这种情况下,使用MetaStudio编辑翻页和抓取网友评论的信息结构时,需要在Clue Editor工作台上定义翻页线索,无需在其他信息结构的Clue Editor工作台上定义任何规则。因此,这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。
为了解决以上问题,DataScraper已经升级到V4.11.5版本,请下载升级。
但是,这个版本并没有完全清除这个错误。为了避免遇到这个bug,用户在创建信息结构时需要保证约定的顺序:如果多个同一个主题名称的信息结构差别很大,即在Bucket Editor和MetaStudio的Clue Editor工作台上,其中之一有些信息结构的两个工作台是空的,所以先创建这种类型的信息结构,最后再在工作台上创建一个不为空的信息结构。这样就可以避免这个bug。彻底解决这个bug的计划是版本V4.12.1。
抓取网页新闻( 关于利用python实现最简单的网页爬虫的相关资料介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-10-17 08:29
关于利用python实现最简单的网页爬虫的相关资料介绍)
python爬虫实战最简单的网络爬虫教程
更新时间:2017-08-13 10:08:49 作者:xiaomi
当我们在互联网上浏览网页时,我们经常会看到一些漂亮的图片。我们希望将这些图片保存和下载,或者用作桌面壁纸或设计材料。下面的文章文章就在这里给大家介绍一个最简单的使用python的网络爬虫。有需要的朋友可以参考。让我们来看看。
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。最近对python爬虫产生了浓厚的兴趣。我在这里分享我的学习路径。欢迎您提出建议。我们相互交流,共同进步。话不多说,一起来看看详细介绍:
1.开发工具
我使用的工具是sublime text3,它简短而强大(可能男人不喜欢这个词)让我着迷。推荐大家使用,当然如果你的电脑配置好,pycharm可能更适合你。
推荐用sublime text3搭建python开发环境查看这个文章:
[Sublime搭建python开发环境][]
2.爬虫介绍
爬虫,顾名思义,就像蠕虫一样,在大互联网、互联网上爬行。这样,我们就可以得到我们想要的。
既然要在互联网上爬取,就需要了解URL、合法名称“Uniform Resource Locator”、昵称“Link”。其结构主要由三部分组成:
(1)Protocol:比如我们网站常用的HTTP协议。
(2)Domain name or IP address:域名,如:,IP地址,即域名解析后对应的IP。
(3) 路径:即目录或文件等
3.urllib 开发最简单的爬虫
(1)urllib 简介
模块介绍
urllib.error
由 urllib.request 引发的异常类。
urllib.parse
将 URL 解析为组件或从组件组装它们。
urllib.request
用于打开 URL 的可扩展库。
urllib.response
urllib 使用的响应类。
urllib.robotparser
加载 robots.txt 文件并回答有关其他 URL 可提取性的问题。
(2)开发最简单的爬虫
百度首页简洁大方,非常适合我们的爬虫。
爬虫代码如下:
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()
结果如下:
我们可以通过右键点击百度首页的空白处,查看评论元素来与我们的运行结果进行对比。
当然request也可以生成一个request对象,可以用urlopen方法打开。
代码显示如下:
from urllib import request
def vists_baidu():
# create a request obkect
req = request.Request('http://www.baidu.com')
# open the request object
response = request.urlopen(req)
# read the response
html = response.read()
html = html.decode('utf-8')
print(html)
if __name__ == '__main__':
vists_baidu()
操作的结果和之前一样。
(3)错误处理
错误处理由 urllib 模块处理,主要包括 URLError 和 HTTPError。HTTPError 是 URLError 的子类,即 HTTRPError 也可以被 URLError 捕获。 查看全部
抓取网页新闻(
关于利用python实现最简单的网页爬虫的相关资料介绍)
python爬虫实战最简单的网络爬虫教程
更新时间:2017-08-13 10:08:49 作者:xiaomi
当我们在互联网上浏览网页时,我们经常会看到一些漂亮的图片。我们希望将这些图片保存和下载,或者用作桌面壁纸或设计材料。下面的文章文章就在这里给大家介绍一个最简单的使用python的网络爬虫。有需要的朋友可以参考。让我们来看看。
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。最近对python爬虫产生了浓厚的兴趣。我在这里分享我的学习路径。欢迎您提出建议。我们相互交流,共同进步。话不多说,一起来看看详细介绍:
1.开发工具
我使用的工具是sublime text3,它简短而强大(可能男人不喜欢这个词)让我着迷。推荐大家使用,当然如果你的电脑配置好,pycharm可能更适合你。
推荐用sublime text3搭建python开发环境查看这个文章:
[Sublime搭建python开发环境][]
2.爬虫介绍
爬虫,顾名思义,就像蠕虫一样,在大互联网、互联网上爬行。这样,我们就可以得到我们想要的。
既然要在互联网上爬取,就需要了解URL、合法名称“Uniform Resource Locator”、昵称“Link”。其结构主要由三部分组成:
(1)Protocol:比如我们网站常用的HTTP协议。
(2)Domain name or IP address:域名,如:,IP地址,即域名解析后对应的IP。
(3) 路径:即目录或文件等
3.urllib 开发最简单的爬虫
(1)urllib 简介
模块介绍
urllib.error
由 urllib.request 引发的异常类。
urllib.parse
将 URL 解析为组件或从组件组装它们。
urllib.request
用于打开 URL 的可扩展库。
urllib.response
urllib 使用的响应类。
urllib.robotparser
加载 robots.txt 文件并回答有关其他 URL 可提取性的问题。
(2)开发最简单的爬虫
百度首页简洁大方,非常适合我们的爬虫。
爬虫代码如下:
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()
结果如下:

我们可以通过右键点击百度首页的空白处,查看评论元素来与我们的运行结果进行对比。
当然request也可以生成一个request对象,可以用urlopen方法打开。
代码显示如下:
from urllib import request
def vists_baidu():
# create a request obkect
req = request.Request('http://www.baidu.com')
# open the request object
response = request.urlopen(req)
# read the response
html = response.read()
html = html.decode('utf-8')
print(html)
if __name__ == '__main__':
vists_baidu()
操作的结果和之前一样。
(3)错误处理
错误处理由 urllib 模块处理,主要包括 URLError 和 HTTPError。HTTPError 是 URLError 的子类,即 HTTRPError 也可以被 URLError 捕获。
抓取网页新闻(之前关键句筛选单句切分之后对句子的集合做一下筛选)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-17 08:27
之前用R做过一些文本处理工作,主要是对新闻进行分类,提取关键词之类的。您可以通过 jiebaR 包和自定义词典轻松完成大部分工作。分类是对每个项目进行分类。类别的特征和运行一个分类模型可以得到比较满意的结果。只是自动生成summary还没有找到好的解决方案,也没有找到R中现成的工具包。因为写代码的能力也比较上口,参考java和python中的代码,还是不可能写出像样的程序。所以最后的解决办法就是把文章的前几句剪下来作为总结,效果可想而知……
随着对R和python越来越熟悉,最近看了一篇文章,详细讲解了textRank算法在python中的实现文章(《还在被题主欺骗吗?是时候试试了文本摘要技术(附)源代码)》),所以我尝试将其更改为R代码。经过一番“辛苦”的处理,终于可以实现R中自动提取摘要的功能。
textRank算法的原理就不过多介绍了(想了解的可以参考这里),直接说代码:
1. 加载包
<p>if(!"jiebaR" %in% (.packages())) library(jiebaR)
if(!"dplyr" %in% (.packages())) library(dplyr)
keys 查看全部
抓取网页新闻(之前关键句筛选单句切分之后对句子的集合做一下筛选)
之前用R做过一些文本处理工作,主要是对新闻进行分类,提取关键词之类的。您可以通过 jiebaR 包和自定义词典轻松完成大部分工作。分类是对每个项目进行分类。类别的特征和运行一个分类模型可以得到比较满意的结果。只是自动生成summary还没有找到好的解决方案,也没有找到R中现成的工具包。因为写代码的能力也比较上口,参考java和python中的代码,还是不可能写出像样的程序。所以最后的解决办法就是把文章的前几句剪下来作为总结,效果可想而知……
随着对R和python越来越熟悉,最近看了一篇文章,详细讲解了textRank算法在python中的实现文章(《还在被题主欺骗吗?是时候试试了文本摘要技术(附)源代码)》),所以我尝试将其更改为R代码。经过一番“辛苦”的处理,终于可以实现R中自动提取摘要的功能。
textRank算法的原理就不过多介绍了(想了解的可以参考这里),直接说代码:
1. 加载包
<p>if(!"jiebaR" %in% (.packages())) library(jiebaR)
if(!"dplyr" %in% (.packages())) library(dplyr)
keys
抓取网页新闻(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-14 08:15
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站有很多不同类型的传输规律。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这一系列问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。
如何监控行业网站信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,可以使用蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需的行业网站信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
查看全部
抓取网页新闻(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站有很多不同类型的传输规律。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统

接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这一系列问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。

如何监控行业网站信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,可以使用蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需的行业网站信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
抓取网页新闻(网上谷歌人家的开发经验写下来与别人分享下。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-14 08:12
我已经工作近两年了,我一直在学习谷歌人在互联网上的经验。这次也把自己的开发心得写下来分享给大家。很快,我换了一份新工作,新公司刚结束了一个网站。网站 新闻内容是自己编辑添加的,都是手动的,所以我接受任务,做一个自动更新新闻内容的功能。
开始整理思路,第一步通过网站URL获取整个网站新闻链接的所有URL,第二步将获取到的URL返回到其源码中,第三步解析源代码中的内容和标题,第四步存入数据库。最后,使用java timer自动更新。
过程中最棘手的部分是解析HTML源代码,果断决定用htmlparser,废话少说,上部分代码。部分代码注释写得不好,请指教。
/**<br /> * 返回网页中所有URL<br /> * @return type:NodeList<br /> */<br /> public static NodeList getAllUrl(String Url) throws Exception {<br /><br /> //使用htmlparser获取<br /> Parser parser = new Parser();<br /> parser.setResource(Url);<br /> //待定的编码格式<br /> parser.setEncoding("gbk");<br /> //遍历所有节点 自定义内部类(自定义过滤器)<br /> NodeList nodeList = parser.extractAllNodesThatMatch(new NodeFilter() {<br /> private static final long serialVersionUID = 1L;<br /><br /> public boolean accept(Node node) {<br /> //判断node是否是LinkTag的一个实例<br /> if (node instanceof LinkTag)<br /> return true;<br /> else{<br /> return false;<br /> }<br /> }<br /> });<br /> return nodeList;<br /> }
<p><br /><br /> /*<br /> * 返回新闻内容<br /> */<br /> public static String getContent(String urlpath){<br /> Parser parser = new Parser();<br /> String content = "";<br /> try {<br /> parser.setResource(urlpath);//传入url<br /> NodeFilter divFilter = new NodeClassFilter(Div.class);//自定义过滤器<br /> NodeList divlist = parser.parse(divFilter);//加载过滤器 <br /> for(int i=0;i 查看全部
抓取网页新闻(网上谷歌人家的开发经验写下来与别人分享下。)
我已经工作近两年了,我一直在学习谷歌人在互联网上的经验。这次也把自己的开发心得写下来分享给大家。很快,我换了一份新工作,新公司刚结束了一个网站。网站 新闻内容是自己编辑添加的,都是手动的,所以我接受任务,做一个自动更新新闻内容的功能。
开始整理思路,第一步通过网站URL获取整个网站新闻链接的所有URL,第二步将获取到的URL返回到其源码中,第三步解析源代码中的内容和标题,第四步存入数据库。最后,使用java timer自动更新。
过程中最棘手的部分是解析HTML源代码,果断决定用htmlparser,废话少说,上部分代码。部分代码注释写得不好,请指教。
/**<br /> * 返回网页中所有URL<br /> * @return type:NodeList<br /> */<br /> public static NodeList getAllUrl(String Url) throws Exception {<br /><br /> //使用htmlparser获取<br /> Parser parser = new Parser();<br /> parser.setResource(Url);<br /> //待定的编码格式<br /> parser.setEncoding("gbk");<br /> //遍历所有节点 自定义内部类(自定义过滤器)<br /> NodeList nodeList = parser.extractAllNodesThatMatch(new NodeFilter() {<br /> private static final long serialVersionUID = 1L;<br /><br /> public boolean accept(Node node) {<br /> //判断node是否是LinkTag的一个实例<br /> if (node instanceof LinkTag)<br /> return true;<br /> else{<br /> return false;<br /> }<br /> }<br /> });<br /> return nodeList;<br /> }
<p><br /><br /> /*<br /> * 返回新闻内容<br /> */<br /> public static String getContent(String urlpath){<br /> Parser parser = new Parser();<br /> String content = "";<br /> try {<br /> parser.setResource(urlpath);//传入url<br /> NodeFilter divFilter = new NodeClassFilter(Div.class);//自定义过滤器<br /> NodeList divlist = parser.parse(divFilter);//加载过滤器 <br /> for(int i=0;i
抓取网页新闻(常见的几种数据来源方式和抓取方式,是如何实现的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-14 08:09
很多人想知道网站和app中的手机号码数据是如何抓取的,是如何实现的。我将在这里谈论它。
一、数据来源
有很多数据来源。给大家介绍几种常见的数据来源和抓取方法。
1、操作员数据。在这个源方法中,操作员将有一个 http 报告。每个访问者访问了哪些网站 APP,他的4G流量以及他消耗了多少流量都记录在其中。这样,访客的消费行为和近期需求
$(document).ready(function () {
$("#phone").focusout(function () {
$("#phone").val($("#phone").val().substring(0, 3) + "****" + $("#phone").val() .substring(7, 11));
});
});
寻求非常精确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站商网联盟的必备神器,可以放心使用。
2、 爬虫爬取,URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花掉。一个半天写代码懒得学第三方工具的人,靠自己写代码实现了。
网站 获取访问者的手机号码。例如,如果您正在浏览今日头条,我们可以通过您浏览到今日头条的手机号码获取您的手机号码,然后您就可以向该手机号码发送短信。
获取网站访客用户手机号的值
1、时间上:时间大大缩短,短平快
2、 招投标上:直接跳过招投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营:提供专属VIP后台账号,供客户查看和导出数据。然后主动打电话给客户,发短信,添加微信手机网站访客手机号获取好友,大大增加企业咨询采购量,让访客成为客户。对医疗、教育、企业、股票等诸多行业的帮助非常有用。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、App截取手机号,以及联通电信移动运营商大数据等数据,有兴趣的可以联系我测试一下。 查看全部
抓取网页新闻(常见的几种数据来源方式和抓取方式,是如何实现的)
很多人想知道网站和app中的手机号码数据是如何抓取的,是如何实现的。我将在这里谈论它。
一、数据来源
有很多数据来源。给大家介绍几种常见的数据来源和抓取方法。
1、操作员数据。在这个源方法中,操作员将有一个 http 报告。每个访问者访问了哪些网站 APP,他的4G流量以及他消耗了多少流量都记录在其中。这样,访客的消费行为和近期需求
$(document).ready(function () {
$("#phone").focusout(function () {
$("#phone").val($("#phone").val().substring(0, 3) + "****" + $("#phone").val() .substring(7, 11));
});
});
寻求非常精确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站商网联盟的必备神器,可以放心使用。
2、 爬虫爬取,URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花掉。一个半天写代码懒得学第三方工具的人,靠自己写代码实现了。
网站 获取访问者的手机号码。例如,如果您正在浏览今日头条,我们可以通过您浏览到今日头条的手机号码获取您的手机号码,然后您就可以向该手机号码发送短信。
获取网站访客用户手机号的值
1、时间上:时间大大缩短,短平快
2、 招投标上:直接跳过招投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营:提供专属VIP后台账号,供客户查看和导出数据。然后主动打电话给客户,发短信,添加微信手机网站访客手机号获取好友,大大增加企业咨询采购量,让访客成为客户。对医疗、教育、企业、股票等诸多行业的帮助非常有用。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、App截取手机号,以及联通电信移动运营商大数据等数据,有兴趣的可以联系我测试一下。
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-25 06:23
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享
)
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(基于行块分布函数的通用网页正文抽取算法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-24 07:00
问题:如何提取任意网页的正文内容(尤其是新闻和资讯),提取与文章内容相关的图片,源码见:extractor.py。
抓取单个网站网页内容时,通常使用正则匹配。但是不同的网站的结构实在是太奇怪了,很难用统一的正则表达式来匹配。《基于行块分布函数的通用网页文本提取算法》作者总结了从网页中提取文章文本的通用方法,提出了一种基于行块分布的文本提取算法,并给出了PHP等实现和爪哇。. 该算法的主要原理基于两点:
正文区域密度:去除HTML中所有标签后,正文区域字符密度更高,多行空白更少;行块长度:单个标签(行块)中非文本区域的内容一般较短。
算法步骤如下:
reCOMM = r''
reTRIM = r'([\s\S]*?)'
reTAG = r'|[ \t\r\f\v]'
def processTags(body=""):
body = re.sub(reCOMM, "", body)
body = re.sub(reTRIM.format("script"), "" ,re.sub(reTRIM.format("style"), "", body))
body = re.sub(reTAG, "", body)
return body
def processBlocks(body=""):
ctexts = body.split("\n")
textLens = [len(text) for text in ctexts]
cblocks = [0] * (len(ctexts) - blockSize)
lines = len(ctexts)
for i in range(blockSize):
cblocks = list(map(lambda x,y: x+y, textLens[i : lines-1-blockSize+i], cblocks))
return cblocks
def getContext(ctexts, cblocks):
maxTextLen = max(cblocks)
start = end = cblocks.index(maxTextLen)
while start > 0 and cblocks[start] > min(textLens):
start -= 1
while end min(textLens):
self.end += 1
return "".join(ctexts[start:end])
reIMG = re.compile(r'')
def processImages(body):
return reIMG.sub(r'{{\1}}', body)
总结
上述算法基本可以处理大部分(中文)网页文本的提取。对于某些网站文字图片多于文字的情况,可以使用retention
在标签中链接图像的方法增加了文本的密度。目前在少数测试中发现的问题包括:1)文章分页或动态加载网页;2) 网页评论太长。
参考
推特脸书谷歌+
Python算法 查看全部
抓取网页新闻(基于行块分布函数的通用网页正文抽取算法(图))
问题:如何提取任意网页的正文内容(尤其是新闻和资讯),提取与文章内容相关的图片,源码见:extractor.py。
抓取单个网站网页内容时,通常使用正则匹配。但是不同的网站的结构实在是太奇怪了,很难用统一的正则表达式来匹配。《基于行块分布函数的通用网页文本提取算法》作者总结了从网页中提取文章文本的通用方法,提出了一种基于行块分布的文本提取算法,并给出了PHP等实现和爪哇。. 该算法的主要原理基于两点:
正文区域密度:去除HTML中所有标签后,正文区域字符密度更高,多行空白更少;行块长度:单个标签(行块)中非文本区域的内容一般较短。
算法步骤如下:
reCOMM = r''
reTRIM = r'([\s\S]*?)'
reTAG = r'|[ \t\r\f\v]'
def processTags(body=""):
body = re.sub(reCOMM, "", body)
body = re.sub(reTRIM.format("script"), "" ,re.sub(reTRIM.format("style"), "", body))
body = re.sub(reTAG, "", body)
return body
def processBlocks(body=""):
ctexts = body.split("\n")
textLens = [len(text) for text in ctexts]
cblocks = [0] * (len(ctexts) - blockSize)
lines = len(ctexts)
for i in range(blockSize):
cblocks = list(map(lambda x,y: x+y, textLens[i : lines-1-blockSize+i], cblocks))
return cblocks
def getContext(ctexts, cblocks):
maxTextLen = max(cblocks)
start = end = cblocks.index(maxTextLen)
while start > 0 and cblocks[start] > min(textLens):
start -= 1
while end min(textLens):
self.end += 1
return "".join(ctexts[start:end])
reIMG = re.compile(r'')
def processImages(body):
return reIMG.sub(r'{{\1}}', body)
总结
上述算法基本可以处理大部分(中文)网页文本的提取。对于某些网站文字图片多于文字的情况,可以使用retention
在标签中链接图像的方法增加了文本的密度。目前在少数测试中发现的问题包括:1)文章分页或动态加载网页;2) 网页评论太长。
参考
推特脸书谷歌+
Python算法
抓取网页新闻(百度新闻()收录的大约两千多家的两千多后大所收获)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-24 06:22
小编给大家分享一下Python异步新闻抓取百度新闻爬虫的案例。希望大家看完这篇文章能有所收获,一起来讨论一下吧!
要爬取新闻,首先要有一个新闻源,即爬取的目标网站。国内新闻网站,从中央到地方,从一般行业到垂直行业,大小不一的新闻网站上千条。百度新闻()收录有两千左右。那么我们先从百度新闻说起。
打开百度新闻的网站首页:
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻标题和它们的原创链接。如图所示:
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
按照这个简单的流程,我们先实现如下简单的代码:
#!/usr/bin/env python3
# Author: veelion
import re
import time
import requests
import tldextract
def save_to_db(url, html):
# 保存网页到数据库,我们暂时用打印相关信息代替
print('%s : %s' % (url, len(html)))
def crawl():
# 1. download baidu news
hub_url = 'http://news.baidu.com/'
res = requests.get(hub_url)
html = res.text
# 2. extract news links
## 2.1 extract all links with 'href'
links = re.findall(r'href=[\'"]?(.*?)[\'"\s]', html)
print('find links:', len(links))
news_links = []
## 2.2 filter non-news link
for link in links:
if not link.startswith('http'):
continue
tld = tldextract.extract(link)
if tld.domain == 'baidu':
continue
news_links.append(link)
print('find news links:', len(news_links))
# 3. download news and save to database
for link in news_links:
html = requests.get(link).text
save_to_db(link, html)
print('works done!')
def main():
while 1:
crawl()
time.sleep(300)
if __name__ == '__main__':
main()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 首先用正则表达式提取a标签的href属性,也就是网页中的链接;然后假设非百度外部链接都是新闻链接,找到新闻链接
3. 将找到的所有新闻链接一一下载并存入数据库;保存到数据库的功能暂时被打印相关信息代替。
4. 每 300 秒重复步骤 1-3 以获取更新的新闻。
上面的代码可以工作,但只能工作。没有一点点槽点,所以让我们谈谈并改进这个爬虫。
1. 添加异常处理
在写爬虫的时候,尤其是和网络请求相关的代码,一定要有异常处理。目标服务器是否正常,当时的网络连接是否畅通(超时)等都是爬虫无法控制的,所以在处理网络请求时必须处理异常。最好为网络请求设置超时时间,不要在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301.该URL永久转移到其他URL,以后请求会请求转移的URL
404,基本上这个网站已经过期了,以后不要试了
500,服务器出现内部错误,可能是暂时的,请稍后再试
3. 管理 URL 的状态
记录失败的 URL,以便稍后重试。对于超时的URL,后面需要重新获取,所以需要记录所有URL的各种状态,包括:
已成功下载
多次下载失败,无需重新下载
下载
下载失败并重试
加上对网络请求的各种处理,这个爬虫就强大了很多,不会动不动就异常退出,给后续的运维带来很大的工作量。
Python爬虫知识点
在本节中,我们使用了 Python 的几个模块。它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET 和 POST 很容易获得:
import requests
res = requests.get(url, timeout=5, headers=my_headers)
res2 = requests.post(url, data=post_data, timeout=5, headers=my_headers)
get() 和 post() 函数有许多参数可供选择。上面使用了超时设置和自定义标头。更多参数请参考requests文档。
无论get()还是post(),Requests都会返回一个Response对象,下载的内容就是通过这个对象获取的:
res.content 是获取到的二进制内容,类型为字节;
res.text为二进制内容解码后的str内容;
它首先从响应头中找到编码,如果找不到则通过chardet自动确定编码,并赋值给res.encoding,最后将二进制内容解密为str类型。
In [1]: import requests
In [2]: r = requests.get('http://epaper.sxrb.com/')
In [3]: r.encoding
Out[3]: 'ISO-8859-1'
In [4]: import chardet
In [5]: chardet.detect(r.content)
Out[5]: {'confidence': 0.99, 'encoding': 'utf-8', 'language': ''}
以上是用ipython交互式解释器的演示(强烈推荐ipython,比Python自带的解释器好很多)。开通的网站是山西日报数字报。网页源码的代码是utf8,chardet得到的代码也是utf8。而requests判断的编码是ISO-8859-1,那么它返回的文本的中文也会出现乱码。
请求的另一个有用方面是 Session,它部分类似于浏览器并保存 cookie。您可以稍后使用其会话登录以及与 cookie 相关的爬虫。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,建议使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要 pip install tldextract 来安装它。表示顶级域提取,即顶级域提取。前面我们讲了URL的结构,叫做host,是注册域名的子域,com是顶级域TLD。它的结果是这样的:
In [6]: import tldextract
In [7]: tldextract.extract('http://news.baidu.com/')
Out[7]: ExtractResult(subdomain='news', domain='baidu', suffix='com')
返回结构收录三部分:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。time模块是一个提供时间相关功能的模块。同时还有一个模块 datetime 也是和时间相关的,可以根据情况使用。
看完这篇文章,相信你对Python异步新闻抓取百度新闻爬虫的案例有了一定的了解。如果您想了解更多,欢迎关注易宿云行业资讯频道,感谢阅读! 查看全部
抓取网页新闻(百度新闻()收录的大约两千多家的两千多后大所收获)
小编给大家分享一下Python异步新闻抓取百度新闻爬虫的案例。希望大家看完这篇文章能有所收获,一起来讨论一下吧!
要爬取新闻,首先要有一个新闻源,即爬取的目标网站。国内新闻网站,从中央到地方,从一般行业到垂直行业,大小不一的新闻网站上千条。百度新闻()收录有两千左右。那么我们先从百度新闻说起。
打开百度新闻的网站首页:
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻标题和它们的原创链接。如图所示:
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
按照这个简单的流程,我们先实现如下简单的代码:
#!/usr/bin/env python3
# Author: veelion
import re
import time
import requests
import tldextract
def save_to_db(url, html):
# 保存网页到数据库,我们暂时用打印相关信息代替
print('%s : %s' % (url, len(html)))
def crawl():
# 1. download baidu news
hub_url = 'http://news.baidu.com/'
res = requests.get(hub_url)
html = res.text
# 2. extract news links
## 2.1 extract all links with 'href'
links = re.findall(r'href=[\'"]?(.*?)[\'"\s]', html)
print('find links:', len(links))
news_links = []
## 2.2 filter non-news link
for link in links:
if not link.startswith('http'):
continue
tld = tldextract.extract(link)
if tld.domain == 'baidu':
continue
news_links.append(link)
print('find news links:', len(news_links))
# 3. download news and save to database
for link in news_links:
html = requests.get(link).text
save_to_db(link, html)
print('works done!')
def main():
while 1:
crawl()
time.sleep(300)
if __name__ == '__main__':
main()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 首先用正则表达式提取a标签的href属性,也就是网页中的链接;然后假设非百度外部链接都是新闻链接,找到新闻链接
3. 将找到的所有新闻链接一一下载并存入数据库;保存到数据库的功能暂时被打印相关信息代替。
4. 每 300 秒重复步骤 1-3 以获取更新的新闻。
上面的代码可以工作,但只能工作。没有一点点槽点,所以让我们谈谈并改进这个爬虫。
1. 添加异常处理
在写爬虫的时候,尤其是和网络请求相关的代码,一定要有异常处理。目标服务器是否正常,当时的网络连接是否畅通(超时)等都是爬虫无法控制的,所以在处理网络请求时必须处理异常。最好为网络请求设置超时时间,不要在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301.该URL永久转移到其他URL,以后请求会请求转移的URL
404,基本上这个网站已经过期了,以后不要试了
500,服务器出现内部错误,可能是暂时的,请稍后再试
3. 管理 URL 的状态
记录失败的 URL,以便稍后重试。对于超时的URL,后面需要重新获取,所以需要记录所有URL的各种状态,包括:
已成功下载
多次下载失败,无需重新下载
下载
下载失败并重试
加上对网络请求的各种处理,这个爬虫就强大了很多,不会动不动就异常退出,给后续的运维带来很大的工作量。
Python爬虫知识点
在本节中,我们使用了 Python 的几个模块。它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET 和 POST 很容易获得:
import requests
res = requests.get(url, timeout=5, headers=my_headers)
res2 = requests.post(url, data=post_data, timeout=5, headers=my_headers)
get() 和 post() 函数有许多参数可供选择。上面使用了超时设置和自定义标头。更多参数请参考requests文档。
无论get()还是post(),Requests都会返回一个Response对象,下载的内容就是通过这个对象获取的:
res.content 是获取到的二进制内容,类型为字节;
res.text为二进制内容解码后的str内容;
它首先从响应头中找到编码,如果找不到则通过chardet自动确定编码,并赋值给res.encoding,最后将二进制内容解密为str类型。
In [1]: import requests
In [2]: r = requests.get('http://epaper.sxrb.com/')
In [3]: r.encoding
Out[3]: 'ISO-8859-1'
In [4]: import chardet
In [5]: chardet.detect(r.content)
Out[5]: {'confidence': 0.99, 'encoding': 'utf-8', 'language': ''}
以上是用ipython交互式解释器的演示(强烈推荐ipython,比Python自带的解释器好很多)。开通的网站是山西日报数字报。网页源码的代码是utf8,chardet得到的代码也是utf8。而requests判断的编码是ISO-8859-1,那么它返回的文本的中文也会出现乱码。
请求的另一个有用方面是 Session,它部分类似于浏览器并保存 cookie。您可以稍后使用其会话登录以及与 cookie 相关的爬虫。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,建议使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要 pip install tldextract 来安装它。表示顶级域提取,即顶级域提取。前面我们讲了URL的结构,叫做host,是注册域名的子域,com是顶级域TLD。它的结果是这样的:
In [6]: import tldextract
In [7]: tldextract.extract('http://news.baidu.com/')
Out[7]: ExtractResult(subdomain='news', domain='baidu', suffix='com')
返回结构收录三部分:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。time模块是一个提供时间相关功能的模块。同时还有一个模块 datetime 也是和时间相关的,可以根据情况使用。
看完这篇文章,相信你对Python异步新闻抓取百度新闻爬虫的案例有了一定的了解。如果您想了解更多,欢迎关注易宿云行业资讯频道,感谢阅读!
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-23 13:16
用python写爬虫的人越来越多,这也说明用python写爬虫比其他语言更方便。很多新闻网站没有反爬虫策略,所以爬取新闻网站的数据比较方便。然而,这么多新闻网站,我们应该怎么爬?你从哪里开始?这是我们首先需要考虑的问题。
您需要的是异步 IO 来实现高效的爬虫。
下面我们来看看基于asyncio的Python3新闻爬虫,以及如何高效实现。
从 Python3.5 开始,增加了新的语法,关键字 async 和 await,asyncio 也成为了标准库。这与我们可以编写异步 IO 程序一样强大。让我们轻松实现一个。用于有针对性地抓取新闻的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:标准异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url网站的模块;logging:记录爬虫日志;leveldb:Google 的 Key-Value 数据库,用于记录 URL 的状态;farmhash:将 URL 散列作为 URL 的唯一标识符;sanicdb:封装aiomysql,更方便的数据库mysql操作;2. 异步爬虫实现过程 2.1 新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些URL指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章 首次发表在我的技术博客猿人学习Python基础教程 查看全部
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
用python写爬虫的人越来越多,这也说明用python写爬虫比其他语言更方便。很多新闻网站没有反爬虫策略,所以爬取新闻网站的数据比较方便。然而,这么多新闻网站,我们应该怎么爬?你从哪里开始?这是我们首先需要考虑的问题。
您需要的是异步 IO 来实现高效的爬虫。
下面我们来看看基于asyncio的Python3新闻爬虫,以及如何高效实现。
从 Python3.5 开始,增加了新的语法,关键字 async 和 await,asyncio 也成为了标准库。这与我们可以编写异步 IO 程序一样强大。让我们轻松实现一个。用于有针对性地抓取新闻的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:标准异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url网站的模块;logging:记录爬虫日志;leveldb:Google 的 Key-Value 数据库,用于记录 URL 的状态;farmhash:将 URL 散列作为 URL 的唯一标识符;sanicdb:封装aiomysql,更方便的数据库mysql操作;2. 异步爬虫实现过程 2.1 新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些URL指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章 首次发表在我的技术博客猿人学习Python基础教程
抓取网页新闻(企业网站的结构不合理是提高排名和网站权重的关键)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-23 05:22
一是企业网站的结构不合理。许多企业站点的结构往往不是很合理。主要表现就是往往是一个传入的页面。进入后,在栏目页下增加一个flash。我们都知道蜘蛛对flash的爬行不是很好,也不是很理想。很明显,很多类似的企业网站收录并不理想。其次,网站的用户体验较差。最突出的表现就是很多公司在网站的左右两边放了一些客服代码。这些代码虽然可以增加交互性,但降低了用户阅读网站的体验,增加了网站的跳出率,降低了网站的权重。你可以想象收录
2
/5
其次,站点中的示例文本过多。这一点主要是想说明一些固定的栏目和栏目几乎都使用了一些固定的模板文字,比如联系我们、公司介绍、产品展示等。这些模板文本的许多列和部分彼此重复。二是网站新闻列表内容标题与新闻重复度高,相似度高。因为有些产品往往就是那几个特点,我们在围绕特点进行创作的过程中,不经意地回到了自己的写作套路,增加了内容的重复程度。因此,笔者建议在创建文章的时候,尽一切可能减少和降低文章的相似度和重复度,
3
/5
第三,网站外联度低。大家都知道外联是提升排名的关键,也是网站的权重。间接的,是提升收录的重要因素之一。很多企业网站的外联建设一般都很简单,主要表现就是一直在使用机密信息。Outreach,分类信息的权重相对较高,但是outreach的统一是限制了网站权重的增加。笔者建议先增加网站的权重。在Outreach,作者建议大家可以尝试不同的平台操作,比如软文投稿、连接交流平台、问答平台、采集网站。这些平台具有相对较高的权重。合理使用可以增强我们的体重。网站 有益的
4
/5
四、文章的更新频率。很多公司网站更新频率很不稳定,最突出的表现就是更新文章不及时,每三到五次,因为baiduspider根据我们的网站更新抓取网页内容赚取固定收入的情况。作者推荐文章收录定时定量更新文章,以吸引网站蜘蛛和蜘蛛开发访问我们网站的习惯后,这无疑会大大增加我们网站的抓取频率和收录的内容量。因此,笔者建议企业网站也要努力,每天为网站更新优质的文章充实网站。这种做法是必不可少的。
5
/5
综上,笔者分析了网站运行优化过程中收录不理想的问题以及如何改进网站收录。现在,希望对有兴趣改进网站收录的朋友有所帮助。网站优化中的内容建设一直是我们关注的关键因素之一。首先,我们从网站开始考虑,把我们优化好的策略和理念落实到日常工作中,从细节做起,长期坚持收录将不再是问题对于企业网站。 查看全部
抓取网页新闻(企业网站的结构不合理是提高排名和网站权重的关键)
一是企业网站的结构不合理。许多企业站点的结构往往不是很合理。主要表现就是往往是一个传入的页面。进入后,在栏目页下增加一个flash。我们都知道蜘蛛对flash的爬行不是很好,也不是很理想。很明显,很多类似的企业网站收录并不理想。其次,网站的用户体验较差。最突出的表现就是很多公司在网站的左右两边放了一些客服代码。这些代码虽然可以增加交互性,但降低了用户阅读网站的体验,增加了网站的跳出率,降低了网站的权重。你可以想象收录
2
/5
其次,站点中的示例文本过多。这一点主要是想说明一些固定的栏目和栏目几乎都使用了一些固定的模板文字,比如联系我们、公司介绍、产品展示等。这些模板文本的许多列和部分彼此重复。二是网站新闻列表内容标题与新闻重复度高,相似度高。因为有些产品往往就是那几个特点,我们在围绕特点进行创作的过程中,不经意地回到了自己的写作套路,增加了内容的重复程度。因此,笔者建议在创建文章的时候,尽一切可能减少和降低文章的相似度和重复度,
3
/5
第三,网站外联度低。大家都知道外联是提升排名的关键,也是网站的权重。间接的,是提升收录的重要因素之一。很多企业网站的外联建设一般都很简单,主要表现就是一直在使用机密信息。Outreach,分类信息的权重相对较高,但是outreach的统一是限制了网站权重的增加。笔者建议先增加网站的权重。在Outreach,作者建议大家可以尝试不同的平台操作,比如软文投稿、连接交流平台、问答平台、采集网站。这些平台具有相对较高的权重。合理使用可以增强我们的体重。网站 有益的
4
/5
四、文章的更新频率。很多公司网站更新频率很不稳定,最突出的表现就是更新文章不及时,每三到五次,因为baiduspider根据我们的网站更新抓取网页内容赚取固定收入的情况。作者推荐文章收录定时定量更新文章,以吸引网站蜘蛛和蜘蛛开发访问我们网站的习惯后,这无疑会大大增加我们网站的抓取频率和收录的内容量。因此,笔者建议企业网站也要努力,每天为网站更新优质的文章充实网站。这种做法是必不可少的。
5
/5
综上,笔者分析了网站运行优化过程中收录不理想的问题以及如何改进网站收录。现在,希望对有兴趣改进网站收录的朋友有所帮助。网站优化中的内容建设一直是我们关注的关键因素之一。首先,我们从网站开始考虑,把我们优化好的策略和理念落实到日常工作中,从细节做起,长期坚持收录将不再是问题对于企业网站。
抓取网页新闻( 《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-23 05:20
《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
数据新闻实战:大数据驱动的新闻数据抓取
木马童年 2018-12-9 17:20320 0
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。现将数据采集部分放出,供大家分享交流。数据采集部分分为数据源和数据采集两部分。数据来了...
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。
现将数据采集部分放出,供大家分享交流。
数据采集部分分为数据源和数据采集两部分。
数据源主要讲数据的来源网站。
数据抓包主要讲如何抓包数据源的网络数据到本地。
网站数据源
政府网站:建议先选择政府网站。数据更权威,可长期稳定生成数据,数据量大;例如:国家质量监督检验检疫总局网站、环境保护部网站
行业垂直网站:数据更专业,整理更全面;例如:IT橘子| IT互联网公司产品数据库和商业信息服务
百度产品
百度指数:关键词指数和工业经济指数
百度预测:产业经济大数据预测
百度舆情:产业经济舆情分析
百度搜索:多条件搜索
微博指数产品
新浪微博微索引:关键词索引
微信指数产品
新上榜微信索引:关键词索引
数据抓取
网络爬虫:使用python等编程语言编写网络爬虫抓取网页信息
优点:开源、免费、操作灵活
缺点:学习编程和编写爬虫需要更多时间
采集器:使用优采云、优采云等网页采集器抓取网页信息
优点:上手非常快,无需学习编程,可导出为CSV/TXT/EXCEL等格式
缺点:超过一定数量需要付费导出,部分使用异步ajax技术的网页无法全面采集
数据采集就是这么简单,快来试试吧。 查看全部
抓取网页新闻(
《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
数据新闻实战:大数据驱动的新闻数据抓取
木马童年 2018-12-9 17:20320 0
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。现将数据采集部分放出,供大家分享交流。数据采集部分分为数据源和数据采集两部分。数据来了...
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。
现将数据采集部分放出,供大家分享交流。
数据采集部分分为数据源和数据采集两部分。
数据源主要讲数据的来源网站。
数据抓包主要讲如何抓包数据源的网络数据到本地。
网站数据源
政府网站:建议先选择政府网站。数据更权威,可长期稳定生成数据,数据量大;例如:国家质量监督检验检疫总局网站、环境保护部网站
行业垂直网站:数据更专业,整理更全面;例如:IT橘子| IT互联网公司产品数据库和商业信息服务
百度产品
百度指数:关键词指数和工业经济指数
百度预测:产业经济大数据预测
百度舆情:产业经济舆情分析
百度搜索:多条件搜索
微博指数产品
新浪微博微索引:关键词索引
微信指数产品
新上榜微信索引:关键词索引
数据抓取
网络爬虫:使用python等编程语言编写网络爬虫抓取网页信息
优点:开源、免费、操作灵活
缺点:学习编程和编写爬虫需要更多时间
采集器:使用优采云、优采云等网页采集器抓取网页信息
优点:上手非常快,无需学习编程,可导出为CSV/TXT/EXCEL等格式
缺点:超过一定数量需要付费导出,部分使用异步ajax技术的网页无法全面采集
数据采集就是这么简单,快来试试吧。
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-23 05:19
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、有民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发布时间和作者的自动检测和提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键,选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每个元素都是XPath,对应的是你需要提前去除的可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,或者今日头条中的专辑类型文章,提取结果可能不符合预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
验证消息:GNE 查看全部
抓取网页新闻(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我按照论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、有民星空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发布时间和作者的自动检测和提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键,选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每个元素都是XPath,对应的是你需要提前去除的可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,或者今日头条中的专辑类型文章,提取结果可能不符合预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
验证消息:GNE
抓取网页新闻(新闻报道不需要专业基础,你知道吗?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-23 04:01
抓取网页新闻,获取标题和相关信息是主要任务,中间分析数据并提取有用的信息,然后通过分析这些报道。具体数据分析,上网自学即可。至于写报告,分析报告格式要求比较固定,因此用excel就好。报告内容,还是要结合你做的工作,
如果想研究,请查书如果要做,
数据库咯,
其实,新闻报道不需要专业基础。经常一个水平还不错的新闻学学生,某种程度上文科生也是很适合的。至于题主说的学术性方面的研究,恕我无能为力。非专业人士,
1报纸、杂志。2网站的源数据与处理,已经新闻网站类似。3至于市场什么的,没有方法,一切还都靠经验。
没关系,根据具体领域查找数据库。
至少搜狗新闻是的吧
一句话:互联网时代的报道要求过于基础了,需要让读者看到自己想要的,没有深入浅出的讲明白就直接失去价值。而要让读者看到自己想要的,就需要一定的专业背景。比如历史,医学,语言等等。至于网站上的报道,只能说:参差不齐,不过话说回来,现在网络曝光率太高,不论过去还是现在,一些真正的知识是不会被大家所认知的,知识是需要沉淀下来的。所以还是那句话:多看多写。写错了不怕,没写错也不怕,不断的修改和沉淀总能写好。 查看全部
抓取网页新闻(新闻报道不需要专业基础,你知道吗?-八维教育)
抓取网页新闻,获取标题和相关信息是主要任务,中间分析数据并提取有用的信息,然后通过分析这些报道。具体数据分析,上网自学即可。至于写报告,分析报告格式要求比较固定,因此用excel就好。报告内容,还是要结合你做的工作,
如果想研究,请查书如果要做,
数据库咯,
其实,新闻报道不需要专业基础。经常一个水平还不错的新闻学学生,某种程度上文科生也是很适合的。至于题主说的学术性方面的研究,恕我无能为力。非专业人士,
1报纸、杂志。2网站的源数据与处理,已经新闻网站类似。3至于市场什么的,没有方法,一切还都靠经验。
没关系,根据具体领域查找数据库。
至少搜狗新闻是的吧
一句话:互联网时代的报道要求过于基础了,需要让读者看到自己想要的,没有深入浅出的讲明白就直接失去价值。而要让读者看到自己想要的,就需要一定的专业背景。比如历史,医学,语言等等。至于网站上的报道,只能说:参差不齐,不过话说回来,现在网络曝光率太高,不论过去还是现在,一些真正的知识是不会被大家所认知的,知识是需要沉淀下来的。所以还是那句话:多看多写。写错了不怕,没写错也不怕,不断的修改和沉淀总能写好。
抓取网页新闻(7Python爬虫架构主要由五个部分组成的一个调度器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-10-22 11:17
7
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。
调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:收录要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和爬取URL循环。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(官方Python基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,或者按照DOM树的分析方法进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会非常困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三方插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
用一张图来解释调度器坐标是如何工作的:
图片整理自网络,侵删。 查看全部
抓取网页新闻(7Python爬虫架构主要由五个部分组成的一个调度器)
7
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(抓取有价值的数据)。
调度器:相当于一台电脑的CPU,主要负责URL管理器、下载器、解析器之间的调度协调。
URL管理器:收录要爬取的URL地址和已经爬取的URL地址,防止重复爬取URL和爬取URL循环。URL管理器的实现主要有三种方式,分别是通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入URL地址下载网页,并将网页转换为字符串。网页下载器有urllib2(官方Python基础模块),包括登录、代理、cookie、请求(第三方包)
网页解析器:解析一个网页字符串,可以根据我们的需求提取出我们有用的信息,或者按照DOM树的分析方法进行解析。网页解析器有正则表达式(直观上就是通过模糊匹配将网页转成字符串提取有价值的信息。当文档比较复杂时,这种方法提取数据会非常困难)、html。parser(Python内置)、beautifulsoup(第三方插件,可以使用Python内置的html.parser进行解析,也可以使用lxml进行解析,比其他的更强大)、lxml(第三方插件,可以解析xml和HTML),html.parser,beautifulsoup和lxml都是以DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
用一张图来解释调度器坐标是如何工作的:
图片整理自网络,侵删。
抓取网页新闻(百度首页404是什么原因导致的超时,如何操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-21 23:02
抓取网页新闻首先打开百度首页,选择https下面点击看到百度首页右侧有个百度快照。双击百度快文,网址就可以改为自己的了。然后点进去就是我们要找的内容了。点网址右侧的url,可以看到404状态码。目前想到的就这些,有新的再补充。
打开新浪微博客户端,将不知道的链接复制进去,出现浏览器的网址栏后,点击打开,就会有提示是否真实,如果不是真实,并且接近404或是超出当前页面,系统就会提示:该内容未收录;也有可能是直接提示404,并不存在这个页面(网络限制,
亲测成功,
登录wordpress,进入网站空间管理页面,选择首页进入-404。出现404页面,我们就要找是什么原因导致的404或则超时,具体看http状态码,部分网页关闭时是404。可以把所有500代码段的页面代码复制到excel中。代码1:打开wordpress,点击右下角“+”新建博客项目,选择首页博客,把最后的500代码段复制进去。
代码2:把这个excel中复制出来的代码粘贴到网站源代码文件中,让这些代码变成500代码。代码1在网页源代码中的500代码位置,而代码2就在网页源代码目录中。然后根据需要修改500代码就可以了。
没有返回404页面, 查看全部
抓取网页新闻(百度首页404是什么原因导致的超时,如何操作)
抓取网页新闻首先打开百度首页,选择https下面点击看到百度首页右侧有个百度快照。双击百度快文,网址就可以改为自己的了。然后点进去就是我们要找的内容了。点网址右侧的url,可以看到404状态码。目前想到的就这些,有新的再补充。
打开新浪微博客户端,将不知道的链接复制进去,出现浏览器的网址栏后,点击打开,就会有提示是否真实,如果不是真实,并且接近404或是超出当前页面,系统就会提示:该内容未收录;也有可能是直接提示404,并不存在这个页面(网络限制,
亲测成功,
登录wordpress,进入网站空间管理页面,选择首页进入-404。出现404页面,我们就要找是什么原因导致的404或则超时,具体看http状态码,部分网页关闭时是404。可以把所有500代码段的页面代码复制到excel中。代码1:打开wordpress,点击右下角“+”新建博客项目,选择首页博客,把最后的500代码段复制进去。
代码2:把这个excel中复制出来的代码粘贴到网站源代码文件中,让这些代码变成500代码。代码1在网页源代码中的500代码位置,而代码2就在网页源代码目录中。然后根据需要修改500代码就可以了。
没有返回404页面,
抓取网页新闻(【技巧】如何用两个方法来抽去正文内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-20 19:21
我主要使用了两种方法来提取正文内容。第一种方法,比如xpath、css、正则表达式、beautifulsoup,在解析新闻页面的时候,总是遇到各种莫名其妙的问题。,让人头疼不已。后面红色标的是第二种方法,主要推荐报文库
在导师公司,需要使用重搜索引擎尽快获取想要的内容,然后建立语料库,所以我使用python的beautifulsoup和urllib抓取了一些web内容用于训练语料库。
搜索关键词是“公司名称”,其实只需要三步即可完成。第一个是直接在百度首页搜索,然后从百度结果搜索页面上的链接中获取,第二个是在页面主页面输入结果搜索那些链接,然后抓取正文内容。三是保存获取到的正文内容,对内容进行切分。例如,如果您在正文中找到人们说过的话,则可以使用谚语和表达方式。,说起来,曾经用“”来判断,这些就不赘述了,主要是提取正文内容。
提取链接
通过网页的源码发现,这些超链接在标签之间(不同的网站有不同的格式)。最好用beautifulsoup提取。如果使用 urllib 提取其他 url,则不易区分。例如下图
代码显示如下:
<p>#encoding=utf-8
#coding=utf-8
import urllib,urllib2
from bs4 import BeautifulSoup
import re
import os
import string
#得到url的list
def get_url_list(purl):
#连接
req = urllib2.Request(purl,headers={'User-Agent':"Magic Browser"})
page = urllib2.urlopen(req)
soup = BeautifulSoup(page.read())
#读取标签
a_div = soup.find('div',{'class':'main'})
b_div = a_div.find('div',{'class':'left'})
c_div = b_div.find('div',{'class':'newsList'})
links4 = []
#得到url的list
for link_aa in c_div:
for link_bb in link_aa:
links4.append(link_bb.find('a'))
links4 = list(set(links4))
links4.remove(-1)
links4.remove(None)
return links4
#从list中找到想要的新闻链接
#找到要访问的下一个页面的url
def get_url(links):
url = []
url2 = ''
url3 = ''
url4 = ''
i = 0
for link in links:
if link.contents == [u'后一天']:
continue
#上一页 和 下一页 的标签情况比较复杂
#取出“上一页”标签的url(貌似不管用)
if str(link.contents).find(u'/> ') != -1:
continue
#取出“下一页”标签的url
if str(link.contents).find(u' 查看全部
抓取网页新闻(【技巧】如何用两个方法来抽去正文内容?)
我主要使用了两种方法来提取正文内容。第一种方法,比如xpath、css、正则表达式、beautifulsoup,在解析新闻页面的时候,总是遇到各种莫名其妙的问题。,让人头疼不已。后面红色标的是第二种方法,主要推荐报文库
在导师公司,需要使用重搜索引擎尽快获取想要的内容,然后建立语料库,所以我使用python的beautifulsoup和urllib抓取了一些web内容用于训练语料库。
搜索关键词是“公司名称”,其实只需要三步即可完成。第一个是直接在百度首页搜索,然后从百度结果搜索页面上的链接中获取,第二个是在页面主页面输入结果搜索那些链接,然后抓取正文内容。三是保存获取到的正文内容,对内容进行切分。例如,如果您在正文中找到人们说过的话,则可以使用谚语和表达方式。,说起来,曾经用“”来判断,这些就不赘述了,主要是提取正文内容。
提取链接
通过网页的源码发现,这些超链接在标签之间(不同的网站有不同的格式)。最好用beautifulsoup提取。如果使用 urllib 提取其他 url,则不易区分。例如下图
代码显示如下:
<p>#encoding=utf-8
#coding=utf-8
import urllib,urllib2
from bs4 import BeautifulSoup
import re
import os
import string
#得到url的list
def get_url_list(purl):
#连接
req = urllib2.Request(purl,headers={'User-Agent':"Magic Browser"})
page = urllib2.urlopen(req)
soup = BeautifulSoup(page.read())
#读取标签
a_div = soup.find('div',{'class':'main'})
b_div = a_div.find('div',{'class':'left'})
c_div = b_div.find('div',{'class':'newsList'})
links4 = []
#得到url的list
for link_aa in c_div:
for link_bb in link_aa:
links4.append(link_bb.find('a'))
links4 = list(set(links4))
links4.remove(-1)
links4.remove(None)
return links4
#从list中找到想要的新闻链接
#找到要访问的下一个页面的url
def get_url(links):
url = []
url2 = ''
url3 = ''
url4 = ''
i = 0
for link in links:
if link.contents == [u'后一天']:
continue
#上一页 和 下一页 的标签情况比较复杂
#取出“上一页”标签的url(貌似不管用)
if str(link.contents).find(u'/> ') != -1:
continue
#取出“下一页”标签的url
if str(link.contents).find(u'
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-20 18:02
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源代码并没有随着浏览器的查看源代码功能发生变化,无论现在看到哪个Pagination,HTML源代码仍然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,可以完全摒弃嗅探方法,像普通网页一样抓取AJAX网站的内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建一个二级线索(主题名称)就是demo_cnbeta_detail),所谓的Hierarchical crawling summary page转向抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是入门教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页具有代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,则可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。有关关键功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《获取当当网商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,""是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索type ,该类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5所示。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在“Pagination Crawling Amazon”一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站并不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果发现新闻列表中的新闻都是之前爬过的新闻,则停止翻页爬行。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。 查看全部
抓取网页新闻(怎样只抓取最新cnbeta数码产品新采用AJAX技术的网站越来越多)
如何使用AJAX技术只抓取最新的cnbeta数码产品网站越来越多,我们需要通过更多案例来说明如何准确抓取Javascript/JS动态生成的内容。这次我们要在cnbeta网站上抢数码产品新闻。进入这个网站的首页,可以看到一个新闻列表,列表中有多个新闻,每条新闻包括标题、基本信息和摘要。用浏览器访问这个网页,发现新闻列表的第一页和普通网页是一样的。翻到第二页后,可以看到HTML源代码并没有随着浏览器的查看源代码功能发生变化,无论现在看到哪个Pagination,HTML源代码仍然是第一页。原来网站 使用Javascript在翻页时动态刷新新闻列表。这种情况会阻碍普通网络爬虫和普通网络爬虫的工作,因为这类网络爬虫一般都会向目标服务器发送HTTP GET。消息,获取 HTML 文档,然后使用正则表达式或 DOM 解析方法提取网页上的内容。当需要翻到其他页面时,由于其他页面没有独立的URL网址,无法发送HTTP GET消息。通过人工干预,嗅探Javascript向网站发送了什么消息,通过模拟消息获取其他页面的内容。使用MetaSeeker网络爬虫,可以完全摒弃嗅探方法,像普通网页一样抓取AJAX网站的内容。
本文还将讲解另一种抓取技巧:翻页抓取新闻列表时,假设某个页面的新闻之前已经被抓取过,则停止翻页,即只抓取最新的新闻。是跟踪论坛、博客、微博、新闻网站等最常用的技术,也是构建企业竞争情报系统的必备功能。抓取目标分析: 示例页面:名称:demo_cnbeta_list 目的是抓取新闻列表,信息结构如下: 详情页面:是一个URL网页地址,利用这个URL地址创建一个二级线索(主题名称)就是demo_cnbeta_detail),所谓的Hierarchical crawling summary page转向抓取多个页面,之前爬取二级URL的时候,停止爬行过程。注1:可以使用MetaStudio上传信息结构demo_cnbeta_list,阅读更容易理解。请注意,登陆页面的结构可能会发生变化,这可能会导致信息结构加载失败。修改信息结构请参考“修改无效信息结构”。注2:本文不是入门教程。如果您不熟悉MetaSeeker,建议按章节顺序阅读《MetaSeeker 快速指南》。要捕获新闻摘要数据,首先需要定义数据捕获规则。所谓的数据抓取规则指定了如何从网页中抓取新闻列表数据。图 1 显示了数据映射和 FreeFormat 映射的过程。主要步骤如下:以新闻列表中的第一条新闻为例。数据映射和 FreeFormat 映射都在其上执行。为了捕获新闻数据,执行数据映射和FreeFormat 映射。不需要 FreeFormat 映射。如果网页具有代表DOM节点语义的@class或@id属性,可以准确定位抓取到的内容,则进行FreeFormat映射。
详细操作流程请参考“获取京东商品价格”。为了抓取新闻列表中的每一条新闻,都会进行FreeFormat映射,也就是所谓的多实例抓取。FreeFormat 映射不是唯一的方法。这个页面的每条新闻都有@class="newslist",非常适合捕获多个实例。如果您没有合适的 FreeFormat,则可以使用示例复制方法。参考“抓当当商品价格”设置至少一个信息属性的关键特征。有关关键功能的说明,请参阅“MetaStudio 用户手册”。设置关键特性后,DataScraper 可以在加速模式下运行以提高爬行速度。如果不勾选菜单项“配置”->“ 我们将在后面的翻页和抓取多页以翻页的章节中详细说明。要抓取所有页面,您需要创建一个线索。图 4 显示了主要步骤。详情请参考《获取当当网商品价格》:将代表整个页面区域的DOM节点映射到这条线索上,相当于指定了一个网页区域。该区域可以定位到页面超链接。我们使用标记线索类型来定位翻页线索,""是标记映射的标记值,在Clue Editor工作台中会自动填写标记值和标记节点序号来设置内联线索type ,该类型主要用于翻页和抓取。一旦选择了这种类型,
设置AJAX捕获模式如图5所示。选择MetaStudio菜单“配置”->“活动模式”设置AJAX捕获模式。在“Pagination Crawling Amazon”一文中,我们同时设置了“主动模式”和“扩展模式”。这两种模式没有联系在一起。这个目标网站并不是每次翻页都加载另一个网页,而是部分修改网页的内容。因此,设置“扩展模式”是没有意义的。只抓取最新消息。通常我们会每隔一段时间(例如一天)抓取新闻列表。如果发现新的新闻,就会爬取URL,创建下一级线索,让最新的新闻内容抓取下来。如果发现新闻列表中的新闻都是之前爬过的新闻,则停止翻页爬行。这需要使用周期性的自动爬取方法。需要编辑周期取调度指令文件。此文件必须命名为 crontab.xml 并存储在 $HOME/.datascraper 目录中。目录结构的详细说明见《抓当当商品价格》。下面是 crontab。xml文件的内容:也就是说,如果连续3个页面爬取的URL地址有80%之前被爬取过,则翻页将被终止。抓住。:当前版本的MetaSeeker只能判断抓取到的下一级线索的重复率,不能判断抓取到的数据的重复率。: 请不要直接使用上面的crontab。
抓取网页新闻(如何判断是否是蜘蛛对式网页的抓住机制来发表一点看法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-20 18:01
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下保持系统和实际环境中页面的一致性造成压力,这意味着蜘蛛不会抓取所有页面网站。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这就是为什么我们要做好网站的链接结构,然后我就只关注蜘蛛的抓取机制用于翻页网页。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率、文章@的链接不一样> 很可能是把它推送到翻页栏,这样蜘蛛就无法每天从第一个翻页栏爬到第80个,然后再爬一次文章和一个文章到对比数据库,蜘蛛太浪费时间也浪费你网站的收录时间,所以蜘蛛需要对这种特殊类型的翻页网页有额外的爬取机制来保证完整<
如何判断是否是有序翻页?
根据发布时间判断文章是否排列有序,是此类页面的必要条件。下面会讲到pnsqdeLB。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使没有写入发布时间,Spider Writer 也可以根据 文章 本身的实际发布时间进行判断。
爬取机制是如何工作的?
对于这种翻页编程客栈页面,蜘蛛主要记录编程客栈每次抓取网页时找到的文章链接,然后将这次找到的文章链接与找到的链接一起使用在历史上。对比一下,如果有交叉点,说明这次爬取已经找到所有新增的文章,可以停止后面的翻页栏的爬取;否则,说明这次爬取没有找到所有新增内容文章 @文章,需要继续爬下一页甚至后面几页才能找到所有新增内容文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比如网站页面目录新增29篇文章,表示上次最新文章是前30篇,蜘蛛一次抓取10个文章链接,所以蜘蛛抓取第一次爬行的时候是10,和上次没有交集。继续爬行,第二次再抓10。文章,也就是一共抓到了20条,和上次还没有交集,然后继续爬,这次抓到了第30条,也就是和上次有交集,也就是说蜘蛛已经从上次爬取到了本次网站更新的29篇文章文章。
建议
目前百度蜘蛛会对网页的pnsqdeLB类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并进行处理根据实际情况而定,但蜘蛛毕竟做不到识别准确率是100%,所以如果站长在做翻页栏,不要使用它,更不要说FALSH。同时还要经常更新文章,配合蜘蛛的爬行,这样才能大大提高蜘蛛识别的准确率,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛使用这种爬行机制。实际上,许多机制是同时进行的。 查看全部
抓取网页新闻(如何判断是否是蜘蛛对式网页的抓住机制来发表一点看法)
Spider系统的目标是发现并抓取互联网上所有有价值的网页。百度官方表示,蜘蛛只能抓取尽可能多的有价值的资源,并在不给网站经验的情况下保持系统和实际环境中页面的一致性造成压力,这意味着蜘蛛不会抓取所有页面网站。对于这个蜘蛛,有很多爬取策略,尽可能快速、完整地发现资源链接,提高爬取效率。只有这样蜘蛛才能尽量满足网站的大部分,这就是为什么我们要做好网站的链接结构,然后我就只关注蜘蛛的抓取机制用于翻页网页。提出一个观点。
为什么我们需要这种爬虫机制?
目前,大多数网站使用翻页来有序分配网站资源。添加新的文章后,旧资源将移回翻页系列。对于蜘蛛来说,这种特定类型的索引页面是一种有效的抓取渠道,但是蜘蛛的抓取频率与网站文章的更新频率、文章@的链接不一样> 很可能是把它推送到翻页栏,这样蜘蛛就无法每天从第一个翻页栏爬到第80个,然后再爬一次文章和一个文章到对比数据库,蜘蛛太浪费时间也浪费你网站的收录时间,所以蜘蛛需要对这种特殊类型的翻页网页有额外的爬取机制来保证完整<
如何判断是否是有序翻页?
根据发布时间判断文章是否排列有序,是此类页面的必要条件。下面会讲到pnsqdeLB。那么如何根据发布时间判断资源是否排列有序呢?在某些页面上,每个 文章 链接后面都有相应的发布时间。通过文章链接对应的时间集合,判断时间集合是按照从大到小还是从小到大排序。如果是,则说明网页上的资源是按照发布时间有序排列的,反之亦然。即使没有写入发布时间,Spider Writer 也可以根据 文章 本身的实际发布时间进行判断。
爬取机制是如何工作的?
对于这种翻页编程客栈页面,蜘蛛主要记录编程客栈每次抓取网页时找到的文章链接,然后将这次找到的文章链接与找到的链接一起使用在历史上。对比一下,如果有交叉点,说明这次爬取已经找到所有新增的文章,可以停止后面的翻页栏的爬取;否则,说明这次爬取没有找到所有新增内容文章 @文章,需要继续爬下一页甚至后面几页才能找到所有新增内容文章。
听起来可能有点不清楚。Mumu seo 会给你一个非常简单的例子。比如网站页面目录新增29篇文章,表示上次最新文章是前30篇,蜘蛛一次抓取10个文章链接,所以蜘蛛抓取第一次爬行的时候是10,和上次没有交集。继续爬行,第二次再抓10。文章,也就是一共抓到了20条,和上次还没有交集,然后继续爬,这次抓到了第30条,也就是和上次有交集,也就是说蜘蛛已经从上次爬取到了本次网站更新的29篇文章文章。
建议
目前百度蜘蛛会对网页的pnsqdeLB类型、翻页栏在网页中的位置、翻页栏对应的链接、列表是否按时间排序等做出相应的判断,并进行处理根据实际情况而定,但蜘蛛毕竟做不到识别准确率是100%,所以如果站长在做翻页栏,不要使用它,更不要说FALSH。同时还要经常更新文章,配合蜘蛛的爬行,这样才能大大提高蜘蛛识别的准确率,从而提高你的网站中蜘蛛的爬行效率。
再次提醒大家,本文只是对蜘蛛爬行机制的一个解释。这并不意味着蜘蛛使用这种爬行机制。实际上,许多机制是同时进行的。
抓取网页新闻(一下我是如何使用jsoup实现对网页文档的修改和实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-18 23:19
先介绍一下jsoup,他的中文文档:
描述:jsoup 是一个用于处理 HTML 工作的 Java 库。它提供了一个非常方便的 API 来提取和操作数据,使用最好的 DOM、CSS 和类似 jquery 的方法。
具体和详细的文档可以浏览jsoup官方文档:
我主要讲一下我是如何使用jsoup来修改和实现web文档的。先找一个简单的网址:
我们可以用浏览器打开这个地址(推荐使用谷歌浏览器),右击,选择检查,可以查看具体的网页布局HTML。下面是使用jsoup直接获取网页的源码HTML。直接通过依赖导入依赖包:
implementation 'org.jsoup:jsoup:1.11.3'
然后使用方法:
Document document = Jsoup.connect(nowUri)
.timeout(15000)
.get();
可以得到一个 Doucument 文档对象,这个收录网页的 HTML 内容,我们可以使用
document.title()
获取网页标题的方法,也可以使用tostring或outerHtml来获取网页的源代码。如果我们想改变网页文本的标题:
沃顿:今晚赢球对我们来说并不美好,但赢球毕竟是
首先我们需要得到他,我们可以使用方法:
Element element = document.selectFirst("h1");
h1是元素标签,也就是过滤条件,元素是标签对象,可以使用toString()打印标签,也可以使用text()方法获取标签中收录的文本。接下来修改页面标题,如何使用:
element.text("这是我修改过的标题,哈哈哈……");
这是可以实现的。我们可以通过 webview 加载我们修改后的 HTML:
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
URL_HTML 是网页的原创地址,document.outerHtml() 是我们获取到的 HTML。效果图:
下一步就是修改文章的内容,同时也过滤掉文章的内容
Elements elements = document.select("p");
for (int i = 0; i < 4; i++) {
//打印文章的内容
// elements.text();
elements.get(i).appendText("《这段内容结束》");
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
}
因为这里有四段内容,先过滤掉标签为“p”的集合,再修改前四段。这里使用appendText()方法在label内容后追加文本内容,效果图:
我们还可以插入一个新的英文标题:
Element element2 = document.selectFirst("h1");
Element element1 = element2.clone();
element1.text("This is the title's translator");
element2.append(element1.outerHtml());
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
OK,更多的方法,更多的实现可以参考jsoup中给出的各种方法,比如选择器和正则表达式来实现特殊过滤等功能。
源码下载 查看全部
抓取网页新闻(一下我是如何使用jsoup实现对网页文档的修改和实现)
先介绍一下jsoup,他的中文文档:
描述:jsoup 是一个用于处理 HTML 工作的 Java 库。它提供了一个非常方便的 API 来提取和操作数据,使用最好的 DOM、CSS 和类似 jquery 的方法。
具体和详细的文档可以浏览jsoup官方文档:
我主要讲一下我是如何使用jsoup来修改和实现web文档的。先找一个简单的网址:
我们可以用浏览器打开这个地址(推荐使用谷歌浏览器),右击,选择检查,可以查看具体的网页布局HTML。下面是使用jsoup直接获取网页的源码HTML。直接通过依赖导入依赖包:
implementation 'org.jsoup:jsoup:1.11.3'
然后使用方法:
Document document = Jsoup.connect(nowUri)
.timeout(15000)
.get();
可以得到一个 Doucument 文档对象,这个收录网页的 HTML 内容,我们可以使用
document.title()
获取网页标题的方法,也可以使用tostring或outerHtml来获取网页的源代码。如果我们想改变网页文本的标题:
沃顿:今晚赢球对我们来说并不美好,但赢球毕竟是
首先我们需要得到他,我们可以使用方法:
Element element = document.selectFirst("h1");
h1是元素标签,也就是过滤条件,元素是标签对象,可以使用toString()打印标签,也可以使用text()方法获取标签中收录的文本。接下来修改页面标题,如何使用:
element.text("这是我修改过的标题,哈哈哈……");
这是可以实现的。我们可以通过 webview 加载我们修改后的 HTML:
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
URL_HTML 是网页的原创地址,document.outerHtml() 是我们获取到的 HTML。效果图:
下一步就是修改文章的内容,同时也过滤掉文章的内容
Elements elements = document.select("p");
for (int i = 0; i < 4; i++) {
//打印文章的内容
// elements.text();
elements.get(i).appendText("《这段内容结束》");
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
}
因为这里有四段内容,先过滤掉标签为“p”的集合,再修改前四段。这里使用appendText()方法在label内容后追加文本内容,效果图:
我们还可以插入一个新的英文标题:
Element element2 = document.selectFirst("h1");
Element element1 = element2.clone();
element1.text("This is the title's translator");
element2.append(element1.outerHtml());
mWebView.loadDataWithBaseURL(URL_HTML, document.outerHtml(), "text/html", "utf-8", null);
OK,更多的方法,更多的实现可以参考jsoup中给出的各种方法,比如选择器和正则表达式来实现特殊过滤等功能。
源码下载
抓取网页新闻(网页抓取工具包MetaSeeker允许用户在同一个主题名下定义多个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-18 05:20
Web 爬虫工具包 MetaSeeker 允许用户在同一主题名称下定义多个信息结构。这带来了一个好处:如果目标页面结构发生变化,那么可以使用同一主题名称下的不同信息结构来抓取和存储着陆页上的信息。MetaSeeker 工具包中的网络爬虫DataScraper 可以自动找到符合目标网页结构的信息结构及其网络爬取规则。
但是MetaSeeker客户返回的信息显示,之前版本存在一个bug:如果同一主题名下的信息结构差异较大,DataScraper无法正常运行。比如在抓取网易163新闻的网友评论时,有的新闻是热点新闻,很多网友发表评论,有的新闻没有评论。分别定义了两种信息结构,一种用于翻页捕获所有网友的评论,另一种用于识别没有网友评论的网页情况。如何抓取网友评论可以在“MetaSeeker快速指南”中找到。网易新闻评论都是AJAX异步加载的,需要正确设置AJAX选项。在这种情况下,使用MetaStudio编辑翻页和抓取网友评论的信息结构时,需要在Clue Editor工作台上定义翻页线索,无需在其他信息结构的Clue Editor工作台上定义任何规则。因此,这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。
为了解决以上问题,DataScraper已经升级到V4.11.5版本,请下载升级。
但是,这个版本并没有完全清除这个错误。为了避免遇到这个bug,用户在创建信息结构时需要保证约定的顺序:如果多个同一个主题名称的信息结构差别很大,即在Bucket Editor和MetaStudio的Clue Editor工作台上,其中之一有些信息结构的两个工作台是空的,所以先创建这种类型的信息结构,最后再在工作台上创建一个不为空的信息结构。这样就可以避免这个bug。彻底解决这个bug的计划是版本V4.12.1。 查看全部
抓取网页新闻(网页抓取工具包MetaSeeker允许用户在同一个主题名下定义多个)
Web 爬虫工具包 MetaSeeker 允许用户在同一主题名称下定义多个信息结构。这带来了一个好处:如果目标页面结构发生变化,那么可以使用同一主题名称下的不同信息结构来抓取和存储着陆页上的信息。MetaSeeker 工具包中的网络爬虫DataScraper 可以自动找到符合目标网页结构的信息结构及其网络爬取规则。
但是MetaSeeker客户返回的信息显示,之前版本存在一个bug:如果同一主题名下的信息结构差异较大,DataScraper无法正常运行。比如在抓取网易163新闻的网友评论时,有的新闻是热点新闻,很多网友发表评论,有的新闻没有评论。分别定义了两种信息结构,一种用于翻页捕获所有网友的评论,另一种用于识别没有网友评论的网页情况。如何抓取网友评论可以在“MetaSeeker快速指南”中找到。网易新闻评论都是AJAX异步加载的,需要正确设置AJAX选项。在这种情况下,使用MetaStudio编辑翻页和抓取网友评论的信息结构时,需要在Clue Editor工作台上定义翻页线索,无需在其他信息结构的Clue Editor工作台上定义任何规则。因此,这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。这两种信息结构非常不同。在这种情况下,出现了一个错误。如果先创建第一个信息结构,在爬取过程中无法正确翻页;如果先创建第二个信息结构,DataScraper 会在爬取过程中终止网络爬取工作流。
为了解决以上问题,DataScraper已经升级到V4.11.5版本,请下载升级。
但是,这个版本并没有完全清除这个错误。为了避免遇到这个bug,用户在创建信息结构时需要保证约定的顺序:如果多个同一个主题名称的信息结构差别很大,即在Bucket Editor和MetaStudio的Clue Editor工作台上,其中之一有些信息结构的两个工作台是空的,所以先创建这种类型的信息结构,最后再在工作台上创建一个不为空的信息结构。这样就可以避免这个bug。彻底解决这个bug的计划是版本V4.12.1。
抓取网页新闻( 关于利用python实现最简单的网页爬虫的相关资料介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-10-17 08:29
关于利用python实现最简单的网页爬虫的相关资料介绍)
python爬虫实战最简单的网络爬虫教程
更新时间:2017-08-13 10:08:49 作者:xiaomi
当我们在互联网上浏览网页时,我们经常会看到一些漂亮的图片。我们希望将这些图片保存和下载,或者用作桌面壁纸或设计材料。下面的文章文章就在这里给大家介绍一个最简单的使用python的网络爬虫。有需要的朋友可以参考。让我们来看看。
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。最近对python爬虫产生了浓厚的兴趣。我在这里分享我的学习路径。欢迎您提出建议。我们相互交流,共同进步。话不多说,一起来看看详细介绍:
1.开发工具
我使用的工具是sublime text3,它简短而强大(可能男人不喜欢这个词)让我着迷。推荐大家使用,当然如果你的电脑配置好,pycharm可能更适合你。
推荐用sublime text3搭建python开发环境查看这个文章:
[Sublime搭建python开发环境][]
2.爬虫介绍
爬虫,顾名思义,就像蠕虫一样,在大互联网、互联网上爬行。这样,我们就可以得到我们想要的。
既然要在互联网上爬取,就需要了解URL、合法名称“Uniform Resource Locator”、昵称“Link”。其结构主要由三部分组成:
(1)Protocol:比如我们网站常用的HTTP协议。
(2)Domain name or IP address:域名,如:,IP地址,即域名解析后对应的IP。
(3) 路径:即目录或文件等
3.urllib 开发最简单的爬虫
(1)urllib 简介
模块介绍
urllib.error
由 urllib.request 引发的异常类。
urllib.parse
将 URL 解析为组件或从组件组装它们。
urllib.request
用于打开 URL 的可扩展库。
urllib.response
urllib 使用的响应类。
urllib.robotparser
加载 robots.txt 文件并回答有关其他 URL 可提取性的问题。
(2)开发最简单的爬虫
百度首页简洁大方,非常适合我们的爬虫。
爬虫代码如下:
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()
结果如下:
我们可以通过右键点击百度首页的空白处,查看评论元素来与我们的运行结果进行对比。
当然request也可以生成一个request对象,可以用urlopen方法打开。
代码显示如下:
from urllib import request
def vists_baidu():
# create a request obkect
req = request.Request('http://www.baidu.com')
# open the request object
response = request.urlopen(req)
# read the response
html = response.read()
html = html.decode('utf-8')
print(html)
if __name__ == '__main__':
vists_baidu()
操作的结果和之前一样。
(3)错误处理
错误处理由 urllib 模块处理,主要包括 URLError 和 HTTPError。HTTPError 是 URLError 的子类,即 HTTRPError 也可以被 URLError 捕获。 查看全部
抓取网页新闻(
关于利用python实现最简单的网页爬虫的相关资料介绍)
python爬虫实战最简单的网络爬虫教程
更新时间:2017-08-13 10:08:49 作者:xiaomi
当我们在互联网上浏览网页时,我们经常会看到一些漂亮的图片。我们希望将这些图片保存和下载,或者用作桌面壁纸或设计材料。下面的文章文章就在这里给大家介绍一个最简单的使用python的网络爬虫。有需要的朋友可以参考。让我们来看看。
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。最近对python爬虫产生了浓厚的兴趣。我在这里分享我的学习路径。欢迎您提出建议。我们相互交流,共同进步。话不多说,一起来看看详细介绍:
1.开发工具
我使用的工具是sublime text3,它简短而强大(可能男人不喜欢这个词)让我着迷。推荐大家使用,当然如果你的电脑配置好,pycharm可能更适合你。
推荐用sublime text3搭建python开发环境查看这个文章:
[Sublime搭建python开发环境][]
2.爬虫介绍
爬虫,顾名思义,就像蠕虫一样,在大互联网、互联网上爬行。这样,我们就可以得到我们想要的。
既然要在互联网上爬取,就需要了解URL、合法名称“Uniform Resource Locator”、昵称“Link”。其结构主要由三部分组成:
(1)Protocol:比如我们网站常用的HTTP协议。
(2)Domain name or IP address:域名,如:,IP地址,即域名解析后对应的IP。
(3) 路径:即目录或文件等
3.urllib 开发最简单的爬虫
(1)urllib 简介
模块介绍
urllib.error
由 urllib.request 引发的异常类。
urllib.parse
将 URL 解析为组件或从组件组装它们。
urllib.request
用于打开 URL 的可扩展库。
urllib.response
urllib 使用的响应类。
urllib.robotparser
加载 robots.txt 文件并回答有关其他 URL 可提取性的问题。
(2)开发最简单的爬虫
百度首页简洁大方,非常适合我们的爬虫。
爬虫代码如下:
from urllib import request
def visit_baidu():
URL = "http://www.baidu.com"
# open the URL
req = request.urlopen(URL)
# read the URL
html = req.read()
# decode the URL to utf-8
html = html.decode("utf_8")
print(html)
if __name__ == '__main__':
visit_baidu()
结果如下:
我们可以通过右键点击百度首页的空白处,查看评论元素来与我们的运行结果进行对比。
当然request也可以生成一个request对象,可以用urlopen方法打开。
代码显示如下:
from urllib import request
def vists_baidu():
# create a request obkect
req = request.Request('http://www.baidu.com')
# open the request object
response = request.urlopen(req)
# read the response
html = response.read()
html = html.decode('utf-8')
print(html)
if __name__ == '__main__':
vists_baidu()
操作的结果和之前一样。
(3)错误处理
错误处理由 urllib 模块处理,主要包括 URLError 和 HTTPError。HTTPError 是 URLError 的子类,即 HTTRPError 也可以被 URLError 捕获。
抓取网页新闻(之前关键句筛选单句切分之后对句子的集合做一下筛选)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-17 08:27
之前用R做过一些文本处理工作,主要是对新闻进行分类,提取关键词之类的。您可以通过 jiebaR 包和自定义词典轻松完成大部分工作。分类是对每个项目进行分类。类别的特征和运行一个分类模型可以得到比较满意的结果。只是自动生成summary还没有找到好的解决方案,也没有找到R中现成的工具包。因为写代码的能力也比较上口,参考java和python中的代码,还是不可能写出像样的程序。所以最后的解决办法就是把文章的前几句剪下来作为总结,效果可想而知……
随着对R和python越来越熟悉,最近看了一篇文章,详细讲解了textRank算法在python中的实现文章(《还在被题主欺骗吗?是时候试试了文本摘要技术(附)源代码)》),所以我尝试将其更改为R代码。经过一番“辛苦”的处理,终于可以实现R中自动提取摘要的功能。
textRank算法的原理就不过多介绍了(想了解的可以参考这里),直接说代码:
1. 加载包
<p>if(!"jiebaR" %in% (.packages())) library(jiebaR)
if(!"dplyr" %in% (.packages())) library(dplyr)
keys 查看全部
抓取网页新闻(之前关键句筛选单句切分之后对句子的集合做一下筛选)
之前用R做过一些文本处理工作,主要是对新闻进行分类,提取关键词之类的。您可以通过 jiebaR 包和自定义词典轻松完成大部分工作。分类是对每个项目进行分类。类别的特征和运行一个分类模型可以得到比较满意的结果。只是自动生成summary还没有找到好的解决方案,也没有找到R中现成的工具包。因为写代码的能力也比较上口,参考java和python中的代码,还是不可能写出像样的程序。所以最后的解决办法就是把文章的前几句剪下来作为总结,效果可想而知……
随着对R和python越来越熟悉,最近看了一篇文章,详细讲解了textRank算法在python中的实现文章(《还在被题主欺骗吗?是时候试试了文本摘要技术(附)源代码)》),所以我尝试将其更改为R代码。经过一番“辛苦”的处理,终于可以实现R中自动提取摘要的功能。
textRank算法的原理就不过多介绍了(想了解的可以参考这里),直接说代码:
1. 加载包
<p>if(!"jiebaR" %in% (.packages())) library(jiebaR)
if(!"dplyr" %in% (.packages())) library(dplyr)
keys
抓取网页新闻(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-14 08:15
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站有很多不同类型的传输规律。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这一系列问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。
如何监控行业网站信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,可以使用蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需的行业网站信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
查看全部
抓取网页新闻(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站有很多不同类型的传输规律。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这一系列问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。
如何监控行业网站信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,可以使用蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需的行业网站信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
抓取网页新闻(网上谷歌人家的开发经验写下来与别人分享下。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-14 08:12
我已经工作近两年了,我一直在学习谷歌人在互联网上的经验。这次也把自己的开发心得写下来分享给大家。很快,我换了一份新工作,新公司刚结束了一个网站。网站 新闻内容是自己编辑添加的,都是手动的,所以我接受任务,做一个自动更新新闻内容的功能。
开始整理思路,第一步通过网站URL获取整个网站新闻链接的所有URL,第二步将获取到的URL返回到其源码中,第三步解析源代码中的内容和标题,第四步存入数据库。最后,使用java timer自动更新。
过程中最棘手的部分是解析HTML源代码,果断决定用htmlparser,废话少说,上部分代码。部分代码注释写得不好,请指教。
/**<br /> * 返回网页中所有URL<br /> * @return type:NodeList<br /> */<br /> public static NodeList getAllUrl(String Url) throws Exception {<br /><br /> //使用htmlparser获取<br /> Parser parser = new Parser();<br /> parser.setResource(Url);<br /> //待定的编码格式<br /> parser.setEncoding("gbk");<br /> //遍历所有节点 自定义内部类(自定义过滤器)<br /> NodeList nodeList = parser.extractAllNodesThatMatch(new NodeFilter() {<br /> private static final long serialVersionUID = 1L;<br /><br /> public boolean accept(Node node) {<br /> //判断node是否是LinkTag的一个实例<br /> if (node instanceof LinkTag)<br /> return true;<br /> else{<br /> return false;<br /> }<br /> }<br /> });<br /> return nodeList;<br /> }
<p><br /><br /> /*<br /> * 返回新闻内容<br /> */<br /> public static String getContent(String urlpath){<br /> Parser parser = new Parser();<br /> String content = "";<br /> try {<br /> parser.setResource(urlpath);//传入url<br /> NodeFilter divFilter = new NodeClassFilter(Div.class);//自定义过滤器<br /> NodeList divlist = parser.parse(divFilter);//加载过滤器 <br /> for(int i=0;i 查看全部
抓取网页新闻(网上谷歌人家的开发经验写下来与别人分享下。)
我已经工作近两年了,我一直在学习谷歌人在互联网上的经验。这次也把自己的开发心得写下来分享给大家。很快,我换了一份新工作,新公司刚结束了一个网站。网站 新闻内容是自己编辑添加的,都是手动的,所以我接受任务,做一个自动更新新闻内容的功能。
开始整理思路,第一步通过网站URL获取整个网站新闻链接的所有URL,第二步将获取到的URL返回到其源码中,第三步解析源代码中的内容和标题,第四步存入数据库。最后,使用java timer自动更新。
过程中最棘手的部分是解析HTML源代码,果断决定用htmlparser,废话少说,上部分代码。部分代码注释写得不好,请指教。
/**<br /> * 返回网页中所有URL<br /> * @return type:NodeList<br /> */<br /> public static NodeList getAllUrl(String Url) throws Exception {<br /><br /> //使用htmlparser获取<br /> Parser parser = new Parser();<br /> parser.setResource(Url);<br /> //待定的编码格式<br /> parser.setEncoding("gbk");<br /> //遍历所有节点 自定义内部类(自定义过滤器)<br /> NodeList nodeList = parser.extractAllNodesThatMatch(new NodeFilter() {<br /> private static final long serialVersionUID = 1L;<br /><br /> public boolean accept(Node node) {<br /> //判断node是否是LinkTag的一个实例<br /> if (node instanceof LinkTag)<br /> return true;<br /> else{<br /> return false;<br /> }<br /> }<br /> });<br /> return nodeList;<br /> }
<p><br /><br /> /*<br /> * 返回新闻内容<br /> */<br /> public static String getContent(String urlpath){<br /> Parser parser = new Parser();<br /> String content = "";<br /> try {<br /> parser.setResource(urlpath);//传入url<br /> NodeFilter divFilter = new NodeClassFilter(Div.class);//自定义过滤器<br /> NodeList divlist = parser.parse(divFilter);//加载过滤器 <br /> for(int i=0;i
抓取网页新闻(常见的几种数据来源方式和抓取方式,是如何实现的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-10-14 08:09
很多人想知道网站和app中的手机号码数据是如何抓取的,是如何实现的。我将在这里谈论它。
一、数据来源
有很多数据来源。给大家介绍几种常见的数据来源和抓取方法。
1、操作员数据。在这个源方法中,操作员将有一个 http 报告。每个访问者访问了哪些网站 APP,他的4G流量以及他消耗了多少流量都记录在其中。这样,访客的消费行为和近期需求
$(document).ready(function () {
$("#phone").focusout(function () {
$("#phone").val($("#phone").val().substring(0, 3) + "****" + $("#phone").val() .substring(7, 11));
});
});
寻求非常精确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站商网联盟的必备神器,可以放心使用。
2、 爬虫爬取,URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花掉。一个半天写代码懒得学第三方工具的人,靠自己写代码实现了。
网站 获取访问者的手机号码。例如,如果您正在浏览今日头条,我们可以通过您浏览到今日头条的手机号码获取您的手机号码,然后您就可以向该手机号码发送短信。
获取网站访客用户手机号的值
1、时间上:时间大大缩短,短平快
2、 招投标上:直接跳过招投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营:提供专属VIP后台账号,供客户查看和导出数据。然后主动打电话给客户,发短信,添加微信手机网站访客手机号获取好友,大大增加企业咨询采购量,让访客成为客户。对医疗、教育、企业、股票等诸多行业的帮助非常有用。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、App截取手机号,以及联通电信移动运营商大数据等数据,有兴趣的可以联系我测试一下。 查看全部
抓取网页新闻(常见的几种数据来源方式和抓取方式,是如何实现的)
很多人想知道网站和app中的手机号码数据是如何抓取的,是如何实现的。我将在这里谈论它。
一、数据来源
有很多数据来源。给大家介绍几种常见的数据来源和抓取方法。
1、操作员数据。在这个源方法中,操作员将有一个 http 报告。每个访问者访问了哪些网站 APP,他的4G流量以及他消耗了多少流量都记录在其中。这样,访客的消费行为和近期需求
$(document).ready(function () {
$("#phone").focusout(function () {
$("#phone").val($("#phone").val().substring(0, 3) + "****" + $("#phone").val() .substring(7, 11));
});
});
寻求非常精确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站商网联盟的必备神器,可以放心使用。
2、 爬虫爬取,URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿自己花掉。一个半天写代码懒得学第三方工具的人,靠自己写代码实现了。
网站 获取访问者的手机号码。例如,如果您正在浏览今日头条,我们可以通过您浏览到今日头条的手机号码获取您的手机号码,然后您就可以向该手机号码发送短信。
获取网站访客用户手机号的值
1、时间上:时间大大缩短,短平快
2、 招投标上:直接跳过招投标环节和客服环节,节省大量人力物力,大大降低成本。
3、运营:提供专属VIP后台账号,供客户查看和导出数据。然后主动打电话给客户,发短信,添加微信手机网站访客手机号获取好友,大大增加企业咨询采购量,让访客成为客户。对医疗、教育、企业、股票等诸多行业的帮助非常有用。
4、质量:数据,优质资源。
网站手机号获取、网页手机号获取、手机扫码截取、App截取手机号,以及联通电信移动运营商大数据等数据,有兴趣的可以联系我测试一下。

