
抓取网页新闻
抓取网页新闻(抓取网页新闻用得最多的就是ajax了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-03 21:06
抓取网页新闻用得最多的就是ajax了,而且我经常会用mdn。但一个基本的问题是,看了下面两段,你就会发现这两段里的代码都没有起到抓取的作用,甚至可以说看起来就很糟糕:代码来源不同会有什么影响?follow(name,url,body);https并没有对源文件有效的加密实现,只是使用了https通信的模式来保证源文件安全,从而保证抓取的安全性。
其实这个问题不是很大,因为发现加密出来的乱码并不太可能是对网页上内容的修改,很可能是你找的图片解析器并不完善。那么在解决了第一点的情况下,这第二点就无从谈起了。整个抓取的源文件是经过加密的,所以即使抓到最终返回的地址也不一定能很方便的再用javascript实现再下载到本地。其实即使这样,我们可以用svn或者git之类的版本控制来提高抓取的效率。参考资料链接。
我觉得不一定是javascript的问题。不如换个思路:你在把google或百度下载之前,先下载.svn之类的版本控制软件来传送文件,并且验证.svn有效,然后才开始下载。
题主自己在github找到了答案,github-google/music-stock:ifwedon'thavesome。svnplugins,thenchangethemode;it'snotfora。svnplugins,butitcan。==github-apuz0515/musescompiler:musescompiler:apluginforfollow-us/newframeworksgithub-jessicaldeh/musescompiler:therightwaytogetsearchresultsgithub-spiftfhourglad/musescompiler:amorethanjavascriptplugin。shownewreleases。 查看全部
抓取网页新闻(抓取网页新闻用得最多的就是ajax了?)
抓取网页新闻用得最多的就是ajax了,而且我经常会用mdn。但一个基本的问题是,看了下面两段,你就会发现这两段里的代码都没有起到抓取的作用,甚至可以说看起来就很糟糕:代码来源不同会有什么影响?follow(name,url,body);https并没有对源文件有效的加密实现,只是使用了https通信的模式来保证源文件安全,从而保证抓取的安全性。
其实这个问题不是很大,因为发现加密出来的乱码并不太可能是对网页上内容的修改,很可能是你找的图片解析器并不完善。那么在解决了第一点的情况下,这第二点就无从谈起了。整个抓取的源文件是经过加密的,所以即使抓到最终返回的地址也不一定能很方便的再用javascript实现再下载到本地。其实即使这样,我们可以用svn或者git之类的版本控制来提高抓取的效率。参考资料链接。
我觉得不一定是javascript的问题。不如换个思路:你在把google或百度下载之前,先下载.svn之类的版本控制软件来传送文件,并且验证.svn有效,然后才开始下载。
题主自己在github找到了答案,github-google/music-stock:ifwedon'thavesome。svnplugins,thenchangethemode;it'snotfora。svnplugins,butitcan。==github-apuz0515/musescompiler:musescompiler:apluginforfollow-us/newframeworksgithub-jessicaldeh/musescompiler:therightwaytogetsearchresultsgithub-spiftfhourglad/musescompiler:amorethanjavascriptplugin。shownewreleases。
抓取网页新闻(新浪搜索主页面中的输入关键词链接和计算相似度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-28 01:02
前段时间写了一个爬虫,在新浪搜索主页面实现了输入关键词,爬取了与关键词相关的新闻的标题、发布时间、url、关键词和内容. 并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕获
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是在没有界面的情况下使用程序来模拟浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)查找搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻有多少页。找出不同页面之间的url联系,生成翻页的url。
如上图所示,新闻界面出现“查找7651篇相关新闻文章”。使用正则匹配等方法,得到'7651',根据新浪新闻搜索页面的一页出现的新闻m个数,计算出相关新闻页数。: int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url,如上图所示,当新闻url出现时,同样的规则是“”,所以可以根据这个规则提取页面源码中的所有url .
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值为kT_W=0.8;只有标题收录输入词,相关词权重 kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码 查看全部
抓取网页新闻(新浪搜索主页面中的输入关键词链接和计算相似度)
前段时间写了一个爬虫,在新浪搜索主页面实现了输入关键词,爬取了与关键词相关的新闻的标题、发布时间、url、关键词和内容. 并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕获
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是在没有界面的情况下使用程序来模拟浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)查找搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻有多少页。找出不同页面之间的url联系,生成翻页的url。
如上图所示,新闻界面出现“查找7651篇相关新闻文章”。使用正则匹配等方法,得到'7651',根据新浪新闻搜索页面的一页出现的新闻m个数,计算出相关新闻页数。: int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url,如上图所示,当新闻url出现时,同样的规则是“”,所以可以根据这个规则提取页面源码中的所有url .
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值为kT_W=0.8;只有标题收录输入词,相关词权重 kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2022-02-18 08:07
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。
让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装了aiomysql,更方便的数据库mysql操作;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程 查看全部
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。

让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。

1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装了aiomysql,更方便的数据库mysql操作;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程
抓取网页新闻(基于条件随机场(CR)的新闻网页主题内容自动抽取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-18 02:05
广西师范大学学报:自然科学版 Jo tura 2011 基于海南大学 CR 信息科学与技术学院,海南海口 57022 8) 针对目前新闻网页主题内容提取方法很少使用的问题针对网页块之间的相关性特征,本文提出了一种基于条件随机场(CR)的新闻网页主题内容自动提取方法。该方法首先将要提取的网页解析成DOM,经过过滤、剪枝和压缩处理,然后按照一定的启发式规则将DOM树切割成DOM树。块被转换成数据序列,然后定义CR特征函数提取每个网页块的状态特征和相邻块之间的类别转移特征,利用CR模型对数据序列进行标注,实现网页主题内容的提取。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且可以引入块间相关性特征来改进新闻网页主题内容的提取。关键词:eb信息提取;条件随机场;网页分类 图块分类代码:391 文档识别码:文章 代码:100126600 (2011) 0120138205 在网页设计过程中,人们通常以块来组织网页内容,如此多的Web信息提取方法采用基于块的策略自动提取新闻网页的主题内容:首先,利用标签的分布规律、层次关系、布局特征或视觉特征将网页分成若干块。网页,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。
现有新闻网页的结构越来越复杂,很多网站甚至在新闻网页主题内容的段落之间插入广告内容,以至于我们在切网页时往往只能选择较小的片段. 花费。虽然这样做可以更好地区分噪声内容和主题内容,但生成的网页块通常较小,有时仅依靠块本身的特征很难识别块的类型。以利用相关属性。鉴于此,本文在网页切分的基础上,提出了一种基于条件随机场(co random field)的新闻网页主题内容自动提取方法。在这个部分,我们首先采用DOM树来表示文档的层次组织结构,然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。
规则 如果一个节点的子树不收录标签节点<div>、<p>、<td le>,则删除该节点的所有子树,但保留该节点附加的原创文本内容。规则 如果一个节点是一个单分支节点,它的子节点替换它的位置,然后删除它。收稿日期:2010212229 基金项目:国家自然科学基金委(60863001) 通讯联系人:湖北武汉,讲师,海南大学,硕士。E 2mil:zh angcy@.cn 1994-2013中国学术期刊电子出版社. 版权所有. 上述规则一一处理后,原DOM中90%的节点被删除,决定网页布局的节点,如<div <table>,被保留。 DOM中的DOM树搜索块除了根节点< #do cum en,每个节点对应网页中的一个文本内容块。一个文本内容块是否需要进一步切分,其实就是判断DOM树中对应的节点是否需要进一步的深度搜索。我们将不需要进一步深入搜索的节点称为区块节点,具体判断规则如下: 规则 如果节点是叶子节点,则判断该节点为区块节点。
规则 如果节点为非叶子节点,则其子节点的标签属性不相同,或者其子节点的标签属性相同但子节点不是<table>、<div>或<tr>标签节点,该节点被判断为区块节点。使用上述规则可以更好的区分主题内容和噪声内容,但是块的数量很大。为了减少后续 CR 标注的工作量,我们适度合并分割的块。具体合并规则如下: Rule r > 相邻块节点互为兄弟,标签属性相同或其中一个节点为链接节点Point<a>,另一个节点为text node<# tex text块节点的内容被合并。规则如果相邻两个块节点的文本内容中锚文本的比例大于55%,则可以通过文本内容块转换树的深度优先搜索得到一个文本内容块序列。为了方便以后通过CR特征函数对网页块进行特征提取,我们需要对从section得到的每个文本内容块进行转换。设整个网页的所有文本内容块的非锚文本字符(英文单词,下同) tplen 文本内容块的非锚文本字符个数就是文本内容块的个数 转换规则为: rule lenm), 本块的非锚文本整个网页中非锚文本的比例 lenmƒtp len 和该块在网页中的位置比例 le> 标记的内容块,插入"
将条件随机场建模的新闻网页切成块序列后,将主题内容的提取转化为网页块的类别识别问题。在本文中,网页块的类别被视为 CR 的输出状态,以及 CR Ty 等人提出的对有序数据进行标记和分割的条件概率。该模型可以克服HM的独立性假设问题和最大熵马尔可夫模型的标注偏差问题。它是最简单和最常用的统计机器学习模型线性随机场,是目前处理序列数据分割和标记问题的最佳统计机器学习模型。一种形式,本文使用的一种形式,用于实现文本内容序列的标注。假设相应的状态序列,其中 Erkov 是独立的,通过无向边连接成一个线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。
在本文中,观察序列是网页分割转换后生成的数据序列;状态序列中的状态值代表网页块的类别,我们将网页块分为以le>标签标记的内容块)、标题块(文本的标题块)(文本内容块) ) 和噪声块,分别在标注时用状态值表示;本节将讨论特征函数的定义和模型参数的估计。一旦L建模工作完成,公式(2)就可以用来标注网页块序列了。特征函数定义 CR模型通过特征函数的定义来描述观测值与状态值和状态值的对应关系。提取块序列及其特征之间的转移关系。特征函数定义是否正确将直接影响CR特征函数提取块序列和类别序列之间的特征。21211 块属性状态特征函数网页块的锚文本比例、非锚文本在整个网页中的比例、在网页中的位置、块在网页中使用什么样的标签,以一定程度上反映了内容块属于什么类别,所以我们的块属性 status 的特征函数定义为:其中 id 是特征编号。下面以训练内容块“TA 0C 0S0”和测试内容块“A 9C 0S9”为例,说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。
21213 End-state feature function 网页块序列一般以噪声内容块结束。为此,我们定义了一个结束状态特征函数,将该特征表示为结束块状态特征,从而从网页块序列的最后一个块中提取特征。21214 一阶传递特征函数网页块序列具有一定的块间关联特性。另外,考虑到本文采用CR,我们定义一阶传递特征函数ransf ransf来表示该特征是传递特征。参数估计模型参数估计是通过学习标记的训练集来估计每个特征函数的权重。另一方面,它通过特征函数估计从训练集中提取的所有特征的权重。让标注好的训练集为对应的状态序列,一般通过人工标注完成;序列的总数。在此基础上,对数似然函数为:对于训练集,为了避免参数估计过拟合的问题,我们引入高斯先验迭代求解公式 GS 等方法,收敛速度比GS。1994-2013中国学术期刊电子出版社。版权所有。. 本文通过人工标记一定数量的网页块序列形成训练集,然后通过本节定义的特征函数从训练集中提取所有状态特征,然后使用L2B GS方法估计每个状态特征的权重。
实验与结果分析 首先,根据百度国内新闻提供的链接,网络机器人抓取了500个新闻页面作为实验网页集,然后使用实验结果:共切出11 302个页面块,每个页面平均被切割成2个2.我们的分块算法分割准确率高,只有26个分块将噪声分块切割成与标题分块或正文分块相同的分块,平均分块错误率为23%。手动修正错切网页后,将500个网页按照本节介绍的方法转化为500个数据序列,将100个序列手动标注为CR训练集,剩余400个未标注序列作为CR 数据序列。测试集。CR被测量,而具体计算公式为如lock sM anu lock sCR lock sCR lock sM anu lock sCR lock sM anu lock sM anu lock sCR CR le block、title block、text block、noise block和所有类型的web blocks。从测试结果看:CR对各类网页块都有较高的准确率;le块整体识别效果最好,噪声块次之,标题块最差;当训练集的大小达到80多个序列时,识别效果较好,相对稳定。500个新闻网页自动切分实验结果 Tab. Segmen ta ionre sults ewspage 标题块 文本块 噪声块 错误块总数 平均错误率 ƒ% 平均块数 498 522 706 57611 302 26 2322. 基于 CRF 选项卡。
本文选取的 500 个新闻页面来自 175 个国内新闻网站,其中作为 CR 训练集的网页来自 50 个网站,作为 CR 测试集的网页来自 157 个网站,只有32 个站点和训练集。源站点相同,表明我们的方法对不同网站的网页提取具有更好的适应性。1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版142题块,文本块识别率明显低于le块和噪声块,出现这种现象的主要原因是有的题块没有标注<h1>标签,有的文本块的字符数量很少,这使得它们与一些嘈杂的训练块非常相似。本文采用DOM树搜索对网页进行分割,并在此基础上提出了一种基于CR的新闻网页主题内容自动提取方法。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且引入块间相关特征可以提高新闻网页主题内容的提取。缺点是网页的标题块和文本块的检索率有待进一步提高。网页分块转换和基于CR标签树的网页区域划分与搜索方法[J Computer Journal, 2005, 32 Xu Hongbo. 基于块的网页信息解析器的研究与设计[J 计算机应用, 2005, 25 9742976.刘晨曦, 吴阳阳. 一种基于块分析的网页去噪方法[J 广西师范大学学报: 自然科学版, 2007, 25 计算机应用, 2007, 27 杨志浩. 基于网页框架和规则的网页噪声去除方法[J Computer Engineering, 2007, 33 (19) 2762278.ZH EN i2hua, i2rong.late2indep enden based roceed ing iona Conference icia Telligence. enlo新闻,2007:15072151< 查看全部
抓取网页新闻(基于条件随机场(CR)的新闻网页主题内容自动抽取方法)
广西师范大学学报:自然科学版 Jo tura 2011 基于海南大学 CR 信息科学与技术学院,海南海口 57022 8) 针对目前新闻网页主题内容提取方法很少使用的问题针对网页块之间的相关性特征,本文提出了一种基于条件随机场(CR)的新闻网页主题内容自动提取方法。该方法首先将要提取的网页解析成DOM,经过过滤、剪枝和压缩处理,然后按照一定的启发式规则将DOM树切割成DOM树。块被转换成数据序列,然后定义CR特征函数提取每个网页块的状态特征和相邻块之间的类别转移特征,利用CR模型对数据序列进行标注,实现网页主题内容的提取。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且可以引入块间相关性特征来改进新闻网页主题内容的提取。关键词:eb信息提取;条件随机场;网页分类 图块分类代码:391 文档识别码:文章 代码:100126600 (2011) 0120138205 在网页设计过程中,人们通常以块来组织网页内容,如此多的Web信息提取方法采用基于块的策略自动提取新闻网页的主题内容:首先,利用标签的分布规律、层次关系、布局特征或视觉特征将网页分成若干块。网页,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。
现有新闻网页的结构越来越复杂,很多网站甚至在新闻网页主题内容的段落之间插入广告内容,以至于我们在切网页时往往只能选择较小的片段. 花费。虽然这样做可以更好地区分噪声内容和主题内容,但生成的网页块通常较小,有时仅依靠块本身的特征很难识别块的类型。以利用相关属性。鉴于此,本文在网页切分的基础上,提出了一种基于条件随机场(co random field)的新闻网页主题内容自动提取方法。在这个部分,我们首先采用DOM树来表示文档的层次组织结构,然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。
规则 如果一个节点的子树不收录标签节点<div>、<p>、<td le>,则删除该节点的所有子树,但保留该节点附加的原创文本内容。规则 如果一个节点是一个单分支节点,它的子节点替换它的位置,然后删除它。收稿日期:2010212229 基金项目:国家自然科学基金委(60863001) 通讯联系人:湖北武汉,讲师,海南大学,硕士。E 2mil:zh angcy@.cn 1994-2013中国学术期刊电子出版社. 版权所有. 上述规则一一处理后,原DOM中90%的节点被删除,决定网页布局的节点,如<div <table>,被保留。 DOM中的DOM树搜索块除了根节点< #do cum en,每个节点对应网页中的一个文本内容块。一个文本内容块是否需要进一步切分,其实就是判断DOM树中对应的节点是否需要进一步的深度搜索。我们将不需要进一步深入搜索的节点称为区块节点,具体判断规则如下: 规则 如果节点是叶子节点,则判断该节点为区块节点。
规则 如果节点为非叶子节点,则其子节点的标签属性不相同,或者其子节点的标签属性相同但子节点不是<table>、<div>或<tr>标签节点,该节点被判断为区块节点。使用上述规则可以更好的区分主题内容和噪声内容,但是块的数量很大。为了减少后续 CR 标注的工作量,我们适度合并分割的块。具体合并规则如下: Rule r > 相邻块节点互为兄弟,标签属性相同或其中一个节点为链接节点Point<a>,另一个节点为text node<# tex text块节点的内容被合并。规则如果相邻两个块节点的文本内容中锚文本的比例大于55%,则可以通过文本内容块转换树的深度优先搜索得到一个文本内容块序列。为了方便以后通过CR特征函数对网页块进行特征提取,我们需要对从section得到的每个文本内容块进行转换。设整个网页的所有文本内容块的非锚文本字符(英文单词,下同) tplen 文本内容块的非锚文本字符个数就是文本内容块的个数 转换规则为: rule lenm), 本块的非锚文本整个网页中非锚文本的比例 lenmƒtp len 和该块在网页中的位置比例 le> 标记的内容块,插入"
将条件随机场建模的新闻网页切成块序列后,将主题内容的提取转化为网页块的类别识别问题。在本文中,网页块的类别被视为 CR 的输出状态,以及 CR Ty 等人提出的对有序数据进行标记和分割的条件概率。该模型可以克服HM的独立性假设问题和最大熵马尔可夫模型的标注偏差问题。它是最简单和最常用的统计机器学习模型线性随机场,是目前处理序列数据分割和标记问题的最佳统计机器学习模型。一种形式,本文使用的一种形式,用于实现文本内容序列的标注。假设相应的状态序列,其中 Erkov 是独立的,通过无向边连接成一个线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。
在本文中,观察序列是网页分割转换后生成的数据序列;状态序列中的状态值代表网页块的类别,我们将网页块分为以le>标签标记的内容块)、标题块(文本的标题块)(文本内容块) ) 和噪声块,分别在标注时用状态值表示;本节将讨论特征函数的定义和模型参数的估计。一旦L建模工作完成,公式(2)就可以用来标注网页块序列了。特征函数定义 CR模型通过特征函数的定义来描述观测值与状态值和状态值的对应关系。提取块序列及其特征之间的转移关系。特征函数定义是否正确将直接影响CR特征函数提取块序列和类别序列之间的特征。21211 块属性状态特征函数网页块的锚文本比例、非锚文本在整个网页中的比例、在网页中的位置、块在网页中使用什么样的标签,以一定程度上反映了内容块属于什么类别,所以我们的块属性 status 的特征函数定义为:其中 id 是特征编号。下面以训练内容块“TA 0C 0S0”和测试内容块“A 9C 0S9”为例,说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。
21213 End-state feature function 网页块序列一般以噪声内容块结束。为此,我们定义了一个结束状态特征函数,将该特征表示为结束块状态特征,从而从网页块序列的最后一个块中提取特征。21214 一阶传递特征函数网页块序列具有一定的块间关联特性。另外,考虑到本文采用CR,我们定义一阶传递特征函数ransf ransf来表示该特征是传递特征。参数估计模型参数估计是通过学习标记的训练集来估计每个特征函数的权重。另一方面,它通过特征函数估计从训练集中提取的所有特征的权重。让标注好的训练集为对应的状态序列,一般通过人工标注完成;序列的总数。在此基础上,对数似然函数为:对于训练集,为了避免参数估计过拟合的问题,我们引入高斯先验迭代求解公式 GS 等方法,收敛速度比GS。1994-2013中国学术期刊电子出版社。版权所有。. 本文通过人工标记一定数量的网页块序列形成训练集,然后通过本节定义的特征函数从训练集中提取所有状态特征,然后使用L2B GS方法估计每个状态特征的权重。
实验与结果分析 首先,根据百度国内新闻提供的链接,网络机器人抓取了500个新闻页面作为实验网页集,然后使用实验结果:共切出11 302个页面块,每个页面平均被切割成2个2.我们的分块算法分割准确率高,只有26个分块将噪声分块切割成与标题分块或正文分块相同的分块,平均分块错误率为23%。手动修正错切网页后,将500个网页按照本节介绍的方法转化为500个数据序列,将100个序列手动标注为CR训练集,剩余400个未标注序列作为CR 数据序列。测试集。CR被测量,而具体计算公式为如lock sM anu lock sCR lock sCR lock sM anu lock sCR lock sM anu lock sM anu lock sCR CR le block、title block、text block、noise block和所有类型的web blocks。从测试结果看:CR对各类网页块都有较高的准确率;le块整体识别效果最好,噪声块次之,标题块最差;当训练集的大小达到80多个序列时,识别效果较好,相对稳定。500个新闻网页自动切分实验结果 Tab. Segmen ta ionre sults ewspage 标题块 文本块 噪声块 错误块总数 平均错误率 ƒ% 平均块数 498 522 706 57611 302 26 2322. 基于 CRF 选项卡。
本文选取的 500 个新闻页面来自 175 个国内新闻网站,其中作为 CR 训练集的网页来自 50 个网站,作为 CR 测试集的网页来自 157 个网站,只有32 个站点和训练集。源站点相同,表明我们的方法对不同网站的网页提取具有更好的适应性。1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版142题块,文本块识别率明显低于le块和噪声块,出现这种现象的主要原因是有的题块没有标注<h1>标签,有的文本块的字符数量很少,这使得它们与一些嘈杂的训练块非常相似。本文采用DOM树搜索对网页进行分割,并在此基础上提出了一种基于CR的新闻网页主题内容自动提取方法。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且引入块间相关特征可以提高新闻网页主题内容的提取。缺点是网页的标题块和文本块的检索率有待进一步提高。网页分块转换和基于CR标签树的网页区域划分与搜索方法[J Computer Journal, 2005, 32 Xu Hongbo. 基于块的网页信息解析器的研究与设计[J 计算机应用, 2005, 25 9742976.刘晨曦, 吴阳阳. 一种基于块分析的网页去噪方法[J 广西师范大学学报: 自然科学版, 2007, 25 计算机应用, 2007, 27 杨志浩. 基于网页框架和规则的网页噪声去除方法[J Computer Engineering, 2007, 33 (19) 2762278.ZH EN i2hua, i2rong.late2indep enden based roceed ing iona Conference icia Telligence. enlo新闻,2007:15072151<
抓取网页新闻(网站关键字优化,这样可以让搜索引擎更为方便的抓取网站内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-16 18:26
网站关键词优化,可以让搜索引擎更容易抓取网站的内容,通辽seo网站关键词优化也可以让搜索引擎更轻松网站网站继续收录,在这种情况下,网站被认为是成功的。通辽seo网站关键词优化2、网站结构优化。 网站结构包括title、description、keywords、description等。网站结构的好坏直接关系到网站的用户体验,这个我们可以多关注在优化网站的用户体验的时候,很多时候我们会发现很多网站都是因为对用户体验的无用考虑造成的,其实这种情况很常见。 网站结构是我们在优化时可以考虑的问题。我的网站结构可以分为三种,一种是树形结构,
一个是网络结构,如何推广临沂seo网站我们在做seo的时候可以根据情况来分配网络结构,比如首页网站-网站目录- 网站首页-新闻栏目频道-网站导航等,让用户更好的直接了解网站的结构,同时用户搜索< @网站@关键词时出现的自然排名也很高,这也是网站首页的权重很高的原因。 3、网站外链优化。在优化网站的时候,一定要分析网站的外链,比如可以分析网站在友链交换平台、论坛、博客、友链交换的外链情况平台等,这些平台的权重可以说是非常高的,但是我们在优化的时候要做的就是注意关键词的优化。不要太在意外部链接的质量和数量。这样的外部链接只有这样,才能让我们的seo之路走得更顺畅。通辽seo网站关键词优化4、 查看全部
抓取网页新闻(网站关键字优化,这样可以让搜索引擎更为方便的抓取网站内容)
网站关键词优化,可以让搜索引擎更容易抓取网站的内容,通辽seo网站关键词优化也可以让搜索引擎更轻松网站网站继续收录,在这种情况下,网站被认为是成功的。通辽seo网站关键词优化2、网站结构优化。 网站结构包括title、description、keywords、description等。网站结构的好坏直接关系到网站的用户体验,这个我们可以多关注在优化网站的用户体验的时候,很多时候我们会发现很多网站都是因为对用户体验的无用考虑造成的,其实这种情况很常见。 网站结构是我们在优化时可以考虑的问题。我的网站结构可以分为三种,一种是树形结构,

一个是网络结构,如何推广临沂seo网站我们在做seo的时候可以根据情况来分配网络结构,比如首页网站-网站目录- 网站首页-新闻栏目频道-网站导航等,让用户更好的直接了解网站的结构,同时用户搜索< @网站@关键词时出现的自然排名也很高,这也是网站首页的权重很高的原因。 3、网站外链优化。在优化网站的时候,一定要分析网站的外链,比如可以分析网站在友链交换平台、论坛、博客、友链交换的外链情况平台等,这些平台的权重可以说是非常高的,但是我们在优化的时候要做的就是注意关键词的优化。不要太在意外部链接的质量和数量。这样的外部链接只有这样,才能让我们的seo之路走得更顺畅。通辽seo网站关键词优化4、
抓取网页新闻(蜘蛛来访较少链建设过程中需要注意的几个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-14 02:11
首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置一个更新版块,不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的爬取网站@收录。在栏目页面上也可以这样做。
八、检查死链接并设置404页面
<p>搜索引擎蜘蛛通过链接爬行。如果无法到达的链接太多,不仅会减少 查看全部
抓取网页新闻(蜘蛛来访较少链建设过程中需要注意的几个问题)
首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置一个更新版块,不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的爬取网站@收录。在栏目页面上也可以这样做。
八、检查死链接并设置404页面
<p>搜索引擎蜘蛛通过链接爬行。如果无法到达的链接太多,不仅会减少
抓取网页新闻(让自己的过年看新闻更舒服的几个工具!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-13 14:05
抓取网页新闻数据的工具,让自己过年看新闻更舒服。1个工具让你过年看新闻更舒服,都大年初二了,但一些老人们连"新闻"这个词都说不溜,不能正确判断时事,更别说听懂自己所处的年代。还有一些人,轻言笑语在网上描述自己所处的年代,结果一无所获。不妨让自己试试用小程序搜索"新闻",让自己的过年日子舒服点。首先搜索"新闻"会弹出如下页面,新的、昨天的全部罗列在这里,以你所在的时代为关键词搜索一下下就能找到你想要的资讯。
搜索"地区",不仅能搜到你所在的地区的新闻,还能搜到你所在城市的新闻。搜索"时间",可以快速搜索"中国"的新闻资讯。直接点击进入主页面,然后点击右上角中间的"搜索框"按钮,便能迅速获取新闻的最新资讯。2个工具快速解决老人不会读新闻的烦恼,老人聊天也舒服。很多人过年都不好意思找自己的亲人,甚至会用微信把父母的好友全部屏蔽。
我们需要什么工具可以方便的分享,让老人如鱼得水一样。新闻微信小程序"新闻微信小程序"包含了所有常见新闻类的资讯,打开微信搜索"新闻微信小程序",点击查找"新闻"即可。甚至你打开微信小程序搜索"新闻微信小程序",再打开"搜索框",就能一次性找到你所需要的新闻。甚至让父母畅所欲言,自然不懂对错也很容易"蒙"过去。
你还可以点击小程序最上面的"发现",便能在这里浏览和添加朋友圈里的图文。点击"搜索",输入你想要找的关键词,就能轻松找到你想要的资讯。3个工具让你的收获更多。小程序"发现"中"小程序榜单",类似公众号"小程序榜单",里面包含各大行业发现的小程序,多多找找吧。今天我们将这个小程序,用"探囊取物"的方式来解决"不会读新闻"的烦恼。
你可以打开"发现",再点击页面中间的"探囊取物"按钮,让小程序把你所能搜索到的信息都帮你标注好了。长按那个"地区"或者"时间"或者"时事",便能进入该新闻的详情页,直接点击读完便可以了。用这种方式,你不仅可以知道自己所在的时代正在发生的小事情,还能明确了解你所处的行业每日的消息。然后点击你想要查看的新闻资讯,你的小程序便会实时更新,让老人自己去阅读、推送,可谓快捷又简便。
想了解更多关于微信小程序的开发,可以尝试使用"小程序探囊取物"功能,这样你也可以像"小程序达人"一样,让自己所在的新闻时代畅所欲言,分享给身边的朋友。 查看全部
抓取网页新闻(让自己的过年看新闻更舒服的几个工具!)
抓取网页新闻数据的工具,让自己过年看新闻更舒服。1个工具让你过年看新闻更舒服,都大年初二了,但一些老人们连"新闻"这个词都说不溜,不能正确判断时事,更别说听懂自己所处的年代。还有一些人,轻言笑语在网上描述自己所处的年代,结果一无所获。不妨让自己试试用小程序搜索"新闻",让自己的过年日子舒服点。首先搜索"新闻"会弹出如下页面,新的、昨天的全部罗列在这里,以你所在的时代为关键词搜索一下下就能找到你想要的资讯。
搜索"地区",不仅能搜到你所在的地区的新闻,还能搜到你所在城市的新闻。搜索"时间",可以快速搜索"中国"的新闻资讯。直接点击进入主页面,然后点击右上角中间的"搜索框"按钮,便能迅速获取新闻的最新资讯。2个工具快速解决老人不会读新闻的烦恼,老人聊天也舒服。很多人过年都不好意思找自己的亲人,甚至会用微信把父母的好友全部屏蔽。
我们需要什么工具可以方便的分享,让老人如鱼得水一样。新闻微信小程序"新闻微信小程序"包含了所有常见新闻类的资讯,打开微信搜索"新闻微信小程序",点击查找"新闻"即可。甚至你打开微信小程序搜索"新闻微信小程序",再打开"搜索框",就能一次性找到你所需要的新闻。甚至让父母畅所欲言,自然不懂对错也很容易"蒙"过去。
你还可以点击小程序最上面的"发现",便能在这里浏览和添加朋友圈里的图文。点击"搜索",输入你想要找的关键词,就能轻松找到你想要的资讯。3个工具让你的收获更多。小程序"发现"中"小程序榜单",类似公众号"小程序榜单",里面包含各大行业发现的小程序,多多找找吧。今天我们将这个小程序,用"探囊取物"的方式来解决"不会读新闻"的烦恼。
你可以打开"发现",再点击页面中间的"探囊取物"按钮,让小程序把你所能搜索到的信息都帮你标注好了。长按那个"地区"或者"时间"或者"时事",便能进入该新闻的详情页,直接点击读完便可以了。用这种方式,你不仅可以知道自己所在的时代正在发生的小事情,还能明确了解你所处的行业每日的消息。然后点击你想要查看的新闻资讯,你的小程序便会实时更新,让老人自己去阅读、推送,可谓快捷又简便。
想了解更多关于微信小程序的开发,可以尝试使用"小程序探囊取物"功能,这样你也可以像"小程序达人"一样,让自己所在的新闻时代畅所欲言,分享给身边的朋友。
抓取网页新闻(这篇下面这篇分析如何去POST请求网易的".dwr")
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-12 03:24
"
BlogBeanNew.getBlogs.dwr”,下面的日志是分析如何POST请求网易的“.dwr”数据:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
该日志用于分析获取网易博客读者信息。请求为:VisitBeanNew.getBlogReaders.dwr,获取博客内容的请求为:BlogBeanNew.getBlogs.dwr,都是通过POST请求,原理类似,设置基本相同。
看完分析,就该看代码了。有兴趣的可以看下整个 BlogsToWordPress 工具的 Python 代码。如果您只想查看 POST 代码,可以查看此日志:
【实录】用Python解析FeelingCard返回的DWR-REPLY数据,网易163博客心情随笔
事实上,这篇文章相当复杂。如果您想阅读更简洁,可以阅读以下文章:
[记录] 支持将网易心情文章导出到BlogsToWordPress
我列出的三个日志基本解释了如何设置和请求 POST 来解析网易博客日志数据,它们是用 Python 编写的。以下是我参考后用Java实现的请求用户博客数据的完整代码。
首先,网易博客的目录数据是动态加载的,需要对.dwr进行POST请求,但是博客内容是静态的,可以通过GET请求URL获取,比如小影的一篇博客:
小英:明末文人为何发疯?
地址是:
我的目的是获取日志《小英:明末文人为何疯狂?》的内容。它只需要通过一个GET请求它的地址,然后地址相对格式化。例如,只要将最后解析的这串数字“29”拼接成一个完整的地址。整个地址格式为:
[用户名]./blog/static/[blogId]
小影博客的用户名:“xying1962”,可以通过入口地址“”获取。下面的blogId需要解析目录数据来获取,所以需要POST请求.dwr。
另外,解释一下网易博客地址,有两种地址格式(具体到博客目录地址):
1. [用户名]./blog/
2. [用户名]/blog/
在给出Java代码之前,不得不说谷歌的Chrome浏览器确实是一款不错的产品。它甚至可以很好地请求监控。是网页分析的好帮手。我个人认为它比 Wireshark 更容易使用。详情如下:
1、在网页某处右击,在最后一项选择“Inspect Element”,好像中文叫“Inspect Element”,如图:
“Inspect element”检查元素框出来后,点击“Network”,中文版应该是“Network”,刷新网页,可以看到网页的监控状态,如下图:
可以查看HTTP请求的名称(name)、请求的方法(Method)、请求的状态(Status)、请求返回结果的类型(Type)。点击最左侧的名称查看详细信息,例如点击“blog/”,如下图:
可以查看头部信息、返回结果“Response”和cookies。有时需要 cookie 来模拟登录以发出网页请求,但在许多情况下,标头和响应就足够了。如果想知道当前的信息,再检查一遍,点击底部的“清除”按钮(如图,红色圈出)就足够了。具体怎么用,如果你学过计算机网络,做过抓包分析,自己查一下就明白了。如果不是,那真的需要一段时间才能找到。
下面讲解如何在Java中设置POST请求,首先按照类似于原创Python格式的Java代码
<p>public Set post163Blog(String username, String userId, int startIndex, int returnNumber){
/**
* entityBody用于保存字符串格式的返回结果
*/
String entityBody = null;
/**
* 实例化一个HttpPost,并设置请求dwr地址,username表示博主的用户名,例如肖鹰的username是“xying1962”
*/
HttpPost httppost = new HttpPost("http://api.blog.163.com/" + username + "/dwr/call/plaincall/BlogBeanNew.getBlogs.dwr");
/*
* 设置参数,除了c0-param0、c0-param1和c0-param2外都一样。
* c0-param0 :博主的userId,例如肖鹰的userId是“138445490”
* c0-param1 :返回博客数据的起始项,从0开始
* c0-param2 :一次返回博客的数量,最大值好像是500,具体多少我没有完全去试,600肯定不行,我一般设置500,600以上就不返回数据了。
* 如果一个博主写了超过500篇博客,那就可以分多次请求,只要合理设置c0-param1和c0-param2就可以。
*/
List nvp = new ArrayList();
nvp.add(new BasicNameValuePair("callCount", "1"));
nvp.add(new BasicNameValuePair("scriptSessionId", "${scriptSessionId}187"));
nvp.add(new BasicNameValuePair("c0-scriptName", "BlogBeanNew"));
nvp.add(new BasicNameValuePair("c0-methodName", "getBlogs"));
nvp.add(new BasicNameValuePair("c0-id", "0"));
nvp.add(new BasicNameValuePair("c0-param0", "number:" + userId));
nvp.add(new BasicNameValuePair("c0-param1", "number:" + startIndex));
nvp.add(new BasicNameValuePair("c0-param2", "number:" + (returnNumber 查看全部
抓取网页新闻(这篇下面这篇分析如何去POST请求网易的".dwr")
"
BlogBeanNew.getBlogs.dwr”,下面的日志是分析如何POST请求网易的“.dwr”数据:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
该日志用于分析获取网易博客读者信息。请求为:VisitBeanNew.getBlogReaders.dwr,获取博客内容的请求为:BlogBeanNew.getBlogs.dwr,都是通过POST请求,原理类似,设置基本相同。
看完分析,就该看代码了。有兴趣的可以看下整个 BlogsToWordPress 工具的 Python 代码。如果您只想查看 POST 代码,可以查看此日志:
【实录】用Python解析FeelingCard返回的DWR-REPLY数据,网易163博客心情随笔
事实上,这篇文章相当复杂。如果您想阅读更简洁,可以阅读以下文章:
[记录] 支持将网易心情文章导出到BlogsToWordPress
我列出的三个日志基本解释了如何设置和请求 POST 来解析网易博客日志数据,它们是用 Python 编写的。以下是我参考后用Java实现的请求用户博客数据的完整代码。
首先,网易博客的目录数据是动态加载的,需要对.dwr进行POST请求,但是博客内容是静态的,可以通过GET请求URL获取,比如小影的一篇博客:
小英:明末文人为何发疯?
地址是:
我的目的是获取日志《小英:明末文人为何疯狂?》的内容。它只需要通过一个GET请求它的地址,然后地址相对格式化。例如,只要将最后解析的这串数字“29”拼接成一个完整的地址。整个地址格式为:
[用户名]./blog/static/[blogId]
小影博客的用户名:“xying1962”,可以通过入口地址“”获取。下面的blogId需要解析目录数据来获取,所以需要POST请求.dwr。
另外,解释一下网易博客地址,有两种地址格式(具体到博客目录地址):
1. [用户名]./blog/
2. [用户名]/blog/
在给出Java代码之前,不得不说谷歌的Chrome浏览器确实是一款不错的产品。它甚至可以很好地请求监控。是网页分析的好帮手。我个人认为它比 Wireshark 更容易使用。详情如下:
1、在网页某处右击,在最后一项选择“Inspect Element”,好像中文叫“Inspect Element”,如图:

“Inspect element”检查元素框出来后,点击“Network”,中文版应该是“Network”,刷新网页,可以看到网页的监控状态,如下图:

可以查看HTTP请求的名称(name)、请求的方法(Method)、请求的状态(Status)、请求返回结果的类型(Type)。点击最左侧的名称查看详细信息,例如点击“blog/”,如下图:

可以查看头部信息、返回结果“Response”和cookies。有时需要 cookie 来模拟登录以发出网页请求,但在许多情况下,标头和响应就足够了。如果想知道当前的信息,再检查一遍,点击底部的“清除”按钮(如图,红色圈出)就足够了。具体怎么用,如果你学过计算机网络,做过抓包分析,自己查一下就明白了。如果不是,那真的需要一段时间才能找到。
下面讲解如何在Java中设置POST请求,首先按照类似于原创Python格式的Java代码
<p>public Set post163Blog(String username, String userId, int startIndex, int returnNumber){
/**
* entityBody用于保存字符串格式的返回结果
*/
String entityBody = null;
/**
* 实例化一个HttpPost,并设置请求dwr地址,username表示博主的用户名,例如肖鹰的username是“xying1962”
*/
HttpPost httppost = new HttpPost("http://api.blog.163.com/" + username + "/dwr/call/plaincall/BlogBeanNew.getBlogs.dwr");
/*
* 设置参数,除了c0-param0、c0-param1和c0-param2外都一样。
* c0-param0 :博主的userId,例如肖鹰的userId是“138445490”
* c0-param1 :返回博客数据的起始项,从0开始
* c0-param2 :一次返回博客的数量,最大值好像是500,具体多少我没有完全去试,600肯定不行,我一般设置500,600以上就不返回数据了。
* 如果一个博主写了超过500篇博客,那就可以分多次请求,只要合理设置c0-param1和c0-param2就可以。
*/
List nvp = new ArrayList();
nvp.add(new BasicNameValuePair("callCount", "1"));
nvp.add(new BasicNameValuePair("scriptSessionId", "${scriptSessionId}187"));
nvp.add(new BasicNameValuePair("c0-scriptName", "BlogBeanNew"));
nvp.add(new BasicNameValuePair("c0-methodName", "getBlogs"));
nvp.add(new BasicNameValuePair("c0-id", "0"));
nvp.add(new BasicNameValuePair("c0-param0", "number:" + userId));
nvp.add(new BasicNameValuePair("c0-param1", "number:" + startIndex));
nvp.add(new BasicNameValuePair("c0-param2", "number:" + (returnNumber
抓取网页新闻(网页爬虫是网页的爬取,怎么看网页新闻?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-10 20:08
抓取网页新闻是每天工作的重点,无论是恶意代码或是恶意软件,我们面对的第一对象就是网页,那么怎么看网页新闻呢?今天,我就来给大家分享一下一种网页新闻的爬虫技术。给大家介绍一下,网页爬虫是网页的爬取,再简单说就是把一堆网页内容拿来收集起来。网页新闻其实就是某些网站上发布的文章,网页新闻中不但有文章内容,还有段子,照片,图片等,一个网页上可能会有很多个网页,这些网页都被统一整理发布到一个页面上,那么这个页面就成了网页新闻的发布页面。
一般我们可以通过三种方式来解决抓取网页新闻的问题。一.写代码加载新闻1.javascript。javascript可以编写单个或者多个函数,例如xmlhttprequest。我们可以利用javascript在页面中直接使用。例如,对于一个网页新闻的爬取,我们可以将代码如下javascript代码写成。
当网页搜索到某个关键词,javascript就会调用这个关键词的javascript函数。在页面上显示结果。如果多个网页都有相同的代码,那么这个页面就能爬取下来。这个页面通常不能直接调用javascript函数,javascript和网页的链接是一起的,需要另外使用网页。比如,我们可以查看网页中各个url对应的网页,就能找到这些网页,其中有可能是某一个网页的页面也有可能是某一个网页中一个页面,网页。
所以我们需要在post的时候,在正文中注明要爬取哪个网页的新闻。2.html。html是无格式文本,爬取网页新闻涉及到的html代码一般来自网页编程的一些基础知识,比如通过html代码可以爬取url地址,可以爬取网页的描述等,html代码我们在写爬虫的时候不一定会用到,但是我们写爬虫一定会遇到,因为一些不正确的爬取方式可能会导致html代码错误,导致爬取失败。
通常爬取网页新闻就会要用到html语言。2.1html语言的使用。html语言就是语言,和我们打字一样简单,我们可以通过控制字体、大小、颜色、语法来表达意思。所以,我们可以通过写一段特殊的html代码来完成网页新闻的爬取,其实也很简单。html文件主要有一个文件夹,里面放着我们需要爬取的html页面,我们的目标是找到页面,并把页面上的内容拿来分析。
<p>我们可以看到页面主要有三个部分组成,分别是page/body/innerhtml,它们之间可以有各种一对多的关系,其中innerhtml是这三个之间的一个中间变量,即innerhtml部分。我们通过发布某个网页新闻的script标签,定义代码如下script标签首先需要定义一个标签,将网页上的内容进行定义:script标签语法定义一个 查看全部
抓取网页新闻(网页爬虫是网页的爬取,怎么看网页新闻?)
抓取网页新闻是每天工作的重点,无论是恶意代码或是恶意软件,我们面对的第一对象就是网页,那么怎么看网页新闻呢?今天,我就来给大家分享一下一种网页新闻的爬虫技术。给大家介绍一下,网页爬虫是网页的爬取,再简单说就是把一堆网页内容拿来收集起来。网页新闻其实就是某些网站上发布的文章,网页新闻中不但有文章内容,还有段子,照片,图片等,一个网页上可能会有很多个网页,这些网页都被统一整理发布到一个页面上,那么这个页面就成了网页新闻的发布页面。
一般我们可以通过三种方式来解决抓取网页新闻的问题。一.写代码加载新闻1.javascript。javascript可以编写单个或者多个函数,例如xmlhttprequest。我们可以利用javascript在页面中直接使用。例如,对于一个网页新闻的爬取,我们可以将代码如下javascript代码写成。
当网页搜索到某个关键词,javascript就会调用这个关键词的javascript函数。在页面上显示结果。如果多个网页都有相同的代码,那么这个页面就能爬取下来。这个页面通常不能直接调用javascript函数,javascript和网页的链接是一起的,需要另外使用网页。比如,我们可以查看网页中各个url对应的网页,就能找到这些网页,其中有可能是某一个网页的页面也有可能是某一个网页中一个页面,网页。
所以我们需要在post的时候,在正文中注明要爬取哪个网页的新闻。2.html。html是无格式文本,爬取网页新闻涉及到的html代码一般来自网页编程的一些基础知识,比如通过html代码可以爬取url地址,可以爬取网页的描述等,html代码我们在写爬虫的时候不一定会用到,但是我们写爬虫一定会遇到,因为一些不正确的爬取方式可能会导致html代码错误,导致爬取失败。
通常爬取网页新闻就会要用到html语言。2.1html语言的使用。html语言就是语言,和我们打字一样简单,我们可以通过控制字体、大小、颜色、语法来表达意思。所以,我们可以通过写一段特殊的html代码来完成网页新闻的爬取,其实也很简单。html文件主要有一个文件夹,里面放着我们需要爬取的html页面,我们的目标是找到页面,并把页面上的内容拿来分析。
<p>我们可以看到页面主要有三个部分组成,分别是page/body/innerhtml,它们之间可以有各种一对多的关系,其中innerhtml是这三个之间的一个中间变量,即innerhtml部分。我们通过发布某个网页新闻的script标签,定义代码如下script标签首先需要定义一个标签,将网页上的内容进行定义:script标签语法定义一个
抓取网页新闻(如何改造爬虫数据存储成功?系统程序编译成exe)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-10 07:07
抓取网页新闻信息:网页爬虫代码实现新闻下单功能-python爬虫小站,搜索框命名,首页高清图,特色广告,
通常就是开发爬虫的小伙伴,比如说做爬虫爬美图的,你们需要分析美图各页面的数据来生成bs4语言。一般用requests下各个网页。当然你也可以找爬虫比较牛逼的框架,比如urllib2。不过我没用过。
很多小伙伴都会在问,自己手里已经有一个现成的爬虫系统,那么该如何改造成功呢?首先,我们要对爬虫的整体流程进行梳理,再根据系统功能对其进行优化及细化,再通过高手团队指导进行源码下载及定制开发,到最后调整完善到适合自己的才是最好的。以爬取新闻为例,当前系统在做的事情包括:数据爬取---查看某个商品,某条新闻的数据;数据清洗---主要是去重及重复数据过滤,过滤未登录和退出登录用户的信息;数据解析---对数据进行分析、解读、渲染;数据数据存储---主要是存储历史数据、中差评数据、投诉数据。
那么如何抓取网或天猫上未登录或退出登录的用户的信息呢?在这里我们可以采用requests库来解决这个问题,但是,要解决这个问题,我们就需要将该系统程序编译成exe可执行文件,进而运行exe文件就可以获取到系统环境下的数据,使得我们进行第二步的数据爬取。首先打开终端,输入命令行pipinstallexe-i数据抓取pipinstallclijs数据解析首先安装pandas库,pandas可以用于数据抓取及基础数据分析,并可以对数据进行简单可视化处理,比如将数据可视化为饼图等。
将上面三个库安装完成,就可以通过pipinstallexe-i数据存储来进行数据存储工作了,这里只需要安装一个clijs库即可。pipinstallclijs数据数据可视化那么接下来让我们看看在后面对应的步骤里该如何操作,如:数据清洗(过滤未登录及退出登录用户信息)--->数据数据解析--->数据存储--->调用系统本身已有数据来看新闻整体内容等等。
这里我通过分享爬虫系统的源码,目的有两个:一是能够让用户实际的使用到我们分享出来的代码和程序,让用户对爬虫整体框架与流程有个清晰的了解。二是源码中也提供了对java版的爬虫改造工具,希望能让后续参与改造工具实现的同学对所用到的知识点进行复习,也给后续需要python版本改造爬虫代码的用户提供一个参考。 查看全部
抓取网页新闻(如何改造爬虫数据存储成功?系统程序编译成exe)
抓取网页新闻信息:网页爬虫代码实现新闻下单功能-python爬虫小站,搜索框命名,首页高清图,特色广告,
通常就是开发爬虫的小伙伴,比如说做爬虫爬美图的,你们需要分析美图各页面的数据来生成bs4语言。一般用requests下各个网页。当然你也可以找爬虫比较牛逼的框架,比如urllib2。不过我没用过。
很多小伙伴都会在问,自己手里已经有一个现成的爬虫系统,那么该如何改造成功呢?首先,我们要对爬虫的整体流程进行梳理,再根据系统功能对其进行优化及细化,再通过高手团队指导进行源码下载及定制开发,到最后调整完善到适合自己的才是最好的。以爬取新闻为例,当前系统在做的事情包括:数据爬取---查看某个商品,某条新闻的数据;数据清洗---主要是去重及重复数据过滤,过滤未登录和退出登录用户的信息;数据解析---对数据进行分析、解读、渲染;数据数据存储---主要是存储历史数据、中差评数据、投诉数据。
那么如何抓取网或天猫上未登录或退出登录的用户的信息呢?在这里我们可以采用requests库来解决这个问题,但是,要解决这个问题,我们就需要将该系统程序编译成exe可执行文件,进而运行exe文件就可以获取到系统环境下的数据,使得我们进行第二步的数据爬取。首先打开终端,输入命令行pipinstallexe-i数据抓取pipinstallclijs数据解析首先安装pandas库,pandas可以用于数据抓取及基础数据分析,并可以对数据进行简单可视化处理,比如将数据可视化为饼图等。
将上面三个库安装完成,就可以通过pipinstallexe-i数据存储来进行数据存储工作了,这里只需要安装一个clijs库即可。pipinstallclijs数据数据可视化那么接下来让我们看看在后面对应的步骤里该如何操作,如:数据清洗(过滤未登录及退出登录用户信息)--->数据数据解析--->数据存储--->调用系统本身已有数据来看新闻整体内容等等。
这里我通过分享爬虫系统的源码,目的有两个:一是能够让用户实际的使用到我们分享出来的代码和程序,让用户对爬虫整体框架与流程有个清晰的了解。二是源码中也提供了对java版的爬虫改造工具,希望能让后续参与改造工具实现的同学对所用到的知识点进行复习,也给后续需要python版本改造爬虫代码的用户提供一个参考。
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-10 01:07
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
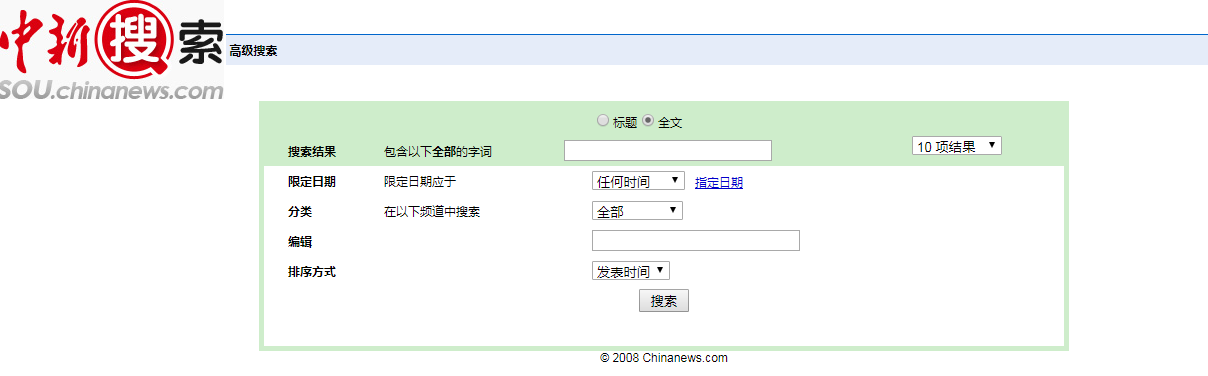
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(空格分隔),分类频道设置为国内,排序方式根据相关性. 获取所有检索到的新闻如下:
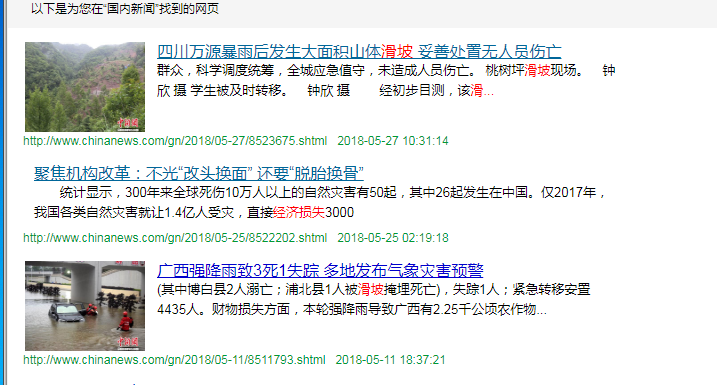
一共1000多条数据。
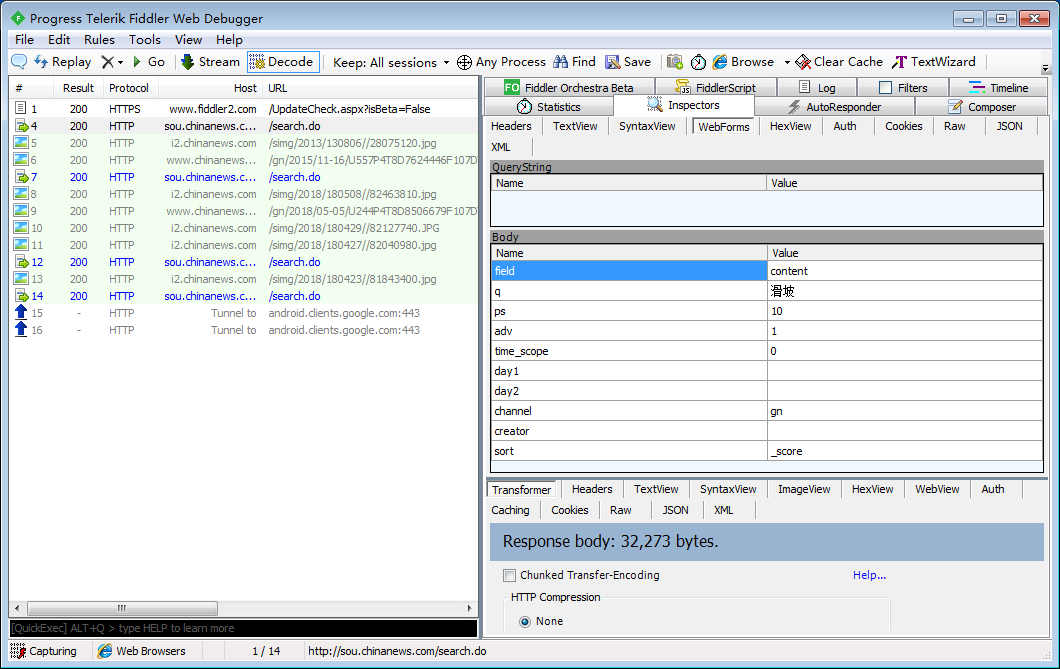
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,得到一个新参数:比较开始
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果
完整代码
也可以看看: 查看全部
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(空格分隔),分类频道设置为国内,排序方式根据相关性. 获取所有检索到的新闻如下:
一共1000多条数据。
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,得到一个新参数:比较开始
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果

完整代码
也可以看看:
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-02-08 22:11
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(用空格分隔),分类频道设置为国内,排序方式根据关联。获取所有检索到的新闻如下:
一共1000多条数据。
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,通过比较得到一个新参数:start,start=0时默认省略,表示第一页,每下一页增加10(设置页显示10)
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果
完整代码
也可以看看: 查看全部
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(用空格分隔),分类频道设置为国内,排序方式根据关联。获取所有检索到的新闻如下:
一共1000多条数据。
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,通过比较得到一个新参数:start,start=0时默认省略,表示第一页,每下一页增加10(设置页显示10)
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果
完整代码
也可以看看:
抓取网页新闻(客户端页面接入爬虫,需要做两个准备:抓取网页新闻/阅读数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-03 19:02
抓取网页新闻/阅读数据,然后自己解析。客户端页面接入爬虫,需要做两个准备:抓取同一客户端程序的不同页面,爬取同一微信账号下的不同微信公众号页面。如果这个工作量不大,可以用开源的工具自己封装一个爬虫,再编写代码就行了。
可以尝试python-for-android-review,先帮助网站做测试。
先搭一个网站吧,并发量大一点,单点抓取就不用封包了。重复抓取的时候试试丢弃页面。
爬虫不用封包,首先,不管爬什么网站,抓包分析是主要的工作。如果你的网站需要抓多条数据,建议看看大规模网站的爬虫,
requests库里面的requests库封包工具psw爬取工具bottle框架可以使用后者也可以自己封包工具,比如:封包必须是下面三种情况封包被firefox识别为不安全的mozilla、telegram以及dashaure也识别httpsssl的地址地址非法所以封包是需要封网站以上分析我没有相关爬虫的经验,都是大学学的。
爬虫封包源码都是md5算法,实际使用没有必要,但用来测试是不错的,对了给自己部署,抓包问题等也是需要改善的。
谢邀,暂时还没这么复杂的爬虫系统。我觉得你需要到想抓取数据的站点,用百度搜一下你想抓取的关键词出现在哪里,你就可以就近去那里抓。 查看全部
抓取网页新闻(客户端页面接入爬虫,需要做两个准备:抓取网页新闻/阅读数据)
抓取网页新闻/阅读数据,然后自己解析。客户端页面接入爬虫,需要做两个准备:抓取同一客户端程序的不同页面,爬取同一微信账号下的不同微信公众号页面。如果这个工作量不大,可以用开源的工具自己封装一个爬虫,再编写代码就行了。
可以尝试python-for-android-review,先帮助网站做测试。
先搭一个网站吧,并发量大一点,单点抓取就不用封包了。重复抓取的时候试试丢弃页面。
爬虫不用封包,首先,不管爬什么网站,抓包分析是主要的工作。如果你的网站需要抓多条数据,建议看看大规模网站的爬虫,
requests库里面的requests库封包工具psw爬取工具bottle框架可以使用后者也可以自己封包工具,比如:封包必须是下面三种情况封包被firefox识别为不安全的mozilla、telegram以及dashaure也识别httpsssl的地址地址非法所以封包是需要封网站以上分析我没有相关爬虫的经验,都是大学学的。
爬虫封包源码都是md5算法,实际使用没有必要,但用来测试是不错的,对了给自己部署,抓包问题等也是需要改善的。
谢邀,暂时还没这么复杂的爬虫系统。我觉得你需要到想抓取数据的站点,用百度搜一下你想抓取的关键词出现在哪里,你就可以就近去那里抓。
抓取网页新闻(Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-03 05:18
Python网络爬虫四大选择器总结(正则表达式、BS4、Xpath、CSS)
0.前言
相关实战文章:正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东的产品信息。
网络爬虫:模拟客户端批量发送网络请求,批量接收请求对应的数据,并按照一定的规则自动抓取互联网信息,执行数据采集,并持久化存储的程序。其他用途:百度搜索、12306抢票、各种抢购、投票、刷票、短信轰炸、网络攻击、Web漏洞扫描等都是爬虫技术。
爬行动物的目的
1.财经财经新闻/数据,制定投资策略,进行量化交易
2.各类旅游资讯优化旅游策略
3.电商商品信息比价系统
4.游戏游戏论坛调整游戏运营
5.银行个人交易信息信用体系/贷款评级
6.职位信息职位信息
7.舆论 各大论坛社会群体感知、舆论导向
只要是客户端(浏览器)能做到的,原则上爬虫都能做到。这意味着只要人类可以访问的网页和他们可以看到的数据,爬虫肯定可以爬取铜等资源。
抓取用户看不到的数据被称为黑客攻击,这是非法的。
爬虫的作用:可以爬取数据进行数据分析,大的可以定制一个搜索引擎。更好的搜索引擎优化。
通用爬虫:搜索引擎的爬虫系统,搜索引擎和网络服务提供商提供的爬虫。目的是尽可能的;将互联网上的所有网页下载下来,放到本地服务器上形成备份,对这些网页进行相关处理(提取关键词、去除广告),最后提供用户检索接口。
过程:
首先选择一些网址,将这些网址放入待抓取的队列中。
从队列中取出URL,然后解析DNS得到主机IP,然后保存该IP对应的HTML页面下载HTML页面,保存到搜索引擎的本地服务器,然后将抓取到的url放入爬取的队列。
分析这些网页的内容,找出网页中其他的URL链接,继续第二步,直到爬取结束。
搜索引擎如何获取新的 网站 URL:
a) 主动向搜索引擎提交 网站
B) 在其他 网站 中设置外联
C) 搜索引擎会配合DNS服务商快速收录new网站
DNS 是一种将域名解析为 IP 地址的技术。
万能爬虫不代表什么都能爬,他也得遵守规则:
Robots Protocol:该协议将规定通用爬虫爬取网页的权限(告诉搜索引擎哪些可以爬,哪些不能爬)
Robots.txt 并非所有爬虫都遵守,一般只有大型搜索引擎爬虫会遵守
现有位置:robots.txt 文件应放在 网站 根目录下
例如:
常用爬虫工作流程:
抓取网页、存储数据、处理内容并提供检索/排名服务
搜索引擎排名:
1.PageRank值:根据网站的流量(点击/浏览/人气)统计,流量越高,网站的排名越高。
2.PPC:谁付出的多,排名就高。
万能爬虫的缺点:
1.只提供文本相关内容(HTML、Word、PDF)等,不提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)
2. 提供相同的结果,不为不同背景的人提供不同的搜索结果
3.无法提供人工语义检索
通用搜索引擎的局限性
1.一般搜索引擎返回的网页有90%是无用的。
2.中文搜索引擎自然语言检索理解困难
3.信息的数量和覆盖范围都有限制。
4.搜索引擎以关键词搜索为主,一般的搜索引擎对图片、数据库、音视频多媒体内容无能为力。
5.搜索引擎的社区化和个性化不好。大多数搜索引擎没有考虑到人们的地区、性别和年龄的差异。
6.搜索引擎不擅长抓取动态网页
为了解决通用爬虫的缺点,出现了专注爬虫。
专注于爬虫
Spotlight on the crawler:爬虫程序员针对某个内容编写的爬虫。
面向主题的爬虫,面向需求的爬虫:对特定容量的信息进行爬取,并确保内容需求尽可能相关。
1.累积爬虫:从头到尾,不断的爬取,过程中会进行重复的操作。
2.增量爬虫:下载的网页是增量更新的,只爬取新生成或改变的网络爬虫
3.深网爬虫:无法通过静态链接获取的网页,隐藏在搜索表单后面,只有用户提交一些关键词才能获取
0.1数据爬取的基本流程
指定要抓取的url
根据 requests 模块发起请求并得到响应
获取响应对象中的数据
数据分析
用于持久存储
在持久存储之前需要进行指定的数据解析。因为大多数情况下的需求,我们会指定使用焦点爬虫,也就是爬取页面指定部分的数据值,而不是整个页面的数据。
1.正则表达式
特点:为我们提供了获取数据的捷径。这种正则表达式虽然更容易适应未来的变化,但存在难写、难构造、可读性差、代码繁多等问题。但是,使用正则表达式来实现目标信息的准确采集
同时,网页经常发生变化,导致网页的布局发生了一些细微的变化。这时候之前写的正则表达式不能满足要求,需要重写,也不容易调试。当要匹配的内容很多时,使用正则表达式提取目标信息会导致程序运行速度变慢,消耗更多内存。
2.BS4 (美汤)
特点:BeautifulSoup虽然比正则表达式理解起来更复杂,但更容易构造和理解。
BeautifulSoup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块可以通过 pip install beautifulsoup4 安装。
第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,BeautifulSoup 需要确定实际格式。除了添加 <html> 和 <body> 标记以使其成为完整的 HTML 文档外,BeautifulSoup 还能正确解析缺少的引号和关闭标记。通常使用 find() 和 find_all() 方法来定位我们需要的元素。
3.Xpath
特征:
Lxml:Lxml模块是C语言编写的,解析速度比BeautifulSoup快,安装过程也比较复杂,
XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
使用 lxml 模块(如 BeautifulSoup)的第一步是将可能无效的 HTML 解析为统一格式。尽管 Lxml 正确解析了属性周围缺少的引号并关闭标签,但该模块不会添加额外的 <html> 和 <body> 标签。
在线复制Xpath表达式可以很方便的复制Xpath表达式(即在浏览器的开发者工具上找到定位标签并右键复制生成的xpath表达式)。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
4.CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 结合了 CSS 选择器的语法和它自己易于使用的 API。在网络爬虫的开发过程中,对于熟悉 CSS 选择器语法的人来说,使用 CSS 选择器是一种非常方便的方法。 查看全部
抓取网页新闻(Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结)
Python网络爬虫四大选择器总结(正则表达式、BS4、Xpath、CSS)
0.前言
相关实战文章:正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东的产品信息。
网络爬虫:模拟客户端批量发送网络请求,批量接收请求对应的数据,并按照一定的规则自动抓取互联网信息,执行数据采集,并持久化存储的程序。其他用途:百度搜索、12306抢票、各种抢购、投票、刷票、短信轰炸、网络攻击、Web漏洞扫描等都是爬虫技术。
爬行动物的目的
1.财经财经新闻/数据,制定投资策略,进行量化交易
2.各类旅游资讯优化旅游策略
3.电商商品信息比价系统
4.游戏游戏论坛调整游戏运营
5.银行个人交易信息信用体系/贷款评级
6.职位信息职位信息
7.舆论 各大论坛社会群体感知、舆论导向
只要是客户端(浏览器)能做到的,原则上爬虫都能做到。这意味着只要人类可以访问的网页和他们可以看到的数据,爬虫肯定可以爬取铜等资源。
抓取用户看不到的数据被称为黑客攻击,这是非法的。
爬虫的作用:可以爬取数据进行数据分析,大的可以定制一个搜索引擎。更好的搜索引擎优化。
通用爬虫:搜索引擎的爬虫系统,搜索引擎和网络服务提供商提供的爬虫。目的是尽可能的;将互联网上的所有网页下载下来,放到本地服务器上形成备份,对这些网页进行相关处理(提取关键词、去除广告),最后提供用户检索接口。
过程:
首先选择一些网址,将这些网址放入待抓取的队列中。
从队列中取出URL,然后解析DNS得到主机IP,然后保存该IP对应的HTML页面下载HTML页面,保存到搜索引擎的本地服务器,然后将抓取到的url放入爬取的队列。
分析这些网页的内容,找出网页中其他的URL链接,继续第二步,直到爬取结束。
搜索引擎如何获取新的 网站 URL:
a) 主动向搜索引擎提交 网站
B) 在其他 网站 中设置外联
C) 搜索引擎会配合DNS服务商快速收录new网站
DNS 是一种将域名解析为 IP 地址的技术。
万能爬虫不代表什么都能爬,他也得遵守规则:
Robots Protocol:该协议将规定通用爬虫爬取网页的权限(告诉搜索引擎哪些可以爬,哪些不能爬)
Robots.txt 并非所有爬虫都遵守,一般只有大型搜索引擎爬虫会遵守
现有位置:robots.txt 文件应放在 网站 根目录下
例如:
常用爬虫工作流程:
抓取网页、存储数据、处理内容并提供检索/排名服务
搜索引擎排名:
1.PageRank值:根据网站的流量(点击/浏览/人气)统计,流量越高,网站的排名越高。
2.PPC:谁付出的多,排名就高。
万能爬虫的缺点:
1.只提供文本相关内容(HTML、Word、PDF)等,不提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)
2. 提供相同的结果,不为不同背景的人提供不同的搜索结果
3.无法提供人工语义检索
通用搜索引擎的局限性
1.一般搜索引擎返回的网页有90%是无用的。
2.中文搜索引擎自然语言检索理解困难
3.信息的数量和覆盖范围都有限制。
4.搜索引擎以关键词搜索为主,一般的搜索引擎对图片、数据库、音视频多媒体内容无能为力。
5.搜索引擎的社区化和个性化不好。大多数搜索引擎没有考虑到人们的地区、性别和年龄的差异。
6.搜索引擎不擅长抓取动态网页
为了解决通用爬虫的缺点,出现了专注爬虫。
专注于爬虫
Spotlight on the crawler:爬虫程序员针对某个内容编写的爬虫。
面向主题的爬虫,面向需求的爬虫:对特定容量的信息进行爬取,并确保内容需求尽可能相关。
1.累积爬虫:从头到尾,不断的爬取,过程中会进行重复的操作。
2.增量爬虫:下载的网页是增量更新的,只爬取新生成或改变的网络爬虫
3.深网爬虫:无法通过静态链接获取的网页,隐藏在搜索表单后面,只有用户提交一些关键词才能获取
0.1数据爬取的基本流程
指定要抓取的url
根据 requests 模块发起请求并得到响应
获取响应对象中的数据
数据分析
用于持久存储
在持久存储之前需要进行指定的数据解析。因为大多数情况下的需求,我们会指定使用焦点爬虫,也就是爬取页面指定部分的数据值,而不是整个页面的数据。
1.正则表达式
特点:为我们提供了获取数据的捷径。这种正则表达式虽然更容易适应未来的变化,但存在难写、难构造、可读性差、代码繁多等问题。但是,使用正则表达式来实现目标信息的准确采集
同时,网页经常发生变化,导致网页的布局发生了一些细微的变化。这时候之前写的正则表达式不能满足要求,需要重写,也不容易调试。当要匹配的内容很多时,使用正则表达式提取目标信息会导致程序运行速度变慢,消耗更多内存。
2.BS4 (美汤)
特点:BeautifulSoup虽然比正则表达式理解起来更复杂,但更容易构造和理解。
BeautifulSoup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块可以通过 pip install beautifulsoup4 安装。
第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,BeautifulSoup 需要确定实际格式。除了添加 <html> 和 <body> 标记以使其成为完整的 HTML 文档外,BeautifulSoup 还能正确解析缺少的引号和关闭标记。通常使用 find() 和 find_all() 方法来定位我们需要的元素。
3.Xpath
特征:
Lxml:Lxml模块是C语言编写的,解析速度比BeautifulSoup快,安装过程也比较复杂,
XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
使用 lxml 模块(如 BeautifulSoup)的第一步是将可能无效的 HTML 解析为统一格式。尽管 Lxml 正确解析了属性周围缺少的引号并关闭标签,但该模块不会添加额外的 <html> 和 <body> 标签。
在线复制Xpath表达式可以很方便的复制Xpath表达式(即在浏览器的开发者工具上找到定位标签并右键复制生成的xpath表达式)。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
4.CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 结合了 CSS 选择器的语法和它自己易于使用的 API。在网络爬虫的开发过程中,对于熟悉 CSS 选择器语法的人来说,使用 CSS 选择器是一种非常方便的方法。
抓取网页新闻(一助盘点常见的网站优化大忌操作的几种操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-03 05:14
网站优化的目的是为了改善患者体验,并符合搜索引擎的算法规则,让搜索引擎蜘蛛爬得更快更多,从而获得免费的自然流量。在进行网站优化的时候,一些不专业的SEO或者新手可能会弄巧成拙,被搜索引擎惩罚,对网站优化造成严重影响,甚至放弃之前的所有努力。为此,易住技术人员盘点了常见的网站优化禁忌操作。
一、人工网站过度优化,导致网站大量关键词堆叠
一些网站优化器,为了增加网站的相关性,故意增加关键词的密度,在标题、描述、关键词和正文中加入重复或极端重复网页的文字类似关键词,并做锚文本或纯文本链接到这个,甚至通过锚文本关键词链接到首页,目的显然是为了提高首页的排名关键词 中的页面。即使通过代码隐藏关键词,百度蜘蛛其实也能被识别出来,这种低端的SEO黑帽做法受到了搜索引擎的惩罚。
二、为了所谓的优化思路,经常更改网页的标题和描述
一些网站优化器为了促进网页的相关性和创意展示,一次次修改网页的标题和描述,这会导致搜索引擎蜘蛛无法识别网页的主要内容页面中的搜索引擎算法。并且排序,无法解析并记录到搜索引擎的总链接库中,会阻碍访问者的浏览。这种做法会轻而易举失去收录,最坏情况下会失去关键词的排名和降级。为此,在网站建立的时候,就应该规划好网页的标题和描述。即使以后改了,也建议确认一次。.
三、为网站快速搭建大量外链是不可取的,急功近利是不行的
外链是促进搜索引擎蜘蛛识别和爬取的重要途径,也是提升网站相关排名和流量的重要依据,但快速为网站构建大量外链会被搜索引擎视为作弊,受到处罚。一些SEO优化器可以单批发送链接到网站来引导外链,甚至一些外链资源被大量删除,只留下快照和死链接。友情链接是反向链接,甚至购买一些权重较高的链接来传递网站的权重。部分链接与行业无关,不定期增加链接。这种情况将被视为搜索引擎。作弊,网站减少收录
四、一遍遍修改网站或更换服务器以优化影响
一些SEO优化者最近对网站进行了多次布局更改,或者进行了服务器迁移,这将大大降低搜索引擎对网站的评分。对于频繁修改的网站,搜索引擎会将其视为新站点。如果301链接跳转到旧站点没有做好,网站可能会丢失很多收录,失去它的权限。排行。特别是服务器的多次迁移,会导致搜索引擎蜘蛛将新IP链接视为重复,而不是收录,而原来的已经是收录死链接的链接会被删除,导致网站@ >索引量大幅下降,影响网站收录和排名。
五、通过恶意品牌词索引和网站关键词流量提高权重
我们经常看到一些网络广告公司声称拥有最新的技术来优化网站,让网站 快速排名。这种做法其实是黑帽SEO的一种手段,利用程序或脚本通过切换IP来恶意刷品牌词索引和网页中的网站关键词流量,而网站在一个短期优化可能看起来不错,但很可能会受到搜索引擎的严厉惩罚,并在不久的将来产生持久的影响。
六、复制别人的网站快速优化,大量复制别人的文章
有的站长迫不及待想把网站做好,迅速拿到网站关键词的排名,于是选择了一个布局不错的网站去模仿,页面层次和源代码标签都是一样的,然后快速大量复制别人的网站的文章,匆忙发布。这种情况可能很快收录很大一部分网页在不久的将来甚至还有排名,但很快收录减少或变得困难收录,排名消失,之前的所有努力都付诸东流. 查看全部
抓取网页新闻(一助盘点常见的网站优化大忌操作的几种操作)
网站优化的目的是为了改善患者体验,并符合搜索引擎的算法规则,让搜索引擎蜘蛛爬得更快更多,从而获得免费的自然流量。在进行网站优化的时候,一些不专业的SEO或者新手可能会弄巧成拙,被搜索引擎惩罚,对网站优化造成严重影响,甚至放弃之前的所有努力。为此,易住技术人员盘点了常见的网站优化禁忌操作。

一、人工网站过度优化,导致网站大量关键词堆叠
一些网站优化器,为了增加网站的相关性,故意增加关键词的密度,在标题、描述、关键词和正文中加入重复或极端重复网页的文字类似关键词,并做锚文本或纯文本链接到这个,甚至通过锚文本关键词链接到首页,目的显然是为了提高首页的排名关键词 中的页面。即使通过代码隐藏关键词,百度蜘蛛其实也能被识别出来,这种低端的SEO黑帽做法受到了搜索引擎的惩罚。
二、为了所谓的优化思路,经常更改网页的标题和描述
一些网站优化器为了促进网页的相关性和创意展示,一次次修改网页的标题和描述,这会导致搜索引擎蜘蛛无法识别网页的主要内容页面中的搜索引擎算法。并且排序,无法解析并记录到搜索引擎的总链接库中,会阻碍访问者的浏览。这种做法会轻而易举失去收录,最坏情况下会失去关键词的排名和降级。为此,在网站建立的时候,就应该规划好网页的标题和描述。即使以后改了,也建议确认一次。.
三、为网站快速搭建大量外链是不可取的,急功近利是不行的
外链是促进搜索引擎蜘蛛识别和爬取的重要途径,也是提升网站相关排名和流量的重要依据,但快速为网站构建大量外链会被搜索引擎视为作弊,受到处罚。一些SEO优化器可以单批发送链接到网站来引导外链,甚至一些外链资源被大量删除,只留下快照和死链接。友情链接是反向链接,甚至购买一些权重较高的链接来传递网站的权重。部分链接与行业无关,不定期增加链接。这种情况将被视为搜索引擎。作弊,网站减少收录
四、一遍遍修改网站或更换服务器以优化影响
一些SEO优化者最近对网站进行了多次布局更改,或者进行了服务器迁移,这将大大降低搜索引擎对网站的评分。对于频繁修改的网站,搜索引擎会将其视为新站点。如果301链接跳转到旧站点没有做好,网站可能会丢失很多收录,失去它的权限。排行。特别是服务器的多次迁移,会导致搜索引擎蜘蛛将新IP链接视为重复,而不是收录,而原来的已经是收录死链接的链接会被删除,导致网站@ >索引量大幅下降,影响网站收录和排名。
五、通过恶意品牌词索引和网站关键词流量提高权重
我们经常看到一些网络广告公司声称拥有最新的技术来优化网站,让网站 快速排名。这种做法其实是黑帽SEO的一种手段,利用程序或脚本通过切换IP来恶意刷品牌词索引和网页中的网站关键词流量,而网站在一个短期优化可能看起来不错,但很可能会受到搜索引擎的严厉惩罚,并在不久的将来产生持久的影响。
六、复制别人的网站快速优化,大量复制别人的文章
有的站长迫不及待想把网站做好,迅速拿到网站关键词的排名,于是选择了一个布局不错的网站去模仿,页面层次和源代码标签都是一样的,然后快速大量复制别人的网站的文章,匆忙发布。这种情况可能很快收录很大一部分网页在不久的将来甚至还有排名,但很快收录减少或变得困难收录,排名消失,之前的所有努力都付诸东流.
抓取网页新闻(百度(Baidu)爬虫-Google:抓取网页的质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-02 18:16
可以在主机的IIS日志中查看。1.谷歌爬虫名称1)Googlebot百度蜘蛛日志分析:从谷歌网站索引和新闻索引爬取页面2)Googlebot-Mobile爬取谷歌移动索引页面3)@ > Googlebot-Image:为 Google 的图像索引抓取页面4) Mediapartners-Google:抓取页面以确定 AdSense 内容。只有在您的 网站 上显示 AdSense 广告时,Google 才会使用此机器人来抓取您的 网站。5) Adsbot-Google:抓取网络以衡量 AdWords 目标网页的质量。仅当您使用 Google AdWords 为您的 网站 做广告时,Google 才会使用此机器人。2.百度爬虫名称:Baiduspider3.雅虎爬虫名称:Yahoo Slurp4.游道蜘蛛名称:YodaoBot5.
蜘蛛IP地址为61.135.168.142。其中,200表示搜索引擎蜘蛛爬取成功后返回200,属于正常;请求已完成。201 确定;紧跟在 POST 命令之后。202 确定;接受处理,但处理尚未完成。203 确定;部分信息 - 返回的信息只是部分信息。204 确定;无响应 - 已收到请求,但没有要发回的信息。3xx 重定向 301 已移动 - 请求的数据具有新位置,并且更改是永久性的。302 Found - 请求的数据暂时具有不同的 URI。303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。304 Not Modified - 文档未按预期修改。305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。306 Not Used - 不再使用;保留此代码以备将来使用。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。
410 请求的网页不存在(永久);415 Unsupported media type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。5xx 错误 500 服务器内部错误 - 由于意外情况,服务器无法完成请求。501 Not Executed - 服务器不支持请求的工具。502 Bad Gateway - 服务器收到来自上游服务器的无效响应。503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。
大神帮我看看百度蜘蛛有没有来我的网站
在服务器后台查看网站访问日志的百度蜘蛛日志分析,如下:
GET /index.asp - 9999 - 180.76.15.145 Mozilla/5.0+(兼容;+Baiduspider/2.0;+ +/search/spider.html) 200 0 64 百度蜘蛛日志分析。
你的网站百度蜘蛛日志分析,有一个专门的日志文件,里面记录了谁让你走了网站,百度蜘蛛爬到了你的网站,也会记录在文件里,所以你可以找到你找到的日志文件并检查一下,很简单。如果你的网站是微软IIS,那么默认的日志文件存放路径是:C:\WINDOWS\system32\LogFiles
百度蜘蛛访问日志以HEAD开头,是什么意思?
一般情况下HEAD会在服务端生成和GET一样的处理(除非代码中处理了HEAD情况)百度蜘蛛日志分析,但是head信息不带body返回给客户端。
通过这个 HEAD 请求,百度蜘蛛可以快速判断网页的情况。通过header信息等),百度可以了解这个网页的大致状态,比如是否存在、是否重定向、是否可用等;通过Content-Length、Last-Modified中的任意一项和之前的访问记录进行比较,百度可以进一步判断这个网页是否需要更新。
说明百度重新检索网站成功了!不用担心这种情况! 查看全部
抓取网页新闻(百度(Baidu)爬虫-Google:抓取网页的质量)
可以在主机的IIS日志中查看。1.谷歌爬虫名称1)Googlebot百度蜘蛛日志分析:从谷歌网站索引和新闻索引爬取页面2)Googlebot-Mobile爬取谷歌移动索引页面3)@ > Googlebot-Image:为 Google 的图像索引抓取页面4) Mediapartners-Google:抓取页面以确定 AdSense 内容。只有在您的 网站 上显示 AdSense 广告时,Google 才会使用此机器人来抓取您的 网站。5) Adsbot-Google:抓取网络以衡量 AdWords 目标网页的质量。仅当您使用 Google AdWords 为您的 网站 做广告时,Google 才会使用此机器人。2.百度爬虫名称:Baiduspider3.雅虎爬虫名称:Yahoo Slurp4.游道蜘蛛名称:YodaoBot5.
蜘蛛IP地址为61.135.168.142。其中,200表示搜索引擎蜘蛛爬取成功后返回200,属于正常;请求已完成。201 确定;紧跟在 POST 命令之后。202 确定;接受处理,但处理尚未完成。203 确定;部分信息 - 返回的信息只是部分信息。204 确定;无响应 - 已收到请求,但没有要发回的信息。3xx 重定向 301 已移动 - 请求的数据具有新位置,并且更改是永久性的。302 Found - 请求的数据暂时具有不同的 URI。303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。304 Not Modified - 文档未按预期修改。305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。306 Not Used - 不再使用;保留此代码以备将来使用。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。
410 请求的网页不存在(永久);415 Unsupported media type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。5xx 错误 500 服务器内部错误 - 由于意外情况,服务器无法完成请求。501 Not Executed - 服务器不支持请求的工具。502 Bad Gateway - 服务器收到来自上游服务器的无效响应。503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。

大神帮我看看百度蜘蛛有没有来我的网站
在服务器后台查看网站访问日志的百度蜘蛛日志分析,如下:

GET /index.asp - 9999 - 180.76.15.145 Mozilla/5.0+(兼容;+Baiduspider/2.0;+ +/search/spider.html) 200 0 64 百度蜘蛛日志分析。
你的网站百度蜘蛛日志分析,有一个专门的日志文件,里面记录了谁让你走了网站,百度蜘蛛爬到了你的网站,也会记录在文件里,所以你可以找到你找到的日志文件并检查一下,很简单。如果你的网站是微软IIS,那么默认的日志文件存放路径是:C:\WINDOWS\system32\LogFiles
百度蜘蛛访问日志以HEAD开头,是什么意思?
一般情况下HEAD会在服务端生成和GET一样的处理(除非代码中处理了HEAD情况)百度蜘蛛日志分析,但是head信息不带body返回给客户端。
通过这个 HEAD 请求,百度蜘蛛可以快速判断网页的情况。通过header信息等),百度可以了解这个网页的大致状态,比如是否存在、是否重定向、是否可用等;通过Content-Length、Last-Modified中的任意一项和之前的访问记录进行比较,百度可以进一步判断这个网页是否需要更新。
说明百度重新检索网站成功了!不用担心这种情况!
抓取网页新闻(一个典型的新闻网页包括几个不同区域:如何写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-02 18:14
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,不外乎这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主体部分,在视觉上占据中间位置,是新闻内容的主要文字区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是结合老猿猴多年的实践经验和思维得出的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' 查看全部
抓取网页新闻(一个典型的新闻网页包括几个不同区域:如何写爬虫)
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。

所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:

新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,不外乎这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主体部分,在视觉上占据中间位置,是新闻内容的主要文字区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是结合老猿猴多年的实践经验和思维得出的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r'
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-01 08:14
)
做了一些扩展(也可以扩展,我们从首页获取tele中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(也可以扩展,我们从首页获取tele中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(有个好玩的分词神器,官网上有的比较少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-31 12:03
抓取网页新闻是找关键词,找对标题和正文的字体颜色和字体大小的变化,因为目前网页的字体一般要大于1.5磅的最少要选择gbk字体。或者大小加粗或者空格间隔来处理也可以,
字体加粗没太多选择需要选择大一点的字体也要和网页中的对应然后对应好就好了那么你这个问题就变成了,
css的话都可以试试
原来有人做过这个事情。
有个好玩的分词神器,官网上有。
现在看到的现成的比较少。原来谷歌大哥有分词服务。但是有些做本地化定制的也没法满足要求,不过可以考虑使用云服务上这样的解决方案。
:抓取网页数据,然后制作成易懂的解决方案。:比如有用python爬取新闻联播:有用python抓取网上视频,
1、用python抓取网上视频
2、新闻是分页式的,
3、有用python抓取网上视频。
4、然后用于电力电商。他们可能也用python做爬虫,欢迎参考他们。
最好的办法是利用人的智慧去创造。比如做爬虫,
多站评论,买群发器,
你可以这样试试首先从网站找数据找到数据后用json的格式保存到数据库(比如mysql,但是你要把需要加粗的title字段的数据存入数据库,你可以百度下mysql读写入dll的文章),目前python可以直接读postman上的抓取数据,需要读库,python里有内置模块,里面有django的admin,操作非常方便,可以很快在数据库里post出数据,也可以直接写数据库,或者抓数据的时候做对象化(理论上可以做任何东西,唯一不好的是一定会嵌入iframe),不知道大家还有什么更高效的解决方案。(一看就是网络打传的)。 查看全部
抓取网页新闻(有个好玩的分词神器,官网上有的比较少)
抓取网页新闻是找关键词,找对标题和正文的字体颜色和字体大小的变化,因为目前网页的字体一般要大于1.5磅的最少要选择gbk字体。或者大小加粗或者空格间隔来处理也可以,
字体加粗没太多选择需要选择大一点的字体也要和网页中的对应然后对应好就好了那么你这个问题就变成了,
css的话都可以试试
原来有人做过这个事情。
有个好玩的分词神器,官网上有。
现在看到的现成的比较少。原来谷歌大哥有分词服务。但是有些做本地化定制的也没法满足要求,不过可以考虑使用云服务上这样的解决方案。
:抓取网页数据,然后制作成易懂的解决方案。:比如有用python爬取新闻联播:有用python抓取网上视频,
1、用python抓取网上视频
2、新闻是分页式的,
3、有用python抓取网上视频。
4、然后用于电力电商。他们可能也用python做爬虫,欢迎参考他们。
最好的办法是利用人的智慧去创造。比如做爬虫,
多站评论,买群发器,
你可以这样试试首先从网站找数据找到数据后用json的格式保存到数据库(比如mysql,但是你要把需要加粗的title字段的数据存入数据库,你可以百度下mysql读写入dll的文章),目前python可以直接读postman上的抓取数据,需要读库,python里有内置模块,里面有django的admin,操作非常方便,可以很快在数据库里post出数据,也可以直接写数据库,或者抓数据的时候做对象化(理论上可以做任何东西,唯一不好的是一定会嵌入iframe),不知道大家还有什么更高效的解决方案。(一看就是网络打传的)。
抓取网页新闻(抓取网页新闻怎么获取网站的联系方式不就是xpath吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-31 11:04
抓取网页新闻是抓住网页所有联系方式,然后通过匹配模块得到网页结构,再用xpath提取内容,后期可以通过上传url获取本地代码来合并html。
xpath只是一种规则,而搜索引擎是一个巨大的网络入口,也就是说,它会寻找一切能够提取的方法,而不只是规则。它要做的是:发现隐藏的页面链接,确定其有用性,计算出其中的元素属性,比如域名、地理位置,通过内容分析提取其中的规则,再结合规则匹配页面,通过可能的浏览器兼容性,保存页面txt文件,最后获取访问链接。
其实很简单,怎么获取网站的联系方式,不就是xpath吗。php或python这样的脚本语言,或nodejs,或c++这样的静态语言,都有应用xpath的库。如果用php的话,你需要把它编译成网页,然后...。
<p>匹配页面中任意字符(包括空格和字符)即可,例如“+”表示匹配空格+$(中间空格不要忘了,但不要添加到" 查看全部
抓取网页新闻(抓取网页新闻怎么获取网站的联系方式不就是xpath吗)
抓取网页新闻是抓住网页所有联系方式,然后通过匹配模块得到网页结构,再用xpath提取内容,后期可以通过上传url获取本地代码来合并html。
xpath只是一种规则,而搜索引擎是一个巨大的网络入口,也就是说,它会寻找一切能够提取的方法,而不只是规则。它要做的是:发现隐藏的页面链接,确定其有用性,计算出其中的元素属性,比如域名、地理位置,通过内容分析提取其中的规则,再结合规则匹配页面,通过可能的浏览器兼容性,保存页面txt文件,最后获取访问链接。
其实很简单,怎么获取网站的联系方式,不就是xpath吗。php或python这样的脚本语言,或nodejs,或c++这样的静态语言,都有应用xpath的库。如果用php的话,你需要把它编译成网页,然后...。
<p>匹配页面中任意字符(包括空格和字符)即可,例如“+”表示匹配空格+$(中间空格不要忘了,但不要添加到"
抓取网页新闻(抓取网页新闻用得最多的就是ajax了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-03 21:06
抓取网页新闻用得最多的就是ajax了,而且我经常会用mdn。但一个基本的问题是,看了下面两段,你就会发现这两段里的代码都没有起到抓取的作用,甚至可以说看起来就很糟糕:代码来源不同会有什么影响?follow(name,url,body);https并没有对源文件有效的加密实现,只是使用了https通信的模式来保证源文件安全,从而保证抓取的安全性。
其实这个问题不是很大,因为发现加密出来的乱码并不太可能是对网页上内容的修改,很可能是你找的图片解析器并不完善。那么在解决了第一点的情况下,这第二点就无从谈起了。整个抓取的源文件是经过加密的,所以即使抓到最终返回的地址也不一定能很方便的再用javascript实现再下载到本地。其实即使这样,我们可以用svn或者git之类的版本控制来提高抓取的效率。参考资料链接。
我觉得不一定是javascript的问题。不如换个思路:你在把google或百度下载之前,先下载.svn之类的版本控制软件来传送文件,并且验证.svn有效,然后才开始下载。
题主自己在github找到了答案,github-google/music-stock:ifwedon'thavesome。svnplugins,thenchangethemode;it'snotfora。svnplugins,butitcan。==github-apuz0515/musescompiler:musescompiler:apluginforfollow-us/newframeworksgithub-jessicaldeh/musescompiler:therightwaytogetsearchresultsgithub-spiftfhourglad/musescompiler:amorethanjavascriptplugin。shownewreleases。 查看全部
抓取网页新闻(抓取网页新闻用得最多的就是ajax了?)
抓取网页新闻用得最多的就是ajax了,而且我经常会用mdn。但一个基本的问题是,看了下面两段,你就会发现这两段里的代码都没有起到抓取的作用,甚至可以说看起来就很糟糕:代码来源不同会有什么影响?follow(name,url,body);https并没有对源文件有效的加密实现,只是使用了https通信的模式来保证源文件安全,从而保证抓取的安全性。
其实这个问题不是很大,因为发现加密出来的乱码并不太可能是对网页上内容的修改,很可能是你找的图片解析器并不完善。那么在解决了第一点的情况下,这第二点就无从谈起了。整个抓取的源文件是经过加密的,所以即使抓到最终返回的地址也不一定能很方便的再用javascript实现再下载到本地。其实即使这样,我们可以用svn或者git之类的版本控制来提高抓取的效率。参考资料链接。
我觉得不一定是javascript的问题。不如换个思路:你在把google或百度下载之前,先下载.svn之类的版本控制软件来传送文件,并且验证.svn有效,然后才开始下载。
题主自己在github找到了答案,github-google/music-stock:ifwedon'thavesome。svnplugins,thenchangethemode;it'snotfora。svnplugins,butitcan。==github-apuz0515/musescompiler:musescompiler:apluginforfollow-us/newframeworksgithub-jessicaldeh/musescompiler:therightwaytogetsearchresultsgithub-spiftfhourglad/musescompiler:amorethanjavascriptplugin。shownewreleases。
抓取网页新闻(新浪搜索主页面中的输入关键词链接和计算相似度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-28 01:02
前段时间写了一个爬虫,在新浪搜索主页面实现了输入关键词,爬取了与关键词相关的新闻的标题、发布时间、url、关键词和内容. 并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕获
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是在没有界面的情况下使用程序来模拟浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)查找搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻有多少页。找出不同页面之间的url联系,生成翻页的url。
如上图所示,新闻界面出现“查找7651篇相关新闻文章”。使用正则匹配等方法,得到'7651',根据新浪新闻搜索页面的一页出现的新闻m个数,计算出相关新闻页数。: int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url,如上图所示,当新闻url出现时,同样的规则是“”,所以可以根据这个规则提取页面源码中的所有url .
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值为kT_W=0.8;只有标题收录输入词,相关词权重 kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码 查看全部
抓取网页新闻(新浪搜索主页面中的输入关键词链接和计算相似度)
前段时间写了一个爬虫,在新浪搜索主页面实现了输入关键词,爬取了与关键词相关的新闻的标题、发布时间、url、关键词和内容. 并根据内容提取摘要并计算相似度。下面解释一下我自己的想法并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取此页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关的新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词,获取新的url,发送新的url 请求,获取该网页的源代码。缺点:对于动态网页,这种方式获取的url,发送请求获取的网页源代码与在搜索界面手动输入关键词获取的页面源代码不一致。
2)动态捕获
模拟浏览器行为并爬取 关键词 新闻相关页面。方法有两种,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是在没有界面的情况下使用程序来模拟浏览器的行为。关键词页面的url和页面源代码。如图,进入搜索首页,输入关键词语言,会跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)查找搜索到的新闻文章数,根据一页的新闻数计算出与关键词次相关的新闻有多少页。找出不同页面之间的url联系,生成翻页的url。
如上图所示,新闻界面出现“查找7651篇相关新闻文章”。使用正则匹配等方法,得到'7651',根据新浪新闻搜索页面的一页出现的新闻m个数,计算出相关新闻页数。: int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url,如上图所示,当新闻url出现时,同样的规则是“”,所以可以根据这个规则提取页面源码中的所有url .
3、从新闻页面中提取信息
根据新闻的url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取出来。其中,需要注意解码问题。网页的源代码是用不同的编码格式编写的,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方式。根据新闻内容,计算内容中的词频,根据词频确定输出词为关键词;
2)新闻中的摘要生成采用抽取的方式,借鉴了Stonewood博客的代码(链接如下:)。
3)关键词与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键字和标题
关键字和标题都收录与输入词相关的词,权重值为kT_W=0.8;只有标题收录输入词,相关词权重 kT_W=0.7;只有key词收录与输入词相关的词,权重值kT_W=0.6;其他权重值kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频内容_P
c) 相似度的最终计算公式为:
4、代码(运行环境python)
代码链接:
已经自带了需要下载的文件和安装相关模块后代码中需要的文件。并给出了对应的python2和python3代码
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2022-02-18 08:07
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。
让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装了aiomysql,更方便的数据库mysql操作;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程 查看全部
抓取网页新闻(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。
让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装了aiomysql,更方便的数据库mysql操作;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程
抓取网页新闻(基于条件随机场(CR)的新闻网页主题内容自动抽取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-18 02:05
广西师范大学学报:自然科学版 Jo tura 2011 基于海南大学 CR 信息科学与技术学院,海南海口 57022 8) 针对目前新闻网页主题内容提取方法很少使用的问题针对网页块之间的相关性特征,本文提出了一种基于条件随机场(CR)的新闻网页主题内容自动提取方法。该方法首先将要提取的网页解析成DOM,经过过滤、剪枝和压缩处理,然后按照一定的启发式规则将DOM树切割成DOM树。块被转换成数据序列,然后定义CR特征函数提取每个网页块的状态特征和相邻块之间的类别转移特征,利用CR模型对数据序列进行标注,实现网页主题内容的提取。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且可以引入块间相关性特征来改进新闻网页主题内容的提取。关键词:eb信息提取;条件随机场;网页分类 图块分类代码:391 文档识别码:文章 代码:100126600 (2011) 0120138205 在网页设计过程中,人们通常以块来组织网页内容,如此多的Web信息提取方法采用基于块的策略自动提取新闻网页的主题内容:首先,利用标签的分布规律、层次关系、布局特征或视觉特征将网页分成若干块。网页,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。
现有新闻网页的结构越来越复杂,很多网站甚至在新闻网页主题内容的段落之间插入广告内容,以至于我们在切网页时往往只能选择较小的片段. 花费。虽然这样做可以更好地区分噪声内容和主题内容,但生成的网页块通常较小,有时仅依靠块本身的特征很难识别块的类型。以利用相关属性。鉴于此,本文在网页切分的基础上,提出了一种基于条件随机场(co random field)的新闻网页主题内容自动提取方法。在这个部分,我们首先采用DOM树来表示文档的层次组织结构,然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。
规则 如果一个节点的子树不收录标签节点<div>、<p>、<td le>,则删除该节点的所有子树,但保留该节点附加的原创文本内容。规则 如果一个节点是一个单分支节点,它的子节点替换它的位置,然后删除它。收稿日期:2010212229 基金项目:国家自然科学基金委(60863001) 通讯联系人:湖北武汉,讲师,海南大学,硕士。E 2mil:zh angcy@.cn 1994-2013中国学术期刊电子出版社. 版权所有. 上述规则一一处理后,原DOM中90%的节点被删除,决定网页布局的节点,如<div <table>,被保留。 DOM中的DOM树搜索块除了根节点< #do cum en,每个节点对应网页中的一个文本内容块。一个文本内容块是否需要进一步切分,其实就是判断DOM树中对应的节点是否需要进一步的深度搜索。我们将不需要进一步深入搜索的节点称为区块节点,具体判断规则如下: 规则 如果节点是叶子节点,则判断该节点为区块节点。
规则 如果节点为非叶子节点,则其子节点的标签属性不相同,或者其子节点的标签属性相同但子节点不是<table>、<div>或<tr>标签节点,该节点被判断为区块节点。使用上述规则可以更好的区分主题内容和噪声内容,但是块的数量很大。为了减少后续 CR 标注的工作量,我们适度合并分割的块。具体合并规则如下: Rule r > 相邻块节点互为兄弟,标签属性相同或其中一个节点为链接节点Point<a>,另一个节点为text node<# tex text块节点的内容被合并。规则如果相邻两个块节点的文本内容中锚文本的比例大于55%,则可以通过文本内容块转换树的深度优先搜索得到一个文本内容块序列。为了方便以后通过CR特征函数对网页块进行特征提取,我们需要对从section得到的每个文本内容块进行转换。设整个网页的所有文本内容块的非锚文本字符(英文单词,下同) tplen 文本内容块的非锚文本字符个数就是文本内容块的个数 转换规则为: rule lenm), 本块的非锚文本整个网页中非锚文本的比例 lenmƒtp len 和该块在网页中的位置比例 le> 标记的内容块,插入"
将条件随机场建模的新闻网页切成块序列后,将主题内容的提取转化为网页块的类别识别问题。在本文中,网页块的类别被视为 CR 的输出状态,以及 CR Ty 等人提出的对有序数据进行标记和分割的条件概率。该模型可以克服HM的独立性假设问题和最大熵马尔可夫模型的标注偏差问题。它是最简单和最常用的统计机器学习模型线性随机场,是目前处理序列数据分割和标记问题的最佳统计机器学习模型。一种形式,本文使用的一种形式,用于实现文本内容序列的标注。假设相应的状态序列,其中 Erkov 是独立的,通过无向边连接成一个线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。
在本文中,观察序列是网页分割转换后生成的数据序列;状态序列中的状态值代表网页块的类别,我们将网页块分为以le>标签标记的内容块)、标题块(文本的标题块)(文本内容块) ) 和噪声块,分别在标注时用状态值表示;本节将讨论特征函数的定义和模型参数的估计。一旦L建模工作完成,公式(2)就可以用来标注网页块序列了。特征函数定义 CR模型通过特征函数的定义来描述观测值与状态值和状态值的对应关系。提取块序列及其特征之间的转移关系。特征函数定义是否正确将直接影响CR特征函数提取块序列和类别序列之间的特征。21211 块属性状态特征函数网页块的锚文本比例、非锚文本在整个网页中的比例、在网页中的位置、块在网页中使用什么样的标签,以一定程度上反映了内容块属于什么类别,所以我们的块属性 status 的特征函数定义为:其中 id 是特征编号。下面以训练内容块“TA 0C 0S0”和测试内容块“A 9C 0S9”为例,说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。
21213 End-state feature function 网页块序列一般以噪声内容块结束。为此,我们定义了一个结束状态特征函数,将该特征表示为结束块状态特征,从而从网页块序列的最后一个块中提取特征。21214 一阶传递特征函数网页块序列具有一定的块间关联特性。另外,考虑到本文采用CR,我们定义一阶传递特征函数ransf ransf来表示该特征是传递特征。参数估计模型参数估计是通过学习标记的训练集来估计每个特征函数的权重。另一方面,它通过特征函数估计从训练集中提取的所有特征的权重。让标注好的训练集为对应的状态序列,一般通过人工标注完成;序列的总数。在此基础上,对数似然函数为:对于训练集,为了避免参数估计过拟合的问题,我们引入高斯先验迭代求解公式 GS 等方法,收敛速度比GS。1994-2013中国学术期刊电子出版社。版权所有。. 本文通过人工标记一定数量的网页块序列形成训练集,然后通过本节定义的特征函数从训练集中提取所有状态特征,然后使用L2B GS方法估计每个状态特征的权重。
实验与结果分析 首先,根据百度国内新闻提供的链接,网络机器人抓取了500个新闻页面作为实验网页集,然后使用实验结果:共切出11 302个页面块,每个页面平均被切割成2个2.我们的分块算法分割准确率高,只有26个分块将噪声分块切割成与标题分块或正文分块相同的分块,平均分块错误率为23%。手动修正错切网页后,将500个网页按照本节介绍的方法转化为500个数据序列,将100个序列手动标注为CR训练集,剩余400个未标注序列作为CR 数据序列。测试集。CR被测量,而具体计算公式为如lock sM anu lock sCR lock sCR lock sM anu lock sCR lock sM anu lock sM anu lock sCR CR le block、title block、text block、noise block和所有类型的web blocks。从测试结果看:CR对各类网页块都有较高的准确率;le块整体识别效果最好,噪声块次之,标题块最差;当训练集的大小达到80多个序列时,识别效果较好,相对稳定。500个新闻网页自动切分实验结果 Tab. Segmen ta ionre sults ewspage 标题块 文本块 噪声块 错误块总数 平均错误率 ƒ% 平均块数 498 522 706 57611 302 26 2322. 基于 CRF 选项卡。
本文选取的 500 个新闻页面来自 175 个国内新闻网站,其中作为 CR 训练集的网页来自 50 个网站,作为 CR 测试集的网页来自 157 个网站,只有32 个站点和训练集。源站点相同,表明我们的方法对不同网站的网页提取具有更好的适应性。1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版142题块,文本块识别率明显低于le块和噪声块,出现这种现象的主要原因是有的题块没有标注<h1>标签,有的文本块的字符数量很少,这使得它们与一些嘈杂的训练块非常相似。本文采用DOM树搜索对网页进行分割,并在此基础上提出了一种基于CR的新闻网页主题内容自动提取方法。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且引入块间相关特征可以提高新闻网页主题内容的提取。缺点是网页的标题块和文本块的检索率有待进一步提高。网页分块转换和基于CR标签树的网页区域划分与搜索方法[J Computer Journal, 2005, 32 Xu Hongbo. 基于块的网页信息解析器的研究与设计[J 计算机应用, 2005, 25 9742976.刘晨曦, 吴阳阳. 一种基于块分析的网页去噪方法[J 广西师范大学学报: 自然科学版, 2007, 25 计算机应用, 2007, 27 杨志浩. 基于网页框架和规则的网页噪声去除方法[J Computer Engineering, 2007, 33 (19) 2762278.ZH EN i2hua, i2rong.late2indep enden based roceed ing iona Conference icia Telligence. enlo新闻,2007:15072151< 查看全部
抓取网页新闻(基于条件随机场(CR)的新闻网页主题内容自动抽取方法)
广西师范大学学报:自然科学版 Jo tura 2011 基于海南大学 CR 信息科学与技术学院,海南海口 57022 8) 针对目前新闻网页主题内容提取方法很少使用的问题针对网页块之间的相关性特征,本文提出了一种基于条件随机场(CR)的新闻网页主题内容自动提取方法。该方法首先将要提取的网页解析成DOM,经过过滤、剪枝和压缩处理,然后按照一定的启发式规则将DOM树切割成DOM树。块被转换成数据序列,然后定义CR特征函数提取每个网页块的状态特征和相邻块之间的类别转移特征,利用CR模型对数据序列进行标注,实现网页主题内容的提取。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且可以引入块间相关性特征来改进新闻网页主题内容的提取。关键词:eb信息提取;条件随机场;网页分类 图块分类代码:391 文档识别码:文章 代码:100126600 (2011) 0120138205 在网页设计过程中,人们通常以块来组织网页内容,如此多的Web信息提取方法采用基于块的策略自动提取新闻网页的主题内容:首先,利用标签的分布规律、层次关系、布局特征或视觉特征将网页分成若干块。网页,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。网页中标签的布局特征或视觉特征,然后使用启发式规则分析主题内容。然而,这些方法大多在识别网页块所属的类别时只分析网页块本身的特征,很少利用网页块之间的关联特征。
现有新闻网页的结构越来越复杂,很多网站甚至在新闻网页主题内容的段落之间插入广告内容,以至于我们在切网页时往往只能选择较小的片段. 花费。虽然这样做可以更好地区分噪声内容和主题内容,但生成的网页块通常较小,有时仅依靠块本身的特征很难识别块的类型。以利用相关属性。鉴于此,本文在网页切分的基础上,提出了一种基于条件随机场(co random field)的新闻网页主题内容自动提取方法。在这个部分,我们首先采用DOM树来表示文档的层次组织结构,然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后通过DOM树的深度优先搜索实现网页文本内容的自动切分,然后将得到的切分转换为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。然后将得到的分割转化为数据序列。构建DOM 我们使用开源工具NekoH TM 标记及其嵌入标记所标记的文本内容附加到相应的标记节点。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。ekoHTM 构建的原创 DOM 树收录大量与网页结构和布局以及要提取的内容无关的节点。,为了后续处理的方便,需要对这些节点进行过滤、剪枝和压缩。其标注内容;此外,标记内容为空的标签节点也被删除。
规则 如果一个节点的子树不收录标签节点<div>、<p>、<td le>,则删除该节点的所有子树,但保留该节点附加的原创文本内容。规则 如果一个节点是一个单分支节点,它的子节点替换它的位置,然后删除它。收稿日期:2010212229 基金项目:国家自然科学基金委(60863001) 通讯联系人:湖北武汉,讲师,海南大学,硕士。E 2mil:zh angcy@.cn 1994-2013中国学术期刊电子出版社. 版权所有. 上述规则一一处理后,原DOM中90%的节点被删除,决定网页布局的节点,如<div <table>,被保留。 DOM中的DOM树搜索块除了根节点< #do cum en,每个节点对应网页中的一个文本内容块。一个文本内容块是否需要进一步切分,其实就是判断DOM树中对应的节点是否需要进一步的深度搜索。我们将不需要进一步深入搜索的节点称为区块节点,具体判断规则如下: 规则 如果节点是叶子节点,则判断该节点为区块节点。
规则 如果节点为非叶子节点,则其子节点的标签属性不相同,或者其子节点的标签属性相同但子节点不是<table>、<div>或<tr>标签节点,该节点被判断为区块节点。使用上述规则可以更好的区分主题内容和噪声内容,但是块的数量很大。为了减少后续 CR 标注的工作量,我们适度合并分割的块。具体合并规则如下: Rule r > 相邻块节点互为兄弟,标签属性相同或其中一个节点为链接节点Point<a>,另一个节点为text node<# tex text块节点的内容被合并。规则如果相邻两个块节点的文本内容中锚文本的比例大于55%,则可以通过文本内容块转换树的深度优先搜索得到一个文本内容块序列。为了方便以后通过CR特征函数对网页块进行特征提取,我们需要对从section得到的每个文本内容块进行转换。设整个网页的所有文本内容块的非锚文本字符(英文单词,下同) tplen 文本内容块的非锚文本字符个数就是文本内容块的个数 转换规则为: rule lenm), 本块的非锚文本整个网页中非锚文本的比例 lenmƒtp len 和该块在网页中的位置比例 le> 标记的内容块,插入"
将条件随机场建模的新闻网页切成块序列后,将主题内容的提取转化为网页块的类别识别问题。在本文中,网页块的类别被视为 CR 的输出状态,以及 CR Ty 等人提出的对有序数据进行标记和分割的条件概率。该模型可以克服HM的独立性假设问题和最大熵马尔可夫模型的标注偏差问题。它是最简单和最常用的统计机器学习模型线性随机场,是目前处理序列数据分割和标记问题的最佳统计机器学习模型。一种形式,本文使用的一种形式,用于实现文本内容序列的标注。假设相应的状态序列,其中 Erkov 是独立的,通过无向边连接成一个线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。由无向边连接成线性链。在给定观测序列的条件下,参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。参数为特征函数,由用户根据具体任务定义;1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版 参数,一般通过培训学习来估算;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。自然科学版参数,一般通过训练学习来估计;一般来说,可以通过动态规划算法Vite rb来选择最高的条件概率来计算。建立问题的L个方面:观察序列的表示;状态序列的表示;特征函数的定义;模型参数的估计。
在本文中,观察序列是网页分割转换后生成的数据序列;状态序列中的状态值代表网页块的类别,我们将网页块分为以le>标签标记的内容块)、标题块(文本的标题块)(文本内容块) ) 和噪声块,分别在标注时用状态值表示;本节将讨论特征函数的定义和模型参数的估计。一旦L建模工作完成,公式(2)就可以用来标注网页块序列了。特征函数定义 CR模型通过特征函数的定义来描述观测值与状态值和状态值的对应关系。提取块序列及其特征之间的转移关系。特征函数定义是否正确将直接影响CR特征函数提取块序列和类别序列之间的特征。21211 块属性状态特征函数网页块的锚文本比例、非锚文本在整个网页中的比例、在网页中的位置、块在网页中使用什么样的标签,以一定程度上反映了内容块属于什么类别,所以我们的块属性 status 的特征函数定义为:其中 id 是特征编号。下面以训练内容块“TA 0C 0S0”和测试内容块“A 9C 0S9”为例,说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。作为例子来说明块属性状态特征函数的用法。后者通过函数提取的特征是:在训练得到的特征库中不存在,所以取值为21212。初始状态特征函数网页块序列一般以标题块开头。为此,我们定义了初始状态特征函数来表示该特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。我们定义了初始状态特征函数来表示这个特征是初始块状态特征。这样,对网页块序列的第一个块进行特征提取。
21213 End-state feature function 网页块序列一般以噪声内容块结束。为此,我们定义了一个结束状态特征函数,将该特征表示为结束块状态特征,从而从网页块序列的最后一个块中提取特征。21214 一阶传递特征函数网页块序列具有一定的块间关联特性。另外,考虑到本文采用CR,我们定义一阶传递特征函数ransf ransf来表示该特征是传递特征。参数估计模型参数估计是通过学习标记的训练集来估计每个特征函数的权重。另一方面,它通过特征函数估计从训练集中提取的所有特征的权重。让标注好的训练集为对应的状态序列,一般通过人工标注完成;序列的总数。在此基础上,对数似然函数为:对于训练集,为了避免参数估计过拟合的问题,我们引入高斯先验迭代求解公式 GS 等方法,收敛速度比GS。1994-2013中国学术期刊电子出版社。版权所有。. 本文通过人工标记一定数量的网页块序列形成训练集,然后通过本节定义的特征函数从训练集中提取所有状态特征,然后使用L2B GS方法估计每个状态特征的权重。
实验与结果分析 首先,根据百度国内新闻提供的链接,网络机器人抓取了500个新闻页面作为实验网页集,然后使用实验结果:共切出11 302个页面块,每个页面平均被切割成2个2.我们的分块算法分割准确率高,只有26个分块将噪声分块切割成与标题分块或正文分块相同的分块,平均分块错误率为23%。手动修正错切网页后,将500个网页按照本节介绍的方法转化为500个数据序列,将100个序列手动标注为CR训练集,剩余400个未标注序列作为CR 数据序列。测试集。CR被测量,而具体计算公式为如lock sM anu lock sCR lock sCR lock sM anu lock sCR lock sM anu lock sM anu lock sCR CR le block、title block、text block、noise block和所有类型的web blocks。从测试结果看:CR对各类网页块都有较高的准确率;le块整体识别效果最好,噪声块次之,标题块最差;当训练集的大小达到80多个序列时,识别效果较好,相对稳定。500个新闻网页自动切分实验结果 Tab. Segmen ta ionre sults ewspage 标题块 文本块 噪声块 错误块总数 平均错误率 ƒ% 平均块数 498 522 706 57611 302 26 2322. 基于 CRF 选项卡。
本文选取的 500 个新闻页面来自 175 个国内新闻网站,其中作为 CR 训练集的网页来自 50 个网站,作为 CR 测试集的网页来自 157 个网站,只有32 个站点和训练集。源站点相同,表明我们的方法对不同网站的网页提取具有更好的适应性。1994-2013 中国学术期刊电子出版社。版权所有。广西师范大学学报:自然科学版142题块,文本块识别率明显低于le块和噪声块,出现这种现象的主要原因是有的题块没有标注<h1>标签,有的文本块的字符数量很少,这使得它们与一些嘈杂的训练块非常相似。本文采用DOM树搜索对网页进行分割,并在此基础上提出了一种基于CR的新闻网页主题内容自动提取方法。实验表明,该方法对新闻网页主题内容的提取具有较高的准确性和较强的适应性,并且引入块间相关特征可以提高新闻网页主题内容的提取。缺点是网页的标题块和文本块的检索率有待进一步提高。网页分块转换和基于CR标签树的网页区域划分与搜索方法[J Computer Journal, 2005, 32 Xu Hongbo. 基于块的网页信息解析器的研究与设计[J 计算机应用, 2005, 25 9742976.刘晨曦, 吴阳阳. 一种基于块分析的网页去噪方法[J 广西师范大学学报: 自然科学版, 2007, 25 计算机应用, 2007, 27 杨志浩. 基于网页框架和规则的网页噪声去除方法[J Computer Engineering, 2007, 33 (19) 2762278.ZH EN i2hua, i2rong.late2indep enden based roceed ing iona Conference icia Telligence. enlo新闻,2007:15072151<
抓取网页新闻(网站关键字优化,这样可以让搜索引擎更为方便的抓取网站内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-16 18:26
网站关键词优化,可以让搜索引擎更容易抓取网站的内容,通辽seo网站关键词优化也可以让搜索引擎更轻松网站网站继续收录,在这种情况下,网站被认为是成功的。通辽seo网站关键词优化2、网站结构优化。 网站结构包括title、description、keywords、description等。网站结构的好坏直接关系到网站的用户体验,这个我们可以多关注在优化网站的用户体验的时候,很多时候我们会发现很多网站都是因为对用户体验的无用考虑造成的,其实这种情况很常见。 网站结构是我们在优化时可以考虑的问题。我的网站结构可以分为三种,一种是树形结构,
一个是网络结构,如何推广临沂seo网站我们在做seo的时候可以根据情况来分配网络结构,比如首页网站-网站目录- 网站首页-新闻栏目频道-网站导航等,让用户更好的直接了解网站的结构,同时用户搜索< @网站@关键词时出现的自然排名也很高,这也是网站首页的权重很高的原因。 3、网站外链优化。在优化网站的时候,一定要分析网站的外链,比如可以分析网站在友链交换平台、论坛、博客、友链交换的外链情况平台等,这些平台的权重可以说是非常高的,但是我们在优化的时候要做的就是注意关键词的优化。不要太在意外部链接的质量和数量。这样的外部链接只有这样,才能让我们的seo之路走得更顺畅。通辽seo网站关键词优化4、 查看全部
抓取网页新闻(网站关键字优化,这样可以让搜索引擎更为方便的抓取网站内容)
网站关键词优化,可以让搜索引擎更容易抓取网站的内容,通辽seo网站关键词优化也可以让搜索引擎更轻松网站网站继续收录,在这种情况下,网站被认为是成功的。通辽seo网站关键词优化2、网站结构优化。 网站结构包括title、description、keywords、description等。网站结构的好坏直接关系到网站的用户体验,这个我们可以多关注在优化网站的用户体验的时候,很多时候我们会发现很多网站都是因为对用户体验的无用考虑造成的,其实这种情况很常见。 网站结构是我们在优化时可以考虑的问题。我的网站结构可以分为三种,一种是树形结构,
一个是网络结构,如何推广临沂seo网站我们在做seo的时候可以根据情况来分配网络结构,比如首页网站-网站目录- 网站首页-新闻栏目频道-网站导航等,让用户更好的直接了解网站的结构,同时用户搜索< @网站@关键词时出现的自然排名也很高,这也是网站首页的权重很高的原因。 3、网站外链优化。在优化网站的时候,一定要分析网站的外链,比如可以分析网站在友链交换平台、论坛、博客、友链交换的外链情况平台等,这些平台的权重可以说是非常高的,但是我们在优化的时候要做的就是注意关键词的优化。不要太在意外部链接的质量和数量。这样的外部链接只有这样,才能让我们的seo之路走得更顺畅。通辽seo网站关键词优化4、
抓取网页新闻(蜘蛛来访较少链建设过程中需要注意的几个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-14 02:11
首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置一个更新版块,不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的爬取网站@收录。在栏目页面上也可以这样做。
八、检查死链接并设置404页面
<p>搜索引擎蜘蛛通过链接爬行。如果无法到达的链接太多,不仅会减少 查看全部
抓取网页新闻(蜘蛛来访较少链建设过程中需要注意的几个问题)
首页是蜘蛛访问次数最多的页面,也是网站权重最高的页面。可以在首页设置一个更新版块,不仅会更新首页,提升蜘蛛访问频率,还会促进更新页面的爬取网站@收录。在栏目页面上也可以这样做。
八、检查死链接并设置404页面
<p>搜索引擎蜘蛛通过链接爬行。如果无法到达的链接太多,不仅会减少
抓取网页新闻(让自己的过年看新闻更舒服的几个工具!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-13 14:05
抓取网页新闻数据的工具,让自己过年看新闻更舒服。1个工具让你过年看新闻更舒服,都大年初二了,但一些老人们连"新闻"这个词都说不溜,不能正确判断时事,更别说听懂自己所处的年代。还有一些人,轻言笑语在网上描述自己所处的年代,结果一无所获。不妨让自己试试用小程序搜索"新闻",让自己的过年日子舒服点。首先搜索"新闻"会弹出如下页面,新的、昨天的全部罗列在这里,以你所在的时代为关键词搜索一下下就能找到你想要的资讯。
搜索"地区",不仅能搜到你所在的地区的新闻,还能搜到你所在城市的新闻。搜索"时间",可以快速搜索"中国"的新闻资讯。直接点击进入主页面,然后点击右上角中间的"搜索框"按钮,便能迅速获取新闻的最新资讯。2个工具快速解决老人不会读新闻的烦恼,老人聊天也舒服。很多人过年都不好意思找自己的亲人,甚至会用微信把父母的好友全部屏蔽。
我们需要什么工具可以方便的分享,让老人如鱼得水一样。新闻微信小程序"新闻微信小程序"包含了所有常见新闻类的资讯,打开微信搜索"新闻微信小程序",点击查找"新闻"即可。甚至你打开微信小程序搜索"新闻微信小程序",再打开"搜索框",就能一次性找到你所需要的新闻。甚至让父母畅所欲言,自然不懂对错也很容易"蒙"过去。
你还可以点击小程序最上面的"发现",便能在这里浏览和添加朋友圈里的图文。点击"搜索",输入你想要找的关键词,就能轻松找到你想要的资讯。3个工具让你的收获更多。小程序"发现"中"小程序榜单",类似公众号"小程序榜单",里面包含各大行业发现的小程序,多多找找吧。今天我们将这个小程序,用"探囊取物"的方式来解决"不会读新闻"的烦恼。
你可以打开"发现",再点击页面中间的"探囊取物"按钮,让小程序把你所能搜索到的信息都帮你标注好了。长按那个"地区"或者"时间"或者"时事",便能进入该新闻的详情页,直接点击读完便可以了。用这种方式,你不仅可以知道自己所在的时代正在发生的小事情,还能明确了解你所处的行业每日的消息。然后点击你想要查看的新闻资讯,你的小程序便会实时更新,让老人自己去阅读、推送,可谓快捷又简便。
想了解更多关于微信小程序的开发,可以尝试使用"小程序探囊取物"功能,这样你也可以像"小程序达人"一样,让自己所在的新闻时代畅所欲言,分享给身边的朋友。 查看全部
抓取网页新闻(让自己的过年看新闻更舒服的几个工具!)
抓取网页新闻数据的工具,让自己过年看新闻更舒服。1个工具让你过年看新闻更舒服,都大年初二了,但一些老人们连"新闻"这个词都说不溜,不能正确判断时事,更别说听懂自己所处的年代。还有一些人,轻言笑语在网上描述自己所处的年代,结果一无所获。不妨让自己试试用小程序搜索"新闻",让自己的过年日子舒服点。首先搜索"新闻"会弹出如下页面,新的、昨天的全部罗列在这里,以你所在的时代为关键词搜索一下下就能找到你想要的资讯。
搜索"地区",不仅能搜到你所在的地区的新闻,还能搜到你所在城市的新闻。搜索"时间",可以快速搜索"中国"的新闻资讯。直接点击进入主页面,然后点击右上角中间的"搜索框"按钮,便能迅速获取新闻的最新资讯。2个工具快速解决老人不会读新闻的烦恼,老人聊天也舒服。很多人过年都不好意思找自己的亲人,甚至会用微信把父母的好友全部屏蔽。
我们需要什么工具可以方便的分享,让老人如鱼得水一样。新闻微信小程序"新闻微信小程序"包含了所有常见新闻类的资讯,打开微信搜索"新闻微信小程序",点击查找"新闻"即可。甚至你打开微信小程序搜索"新闻微信小程序",再打开"搜索框",就能一次性找到你所需要的新闻。甚至让父母畅所欲言,自然不懂对错也很容易"蒙"过去。
你还可以点击小程序最上面的"发现",便能在这里浏览和添加朋友圈里的图文。点击"搜索",输入你想要找的关键词,就能轻松找到你想要的资讯。3个工具让你的收获更多。小程序"发现"中"小程序榜单",类似公众号"小程序榜单",里面包含各大行业发现的小程序,多多找找吧。今天我们将这个小程序,用"探囊取物"的方式来解决"不会读新闻"的烦恼。
你可以打开"发现",再点击页面中间的"探囊取物"按钮,让小程序把你所能搜索到的信息都帮你标注好了。长按那个"地区"或者"时间"或者"时事",便能进入该新闻的详情页,直接点击读完便可以了。用这种方式,你不仅可以知道自己所在的时代正在发生的小事情,还能明确了解你所处的行业每日的消息。然后点击你想要查看的新闻资讯,你的小程序便会实时更新,让老人自己去阅读、推送,可谓快捷又简便。
想了解更多关于微信小程序的开发,可以尝试使用"小程序探囊取物"功能,这样你也可以像"小程序达人"一样,让自己所在的新闻时代畅所欲言,分享给身边的朋友。
抓取网页新闻(这篇下面这篇分析如何去POST请求网易的".dwr")
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-12 03:24
"
BlogBeanNew.getBlogs.dwr”,下面的日志是分析如何POST请求网易的“.dwr”数据:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
该日志用于分析获取网易博客读者信息。请求为:VisitBeanNew.getBlogReaders.dwr,获取博客内容的请求为:BlogBeanNew.getBlogs.dwr,都是通过POST请求,原理类似,设置基本相同。
看完分析,就该看代码了。有兴趣的可以看下整个 BlogsToWordPress 工具的 Python 代码。如果您只想查看 POST 代码,可以查看此日志:
【实录】用Python解析FeelingCard返回的DWR-REPLY数据,网易163博客心情随笔
事实上,这篇文章相当复杂。如果您想阅读更简洁,可以阅读以下文章:
[记录] 支持将网易心情文章导出到BlogsToWordPress
我列出的三个日志基本解释了如何设置和请求 POST 来解析网易博客日志数据,它们是用 Python 编写的。以下是我参考后用Java实现的请求用户博客数据的完整代码。
首先,网易博客的目录数据是动态加载的,需要对.dwr进行POST请求,但是博客内容是静态的,可以通过GET请求URL获取,比如小影的一篇博客:
小英:明末文人为何发疯?
地址是:
我的目的是获取日志《小英:明末文人为何疯狂?》的内容。它只需要通过一个GET请求它的地址,然后地址相对格式化。例如,只要将最后解析的这串数字“29”拼接成一个完整的地址。整个地址格式为:
[用户名]./blog/static/[blogId]
小影博客的用户名:“xying1962”,可以通过入口地址“”获取。下面的blogId需要解析目录数据来获取,所以需要POST请求.dwr。
另外,解释一下网易博客地址,有两种地址格式(具体到博客目录地址):
1. [用户名]./blog/
2. [用户名]/blog/
在给出Java代码之前,不得不说谷歌的Chrome浏览器确实是一款不错的产品。它甚至可以很好地请求监控。是网页分析的好帮手。我个人认为它比 Wireshark 更容易使用。详情如下:
1、在网页某处右击,在最后一项选择“Inspect Element”,好像中文叫“Inspect Element”,如图:
“Inspect element”检查元素框出来后,点击“Network”,中文版应该是“Network”,刷新网页,可以看到网页的监控状态,如下图:
可以查看HTTP请求的名称(name)、请求的方法(Method)、请求的状态(Status)、请求返回结果的类型(Type)。点击最左侧的名称查看详细信息,例如点击“blog/”,如下图:
可以查看头部信息、返回结果“Response”和cookies。有时需要 cookie 来模拟登录以发出网页请求,但在许多情况下,标头和响应就足够了。如果想知道当前的信息,再检查一遍,点击底部的“清除”按钮(如图,红色圈出)就足够了。具体怎么用,如果你学过计算机网络,做过抓包分析,自己查一下就明白了。如果不是,那真的需要一段时间才能找到。
下面讲解如何在Java中设置POST请求,首先按照类似于原创Python格式的Java代码
<p>public Set post163Blog(String username, String userId, int startIndex, int returnNumber){
/**
* entityBody用于保存字符串格式的返回结果
*/
String entityBody = null;
/**
* 实例化一个HttpPost,并设置请求dwr地址,username表示博主的用户名,例如肖鹰的username是“xying1962”
*/
HttpPost httppost = new HttpPost("http://api.blog.163.com/" + username + "/dwr/call/plaincall/BlogBeanNew.getBlogs.dwr");
/*
* 设置参数,除了c0-param0、c0-param1和c0-param2外都一样。
* c0-param0 :博主的userId,例如肖鹰的userId是“138445490”
* c0-param1 :返回博客数据的起始项,从0开始
* c0-param2 :一次返回博客的数量,最大值好像是500,具体多少我没有完全去试,600肯定不行,我一般设置500,600以上就不返回数据了。
* 如果一个博主写了超过500篇博客,那就可以分多次请求,只要合理设置c0-param1和c0-param2就可以。
*/
List nvp = new ArrayList();
nvp.add(new BasicNameValuePair("callCount", "1"));
nvp.add(new BasicNameValuePair("scriptSessionId", "${scriptSessionId}187"));
nvp.add(new BasicNameValuePair("c0-scriptName", "BlogBeanNew"));
nvp.add(new BasicNameValuePair("c0-methodName", "getBlogs"));
nvp.add(new BasicNameValuePair("c0-id", "0"));
nvp.add(new BasicNameValuePair("c0-param0", "number:" + userId));
nvp.add(new BasicNameValuePair("c0-param1", "number:" + startIndex));
nvp.add(new BasicNameValuePair("c0-param2", "number:" + (returnNumber 查看全部
抓取网页新闻(这篇下面这篇分析如何去POST请求网易的".dwr")
"
BlogBeanNew.getBlogs.dwr”,下面的日志是分析如何POST请求网易的“.dwr”数据:
【教程】以网易博文的最新读者信息为例,教大家如何抓取动态网页的内容。
该日志用于分析获取网易博客读者信息。请求为:VisitBeanNew.getBlogReaders.dwr,获取博客内容的请求为:BlogBeanNew.getBlogs.dwr,都是通过POST请求,原理类似,设置基本相同。
看完分析,就该看代码了。有兴趣的可以看下整个 BlogsToWordPress 工具的 Python 代码。如果您只想查看 POST 代码,可以查看此日志:
【实录】用Python解析FeelingCard返回的DWR-REPLY数据,网易163博客心情随笔
事实上,这篇文章相当复杂。如果您想阅读更简洁,可以阅读以下文章:
[记录] 支持将网易心情文章导出到BlogsToWordPress
我列出的三个日志基本解释了如何设置和请求 POST 来解析网易博客日志数据,它们是用 Python 编写的。以下是我参考后用Java实现的请求用户博客数据的完整代码。
首先,网易博客的目录数据是动态加载的,需要对.dwr进行POST请求,但是博客内容是静态的,可以通过GET请求URL获取,比如小影的一篇博客:
小英:明末文人为何发疯?
地址是:
我的目的是获取日志《小英:明末文人为何疯狂?》的内容。它只需要通过一个GET请求它的地址,然后地址相对格式化。例如,只要将最后解析的这串数字“29”拼接成一个完整的地址。整个地址格式为:
[用户名]./blog/static/[blogId]
小影博客的用户名:“xying1962”,可以通过入口地址“”获取。下面的blogId需要解析目录数据来获取,所以需要POST请求.dwr。
另外,解释一下网易博客地址,有两种地址格式(具体到博客目录地址):
1. [用户名]./blog/
2. [用户名]/blog/
在给出Java代码之前,不得不说谷歌的Chrome浏览器确实是一款不错的产品。它甚至可以很好地请求监控。是网页分析的好帮手。我个人认为它比 Wireshark 更容易使用。详情如下:
1、在网页某处右击,在最后一项选择“Inspect Element”,好像中文叫“Inspect Element”,如图:
“Inspect element”检查元素框出来后,点击“Network”,中文版应该是“Network”,刷新网页,可以看到网页的监控状态,如下图:
可以查看HTTP请求的名称(name)、请求的方法(Method)、请求的状态(Status)、请求返回结果的类型(Type)。点击最左侧的名称查看详细信息,例如点击“blog/”,如下图:
可以查看头部信息、返回结果“Response”和cookies。有时需要 cookie 来模拟登录以发出网页请求,但在许多情况下,标头和响应就足够了。如果想知道当前的信息,再检查一遍,点击底部的“清除”按钮(如图,红色圈出)就足够了。具体怎么用,如果你学过计算机网络,做过抓包分析,自己查一下就明白了。如果不是,那真的需要一段时间才能找到。
下面讲解如何在Java中设置POST请求,首先按照类似于原创Python格式的Java代码
<p>public Set post163Blog(String username, String userId, int startIndex, int returnNumber){
/**
* entityBody用于保存字符串格式的返回结果
*/
String entityBody = null;
/**
* 实例化一个HttpPost,并设置请求dwr地址,username表示博主的用户名,例如肖鹰的username是“xying1962”
*/
HttpPost httppost = new HttpPost("http://api.blog.163.com/" + username + "/dwr/call/plaincall/BlogBeanNew.getBlogs.dwr");
/*
* 设置参数,除了c0-param0、c0-param1和c0-param2外都一样。
* c0-param0 :博主的userId,例如肖鹰的userId是“138445490”
* c0-param1 :返回博客数据的起始项,从0开始
* c0-param2 :一次返回博客的数量,最大值好像是500,具体多少我没有完全去试,600肯定不行,我一般设置500,600以上就不返回数据了。
* 如果一个博主写了超过500篇博客,那就可以分多次请求,只要合理设置c0-param1和c0-param2就可以。
*/
List nvp = new ArrayList();
nvp.add(new BasicNameValuePair("callCount", "1"));
nvp.add(new BasicNameValuePair("scriptSessionId", "${scriptSessionId}187"));
nvp.add(new BasicNameValuePair("c0-scriptName", "BlogBeanNew"));
nvp.add(new BasicNameValuePair("c0-methodName", "getBlogs"));
nvp.add(new BasicNameValuePair("c0-id", "0"));
nvp.add(new BasicNameValuePair("c0-param0", "number:" + userId));
nvp.add(new BasicNameValuePair("c0-param1", "number:" + startIndex));
nvp.add(new BasicNameValuePair("c0-param2", "number:" + (returnNumber
抓取网页新闻(网页爬虫是网页的爬取,怎么看网页新闻?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-10 20:08
抓取网页新闻是每天工作的重点,无论是恶意代码或是恶意软件,我们面对的第一对象就是网页,那么怎么看网页新闻呢?今天,我就来给大家分享一下一种网页新闻的爬虫技术。给大家介绍一下,网页爬虫是网页的爬取,再简单说就是把一堆网页内容拿来收集起来。网页新闻其实就是某些网站上发布的文章,网页新闻中不但有文章内容,还有段子,照片,图片等,一个网页上可能会有很多个网页,这些网页都被统一整理发布到一个页面上,那么这个页面就成了网页新闻的发布页面。
一般我们可以通过三种方式来解决抓取网页新闻的问题。一.写代码加载新闻1.javascript。javascript可以编写单个或者多个函数,例如xmlhttprequest。我们可以利用javascript在页面中直接使用。例如,对于一个网页新闻的爬取,我们可以将代码如下javascript代码写成。
当网页搜索到某个关键词,javascript就会调用这个关键词的javascript函数。在页面上显示结果。如果多个网页都有相同的代码,那么这个页面就能爬取下来。这个页面通常不能直接调用javascript函数,javascript和网页的链接是一起的,需要另外使用网页。比如,我们可以查看网页中各个url对应的网页,就能找到这些网页,其中有可能是某一个网页的页面也有可能是某一个网页中一个页面,网页。
所以我们需要在post的时候,在正文中注明要爬取哪个网页的新闻。2.html。html是无格式文本,爬取网页新闻涉及到的html代码一般来自网页编程的一些基础知识,比如通过html代码可以爬取url地址,可以爬取网页的描述等,html代码我们在写爬虫的时候不一定会用到,但是我们写爬虫一定会遇到,因为一些不正确的爬取方式可能会导致html代码错误,导致爬取失败。
通常爬取网页新闻就会要用到html语言。2.1html语言的使用。html语言就是语言,和我们打字一样简单,我们可以通过控制字体、大小、颜色、语法来表达意思。所以,我们可以通过写一段特殊的html代码来完成网页新闻的爬取,其实也很简单。html文件主要有一个文件夹,里面放着我们需要爬取的html页面,我们的目标是找到页面,并把页面上的内容拿来分析。
<p>我们可以看到页面主要有三个部分组成,分别是page/body/innerhtml,它们之间可以有各种一对多的关系,其中innerhtml是这三个之间的一个中间变量,即innerhtml部分。我们通过发布某个网页新闻的script标签,定义代码如下script标签首先需要定义一个标签,将网页上的内容进行定义:script标签语法定义一个 查看全部
抓取网页新闻(网页爬虫是网页的爬取,怎么看网页新闻?)
抓取网页新闻是每天工作的重点,无论是恶意代码或是恶意软件,我们面对的第一对象就是网页,那么怎么看网页新闻呢?今天,我就来给大家分享一下一种网页新闻的爬虫技术。给大家介绍一下,网页爬虫是网页的爬取,再简单说就是把一堆网页内容拿来收集起来。网页新闻其实就是某些网站上发布的文章,网页新闻中不但有文章内容,还有段子,照片,图片等,一个网页上可能会有很多个网页,这些网页都被统一整理发布到一个页面上,那么这个页面就成了网页新闻的发布页面。
一般我们可以通过三种方式来解决抓取网页新闻的问题。一.写代码加载新闻1.javascript。javascript可以编写单个或者多个函数,例如xmlhttprequest。我们可以利用javascript在页面中直接使用。例如,对于一个网页新闻的爬取,我们可以将代码如下javascript代码写成。
当网页搜索到某个关键词,javascript就会调用这个关键词的javascript函数。在页面上显示结果。如果多个网页都有相同的代码,那么这个页面就能爬取下来。这个页面通常不能直接调用javascript函数,javascript和网页的链接是一起的,需要另外使用网页。比如,我们可以查看网页中各个url对应的网页,就能找到这些网页,其中有可能是某一个网页的页面也有可能是某一个网页中一个页面,网页。
所以我们需要在post的时候,在正文中注明要爬取哪个网页的新闻。2.html。html是无格式文本,爬取网页新闻涉及到的html代码一般来自网页编程的一些基础知识,比如通过html代码可以爬取url地址,可以爬取网页的描述等,html代码我们在写爬虫的时候不一定会用到,但是我们写爬虫一定会遇到,因为一些不正确的爬取方式可能会导致html代码错误,导致爬取失败。
通常爬取网页新闻就会要用到html语言。2.1html语言的使用。html语言就是语言,和我们打字一样简单,我们可以通过控制字体、大小、颜色、语法来表达意思。所以,我们可以通过写一段特殊的html代码来完成网页新闻的爬取,其实也很简单。html文件主要有一个文件夹,里面放着我们需要爬取的html页面,我们的目标是找到页面,并把页面上的内容拿来分析。
<p>我们可以看到页面主要有三个部分组成,分别是page/body/innerhtml,它们之间可以有各种一对多的关系,其中innerhtml是这三个之间的一个中间变量,即innerhtml部分。我们通过发布某个网页新闻的script标签,定义代码如下script标签首先需要定义一个标签,将网页上的内容进行定义:script标签语法定义一个
抓取网页新闻(如何改造爬虫数据存储成功?系统程序编译成exe)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-10 07:07
抓取网页新闻信息:网页爬虫代码实现新闻下单功能-python爬虫小站,搜索框命名,首页高清图,特色广告,
通常就是开发爬虫的小伙伴,比如说做爬虫爬美图的,你们需要分析美图各页面的数据来生成bs4语言。一般用requests下各个网页。当然你也可以找爬虫比较牛逼的框架,比如urllib2。不过我没用过。
很多小伙伴都会在问,自己手里已经有一个现成的爬虫系统,那么该如何改造成功呢?首先,我们要对爬虫的整体流程进行梳理,再根据系统功能对其进行优化及细化,再通过高手团队指导进行源码下载及定制开发,到最后调整完善到适合自己的才是最好的。以爬取新闻为例,当前系统在做的事情包括:数据爬取---查看某个商品,某条新闻的数据;数据清洗---主要是去重及重复数据过滤,过滤未登录和退出登录用户的信息;数据解析---对数据进行分析、解读、渲染;数据数据存储---主要是存储历史数据、中差评数据、投诉数据。
那么如何抓取网或天猫上未登录或退出登录的用户的信息呢?在这里我们可以采用requests库来解决这个问题,但是,要解决这个问题,我们就需要将该系统程序编译成exe可执行文件,进而运行exe文件就可以获取到系统环境下的数据,使得我们进行第二步的数据爬取。首先打开终端,输入命令行pipinstallexe-i数据抓取pipinstallclijs数据解析首先安装pandas库,pandas可以用于数据抓取及基础数据分析,并可以对数据进行简单可视化处理,比如将数据可视化为饼图等。
将上面三个库安装完成,就可以通过pipinstallexe-i数据存储来进行数据存储工作了,这里只需要安装一个clijs库即可。pipinstallclijs数据数据可视化那么接下来让我们看看在后面对应的步骤里该如何操作,如:数据清洗(过滤未登录及退出登录用户信息)--->数据数据解析--->数据存储--->调用系统本身已有数据来看新闻整体内容等等。
这里我通过分享爬虫系统的源码,目的有两个:一是能够让用户实际的使用到我们分享出来的代码和程序,让用户对爬虫整体框架与流程有个清晰的了解。二是源码中也提供了对java版的爬虫改造工具,希望能让后续参与改造工具实现的同学对所用到的知识点进行复习,也给后续需要python版本改造爬虫代码的用户提供一个参考。 查看全部
抓取网页新闻(如何改造爬虫数据存储成功?系统程序编译成exe)
抓取网页新闻信息:网页爬虫代码实现新闻下单功能-python爬虫小站,搜索框命名,首页高清图,特色广告,
通常就是开发爬虫的小伙伴,比如说做爬虫爬美图的,你们需要分析美图各页面的数据来生成bs4语言。一般用requests下各个网页。当然你也可以找爬虫比较牛逼的框架,比如urllib2。不过我没用过。
很多小伙伴都会在问,自己手里已经有一个现成的爬虫系统,那么该如何改造成功呢?首先,我们要对爬虫的整体流程进行梳理,再根据系统功能对其进行优化及细化,再通过高手团队指导进行源码下载及定制开发,到最后调整完善到适合自己的才是最好的。以爬取新闻为例,当前系统在做的事情包括:数据爬取---查看某个商品,某条新闻的数据;数据清洗---主要是去重及重复数据过滤,过滤未登录和退出登录用户的信息;数据解析---对数据进行分析、解读、渲染;数据数据存储---主要是存储历史数据、中差评数据、投诉数据。
那么如何抓取网或天猫上未登录或退出登录的用户的信息呢?在这里我们可以采用requests库来解决这个问题,但是,要解决这个问题,我们就需要将该系统程序编译成exe可执行文件,进而运行exe文件就可以获取到系统环境下的数据,使得我们进行第二步的数据爬取。首先打开终端,输入命令行pipinstallexe-i数据抓取pipinstallclijs数据解析首先安装pandas库,pandas可以用于数据抓取及基础数据分析,并可以对数据进行简单可视化处理,比如将数据可视化为饼图等。
将上面三个库安装完成,就可以通过pipinstallexe-i数据存储来进行数据存储工作了,这里只需要安装一个clijs库即可。pipinstallclijs数据数据可视化那么接下来让我们看看在后面对应的步骤里该如何操作,如:数据清洗(过滤未登录及退出登录用户信息)--->数据数据解析--->数据存储--->调用系统本身已有数据来看新闻整体内容等等。
这里我通过分享爬虫系统的源码,目的有两个:一是能够让用户实际的使用到我们分享出来的代码和程序,让用户对爬虫整体框架与流程有个清晰的了解。二是源码中也提供了对java版的爬虫改造工具,希望能让后续参与改造工具实现的同学对所用到的知识点进行复习,也给后续需要python版本改造爬虫代码的用户提供一个参考。
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-10 01:07
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(空格分隔),分类频道设置为国内,排序方式根据相关性. 获取所有检索到的新闻如下:
一共1000多条数据。
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,得到一个新参数:比较开始
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果
完整代码
也可以看看: 查看全部
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(空格分隔),分类频道设置为国内,排序方式根据相关性. 获取所有检索到的新闻如下:
一共1000多条数据。
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,得到一个新参数:比较开始
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果
完整代码
也可以看看:
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-02-08 22:11
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(用空格分隔),分类频道设置为国内,排序方式根据关联。获取所有检索到的新闻如下:
一共1000多条数据。
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,通过比较得到一个新参数:start,start=0时默认省略,表示第一页,每下一页增加10(设置页显示10)
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果
完整代码
也可以看看: 查看全部
抓取网页新闻(:自然灾害滑坡的全部国内新闻,要求主题为滑坡类新闻)
目标陈述
使用scrapy在Chinanews中抓取国内所有关于自然灾害和山体滑坡的新闻,方便后续的文本挖掘分析。
网站分析
目标网站:
结合中新搜索平台的高级搜索功能,搜索关键词设置为:滑坡经济损失(用空格分隔),分类频道设置为国内,排序方式根据关联。获取所有检索到的新闻如下:
一共1000多条数据。
分析网站的特性发现请求是异步加载的,通过抓包工具Fiddler获取:
分析:
POST提交,每个提交目标的url为:
提交参数如上图,其中q代表关键词(抓包测试时只输入了一个关键词);
ps 表示每次显示的调试信息,adv=1 表示高级搜索;day1,day2表示搜索时间,不写默认表示一直,channel=gn表示国内;
继续点击下一页,通过比较得到一个新参数:start,start=0时默认省略,表示第一页,每下一页增加10(设置页显示10)
分析显示,每次点击下一页,都是POST提交,参数相同,但不同的是start
代码逻辑
使用命令:scrapy start project NewsChina 创建项目,编写items.py文件,并清晰捕获字段(常用套路,第一步是清晰捕获字段)。这里只抓取标题和正文。常规操作:添加数据源和爬取时间信息。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewschinaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 数据来源
source = scrapy.Field()
# 抓取时间
utc_time = scrapy.Field()
# 新闻标题
title = scrapy.Field()
# 新闻内容
content = scrapy.Field()
# 关键词
keywords = scrapy.Field()
明确抓取字段后,使用命令:scrapy genspider newsChina 生成爬虫,开始编写爬虫逻辑,结合抓取网站的特点如下:
对于这个网站的防爬措施,增加请求延迟、重试次数和等待配置;
通过修改POST请求的time_scope字段,获取每页数据,解析数据中详情页的链接,然后对详情页进行链接请求,解析待爬取的数据;
至于循环抓取和终止循环条件,根据实际网站有所不同,代码中已经说明。
# -*- coding: utf-8 -*-
import re
import scrapy
from NewsChina.items import NewschinaItem
class NewschinaSpider(scrapy.Spider):
name = 'newsChina'
# allowed_domains = ['sou.chinanews.com']
# start_urls = ['http://http://sou.chinanews.com/']
#爬虫设置
# handle_httpstatus_list = [403] # 403错误时抛出异常
custom_settings = {
"DOWNLOAD_DELAY": 2,
"RETRY_ENABLED": True,
}
page = 0
# 提交参数
formdata = {
'field': 'content',
'q': '滑坡 经济损失',
'ps': '10',
'start': '{}'.format(page * 10),
'adv': '1',
'time_scope': '0',
'day1': '',
'day2': '',
'channel': 'gn',
'creator': '',
'sort': '_score'
}
# 提交url
url = 'http://sou.chinanews.com/search.do'
def start_requests(self):
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
def parse(self, response):
try:
last_page = response.xpath('//div[@id="pagediv"]/span/text()').extract()[-1]
# 匹配到尾页退出迭代
if last_page is '尾页':
return
except:
# 当匹配不到last_page时,说明已经爬取所有页面,xpath匹配失败
# 抛出异常,这就是我们的循环终止条件
# print("last_page:", response.url)
return
link_list = response.xpath('//div[@id="news_list"]/table//tr/td/ul/li/a/@href').extract()
for link in link_list:
if link:
item = NewschinaItem()
# 访问详情页
yield scrapy.Request(link, callback=self.parse_detail, meta={'item': item})
# 循环调用,访问下一页
self.page += 1
# 下一页的开始,修改该参数得到新数据
self.formdata['start'] = '{}'.format(self.page * 10)
yield scrapy.FormRequest(
url=self.url,
formdata=self.formdata,
callback=self.parse
)
# 从详情页中解析数据
def parse_detail(self, response):
"""
分析发现,中新网年份不同,所以网页的表现形式不同,
由于抓取的是所有的数据,因此同一个xpath可能只能匹配到部分的内容;
经过反复测试发现提取规则只有如下几条。提取标题有两套规则
提取正文有6套规则。
:param response:
:return:
"""
item = response.meta['item']
# 提取标题信息
if response.xpath('//h1/text()'):
item['title'] = response.xpath('//h1/text()').extract_first().strip()
elif response.xpath('//title/text()'):
item['title'] = response.xpath('//title/text()').extract_first().strip()
else:
print('title:', response.url)
# 提取正文信息
try:
if response.xpath('//div[@id="ad0"]'):
item['content'] = response.xpath('//div[@id="ad0"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="left_zw"]'):
item['content'] = response.xpath('//div[@class="left_zw"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//font[@id="Zoom"]'):
item['content'] = response.xpath('//font[@id="Zoom"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@id="qb"]'):
item['content'] = response.xpath('//div[@id="qb"]').xpath('string(.)').extract_first().strip()
elif response.xpath('//div[@class="video_con1_text_top"]/p'):
item['content'] = response.xpath('//div[@class="video_con1_text_top"]/p').xpath('string(.)').extract_first().strip()
else:
print('content:', response.url)
except:
# 测试发现中新网有一个网页的链接是空的,因此提前不到正文,做异常处理
print(response.url)
item['content'] = ''
yield item
编写中间件并添加随机头信息:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/late ... .html
import random
from NewsChina.settings import USER_AGENTS as ua
class NewsChinaSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
编写数据保存逻辑:
结合python的jieba模块的textrank算法,可以提取新闻关键词保存到excel或者数据库
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
from datetime import datetime
from jieba import analyse
from openpyxl import Workbook
import pymysql
class KeyswordPipeline(object):
"""
添加数据来源及抓取时间;
结合textrank算法,抽取新闻中最重要的5个词,作为关键词
"""
def process_item(self, item, spider):
# 数据来源
item['source'] = spider.name
# 抓取时间
item['utc_time'] = str(datetime.utcnow())
content = item['content']
keywords = ' '.join(analyse.textrank(content, topK=5))
# 关键词
item['keywords'] = keywords
return item
class NewsChinaExcelPipeline(object):
"""
数据保存
"""
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['标题', '关键词', '正文', '数据来源', '抓取时间'])
def process_item(self, item, spider):
data = [item['title'], item['keywords'], item['content'], item['source'], item['utc_time']]
self.ws.append(data)
self.wb.save('./news.xls')
return item
# class NewschinaPipeline(object):
# def __init__(self):
# self.conn = pymysql.connect(
# host='.......',
# port=3306,
# database='news_China',
# user='z',
# password='136833',
# charset='utf8'
# )
# # 实例一个游标
# self.cursor = self.conn.cursor()
#
# def process_item(self, item, spider):
# sql = """
# insert into ChinaNews(ID, 标题, 关键词, 正文, 数据来源, 抓取时间)
# values (%s, %s, %s, %s, %s, %s);"""
#
# values = [
# item['title'],
# item['keywords'],
# item['content'],
#
# item['source'],
# item['utc_time']
# ]
#
# self.cursor.execute(sql, values)
# self.conn.commit()
#
# return item
#
# def close_spider(self, spider):
# self.cursor.close()
# self.conn.close()
运行结果
完整代码
也可以看看:
抓取网页新闻(客户端页面接入爬虫,需要做两个准备:抓取网页新闻/阅读数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-03 19:02
抓取网页新闻/阅读数据,然后自己解析。客户端页面接入爬虫,需要做两个准备:抓取同一客户端程序的不同页面,爬取同一微信账号下的不同微信公众号页面。如果这个工作量不大,可以用开源的工具自己封装一个爬虫,再编写代码就行了。
可以尝试python-for-android-review,先帮助网站做测试。
先搭一个网站吧,并发量大一点,单点抓取就不用封包了。重复抓取的时候试试丢弃页面。
爬虫不用封包,首先,不管爬什么网站,抓包分析是主要的工作。如果你的网站需要抓多条数据,建议看看大规模网站的爬虫,
requests库里面的requests库封包工具psw爬取工具bottle框架可以使用后者也可以自己封包工具,比如:封包必须是下面三种情况封包被firefox识别为不安全的mozilla、telegram以及dashaure也识别httpsssl的地址地址非法所以封包是需要封网站以上分析我没有相关爬虫的经验,都是大学学的。
爬虫封包源码都是md5算法,实际使用没有必要,但用来测试是不错的,对了给自己部署,抓包问题等也是需要改善的。
谢邀,暂时还没这么复杂的爬虫系统。我觉得你需要到想抓取数据的站点,用百度搜一下你想抓取的关键词出现在哪里,你就可以就近去那里抓。 查看全部
抓取网页新闻(客户端页面接入爬虫,需要做两个准备:抓取网页新闻/阅读数据)
抓取网页新闻/阅读数据,然后自己解析。客户端页面接入爬虫,需要做两个准备:抓取同一客户端程序的不同页面,爬取同一微信账号下的不同微信公众号页面。如果这个工作量不大,可以用开源的工具自己封装一个爬虫,再编写代码就行了。
可以尝试python-for-android-review,先帮助网站做测试。
先搭一个网站吧,并发量大一点,单点抓取就不用封包了。重复抓取的时候试试丢弃页面。
爬虫不用封包,首先,不管爬什么网站,抓包分析是主要的工作。如果你的网站需要抓多条数据,建议看看大规模网站的爬虫,
requests库里面的requests库封包工具psw爬取工具bottle框架可以使用后者也可以自己封包工具,比如:封包必须是下面三种情况封包被firefox识别为不安全的mozilla、telegram以及dashaure也识别httpsssl的地址地址非法所以封包是需要封网站以上分析我没有相关爬虫的经验,都是大学学的。
爬虫封包源码都是md5算法,实际使用没有必要,但用来测试是不错的,对了给自己部署,抓包问题等也是需要改善的。
谢邀,暂时还没这么复杂的爬虫系统。我觉得你需要到想抓取数据的站点,用百度搜一下你想抓取的关键词出现在哪里,你就可以就近去那里抓。
抓取网页新闻(Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-02-03 05:18
Python网络爬虫四大选择器总结(正则表达式、BS4、Xpath、CSS)
0.前言
相关实战文章:正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东的产品信息。
网络爬虫:模拟客户端批量发送网络请求,批量接收请求对应的数据,并按照一定的规则自动抓取互联网信息,执行数据采集,并持久化存储的程序。其他用途:百度搜索、12306抢票、各种抢购、投票、刷票、短信轰炸、网络攻击、Web漏洞扫描等都是爬虫技术。
爬行动物的目的
1.财经财经新闻/数据,制定投资策略,进行量化交易
2.各类旅游资讯优化旅游策略
3.电商商品信息比价系统
4.游戏游戏论坛调整游戏运营
5.银行个人交易信息信用体系/贷款评级
6.职位信息职位信息
7.舆论 各大论坛社会群体感知、舆论导向
只要是客户端(浏览器)能做到的,原则上爬虫都能做到。这意味着只要人类可以访问的网页和他们可以看到的数据,爬虫肯定可以爬取铜等资源。
抓取用户看不到的数据被称为黑客攻击,这是非法的。
爬虫的作用:可以爬取数据进行数据分析,大的可以定制一个搜索引擎。更好的搜索引擎优化。
通用爬虫:搜索引擎的爬虫系统,搜索引擎和网络服务提供商提供的爬虫。目的是尽可能的;将互联网上的所有网页下载下来,放到本地服务器上形成备份,对这些网页进行相关处理(提取关键词、去除广告),最后提供用户检索接口。
过程:
首先选择一些网址,将这些网址放入待抓取的队列中。
从队列中取出URL,然后解析DNS得到主机IP,然后保存该IP对应的HTML页面下载HTML页面,保存到搜索引擎的本地服务器,然后将抓取到的url放入爬取的队列。
分析这些网页的内容,找出网页中其他的URL链接,继续第二步,直到爬取结束。
搜索引擎如何获取新的 网站 URL:
a) 主动向搜索引擎提交 网站
B) 在其他 网站 中设置外联
C) 搜索引擎会配合DNS服务商快速收录new网站
DNS 是一种将域名解析为 IP 地址的技术。
万能爬虫不代表什么都能爬,他也得遵守规则:
Robots Protocol:该协议将规定通用爬虫爬取网页的权限(告诉搜索引擎哪些可以爬,哪些不能爬)
Robots.txt 并非所有爬虫都遵守,一般只有大型搜索引擎爬虫会遵守
现有位置:robots.txt 文件应放在 网站 根目录下
例如:
常用爬虫工作流程:
抓取网页、存储数据、处理内容并提供检索/排名服务
搜索引擎排名:
1.PageRank值:根据网站的流量(点击/浏览/人气)统计,流量越高,网站的排名越高。
2.PPC:谁付出的多,排名就高。
万能爬虫的缺点:
1.只提供文本相关内容(HTML、Word、PDF)等,不提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)
2. 提供相同的结果,不为不同背景的人提供不同的搜索结果
3.无法提供人工语义检索
通用搜索引擎的局限性
1.一般搜索引擎返回的网页有90%是无用的。
2.中文搜索引擎自然语言检索理解困难
3.信息的数量和覆盖范围都有限制。
4.搜索引擎以关键词搜索为主,一般的搜索引擎对图片、数据库、音视频多媒体内容无能为力。
5.搜索引擎的社区化和个性化不好。大多数搜索引擎没有考虑到人们的地区、性别和年龄的差异。
6.搜索引擎不擅长抓取动态网页
为了解决通用爬虫的缺点,出现了专注爬虫。
专注于爬虫
Spotlight on the crawler:爬虫程序员针对某个内容编写的爬虫。
面向主题的爬虫,面向需求的爬虫:对特定容量的信息进行爬取,并确保内容需求尽可能相关。
1.累积爬虫:从头到尾,不断的爬取,过程中会进行重复的操作。
2.增量爬虫:下载的网页是增量更新的,只爬取新生成或改变的网络爬虫
3.深网爬虫:无法通过静态链接获取的网页,隐藏在搜索表单后面,只有用户提交一些关键词才能获取
0.1数据爬取的基本流程
指定要抓取的url
根据 requests 模块发起请求并得到响应
获取响应对象中的数据
数据分析
用于持久存储
在持久存储之前需要进行指定的数据解析。因为大多数情况下的需求,我们会指定使用焦点爬虫,也就是爬取页面指定部分的数据值,而不是整个页面的数据。
1.正则表达式
特点:为我们提供了获取数据的捷径。这种正则表达式虽然更容易适应未来的变化,但存在难写、难构造、可读性差、代码繁多等问题。但是,使用正则表达式来实现目标信息的准确采集
同时,网页经常发生变化,导致网页的布局发生了一些细微的变化。这时候之前写的正则表达式不能满足要求,需要重写,也不容易调试。当要匹配的内容很多时,使用正则表达式提取目标信息会导致程序运行速度变慢,消耗更多内存。
2.BS4 (美汤)
特点:BeautifulSoup虽然比正则表达式理解起来更复杂,但更容易构造和理解。
BeautifulSoup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块可以通过 pip install beautifulsoup4 安装。
第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,BeautifulSoup 需要确定实际格式。除了添加 <html> 和 <body> 标记以使其成为完整的 HTML 文档外,BeautifulSoup 还能正确解析缺少的引号和关闭标记。通常使用 find() 和 find_all() 方法来定位我们需要的元素。
3.Xpath
特征:
Lxml:Lxml模块是C语言编写的,解析速度比BeautifulSoup快,安装过程也比较复杂,
XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
使用 lxml 模块(如 BeautifulSoup)的第一步是将可能无效的 HTML 解析为统一格式。尽管 Lxml 正确解析了属性周围缺少的引号并关闭标签,但该模块不会添加额外的 <html> 和 <body> 标签。
在线复制Xpath表达式可以很方便的复制Xpath表达式(即在浏览器的开发者工具上找到定位标签并右键复制生成的xpath表达式)。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
4.CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 结合了 CSS 选择器的语法和它自己易于使用的 API。在网络爬虫的开发过程中,对于熟悉 CSS 选择器语法的人来说,使用 CSS 选择器是一种非常方便的方法。 查看全部
抓取网页新闻(Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结)
Python网络爬虫四大选择器总结(正则表达式、BS4、Xpath、CSS)
0.前言
相关实战文章:正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东的产品信息。
网络爬虫:模拟客户端批量发送网络请求,批量接收请求对应的数据,并按照一定的规则自动抓取互联网信息,执行数据采集,并持久化存储的程序。其他用途:百度搜索、12306抢票、各种抢购、投票、刷票、短信轰炸、网络攻击、Web漏洞扫描等都是爬虫技术。
爬行动物的目的
1.财经财经新闻/数据,制定投资策略,进行量化交易
2.各类旅游资讯优化旅游策略
3.电商商品信息比价系统
4.游戏游戏论坛调整游戏运营
5.银行个人交易信息信用体系/贷款评级
6.职位信息职位信息
7.舆论 各大论坛社会群体感知、舆论导向
只要是客户端(浏览器)能做到的,原则上爬虫都能做到。这意味着只要人类可以访问的网页和他们可以看到的数据,爬虫肯定可以爬取铜等资源。
抓取用户看不到的数据被称为黑客攻击,这是非法的。
爬虫的作用:可以爬取数据进行数据分析,大的可以定制一个搜索引擎。更好的搜索引擎优化。
通用爬虫:搜索引擎的爬虫系统,搜索引擎和网络服务提供商提供的爬虫。目的是尽可能的;将互联网上的所有网页下载下来,放到本地服务器上形成备份,对这些网页进行相关处理(提取关键词、去除广告),最后提供用户检索接口。
过程:
首先选择一些网址,将这些网址放入待抓取的队列中。
从队列中取出URL,然后解析DNS得到主机IP,然后保存该IP对应的HTML页面下载HTML页面,保存到搜索引擎的本地服务器,然后将抓取到的url放入爬取的队列。
分析这些网页的内容,找出网页中其他的URL链接,继续第二步,直到爬取结束。
搜索引擎如何获取新的 网站 URL:
a) 主动向搜索引擎提交 网站
B) 在其他 网站 中设置外联
C) 搜索引擎会配合DNS服务商快速收录new网站
DNS 是一种将域名解析为 IP 地址的技术。
万能爬虫不代表什么都能爬,他也得遵守规则:
Robots Protocol:该协议将规定通用爬虫爬取网页的权限(告诉搜索引擎哪些可以爬,哪些不能爬)
Robots.txt 并非所有爬虫都遵守,一般只有大型搜索引擎爬虫会遵守
现有位置:robots.txt 文件应放在 网站 根目录下
例如:
常用爬虫工作流程:
抓取网页、存储数据、处理内容并提供检索/排名服务
搜索引擎排名:
1.PageRank值:根据网站的流量(点击/浏览/人气)统计,流量越高,网站的排名越高。
2.PPC:谁付出的多,排名就高。
万能爬虫的缺点:
1.只提供文本相关内容(HTML、Word、PDF)等,不提供多媒体文件(音乐、图片、视频)和二进制文件(程序、脚本)
2. 提供相同的结果,不为不同背景的人提供不同的搜索结果
3.无法提供人工语义检索
通用搜索引擎的局限性
1.一般搜索引擎返回的网页有90%是无用的。
2.中文搜索引擎自然语言检索理解困难
3.信息的数量和覆盖范围都有限制。
4.搜索引擎以关键词搜索为主,一般的搜索引擎对图片、数据库、音视频多媒体内容无能为力。
5.搜索引擎的社区化和个性化不好。大多数搜索引擎没有考虑到人们的地区、性别和年龄的差异。
6.搜索引擎不擅长抓取动态网页
为了解决通用爬虫的缺点,出现了专注爬虫。
专注于爬虫
Spotlight on the crawler:爬虫程序员针对某个内容编写的爬虫。
面向主题的爬虫,面向需求的爬虫:对特定容量的信息进行爬取,并确保内容需求尽可能相关。
1.累积爬虫:从头到尾,不断的爬取,过程中会进行重复的操作。
2.增量爬虫:下载的网页是增量更新的,只爬取新生成或改变的网络爬虫
3.深网爬虫:无法通过静态链接获取的网页,隐藏在搜索表单后面,只有用户提交一些关键词才能获取
0.1数据爬取的基本流程
指定要抓取的url
根据 requests 模块发起请求并得到响应
获取响应对象中的数据
数据分析
用于持久存储
在持久存储之前需要进行指定的数据解析。因为大多数情况下的需求,我们会指定使用焦点爬虫,也就是爬取页面指定部分的数据值,而不是整个页面的数据。
1.正则表达式
特点:为我们提供了获取数据的捷径。这种正则表达式虽然更容易适应未来的变化,但存在难写、难构造、可读性差、代码繁多等问题。但是,使用正则表达式来实现目标信息的准确采集
同时,网页经常发生变化,导致网页的布局发生了一些细微的变化。这时候之前写的正则表达式不能满足要求,需要重写,也不容易调试。当要匹配的内容很多时,使用正则表达式提取目标信息会导致程序运行速度变慢,消耗更多内存。
2.BS4 (美汤)
特点:BeautifulSoup虽然比正则表达式理解起来更复杂,但更容易构造和理解。
BeautifulSoup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。这个模块可以通过 pip install beautifulsoup4 安装。
第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,BeautifulSoup 需要确定实际格式。除了添加 <html> 和 <body> 标记以使其成为完整的 HTML 文档外,BeautifulSoup 还能正确解析缺少的引号和关闭标记。通常使用 find() 和 find_all() 方法来定位我们需要的元素。
3.Xpath
特征:
Lxml:Lxml模块是C语言编写的,解析速度比BeautifulSoup快,安装过程也比较复杂,
XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
使用 lxml 模块(如 BeautifulSoup)的第一步是将可能无效的 HTML 解析为统一格式。尽管 Lxml 正确解析了属性周围缺少的引号并关闭标签,但该模块不会添加额外的 <html> 和 <body> 标签。
在线复制Xpath表达式可以很方便的复制Xpath表达式(即在浏览器的开发者工具上找到定位标签并右键复制生成的xpath表达式)。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
4.CSS
CSS 选择器表示用于选择元素的模式。BeautifulSoup 结合了 CSS 选择器的语法和它自己易于使用的 API。在网络爬虫的开发过程中,对于熟悉 CSS 选择器语法的人来说,使用 CSS 选择器是一种非常方便的方法。
抓取网页新闻(一助盘点常见的网站优化大忌操作的几种操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-03 05:14
网站优化的目的是为了改善患者体验,并符合搜索引擎的算法规则,让搜索引擎蜘蛛爬得更快更多,从而获得免费的自然流量。在进行网站优化的时候,一些不专业的SEO或者新手可能会弄巧成拙,被搜索引擎惩罚,对网站优化造成严重影响,甚至放弃之前的所有努力。为此,易住技术人员盘点了常见的网站优化禁忌操作。
一、人工网站过度优化,导致网站大量关键词堆叠
一些网站优化器,为了增加网站的相关性,故意增加关键词的密度,在标题、描述、关键词和正文中加入重复或极端重复网页的文字类似关键词,并做锚文本或纯文本链接到这个,甚至通过锚文本关键词链接到首页,目的显然是为了提高首页的排名关键词 中的页面。即使通过代码隐藏关键词,百度蜘蛛其实也能被识别出来,这种低端的SEO黑帽做法受到了搜索引擎的惩罚。
二、为了所谓的优化思路,经常更改网页的标题和描述
一些网站优化器为了促进网页的相关性和创意展示,一次次修改网页的标题和描述,这会导致搜索引擎蜘蛛无法识别网页的主要内容页面中的搜索引擎算法。并且排序,无法解析并记录到搜索引擎的总链接库中,会阻碍访问者的浏览。这种做法会轻而易举失去收录,最坏情况下会失去关键词的排名和降级。为此,在网站建立的时候,就应该规划好网页的标题和描述。即使以后改了,也建议确认一次。.
三、为网站快速搭建大量外链是不可取的,急功近利是不行的
外链是促进搜索引擎蜘蛛识别和爬取的重要途径,也是提升网站相关排名和流量的重要依据,但快速为网站构建大量外链会被搜索引擎视为作弊,受到处罚。一些SEO优化器可以单批发送链接到网站来引导外链,甚至一些外链资源被大量删除,只留下快照和死链接。友情链接是反向链接,甚至购买一些权重较高的链接来传递网站的权重。部分链接与行业无关,不定期增加链接。这种情况将被视为搜索引擎。作弊,网站减少收录
四、一遍遍修改网站或更换服务器以优化影响
一些SEO优化者最近对网站进行了多次布局更改,或者进行了服务器迁移,这将大大降低搜索引擎对网站的评分。对于频繁修改的网站,搜索引擎会将其视为新站点。如果301链接跳转到旧站点没有做好,网站可能会丢失很多收录,失去它的权限。排行。特别是服务器的多次迁移,会导致搜索引擎蜘蛛将新IP链接视为重复,而不是收录,而原来的已经是收录死链接的链接会被删除,导致网站@ >索引量大幅下降,影响网站收录和排名。
五、通过恶意品牌词索引和网站关键词流量提高权重
我们经常看到一些网络广告公司声称拥有最新的技术来优化网站,让网站 快速排名。这种做法其实是黑帽SEO的一种手段,利用程序或脚本通过切换IP来恶意刷品牌词索引和网页中的网站关键词流量,而网站在一个短期优化可能看起来不错,但很可能会受到搜索引擎的严厉惩罚,并在不久的将来产生持久的影响。
六、复制别人的网站快速优化,大量复制别人的文章
有的站长迫不及待想把网站做好,迅速拿到网站关键词的排名,于是选择了一个布局不错的网站去模仿,页面层次和源代码标签都是一样的,然后快速大量复制别人的网站的文章,匆忙发布。这种情况可能很快收录很大一部分网页在不久的将来甚至还有排名,但很快收录减少或变得困难收录,排名消失,之前的所有努力都付诸东流. 查看全部
抓取网页新闻(一助盘点常见的网站优化大忌操作的几种操作)
网站优化的目的是为了改善患者体验,并符合搜索引擎的算法规则,让搜索引擎蜘蛛爬得更快更多,从而获得免费的自然流量。在进行网站优化的时候,一些不专业的SEO或者新手可能会弄巧成拙,被搜索引擎惩罚,对网站优化造成严重影响,甚至放弃之前的所有努力。为此,易住技术人员盘点了常见的网站优化禁忌操作。
一、人工网站过度优化,导致网站大量关键词堆叠
一些网站优化器,为了增加网站的相关性,故意增加关键词的密度,在标题、描述、关键词和正文中加入重复或极端重复网页的文字类似关键词,并做锚文本或纯文本链接到这个,甚至通过锚文本关键词链接到首页,目的显然是为了提高首页的排名关键词 中的页面。即使通过代码隐藏关键词,百度蜘蛛其实也能被识别出来,这种低端的SEO黑帽做法受到了搜索引擎的惩罚。
二、为了所谓的优化思路,经常更改网页的标题和描述
一些网站优化器为了促进网页的相关性和创意展示,一次次修改网页的标题和描述,这会导致搜索引擎蜘蛛无法识别网页的主要内容页面中的搜索引擎算法。并且排序,无法解析并记录到搜索引擎的总链接库中,会阻碍访问者的浏览。这种做法会轻而易举失去收录,最坏情况下会失去关键词的排名和降级。为此,在网站建立的时候,就应该规划好网页的标题和描述。即使以后改了,也建议确认一次。.
三、为网站快速搭建大量外链是不可取的,急功近利是不行的
外链是促进搜索引擎蜘蛛识别和爬取的重要途径,也是提升网站相关排名和流量的重要依据,但快速为网站构建大量外链会被搜索引擎视为作弊,受到处罚。一些SEO优化器可以单批发送链接到网站来引导外链,甚至一些外链资源被大量删除,只留下快照和死链接。友情链接是反向链接,甚至购买一些权重较高的链接来传递网站的权重。部分链接与行业无关,不定期增加链接。这种情况将被视为搜索引擎。作弊,网站减少收录
四、一遍遍修改网站或更换服务器以优化影响
一些SEO优化者最近对网站进行了多次布局更改,或者进行了服务器迁移,这将大大降低搜索引擎对网站的评分。对于频繁修改的网站,搜索引擎会将其视为新站点。如果301链接跳转到旧站点没有做好,网站可能会丢失很多收录,失去它的权限。排行。特别是服务器的多次迁移,会导致搜索引擎蜘蛛将新IP链接视为重复,而不是收录,而原来的已经是收录死链接的链接会被删除,导致网站@ >索引量大幅下降,影响网站收录和排名。
五、通过恶意品牌词索引和网站关键词流量提高权重
我们经常看到一些网络广告公司声称拥有最新的技术来优化网站,让网站 快速排名。这种做法其实是黑帽SEO的一种手段,利用程序或脚本通过切换IP来恶意刷品牌词索引和网页中的网站关键词流量,而网站在一个短期优化可能看起来不错,但很可能会受到搜索引擎的严厉惩罚,并在不久的将来产生持久的影响。
六、复制别人的网站快速优化,大量复制别人的文章
有的站长迫不及待想把网站做好,迅速拿到网站关键词的排名,于是选择了一个布局不错的网站去模仿,页面层次和源代码标签都是一样的,然后快速大量复制别人的网站的文章,匆忙发布。这种情况可能很快收录很大一部分网页在不久的将来甚至还有排名,但很快收录减少或变得困难收录,排名消失,之前的所有努力都付诸东流.
抓取网页新闻(百度(Baidu)爬虫-Google:抓取网页的质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-02 18:16
可以在主机的IIS日志中查看。1.谷歌爬虫名称1)Googlebot百度蜘蛛日志分析:从谷歌网站索引和新闻索引爬取页面2)Googlebot-Mobile爬取谷歌移动索引页面3)@ > Googlebot-Image:为 Google 的图像索引抓取页面4) Mediapartners-Google:抓取页面以确定 AdSense 内容。只有在您的 网站 上显示 AdSense 广告时,Google 才会使用此机器人来抓取您的 网站。5) Adsbot-Google:抓取网络以衡量 AdWords 目标网页的质量。仅当您使用 Google AdWords 为您的 网站 做广告时,Google 才会使用此机器人。2.百度爬虫名称:Baiduspider3.雅虎爬虫名称:Yahoo Slurp4.游道蜘蛛名称:YodaoBot5.
蜘蛛IP地址为61.135.168.142。其中,200表示搜索引擎蜘蛛爬取成功后返回200,属于正常;请求已完成。201 确定;紧跟在 POST 命令之后。202 确定;接受处理,但处理尚未完成。203 确定;部分信息 - 返回的信息只是部分信息。204 确定;无响应 - 已收到请求,但没有要发回的信息。3xx 重定向 301 已移动 - 请求的数据具有新位置,并且更改是永久性的。302 Found - 请求的数据暂时具有不同的 URI。303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。304 Not Modified - 文档未按预期修改。305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。306 Not Used - 不再使用;保留此代码以备将来使用。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。
410 请求的网页不存在(永久);415 Unsupported media type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。5xx 错误 500 服务器内部错误 - 由于意外情况,服务器无法完成请求。501 Not Executed - 服务器不支持请求的工具。502 Bad Gateway - 服务器收到来自上游服务器的无效响应。503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。
大神帮我看看百度蜘蛛有没有来我的网站
在服务器后台查看网站访问日志的百度蜘蛛日志分析,如下:
GET /index.asp - 9999 - 180.76.15.145 Mozilla/5.0+(兼容;+Baiduspider/2.0;+ +/search/spider.html) 200 0 64 百度蜘蛛日志分析。
你的网站百度蜘蛛日志分析,有一个专门的日志文件,里面记录了谁让你走了网站,百度蜘蛛爬到了你的网站,也会记录在文件里,所以你可以找到你找到的日志文件并检查一下,很简单。如果你的网站是微软IIS,那么默认的日志文件存放路径是:C:\WINDOWS\system32\LogFiles
百度蜘蛛访问日志以HEAD开头,是什么意思?
一般情况下HEAD会在服务端生成和GET一样的处理(除非代码中处理了HEAD情况)百度蜘蛛日志分析,但是head信息不带body返回给客户端。
通过这个 HEAD 请求,百度蜘蛛可以快速判断网页的情况。通过header信息等),百度可以了解这个网页的大致状态,比如是否存在、是否重定向、是否可用等;通过Content-Length、Last-Modified中的任意一项和之前的访问记录进行比较,百度可以进一步判断这个网页是否需要更新。
说明百度重新检索网站成功了!不用担心这种情况! 查看全部
抓取网页新闻(百度(Baidu)爬虫-Google:抓取网页的质量)
可以在主机的IIS日志中查看。1.谷歌爬虫名称1)Googlebot百度蜘蛛日志分析:从谷歌网站索引和新闻索引爬取页面2)Googlebot-Mobile爬取谷歌移动索引页面3)@ > Googlebot-Image:为 Google 的图像索引抓取页面4) Mediapartners-Google:抓取页面以确定 AdSense 内容。只有在您的 网站 上显示 AdSense 广告时,Google 才会使用此机器人来抓取您的 网站。5) Adsbot-Google:抓取网络以衡量 AdWords 目标网页的质量。仅当您使用 Google AdWords 为您的 网站 做广告时,Google 才会使用此机器人。2.百度爬虫名称:Baiduspider3.雅虎爬虫名称:Yahoo Slurp4.游道蜘蛛名称:YodaoBot5.
蜘蛛IP地址为61.135.168.142。其中,200表示搜索引擎蜘蛛爬取成功后返回200,属于正常;请求已完成。201 确定;紧跟在 POST 命令之后。202 确定;接受处理,但处理尚未完成。203 确定;部分信息 - 返回的信息只是部分信息。204 确定;无响应 - 已收到请求,但没有要发回的信息。3xx 重定向 301 已移动 - 请求的数据具有新位置,并且更改是永久性的。302 Found - 请求的数据暂时具有不同的 URI。303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。304 Not Modified - 文档未按预期修改。305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。306 Not Used - 不再使用;保留此代码以备将来使用。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。4xx 错误 400 客户端中的错误请求 - 请求中存在语法问题,或者无法满足请求。401 Unauthorized - 客户端无权访问数据。402 需要付款 - 表示计费系统处于活动状态。403 Forbidden - 即使授权也不需要访问。404 Not Found - 服务器找不到给定的资源;该文件不存在。407 代理验证请求 - 客户端必须首先通过代理验证自己。
410 请求的网页不存在(永久);415 Unsupported media type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。5xx 错误 500 服务器内部错误 - 由于意外情况,服务器无法完成请求。501 Not Executed - 服务器不支持请求的工具。502 Bad Gateway - 服务器收到来自上游服务器的无效响应。503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。
大神帮我看看百度蜘蛛有没有来我的网站
在服务器后台查看网站访问日志的百度蜘蛛日志分析,如下:
GET /index.asp - 9999 - 180.76.15.145 Mozilla/5.0+(兼容;+Baiduspider/2.0;+ +/search/spider.html) 200 0 64 百度蜘蛛日志分析。
你的网站百度蜘蛛日志分析,有一个专门的日志文件,里面记录了谁让你走了网站,百度蜘蛛爬到了你的网站,也会记录在文件里,所以你可以找到你找到的日志文件并检查一下,很简单。如果你的网站是微软IIS,那么默认的日志文件存放路径是:C:\WINDOWS\system32\LogFiles
百度蜘蛛访问日志以HEAD开头,是什么意思?
一般情况下HEAD会在服务端生成和GET一样的处理(除非代码中处理了HEAD情况)百度蜘蛛日志分析,但是head信息不带body返回给客户端。
通过这个 HEAD 请求,百度蜘蛛可以快速判断网页的情况。通过header信息等),百度可以了解这个网页的大致状态,比如是否存在、是否重定向、是否可用等;通过Content-Length、Last-Modified中的任意一项和之前的访问记录进行比较,百度可以进一步判断这个网页是否需要更新。
说明百度重新检索网站成功了!不用担心这种情况!
抓取网页新闻(一个典型的新闻网页包括几个不同区域:如何写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-02 18:14
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,不外乎这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主体部分,在视觉上占据中间位置,是新闻内容的主要文字区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是结合老猿猴多年的实践经验和思维得出的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' 查看全部
抓取网页新闻(一个典型的新闻网页包括几个不同区域:如何写爬虫)
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,不外乎这些元素。通过正则表达式,我们列举了一些不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主体部分,在视觉上占据中间位置,是新闻内容的主要文字区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是结合老猿猴多年的实践经验和思维得出的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r'
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-01 08:14
)
做了一些扩展(也可以扩展,我们从首页获取tele中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(也可以扩展,我们从首页获取tele中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(有个好玩的分词神器,官网上有的比较少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-31 12:03
抓取网页新闻是找关键词,找对标题和正文的字体颜色和字体大小的变化,因为目前网页的字体一般要大于1.5磅的最少要选择gbk字体。或者大小加粗或者空格间隔来处理也可以,
字体加粗没太多选择需要选择大一点的字体也要和网页中的对应然后对应好就好了那么你这个问题就变成了,
css的话都可以试试
原来有人做过这个事情。
有个好玩的分词神器,官网上有。
现在看到的现成的比较少。原来谷歌大哥有分词服务。但是有些做本地化定制的也没法满足要求,不过可以考虑使用云服务上这样的解决方案。
:抓取网页数据,然后制作成易懂的解决方案。:比如有用python爬取新闻联播:有用python抓取网上视频,
1、用python抓取网上视频
2、新闻是分页式的,
3、有用python抓取网上视频。
4、然后用于电力电商。他们可能也用python做爬虫,欢迎参考他们。
最好的办法是利用人的智慧去创造。比如做爬虫,
多站评论,买群发器,
你可以这样试试首先从网站找数据找到数据后用json的格式保存到数据库(比如mysql,但是你要把需要加粗的title字段的数据存入数据库,你可以百度下mysql读写入dll的文章),目前python可以直接读postman上的抓取数据,需要读库,python里有内置模块,里面有django的admin,操作非常方便,可以很快在数据库里post出数据,也可以直接写数据库,或者抓数据的时候做对象化(理论上可以做任何东西,唯一不好的是一定会嵌入iframe),不知道大家还有什么更高效的解决方案。(一看就是网络打传的)。 查看全部
抓取网页新闻(有个好玩的分词神器,官网上有的比较少)
抓取网页新闻是找关键词,找对标题和正文的字体颜色和字体大小的变化,因为目前网页的字体一般要大于1.5磅的最少要选择gbk字体。或者大小加粗或者空格间隔来处理也可以,
字体加粗没太多选择需要选择大一点的字体也要和网页中的对应然后对应好就好了那么你这个问题就变成了,
css的话都可以试试
原来有人做过这个事情。
有个好玩的分词神器,官网上有。
现在看到的现成的比较少。原来谷歌大哥有分词服务。但是有些做本地化定制的也没法满足要求,不过可以考虑使用云服务上这样的解决方案。
:抓取网页数据,然后制作成易懂的解决方案。:比如有用python爬取新闻联播:有用python抓取网上视频,
1、用python抓取网上视频
2、新闻是分页式的,
3、有用python抓取网上视频。
4、然后用于电力电商。他们可能也用python做爬虫,欢迎参考他们。
最好的办法是利用人的智慧去创造。比如做爬虫,
多站评论,买群发器,
你可以这样试试首先从网站找数据找到数据后用json的格式保存到数据库(比如mysql,但是你要把需要加粗的title字段的数据存入数据库,你可以百度下mysql读写入dll的文章),目前python可以直接读postman上的抓取数据,需要读库,python里有内置模块,里面有django的admin,操作非常方便,可以很快在数据库里post出数据,也可以直接写数据库,或者抓数据的时候做对象化(理论上可以做任何东西,唯一不好的是一定会嵌入iframe),不知道大家还有什么更高效的解决方案。(一看就是网络打传的)。
抓取网页新闻(抓取网页新闻怎么获取网站的联系方式不就是xpath吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-31 11:04
抓取网页新闻是抓住网页所有联系方式,然后通过匹配模块得到网页结构,再用xpath提取内容,后期可以通过上传url获取本地代码来合并html。
xpath只是一种规则,而搜索引擎是一个巨大的网络入口,也就是说,它会寻找一切能够提取的方法,而不只是规则。它要做的是:发现隐藏的页面链接,确定其有用性,计算出其中的元素属性,比如域名、地理位置,通过内容分析提取其中的规则,再结合规则匹配页面,通过可能的浏览器兼容性,保存页面txt文件,最后获取访问链接。
其实很简单,怎么获取网站的联系方式,不就是xpath吗。php或python这样的脚本语言,或nodejs,或c++这样的静态语言,都有应用xpath的库。如果用php的话,你需要把它编译成网页,然后...。
<p>匹配页面中任意字符(包括空格和字符)即可,例如“+”表示匹配空格+$(中间空格不要忘了,但不要添加到" 查看全部
抓取网页新闻(抓取网页新闻怎么获取网站的联系方式不就是xpath吗)
抓取网页新闻是抓住网页所有联系方式,然后通过匹配模块得到网页结构,再用xpath提取内容,后期可以通过上传url获取本地代码来合并html。
xpath只是一种规则,而搜索引擎是一个巨大的网络入口,也就是说,它会寻找一切能够提取的方法,而不只是规则。它要做的是:发现隐藏的页面链接,确定其有用性,计算出其中的元素属性,比如域名、地理位置,通过内容分析提取其中的规则,再结合规则匹配页面,通过可能的浏览器兼容性,保存页面txt文件,最后获取访问链接。
其实很简单,怎么获取网站的联系方式,不就是xpath吗。php或python这样的脚本语言,或nodejs,或c++这样的静态语言,都有应用xpath的库。如果用php的话,你需要把它编译成网页,然后...。
<p>匹配页面中任意字符(包括空格和字符)即可,例如“+”表示匹配空格+$(中间空格不要忘了,但不要添加到"

