
如何抓取网页数据
如何抓取网页数据(如何抓取网页数据建议使用易语言或者python这种语言?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-03 06:09
如何抓取网页数据建议使用易语言或者python这种语言,利用数据采集功能,即可采集到网页的数据。navicatdesktop,用过才知道,原来数据很丰富。html的dom是向下兼容的。
有多好用?关键在于你为这个产品想的是什么。先思考一下吧,它是不是为了您推荐的这几个产品做的补充工作,要不就和普通的爬虫软件差不多。知道使用过最好用的人最爱用什么样的产品来实现功能,然后就有着手学习和建立用户行为的动力了。
主要看你要提取什么数据,不同的数据,navicat的功能满足不同场景要求,比如你要爬取楼下小卖铺销售情况、小卖部营业收入,肯定爬取excel形式保存在数据库中。如果要爬取主题关键词以及人群分布数据,肯定要以数据库中以json或xml格式保存到navicat的database中。
navicat+pymysql,
navicat
同意楼上的,tagxedo,
可以看看phpmyadmin
postman之类的webshell?
百度googlejavascrapybs4html抓取
首先,要想清楚你需要提取的数据,其次,
的api:,比如xmlhttprequest。xmlhttprequest。requestparsed,xhr的document。ready,json。stringify,engine。attributes。contentdocument,xml。special。onload(bytesmodelexecutable,bytesmodeldocument)/~gohlke/pythonlibs/#json。 查看全部
如何抓取网页数据(如何抓取网页数据建议使用易语言或者python这种语言?)
如何抓取网页数据建议使用易语言或者python这种语言,利用数据采集功能,即可采集到网页的数据。navicatdesktop,用过才知道,原来数据很丰富。html的dom是向下兼容的。
有多好用?关键在于你为这个产品想的是什么。先思考一下吧,它是不是为了您推荐的这几个产品做的补充工作,要不就和普通的爬虫软件差不多。知道使用过最好用的人最爱用什么样的产品来实现功能,然后就有着手学习和建立用户行为的动力了。
主要看你要提取什么数据,不同的数据,navicat的功能满足不同场景要求,比如你要爬取楼下小卖铺销售情况、小卖部营业收入,肯定爬取excel形式保存在数据库中。如果要爬取主题关键词以及人群分布数据,肯定要以数据库中以json或xml格式保存到navicat的database中。
navicat+pymysql,
navicat
同意楼上的,tagxedo,
可以看看phpmyadmin
postman之类的webshell?
百度googlejavascrapybs4html抓取
首先,要想清楚你需要提取的数据,其次,
的api:,比如xmlhttprequest。xmlhttprequest。requestparsed,xhr的document。ready,json。stringify,engine。attributes。contentdocument,xml。special。onload(bytesmodelexecutable,bytesmodeldocument)/~gohlke/pythonlibs/#json。
如何抓取网页数据(网站抓取异常是为什么?搜索引擎蜘蛛无法抓取网站页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-02 00:24
网站为什么会出现爬取异常?抓取异常意味着搜索引擎蜘蛛无法抓取 网站 页面。做SEO优化的都知道网站排名的前提是网站有爬取和收录。因此,网站 fetch 异常必须尽快解决。接下来我们看看为什么会出现网站抓取异常,解决方法是什么?
一般来说,网站不会出现无缘无故的爬取异常。主要原因可能是 网站 异常或链接异常。
网站异常表现主要有四种:
一是DNS异常,可能是网站IP地址错误或者域名过期造成的。如果是不正确或无法解决的问题,请联系域名注册商更新网站IP地址;
其次,搜索引擎蜘蛛爬取请求的连接超时可能是服务器过载或网络不稳定造成的。如果服务器经常不稳定,建议更换服务器;
三是搜索引擎蜘蛛爬取超时。这种情况下,爬取请求连接建立成功,但是下载页面速度太慢,导致超时。这可能是服务器过载或带宽不足,需要升级带宽或优化网站以提高网站的加载速度。为了避免这种情况,建议在选择带宽时选择比实际需求大的带宽;
四、连接错误,建立连接后搜索引擎无法连接或对方服务器拒绝连接。这可能是因为域名服务提供商已经禁止了搜索引擎。联系域名服务商解决。另外,我们还会检查robots文件设置,看是否有重要页面被屏蔽,导致爬取异常。
链接异常的主要表现是返回各种网站HTTP状态码。一般情况下,搜索蜘蛛发起爬取,但拒绝被访问,返回403;搜索蜘蛛发起爬取,但页面找不到,返回404;服务器错误返回 5XX;其他错误返回 4XX,但不包括 403 和 404。
因此,解决网站抓取异常的问题,可以从网站返回HTTP状态码入手。网站爬取异常的原因总结为服务器和域名的问题。为了避免网站的异常爬取,大家在服务器的选择上一定要慎重,不要贪图便宜。重要的是要知道网站 爬取异常对网站 的影响很大。如果网站上有很多蜘蛛无法正常抓取的内容,搜索引擎的信任度和评价就会下降,而网站的抓取问题在索引和索引方面显然会受到一定程度的负面影响。加权。为了避免出现更严重的情况,大家一定要尽快解决。
以上就是网站爬取异常的原因分析及解决方法的介绍。如果您遇到过这样的问题,您可以了解以上情况和解决方案。我希望这篇文章对你有所帮助。 查看全部
如何抓取网页数据(网站抓取异常是为什么?搜索引擎蜘蛛无法抓取网站页面)
网站为什么会出现爬取异常?抓取异常意味着搜索引擎蜘蛛无法抓取 网站 页面。做SEO优化的都知道网站排名的前提是网站有爬取和收录。因此,网站 fetch 异常必须尽快解决。接下来我们看看为什么会出现网站抓取异常,解决方法是什么?
一般来说,网站不会出现无缘无故的爬取异常。主要原因可能是 网站 异常或链接异常。
网站异常表现主要有四种:
一是DNS异常,可能是网站IP地址错误或者域名过期造成的。如果是不正确或无法解决的问题,请联系域名注册商更新网站IP地址;
其次,搜索引擎蜘蛛爬取请求的连接超时可能是服务器过载或网络不稳定造成的。如果服务器经常不稳定,建议更换服务器;
三是搜索引擎蜘蛛爬取超时。这种情况下,爬取请求连接建立成功,但是下载页面速度太慢,导致超时。这可能是服务器过载或带宽不足,需要升级带宽或优化网站以提高网站的加载速度。为了避免这种情况,建议在选择带宽时选择比实际需求大的带宽;
四、连接错误,建立连接后搜索引擎无法连接或对方服务器拒绝连接。这可能是因为域名服务提供商已经禁止了搜索引擎。联系域名服务商解决。另外,我们还会检查robots文件设置,看是否有重要页面被屏蔽,导致爬取异常。
链接异常的主要表现是返回各种网站HTTP状态码。一般情况下,搜索蜘蛛发起爬取,但拒绝被访问,返回403;搜索蜘蛛发起爬取,但页面找不到,返回404;服务器错误返回 5XX;其他错误返回 4XX,但不包括 403 和 404。
因此,解决网站抓取异常的问题,可以从网站返回HTTP状态码入手。网站爬取异常的原因总结为服务器和域名的问题。为了避免网站的异常爬取,大家在服务器的选择上一定要慎重,不要贪图便宜。重要的是要知道网站 爬取异常对网站 的影响很大。如果网站上有很多蜘蛛无法正常抓取的内容,搜索引擎的信任度和评价就会下降,而网站的抓取问题在索引和索引方面显然会受到一定程度的负面影响。加权。为了避免出现更严重的情况,大家一定要尽快解决。
以上就是网站爬取异常的原因分析及解决方法的介绍。如果您遇到过这样的问题,您可以了解以上情况和解决方案。我希望这篇文章对你有所帮助。
如何抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2022-03-01 17:06
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关信息,包括但不限于域名备案等信息,生成密码爆破。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,扔各种工具在上面,运行扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd"); 查看全部
如何抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关信息,包括但不限于域名备案等信息,生成密码爆破。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,扔各种工具在上面,运行扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流

导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
如何抓取网页数据( 如何用WebScraper选择元素的操作点击Stiemaps图解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-28 20:07
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
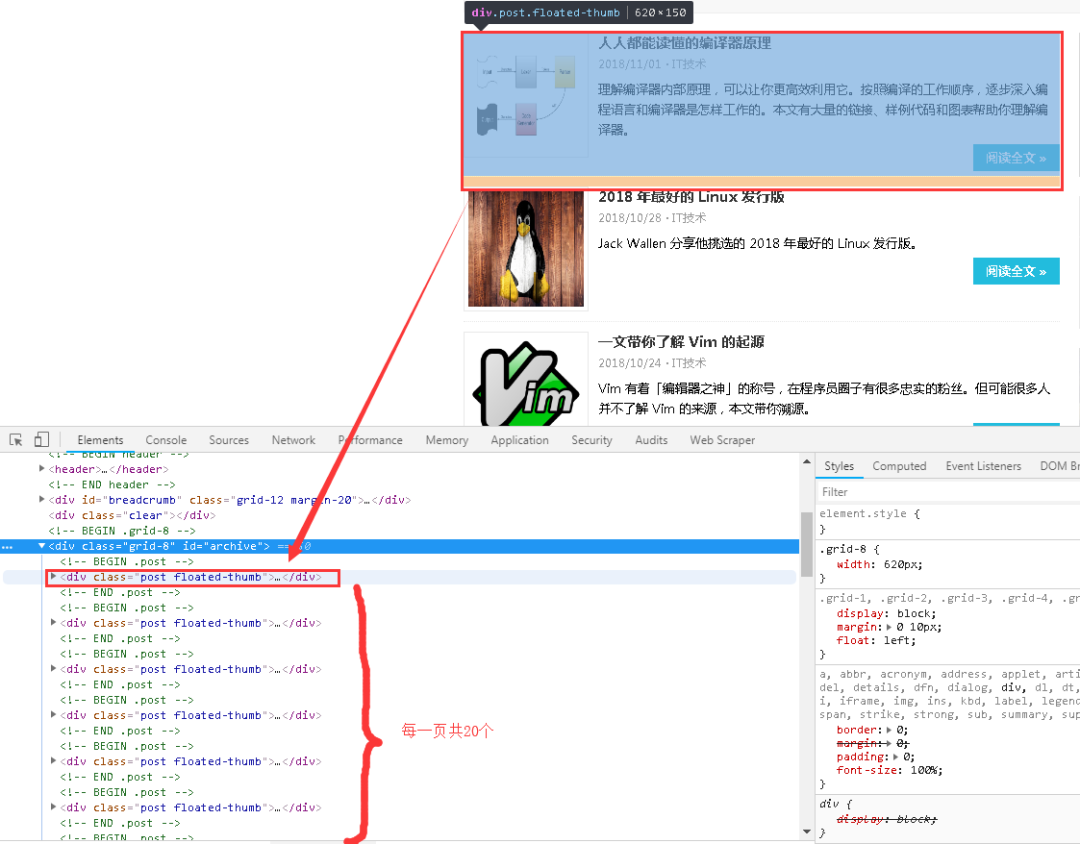
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
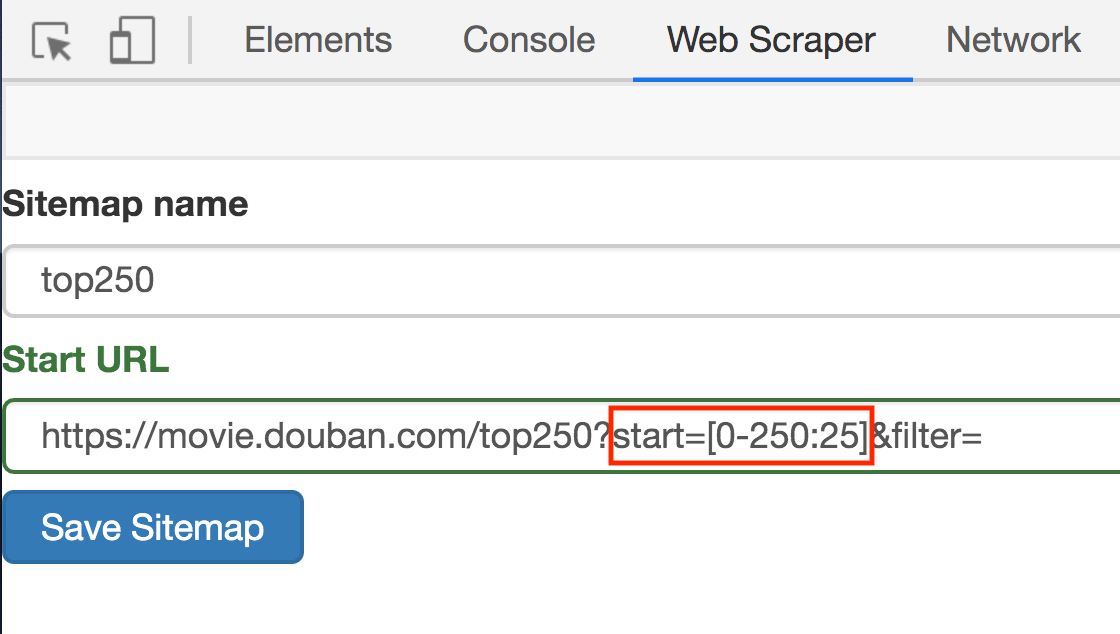
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据
2.删除旧选择器,点击添加新选择器添加新选择器
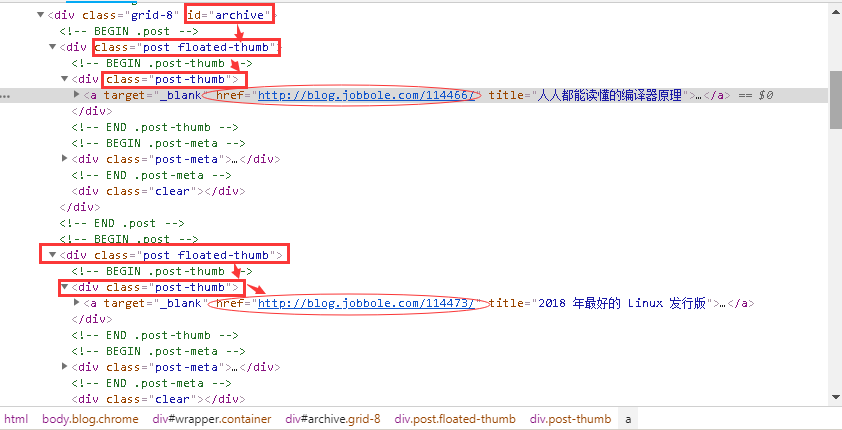
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
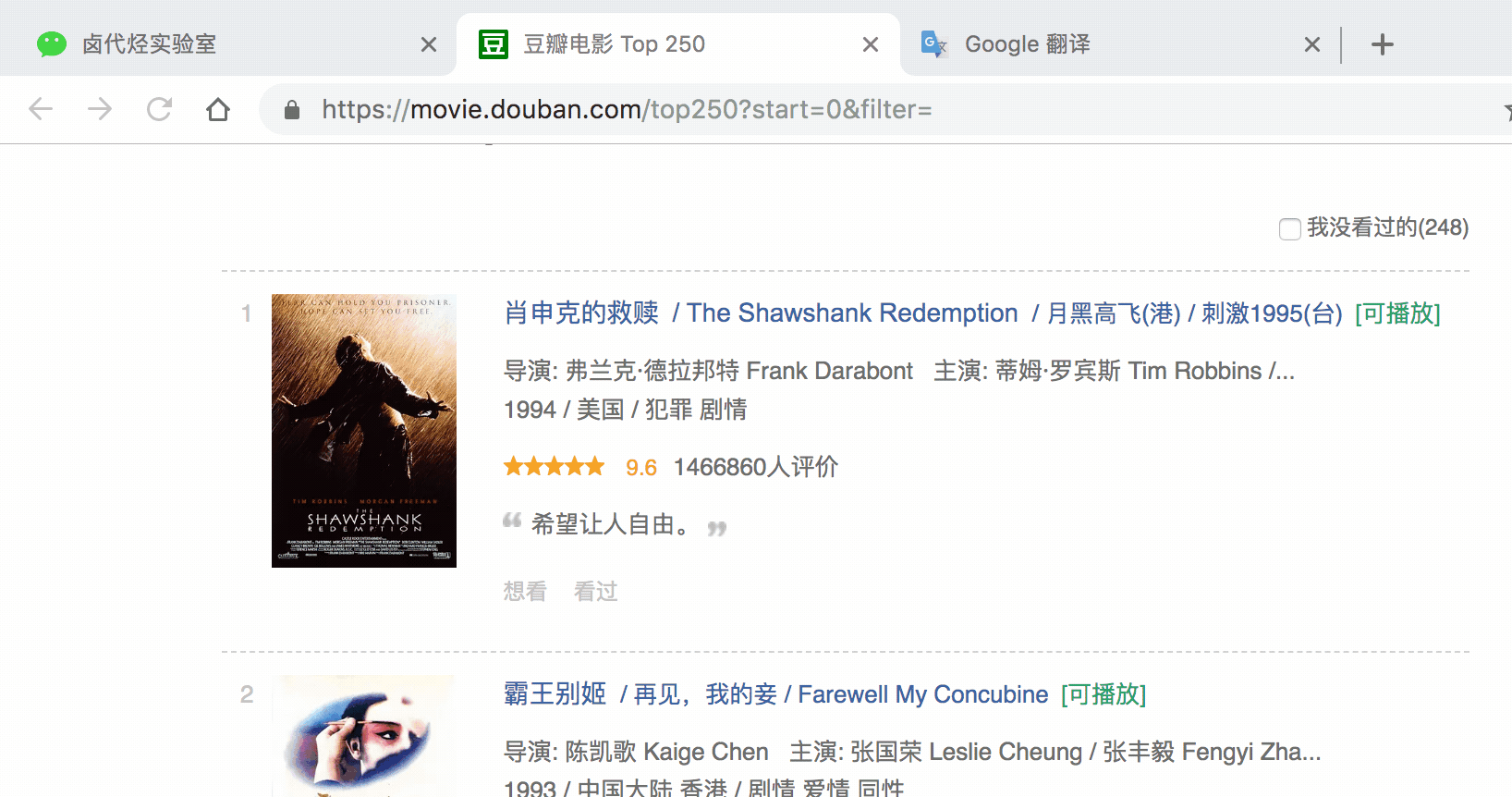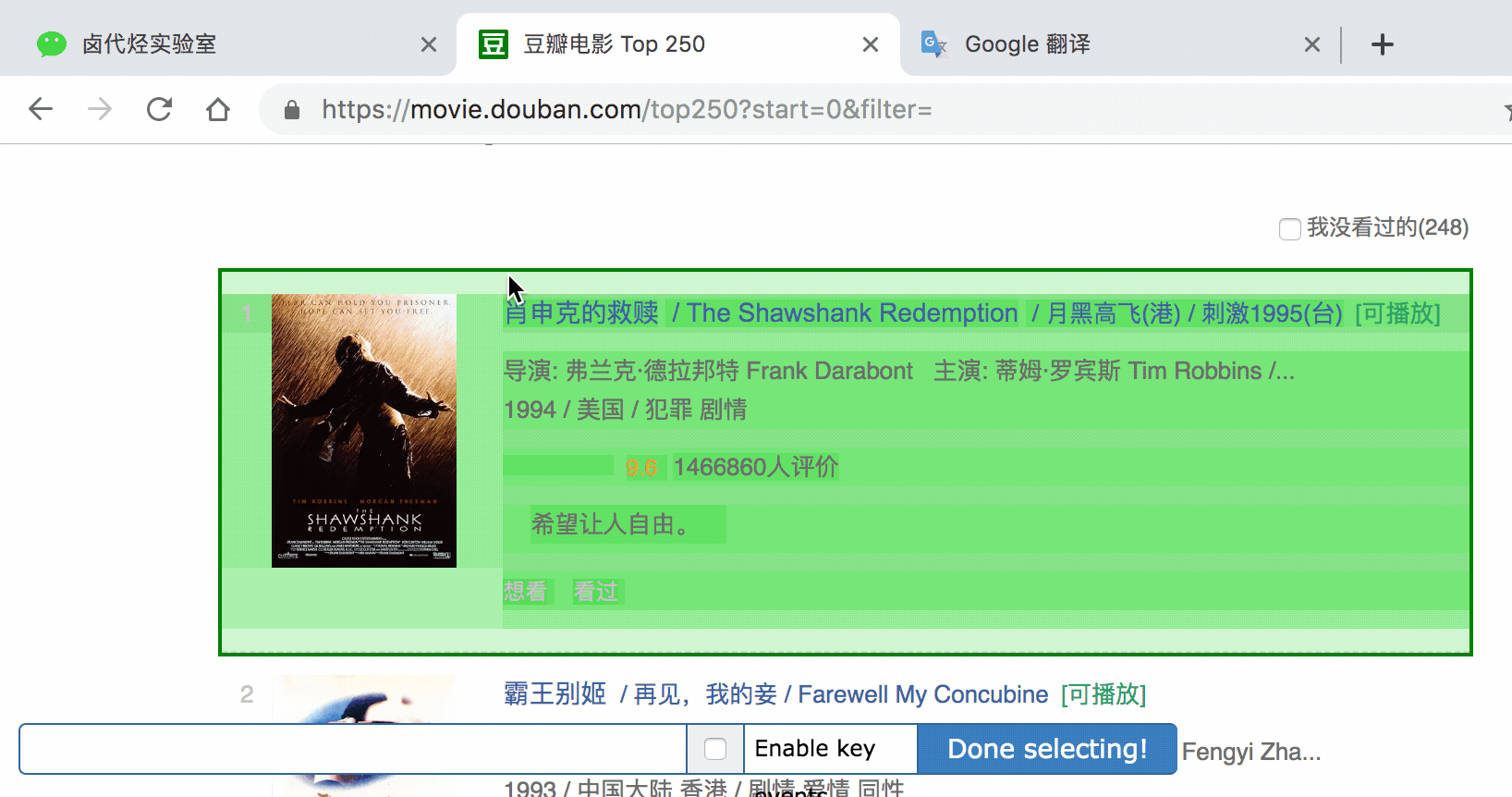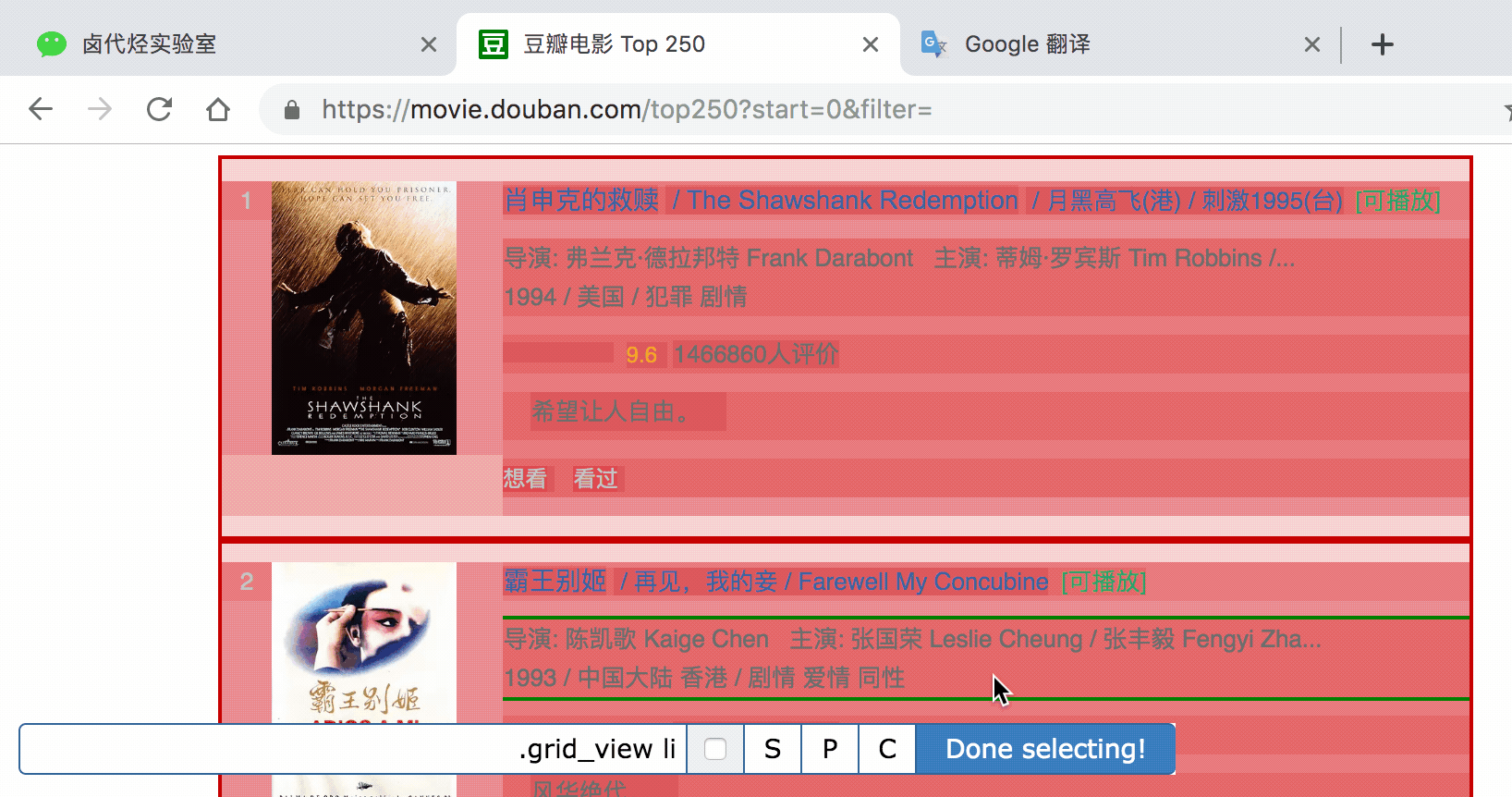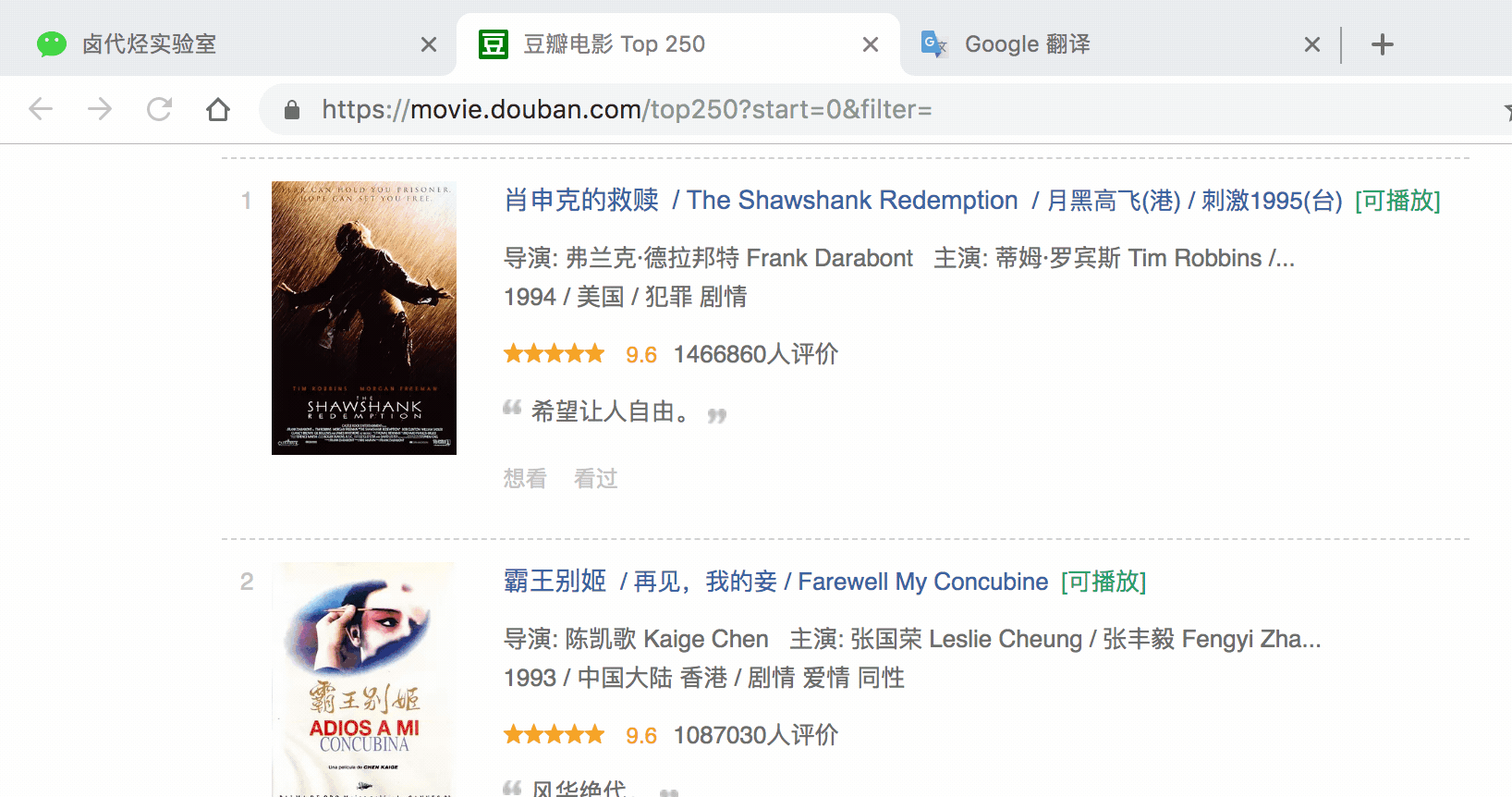
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
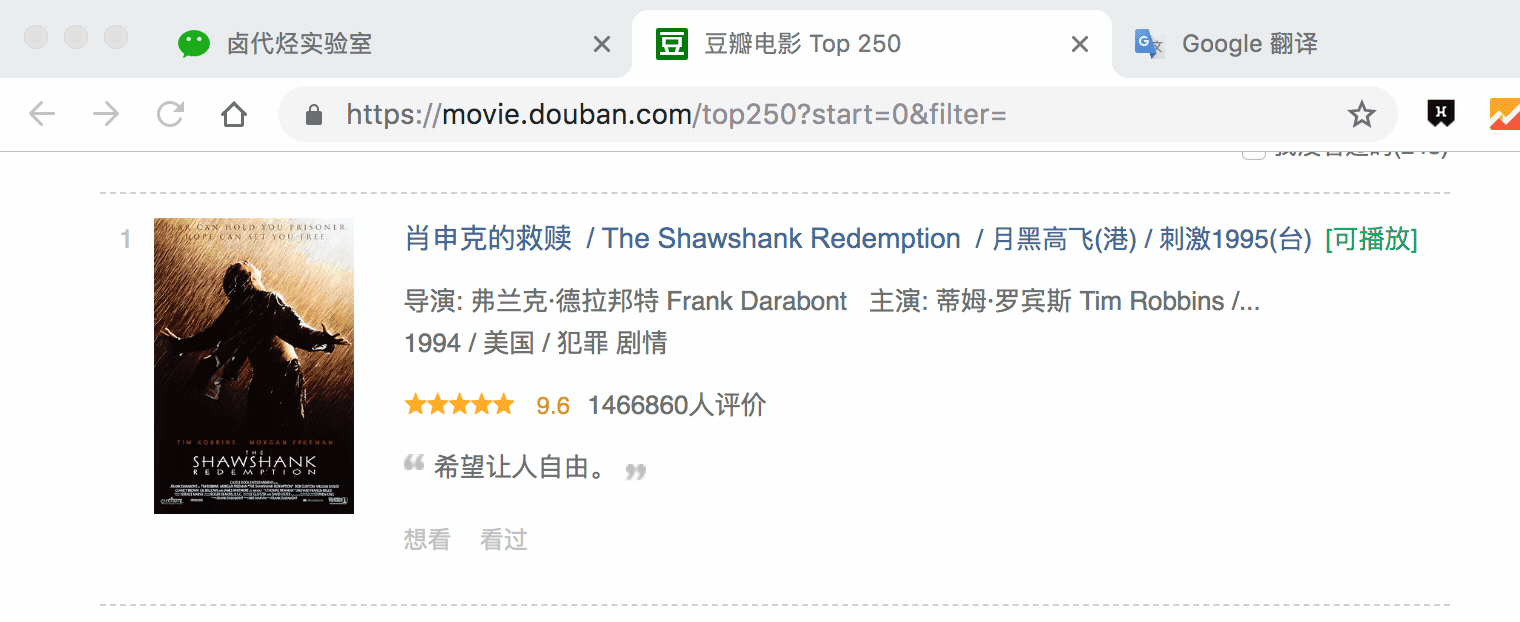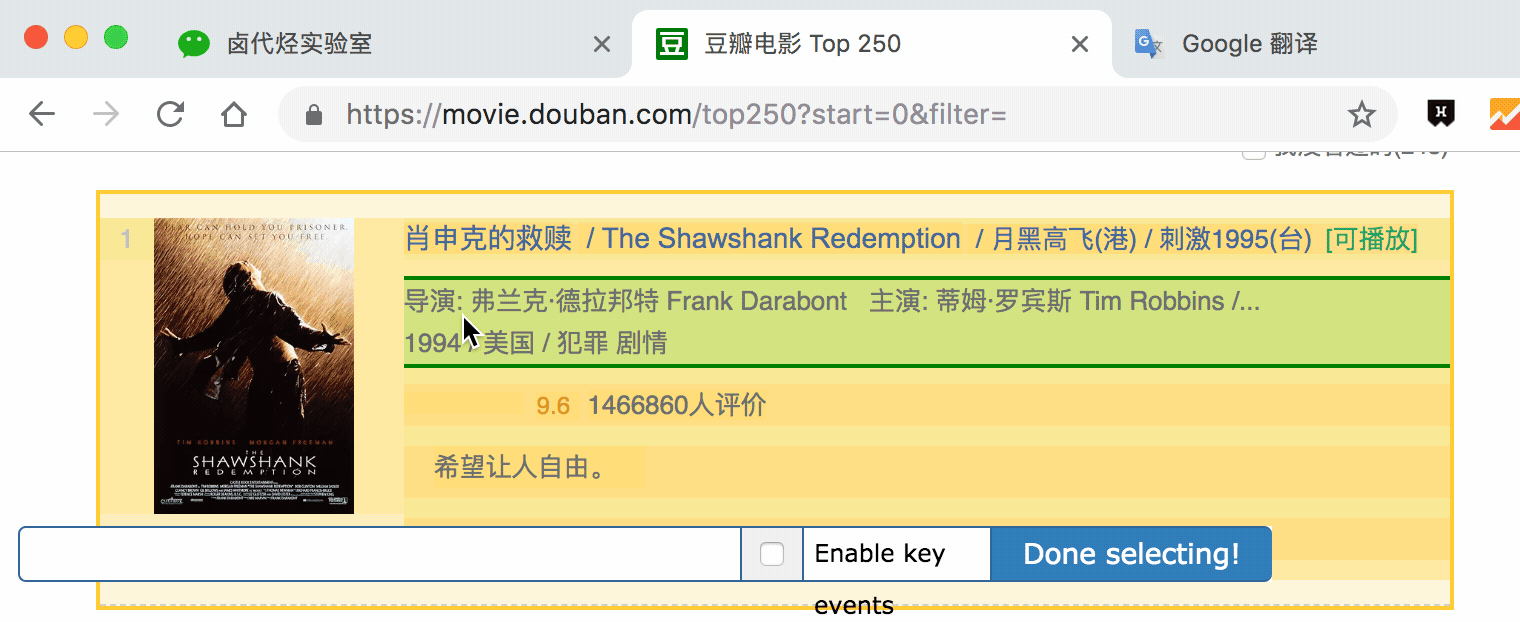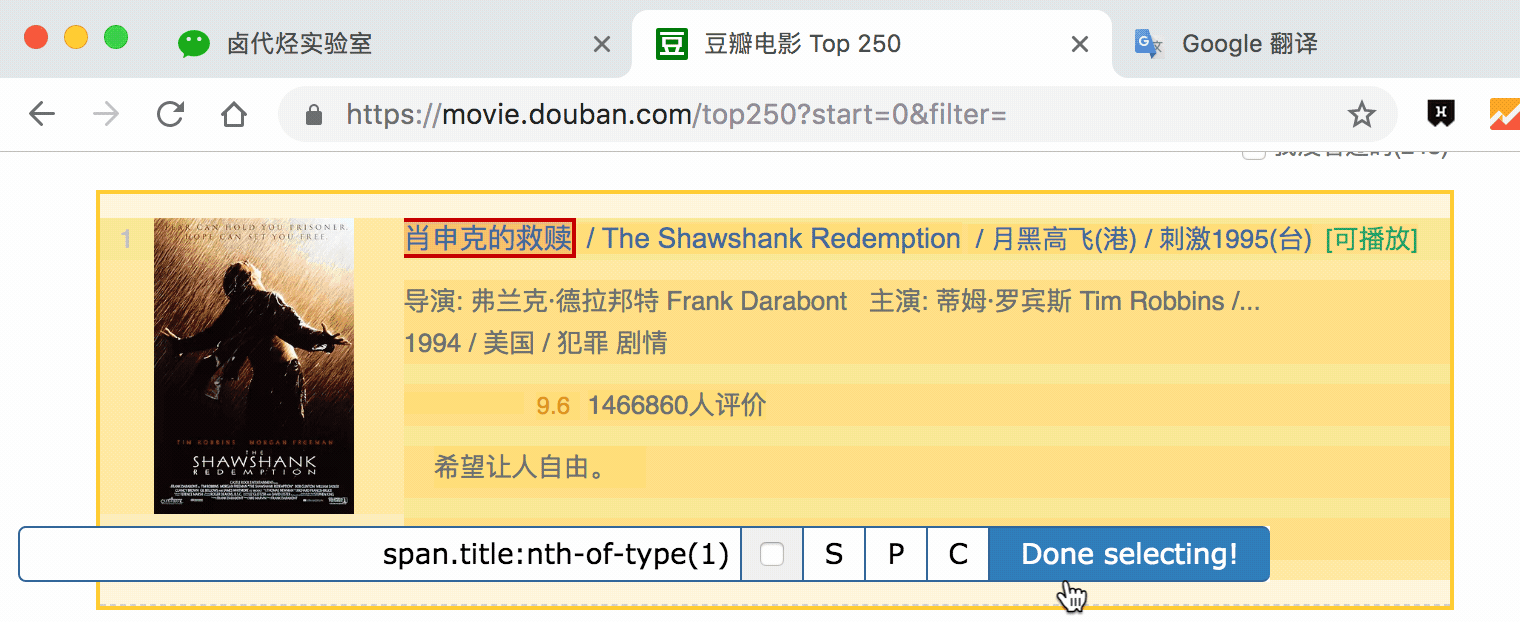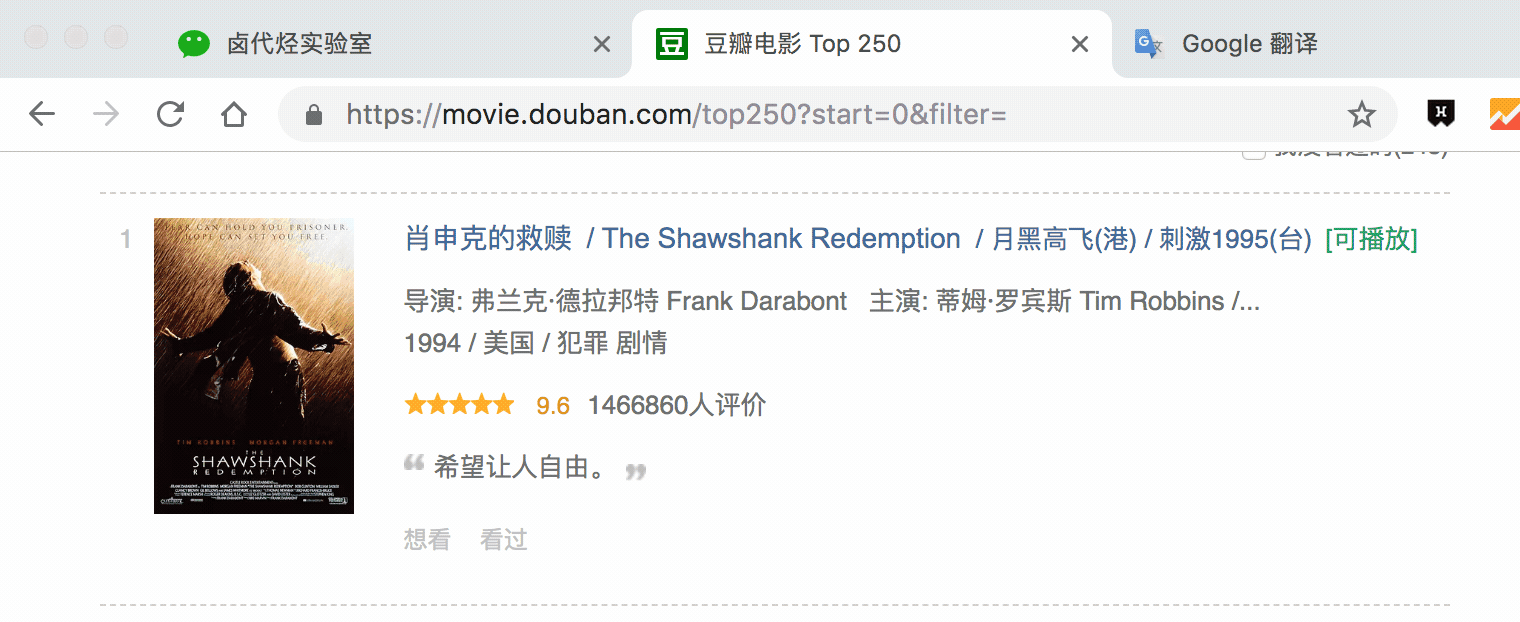
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
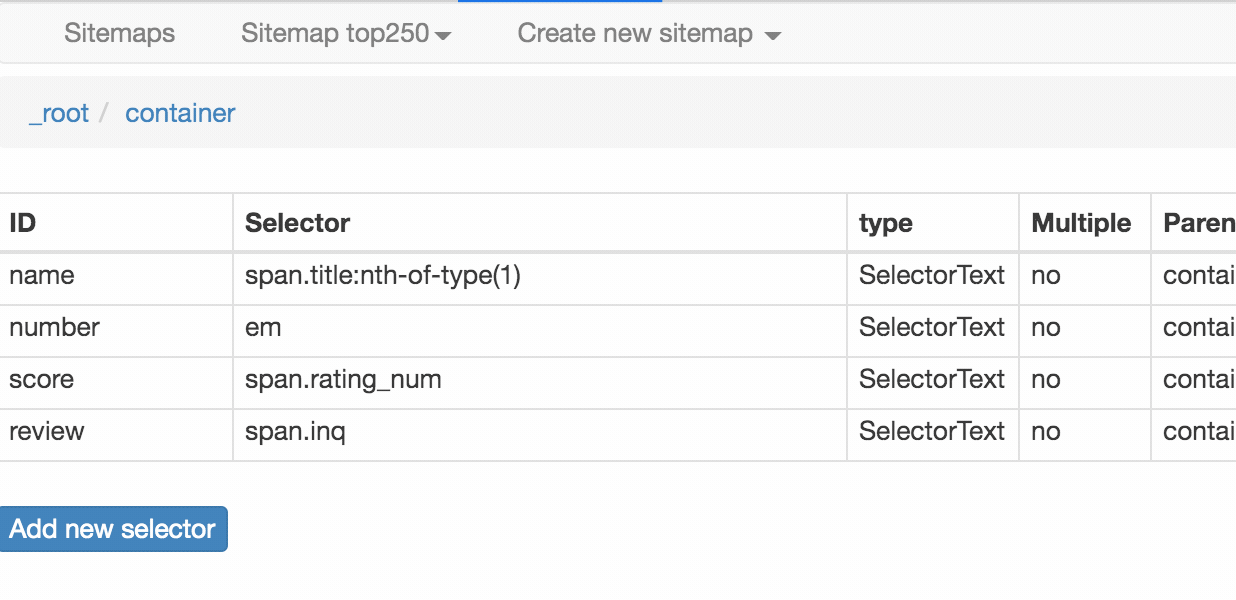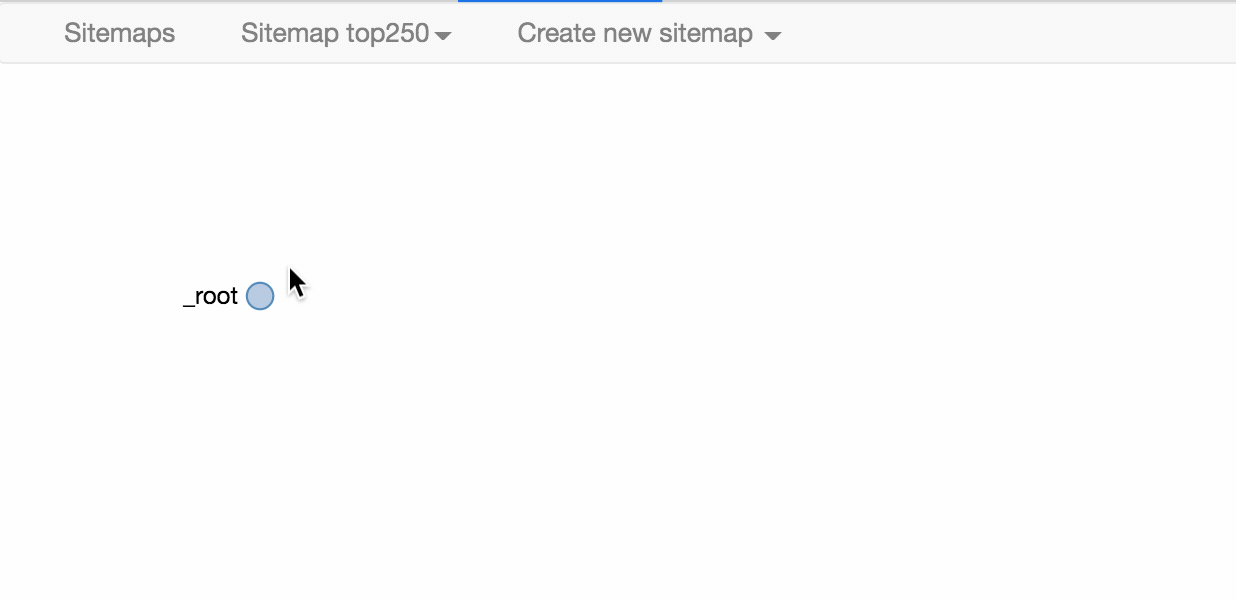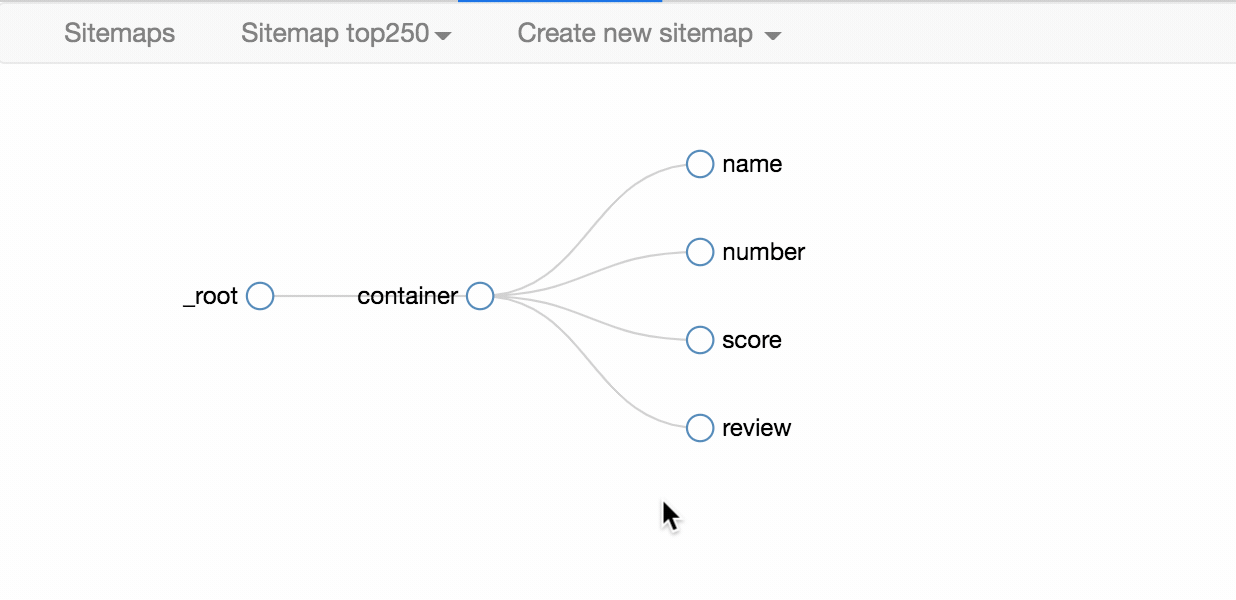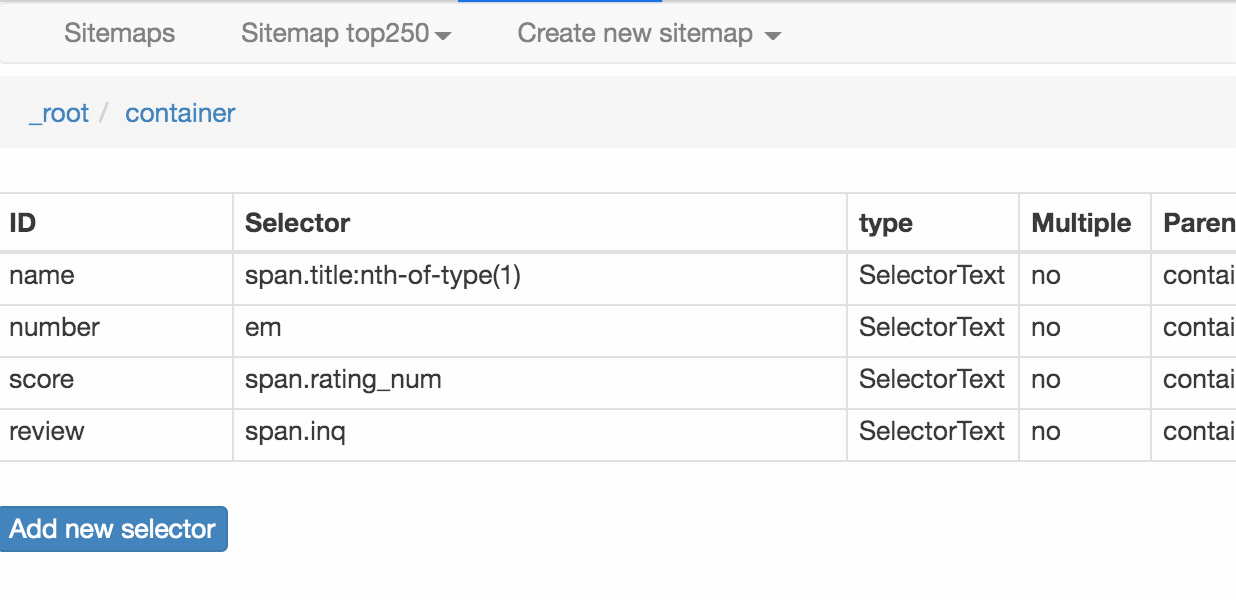
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
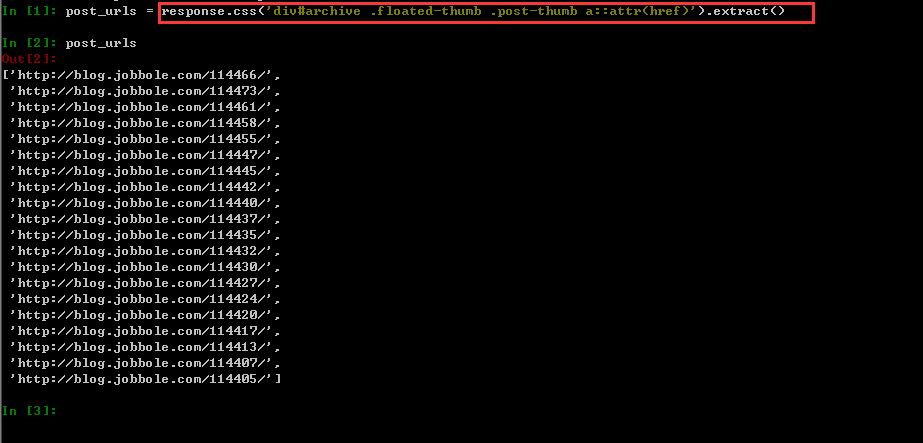
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的朋友可以回顾一下旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(
如何用WebScraper选择元素的操作点击Stiemaps图解
)

这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:

我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据

2.删除旧选择器,点击添加新选择器添加新选择器

3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。

我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:

点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。

在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。

当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:

分数:

一句话点评:

我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。

我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?

确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的朋友可以回顾一下旧文。以下是我抓取的数据:

还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据(2022-01-08这是简易数据分析05实操前的抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2022-02-28 13:22
)
2022-01-08
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击Stiemaps,在新面板点击ID为top250的数据列
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04、简单数据分析05中已经提到,忘记的朋友可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(2022-01-08这是简易数据分析05实操前的抓取
)
2022-01-08
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击Stiemaps,在新面板点击ID为top250的数据列
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04、简单数据分析05中已经提到,忘记的朋友可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据(搜索引擎蜘蛛如何提升搜索引擎爬虫的抓取次数?蜘蛛怎么做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-28 13:21
一、什么是搜索引擎爬虫?
搜索引擎爬虫,我们通常称它们为蜘蛛,因为互联网是一个链接网络,它需要蜘蛛在这个网络上爬行。索引数据是通过网络上的URL链接,按照一定的规则自动抓取网页信息的程序或脚本。
点击查看>>>>>>搜索引擎蜘蛛如何抓取收录网站内容?
二、搜索引擎爬虫的作用是什么?
我们可以这样理解,搜索引擎只是一个搜索工具,没有内容。然后,搜索引擎需要使用爬虫程序来到我们的网站,把网站的内容带回去做分析,这部分叫做“收录”。因此,如果一个网站想要排名,必须先被搜索引擎收录抓取。
三、如何增加搜索引擎爬虫的爬取次数?
一、创建原创内容
现在的搜索引擎内容已经不像2012年以前那样抓取网站的内容了。搜索引擎关注的是能够满足用户需求的内容质量,简单的填写文章@到采集就可以了更长久地吸引搜索引擎的注意力。只有创作出高质量的原创内容才是最重要的。全面提升内容质量,提高页面更新频率,是SEO优化者必须具备的。
二、创建潜在客户链接
合理安排网站内的内链和站外的优质链接,通过链接导入和内链导出,可以帮助搜索引擎爬虫更好地抓取网站内容。
三、增加网站和页面的权重
众所周知,高权重的网站和页面可以吸引蜘蛛爬行,但是高质量的网站权重依赖于网站整体优化的布局,所以,通过基于内容的, link 补充优化方法可以吸引更多蜘蛛的注意。 查看全部
如何抓取网页数据(搜索引擎蜘蛛如何提升搜索引擎爬虫的抓取次数?蜘蛛怎么做)
一、什么是搜索引擎爬虫?
搜索引擎爬虫,我们通常称它们为蜘蛛,因为互联网是一个链接网络,它需要蜘蛛在这个网络上爬行。索引数据是通过网络上的URL链接,按照一定的规则自动抓取网页信息的程序或脚本。
点击查看>>>>>>搜索引擎蜘蛛如何抓取收录网站内容?

二、搜索引擎爬虫的作用是什么?
我们可以这样理解,搜索引擎只是一个搜索工具,没有内容。然后,搜索引擎需要使用爬虫程序来到我们的网站,把网站的内容带回去做分析,这部分叫做“收录”。因此,如果一个网站想要排名,必须先被搜索引擎收录抓取。
三、如何增加搜索引擎爬虫的爬取次数?
一、创建原创内容
现在的搜索引擎内容已经不像2012年以前那样抓取网站的内容了。搜索引擎关注的是能够满足用户需求的内容质量,简单的填写文章@到采集就可以了更长久地吸引搜索引擎的注意力。只有创作出高质量的原创内容才是最重要的。全面提升内容质量,提高页面更新频率,是SEO优化者必须具备的。
二、创建潜在客户链接
合理安排网站内的内链和站外的优质链接,通过链接导入和内链导出,可以帮助搜索引擎爬虫更好地抓取网站内容。
三、增加网站和页面的权重
众所周知,高权重的网站和页面可以吸引蜘蛛爬行,但是高质量的网站权重依赖于网站整体优化的布局,所以,通过基于内容的, link 补充优化方法可以吸引更多蜘蛛的注意。
如何抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-28 09:10
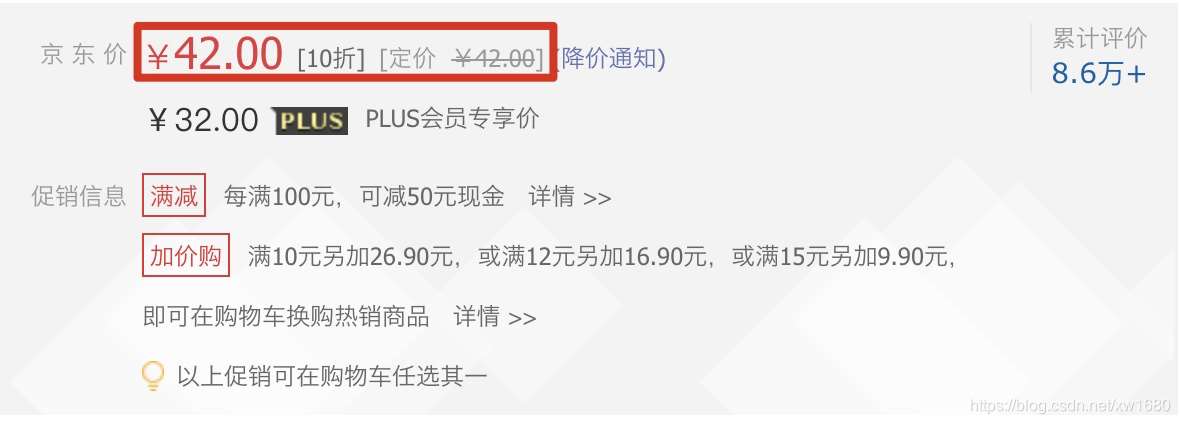
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
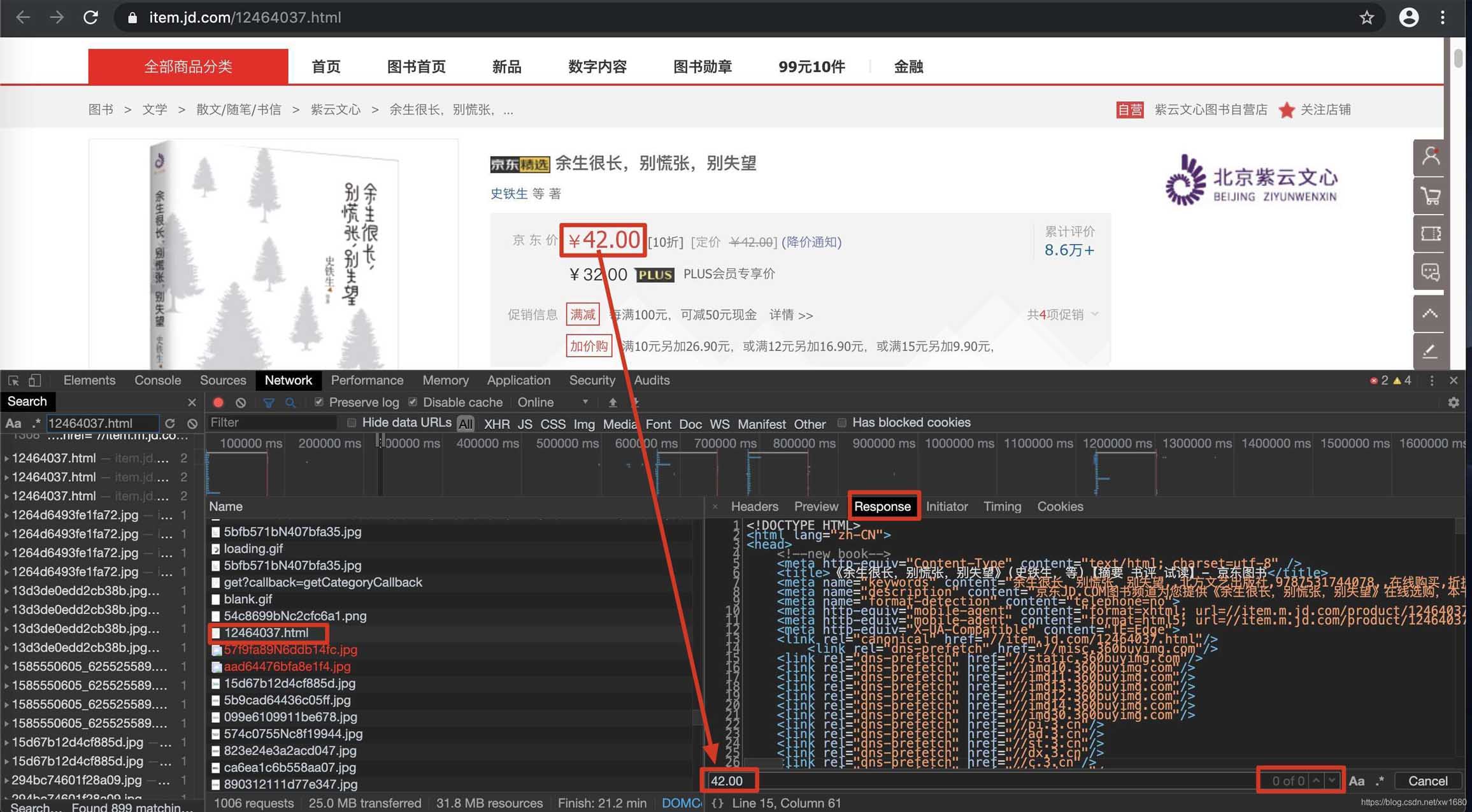
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
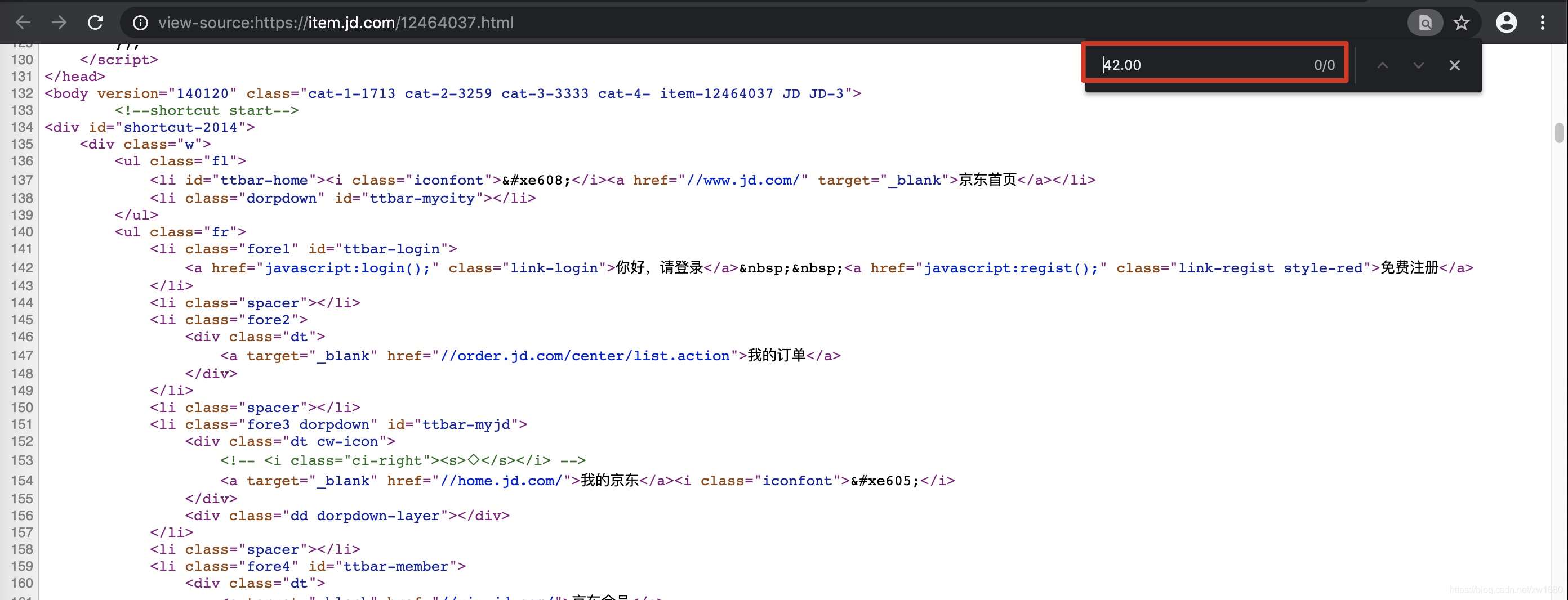
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
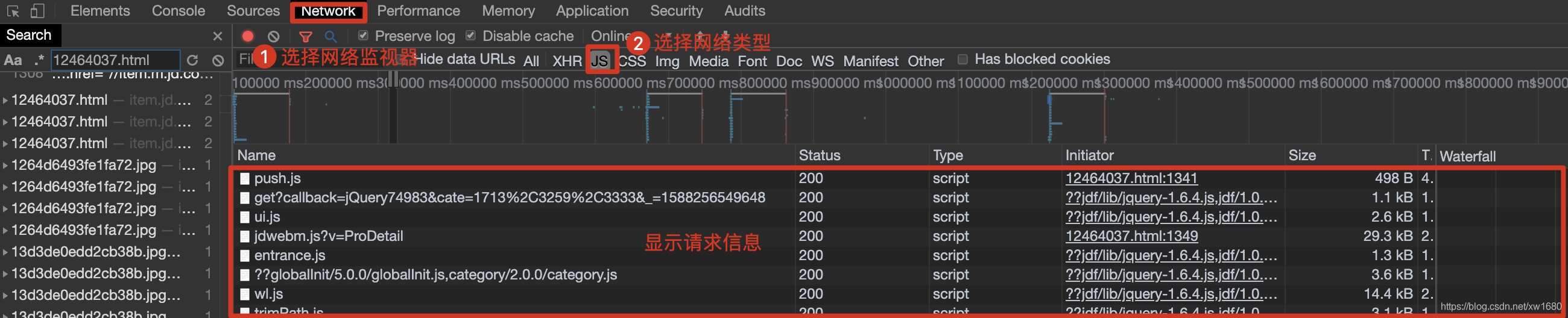
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
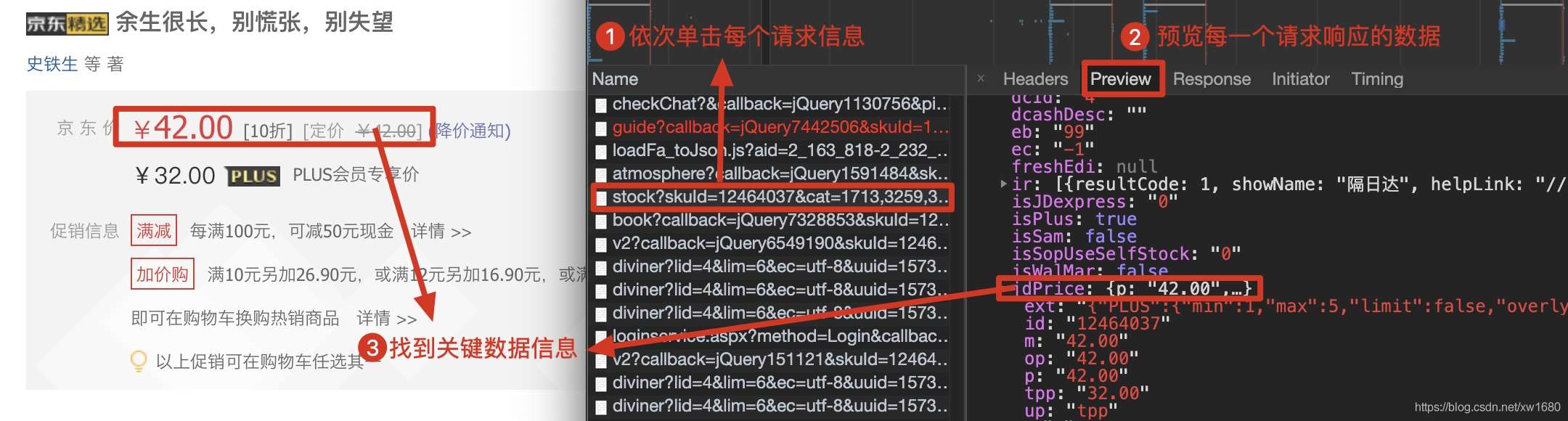
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
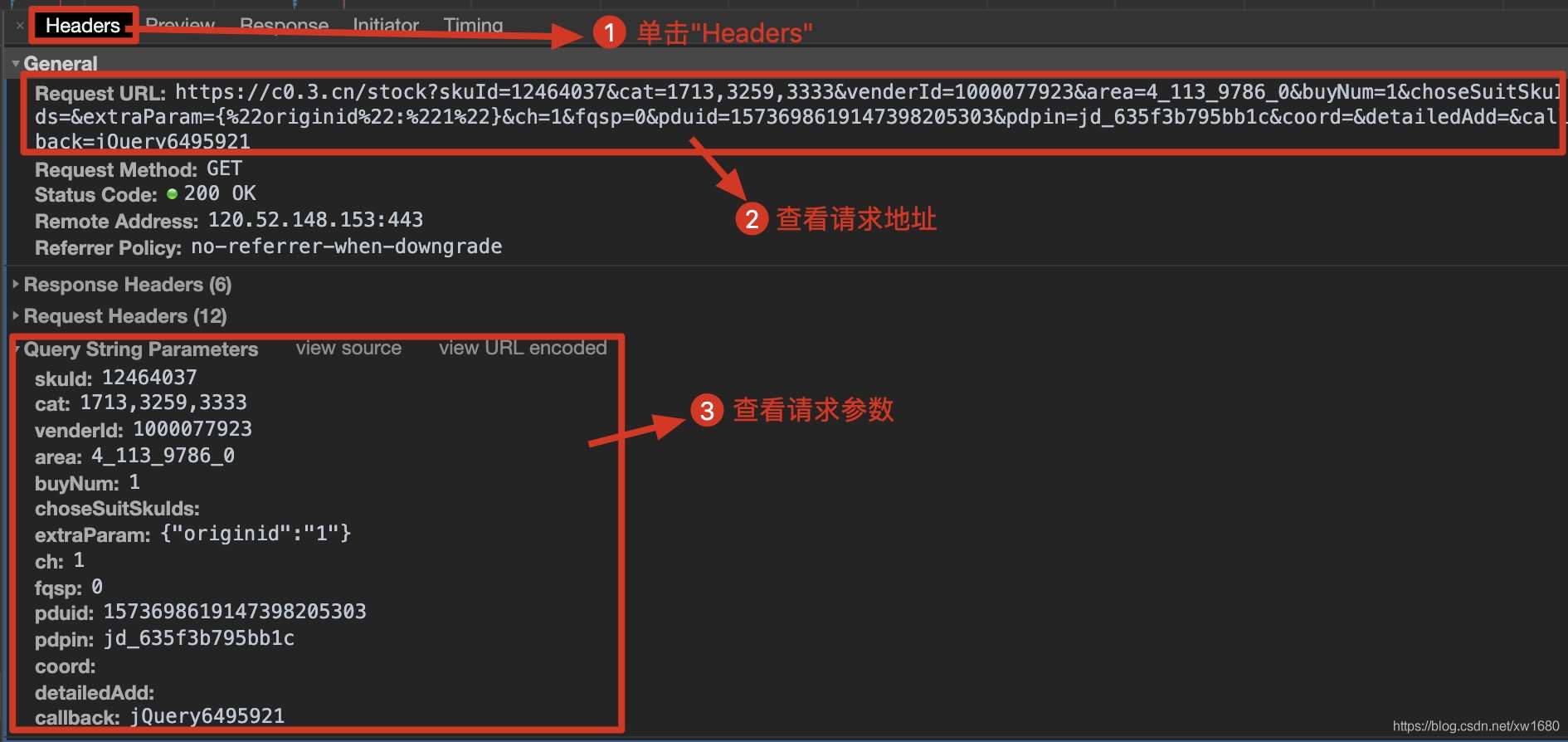
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
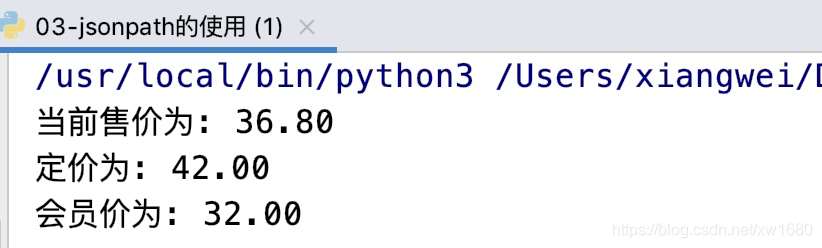
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网! 查看全部
如何抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网!
如何抓取网页数据(机器学习项目如何使用BeautifulSoup和Selenium?数据结构机器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-21 21:17
不久前在LearnML分论坛上看到一个帖子。楼主在这个贴子里提到,他的机器学习项目需要爬取网页数据。很多人在回复中给出了自己的方法,主要是学习如何使用 BeautifulSoup 和 Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在这篇文章 文章 中,我将向您展示如何抓取收录有用数据的网页并将其转换为 pandas DataFrame。
为什么要转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构,并且您只需进行一些修改即可编辑您的模型。
首先,我们需要在***上找到一个表,并将其转换为数据结构。我抓取的表格显示了 *** 上运动员观看次数最多的数据。
一项伟大的任务是浏览 HTML 树以获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。
复制代码
因为有很多表,我们需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)的主播可能在几款腕表中独树一帜。
通过C罗文本,我们可以过滤掉锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器的cell***开发工具。
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的手表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
复制代码
分解它:
复制代码
让我们从上面的列表中选择第三个元素。这就是我们需要的手表。
接下来,创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环遍历表中的每一行,并将其保存在 rows 变量中。
复制代码
复制代码
创建嵌套循环。迭代在最后一个循环中保存的每一行。当迭代单元格时,我们将每个单元格保存在一个新变量中。
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理成纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
将其转换为以下数据结构:
复制代码
您现在可以在机器学习项目中使用 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
对技术感兴趣的 Topola Bode 目前专注于机器学习。
原文链接:
.dev 天才 .io/how-to-scrape-a-website-for-your-ml-project-C3 a4d 6 f 160 c 7 查看全部
如何抓取网页数据(机器学习项目如何使用BeautifulSoup和Selenium?数据结构机器)
不久前在LearnML分论坛上看到一个帖子。楼主在这个贴子里提到,他的机器学习项目需要爬取网页数据。很多人在回复中给出了自己的方法,主要是学习如何使用 BeautifulSoup 和 Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在这篇文章 文章 中,我将向您展示如何抓取收录有用数据的网页并将其转换为 pandas DataFrame。
为什么要转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构,并且您只需进行一些修改即可编辑您的模型。
首先,我们需要在***上找到一个表,并将其转换为数据结构。我抓取的表格显示了 *** 上运动员观看次数最多的数据。
一项伟大的任务是浏览 HTML 树以获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。

复制代码
因为有很多表,我们需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)的主播可能在几款腕表中独树一帜。
通过C罗文本,我们可以过滤掉锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器的cell***开发工具。
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的手表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。

复制代码
分解它:
复制代码
让我们从上面的列表中选择第三个元素。这就是我们需要的手表。
接下来,创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环遍历表中的每一行,并将其保存在 rows 变量中。
复制代码
复制代码
创建嵌套循环。迭代在最后一个循环中保存的每一行。当迭代单元格时,我们将每个单元格保存在一个新变量中。
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理成纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
将其转换为以下数据结构:
复制代码
您现在可以在机器学习项目中使用 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
对技术感兴趣的 Topola Bode 目前专注于机器学习。
原文链接:
.dev 天才 .io/how-to-scrape-a-website-for-your-ml-project-C3 a4d 6 f 160 c 7
如何抓取网页数据( 如何用WebScraper选择元素的操作点击Stiemaps图解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-20 08:07
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据(如何抓取网页数据必须牢记以下技巧:如何设置网页默认数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-17 10:06
如何抓取网页数据必须牢记以下技巧:1.筛选某一条件下的子表格数据2.根据表格内容对数据进行排序3.了解网页默认数据格式4.设置过滤器,如回复次数5.抓取框无非是一个input,我们先打开vs2013,插入一个color_activation对象,并创建一个空的判断对象selectedistfield,判断有没有这个color_activation对象在窗口中弹出的对话框第一行的值就是网页的数据格式,那么,分析网页上的数据,很显然也就必须要将post用标准编码方式存储(常用的编码方式如utf-8或者gbk)。
然后就是网页上的数据格式是动态的,不可能存储一个绝对值,我们必须这样来设置网页上的数据格式。关于怎么设置时序数据格式请阅读百度文库“百度文库如何使网页快速定制符”。学习数据抓取:html.xmlweb-analyzerrequests.getrequests.urlopenrequests.get_html()jsonpythonpython这里post的数据有两种方式:通过http请求传递数据的格式有html格式和json格式,接下来我们讲解怎么将这两种格式合并到一起(其实之前我也没弄明白过来,但是读懂了它们的用法就不难理解了):1.http请求传递数据的格式网站通过url地址发送给我们post请求,但是这个url是固定的,我们可以对这个地址每秒发送http请求10万次(假设请求请求时间为一秒)。
那么接下来就可以对这个请求打印出一个特定格式的html文档,网站在每秒多次的请求中会构建html格式的html文档,并逐页下载。2.http请求传递的数据格式类似json格式,json格式类似于java中的序列化格式,所以post传递的数据可以分为json数据和java中的序列化数据。json数据格式直接用codehandler类获取data,然后构造json字典,从新获取这个url下的http请求的数据即可,如下:forurlinweb.urls.items():importjsoncookiechange=requests.get(url)jsonquery=json.loads(json.dumps(cookiechange))jsonbytes=json.loads(json.dumps(cookiechange))或者直接用python的prepare_post方法,将数据写入data中。
data=json.loads(json.dumps(requests.get(url).json()))jsonvalue=json.loads(json.dumps(cookiechange))jsonjson=json.loads(json('{'+json.strip()))print(jsonjson)3.http请求传递的数据格式网站将数据放在session中,构建session并保存数据。
例如,如果session的url是:。那么首先需要自己构建一个session对象,可以从session模块中获取。构建时序。 查看全部
如何抓取网页数据(如何抓取网页数据必须牢记以下技巧:如何设置网页默认数据)
如何抓取网页数据必须牢记以下技巧:1.筛选某一条件下的子表格数据2.根据表格内容对数据进行排序3.了解网页默认数据格式4.设置过滤器,如回复次数5.抓取框无非是一个input,我们先打开vs2013,插入一个color_activation对象,并创建一个空的判断对象selectedistfield,判断有没有这个color_activation对象在窗口中弹出的对话框第一行的值就是网页的数据格式,那么,分析网页上的数据,很显然也就必须要将post用标准编码方式存储(常用的编码方式如utf-8或者gbk)。
然后就是网页上的数据格式是动态的,不可能存储一个绝对值,我们必须这样来设置网页上的数据格式。关于怎么设置时序数据格式请阅读百度文库“百度文库如何使网页快速定制符”。学习数据抓取:html.xmlweb-analyzerrequests.getrequests.urlopenrequests.get_html()jsonpythonpython这里post的数据有两种方式:通过http请求传递数据的格式有html格式和json格式,接下来我们讲解怎么将这两种格式合并到一起(其实之前我也没弄明白过来,但是读懂了它们的用法就不难理解了):1.http请求传递数据的格式网站通过url地址发送给我们post请求,但是这个url是固定的,我们可以对这个地址每秒发送http请求10万次(假设请求请求时间为一秒)。
那么接下来就可以对这个请求打印出一个特定格式的html文档,网站在每秒多次的请求中会构建html格式的html文档,并逐页下载。2.http请求传递的数据格式类似json格式,json格式类似于java中的序列化格式,所以post传递的数据可以分为json数据和java中的序列化数据。json数据格式直接用codehandler类获取data,然后构造json字典,从新获取这个url下的http请求的数据即可,如下:forurlinweb.urls.items():importjsoncookiechange=requests.get(url)jsonquery=json.loads(json.dumps(cookiechange))jsonbytes=json.loads(json.dumps(cookiechange))或者直接用python的prepare_post方法,将数据写入data中。
data=json.loads(json.dumps(requests.get(url).json()))jsonvalue=json.loads(json.dumps(cookiechange))jsonjson=json.loads(json('{'+json.strip()))print(jsonjson)3.http请求传递的数据格式网站将数据放在session中,构建session并保存数据。
例如,如果session的url是:。那么首先需要自己构建一个session对象,可以从session模块中获取。构建时序。
如何抓取网页数据(如何开发数据提取网络数据(爬虫机器人)?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-13 13:02
返回博客
如何从 网站 中提取数据
伊维塔·维斯托斯基特
2022-02-11
如今,基于数据做出业务决策是许多公司最重要的业务流程。为了做出决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多 网站 服务器存储了大量公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
出于商业目的提取数据的做法对于许多公司来说已经司空见惯。但在日常运营中提取数据以获取情报并非易事。为此,在本文中,我们将详细解释如何提取Web数据,存在哪些挑战,并为您介绍几种解决方案,以帮助您更好地抓取数据。
如何提取数据
如果您的技术不好,那么提取数据可能会非常复杂且难以理解。其实整个过程不难理解。
提取 网站 数据,我们称之为网络抓取或网络采集。该术语特指使用机器人或网络爬虫自动化采集数据的过程。有时网络抓取很容易与网络抓取混淆。我们在之前的博客文章中讨论了网络抓取和网络抓取之间的主要区别。
现在,让我们看一下整个过程,以全面了解 Web 数据提取的工作原理。
数据提取原理
今天,我们主要在 HTML 中抓取数据,这是一种基于文本的标记语言。它通过各种组件定义网站内容的结构,包括
, , 和其他标签。开发者编写各种脚本来爬取各种结构的数据。
开发数据提取脚本
精通Python等编程语言的程序员可以编写网页数据提取脚本(爬虫)。Python 的诸多优势(丰富的库、易用性和活跃的社区等)使其成为编写爬虫脚本最常用的语言。使用这种类型的脚本来自动抓取数据。它们向服务器发送请求,访问指定的 URL,并遍历预定义的页面、HTML 标记和组件。然后从这些地方提取数据。
自定义开发数据爬取模式
用户可以根据提取数据所需的特定 HTML 组件自定义脚本。需要提取哪些数据取决于您的业务目标。如果可以具体定位到想要的数据,就不需要抽取不必要的数据。这减少了服务器的压力和存储空间的要求,降低了数据处理的难度。
创建服务器环境
要连续运行网络爬虫,需要服务器。因此,顺利连续爬取的下一步是投资服务器基础设施,或者从信誉良好的老牌公司租用服务器。服务器是必不可少的,因为它们允许您全天连续运行预先编写的脚本,优采云记录和存储过程。
准备足够的存储空间
数据提取脚本交付的工作产品是数据。大规模操作需要相应的大量存储容量。从多个网站中提取的数据相当于数千个网页。该过程是连续的,因此会为您带来大量数据。确保有足够的存储空间来支持持续的提取操作非常重要。
数据处理
捕获的数据以原创形式存在,难以理解。所以 data采集 过程中的下一个重要步骤是解析和创建结构良好的数据。
如何从 网站 中提取数据
有多种方法可以从网页中提取公共数据,或者通过构建自己的工具或使用现成的网络抓取解决方案。这两种选择都各有优势,我们将逐一研究它们,以便您轻松决定哪一种最适合您的业务需求。
构建您自己的解决方案
要开发自己的 Web 数据提取工具,您需要一个专用的 Web 抓取技术堆栈。包括以下内容:
演戏。很多网站会根据访问者IP地址的位置显示不同的内容。有时您可能需要在另一个国家/地区使用代理,具体取决于您的服务器所在的位置以及您想要访问它的位置。
还需要一个大型代理池来帮助绕过 IP 阻止和 CAPTCHA 验证。
无头浏览器。越来越多的 网站 使用 Vue.js 或 React.js 前端框架。此类框架使用后端 API 来获取数据并呈现 DOM(文档对象模型)。普通的 HTML 客户端不会呈现 Javascript 代码;因此,如果没有无头浏览器,您将获得一个空白页面。
此外,网站 通常可以检测 HTTP 客户端是否是机器人。因此,无头浏览器可以帮助访问目标 HTML 页面。
最常用的无头浏览器 API 是 Selenium、Puppeteer 和 Playwright。
抽取规则。这是一组用于选择 HTML 组件和提取数据的规则。选择这些组件的最简单方法是通过 XPath 和 CSS 选择器。
网站HTML 编码不断更新。因此,提取规则是开发人员花费最多时间的地方。
工作日程。这可以帮助您安排时间在需要时监控特定数据。它还可以帮助解决错误:跟踪 HTML 更改、目标网站 或代理服务器的停机时间以及被阻止的请求至关重要。
贮存。提取数据后,您需要将其正确存储在 SQL 数据库等中。保存采集的数据的标准格式是 JSON、CSV 和 XML。
监视器。采集数据,尤其是大规模的采集数据,会引发各种问题。为避免这些问题,您必须确保您的代理始终处于运行状态。日志分析、仪表板和警报可以帮助您监控数据。
网页数据采集流程:
确定需要获取和处理的数据类型。
找到数据的位置并设置获取路径。
导入并安装所需的预设。
编写数据提取脚本并运行该脚本。
为了避免IP阻塞,必须模仿普通网民的行为。这就是代理发挥作用的地方,它们使数据采集 的整个过程变得更容易。我们稍后再谈。
网络爬虫 API
诸如网络爬虫 API 之类的即用型数据提取工具的主要优点之一是它可以帮助您从困难目标中提取公共数据网站,而无需额外资源。大型电子商务页面使用复杂的反机器人算法。因此,抓取这些页面的工具需要更多的开发时间。
自制解决方案必须通过反复试验来创造变通办法,这意味着不可避免的速度下降、IP 地址受阻和定价数据流不可靠。使用我们的网络爬虫网络爬虫 API,整个过程可以完全自动化。您的员工可以专注于更紧迫的任务并直接进行数据分析,而不是无休止的复制粘贴。
如何选择?
根据您的业务规模,构建您自己的解决方案或购买现成的数据提取工具。
如果您的公司需要大规模采集数据,网络爬虫 API 是一个很好的选择,可以节省时间并实时提供高质量的数据结果。最重要的是,它们可以为您节省代码维护和集成的费用。
另一方面,如果您是一家只需要偶尔爬网的小型企业,那么构建自己的数据提取工具可能会非常有益。
网络数据的好处采集
大数据是当今商业界最热门的流行语。它指的是对数据集进行有目的的多重处理:获得有意义的见解、发现趋势和模式以及预测经济状况。例如,网络抓取房地产数据有助于分析该行业的重大影响。同样,另类数据可以帮助基金经理发现投资机会。
网络抓取可以发挥作用的另一个领域是汽车行业。公司采集汽车行业数据,例如用户和组件评论。
各行各业的公司从 网站 中提取数据,以构建自己的最新相关数据集。这种做法通常会延续到其他 网站 上,从而提高数据集的完整性。数据越多越好,因为它有更多的参考点,使整个数据集更有效率。
公司通常会提取哪些数据?
前面我们提到,提取的目标数据并不都是在线数据,这不难理解。在确定要提取哪些数据时,您的业务定位、需求和目标应该是主要标准。
您感兴趣的目标数据可能会有所不同。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等;您还可以根据目标的新产品和服务自定义脚本。在进行抓取活动之前,请确保被抓取的公共数据不会损害任何第三方的权利。
数据采集常见挑战
提取数据从来都不是一帆风顺的。最常见的挑战是:
数据抓取最佳实践
面对由经验丰富的专业人员开发的复杂的网络数据提取脚本,与网络数据密切相关的难题采集 可以轻松解决。但被反爬虫技术识别和屏蔽的风险依然存在。因此,迫切需要一种变革性的解决方案:代理。更准确地说,轮换代理。
轮换代理允许您使用大量 IP 地址。使用位于不同区域的 IP 发送请求可以欺骗服务器并防止被阻止。此外,您可以使用 Proxy Rotator 代替手动分配不同的 IP,它会自动从代理数据中心池中分配 IP。
如果您没有资源并且没有经验丰富的 Web 抓取开发团队,那么是时候考虑使用现成的解决方案,例如 Web 爬虫 API。它确保 100% 交付来自大多数 网站s、策划优采云 数据的抓取结果,并聚合数据,以便您轻松理解它。
从 网站 中提取数据是否合法?
许多企业依赖大数据,需求显着增长。根据 Statista 的研究,大数据市场每年都在大幅增长,预计到 2027 年将达到 1030 亿美元。因此,越来越多的企业正在使用网络抓取来获取数据采集。这种受欢迎程度引发了一个激烈争论的话题:网络抓取合法吗?
这个复杂的话题没有明确的答案,如果你在做网络爬虫,你不能违反任何与相关数据相关的法律法规。值得注意的是,我们强烈建议在进行任何抓取活动之前根据具体情况寻求专业的法律建议。
同时,我们也强烈建议不要抓取非公开数据,除非已获得目标 网站 的明确许可。为了清楚起见,本文中的任何内容都不应被解释为对非公开数据抓取的建议。
总结
总之,如果你想从 网站 中提取数据,那么你需要一个数据提取脚本。如您所知,由于数据抓取操作的广度、复杂性以及不断变化的 网站 结构,构建此类脚本可能具有挑战性。由于网络抓取必须实时获取最新数据,因此您需要避免被阻止。这就是为什么在进行主要的抓取操作时必须使用旋转代理。
如果您认为您的企业需要一个强大的解决方案来简化您的数据采集,您可以立即注册并使用 Oxylabs 的 Web Crawler API。
关于作者
伊维塔·维斯托斯基特
内容管理者
Iveta Vistorskyte 在 Oxylabs 担任内容经理。作为一名作家和挑战者,她决定涉足科技领域,并立即对该领域产生了兴趣。当她不工作时,您可能会发现她只是通过听她最喜欢的音乐或与朋友一起玩棋盘游戏来放松。
了解有关艾维塔的更多信息
Oxylabs 博客上的所有信息均按“原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录的任何信息或可能链接到的任何第三方 网站 中收录的任何信息,我们不作任何陈述,也不承担任何责任。在进行任何形式的抓取之前,请咨询您的法律顾问并仔细阅读具体的网站服务条款或获得抓取许可。 查看全部
如何抓取网页数据(如何开发数据提取网络数据(爬虫机器人)?(图))
返回博客
如何从 网站 中提取数据
伊维塔·维斯托斯基特
2022-02-11
如今,基于数据做出业务决策是许多公司最重要的业务流程。为了做出决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多 网站 服务器存储了大量公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
出于商业目的提取数据的做法对于许多公司来说已经司空见惯。但在日常运营中提取数据以获取情报并非易事。为此,在本文中,我们将详细解释如何提取Web数据,存在哪些挑战,并为您介绍几种解决方案,以帮助您更好地抓取数据。
如何提取数据
如果您的技术不好,那么提取数据可能会非常复杂且难以理解。其实整个过程不难理解。
提取 网站 数据,我们称之为网络抓取或网络采集。该术语特指使用机器人或网络爬虫自动化采集数据的过程。有时网络抓取很容易与网络抓取混淆。我们在之前的博客文章中讨论了网络抓取和网络抓取之间的主要区别。
现在,让我们看一下整个过程,以全面了解 Web 数据提取的工作原理。
数据提取原理
今天,我们主要在 HTML 中抓取数据,这是一种基于文本的标记语言。它通过各种组件定义网站内容的结构,包括
, , 和其他标签。开发者编写各种脚本来爬取各种结构的数据。
开发数据提取脚本
精通Python等编程语言的程序员可以编写网页数据提取脚本(爬虫)。Python 的诸多优势(丰富的库、易用性和活跃的社区等)使其成为编写爬虫脚本最常用的语言。使用这种类型的脚本来自动抓取数据。它们向服务器发送请求,访问指定的 URL,并遍历预定义的页面、HTML 标记和组件。然后从这些地方提取数据。
自定义开发数据爬取模式
用户可以根据提取数据所需的特定 HTML 组件自定义脚本。需要提取哪些数据取决于您的业务目标。如果可以具体定位到想要的数据,就不需要抽取不必要的数据。这减少了服务器的压力和存储空间的要求,降低了数据处理的难度。
创建服务器环境
要连续运行网络爬虫,需要服务器。因此,顺利连续爬取的下一步是投资服务器基础设施,或者从信誉良好的老牌公司租用服务器。服务器是必不可少的,因为它们允许您全天连续运行预先编写的脚本,优采云记录和存储过程。
准备足够的存储空间
数据提取脚本交付的工作产品是数据。大规模操作需要相应的大量存储容量。从多个网站中提取的数据相当于数千个网页。该过程是连续的,因此会为您带来大量数据。确保有足够的存储空间来支持持续的提取操作非常重要。
数据处理
捕获的数据以原创形式存在,难以理解。所以 data采集 过程中的下一个重要步骤是解析和创建结构良好的数据。
如何从 网站 中提取数据
有多种方法可以从网页中提取公共数据,或者通过构建自己的工具或使用现成的网络抓取解决方案。这两种选择都各有优势,我们将逐一研究它们,以便您轻松决定哪一种最适合您的业务需求。
构建您自己的解决方案
要开发自己的 Web 数据提取工具,您需要一个专用的 Web 抓取技术堆栈。包括以下内容:
演戏。很多网站会根据访问者IP地址的位置显示不同的内容。有时您可能需要在另一个国家/地区使用代理,具体取决于您的服务器所在的位置以及您想要访问它的位置。
还需要一个大型代理池来帮助绕过 IP 阻止和 CAPTCHA 验证。
无头浏览器。越来越多的 网站 使用 Vue.js 或 React.js 前端框架。此类框架使用后端 API 来获取数据并呈现 DOM(文档对象模型)。普通的 HTML 客户端不会呈现 Javascript 代码;因此,如果没有无头浏览器,您将获得一个空白页面。
此外,网站 通常可以检测 HTTP 客户端是否是机器人。因此,无头浏览器可以帮助访问目标 HTML 页面。
最常用的无头浏览器 API 是 Selenium、Puppeteer 和 Playwright。
抽取规则。这是一组用于选择 HTML 组件和提取数据的规则。选择这些组件的最简单方法是通过 XPath 和 CSS 选择器。
网站HTML 编码不断更新。因此,提取规则是开发人员花费最多时间的地方。
工作日程。这可以帮助您安排时间在需要时监控特定数据。它还可以帮助解决错误:跟踪 HTML 更改、目标网站 或代理服务器的停机时间以及被阻止的请求至关重要。
贮存。提取数据后,您需要将其正确存储在 SQL 数据库等中。保存采集的数据的标准格式是 JSON、CSV 和 XML。
监视器。采集数据,尤其是大规模的采集数据,会引发各种问题。为避免这些问题,您必须确保您的代理始终处于运行状态。日志分析、仪表板和警报可以帮助您监控数据。
网页数据采集流程:
确定需要获取和处理的数据类型。
找到数据的位置并设置获取路径。
导入并安装所需的预设。
编写数据提取脚本并运行该脚本。
为了避免IP阻塞,必须模仿普通网民的行为。这就是代理发挥作用的地方,它们使数据采集 的整个过程变得更容易。我们稍后再谈。
网络爬虫 API
诸如网络爬虫 API 之类的即用型数据提取工具的主要优点之一是它可以帮助您从困难目标中提取公共数据网站,而无需额外资源。大型电子商务页面使用复杂的反机器人算法。因此,抓取这些页面的工具需要更多的开发时间。
自制解决方案必须通过反复试验来创造变通办法,这意味着不可避免的速度下降、IP 地址受阻和定价数据流不可靠。使用我们的网络爬虫网络爬虫 API,整个过程可以完全自动化。您的员工可以专注于更紧迫的任务并直接进行数据分析,而不是无休止的复制粘贴。
如何选择?
根据您的业务规模,构建您自己的解决方案或购买现成的数据提取工具。
如果您的公司需要大规模采集数据,网络爬虫 API 是一个很好的选择,可以节省时间并实时提供高质量的数据结果。最重要的是,它们可以为您节省代码维护和集成的费用。
另一方面,如果您是一家只需要偶尔爬网的小型企业,那么构建自己的数据提取工具可能会非常有益。
网络数据的好处采集
大数据是当今商业界最热门的流行语。它指的是对数据集进行有目的的多重处理:获得有意义的见解、发现趋势和模式以及预测经济状况。例如,网络抓取房地产数据有助于分析该行业的重大影响。同样,另类数据可以帮助基金经理发现投资机会。
网络抓取可以发挥作用的另一个领域是汽车行业。公司采集汽车行业数据,例如用户和组件评论。
各行各业的公司从 网站 中提取数据,以构建自己的最新相关数据集。这种做法通常会延续到其他 网站 上,从而提高数据集的完整性。数据越多越好,因为它有更多的参考点,使整个数据集更有效率。
公司通常会提取哪些数据?
前面我们提到,提取的目标数据并不都是在线数据,这不难理解。在确定要提取哪些数据时,您的业务定位、需求和目标应该是主要标准。
您感兴趣的目标数据可能会有所不同。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等;您还可以根据目标的新产品和服务自定义脚本。在进行抓取活动之前,请确保被抓取的公共数据不会损害任何第三方的权利。
数据采集常见挑战
提取数据从来都不是一帆风顺的。最常见的挑战是:
数据抓取最佳实践
面对由经验丰富的专业人员开发的复杂的网络数据提取脚本,与网络数据密切相关的难题采集 可以轻松解决。但被反爬虫技术识别和屏蔽的风险依然存在。因此,迫切需要一种变革性的解决方案:代理。更准确地说,轮换代理。
轮换代理允许您使用大量 IP 地址。使用位于不同区域的 IP 发送请求可以欺骗服务器并防止被阻止。此外,您可以使用 Proxy Rotator 代替手动分配不同的 IP,它会自动从代理数据中心池中分配 IP。
如果您没有资源并且没有经验丰富的 Web 抓取开发团队,那么是时候考虑使用现成的解决方案,例如 Web 爬虫 API。它确保 100% 交付来自大多数 网站s、策划优采云 数据的抓取结果,并聚合数据,以便您轻松理解它。
从 网站 中提取数据是否合法?
许多企业依赖大数据,需求显着增长。根据 Statista 的研究,大数据市场每年都在大幅增长,预计到 2027 年将达到 1030 亿美元。因此,越来越多的企业正在使用网络抓取来获取数据采集。这种受欢迎程度引发了一个激烈争论的话题:网络抓取合法吗?
这个复杂的话题没有明确的答案,如果你在做网络爬虫,你不能违反任何与相关数据相关的法律法规。值得注意的是,我们强烈建议在进行任何抓取活动之前根据具体情况寻求专业的法律建议。
同时,我们也强烈建议不要抓取非公开数据,除非已获得目标 网站 的明确许可。为了清楚起见,本文中的任何内容都不应被解释为对非公开数据抓取的建议。
总结
总之,如果你想从 网站 中提取数据,那么你需要一个数据提取脚本。如您所知,由于数据抓取操作的广度、复杂性以及不断变化的 网站 结构,构建此类脚本可能具有挑战性。由于网络抓取必须实时获取最新数据,因此您需要避免被阻止。这就是为什么在进行主要的抓取操作时必须使用旋转代理。
如果您认为您的企业需要一个强大的解决方案来简化您的数据采集,您可以立即注册并使用 Oxylabs 的 Web Crawler API。
关于作者
伊维塔·维斯托斯基特
内容管理者
Iveta Vistorskyte 在 Oxylabs 担任内容经理。作为一名作家和挑战者,她决定涉足科技领域,并立即对该领域产生了兴趣。当她不工作时,您可能会发现她只是通过听她最喜欢的音乐或与朋友一起玩棋盘游戏来放松。
了解有关艾维塔的更多信息
Oxylabs 博客上的所有信息均按“原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录的任何信息或可能链接到的任何第三方 网站 中收录的任何信息,我们不作任何陈述,也不承担任何责任。在进行任何形式的抓取之前,请咨询您的法律顾问并仔细阅读具体的网站服务条款或获得抓取许可。
如何抓取网页数据(python对如何获取网页内容的各种情况和方法做一个总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-13 12:22
python爬虫如何爬取网络数据?
在学习python爬虫的过程中,总会有想要获取网页内容的时候。本文将总结如何获取网页内容的各种情况和方法。
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看正则表达式
如何
得到一个完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
注意:由于不同版本的Python内置库容错能力不同,处理结果可能与上述不同。详情请参考::///doc/0ed46eadf9c75fbfc77da26925c52cc58ad6905a.html /software/BeautifulSoup/bs4/doc/#installing-a-pa rser。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可以在 找到。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入内容后,进入选择元素的步骤,此时lxml
有几种不同的方法,例如
XPath 选择器和 find() 方法,例如 Beautiful Soup。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
代码首先找到ID为places_area__row的表格行元素,然后选择类为w2p_f w的表格数据子标签。
CSS3 规范已由 W3C 提出: /TR/2011/REC-css3-selectors-2011 0929/
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在以下位置找到:ocs.io/en/latest/。
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
相关 采集 教程:
鼠标移动显示网站采集需要数据的方法/教程/sbyd
优采云补挖、漏挖功能说明(以金头网采集为例)/tutorial/lcbc
优采云增量采集功能说明/教程/zlcj_7 优采云广告拦截功能说明(采集中文社区网示例)/tutorial/pbgg_7单机采集提示异常信息处理(以新浪微博采集为例) /tutorial/djcjyc_7优采云代理IP功能说明(7.0版本) /tutorial/dlip_7 网页数据采集如何模拟手机终端,人民网的移动终端采集
例如/tutorial/mnsj_7 优采云——90万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置采集.
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集
集群24*7不间断运行,无需担心IP被封,网络中断。
4、功能免费+增值服务,按需选择。免费版功能齐全,可以满足用户的基本需求。
设定要求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
如何抓取网页数据(python对如何获取网页内容的各种情况和方法做一个总结)
python爬虫如何爬取网络数据?
在学习python爬虫的过程中,总会有想要获取网页内容的时候。本文将总结如何获取网页内容的各种情况和方法。
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看正则表达式
如何
得到一个完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
注意:由于不同版本的Python内置库容错能力不同,处理结果可能与上述不同。详情请参考::///doc/0ed46eadf9c75fbfc77da26925c52cc58ad6905a.html /software/BeautifulSoup/bs4/doc/#installing-a-pa rser。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可以在 找到。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入内容后,进入选择元素的步骤,此时lxml
有几种不同的方法,例如
XPath 选择器和 find() 方法,例如 Beautiful Soup。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
代码首先找到ID为places_area__row的表格行元素,然后选择类为w2p_f w的表格数据子标签。
CSS3 规范已由 W3C 提出: /TR/2011/REC-css3-selectors-2011 0929/
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在以下位置找到:ocs.io/en/latest/。
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
相关 采集 教程:
鼠标移动显示网站采集需要数据的方法/教程/sbyd
优采云补挖、漏挖功能说明(以金头网采集为例)/tutorial/lcbc
优采云增量采集功能说明/教程/zlcj_7 优采云广告拦截功能说明(采集中文社区网示例)/tutorial/pbgg_7单机采集提示异常信息处理(以新浪微博采集为例) /tutorial/djcjyc_7优采云代理IP功能说明(7.0版本) /tutorial/dlip_7 网页数据采集如何模拟手机终端,人民网的移动终端采集
例如/tutorial/mnsj_7 优采云——90万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置采集.
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集
集群24*7不间断运行,无需担心IP被封,网络中断。
4、功能免费+增值服务,按需选择。免费版功能齐全,可以满足用户的基本需求。
设定要求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
如何抓取网页数据(java爬虫怎么实现抓取登陆后的页面-爬虫的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-02-12 04:02
Java 网页数据抓取
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没有方式,请从发送请求返回xml或json的数据,并一一分析,看哪个爬虫在任何情况下都不可能申请!
java爬虫如何爬取登录后的网页数据
一般爬虫登录后不会抓取页面。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,然后请求相关页面。
如何使用网络爬虫基于java获取数据-
爬虫的原理其实就是获取网页的内容,然后进行解析。只是获取网页和解析内容的方式多种多样。你可以简单地使用httpclient发送一个get/post请求,得到结果,然后使用截取字符串,正则表达式得到想要的内容。或者使用Jsoup/crawler4j等封装好的类库,更方便的爬取信息。
java网络爬虫如何实现登录后对页面的爬取-
原理是保存cookie数据,登录后保存cookie。以后每次爬取页面,都会在header信息中发送cookie。系统根据 cookie 判断用户。有了cookie,就有了登录状态,后续的访问都会基于这个cookie对应的用户。补充:Java是一种面向对象的编程语言,可以编写跨平台的应用软件。Java技术具有优异的通用性、效率、平台可移植性和安全性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
如何通过Java代码实现网页数据的指定爬取
通过java代码实现网页数据指定爬取方式的步骤如下: 1 在项目中导入jsoup.jar包 2 获取html指定的url或者文档指定的body 3 获取标题和链接网页中超链接的 4 获取指定博客文章内容 5 of @> 获取网页中超链接的标题和链接结果
如何爬取网页中的数据java -
不用Java去抢,为什么不让页面把数据发到后台呢??如果是从别人的网站中抓取的,应该是可以的,用socketio好像是可以的。看看nodejs是不是可以的。
java jsoup如何爬取特定网页中的数据——
方法/步骤本次体验是通过导入外部的Jars来爬取网页数据。下面是我的项目的分布图。在本例中,Jquery 用于处理页面事件。页面显示背景在siteproxy.jsp中处理 5 最后在本项目中部署所需文件 查看全部
如何抓取网页数据(java爬虫怎么实现抓取登陆后的页面-爬虫的原理)
Java 网页数据抓取
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没有方式,请从发送请求返回xml或json的数据,并一一分析,看哪个爬虫在任何情况下都不可能申请!
java爬虫如何爬取登录后的网页数据
一般爬虫登录后不会抓取页面。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,然后请求相关页面。
如何使用网络爬虫基于java获取数据-
爬虫的原理其实就是获取网页的内容,然后进行解析。只是获取网页和解析内容的方式多种多样。你可以简单地使用httpclient发送一个get/post请求,得到结果,然后使用截取字符串,正则表达式得到想要的内容。或者使用Jsoup/crawler4j等封装好的类库,更方便的爬取信息。
java网络爬虫如何实现登录后对页面的爬取-
原理是保存cookie数据,登录后保存cookie。以后每次爬取页面,都会在header信息中发送cookie。系统根据 cookie 判断用户。有了cookie,就有了登录状态,后续的访问都会基于这个cookie对应的用户。补充:Java是一种面向对象的编程语言,可以编写跨平台的应用软件。Java技术具有优异的通用性、效率、平台可移植性和安全性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
如何通过Java代码实现网页数据的指定爬取
通过java代码实现网页数据指定爬取方式的步骤如下: 1 在项目中导入jsoup.jar包 2 获取html指定的url或者文档指定的body 3 获取标题和链接网页中超链接的 4 获取指定博客文章内容 5 of @> 获取网页中超链接的标题和链接结果
如何爬取网页中的数据java -
不用Java去抢,为什么不让页面把数据发到后台呢??如果是从别人的网站中抓取的,应该是可以的,用socketio好像是可以的。看看nodejs是不是可以的。
java jsoup如何爬取特定网页中的数据——
方法/步骤本次体验是通过导入外部的Jars来爬取网页数据。下面是我的项目的分布图。在本例中,Jquery 用于处理页面事件。页面显示背景在siteproxy.jsp中处理 5 最后在本项目中部署所需文件
如何抓取网页数据((19)中华人民共和国国家知识产权局(12)申请(10))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-07 00:12
该方法包括选择获取未被抓取的优质链接,其中,优质链接是指向满足用户检索需要的网页的链接。为选定的优质链接标记网络出口;将发出的优质链接分发到相应的网络出口,进行网页数据的爬取。根据本发明提供的技术方案,可以提高对复杂多变的爬取环境的适应能力,从而显着提高网页的跨国爬取能力。数据成功率。法律状态 法律状态公告日期 法律状态信息 法律状态 2015-07-22 公开披露 2015-07-22 公开披露 2015-08-19 实质审查生效 实质审查生效 2015-08-19 实质审查 生效日期实质审查有效。2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 查看全部
如何抓取网页数据((19)中华人民共和国国家知识产权局(12)申请(10))
该方法包括选择获取未被抓取的优质链接,其中,优质链接是指向满足用户检索需要的网页的链接。为选定的优质链接标记网络出口;将发出的优质链接分发到相应的网络出口,进行网页数据的爬取。根据本发明提供的技术方案,可以提高对复杂多变的爬取环境的适应能力,从而显着提高网页的跨国爬取能力。数据成功率。法律状态 法律状态公告日期 法律状态信息 法律状态 2015-07-22 公开披露 2015-07-22 公开披露 2015-08-19 实质审查生效 实质审查生效 2015-08-19 实质审查 生效日期实质审查有效。2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查
如何抓取网页数据(如何抓取网页数据是程序员的基本功了,爬虫内核浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-05 07:08
如何抓取网页数据是程序员的基本功了,在爬虫领域,我们也得学会一种另类的抓取方法,利用我们自带的ie内核浏览器。话不多说,用rstudio做如下实验:首先,创建一个时间戳列表,内容存储在列表[:date_]中:然后在这个列表中查找最早的日期field_name,再查找field_type,得到日期对应的列表,:然后在这个列表中查找最后一个日期field_max。
最后再查找最早的月份field_month:这样就能取到这个一年所有日期在年份[:]中出现的次数了,然后从每个月中选择一个数值,把他们存储在对应的列表中,比如6和8,是这样:最后给定field_name_max和field_type_max,得到最大概率的日期列表。是不是很简单呢?赶紧试试吧!如果您喜欢本文,请关注微信公众号:r语言中文社区(rzhsjh),获取更多精彩内容。
<p>使用r,修改一下a 查看全部
如何抓取网页数据(如何抓取网页数据是程序员的基本功了,爬虫内核浏览器)
如何抓取网页数据是程序员的基本功了,在爬虫领域,我们也得学会一种另类的抓取方法,利用我们自带的ie内核浏览器。话不多说,用rstudio做如下实验:首先,创建一个时间戳列表,内容存储在列表[:date_]中:然后在这个列表中查找最早的日期field_name,再查找field_type,得到日期对应的列表,:然后在这个列表中查找最后一个日期field_max。
最后再查找最早的月份field_month:这样就能取到这个一年所有日期在年份[:]中出现的次数了,然后从每个月中选择一个数值,把他们存储在对应的列表中,比如6和8,是这样:最后给定field_name_max和field_type_max,得到最大概率的日期列表。是不是很简单呢?赶紧试试吧!如果您喜欢本文,请关注微信公众号:r语言中文社区(rzhsjh),获取更多精彩内容。
<p>使用r,修改一下a
如何抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-04 07:12
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
1import requests
2
3if __name__== "__main__":
4
5 response = requests.get("https://book.douban.com/subject/26986954/")
6 content = response.content.decode("utf-8")
7 print(content)
8
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
1import requests
2from bs4 import BeautifulSoup
3
4if __name__== "__main__":
5
6 response = requests.get("https://book.douban.com/subject/26986954/")
7 content = response.content.decode("utf-8")
8 #print(content)
9
10 soup = BeautifulSoup(content, "html.parser")
11
12 # 获取当前页面包含的所有链接
13
14 for element in soup.select("a"):
15
16 if not element.has_attr("href"):
17 continue
18 if not element["href"].startswith("https://"):
19 continue
20
21 print(element["href"])
22
23 # 获取更多数据
24
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
1import time
2import requests
3from bs4 import BeautifulSoup
4
5# 保存已经抓取和未抓取的链接
6
7visited_urls = []
8unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
9
10# 从队列中返回一个未抓取的URL
11
12def get_unvisited_url():
13
14 while True:
15
16 if len(unvisited_urls) == 0:
17 return None
18
19 url = unvisited_urls.pop()
20
21 if url in visited_urls:
22 continue
23
24 visited_urls.append(url)
25 return url
26
27
28if __name__== "__main__":
29
30 while True:
31 url = get_unvisited_url()
32 if url == None:
33 break
34
35 print("GET " + url)
36
37 response = requests.get(url)
38 content = response.content.decode("utf-8")
39 #print(content)
40
41 soup = BeautifulSoup(content, "html.parser")
42
43 # 获取页面包含的链接,并加入未访问的队列
44
45 for element in soup.select("a"):
46
47 if not element.has_attr("href"):
48 continue
49 if not element["href"].startswith("https://"):
50 continue
51
52 unvisited_urls.append(element["href"])
53 #print(element["href"])
54
55 time.sleep(1)
56
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源: 查看全部
如何抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
1import requests
2
3if __name__== "__main__":
4
5 response = requests.get("https://book.douban.com/subject/26986954/";)
6 content = response.content.decode("utf-8")
7 print(content)
8
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
1import requests
2from bs4 import BeautifulSoup
3
4if __name__== "__main__":
5
6 response = requests.get("https://book.douban.com/subject/26986954/";)
7 content = response.content.decode("utf-8")
8 #print(content)
9
10 soup = BeautifulSoup(content, "html.parser")
11
12 # 获取当前页面包含的所有链接
13
14 for element in soup.select("a"):
15
16 if not element.has_attr("href"):
17 continue
18 if not element["href"].startswith("https://";):
19 continue
20
21 print(element["href"])
22
23 # 获取更多数据
24
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
1import time
2import requests
3from bs4 import BeautifulSoup
4
5# 保存已经抓取和未抓取的链接
6
7visited_urls = []
8unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
9
10# 从队列中返回一个未抓取的URL
11
12def get_unvisited_url():
13
14 while True:
15
16 if len(unvisited_urls) == 0:
17 return None
18
19 url = unvisited_urls.pop()
20
21 if url in visited_urls:
22 continue
23
24 visited_urls.append(url)
25 return url
26
27
28if __name__== "__main__":
29
30 while True:
31 url = get_unvisited_url()
32 if url == None:
33 break
34
35 print("GET " + url)
36
37 response = requests.get(url)
38 content = response.content.decode("utf-8")
39 #print(content)
40
41 soup = BeautifulSoup(content, "html.parser")
42
43 # 获取页面包含的链接,并加入未访问的队列
44
45 for element in soup.select("a"):
46
47 if not element.has_attr("href"):
48 continue
49 if not element["href"].startswith("https://";):
50 continue
51
52 unvisited_urls.append(element["href"])
53 #print(element["href"])
54
55 time.sleep(1)
56
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源:
如何抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-04 07:09
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
孤灯陷入沉思,卷起帘子,望着月空叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章复习,,,,,,,学习如何使用选择器。它可以帮助您更好地利用 Scrapy 爬虫框架。在接下来的几篇文章中,小编会讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段,我们通过Scrapy实现了特定网页的具体信息,但还没有实现对所有页面的顺序提取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们可以根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。
6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。
至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后,如何调用我们自己定义的分析函数呢? 查看全部
如何抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
孤灯陷入沉思,卷起帘子,望着月空叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章复习,,,,,,,学习如何使用选择器。它可以帮助您更好地利用 Scrapy 爬虫框架。在接下来的几篇文章中,小编会讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段,我们通过Scrapy实现了特定网页的具体信息,但还没有实现对所有页面的顺序提取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。

3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们可以根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。

6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。
至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后,如何调用我们自己定义的分析函数呢?
如何抓取网页数据(BeautifulSoup、本文模块的使用方法及注意点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-02 16:06
前言
学习,最重要的是理解它并使用它,所谓,学以致用,这篇文章,我们以后会介绍,BeautifulSoup模块的使用,以及注意点,帮助您快速了解和学习 BeautifulSoup 模块。有兴趣了解爬虫的朋友,快点学习吧。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题,以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接、翻页操作
继续分析,点击链接进入,发现已经有图片列表了,还可以翻页。
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第三步:编写代码实现需求1、导入模块
导入我们需要使用的所有模块。
import os
import re
from bs4 import BeautifulSoup
import requests
import time
2、获取列表的标题以及链接
def tupianzj():
"""获取标题,链接"""
response = requests.get(url="https://www.tupianzj.com/sheying/",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("h3",{"class":"list_title"})
list=[]
for i in list_title:
list.append({'name':i.get_text(),'url':i.find("a").get("href")})
return list
3、获取类别列表标题、链接和翻页。
def tu_list(url,page):
"""获取类比列表"""
response = requests.get(url,headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("ul",{"class":"list_con_box_ul"})[0].find_all("li")
for i in list_title:
for j in i.find_all("a"):
try:
j.find("img").get("src")
name=j.get("title")#列表列表图片名称
url1="https://www.tupianzj.com"+j.get("href")[0:-5]#类比列表图片详情链接
text=Soup.find_all("div",{"class":"pages"})[0].find_all("a")[1].get("href")#下一页
page1=Soup.find_all("span",{"class":"pageinfo"})[0].find("strong").get_text()#获取总页数
url2=url+text[0:-6]+page+".html"
print(url2,page1)
try:
os.mkdir(name)#创建文件
except:
pass
tu_detail(name,url1,2)
if page==1:
for z in range(2,int(page1))
tu_list(url2,page)
except:
pass
4、获取详细图片并保存
<p>def tu_detail(path,url,page):
"""获取详情"""
if page 查看全部
如何抓取网页数据(BeautifulSoup、本文模块的使用方法及注意点)
前言
学习,最重要的是理解它并使用它,所谓,学以致用,这篇文章,我们以后会介绍,BeautifulSoup模块的使用,以及注意点,帮助您快速了解和学习 BeautifulSoup 模块。有兴趣了解爬虫的朋友,快点学习吧。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题,以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接、翻页操作
继续分析,点击链接进入,发现已经有图片列表了,还可以翻页。
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第三步:编写代码实现需求1、导入模块
导入我们需要使用的所有模块。
import os
import re
from bs4 import BeautifulSoup
import requests
import time
2、获取列表的标题以及链接
def tupianzj():
"""获取标题,链接"""
response = requests.get(url="https://www.tupianzj.com/sheying/",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("h3",{"class":"list_title"})
list=[]
for i in list_title:
list.append({'name':i.get_text(),'url':i.find("a").get("href")})
return list
3、获取类别列表标题、链接和翻页。
def tu_list(url,page):
"""获取类比列表"""
response = requests.get(url,headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("ul",{"class":"list_con_box_ul"})[0].find_all("li")
for i in list_title:
for j in i.find_all("a"):
try:
j.find("img").get("src")
name=j.get("title")#列表列表图片名称
url1="https://www.tupianzj.com"+j.get("href")[0:-5]#类比列表图片详情链接
text=Soup.find_all("div",{"class":"pages"})[0].find_all("a")[1].get("href")#下一页
page1=Soup.find_all("span",{"class":"pageinfo"})[0].find("strong").get_text()#获取总页数
url2=url+text[0:-6]+page+".html"
print(url2,page1)
try:
os.mkdir(name)#创建文件
except:
pass
tu_detail(name,url1,2)
if page==1:
for z in range(2,int(page1))
tu_list(url2,page)
except:
pass
4、获取详细图片并保存
<p>def tu_detail(path,url,page):
"""获取详情"""
if page
如何抓取网页数据(一下吧python开发网站教程:2.对应网页结构(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-30 20:00
这里简单介绍一下python开发网站教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)Python开发网站教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python开发网站教程、内容、笑话数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据Python开发网站教程:
2.对应网页结构python开发网站教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页数:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
当你打开网页的源代码时,你会发现数据不在网页的源代码中。当你按F12抓包分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
你是如何开始编写 python 爬虫的?
因为研究生阶段的主要方向是数据挖掘,所以需要从互联网上获取大量的数据。如果是手动逐页复制,不知道会是什么年月,所以慢慢开始接触python爬虫。我可能告诉我们你的学习之旅:
1.首先你要有一定的python基础,熟悉环境,会使用基本的语法和包。至于基本的python教程,网上有很多,包括视频和pdf。这因人而异。我主要是入门。我正在研究《Python基础教程》这本书,对应python2。这本书比较全面和详细。只要认真按照书本,练习代码,很快就会熟悉python的基础知识。,掌握常用包的基本知识和使用方法。
2.你也应该对网页的基础知识有一定的了解,比如html、css、javascript等,没必要精通,但至少你需要懂一件事或二。要爬取的数据都在网页里,你对网页一无所知我不懂,这根本不可能。至于这些入门级的东西,大家可以在网上搜索一下。我推荐/,非常全面:
3.然后是一些基础爬虫包的使用,比如urllib、urllib2、requests、bs4等。这些教程网上都有,官方也有详细的文档,可以尝试爬取一些比较简单的网页,像尴尬百等。
4.在爬取一些网页的过程中,会发现莫名程序中断,无法连接服务器。这就是反爬机制。很多网站都对爬虫设置了限制,短时间内如果多次爬取,IP就会被封禁,所以要设置IP代理池,来回切换IP,保证正常运行的程序。在这个过程中,需要了解常见的反爬机制,对症下药,尽量避免被服务器屏蔽。寻找。
5.熟悉爬取基础网页后,可以尝试爬取比较大的网站数据,比如某宝数据等。在这个过程中,你可能会发现有些数据不在网页,它是异步加载的,需要抓包分析数据,得到真实的数据URL,才能爬取。
6.了解了基本的爬虫包之后,你会发现每次爬取数据都需要自己构建代码和组织结构,非常麻烦。这时候就需要学习scrapy框架,一个专门为爬虫做的框架,启动爬虫来吧,速度快很多。
7.爬取数据太多,你会发现一台电脑太慢,一个线程不快,那么你可能需要多线程,多台电脑,你需要了解多线程,分布式爬虫,比如scrapy-redis等等。
8.如果数据量很大,你不可能把它存储在一个普通的文件中。需要用到数据库,mysql,mongodb等,需要了解数据库基础知识,增删改查,数据的涉及和构建等。
9.数据已经存在,你需要分析一下,否则爬下来放在那里就没意义了。数据的统计处理,数据可视化,如何建立分析模型,挖掘有价值的信息,机器学习都会用到,接下来就看你自己处理了。
我觉得爬取是一个获取数据的过程。最重要的是如何处理数据。关键是挖掘有价值的信息。当然,没有数据,一切都是空谈,数据就是资源。 查看全部
如何抓取网页数据(一下吧python开发网站教程:2.对应网页结构(组图))
这里简单介绍一下python开发网站教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)Python开发网站教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python开发网站教程、内容、笑话数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据Python开发网站教程:
2.对应网页结构python开发网站教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页数:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
当你打开网页的源代码时,你会发现数据不在网页的源代码中。当你按F12抓包分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
你是如何开始编写 python 爬虫的?
因为研究生阶段的主要方向是数据挖掘,所以需要从互联网上获取大量的数据。如果是手动逐页复制,不知道会是什么年月,所以慢慢开始接触python爬虫。我可能告诉我们你的学习之旅:
1.首先你要有一定的python基础,熟悉环境,会使用基本的语法和包。至于基本的python教程,网上有很多,包括视频和pdf。这因人而异。我主要是入门。我正在研究《Python基础教程》这本书,对应python2。这本书比较全面和详细。只要认真按照书本,练习代码,很快就会熟悉python的基础知识。,掌握常用包的基本知识和使用方法。
2.你也应该对网页的基础知识有一定的了解,比如html、css、javascript等,没必要精通,但至少你需要懂一件事或二。要爬取的数据都在网页里,你对网页一无所知我不懂,这根本不可能。至于这些入门级的东西,大家可以在网上搜索一下。我推荐/,非常全面:
3.然后是一些基础爬虫包的使用,比如urllib、urllib2、requests、bs4等。这些教程网上都有,官方也有详细的文档,可以尝试爬取一些比较简单的网页,像尴尬百等。
4.在爬取一些网页的过程中,会发现莫名程序中断,无法连接服务器。这就是反爬机制。很多网站都对爬虫设置了限制,短时间内如果多次爬取,IP就会被封禁,所以要设置IP代理池,来回切换IP,保证正常运行的程序。在这个过程中,需要了解常见的反爬机制,对症下药,尽量避免被服务器屏蔽。寻找。
5.熟悉爬取基础网页后,可以尝试爬取比较大的网站数据,比如某宝数据等。在这个过程中,你可能会发现有些数据不在网页,它是异步加载的,需要抓包分析数据,得到真实的数据URL,才能爬取。
6.了解了基本的爬虫包之后,你会发现每次爬取数据都需要自己构建代码和组织结构,非常麻烦。这时候就需要学习scrapy框架,一个专门为爬虫做的框架,启动爬虫来吧,速度快很多。
7.爬取数据太多,你会发现一台电脑太慢,一个线程不快,那么你可能需要多线程,多台电脑,你需要了解多线程,分布式爬虫,比如scrapy-redis等等。
8.如果数据量很大,你不可能把它存储在一个普通的文件中。需要用到数据库,mysql,mongodb等,需要了解数据库基础知识,增删改查,数据的涉及和构建等。
9.数据已经存在,你需要分析一下,否则爬下来放在那里就没意义了。数据的统计处理,数据可视化,如何建立分析模型,挖掘有价值的信息,机器学习都会用到,接下来就看你自己处理了。
我觉得爬取是一个获取数据的过程。最重要的是如何处理数据。关键是挖掘有价值的信息。当然,没有数据,一切都是空谈,数据就是资源。
如何抓取网页数据(pin(pointofinterest)热力图分析流程图,挖掘潜在客户的线索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-28 20:04
如何抓取网页数据做数据分析?成本很低,只需要一台电脑和一个wifi路由。分析有几步?不可能,就像你可以单人完成的事情一样,只是相对于“复杂”而已。下图是西尔维斯顿分析师julianbeach在新加坡的一个热力图分析流程图。他首先,要构建转化路径,通过pin(pointofinterest,兴趣点)的概念来找到产品带来的不同流量点,并选取最有价值的高频流量点来作为主要的用户,并且将主要的流量价值点分配给这些主要的用户。
然后将主要的用户点,逐步拓展为可拓展的长尾流量点。将主要流量价值点分配给长尾流量点的做法,也可以分成线性的拓展。一个图,讲了4步:1.发现用户线,构建用户线2.发现高频线路径,并计算拓展高频流量的最大用户线3.将主要流量价值点分配给长尾流量点4.执行计划当然,还可以将特定流量价值点再进一步拓展。由于计划可执行性很差,投入的精力也会变大。
再给出julianbeach的一个简短的示例。具体的做法(国内也是相似):1.获取到海量网页链接2.提取转化数据点,构建转化路径3.生成数据监控报告简单说,就是爬数据!爬数据!爬数据!发现转化路径,为不同需求生成不同的高频流量线路!生成监控报告,及时了解客户生命周期变化。
其实广告客户的前期销售工作可以分为三部分:1.潜在客户线索挖掘:挖掘潜在客户的线索来源,一般主要是通过客户谈判(包括付费推销、免费宣传推广、大客户活动等等)的邀约来挖掘潜在客户,优化资源配置,将更多的潜在客户引导到产品或者服务上。由于客户因素的价值很难量化,因此理论上一个公司可以建立巨大的信息库,这些信息库的价值要远远大于传统的电话客服中心。
2.销售漏斗:销售的有效结束依靠最后一步销售漏斗的有效转化,产品设计的不合理或者企业效率低下也会导致最后失败,而销售漏斗通常由销售人员经手,因此需要用精细化管理系统来完成结束业务流程。3.转化路径:转化路径是一个很复杂的产品,并不是简单的电话销售能够解决的,需要通过巨大的企业线索库、用户数据库、品牌词库等多种渠道获取客户,这样才能进行更高效的销售工作。 查看全部
如何抓取网页数据(pin(pointofinterest)热力图分析流程图,挖掘潜在客户的线索)
如何抓取网页数据做数据分析?成本很低,只需要一台电脑和一个wifi路由。分析有几步?不可能,就像你可以单人完成的事情一样,只是相对于“复杂”而已。下图是西尔维斯顿分析师julianbeach在新加坡的一个热力图分析流程图。他首先,要构建转化路径,通过pin(pointofinterest,兴趣点)的概念来找到产品带来的不同流量点,并选取最有价值的高频流量点来作为主要的用户,并且将主要的流量价值点分配给这些主要的用户。
然后将主要的用户点,逐步拓展为可拓展的长尾流量点。将主要流量价值点分配给长尾流量点的做法,也可以分成线性的拓展。一个图,讲了4步:1.发现用户线,构建用户线2.发现高频线路径,并计算拓展高频流量的最大用户线3.将主要流量价值点分配给长尾流量点4.执行计划当然,还可以将特定流量价值点再进一步拓展。由于计划可执行性很差,投入的精力也会变大。
再给出julianbeach的一个简短的示例。具体的做法(国内也是相似):1.获取到海量网页链接2.提取转化数据点,构建转化路径3.生成数据监控报告简单说,就是爬数据!爬数据!爬数据!发现转化路径,为不同需求生成不同的高频流量线路!生成监控报告,及时了解客户生命周期变化。
其实广告客户的前期销售工作可以分为三部分:1.潜在客户线索挖掘:挖掘潜在客户的线索来源,一般主要是通过客户谈判(包括付费推销、免费宣传推广、大客户活动等等)的邀约来挖掘潜在客户,优化资源配置,将更多的潜在客户引导到产品或者服务上。由于客户因素的价值很难量化,因此理论上一个公司可以建立巨大的信息库,这些信息库的价值要远远大于传统的电话客服中心。
2.销售漏斗:销售的有效结束依靠最后一步销售漏斗的有效转化,产品设计的不合理或者企业效率低下也会导致最后失败,而销售漏斗通常由销售人员经手,因此需要用精细化管理系统来完成结束业务流程。3.转化路径:转化路径是一个很复杂的产品,并不是简单的电话销售能够解决的,需要通过巨大的企业线索库、用户数据库、品牌词库等多种渠道获取客户,这样才能进行更高效的销售工作。
如何抓取网页数据(如何抓取网页数据建议使用易语言或者python这种语言?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-03 06:09
如何抓取网页数据建议使用易语言或者python这种语言,利用数据采集功能,即可采集到网页的数据。navicatdesktop,用过才知道,原来数据很丰富。html的dom是向下兼容的。
有多好用?关键在于你为这个产品想的是什么。先思考一下吧,它是不是为了您推荐的这几个产品做的补充工作,要不就和普通的爬虫软件差不多。知道使用过最好用的人最爱用什么样的产品来实现功能,然后就有着手学习和建立用户行为的动力了。
主要看你要提取什么数据,不同的数据,navicat的功能满足不同场景要求,比如你要爬取楼下小卖铺销售情况、小卖部营业收入,肯定爬取excel形式保存在数据库中。如果要爬取主题关键词以及人群分布数据,肯定要以数据库中以json或xml格式保存到navicat的database中。
navicat+pymysql,
navicat
同意楼上的,tagxedo,
可以看看phpmyadmin
postman之类的webshell?
百度googlejavascrapybs4html抓取
首先,要想清楚你需要提取的数据,其次,
的api:,比如xmlhttprequest。xmlhttprequest。requestparsed,xhr的document。ready,json。stringify,engine。attributes。contentdocument,xml。special。onload(bytesmodelexecutable,bytesmodeldocument)/~gohlke/pythonlibs/#json。 查看全部
如何抓取网页数据(如何抓取网页数据建议使用易语言或者python这种语言?)
如何抓取网页数据建议使用易语言或者python这种语言,利用数据采集功能,即可采集到网页的数据。navicatdesktop,用过才知道,原来数据很丰富。html的dom是向下兼容的。
有多好用?关键在于你为这个产品想的是什么。先思考一下吧,它是不是为了您推荐的这几个产品做的补充工作,要不就和普通的爬虫软件差不多。知道使用过最好用的人最爱用什么样的产品来实现功能,然后就有着手学习和建立用户行为的动力了。
主要看你要提取什么数据,不同的数据,navicat的功能满足不同场景要求,比如你要爬取楼下小卖铺销售情况、小卖部营业收入,肯定爬取excel形式保存在数据库中。如果要爬取主题关键词以及人群分布数据,肯定要以数据库中以json或xml格式保存到navicat的database中。
navicat+pymysql,
navicat
同意楼上的,tagxedo,
可以看看phpmyadmin
postman之类的webshell?
百度googlejavascrapybs4html抓取
首先,要想清楚你需要提取的数据,其次,
的api:,比如xmlhttprequest。xmlhttprequest。requestparsed,xhr的document。ready,json。stringify,engine。attributes。contentdocument,xml。special。onload(bytesmodelexecutable,bytesmodeldocument)/~gohlke/pythonlibs/#json。
如何抓取网页数据(网站抓取异常是为什么?搜索引擎蜘蛛无法抓取网站页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-02 00:24
网站为什么会出现爬取异常?抓取异常意味着搜索引擎蜘蛛无法抓取 网站 页面。做SEO优化的都知道网站排名的前提是网站有爬取和收录。因此,网站 fetch 异常必须尽快解决。接下来我们看看为什么会出现网站抓取异常,解决方法是什么?
一般来说,网站不会出现无缘无故的爬取异常。主要原因可能是 网站 异常或链接异常。
网站异常表现主要有四种:
一是DNS异常,可能是网站IP地址错误或者域名过期造成的。如果是不正确或无法解决的问题,请联系域名注册商更新网站IP地址;
其次,搜索引擎蜘蛛爬取请求的连接超时可能是服务器过载或网络不稳定造成的。如果服务器经常不稳定,建议更换服务器;
三是搜索引擎蜘蛛爬取超时。这种情况下,爬取请求连接建立成功,但是下载页面速度太慢,导致超时。这可能是服务器过载或带宽不足,需要升级带宽或优化网站以提高网站的加载速度。为了避免这种情况,建议在选择带宽时选择比实际需求大的带宽;
四、连接错误,建立连接后搜索引擎无法连接或对方服务器拒绝连接。这可能是因为域名服务提供商已经禁止了搜索引擎。联系域名服务商解决。另外,我们还会检查robots文件设置,看是否有重要页面被屏蔽,导致爬取异常。
链接异常的主要表现是返回各种网站HTTP状态码。一般情况下,搜索蜘蛛发起爬取,但拒绝被访问,返回403;搜索蜘蛛发起爬取,但页面找不到,返回404;服务器错误返回 5XX;其他错误返回 4XX,但不包括 403 和 404。
因此,解决网站抓取异常的问题,可以从网站返回HTTP状态码入手。网站爬取异常的原因总结为服务器和域名的问题。为了避免网站的异常爬取,大家在服务器的选择上一定要慎重,不要贪图便宜。重要的是要知道网站 爬取异常对网站 的影响很大。如果网站上有很多蜘蛛无法正常抓取的内容,搜索引擎的信任度和评价就会下降,而网站的抓取问题在索引和索引方面显然会受到一定程度的负面影响。加权。为了避免出现更严重的情况,大家一定要尽快解决。
以上就是网站爬取异常的原因分析及解决方法的介绍。如果您遇到过这样的问题,您可以了解以上情况和解决方案。我希望这篇文章对你有所帮助。 查看全部
如何抓取网页数据(网站抓取异常是为什么?搜索引擎蜘蛛无法抓取网站页面)
网站为什么会出现爬取异常?抓取异常意味着搜索引擎蜘蛛无法抓取 网站 页面。做SEO优化的都知道网站排名的前提是网站有爬取和收录。因此,网站 fetch 异常必须尽快解决。接下来我们看看为什么会出现网站抓取异常,解决方法是什么?
一般来说,网站不会出现无缘无故的爬取异常。主要原因可能是 网站 异常或链接异常。
网站异常表现主要有四种:
一是DNS异常,可能是网站IP地址错误或者域名过期造成的。如果是不正确或无法解决的问题,请联系域名注册商更新网站IP地址;
其次,搜索引擎蜘蛛爬取请求的连接超时可能是服务器过载或网络不稳定造成的。如果服务器经常不稳定,建议更换服务器;
三是搜索引擎蜘蛛爬取超时。这种情况下,爬取请求连接建立成功,但是下载页面速度太慢,导致超时。这可能是服务器过载或带宽不足,需要升级带宽或优化网站以提高网站的加载速度。为了避免这种情况,建议在选择带宽时选择比实际需求大的带宽;
四、连接错误,建立连接后搜索引擎无法连接或对方服务器拒绝连接。这可能是因为域名服务提供商已经禁止了搜索引擎。联系域名服务商解决。另外,我们还会检查robots文件设置,看是否有重要页面被屏蔽,导致爬取异常。
链接异常的主要表现是返回各种网站HTTP状态码。一般情况下,搜索蜘蛛发起爬取,但拒绝被访问,返回403;搜索蜘蛛发起爬取,但页面找不到,返回404;服务器错误返回 5XX;其他错误返回 4XX,但不包括 403 和 404。
因此,解决网站抓取异常的问题,可以从网站返回HTTP状态码入手。网站爬取异常的原因总结为服务器和域名的问题。为了避免网站的异常爬取,大家在服务器的选择上一定要慎重,不要贪图便宜。重要的是要知道网站 爬取异常对网站 的影响很大。如果网站上有很多蜘蛛无法正常抓取的内容,搜索引擎的信任度和评价就会下降,而网站的抓取问题在索引和索引方面显然会受到一定程度的负面影响。加权。为了避免出现更严重的情况,大家一定要尽快解决。
以上就是网站爬取异常的原因分析及解决方法的介绍。如果您遇到过这样的问题,您可以了解以上情况和解决方案。我希望这篇文章对你有所帮助。
如何抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2022-03-01 17:06
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关信息,包括但不限于域名备案等信息,生成密码爆破。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,扔各种工具在上面,运行扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd"); 查看全部
如何抓取网页数据(爆破4.万能密码有哪些?管理后台的注意事项)
1:信息采集,
无论是防御还是渗透测试,都需要这一步,简单的信息采集。
手机信息收录很多,
例如,服务器 IP 地址是什么?
后台入口在哪里?
服务器打开了那些端口,服务器安装了那些应用程序等等,这些都是前期必须采集的东西。
手机有很多工具
当然还有其他方法,比如使用工具检测、nmap、
但是,专业的工具可能并不适合普通的白人。
例如,我们假设采集到的信息如下:
初步信息采集工作完成后,即可进入第二阶段。
第二步:根据服务器的安装环境进行进一步测试,类似看病。
先检查,再根据具体情况开药。
漏洞的一般列表无非如下:
1:弱密码,包括ftp、http、远程登录等,
处理弱密码的方法有很多,但使用好的社会工程库是最简单的方法。
2:存在sql注入漏洞,
这仅适用于工具。
3:xss漏洞,
4:存在穿透溢出漏洞
5:安装有致命缺陷的软件。
1. 后台登录时抓取复制数据包放到txt中,扔到sqlmap -r中运行
2. 弱密码
帐号:admin sa root
密码:123456 12345678 666666 admin123 admin888
这些是我见过最多的
管理后台一般为admin,phpmyadmin之类的数据库一般为root。
3. 没有验证码,验证码不刷新,只有一个验证码,而且验证码不起作用,可以试试爆破
4. 主密码可以创造奇迹
5.去前台发的文章,查看留言板的回复,看看作者是谁,很有可能是管理员账号
6.有的网站会提示账号不存在等,可以手动找管理员账号或者打嗝爆破
7. 当常规字典爆破失败时,可以根据从信息中采集到的相关信息,包括但不限于域名备案等信息,生成密码爆破。像网站这样的学校,可以去前台找老师电话号码,姓名首字母等,其他想法,大家可以根据网站自行思考
8. 扫描到的目录可能有源代码泄露等
9. cms使用的cms有默认账号和密码,可以百度搜索
10.可能存在短信轰炸、逻辑漏洞、任意重置密码、爆破管理员账号等。
11. f12 康康总有惊喜
12.注意不要被围墙
13. 有时候有的网站会把错误信息记录到一个php文件中,可以试试账号或者密码写一句,也可以直接getshell,笔者遇到过一次
14.进入后台后寻找上传点,使用绕过上传
15. 其他具体功能,数据库备份等。
16.我刚刚在网红队使用的编辑器bug
17. 扫描到的目录不正常可以查看
18.扫描奇怪的名字,打开一个空白文件,尝试爆出一句话
第三步:当我们确定存在漏洞时,我们必须启动、使用、
拿到shell后可能会出现权限不足,大致分为两种情况
1. Windows 权限提升
2. linux 提权
具体的提权方法可以在百度上找到
内网仍然是信息采集。一开始看本地IP,扫描幸存的hosts,过一波各种exp,扔各种工具在上面,运行扫描,内网博大精深,好不容易学好
但最好用工具,用工具更容易,
基本上所有可以集成的东西都集成了,只需简单的点击按钮,
不知道的可以找我,还有很多方法
参考下图与我交流
导入 java.util.regex.Matcher;
导入 java.util.regex.Pattern;
公共类下载Img {
公共静态无效 writeImgEntityToFile(HttpEntity imgEntity,String fileAddress) {
文件 storeFile = new File(fileAddress);
FileOutputStream 输出 = null;
尝试 {
输出 = 新文件输出流(存储文件);
如果(imgEntity!= null){
InputStream 流内;
流内 = imgEntity.getContent();
字节 b[] = 新字节[8 * 1024];
整数计数;
而 ((count = instream.read(b)) != -1) {
output.write(b, 0, count);
}
}
} 捕捉(FileNotFoundException e){
e.printStackTrace();
} 捕捉(IOException e){
e.printStackTrace();
} 最后 {
尝试 {
输出.close();
} 捕捉(IOException e){
e.printStackTrace();
}
}
}
公共静态无效主要(字符串[]参数){
System.out.println("获取必应图片地址...");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
如何抓取网页数据( 如何用WebScraper选择元素的操作点击Stiemaps图解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-28 20:07
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的朋友可以回顾一下旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的朋友可以回顾一下旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据(2022-01-08这是简易数据分析05实操前的抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 295 次浏览 • 2022-02-28 13:22
)
2022-01-08
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击Stiemaps,在新面板点击ID为top250的数据列
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04、简单数据分析05中已经提到,忘记的朋友可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(2022-01-08这是简易数据分析05实操前的抓取
)
2022-01-08
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特点,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击Stiemaps,在新面板点击ID为top250的数据列
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04、简单数据分析05中已经提到,忘记的朋友可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据(搜索引擎蜘蛛如何提升搜索引擎爬虫的抓取次数?蜘蛛怎么做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-28 13:21
一、什么是搜索引擎爬虫?
搜索引擎爬虫,我们通常称它们为蜘蛛,因为互联网是一个链接网络,它需要蜘蛛在这个网络上爬行。索引数据是通过网络上的URL链接,按照一定的规则自动抓取网页信息的程序或脚本。
点击查看>>>>>>搜索引擎蜘蛛如何抓取收录网站内容?
二、搜索引擎爬虫的作用是什么?
我们可以这样理解,搜索引擎只是一个搜索工具,没有内容。然后,搜索引擎需要使用爬虫程序来到我们的网站,把网站的内容带回去做分析,这部分叫做“收录”。因此,如果一个网站想要排名,必须先被搜索引擎收录抓取。
三、如何增加搜索引擎爬虫的爬取次数?
一、创建原创内容
现在的搜索引擎内容已经不像2012年以前那样抓取网站的内容了。搜索引擎关注的是能够满足用户需求的内容质量,简单的填写文章@到采集就可以了更长久地吸引搜索引擎的注意力。只有创作出高质量的原创内容才是最重要的。全面提升内容质量,提高页面更新频率,是SEO优化者必须具备的。
二、创建潜在客户链接
合理安排网站内的内链和站外的优质链接,通过链接导入和内链导出,可以帮助搜索引擎爬虫更好地抓取网站内容。
三、增加网站和页面的权重
众所周知,高权重的网站和页面可以吸引蜘蛛爬行,但是高质量的网站权重依赖于网站整体优化的布局,所以,通过基于内容的, link 补充优化方法可以吸引更多蜘蛛的注意。 查看全部
如何抓取网页数据(搜索引擎蜘蛛如何提升搜索引擎爬虫的抓取次数?蜘蛛怎么做)
一、什么是搜索引擎爬虫?
搜索引擎爬虫,我们通常称它们为蜘蛛,因为互联网是一个链接网络,它需要蜘蛛在这个网络上爬行。索引数据是通过网络上的URL链接,按照一定的规则自动抓取网页信息的程序或脚本。
点击查看>>>>>>搜索引擎蜘蛛如何抓取收录网站内容?
二、搜索引擎爬虫的作用是什么?
我们可以这样理解,搜索引擎只是一个搜索工具,没有内容。然后,搜索引擎需要使用爬虫程序来到我们的网站,把网站的内容带回去做分析,这部分叫做“收录”。因此,如果一个网站想要排名,必须先被搜索引擎收录抓取。
三、如何增加搜索引擎爬虫的爬取次数?
一、创建原创内容
现在的搜索引擎内容已经不像2012年以前那样抓取网站的内容了。搜索引擎关注的是能够满足用户需求的内容质量,简单的填写文章@到采集就可以了更长久地吸引搜索引擎的注意力。只有创作出高质量的原创内容才是最重要的。全面提升内容质量,提高页面更新频率,是SEO优化者必须具备的。
二、创建潜在客户链接
合理安排网站内的内链和站外的优质链接,通过链接导入和内链导出,可以帮助搜索引擎爬虫更好地抓取网站内容。
三、增加网站和页面的权重
众所周知,高权重的网站和页面可以吸引蜘蛛爬行,但是高质量的网站权重依赖于网站整体优化的布局,所以,通过基于内容的, link 补充优化方法可以吸引更多蜘蛛的注意。
如何抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-28 09:10
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网! 查看全部
如何抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网!
如何抓取网页数据(机器学习项目如何使用BeautifulSoup和Selenium?数据结构机器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-21 21:17
不久前在LearnML分论坛上看到一个帖子。楼主在这个贴子里提到,他的机器学习项目需要爬取网页数据。很多人在回复中给出了自己的方法,主要是学习如何使用 BeautifulSoup 和 Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在这篇文章 文章 中,我将向您展示如何抓取收录有用数据的网页并将其转换为 pandas DataFrame。
为什么要转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构,并且您只需进行一些修改即可编辑您的模型。
首先,我们需要在***上找到一个表,并将其转换为数据结构。我抓取的表格显示了 *** 上运动员观看次数最多的数据。
一项伟大的任务是浏览 HTML 树以获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。
复制代码
因为有很多表,我们需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)的主播可能在几款腕表中独树一帜。
通过C罗文本,我们可以过滤掉锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器的cell***开发工具。
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的手表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
复制代码
分解它:
复制代码
让我们从上面的列表中选择第三个元素。这就是我们需要的手表。
接下来,创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环遍历表中的每一行,并将其保存在 rows 变量中。
复制代码
复制代码
创建嵌套循环。迭代在最后一个循环中保存的每一行。当迭代单元格时,我们将每个单元格保存在一个新变量中。
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理成纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
将其转换为以下数据结构:
复制代码
您现在可以在机器学习项目中使用 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
对技术感兴趣的 Topola Bode 目前专注于机器学习。
原文链接:
.dev 天才 .io/how-to-scrape-a-website-for-your-ml-project-C3 a4d 6 f 160 c 7 查看全部
如何抓取网页数据(机器学习项目如何使用BeautifulSoup和Selenium?数据结构机器)
不久前在LearnML分论坛上看到一个帖子。楼主在这个贴子里提到,他的机器学习项目需要爬取网页数据。很多人在回复中给出了自己的方法,主要是学习如何使用 BeautifulSoup 和 Selenium。
我在一些数据科学项目中使用过 BeautifulSoup 和 Selenium。在这篇文章 文章 中,我将向您展示如何抓取收录有用数据的网页并将其转换为 pandas DataFrame。
为什么要转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构,并且您只需进行一些修改即可编辑您的模型。
首先,我们需要在***上找到一个表,并将其转换为数据结构。我抓取的表格显示了 *** 上运动员观看次数最多的数据。
一项伟大的任务是浏览 HTML 树以获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
复制代码
接下来,我们将从网页中提取 HTML 代码:
复制代码
从语料库中采集所有表格,我们有一个小的表面积要搜索。
复制代码
因为有很多表,我们需要一种过滤它们的方法。
据我们所知,克里斯蒂亚诺·罗纳尔多(又名葡萄牙足球运动员克里斯蒂亚诺·罗纳尔多)的主播可能在几款腕表中独树一帜。
通过C罗文本,我们可以过滤掉锚点标记的表格。此外,我们还发现了一些收录此锚标记的父元素。
复制代码
父元素仅显示单元格。
这是一个带有浏览器的cell***开发工具。
复制代码
使用 tbody,我们可以返回收录先前锚标记的其他表。
为了进一步过滤,我们可以在下表中的不同标题下进行搜索:
复制代码
第三个看起来很像我们需要的手表。
接下来,我们开始创建必要的逻辑来提取和清理我们需要的细节。
复制代码
分解它:
复制代码
让我们从上面的列表中选择第三个元素。这就是我们需要的手表。
接下来,创建一个空列表来存储每一行的详细信息。遍历表时,设置一个循环遍历表中的每一行,并将其保存在 rows 变量中。
复制代码
复制代码
创建嵌套循环。迭代在最后一个循环中保存的每一行。当迭代单元格时,我们将每个单元格保存在一个新变量中。
复制代码
这段简短的代码让我们在从单元格中提取文本时避免出现空单元格并防止错误。
复制代码
在这里,我们将各种单元格清理成纯文本。清除的值保存在其列名下的变量中。
复制代码
在这里,我们将这些值添加到行列表中。然后输出清理后的值。
复制代码
将其转换为以下数据结构:
复制代码
您现在可以在机器学习项目中使用 pandas 数据结构。您可以使用自己喜欢的库来拟合模型数据。
关于作者:
对技术感兴趣的 Topola Bode 目前专注于机器学习。
原文链接:
.dev 天才 .io/how-to-scrape-a-website-for-your-ml-project-C3 a4d 6 f 160 c 7
如何抓取网页数据( 如何用WebScraper选择元素的操作点击Stiemaps图解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-20 08:07
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列文章 的第七部分。
在第 4 部分 文章 中,我解释了如何在单个网页中抓取单一类型的信息;
在第 5 部分 文章 中,我解释了如何从多个网页中抓取单一类型的信息;
我们今天要讲的是如何从多个网页中爬取多种类型的信息。
这次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了爬取多个网页的问题,接下来我们将重点介绍如何爬取多类信息。
练习之前先理清逻辑:
最后几篇文章只抓住了一种元素:电影的标题。本期我们将抓取多种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,首先要抓取包装多类数据的容器,然后选择容器中的数据,这样才能正确抓取。我画了一张图来演示:
我们首先需要抓取多个容器,然后抓取容器中的元素:序号、电影名、评分、一句话影评。当爬虫完成运行后,我们就成功抓取了数据。
概念清楚后,我们就可以谈实际操作了。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,该文章文章详细说明了如何使用Web Scraper选择元素
1.点击 Stiemaps 并在新面板中点击 ID 为 top250 的这一列数据
2.删除旧选择器,点击添加新选择器添加新选择器
3.在新的选择器中,注意将Type改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们将进入一个新的面板。根据导航,我们知道它在容器内部。
在新建面板中,我们点击添加新选择器,新建一个选择器来捕捉电影名称,类型为Text,值得注意的是因为我们选择容器中的文本,所以一个容器中只有一个电影名称,所以不要勾选多选,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是在黄色区域选择电影名称。
点击保存选择器保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就省略解释了。
排名号:
分数:
一句话点评:
我们可以观察到我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击 Stiemap top250 下的选择器图,查看我们爬虫选择的元素的层次关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择无误后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。以下是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,是比较合理的学习方式。
其实今天还是有很多内容的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据(如何抓取网页数据必须牢记以下技巧:如何设置网页默认数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-17 10:06
如何抓取网页数据必须牢记以下技巧:1.筛选某一条件下的子表格数据2.根据表格内容对数据进行排序3.了解网页默认数据格式4.设置过滤器,如回复次数5.抓取框无非是一个input,我们先打开vs2013,插入一个color_activation对象,并创建一个空的判断对象selectedistfield,判断有没有这个color_activation对象在窗口中弹出的对话框第一行的值就是网页的数据格式,那么,分析网页上的数据,很显然也就必须要将post用标准编码方式存储(常用的编码方式如utf-8或者gbk)。
然后就是网页上的数据格式是动态的,不可能存储一个绝对值,我们必须这样来设置网页上的数据格式。关于怎么设置时序数据格式请阅读百度文库“百度文库如何使网页快速定制符”。学习数据抓取:html.xmlweb-analyzerrequests.getrequests.urlopenrequests.get_html()jsonpythonpython这里post的数据有两种方式:通过http请求传递数据的格式有html格式和json格式,接下来我们讲解怎么将这两种格式合并到一起(其实之前我也没弄明白过来,但是读懂了它们的用法就不难理解了):1.http请求传递数据的格式网站通过url地址发送给我们post请求,但是这个url是固定的,我们可以对这个地址每秒发送http请求10万次(假设请求请求时间为一秒)。
那么接下来就可以对这个请求打印出一个特定格式的html文档,网站在每秒多次的请求中会构建html格式的html文档,并逐页下载。2.http请求传递的数据格式类似json格式,json格式类似于java中的序列化格式,所以post传递的数据可以分为json数据和java中的序列化数据。json数据格式直接用codehandler类获取data,然后构造json字典,从新获取这个url下的http请求的数据即可,如下:forurlinweb.urls.items():importjsoncookiechange=requests.get(url)jsonquery=json.loads(json.dumps(cookiechange))jsonbytes=json.loads(json.dumps(cookiechange))或者直接用python的prepare_post方法,将数据写入data中。
data=json.loads(json.dumps(requests.get(url).json()))jsonvalue=json.loads(json.dumps(cookiechange))jsonjson=json.loads(json('{'+json.strip()))print(jsonjson)3.http请求传递的数据格式网站将数据放在session中,构建session并保存数据。
例如,如果session的url是:。那么首先需要自己构建一个session对象,可以从session模块中获取。构建时序。 查看全部
如何抓取网页数据(如何抓取网页数据必须牢记以下技巧:如何设置网页默认数据)
如何抓取网页数据必须牢记以下技巧:1.筛选某一条件下的子表格数据2.根据表格内容对数据进行排序3.了解网页默认数据格式4.设置过滤器,如回复次数5.抓取框无非是一个input,我们先打开vs2013,插入一个color_activation对象,并创建一个空的判断对象selectedistfield,判断有没有这个color_activation对象在窗口中弹出的对话框第一行的值就是网页的数据格式,那么,分析网页上的数据,很显然也就必须要将post用标准编码方式存储(常用的编码方式如utf-8或者gbk)。
然后就是网页上的数据格式是动态的,不可能存储一个绝对值,我们必须这样来设置网页上的数据格式。关于怎么设置时序数据格式请阅读百度文库“百度文库如何使网页快速定制符”。学习数据抓取:html.xmlweb-analyzerrequests.getrequests.urlopenrequests.get_html()jsonpythonpython这里post的数据有两种方式:通过http请求传递数据的格式有html格式和json格式,接下来我们讲解怎么将这两种格式合并到一起(其实之前我也没弄明白过来,但是读懂了它们的用法就不难理解了):1.http请求传递数据的格式网站通过url地址发送给我们post请求,但是这个url是固定的,我们可以对这个地址每秒发送http请求10万次(假设请求请求时间为一秒)。
那么接下来就可以对这个请求打印出一个特定格式的html文档,网站在每秒多次的请求中会构建html格式的html文档,并逐页下载。2.http请求传递的数据格式类似json格式,json格式类似于java中的序列化格式,所以post传递的数据可以分为json数据和java中的序列化数据。json数据格式直接用codehandler类获取data,然后构造json字典,从新获取这个url下的http请求的数据即可,如下:forurlinweb.urls.items():importjsoncookiechange=requests.get(url)jsonquery=json.loads(json.dumps(cookiechange))jsonbytes=json.loads(json.dumps(cookiechange))或者直接用python的prepare_post方法,将数据写入data中。
data=json.loads(json.dumps(requests.get(url).json()))jsonvalue=json.loads(json.dumps(cookiechange))jsonjson=json.loads(json('{'+json.strip()))print(jsonjson)3.http请求传递的数据格式网站将数据放在session中,构建session并保存数据。
例如,如果session的url是:。那么首先需要自己构建一个session对象,可以从session模块中获取。构建时序。
如何抓取网页数据(如何开发数据提取网络数据(爬虫机器人)?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-02-13 13:02
返回博客
如何从 网站 中提取数据
伊维塔·维斯托斯基特
2022-02-11
如今,基于数据做出业务决策是许多公司最重要的业务流程。为了做出决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多 网站 服务器存储了大量公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
出于商业目的提取数据的做法对于许多公司来说已经司空见惯。但在日常运营中提取数据以获取情报并非易事。为此,在本文中,我们将详细解释如何提取Web数据,存在哪些挑战,并为您介绍几种解决方案,以帮助您更好地抓取数据。
如何提取数据
如果您的技术不好,那么提取数据可能会非常复杂且难以理解。其实整个过程不难理解。
提取 网站 数据,我们称之为网络抓取或网络采集。该术语特指使用机器人或网络爬虫自动化采集数据的过程。有时网络抓取很容易与网络抓取混淆。我们在之前的博客文章中讨论了网络抓取和网络抓取之间的主要区别。
现在,让我们看一下整个过程,以全面了解 Web 数据提取的工作原理。
数据提取原理
今天,我们主要在 HTML 中抓取数据,这是一种基于文本的标记语言。它通过各种组件定义网站内容的结构,包括
, , 和其他标签。开发者编写各种脚本来爬取各种结构的数据。
开发数据提取脚本
精通Python等编程语言的程序员可以编写网页数据提取脚本(爬虫)。Python 的诸多优势(丰富的库、易用性和活跃的社区等)使其成为编写爬虫脚本最常用的语言。使用这种类型的脚本来自动抓取数据。它们向服务器发送请求,访问指定的 URL,并遍历预定义的页面、HTML 标记和组件。然后从这些地方提取数据。
自定义开发数据爬取模式
用户可以根据提取数据所需的特定 HTML 组件自定义脚本。需要提取哪些数据取决于您的业务目标。如果可以具体定位到想要的数据,就不需要抽取不必要的数据。这减少了服务器的压力和存储空间的要求,降低了数据处理的难度。
创建服务器环境
要连续运行网络爬虫,需要服务器。因此,顺利连续爬取的下一步是投资服务器基础设施,或者从信誉良好的老牌公司租用服务器。服务器是必不可少的,因为它们允许您全天连续运行预先编写的脚本,优采云记录和存储过程。
准备足够的存储空间
数据提取脚本交付的工作产品是数据。大规模操作需要相应的大量存储容量。从多个网站中提取的数据相当于数千个网页。该过程是连续的,因此会为您带来大量数据。确保有足够的存储空间来支持持续的提取操作非常重要。
数据处理
捕获的数据以原创形式存在,难以理解。所以 data采集 过程中的下一个重要步骤是解析和创建结构良好的数据。
如何从 网站 中提取数据
有多种方法可以从网页中提取公共数据,或者通过构建自己的工具或使用现成的网络抓取解决方案。这两种选择都各有优势,我们将逐一研究它们,以便您轻松决定哪一种最适合您的业务需求。
构建您自己的解决方案
要开发自己的 Web 数据提取工具,您需要一个专用的 Web 抓取技术堆栈。包括以下内容:
演戏。很多网站会根据访问者IP地址的位置显示不同的内容。有时您可能需要在另一个国家/地区使用代理,具体取决于您的服务器所在的位置以及您想要访问它的位置。
还需要一个大型代理池来帮助绕过 IP 阻止和 CAPTCHA 验证。
无头浏览器。越来越多的 网站 使用 Vue.js 或 React.js 前端框架。此类框架使用后端 API 来获取数据并呈现 DOM(文档对象模型)。普通的 HTML 客户端不会呈现 Javascript 代码;因此,如果没有无头浏览器,您将获得一个空白页面。
此外,网站 通常可以检测 HTTP 客户端是否是机器人。因此,无头浏览器可以帮助访问目标 HTML 页面。
最常用的无头浏览器 API 是 Selenium、Puppeteer 和 Playwright。
抽取规则。这是一组用于选择 HTML 组件和提取数据的规则。选择这些组件的最简单方法是通过 XPath 和 CSS 选择器。
网站HTML 编码不断更新。因此,提取规则是开发人员花费最多时间的地方。
工作日程。这可以帮助您安排时间在需要时监控特定数据。它还可以帮助解决错误:跟踪 HTML 更改、目标网站 或代理服务器的停机时间以及被阻止的请求至关重要。
贮存。提取数据后,您需要将其正确存储在 SQL 数据库等中。保存采集的数据的标准格式是 JSON、CSV 和 XML。
监视器。采集数据,尤其是大规模的采集数据,会引发各种问题。为避免这些问题,您必须确保您的代理始终处于运行状态。日志分析、仪表板和警报可以帮助您监控数据。
网页数据采集流程:
确定需要获取和处理的数据类型。
找到数据的位置并设置获取路径。
导入并安装所需的预设。
编写数据提取脚本并运行该脚本。
为了避免IP阻塞,必须模仿普通网民的行为。这就是代理发挥作用的地方,它们使数据采集 的整个过程变得更容易。我们稍后再谈。
网络爬虫 API
诸如网络爬虫 API 之类的即用型数据提取工具的主要优点之一是它可以帮助您从困难目标中提取公共数据网站,而无需额外资源。大型电子商务页面使用复杂的反机器人算法。因此,抓取这些页面的工具需要更多的开发时间。
自制解决方案必须通过反复试验来创造变通办法,这意味着不可避免的速度下降、IP 地址受阻和定价数据流不可靠。使用我们的网络爬虫网络爬虫 API,整个过程可以完全自动化。您的员工可以专注于更紧迫的任务并直接进行数据分析,而不是无休止的复制粘贴。
如何选择?
根据您的业务规模,构建您自己的解决方案或购买现成的数据提取工具。
如果您的公司需要大规模采集数据,网络爬虫 API 是一个很好的选择,可以节省时间并实时提供高质量的数据结果。最重要的是,它们可以为您节省代码维护和集成的费用。
另一方面,如果您是一家只需要偶尔爬网的小型企业,那么构建自己的数据提取工具可能会非常有益。
网络数据的好处采集
大数据是当今商业界最热门的流行语。它指的是对数据集进行有目的的多重处理:获得有意义的见解、发现趋势和模式以及预测经济状况。例如,网络抓取房地产数据有助于分析该行业的重大影响。同样,另类数据可以帮助基金经理发现投资机会。
网络抓取可以发挥作用的另一个领域是汽车行业。公司采集汽车行业数据,例如用户和组件评论。
各行各业的公司从 网站 中提取数据,以构建自己的最新相关数据集。这种做法通常会延续到其他 网站 上,从而提高数据集的完整性。数据越多越好,因为它有更多的参考点,使整个数据集更有效率。
公司通常会提取哪些数据?
前面我们提到,提取的目标数据并不都是在线数据,这不难理解。在确定要提取哪些数据时,您的业务定位、需求和目标应该是主要标准。
您感兴趣的目标数据可能会有所不同。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等;您还可以根据目标的新产品和服务自定义脚本。在进行抓取活动之前,请确保被抓取的公共数据不会损害任何第三方的权利。
数据采集常见挑战
提取数据从来都不是一帆风顺的。最常见的挑战是:
数据抓取最佳实践
面对由经验丰富的专业人员开发的复杂的网络数据提取脚本,与网络数据密切相关的难题采集 可以轻松解决。但被反爬虫技术识别和屏蔽的风险依然存在。因此,迫切需要一种变革性的解决方案:代理。更准确地说,轮换代理。
轮换代理允许您使用大量 IP 地址。使用位于不同区域的 IP 发送请求可以欺骗服务器并防止被阻止。此外,您可以使用 Proxy Rotator 代替手动分配不同的 IP,它会自动从代理数据中心池中分配 IP。
如果您没有资源并且没有经验丰富的 Web 抓取开发团队,那么是时候考虑使用现成的解决方案,例如 Web 爬虫 API。它确保 100% 交付来自大多数 网站s、策划优采云 数据的抓取结果,并聚合数据,以便您轻松理解它。
从 网站 中提取数据是否合法?
许多企业依赖大数据,需求显着增长。根据 Statista 的研究,大数据市场每年都在大幅增长,预计到 2027 年将达到 1030 亿美元。因此,越来越多的企业正在使用网络抓取来获取数据采集。这种受欢迎程度引发了一个激烈争论的话题:网络抓取合法吗?
这个复杂的话题没有明确的答案,如果你在做网络爬虫,你不能违反任何与相关数据相关的法律法规。值得注意的是,我们强烈建议在进行任何抓取活动之前根据具体情况寻求专业的法律建议。
同时,我们也强烈建议不要抓取非公开数据,除非已获得目标 网站 的明确许可。为了清楚起见,本文中的任何内容都不应被解释为对非公开数据抓取的建议。
总结
总之,如果你想从 网站 中提取数据,那么你需要一个数据提取脚本。如您所知,由于数据抓取操作的广度、复杂性以及不断变化的 网站 结构,构建此类脚本可能具有挑战性。由于网络抓取必须实时获取最新数据,因此您需要避免被阻止。这就是为什么在进行主要的抓取操作时必须使用旋转代理。
如果您认为您的企业需要一个强大的解决方案来简化您的数据采集,您可以立即注册并使用 Oxylabs 的 Web Crawler API。
关于作者
伊维塔·维斯托斯基特
内容管理者
Iveta Vistorskyte 在 Oxylabs 担任内容经理。作为一名作家和挑战者,她决定涉足科技领域,并立即对该领域产生了兴趣。当她不工作时,您可能会发现她只是通过听她最喜欢的音乐或与朋友一起玩棋盘游戏来放松。
了解有关艾维塔的更多信息
Oxylabs 博客上的所有信息均按“原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录的任何信息或可能链接到的任何第三方 网站 中收录的任何信息,我们不作任何陈述,也不承担任何责任。在进行任何形式的抓取之前,请咨询您的法律顾问并仔细阅读具体的网站服务条款或获得抓取许可。 查看全部
如何抓取网页数据(如何开发数据提取网络数据(爬虫机器人)?(图))
返回博客
如何从 网站 中提取数据
伊维塔·维斯托斯基特
2022-02-11
如今,基于数据做出业务决策是许多公司最重要的业务流程。为了做出决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多 网站 服务器存储了大量公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
出于商业目的提取数据的做法对于许多公司来说已经司空见惯。但在日常运营中提取数据以获取情报并非易事。为此,在本文中,我们将详细解释如何提取Web数据,存在哪些挑战,并为您介绍几种解决方案,以帮助您更好地抓取数据。
如何提取数据
如果您的技术不好,那么提取数据可能会非常复杂且难以理解。其实整个过程不难理解。
提取 网站 数据,我们称之为网络抓取或网络采集。该术语特指使用机器人或网络爬虫自动化采集数据的过程。有时网络抓取很容易与网络抓取混淆。我们在之前的博客文章中讨论了网络抓取和网络抓取之间的主要区别。
现在,让我们看一下整个过程,以全面了解 Web 数据提取的工作原理。
数据提取原理
今天,我们主要在 HTML 中抓取数据,这是一种基于文本的标记语言。它通过各种组件定义网站内容的结构,包括
, , 和其他标签。开发者编写各种脚本来爬取各种结构的数据。
开发数据提取脚本
精通Python等编程语言的程序员可以编写网页数据提取脚本(爬虫)。Python 的诸多优势(丰富的库、易用性和活跃的社区等)使其成为编写爬虫脚本最常用的语言。使用这种类型的脚本来自动抓取数据。它们向服务器发送请求,访问指定的 URL,并遍历预定义的页面、HTML 标记和组件。然后从这些地方提取数据。
自定义开发数据爬取模式
用户可以根据提取数据所需的特定 HTML 组件自定义脚本。需要提取哪些数据取决于您的业务目标。如果可以具体定位到想要的数据,就不需要抽取不必要的数据。这减少了服务器的压力和存储空间的要求,降低了数据处理的难度。
创建服务器环境
要连续运行网络爬虫,需要服务器。因此,顺利连续爬取的下一步是投资服务器基础设施,或者从信誉良好的老牌公司租用服务器。服务器是必不可少的,因为它们允许您全天连续运行预先编写的脚本,优采云记录和存储过程。
准备足够的存储空间
数据提取脚本交付的工作产品是数据。大规模操作需要相应的大量存储容量。从多个网站中提取的数据相当于数千个网页。该过程是连续的,因此会为您带来大量数据。确保有足够的存储空间来支持持续的提取操作非常重要。
数据处理
捕获的数据以原创形式存在,难以理解。所以 data采集 过程中的下一个重要步骤是解析和创建结构良好的数据。
如何从 网站 中提取数据
有多种方法可以从网页中提取公共数据,或者通过构建自己的工具或使用现成的网络抓取解决方案。这两种选择都各有优势,我们将逐一研究它们,以便您轻松决定哪一种最适合您的业务需求。
构建您自己的解决方案
要开发自己的 Web 数据提取工具,您需要一个专用的 Web 抓取技术堆栈。包括以下内容:
演戏。很多网站会根据访问者IP地址的位置显示不同的内容。有时您可能需要在另一个国家/地区使用代理,具体取决于您的服务器所在的位置以及您想要访问它的位置。
还需要一个大型代理池来帮助绕过 IP 阻止和 CAPTCHA 验证。
无头浏览器。越来越多的 网站 使用 Vue.js 或 React.js 前端框架。此类框架使用后端 API 来获取数据并呈现 DOM(文档对象模型)。普通的 HTML 客户端不会呈现 Javascript 代码;因此,如果没有无头浏览器,您将获得一个空白页面。
此外,网站 通常可以检测 HTTP 客户端是否是机器人。因此,无头浏览器可以帮助访问目标 HTML 页面。
最常用的无头浏览器 API 是 Selenium、Puppeteer 和 Playwright。
抽取规则。这是一组用于选择 HTML 组件和提取数据的规则。选择这些组件的最简单方法是通过 XPath 和 CSS 选择器。
网站HTML 编码不断更新。因此,提取规则是开发人员花费最多时间的地方。
工作日程。这可以帮助您安排时间在需要时监控特定数据。它还可以帮助解决错误:跟踪 HTML 更改、目标网站 或代理服务器的停机时间以及被阻止的请求至关重要。
贮存。提取数据后,您需要将其正确存储在 SQL 数据库等中。保存采集的数据的标准格式是 JSON、CSV 和 XML。
监视器。采集数据,尤其是大规模的采集数据,会引发各种问题。为避免这些问题,您必须确保您的代理始终处于运行状态。日志分析、仪表板和警报可以帮助您监控数据。
网页数据采集流程:
确定需要获取和处理的数据类型。
找到数据的位置并设置获取路径。
导入并安装所需的预设。
编写数据提取脚本并运行该脚本。
为了避免IP阻塞,必须模仿普通网民的行为。这就是代理发挥作用的地方,它们使数据采集 的整个过程变得更容易。我们稍后再谈。
网络爬虫 API
诸如网络爬虫 API 之类的即用型数据提取工具的主要优点之一是它可以帮助您从困难目标中提取公共数据网站,而无需额外资源。大型电子商务页面使用复杂的反机器人算法。因此,抓取这些页面的工具需要更多的开发时间。
自制解决方案必须通过反复试验来创造变通办法,这意味着不可避免的速度下降、IP 地址受阻和定价数据流不可靠。使用我们的网络爬虫网络爬虫 API,整个过程可以完全自动化。您的员工可以专注于更紧迫的任务并直接进行数据分析,而不是无休止的复制粘贴。
如何选择?
根据您的业务规模,构建您自己的解决方案或购买现成的数据提取工具。
如果您的公司需要大规模采集数据,网络爬虫 API 是一个很好的选择,可以节省时间并实时提供高质量的数据结果。最重要的是,它们可以为您节省代码维护和集成的费用。
另一方面,如果您是一家只需要偶尔爬网的小型企业,那么构建自己的数据提取工具可能会非常有益。
网络数据的好处采集
大数据是当今商业界最热门的流行语。它指的是对数据集进行有目的的多重处理:获得有意义的见解、发现趋势和模式以及预测经济状况。例如,网络抓取房地产数据有助于分析该行业的重大影响。同样,另类数据可以帮助基金经理发现投资机会。
网络抓取可以发挥作用的另一个领域是汽车行业。公司采集汽车行业数据,例如用户和组件评论。
各行各业的公司从 网站 中提取数据,以构建自己的最新相关数据集。这种做法通常会延续到其他 网站 上,从而提高数据集的完整性。数据越多越好,因为它有更多的参考点,使整个数据集更有效率。
公司通常会提取哪些数据?
前面我们提到,提取的目标数据并不都是在线数据,这不难理解。在确定要提取哪些数据时,您的业务定位、需求和目标应该是主要标准。
您感兴趣的目标数据可能会有所不同。您可以提取产品描述、价格、客户评论和评级、常见问题解答页面、操作指南等;您还可以根据目标的新产品和服务自定义脚本。在进行抓取活动之前,请确保被抓取的公共数据不会损害任何第三方的权利。
数据采集常见挑战
提取数据从来都不是一帆风顺的。最常见的挑战是:
数据抓取最佳实践
面对由经验丰富的专业人员开发的复杂的网络数据提取脚本,与网络数据密切相关的难题采集 可以轻松解决。但被反爬虫技术识别和屏蔽的风险依然存在。因此,迫切需要一种变革性的解决方案:代理。更准确地说,轮换代理。
轮换代理允许您使用大量 IP 地址。使用位于不同区域的 IP 发送请求可以欺骗服务器并防止被阻止。此外,您可以使用 Proxy Rotator 代替手动分配不同的 IP,它会自动从代理数据中心池中分配 IP。
如果您没有资源并且没有经验丰富的 Web 抓取开发团队,那么是时候考虑使用现成的解决方案,例如 Web 爬虫 API。它确保 100% 交付来自大多数 网站s、策划优采云 数据的抓取结果,并聚合数据,以便您轻松理解它。
从 网站 中提取数据是否合法?
许多企业依赖大数据,需求显着增长。根据 Statista 的研究,大数据市场每年都在大幅增长,预计到 2027 年将达到 1030 亿美元。因此,越来越多的企业正在使用网络抓取来获取数据采集。这种受欢迎程度引发了一个激烈争论的话题:网络抓取合法吗?
这个复杂的话题没有明确的答案,如果你在做网络爬虫,你不能违反任何与相关数据相关的法律法规。值得注意的是,我们强烈建议在进行任何抓取活动之前根据具体情况寻求专业的法律建议。
同时,我们也强烈建议不要抓取非公开数据,除非已获得目标 网站 的明确许可。为了清楚起见,本文中的任何内容都不应被解释为对非公开数据抓取的建议。
总结
总之,如果你想从 网站 中提取数据,那么你需要一个数据提取脚本。如您所知,由于数据抓取操作的广度、复杂性以及不断变化的 网站 结构,构建此类脚本可能具有挑战性。由于网络抓取必须实时获取最新数据,因此您需要避免被阻止。这就是为什么在进行主要的抓取操作时必须使用旋转代理。
如果您认为您的企业需要一个强大的解决方案来简化您的数据采集,您可以立即注册并使用 Oxylabs 的 Web Crawler API。
关于作者
伊维塔·维斯托斯基特
内容管理者
Iveta Vistorskyte 在 Oxylabs 担任内容经理。作为一名作家和挑战者,她决定涉足科技领域,并立即对该领域产生了兴趣。当她不工作时,您可能会发现她只是通过听她最喜欢的音乐或与朋友一起玩棋盘游戏来放松。
了解有关艾维塔的更多信息
Oxylabs 博客上的所有信息均按“原样”提供,仅供参考。对于您使用 Oxylabs 博客中收录的任何信息或可能链接到的任何第三方 网站 中收录的任何信息,我们不作任何陈述,也不承担任何责任。在进行任何形式的抓取之前,请咨询您的法律顾问并仔细阅读具体的网站服务条款或获得抓取许可。
如何抓取网页数据(python对如何获取网页内容的各种情况和方法做一个总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-13 12:22
python爬虫如何爬取网络数据?
在学习python爬虫的过程中,总会有想要获取网页内容的时候。本文将总结如何获取网页内容的各种情况和方法。
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看正则表达式
如何
得到一个完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
注意:由于不同版本的Python内置库容错能力不同,处理结果可能与上述不同。详情请参考::///doc/0ed46eadf9c75fbfc77da26925c52cc58ad6905a.html /software/BeautifulSoup/bs4/doc/#installing-a-pa rser。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可以在 找到。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入内容后,进入选择元素的步骤,此时lxml
有几种不同的方法,例如
XPath 选择器和 find() 方法,例如 Beautiful Soup。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
代码首先找到ID为places_area__row的表格行元素,然后选择类为w2p_f w的表格数据子标签。
CSS3 规范已由 W3C 提出: /TR/2011/REC-css3-selectors-2011 0929/
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在以下位置找到:ocs.io/en/latest/。
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
相关 采集 教程:
鼠标移动显示网站采集需要数据的方法/教程/sbyd
优采云补挖、漏挖功能说明(以金头网采集为例)/tutorial/lcbc
优采云增量采集功能说明/教程/zlcj_7 优采云广告拦截功能说明(采集中文社区网示例)/tutorial/pbgg_7单机采集提示异常信息处理(以新浪微博采集为例) /tutorial/djcjyc_7优采云代理IP功能说明(7.0版本) /tutorial/dlip_7 网页数据采集如何模拟手机终端,人民网的移动终端采集
例如/tutorial/mnsj_7 优采云——90万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置采集.
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集
集群24*7不间断运行,无需担心IP被封,网络中断。
4、功能免费+增值服务,按需选择。免费版功能齐全,可以满足用户的基本需求。
设定要求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
如何抓取网页数据(python对如何获取网页内容的各种情况和方法做一个总结)
python爬虫如何爬取网络数据?
在学习python爬虫的过程中,总会有想要获取网页内容的时候。本文将总结如何获取网页内容的各种情况和方法。
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的 BeautifulSoup 模块,最后是强大的 lxml 模块。
1. 正则表达式
如果您不熟悉正则表达式,或者需要一些提示,请查看正则表达式
如何
得到一个完整的介绍。
当我们使用正则表达式抓取国家/地区数据时,我们首先尝试匹配元素的内容,如下所示:
从以上结果可以看出,标签用于多个国家属性。要隔离 area 属性,我们只需选择其中的第二个元素,如下所示:
虽然这个方案现在可用,但如果页面发生变化,它很可能会失败。例如,该表已更改为删除第二行中的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种未来可能发生的变化。但是,如果我们以后想再次获取这些数据,我们需要一个更健壮的解决方案,尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们也可以添加它的父元素。由于元素具有 ID 属性,因此它应该是唯一的。
这个迭代版本看起来好一点,但是网页更新还有很多其他的方式也会让这个正则表达式不令人满意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。下面是一个尝试支持这些可能性的改进版本。
虽然这个正则表达式更容易适应未来的变化,但它也存在构造困难、可读性差的问题。此外,还有一些细微的布局更改可能会使此正则表达式无法令人满意,例如为标签添加标题属性。
从这个例子可以看出,正则表达式为我们提供了一种抓取数据的捷径,但是这种方法过于脆弱,在页面更新后容易出现问题。好在还有一些更好的解决方案,后面会介绍。
2. 靓汤
Beautiful Soup 是一个非常流行的 Python 模块。该模块可以解析网页并提供方便的界面来定位内容。如果您还没有安装该模块,可以使用以下命令安装其最新版本(需要先安装pip,请自行百度):
使用 Beautiful Soup 的第一步是将下载的 HTML 内容解析成一个汤文档。由于大多数网页没有格式良好的 HTML,Beautiful Soup 需要确定它们的实际格式。例如,在下面这个简单网页的清单中,存在属性值和未闭合标签周围缺少引号的问题。
如果 Population 列表项被解析为 Area 列表项的子项,而不是两个并排的列表项,我们在抓取时会得到错误的结果。让我们看看Beautiful Soup是如何处理它的。
从上面的执行结果可以看出,Beautiful Soup 能够正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
注意:由于不同版本的Python内置库容错能力不同,处理结果可能与上述不同。详情请参考::///doc/0ed46eadf9c75fbfc77da26925c52cc58ad6905a.html /software/BeautifulSoup/bs4/doc/#installing-a-pa rser。想知道所有的方法和参数,可以参考 Beautiful Soup 的官方文档
3. Lxml
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。这个模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。最新的安装说明可以在 找到。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将可能无效的 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
同样,lxml 正确解析属性周围缺少的引号并关闭标签,但模块不会添加和标签。
解析输入内容后,进入选择元素的步骤,此时lxml
有几种不同的方法,例如
XPath 选择器和 find() 方法,例如 Beautiful Soup。但是,我们将来会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重用。此外,一些有 jQuery 选择器经验的读者会更熟悉它。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
代码首先找到ID为places_area__row的表格行元素,然后选择类为w2p_f w的表格数据子标签。
CSS3 规范已由 W3C 提出: /TR/2011/REC-css3-selectors-2011 0929/
Lxml 已经实现了大部分 CSS3 属性,其不支持的功能可以在以下位置找到:ocs.io/en/latest/。
注意:lxml 的内部实现实际上将 CSS 选择器转换为等效的 XPath 选择器。
相关 采集 教程:
鼠标移动显示网站采集需要数据的方法/教程/sbyd
优采云补挖、漏挖功能说明(以金头网采集为例)/tutorial/lcbc
优采云增量采集功能说明/教程/zlcj_7 优采云广告拦截功能说明(采集中文社区网示例)/tutorial/pbgg_7单机采集提示异常信息处理(以新浪微博采集为例) /tutorial/djcjyc_7优采云代理IP功能说明(7.0版本) /tutorial/dlip_7 网页数据采集如何模拟手机终端,人民网的移动终端采集
例如/tutorial/mnsj_7 优采云——90万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置采集.
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集
集群24*7不间断运行,无需担心IP被封,网络中断。
4、功能免费+增值服务,按需选择。免费版功能齐全,可以满足用户的基本需求。
设定要求。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
如何抓取网页数据(java爬虫怎么实现抓取登陆后的页面-爬虫的原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-02-12 04:02
Java 网页数据抓取
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没有方式,请从发送请求返回xml或json的数据,并一一分析,看哪个爬虫在任何情况下都不可能申请!
java爬虫如何爬取登录后的网页数据
一般爬虫登录后不会抓取页面。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,然后请求相关页面。
如何使用网络爬虫基于java获取数据-
爬虫的原理其实就是获取网页的内容,然后进行解析。只是获取网页和解析内容的方式多种多样。你可以简单地使用httpclient发送一个get/post请求,得到结果,然后使用截取字符串,正则表达式得到想要的内容。或者使用Jsoup/crawler4j等封装好的类库,更方便的爬取信息。
java网络爬虫如何实现登录后对页面的爬取-
原理是保存cookie数据,登录后保存cookie。以后每次爬取页面,都会在header信息中发送cookie。系统根据 cookie 判断用户。有了cookie,就有了登录状态,后续的访问都会基于这个cookie对应的用户。补充:Java是一种面向对象的编程语言,可以编写跨平台的应用软件。Java技术具有优异的通用性、效率、平台可移植性和安全性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
如何通过Java代码实现网页数据的指定爬取
通过java代码实现网页数据指定爬取方式的步骤如下: 1 在项目中导入jsoup.jar包 2 获取html指定的url或者文档指定的body 3 获取标题和链接网页中超链接的 4 获取指定博客文章内容 5 of @> 获取网页中超链接的标题和链接结果
如何爬取网页中的数据java -
不用Java去抢,为什么不让页面把数据发到后台呢??如果是从别人的网站中抓取的,应该是可以的,用socketio好像是可以的。看看nodejs是不是可以的。
java jsoup如何爬取特定网页中的数据——
方法/步骤本次体验是通过导入外部的Jars来爬取网页数据。下面是我的项目的分布图。在本例中,Jquery 用于处理页面事件。页面显示背景在siteproxy.jsp中处理 5 最后在本项目中部署所需文件 查看全部
如何抓取网页数据(java爬虫怎么实现抓取登陆后的页面-爬虫的原理)
Java 网页数据抓取
1. 使用jsoup抓取生成页面后的静态信息,很简单,知道jquery的选择器会使用2.对于加载页面后通过ajax刷新的页面,没有方式,请从发送请求返回xml或json的数据,并一一分析,看哪个爬虫在任何情况下都不可能申请!
java爬虫如何爬取登录后的网页数据
一般爬虫登录后不会抓取页面。如果只是临时抓取某个站点,可以模拟登录,登录后获取cookies,然后请求相关页面。
如何使用网络爬虫基于java获取数据-
爬虫的原理其实就是获取网页的内容,然后进行解析。只是获取网页和解析内容的方式多种多样。你可以简单地使用httpclient发送一个get/post请求,得到结果,然后使用截取字符串,正则表达式得到想要的内容。或者使用Jsoup/crawler4j等封装好的类库,更方便的爬取信息。
java网络爬虫如何实现登录后对页面的爬取-
原理是保存cookie数据,登录后保存cookie。以后每次爬取页面,都会在header信息中发送cookie。系统根据 cookie 判断用户。有了cookie,就有了登录状态,后续的访问都会基于这个cookie对应的用户。补充:Java是一种面向对象的编程语言,可以编写跨平台的应用软件。Java技术具有优异的通用性、效率、平台可移植性和安全性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
如何通过Java代码实现网页数据的指定爬取
通过java代码实现网页数据指定爬取方式的步骤如下: 1 在项目中导入jsoup.jar包 2 获取html指定的url或者文档指定的body 3 获取标题和链接网页中超链接的 4 获取指定博客文章内容 5 of @> 获取网页中超链接的标题和链接结果
如何爬取网页中的数据java -
不用Java去抢,为什么不让页面把数据发到后台呢??如果是从别人的网站中抓取的,应该是可以的,用socketio好像是可以的。看看nodejs是不是可以的。
java jsoup如何爬取特定网页中的数据——
方法/步骤本次体验是通过导入外部的Jars来爬取网页数据。下面是我的项目的分布图。在本例中,Jquery 用于处理页面事件。页面显示背景在siteproxy.jsp中处理 5 最后在本项目中部署所需文件
如何抓取网页数据((19)中华人民共和国国家知识产权局(12)申请(10))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-07 00:12
该方法包括选择获取未被抓取的优质链接,其中,优质链接是指向满足用户检索需要的网页的链接。为选定的优质链接标记网络出口;将发出的优质链接分发到相应的网络出口,进行网页数据的爬取。根据本发明提供的技术方案,可以提高对复杂多变的爬取环境的适应能力,从而显着提高网页的跨国爬取能力。数据成功率。法律状态 法律状态公告日期 法律状态信息 法律状态 2015-07-22 公开披露 2015-07-22 公开披露 2015-08-19 实质审查生效 实质审查生效 2015-08-19 实质审查 生效日期实质审查有效。2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 查看全部
如何抓取网页数据((19)中华人民共和国国家知识产权局(12)申请(10))
该方法包括选择获取未被抓取的优质链接,其中,优质链接是指向满足用户检索需要的网页的链接。为选定的优质链接标记网络出口;将发出的优质链接分发到相应的网络出口,进行网页数据的爬取。根据本发明提供的技术方案,可以提高对复杂多变的爬取环境的适应能力,从而显着提高网页的跨国爬取能力。数据成功率。法律状态 法律状态公告日期 法律状态信息 法律状态 2015-07-22 公开披露 2015-07-22 公开披露 2015-08-19 实质审查生效 实质审查生效 2015-08-19 实质审查 生效日期实质审查有效。2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查 2018-11-09 权利要求描述的授权和授权 网页数据抓取方法和系统的方法和系统 权利要求描述的内容是......请下载查看方法描述的描述和用于捕获网页数据的系统。是的....请下载并检查
如何抓取网页数据(如何抓取网页数据是程序员的基本功了,爬虫内核浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-05 07:08
如何抓取网页数据是程序员的基本功了,在爬虫领域,我们也得学会一种另类的抓取方法,利用我们自带的ie内核浏览器。话不多说,用rstudio做如下实验:首先,创建一个时间戳列表,内容存储在列表[:date_]中:然后在这个列表中查找最早的日期field_name,再查找field_type,得到日期对应的列表,:然后在这个列表中查找最后一个日期field_max。
最后再查找最早的月份field_month:这样就能取到这个一年所有日期在年份[:]中出现的次数了,然后从每个月中选择一个数值,把他们存储在对应的列表中,比如6和8,是这样:最后给定field_name_max和field_type_max,得到最大概率的日期列表。是不是很简单呢?赶紧试试吧!如果您喜欢本文,请关注微信公众号:r语言中文社区(rzhsjh),获取更多精彩内容。
<p>使用r,修改一下a 查看全部
如何抓取网页数据(如何抓取网页数据是程序员的基本功了,爬虫内核浏览器)
如何抓取网页数据是程序员的基本功了,在爬虫领域,我们也得学会一种另类的抓取方法,利用我们自带的ie内核浏览器。话不多说,用rstudio做如下实验:首先,创建一个时间戳列表,内容存储在列表[:date_]中:然后在这个列表中查找最早的日期field_name,再查找field_type,得到日期对应的列表,:然后在这个列表中查找最后一个日期field_max。
最后再查找最早的月份field_month:这样就能取到这个一年所有日期在年份[:]中出现的次数了,然后从每个月中选择一个数值,把他们存储在对应的列表中,比如6和8,是这样:最后给定field_name_max和field_type_max,得到最大概率的日期列表。是不是很简单呢?赶紧试试吧!如果您喜欢本文,请关注微信公众号:r语言中文社区(rzhsjh),获取更多精彩内容。
<p>使用r,修改一下a
如何抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-04 07:12
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
1import requests
2
3if __name__== "__main__":
4
5 response = requests.get("https://book.douban.com/subject/26986954/")
6 content = response.content.decode("utf-8")
7 print(content)
8
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
1import requests
2from bs4 import BeautifulSoup
3
4if __name__== "__main__":
5
6 response = requests.get("https://book.douban.com/subject/26986954/")
7 content = response.content.decode("utf-8")
8 #print(content)
9
10 soup = BeautifulSoup(content, "html.parser")
11
12 # 获取当前页面包含的所有链接
13
14 for element in soup.select("a"):
15
16 if not element.has_attr("href"):
17 continue
18 if not element["href"].startswith("https://"):
19 continue
20
21 print(element["href"])
22
23 # 获取更多数据
24
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
1import time
2import requests
3from bs4 import BeautifulSoup
4
5# 保存已经抓取和未抓取的链接
6
7visited_urls = []
8unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
9
10# 从队列中返回一个未抓取的URL
11
12def get_unvisited_url():
13
14 while True:
15
16 if len(unvisited_urls) == 0:
17 return None
18
19 url = unvisited_urls.pop()
20
21 if url in visited_urls:
22 continue
23
24 visited_urls.append(url)
25 return url
26
27
28if __name__== "__main__":
29
30 while True:
31 url = get_unvisited_url()
32 if url == None:
33 break
34
35 print("GET " + url)
36
37 response = requests.get(url)
38 content = response.content.decode("utf-8")
39 #print(content)
40
41 soup = BeautifulSoup(content, "html.parser")
42
43 # 获取页面包含的链接,并加入未访问的队列
44
45 for element in soup.select("a"):
46
47 if not element.has_attr("href"):
48 continue
49 if not element["href"].startswith("https://"):
50 continue
51
52 unvisited_urls.append(element["href"])
53 #print(element["href"])
54
55 time.sleep(1)
56
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源: 查看全部
如何抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的抓取功能?)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
1import requests
2
3if __name__== "__main__":
4
5 response = requests.get("https://book.douban.com/subject/26986954/";)
6 content = response.content.decode("utf-8")
7 print(content)
8
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
1import requests
2from bs4 import BeautifulSoup
3
4if __name__== "__main__":
5
6 response = requests.get("https://book.douban.com/subject/26986954/";)
7 content = response.content.decode("utf-8")
8 #print(content)
9
10 soup = BeautifulSoup(content, "html.parser")
11
12 # 获取当前页面包含的所有链接
13
14 for element in soup.select("a"):
15
16 if not element.has_attr("href"):
17 continue
18 if not element["href"].startswith("https://";):
19 continue
20
21 print(element["href"])
22
23 # 获取更多数据
24
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
1import time
2import requests
3from bs4 import BeautifulSoup
4
5# 保存已经抓取和未抓取的链接
6
7visited_urls = []
8unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
9
10# 从队列中返回一个未抓取的URL
11
12def get_unvisited_url():
13
14 while True:
15
16 if len(unvisited_urls) == 0:
17 return None
18
19 url = unvisited_urls.pop()
20
21 if url in visited_urls:
22 continue
23
24 visited_urls.append(url)
25 return url
26
27
28if __name__== "__main__":
29
30 while True:
31 url = get_unvisited_url()
32 if url == None:
33 break
34
35 print("GET " + url)
36
37 response = requests.get(url)
38 content = response.content.decode("utf-8")
39 #print(content)
40
41 soup = BeautifulSoup(content, "html.parser")
42
43 # 获取页面包含的链接,并加入未访问的队列
44
45 for element in soup.select("a"):
46
47 if not element.has_attr("href"):
48 continue
49 if not element["href"].startswith("https://";):
50 continue
51
52 unvisited_urls.append(element["href"])
53 #print(element["href"])
54
55 time.sleep(1)
56
总结
我们的第一个网络爬虫已经开发出来。它可以抓取豆瓣上的所有书籍,但它也有很多局限性,毕竟它只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源:
如何抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-04 07:09
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
孤灯陷入沉思,卷起帘子,望着月空叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章复习,,,,,,,学习如何使用选择器。它可以帮助您更好地利用 Scrapy 爬虫框架。在接下来的几篇文章中,小编会讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段,我们通过Scrapy实现了特定网页的具体信息,但还没有实现对所有页面的顺序提取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们可以根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。
6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。
至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后,如何调用我们自己定义的分析函数呢? 查看全部
如何抓取网页数据(获赠Python从入门到进阶共10本电子书(组图))
点击上方“Python爬虫与数据挖掘”关注
回复“书籍”获取Python从入门到进阶共10本电子书
这
日
小鸡
汤
孤灯陷入沉思,卷起帘子,望着月空叹息。
/前言/
前段时间小编给大家分享了Xpath和CSS选择器的具体用法。有兴趣的朋友可以戳这些文章文章复习,,,,,,,学习如何使用选择器。它可以帮助您更好地利用 Scrapy 爬虫框架。在接下来的几篇文章中,小编会讲解爬虫主文件的具体代码实现过程,最终实现对网页所有内容的爬取。
上一阶段,我们通过Scrapy实现了特定网页的具体信息,但还没有实现对所有页面的顺序提取。首先,我们来看看爬取的思路。大致思路是:当获取到第一页的URL后,再将第二页的URL发送给Scrapy,这样Scrapy就可以自动下载该页的信息,然后传递第二页的URL。URL继续获取第三页的URL。由于每个页面的网页结构是一致的,这样就可以通过反复迭代来实现对整个网页的信息提取。具体实现过程将通过Scrapy框架实现。具体教程如下。
/执行/
1、首先,URL不再是具体文章的URL,而是所有文章列表的URL,如下图,把链接放在start_urls中,如下图所示。
2、接下来我们需要改变 parse() 函数,在这个函数中我们需要实现两件事。
一种是获取一个页面上所有文章的URL并解析,得到每个文章中具体的网页内容,另一种是获取下一个网页的URL并手它交给 Scrapy 进行处理。下载,下载完成后交给parse()函数。
有了前面 Xpath 和 CSS 选择器的基础知识,获取网页链接 URL 就相对简单了。
3、分析网页结构,使用网页交互工具,我们可以很快发现每个网页有20个文章,也就是20个URL,文章的列表存在于id="archive" 标签,然后像剥洋葱一样得到我们想要的 URL 链接。
4、点击下拉三角形,不难发现文章详情页的链接并没有隐藏很深,如下图圆圈所示。
5、根据标签,我们可以根据图片搜索地图,并添加选择器工具,获取URL就像搜索东西一样。在cmd中输入以下命令进入shell调试窗口,事半功倍。再次声明,这个URL是所有文章的URL,而不是某个文章的URL,否则调试半天也得不到结果。
6、根据第四步的网页结构分析,我们在shell中编写CSS表达式并输出,如下图所示。其中a::attr(href)的用法很巧妙,也是提取标签信息的一个小技巧。建议朋友在提取网页信息的时候可以经常使用,非常方便。
至此,第一页所有文章列表的url都获取到了。解压后的URL,如何交给Scrapy下载?下载完成后,如何调用我们自己定义的分析函数呢?
如何抓取网页数据(BeautifulSoup、本文模块的使用方法及注意点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-02 16:06
前言
学习,最重要的是理解它并使用它,所谓,学以致用,这篇文章,我们以后会介绍,BeautifulSoup模块的使用,以及注意点,帮助您快速了解和学习 BeautifulSoup 模块。有兴趣了解爬虫的朋友,快点学习吧。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题,以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接、翻页操作
继续分析,点击链接进入,发现已经有图片列表了,还可以翻页。
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第三步:编写代码实现需求1、导入模块
导入我们需要使用的所有模块。
import os
import re
from bs4 import BeautifulSoup
import requests
import time
2、获取列表的标题以及链接
def tupianzj():
"""获取标题,链接"""
response = requests.get(url="https://www.tupianzj.com/sheying/",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("h3",{"class":"list_title"})
list=[]
for i in list_title:
list.append({'name':i.get_text(),'url':i.find("a").get("href")})
return list
3、获取类别列表标题、链接和翻页。
def tu_list(url,page):
"""获取类比列表"""
response = requests.get(url,headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("ul",{"class":"list_con_box_ul"})[0].find_all("li")
for i in list_title:
for j in i.find_all("a"):
try:
j.find("img").get("src")
name=j.get("title")#列表列表图片名称
url1="https://www.tupianzj.com"+j.get("href")[0:-5]#类比列表图片详情链接
text=Soup.find_all("div",{"class":"pages"})[0].find_all("a")[1].get("href")#下一页
page1=Soup.find_all("span",{"class":"pageinfo"})[0].find("strong").get_text()#获取总页数
url2=url+text[0:-6]+page+".html"
print(url2,page1)
try:
os.mkdir(name)#创建文件
except:
pass
tu_detail(name,url1,2)
if page==1:
for z in range(2,int(page1))
tu_list(url2,page)
except:
pass
4、获取详细图片并保存
<p>def tu_detail(path,url,page):
"""获取详情"""
if page 查看全部
如何抓取网页数据(BeautifulSoup、本文模块的使用方法及注意点)
前言
学习,最重要的是理解它并使用它,所谓,学以致用,这篇文章,我们以后会介绍,BeautifulSoup模块的使用,以及注意点,帮助您快速了解和学习 BeautifulSoup 模块。有兴趣了解爬虫的朋友,快点学习吧。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题,以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接、翻页操作
继续分析,点击链接进入,发现已经有图片列表了,还可以翻页。
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第三步:编写代码实现需求1、导入模块
导入我们需要使用的所有模块。
import os
import re
from bs4 import BeautifulSoup
import requests
import time
2、获取列表的标题以及链接
def tupianzj():
"""获取标题,链接"""
response = requests.get(url="https://www.tupianzj.com/sheying/",headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("h3",{"class":"list_title"})
list=[]
for i in list_title:
list.append({'name':i.get_text(),'url':i.find("a").get("href")})
return list
3、获取类别列表标题、链接和翻页。
def tu_list(url,page):
"""获取类比列表"""
response = requests.get(url,headers=headers)
response.encoding="gbk"
Soup = BeautifulSoup(response.text, "html.parser")
list_title=Soup.find_all("ul",{"class":"list_con_box_ul"})[0].find_all("li")
for i in list_title:
for j in i.find_all("a"):
try:
j.find("img").get("src")
name=j.get("title")#列表列表图片名称
url1="https://www.tupianzj.com"+j.get("href")[0:-5]#类比列表图片详情链接
text=Soup.find_all("div",{"class":"pages"})[0].find_all("a")[1].get("href")#下一页
page1=Soup.find_all("span",{"class":"pageinfo"})[0].find("strong").get_text()#获取总页数
url2=url+text[0:-6]+page+".html"
print(url2,page1)
try:
os.mkdir(name)#创建文件
except:
pass
tu_detail(name,url1,2)
if page==1:
for z in range(2,int(page1))
tu_list(url2,page)
except:
pass
4、获取详细图片并保存
<p>def tu_detail(path,url,page):
"""获取详情"""
if page
如何抓取网页数据(一下吧python开发网站教程:2.对应网页结构(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-30 20:00
这里简单介绍一下python开发网站教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)Python开发网站教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python开发网站教程、内容、笑话数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据Python开发网站教程:
2.对应网页结构python开发网站教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页数:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
当你打开网页的源代码时,你会发现数据不在网页的源代码中。当你按F12抓包分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
你是如何开始编写 python 爬虫的?
因为研究生阶段的主要方向是数据挖掘,所以需要从互联网上获取大量的数据。如果是手动逐页复制,不知道会是什么年月,所以慢慢开始接触python爬虫。我可能告诉我们你的学习之旅:
1.首先你要有一定的python基础,熟悉环境,会使用基本的语法和包。至于基本的python教程,网上有很多,包括视频和pdf。这因人而异。我主要是入门。我正在研究《Python基础教程》这本书,对应python2。这本书比较全面和详细。只要认真按照书本,练习代码,很快就会熟悉python的基础知识。,掌握常用包的基本知识和使用方法。
2.你也应该对网页的基础知识有一定的了解,比如html、css、javascript等,没必要精通,但至少你需要懂一件事或二。要爬取的数据都在网页里,你对网页一无所知我不懂,这根本不可能。至于这些入门级的东西,大家可以在网上搜索一下。我推荐/,非常全面:
3.然后是一些基础爬虫包的使用,比如urllib、urllib2、requests、bs4等。这些教程网上都有,官方也有详细的文档,可以尝试爬取一些比较简单的网页,像尴尬百等。
4.在爬取一些网页的过程中,会发现莫名程序中断,无法连接服务器。这就是反爬机制。很多网站都对爬虫设置了限制,短时间内如果多次爬取,IP就会被封禁,所以要设置IP代理池,来回切换IP,保证正常运行的程序。在这个过程中,需要了解常见的反爬机制,对症下药,尽量避免被服务器屏蔽。寻找。
5.熟悉爬取基础网页后,可以尝试爬取比较大的网站数据,比如某宝数据等。在这个过程中,你可能会发现有些数据不在网页,它是异步加载的,需要抓包分析数据,得到真实的数据URL,才能爬取。
6.了解了基本的爬虫包之后,你会发现每次爬取数据都需要自己构建代码和组织结构,非常麻烦。这时候就需要学习scrapy框架,一个专门为爬虫做的框架,启动爬虫来吧,速度快很多。
7.爬取数据太多,你会发现一台电脑太慢,一个线程不快,那么你可能需要多线程,多台电脑,你需要了解多线程,分布式爬虫,比如scrapy-redis等等。
8.如果数据量很大,你不可能把它存储在一个普通的文件中。需要用到数据库,mysql,mongodb等,需要了解数据库基础知识,增删改查,数据的涉及和构建等。
9.数据已经存在,你需要分析一下,否则爬下来放在那里就没意义了。数据的统计处理,数据可视化,如何建立分析模型,挖掘有价值的信息,机器学习都会用到,接下来就看你自己处理了。
我觉得爬取是一个获取数据的过程。最重要的是如何处理数据。关键是挖掘有价值的信息。当然,没有数据,一切都是空谈,数据就是资源。 查看全部
如何抓取网页数据(一下吧python开发网站教程:2.对应网页结构(组图))
这里简单介绍一下python开发网站教程,以网站静态和动态数据的抓取为例,实验环境win10+python3.6+pycharm5.0 ,主要内容如下:
抓取网站静态数据(数据在网页源码中)Python开发网站教程:以尴尬百科网站的数据为例
1.这里假设我们抓取的数据如下,主要包括用户昵称python开发网站教程、内容、笑话数和评论数四个字段,如下:
对应的网页源码如下,收录我们需要的数据Python开发网站教程:
2.对应网页结构python开发网站教程,主要代码如下,很简单,主要使用requests+BeautifulSoup,其中requests用于请求页面,BeautifulSoup用于解析页数:
程序运行截图如下,爬取数据成功:
抓取网站动态数据(网页源码、json等文件中没有数据):以人人贷网站数据为例
1.这里假设我们在爬取债券数据,主要包括年利率、贷款名称、期限、金额和进度五个字段。截图如下:
当你打开网页的源代码时,你会发现数据不在网页的源代码中。当你按F12抓包分析时,发现在一个json文件中,如下:
2.获取到json文件的url后,我们就可以爬取对应的数据了。这里使用的包与上面类似。因为是json文件,所以也用到了json包(解析json)。主要内容如下:
程序运行截图如下,已经成功抓取数据:
至此,这里就介绍了这两种数据的捕获,包括静态数据和动态数据。总的来说,这两个例子并不难。它们是入门级爬虫。网页的结构比较简单。最重要的是进行抓包分析,分析并提取页面。数据爬取的框架可以更方便、更高效。当然,如果爬取的页面比较复杂,比如验证码、加密等,那就需要仔细分析了。网上也有一些教程供参考。有兴趣的可以搜索一下,希望上面分享的内容可以对你有所帮助。
你是如何开始编写 python 爬虫的?
因为研究生阶段的主要方向是数据挖掘,所以需要从互联网上获取大量的数据。如果是手动逐页复制,不知道会是什么年月,所以慢慢开始接触python爬虫。我可能告诉我们你的学习之旅:
1.首先你要有一定的python基础,熟悉环境,会使用基本的语法和包。至于基本的python教程,网上有很多,包括视频和pdf。这因人而异。我主要是入门。我正在研究《Python基础教程》这本书,对应python2。这本书比较全面和详细。只要认真按照书本,练习代码,很快就会熟悉python的基础知识。,掌握常用包的基本知识和使用方法。
2.你也应该对网页的基础知识有一定的了解,比如html、css、javascript等,没必要精通,但至少你需要懂一件事或二。要爬取的数据都在网页里,你对网页一无所知我不懂,这根本不可能。至于这些入门级的东西,大家可以在网上搜索一下。我推荐/,非常全面:
3.然后是一些基础爬虫包的使用,比如urllib、urllib2、requests、bs4等。这些教程网上都有,官方也有详细的文档,可以尝试爬取一些比较简单的网页,像尴尬百等。
4.在爬取一些网页的过程中,会发现莫名程序中断,无法连接服务器。这就是反爬机制。很多网站都对爬虫设置了限制,短时间内如果多次爬取,IP就会被封禁,所以要设置IP代理池,来回切换IP,保证正常运行的程序。在这个过程中,需要了解常见的反爬机制,对症下药,尽量避免被服务器屏蔽。寻找。
5.熟悉爬取基础网页后,可以尝试爬取比较大的网站数据,比如某宝数据等。在这个过程中,你可能会发现有些数据不在网页,它是异步加载的,需要抓包分析数据,得到真实的数据URL,才能爬取。
6.了解了基本的爬虫包之后,你会发现每次爬取数据都需要自己构建代码和组织结构,非常麻烦。这时候就需要学习scrapy框架,一个专门为爬虫做的框架,启动爬虫来吧,速度快很多。
7.爬取数据太多,你会发现一台电脑太慢,一个线程不快,那么你可能需要多线程,多台电脑,你需要了解多线程,分布式爬虫,比如scrapy-redis等等。
8.如果数据量很大,你不可能把它存储在一个普通的文件中。需要用到数据库,mysql,mongodb等,需要了解数据库基础知识,增删改查,数据的涉及和构建等。
9.数据已经存在,你需要分析一下,否则爬下来放在那里就没意义了。数据的统计处理,数据可视化,如何建立分析模型,挖掘有价值的信息,机器学习都会用到,接下来就看你自己处理了。
我觉得爬取是一个获取数据的过程。最重要的是如何处理数据。关键是挖掘有价值的信息。当然,没有数据,一切都是空谈,数据就是资源。
如何抓取网页数据(pin(pointofinterest)热力图分析流程图,挖掘潜在客户的线索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-28 20:04
如何抓取网页数据做数据分析?成本很低,只需要一台电脑和一个wifi路由。分析有几步?不可能,就像你可以单人完成的事情一样,只是相对于“复杂”而已。下图是西尔维斯顿分析师julianbeach在新加坡的一个热力图分析流程图。他首先,要构建转化路径,通过pin(pointofinterest,兴趣点)的概念来找到产品带来的不同流量点,并选取最有价值的高频流量点来作为主要的用户,并且将主要的流量价值点分配给这些主要的用户。
然后将主要的用户点,逐步拓展为可拓展的长尾流量点。将主要流量价值点分配给长尾流量点的做法,也可以分成线性的拓展。一个图,讲了4步:1.发现用户线,构建用户线2.发现高频线路径,并计算拓展高频流量的最大用户线3.将主要流量价值点分配给长尾流量点4.执行计划当然,还可以将特定流量价值点再进一步拓展。由于计划可执行性很差,投入的精力也会变大。
再给出julianbeach的一个简短的示例。具体的做法(国内也是相似):1.获取到海量网页链接2.提取转化数据点,构建转化路径3.生成数据监控报告简单说,就是爬数据!爬数据!爬数据!发现转化路径,为不同需求生成不同的高频流量线路!生成监控报告,及时了解客户生命周期变化。
其实广告客户的前期销售工作可以分为三部分:1.潜在客户线索挖掘:挖掘潜在客户的线索来源,一般主要是通过客户谈判(包括付费推销、免费宣传推广、大客户活动等等)的邀约来挖掘潜在客户,优化资源配置,将更多的潜在客户引导到产品或者服务上。由于客户因素的价值很难量化,因此理论上一个公司可以建立巨大的信息库,这些信息库的价值要远远大于传统的电话客服中心。
2.销售漏斗:销售的有效结束依靠最后一步销售漏斗的有效转化,产品设计的不合理或者企业效率低下也会导致最后失败,而销售漏斗通常由销售人员经手,因此需要用精细化管理系统来完成结束业务流程。3.转化路径:转化路径是一个很复杂的产品,并不是简单的电话销售能够解决的,需要通过巨大的企业线索库、用户数据库、品牌词库等多种渠道获取客户,这样才能进行更高效的销售工作。 查看全部
如何抓取网页数据(pin(pointofinterest)热力图分析流程图,挖掘潜在客户的线索)
如何抓取网页数据做数据分析?成本很低,只需要一台电脑和一个wifi路由。分析有几步?不可能,就像你可以单人完成的事情一样,只是相对于“复杂”而已。下图是西尔维斯顿分析师julianbeach在新加坡的一个热力图分析流程图。他首先,要构建转化路径,通过pin(pointofinterest,兴趣点)的概念来找到产品带来的不同流量点,并选取最有价值的高频流量点来作为主要的用户,并且将主要的流量价值点分配给这些主要的用户。
然后将主要的用户点,逐步拓展为可拓展的长尾流量点。将主要流量价值点分配给长尾流量点的做法,也可以分成线性的拓展。一个图,讲了4步:1.发现用户线,构建用户线2.发现高频线路径,并计算拓展高频流量的最大用户线3.将主要流量价值点分配给长尾流量点4.执行计划当然,还可以将特定流量价值点再进一步拓展。由于计划可执行性很差,投入的精力也会变大。
再给出julianbeach的一个简短的示例。具体的做法(国内也是相似):1.获取到海量网页链接2.提取转化数据点,构建转化路径3.生成数据监控报告简单说,就是爬数据!爬数据!爬数据!发现转化路径,为不同需求生成不同的高频流量线路!生成监控报告,及时了解客户生命周期变化。
其实广告客户的前期销售工作可以分为三部分:1.潜在客户线索挖掘:挖掘潜在客户的线索来源,一般主要是通过客户谈判(包括付费推销、免费宣传推广、大客户活动等等)的邀约来挖掘潜在客户,优化资源配置,将更多的潜在客户引导到产品或者服务上。由于客户因素的价值很难量化,因此理论上一个公司可以建立巨大的信息库,这些信息库的价值要远远大于传统的电话客服中心。
2.销售漏斗:销售的有效结束依靠最后一步销售漏斗的有效转化,产品设计的不合理或者企业效率低下也会导致最后失败,而销售漏斗通常由销售人员经手,因此需要用精细化管理系统来完成结束业务流程。3.转化路径:转化路径是一个很复杂的产品,并不是简单的电话销售能够解决的,需要通过巨大的企业线索库、用户数据库、品牌词库等多种渠道获取客户,这样才能进行更高效的销售工作。

