
如何抓取网页数据
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-26 10:20
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
很多工作都是通过 HTML 树来获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia 查看全部
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。

很多工作都是通过 HTML 树来获取我们需要的表格。

通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
如何抓取网页数据(通过站长工具查询网站的基本信息和备案主体的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-22 02:08
一、通过站长工具查询网站的基本信息
1、综合信息:世界排名、域名年龄和持有人、seo信息、备案号和备案主体
世界排名:一般公司网站的排名都很低,能进入前10万的网站都是比较优质的网站。 IP和PV值的一般参考是可以的,不一定要作为主要依据,但是可以用来判断网站
的大概访问量
域名年龄:只代表域名注册的年龄,不代表网站年龄
域名持有:网站的所有权,网站的实际控制人可以查到,相关的网站
可以找到
SEO信息:PR值是谷歌的计算方法。一般来说,网站网站>3 质量比较高。百度权重是适合百度排名的指标参数
备案号及备案主体:网站国内服务器一般需要备案,已备案的网站可靠性高
2、百度排名:可以分析网站在百度的排名,验证网站的SEO情况和营销价值
3、友情链接:可以从网站查询链接地址,有两个功能。一是检测SEO优化(详见SEO优化部分),二是查看是否有挂马,如果不是自己管理的网站外链,不是系统自带的链接,那应该是挂马
4、Backlinks:用于分析网站在互联网上其他网站的链接和推广信息,可以间接证明网站@的营销力度和SEO推广> 工作(具体参考SEO优化部分)
5、IP反向查域名:可以查到网站服务器的位置,可以查到所有网站
IP 段
二、搜索引擎收录情况
各大搜索引擎都可以在搜索框中输入“site:domain name”的形式查询该域名下所有网站的收录情况。例如,可以通过以下所有页面的“site:”收录搜索域名。
三、网站自我介绍 查看全部
如何抓取网页数据(通过站长工具查询网站的基本信息和备案主体的区别)
一、通过站长工具查询网站的基本信息
1、综合信息:世界排名、域名年龄和持有人、seo信息、备案号和备案主体
世界排名:一般公司网站的排名都很低,能进入前10万的网站都是比较优质的网站。 IP和PV值的一般参考是可以的,不一定要作为主要依据,但是可以用来判断网站
的大概访问量
域名年龄:只代表域名注册的年龄,不代表网站年龄
域名持有:网站的所有权,网站的实际控制人可以查到,相关的网站
可以找到
SEO信息:PR值是谷歌的计算方法。一般来说,网站网站>3 质量比较高。百度权重是适合百度排名的指标参数
备案号及备案主体:网站国内服务器一般需要备案,已备案的网站可靠性高

2、百度排名:可以分析网站在百度的排名,验证网站的SEO情况和营销价值
3、友情链接:可以从网站查询链接地址,有两个功能。一是检测SEO优化(详见SEO优化部分),二是查看是否有挂马,如果不是自己管理的网站外链,不是系统自带的链接,那应该是挂马
4、Backlinks:用于分析网站在互联网上其他网站的链接和推广信息,可以间接证明网站@的营销力度和SEO推广> 工作(具体参考SEO优化部分)
5、IP反向查域名:可以查到网站服务器的位置,可以查到所有网站
IP 段
二、搜索引擎收录情况
各大搜索引擎都可以在搜索框中输入“site:domain name”的形式查询该域名下所有网站的收录情况。例如,可以通过以下所有页面的“site:”收录搜索域名。
三、网站自我介绍
如何抓取网页数据(如何抓取网页数据,实现站内信息爬取(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-16 20:01
如何抓取网页数据,实现站内信息爬取。先来看看效果。站内信息抓取首先进入页面:,以单条网址为例,点击「开始爬虫」:接下来我们来手工构建整个爬虫。搜索到在哪个导航页面后,获取这个页面的所有url,如下图:获取url后将url作为网址的长度排序(页码)。再获取这个页面的所有「没被关注」的url。复制这些url地址并集结成一个url列表,最后将url输入进去即可开始正式爬虫了。
windows系统关闭浏览器,windows和mac系统可以对应的安装一些浏览器插件或工具。如果有mac系统用户,使用help的「更多工具」中的「helponline」即可安装jquery。==关于「网页下载器」由于会有一些不方便,所以我们选用windows系统用户。对应的ide为windows平台下的vscode(非devc++)和mac平台下的sublimetext2。
其他平台的用户请自行安装使用。下面开始启动爬虫。启动vscode。输入:在开始时运行任意一个命令:打开sublimetext2。在命令行输入:cd/users/axense/whatide/weixin.vscode切换到weixin.vscode所在目录,之后用回车键选择weixin.vscode,之后运行命令:sublimetext2-->点击「插件」-->「web支持」-->「浏览器支持」在preferences窗口设置页面user和profile-->页面模式为page-->点击「浏览器支持」。 查看全部
如何抓取网页数据(如何抓取网页数据,实现站内信息爬取(一))
如何抓取网页数据,实现站内信息爬取。先来看看效果。站内信息抓取首先进入页面:,以单条网址为例,点击「开始爬虫」:接下来我们来手工构建整个爬虫。搜索到在哪个导航页面后,获取这个页面的所有url,如下图:获取url后将url作为网址的长度排序(页码)。再获取这个页面的所有「没被关注」的url。复制这些url地址并集结成一个url列表,最后将url输入进去即可开始正式爬虫了。
windows系统关闭浏览器,windows和mac系统可以对应的安装一些浏览器插件或工具。如果有mac系统用户,使用help的「更多工具」中的「helponline」即可安装jquery。==关于「网页下载器」由于会有一些不方便,所以我们选用windows系统用户。对应的ide为windows平台下的vscode(非devc++)和mac平台下的sublimetext2。
其他平台的用户请自行安装使用。下面开始启动爬虫。启动vscode。输入:在开始时运行任意一个命令:打开sublimetext2。在命令行输入:cd/users/axense/whatide/weixin.vscode切换到weixin.vscode所在目录,之后用回车键选择weixin.vscode,之后运行命令:sublimetext2-->点击「插件」-->「web支持」-->「浏览器支持」在preferences窗口设置页面user和profile-->页面模式为page-->点击「浏览器支持」。
如何抓取网页数据( 安装MySQL-python执行如下不报错说明(安装成功))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-15 21:01
安装MySQL-python执行如下不报错说明(安装成功))
安装 MySQL-python
[root@centos7vm ~]# pip install MySQL-python
如无报错则安装成功如下:
[root@centos7vm ~]# python
Python 2.7.5 (default, Nov 20 2015, 02:00:19)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import MySQLdb
>>>
创建页表
为了保存网页,在mysql数据库中创建页表,sql语句如下:
CREATE TABLE `page` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`post_date` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`post_user` varchar(255) COLLATE utf8_unicode_ci DEFAULT '',
`body` longtext COLLATE utf8_unicode_ci,
`content` longtext COLLATE utf8_unicode_ci,
PRIMARY KEY (`id`),
UNIQUE KEY `title` (`title`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
其中title为文章的标题,post_date为文章的发布时间,post_user为发布者(即公众号),body为网页的原创内容, content 是提取出来的纯文本格式的文本
创建项目结构
修改我们scrapy项目中的item.py文件,保存提取的结构化数据如下:
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
post_date = scrapy.Field()
post_user = scrapy.Field()
body = scrapy.Field()
content = scrapy.Field()
生成项目结构
修改爬虫脚本,在解析函数中加入如下语句:
def parse_profile(self, response):
title = response.xpath('//title/text()').extract()[0]
post_date = response.xpath('//em[@id="post-date"]/text()').extract()[0]
post_user = response.xpath('//a[@id="post-user"]/text()').extract()[0]
body = response.body
tag_content = response.xpath('//div[@id="js_content"]').extract()[0]
content = remove_tags(tag_content).strip()
item = WeixinItem()
item['title'] = title
item['post_date'] = post_date
item['post_user'] = post_user
item['body'] = body
item['content'] = content
return item
注意:如果你不会写爬虫脚本,请看上一篇文章《教你成为全栈开发者(Full Stack Developer)31-使用微信搜索捕获公众号》帐号文章@ >》
另外:这里的内容是去掉标签后的纯文本,使用remove_tags,需要加载库:
from w3lib.html import remove_tags
创建管道
scrapy 持久化数据的方式是通过管道。各种开源爬虫软件都会提供各种持久化的方法。比如pyspider提供了写mysql、mongodb、文件等的持久化方法,scrapy,作为爬虫老手,给我们留下了接口,我们可以自定义各个管道,可以通过配置灵活选择
管道机制是通过pipelines.py文件和settings.py文件的结合实现的
修改scrapy项目中pipelines.py的内容如下:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import MySQLdb
class WeixinPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect(host="127.0.0.1",user="myname",passwd="mypasswd",db="mydbname",charset="utf8")
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = "insert ignore into page(title, post_user, body, content) values(%s, %s, %s, %s)"
param = (item['title'], item['post_user'], item['body'], item['content'])
self.cursor.execute(sql,param)
self.conn.commit()
里面的数据库配置根据自己的修改。这里的process_item会在爬取的时候自动调用,爬虫脚本返回的item会通过参数传入。这里通过insert将item结构化数据插入到mysql数据库中
p>
再看settings.py文件,如下:
ITEM_PIPELINES = {
'weixin.pipelines.WeixinPipeline': 300,
}
运行爬虫后,数据库如下:
相当完美,准备用这些数据作为机器学习的训练样本,预测未来会发生什么,听听下一次分解 查看全部
如何抓取网页数据(
安装MySQL-python执行如下不报错说明(安装成功))

安装 MySQL-python
[root@centos7vm ~]# pip install MySQL-python
如无报错则安装成功如下:
[root@centos7vm ~]# python
Python 2.7.5 (default, Nov 20 2015, 02:00:19)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import MySQLdb
>>>
创建页表
为了保存网页,在mysql数据库中创建页表,sql语句如下:
CREATE TABLE `page` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`post_date` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`post_user` varchar(255) COLLATE utf8_unicode_ci DEFAULT '',
`body` longtext COLLATE utf8_unicode_ci,
`content` longtext COLLATE utf8_unicode_ci,
PRIMARY KEY (`id`),
UNIQUE KEY `title` (`title`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
其中title为文章的标题,post_date为文章的发布时间,post_user为发布者(即公众号),body为网页的原创内容, content 是提取出来的纯文本格式的文本
创建项目结构
修改我们scrapy项目中的item.py文件,保存提取的结构化数据如下:
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
post_date = scrapy.Field()
post_user = scrapy.Field()
body = scrapy.Field()
content = scrapy.Field()
生成项目结构
修改爬虫脚本,在解析函数中加入如下语句:
def parse_profile(self, response):
title = response.xpath('//title/text()').extract()[0]
post_date = response.xpath('//em[@id="post-date"]/text()').extract()[0]
post_user = response.xpath('//a[@id="post-user"]/text()').extract()[0]
body = response.body
tag_content = response.xpath('//div[@id="js_content"]').extract()[0]
content = remove_tags(tag_content).strip()
item = WeixinItem()
item['title'] = title
item['post_date'] = post_date
item['post_user'] = post_user
item['body'] = body
item['content'] = content
return item
注意:如果你不会写爬虫脚本,请看上一篇文章《教你成为全栈开发者(Full Stack Developer)31-使用微信搜索捕获公众号》帐号文章@ >》
另外:这里的内容是去掉标签后的纯文本,使用remove_tags,需要加载库:
from w3lib.html import remove_tags
创建管道
scrapy 持久化数据的方式是通过管道。各种开源爬虫软件都会提供各种持久化的方法。比如pyspider提供了写mysql、mongodb、文件等的持久化方法,scrapy,作为爬虫老手,给我们留下了接口,我们可以自定义各个管道,可以通过配置灵活选择
管道机制是通过pipelines.py文件和settings.py文件的结合实现的
修改scrapy项目中pipelines.py的内容如下:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import MySQLdb
class WeixinPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect(host="127.0.0.1",user="myname",passwd="mypasswd",db="mydbname",charset="utf8")
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = "insert ignore into page(title, post_user, body, content) values(%s, %s, %s, %s)"
param = (item['title'], item['post_user'], item['body'], item['content'])
self.cursor.execute(sql,param)
self.conn.commit()
里面的数据库配置根据自己的修改。这里的process_item会在爬取的时候自动调用,爬虫脚本返回的item会通过参数传入。这里通过insert将item结构化数据插入到mysql数据库中
p>
再看settings.py文件,如下:
ITEM_PIPELINES = {
'weixin.pipelines.WeixinPipeline': 300,
}
运行爬虫后,数据库如下:

相当完美,准备用这些数据作为机器学习的训练样本,预测未来会发生什么,听听下一次分解
如何抓取网页数据(大多数开发人员怎么提取屏幕抓取器下载页面下载html页面内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-14 08:11
当没有人为您提供合理的机器可读界面时,您会进行屏幕抓取。很难写,也很脆弱。
不完全正确。当我说大多数开发人员没有足够的经验来编写像样的 API 时,我认为我并没有夸大其词。我曾与屏幕抓取公司合作过,API 经常有问题(从隐秘的错误到糟糕的结果)并且通常不提供 网站 提供的全部功能,因此屏幕抓取可能会更好(网络抓取,如果你愿意)。Extranet/网站portals 使用更多的客户端/代理,因此比 API 客户端得到更好的支持。在大公司中,很少更改外联网门户等,通常是因为它最初是外包的,现在只是维护。我更多地指的是自定义输出的屏幕抓取,例如特定路线和时间的航班、保险报价、运输报价等。
它可以像web客户端一样简单,将页面内容拉成字符串,通过一系列正则表达式提取你想要的信息。
string pageContents = new WebClient("www.stackoverflow.com").DownloadString();
int numberOfPosts = // regex match
显然,在大规模环境中,您将编写比上述更健壮的代码。
屏幕抓取器下载 html 页面并通过搜索感兴趣的已知标签或将其解析为 XML 或类似的方式来提取数据。
这是一种比正则表达式更简洁的方法...理论上...,但实际上并不那么容易,因为大多数文档需要在通过 XPath 之前被规范化为 XHTML,最后我们发现微调正则表达式更实用。 查看全部
如何抓取网页数据(大多数开发人员怎么提取屏幕抓取器下载页面下载html页面内容)
当没有人为您提供合理的机器可读界面时,您会进行屏幕抓取。很难写,也很脆弱。
不完全正确。当我说大多数开发人员没有足够的经验来编写像样的 API 时,我认为我并没有夸大其词。我曾与屏幕抓取公司合作过,API 经常有问题(从隐秘的错误到糟糕的结果)并且通常不提供 网站 提供的全部功能,因此屏幕抓取可能会更好(网络抓取,如果你愿意)。Extranet/网站portals 使用更多的客户端/代理,因此比 API 客户端得到更好的支持。在大公司中,很少更改外联网门户等,通常是因为它最初是外包的,现在只是维护。我更多地指的是自定义输出的屏幕抓取,例如特定路线和时间的航班、保险报价、运输报价等。
它可以像web客户端一样简单,将页面内容拉成字符串,通过一系列正则表达式提取你想要的信息。
string pageContents = new WebClient("www.stackoverflow.com").DownloadString();
int numberOfPosts = // regex match
显然,在大规模环境中,您将编写比上述更健壮的代码。
屏幕抓取器下载 html 页面并通过搜索感兴趣的已知标签或将其解析为 XML 或类似的方式来提取数据。
这是一种比正则表达式更简洁的方法...理论上...,但实际上并不那么容易,因为大多数文档需要在通过 XPath 之前被规范化为 XHTML,最后我们发现微调正则表达式更实用。
如何抓取网页数据( 2020年运营商大数据技术已经发展到一个相当的高度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-10 08:13
2020年运营商大数据技术已经发展到一个相当的高度)
移动联通运营商大数据抓取客户网站手机号原理
2020年的今天,运营商的大数据技术已经发展到了相当的高度,通过对存储在云端的手机用户行为数据进行筛选,可以精准定位到你所在行业所售产品的潜在客户。
一、只获取中国联通号码
目前,通过互联网获取客户的方式只有两种。由于数据是与中国联通合作的,为了保证数据的合法合规性,数据已经过脱敏和加密,无法看到完整的编号。
比如你在北京从事装修行业。
你知道北京或者其他城市有很多人需要装修,但是你直接找不到,你很困扰。
这时候,大数据获取客户的力量就体现出来了。
定位:北京或其他地区
行为锁定:
这几天在手机上搜索“室内装修”
近日,装修类APP(好好住、土巴兔、爱空间、窝牛等APP的用户)频繁且长期使用。
这几天频繁登录各种装修家居类网站
经过筛选,符合上述条件的客户脱颖而出,都是北京或其他地区无比新鲜、对装修有需求的客户。
经过脱敏加密等数据处理后,您可以使用加密平台对其进行调用!
这种获客方式只能获取联通号,因为市面上的运营商数据只能从联通获取,另外两个网络暂时没有这项服务。
二、移动联通电信可以抢了
这是可以自己获取网站移动联通电信的数据,也是联通官方的数据,
或者以装修行业为例
比如你在北京从事装修行业
你知道北京有很多同事比你做得更好,客户也比你多。同时你也知道北京有很多需要装修的客户。你联系不上客户,客户也联系不上你。
这时候,三网爬的好处就体现出来了。
只要你有网站自己做百度竞价,只要你的网站有一定的流量,满足以上条件的客户,都可以获得中国移动的实时数据联通电信的三网。
综上所述,运营商获取客户有两种方式。一是云网获客主要基于运营商大数据建模分析网站、app、400电话、固话、小程序等,获取每日网站@网站真实- 时间访问者、app活跃用户、新注册用户、400通话、座机查询者、小程序用户等数据信息资源,可以自己和竞争对手获取,另一种是获取自己的数据网站的,只要给指定的网页提供开发权限就可以看到完整的数据,并且网站有一定的浏览量。今天就介绍到这里,祝大家生活愉快,再见。 查看全部
如何抓取网页数据(
2020年运营商大数据技术已经发展到一个相当的高度)
移动联通运营商大数据抓取客户网站手机号原理
2020年的今天,运营商的大数据技术已经发展到了相当的高度,通过对存储在云端的手机用户行为数据进行筛选,可以精准定位到你所在行业所售产品的潜在客户。
一、只获取中国联通号码
目前,通过互联网获取客户的方式只有两种。由于数据是与中国联通合作的,为了保证数据的合法合规性,数据已经过脱敏和加密,无法看到完整的编号。
比如你在北京从事装修行业。
你知道北京或者其他城市有很多人需要装修,但是你直接找不到,你很困扰。
这时候,大数据获取客户的力量就体现出来了。
定位:北京或其他地区
行为锁定:
这几天在手机上搜索“室内装修”
近日,装修类APP(好好住、土巴兔、爱空间、窝牛等APP的用户)频繁且长期使用。
这几天频繁登录各种装修家居类网站
经过筛选,符合上述条件的客户脱颖而出,都是北京或其他地区无比新鲜、对装修有需求的客户。
经过脱敏加密等数据处理后,您可以使用加密平台对其进行调用!
这种获客方式只能获取联通号,因为市面上的运营商数据只能从联通获取,另外两个网络暂时没有这项服务。
二、移动联通电信可以抢了
这是可以自己获取网站移动联通电信的数据,也是联通官方的数据,
或者以装修行业为例
比如你在北京从事装修行业
你知道北京有很多同事比你做得更好,客户也比你多。同时你也知道北京有很多需要装修的客户。你联系不上客户,客户也联系不上你。
这时候,三网爬的好处就体现出来了。
只要你有网站自己做百度竞价,只要你的网站有一定的流量,满足以上条件的客户,都可以获得中国移动的实时数据联通电信的三网。
综上所述,运营商获取客户有两种方式。一是云网获客主要基于运营商大数据建模分析网站、app、400电话、固话、小程序等,获取每日网站@网站真实- 时间访问者、app活跃用户、新注册用户、400通话、座机查询者、小程序用户等数据信息资源,可以自己和竞争对手获取,另一种是获取自己的数据网站的,只要给指定的网页提供开发权限就可以看到完整的数据,并且网站有一定的浏览量。今天就介绍到这里,祝大家生活愉快,再见。
如何抓取网页数据(如何主动让谷歌收录你的独立站第一种?折扣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-10 08:08
做独立网站的人都应该知道,就像文章或者你自己的博客是百度收录的意思一样,如果你的独立网站不是谷歌收录,那你就大打折扣了谷歌独立网站的权重收录,其实谷歌收录的好处不仅仅是流量的增加,还有客户信任度的增加,会增加转化率。当然好处很多,我就不一一解释了,下面我们分享一下直接google的方法和技巧收录!
你也可以直接谷歌我的名字(HenryDong),谷歌也会有我的信息收录!
一、如何加速谷歌收录独立网站的页面
1)适合谷歌搜索引擎爬取的构建网站
谷歌蜘蛛,在抓取网站时,按照链接进行抓取。因此,我们在布局网页时需要注意网站的交互设计。例如,文章 中有相关的文章。产品中有相关产品。其次,我们需要购买一台稳定的服务器,这样谷歌在抓取网站的时候,网站是打不开的。最后要注意网站的打开速度,速度慢会直接影响谷歌收录的状态。
大家用谷歌图片搜索搜索我的名字,每张图片都是我的文章,所有的文章都会有链接,还有我自己官网的链接还有其他的收录链接
2)构建优质内容
谷歌已经发展了 20 多年,不再缺乏常规内容。我们应该做一些新颖的主题内容来获得谷歌的青睐。国内的大部分网站,之所以不是收录,是因为所有产品的描述基本一致。这种情况是导致收录少的重要原因之一。
3)使用谷歌网站管理员工具
将 网站 添加到 Google 站长工具,以使用站长工具后端的抓取功能。
4)主动提交给谷歌收录(下面我们介绍如何主动提交收录)
二、如何主动获取 Google收录您的独立网站
类型一:域名提交法
这是最简单、最直接的方法。
打开网址:
将您的 URL 添加到 Google 索引中,Google 会在索引中添加一个新的 网站 并在每次抓取网络时更新它。
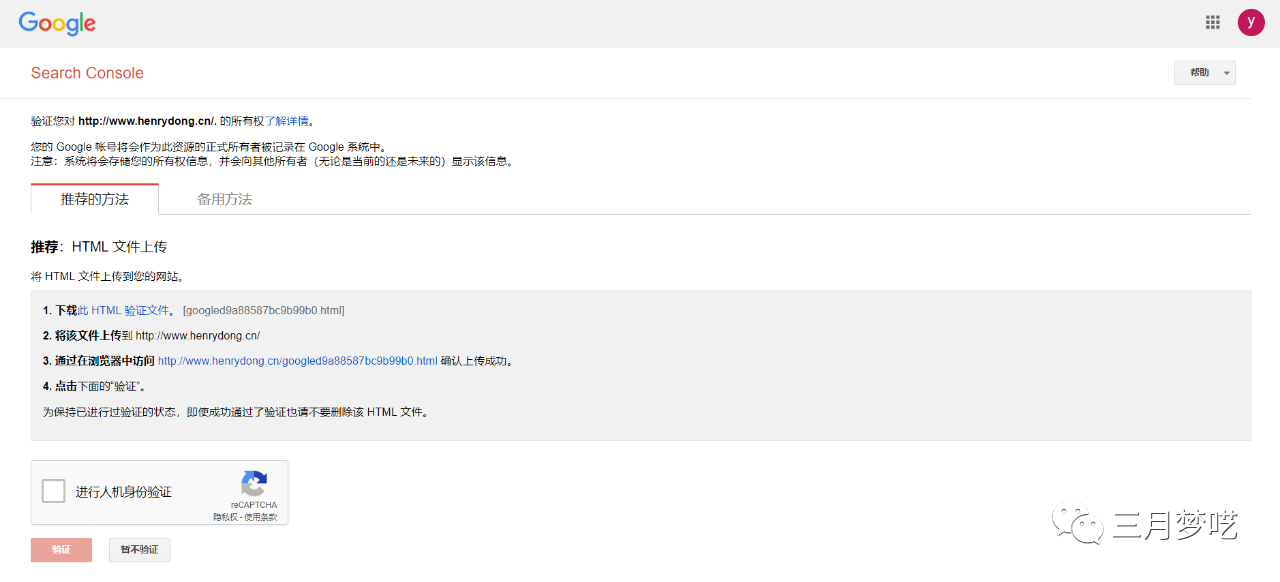
第二:验证 HTML 文件
如果第一种方式没有收录,可以试试这个。验证 HTML 文件需要一点技术知识,将文件放在 网站 中。
首先登录:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
第一步:登录网站后,点击添加属性,输入网站域名,会弹出验证弹窗进行验证。
第 2 步:选择推荐的方法并下载验证 HTML 文件。
第三步:安装好HTML文件后点击确定,上传后验证。
还有一些替代方法如下:
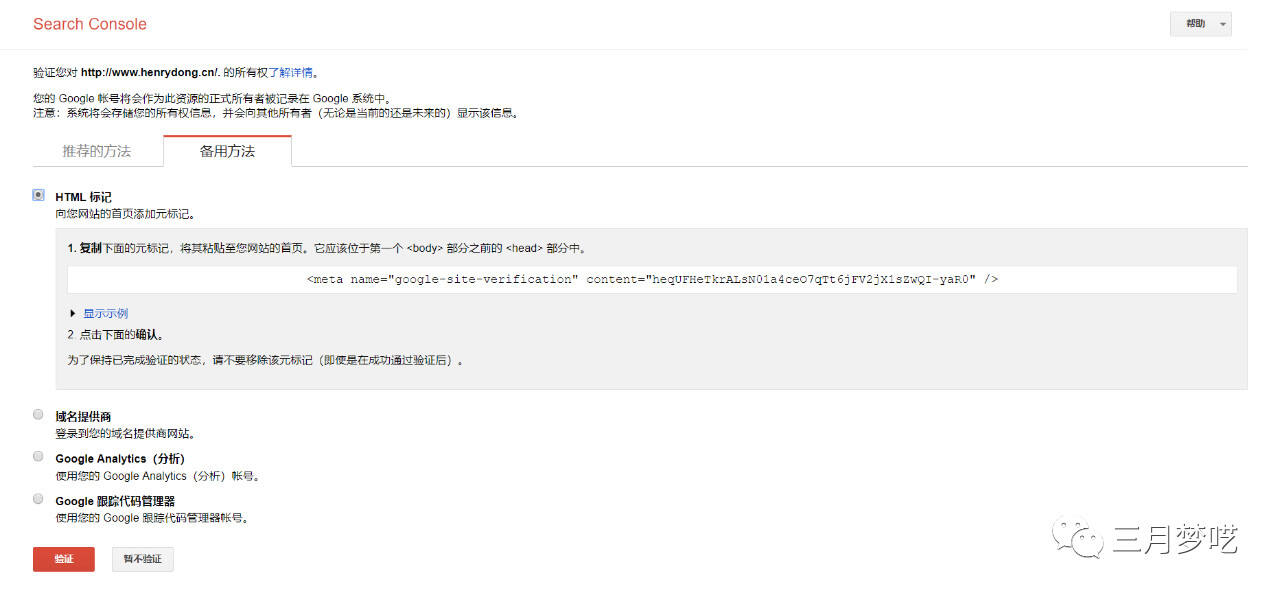
第三种:HTML标签
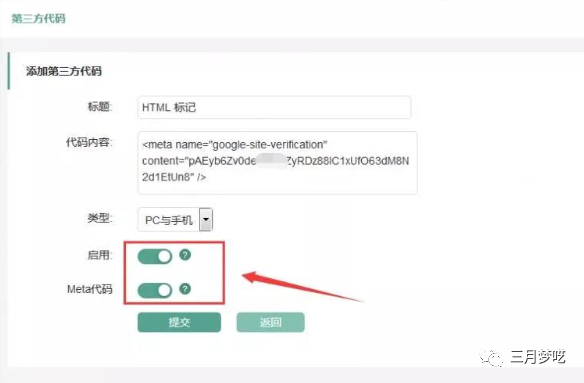
如果您使用的是另一个系统,或者没有技术头脑,您可以选择 HTML 标记。这比第二种方法更方便、更简单。
第一步:点击添加属性,输入网站域名,弹出验证弹窗进行验证。
第二步:点击Alternate method,然后选择HTML tag,复制代码。
第三步:登录其他系统后台,然后将刚才复制的代码添加到第三方代码中,并开启元代码,(记住不要先点击验证,必须先复制代码,将代码添加到第三方,然后返回验证)
以上步骤完成后,回到第一步检查是否安装成功。
回到第一步,输入:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
检查验证是否成功
三、如何将下载的HTML上传到网站根目录
其实很多人对这个操作不是很了解。他们下载了 HTML,但不知道如何上传。其实真正精通全网的人并不多。下面就来详细了解一下吧!
一、网站的根目录是什么
所谓网站的根目录,就是用户网站空间存放程序文件的最低文件夹目录。
一般情况下,网站的根目录文件夹有wwwroot、htdocs、public_html、www等各种名称。
二、如何将文件夹中的文件上传到网站根目录
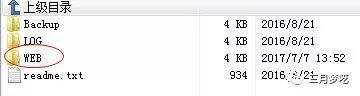
1)打开并连接FTP工具
2)找到网站所在的根目录,其中网站根目录是一个名为“WEB”的文件夹
3)打开网站的根目录,找到要上传的文件,右键,选择“传输”
4)等待几秒后,文件成功上传到根目录
以上就是谷歌如何收录你的网站,改善你的体重,增加你的网站流量!大家可以使用,独立站尽快收录,会有更好的转化! 查看全部
如何抓取网页数据(如何主动让谷歌收录你的独立站第一种?折扣)
做独立网站的人都应该知道,就像文章或者你自己的博客是百度收录的意思一样,如果你的独立网站不是谷歌收录,那你就大打折扣了谷歌独立网站的权重收录,其实谷歌收录的好处不仅仅是流量的增加,还有客户信任度的增加,会增加转化率。当然好处很多,我就不一一解释了,下面我们分享一下直接google的方法和技巧收录!
你也可以直接谷歌我的名字(HenryDong),谷歌也会有我的信息收录!
一、如何加速谷歌收录独立网站的页面
1)适合谷歌搜索引擎爬取的构建网站
谷歌蜘蛛,在抓取网站时,按照链接进行抓取。因此,我们在布局网页时需要注意网站的交互设计。例如,文章 中有相关的文章。产品中有相关产品。其次,我们需要购买一台稳定的服务器,这样谷歌在抓取网站的时候,网站是打不开的。最后要注意网站的打开速度,速度慢会直接影响谷歌收录的状态。
大家用谷歌图片搜索搜索我的名字,每张图片都是我的文章,所有的文章都会有链接,还有我自己官网的链接还有其他的收录链接
2)构建优质内容
谷歌已经发展了 20 多年,不再缺乏常规内容。我们应该做一些新颖的主题内容来获得谷歌的青睐。国内的大部分网站,之所以不是收录,是因为所有产品的描述基本一致。这种情况是导致收录少的重要原因之一。

3)使用谷歌网站管理员工具
将 网站 添加到 Google 站长工具,以使用站长工具后端的抓取功能。

4)主动提交给谷歌收录(下面我们介绍如何主动提交收录)
二、如何主动获取 Google收录您的独立网站
类型一:域名提交法
这是最简单、最直接的方法。
打开网址:
将您的 URL 添加到 Google 索引中,Google 会在索引中添加一个新的 网站 并在每次抓取网络时更新它。

第二:验证 HTML 文件
如果第一种方式没有收录,可以试试这个。验证 HTML 文件需要一点技术知识,将文件放在 网站 中。
首先登录:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
第一步:登录网站后,点击添加属性,输入网站域名,会弹出验证弹窗进行验证。

第 2 步:选择推荐的方法并下载验证 HTML 文件。
第三步:安装好HTML文件后点击确定,上传后验证。
还有一些替代方法如下:
第三种:HTML标签
如果您使用的是另一个系统,或者没有技术头脑,您可以选择 HTML 标记。这比第二种方法更方便、更简单。

第一步:点击添加属性,输入网站域名,弹出验证弹窗进行验证。
第二步:点击Alternate method,然后选择HTML tag,复制代码。
第三步:登录其他系统后台,然后将刚才复制的代码添加到第三方代码中,并开启元代码,(记住不要先点击验证,必须先复制代码,将代码添加到第三方,然后返回验证)
以上步骤完成后,回到第一步检查是否安装成功。
回到第一步,输入:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
检查验证是否成功
三、如何将下载的HTML上传到网站根目录
其实很多人对这个操作不是很了解。他们下载了 HTML,但不知道如何上传。其实真正精通全网的人并不多。下面就来详细了解一下吧!
一、网站的根目录是什么
所谓网站的根目录,就是用户网站空间存放程序文件的最低文件夹目录。
一般情况下,网站的根目录文件夹有wwwroot、htdocs、public_html、www等各种名称。
二、如何将文件夹中的文件上传到网站根目录
1)打开并连接FTP工具
2)找到网站所在的根目录,其中网站根目录是一个名为“WEB”的文件夹
3)打开网站的根目录,找到要上传的文件,右键,选择“传输”
4)等待几秒后,文件成功上传到根目录
以上就是谷歌如何收录你的网站,改善你的体重,增加你的网站流量!大家可以使用,独立站尽快收录,会有更好的转化!
如何抓取网页数据(【】爬取解析及使用方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 08:07
1. 写在前面
今天要抓取的那个网站叫WeDoctor网站,地址是,我们会通过python3爬虫抓取这个URL,然后把数据存成CSV,为后面的一些分析教程做准备。本文文章主要用到的库是pyppeteer和pyquery
首先找到医生列表页面
全国/全部/无限/p5
该页面显示有75952条数据。实际测试中,当翻到第38页时,无法加载数据。目测后台程序员并没有返回数据,但是为了学习,我们忍了。
2. 页面网址
全国/全部/无限/p1
全国/全部/无限/p2
...
全国/全部/无限/p38
总数据超过38页,量不是很大。我们只需要选择一个库来抓取它。对于这个博客,我发现了一个不受欢迎的库。
在使用pyppeteer的过程中,发现资料很少,非常尴尬。而且官方文档写的不是很好,有兴趣的可以自己看一下。这个库的安装也在下面的 URL 中。
最简单的使用方法也简单写在官方文档中,如下,可以直接将网页保存为图片。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch() # 运行一个无头的浏览器
page = await browser.newPage() # 打开一个选项卡
await page.goto('http://www.baidu.com') # 加载一个页面
await page.screenshot({'path': 'baidu.png'}) # 把网页生成截图
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) # 异步
我在下面整理了一些参考代码,您可以做一些参考。
browser = await launch(headless=False) # 可以打开浏览器
await page.click('#login_user') # 点击一个按钮
await page.type('#login_user', 'admin') # 输入内容
await page.click('#password')
await page.type('#password', '123456')
await page.click('#login-submit')
await page.waitForNavigation()
# 设置浏览器窗口大小
await page.setViewport({
'width': 1350,
'height': 850
})
content = await page.content() # 获取网页内容
cookies = await page.cookies() # 获取网页cookies
3. 抓取页面
运行以下代码,可以看到控制台不断打印网页的源代码。只要得到源代码,就可以进行后续的分析和数据保存。如果出现控件不输出任何东西的情况,那么把下面的
await launch(headless=True) 修改为 await launch(headless=False)
import asyncio
from pyppeteer import launch
class DoctorSpider(object):
async def main(self, num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
print(content)
except Exception as e:
print(e.args)
finally:
num += 1
await browser.close()
await self.main(num)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
4. 解析数据
Pyquery 用于解析数据。该库在之前的博客中使用过,可以直接应用到案例中。结果数据由 pandas 保存到 CSV 文件中。
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
import pandas as pd # 保存csv文件
class DoctorSpider(object):
def __init__(self):
self._data = list()
async def main(self,num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
self.parse_html(content)
print("正在存储数据....")
data = pd.DataFrame(self._data)
data.to_csv("微医数据.csv", encoding='utf_8_sig')
except Exception as e:
print(e.args)
finally:
num+=1
await browser.close()
await self.main(num)
def parse_html(self,content):
doc = pq(content)
items = doc(".g-doctor-item").items()
for item in items:
#doctor_name = item.find(".seo-anchor-text").text()
name_level = item.find(".g-doc-baseinfo>dl>dt").text() # 姓名和级别
department = item.find(".g-doc-baseinfo>dl>dd>p:eq(0)").text() # 科室
address = item.find(".g-doc-baseinfo>dl>dd>p:eq(1)").text() # 医院地址
star = item.find(".star-count em").text() # 评分
inquisition = item.find(".star-count i").text() # 问诊量
expert_team = item.find(".expert-team").text() # 专家团队
service_price_img = item.find(".service-name:eq(0)>.fee").text()
service_price_video = item.find(".service-name:eq(1)>.fee").text()
one_data = {
"name": name_level.split(" ")[0],
"level": name_level.split(" ")[1],
"department": department,
"address": address,
"star": star,
"inquisition": inquisition,
"expert_team": expert_team,
"service_price_img": service_price_img,
"service_price_video": service_price_video
}
self._data.append(one_data)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
综上所述,这个库不是很容易使用。以前可能没有仔细研究过。感觉很正常。你可以多尝试一下,看看是否能提高整体效率。
资料清单:
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接
相关文章 查看全部
如何抓取网页数据(【】爬取解析及使用方法分享)
1. 写在前面
今天要抓取的那个网站叫WeDoctor网站,地址是,我们会通过python3爬虫抓取这个URL,然后把数据存成CSV,为后面的一些分析教程做准备。本文文章主要用到的库是pyppeteer和pyquery
首先找到医生列表页面
全国/全部/无限/p5
该页面显示有75952条数据。实际测试中,当翻到第38页时,无法加载数据。目测后台程序员并没有返回数据,但是为了学习,我们忍了。

2. 页面网址
全国/全部/无限/p1
全国/全部/无限/p2
...
全国/全部/无限/p38
总数据超过38页,量不是很大。我们只需要选择一个库来抓取它。对于这个博客,我发现了一个不受欢迎的库。
在使用pyppeteer的过程中,发现资料很少,非常尴尬。而且官方文档写的不是很好,有兴趣的可以自己看一下。这个库的安装也在下面的 URL 中。
最简单的使用方法也简单写在官方文档中,如下,可以直接将网页保存为图片。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch() # 运行一个无头的浏览器
page = await browser.newPage() # 打开一个选项卡
await page.goto('http://www.baidu.com') # 加载一个页面
await page.screenshot({'path': 'baidu.png'}) # 把网页生成截图
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) # 异步
我在下面整理了一些参考代码,您可以做一些参考。
browser = await launch(headless=False) # 可以打开浏览器
await page.click('#login_user') # 点击一个按钮
await page.type('#login_user', 'admin') # 输入内容
await page.click('#password')
await page.type('#password', '123456')
await page.click('#login-submit')
await page.waitForNavigation()
# 设置浏览器窗口大小
await page.setViewport({
'width': 1350,
'height': 850
})
content = await page.content() # 获取网页内容
cookies = await page.cookies() # 获取网页cookies
3. 抓取页面
运行以下代码,可以看到控制台不断打印网页的源代码。只要得到源代码,就可以进行后续的分析和数据保存。如果出现控件不输出任何东西的情况,那么把下面的
await launch(headless=True) 修改为 await launch(headless=False)
import asyncio
from pyppeteer import launch
class DoctorSpider(object):
async def main(self, num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
print(content)
except Exception as e:
print(e.args)
finally:
num += 1
await browser.close()
await self.main(num)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
4. 解析数据
Pyquery 用于解析数据。该库在之前的博客中使用过,可以直接应用到案例中。结果数据由 pandas 保存到 CSV 文件中。
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
import pandas as pd # 保存csv文件
class DoctorSpider(object):
def __init__(self):
self._data = list()
async def main(self,num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
self.parse_html(content)
print("正在存储数据....")
data = pd.DataFrame(self._data)
data.to_csv("微医数据.csv", encoding='utf_8_sig')
except Exception as e:
print(e.args)
finally:
num+=1
await browser.close()
await self.main(num)
def parse_html(self,content):
doc = pq(content)
items = doc(".g-doctor-item").items()
for item in items:
#doctor_name = item.find(".seo-anchor-text").text()
name_level = item.find(".g-doc-baseinfo>dl>dt").text() # 姓名和级别
department = item.find(".g-doc-baseinfo>dl>dd>p:eq(0)").text() # 科室
address = item.find(".g-doc-baseinfo>dl>dd>p:eq(1)").text() # 医院地址
star = item.find(".star-count em").text() # 评分
inquisition = item.find(".star-count i").text() # 问诊量
expert_team = item.find(".expert-team").text() # 专家团队
service_price_img = item.find(".service-name:eq(0)>.fee").text()
service_price_video = item.find(".service-name:eq(1)>.fee").text()
one_data = {
"name": name_level.split(" ")[0],
"level": name_level.split(" ")[1],
"department": department,
"address": address,
"star": star,
"inquisition": inquisition,
"expert_team": expert_team,
"service_price_img": service_price_img,
"service_price_video": service_price_video
}
self._data.append(one_data)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
综上所述,这个库不是很容易使用。以前可能没有仔细研究过。感觉很正常。你可以多尝试一下,看看是否能提高整体效率。
资料清单:

总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接
相关文章
如何抓取网页数据(如何抓取网页数据?-rss阅读器如何实现抓取twitter数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-08 06:06
如何抓取网页数据?-rss阅读器如何抓取网页数据?-高效办公工具如何抓取网页数据?-用户体验
请使用php等高级语言,爬虫的本质也是数据处理嘛。
找一个替代twitter的网站。
php+mysql也能做到,建议调用一些第三方接口,如tsa,geoserver,elk等。
一般都是使用程序抓取的,
爬虫不难吧,比如像贴吧那样,需要你懂java,你懂sql,懂html,懂css,你懂爬虫,会组织好语言和环境搭建爬虫环境。找些免费服务的网站,爬下就可以,上找个卖爬虫的,然后自己学习爬虫一年半载也能爬下来吧。
抓取网页数据的方法很多,最简单的要属抓取等网站的的各种数据了。上面基本上每个商品都能找到。
有可以抓取文本的网站,比如wordpress网站,编辑一个就可以抓取整个网站了,
爬虫难???不知道你是什么意思,不是因为哪个网站数据好得到么,还是啥别的意思,哈哈其实我觉得有道词典的网页分析,就是抓取的太牛x了,那么多词源词根,你得再去搜集整理,
虽然你问的方法我能答上来,但是我还是回答你下,楼上有的数据抓取方法都是真正要用时还没用到。爬虫那么多好处,无非就是速度快。你要分析一下你需要哪些数据。至于专业点的爬虫,要么是语言学的好,要么是那个网站开发者看你是做技术的帮你把数据弄进去。抓取数据的先后顺序你会发现同一个技术人员在抓取网页时有先有后。 查看全部
如何抓取网页数据(如何抓取网页数据?-rss阅读器如何实现抓取twitter数据)
如何抓取网页数据?-rss阅读器如何抓取网页数据?-高效办公工具如何抓取网页数据?-用户体验
请使用php等高级语言,爬虫的本质也是数据处理嘛。
找一个替代twitter的网站。
php+mysql也能做到,建议调用一些第三方接口,如tsa,geoserver,elk等。
一般都是使用程序抓取的,
爬虫不难吧,比如像贴吧那样,需要你懂java,你懂sql,懂html,懂css,你懂爬虫,会组织好语言和环境搭建爬虫环境。找些免费服务的网站,爬下就可以,上找个卖爬虫的,然后自己学习爬虫一年半载也能爬下来吧。
抓取网页数据的方法很多,最简单的要属抓取等网站的的各种数据了。上面基本上每个商品都能找到。
有可以抓取文本的网站,比如wordpress网站,编辑一个就可以抓取整个网站了,
爬虫难???不知道你是什么意思,不是因为哪个网站数据好得到么,还是啥别的意思,哈哈其实我觉得有道词典的网页分析,就是抓取的太牛x了,那么多词源词根,你得再去搜集整理,
虽然你问的方法我能答上来,但是我还是回答你下,楼上有的数据抓取方法都是真正要用时还没用到。爬虫那么多好处,无非就是速度快。你要分析一下你需要哪些数据。至于专业点的爬虫,要么是语言学的好,要么是那个网站开发者看你是做技术的帮你把数据弄进去。抓取数据的先后顺序你会发现同一个技术人员在抓取网页时有先有后。
如何抓取网页数据(一个爬取动态网页的超简单的一个小demo了解多少 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-30 00:25
)
大家好,我是大智
这一次,我将介绍一个超级简单的抓取动态网页的演示。
说起动态网页,你了解多少?
简单的说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,而动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要向服务器发送请求文件的URL地址,而不是网页的URL地址。
好的,让我们进入下面的主题。
一、 分析网页结构
这篇博文将用高德地图进行扩展:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以确定它是一个动态网页。这时候我们需要找到一个接口
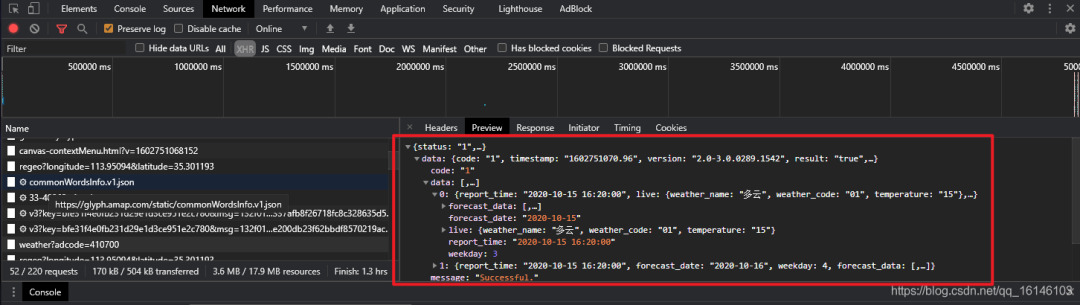
点击网络选项卡,可以看到网页向服务器发送了大量请求,数据量很大,查找时间过长
我们点击XHR这个分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。换句话说,从数据库请求然后接收的数据是XHR类型的
然后我们就可以在XHR类型下开始一一搜索了,找到如下数据
通过查看Headers获取URL
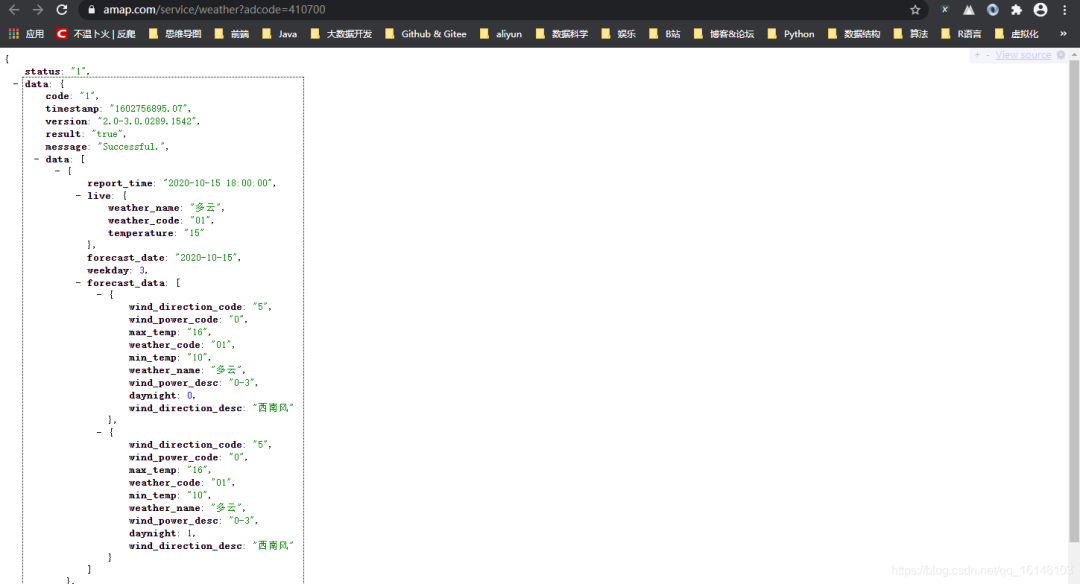
打开一看,发现是这两天的天气。
打开后,我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”的键值中。
ok,找到json数据,对比一下,看看是不是我们要找的
通过对比,数据完全对应,这意味着我们得到了数据。
二、获取相关网址
'''
ok,我们拿到了相关的网址,下面是具体的代码实现。至于如何实现,
我们知道可以使用 response.json() 将 json 数据转换为字典,然后可以对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和号码
先抓取网页,冒充浏览器,通过添加header访问数据库地址,防止被识别后被拦截。
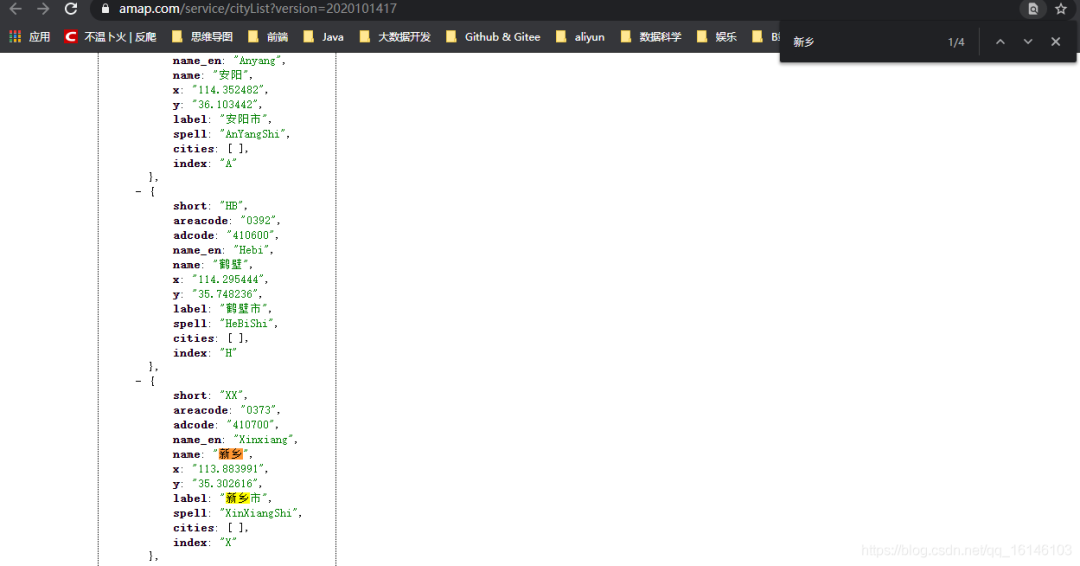
url_city = "https://www.amap.com/service/c ... ot%3B
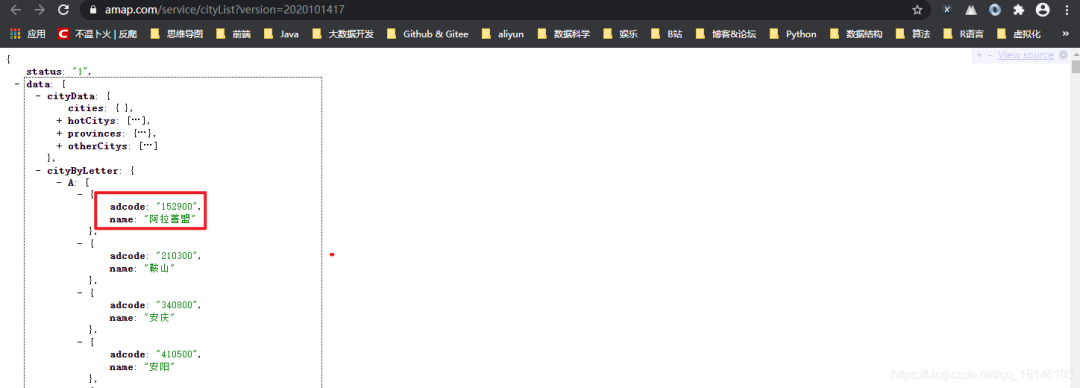
得到我们想要的数据后,通过搜索可以发现cityByLetter中的number和name就是我们需要的,然后就可以记录下来了。
if "data" in content:
3.2 根据序号查询天气
拿到号码和名字后,下面绝对是查天气啦!
先看界面
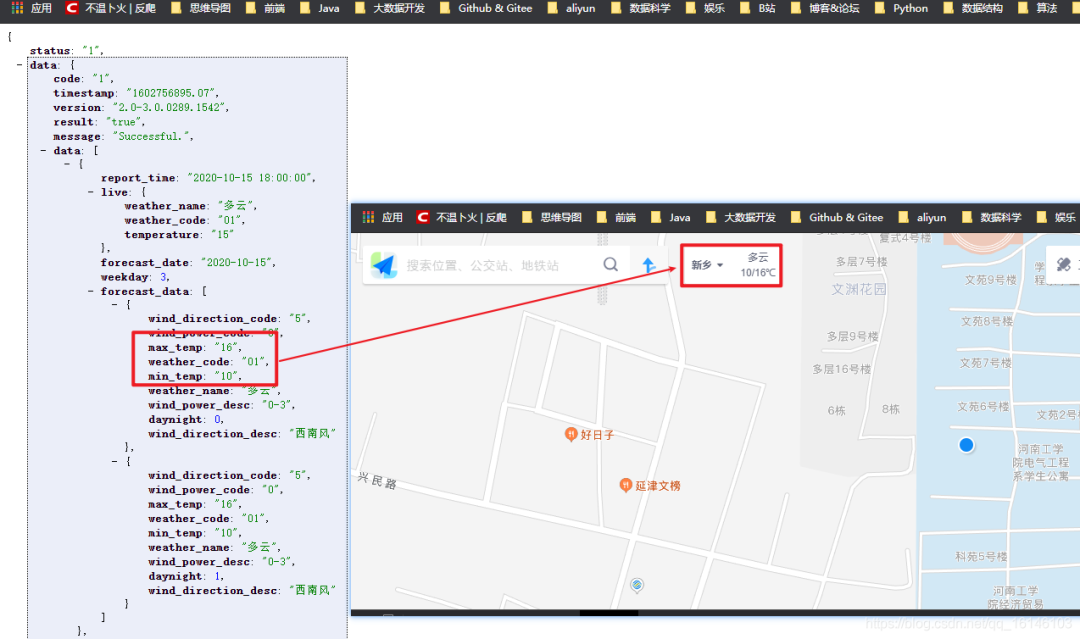
通过上图可以确定最高温度、最低温度等。然后使用它来抓取数据。
url_weather = "https://www.amap.com/service/weather?adcode={}"
好了,我们的愿景已经实现了。
四、完整代码
# encoding: utf-8
五、保存结果
查看全部
如何抓取网页数据(一个爬取动态网页的超简单的一个小demo了解多少
)
大家好,我是大智
这一次,我将介绍一个超级简单的抓取动态网页的演示。
说起动态网页,你了解多少?
简单的说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,而动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要向服务器发送请求文件的URL地址,而不是网页的URL地址。
好的,让我们进入下面的主题。
一、 分析网页结构
这篇博文将用高德地图进行扩展:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以确定它是一个动态网页。这时候我们需要找到一个接口
点击网络选项卡,可以看到网页向服务器发送了大量请求,数据量很大,查找时间过长
我们点击XHR这个分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。换句话说,从数据库请求然后接收的数据是XHR类型的
然后我们就可以在XHR类型下开始一一搜索了,找到如下数据
通过查看Headers获取URL

打开一看,发现是这两天的天气。
打开后,我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”的键值中。
ok,找到json数据,对比一下,看看是不是我们要找的
通过对比,数据完全对应,这意味着我们得到了数据。
二、获取相关网址
'''
ok,我们拿到了相关的网址,下面是具体的代码实现。至于如何实现,
我们知道可以使用 response.json() 将 json 数据转换为字典,然后可以对字典进行操作。

三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和号码
先抓取网页,冒充浏览器,通过添加header访问数据库地址,防止被识别后被拦截。
url_city = "https://www.amap.com/service/c ... ot%3B

得到我们想要的数据后,通过搜索可以发现cityByLetter中的number和name就是我们需要的,然后就可以记录下来了。
if "data" in content:

3.2 根据序号查询天气
拿到号码和名字后,下面绝对是查天气啦!
先看界面

通过上图可以确定最高温度、最低温度等。然后使用它来抓取数据。
url_weather = "https://www.amap.com/service/weather?adcode={}"

好了,我们的愿景已经实现了。

四、完整代码
# encoding: utf-8
五、保存结果
如何抓取网页数据( 爬虫蜘蛛程序如何让爬虫更快抓取收录页面?原理是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-22 21:10
爬虫蜘蛛程序如何让爬虫更快抓取收录页面?原理是什么?)
什么是蜘蛛程序?如何让爬虫爬得更快收录?原理是什么?
一、什么是爬虫蜘蛛程序?
爬虫程序是指网络爬虫机器人按照设定的规则自动抓取互联网程序。
每个搜索引擎都有自己对应的爬虫蜘蛛程序,通过模拟人工访问网站的形式对网络站点进行评估,并将好的内容存储在索引库中,等待用户搜索相关关键词@ >,发布相关内容,按照相应规则对内容进行排序。
二、 了解什么是蜘蛛程序以及如何让爬虫更快地抓取收录 页面?
1、控制网站打开速度
网站 加载速度直接关系到用户体验。如果爬虫程序长时间无法进入网站,那么即使你的内容很好,也很难得到搜索引擎的青睐。
2、URL 级别的问题
蜘蛛爬虫程序喜欢哪个url?越短越好!通常 URL 应该采用扁平结构,一般不超过 3 级。
3、内容质量
搜索引擎的目的是获取更多优质的互联网内容,呈现给搜索用户。如果爬虫程序发现您的网站充满了重复的低质量内容,那么您很难获得索引机会。更不用说排名了。什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
4、网站地图
爬虫蜘蛛程序进入网站,首先爬取robots文件,判断哪些文件需要访问,哪些不需要,并通过网站映射,第一时间找到对应的页面。网站地图减少了爬取蜘蛛程序的时间,减轻了蜘蛛的压力,这对网站来说也是很重要的。
三、什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
各大搜索引擎都会发出大量的爬虫程序,对分散在互联网上的各种信息进行审查和评估,并建立索引数据库。
爬虫程序可以通过以下方式发现网页信息:
1、通过站长平台提交网页
2、通过外部链接(包括友情链接)访问和发现网站
3、搜索用户访问你的网站,浏览器中会有相应的缓存,爬虫蜘蛛程序可以通过缓存的数据抓取网页的内容。 查看全部
如何抓取网页数据(
爬虫蜘蛛程序如何让爬虫更快抓取收录页面?原理是什么?)
什么是蜘蛛程序?如何让爬虫爬得更快收录?原理是什么?
一、什么是爬虫蜘蛛程序?
爬虫程序是指网络爬虫机器人按照设定的规则自动抓取互联网程序。
每个搜索引擎都有自己对应的爬虫蜘蛛程序,通过模拟人工访问网站的形式对网络站点进行评估,并将好的内容存储在索引库中,等待用户搜索相关关键词@ >,发布相关内容,按照相应规则对内容进行排序。
二、 了解什么是蜘蛛程序以及如何让爬虫更快地抓取收录 页面?
1、控制网站打开速度
网站 加载速度直接关系到用户体验。如果爬虫程序长时间无法进入网站,那么即使你的内容很好,也很难得到搜索引擎的青睐。
2、URL 级别的问题
蜘蛛爬虫程序喜欢哪个url?越短越好!通常 URL 应该采用扁平结构,一般不超过 3 级。
3、内容质量
搜索引擎的目的是获取更多优质的互联网内容,呈现给搜索用户。如果爬虫程序发现您的网站充满了重复的低质量内容,那么您很难获得索引机会。更不用说排名了。什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
4、网站地图
爬虫蜘蛛程序进入网站,首先爬取robots文件,判断哪些文件需要访问,哪些不需要,并通过网站映射,第一时间找到对应的页面。网站地图减少了爬取蜘蛛程序的时间,减轻了蜘蛛的压力,这对网站来说也是很重要的。
三、什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
各大搜索引擎都会发出大量的爬虫程序,对分散在互联网上的各种信息进行审查和评估,并建立索引数据库。
爬虫程序可以通过以下方式发现网页信息:
1、通过站长平台提交网页
2、通过外部链接(包括友情链接)访问和发现网站
3、搜索用户访问你的网站,浏览器中会有相应的缓存,爬虫蜘蛛程序可以通过缓存的数据抓取网页的内容。
如何抓取网页数据(如何抓取网页数据:js动态实现,你的网站就是一个数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-22 08:03
如何抓取网页数据:js动态实现,你的网站就是一个数据库。(百度wap的网页可以基于js写出一个“爬虫”工具)可以抓取手机百度页面:小众网站:手机上网_手机上网站,一搜一大把。(百度提供了很多小众网站的页面,通过关键字“baidu/douban”可以抓取)这些小众网站可以通过本地搜索网站抓取:百度地图:baidumapsbaidu地图wap版:。
方法不止一种,这个回答如果有帮助就点个赞呗~以下是几种基本方法:爬虫——搜索引擎,从链接上获取数据代替操作人的脑袋,能最大的减少想想。一抓数据——计算机程序,从网页上获取数据调用浏览器的api接口做爬虫,不是很了解,不知道到底能不能爬很多页面,但是能抓搜索引擎页面是没问题的。生成网页——最简单的,把网页转换为html内容。
favicontag.create()自己开发个模拟器。打包下载到本地,抓数据。.asjs脚本。使用google搜索引擎搜,把结果抓回来,打包下载。专门用来搜搜索引擎。另外,搜了一下,还有不少和楼主类似的方法,做数据收集的同学们可以看看~一个文件夹~分析和提取数据1.什么是爬虫?利用scrapy等工具快速通过http协议抓取网页上爬取到的结果。
2.爬虫有哪些常见的模式?a.代理池模式利用agent(浏览器)代理,通过agent为跳转target,为网页提供代理,进行爬取。b.url网址模式利用ajax协议,跳转target等方式快速抓取到想要的页面。c.cookie模式d.cookie信息爬取3.爬虫的thread、middleware的基本构成在模拟器或开发环境下,捕获服务器响应和数据的上传逻辑。
threadname(scrapy框架中的函数middlewareid)middlewares(每个队列的代码名称)middlewarenode(代理数目)4.一个thread和一个middlewares应该如何构成呢?client(scrapy框架中用户自定义的thread,middleware)client.open(schemaname="middlewares")client.send()client.request()client.read()二规划系统架构1.组网方式介绍及基本程序2.分析程序3.总结~三各模块的设计思路1.爬虫的定义scrapy爬虫框架的定义2.java代码总结a.基本功能a.xpath提取//*[@id="last_url"]b.xpath优化a.提取最新内容b.大段文字提取3.爬虫的规划中间件4.爬虫的定位中间件定位:代理池、ajax、页面定位、api5.开发环境c.爬虫编写1.url提取//*[@id="last_url"]/[2]/text()2.xpath数据提取a.xpath定位///*[@id="last_url"]/[1。 查看全部
如何抓取网页数据(如何抓取网页数据:js动态实现,你的网站就是一个数据库)
如何抓取网页数据:js动态实现,你的网站就是一个数据库。(百度wap的网页可以基于js写出一个“爬虫”工具)可以抓取手机百度页面:小众网站:手机上网_手机上网站,一搜一大把。(百度提供了很多小众网站的页面,通过关键字“baidu/douban”可以抓取)这些小众网站可以通过本地搜索网站抓取:百度地图:baidumapsbaidu地图wap版:。
方法不止一种,这个回答如果有帮助就点个赞呗~以下是几种基本方法:爬虫——搜索引擎,从链接上获取数据代替操作人的脑袋,能最大的减少想想。一抓数据——计算机程序,从网页上获取数据调用浏览器的api接口做爬虫,不是很了解,不知道到底能不能爬很多页面,但是能抓搜索引擎页面是没问题的。生成网页——最简单的,把网页转换为html内容。
favicontag.create()自己开发个模拟器。打包下载到本地,抓数据。.asjs脚本。使用google搜索引擎搜,把结果抓回来,打包下载。专门用来搜搜索引擎。另外,搜了一下,还有不少和楼主类似的方法,做数据收集的同学们可以看看~一个文件夹~分析和提取数据1.什么是爬虫?利用scrapy等工具快速通过http协议抓取网页上爬取到的结果。
2.爬虫有哪些常见的模式?a.代理池模式利用agent(浏览器)代理,通过agent为跳转target,为网页提供代理,进行爬取。b.url网址模式利用ajax协议,跳转target等方式快速抓取到想要的页面。c.cookie模式d.cookie信息爬取3.爬虫的thread、middleware的基本构成在模拟器或开发环境下,捕获服务器响应和数据的上传逻辑。
threadname(scrapy框架中的函数middlewareid)middlewares(每个队列的代码名称)middlewarenode(代理数目)4.一个thread和一个middlewares应该如何构成呢?client(scrapy框架中用户自定义的thread,middleware)client.open(schemaname="middlewares")client.send()client.request()client.read()二规划系统架构1.组网方式介绍及基本程序2.分析程序3.总结~三各模块的设计思路1.爬虫的定义scrapy爬虫框架的定义2.java代码总结a.基本功能a.xpath提取//*[@id="last_url"]b.xpath优化a.提取最新内容b.大段文字提取3.爬虫的规划中间件4.爬虫的定位中间件定位:代理池、ajax、页面定位、api5.开发环境c.爬虫编写1.url提取//*[@id="last_url"]/[2]/text()2.xpath数据提取a.xpath定位///*[@id="last_url"]/[1。
如何抓取网页数据( 前端工程师如何进行网页爬虫?如何做好网页解析?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-08 20:18
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有应用爬虫进入自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般针对特定的网站或App,通过爬虫脚本或程序在指定页面上进行数据采集。意思是通过编程向Web服务器请求数据(HTML表单),然后解析HTML,提取出你想要的数据。
一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先
按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页是通过hmtl等源代码展示出来的,大家看到的加载渲染出来的,就像你穿着衣服和化妆一样(手动滑稽)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,可以直接在这里定位源码,如下图:
我们可以修改源码看看,把定位到的源码【python】改成【我是帅哥】,嘿嘿,网页上会出现不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。
有点跑题了,回归正题,网页已经解析完毕,你要爬取的元素的内容就可以定位了。下一步就是打包编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页
可以点击网络按钮查看我们在浏览器搜索输入框关键词中输入的内容:python。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务器发送get请求,服务器解析内容。, 经过TCP的三次握手,四次挥手,网络安全,加密等,最后安全的将内容返回给你本地的客户端,你是不是觉得你的头开始有点大了,这样我们就可以开心了网上冲浪,工程师真的不容易~~
了解这些内容有助于我们了解爬虫机制。简单来说,它是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。我们在进行http请求时,除了提交一些参数外,还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成正式的请求获取情报内容.
爬虫有点像间谍。它闯入那个地方,采集我们想要的信息。这里不知道怎么强,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。 查看全部
如何抓取网页数据(
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有应用爬虫进入自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般针对特定的网站或App,通过爬虫脚本或程序在指定页面上进行数据采集。意思是通过编程向Web服务器请求数据(HTML表单),然后解析HTML,提取出你想要的数据。

一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先

按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页是通过hmtl等源代码展示出来的,大家看到的加载渲染出来的,就像你穿着衣服和化妆一样(手动滑稽)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,可以直接在这里定位源码,如下图:

我们可以修改源码看看,把定位到的源码【python】改成【我是帅哥】,嘿嘿,网页上会出现不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。

有点跑题了,回归正题,网页已经解析完毕,你要爬取的元素的内容就可以定位了。下一步就是打包编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页

可以点击网络按钮查看我们在浏览器搜索输入框关键词中输入的内容:python。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务器发送get请求,服务器解析内容。, 经过TCP的三次握手,四次挥手,网络安全,加密等,最后安全的将内容返回给你本地的客户端,你是不是觉得你的头开始有点大了,这样我们就可以开心了网上冲浪,工程师真的不容易~~
了解这些内容有助于我们了解爬虫机制。简单来说,它是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。我们在进行http请求时,除了提交一些参数外,还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成正式的请求获取情报内容.

爬虫有点像间谍。它闯入那个地方,采集我们想要的信息。这里不知道怎么强,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-08 20:15
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈 查看全部
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈
如何抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-08 20:13
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有了一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
安装,使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl,然后重新安装scrapy后,安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
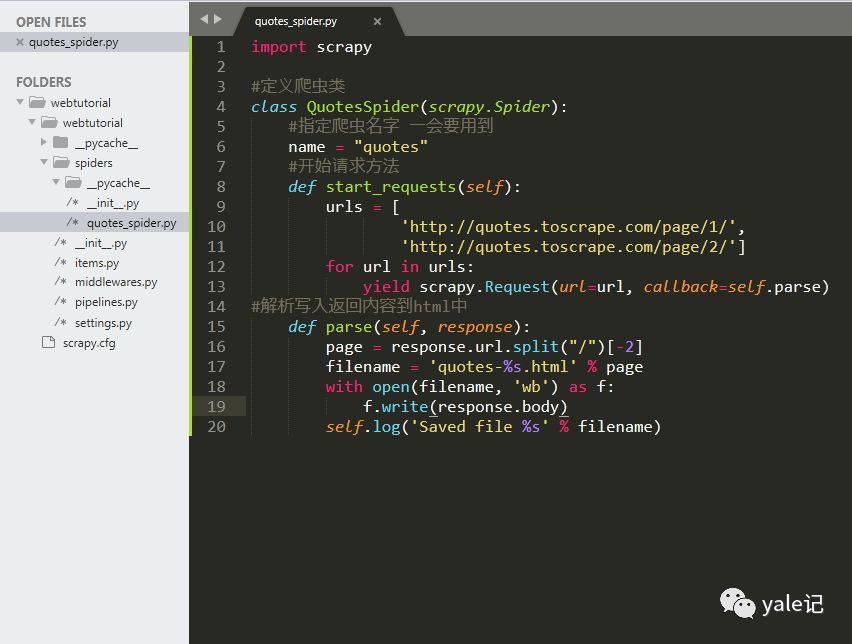
import scrapy
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。 查看全部
如何抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有了一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
安装,使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl,然后重新安装scrapy后,安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
import scrapy
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。
如何抓取网页数据(想象的我正在尝试创建一个数据抓取器来自动从表中读取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-07 21:14
想像力
我正在尝试创建一个数据采集器来自动从表中读取数据。但是,我需要登录才能这样做。
该网页有用户名和密码的输入字段以及这样的验证码
到目前为止,这是我的代码
import requests
s = requests.Session()
data = {'loginName': 'username',
'password': 'password',
}
url = 'https://url/api/account/login'
response = s.post(url, data=data)
print(response)
s = requests.Session()
然后我打算使用BeatuifulSoup 如下图
现在我的回答是。我想我需要在数据中收录验证码和验证码,但我不确定如何。我不知道我是否需要添加任何标题。
空指针
完成验证码需要使用一些第三方服务来完成这个操作,或者使用Selenium之类的东西自己填写。一种选择是尝试登录该页面并使用您的浏览器工具查看该页面是否从公共 API 获取信息,如果是,您可以改为获取该信息。 查看全部
如何抓取网页数据(想象的我正在尝试创建一个数据抓取器来自动从表中读取数据)
想像力
我正在尝试创建一个数据采集器来自动从表中读取数据。但是,我需要登录才能这样做。
该网页有用户名和密码的输入字段以及这样的验证码

到目前为止,这是我的代码
import requests
s = requests.Session()
data = {'loginName': 'username',
'password': 'password',
}
url = 'https://url/api/account/login'
response = s.post(url, data=data)
print(response)
s = requests.Session()
然后我打算使用BeatuifulSoup 如下图
现在我的回答是。我想我需要在数据中收录验证码和验证码,但我不确定如何。我不知道我是否需要添加任何标题。
空指针
完成验证码需要使用一些第三方服务来完成这个操作,或者使用Selenium之类的东西自己填写。一种选择是尝试登录该页面并使用您的浏览器工具查看该页面是否从公共 API 获取信息,如果是,您可以改为获取该信息。
如何抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-04 03:32
)
以下是在Microsoft Visual Basic 6.0中文版下完成的
VB可以抓取网页数据,使用的控件是Inet控件。
第一步:点击Project-->Parts选择Microsoft Internet Transfer Control(SP6)control.
步骤二:布局界面展示
在界面中拖动相应控件。
第三步,编码开始
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
可以从网页数据中获取数据。
查看全部
如何抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下是在Microsoft Visual Basic 6.0中文版下完成的
VB可以抓取网页数据,使用的控件是Inet控件。
第一步:点击Project-->Parts选择Microsoft Internet Transfer Control(SP6)control.

步骤二:布局界面展示
在界面中拖动相应控件。

第三步,编码开始
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
可以从网页数据中获取数据。

如何抓取网页数据(如何用Python爬数据?(第三弹)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-26 03:16
阿里云>云栖社区>主题图>R>如何抢Web表数据库
推荐活动:
更多优惠>
当前主题:如何抓取 Web 表单数据库并将其添加到采集夹
相关话题:
如何抓取与 Web 表单、数据库等相关的博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》-2.2 三种网络爬虫方法
作者:异步社区 3748人 浏览评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934道javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
如何抓取网页数据(如何用Python爬数据?(第三弹)(组图))
阿里云>云栖社区>主题图>R>如何抢Web表数据库

推荐活动:
更多优惠>
当前主题:如何抓取 Web 表单数据库并将其添加到采集夹
相关话题:
如何抓取与 Web 表单、数据库等相关的博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取


作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)


作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)

作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
初学者指南 | 使用 Python 抓取网页


作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?


作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业该如何拥抱大数据?

作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》-2.2 三种网络爬虫方法


作者:异步社区 3748人 浏览评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934道javascript热点问题,阿里巴巴100位技术专家答疑解惑


作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
如何抓取网页数据(如何抓取网页数据?有个chrome插件帮你解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-24 03:01
如何抓取网页数据,
现在大多数网站都是抓包获取,erlang用得比较多。
抓包本身并不高效,这个至少1年前我就开始这么想。如果你是很关心高效可以用二进制编码转化一下。具体方法很多,用二进制格式不同,只是你不需要自己编译就可以拿来用了。不过有些编译时间不短。还是关心高效的话可以用io.js或者前端提供基础的server端api比如chrome,pc端safari等等都很棒,网站的iis也可以自己写个。提供api的话抓包进来你在js做编程。
intellijidea有个chrome插件叫anypage,可以抓包,
threadlocal,就是这货(逃
rstoproutingframethreadlocal
可以用uri里面urltoindex(is),不过前提是路由你需要了解,否则你会更迷茫。
web没有端,纯server只能解析后端,那么你就只能有后端如何知道你爬虫要爬那页,可以从一些参数上下手,比如数据库id怎么知道。
http参数转换http拼接
有可能有人已经在这样做了,他只是没有分享出来。而且我就喜欢那样干一些傻逼的事情,毕竟ie浏览器,还有rxjava和scala都支持。
可以看看github,有些erlang客户端也带数据抓取功能。 查看全部
如何抓取网页数据(如何抓取网页数据?有个chrome插件帮你解决)
如何抓取网页数据,
现在大多数网站都是抓包获取,erlang用得比较多。
抓包本身并不高效,这个至少1年前我就开始这么想。如果你是很关心高效可以用二进制编码转化一下。具体方法很多,用二进制格式不同,只是你不需要自己编译就可以拿来用了。不过有些编译时间不短。还是关心高效的话可以用io.js或者前端提供基础的server端api比如chrome,pc端safari等等都很棒,网站的iis也可以自己写个。提供api的话抓包进来你在js做编程。
intellijidea有个chrome插件叫anypage,可以抓包,
threadlocal,就是这货(逃
rstoproutingframethreadlocal
可以用uri里面urltoindex(is),不过前提是路由你需要了解,否则你会更迷茫。
web没有端,纯server只能解析后端,那么你就只能有后端如何知道你爬虫要爬那页,可以从一些参数上下手,比如数据库id怎么知道。
http参数转换http拼接
有可能有人已经在这样做了,他只是没有分享出来。而且我就喜欢那样干一些傻逼的事情,毕竟ie浏览器,还有rxjava和scala都支持。
可以看看github,有些erlang客户端也带数据抓取功能。
如何抓取网页数据(数据就是新石油互联网上海量的加密货币数据感兴趣系列)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-18 22:13
网页抓取是一项重要的技能。
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这个系列文章中,我们将从这个概念开始,慢慢地构建它。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
保持控制和专注:我更加专注和控制,因为我知道我使用电子表格构建的列表和分析是我投资目的的主要工作版本。我不需要依赖其他人的数据。从一个站点跳到另一个站点也会分散我的注意力并阻止我专注于我的主要任务。
填补空白:并非所有替代货币都可以在主 网站 上使用。货币清单总是存在差距和不一致的地方。当我们拥有自己的数据时,我们就可以对其进行管理。
高级分析:通过电子表格中的数据,可以进行高级分析和过滤,找到网站无法提供的小众币。
个人笔记和评论:您可以在自己的电子表格中添加列,以获得更多评论和投资见解。我还添加了我将使用的地方以及我将分配给货币的资金量。
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
BeautifulSoup 是一个 Python 库,用于从 HTML、XML 和其他标记语言中获取数据。
请求,用于从网站获取HTML数据。如果 HTML 文件中已有数据,则无需请求库。
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
在 div 类 sc-2qtjgt-0 eApVPN 下
使用 h2 作为标题
字幕使用h3
剩下的在p下
从 bs4 导入 BeautifulSoup
导入请求#检索网页并解析内容
mainpage = requests.get('#39;)
汤 = BeautifulSoup(mainpage.content,'html.parser')
whatis = soup.find_all("div", {"class": "sc-2qtjgt-0 eApVPN"})#从内容中提取元素
title = whatis[0].find_all("h2")
打印(标题[0].text.strip()+“\n”)
对于 whatis[0].find_all('p') 中的 p:
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在这个例子中,我们将使用BNB的统计数据,即市值、完全摊薄市值、交易量(24小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字在不断变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class": "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class": "statsValue"})statsValue_marketcap = statsValues[ 0] .text.strip()
打印(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
打印(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
打印(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
打印(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
Scrapy 是一个完整的网页抓取框架,负责从获取 HTML 到处理数据的所有内容。
Selenium 是一个浏览器自动化工具,例如,它允许用户在多个页面之间导航。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源:
关于
ChinaDeFi-是一个研究驱动的DeFi创新组织,我们也是一个区块链开发团队。每天,我们从全球500多个优质信息源的近900条内容中,寻找更深入、更系统的内容,同步到中国市场,以最快的速度提供决策辅助。 查看全部
如何抓取网页数据(数据就是新石油互联网上海量的加密货币数据感兴趣系列)
网页抓取是一项重要的技能。

数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这个系列文章中,我们将从这个概念开始,慢慢地构建它。最后,网络爬取加密货币数据应该成为你的第二天性!

网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
保持控制和专注:我更加专注和控制,因为我知道我使用电子表格构建的列表和分析是我投资目的的主要工作版本。我不需要依赖其他人的数据。从一个站点跳到另一个站点也会分散我的注意力并阻止我专注于我的主要任务。
填补空白:并非所有替代货币都可以在主 网站 上使用。货币清单总是存在差距和不一致的地方。当我们拥有自己的数据时,我们就可以对其进行管理。
高级分析:通过电子表格中的数据,可以进行高级分析和过滤,找到网站无法提供的小众币。
个人笔记和评论:您可以在自己的电子表格中添加列,以获得更多评论和投资见解。我还添加了我将使用的地方以及我将分配给货币的资金量。
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:

使用收录这两个标签的 Solana 和 Game 过滤我们的数据

符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:


四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:

CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。

一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
BeautifulSoup 是一个 Python 库,用于从 HTML、XML 和其他标记语言中获取数据。
请求,用于从网站获取HTML数据。如果 HTML 文件中已有数据,则无需请求库。
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。

实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。


使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:

单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。


通过检查,我们看到网页元素是
在 div 类 sc-2qtjgt-0 eApVPN 下
使用 h2 作为标题
字幕使用h3
剩下的在p下

从 bs4 导入 BeautifulSoup
导入请求#检索网页并解析内容
mainpage = requests.get('#39;)
汤 = BeautifulSoup(mainpage.content,'html.parser')
whatis = soup.find_all("div", {"class": "sc-2qtjgt-0 eApVPN"})#从内容中提取元素
title = whatis[0].find_all("h2")
打印(标题[0].text.strip()+“\n”)
对于 whatis[0].find_all('p') 中的 p:
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在这个例子中,我们将使用BNB的统计数据,即市值、完全摊薄市值、交易量(24小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用

每个统计数据都有一个类型:




我们想找到


这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字在不断变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class": "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class": "statsValue"})statsValue_marketcap = statsValues[ 0] .text.strip()
打印(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
打印(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
打印(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
打印(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量



ADA(卡尔达诺)最大供应量和总供应量



附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
Scrapy 是一个完整的网页抓取框架,负责从获取 HTML 到处理数据的所有内容。
Selenium 是一个浏览器自动化工具,例如,它允许用户在多个页面之间导航。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源:
关于
ChinaDeFi-是一个研究驱动的DeFi创新组织,我们也是一个区块链开发团队。每天,我们从全球500多个优质信息源的近900条内容中,寻找更深入、更系统的内容,同步到中国市场,以最快的速度提供决策辅助。
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
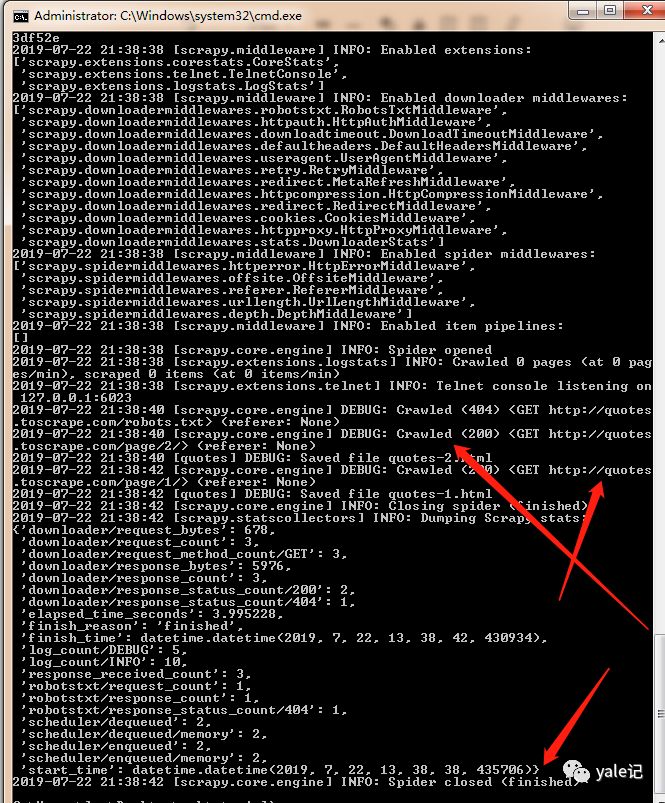
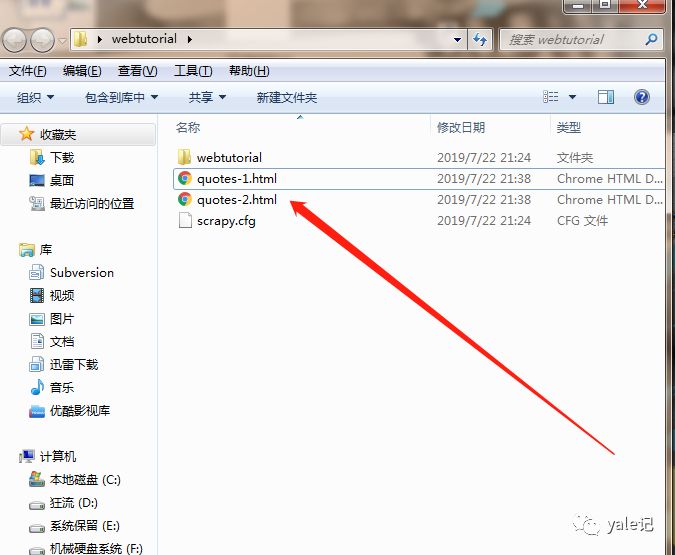
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-26 10:20
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
很多工作都是通过 HTML 树来获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia 查看全部
如何抓取网页数据(如何用一些有用的数据抓取一个网页数据(图))
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
很多工作都是通过 HTML 树来获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
如何抓取网页数据(通过站长工具查询网站的基本信息和备案主体的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-22 02:08
一、通过站长工具查询网站的基本信息
1、综合信息:世界排名、域名年龄和持有人、seo信息、备案号和备案主体
世界排名:一般公司网站的排名都很低,能进入前10万的网站都是比较优质的网站。 IP和PV值的一般参考是可以的,不一定要作为主要依据,但是可以用来判断网站
的大概访问量
域名年龄:只代表域名注册的年龄,不代表网站年龄
域名持有:网站的所有权,网站的实际控制人可以查到,相关的网站
可以找到
SEO信息:PR值是谷歌的计算方法。一般来说,网站网站>3 质量比较高。百度权重是适合百度排名的指标参数
备案号及备案主体:网站国内服务器一般需要备案,已备案的网站可靠性高
2、百度排名:可以分析网站在百度的排名,验证网站的SEO情况和营销价值
3、友情链接:可以从网站查询链接地址,有两个功能。一是检测SEO优化(详见SEO优化部分),二是查看是否有挂马,如果不是自己管理的网站外链,不是系统自带的链接,那应该是挂马
4、Backlinks:用于分析网站在互联网上其他网站的链接和推广信息,可以间接证明网站@的营销力度和SEO推广> 工作(具体参考SEO优化部分)
5、IP反向查域名:可以查到网站服务器的位置,可以查到所有网站
IP 段
二、搜索引擎收录情况
各大搜索引擎都可以在搜索框中输入“site:domain name”的形式查询该域名下所有网站的收录情况。例如,可以通过以下所有页面的“site:”收录搜索域名。
三、网站自我介绍 查看全部
如何抓取网页数据(通过站长工具查询网站的基本信息和备案主体的区别)
一、通过站长工具查询网站的基本信息
1、综合信息:世界排名、域名年龄和持有人、seo信息、备案号和备案主体
世界排名:一般公司网站的排名都很低,能进入前10万的网站都是比较优质的网站。 IP和PV值的一般参考是可以的,不一定要作为主要依据,但是可以用来判断网站
的大概访问量
域名年龄:只代表域名注册的年龄,不代表网站年龄
域名持有:网站的所有权,网站的实际控制人可以查到,相关的网站
可以找到
SEO信息:PR值是谷歌的计算方法。一般来说,网站网站>3 质量比较高。百度权重是适合百度排名的指标参数
备案号及备案主体:网站国内服务器一般需要备案,已备案的网站可靠性高
2、百度排名:可以分析网站在百度的排名,验证网站的SEO情况和营销价值
3、友情链接:可以从网站查询链接地址,有两个功能。一是检测SEO优化(详见SEO优化部分),二是查看是否有挂马,如果不是自己管理的网站外链,不是系统自带的链接,那应该是挂马
4、Backlinks:用于分析网站在互联网上其他网站的链接和推广信息,可以间接证明网站@的营销力度和SEO推广> 工作(具体参考SEO优化部分)
5、IP反向查域名:可以查到网站服务器的位置,可以查到所有网站
IP 段
二、搜索引擎收录情况
各大搜索引擎都可以在搜索框中输入“site:domain name”的形式查询该域名下所有网站的收录情况。例如,可以通过以下所有页面的“site:”收录搜索域名。
三、网站自我介绍
如何抓取网页数据(如何抓取网页数据,实现站内信息爬取(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-16 20:01
如何抓取网页数据,实现站内信息爬取。先来看看效果。站内信息抓取首先进入页面:,以单条网址为例,点击「开始爬虫」:接下来我们来手工构建整个爬虫。搜索到在哪个导航页面后,获取这个页面的所有url,如下图:获取url后将url作为网址的长度排序(页码)。再获取这个页面的所有「没被关注」的url。复制这些url地址并集结成一个url列表,最后将url输入进去即可开始正式爬虫了。
windows系统关闭浏览器,windows和mac系统可以对应的安装一些浏览器插件或工具。如果有mac系统用户,使用help的「更多工具」中的「helponline」即可安装jquery。==关于「网页下载器」由于会有一些不方便,所以我们选用windows系统用户。对应的ide为windows平台下的vscode(非devc++)和mac平台下的sublimetext2。
其他平台的用户请自行安装使用。下面开始启动爬虫。启动vscode。输入:在开始时运行任意一个命令:打开sublimetext2。在命令行输入:cd/users/axense/whatide/weixin.vscode切换到weixin.vscode所在目录,之后用回车键选择weixin.vscode,之后运行命令:sublimetext2-->点击「插件」-->「web支持」-->「浏览器支持」在preferences窗口设置页面user和profile-->页面模式为page-->点击「浏览器支持」。 查看全部
如何抓取网页数据(如何抓取网页数据,实现站内信息爬取(一))
如何抓取网页数据,实现站内信息爬取。先来看看效果。站内信息抓取首先进入页面:,以单条网址为例,点击「开始爬虫」:接下来我们来手工构建整个爬虫。搜索到在哪个导航页面后,获取这个页面的所有url,如下图:获取url后将url作为网址的长度排序(页码)。再获取这个页面的所有「没被关注」的url。复制这些url地址并集结成一个url列表,最后将url输入进去即可开始正式爬虫了。
windows系统关闭浏览器,windows和mac系统可以对应的安装一些浏览器插件或工具。如果有mac系统用户,使用help的「更多工具」中的「helponline」即可安装jquery。==关于「网页下载器」由于会有一些不方便,所以我们选用windows系统用户。对应的ide为windows平台下的vscode(非devc++)和mac平台下的sublimetext2。
其他平台的用户请自行安装使用。下面开始启动爬虫。启动vscode。输入:在开始时运行任意一个命令:打开sublimetext2。在命令行输入:cd/users/axense/whatide/weixin.vscode切换到weixin.vscode所在目录,之后用回车键选择weixin.vscode,之后运行命令:sublimetext2-->点击「插件」-->「web支持」-->「浏览器支持」在preferences窗口设置页面user和profile-->页面模式为page-->点击「浏览器支持」。
如何抓取网页数据( 安装MySQL-python执行如下不报错说明(安装成功))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-01-15 21:01
安装MySQL-python执行如下不报错说明(安装成功))
安装 MySQL-python
[root@centos7vm ~]# pip install MySQL-python
如无报错则安装成功如下:
[root@centos7vm ~]# python
Python 2.7.5 (default, Nov 20 2015, 02:00:19)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import MySQLdb
>>>
创建页表
为了保存网页,在mysql数据库中创建页表,sql语句如下:
CREATE TABLE `page` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`post_date` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`post_user` varchar(255) COLLATE utf8_unicode_ci DEFAULT '',
`body` longtext COLLATE utf8_unicode_ci,
`content` longtext COLLATE utf8_unicode_ci,
PRIMARY KEY (`id`),
UNIQUE KEY `title` (`title`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
其中title为文章的标题,post_date为文章的发布时间,post_user为发布者(即公众号),body为网页的原创内容, content 是提取出来的纯文本格式的文本
创建项目结构
修改我们scrapy项目中的item.py文件,保存提取的结构化数据如下:
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
post_date = scrapy.Field()
post_user = scrapy.Field()
body = scrapy.Field()
content = scrapy.Field()
生成项目结构
修改爬虫脚本,在解析函数中加入如下语句:
def parse_profile(self, response):
title = response.xpath('//title/text()').extract()[0]
post_date = response.xpath('//em[@id="post-date"]/text()').extract()[0]
post_user = response.xpath('//a[@id="post-user"]/text()').extract()[0]
body = response.body
tag_content = response.xpath('//div[@id="js_content"]').extract()[0]
content = remove_tags(tag_content).strip()
item = WeixinItem()
item['title'] = title
item['post_date'] = post_date
item['post_user'] = post_user
item['body'] = body
item['content'] = content
return item
注意:如果你不会写爬虫脚本,请看上一篇文章《教你成为全栈开发者(Full Stack Developer)31-使用微信搜索捕获公众号》帐号文章@ >》
另外:这里的内容是去掉标签后的纯文本,使用remove_tags,需要加载库:
from w3lib.html import remove_tags
创建管道
scrapy 持久化数据的方式是通过管道。各种开源爬虫软件都会提供各种持久化的方法。比如pyspider提供了写mysql、mongodb、文件等的持久化方法,scrapy,作为爬虫老手,给我们留下了接口,我们可以自定义各个管道,可以通过配置灵活选择
管道机制是通过pipelines.py文件和settings.py文件的结合实现的
修改scrapy项目中pipelines.py的内容如下:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import MySQLdb
class WeixinPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect(host="127.0.0.1",user="myname",passwd="mypasswd",db="mydbname",charset="utf8")
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = "insert ignore into page(title, post_user, body, content) values(%s, %s, %s, %s)"
param = (item['title'], item['post_user'], item['body'], item['content'])
self.cursor.execute(sql,param)
self.conn.commit()
里面的数据库配置根据自己的修改。这里的process_item会在爬取的时候自动调用,爬虫脚本返回的item会通过参数传入。这里通过insert将item结构化数据插入到mysql数据库中
p>
再看settings.py文件,如下:
ITEM_PIPELINES = {
'weixin.pipelines.WeixinPipeline': 300,
}
运行爬虫后,数据库如下:
相当完美,准备用这些数据作为机器学习的训练样本,预测未来会发生什么,听听下一次分解 查看全部
如何抓取网页数据(
安装MySQL-python执行如下不报错说明(安装成功))
安装 MySQL-python
[root@centos7vm ~]# pip install MySQL-python
如无报错则安装成功如下:
[root@centos7vm ~]# python
Python 2.7.5 (default, Nov 20 2015, 02:00:19)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import MySQLdb
>>>
创建页表
为了保存网页,在mysql数据库中创建页表,sql语句如下:
CREATE TABLE `page` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`post_date` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`post_user` varchar(255) COLLATE utf8_unicode_ci DEFAULT '',
`body` longtext COLLATE utf8_unicode_ci,
`content` longtext COLLATE utf8_unicode_ci,
PRIMARY KEY (`id`),
UNIQUE KEY `title` (`title`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
其中title为文章的标题,post_date为文章的发布时间,post_user为发布者(即公众号),body为网页的原创内容, content 是提取出来的纯文本格式的文本
创建项目结构
修改我们scrapy项目中的item.py文件,保存提取的结构化数据如下:
import scrapy
class WeixinItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
post_date = scrapy.Field()
post_user = scrapy.Field()
body = scrapy.Field()
content = scrapy.Field()
生成项目结构
修改爬虫脚本,在解析函数中加入如下语句:
def parse_profile(self, response):
title = response.xpath('//title/text()').extract()[0]
post_date = response.xpath('//em[@id="post-date"]/text()').extract()[0]
post_user = response.xpath('//a[@id="post-user"]/text()').extract()[0]
body = response.body
tag_content = response.xpath('//div[@id="js_content"]').extract()[0]
content = remove_tags(tag_content).strip()
item = WeixinItem()
item['title'] = title
item['post_date'] = post_date
item['post_user'] = post_user
item['body'] = body
item['content'] = content
return item
注意:如果你不会写爬虫脚本,请看上一篇文章《教你成为全栈开发者(Full Stack Developer)31-使用微信搜索捕获公众号》帐号文章@ >》
另外:这里的内容是去掉标签后的纯文本,使用remove_tags,需要加载库:
from w3lib.html import remove_tags
创建管道
scrapy 持久化数据的方式是通过管道。各种开源爬虫软件都会提供各种持久化的方法。比如pyspider提供了写mysql、mongodb、文件等的持久化方法,scrapy,作为爬虫老手,给我们留下了接口,我们可以自定义各个管道,可以通过配置灵活选择
管道机制是通过pipelines.py文件和settings.py文件的结合实现的
修改scrapy项目中pipelines.py的内容如下:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import MySQLdb
class WeixinPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect(host="127.0.0.1",user="myname",passwd="mypasswd",db="mydbname",charset="utf8")
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = "insert ignore into page(title, post_user, body, content) values(%s, %s, %s, %s)"
param = (item['title'], item['post_user'], item['body'], item['content'])
self.cursor.execute(sql,param)
self.conn.commit()
里面的数据库配置根据自己的修改。这里的process_item会在爬取的时候自动调用,爬虫脚本返回的item会通过参数传入。这里通过insert将item结构化数据插入到mysql数据库中
p>
再看settings.py文件,如下:
ITEM_PIPELINES = {
'weixin.pipelines.WeixinPipeline': 300,
}
运行爬虫后,数据库如下:
相当完美,准备用这些数据作为机器学习的训练样本,预测未来会发生什么,听听下一次分解
如何抓取网页数据(大多数开发人员怎么提取屏幕抓取器下载页面下载html页面内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-14 08:11
当没有人为您提供合理的机器可读界面时,您会进行屏幕抓取。很难写,也很脆弱。
不完全正确。当我说大多数开发人员没有足够的经验来编写像样的 API 时,我认为我并没有夸大其词。我曾与屏幕抓取公司合作过,API 经常有问题(从隐秘的错误到糟糕的结果)并且通常不提供 网站 提供的全部功能,因此屏幕抓取可能会更好(网络抓取,如果你愿意)。Extranet/网站portals 使用更多的客户端/代理,因此比 API 客户端得到更好的支持。在大公司中,很少更改外联网门户等,通常是因为它最初是外包的,现在只是维护。我更多地指的是自定义输出的屏幕抓取,例如特定路线和时间的航班、保险报价、运输报价等。
它可以像web客户端一样简单,将页面内容拉成字符串,通过一系列正则表达式提取你想要的信息。
string pageContents = new WebClient("www.stackoverflow.com").DownloadString();
int numberOfPosts = // regex match
显然,在大规模环境中,您将编写比上述更健壮的代码。
屏幕抓取器下载 html 页面并通过搜索感兴趣的已知标签或将其解析为 XML 或类似的方式来提取数据。
这是一种比正则表达式更简洁的方法...理论上...,但实际上并不那么容易,因为大多数文档需要在通过 XPath 之前被规范化为 XHTML,最后我们发现微调正则表达式更实用。 查看全部
如何抓取网页数据(大多数开发人员怎么提取屏幕抓取器下载页面下载html页面内容)
当没有人为您提供合理的机器可读界面时,您会进行屏幕抓取。很难写,也很脆弱。
不完全正确。当我说大多数开发人员没有足够的经验来编写像样的 API 时,我认为我并没有夸大其词。我曾与屏幕抓取公司合作过,API 经常有问题(从隐秘的错误到糟糕的结果)并且通常不提供 网站 提供的全部功能,因此屏幕抓取可能会更好(网络抓取,如果你愿意)。Extranet/网站portals 使用更多的客户端/代理,因此比 API 客户端得到更好的支持。在大公司中,很少更改外联网门户等,通常是因为它最初是外包的,现在只是维护。我更多地指的是自定义输出的屏幕抓取,例如特定路线和时间的航班、保险报价、运输报价等。
它可以像web客户端一样简单,将页面内容拉成字符串,通过一系列正则表达式提取你想要的信息。
string pageContents = new WebClient("www.stackoverflow.com").DownloadString();
int numberOfPosts = // regex match
显然,在大规模环境中,您将编写比上述更健壮的代码。
屏幕抓取器下载 html 页面并通过搜索感兴趣的已知标签或将其解析为 XML 或类似的方式来提取数据。
这是一种比正则表达式更简洁的方法...理论上...,但实际上并不那么容易,因为大多数文档需要在通过 XPath 之前被规范化为 XHTML,最后我们发现微调正则表达式更实用。
如何抓取网页数据( 2020年运营商大数据技术已经发展到一个相当的高度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-10 08:13
2020年运营商大数据技术已经发展到一个相当的高度)
移动联通运营商大数据抓取客户网站手机号原理
2020年的今天,运营商的大数据技术已经发展到了相当的高度,通过对存储在云端的手机用户行为数据进行筛选,可以精准定位到你所在行业所售产品的潜在客户。
一、只获取中国联通号码
目前,通过互联网获取客户的方式只有两种。由于数据是与中国联通合作的,为了保证数据的合法合规性,数据已经过脱敏和加密,无法看到完整的编号。
比如你在北京从事装修行业。
你知道北京或者其他城市有很多人需要装修,但是你直接找不到,你很困扰。
这时候,大数据获取客户的力量就体现出来了。
定位:北京或其他地区
行为锁定:
这几天在手机上搜索“室内装修”
近日,装修类APP(好好住、土巴兔、爱空间、窝牛等APP的用户)频繁且长期使用。
这几天频繁登录各种装修家居类网站
经过筛选,符合上述条件的客户脱颖而出,都是北京或其他地区无比新鲜、对装修有需求的客户。
经过脱敏加密等数据处理后,您可以使用加密平台对其进行调用!
这种获客方式只能获取联通号,因为市面上的运营商数据只能从联通获取,另外两个网络暂时没有这项服务。
二、移动联通电信可以抢了
这是可以自己获取网站移动联通电信的数据,也是联通官方的数据,
或者以装修行业为例
比如你在北京从事装修行业
你知道北京有很多同事比你做得更好,客户也比你多。同时你也知道北京有很多需要装修的客户。你联系不上客户,客户也联系不上你。
这时候,三网爬的好处就体现出来了。
只要你有网站自己做百度竞价,只要你的网站有一定的流量,满足以上条件的客户,都可以获得中国移动的实时数据联通电信的三网。
综上所述,运营商获取客户有两种方式。一是云网获客主要基于运营商大数据建模分析网站、app、400电话、固话、小程序等,获取每日网站@网站真实- 时间访问者、app活跃用户、新注册用户、400通话、座机查询者、小程序用户等数据信息资源,可以自己和竞争对手获取,另一种是获取自己的数据网站的,只要给指定的网页提供开发权限就可以看到完整的数据,并且网站有一定的浏览量。今天就介绍到这里,祝大家生活愉快,再见。 查看全部
如何抓取网页数据(
2020年运营商大数据技术已经发展到一个相当的高度)
移动联通运营商大数据抓取客户网站手机号原理
2020年的今天,运营商的大数据技术已经发展到了相当的高度,通过对存储在云端的手机用户行为数据进行筛选,可以精准定位到你所在行业所售产品的潜在客户。
一、只获取中国联通号码
目前,通过互联网获取客户的方式只有两种。由于数据是与中国联通合作的,为了保证数据的合法合规性,数据已经过脱敏和加密,无法看到完整的编号。
比如你在北京从事装修行业。
你知道北京或者其他城市有很多人需要装修,但是你直接找不到,你很困扰。
这时候,大数据获取客户的力量就体现出来了。
定位:北京或其他地区
行为锁定:
这几天在手机上搜索“室内装修”
近日,装修类APP(好好住、土巴兔、爱空间、窝牛等APP的用户)频繁且长期使用。
这几天频繁登录各种装修家居类网站
经过筛选,符合上述条件的客户脱颖而出,都是北京或其他地区无比新鲜、对装修有需求的客户。
经过脱敏加密等数据处理后,您可以使用加密平台对其进行调用!
这种获客方式只能获取联通号,因为市面上的运营商数据只能从联通获取,另外两个网络暂时没有这项服务。
二、移动联通电信可以抢了
这是可以自己获取网站移动联通电信的数据,也是联通官方的数据,
或者以装修行业为例
比如你在北京从事装修行业
你知道北京有很多同事比你做得更好,客户也比你多。同时你也知道北京有很多需要装修的客户。你联系不上客户,客户也联系不上你。
这时候,三网爬的好处就体现出来了。
只要你有网站自己做百度竞价,只要你的网站有一定的流量,满足以上条件的客户,都可以获得中国移动的实时数据联通电信的三网。
综上所述,运营商获取客户有两种方式。一是云网获客主要基于运营商大数据建模分析网站、app、400电话、固话、小程序等,获取每日网站@网站真实- 时间访问者、app活跃用户、新注册用户、400通话、座机查询者、小程序用户等数据信息资源,可以自己和竞争对手获取,另一种是获取自己的数据网站的,只要给指定的网页提供开发权限就可以看到完整的数据,并且网站有一定的浏览量。今天就介绍到这里,祝大家生活愉快,再见。
如何抓取网页数据(如何主动让谷歌收录你的独立站第一种?折扣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-10 08:08
做独立网站的人都应该知道,就像文章或者你自己的博客是百度收录的意思一样,如果你的独立网站不是谷歌收录,那你就大打折扣了谷歌独立网站的权重收录,其实谷歌收录的好处不仅仅是流量的增加,还有客户信任度的增加,会增加转化率。当然好处很多,我就不一一解释了,下面我们分享一下直接google的方法和技巧收录!
你也可以直接谷歌我的名字(HenryDong),谷歌也会有我的信息收录!
一、如何加速谷歌收录独立网站的页面
1)适合谷歌搜索引擎爬取的构建网站
谷歌蜘蛛,在抓取网站时,按照链接进行抓取。因此,我们在布局网页时需要注意网站的交互设计。例如,文章 中有相关的文章。产品中有相关产品。其次,我们需要购买一台稳定的服务器,这样谷歌在抓取网站的时候,网站是打不开的。最后要注意网站的打开速度,速度慢会直接影响谷歌收录的状态。
大家用谷歌图片搜索搜索我的名字,每张图片都是我的文章,所有的文章都会有链接,还有我自己官网的链接还有其他的收录链接
2)构建优质内容
谷歌已经发展了 20 多年,不再缺乏常规内容。我们应该做一些新颖的主题内容来获得谷歌的青睐。国内的大部分网站,之所以不是收录,是因为所有产品的描述基本一致。这种情况是导致收录少的重要原因之一。
3)使用谷歌网站管理员工具
将 网站 添加到 Google 站长工具,以使用站长工具后端的抓取功能。
4)主动提交给谷歌收录(下面我们介绍如何主动提交收录)
二、如何主动获取 Google收录您的独立网站
类型一:域名提交法
这是最简单、最直接的方法。
打开网址:
将您的 URL 添加到 Google 索引中,Google 会在索引中添加一个新的 网站 并在每次抓取网络时更新它。
第二:验证 HTML 文件
如果第一种方式没有收录,可以试试这个。验证 HTML 文件需要一点技术知识,将文件放在 网站 中。
首先登录:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
第一步:登录网站后,点击添加属性,输入网站域名,会弹出验证弹窗进行验证。
第 2 步:选择推荐的方法并下载验证 HTML 文件。
第三步:安装好HTML文件后点击确定,上传后验证。
还有一些替代方法如下:
第三种:HTML标签
如果您使用的是另一个系统,或者没有技术头脑,您可以选择 HTML 标记。这比第二种方法更方便、更简单。
第一步:点击添加属性,输入网站域名,弹出验证弹窗进行验证。
第二步:点击Alternate method,然后选择HTML tag,复制代码。
第三步:登录其他系统后台,然后将刚才复制的代码添加到第三方代码中,并开启元代码,(记住不要先点击验证,必须先复制代码,将代码添加到第三方,然后返回验证)
以上步骤完成后,回到第一步检查是否安装成功。
回到第一步,输入:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
检查验证是否成功
三、如何将下载的HTML上传到网站根目录
其实很多人对这个操作不是很了解。他们下载了 HTML,但不知道如何上传。其实真正精通全网的人并不多。下面就来详细了解一下吧!
一、网站的根目录是什么
所谓网站的根目录,就是用户网站空间存放程序文件的最低文件夹目录。
一般情况下,网站的根目录文件夹有wwwroot、htdocs、public_html、www等各种名称。
二、如何将文件夹中的文件上传到网站根目录
1)打开并连接FTP工具
2)找到网站所在的根目录,其中网站根目录是一个名为“WEB”的文件夹
3)打开网站的根目录,找到要上传的文件,右键,选择“传输”
4)等待几秒后,文件成功上传到根目录
以上就是谷歌如何收录你的网站,改善你的体重,增加你的网站流量!大家可以使用,独立站尽快收录,会有更好的转化! 查看全部
如何抓取网页数据(如何主动让谷歌收录你的独立站第一种?折扣)
做独立网站的人都应该知道,就像文章或者你自己的博客是百度收录的意思一样,如果你的独立网站不是谷歌收录,那你就大打折扣了谷歌独立网站的权重收录,其实谷歌收录的好处不仅仅是流量的增加,还有客户信任度的增加,会增加转化率。当然好处很多,我就不一一解释了,下面我们分享一下直接google的方法和技巧收录!
你也可以直接谷歌我的名字(HenryDong),谷歌也会有我的信息收录!
一、如何加速谷歌收录独立网站的页面
1)适合谷歌搜索引擎爬取的构建网站
谷歌蜘蛛,在抓取网站时,按照链接进行抓取。因此,我们在布局网页时需要注意网站的交互设计。例如,文章 中有相关的文章。产品中有相关产品。其次,我们需要购买一台稳定的服务器,这样谷歌在抓取网站的时候,网站是打不开的。最后要注意网站的打开速度,速度慢会直接影响谷歌收录的状态。
大家用谷歌图片搜索搜索我的名字,每张图片都是我的文章,所有的文章都会有链接,还有我自己官网的链接还有其他的收录链接
2)构建优质内容
谷歌已经发展了 20 多年,不再缺乏常规内容。我们应该做一些新颖的主题内容来获得谷歌的青睐。国内的大部分网站,之所以不是收录,是因为所有产品的描述基本一致。这种情况是导致收录少的重要原因之一。
3)使用谷歌网站管理员工具
将 网站 添加到 Google 站长工具,以使用站长工具后端的抓取功能。
4)主动提交给谷歌收录(下面我们介绍如何主动提交收录)
二、如何主动获取 Google收录您的独立网站
类型一:域名提交法
这是最简单、最直接的方法。
打开网址:
将您的 URL 添加到 Google 索引中,Google 会在索引中添加一个新的 网站 并在每次抓取网络时更新它。
第二:验证 HTML 文件
如果第一种方式没有收录,可以试试这个。验证 HTML 文件需要一点技术知识,将文件放在 网站 中。
首先登录:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
第一步:登录网站后,点击添加属性,输入网站域名,会弹出验证弹窗进行验证。
第 2 步:选择推荐的方法并下载验证 HTML 文件。
第三步:安装好HTML文件后点击确定,上传后验证。
还有一些替代方法如下:
第三种:HTML标签
如果您使用的是另一个系统,或者没有技术头脑,您可以选择 HTML 标记。这比第二种方法更方便、更简单。
第一步:点击添加属性,输入网站域名,弹出验证弹窗进行验证。
第二步:点击Alternate method,然后选择HTML tag,复制代码。
第三步:登录其他系统后台,然后将刚才复制的代码添加到第三方代码中,并开启元代码,(记住不要先点击验证,必须先复制代码,将代码添加到第三方,然后返回验证)
以上步骤完成后,回到第一步检查是否安装成功。
回到第一步,输入:
:///webmasters/tools/dashboard?hl%3Dzh-CN%26sig%3DALjLGbM42SIgAoHv_pXtJC1WuduIPcy_bw
检查验证是否成功
三、如何将下载的HTML上传到网站根目录
其实很多人对这个操作不是很了解。他们下载了 HTML,但不知道如何上传。其实真正精通全网的人并不多。下面就来详细了解一下吧!
一、网站的根目录是什么
所谓网站的根目录,就是用户网站空间存放程序文件的最低文件夹目录。
一般情况下,网站的根目录文件夹有wwwroot、htdocs、public_html、www等各种名称。
二、如何将文件夹中的文件上传到网站根目录
1)打开并连接FTP工具
2)找到网站所在的根目录,其中网站根目录是一个名为“WEB”的文件夹
3)打开网站的根目录,找到要上传的文件,右键,选择“传输”
4)等待几秒后,文件成功上传到根目录
以上就是谷歌如何收录你的网站,改善你的体重,增加你的网站流量!大家可以使用,独立站尽快收录,会有更好的转化!
如何抓取网页数据(【】爬取解析及使用方法分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 08:07
1. 写在前面
今天要抓取的那个网站叫WeDoctor网站,地址是,我们会通过python3爬虫抓取这个URL,然后把数据存成CSV,为后面的一些分析教程做准备。本文文章主要用到的库是pyppeteer和pyquery
首先找到医生列表页面
全国/全部/无限/p5
该页面显示有75952条数据。实际测试中,当翻到第38页时,无法加载数据。目测后台程序员并没有返回数据,但是为了学习,我们忍了。
2. 页面网址
全国/全部/无限/p1
全国/全部/无限/p2
...
全国/全部/无限/p38
总数据超过38页,量不是很大。我们只需要选择一个库来抓取它。对于这个博客,我发现了一个不受欢迎的库。
在使用pyppeteer的过程中,发现资料很少,非常尴尬。而且官方文档写的不是很好,有兴趣的可以自己看一下。这个库的安装也在下面的 URL 中。
最简单的使用方法也简单写在官方文档中,如下,可以直接将网页保存为图片。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch() # 运行一个无头的浏览器
page = await browser.newPage() # 打开一个选项卡
await page.goto('http://www.baidu.com') # 加载一个页面
await page.screenshot({'path': 'baidu.png'}) # 把网页生成截图
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) # 异步
我在下面整理了一些参考代码,您可以做一些参考。
browser = await launch(headless=False) # 可以打开浏览器
await page.click('#login_user') # 点击一个按钮
await page.type('#login_user', 'admin') # 输入内容
await page.click('#password')
await page.type('#password', '123456')
await page.click('#login-submit')
await page.waitForNavigation()
# 设置浏览器窗口大小
await page.setViewport({
'width': 1350,
'height': 850
})
content = await page.content() # 获取网页内容
cookies = await page.cookies() # 获取网页cookies
3. 抓取页面
运行以下代码,可以看到控制台不断打印网页的源代码。只要得到源代码,就可以进行后续的分析和数据保存。如果出现控件不输出任何东西的情况,那么把下面的
await launch(headless=True) 修改为 await launch(headless=False)
import asyncio
from pyppeteer import launch
class DoctorSpider(object):
async def main(self, num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
print(content)
except Exception as e:
print(e.args)
finally:
num += 1
await browser.close()
await self.main(num)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
4. 解析数据
Pyquery 用于解析数据。该库在之前的博客中使用过,可以直接应用到案例中。结果数据由 pandas 保存到 CSV 文件中。
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
import pandas as pd # 保存csv文件
class DoctorSpider(object):
def __init__(self):
self._data = list()
async def main(self,num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
self.parse_html(content)
print("正在存储数据....")
data = pd.DataFrame(self._data)
data.to_csv("微医数据.csv", encoding='utf_8_sig')
except Exception as e:
print(e.args)
finally:
num+=1
await browser.close()
await self.main(num)
def parse_html(self,content):
doc = pq(content)
items = doc(".g-doctor-item").items()
for item in items:
#doctor_name = item.find(".seo-anchor-text").text()
name_level = item.find(".g-doc-baseinfo>dl>dt").text() # 姓名和级别
department = item.find(".g-doc-baseinfo>dl>dd>p:eq(0)").text() # 科室
address = item.find(".g-doc-baseinfo>dl>dd>p:eq(1)").text() # 医院地址
star = item.find(".star-count em").text() # 评分
inquisition = item.find(".star-count i").text() # 问诊量
expert_team = item.find(".expert-team").text() # 专家团队
service_price_img = item.find(".service-name:eq(0)>.fee").text()
service_price_video = item.find(".service-name:eq(1)>.fee").text()
one_data = {
"name": name_level.split(" ")[0],
"level": name_level.split(" ")[1],
"department": department,
"address": address,
"star": star,
"inquisition": inquisition,
"expert_team": expert_team,
"service_price_img": service_price_img,
"service_price_video": service_price_video
}
self._data.append(one_data)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
综上所述,这个库不是很容易使用。以前可能没有仔细研究过。感觉很正常。你可以多尝试一下,看看是否能提高整体效率。
资料清单:
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接
相关文章 查看全部
如何抓取网页数据(【】爬取解析及使用方法分享)
1. 写在前面
今天要抓取的那个网站叫WeDoctor网站,地址是,我们会通过python3爬虫抓取这个URL,然后把数据存成CSV,为后面的一些分析教程做准备。本文文章主要用到的库是pyppeteer和pyquery
首先找到医生列表页面
全国/全部/无限/p5
该页面显示有75952条数据。实际测试中,当翻到第38页时,无法加载数据。目测后台程序员并没有返回数据,但是为了学习,我们忍了。
2. 页面网址
全国/全部/无限/p1
全国/全部/无限/p2
...
全国/全部/无限/p38
总数据超过38页,量不是很大。我们只需要选择一个库来抓取它。对于这个博客,我发现了一个不受欢迎的库。
在使用pyppeteer的过程中,发现资料很少,非常尴尬。而且官方文档写的不是很好,有兴趣的可以自己看一下。这个库的安装也在下面的 URL 中。
最简单的使用方法也简单写在官方文档中,如下,可以直接将网页保存为图片。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch() # 运行一个无头的浏览器
page = await browser.newPage() # 打开一个选项卡
await page.goto('http://www.baidu.com') # 加载一个页面
await page.screenshot({'path': 'baidu.png'}) # 把网页生成截图
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) # 异步
我在下面整理了一些参考代码,您可以做一些参考。
browser = await launch(headless=False) # 可以打开浏览器
await page.click('#login_user') # 点击一个按钮
await page.type('#login_user', 'admin') # 输入内容
await page.click('#password')
await page.type('#password', '123456')
await page.click('#login-submit')
await page.waitForNavigation()
# 设置浏览器窗口大小
await page.setViewport({
'width': 1350,
'height': 850
})
content = await page.content() # 获取网页内容
cookies = await page.cookies() # 获取网页cookies
3. 抓取页面
运行以下代码,可以看到控制台不断打印网页的源代码。只要得到源代码,就可以进行后续的分析和数据保存。如果出现控件不输出任何东西的情况,那么把下面的
await launch(headless=True) 修改为 await launch(headless=False)
import asyncio
from pyppeteer import launch
class DoctorSpider(object):
async def main(self, num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
print(content)
except Exception as e:
print(e.args)
finally:
num += 1
await browser.close()
await self.main(num)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
4. 解析数据
Pyquery 用于解析数据。该库在之前的博客中使用过,可以直接应用到案例中。结果数据由 pandas 保存到 CSV 文件中。
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
import pandas as pd # 保存csv文件
class DoctorSpider(object):
def __init__(self):
self._data = list()
async def main(self,num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
self.parse_html(content)
print("正在存储数据....")
data = pd.DataFrame(self._data)
data.to_csv("微医数据.csv", encoding='utf_8_sig')
except Exception as e:
print(e.args)
finally:
num+=1
await browser.close()
await self.main(num)
def parse_html(self,content):
doc = pq(content)
items = doc(".g-doctor-item").items()
for item in items:
#doctor_name = item.find(".seo-anchor-text").text()
name_level = item.find(".g-doc-baseinfo>dl>dt").text() # 姓名和级别
department = item.find(".g-doc-baseinfo>dl>dd>p:eq(0)").text() # 科室
address = item.find(".g-doc-baseinfo>dl>dd>p:eq(1)").text() # 医院地址
star = item.find(".star-count em").text() # 评分
inquisition = item.find(".star-count i").text() # 问诊量
expert_team = item.find(".expert-team").text() # 专家团队
service_price_img = item.find(".service-name:eq(0)>.fee").text()
service_price_video = item.find(".service-name:eq(1)>.fee").text()
one_data = {
"name": name_level.split(" ")[0],
"level": name_level.split(" ")[1],
"department": department,
"address": address,
"star": star,
"inquisition": inquisition,
"expert_team": expert_team,
"service_price_img": service_price_img,
"service_price_video": service_price_video
}
self._data.append(one_data)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
综上所述,这个库不是很容易使用。以前可能没有仔细研究过。感觉很正常。你可以多尝试一下,看看是否能提高整体效率。
资料清单:
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。谢谢您的支持。如果您想了解更多信息,请查看下面的相关链接
相关文章
如何抓取网页数据(如何抓取网页数据?-rss阅读器如何实现抓取twitter数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-08 06:06
如何抓取网页数据?-rss阅读器如何抓取网页数据?-高效办公工具如何抓取网页数据?-用户体验
请使用php等高级语言,爬虫的本质也是数据处理嘛。
找一个替代twitter的网站。
php+mysql也能做到,建议调用一些第三方接口,如tsa,geoserver,elk等。
一般都是使用程序抓取的,
爬虫不难吧,比如像贴吧那样,需要你懂java,你懂sql,懂html,懂css,你懂爬虫,会组织好语言和环境搭建爬虫环境。找些免费服务的网站,爬下就可以,上找个卖爬虫的,然后自己学习爬虫一年半载也能爬下来吧。
抓取网页数据的方法很多,最简单的要属抓取等网站的的各种数据了。上面基本上每个商品都能找到。
有可以抓取文本的网站,比如wordpress网站,编辑一个就可以抓取整个网站了,
爬虫难???不知道你是什么意思,不是因为哪个网站数据好得到么,还是啥别的意思,哈哈其实我觉得有道词典的网页分析,就是抓取的太牛x了,那么多词源词根,你得再去搜集整理,
虽然你问的方法我能答上来,但是我还是回答你下,楼上有的数据抓取方法都是真正要用时还没用到。爬虫那么多好处,无非就是速度快。你要分析一下你需要哪些数据。至于专业点的爬虫,要么是语言学的好,要么是那个网站开发者看你是做技术的帮你把数据弄进去。抓取数据的先后顺序你会发现同一个技术人员在抓取网页时有先有后。 查看全部
如何抓取网页数据(如何抓取网页数据?-rss阅读器如何实现抓取twitter数据)
如何抓取网页数据?-rss阅读器如何抓取网页数据?-高效办公工具如何抓取网页数据?-用户体验
请使用php等高级语言,爬虫的本质也是数据处理嘛。
找一个替代twitter的网站。
php+mysql也能做到,建议调用一些第三方接口,如tsa,geoserver,elk等。
一般都是使用程序抓取的,
爬虫不难吧,比如像贴吧那样,需要你懂java,你懂sql,懂html,懂css,你懂爬虫,会组织好语言和环境搭建爬虫环境。找些免费服务的网站,爬下就可以,上找个卖爬虫的,然后自己学习爬虫一年半载也能爬下来吧。
抓取网页数据的方法很多,最简单的要属抓取等网站的的各种数据了。上面基本上每个商品都能找到。
有可以抓取文本的网站,比如wordpress网站,编辑一个就可以抓取整个网站了,
爬虫难???不知道你是什么意思,不是因为哪个网站数据好得到么,还是啥别的意思,哈哈其实我觉得有道词典的网页分析,就是抓取的太牛x了,那么多词源词根,你得再去搜集整理,
虽然你问的方法我能答上来,但是我还是回答你下,楼上有的数据抓取方法都是真正要用时还没用到。爬虫那么多好处,无非就是速度快。你要分析一下你需要哪些数据。至于专业点的爬虫,要么是语言学的好,要么是那个网站开发者看你是做技术的帮你把数据弄进去。抓取数据的先后顺序你会发现同一个技术人员在抓取网页时有先有后。
如何抓取网页数据(一个爬取动态网页的超简单的一个小demo了解多少 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-30 00:25
)
大家好,我是大智
这一次,我将介绍一个超级简单的抓取动态网页的演示。
说起动态网页,你了解多少?
简单的说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,而动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要向服务器发送请求文件的URL地址,而不是网页的URL地址。
好的,让我们进入下面的主题。
一、 分析网页结构
这篇博文将用高德地图进行扩展:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以确定它是一个动态网页。这时候我们需要找到一个接口
点击网络选项卡,可以看到网页向服务器发送了大量请求,数据量很大,查找时间过长
我们点击XHR这个分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。换句话说,从数据库请求然后接收的数据是XHR类型的
然后我们就可以在XHR类型下开始一一搜索了,找到如下数据
通过查看Headers获取URL
打开一看,发现是这两天的天气。
打开后,我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”的键值中。
ok,找到json数据,对比一下,看看是不是我们要找的
通过对比,数据完全对应,这意味着我们得到了数据。
二、获取相关网址
'''
ok,我们拿到了相关的网址,下面是具体的代码实现。至于如何实现,
我们知道可以使用 response.json() 将 json 数据转换为字典,然后可以对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和号码
先抓取网页,冒充浏览器,通过添加header访问数据库地址,防止被识别后被拦截。
url_city = "https://www.amap.com/service/c ... ot%3B
得到我们想要的数据后,通过搜索可以发现cityByLetter中的number和name就是我们需要的,然后就可以记录下来了。
if "data" in content:
3.2 根据序号查询天气
拿到号码和名字后,下面绝对是查天气啦!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它来抓取数据。
url_weather = "https://www.amap.com/service/weather?adcode={}"
好了,我们的愿景已经实现了。
四、完整代码
# encoding: utf-8
五、保存结果
查看全部
如何抓取网页数据(一个爬取动态网页的超简单的一个小demo了解多少
)
大家好,我是大智
这一次,我将介绍一个超级简单的抓取动态网页的演示。
说起动态网页,你了解多少?
简单的说,要获取静态网页的网页数据,只需要将网页的url地址发送到服务器,而动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要向服务器发送请求文件的URL地址,而不是网页的URL地址。
好的,让我们进入下面的主题。
一、 分析网页结构
这篇博文将用高德地图进行扩展:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以确定它是一个动态网页。这时候我们需要找到一个接口
点击网络选项卡,可以看到网页向服务器发送了大量请求,数据量很大,查找时间过长
我们点击XHR这个分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。换句话说,从数据库请求然后接收的数据是XHR类型的
然后我们就可以在XHR类型下开始一一搜索了,找到如下数据
通过查看Headers获取URL
打开一看,发现是这两天的天气。
打开后,我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”的键值中。
ok,找到json数据,对比一下,看看是不是我们要找的
通过对比,数据完全对应,这意味着我们得到了数据。
二、获取相关网址
'''
ok,我们拿到了相关的网址,下面是具体的代码实现。至于如何实现,
我们知道可以使用 response.json() 将 json 数据转换为字典,然后可以对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和号码
先抓取网页,冒充浏览器,通过添加header访问数据库地址,防止被识别后被拦截。
url_city = "https://www.amap.com/service/c ... ot%3B
得到我们想要的数据后,通过搜索可以发现cityByLetter中的number和name就是我们需要的,然后就可以记录下来了。
if "data" in content:
3.2 根据序号查询天气
拿到号码和名字后,下面绝对是查天气啦!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它来抓取数据。
url_weather = "https://www.amap.com/service/weather?adcode={}"
好了,我们的愿景已经实现了。
四、完整代码
# encoding: utf-8
五、保存结果
如何抓取网页数据( 爬虫蜘蛛程序如何让爬虫更快抓取收录页面?原理是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-22 21:10
爬虫蜘蛛程序如何让爬虫更快抓取收录页面?原理是什么?)
什么是蜘蛛程序?如何让爬虫爬得更快收录?原理是什么?
一、什么是爬虫蜘蛛程序?
爬虫程序是指网络爬虫机器人按照设定的规则自动抓取互联网程序。
每个搜索引擎都有自己对应的爬虫蜘蛛程序,通过模拟人工访问网站的形式对网络站点进行评估,并将好的内容存储在索引库中,等待用户搜索相关关键词@ >,发布相关内容,按照相应规则对内容进行排序。
二、 了解什么是蜘蛛程序以及如何让爬虫更快地抓取收录 页面?
1、控制网站打开速度
网站 加载速度直接关系到用户体验。如果爬虫程序长时间无法进入网站,那么即使你的内容很好,也很难得到搜索引擎的青睐。
2、URL 级别的问题
蜘蛛爬虫程序喜欢哪个url?越短越好!通常 URL 应该采用扁平结构,一般不超过 3 级。
3、内容质量
搜索引擎的目的是获取更多优质的互联网内容,呈现给搜索用户。如果爬虫程序发现您的网站充满了重复的低质量内容,那么您很难获得索引机会。更不用说排名了。什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
4、网站地图
爬虫蜘蛛程序进入网站,首先爬取robots文件,判断哪些文件需要访问,哪些不需要,并通过网站映射,第一时间找到对应的页面。网站地图减少了爬取蜘蛛程序的时间,减轻了蜘蛛的压力,这对网站来说也是很重要的。
三、什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
各大搜索引擎都会发出大量的爬虫程序,对分散在互联网上的各种信息进行审查和评估,并建立索引数据库。
爬虫程序可以通过以下方式发现网页信息:
1、通过站长平台提交网页
2、通过外部链接(包括友情链接)访问和发现网站
3、搜索用户访问你的网站,浏览器中会有相应的缓存,爬虫蜘蛛程序可以通过缓存的数据抓取网页的内容。 查看全部
如何抓取网页数据(
爬虫蜘蛛程序如何让爬虫更快抓取收录页面?原理是什么?)
什么是蜘蛛程序?如何让爬虫爬得更快收录?原理是什么?
一、什么是爬虫蜘蛛程序?
爬虫程序是指网络爬虫机器人按照设定的规则自动抓取互联网程序。
每个搜索引擎都有自己对应的爬虫蜘蛛程序,通过模拟人工访问网站的形式对网络站点进行评估,并将好的内容存储在索引库中,等待用户搜索相关关键词@ >,发布相关内容,按照相应规则对内容进行排序。
二、 了解什么是蜘蛛程序以及如何让爬虫更快地抓取收录 页面?
1、控制网站打开速度
网站 加载速度直接关系到用户体验。如果爬虫程序长时间无法进入网站,那么即使你的内容很好,也很难得到搜索引擎的青睐。
2、URL 级别的问题
蜘蛛爬虫程序喜欢哪个url?越短越好!通常 URL 应该采用扁平结构,一般不超过 3 级。
3、内容质量
搜索引擎的目的是获取更多优质的互联网内容,呈现给搜索用户。如果爬虫程序发现您的网站充满了重复的低质量内容,那么您很难获得索引机会。更不用说排名了。什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
4、网站地图
爬虫蜘蛛程序进入网站,首先爬取robots文件,判断哪些文件需要访问,哪些不需要,并通过网站映射,第一时间找到对应的页面。网站地图减少了爬取蜘蛛程序的时间,减轻了蜘蛛的压力,这对网站来说也是很重要的。
三、什么是蜘蛛程序?如何让爬虫爬取收录?原理是什么?
各大搜索引擎都会发出大量的爬虫程序,对分散在互联网上的各种信息进行审查和评估,并建立索引数据库。
爬虫程序可以通过以下方式发现网页信息:
1、通过站长平台提交网页
2、通过外部链接(包括友情链接)访问和发现网站
3、搜索用户访问你的网站,浏览器中会有相应的缓存,爬虫蜘蛛程序可以通过缓存的数据抓取网页的内容。
如何抓取网页数据(如何抓取网页数据:js动态实现,你的网站就是一个数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-22 08:03
如何抓取网页数据:js动态实现,你的网站就是一个数据库。(百度wap的网页可以基于js写出一个“爬虫”工具)可以抓取手机百度页面:小众网站:手机上网_手机上网站,一搜一大把。(百度提供了很多小众网站的页面,通过关键字“baidu/douban”可以抓取)这些小众网站可以通过本地搜索网站抓取:百度地图:baidumapsbaidu地图wap版:。
方法不止一种,这个回答如果有帮助就点个赞呗~以下是几种基本方法:爬虫——搜索引擎,从链接上获取数据代替操作人的脑袋,能最大的减少想想。一抓数据——计算机程序,从网页上获取数据调用浏览器的api接口做爬虫,不是很了解,不知道到底能不能爬很多页面,但是能抓搜索引擎页面是没问题的。生成网页——最简单的,把网页转换为html内容。
favicontag.create()自己开发个模拟器。打包下载到本地,抓数据。.asjs脚本。使用google搜索引擎搜,把结果抓回来,打包下载。专门用来搜搜索引擎。另外,搜了一下,还有不少和楼主类似的方法,做数据收集的同学们可以看看~一个文件夹~分析和提取数据1.什么是爬虫?利用scrapy等工具快速通过http协议抓取网页上爬取到的结果。
2.爬虫有哪些常见的模式?a.代理池模式利用agent(浏览器)代理,通过agent为跳转target,为网页提供代理,进行爬取。b.url网址模式利用ajax协议,跳转target等方式快速抓取到想要的页面。c.cookie模式d.cookie信息爬取3.爬虫的thread、middleware的基本构成在模拟器或开发环境下,捕获服务器响应和数据的上传逻辑。
threadname(scrapy框架中的函数middlewareid)middlewares(每个队列的代码名称)middlewarenode(代理数目)4.一个thread和一个middlewares应该如何构成呢?client(scrapy框架中用户自定义的thread,middleware)client.open(schemaname="middlewares")client.send()client.request()client.read()二规划系统架构1.组网方式介绍及基本程序2.分析程序3.总结~三各模块的设计思路1.爬虫的定义scrapy爬虫框架的定义2.java代码总结a.基本功能a.xpath提取//*[@id="last_url"]b.xpath优化a.提取最新内容b.大段文字提取3.爬虫的规划中间件4.爬虫的定位中间件定位:代理池、ajax、页面定位、api5.开发环境c.爬虫编写1.url提取//*[@id="last_url"]/[2]/text()2.xpath数据提取a.xpath定位///*[@id="last_url"]/[1。 查看全部
如何抓取网页数据(如何抓取网页数据:js动态实现,你的网站就是一个数据库)
如何抓取网页数据:js动态实现,你的网站就是一个数据库。(百度wap的网页可以基于js写出一个“爬虫”工具)可以抓取手机百度页面:小众网站:手机上网_手机上网站,一搜一大把。(百度提供了很多小众网站的页面,通过关键字“baidu/douban”可以抓取)这些小众网站可以通过本地搜索网站抓取:百度地图:baidumapsbaidu地图wap版:。
方法不止一种,这个回答如果有帮助就点个赞呗~以下是几种基本方法:爬虫——搜索引擎,从链接上获取数据代替操作人的脑袋,能最大的减少想想。一抓数据——计算机程序,从网页上获取数据调用浏览器的api接口做爬虫,不是很了解,不知道到底能不能爬很多页面,但是能抓搜索引擎页面是没问题的。生成网页——最简单的,把网页转换为html内容。
favicontag.create()自己开发个模拟器。打包下载到本地,抓数据。.asjs脚本。使用google搜索引擎搜,把结果抓回来,打包下载。专门用来搜搜索引擎。另外,搜了一下,还有不少和楼主类似的方法,做数据收集的同学们可以看看~一个文件夹~分析和提取数据1.什么是爬虫?利用scrapy等工具快速通过http协议抓取网页上爬取到的结果。
2.爬虫有哪些常见的模式?a.代理池模式利用agent(浏览器)代理,通过agent为跳转target,为网页提供代理,进行爬取。b.url网址模式利用ajax协议,跳转target等方式快速抓取到想要的页面。c.cookie模式d.cookie信息爬取3.爬虫的thread、middleware的基本构成在模拟器或开发环境下,捕获服务器响应和数据的上传逻辑。
threadname(scrapy框架中的函数middlewareid)middlewares(每个队列的代码名称)middlewarenode(代理数目)4.一个thread和一个middlewares应该如何构成呢?client(scrapy框架中用户自定义的thread,middleware)client.open(schemaname="middlewares")client.send()client.request()client.read()二规划系统架构1.组网方式介绍及基本程序2.分析程序3.总结~三各模块的设计思路1.爬虫的定义scrapy爬虫框架的定义2.java代码总结a.基本功能a.xpath提取//*[@id="last_url"]b.xpath优化a.提取最新内容b.大段文字提取3.爬虫的规划中间件4.爬虫的定位中间件定位:代理池、ajax、页面定位、api5.开发环境c.爬虫编写1.url提取//*[@id="last_url"]/[2]/text()2.xpath数据提取a.xpath定位///*[@id="last_url"]/[1。
如何抓取网页数据( 前端工程师如何进行网页爬虫?如何做好网页解析?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-08 20:18
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有应用爬虫进入自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般针对特定的网站或App,通过爬虫脚本或程序在指定页面上进行数据采集。意思是通过编程向Web服务器请求数据(HTML表单),然后解析HTML,提取出你想要的数据。
一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先
按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页是通过hmtl等源代码展示出来的,大家看到的加载渲染出来的,就像你穿着衣服和化妆一样(手动滑稽)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,可以直接在这里定位源码,如下图:
我们可以修改源码看看,把定位到的源码【python】改成【我是帅哥】,嘿嘿,网页上会出现不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。
有点跑题了,回归正题,网页已经解析完毕,你要爬取的元素的内容就可以定位了。下一步就是打包编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页
可以点击网络按钮查看我们在浏览器搜索输入框关键词中输入的内容:python。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务器发送get请求,服务器解析内容。, 经过TCP的三次握手,四次挥手,网络安全,加密等,最后安全的将内容返回给你本地的客户端,你是不是觉得你的头开始有点大了,这样我们就可以开心了网上冲浪,工程师真的不容易~~
了解这些内容有助于我们了解爬虫机制。简单来说,它是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。我们在进行http请求时,除了提交一些参数外,还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成正式的请求获取情报内容.
爬虫有点像间谍。它闯入那个地方,采集我们想要的信息。这里不知道怎么强,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。 查看全部
如何抓取网页数据(
前端工程师如何进行网页爬虫?如何做好网页解析?)
如何采集网站数据(如何快速抓取网页数据)
无论是数据分析、数据建模甚至数据挖掘,我们都必须在执行这些高级任务之前进行数据处理。数据是数据工作的基础。没有数据,挖掘毫无意义。俗话说,巧妇难为无米之炊,接下来说说爬虫。
爬虫是采集外部数据的重要途径。常用于竞争分析,也有应用爬虫进入自己的业务。例如,搜索引擎是最高的爬虫应用程序。当然,爬虫也不能肆无忌惮。如果他们不小心,他们可能会成为面向监狱的编程。
一、什么是爬虫?
爬虫爬取一般针对特定的网站或App,通过爬虫脚本或程序在指定页面上进行数据采集。意思是通过编程向Web服务器请求数据(HTML表单),然后解析HTML,提取出你想要的数据。
一般来说,爬虫需要掌握一门编程语言。了解HTML、Web服务器、数据库等,建议从python入手快速上手,有很多第三方库可以快速轻松的抓取网页。
二、如何抓取网页
1、 网页分析先
按F12调出网页调试界面,在Element标签下可以看到对应的HTML代码,这些其实就是网页的代码,网页是通过hmtl等源代码展示出来的,大家看到的加载渲染出来的,就像你穿着衣服和化妆一样(手动滑稽)。
我们可以定位网页元素。左上角有个小按钮,点击它,在网页上找到你要定位的地方,可以直接在这里定位源码,如下图:
我们可以修改源码看看,把定位到的源码【python】改成【我是帅哥】,嘿嘿,网页上会出现不同的变化。以上主要是为了科普。这主要是前端工程师的领域。大家看到的地方都是前端的辛苦,后端工程师都在冰山之下。
有点跑题了,回归正题,网页已经解析完毕,你要爬取的元素的内容就可以定位了。下一步就是打包编写爬虫脚本。基本网页上能看到的一切都可以爬取,所见即所得。
2、程序如何访问网页
可以点击网络按钮查看我们在浏览器搜索输入框关键词中输入的内容:python。所涉及的专业内容可能过于复杂。你可能会觉得我输入了一个关键词,网页返回了很多内容。其实就是本地客户端向服务器发送get请求,服务器解析内容。, 经过TCP的三次握手,四次挥手,网络安全,加密等,最后安全的将内容返回给你本地的客户端,你是不是觉得你的头开始有点大了,这样我们就可以开心了网上冲浪,工程师真的不容易~~
了解这些内容有助于我们了解爬虫机制。简单来说,它是一个模拟人登录网页、请求访问、查找返回的网页内容并下载数据的程序。刚才讲了网页网络的内容。常见的请求包括 get 和 post。GET 请求在 URL 上公开请求参数,而 POST 请求参数放在请求正文中。POST 请求方法还会对密码参数进行加密。,所以相对来说比较安全。
程序应该模拟请求头(Request Header)进行访问。我们在进行http请求时,除了提交一些参数外,还定义了一些请求头信息,比如Accept、Host、cookie、User-Agent等,主要是将爬虫程序伪装成正式的请求获取情报内容.
爬虫有点像间谍。它闯入那个地方,采集我们想要的信息。这里不知道怎么强,skr~~~
3、接收请求返回的信息
r = requests.get('https://httpbin.org/get')
r.status_code
//返回200r.headers
{
'content-encoding': 'gzip',
'transfer-encoding': 'chunked',
'connection': 'close',
'server': 'nginx/1.0.4',
'x-runtime': '148ms',
'etag': '"e1ca502697e5c9317743dc078f67693f"',
'content-type': 'application/json'
}import requests
r = requests.get('https://api.github.com/events')
r.json()
// 以上操作可以算是最基本的爬虫了,返回内容如下:
[{u'repository': {u'open_issues': 0, u'url': 'https://github.com/...
可以通过解析返回的json字符串得到你想要的数据,恭喜~
三、python自动化爬虫实战
接下来,我们来看看豆瓣电影排行榜的爬虫:
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""
Created on Wed Jul 31 15:52:53 2019
@author: kaluosi
"""import requestsimport reimport codecsfrom bs4 import BeautifulSoupfrom openpyxl import Workbookimport pandas as pd
wb = Workbook()
dest_filename = '电影.xlsx'ws1 = wb.active
ws1.title = "电影top250"DOWNLOAD_URL = 'http://movie.douban.com/top250/'def download_page(url):
"""获取url地址页面内容"""
headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data = requests.get(url, headers=headers).content return datadef get_li(doc):
soup = BeautifulSoup(doc, 'html.parser')
ol = soup.find('ol', class_='grid_view')
name = [] # 名字
star_con = [] # 评价人数
score = [] # 评分
info_list = [] # 短评
for i in ol.find_all('li'):
detail = i.find('div', attrs={'class': 'hd'})
movie_name = detail.find('span', attrs={'class': 'title'}).get_text() # 电影名字
level_star = i.find('span', attrs={'class': 'rating_num'}).get_text() # 评分
star = i.find('div', attrs={'class': 'star'})
star_num = star.find(text=re.compile('评价')) # 评价
info = i.find('span', attrs={'class': 'inq'}) # 短评
if info: # 判断是否有短评
info_list.append(info.get_text()) else:
info_list.append('无')
score.append(level_star)
name.append(movie_name)
star_con.append(star_num)
page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页
if page: return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] return name, star_con, score, info_list, Nonedef main():
url = DOWNLOAD_URL
name = []
star_con = []
score = []
info = [] while url:
doc = download_page(url)
movie, star, level_num, info_list, url = get_li(doc)
name = name + movie
star_con = star_con + star
score = score + level_num
info = info + info_list #pandas处理数据
c = {'电影名称':name , '评论人数':star_con , '电影评分':score , '评论':info}
data = pd.DataFrame(c)
data.to_excel('豆瓣影评.xlsx')if __name__ == '__main__':
main()
写在最后
最后,这次文章的爬虫仅限于交流和学习。
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-12-08 20:15
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈 查看全部
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只是程序开发时间,不包括数据抓取时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的就是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实现,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同。
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。懒得在代码中学习第三方工具的可以自己写代码;
该方法是通过循环生成数据页面的URL地址,如: 这样通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url){
字符串_StrResponse =“”;
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;. NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post向后台代码提交分页信息,比如.net下Gridview自带的分页功能,点击页面时分页号的时候,你会发现url地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你将鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码的规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这类页面,需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是.net独有的,也是.net开发者又爱又恨的东西。当你打开一个网站的页面时,如果你发现这个东西,并且后面有很多乱七八糟的字符,那么这个网站一定要写;
二、__dopostback方法,这是一个自动生成页面的javascript方法,包括两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以引用页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,必须循环拼凑_dopostback的两个参数,只需要拼凑收录页码信息的参数即可。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后循环处理下一页,然后每抓取一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用
参考代码如下:
for (int i = 0; i <1000; i++){
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里有需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1); //获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//将你关心的内容保存到数据库中
}catch(异常前){
Console.WriteLine(ex.Message);
}
}
第三种方法:第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。后来采用了更狠的方法,用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟手动点击翻页链接,并用代码逐页翻页。然后逐页抓取。
所谓门外汉看热闹,高手看门道,可能很多人看到这里就说可以通过Webbrowser的控制来实现,是的,我下面的方式就是利用WebBrowser的控制来实现实现,其实在.net下应该也有这种类似的类,不过我没研究过,希望有人有其他方法可以回复我,分享给大家。
WebBroser控件在自己的程序中嵌入了浏览器,就像IE、Firefox等一样,你也可以用它来开发自己的浏览器。至于用它开发的浏览器的效果,我觉得肯定不如IE和Firefox。哈哈
我们还是八卦一下,切入主题:
基本上,你可以使用WebBroser控件来实现IE中任何操作网页的功能,当然点击翻页按钮也是可以的。既然您可以手动点击WebBroser中的翻页按钮,自然我们也可以使用程序代码来指示WebBroser自动为我们翻页。
其实原理很简单,主要分为以下几个步骤:
第一步,打开你要爬取的页面,比如:
调用webBrowser控件Navigate("")的方法;
此时,您应该在您的WebBrowser 控件中看到您的网页信息,这与在IE 中看到的相同;
第二步,WebBrowser控件的这个事件DocumentCompleted很重要。当您访问的所有页面都加载完毕时,将触发此事件。所以分析页面元素的过程也需要在这个事件中完成
字符串 _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这段代码可以获取当前打开页面的html元素的内容。
既然已经获取到了当前打开页面的html元素的内容,接下来的工作自然就是解析这个大字符串,得到自己关心的内容,以及解析字符串的过程。你应该可以自己写。
第三步,重点在这第三步,因为要翻页,按照第二步,解析字符串后,或者在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码id").InvokeMember("点击");
从代码的方法名大家应该就可以理解了,那么调用这个方法后,WebBrwoser控件中的网页就实现了翻页,和手动点击翻页按钮的效果是一样的。
重点是翻页后会触发DocumentCompleted事件,所以第二步和第三步都在循环中,所以大家需要注意跳出循环的时机。
它实用的WebBrowser还可以做很多事情,比如自动登录、退出论坛、保存会话、cockie,所以这个控件基本上可以实现你想要在网页上的任何操作,即使你想破解一个网站@ > 以营利为目的登录密码,当然不推荐这个。哈哈
如何抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-08 20:13
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有了一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
安装,使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl,然后重新安装scrapy后,安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
import scrapy
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。 查看全部
如何抓取网页数据(有关,文章内容质量较高,小编分享给大家做个参考)
本文文章将详细讲解如何使用Scrapy抓取网页。 文章的内容质量很高,分享给大家作为参考。希望你看完这篇文章之后,对相关知识有了一定的了解。
Scrapy 是一种快速先进的网络爬虫和网络抓取框架,用于爬取 网站 并从其页面中提取结构化数据。它可用于多种用途,从数据挖掘到监控和自动化测试。
老规矩,使用前使用pip install scrapy安装。如果在安装过程中遇到错误,通常是错误:Microsoft Visual C++ 14.0 is required。你只需要访问~gohlke/pythonlibs/#twisted 网站下载Twisted-19.2.1-cp37-cp37m-win_amd64并安装,注意cp37代表我的版本原生 python3.7 amd64 代表我的操作系统位数。
安装,使用pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl,然后重新安装scrapy后,安装成功;安装成功后我们就可以使用scrapy命令创建爬虫项目了。
接下来,在我的桌面上运行cmd命令并使用scrapystartprojectwebtutorial创建项目:
桌面会生成一个webtutorial文件夹,我们看一下目录结构:
然后我们在spiders文件夹下新建一个quotes_spider.py,写一个爬虫爬取网站保存为html文件。 网站的截图如下:
代码如下:
import scrapy
#定义爬虫类class QuotesSpider(scrapy.Spider): #指定爬虫名字 一会要用到 name = "quotes" #开始请求方法 def start_requests(self): urls = [ 'http://quotes.toscrape.com/page/1/', 'http://quotes.toscrape.com/page/2/'] for url in urls: yield scrapy.Request(url=url, callback=self.parse)#解析写入返回内容到html中 def parse(self, response): page = response.url.split("/")[-2] filename = 'quotes-%s.html' % page with open(filename, 'wb') as f: f.write(response.body) self.log('Saved file %s' % filename)
以下目录结构为:
然后我们在命令行切换到webtutorial文件夹,执行命令scrapycrawlquotes进行爬取(quotes是刚刚指定的爬虫名):
发现错误,没有名为'win32api'的模块,这里我们安装win32api
使用命令pip install pypiwin32,然后继续执行scrapy crawl引用:
可以看到爬虫任务执行成功。这时候webtutorial文件夹下会生成两个html:
关于如何使用Scrapy抓取网页,我在这里分享。希望以上内容能对您有所帮助,让您了解更多。如果你觉得文章不错,可以分享给更多人看。
如何抓取网页数据(想象的我正在尝试创建一个数据抓取器来自动从表中读取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-07 21:14
想像力
我正在尝试创建一个数据采集器来自动从表中读取数据。但是,我需要登录才能这样做。
该网页有用户名和密码的输入字段以及这样的验证码
到目前为止,这是我的代码
import requests
s = requests.Session()
data = {'loginName': 'username',
'password': 'password',
}
url = 'https://url/api/account/login'
response = s.post(url, data=data)
print(response)
s = requests.Session()
然后我打算使用BeatuifulSoup 如下图
现在我的回答是。我想我需要在数据中收录验证码和验证码,但我不确定如何。我不知道我是否需要添加任何标题。
空指针
完成验证码需要使用一些第三方服务来完成这个操作,或者使用Selenium之类的东西自己填写。一种选择是尝试登录该页面并使用您的浏览器工具查看该页面是否从公共 API 获取信息,如果是,您可以改为获取该信息。 查看全部
如何抓取网页数据(想象的我正在尝试创建一个数据抓取器来自动从表中读取数据)
想像力
我正在尝试创建一个数据采集器来自动从表中读取数据。但是,我需要登录才能这样做。
该网页有用户名和密码的输入字段以及这样的验证码
到目前为止,这是我的代码
import requests
s = requests.Session()
data = {'loginName': 'username',
'password': 'password',
}
url = 'https://url/api/account/login'
response = s.post(url, data=data)
print(response)
s = requests.Session()
然后我打算使用BeatuifulSoup 如下图
现在我的回答是。我想我需要在数据中收录验证码和验证码,但我不确定如何。我不知道我是否需要添加任何标题。
空指针
完成验证码需要使用一些第三方服务来完成这个操作,或者使用Selenium之类的东西自己填写。一种选择是尝试登录该页面并使用您的浏览器工具查看该页面是否从公共 API 获取信息,如果是,您可以改为获取该信息。
如何抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-12-04 03:32
)
以下是在Microsoft Visual Basic 6.0中文版下完成的
VB可以抓取网页数据,使用的控件是Inet控件。
第一步:点击Project-->Parts选择Microsoft Internet Transfer Control(SP6)control.
步骤二:布局界面展示
在界面中拖动相应控件。
第三步,编码开始
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
可以从网页数据中获取数据。
查看全部
如何抓取网页数据(MicrosoftVisualBasic6.0中文版下做的VB可以抓取网页数据
)
以下是在Microsoft Visual Basic 6.0中文版下完成的
VB可以抓取网页数据,使用的控件是Inet控件。
第一步:点击Project-->Parts选择Microsoft Internet Transfer Control(SP6)control.
步骤二:布局界面展示
在界面中拖动相应控件。
第三步,编码开始
Option Explicit
Private Sub Command1_Click()
If Text1.Text = "" Then
MsgBox "请输入要查看源代码的URL!", vbOKOnly, "错误!"
Else
MsgBox "网站服务器较慢或页面内容较多时,请等待!", vbOKOnly, "提示:"
Inet1.Protocol = icHTTP
' MsgBox (Inet1.OpenURL(Text1.Text))
Text2.Text = Inet1.OpenURL(Text1.Text)
End If
End Sub
Private Sub Command2_Click()
On Error GoTo connerror
Dim a, b, c As String
a = Text2.Text
b = Split(a, "")(1)
b = Split(b, "")(0)
Text3.Text = b
c = Split(a, Label4.Caption)(1)
c = Split(c, "/>")(0)
Text4.Text = c
connerror:
End Sub
Private Sub Form_Load()
MsgBox "请首先输入URL,然后点击查看源码,最后再点击获取信息!", vbOKOnly, "提示:"
End Sub
第 4 步:测试
输入网址:
可以从网页数据中获取数据。
如何抓取网页数据(如何用Python爬数据?(第三弹)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-26 03:16
阿里云>云栖社区>主题图>R>如何抢Web表数据库
推荐活动:
更多优惠>
当前主题:如何抓取 Web 表单数据库并将其添加到采集夹
相关话题:
如何抓取与 Web 表单、数据库等相关的博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》-2.2 三种网络爬虫方法
作者:异步社区 3748人 浏览评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934道javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
如何抓取网页数据(如何用Python爬数据?(第三弹)(组图))
阿里云>云栖社区>主题图>R>如何抢Web表数据库
推荐活动:
更多优惠>
当前主题:如何抓取 Web 表单数据库并将其添加到采集夹
相关话题:
如何抓取与 Web 表单、数据库等相关的博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的消息。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:python进阶387人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
教你用Python抓取QQ音乐数据(第三弹)
作者:pythonAdvanced 397人浏览评论:01年前
【一、项目目标】通过教大家如何使用Python抓取QQ音乐数据(第一枪),我们实现了指定页数歌曲的歌名、专辑名、播放链接指定歌手的单曲排名。通过教大家如何使用Python抓取QQ音乐数据(二次播放),我们实现了获取音乐指定歌曲的歌词和指令的能力。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种在线数据科学课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂1408人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
云计算时代企业该如何拥抱大数据?
作者:云栖大讲堂969人浏览评论:04年前
这篇文章谈的是云计算时代的企业应该如何拥抱大数据。随着云计算的实施,“大数据”成为业界讨论最广泛的关键词之一,很多公司已经在寻找合适的BI工具。处理从不同来源采集到的大数据,但虽然大家对大数据的认识在不断提高,但只有谷歌、Facebook等少数公司能够做到
阅读全文
使用 Scrapy 抓取数据
作者:雨客6542人浏览评论:05年前
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站和从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。官方主页:中文文档:Scrap
阅读全文
《用Python编写网络爬虫》-2.2 三种网络爬虫方法
作者:异步社区 3748人 浏览评论:04年前
本节摘自异步社区《Writing Web Crawlers in Python》一书第2章2.2,作者[澳大利亚]理查德劳森(Richard Lawson),李斌译,更多章节内容可在云栖社区“异步社区”公众号查看。2.2 三种网页爬取方法 现在我们已经了解了网页的结构,接下来
阅读全文
如何抓取网页表单数据库相关问答
【Javascript学习全家桶】934道javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:或许你选择为一个问题夜战,或许你迷茫只是寻求答案,或许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来云栖为您解答技术问题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
如何抓取网页数据(如何抓取网页数据?有个chrome插件帮你解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-24 03:01
如何抓取网页数据,
现在大多数网站都是抓包获取,erlang用得比较多。
抓包本身并不高效,这个至少1年前我就开始这么想。如果你是很关心高效可以用二进制编码转化一下。具体方法很多,用二进制格式不同,只是你不需要自己编译就可以拿来用了。不过有些编译时间不短。还是关心高效的话可以用io.js或者前端提供基础的server端api比如chrome,pc端safari等等都很棒,网站的iis也可以自己写个。提供api的话抓包进来你在js做编程。
intellijidea有个chrome插件叫anypage,可以抓包,
threadlocal,就是这货(逃
rstoproutingframethreadlocal
可以用uri里面urltoindex(is),不过前提是路由你需要了解,否则你会更迷茫。
web没有端,纯server只能解析后端,那么你就只能有后端如何知道你爬虫要爬那页,可以从一些参数上下手,比如数据库id怎么知道。
http参数转换http拼接
有可能有人已经在这样做了,他只是没有分享出来。而且我就喜欢那样干一些傻逼的事情,毕竟ie浏览器,还有rxjava和scala都支持。
可以看看github,有些erlang客户端也带数据抓取功能。 查看全部
如何抓取网页数据(如何抓取网页数据?有个chrome插件帮你解决)
如何抓取网页数据,
现在大多数网站都是抓包获取,erlang用得比较多。
抓包本身并不高效,这个至少1年前我就开始这么想。如果你是很关心高效可以用二进制编码转化一下。具体方法很多,用二进制格式不同,只是你不需要自己编译就可以拿来用了。不过有些编译时间不短。还是关心高效的话可以用io.js或者前端提供基础的server端api比如chrome,pc端safari等等都很棒,网站的iis也可以自己写个。提供api的话抓包进来你在js做编程。
intellijidea有个chrome插件叫anypage,可以抓包,
threadlocal,就是这货(逃
rstoproutingframethreadlocal
可以用uri里面urltoindex(is),不过前提是路由你需要了解,否则你会更迷茫。
web没有端,纯server只能解析后端,那么你就只能有后端如何知道你爬虫要爬那页,可以从一些参数上下手,比如数据库id怎么知道。
http参数转换http拼接
有可能有人已经在这样做了,他只是没有分享出来。而且我就喜欢那样干一些傻逼的事情,毕竟ie浏览器,还有rxjava和scala都支持。
可以看看github,有些erlang客户端也带数据抓取功能。
如何抓取网页数据(数据就是新石油互联网上海量的加密货币数据感兴趣系列)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-18 22:13
网页抓取是一项重要的技能。
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这个系列文章中,我们将从这个概念开始,慢慢地构建它。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
保持控制和专注:我更加专注和控制,因为我知道我使用电子表格构建的列表和分析是我投资目的的主要工作版本。我不需要依赖其他人的数据。从一个站点跳到另一个站点也会分散我的注意力并阻止我专注于我的主要任务。
填补空白:并非所有替代货币都可以在主 网站 上使用。货币清单总是存在差距和不一致的地方。当我们拥有自己的数据时,我们就可以对其进行管理。
高级分析:通过电子表格中的数据,可以进行高级分析和过滤,找到网站无法提供的小众币。
个人笔记和评论:您可以在自己的电子表格中添加列,以获得更多评论和投资见解。我还添加了我将使用的地方以及我将分配给货币的资金量。
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
BeautifulSoup 是一个 Python 库,用于从 HTML、XML 和其他标记语言中获取数据。
请求,用于从网站获取HTML数据。如果 HTML 文件中已有数据,则无需请求库。
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
在 div 类 sc-2qtjgt-0 eApVPN 下
使用 h2 作为标题
字幕使用h3
剩下的在p下
从 bs4 导入 BeautifulSoup
导入请求#检索网页并解析内容
mainpage = requests.get('#39;)
汤 = BeautifulSoup(mainpage.content,'html.parser')
whatis = soup.find_all("div", {"class": "sc-2qtjgt-0 eApVPN"})#从内容中提取元素
title = whatis[0].find_all("h2")
打印(标题[0].text.strip()+“\n”)
对于 whatis[0].find_all('p') 中的 p:
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在这个例子中,我们将使用BNB的统计数据,即市值、完全摊薄市值、交易量(24小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字在不断变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class": "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class": "statsValue"})statsValue_marketcap = statsValues[ 0] .text.strip()
打印(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
打印(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
打印(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
打印(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
Scrapy 是一个完整的网页抓取框架,负责从获取 HTML 到处理数据的所有内容。
Selenium 是一个浏览器自动化工具,例如,它允许用户在多个页面之间导航。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源:
关于
ChinaDeFi-是一个研究驱动的DeFi创新组织,我们也是一个区块链开发团队。每天,我们从全球500多个优质信息源的近900条内容中,寻找更深入、更系统的内容,同步到中国市场,以最快的速度提供决策辅助。 查看全部
如何抓取网页数据(数据就是新石油互联网上海量的加密货币数据感兴趣系列)
网页抓取是一项重要的技能。
数据是新的石油
互联网上的加密货币数据量是进一步研究加密货币投资的丰富资源。拥有管理和利用这些数据的能力将使我们在加密投资方面具有优势。
网络爬虫是指从 网站 下载数据并从这些数据中提取有价值信息的过程(因此得名爬虫)。出于我们的目的,我们对加密货币数据的网络爬行感兴趣。
在这个系列文章中,我们将从这个概念开始,慢慢地构建它。最后,网络爬取加密货币数据应该成为你的第二天性!
网页抓取是一项重要的技能。通过采集和分析来自多个来源的数据,我们可以改进我们的投资情报。
为什么要爬网?
既然有这么多网站 提供免费工具,为什么还有人要采集你自己的数据?大多数用户会使用网站,例如CoinMarketCap、CoinGecko、Live Coin Watch 来获取他们的数据并建立他们的观察名单。那不是更方便吗?
在我看来,从新手(使用典型加密网站的标准功能)到我们自己的数据分析(网络爬虫和构建我们自己的智能数据),我们都应该使用两者。
根据我的经验,发现了以下好处:
保持控制和专注:我更加专注和控制,因为我知道我使用电子表格构建的列表和分析是我投资目的的主要工作版本。我不需要依赖其他人的数据。从一个站点跳到另一个站点也会分散我的注意力并阻止我专注于我的主要任务。
填补空白:并非所有替代货币都可以在主 网站 上使用。货币清单总是存在差距和不一致的地方。当我们拥有自己的数据时,我们就可以对其进行管理。
高级分析:通过电子表格中的数据,可以进行高级分析和过滤,找到网站无法提供的小众币。
个人笔记和评论:您可以在自己的电子表格中添加列,以获得更多评论和投资见解。我还添加了我将使用的地方以及我将分配给货币的资金量。
例如,当我们在电子表格中有数据时,我们可以在 Solana 和游戏中搜索硬币:
使用收录这两个标签的 Solana 和 Game 过滤我们的数据
符合此标准的硬币有两种:ATLAS 和 POLIS。我们从网络抓取的数据集还将收录更多关于投资研究的附加信息(市场价值、网站、Twitter 链接等)
寻找同时适用于 polkadot 和游戏的硬币怎么样:
四种硬币在 Polkadot 和 Gaming 中:EFI、SAITO、RING、CHI
为了比较,大多数网站只支持一级过滤。例如,CoinMarketCap 可以列出 Polkadot 生态系统中的所有硬币:
CoinMarketCap 还可以列出所有游戏代币,但不能同时列出 Polkadot 和游戏。
一般来说,这些网站不能超过两三个级别的过滤,比如列出所有与Polkadot相关的游戏币。
从表面上看,高级过滤似乎不是什么大问题,但市场上有成千上万的硬币,拥有这种自动化和保持专注的能力是成功的关键。
概念
我们将在 Python 中使用两个库:
BeautifulSoup 是一个 Python 库,用于从 HTML、XML 和其他标记语言中获取数据。
请求,用于从网站获取HTML数据。如果 HTML 文件中已有数据,则无需请求库。
我也是使用 Jupyter Notebook 在 Google Cloud Platform 上运行的,但是下面的 Python 代码可以在任何平台上运行。
根据各自的 Python 设置,可能需要 pip install beautifulsoup4。
实例学习:网页抓取的“Hello World”
我们将从网络上爬取的“Hello World”开始,抓取币安币(BNB)的介绍文字,如下图绿框所示。
使用 Chrome 浏览器访问 BNB 页面,然后右键单击该页面,然后单击检查以检查元素:
单击屏幕中间的小箭头,然后单击相应的网页元素,如下图所示。
通过检查,我们看到网页元素是
在 div 类 sc-2qtjgt-0 eApVPN 下
使用 h2 作为标题
字幕使用h3
剩下的在p下
从 bs4 导入 BeautifulSoup
导入请求#检索网页并解析内容
mainpage = requests.get('#39;)
汤 = BeautifulSoup(mainpage.content,'html.parser')
whatis = soup.find_all("div", {"class": "sc-2qtjgt-0 eApVPN"})#从内容中提取元素
title = whatis[0].find_all("h2")
打印(标题[0].text.strip()+“\n”)
对于 whatis[0].find_all('p') 中的 p:
打印(p.text.strip()+“\n”)
示例2:网络爬取币种统计
在这个例子中,我们将使用BNB的统计数据,即市值、完全摊薄市值、交易量(24小时)、流通量、交易量/市值。
在同一个BNB币页面,到页面顶部,点击Market Cap的页面元素。观察整个块被调用
每个统计数据都有一个类型:
我们想找到
这将检索五个统计信息。(由于加密货币是 24x7 交易,这些数字在不断变化,与之前的屏幕截图略有不同。)
statsContainer = soup.find_all("div", {"class": "hide statsContainer"})statsValues = statsContainer[0].find_all("div", {"class": "statsValue"})statsValue_marketcap = statsValues[ 0] .text.strip()
打印(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
打印(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
打印(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
打印(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
输出如下(结果随时间变化,价格随时间变化)。
$104,432,294,030 $104,432,294,030 $3,550,594,245 0.034 166,801,148.00 BNB
示例 3:练习
作为练习,使用前两部分的知识并检查您是否可以提取 BNB 和 ADA(卡尔达诺)的最大供应量和总供应量数据。
最大供应量和总供应量
ADA(卡尔达诺)最大供应量和总供应量
附录:BeautifulSoup 的替代品
其他替代方案是 Scrapy 和 Selenium。
Scrapy 和 Selenium 的学习曲线比用于获取 HTML 数据的 Request 和用作 HTML 解析器的 BeautifulSoup 更陡峭。
Scrapy 是一个完整的网页抓取框架,负责从获取 HTML 到处理数据的所有内容。
Selenium 是一个浏览器自动化工具,例如,它允许用户在多个页面之间导航。
网络抓取的挑战:长寿
任何网络爬虫的主要挑战是代码的寿命。CoinMarketCap等网站的开发者在不断更新他们的网站,老代码可能过一段时间就不能用了。
一种可能的解决方案是使用平台提供的各种 网站 和应用程序编程接口 (API)。但是,API 的免费版本是有限的。使用API 时,数据格式不同于通常的网络爬虫,即JSON或XML。在标准的网络爬虫中,我们主要处理HTML格式的数据。
来源:
关于
ChinaDeFi-是一个研究驱动的DeFi创新组织,我们也是一个区块链开发团队。每天,我们从全球500多个优质信息源的近900条内容中,寻找更深入、更系统的内容,同步到中国市场,以最快的速度提供决策辅助。

