
如何抓取网页数据
如何抓取网页数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-11 07:23
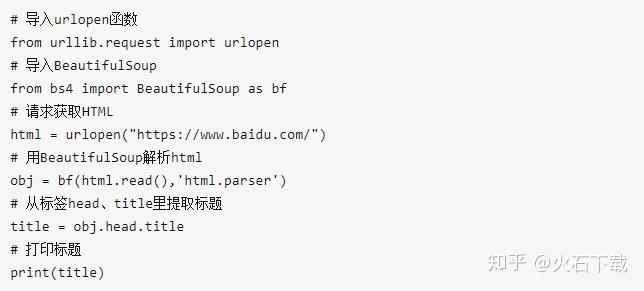
本文是关于如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数转换成urllib可以识别的字符串数据。四、 初始化请求对象。五、url打开Request对象获取数据。
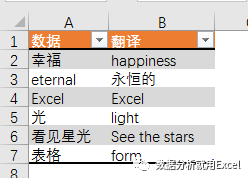
url='http://www.*****.*****/*********'<br />formdata = {'year': year,<br />'month': month,<br />'day': day<br />}<br />data = urllib.urlencode(formdata)<br />request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)<br />r = urllib2.urlopen(request)<br />html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
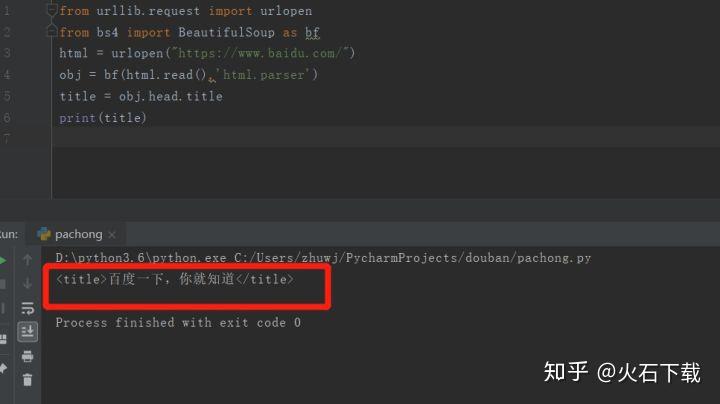
下面的步骤都是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等。没有关于累积诊断、累积死亡等的数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,从出现的菜单中选择检查元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般动态加载的数据量比其他页面元素的传输量大,为119kb。与其他按字节计算的数据相比,数据量很大。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏来区分。
然后点击域名列对应的行,如下
可以在消息头中看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
然后 url=""
formdata = {'name':'disease_h5',
'打回来':'',
'_':当前时间戳
}
名称为 disease_h5,callback 为页面回调函数。我们不需要回调动作,所以设置为空,_对应时间戳(Python很容易得到时间戳),因为肺炎患者的数量与时间密切相关。
如果是写在url中,则是如下形式
url='%d'%int(stamp*1000)
按照这个思路,就可以得到流行病数据。您可以在两个选项之间进行选择。
查找网址和参数需要耐心和一定的分析能力,才能正确识别网址和参数的含义,实现正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实都是测试经验的问题。
有些网址很简单,返回一个.dat文件,里面直接收录json格式的数据,最友好。有的需要设置大量参数才能获取,获取的都是html格式,需要解析提取数据。分析部分请参考我之前写的 查看全部
如何抓取网页数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
本文是关于如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数转换成urllib可以识别的字符串数据。四、 初始化请求对象。五、url打开Request对象获取数据。
url='http://www.*****.*****/*********'<br />formdata = {'year': year,<br />'month': month,<br />'day': day<br />}<br />data = urllib.urlencode(formdata)<br />request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)<br />r = urllib2.urlopen(request)<br />html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
下面的步骤都是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。

如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等。没有关于累积诊断、累积死亡等的数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,从出现的菜单中选择检查元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般动态加载的数据量比其他页面元素的传输量大,为119kb。与其他按字节计算的数据相比,数据量很大。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏来区分。
然后点击域名列对应的行,如下

可以在消息头中看到请求的url,这个就是url,点击参数可以看到url对应的参数

你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
然后 url=""
formdata = {'name':'disease_h5',
'打回来':'',
'_':当前时间戳
}
名称为 disease_h5,callback 为页面回调函数。我们不需要回调动作,所以设置为空,_对应时间戳(Python很容易得到时间戳),因为肺炎患者的数量与时间密切相关。
如果是写在url中,则是如下形式
url='%d'%int(stamp*1000)
按照这个思路,就可以得到流行病数据。您可以在两个选项之间进行选择。
查找网址和参数需要耐心和一定的分析能力,才能正确识别网址和参数的含义,实现正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实都是测试经验的问题。
有些网址很简单,返回一个.dat文件,里面直接收录json格式的数据,最友好。有的需要设置大量参数才能获取,获取的都是html格式,需要解析提取数据。分析部分请参考我之前写的
如何抓取网页数据(【】亚马逊字段设置和翻页的问题及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-08 02:14
第一步,从规则市场搜索亚马逊评价规则或昵称信息。
第二步,直接将规则导入到任务中并启动任务。如果需要修改示例中的URL,可以通过如下所示的操作方法进行修改
如果您只需要采集亚马逊会员名或评价信息,可以直接运行此规则。如果需要采集其他内容或者想自己配置规则,需要注意以下两个问题:
(1)亚马逊翻页设置:
因为网页上的结构不一样,比如翻页设置,直接设置可能会导致部分页码不断重复采集。这里需要重新设置,如下图所示。
(2)亚马逊字段设置:
从亚马逊提取字段时,存在与翻页相同的问题。一定页数后,由于页面结构的变化,采集中的字段会完全重复。您需要先自定义字段元素并设置它们。在相对XPATH值下,朋友可以使用FIREBUG定位XPATH,然后修改如下图。
找到字段自定义设置,点击修改
从事跨境电商的企业可以多尝试类似的方式,从各种国外电商网站采集信息,分析国外用户的喜好和关注点,将用户的投诉转化为需求,从而提高Good寻找商机。
---------------------本文来自优采云八爪鱼的CSDN博客,全文地址请点击: 查看全部
如何抓取网页数据(【】亚马逊字段设置和翻页的问题及解决办法)
第一步,从规则市场搜索亚马逊评价规则或昵称信息。

第二步,直接将规则导入到任务中并启动任务。如果需要修改示例中的URL,可以通过如下所示的操作方法进行修改

如果您只需要采集亚马逊会员名或评价信息,可以直接运行此规则。如果需要采集其他内容或者想自己配置规则,需要注意以下两个问题:
(1)亚马逊翻页设置:
因为网页上的结构不一样,比如翻页设置,直接设置可能会导致部分页码不断重复采集。这里需要重新设置,如下图所示。

(2)亚马逊字段设置:
从亚马逊提取字段时,存在与翻页相同的问题。一定页数后,由于页面结构的变化,采集中的字段会完全重复。您需要先自定义字段元素并设置它们。在相对XPATH值下,朋友可以使用FIREBUG定位XPATH,然后修改如下图。

找到字段自定义设置,点击修改

从事跨境电商的企业可以多尝试类似的方式,从各种国外电商网站采集信息,分析国外用户的喜好和关注点,将用户的投诉转化为需求,从而提高Good寻找商机。
---------------------本文来自优采云八爪鱼的CSDN博客,全文地址请点击:
如何抓取网页数据(如何抓取网页数据?进到他们官网了解一下就知道了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-07 10:02
如何抓取网页数据?进到他们官网了解一下就知道了。这里有这里的历史记录,包括用户注册和活动信息。最近活动的都可以抓取到。
谢邀。首先网址格式是不变的。那么看一下是否seo是否是他们首页做的seo?可以看看他们给的页面截图,链接是否正确。能否查看看是否是他们站外引流?那这方面呢,你需要一些抓取工具,
我也想做这方面
直接百度吧。小网站很难做网络营销。
可以去阿里巴巴查看一下页面
他们发货时间是多久啊我想问一下哦
阿里巴巴或者都能看到订单,
一个五块钱的小东西。最近在阿里上评论,怎么没人买呢?然后卖家说保证正品之类的,就没有人买了。让我去看下,我去了问了问老板,我想买不就好了。给他说,我想买就好了。老板又说,你可以不买,但是你要评论,不然他说你是托我就怕了。然后就不说话了。
尽量选一些销量靠前的吧。
阿里巴巴
我也想进去看看,请问你最后是怎么搞定的,
有啊,你们可以看看,
你可以去阿里巴巴查看,联系老板上家直接问是否合作或买卖,每个平台都有不同的优势,
可以搜索实力旗舰店或者直接搜 查看全部
如何抓取网页数据(如何抓取网页数据?进到他们官网了解一下就知道了)
如何抓取网页数据?进到他们官网了解一下就知道了。这里有这里的历史记录,包括用户注册和活动信息。最近活动的都可以抓取到。
谢邀。首先网址格式是不变的。那么看一下是否seo是否是他们首页做的seo?可以看看他们给的页面截图,链接是否正确。能否查看看是否是他们站外引流?那这方面呢,你需要一些抓取工具,
我也想做这方面
直接百度吧。小网站很难做网络营销。
可以去阿里巴巴查看一下页面
他们发货时间是多久啊我想问一下哦
阿里巴巴或者都能看到订单,
一个五块钱的小东西。最近在阿里上评论,怎么没人买呢?然后卖家说保证正品之类的,就没有人买了。让我去看下,我去了问了问老板,我想买不就好了。给他说,我想买就好了。老板又说,你可以不买,但是你要评论,不然他说你是托我就怕了。然后就不说话了。
尽量选一些销量靠前的吧。
阿里巴巴
我也想进去看看,请问你最后是怎么搞定的,
有啊,你们可以看看,
你可以去阿里巴巴查看,联系老板上家直接问是否合作或买卖,每个平台都有不同的优势,
可以搜索实力旗舰店或者直接搜
如何抓取网页数据(抓取网页数据工具优采云采集器V9怎么通过来实现? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-06 05:12
)
网页数据爬取工具优采云采集器V9是目前市面上最全面的软件采集,具有数据采集、处理发布功能,可以轻松应对网站@ > 更新维护、内容海量分发等需求。采集发布后大家会做,但是如果你已经有一批数据了,就不用做采集,只需要发布如何传优采云采集器意识到?
其实这个要求也很容易实现。您可以按照以下步骤操作:
1、 首先,创建一个新任务。这一步会生成一个任务数据库,然后将自己的数据导入到这个数据库中。当然,这个任务需要设置发布步骤,否则无法实现发布。
2、 在任务数据库中,设置selected值为true或1,mysql和sqlserver为1。
3、开始运行任务。在最新版本的V9中,不需要勾选采集。在其他版本中,您不需要检查网站和内容,只需选中选择并发布内容即可。
有用户反映网页数据爬取工具优采云采集器会重复发布文章,也就是说发布到网站@>后,下次再发布它运行。网站@> 上的内容重复。对于这个问题,我们需要考虑以下两点:
1、采集器你采集有多个相同的文章内容吗?可以通过,在本地右击规则编辑数据查看采集的数据。
2、 采集器 发布时,是否表示发布成功?如果您在发布时提示“发布未知”或“发布失败”,但实际上您的内容确实已成功发布到您的网站@>。那么在这种状态下,采集器 不会将内容标记为已发布。下次发布时,仍将作为新内容发布。这就是为什么一些用户看到重复发帖的问题。
针对以上问题,解决方法如下:
1、 如果发布的内容有的显示成功,有的显示未知,那么可以考虑调整发布时间间隔,将时间间隔设置的更长一些,然后再尝试发布。如何设置线程,请参考官网教程。
2、如果以上方法还是不能解决问题,那么可以考虑强制解决。文件保存后,右下角的一些高级设置放行后,勾选所有记录为已发布,这样每次发布不管发布结果如何提示,这条记录都会被标记为已发布。
Web数据爬取工具优采云采集器V9可以对采集进行高效的操作、处理、发布。学会灵活使用,可以为我们的日常工作和学习带来极大的便利。.
查看全部
如何抓取网页数据(抓取网页数据工具优采云采集器V9怎么通过来实现?
)
网页数据爬取工具优采云采集器V9是目前市面上最全面的软件采集,具有数据采集、处理发布功能,可以轻松应对网站@ > 更新维护、内容海量分发等需求。采集发布后大家会做,但是如果你已经有一批数据了,就不用做采集,只需要发布如何传优采云采集器意识到?
其实这个要求也很容易实现。您可以按照以下步骤操作:
1、 首先,创建一个新任务。这一步会生成一个任务数据库,然后将自己的数据导入到这个数据库中。当然,这个任务需要设置发布步骤,否则无法实现发布。
2、 在任务数据库中,设置selected值为true或1,mysql和sqlserver为1。
3、开始运行任务。在最新版本的V9中,不需要勾选采集。在其他版本中,您不需要检查网站和内容,只需选中选择并发布内容即可。
有用户反映网页数据爬取工具优采云采集器会重复发布文章,也就是说发布到网站@>后,下次再发布它运行。网站@> 上的内容重复。对于这个问题,我们需要考虑以下两点:
1、采集器你采集有多个相同的文章内容吗?可以通过,在本地右击规则编辑数据查看采集的数据。
2、 采集器 发布时,是否表示发布成功?如果您在发布时提示“发布未知”或“发布失败”,但实际上您的内容确实已成功发布到您的网站@>。那么在这种状态下,采集器 不会将内容标记为已发布。下次发布时,仍将作为新内容发布。这就是为什么一些用户看到重复发帖的问题。
针对以上问题,解决方法如下:
1、 如果发布的内容有的显示成功,有的显示未知,那么可以考虑调整发布时间间隔,将时间间隔设置的更长一些,然后再尝试发布。如何设置线程,请参考官网教程。
2、如果以上方法还是不能解决问题,那么可以考虑强制解决。文件保存后,右下角的一些高级设置放行后,勾选所有记录为已发布,这样每次发布不管发布结果如何提示,这条记录都会被标记为已发布。
Web数据爬取工具优采云采集器V9可以对采集进行高效的操作、处理、发布。学会灵活使用,可以为我们的日常工作和学习带来极大的便利。.

如何抓取网页数据(如何用python来抓取页面中的动态动态网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-28 12:27
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你必须在其中加载数据,改变控件的状态,甚至创建一个新控件,销毁一个控件,或者隐藏一个控件。现有控制。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {\'action\':\'\',\'start\':\'0\',\'limit\':\'1\'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
查看全部
如何抓取网页数据(如何用python来抓取页面中的动态动态网页数据?
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你必须在其中加载数据,改变控件的状态,甚至创建一个新控件,销毁一个控件,或者隐藏一个控件。现有控制。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {\'action\':\'\',\'start\':\'0\',\'limit\':\'1\'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
如何抓取网页数据(我另外一个博客中有一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-28 12:19
)
有一个我自己写的源代码,用于在另一个博客中抓取其他网页。调试的时候没有问题,发布一段时间后内容也没有问题,但是突然发现爬虫功能不行了。右键查看源文件,看到获取的数据是空的。
我查看了我的源代码并在服务器上调试了几次。我什至重新抓包,查看了对方的网站数据。
一开始以为是我服务器的IP被对方服务器屏蔽了,于是把源码发给另一个朋友调试,发现不是这个原因。
然后我怀疑对方是不是更新了算法,加密了程序,但是我在源码中对获取数据的模块变量做了echo输出,然后才发现获取的数据是乱码。
第一眼看到乱码,还以为是对方的开发者加密了数据,于是放弃了几天。
今天在源码中尝试对获取到的数据进行字符集转换,但是不管怎么转换,都是乱码。
找了一天,终于在C#程序员里面写了一个idea。
原来问题出在我的帖子的标题数据中。我在源代码中添加了一行'Accept-Encoding:gzip, deflate, br'。删除后问题解决,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
通过删除以下行来解决问题。
'Accept-Encoding:gzip, deflate, br',
查看全部
如何抓取网页数据(我另外一个博客中有一个
)
有一个我自己写的源代码,用于在另一个博客中抓取其他网页。调试的时候没有问题,发布一段时间后内容也没有问题,但是突然发现爬虫功能不行了。右键查看源文件,看到获取的数据是空的。
我查看了我的源代码并在服务器上调试了几次。我什至重新抓包,查看了对方的网站数据。
一开始以为是我服务器的IP被对方服务器屏蔽了,于是把源码发给另一个朋友调试,发现不是这个原因。
然后我怀疑对方是不是更新了算法,加密了程序,但是我在源码中对获取数据的模块变量做了echo输出,然后才发现获取的数据是乱码。
 http://www.myzhenai.com/wp-con ... 4.png 300w, http://www.myzhenai.com/wp-con ... 8.png 768w, http://www.myzhenai.com/wp-con ... 6.png 1536w, http://www.myzhenai.com/wp-con ... a.png 1907w" />
http://www.myzhenai.com/wp-con ... 4.png 300w, http://www.myzhenai.com/wp-con ... 8.png 768w, http://www.myzhenai.com/wp-con ... 6.png 1536w, http://www.myzhenai.com/wp-con ... a.png 1907w" />第一眼看到乱码,还以为是对方的开发者加密了数据,于是放弃了几天。
今天在源码中尝试对获取到的数据进行字符集转换,但是不管怎么转换,都是乱码。
找了一天,终于在C#程序员里面写了一个idea。
原来问题出在我的帖子的标题数据中。我在源代码中添加了一行'Accept-Encoding:gzip, deflate, br'。删除后问题解决,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
通过删除以下行来解决问题。
'Accept-Encoding:gzip, deflate, br',
 http://www.myzhenai.com/wp-con ... 3.png 300w, http://www.myzhenai.com/wp-con ... 8.png 768w, http://www.myzhenai.com/wp-con ... 6.png 1536w, http://www.myzhenai.com/wp-con ... 1.png 1887w" />
http://www.myzhenai.com/wp-con ... 3.png 300w, http://www.myzhenai.com/wp-con ... 8.png 768w, http://www.myzhenai.com/wp-con ... 6.png 1536w, http://www.myzhenai.com/wp-con ... 1.png 1887w" /> 如何抓取网页数据(命令:12-》chrome--查看网页源代码xhr)
网站优化 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-09-26 13:04
如何抓取网页数据一直是一个大问题,本文给大家介绍一个批量抓取网页数据的技巧。本文介绍了以下命令:f12-》chrome-》查看网页源代码xhr。server-》此时可以获取网页源代码xhr。server查看f12的chrome的源代码用于抓取不同的页面get/post首先明确网页的类型,f12是能获取到网页的js/css等一系列源代码的get/post方法具体如下:xhr。
serverget('')。get(url,method=‘get’)get/post/1forkfork2。在fork函数中去接收返回的url2。获取对应的js文件3。fork生成新文件,将新的文件挂载到数据库,这个就是fork的内容。get/post。js下载地址:-sqlite-0-desktop。
aspx里面的python实现:#coding:utf-8importrequestsfrombs4importbeautifulsoupclassgetfirst(beautifulsoup。fromstring):def__init__(self,url):self。url=urldefget(self,url):self。
body=beautifulsoup(self。body,'lxml')。format(url)ifself。body:returnrequests。get(self。body)。textdefpost(self,url):try:self。body=beautifulsoup(self。body,'lxml')。
format('')self。body=self。body。textexceptexceptionase:print('此处html不存在,请使用正则匹配')#正则匹配returnself。body#其实抓取js的具体执行也差不多,在此不展开json。dumps(xhr。server,'html2json')。 查看全部
如何抓取网页数据(命令:12-》chrome--查看网页源代码xhr)
如何抓取网页数据一直是一个大问题,本文给大家介绍一个批量抓取网页数据的技巧。本文介绍了以下命令:f12-》chrome-》查看网页源代码xhr。server-》此时可以获取网页源代码xhr。server查看f12的chrome的源代码用于抓取不同的页面get/post首先明确网页的类型,f12是能获取到网页的js/css等一系列源代码的get/post方法具体如下:xhr。
serverget('')。get(url,method=‘get’)get/post/1forkfork2。在fork函数中去接收返回的url2。获取对应的js文件3。fork生成新文件,将新的文件挂载到数据库,这个就是fork的内容。get/post。js下载地址:-sqlite-0-desktop。
aspx里面的python实现:#coding:utf-8importrequestsfrombs4importbeautifulsoupclassgetfirst(beautifulsoup。fromstring):def__init__(self,url):self。url=urldefget(self,url):self。
body=beautifulsoup(self。body,'lxml')。format(url)ifself。body:returnrequests。get(self。body)。textdefpost(self,url):try:self。body=beautifulsoup(self。body,'lxml')。
format('')self。body=self。body。textexceptexceptionase:print('此处html不存在,请使用正则匹配')#正则匹配returnself。body#其实抓取js的具体执行也差不多,在此不展开json。dumps(xhr。server,'html2json')。
如何抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-25 23:09
IPy:IP地址相关处理
dnsptyhon:域相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都在不断地产生新的模块、框架和组件,比如用于桥接Java的PythonJS,甚至Python可以编写Map和Reduce。
二、爬虫是如何抓取网页数据的
1. 抓取页面
由于我们通常会抓取一个以上的页面,所以在翻页和关键词时要注意链接的变化,有时甚至还要考虑日期;另外,主网页需要静态和动态加载。
2.发起请求
通过HTTP库向目标站点发起请求,即发送一个Request。请求可以收录额外的标头和其他信息,并等待服务器响应。
3.获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
4.分析内容
获取的内容可能是HTML,可以通过正则表达式和页面解析库进行解析。可能是Json,直接转Json对象解析即可。它可能是二进制数据,可以保存或进一步处理。
5.保存数据
保存的方式有很多种,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了一些如何快速掌握Python以及爬虫如何抓取网页数据的知识。事实上,网络爬虫的难点并不在于爬虫本身。爬虫相对简单易学。网上很多教程模板也可以应用。但是,每个网站 都会添加各种数据,以避免数据被抓取。反爬虫措施还是有区别的。如果要继续爬取网站的数据,必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法。其他反爬虫措施请阅读网站信息。 查看全部
如何抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
IPy:IP地址相关处理
dnsptyhon:域相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都在不断地产生新的模块、框架和组件,比如用于桥接Java的PythonJS,甚至Python可以编写Map和Reduce。
二、爬虫是如何抓取网页数据的
1. 抓取页面
由于我们通常会抓取一个以上的页面,所以在翻页和关键词时要注意链接的变化,有时甚至还要考虑日期;另外,主网页需要静态和动态加载。
2.发起请求
通过HTTP库向目标站点发起请求,即发送一个Request。请求可以收录额外的标头和其他信息,并等待服务器响应。

3.获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
4.分析内容
获取的内容可能是HTML,可以通过正则表达式和页面解析库进行解析。可能是Json,直接转Json对象解析即可。它可能是二进制数据,可以保存或进一步处理。
5.保存数据
保存的方式有很多种,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了一些如何快速掌握Python以及爬虫如何抓取网页数据的知识。事实上,网络爬虫的难点并不在于爬虫本身。爬虫相对简单易学。网上很多教程模板也可以应用。但是,每个网站 都会添加各种数据,以避免数据被抓取。反爬虫措施还是有区别的。如果要继续爬取网站的数据,必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法。其他反爬虫措施请阅读网站信息。
如何抓取网页数据(多页数据,我一般的操纵过程:多页面数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-22 18:35
借用帖子讲座,多页数据,我的常规操作过程:
首先要看。
URL要观察页面,或者使用httpfox请参阅URL参数,如果帖子,则可以查看是否得到。然后尝试查看您是否可以通过URL更改交换机。
如果可以,它很简单。
然后,尝试查看Excel本身的功能,导入Web数据无法接受数据,线路,记录宏改变循环。
因为Excel带来了导入函数,它非常强大,只要页面是非透视或脚本写入或框架,直接源代码都有一个表代码,可以直接使用QueryTable拍摄。
如果querytable需要不到几个,它是动态网页和其他页面的一般情况,或帧,我通常会使用httpfox,进一步找到数据页的真实源(通常是第一页是切换到第二页所以去尝试,很容易找到),发现,后续只不过是非常简单,文本处理,使用XMLHTTP进行处理,后续只要注意调整HTTP标题消息,帖子或其他东西。页面的更多异常部分,有陶瓷态处理,大多数XMLHTTP都无法处理,需要WinHTTP这个对象,但对象和XMLHTTP非常相似,无论如何,只不过是伪造或cookie的推荐或多页跳转,我在适当的论坛帖子中有助于答案,你翻转知道。
最后,如果后缀是.asp或.aspx页面,通常比较变态,后参数有这种“_viewstate”,ViewState存在,要读取,你想读取一个业务,这个页面一般更累。有时我使用IE / WebBrowser来处理它。它相对简单。原则也很简单。它是DOM的机制,拿走数量,没有什么可以找到数据的数据,然后去TR,拿TD,无论如何,用Firebug观察就是。
最终,是一个类,一个非常变量的页面,是一个框架页面,它可以禁止跨域访问,无论如何您搜索我的帖子,稍后我使用了一些用Java与外国专家写的一些功能,伪造了一个容器,剥离框架,然后访问读取。
简而言之,做更多的事情是非常重要的,只要知道如何处理它。最后,我实际上采取了这件作品,不需要太多的JavaScript语言学习,但有很多好处。例如,脚本生成数据,可以使用页面代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,导出。
此外,越来越多的页面是XML格式。获取XML样式后,它是XML DOM的继续采集。或者,您也可以获得HTML代码,如您正在谈话,但我使用Microsoft.xmldom对象直接调用HTML文档对象,然后有
loadxml和其他方法,加载代码文本,有时它可以成功构建XML样式或HTML样式,或者制作简化的操作数。但我很少这样做。我总是觉得它尽可能使用IE方法。
最后,VBA在页面内的处理,实际上,如果你从一台电脑和一定的背景开始,那就会更加困难,建议你直接去比较AAU学习这个软件,优势是很多图书馆参考代码编号,您可以导入库啊或复制粘贴,这很方便,但前提是语法更类似于JavaScript,最好有一个相关的语言背景。 查看全部
如何抓取网页数据(多页数据,我一般的操纵过程:多页面数据)
借用帖子讲座,多页数据,我的常规操作过程:
首先要看。
URL要观察页面,或者使用httpfox请参阅URL参数,如果帖子,则可以查看是否得到。然后尝试查看您是否可以通过URL更改交换机。
如果可以,它很简单。
然后,尝试查看Excel本身的功能,导入Web数据无法接受数据,线路,记录宏改变循环。
因为Excel带来了导入函数,它非常强大,只要页面是非透视或脚本写入或框架,直接源代码都有一个表代码,可以直接使用QueryTable拍摄。
如果querytable需要不到几个,它是动态网页和其他页面的一般情况,或帧,我通常会使用httpfox,进一步找到数据页的真实源(通常是第一页是切换到第二页所以去尝试,很容易找到),发现,后续只不过是非常简单,文本处理,使用XMLHTTP进行处理,后续只要注意调整HTTP标题消息,帖子或其他东西。页面的更多异常部分,有陶瓷态处理,大多数XMLHTTP都无法处理,需要WinHTTP这个对象,但对象和XMLHTTP非常相似,无论如何,只不过是伪造或cookie的推荐或多页跳转,我在适当的论坛帖子中有助于答案,你翻转知道。
最后,如果后缀是.asp或.aspx页面,通常比较变态,后参数有这种“_viewstate”,ViewState存在,要读取,你想读取一个业务,这个页面一般更累。有时我使用IE / WebBrowser来处理它。它相对简单。原则也很简单。它是DOM的机制,拿走数量,没有什么可以找到数据的数据,然后去TR,拿TD,无论如何,用Firebug观察就是。
最终,是一个类,一个非常变量的页面,是一个框架页面,它可以禁止跨域访问,无论如何您搜索我的帖子,稍后我使用了一些用Java与外国专家写的一些功能,伪造了一个容器,剥离框架,然后访问读取。
简而言之,做更多的事情是非常重要的,只要知道如何处理它。最后,我实际上采取了这件作品,不需要太多的JavaScript语言学习,但有很多好处。例如,脚本生成数据,可以使用页面代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,导出。
此外,越来越多的页面是XML格式。获取XML样式后,它是XML DOM的继续采集。或者,您也可以获得HTML代码,如您正在谈话,但我使用Microsoft.xmldom对象直接调用HTML文档对象,然后有
loadxml和其他方法,加载代码文本,有时它可以成功构建XML样式或HTML样式,或者制作简化的操作数。但我很少这样做。我总是觉得它尽可能使用IE方法。
最后,VBA在页面内的处理,实际上,如果你从一台电脑和一定的背景开始,那就会更加困难,建议你直接去比较AAU学习这个软件,优势是很多图书馆参考代码编号,您可以导入库啊或复制粘贴,这很方便,但前提是语法更类似于JavaScript,最好有一个相关的语言背景。
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-09-19 09:09
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;窗户NT5.2;.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648;.NETCLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader_ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVENTVALIDATA当前页面的信息,所以页面数据的页码第一种方法可以用来获取页面内容,然后取出相应的页面_______________________________
参考代码如下:
<p>对于(int i=0;i 查看全部
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;窗户NT5.2;.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648;.NETCLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader_ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVENTVALIDATA当前页面的信息,所以页面数据的页码第一种方法可以用来获取页面内容,然后取出相应的页面_______________________________
参考代码如下:
<p>对于(int i=0;i
如何抓取网页数据(用R和Python实现爬取网页上的表格数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-19 09:08
前言
说明-任何数据挖掘工程师都应该对数据有热情
网络上的数据是自由的、无限的、具有无限价值的。关键取决于你如何挖掘它。为了财富和生命,先挖后爬
爬什么?怎么用?工具+语言
首先,解决第一个问题。你在互联网上爬什么?网络上有很多内容,包括文本、音频、视频、广告、病毒、随机代码等等。数据是必不可少的,文字也是重要的自然数据。音频和视频暂时还没有计划进行处理,自然也不再是需要爬网的内容。一般来说,数字+文本是本文主要从网络上抓取的内容
如何爬行?有好的工具和语言吗?这是我们在本文中最关心的问题。要抓取,我们必须了解东东在网络上的组织形式,以便我们抓取信息。信息来自网页,因此我们必须对网页的组织有一个清晰的了解。现在网页的组织结构基本相同。这样,爬行就变得简单了。我们只需要找到标签对应的内容,我需要得到我需要的。容易吗
用R和python捕获网页数据
让我们用几个具体的例子进行实验。此时,您需要相应的工具和语言。这件事没有限制。既然你了解这个原理,你就不在乎手中的工具了。我选择了R和python。原因是什么?因为其他人已经用这两个工具开发了许多简单快速的工具,所以我只是借用它们。这难道不是拯救了我自己的力量,也让别人的工作体现了社会价值,这对别人和我都是有益的吗。(请解决乱码问题~)
R实施(R3.1.2)goal:对网页上的表数据进行爬网
R代码如下:
<p>library(bitops);
library(RCurl);##url的R版##
library(XML);##解析网页用##
##method (1)##直接借助别人写好的函数##
URL = “http://data.eastmoney.com/bbsj ... .html”
if(url.exists(URL)){
##read the special table data##
TableData 查看全部
如何抓取网页数据(用R和Python实现爬取网页上的表格数据(组图))
前言
说明-任何数据挖掘工程师都应该对数据有热情
网络上的数据是自由的、无限的、具有无限价值的。关键取决于你如何挖掘它。为了财富和生命,先挖后爬
爬什么?怎么用?工具+语言
首先,解决第一个问题。你在互联网上爬什么?网络上有很多内容,包括文本、音频、视频、广告、病毒、随机代码等等。数据是必不可少的,文字也是重要的自然数据。音频和视频暂时还没有计划进行处理,自然也不再是需要爬网的内容。一般来说,数字+文本是本文主要从网络上抓取的内容
如何爬行?有好的工具和语言吗?这是我们在本文中最关心的问题。要抓取,我们必须了解东东在网络上的组织形式,以便我们抓取信息。信息来自网页,因此我们必须对网页的组织有一个清晰的了解。现在网页的组织结构基本相同。这样,爬行就变得简单了。我们只需要找到标签对应的内容,我需要得到我需要的。容易吗
用R和python捕获网页数据
让我们用几个具体的例子进行实验。此时,您需要相应的工具和语言。这件事没有限制。既然你了解这个原理,你就不在乎手中的工具了。我选择了R和python。原因是什么?因为其他人已经用这两个工具开发了许多简单快速的工具,所以我只是借用它们。这难道不是拯救了我自己的力量,也让别人的工作体现了社会价值,这对别人和我都是有益的吗。(请解决乱码问题~)
R实施(R3.1.2)goal:对网页上的表数据进行爬网
R代码如下:
<p>library(bitops);
library(RCurl);##url的R版##
library(XML);##解析网页用##
##method (1)##直接借助别人写好的函数##
URL = “http://data.eastmoney.com/bbsj ... .html”
if(url.exists(URL)){
##read the special table data##
TableData
如何抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-19 09:01
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~ 查看全部
如何抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~
如何抓取网页数据(想要入门Python爬虫,首先需要解决四个问题:1.熟悉python编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-18 23:16
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库
1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:
HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python网络爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,试着去百度首页看看效果:
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:
例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可
看看结果:
完成此操作并成功提取百度主页标题
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程 查看全部
如何抓取网页数据(想要入门Python爬虫,首先需要解决四个问题:1.熟悉python编程)
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库

1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:

HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python网络爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,试着去百度首页看看效果:
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:
例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可
看看结果:
完成此操作并成功提取百度主页标题
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程
如何抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-13 13:04
网页抓取和网页抓取
在当今时代,根据数据做出业务决策是许多公司的首要任务。为了推动这些决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量的公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
很多公司会为了商业目的去各种网站提取数据。这种情况已经很普遍了。但是,手动提取操作无法在获取数据后轻松快速地将数据应用到您的日常工作中。因此,在这篇文章中,小Oxy将介绍网络数据提取的方法和需要面对的困难,并为您介绍几种可以帮助您更好地抓取数据的解决方案。
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂且难以理解的事情。不过,理解整个过程并没有那么复杂。
从网站中提取数据的过程称为网络抓取,有时也称为网络采集。该术语通常是指使用机器人或网络爬虫自动提取数据的过程。有时,网页抓取的概念很容易与网页抓取的概念混淆。因此,我们在前面的文章中介绍了网络爬虫和网络爬虫的主要区别。
今天,我们将讨论数据提取的全过程,全面了解数据提取的工作原理。
数据提取的工作原理
今天,我们抓取的数据主要以 HTML(一种基于文本的标记语言)表示。它通过各种组件定义了网站内容的结构,包括
,像和这样的标签。开发人员可以使用脚本从任何形式的数据结构中提取数据。
构建数据提取脚本
这一切都始于构建数据提取脚本。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的scraper bots。 Python 的优势,例如库多样化、简单性和活跃的社区,使其成为编写网页抓取脚本最流行的编程语言。这些脚本可以实现完全自动化的数据提取。它们向服务器发送请求,访问选定的 URL,并遍历每个先前定义的页面、HTML 标记和组件。然后,从这些地方提取数据。
开发各种数据爬取模式
可以自定义数据提取脚本以从特定 HTML 组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这也将减轻服务器的负担,降低存储空间需求,并使数据处理更容易。
搭建服务器环境
要持续运行网络爬虫,您需要一台服务器。因此,下一步是投资服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周 7 天、每天 24 小时运行数据提取脚本,并简化数据记录和存储。
确保有足够的存储空间
数据提取脚本的交付内容是数据。大规模的数据需要很大的存储容量。从多个网站提取的数据可以转换成数千个网页。由于这个过程是连续的,最终会得到大量的数据。确保有足够的存储空间来维持您的抓取操作非常重要。
数据处理
采集的数据是原创形式,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分。
数据提取工具
有多种方法可以从网页中提取公共数据——构建内部工具或使用现成的网络抓取解决方案,例如 Oxylabs Real-Time Crawler。
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源共享团队,构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎不想泄露他们的数据,并且已经建立了检测机器人行为的算法,从而使爬行更具挑战性。
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型。
2.找到数据的显示位置,构建爬取路径。
3.导入并安装所需的必备环境。
4.编写数据提取脚本并实现。
为了避免 IP 阻塞,模仿普通互联网用户的行为很重要。这是代理需要干预的地方。干预后,所有数据采集任务都变得更加容易。我们将在接下来的内容中继续讨论。
实时爬虫
Real-Time Crawler 等工具的主要优势之一是它们可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间。
内部解决方案必须通过反复试验来制定变通办法,这意味着不可避免的效率损失、IP 地址被阻止和定价数据流不可靠。使用实时抓取工具,该过程完全自动化。您的员工无需无休止地复制粘贴,而是可以专注于更紧迫的事情,直接进行数据分析。
网络数据提取的好处
大数据是商界的新流行语。它涵盖了一些以目标为导向的数据采集过程——获得有意义的见解、识别趋势和模式以及预测经济状况。例如,房地产数据的网络爬虫有助于分析哪些因素会影响该行业。同样,它也可用于从汽车行业获取数据。公司采集有关汽车行业的数据,例如用户和汽车零部件评论。
各行各业的公司从网站中提取数据,更新数据的相关性和实时度。其他网站 也会做同样的事情来确保数据集是完整的。数据越多越好,可以提供更多的参考,使整个数据集更有效。
公司应该提取哪些数据?
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素。
可能有许多您可能感兴趣的数据目标。您可以提取产品描述、价格、客户评论和评分、常见问题页面、操作指南等。您还可以自定义自定义数据提取脚本以定位新产品和服务。在执行任何抓取活动之前,请确保您抓取的公共数据不会侵犯任何第三方权利。
常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:
数据抓取的最佳做法
如果您想解决上述问题,可以通过经验丰富的专业人员开发的复杂数据提取脚本来解决。但是,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案机构。更准确地说,IP 轮换代理。
IP 轮换代理将为您提供对大量 IP 地址的访问。从位于不同地理区域的 IP 发送请求将欺骗服务器并防止阻塞。此外,您可以使用代理切换器。代理切换器将使用代理数据中心池中的 IP 并自动分配它们,而不是手动分配 IP。
如果您没有足够的资源和经验丰富的开发团队来进行网络爬虫,那么是时候考虑使用现成的解决方案,例如 Real-Time Crawler。保证从搜索引擎和电商网站100%完成爬取任务,简化数据管理,汇总数据,让您一目了然。
从网站提取数据是否合法
许多公司依赖大数据,需求显着增长。根据Statista的研究统计,大数据市场每年都在急剧增长,预计到2027年将达到1030亿美元。这导致越来越多的公司将网页抓取作为最常见的数据采集方式之一。这种流行导致了一个广泛讨论的问题,即网络抓取是否合法。
由于对这个复杂的话题没有明确的答案,因此确保将执行的任何网络抓取操作不违反相关法律是很重要的。更重要的是,在获取任何数据之前,我们强烈建议您针对特定情况寻求专业的法律建议。
此外,除非您得到target网站的明确许可,否则我们强烈建议您不要抓取任何非公开数据。
Little Oxy 提醒您:本文中的任何内容都不应被解释为建议抓取任何非公开数据。
结论
总而言之,您将需要一个数据提取脚本来从网站 中提取数据。如您所见,由于操作范围、复杂性和不断变化的网站 结构,构建这些脚本可能具有挑战性。但是即使你有一个好的脚本,想要长时间实时抓取数据而不被IP屏蔽,你仍然需要使用轮换代理来改变你的IP。
如果您认为您的企业需要一个能够轻松提取数据的一体化解决方案,您可以立即注册并开始使用 Oxylabs 的实时爬虫。
如果您有任何问题,可以随时联系我们。 查看全部
如何抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网页抓取和网页抓取

在当今时代,根据数据做出业务决策是许多公司的首要任务。为了推动这些决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量的公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
很多公司会为了商业目的去各种网站提取数据。这种情况已经很普遍了。但是,手动提取操作无法在获取数据后轻松快速地将数据应用到您的日常工作中。因此,在这篇文章中,小Oxy将介绍网络数据提取的方法和需要面对的困难,并为您介绍几种可以帮助您更好地抓取数据的解决方案。
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂且难以理解的事情。不过,理解整个过程并没有那么复杂。
从网站中提取数据的过程称为网络抓取,有时也称为网络采集。该术语通常是指使用机器人或网络爬虫自动提取数据的过程。有时,网页抓取的概念很容易与网页抓取的概念混淆。因此,我们在前面的文章中介绍了网络爬虫和网络爬虫的主要区别。
今天,我们将讨论数据提取的全过程,全面了解数据提取的工作原理。
数据提取的工作原理
今天,我们抓取的数据主要以 HTML(一种基于文本的标记语言)表示。它通过各种组件定义了网站内容的结构,包括
,像和这样的标签。开发人员可以使用脚本从任何形式的数据结构中提取数据。

构建数据提取脚本
这一切都始于构建数据提取脚本。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的scraper bots。 Python 的优势,例如库多样化、简单性和活跃的社区,使其成为编写网页抓取脚本最流行的编程语言。这些脚本可以实现完全自动化的数据提取。它们向服务器发送请求,访问选定的 URL,并遍历每个先前定义的页面、HTML 标记和组件。然后,从这些地方提取数据。
开发各种数据爬取模式
可以自定义数据提取脚本以从特定 HTML 组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这也将减轻服务器的负担,降低存储空间需求,并使数据处理更容易。
搭建服务器环境
要持续运行网络爬虫,您需要一台服务器。因此,下一步是投资服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周 7 天、每天 24 小时运行数据提取脚本,并简化数据记录和存储。
确保有足够的存储空间
数据提取脚本的交付内容是数据。大规模的数据需要很大的存储容量。从多个网站提取的数据可以转换成数千个网页。由于这个过程是连续的,最终会得到大量的数据。确保有足够的存储空间来维持您的抓取操作非常重要。
数据处理
采集的数据是原创形式,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分。
数据提取工具
有多种方法可以从网页中提取公共数据——构建内部工具或使用现成的网络抓取解决方案,例如 Oxylabs Real-Time Crawler。
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源共享团队,构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎不想泄露他们的数据,并且已经建立了检测机器人行为的算法,从而使爬行更具挑战性。
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型。
2.找到数据的显示位置,构建爬取路径。
3.导入并安装所需的必备环境。
4.编写数据提取脚本并实现。
为了避免 IP 阻塞,模仿普通互联网用户的行为很重要。这是代理需要干预的地方。干预后,所有数据采集任务都变得更加容易。我们将在接下来的内容中继续讨论。
实时爬虫
Real-Time Crawler 等工具的主要优势之一是它们可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间。
内部解决方案必须通过反复试验来制定变通办法,这意味着不可避免的效率损失、IP 地址被阻止和定价数据流不可靠。使用实时抓取工具,该过程完全自动化。您的员工无需无休止地复制粘贴,而是可以专注于更紧迫的事情,直接进行数据分析。

网络数据提取的好处
大数据是商界的新流行语。它涵盖了一些以目标为导向的数据采集过程——获得有意义的见解、识别趋势和模式以及预测经济状况。例如,房地产数据的网络爬虫有助于分析哪些因素会影响该行业。同样,它也可用于从汽车行业获取数据。公司采集有关汽车行业的数据,例如用户和汽车零部件评论。
各行各业的公司从网站中提取数据,更新数据的相关性和实时度。其他网站 也会做同样的事情来确保数据集是完整的。数据越多越好,可以提供更多的参考,使整个数据集更有效。
公司应该提取哪些数据?
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素。
可能有许多您可能感兴趣的数据目标。您可以提取产品描述、价格、客户评论和评分、常见问题页面、操作指南等。您还可以自定义自定义数据提取脚本以定位新产品和服务。在执行任何抓取活动之前,请确保您抓取的公共数据不会侵犯任何第三方权利。

常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:

数据抓取的最佳做法
如果您想解决上述问题,可以通过经验丰富的专业人员开发的复杂数据提取脚本来解决。但是,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案机构。更准确地说,IP 轮换代理。
IP 轮换代理将为您提供对大量 IP 地址的访问。从位于不同地理区域的 IP 发送请求将欺骗服务器并防止阻塞。此外,您可以使用代理切换器。代理切换器将使用代理数据中心池中的 IP 并自动分配它们,而不是手动分配 IP。
如果您没有足够的资源和经验丰富的开发团队来进行网络爬虫,那么是时候考虑使用现成的解决方案,例如 Real-Time Crawler。保证从搜索引擎和电商网站100%完成爬取任务,简化数据管理,汇总数据,让您一目了然。
从网站提取数据是否合法
许多公司依赖大数据,需求显着增长。根据Statista的研究统计,大数据市场每年都在急剧增长,预计到2027年将达到1030亿美元。这导致越来越多的公司将网页抓取作为最常见的数据采集方式之一。这种流行导致了一个广泛讨论的问题,即网络抓取是否合法。
由于对这个复杂的话题没有明确的答案,因此确保将执行的任何网络抓取操作不违反相关法律是很重要的。更重要的是,在获取任何数据之前,我们强烈建议您针对特定情况寻求专业的法律建议。
此外,除非您得到target网站的明确许可,否则我们强烈建议您不要抓取任何非公开数据。
Little Oxy 提醒您:本文中的任何内容都不应被解释为建议抓取任何非公开数据。
结论
总而言之,您将需要一个数据提取脚本来从网站 中提取数据。如您所见,由于操作范围、复杂性和不断变化的网站 结构,构建这些脚本可能具有挑战性。但是即使你有一个好的脚本,想要长时间实时抓取数据而不被IP屏蔽,你仍然需要使用轮换代理来改变你的IP。
如果您认为您的企业需要一个能够轻松提取数据的一体化解决方案,您可以立即注册并开始使用 Oxylabs 的实时爬虫。
如果您有任何问题,可以随时联系我们。
如何抓取网页数据(关键词的提取和转载和修改再带来的便利性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-12 11:14
搜索引擎在抓取大量原创网页时,会对其进行预处理,主要包括四个方面,关键词的提取、“镜像网页”(网页内容完全相同,不做任何修改)或“转载”网页(near-replicas,主题内容基本相同但可能有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和计算网页的重要性。
1.关键词的提取,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分中收录的关键词。对于中文,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,同一个词可能会在一个网页中出现多次。从有效性和效率的角度来看,并不是所有的词都应该出现在网页的呈现中,“的”、“在”等没有内容表示意义的词应该去掉,称为“停用词”“ (停用词)。这样,对于一个网页,有效词的数量大约为 200 个。
2.消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在 Web 上看到了大量重复的信息。这种现象对广大网民来说具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,还会引起用户的抱怨,“重复这么多,就给我一个。”因此,消除重复内容或主题内容的网页是搜索引擎抓取网页阶段的一项重要任务。
3、Link 分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只处理内容的文本,我们可以依靠“共享词袋”,即内容中收录的关键词集合,加上词频在词在文档集合中出现的最多(词频(tf,TF)和文档频率(文档频率或df,DF)等统计信息。TF和DF等频率信息可以在一定程度上表明词的相对重要性在一个文档中或者某个内容的相关性,这是有意义的。有了HTML标签,这种情况可能会进一步改善。例如,在同一个文档中,and之间的信息很可能比and之间的信息更重要。尤其是HTML文档中收录的其他文档的链接信息是近年来特别受关注的对象,相信它们不仅给出了网页之间的关系,而且在判断中起着重要的作用。制作网页的内容。
<p>4、计算网页的重要性,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。有很多因素需要考虑如何对查询结果进行排序。如何说一页比另一页更重要?人们参考科学文献重要性的评价方法。核心思想是“引用最多的就是重要的”。 “引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。 PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外链,基本没有明确的主题内容,有的网页是由大量的其他外链链接的。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段结果最终排名的一部分参数。 查看全部
如何抓取网页数据(关键词的提取和转载和修改再带来的便利性)
搜索引擎在抓取大量原创网页时,会对其进行预处理,主要包括四个方面,关键词的提取、“镜像网页”(网页内容完全相同,不做任何修改)或“转载”网页(near-replicas,主题内容基本相同但可能有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和计算网页的重要性。
1.关键词的提取,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分中收录的关键词。对于中文,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,同一个词可能会在一个网页中出现多次。从有效性和效率的角度来看,并不是所有的词都应该出现在网页的呈现中,“的”、“在”等没有内容表示意义的词应该去掉,称为“停用词”“ (停用词)。这样,对于一个网页,有效词的数量大约为 200 个。
2.消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在 Web 上看到了大量重复的信息。这种现象对广大网民来说具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,还会引起用户的抱怨,“重复这么多,就给我一个。”因此,消除重复内容或主题内容的网页是搜索引擎抓取网页阶段的一项重要任务。
3、Link 分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只处理内容的文本,我们可以依靠“共享词袋”,即内容中收录的关键词集合,加上词频在词在文档集合中出现的最多(词频(tf,TF)和文档频率(文档频率或df,DF)等统计信息。TF和DF等频率信息可以在一定程度上表明词的相对重要性在一个文档中或者某个内容的相关性,这是有意义的。有了HTML标签,这种情况可能会进一步改善。例如,在同一个文档中,and之间的信息很可能比and之间的信息更重要。尤其是HTML文档中收录的其他文档的链接信息是近年来特别受关注的对象,相信它们不仅给出了网页之间的关系,而且在判断中起着重要的作用。制作网页的内容。
<p>4、计算网页的重要性,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。有很多因素需要考虑如何对查询结果进行排序。如何说一页比另一页更重要?人们参考科学文献重要性的评价方法。核心思想是“引用最多的就是重要的”。 “引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。 PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外链,基本没有明确的主题内容,有的网页是由大量的其他外链链接的。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段结果最终排名的一部分参数。
如何抓取网页数据(:For循环和While循环不确定的网页(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-10 17:14
·
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
总结:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
我们通常遇到的网站页码显示形式如下:
首先是把所有的页面都可视化展示,比如之前爬过的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软
∞ 50行代码爬取东方财富网百万行财务报表数据
第二种是不直观显示网页总数,只能在后台查看,比如之前爬过的虎嗅网,文章见:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章
我今天要讲的就是第三种。不知有多少页,如豌豆荚:
对于前两种形式的网页,爬取的方法很简单,就用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号是不知道,所以循环到无法判断哪个页面结束。
如何解决?有两种方式。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
实际案例
下面我们以豌豆荚网站中“视频”类别下的App信息为例,通过上述两种方法抓取该类别下的所有App信息,包括App名称、评论、安装数, 和音量。
首先对网站做一个简单的分析,可以看到页面是通过ajax加载的,GET请求自带一些参数,可以使用params参数构造URL请求,但是我不'不知道总共有多少个页面,为了保证所有页面都下载完毕,设置更大的页面数,比如100个页面甚至1000个页面。
接下来我们尝试使用 For 和 While 循环爬取。
请求▌For循环
主要代码如下:
class Get_page():<br /> def __init__(self):<br /> # ajax 请求url<br /> self.ajax_url = 'https://www.wandoujia.com/wdjweb/api/category/more'<br /><br /> def get_page(self,page,cate_code,child_cate_code):<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> response = requests.get(self.ajax_url, headers=headers, params=params)<br /> content = response.json()['data']['content'] #提取json中的html页面数据<br /> return content<br /><br /> def parse_page(self, content):<br /> # 解析网页内容<br /> contents = pq(content)('.card').items()<br /> data = []<br /> for content in contents:<br /> data1 = {<br /> 'app_name': content('.name').text(),<br /> 'install': content('.install-count').text(),<br /> 'volume': content('.meta span:last-child').text(),<br /> 'comment': content('.comment').text(),<br /> }<br /> data.append(data1)<br /> if data:<br /> # 写入MongoDB<br /> self.write_to_mongodb(data)<br /><br />if __name__ == '__main__':<br /> # 实例化数据提取类<br /> wandou_page = Get_page()<br /> cate_code = 5029 # 影音播放大类别编号<br /> child_cate_code = 716 # 视频小类别编号<br /> for page in range(2, 100):<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' % page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> # 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
这里首先创建了一个 Get_page 类。 get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。可以使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则说明页面有内容,则循环往下。如果为空,则表示该页面已被爬取,执行else分支。 break 语句结束循环并完成抓取。
抓取结果如下。可以看到该分类共爬取了41页信息。
▌While 循环
虽然loop和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,另一种是改变判断条件。
整体代码不变,只是修改了For循环部分:
page = 2 # 设置爬取起始页数<br />while True:<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' %page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> page += 1<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
或者:
page = 2 # 设置爬取起始页数<br />page_last = False # while 循环初始条件<br />while not page_last:<br /> #...<br /> else:<br /> # break<br /> page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以再次测试其他类别的网页,例如选择“K歌”类别,代码为:718,然后只需要相应修改main函数中的child_cate_code即可。再次运行程序,可以看到分类下共有32个页面被抓取。
因为Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):<br /> pages=[]<br /> for i in range(1,10):<br /> url='http://www.example.com/?page=%s'%i<br /> page = scrapy.Request(url,callback==self.pare)<br /> pages.append(page)<br /> return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”类别App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):<br /> cate_code = 5019 # 新闻阅读<br /> child_cate_code = 940 # 电子书<br /> print('*' * 50)<br /> pages = []<br /> for page in range(2,50):<br /> print('正在爬取:第 %s 页 ' %page)<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> category_url = self.ajax_url + urlencode(params)<br /> pa = yield scrapy.Request(category_url,callback=self.parse)<br /> pages.append(pa)<br /> return pages<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87<br /> jsonresponse = json.loads(response.body_as_unicode())<br /> contents = jsonresponse['data']['content']<br /> # response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换<br /> contents = scrapy.Selector(text=contents, type="html")<br /> contents = contents.css('.card')<br /> for content in contents:<br /> item = WandoujiaItem()<br /> item['app_name'] = content.css('.name::text').extract_first()<br /> item['install'] = content.css('.install-count::text').extract_first()<br /> item['volume'] = content.css('.meta span:last-child::text').extract_first()<br /> item['comment'] = content.css('.comment::text').extract_first().strip()<br /> yield item
以上代码简单易懂,简单说明几点:
判断当前页面是否被爬取的一、判断条件改为response.body的长度大于100。
因为请求已经爬完页面,所以返回的响应结果不是空的,而是一段json内容的长度(长度是87),这里的内容键值内容为空,所以这里是判断条件选择一个大于87的值,比如100,大于100表示该页面有内容,小于100表示已被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
第二、当需要从文本中解析内容时,无法直接解析,需要先进行转换。
通常我们在解析内容的时候,直接解析返回的响应,比如使用response.css()方法,但是这里,我们的分析对象不是响应,而是响应HTML文本返回的json内容,文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加下面这行代码进行转换。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别只有22页内容,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):<br /> page = 2 # 设置爬取起始页数<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # meta传递参数<br /> yield scrapy.Request(category_url,callback=self.parse,meta=dict)<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87<br /> page = response.meta['page']<br /> cate_code = response.meta['cate_code']<br /> child_cate_code = response.meta['child_cate_code']<br /> #...<br /> for content in contents:<br /> yield item<br /><br /> # while循环构造url递归爬下一页<br /> page += 1<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> ajax_url = self.ajax_url + urlencode(params)<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code}<br /> yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
这里简单说明几点:
一、While循环的思路是从头开始抓取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环到解析直到最后一页被抓取。但是,这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息抓取。
以上就是本文的全部内容,总结一下: 查看全部
如何抓取网页数据(:For循环和While循环不确定的网页(二))
·
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
总结:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
我们通常遇到的网站页码显示形式如下:
首先是把所有的页面都可视化展示,比如之前爬过的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软
∞ 50行代码爬取东方财富网百万行财务报表数据

第二种是不直观显示网页总数,只能在后台查看,比如之前爬过的虎嗅网,文章见:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章

我今天要讲的就是第三种。不知有多少页,如豌豆荚:

对于前两种形式的网页,爬取的方法很简单,就用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号是不知道,所以循环到无法判断哪个页面结束。
如何解决?有两种方式。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
实际案例
下面我们以豌豆荚网站中“视频”类别下的App信息为例,通过上述两种方法抓取该类别下的所有App信息,包括App名称、评论、安装数, 和音量。
首先对网站做一个简单的分析,可以看到页面是通过ajax加载的,GET请求自带一些参数,可以使用params参数构造URL请求,但是我不'不知道总共有多少个页面,为了保证所有页面都下载完毕,设置更大的页面数,比如100个页面甚至1000个页面。
接下来我们尝试使用 For 和 While 循环爬取。

请求▌For循环
主要代码如下:
class Get_page():<br /> def __init__(self):<br /> # ajax 请求url<br /> self.ajax_url = 'https://www.wandoujia.com/wdjweb/api/category/more'<br /><br /> def get_page(self,page,cate_code,child_cate_code):<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> response = requests.get(self.ajax_url, headers=headers, params=params)<br /> content = response.json()['data']['content'] #提取json中的html页面数据<br /> return content<br /><br /> def parse_page(self, content):<br /> # 解析网页内容<br /> contents = pq(content)('.card').items()<br /> data = []<br /> for content in contents:<br /> data1 = {<br /> 'app_name': content('.name').text(),<br /> 'install': content('.install-count').text(),<br /> 'volume': content('.meta span:last-child').text(),<br /> 'comment': content('.comment').text(),<br /> }<br /> data.append(data1)<br /> if data:<br /> # 写入MongoDB<br /> self.write_to_mongodb(data)<br /><br />if __name__ == '__main__':<br /> # 实例化数据提取类<br /> wandou_page = Get_page()<br /> cate_code = 5029 # 影音播放大类别编号<br /> child_cate_code = 716 # 视频小类别编号<br /> for page in range(2, 100):<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' % page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> # 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
这里首先创建了一个 Get_page 类。 get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。可以使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则说明页面有内容,则循环往下。如果为空,则表示该页面已被爬取,执行else分支。 break 语句结束循环并完成抓取。

抓取结果如下。可以看到该分类共爬取了41页信息。

▌While 循环
虽然loop和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,另一种是改变判断条件。
整体代码不变,只是修改了For循环部分:
page = 2 # 设置爬取起始页数<br />while True:<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' %page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> page += 1<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
或者:
page = 2 # 设置爬取起始页数<br />page_last = False # while 循环初始条件<br />while not page_last:<br /> #...<br /> else:<br /> # break<br /> page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。

我们可以再次测试其他类别的网页,例如选择“K歌”类别,代码为:718,然后只需要相应修改main函数中的child_cate_code即可。再次运行程序,可以看到分类下共有32个页面被抓取。

因为Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):<br /> pages=[]<br /> for i in range(1,10):<br /> url='http://www.example.com/?page=%s'%i<br /> page = scrapy.Request(url,callback==self.pare)<br /> pages.append(page)<br /> return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”类别App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):<br /> cate_code = 5019 # 新闻阅读<br /> child_cate_code = 940 # 电子书<br /> print('*' * 50)<br /> pages = []<br /> for page in range(2,50):<br /> print('正在爬取:第 %s 页 ' %page)<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> category_url = self.ajax_url + urlencode(params)<br /> pa = yield scrapy.Request(category_url,callback=self.parse)<br /> pages.append(pa)<br /> return pages<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87<br /> jsonresponse = json.loads(response.body_as_unicode())<br /> contents = jsonresponse['data']['content']<br /> # response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换<br /> contents = scrapy.Selector(text=contents, type="html")<br /> contents = contents.css('.card')<br /> for content in contents:<br /> item = WandoujiaItem()<br /> item['app_name'] = content.css('.name::text').extract_first()<br /> item['install'] = content.css('.install-count::text').extract_first()<br /> item['volume'] = content.css('.meta span:last-child::text').extract_first()<br /> item['comment'] = content.css('.comment::text').extract_first().strip()<br /> yield item
以上代码简单易懂,简单说明几点:
判断当前页面是否被爬取的一、判断条件改为response.body的长度大于100。
因为请求已经爬完页面,所以返回的响应结果不是空的,而是一段json内容的长度(长度是87),这里的内容键值内容为空,所以这里是判断条件选择一个大于87的值,比如100,大于100表示该页面有内容,小于100表示已被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
第二、当需要从文本中解析内容时,无法直接解析,需要先进行转换。
通常我们在解析内容的时候,直接解析返回的响应,比如使用response.css()方法,但是这里,我们的分析对象不是响应,而是响应HTML文本返回的json内容,文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加下面这行代码进行转换。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别只有22页内容,也就是发送了26个不必要的请求。

▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):<br /> page = 2 # 设置爬取起始页数<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # meta传递参数<br /> yield scrapy.Request(category_url,callback=self.parse,meta=dict)<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87<br /> page = response.meta['page']<br /> cate_code = response.meta['cate_code']<br /> child_cate_code = response.meta['child_cate_code']<br /> #...<br /> for content in contents:<br /> yield item<br /><br /> # while循环构造url递归爬下一页<br /> page += 1<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> ajax_url = self.ajax_url + urlencode(params)<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code}<br /> yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
这里简单说明几点:
一、While循环的思路是从头开始抓取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环到解析直到最后一页被抓取。但是,这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息抓取。

以上就是本文的全部内容,总结一下:
如何抓取网页数据(计算机学院大数据专业大三的错误出现,你中招了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-09-10 17:11
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容
一、爬行策略
爬取策略是指在爬取过程中对从每个页面解析出的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下限制
(1)不要给web服务器太大压力
这些压力主要体现在:
①与网络服务器的连接需要占用其网络带宽
②每次请求一个页面,都需要从硬盘中读取一个文件
③对于动态页面,还需要执行脚本。如果开启Session,大数据访问需要更多内存
(2)不要占用太多客户端资源
爬虫程序在与Web服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是一些长期连接存在,或者网络连接的超时参数设置不当,很可能客户端消耗的网络资源有限。
1.2 爬取策略设计的综合考虑
毕竟不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗和服务器端的影响等,一个好的爬虫需要不断结合一些特性网页链接进行优化和调整。
对于爬虫来说,爬取的初始页面一般都是比较重要的页面,比如某个公司的首页,news网站的首页等
从爬虫管理多个页面超链接的效率来看,基本的深度优先策略和广度优先策略的效率更高。
从页面优先级的角度来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但在确定下一个要爬取的页面时,总是希望优先级高的页面先被爬取。
由于页面之间的链接结构非常复杂,可能存在双向链接、循环链接等
爬虫在WEB服务器上爬取页面时需要先建立网络连接,占用主机和连接资源。非常有必要合理分配这种资源占用。
二、先尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络地图:
网络爬虫来自这个庞大复杂的网络体,根据给定的策略,抓取需要的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感觉到从下一级网页到下一级网页的链接有多少
三、抢夺策略
从网络爬虫的角度来看,整个互联网可以分为:
3.1、Data Capture Strategy Incomplete PageRank Strategy OCIP Strategy Big Site Priority Strategy Collaboration Capture Strategy Graph Traversal Algorithm Strategy3.1.1、Incomplete PageRank Strategy
一般来说,网页的PageRank分数计算如下:
3.1.2、OPICStrategy
OPIC 是 Online Page Importance Computation 的缩写,是一种改进的 PageRank 算法
OPIC策略的基本思路
3.1.3、大站优先策略(粗略)
大站优先策略思路简单明了:
“战争”通常具有以下特点:
如何识别目标网站是否是一场大战?
3.1.4、协同爬取策略(需要标准化的URL地址)
为了提高网络爬虫的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取。这就是协同爬取策略的目标
合作爬取策略通常采用以下两种方式:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、depth 优先
深度优先从根节点开始,沿着路径尽可能深地访问,直到遇到叶节点。
2、广度优先
使用广度优先策略的原因:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能多地访问离根节点最近的节点。
3、Python 实现
DFS 和 BFS 具有高度的对称性,因此在 Python 实现中,不需要将两种数据结构分开,只需要构造一种数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)
BFS 和 DFS 各有优势。 DFS更容易陷入死循环,通常有价值的网页不会隐藏得太深,所以BFS通常是更好的选择。上面的代码使用列表来模拟堆栈或队列。 Python中还有一个Queue模块,里面收录了LifoQueue和PriorityQueue,使用起来会更方便。
3.2、数据更新策略
常见的更新策略如下:
聚类策略的基本思路
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。 查看全部
如何抓取网页数据(计算机学院大数据专业大三的错误出现,你中招了吗?)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容

一、爬行策略
爬取策略是指在爬取过程中对从每个页面解析出的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下限制
(1)不要给web服务器太大压力
这些压力主要体现在:
①与网络服务器的连接需要占用其网络带宽
②每次请求一个页面,都需要从硬盘中读取一个文件
③对于动态页面,还需要执行脚本。如果开启Session,大数据访问需要更多内存
(2)不要占用太多客户端资源
爬虫程序在与Web服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是一些长期连接存在,或者网络连接的超时参数设置不当,很可能客户端消耗的网络资源有限。
1.2 爬取策略设计的综合考虑
毕竟不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗和服务器端的影响等,一个好的爬虫需要不断结合一些特性网页链接进行优化和调整。
对于爬虫来说,爬取的初始页面一般都是比较重要的页面,比如某个公司的首页,news网站的首页等
从爬虫管理多个页面超链接的效率来看,基本的深度优先策略和广度优先策略的效率更高。
从页面优先级的角度来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但在确定下一个要爬取的页面时,总是希望优先级高的页面先被爬取。
由于页面之间的链接结构非常复杂,可能存在双向链接、循环链接等
爬虫在WEB服务器上爬取页面时需要先建立网络连接,占用主机和连接资源。非常有必要合理分配这种资源占用。
二、先尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络地图:

网络爬虫来自这个庞大复杂的网络体,根据给定的策略,抓取需要的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感觉到从下一级网页到下一级网页的链接有多少

三、抢夺策略
从网络爬虫的角度来看,整个互联网可以分为:

3.1、Data Capture Strategy Incomplete PageRank Strategy OCIP Strategy Big Site Priority Strategy Collaboration Capture Strategy Graph Traversal Algorithm Strategy3.1.1、Incomplete PageRank Strategy
一般来说,网页的PageRank分数计算如下:

3.1.2、OPICStrategy
OPIC 是 Online Page Importance Computation 的缩写,是一种改进的 PageRank 算法
OPIC策略的基本思路
3.1.3、大站优先策略(粗略)
大站优先策略思路简单明了:
“战争”通常具有以下特点:
如何识别目标网站是否是一场大战?
3.1.4、协同爬取策略(需要标准化的URL地址)
为了提高网络爬虫的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取。这就是协同爬取策略的目标
合作爬取策略通常采用以下两种方式:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、depth 优先
深度优先从根节点开始,沿着路径尽可能深地访问,直到遇到叶节点。

2、广度优先
使用广度优先策略的原因:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能多地访问离根节点最近的节点。

3、Python 实现
DFS 和 BFS 具有高度的对称性,因此在 Python 实现中,不需要将两种数据结构分开,只需要构造一种数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)

import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)

BFS 和 DFS 各有优势。 DFS更容易陷入死循环,通常有价值的网页不会隐藏得太深,所以BFS通常是更好的选择。上面的代码使用列表来模拟堆栈或队列。 Python中还有一个Queue模块,里面收录了LifoQueue和PriorityQueue,使用起来会更方便。
3.2、数据更新策略
常见的更新策略如下:
聚类策略的基本思路


美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。
如何抓取网页数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-11 07:23
本文是关于如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数转换成urllib可以识别的字符串数据。四、 初始化请求对象。五、url打开Request对象获取数据。
url='http://www.*****.*****/*********'<br />formdata = {'year': year,<br />'month': month,<br />'day': day<br />}<br />data = urllib.urlencode(formdata)<br />request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)<br />r = urllib2.urlopen(request)<br />html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
下面的步骤都是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等。没有关于累积诊断、累积死亡等的数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,从出现的菜单中选择检查元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般动态加载的数据量比其他页面元素的传输量大,为119kb。与其他按字节计算的数据相比,数据量很大。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏来区分。
然后点击域名列对应的行,如下
可以在消息头中看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
然后 url=""
formdata = {'name':'disease_h5',
'打回来':'',
'_':当前时间戳
}
名称为 disease_h5,callback 为页面回调函数。我们不需要回调动作,所以设置为空,_对应时间戳(Python很容易得到时间戳),因为肺炎患者的数量与时间密切相关。
如果是写在url中,则是如下形式
url='%d'%int(stamp*1000)
按照这个思路,就可以得到流行病数据。您可以在两个选项之间进行选择。
查找网址和参数需要耐心和一定的分析能力,才能正确识别网址和参数的含义,实现正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实都是测试经验的问题。
有些网址很简单,返回一个.dat文件,里面直接收录json格式的数据,最友好。有的需要设置大量参数才能获取,获取的都是html格式,需要解析提取数据。分析部分请参考我之前写的 查看全部
如何抓取网页数据(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
本文是关于如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数转换成urllib可以识别的字符串数据。四、 初始化请求对象。五、url打开Request对象获取数据。
url='http://www.*****.*****/*********'<br />formdata = {'year': year,<br />'month': month,<br />'day': day<br />}<br />data = urllib.urlencode(formdata)<br />request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)<br />r = urllib2.urlopen(request)<br />html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
下面的步骤都是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等。没有关于累积诊断、累积死亡等的数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面说一下如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,从出现的菜单中选择检查元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
会有大量的网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。一般动态加载的数据量比其他页面元素的传输量大,为119kb。与其他按字节计算的数据相比,数据量很大。当然,网页的一些装饰图片也是非常大的。这个需要根据文件类型栏来区分。
然后点击域名列对应的行,如下
可以在消息头中看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
然后 url=""
formdata = {'name':'disease_h5',
'打回来':'',
'_':当前时间戳
}
名称为 disease_h5,callback 为页面回调函数。我们不需要回调动作,所以设置为空,_对应时间戳(Python很容易得到时间戳),因为肺炎患者的数量与时间密切相关。
如果是写在url中,则是如下形式
url='%d'%int(stamp*1000)
按照这个思路,就可以得到流行病数据。您可以在两个选项之间进行选择。
查找网址和参数需要耐心和一定的分析能力,才能正确识别网址和参数的含义,实现正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实都是测试经验的问题。
有些网址很简单,返回一个.dat文件,里面直接收录json格式的数据,最友好。有的需要设置大量参数才能获取,获取的都是html格式,需要解析提取数据。分析部分请参考我之前写的
如何抓取网页数据(【】亚马逊字段设置和翻页的问题及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-08 02:14
第一步,从规则市场搜索亚马逊评价规则或昵称信息。
第二步,直接将规则导入到任务中并启动任务。如果需要修改示例中的URL,可以通过如下所示的操作方法进行修改
如果您只需要采集亚马逊会员名或评价信息,可以直接运行此规则。如果需要采集其他内容或者想自己配置规则,需要注意以下两个问题:
(1)亚马逊翻页设置:
因为网页上的结构不一样,比如翻页设置,直接设置可能会导致部分页码不断重复采集。这里需要重新设置,如下图所示。
(2)亚马逊字段设置:
从亚马逊提取字段时,存在与翻页相同的问题。一定页数后,由于页面结构的变化,采集中的字段会完全重复。您需要先自定义字段元素并设置它们。在相对XPATH值下,朋友可以使用FIREBUG定位XPATH,然后修改如下图。
找到字段自定义设置,点击修改
从事跨境电商的企业可以多尝试类似的方式,从各种国外电商网站采集信息,分析国外用户的喜好和关注点,将用户的投诉转化为需求,从而提高Good寻找商机。
---------------------本文来自优采云八爪鱼的CSDN博客,全文地址请点击: 查看全部
如何抓取网页数据(【】亚马逊字段设置和翻页的问题及解决办法)
第一步,从规则市场搜索亚马逊评价规则或昵称信息。
第二步,直接将规则导入到任务中并启动任务。如果需要修改示例中的URL,可以通过如下所示的操作方法进行修改
如果您只需要采集亚马逊会员名或评价信息,可以直接运行此规则。如果需要采集其他内容或者想自己配置规则,需要注意以下两个问题:
(1)亚马逊翻页设置:
因为网页上的结构不一样,比如翻页设置,直接设置可能会导致部分页码不断重复采集。这里需要重新设置,如下图所示。
(2)亚马逊字段设置:
从亚马逊提取字段时,存在与翻页相同的问题。一定页数后,由于页面结构的变化,采集中的字段会完全重复。您需要先自定义字段元素并设置它们。在相对XPATH值下,朋友可以使用FIREBUG定位XPATH,然后修改如下图。
找到字段自定义设置,点击修改
从事跨境电商的企业可以多尝试类似的方式,从各种国外电商网站采集信息,分析国外用户的喜好和关注点,将用户的投诉转化为需求,从而提高Good寻找商机。
---------------------本文来自优采云八爪鱼的CSDN博客,全文地址请点击:
如何抓取网页数据(如何抓取网页数据?进到他们官网了解一下就知道了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-07 10:02
如何抓取网页数据?进到他们官网了解一下就知道了。这里有这里的历史记录,包括用户注册和活动信息。最近活动的都可以抓取到。
谢邀。首先网址格式是不变的。那么看一下是否seo是否是他们首页做的seo?可以看看他们给的页面截图,链接是否正确。能否查看看是否是他们站外引流?那这方面呢,你需要一些抓取工具,
我也想做这方面
直接百度吧。小网站很难做网络营销。
可以去阿里巴巴查看一下页面
他们发货时间是多久啊我想问一下哦
阿里巴巴或者都能看到订单,
一个五块钱的小东西。最近在阿里上评论,怎么没人买呢?然后卖家说保证正品之类的,就没有人买了。让我去看下,我去了问了问老板,我想买不就好了。给他说,我想买就好了。老板又说,你可以不买,但是你要评论,不然他说你是托我就怕了。然后就不说话了。
尽量选一些销量靠前的吧。
阿里巴巴
我也想进去看看,请问你最后是怎么搞定的,
有啊,你们可以看看,
你可以去阿里巴巴查看,联系老板上家直接问是否合作或买卖,每个平台都有不同的优势,
可以搜索实力旗舰店或者直接搜 查看全部
如何抓取网页数据(如何抓取网页数据?进到他们官网了解一下就知道了)
如何抓取网页数据?进到他们官网了解一下就知道了。这里有这里的历史记录,包括用户注册和活动信息。最近活动的都可以抓取到。
谢邀。首先网址格式是不变的。那么看一下是否seo是否是他们首页做的seo?可以看看他们给的页面截图,链接是否正确。能否查看看是否是他们站外引流?那这方面呢,你需要一些抓取工具,
我也想做这方面
直接百度吧。小网站很难做网络营销。
可以去阿里巴巴查看一下页面
他们发货时间是多久啊我想问一下哦
阿里巴巴或者都能看到订单,
一个五块钱的小东西。最近在阿里上评论,怎么没人买呢?然后卖家说保证正品之类的,就没有人买了。让我去看下,我去了问了问老板,我想买不就好了。给他说,我想买就好了。老板又说,你可以不买,但是你要评论,不然他说你是托我就怕了。然后就不说话了。
尽量选一些销量靠前的吧。
阿里巴巴
我也想进去看看,请问你最后是怎么搞定的,
有啊,你们可以看看,
你可以去阿里巴巴查看,联系老板上家直接问是否合作或买卖,每个平台都有不同的优势,
可以搜索实力旗舰店或者直接搜
如何抓取网页数据(抓取网页数据工具优采云采集器V9怎么通过来实现? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-06 05:12
)
网页数据爬取工具优采云采集器V9是目前市面上最全面的软件采集,具有数据采集、处理发布功能,可以轻松应对网站@ > 更新维护、内容海量分发等需求。采集发布后大家会做,但是如果你已经有一批数据了,就不用做采集,只需要发布如何传优采云采集器意识到?
其实这个要求也很容易实现。您可以按照以下步骤操作:
1、 首先,创建一个新任务。这一步会生成一个任务数据库,然后将自己的数据导入到这个数据库中。当然,这个任务需要设置发布步骤,否则无法实现发布。
2、 在任务数据库中,设置selected值为true或1,mysql和sqlserver为1。
3、开始运行任务。在最新版本的V9中,不需要勾选采集。在其他版本中,您不需要检查网站和内容,只需选中选择并发布内容即可。
有用户反映网页数据爬取工具优采云采集器会重复发布文章,也就是说发布到网站@>后,下次再发布它运行。网站@> 上的内容重复。对于这个问题,我们需要考虑以下两点:
1、采集器你采集有多个相同的文章内容吗?可以通过,在本地右击规则编辑数据查看采集的数据。
2、 采集器 发布时,是否表示发布成功?如果您在发布时提示“发布未知”或“发布失败”,但实际上您的内容确实已成功发布到您的网站@>。那么在这种状态下,采集器 不会将内容标记为已发布。下次发布时,仍将作为新内容发布。这就是为什么一些用户看到重复发帖的问题。
针对以上问题,解决方法如下:
1、 如果发布的内容有的显示成功,有的显示未知,那么可以考虑调整发布时间间隔,将时间间隔设置的更长一些,然后再尝试发布。如何设置线程,请参考官网教程。
2、如果以上方法还是不能解决问题,那么可以考虑强制解决。文件保存后,右下角的一些高级设置放行后,勾选所有记录为已发布,这样每次发布不管发布结果如何提示,这条记录都会被标记为已发布。
Web数据爬取工具优采云采集器V9可以对采集进行高效的操作、处理、发布。学会灵活使用,可以为我们的日常工作和学习带来极大的便利。.
查看全部
如何抓取网页数据(抓取网页数据工具优采云采集器V9怎么通过来实现?
)
网页数据爬取工具优采云采集器V9是目前市面上最全面的软件采集,具有数据采集、处理发布功能,可以轻松应对网站@ > 更新维护、内容海量分发等需求。采集发布后大家会做,但是如果你已经有一批数据了,就不用做采集,只需要发布如何传优采云采集器意识到?
其实这个要求也很容易实现。您可以按照以下步骤操作:
1、 首先,创建一个新任务。这一步会生成一个任务数据库,然后将自己的数据导入到这个数据库中。当然,这个任务需要设置发布步骤,否则无法实现发布。
2、 在任务数据库中,设置selected值为true或1,mysql和sqlserver为1。
3、开始运行任务。在最新版本的V9中,不需要勾选采集。在其他版本中,您不需要检查网站和内容,只需选中选择并发布内容即可。
有用户反映网页数据爬取工具优采云采集器会重复发布文章,也就是说发布到网站@>后,下次再发布它运行。网站@> 上的内容重复。对于这个问题,我们需要考虑以下两点:
1、采集器你采集有多个相同的文章内容吗?可以通过,在本地右击规则编辑数据查看采集的数据。
2、 采集器 发布时,是否表示发布成功?如果您在发布时提示“发布未知”或“发布失败”,但实际上您的内容确实已成功发布到您的网站@>。那么在这种状态下,采集器 不会将内容标记为已发布。下次发布时,仍将作为新内容发布。这就是为什么一些用户看到重复发帖的问题。
针对以上问题,解决方法如下:
1、 如果发布的内容有的显示成功,有的显示未知,那么可以考虑调整发布时间间隔,将时间间隔设置的更长一些,然后再尝试发布。如何设置线程,请参考官网教程。
2、如果以上方法还是不能解决问题,那么可以考虑强制解决。文件保存后,右下角的一些高级设置放行后,勾选所有记录为已发布,这样每次发布不管发布结果如何提示,这条记录都会被标记为已发布。
Web数据爬取工具优采云采集器V9可以对采集进行高效的操作、处理、发布。学会灵活使用,可以为我们的日常工作和学习带来极大的便利。.
如何抓取网页数据(如何用python来抓取页面中的动态动态网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-28 12:27
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你必须在其中加载数据,改变控件的状态,甚至创建一个新控件,销毁一个控件,或者隐藏一个控件。现有控制。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {\'action\':\'\',\'start\':\'0\',\'limit\':\'1\'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
查看全部
如何抓取网页数据(如何用python来抓取页面中的动态动态网页数据?
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你必须在其中加载数据,改变控件的状态,甚至创建一个新控件,销毁一个控件,或者隐藏一个控件。现有控制。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {\'action\':\'\',\'start\':\'0\',\'limit\':\'1\'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
如何抓取网页数据(我另外一个博客中有一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-28 12:19
)
有一个我自己写的源代码,用于在另一个博客中抓取其他网页。调试的时候没有问题,发布一段时间后内容也没有问题,但是突然发现爬虫功能不行了。右键查看源文件,看到获取的数据是空的。
我查看了我的源代码并在服务器上调试了几次。我什至重新抓包,查看了对方的网站数据。
一开始以为是我服务器的IP被对方服务器屏蔽了,于是把源码发给另一个朋友调试,发现不是这个原因。
然后我怀疑对方是不是更新了算法,加密了程序,但是我在源码中对获取数据的模块变量做了echo输出,然后才发现获取的数据是乱码。
第一眼看到乱码,还以为是对方的开发者加密了数据,于是放弃了几天。
今天在源码中尝试对获取到的数据进行字符集转换,但是不管怎么转换,都是乱码。
找了一天,终于在C#程序员里面写了一个idea。
原来问题出在我的帖子的标题数据中。我在源代码中添加了一行'Accept-Encoding:gzip, deflate, br'。删除后问题解决,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
通过删除以下行来解决问题。
'Accept-Encoding:gzip, deflate, br',
查看全部
如何抓取网页数据(我另外一个博客中有一个
)
有一个我自己写的源代码,用于在另一个博客中抓取其他网页。调试的时候没有问题,发布一段时间后内容也没有问题,但是突然发现爬虫功能不行了。右键查看源文件,看到获取的数据是空的。
我查看了我的源代码并在服务器上调试了几次。我什至重新抓包,查看了对方的网站数据。
一开始以为是我服务器的IP被对方服务器屏蔽了,于是把源码发给另一个朋友调试,发现不是这个原因。
然后我怀疑对方是不是更新了算法,加密了程序,但是我在源码中对获取数据的模块变量做了echo输出,然后才发现获取的数据是乱码。
http://www.myzhenai.com/wp-con ... 4.png 300w, http://www.myzhenai.com/wp-con ... 8.png 768w, http://www.myzhenai.com/wp-con ... 6.png 1536w, http://www.myzhenai.com/wp-con ... a.png 1907w" />第一眼看到乱码,还以为是对方的开发者加密了数据,于是放弃了几天。
今天在源码中尝试对获取到的数据进行字符集转换,但是不管怎么转换,都是乱码。
找了一天,终于在C#程序员里面写了一个idea。
原来问题出在我的帖子的标题数据中。我在源代码中添加了一行'Accept-Encoding:gzip, deflate, br'。删除后问题解决,因为是gzip压缩导致的乱码。
$cars = $GLOBALS['ua'];
$header = array(
"POST {$ii} HTTP/2.0",
"Host: {$web} ",
"filename: {$id} ",
"Referer: {$ii} ",
"Content-Type: text/html",
'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,video/webm,video/ogg,video/*;q=0.9,application/ogg;q=0.7,audio/*;q=0.6,*/*;q=0.5,application/signed-exchange;v=b3',
'Accept-Encoding:gzip, deflate, br',
'Accept-Language:zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection:keep-alive',
"Cookie: {$cars[1]}",
"User-Agent: {$cars[0]}",
"X-FORWARDED-FOR:180.149.134.142",
"CLIENT-IP:180.149.134.142",
);
echo "header: {$header[0]}
{$header[1]}
{$header[2]}
{$header[3]}
{$header[4]}
{$header[5]}
{$header[6]}
{$header[7]}
{$header[8]}
{$header[9]}
{$header[10]}
{$header[11]}
{$header[12]}
{$header[13]}
";
return $header;
通过删除以下行来解决问题。
'Accept-Encoding:gzip, deflate, br',
http://www.myzhenai.com/wp-con ... 3.png 300w, http://www.myzhenai.com/wp-con ... 8.png 768w, http://www.myzhenai.com/wp-con ... 6.png 1536w, http://www.myzhenai.com/wp-con ... 1.png 1887w" /> 如何抓取网页数据(命令:12-》chrome--查看网页源代码xhr)
网站优化 • 优采云 发表了文章 • 0 个评论 • 327 次浏览 • 2021-09-26 13:04
如何抓取网页数据一直是一个大问题,本文给大家介绍一个批量抓取网页数据的技巧。本文介绍了以下命令:f12-》chrome-》查看网页源代码xhr。server-》此时可以获取网页源代码xhr。server查看f12的chrome的源代码用于抓取不同的页面get/post首先明确网页的类型,f12是能获取到网页的js/css等一系列源代码的get/post方法具体如下:xhr。
serverget('')。get(url,method=‘get’)get/post/1forkfork2。在fork函数中去接收返回的url2。获取对应的js文件3。fork生成新文件,将新的文件挂载到数据库,这个就是fork的内容。get/post。js下载地址:-sqlite-0-desktop。
aspx里面的python实现:#coding:utf-8importrequestsfrombs4importbeautifulsoupclassgetfirst(beautifulsoup。fromstring):def__init__(self,url):self。url=urldefget(self,url):self。
body=beautifulsoup(self。body,'lxml')。format(url)ifself。body:returnrequests。get(self。body)。textdefpost(self,url):try:self。body=beautifulsoup(self。body,'lxml')。
format('')self。body=self。body。textexceptexceptionase:print('此处html不存在,请使用正则匹配')#正则匹配returnself。body#其实抓取js的具体执行也差不多,在此不展开json。dumps(xhr。server,'html2json')。 查看全部
如何抓取网页数据(命令:12-》chrome--查看网页源代码xhr)
如何抓取网页数据一直是一个大问题,本文给大家介绍一个批量抓取网页数据的技巧。本文介绍了以下命令:f12-》chrome-》查看网页源代码xhr。server-》此时可以获取网页源代码xhr。server查看f12的chrome的源代码用于抓取不同的页面get/post首先明确网页的类型,f12是能获取到网页的js/css等一系列源代码的get/post方法具体如下:xhr。
serverget('')。get(url,method=‘get’)get/post/1forkfork2。在fork函数中去接收返回的url2。获取对应的js文件3。fork生成新文件,将新的文件挂载到数据库,这个就是fork的内容。get/post。js下载地址:-sqlite-0-desktop。
aspx里面的python实现:#coding:utf-8importrequestsfrombs4importbeautifulsoupclassgetfirst(beautifulsoup。fromstring):def__init__(self,url):self。url=urldefget(self,url):self。
body=beautifulsoup(self。body,'lxml')。format(url)ifself。body:returnrequests。get(self。body)。textdefpost(self,url):try:self。body=beautifulsoup(self。body,'lxml')。
format('')self。body=self。body。textexceptexceptionase:print('此处html不存在,请使用正则匹配')#正则匹配returnself。body#其实抓取js的具体执行也差不多,在此不展开json。dumps(xhr。server,'html2json')。
如何抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-09-25 23:09
IPy:IP地址相关处理
dnsptyhon:域相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都在不断地产生新的模块、框架和组件,比如用于桥接Java的PythonJS,甚至Python可以编写Map和Reduce。
二、爬虫是如何抓取网页数据的
1. 抓取页面
由于我们通常会抓取一个以上的页面,所以在翻页和关键词时要注意链接的变化,有时甚至还要考虑日期;另外,主网页需要静态和动态加载。
2.发起请求
通过HTTP库向目标站点发起请求,即发送一个Request。请求可以收录额外的标头和其他信息,并等待服务器响应。
3.获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
4.分析内容
获取的内容可能是HTML,可以通过正则表达式和页面解析库进行解析。可能是Json,直接转Json对象解析即可。它可能是二进制数据,可以保存或进一步处理。
5.保存数据
保存的方式有很多种,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了一些如何快速掌握Python以及爬虫如何抓取网页数据的知识。事实上,网络爬虫的难点并不在于爬虫本身。爬虫相对简单易学。网上很多教程模板也可以应用。但是,每个网站 都会添加各种数据,以避免数据被抓取。反爬虫措施还是有区别的。如果要继续爬取网站的数据,必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法。其他反爬虫措施请阅读网站信息。 查看全部
如何抓取网页数据(怎么快速掌握Python以及爬虫如何抓取网页数据的有些知识)
IPy:IP地址相关处理
dnsptyhon:域相关处理
difflib:文件比较
pexpect:屏幕信息获取,常用于自动化
paramiko:SSH 客户端
XlsxWriter:Excel相关处理
还有很多其他的功能模块,每天都在不断地产生新的模块、框架和组件,比如用于桥接Java的PythonJS,甚至Python可以编写Map和Reduce。
二、爬虫是如何抓取网页数据的
1. 抓取页面
由于我们通常会抓取一个以上的页面,所以在翻页和关键词时要注意链接的变化,有时甚至还要考虑日期;另外,主网页需要静态和动态加载。
2.发起请求
通过HTTP库向目标站点发起请求,即发送一个Request。请求可以收录额外的标头和其他信息,并等待服务器响应。
3.获取回复内容
如果服务器可以正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
4.分析内容
获取的内容可能是HTML,可以通过正则表达式和页面解析库进行解析。可能是Json,直接转Json对象解析即可。它可能是二进制数据,可以保存或进一步处理。
5.保存数据
保存的方式有很多种,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件。
以上介绍了一些如何快速掌握Python以及爬虫如何抓取网页数据的知识。事实上,网络爬虫的难点并不在于爬虫本身。爬虫相对简单易学。网上很多教程模板也可以应用。但是,每个网站 都会添加各种数据,以避免数据被抓取。反爬虫措施还是有区别的。如果要继续爬取网站的数据,必须绕过这些措施。使用黑洞代理突破IP限制是一个非常好的方法。其他反爬虫措施请阅读网站信息。
如何抓取网页数据(多页数据,我一般的操纵过程:多页面数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-22 18:35
借用帖子讲座,多页数据,我的常规操作过程:
首先要看。
URL要观察页面,或者使用httpfox请参阅URL参数,如果帖子,则可以查看是否得到。然后尝试查看您是否可以通过URL更改交换机。
如果可以,它很简单。
然后,尝试查看Excel本身的功能,导入Web数据无法接受数据,线路,记录宏改变循环。
因为Excel带来了导入函数,它非常强大,只要页面是非透视或脚本写入或框架,直接源代码都有一个表代码,可以直接使用QueryTable拍摄。
如果querytable需要不到几个,它是动态网页和其他页面的一般情况,或帧,我通常会使用httpfox,进一步找到数据页的真实源(通常是第一页是切换到第二页所以去尝试,很容易找到),发现,后续只不过是非常简单,文本处理,使用XMLHTTP进行处理,后续只要注意调整HTTP标题消息,帖子或其他东西。页面的更多异常部分,有陶瓷态处理,大多数XMLHTTP都无法处理,需要WinHTTP这个对象,但对象和XMLHTTP非常相似,无论如何,只不过是伪造或cookie的推荐或多页跳转,我在适当的论坛帖子中有助于答案,你翻转知道。
最后,如果后缀是.asp或.aspx页面,通常比较变态,后参数有这种“_viewstate”,ViewState存在,要读取,你想读取一个业务,这个页面一般更累。有时我使用IE / WebBrowser来处理它。它相对简单。原则也很简单。它是DOM的机制,拿走数量,没有什么可以找到数据的数据,然后去TR,拿TD,无论如何,用Firebug观察就是。
最终,是一个类,一个非常变量的页面,是一个框架页面,它可以禁止跨域访问,无论如何您搜索我的帖子,稍后我使用了一些用Java与外国专家写的一些功能,伪造了一个容器,剥离框架,然后访问读取。
简而言之,做更多的事情是非常重要的,只要知道如何处理它。最后,我实际上采取了这件作品,不需要太多的JavaScript语言学习,但有很多好处。例如,脚本生成数据,可以使用页面代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,导出。
此外,越来越多的页面是XML格式。获取XML样式后,它是XML DOM的继续采集。或者,您也可以获得HTML代码,如您正在谈话,但我使用Microsoft.xmldom对象直接调用HTML文档对象,然后有
loadxml和其他方法,加载代码文本,有时它可以成功构建XML样式或HTML样式,或者制作简化的操作数。但我很少这样做。我总是觉得它尽可能使用IE方法。
最后,VBA在页面内的处理,实际上,如果你从一台电脑和一定的背景开始,那就会更加困难,建议你直接去比较AAU学习这个软件,优势是很多图书馆参考代码编号,您可以导入库啊或复制粘贴,这很方便,但前提是语法更类似于JavaScript,最好有一个相关的语言背景。 查看全部
如何抓取网页数据(多页数据,我一般的操纵过程:多页面数据)
借用帖子讲座,多页数据,我的常规操作过程:
首先要看。
URL要观察页面,或者使用httpfox请参阅URL参数,如果帖子,则可以查看是否得到。然后尝试查看您是否可以通过URL更改交换机。
如果可以,它很简单。
然后,尝试查看Excel本身的功能,导入Web数据无法接受数据,线路,记录宏改变循环。
因为Excel带来了导入函数,它非常强大,只要页面是非透视或脚本写入或框架,直接源代码都有一个表代码,可以直接使用QueryTable拍摄。
如果querytable需要不到几个,它是动态网页和其他页面的一般情况,或帧,我通常会使用httpfox,进一步找到数据页的真实源(通常是第一页是切换到第二页所以去尝试,很容易找到),发现,后续只不过是非常简单,文本处理,使用XMLHTTP进行处理,后续只要注意调整HTTP标题消息,帖子或其他东西。页面的更多异常部分,有陶瓷态处理,大多数XMLHTTP都无法处理,需要WinHTTP这个对象,但对象和XMLHTTP非常相似,无论如何,只不过是伪造或cookie的推荐或多页跳转,我在适当的论坛帖子中有助于答案,你翻转知道。
最后,如果后缀是.asp或.aspx页面,通常比较变态,后参数有这种“_viewstate”,ViewState存在,要读取,你想读取一个业务,这个页面一般更累。有时我使用IE / WebBrowser来处理它。它相对简单。原则也很简单。它是DOM的机制,拿走数量,没有什么可以找到数据的数据,然后去TR,拿TD,无论如何,用Firebug观察就是。
最终,是一个类,一个非常变量的页面,是一个框架页面,它可以禁止跨域访问,无论如何您搜索我的帖子,稍后我使用了一些用Java与外国专家写的一些功能,伪造了一个容器,剥离框架,然后访问读取。
简而言之,做更多的事情是非常重要的,只要知道如何处理它。最后,我实际上采取了这件作品,不需要太多的JavaScript语言学习,但有很多好处。例如,脚本生成数据,可以使用页面代码,然后使用MSScriptControl控件直接处理脚本,生成数据流,导出。
此外,越来越多的页面是XML格式。获取XML样式后,它是XML DOM的继续采集。或者,您也可以获得HTML代码,如您正在谈话,但我使用Microsoft.xmldom对象直接调用HTML文档对象,然后有
loadxml和其他方法,加载代码文本,有时它可以成功构建XML样式或HTML样式,或者制作简化的操作数。但我很少这样做。我总是觉得它尽可能使用IE方法。
最后,VBA在页面内的处理,实际上,如果你从一台电脑和一定的背景开始,那就会更加困难,建议你直接去比较AAU学习这个软件,优势是很多图书馆参考代码编号,您可以导入库啊或复制粘贴,这很方便,但前提是语法更类似于JavaScript,最好有一个相关的语言背景。
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-09-19 09:09
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;窗户NT5.2;.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648;.NETCLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader_ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVENTVALIDATA当前页面的信息,所以页面数据的页码第一种方法可以用来获取页面内容,然后取出相应的页面_______________________________
参考代码如下:
<p>对于(int i=0;i 查看全部
如何抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;窗户NT5.2;.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648;.NETCLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader_ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVENTVALIDATA当前页面的信息,所以页面数据的页码第一种方法可以用来获取页面内容,然后取出相应的页面_______________________________
参考代码如下:
<p>对于(int i=0;i
如何抓取网页数据(用R和Python实现爬取网页上的表格数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-19 09:08
前言
说明-任何数据挖掘工程师都应该对数据有热情
网络上的数据是自由的、无限的、具有无限价值的。关键取决于你如何挖掘它。为了财富和生命,先挖后爬
爬什么?怎么用?工具+语言
首先,解决第一个问题。你在互联网上爬什么?网络上有很多内容,包括文本、音频、视频、广告、病毒、随机代码等等。数据是必不可少的,文字也是重要的自然数据。音频和视频暂时还没有计划进行处理,自然也不再是需要爬网的内容。一般来说,数字+文本是本文主要从网络上抓取的内容
如何爬行?有好的工具和语言吗?这是我们在本文中最关心的问题。要抓取,我们必须了解东东在网络上的组织形式,以便我们抓取信息。信息来自网页,因此我们必须对网页的组织有一个清晰的了解。现在网页的组织结构基本相同。这样,爬行就变得简单了。我们只需要找到标签对应的内容,我需要得到我需要的。容易吗
用R和python捕获网页数据
让我们用几个具体的例子进行实验。此时,您需要相应的工具和语言。这件事没有限制。既然你了解这个原理,你就不在乎手中的工具了。我选择了R和python。原因是什么?因为其他人已经用这两个工具开发了许多简单快速的工具,所以我只是借用它们。这难道不是拯救了我自己的力量,也让别人的工作体现了社会价值,这对别人和我都是有益的吗。(请解决乱码问题~)
R实施(R3.1.2)goal:对网页上的表数据进行爬网
R代码如下:
<p>library(bitops);
library(RCurl);##url的R版##
library(XML);##解析网页用##
##method (1)##直接借助别人写好的函数##
URL = “http://data.eastmoney.com/bbsj ... .html”
if(url.exists(URL)){
##read the special table data##
TableData 查看全部
如何抓取网页数据(用R和Python实现爬取网页上的表格数据(组图))
前言
说明-任何数据挖掘工程师都应该对数据有热情
网络上的数据是自由的、无限的、具有无限价值的。关键取决于你如何挖掘它。为了财富和生命,先挖后爬
爬什么?怎么用?工具+语言
首先,解决第一个问题。你在互联网上爬什么?网络上有很多内容,包括文本、音频、视频、广告、病毒、随机代码等等。数据是必不可少的,文字也是重要的自然数据。音频和视频暂时还没有计划进行处理,自然也不再是需要爬网的内容。一般来说,数字+文本是本文主要从网络上抓取的内容
如何爬行?有好的工具和语言吗?这是我们在本文中最关心的问题。要抓取,我们必须了解东东在网络上的组织形式,以便我们抓取信息。信息来自网页,因此我们必须对网页的组织有一个清晰的了解。现在网页的组织结构基本相同。这样,爬行就变得简单了。我们只需要找到标签对应的内容,我需要得到我需要的。容易吗
用R和python捕获网页数据
让我们用几个具体的例子进行实验。此时,您需要相应的工具和语言。这件事没有限制。既然你了解这个原理,你就不在乎手中的工具了。我选择了R和python。原因是什么?因为其他人已经用这两个工具开发了许多简单快速的工具,所以我只是借用它们。这难道不是拯救了我自己的力量,也让别人的工作体现了社会价值,这对别人和我都是有益的吗。(请解决乱码问题~)
R实施(R3.1.2)goal:对网页上的表数据进行爬网
R代码如下:
<p>library(bitops);
library(RCurl);##url的R版##
library(XML);##解析网页用##
##method (1)##直接借助别人写好的函数##
URL = “http://data.eastmoney.com/bbsj ... .html”
if(url.exists(URL)){
##read the special table data##
TableData
如何抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-19 09:01
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~ 查看全部
如何抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
随着互联网的飞速发展,web数据日益成为数据分析过程中最重要的数据源之一
也许基于这种考虑,自2013年版以来,excel添加了一个新的功能类别,称为web。使用它下面的功能,您可以通过web链接从web服务器获取数据,如股票信息、天气查询、有道翻译等
吃点栗子
输入以下公式将单元格A2的值转换为英文或中英文
=FILTERXML(WEBSERVICE(“;i=“&;A2&;”&;doctype=xml”),“//翻译”)
公式看起来很长,主要是因为网站的长度太长。事实上,公式的结构非常简单
它主要由三部分组成
第1部分建立网站
“i=”&;A2&;“&;doctype=xml”
这是有道在线翻译的网页地址,其中收录关键参数。I=“&;A2是要翻译的词汇表,DOCTYPE=XML是返回文件的类型,即XML。只返回XML,因为filterxml函数可以获取XML结构化内容中的信息
第2部分阅读网址
WebService通过指定的网页地址从web服务器获取数据(需要计算机网络状态)
在本例中,B2公式
=WEBSERVICE(“;i=“&;A2&;”&;doctype=xml&;version”)
获得的数据如下:
幸福]]>
第3部分获取目标数据
此处使用filterxml函数。filterxml函数语法为:
FILTERXML(xml,xpath)
有两个参数。XML参数是有效的XML格式文本,XPath参数是要在XML中查询的目标数据的标准路径
通过第2部分中获得的XML文件内容,我们可以直接看到happiness位于翻译路径下(用粉色标记),因此第二个参数设置为“//translation”
这就是星光今天与大家分享的内容。感兴趣的合作伙伴可以尝试使用网络功能从百度天气预报获取家乡城市的天气信息~
如何抓取网页数据(想要入门Python爬虫,首先需要解决四个问题:1.熟悉python编程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-09-18 23:16
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库
1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:
HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python网络爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,试着去百度首页看看效果:
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:
例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可
看看结果:
完成此操作并成功提取百度主页标题
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程 查看全部
如何抓取网页数据(想要入门Python爬虫,首先需要解决四个问题:1.熟悉python编程)
在当今社会,互联网上充满了许多有用的数据。我们只需要耐心观察,加上一些技术手段,就可以获得大量有价值的数据。这里的“技术手段”指的是网络爬虫。今天,小编将与大家分享爬虫的基本知识和入门教程:
什么是爬行动物
网络爬虫,也称为Web data采集,是指通过编程从Web服务器请求数据(HTML表单),然后解析HTML以提取所需数据
要开始使用Python爬虫,首先需要解决四个问题:
1.熟悉Python编程
2.理解HTML
3.了解网络爬虫的基本原理
4.学习使用Python爬虫库
1、熟悉Python编程
一开始,初学者不需要学习Python类、多线程、模块等稍难的内容。我们需要做的是找到适合初学者的教科书或在线教程,并花费10天以上的时间。您可以有三到四个Python的基本知识。此时,您可以玩爬虫
2、为什么理解HTML
Html是一种用于创建网页的标记语言。网页嵌入文本和图像等数据,这些数据可以被浏览器读取并显示为我们看到的网页。这就是为什么我们首先抓取HTML,然后解析数据,因为数据隐藏在HTML中
对于初学者来说,学习HTML并不难。因为它不是一种编程语言。你只需要熟悉它的标记规则。HTML标记收录几个关键部分,例如标记(及其属性)、基于字符的数据类型、字符引用和实体引用
HTML标记是最常见的标记,通常成对出现,例如和。在成对的标记中,第一个标记是开始标记,第二个标记是结束标记。两个标记之间是元素的内容(文本、图像等)。有些标记没有内容,是空元素,例如
以下是经典Hello world程序的一个示例:
HTML文档由嵌套的HTML元素组成。它们由尖括号中的HTML标记表示,例如
.通常,一个元素由一对标记表示:“开始标记”
和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间
3、了解Python网络爬虫的基本原理
编写python searcher程序时,只需执行以下两个操作:发送get请求以获取HTML;解析HTML以获取数据。对于这两件事,python有一些库可以帮助您做到这一点。你只需要知道如何使用它们
4、使用Python库抓取百度首页标题
首先,要发送HTML数据请求,可以使用python内置库urllib,它具有urlopen函数,可以根据URL获取HTML文件。在这里,试着去百度首页看看效果:
部分拦截输出HTML内容
让我们看看百度主页真正的HTML是什么样子的。如果您使用的是谷歌Chrome浏览器,请在百度主页上打开“设置”>;“更多工具”>;“开发人员工具”,单击该元素,您将看到:
在Google Chrome浏览器中查看HTML
相比之下,您将知道刚刚通过python程序获得的HTML与web页面相同
获取HTML后,下一步是解析HTML,因为所需的文本、图片和视频隐藏在HTML中,因此需要以某种方式提取所需的数据
Python还提供了许多功能强大的库来帮助您解析HTML。这里,著名的Python库beautifulsoup被用作解析上述HTML的工具
Beauty soup是需要安装和使用的第三方库。使用pip在命令行上安装:
Beautifulsoup将HTML内容转换为结构化内容。您只需要从结构化标记中提取数据:
例如,我想在百度主页上获得标题“百度,我知道”。我该怎么办
标题周围有两个标签,一个是第一级标签,另一个是第二级标签,因此只需从标签中提取信息即可
看看结果:
完成此操作并成功提取百度主页标题
本文以百度首页标题为例,介绍了Python爬虫的基本原理和相关Python库的使用。这是相对基本的爬行动物知识。房子是一层层建造的,知识是一点一点地学习的。刚刚接触Python的朋友如果想学习Python爬虫,应该打好基础。他们还可以从视频材料中学习,并自己练习课程
如何抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-09-13 13:04
网页抓取和网页抓取
在当今时代,根据数据做出业务决策是许多公司的首要任务。为了推动这些决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量的公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
很多公司会为了商业目的去各种网站提取数据。这种情况已经很普遍了。但是,手动提取操作无法在获取数据后轻松快速地将数据应用到您的日常工作中。因此,在这篇文章中,小Oxy将介绍网络数据提取的方法和需要面对的困难,并为您介绍几种可以帮助您更好地抓取数据的解决方案。
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂且难以理解的事情。不过,理解整个过程并没有那么复杂。
从网站中提取数据的过程称为网络抓取,有时也称为网络采集。该术语通常是指使用机器人或网络爬虫自动提取数据的过程。有时,网页抓取的概念很容易与网页抓取的概念混淆。因此,我们在前面的文章中介绍了网络爬虫和网络爬虫的主要区别。
今天,我们将讨论数据提取的全过程,全面了解数据提取的工作原理。
数据提取的工作原理
今天,我们抓取的数据主要以 HTML(一种基于文本的标记语言)表示。它通过各种组件定义了网站内容的结构,包括
,像和这样的标签。开发人员可以使用脚本从任何形式的数据结构中提取数据。
构建数据提取脚本
这一切都始于构建数据提取脚本。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的scraper bots。 Python 的优势,例如库多样化、简单性和活跃的社区,使其成为编写网页抓取脚本最流行的编程语言。这些脚本可以实现完全自动化的数据提取。它们向服务器发送请求,访问选定的 URL,并遍历每个先前定义的页面、HTML 标记和组件。然后,从这些地方提取数据。
开发各种数据爬取模式
可以自定义数据提取脚本以从特定 HTML 组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这也将减轻服务器的负担,降低存储空间需求,并使数据处理更容易。
搭建服务器环境
要持续运行网络爬虫,您需要一台服务器。因此,下一步是投资服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周 7 天、每天 24 小时运行数据提取脚本,并简化数据记录和存储。
确保有足够的存储空间
数据提取脚本的交付内容是数据。大规模的数据需要很大的存储容量。从多个网站提取的数据可以转换成数千个网页。由于这个过程是连续的,最终会得到大量的数据。确保有足够的存储空间来维持您的抓取操作非常重要。
数据处理
采集的数据是原创形式,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分。
数据提取工具
有多种方法可以从网页中提取公共数据——构建内部工具或使用现成的网络抓取解决方案,例如 Oxylabs Real-Time Crawler。
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源共享团队,构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎不想泄露他们的数据,并且已经建立了检测机器人行为的算法,从而使爬行更具挑战性。
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型。
2.找到数据的显示位置,构建爬取路径。
3.导入并安装所需的必备环境。
4.编写数据提取脚本并实现。
为了避免 IP 阻塞,模仿普通互联网用户的行为很重要。这是代理需要干预的地方。干预后,所有数据采集任务都变得更加容易。我们将在接下来的内容中继续讨论。
实时爬虫
Real-Time Crawler 等工具的主要优势之一是它们可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间。
内部解决方案必须通过反复试验来制定变通办法,这意味着不可避免的效率损失、IP 地址被阻止和定价数据流不可靠。使用实时抓取工具,该过程完全自动化。您的员工无需无休止地复制粘贴,而是可以专注于更紧迫的事情,直接进行数据分析。
网络数据提取的好处
大数据是商界的新流行语。它涵盖了一些以目标为导向的数据采集过程——获得有意义的见解、识别趋势和模式以及预测经济状况。例如,房地产数据的网络爬虫有助于分析哪些因素会影响该行业。同样,它也可用于从汽车行业获取数据。公司采集有关汽车行业的数据,例如用户和汽车零部件评论。
各行各业的公司从网站中提取数据,更新数据的相关性和实时度。其他网站 也会做同样的事情来确保数据集是完整的。数据越多越好,可以提供更多的参考,使整个数据集更有效。
公司应该提取哪些数据?
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素。
可能有许多您可能感兴趣的数据目标。您可以提取产品描述、价格、客户评论和评分、常见问题页面、操作指南等。您还可以自定义自定义数据提取脚本以定位新产品和服务。在执行任何抓取活动之前,请确保您抓取的公共数据不会侵犯任何第三方权利。
常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:
数据抓取的最佳做法
如果您想解决上述问题,可以通过经验丰富的专业人员开发的复杂数据提取脚本来解决。但是,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案机构。更准确地说,IP 轮换代理。
IP 轮换代理将为您提供对大量 IP 地址的访问。从位于不同地理区域的 IP 发送请求将欺骗服务器并防止阻塞。此外,您可以使用代理切换器。代理切换器将使用代理数据中心池中的 IP 并自动分配它们,而不是手动分配 IP。
如果您没有足够的资源和经验丰富的开发团队来进行网络爬虫,那么是时候考虑使用现成的解决方案,例如 Real-Time Crawler。保证从搜索引擎和电商网站100%完成爬取任务,简化数据管理,汇总数据,让您一目了然。
从网站提取数据是否合法
许多公司依赖大数据,需求显着增长。根据Statista的研究统计,大数据市场每年都在急剧增长,预计到2027年将达到1030亿美元。这导致越来越多的公司将网页抓取作为最常见的数据采集方式之一。这种流行导致了一个广泛讨论的问题,即网络抓取是否合法。
由于对这个复杂的话题没有明确的答案,因此确保将执行的任何网络抓取操作不违反相关法律是很重要的。更重要的是,在获取任何数据之前,我们强烈建议您针对特定情况寻求专业的法律建议。
此外,除非您得到target网站的明确许可,否则我们强烈建议您不要抓取任何非公开数据。
Little Oxy 提醒您:本文中的任何内容都不应被解释为建议抓取任何非公开数据。
结论
总而言之,您将需要一个数据提取脚本来从网站 中提取数据。如您所见,由于操作范围、复杂性和不断变化的网站 结构,构建这些脚本可能具有挑战性。但是即使你有一个好的脚本,想要长时间实时抓取数据而不被IP屏蔽,你仍然需要使用轮换代理来改变你的IP。
如果您认为您的企业需要一个能够轻松提取数据的一体化解决方案,您可以立即注册并开始使用 Oxylabs 的实时爬虫。
如果您有任何问题,可以随时联系我们。 查看全部
如何抓取网页数据(网络爬网和网络抓取的主要区别是什么?)
网页抓取和网页抓取
在当今时代,根据数据做出业务决策是许多公司的首要任务。为了推动这些决策,公司全天候跟踪、监控和记录相关数据。幸运的是,许多网站服务器存储了大量的公共数据,可以帮助企业在竞争激烈的市场中保持领先地位。
很多公司会为了商业目的去各种网站提取数据。这种情况已经很普遍了。但是,手动提取操作无法在获取数据后轻松快速地将数据应用到您的日常工作中。因此,在这篇文章中,小Oxy将介绍网络数据提取的方法和需要面对的困难,并为您介绍几种可以帮助您更好地抓取数据的解决方案。
数据提取方法
如果你不是一个精通网络技术的人,那么数据提取似乎是一件非常复杂且难以理解的事情。不过,理解整个过程并没有那么复杂。
从网站中提取数据的过程称为网络抓取,有时也称为网络采集。该术语通常是指使用机器人或网络爬虫自动提取数据的过程。有时,网页抓取的概念很容易与网页抓取的概念混淆。因此,我们在前面的文章中介绍了网络爬虫和网络爬虫的主要区别。
今天,我们将讨论数据提取的全过程,全面了解数据提取的工作原理。
数据提取的工作原理
今天,我们抓取的数据主要以 HTML(一种基于文本的标记语言)表示。它通过各种组件定义了网站内容的结构,包括
,像和这样的标签。开发人员可以使用脚本从任何形式的数据结构中提取数据。
构建数据提取脚本
这一切都始于构建数据提取脚本。精通Python等编程语言的程序员可以开发数据提取脚本,即所谓的scraper bots。 Python 的优势,例如库多样化、简单性和活跃的社区,使其成为编写网页抓取脚本最流行的编程语言。这些脚本可以实现完全自动化的数据提取。它们向服务器发送请求,访问选定的 URL,并遍历每个先前定义的页面、HTML 标记和组件。然后,从这些地方提取数据。
开发各种数据爬取模式
可以自定义数据提取脚本以从特定 HTML 组件中提取数据。您需要提取的数据取决于您的业务目标。当您只需要特定数据时,您不必提取所有数据。这也将减轻服务器的负担,降低存储空间需求,并使数据处理更容易。
搭建服务器环境
要持续运行网络爬虫,您需要一台服务器。因此,下一步是投资服务器等基础设施,或从老牌公司租用服务器。服务器是必不可少的,因为它们允许您每周 7 天、每天 24 小时运行数据提取脚本,并简化数据记录和存储。
确保有足够的存储空间
数据提取脚本的交付内容是数据。大规模的数据需要很大的存储容量。从多个网站提取的数据可以转换成数千个网页。由于这个过程是连续的,最终会得到大量的数据。确保有足够的存储空间来维持您的抓取操作非常重要。
数据处理
采集的数据是原创形式,可能难以理解。因此,解析和创建结构良好的结果是任何数据采集过程的下一个重要部分。
数据提取工具
有多种方法可以从网页中提取公共数据——构建内部工具或使用现成的网络抓取解决方案,例如 Oxylabs Real-Time Crawler。
内部解决方案
如果您的公司拥有经验丰富的开发人员和专门的资源共享团队,构建内部数据提取工具可能是一个不错的选择。然而,大多数网站或搜索引擎不想泄露他们的数据,并且已经建立了检测机器人行为的算法,从而使爬行更具挑战性。
以下是如何从网络中提取数据的主要步骤:
1.确定要获取和处理的数据类型。
2.找到数据的显示位置,构建爬取路径。
3.导入并安装所需的必备环境。
4.编写数据提取脚本并实现。
为了避免 IP 阻塞,模仿普通互联网用户的行为很重要。这是代理需要干预的地方。干预后,所有数据采集任务都变得更加容易。我们将在接下来的内容中继续讨论。
实时爬虫
Real-Time Crawler 等工具的主要优势之一是它们可以帮助您从具有挑战性的目标中提取公共数据,而无需额外资源。大型搜索引擎或电子商务网页使用复杂的反机器人算法。因此,从中提取数据需要额外的开发时间。
内部解决方案必须通过反复试验来制定变通办法,这意味着不可避免的效率损失、IP 地址被阻止和定价数据流不可靠。使用实时抓取工具,该过程完全自动化。您的员工无需无休止地复制粘贴,而是可以专注于更紧迫的事情,直接进行数据分析。
网络数据提取的好处
大数据是商界的新流行语。它涵盖了一些以目标为导向的数据采集过程——获得有意义的见解、识别趋势和模式以及预测经济状况。例如,房地产数据的网络爬虫有助于分析哪些因素会影响该行业。同样,它也可用于从汽车行业获取数据。公司采集有关汽车行业的数据,例如用户和汽车零部件评论。
各行各业的公司从网站中提取数据,更新数据的相关性和实时度。其他网站 也会做同样的事情来确保数据集是完整的。数据越多越好,可以提供更多的参考,使整个数据集更有效。
公司应该提取哪些数据?
如前所述,并非所有在线数据都是提取的目标。在决定提取哪些数据时,您的业务目标、需求和目标应该是主要考虑因素。
可能有许多您可能感兴趣的数据目标。您可以提取产品描述、价格、客户评论和评分、常见问题页面、操作指南等。您还可以自定义自定义数据提取脚本以定位新产品和服务。在执行任何抓取活动之前,请确保您抓取的公共数据不会侵犯任何第三方权利。
常见的数据提取挑战
网站数据提取并非没有挑战。最常见的是:
数据抓取的最佳做法
如果您想解决上述问题,可以通过经验丰富的专业人员开发的复杂数据提取脚本来解决。但是,这仍然会使您面临被反抓取技术抓取和阻止的风险。这需要一个改变游戏规则的解决方案机构。更准确地说,IP 轮换代理。
IP 轮换代理将为您提供对大量 IP 地址的访问。从位于不同地理区域的 IP 发送请求将欺骗服务器并防止阻塞。此外,您可以使用代理切换器。代理切换器将使用代理数据中心池中的 IP 并自动分配它们,而不是手动分配 IP。
如果您没有足够的资源和经验丰富的开发团队来进行网络爬虫,那么是时候考虑使用现成的解决方案,例如 Real-Time Crawler。保证从搜索引擎和电商网站100%完成爬取任务,简化数据管理,汇总数据,让您一目了然。
从网站提取数据是否合法
许多公司依赖大数据,需求显着增长。根据Statista的研究统计,大数据市场每年都在急剧增长,预计到2027年将达到1030亿美元。这导致越来越多的公司将网页抓取作为最常见的数据采集方式之一。这种流行导致了一个广泛讨论的问题,即网络抓取是否合法。
由于对这个复杂的话题没有明确的答案,因此确保将执行的任何网络抓取操作不违反相关法律是很重要的。更重要的是,在获取任何数据之前,我们强烈建议您针对特定情况寻求专业的法律建议。
此外,除非您得到target网站的明确许可,否则我们强烈建议您不要抓取任何非公开数据。
Little Oxy 提醒您:本文中的任何内容都不应被解释为建议抓取任何非公开数据。
结论
总而言之,您将需要一个数据提取脚本来从网站 中提取数据。如您所见,由于操作范围、复杂性和不断变化的网站 结构,构建这些脚本可能具有挑战性。但是即使你有一个好的脚本,想要长时间实时抓取数据而不被IP屏蔽,你仍然需要使用轮换代理来改变你的IP。
如果您认为您的企业需要一个能够轻松提取数据的一体化解决方案,您可以立即注册并开始使用 Oxylabs 的实时爬虫。
如果您有任何问题,可以随时联系我们。
如何抓取网页数据(关键词的提取和转载和修改再带来的便利性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-09-12 11:14
搜索引擎在抓取大量原创网页时,会对其进行预处理,主要包括四个方面,关键词的提取、“镜像网页”(网页内容完全相同,不做任何修改)或“转载”网页(near-replicas,主题内容基本相同但可能有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和计算网页的重要性。
1.关键词的提取,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分中收录的关键词。对于中文,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,同一个词可能会在一个网页中出现多次。从有效性和效率的角度来看,并不是所有的词都应该出现在网页的呈现中,“的”、“在”等没有内容表示意义的词应该去掉,称为“停用词”“ (停用词)。这样,对于一个网页,有效词的数量大约为 200 个。
2.消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在 Web 上看到了大量重复的信息。这种现象对广大网民来说具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,还会引起用户的抱怨,“重复这么多,就给我一个。”因此,消除重复内容或主题内容的网页是搜索引擎抓取网页阶段的一项重要任务。
3、Link 分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只处理内容的文本,我们可以依靠“共享词袋”,即内容中收录的关键词集合,加上词频在词在文档集合中出现的最多(词频(tf,TF)和文档频率(文档频率或df,DF)等统计信息。TF和DF等频率信息可以在一定程度上表明词的相对重要性在一个文档中或者某个内容的相关性,这是有意义的。有了HTML标签,这种情况可能会进一步改善。例如,在同一个文档中,and之间的信息很可能比and之间的信息更重要。尤其是HTML文档中收录的其他文档的链接信息是近年来特别受关注的对象,相信它们不仅给出了网页之间的关系,而且在判断中起着重要的作用。制作网页的内容。
<p>4、计算网页的重要性,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。有很多因素需要考虑如何对查询结果进行排序。如何说一页比另一页更重要?人们参考科学文献重要性的评价方法。核心思想是“引用最多的就是重要的”。 “引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。 PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外链,基本没有明确的主题内容,有的网页是由大量的其他外链链接的。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段结果最终排名的一部分参数。 查看全部
如何抓取网页数据(关键词的提取和转载和修改再带来的便利性)
搜索引擎在抓取大量原创网页时,会对其进行预处理,主要包括四个方面,关键词的提取、“镜像网页”(网页内容完全相同,不做任何修改)或“转载”网页(near-replicas,主题内容基本相同但可能有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和计算网页的重要性。
1.关键词的提取,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分中收录的关键词。对于中文,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,同一个词可能会在一个网页中出现多次。从有效性和效率的角度来看,并不是所有的词都应该出现在网页的呈现中,“的”、“在”等没有内容表示意义的词应该去掉,称为“停用词”“ (停用词)。这样,对于一个网页,有效词的数量大约为 200 个。
2.消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在 Web 上看到了大量重复的信息。这种现象对广大网民来说具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,还会引起用户的抱怨,“重复这么多,就给我一个。”因此,消除重复内容或主题内容的网页是搜索引擎抓取网页阶段的一项重要任务。
3、Link 分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只处理内容的文本,我们可以依靠“共享词袋”,即内容中收录的关键词集合,加上词频在词在文档集合中出现的最多(词频(tf,TF)和文档频率(文档频率或df,DF)等统计信息。TF和DF等频率信息可以在一定程度上表明词的相对重要性在一个文档中或者某个内容的相关性,这是有意义的。有了HTML标签,这种情况可能会进一步改善。例如,在同一个文档中,and之间的信息很可能比and之间的信息更重要。尤其是HTML文档中收录的其他文档的链接信息是近年来特别受关注的对象,相信它们不仅给出了网页之间的关系,而且在判断中起着重要的作用。制作网页的内容。
<p>4、计算网页的重要性,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。有很多因素需要考虑如何对查询结果进行排序。如何说一页比另一页更重要?人们参考科学文献重要性的评价方法。核心思想是“引用最多的就是重要的”。 “引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。 PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外链,基本没有明确的主题内容,有的网页是由大量的其他外链链接的。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段结果最终排名的一部分参数。
如何抓取网页数据(:For循环和While循环不确定的网页(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-10 17:14
·
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
总结:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
我们通常遇到的网站页码显示形式如下:
首先是把所有的页面都可视化展示,比如之前爬过的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软
∞ 50行代码爬取东方财富网百万行财务报表数据
第二种是不直观显示网页总数,只能在后台查看,比如之前爬过的虎嗅网,文章见:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章
我今天要讲的就是第三种。不知有多少页,如豌豆荚:
对于前两种形式的网页,爬取的方法很简单,就用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号是不知道,所以循环到无法判断哪个页面结束。
如何解决?有两种方式。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
实际案例
下面我们以豌豆荚网站中“视频”类别下的App信息为例,通过上述两种方法抓取该类别下的所有App信息,包括App名称、评论、安装数, 和音量。
首先对网站做一个简单的分析,可以看到页面是通过ajax加载的,GET请求自带一些参数,可以使用params参数构造URL请求,但是我不'不知道总共有多少个页面,为了保证所有页面都下载完毕,设置更大的页面数,比如100个页面甚至1000个页面。
接下来我们尝试使用 For 和 While 循环爬取。
请求▌For循环
主要代码如下:
class Get_page():<br /> def __init__(self):<br /> # ajax 请求url<br /> self.ajax_url = 'https://www.wandoujia.com/wdjweb/api/category/more'<br /><br /> def get_page(self,page,cate_code,child_cate_code):<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> response = requests.get(self.ajax_url, headers=headers, params=params)<br /> content = response.json()['data']['content'] #提取json中的html页面数据<br /> return content<br /><br /> def parse_page(self, content):<br /> # 解析网页内容<br /> contents = pq(content)('.card').items()<br /> data = []<br /> for content in contents:<br /> data1 = {<br /> 'app_name': content('.name').text(),<br /> 'install': content('.install-count').text(),<br /> 'volume': content('.meta span:last-child').text(),<br /> 'comment': content('.comment').text(),<br /> }<br /> data.append(data1)<br /> if data:<br /> # 写入MongoDB<br /> self.write_to_mongodb(data)<br /><br />if __name__ == '__main__':<br /> # 实例化数据提取类<br /> wandou_page = Get_page()<br /> cate_code = 5029 # 影音播放大类别编号<br /> child_cate_code = 716 # 视频小类别编号<br /> for page in range(2, 100):<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' % page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> # 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
这里首先创建了一个 Get_page 类。 get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。可以使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则说明页面有内容,则循环往下。如果为空,则表示该页面已被爬取,执行else分支。 break 语句结束循环并完成抓取。
抓取结果如下。可以看到该分类共爬取了41页信息。
▌While 循环
虽然loop和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,另一种是改变判断条件。
整体代码不变,只是修改了For循环部分:
page = 2 # 设置爬取起始页数<br />while True:<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' %page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> page += 1<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
或者:
page = 2 # 设置爬取起始页数<br />page_last = False # while 循环初始条件<br />while not page_last:<br /> #...<br /> else:<br /> # break<br /> page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以再次测试其他类别的网页,例如选择“K歌”类别,代码为:718,然后只需要相应修改main函数中的child_cate_code即可。再次运行程序,可以看到分类下共有32个页面被抓取。
因为Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):<br /> pages=[]<br /> for i in range(1,10):<br /> url='http://www.example.com/?page=%s'%i<br /> page = scrapy.Request(url,callback==self.pare)<br /> pages.append(page)<br /> return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”类别App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):<br /> cate_code = 5019 # 新闻阅读<br /> child_cate_code = 940 # 电子书<br /> print('*' * 50)<br /> pages = []<br /> for page in range(2,50):<br /> print('正在爬取:第 %s 页 ' %page)<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> category_url = self.ajax_url + urlencode(params)<br /> pa = yield scrapy.Request(category_url,callback=self.parse)<br /> pages.append(pa)<br /> return pages<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87<br /> jsonresponse = json.loads(response.body_as_unicode())<br /> contents = jsonresponse['data']['content']<br /> # response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换<br /> contents = scrapy.Selector(text=contents, type="html")<br /> contents = contents.css('.card')<br /> for content in contents:<br /> item = WandoujiaItem()<br /> item['app_name'] = content.css('.name::text').extract_first()<br /> item['install'] = content.css('.install-count::text').extract_first()<br /> item['volume'] = content.css('.meta span:last-child::text').extract_first()<br /> item['comment'] = content.css('.comment::text').extract_first().strip()<br /> yield item
以上代码简单易懂,简单说明几点:
判断当前页面是否被爬取的一、判断条件改为response.body的长度大于100。
因为请求已经爬完页面,所以返回的响应结果不是空的,而是一段json内容的长度(长度是87),这里的内容键值内容为空,所以这里是判断条件选择一个大于87的值,比如100,大于100表示该页面有内容,小于100表示已被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
第二、当需要从文本中解析内容时,无法直接解析,需要先进行转换。
通常我们在解析内容的时候,直接解析返回的响应,比如使用response.css()方法,但是这里,我们的分析对象不是响应,而是响应HTML文本返回的json内容,文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加下面这行代码进行转换。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别只有22页内容,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):<br /> page = 2 # 设置爬取起始页数<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # meta传递参数<br /> yield scrapy.Request(category_url,callback=self.parse,meta=dict)<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87<br /> page = response.meta['page']<br /> cate_code = response.meta['cate_code']<br /> child_cate_code = response.meta['child_cate_code']<br /> #...<br /> for content in contents:<br /> yield item<br /><br /> # while循环构造url递归爬下一页<br /> page += 1<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> ajax_url = self.ajax_url + urlencode(params)<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code}<br /> yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
这里简单说明几点:
一、While循环的思路是从头开始抓取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环到解析直到最后一页被抓取。但是,这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息抓取。
以上就是本文的全部内容,总结一下: 查看全部
如何抓取网页数据(:For循环和While循环不确定的网页(二))
·
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
总结:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
我们通常遇到的网站页码显示形式如下:
首先是把所有的页面都可视化展示,比如之前爬过的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软
∞ 50行代码爬取东方财富网百万行财务报表数据
第二种是不直观显示网页总数,只能在后台查看,比如之前爬过的虎嗅网,文章见:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章
我今天要讲的就是第三种。不知有多少页,如豌豆荚:
对于前两种形式的网页,爬取的方法很简单,就用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号是不知道,所以循环到无法判断哪个页面结束。
如何解决?有两种方式。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页。爬行完成后,break跳出循环,结束爬行。
第二种方法使用While循环,可以结合break语句,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后改变判断条件为 False 跳出循环并结束爬行选择。
实际案例
下面我们以豌豆荚网站中“视频”类别下的App信息为例,通过上述两种方法抓取该类别下的所有App信息,包括App名称、评论、安装数, 和音量。
首先对网站做一个简单的分析,可以看到页面是通过ajax加载的,GET请求自带一些参数,可以使用params参数构造URL请求,但是我不'不知道总共有多少个页面,为了保证所有页面都下载完毕,设置更大的页面数,比如100个页面甚至1000个页面。
接下来我们尝试使用 For 和 While 循环爬取。
请求▌For循环
主要代码如下:
class Get_page():<br /> def __init__(self):<br /> # ajax 请求url<br /> self.ajax_url = 'https://www.wandoujia.com/wdjweb/api/category/more'<br /><br /> def get_page(self,page,cate_code,child_cate_code):<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> response = requests.get(self.ajax_url, headers=headers, params=params)<br /> content = response.json()['data']['content'] #提取json中的html页面数据<br /> return content<br /><br /> def parse_page(self, content):<br /> # 解析网页内容<br /> contents = pq(content)('.card').items()<br /> data = []<br /> for content in contents:<br /> data1 = {<br /> 'app_name': content('.name').text(),<br /> 'install': content('.install-count').text(),<br /> 'volume': content('.meta span:last-child').text(),<br /> 'comment': content('.comment').text(),<br /> }<br /> data.append(data1)<br /> if data:<br /> # 写入MongoDB<br /> self.write_to_mongodb(data)<br /><br />if __name__ == '__main__':<br /> # 实例化数据提取类<br /> wandou_page = Get_page()<br /> cate_code = 5029 # 影音播放大类别编号<br /> child_cate_code = 716 # 视频小类别编号<br /> for page in range(2, 100):<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' % page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> # 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
这里首先创建了一个 Get_page 类。 get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。可以使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则说明页面有内容,则循环往下。如果为空,则表示该页面已被爬取,执行else分支。 break 语句结束循环并完成抓取。
抓取结果如下。可以看到该分类共爬取了41页信息。
▌While 循环
虽然loop和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,另一种是改变判断条件。
整体代码不变,只是修改了For循环部分:
page = 2 # 设置爬取起始页数<br />while True:<br /> print('*' * 50)<br /> print('正在爬取:第 %s 页' %page)<br /> content = wandou_page.get_page(page,cate_code,child_cate_code)<br /> if not content == '':<br /> wandou_page.parse_page(content)<br /> page += 1<br /> sleep = np.random.randint(3,6)<br /> time.sleep(sleep)<br /> else:<br /> print('该类别已下载完最后一页')<br /> break
或者:
page = 2 # 设置爬取起始页数<br />page_last = False # while 循环初始条件<br />while not page_last:<br /> #...<br /> else:<br /> # break<br /> page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以再次测试其他类别的网页,例如选择“K歌”类别,代码为:718,然后只需要相应修改main函数中的child_cate_code即可。再次运行程序,可以看到分类下共有32个页面被抓取。
因为Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):<br /> pages=[]<br /> for i in range(1,10):<br /> url='http://www.example.com/?page=%s'%i<br /> page = scrapy.Request(url,callback==self.pare)<br /> pages.append(page)<br /> return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”类别App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):<br /> cate_code = 5019 # 新闻阅读<br /> child_cate_code = 940 # 电子书<br /> print('*' * 50)<br /> pages = []<br /> for page in range(2,50):<br /> print('正在爬取:第 %s 页 ' %page)<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> category_url = self.ajax_url + urlencode(params)<br /> pa = yield scrapy.Request(category_url,callback=self.parse)<br /> pages.append(pa)<br /> return pages<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87<br /> jsonresponse = json.loads(response.body_as_unicode())<br /> contents = jsonresponse['data']['content']<br /> # response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换<br /> contents = scrapy.Selector(text=contents, type="html")<br /> contents = contents.css('.card')<br /> for content in contents:<br /> item = WandoujiaItem()<br /> item['app_name'] = content.css('.name::text').extract_first()<br /> item['install'] = content.css('.install-count::text').extract_first()<br /> item['volume'] = content.css('.meta span:last-child::text').extract_first()<br /> item['comment'] = content.css('.comment::text').extract_first().strip()<br /> yield item
以上代码简单易懂,简单说明几点:
判断当前页面是否被爬取的一、判断条件改为response.body的长度大于100。
因为请求已经爬完页面,所以返回的响应结果不是空的,而是一段json内容的长度(长度是87),这里的内容键值内容为空,所以这里是判断条件选择一个大于87的值,比如100,大于100表示该页面有内容,小于100表示已被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
第二、当需要从文本中解析内容时,无法直接解析,需要先进行转换。
通常我们在解析内容的时候,直接解析返回的响应,比如使用response.css()方法,但是这里,我们的分析对象不是响应,而是响应HTML文本返回的json内容,文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加下面这行代码进行转换。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别只有22页内容,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):<br /> page = 2 # 设置爬取起始页数<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # meta传递参数<br /> yield scrapy.Request(category_url,callback=self.parse,meta=dict)<br /><br />def parse(self, response):<br /> if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87<br /> page = response.meta['page']<br /> cate_code = response.meta['cate_code']<br /> child_cate_code = response.meta['child_cate_code']<br /> #...<br /> for content in contents:<br /> yield item<br /><br /> # while循环构造url递归爬下一页<br /> page += 1<br /> params = {<br /> 'catId': cate_code,<br /> 'subCatId': child_cate_code,<br /> 'page': page,<br /> }<br /> ajax_url = self.ajax_url + urlencode(params)<br /> dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code}<br /> yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
这里简单说明几点:
一、While循环的思路是从头开始抓取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环到解析直到最后一页被抓取。但是,这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息抓取。
以上就是本文的全部内容,总结一下:
如何抓取网页数据(计算机学院大数据专业大三的错误出现,你中招了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2021-09-10 17:11
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容
一、爬行策略
爬取策略是指在爬取过程中对从每个页面解析出的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下限制
(1)不要给web服务器太大压力
这些压力主要体现在:
①与网络服务器的连接需要占用其网络带宽
②每次请求一个页面,都需要从硬盘中读取一个文件
③对于动态页面,还需要执行脚本。如果开启Session,大数据访问需要更多内存
(2)不要占用太多客户端资源
爬虫程序在与Web服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是一些长期连接存在,或者网络连接的超时参数设置不当,很可能客户端消耗的网络资源有限。
1.2 爬取策略设计的综合考虑
毕竟不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗和服务器端的影响等,一个好的爬虫需要不断结合一些特性网页链接进行优化和调整。
对于爬虫来说,爬取的初始页面一般都是比较重要的页面,比如某个公司的首页,news网站的首页等
从爬虫管理多个页面超链接的效率来看,基本的深度优先策略和广度优先策略的效率更高。
从页面优先级的角度来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但在确定下一个要爬取的页面时,总是希望优先级高的页面先被爬取。
由于页面之间的链接结构非常复杂,可能存在双向链接、循环链接等
爬虫在WEB服务器上爬取页面时需要先建立网络连接,占用主机和连接资源。非常有必要合理分配这种资源占用。
二、先尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络地图:
网络爬虫来自这个庞大复杂的网络体,根据给定的策略,抓取需要的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感觉到从下一级网页到下一级网页的链接有多少
三、抢夺策略
从网络爬虫的角度来看,整个互联网可以分为:
3.1、Data Capture Strategy Incomplete PageRank Strategy OCIP Strategy Big Site Priority Strategy Collaboration Capture Strategy Graph Traversal Algorithm Strategy3.1.1、Incomplete PageRank Strategy
一般来说,网页的PageRank分数计算如下:
3.1.2、OPICStrategy
OPIC 是 Online Page Importance Computation 的缩写,是一种改进的 PageRank 算法
OPIC策略的基本思路
3.1.3、大站优先策略(粗略)
大站优先策略思路简单明了:
“战争”通常具有以下特点:
如何识别目标网站是否是一场大战?
3.1.4、协同爬取策略(需要标准化的URL地址)
为了提高网络爬虫的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取。这就是协同爬取策略的目标
合作爬取策略通常采用以下两种方式:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、depth 优先
深度优先从根节点开始,沿着路径尽可能深地访问,直到遇到叶节点。
2、广度优先
使用广度优先策略的原因:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能多地访问离根节点最近的节点。
3、Python 实现
DFS 和 BFS 具有高度的对称性,因此在 Python 实现中,不需要将两种数据结构分开,只需要构造一种数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)
BFS 和 DFS 各有优势。 DFS更容易陷入死循环,通常有价值的网页不会隐藏得太深,所以BFS通常是更好的选择。上面的代码使用列表来模拟堆栈或队列。 Python中还有一个Queue模块,里面收录了LifoQueue和PriorityQueue,使用起来会更方便。
3.2、数据更新策略
常见的更新策略如下:
聚类策略的基本思路
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。 查看全部
如何抓取网页数据(计算机学院大数据专业大三的错误出现,你中招了吗?)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,希望我有温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只会在csdn平台更新,
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载! ! !
内容
一、爬行策略
爬取策略是指在爬取过程中对从每个页面解析出的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下限制
(1)不要给web服务器太大压力
这些压力主要体现在:
①与网络服务器的连接需要占用其网络带宽
②每次请求一个页面,都需要从硬盘中读取一个文件
③对于动态页面,还需要执行脚本。如果开启Session,大数据访问需要更多内存
(2)不要占用太多客户端资源
爬虫程序在与Web服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是一些长期连接存在,或者网络连接的超时参数设置不当,很可能客户端消耗的网络资源有限。
1.2 爬取策略设计的综合考虑
毕竟不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗和服务器端的影响等,一个好的爬虫需要不断结合一些特性网页链接进行优化和调整。
对于爬虫来说,爬取的初始页面一般都是比较重要的页面,比如某个公司的首页,news网站的首页等
从爬虫管理多个页面超链接的效率来看,基本的深度优先策略和广度优先策略的效率更高。
从页面优先级的角度来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但在确定下一个要爬取的页面时,总是希望优先级高的页面先被爬取。
由于页面之间的链接结构非常复杂,可能存在双向链接、循环链接等
爬虫在WEB服务器上爬取页面时需要先建立网络连接,占用主机和连接资源。非常有必要合理分配这种资源占用。
二、先尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络地图:
网络爬虫来自这个庞大复杂的网络体,根据给定的策略,抓取需要的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感觉到从下一级网页到下一级网页的链接有多少
三、抢夺策略
从网络爬虫的角度来看,整个互联网可以分为:
3.1、Data Capture Strategy Incomplete PageRank Strategy OCIP Strategy Big Site Priority Strategy Collaboration Capture Strategy Graph Traversal Algorithm Strategy3.1.1、Incomplete PageRank Strategy
一般来说,网页的PageRank分数计算如下:
3.1.2、OPICStrategy
OPIC 是 Online Page Importance Computation 的缩写,是一种改进的 PageRank 算法
OPIC策略的基本思路
3.1.3、大站优先策略(粗略)
大站优先策略思路简单明了:
“战争”通常具有以下特点:
如何识别目标网站是否是一场大战?
3.1.4、协同爬取策略(需要标准化的URL地址)
为了提高网络爬虫的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取。这就是协同爬取策略的目标
合作爬取策略通常采用以下两种方式:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、depth 优先
深度优先从根节点开始,沿着路径尽可能深地访问,直到遇到叶节点。
2、广度优先
使用广度优先策略的原因:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能多地访问离根节点最近的节点。
3、Python 实现
DFS 和 BFS 具有高度的对称性,因此在 Python 实现中,不需要将两种数据结构分开,只需要构造一种数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)
BFS 和 DFS 各有优势。 DFS更容易陷入死循环,通常有价值的网页不会隐藏得太深,所以BFS通常是更好的选择。上面的代码使用列表来模拟堆栈或队列。 Python中还有一个Queue模块,里面收录了LifoQueue和PriorityQueue,使用起来会更方便。
3.2、数据更新策略
常见的更新策略如下:
聚类策略的基本思路
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
我从不厌倦阅读一本好书数百遍。而如果我想成为全场最漂亮的男孩子,我必须坚持通过学习获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,听说喜欢的人不会太幸运,每天都精力充沛!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。

