
如何抓取网页数据
如何抓取网页数据(如何直接从网页里去找到这个url地址呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-18 07:06
如何抓取网页数据学习css和爬虫,是一件很耗时很费心思的事情,当你已经把一个页面爬过来,得到各种数据,并分析爬取到的内容,改变分析这个页面的思路,你将可以清晰看到这个页面的整体网页结构。无论是看看baidu,google这些大佬的服务器网页代码,还是网页中的各种元素,或者是看看idc对标准数据库的整理。
这些都是必不可少的,你才会知道这个服务为什么有这么大量的资源投入。比如我今天,想要抓取下面这个页面,但是它是css和html混合的。为了搞清楚这个结构是怎么回事,这是最基础的,才开始抓取这个页面。因为我只抓取标题和倒数第三行的百度广告字样,至于它里面的其他东西,比如数据结构怎么写、怎么布局、前端过滤的方法这些知识和过程,我已经完全不懂了。
所以这个事情也只能通过直觉,去判断这些元素:后面会慢慢讲到,让我们一起抓取这个页面吧。上述的代码,大部分内容都在下面的文件。这个页面看似很复杂,很多地方不得不重复写,比如,在img标签里可以添加data-content属性,来绑定容器里面的图片内容。但是,当你通过上面所有的方法,把整个页面抓下来,你会发现,这些img标签里面的数据,并不是很难理解。
因为你对整个页面进行分析,可以发现这些img的data-content属性,最终都会转换成url来显示。其实就是把元素名字拼起来,形成一个链接地址,然后到浏览器输入搜索。那如何直接从网页里去找到这个url地址呢?在爬虫小白课堂第一课里,我们的课程老师讲解了「urlconnection」函数,该函数会返回request对象,从而可以从这个对象里,获取到整个链接地址的网页内容。
(也就是javascript里那个callback函数)我们就以这个小程序为例,来看看怎么从小程序抓取a页面内容。image/png0.导入库在实际爬虫里,有一个connection函数,要在浏览器调用,另外一个函数,是找这个链接地址到小程序的函数。第一个函数用来定义urlconnection对象。每次调用的时候,向浏览器发送网络请求,从而在浏览器中把小程序发给服务器。
这个函数的大部分功能,在小程序文档里都有,这里只简单说下。varconnection=request.urlconnection;urlconnection有很多参数,基本都是request的三个参数(scheme,connection,schemecode)这里简单讲下schemecode。schemecode是一串固定的不会变的字符串,即scheme标识。
在我们定义小程序请求对象的时候,需要将schemecode放在connection的attribute里。baidu页面的urlconnection函数定义了整个页面的schemecode。urlconnection实际上是一个非常轻量级的函数,reques。 查看全部
如何抓取网页数据(如何直接从网页里去找到这个url地址呢?(图))
如何抓取网页数据学习css和爬虫,是一件很耗时很费心思的事情,当你已经把一个页面爬过来,得到各种数据,并分析爬取到的内容,改变分析这个页面的思路,你将可以清晰看到这个页面的整体网页结构。无论是看看baidu,google这些大佬的服务器网页代码,还是网页中的各种元素,或者是看看idc对标准数据库的整理。
这些都是必不可少的,你才会知道这个服务为什么有这么大量的资源投入。比如我今天,想要抓取下面这个页面,但是它是css和html混合的。为了搞清楚这个结构是怎么回事,这是最基础的,才开始抓取这个页面。因为我只抓取标题和倒数第三行的百度广告字样,至于它里面的其他东西,比如数据结构怎么写、怎么布局、前端过滤的方法这些知识和过程,我已经完全不懂了。
所以这个事情也只能通过直觉,去判断这些元素:后面会慢慢讲到,让我们一起抓取这个页面吧。上述的代码,大部分内容都在下面的文件。这个页面看似很复杂,很多地方不得不重复写,比如,在img标签里可以添加data-content属性,来绑定容器里面的图片内容。但是,当你通过上面所有的方法,把整个页面抓下来,你会发现,这些img标签里面的数据,并不是很难理解。
因为你对整个页面进行分析,可以发现这些img的data-content属性,最终都会转换成url来显示。其实就是把元素名字拼起来,形成一个链接地址,然后到浏览器输入搜索。那如何直接从网页里去找到这个url地址呢?在爬虫小白课堂第一课里,我们的课程老师讲解了「urlconnection」函数,该函数会返回request对象,从而可以从这个对象里,获取到整个链接地址的网页内容。
(也就是javascript里那个callback函数)我们就以这个小程序为例,来看看怎么从小程序抓取a页面内容。image/png0.导入库在实际爬虫里,有一个connection函数,要在浏览器调用,另外一个函数,是找这个链接地址到小程序的函数。第一个函数用来定义urlconnection对象。每次调用的时候,向浏览器发送网络请求,从而在浏览器中把小程序发给服务器。
这个函数的大部分功能,在小程序文档里都有,这里只简单说下。varconnection=request.urlconnection;urlconnection有很多参数,基本都是request的三个参数(scheme,connection,schemecode)这里简单讲下schemecode。schemecode是一串固定的不会变的字符串,即scheme标识。
在我们定义小程序请求对象的时候,需要将schemecode放在connection的attribute里。baidu页面的urlconnection函数定义了整个页面的schemecode。urlconnection实际上是一个非常轻量级的函数,reques。
如何抓取网页数据(如何利用Python网络爬虫抓取微信朋友圈的动态(上)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2022-04-14 20:16
阿里云 > 云栖社区 > 主题地图 > Z > 如何使用爬虫抓取数据
推荐活动:
更多优惠>
当前主题:如何使用网络爬虫爬取数据添加到采集夹
相关话题:
如何使用网络爬虫爬取数据相关博客查看更多博客
如何使用Python网络爬虫抓取微信朋友圈动态(上)
作者:python进阶2219人查看评论:03年前
今天小编就和大家分享一下如何使用Python网络爬虫抓取微信朋友圈的动态信息。其实单独抓取朋友圈会很困难,因为微信并没有提供网易云音乐的API接口。,所以很容易找到门。不过不要慌,小编在网上找了个第三方工具,可以导出朋友圈,然后
阅读全文
【网络爬虫】获取百度关键词搜索数据的网络爬虫
作者:安毅 1247人浏览评论:05年前
转载请注明出处:本文来自【大学之旅_安易博客】只需通过关键词,爬取一些百度知道的搜索数据。例如:提问、提问时间;回答文字、回答时间、点赞数、积木数、回答者、回答者等级、搜索关键字等。
阅读全文
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接
作者:python进阶1047人查看评论:01年前
[一、项目背景]相信大家都有一个很头疼的经历,下载电影很辛苦吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python网络爬虫2----scrapy爬虫架构介绍及初步测试
作者:陈国林 1397 浏览评论:08年前
原文出处:上一篇文章的环境搭建是一个相对于手工操作的过程,你可能会有这个疑问,什么是scrapy?为什么要使用scrapy?以下主要是对这两个问题的简要回答。请尊重作者
阅读全文
实现网络图片爬虫,仅需5秒快速下载整个网页所有图片并打包zip
作者:晃哥706查看评论:03年前
我们经常需要使用互联网上的一些共享资源。图片是一种资源。如何批量下载网页上的图片?有时候我们需要下载网页上的图片,但是网页上的图片那么多,我们要怎么下载呢?如果这个网页就是我们想要的所有图片,还需要一张一张吗?右键下载?当然不是,这个
阅读全文
Python爬虫笔记(一):爬虫基本介绍
作者:angel_kitty1794 观众评论:04年前
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。这是本项目的第一篇文章。这次就简单介绍一下Python爬虫,会根据项目进度不断更新。一、网络爬虫是什么概念网络爬虫
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:04年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
爬虫的“海盗有办法”——机器人协议
作者:尤迪1239 浏览评论:04年前
网络爬虫君子协议专用于网络爬虫大小,规模小,数量少,对爬取速度不敏感,中等规模的requests库,大数据规模,对爬取速度敏感,大型scrapy库,搜索引擎,和关键定制开发爬虫爬网玩网络爬虫网站爬虫系列网站爬虫引起的问题
阅读全文 查看全部
如何抓取网页数据(如何利用Python网络爬虫抓取微信朋友圈的动态(上)(组图))
阿里云 > 云栖社区 > 主题地图 > Z > 如何使用爬虫抓取数据

推荐活动:
更多优惠>
当前主题:如何使用网络爬虫爬取数据添加到采集夹
相关话题:
如何使用网络爬虫爬取数据相关博客查看更多博客
如何使用Python网络爬虫抓取微信朋友圈动态(上)


作者:python进阶2219人查看评论:03年前
今天小编就和大家分享一下如何使用Python网络爬虫抓取微信朋友圈的动态信息。其实单独抓取朋友圈会很困难,因为微信并没有提供网易云音乐的API接口。,所以很容易找到门。不过不要慌,小编在网上找了个第三方工具,可以导出朋友圈,然后
阅读全文
【网络爬虫】获取百度关键词搜索数据的网络爬虫


作者:安毅 1247人浏览评论:05年前
转载请注明出处:本文来自【大学之旅_安易博客】只需通过关键词,爬取一些百度知道的搜索数据。例如:提问、提问时间;回答文字、回答时间、点赞数、积木数、回答者、回答者等级、搜索关键字等。
阅读全文
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接

作者:python进阶1047人查看评论:01年前
[一、项目背景]相信大家都有一个很头疼的经历,下载电影很辛苦吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python网络爬虫2----scrapy爬虫架构介绍及初步测试


作者:陈国林 1397 浏览评论:08年前
原文出处:上一篇文章的环境搭建是一个相对于手工操作的过程,你可能会有这个疑问,什么是scrapy?为什么要使用scrapy?以下主要是对这两个问题的简要回答。请尊重作者
阅读全文
实现网络图片爬虫,仅需5秒快速下载整个网页所有图片并打包zip

作者:晃哥706查看评论:03年前
我们经常需要使用互联网上的一些共享资源。图片是一种资源。如何批量下载网页上的图片?有时候我们需要下载网页上的图片,但是网页上的图片那么多,我们要怎么下载呢?如果这个网页就是我们想要的所有图片,还需要一张一张吗?右键下载?当然不是,这个
阅读全文
Python爬虫笔记(一):爬虫基本介绍


作者:angel_kitty1794 观众评论:04年前
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。这是本项目的第一篇文章。这次就简单介绍一下Python爬虫,会根据项目进度不断更新。一、网络爬虫是什么概念网络爬虫
阅读全文
如何使用 Python 抓取数据?(一)网页抓取


作者:王淑仪2089 浏览评论:04年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
爬虫的“海盗有办法”——机器人协议

作者:尤迪1239 浏览评论:04年前
网络爬虫君子协议专用于网络爬虫大小,规模小,数量少,对爬取速度不敏感,中等规模的requests库,大数据规模,对爬取速度敏感,大型scrapy库,搜索引擎,和关键定制开发爬虫爬网玩网络爬虫网站爬虫系列网站爬虫引起的问题
阅读全文
如何抓取网页数据(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-12 12:42
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。 查看全部
如何抓取网页数据(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。
如何抓取网页数据(爬虫优化:爬虫最重要的部分做出详细介绍:获取网页爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-10 08:32
爬行动物基础:
简单地说,爬虫是一个自动程序,它请求网页并提取数据并保存信息。
人们经常把爬虫比作爬网的蜘蛛,把网络的节点比作网页。爬虫爬取时,相当于访问页面获取其信息。节点之间的连接可以比作网页之间的连接。链接关系,让蜘蛛在经过一个节点后可以继续沿着该节点连接爬到下一个节点,也就是通过一个网页继续获取后续页面,从而可以爬取整个网页的节点蜘蛛,所以 网站@ > 数据可以被捕获。
简单流程介绍:
下面说一下爬虫的具体流程,一般分为四个步骤:
发起请求,通过请求库向目标站点发起请求,我们可以模拟携带浏览器信息、cookie值、关键字查询等信息访问服务器,然后等待服务器响应
解析内容:服务器响应的内容可能是HTML纯文本、json格式数据,也可能是二进制(如图片、视频等),我们可以使用相关的解析库进行解析、保存或进一步处理。
处理信息:一般来说,解析库解析出来的内容比较复杂,晦涩难懂。我们使用格式或切片等技术使内容清晰明了。只有这样,它才能被认为是有用的信息。接下来,我们可以将信息存储在本地、数据库或远程服务器等。
爬虫优化:爬虫优化有很多方面,比如控制爬虫速率、使用高安全代理服务器、使用分布式爬虫、处理异常……
接下来,作者将对爬虫最重要的部分进行详细介绍:
获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站@>的服务器发送一个Request,返回的Response的body就是网页的源代码。
所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。在python3中,相关库有:urllib(python自带库)、requests(优雅的第三方库)
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
可以捕获什么样的数据:
JavaScript 呈现页面:
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。
因此,当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。这种情况下,我们可以在后台分析Ajax接口,通过模拟Ajax请求得到渲染的页面,也可以使用Selenium等库来模拟JavaScript。
本期对爬虫基本原理的描述就到这里啦~
下一篇预告:《使用urllib请求库》,文章讲述如何编写Python爬虫脚本,你期待吗hhh
跟着我,不要迷路!!
欢迎朋友们在评论区指出up主的不足之处。有学习问题也可以找他们交流学习~ 查看全部
如何抓取网页数据(爬虫优化:爬虫最重要的部分做出详细介绍:获取网页爬虫)
爬行动物基础:
简单地说,爬虫是一个自动程序,它请求网页并提取数据并保存信息。
人们经常把爬虫比作爬网的蜘蛛,把网络的节点比作网页。爬虫爬取时,相当于访问页面获取其信息。节点之间的连接可以比作网页之间的连接。链接关系,让蜘蛛在经过一个节点后可以继续沿着该节点连接爬到下一个节点,也就是通过一个网页继续获取后续页面,从而可以爬取整个网页的节点蜘蛛,所以 网站@ > 数据可以被捕获。
简单流程介绍:
下面说一下爬虫的具体流程,一般分为四个步骤:
发起请求,通过请求库向目标站点发起请求,我们可以模拟携带浏览器信息、cookie值、关键字查询等信息访问服务器,然后等待服务器响应
解析内容:服务器响应的内容可能是HTML纯文本、json格式数据,也可能是二进制(如图片、视频等),我们可以使用相关的解析库进行解析、保存或进一步处理。
处理信息:一般来说,解析库解析出来的内容比较复杂,晦涩难懂。我们使用格式或切片等技术使内容清晰明了。只有这样,它才能被认为是有用的信息。接下来,我们可以将信息存储在本地、数据库或远程服务器等。
爬虫优化:爬虫优化有很多方面,比如控制爬虫速率、使用高安全代理服务器、使用分布式爬虫、处理异常……
接下来,作者将对爬虫最重要的部分进行详细介绍:

获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站@>的服务器发送一个Request,返回的Response的body就是网页的源代码。
所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。在python3中,相关库有:urllib(python自带库)、requests(优雅的第三方库)
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
可以捕获什么样的数据:
JavaScript 呈现页面:
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。
因此,当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。这种情况下,我们可以在后台分析Ajax接口,通过模拟Ajax请求得到渲染的页面,也可以使用Selenium等库来模拟JavaScript。
本期对爬虫基本原理的描述就到这里啦~
下一篇预告:《使用urllib请求库》,文章讲述如何编写Python爬虫脚本,你期待吗hhh
跟着我,不要迷路!!
欢迎朋友们在评论区指出up主的不足之处。有学习问题也可以找他们交流学习~
如何抓取网页数据(外贸网站建设优化的技巧你知道吗的工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-05 04:07
搜索引擎工作流程:一个搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。
当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。
蜘蛛爬行和爬行
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。
搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。相关阅读:外贸技巧你知道吗网站建设优化
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、词序分离、去除关键词 个单词。停用词,确定是否需要启动综合搜索,确定是否存在拼写错误或拼写错误等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。
虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。
搜索引擎排名
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。
当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,蜘蛛不仅会爬取网站的内容,还会爬取内部链结构、爬取速度、服务器响应速度等一系列技术指标。蜘蛛爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量的网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重、网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <
搜索引擎每天都在重复上述过程。通过不断更新索引数据和排序算法,用户可以搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。
AB客户专业的Google SEO团队,确保您的官网排名第一。 查看全部
如何抓取网页数据(外贸网站建设优化的技巧你知道吗的工作流程)
搜索引擎工作流程:一个搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。
当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。

蜘蛛爬行和爬行
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。
搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。相关阅读:外贸技巧你知道吗网站建设优化
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、词序分离、去除关键词 个单词。停用词,确定是否需要启动综合搜索,确定是否存在拼写错误或拼写错误等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。
虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。

搜索引擎排名
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。
当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,蜘蛛不仅会爬取网站的内容,还会爬取内部链结构、爬取速度、服务器响应速度等一系列技术指标。蜘蛛爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量的网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重、网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <
搜索引擎每天都在重复上述过程。通过不断更新索引数据和排序算法,用户可以搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。
AB客户专业的Google SEO团队,确保您的官网排名第一。
如何抓取网页数据(如何抓取网页数据才是值得学习的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-01 11:04
如何抓取网页数据才是值得学习的?抓取网页数据,只需要能抓住网页的变化,那基本上就能获取到网页中所需要的数据了。这里为大家整理了主流网站中常用的9大抓取工具,分为两大类:一类是网页html解析工具,另一类是网页爬虫。网页数据解析工具常用的有selenium/webdriver两大工具。一:网页html解析工具nimojs,可以将任意文件的标题格式化,并获取编码所需要的字符集。
nimojs之所以非常受欢迎,主要是因为该工具提供了丰富的插件,包括dateformat、includekeyword、renderfield等。下面是官方对nimojs的介绍:(1)nimojs特色:①nimojs提供了丰富的、对html和request结构模式支持完整的解析工具;②可以根据html文件中的内容获取重要的元素的html标签名称,并实现相应的id映射;③可以应用html格式转换库,比如xpath和parser等;④structuredhelper可以输出、合并或者拆分网页中的布局;⑤无需安装在任何浏览器上;⑥使用不同的解析工具,可以以便宜、快速和高质量的方式获取html文件。
nimojs极大地提高了开发者的效率,可以轻松完成像发布个人博客一样的html文件的发布及爬取任务。nimojs的用户类型也非常丰富,不管是初级初学者还是资深网站数据工程师都可以找到相应的产品。它的tinyhub是一个用于网页数据抓取的应用程序,它通过用户搜索引擎进行同名网站数据抓取。urlahtml工具不仅基于webpathread来获取html网页,同时支持http协议栈的请求和响应。
在使用这个工具时,你只需要提供一个python文件,当请求成功后把获取的html文件文件传给urlahtml即可,urlahtml将对数据文件进行解析处理并返回一个python结构数据。在新建urlhtml程序时,你不需要安装这个工具。urlhtml工具还支持pyspider,scrapy等工具,用起来非常方便。
此外,这个工具还支持python和matlab混合编程,可以运行在windows、linux、macos等不同的操作系统上。pipto4js是一个开源项目,它是以python语言为基础,直接调用编译好的python字节码(bytecode),从而完成对网页中javascript、css、图片的查找及解析任务。
同时也支持requests,beautifulsoup,lxml等主流数据包。piptapy是由pipto4js衍生而来的,它包含了pipto4js的一切。pipto4js提供了各种数据包解析相关的包。比如pipto4,pipto4j,math.floor,numpy和scipy等等。当你在用pipto4js来抓取一个网页的时候,你不需要安装任何程序或包。你可以使用pipto4js直接开启web程序。 查看全部
如何抓取网页数据(如何抓取网页数据才是值得学习的?(图))
如何抓取网页数据才是值得学习的?抓取网页数据,只需要能抓住网页的变化,那基本上就能获取到网页中所需要的数据了。这里为大家整理了主流网站中常用的9大抓取工具,分为两大类:一类是网页html解析工具,另一类是网页爬虫。网页数据解析工具常用的有selenium/webdriver两大工具。一:网页html解析工具nimojs,可以将任意文件的标题格式化,并获取编码所需要的字符集。
nimojs之所以非常受欢迎,主要是因为该工具提供了丰富的插件,包括dateformat、includekeyword、renderfield等。下面是官方对nimojs的介绍:(1)nimojs特色:①nimojs提供了丰富的、对html和request结构模式支持完整的解析工具;②可以根据html文件中的内容获取重要的元素的html标签名称,并实现相应的id映射;③可以应用html格式转换库,比如xpath和parser等;④structuredhelper可以输出、合并或者拆分网页中的布局;⑤无需安装在任何浏览器上;⑥使用不同的解析工具,可以以便宜、快速和高质量的方式获取html文件。
nimojs极大地提高了开发者的效率,可以轻松完成像发布个人博客一样的html文件的发布及爬取任务。nimojs的用户类型也非常丰富,不管是初级初学者还是资深网站数据工程师都可以找到相应的产品。它的tinyhub是一个用于网页数据抓取的应用程序,它通过用户搜索引擎进行同名网站数据抓取。urlahtml工具不仅基于webpathread来获取html网页,同时支持http协议栈的请求和响应。
在使用这个工具时,你只需要提供一个python文件,当请求成功后把获取的html文件文件传给urlahtml即可,urlahtml将对数据文件进行解析处理并返回一个python结构数据。在新建urlhtml程序时,你不需要安装这个工具。urlhtml工具还支持pyspider,scrapy等工具,用起来非常方便。
此外,这个工具还支持python和matlab混合编程,可以运行在windows、linux、macos等不同的操作系统上。pipto4js是一个开源项目,它是以python语言为基础,直接调用编译好的python字节码(bytecode),从而完成对网页中javascript、css、图片的查找及解析任务。
同时也支持requests,beautifulsoup,lxml等主流数据包。piptapy是由pipto4js衍生而来的,它包含了pipto4js的一切。pipto4js提供了各种数据包解析相关的包。比如pipto4,pipto4j,math.floor,numpy和scipy等等。当你在用pipto4js来抓取一个网页的时候,你不需要安装任何程序或包。你可以使用pipto4js直接开启web程序。
如何抓取网页数据(怎么用谷歌来分析网站的API,怎么才能获得浏览器的数据报告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 595 次浏览 • 2022-04-01 08:06
有很多网友担心如何用谷歌分析网站的API,如何获取浏览器的数据报告,让小编为大家带来详细的分析方法。
1.注册谷歌分析
注:以下操作基本需要爬墙,请自备梯子。
登录您的 Google 帐户,注册 [Google Analytics]
然后设置你的账户基本信息
获取跟踪 ID 并同意协议。
2.将 Google Analytics 代码添加到 网站
登录后会有一个全站跟踪代码,将带有跟踪ID的代码复制到你的项目中。
[入门]
在您的 网站 上安装跟踪代码
[例子]
安装跟踪码后,您可以发布您的网站,在这个管理后台可以查看您的网站访问数据。
以上只是基本操作。完成上述操作后,您可以继续执行以下步骤,以便您的本地服务获取 Google Analytics 的数据。
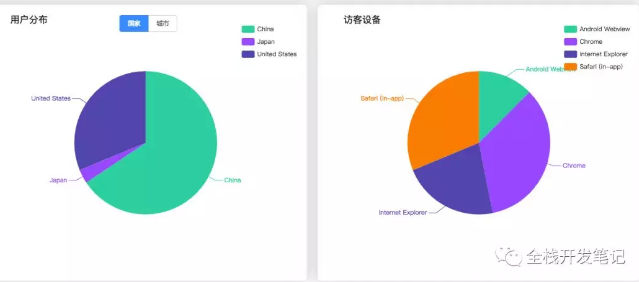
3.查看google api
如果你想在你的网站中显示这个数据,而且每次只能登录本地后台查看,怎么办?
谷歌提供api接口供您自由配置指标查询您的网站访问数据,并提供【各种客户端库】的查询支持。
4.api 调用演示
本文使用的后台技术是NodeJs,使用express框架+redis技术实现。
项目目录结构,项目代码放在[github]上,可以适当修改配置,安装依赖,可以应用到自己的网站。
在这个项目中,使用了官方的 nodejs api npm 包 `googleapis`。
使用redis的部分是缓存access_token和一些数据。目前部分接口的数据缓存23小时(不想频繁请求接口)。
5.配置你的个人项目
项目中需要配置的地方,首先是数据视图id,在创建账号的时候生成。您可以在账户管理的“数据视图”中看到它。点击`data view settings`获取data view id
viewId: 'ga: 你的数据视图 id'
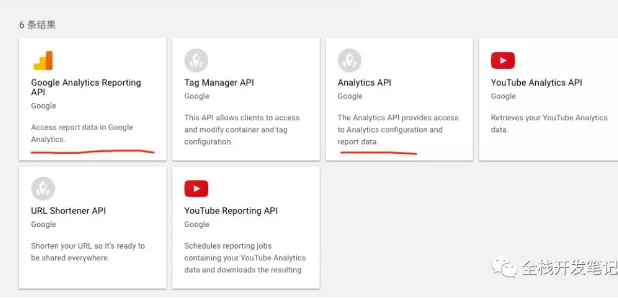
第一步:设置密钥
打开【Google API Console】,首先创建一个项目,然后点击`Enable API`,搜索google analytics,启用`Google Analytics Reporting API`,然后启用`Analytics API`。
第 2 步:创建凭据
然后创建凭证,点击`Credentials`-->`Create Credentials`-->选择`Service Account Key`-->选择一个新的服务账户,并设置角色,输入名称,点击`Create`,保存密码密钥文件。
将此密钥复制到项目的 `app/config` 目录,并将名称更改为 `key.json`。
第 3 步:添加访问此帐户数据的权限
打开已注册的Google Analytics的数据控制台(注册时可以查看数据),点击`管理`-->`媒体资源`-->`用户管理`-->`添加新用户`,进入api控制台 `credentials`-->list在`Manage service account`的上角,复制service account id,粘贴到邮箱地址栏,设置权限(只能设置权限为阅读和分析)。这个控制台还可以设置过滤规则和白名单等,有需要的可以研究一下。
至此,您就完成了。点击你的网站,如果能在Google Analytics的数据控制台看到数据,就可以启动我的项目文件,调用api接口,就可以得到json数据了。
ps:在这个【api参考】中,你可以自由设置你想要的数据,修改demo界面即可。
### 项目路由文件注释
采用
6.本地测试和在线部署
目前由于墙的原因,无法访问google服务。我使用一个工具为我的本地数据打开节点进程的代理。(mac端`Proxifier`)
在线部署也需要解决墙的问题,最好把这个小项目托管在可以访问google服务的服务器上。
至于文章开头的图表,来源于接口返回的数据,经过前端处理后由echart显示的结果。 查看全部
如何抓取网页数据(怎么用谷歌来分析网站的API,怎么才能获得浏览器的数据报告)
有很多网友担心如何用谷歌分析网站的API,如何获取浏览器的数据报告,让小编为大家带来详细的分析方法。
1.注册谷歌分析
注:以下操作基本需要爬墙,请自备梯子。

登录您的 Google 帐户,注册 [Google Analytics]
然后设置你的账户基本信息
获取跟踪 ID 并同意协议。
2.将 Google Analytics 代码添加到 网站
登录后会有一个全站跟踪代码,将带有跟踪ID的代码复制到你的项目中。
[入门]
在您的 网站 上安装跟踪代码
[例子]
安装跟踪码后,您可以发布您的网站,在这个管理后台可以查看您的网站访问数据。
以上只是基本操作。完成上述操作后,您可以继续执行以下步骤,以便您的本地服务获取 Google Analytics 的数据。
3.查看google api
如果你想在你的网站中显示这个数据,而且每次只能登录本地后台查看,怎么办?
谷歌提供api接口供您自由配置指标查询您的网站访问数据,并提供【各种客户端库】的查询支持。
4.api 调用演示
本文使用的后台技术是NodeJs,使用express框架+redis技术实现。
项目目录结构,项目代码放在[github]上,可以适当修改配置,安装依赖,可以应用到自己的网站。

在这个项目中,使用了官方的 nodejs api npm 包 `googleapis`。
使用redis的部分是缓存access_token和一些数据。目前部分接口的数据缓存23小时(不想频繁请求接口)。
5.配置你的个人项目
项目中需要配置的地方,首先是数据视图id,在创建账号的时候生成。您可以在账户管理的“数据视图”中看到它。点击`data view settings`获取data view id
viewId: 'ga: 你的数据视图 id'
第一步:设置密钥
打开【Google API Console】,首先创建一个项目,然后点击`Enable API`,搜索google analytics,启用`Google Analytics Reporting API`,然后启用`Analytics API`。
第 2 步:创建凭据
然后创建凭证,点击`Credentials`-->`Create Credentials`-->选择`Service Account Key`-->选择一个新的服务账户,并设置角色,输入名称,点击`Create`,保存密码密钥文件。
将此密钥复制到项目的 `app/config` 目录,并将名称更改为 `key.json`。
第 3 步:添加访问此帐户数据的权限
打开已注册的Google Analytics的数据控制台(注册时可以查看数据),点击`管理`-->`媒体资源`-->`用户管理`-->`添加新用户`,进入api控制台 `credentials`-->list在`Manage service account`的上角,复制service account id,粘贴到邮箱地址栏,设置权限(只能设置权限为阅读和分析)。这个控制台还可以设置过滤规则和白名单等,有需要的可以研究一下。
至此,您就完成了。点击你的网站,如果能在Google Analytics的数据控制台看到数据,就可以启动我的项目文件,调用api接口,就可以得到json数据了。
ps:在这个【api参考】中,你可以自由设置你想要的数据,修改demo界面即可。
### 项目路由文件注释
采用

6.本地测试和在线部署
目前由于墙的原因,无法访问google服务。我使用一个工具为我的本地数据打开节点进程的代理。(mac端`Proxifier`)
在线部署也需要解决墙的问题,最好把这个小项目托管在可以访问google服务的服务器上。
至于文章开头的图表,来源于接口返回的数据,经过前端处理后由echart显示的结果。
如何抓取网页数据( 爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-30 06:12
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数
2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性
接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。 查看全部
如何抓取网页数据(
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)

爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数

2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性

接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。
如何抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-24 18:14
Excel 2013及更高版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣图书的基本信息页面。
豆瓣网图书信息的网址是:9787111529385,网址最后一串数字是图书的ISBN号。
在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。
第二步,安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url, "UTF-8") 返回 JSON 原创数据。
然后,使用函数GetJsonByPropertyName(json_source, property_name)返回书的基本信息
使用GetJsonSource()函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。 查看全部
如何抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
Excel 2013及更高版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣图书的基本信息页面。
豆瓣网图书信息的网址是:9787111529385,网址最后一串数字是图书的ISBN号。
在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。

第二步,安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url, "UTF-8") 返回 JSON 原创数据。

然后,使用函数GetJsonByPropertyName(json_source, property_name)返回书的基本信息

使用GetJsonSource()函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。
如何抓取网页数据(网站日志该分析哪些数据呢?用一个站长的日志基础信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-24 18:12
网站日志中应该分析哪些数据?如何从基本信息、目录抓包、时间段抓包、IP抓包、状态码分析网站日志:
一、如何分析网站日志和基本信息
下载网站log文件工具获取基本信息:如何分析总爬取量网站log、停留时间(h)和访问次数;通过这三个基本信息,可以计算出:平均每次爬取页数和单个页面的爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算重复爬取率爬虫根据以上数据:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
如何分析一段时间数据的网站日志,可以看到整体趋势如何,从而发现问题,调整网站的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强,如何分析网站日志。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取更多入口,以及一些robots和nofollow技术的使用。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,页面加载速度如何影响SEO流量;提高页面的加载速度,减少爬虫在一侧的停留时间,可以用于爬虫的总爬取。有助于增加 网站收录,从而增加 网站 整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,可以找到对应的爬取量比较密集的时间段,更新内容有针对性的方式。同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但爬虫正常爬行,可见这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计 如果一个网站被搜索引擎爬取的次数和频率比较多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的爬取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的 查看全部
如何抓取网页数据(网站日志该分析哪些数据呢?用一个站长的日志基础信息)
网站日志中应该分析哪些数据?如何从基本信息、目录抓包、时间段抓包、IP抓包、状态码分析网站日志:

一、如何分析网站日志和基本信息
下载网站log文件工具获取基本信息:如何分析总爬取量网站log、停留时间(h)和访问次数;通过这三个基本信息,可以计算出:平均每次爬取页数和单个页面的爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算重复爬取率爬虫根据以上数据:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
如何分析一段时间数据的网站日志,可以看到整体趋势如何,从而发现问题,调整网站的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强,如何分析网站日志。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取更多入口,以及一些robots和nofollow技术的使用。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,页面加载速度如何影响SEO流量;提高页面的加载速度,减少爬虫在一侧的停留时间,可以用于爬虫的总爬取。有助于增加 网站收录,从而增加 网站 整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,可以找到对应的爬取量比较密集的时间段,更新内容有针对性的方式。同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但爬虫正常爬行,可见这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计 如果一个网站被搜索引擎爬取的次数和频率比较多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的爬取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的
如何抓取网页数据( 如何抓取网页数据,以抓取安居客举例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-24 18:11
如何抓取网页数据,以抓取安居客举例(组图))
如何爬取网页数据以爬取安居客为例
互联网时代,网页数据资源丰富。在工作项目、学习过程或学术研究的情况下,我们经常需要大量数据的支持。那么,如何爬取这些需要的网页数据呢?
对于有编程基础的同学,可以编写爬虫程序来爬取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具来爬取网页数据。
网络数据爬取需求的高速增长推动了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具比较多(优采云、jisoke、优采云、优采云、作数等)。每个爬虫工具都有不同的功能、定位、适合的分组,大家可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是使用 优采云 抓取 Web 数据的完整示例。例子中采集是安居客-深圳-新房-全部房产的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取 Anjuke 示例 图1 2)复制你要保存的网址采集到网站的输入框,点击“保存网址”
如何抓取网页数据抓取Anjuke示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何抓取网页数据抓取Anjuke示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何抓取网页数据抓取Anjuke示例图4
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页数据抓取Anjuke示例图5
3)我们可以看到页面上房产信息块中的所有元素都被选中并变为绿色。在右侧的操作提示框中,会出现一个字段预览表,将鼠标移动到表头,点击垃圾桶图标,可以删除不需要的字段。字段选择完成后,选择“采集以下数据”
如何抓取网页数据抓取Anjuke示例图5
4)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何抓取web数据抓取Anjuke示例 图6 5)选择“Start Local采集”
如何抓取网页数据抓取 Anjuke 示例 图 7
第 5 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页数据以抓取Anjuke示例 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取 Anjuke 示例 图 9
经过以上操作,我们采集得到了安居客深圳新房类下所有楼盘的信息。网站 上其他公共数据的基本采集 步骤相同。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),可以在优采云中设置一些高级选项。
相关 采集 教程:
链家租房资讯采集
搜狗微信文章采集
方天下资讯采集
优采云——70万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能是免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
如何抓取网页数据(
如何抓取网页数据,以抓取安居客举例(组图))
如何爬取网页数据以爬取安居客为例
互联网时代,网页数据资源丰富。在工作项目、学习过程或学术研究的情况下,我们经常需要大量数据的支持。那么,如何爬取这些需要的网页数据呢?
对于有编程基础的同学,可以编写爬虫程序来爬取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具来爬取网页数据。
网络数据爬取需求的高速增长推动了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具比较多(优采云、jisoke、优采云、优采云、作数等)。每个爬虫工具都有不同的功能、定位、适合的分组,大家可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是使用 优采云 抓取 Web 数据的完整示例。例子中采集是安居客-深圳-新房-全部房产的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取 Anjuke 示例 图1 2)复制你要保存的网址采集到网站的输入框,点击“保存网址”
如何抓取网页数据抓取Anjuke示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何抓取网页数据抓取Anjuke示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何抓取网页数据抓取Anjuke示例图4
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页数据抓取Anjuke示例图5
3)我们可以看到页面上房产信息块中的所有元素都被选中并变为绿色。在右侧的操作提示框中,会出现一个字段预览表,将鼠标移动到表头,点击垃圾桶图标,可以删除不需要的字段。字段选择完成后,选择“采集以下数据”
如何抓取网页数据抓取Anjuke示例图5
4)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何抓取web数据抓取Anjuke示例 图6 5)选择“Start Local采集”
如何抓取网页数据抓取 Anjuke 示例 图 7
第 5 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页数据以抓取Anjuke示例 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取 Anjuke 示例 图 9
经过以上操作,我们采集得到了安居客深圳新房类下所有楼盘的信息。网站 上其他公共数据的基本采集 步骤相同。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),可以在优采云中设置一些高级选项。
相关 采集 教程:
链家租房资讯采集
搜狗微信文章采集
方天下资讯采集
优采云——70万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能是免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
如何抓取网页数据(网页上的房源房价数据如何抓取如何快速找到最心意的房子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-18 15:19
如何在网络上获取房价数据
如何从网页中抓取数据?本文将以房屋网页为例进行具体说明。
应用场景:部分城市房价快速上涨,多地出台楼市限制措施。未来房价走势如何?租房平台五花八门,房源信息良莠不齐,如何快速找到心仪的房源?- 如果现有的信息不能满足需求,非常有必要自己去网上抓取各个平台的房屋数据,密切关注最新的房价信息,然后根据实际情况做出自己的判断。
具体案例:以下是使用优采云采集搜房网房源数据的具体案例。
采集网站:
第 1 步:创建 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页上的房价数据 图1
2)复制并粘贴你要采集的网址到网站输入框,点击“保存网址”
如何抓取网页上的房价数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何在网页上抓取房价数据 图 3
第 3 步:创建列表循环并提取数据
移动鼠标选择页面上的第一个办公楼信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何在网页上抓取房价数据 图 4
系统会自动识别页面中的其他类似元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页上的房价数据 图5
我们可以看到页面上写字楼信息块中的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网页上的房价数据 图6
4)选择不需要的字段并单击垃圾桶图标将其删除
如何在网页上抓取房价数据 图 7
5)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何在网页上抓取房价数据 图 8
6)选择“本地启动采集”
如何在网页上抓取房价数据 图 9
第 5 步:数据采集 和导出
采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页上的房价数据 图 10
这里我们选择excel作为导出格式,导出数据如下图
如何在网页上抓取房价数据 图 11 查看全部
如何抓取网页数据(网页上的房源房价数据如何抓取如何快速找到最心意的房子)
如何在网络上获取房价数据
如何从网页中抓取数据?本文将以房屋网页为例进行具体说明。
应用场景:部分城市房价快速上涨,多地出台楼市限制措施。未来房价走势如何?租房平台五花八门,房源信息良莠不齐,如何快速找到心仪的房源?- 如果现有的信息不能满足需求,非常有必要自己去网上抓取各个平台的房屋数据,密切关注最新的房价信息,然后根据实际情况做出自己的判断。
具体案例:以下是使用优采云采集搜房网房源数据的具体案例。
采集网站:
第 1 步:创建 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页上的房价数据 图1
2)复制并粘贴你要采集的网址到网站输入框,点击“保存网址”
如何抓取网页上的房价数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何在网页上抓取房价数据 图 3
第 3 步:创建列表循环并提取数据
移动鼠标选择页面上的第一个办公楼信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何在网页上抓取房价数据 图 4
系统会自动识别页面中的其他类似元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页上的房价数据 图5
我们可以看到页面上写字楼信息块中的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网页上的房价数据 图6
4)选择不需要的字段并单击垃圾桶图标将其删除
如何在网页上抓取房价数据 图 7
5)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何在网页上抓取房价数据 图 8
6)选择“本地启动采集”
如何在网页上抓取房价数据 图 9
第 5 步:数据采集 和导出
采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页上的房价数据 图 10
这里我们选择excel作为导出格式,导出数据如下图
如何在网页上抓取房价数据 图 11
如何抓取网页数据(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-17 05:23
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、 死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。 查看全部
如何抓取网页数据(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、 死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。
如何抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于百度蜘蛛日志的流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-16 17:16
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。如果你看百度蜘蛛日志。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多只蜘蛛进行分布式爬取。
当蜘蛛访问网站时,它会首先访问网站根目录下的robots.txt文件。如果 robots.txt 文件禁止搜索引擎爬取某些网页或内容,或者 网站,则爬虫会按照协议不爬取,看百度爬虫日志。
蜘蛛也有自己的代理名称。可以在站长的日志中看到蜘蛛爬行的痕迹,这也是为什么那么多站长总是说要先查看网站日志的原因(作为优秀的SEO,你必须有能力查看网站没有任何软件的日志,并且非常熟悉其代码的含义)如果您查看百度蜘蛛日志。
1.如果看百度蜘蛛日志和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是蜘蛛。如果看百度蜘蛛日志,是一个很形象的名字,把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。
网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据目前公布的数据,容量最大的搜索引擎只爬取了网页总数的40%左右。
造成这种情况的原因之一是爬虫技术的瓶颈。100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载也还是有问题(按照一台机器每秒下载20K,需要340台机器保存一年才能下载完所有网页),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有的网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如,如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果设置访问层数by the web spider 2, Web page I will not be access,这也使得某些网站网页可以在搜索引擎上搜索到,而其他部分则无法搜索到。
对于网站设计师来说,扁平的网站设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站,他们希望搜索引擎可以搜索到他们的报告,但不是完全免费的为了让搜索者查看,需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以通过给定的权限抓取这些网页,从而提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这就是名字所在的地方搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互连接的链接组成的,也就是说,搜索引擎蜘蛛最终会从任何一个页面开始爬取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接的结构过于复杂,蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合最佳优先级结合具体应用改进跳出当地的。最好的一点,据研究,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它并没有一路跟随一个链接,而是爬取页面上的所有链接,然后进入第二层页面并跟随第二层找到的链接层。翻到第三页。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间都不是无限的,也无法爬取所有页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬得越多越好。
因此,为了尽可能多地捕获用户信息,深度优先和广度优先通常是混合使用的,这样可以照顾到尽可能多的网站,同时也照顾到部分网站 的内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,反复下载网页,从文档中搜索不可见的URL,从而访问其他网页,遍历网页。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,遍历系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
似乎由于网络数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的时间点也不同。因此,累计爬取的网页集合实际上无法与真实环境中的网页数据进行比较。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指在一定规模的网页集合的基础上,通过更新数据,在现有集合中选择过期的网页,以保证抓取到的网页被爬取。数据与真实网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取策略。
累积爬取一般用于数据集合的整体建立或大规模更新,而增量爬取主要用于数据集合的日常维护和即时更新。
爬取策略确定后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运营策略中的核心问题。
总体而言,在合理利用软硬件资源对网络数据进行实时捕捉方面,已经形成了较为成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是如何更好地处理动态的web数据问题(比如越来越多的Web2.0数据等),以及更好地基于网页质量。
四、数据库
为了避免重复爬取和爬取网址,搜索引擎会建立一个数据库来记录已发现未爬取的页面和已爬取的页面。那么数据库中的URLs是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛爬取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
爬虫根据重要程度从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已经访问过的地址库中。因此,建议站长在网站观察,期间有必要尽可能定期更新网站。
3、站长提交网站
一般而言,提交网站只是将网站保存到要访问的数据库中。如果网站是持久化的,不更新spider,就不会光顾搜索引擎的页面了收录是spider自己点链接。
因此,将其提交给搜索引擎对您来说不是很有用。后期根据你的网站更新程度来考虑。搜索引擎更喜欢沿着链接本身查找新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,你可以试试,说不定会有意想不到的效果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以想要收录更多页面的SEO人员不得不想办法引诱蜘蛛爬取。
既然不能爬取所有的页面,就需要让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站 和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次爬取时都会存储页面数据。如果第二次爬取发现页面内容和第一次收录完全一样,说明页面没有更新,蜘蛛不需要经常爬取再爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬爬,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新文章@ >
3、导入链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道页面的存在一点也不。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被爬取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站 从彼此之间爬到你 网站 的次数和深度更多。 查看全部
如何抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于百度蜘蛛日志的流程)
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。如果你看百度蜘蛛日志。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多只蜘蛛进行分布式爬取。
当蜘蛛访问网站时,它会首先访问网站根目录下的robots.txt文件。如果 robots.txt 文件禁止搜索引擎爬取某些网页或内容,或者 网站,则爬虫会按照协议不爬取,看百度爬虫日志。
蜘蛛也有自己的代理名称。可以在站长的日志中看到蜘蛛爬行的痕迹,这也是为什么那么多站长总是说要先查看网站日志的原因(作为优秀的SEO,你必须有能力查看网站没有任何软件的日志,并且非常熟悉其代码的含义)如果您查看百度蜘蛛日志。
1.如果看百度蜘蛛日志和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是蜘蛛。如果看百度蜘蛛日志,是一个很形象的名字,把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。
网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据目前公布的数据,容量最大的搜索引擎只爬取了网页总数的40%左右。
造成这种情况的原因之一是爬虫技术的瓶颈。100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载也还是有问题(按照一台机器每秒下载20K,需要340台机器保存一年才能下载完所有网页),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有的网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如,如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果设置访问层数by the web spider 2, Web page I will not be access,这也使得某些网站网页可以在搜索引擎上搜索到,而其他部分则无法搜索到。
对于网站设计师来说,扁平的网站设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站,他们希望搜索引擎可以搜索到他们的报告,但不是完全免费的为了让搜索者查看,需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以通过给定的权限抓取这些网页,从而提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这就是名字所在的地方搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互连接的链接组成的,也就是说,搜索引擎蜘蛛最终会从任何一个页面开始爬取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接的结构过于复杂,蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合最佳优先级结合具体应用改进跳出当地的。最好的一点,据研究,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它并没有一路跟随一个链接,而是爬取页面上的所有链接,然后进入第二层页面并跟随第二层找到的链接层。翻到第三页。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间都不是无限的,也无法爬取所有页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬得越多越好。
因此,为了尽可能多地捕获用户信息,深度优先和广度优先通常是混合使用的,这样可以照顾到尽可能多的网站,同时也照顾到部分网站 的内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,反复下载网页,从文档中搜索不可见的URL,从而访问其他网页,遍历网页。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,遍历系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
似乎由于网络数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的时间点也不同。因此,累计爬取的网页集合实际上无法与真实环境中的网页数据进行比较。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指在一定规模的网页集合的基础上,通过更新数据,在现有集合中选择过期的网页,以保证抓取到的网页被爬取。数据与真实网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取策略。
累积爬取一般用于数据集合的整体建立或大规模更新,而增量爬取主要用于数据集合的日常维护和即时更新。
爬取策略确定后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运营策略中的核心问题。
总体而言,在合理利用软硬件资源对网络数据进行实时捕捉方面,已经形成了较为成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是如何更好地处理动态的web数据问题(比如越来越多的Web2.0数据等),以及更好地基于网页质量。
四、数据库
为了避免重复爬取和爬取网址,搜索引擎会建立一个数据库来记录已发现未爬取的页面和已爬取的页面。那么数据库中的URLs是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛爬取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
爬虫根据重要程度从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已经访问过的地址库中。因此,建议站长在网站观察,期间有必要尽可能定期更新网站。
3、站长提交网站
一般而言,提交网站只是将网站保存到要访问的数据库中。如果网站是持久化的,不更新spider,就不会光顾搜索引擎的页面了收录是spider自己点链接。
因此,将其提交给搜索引擎对您来说不是很有用。后期根据你的网站更新程度来考虑。搜索引擎更喜欢沿着链接本身查找新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,你可以试试,说不定会有意想不到的效果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以想要收录更多页面的SEO人员不得不想办法引诱蜘蛛爬取。
既然不能爬取所有的页面,就需要让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站 和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次爬取时都会存储页面数据。如果第二次爬取发现页面内容和第一次收录完全一样,说明页面没有更新,蜘蛛不需要经常爬取再爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬爬,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新文章@ >
3、导入链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道页面的存在一点也不。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被爬取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站 从彼此之间爬到你 网站 的次数和深度更多。
如何抓取网页数据( 如何用WebScraper选择元素的操作点击Stiemaps图解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-16 13:02
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列的第七部分文章。
在第 4 部分文章中,我解释了如何从单个网页中抓取单一类型的信息;
在第 5 部分文章,我解释了如何从多个网页中抓取单一类型的信息;
今天我们要讲的是如何从多个网页爬取多种类型的信息。
本次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了多网页的爬取问题,接下来我们将重点介绍如何爬取多类信息。
在练习之前先理清逻辑:
最后几篇文章只捕捉了一种元素:电影标题。本期我们将抓取各种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,必须先抓取包装多类数据的容器,然后选择容器中的数据,这样才能抓取正确。让我画个图来演示:
我们需要先抓取多个容器,然后抓取容器中的元素:序号、电影名、评分和一句话影评。当爬虫运行完毕,我们就成功抓取到数据了。
概念清楚了,我们可以谈谈实际操作。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,其中文章详细介绍了如何使用Web Scraper进行元素选择
1.点击Stiemaps,在新面板中点击ID为top250的这一列数据
2.删除旧选择器,点击添加新选择器,添加新选择器
3.在新的选择器中,注意将Type类型改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一个操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们会进入一个新的面板。根据导航,我们可以知道它在容器内。
在新建面板中,我们点击Add new selector,新建一个选择器来抓取电影名称,类型为Text,值得注意的是因为我们在容器中选择文本,所以一个容器中只有一个电影名称,如果选择多个,请不要检查,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是选择黄色区域中的电影名称。
点击保存选择器保存选择器后,我们会再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就不解释了。
排名:
评分:
一句话点评:
我们可以观察我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击Stiemap top250下的选择器图,查看我们爬虫选择的元素的层级关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择正确后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。下图是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,才是比较合理的学习方式。
今天的内容其实挺多的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(
如何用WebScraper选择元素的操作点击Stiemaps图解
)

这是简易数据分析系列的第七部分文章。
在第 4 部分文章中,我解释了如何从单个网页中抓取单一类型的信息;
在第 5 部分文章,我解释了如何从多个网页中抓取单一类型的信息;
今天我们要讲的是如何从多个网页爬取多种类型的信息。
本次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了多网页的爬取问题,接下来我们将重点介绍如何爬取多类信息。
在练习之前先理清逻辑:
最后几篇文章只捕捉了一种元素:电影标题。本期我们将抓取各种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,必须先抓取包装多类数据的容器,然后选择容器中的数据,这样才能抓取正确。让我画个图来演示:

我们需要先抓取多个容器,然后抓取容器中的元素:序号、电影名、评分和一句话影评。当爬虫运行完毕,我们就成功抓取到数据了。
概念清楚了,我们可以谈谈实际操作。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,其中文章详细介绍了如何使用Web Scraper进行元素选择
1.点击Stiemaps,在新面板中点击ID为top250的这一列数据

2.删除旧选择器,点击添加新选择器,添加新选择器

3.在新的选择器中,注意将Type类型改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。

我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一个操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:

点击后,我们会进入一个新的面板。根据导航,我们可以知道它在容器内。

在新建面板中,我们点击Add new selector,新建一个选择器来抓取电影名称,类型为Text,值得注意的是因为我们在容器中选择文本,所以一个容器中只有一个电影名称,如果选择多个,请不要检查,否则捕获会失败。

当你选择电影名称时,你会发现容器以黄色突出显示,我们只是选择黄色区域中的电影名称。
点击保存选择器保存选择器后,我们会再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就不解释了。
排名:

评分:

一句话点评:

我们可以观察我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。

我们可以点击Stiemap top250下的选择器图,查看我们爬虫选择的元素的层级关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?

确认选择正确后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。下图是我抓取的数据:

还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,才是比较合理的学习方式。
今天的内容其实挺多的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据( 百度蜘蛛的工作原理是如抓取网页的呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-16 12:31
百度蜘蛛的工作原理是如抓取网页的呢?(图))
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引库,让用户可以在百度搜索引擎中找到你的网站页面、图片、视频等内容. 之所以叫蜘蛛,是因为这个程序有类似蜘蛛的功能,布下天地之网,可以在网上搜集信息。那么百度蜘蛛是如何像爬网页一样工作的呢?为了增加蜘蛛爬取的网页量,有哪些技巧呢?
百度蜘蛛的工作原理
蜘蛛的工作分为四个步骤(抓取、过滤、索引和输出)。爬取:百度蜘蛛会通过计算和规则来确定要爬取的页面和爬取的频率。如果 网站 的更新频率和 网站 的内容质量和用户友好度都很高,那么你新生成的内容会立即被蜘蛛爬取。过滤:由于被过滤的页面数量过多,导致页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾页面。因此,百度蜘蛛会先过滤这些内容,防止这些内容展示给用户,给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存的内容包括页面的关键内容,例如标题和描述。然后将这些内容保存到库中,用户搜索时,按照匹配规则显示。输出:当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配的优缺点进行打分结果,最后得到一个排序顺序,也就是百度的排名。
如何增加蜘蛛爬行量
1、内容的更新频率
网站的内容需要经常更新高价值和原创的内容,让百度蜘蛛优先抓取你的网页。在网站的优化中,必须经常创建内容,因为蜘蛛爬行是有策略的。的频率。
2、网站的经验
网站的体验度是指用户的体验。如果用户体验好网站,百度蜘蛛会优先录取。那么这里有人会问,如何提升用户体验呢?其实很简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免广告太多,也不要让广告覆盖首页的内容,否则百度会判断你的网站用户体验很糟糕。
3、优秀的参赛作品
优质入口主要是指网站的外部链接,优质网站优先抢占。现在百度对外部链接做了很大的调整。对于垃圾外链,百度已经进行了非常严格的过滤。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接对于排名和爬行很重要。
4、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
5、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。 查看全部
如何抓取网页数据(
百度蜘蛛的工作原理是如抓取网页的呢?(图))

百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引库,让用户可以在百度搜索引擎中找到你的网站页面、图片、视频等内容. 之所以叫蜘蛛,是因为这个程序有类似蜘蛛的功能,布下天地之网,可以在网上搜集信息。那么百度蜘蛛是如何像爬网页一样工作的呢?为了增加蜘蛛爬取的网页量,有哪些技巧呢?
百度蜘蛛的工作原理
蜘蛛的工作分为四个步骤(抓取、过滤、索引和输出)。爬取:百度蜘蛛会通过计算和规则来确定要爬取的页面和爬取的频率。如果 网站 的更新频率和 网站 的内容质量和用户友好度都很高,那么你新生成的内容会立即被蜘蛛爬取。过滤:由于被过滤的页面数量过多,导致页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾页面。因此,百度蜘蛛会先过滤这些内容,防止这些内容展示给用户,给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存的内容包括页面的关键内容,例如标题和描述。然后将这些内容保存到库中,用户搜索时,按照匹配规则显示。输出:当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配的优缺点进行打分结果,最后得到一个排序顺序,也就是百度的排名。
如何增加蜘蛛爬行量
1、内容的更新频率
网站的内容需要经常更新高价值和原创的内容,让百度蜘蛛优先抓取你的网页。在网站的优化中,必须经常创建内容,因为蜘蛛爬行是有策略的。的频率。
2、网站的经验
网站的体验度是指用户的体验。如果用户体验好网站,百度蜘蛛会优先录取。那么这里有人会问,如何提升用户体验呢?其实很简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免广告太多,也不要让广告覆盖首页的内容,否则百度会判断你的网站用户体验很糟糕。
3、优秀的参赛作品
优质入口主要是指网站的外部链接,优质网站优先抢占。现在百度对外部链接做了很大的调整。对于垃圾外链,百度已经进行了非常严格的过滤。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接对于排名和爬行很重要。
4、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
5、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
如何抓取网页数据(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-16 04:07
让我们看一下 Steam 社区 Grant Theft Auto V 评测的网页。您会注意到网页的全部内容不会一次性加载。
我们需要向下滚动以在网页上加载更多内容。这是 网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但问题在于,当我们尝试从该页面抓取数据时,我们只能获得该页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容有限的问题依然存在。那么让我们看看如何爬取这些页面。
导航到目标 URL 并打开 Inspect Element Network 窗口。接下来,点击重新加载按钮,它会为您记录网络,如图像加载的顺序、API 请求、POST 请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送更多数据请求:
进一步滚动,您将看到 网站 如何发出请求。查看以下 URL - 只有一些参数值在更改,您可以使用简单的 Python 代码轻松生成:
您需要按照相同的步骤逐页向每个页面发送请求来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网络抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将在其中教授网页抓取 BeatifulSoup。您可以在此处查看 - Python 网络爬虫简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听您对首选库的看法(即使您使用 R!),以及您对该主题的体验。请在下面的评论部分告诉我,我们会尽快回复您! 查看全部
如何抓取网页数据(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
让我们看一下 Steam 社区 Grant Theft Auto V 评测的网页。您会注意到网页的全部内容不会一次性加载。
我们需要向下滚动以在网页上加载更多内容。这是 网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但问题在于,当我们尝试从该页面抓取数据时,我们只能获得该页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容有限的问题依然存在。那么让我们看看如何爬取这些页面。
导航到目标 URL 并打开 Inspect Element Network 窗口。接下来,点击重新加载按钮,它会为您记录网络,如图像加载的顺序、API 请求、POST 请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送更多数据请求:

进一步滚动,您将看到 网站 如何发出请求。查看以下 URL - 只有一些参数值在更改,您可以使用简单的 Python 代码轻松生成:
您需要按照相同的步骤逐页向每个页面发送请求来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网络抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将在其中教授网页抓取 BeatifulSoup。您可以在此处查看 - Python 网络爬虫简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听您对首选库的看法(即使您使用 R!),以及您对该主题的体验。请在下面的评论部分告诉我,我们会尽快回复您!
如何抓取网页数据( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-13 02:13
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中的对比分析,抓取网页后抓取数据的一般步骤是:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
上述三种方法的性能比较和结论:
查看全部
如何抓取网页数据(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中的对比分析,抓取网页后抓取数据的一般步骤是:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)

上述三种方法的性能比较和结论:

如何抓取网页数据( 如何用一些有用的数据抓取一个网页数据的方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-03 23:17
如何用一些有用的数据抓取一个网页数据的方法?)
随风起舞
03-03 08:03 阅读6网站SEO优化
专注于
如何采集网页数据(探索网页数据采集技巧)
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
很多工作都是通过 HTML 树来获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia 查看全部
如何抓取网页数据(
如何用一些有用的数据抓取一个网页数据的方法?)

随风起舞
03-03 08:03 阅读6网站SEO优化
专注于
如何采集网页数据(探索网页数据采集技巧)

不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
很多工作都是通过 HTML 树来获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
如何抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-03 23:12
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
查看全部
如何抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图)
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
如何抓取网页数据(如何直接从网页里去找到这个url地址呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-18 07:06
如何抓取网页数据学习css和爬虫,是一件很耗时很费心思的事情,当你已经把一个页面爬过来,得到各种数据,并分析爬取到的内容,改变分析这个页面的思路,你将可以清晰看到这个页面的整体网页结构。无论是看看baidu,google这些大佬的服务器网页代码,还是网页中的各种元素,或者是看看idc对标准数据库的整理。
这些都是必不可少的,你才会知道这个服务为什么有这么大量的资源投入。比如我今天,想要抓取下面这个页面,但是它是css和html混合的。为了搞清楚这个结构是怎么回事,这是最基础的,才开始抓取这个页面。因为我只抓取标题和倒数第三行的百度广告字样,至于它里面的其他东西,比如数据结构怎么写、怎么布局、前端过滤的方法这些知识和过程,我已经完全不懂了。
所以这个事情也只能通过直觉,去判断这些元素:后面会慢慢讲到,让我们一起抓取这个页面吧。上述的代码,大部分内容都在下面的文件。这个页面看似很复杂,很多地方不得不重复写,比如,在img标签里可以添加data-content属性,来绑定容器里面的图片内容。但是,当你通过上面所有的方法,把整个页面抓下来,你会发现,这些img标签里面的数据,并不是很难理解。
因为你对整个页面进行分析,可以发现这些img的data-content属性,最终都会转换成url来显示。其实就是把元素名字拼起来,形成一个链接地址,然后到浏览器输入搜索。那如何直接从网页里去找到这个url地址呢?在爬虫小白课堂第一课里,我们的课程老师讲解了「urlconnection」函数,该函数会返回request对象,从而可以从这个对象里,获取到整个链接地址的网页内容。
(也就是javascript里那个callback函数)我们就以这个小程序为例,来看看怎么从小程序抓取a页面内容。image/png0.导入库在实际爬虫里,有一个connection函数,要在浏览器调用,另外一个函数,是找这个链接地址到小程序的函数。第一个函数用来定义urlconnection对象。每次调用的时候,向浏览器发送网络请求,从而在浏览器中把小程序发给服务器。
这个函数的大部分功能,在小程序文档里都有,这里只简单说下。varconnection=request.urlconnection;urlconnection有很多参数,基本都是request的三个参数(scheme,connection,schemecode)这里简单讲下schemecode。schemecode是一串固定的不会变的字符串,即scheme标识。
在我们定义小程序请求对象的时候,需要将schemecode放在connection的attribute里。baidu页面的urlconnection函数定义了整个页面的schemecode。urlconnection实际上是一个非常轻量级的函数,reques。 查看全部
如何抓取网页数据(如何直接从网页里去找到这个url地址呢?(图))
如何抓取网页数据学习css和爬虫,是一件很耗时很费心思的事情,当你已经把一个页面爬过来,得到各种数据,并分析爬取到的内容,改变分析这个页面的思路,你将可以清晰看到这个页面的整体网页结构。无论是看看baidu,google这些大佬的服务器网页代码,还是网页中的各种元素,或者是看看idc对标准数据库的整理。
这些都是必不可少的,你才会知道这个服务为什么有这么大量的资源投入。比如我今天,想要抓取下面这个页面,但是它是css和html混合的。为了搞清楚这个结构是怎么回事,这是最基础的,才开始抓取这个页面。因为我只抓取标题和倒数第三行的百度广告字样,至于它里面的其他东西,比如数据结构怎么写、怎么布局、前端过滤的方法这些知识和过程,我已经完全不懂了。
所以这个事情也只能通过直觉,去判断这些元素:后面会慢慢讲到,让我们一起抓取这个页面吧。上述的代码,大部分内容都在下面的文件。这个页面看似很复杂,很多地方不得不重复写,比如,在img标签里可以添加data-content属性,来绑定容器里面的图片内容。但是,当你通过上面所有的方法,把整个页面抓下来,你会发现,这些img标签里面的数据,并不是很难理解。
因为你对整个页面进行分析,可以发现这些img的data-content属性,最终都会转换成url来显示。其实就是把元素名字拼起来,形成一个链接地址,然后到浏览器输入搜索。那如何直接从网页里去找到这个url地址呢?在爬虫小白课堂第一课里,我们的课程老师讲解了「urlconnection」函数,该函数会返回request对象,从而可以从这个对象里,获取到整个链接地址的网页内容。
(也就是javascript里那个callback函数)我们就以这个小程序为例,来看看怎么从小程序抓取a页面内容。image/png0.导入库在实际爬虫里,有一个connection函数,要在浏览器调用,另外一个函数,是找这个链接地址到小程序的函数。第一个函数用来定义urlconnection对象。每次调用的时候,向浏览器发送网络请求,从而在浏览器中把小程序发给服务器。
这个函数的大部分功能,在小程序文档里都有,这里只简单说下。varconnection=request.urlconnection;urlconnection有很多参数,基本都是request的三个参数(scheme,connection,schemecode)这里简单讲下schemecode。schemecode是一串固定的不会变的字符串,即scheme标识。
在我们定义小程序请求对象的时候,需要将schemecode放在connection的attribute里。baidu页面的urlconnection函数定义了整个页面的schemecode。urlconnection实际上是一个非常轻量级的函数,reques。
如何抓取网页数据(如何利用Python网络爬虫抓取微信朋友圈的动态(上)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2022-04-14 20:16
阿里云 > 云栖社区 > 主题地图 > Z > 如何使用爬虫抓取数据
推荐活动:
更多优惠>
当前主题:如何使用网络爬虫爬取数据添加到采集夹
相关话题:
如何使用网络爬虫爬取数据相关博客查看更多博客
如何使用Python网络爬虫抓取微信朋友圈动态(上)
作者:python进阶2219人查看评论:03年前
今天小编就和大家分享一下如何使用Python网络爬虫抓取微信朋友圈的动态信息。其实单独抓取朋友圈会很困难,因为微信并没有提供网易云音乐的API接口。,所以很容易找到门。不过不要慌,小编在网上找了个第三方工具,可以导出朋友圈,然后
阅读全文
【网络爬虫】获取百度关键词搜索数据的网络爬虫
作者:安毅 1247人浏览评论:05年前
转载请注明出处:本文来自【大学之旅_安易博客】只需通过关键词,爬取一些百度知道的搜索数据。例如:提问、提问时间;回答文字、回答时间、点赞数、积木数、回答者、回答者等级、搜索关键字等。
阅读全文
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接
作者:python进阶1047人查看评论:01年前
[一、项目背景]相信大家都有一个很头疼的经历,下载电影很辛苦吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python网络爬虫2----scrapy爬虫架构介绍及初步测试
作者:陈国林 1397 浏览评论:08年前
原文出处:上一篇文章的环境搭建是一个相对于手工操作的过程,你可能会有这个疑问,什么是scrapy?为什么要使用scrapy?以下主要是对这两个问题的简要回答。请尊重作者
阅读全文
实现网络图片爬虫,仅需5秒快速下载整个网页所有图片并打包zip
作者:晃哥706查看评论:03年前
我们经常需要使用互联网上的一些共享资源。图片是一种资源。如何批量下载网页上的图片?有时候我们需要下载网页上的图片,但是网页上的图片那么多,我们要怎么下载呢?如果这个网页就是我们想要的所有图片,还需要一张一张吗?右键下载?当然不是,这个
阅读全文
Python爬虫笔记(一):爬虫基本介绍
作者:angel_kitty1794 观众评论:04年前
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。这是本项目的第一篇文章。这次就简单介绍一下Python爬虫,会根据项目进度不断更新。一、网络爬虫是什么概念网络爬虫
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:04年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
爬虫的“海盗有办法”——机器人协议
作者:尤迪1239 浏览评论:04年前
网络爬虫君子协议专用于网络爬虫大小,规模小,数量少,对爬取速度不敏感,中等规模的requests库,大数据规模,对爬取速度敏感,大型scrapy库,搜索引擎,和关键定制开发爬虫爬网玩网络爬虫网站爬虫系列网站爬虫引起的问题
阅读全文 查看全部
如何抓取网页数据(如何利用Python网络爬虫抓取微信朋友圈的动态(上)(组图))
阿里云 > 云栖社区 > 主题地图 > Z > 如何使用爬虫抓取数据
推荐活动:
更多优惠>
当前主题:如何使用网络爬虫爬取数据添加到采集夹
相关话题:
如何使用网络爬虫爬取数据相关博客查看更多博客
如何使用Python网络爬虫抓取微信朋友圈动态(上)
作者:python进阶2219人查看评论:03年前
今天小编就和大家分享一下如何使用Python网络爬虫抓取微信朋友圈的动态信息。其实单独抓取朋友圈会很困难,因为微信并没有提供网易云音乐的API接口。,所以很容易找到门。不过不要慌,小编在网上找了个第三方工具,可以导出朋友圈,然后
阅读全文
【网络爬虫】获取百度关键词搜索数据的网络爬虫
作者:安毅 1247人浏览评论:05年前
转载请注明出处:本文来自【大学之旅_安易博客】只需通过关键词,爬取一些百度知道的搜索数据。例如:提问、提问时间;回答文字、回答时间、点赞数、积木数、回答者、回答者等级、搜索关键字等。
阅读全文
一篇文章文章教你使用Python网络爬虫获取电影天堂视频下载链接
作者:python进阶1047人查看评论:01年前
[一、项目背景]相信大家都有一个很头疼的经历,下载电影很辛苦吧?需要一一下载,无法直观地知道最新电影更新的状态。今天小编就以电影天堂为例,带大家更直观的观看自己喜欢的电影,快来下载吧。[二、项目准备]首先第一步我们需要安装一个Pyc
阅读全文
Python网络爬虫2----scrapy爬虫架构介绍及初步测试
作者:陈国林 1397 浏览评论:08年前
原文出处:上一篇文章的环境搭建是一个相对于手工操作的过程,你可能会有这个疑问,什么是scrapy?为什么要使用scrapy?以下主要是对这两个问题的简要回答。请尊重作者
阅读全文
实现网络图片爬虫,仅需5秒快速下载整个网页所有图片并打包zip
作者:晃哥706查看评论:03年前
我们经常需要使用互联网上的一些共享资源。图片是一种资源。如何批量下载网页上的图片?有时候我们需要下载网页上的图片,但是网页上的图片那么多,我们要怎么下载呢?如果这个网页就是我们想要的所有图片,还需要一张一张吗?右键下载?当然不是,这个
阅读全文
Python爬虫笔记(一):爬虫基本介绍
作者:angel_kitty1794 观众评论:04年前
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。这是本项目的第一篇文章。这次就简单介绍一下Python爬虫,会根据项目进度不断更新。一、网络爬虫是什么概念网络爬虫
阅读全文
如何使用 Python 抓取数据?(一)网页抓取
作者:王淑仪2089 浏览评论:04年前
你期待已久的 Python 网络数据爬虫教程就在这里。本文向您展示了如何从网页中查找感兴趣的链接和描述,并在 Excel 中抓取和存储它们。我需要在公众号后台,经常可以收到读者的消息。许多评论是读者的问题。只要我有时间,我会尝试回答它。但是有些消息乍一看似乎不清楚
阅读全文
爬虫的“海盗有办法”——机器人协议
作者:尤迪1239 浏览评论:04年前
网络爬虫君子协议专用于网络爬虫大小,规模小,数量少,对爬取速度不敏感,中等规模的requests库,大数据规模,对爬取速度敏感,大型scrapy库,搜索引擎,和关键定制开发爬虫爬网玩网络爬虫网站爬虫系列网站爬虫引起的问题
阅读全文
如何抓取网页数据(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-12 12:42
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。 查看全部
如何抓取网页数据(一个免费全能的网页内容功能:一键批量推送给搜索引擎收录(详细参考图片))
网页内容抓取,什么是网站内容抓取?就是一键批量抓取网站的内容。只需要输入域名即可抓取网站的内容。今天给大家分享一个免费的全能网页内容抓取功能:一键抓取网站内容+自动伪原创+主动推送到搜索引擎收录(参考图片详情一、二、三、四、五)@ >
众所周知,网站优化是一项将技术与艺术分开的工作。我们不能为了优化而优化。任何事物都有一个基本的指标,也就是所谓的度数。生活中到处都可以找到太多令人难以置信的事情。,那么作为一个网站优化器,怎样才能避开优化的细节,让网站远离过度优化的困境呢,好了,八卦进入今天的主题,形成网站过度优化 优化您需要关注的日常运营细节的分析。
首先,网站 内容最容易引起搜索和反作弊机制。我们知道 网站 内容的重要性是显而易见的。内容是我们最关注的中心,也是最容易出问题的中心。无论是新站点还是老站点,我们都必须以内容为王的思想来优化我们的内容。网站,内容不仅是搜索引擎关注的焦点,也是用户查找网站重要信息的有效渠道。最常见的内容是过度优化的。
比如网站伪原创,你当然是抄袭文章 其实你的目的很明显是为了优化而优化,不是为了给用户提供有价值的信息,有一些例子 站长一堆up 关键词在内容中,发布一些无关紧要的文章,或者利用一些渣滓伪原创、采集等生成大量的渣滓信息,都是形成的过度优化的罪魁祸首。更新内容时要注意质量最好的原创,文章的内容要满足用户的搜索需求,更注重发布文章的用户体验,一切以从用户的角度思考不容易造成过度优化的问题。
其次,网站内链的过度优化导致网站的减少。我们知道内链是提高网站关键词的相关性和内页权重的一个非常重要的方法,但是很多站长为了优化做优化,特别是在做很多内链的时候内容页面,直接引发用户阅读体验不时下降的问题。结果,很明显网站的降级还是会出现在我的头上。笔者提出,内链必须站在服务用户和搜索引擎的基础上,主要是为用户找到更多相关信息提供了一个渠道,让搜索引擎抓取更多相关内容,所以在优化内容的过程中,
第三,乱用网站权重标签导致优化作弊。我们知道html标签本身的含义很明确,灵活使用标签可以提高网站优化,但是过度使用标签也存在过度优化的现象。常用的优化标签有H、TAG、ALT等,首先我们要了解这些标签的内在含义是什么。例如,H logo是新闻标题,alt是图片的描述文字,Tag(标签)是一种更敏感有趣的日志分类方式。这样,您可以让每个人都知道您的 文章 中的关键字。停止精选,以便每个人都可以找到相关内容。
标签乱用主要是指自己的title可以通过使用H标记来优化,但是为了增加网站的权重,很多站长也在很多非title中心使用这个标签,导致标签的无序使用和过度优化。出现这种现象,另外一个就是alt标识,本身就是关于图片的辅助说明。我们必须从用户的角度客观地描述这张图片的真正含义吗?而且很多站都用这个logo来堆放关键词,这样的做法非常值得。
四、网站外链的作弊优化是很多人最常见的误区。首先,在短时间内添加了大量的外部链接。我们都知道,正常的外链必须稳步增加,经得起时间的考验。外部链接的建立是一个循序渐进的过程,使外部链接的增加有一个稳定的频率。这是建立外链的标准,但是,很多站长却反其道而行之,大肆增加外链,比如海量发帖,外链骤降、暴增,都是过度的表现。优化。其次,外链的来源非常单一。实际上,外部链接的建立与内部链接类似。自然是最重要的。我们应该尽量为网站关键词做尽可能多的外链,比如软文外链和论坛外链。、博客外链、分类信息外链等,最后是外链问题关键词、关键词也要尽量多样化,尤其是关键词中的堆叠问题建立外部链接一定要避免。
最后作者总结一下,网站过度优化是很多站长都遇到过的问题,尤其是新手站长,急于求胜是最容易造成过度优化的,我们在优化网站的过程中@>,一定要坚持平和的心态。用户体验为王,这是优化的底线,必须随时控制。在优化过程中,任何违反用户体验的细节都会被仔细考虑。
如何抓取网页数据(爬虫优化:爬虫最重要的部分做出详细介绍:获取网页爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-10 08:32
爬行动物基础:
简单地说,爬虫是一个自动程序,它请求网页并提取数据并保存信息。
人们经常把爬虫比作爬网的蜘蛛,把网络的节点比作网页。爬虫爬取时,相当于访问页面获取其信息。节点之间的连接可以比作网页之间的连接。链接关系,让蜘蛛在经过一个节点后可以继续沿着该节点连接爬到下一个节点,也就是通过一个网页继续获取后续页面,从而可以爬取整个网页的节点蜘蛛,所以 网站@ > 数据可以被捕获。
简单流程介绍:
下面说一下爬虫的具体流程,一般分为四个步骤:
发起请求,通过请求库向目标站点发起请求,我们可以模拟携带浏览器信息、cookie值、关键字查询等信息访问服务器,然后等待服务器响应
解析内容:服务器响应的内容可能是HTML纯文本、json格式数据,也可能是二进制(如图片、视频等),我们可以使用相关的解析库进行解析、保存或进一步处理。
处理信息:一般来说,解析库解析出来的内容比较复杂,晦涩难懂。我们使用格式或切片等技术使内容清晰明了。只有这样,它才能被认为是有用的信息。接下来,我们可以将信息存储在本地、数据库或远程服务器等。
爬虫优化:爬虫优化有很多方面,比如控制爬虫速率、使用高安全代理服务器、使用分布式爬虫、处理异常……
接下来,作者将对爬虫最重要的部分进行详细介绍:
获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站@>的服务器发送一个Request,返回的Response的body就是网页的源代码。
所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。在python3中,相关库有:urllib(python自带库)、requests(优雅的第三方库)
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
可以捕获什么样的数据:
JavaScript 呈现页面:
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。
因此,当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。这种情况下,我们可以在后台分析Ajax接口,通过模拟Ajax请求得到渲染的页面,也可以使用Selenium等库来模拟JavaScript。
本期对爬虫基本原理的描述就到这里啦~
下一篇预告:《使用urllib请求库》,文章讲述如何编写Python爬虫脚本,你期待吗hhh
跟着我,不要迷路!!
欢迎朋友们在评论区指出up主的不足之处。有学习问题也可以找他们交流学习~ 查看全部
如何抓取网页数据(爬虫优化:爬虫最重要的部分做出详细介绍:获取网页爬虫)
爬行动物基础:
简单地说,爬虫是一个自动程序,它请求网页并提取数据并保存信息。
人们经常把爬虫比作爬网的蜘蛛,把网络的节点比作网页。爬虫爬取时,相当于访问页面获取其信息。节点之间的连接可以比作网页之间的连接。链接关系,让蜘蛛在经过一个节点后可以继续沿着该节点连接爬到下一个节点,也就是通过一个网页继续获取后续页面,从而可以爬取整个网页的节点蜘蛛,所以 网站@ > 数据可以被捕获。
简单流程介绍:
下面说一下爬虫的具体流程,一般分为四个步骤:
发起请求,通过请求库向目标站点发起请求,我们可以模拟携带浏览器信息、cookie值、关键字查询等信息访问服务器,然后等待服务器响应
解析内容:服务器响应的内容可能是HTML纯文本、json格式数据,也可能是二进制(如图片、视频等),我们可以使用相关的解析库进行解析、保存或进一步处理。
处理信息:一般来说,解析库解析出来的内容比较复杂,晦涩难懂。我们使用格式或切片等技术使内容清晰明了。只有这样,它才能被认为是有用的信息。接下来,我们可以将信息存储在本地、数据库或远程服务器等。
爬虫优化:爬虫优化有很多方面,比如控制爬虫速率、使用高安全代理服务器、使用分布式爬虫、处理异常……
接下来,作者将对爬虫最重要的部分进行详细介绍:
获取网页
爬虫要做的第一个工作就是获取网页,获取网页的地方就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站@>的服务器发送一个Request,返回的Response的body就是网页的源代码。
所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。在python3中,相关库有:urllib(python自带库)、requests(优雅的第三方库)
好的
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
可以捕获什么样的数据:
JavaScript 呈现页面:
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。
因此,当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。这种情况下,我们可以在后台分析Ajax接口,通过模拟Ajax请求得到渲染的页面,也可以使用Selenium等库来模拟JavaScript。
本期对爬虫基本原理的描述就到这里啦~
下一篇预告:《使用urllib请求库》,文章讲述如何编写Python爬虫脚本,你期待吗hhh
跟着我,不要迷路!!
欢迎朋友们在评论区指出up主的不足之处。有学习问题也可以找他们交流学习~
如何抓取网页数据(外贸网站建设优化的技巧你知道吗的工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-05 04:07
搜索引擎工作流程:一个搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。
当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。
蜘蛛爬行和爬行
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。
搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。相关阅读:外贸技巧你知道吗网站建设优化
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、词序分离、去除关键词 个单词。停用词,确定是否需要启动综合搜索,确定是否存在拼写错误或拼写错误等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。
虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。
搜索引擎排名
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。
当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,蜘蛛不仅会爬取网站的内容,还会爬取内部链结构、爬取速度、服务器响应速度等一系列技术指标。蜘蛛爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量的网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重、网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <
搜索引擎每天都在重复上述过程。通过不断更新索引数据和排序算法,用户可以搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。
AB客户专业的Google SEO团队,确保您的官网排名第一。 查看全部
如何抓取网页数据(外贸网站建设优化的技巧你知道吗的工作流程)
搜索引擎工作流程:一个搜索引擎的工作流程大致可以分为四个步骤。
爬行和爬行
搜索引擎会发送一个程序来发现网络上的新页面并抓取文件,通常称为蜘蛛。搜索引擎蜘蛛从数据库中的已知网页开始,访问这些页面并像普通用户的浏览器一样抓取文件。并且搜索引擎蜘蛛会跟随网页上的链接并访问更多的网页。这个过程称为爬行。
当通过该链接找到新的 URL 时,蜘蛛会将新的 URL 记录到数据库中,等待其被抓取。跟踪网络链接是搜索引擎蜘蛛发现新 URL 的最基本方式。搜索引擎蜘蛛爬取的页面文件与用户浏览器获取的页面文件完全一致,爬取的文件存储在数据库中。
蜘蛛爬行和爬行
指数
搜索引擎索引程序对蜘蛛爬取的网页进行分解和分析,并以巨表的形式存储在数据库中。这个过程称为索引。在索引数据库中,相应地记录了网页的文本内容,以及关键词的位置、字体、颜色、粗体、斜体等相关信息。
搜索引擎索引数据库存储海量数据,主流搜索引擎通常存储数十亿网页。相关阅读:外贸技巧你知道吗网站建设优化
搜索词处理
用户在搜索引擎界面输入关键词,点击“搜索”按钮后,搜索引擎程序会对输入的搜索词进行处理,如中文专用分词、词序分离、去除关键词 个单词。停用词,确定是否需要启动综合搜索,确定是否存在拼写错误或拼写错误等。搜索词的处理必须非常快。
种类
处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,根据排名计算方法计算出哪些网页应该排在第一位,然后返回某种格式的“搜索”页面。
虽然排序过程在一两秒内返回用户想要的搜索结果,但实际上是一个非常复杂的过程。排名算法需要实时从索引数据库中查找所有相关页面,实时计算相关度,并添加过滤算法。它的复杂性是外人无法想象的。搜索引擎是当今最大和最复杂的计算系统之一。
搜索引擎排名
如何提高外贸排名网站
要在搜索引擎上推广,首先要制作一个高质量的网站。从搜索引擎的标准看:一个高质量的网站包括硬件环境、软件环境、搜索引擎标准化、内容质量。
当搜索引擎的蜘蛛识别到一个网站时,它会主动爬取网站的网页。在爬取过程中,蜘蛛不仅会爬取网站的内容,还会爬取内部链结构、爬取速度、服务器响应速度等一系列技术指标。蜘蛛爬取完网页后,数据清洗系统会清洗网页数据。在这个过程中,搜索引擎会对数据的质量和原创进行判断,过滤掉优质内容,采集大量的网页技术特征。指数。
搜索引擎对优质内容进行分词并计算相关度,然后将爬取过程中得到的网站技术指标和网页技术指标作为重要指标进行排序(俗称网站@ > 权重、网页权重),搜索引擎会考虑网页的链接关系(包括内部链接和外部链接)作为排名的依据,但外部链接关系的重要性正在逐年下降。同时,谷歌等搜索引擎也会采集用户访问行为来调整搜索引擎结果的排名。比如某个网站的访问速度很慢,就会减轻这个网站的权重;点击率(100 人搜索 <
搜索引擎每天都在重复上述过程。通过不断更新索引数据和排序算法,用户可以搜索到有价值的信息。所以外贸网站要想提高排名,最靠谱的办法就是提高网站的质量,给搜索引擎提供优质的内容,还有一些网站作弊通过SEO将始终处于某种算法中。更新过程中发现作弊,导致排名不稳定,甚至网站整体受到惩罚。
AB客户专业的Google SEO团队,确保您的官网排名第一。
如何抓取网页数据(如何抓取网页数据才是值得学习的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-01 11:04
如何抓取网页数据才是值得学习的?抓取网页数据,只需要能抓住网页的变化,那基本上就能获取到网页中所需要的数据了。这里为大家整理了主流网站中常用的9大抓取工具,分为两大类:一类是网页html解析工具,另一类是网页爬虫。网页数据解析工具常用的有selenium/webdriver两大工具。一:网页html解析工具nimojs,可以将任意文件的标题格式化,并获取编码所需要的字符集。
nimojs之所以非常受欢迎,主要是因为该工具提供了丰富的插件,包括dateformat、includekeyword、renderfield等。下面是官方对nimojs的介绍:(1)nimojs特色:①nimojs提供了丰富的、对html和request结构模式支持完整的解析工具;②可以根据html文件中的内容获取重要的元素的html标签名称,并实现相应的id映射;③可以应用html格式转换库,比如xpath和parser等;④structuredhelper可以输出、合并或者拆分网页中的布局;⑤无需安装在任何浏览器上;⑥使用不同的解析工具,可以以便宜、快速和高质量的方式获取html文件。
nimojs极大地提高了开发者的效率,可以轻松完成像发布个人博客一样的html文件的发布及爬取任务。nimojs的用户类型也非常丰富,不管是初级初学者还是资深网站数据工程师都可以找到相应的产品。它的tinyhub是一个用于网页数据抓取的应用程序,它通过用户搜索引擎进行同名网站数据抓取。urlahtml工具不仅基于webpathread来获取html网页,同时支持http协议栈的请求和响应。
在使用这个工具时,你只需要提供一个python文件,当请求成功后把获取的html文件文件传给urlahtml即可,urlahtml将对数据文件进行解析处理并返回一个python结构数据。在新建urlhtml程序时,你不需要安装这个工具。urlhtml工具还支持pyspider,scrapy等工具,用起来非常方便。
此外,这个工具还支持python和matlab混合编程,可以运行在windows、linux、macos等不同的操作系统上。pipto4js是一个开源项目,它是以python语言为基础,直接调用编译好的python字节码(bytecode),从而完成对网页中javascript、css、图片的查找及解析任务。
同时也支持requests,beautifulsoup,lxml等主流数据包。piptapy是由pipto4js衍生而来的,它包含了pipto4js的一切。pipto4js提供了各种数据包解析相关的包。比如pipto4,pipto4j,math.floor,numpy和scipy等等。当你在用pipto4js来抓取一个网页的时候,你不需要安装任何程序或包。你可以使用pipto4js直接开启web程序。 查看全部
如何抓取网页数据(如何抓取网页数据才是值得学习的?(图))
如何抓取网页数据才是值得学习的?抓取网页数据,只需要能抓住网页的变化,那基本上就能获取到网页中所需要的数据了。这里为大家整理了主流网站中常用的9大抓取工具,分为两大类:一类是网页html解析工具,另一类是网页爬虫。网页数据解析工具常用的有selenium/webdriver两大工具。一:网页html解析工具nimojs,可以将任意文件的标题格式化,并获取编码所需要的字符集。
nimojs之所以非常受欢迎,主要是因为该工具提供了丰富的插件,包括dateformat、includekeyword、renderfield等。下面是官方对nimojs的介绍:(1)nimojs特色:①nimojs提供了丰富的、对html和request结构模式支持完整的解析工具;②可以根据html文件中的内容获取重要的元素的html标签名称,并实现相应的id映射;③可以应用html格式转换库,比如xpath和parser等;④structuredhelper可以输出、合并或者拆分网页中的布局;⑤无需安装在任何浏览器上;⑥使用不同的解析工具,可以以便宜、快速和高质量的方式获取html文件。
nimojs极大地提高了开发者的效率,可以轻松完成像发布个人博客一样的html文件的发布及爬取任务。nimojs的用户类型也非常丰富,不管是初级初学者还是资深网站数据工程师都可以找到相应的产品。它的tinyhub是一个用于网页数据抓取的应用程序,它通过用户搜索引擎进行同名网站数据抓取。urlahtml工具不仅基于webpathread来获取html网页,同时支持http协议栈的请求和响应。
在使用这个工具时,你只需要提供一个python文件,当请求成功后把获取的html文件文件传给urlahtml即可,urlahtml将对数据文件进行解析处理并返回一个python结构数据。在新建urlhtml程序时,你不需要安装这个工具。urlhtml工具还支持pyspider,scrapy等工具,用起来非常方便。
此外,这个工具还支持python和matlab混合编程,可以运行在windows、linux、macos等不同的操作系统上。pipto4js是一个开源项目,它是以python语言为基础,直接调用编译好的python字节码(bytecode),从而完成对网页中javascript、css、图片的查找及解析任务。
同时也支持requests,beautifulsoup,lxml等主流数据包。piptapy是由pipto4js衍生而来的,它包含了pipto4js的一切。pipto4js提供了各种数据包解析相关的包。比如pipto4,pipto4j,math.floor,numpy和scipy等等。当你在用pipto4js来抓取一个网页的时候,你不需要安装任何程序或包。你可以使用pipto4js直接开启web程序。
如何抓取网页数据(怎么用谷歌来分析网站的API,怎么才能获得浏览器的数据报告)
网站优化 • 优采云 发表了文章 • 0 个评论 • 595 次浏览 • 2022-04-01 08:06
有很多网友担心如何用谷歌分析网站的API,如何获取浏览器的数据报告,让小编为大家带来详细的分析方法。
1.注册谷歌分析
注:以下操作基本需要爬墙,请自备梯子。
登录您的 Google 帐户,注册 [Google Analytics]
然后设置你的账户基本信息
获取跟踪 ID 并同意协议。
2.将 Google Analytics 代码添加到 网站
登录后会有一个全站跟踪代码,将带有跟踪ID的代码复制到你的项目中。
[入门]
在您的 网站 上安装跟踪代码
[例子]
安装跟踪码后,您可以发布您的网站,在这个管理后台可以查看您的网站访问数据。
以上只是基本操作。完成上述操作后,您可以继续执行以下步骤,以便您的本地服务获取 Google Analytics 的数据。
3.查看google api
如果你想在你的网站中显示这个数据,而且每次只能登录本地后台查看,怎么办?
谷歌提供api接口供您自由配置指标查询您的网站访问数据,并提供【各种客户端库】的查询支持。
4.api 调用演示
本文使用的后台技术是NodeJs,使用express框架+redis技术实现。
项目目录结构,项目代码放在[github]上,可以适当修改配置,安装依赖,可以应用到自己的网站。
在这个项目中,使用了官方的 nodejs api npm 包 `googleapis`。
使用redis的部分是缓存access_token和一些数据。目前部分接口的数据缓存23小时(不想频繁请求接口)。
5.配置你的个人项目
项目中需要配置的地方,首先是数据视图id,在创建账号的时候生成。您可以在账户管理的“数据视图”中看到它。点击`data view settings`获取data view id
viewId: 'ga: 你的数据视图 id'
第一步:设置密钥
打开【Google API Console】,首先创建一个项目,然后点击`Enable API`,搜索google analytics,启用`Google Analytics Reporting API`,然后启用`Analytics API`。
第 2 步:创建凭据
然后创建凭证,点击`Credentials`-->`Create Credentials`-->选择`Service Account Key`-->选择一个新的服务账户,并设置角色,输入名称,点击`Create`,保存密码密钥文件。
将此密钥复制到项目的 `app/config` 目录,并将名称更改为 `key.json`。
第 3 步:添加访问此帐户数据的权限
打开已注册的Google Analytics的数据控制台(注册时可以查看数据),点击`管理`-->`媒体资源`-->`用户管理`-->`添加新用户`,进入api控制台 `credentials`-->list在`Manage service account`的上角,复制service account id,粘贴到邮箱地址栏,设置权限(只能设置权限为阅读和分析)。这个控制台还可以设置过滤规则和白名单等,有需要的可以研究一下。
至此,您就完成了。点击你的网站,如果能在Google Analytics的数据控制台看到数据,就可以启动我的项目文件,调用api接口,就可以得到json数据了。
ps:在这个【api参考】中,你可以自由设置你想要的数据,修改demo界面即可。
### 项目路由文件注释
采用
6.本地测试和在线部署
目前由于墙的原因,无法访问google服务。我使用一个工具为我的本地数据打开节点进程的代理。(mac端`Proxifier`)
在线部署也需要解决墙的问题,最好把这个小项目托管在可以访问google服务的服务器上。
至于文章开头的图表,来源于接口返回的数据,经过前端处理后由echart显示的结果。 查看全部
如何抓取网页数据(怎么用谷歌来分析网站的API,怎么才能获得浏览器的数据报告)
有很多网友担心如何用谷歌分析网站的API,如何获取浏览器的数据报告,让小编为大家带来详细的分析方法。
1.注册谷歌分析
注:以下操作基本需要爬墙,请自备梯子。
登录您的 Google 帐户,注册 [Google Analytics]
然后设置你的账户基本信息
获取跟踪 ID 并同意协议。
2.将 Google Analytics 代码添加到 网站
登录后会有一个全站跟踪代码,将带有跟踪ID的代码复制到你的项目中。
[入门]
在您的 网站 上安装跟踪代码
[例子]
安装跟踪码后,您可以发布您的网站,在这个管理后台可以查看您的网站访问数据。
以上只是基本操作。完成上述操作后,您可以继续执行以下步骤,以便您的本地服务获取 Google Analytics 的数据。
3.查看google api
如果你想在你的网站中显示这个数据,而且每次只能登录本地后台查看,怎么办?
谷歌提供api接口供您自由配置指标查询您的网站访问数据,并提供【各种客户端库】的查询支持。
4.api 调用演示
本文使用的后台技术是NodeJs,使用express框架+redis技术实现。
项目目录结构,项目代码放在[github]上,可以适当修改配置,安装依赖,可以应用到自己的网站。
在这个项目中,使用了官方的 nodejs api npm 包 `googleapis`。
使用redis的部分是缓存access_token和一些数据。目前部分接口的数据缓存23小时(不想频繁请求接口)。
5.配置你的个人项目
项目中需要配置的地方,首先是数据视图id,在创建账号的时候生成。您可以在账户管理的“数据视图”中看到它。点击`data view settings`获取data view id
viewId: 'ga: 你的数据视图 id'
第一步:设置密钥
打开【Google API Console】,首先创建一个项目,然后点击`Enable API`,搜索google analytics,启用`Google Analytics Reporting API`,然后启用`Analytics API`。
第 2 步:创建凭据
然后创建凭证,点击`Credentials`-->`Create Credentials`-->选择`Service Account Key`-->选择一个新的服务账户,并设置角色,输入名称,点击`Create`,保存密码密钥文件。
将此密钥复制到项目的 `app/config` 目录,并将名称更改为 `key.json`。
第 3 步:添加访问此帐户数据的权限
打开已注册的Google Analytics的数据控制台(注册时可以查看数据),点击`管理`-->`媒体资源`-->`用户管理`-->`添加新用户`,进入api控制台 `credentials`-->list在`Manage service account`的上角,复制service account id,粘贴到邮箱地址栏,设置权限(只能设置权限为阅读和分析)。这个控制台还可以设置过滤规则和白名单等,有需要的可以研究一下。
至此,您就完成了。点击你的网站,如果能在Google Analytics的数据控制台看到数据,就可以启动我的项目文件,调用api接口,就可以得到json数据了。
ps:在这个【api参考】中,你可以自由设置你想要的数据,修改demo界面即可。
### 项目路由文件注释
采用
6.本地测试和在线部署
目前由于墙的原因,无法访问google服务。我使用一个工具为我的本地数据打开节点进程的代理。(mac端`Proxifier`)
在线部署也需要解决墙的问题,最好把这个小项目托管在可以访问google服务的服务器上。
至于文章开头的图表,来源于接口返回的数据,经过前端处理后由echart显示的结果。
如何抓取网页数据( 爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-30 06:12
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数
2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性
接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。 查看全部
如何抓取网页数据(
爬取网页其实就是通过URL获取网页信息的实质是一段添加了JavaScript和CSS的HTML代码)
爬取网页实际上是通过 URL 获取网页信息。网页信息的本质是一段添加了 JavaScript 和 CSS 的 HTML 代码。Python 提供了第三方请求模块,用于抓取网页信息。requests 模块自称为“HTTP for Humans”,字面意思是专为人类设计的 HTTP 模块。该模块支持发送请求和获取响应。
1.发送请求
requests 模块提供了许多发送 HTTP 请求的功能。常用的请求函数如表10-1所示。
表 10-1 requests 模块的请求函数
2.得到响应
requests模块提供的Response类对象用于动态响应客户端的请求,控制发送给用户的信息,动态生成响应,包括状态码、网页内容等。接下来用一张表来列出Response类可以获取的信息,如表10-2所示。
表 10-2 Response 类的常用属性
接下来通过一个案例来演示如何使用requests模块爬取百度网页。具体代码如下:
# 01 requests baidu
import requests
base_url = 'http://www.baidu.com'
#发送GET请求
res = requests.get (base_url)
print("响应状态码:{}".format(res.status_code)) #获取响应状态码
print("编码方式:{}".format(res.encoding)) #获取响应内容的编码方式
res.encoding = 'utf-8' #更新响应内容的编码方式为UIE-8
print("网页源代码:\n{}".format(res.text)) #获取响应内容
在上面的代码中,第 2 行使用 import 来导入 requests 模块;第3~4行根据URL向服务器发送GET请求,并使用变量res接收服务器返回的响应内容;第 5~6 行打印响应内容的状态码和编码;第 7 行将响应内容的编码更改为“utf-8”;第 8 行打印响应内容。运行程序,程序的输出如下:
响应状态码:200
编码方式:ISO-8859-1
网页源代码:
百度一下,你就知道
…省略N行…
值得一提的是,在使用requests模块爬取网页时,可能会因未连接网络、服务器连接失败等原因出现各种异常,其中最常见的两个异常是URLError和HTTPError。这些网络异常可以与 try... except 语句捕获和处理一起使用。
如何抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-24 18:14
Excel 2013及更高版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣图书的基本信息页面。
豆瓣网图书信息的网址是:9787111529385,网址最后一串数字是图书的ISBN号。
在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。
第二步,安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url, "UTF-8") 返回 JSON 原创数据。
然后,使用函数GetJsonByPropertyName(json_source, property_name)返回书的基本信息
使用GetJsonSource()函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。 查看全部
如何抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?)
Excel 2013及更高版本提供WEBSERVICE和FILTERXML函数,可用于网页数据采集,但只能采集XML格式的数据。现在很多网站网页或者界面返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?
今天笔者就以豆瓣图书的基本信息为例,介绍如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步是找到豆瓣图书的基本信息页面。
豆瓣网图书信息的网址是:9787111529385,网址最后一串数字是图书的ISBN号。
在火狐浏览器下,这个URL会返回如下信息,都是标准的JSON格式。蓝色字体为属性名称,红色字体为对应的属性值。
第二步,安装ExcelAPI网络函数库。
访问ExcelAPI网络函数库官网,根据帮助文件安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url, "UTF-8") 返回 JSON 原创数据。
然后,使用函数GetJsonByPropertyName(json_source, property_name)返回书的基本信息
使用GetJsonSource()函数可以一次抓取所有数据,然后按需抓取。这样做的目的是提高抓取速度。毕竟,访问网页需要时间。
如何抓取网页数据(网站日志该分析哪些数据呢?用一个站长的日志基础信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-24 18:12
网站日志中应该分析哪些数据?如何从基本信息、目录抓包、时间段抓包、IP抓包、状态码分析网站日志:
一、如何分析网站日志和基本信息
下载网站log文件工具获取基本信息:如何分析总爬取量网站log、停留时间(h)和访问次数;通过这三个基本信息,可以计算出:平均每次爬取页数和单个页面的爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算重复爬取率爬虫根据以上数据:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
如何分析一段时间数据的网站日志,可以看到整体趋势如何,从而发现问题,调整网站的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强,如何分析网站日志。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取更多入口,以及一些robots和nofollow技术的使用。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,页面加载速度如何影响SEO流量;提高页面的加载速度,减少爬虫在一侧的停留时间,可以用于爬虫的总爬取。有助于增加 网站收录,从而增加 网站 整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,可以找到对应的爬取量比较密集的时间段,更新内容有针对性的方式。同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但爬虫正常爬行,可见这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计 如果一个网站被搜索引擎爬取的次数和频率比较多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的爬取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的 查看全部
如何抓取网页数据(网站日志该分析哪些数据呢?用一个站长的日志基础信息)
网站日志中应该分析哪些数据?如何从基本信息、目录抓包、时间段抓包、IP抓包、状态码分析网站日志:
一、如何分析网站日志和基本信息
下载网站log文件工具获取基本信息:如何分析总爬取量网站log、停留时间(h)和访问次数;通过这三个基本信息,可以计算出:平均每次爬取页数和单个页面的爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算重复爬取率爬虫根据以上数据:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
如何分析一段时间数据的网站日志,可以看到整体趋势如何,从而发现问题,调整网站的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强,如何分析网站日志。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取更多入口,以及一些robots和nofollow技术的使用。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,页面加载速度如何影响SEO流量;提高页面的加载速度,减少爬虫在一侧的停留时间,可以用于爬虫的总爬取。有助于增加 网站收录,从而增加 网站 整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,可以找到对应的爬取量比较密集的时间段,更新内容有针对性的方式。同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但爬虫正常爬行,可见这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计 如果一个网站被搜索引擎爬取的次数和频率比较多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的爬取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的
如何抓取网页数据( 如何抓取网页数据,以抓取安居客举例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-24 18:11
如何抓取网页数据,以抓取安居客举例(组图))
如何爬取网页数据以爬取安居客为例
互联网时代,网页数据资源丰富。在工作项目、学习过程或学术研究的情况下,我们经常需要大量数据的支持。那么,如何爬取这些需要的网页数据呢?
对于有编程基础的同学,可以编写爬虫程序来爬取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具来爬取网页数据。
网络数据爬取需求的高速增长推动了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具比较多(优采云、jisoke、优采云、优采云、作数等)。每个爬虫工具都有不同的功能、定位、适合的分组,大家可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是使用 优采云 抓取 Web 数据的完整示例。例子中采集是安居客-深圳-新房-全部房产的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取 Anjuke 示例 图1 2)复制你要保存的网址采集到网站的输入框,点击“保存网址”
如何抓取网页数据抓取Anjuke示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何抓取网页数据抓取Anjuke示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何抓取网页数据抓取Anjuke示例图4
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页数据抓取Anjuke示例图5
3)我们可以看到页面上房产信息块中的所有元素都被选中并变为绿色。在右侧的操作提示框中,会出现一个字段预览表,将鼠标移动到表头,点击垃圾桶图标,可以删除不需要的字段。字段选择完成后,选择“采集以下数据”
如何抓取网页数据抓取Anjuke示例图5
4)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何抓取web数据抓取Anjuke示例 图6 5)选择“Start Local采集”
如何抓取网页数据抓取 Anjuke 示例 图 7
第 5 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页数据以抓取Anjuke示例 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取 Anjuke 示例 图 9
经过以上操作,我们采集得到了安居客深圳新房类下所有楼盘的信息。网站 上其他公共数据的基本采集 步骤相同。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),可以在优采云中设置一些高级选项。
相关 采集 教程:
链家租房资讯采集
搜狗微信文章采集
方天下资讯采集
优采云——70万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能是免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
如何抓取网页数据(
如何抓取网页数据,以抓取安居客举例(组图))
如何爬取网页数据以爬取安居客为例
互联网时代,网页数据资源丰富。在工作项目、学习过程或学术研究的情况下,我们经常需要大量数据的支持。那么,如何爬取这些需要的网页数据呢?
对于有编程基础的同学,可以编写爬虫程序来爬取网页数据。对于没有编程基础的同学,可以选择合适的爬虫工具来爬取网页数据。
网络数据爬取需求的高速增长推动了爬虫工具市场的形成和繁荣。目前市面上的爬虫工具比较多(优采云、jisoke、优采云、优采云、作数等)。每个爬虫工具都有不同的功能、定位、适合的分组,大家可以根据自己的需要进行选择。本文使用简单而强大的优采云采集器。下面是使用 优采云 抓取 Web 数据的完整示例。例子中采集是安居客-深圳-新房-全部房产的数据。
采集网站::///doc/11cece9859f5f61fb7360b4c2e3f5727a5e924d2.html /loupan/all/p2/
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页数据抓取 Anjuke 示例 图1 2)复制你要保存的网址采集到网站的输入框,点击“保存网址”
如何抓取网页数据抓取Anjuke示例图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何抓取网页数据抓取Anjuke示例图3
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个房地产信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何抓取网页数据抓取Anjuke示例图4
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页数据抓取Anjuke示例图5
3)我们可以看到页面上房产信息块中的所有元素都被选中并变为绿色。在右侧的操作提示框中,会出现一个字段预览表,将鼠标移动到表头,点击垃圾桶图标,可以删除不需要的字段。字段选择完成后,选择“采集以下数据”
如何抓取网页数据抓取Anjuke示例图5
4)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何抓取web数据抓取Anjuke示例 图6 5)选择“Start Local采集”
如何抓取网页数据抓取 Anjuke 示例 图 7
第 5 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页数据以抓取Anjuke示例 图8
2)这里我们选择excel作为导出格式,导出数据如下图
如何抓取网页数据抓取 Anjuke 示例 图 9
经过以上操作,我们采集得到了安居客深圳新房类下所有楼盘的信息。网站 上其他公共数据的基本采集 步骤相同。有些网页比较复杂(涉及点击、登录、翻页、识别验证码、瀑布流、Ajax),可以在优采云中设置一些高级选项。
相关 采集 教程:
链家租房资讯采集
搜狗微信文章采集
方天下资讯采集
优采云——70万用户选择的网页数据采集器。
1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。
2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。
3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。庞大的云采集集群24*7不间断运行,无需担心IP阻塞和网络中断。
4、功能是免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
如何抓取网页数据(网页上的房源房价数据如何抓取如何快速找到最心意的房子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-18 15:19
如何在网络上获取房价数据
如何从网页中抓取数据?本文将以房屋网页为例进行具体说明。
应用场景:部分城市房价快速上涨,多地出台楼市限制措施。未来房价走势如何?租房平台五花八门,房源信息良莠不齐,如何快速找到心仪的房源?- 如果现有的信息不能满足需求,非常有必要自己去网上抓取各个平台的房屋数据,密切关注最新的房价信息,然后根据实际情况做出自己的判断。
具体案例:以下是使用优采云采集搜房网房源数据的具体案例。
采集网站:
第 1 步:创建 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页上的房价数据 图1
2)复制并粘贴你要采集的网址到网站输入框,点击“保存网址”
如何抓取网页上的房价数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何在网页上抓取房价数据 图 3
第 3 步:创建列表循环并提取数据
移动鼠标选择页面上的第一个办公楼信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何在网页上抓取房价数据 图 4
系统会自动识别页面中的其他类似元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页上的房价数据 图5
我们可以看到页面上写字楼信息块中的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网页上的房价数据 图6
4)选择不需要的字段并单击垃圾桶图标将其删除
如何在网页上抓取房价数据 图 7
5)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何在网页上抓取房价数据 图 8
6)选择“本地启动采集”
如何在网页上抓取房价数据 图 9
第 5 步:数据采集 和导出
采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页上的房价数据 图 10
这里我们选择excel作为导出格式,导出数据如下图
如何在网页上抓取房价数据 图 11 查看全部
如何抓取网页数据(网页上的房源房价数据如何抓取如何快速找到最心意的房子)
如何在网络上获取房价数据
如何从网页中抓取数据?本文将以房屋网页为例进行具体说明。
应用场景:部分城市房价快速上涨,多地出台楼市限制措施。未来房价走势如何?租房平台五花八门,房源信息良莠不齐,如何快速找到心仪的房源?- 如果现有的信息不能满足需求,非常有必要自己去网上抓取各个平台的房屋数据,密切关注最新的房价信息,然后根据实际情况做出自己的判断。
具体案例:以下是使用优采云采集搜房网房源数据的具体案例。
采集网站:
第 1 步:创建 采集 任务
1)进入主界面,选择“自定义模式”
如何抓取网页上的房价数据 图1
2)复制并粘贴你要采集的网址到网站输入框,点击“保存网址”
如何抓取网页上的房价数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。将页面下拉至最下方,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”,创建翻页循环
如何在网页上抓取房价数据 图 3
第 3 步:创建列表循环并提取数据
移动鼠标选择页面上的第一个办公楼信息块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
如何在网页上抓取房价数据 图 4
系统会自动识别页面中的其他类似元素。在操作提示框中,选择“全选”创建列表循环
如何抓取网页上的房价数据 图5
我们可以看到页面上写字楼信息块中的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网页上的房价数据 图6
4)选择不需要的字段并单击垃圾桶图标将其删除
如何在网页上抓取房价数据 图 7
5)字段选择完成后,选择对应字段,自定义字段名称。完成后点击左上角的“Save and Launch”启动采集任务
如何在网页上抓取房价数据 图 8
6)选择“本地启动采集”
如何在网页上抓取房价数据 图 9
第 5 步:数据采集 和导出
采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
如何抓取网页上的房价数据 图 10
这里我们选择excel作为导出格式,导出数据如下图
如何在网页上抓取房价数据 图 11
如何抓取网页数据(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-17 05:23
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、 死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。 查看全部
如何抓取网页数据(如何提高百度蜘蛛抓取频次起重要影响,如何做好)
3、robots协议:这个文件是百度蜘蛛第一个访问的文件,它会告诉百度蜘蛛哪些页面可以爬,哪些页面不能爬。
三、如何提高百度蜘蛛抓取的频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站权重:权重越高网站百度蜘蛛爬得越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛就会越多
3、网站内容质量:如果网站内容原创质量高,能解决用户问题,百度会提高爬取频率。
4、传入链接:链接是页面的入口,优质的链接可以更好地引导百度蜘蛛进入和抓取。
5、页面深度:页面是否有首页的入口,首页的入口能更好的被爬取和收录。
6、爬取的频率决定了有多少页面网站会被建入数据库收录,这么重要内容的站长应该去哪里了解和修改,你可以去百度站长平台爬频功能了解
四、什么情况下会导致百度蜘蛛抓取失败等异常情况
有一些网站的网页,内容优质,用户访问正常,但是百度蜘蛛无法抓取,不仅会流失流量和用户,还被百度认为是网站@ > 不友好,导致网站减权、减收视、减少进口网站流量等问题。
这里简单介绍一下百度蜘蛛爬行的原因:
1、服务器连接异常:异常有两种情况,一种是网站不稳定导致百度蜘蛛无法爬取,另一种是百度蜘蛛一直无法连接到服务器。仔细检查。
2、网络运营商异常:目前国内网络运营商分为电信和联通。如果百度蜘蛛无法通过其中之一访问您的网站,请联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以通过WHOIS查看您的网站IP是否可以解析,如果无法解析,则需要联系域名注册商解决。
4、IP封禁:IP封禁就是对IP进行限制,这个操作只有在特定情况下才会做,所以如果你想让网站百度蜘蛛正常访问你的网站别不要这样做。
5、 死链接:表示页面无效,无法提供有效信息。此时可以通过百度站长平台提交死链接。
通过以上信息,可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保障,而百度蜘蛛爬取是收录的保障,所以网站只有按照百度蜘蛛的爬取规则才能获得更好的排名和交通。
如何抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于百度蜘蛛日志的流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-16 17:16
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。如果你看百度蜘蛛日志。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多只蜘蛛进行分布式爬取。
当蜘蛛访问网站时,它会首先访问网站根目录下的robots.txt文件。如果 robots.txt 文件禁止搜索引擎爬取某些网页或内容,或者 网站,则爬虫会按照协议不爬取,看百度爬虫日志。
蜘蛛也有自己的代理名称。可以在站长的日志中看到蜘蛛爬行的痕迹,这也是为什么那么多站长总是说要先查看网站日志的原因(作为优秀的SEO,你必须有能力查看网站没有任何软件的日志,并且非常熟悉其代码的含义)如果您查看百度蜘蛛日志。
1.如果看百度蜘蛛日志和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是蜘蛛。如果看百度蜘蛛日志,是一个很形象的名字,把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。
网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据目前公布的数据,容量最大的搜索引擎只爬取了网页总数的40%左右。
造成这种情况的原因之一是爬虫技术的瓶颈。100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载也还是有问题(按照一台机器每秒下载20K,需要340台机器保存一年才能下载完所有网页),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有的网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如,如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果设置访问层数by the web spider 2, Web page I will not be access,这也使得某些网站网页可以在搜索引擎上搜索到,而其他部分则无法搜索到。
对于网站设计师来说,扁平的网站设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站,他们希望搜索引擎可以搜索到他们的报告,但不是完全免费的为了让搜索者查看,需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以通过给定的权限抓取这些网页,从而提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这就是名字所在的地方搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互连接的链接组成的,也就是说,搜索引擎蜘蛛最终会从任何一个页面开始爬取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接的结构过于复杂,蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合最佳优先级结合具体应用改进跳出当地的。最好的一点,据研究,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它并没有一路跟随一个链接,而是爬取页面上的所有链接,然后进入第二层页面并跟随第二层找到的链接层。翻到第三页。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间都不是无限的,也无法爬取所有页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬得越多越好。
因此,为了尽可能多地捕获用户信息,深度优先和广度优先通常是混合使用的,这样可以照顾到尽可能多的网站,同时也照顾到部分网站 的内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,反复下载网页,从文档中搜索不可见的URL,从而访问其他网页,遍历网页。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,遍历系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
似乎由于网络数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的时间点也不同。因此,累计爬取的网页集合实际上无法与真实环境中的网页数据进行比较。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指在一定规模的网页集合的基础上,通过更新数据,在现有集合中选择过期的网页,以保证抓取到的网页被爬取。数据与真实网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取策略。
累积爬取一般用于数据集合的整体建立或大规模更新,而增量爬取主要用于数据集合的日常维护和即时更新。
爬取策略确定后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运营策略中的核心问题。
总体而言,在合理利用软硬件资源对网络数据进行实时捕捉方面,已经形成了较为成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是如何更好地处理动态的web数据问题(比如越来越多的Web2.0数据等),以及更好地基于网页质量。
四、数据库
为了避免重复爬取和爬取网址,搜索引擎会建立一个数据库来记录已发现未爬取的页面和已爬取的页面。那么数据库中的URLs是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛爬取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
爬虫根据重要程度从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已经访问过的地址库中。因此,建议站长在网站观察,期间有必要尽可能定期更新网站。
3、站长提交网站
一般而言,提交网站只是将网站保存到要访问的数据库中。如果网站是持久化的,不更新spider,就不会光顾搜索引擎的页面了收录是spider自己点链接。
因此,将其提交给搜索引擎对您来说不是很有用。后期根据你的网站更新程度来考虑。搜索引擎更喜欢沿着链接本身查找新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,你可以试试,说不定会有意想不到的效果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以想要收录更多页面的SEO人员不得不想办法引诱蜘蛛爬取。
既然不能爬取所有的页面,就需要让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站 和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次爬取时都会存储页面数据。如果第二次爬取发现页面内容和第一次收录完全一样,说明页面没有更新,蜘蛛不需要经常爬取再爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬爬,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新文章@ >
3、导入链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道页面的存在一点也不。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被爬取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站 从彼此之间爬到你 网站 的次数和深度更多。 查看全部
如何抓取网页数据(搜索引擎蜘蛛的基本原理及工作流程对于百度蜘蛛日志的流程)
搜索引擎用来抓取和访问页面的程序称为蜘蛛,也称为机器人。如果你看百度蜘蛛日志。当搜索引擎蜘蛛访问网站的页面时,它类似于普通用户使用浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。为了提高搜索引擎的爬取和爬取速度,都使用了多只蜘蛛进行分布式爬取。
当蜘蛛访问网站时,它会首先访问网站根目录下的robots.txt文件。如果 robots.txt 文件禁止搜索引擎爬取某些网页或内容,或者 网站,则爬虫会按照协议不爬取,看百度爬虫日志。
蜘蛛也有自己的代理名称。可以在站长的日志中看到蜘蛛爬行的痕迹,这也是为什么那么多站长总是说要先查看网站日志的原因(作为优秀的SEO,你必须有能力查看网站没有任何软件的日志,并且非常熟悉其代码的含义)如果您查看百度蜘蛛日志。
1.如果看百度蜘蛛日志和搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛是蜘蛛。如果看百度蜘蛛日志,是一个很形象的名字,把互联网比作蜘蛛网,那么蜘蛛就是在网上四处爬行的蜘蛛。
网络蜘蛛通过网页的链接地址寻找网页,从网站的某个页面(通常是首页)开始,读取网页的内容,寻找网页中的其他链接地址,然后通过这些链接地址寻找下一页。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。
如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,几乎不可能爬取互联网上的所有网页。根据目前公布的数据,容量最大的搜索引擎只爬取了网页总数的40%左右。
造成这种情况的原因之一是爬虫技术的瓶颈。100 亿个网页的容量是 100×2000G 字节。就算能存起来,下载也还是有问题(按照一台机器每秒下载20K,需要340台机器保存一年才能下载完所有网页),同时,由于数据量大,在提供搜索时也会对效率产生影响。
因此,很多搜索引擎的网络蜘蛛只抓取那些重要的网页,而在抓取时评估重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有的网页,所以有些网络蜘蛛为一些不太重要的网站设置了要访问的层数,例如,如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始页,属于第0层,B,C,D,E,F属于第1层,G,H属于第2层,I属于第3层,如果设置访问层数by the web spider 2, Web page I will not be access,这也使得某些网站网页可以在搜索引擎上搜索到,而其他部分则无法搜索到。
对于网站设计师来说,扁平的网站设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站网页时,经常会遇到加密数据和网页权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以让网络蜘蛛不按约定爬取,但是对于一些卖报告的网站,他们希望搜索引擎可以搜索到他们的报告,但不是完全免费的为了让搜索者查看,需要向网络蜘蛛提供相应的用户名和密码。
网络蜘蛛可以通过给定的权限抓取这些网页,从而提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、点击链接
为了在网络上抓取尽可能多的页面,搜索引擎蜘蛛会跟随网页上的链接,从一个页面爬到下一页,就像蜘蛛在蜘蛛网上爬行一样,这就是名字所在的地方搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互连接的链接组成的,也就是说,搜索引擎蜘蛛最终会从任何一个页面开始爬取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接的结构过于复杂,蜘蛛只能通过一定的方法爬取所有页面。据了解,最简单的爬取策略有以下三种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。算法预测为“有用”的网页。
存在的一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要结合最佳优先级结合具体应用改进跳出当地的。最好的一点,据研究,这样的闭环调整可以将不相关网页的数量减少30%到90%。
2、深度优先
深度优先是指蜘蛛沿着找到的链接爬行,直到前面没有其他链接,然后返回第一页,沿着另一个链接爬行。
3、广度优先
广度优先是指当蜘蛛在一个页面上发现多个链接时,它并没有一路跟随一个链接,而是爬取页面上的所有链接,然后进入第二层页面并跟随第二层找到的链接层。翻到第三页。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间都不是无限的,也无法爬取所有页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬得越多越好。
因此,为了尽可能多地捕获用户信息,深度优先和广度优先通常是混合使用的,这样可以照顾到尽可能多的网站,同时也照顾到部分网站 的内页。
三、搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络爬虫都是从种子网页开始,反复下载网页,从文档中搜索不可见的URL,从而访问其他网页,遍历网页。
而它的工作策略一般可以分为累积爬取(cumulative crawling)和增量爬取(incremental crawling)两种。
1、累积爬取
累积爬取是指从某个时间点开始,遍历系统允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证爬取相当大的网页集合。
似乎由于网络数据的动态特性,集合中的网页被爬取的时间点不同,页面更新的时间点也不同。因此,累计爬取的网页集合实际上无法与真实环境中的网页数据进行比较。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指在一定规模的网页集合的基础上,通过更新数据,在现有集合中选择过期的网页,以保证抓取到的网页被爬取。数据与真实网络数据足够接近。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间的信息。在针对实际应用环境的网络爬虫设计中,通常会同时收录累积爬取和增量爬取策略。
累积爬取一般用于数据集合的整体建立或大规模更新,而增量爬取主要用于数据集合的日常维护和即时更新。
爬取策略确定后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运营策略中的核心问题。
总体而言,在合理利用软硬件资源对网络数据进行实时捕捉方面,已经形成了较为成熟的技术和实用的解决方案。我认为这方面需要解决的主要问题是如何更好地处理动态的web数据问题(比如越来越多的Web2.0数据等),以及更好地基于网页质量。
四、数据库
为了避免重复爬取和爬取网址,搜索引擎会建立一个数据库来记录已发现未爬取的页面和已爬取的页面。那么数据库中的URLs是怎么来的呢?
1、手动输入种子网站
简单来说就是我们建站后提交给百度、谷歌或者360的URL收录。
2、蜘蛛爬取页面
如果搜索引擎蜘蛛在爬取过程中发现了新的连接URL,但不在数据库中,则将其存入待访问的数据库中(网站观察期)。
爬虫根据重要程度从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址库中删除该URL,放入已经访问过的地址库中。因此,建议站长在网站观察,期间有必要尽可能定期更新网站。
3、站长提交网站
一般而言,提交网站只是将网站保存到要访问的数据库中。如果网站是持久化的,不更新spider,就不会光顾搜索引擎的页面了收录是spider自己点链接。
因此,将其提交给搜索引擎对您来说不是很有用。后期根据你的网站更新程度来考虑。搜索引擎更喜欢沿着链接本身查找新页面。当然,如果你的SEO技术足够成熟,并且有这个能力,你可以试试,说不定会有意想不到的效果。不过对于一般站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以爬取所有页面,但在实践中是不可能的,所以想要收录更多页面的SEO人员不得不想办法引诱蜘蛛爬取。
既然不能爬取所有的页面,就需要让它爬取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我特意整理了以下几个我认为比较重要的页面,具有以下特点:
1、网站 和页面权重
优质老网站被赋予高权重,而这个网站上的页面爬取深度更高,所以更多的内页会是收录。
2、页面更新
蜘蛛每次爬取时都会存储页面数据。如果第二次爬取发现页面内容和第一次收录完全一样,说明页面没有更新,蜘蛛不需要经常爬取再爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬爬,那么页面上的新链接自然会被蜘蛛更快地跟踪和爬取,这也是为什么需要每天更新文章@ >
3、导入链接
无论是外部链接还是同一个网站的内部链接,为了被蜘蛛爬取,必须有传入链接才能进入页面,否则蜘蛛不会知道页面的存在一点也不。这时候URL链接就起到了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接也往往会增加页面上的出站链接被爬取的深度。
这就是为什么大多数网站管理员或 SEO 都想要高质量的附属链接,因为蜘蛛 网站 从彼此之间爬到你 网站 的次数和深度更多。
如何抓取网页数据( 如何用WebScraper选择元素的操作点击Stiemaps图解 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-16 13:02
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列的第七部分文章。
在第 4 部分文章中,我解释了如何从单个网页中抓取单一类型的信息;
在第 5 部分文章,我解释了如何从多个网页中抓取单一类型的信息;
今天我们要讲的是如何从多个网页爬取多种类型的信息。
本次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了多网页的爬取问题,接下来我们将重点介绍如何爬取多类信息。
在练习之前先理清逻辑:
最后几篇文章只捕捉了一种元素:电影标题。本期我们将抓取各种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,必须先抓取包装多类数据的容器,然后选择容器中的数据,这样才能抓取正确。让我画个图来演示:
我们需要先抓取多个容器,然后抓取容器中的元素:序号、电影名、评分和一句话影评。当爬虫运行完毕,我们就成功抓取到数据了。
概念清楚了,我们可以谈谈实际操作。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,其中文章详细介绍了如何使用Web Scraper进行元素选择
1.点击Stiemaps,在新面板中点击ID为top250的这一列数据
2.删除旧选择器,点击添加新选择器,添加新选择器
3.在新的选择器中,注意将Type类型改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一个操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们会进入一个新的面板。根据导航,我们可以知道它在容器内。
在新建面板中,我们点击Add new selector,新建一个选择器来抓取电影名称,类型为Text,值得注意的是因为我们在容器中选择文本,所以一个容器中只有一个电影名称,如果选择多个,请不要检查,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是选择黄色区域中的电影名称。
点击保存选择器保存选择器后,我们会再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就不解释了。
排名:
评分:
一句话点评:
我们可以观察我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击Stiemap top250下的选择器图,查看我们爬虫选择的元素的层级关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择正确后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。下图是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,才是比较合理的学习方式。
今天的内容其实挺多的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
查看全部
如何抓取网页数据(
如何用WebScraper选择元素的操作点击Stiemaps图解
)
这是简易数据分析系列的第七部分文章。
在第 4 部分文章中,我解释了如何从单个网页中抓取单一类型的信息;
在第 5 部分文章,我解释了如何从多个网页中抓取单一类型的信息;
今天我们要讲的是如何从多个网页爬取多种类型的信息。
本次爬取是在简单数据分析05的基础上进行的,所以我们从一开始就解决了多网页的爬取问题,接下来我们将重点介绍如何爬取多类信息。
在练习之前先理清逻辑:
最后几篇文章只捕捉了一种元素:电影标题。本期我们将抓取各种元素:排名、片名、收视率、一句话影评。
根据Web Scraper的特性,如果要抓取多类数据,必须先抓取包装多类数据的容器,然后选择容器中的数据,这样才能抓取正确。让我画个图来演示:
我们需要先抓取多个容器,然后抓取容器中的元素:序号、电影名、评分和一句话影评。当爬虫运行完毕,我们就成功抓取到数据了。
概念清楚了,我们可以谈谈实际操作。
如果您对以下操作有任何疑问,可以阅读简单数据分析04的内容,其中文章详细介绍了如何使用Web Scraper进行元素选择
1.点击Stiemaps,在新面板中点击ID为top250的这一列数据
2.删除旧选择器,点击添加新选择器,添加新选择器
3.在新的选择器中,注意将Type类型改为Element(元素),因为在Web Scraper中,只有元素类型可以收录多个内容。
我们检查的元素区域如下图所示。确认无误后,点击保存选择器按钮,返回上一个操作面板。
在新面板中,单击您刚刚创建的选择器的数据行:
点击后,我们会进入一个新的面板。根据导航,我们可以知道它在容器内。
在新建面板中,我们点击Add new selector,新建一个选择器来抓取电影名称,类型为Text,值得注意的是因为我们在容器中选择文本,所以一个容器中只有一个电影名称,如果选择多个,请不要检查,否则捕获会失败。
当你选择电影名称时,你会发现容器以黄色突出显示,我们只是选择黄色区域中的电影名称。
点击保存选择器保存选择器后,我们会再创建三个选择器,分别选择编号、评分和一句话影评。因为操作和上面一模一样,这里就不解释了。
排名:
评分:
一句话点评:
我们可以观察我们在面板中选择的多个元素。总共有四个要素:姓名、编号、分数和评论。类型均为Text,无需多选。父选择器都是容器。
我们可以点击Stiemap top250下的选择器图,查看我们爬虫选择的元素的层级关系。确认无误后,我们点击Stiemap top250下的Selectors,返回选择器显示面板。
下图是我们这次爬虫的层级关系。和我们之前的理论分析一样吗?
确认选择正确后,我们就可以抓取数据了。该操作在简单数据分析04和简单数据分析05中已经提到过,忘记的可以复习旧文。下图是我抓取的数据:
还是和之前一样,数据是乱序的,不过这个没关系,因为排序属于数据清洗的内容,我们现在的话题是数据抓取。先完成相关知识点,再攻克下一个知识点,才是比较合理的学习方式。
今天的内容其实挺多的。你可以先消化一下。在下一篇文章中,我们将讨论如何抓取点击“Load More”加载数据的网页内容。
如何抓取网页数据( 百度蜘蛛的工作原理是如抓取网页的呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-16 12:31
百度蜘蛛的工作原理是如抓取网页的呢?(图))
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引库,让用户可以在百度搜索引擎中找到你的网站页面、图片、视频等内容. 之所以叫蜘蛛,是因为这个程序有类似蜘蛛的功能,布下天地之网,可以在网上搜集信息。那么百度蜘蛛是如何像爬网页一样工作的呢?为了增加蜘蛛爬取的网页量,有哪些技巧呢?
百度蜘蛛的工作原理
蜘蛛的工作分为四个步骤(抓取、过滤、索引和输出)。爬取:百度蜘蛛会通过计算和规则来确定要爬取的页面和爬取的频率。如果 网站 的更新频率和 网站 的内容质量和用户友好度都很高,那么你新生成的内容会立即被蜘蛛爬取。过滤:由于被过滤的页面数量过多,导致页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾页面。因此,百度蜘蛛会先过滤这些内容,防止这些内容展示给用户,给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存的内容包括页面的关键内容,例如标题和描述。然后将这些内容保存到库中,用户搜索时,按照匹配规则显示。输出:当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配的优缺点进行打分结果,最后得到一个排序顺序,也就是百度的排名。
如何增加蜘蛛爬行量
1、内容的更新频率
网站的内容需要经常更新高价值和原创的内容,让百度蜘蛛优先抓取你的网页。在网站的优化中,必须经常创建内容,因为蜘蛛爬行是有策略的。的频率。
2、网站的经验
网站的体验度是指用户的体验。如果用户体验好网站,百度蜘蛛会优先录取。那么这里有人会问,如何提升用户体验呢?其实很简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免广告太多,也不要让广告覆盖首页的内容,否则百度会判断你的网站用户体验很糟糕。
3、优秀的参赛作品
优质入口主要是指网站的外部链接,优质网站优先抢占。现在百度对外部链接做了很大的调整。对于垃圾外链,百度已经进行了非常严格的过滤。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接对于排名和爬行很重要。
4、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
5、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。 查看全部
如何抓取网页数据(
百度蜘蛛的工作原理是如抓取网页的呢?(图))
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问和采集互联网上的网页、图片、视频等内容,然后建立索引库,让用户可以在百度搜索引擎中找到你的网站页面、图片、视频等内容. 之所以叫蜘蛛,是因为这个程序有类似蜘蛛的功能,布下天地之网,可以在网上搜集信息。那么百度蜘蛛是如何像爬网页一样工作的呢?为了增加蜘蛛爬取的网页量,有哪些技巧呢?
百度蜘蛛的工作原理
蜘蛛的工作分为四个步骤(抓取、过滤、索引和输出)。爬取:百度蜘蛛会通过计算和规则来确定要爬取的页面和爬取的频率。如果 网站 的更新频率和 网站 的内容质量和用户友好度都很高,那么你新生成的内容会立即被蜘蛛爬取。过滤:由于被过滤的页面数量过多,导致页面质量参差不齐,甚至出现诈骗页面、死链接等垃圾页面。因此,百度蜘蛛会先过滤这些内容,防止这些内容展示给用户,给用户带来不好的用户体验。索引:百度索引会对过滤后的内容进行标记、识别和分类,并存储数据结构。保存的内容包括页面的关键内容,例如标题和描述。然后将这些内容保存到库中,用户搜索时,按照匹配规则显示。输出:当用户搜索一个关键词时,搜索引擎会根据一系列算法和规则对索引库中的内容进行匹配,同时对匹配的优缺点进行打分结果,最后得到一个排序顺序,也就是百度的排名。
如何增加蜘蛛爬行量
1、内容的更新频率
网站的内容需要经常更新高价值和原创的内容,让百度蜘蛛优先抓取你的网页。在网站的优化中,必须经常创建内容,因为蜘蛛爬行是有策略的。的频率。
2、网站的经验
网站的体验度是指用户的体验。如果用户体验好网站,百度蜘蛛会优先录取。那么这里有人会问,如何提升用户体验呢?其实很简单。首先网站的装修和页面布局一定要合理,最重要的就是广告。尽量避免广告太多,也不要让广告覆盖首页的内容,否则百度会判断你的网站用户体验很糟糕。
3、优秀的参赛作品
优质入口主要是指网站的外部链接,优质网站优先抢占。现在百度对外部链接做了很大的调整。对于垃圾外链,百度已经进行了非常严格的过滤。基本上,如果您在论坛或留言板上发送外部链接,百度会在后台对其进行过滤。但真正高质量的反向链接对于排名和爬行很重要。
4、历史爬取效果不错
无论百度是排名还是爬虫,历史记录都很重要。如果他们以前作弊,这就像一个人的历史。那会留下污点。网站同样如此。切记不要在网站的优化中作弊,一旦留下污点,会降低百度蜘蛛对站点的信任,影响爬取网站的时间和深度。不断更新高质量的内容非常重要。
5、服务器稳定,抢优先级
2015年以来,百度在服务器稳定性因素的权重上做了很大的提升。服务器稳定性包括稳定性和速度。服务器越快,植物抓取效率越高。服务器越稳定,爬虫的连接率就越高。此外,拥有高速稳定的服务器对于用户体验来说也是非常重要的事情。
6、安全记录优秀的网站,优先爬取
网络安全变得越来越重要。对于经常受到攻击(被黑)的网站,它会严重危害用户。所以,在SEO优化的过程中,要注意网站的安全。
如何抓取网页数据(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-16 04:07
让我们看一下 Steam 社区 Grant Theft Auto V 评测的网页。您会注意到网页的全部内容不会一次性加载。
我们需要向下滚动以在网页上加载更多内容。这是 网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但问题在于,当我们尝试从该页面抓取数据时,我们只能获得该页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容有限的问题依然存在。那么让我们看看如何爬取这些页面。
导航到目标 URL 并打开 Inspect Element Network 窗口。接下来,点击重新加载按钮,它会为您记录网络,如图像加载的顺序、API 请求、POST 请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送更多数据请求:
进一步滚动,您将看到 网站 如何发出请求。查看以下 URL - 只有一些参数值在更改,您可以使用简单的 Python 代码轻松生成:
您需要按照相同的步骤逐页向每个页面发送请求来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网络抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将在其中教授网页抓取 BeatifulSoup。您可以在此处查看 - Python 网络爬虫简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听您对首选库的看法(即使您使用 R!),以及您对该主题的体验。请在下面的评论部分告诉我,我们会尽快回复您! 查看全部
如何抓取网页数据(让我们看一下Steam社区GrantTheftAutoVReviews的网页)
让我们看一下 Steam 社区 Grant Theft Auto V 评测的网页。您会注意到网页的全部内容不会一次性加载。
我们需要向下滚动以在网页上加载更多内容。这是 网站 后端开发人员使用的一种称为“延迟加载”的优化技术。
但问题在于,当我们尝试从该页面抓取数据时,我们只能获得该页面的有限内容:
一些 网站 还创建了“加载更多”按钮,而不是无休止的滚动想法。只有当您单击按钮时,它才会加载更多内容。内容有限的问题依然存在。那么让我们看看如何爬取这些页面。
导航到目标 URL 并打开 Inspect Element Network 窗口。接下来,点击重新加载按钮,它会为您记录网络,如图像加载的顺序、API 请求、POST 请求等。
清除当前记录并向下滚动。您会注意到,当您向下滚动时,页面正在发送更多数据请求:
进一步滚动,您将看到 网站 如何发出请求。查看以下 URL - 只有一些参数值在更改,您可以使用简单的 Python 代码轻松生成:
您需要按照相同的步骤逐页向每个页面发送请求来获取和存储数据。
尾注
这是使用强大的 BeautifulSoup 库在 Python 中进行网络抓取的简单且适合初学者的介绍。老实说,当我在寻找新项目或需要现有项目的信息时,我发现网络抓取非常有用。
注意:如果您想以更结构化的形式学习本教程,我们有一个免费课程,我们将在其中教授网页抓取 BeatifulSoup。您可以在此处查看 - Python 网络爬虫简介。
如前所述,还有其他库可用于执行网页抓取。我很想听听您对首选库的看法(即使您使用 R!),以及您对该主题的体验。请在下面的评论部分告诉我,我们会尽快回复您!
如何抓取网页数据( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-13 02:13
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中的对比分析,抓取网页后抓取数据的一般步骤是:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
上述三种方法的性能比较和结论:
查看全部
如何抓取网页数据(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 XML 解析库 libxml2 的 Python 包。这个模块是用C语言编写的,解析速度比BeautifulSoup还要快。经过书中的对比分析,抓取网页后抓取数据的一般步骤是:先解析网页源码(这三种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
上述三种方法的性能比较和结论:
如何抓取网页数据( 如何用一些有用的数据抓取一个网页数据的方法?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-03 23:17
如何用一些有用的数据抓取一个网页数据的方法?)
随风起舞
03-03 08:03 阅读6网站SEO优化
专注于
如何采集网页数据(探索网页数据采集技巧)
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
很多工作都是通过 HTML 树来获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia 查看全部
如何抓取网页数据(
如何用一些有用的数据抓取一个网页数据的方法?)
随风起舞
03-03 08:03 阅读6网站SEO优化
专注于
如何采集网页数据(探索网页数据采集技巧)
不久前,我在LearnML 子论坛上看到了一个帖子。楼主在这篇文章中提到,他的机器学习项目需要抓取网络数据。很多人在回复中给出了自己的方法,主要是学习BeautifulSoup和Selenium的使用方法。
我在一些数据科学项目中使用了 BeautifulSoup 和 Selenium。在本文中,我将向您展示如何使用一些有用的数据抓取网页并将其转换为 pandas 数据结构(DataFrame)。
为什么要将其转换为数据结构?这是因为大多数机器学习库都可以处理 pandas 数据结构并以最少的修改来编辑您的模型。
首先,我们将在 Wikipedia 上找到一个表以转换为数据结构。我抓取的这张表显示了维基百科上浏览次数最多的运动员数据。
很多工作都是通过 HTML 树来获取我们需要的表格。
通过 request 和 regex 库,我们开始使用 BeautifulSoup。
from bs4 import BeautifulSoup
import requests
import re
import pandas as pd
复制代码
接下来,我们将从网页中提取 HTML 代码:
<p>website_url = requests.get('https://en.wikipedia.org/wiki/Wikipedia:Multiyear_ranking_of_most_viewed_pages').text
soup = BeautifulSoup(website_url, 'lxml')
print(soup.prettify())
</a>
Disclaimers
Contact Wikipedia
如何抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-03 23:12
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。
查看全部
如何抓取网页数据(一点python介绍如何编写一个网络爬虫数据数据采集(图)
)
从各种搜索引擎到日常小数据采集,都离不开网络爬虫。爬虫的基本原理很简单。它遍历网络中的网页并抓取感兴趣的数据内容。本期文章将介绍如何编写一个网络爬虫从零开始爬取数据,然后逐步完善爬虫的爬取功能。
我们使用 python 3.x 作为我们的开发语言,一点点 python 就可以了。让我们先从基础开始。
工具安装
我们需要安装python、python的requests和BeautifulSoup库。我们使用 Requests 库来抓取网页内容,并使用 BeautifulSoup 库从网页中提取数据。
安装蟒蛇
运行 pip 安装请求
运行 pip install BeautifulSoup
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以它为例,首先看一下如何爬取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容。代码如下:
提取内容
爬取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个示例中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用 BeautifulSoup,我们可以轻松提取网页的具体内容。
连续爬网
至此,我们已经可以爬取单个页面的内容了,下面我们来看看如何爬取整个网站的内容。我们知道网页是通过超链接相互连接的,通过超链接我们可以访问整个网络。所以我们可以从每个页面中提取到其他页面的链接,然后反复爬取新的链接。

