
excel抓取网页动态数据
excel抓取网页动态数据(找个星座分析的网站试试,看看能不能抓数据(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-04 14:02
)
#星座分析组#
头条活动星座分析群,我们找个星座分析网站试试看能不能抓到数据。
就是这样,图片看起来很可爱。
网站分析
网站 保护做得好,没办法看到数据,只能从网站分析入手。
一般来说,网站 可以通过一些查询参数进行查询。我们编写查询函数来捕获数据。一些网站有静态URL,我们可以直接根据显示的静态URL来判断。来抓。
这种爬取是最简单的,但也是最麻烦的,因为它依赖于html代码从代码中寻找需要的数据。
上图中提供了各个星座的url,以及对应的运势查询。我们要做的就是复制上面两段代码,准备爬取,提取星座url和财富url。
像这样的东西:
也:
这个过程是最基本的文本处理。首先使用Web.BrowserContents函数读取html文本,然后拆分我们想要的那段代码,就可以使用Text.Split函数了。您还可以将所需的代码片段直接复制并粘贴到 html 文本中。
Power Query 在这一点上更好。可视化操作。为了稍后自动刷新数据,我们必须区分数据是否为常量。如果是常量,我们可以复制粘贴。如果有变化,最好从头开始使用Functions和公式,以确保刷新数据时不会出现问题。
我们只想要一些文本,所以直接使用html表单。
Html.Table(Web.BrowserContents([url]&[u1]), {{"Column1", ".c_cont STRONG"}, {"Column2", ".c_cont SPAN"}}, [RowSelector="P"] )
无需定义函数,直接添加一列即可抓取。
抓
经过上面的分析,我们直接使用自定义列来抓取数据:
你会说Html.Table函数的参数写不出来,其实我不会,这个没关系,你可以尝试抓取一个页面,让向导自动生成,然后我们复制超过:
然后看代码:
我们可以将前两行合并为一行。
最后,我们看一下捕获的数据:
同样的,我们可以试着把握明天的运势,一周的运势等等,这里就不做示范了。
最后,我们来做一个可视化的图表来看看:
查看全部
excel抓取网页动态数据(找个星座分析的网站试试,看看能不能抓数据(组图)
)
#星座分析组#
头条活动星座分析群,我们找个星座分析网站试试看能不能抓到数据。
就是这样,图片看起来很可爱。
网站分析
网站 保护做得好,没办法看到数据,只能从网站分析入手。
一般来说,网站 可以通过一些查询参数进行查询。我们编写查询函数来捕获数据。一些网站有静态URL,我们可以直接根据显示的静态URL来判断。来抓。
这种爬取是最简单的,但也是最麻烦的,因为它依赖于html代码从代码中寻找需要的数据。
上图中提供了各个星座的url,以及对应的运势查询。我们要做的就是复制上面两段代码,准备爬取,提取星座url和财富url。
像这样的东西:
也:
这个过程是最基本的文本处理。首先使用Web.BrowserContents函数读取html文本,然后拆分我们想要的那段代码,就可以使用Text.Split函数了。您还可以将所需的代码片段直接复制并粘贴到 html 文本中。
Power Query 在这一点上更好。可视化操作。为了稍后自动刷新数据,我们必须区分数据是否为常量。如果是常量,我们可以复制粘贴。如果有变化,最好从头开始使用Functions和公式,以确保刷新数据时不会出现问题。
我们只想要一些文本,所以直接使用html表单。
Html.Table(Web.BrowserContents([url]&[u1]), {{"Column1", ".c_cont STRONG"}, {"Column2", ".c_cont SPAN"}}, [RowSelector="P"] )
无需定义函数,直接添加一列即可抓取。
抓
经过上面的分析,我们直接使用自定义列来抓取数据:
你会说Html.Table函数的参数写不出来,其实我不会,这个没关系,你可以尝试抓取一个页面,让向导自动生成,然后我们复制超过:
然后看代码:
我们可以将前两行合并为一行。
最后,我们看一下捕获的数据:
同样的,我们可以试着把握明天的运势,一周的运势等等,这里就不做示范了。
最后,我们来做一个可视化的图表来看看:
excel抓取网页动态数据(一个基于浏览器的爬虫插件InstantDataScraper抓取评论(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-04 13:12
使用 Chrome 插件 Instant Data Scraper 抓取评论
通常我们要分析一个产品的负面评论,我们需要捕获所有负面评论(1、2、3 星)进行分析和总结。一般的做法是将评论一条一条的复制到表格中,但是这种做法效率太低了。今天推荐一个基于Chrome浏览器的爬虫插件Instant Data Scraper。
插件安装地址:(需要VPN翻墙)
使用方法如下:
1. 进入要提取差评的listing详情页面,进入评论列表页面,删除差评
2. 在这个页面打开 Instant Data Scraper 插件
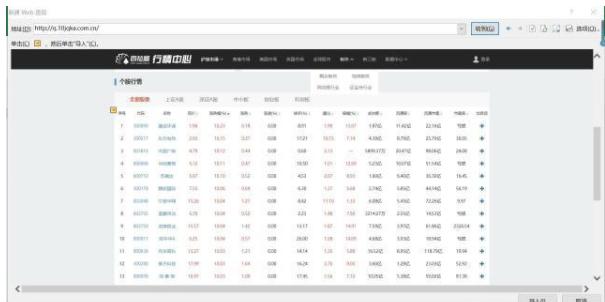
图中红框是插件自动识别的数据表。默认是拉出整个页面的数据,但是我们只想评论,所以需要切换我们需要的数据表。
3. 找到我们需要的数据表
点击“Try another table”按钮,插件会自动识别当前页面的其他数据表,提取的数据会显示在插件下方的表格中。我们需要检查提取的数据是否正确。如果不是我们想要的,那么继续点击“Try another table”按钮,让插件继续寻找其他数据表;如果检查表中的数据是我们想要的,那么我们可以进行下一步。
4. 设置下一页按钮(不是必须的,如果插件检测到下一页按钮就不需要设置,如果没有检测到我们需要设置)
比如一个产品有10页的差评,如果我们想一次性完成爬取,就要告诉插件哪个按钮是下一页,这样插件才能自动翻页爬取它。
如果插件页面出现Locate“Next”按钮,说明插件无法识别下一页是哪个按钮。这时候我们需要点击这个按钮,然后点击页面上的下一步按钮。
5. 获取数据
设置好数据表和下一页按钮后,就可以开始取数据了。点击“开始爬取”按钮开始爬取数据。
6. 数据导出
插件提供“CSV(逗号分隔值,通用数据表格式,几乎兼容所有电子表格软件)”、“XLSX(Excel电子表格)”、“COPYALL(复制到剪贴板)”,点击相应按钮即可获取对应的文件或数据。
备注:Instant Data Scraper是一款基于Chrome的爬虫工具,用途非常广泛。你可以尽情发挥你的想象力,爬取几乎所有你能看到的东西。 查看全部
excel抓取网页动态数据(一个基于浏览器的爬虫插件InstantDataScraper抓取评论(一))
使用 Chrome 插件 Instant Data Scraper 抓取评论
通常我们要分析一个产品的负面评论,我们需要捕获所有负面评论(1、2、3 星)进行分析和总结。一般的做法是将评论一条一条的复制到表格中,但是这种做法效率太低了。今天推荐一个基于Chrome浏览器的爬虫插件Instant Data Scraper。
插件安装地址:(需要VPN翻墙)
使用方法如下:
1. 进入要提取差评的listing详情页面,进入评论列表页面,删除差评
2. 在这个页面打开 Instant Data Scraper 插件
图中红框是插件自动识别的数据表。默认是拉出整个页面的数据,但是我们只想评论,所以需要切换我们需要的数据表。
3. 找到我们需要的数据表
点击“Try another table”按钮,插件会自动识别当前页面的其他数据表,提取的数据会显示在插件下方的表格中。我们需要检查提取的数据是否正确。如果不是我们想要的,那么继续点击“Try another table”按钮,让插件继续寻找其他数据表;如果检查表中的数据是我们想要的,那么我们可以进行下一步。
4. 设置下一页按钮(不是必须的,如果插件检测到下一页按钮就不需要设置,如果没有检测到我们需要设置)
比如一个产品有10页的差评,如果我们想一次性完成爬取,就要告诉插件哪个按钮是下一页,这样插件才能自动翻页爬取它。
如果插件页面出现Locate“Next”按钮,说明插件无法识别下一页是哪个按钮。这时候我们需要点击这个按钮,然后点击页面上的下一步按钮。
5. 获取数据
设置好数据表和下一页按钮后,就可以开始取数据了。点击“开始爬取”按钮开始爬取数据。
6. 数据导出
插件提供“CSV(逗号分隔值,通用数据表格式,几乎兼容所有电子表格软件)”、“XLSX(Excel电子表格)”、“COPYALL(复制到剪贴板)”,点击相应按钮即可获取对应的文件或数据。
备注:Instant Data Scraper是一款基于Chrome的爬虫工具,用途非常广泛。你可以尽情发挥你的想象力,爬取几乎所有你能看到的东西。
excel抓取网页动态数据(Listly|在线网页内容转Excel工具()(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-01 14:02
网站标志:
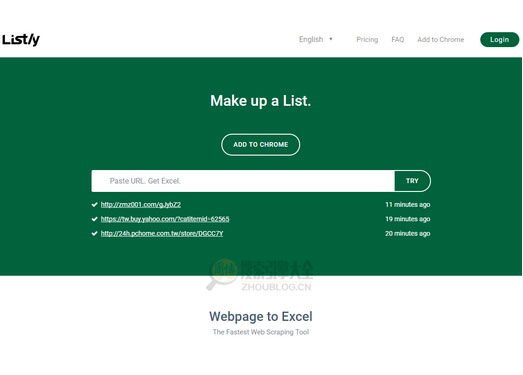
网站姓名:Listly|在线网页内容转Excel工具
网站地址:
网站缩略图:
网站简介:
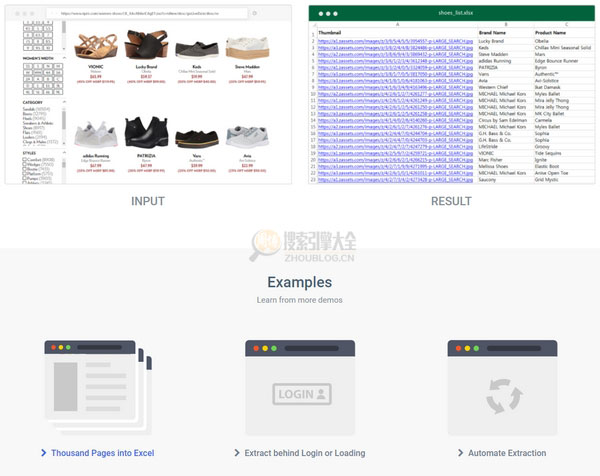
Listly 是一款基于网页的网页抓取内容,内容自动整理成 Excel 格式的工具,特别适合抓取带有产品数据或其他相关信息的网页,方便用户整理成 Excel 格式进行分析数据整理统计。
Listly 是一款免费工具,可以快速导出网页并将其转换为 Excel 电子表格。只需输入网址,它就会自动确定网页的所有部分,并将信息转换为我们需要的 Excel 文件,可能不是一次全部完成。 100%到位,但是既然是半成品,稍微修改一下应该就可以完成我们想要的内容了。更重要的是,Listly 还全面支持中文内容,并提供 Google Chrome 扩展程序供用户免费下载。
Listly网站列举了一些可用的方法,例如:让企业创造潜在客户、监控电子商务网站零售商的价格变化、为研究机构建立数据集、为营销采集反馈信息、排序搜索结果以进行 SEO 监控或提供分析数据以供使用。
然而,Listly 只提供免费用户每天转换三页的配额。注册并登录后,可增加至十个配额(每月)。还有一个可以使用的时间表和自动更新,这对于少量来说就足够了。 , 付款后可以扩大额度,价格也不算太贵,可能只是拿钱换时间吧!有兴趣的朋友可以试试。 查看全部
excel抓取网页动态数据(Listly|在线网页内容转Excel工具()(图))
网站标志:

网站姓名:Listly|在线网页内容转Excel工具
网站地址:
网站缩略图:
网站简介:
Listly 是一款基于网页的网页抓取内容,内容自动整理成 Excel 格式的工具,特别适合抓取带有产品数据或其他相关信息的网页,方便用户整理成 Excel 格式进行分析数据整理统计。
Listly 是一款免费工具,可以快速导出网页并将其转换为 Excel 电子表格。只需输入网址,它就会自动确定网页的所有部分,并将信息转换为我们需要的 Excel 文件,可能不是一次全部完成。 100%到位,但是既然是半成品,稍微修改一下应该就可以完成我们想要的内容了。更重要的是,Listly 还全面支持中文内容,并提供 Google Chrome 扩展程序供用户免费下载。
Listly网站列举了一些可用的方法,例如:让企业创造潜在客户、监控电子商务网站零售商的价格变化、为研究机构建立数据集、为营销采集反馈信息、排序搜索结果以进行 SEO 监控或提供分析数据以供使用。
然而,Listly 只提供免费用户每天转换三页的配额。注册并登录后,可增加至十个配额(每月)。还有一个可以使用的时间表和自动更新,这对于少量来说就足够了。 , 付款后可以扩大额度,价格也不算太贵,可能只是拿钱换时间吧!有兴趣的朋友可以试试。
excel抓取网页动态数据(excel抓取网页动态数据,不同网站服务商有区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-30 14:09
excel抓取网页动态数据,不同网站服务商有区别,你抓取的太早了,抓取的数据可能已经过期了。1、excel可以借助插件“网页数据分析”实现抓取网页动态数据。2、在分析网页的时候,用到“相同字段”可以知道几种可能的查询关键字,如gdp,qs,gdp预测,周期预测等。
可以用excel2010以上版本自带的web信息抓取功能。用“相同字段”能知道大部分的用户浏览历史和动态网页产生的消息数据(即抓取的用户信息)可以使用excel的web统计分析功能,也可以使用everything一类的,然后python或其他统计语言抓取网页历史信息。
这不是excel的问题,是爬虫的问题。你想用用api,excel上都有,你想用爬虫,
可以发邮件要数据,内嵌一个小爬虫,
基本上这个属于行业内都有的问题,拿回来自己做一下网页编程分析就可以解决了。
excel..可以采集常见网站的信息,
求题主给大家看一下我的观点:如果是重要数据源(公司数据库),使用api.scrapy框架。如果数据质量不高、丢失或者需要做大规模去重,这个组合有一些短板,我会考虑使用第三方的scrapy中间件,而不是用api获取。在这个基础上,可以考虑post数据提交。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,不同网站服务商有区别)
excel抓取网页动态数据,不同网站服务商有区别,你抓取的太早了,抓取的数据可能已经过期了。1、excel可以借助插件“网页数据分析”实现抓取网页动态数据。2、在分析网页的时候,用到“相同字段”可以知道几种可能的查询关键字,如gdp,qs,gdp预测,周期预测等。
可以用excel2010以上版本自带的web信息抓取功能。用“相同字段”能知道大部分的用户浏览历史和动态网页产生的消息数据(即抓取的用户信息)可以使用excel的web统计分析功能,也可以使用everything一类的,然后python或其他统计语言抓取网页历史信息。
这不是excel的问题,是爬虫的问题。你想用用api,excel上都有,你想用爬虫,
可以发邮件要数据,内嵌一个小爬虫,
基本上这个属于行业内都有的问题,拿回来自己做一下网页编程分析就可以解决了。
excel..可以采集常见网站的信息,
求题主给大家看一下我的观点:如果是重要数据源(公司数据库),使用api.scrapy框架。如果数据质量不高、丢失或者需要做大规模去重,这个组合有一些短板,我会考虑使用第三方的scrapy中间件,而不是用api获取。在这个基础上,可以考虑post数据提交。
excel抓取网页动态数据(彩票数据获取并写入excel表格数据来源自己看吧~用外链通不过 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-29 22:17
)
快下班了,正要买彩票,所以写了2个脚本,一个下载最新开奖数据,一个统计开奖号码,分享给大家!
获取彩票数据写入excel表格
自己看资料来源~ 外链是打不通的。. .
使用的库:xlwt、requests、lxml
有几点需要注意:
1、建立列表。因为保存excel文件时用到了列表,所以新建了一个函数,取网页上的5个数据:时间、周期、抽奖123,然后将每个页面嵌套写入列表中。类似的结构是[[time, period Number, lottery 1, 2, 3], [time, period, lottery 1, 2, 3]......],在循环页面,获取所有数据!注意列表的形式和列表的结果,这在你写表的时候很重要!
2、写入数据。xlwt写入文件的方法是ws.write(line, column, data),将文件逐行写入,因此新建一个变量行(代码第36行),每次增加1行写。
其他方面很简单,没有反爬,只是为了获取数据,方便分析!
最终excel表中的数据
是这样的:
最后大概有4840行数据,足够我们分析了!
数据处理
可以用xlrd库~xlwt库和xlrd库好像一个是写数据的,一个是读数据的。. .
我写了一个抢手的热门号码,也就是最频繁的号码。如果您有更好的想法或玩法,可以自己实现!
先读取数据,然后得到2.3.每行的4列,每列写一个list(现在后悔了,不应该写这么多数据进去),然后合并将3个列表合为一个总列表,所以我们有4个列表,取出每个列表中出现频率最高的数字,代码如下:
出现频率最高的第一个数字是 [3]
出现频率最高的第二个数字是[6]
频率最高的第三个数字是[8]
单数出现频率最高[3]
因为赶时间下班。. 我使用了所有列表推导式,我没有使用 Pandas 或可视化库来制作很酷的图表。当我制定一个完美的预测计划时,我正在做[Manual Cry],但按照目前的趋势,没有希望。向上。. .
最后我想说的是,从开始研究分析各种数据到现在买彩票的习惯,我从来没有中过大奖(超过200个算大奖)!果然,童话都是骗人的……还是学python更好玩!
查看全部
excel抓取网页动态数据(彩票数据获取并写入excel表格数据来源自己看吧~用外链通不过
)
快下班了,正要买彩票,所以写了2个脚本,一个下载最新开奖数据,一个统计开奖号码,分享给大家!
获取彩票数据写入excel表格
自己看资料来源~ 外链是打不通的。. .
使用的库:xlwt、requests、lxml
有几点需要注意:
1、建立列表。因为保存excel文件时用到了列表,所以新建了一个函数,取网页上的5个数据:时间、周期、抽奖123,然后将每个页面嵌套写入列表中。类似的结构是[[time, period Number, lottery 1, 2, 3], [time, period, lottery 1, 2, 3]......],在循环页面,获取所有数据!注意列表的形式和列表的结果,这在你写表的时候很重要!
2、写入数据。xlwt写入文件的方法是ws.write(line, column, data),将文件逐行写入,因此新建一个变量行(代码第36行),每次增加1行写。
其他方面很简单,没有反爬,只是为了获取数据,方便分析!
最终excel表中的数据
是这样的:
最后大概有4840行数据,足够我们分析了!
数据处理
可以用xlrd库~xlwt库和xlrd库好像一个是写数据的,一个是读数据的。. .
我写了一个抢手的热门号码,也就是最频繁的号码。如果您有更好的想法或玩法,可以自己实现!
先读取数据,然后得到2.3.每行的4列,每列写一个list(现在后悔了,不应该写这么多数据进去),然后合并将3个列表合为一个总列表,所以我们有4个列表,取出每个列表中出现频率最高的数字,代码如下:
出现频率最高的第一个数字是 [3]
出现频率最高的第二个数字是[6]
频率最高的第三个数字是[8]
单数出现频率最高[3]
因为赶时间下班。. 我使用了所有列表推导式,我没有使用 Pandas 或可视化库来制作很酷的图表。当我制定一个完美的预测计划时,我正在做[Manual Cry],但按照目前的趋势,没有希望。向上。. .
最后我想说的是,从开始研究分析各种数据到现在买彩票的习惯,我从来没有中过大奖(超过200个算大奖)!果然,童话都是骗人的……还是学python更好玩!
excel抓取网页动态数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-28 20:11
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这个目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
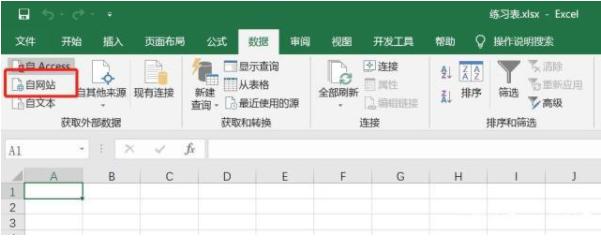
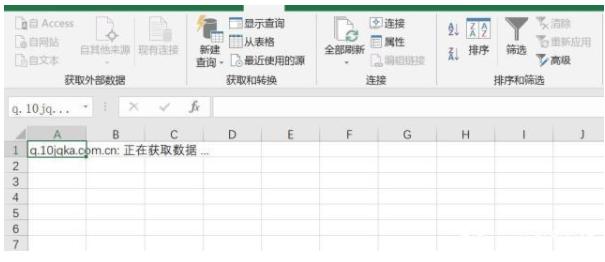
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站的,会弹出一个新的网页查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
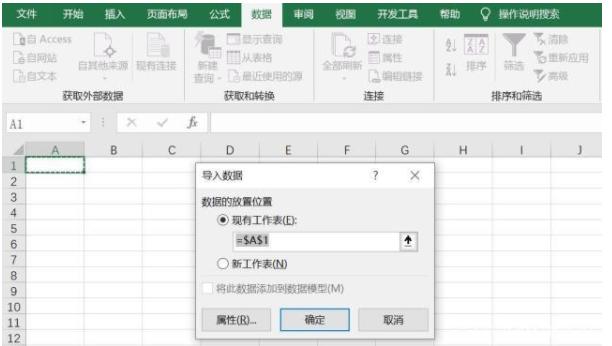
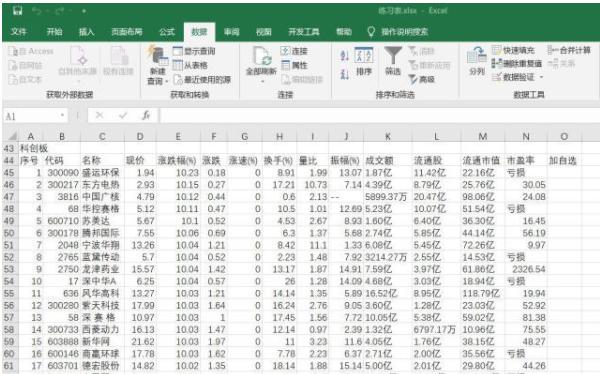
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
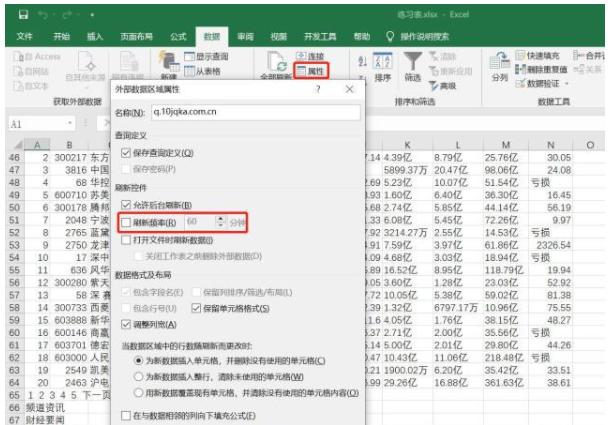
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及是否允许后台刷新,或打开文件时刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:
预防措施:
某些网站的数据是加密的,可能无法导出。这不是软件可以做到的。需要的是黑客。
如何在Excel中查询网页数据并实时更新。相关文章:
1.如何使用excel2013web查询和采集
网页数据
2.中小学优秀作文作文
3.excel如何采集
网页数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号 查看全部
excel抓取网页动态数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这个目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站的,会弹出一个新的网页查询对话框,如下图:

将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。


在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。

使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。

数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及是否允许后台刷新,或打开文件时刷新。


另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:

预防措施:
某些网站的数据是加密的,可能无法导出。这不是软件可以做到的。需要的是黑客。
如何在Excel中查询网页数据并实时更新。相关文章:
1.如何使用excel2013web查询和采集
网页数据
2.中小学优秀作文作文
3.excel如何采集
网页数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号
excel抓取网页动态数据(PowerQueryBarChart抓取部分的工作要分成(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-25 21:04
昨天我看到 Animated Bar Chart Race 需要数据来进行更好的展示。有网友想抓取上市公司的财报进行股票分析。我前几天也试过了。它应该能够捕获主要的财务数据。, 大多数金融网站提供上市公司的实时股票信息和财务数据。数据采集就是对网站所能提供的数据进行分析,然后采取相应的方法进行采集。
Power Query 爬网
Power Query爬取部分的工作应该分为三个步骤:
第一步:网站分析
这部分主要是寻找网站数据的位置和数据排列的规律。谷歌浏览器用来做网站分析,Power Query用来做单个网页的爬行测试。
有必要抢股票代码。综合报价网站提供沪深股市所有股票代码。这里显示了 151 页,每页 24 行数据。页码为 0-150。特定的 URL 由 Google 浏览器检查并右键单击。可以在网络上查看。
然后是具体的财务数据。打开任意一家公司的页面,中间的财务分析下会有相应的财务数据。这里我只需要主要的财务数据。真正的 URL 是通过股票代码访问的。
第二步:自定义fetch函数
1、 首先是抓取股票代码列表的自定义函数:
事实上,定制部分非常简单。首先,我们需要正常从网页上建立一个查询,然后通过一步一步的操作找到这个页面最后的24个股票代码:在这个例子中,股票代码隐藏在一个JSON格式的数据中。, 要通过 JSON 解析。
然后右键单击此查询> 创建函数
会有一个没有参数的提示。要跳过提示,请命名函数:
直接打开高级编辑器,进行修改,在空括号中输入p作为该函数的参数,在url中找到&page=0&,将0替换为“&p&”。更换后的样子是这样的:
&page="&p&"&
这样,这个自定义函数就写好了。有一点需要注意。这里,p 是文本。如果在使用时创建了0-150的列表,请记得在使用该功能之前将其转换为文本。
2、 捕获特定数据的自定义函数:
还需要先抓取一页数据,包中间的处理步骤:不想多行,直接给出逆透视图。
同理,右击创建函数,修改参数。这在两个修改的地方可以清楚地看到。
第 3 步:抓取数据
首先创建一个列表,将其转换为表格,将其设置为文本,并使用第一个获取股票代码的函数生成一个股票代码列表:
然后按以下顺序排序:
然后调用抓取数据的函数来获取数据:
展开以获得所需的结果:
至此,捕获数据的工作已经准备就绪,但是捕获是一个漫长的过程。我用8核16G内存近2小时捕获了300万行数据。
40 分钟 150 万行
动画条形图竞赛
这个比较简单。这是要写入的测量值。财务数据基本上是当期的累计值。一年有四个季度。如果一年是跨度,就需要看年报数据,所以写一个测量值,把一年4份报表中日期最晚的报表对应的数据拿出来就行了。
然后就是要注意修改年份的非汇总:
最后放个录音效果:
有关 Power Query 网页抓取的详细信息,请观看: 查看全部
excel抓取网页动态数据(PowerQueryBarChart抓取部分的工作要分成(组图))
昨天我看到 Animated Bar Chart Race 需要数据来进行更好的展示。有网友想抓取上市公司的财报进行股票分析。我前几天也试过了。它应该能够捕获主要的财务数据。, 大多数金融网站提供上市公司的实时股票信息和财务数据。数据采集就是对网站所能提供的数据进行分析,然后采取相应的方法进行采集。
Power Query 爬网
Power Query爬取部分的工作应该分为三个步骤:
第一步:网站分析
这部分主要是寻找网站数据的位置和数据排列的规律。谷歌浏览器用来做网站分析,Power Query用来做单个网页的爬行测试。
有必要抢股票代码。综合报价网站提供沪深股市所有股票代码。这里显示了 151 页,每页 24 行数据。页码为 0-150。特定的 URL 由 Google 浏览器检查并右键单击。可以在网络上查看。
然后是具体的财务数据。打开任意一家公司的页面,中间的财务分析下会有相应的财务数据。这里我只需要主要的财务数据。真正的 URL 是通过股票代码访问的。
第二步:自定义fetch函数
1、 首先是抓取股票代码列表的自定义函数:
事实上,定制部分非常简单。首先,我们需要正常从网页上建立一个查询,然后通过一步一步的操作找到这个页面最后的24个股票代码:在这个例子中,股票代码隐藏在一个JSON格式的数据中。, 要通过 JSON 解析。
然后右键单击此查询> 创建函数
会有一个没有参数的提示。要跳过提示,请命名函数:
直接打开高级编辑器,进行修改,在空括号中输入p作为该函数的参数,在url中找到&page=0&,将0替换为“&p&”。更换后的样子是这样的:
&page="&p&"&
这样,这个自定义函数就写好了。有一点需要注意。这里,p 是文本。如果在使用时创建了0-150的列表,请记得在使用该功能之前将其转换为文本。
2、 捕获特定数据的自定义函数:
还需要先抓取一页数据,包中间的处理步骤:不想多行,直接给出逆透视图。
同理,右击创建函数,修改参数。这在两个修改的地方可以清楚地看到。
第 3 步:抓取数据
首先创建一个列表,将其转换为表格,将其设置为文本,并使用第一个获取股票代码的函数生成一个股票代码列表:
然后按以下顺序排序:
然后调用抓取数据的函数来获取数据:
展开以获得所需的结果:
至此,捕获数据的工作已经准备就绪,但是捕获是一个漫长的过程。我用8核16G内存近2小时捕获了300万行数据。
40 分钟 150 万行
动画条形图竞赛
这个比较简单。这是要写入的测量值。财务数据基本上是当期的累计值。一年有四个季度。如果一年是跨度,就需要看年报数据,所以写一个测量值,把一年4份报表中日期最晚的报表对应的数据拿出来就行了。
然后就是要注意修改年份的非汇总:
最后放个录音效果:
有关 Power Query 网页抓取的详细信息,请观看:
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-25 14:07
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
一时兴起,在知乎搜索Excel,想学习如何写好评文章。
看到这些标题,看完的时候,一下子就勾起了下载采集
的欲望!
如何捕捉所有高赞的文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。
你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。我总是第一个排队,挑最好的!
好,我们来看看这个表格是怎么制作的。
大致可以分为4个步骤:
❶ 获取JSON数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
您可能不知道 Power Query 可以捕获 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
把我们之前得到的链接粘贴到PQ中,这个链接就可以用来抓取数据了。
然后得到的是网页的数据格式。如何获取具体的文章数据?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
我们此时得到的数据会有一些不必要的额外数据。
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留您需要的文章的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录
的搜索词尚未更新。
所以在这一步,我们需要配置这个数据链,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后得到这个搜索词,以变量的形式放到搜索地址中,搜索地址的配置就完成了。
修改后的地址代码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果要查看原知乎页面,还需要复制超链接在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用HYPERLINK函数来生成一个可点击的超链接,这样访问就简单多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!
02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 阅读过的文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具来绘制和绘制电子表格以及编写公式。
请记住以下 Excel 新功能。这些功能让 Excel 成长为功能强大的数据统计和数据分析软件,它不再只是您脑海中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表中的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
... 查看全部
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
一时兴起,在知乎搜索Excel,想学习如何写好评文章。
看到这些标题,看完的时候,一下子就勾起了下载采集
的欲望!
如何捕捉所有高赞的文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。
你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。我总是第一个排队,挑最好的!
好,我们来看看这个表格是怎么制作的。
大致可以分为4个步骤:
❶ 获取JSON数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
您可能不知道 Power Query 可以捕获 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
把我们之前得到的链接粘贴到PQ中,这个链接就可以用来抓取数据了。
然后得到的是网页的数据格式。如何获取具体的文章数据?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
我们此时得到的数据会有一些不必要的额外数据。
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留您需要的文章的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录
的搜索词尚未更新。
所以在这一步,我们需要配置这个数据链,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后得到这个搜索词,以变量的形式放到搜索地址中,搜索地址的配置就完成了。
修改后的地址代码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果要查看原知乎页面,还需要复制超链接在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用HYPERLINK函数来生成一个可点击的超链接,这样访问就简单多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!
02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 阅读过的文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具来绘制和绘制电子表格以及编写公式。
请记住以下 Excel 新功能。这些功能让 Excel 成长为功能强大的数据统计和数据分析软件,它不再只是您脑海中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表中的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
...
excel抓取网页动态数据(文章目录Selenium安装SeleniumSelenium对象访问查找节点节点交互获取节点信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 11:26
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章 目录 Selenium 安装 Selenium Selenium 基本用法 声明浏览器对象访问页面 查找节点 节点交互 获取节点信息 Selenium
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 看看您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。总之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip 安装硒
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriverbrowser = webdriver.Chrome()browser = webdriver.Firefox()browser = webdriver.Edge()browser = webdriver.PhantomJS()browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriverbrowser = webdriver.Chrome()browser.get('')print(browser.page_source)browser.close() 查找单个节点
网页由超文本标记语言组成。这些是网页的节点。如果我们想要获取某些信息,我们需要知道该信息位于何处。所以这里你要查看网页的源代码。
查看全部
excel抓取网页动态数据(文章目录Selenium安装SeleniumSelenium对象访问查找节点节点交互获取节点信息
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章 目录 Selenium 安装 Selenium Selenium 基本用法 声明浏览器对象访问页面 查找节点 节点交互 获取节点信息 Selenium
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 看看您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。总之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip 安装硒
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriverbrowser = webdriver.Chrome()browser = webdriver.Firefox()browser = webdriver.Edge()browser = webdriver.PhantomJS()browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriverbrowser = webdriver.Chrome()browser.get('')print(browser.page_source)browser.close() 查找单个节点
网页由超文本标记语言组成。这些是网页的节点。如果我们想要获取某些信息,我们需要知道该信息位于何处。所以这里你要查看网页的源代码。

excel抓取网页动态数据(爬取页面中的新闻数据对应的数据包url和新闻详情数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-14 18:29
要求:抓取页面中的新闻数据。
分析:
1. 首先通过对页面的分析,会发现页面中的新闻数据是动态加载的,通过抓包工具抓取数据,可以发现动态数据并不是获取到的动态数据被ajax请求(因为没有捕获到ajax请求的数据包),那么就只剩下一种可能了,动态数据由js动态生成。
2. 使用抓包工具找出是哪个js请求产生了动态数据:打开抓包工具,然后向首页url(要求第一行的url)发起请求,抓包所有的请求的数据包。
分析响应js包返回的数据:
响应数据对应的url可以在抓包工具对应的数据包的header选项卡中获取。获取到url后,发起请求获取上图中选择的对应数据。响应数据类型为application/javascript类型,所以可以通过正则表达式提取得到的响应数据,提取外大括号中的数据,然后使用json.loads转换为字典类型,然后逐步解析出数据中所有新闻详情页面的 URL。
- 获取详情页对应的新闻详情数据:向详情页发出请求后,会发现详情页的新闻数据也是动态加载的,所以和上面的步骤一样,获取详情页中的部分数据在抓包工具中查看详情页搜索并定位到指定的js数据包:
js数据包的url为:
获取到详情页url后,可以请求数据包对应的响应数据,对应的数据中收录对应的新闻详情数据。注意响应数据类型也是application/javascript,所以数据分析同上!
分析首页所有新闻详情页的url与新闻详情数据对应的js数据包的url的关联:
-首页新闻详情页url:5c39c314138da31babf0b16af5a55da4/e43e220633a65f9b6d8b53712cba9caa.html
-新闻详情数据对应的js数据包url:5c39c314138da31babf0b16af5a55da4/datae43e220633a65f9b6d8b53712cba9caa.js
-所有新闻详情对应的js数据包黄色选中部分除了红色部分不同外都是一样的,但是红色部分和新闻详情页url中红色部分是一样的!!!新闻详情页的url可以在上面的过程中解析出来。所以,现在可以批量生成js数据包对应的详细数据的url,然后批量数据请求,获取响应数据,再解析响应数据,完成最终的需求! 查看全部
excel抓取网页动态数据(爬取页面中的新闻数据对应的数据包url和新闻详情数据)
要求:抓取页面中的新闻数据。
分析:
1. 首先通过对页面的分析,会发现页面中的新闻数据是动态加载的,通过抓包工具抓取数据,可以发现动态数据并不是获取到的动态数据被ajax请求(因为没有捕获到ajax请求的数据包),那么就只剩下一种可能了,动态数据由js动态生成。
2. 使用抓包工具找出是哪个js请求产生了动态数据:打开抓包工具,然后向首页url(要求第一行的url)发起请求,抓包所有的请求的数据包。
分析响应js包返回的数据:
响应数据对应的url可以在抓包工具对应的数据包的header选项卡中获取。获取到url后,发起请求获取上图中选择的对应数据。响应数据类型为application/javascript类型,所以可以通过正则表达式提取得到的响应数据,提取外大括号中的数据,然后使用json.loads转换为字典类型,然后逐步解析出数据中所有新闻详情页面的 URL。
- 获取详情页对应的新闻详情数据:向详情页发出请求后,会发现详情页的新闻数据也是动态加载的,所以和上面的步骤一样,获取详情页中的部分数据在抓包工具中查看详情页搜索并定位到指定的js数据包:
js数据包的url为:
获取到详情页url后,可以请求数据包对应的响应数据,对应的数据中收录对应的新闻详情数据。注意响应数据类型也是application/javascript,所以数据分析同上!
分析首页所有新闻详情页的url与新闻详情数据对应的js数据包的url的关联:
-首页新闻详情页url:5c39c314138da31babf0b16af5a55da4/e43e220633a65f9b6d8b53712cba9caa.html
-新闻详情数据对应的js数据包url:5c39c314138da31babf0b16af5a55da4/datae43e220633a65f9b6d8b53712cba9caa.js
-所有新闻详情对应的js数据包黄色选中部分除了红色部分不同外都是一样的,但是红色部分和新闻详情页url中红色部分是一样的!!!新闻详情页的url可以在上面的过程中解析出来。所以,现在可以批量生成js数据包对应的详细数据的url,然后批量数据请求,获取响应数据,再解析响应数据,完成最终的需求!
excel抓取网页动态数据(本文实例讲述Python实现抓取网页生优游Excel文件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-12 22:21
本文介绍了如何使用 Python 从网页中捕获 Excel 文件的示例。分享给大有游,供大有游参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步就是用Notepad++打开company.csv,然后转成优优ANSI编码格式,保存。然后用Excel软件打开这个csv文件并保存为Excel文件
更多对Python相关内容感兴趣的读者可以查看本站主题:“”、“”、“”、“”、“”、“”和“”
希望本文中的描述对您设计大有游的 Python 程序有所帮助。 查看全部
excel抓取网页动态数据(本文实例讲述Python实现抓取网页生优游Excel文件的方法)
本文介绍了如何使用 Python 从网页中捕获 Excel 文件的示例。分享给大有游,供大有游参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步就是用Notepad++打开company.csv,然后转成优优ANSI编码格式,保存。然后用Excel软件打开这个csv文件并保存为Excel文件
更多对Python相关内容感兴趣的读者可以查看本站主题:“”、“”、“”、“”、“”、“”和“”
希望本文中的描述对您设计大有游的 Python 程序有所帮助。
excel抓取网页动态数据(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-11 03:18
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response 查看全部
excel抓取网页动态数据(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response
excel抓取网页动态数据(快速入门selenium常用操作方法解析及入门常用操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-10 13:02
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
. 查看全部
excel抓取网页动态数据(快速入门selenium常用操作方法解析及入门常用操作)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
excel抓取网页动态数据(如何使用Excel快速网页数据?来说并不好的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-10 13:00
推荐使用:Excel数据采集软件(免费下载,像Excel一样快速上手,灵活可定制的企业管理软件)
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常会听到一个叫“爬虫”的词,它可以快速抓取网页上的数据。这对于数据分析相关的工作非常重要,也是必备的技能之一。然而,大多数爬行动物都需要编程知识,这对普通人来说并不好。今天就给大家讲解一下如何使用Excel快速抓取网页数据。
1.首先打开要抓取的数据的网站,复制网站地址。
2.新建一个Excel工作簿,点击“数据”菜单的“获取外部数据”选项卡中的“来自网站”选项。
在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网址,然后点击“开始”
点击黄色导入箭头,选择要抓取的部分,如图。单击导入。
3.选择存放数据的位置(默认选中的单元格),然后点击“确定”。一般建议将数据存储在“A1”单元格中。
4. 如果要根据网站数据自动实时更新Excel工作簿数据,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
获得数据后,需要对数据进行处理。处理数据是一个比较重要的环节。 查看全部
excel抓取网页动态数据(如何使用Excel快速网页数据?来说并不好的方法)
推荐使用:Excel数据采集软件(免费下载,像Excel一样快速上手,灵活可定制的企业管理软件)
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常会听到一个叫“爬虫”的词,它可以快速抓取网页上的数据。这对于数据分析相关的工作非常重要,也是必备的技能之一。然而,大多数爬行动物都需要编程知识,这对普通人来说并不好。今天就给大家讲解一下如何使用Excel快速抓取网页数据。
1.首先打开要抓取的数据的网站,复制网站地址。
2.新建一个Excel工作簿,点击“数据”菜单的“获取外部数据”选项卡中的“来自网站”选项。
在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网址,然后点击“开始”
点击黄色导入箭头,选择要抓取的部分,如图。单击导入。
3.选择存放数据的位置(默认选中的单元格),然后点击“确定”。一般建议将数据存储在“A1”单元格中。
4. 如果要根据网站数据自动实时更新Excel工作簿数据,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
获得数据后,需要对数据进行处理。处理数据是一个比较重要的环节。
excel抓取网页动态数据(一个网页中有表格,怎样爬取下来?的read_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-07 00:47
本期内容,小编将为大家带来Pandas如何使用Python爬虫爬取HTML网页表单并保存到Excel文件的信息。文章内容丰富,从专业角度分析叙述。看完这篇文章文章希望大家能有所收获。
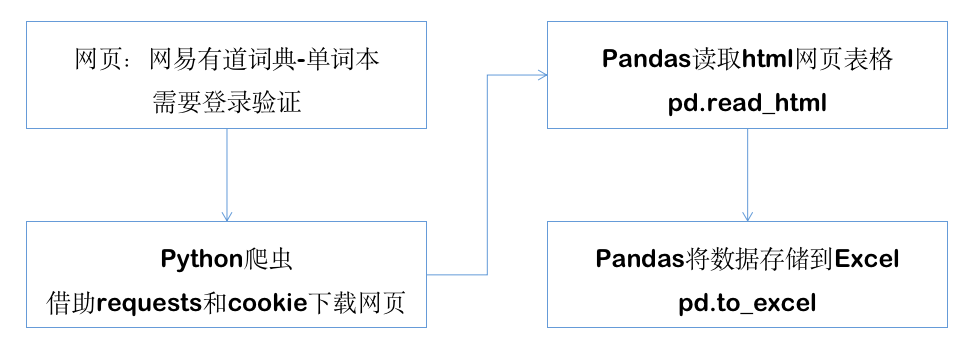
如果 HTML 页面中有表格,如何抓取它们?
Pandas 的 read_html 可以轻松解析 HTML 代码中的 URL 地址或表格,并直接将其转换为数据帧,以便后续处理、分析和导出。
比如有这样一个案例,我经常用网易有道词典查英文单词,也经常在词汇书里加生词,这些年积累的单词越来越多。我想将这些词导出到excel。怎样才能专心复习,甚至打印出来看看。
但是网易有道词典没有导出所有单词的功能。
幸运的是,我在网易有道有道PC版上找到了这个单词书页面:
使用这样的技术组合,我可以轻松抓取整个网页,实现表格解析,并输出到Excel文件:
过程是这样的:
最后保存的 excel 是我想要的所有单词的列表:
Python爬虫+Pandas数据分析处理的好搭档
以上就是 Pandas 如何使用 Python 爬虫爬取 HTML 网页表单并保存到 Excel 文件。如果你碰巧也有类似的疑惑,不妨参考上面的分析来了解一下。如果您想了解更多相关知识,请关注易速云行业资讯频道。 查看全部
excel抓取网页动态数据(一个网页中有表格,怎样爬取下来?的read_html)
本期内容,小编将为大家带来Pandas如何使用Python爬虫爬取HTML网页表单并保存到Excel文件的信息。文章内容丰富,从专业角度分析叙述。看完这篇文章文章希望大家能有所收获。
如果 HTML 页面中有表格,如何抓取它们?
Pandas 的 read_html 可以轻松解析 HTML 代码中的 URL 地址或表格,并直接将其转换为数据帧,以便后续处理、分析和导出。
比如有这样一个案例,我经常用网易有道词典查英文单词,也经常在词汇书里加生词,这些年积累的单词越来越多。我想将这些词导出到excel。怎样才能专心复习,甚至打印出来看看。
但是网易有道词典没有导出所有单词的功能。
幸运的是,我在网易有道有道PC版上找到了这个单词书页面:

使用这样的技术组合,我可以轻松抓取整个网页,实现表格解析,并输出到Excel文件:
过程是这样的:
最后保存的 excel 是我想要的所有单词的列表:

Python爬虫+Pandas数据分析处理的好搭档
以上就是 Pandas 如何使用 Python 爬虫爬取 HTML 网页表单并保存到 Excel 文件。如果你碰巧也有类似的疑惑,不妨参考上面的分析来了解一下。如果您想了解更多相关知识,请关注易速云行业资讯频道。
excel抓取网页动态数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-06 03:14
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以简单地使用浏览器自带的开发者工具来响应请求,例如Firefox的FireBug等,只要按F12,所有请求的信息都会详细显示在您的面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想从哪里获取信息是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = {
3 'Host': 'www.lagou.com',
4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
6 'Connection': 'keep-alive'
7 }
8 if page_num == 1:
9 boo = 'true'
10 else:
11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo),
14 ('pn', page_num),
15 ('kd', keyword)
16 ])
17 req = request.Request(url, headers=page_headers)
18 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
19 page = page.decode('utf-8')
20 return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3捕获数据的适用方法。可以根据实际情况使用其中一种,也可以多种组合使用。
1 def read_tag(page, tag):
2 page_json = json.loads(page)
3 page_json = page_json['content']['result']
4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15):
7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag:
9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8])
11 return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name):
2 book = Workbook(encoding='utf-8')
3 tmp = book.add_sheet('sheet')
4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0:
7 for tag_name_i in tag_name:
8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
9 else:
10 for tag_list in range(len(tag_name)):
11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet()
4 row_num = len(fin_result)
5 for i in range(1, row_num):
6 if i == 1:
7 tag_pos = 'A%s' % i
8 tmp.write_row(tag_pos, tag_name)
9 else:
10 con_pos = 'A%s' % i
11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content)
13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse
4 from bs4 import BeautifulSoup as BS
5 import json
6 import datetime
7 import xlsxwriter
8
9 starttime = datetime.datetime.now()
10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = {
22 'Host': 'www.lagou.com',
23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
25 'Connection': 'keep-alive'
26 }
27 if page_num == 1:
28 boo = 'true'
29 else:
30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo),
33 ('pn', page_num),
34 ('kd', keyword)
35 ])
36 req = request.Request(url, headers=page_headers)
37 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
38 page = page.decode('utf-8')
39 return page
40
41
42 def read_tag(page, tag):
43 page_json = json.loads(page)
44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15):
47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag:
49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8])
51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page)
56 max_page_num = page_json['content']['totalPageCount']
57 if max_page_num > 30:
58 max_page_num = 30
59 return max_page_num
60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet()
65 row_num = len(fin_result)
66 for i in range(1, row_num):
67 if i == 1:
68 tag_pos = 'A%s' % i
69 tmp.write_row(tag_pos, tag_name)
70 else:
71 con_pos = 'A%s' % i
72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content)
74 book.close()
75
76
77 if __name__ == '__main__':
78 print('**********************************即将进行抓取**********************************')
79 keyword = input('请输入您要搜索的语言类型:')
80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword))
82 for page_num in range(1, max_page_num):
83 print('******************************正在下载第%s页内容*********************************' % page_num)
84 page = read_page(url, page_num, keyword)
85 page_result = read_tag(page, tag)
86 fin_result.extend(page_result)
87 file_name = input('抓取完成,输入文件名保存:')
88 save_excel(fin_result, tag_name, file_name)
89 endtime = datetime.datetime.now()
90 time = (endtime - starttime).seconds
91 print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请玉,欢迎交流,请注明出处供转载~(^ _ ^)/ ~~ 查看全部
excel抓取网页动态数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。

可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以简单地使用浏览器自带的开发者工具来响应请求,例如Firefox的FireBug等,只要按F12,所有请求的信息都会详细显示在您的面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。

我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。

可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想从哪里获取信息是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = {
3 'Host': 'www.lagou.com',
4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
6 'Connection': 'keep-alive'
7 }
8 if page_num == 1:
9 boo = 'true'
10 else:
11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo),
14 ('pn', page_num),
15 ('kd', keyword)
16 ])
17 req = request.Request(url, headers=page_headers)
18 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
19 page = page.decode('utf-8')
20 return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3捕获数据的适用方法。可以根据实际情况使用其中一种,也可以多种组合使用。
1 def read_tag(page, tag):
2 page_json = json.loads(page)
3 page_json = page_json['content']['result']
4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15):
7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag:
9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8])
11 return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name):
2 book = Workbook(encoding='utf-8')
3 tmp = book.add_sheet('sheet')
4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0:
7 for tag_name_i in tag_name:
8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
9 else:
10 for tag_list in range(len(tag_name)):
11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:

我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet()
4 row_num = len(fin_result)
5 for i in range(1, row_num):
6 if i == 1:
7 tag_pos = 'A%s' % i
8 tmp.write_row(tag_pos, tag_name)
9 else:
10 con_pos = 'A%s' % i
11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content)
13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse
4 from bs4 import BeautifulSoup as BS
5 import json
6 import datetime
7 import xlsxwriter
8
9 starttime = datetime.datetime.now()
10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = {
22 'Host': 'www.lagou.com',
23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
25 'Connection': 'keep-alive'
26 }
27 if page_num == 1:
28 boo = 'true'
29 else:
30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo),
33 ('pn', page_num),
34 ('kd', keyword)
35 ])
36 req = request.Request(url, headers=page_headers)
37 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
38 page = page.decode('utf-8')
39 return page
40
41
42 def read_tag(page, tag):
43 page_json = json.loads(page)
44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15):
47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag:
49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8])
51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page)
56 max_page_num = page_json['content']['totalPageCount']
57 if max_page_num > 30:
58 max_page_num = 30
59 return max_page_num
60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet()
65 row_num = len(fin_result)
66 for i in range(1, row_num):
67 if i == 1:
68 tag_pos = 'A%s' % i
69 tmp.write_row(tag_pos, tag_name)
70 else:
71 con_pos = 'A%s' % i
72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content)
74 book.close()
75
76
77 if __name__ == '__main__':
78 print('**********************************即将进行抓取**********************************')
79 keyword = input('请输入您要搜索的语言类型:')
80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword))
82 for page_num in range(1, max_page_num):
83 print('******************************正在下载第%s页内容*********************************' % page_num)
84 page = read_page(url, page_num, keyword)
85 page_result = read_tag(page, tag)
86 fin_result.extend(page_result)
87 file_name = input('抓取完成,输入文件名保存:')
88 save_excel(fin_result, tag_name, file_name)
89 endtime = datetime.datetime.now()
90 time = (endtime - starttime).seconds
91 print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请玉,欢迎交流,请注明出处供转载~(^ _ ^)/ ~~
excel抓取网页动态数据(程序语言组织有可能欠佳,判断布局正确的定位元素 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-30 12:07
)
直接上传代码并分析,代码应该比较简单,基本上每一行都已经注释掉了,具体的代码准备,可以参考我写的代码,相信你可以很快的写出自己的程序
语言组织可能很差,希望你能凑合一下。如果有不明白的,有更简单严谨的代码,欢迎贴出来一起讨论。
1. 有搜索结果截图确定使用的定位元素
2. 没有搜索结果的截图,确定布局正确的定位元素
3. 没有搜索结果和错误布局的截图
4.excel文件中的数据,以行为单位
import xlrd
from selenium import webdriver
import time
class chromedriver:
driver=webdriver.Chrome()
#也可使用其他的webdriver,Firefox/ie
driver.maximize_window()
#有些网站缩小之后布局也会改变,所以需要用maximize_window()控制页面的大小
driver.get("URL")
# 获得需要访问的url地址
def null_search(self):
data=xlrd.open_workbook("excel文件路径")
#open一个excel文件,需要注意的是,有时候直接复制过来的路径中,\在Python中有特殊含义,需要统一换成/
table=data.sheets()[0]
#获取第一个sheet1,0表示第一个表
now=table.nrows
#表格中的行数,以便下面做for循环
for i in range(now):
now_data=''.join(table.row_values(i))
#直接获取的.row_values(i)为列表参数,无法直接在文本框中send_keys,所以需要将其转换成字符
text=chromedriver .driver .find_element_by_name("apachesolr_panels_search_form")
#需要注意的是需要在for循环中定位参数,如果直接在def以外定义
#则会出现报错:stale element reference: element is not attached to the page document,意思是这个element已经失效了,需要重新定义
#text.clear()
text.send_keys(now_data ) #将表格中的数据通过行循环,一个个写入到文本框
chromedriver .driver.find_element_by_css_selector("input.form-submit").click() #点击搜索按钮
time.sleep(5)
#一定要这是time.sleep(),因为不写等待时间,会导致最后出来的结果不准确,例如第一个数据是a,第二个数据为b,当不设置等待时间时,在搜索第二个数据时,本应输入b,然而在文本框中输入的为ab,此时得到的测试结果当然为不准确的
chromedriver.driver.switch_to_window(chromedriver.driver.window_handles [-1])
#定位到第二个页面,这样我们就可以定位第二个页面中的参数了
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-info") #当有搜索结果时,可以定位的参数
except: #当定位不到该参数时,结果有2种:1,无搜索结果,搜索的结果不符合布局 2,无搜索结果,符合布局,所以里面还需要一个try语句来判断情况
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-result>h2").text #判断当无搜索结果时,布局是否正确
except:
print(now_data +' '+ "无搜索结果,布局错误" )
else:
print(now_data +' '+ "无搜索结果,布局正确" )
else:
print(now_data +' '+ "有搜索结果")
if __name__ == '__main__':
run=chromedriver()
run.null_search()
5. 结果截图
查看全部
excel抓取网页动态数据(程序语言组织有可能欠佳,判断布局正确的定位元素
)
直接上传代码并分析,代码应该比较简单,基本上每一行都已经注释掉了,具体的代码准备,可以参考我写的代码,相信你可以很快的写出自己的程序
语言组织可能很差,希望你能凑合一下。如果有不明白的,有更简单严谨的代码,欢迎贴出来一起讨论。
1. 有搜索结果截图确定使用的定位元素
2. 没有搜索结果的截图,确定布局正确的定位元素

3. 没有搜索结果和错误布局的截图

4.excel文件中的数据,以行为单位

import xlrd
from selenium import webdriver
import time
class chromedriver:
driver=webdriver.Chrome()
#也可使用其他的webdriver,Firefox/ie
driver.maximize_window()
#有些网站缩小之后布局也会改变,所以需要用maximize_window()控制页面的大小
driver.get("URL")
# 获得需要访问的url地址
def null_search(self):
data=xlrd.open_workbook("excel文件路径")
#open一个excel文件,需要注意的是,有时候直接复制过来的路径中,\在Python中有特殊含义,需要统一换成/
table=data.sheets()[0]
#获取第一个sheet1,0表示第一个表
now=table.nrows
#表格中的行数,以便下面做for循环
for i in range(now):
now_data=''.join(table.row_values(i))
#直接获取的.row_values(i)为列表参数,无法直接在文本框中send_keys,所以需要将其转换成字符
text=chromedriver .driver .find_element_by_name("apachesolr_panels_search_form")
#需要注意的是需要在for循环中定位参数,如果直接在def以外定义
#则会出现报错:stale element reference: element is not attached to the page document,意思是这个element已经失效了,需要重新定义
#text.clear()
text.send_keys(now_data ) #将表格中的数据通过行循环,一个个写入到文本框
chromedriver .driver.find_element_by_css_selector("input.form-submit").click() #点击搜索按钮
time.sleep(5)
#一定要这是time.sleep(),因为不写等待时间,会导致最后出来的结果不准确,例如第一个数据是a,第二个数据为b,当不设置等待时间时,在搜索第二个数据时,本应输入b,然而在文本框中输入的为ab,此时得到的测试结果当然为不准确的
chromedriver.driver.switch_to_window(chromedriver.driver.window_handles [-1])
#定位到第二个页面,这样我们就可以定位第二个页面中的参数了
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-info") #当有搜索结果时,可以定位的参数
except: #当定位不到该参数时,结果有2种:1,无搜索结果,搜索的结果不符合布局 2,无搜索结果,符合布局,所以里面还需要一个try语句来判断情况
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-result>h2").text #判断当无搜索结果时,布局是否正确
except:
print(now_data +' '+ "无搜索结果,布局错误" )
else:
print(now_data +' '+ "无搜索结果,布局正确" )
else:
print(now_data +' '+ "有搜索结果")
if __name__ == '__main__':
run=chromedriver()
run.null_search()
5. 结果截图

excel抓取网页动态数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-30 03:23
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页动态数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)

PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。

数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;

不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:

点击确定后,会出现一个预览窗口,

点击编辑进入查询编辑器,

外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-27 15:03
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,在浏览器中渲染数据,在右键->查看网页源码中也看不到ajax加载的数据,只能看到使用this加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装
Selenium
:
Selenium
有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id
: 根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name
: 根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name
:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name
:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath
: 根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
得到所有
cookie
:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个
cookie
:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,在浏览器中渲染数据,在右键->查看网页源码中也看不到ajax加载的数据,只能看到使用this加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装
Selenium
:
Selenium
有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id
: 根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name
: 根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name
:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name
:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath
: 根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
得到所有
cookie
:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个
cookie
:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
excel抓取网页动态数据(STM32网页分框架(): )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-22 07:02
)
如何抓取动态网页生成的数据?这个动态的asp网页是分帧的,点击左边网页的链接比如javascript:top.market.Openmarket(185)会在右边的frame中显示数据
如何获取这些数据?
Email:非常感谢!!--------------------编程问答----------------- -- -javascript:top.market.document.InnerHTML------------编程问答-------------- ---- --usingmshtml;
///
///在 Web 浏览器控件的顶级文档中返回对框架窗口的引用,并带有指定索引
///
///
指定框架窗口索引的基于零的索引
[CLSCompliant(false)]
publicIHTMLWindow2GetFrameByIndex(intframeIndex)
{
IHTMLDocument2htmlDocument=(IHTMLDocument2)this.Document.DomDocument;
returnGetFrameByIndex(frameIndex,htmlDocument);
}
///
///ReturnsareferencetotheframewindowwithangivenindexinanHTMLdocument
///
///
指定框架窗口索引的基于零的索引
///
要搜索的 HTML 文档
[CLSCompliant(false),ComVisible(false)]
staticpublicIHTMLWindow2GetFrameByIndex(intframeIndex,IHTMLDocument2htmlDocument)
{
if(htmlDocument==null)
returnnull;
objectoIndex=frameIndex;
objectoFrame=htmlDocument.frames.item(refoIndex);
if(oFrame==null)returnnull;
返回(IHTMLWindow2)oFrame;
}--------------------编程问答--------------------点击这个javascript: top.market.Openmarket(185)会去链接……/…….asp?185,然后这个数据怎么抓取保存呢?还有180165号不固定,每更新一次天,我怎么能每天自动分析这个数字,然后抓取这些页面上的数据并保存?--------------------编程问答---------- ----------up------------编程问答------- ---------- ---我一直在用HttpWebRequest--------------------编程问答--------- ----------II 也用这个,但是对于这个网站 好像不能单独用httpwebrequest 检索数据---------------- ----编程问答--------- -------------阅读C#中的javascript代码并重写函数。------------编程Q&A ------------ --------functionDisplaynums(numsSource,VolumeSource){
varnums=document.getElementsByName('nums');
varVolume=document.getElementsByName('Volume');
if(numsSource.length==nums.length){
for(i=0;i
if(numsSource[i]=='0'){
nums[i].innerHTML='';//! ! !这里的 nums[i] 是我想要获取的数据
Volume[i].innerHTML='';}
其他{
/*
//更改市场颜色
if(nums[i].innerHTML!=``&&Volume[i].innerHTML!=''&&(nums[i].innerHTML!=numsSource[i]||Volume[i].innerHTML!=VolumeSource [i])){
nums[i].style.color='#FFFFFF';
音量[i].style.color='#FFFFFF';
}
*/
nums[i].innerHTML=numsSource[i];
Volume[i].innerHTML=VolumeSource[i];
}
}
}
其他{
window.location.reload();
}
}
我读了这段代码。我想获取 nums[i] 的数据。我如何获得这些数据?非常感谢兄弟~! --------------------编程问答 --------------------以上是错误的,应该是numsSource [i] 是我需要的数据。 --------------------编程问答--------------------江城高手请帮忙,如何?在client端调用server端的java函数,实在想不出办法-------------------- 编程问答---- ------- -------调用相同的DOM方法
HtmlWindowPopupOptionWindow()
{
IHTMLAnchorElementae=extendedWebBrowser1.GetLinkByHref("popupEligiNewRT");
if(ae!=null)
{
Debug.WriteLine(ae.href);
//javascript:popupEligiNewRT('DIANA%20JOHN%20W',%20'SUB','form0')
//functionpopupEligiNewRT(name,opt,form){
//varstr="eligipopup.jsp?&name="+name+"&opt="+opt+"&form="+form;
//window.open(str,'popupeligiwin','width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no');
//}
stringhref=ae.href;
href=href.Substring(
href.IndexOf("("));
Stringdelim="()";
href=href.Trim(delim.ToCharArray());
string[]parameters=href.Split(",".ToCharArray());
delim="'";
stringname=parameters[0].Trim(delim.ToCharArray());
stringopt=parameters[1].Trim(delim.ToCharArray());
stringform=parameters[2].Trim(delim.ToCharArray());
stringPopupURL=string.Format("{0}&opt={1}&form={2}",name,opt,form);
returnextendedWebBrowser1.Document.Window.Open(PopupURL,"autopopupeligiwin","width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no" ,假);
}
returnnull;
}
补充:.NET技术 , C# 查看全部
excel抓取网页动态数据(STM32网页分框架():
)
如何抓取动态网页生成的数据?这个动态的asp网页是分帧的,点击左边网页的链接比如javascript:top.market.Openmarket(185)会在右边的frame中显示数据
如何获取这些数据?
Email:非常感谢!!--------------------编程问答----------------- -- -javascript:top.market.document.InnerHTML------------编程问答-------------- ---- --usingmshtml;
///
///在 Web 浏览器控件的顶级文档中返回对框架窗口的引用,并带有指定索引
///
///
指定框架窗口索引的基于零的索引
[CLSCompliant(false)]
publicIHTMLWindow2GetFrameByIndex(intframeIndex)
{
IHTMLDocument2htmlDocument=(IHTMLDocument2)this.Document.DomDocument;
returnGetFrameByIndex(frameIndex,htmlDocument);
}
///
///ReturnsareferencetotheframewindowwithangivenindexinanHTMLdocument
///
///
指定框架窗口索引的基于零的索引
///
要搜索的 HTML 文档
[CLSCompliant(false),ComVisible(false)]
staticpublicIHTMLWindow2GetFrameByIndex(intframeIndex,IHTMLDocument2htmlDocument)
{
if(htmlDocument==null)
returnnull;
objectoIndex=frameIndex;
objectoFrame=htmlDocument.frames.item(refoIndex);
if(oFrame==null)returnnull;
返回(IHTMLWindow2)oFrame;
}--------------------编程问答--------------------点击这个javascript: top.market.Openmarket(185)会去链接……/…….asp?185,然后这个数据怎么抓取保存呢?还有180165号不固定,每更新一次天,我怎么能每天自动分析这个数字,然后抓取这些页面上的数据并保存?--------------------编程问答---------- ----------up------------编程问答------- ---------- ---我一直在用HttpWebRequest--------------------编程问答--------- ----------II 也用这个,但是对于这个网站 好像不能单独用httpwebrequest 检索数据---------------- ----编程问答--------- -------------阅读C#中的javascript代码并重写函数。------------编程Q&A ------------ --------functionDisplaynums(numsSource,VolumeSource){
varnums=document.getElementsByName('nums');
varVolume=document.getElementsByName('Volume');
if(numsSource.length==nums.length){
for(i=0;i
if(numsSource[i]=='0'){
nums[i].innerHTML='';//! ! !这里的 nums[i] 是我想要获取的数据
Volume[i].innerHTML='';}
其他{
/*
//更改市场颜色
if(nums[i].innerHTML!=``&&Volume[i].innerHTML!=''&&(nums[i].innerHTML!=numsSource[i]||Volume[i].innerHTML!=VolumeSource [i])){
nums[i].style.color='#FFFFFF';
音量[i].style.color='#FFFFFF';
}
*/
nums[i].innerHTML=numsSource[i];
Volume[i].innerHTML=VolumeSource[i];
}
}
}
其他{
window.location.reload();
}
}
我读了这段代码。我想获取 nums[i] 的数据。我如何获得这些数据?非常感谢兄弟~! --------------------编程问答 --------------------以上是错误的,应该是numsSource [i] 是我需要的数据。 --------------------编程问答--------------------江城高手请帮忙,如何?在client端调用server端的java函数,实在想不出办法-------------------- 编程问答---- ------- -------调用相同的DOM方法
HtmlWindowPopupOptionWindow()
{
IHTMLAnchorElementae=extendedWebBrowser1.GetLinkByHref("popupEligiNewRT");
if(ae!=null)
{
Debug.WriteLine(ae.href);
//javascript:popupEligiNewRT('DIANA%20JOHN%20W',%20'SUB','form0')
//functionpopupEligiNewRT(name,opt,form){
//varstr="eligipopup.jsp?&name="+name+"&opt="+opt+"&form="+form;
//window.open(str,'popupeligiwin','width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no');
//}
stringhref=ae.href;
href=href.Substring(
href.IndexOf("("));
Stringdelim="()";
href=href.Trim(delim.ToCharArray());
string[]parameters=href.Split(",".ToCharArray());
delim="'";
stringname=parameters[0].Trim(delim.ToCharArray());
stringopt=parameters[1].Trim(delim.ToCharArray());
stringform=parameters[2].Trim(delim.ToCharArray());
stringPopupURL=string.Format("{0}&opt={1}&form={2}",name,opt,form);
returnextendedWebBrowser1.Document.Window.Open(PopupURL,"autopopupeligiwin","width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no" ,假);
}
returnnull;
}
补充:.NET技术 , C#
excel抓取网页动态数据(找个星座分析的网站试试,看看能不能抓数据(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-04 14:02
)
#星座分析组#
头条活动星座分析群,我们找个星座分析网站试试看能不能抓到数据。
就是这样,图片看起来很可爱。
网站分析
网站 保护做得好,没办法看到数据,只能从网站分析入手。
一般来说,网站 可以通过一些查询参数进行查询。我们编写查询函数来捕获数据。一些网站有静态URL,我们可以直接根据显示的静态URL来判断。来抓。
这种爬取是最简单的,但也是最麻烦的,因为它依赖于html代码从代码中寻找需要的数据。
上图中提供了各个星座的url,以及对应的运势查询。我们要做的就是复制上面两段代码,准备爬取,提取星座url和财富url。
像这样的东西:
也:
这个过程是最基本的文本处理。首先使用Web.BrowserContents函数读取html文本,然后拆分我们想要的那段代码,就可以使用Text.Split函数了。您还可以将所需的代码片段直接复制并粘贴到 html 文本中。
Power Query 在这一点上更好。可视化操作。为了稍后自动刷新数据,我们必须区分数据是否为常量。如果是常量,我们可以复制粘贴。如果有变化,最好从头开始使用Functions和公式,以确保刷新数据时不会出现问题。
我们只想要一些文本,所以直接使用html表单。
Html.Table(Web.BrowserContents([url]&[u1]), {{"Column1", ".c_cont STRONG"}, {"Column2", ".c_cont SPAN"}}, [RowSelector="P"] )
无需定义函数,直接添加一列即可抓取。
抓
经过上面的分析,我们直接使用自定义列来抓取数据:
你会说Html.Table函数的参数写不出来,其实我不会,这个没关系,你可以尝试抓取一个页面,让向导自动生成,然后我们复制超过:
然后看代码:
我们可以将前两行合并为一行。
最后,我们看一下捕获的数据:
同样的,我们可以试着把握明天的运势,一周的运势等等,这里就不做示范了。
最后,我们来做一个可视化的图表来看看:
查看全部
excel抓取网页动态数据(找个星座分析的网站试试,看看能不能抓数据(组图)
)
#星座分析组#
头条活动星座分析群,我们找个星座分析网站试试看能不能抓到数据。
就是这样,图片看起来很可爱。
网站分析
网站 保护做得好,没办法看到数据,只能从网站分析入手。
一般来说,网站 可以通过一些查询参数进行查询。我们编写查询函数来捕获数据。一些网站有静态URL,我们可以直接根据显示的静态URL来判断。来抓。
这种爬取是最简单的,但也是最麻烦的,因为它依赖于html代码从代码中寻找需要的数据。
上图中提供了各个星座的url,以及对应的运势查询。我们要做的就是复制上面两段代码,准备爬取,提取星座url和财富url。
像这样的东西:
也:
这个过程是最基本的文本处理。首先使用Web.BrowserContents函数读取html文本,然后拆分我们想要的那段代码,就可以使用Text.Split函数了。您还可以将所需的代码片段直接复制并粘贴到 html 文本中。
Power Query 在这一点上更好。可视化操作。为了稍后自动刷新数据,我们必须区分数据是否为常量。如果是常量,我们可以复制粘贴。如果有变化,最好从头开始使用Functions和公式,以确保刷新数据时不会出现问题。
我们只想要一些文本,所以直接使用html表单。
Html.Table(Web.BrowserContents([url]&[u1]), {{"Column1", ".c_cont STRONG"}, {"Column2", ".c_cont SPAN"}}, [RowSelector="P"] )
无需定义函数,直接添加一列即可抓取。
抓
经过上面的分析,我们直接使用自定义列来抓取数据:
你会说Html.Table函数的参数写不出来,其实我不会,这个没关系,你可以尝试抓取一个页面,让向导自动生成,然后我们复制超过:
然后看代码:
我们可以将前两行合并为一行。
最后,我们看一下捕获的数据:
同样的,我们可以试着把握明天的运势,一周的运势等等,这里就不做示范了。
最后,我们来做一个可视化的图表来看看:
excel抓取网页动态数据(一个基于浏览器的爬虫插件InstantDataScraper抓取评论(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-01-04 13:12
使用 Chrome 插件 Instant Data Scraper 抓取评论
通常我们要分析一个产品的负面评论,我们需要捕获所有负面评论(1、2、3 星)进行分析和总结。一般的做法是将评论一条一条的复制到表格中,但是这种做法效率太低了。今天推荐一个基于Chrome浏览器的爬虫插件Instant Data Scraper。
插件安装地址:(需要VPN翻墙)
使用方法如下:
1. 进入要提取差评的listing详情页面,进入评论列表页面,删除差评
2. 在这个页面打开 Instant Data Scraper 插件
图中红框是插件自动识别的数据表。默认是拉出整个页面的数据,但是我们只想评论,所以需要切换我们需要的数据表。
3. 找到我们需要的数据表
点击“Try another table”按钮,插件会自动识别当前页面的其他数据表,提取的数据会显示在插件下方的表格中。我们需要检查提取的数据是否正确。如果不是我们想要的,那么继续点击“Try another table”按钮,让插件继续寻找其他数据表;如果检查表中的数据是我们想要的,那么我们可以进行下一步。
4. 设置下一页按钮(不是必须的,如果插件检测到下一页按钮就不需要设置,如果没有检测到我们需要设置)
比如一个产品有10页的差评,如果我们想一次性完成爬取,就要告诉插件哪个按钮是下一页,这样插件才能自动翻页爬取它。
如果插件页面出现Locate“Next”按钮,说明插件无法识别下一页是哪个按钮。这时候我们需要点击这个按钮,然后点击页面上的下一步按钮。
5. 获取数据
设置好数据表和下一页按钮后,就可以开始取数据了。点击“开始爬取”按钮开始爬取数据。
6. 数据导出
插件提供“CSV(逗号分隔值,通用数据表格式,几乎兼容所有电子表格软件)”、“XLSX(Excel电子表格)”、“COPYALL(复制到剪贴板)”,点击相应按钮即可获取对应的文件或数据。
备注:Instant Data Scraper是一款基于Chrome的爬虫工具,用途非常广泛。你可以尽情发挥你的想象力,爬取几乎所有你能看到的东西。 查看全部
excel抓取网页动态数据(一个基于浏览器的爬虫插件InstantDataScraper抓取评论(一))
使用 Chrome 插件 Instant Data Scraper 抓取评论
通常我们要分析一个产品的负面评论,我们需要捕获所有负面评论(1、2、3 星)进行分析和总结。一般的做法是将评论一条一条的复制到表格中,但是这种做法效率太低了。今天推荐一个基于Chrome浏览器的爬虫插件Instant Data Scraper。
插件安装地址:(需要VPN翻墙)
使用方法如下:
1. 进入要提取差评的listing详情页面,进入评论列表页面,删除差评
2. 在这个页面打开 Instant Data Scraper 插件
图中红框是插件自动识别的数据表。默认是拉出整个页面的数据,但是我们只想评论,所以需要切换我们需要的数据表。
3. 找到我们需要的数据表
点击“Try another table”按钮,插件会自动识别当前页面的其他数据表,提取的数据会显示在插件下方的表格中。我们需要检查提取的数据是否正确。如果不是我们想要的,那么继续点击“Try another table”按钮,让插件继续寻找其他数据表;如果检查表中的数据是我们想要的,那么我们可以进行下一步。
4. 设置下一页按钮(不是必须的,如果插件检测到下一页按钮就不需要设置,如果没有检测到我们需要设置)
比如一个产品有10页的差评,如果我们想一次性完成爬取,就要告诉插件哪个按钮是下一页,这样插件才能自动翻页爬取它。
如果插件页面出现Locate“Next”按钮,说明插件无法识别下一页是哪个按钮。这时候我们需要点击这个按钮,然后点击页面上的下一步按钮。
5. 获取数据
设置好数据表和下一页按钮后,就可以开始取数据了。点击“开始爬取”按钮开始爬取数据。
6. 数据导出
插件提供“CSV(逗号分隔值,通用数据表格式,几乎兼容所有电子表格软件)”、“XLSX(Excel电子表格)”、“COPYALL(复制到剪贴板)”,点击相应按钮即可获取对应的文件或数据。
备注:Instant Data Scraper是一款基于Chrome的爬虫工具,用途非常广泛。你可以尽情发挥你的想象力,爬取几乎所有你能看到的东西。
excel抓取网页动态数据(Listly|在线网页内容转Excel工具()(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-01 14:02
网站标志:
网站姓名:Listly|在线网页内容转Excel工具
网站地址:
网站缩略图:
网站简介:
Listly 是一款基于网页的网页抓取内容,内容自动整理成 Excel 格式的工具,特别适合抓取带有产品数据或其他相关信息的网页,方便用户整理成 Excel 格式进行分析数据整理统计。
Listly 是一款免费工具,可以快速导出网页并将其转换为 Excel 电子表格。只需输入网址,它就会自动确定网页的所有部分,并将信息转换为我们需要的 Excel 文件,可能不是一次全部完成。 100%到位,但是既然是半成品,稍微修改一下应该就可以完成我们想要的内容了。更重要的是,Listly 还全面支持中文内容,并提供 Google Chrome 扩展程序供用户免费下载。
Listly网站列举了一些可用的方法,例如:让企业创造潜在客户、监控电子商务网站零售商的价格变化、为研究机构建立数据集、为营销采集反馈信息、排序搜索结果以进行 SEO 监控或提供分析数据以供使用。
然而,Listly 只提供免费用户每天转换三页的配额。注册并登录后,可增加至十个配额(每月)。还有一个可以使用的时间表和自动更新,这对于少量来说就足够了。 , 付款后可以扩大额度,价格也不算太贵,可能只是拿钱换时间吧!有兴趣的朋友可以试试。 查看全部
excel抓取网页动态数据(Listly|在线网页内容转Excel工具()(图))
网站标志:
网站姓名:Listly|在线网页内容转Excel工具
网站地址:
网站缩略图:
网站简介:
Listly 是一款基于网页的网页抓取内容,内容自动整理成 Excel 格式的工具,特别适合抓取带有产品数据或其他相关信息的网页,方便用户整理成 Excel 格式进行分析数据整理统计。
Listly 是一款免费工具,可以快速导出网页并将其转换为 Excel 电子表格。只需输入网址,它就会自动确定网页的所有部分,并将信息转换为我们需要的 Excel 文件,可能不是一次全部完成。 100%到位,但是既然是半成品,稍微修改一下应该就可以完成我们想要的内容了。更重要的是,Listly 还全面支持中文内容,并提供 Google Chrome 扩展程序供用户免费下载。
Listly网站列举了一些可用的方法,例如:让企业创造潜在客户、监控电子商务网站零售商的价格变化、为研究机构建立数据集、为营销采集反馈信息、排序搜索结果以进行 SEO 监控或提供分析数据以供使用。
然而,Listly 只提供免费用户每天转换三页的配额。注册并登录后,可增加至十个配额(每月)。还有一个可以使用的时间表和自动更新,这对于少量来说就足够了。 , 付款后可以扩大额度,价格也不算太贵,可能只是拿钱换时间吧!有兴趣的朋友可以试试。
excel抓取网页动态数据(excel抓取网页动态数据,不同网站服务商有区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-30 14:09
excel抓取网页动态数据,不同网站服务商有区别,你抓取的太早了,抓取的数据可能已经过期了。1、excel可以借助插件“网页数据分析”实现抓取网页动态数据。2、在分析网页的时候,用到“相同字段”可以知道几种可能的查询关键字,如gdp,qs,gdp预测,周期预测等。
可以用excel2010以上版本自带的web信息抓取功能。用“相同字段”能知道大部分的用户浏览历史和动态网页产生的消息数据(即抓取的用户信息)可以使用excel的web统计分析功能,也可以使用everything一类的,然后python或其他统计语言抓取网页历史信息。
这不是excel的问题,是爬虫的问题。你想用用api,excel上都有,你想用爬虫,
可以发邮件要数据,内嵌一个小爬虫,
基本上这个属于行业内都有的问题,拿回来自己做一下网页编程分析就可以解决了。
excel..可以采集常见网站的信息,
求题主给大家看一下我的观点:如果是重要数据源(公司数据库),使用api.scrapy框架。如果数据质量不高、丢失或者需要做大规模去重,这个组合有一些短板,我会考虑使用第三方的scrapy中间件,而不是用api获取。在这个基础上,可以考虑post数据提交。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,不同网站服务商有区别)
excel抓取网页动态数据,不同网站服务商有区别,你抓取的太早了,抓取的数据可能已经过期了。1、excel可以借助插件“网页数据分析”实现抓取网页动态数据。2、在分析网页的时候,用到“相同字段”可以知道几种可能的查询关键字,如gdp,qs,gdp预测,周期预测等。
可以用excel2010以上版本自带的web信息抓取功能。用“相同字段”能知道大部分的用户浏览历史和动态网页产生的消息数据(即抓取的用户信息)可以使用excel的web统计分析功能,也可以使用everything一类的,然后python或其他统计语言抓取网页历史信息。
这不是excel的问题,是爬虫的问题。你想用用api,excel上都有,你想用爬虫,
可以发邮件要数据,内嵌一个小爬虫,
基本上这个属于行业内都有的问题,拿回来自己做一下网页编程分析就可以解决了。
excel..可以采集常见网站的信息,
求题主给大家看一下我的观点:如果是重要数据源(公司数据库),使用api.scrapy框架。如果数据质量不高、丢失或者需要做大规模去重,这个组合有一些短板,我会考虑使用第三方的scrapy中间件,而不是用api获取。在这个基础上,可以考虑post数据提交。
excel抓取网页动态数据(彩票数据获取并写入excel表格数据来源自己看吧~用外链通不过 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-12-29 22:17
)
快下班了,正要买彩票,所以写了2个脚本,一个下载最新开奖数据,一个统计开奖号码,分享给大家!
获取彩票数据写入excel表格
自己看资料来源~ 外链是打不通的。. .
使用的库:xlwt、requests、lxml
有几点需要注意:
1、建立列表。因为保存excel文件时用到了列表,所以新建了一个函数,取网页上的5个数据:时间、周期、抽奖123,然后将每个页面嵌套写入列表中。类似的结构是[[time, period Number, lottery 1, 2, 3], [time, period, lottery 1, 2, 3]......],在循环页面,获取所有数据!注意列表的形式和列表的结果,这在你写表的时候很重要!
2、写入数据。xlwt写入文件的方法是ws.write(line, column, data),将文件逐行写入,因此新建一个变量行(代码第36行),每次增加1行写。
其他方面很简单,没有反爬,只是为了获取数据,方便分析!
最终excel表中的数据
是这样的:
最后大概有4840行数据,足够我们分析了!
数据处理
可以用xlrd库~xlwt库和xlrd库好像一个是写数据的,一个是读数据的。. .
我写了一个抢手的热门号码,也就是最频繁的号码。如果您有更好的想法或玩法,可以自己实现!
先读取数据,然后得到2.3.每行的4列,每列写一个list(现在后悔了,不应该写这么多数据进去),然后合并将3个列表合为一个总列表,所以我们有4个列表,取出每个列表中出现频率最高的数字,代码如下:
出现频率最高的第一个数字是 [3]
出现频率最高的第二个数字是[6]
频率最高的第三个数字是[8]
单数出现频率最高[3]
因为赶时间下班。. 我使用了所有列表推导式,我没有使用 Pandas 或可视化库来制作很酷的图表。当我制定一个完美的预测计划时,我正在做[Manual Cry],但按照目前的趋势,没有希望。向上。. .
最后我想说的是,从开始研究分析各种数据到现在买彩票的习惯,我从来没有中过大奖(超过200个算大奖)!果然,童话都是骗人的……还是学python更好玩!
查看全部
excel抓取网页动态数据(彩票数据获取并写入excel表格数据来源自己看吧~用外链通不过
)
快下班了,正要买彩票,所以写了2个脚本,一个下载最新开奖数据,一个统计开奖号码,分享给大家!
获取彩票数据写入excel表格
自己看资料来源~ 外链是打不通的。. .
使用的库:xlwt、requests、lxml
有几点需要注意:
1、建立列表。因为保存excel文件时用到了列表,所以新建了一个函数,取网页上的5个数据:时间、周期、抽奖123,然后将每个页面嵌套写入列表中。类似的结构是[[time, period Number, lottery 1, 2, 3], [time, period, lottery 1, 2, 3]......],在循环页面,获取所有数据!注意列表的形式和列表的结果,这在你写表的时候很重要!
2、写入数据。xlwt写入文件的方法是ws.write(line, column, data),将文件逐行写入,因此新建一个变量行(代码第36行),每次增加1行写。
其他方面很简单,没有反爬,只是为了获取数据,方便分析!
最终excel表中的数据
是这样的:
最后大概有4840行数据,足够我们分析了!
数据处理
可以用xlrd库~xlwt库和xlrd库好像一个是写数据的,一个是读数据的。. .
我写了一个抢手的热门号码,也就是最频繁的号码。如果您有更好的想法或玩法,可以自己实现!
先读取数据,然后得到2.3.每行的4列,每列写一个list(现在后悔了,不应该写这么多数据进去),然后合并将3个列表合为一个总列表,所以我们有4个列表,取出每个列表中出现频率最高的数字,代码如下:
出现频率最高的第一个数字是 [3]
出现频率最高的第二个数字是[6]
频率最高的第三个数字是[8]
单数出现频率最高[3]
因为赶时间下班。. 我使用了所有列表推导式,我没有使用 Pandas 或可视化库来制作很酷的图表。当我制定一个完美的预测计划时,我正在做[Manual Cry],但按照目前的趋势,没有希望。向上。. .
最后我想说的是,从开始研究分析各种数据到现在买彩票的习惯,我从来没有中过大奖(超过200个算大奖)!果然,童话都是骗人的……还是学python更好玩!
excel抓取网页动态数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-28 20:11
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这个目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站的,会弹出一个新的网页查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及是否允许后台刷新,或打开文件时刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:
预防措施:
某些网站的数据是加密的,可能无法导出。这不是软件可以做到的。需要的是黑客。
如何在Excel中查询网页数据并实时更新。相关文章:
1.如何使用excel2013web查询和采集
网页数据
2.中小学优秀作文作文
3.excel如何采集
网页数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号 查看全部
excel抓取网页动态数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这个目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站的,会弹出一个新的网页查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及是否允许后台刷新,或打开文件时刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:
预防措施:
某些网站的数据是加密的,可能无法导出。这不是软件可以做到的。需要的是黑客。
如何在Excel中查询网页数据并实时更新。相关文章:
1.如何使用excel2013web查询和采集
网页数据
2.中小学优秀作文作文
3.excel如何采集
网页数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号
excel抓取网页动态数据(PowerQueryBarChart抓取部分的工作要分成(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-25 21:04
昨天我看到 Animated Bar Chart Race 需要数据来进行更好的展示。有网友想抓取上市公司的财报进行股票分析。我前几天也试过了。它应该能够捕获主要的财务数据。, 大多数金融网站提供上市公司的实时股票信息和财务数据。数据采集就是对网站所能提供的数据进行分析,然后采取相应的方法进行采集。
Power Query 爬网
Power Query爬取部分的工作应该分为三个步骤:
第一步:网站分析
这部分主要是寻找网站数据的位置和数据排列的规律。谷歌浏览器用来做网站分析,Power Query用来做单个网页的爬行测试。
有必要抢股票代码。综合报价网站提供沪深股市所有股票代码。这里显示了 151 页,每页 24 行数据。页码为 0-150。特定的 URL 由 Google 浏览器检查并右键单击。可以在网络上查看。
然后是具体的财务数据。打开任意一家公司的页面,中间的财务分析下会有相应的财务数据。这里我只需要主要的财务数据。真正的 URL 是通过股票代码访问的。
第二步:自定义fetch函数
1、 首先是抓取股票代码列表的自定义函数:
事实上,定制部分非常简单。首先,我们需要正常从网页上建立一个查询,然后通过一步一步的操作找到这个页面最后的24个股票代码:在这个例子中,股票代码隐藏在一个JSON格式的数据中。, 要通过 JSON 解析。
然后右键单击此查询> 创建函数
会有一个没有参数的提示。要跳过提示,请命名函数:
直接打开高级编辑器,进行修改,在空括号中输入p作为该函数的参数,在url中找到&page=0&,将0替换为“&p&”。更换后的样子是这样的:
&page="&p&"&
这样,这个自定义函数就写好了。有一点需要注意。这里,p 是文本。如果在使用时创建了0-150的列表,请记得在使用该功能之前将其转换为文本。
2、 捕获特定数据的自定义函数:
还需要先抓取一页数据,包中间的处理步骤:不想多行,直接给出逆透视图。
同理,右击创建函数,修改参数。这在两个修改的地方可以清楚地看到。
第 3 步:抓取数据
首先创建一个列表,将其转换为表格,将其设置为文本,并使用第一个获取股票代码的函数生成一个股票代码列表:
然后按以下顺序排序:
然后调用抓取数据的函数来获取数据:
展开以获得所需的结果:
至此,捕获数据的工作已经准备就绪,但是捕获是一个漫长的过程。我用8核16G内存近2小时捕获了300万行数据。
40 分钟 150 万行
动画条形图竞赛
这个比较简单。这是要写入的测量值。财务数据基本上是当期的累计值。一年有四个季度。如果一年是跨度,就需要看年报数据,所以写一个测量值,把一年4份报表中日期最晚的报表对应的数据拿出来就行了。
然后就是要注意修改年份的非汇总:
最后放个录音效果:
有关 Power Query 网页抓取的详细信息,请观看: 查看全部
excel抓取网页动态数据(PowerQueryBarChart抓取部分的工作要分成(组图))
昨天我看到 Animated Bar Chart Race 需要数据来进行更好的展示。有网友想抓取上市公司的财报进行股票分析。我前几天也试过了。它应该能够捕获主要的财务数据。, 大多数金融网站提供上市公司的实时股票信息和财务数据。数据采集就是对网站所能提供的数据进行分析,然后采取相应的方法进行采集。
Power Query 爬网
Power Query爬取部分的工作应该分为三个步骤:
第一步:网站分析
这部分主要是寻找网站数据的位置和数据排列的规律。谷歌浏览器用来做网站分析,Power Query用来做单个网页的爬行测试。
有必要抢股票代码。综合报价网站提供沪深股市所有股票代码。这里显示了 151 页,每页 24 行数据。页码为 0-150。特定的 URL 由 Google 浏览器检查并右键单击。可以在网络上查看。
然后是具体的财务数据。打开任意一家公司的页面,中间的财务分析下会有相应的财务数据。这里我只需要主要的财务数据。真正的 URL 是通过股票代码访问的。
第二步:自定义fetch函数
1、 首先是抓取股票代码列表的自定义函数:
事实上,定制部分非常简单。首先,我们需要正常从网页上建立一个查询,然后通过一步一步的操作找到这个页面最后的24个股票代码:在这个例子中,股票代码隐藏在一个JSON格式的数据中。, 要通过 JSON 解析。
然后右键单击此查询> 创建函数
会有一个没有参数的提示。要跳过提示,请命名函数:
直接打开高级编辑器,进行修改,在空括号中输入p作为该函数的参数,在url中找到&page=0&,将0替换为“&p&”。更换后的样子是这样的:
&page="&p&"&
这样,这个自定义函数就写好了。有一点需要注意。这里,p 是文本。如果在使用时创建了0-150的列表,请记得在使用该功能之前将其转换为文本。
2、 捕获特定数据的自定义函数:
还需要先抓取一页数据,包中间的处理步骤:不想多行,直接给出逆透视图。
同理,右击创建函数,修改参数。这在两个修改的地方可以清楚地看到。
第 3 步:抓取数据
首先创建一个列表,将其转换为表格,将其设置为文本,并使用第一个获取股票代码的函数生成一个股票代码列表:
然后按以下顺序排序:
然后调用抓取数据的函数来获取数据:
展开以获得所需的结果:
至此,捕获数据的工作已经准备就绪,但是捕获是一个漫长的过程。我用8核16G内存近2小时捕获了300万行数据。
40 分钟 150 万行
动画条形图竞赛
这个比较简单。这是要写入的测量值。财务数据基本上是当期的累计值。一年有四个季度。如果一年是跨度,就需要看年报数据,所以写一个测量值,把一年4份报表中日期最晚的报表对应的数据拿出来就行了。
然后就是要注意修改年份的非汇总:
最后放个录音效果:
有关 Power Query 网页抓取的详细信息,请观看:
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-25 14:07
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
一时兴起,在知乎搜索Excel,想学习如何写好评文章。
看到这些标题,看完的时候,一下子就勾起了下载采集
的欲望!
如何捕捉所有高赞的文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。
你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。我总是第一个排队,挑最好的!
好,我们来看看这个表格是怎么制作的。
大致可以分为4个步骤:
❶ 获取JSON数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
您可能不知道 Power Query 可以捕获 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
把我们之前得到的链接粘贴到PQ中,这个链接就可以用来抓取数据了。
然后得到的是网页的数据格式。如何获取具体的文章数据?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
我们此时得到的数据会有一些不必要的额外数据。
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留您需要的文章的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录
的搜索词尚未更新。
所以在这一步,我们需要配置这个数据链,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后得到这个搜索词,以变量的形式放到搜索地址中,搜索地址的配置就完成了。
修改后的地址代码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果要查看原知乎页面,还需要复制超链接在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用HYPERLINK函数来生成一个可点击的超链接,这样访问就简单多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!
02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 阅读过的文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具来绘制和绘制电子表格以及编写公式。
请记住以下 Excel 新功能。这些功能让 Excel 成长为功能强大的数据统计和数据分析软件,它不再只是您脑海中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表中的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
... 查看全部
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
一时兴起,在知乎搜索Excel,想学习如何写好评文章。
看到这些标题,看完的时候,一下子就勾起了下载采集
的欲望!
如何捕捉所有高赞的文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。
你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。我总是第一个排队,挑最好的!
好,我们来看看这个表格是怎么制作的。
大致可以分为4个步骤:
❶ 获取JSON数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
您可能不知道 Power Query 可以捕获 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
把我们之前得到的链接粘贴到PQ中,这个链接就可以用来抓取数据了。
然后得到的是网页的数据格式。如何获取具体的文章数据?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
我们此时得到的数据会有一些不必要的额外数据。
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留您需要的文章的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录
的搜索词尚未更新。
所以在这一步,我们需要配置这个数据链,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后得到这个搜索词,以变量的形式放到搜索地址中,搜索地址的配置就完成了。
修改后的地址代码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果要查看原知乎页面,还需要复制超链接在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用HYPERLINK函数来生成一个可点击的超链接,这样访问就简单多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!
02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 阅读过的文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具来绘制和绘制电子表格以及编写公式。
请记住以下 Excel 新功能。这些功能让 Excel 成长为功能强大的数据统计和数据分析软件,它不再只是您脑海中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表中的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
...
excel抓取网页动态数据(文章目录Selenium安装SeleniumSelenium对象访问查找节点节点交互获取节点信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 11:26
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章 目录 Selenium 安装 Selenium Selenium 基本用法 声明浏览器对象访问页面 查找节点 节点交互 获取节点信息 Selenium
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 看看您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。总之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip 安装硒
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriverbrowser = webdriver.Chrome()browser = webdriver.Firefox()browser = webdriver.Edge()browser = webdriver.PhantomJS()browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriverbrowser = webdriver.Chrome()browser.get('')print(browser.page_source)browser.close() 查找单个节点
网页由超文本标记语言组成。这些是网页的节点。如果我们想要获取某些信息,我们需要知道该信息位于何处。所以这里你要查看网页的源代码。
查看全部
excel抓取网页动态数据(文章目录Selenium安装SeleniumSelenium对象访问查找节点节点交互获取节点信息
)
如上所述,我们可以通过分析Ajax访问服务器的方式来获取Ajax数据。Ajax 也是一种动态渲染页面。因此,也可以抓取动态页面。
文章 目录 Selenium 安装 Selenium Selenium 基本用法 声明浏览器对象访问页面 查找节点 节点交互 获取节点信息 Selenium
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。本工具的主要功能包括: 测试与浏览器的兼容性-test 看看您的应用程序可以在不同的浏览器和操作系统上运行良好测试系统功能-创建回归测试以验证软件功能和用户需求支持自动记录动作和自动生成.Net、Java、Perl等多种语言的测试脚本。总之,Selenium 可以模拟用户对浏览器的操作,因此也可以提取动态页面。
安装硒
在cmd下输入:
pip 安装硒
同时下载相应版本浏览器的驱动。
Chrome:点击下载
火狐:点击下载
IE:点击下载
下载后解压到python安装目录下的scripts中。
Selenium 基本使用方法来声明浏览器对象
Selenium 支持很多浏览器,我们首先需要让系统知道你使用的是什么浏览器,我们可以通过以下方式对其进行初始化:
from selenium import webdriverbrowser = webdriver.Chrome()browser = webdriver.Firefox()browser = webdriver.Edge()browser = webdriver.PhantomJS()browser = webdriver.Sarari()
之后我们就可以使用浏览器对象来执行各种动作来模拟浏览器操作
访问页面
我们使用get()方法来请求一个网页,只需要传入URL即可。这里我们访问百度页面并打印出源代码:
from selenium import webdriverbrowser = webdriver.Chrome()browser.get('')print(browser.page_source)browser.close() 查找单个节点
网页由超文本标记语言组成。这些是网页的节点。如果我们想要获取某些信息,我们需要知道该信息位于何处。所以这里你要查看网页的源代码。
excel抓取网页动态数据(爬取页面中的新闻数据对应的数据包url和新闻详情数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-14 18:29
要求:抓取页面中的新闻数据。
分析:
1. 首先通过对页面的分析,会发现页面中的新闻数据是动态加载的,通过抓包工具抓取数据,可以发现动态数据并不是获取到的动态数据被ajax请求(因为没有捕获到ajax请求的数据包),那么就只剩下一种可能了,动态数据由js动态生成。
2. 使用抓包工具找出是哪个js请求产生了动态数据:打开抓包工具,然后向首页url(要求第一行的url)发起请求,抓包所有的请求的数据包。
分析响应js包返回的数据:
响应数据对应的url可以在抓包工具对应的数据包的header选项卡中获取。获取到url后,发起请求获取上图中选择的对应数据。响应数据类型为application/javascript类型,所以可以通过正则表达式提取得到的响应数据,提取外大括号中的数据,然后使用json.loads转换为字典类型,然后逐步解析出数据中所有新闻详情页面的 URL。
- 获取详情页对应的新闻详情数据:向详情页发出请求后,会发现详情页的新闻数据也是动态加载的,所以和上面的步骤一样,获取详情页中的部分数据在抓包工具中查看详情页搜索并定位到指定的js数据包:
js数据包的url为:
获取到详情页url后,可以请求数据包对应的响应数据,对应的数据中收录对应的新闻详情数据。注意响应数据类型也是application/javascript,所以数据分析同上!
分析首页所有新闻详情页的url与新闻详情数据对应的js数据包的url的关联:
-首页新闻详情页url:5c39c314138da31babf0b16af5a55da4/e43e220633a65f9b6d8b53712cba9caa.html
-新闻详情数据对应的js数据包url:5c39c314138da31babf0b16af5a55da4/datae43e220633a65f9b6d8b53712cba9caa.js
-所有新闻详情对应的js数据包黄色选中部分除了红色部分不同外都是一样的,但是红色部分和新闻详情页url中红色部分是一样的!!!新闻详情页的url可以在上面的过程中解析出来。所以,现在可以批量生成js数据包对应的详细数据的url,然后批量数据请求,获取响应数据,再解析响应数据,完成最终的需求! 查看全部
excel抓取网页动态数据(爬取页面中的新闻数据对应的数据包url和新闻详情数据)
要求:抓取页面中的新闻数据。
分析:
1. 首先通过对页面的分析,会发现页面中的新闻数据是动态加载的,通过抓包工具抓取数据,可以发现动态数据并不是获取到的动态数据被ajax请求(因为没有捕获到ajax请求的数据包),那么就只剩下一种可能了,动态数据由js动态生成。
2. 使用抓包工具找出是哪个js请求产生了动态数据:打开抓包工具,然后向首页url(要求第一行的url)发起请求,抓包所有的请求的数据包。
分析响应js包返回的数据:
响应数据对应的url可以在抓包工具对应的数据包的header选项卡中获取。获取到url后,发起请求获取上图中选择的对应数据。响应数据类型为application/javascript类型,所以可以通过正则表达式提取得到的响应数据,提取外大括号中的数据,然后使用json.loads转换为字典类型,然后逐步解析出数据中所有新闻详情页面的 URL。
- 获取详情页对应的新闻详情数据:向详情页发出请求后,会发现详情页的新闻数据也是动态加载的,所以和上面的步骤一样,获取详情页中的部分数据在抓包工具中查看详情页搜索并定位到指定的js数据包:
js数据包的url为:
获取到详情页url后,可以请求数据包对应的响应数据,对应的数据中收录对应的新闻详情数据。注意响应数据类型也是application/javascript,所以数据分析同上!
分析首页所有新闻详情页的url与新闻详情数据对应的js数据包的url的关联:
-首页新闻详情页url:5c39c314138da31babf0b16af5a55da4/e43e220633a65f9b6d8b53712cba9caa.html
-新闻详情数据对应的js数据包url:5c39c314138da31babf0b16af5a55da4/datae43e220633a65f9b6d8b53712cba9caa.js
-所有新闻详情对应的js数据包黄色选中部分除了红色部分不同外都是一样的,但是红色部分和新闻详情页url中红色部分是一样的!!!新闻详情页的url可以在上面的过程中解析出来。所以,现在可以批量生成js数据包对应的详细数据的url,然后批量数据请求,获取响应数据,再解析响应数据,完成最终的需求!
excel抓取网页动态数据(本文实例讲述Python实现抓取网页生优游Excel文件的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-12 22:21
本文介绍了如何使用 Python 从网页中捕获 Excel 文件的示例。分享给大有游,供大有游参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步就是用Notepad++打开company.csv,然后转成优优ANSI编码格式,保存。然后用Excel软件打开这个csv文件并保存为Excel文件
更多对Python相关内容感兴趣的读者可以查看本站主题:“”、“”、“”、“”、“”、“”和“”
希望本文中的描述对您设计大有游的 Python 程序有所帮助。 查看全部
excel抓取网页动态数据(本文实例讲述Python实现抓取网页生优游Excel文件的方法)
本文介绍了如何使用 Python 从网页中捕获 Excel 文件的示例。分享给大有游,供大有游参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步就是用Notepad++打开company.csv,然后转成优优ANSI编码格式,保存。然后用Excel软件打开这个csv文件并保存为Excel文件
更多对Python相关内容感兴趣的读者可以查看本站主题:“”、“”、“”、“”、“”、“”和“”
希望本文中的描述对您设计大有游的 Python 程序有所帮助。
excel抓取网页动态数据(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-11 03:18
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response 查看全部
excel抓取网页动态数据(接下来就是使用xlwt及xlwt模块实现urllib2有用过,可参看
)
一直想做一个网页的excel导出功能。最近抽时间研究了一下,用urllib2和BeautifulSoup和xlwt模块实现了
之前使用过urllib2模块。 BeautifulSoup模块请参考,介绍更详细。
以下是部分视图代码:
首先使用urlopen解析网页数据
urlfile = urllib2.urlopen('要解析的url地址')
html = urlfile.read()
创建一个 BeautifulSoup 对象
soup = BeautifulSoup(html)
以表格数据为例,使用findAll获取所有标签数据并将其内容添加到列表中。
result=[]
for line in soup.findAll('td'):
result.append(line.string)
下一步就是使用xlwt模块生成excel实现
创建excel文件
workbook = xlwt.Workbook(encoding = 'utf8')
worksheet = workbook.add_sheet('My Worksheet')
在excel文件中插入数据
for tag in range(0,8):
worksheet.write(0, tag, label = result[tag])
返回结果到网页,然后网页上就可以生成excel了
response = HttpResponse(content_type='application/msexcel')
response['Content-Disposition'] = 'attachment; filename=example.xls'
workbook.save(response)
return response
excel抓取网页动态数据(快速入门selenium常用操作方法解析及入门常用操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-10 13:02
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
. 查看全部
excel抓取网页动态数据(快速入门selenium常用操作方法解析及入门常用操作)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
大大地
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作checkbox:因为要选中checkbox标签,所以在网页上用鼠标点击。所以,如果要选中checkbox标签,先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前已经建立了某种条件。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
excel抓取网页动态数据(如何使用Excel快速网页数据?来说并不好的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-12-10 13:00
推荐使用:Excel数据采集软件(免费下载,像Excel一样快速上手,灵活可定制的企业管理软件)
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常会听到一个叫“爬虫”的词,它可以快速抓取网页上的数据。这对于数据分析相关的工作非常重要,也是必备的技能之一。然而,大多数爬行动物都需要编程知识,这对普通人来说并不好。今天就给大家讲解一下如何使用Excel快速抓取网页数据。
1.首先打开要抓取的数据的网站,复制网站地址。
2.新建一个Excel工作簿,点击“数据”菜单的“获取外部数据”选项卡中的“来自网站”选项。
在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网址,然后点击“开始”
点击黄色导入箭头,选择要抓取的部分,如图。单击导入。
3.选择存放数据的位置(默认选中的单元格),然后点击“确定”。一般建议将数据存储在“A1”单元格中。
4. 如果要根据网站数据自动实时更新Excel工作簿数据,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
获得数据后,需要对数据进行处理。处理数据是一个比较重要的环节。 查看全部
excel抓取网页动态数据(如何使用Excel快速网页数据?来说并不好的方法)
推荐使用:Excel数据采集软件(免费下载,像Excel一样快速上手,灵活可定制的企业管理软件)
网站上的数据源是我们统计分析的重要信息来源。我们在生活中经常会听到一个叫“爬虫”的词,它可以快速抓取网页上的数据。这对于数据分析相关的工作非常重要,也是必备的技能之一。然而,大多数爬行动物都需要编程知识,这对普通人来说并不好。今天就给大家讲解一下如何使用Excel快速抓取网页数据。
1.首先打开要抓取的数据的网站,复制网站地址。
2.新建一个Excel工作簿,点击“数据”菜单的“获取外部数据”选项卡中的“来自网站”选项。
在弹出的“新建网页查询”对话框中,在地址栏中输入要爬取的网址,然后点击“开始”
点击黄色导入箭头,选择要抓取的部分,如图。单击导入。
3.选择存放数据的位置(默认选中的单元格),然后点击“确定”。一般建议将数据存储在“A1”单元格中。
4. 如果要根据网站数据自动实时更新Excel工作簿数据,那么我们需要在“属性”中进行设置。您可以设置“允许后台刷新”、“刷新频率”、“打开文件时刷新数据”等。
获得数据后,需要对数据进行处理。处理数据是一个比较重要的环节。
excel抓取网页动态数据(一个网页中有表格,怎样爬取下来?的read_html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-07 00:47
本期内容,小编将为大家带来Pandas如何使用Python爬虫爬取HTML网页表单并保存到Excel文件的信息。文章内容丰富,从专业角度分析叙述。看完这篇文章文章希望大家能有所收获。
如果 HTML 页面中有表格,如何抓取它们?
Pandas 的 read_html 可以轻松解析 HTML 代码中的 URL 地址或表格,并直接将其转换为数据帧,以便后续处理、分析和导出。
比如有这样一个案例,我经常用网易有道词典查英文单词,也经常在词汇书里加生词,这些年积累的单词越来越多。我想将这些词导出到excel。怎样才能专心复习,甚至打印出来看看。
但是网易有道词典没有导出所有单词的功能。
幸运的是,我在网易有道有道PC版上找到了这个单词书页面:
使用这样的技术组合,我可以轻松抓取整个网页,实现表格解析,并输出到Excel文件:
过程是这样的:
最后保存的 excel 是我想要的所有单词的列表:
Python爬虫+Pandas数据分析处理的好搭档
以上就是 Pandas 如何使用 Python 爬虫爬取 HTML 网页表单并保存到 Excel 文件。如果你碰巧也有类似的疑惑,不妨参考上面的分析来了解一下。如果您想了解更多相关知识,请关注易速云行业资讯频道。 查看全部
excel抓取网页动态数据(一个网页中有表格,怎样爬取下来?的read_html)
本期内容,小编将为大家带来Pandas如何使用Python爬虫爬取HTML网页表单并保存到Excel文件的信息。文章内容丰富,从专业角度分析叙述。看完这篇文章文章希望大家能有所收获。
如果 HTML 页面中有表格,如何抓取它们?
Pandas 的 read_html 可以轻松解析 HTML 代码中的 URL 地址或表格,并直接将其转换为数据帧,以便后续处理、分析和导出。
比如有这样一个案例,我经常用网易有道词典查英文单词,也经常在词汇书里加生词,这些年积累的单词越来越多。我想将这些词导出到excel。怎样才能专心复习,甚至打印出来看看。
但是网易有道词典没有导出所有单词的功能。
幸运的是,我在网易有道有道PC版上找到了这个单词书页面:
使用这样的技术组合,我可以轻松抓取整个网页,实现表格解析,并输出到Excel文件:
过程是这样的:
最后保存的 excel 是我想要的所有单词的列表:
Python爬虫+Pandas数据分析处理的好搭档
以上就是 Pandas 如何使用 Python 爬虫爬取 HTML 网页表单并保存到 Excel 文件。如果你碰巧也有类似的疑惑,不妨参考上面的分析来了解一下。如果您想了解更多相关知识,请关注易速云行业资讯频道。
excel抓取网页动态数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-06 03:14
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以简单地使用浏览器自带的开发者工具来响应请求,例如Firefox的FireBug等,只要按F12,所有请求的信息都会详细显示在您的面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想从哪里获取信息是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = {
3 'Host': 'www.lagou.com',
4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
6 'Connection': 'keep-alive'
7 }
8 if page_num == 1:
9 boo = 'true'
10 else:
11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo),
14 ('pn', page_num),
15 ('kd', keyword)
16 ])
17 req = request.Request(url, headers=page_headers)
18 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
19 page = page.decode('utf-8')
20 return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3捕获数据的适用方法。可以根据实际情况使用其中一种,也可以多种组合使用。
1 def read_tag(page, tag):
2 page_json = json.loads(page)
3 page_json = page_json['content']['result']
4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15):
7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag:
9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8])
11 return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name):
2 book = Workbook(encoding='utf-8')
3 tmp = book.add_sheet('sheet')
4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0:
7 for tag_name_i in tag_name:
8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
9 else:
10 for tag_list in range(len(tag_name)):
11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet()
4 row_num = len(fin_result)
5 for i in range(1, row_num):
6 if i == 1:
7 tag_pos = 'A%s' % i
8 tmp.write_row(tag_pos, tag_name)
9 else:
10 con_pos = 'A%s' % i
11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content)
13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse
4 from bs4 import BeautifulSoup as BS
5 import json
6 import datetime
7 import xlsxwriter
8
9 starttime = datetime.datetime.now()
10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = {
22 'Host': 'www.lagou.com',
23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
25 'Connection': 'keep-alive'
26 }
27 if page_num == 1:
28 boo = 'true'
29 else:
30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo),
33 ('pn', page_num),
34 ('kd', keyword)
35 ])
36 req = request.Request(url, headers=page_headers)
37 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
38 page = page.decode('utf-8')
39 return page
40
41
42 def read_tag(page, tag):
43 page_json = json.loads(page)
44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15):
47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag:
49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8])
51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page)
56 max_page_num = page_json['content']['totalPageCount']
57 if max_page_num > 30:
58 max_page_num = 30
59 return max_page_num
60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet()
65 row_num = len(fin_result)
66 for i in range(1, row_num):
67 if i == 1:
68 tag_pos = 'A%s' % i
69 tmp.write_row(tag_pos, tag_name)
70 else:
71 con_pos = 'A%s' % i
72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content)
74 book.close()
75
76
77 if __name__ == '__main__':
78 print('**********************************即将进行抓取**********************************')
79 keyword = input('请输入您要搜索的语言类型:')
80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword))
82 for page_num in range(1, max_page_num):
83 print('******************************正在下载第%s页内容*********************************' % page_num)
84 page = read_page(url, page_num, keyword)
85 page_result = read_tag(page, tag)
86 fin_result.extend(page_result)
87 file_name = input('抓取完成,输入文件名保存:')
88 save_excel(fin_result, tag_name, file_name)
89 endtime = datetime.datetime.now()
90 time = (endtime - starttime).seconds
91 print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请玉,欢迎交流,请注明出处供转载~(^ _ ^)/ ~~ 查看全部
excel抓取网页动态数据(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以简单地使用浏览器自带的开发者工具来响应请求,例如Firefox的FireBug等,只要按F12,所有请求的信息都会详细显示在您的面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想从哪里获取信息是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = {
3 'Host': 'www.lagou.com',
4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
6 'Connection': 'keep-alive'
7 }
8 if page_num == 1:
9 boo = 'true'
10 else:
11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo),
14 ('pn', page_num),
15 ('kd', keyword)
16 ])
17 req = request.Request(url, headers=page_headers)
18 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
19 page = page.decode('utf-8')
20 return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3捕获数据的适用方法。可以根据实际情况使用其中一种,也可以多种组合使用。
1 def read_tag(page, tag):
2 page_json = json.loads(page)
3 page_json = page_json['content']['result']
4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15):
7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag:
9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8])
11 return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name):
2 book = Workbook(encoding='utf-8')
3 tmp = book.add_sheet('sheet')
4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0:
7 for tag_name_i in tag_name:
8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
9 else:
10 for tag_list in range(len(tag_name)):
11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet()
4 row_num = len(fin_result)
5 for i in range(1, row_num):
6 if i == 1:
7 tag_pos = 'A%s' % i
8 tmp.write_row(tag_pos, tag_name)
9 else:
10 con_pos = 'A%s' % i
11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content)
13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse
4 from bs4 import BeautifulSoup as BS
5 import json
6 import datetime
7 import xlsxwriter
8
9 starttime = datetime.datetime.now()
10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = {
22 'Host': 'www.lagou.com',
23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
25 'Connection': 'keep-alive'
26 }
27 if page_num == 1:
28 boo = 'true'
29 else:
30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo),
33 ('pn', page_num),
34 ('kd', keyword)
35 ])
36 req = request.Request(url, headers=page_headers)
37 page = request.urlopen(req, data=page_data.encode('utf-8')).read()
38 page = page.decode('utf-8')
39 return page
40
41
42 def read_tag(page, tag):
43 page_json = json.loads(page)
44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15):
47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag:
49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8])
51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page)
56 max_page_num = page_json['content']['totalPageCount']
57 if max_page_num > 30:
58 max_page_num = 30
59 return max_page_num
60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet()
65 row_num = len(fin_result)
66 for i in range(1, row_num):
67 if i == 1:
68 tag_pos = 'A%s' % i
69 tmp.write_row(tag_pos, tag_name)
70 else:
71 con_pos = 'A%s' % i
72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content)
74 book.close()
75
76
77 if __name__ == '__main__':
78 print('**********************************即将进行抓取**********************************')
79 keyword = input('请输入您要搜索的语言类型:')
80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword))
82 for page_num in range(1, max_page_num):
83 print('******************************正在下载第%s页内容*********************************' % page_num)
84 page = read_page(url, page_num, keyword)
85 page_result = read_tag(page, tag)
86 fin_result.extend(page_result)
87 file_name = input('抓取完成,输入文件名保存:')
88 save_excel(fin_result, tag_name, file_name)
89 endtime = datetime.datetime.now()
90 time = (endtime - starttime).seconds
91 print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请玉,欢迎交流,请注明出处供转载~(^ _ ^)/ ~~
excel抓取网页动态数据(程序语言组织有可能欠佳,判断布局正确的定位元素 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-30 12:07
)
直接上传代码并分析,代码应该比较简单,基本上每一行都已经注释掉了,具体的代码准备,可以参考我写的代码,相信你可以很快的写出自己的程序
语言组织可能很差,希望你能凑合一下。如果有不明白的,有更简单严谨的代码,欢迎贴出来一起讨论。
1. 有搜索结果截图确定使用的定位元素
2. 没有搜索结果的截图,确定布局正确的定位元素
3. 没有搜索结果和错误布局的截图
4.excel文件中的数据,以行为单位
import xlrd
from selenium import webdriver
import time
class chromedriver:
driver=webdriver.Chrome()
#也可使用其他的webdriver,Firefox/ie
driver.maximize_window()
#有些网站缩小之后布局也会改变,所以需要用maximize_window()控制页面的大小
driver.get("URL")
# 获得需要访问的url地址
def null_search(self):
data=xlrd.open_workbook("excel文件路径")
#open一个excel文件,需要注意的是,有时候直接复制过来的路径中,\在Python中有特殊含义,需要统一换成/
table=data.sheets()[0]
#获取第一个sheet1,0表示第一个表
now=table.nrows
#表格中的行数,以便下面做for循环
for i in range(now):
now_data=''.join(table.row_values(i))
#直接获取的.row_values(i)为列表参数,无法直接在文本框中send_keys,所以需要将其转换成字符
text=chromedriver .driver .find_element_by_name("apachesolr_panels_search_form")
#需要注意的是需要在for循环中定位参数,如果直接在def以外定义
#则会出现报错:stale element reference: element is not attached to the page document,意思是这个element已经失效了,需要重新定义
#text.clear()
text.send_keys(now_data ) #将表格中的数据通过行循环,一个个写入到文本框
chromedriver .driver.find_element_by_css_selector("input.form-submit").click() #点击搜索按钮
time.sleep(5)
#一定要这是time.sleep(),因为不写等待时间,会导致最后出来的结果不准确,例如第一个数据是a,第二个数据为b,当不设置等待时间时,在搜索第二个数据时,本应输入b,然而在文本框中输入的为ab,此时得到的测试结果当然为不准确的
chromedriver.driver.switch_to_window(chromedriver.driver.window_handles [-1])
#定位到第二个页面,这样我们就可以定位第二个页面中的参数了
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-info") #当有搜索结果时,可以定位的参数
except: #当定位不到该参数时,结果有2种:1,无搜索结果,搜索的结果不符合布局 2,无搜索结果,符合布局,所以里面还需要一个try语句来判断情况
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-result>h2").text #判断当无搜索结果时,布局是否正确
except:
print(now_data +' '+ "无搜索结果,布局错误" )
else:
print(now_data +' '+ "无搜索结果,布局正确" )
else:
print(now_data +' '+ "有搜索结果")
if __name__ == '__main__':
run=chromedriver()
run.null_search()
5. 结果截图
查看全部
excel抓取网页动态数据(程序语言组织有可能欠佳,判断布局正确的定位元素
)
直接上传代码并分析,代码应该比较简单,基本上每一行都已经注释掉了,具体的代码准备,可以参考我写的代码,相信你可以很快的写出自己的程序
语言组织可能很差,希望你能凑合一下。如果有不明白的,有更简单严谨的代码,欢迎贴出来一起讨论。
1. 有搜索结果截图确定使用的定位元素
2. 没有搜索结果的截图,确定布局正确的定位元素
3. 没有搜索结果和错误布局的截图
4.excel文件中的数据,以行为单位
import xlrd
from selenium import webdriver
import time
class chromedriver:
driver=webdriver.Chrome()
#也可使用其他的webdriver,Firefox/ie
driver.maximize_window()
#有些网站缩小之后布局也会改变,所以需要用maximize_window()控制页面的大小
driver.get("URL")
# 获得需要访问的url地址
def null_search(self):
data=xlrd.open_workbook("excel文件路径")
#open一个excel文件,需要注意的是,有时候直接复制过来的路径中,\在Python中有特殊含义,需要统一换成/
table=data.sheets()[0]
#获取第一个sheet1,0表示第一个表
now=table.nrows
#表格中的行数,以便下面做for循环
for i in range(now):
now_data=''.join(table.row_values(i))
#直接获取的.row_values(i)为列表参数,无法直接在文本框中send_keys,所以需要将其转换成字符
text=chromedriver .driver .find_element_by_name("apachesolr_panels_search_form")
#需要注意的是需要在for循环中定位参数,如果直接在def以外定义
#则会出现报错:stale element reference: element is not attached to the page document,意思是这个element已经失效了,需要重新定义
#text.clear()
text.send_keys(now_data ) #将表格中的数据通过行循环,一个个写入到文本框
chromedriver .driver.find_element_by_css_selector("input.form-submit").click() #点击搜索按钮
time.sleep(5)
#一定要这是time.sleep(),因为不写等待时间,会导致最后出来的结果不准确,例如第一个数据是a,第二个数据为b,当不设置等待时间时,在搜索第二个数据时,本应输入b,然而在文本框中输入的为ab,此时得到的测试结果当然为不准确的
chromedriver.driver.switch_to_window(chromedriver.driver.window_handles [-1])
#定位到第二个页面,这样我们就可以定位第二个页面中的参数了
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-info") #当有搜索结果时,可以定位的参数
except: #当定位不到该参数时,结果有2种:1,无搜索结果,搜索的结果不符合布局 2,无搜索结果,符合布局,所以里面还需要一个try语句来判断情况
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-result>h2").text #判断当无搜索结果时,布局是否正确
except:
print(now_data +' '+ "无搜索结果,布局错误" )
else:
print(now_data +' '+ "无搜索结果,布局正确" )
else:
print(now_data +' '+ "有搜索结果")
if __name__ == '__main__':
run=chromedriver()
run.null_search()
5. 结果截图
excel抓取网页动态数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-30 03:23
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页动态数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抢外汇报价的第一页。其实,抓取多页数据也是可以的。后面介绍M函数后,我会专门写一篇文章。
以后无需手动从网页中复制数据并将其粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-27 15:03
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,在浏览器中渲染数据,在右键->查看网页源码中也看不到ajax加载的数据,只能看到使用this加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装
Selenium
:
Selenium
有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id
: 根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name
: 根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name
:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name
:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath
: 根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
得到所有
cookie
:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个
cookie
:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用ajax加载的数据,即使使用js,在浏览器中渲染数据,在右键->查看网页源码中也看不到ajax加载的数据,只能看到使用this加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装
Selenium
:
Selenium
有多种语言版本,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面以获取百度首页的简单例子来谈谈如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id
: 根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name
: 根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name
:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name
:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath
: 根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时,selenium 专门为select 标签提供了一个类selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
得到所有
cookie
:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个
cookie
:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
excel抓取网页动态数据(STM32网页分框架(): )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-22 07:02
)
如何抓取动态网页生成的数据?这个动态的asp网页是分帧的,点击左边网页的链接比如javascript:top.market.Openmarket(185)会在右边的frame中显示数据
如何获取这些数据?
Email:非常感谢!!--------------------编程问答----------------- -- -javascript:top.market.document.InnerHTML------------编程问答-------------- ---- --usingmshtml;
///
///在 Web 浏览器控件的顶级文档中返回对框架窗口的引用,并带有指定索引
///
///
指定框架窗口索引的基于零的索引
[CLSCompliant(false)]
publicIHTMLWindow2GetFrameByIndex(intframeIndex)
{
IHTMLDocument2htmlDocument=(IHTMLDocument2)this.Document.DomDocument;
returnGetFrameByIndex(frameIndex,htmlDocument);
}
///
///ReturnsareferencetotheframewindowwithangivenindexinanHTMLdocument
///
///
指定框架窗口索引的基于零的索引
///
要搜索的 HTML 文档
[CLSCompliant(false),ComVisible(false)]
staticpublicIHTMLWindow2GetFrameByIndex(intframeIndex,IHTMLDocument2htmlDocument)
{
if(htmlDocument==null)
returnnull;
objectoIndex=frameIndex;
objectoFrame=htmlDocument.frames.item(refoIndex);
if(oFrame==null)returnnull;
返回(IHTMLWindow2)oFrame;
}--------------------编程问答--------------------点击这个javascript: top.market.Openmarket(185)会去链接……/…….asp?185,然后这个数据怎么抓取保存呢?还有180165号不固定,每更新一次天,我怎么能每天自动分析这个数字,然后抓取这些页面上的数据并保存?--------------------编程问答---------- ----------up------------编程问答------- ---------- ---我一直在用HttpWebRequest--------------------编程问答--------- ----------II 也用这个,但是对于这个网站 好像不能单独用httpwebrequest 检索数据---------------- ----编程问答--------- -------------阅读C#中的javascript代码并重写函数。------------编程Q&A ------------ --------functionDisplaynums(numsSource,VolumeSource){
varnums=document.getElementsByName('nums');
varVolume=document.getElementsByName('Volume');
if(numsSource.length==nums.length){
for(i=0;i
if(numsSource[i]=='0'){
nums[i].innerHTML='';//! ! !这里的 nums[i] 是我想要获取的数据
Volume[i].innerHTML='';}
其他{
/*
//更改市场颜色
if(nums[i].innerHTML!=``&&Volume[i].innerHTML!=''&&(nums[i].innerHTML!=numsSource[i]||Volume[i].innerHTML!=VolumeSource [i])){
nums[i].style.color='#FFFFFF';
音量[i].style.color='#FFFFFF';
}
*/
nums[i].innerHTML=numsSource[i];
Volume[i].innerHTML=VolumeSource[i];
}
}
}
其他{
window.location.reload();
}
}
我读了这段代码。我想获取 nums[i] 的数据。我如何获得这些数据?非常感谢兄弟~! --------------------编程问答 --------------------以上是错误的,应该是numsSource [i] 是我需要的数据。 --------------------编程问答--------------------江城高手请帮忙,如何?在client端调用server端的java函数,实在想不出办法-------------------- 编程问答---- ------- -------调用相同的DOM方法
HtmlWindowPopupOptionWindow()
{
IHTMLAnchorElementae=extendedWebBrowser1.GetLinkByHref("popupEligiNewRT");
if(ae!=null)
{
Debug.WriteLine(ae.href);
//javascript:popupEligiNewRT('DIANA%20JOHN%20W',%20'SUB','form0')
//functionpopupEligiNewRT(name,opt,form){
//varstr="eligipopup.jsp?&name="+name+"&opt="+opt+"&form="+form;
//window.open(str,'popupeligiwin','width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no');
//}
stringhref=ae.href;
href=href.Substring(
href.IndexOf("("));
Stringdelim="()";
href=href.Trim(delim.ToCharArray());
string[]parameters=href.Split(",".ToCharArray());
delim="'";
stringname=parameters[0].Trim(delim.ToCharArray());
stringopt=parameters[1].Trim(delim.ToCharArray());
stringform=parameters[2].Trim(delim.ToCharArray());
stringPopupURL=string.Format("{0}&opt={1}&form={2}",name,opt,form);
returnextendedWebBrowser1.Document.Window.Open(PopupURL,"autopopupeligiwin","width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no" ,假);
}
returnnull;
}
补充:.NET技术 , C# 查看全部
excel抓取网页动态数据(STM32网页分框架():
)
如何抓取动态网页生成的数据?这个动态的asp网页是分帧的,点击左边网页的链接比如javascript:top.market.Openmarket(185)会在右边的frame中显示数据
如何获取这些数据?
Email:非常感谢!!--------------------编程问答----------------- -- -javascript:top.market.document.InnerHTML------------编程问答-------------- ---- --usingmshtml;
///
///在 Web 浏览器控件的顶级文档中返回对框架窗口的引用,并带有指定索引
///
///
指定框架窗口索引的基于零的索引
[CLSCompliant(false)]
publicIHTMLWindow2GetFrameByIndex(intframeIndex)
{
IHTMLDocument2htmlDocument=(IHTMLDocument2)this.Document.DomDocument;
returnGetFrameByIndex(frameIndex,htmlDocument);
}
///
///ReturnsareferencetotheframewindowwithangivenindexinanHTMLdocument
///
///
指定框架窗口索引的基于零的索引
///
要搜索的 HTML 文档
[CLSCompliant(false),ComVisible(false)]
staticpublicIHTMLWindow2GetFrameByIndex(intframeIndex,IHTMLDocument2htmlDocument)
{
if(htmlDocument==null)
returnnull;
objectoIndex=frameIndex;
objectoFrame=htmlDocument.frames.item(refoIndex);
if(oFrame==null)returnnull;
返回(IHTMLWindow2)oFrame;
}--------------------编程问答--------------------点击这个javascript: top.market.Openmarket(185)会去链接……/…….asp?185,然后这个数据怎么抓取保存呢?还有180165号不固定,每更新一次天,我怎么能每天自动分析这个数字,然后抓取这些页面上的数据并保存?--------------------编程问答---------- ----------up------------编程问答------- ---------- ---我一直在用HttpWebRequest--------------------编程问答--------- ----------II 也用这个,但是对于这个网站 好像不能单独用httpwebrequest 检索数据---------------- ----编程问答--------- -------------阅读C#中的javascript代码并重写函数。------------编程Q&A ------------ --------functionDisplaynums(numsSource,VolumeSource){
varnums=document.getElementsByName('nums');
varVolume=document.getElementsByName('Volume');
if(numsSource.length==nums.length){
for(i=0;i
if(numsSource[i]=='0'){
nums[i].innerHTML='';//! ! !这里的 nums[i] 是我想要获取的数据
Volume[i].innerHTML='';}
其他{
/*
//更改市场颜色
if(nums[i].innerHTML!=``&&Volume[i].innerHTML!=''&&(nums[i].innerHTML!=numsSource[i]||Volume[i].innerHTML!=VolumeSource [i])){
nums[i].style.color='#FFFFFF';
音量[i].style.color='#FFFFFF';
}
*/
nums[i].innerHTML=numsSource[i];
Volume[i].innerHTML=VolumeSource[i];
}
}
}
其他{
window.location.reload();
}
}
我读了这段代码。我想获取 nums[i] 的数据。我如何获得这些数据?非常感谢兄弟~! --------------------编程问答 --------------------以上是错误的,应该是numsSource [i] 是我需要的数据。 --------------------编程问答--------------------江城高手请帮忙,如何?在client端调用server端的java函数,实在想不出办法-------------------- 编程问答---- ------- -------调用相同的DOM方法
HtmlWindowPopupOptionWindow()
{
IHTMLAnchorElementae=extendedWebBrowser1.GetLinkByHref("popupEligiNewRT");
if(ae!=null)
{
Debug.WriteLine(ae.href);
//javascript:popupEligiNewRT('DIANA%20JOHN%20W',%20'SUB','form0')
//functionpopupEligiNewRT(name,opt,form){
//varstr="eligipopup.jsp?&name="+name+"&opt="+opt+"&form="+form;
//window.open(str,'popupeligiwin','width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no');
//}
stringhref=ae.href;
href=href.Substring(
href.IndexOf("("));
Stringdelim="()";
href=href.Trim(delim.ToCharArray());
string[]parameters=href.Split(",".ToCharArray());
delim="'";
stringname=parameters[0].Trim(delim.ToCharArray());
stringopt=parameters[1].Trim(delim.ToCharArray());
stringform=parameters[2].Trim(delim.ToCharArray());
stringPopupURL=string.Format("{0}&opt={1}&form={2}",name,opt,form);
returnextendedWebBrowser1.Document.Window.Open(PopupURL,"autopopupeligiwin","width=600,height=375,left=250,top=100,menubar=yes,status=yes,toolbar=no" ,假);
}
returnnull;
}
补充:.NET技术 , C#

