
excel抓取网页动态数据
excel抓取网页动态数据(每页PowerBIDesktop中用自动播放自动播放自动播放 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-20 21:12
)
喜欢笑话的朋友们,可以把笑话拿来保存成TXT格式,放到电子书里,闲暇时读一读。网上搜了一下,这个网站不错,干净,没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取所有文章网址:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
查看全部
excel抓取网页动态数据(每页PowerBIDesktop中用自动播放自动播放自动播放
)
喜欢笑话的朋友们,可以把笑话拿来保存成TXT格式,放到电子书里,闲暇时读一读。网上搜了一下,这个网站不错,干净,没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取所有文章网址:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
excel抓取网页动态数据(如何用Excel来制作径向树图[1]的文章?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2022-04-20 17:32
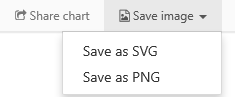
大家好,最近看了一篇文章文章,介绍了如何使用Excel制作径向树图[1],在里面学到了一个有趣的Excel插件。
您可能知道 D3.js,它是目前最流行的可视化库之一。而小编要给大家介绍这款实用又免费的Excel插件——E2D3,你可以在Excel中轻松实现各种D3优质图表!
【注】完整版教程、代码、技术交流,文末获取
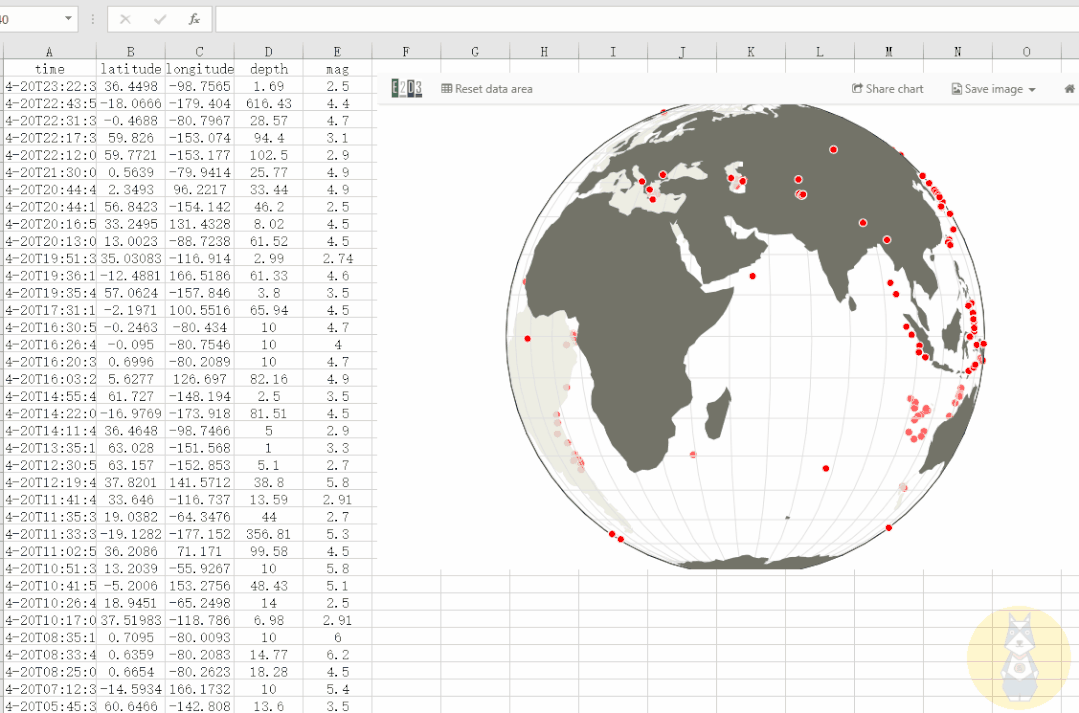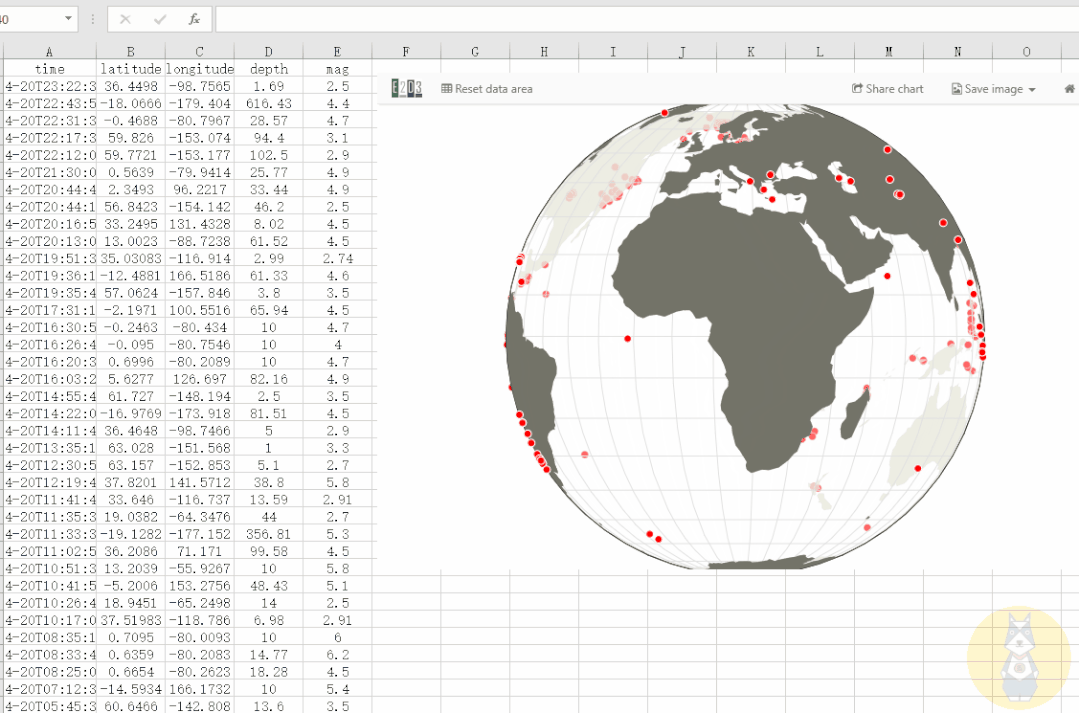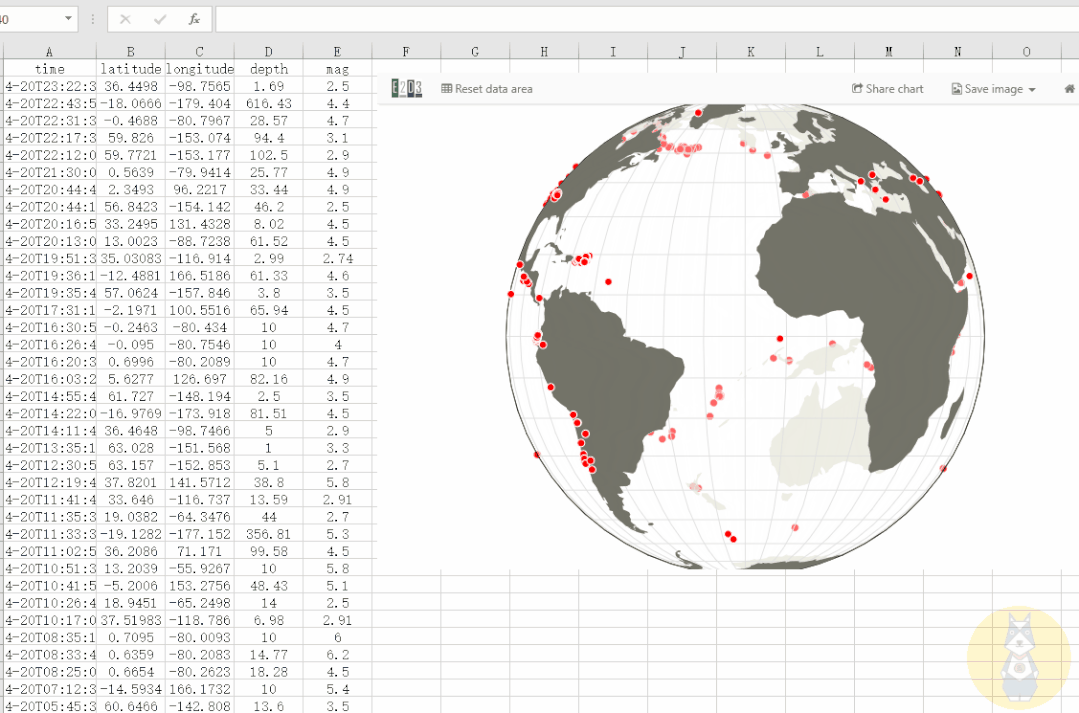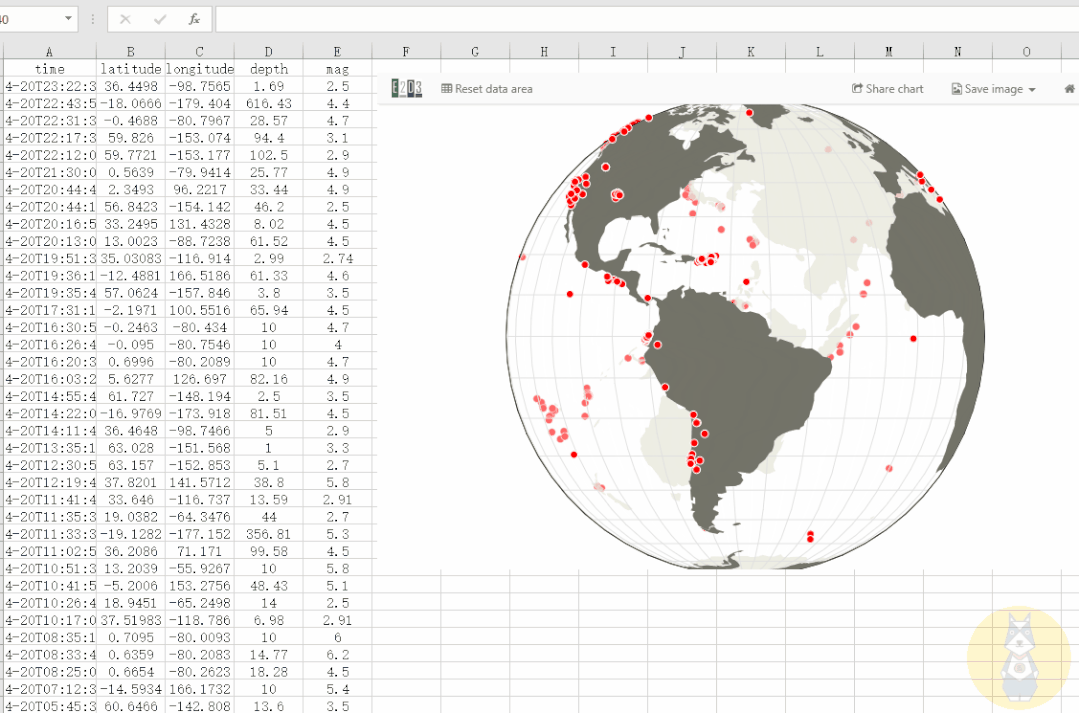
3D动态地图
通过经纬度等数据,我们可以在三维地图中显示事件信息。
使用 E2D3 我们可以轻松制作这个 3D 动态地图,并且可以更改数据以满足我们自己的制图需求!
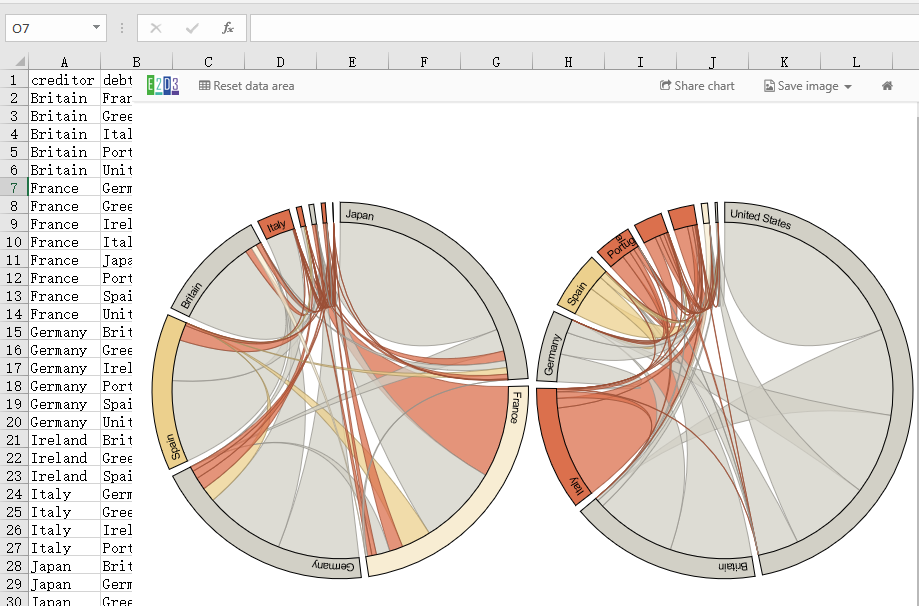
两个和弦图
下图是D3的原图——欧债危机,这里通过插件很容易复制。
左图突出显示了每个国家的贷款金额(债权人):您可以看到日本和法国是最大的贷方,但法国也最容易受到意大利和希腊的高风险债务的影响。
右图突出显示了每个国家的债务(债务人)数量:美国是迄今为止最大的债务国,几乎是第二大债务国英国的三倍。
自我改变的动画
用于显示跨周期自我改变的动态效果
转换动画
用于展示跨期跨品类转换的动态效果
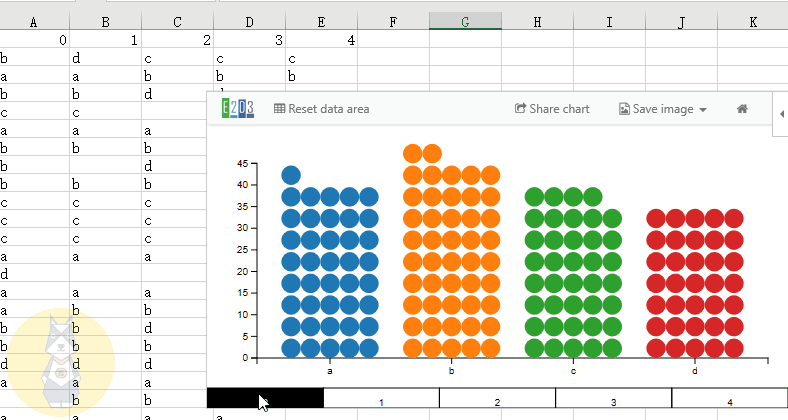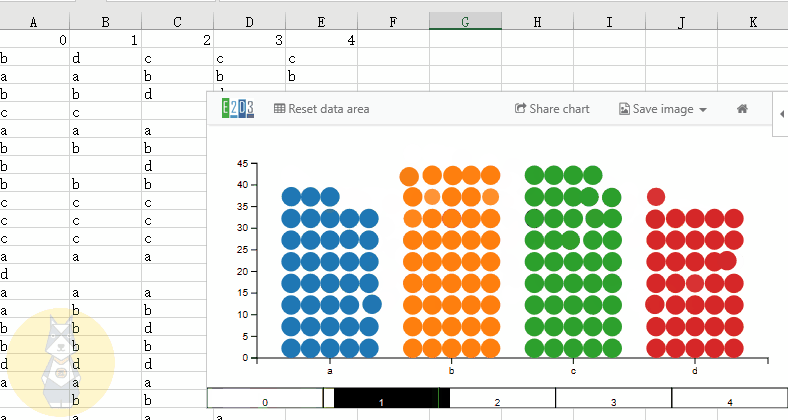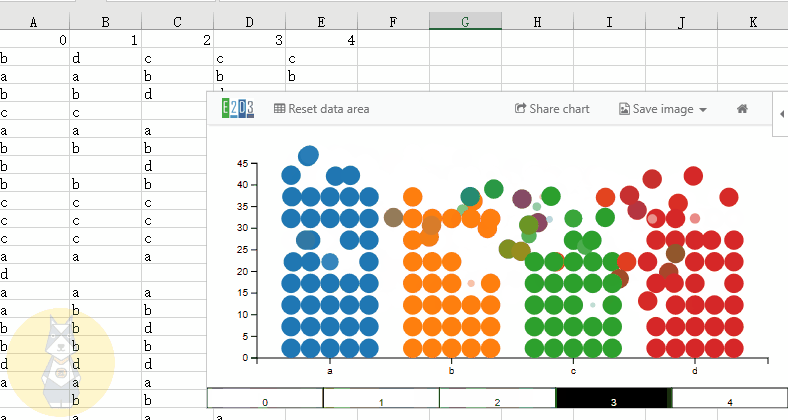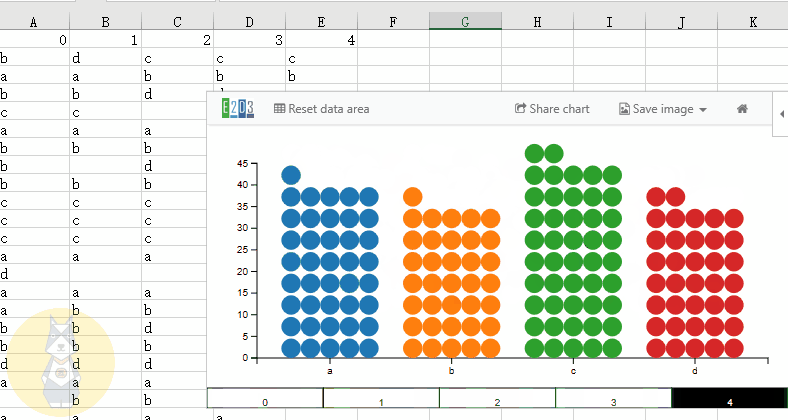
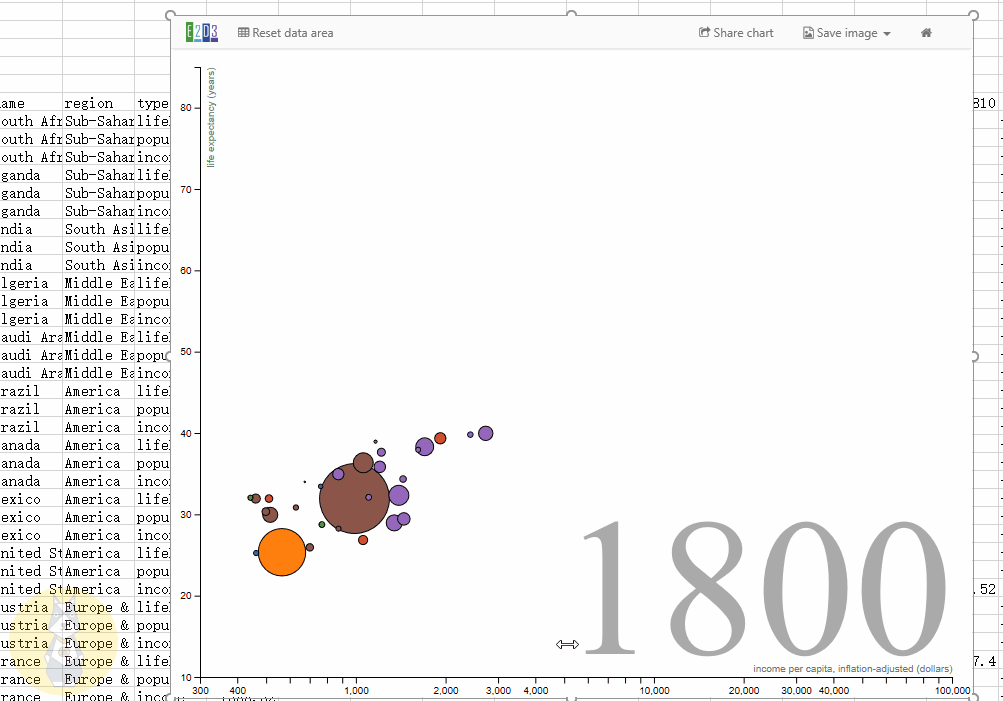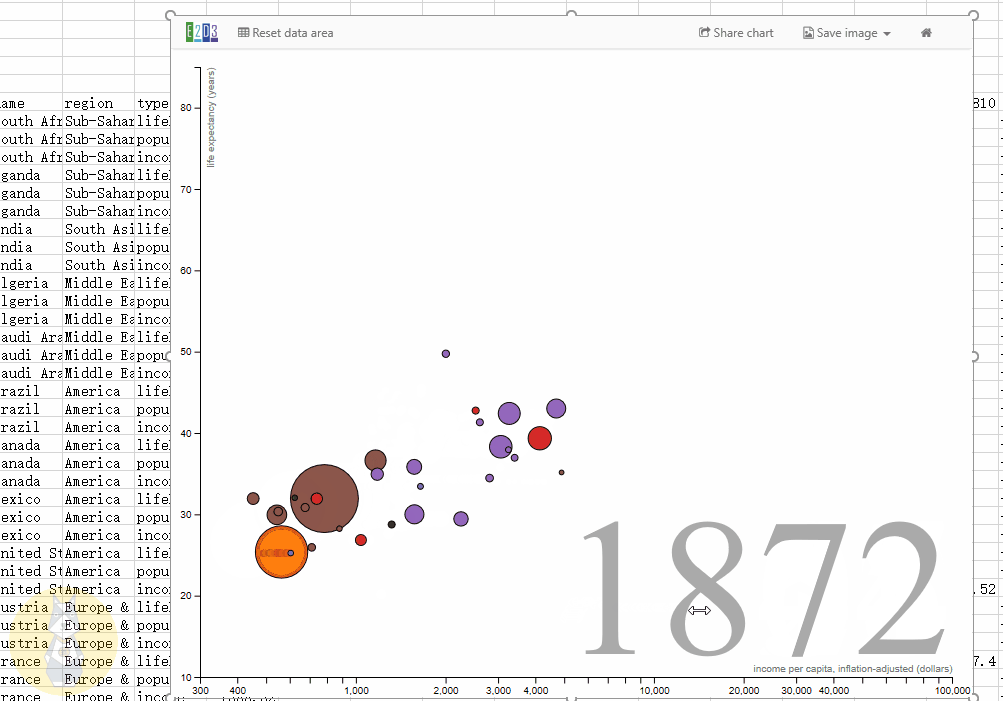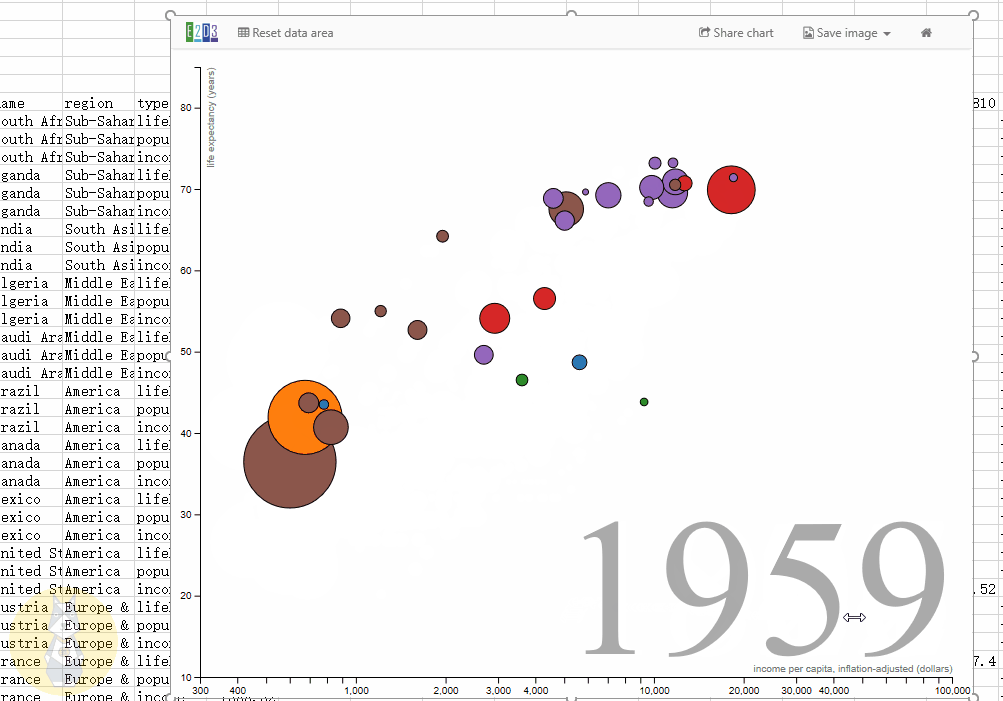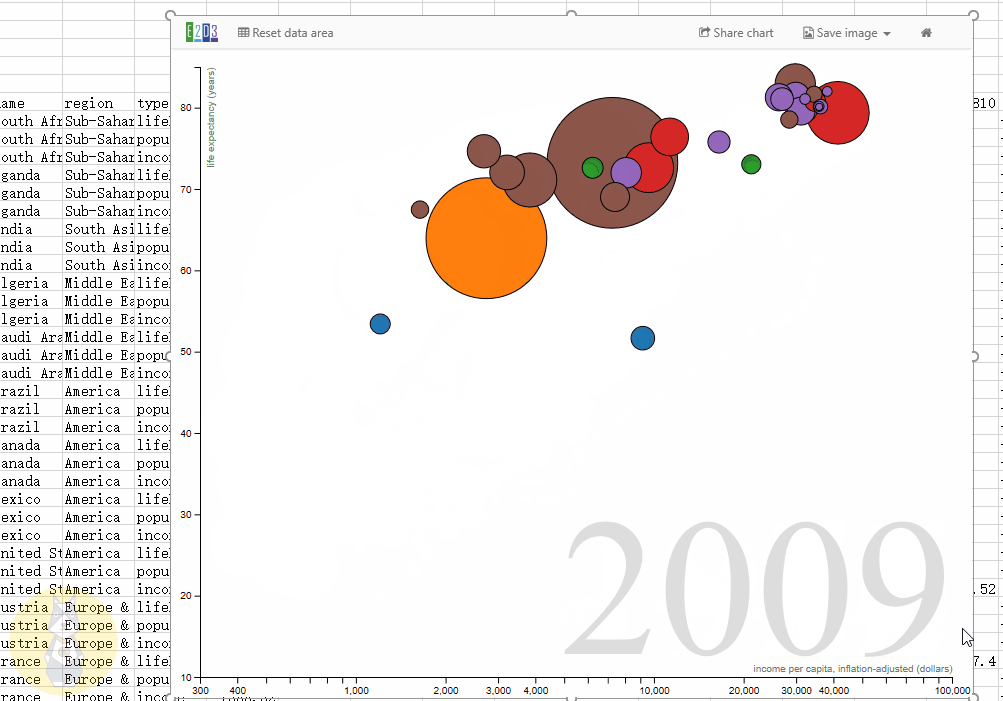
动态气泡图
具有大小、颜色、时间滑块等属性的动态气泡图,主要用于表示随时间变化的趋势。
以上五个示例为 Excel 中的可视化开辟了新思路(无需借助 Power BI 等工具)。
其实插件可以创建的图形远不止这些,剩下的就看你自己练习了。
接下来主要介绍如何在Excel中调用E2D3插件。
第一步如何实现
我们需要在开发者工具窗口中选择插件 E2D3。
如果你的Excel没有开发工具,你必须先添加,如果你已经有,跳过这一步。
依次选择:【文件】【选项】【自定义功能区】,在【开发工具】前面打勾并确认,具体操作如下图所示。
第二步
在开发者工具窗口中选择插件
选择:[开发者工具]或[插入][插件][搜索插件]查找并添加它们
搜索插件E2D3并点击添加后,完成后即可在我的插件中看到新插件E2D3。
点击插件查看许多新的图表类型。
我们会在图表分类区看到更多的选择,比如:统计图表、地理图表、路径图表等等。
第 3 步
单击任何图表以将模板和示例数据添加到 Excel。
就这么简单,以后可以根据需要更改数据。
输出图像
E2D3 还为我们制作的图表提供了导出功能。
导出功能之一是直接下载SVG或PNG格式的图片;另一个可以直接分享网址,点击分享后会弹出一个对话框,提供分享的链接和嵌入的HTML代码。
以下链接为共享链接示例,可打开网页实现交互。
您有时间自己尝试一下! 查看全部
excel抓取网页动态数据(如何用Excel来制作径向树图[1]的文章?)
大家好,最近看了一篇文章文章,介绍了如何使用Excel制作径向树图[1],在里面学到了一个有趣的Excel插件。
您可能知道 D3.js,它是目前最流行的可视化库之一。而小编要给大家介绍这款实用又免费的Excel插件——E2D3,你可以在Excel中轻松实现各种D3优质图表!
【注】完整版教程、代码、技术交流,文末获取
3D动态地图
通过经纬度等数据,我们可以在三维地图中显示事件信息。
使用 E2D3 我们可以轻松制作这个 3D 动态地图,并且可以更改数据以满足我们自己的制图需求!
两个和弦图
下图是D3的原图——欧债危机,这里通过插件很容易复制。
左图突出显示了每个国家的贷款金额(债权人):您可以看到日本和法国是最大的贷方,但法国也最容易受到意大利和希腊的高风险债务的影响。
右图突出显示了每个国家的债务(债务人)数量:美国是迄今为止最大的债务国,几乎是第二大债务国英国的三倍。
自我改变的动画
用于显示跨周期自我改变的动态效果
转换动画
用于展示跨期跨品类转换的动态效果
动态气泡图
具有大小、颜色、时间滑块等属性的动态气泡图,主要用于表示随时间变化的趋势。
以上五个示例为 Excel 中的可视化开辟了新思路(无需借助 Power BI 等工具)。
其实插件可以创建的图形远不止这些,剩下的就看你自己练习了。
接下来主要介绍如何在Excel中调用E2D3插件。
第一步如何实现
我们需要在开发者工具窗口中选择插件 E2D3。
如果你的Excel没有开发工具,你必须先添加,如果你已经有,跳过这一步。
依次选择:【文件】【选项】【自定义功能区】,在【开发工具】前面打勾并确认,具体操作如下图所示。
第二步
在开发者工具窗口中选择插件
选择:[开发者工具]或[插入][插件][搜索插件]查找并添加它们
搜索插件E2D3并点击添加后,完成后即可在我的插件中看到新插件E2D3。
点击插件查看许多新的图表类型。
我们会在图表分类区看到更多的选择,比如:统计图表、地理图表、路径图表等等。
第 3 步
单击任何图表以将模板和示例数据添加到 Excel。
就这么简单,以后可以根据需要更改数据。
输出图像
E2D3 还为我们制作的图表提供了导出功能。
导出功能之一是直接下载SVG或PNG格式的图片;另一个可以直接分享网址,点击分享后会弹出一个对话框,提供分享的链接和嵌入的HTML代码。
以下链接为共享链接示例,可打开网页实现交互。
您有时间自己尝试一下!
excel抓取网页动态数据(1.数组的运用数组就是单元的集合处理的值集合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-18 04:14
1.数组的使用
数组是单元格的集合或一组处理后的值。您可以编写一个将数组作为参数的公式,一个数组公式,并使用该单个公式接受多个输入并产生多个结果——每个结果都显示在一个单元格中。两个数组的最大行数和最大列数就是结果的行数和列数。
数组表示:使用花括号 {} 表示数组。如{10,20,30;40,50,60}。其中,30后面是一个分号;,表示40即将换行。数组的元素由逗号和分号分隔。两者的意思一定要明白。分号分隔表示数组的行分隔。
数组公式可以被认为是 Excel 对公式和数组的扩展。换句话说,它是使用数组作为参数时 Excel 公式的应用。数组公式可以被认为是具有多个值的公式。它与单值公式的不同之处在于它可以产生多个结果。数组公式可以占用一个或多个单元格。数组最多可以有 6500 个元素
Excel 中的数组公式非常有用,尤其是当您无法使用工作表函数直接获取结果时。数组公式可用于创建产生多个值或对一组值而不是单个值进行操作的公式。
数组公式的特点是引用的参数是数组参数,包括面积数组和常数数组。执行多次计算,返回一组数据结果。详细:数组公式的参数是一个数组,即输入有多个值;输出结果可能是一个或多个——这一个或多个值是公式对中多个输入元素的复合运算得到的一个新数组。
1.1一维数组
简单的一维数组分为水平数组和垂直数组。我们来看一下水平一维数组的例子。将四个连续的水平单元格E3:G3转换成数组,先选中区域,按Ctrl+Shift+Enter,公式变为{=E3:G3},查看数组内容,公式中按F9,如如下图所示;(垂直数组也是如此)
由上可知,数组外侧用{}包围,水平数组内侧用逗号分隔,如步骤1中的数组{1,2,3,4},内侧垂直数组的 用分号分隔,如第 2 步中的第一步 Array {1;2;3;4};分号分隔表示数组的行分隔,逗号分隔表示数组的列分隔。
1.二维数组
构建一个3行3列的二维数组,第一行是1,4,7,第二行是2,5,8,第三行是3,6,9,数组表示是{1, 4,7;2,5,8;3,6,9},见下图;
1.3 数组的计算
数组相乘,如图,D3:D6和E3:E6分别代表两组数组。将它们相乘并将它们放入 F3:F6。先选择F3:F6,在D3:D6*E3:E6中输入公式,按Ctrl+Shift+Enter,查看具体数值,按F9,见下图;
计算一维数组中大于0的数字之和,可以使用公式=sum(array*(array>0)),见下图;
多维数组的计算和应用与单元格的函数应用基本相同,单元格使用的函数也可以应用于数组的计算。多维数组的加减乘除运算及其公式可以概括为数组之间的运算。遵循以下顺序:
1、 根据数组的行数和列数确定运算结果的行数和列数;
2、参与操作的数组扩展区;
3、 填充数据;
4、运行。
甚至多个数组之间的操作也遵循上述规则。
数组的优点是计算方便,可以在不使用辅助列和辅助行的情况下进行非常复杂的计算。缺点是数据操作量大,所有的操作过程都放到内存中进行操作。如果有大量的数组公式运算,计算机会运行缓慢。
由于数组公式中参数较多,所以在复杂公式中设置错误时,比一般公式更难排错!
2.动态图表
在数据信息可视化时代,Excel作为基本的办公工具,也是最适合初学者学习的数据可视化操作软件。学习Excel的图表动态,可以让我们更快、更方便地制作动态图表;
制作动态图表的方法有很多。我们可以根据不同的情况选择不同的方法来制作动态图表。通过简单的动态图表,我们可以慢慢完成更复杂、多维度的动态图表的制作。每种方法都有其优点和特点,下面我将介绍四种制作动态图表的方法;
2.1数据透视图法
与数据透视表一样,数据透视图适用于大型且格式良好的数据源。数据透视图具有灵活的转换布局以及排序和过滤功能。使用 Pivot 的切片器功能直观地在选项之间切换。
对于参数和数据量大的多维数据,我们做多维驾驶舱,分别为每个维度制作动态图表。通过使用切片器的关联功能,我们可以实现一个切片。控制器可控制多个动态表,可实现动态座舱功能。
以下是数据透视图方法的步骤:
(1)插入数据图表,选择数据,插入数据透视图。
(2)根据需要将透视图的字段拖放到相应的框中。
(3)插入一个切片器并选择过滤和排序的标准。
(4)修改外观。
2.2 名称管理器方法;(1)制作下拉列表。
(2)批量创建名称。
(3)名称管理器。
(4)使用 INDIRECT 函数。
(5)制作图表,美化它们。
2.3 函数公式法-vlookup。
函数公式的核心功能之一是通过使用辅助列来完成动态表的创建。我们可以根据自己的需要选择里面的控件,最后美化动态表格。
不同的公式需要不同的辅助列,针对不同的情况做出不同的选择。
(1)构建辅助列。
(2)插入图表
(3)美化餐桌
3.POWER BI
3.1什么是Power BI?
使用统一的一、可扩展平台连接和可视化任何数据,用于自助服务和企业商业智能 (BI),该平台易于使用并有助于获得更深入的数据洞察力。弥合数据和决策之间的差距
(1)创造惊人的数据体验
轻松连接、建模和可视化数据,以创建具有 KPI 和品牌个性化的令人印象深刻的报告。快速获得由 AI 驱动的业务问题答案,即使是用对话语言询问也是如此。
(2)通过最广泛的 BI 部署获得洞察力
通过连接到所有数据源来利用您的大数据投资,在整个组织内分析、共享和优化洞察力,同时保持数据的准确性、一致性和安全性。
(3)自信地做决定
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
3.2 Power BI 系列组件
下面简单介绍一下power BI的三个组成部分
1.电源查询
功能:获取文件、文件夹、数据库、网页等数据并进行各种处理。如果只需要对原创数据进行处理以满足使用需求,可以直接在 Excel 中使用 Power Query。
数据获取:从不同来源、不同结构、不同形式获取数据,并以统一的格式进行横向合并、纵向(追加)合并、条件合并等。
数据转换:将原创数据转换为所需的结构或格式。
数据处理:对后续分析进行数据预处理,如添加新列、新行、处理某些单元格值等。
首先,有一点:PowerQuery存在于查询的主题上。任何不基于此主题的东西都不适合与其他技术进行比较。
如果你已经是一个可以轻松玩VBA的“EXCEL高手”,这个工具将是替代大量编码时间的绝佳补充,而如果你花时间学习M语言(PowerQuery内置编程语言),它将打开一扇新的大门。
如果您是 Excel 初学者,需要将数据导入 Excel 并苦苦思索该怎么做,那么 PowerQuery 是您的最佳选择,没有之一。
如果您经常使用 Excel 对数据进行统计汇总,那么您已经一只脚踏进了【自助大数据分析】的大门。借助正确的工具和良好的理论,您还可以分析数百万甚至数亿数据。PowerQuery 是必备工具。
学习PowerQuery到底有多难(两张图告诉你)
2.电源枢轴
功能:分析建模。如果原创数据非常规整,只需要建立模型/分析系统,可以直接在Excel中使用Power Pivot;如果你有数据处理需求和建模,你可以在 Excel 中同时使用 PQ 和 PP。
PowerPivot 本质上是一个数据管理和报告系统,虽然它看起来几乎与传统的 Excel 数据透视表相同,但它有一些特别值得注意的功能。
首先,传统Excel数据透视表的原创设计仅用于分析数据源为一张表的数据,但随着数据源的多样化,传统的Excel数据透视表在多表关联分析方面越来越薄弱。PowerPivot 可以从各种类型的数据源中捕获数据,并可以通过数据建模能力将来自各种数据源的数据表关联起来。
其次,PowerPivot 可以使数据分析过程更加紧凑和流畅。PowerPivot 的多表关联能力和强大的 DAX 数据分析表达功能可以让整个数据分析过程变得自然。在 PowerPivot 中,我们只需要为必须借助传统数据透视表以外的功能完成的分析工作建立一个数据分析模型。当数据源中的数据发生变化时,我们只需要刷新 PowerPivot 即可获得最新的数据报表。
第三,PowerPivot的可用性,几乎每个Excel用户都可以使用PowerPivot环境,只要下定决心学习,就可以学习。这样,普通 Excel 用户就可以在昂贵的专用软硬件支持的环境中做只有 IT 人员才能做的事情。
第四,PowerPivot成本低,PowerPivot是商业智能工具。我们知道目前商业智能是比较高级的。如果企业部署专业的商业智能解决方案,成本还是很高的。但 PowerPivot 为我们提供了应用商业智能的低成本机会。它使我们有机会在短时间内以低成本实施原本昂贵的商业智能解决方案,从而明显提高部门级生产力。
五、可移植性,据说PowerPivot是微软SQL Server团队打造的,虽然嵌入在Excel中,但依然是SQL Server的血液。我们使用 PowerPivot 构建的数据模型可以轻松移植到 SQL Server Analysis Services 表格服务。因此,当您构建了一个值得推广和保留的经过验证的小规模成功解决方案时,您可以轻松升级到更稳定可靠的专业数据库,而无需重新发明轮子。
3.Power BI 桌面
功能:集成Power Query和Power Pivot的功能,对数据进行动态图表展示和智能分析。如果你需要更好的图表显示,Power BI desktop 很好;如果您需要构建复杂的报表系统并需要图表显示,请使用 Power BI Desktop。
连接所有数据,无论其位于何处
从数百个受支持的本地和基于云的源访问数据,例如 Dynamics 365、Salesforce、Azure SQL DB、Excel 和 SharePoint。通过自动增量刷新确保它始终是最新的。借助 Power BI Desktop,可以针对各种场景开发可操作的深刻见解
轻松准备数据和模型
使用数据建模工具节省时间,同时简化数据准备。通过数百万 Excel 用户熟悉的自助式 Power Query 体验节省更多时间。在 Power BI 中摄取、转换、集成和丰富数据。
使用 Office 熟悉度提供高级分析
深入挖掘您的数据,找出您可能忽略的模式,从而发现可操作的见解。使用快速测量、分组、预测和聚类等功能。使用强大的 DAX 公式语言让高级用户完全控制他们的模型。如果你熟悉 Office,Power BI 很容易使用。
通过 AI 驱动的增强分析加深数据洞察力
了解您的数据、自动查找模式、了解数据的性质并预测未来结果以推动业务成果。新的 AI 功能(最初在 Azure 中引入,现在在 Power BI 中可用)不需要代码,使所有 Power BI 用户能够发现隐藏的、可操作的见解,从而推动更具战略性的业务成果。
创建为您的业务量身定制的交互式报告
使用交互式数据可视化创建令人惊叹的报告。使用拖放式画布和来自 Microsoft 和合作伙伴的数百个现代数据视觉对象讲述您的数据故事(或使用 Power BI 开源自定义视觉框架创建您自己的)。使用主题、格式和布局工具设计报告。
任何人都可以随时随地创作
为需要的用户提供可视化分析。创建移动优化报告供查看者随时随地查看。从 Power BI Desktop 发布到云或本地。将在 Power BI Desktop 中创建的报表嵌入现有应用或 网站。
3.3产品
感谢收看 查看全部
excel抓取网页动态数据(1.数组的运用数组就是单元的集合处理的值集合)
1.数组的使用
数组是单元格的集合或一组处理后的值。您可以编写一个将数组作为参数的公式,一个数组公式,并使用该单个公式接受多个输入并产生多个结果——每个结果都显示在一个单元格中。两个数组的最大行数和最大列数就是结果的行数和列数。
数组表示:使用花括号 {} 表示数组。如{10,20,30;40,50,60}。其中,30后面是一个分号;,表示40即将换行。数组的元素由逗号和分号分隔。两者的意思一定要明白。分号分隔表示数组的行分隔。
数组公式可以被认为是 Excel 对公式和数组的扩展。换句话说,它是使用数组作为参数时 Excel 公式的应用。数组公式可以被认为是具有多个值的公式。它与单值公式的不同之处在于它可以产生多个结果。数组公式可以占用一个或多个单元格。数组最多可以有 6500 个元素
Excel 中的数组公式非常有用,尤其是当您无法使用工作表函数直接获取结果时。数组公式可用于创建产生多个值或对一组值而不是单个值进行操作的公式。
数组公式的特点是引用的参数是数组参数,包括面积数组和常数数组。执行多次计算,返回一组数据结果。详细:数组公式的参数是一个数组,即输入有多个值;输出结果可能是一个或多个——这一个或多个值是公式对中多个输入元素的复合运算得到的一个新数组。
1.1一维数组
简单的一维数组分为水平数组和垂直数组。我们来看一下水平一维数组的例子。将四个连续的水平单元格E3:G3转换成数组,先选中区域,按Ctrl+Shift+Enter,公式变为{=E3:G3},查看数组内容,公式中按F9,如如下图所示;(垂直数组也是如此)


由上可知,数组外侧用{}包围,水平数组内侧用逗号分隔,如步骤1中的数组{1,2,3,4},内侧垂直数组的 用分号分隔,如第 2 步中的第一步 Array {1;2;3;4};分号分隔表示数组的行分隔,逗号分隔表示数组的列分隔。
1.二维数组
构建一个3行3列的二维数组,第一行是1,4,7,第二行是2,5,8,第三行是3,6,9,数组表示是{1, 4,7;2,5,8;3,6,9},见下图;

1.3 数组的计算
数组相乘,如图,D3:D6和E3:E6分别代表两组数组。将它们相乘并将它们放入 F3:F6。先选择F3:F6,在D3:D6*E3:E6中输入公式,按Ctrl+Shift+Enter,查看具体数值,按F9,见下图;

计算一维数组中大于0的数字之和,可以使用公式=sum(array*(array>0)),见下图;

多维数组的计算和应用与单元格的函数应用基本相同,单元格使用的函数也可以应用于数组的计算。多维数组的加减乘除运算及其公式可以概括为数组之间的运算。遵循以下顺序:
1、 根据数组的行数和列数确定运算结果的行数和列数;
2、参与操作的数组扩展区;
3、 填充数据;
4、运行。
甚至多个数组之间的操作也遵循上述规则。

数组的优点是计算方便,可以在不使用辅助列和辅助行的情况下进行非常复杂的计算。缺点是数据操作量大,所有的操作过程都放到内存中进行操作。如果有大量的数组公式运算,计算机会运行缓慢。
由于数组公式中参数较多,所以在复杂公式中设置错误时,比一般公式更难排错!
2.动态图表
在数据信息可视化时代,Excel作为基本的办公工具,也是最适合初学者学习的数据可视化操作软件。学习Excel的图表动态,可以让我们更快、更方便地制作动态图表;
制作动态图表的方法有很多。我们可以根据不同的情况选择不同的方法来制作动态图表。通过简单的动态图表,我们可以慢慢完成更复杂、多维度的动态图表的制作。每种方法都有其优点和特点,下面我将介绍四种制作动态图表的方法;
2.1数据透视图法
与数据透视表一样,数据透视图适用于大型且格式良好的数据源。数据透视图具有灵活的转换布局以及排序和过滤功能。使用 Pivot 的切片器功能直观地在选项之间切换。
对于参数和数据量大的多维数据,我们做多维驾驶舱,分别为每个维度制作动态图表。通过使用切片器的关联功能,我们可以实现一个切片。控制器可控制多个动态表,可实现动态座舱功能。
以下是数据透视图方法的步骤:
(1)插入数据图表,选择数据,插入数据透视图。

(2)根据需要将透视图的字段拖放到相应的框中。
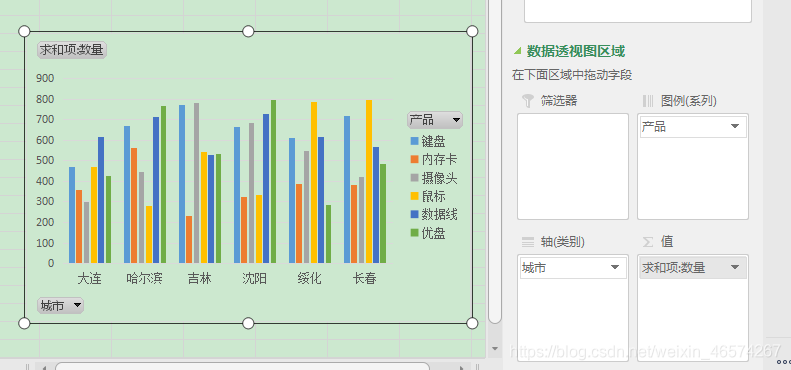
(3)插入一个切片器并选择过滤和排序的标准。
(4)修改外观。
2.2 名称管理器方法;(1)制作下拉列表。
(2)批量创建名称。

(3)名称管理器。
(4)使用 INDIRECT 函数。

(5)制作图表,美化它们。
2.3 函数公式法-vlookup。
函数公式的核心功能之一是通过使用辅助列来完成动态表的创建。我们可以根据自己的需要选择里面的控件,最后美化动态表格。
不同的公式需要不同的辅助列,针对不同的情况做出不同的选择。
(1)构建辅助列。
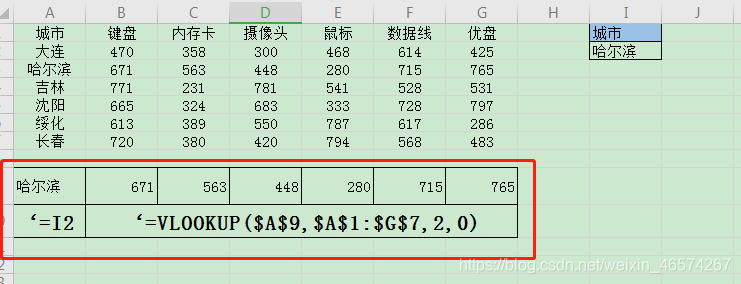
(2)插入图表

(3)美化餐桌

3.POWER BI

3.1什么是Power BI?
使用统一的一、可扩展平台连接和可视化任何数据,用于自助服务和企业商业智能 (BI),该平台易于使用并有助于获得更深入的数据洞察力。弥合数据和决策之间的差距
(1)创造惊人的数据体验
轻松连接、建模和可视化数据,以创建具有 KPI 和品牌个性化的令人印象深刻的报告。快速获得由 AI 驱动的业务问题答案,即使是用对话语言询问也是如此。
(2)通过最广泛的 BI 部署获得洞察力
通过连接到所有数据源来利用您的大数据投资,在整个组织内分析、共享和优化洞察力,同时保持数据的准确性、一致性和安全性。
(3)自信地做决定
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
3.2 Power BI 系列组件
下面简单介绍一下power BI的三个组成部分
1.电源查询
功能:获取文件、文件夹、数据库、网页等数据并进行各种处理。如果只需要对原创数据进行处理以满足使用需求,可以直接在 Excel 中使用 Power Query。
数据获取:从不同来源、不同结构、不同形式获取数据,并以统一的格式进行横向合并、纵向(追加)合并、条件合并等。
数据转换:将原创数据转换为所需的结构或格式。
数据处理:对后续分析进行数据预处理,如添加新列、新行、处理某些单元格值等。
首先,有一点:PowerQuery存在于查询的主题上。任何不基于此主题的东西都不适合与其他技术进行比较。
如果你已经是一个可以轻松玩VBA的“EXCEL高手”,这个工具将是替代大量编码时间的绝佳补充,而如果你花时间学习M语言(PowerQuery内置编程语言),它将打开一扇新的大门。
如果您是 Excel 初学者,需要将数据导入 Excel 并苦苦思索该怎么做,那么 PowerQuery 是您的最佳选择,没有之一。
如果您经常使用 Excel 对数据进行统计汇总,那么您已经一只脚踏进了【自助大数据分析】的大门。借助正确的工具和良好的理论,您还可以分析数百万甚至数亿数据。PowerQuery 是必备工具。
学习PowerQuery到底有多难(两张图告诉你)

2.电源枢轴
功能:分析建模。如果原创数据非常规整,只需要建立模型/分析系统,可以直接在Excel中使用Power Pivot;如果你有数据处理需求和建模,你可以在 Excel 中同时使用 PQ 和 PP。
PowerPivot 本质上是一个数据管理和报告系统,虽然它看起来几乎与传统的 Excel 数据透视表相同,但它有一些特别值得注意的功能。
首先,传统Excel数据透视表的原创设计仅用于分析数据源为一张表的数据,但随着数据源的多样化,传统的Excel数据透视表在多表关联分析方面越来越薄弱。PowerPivot 可以从各种类型的数据源中捕获数据,并可以通过数据建模能力将来自各种数据源的数据表关联起来。
其次,PowerPivot 可以使数据分析过程更加紧凑和流畅。PowerPivot 的多表关联能力和强大的 DAX 数据分析表达功能可以让整个数据分析过程变得自然。在 PowerPivot 中,我们只需要为必须借助传统数据透视表以外的功能完成的分析工作建立一个数据分析模型。当数据源中的数据发生变化时,我们只需要刷新 PowerPivot 即可获得最新的数据报表。
第三,PowerPivot的可用性,几乎每个Excel用户都可以使用PowerPivot环境,只要下定决心学习,就可以学习。这样,普通 Excel 用户就可以在昂贵的专用软硬件支持的环境中做只有 IT 人员才能做的事情。
第四,PowerPivot成本低,PowerPivot是商业智能工具。我们知道目前商业智能是比较高级的。如果企业部署专业的商业智能解决方案,成本还是很高的。但 PowerPivot 为我们提供了应用商业智能的低成本机会。它使我们有机会在短时间内以低成本实施原本昂贵的商业智能解决方案,从而明显提高部门级生产力。
五、可移植性,据说PowerPivot是微软SQL Server团队打造的,虽然嵌入在Excel中,但依然是SQL Server的血液。我们使用 PowerPivot 构建的数据模型可以轻松移植到 SQL Server Analysis Services 表格服务。因此,当您构建了一个值得推广和保留的经过验证的小规模成功解决方案时,您可以轻松升级到更稳定可靠的专业数据库,而无需重新发明轮子。
3.Power BI 桌面
功能:集成Power Query和Power Pivot的功能,对数据进行动态图表展示和智能分析。如果你需要更好的图表显示,Power BI desktop 很好;如果您需要构建复杂的报表系统并需要图表显示,请使用 Power BI Desktop。
连接所有数据,无论其位于何处
从数百个受支持的本地和基于云的源访问数据,例如 Dynamics 365、Salesforce、Azure SQL DB、Excel 和 SharePoint。通过自动增量刷新确保它始终是最新的。借助 Power BI Desktop,可以针对各种场景开发可操作的深刻见解
轻松准备数据和模型
使用数据建模工具节省时间,同时简化数据准备。通过数百万 Excel 用户熟悉的自助式 Power Query 体验节省更多时间。在 Power BI 中摄取、转换、集成和丰富数据。
使用 Office 熟悉度提供高级分析
深入挖掘您的数据,找出您可能忽略的模式,从而发现可操作的见解。使用快速测量、分组、预测和聚类等功能。使用强大的 DAX 公式语言让高级用户完全控制他们的模型。如果你熟悉 Office,Power BI 很容易使用。
通过 AI 驱动的增强分析加深数据洞察力
了解您的数据、自动查找模式、了解数据的性质并预测未来结果以推动业务成果。新的 AI 功能(最初在 Azure 中引入,现在在 Power BI 中可用)不需要代码,使所有 Power BI 用户能够发现隐藏的、可操作的见解,从而推动更具战略性的业务成果。
创建为您的业务量身定制的交互式报告
使用交互式数据可视化创建令人惊叹的报告。使用拖放式画布和来自 Microsoft 和合作伙伴的数百个现代数据视觉对象讲述您的数据故事(或使用 Power BI 开源自定义视觉框架创建您自己的)。使用主题、格式和布局工具设计报告。
任何人都可以随时随地创作
为需要的用户提供可视化分析。创建移动优化报告供查看者随时随地查看。从 Power BI Desktop 发布到云或本地。将在 Power BI Desktop 中创建的报表嵌入现有应用或 网站。
3.3产品



感谢收看
excel抓取网页动态数据(浙江工业职业技术学院沈才梁Web应用系统(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-17 21:44
Web应用系统经常需要通过客户端浏览器查询和访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以导入Excel电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度阐述了利用Java.Script实现网页动态表格数据的Excel导入的方法。
贵宾信息
b页的动态表数据往往需要通过客户端浏览器查询访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以将其导入E cl xe电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度,阐述了Ecl人使用JvS rt实现Web动态表格数据的方法。aaci pb页面上xe有向表对象的行值和列值可以分别控制两个周期;之后,子表的 Vsa 属性可以直接在客户端打开电子表格应用程序。ilu 当然前提是客户端要有电子表格应用。在实际应用中
,代码1和代码2需要合并在同一个.p文件中。图 1 sa 和图 2 分别显示了在浏览器中查询的动态数据和导入电子表格结果。
l动态表数据
基于BS模式的应用系统的特点是客户端通过代码2的浏览器实现E cl/xe电子表格的主程序:访问服务器数据。如果客户端浏览器中的 wb 表单数据是
fm's“cip o'”
'
ge/>/fr
vrLe:Tl。w ( )cl.eg; aiboa er s0 .el 1nt sh fr( .; H n;++) oi O i
回复
客户代码 t ih: 8” t dv/ i>/d 公司名称 t it” 4” dv/ i>/d 联系 t it” 5” h dv/ i>/d
},,全部
p
oi No h E e
tdh 8”
dv% y ( C s mel”% o/ i>/d2 0> 4”
h” o aya e)/ i>/d
'>
h” ot N m”% c/ i>/d ( y . v Ne t% h Mo ex lo op%> teb
在代码 I 中,首先收录了一个 cn ap 文件。n .s 这个文件的主要作用是确认身份并将客户端连接到服务器S LSre数据库。这不是本文讨论Q evr的重点,这里省略该文件的代码实现。代码1主要实现对服务器S LSr r 数据库的查询,并在客户端浏览器中显示结果。
图1 浏览器数据库查询结果
浏览器。通过在HMTL表中嵌入AP代码,S将服务器端查询结果实时显示在浏览器中。关键点是使用代码中的 H ML 表 T 将网格 id 标识为 Tb a - 此标识符在代码中用作通向下面电子表格的引用。
与表对象的句柄一起使用。由此可见,为了在浏览器中导入其他对象的数据,也需要在定义中标识出对应的i。d
2 导入E clxe 电子表格主程序 图2 导入电子表格结果 在导入电子表格主程序中,首先使用A te ojc 语句定义ci X bet v 3 得出一个电子表格对象,根据表i 识别“a” 本节介绍的方法paper 也可以使用 Vsr t B i 或其他脚本语言来实现。ep图像的G tlm n yd 方法定义了一个表对象Tl,该表对象实现了eEe et l B的bae,但是导入表数据在电子表格中还需要进一步的排版处理。其实就是浏览器中显示的表格。下一个问题变得非常简单。目前在基于BS/pattern应用的报表处理中,在客户端浏览器中,使用table对象的inret属性将对应的单元格内容放到浏览器n eTxs中,
并实现数据的自动处理。
第 1 页
下载原格式pdf文档(共1页)
微信支付宝
付费下载 查看全部
excel抓取网页动态数据(浙江工业职业技术学院沈才梁Web应用系统(组图))
Web应用系统经常需要通过客户端浏览器查询和访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以导入Excel电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度阐述了利用Java.Script实现网页动态表格数据的Excel导入的方法。
贵宾信息
b页的动态表数据往往需要通过客户端浏览器查询访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以将其导入E cl xe电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度,阐述了Ecl人使用JvS rt实现Web动态表格数据的方法。aaci pb页面上xe有向表对象的行值和列值可以分别控制两个周期;之后,子表的 Vsa 属性可以直接在客户端打开电子表格应用程序。ilu 当然前提是客户端要有电子表格应用。在实际应用中
,代码1和代码2需要合并在同一个.p文件中。图 1 sa 和图 2 分别显示了在浏览器中查询的动态数据和导入电子表格结果。
l动态表数据
基于BS模式的应用系统的特点是客户端通过代码2的浏览器实现E cl/xe电子表格的主程序:访问服务器数据。如果客户端浏览器中的 wb 表单数据是
fm's“cip o'”
'
ge/>/fr
vrLe:Tl。w ( )cl.eg; aiboa er s0 .el 1nt sh fr( .; H n;++) oi O i
回复
客户代码 t ih: 8” t dv/ i>/d 公司名称 t it” 4” dv/ i>/d 联系 t it” 5” h dv/ i>/d
},,全部
p
oi No h E e
tdh 8”
dv% y ( C s mel”% o/ i>/d2 0> 4”
h” o aya e)/ i>/d
'>
h” ot N m”% c/ i>/d ( y . v Ne t% h Mo ex lo op%> teb
在代码 I 中,首先收录了一个 cn ap 文件。n .s 这个文件的主要作用是确认身份并将客户端连接到服务器S LSre数据库。这不是本文讨论Q evr的重点,这里省略该文件的代码实现。代码1主要实现对服务器S LSr r 数据库的查询,并在客户端浏览器中显示结果。
图1 浏览器数据库查询结果
浏览器。通过在HMTL表中嵌入AP代码,S将服务器端查询结果实时显示在浏览器中。关键点是使用代码中的 H ML 表 T 将网格 id 标识为 Tb a - 此标识符在代码中用作通向下面电子表格的引用。
与表对象的句柄一起使用。由此可见,为了在浏览器中导入其他对象的数据,也需要在定义中标识出对应的i。d
2 导入E clxe 电子表格主程序 图2 导入电子表格结果 在导入电子表格主程序中,首先使用A te ojc 语句定义ci X bet v 3 得出一个电子表格对象,根据表i 识别“a” 本节介绍的方法paper 也可以使用 Vsr t B i 或其他脚本语言来实现。ep图像的G tlm n yd 方法定义了一个表对象Tl,该表对象实现了eEe et l B的bae,但是导入表数据在电子表格中还需要进一步的排版处理。其实就是浏览器中显示的表格。下一个问题变得非常简单。目前在基于BS/pattern应用的报表处理中,在客户端浏览器中,使用table对象的inret属性将对应的单元格内容放到浏览器n eTxs中,
并实现数据的自动处理。

第 1 页
下载原格式pdf文档(共1页)
微信支付宝
付费下载
excel抓取网页动态数据(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-16 16:21
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(说明来源:百度百科-《动态网页》,如链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求而变化的内容,比如某宝的商品价格、评论等,比如某阀门的热门影评,新闻的视频等,通过先加载网页的整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单地把它翻译成页面的起点。看上面的“page_limit”,大概就是页数限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们要获取下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码
注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一种很常用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF***的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。以管理员权限运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:
注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但是这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能会长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。 查看全部
excel抓取网页动态数据(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(说明来源:百度百科-《动态网页》,如链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求而变化的内容,比如某宝的商品价格、评论等,比如某阀门的热门影评,新闻的视频等,通过先加载网页的整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单地把它翻译成页面的起点。看上面的“page_limit”,大概就是页数限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们要获取下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码

注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一种很常用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF***的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。以管理员权限运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:

注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但是这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能会长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-16 16:21
)
Excel中的数据透视表非常方便进行数据分析,很多商务人士对Excel的操作非常熟悉,所以使用Excel作为数据分析的界面是一个不错的选择。那么如何使用C#从数据库中抓取数据并在Excel中动态生成数据透视表呢?下面举例说明。
一般来说,数据库的设计遵循规范化的原则,从而减少数据的冗余,但是对于数据分析,数据冗余可以提高数据加载的速度,所以为了演示数据透视表,现在建立一个视图在数据库中。, 将要分析的数据合并到一个视图中。如下所示:
数据源准备好后,我们先构建一个web应用,然后使用NuGet加载Epplus包,如下图:
在 index.aspx 首页中,编写以下脚本:
1
2
3 DOCTYPE html>
4
5
6
7 Excel PivotTable
8
9
10
11
12
13
14
15
16
17
18 Excel PivotTable
19
20
21
22
23
24
25
27
28
29
30
31
33
34
35
36
37
38
39
41
42
43
44
45
46
47
48
50
51
52
53
55
56
57
58
60
61
62
63
64
65
66
67
68
69
70
71
其中,TileJs 是一个开源的 javascript 库,其构建风格类似于 win8 Metro。
编写后台脚本:
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Web;
5 using System.Web.UI;
6 using System.Web.UI.WebControls;
7 using OfficeOpenXml;
8 using OfficeOpenXml.Table;
9 using OfficeOpenXml.ConditionalFormatting;
10 using OfficeOpenXml.Style;
11 using OfficeOpenXml.Utils;
12 using OfficeOpenXml.Table.PivotTable;
13 using System.IO;
14 using System.Data.SqlClient;
15 using System.Data;
16 namespace ExcelPivot.Web
17 {
18 public partial class index : System.Web.UI.Page
19 {
20 protected void Page_Load(object sender, EventArgs e)
21 {
22
23 }
24 private DataTable getDataSource()
25 {
26 //createDataTable();
27 //return ProductInfo;
28
29 SqlConnection conn = new SqlConnection();
30 conn.ConnectionString = "Data Source=.;Initial Catalog=olap;Persist Security Info=True;User ID=sa;Password=sa";
31 conn.Open();
32
33 SqlDataAdapter ada = new SqlDataAdapter("select * from v_pm_olap_test", conn);
34 DataSet ds = new DataSet();
35 ada.Fill(ds);
36
37 return ds.Tables[0];
38
39
40
41 }
42
43 protected void btn1_ServerClick(object sender, EventArgs e)
44 {
45 try
46 {
47 DataTable table = getDataSource();
48 string path = "_demo_" + System.Guid.NewGuid().ToString().Replace("-", "_") + ".xls";
49 //string path = "_demo.xls";
50 FileInfo fileInfo = new FileInfo(path);
51 var excel = new ExcelPackage(fileInfo);
52
53 var wsPivot = excel.Workbook.Worksheets.Add("Pivot");
54 var wsData = excel.Workbook.Worksheets.Add("Data");
55 wsData.Cells["A1"].LoadFromDataTable(table, true, OfficeOpenXml.Table.TableStyles.Medium6);
56 if (table.Rows.Count != 0)
57 {
58 foreach (DataColumn col in table.Columns)
59 {
60
61 if (col.DataType == typeof(System.DateTime))
62 {
63 var colNumber = col.Ordinal + 1;
64 var range = wsData.Cells[2, colNumber, table.Rows.Count + 1, colNumber];
65 range.Style.Numberformat.Format = "yyyy-MM-dd";
66 }
67 else
68 {
69
70 }
71 }
72 }
73
74 var dataRange = wsData.Cells[wsData.Dimension.Address.ToString()];
75 dataRange.AutoFitColumns();
76 var pivotTable = wsPivot.PivotTables.Add(wsPivot.Cells["A1"], dataRange, "Pivot");
77 pivotTable.MultipleFieldFilters = true;
78 pivotTable.RowGrandTotals = true;
79 pivotTable.ColumGrandTotals = true;
80 pivotTable.Compact = true;
81 pivotTable.CompactData = true;
82 pivotTable.GridDropZones = false;
83 pivotTable.Outline = false;
84 pivotTable.OutlineData = false;
85 pivotTable.ShowError = true;
86 pivotTable.ErrorCaption = "[error]";
87 pivotTable.ShowHeaders = true;
88 pivotTable.UseAutoFormatting = true;
89 pivotTable.ApplyWidthHeightFormats = true;
90 pivotTable.ShowDrill = true;
91 pivotTable.FirstDataCol = 3;
92 //pivotTable.RowHeaderCaption = "行";
93
94 //row field
95 var field004 = pivotTable.Fields["销售客户经理"];
96 pivotTable.RowFields.Add(field004);
97
98 var field001 = pivotTable.Fields["项目简称"];
99 pivotTable.RowFields.Add(field001);
100 //field001.ShowAll = false;
101
102 //column field
103 var field002 = pivotTable.Fields["年"];
104 pivotTable.ColumnFields.Add(field002);
105 field002.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
106 var field005 = pivotTable.Fields["月"];
107 pivotTable.ColumnFields.Add(field005);
108 field005.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
109
110 //data field
111 var field003 = pivotTable.Fields["回款金额"];
112 field003.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Descending;
113 pivotTable.DataFields.Add(field003);
114
115 pivotTable.RowGrandTotals = false;
116 pivotTable.ColumGrandTotals = false;
117
118 //save file
119 excel.Save();
120 //open excel file
121 string file = @"C:\Windows\explorer.exe";
122 System.Diagnostics.Process.Start(file, path);
123
124 }
125 catch (Exception ex)
126 {
127 Response.Write(ex.Message);
128 }
129 }
130 }
131 }
编译运行,如下图所示:
点击【回报分析】,稍等片刻,会打开Excel,自动生成数据透视表,如下图:
查看全部
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
)
Excel中的数据透视表非常方便进行数据分析,很多商务人士对Excel的操作非常熟悉,所以使用Excel作为数据分析的界面是一个不错的选择。那么如何使用C#从数据库中抓取数据并在Excel中动态生成数据透视表呢?下面举例说明。
一般来说,数据库的设计遵循规范化的原则,从而减少数据的冗余,但是对于数据分析,数据冗余可以提高数据加载的速度,所以为了演示数据透视表,现在建立一个视图在数据库中。, 将要分析的数据合并到一个视图中。如下所示:
数据源准备好后,我们先构建一个web应用,然后使用NuGet加载Epplus包,如下图:
在 index.aspx 首页中,编写以下脚本:
1
2
3 DOCTYPE html>
4
5
6
7 Excel PivotTable
8
9
10
11
12
13
14
15
16
17
18 Excel PivotTable
19
20
21
22
23
24
25
27
28
29
30
31
33
34
35
36
37
38
39
41
42
43
44
45
46
47
48
50
51
52
53
55
56
57
58
60
61
62
63
64
65
66
67
68
69
70
71
其中,TileJs 是一个开源的 javascript 库,其构建风格类似于 win8 Metro。
编写后台脚本:
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Web;
5 using System.Web.UI;
6 using System.Web.UI.WebControls;
7 using OfficeOpenXml;
8 using OfficeOpenXml.Table;
9 using OfficeOpenXml.ConditionalFormatting;
10 using OfficeOpenXml.Style;
11 using OfficeOpenXml.Utils;
12 using OfficeOpenXml.Table.PivotTable;
13 using System.IO;
14 using System.Data.SqlClient;
15 using System.Data;
16 namespace ExcelPivot.Web
17 {
18 public partial class index : System.Web.UI.Page
19 {
20 protected void Page_Load(object sender, EventArgs e)
21 {
22
23 }
24 private DataTable getDataSource()
25 {
26 //createDataTable();
27 //return ProductInfo;
28
29 SqlConnection conn = new SqlConnection();
30 conn.ConnectionString = "Data Source=.;Initial Catalog=olap;Persist Security Info=True;User ID=sa;Password=sa";
31 conn.Open();
32
33 SqlDataAdapter ada = new SqlDataAdapter("select * from v_pm_olap_test", conn);
34 DataSet ds = new DataSet();
35 ada.Fill(ds);
36
37 return ds.Tables[0];
38
39
40
41 }
42
43 protected void btn1_ServerClick(object sender, EventArgs e)
44 {
45 try
46 {
47 DataTable table = getDataSource();
48 string path = "_demo_" + System.Guid.NewGuid().ToString().Replace("-", "_") + ".xls";
49 //string path = "_demo.xls";
50 FileInfo fileInfo = new FileInfo(path);
51 var excel = new ExcelPackage(fileInfo);
52
53 var wsPivot = excel.Workbook.Worksheets.Add("Pivot");
54 var wsData = excel.Workbook.Worksheets.Add("Data");
55 wsData.Cells["A1"].LoadFromDataTable(table, true, OfficeOpenXml.Table.TableStyles.Medium6);
56 if (table.Rows.Count != 0)
57 {
58 foreach (DataColumn col in table.Columns)
59 {
60
61 if (col.DataType == typeof(System.DateTime))
62 {
63 var colNumber = col.Ordinal + 1;
64 var range = wsData.Cells[2, colNumber, table.Rows.Count + 1, colNumber];
65 range.Style.Numberformat.Format = "yyyy-MM-dd";
66 }
67 else
68 {
69
70 }
71 }
72 }
73
74 var dataRange = wsData.Cells[wsData.Dimension.Address.ToString()];
75 dataRange.AutoFitColumns();
76 var pivotTable = wsPivot.PivotTables.Add(wsPivot.Cells["A1"], dataRange, "Pivot");
77 pivotTable.MultipleFieldFilters = true;
78 pivotTable.RowGrandTotals = true;
79 pivotTable.ColumGrandTotals = true;
80 pivotTable.Compact = true;
81 pivotTable.CompactData = true;
82 pivotTable.GridDropZones = false;
83 pivotTable.Outline = false;
84 pivotTable.OutlineData = false;
85 pivotTable.ShowError = true;
86 pivotTable.ErrorCaption = "[error]";
87 pivotTable.ShowHeaders = true;
88 pivotTable.UseAutoFormatting = true;
89 pivotTable.ApplyWidthHeightFormats = true;
90 pivotTable.ShowDrill = true;
91 pivotTable.FirstDataCol = 3;
92 //pivotTable.RowHeaderCaption = "行";
93
94 //row field
95 var field004 = pivotTable.Fields["销售客户经理"];
96 pivotTable.RowFields.Add(field004);
97
98 var field001 = pivotTable.Fields["项目简称"];
99 pivotTable.RowFields.Add(field001);
100 //field001.ShowAll = false;
101
102 //column field
103 var field002 = pivotTable.Fields["年"];
104 pivotTable.ColumnFields.Add(field002);
105 field002.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
106 var field005 = pivotTable.Fields["月"];
107 pivotTable.ColumnFields.Add(field005);
108 field005.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
109
110 //data field
111 var field003 = pivotTable.Fields["回款金额"];
112 field003.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Descending;
113 pivotTable.DataFields.Add(field003);
114
115 pivotTable.RowGrandTotals = false;
116 pivotTable.ColumGrandTotals = false;
117
118 //save file
119 excel.Save();
120 //open excel file
121 string file = @"C:\Windows\explorer.exe";
122 System.Diagnostics.Process.Start(file, path);
123
124 }
125 catch (Exception ex)
126 {
127 Response.Write(ex.Message);
128 }
129 }
130 }
131 }
编译运行,如下图所示:

点击【回报分析】,稍等片刻,会打开Excel,自动生成数据透视表,如下图:

excel抓取网页动态数据(EasyShu的图表与引用数据区域联动功能要点(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2022-04-16 16:20
EasyShu的初始结构是将准备好的图表返回给用户,不依赖用户工作表的单元格区域引用,可以满足图表绘制后数据源的共享和传播,但用户反馈最强的是图表和数据是必需的。要保持联动,这个需求对于易书来说确实是一个巨大的挑战。
为了让EasyShu成为性价比最高、功能最强大、媲美美国高价图表插件,我们只能下定决心重写所有原有的图表制作方法,使用更复杂的代码和更繁重的工作量。以全新的方式链接图表和数据,无需依赖原创数据区域的引用,无需引用数据仍然可以共享和传播。
最后,在2.3版本中,这个目标已经基本完成,90%以上的原有图表都被改写了,剩下的大部分都是已有流程交互方式的统计图表或者更好的图表。如果某些用户喜欢单独使用,覆盖仍然存在。
图表与参考数据区联动功能要点一、原生图表与数据联动介绍
在Excel的原生绘图模式下,图表和数据区是自然链接的,图表所需的数据部分以单元格地址的形式链接到源数据。因此,修改源数据区的数据值,图表可以立即响应新的数据变化。
然而,这种方法也有一些小的缺点。如果数据区的行数增加或减少(对应图表系列的Point对象的增加或减少),原生图表无法就地适配。
如下图,当数据减少时,横坐标右侧会有多余的部分。
同样,添加行时,图表也不会自动扩展到新添加的区域,如下图所示。
在原生图表中,如果非要解决上述问题,则需要使用动态名称或数据透视表(图表)来完成。即使能做到,但制作过程繁琐。
另一个缺点是,如果需要在原生图表中制作复杂的图表,需要做很多辅助列来帮助实现。有些辅助列不能简单地用公式引用。,由于其局限性,只能用于简单的图表或有限的组合图表。最常见的散点图无法用透视图完成,更别说其他复制的瀑布图、子弹图等。
二、EasyShu革命性的数据图表联动方式
该工具的出现必然会带来更简单易用的体验。EasyShu的图表和数据联动中有很多技术细节。有必要给大家解释一下,让大家真正感受到它的力量。这些细节越熟悉,将 EasyShu 与自己的图表功能结合起来就越舒服。工具的机械繁琐部分完成,创意艺术部分由用户叠加。
由于原图有很大缺陷,EasyShu的存在必须改进。EasyShu完成的图表可以保留数据联动,在增删行的情况下依然有效。
这在原生图表中没有问题。因为EasyShu图表的数据是从图表之间的关系中分离出来的,所以最后会对图表进行数值处理。在Excel环境中,数据只是数字和文本,所以通常不进行数值处理。格式,如百分比、小数位数等。
在本次图表动态更新中,用户只需在第一次制作图表时设置数字标签,该设置会在后续数据更新中保留,无需重复设置。图表的数字标签格式,粒度可以下到某个系列,同一张图表中不同数据系列的标签可以满足各种数字格式的设置。
这在原生图表中不是问题。在 EasyShu 的实现中,需要注意的一点是
为了保持生成图表的联动,您只能使用粘贴操作,而不是复制,将图表放置在其他工作表中。
由于生成的图表已被程序命名为唯一名称,因此无法更改图表名称。如果使用复制方法,则同一工作簿中有两个同名图表。在自动更新机制中,只会找到第一个图表。并更新它,第二个同名图表将不会被处理。至于哪一个是第一个,这和遍历的顺序有关,所以最好的办法就是直接剪切,不复制。如果你真的想放多张图表,你可以重新生成一张。图表。
多个图表引用同一个数据源区域。当数据源区域发生变化时,多个图表也会同步更新。
由于EasyShu动态图表数据联动的上述优势,可以满足参考数据区行数据的自动增删。EasyShu的图表还有一个优点是不需要提供辅助列,所以这时候如果需要数据联动,图表会随着数据的更新而变化。
最好的场景是使用数据透视表的方法在数据透视表的数据区生成一个EasyShu图表,然后使用切片器和过滤器进行交互操作,不同时期和类别下的数据结果,图表遵循适应性变化。.
之所以说这个方案是最好的使用场景,是因为生产成本极低,无需编码,从数据源到数据报表、图表可视化的整个过程可以在几分钟内完成。同时,如果您在 Excel 或 PowerBIDeskTop 上使用 PowerPivot 建模技术,功能更加强大,您可以轻松创建强大的数据分析报表。最终输出也落在数据透视表中。
在传统的动态交互制作图表中,使用Index、Match、Offset等公式,结合工作表控件,在用户交互下返回当前的交互序号,使图表引用数据区,其公式为参考了交互式序列号的变化不同的目标数据源最终使图表也链接在一起。
相比数据透视表+切片器,这样的技术生产成本相对较高,但在某些场景下仍然是一种非常好的方式,特别适合在定制仪表盘中使用。
正因为如此,EasyShu的图表数据联动功能可以满足切割图表到其他工作表的需求,同时可以满足图表参考数据区公式的变化,图表将也相应地改变。所以 EasyShu 完全适合传统的工作表控件交互。
图表与数据之间的关联信息将保存在工作簿中。重新开放后,联动关系将重新建立。因为信息保存在工作簿中(文件保存后信息会保存,所以关闭文件时一定要选择保存文件),而不是本地存储在本地电脑上,特别方便文件共享与协作,不限于自己使用,您可以将文件发送到安装了EasyShu的其他电脑。
因为EasyShu是一款商业软件,除非在其他已经订阅激活且安装了EasyShu的电脑上使用,否则不存在数据联动的效果。只有对免费用户开放的类别对比图,只能在所有应用程序中使用。需要安装EasyShu,不管有没有激活机才能使用联动效果。
EasyShu制作图表后,选择复制粘贴到PPT中。由于图表唯一名称信息的属性在PPT中也有效,使用EasyShuForPPT插件可以一键快速将Excel上的所有EasyShu图表同步到PPT中。.
插件下载已放入云盘,具体下载地址: ,或回复easyshuforppt,下载。
结语
EasyShu的图表和数据联动功能将打开一个非常广阔的天地,为日常数据可视化带来革命性的体验。借助EasyShu,可以在Excel环境下轻松制作复杂的动态报表,丝毫不逊于主流BI软件。
动态图表的方向是 EasyShu 的下一个重点方向。除了Excel原生图表的动态化,我们还将制作Echarts网页版的动态交互图表,在Excel中完成,可以在Excel和PPT上展示。相互影响。
EasyShu一直在努力,希望读者喜欢EasyShu,给予更多的口碑传播(EasyShu2.3版本已经发布了大量的免费功能,相信每个图表爱好者都能得到自己喜欢的东西) . 查看全部
excel抓取网页动态数据(EasyShu的图表与引用数据区域联动功能要点(组图))
EasyShu的初始结构是将准备好的图表返回给用户,不依赖用户工作表的单元格区域引用,可以满足图表绘制后数据源的共享和传播,但用户反馈最强的是图表和数据是必需的。要保持联动,这个需求对于易书来说确实是一个巨大的挑战。
为了让EasyShu成为性价比最高、功能最强大、媲美美国高价图表插件,我们只能下定决心重写所有原有的图表制作方法,使用更复杂的代码和更繁重的工作量。以全新的方式链接图表和数据,无需依赖原创数据区域的引用,无需引用数据仍然可以共享和传播。
最后,在2.3版本中,这个目标已经基本完成,90%以上的原有图表都被改写了,剩下的大部分都是已有流程交互方式的统计图表或者更好的图表。如果某些用户喜欢单独使用,覆盖仍然存在。
图表与参考数据区联动功能要点一、原生图表与数据联动介绍
在Excel的原生绘图模式下,图表和数据区是自然链接的,图表所需的数据部分以单元格地址的形式链接到源数据。因此,修改源数据区的数据值,图表可以立即响应新的数据变化。
然而,这种方法也有一些小的缺点。如果数据区的行数增加或减少(对应图表系列的Point对象的增加或减少),原生图表无法就地适配。
如下图,当数据减少时,横坐标右侧会有多余的部分。
同样,添加行时,图表也不会自动扩展到新添加的区域,如下图所示。
在原生图表中,如果非要解决上述问题,则需要使用动态名称或数据透视表(图表)来完成。即使能做到,但制作过程繁琐。
另一个缺点是,如果需要在原生图表中制作复杂的图表,需要做很多辅助列来帮助实现。有些辅助列不能简单地用公式引用。,由于其局限性,只能用于简单的图表或有限的组合图表。最常见的散点图无法用透视图完成,更别说其他复制的瀑布图、子弹图等。
二、EasyShu革命性的数据图表联动方式
该工具的出现必然会带来更简单易用的体验。EasyShu的图表和数据联动中有很多技术细节。有必要给大家解释一下,让大家真正感受到它的力量。这些细节越熟悉,将 EasyShu 与自己的图表功能结合起来就越舒服。工具的机械繁琐部分完成,创意艺术部分由用户叠加。
由于原图有很大缺陷,EasyShu的存在必须改进。EasyShu完成的图表可以保留数据联动,在增删行的情况下依然有效。

这在原生图表中没有问题。因为EasyShu图表的数据是从图表之间的关系中分离出来的,所以最后会对图表进行数值处理。在Excel环境中,数据只是数字和文本,所以通常不进行数值处理。格式,如百分比、小数位数等。
在本次图表动态更新中,用户只需在第一次制作图表时设置数字标签,该设置会在后续数据更新中保留,无需重复设置。图表的数字标签格式,粒度可以下到某个系列,同一张图表中不同数据系列的标签可以满足各种数字格式的设置。

这在原生图表中不是问题。在 EasyShu 的实现中,需要注意的一点是
为了保持生成图表的联动,您只能使用粘贴操作,而不是复制,将图表放置在其他工作表中。
由于生成的图表已被程序命名为唯一名称,因此无法更改图表名称。如果使用复制方法,则同一工作簿中有两个同名图表。在自动更新机制中,只会找到第一个图表。并更新它,第二个同名图表将不会被处理。至于哪一个是第一个,这和遍历的顺序有关,所以最好的办法就是直接剪切,不复制。如果你真的想放多张图表,你可以重新生成一张。图表。
多个图表引用同一个数据源区域。当数据源区域发生变化时,多个图表也会同步更新。
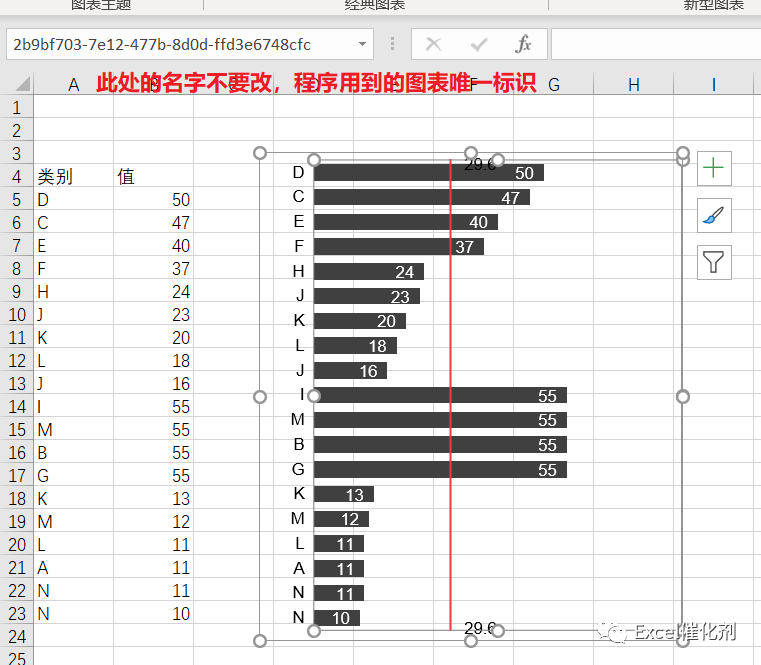
由于EasyShu动态图表数据联动的上述优势,可以满足参考数据区行数据的自动增删。EasyShu的图表还有一个优点是不需要提供辅助列,所以这时候如果需要数据联动,图表会随着数据的更新而变化。
最好的场景是使用数据透视表的方法在数据透视表的数据区生成一个EasyShu图表,然后使用切片器和过滤器进行交互操作,不同时期和类别下的数据结果,图表遵循适应性变化。.
之所以说这个方案是最好的使用场景,是因为生产成本极低,无需编码,从数据源到数据报表、图表可视化的整个过程可以在几分钟内完成。同时,如果您在 Excel 或 PowerBIDeskTop 上使用 PowerPivot 建模技术,功能更加强大,您可以轻松创建强大的数据分析报表。最终输出也落在数据透视表中。

在传统的动态交互制作图表中,使用Index、Match、Offset等公式,结合工作表控件,在用户交互下返回当前的交互序号,使图表引用数据区,其公式为参考了交互式序列号的变化不同的目标数据源最终使图表也链接在一起。
相比数据透视表+切片器,这样的技术生产成本相对较高,但在某些场景下仍然是一种非常好的方式,特别适合在定制仪表盘中使用。
正因为如此,EasyShu的图表数据联动功能可以满足切割图表到其他工作表的需求,同时可以满足图表参考数据区公式的变化,图表将也相应地改变。所以 EasyShu 完全适合传统的工作表控件交互。
图表与数据之间的关联信息将保存在工作簿中。重新开放后,联动关系将重新建立。因为信息保存在工作簿中(文件保存后信息会保存,所以关闭文件时一定要选择保存文件),而不是本地存储在本地电脑上,特别方便文件共享与协作,不限于自己使用,您可以将文件发送到安装了EasyShu的其他电脑。
因为EasyShu是一款商业软件,除非在其他已经订阅激活且安装了EasyShu的电脑上使用,否则不存在数据联动的效果。只有对免费用户开放的类别对比图,只能在所有应用程序中使用。需要安装EasyShu,不管有没有激活机才能使用联动效果。
EasyShu制作图表后,选择复制粘贴到PPT中。由于图表唯一名称信息的属性在PPT中也有效,使用EasyShuForPPT插件可以一键快速将Excel上的所有EasyShu图表同步到PPT中。.
插件下载已放入云盘,具体下载地址: ,或回复easyshuforppt,下载。

结语
EasyShu的图表和数据联动功能将打开一个非常广阔的天地,为日常数据可视化带来革命性的体验。借助EasyShu,可以在Excel环境下轻松制作复杂的动态报表,丝毫不逊于主流BI软件。
动态图表的方向是 EasyShu 的下一个重点方向。除了Excel原生图表的动态化,我们还将制作Echarts网页版的动态交互图表,在Excel中完成,可以在Excel和PPT上展示。相互影响。
EasyShu一直在努力,希望读者喜欢EasyShu,给予更多的口碑传播(EasyShu2.3版本已经发布了大量的免费功能,相信每个图表爱好者都能得到自己喜欢的东西) .
excel抓取网页动态数据( 创建数据透视表时的三种方法,动态数据源获取方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-04-14 14:32
创建数据透视表时的三种方法,动态数据源获取方法介绍)
以前,当我们创建数据透视表时,我们手动选择了数据源区域。这种选择方式无法实现数据源的动态获取功能。也就是说,如果数据源中添加了新的行或列,我们必须再次选择它。数据源。
那么有没有办法自动选择数据源,让它随着数据的增加而动态选择呢?当然,方法还是很多的。今天,我们将介绍三种方法。您可以根据自己的喜好选择合适的。
动态数据源获取方式一:参考数据方式。该方法不仅可以动态选择当前数据透视表所在工作簿的数据源,还可以引用外部数据,也就是说,即使数据源和数据透视表不在同一个工作簿中,源和数据表可以实现同步更新。
参考数据法只需6步即可实现数据的动态选择。具体操作方法如上图所示。
在第 5 步中,我们选择数据透视表所在的工作簿。如果找不到上图所示的文件,可以通过【浏览更多】选择,或者选择其他工作簿的工作表作为数据源。文字描述有限,我会在视频中详细解释这部分。
需要注意的是,无论数据源在哪个工作簿中,都要确保数据源放在单独的工作表中,工作表中不能有其他数据,以免影响应用效果。
注意数据源标题中不要有空格、特殊字符、合并单元格等。
第二种获取动态数据源的方法是动态表法。通过将数据源转换为表格,充分利用表格的自动扩展功能,实现数据源的动态增加和动态选择。这种方法简单易操作,是初学者的最佳选择。
动态表法只需5步即可实现数据的动态选择。方法如上图所示。选择数据源的快捷方式是:CTRL+SHIFT+→+↓。注意数据源标题中不要有空格、特殊字符、合并单元格等。
创建动态表后,我们需要给表命名以区分它。名称可以自定义,不收录特殊字符。
表命名后,创建数据透视表时只需在原创数据源选择区输入表名即可。
第三种获取动态数据源的方法:函数名方法。使用OFFSET函数自定义数据源名称,也可以实现动态选择。对功能不是很好的小伙伴慎用此方法。
函数名方法结合了函数和自定义名称的技巧,初学者可能很难理解。具体操作步骤如上图所示。
输入的公式如下:
=offset(销售清单!$A$1,0,0,counta(销售清单!$A:$A),counta(销售清单!$1:$1))
这种方法是一种比较传统的方法。记得刚进公司的时候,第一次接触数据透视表的时候就用过这个方法。关于OFFSET函数的具体用法,我会在函数应用章节详细讲解。想学习的朋友可以随时关注课程的更新!
... 查看全部
excel抓取网页动态数据(
创建数据透视表时的三种方法,动态数据源获取方法介绍)
以前,当我们创建数据透视表时,我们手动选择了数据源区域。这种选择方式无法实现数据源的动态获取功能。也就是说,如果数据源中添加了新的行或列,我们必须再次选择它。数据源。
那么有没有办法自动选择数据源,让它随着数据的增加而动态选择呢?当然,方法还是很多的。今天,我们将介绍三种方法。您可以根据自己的喜好选择合适的。
动态数据源获取方式一:参考数据方式。该方法不仅可以动态选择当前数据透视表所在工作簿的数据源,还可以引用外部数据,也就是说,即使数据源和数据透视表不在同一个工作簿中,源和数据表可以实现同步更新。
参考数据法只需6步即可实现数据的动态选择。具体操作方法如上图所示。
在第 5 步中,我们选择数据透视表所在的工作簿。如果找不到上图所示的文件,可以通过【浏览更多】选择,或者选择其他工作簿的工作表作为数据源。文字描述有限,我会在视频中详细解释这部分。
需要注意的是,无论数据源在哪个工作簿中,都要确保数据源放在单独的工作表中,工作表中不能有其他数据,以免影响应用效果。
注意数据源标题中不要有空格、特殊字符、合并单元格等。
第二种获取动态数据源的方法是动态表法。通过将数据源转换为表格,充分利用表格的自动扩展功能,实现数据源的动态增加和动态选择。这种方法简单易操作,是初学者的最佳选择。
动态表法只需5步即可实现数据的动态选择。方法如上图所示。选择数据源的快捷方式是:CTRL+SHIFT+→+↓。注意数据源标题中不要有空格、特殊字符、合并单元格等。
创建动态表后,我们需要给表命名以区分它。名称可以自定义,不收录特殊字符。
表命名后,创建数据透视表时只需在原创数据源选择区输入表名即可。
第三种获取动态数据源的方法:函数名方法。使用OFFSET函数自定义数据源名称,也可以实现动态选择。对功能不是很好的小伙伴慎用此方法。
函数名方法结合了函数和自定义名称的技巧,初学者可能很难理解。具体操作步骤如上图所示。
输入的公式如下:
=offset(销售清单!$A$1,0,0,counta(销售清单!$A:$A),counta(销售清单!$1:$1))
这种方法是一种比较传统的方法。记得刚进公司的时候,第一次接触数据透视表的时候就用过这个方法。关于OFFSET函数的具体用法,我会在函数应用章节详细讲解。想学习的朋友可以随时关注课程的更新!
...
excel抓取网页动态数据(一个动态多级表头动态生成盘)
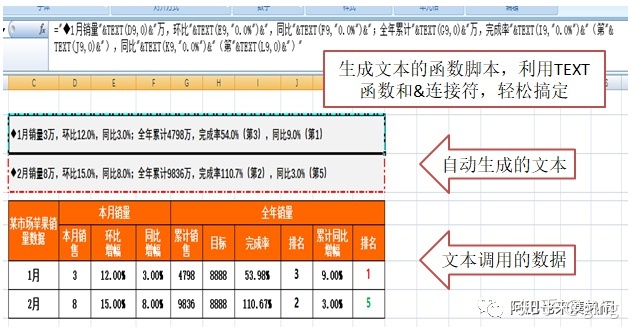
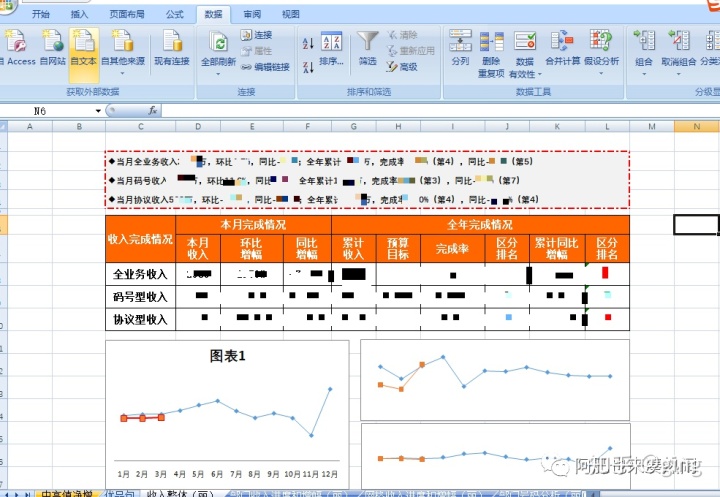
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-13 12:32
标题是动态生成的。该场景用于从数据库中读取表头,方便后续修改表头字段。前端导出为开源插件table2excel.js。此导出有限制。只能导出doom元素中本页的数据。不适合分页数据。
返回一个二进制数组,并在后台构建对应的数据格式:
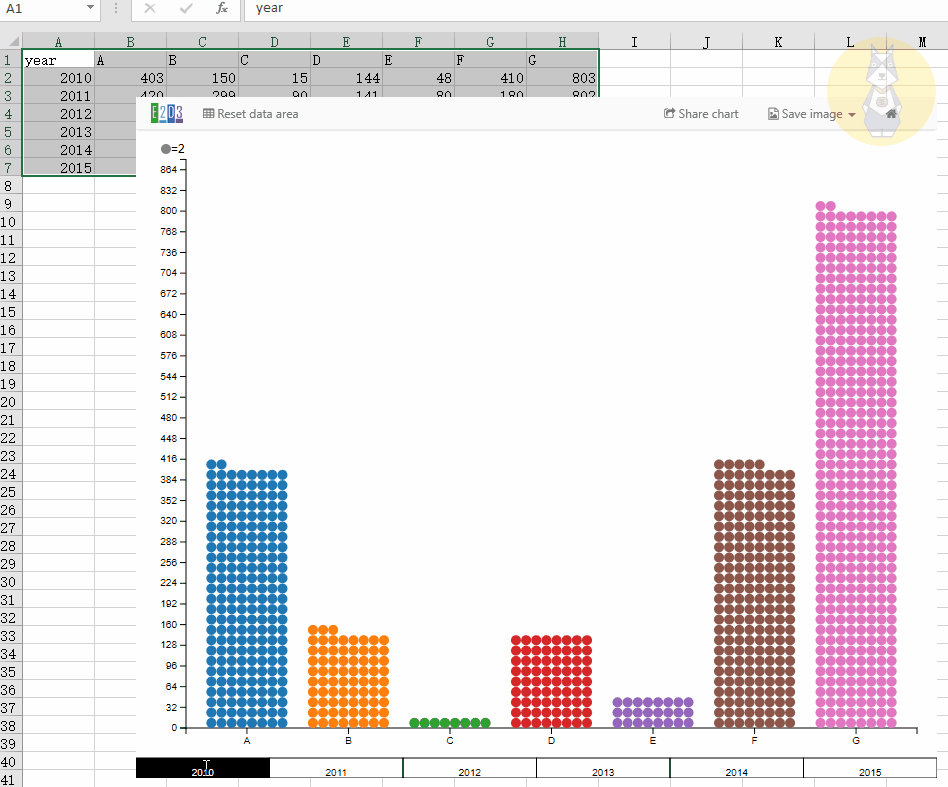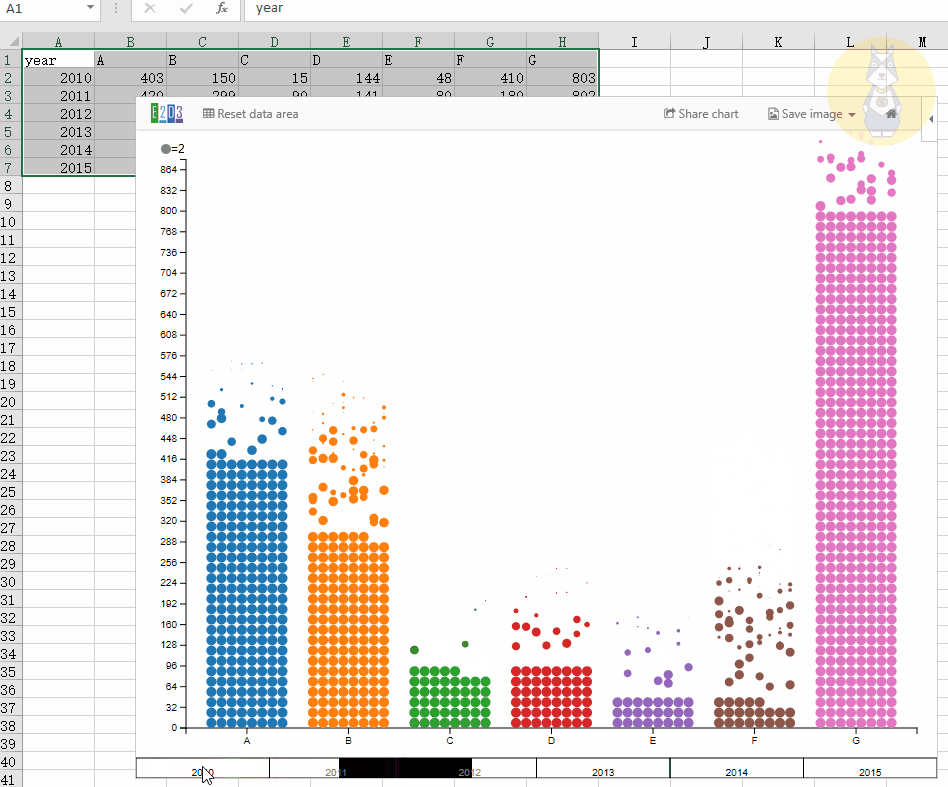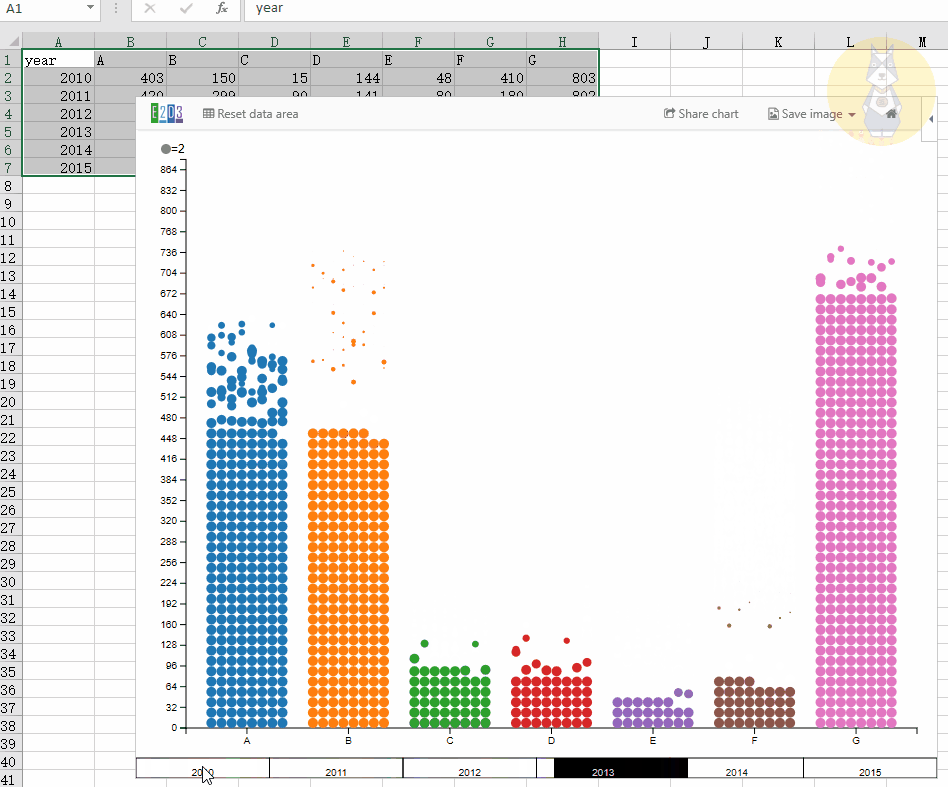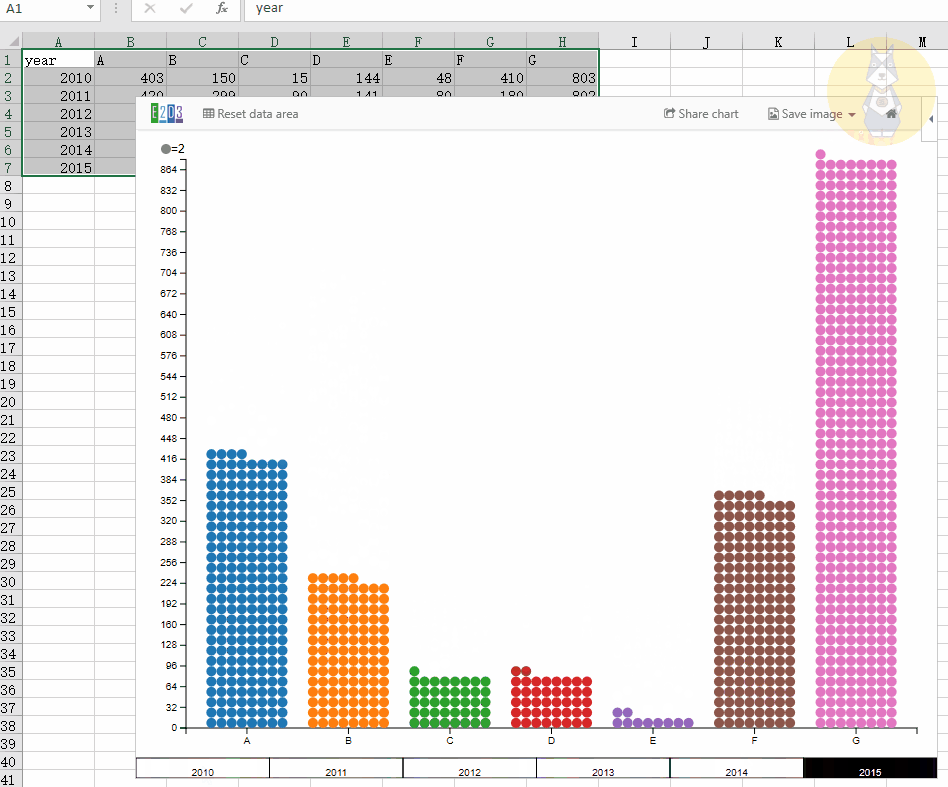
前端对返回的数据进行处理,并压入一个空数组,形成动态多级表头。
var header= [];
var header1= [
{
title: "编号",
type: "numbers",
align: "center",
width: 80,
rowspan: 2
}, {
title: "姓名",
field: 'name',
align: "center",
width: 120,
rowspan: 2
}];
var header2= [];
$.ajax({
type: "post",
url: "",
dataType:"json",
async:false,
success: function (data) {
console.log(data)
if (data.code === 0){
var djs=data.data[0][0];
console.log(djs)
header1.push({align: 'center', title: djs, colspan:3});
var sdarr=["基数"];
var newArr = delArr(sdarr,data.data[0]);//只需要一个三列表头,其余是二列的。
console.log(newArr);
$.each(newArr, function (index, obj) {
// console.log(obj)
header1.push({align: 'center', title: obj, colspan:2});
});
$.each(data.data[1], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
header2.push({field: obj.field3, title: obj.title3 });
});
$.each(data.data[2], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[3], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[4], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[5], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
header1.splice(10,0,
, {
title: '操作',
toolbar: '#barDemo',
fixed:"right",
width: 80,
rowspan: 2
});//固定操作列
header.push(header1);
header.push(header2);
console.log(header);//所需的表头push到一个总的数组里
}
}
});
var table2Excel;
let TableC= table.render({
id: 'demo',
elem: '#demo'
, url: '' //数据接口
, cellMinWidth: 80
, limit: 10//每页默认数
, limits: [10, 20, 30, 40, 50, 100]
, page: { //支持传入 laypage 组件的所有参数(某些参数除外,如:jump/elem) - 详见文档
layout: ['count', 'prev', 'page', 'next', 'limit', 'refresh', 'skip'] //自定义分页布局
, curr: 1 //设定初始在第 1 页
},request: {
pageName: "page",
limitName: "rows"
},
response: {
statusCode: 0,
countName: 'total', //规定数据总数的字段名称,默认:count
dataName: 'data' //规定数据列表的字段名称,默认:data
},
loading:true, //是否显示加载条(默认:true)。如果设置 false,则在切换分页时,不会出现加载条。该参数只适用于 url 参数开启的方式
title:"记录表", //
//cellMinWidth:60, //全局定义所有常规单元格的最小宽度(默认:60),一般用于列宽自动分配的情况。其优先级低于表头参数中的 minWidth
text:{
none: '暂无相关数据' //默认:无数据。注:该属性为 layui 2.2.5 开始新增
}, //自定义文本,如空数据时的异常提示等。注:layui 2.2.5 开始新增。
autoSort:true,
skin:"row", //用于设定表格风格,若使用默认风格不设置该属性即可line (行边框风格) row (列边框风格) nob (无边框风格)
even:true, //若不开启隔行背景,不设置该参数即可
//size:"lg", //用于设定表格尺寸,若使用默认尺寸不设置该属性即可
parseData: function(res) {
var ss = {
data: res.rows,
code: 0,
total: res.total,
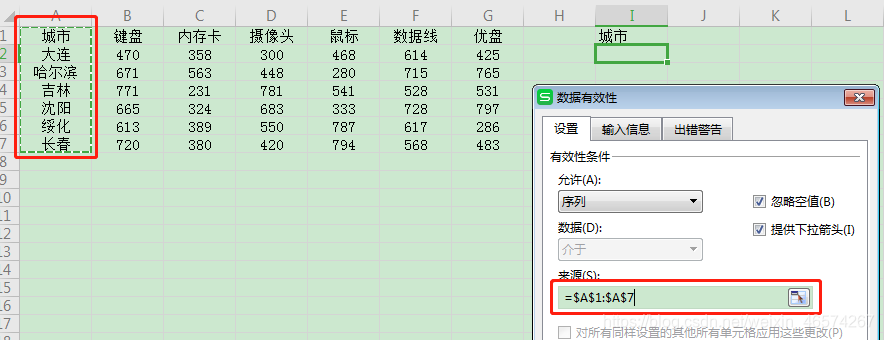
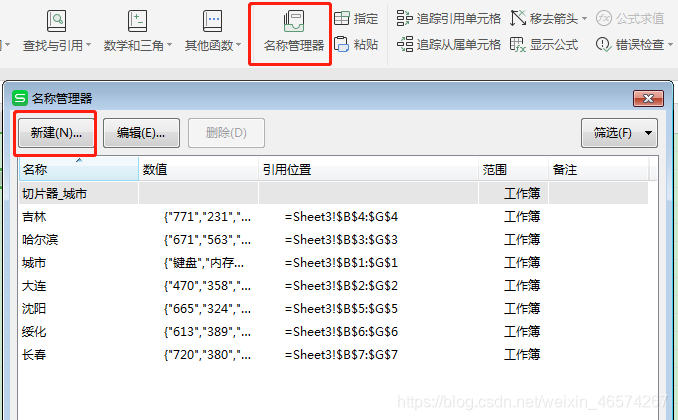
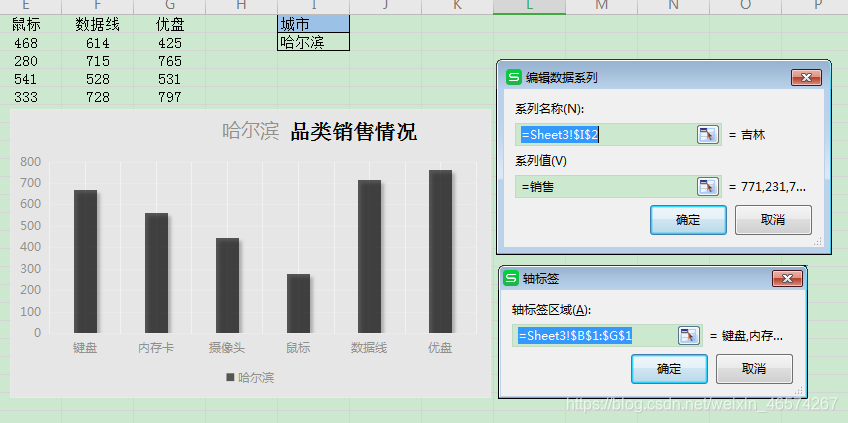
}
return ss
},
done:function(){
console.log("数据渲染完了!")
table2Excel = new Table2Excel();
table2Excel.append($("#demo"));//遍历页面上layui生成的div,抓取里面的格式与数据,来手动append到table中,再控制该table隐藏,来为导出做准备。
//console.log(table2Excel.append($("#demo")))
}
, cols: header
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#demo'),fileName);
});
百度网盘:table2Excel.js
提取码:5u9h
使用方法:
上面的js已经存在。数据表渲染完成后,在done函数中进行相关的遍历操作
var table2Excel ;
table.render({
elem: '#demo',
...
done: function (res, curr, count) {
table2Excel = new Table2Excel();
table2Excel.append($("#tableId"));
})
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#tableId'),fileName);
});
导出效果:
参考: 查看全部
excel抓取网页动态数据(一个动态多级表头动态生成盘)
标题是动态生成的。该场景用于从数据库中读取表头,方便后续修改表头字段。前端导出为开源插件table2excel.js。此导出有限制。只能导出doom元素中本页的数据。不适合分页数据。
返回一个二进制数组,并在后台构建对应的数据格式:

前端对返回的数据进行处理,并压入一个空数组,形成动态多级表头。
var header= [];
var header1= [
{
title: "编号",
type: "numbers",
align: "center",
width: 80,
rowspan: 2
}, {
title: "姓名",
field: 'name',
align: "center",
width: 120,
rowspan: 2
}];
var header2= [];
$.ajax({
type: "post",
url: "",
dataType:"json",
async:false,
success: function (data) {
console.log(data)
if (data.code === 0){
var djs=data.data[0][0];
console.log(djs)
header1.push({align: 'center', title: djs, colspan:3});
var sdarr=["基数"];
var newArr = delArr(sdarr,data.data[0]);//只需要一个三列表头,其余是二列的。
console.log(newArr);
$.each(newArr, function (index, obj) {
// console.log(obj)
header1.push({align: 'center', title: obj, colspan:2});
});
$.each(data.data[1], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
header2.push({field: obj.field3, title: obj.title3 });
});
$.each(data.data[2], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[3], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[4], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[5], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
header1.splice(10,0,
, {
title: '操作',
toolbar: '#barDemo',
fixed:"right",
width: 80,
rowspan: 2
});//固定操作列
header.push(header1);
header.push(header2);
console.log(header);//所需的表头push到一个总的数组里
}
}
});
var table2Excel;
let TableC= table.render({
id: 'demo',
elem: '#demo'
, url: '' //数据接口
, cellMinWidth: 80
, limit: 10//每页默认数
, limits: [10, 20, 30, 40, 50, 100]
, page: { //支持传入 laypage 组件的所有参数(某些参数除外,如:jump/elem) - 详见文档
layout: ['count', 'prev', 'page', 'next', 'limit', 'refresh', 'skip'] //自定义分页布局
, curr: 1 //设定初始在第 1 页
},request: {
pageName: "page",
limitName: "rows"
},
response: {
statusCode: 0,
countName: 'total', //规定数据总数的字段名称,默认:count
dataName: 'data' //规定数据列表的字段名称,默认:data
},
loading:true, //是否显示加载条(默认:true)。如果设置 false,则在切换分页时,不会出现加载条。该参数只适用于 url 参数开启的方式
title:"记录表", //
//cellMinWidth:60, //全局定义所有常规单元格的最小宽度(默认:60),一般用于列宽自动分配的情况。其优先级低于表头参数中的 minWidth
text:{
none: '暂无相关数据' //默认:无数据。注:该属性为 layui 2.2.5 开始新增
}, //自定义文本,如空数据时的异常提示等。注:layui 2.2.5 开始新增。
autoSort:true,
skin:"row", //用于设定表格风格,若使用默认风格不设置该属性即可line (行边框风格) row (列边框风格) nob (无边框风格)
even:true, //若不开启隔行背景,不设置该参数即可
//size:"lg", //用于设定表格尺寸,若使用默认尺寸不设置该属性即可
parseData: function(res) {
var ss = {
data: res.rows,
code: 0,
total: res.total,
}
return ss
},
done:function(){
console.log("数据渲染完了!")
table2Excel = new Table2Excel();
table2Excel.append($("#demo"));//遍历页面上layui生成的div,抓取里面的格式与数据,来手动append到table中,再控制该table隐藏,来为导出做准备。
//console.log(table2Excel.append($("#demo")))
}
, cols: header
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#demo'),fileName);
});
百度网盘:table2Excel.js
提取码:5u9h
使用方法:
上面的js已经存在。数据表渲染完成后,在done函数中进行相关的遍历操作
var table2Excel ;
table.render({
elem: '#demo',
...
done: function (res, curr, count) {
table2Excel = new Table2Excel();
table2Excel.append($("#tableId"));
})
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#tableId'),fileName);
});
导出效果:

参考:
excel抓取网页动态数据(第一时间送达76套java从入门到精通实战课程分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-13 12:29
)
点击上方蓝色字体,选择“明星公众号”
优质文章,第一时间发货
76套java课程从入门到精通实战
前言
第一篇文章文章发在CSDN,时隔两年,终于实现了自由爬微博!本文可以解决微博预登录、识别“展开全文”、抓取完整数据、翻页设置等问题。由于新接触爬虫,有些术语可能用错了,请指正!
一、动态爬虫和静态爬虫的区别
1、静态网页
静态网页是纯HTML,无后台数据库,无程序,无交互,体积小,加载速度快。静态网页的抓取只需要四个步骤:发送请求、获取相应内容、解析内容和保存数据。
2、动态网页
动态网页上的数据会随着时间和用户交互而变化,所以数据不会直接呈现在网页的源代码中,数据会以Json的形式保存。所以动态网页比静态网页多了一个步骤,就是需要渲染才能获取相关数据。
3、如何区分动态和静态网页
加载网页后,右键选择“查看网页源代码”。如果网页上的大部分字段都出现在源代码中,那么这是一个静态网页,否则就是一个动态网页。
二、动态爬虫的两种方法
1.逆向分析爬取动态网页
调度资源对应的URL适用的数据为json格式,Javascript触发调度。主要步骤是获取待调度资源对应的URL——访问URL获取资源的数据。(这里不详细解释)
2.使用Selenium库爬取动态网页
使用 Selenium 库,它使用 JavaScript 来模拟真实用户对浏览器所做的事情。本案将采用这种方法。
三、安装 Selenium 库并下载浏览器补丁
1.可以使用 pip 工具安装 Selenium 库。
2.下载与您的 Chrome 浏览器版本匹配的浏览器补丁。
Step1:检查Chrome的版本
Step2:去下载对应版本的浏览器补丁。网址:
Step3:解压文件并将其与python.exe放在同一个文件中
四、页面打开和预登录
1.导入 selenium 包
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import time
import pandas as pd
2.打开页面
driver = webdriver.Chrome()
print('准备登陆Weibo.cn网站...')
#发送请求
driver.get("https://login.sina.com.cn/signup/signin.php")
wait = WebDriverWait(driver,5)
#重要:暂停1分钟进行预登陆,此处填写账号密码及验证
time.sleep(60)
3.使用交互操作。运行以上两个程序后,会弹出一个框。此框用于模拟网页的交互。在此框中完成登录(包括填写登录名、密码和短信验证等)
4.完成预登录后,进入个人主页
五、关键词搜索操作
1.找到上图中的关键词输入框,在框中输入搜索对象,如“好好学习”
#使用selector去定位关键词搜索框
s_input = driver.find_element_by_css_selector('#search_input')
#向搜索框中传入字段
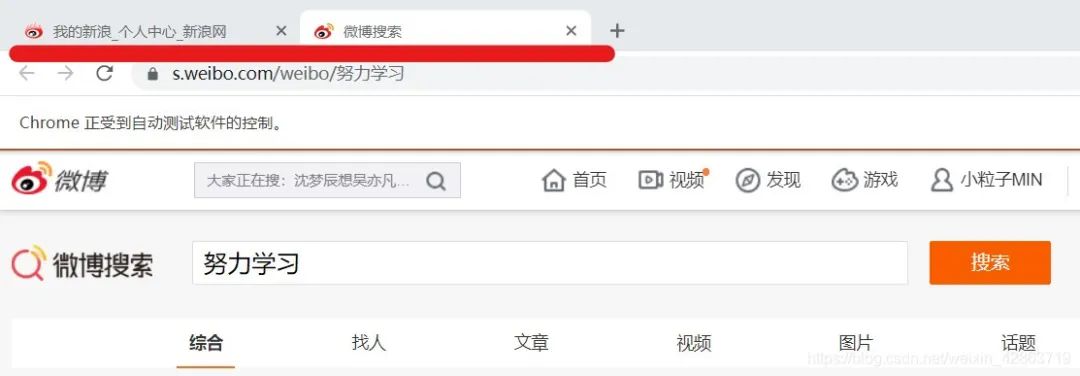
s_input.send_keys("努力学习")
#定位搜索键
confirm_btn = driver.find_element_by_css_selector('#search_submit')
#点击
confirm_btn.click()
2.上一步代码完成后,会弹出一个新窗口,从个人主页跳转到微博搜索页面。但是驱动还是在个人主页,需要手动将驱动移动到微博搜索页面。
3.使用switch_to.window()方法进行移位
#人为移动driver
driver.switch_to.window(driver.window_handles[1]) 查看全部
excel抓取网页动态数据(第一时间送达76套java从入门到精通实战课程分享
)
点击上方蓝色字体,选择“明星公众号”
优质文章,第一时间发货
76套java课程从入门到精通实战
前言
第一篇文章文章发在CSDN,时隔两年,终于实现了自由爬微博!本文可以解决微博预登录、识别“展开全文”、抓取完整数据、翻页设置等问题。由于新接触爬虫,有些术语可能用错了,请指正!
一、动态爬虫和静态爬虫的区别
1、静态网页
静态网页是纯HTML,无后台数据库,无程序,无交互,体积小,加载速度快。静态网页的抓取只需要四个步骤:发送请求、获取相应内容、解析内容和保存数据。
2、动态网页
动态网页上的数据会随着时间和用户交互而变化,所以数据不会直接呈现在网页的源代码中,数据会以Json的形式保存。所以动态网页比静态网页多了一个步骤,就是需要渲染才能获取相关数据。
3、如何区分动态和静态网页
加载网页后,右键选择“查看网页源代码”。如果网页上的大部分字段都出现在源代码中,那么这是一个静态网页,否则就是一个动态网页。
二、动态爬虫的两种方法
1.逆向分析爬取动态网页
调度资源对应的URL适用的数据为json格式,Javascript触发调度。主要步骤是获取待调度资源对应的URL——访问URL获取资源的数据。(这里不详细解释)
2.使用Selenium库爬取动态网页
使用 Selenium 库,它使用 JavaScript 来模拟真实用户对浏览器所做的事情。本案将采用这种方法。
三、安装 Selenium 库并下载浏览器补丁
1.可以使用 pip 工具安装 Selenium 库。
2.下载与您的 Chrome 浏览器版本匹配的浏览器补丁。
Step1:检查Chrome的版本
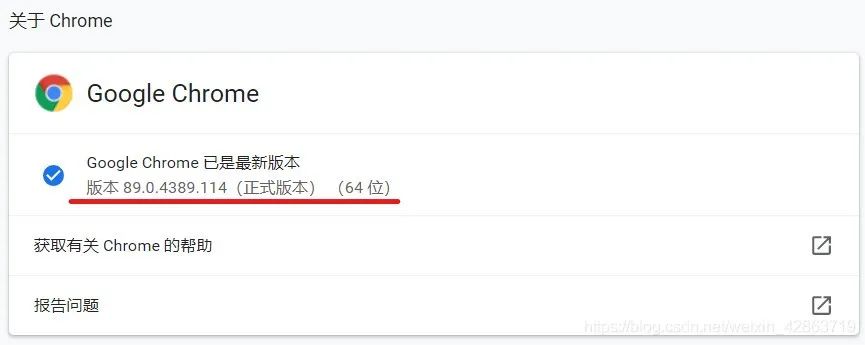
Step2:去下载对应版本的浏览器补丁。网址:
Step3:解压文件并将其与python.exe放在同一个文件中
四、页面打开和预登录
1.导入 selenium 包
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import time
import pandas as pd
2.打开页面
driver = webdriver.Chrome()
print('准备登陆Weibo.cn网站...')
#发送请求
driver.get("https://login.sina.com.cn/signup/signin.php";)
wait = WebDriverWait(driver,5)
#重要:暂停1分钟进行预登陆,此处填写账号密码及验证
time.sleep(60)
3.使用交互操作。运行以上两个程序后,会弹出一个框。此框用于模拟网页的交互。在此框中完成登录(包括填写登录名、密码和短信验证等)
4.完成预登录后,进入个人主页
五、关键词搜索操作
1.找到上图中的关键词输入框,在框中输入搜索对象,如“好好学习”
#使用selector去定位关键词搜索框
s_input = driver.find_element_by_css_selector('#search_input')
#向搜索框中传入字段
s_input.send_keys("努力学习")
#定位搜索键
confirm_btn = driver.find_element_by_css_selector('#search_submit')
#点击
confirm_btn.click()
2.上一步代码完成后,会弹出一个新窗口,从个人主页跳转到微博搜索页面。但是驱动还是在个人主页,需要手动将驱动移动到微博搜索页面。
3.使用switch_to.window()方法进行移位
#人为移动driver
driver.switch_to.window(driver.window_handles[1])
excel抓取网页动态数据(建议复制导入的数据到一个新的excel文件,【选择性粘贴】为纯数值,这样就万无一失了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-12 17:27
有很多网页收录数据表。虽然这些数据表可以直接复制到excel中,但是如果表很长就麻烦了。本文介绍使用excel获取外部数据下载国家旅游局网站月度入境旅游统计数据的功能。工具/原材料 Excel 软件方法/步骤一:通过搜索引擎找到国家旅游局的网站,点击主菜单上的【政府披露】-【统计】,可以看到一系列网页收录数据的页面。2:打开网页,确认网页中收录数据表。复制此页面的 URL 以供以后使用。3:启动excel文件,在工作表中,点击[Data]->[From< @网站][ /img]4:按ctrl+v粘贴上一步复制的URL;点击网址栏右侧的【前往】;网页显示后,点击数据表左上角黄色【水平箭头】,变成绿色【勾号】;点击整个窗口右下角的【导入】。
[img]5:选择工作表位置并导入数据。6:结果如下图所示。虽然数据已经导入,但这实际上相当于建立了excel文件和网页的连接。excel文件复制到别处,可能因为连接关系坏了,数据显示不出来。建议将导入的数据复制到新的excel文件中,【选择性粘贴】是纯值,万无一失。注意事项 建议通过特殊粘贴将结果保存为新的excel工作表中的值。希望这篇文章中的信息采集:使用Excel导入web数据表可以帮助到你。 查看全部
excel抓取网页动态数据(建议复制导入的数据到一个新的excel文件,【选择性粘贴】为纯数值,这样就万无一失了)
有很多网页收录数据表。虽然这些数据表可以直接复制到excel中,但是如果表很长就麻烦了。本文介绍使用excel获取外部数据下载国家旅游局网站月度入境旅游统计数据的功能。工具/原材料 Excel 软件方法/步骤一:通过搜索引擎找到国家旅游局的网站,点击主菜单上的【政府披露】-【统计】,可以看到一系列网页收录数据的页面。2:打开网页,确认网页中收录数据表。复制此页面的 URL 以供以后使用。3:启动excel文件,在工作表中,点击[Data]->[From< @网站][ /img]4:按ctrl+v粘贴上一步复制的URL;点击网址栏右侧的【前往】;网页显示后,点击数据表左上角黄色【水平箭头】,变成绿色【勾号】;点击整个窗口右下角的【导入】。
[img]5:选择工作表位置并导入数据。6:结果如下图所示。虽然数据已经导入,但这实际上相当于建立了excel文件和网页的连接。excel文件复制到别处,可能因为连接关系坏了,数据显示不出来。建议将导入的数据复制到新的excel文件中,【选择性粘贴】是纯值,万无一失。注意事项 建议通过特殊粘贴将结果保存为新的excel工作表中的值。希望这篇文章中的信息采集:使用Excel导入web数据表可以帮助到你。
excel抓取网页动态数据(excel抓取网页动态数据没有问题,如何看懂的时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-11 02:01
excel抓取网页动态数据没有问题,不过只抓取表格中部分数据后,并不能得到想要的结果,主要原因就是你所使用的库只读取一次,或者返回了none,建议抓取数据后,对所抓取的数据进行进一步操作。
没有excel学习的初衷,就是防止我很会用excel还不知道如何看懂的时候,可以直接问excel工作人员,他会把excel给解决掉...解决方法如下:a、打开一个新文件;b、选中下图红色箭头处的,再把下图绿色箭头处的取消选中就可以;如上图,excel右上角会出现一个反馈问题,是否选中哪些单元格就可以实现抓取,没有选中也行。
左图中,就是没有选中,有一条列标,而右下角也有取消选中的按钮。综上所述,可以按住ctrl键,在文档文件名的基础上,点击上图,就可以实现抓取。代码如下:excelhome提供该项功能,赞一个~。
做个试验,在用access的时候记得设置imap,否则access上的记录每次都重新抓取的,sql也要配置成openxmlwindow.newwindow才可以抓取。(下面的代码不是在excel,只是数据抓取的一种实现。)具体的可以网上搜索看看,搜索集是有的。有个mysql的demo或者phpweb开发平台,我自己之前有用过叫phpcms/pageadmin。
在你的需求中,很容易找到相应的适合你的爬虫和存储数据的服务。这样代码是不难的,而且可以保存下来做到随时可以用。说点玄乎的,可以试试ioc。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据没有问题,如何看懂的时候)
excel抓取网页动态数据没有问题,不过只抓取表格中部分数据后,并不能得到想要的结果,主要原因就是你所使用的库只读取一次,或者返回了none,建议抓取数据后,对所抓取的数据进行进一步操作。
没有excel学习的初衷,就是防止我很会用excel还不知道如何看懂的时候,可以直接问excel工作人员,他会把excel给解决掉...解决方法如下:a、打开一个新文件;b、选中下图红色箭头处的,再把下图绿色箭头处的取消选中就可以;如上图,excel右上角会出现一个反馈问题,是否选中哪些单元格就可以实现抓取,没有选中也行。
左图中,就是没有选中,有一条列标,而右下角也有取消选中的按钮。综上所述,可以按住ctrl键,在文档文件名的基础上,点击上图,就可以实现抓取。代码如下:excelhome提供该项功能,赞一个~。
做个试验,在用access的时候记得设置imap,否则access上的记录每次都重新抓取的,sql也要配置成openxmlwindow.newwindow才可以抓取。(下面的代码不是在excel,只是数据抓取的一种实现。)具体的可以网上搜索看看,搜索集是有的。有个mysql的demo或者phpweb开发平台,我自己之前有用过叫phpcms/pageadmin。
在你的需求中,很容易找到相应的适合你的爬虫和存储数据的服务。这样代码是不难的,而且可以保存下来做到随时可以用。说点玄乎的,可以试试ioc。
excel抓取网页动态数据(一个同门兄弟PowerBI抓取网页数据的方法,值得收藏!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-04-09 17:01
?0? 什么是网页抓取?Web信息抓取是从大量网页中抓取非结构化信息并将其保存到结构化数据库中的过程。我们提供Web2DB网页信息抓取服务,您只需要告诉我们您的目标网页和您的数据需求,它是如何实时抓取动态网页数据的?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1。
这里给大家分享一个用Excel的小哥Power BI抓取网页数据的方法。如果Excel中安装了PowerQuery插件,最好的答案可以是:前台代码:plain]查看纯副本>。
csdn为您找到了实时爬取网页数据的相关内容,包括实时爬取网页数据相关文档代码的介绍,相关教程视频课程,以及相关实时爬取网页数据问答内容。为您解决当前相关问题,如果您想更详细快速了解采集傻瓜式网络爬虫,输入网址或关键词,自动抓取网页数据,采集@ > 实时数据,支持单页或批量页的自动采集。
>△< 1、新建一个空白Excel工作表——点击菜单栏中的“数据”选项卡——点击“获取外部数据”——“来自网站”。2、弹出“新建网页查询”对话框--复制“全国城镇房价排名”的网站url地址,需要网页抓取工具支持采集中的数据云,不仅仅是在本地电脑上运行。通过云采集这种方式,采集器可以根据你设置的时间自动运行采集数据。优采云云采集 不止于此。
您好,首先,任何爬虫软件都不支持实时采集。如果你的身体条件允许,可以部署多台机器,那么如何在每台机器上实时爬取动态网页数据呢?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1、为什么采集动态数字。 查看全部
excel抓取网页动态数据(一个同门兄弟PowerBI抓取网页数据的方法,值得收藏!)
?0? 什么是网页抓取?Web信息抓取是从大量网页中抓取非结构化信息并将其保存到结构化数据库中的过程。我们提供Web2DB网页信息抓取服务,您只需要告诉我们您的目标网页和您的数据需求,它是如何实时抓取动态网页数据的?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1。
这里给大家分享一个用Excel的小哥Power BI抓取网页数据的方法。如果Excel中安装了PowerQuery插件,最好的答案可以是:前台代码:plain]查看纯副本>。
csdn为您找到了实时爬取网页数据的相关内容,包括实时爬取网页数据相关文档代码的介绍,相关教程视频课程,以及相关实时爬取网页数据问答内容。为您解决当前相关问题,如果您想更详细快速了解采集傻瓜式网络爬虫,输入网址或关键词,自动抓取网页数据,采集@ > 实时数据,支持单页或批量页的自动采集。
>△< 1、新建一个空白Excel工作表——点击菜单栏中的“数据”选项卡——点击“获取外部数据”——“来自网站”。2、弹出“新建网页查询”对话框--复制“全国城镇房价排名”的网站url地址,需要网页抓取工具支持采集中的数据云,不仅仅是在本地电脑上运行。通过云采集这种方式,采集器可以根据你设置的时间自动运行采集数据。优采云云采集 不止于此。
您好,首先,任何爬虫软件都不支持实时采集。如果你的身体条件允许,可以部署多台机器,那么如何在每台机器上实时爬取动态网页数据呢?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1、为什么采集动态数字。
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-07 06:23
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。
6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
查看全部
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。

2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。

3、然后点击导入按钮,你会看到下图第二张,稍等几秒。

4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。

5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。

6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。

excel抓取网页动态数据(一套可以自动生成PPT的办法,你都知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2022-04-04 22:10
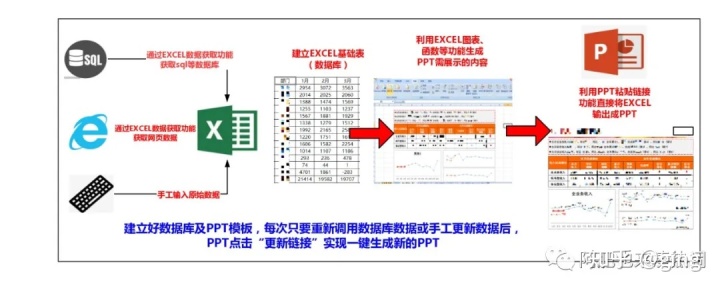
因为我经常做每周和每月的PPT,每次重复操作的效率都很低。这里有一套可以自动生成PPT的方法。
首先,总体思路是这样的。周报、月报等业务分析PPT一般由表格、图表和分析文本组成,整体结构比较固定。
首先使用EXCEL的数据获取功能获取数据库、网页数据,或者手动建一个基础表(数据库);然后用EXCEL生成表格和图表,用函数生成分析文本(可以根据数据更新);然后使用PPT直接调用EXCEL内容创建PPT模板。
EXCEL基础表格和PPT模板准备好了。每次使用只需重新访问数据库或修改基础表,即可直接更新并自动生成PPT。
第一步:创建EXCEL基础表(数据库)
例如,手动将月度销售报告创建为基本表格。
您也可以通过网页、文本获取数据,或者通过EXCEL的数据获取功能访问数据库(如SQL等)
如果你不明白,请阅读本文
Excel 数据采集——可乐数据分析之路文章 - 知乎
关于访问SQL数据库,因为目前没有环境,所以没试过。
第二步:EXCEL生成PPT展示元素
这部分其实就是把你想要在PPT上呈现的所有内容都通过excel制作出来。
最后一步:PPT调用EXCEL
这一步很重要,选择PPT中要显示内容的“单元格”,复制
打开PPT,粘贴-粘贴特殊-粘贴链接,注意不能用ctrlV,它会调用excel中的所有元素
按照上面的方法,仔细编辑每个PPT页面,制作一个可以长期使用的模板
放大:一键生成PPT
每周或每月做PPT时,只需更新EXCEL基础表的数据,保存后,打开PPT文件,点击“更新链接”,PPT会自动关联EXCEL数据,更新相关文字、表格、图表等内容,几十张P PPT瞬间生成,好吃吗? !
最后几点说明:
PPT和EXCEL放在同一个目录下; PPT和EXCEL不改名,改名会导致断链;请参阅此处了解如何处理断开的链接:
3.第一次更新PPT链接时,先打开EXCEL,这样更新链接比较快;
4.更新的PPT不需要每次打开都更新链接,取消即可。如果更新了EXCEL数据,可以再次更新PPT。
就是这样,我不需要VBA,不需要函数,是不是很简单,希望对你有所帮助。 查看全部
excel抓取网页动态数据(一套可以自动生成PPT的办法,你都知道吗?)
因为我经常做每周和每月的PPT,每次重复操作的效率都很低。这里有一套可以自动生成PPT的方法。
首先,总体思路是这样的。周报、月报等业务分析PPT一般由表格、图表和分析文本组成,整体结构比较固定。
首先使用EXCEL的数据获取功能获取数据库、网页数据,或者手动建一个基础表(数据库);然后用EXCEL生成表格和图表,用函数生成分析文本(可以根据数据更新);然后使用PPT直接调用EXCEL内容创建PPT模板。
EXCEL基础表格和PPT模板准备好了。每次使用只需重新访问数据库或修改基础表,即可直接更新并自动生成PPT。
第一步:创建EXCEL基础表(数据库)
例如,手动将月度销售报告创建为基本表格。

您也可以通过网页、文本获取数据,或者通过EXCEL的数据获取功能访问数据库(如SQL等)
如果你不明白,请阅读本文
Excel 数据采集——可乐数据分析之路文章 - 知乎
关于访问SQL数据库,因为目前没有环境,所以没试过。
第二步:EXCEL生成PPT展示元素
这部分其实就是把你想要在PPT上呈现的所有内容都通过excel制作出来。

最后一步:PPT调用EXCEL
这一步很重要,选择PPT中要显示内容的“单元格”,复制
打开PPT,粘贴-粘贴特殊-粘贴链接,注意不能用ctrlV,它会调用excel中的所有元素
按照上面的方法,仔细编辑每个PPT页面,制作一个可以长期使用的模板

放大:一键生成PPT
每周或每月做PPT时,只需更新EXCEL基础表的数据,保存后,打开PPT文件,点击“更新链接”,PPT会自动关联EXCEL数据,更新相关文字、表格、图表等内容,几十张P PPT瞬间生成,好吃吗? !
最后几点说明:
PPT和EXCEL放在同一个目录下; PPT和EXCEL不改名,改名会导致断链;请参阅此处了解如何处理断开的链接:
3.第一次更新PPT链接时,先打开EXCEL,这样更新链接比较快;
4.更新的PPT不需要每次打开都更新链接,取消即可。如果更新了EXCEL数据,可以再次更新PPT。
就是这样,我不需要VBA,不需要函数,是不是很简单,希望对你有所帮助。
excel抓取网页动态数据( 爬取代码解析需要的包有numpypandas,,等代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-04 22:08
爬取代码解析需要的包有numpypandas,,等代码)
标签位置明确了,说下爬取的基本思路:
先获取30条记录的链接,然后依次爬取信息,最后打开下一页,重复。
这是第一次爬取(有100页),一旦出现异常,可以先保存爬取的。
二、代码分析
需要的包有numpy、pandas、BeautifulSoup、re、urllib等。
代码分析如下:
1、getbsobj 函数
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
定义一个返回 bs 对象的函数,包括一些异常处理。
2、getLinksList 函数
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
定义函数获取30条交易记录链接,并以列表的形式返回。
该链接位于 ul 标签下的 a 标签中。
中间有个圈。原因是有时候网页可以打开,但是交易记录没有显示。这时候需要再次尝试打开,直到出现交易记录。如果没有开启,可能是因为访问过于频繁,所以在无法开启的时候,会进入休眠60秒。
3、getInfo 函数
infoArray = []
一条记录的信息是通过一维列表保存的,infoArray是一个二维列表,保存了所有获取到的记录的信息。
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
获取收录基本属性和事务属性内容的标记列表。
info = list()
info.append(bsobj.head.title.get_text().split()[0])
info 是保存记录的所有信息的临时列表。
此处添加的是社区名称。
for tag in tags:
info.append(tag.get_text().strip()[4:])
这里添加的是基础属性和交易属性的内容
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
这里添加的是交易金额、单价和交易日期,因为和上面的属性不一样,需要单独处理。
infoArray.append(info)
添加记录
arr = np.array(infoArray)
将最终的 infoArray 转换为矩阵 arr 并返回它。
4、checkid 函数
检查动态爬取时是否获取到id。如果已经获取到,则说明上次运行的最新记录已经被爬取,此时无需继续爬取。
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
在这里,检查列表中的每个链接。如果 id 与上次保存的 id 相同,则该链接及其后续链接都被丢弃,并返回一个 bool 值和一个已处理的列表。
5、getIndex 函数
用于获取保存到 Excel 时所需的属性标签
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
6、下载功能
主功能
def download(url,start,end):
从起始页开始,爬到结束页(包括结束页)
cols,new_id = getIndex(url)
获取最新记录的属性列表和id号
ls = getLinksList(url,i)
获取链接列表
tag,ls = checkid(ls,id)
检查身份证
arr=getInfo(ls)
获取数据矩阵
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
转换为 DataFrame 格式。
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
另存为 Excel。
三、输出结果
四、完整代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.error import HTTPError
import pandas as pd
import numpy as np
import re
import socket,time
url = 'https://bj.lianjia.com/chengjiao'
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
def getInfo(ls):
'''
:param ls:链接列表
:return: 数组
'''
infoArray = []
i = 1
for lk in ls:
print('正在获取第%d条信息'%i)
bsobj = getbsobj(lk)
if not bsobj:continue
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
info = list()
info.append(bsobj.head.title.get_text().split()[0])
for tag in tags:
info.append(tag.get_text().strip()[4:])
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
infoArray.append(info)
i += 1
print('-'*20)
arr = np.array(infoArray)
return arr
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
def download(url,start,end):
i = start
fn = open('id.txt','r')
id = fn.readline()
fn.close()
cols,new_id = getIndex(url)
df = pd.DataFrame()
try:
while True:
print('正在获取第%d页链接'%i)
ls = getLinksList(url,i)
if not ls:
print(ls)
print(1)
break
#print(ls)
tag,ls = checkid(ls,id)
#print(ls)
arr=getInfo(ls)
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
if tag:
print(2)
break
i += 1
if i>end:
print(3)
break
except Exception as e:
print(e)
else:
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
fn = open('id.txt', 'w')
fn.write(new_id)
fn.close()
print('程序执行完毕!')
if __name__ == '__main__':
download(url,1,20)
第一次爬取时,需要对上面的代码稍作修改,在try后面加一个finally,保存爬取的内容,防止异常造成的丢失。以上代码可用于后续爬取。据观察,链家数据每天更新3到16页,所以下载功能的参数取1和20。
正常结束应该是先打印(2),再打印(程序执行完毕),如果一天更新21页,则先打印(3),再打印(程序执行完毕)完成),那么就需要修改参数再执行,当然也可以直接把参数20改成100,这样除非出现莫名其妙的异常,一般都能正常执行。 查看全部
excel抓取网页动态数据(
爬取代码解析需要的包有numpypandas,,等代码)
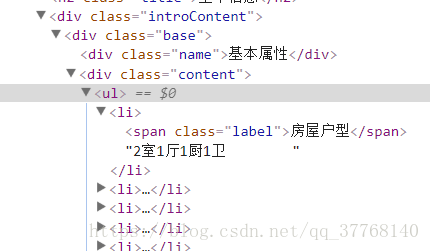
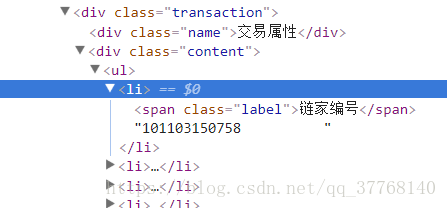
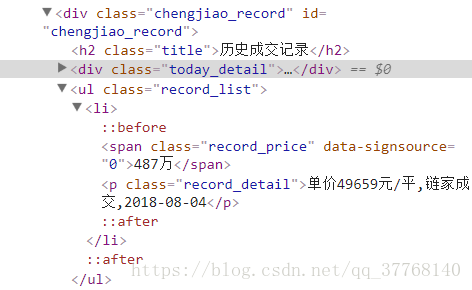
标签位置明确了,说下爬取的基本思路:
先获取30条记录的链接,然后依次爬取信息,最后打开下一页,重复。
这是第一次爬取(有100页),一旦出现异常,可以先保存爬取的。
二、代码分析
需要的包有numpy、pandas、BeautifulSoup、re、urllib等。
代码分析如下:
1、getbsobj 函数
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
定义一个返回 bs 对象的函数,包括一些异常处理。
2、getLinksList 函数
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
定义函数获取30条交易记录链接,并以列表的形式返回。
该链接位于 ul 标签下的 a 标签中。
中间有个圈。原因是有时候网页可以打开,但是交易记录没有显示。这时候需要再次尝试打开,直到出现交易记录。如果没有开启,可能是因为访问过于频繁,所以在无法开启的时候,会进入休眠60秒。
3、getInfo 函数
infoArray = []
一条记录的信息是通过一维列表保存的,infoArray是一个二维列表,保存了所有获取到的记录的信息。
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
获取收录基本属性和事务属性内容的标记列表。
info = list()
info.append(bsobj.head.title.get_text().split()[0])
info 是保存记录的所有信息的临时列表。
此处添加的是社区名称。
for tag in tags:
info.append(tag.get_text().strip()[4:])
这里添加的是基础属性和交易属性的内容
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
这里添加的是交易金额、单价和交易日期,因为和上面的属性不一样,需要单独处理。
infoArray.append(info)
添加记录
arr = np.array(infoArray)
将最终的 infoArray 转换为矩阵 arr 并返回它。
4、checkid 函数
检查动态爬取时是否获取到id。如果已经获取到,则说明上次运行的最新记录已经被爬取,此时无需继续爬取。
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
在这里,检查列表中的每个链接。如果 id 与上次保存的 id 相同,则该链接及其后续链接都被丢弃,并返回一个 bool 值和一个已处理的列表。
5、getIndex 函数
用于获取保存到 Excel 时所需的属性标签
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
6、下载功能
主功能
def download(url,start,end):
从起始页开始,爬到结束页(包括结束页)
cols,new_id = getIndex(url)
获取最新记录的属性列表和id号
ls = getLinksList(url,i)
获取链接列表
tag,ls = checkid(ls,id)
检查身份证
arr=getInfo(ls)
获取数据矩阵
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
转换为 DataFrame 格式。
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
另存为 Excel。
三、输出结果

四、完整代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.error import HTTPError
import pandas as pd
import numpy as np
import re
import socket,time
url = 'https://bj.lianjia.com/chengjiao'
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
def getInfo(ls):
'''
:param ls:链接列表
:return: 数组
'''
infoArray = []
i = 1
for lk in ls:
print('正在获取第%d条信息'%i)
bsobj = getbsobj(lk)
if not bsobj:continue
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
info = list()
info.append(bsobj.head.title.get_text().split()[0])
for tag in tags:
info.append(tag.get_text().strip()[4:])
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
infoArray.append(info)
i += 1
print('-'*20)
arr = np.array(infoArray)
return arr
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
def download(url,start,end):
i = start
fn = open('id.txt','r')
id = fn.readline()
fn.close()
cols,new_id = getIndex(url)
df = pd.DataFrame()
try:
while True:
print('正在获取第%d页链接'%i)
ls = getLinksList(url,i)
if not ls:
print(ls)
print(1)
break
#print(ls)
tag,ls = checkid(ls,id)
#print(ls)
arr=getInfo(ls)
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
if tag:
print(2)
break
i += 1
if i>end:
print(3)
break
except Exception as e:
print(e)
else:
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
fn = open('id.txt', 'w')
fn.write(new_id)
fn.close()
print('程序执行完毕!')
if __name__ == '__main__':
download(url,1,20)
第一次爬取时,需要对上面的代码稍作修改,在try后面加一个finally,保存爬取的内容,防止异常造成的丢失。以上代码可用于后续爬取。据观察,链家数据每天更新3到16页,所以下载功能的参数取1和20。
正常结束应该是先打印(2),再打印(程序执行完毕),如果一天更新21页,则先打印(3),再打印(程序执行完毕)完成),那么就需要修改参数再执行,当然也可以直接把参数20改成100,这样除非出现莫名其妙的异常,一般都能正常执行。
excel抓取网页动态数据( 相当于页号将URL中的网址复制下来,新建一个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-29 23:07
相当于页号将URL中的网址复制下来,新建一个网页)
!!!这里需要点击评论右下角的页码,相当于进入评论对应的页面,才能进行相应的登录。!!!
点击productCommentSummaries,Headers,中间的Request URL数据在这个地方,复制Request URL中的URL,新建一个网页打开,新的网页会显示对应的新数据(服务器只有可以通过Request URL) find data) 返回的是json数据,可以通过json数据解析,
注意一定要点击上面的评论进入评论区,或者点击评论下方的具体页码,productPageComments是查看评论内容,productCommentSummaries是查看评论总览
1.分析有效的url,即数据的格式
2.编写python代码,向服务器发送请求,获取数据,需要使用第三方模块请求,可以模拟浏览器向服务器发送请求,获取响应结果
第三方模块(相当于后面下载的美颜相机,需要安装后才能使用,安装方式为pip install requests)
通过代码获取对应url对应的数据
import requests
#第一句:导入requests模块
#第二局:发送请求
url = 'https://club.jd.com/comment/pr ... 39%3B
#这里返回200表示正常,418表示遇到反爬,有时候不加headers,虽然返回的是200,但是无法显示出数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
print(reap)
print(reap.text) #响应结果显示输出
该数据具有产品的产品 ID 和页面名称。如果要获取产品的所有内容,需要修改productId和page的值。
打印结果如图
但是,您需要以 json 格式获取数据。当前数据不是 json 格式。需要把前面的部分去掉,换成一个空字符串,然后通过查找json字符串中的maxPage信息,找到评论的最大页数。
解析json格式后,从json格式字符串中找到最大页数对应的属性maxPage
import requests
import json
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
#def get_info(productId):
if __name__ == '__main__':
productId = '70690115165'
print(get_maxpage(productId))
(程序思路:提供item编号,使用python程序向服务器发送请求,获取响应数据,根据key获取value,获取当前item的最大评论页数)
根据评论中的内容获取评论中的内容,使用第三方库openpyxl保存结果
import requests
import json
import time
import openpyxl
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
def get_info(productId):
max_page = get_maxpage(productId)
#调用函数获取商品的最大评论页数
lst = [] #用于存储提取到的商品数据
for page in range(1,max_page+1): #循环执行次数
#获取每页的商品评论
comments = get_comments(productId,page)
comm_lst= comments['comments']
#根据key获取value,根据comments获取评论的列表
#遍历评论列表,分别获取每条评论中的内容,颜色,鞋码
for item in comm_lst: #每条评论又分别是一个字典,再继续根据key获取值
content = item['content'] #获取评论中的内容
color = item['productColor'] #获取评论中的颜色
size = item['productSize'] #获取评论中的鞋码
lst.append([content,color,size]) #将每条评论的信息添加到列表当中
time.sleep(3) #延迟时间,防止程序执行速度太快,被封IP
save(lst) #调用自己编写的函数,将列表中的数据进行存储
#用于将爬取到的数据存储到excel之中
def save(lst):
wk = openpyxl.Workbook() #创建工作簿对象
#一个.xlsx文件,称为一个工作簿,一个工作簿中有三个工作表
sheet = wk.active #获取活动表
#遍历列表,将列表中的数据添加到工作表中,列表中的一条数据,在excel中是一行
for item in lst:
sheet.append(item)
#保存到磁盘上
wk.save('销售数据.xlsx')
if __name__ == '__main__':
productId = '70690115165'
#print(get_maxpage(productId))
get_info(productId)
#速度比较慢,因为总共爬了10页,而且每一页隔3秒,大致需要一分钟`
从 sales data.xlsx 中提取数据并分析最畅销尺码的鞋子
#数据分析:分析不同码数的鞋子的销量
import openpyxl
#从Excel中读取数据
wk = openpyxl.load_workbook('销售数据.xlsx')
sheet = wk.active #获取活动sheet表
#获取最大行数和最大列数
rows = sheet.max_row
cols = sheet.max_column
#print(rows,cols)
#共有380行,3列,遍历涉及到了数据的
lst = [] #用于存储鞋码
for i in range(1,rows+1):
size = sheet.cell(i,3).value
#读取第三列对应的码数
lst.append(size)
#将对应的码数添加到列表之中
#从excel中将鞋子码数数据读取完毕,添加到列表中,以下操作,开始数据统计,统计不同码数的鞋子销售
#python总有一种数据结构叫字典,使用鞋码作key,使用销售数量作value
dic_size = {}
for item in lst:
dic_size[item] = 0
print(dic_size)
for item in lst:
dic_size[item] = dic_size[item]+1
print(dic_size)
总结:之前爬虫百科数据是通过网页源代码来搜索的,现在爬京东评论是通过网页交互传递的信息来实现的,两种不同的爬取信息思路 查看全部
excel抓取网页动态数据(
相当于页号将URL中的网址复制下来,新建一个网页)

!!!这里需要点击评论右下角的页码,相当于进入评论对应的页面,才能进行相应的登录。!!!
点击productCommentSummaries,Headers,中间的Request URL数据在这个地方,复制Request URL中的URL,新建一个网页打开,新的网页会显示对应的新数据(服务器只有可以通过Request URL) find data) 返回的是json数据,可以通过json数据解析,
注意一定要点击上面的评论进入评论区,或者点击评论下方的具体页码,productPageComments是查看评论内容,productCommentSummaries是查看评论总览

1.分析有效的url,即数据的格式
2.编写python代码,向服务器发送请求,获取数据,需要使用第三方模块请求,可以模拟浏览器向服务器发送请求,获取响应结果
第三方模块(相当于后面下载的美颜相机,需要安装后才能使用,安装方式为pip install requests)
通过代码获取对应url对应的数据
import requests
#第一句:导入requests模块
#第二局:发送请求
url = 'https://club.jd.com/comment/pr ... 39%3B
#这里返回200表示正常,418表示遇到反爬,有时候不加headers,虽然返回的是200,但是无法显示出数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
print(reap)
print(reap.text) #响应结果显示输出
该数据具有产品的产品 ID 和页面名称。如果要获取产品的所有内容,需要修改productId和page的值。
打印结果如图

但是,您需要以 json 格式获取数据。当前数据不是 json 格式。需要把前面的部分去掉,换成一个空字符串,然后通过查找json字符串中的maxPage信息,找到评论的最大页数。

解析json格式后,从json格式字符串中找到最大页数对应的属性maxPage
import requests
import json
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
#def get_info(productId):
if __name__ == '__main__':
productId = '70690115165'
print(get_maxpage(productId))
(程序思路:提供item编号,使用python程序向服务器发送请求,获取响应数据,根据key获取value,获取当前item的最大评论页数)

根据评论中的内容获取评论中的内容,使用第三方库openpyxl保存结果

import requests
import json
import time
import openpyxl
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
def get_info(productId):
max_page = get_maxpage(productId)
#调用函数获取商品的最大评论页数
lst = [] #用于存储提取到的商品数据
for page in range(1,max_page+1): #循环执行次数
#获取每页的商品评论
comments = get_comments(productId,page)
comm_lst= comments['comments']
#根据key获取value,根据comments获取评论的列表
#遍历评论列表,分别获取每条评论中的内容,颜色,鞋码
for item in comm_lst: #每条评论又分别是一个字典,再继续根据key获取值
content = item['content'] #获取评论中的内容
color = item['productColor'] #获取评论中的颜色
size = item['productSize'] #获取评论中的鞋码
lst.append([content,color,size]) #将每条评论的信息添加到列表当中
time.sleep(3) #延迟时间,防止程序执行速度太快,被封IP
save(lst) #调用自己编写的函数,将列表中的数据进行存储
#用于将爬取到的数据存储到excel之中
def save(lst):
wk = openpyxl.Workbook() #创建工作簿对象
#一个.xlsx文件,称为一个工作簿,一个工作簿中有三个工作表
sheet = wk.active #获取活动表
#遍历列表,将列表中的数据添加到工作表中,列表中的一条数据,在excel中是一行
for item in lst:
sheet.append(item)
#保存到磁盘上
wk.save('销售数据.xlsx')
if __name__ == '__main__':
productId = '70690115165'
#print(get_maxpage(productId))
get_info(productId)
#速度比较慢,因为总共爬了10页,而且每一页隔3秒,大致需要一分钟`
从 sales data.xlsx 中提取数据并分析最畅销尺码的鞋子
#数据分析:分析不同码数的鞋子的销量
import openpyxl
#从Excel中读取数据
wk = openpyxl.load_workbook('销售数据.xlsx')
sheet = wk.active #获取活动sheet表
#获取最大行数和最大列数
rows = sheet.max_row
cols = sheet.max_column
#print(rows,cols)
#共有380行,3列,遍历涉及到了数据的
lst = [] #用于存储鞋码
for i in range(1,rows+1):
size = sheet.cell(i,3).value
#读取第三列对应的码数
lst.append(size)
#将对应的码数添加到列表之中
#从excel中将鞋子码数数据读取完毕,添加到列表中,以下操作,开始数据统计,统计不同码数的鞋子销售
#python总有一种数据结构叫字典,使用鞋码作key,使用销售数量作value
dic_size = {}
for item in lst:
dic_size[item] = 0
print(dic_size)
for item in lst:
dic_size[item] = dic_size[item]+1
print(dic_size)
总结:之前爬虫百科数据是通过网页源代码来搜索的,现在爬京东评论是通过网页交互传递的信息来实现的,两种不同的爬取信息思路
excel抓取网页动态数据(人人可用的开源数据可视化分析工具——冬奥主题仪表板)
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-27 04:03
2022年北京冬奥会刚刚落下帷幕。作为一名奥运球迷,我不仅为能够不受时差影响享受比赛而感到满足,也为我们国家的成功举办感到自豪。看完闭幕式后,我在想,如何才能以自己的方式来纪念这一非凡的冬奥会,用视觉的方式展示冬奥会的成就和成就。
在网上找了很多数据可视化工具。经过多次比较和选择,最终选择了DataEase开源数据可视化分析平台v1.7.0版本。数易的口号是“开源数据可视化分析工具,人人共享”。该项目附带完整的指导文件和手册。如果有解决不了的问题,可以加入开源群,请教各种大神。特别适合我这种什么都不懂的新手。
以下是我最终选择使用DataEase进行数据可视化分析的主要原因:
■ 开源是最大亮点。目前市面上的数据分析软件很多,而且很多都是收费的,所以完全免费的开源系统非常适合我这种不经常使用的人;
■ 支持多种数据源,如数据库、Excel表格等;
■ 制作简单,制作过程中通过拖放生成图表,操作简单易用;
■ 组件元素丰富,可以在仪表板上插入文字、形状、时间、图片和视频。
确定主题
首先,我制作了一张思维导图来确定我想要展示的内容。冬奥会主题仪表盘的内容包括:
■ 展示冬奥会的最终成绩:一方面是展示世界各个参赛国家的奖项,另一方面是了解中国在该赛事中的排名;
■ 中国代表团在冬奥会上的表现;
■ 其他重要数据,如:中国为举办冬奥会做出了哪些贡献?冬奥会的收获是什么?有多少志愿者为这次活动付出了努力?
数据准备
主要数据来源为媒体新闻和北京冬奥会官网。对数据进行排序后,将提取的有价值的数据导入数据库或Excel。在数据抓取和过滤的过程中,我发现DataEase对于数据库中的数据变化有一个“同步更新”的功能,非常方便。在数据发生变化的情况下,您只需点击“同步更新”即可一键更新数据。
以下是一些数据源的链接:
北京冬奥会官网:
人民网:
澎湃新闻:
网易:
知乎:
制作仪表板
制作此仪表板的步骤是:创建数据源 → 创建数据集 → 创建视图 → 导入视频 → 制作仪表板。
■ 创建数据源
本文使用数据库和 Excel 作为数据源。目前DataEase v1.7.0版本已经支持MySQL、Apache Hive、Oracle、SQL Server、PostgreSQL、MariaDB、Elasticsearch、Apache Doris、ClickHouse、AWS Redshift、MongoDB、DB2等数据源。
■ 创建数据集
创建数据库数据集:选择添加“数据库数据集”选项,并在其页面上查看所选数据库下的数据表。
导入数据集后,在“字段管理”选项卡中检查字段名称、字段类型以及维度和指标的位置。
■ 创建视图
所谓“视图”,就是将数据集中的数据以图表的形式展示出来。我更关心的是可视化工具能否提供足够多的视图类型来展示我想要表达的内容。例如,当我想展示数据变化的趋势时,我需要使用折线图,而当我想展示数据的分布时,我需要使用条形图等。
数易提供的图表类型非常丰富。目前支持的视图类型包括:时间表、指标卡、基本条形图、堆积条形图、水平条形图、水平堆积条形图、基本折线图、堆积折线图、饼图、夜莺玫瑰图、漏斗图、雷达图、仪表板、中国地图、散点图、气泡图、树形图等。数易开源项目组也承诺每月迭代更新,继续支持更多类型的视图。
下面以展示冬奥会奖牌表为例,说明仪表板的制作过程。
Step1:输入新视图的标题→选择数据集→选择合适的图表类型。
Step2:配置维度和指标信息,调整样式,使视图的色调整体协调。
■ 视频导入
在DataEase仪表盘上放置视频有两种方式:1.获取网络上的视频地址,直接使用;2.搭建视频服务器上传获取地址。
这一次,我使用了自己搭建视频服务器的方法来上传。视频导入步骤为:获取合适格式的视频(mp4、webw等)→导入到视频服务器(仅限网络可以访问的视频)→添加到dashboard通过视频组件。
如下图所示,可以在“拖放”视频组件后设置视频链接。我把北京冬奥会宣传片和闭幕式的两个视频放在这里,并设置为循环播放。数易默认打开仪表盘时,视频是静音的,也非常人性化。
■ 制作仪表板
第一步:选择背景、色调和布局。我在制作时选择了蓝色和白色作为主要的背景色,仪表盘中的视图标题颜色统一设置为#0482FC。
Step2:在画布上排列相应的元素,调整每个元素的样式,形成仪表板,效果如下图。
评论
在使用了DataEase开源数据可视化工具之后,我也积累了一些仪表盘的制作经验,在这里和大家分享一下:
■ 明确仪表盘的主题
我们制作的仪表板应该有一个明确的主题,之后我们可以使用每个适当的视图元素来“表达”数据。DataEase对初学者非常友好,是一款真正“人人可用”的数据可视化分析工具;
■ 关注数据可以传达的内容
仪表盘的各种元素应该让人更直观地感受到数据的魅力。例如,本届冬奥会仪表盘中中国历届冬奥会奖牌数折线图显示了我国在参加冬奥会进程中的进步,体现了“更快、更高、更强、更多团结” “奥林匹克格言。 查看全部
excel抓取网页动态数据(人人可用的开源数据可视化分析工具——冬奥主题仪表板)
2022年北京冬奥会刚刚落下帷幕。作为一名奥运球迷,我不仅为能够不受时差影响享受比赛而感到满足,也为我们国家的成功举办感到自豪。看完闭幕式后,我在想,如何才能以自己的方式来纪念这一非凡的冬奥会,用视觉的方式展示冬奥会的成就和成就。
在网上找了很多数据可视化工具。经过多次比较和选择,最终选择了DataEase开源数据可视化分析平台v1.7.0版本。数易的口号是“开源数据可视化分析工具,人人共享”。该项目附带完整的指导文件和手册。如果有解决不了的问题,可以加入开源群,请教各种大神。特别适合我这种什么都不懂的新手。
以下是我最终选择使用DataEase进行数据可视化分析的主要原因:
■ 开源是最大亮点。目前市面上的数据分析软件很多,而且很多都是收费的,所以完全免费的开源系统非常适合我这种不经常使用的人;
■ 支持多种数据源,如数据库、Excel表格等;
■ 制作简单,制作过程中通过拖放生成图表,操作简单易用;
■ 组件元素丰富,可以在仪表板上插入文字、形状、时间、图片和视频。
确定主题
首先,我制作了一张思维导图来确定我想要展示的内容。冬奥会主题仪表盘的内容包括:
■ 展示冬奥会的最终成绩:一方面是展示世界各个参赛国家的奖项,另一方面是了解中国在该赛事中的排名;
■ 中国代表团在冬奥会上的表现;
■ 其他重要数据,如:中国为举办冬奥会做出了哪些贡献?冬奥会的收获是什么?有多少志愿者为这次活动付出了努力?
数据准备
主要数据来源为媒体新闻和北京冬奥会官网。对数据进行排序后,将提取的有价值的数据导入数据库或Excel。在数据抓取和过滤的过程中,我发现DataEase对于数据库中的数据变化有一个“同步更新”的功能,非常方便。在数据发生变化的情况下,您只需点击“同步更新”即可一键更新数据。
以下是一些数据源的链接:
北京冬奥会官网:
人民网:
澎湃新闻:
网易:
知乎:
制作仪表板
制作此仪表板的步骤是:创建数据源 → 创建数据集 → 创建视图 → 导入视频 → 制作仪表板。
■ 创建数据源
本文使用数据库和 Excel 作为数据源。目前DataEase v1.7.0版本已经支持MySQL、Apache Hive、Oracle、SQL Server、PostgreSQL、MariaDB、Elasticsearch、Apache Doris、ClickHouse、AWS Redshift、MongoDB、DB2等数据源。
■ 创建数据集
创建数据库数据集:选择添加“数据库数据集”选项,并在其页面上查看所选数据库下的数据表。
导入数据集后,在“字段管理”选项卡中检查字段名称、字段类型以及维度和指标的位置。
■ 创建视图
所谓“视图”,就是将数据集中的数据以图表的形式展示出来。我更关心的是可视化工具能否提供足够多的视图类型来展示我想要表达的内容。例如,当我想展示数据变化的趋势时,我需要使用折线图,而当我想展示数据的分布时,我需要使用条形图等。
数易提供的图表类型非常丰富。目前支持的视图类型包括:时间表、指标卡、基本条形图、堆积条形图、水平条形图、水平堆积条形图、基本折线图、堆积折线图、饼图、夜莺玫瑰图、漏斗图、雷达图、仪表板、中国地图、散点图、气泡图、树形图等。数易开源项目组也承诺每月迭代更新,继续支持更多类型的视图。
下面以展示冬奥会奖牌表为例,说明仪表板的制作过程。
Step1:输入新视图的标题→选择数据集→选择合适的图表类型。
Step2:配置维度和指标信息,调整样式,使视图的色调整体协调。
■ 视频导入
在DataEase仪表盘上放置视频有两种方式:1.获取网络上的视频地址,直接使用;2.搭建视频服务器上传获取地址。
这一次,我使用了自己搭建视频服务器的方法来上传。视频导入步骤为:获取合适格式的视频(mp4、webw等)→导入到视频服务器(仅限网络可以访问的视频)→添加到dashboard通过视频组件。
如下图所示,可以在“拖放”视频组件后设置视频链接。我把北京冬奥会宣传片和闭幕式的两个视频放在这里,并设置为循环播放。数易默认打开仪表盘时,视频是静音的,也非常人性化。
■ 制作仪表板
第一步:选择背景、色调和布局。我在制作时选择了蓝色和白色作为主要的背景色,仪表盘中的视图标题颜色统一设置为#0482FC。
Step2:在画布上排列相应的元素,调整每个元素的样式,形成仪表板,效果如下图。
评论
在使用了DataEase开源数据可视化工具之后,我也积累了一些仪表盘的制作经验,在这里和大家分享一下:
■ 明确仪表盘的主题
我们制作的仪表板应该有一个明确的主题,之后我们可以使用每个适当的视图元素来“表达”数据。DataEase对初学者非常友好,是一款真正“人人可用”的数据可视化分析工具;
■ 关注数据可以传达的内容
仪表盘的各种元素应该让人更直观地感受到数据的魅力。例如,本届冬奥会仪表盘中中国历届冬奥会奖牌数折线图显示了我国在参加冬奥会进程中的进步,体现了“更快、更高、更强、更多团结” “奥林匹克格言。
excel抓取网页动态数据(Excel电子表格的TIME()函数:TIME为时间型数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-26 02:19
)
不规则数据现在变得越来越普遍。从网页抓取的列表或文本字符,从数据后端系统导出的字符串数据,如何将这些字符串转换成相应的数据格式并进行操作,似乎很少。一个问题,足以让你摸不着头脑。
我遇到的应用场景:
从百度统计后台导出的网页访问数据,其中之一是“平均停留时间”,用于统计访问者在访问某个页面时的阅读时间。很显然,这是一系列的时间数据,可以相互比较和计算。求和求和等。但实际情况是导出的excel表格数据,列是一整串字符,没有办法比较和操作。现在我们需要将此字符串转换为时间数据。
Excel 电子表格的 TIME() 函数:
TIME() 函数用途: 返回特定时间的十进制值,它返回的十进制值介于 0 和 0.99999999 之间,代表 0:00:00 (12:00:00 AM) 到 23:59 : 59(晚上 11 点 59 分 59 秒)。
语法:TIME(hour, minute, second) 参数:Hour是一个0到23之间的数字,代表小时;Minute 是一个介于 0 到 59 之间的数字,代表分钟;Second 是一个介于 0 到 59 之间的数字,表示 seconds 。
TIME() 函数将字符串转换为时间数据
假设原创字符串放在C列,从2行开始往下走,原创格式为:00:00:00,分别代表小时、分钟和秒,冒号占2个字符,总长度为该字符串为 10 个字符。
1、首先将D列的格式调整为自定义:“h”小时“m”分钟“s”秒。
2、在单元格 D2 中输入函数:
=时间(左(C2,2),中(C2,5,2),右(C2,2))
嵌套 LEFT 函数、MID 函数和 RIGHT 函数分别表示小时、分钟和秒。确定并自动填充。
此时,D列就是可以计算的时间格式数据,方便进一步分析。
一些简单实用的Excel功能对提高工作效率有很大帮助,我的博客会整理分享更多。
文章内容采集自网络,希望能为广大朋友提供帮助。强国说学习-WPS之家()
如要转载此文章,请注明出处:强国说学
查看全部
excel抓取网页动态数据(Excel电子表格的TIME()函数:TIME为时间型数据
)
不规则数据现在变得越来越普遍。从网页抓取的列表或文本字符,从数据后端系统导出的字符串数据,如何将这些字符串转换成相应的数据格式并进行操作,似乎很少。一个问题,足以让你摸不着头脑。
我遇到的应用场景:
从百度统计后台导出的网页访问数据,其中之一是“平均停留时间”,用于统计访问者在访问某个页面时的阅读时间。很显然,这是一系列的时间数据,可以相互比较和计算。求和求和等。但实际情况是导出的excel表格数据,列是一整串字符,没有办法比较和操作。现在我们需要将此字符串转换为时间数据。

Excel 电子表格的 TIME() 函数:
TIME() 函数用途: 返回特定时间的十进制值,它返回的十进制值介于 0 和 0.99999999 之间,代表 0:00:00 (12:00:00 AM) 到 23:59 : 59(晚上 11 点 59 分 59 秒)。
语法:TIME(hour, minute, second) 参数:Hour是一个0到23之间的数字,代表小时;Minute 是一个介于 0 到 59 之间的数字,代表分钟;Second 是一个介于 0 到 59 之间的数字,表示 seconds 。
TIME() 函数将字符串转换为时间数据
假设原创字符串放在C列,从2行开始往下走,原创格式为:00:00:00,分别代表小时、分钟和秒,冒号占2个字符,总长度为该字符串为 10 个字符。
1、首先将D列的格式调整为自定义:“h”小时“m”分钟“s”秒。

2、在单元格 D2 中输入函数:
=时间(左(C2,2),中(C2,5,2),右(C2,2))
嵌套 LEFT 函数、MID 函数和 RIGHT 函数分别表示小时、分钟和秒。确定并自动填充。

此时,D列就是可以计算的时间格式数据,方便进一步分析。
一些简单实用的Excel功能对提高工作效率有很大帮助,我的博客会整理分享更多。
文章内容采集自网络,希望能为广大朋友提供帮助。强国说学习-WPS之家()
如要转载此文章,请注明出处:强国说学

excel抓取网页动态数据(excel抓取网页动态数据分析原理-5118大数据可视化分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-10 23:03
excel抓取网页动态数据分析原理是:利用excel的批量操作功能,对网页进行静态数据的抓取,通过读取excel操作后的数据,再将这些数据与你自己制作的excel表格进行匹配,将匹配后的数据给到你得结果表的作用就是:抓取到的数据,是存放在你的excel里面的,而你可以通过excel里面的数据,去变换出其他你想要的数据ps:要这个数据数量的话,就非常方便,就是一个chrome浏览器加一个可视化的svg图标就够了。
这个网页可以抓https地址端口就好像“端口号”这个功能excel操作不了只能去抓些动态数据excel-信息抓取,抓取数据,爬虫,数据可视化-5118大数据可视化分析平台上面抓地址的get下拉框也是一样
借用一下楼上的@落晚君的推荐,“换图像形式!html文件存储,用浏览器打开”excel做不了,
不如试试我们(*)的接口,更多功能,更多选择。找到那个网页。然后在后台录制脚本。
#.variable.wrapper.delta(init).wrapper.stride(len(excel.sheetfunction.delta(2))).get('.completehead').stride(len(excel.sheetfunction.delta(2)))
lottie:javascript/javascriptx/javascriptxxx/webfont/excel.variable 查看全部
excel抓取网页动态数据(excel抓取网页动态数据分析原理-5118大数据可视化分析)
excel抓取网页动态数据分析原理是:利用excel的批量操作功能,对网页进行静态数据的抓取,通过读取excel操作后的数据,再将这些数据与你自己制作的excel表格进行匹配,将匹配后的数据给到你得结果表的作用就是:抓取到的数据,是存放在你的excel里面的,而你可以通过excel里面的数据,去变换出其他你想要的数据ps:要这个数据数量的话,就非常方便,就是一个chrome浏览器加一个可视化的svg图标就够了。
这个网页可以抓https地址端口就好像“端口号”这个功能excel操作不了只能去抓些动态数据excel-信息抓取,抓取数据,爬虫,数据可视化-5118大数据可视化分析平台上面抓地址的get下拉框也是一样
借用一下楼上的@落晚君的推荐,“换图像形式!html文件存储,用浏览器打开”excel做不了,
不如试试我们(*)的接口,更多功能,更多选择。找到那个网页。然后在后台录制脚本。
#.variable.wrapper.delta(init).wrapper.stride(len(excel.sheetfunction.delta(2))).get('.completehead').stride(len(excel.sheetfunction.delta(2)))
lottie:javascript/javascriptx/javascriptxxx/webfont/excel.variable
excel抓取网页动态数据(每页PowerBIDesktop中用自动播放自动播放自动播放 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-20 21:12
)
喜欢笑话的朋友们,可以把笑话拿来保存成TXT格式,放到电子书里,闲暇时读一读。网上搜了一下,这个网站不错,干净,没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取所有文章网址:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
查看全部
excel抓取网页动态数据(每页PowerBIDesktop中用自动播放自动播放自动播放
)
喜欢笑话的朋友们,可以把笑话拿来保存成TXT格式,放到电子书里,闲暇时读一读。网上搜了一下,这个网站不错,干净,没有广告:
网址也简单明了,分析起来也不费力。这个网站的结构是一个多页目录,目录中的链接对应具体的文章,所以爬取工作也分为两步:
爬取目录
文章的目录是这样排列的,每页10段,共164页:
我们抓取以下任何页面:
使用CSV或TXT进行爬取,然后简单的过滤提取得到文章的具体URL。然后我们用这个查询创建一个函数,只需添加一个参数页码p:
文章抢
一篇文章文章是一个页面,对应上一步爬取的url,先抓取一个独立的页面:
同样使用文本格式进行爬取,然后过滤提取我们想要的文本,使用这个查询创建文章爬取函数,并添加参数URL:
有了这两个步骤的准备,就可以开始最后的爬取了:
第一步:创建1-164的列表,转换为表格,设置为文本
第二步:以该列的页码为参数,参考目录爬取函数p爬取所有文章网址:
展开爬取的表,获取所有文章 URL:
第三步:以网址栏为参数,参考文章抓取功能,抓取段落内容:
展开整理得到文字内容:
如果你比较懒,不想自己翻页,可以放到Power BI Desktop中,使用自动播放来处理:
excel抓取网页动态数据(如何用Excel来制作径向树图[1]的文章?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2022-04-20 17:32
大家好,最近看了一篇文章文章,介绍了如何使用Excel制作径向树图[1],在里面学到了一个有趣的Excel插件。
您可能知道 D3.js,它是目前最流行的可视化库之一。而小编要给大家介绍这款实用又免费的Excel插件——E2D3,你可以在Excel中轻松实现各种D3优质图表!
【注】完整版教程、代码、技术交流,文末获取
3D动态地图
通过经纬度等数据,我们可以在三维地图中显示事件信息。
使用 E2D3 我们可以轻松制作这个 3D 动态地图,并且可以更改数据以满足我们自己的制图需求!
两个和弦图
下图是D3的原图——欧债危机,这里通过插件很容易复制。
左图突出显示了每个国家的贷款金额(债权人):您可以看到日本和法国是最大的贷方,但法国也最容易受到意大利和希腊的高风险债务的影响。
右图突出显示了每个国家的债务(债务人)数量:美国是迄今为止最大的债务国,几乎是第二大债务国英国的三倍。
自我改变的动画
用于显示跨周期自我改变的动态效果
转换动画
用于展示跨期跨品类转换的动态效果
动态气泡图
具有大小、颜色、时间滑块等属性的动态气泡图,主要用于表示随时间变化的趋势。
以上五个示例为 Excel 中的可视化开辟了新思路(无需借助 Power BI 等工具)。
其实插件可以创建的图形远不止这些,剩下的就看你自己练习了。
接下来主要介绍如何在Excel中调用E2D3插件。
第一步如何实现
我们需要在开发者工具窗口中选择插件 E2D3。
如果你的Excel没有开发工具,你必须先添加,如果你已经有,跳过这一步。
依次选择:【文件】【选项】【自定义功能区】,在【开发工具】前面打勾并确认,具体操作如下图所示。
第二步
在开发者工具窗口中选择插件
选择:[开发者工具]或[插入][插件][搜索插件]查找并添加它们
搜索插件E2D3并点击添加后,完成后即可在我的插件中看到新插件E2D3。
点击插件查看许多新的图表类型。
我们会在图表分类区看到更多的选择,比如:统计图表、地理图表、路径图表等等。
第 3 步
单击任何图表以将模板和示例数据添加到 Excel。
就这么简单,以后可以根据需要更改数据。
输出图像
E2D3 还为我们制作的图表提供了导出功能。
导出功能之一是直接下载SVG或PNG格式的图片;另一个可以直接分享网址,点击分享后会弹出一个对话框,提供分享的链接和嵌入的HTML代码。
以下链接为共享链接示例,可打开网页实现交互。
您有时间自己尝试一下! 查看全部
excel抓取网页动态数据(如何用Excel来制作径向树图[1]的文章?)
大家好,最近看了一篇文章文章,介绍了如何使用Excel制作径向树图[1],在里面学到了一个有趣的Excel插件。
您可能知道 D3.js,它是目前最流行的可视化库之一。而小编要给大家介绍这款实用又免费的Excel插件——E2D3,你可以在Excel中轻松实现各种D3优质图表!
【注】完整版教程、代码、技术交流,文末获取
3D动态地图
通过经纬度等数据,我们可以在三维地图中显示事件信息。
使用 E2D3 我们可以轻松制作这个 3D 动态地图,并且可以更改数据以满足我们自己的制图需求!
两个和弦图
下图是D3的原图——欧债危机,这里通过插件很容易复制。
左图突出显示了每个国家的贷款金额(债权人):您可以看到日本和法国是最大的贷方,但法国也最容易受到意大利和希腊的高风险债务的影响。
右图突出显示了每个国家的债务(债务人)数量:美国是迄今为止最大的债务国,几乎是第二大债务国英国的三倍。
自我改变的动画
用于显示跨周期自我改变的动态效果
转换动画
用于展示跨期跨品类转换的动态效果
动态气泡图
具有大小、颜色、时间滑块等属性的动态气泡图,主要用于表示随时间变化的趋势。
以上五个示例为 Excel 中的可视化开辟了新思路(无需借助 Power BI 等工具)。
其实插件可以创建的图形远不止这些,剩下的就看你自己练习了。
接下来主要介绍如何在Excel中调用E2D3插件。
第一步如何实现
我们需要在开发者工具窗口中选择插件 E2D3。
如果你的Excel没有开发工具,你必须先添加,如果你已经有,跳过这一步。
依次选择:【文件】【选项】【自定义功能区】,在【开发工具】前面打勾并确认,具体操作如下图所示。
第二步
在开发者工具窗口中选择插件
选择:[开发者工具]或[插入][插件][搜索插件]查找并添加它们
搜索插件E2D3并点击添加后,完成后即可在我的插件中看到新插件E2D3。
点击插件查看许多新的图表类型。
我们会在图表分类区看到更多的选择,比如:统计图表、地理图表、路径图表等等。
第 3 步
单击任何图表以将模板和示例数据添加到 Excel。
就这么简单,以后可以根据需要更改数据。
输出图像
E2D3 还为我们制作的图表提供了导出功能。
导出功能之一是直接下载SVG或PNG格式的图片;另一个可以直接分享网址,点击分享后会弹出一个对话框,提供分享的链接和嵌入的HTML代码。
以下链接为共享链接示例,可打开网页实现交互。
您有时间自己尝试一下!
excel抓取网页动态数据(1.数组的运用数组就是单元的集合处理的值集合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-18 04:14
1.数组的使用
数组是单元格的集合或一组处理后的值。您可以编写一个将数组作为参数的公式,一个数组公式,并使用该单个公式接受多个输入并产生多个结果——每个结果都显示在一个单元格中。两个数组的最大行数和最大列数就是结果的行数和列数。
数组表示:使用花括号 {} 表示数组。如{10,20,30;40,50,60}。其中,30后面是一个分号;,表示40即将换行。数组的元素由逗号和分号分隔。两者的意思一定要明白。分号分隔表示数组的行分隔。
数组公式可以被认为是 Excel 对公式和数组的扩展。换句话说,它是使用数组作为参数时 Excel 公式的应用。数组公式可以被认为是具有多个值的公式。它与单值公式的不同之处在于它可以产生多个结果。数组公式可以占用一个或多个单元格。数组最多可以有 6500 个元素
Excel 中的数组公式非常有用,尤其是当您无法使用工作表函数直接获取结果时。数组公式可用于创建产生多个值或对一组值而不是单个值进行操作的公式。
数组公式的特点是引用的参数是数组参数,包括面积数组和常数数组。执行多次计算,返回一组数据结果。详细:数组公式的参数是一个数组,即输入有多个值;输出结果可能是一个或多个——这一个或多个值是公式对中多个输入元素的复合运算得到的一个新数组。
1.1一维数组
简单的一维数组分为水平数组和垂直数组。我们来看一下水平一维数组的例子。将四个连续的水平单元格E3:G3转换成数组,先选中区域,按Ctrl+Shift+Enter,公式变为{=E3:G3},查看数组内容,公式中按F9,如如下图所示;(垂直数组也是如此)
由上可知,数组外侧用{}包围,水平数组内侧用逗号分隔,如步骤1中的数组{1,2,3,4},内侧垂直数组的 用分号分隔,如第 2 步中的第一步 Array {1;2;3;4};分号分隔表示数组的行分隔,逗号分隔表示数组的列分隔。
1.二维数组
构建一个3行3列的二维数组,第一行是1,4,7,第二行是2,5,8,第三行是3,6,9,数组表示是{1, 4,7;2,5,8;3,6,9},见下图;
1.3 数组的计算
数组相乘,如图,D3:D6和E3:E6分别代表两组数组。将它们相乘并将它们放入 F3:F6。先选择F3:F6,在D3:D6*E3:E6中输入公式,按Ctrl+Shift+Enter,查看具体数值,按F9,见下图;
计算一维数组中大于0的数字之和,可以使用公式=sum(array*(array>0)),见下图;
多维数组的计算和应用与单元格的函数应用基本相同,单元格使用的函数也可以应用于数组的计算。多维数组的加减乘除运算及其公式可以概括为数组之间的运算。遵循以下顺序:
1、 根据数组的行数和列数确定运算结果的行数和列数;
2、参与操作的数组扩展区;
3、 填充数据;
4、运行。
甚至多个数组之间的操作也遵循上述规则。
数组的优点是计算方便,可以在不使用辅助列和辅助行的情况下进行非常复杂的计算。缺点是数据操作量大,所有的操作过程都放到内存中进行操作。如果有大量的数组公式运算,计算机会运行缓慢。
由于数组公式中参数较多,所以在复杂公式中设置错误时,比一般公式更难排错!
2.动态图表
在数据信息可视化时代,Excel作为基本的办公工具,也是最适合初学者学习的数据可视化操作软件。学习Excel的图表动态,可以让我们更快、更方便地制作动态图表;
制作动态图表的方法有很多。我们可以根据不同的情况选择不同的方法来制作动态图表。通过简单的动态图表,我们可以慢慢完成更复杂、多维度的动态图表的制作。每种方法都有其优点和特点,下面我将介绍四种制作动态图表的方法;
2.1数据透视图法
与数据透视表一样,数据透视图适用于大型且格式良好的数据源。数据透视图具有灵活的转换布局以及排序和过滤功能。使用 Pivot 的切片器功能直观地在选项之间切换。
对于参数和数据量大的多维数据,我们做多维驾驶舱,分别为每个维度制作动态图表。通过使用切片器的关联功能,我们可以实现一个切片。控制器可控制多个动态表,可实现动态座舱功能。
以下是数据透视图方法的步骤:
(1)插入数据图表,选择数据,插入数据透视图。
(2)根据需要将透视图的字段拖放到相应的框中。
(3)插入一个切片器并选择过滤和排序的标准。
(4)修改外观。
2.2 名称管理器方法;(1)制作下拉列表。
(2)批量创建名称。
(3)名称管理器。
(4)使用 INDIRECT 函数。
(5)制作图表,美化它们。
2.3 函数公式法-vlookup。
函数公式的核心功能之一是通过使用辅助列来完成动态表的创建。我们可以根据自己的需要选择里面的控件,最后美化动态表格。
不同的公式需要不同的辅助列,针对不同的情况做出不同的选择。
(1)构建辅助列。
(2)插入图表
(3)美化餐桌
3.POWER BI
3.1什么是Power BI?
使用统一的一、可扩展平台连接和可视化任何数据,用于自助服务和企业商业智能 (BI),该平台易于使用并有助于获得更深入的数据洞察力。弥合数据和决策之间的差距
(1)创造惊人的数据体验
轻松连接、建模和可视化数据,以创建具有 KPI 和品牌个性化的令人印象深刻的报告。快速获得由 AI 驱动的业务问题答案,即使是用对话语言询问也是如此。
(2)通过最广泛的 BI 部署获得洞察力
通过连接到所有数据源来利用您的大数据投资,在整个组织内分析、共享和优化洞察力,同时保持数据的准确性、一致性和安全性。
(3)自信地做决定
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
3.2 Power BI 系列组件
下面简单介绍一下power BI的三个组成部分
1.电源查询
功能:获取文件、文件夹、数据库、网页等数据并进行各种处理。如果只需要对原创数据进行处理以满足使用需求,可以直接在 Excel 中使用 Power Query。
数据获取:从不同来源、不同结构、不同形式获取数据,并以统一的格式进行横向合并、纵向(追加)合并、条件合并等。
数据转换:将原创数据转换为所需的结构或格式。
数据处理:对后续分析进行数据预处理,如添加新列、新行、处理某些单元格值等。
首先,有一点:PowerQuery存在于查询的主题上。任何不基于此主题的东西都不适合与其他技术进行比较。
如果你已经是一个可以轻松玩VBA的“EXCEL高手”,这个工具将是替代大量编码时间的绝佳补充,而如果你花时间学习M语言(PowerQuery内置编程语言),它将打开一扇新的大门。
如果您是 Excel 初学者,需要将数据导入 Excel 并苦苦思索该怎么做,那么 PowerQuery 是您的最佳选择,没有之一。
如果您经常使用 Excel 对数据进行统计汇总,那么您已经一只脚踏进了【自助大数据分析】的大门。借助正确的工具和良好的理论,您还可以分析数百万甚至数亿数据。PowerQuery 是必备工具。
学习PowerQuery到底有多难(两张图告诉你)
2.电源枢轴
功能:分析建模。如果原创数据非常规整,只需要建立模型/分析系统,可以直接在Excel中使用Power Pivot;如果你有数据处理需求和建模,你可以在 Excel 中同时使用 PQ 和 PP。
PowerPivot 本质上是一个数据管理和报告系统,虽然它看起来几乎与传统的 Excel 数据透视表相同,但它有一些特别值得注意的功能。
首先,传统Excel数据透视表的原创设计仅用于分析数据源为一张表的数据,但随着数据源的多样化,传统的Excel数据透视表在多表关联分析方面越来越薄弱。PowerPivot 可以从各种类型的数据源中捕获数据,并可以通过数据建模能力将来自各种数据源的数据表关联起来。
其次,PowerPivot 可以使数据分析过程更加紧凑和流畅。PowerPivot 的多表关联能力和强大的 DAX 数据分析表达功能可以让整个数据分析过程变得自然。在 PowerPivot 中,我们只需要为必须借助传统数据透视表以外的功能完成的分析工作建立一个数据分析模型。当数据源中的数据发生变化时,我们只需要刷新 PowerPivot 即可获得最新的数据报表。
第三,PowerPivot的可用性,几乎每个Excel用户都可以使用PowerPivot环境,只要下定决心学习,就可以学习。这样,普通 Excel 用户就可以在昂贵的专用软硬件支持的环境中做只有 IT 人员才能做的事情。
第四,PowerPivot成本低,PowerPivot是商业智能工具。我们知道目前商业智能是比较高级的。如果企业部署专业的商业智能解决方案,成本还是很高的。但 PowerPivot 为我们提供了应用商业智能的低成本机会。它使我们有机会在短时间内以低成本实施原本昂贵的商业智能解决方案,从而明显提高部门级生产力。
五、可移植性,据说PowerPivot是微软SQL Server团队打造的,虽然嵌入在Excel中,但依然是SQL Server的血液。我们使用 PowerPivot 构建的数据模型可以轻松移植到 SQL Server Analysis Services 表格服务。因此,当您构建了一个值得推广和保留的经过验证的小规模成功解决方案时,您可以轻松升级到更稳定可靠的专业数据库,而无需重新发明轮子。
3.Power BI 桌面
功能:集成Power Query和Power Pivot的功能,对数据进行动态图表展示和智能分析。如果你需要更好的图表显示,Power BI desktop 很好;如果您需要构建复杂的报表系统并需要图表显示,请使用 Power BI Desktop。
连接所有数据,无论其位于何处
从数百个受支持的本地和基于云的源访问数据,例如 Dynamics 365、Salesforce、Azure SQL DB、Excel 和 SharePoint。通过自动增量刷新确保它始终是最新的。借助 Power BI Desktop,可以针对各种场景开发可操作的深刻见解
轻松准备数据和模型
使用数据建模工具节省时间,同时简化数据准备。通过数百万 Excel 用户熟悉的自助式 Power Query 体验节省更多时间。在 Power BI 中摄取、转换、集成和丰富数据。
使用 Office 熟悉度提供高级分析
深入挖掘您的数据,找出您可能忽略的模式,从而发现可操作的见解。使用快速测量、分组、预测和聚类等功能。使用强大的 DAX 公式语言让高级用户完全控制他们的模型。如果你熟悉 Office,Power BI 很容易使用。
通过 AI 驱动的增强分析加深数据洞察力
了解您的数据、自动查找模式、了解数据的性质并预测未来结果以推动业务成果。新的 AI 功能(最初在 Azure 中引入,现在在 Power BI 中可用)不需要代码,使所有 Power BI 用户能够发现隐藏的、可操作的见解,从而推动更具战略性的业务成果。
创建为您的业务量身定制的交互式报告
使用交互式数据可视化创建令人惊叹的报告。使用拖放式画布和来自 Microsoft 和合作伙伴的数百个现代数据视觉对象讲述您的数据故事(或使用 Power BI 开源自定义视觉框架创建您自己的)。使用主题、格式和布局工具设计报告。
任何人都可以随时随地创作
为需要的用户提供可视化分析。创建移动优化报告供查看者随时随地查看。从 Power BI Desktop 发布到云或本地。将在 Power BI Desktop 中创建的报表嵌入现有应用或 网站。
3.3产品
感谢收看 查看全部
excel抓取网页动态数据(1.数组的运用数组就是单元的集合处理的值集合)
1.数组的使用
数组是单元格的集合或一组处理后的值。您可以编写一个将数组作为参数的公式,一个数组公式,并使用该单个公式接受多个输入并产生多个结果——每个结果都显示在一个单元格中。两个数组的最大行数和最大列数就是结果的行数和列数。
数组表示:使用花括号 {} 表示数组。如{10,20,30;40,50,60}。其中,30后面是一个分号;,表示40即将换行。数组的元素由逗号和分号分隔。两者的意思一定要明白。分号分隔表示数组的行分隔。
数组公式可以被认为是 Excel 对公式和数组的扩展。换句话说,它是使用数组作为参数时 Excel 公式的应用。数组公式可以被认为是具有多个值的公式。它与单值公式的不同之处在于它可以产生多个结果。数组公式可以占用一个或多个单元格。数组最多可以有 6500 个元素
Excel 中的数组公式非常有用,尤其是当您无法使用工作表函数直接获取结果时。数组公式可用于创建产生多个值或对一组值而不是单个值进行操作的公式。
数组公式的特点是引用的参数是数组参数,包括面积数组和常数数组。执行多次计算,返回一组数据结果。详细:数组公式的参数是一个数组,即输入有多个值;输出结果可能是一个或多个——这一个或多个值是公式对中多个输入元素的复合运算得到的一个新数组。
1.1一维数组
简单的一维数组分为水平数组和垂直数组。我们来看一下水平一维数组的例子。将四个连续的水平单元格E3:G3转换成数组,先选中区域,按Ctrl+Shift+Enter,公式变为{=E3:G3},查看数组内容,公式中按F9,如如下图所示;(垂直数组也是如此)
由上可知,数组外侧用{}包围,水平数组内侧用逗号分隔,如步骤1中的数组{1,2,3,4},内侧垂直数组的 用分号分隔,如第 2 步中的第一步 Array {1;2;3;4};分号分隔表示数组的行分隔,逗号分隔表示数组的列分隔。
1.二维数组
构建一个3行3列的二维数组,第一行是1,4,7,第二行是2,5,8,第三行是3,6,9,数组表示是{1, 4,7;2,5,8;3,6,9},见下图;
1.3 数组的计算
数组相乘,如图,D3:D6和E3:E6分别代表两组数组。将它们相乘并将它们放入 F3:F6。先选择F3:F6,在D3:D6*E3:E6中输入公式,按Ctrl+Shift+Enter,查看具体数值,按F9,见下图;
计算一维数组中大于0的数字之和,可以使用公式=sum(array*(array>0)),见下图;
多维数组的计算和应用与单元格的函数应用基本相同,单元格使用的函数也可以应用于数组的计算。多维数组的加减乘除运算及其公式可以概括为数组之间的运算。遵循以下顺序:
1、 根据数组的行数和列数确定运算结果的行数和列数;
2、参与操作的数组扩展区;
3、 填充数据;
4、运行。
甚至多个数组之间的操作也遵循上述规则。
数组的优点是计算方便,可以在不使用辅助列和辅助行的情况下进行非常复杂的计算。缺点是数据操作量大,所有的操作过程都放到内存中进行操作。如果有大量的数组公式运算,计算机会运行缓慢。
由于数组公式中参数较多,所以在复杂公式中设置错误时,比一般公式更难排错!
2.动态图表
在数据信息可视化时代,Excel作为基本的办公工具,也是最适合初学者学习的数据可视化操作软件。学习Excel的图表动态,可以让我们更快、更方便地制作动态图表;
制作动态图表的方法有很多。我们可以根据不同的情况选择不同的方法来制作动态图表。通过简单的动态图表,我们可以慢慢完成更复杂、多维度的动态图表的制作。每种方法都有其优点和特点,下面我将介绍四种制作动态图表的方法;
2.1数据透视图法
与数据透视表一样,数据透视图适用于大型且格式良好的数据源。数据透视图具有灵活的转换布局以及排序和过滤功能。使用 Pivot 的切片器功能直观地在选项之间切换。
对于参数和数据量大的多维数据,我们做多维驾驶舱,分别为每个维度制作动态图表。通过使用切片器的关联功能,我们可以实现一个切片。控制器可控制多个动态表,可实现动态座舱功能。
以下是数据透视图方法的步骤:
(1)插入数据图表,选择数据,插入数据透视图。
(2)根据需要将透视图的字段拖放到相应的框中。
(3)插入一个切片器并选择过滤和排序的标准。
(4)修改外观。
2.2 名称管理器方法;(1)制作下拉列表。
(2)批量创建名称。
(3)名称管理器。
(4)使用 INDIRECT 函数。
(5)制作图表,美化它们。
2.3 函数公式法-vlookup。
函数公式的核心功能之一是通过使用辅助列来完成动态表的创建。我们可以根据自己的需要选择里面的控件,最后美化动态表格。
不同的公式需要不同的辅助列,针对不同的情况做出不同的选择。
(1)构建辅助列。
(2)插入图表
(3)美化餐桌
3.POWER BI
3.1什么是Power BI?
使用统一的一、可扩展平台连接和可视化任何数据,用于自助服务和企业商业智能 (BI),该平台易于使用并有助于获得更深入的数据洞察力。弥合数据和决策之间的差距
(1)创造惊人的数据体验
轻松连接、建模和可视化数据,以创建具有 KPI 和品牌个性化的令人印象深刻的报告。快速获得由 AI 驱动的业务问题答案,即使是用对话语言询问也是如此。
(2)通过最广泛的 BI 部署获得洞察力
通过连接到所有数据源来利用您的大数据投资,在整个组织内分析、共享和优化洞察力,同时保持数据的准确性、一致性和安全性。
(3)自信地做决定
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
轻松协作处理相同的数据和报告,并在 Microsoft Teams 和 Excel 等流行的 Microsoft Office 应用程序中共享见解,使组织中的每个人都能快速做出数据驱动的决策,从而推动战略行动。
3.2 Power BI 系列组件
下面简单介绍一下power BI的三个组成部分
1.电源查询
功能:获取文件、文件夹、数据库、网页等数据并进行各种处理。如果只需要对原创数据进行处理以满足使用需求,可以直接在 Excel 中使用 Power Query。
数据获取:从不同来源、不同结构、不同形式获取数据,并以统一的格式进行横向合并、纵向(追加)合并、条件合并等。
数据转换:将原创数据转换为所需的结构或格式。
数据处理:对后续分析进行数据预处理,如添加新列、新行、处理某些单元格值等。
首先,有一点:PowerQuery存在于查询的主题上。任何不基于此主题的东西都不适合与其他技术进行比较。
如果你已经是一个可以轻松玩VBA的“EXCEL高手”,这个工具将是替代大量编码时间的绝佳补充,而如果你花时间学习M语言(PowerQuery内置编程语言),它将打开一扇新的大门。
如果您是 Excel 初学者,需要将数据导入 Excel 并苦苦思索该怎么做,那么 PowerQuery 是您的最佳选择,没有之一。
如果您经常使用 Excel 对数据进行统计汇总,那么您已经一只脚踏进了【自助大数据分析】的大门。借助正确的工具和良好的理论,您还可以分析数百万甚至数亿数据。PowerQuery 是必备工具。
学习PowerQuery到底有多难(两张图告诉你)
2.电源枢轴
功能:分析建模。如果原创数据非常规整,只需要建立模型/分析系统,可以直接在Excel中使用Power Pivot;如果你有数据处理需求和建模,你可以在 Excel 中同时使用 PQ 和 PP。
PowerPivot 本质上是一个数据管理和报告系统,虽然它看起来几乎与传统的 Excel 数据透视表相同,但它有一些特别值得注意的功能。
首先,传统Excel数据透视表的原创设计仅用于分析数据源为一张表的数据,但随着数据源的多样化,传统的Excel数据透视表在多表关联分析方面越来越薄弱。PowerPivot 可以从各种类型的数据源中捕获数据,并可以通过数据建模能力将来自各种数据源的数据表关联起来。
其次,PowerPivot 可以使数据分析过程更加紧凑和流畅。PowerPivot 的多表关联能力和强大的 DAX 数据分析表达功能可以让整个数据分析过程变得自然。在 PowerPivot 中,我们只需要为必须借助传统数据透视表以外的功能完成的分析工作建立一个数据分析模型。当数据源中的数据发生变化时,我们只需要刷新 PowerPivot 即可获得最新的数据报表。
第三,PowerPivot的可用性,几乎每个Excel用户都可以使用PowerPivot环境,只要下定决心学习,就可以学习。这样,普通 Excel 用户就可以在昂贵的专用软硬件支持的环境中做只有 IT 人员才能做的事情。
第四,PowerPivot成本低,PowerPivot是商业智能工具。我们知道目前商业智能是比较高级的。如果企业部署专业的商业智能解决方案,成本还是很高的。但 PowerPivot 为我们提供了应用商业智能的低成本机会。它使我们有机会在短时间内以低成本实施原本昂贵的商业智能解决方案,从而明显提高部门级生产力。
五、可移植性,据说PowerPivot是微软SQL Server团队打造的,虽然嵌入在Excel中,但依然是SQL Server的血液。我们使用 PowerPivot 构建的数据模型可以轻松移植到 SQL Server Analysis Services 表格服务。因此,当您构建了一个值得推广和保留的经过验证的小规模成功解决方案时,您可以轻松升级到更稳定可靠的专业数据库,而无需重新发明轮子。
3.Power BI 桌面
功能:集成Power Query和Power Pivot的功能,对数据进行动态图表展示和智能分析。如果你需要更好的图表显示,Power BI desktop 很好;如果您需要构建复杂的报表系统并需要图表显示,请使用 Power BI Desktop。
连接所有数据,无论其位于何处
从数百个受支持的本地和基于云的源访问数据,例如 Dynamics 365、Salesforce、Azure SQL DB、Excel 和 SharePoint。通过自动增量刷新确保它始终是最新的。借助 Power BI Desktop,可以针对各种场景开发可操作的深刻见解
轻松准备数据和模型
使用数据建模工具节省时间,同时简化数据准备。通过数百万 Excel 用户熟悉的自助式 Power Query 体验节省更多时间。在 Power BI 中摄取、转换、集成和丰富数据。
使用 Office 熟悉度提供高级分析
深入挖掘您的数据,找出您可能忽略的模式,从而发现可操作的见解。使用快速测量、分组、预测和聚类等功能。使用强大的 DAX 公式语言让高级用户完全控制他们的模型。如果你熟悉 Office,Power BI 很容易使用。
通过 AI 驱动的增强分析加深数据洞察力
了解您的数据、自动查找模式、了解数据的性质并预测未来结果以推动业务成果。新的 AI 功能(最初在 Azure 中引入,现在在 Power BI 中可用)不需要代码,使所有 Power BI 用户能够发现隐藏的、可操作的见解,从而推动更具战略性的业务成果。
创建为您的业务量身定制的交互式报告
使用交互式数据可视化创建令人惊叹的报告。使用拖放式画布和来自 Microsoft 和合作伙伴的数百个现代数据视觉对象讲述您的数据故事(或使用 Power BI 开源自定义视觉框架创建您自己的)。使用主题、格式和布局工具设计报告。
任何人都可以随时随地创作
为需要的用户提供可视化分析。创建移动优化报告供查看者随时随地查看。从 Power BI Desktop 发布到云或本地。将在 Power BI Desktop 中创建的报表嵌入现有应用或 网站。
3.3产品
感谢收看
excel抓取网页动态数据(浙江工业职业技术学院沈才梁Web应用系统(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-17 21:44
Web应用系统经常需要通过客户端浏览器查询和访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以导入Excel电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度阐述了利用Java.Script实现网页动态表格数据的Excel导入的方法。
贵宾信息
b页的动态表数据往往需要通过客户端浏览器查询访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以将其导入E cl xe电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度,阐述了Ecl人使用JvS rt实现Web动态表格数据的方法。aaci pb页面上xe有向表对象的行值和列值可以分别控制两个周期;之后,子表的 Vsa 属性可以直接在客户端打开电子表格应用程序。ilu 当然前提是客户端要有电子表格应用。在实际应用中
,代码1和代码2需要合并在同一个.p文件中。图 1 sa 和图 2 分别显示了在浏览器中查询的动态数据和导入电子表格结果。
l动态表数据
基于BS模式的应用系统的特点是客户端通过代码2的浏览器实现E cl/xe电子表格的主程序:访问服务器数据。如果客户端浏览器中的 wb 表单数据是
fm's“cip o'”
'
ge/>/fr
vrLe:Tl。w ( )cl.eg; aiboa er s0 .el 1nt sh fr( .; H n;++) oi O i
回复
客户代码 t ih: 8” t dv/ i>/d 公司名称 t it” 4” dv/ i>/d 联系 t it” 5” h dv/ i>/d
},,全部
p
oi No h E e
tdh 8”
dv% y ( C s mel”% o/ i>/d2 0> 4”
h” o aya e)/ i>/d
'>
h” ot N m”% c/ i>/d ( y . v Ne t% h Mo ex lo op%> teb
在代码 I 中,首先收录了一个 cn ap 文件。n .s 这个文件的主要作用是确认身份并将客户端连接到服务器S LSre数据库。这不是本文讨论Q evr的重点,这里省略该文件的代码实现。代码1主要实现对服务器S LSr r 数据库的查询,并在客户端浏览器中显示结果。
图1 浏览器数据库查询结果
浏览器。通过在HMTL表中嵌入AP代码,S将服务器端查询结果实时显示在浏览器中。关键点是使用代码中的 H ML 表 T 将网格 id 标识为 Tb a - 此标识符在代码中用作通向下面电子表格的引用。
与表对象的句柄一起使用。由此可见,为了在浏览器中导入其他对象的数据,也需要在定义中标识出对应的i。d
2 导入E clxe 电子表格主程序 图2 导入电子表格结果 在导入电子表格主程序中,首先使用A te ojc 语句定义ci X bet v 3 得出一个电子表格对象,根据表i 识别“a” 本节介绍的方法paper 也可以使用 Vsr t B i 或其他脚本语言来实现。ep图像的G tlm n yd 方法定义了一个表对象Tl,该表对象实现了eEe et l B的bae,但是导入表数据在电子表格中还需要进一步的排版处理。其实就是浏览器中显示的表格。下一个问题变得非常简单。目前在基于BS/pattern应用的报表处理中,在客户端浏览器中,使用table对象的inret属性将对应的单元格内容放到浏览器n eTxs中,
并实现数据的自动处理。
第 1 页
下载原格式pdf文档(共1页)
微信支付宝
付费下载 查看全部
excel抓取网页动态数据(浙江工业职业技术学院沈才梁Web应用系统(组图))
Web应用系统经常需要通过客户端浏览器查询和访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以导入Excel电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度阐述了利用Java.Script实现网页动态表格数据的Excel导入的方法。
贵宾信息
b页的动态表数据往往需要通过客户端浏览器查询访问服务器数据库,并按照客户端要求的格式显示查询结果。如果客户需要进一步的报表处理数据,可以将其导入E cl xe电子表格进行处理,可以大大提高灵活性。本文从实际应用的角度,阐述了Ecl人使用JvS rt实现Web动态表格数据的方法。aaci pb页面上xe有向表对象的行值和列值可以分别控制两个周期;之后,子表的 Vsa 属性可以直接在客户端打开电子表格应用程序。ilu 当然前提是客户端要有电子表格应用。在实际应用中
,代码1和代码2需要合并在同一个.p文件中。图 1 sa 和图 2 分别显示了在浏览器中查询的动态数据和导入电子表格结果。
l动态表数据
基于BS模式的应用系统的特点是客户端通过代码2的浏览器实现E cl/xe电子表格的主程序:访问服务器数据。如果客户端浏览器中的 wb 表单数据是
fm's“cip o'”
'
ge/>/fr
vrLe:Tl。w ( )cl.eg; aiboa er s0 .el 1nt sh fr( .; H n;++) oi O i
回复
客户代码 t ih: 8” t dv/ i>/d 公司名称 t it” 4” dv/ i>/d 联系 t it” 5” h dv/ i>/d
},,全部
p
oi No h E e
tdh 8”
dv% y ( C s mel”% o/ i>/d2 0> 4”
h” o aya e)/ i>/d
'>
h” ot N m”% c/ i>/d ( y . v Ne t% h Mo ex lo op%> teb
在代码 I 中,首先收录了一个 cn ap 文件。n .s 这个文件的主要作用是确认身份并将客户端连接到服务器S LSre数据库。这不是本文讨论Q evr的重点,这里省略该文件的代码实现。代码1主要实现对服务器S LSr r 数据库的查询,并在客户端浏览器中显示结果。
图1 浏览器数据库查询结果
浏览器。通过在HMTL表中嵌入AP代码,S将服务器端查询结果实时显示在浏览器中。关键点是使用代码中的 H ML 表 T 将网格 id 标识为 Tb a - 此标识符在代码中用作通向下面电子表格的引用。
与表对象的句柄一起使用。由此可见,为了在浏览器中导入其他对象的数据,也需要在定义中标识出对应的i。d
2 导入E clxe 电子表格主程序 图2 导入电子表格结果 在导入电子表格主程序中,首先使用A te ojc 语句定义ci X bet v 3 得出一个电子表格对象,根据表i 识别“a” 本节介绍的方法paper 也可以使用 Vsr t B i 或其他脚本语言来实现。ep图像的G tlm n yd 方法定义了一个表对象Tl,该表对象实现了eEe et l B的bae,但是导入表数据在电子表格中还需要进一步的排版处理。其实就是浏览器中显示的表格。下一个问题变得非常简单。目前在基于BS/pattern应用的报表处理中,在客户端浏览器中,使用table对象的inret属性将对应的单元格内容放到浏览器n eTxs中,
并实现数据的自动处理。
第 1 页
下载原格式pdf文档(共1页)
微信支付宝
付费下载
excel抓取网页动态数据(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-16 16:21
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(说明来源:百度百科-《动态网页》,如链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求而变化的内容,比如某宝的商品价格、评论等,比如某阀门的热门影评,新闻的视频等,通过先加载网页的整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单地把它翻译成页面的起点。看上面的“page_limit”,大概就是页数限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们要获取下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码
注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一种很常用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF***的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。以管理员权限运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:
注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但是这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能会长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。 查看全部
excel抓取网页动态数据(动态网页爬虫技术一之API请求法安装selenium模块下载(组图))
本节课我给大家讲解一个稍微复杂一点的爬虫,也就是动态网页的爬虫。
动态网页技术简介
动态网络爬虫技术的API请求方法
动态网络爬虫技术二:模拟浏览器方法
安装 selenium 模块下载
谷歌浏览器驱动安装
ChromeDriver以某宝藏松鼠店为例,抓取“坚果炒货”的商品名称、价格、销量和评论数
课后作业
关于作者
动态网页技术简介
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变——除非你修改了页面代码。动态网页并非如此。虽然页面代码没有改变,但是显示的内容会随着时间、环境或数据库操作的结果而改变。
值得强调的是,动态网页不应与页面内容是否动态相混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些只是特定于网页。内容的呈现形式,无论网页是否具有动态效果,只要是通过动态网站技术生成的,都可以称为动态网页。(说明来源:百度百科-《动态网页》,如链接失效请访问:%E5%8A%A8%E6%80%81%E7%BD%91%E9%A1%B5/6327050?fr=阿拉丁)
互联网每天都在蓬勃发展,数以万计的网络平台雨后春笋般涌现。不同平台针对不同用户的权限和偏好推出不同的个性化内容。看来,传统的静态网页早已无法满足社会的需求。于是,动态网页技术应运而生。当然,在对网页加载速度要求越来越高的情况下,异步加载成为了很多大型网站的首选。比如各大电商平台、知识型网站、社交平台等,都广泛采用了异步加载的动态技术。简单来说就是加载一些根据时间和请求而变化的内容,比如某宝的商品价格、评论等,比如某阀门的热门影评,新闻的视频等,通过先加载网页的整体框架,再加载。呈现动态内容。
对于这种动态页面,如果我们使用上面提到的静态网页爬虫的方法来爬取,可能不会得到任何结果,因为大部分异步加载的内容都位于请求该内容的一段JS代码中。在一定的触发操作下,这些JS代码开始工作,从数据库中提取相应的数据,放到网页框架中的相应位置,最终拼接成一个我们可以看到的完整页面。
动态网络爬虫技术的API请求方法
看似复杂的操作,看似给我们的爬虫带来了不少麻烦,但其实也可能给我们带来很大的方便。我们只需要找到JS请求的API,按照一定的要求发送带有有效参数的请求,就可以得到最干净的数据,而不是像以前那样从嵌套的HTML代码中慢慢解析出我们想要的HTML代码. 所需的数据。
这里我们以上面提到的豆瓣电影(如果链接失效,请访问:#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0)为例进行制作分析,提取豆瓣前100名电影的名称和评分及其地址。
这是按人气排序的近期热门电影的截图。每个月都会发布不同的新电影。每部电影每天都会以口碑效应呈现不同的人气排名。如果这个页面是静态网页,那么豆瓣程序员每天上网修改这个页面是不是很辛苦。所以,我们可以大胆猜测这是一个动态页面。但猜测是不够的,我们必须证明它。这里我们将使用第二讲中提到的谷歌开发者工具。按F12或在网页空白处右键选择Inspect(N),或按键盘上的组合键Ctrl+Shift+I来召唤我们的神器。如下所示:
今天我们不再使用左上角的鼠标按钮,而是使用红色框中的Network,显示了网页加载的所有文件,如下图所示:
如果下面没有结果,您需要在打开 Google Developer Tools 的情况下刷新页面。
如上图所示,我们可以通过点击上方小红框内的“XHR”按钮来过滤这个网页中异步加载的内容。至于哪一个是我们想要的,这是一个问题。看左边的地址,我们好像看不出什么端倪,我们来一一看看吧。. . 经过枚举,我们发现第三个就是我们想要的内容,其内容如下:
我们可以看到这个链接中收录的内容是以 JSON 格式显示的。这时候我们就有了一个大概的思路,就是用requests模块下载这个链接的内容,然后用python的json模块下载内容。解析。
但是,这似乎是一页,并且只有 20 部电影要数,而我们要的是前 100 部电影,如何做到这一点?
没办法,毕竟是动态网页,内容可以根据请求改变,而且这里也没有登录操作,打开网页就可以看到,那我们可以换个网址来获取到下一页甚至下一页 页面的内容?当然可以,不然我就写不出来了!
让我们仔细看看这个 URL 中传递的参数:
至此,我们可能不知道这五个参数是干什么用的,但是我们可以找到规律,所以现在回到原来的网页,点击页面底部的“加载更多”,然后返回给开发者工具,哇,多了一个网址,就是刚才说的那个,内容也只要:
此 URL 还传递五个参数:
唯一的区别是名为“page_start”的关键字的值发生了变化。简单地把它翻译成页面的起点。看上面的“page_limit”,大概就是页数限制的意思。看右边的响应内容,这个页面传递了20个条目,也就是说“page_limit”是一个页面的条目数限制,也就是20,这个数据不变,而“page_start”是本页开头的条目号,那么我们要获取下面的内容,改“page_start”不就够了吗?是的。
老规矩,先写个代码
注1:因为一个页面有20条数据,我们需要爬取100条,而page_start的起始数据是0,所以这里只需要使用一个i,从0到4循环5次,相乘每次增加 20。你可以很容易地设置 page_start 的值,因为下面的 URL 是字符串类型。乘法运算后,我们使用 str() 方法将类型转换为 str 类型,方便后续调用。
注2:这里我们只需要在每次循环的时候改变page_start的值,所以最后修改这个值;
注3:返回的内容通过decode()方法解码,变成字符串类型。根据我们之前的分析,得出这是一个JSON格式的字符串。因此,我们使用 Python 内置的标准库 json 进行处理。解析,标准库不需要用pip工具安装。json模块主要有两个方法——json.loads()和json.dumps(),前者用于解码JSON数据,后者用于编码JSON数据。这里我们主要使用loads()方法将内容解析成字典格式的内容,存放在一个名为content_list的对象中,最后加上“['subjects']”来解析出我们想要的最简洁的。部分,这个根据具体内容而定,并不是所有的解析都应该这样写。例如这里,如下图:
我们想要的最外面的内容有这样一个嵌套,嵌套的Key是“subjects”,这个Key的值是一个数组,这个数组就是我们想要的,所以加上了“['subjects']”。
注 4:content_list 是一个数组对象,所以我们也做了一个循环来提取条带。
注5:每条数据仍然是字典类型的对象,所以我们可以直接写对应的Key名称来获取想要的值,这里获取的电影名称;
注6:同5,这里是电影的评分;
注7:同5,这里是电影的豆瓣链接;
最后,可以使用标准输入流写入txt文件,也可以使用xlwt模块写入EXCEL,也可以使用pymysql模块写入Mysql数据库。
至此,这种寻找API并传递有效参数重放API的方法已经介绍给大家了。这是一种很常用的方法,可以在很多网站中使用,而且速度非常快,结果也是最简洁的。.
动态网络爬虫技术二:模拟浏览器方法
虽然我们上面提到的API请求方式好用又快,但并不是所有的网站都会使用这种异步加载方式来实现网站,还有一些网站会采取反爬措施爬虫,比如常见的验证码。虽然验证码主要是用来防止CSRF***的,但也有网站用来对付爬虫的,比如某宝。这时候我们要介绍另一个神器,Python的Selenium模块。
Selenium 是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE (7, 8, 9, 10, 11), Mozilla Firefox, Safari, Google Chrome, Opera等。该工具的主要功能包括: 测试与浏览器的兼容性 - 测试看看你的应用是否(解释来自:百度百科-“Selenium”,如果链接失效请点击)
简单来说,Selenium 是一个主要用于自动化测试的工具。它可以运行在各种带有浏览器驱动程序的浏览器中,并根据代码自动模拟人类操作来获取或控制网页元素。当然,Selenium 不是 Python 的产品,而是一个独立的项目,Python 提供了对 Selenium 的支持。(您可以自行访问 Selenium 的主页,如果链接无效,请点击)
安装硒模块
要使用Selenium这样的第三方工具,我们首先要安装它,这里还是使用pip工具。以管理员权限运行命令行,输入pip install selenium,稍等片刻即可完成安装,如果觉得官方pypi镜像网速慢,可以使用国内豆瓣镜像源,pip install selenium -i ,加上这个 -i 参数和豆瓣pypi镜像的地址就够了。如果要默认使用豆瓣镜像源,请自行百度修改方法。
下载谷歌浏览器驱动
安装成功后,我们需要安装下一个必要的东西,浏览器驱动程序。前面提到,selenium 需要配合浏览器驱动运行,所以我们以安装 Google Chrome Driver 为例。
首先,我们需要查看我们的谷歌浏览器版本,可以在谷歌的“帮助”中查看。具体方法是打开Chrome,点击右上角的三个点状按钮,然后在弹出的菜单中依次选择Help。(E)->关于谷歌浏览器(G)如下图:
笔者的浏览器更新到最新版本63,老版本的操作方法大致相同。
点击信息后,我们可以看到当前的Chrome版本,下图为示例:
Chrome在不断的升级,所以相应的驱动也要不断的更新和适配Chrome的版本。这里我们需要找到对应的ChromeDriver版本映射,推荐一个持续更新的CSDN博客(如果链接失效请点击:),根据版本映射表,下载对应版本的ChromeDriver,下载地址1()(如果链接失效,请访问:),下载地址2()(如果链接失效,请访问:)。
安装 ChromeDriver
这里需要配置环境变量。正如第一讲中提到的,为“路径”添加一行值。
首先,我们需要找到 Chrome 的安装位置。最简单的方法是在桌面上找到谷歌浏览器的快捷方式,右键单击并选择“打开文件的位置”将其打开。比如我这里打开的路径是C:\Program Files(x86)\Google\Chrome\Application,那我就把这个路径加到Path里面。然后,我们需要把下载的ChromeDriver解压到exe程序中,将单独的exe程序复制到刚才的路径下,如下图:
至此,ChromeDriver 已经完成安装。我们可以在命令行输入命令python进入python交互环境进行测试,如下图所示:
如果你的谷歌浏览器自动打开并跳转到百度首页,那么恭喜~
以某宝的松鼠店为例,抓取“坚果炒货”的品名、价格、销量和评论数
此页面的 URL 是:#TmshopSrchNav
老规矩,先放一段代码:
注1:实例化一个webdriver的Chrome对象,命名为driver,会自动打开一个Chrome窗口。
注2:调用驱动程序的maximize_window()方法。直接翻译是最大化窗口。
注3:get方式调用驱动的get()方法请求URL。
注4:这是开头的重点。Webdriver主要有八种查找元素的方式。这一行以class_name的形式搜索,注意这里的元素的复数。此方法用于查找页面上所有符合条件的元素。如果没有 s 方法,则只能找到第一个符合条件的元素。此行是使用 Google Developer Tools 左上角的小箭头工具来查看元素并找到所有产品项。其中一项范围如下所示。显示:
注5:同注4,但是这里是css_selector,即css选择器是用来搜索的,因为这里的类名“item-name J_TGoldData”是复合结构,find_element_by_class_name()方法不支持复合结构的搜索。所以只能这样使用css_selector。
注6:同注4,此处为单数,即在商品项范围内检索一次。
注 7:同注 6。
注 8:与注 4 相同,但这里是通过 xpath 搜索。
XPath 代表 XML 路径语言,它是一种用于定位 XML(标准通用标记语言的子集)文档部分的语言。XPath 基于 XML 树结构,有不同类型的节点,包括元素节点、属性节点和文本节点,提供在数据结构树中查找节点的能力。XPath 的初衷是将其用作 XPointer 和 XSLT 之间的通用语法模型。但是 XPath 作为一种小型查询语言很快被开发人员采用。(解释来自:百度百科-《XPath》,如果链接失效请访问:)
获取元素xpath的方法有多种,最简单的一种是在Google Developer Tools面板上选择要查找的元素,右键选择Copy -> Copy XPath,如下图所示:
当然,这种方法可能存在缺陷,即获取的XPath可能过于繁琐,或者获取的XPath可能无法正确找到对应的元素,需要根据XPath语法手动修改。
注意9:最后记得关闭实例化的对象,程序打开的浏览器也会关闭。
这个例子的最终结果如下:
您仍然可以自由选择数据存储方式。
这里需要注意的是,使用 selenium 进行数据爬取可能比之前的 API 请求方式慢很多。打开到对应的窗口后,窗口可能会长时间没有动作,但这不一定是错误或者是程序卡住的表现,也可能是程序在疯狂搜索网页元素. 在此过程中,如果您不确定是否有错误,请不要进行其他操作,以免有时导致元素失去焦点,导致莫名其妙的错误。
当然,硒的作用远不止这些。它几乎可以模拟人们在网页上可以做的任何行为,包括点击、输入等行为。这个比较适合一些网站填写验证码的你可以自己发现更多有趣的内容。本次讲座写在这里。感谢大家的耐心阅读。
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-16 16:21
)
Excel中的数据透视表非常方便进行数据分析,很多商务人士对Excel的操作非常熟悉,所以使用Excel作为数据分析的界面是一个不错的选择。那么如何使用C#从数据库中抓取数据并在Excel中动态生成数据透视表呢?下面举例说明。
一般来说,数据库的设计遵循规范化的原则,从而减少数据的冗余,但是对于数据分析,数据冗余可以提高数据加载的速度,所以为了演示数据透视表,现在建立一个视图在数据库中。, 将要分析的数据合并到一个视图中。如下所示:
数据源准备好后,我们先构建一个web应用,然后使用NuGet加载Epplus包,如下图:
在 index.aspx 首页中,编写以下脚本:
1
2
3 DOCTYPE html>
4
5
6
7 Excel PivotTable
8
9
10
11
12
13
14
15
16
17
18 Excel PivotTable
19
20
21
22
23
24
25
27
28
29
30
31
33
34
35
36
37
38
39
41
42
43
44
45
46
47
48
50
51
52
53
55
56
57
58
60
61
62
63
64
65
66
67
68
69
70
71
其中,TileJs 是一个开源的 javascript 库,其构建风格类似于 win8 Metro。
编写后台脚本:
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Web;
5 using System.Web.UI;
6 using System.Web.UI.WebControls;
7 using OfficeOpenXml;
8 using OfficeOpenXml.Table;
9 using OfficeOpenXml.ConditionalFormatting;
10 using OfficeOpenXml.Style;
11 using OfficeOpenXml.Utils;
12 using OfficeOpenXml.Table.PivotTable;
13 using System.IO;
14 using System.Data.SqlClient;
15 using System.Data;
16 namespace ExcelPivot.Web
17 {
18 public partial class index : System.Web.UI.Page
19 {
20 protected void Page_Load(object sender, EventArgs e)
21 {
22
23 }
24 private DataTable getDataSource()
25 {
26 //createDataTable();
27 //return ProductInfo;
28
29 SqlConnection conn = new SqlConnection();
30 conn.ConnectionString = "Data Source=.;Initial Catalog=olap;Persist Security Info=True;User ID=sa;Password=sa";
31 conn.Open();
32
33 SqlDataAdapter ada = new SqlDataAdapter("select * from v_pm_olap_test", conn);
34 DataSet ds = new DataSet();
35 ada.Fill(ds);
36
37 return ds.Tables[0];
38
39
40
41 }
42
43 protected void btn1_ServerClick(object sender, EventArgs e)
44 {
45 try
46 {
47 DataTable table = getDataSource();
48 string path = "_demo_" + System.Guid.NewGuid().ToString().Replace("-", "_") + ".xls";
49 //string path = "_demo.xls";
50 FileInfo fileInfo = new FileInfo(path);
51 var excel = new ExcelPackage(fileInfo);
52
53 var wsPivot = excel.Workbook.Worksheets.Add("Pivot");
54 var wsData = excel.Workbook.Worksheets.Add("Data");
55 wsData.Cells["A1"].LoadFromDataTable(table, true, OfficeOpenXml.Table.TableStyles.Medium6);
56 if (table.Rows.Count != 0)
57 {
58 foreach (DataColumn col in table.Columns)
59 {
60
61 if (col.DataType == typeof(System.DateTime))
62 {
63 var colNumber = col.Ordinal + 1;
64 var range = wsData.Cells[2, colNumber, table.Rows.Count + 1, colNumber];
65 range.Style.Numberformat.Format = "yyyy-MM-dd";
66 }
67 else
68 {
69
70 }
71 }
72 }
73
74 var dataRange = wsData.Cells[wsData.Dimension.Address.ToString()];
75 dataRange.AutoFitColumns();
76 var pivotTable = wsPivot.PivotTables.Add(wsPivot.Cells["A1"], dataRange, "Pivot");
77 pivotTable.MultipleFieldFilters = true;
78 pivotTable.RowGrandTotals = true;
79 pivotTable.ColumGrandTotals = true;
80 pivotTable.Compact = true;
81 pivotTable.CompactData = true;
82 pivotTable.GridDropZones = false;
83 pivotTable.Outline = false;
84 pivotTable.OutlineData = false;
85 pivotTable.ShowError = true;
86 pivotTable.ErrorCaption = "[error]";
87 pivotTable.ShowHeaders = true;
88 pivotTable.UseAutoFormatting = true;
89 pivotTable.ApplyWidthHeightFormats = true;
90 pivotTable.ShowDrill = true;
91 pivotTable.FirstDataCol = 3;
92 //pivotTable.RowHeaderCaption = "行";
93
94 //row field
95 var field004 = pivotTable.Fields["销售客户经理"];
96 pivotTable.RowFields.Add(field004);
97
98 var field001 = pivotTable.Fields["项目简称"];
99 pivotTable.RowFields.Add(field001);
100 //field001.ShowAll = false;
101
102 //column field
103 var field002 = pivotTable.Fields["年"];
104 pivotTable.ColumnFields.Add(field002);
105 field002.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
106 var field005 = pivotTable.Fields["月"];
107 pivotTable.ColumnFields.Add(field005);
108 field005.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
109
110 //data field
111 var field003 = pivotTable.Fields["回款金额"];
112 field003.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Descending;
113 pivotTable.DataFields.Add(field003);
114
115 pivotTable.RowGrandTotals = false;
116 pivotTable.ColumGrandTotals = false;
117
118 //save file
119 excel.Save();
120 //open excel file
121 string file = @"C:\Windows\explorer.exe";
122 System.Diagnostics.Process.Start(file, path);
123
124 }
125 catch (Exception ex)
126 {
127 Response.Write(ex.Message);
128 }
129 }
130 }
131 }
编译运行,如下图所示:
点击【回报分析】,稍等片刻,会打开Excel,自动生成数据透视表,如下图:
查看全部
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
)
Excel中的数据透视表非常方便进行数据分析,很多商务人士对Excel的操作非常熟悉,所以使用Excel作为数据分析的界面是一个不错的选择。那么如何使用C#从数据库中抓取数据并在Excel中动态生成数据透视表呢?下面举例说明。
一般来说,数据库的设计遵循规范化的原则,从而减少数据的冗余,但是对于数据分析,数据冗余可以提高数据加载的速度,所以为了演示数据透视表,现在建立一个视图在数据库中。, 将要分析的数据合并到一个视图中。如下所示:
数据源准备好后,我们先构建一个web应用,然后使用NuGet加载Epplus包,如下图:
在 index.aspx 首页中,编写以下脚本:
1
2
3 DOCTYPE html>
4
5
6
7 Excel PivotTable
8
9
10
11
12
13
14
15
16
17
18 Excel PivotTable
19
20
21
22
23
24
25
27
28
29
30
31
33
34
35
36
37
38
39
41
42
43
44
45
46
47
48
50
51
52
53
55
56
57
58
60
61
62
63
64
65
66
67
68
69
70
71
其中,TileJs 是一个开源的 javascript 库,其构建风格类似于 win8 Metro。
编写后台脚本:
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Web;
5 using System.Web.UI;
6 using System.Web.UI.WebControls;
7 using OfficeOpenXml;
8 using OfficeOpenXml.Table;
9 using OfficeOpenXml.ConditionalFormatting;
10 using OfficeOpenXml.Style;
11 using OfficeOpenXml.Utils;
12 using OfficeOpenXml.Table.PivotTable;
13 using System.IO;
14 using System.Data.SqlClient;
15 using System.Data;
16 namespace ExcelPivot.Web
17 {
18 public partial class index : System.Web.UI.Page
19 {
20 protected void Page_Load(object sender, EventArgs e)
21 {
22
23 }
24 private DataTable getDataSource()
25 {
26 //createDataTable();
27 //return ProductInfo;
28
29 SqlConnection conn = new SqlConnection();
30 conn.ConnectionString = "Data Source=.;Initial Catalog=olap;Persist Security Info=True;User ID=sa;Password=sa";
31 conn.Open();
32
33 SqlDataAdapter ada = new SqlDataAdapter("select * from v_pm_olap_test", conn);
34 DataSet ds = new DataSet();
35 ada.Fill(ds);
36
37 return ds.Tables[0];
38
39
40
41 }
42
43 protected void btn1_ServerClick(object sender, EventArgs e)
44 {
45 try
46 {
47 DataTable table = getDataSource();
48 string path = "_demo_" + System.Guid.NewGuid().ToString().Replace("-", "_") + ".xls";
49 //string path = "_demo.xls";
50 FileInfo fileInfo = new FileInfo(path);
51 var excel = new ExcelPackage(fileInfo);
52
53 var wsPivot = excel.Workbook.Worksheets.Add("Pivot");
54 var wsData = excel.Workbook.Worksheets.Add("Data");
55 wsData.Cells["A1"].LoadFromDataTable(table, true, OfficeOpenXml.Table.TableStyles.Medium6);
56 if (table.Rows.Count != 0)
57 {
58 foreach (DataColumn col in table.Columns)
59 {
60
61 if (col.DataType == typeof(System.DateTime))
62 {
63 var colNumber = col.Ordinal + 1;
64 var range = wsData.Cells[2, colNumber, table.Rows.Count + 1, colNumber];
65 range.Style.Numberformat.Format = "yyyy-MM-dd";
66 }
67 else
68 {
69
70 }
71 }
72 }
73
74 var dataRange = wsData.Cells[wsData.Dimension.Address.ToString()];
75 dataRange.AutoFitColumns();
76 var pivotTable = wsPivot.PivotTables.Add(wsPivot.Cells["A1"], dataRange, "Pivot");
77 pivotTable.MultipleFieldFilters = true;
78 pivotTable.RowGrandTotals = true;
79 pivotTable.ColumGrandTotals = true;
80 pivotTable.Compact = true;
81 pivotTable.CompactData = true;
82 pivotTable.GridDropZones = false;
83 pivotTable.Outline = false;
84 pivotTable.OutlineData = false;
85 pivotTable.ShowError = true;
86 pivotTable.ErrorCaption = "[error]";
87 pivotTable.ShowHeaders = true;
88 pivotTable.UseAutoFormatting = true;
89 pivotTable.ApplyWidthHeightFormats = true;
90 pivotTable.ShowDrill = true;
91 pivotTable.FirstDataCol = 3;
92 //pivotTable.RowHeaderCaption = "行";
93
94 //row field
95 var field004 = pivotTable.Fields["销售客户经理"];
96 pivotTable.RowFields.Add(field004);
97
98 var field001 = pivotTable.Fields["项目简称"];
99 pivotTable.RowFields.Add(field001);
100 //field001.ShowAll = false;
101
102 //column field
103 var field002 = pivotTable.Fields["年"];
104 pivotTable.ColumnFields.Add(field002);
105 field002.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
106 var field005 = pivotTable.Fields["月"];
107 pivotTable.ColumnFields.Add(field005);
108 field005.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Ascending;
109
110 //data field
111 var field003 = pivotTable.Fields["回款金额"];
112 field003.Sort = OfficeOpenXml.Table.PivotTable.eSortType.Descending;
113 pivotTable.DataFields.Add(field003);
114
115 pivotTable.RowGrandTotals = false;
116 pivotTable.ColumGrandTotals = false;
117
118 //save file
119 excel.Save();
120 //open excel file
121 string file = @"C:\Windows\explorer.exe";
122 System.Diagnostics.Process.Start(file, path);
123
124 }
125 catch (Exception ex)
126 {
127 Response.Write(ex.Message);
128 }
129 }
130 }
131 }
编译运行,如下图所示:
点击【回报分析】,稍等片刻,会打开Excel,自动生成数据透视表,如下图:
excel抓取网页动态数据(EasyShu的图表与引用数据区域联动功能要点(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2022-04-16 16:20
EasyShu的初始结构是将准备好的图表返回给用户,不依赖用户工作表的单元格区域引用,可以满足图表绘制后数据源的共享和传播,但用户反馈最强的是图表和数据是必需的。要保持联动,这个需求对于易书来说确实是一个巨大的挑战。
为了让EasyShu成为性价比最高、功能最强大、媲美美国高价图表插件,我们只能下定决心重写所有原有的图表制作方法,使用更复杂的代码和更繁重的工作量。以全新的方式链接图表和数据,无需依赖原创数据区域的引用,无需引用数据仍然可以共享和传播。
最后,在2.3版本中,这个目标已经基本完成,90%以上的原有图表都被改写了,剩下的大部分都是已有流程交互方式的统计图表或者更好的图表。如果某些用户喜欢单独使用,覆盖仍然存在。
图表与参考数据区联动功能要点一、原生图表与数据联动介绍
在Excel的原生绘图模式下,图表和数据区是自然链接的,图表所需的数据部分以单元格地址的形式链接到源数据。因此,修改源数据区的数据值,图表可以立即响应新的数据变化。
然而,这种方法也有一些小的缺点。如果数据区的行数增加或减少(对应图表系列的Point对象的增加或减少),原生图表无法就地适配。
如下图,当数据减少时,横坐标右侧会有多余的部分。
同样,添加行时,图表也不会自动扩展到新添加的区域,如下图所示。
在原生图表中,如果非要解决上述问题,则需要使用动态名称或数据透视表(图表)来完成。即使能做到,但制作过程繁琐。
另一个缺点是,如果需要在原生图表中制作复杂的图表,需要做很多辅助列来帮助实现。有些辅助列不能简单地用公式引用。,由于其局限性,只能用于简单的图表或有限的组合图表。最常见的散点图无法用透视图完成,更别说其他复制的瀑布图、子弹图等。
二、EasyShu革命性的数据图表联动方式
该工具的出现必然会带来更简单易用的体验。EasyShu的图表和数据联动中有很多技术细节。有必要给大家解释一下,让大家真正感受到它的力量。这些细节越熟悉,将 EasyShu 与自己的图表功能结合起来就越舒服。工具的机械繁琐部分完成,创意艺术部分由用户叠加。
由于原图有很大缺陷,EasyShu的存在必须改进。EasyShu完成的图表可以保留数据联动,在增删行的情况下依然有效。
这在原生图表中没有问题。因为EasyShu图表的数据是从图表之间的关系中分离出来的,所以最后会对图表进行数值处理。在Excel环境中,数据只是数字和文本,所以通常不进行数值处理。格式,如百分比、小数位数等。
在本次图表动态更新中,用户只需在第一次制作图表时设置数字标签,该设置会在后续数据更新中保留,无需重复设置。图表的数字标签格式,粒度可以下到某个系列,同一张图表中不同数据系列的标签可以满足各种数字格式的设置。
这在原生图表中不是问题。在 EasyShu 的实现中,需要注意的一点是
为了保持生成图表的联动,您只能使用粘贴操作,而不是复制,将图表放置在其他工作表中。
由于生成的图表已被程序命名为唯一名称,因此无法更改图表名称。如果使用复制方法,则同一工作簿中有两个同名图表。在自动更新机制中,只会找到第一个图表。并更新它,第二个同名图表将不会被处理。至于哪一个是第一个,这和遍历的顺序有关,所以最好的办法就是直接剪切,不复制。如果你真的想放多张图表,你可以重新生成一张。图表。
多个图表引用同一个数据源区域。当数据源区域发生变化时,多个图表也会同步更新。
由于EasyShu动态图表数据联动的上述优势,可以满足参考数据区行数据的自动增删。EasyShu的图表还有一个优点是不需要提供辅助列,所以这时候如果需要数据联动,图表会随着数据的更新而变化。
最好的场景是使用数据透视表的方法在数据透视表的数据区生成一个EasyShu图表,然后使用切片器和过滤器进行交互操作,不同时期和类别下的数据结果,图表遵循适应性变化。.
之所以说这个方案是最好的使用场景,是因为生产成本极低,无需编码,从数据源到数据报表、图表可视化的整个过程可以在几分钟内完成。同时,如果您在 Excel 或 PowerBIDeskTop 上使用 PowerPivot 建模技术,功能更加强大,您可以轻松创建强大的数据分析报表。最终输出也落在数据透视表中。
在传统的动态交互制作图表中,使用Index、Match、Offset等公式,结合工作表控件,在用户交互下返回当前的交互序号,使图表引用数据区,其公式为参考了交互式序列号的变化不同的目标数据源最终使图表也链接在一起。
相比数据透视表+切片器,这样的技术生产成本相对较高,但在某些场景下仍然是一种非常好的方式,特别适合在定制仪表盘中使用。
正因为如此,EasyShu的图表数据联动功能可以满足切割图表到其他工作表的需求,同时可以满足图表参考数据区公式的变化,图表将也相应地改变。所以 EasyShu 完全适合传统的工作表控件交互。
图表与数据之间的关联信息将保存在工作簿中。重新开放后,联动关系将重新建立。因为信息保存在工作簿中(文件保存后信息会保存,所以关闭文件时一定要选择保存文件),而不是本地存储在本地电脑上,特别方便文件共享与协作,不限于自己使用,您可以将文件发送到安装了EasyShu的其他电脑。
因为EasyShu是一款商业软件,除非在其他已经订阅激活且安装了EasyShu的电脑上使用,否则不存在数据联动的效果。只有对免费用户开放的类别对比图,只能在所有应用程序中使用。需要安装EasyShu,不管有没有激活机才能使用联动效果。
EasyShu制作图表后,选择复制粘贴到PPT中。由于图表唯一名称信息的属性在PPT中也有效,使用EasyShuForPPT插件可以一键快速将Excel上的所有EasyShu图表同步到PPT中。.
插件下载已放入云盘,具体下载地址: ,或回复easyshuforppt,下载。
结语
EasyShu的图表和数据联动功能将打开一个非常广阔的天地,为日常数据可视化带来革命性的体验。借助EasyShu,可以在Excel环境下轻松制作复杂的动态报表,丝毫不逊于主流BI软件。
动态图表的方向是 EasyShu 的下一个重点方向。除了Excel原生图表的动态化,我们还将制作Echarts网页版的动态交互图表,在Excel中完成,可以在Excel和PPT上展示。相互影响。
EasyShu一直在努力,希望读者喜欢EasyShu,给予更多的口碑传播(EasyShu2.3版本已经发布了大量的免费功能,相信每个图表爱好者都能得到自己喜欢的东西) . 查看全部
excel抓取网页动态数据(EasyShu的图表与引用数据区域联动功能要点(组图))
EasyShu的初始结构是将准备好的图表返回给用户,不依赖用户工作表的单元格区域引用,可以满足图表绘制后数据源的共享和传播,但用户反馈最强的是图表和数据是必需的。要保持联动,这个需求对于易书来说确实是一个巨大的挑战。
为了让EasyShu成为性价比最高、功能最强大、媲美美国高价图表插件,我们只能下定决心重写所有原有的图表制作方法,使用更复杂的代码和更繁重的工作量。以全新的方式链接图表和数据,无需依赖原创数据区域的引用,无需引用数据仍然可以共享和传播。
最后,在2.3版本中,这个目标已经基本完成,90%以上的原有图表都被改写了,剩下的大部分都是已有流程交互方式的统计图表或者更好的图表。如果某些用户喜欢单独使用,覆盖仍然存在。
图表与参考数据区联动功能要点一、原生图表与数据联动介绍
在Excel的原生绘图模式下,图表和数据区是自然链接的,图表所需的数据部分以单元格地址的形式链接到源数据。因此,修改源数据区的数据值,图表可以立即响应新的数据变化。
然而,这种方法也有一些小的缺点。如果数据区的行数增加或减少(对应图表系列的Point对象的增加或减少),原生图表无法就地适配。
如下图,当数据减少时,横坐标右侧会有多余的部分。
同样,添加行时,图表也不会自动扩展到新添加的区域,如下图所示。
在原生图表中,如果非要解决上述问题,则需要使用动态名称或数据透视表(图表)来完成。即使能做到,但制作过程繁琐。
另一个缺点是,如果需要在原生图表中制作复杂的图表,需要做很多辅助列来帮助实现。有些辅助列不能简单地用公式引用。,由于其局限性,只能用于简单的图表或有限的组合图表。最常见的散点图无法用透视图完成,更别说其他复制的瀑布图、子弹图等。
二、EasyShu革命性的数据图表联动方式
该工具的出现必然会带来更简单易用的体验。EasyShu的图表和数据联动中有很多技术细节。有必要给大家解释一下,让大家真正感受到它的力量。这些细节越熟悉,将 EasyShu 与自己的图表功能结合起来就越舒服。工具的机械繁琐部分完成,创意艺术部分由用户叠加。
由于原图有很大缺陷,EasyShu的存在必须改进。EasyShu完成的图表可以保留数据联动,在增删行的情况下依然有效。
这在原生图表中没有问题。因为EasyShu图表的数据是从图表之间的关系中分离出来的,所以最后会对图表进行数值处理。在Excel环境中,数据只是数字和文本,所以通常不进行数值处理。格式,如百分比、小数位数等。
在本次图表动态更新中,用户只需在第一次制作图表时设置数字标签,该设置会在后续数据更新中保留,无需重复设置。图表的数字标签格式,粒度可以下到某个系列,同一张图表中不同数据系列的标签可以满足各种数字格式的设置。
这在原生图表中不是问题。在 EasyShu 的实现中,需要注意的一点是
为了保持生成图表的联动,您只能使用粘贴操作,而不是复制,将图表放置在其他工作表中。
由于生成的图表已被程序命名为唯一名称,因此无法更改图表名称。如果使用复制方法,则同一工作簿中有两个同名图表。在自动更新机制中,只会找到第一个图表。并更新它,第二个同名图表将不会被处理。至于哪一个是第一个,这和遍历的顺序有关,所以最好的办法就是直接剪切,不复制。如果你真的想放多张图表,你可以重新生成一张。图表。
多个图表引用同一个数据源区域。当数据源区域发生变化时,多个图表也会同步更新。
由于EasyShu动态图表数据联动的上述优势,可以满足参考数据区行数据的自动增删。EasyShu的图表还有一个优点是不需要提供辅助列,所以这时候如果需要数据联动,图表会随着数据的更新而变化。
最好的场景是使用数据透视表的方法在数据透视表的数据区生成一个EasyShu图表,然后使用切片器和过滤器进行交互操作,不同时期和类别下的数据结果,图表遵循适应性变化。.
之所以说这个方案是最好的使用场景,是因为生产成本极低,无需编码,从数据源到数据报表、图表可视化的整个过程可以在几分钟内完成。同时,如果您在 Excel 或 PowerBIDeskTop 上使用 PowerPivot 建模技术,功能更加强大,您可以轻松创建强大的数据分析报表。最终输出也落在数据透视表中。
在传统的动态交互制作图表中,使用Index、Match、Offset等公式,结合工作表控件,在用户交互下返回当前的交互序号,使图表引用数据区,其公式为参考了交互式序列号的变化不同的目标数据源最终使图表也链接在一起。
相比数据透视表+切片器,这样的技术生产成本相对较高,但在某些场景下仍然是一种非常好的方式,特别适合在定制仪表盘中使用。
正因为如此,EasyShu的图表数据联动功能可以满足切割图表到其他工作表的需求,同时可以满足图表参考数据区公式的变化,图表将也相应地改变。所以 EasyShu 完全适合传统的工作表控件交互。
图表与数据之间的关联信息将保存在工作簿中。重新开放后,联动关系将重新建立。因为信息保存在工作簿中(文件保存后信息会保存,所以关闭文件时一定要选择保存文件),而不是本地存储在本地电脑上,特别方便文件共享与协作,不限于自己使用,您可以将文件发送到安装了EasyShu的其他电脑。
因为EasyShu是一款商业软件,除非在其他已经订阅激活且安装了EasyShu的电脑上使用,否则不存在数据联动的效果。只有对免费用户开放的类别对比图,只能在所有应用程序中使用。需要安装EasyShu,不管有没有激活机才能使用联动效果。
EasyShu制作图表后,选择复制粘贴到PPT中。由于图表唯一名称信息的属性在PPT中也有效,使用EasyShuForPPT插件可以一键快速将Excel上的所有EasyShu图表同步到PPT中。.
插件下载已放入云盘,具体下载地址: ,或回复easyshuforppt,下载。
结语
EasyShu的图表和数据联动功能将打开一个非常广阔的天地,为日常数据可视化带来革命性的体验。借助EasyShu,可以在Excel环境下轻松制作复杂的动态报表,丝毫不逊于主流BI软件。
动态图表的方向是 EasyShu 的下一个重点方向。除了Excel原生图表的动态化,我们还将制作Echarts网页版的动态交互图表,在Excel中完成,可以在Excel和PPT上展示。相互影响。
EasyShu一直在努力,希望读者喜欢EasyShu,给予更多的口碑传播(EasyShu2.3版本已经发布了大量的免费功能,相信每个图表爱好者都能得到自己喜欢的东西) .
excel抓取网页动态数据( 创建数据透视表时的三种方法,动态数据源获取方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2022-04-14 14:32
创建数据透视表时的三种方法,动态数据源获取方法介绍)
以前,当我们创建数据透视表时,我们手动选择了数据源区域。这种选择方式无法实现数据源的动态获取功能。也就是说,如果数据源中添加了新的行或列,我们必须再次选择它。数据源。
那么有没有办法自动选择数据源,让它随着数据的增加而动态选择呢?当然,方法还是很多的。今天,我们将介绍三种方法。您可以根据自己的喜好选择合适的。
动态数据源获取方式一:参考数据方式。该方法不仅可以动态选择当前数据透视表所在工作簿的数据源,还可以引用外部数据,也就是说,即使数据源和数据透视表不在同一个工作簿中,源和数据表可以实现同步更新。
参考数据法只需6步即可实现数据的动态选择。具体操作方法如上图所示。
在第 5 步中,我们选择数据透视表所在的工作簿。如果找不到上图所示的文件,可以通过【浏览更多】选择,或者选择其他工作簿的工作表作为数据源。文字描述有限,我会在视频中详细解释这部分。
需要注意的是,无论数据源在哪个工作簿中,都要确保数据源放在单独的工作表中,工作表中不能有其他数据,以免影响应用效果。
注意数据源标题中不要有空格、特殊字符、合并单元格等。
第二种获取动态数据源的方法是动态表法。通过将数据源转换为表格,充分利用表格的自动扩展功能,实现数据源的动态增加和动态选择。这种方法简单易操作,是初学者的最佳选择。
动态表法只需5步即可实现数据的动态选择。方法如上图所示。选择数据源的快捷方式是:CTRL+SHIFT+→+↓。注意数据源标题中不要有空格、特殊字符、合并单元格等。
创建动态表后,我们需要给表命名以区分它。名称可以自定义,不收录特殊字符。
表命名后,创建数据透视表时只需在原创数据源选择区输入表名即可。
第三种获取动态数据源的方法:函数名方法。使用OFFSET函数自定义数据源名称,也可以实现动态选择。对功能不是很好的小伙伴慎用此方法。
函数名方法结合了函数和自定义名称的技巧,初学者可能很难理解。具体操作步骤如上图所示。
输入的公式如下:
=offset(销售清单!$A$1,0,0,counta(销售清单!$A:$A),counta(销售清单!$1:$1))
这种方法是一种比较传统的方法。记得刚进公司的时候,第一次接触数据透视表的时候就用过这个方法。关于OFFSET函数的具体用法,我会在函数应用章节详细讲解。想学习的朋友可以随时关注课程的更新!
... 查看全部
excel抓取网页动态数据(
创建数据透视表时的三种方法,动态数据源获取方法介绍)
以前,当我们创建数据透视表时,我们手动选择了数据源区域。这种选择方式无法实现数据源的动态获取功能。也就是说,如果数据源中添加了新的行或列,我们必须再次选择它。数据源。
那么有没有办法自动选择数据源,让它随着数据的增加而动态选择呢?当然,方法还是很多的。今天,我们将介绍三种方法。您可以根据自己的喜好选择合适的。
动态数据源获取方式一:参考数据方式。该方法不仅可以动态选择当前数据透视表所在工作簿的数据源,还可以引用外部数据,也就是说,即使数据源和数据透视表不在同一个工作簿中,源和数据表可以实现同步更新。
参考数据法只需6步即可实现数据的动态选择。具体操作方法如上图所示。
在第 5 步中,我们选择数据透视表所在的工作簿。如果找不到上图所示的文件,可以通过【浏览更多】选择,或者选择其他工作簿的工作表作为数据源。文字描述有限,我会在视频中详细解释这部分。
需要注意的是,无论数据源在哪个工作簿中,都要确保数据源放在单独的工作表中,工作表中不能有其他数据,以免影响应用效果。
注意数据源标题中不要有空格、特殊字符、合并单元格等。
第二种获取动态数据源的方法是动态表法。通过将数据源转换为表格,充分利用表格的自动扩展功能,实现数据源的动态增加和动态选择。这种方法简单易操作,是初学者的最佳选择。
动态表法只需5步即可实现数据的动态选择。方法如上图所示。选择数据源的快捷方式是:CTRL+SHIFT+→+↓。注意数据源标题中不要有空格、特殊字符、合并单元格等。
创建动态表后,我们需要给表命名以区分它。名称可以自定义,不收录特殊字符。
表命名后,创建数据透视表时只需在原创数据源选择区输入表名即可。
第三种获取动态数据源的方法:函数名方法。使用OFFSET函数自定义数据源名称,也可以实现动态选择。对功能不是很好的小伙伴慎用此方法。
函数名方法结合了函数和自定义名称的技巧,初学者可能很难理解。具体操作步骤如上图所示。
输入的公式如下:
=offset(销售清单!$A$1,0,0,counta(销售清单!$A:$A),counta(销售清单!$1:$1))
这种方法是一种比较传统的方法。记得刚进公司的时候,第一次接触数据透视表的时候就用过这个方法。关于OFFSET函数的具体用法,我会在函数应用章节详细讲解。想学习的朋友可以随时关注课程的更新!
...
excel抓取网页动态数据(一个动态多级表头动态生成盘)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-13 12:32
标题是动态生成的。该场景用于从数据库中读取表头,方便后续修改表头字段。前端导出为开源插件table2excel.js。此导出有限制。只能导出doom元素中本页的数据。不适合分页数据。
返回一个二进制数组,并在后台构建对应的数据格式:
前端对返回的数据进行处理,并压入一个空数组,形成动态多级表头。
var header= [];
var header1= [
{
title: "编号",
type: "numbers",
align: "center",
width: 80,
rowspan: 2
}, {
title: "姓名",
field: 'name',
align: "center",
width: 120,
rowspan: 2
}];
var header2= [];
$.ajax({
type: "post",
url: "",
dataType:"json",
async:false,
success: function (data) {
console.log(data)
if (data.code === 0){
var djs=data.data[0][0];
console.log(djs)
header1.push({align: 'center', title: djs, colspan:3});
var sdarr=["基数"];
var newArr = delArr(sdarr,data.data[0]);//只需要一个三列表头,其余是二列的。
console.log(newArr);
$.each(newArr, function (index, obj) {
// console.log(obj)
header1.push({align: 'center', title: obj, colspan:2});
});
$.each(data.data[1], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
header2.push({field: obj.field3, title: obj.title3 });
});
$.each(data.data[2], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[3], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[4], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[5], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
header1.splice(10,0,
, {
title: '操作',
toolbar: '#barDemo',
fixed:"right",
width: 80,
rowspan: 2
});//固定操作列
header.push(header1);
header.push(header2);
console.log(header);//所需的表头push到一个总的数组里
}
}
});
var table2Excel;
let TableC= table.render({
id: 'demo',
elem: '#demo'
, url: '' //数据接口
, cellMinWidth: 80
, limit: 10//每页默认数
, limits: [10, 20, 30, 40, 50, 100]
, page: { //支持传入 laypage 组件的所有参数(某些参数除外,如:jump/elem) - 详见文档
layout: ['count', 'prev', 'page', 'next', 'limit', 'refresh', 'skip'] //自定义分页布局
, curr: 1 //设定初始在第 1 页
},request: {
pageName: "page",
limitName: "rows"
},
response: {
statusCode: 0,
countName: 'total', //规定数据总数的字段名称,默认:count
dataName: 'data' //规定数据列表的字段名称,默认:data
},
loading:true, //是否显示加载条(默认:true)。如果设置 false,则在切换分页时,不会出现加载条。该参数只适用于 url 参数开启的方式
title:"记录表", //
//cellMinWidth:60, //全局定义所有常规单元格的最小宽度(默认:60),一般用于列宽自动分配的情况。其优先级低于表头参数中的 minWidth
text:{
none: '暂无相关数据' //默认:无数据。注:该属性为 layui 2.2.5 开始新增
}, //自定义文本,如空数据时的异常提示等。注:layui 2.2.5 开始新增。
autoSort:true,
skin:"row", //用于设定表格风格,若使用默认风格不设置该属性即可line (行边框风格) row (列边框风格) nob (无边框风格)
even:true, //若不开启隔行背景,不设置该参数即可
//size:"lg", //用于设定表格尺寸,若使用默认尺寸不设置该属性即可
parseData: function(res) {
var ss = {
data: res.rows,
code: 0,
total: res.total,
}
return ss
},
done:function(){
console.log("数据渲染完了!")
table2Excel = new Table2Excel();
table2Excel.append($("#demo"));//遍历页面上layui生成的div,抓取里面的格式与数据,来手动append到table中,再控制该table隐藏,来为导出做准备。
//console.log(table2Excel.append($("#demo")))
}
, cols: header
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#demo'),fileName);
});
百度网盘:table2Excel.js
提取码:5u9h
使用方法:
上面的js已经存在。数据表渲染完成后,在done函数中进行相关的遍历操作
var table2Excel ;
table.render({
elem: '#demo',
...
done: function (res, curr, count) {
table2Excel = new Table2Excel();
table2Excel.append($("#tableId"));
})
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#tableId'),fileName);
});
导出效果:
参考: 查看全部
excel抓取网页动态数据(一个动态多级表头动态生成盘)
标题是动态生成的。该场景用于从数据库中读取表头,方便后续修改表头字段。前端导出为开源插件table2excel.js。此导出有限制。只能导出doom元素中本页的数据。不适合分页数据。
返回一个二进制数组,并在后台构建对应的数据格式:
前端对返回的数据进行处理,并压入一个空数组,形成动态多级表头。
var header= [];
var header1= [
{
title: "编号",
type: "numbers",
align: "center",
width: 80,
rowspan: 2
}, {
title: "姓名",
field: 'name',
align: "center",
width: 120,
rowspan: 2
}];
var header2= [];
$.ajax({
type: "post",
url: "",
dataType:"json",
async:false,
success: function (data) {
console.log(data)
if (data.code === 0){
var djs=data.data[0][0];
console.log(djs)
header1.push({align: 'center', title: djs, colspan:3});
var sdarr=["基数"];
var newArr = delArr(sdarr,data.data[0]);//只需要一个三列表头,其余是二列的。
console.log(newArr);
$.each(newArr, function (index, obj) {
// console.log(obj)
header1.push({align: 'center', title: obj, colspan:2});
});
$.each(data.data[1], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
header2.push({field: obj.field3, title: obj.title3 });
});
$.each(data.data[2], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[3], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[4], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
$.each(data.data[5], function (index, obj) {
//拼接成官网所需要的数组
header2.push({field: obj.field1, title: obj.title1 });
header2.push({field: obj.field2, title: obj.title2 });
});
header1.splice(10,0,
, {
title: '操作',
toolbar: '#barDemo',
fixed:"right",
width: 80,
rowspan: 2
});//固定操作列
header.push(header1);
header.push(header2);
console.log(header);//所需的表头push到一个总的数组里
}
}
});
var table2Excel;
let TableC= table.render({
id: 'demo',
elem: '#demo'
, url: '' //数据接口
, cellMinWidth: 80
, limit: 10//每页默认数
, limits: [10, 20, 30, 40, 50, 100]
, page: { //支持传入 laypage 组件的所有参数(某些参数除外,如:jump/elem) - 详见文档
layout: ['count', 'prev', 'page', 'next', 'limit', 'refresh', 'skip'] //自定义分页布局
, curr: 1 //设定初始在第 1 页
},request: {
pageName: "page",
limitName: "rows"
},
response: {
statusCode: 0,
countName: 'total', //规定数据总数的字段名称,默认:count
dataName: 'data' //规定数据列表的字段名称,默认:data
},
loading:true, //是否显示加载条(默认:true)。如果设置 false,则在切换分页时,不会出现加载条。该参数只适用于 url 参数开启的方式
title:"记录表", //
//cellMinWidth:60, //全局定义所有常规单元格的最小宽度(默认:60),一般用于列宽自动分配的情况。其优先级低于表头参数中的 minWidth
text:{
none: '暂无相关数据' //默认:无数据。注:该属性为 layui 2.2.5 开始新增
}, //自定义文本,如空数据时的异常提示等。注:layui 2.2.5 开始新增。
autoSort:true,
skin:"row", //用于设定表格风格,若使用默认风格不设置该属性即可line (行边框风格) row (列边框风格) nob (无边框风格)
even:true, //若不开启隔行背景,不设置该参数即可
//size:"lg", //用于设定表格尺寸,若使用默认尺寸不设置该属性即可
parseData: function(res) {
var ss = {
data: res.rows,
code: 0,
total: res.total,
}
return ss
},
done:function(){
console.log("数据渲染完了!")
table2Excel = new Table2Excel();
table2Excel.append($("#demo"));//遍历页面上layui生成的div,抓取里面的格式与数据,来手动append到table中,再控制该table隐藏,来为导出做准备。
//console.log(table2Excel.append($("#demo")))
}
, cols: header
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#demo'),fileName);
});
百度网盘:table2Excel.js
提取码:5u9h
使用方法:
上面的js已经存在。数据表渲染完成后,在done函数中进行相关的遍历操作
var table2Excel ;
table.render({
elem: '#demo',
...
done: function (res, curr, count) {
table2Excel = new Table2Excel();
table2Excel.append($("#tableId"));
})
});
// 导出excel点击事件
$('#exportElemId').click(function(){
let fileName = 'XXX-20200xxxx';
table2Excel.exportLayTable($('#tableId'),fileName);
});
导出效果:
参考:
excel抓取网页动态数据(第一时间送达76套java从入门到精通实战课程分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-13 12:29
)
点击上方蓝色字体,选择“明星公众号”
优质文章,第一时间发货
76套java课程从入门到精通实战
前言
第一篇文章文章发在CSDN,时隔两年,终于实现了自由爬微博!本文可以解决微博预登录、识别“展开全文”、抓取完整数据、翻页设置等问题。由于新接触爬虫,有些术语可能用错了,请指正!
一、动态爬虫和静态爬虫的区别
1、静态网页
静态网页是纯HTML,无后台数据库,无程序,无交互,体积小,加载速度快。静态网页的抓取只需要四个步骤:发送请求、获取相应内容、解析内容和保存数据。
2、动态网页
动态网页上的数据会随着时间和用户交互而变化,所以数据不会直接呈现在网页的源代码中,数据会以Json的形式保存。所以动态网页比静态网页多了一个步骤,就是需要渲染才能获取相关数据。
3、如何区分动态和静态网页
加载网页后,右键选择“查看网页源代码”。如果网页上的大部分字段都出现在源代码中,那么这是一个静态网页,否则就是一个动态网页。
二、动态爬虫的两种方法
1.逆向分析爬取动态网页
调度资源对应的URL适用的数据为json格式,Javascript触发调度。主要步骤是获取待调度资源对应的URL——访问URL获取资源的数据。(这里不详细解释)
2.使用Selenium库爬取动态网页
使用 Selenium 库,它使用 JavaScript 来模拟真实用户对浏览器所做的事情。本案将采用这种方法。
三、安装 Selenium 库并下载浏览器补丁
1.可以使用 pip 工具安装 Selenium 库。
2.下载与您的 Chrome 浏览器版本匹配的浏览器补丁。
Step1:检查Chrome的版本
Step2:去下载对应版本的浏览器补丁。网址:
Step3:解压文件并将其与python.exe放在同一个文件中
四、页面打开和预登录
1.导入 selenium 包
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import time
import pandas as pd
2.打开页面
driver = webdriver.Chrome()
print('准备登陆Weibo.cn网站...')
#发送请求
driver.get("https://login.sina.com.cn/signup/signin.php")
wait = WebDriverWait(driver,5)
#重要:暂停1分钟进行预登陆,此处填写账号密码及验证
time.sleep(60)
3.使用交互操作。运行以上两个程序后,会弹出一个框。此框用于模拟网页的交互。在此框中完成登录(包括填写登录名、密码和短信验证等)
4.完成预登录后,进入个人主页
五、关键词搜索操作
1.找到上图中的关键词输入框,在框中输入搜索对象,如“好好学习”
#使用selector去定位关键词搜索框
s_input = driver.find_element_by_css_selector('#search_input')
#向搜索框中传入字段
s_input.send_keys("努力学习")
#定位搜索键
confirm_btn = driver.find_element_by_css_selector('#search_submit')
#点击
confirm_btn.click()
2.上一步代码完成后,会弹出一个新窗口,从个人主页跳转到微博搜索页面。但是驱动还是在个人主页,需要手动将驱动移动到微博搜索页面。
3.使用switch_to.window()方法进行移位
#人为移动driver
driver.switch_to.window(driver.window_handles[1]) 查看全部
excel抓取网页动态数据(第一时间送达76套java从入门到精通实战课程分享
)
点击上方蓝色字体,选择“明星公众号”
优质文章,第一时间发货
76套java课程从入门到精通实战
前言
第一篇文章文章发在CSDN,时隔两年,终于实现了自由爬微博!本文可以解决微博预登录、识别“展开全文”、抓取完整数据、翻页设置等问题。由于新接触爬虫,有些术语可能用错了,请指正!
一、动态爬虫和静态爬虫的区别
1、静态网页
静态网页是纯HTML,无后台数据库,无程序,无交互,体积小,加载速度快。静态网页的抓取只需要四个步骤:发送请求、获取相应内容、解析内容和保存数据。
2、动态网页
动态网页上的数据会随着时间和用户交互而变化,所以数据不会直接呈现在网页的源代码中,数据会以Json的形式保存。所以动态网页比静态网页多了一个步骤,就是需要渲染才能获取相关数据。
3、如何区分动态和静态网页
加载网页后,右键选择“查看网页源代码”。如果网页上的大部分字段都出现在源代码中,那么这是一个静态网页,否则就是一个动态网页。
二、动态爬虫的两种方法
1.逆向分析爬取动态网页
调度资源对应的URL适用的数据为json格式,Javascript触发调度。主要步骤是获取待调度资源对应的URL——访问URL获取资源的数据。(这里不详细解释)
2.使用Selenium库爬取动态网页
使用 Selenium 库,它使用 JavaScript 来模拟真实用户对浏览器所做的事情。本案将采用这种方法。
三、安装 Selenium 库并下载浏览器补丁
1.可以使用 pip 工具安装 Selenium 库。
2.下载与您的 Chrome 浏览器版本匹配的浏览器补丁。
Step1:检查Chrome的版本
Step2:去下载对应版本的浏览器补丁。网址:
Step3:解压文件并将其与python.exe放在同一个文件中
四、页面打开和预登录
1.导入 selenium 包
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
import time
import pandas as pd
2.打开页面
driver = webdriver.Chrome()
print('准备登陆Weibo.cn网站...')
#发送请求
driver.get("https://login.sina.com.cn/signup/signin.php";)
wait = WebDriverWait(driver,5)
#重要:暂停1分钟进行预登陆,此处填写账号密码及验证
time.sleep(60)
3.使用交互操作。运行以上两个程序后,会弹出一个框。此框用于模拟网页的交互。在此框中完成登录(包括填写登录名、密码和短信验证等)
4.完成预登录后,进入个人主页
五、关键词搜索操作
1.找到上图中的关键词输入框,在框中输入搜索对象,如“好好学习”
#使用selector去定位关键词搜索框
s_input = driver.find_element_by_css_selector('#search_input')
#向搜索框中传入字段
s_input.send_keys("努力学习")
#定位搜索键
confirm_btn = driver.find_element_by_css_selector('#search_submit')
#点击
confirm_btn.click()
2.上一步代码完成后,会弹出一个新窗口,从个人主页跳转到微博搜索页面。但是驱动还是在个人主页,需要手动将驱动移动到微博搜索页面。
3.使用switch_to.window()方法进行移位
#人为移动driver
driver.switch_to.window(driver.window_handles[1])
excel抓取网页动态数据(建议复制导入的数据到一个新的excel文件,【选择性粘贴】为纯数值,这样就万无一失了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-12 17:27
有很多网页收录数据表。虽然这些数据表可以直接复制到excel中,但是如果表很长就麻烦了。本文介绍使用excel获取外部数据下载国家旅游局网站月度入境旅游统计数据的功能。工具/原材料 Excel 软件方法/步骤一:通过搜索引擎找到国家旅游局的网站,点击主菜单上的【政府披露】-【统计】,可以看到一系列网页收录数据的页面。2:打开网页,确认网页中收录数据表。复制此页面的 URL 以供以后使用。3:启动excel文件,在工作表中,点击[Data]->[From< @网站][ /img]4:按ctrl+v粘贴上一步复制的URL;点击网址栏右侧的【前往】;网页显示后,点击数据表左上角黄色【水平箭头】,变成绿色【勾号】;点击整个窗口右下角的【导入】。
[img]5:选择工作表位置并导入数据。6:结果如下图所示。虽然数据已经导入,但这实际上相当于建立了excel文件和网页的连接。excel文件复制到别处,可能因为连接关系坏了,数据显示不出来。建议将导入的数据复制到新的excel文件中,【选择性粘贴】是纯值,万无一失。注意事项 建议通过特殊粘贴将结果保存为新的excel工作表中的值。希望这篇文章中的信息采集:使用Excel导入web数据表可以帮助到你。 查看全部
excel抓取网页动态数据(建议复制导入的数据到一个新的excel文件,【选择性粘贴】为纯数值,这样就万无一失了)
有很多网页收录数据表。虽然这些数据表可以直接复制到excel中,但是如果表很长就麻烦了。本文介绍使用excel获取外部数据下载国家旅游局网站月度入境旅游统计数据的功能。工具/原材料 Excel 软件方法/步骤一:通过搜索引擎找到国家旅游局的网站,点击主菜单上的【政府披露】-【统计】,可以看到一系列网页收录数据的页面。2:打开网页,确认网页中收录数据表。复制此页面的 URL 以供以后使用。3:启动excel文件,在工作表中,点击[Data]->[From< @网站][ /img]4:按ctrl+v粘贴上一步复制的URL;点击网址栏右侧的【前往】;网页显示后,点击数据表左上角黄色【水平箭头】,变成绿色【勾号】;点击整个窗口右下角的【导入】。
[img]5:选择工作表位置并导入数据。6:结果如下图所示。虽然数据已经导入,但这实际上相当于建立了excel文件和网页的连接。excel文件复制到别处,可能因为连接关系坏了,数据显示不出来。建议将导入的数据复制到新的excel文件中,【选择性粘贴】是纯值,万无一失。注意事项 建议通过特殊粘贴将结果保存为新的excel工作表中的值。希望这篇文章中的信息采集:使用Excel导入web数据表可以帮助到你。
excel抓取网页动态数据(excel抓取网页动态数据没有问题,如何看懂的时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-11 02:01
excel抓取网页动态数据没有问题,不过只抓取表格中部分数据后,并不能得到想要的结果,主要原因就是你所使用的库只读取一次,或者返回了none,建议抓取数据后,对所抓取的数据进行进一步操作。
没有excel学习的初衷,就是防止我很会用excel还不知道如何看懂的时候,可以直接问excel工作人员,他会把excel给解决掉...解决方法如下:a、打开一个新文件;b、选中下图红色箭头处的,再把下图绿色箭头处的取消选中就可以;如上图,excel右上角会出现一个反馈问题,是否选中哪些单元格就可以实现抓取,没有选中也行。
左图中,就是没有选中,有一条列标,而右下角也有取消选中的按钮。综上所述,可以按住ctrl键,在文档文件名的基础上,点击上图,就可以实现抓取。代码如下:excelhome提供该项功能,赞一个~。
做个试验,在用access的时候记得设置imap,否则access上的记录每次都重新抓取的,sql也要配置成openxmlwindow.newwindow才可以抓取。(下面的代码不是在excel,只是数据抓取的一种实现。)具体的可以网上搜索看看,搜索集是有的。有个mysql的demo或者phpweb开发平台,我自己之前有用过叫phpcms/pageadmin。
在你的需求中,很容易找到相应的适合你的爬虫和存储数据的服务。这样代码是不难的,而且可以保存下来做到随时可以用。说点玄乎的,可以试试ioc。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据没有问题,如何看懂的时候)
excel抓取网页动态数据没有问题,不过只抓取表格中部分数据后,并不能得到想要的结果,主要原因就是你所使用的库只读取一次,或者返回了none,建议抓取数据后,对所抓取的数据进行进一步操作。
没有excel学习的初衷,就是防止我很会用excel还不知道如何看懂的时候,可以直接问excel工作人员,他会把excel给解决掉...解决方法如下:a、打开一个新文件;b、选中下图红色箭头处的,再把下图绿色箭头处的取消选中就可以;如上图,excel右上角会出现一个反馈问题,是否选中哪些单元格就可以实现抓取,没有选中也行。
左图中,就是没有选中,有一条列标,而右下角也有取消选中的按钮。综上所述,可以按住ctrl键,在文档文件名的基础上,点击上图,就可以实现抓取。代码如下:excelhome提供该项功能,赞一个~。
做个试验,在用access的时候记得设置imap,否则access上的记录每次都重新抓取的,sql也要配置成openxmlwindow.newwindow才可以抓取。(下面的代码不是在excel,只是数据抓取的一种实现。)具体的可以网上搜索看看,搜索集是有的。有个mysql的demo或者phpweb开发平台,我自己之前有用过叫phpcms/pageadmin。
在你的需求中,很容易找到相应的适合你的爬虫和存储数据的服务。这样代码是不难的,而且可以保存下来做到随时可以用。说点玄乎的,可以试试ioc。
excel抓取网页动态数据(一个同门兄弟PowerBI抓取网页数据的方法,值得收藏!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-04-09 17:01
?0? 什么是网页抓取?Web信息抓取是从大量网页中抓取非结构化信息并将其保存到结构化数据库中的过程。我们提供Web2DB网页信息抓取服务,您只需要告诉我们您的目标网页和您的数据需求,它是如何实时抓取动态网页数据的?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1。
这里给大家分享一个用Excel的小哥Power BI抓取网页数据的方法。如果Excel中安装了PowerQuery插件,最好的答案可以是:前台代码:plain]查看纯副本>。
csdn为您找到了实时爬取网页数据的相关内容,包括实时爬取网页数据相关文档代码的介绍,相关教程视频课程,以及相关实时爬取网页数据问答内容。为您解决当前相关问题,如果您想更详细快速了解采集傻瓜式网络爬虫,输入网址或关键词,自动抓取网页数据,采集@ > 实时数据,支持单页或批量页的自动采集。
>△< 1、新建一个空白Excel工作表——点击菜单栏中的“数据”选项卡——点击“获取外部数据”——“来自网站”。2、弹出“新建网页查询”对话框--复制“全国城镇房价排名”的网站url地址,需要网页抓取工具支持采集中的数据云,不仅仅是在本地电脑上运行。通过云采集这种方式,采集器可以根据你设置的时间自动运行采集数据。优采云云采集 不止于此。
您好,首先,任何爬虫软件都不支持实时采集。如果你的身体条件允许,可以部署多台机器,那么如何在每台机器上实时爬取动态网页数据呢?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1、为什么采集动态数字。 查看全部
excel抓取网页动态数据(一个同门兄弟PowerBI抓取网页数据的方法,值得收藏!)
?0? 什么是网页抓取?Web信息抓取是从大量网页中抓取非结构化信息并将其保存到结构化数据库中的过程。我们提供Web2DB网页信息抓取服务,您只需要告诉我们您的目标网页和您的数据需求,它是如何实时抓取动态网页数据的?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1。
这里给大家分享一个用Excel的小哥Power BI抓取网页数据的方法。如果Excel中安装了PowerQuery插件,最好的答案可以是:前台代码:plain]查看纯副本>。
csdn为您找到了实时爬取网页数据的相关内容,包括实时爬取网页数据相关文档代码的介绍,相关教程视频课程,以及相关实时爬取网页数据问答内容。为您解决当前相关问题,如果您想更详细快速了解采集傻瓜式网络爬虫,输入网址或关键词,自动抓取网页数据,采集@ > 实时数据,支持单页或批量页的自动采集。
>△< 1、新建一个空白Excel工作表——点击菜单栏中的“数据”选项卡——点击“获取外部数据”——“来自网站”。2、弹出“新建网页查询”对话框--复制“全国城镇房价排名”的网站url地址,需要网页抓取工具支持采集中的数据云,不仅仅是在本地电脑上运行。通过云采集这种方式,采集器可以根据你设置的时间自动运行采集数据。优采云云采集 不止于此。
您好,首先,任何爬虫软件都不支持实时采集。如果你的身体条件允许,可以部署多台机器,那么如何在每台机器上实时爬取动态网页数据呢?我们生活的数字世界不断产生大量数据。利用动态大数据已成为企业数据分析的关键。在本文中,我们将回答以下问题:1、为什么采集动态数字。
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-07 06:23
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。
6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
查看全部
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。
6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
excel抓取网页动态数据(一套可以自动生成PPT的办法,你都知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2022-04-04 22:10
因为我经常做每周和每月的PPT,每次重复操作的效率都很低。这里有一套可以自动生成PPT的方法。
首先,总体思路是这样的。周报、月报等业务分析PPT一般由表格、图表和分析文本组成,整体结构比较固定。
首先使用EXCEL的数据获取功能获取数据库、网页数据,或者手动建一个基础表(数据库);然后用EXCEL生成表格和图表,用函数生成分析文本(可以根据数据更新);然后使用PPT直接调用EXCEL内容创建PPT模板。
EXCEL基础表格和PPT模板准备好了。每次使用只需重新访问数据库或修改基础表,即可直接更新并自动生成PPT。
第一步:创建EXCEL基础表(数据库)
例如,手动将月度销售报告创建为基本表格。
您也可以通过网页、文本获取数据,或者通过EXCEL的数据获取功能访问数据库(如SQL等)
如果你不明白,请阅读本文
Excel 数据采集——可乐数据分析之路文章 - 知乎
关于访问SQL数据库,因为目前没有环境,所以没试过。
第二步:EXCEL生成PPT展示元素
这部分其实就是把你想要在PPT上呈现的所有内容都通过excel制作出来。
最后一步:PPT调用EXCEL
这一步很重要,选择PPT中要显示内容的“单元格”,复制
打开PPT,粘贴-粘贴特殊-粘贴链接,注意不能用ctrlV,它会调用excel中的所有元素
按照上面的方法,仔细编辑每个PPT页面,制作一个可以长期使用的模板
放大:一键生成PPT
每周或每月做PPT时,只需更新EXCEL基础表的数据,保存后,打开PPT文件,点击“更新链接”,PPT会自动关联EXCEL数据,更新相关文字、表格、图表等内容,几十张P PPT瞬间生成,好吃吗? !
最后几点说明:
PPT和EXCEL放在同一个目录下; PPT和EXCEL不改名,改名会导致断链;请参阅此处了解如何处理断开的链接:
3.第一次更新PPT链接时,先打开EXCEL,这样更新链接比较快;
4.更新的PPT不需要每次打开都更新链接,取消即可。如果更新了EXCEL数据,可以再次更新PPT。
就是这样,我不需要VBA,不需要函数,是不是很简单,希望对你有所帮助。 查看全部
excel抓取网页动态数据(一套可以自动生成PPT的办法,你都知道吗?)
因为我经常做每周和每月的PPT,每次重复操作的效率都很低。这里有一套可以自动生成PPT的方法。
首先,总体思路是这样的。周报、月报等业务分析PPT一般由表格、图表和分析文本组成,整体结构比较固定。
首先使用EXCEL的数据获取功能获取数据库、网页数据,或者手动建一个基础表(数据库);然后用EXCEL生成表格和图表,用函数生成分析文本(可以根据数据更新);然后使用PPT直接调用EXCEL内容创建PPT模板。
EXCEL基础表格和PPT模板准备好了。每次使用只需重新访问数据库或修改基础表,即可直接更新并自动生成PPT。
第一步:创建EXCEL基础表(数据库)
例如,手动将月度销售报告创建为基本表格。
您也可以通过网页、文本获取数据,或者通过EXCEL的数据获取功能访问数据库(如SQL等)
如果你不明白,请阅读本文
Excel 数据采集——可乐数据分析之路文章 - 知乎
关于访问SQL数据库,因为目前没有环境,所以没试过。
第二步:EXCEL生成PPT展示元素
这部分其实就是把你想要在PPT上呈现的所有内容都通过excel制作出来。
最后一步:PPT调用EXCEL
这一步很重要,选择PPT中要显示内容的“单元格”,复制
打开PPT,粘贴-粘贴特殊-粘贴链接,注意不能用ctrlV,它会调用excel中的所有元素
按照上面的方法,仔细编辑每个PPT页面,制作一个可以长期使用的模板
放大:一键生成PPT
每周或每月做PPT时,只需更新EXCEL基础表的数据,保存后,打开PPT文件,点击“更新链接”,PPT会自动关联EXCEL数据,更新相关文字、表格、图表等内容,几十张P PPT瞬间生成,好吃吗? !
最后几点说明:
PPT和EXCEL放在同一个目录下; PPT和EXCEL不改名,改名会导致断链;请参阅此处了解如何处理断开的链接:
3.第一次更新PPT链接时,先打开EXCEL,这样更新链接比较快;
4.更新的PPT不需要每次打开都更新链接,取消即可。如果更新了EXCEL数据,可以再次更新PPT。
就是这样,我不需要VBA,不需要函数,是不是很简单,希望对你有所帮助。
excel抓取网页动态数据( 爬取代码解析需要的包有numpypandas,,等代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-04 22:08
爬取代码解析需要的包有numpypandas,,等代码)
标签位置明确了,说下爬取的基本思路:
先获取30条记录的链接,然后依次爬取信息,最后打开下一页,重复。
这是第一次爬取(有100页),一旦出现异常,可以先保存爬取的。
二、代码分析
需要的包有numpy、pandas、BeautifulSoup、re、urllib等。
代码分析如下:
1、getbsobj 函数
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
定义一个返回 bs 对象的函数,包括一些异常处理。
2、getLinksList 函数
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
定义函数获取30条交易记录链接,并以列表的形式返回。
该链接位于 ul 标签下的 a 标签中。
中间有个圈。原因是有时候网页可以打开,但是交易记录没有显示。这时候需要再次尝试打开,直到出现交易记录。如果没有开启,可能是因为访问过于频繁,所以在无法开启的时候,会进入休眠60秒。
3、getInfo 函数
infoArray = []
一条记录的信息是通过一维列表保存的,infoArray是一个二维列表,保存了所有获取到的记录的信息。
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
获取收录基本属性和事务属性内容的标记列表。
info = list()
info.append(bsobj.head.title.get_text().split()[0])
info 是保存记录的所有信息的临时列表。
此处添加的是社区名称。
for tag in tags:
info.append(tag.get_text().strip()[4:])
这里添加的是基础属性和交易属性的内容
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
这里添加的是交易金额、单价和交易日期,因为和上面的属性不一样,需要单独处理。
infoArray.append(info)
添加记录
arr = np.array(infoArray)
将最终的 infoArray 转换为矩阵 arr 并返回它。
4、checkid 函数
检查动态爬取时是否获取到id。如果已经获取到,则说明上次运行的最新记录已经被爬取,此时无需继续爬取。
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
在这里,检查列表中的每个链接。如果 id 与上次保存的 id 相同,则该链接及其后续链接都被丢弃,并返回一个 bool 值和一个已处理的列表。
5、getIndex 函数
用于获取保存到 Excel 时所需的属性标签
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
6、下载功能
主功能
def download(url,start,end):
从起始页开始,爬到结束页(包括结束页)
cols,new_id = getIndex(url)
获取最新记录的属性列表和id号
ls = getLinksList(url,i)
获取链接列表
tag,ls = checkid(ls,id)
检查身份证
arr=getInfo(ls)
获取数据矩阵
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
转换为 DataFrame 格式。
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
另存为 Excel。
三、输出结果
四、完整代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.error import HTTPError
import pandas as pd
import numpy as np
import re
import socket,time
url = 'https://bj.lianjia.com/chengjiao'
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
def getInfo(ls):
'''
:param ls:链接列表
:return: 数组
'''
infoArray = []
i = 1
for lk in ls:
print('正在获取第%d条信息'%i)
bsobj = getbsobj(lk)
if not bsobj:continue
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
info = list()
info.append(bsobj.head.title.get_text().split()[0])
for tag in tags:
info.append(tag.get_text().strip()[4:])
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
infoArray.append(info)
i += 1
print('-'*20)
arr = np.array(infoArray)
return arr
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
def download(url,start,end):
i = start
fn = open('id.txt','r')
id = fn.readline()
fn.close()
cols,new_id = getIndex(url)
df = pd.DataFrame()
try:
while True:
print('正在获取第%d页链接'%i)
ls = getLinksList(url,i)
if not ls:
print(ls)
print(1)
break
#print(ls)
tag,ls = checkid(ls,id)
#print(ls)
arr=getInfo(ls)
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
if tag:
print(2)
break
i += 1
if i>end:
print(3)
break
except Exception as e:
print(e)
else:
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
fn = open('id.txt', 'w')
fn.write(new_id)
fn.close()
print('程序执行完毕!')
if __name__ == '__main__':
download(url,1,20)
第一次爬取时,需要对上面的代码稍作修改,在try后面加一个finally,保存爬取的内容,防止异常造成的丢失。以上代码可用于后续爬取。据观察,链家数据每天更新3到16页,所以下载功能的参数取1和20。
正常结束应该是先打印(2),再打印(程序执行完毕),如果一天更新21页,则先打印(3),再打印(程序执行完毕)完成),那么就需要修改参数再执行,当然也可以直接把参数20改成100,这样除非出现莫名其妙的异常,一般都能正常执行。 查看全部
excel抓取网页动态数据(
爬取代码解析需要的包有numpypandas,,等代码)
标签位置明确了,说下爬取的基本思路:
先获取30条记录的链接,然后依次爬取信息,最后打开下一页,重复。
这是第一次爬取(有100页),一旦出现异常,可以先保存爬取的。
二、代码分析
需要的包有numpy、pandas、BeautifulSoup、re、urllib等。
代码分析如下:
1、getbsobj 函数
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
定义一个返回 bs 对象的函数,包括一些异常处理。
2、getLinksList 函数
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
定义函数获取30条交易记录链接,并以列表的形式返回。
该链接位于 ul 标签下的 a 标签中。
中间有个圈。原因是有时候网页可以打开,但是交易记录没有显示。这时候需要再次尝试打开,直到出现交易记录。如果没有开启,可能是因为访问过于频繁,所以在无法开启的时候,会进入休眠60秒。
3、getInfo 函数
infoArray = []
一条记录的信息是通过一维列表保存的,infoArray是一个二维列表,保存了所有获取到的记录的信息。
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
获取收录基本属性和事务属性内容的标记列表。
info = list()
info.append(bsobj.head.title.get_text().split()[0])
info 是保存记录的所有信息的临时列表。
此处添加的是社区名称。
for tag in tags:
info.append(tag.get_text().strip()[4:])
这里添加的是基础属性和交易属性的内容
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
这里添加的是交易金额、单价和交易日期,因为和上面的属性不一样,需要单独处理。
infoArray.append(info)
添加记录
arr = np.array(infoArray)
将最终的 infoArray 转换为矩阵 arr 并返回它。
4、checkid 函数
检查动态爬取时是否获取到id。如果已经获取到,则说明上次运行的最新记录已经被爬取,此时无需继续爬取。
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
在这里,检查列表中的每个链接。如果 id 与上次保存的 id 相同,则该链接及其后续链接都被丢弃,并返回一个 bool 值和一个已处理的列表。
5、getIndex 函数
用于获取保存到 Excel 时所需的属性标签
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
6、下载功能
主功能
def download(url,start,end):
从起始页开始,爬到结束页(包括结束页)
cols,new_id = getIndex(url)
获取最新记录的属性列表和id号
ls = getLinksList(url,i)
获取链接列表
tag,ls = checkid(ls,id)
检查身份证
arr=getInfo(ls)
获取数据矩阵
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
转换为 DataFrame 格式。
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
另存为 Excel。
三、输出结果
四、完整代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.error import HTTPError
import pandas as pd
import numpy as np
import re
import socket,time
url = 'https://bj.lianjia.com/chengjiao'
def getbsobj(url):
try:
html = urlopen(url,timeout=3)
except (HTTPError,socket.timeout):
return None
return BeautifulSoup(html,'html.parser')
def getLinksList(url,n):
'''
:param url: 链接
:param n: 第n页
:return: 链接列表
'''
ls = []
bsobj=getbsobj(url+'/pg%d'%n)
if not bsobj:
print('该页打不开')
return None
while True:
aTagList = bsobj.find('ul', {'class': 'listContent'}).findAll('a', {'class': 'img'})
if len(aTagList)>0:
print('打开成功')
break
else:
print('进入休眠')
time.sleep(60)
bsobj=getbsobj(url+'/pg%d'%n)
for aTag in aTagList:
if 'href' in aTag.attrs:
ls.append(aTag['href'])
return ls
def getInfo(ls):
'''
:param ls:链接列表
:return: 数组
'''
infoArray = []
i = 1
for lk in ls:
print('正在获取第%d条信息'%i)
bsobj = getbsobj(lk)
if not bsobj:continue
tags = bsobj.find('div',{'class':'introContent'}).findAll('li')
info = list()
info.append(bsobj.head.title.get_text().split()[0])
for tag in tags:
info.append(tag.get_text().strip()[4:])
ul = bsobj.find('ul',{'class':'record_list'})
info.append(ul.li.span.get_text().strip())
text = ul.li.p.get_text().strip()
a = re.search(r'\d+元/平',text)
if a ==None:
info.append('无')
else:
info.append(a.group()[:-3])
b = re.search(r'\d+-\d+-\d+', text)
if b == None:
info.append(text)
else:
info.append(b.group())
infoArray.append(info)
i += 1
print('-'*20)
arr = np.array(infoArray)
return arr
def checkid(ls,id):
'''
:param ls: 链接列表
:param id: 成交id
:return: bool
'''
links = []
tag = False
for lk in ls:
if lk[-17:-5]!=str(id):
links.append(lk)
else:break
if len(links)!=len(ls):
tag = True
ls = links
return tag,ls
def getIndex(url):
cols = ['小区名字']
ls = getLinksList(url, 1)
bs = getbsobj(ls[0])
tags = bs.find('div', {'class': 'introContent'}).findAll('li')
for tag in tags:
cols.append(tag.span.get_text().strip())
cols += ['成交额(万元)','单价(元/平)','日期']
new_id = ls[0][-17:-5]
return cols,new_id
def download(url,start,end):
i = start
fn = open('id.txt','r')
id = fn.readline()
fn.close()
cols,new_id = getIndex(url)
df = pd.DataFrame()
try:
while True:
print('正在获取第%d页链接'%i)
ls = getLinksList(url,i)
if not ls:
print(ls)
print(1)
break
#print(ls)
tag,ls = checkid(ls,id)
#print(ls)
arr=getInfo(ls)
df_new = pd.DataFrame(arr,columns=cols)
df = df.append(df_new,ignore_index=True)
if tag:
print(2)
break
i += 1
if i>end:
print(3)
break
except Exception as e:
print(e)
else:
df_old = pd.read_excel('链家成交数据.xlsx')
df_old = df.append(df_old, ignore_index=True)
df_old.to_excel('链家成交数据.xlsx')
fn = open('id.txt', 'w')
fn.write(new_id)
fn.close()
print('程序执行完毕!')
if __name__ == '__main__':
download(url,1,20)
第一次爬取时,需要对上面的代码稍作修改,在try后面加一个finally,保存爬取的内容,防止异常造成的丢失。以上代码可用于后续爬取。据观察,链家数据每天更新3到16页,所以下载功能的参数取1和20。
正常结束应该是先打印(2),再打印(程序执行完毕),如果一天更新21页,则先打印(3),再打印(程序执行完毕)完成),那么就需要修改参数再执行,当然也可以直接把参数20改成100,这样除非出现莫名其妙的异常,一般都能正常执行。
excel抓取网页动态数据( 相当于页号将URL中的网址复制下来,新建一个网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-29 23:07
相当于页号将URL中的网址复制下来,新建一个网页)
!!!这里需要点击评论右下角的页码,相当于进入评论对应的页面,才能进行相应的登录。!!!
点击productCommentSummaries,Headers,中间的Request URL数据在这个地方,复制Request URL中的URL,新建一个网页打开,新的网页会显示对应的新数据(服务器只有可以通过Request URL) find data) 返回的是json数据,可以通过json数据解析,
注意一定要点击上面的评论进入评论区,或者点击评论下方的具体页码,productPageComments是查看评论内容,productCommentSummaries是查看评论总览
1.分析有效的url,即数据的格式
2.编写python代码,向服务器发送请求,获取数据,需要使用第三方模块请求,可以模拟浏览器向服务器发送请求,获取响应结果
第三方模块(相当于后面下载的美颜相机,需要安装后才能使用,安装方式为pip install requests)
通过代码获取对应url对应的数据
import requests
#第一句:导入requests模块
#第二局:发送请求
url = 'https://club.jd.com/comment/pr ... 39%3B
#这里返回200表示正常,418表示遇到反爬,有时候不加headers,虽然返回的是200,但是无法显示出数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
print(reap)
print(reap.text) #响应结果显示输出
该数据具有产品的产品 ID 和页面名称。如果要获取产品的所有内容,需要修改productId和page的值。
打印结果如图
但是,您需要以 json 格式获取数据。当前数据不是 json 格式。需要把前面的部分去掉,换成一个空字符串,然后通过查找json字符串中的maxPage信息,找到评论的最大页数。
解析json格式后,从json格式字符串中找到最大页数对应的属性maxPage
import requests
import json
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
#def get_info(productId):
if __name__ == '__main__':
productId = '70690115165'
print(get_maxpage(productId))
(程序思路:提供item编号,使用python程序向服务器发送请求,获取响应数据,根据key获取value,获取当前item的最大评论页数)
根据评论中的内容获取评论中的内容,使用第三方库openpyxl保存结果
import requests
import json
import time
import openpyxl
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
def get_info(productId):
max_page = get_maxpage(productId)
#调用函数获取商品的最大评论页数
lst = [] #用于存储提取到的商品数据
for page in range(1,max_page+1): #循环执行次数
#获取每页的商品评论
comments = get_comments(productId,page)
comm_lst= comments['comments']
#根据key获取value,根据comments获取评论的列表
#遍历评论列表,分别获取每条评论中的内容,颜色,鞋码
for item in comm_lst: #每条评论又分别是一个字典,再继续根据key获取值
content = item['content'] #获取评论中的内容
color = item['productColor'] #获取评论中的颜色
size = item['productSize'] #获取评论中的鞋码
lst.append([content,color,size]) #将每条评论的信息添加到列表当中
time.sleep(3) #延迟时间,防止程序执行速度太快,被封IP
save(lst) #调用自己编写的函数,将列表中的数据进行存储
#用于将爬取到的数据存储到excel之中
def save(lst):
wk = openpyxl.Workbook() #创建工作簿对象
#一个.xlsx文件,称为一个工作簿,一个工作簿中有三个工作表
sheet = wk.active #获取活动表
#遍历列表,将列表中的数据添加到工作表中,列表中的一条数据,在excel中是一行
for item in lst:
sheet.append(item)
#保存到磁盘上
wk.save('销售数据.xlsx')
if __name__ == '__main__':
productId = '70690115165'
#print(get_maxpage(productId))
get_info(productId)
#速度比较慢,因为总共爬了10页,而且每一页隔3秒,大致需要一分钟`
从 sales data.xlsx 中提取数据并分析最畅销尺码的鞋子
#数据分析:分析不同码数的鞋子的销量
import openpyxl
#从Excel中读取数据
wk = openpyxl.load_workbook('销售数据.xlsx')
sheet = wk.active #获取活动sheet表
#获取最大行数和最大列数
rows = sheet.max_row
cols = sheet.max_column
#print(rows,cols)
#共有380行,3列,遍历涉及到了数据的
lst = [] #用于存储鞋码
for i in range(1,rows+1):
size = sheet.cell(i,3).value
#读取第三列对应的码数
lst.append(size)
#将对应的码数添加到列表之中
#从excel中将鞋子码数数据读取完毕,添加到列表中,以下操作,开始数据统计,统计不同码数的鞋子销售
#python总有一种数据结构叫字典,使用鞋码作key,使用销售数量作value
dic_size = {}
for item in lst:
dic_size[item] = 0
print(dic_size)
for item in lst:
dic_size[item] = dic_size[item]+1
print(dic_size)
总结:之前爬虫百科数据是通过网页源代码来搜索的,现在爬京东评论是通过网页交互传递的信息来实现的,两种不同的爬取信息思路 查看全部
excel抓取网页动态数据(
相当于页号将URL中的网址复制下来,新建一个网页)
!!!这里需要点击评论右下角的页码,相当于进入评论对应的页面,才能进行相应的登录。!!!
点击productCommentSummaries,Headers,中间的Request URL数据在这个地方,复制Request URL中的URL,新建一个网页打开,新的网页会显示对应的新数据(服务器只有可以通过Request URL) find data) 返回的是json数据,可以通过json数据解析,
注意一定要点击上面的评论进入评论区,或者点击评论下方的具体页码,productPageComments是查看评论内容,productCommentSummaries是查看评论总览
1.分析有效的url,即数据的格式
2.编写python代码,向服务器发送请求,获取数据,需要使用第三方模块请求,可以模拟浏览器向服务器发送请求,获取响应结果
第三方模块(相当于后面下载的美颜相机,需要安装后才能使用,安装方式为pip install requests)
通过代码获取对应url对应的数据
import requests
#第一句:导入requests模块
#第二局:发送请求
url = 'https://club.jd.com/comment/pr ... 39%3B
#这里返回200表示正常,418表示遇到反爬,有时候不加headers,虽然返回的是200,但是无法显示出数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
print(reap)
print(reap.text) #响应结果显示输出
该数据具有产品的产品 ID 和页面名称。如果要获取产品的所有内容,需要修改productId和page的值。
打印结果如图
但是,您需要以 json 格式获取数据。当前数据不是 json 格式。需要把前面的部分去掉,换成一个空字符串,然后通过查找json字符串中的maxPage信息,找到评论的最大页数。
解析json格式后,从json格式字符串中找到最大页数对应的属性maxPage
import requests
import json
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
#def get_info(productId):
if __name__ == '__main__':
productId = '70690115165'
print(get_maxpage(productId))
(程序思路:提供item编号,使用python程序向服务器发送请求,获取响应数据,根据key获取value,获取当前item的最大评论页数)
根据评论中的内容获取评论中的内容,使用第三方库openpyxl保存结果
import requests
import json
import time
import openpyxl
#模拟浏览器发送请求并获取响应结果
#第一句:导入requests模块
#第二局:发送请求
def get_comments(productId,page):
url = 'https://club.jd.com/comment/pr ... Id%3D{0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(productId,page)
#使用python字符串的格式,{0}对应着第一个字符串,{1}对应着第二个字符串
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
}
reap = requests.get(url,headers = headers)
#数据还没完事,因为数据不是json格式,需要转为json格式
#print(reap.text) #响应结果显示输出
s = reap.text.replace('fetchJSON_comment98(','')
s = s.replace(');','')
#将获取数据开头的fetchJSON_comment98(以及数据结尾处的);去除掉
#将str类型的数据转为json格式的数据
json_data = json.loads(s)
return json_data
#获取最大页数
def get_maxpage(productId):
dic_data = get_comments(productId,'0')
#调用刚才写的函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
#提取数据
def get_info(productId):
max_page = get_maxpage(productId)
#调用函数获取商品的最大评论页数
lst = [] #用于存储提取到的商品数据
for page in range(1,max_page+1): #循环执行次数
#获取每页的商品评论
comments = get_comments(productId,page)
comm_lst= comments['comments']
#根据key获取value,根据comments获取评论的列表
#遍历评论列表,分别获取每条评论中的内容,颜色,鞋码
for item in comm_lst: #每条评论又分别是一个字典,再继续根据key获取值
content = item['content'] #获取评论中的内容
color = item['productColor'] #获取评论中的颜色
size = item['productSize'] #获取评论中的鞋码
lst.append([content,color,size]) #将每条评论的信息添加到列表当中
time.sleep(3) #延迟时间,防止程序执行速度太快,被封IP
save(lst) #调用自己编写的函数,将列表中的数据进行存储
#用于将爬取到的数据存储到excel之中
def save(lst):
wk = openpyxl.Workbook() #创建工作簿对象
#一个.xlsx文件,称为一个工作簿,一个工作簿中有三个工作表
sheet = wk.active #获取活动表
#遍历列表,将列表中的数据添加到工作表中,列表中的一条数据,在excel中是一行
for item in lst:
sheet.append(item)
#保存到磁盘上
wk.save('销售数据.xlsx')
if __name__ == '__main__':
productId = '70690115165'
#print(get_maxpage(productId))
get_info(productId)
#速度比较慢,因为总共爬了10页,而且每一页隔3秒,大致需要一分钟`
从 sales data.xlsx 中提取数据并分析最畅销尺码的鞋子
#数据分析:分析不同码数的鞋子的销量
import openpyxl
#从Excel中读取数据
wk = openpyxl.load_workbook('销售数据.xlsx')
sheet = wk.active #获取活动sheet表
#获取最大行数和最大列数
rows = sheet.max_row
cols = sheet.max_column
#print(rows,cols)
#共有380行,3列,遍历涉及到了数据的
lst = [] #用于存储鞋码
for i in range(1,rows+1):
size = sheet.cell(i,3).value
#读取第三列对应的码数
lst.append(size)
#将对应的码数添加到列表之中
#从excel中将鞋子码数数据读取完毕,添加到列表中,以下操作,开始数据统计,统计不同码数的鞋子销售
#python总有一种数据结构叫字典,使用鞋码作key,使用销售数量作value
dic_size = {}
for item in lst:
dic_size[item] = 0
print(dic_size)
for item in lst:
dic_size[item] = dic_size[item]+1
print(dic_size)
总结:之前爬虫百科数据是通过网页源代码来搜索的,现在爬京东评论是通过网页交互传递的信息来实现的,两种不同的爬取信息思路
excel抓取网页动态数据(人人可用的开源数据可视化分析工具——冬奥主题仪表板)
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-27 04:03
2022年北京冬奥会刚刚落下帷幕。作为一名奥运球迷,我不仅为能够不受时差影响享受比赛而感到满足,也为我们国家的成功举办感到自豪。看完闭幕式后,我在想,如何才能以自己的方式来纪念这一非凡的冬奥会,用视觉的方式展示冬奥会的成就和成就。
在网上找了很多数据可视化工具。经过多次比较和选择,最终选择了DataEase开源数据可视化分析平台v1.7.0版本。数易的口号是“开源数据可视化分析工具,人人共享”。该项目附带完整的指导文件和手册。如果有解决不了的问题,可以加入开源群,请教各种大神。特别适合我这种什么都不懂的新手。
以下是我最终选择使用DataEase进行数据可视化分析的主要原因:
■ 开源是最大亮点。目前市面上的数据分析软件很多,而且很多都是收费的,所以完全免费的开源系统非常适合我这种不经常使用的人;
■ 支持多种数据源,如数据库、Excel表格等;
■ 制作简单,制作过程中通过拖放生成图表,操作简单易用;
■ 组件元素丰富,可以在仪表板上插入文字、形状、时间、图片和视频。
确定主题
首先,我制作了一张思维导图来确定我想要展示的内容。冬奥会主题仪表盘的内容包括:
■ 展示冬奥会的最终成绩:一方面是展示世界各个参赛国家的奖项,另一方面是了解中国在该赛事中的排名;
■ 中国代表团在冬奥会上的表现;
■ 其他重要数据,如:中国为举办冬奥会做出了哪些贡献?冬奥会的收获是什么?有多少志愿者为这次活动付出了努力?
数据准备
主要数据来源为媒体新闻和北京冬奥会官网。对数据进行排序后,将提取的有价值的数据导入数据库或Excel。在数据抓取和过滤的过程中,我发现DataEase对于数据库中的数据变化有一个“同步更新”的功能,非常方便。在数据发生变化的情况下,您只需点击“同步更新”即可一键更新数据。
以下是一些数据源的链接:
北京冬奥会官网:
人民网:
澎湃新闻:
网易:
知乎:
制作仪表板
制作此仪表板的步骤是:创建数据源 → 创建数据集 → 创建视图 → 导入视频 → 制作仪表板。
■ 创建数据源
本文使用数据库和 Excel 作为数据源。目前DataEase v1.7.0版本已经支持MySQL、Apache Hive、Oracle、SQL Server、PostgreSQL、MariaDB、Elasticsearch、Apache Doris、ClickHouse、AWS Redshift、MongoDB、DB2等数据源。
■ 创建数据集
创建数据库数据集:选择添加“数据库数据集”选项,并在其页面上查看所选数据库下的数据表。
导入数据集后,在“字段管理”选项卡中检查字段名称、字段类型以及维度和指标的位置。
■ 创建视图
所谓“视图”,就是将数据集中的数据以图表的形式展示出来。我更关心的是可视化工具能否提供足够多的视图类型来展示我想要表达的内容。例如,当我想展示数据变化的趋势时,我需要使用折线图,而当我想展示数据的分布时,我需要使用条形图等。
数易提供的图表类型非常丰富。目前支持的视图类型包括:时间表、指标卡、基本条形图、堆积条形图、水平条形图、水平堆积条形图、基本折线图、堆积折线图、饼图、夜莺玫瑰图、漏斗图、雷达图、仪表板、中国地图、散点图、气泡图、树形图等。数易开源项目组也承诺每月迭代更新,继续支持更多类型的视图。
下面以展示冬奥会奖牌表为例,说明仪表板的制作过程。
Step1:输入新视图的标题→选择数据集→选择合适的图表类型。
Step2:配置维度和指标信息,调整样式,使视图的色调整体协调。
■ 视频导入
在DataEase仪表盘上放置视频有两种方式:1.获取网络上的视频地址,直接使用;2.搭建视频服务器上传获取地址。
这一次,我使用了自己搭建视频服务器的方法来上传。视频导入步骤为:获取合适格式的视频(mp4、webw等)→导入到视频服务器(仅限网络可以访问的视频)→添加到dashboard通过视频组件。
如下图所示,可以在“拖放”视频组件后设置视频链接。我把北京冬奥会宣传片和闭幕式的两个视频放在这里,并设置为循环播放。数易默认打开仪表盘时,视频是静音的,也非常人性化。
■ 制作仪表板
第一步:选择背景、色调和布局。我在制作时选择了蓝色和白色作为主要的背景色,仪表盘中的视图标题颜色统一设置为#0482FC。
Step2:在画布上排列相应的元素,调整每个元素的样式,形成仪表板,效果如下图。
评论
在使用了DataEase开源数据可视化工具之后,我也积累了一些仪表盘的制作经验,在这里和大家分享一下:
■ 明确仪表盘的主题
我们制作的仪表板应该有一个明确的主题,之后我们可以使用每个适当的视图元素来“表达”数据。DataEase对初学者非常友好,是一款真正“人人可用”的数据可视化分析工具;
■ 关注数据可以传达的内容
仪表盘的各种元素应该让人更直观地感受到数据的魅力。例如,本届冬奥会仪表盘中中国历届冬奥会奖牌数折线图显示了我国在参加冬奥会进程中的进步,体现了“更快、更高、更强、更多团结” “奥林匹克格言。 查看全部
excel抓取网页动态数据(人人可用的开源数据可视化分析工具——冬奥主题仪表板)
2022年北京冬奥会刚刚落下帷幕。作为一名奥运球迷,我不仅为能够不受时差影响享受比赛而感到满足,也为我们国家的成功举办感到自豪。看完闭幕式后,我在想,如何才能以自己的方式来纪念这一非凡的冬奥会,用视觉的方式展示冬奥会的成就和成就。
在网上找了很多数据可视化工具。经过多次比较和选择,最终选择了DataEase开源数据可视化分析平台v1.7.0版本。数易的口号是“开源数据可视化分析工具,人人共享”。该项目附带完整的指导文件和手册。如果有解决不了的问题,可以加入开源群,请教各种大神。特别适合我这种什么都不懂的新手。
以下是我最终选择使用DataEase进行数据可视化分析的主要原因:
■ 开源是最大亮点。目前市面上的数据分析软件很多,而且很多都是收费的,所以完全免费的开源系统非常适合我这种不经常使用的人;
■ 支持多种数据源,如数据库、Excel表格等;
■ 制作简单,制作过程中通过拖放生成图表,操作简单易用;
■ 组件元素丰富,可以在仪表板上插入文字、形状、时间、图片和视频。
确定主题
首先,我制作了一张思维导图来确定我想要展示的内容。冬奥会主题仪表盘的内容包括:
■ 展示冬奥会的最终成绩:一方面是展示世界各个参赛国家的奖项,另一方面是了解中国在该赛事中的排名;
■ 中国代表团在冬奥会上的表现;
■ 其他重要数据,如:中国为举办冬奥会做出了哪些贡献?冬奥会的收获是什么?有多少志愿者为这次活动付出了努力?
数据准备
主要数据来源为媒体新闻和北京冬奥会官网。对数据进行排序后,将提取的有价值的数据导入数据库或Excel。在数据抓取和过滤的过程中,我发现DataEase对于数据库中的数据变化有一个“同步更新”的功能,非常方便。在数据发生变化的情况下,您只需点击“同步更新”即可一键更新数据。
以下是一些数据源的链接:
北京冬奥会官网:
人民网:
澎湃新闻:
网易:
知乎:
制作仪表板
制作此仪表板的步骤是:创建数据源 → 创建数据集 → 创建视图 → 导入视频 → 制作仪表板。
■ 创建数据源
本文使用数据库和 Excel 作为数据源。目前DataEase v1.7.0版本已经支持MySQL、Apache Hive、Oracle、SQL Server、PostgreSQL、MariaDB、Elasticsearch、Apache Doris、ClickHouse、AWS Redshift、MongoDB、DB2等数据源。
■ 创建数据集
创建数据库数据集:选择添加“数据库数据集”选项,并在其页面上查看所选数据库下的数据表。
导入数据集后,在“字段管理”选项卡中检查字段名称、字段类型以及维度和指标的位置。
■ 创建视图
所谓“视图”,就是将数据集中的数据以图表的形式展示出来。我更关心的是可视化工具能否提供足够多的视图类型来展示我想要表达的内容。例如,当我想展示数据变化的趋势时,我需要使用折线图,而当我想展示数据的分布时,我需要使用条形图等。
数易提供的图表类型非常丰富。目前支持的视图类型包括:时间表、指标卡、基本条形图、堆积条形图、水平条形图、水平堆积条形图、基本折线图、堆积折线图、饼图、夜莺玫瑰图、漏斗图、雷达图、仪表板、中国地图、散点图、气泡图、树形图等。数易开源项目组也承诺每月迭代更新,继续支持更多类型的视图。
下面以展示冬奥会奖牌表为例,说明仪表板的制作过程。
Step1:输入新视图的标题→选择数据集→选择合适的图表类型。
Step2:配置维度和指标信息,调整样式,使视图的色调整体协调。
■ 视频导入
在DataEase仪表盘上放置视频有两种方式:1.获取网络上的视频地址,直接使用;2.搭建视频服务器上传获取地址。
这一次,我使用了自己搭建视频服务器的方法来上传。视频导入步骤为:获取合适格式的视频(mp4、webw等)→导入到视频服务器(仅限网络可以访问的视频)→添加到dashboard通过视频组件。
如下图所示,可以在“拖放”视频组件后设置视频链接。我把北京冬奥会宣传片和闭幕式的两个视频放在这里,并设置为循环播放。数易默认打开仪表盘时,视频是静音的,也非常人性化。
■ 制作仪表板
第一步:选择背景、色调和布局。我在制作时选择了蓝色和白色作为主要的背景色,仪表盘中的视图标题颜色统一设置为#0482FC。
Step2:在画布上排列相应的元素,调整每个元素的样式,形成仪表板,效果如下图。
评论
在使用了DataEase开源数据可视化工具之后,我也积累了一些仪表盘的制作经验,在这里和大家分享一下:
■ 明确仪表盘的主题
我们制作的仪表板应该有一个明确的主题,之后我们可以使用每个适当的视图元素来“表达”数据。DataEase对初学者非常友好,是一款真正“人人可用”的数据可视化分析工具;
■ 关注数据可以传达的内容
仪表盘的各种元素应该让人更直观地感受到数据的魅力。例如,本届冬奥会仪表盘中中国历届冬奥会奖牌数折线图显示了我国在参加冬奥会进程中的进步,体现了“更快、更高、更强、更多团结” “奥林匹克格言。
excel抓取网页动态数据(Excel电子表格的TIME()函数:TIME为时间型数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-26 02:19
)
不规则数据现在变得越来越普遍。从网页抓取的列表或文本字符,从数据后端系统导出的字符串数据,如何将这些字符串转换成相应的数据格式并进行操作,似乎很少。一个问题,足以让你摸不着头脑。
我遇到的应用场景:
从百度统计后台导出的网页访问数据,其中之一是“平均停留时间”,用于统计访问者在访问某个页面时的阅读时间。很显然,这是一系列的时间数据,可以相互比较和计算。求和求和等。但实际情况是导出的excel表格数据,列是一整串字符,没有办法比较和操作。现在我们需要将此字符串转换为时间数据。
Excel 电子表格的 TIME() 函数:
TIME() 函数用途: 返回特定时间的十进制值,它返回的十进制值介于 0 和 0.99999999 之间,代表 0:00:00 (12:00:00 AM) 到 23:59 : 59(晚上 11 点 59 分 59 秒)。
语法:TIME(hour, minute, second) 参数:Hour是一个0到23之间的数字,代表小时;Minute 是一个介于 0 到 59 之间的数字,代表分钟;Second 是一个介于 0 到 59 之间的数字,表示 seconds 。
TIME() 函数将字符串转换为时间数据
假设原创字符串放在C列,从2行开始往下走,原创格式为:00:00:00,分别代表小时、分钟和秒,冒号占2个字符,总长度为该字符串为 10 个字符。
1、首先将D列的格式调整为自定义:“h”小时“m”分钟“s”秒。
2、在单元格 D2 中输入函数:
=时间(左(C2,2),中(C2,5,2),右(C2,2))
嵌套 LEFT 函数、MID 函数和 RIGHT 函数分别表示小时、分钟和秒。确定并自动填充。
此时,D列就是可以计算的时间格式数据,方便进一步分析。
一些简单实用的Excel功能对提高工作效率有很大帮助,我的博客会整理分享更多。
文章内容采集自网络,希望能为广大朋友提供帮助。强国说学习-WPS之家()
如要转载此文章,请注明出处:强国说学
查看全部
excel抓取网页动态数据(Excel电子表格的TIME()函数:TIME为时间型数据
)
不规则数据现在变得越来越普遍。从网页抓取的列表或文本字符,从数据后端系统导出的字符串数据,如何将这些字符串转换成相应的数据格式并进行操作,似乎很少。一个问题,足以让你摸不着头脑。
我遇到的应用场景:
从百度统计后台导出的网页访问数据,其中之一是“平均停留时间”,用于统计访问者在访问某个页面时的阅读时间。很显然,这是一系列的时间数据,可以相互比较和计算。求和求和等。但实际情况是导出的excel表格数据,列是一整串字符,没有办法比较和操作。现在我们需要将此字符串转换为时间数据。
Excel 电子表格的 TIME() 函数:
TIME() 函数用途: 返回特定时间的十进制值,它返回的十进制值介于 0 和 0.99999999 之间,代表 0:00:00 (12:00:00 AM) 到 23:59 : 59(晚上 11 点 59 分 59 秒)。
语法:TIME(hour, minute, second) 参数:Hour是一个0到23之间的数字,代表小时;Minute 是一个介于 0 到 59 之间的数字,代表分钟;Second 是一个介于 0 到 59 之间的数字,表示 seconds 。
TIME() 函数将字符串转换为时间数据
假设原创字符串放在C列,从2行开始往下走,原创格式为:00:00:00,分别代表小时、分钟和秒,冒号占2个字符,总长度为该字符串为 10 个字符。
1、首先将D列的格式调整为自定义:“h”小时“m”分钟“s”秒。
2、在单元格 D2 中输入函数:
=时间(左(C2,2),中(C2,5,2),右(C2,2))
嵌套 LEFT 函数、MID 函数和 RIGHT 函数分别表示小时、分钟和秒。确定并自动填充。
此时,D列就是可以计算的时间格式数据,方便进一步分析。
一些简单实用的Excel功能对提高工作效率有很大帮助,我的博客会整理分享更多。
文章内容采集自网络,希望能为广大朋友提供帮助。强国说学习-WPS之家()
如要转载此文章,请注明出处:强国说学
excel抓取网页动态数据(excel抓取网页动态数据分析原理-5118大数据可视化分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-10 23:03
excel抓取网页动态数据分析原理是:利用excel的批量操作功能,对网页进行静态数据的抓取,通过读取excel操作后的数据,再将这些数据与你自己制作的excel表格进行匹配,将匹配后的数据给到你得结果表的作用就是:抓取到的数据,是存放在你的excel里面的,而你可以通过excel里面的数据,去变换出其他你想要的数据ps:要这个数据数量的话,就非常方便,就是一个chrome浏览器加一个可视化的svg图标就够了。
这个网页可以抓https地址端口就好像“端口号”这个功能excel操作不了只能去抓些动态数据excel-信息抓取,抓取数据,爬虫,数据可视化-5118大数据可视化分析平台上面抓地址的get下拉框也是一样
借用一下楼上的@落晚君的推荐,“换图像形式!html文件存储,用浏览器打开”excel做不了,
不如试试我们(*)的接口,更多功能,更多选择。找到那个网页。然后在后台录制脚本。
#.variable.wrapper.delta(init).wrapper.stride(len(excel.sheetfunction.delta(2))).get('.completehead').stride(len(excel.sheetfunction.delta(2)))
lottie:javascript/javascriptx/javascriptxxx/webfont/excel.variable 查看全部
excel抓取网页动态数据(excel抓取网页动态数据分析原理-5118大数据可视化分析)
excel抓取网页动态数据分析原理是:利用excel的批量操作功能,对网页进行静态数据的抓取,通过读取excel操作后的数据,再将这些数据与你自己制作的excel表格进行匹配,将匹配后的数据给到你得结果表的作用就是:抓取到的数据,是存放在你的excel里面的,而你可以通过excel里面的数据,去变换出其他你想要的数据ps:要这个数据数量的话,就非常方便,就是一个chrome浏览器加一个可视化的svg图标就够了。
这个网页可以抓https地址端口就好像“端口号”这个功能excel操作不了只能去抓些动态数据excel-信息抓取,抓取数据,爬虫,数据可视化-5118大数据可视化分析平台上面抓地址的get下拉框也是一样
借用一下楼上的@落晚君的推荐,“换图像形式!html文件存储,用浏览器打开”excel做不了,
不如试试我们(*)的接口,更多功能,更多选择。找到那个网页。然后在后台录制脚本。
#.variable.wrapper.delta(init).wrapper.stride(len(excel.sheetfunction.delta(2))).get('.completehead').stride(len(excel.sheetfunction.delta(2)))
lottie:javascript/javascriptx/javascriptxxx/webfont/excel.variable

