excel抓取网页动态数据(程序语言组织有可能欠佳,判断布局正确的定位元素 )
优采云 发布时间: 2021-11-30 12:07excel抓取网页动态数据(程序语言组织有可能欠佳,判断布局正确的定位元素
)
直接上传代码并分析,代码应该比较简单,基本上每一行都已经注释掉了,具体的代码准备,可以参考我写的代码,相信你可以很快的写出自己的程序
语言组织可能很差,希望你能凑合一下。如果有不明白的,有更简单严谨的代码,欢迎贴出来一起讨论。
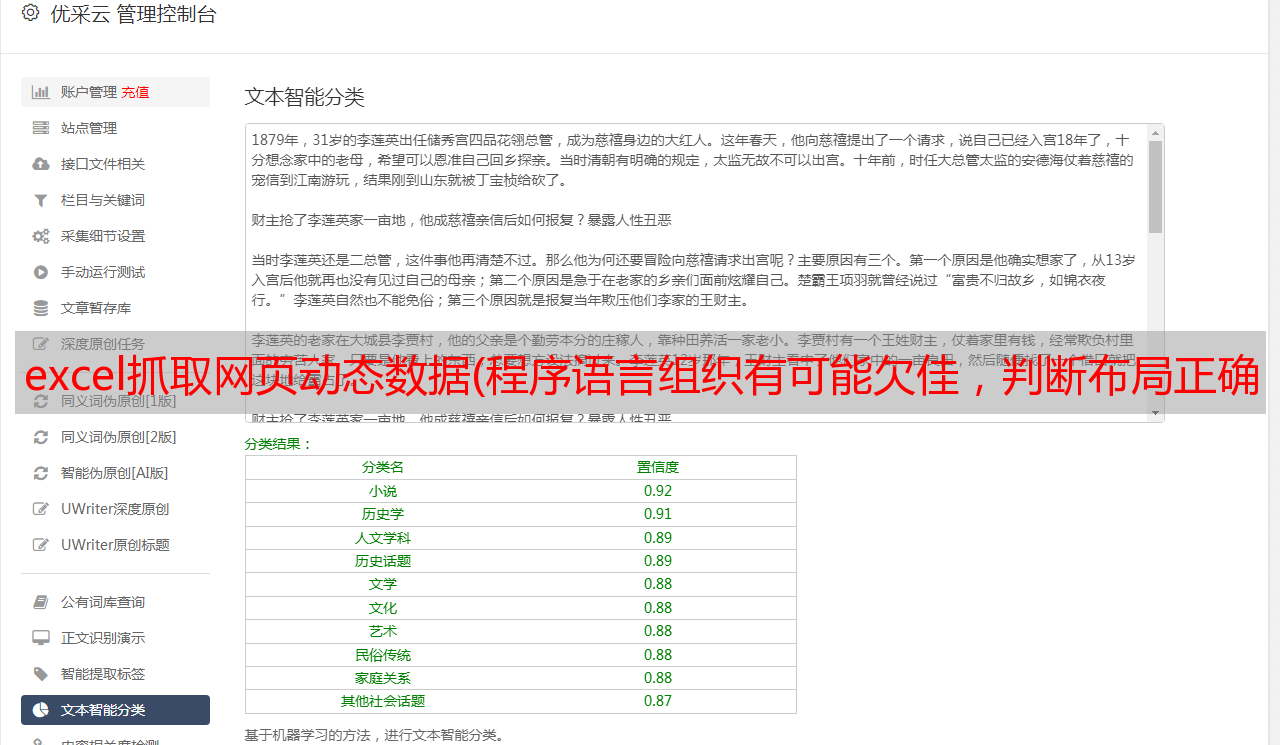
1. 有搜索结果截图确定使用的定位元素
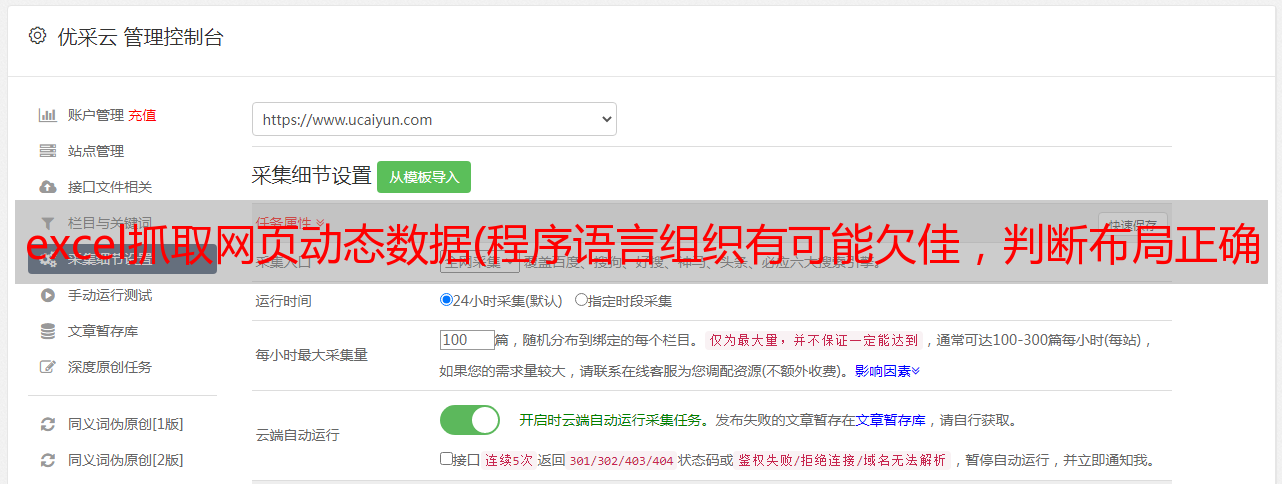
2. 没有搜索结果的截图,确定布局正确的定位元素
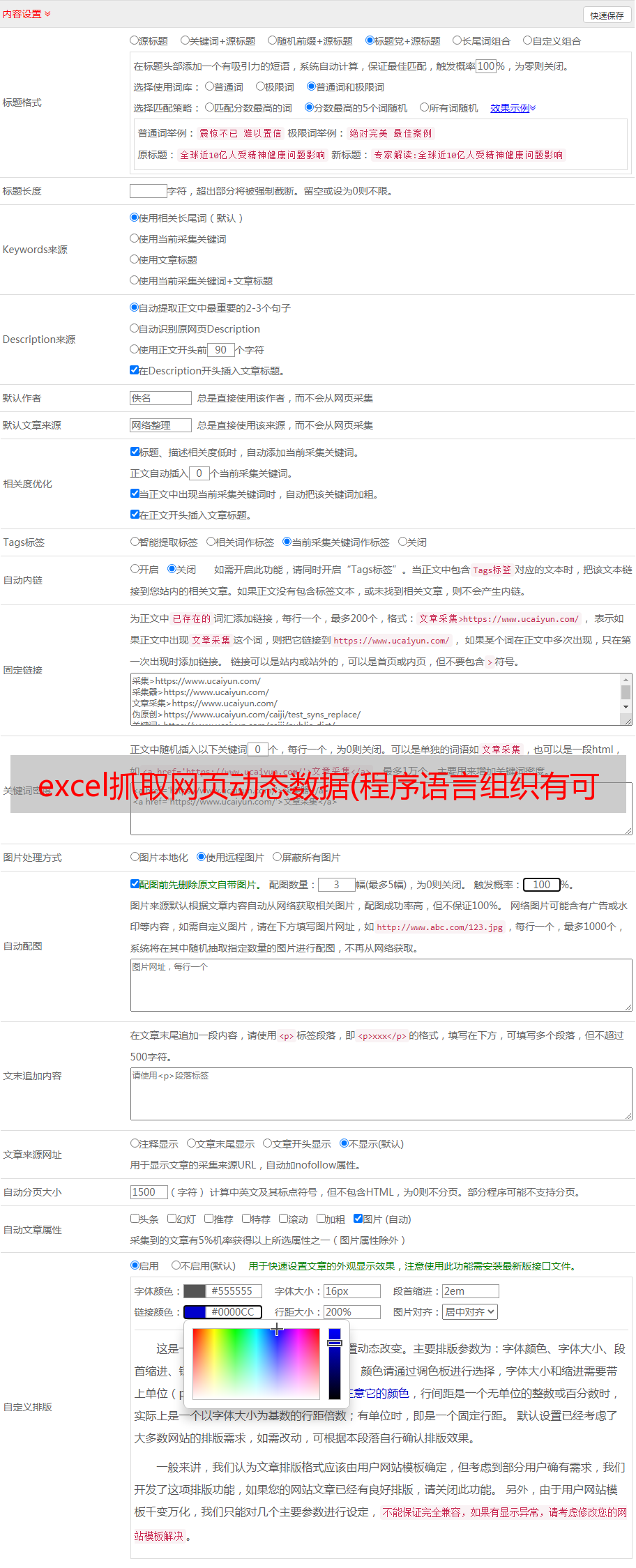
3. 没有搜索结果和错误布局的截图
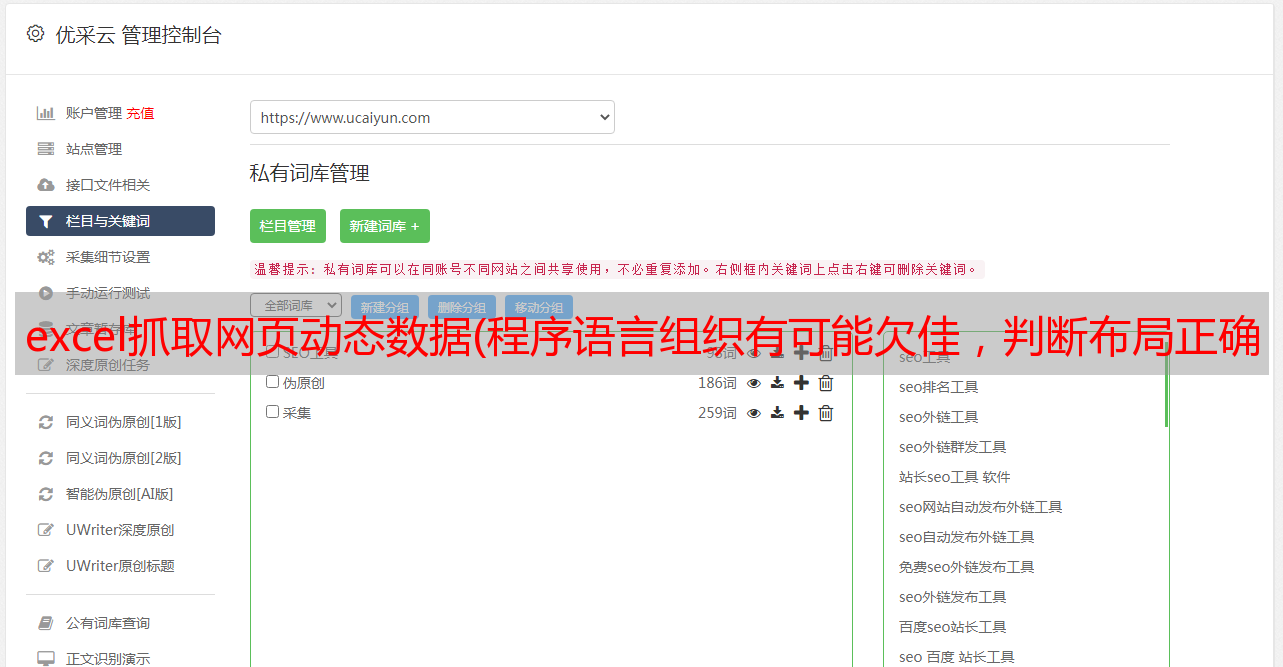
4.excel文件中的数据,以行为单位
import xlrd
from selenium import webdriver
import time
class chromedriver:
driver=webdriver.Chrome()
#也可使用其他的webdriver,Firefox/ie
driver.maximize_window()
#有些网站缩小之后布局也会改变,所以需要用maximize_window()控制页面的大小
driver.get("URL")
# 获得需要访问的url地址
def null_search(self):
data=xlrd.open_workbook("excel文件路径")
#open一个excel文件,需要注意的是,有时候直接复制过来的路径中,\在Python中有特殊含义,需要统一换成/
table=data.sheets()[0]
#获取第一个sheet1,0表示第一个表
now=table.nrows
#表格中的行数,以便下面做for循环
for i in range(now):
now_data=''.join(table.row_values(i))
#直接获取的.row_values(i)为列表参数,无法直接在文本框中send_keys,所以需要将其转换成字符
text=chromedriver .driver .find_element_by_name("apachesolr_panels_search_form")
#需要注意的是需要在for循环中定位参数,如果直接在def以外定义
#则会出现报错:stale element reference: element is not attached to the page document,意思是这个element已经失效了,需要重新定义
#text.clear()
text.send_keys(now_data ) #将表格中的数据通过行循环,一个个写入到文本框
chromedriver .driver.find_element_by_css_selector("input.form-submit").click() #点击搜索按钮
time.sleep(5)
#一定要这是time.sleep(),因为不写等待时间,会导致最后出来的结果不准确,例如第一个数据是a,第二个数据为b,当不设置等待时间时,在搜索第二个数据时,本应输入b,然而在文本框中输入的为ab,此时得到的测试结果当然为不准确的
chromedriver.driver.switch_to_window(chromedriver.driver.window_handles [-1])
#定位到第二个页面,这样我们就可以定位第二个页面中的参数了
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-info") #当有搜索结果时,可以定位的参数
except: #当定位不到该参数时,结果有2种:1,无搜索结果,搜索的结果不符合布局 2,无搜索结果,符合布局,所以里面还需要一个try语句来判断情况
try:
chromedriver.driver.find_element_by_css_selector("div.panel-pane.pane-apachesolr-result>h2").text #判断当无搜索结果时,布局是否正确
except:
print(now_data +' '+ "无搜索结果,布局错误" )
else:
print(now_data +' '+ "无搜索结果,布局正确" )
else:
print(now_data +' '+ "有搜索结果")
if __name__ == '__main__':
run=chromedriver()
run.null_search()
5. 结果截图