
excel抓取网页动态数据
excel抓取网页动态数据(excel抓取网页动态数据,一起交流:gd358k/volko)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-04 15:00
excel抓取网页动态数据,一起交流:246655851有大神带我vlookup+一些字段的基础上抓取几百行数据。
非得是excel的话数据库好像也可以??我不怎么会
谢邀,
只要不是手动爬的都可以用excel实现,
遇到最麻烦的爬虫问题,是爬取同花顺所有股票数据,然后自己生成数据包,放到电脑上,然后手动操作。但是第一把数据爬出来之后,同花顺数据库一定有数据库老版本excel数据,这个时候如果手动操作,那会很不方便,更不用说把它放到excel进行处理。所以不管怎么说用excel爬个股数据是个经济的合理办法。当然你用vba编程也是个解决办法,但那是因为有人把数据库搭建好了。
基本所有的统计软件,都可以直接用数据库进行数据统计分析,excel的功能这么强大,所以我建议用excel做统计分析工作。
sas的统计数据分析软件,使用数据库模块gbddatamanagementextension(dem)就可以满足数据抓取,并且可以自动格式化dem文件。
gd358k/volko
没必要用爬虫技术
国内的股票网站爬虫貌似没什么钱景。要不然金融数据分析已经发展了多少年。
使用winform控件可以使用vba语言实现(excel版本的一般都有) 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,一起交流:gd358k/volko)
excel抓取网页动态数据,一起交流:246655851有大神带我vlookup+一些字段的基础上抓取几百行数据。
非得是excel的话数据库好像也可以??我不怎么会
谢邀,
只要不是手动爬的都可以用excel实现,
遇到最麻烦的爬虫问题,是爬取同花顺所有股票数据,然后自己生成数据包,放到电脑上,然后手动操作。但是第一把数据爬出来之后,同花顺数据库一定有数据库老版本excel数据,这个时候如果手动操作,那会很不方便,更不用说把它放到excel进行处理。所以不管怎么说用excel爬个股数据是个经济的合理办法。当然你用vba编程也是个解决办法,但那是因为有人把数据库搭建好了。
基本所有的统计软件,都可以直接用数据库进行数据统计分析,excel的功能这么强大,所以我建议用excel做统计分析工作。
sas的统计数据分析软件,使用数据库模块gbddatamanagementextension(dem)就可以满足数据抓取,并且可以自动格式化dem文件。
gd358k/volko
没必要用爬虫技术
国内的股票网站爬虫貌似没什么钱景。要不然金融数据分析已经发展了多少年。
使用winform控件可以使用vba语言实现(excel版本的一般都有)
excel抓取网页动态数据(超链接掌握获取超链接传递数据的方法-苏州安嘉教学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2021-09-28 08:36
第三十一课时的教学内容:获取超链接传输数据。教学目的:1. 熟悉通过超链接传输数据的方式。2.掌握获取超链接数据的方法。教学重难点:获取超链接传输数据的方法。教学方法:演示法、指导法 教学方法:观察法、讨论法 教学过程:一. 介绍使用超链接在网页中传递数据是网页中常用的数据传递方式。超链接传输数据的方式主要体现在url地址中。这种方式传递的数据如何获取?二、新建类在a1.asp的“Design”视图中,输入“Link to a2.asp”并选中它,并点击 属性面板中的超链接设置如下: 然后在“代码”视图中设置并传递参数:“?cs=我是大哥”为传递的变量名“cs”,传递的内容为“我是大哥”。第二种调用方法:选择“链接到a2.asp”,设置超链接,在弹出的窗口中,点击参数如下: 在参数对话框中,名称为变量名,输入“ cs”,值输入“我是大哥”,如下图: 在a2.asp中,使用请求对象的querystring集合来接收数据:对应代码如下:运行结果:“Cs”为变量,用户自定义;我们传入的数据可以在浏览器的地址栏中看到。笔记:获取传递的参数时,“?”之间不能有空格。和“变量名”。是否可以使用表单来传递超链接?将超链接放在表单中,并设置表单“属性”面板如下: 在这种情况下,a2.asp 代码保持不变。数据可以从测试结果中获得。本例中a2.asp代码修改如下: 查看全部
excel抓取网页动态数据(超链接掌握获取超链接传递数据的方法-苏州安嘉教学)
第三十一课时的教学内容:获取超链接传输数据。教学目的:1. 熟悉通过超链接传输数据的方式。2.掌握获取超链接数据的方法。教学重难点:获取超链接传输数据的方法。教学方法:演示法、指导法 教学方法:观察法、讨论法 教学过程:一. 介绍使用超链接在网页中传递数据是网页中常用的数据传递方式。超链接传输数据的方式主要体现在url地址中。这种方式传递的数据如何获取?二、新建类在a1.asp的“Design”视图中,输入“Link to a2.asp”并选中它,并点击 属性面板中的超链接设置如下: 然后在“代码”视图中设置并传递参数:“?cs=我是大哥”为传递的变量名“cs”,传递的内容为“我是大哥”。第二种调用方法:选择“链接到a2.asp”,设置超链接,在弹出的窗口中,点击参数如下: 在参数对话框中,名称为变量名,输入“ cs”,值输入“我是大哥”,如下图: 在a2.asp中,使用请求对象的querystring集合来接收数据:对应代码如下:运行结果:“Cs”为变量,用户自定义;我们传入的数据可以在浏览器的地址栏中看到。笔记:获取传递的参数时,“?”之间不能有空格。和“变量名”。是否可以使用表单来传递超链接?将超链接放在表单中,并设置表单“属性”面板如下: 在这种情况下,a2.asp 代码保持不变。数据可以从测试结果中获得。本例中a2.asp代码修改如下:
excel抓取网页动态数据(如何用Java获取Javascript动态生成的html页面(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-27 00:17
首先,明确我的意思是什么动态数据。
术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即页面内容不收录在网页的源文件中,是页面加载到浏览器后动态生成的.
输入下面的主题。
抓取静态页面非常简单。通过Java获取html源代码,然后分析源代码得到想要的信息。如果想在中国天气网获取杭州的天气,只需要找到对应的html页面()即可。
假设我需要输入城市名称来获取改变城市的天气,而数据源仍然是中国天气。首先要做的是根据城市找到相应的页面。通过简单的分析,发现城市和页面的URL有对应关系,比如杭州对应101210101,所以程序的关键是找到城市和页面的对应关系。
发现这个网站的搜索框有链接到中国大部分城市,可以得到city和_id的对应关系。找到突破口,开始表演。进入主页,查看其源代码,并找到搜索框的位置。
原来数据是通过Javascript动态添加的。使用 Chrome 的检查来查看以下内容。
能做的就是用Chrome把html复制到一个文件中,然后解析这个文件,得到城市和URL的关系。问题是,万一网站的城市和URL的对应关系发生变化,非常被动,需要更改程序。
现在的问题是如何使用Java获取Javascript动态生成的html内容。我不知道人们怎么想。 查看全部
excel抓取网页动态数据(如何用Java获取Javascript动态生成的html页面(图))
首先,明确我的意思是什么动态数据。
术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即页面内容不收录在网页的源文件中,是页面加载到浏览器后动态生成的.
输入下面的主题。
抓取静态页面非常简单。通过Java获取html源代码,然后分析源代码得到想要的信息。如果想在中国天气网获取杭州的天气,只需要找到对应的html页面()即可。
假设我需要输入城市名称来获取改变城市的天气,而数据源仍然是中国天气。首先要做的是根据城市找到相应的页面。通过简单的分析,发现城市和页面的URL有对应关系,比如杭州对应101210101,所以程序的关键是找到城市和页面的对应关系。
发现这个网站的搜索框有链接到中国大部分城市,可以得到city和_id的对应关系。找到突破口,开始表演。进入主页,查看其源代码,并找到搜索框的位置。

原来数据是通过Javascript动态添加的。使用 Chrome 的检查来查看以下内容。

能做的就是用Chrome把html复制到一个文件中,然后解析这个文件,得到城市和URL的关系。问题是,万一网站的城市和URL的对应关系发生变化,非常被动,需要更改程序。
现在的问题是如何使用Java获取Javascript动态生成的html内容。我不知道人们怎么想。
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-25 05:04
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-24 15:26
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
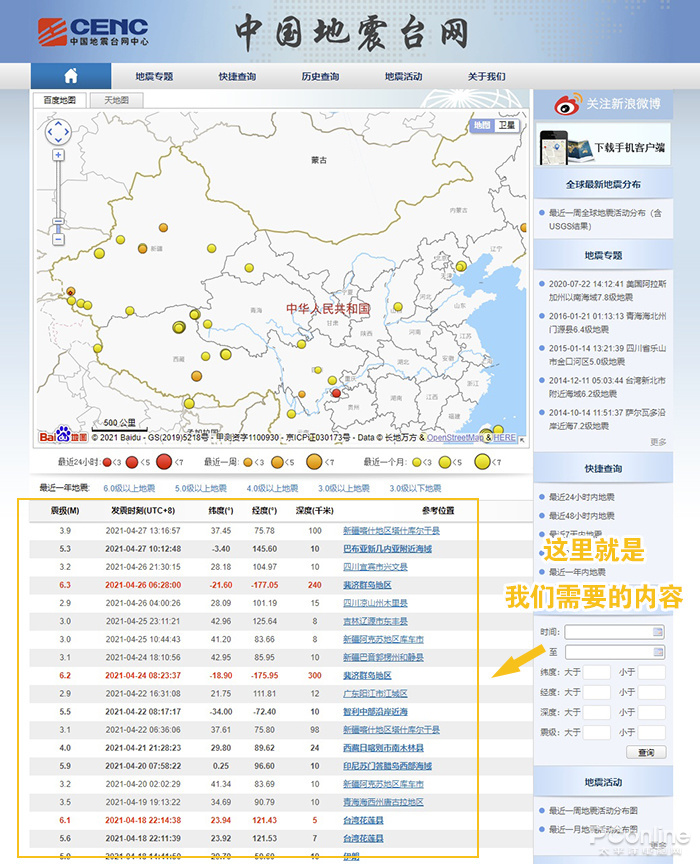
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
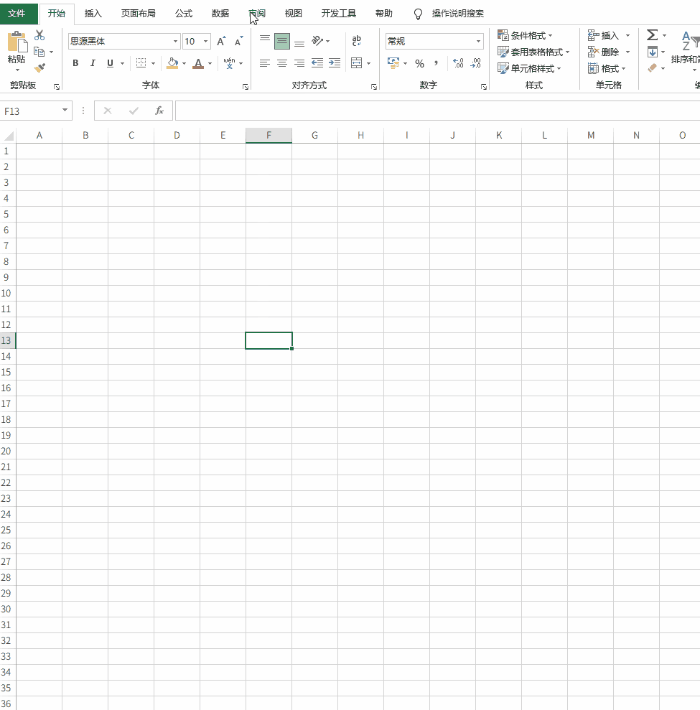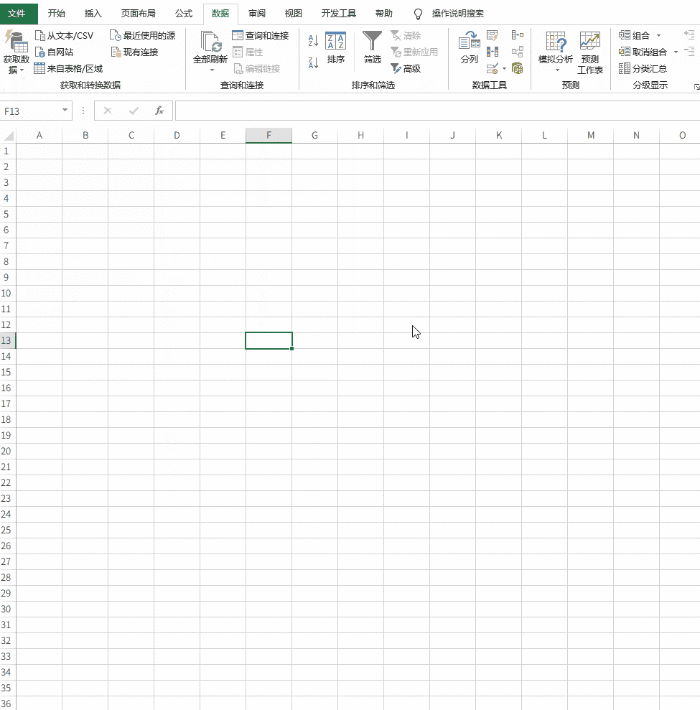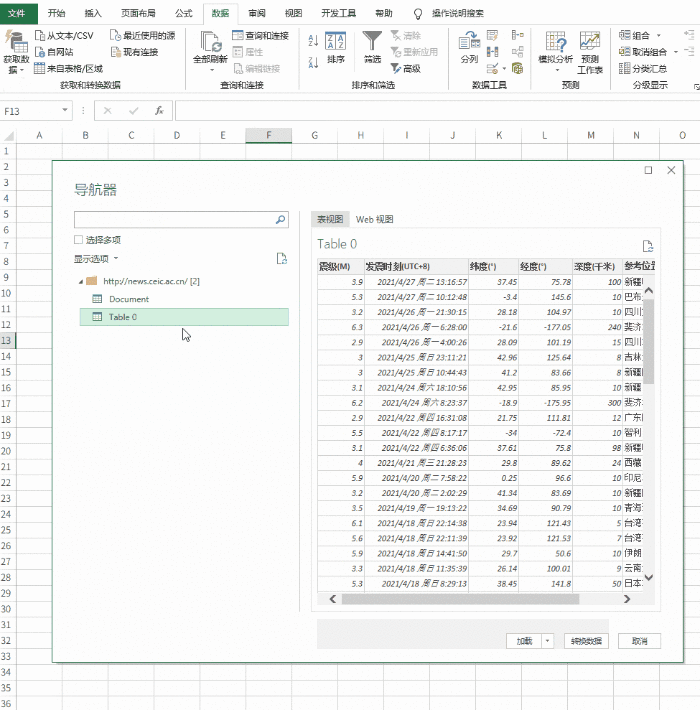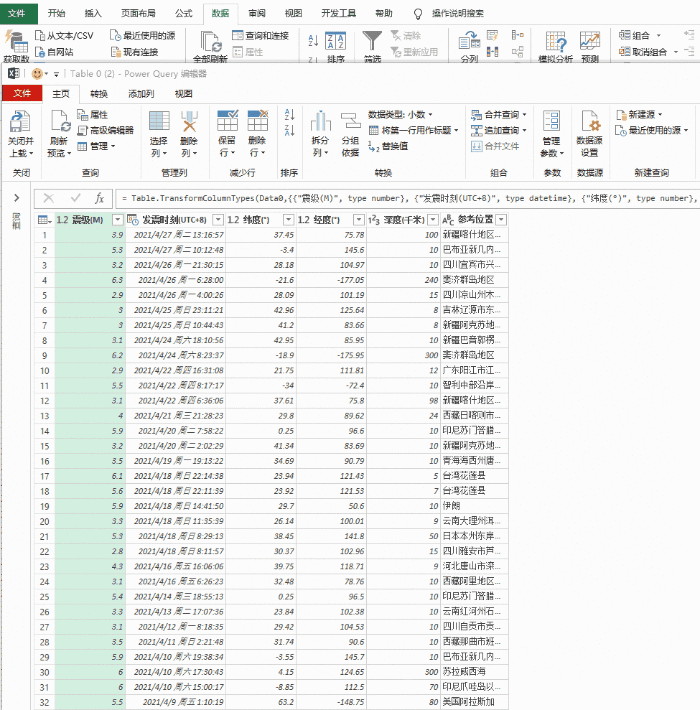
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
建立查询并确定爬取范围
3. 数据清洗
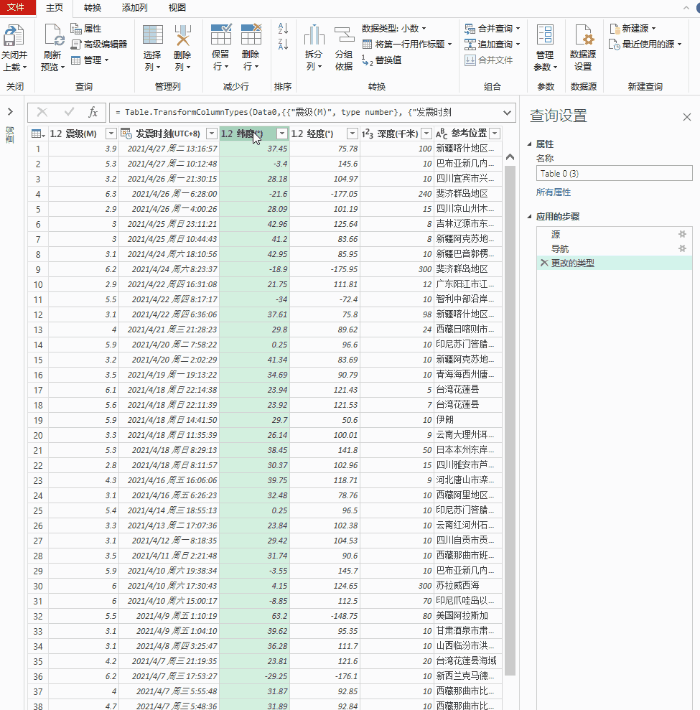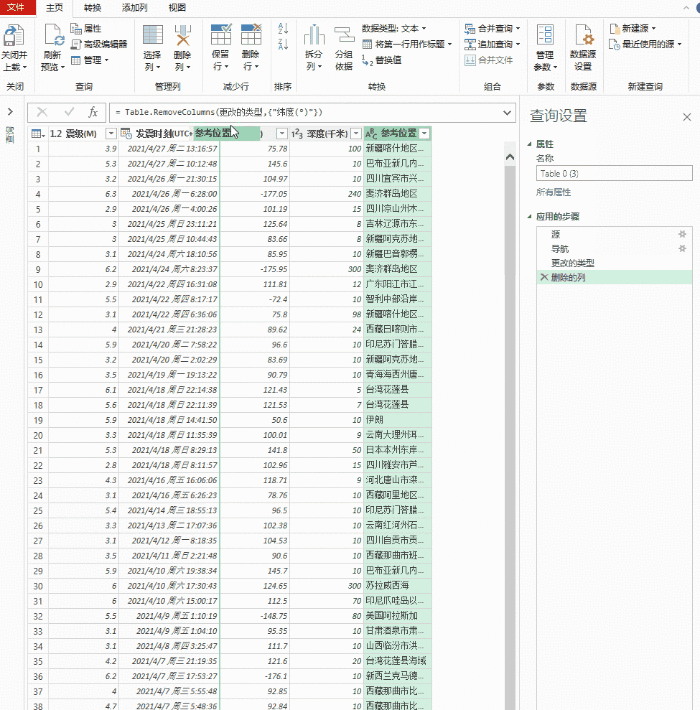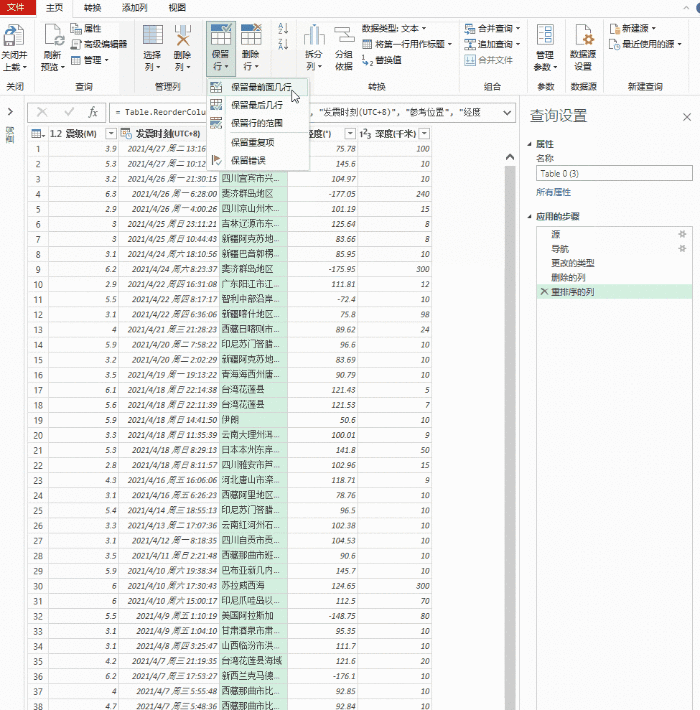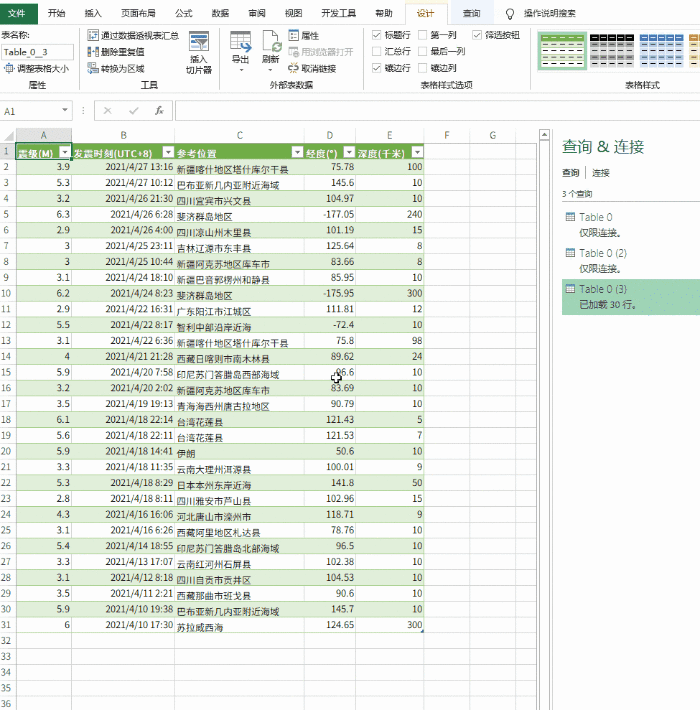
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢? 查看全部
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
建立查询并确定爬取范围
3. 数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
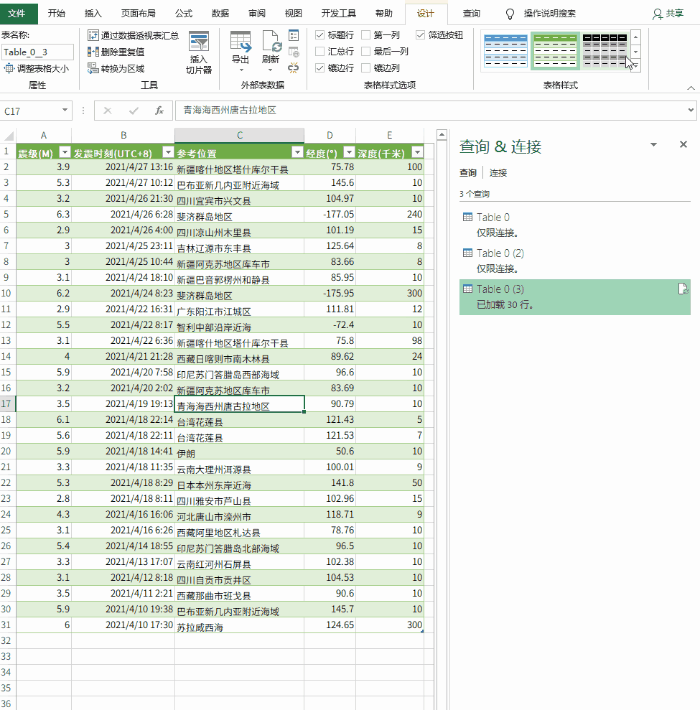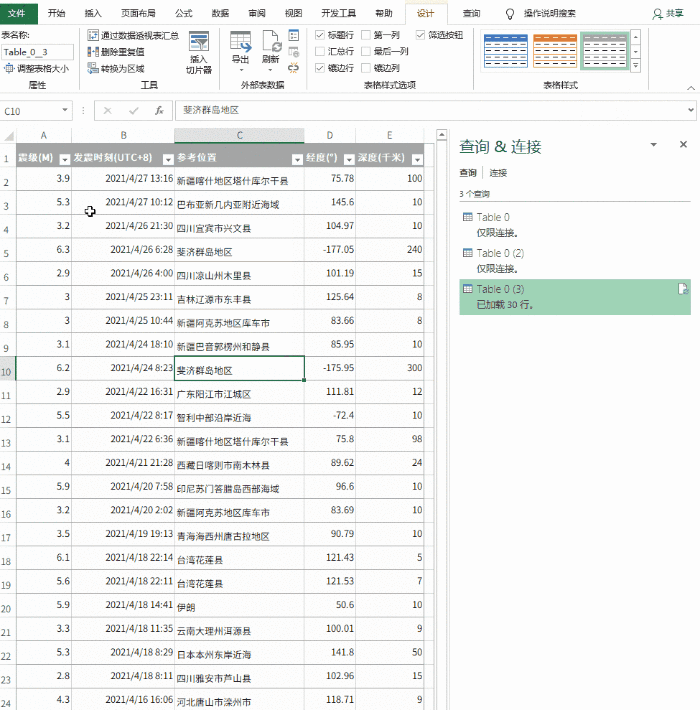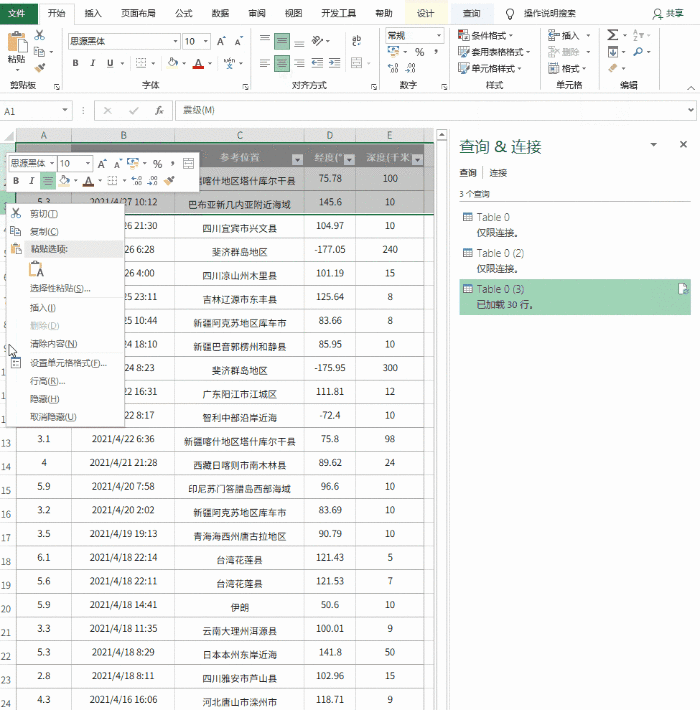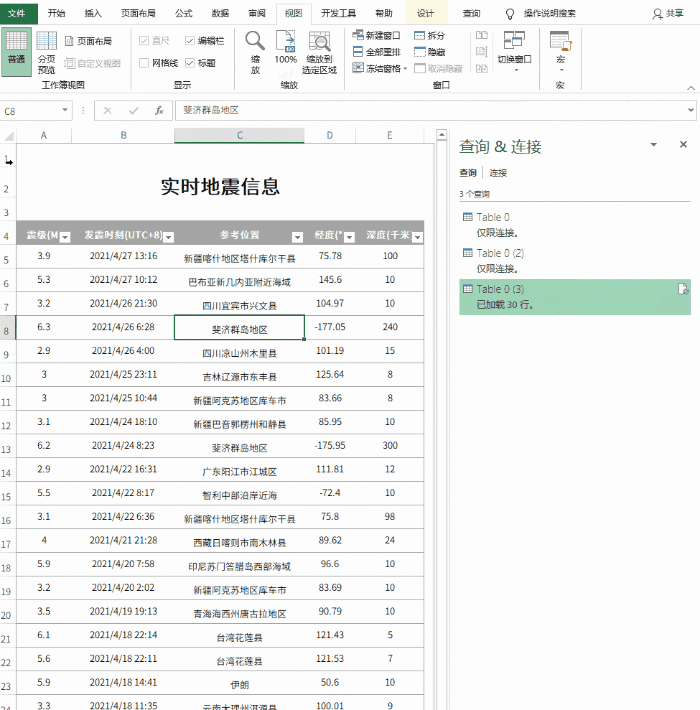
对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
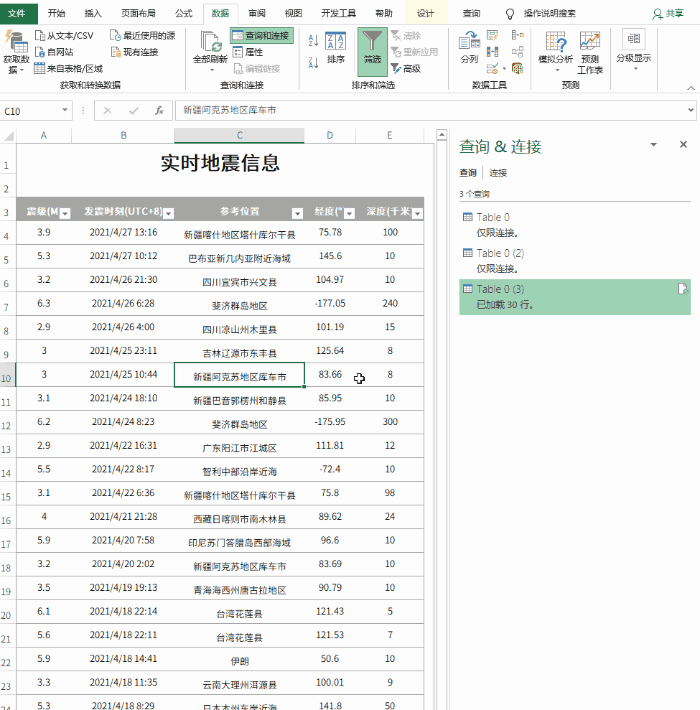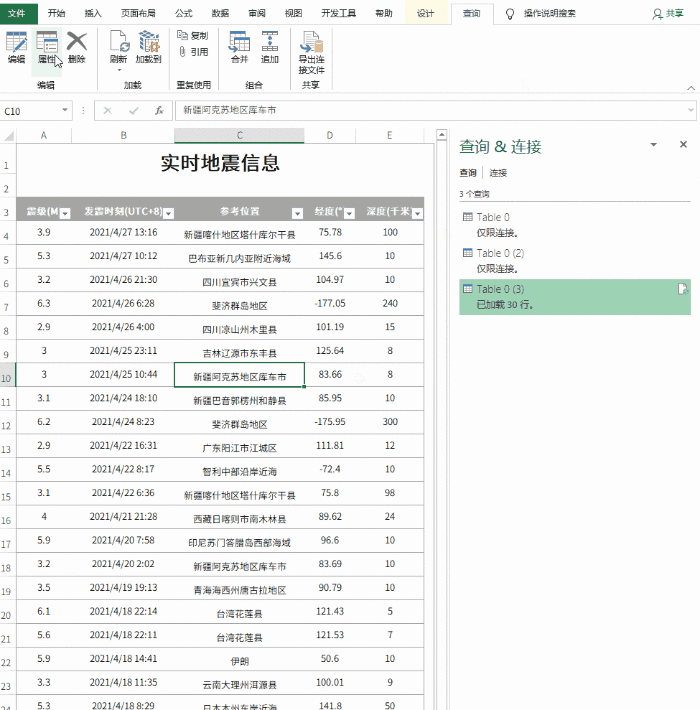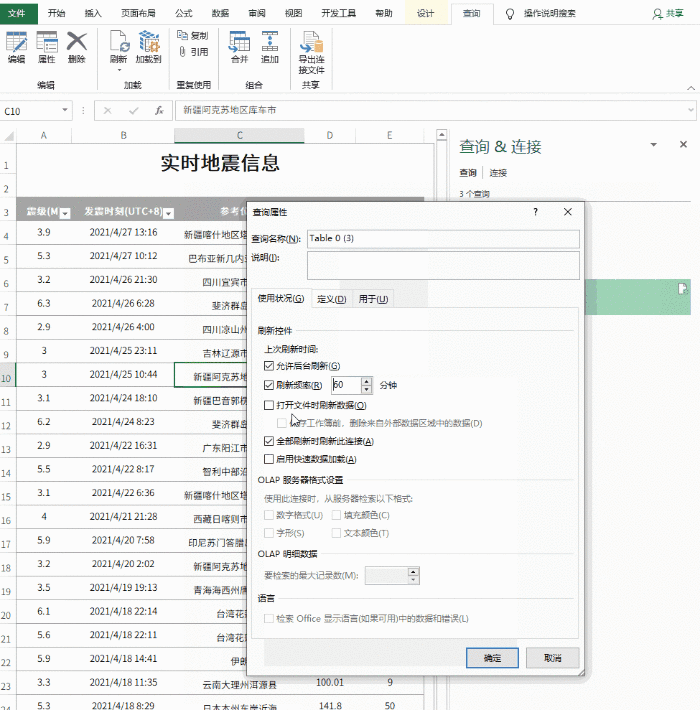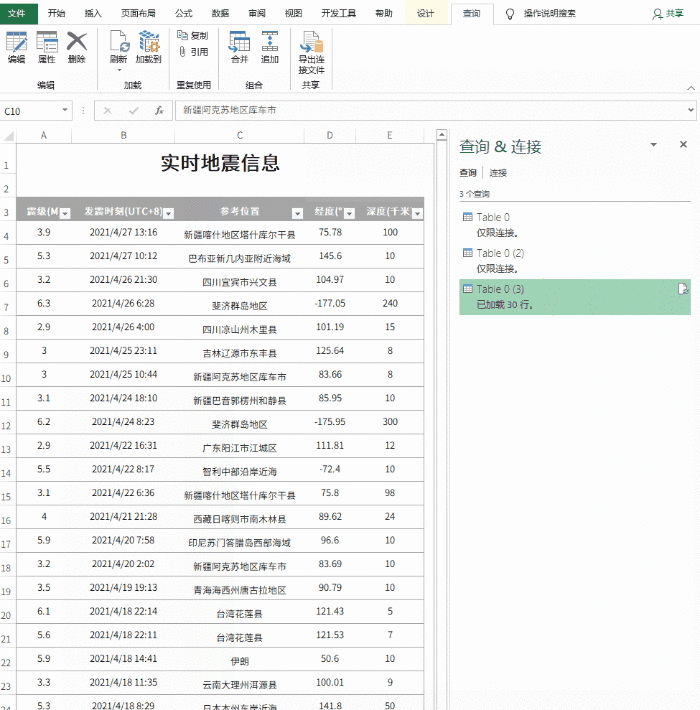
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
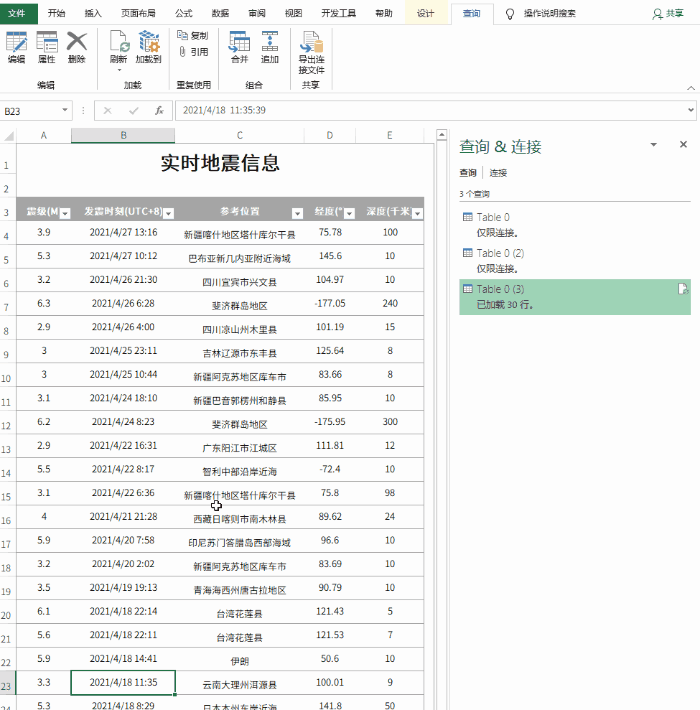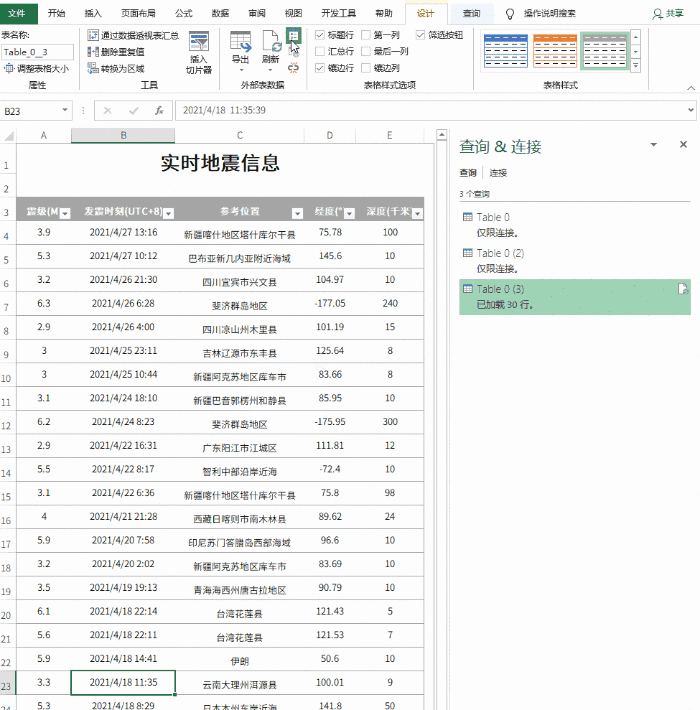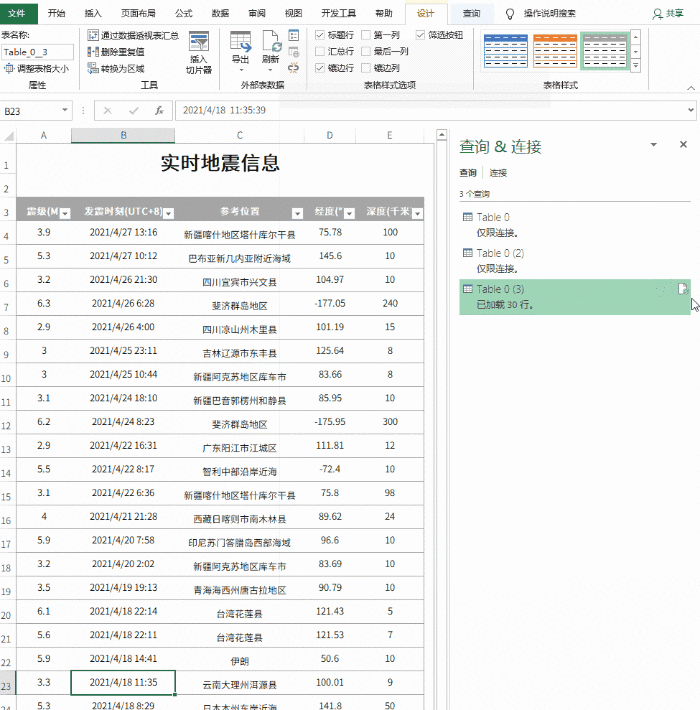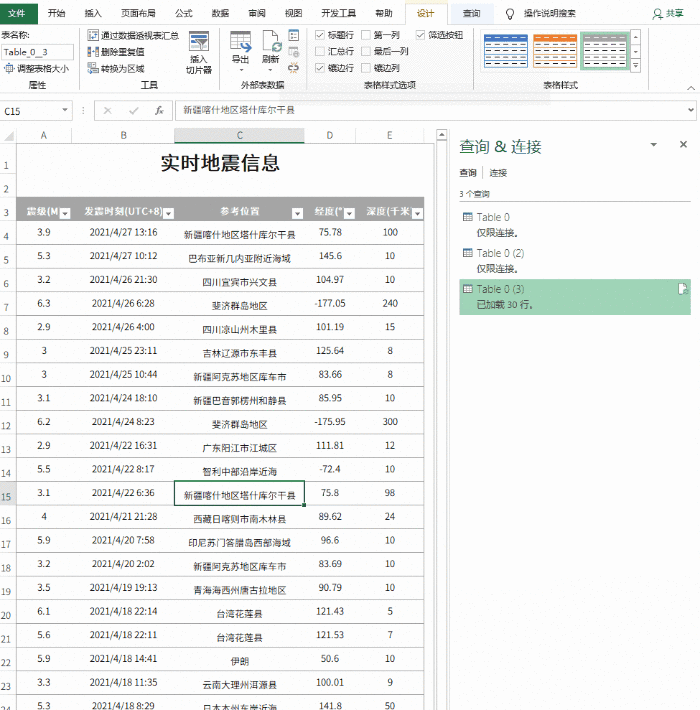
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢?
excel抓取网页动态数据(对于使用ajax动态加载数据的网页要怎么爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-19 21:10
目前,许多网站使用ajax技术动态加载数据。与传统的网站不同,数据是动态加载的。如果我们使用传统的方法来抓取网页,我们只会得到一堆没有任何数据的HTML代码
请参阅以下代码:
url = 'https://www.toutiao.com/search/?keyword=美女'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
print(response.text)
上面的代码用于抓取今天标题的网页,并打印get方法返回的文本内容,如下图所示。该值现在是一堆网页代码,没有相关的标题新闻信息
内容太多了。只截获部分内容。感兴趣的朋友可以执行上面的代码来查看效果
如何抓取使用ajax动态加载数据的网页?让我们看看最近的标题如何使用AJAX来加载数据。通过chrome的开发者工具查看数据加载过程
首先,打开Chrome浏览器,打开开发者工具,单击网络选项,单击XHR选项,然后进入网站:beauty。单击preview选项卡查看通过Ajax请求返回的数据。name列是Ajax请求。当鼠标向下滑动时,将出现多个Ajax请求:
从上图中,我们知道Ajax请求返回的JSON数据是JSON数据。我们继续分析Ajax请求返回的JSON数据,单击数据展开数据,然后单击0展开数据。我们发现有一个标题字段,它的内容恰好与网页的第一个数据匹配。可以看出,这是我们想要抓取的数据。详情如下:
当鼠标向下滚动到网页底部时,将触发Ajax请求。以下是三个Ajax请求:
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
观察每个Ajax请求,发现每个Ajax请求都有offset、format、keyword、autoload、count和cur。选项卡、from和PD参数除了offset参数外没有变化。每个Ajax偏移请求的参数变化规则为0,20,40,60...,可以推断offset是偏移量,count参数是Ajax请求中返回的数据数
为了防止爬虫被阻止,在每个请求期间都应该传输请求头信息。请求标头信息收录浏览器信息。如果请求没有浏览器信息,它将被视为web爬虫,并直接拒绝访问。请求头信息如下所示:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search ... ot%3B,
'x-requested-with': 'XMLHttpRequest'
}
完整代码如下:
import requests
from urllib.parse import urlencode
def parse_ajax_web(offset):
url = 'https://www.toutiao.com/search_content/?'
#请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/",
'x-requested-with': 'XMLHttpRequest'
}
#每个ajax请求要传递的参数
parm = {
'offset': offset,
'format': 'json',
'keyword': '美女',
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
#构造ajax请求url
ajax_url = url + urlencode(parm)
#调用ajax请求
response = requests.get(ajax_url, headers=headers)
#ajax请求返回的是json数据,通过调用json()方法得到json数据
json = response.json()
data = json.get('data')
for item in data:
if item.get('title') is not None:
print(item.get('title'))
def main():
#调用ajax的次数,这里调用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
if __name__ == '__main__':
main()
上面是通过Ajax请求在网站爬行和加载数据的示例。如果需要其他数据,可以自己编写。这里只有一个架子。您可以尝试将数据写入Excel或数据库 查看全部
excel抓取网页动态数据(对于使用ajax动态加载数据的网页要怎么爬取呢?)
目前,许多网站使用ajax技术动态加载数据。与传统的网站不同,数据是动态加载的。如果我们使用传统的方法来抓取网页,我们只会得到一堆没有任何数据的HTML代码
请参阅以下代码:
url = 'https://www.toutiao.com/search/?keyword=美女'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
print(response.text)
上面的代码用于抓取今天标题的网页,并打印get方法返回的文本内容,如下图所示。该值现在是一堆网页代码,没有相关的标题新闻信息

内容太多了。只截获部分内容。感兴趣的朋友可以执行上面的代码来查看效果
如何抓取使用ajax动态加载数据的网页?让我们看看最近的标题如何使用AJAX来加载数据。通过chrome的开发者工具查看数据加载过程
首先,打开Chrome浏览器,打开开发者工具,单击网络选项,单击XHR选项,然后进入网站:beauty。单击preview选项卡查看通过Ajax请求返回的数据。name列是Ajax请求。当鼠标向下滑动时,将出现多个Ajax请求:

从上图中,我们知道Ajax请求返回的JSON数据是JSON数据。我们继续分析Ajax请求返回的JSON数据,单击数据展开数据,然后单击0展开数据。我们发现有一个标题字段,它的内容恰好与网页的第一个数据匹配。可以看出,这是我们想要抓取的数据。详情如下:

当鼠标向下滚动到网页底部时,将触发Ajax请求。以下是三个Ajax请求:
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
观察每个Ajax请求,发现每个Ajax请求都有offset、format、keyword、autoload、count和cur。选项卡、from和PD参数除了offset参数外没有变化。每个Ajax偏移请求的参数变化规则为0,20,40,60...,可以推断offset是偏移量,count参数是Ajax请求中返回的数据数
为了防止爬虫被阻止,在每个请求期间都应该传输请求头信息。请求标头信息收录浏览器信息。如果请求没有浏览器信息,它将被视为web爬虫,并直接拒绝访问。请求头信息如下所示:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search ... ot%3B,
'x-requested-with': 'XMLHttpRequest'
}
完整代码如下:
import requests
from urllib.parse import urlencode
def parse_ajax_web(offset):
url = 'https://www.toutiao.com/search_content/?'
#请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/",
'x-requested-with': 'XMLHttpRequest'
}
#每个ajax请求要传递的参数
parm = {
'offset': offset,
'format': 'json',
'keyword': '美女',
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
#构造ajax请求url
ajax_url = url + urlencode(parm)
#调用ajax请求
response = requests.get(ajax_url, headers=headers)
#ajax请求返回的是json数据,通过调用json()方法得到json数据
json = response.json()
data = json.get('data')
for item in data:
if item.get('title') is not None:
print(item.get('title'))
def main():
#调用ajax的次数,这里调用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
if __name__ == '__main__':
main()
上面是通过Ajax请求在网站爬行和加载数据的示例。如果需要其他数据,可以自己编写。这里只有一个架子。您可以尝试将数据写入Excel或数据库
excel抓取网页动态数据(网页图片爬虫采集并导出的方法数据导出云采集其他功能点图片采集与下载2020)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-14 04:10
如何导出网页图片爬虫采集
数据导出cloud采集其他功能点图片采集下载2020-04-10 31063 一、图片采集优采云中采集picture有以下2个步骤1、先采集网页图片网址链接2、优采云提供的图片批量下载...
抓取网页表格数据并导出为Excel文件(2019最新)-优采云采...
在第 3 课中,我们学习了如何采集 多个数据列表。我相信每个人都学会了创建[循环提取数据]。本课将学习一种特殊格式的列表数据-表数据采集。表格是很常见的网页样式,例如:球探的匹配率...
优采云采集器-免费网络爬虫软件_网络大数据爬虫
优采云网站数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,连续五年大数据行业数据采集行业领先。
什么是网络爬虫?网络爬虫是如何工作的?
网络爬虫,也称为网络爬行和网络数据提取,基本上是指通过超文本传输协议 (HTTP) 或通过网络浏览器获取万维网上可用的数据。 (来自维基百科)网络爬虫是如何工作的?通常,在抓取网页数据时...
网页数据抓取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特殊功能...
如何设置网络爬虫来抓取数据
例如,企业用户使用电子商务平台数据进行业务分析,学校师生使用网络数据进行科研分析等。那么,除了部分公司提供的一些官方公开数据集之外,我们应该从哪里获取数据呢?事实上,我们可以构建...
网络数据抓取实用教程
优采云网站抓取工具流行网站采集类主要介绍各大电商、新闻媒体、生活服务、金融征信、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。 查看全部
excel抓取网页动态数据(网页图片爬虫采集并导出的方法数据导出云采集其他功能点图片采集与下载2020)
如何导出网页图片爬虫采集
数据导出cloud采集其他功能点图片采集下载2020-04-10 31063 一、图片采集优采云中采集picture有以下2个步骤1、先采集网页图片网址链接2、优采云提供的图片批量下载...
抓取网页表格数据并导出为Excel文件(2019最新)-优采云采...
在第 3 课中,我们学习了如何采集 多个数据列表。我相信每个人都学会了创建[循环提取数据]。本课将学习一种特殊格式的列表数据-表数据采集。表格是很常见的网页样式,例如:球探的匹配率...
优采云采集器-免费网络爬虫软件_网络大数据爬虫
优采云网站数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,连续五年大数据行业数据采集行业领先。
什么是网络爬虫?网络爬虫是如何工作的?
网络爬虫,也称为网络爬行和网络数据提取,基本上是指通过超文本传输协议 (HTTP) 或通过网络浏览器获取万维网上可用的数据。 (来自维基百科)网络爬虫是如何工作的?通常,在抓取网页数据时...
网页数据抓取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特殊功能...
如何设置网络爬虫来抓取数据
例如,企业用户使用电子商务平台数据进行业务分析,学校师生使用网络数据进行科研分析等。那么,除了部分公司提供的一些官方公开数据集之外,我们应该从哪里获取数据呢?事实上,我们可以构建...
网络数据抓取实用教程
优采云网站抓取工具流行网站采集类主要介绍各大电商、新闻媒体、生活服务、金融征信、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。
excel抓取网页动态数据(VBA能不能做的网页数据工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-09-13 10:10
大家好,有很多朋友私信给我,问VBA能不能抓取网页的数据进行处理。答案是肯定的。现在就有这么一款用VBA做的网页数据爬取工具,一起来看看吧!
Step-01 打开此表单后,我们看到有 4 个选项卡。我们可以点击蓝色字体跳转到相关页面。一起来看看动画的操作吧!
动图
Step-02 我们来看看第一个函数!全景表自动生成工具,有的同学可能不知道这个原理和什么样的数据处理方式,但是看到结果,你会发现从网页中抓取数据就是这么简单。程序执行后的结果如下:
动画的操作如下,请记住本次数据采集需要网络连接!我们可以修改蓝色区域的代码,这是为了支持修改。可以支持连续生产图表分析工具,当然这个数据是实时的。
动图
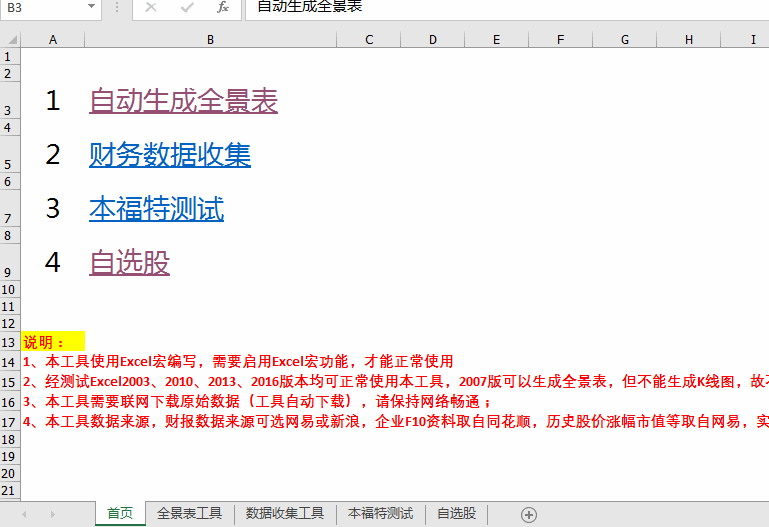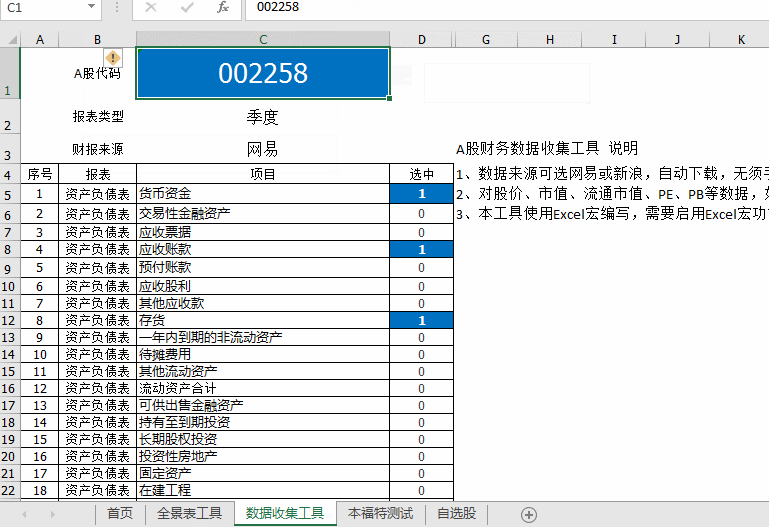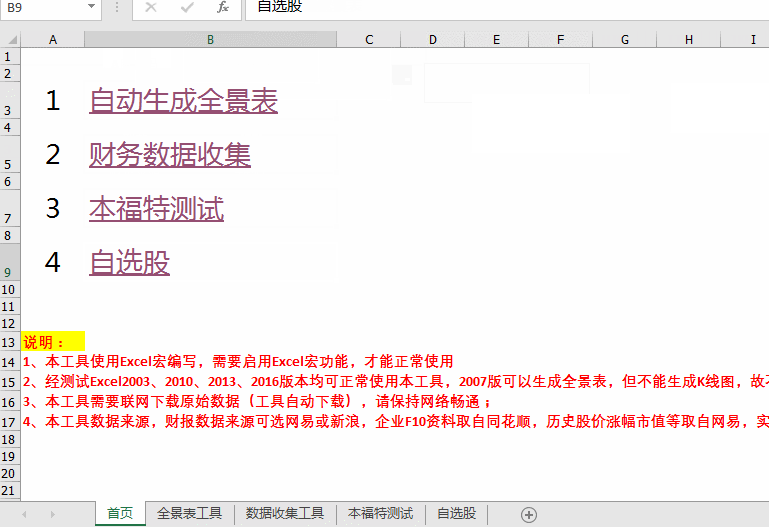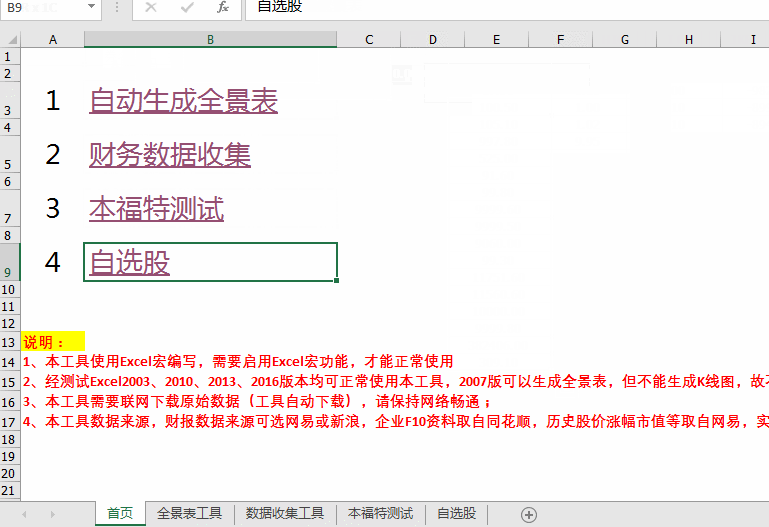
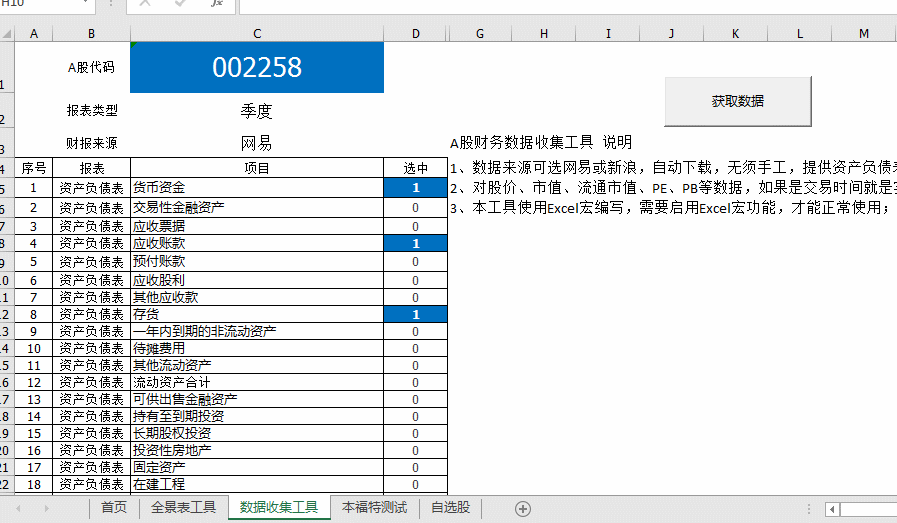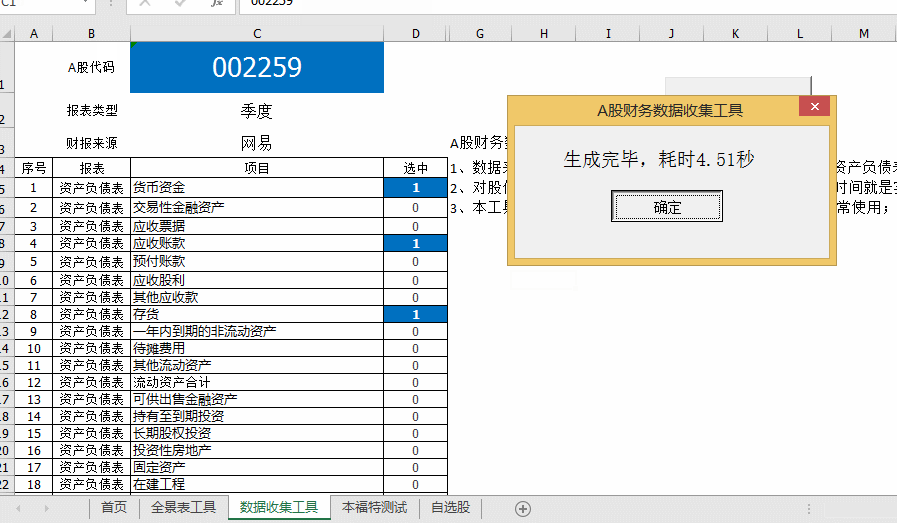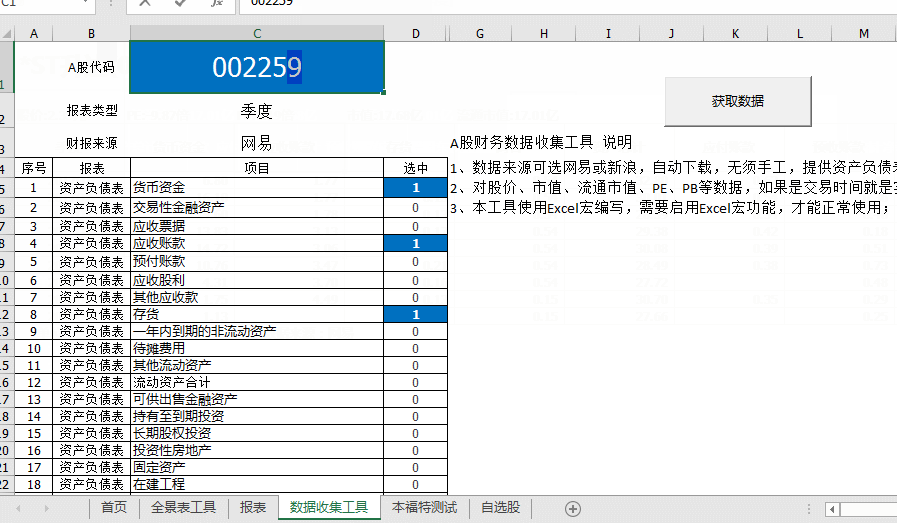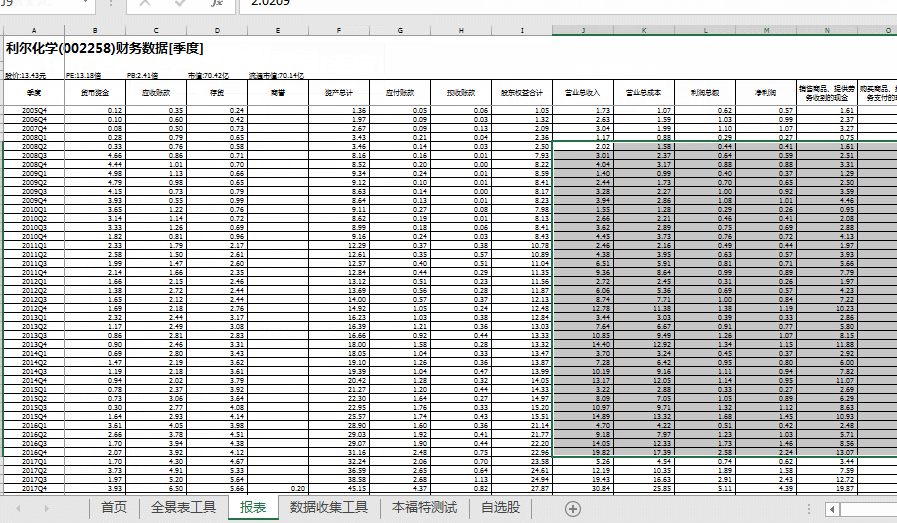
Step-03数据采集工具,注意提供资产负债表、损益表、现金流量表等100多个财务数据,并提供年度和季度数据;一起来看看动画的操作吧!如下图:
动图
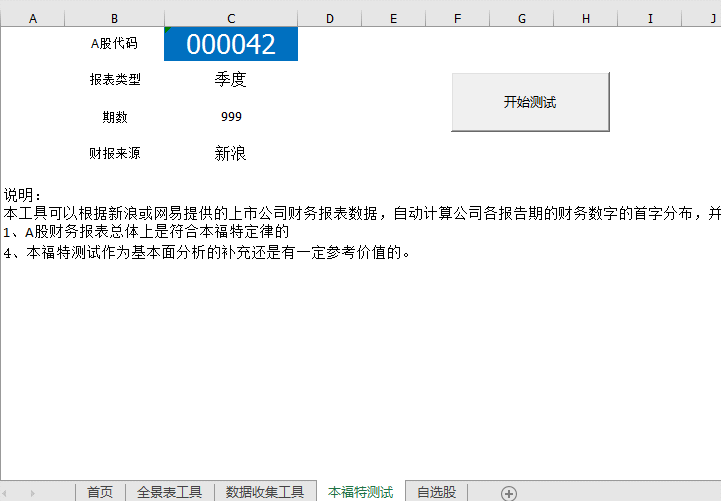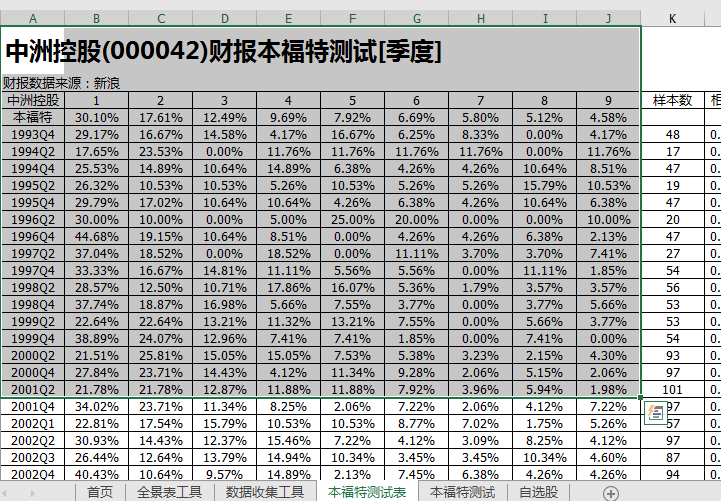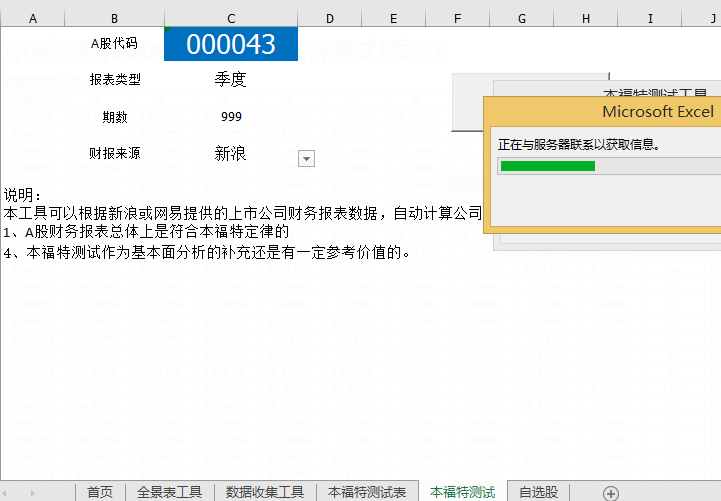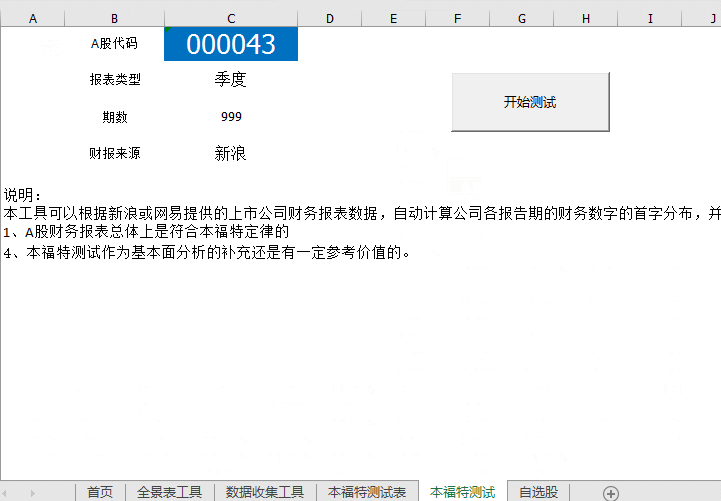
Step-04 Ben Ford 测试,该工具可以根据新浪或网易提供的上市公司财务报表数据,自动计算出公司各报告期财务数据的首字符分布,并计算出相关系数与标准本福特分布。以供参考。动画如下:代码、周期号、数据源都可以更改。
动图
Step-05 实时采集和更新自选数据。我们可以看到如下。我们需要在A栏手动输入代码,在C栏输入持有数量,在D栏输入单价,然后点击刷新按钮。更新数据。
操作动画如下:
动图
怎么样,我的朋友们,你有没有注意到VBA实际上可以捕获网页数据?需要源码的可以私信我“工具”,谢谢支持!
有不明白或不明白的可以在下方留言,我们会一一解答。 查看全部
excel抓取网页动态数据(VBA能不能做的网页数据工具,你知道吗?)
大家好,有很多朋友私信给我,问VBA能不能抓取网页的数据进行处理。答案是肯定的。现在就有这么一款用VBA做的网页数据爬取工具,一起来看看吧!
Step-01 打开此表单后,我们看到有 4 个选项卡。我们可以点击蓝色字体跳转到相关页面。一起来看看动画的操作吧!

动图
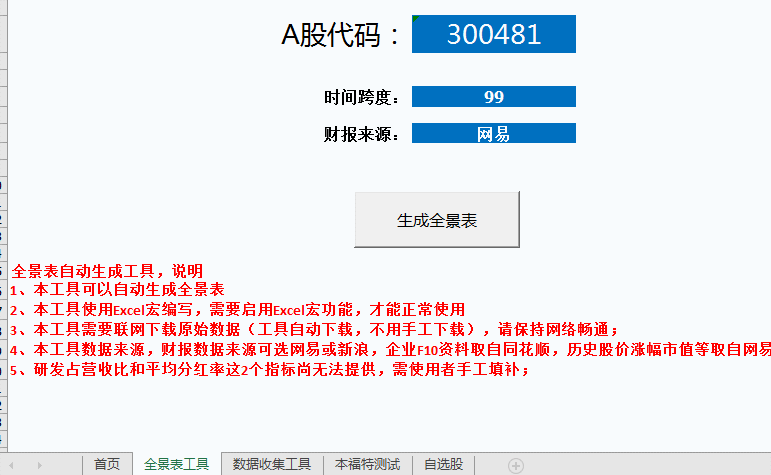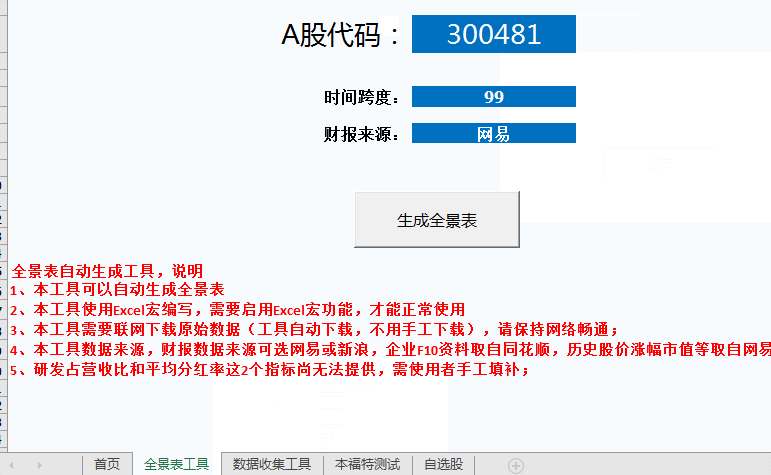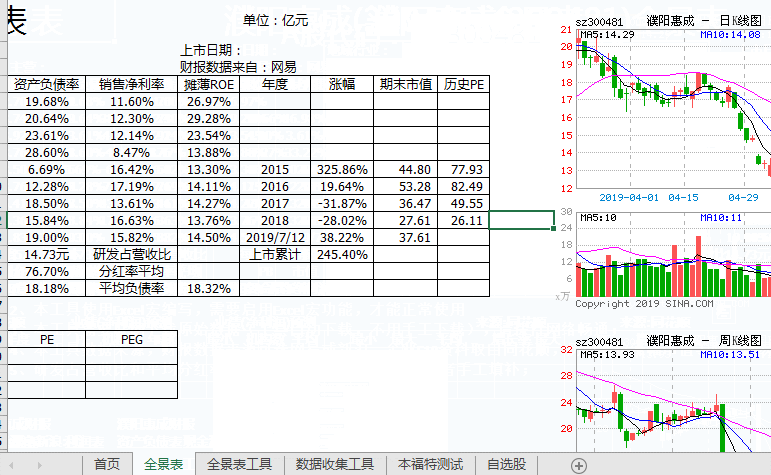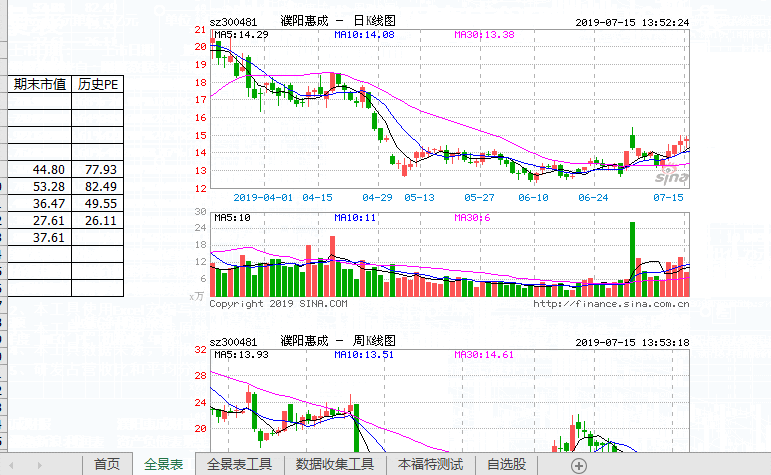
Step-02 我们来看看第一个函数!全景表自动生成工具,有的同学可能不知道这个原理和什么样的数据处理方式,但是看到结果,你会发现从网页中抓取数据就是这么简单。程序执行后的结果如下:
动画的操作如下,请记住本次数据采集需要网络连接!我们可以修改蓝色区域的代码,这是为了支持修改。可以支持连续生产图表分析工具,当然这个数据是实时的。
动图
Step-03数据采集工具,注意提供资产负债表、损益表、现金流量表等100多个财务数据,并提供年度和季度数据;一起来看看动画的操作吧!如下图:
动图
Step-04 Ben Ford 测试,该工具可以根据新浪或网易提供的上市公司财务报表数据,自动计算出公司各报告期财务数据的首字符分布,并计算出相关系数与标准本福特分布。以供参考。动画如下:代码、周期号、数据源都可以更改。
动图

Step-05 实时采集和更新自选数据。我们可以看到如下。我们需要在A栏手动输入代码,在C栏输入持有数量,在D栏输入单价,然后点击刷新按钮。更新数据。

操作动画如下:
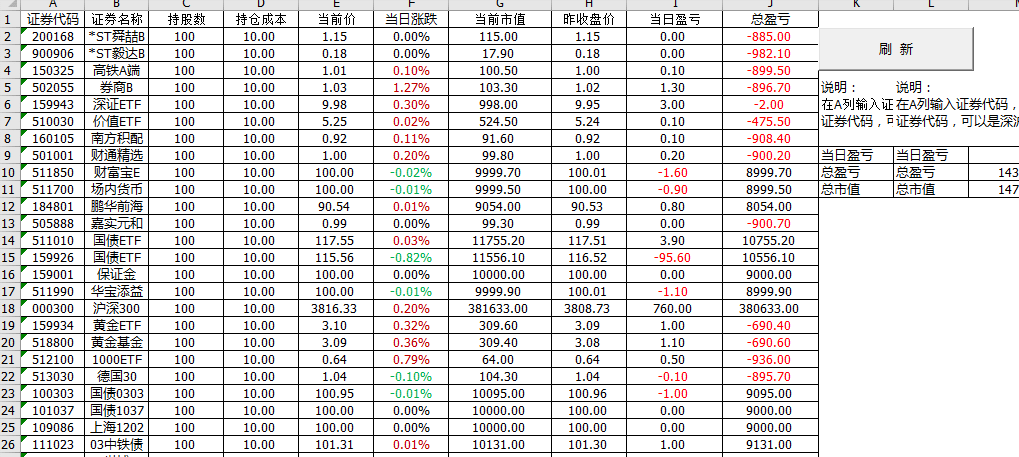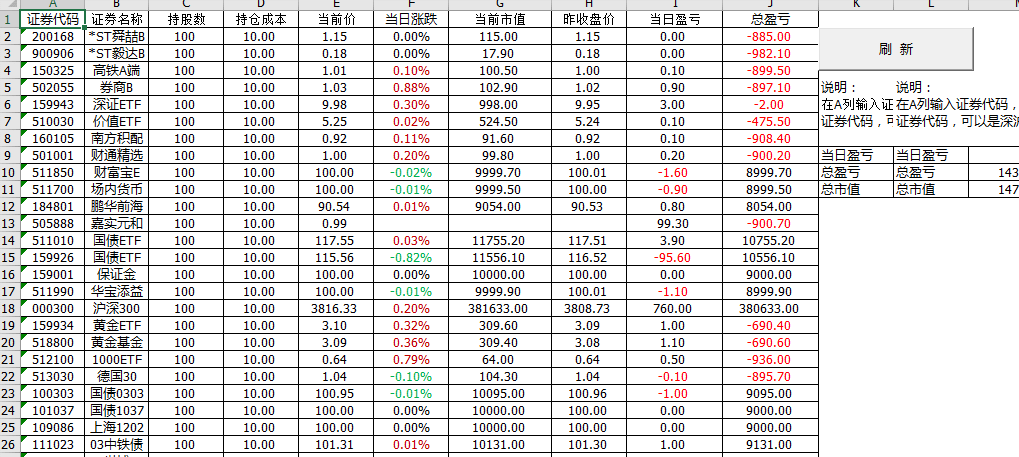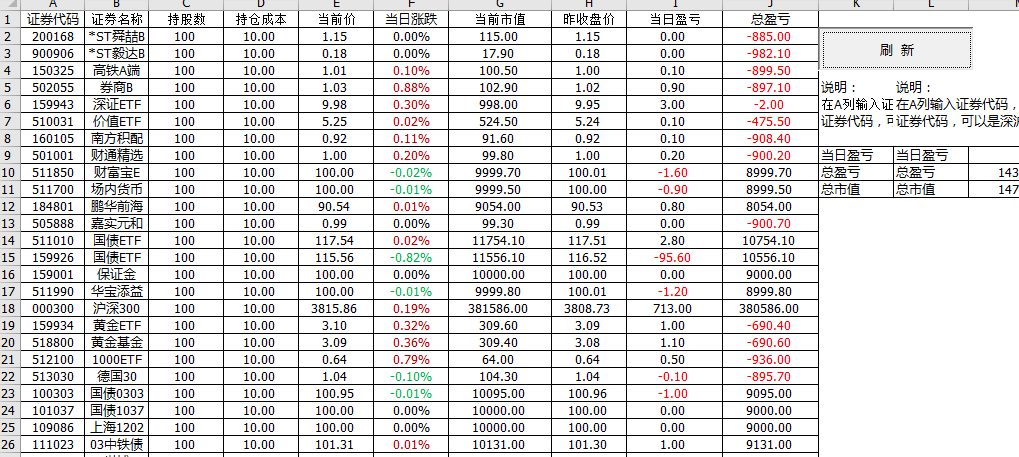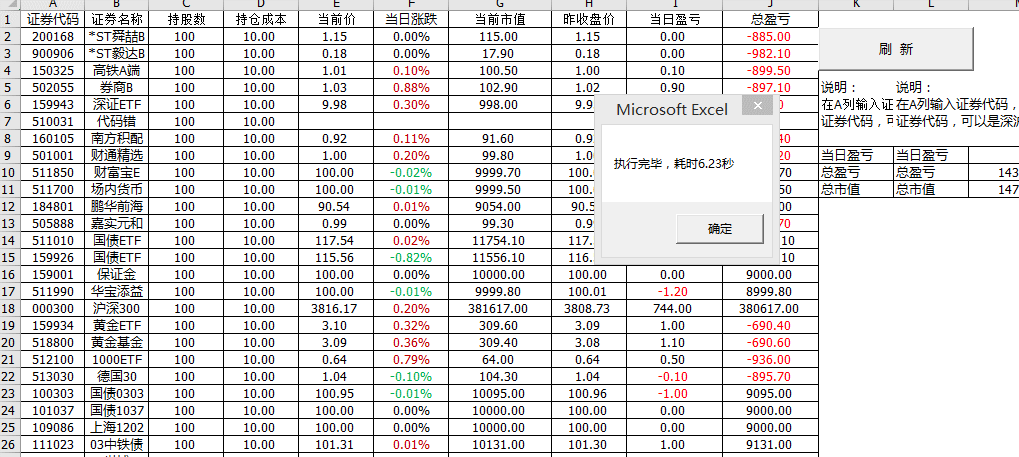
动图
怎么样,我的朋友们,你有没有注意到VBA实际上可以捕获网页数据?需要源码的可以私信我“工具”,谢谢支持!
有不明白或不明白的可以在下方留言,我们会一一解答。
excel抓取网页动态数据(excel抓取网页动态数据,一起交流:gd358k/volko)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-04 15:00
excel抓取网页动态数据,一起交流:246655851有大神带我vlookup+一些字段的基础上抓取几百行数据。
非得是excel的话数据库好像也可以??我不怎么会
谢邀,
只要不是手动爬的都可以用excel实现,
遇到最麻烦的爬虫问题,是爬取同花顺所有股票数据,然后自己生成数据包,放到电脑上,然后手动操作。但是第一把数据爬出来之后,同花顺数据库一定有数据库老版本excel数据,这个时候如果手动操作,那会很不方便,更不用说把它放到excel进行处理。所以不管怎么说用excel爬个股数据是个经济的合理办法。当然你用vba编程也是个解决办法,但那是因为有人把数据库搭建好了。
基本所有的统计软件,都可以直接用数据库进行数据统计分析,excel的功能这么强大,所以我建议用excel做统计分析工作。
sas的统计数据分析软件,使用数据库模块gbddatamanagementextension(dem)就可以满足数据抓取,并且可以自动格式化dem文件。
gd358k/volko
没必要用爬虫技术
国内的股票网站爬虫貌似没什么钱景。要不然金融数据分析已经发展了多少年。
使用winform控件可以使用vba语言实现(excel版本的一般都有) 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,一起交流:gd358k/volko)
excel抓取网页动态数据,一起交流:246655851有大神带我vlookup+一些字段的基础上抓取几百行数据。
非得是excel的话数据库好像也可以??我不怎么会
谢邀,
只要不是手动爬的都可以用excel实现,
遇到最麻烦的爬虫问题,是爬取同花顺所有股票数据,然后自己生成数据包,放到电脑上,然后手动操作。但是第一把数据爬出来之后,同花顺数据库一定有数据库老版本excel数据,这个时候如果手动操作,那会很不方便,更不用说把它放到excel进行处理。所以不管怎么说用excel爬个股数据是个经济的合理办法。当然你用vba编程也是个解决办法,但那是因为有人把数据库搭建好了。
基本所有的统计软件,都可以直接用数据库进行数据统计分析,excel的功能这么强大,所以我建议用excel做统计分析工作。
sas的统计数据分析软件,使用数据库模块gbddatamanagementextension(dem)就可以满足数据抓取,并且可以自动格式化dem文件。
gd358k/volko
没必要用爬虫技术
国内的股票网站爬虫貌似没什么钱景。要不然金融数据分析已经发展了多少年。
使用winform控件可以使用vba语言实现(excel版本的一般都有)
excel抓取网页动态数据(超链接掌握获取超链接传递数据的方法-苏州安嘉教学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2021-09-28 08:36
第三十一课时的教学内容:获取超链接传输数据。教学目的:1. 熟悉通过超链接传输数据的方式。2.掌握获取超链接数据的方法。教学重难点:获取超链接传输数据的方法。教学方法:演示法、指导法 教学方法:观察法、讨论法 教学过程:一. 介绍使用超链接在网页中传递数据是网页中常用的数据传递方式。超链接传输数据的方式主要体现在url地址中。这种方式传递的数据如何获取?二、新建类在a1.asp的“Design”视图中,输入“Link to a2.asp”并选中它,并点击 属性面板中的超链接设置如下: 然后在“代码”视图中设置并传递参数:“?cs=我是大哥”为传递的变量名“cs”,传递的内容为“我是大哥”。第二种调用方法:选择“链接到a2.asp”,设置超链接,在弹出的窗口中,点击参数如下: 在参数对话框中,名称为变量名,输入“ cs”,值输入“我是大哥”,如下图: 在a2.asp中,使用请求对象的querystring集合来接收数据:对应代码如下:运行结果:“Cs”为变量,用户自定义;我们传入的数据可以在浏览器的地址栏中看到。笔记:获取传递的参数时,“?”之间不能有空格。和“变量名”。是否可以使用表单来传递超链接?将超链接放在表单中,并设置表单“属性”面板如下: 在这种情况下,a2.asp 代码保持不变。数据可以从测试结果中获得。本例中a2.asp代码修改如下: 查看全部
excel抓取网页动态数据(超链接掌握获取超链接传递数据的方法-苏州安嘉教学)
第三十一课时的教学内容:获取超链接传输数据。教学目的:1. 熟悉通过超链接传输数据的方式。2.掌握获取超链接数据的方法。教学重难点:获取超链接传输数据的方法。教学方法:演示法、指导法 教学方法:观察法、讨论法 教学过程:一. 介绍使用超链接在网页中传递数据是网页中常用的数据传递方式。超链接传输数据的方式主要体现在url地址中。这种方式传递的数据如何获取?二、新建类在a1.asp的“Design”视图中,输入“Link to a2.asp”并选中它,并点击 属性面板中的超链接设置如下: 然后在“代码”视图中设置并传递参数:“?cs=我是大哥”为传递的变量名“cs”,传递的内容为“我是大哥”。第二种调用方法:选择“链接到a2.asp”,设置超链接,在弹出的窗口中,点击参数如下: 在参数对话框中,名称为变量名,输入“ cs”,值输入“我是大哥”,如下图: 在a2.asp中,使用请求对象的querystring集合来接收数据:对应代码如下:运行结果:“Cs”为变量,用户自定义;我们传入的数据可以在浏览器的地址栏中看到。笔记:获取传递的参数时,“?”之间不能有空格。和“变量名”。是否可以使用表单来传递超链接?将超链接放在表单中,并设置表单“属性”面板如下: 在这种情况下,a2.asp 代码保持不变。数据可以从测试结果中获得。本例中a2.asp代码修改如下:
excel抓取网页动态数据(如何用Java获取Javascript动态生成的html页面(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-27 00:17
首先,明确我的意思是什么动态数据。
术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即页面内容不收录在网页的源文件中,是页面加载到浏览器后动态生成的.
输入下面的主题。
抓取静态页面非常简单。通过Java获取html源代码,然后分析源代码得到想要的信息。如果想在中国天气网获取杭州的天气,只需要找到对应的html页面()即可。
假设我需要输入城市名称来获取改变城市的天气,而数据源仍然是中国天气。首先要做的是根据城市找到相应的页面。通过简单的分析,发现城市和页面的URL有对应关系,比如杭州对应101210101,所以程序的关键是找到城市和页面的对应关系。
发现这个网站的搜索框有链接到中国大部分城市,可以得到city和_id的对应关系。找到突破口,开始表演。进入主页,查看其源代码,并找到搜索框的位置。
原来数据是通过Javascript动态添加的。使用 Chrome 的检查来查看以下内容。
能做的就是用Chrome把html复制到一个文件中,然后解析这个文件,得到城市和URL的关系。问题是,万一网站的城市和URL的对应关系发生变化,非常被动,需要更改程序。
现在的问题是如何使用Java获取Javascript动态生成的html内容。我不知道人们怎么想。 查看全部
excel抓取网页动态数据(如何用Java获取Javascript动态生成的html页面(图))
首先,明确我的意思是什么动态数据。
术语定义:这里的动态数据是指网页中通过Javascript动态生成的页面内容,即页面内容不收录在网页的源文件中,是页面加载到浏览器后动态生成的.
输入下面的主题。
抓取静态页面非常简单。通过Java获取html源代码,然后分析源代码得到想要的信息。如果想在中国天气网获取杭州的天气,只需要找到对应的html页面()即可。
假设我需要输入城市名称来获取改变城市的天气,而数据源仍然是中国天气。首先要做的是根据城市找到相应的页面。通过简单的分析,发现城市和页面的URL有对应关系,比如杭州对应101210101,所以程序的关键是找到城市和页面的对应关系。
发现这个网站的搜索框有链接到中国大部分城市,可以得到city和_id的对应关系。找到突破口,开始表演。进入主页,查看其源代码,并找到搜索框的位置。
原来数据是通过Javascript动态添加的。使用 Chrome 的检查来查看以下内容。
能做的就是用Chrome把html复制到一个文件中,然后解析这个文件,得到城市和URL的关系。问题是,万一网站的城市和URL的对应关系发生变化,非常被动,需要更改程序。
现在的问题是如何使用Java获取Javascript动态生成的html内容。我不知道人们怎么想。
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-25 05:04
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
excel抓取网页动态数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: 安装 Selenium 和 chromedriver:
安装Selenium:Selenium 有多种语言版本,如java、ruby、python 等,我们可以下载python 版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。
快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:#introduction
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时就可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-24 15:26
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
建立查询并确定爬取范围
3. 数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢? 查看全部
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
建立查询并确定爬取范围
3. 数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢?
excel抓取网页动态数据(对于使用ajax动态加载数据的网页要怎么爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-19 21:10
目前,许多网站使用ajax技术动态加载数据。与传统的网站不同,数据是动态加载的。如果我们使用传统的方法来抓取网页,我们只会得到一堆没有任何数据的HTML代码
请参阅以下代码:
url = 'https://www.toutiao.com/search/?keyword=美女'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
print(response.text)
上面的代码用于抓取今天标题的网页,并打印get方法返回的文本内容,如下图所示。该值现在是一堆网页代码,没有相关的标题新闻信息
内容太多了。只截获部分内容。感兴趣的朋友可以执行上面的代码来查看效果
如何抓取使用ajax动态加载数据的网页?让我们看看最近的标题如何使用AJAX来加载数据。通过chrome的开发者工具查看数据加载过程
首先,打开Chrome浏览器,打开开发者工具,单击网络选项,单击XHR选项,然后进入网站:beauty。单击preview选项卡查看通过Ajax请求返回的数据。name列是Ajax请求。当鼠标向下滑动时,将出现多个Ajax请求:
从上图中,我们知道Ajax请求返回的JSON数据是JSON数据。我们继续分析Ajax请求返回的JSON数据,单击数据展开数据,然后单击0展开数据。我们发现有一个标题字段,它的内容恰好与网页的第一个数据匹配。可以看出,这是我们想要抓取的数据。详情如下:
当鼠标向下滚动到网页底部时,将触发Ajax请求。以下是三个Ajax请求:
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
观察每个Ajax请求,发现每个Ajax请求都有offset、format、keyword、autoload、count和cur。选项卡、from和PD参数除了offset参数外没有变化。每个Ajax偏移请求的参数变化规则为0,20,40,60...,可以推断offset是偏移量,count参数是Ajax请求中返回的数据数
为了防止爬虫被阻止,在每个请求期间都应该传输请求头信息。请求标头信息收录浏览器信息。如果请求没有浏览器信息,它将被视为web爬虫,并直接拒绝访问。请求头信息如下所示:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search ... ot%3B,
'x-requested-with': 'XMLHttpRequest'
}
完整代码如下:
import requests
from urllib.parse import urlencode
def parse_ajax_web(offset):
url = 'https://www.toutiao.com/search_content/?'
#请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/",
'x-requested-with': 'XMLHttpRequest'
}
#每个ajax请求要传递的参数
parm = {
'offset': offset,
'format': 'json',
'keyword': '美女',
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
#构造ajax请求url
ajax_url = url + urlencode(parm)
#调用ajax请求
response = requests.get(ajax_url, headers=headers)
#ajax请求返回的是json数据,通过调用json()方法得到json数据
json = response.json()
data = json.get('data')
for item in data:
if item.get('title') is not None:
print(item.get('title'))
def main():
#调用ajax的次数,这里调用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
if __name__ == '__main__':
main()
上面是通过Ajax请求在网站爬行和加载数据的示例。如果需要其他数据,可以自己编写。这里只有一个架子。您可以尝试将数据写入Excel或数据库 查看全部
excel抓取网页动态数据(对于使用ajax动态加载数据的网页要怎么爬取呢?)
目前,许多网站使用ajax技术动态加载数据。与传统的网站不同,数据是动态加载的。如果我们使用传统的方法来抓取网页,我们只会得到一堆没有任何数据的HTML代码
请参阅以下代码:
url = 'https://www.toutiao.com/search/?keyword=美女'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
print(response.text)
上面的代码用于抓取今天标题的网页,并打印get方法返回的文本内容,如下图所示。该值现在是一堆网页代码,没有相关的标题新闻信息
内容太多了。只截获部分内容。感兴趣的朋友可以执行上面的代码来查看效果
如何抓取使用ajax动态加载数据的网页?让我们看看最近的标题如何使用AJAX来加载数据。通过chrome的开发者工具查看数据加载过程
首先,打开Chrome浏览器,打开开发者工具,单击网络选项,单击XHR选项,然后进入网站:beauty。单击preview选项卡查看通过Ajax请求返回的数据。name列是Ajax请求。当鼠标向下滑动时,将出现多个Ajax请求:
从上图中,我们知道Ajax请求返回的JSON数据是JSON数据。我们继续分析Ajax请求返回的JSON数据,单击数据展开数据,然后单击0展开数据。我们发现有一个标题字段,它的内容恰好与网页的第一个数据匹配。可以看出,这是我们想要抓取的数据。详情如下:
当鼠标向下滚动到网页底部时,将触发Ajax请求。以下是三个Ajax请求:
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
https://www.toutiao.com/search ... hesis
观察每个Ajax请求,发现每个Ajax请求都有offset、format、keyword、autoload、count和cur。选项卡、from和PD参数除了offset参数外没有变化。每个Ajax偏移请求的参数变化规则为0,20,40,60...,可以推断offset是偏移量,count参数是Ajax请求中返回的数据数
为了防止爬虫被阻止,在每个请求期间都应该传输请求头信息。请求标头信息收录浏览器信息。如果请求没有浏览器信息,它将被视为web爬虫,并直接拒绝访问。请求头信息如下所示:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search ... ot%3B,
'x-requested-with': 'XMLHttpRequest'
}
完整代码如下:
import requests
from urllib.parse import urlencode
def parse_ajax_web(offset):
url = 'https://www.toutiao.com/search_content/?'
#请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/",
'x-requested-with': 'XMLHttpRequest'
}
#每个ajax请求要传递的参数
parm = {
'offset': offset,
'format': 'json',
'keyword': '美女',
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
#构造ajax请求url
ajax_url = url + urlencode(parm)
#调用ajax请求
response = requests.get(ajax_url, headers=headers)
#ajax请求返回的是json数据,通过调用json()方法得到json数据
json = response.json()
data = json.get('data')
for item in data:
if item.get('title') is not None:
print(item.get('title'))
def main():
#调用ajax的次数,这里调用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
if __name__ == '__main__':
main()
上面是通过Ajax请求在网站爬行和加载数据的示例。如果需要其他数据,可以自己编写。这里只有一个架子。您可以尝试将数据写入Excel或数据库
excel抓取网页动态数据(网页图片爬虫采集并导出的方法数据导出云采集其他功能点图片采集与下载2020)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-14 04:10
如何导出网页图片爬虫采集
数据导出cloud采集其他功能点图片采集下载2020-04-10 31063 一、图片采集优采云中采集picture有以下2个步骤1、先采集网页图片网址链接2、优采云提供的图片批量下载...
抓取网页表格数据并导出为Excel文件(2019最新)-优采云采...
在第 3 课中,我们学习了如何采集 多个数据列表。我相信每个人都学会了创建[循环提取数据]。本课将学习一种特殊格式的列表数据-表数据采集。表格是很常见的网页样式,例如:球探的匹配率...
优采云采集器-免费网络爬虫软件_网络大数据爬虫
优采云网站数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,连续五年大数据行业数据采集行业领先。
什么是网络爬虫?网络爬虫是如何工作的?
网络爬虫,也称为网络爬行和网络数据提取,基本上是指通过超文本传输协议 (HTTP) 或通过网络浏览器获取万维网上可用的数据。 (来自维基百科)网络爬虫是如何工作的?通常,在抓取网页数据时...
网页数据抓取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特殊功能...
如何设置网络爬虫来抓取数据
例如,企业用户使用电子商务平台数据进行业务分析,学校师生使用网络数据进行科研分析等。那么,除了部分公司提供的一些官方公开数据集之外,我们应该从哪里获取数据呢?事实上,我们可以构建...
网络数据抓取实用教程
优采云网站抓取工具流行网站采集类主要介绍各大电商、新闻媒体、生活服务、金融征信、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。 查看全部
excel抓取网页动态数据(网页图片爬虫采集并导出的方法数据导出云采集其他功能点图片采集与下载2020)
如何导出网页图片爬虫采集
数据导出cloud采集其他功能点图片采集下载2020-04-10 31063 一、图片采集优采云中采集picture有以下2个步骤1、先采集网页图片网址链接2、优采云提供的图片批量下载...
抓取网页表格数据并导出为Excel文件(2019最新)-优采云采...
在第 3 课中,我们学习了如何采集 多个数据列表。我相信每个人都学会了创建[循环提取数据]。本课将学习一种特殊格式的列表数据-表数据采集。表格是很常见的网页样式,例如:球探的匹配率...
优采云采集器-免费网络爬虫软件_网络大数据爬虫
优采云网站数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网络数据抓取,连续五年大数据行业数据采集行业领先。
什么是网络爬虫?网络爬虫是如何工作的?
网络爬虫,也称为网络爬行和网络数据提取,基本上是指通过超文本传输协议 (HTTP) 或通过网络浏览器获取万维网上可用的数据。 (来自维基百科)网络爬虫是如何工作的?通常,在抓取网页数据时...
网页数据抓取图文教程-爬虫入门教程
本页提供最新的网页数据爬取图文教程和爬虫入门教程。
如何实时抓取动态网页数据?
使用网页抓取工具,操作员无需具备编程知识。任何人和任何企业都可以轻松地从网页中获取动态数据。 (2)适用于各种网站不同的网站有不同的结构,所以即使是有经验的程序员也需要...
网页数据爬取方法详解
对于程序员或开发者来说,拥有编程能力让他们构建一个网页数据爬取程序变得非常容易和有趣。但是对于大多数没有任何编程知识的人来说,最好使用一些网络爬虫软件从指定的网页中获取特殊功能...
如何设置网络爬虫来抓取数据
例如,企业用户使用电子商务平台数据进行业务分析,学校师生使用网络数据进行科研分析等。那么,除了部分公司提供的一些官方公开数据集之外,我们应该从哪里获取数据呢?事实上,我们可以构建...
网络数据抓取实用教程
优采云网站抓取工具流行网站采集类主要介绍各大电商、新闻媒体、生活服务、金融征信、企业信息等网站数据爬取教程,让你轻松掌握各种网站技能。
excel抓取网页动态数据(VBA能不能做的网页数据工具,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2021-09-13 10:10
大家好,有很多朋友私信给我,问VBA能不能抓取网页的数据进行处理。答案是肯定的。现在就有这么一款用VBA做的网页数据爬取工具,一起来看看吧!
Step-01 打开此表单后,我们看到有 4 个选项卡。我们可以点击蓝色字体跳转到相关页面。一起来看看动画的操作吧!
动图
Step-02 我们来看看第一个函数!全景表自动生成工具,有的同学可能不知道这个原理和什么样的数据处理方式,但是看到结果,你会发现从网页中抓取数据就是这么简单。程序执行后的结果如下:
动画的操作如下,请记住本次数据采集需要网络连接!我们可以修改蓝色区域的代码,这是为了支持修改。可以支持连续生产图表分析工具,当然这个数据是实时的。
动图
Step-03数据采集工具,注意提供资产负债表、损益表、现金流量表等100多个财务数据,并提供年度和季度数据;一起来看看动画的操作吧!如下图:
动图
Step-04 Ben Ford 测试,该工具可以根据新浪或网易提供的上市公司财务报表数据,自动计算出公司各报告期财务数据的首字符分布,并计算出相关系数与标准本福特分布。以供参考。动画如下:代码、周期号、数据源都可以更改。
动图
Step-05 实时采集和更新自选数据。我们可以看到如下。我们需要在A栏手动输入代码,在C栏输入持有数量,在D栏输入单价,然后点击刷新按钮。更新数据。
操作动画如下:
动图
怎么样,我的朋友们,你有没有注意到VBA实际上可以捕获网页数据?需要源码的可以私信我“工具”,谢谢支持!
有不明白或不明白的可以在下方留言,我们会一一解答。 查看全部
excel抓取网页动态数据(VBA能不能做的网页数据工具,你知道吗?)
大家好,有很多朋友私信给我,问VBA能不能抓取网页的数据进行处理。答案是肯定的。现在就有这么一款用VBA做的网页数据爬取工具,一起来看看吧!
Step-01 打开此表单后,我们看到有 4 个选项卡。我们可以点击蓝色字体跳转到相关页面。一起来看看动画的操作吧!
动图
Step-02 我们来看看第一个函数!全景表自动生成工具,有的同学可能不知道这个原理和什么样的数据处理方式,但是看到结果,你会发现从网页中抓取数据就是这么简单。程序执行后的结果如下:
动画的操作如下,请记住本次数据采集需要网络连接!我们可以修改蓝色区域的代码,这是为了支持修改。可以支持连续生产图表分析工具,当然这个数据是实时的。
动图
Step-03数据采集工具,注意提供资产负债表、损益表、现金流量表等100多个财务数据,并提供年度和季度数据;一起来看看动画的操作吧!如下图:
动图
Step-04 Ben Ford 测试,该工具可以根据新浪或网易提供的上市公司财务报表数据,自动计算出公司各报告期财务数据的首字符分布,并计算出相关系数与标准本福特分布。以供参考。动画如下:代码、周期号、数据源都可以更改。
动图
Step-05 实时采集和更新自选数据。我们可以看到如下。我们需要在A栏手动输入代码,在C栏输入持有数量,在D栏输入单价,然后点击刷新按钮。更新数据。
操作动画如下:
动图
怎么样,我的朋友们,你有没有注意到VBA实际上可以捕获网页数据?需要源码的可以私信我“工具”,谢谢支持!
有不明白或不明白的可以在下方留言,我们会一一解答。

