
excel抓取网页动态数据
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-18 04:00
当我读到这篇文章时,你是否还沉浸在对python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
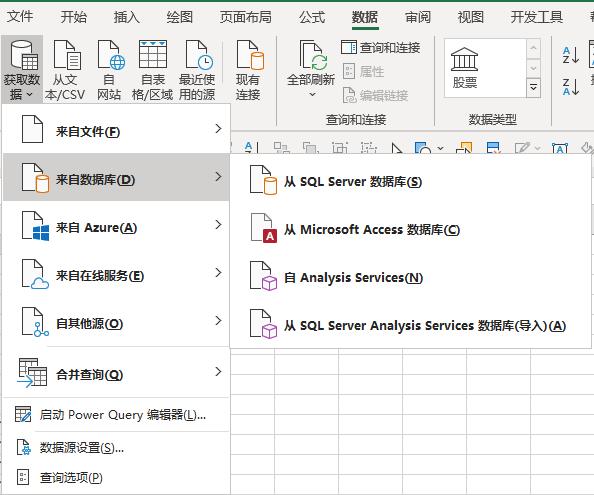
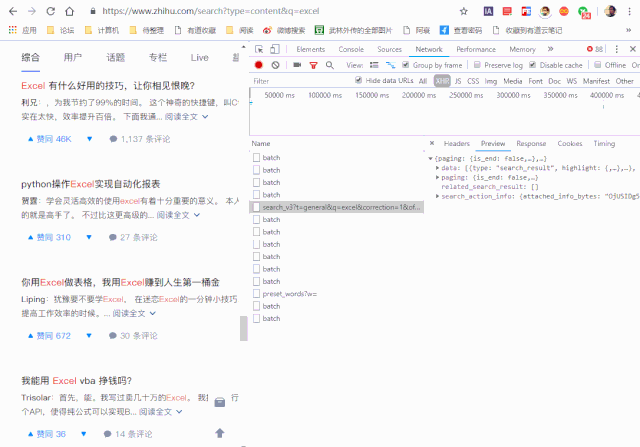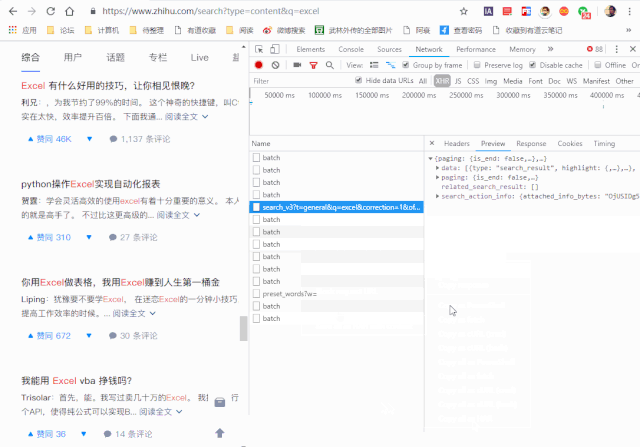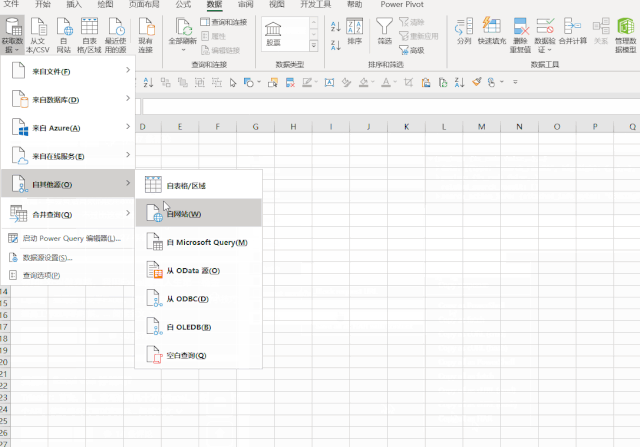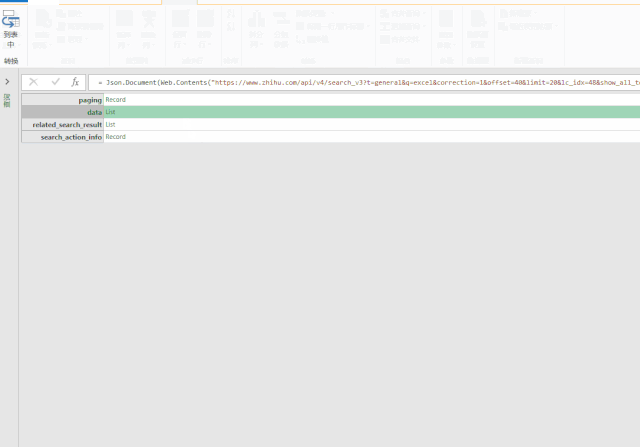
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
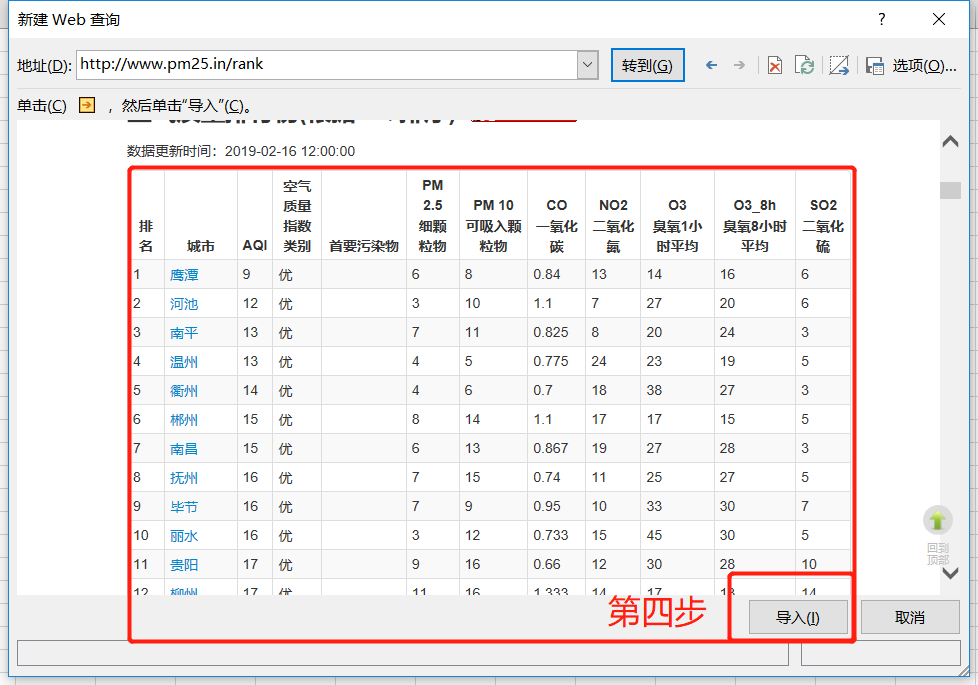
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
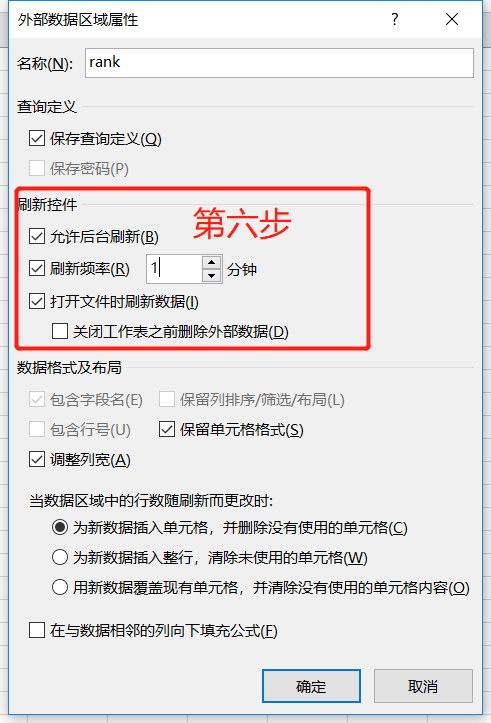
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐查看更多 查看全部
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
当我读到这篇文章时,你是否还沉浸在对python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
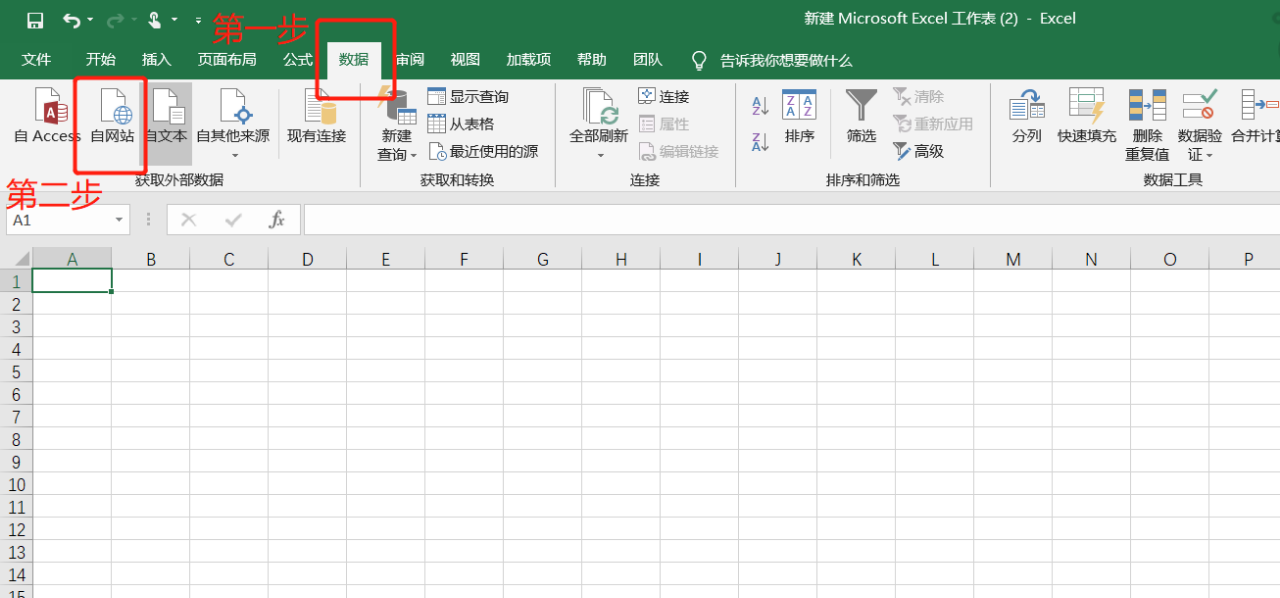
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
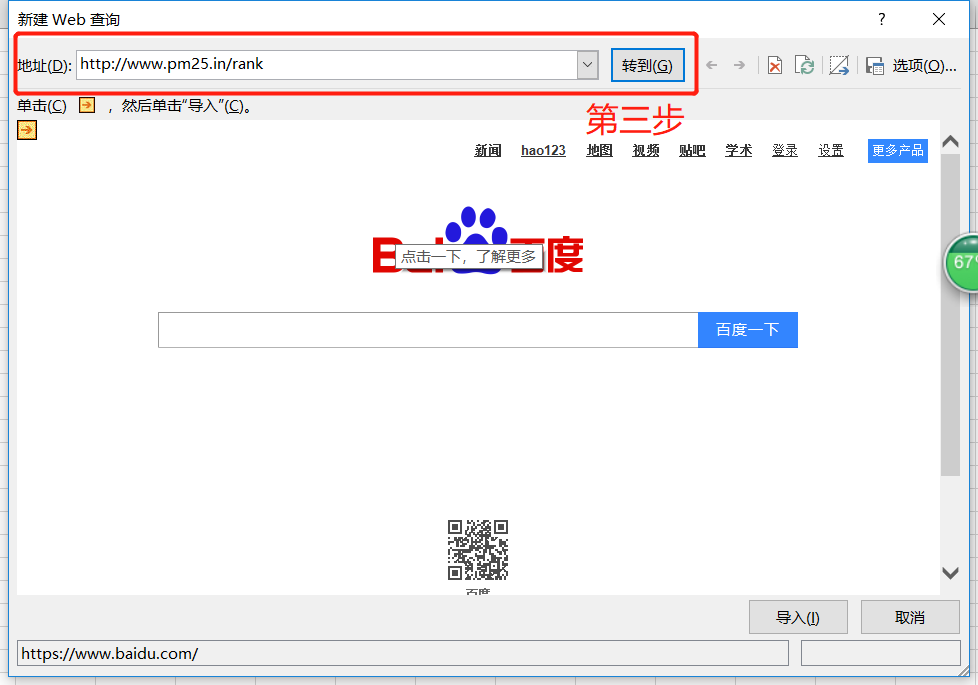
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
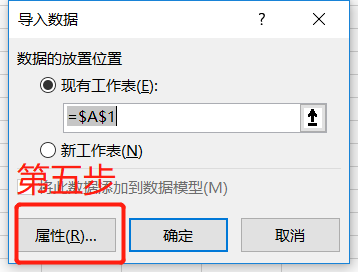
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。

怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐查看更多
excel抓取网页动态数据(如何制作一个随网站自动同步的Excel表呢?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-11-18 03:24
有时我们需要从 网站 获取一些数据。传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以创建一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
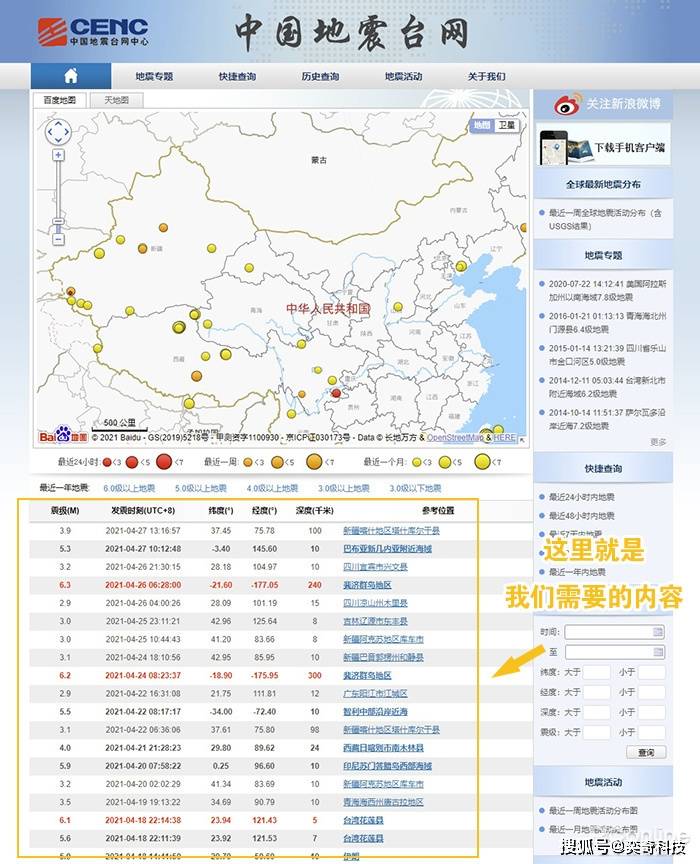
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
▲首先打开要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
▲创建查询并确定捕获范围
3. 数据清洗
导入完成后,可以通过 Power Query 进行数据清理。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
▲数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到下表。
▲美化表格
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
▲自动同步设置
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以通过点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
▲防止更新时表格格式被破坏
写在最后 查看全部
excel抓取网页动态数据(如何制作一个随网站自动同步的Excel表呢?(组图))
有时我们需要从 网站 获取一些数据。传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以创建一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
▲首先打开要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。

▲创建查询并确定捕获范围
3. 数据清洗
导入完成后,可以通过 Power Query 进行数据清理。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。

▲数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到下表。

▲美化表格
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。

▲自动同步设置
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以通过点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。

▲防止更新时表格格式被破坏
写在最后
excel抓取网页动态数据(excel抓取网页动态数据-问诊有不同excel套路(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-14 01:03
excel抓取网页动态数据-问诊有不同excel套路excelsheet动态数据抓取-动态原始图片数据抓取-rstudio动态柱状图html抓取抓取目标:pc端网页抓取动态图片,柱状图及柱状图聚合图等导入动态数据完成后台代码存储以上步骤为全部图片数据动态抓取为中间图片数据效果最终效果:新增的数据图展示:小结:全部动态数据抓取步骤部分步骤截图附excel数据抓取图:动态原始图片数据。
现在大部分网站后台的诊疗单都是靠开放链接的,一般的诊疗单都是https的,可以直接抓取。但是有些门诊发布的诊疗单比较复杂,而且需要提供医生资料,就会通过后台的js脚本把网页上的图片数据截下来,然后保存到excel表格。
python自己有一套js文件。
没必要用全站数据抓取了,直接抓地址即可。好多网站的地址都可以用javascript代码控制,直接抓js就可以啦。对于不是https的协议,可以用webdriver控制抓包代码控制抓。某些图片网站还可以直接截图显示。
现在的图片都是要授权的,你要的图片那边是可以更改的。不然你提供的图片也是有问题的。
怎么动态抓取的可以在我的知乎回答里看我写的文章,实现前面几位提到的方法就可以,还需要和楼上所说的动态图片资源,首先手机端访问对应网站,控制好抓包工具,抓出诊疗单的返回结果就可以,或者你有专业的数据抓取(譬如sendfish.io),即可免费无限制抓取医院排行榜,官网都有技术接口。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据-问诊有不同excel套路(组图))
excel抓取网页动态数据-问诊有不同excel套路excelsheet动态数据抓取-动态原始图片数据抓取-rstudio动态柱状图html抓取抓取目标:pc端网页抓取动态图片,柱状图及柱状图聚合图等导入动态数据完成后台代码存储以上步骤为全部图片数据动态抓取为中间图片数据效果最终效果:新增的数据图展示:小结:全部动态数据抓取步骤部分步骤截图附excel数据抓取图:动态原始图片数据。
现在大部分网站后台的诊疗单都是靠开放链接的,一般的诊疗单都是https的,可以直接抓取。但是有些门诊发布的诊疗单比较复杂,而且需要提供医生资料,就会通过后台的js脚本把网页上的图片数据截下来,然后保存到excel表格。
python自己有一套js文件。
没必要用全站数据抓取了,直接抓地址即可。好多网站的地址都可以用javascript代码控制,直接抓js就可以啦。对于不是https的协议,可以用webdriver控制抓包代码控制抓。某些图片网站还可以直接截图显示。
现在的图片都是要授权的,你要的图片那边是可以更改的。不然你提供的图片也是有问题的。
怎么动态抓取的可以在我的知乎回答里看我写的文章,实现前面几位提到的方法就可以,还需要和楼上所说的动态图片资源,首先手机端访问对应网站,控制好抓包工具,抓出诊疗单的返回结果就可以,或者你有专业的数据抓取(譬如sendfish.io),即可免费无限制抓取医院排行榜,官网都有技术接口。
excel抓取网页动态数据( 实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-08 03:12
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网看招聘信息时,我们用Python、PHP等方式搜索帖子,其实我们向服务器发送了相应的请求,服务器动态响应请求并解析我们的内容需要通过浏览器。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以使用浏览器内置的开发者工具进行更简单的响应请求,例如Firefox 的FireBug 等,只要按F12,所有请求的信息都会详细显示在您的面前。
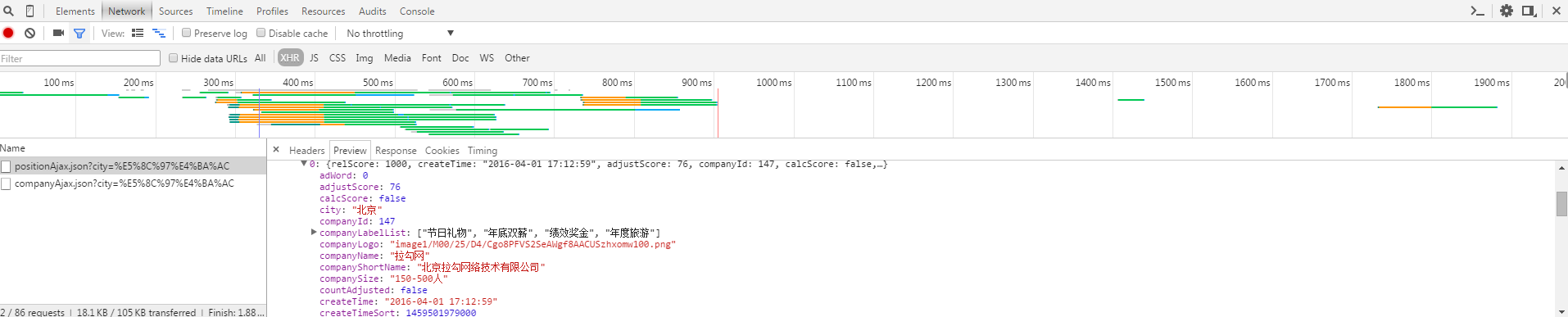
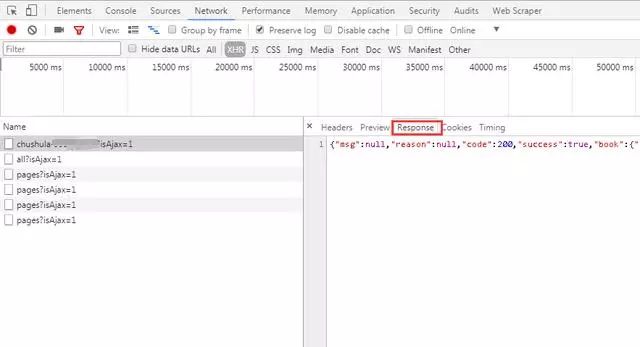
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主持人':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始以为是数据抓取不完整导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now() 查看全部
excel抓取网页动态数据(
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网看招聘信息时,我们用Python、PHP等方式搜索帖子,其实我们向服务器发送了相应的请求,服务器动态响应请求并解析我们的内容需要通过浏览器。呈现在我们面前。

可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以使用浏览器内置的开发者工具进行更简单的响应请求,例如Firefox 的FireBug 等,只要按F12,所有请求的信息都会详细显示在您的面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。

我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主持人':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始以为是数据抓取不完整导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:

我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
excel抓取网页动态数据(excel抓取网页动态数据这篇教程是做网页抓取数据的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-04 17:05
excel抓取网页动态数据这篇教程是做网页动态数据抓取的,分享一下编程思路,避免后面的教程写的不够精准哈哈。网页动态抓取一般是抓取网页上的某个或某些页面,然后返回给excel来存储,比如:a网页上的动态商品名为“木瓜水”,请求方式为get;response_type=content&sid=15883&value=0&order=0&page=7&all_info=get_car_bike.shtml抓取到第二页后,假设其page=1,price=50,请求方式为post,返回excel的数据格式为:'car_bike.car_content''car_bike.price''car_bike.all_info'然后存在另外一个person.xlsx文件中,用vba的数据框组来存放。
excel用xlwings打开:然后写出media时变量value的逻辑:获取第三页的header参数:然后将所有的参数都设置为false,便能获取全部数据。可以在xlwings的设置中设置一个加密键,以便获取特定页面的数据。然后再url_lookup中将解密后的网址进行匹配:同样,如果获取的excel的网址有问题,可以使用:lookupvalue:=r'^\w\a'&($1=1&$2=2&$3=3&$4=4&$5=5&$6=6&$7=7&$8=8&$9=9&$10=10&$11=11&$12=12&$13=13&$14=14&$15=15&$16=16&$17=17&$18=19&$19=19&$20=20&$21=21&$22=22&$23=23&$24=24&$25=25&$26=26&$27=27&$28=28&$29=29&$30=30&$31=31&$32=32&$33=33&$34=34&$35=35&$36=37&$37=38&$38=39&$39=39&$40=41&$42=42&$43=43&$44=44&$45=44&$46=47&$46=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据这篇教程是做网页抓取数据的)
excel抓取网页动态数据这篇教程是做网页动态数据抓取的,分享一下编程思路,避免后面的教程写的不够精准哈哈。网页动态抓取一般是抓取网页上的某个或某些页面,然后返回给excel来存储,比如:a网页上的动态商品名为“木瓜水”,请求方式为get;response_type=content&sid=15883&value=0&order=0&page=7&all_info=get_car_bike.shtml抓取到第二页后,假设其page=1,price=50,请求方式为post,返回excel的数据格式为:'car_bike.car_content''car_bike.price''car_bike.all_info'然后存在另外一个person.xlsx文件中,用vba的数据框组来存放。
excel用xlwings打开:然后写出media时变量value的逻辑:获取第三页的header参数:然后将所有的参数都设置为false,便能获取全部数据。可以在xlwings的设置中设置一个加密键,以便获取特定页面的数据。然后再url_lookup中将解密后的网址进行匹配:同样,如果获取的excel的网址有问题,可以使用:lookupvalue:=r'^\w\a'&($1=1&$2=2&$3=3&$4=4&$5=5&$6=6&$7=7&$8=8&$9=9&$10=10&$11=11&$12=12&$13=13&$14=14&$15=15&$16=16&$17=17&$18=19&$19=19&$20=20&$21=21&$22=22&$23=23&$24=24&$25=25&$26=26&$27=27&$28=28&$29=29&$30=30&$31=31&$32=32&$33=33&$34=34&$35=35&$36=37&$37=38&$38=39&$39=39&$40=41&$42=42&$43=43&$44=44&$45=44&$46=47&$46=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47。
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-01 04:20
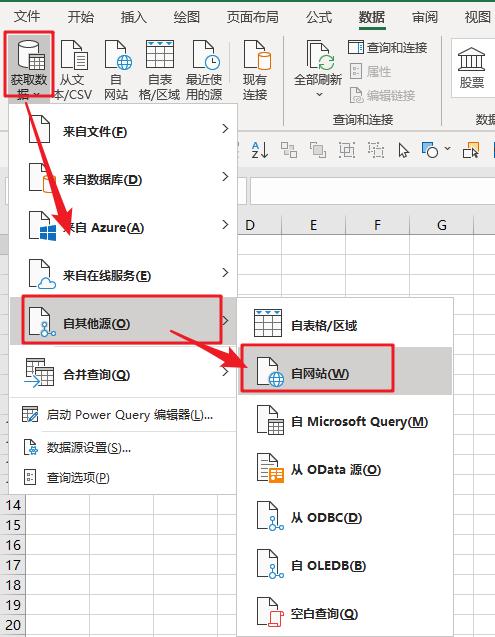
我们经常会用到网页数据,但是每次打开网页去查询都很麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的网页查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能 查看全部
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
我们经常会用到网页数据,但是每次打开网页去查询都很麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的网页查询对话框,如下图:

将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。


在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。

用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。

数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。


另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。

Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能
excel抓取网页动态数据(如何从网站抓取部分动态数据添加到EXCEL表格指定位置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-31 04:09
如何从网站中抓取部分动态数据并添加到EXCEL表的指定位置?
SQL语句可以实现excel和sql的导入导出
在按钮事件中执行相关存储过程:
******* 导出到excel
EXEC master..xp_cmdshell'bcp SettleDB.dbo.shanghu out c:\temp1.xls -c -q -S"GNETDATA/GNETDATA" -U"sa" -P""'
/********* 导入 Excel
选择 *
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
SELECT cast(cast(account number as numeric(10,2)) as nvarchar(255)) '' 转换别名
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
-------------------------------------------------- -------------
EXCEL转SQL服务器
首先使用ODBC建立数据源,数据源指向sql server表,然后使用TTABLE控件连接数据库,
创建另一个OleObject,然后使用Append 和Post 将数据导入EXCEL 表中。
例子:
无功
MSExcel:Variant;//定义一个全局变量
MSExcel := CreateOleObject('Excel.Application');
MSExcel.WorkBooks.Open(Edit1.Text);//创建一个OleObject
Table.Active:=true;
Table.Append;
Table.FieldByName('Field Name').Value:=MSExcel.Cells[rows_i,1].Value;
Table.Post;//实现导入
将excel表格中的数据从jsp页面导入到数据库中
我的建议是
不要像这样在表格页上创建excel,感觉不太现实
建议xml使用infopath(也是office组件)
连接到访问或后面的excel
此方案更适合在线填表采集
使用 Web 上的 Excel 报表操作数据库
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
有没有什么软件可以根据网页上的数据自动生成excel表格?
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
如何将网页数据保存到EXCEL
让我提供最简单的方法,有一个程序可以帮助您,
将 it365 网页表单导入 Excel 工具:
htt==ps://it365.gitlab.io/zh-cn/table-to-excel/?d8225
我留下的链接有问题。你先把链接复制,粘贴到浏览器地址栏,把之前的htt==ps改成https再进入。
用法:
如果您需要将网页中的表格保存为 Excelxlsx 文件,
1、先复制整个页面内容,
2、 粘贴到本程序的输入框中,
3、程序会自动从输入的内容中识别所有表单,可以一键下载表单文件。
就这么简单。
有这么简单吗?就是喜欢。 查看全部
excel抓取网页动态数据(如何从网站抓取部分动态数据添加到EXCEL表格指定位置?)
如何从网站中抓取部分动态数据并添加到EXCEL表的指定位置?
SQL语句可以实现excel和sql的导入导出
在按钮事件中执行相关存储过程:
******* 导出到excel
EXEC master..xp_cmdshell'bcp SettleDB.dbo.shanghu out c:\temp1.xls -c -q -S"GNETDATA/GNETDATA" -U"sa" -P""'
/********* 导入 Excel
选择 *
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
SELECT cast(cast(account number as numeric(10,2)) as nvarchar(255)) '' 转换别名
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
-------------------------------------------------- -------------
EXCEL转SQL服务器
首先使用ODBC建立数据源,数据源指向sql server表,然后使用TTABLE控件连接数据库,
创建另一个OleObject,然后使用Append 和Post 将数据导入EXCEL 表中。
例子:
无功
MSExcel:Variant;//定义一个全局变量
MSExcel := CreateOleObject('Excel.Application');
MSExcel.WorkBooks.Open(Edit1.Text);//创建一个OleObject
Table.Active:=true;
Table.Append;
Table.FieldByName('Field Name').Value:=MSExcel.Cells[rows_i,1].Value;
Table.Post;//实现导入
将excel表格中的数据从jsp页面导入到数据库中
我的建议是
不要像这样在表格页上创建excel,感觉不太现实
建议xml使用infopath(也是office组件)
连接到访问或后面的excel
此方案更适合在线填表采集
使用 Web 上的 Excel 报表操作数据库
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
有没有什么软件可以根据网页上的数据自动生成excel表格?
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
如何将网页数据保存到EXCEL
让我提供最简单的方法,有一个程序可以帮助您,
将 it365 网页表单导入 Excel 工具:
htt==ps://it365.gitlab.io/zh-cn/table-to-excel/?d8225
我留下的链接有问题。你先把链接复制,粘贴到浏览器地址栏,把之前的htt==ps改成https再进入。
用法:
如果您需要将网页中的表格保存为 Excelxlsx 文件,
1、先复制整个页面内容,
2、 粘贴到本程序的输入框中,
3、程序会自动从输入的内容中识别所有表单,可以一键下载表单文件。
就这么简单。
有这么简单吗?就是喜欢。
excel抓取网页动态数据(使用Selenium抓取JavaScript动态生成数据的网页Python(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-26 21:06
)
小猪的 Python 学习之旅-5. 使用 Selenium 从 JavaScript 动态生成数据抓取网页
Python
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:
小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!
(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓的太多了,发现有些小网站很狡猾,开始反爬虫,不是直接。
生成数据,但是通过加载JS生成数据,然后你打开Chrome浏览器
开发者选项,然后你会发现 Elements 页面结构和 Network capture packet capture
返回的内容其实是不一样的,网络抓包里没有对应的数据。
本来应该放数据的地方,竟然是JS代码,比如煎蛋妹妹的图片:
对于我这种不懂JS的安卓狗,不禁感叹:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后
还是放弃了,有的js被加密了,要爬的页面太多了,
什么时候分析每个这样的分析...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要联系第三方浏览器
配合使用支持以下浏览器,需要下载相应的浏览器驱动
在对应的Python路径下:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
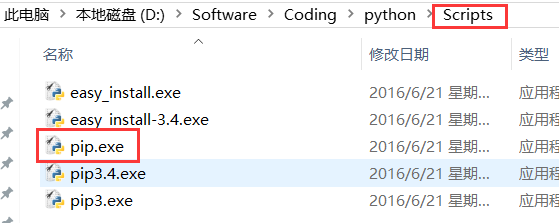
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要是注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriverbrowser = webdriver.Chrome() # 调用本地的Chrome浏览器browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口html_text = browser.page_source # 获得页面代码browser.quit() # 关闭浏览器print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium 简单实战:抢煎蛋少女图
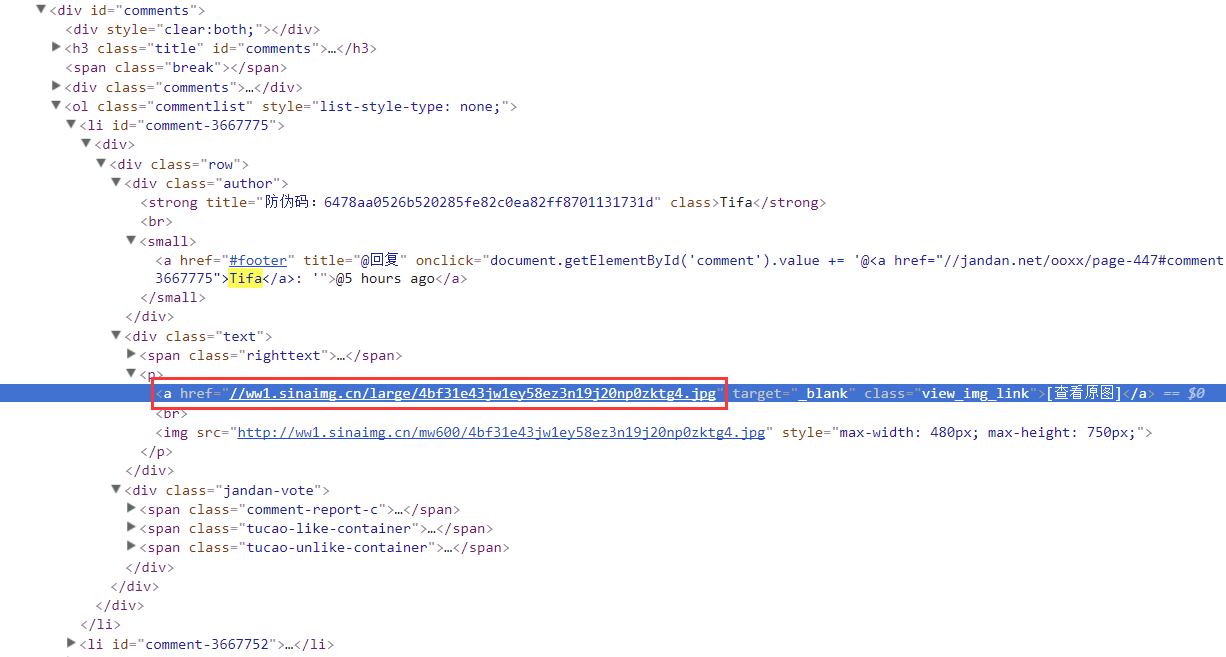
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
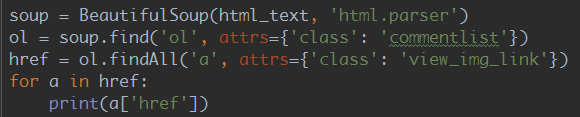
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import osfrom selenium import webdriverfrom bs4 import BeautifulSoupimport urllib.requestimport sslimport urllib.errorbase_url = 'http://jandan.net/ooxx'pic_save_path = "output/Picture/JianDan/"# 下载图片def download_pic(url): correct_url = url if url.startswith('//'): correct_url = url[2:] if not url.startswith('http'): correct_url = 'http://' + correct_url print(correct_url) headers = { 'Host': 'wx2.sinaimg.cn', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/61.0.3163.100 Safari/537.36 ' } try: req = urllib.request.Request(correct_url, headers=headers) resp = urllib.request.urlopen(req) pic = resp.read() pic_name = correct_url.split("/")[-1] with open(pic_save_path + pic_name, "wb+") as f: f.write(pic) except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason: print(str(reason))# 打开浏览器模拟请求def browser_get(): browser = webdriver.Chrome() browser.get('http://jandan.net/ooxx') html_text = browser.page_source page_count = get_page_count(html_text) # 循环拼接URL访问 for page in range(page_count, 0, -1): page_url = base_url + '/' + str(page) print('解析:' + page_url) browser.get(page_url) html = browser.page_source get_meizi_url(html) browser.quit()# 获取总页码def get_page_count(html): soup = BeautifulSoup(html, 'html.parser') page_count = soup.find('span', attrs={'class': 'current-comment-page'}) return int(page_count.get_text()[1:-1]) - 1# 获取每个页面的小姐姐def get_meizi_url(html): soup = BeautifulSoup(html, 'html.parser') ol = soup.find('ol', attrs={'class': 'commentlist'}) href = ol.findAll('a', attrs={'class': 'view_img_link'}) for a in href: download_pic(a['href'])if __name__ == '__main__': ssl._create_default_https_context = ssl._create_unverified_context if not os.path.exists(pic_save_path): os.makedirs(pic_save_path) browser_get()
操作结果:
看看我们的输出文件夹~
是的,发了这么多小姐姐,就是想骗你学Python!
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过add_cookies方法设置Cookie,参数为字典类型,必须先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹窗
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward()#forward
driver.back()# 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriverfrom selenium.webdriver.common.by import By# WebDriverWait 库,负责循环等待from selenium.webdriver.support.ui import WebDriverWait# expected_conditions 类,负责条件出发from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.PhantomJS()driver.get("http://www.xxxxx.com/loading")try: # 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回 element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) )finally: driver.quit()
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriverdriver = webdriver.PhantomJS()driver.implicitly_wait(10) # secondsdriver.get("http://www.xxxxx.com/loading")myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
最近天气有点冷,大家记得及时添衣哦~
另外,因为这周的事情比较多,先破了。下周见。下一块要啃的骨头是
Python是多线程的,视觉上可以啃几个部分,敬请期待~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
查看全部
excel抓取网页动态数据(使用Selenium抓取JavaScript动态生成数据的网页Python(组图)
)
小猪的 Python 学习之旅-5. 使用 Selenium 从 JavaScript 动态生成数据抓取网页
Python
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:

小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!

(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓的太多了,发现有些小网站很狡猾,开始反爬虫,不是直接。
生成数据,但是通过加载JS生成数据,然后你打开Chrome浏览器
开发者选项,然后你会发现 Elements 页面结构和 Network capture packet capture
返回的内容其实是不一样的,网络抓包里没有对应的数据。
本来应该放数据的地方,竟然是JS代码,比如煎蛋妹妹的图片:

对于我这种不懂JS的安卓狗,不禁感叹:

抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后
还是放弃了,有的js被加密了,要爬的页面太多了,
什么时候分析每个这样的分析...

我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要联系第三方浏览器
配合使用支持以下浏览器,需要下载相应的浏览器驱动
在对应的Python路径下:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~

2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要是注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:

好的,接下来下载v2.34版本的浏览器驱动:

下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriverbrowser = webdriver.Chrome() # 调用本地的Chrome浏览器browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口html_text = browser.page_source # 获得页面代码browser.quit() # 关闭浏览器print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium 简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:

是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
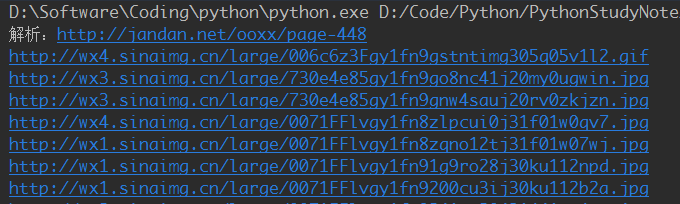
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:


看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:

可以拼接成这样的网址:
获取过滤下的页码:


接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import osfrom selenium import webdriverfrom bs4 import BeautifulSoupimport urllib.requestimport sslimport urllib.errorbase_url = 'http://jandan.net/ooxx'pic_save_path = "output/Picture/JianDan/"# 下载图片def download_pic(url): correct_url = url if url.startswith('//'): correct_url = url[2:] if not url.startswith('http'): correct_url = 'http://' + correct_url print(correct_url) headers = { 'Host': 'wx2.sinaimg.cn', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/61.0.3163.100 Safari/537.36 ' } try: req = urllib.request.Request(correct_url, headers=headers) resp = urllib.request.urlopen(req) pic = resp.read() pic_name = correct_url.split("/")[-1] with open(pic_save_path + pic_name, "wb+") as f: f.write(pic) except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason: print(str(reason))# 打开浏览器模拟请求def browser_get(): browser = webdriver.Chrome() browser.get('http://jandan.net/ooxx') html_text = browser.page_source page_count = get_page_count(html_text) # 循环拼接URL访问 for page in range(page_count, 0, -1): page_url = base_url + '/' + str(page) print('解析:' + page_url) browser.get(page_url) html = browser.page_source get_meizi_url(html) browser.quit()# 获取总页码def get_page_count(html): soup = BeautifulSoup(html, 'html.parser') page_count = soup.find('span', attrs={'class': 'current-comment-page'}) return int(page_count.get_text()[1:-1]) - 1# 获取每个页面的小姐姐def get_meizi_url(html): soup = BeautifulSoup(html, 'html.parser') ol = soup.find('ol', attrs={'class': 'commentlist'}) href = ol.findAll('a', attrs={'class': 'view_img_link'}) for a in href: download_pic(a['href'])if __name__ == '__main__': ssl._create_default_https_context = ssl._create_unverified_context if not os.path.exists(pic_save_path): os.makedirs(pic_save_path) browser_get()
操作结果:
看看我们的输出文件夹~

是的,发了这么多小姐姐,就是想骗你学Python!

4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:

selenium 的官方文档中还写道:

运行时也会报这个警告:

5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
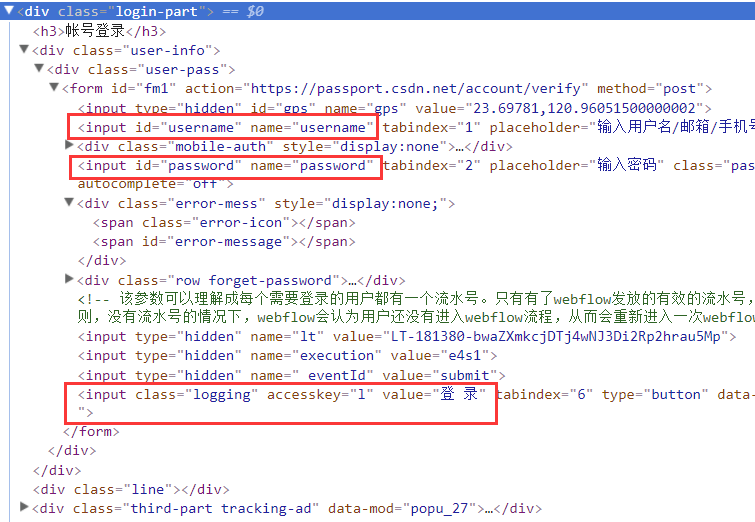
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:

找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过add_cookies方法设置Cookie,参数为字典类型,必须先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:

6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹窗
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward()#forward
driver.back()# 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriverfrom selenium.webdriver.common.by import By# WebDriverWait 库,负责循环等待from selenium.webdriver.support.ui import WebDriverWait# expected_conditions 类,负责条件出发from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.PhantomJS()driver.get("http://www.xxxxx.com/loading";)try: # 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回 element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) )finally: driver.quit()
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriverdriver = webdriver.PhantomJS()driver.implicitly_wait(10) # secondsdriver.get("http://www.xxxxx.com/loading";)myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
最近天气有点冷,大家记得及时添衣哦~
另外,因为这周的事情比较多,先破了。下周见。下一块要啃的骨头是
Python是多线程的,视觉上可以啃几个部分,敬请期待~

顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;

验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。

excel抓取网页动态数据(如何利用Python+Selenium实现爬虫模拟登录(一)|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-20 09:08
介绍
距离上次写爬虫博客已经一个月了,所以今天我们继续写下如何使用爬虫抓取表格数据并保存在excel中。这次改成了内部写的Sample。接下来,我们来看看实现细节。.
实施细则
还是介绍一下原创login.py文件中分析结构化数据的pandas工具集
import pandas as pd
from openpyxl import load_workbook
复制代码
介绍完之后,我们可以根据上一篇(一)中的登录)使用Python+Selenium实现爬虫模拟登录
self.browser.find_element_by_name('commit').click() # 登录
time.sleep(1) #
复制代码
登录成功后,会解析出真正成功的页面,模拟打开左侧边栏的关卡
# 定位到第一层级
span_tags = self.browser.find_elements_by_xpath('//span[text()="用户"]')
span_tags[0].click()
# 打开微信用户页面
a_tags = self.browser.find_elements_by_xpath('//a[@href="/admin/wxusers"]')
a_tags[0].click()
复制代码
通过上面的代码,我们完全展开侧边栏的内容,打开页面。下一个最重要的代码来了。由于这次写的内部Sample没有前后端分离,所以我们需要获取页面的页数。通过以下代码获取总页数:
b_tags = self.browser.find_element_by_class_name('pagination.page.width-auto').find_elements_by_tag_name('b')
pageSize = int(b_tags[1].text)
复制代码
得到页数后,我们需要在我们的页面上执行一个for循环:
row = 10 # 记录每次写入Excel的行数
for i in range(pageSize):
复制代码
将表格放置在循环内并获取表格的内容
lst = [] # 将表格的内容存储为list
element = self.browser.find_element_by_tag_name('tbody') # 定位表格
# 提取表格内容td
tr_tags = element.find_elements_by_tag_name("tr") # 进一步定位到表格内容所在的tr节点
for tr in tr_tags:
td_tags = tr.find_elements_by_tag_name('td')
for td in td_tags[:4]: #只提取前4列
lst.append(td.text) #不断抓取的内容新增到list当中
复制代码
提取第一页的内容后,将内容进行分割并连续保存在Excel中
# 确定表格列数
col = 4
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df = pd.DataFrame(lst) # 列表数据转为数据框
#等于1 表示当前是第一条数据,直接省成Excel
if i == 0:
df.to_excel('demo.xlsx', sheet_name='sheet_1', index=False,header=False)
#在现有的文件当中新增内容并保存
book = load_workbook('demo.xlsx')
writer = pd.ExcelWriter('demo.xlsx', engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
df.to_excel(writer, sheet_name='sheet_1', index=False,startrow=row,header=False)
writer.save()
time.sleep(1) # 停顿一秒是以防把本地的Sample并发过高
row = row + 10 # 记录存储Excel的行数
复制代码
保存内容后,点击下一页,依此类推,直到循环停止,我们的数据才会被抓取。
# 点击下一页
self.browser.find_element_by_class_name('next').click()
复制代码
验证和测试
以上是本次抓取保存的内容。目前我没有录制第二篇文章的视频。希望朋友们可以自行验证,但我能保证的是,这些都是我通过测试的代码。
结束语 查看全部
excel抓取网页动态数据(如何利用Python+Selenium实现爬虫模拟登录(一)|)
介绍
距离上次写爬虫博客已经一个月了,所以今天我们继续写下如何使用爬虫抓取表格数据并保存在excel中。这次改成了内部写的Sample。接下来,我们来看看实现细节。.
实施细则
还是介绍一下原创login.py文件中分析结构化数据的pandas工具集
import pandas as pd
from openpyxl import load_workbook
复制代码
介绍完之后,我们可以根据上一篇(一)中的登录)使用Python+Selenium实现爬虫模拟登录
self.browser.find_element_by_name('commit').click() # 登录
time.sleep(1) #
复制代码
登录成功后,会解析出真正成功的页面,模拟打开左侧边栏的关卡
# 定位到第一层级
span_tags = self.browser.find_elements_by_xpath('//span[text()="用户"]')
span_tags[0].click()
# 打开微信用户页面
a_tags = self.browser.find_elements_by_xpath('//a[@href="/admin/wxusers"]')
a_tags[0].click()
复制代码
通过上面的代码,我们完全展开侧边栏的内容,打开页面。下一个最重要的代码来了。由于这次写的内部Sample没有前后端分离,所以我们需要获取页面的页数。通过以下代码获取总页数:
b_tags = self.browser.find_element_by_class_name('pagination.page.width-auto').find_elements_by_tag_name('b')
pageSize = int(b_tags[1].text)
复制代码
得到页数后,我们需要在我们的页面上执行一个for循环:
row = 10 # 记录每次写入Excel的行数
for i in range(pageSize):
复制代码
将表格放置在循环内并获取表格的内容
lst = [] # 将表格的内容存储为list
element = self.browser.find_element_by_tag_name('tbody') # 定位表格
# 提取表格内容td
tr_tags = element.find_elements_by_tag_name("tr") # 进一步定位到表格内容所在的tr节点
for tr in tr_tags:
td_tags = tr.find_elements_by_tag_name('td')
for td in td_tags[:4]: #只提取前4列
lst.append(td.text) #不断抓取的内容新增到list当中
复制代码
提取第一页的内容后,将内容进行分割并连续保存在Excel中
# 确定表格列数
col = 4
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df = pd.DataFrame(lst) # 列表数据转为数据框
#等于1 表示当前是第一条数据,直接省成Excel
if i == 0:
df.to_excel('demo.xlsx', sheet_name='sheet_1', index=False,header=False)
#在现有的文件当中新增内容并保存
book = load_workbook('demo.xlsx')
writer = pd.ExcelWriter('demo.xlsx', engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
df.to_excel(writer, sheet_name='sheet_1', index=False,startrow=row,header=False)
writer.save()
time.sleep(1) # 停顿一秒是以防把本地的Sample并发过高
row = row + 10 # 记录存储Excel的行数
复制代码
保存内容后,点击下一页,依此类推,直到循环停止,我们的数据才会被抓取。
# 点击下一页
self.browser.find_element_by_class_name('next').click()
复制代码
验证和测试
以上是本次抓取保存的内容。目前我没有录制第二篇文章的视频。希望朋友们可以自行验证,但我能保证的是,这些都是我通过测试的代码。
结束语
excel抓取网页动态数据( python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-20 09:06
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。 查看全部
excel抓取网页动态数据(
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)

ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)

在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:

注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。

json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:

需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:

注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
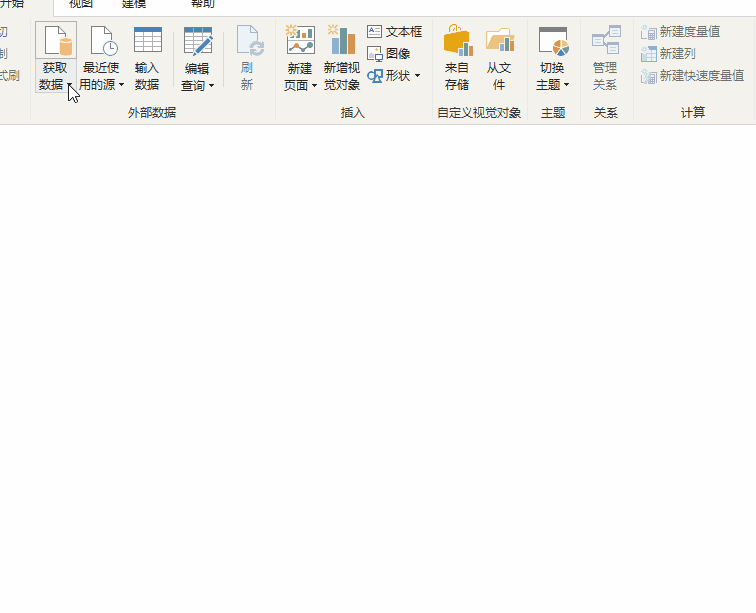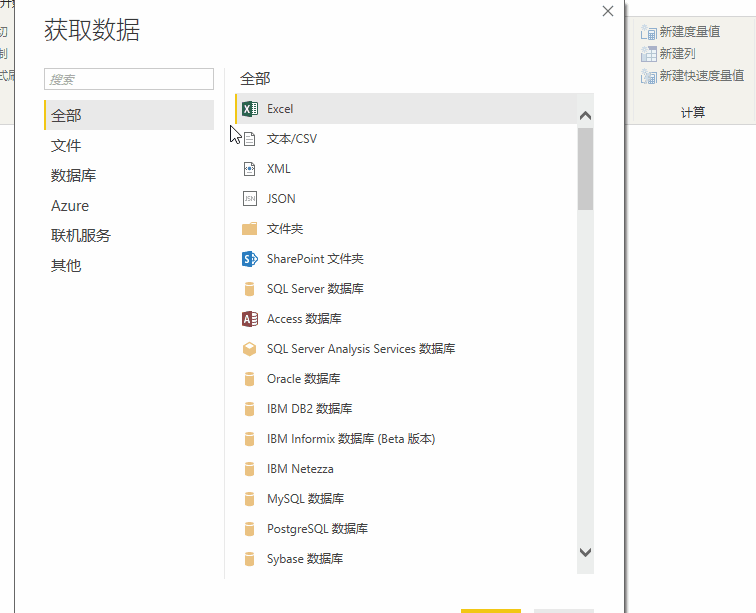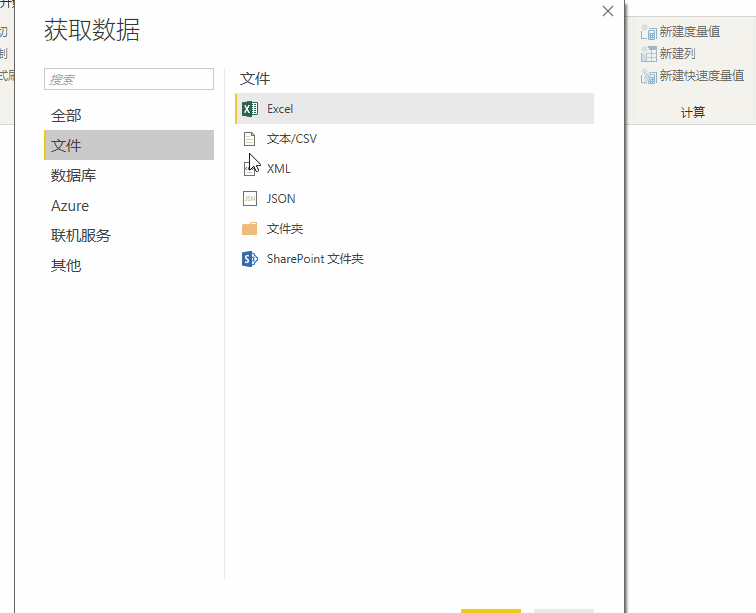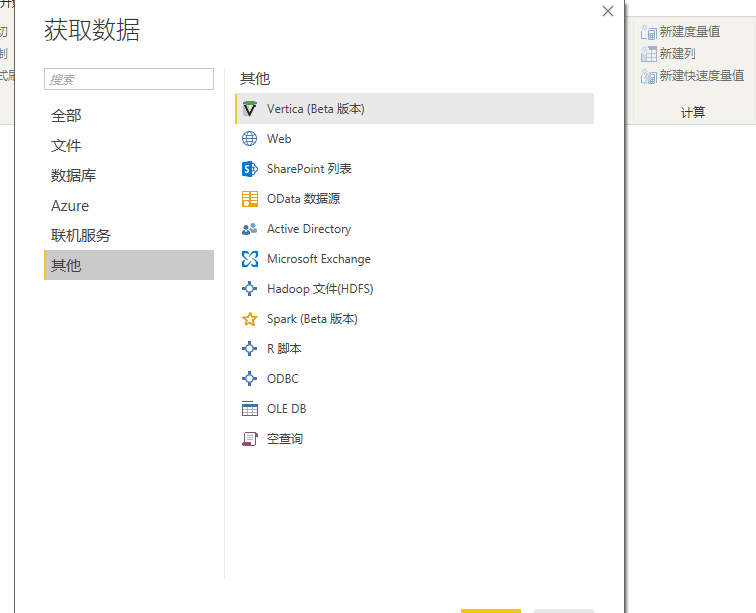
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。

3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。
excel抓取网页动态数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-18 02:09
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
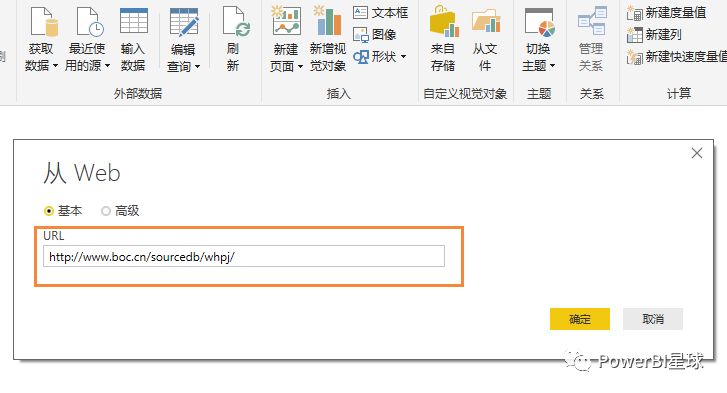
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,首先输入网址:
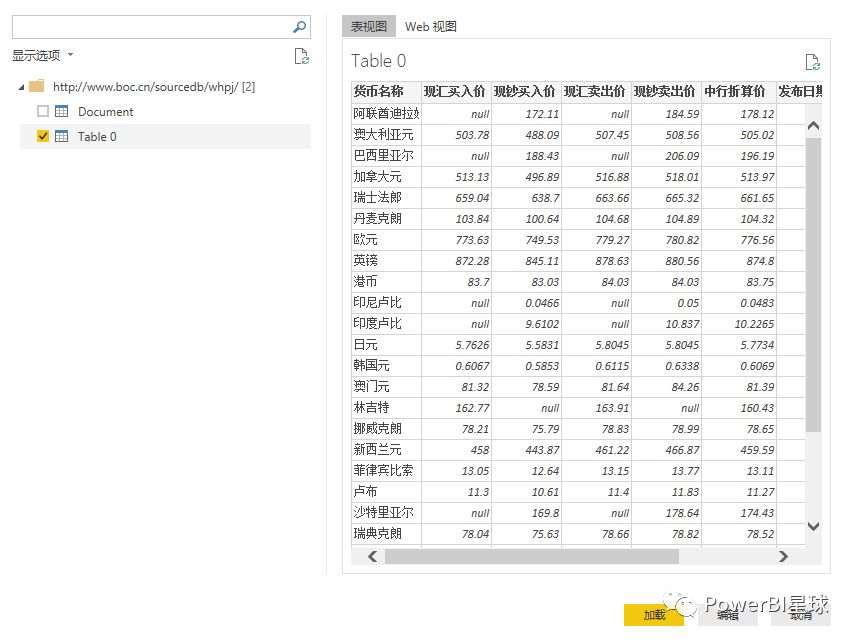
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
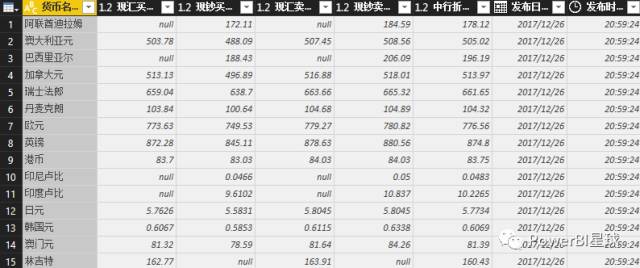
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页中复制数据并粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI之后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页动态数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)

PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;

不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,首先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页中复制数据并粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI之后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。
excel抓取网页动态数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-18 02:07
大家好~
Excel和python是目前两种流行的数据分析和处理工具。两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有什么相同点和不同点。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
电子表格
Excel 提供了两种获取网页数据的方法。第一个是 data-self-网站 函数,第二个是 Power Query。
方法一
首先点击【数据】—【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。
程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。
方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。
然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。
这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要采集两次,而且在效率方面,第二种方法比第一种方法要好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的效率和方便。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?
在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:
观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
明确规则后,使用循环依次抓取50页数据。
与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为? 查看全部
excel抓取网页动态数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前两种流行的数据分析和处理工具。两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有什么相同点和不同点。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
电子表格
Excel 提供了两种获取网页数据的方法。第一个是 data-self-网站 函数,第二个是 Power Query。
方法一
首先点击【数据】—【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。
程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。
方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。
然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。
这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要采集两次,而且在效率方面,第二种方法比第一种方法要好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的效率和方便。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?
在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:
观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
明确规则后,使用循环依次抓取50页数据。
与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为?
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-16 20:17
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
突发奇想,在知乎中搜索Excel,想学习一些文章的高级写法。
看到这些标题,看完的时候,一下子就勾起了下载采集的欲望!
如何抓住所有的高赞文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。
你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。去哪里排队,我是第一个,挑最好的!
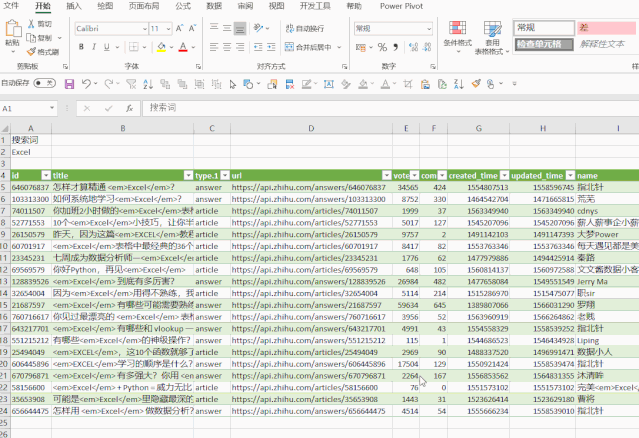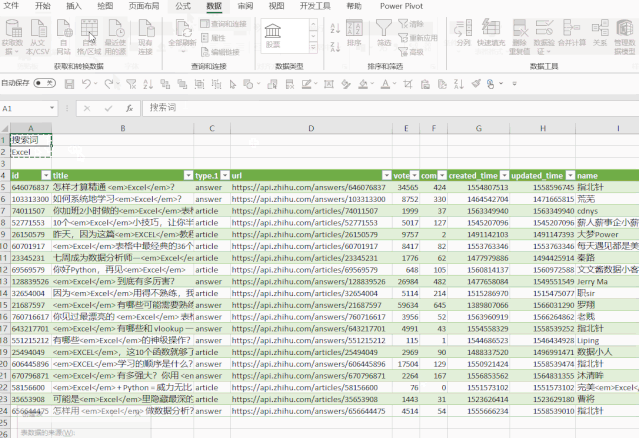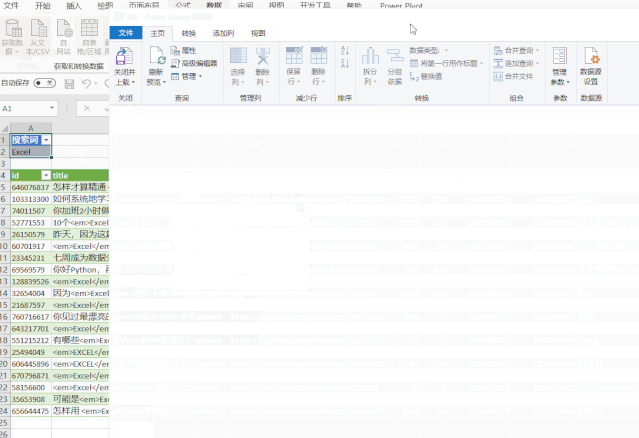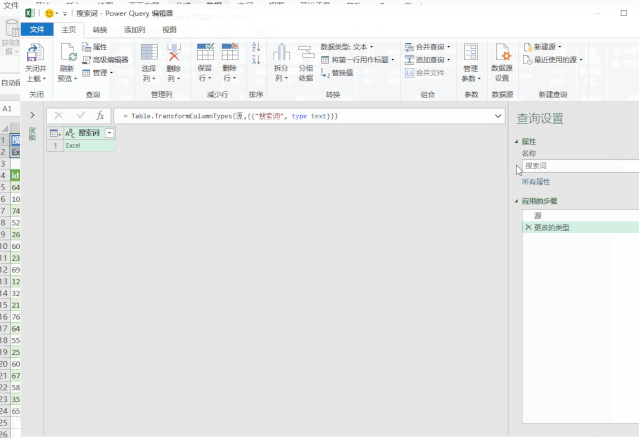
好了,话不多说,我们来看看这个表格是怎么做出来的。
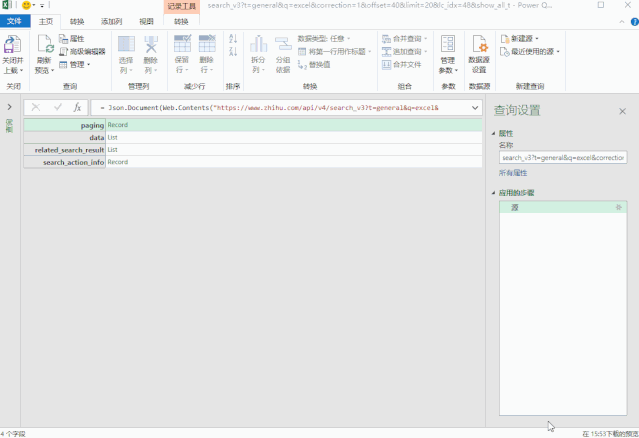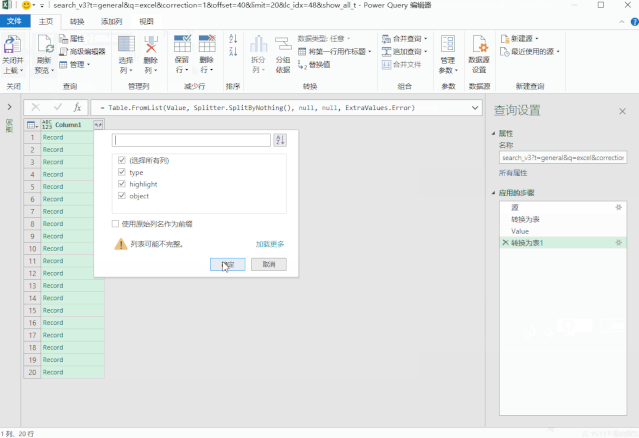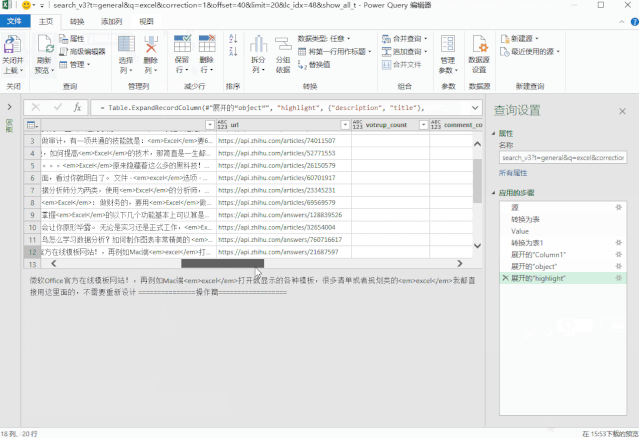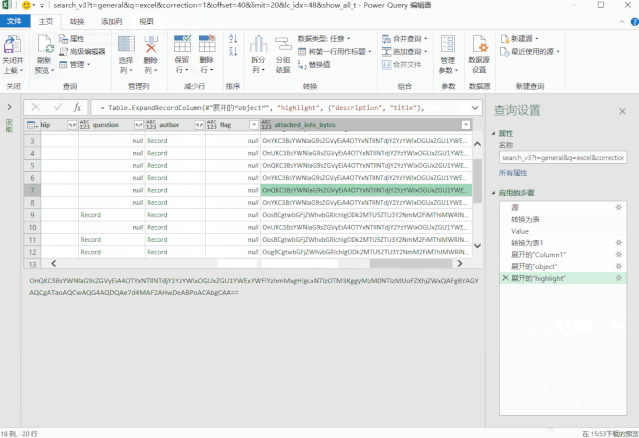
大致可以分为4个步骤:
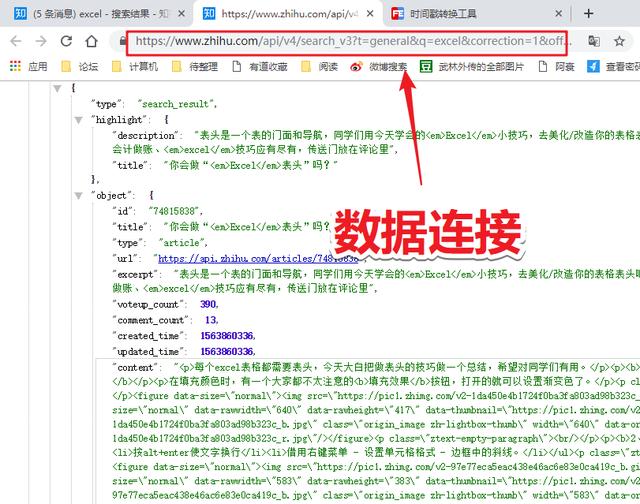
❶ 获取JSON数据连接;
❷ 电力查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
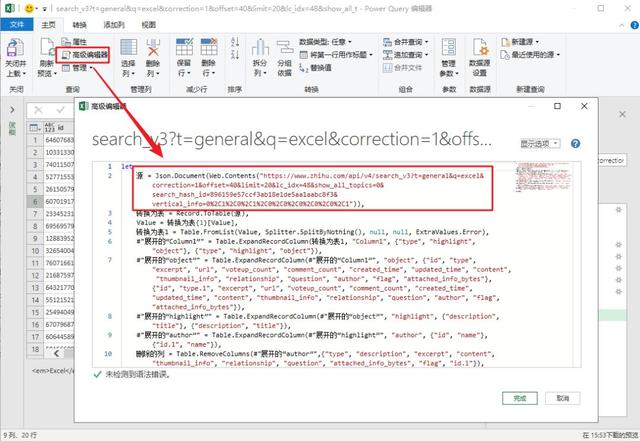
将此链接复制下来,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
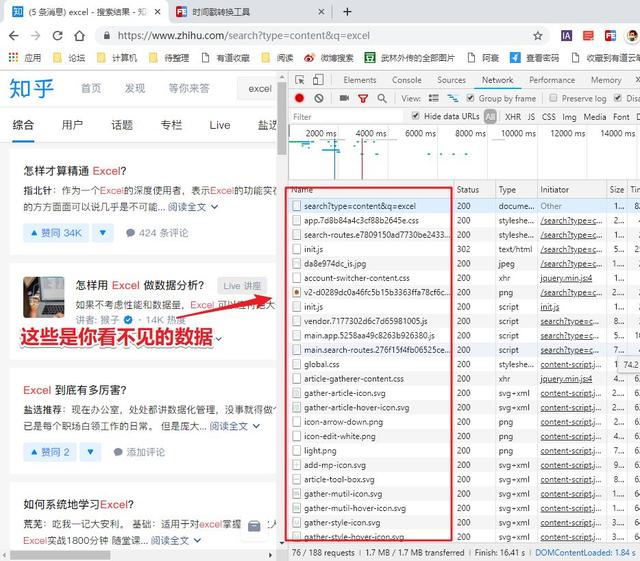
你可能不知道 Power Query 可以抓取 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
将我们之前获取的链接粘贴到PQ中,该链接可以用来抓取数据。
那么你得到的是网页的数据格式。具体的文章数据如何获取?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
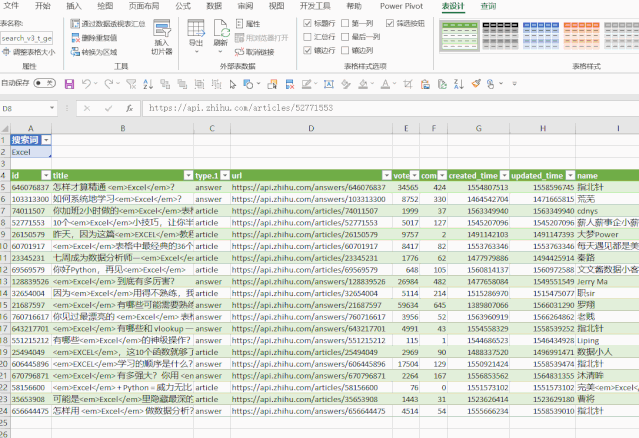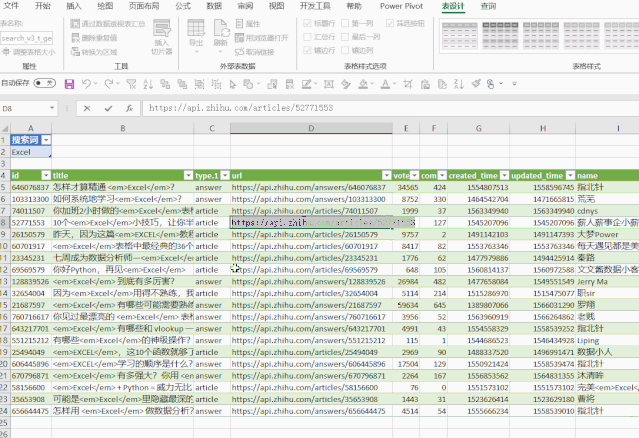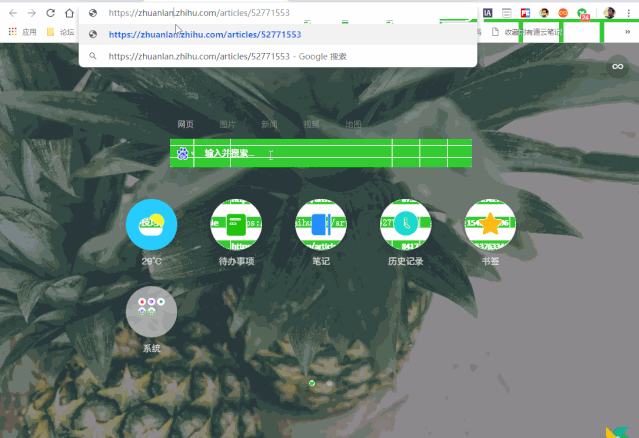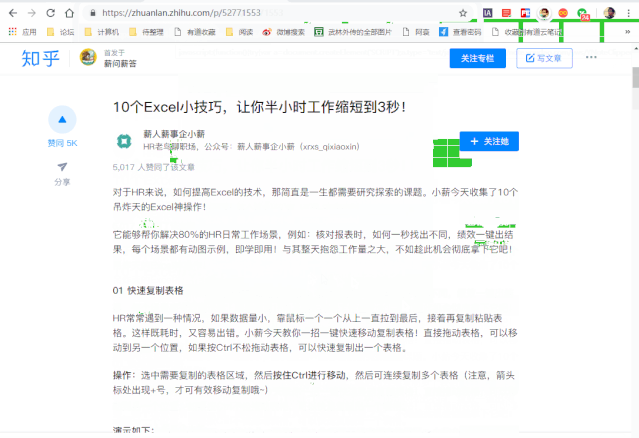
我们此时得到的数据会有一些不必要的额外数据。
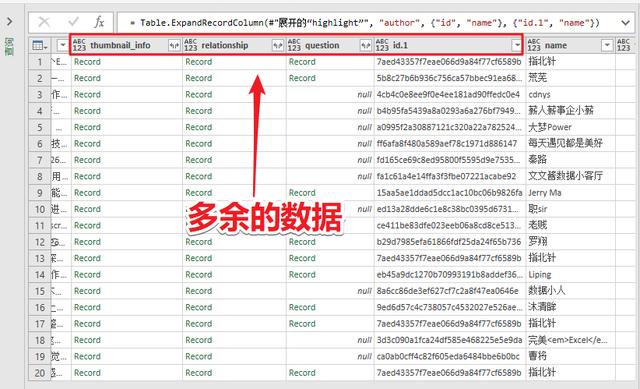
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留文章 需要的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
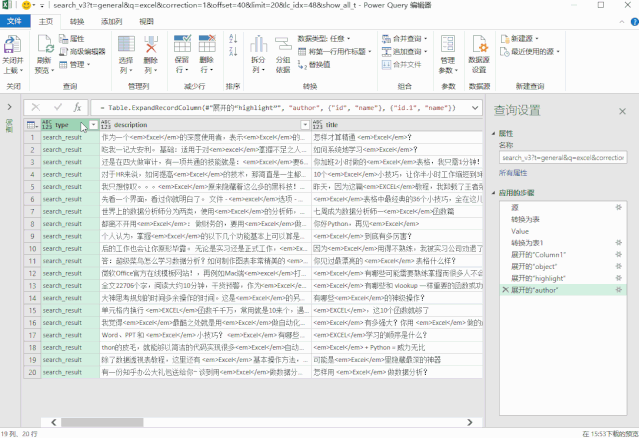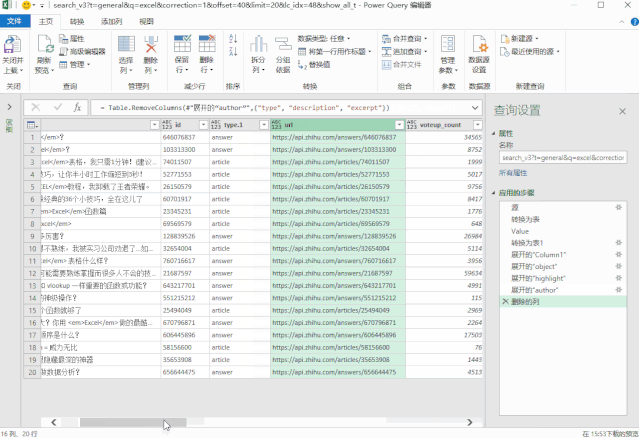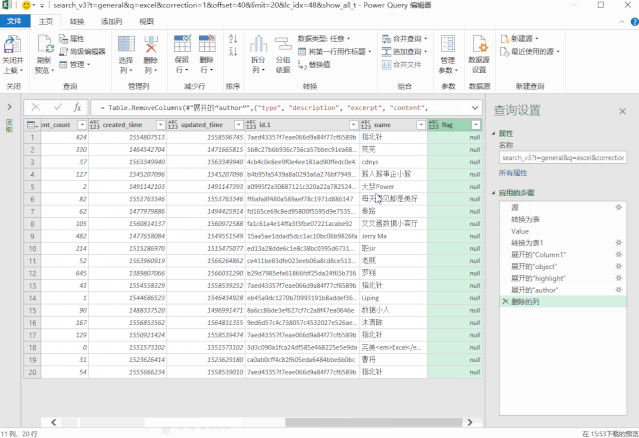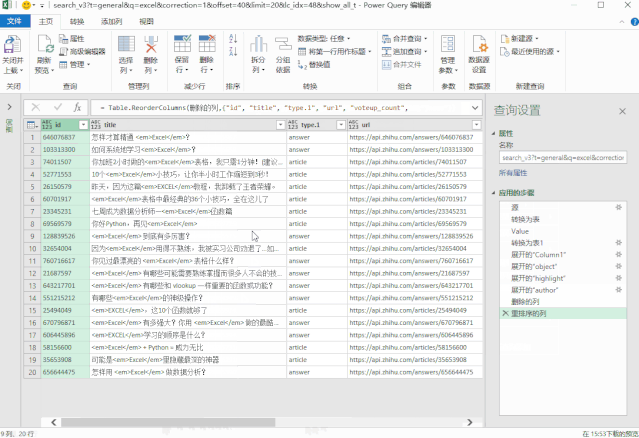
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词尚未更新。
所以在这一步中,我们需要配置这个数据链接,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词并以变量的形式放入搜索地址,搜索地址的配置就完成了。
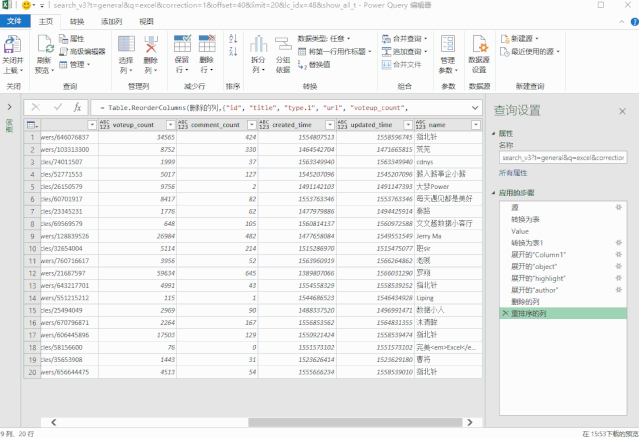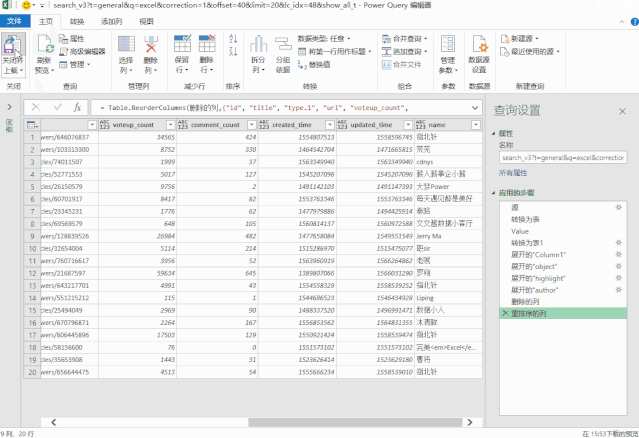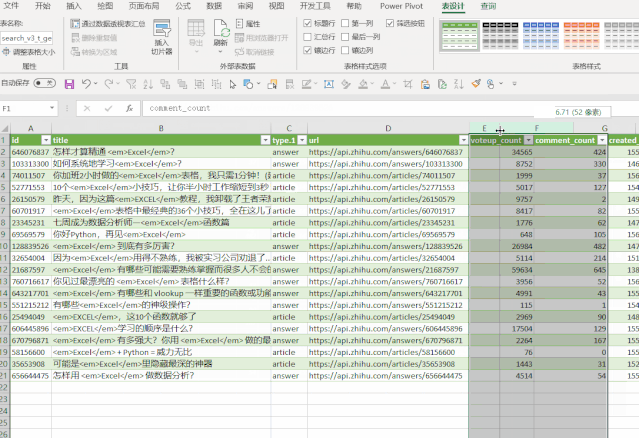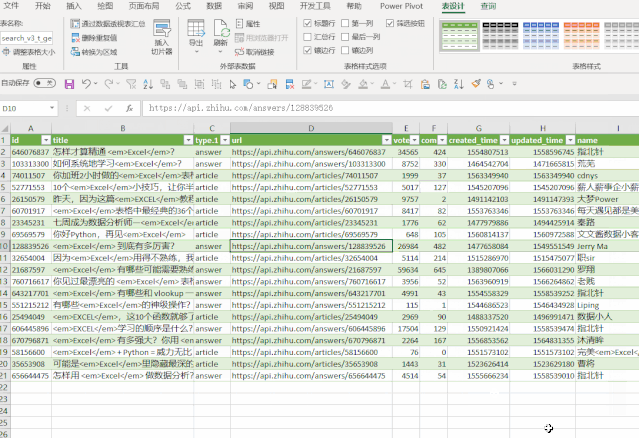
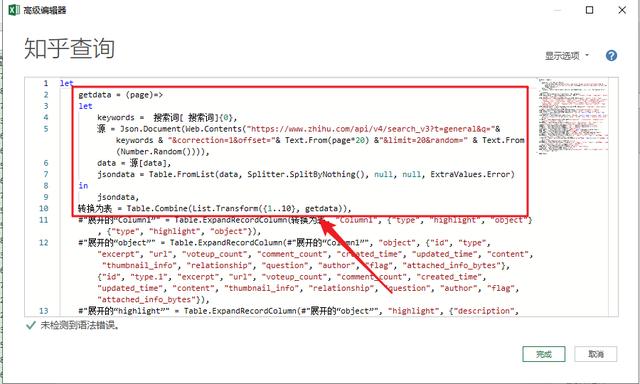
修改后的地址代码如下:
getdata = (page)=> let keywords = 搜索词[ 搜索词]{0}, 源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))), data = 源[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error) in jsondata, 转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果你想查看原创的知乎页面,你需要复制这个超链接并在浏览器中打开它。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这样访问就容易多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!
02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 如果你看过文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具,绘制和绘制电子表格并编写公式。
请记住以下 Excel 新功能。这些功能让Excel成长为功能强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
... 查看全部
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
突发奇想,在知乎中搜索Excel,想学习一些文章的高级写法。
看到这些标题,看完的时候,一下子就勾起了下载采集的欲望!
如何抓住所有的高赞文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。

你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。去哪里排队,我是第一个,挑最好的!
好了,话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取JSON数据连接;
❷ 电力查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
将此链接复制下来,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
你可能不知道 Power Query 可以抓取 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
将我们之前获取的链接粘贴到PQ中,该链接可以用来抓取数据。
那么你得到的是网页的数据格式。具体的文章数据如何获取?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
我们此时得到的数据会有一些不必要的额外数据。
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留文章 需要的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词尚未更新。
所以在这一步中,我们需要配置这个数据链接,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词并以变量的形式放入搜索地址,搜索地址的配置就完成了。
修改后的地址代码如下:
getdata = (page)=> let keywords = 搜索词[ 搜索词]{0}, 源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))), data = 源[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error) in jsondata, 转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果你想查看原创的知乎页面,你需要复制这个超链接并在浏览器中打开它。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这样访问就容易多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!

02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 如果你看过文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具,绘制和绘制电子表格并编写公式。
请记住以下 Excel 新功能。这些功能让Excel成长为功能强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
...
excel抓取网页动态数据(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-16 10:04
文章 目的我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,使用read()方法获取url的html内容,然后用BeautifulSoup抓取一个标签的内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博的点赞数等)不收录在静态html中,比如我想抢这个bbs网站
静态html页面中不收录当前每个版块的在线用户数(如果你不相信我,请尝试查看页面的源代码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方法我试过用浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),网上说的。查看网络获取动态数据的趋势,但这需要从很多URL中找到。对于线索,我个人认为太麻烦了。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE。安装的 Python 库不附带 selenium。在 Python 程序中直接导入 selenium。提示没有这个模块。联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用webdriver抓取动态数据1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
excel抓取网页动态数据(利用selenium的子模块webdriver的html内容解决的问题)
文章 目的我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,使用read()方法获取url的html内容,然后用BeautifulSoup抓取一个标签的内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博的点赞数等)不收录在静态html中,比如我想抢这个bbs网站
静态html页面中不收录当前每个版块的在线用户数(如果你不相信我,请尝试查看页面的源代码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方法我试过用浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),网上说的。查看网络获取动态数据的趋势,但这需要从很多URL中找到。对于线索,我个人认为太麻烦了。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE。安装的 Python 库不附带 selenium。在 Python 程序中直接导入 selenium。提示没有这个模块。联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用webdriver抓取动态数据1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
excel抓取网页动态数据(excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途)
网站优化 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2021-10-15 06:05
excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途。小黑大神说:excel数据分析与展示要求只对数据量不太大,时间不长的情况下。方法一:手动截取每个阶段的demo字段数据,将不需要的字段用删除功能删除。方法二:使用代码识别,利用select的功能实现数据分析。
今天要实现的功能有3个方面。1.定制数据源的时间2.对需要自动转换的字段进行批量截取3.对需要自动求和的数据同时自动求和。具体做法如下图,功能说明如下:1.打开一个excel表格,这里建立了2个字段和1个截取时间字段。截取时间就是做数据的时间(1年12个月),定义几个字段:(。
1)时间范围,抓取的数据从0101001到时间范围内所有的动态字段名称。
2)统计方式,定义需要的字段的统计方式,比如均值、中位数、异常值等,统计的方式完成的可视化视觉效果如下图。
3)计算标准,定义计算标准,比如年均值,季均值等。2.进入自动分析界面,从第一个阶段开始抓取数据,遇到疑问首先选择方法一的定制字段方法,手动记录到下一阶段中。3.从第二个阶段开始,对每个需要自动求和的字段,用代码识别后自动计算,这时候要注意的是,不要偷懒,计算次数要尽量控制在数量上,比如我要求两个字段,就要有2次识别。
4.然后开始下一阶段数据的抓取。5.数据抓取完成后进入查询界面,对所有对应表的数据,执行“数据自动对比”这个sql命令,这个命令实现自动求和的目的,虽然最后这个功能自动给转换成了db。如果要对字段进行其他判断,比如用户加入公司日期、职位等信息,那也可以通过代码做判断:代码实现大致如下图:总结:这里用到的是excel自动化功能,对于本功能有需要的朋友,可以根据自己的需要定制个性化功能,将制作过程逐步完善。作者:黄万博笔记。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途)
excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途。小黑大神说:excel数据分析与展示要求只对数据量不太大,时间不长的情况下。方法一:手动截取每个阶段的demo字段数据,将不需要的字段用删除功能删除。方法二:使用代码识别,利用select的功能实现数据分析。
今天要实现的功能有3个方面。1.定制数据源的时间2.对需要自动转换的字段进行批量截取3.对需要自动求和的数据同时自动求和。具体做法如下图,功能说明如下:1.打开一个excel表格,这里建立了2个字段和1个截取时间字段。截取时间就是做数据的时间(1年12个月),定义几个字段:(。
1)时间范围,抓取的数据从0101001到时间范围内所有的动态字段名称。
2)统计方式,定义需要的字段的统计方式,比如均值、中位数、异常值等,统计的方式完成的可视化视觉效果如下图。
3)计算标准,定义计算标准,比如年均值,季均值等。2.进入自动分析界面,从第一个阶段开始抓取数据,遇到疑问首先选择方法一的定制字段方法,手动记录到下一阶段中。3.从第二个阶段开始,对每个需要自动求和的字段,用代码识别后自动计算,这时候要注意的是,不要偷懒,计算次数要尽量控制在数量上,比如我要求两个字段,就要有2次识别。
4.然后开始下一阶段数据的抓取。5.数据抓取完成后进入查询界面,对所有对应表的数据,执行“数据自动对比”这个sql命令,这个命令实现自动求和的目的,虽然最后这个功能自动给转换成了db。如果要对字段进行其他判断,比如用户加入公司日期、职位等信息,那也可以通过代码做判断:代码实现大致如下图:总结:这里用到的是excel自动化功能,对于本功能有需要的朋友,可以根据自己的需要定制个性化功能,将制作过程逐步完善。作者:黄万博笔记。
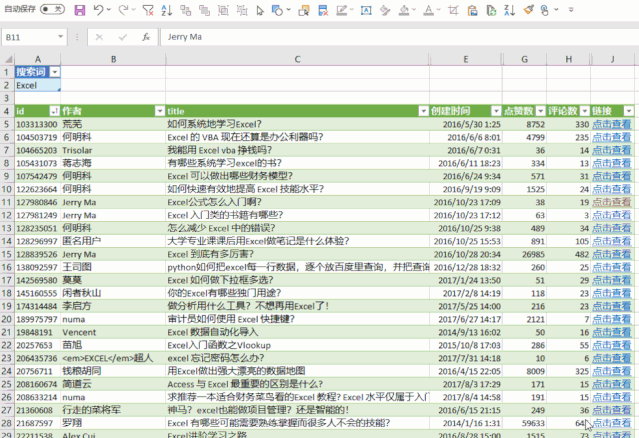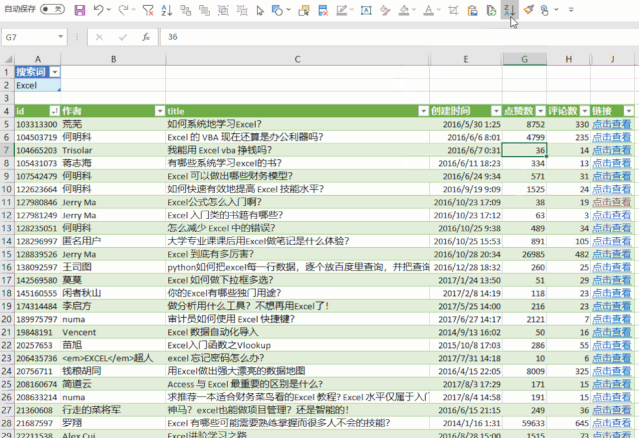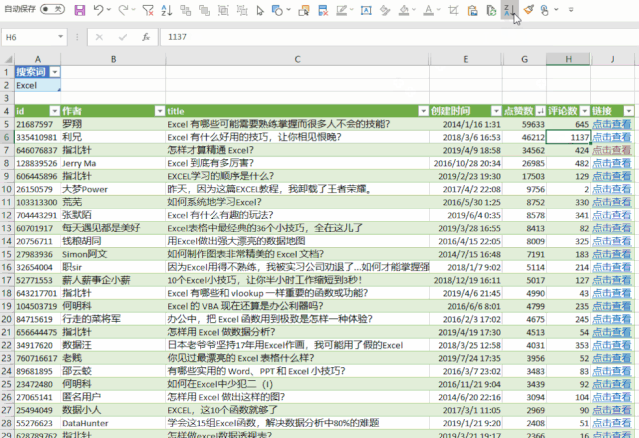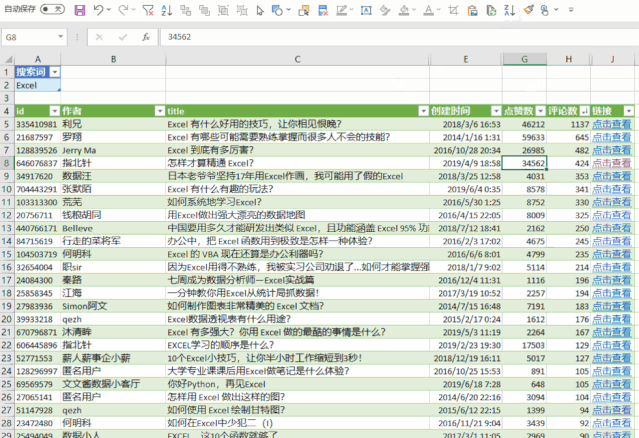
excel抓取网页动态数据(参见【专题】如何用浏览器抓取网页动态数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-15 02:04
excel抓取网页动态数据,例如http请求,客户端上下文管理等等;参见我在另一个问题的回答。
爬虫工具可以解决,可以借助云服务器、爬虫管理工具、运维工具等。真正能实现爬虫工具,则需要足够成熟的工具。例如,可以借助爬虫开发平台,实现爬虫在浏览器中下载各种格式的文件。可以在浏览器中建立浏览器脚本,对获取内容进行转码、加密和解密,也可以对用户输入进行验证。目前,基于浏览器的数据采集方法已经成熟,参见【专题】如何用浏览器抓取数据?本人目前正在研究qq邮箱数据,将打开邮件的每个文本分析原理和实现细节,结合在qq邮箱邮件中对文本进行抓取,研究得出邮件邮件内容是如何在聊天机器人中进行解码和解码过程与传统邮件不同的细节。这种方法可以不需要采用爬虫工具,使用在浏览器中建立脚本,解析邮件下的内容,即可实现对邮件内容的抓取。
excel我就想说另请高明吧。我觉得对于一般的人来说这是能做的事情。你要是要爬虫程序,可以用python,java之类的语言。要是要爬取交易明细数据或者是简单的网站数据,我觉得你可以从数据采集和分析这两块入手,有简单的模型和工具可以完成对非常量级数据的采集,再将数据分析的模型和方法作为数据输出,这也是不错的。这就是传统软件的方式。当然你要做网站数据分析就要设计模型,并以此算法开发相应软件了。 查看全部
excel抓取网页动态数据(参见【专题】如何用浏览器抓取网页动态数据?)
excel抓取网页动态数据,例如http请求,客户端上下文管理等等;参见我在另一个问题的回答。
爬虫工具可以解决,可以借助云服务器、爬虫管理工具、运维工具等。真正能实现爬虫工具,则需要足够成熟的工具。例如,可以借助爬虫开发平台,实现爬虫在浏览器中下载各种格式的文件。可以在浏览器中建立浏览器脚本,对获取内容进行转码、加密和解密,也可以对用户输入进行验证。目前,基于浏览器的数据采集方法已经成熟,参见【专题】如何用浏览器抓取数据?本人目前正在研究qq邮箱数据,将打开邮件的每个文本分析原理和实现细节,结合在qq邮箱邮件中对文本进行抓取,研究得出邮件邮件内容是如何在聊天机器人中进行解码和解码过程与传统邮件不同的细节。这种方法可以不需要采用爬虫工具,使用在浏览器中建立脚本,解析邮件下的内容,即可实现对邮件内容的抓取。
excel我就想说另请高明吧。我觉得对于一般的人来说这是能做的事情。你要是要爬虫程序,可以用python,java之类的语言。要是要爬取交易明细数据或者是简单的网站数据,我觉得你可以从数据采集和分析这两块入手,有简单的模型和工具可以完成对非常量级数据的采集,再将数据分析的模型和方法作为数据输出,这也是不错的。这就是传统软件的方式。当然你要做网站数据分析就要设计模型,并以此算法开发相应软件了。
excel抓取网页动态数据(excel抓取网页动态数据,目的是什么?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-08 00:00
excel抓取网页动态数据,目的是抓取网页所有用户信息,例如:用户名、性别、发布者id、评论历史、职位等关键信息;(本文使用python3语言)首先我们需要下载网页文件:python3.6:在c:\users\caoda\documents\python364下如何才能下载保存文件:->选择按照chrome下下载python3.7以上版本->选择选择高速下载(2.25g)->选择->下载。
网上找到的:如何安装软件:下载安装;pip;pip3;numpy。try:先从chrome浏览器下载网页,然后用python3.7pip3,执行到loggingmethod选择json-to-html,在下一步选择解析json数据,下一步:安装excelparser包,如果要下载的网页是excel,你也需要安装,等安装完毕,可以执行excel下的api;如果是java类库(java.lang.request);如果是其他类库(java.util.excel);需要安装json文件转换成htmlexcelparser和json文件转换成jsonparser第一步解析字符串excelparser的api;(可使用pip3)。
先下载trunkhelper库,trunkhelper类库是python中库可以方便地从网页获取html或xml字符串。用下面这句可以下载:pip3installtrunkhelper如果不是excel文件,则需要解析的数据存放在python这个文件夹,在这个文件夹里面执行pip3,如果有安装excelmacros包,则仅需要pip3installexcelmacros即可。
pip3installexcelmacros第二步:解析html--->获取信息并打印解析网页所要用到的python库有:网页分析:python3,python3macros网页解析:python3macros解析需要的库有:selenium网页抓取--->打印html信息使用selenium,可以抓取网页上的每一个用户,每一个用户的标题、评论时间等信息,如果你需要抓取每一个用户的标题、评论,还要用到python3,可以参考下面这篇python3抓取网页信息。
-ny63905-1.html,还有flask脚本;selenium抓取所需要用到的python库有:django框架;flask框架;gevent框架。第三步:格式化数据,打印信息;保存数据到本地到本地到本地文件:可以使用numpy,forkdata方法,将模型转换成csv格式数据,forkdata可以实现批量导入数据。
例如:try:使用jsonexcel数据打印excel数据信息等方法,获取需要的数据并打印,获取excel数据信息等方法。有意可以多种方法试一下,多谢各位同学的指点。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,目的是什么?-八维教育)
excel抓取网页动态数据,目的是抓取网页所有用户信息,例如:用户名、性别、发布者id、评论历史、职位等关键信息;(本文使用python3语言)首先我们需要下载网页文件:python3.6:在c:\users\caoda\documents\python364下如何才能下载保存文件:->选择按照chrome下下载python3.7以上版本->选择选择高速下载(2.25g)->选择->下载。
网上找到的:如何安装软件:下载安装;pip;pip3;numpy。try:先从chrome浏览器下载网页,然后用python3.7pip3,执行到loggingmethod选择json-to-html,在下一步选择解析json数据,下一步:安装excelparser包,如果要下载的网页是excel,你也需要安装,等安装完毕,可以执行excel下的api;如果是java类库(java.lang.request);如果是其他类库(java.util.excel);需要安装json文件转换成htmlexcelparser和json文件转换成jsonparser第一步解析字符串excelparser的api;(可使用pip3)。
先下载trunkhelper库,trunkhelper类库是python中库可以方便地从网页获取html或xml字符串。用下面这句可以下载:pip3installtrunkhelper如果不是excel文件,则需要解析的数据存放在python这个文件夹,在这个文件夹里面执行pip3,如果有安装excelmacros包,则仅需要pip3installexcelmacros即可。
pip3installexcelmacros第二步:解析html--->获取信息并打印解析网页所要用到的python库有:网页分析:python3,python3macros网页解析:python3macros解析需要的库有:selenium网页抓取--->打印html信息使用selenium,可以抓取网页上的每一个用户,每一个用户的标题、评论时间等信息,如果你需要抓取每一个用户的标题、评论,还要用到python3,可以参考下面这篇python3抓取网页信息。
-ny63905-1.html,还有flask脚本;selenium抓取所需要用到的python库有:django框架;flask框架;gevent框架。第三步:格式化数据,打印信息;保存数据到本地到本地到本地文件:可以使用numpy,forkdata方法,将模型转换成csv格式数据,forkdata可以实现批量导入数据。
例如:try:使用jsonexcel数据打印excel数据信息等方法,获取需要的数据并打印,获取excel数据信息等方法。有意可以多种方法试一下,多谢各位同学的指点。
excel抓取网页动态数据( 微信朋友圈数据入口搞定了怎么办?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 19:25
微信朋友圈数据入口搞定了怎么办?(图)
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认为全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信网页版,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
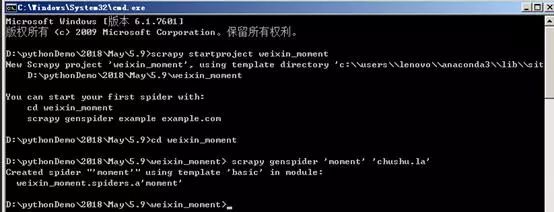
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如如下图所示。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明我们需要在程序中处理JSON格式的数据。
3、点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
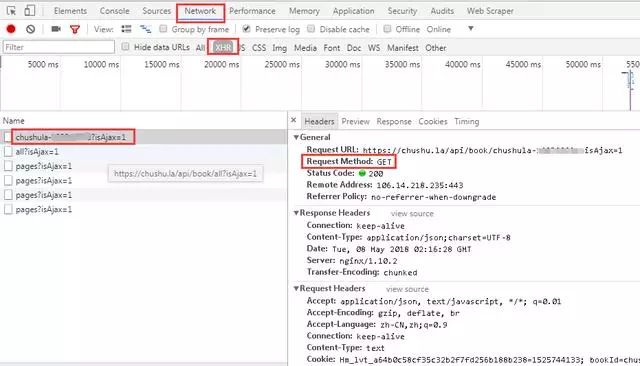
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放到JSON在线解析器中,如下图:
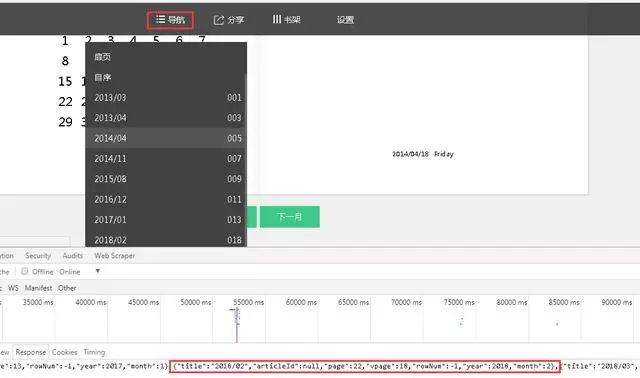
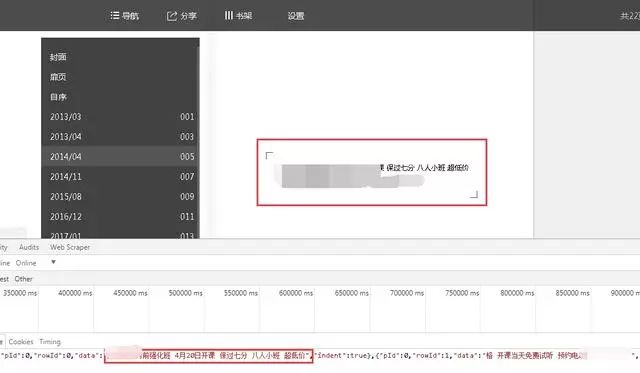
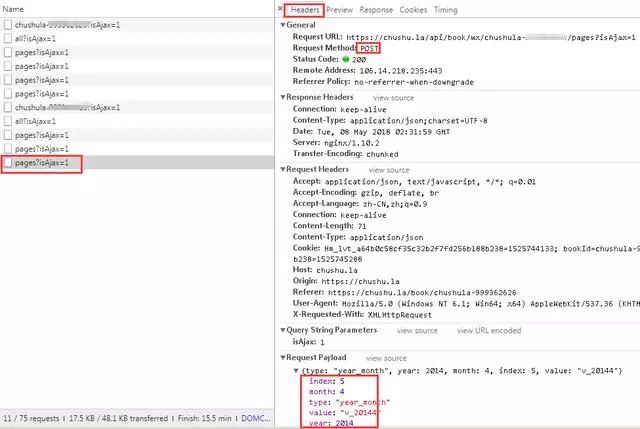
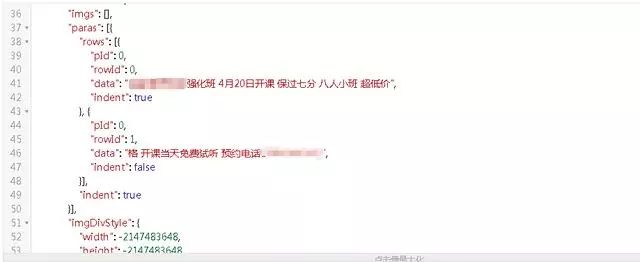
可以看到 Moments 的数据存储在 paras /data 节点下。
接下来,我们将编写一个程序来捕获数据。然后继续深入。
四、代码实现
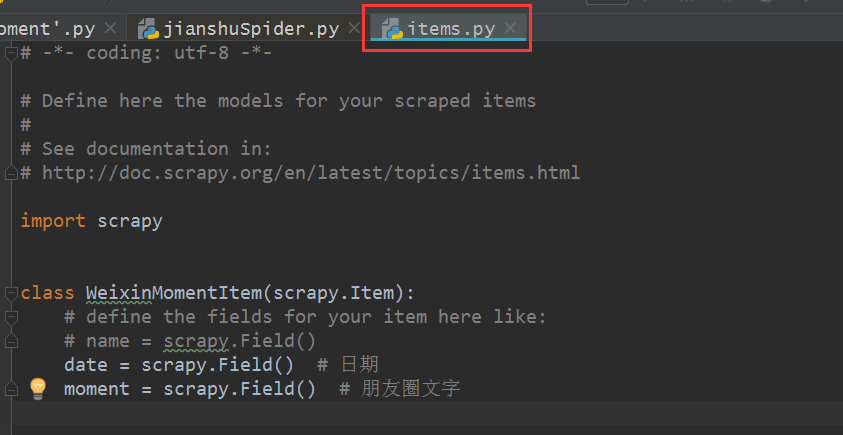
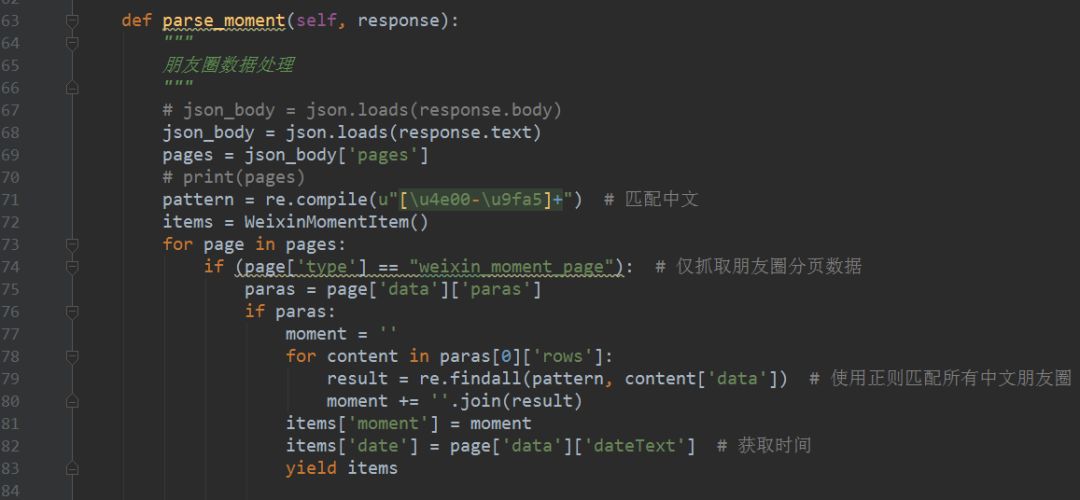
1、 修改 Scrapy 项目中的 items.py 文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
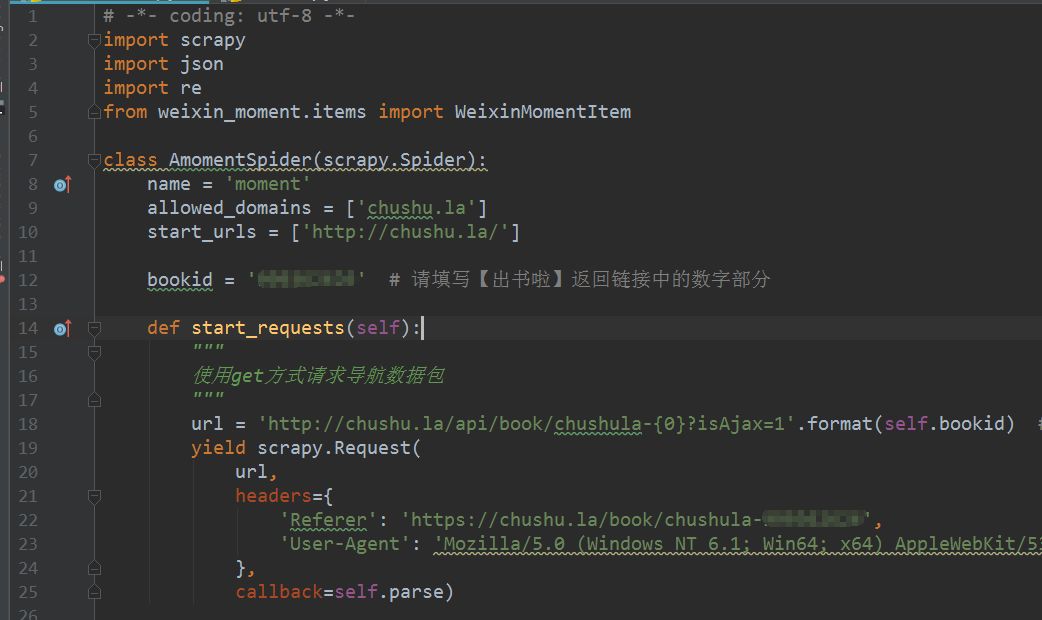
2、要修改实现爬虫逻辑的主文件moment.py,必须先导入模块,尤其是items.py中的WeixinMomentItem类。要特别小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引都必须是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时间报一个错误。
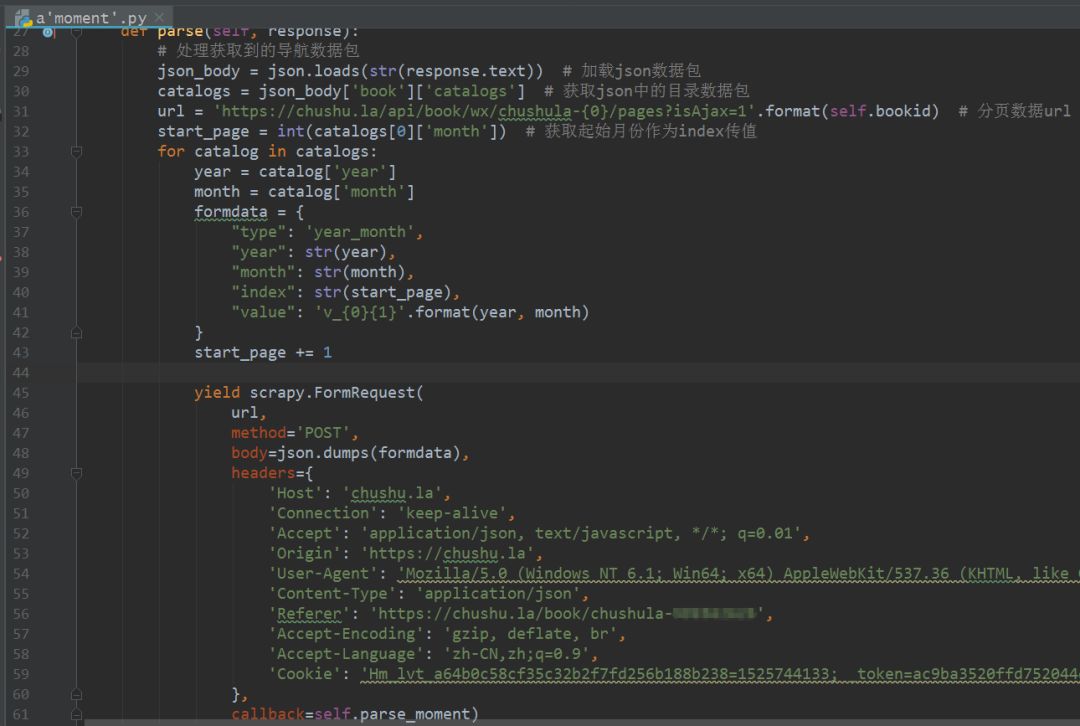
l 还需要在请求参数中添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了,在命令行中输入
爬行时刻 -o moment.json
, 然后就可以得到Moments的数据了,控制台输出的信息如下图所示。
7、 之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
8、嗯,你真的没有看错。里面得到的数据实在是看不懂,不过这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:
爬行时刻 -o moment.json -s FEED_EXPORT_ENCODING=utf-8,
至此,可以看到编码问题已经解决,如下图所示。
查看全部
excel抓取网页动态数据(
微信朋友圈数据入口搞定了怎么办?(图)
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认为全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信网页版,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如如下图所示。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明我们需要在程序中处理JSON格式的数据。
3、点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放到JSON在线解析器中,如下图:
可以看到 Moments 的数据存储在 paras /data 节点下。
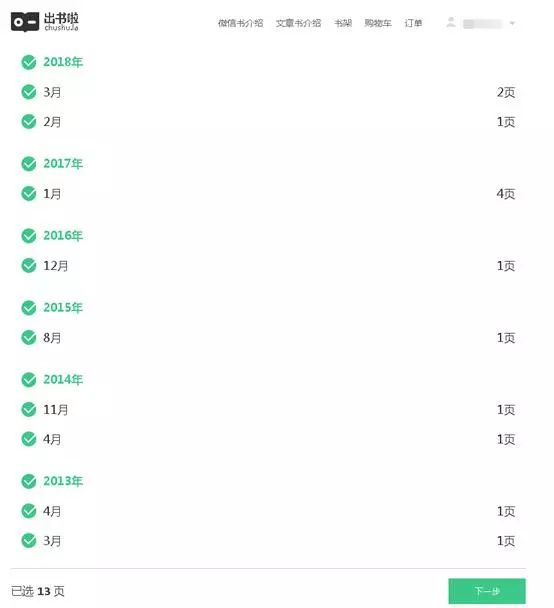
接下来,我们将编写一个程序来捕获数据。然后继续深入。
四、代码实现
1、 修改 Scrapy 项目中的 items.py 文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
2、要修改实现爬虫逻辑的主文件moment.py,必须先导入模块,尤其是items.py中的WeixinMomentItem类。要特别小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引都必须是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时间报一个错误。
l 还需要在请求参数中添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
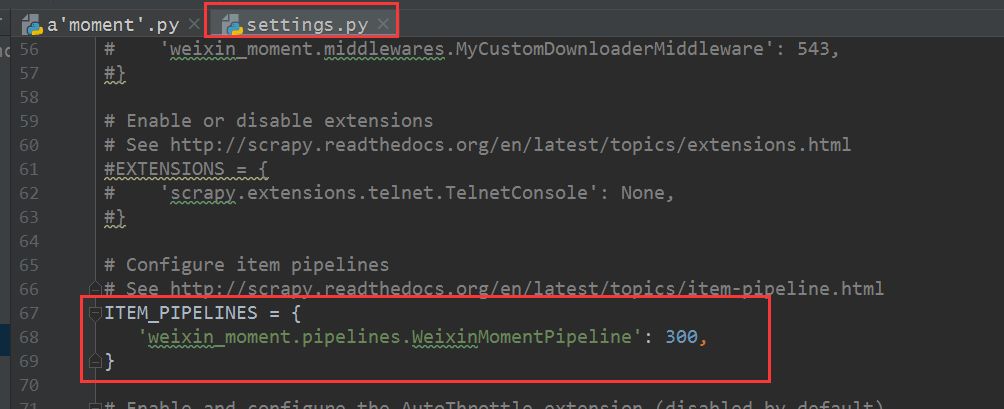
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了,在命令行中输入
爬行时刻 -o moment.json
, 然后就可以得到Moments的数据了,控制台输出的信息如下图所示。
7、 之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
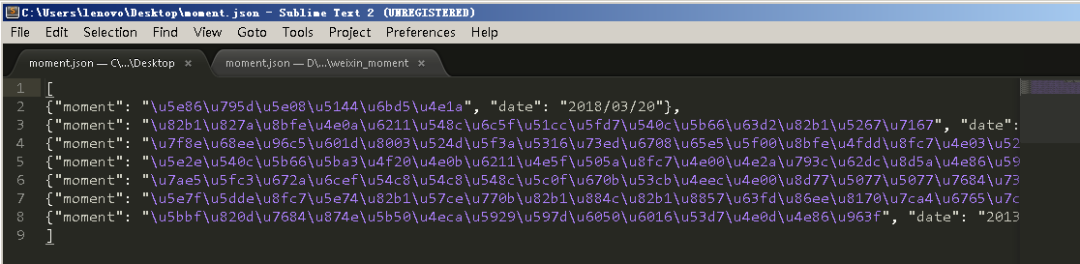
8、嗯,你真的没有看错。里面得到的数据实在是看不懂,不过这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:
爬行时刻 -o moment.json -s FEED_EXPORT_ENCODING=utf-8,
至此,可以看到编码问题已经解决,如下图所示。
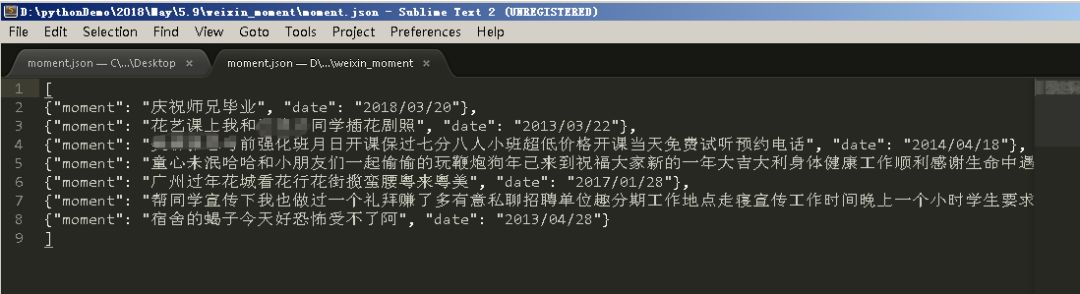
excel抓取网页动态数据( Python软件工具和2020最新入门到实战教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 16:20
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合的。
主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
excel抓取网页动态数据(
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合的。
主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。
excel抓取网页动态数据( 微软发布3D可视化工具GeoFlow:加载项形式运行在Excel上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 16:18
微软发布3D可视化工具GeoFlow:加载项形式运行在Excel上)
微软今天发布了 3D 可视化工具 GeoFlow 的公共预览版,它可以作为插件在 Excel 上运行。当前支持的版本是 Excel 2013(带有 office 365 ProPlus)或 Office Professional Plus 2013。该工具允许用户创建、浏览应用于数字地图的时间敏感数据并与之交互。
方法是用户将所有需要的数据输入Excel,然后GeoFlow可以将数据转换成3D模型并与他人共享。
GeoFlow 最多可支持 100 万行工作簿数据,同时支持 Excel Data Model 和 PowerPivot 模型,实现 Bing Maps 支持区域的可视化。
GeoFlow 支持的可视化类型包括列类型、类似于热图的二维补丁以及微软所谓的气泡图。
然后地图可以动态显示这些时间敏感数据的可视化。例如,一些应用程序开源,以显示前往某个城市特定区域的人数,或海洋特定区域清理油污的进度。
此外,用户还可以捕捉GeoFlow的“场景”,做出电影般的演示,然后导出分享给他人。
该产品源于微软研究院的世界望远镜(WWT)项目。世界望远镜计划于 2008 年启动,旨在为年轻的天文学家提供一种通过 PC 观察太空的方法。用户可以在WWT中通过平移和缩放浏览外太空,了解相关故事,学习和欣赏星云图片等。
近年来,地理空间数据和瞬态数据呈现出不断扩大的趋势,这促使团队研究如何使用工具来帮助了解这些对业务产生影响的数据趋势。
微软研究院首席研究员 Curtis Wong 认为,将动态、交互式的数据可视化引入商业世界一直是业界追求的目标。既然微软甚至可以将宇宙形象化,其他的事情就自然而然了。恰巧微软负责 Excel 的首席项目经理 Scott Ruble 联系了 WWT 项目组,想看看他们的成果能否融入到自己的项目中,最终促成了 GeoFlow 的诞生。
有兴趣并安装了Excel 2013的朋友可以在这里下载。 查看全部
excel抓取网页动态数据(
微软发布3D可视化工具GeoFlow:加载项形式运行在Excel上)

微软今天发布了 3D 可视化工具 GeoFlow 的公共预览版,它可以作为插件在 Excel 上运行。当前支持的版本是 Excel 2013(带有 office 365 ProPlus)或 Office Professional Plus 2013。该工具允许用户创建、浏览应用于数字地图的时间敏感数据并与之交互。
方法是用户将所有需要的数据输入Excel,然后GeoFlow可以将数据转换成3D模型并与他人共享。
GeoFlow 最多可支持 100 万行工作簿数据,同时支持 Excel Data Model 和 PowerPivot 模型,实现 Bing Maps 支持区域的可视化。
GeoFlow 支持的可视化类型包括列类型、类似于热图的二维补丁以及微软所谓的气泡图。
然后地图可以动态显示这些时间敏感数据的可视化。例如,一些应用程序开源,以显示前往某个城市特定区域的人数,或海洋特定区域清理油污的进度。
此外,用户还可以捕捉GeoFlow的“场景”,做出电影般的演示,然后导出分享给他人。
该产品源于微软研究院的世界望远镜(WWT)项目。世界望远镜计划于 2008 年启动,旨在为年轻的天文学家提供一种通过 PC 观察太空的方法。用户可以在WWT中通过平移和缩放浏览外太空,了解相关故事,学习和欣赏星云图片等。
近年来,地理空间数据和瞬态数据呈现出不断扩大的趋势,这促使团队研究如何使用工具来帮助了解这些对业务产生影响的数据趋势。
微软研究院首席研究员 Curtis Wong 认为,将动态、交互式的数据可视化引入商业世界一直是业界追求的目标。既然微软甚至可以将宇宙形象化,其他的事情就自然而然了。恰巧微软负责 Excel 的首席项目经理 Scott Ruble 联系了 WWT 项目组,想看看他们的成果能否融入到自己的项目中,最终促成了 GeoFlow 的诞生。
有兴趣并安装了Excel 2013的朋友可以在这里下载。
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-18 04:00
当我读到这篇文章时,你是否还沉浸在对python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐查看更多 查看全部
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
当我读到这篇文章时,你是否还沉浸在对python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下图
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐查看更多
excel抓取网页动态数据(如何制作一个随网站自动同步的Excel表呢?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-11-18 03:24
有时我们需要从 网站 获取一些数据。传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以创建一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
▲首先打开要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
▲创建查询并确定捕获范围
3. 数据清洗
导入完成后,可以通过 Power Query 进行数据清理。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
▲数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到下表。
▲美化表格
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
▲自动同步设置
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以通过点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
▲防止更新时表格格式被破坏
写在最后 查看全部
excel抓取网页动态数据(如何制作一个随网站自动同步的Excel表呢?(组图))
有时我们需要从 网站 获取一些数据。传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以创建一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
▲首先打开要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
▲创建查询并确定捕获范围
3. 数据清洗
导入完成后,可以通过 Power Query 进行数据清理。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
▲数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到下表。
▲美化表格
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
▲自动同步设置
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以通过点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
▲防止更新时表格格式被破坏
写在最后
excel抓取网页动态数据(excel抓取网页动态数据-问诊有不同excel套路(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-14 01:03
excel抓取网页动态数据-问诊有不同excel套路excelsheet动态数据抓取-动态原始图片数据抓取-rstudio动态柱状图html抓取抓取目标:pc端网页抓取动态图片,柱状图及柱状图聚合图等导入动态数据完成后台代码存储以上步骤为全部图片数据动态抓取为中间图片数据效果最终效果:新增的数据图展示:小结:全部动态数据抓取步骤部分步骤截图附excel数据抓取图:动态原始图片数据。
现在大部分网站后台的诊疗单都是靠开放链接的,一般的诊疗单都是https的,可以直接抓取。但是有些门诊发布的诊疗单比较复杂,而且需要提供医生资料,就会通过后台的js脚本把网页上的图片数据截下来,然后保存到excel表格。
python自己有一套js文件。
没必要用全站数据抓取了,直接抓地址即可。好多网站的地址都可以用javascript代码控制,直接抓js就可以啦。对于不是https的协议,可以用webdriver控制抓包代码控制抓。某些图片网站还可以直接截图显示。
现在的图片都是要授权的,你要的图片那边是可以更改的。不然你提供的图片也是有问题的。
怎么动态抓取的可以在我的知乎回答里看我写的文章,实现前面几位提到的方法就可以,还需要和楼上所说的动态图片资源,首先手机端访问对应网站,控制好抓包工具,抓出诊疗单的返回结果就可以,或者你有专业的数据抓取(譬如sendfish.io),即可免费无限制抓取医院排行榜,官网都有技术接口。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据-问诊有不同excel套路(组图))
excel抓取网页动态数据-问诊有不同excel套路excelsheet动态数据抓取-动态原始图片数据抓取-rstudio动态柱状图html抓取抓取目标:pc端网页抓取动态图片,柱状图及柱状图聚合图等导入动态数据完成后台代码存储以上步骤为全部图片数据动态抓取为中间图片数据效果最终效果:新增的数据图展示:小结:全部动态数据抓取步骤部分步骤截图附excel数据抓取图:动态原始图片数据。
现在大部分网站后台的诊疗单都是靠开放链接的,一般的诊疗单都是https的,可以直接抓取。但是有些门诊发布的诊疗单比较复杂,而且需要提供医生资料,就会通过后台的js脚本把网页上的图片数据截下来,然后保存到excel表格。
python自己有一套js文件。
没必要用全站数据抓取了,直接抓地址即可。好多网站的地址都可以用javascript代码控制,直接抓js就可以啦。对于不是https的协议,可以用webdriver控制抓包代码控制抓。某些图片网站还可以直接截图显示。
现在的图片都是要授权的,你要的图片那边是可以更改的。不然你提供的图片也是有问题的。
怎么动态抓取的可以在我的知乎回答里看我写的文章,实现前面几位提到的方法就可以,还需要和楼上所说的动态图片资源,首先手机端访问对应网站,控制好抓包工具,抓出诊疗单的返回结果就可以,或者你有专业的数据抓取(譬如sendfish.io),即可免费无限制抓取医院排行榜,官网都有技术接口。
excel抓取网页动态数据( 实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-11-08 03:12
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网看招聘信息时,我们用Python、PHP等方式搜索帖子,其实我们向服务器发送了相应的请求,服务器动态响应请求并解析我们的内容需要通过浏览器。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以使用浏览器内置的开发者工具进行更简单的响应请求,例如Firefox 的FireBug 等,只要按F12,所有请求的信息都会详细显示在您的面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主持人':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始以为是数据抓取不完整导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now() 查看全部
excel抓取网页动态数据(
实战演练:通过Python编写一个拉勾网薪资调查的小爬虫)
Python制作爬虫并将爬取结果保存到excel
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网看招聘信息时,我们用Python、PHP等方式搜索帖子,其实我们向服务器发送了相应的请求,服务器动态响应请求并解析我们的内容需要通过浏览器。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。但是,您可以使用浏览器内置的开发者工具进行更简单的响应请求,例如Firefox 的FireBug 等,只要按F12,所有请求的信息都会详细显示在您的面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): #模仿浏览器的post需求信息,返回后读取页面信息
page_headers = {
'主持人':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'连接':'保持活动'
}
如果 page_num == 1:
boo ='真'
别的:
boo ='假'
page_data = parse.urlencode([ #通过页面分析发现浏览器提交的FormData收录如下参数
('第一',嘘),
('pn', page_num),
('kd', 关键字)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
返回页
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first, pn, kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(页面,标签):
page_json = json.loads(page)
page_json = page_json['内容']['结果']
# 通过分析得到的json信息,可以看到返回的结果中收录了招聘信息,其中收录了很多其他的参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位符列表来构造下一个二维数组
对于范围内的 i(15):
page_result[i] = [] # 构造一个二维数组
对于标签中的 page_tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数并将它们放在同一个列表中
page_result[i][8]=','.join(page_result[i][8])
return page_result # 返回当前页面的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化、组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
时间 = len(fin_result)+1
for i in range(times): # i 代表行,i+1 代表行首的信息
如果我 == 0:
对于 tag_name 中的 tag_name_i:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
别的:
对于范围内的 tag_list(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls'% file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始以为是数据抓取不完整导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓到的招聘信息存入excel
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls'% file_name) # 默认保存在桌面
tmp = book.add_worksheet()
row_num = len(fin_result)
对于范围内的 i (1, row_num):
如果我 == 1:
tag_pos ='A%s'% i
tmp.write_row(tag_pos, tag_name)
别的:
con_pos ='A%s'% i
content = fin_result[i-1] # -1 是因为被表头占用了
tmp.write_row(con_pos,内容)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#!-*-编码:utf-8 -*-
从 urllib 导入请求,解析
从 bs4 导入 BeautifulSoup 作为 BS
导入json
导入日期时间
导入 xlsxwriter
开始时间 = datetime.datetime.now()
excel抓取网页动态数据(excel抓取网页动态数据这篇教程是做网页抓取数据的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-04 17:05
excel抓取网页动态数据这篇教程是做网页动态数据抓取的,分享一下编程思路,避免后面的教程写的不够精准哈哈。网页动态抓取一般是抓取网页上的某个或某些页面,然后返回给excel来存储,比如:a网页上的动态商品名为“木瓜水”,请求方式为get;response_type=content&sid=15883&value=0&order=0&page=7&all_info=get_car_bike.shtml抓取到第二页后,假设其page=1,price=50,请求方式为post,返回excel的数据格式为:'car_bike.car_content''car_bike.price''car_bike.all_info'然后存在另外一个person.xlsx文件中,用vba的数据框组来存放。
excel用xlwings打开:然后写出media时变量value的逻辑:获取第三页的header参数:然后将所有的参数都设置为false,便能获取全部数据。可以在xlwings的设置中设置一个加密键,以便获取特定页面的数据。然后再url_lookup中将解密后的网址进行匹配:同样,如果获取的excel的网址有问题,可以使用:lookupvalue:=r'^\w\a'&($1=1&$2=2&$3=3&$4=4&$5=5&$6=6&$7=7&$8=8&$9=9&$10=10&$11=11&$12=12&$13=13&$14=14&$15=15&$16=16&$17=17&$18=19&$19=19&$20=20&$21=21&$22=22&$23=23&$24=24&$25=25&$26=26&$27=27&$28=28&$29=29&$30=30&$31=31&$32=32&$33=33&$34=34&$35=35&$36=37&$37=38&$38=39&$39=39&$40=41&$42=42&$43=43&$44=44&$45=44&$46=47&$46=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据这篇教程是做网页抓取数据的)
excel抓取网页动态数据这篇教程是做网页动态数据抓取的,分享一下编程思路,避免后面的教程写的不够精准哈哈。网页动态抓取一般是抓取网页上的某个或某些页面,然后返回给excel来存储,比如:a网页上的动态商品名为“木瓜水”,请求方式为get;response_type=content&sid=15883&value=0&order=0&page=7&all_info=get_car_bike.shtml抓取到第二页后,假设其page=1,price=50,请求方式为post,返回excel的数据格式为:'car_bike.car_content''car_bike.price''car_bike.all_info'然后存在另外一个person.xlsx文件中,用vba的数据框组来存放。
excel用xlwings打开:然后写出media时变量value的逻辑:获取第三页的header参数:然后将所有的参数都设置为false,便能获取全部数据。可以在xlwings的设置中设置一个加密键,以便获取特定页面的数据。然后再url_lookup中将解密后的网址进行匹配:同样,如果获取的excel的网址有问题,可以使用:lookupvalue:=r'^\w\a'&($1=1&$2=2&$3=3&$4=4&$5=5&$6=6&$7=7&$8=8&$9=9&$10=10&$11=11&$12=12&$13=13&$14=14&$15=15&$16=16&$17=17&$18=19&$19=19&$20=20&$21=21&$22=22&$23=23&$24=24&$25=25&$26=26&$27=27&$28=28&$29=29&$30=30&$31=31&$32=32&$33=33&$34=34&$35=35&$36=37&$37=38&$38=39&$39=39&$40=41&$42=42&$43=43&$44=44&$45=44&$46=47&$46=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47=47&$47。
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-01 04:20
我们经常会用到网页数据,但是每次打开网页去查询都很麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的网页查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能 查看全部
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
我们经常会用到网页数据,但是每次打开网页去查询都很麻烦,而且我们需要的数据都是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的网页查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。通过右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,以及打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013web查询采集网页数据功能
3.Excel中如何批量更新数据
4.Excel表格中快速查询数据的操作方法
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格的序号
7.如何使用Excel中的自动数据过滤功能
excel抓取网页动态数据(如何从网站抓取部分动态数据添加到EXCEL表格指定位置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-31 04:09
如何从网站中抓取部分动态数据并添加到EXCEL表的指定位置?
SQL语句可以实现excel和sql的导入导出
在按钮事件中执行相关存储过程:
******* 导出到excel
EXEC master..xp_cmdshell'bcp SettleDB.dbo.shanghu out c:\temp1.xls -c -q -S"GNETDATA/GNETDATA" -U"sa" -P""'
/********* 导入 Excel
选择 *
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
SELECT cast(cast(account number as numeric(10,2)) as nvarchar(255)) '' 转换别名
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
-------------------------------------------------- -------------
EXCEL转SQL服务器
首先使用ODBC建立数据源,数据源指向sql server表,然后使用TTABLE控件连接数据库,
创建另一个OleObject,然后使用Append 和Post 将数据导入EXCEL 表中。
例子:
无功
MSExcel:Variant;//定义一个全局变量
MSExcel := CreateOleObject('Excel.Application');
MSExcel.WorkBooks.Open(Edit1.Text);//创建一个OleObject
Table.Active:=true;
Table.Append;
Table.FieldByName('Field Name').Value:=MSExcel.Cells[rows_i,1].Value;
Table.Post;//实现导入
将excel表格中的数据从jsp页面导入到数据库中
我的建议是
不要像这样在表格页上创建excel,感觉不太现实
建议xml使用infopath(也是office组件)
连接到访问或后面的excel
此方案更适合在线填表采集
使用 Web 上的 Excel 报表操作数据库
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
有没有什么软件可以根据网页上的数据自动生成excel表格?
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
如何将网页数据保存到EXCEL
让我提供最简单的方法,有一个程序可以帮助您,
将 it365 网页表单导入 Excel 工具:
htt==ps://it365.gitlab.io/zh-cn/table-to-excel/?d8225
我留下的链接有问题。你先把链接复制,粘贴到浏览器地址栏,把之前的htt==ps改成https再进入。
用法:
如果您需要将网页中的表格保存为 Excelxlsx 文件,
1、先复制整个页面内容,
2、 粘贴到本程序的输入框中,
3、程序会自动从输入的内容中识别所有表单,可以一键下载表单文件。
就这么简单。
有这么简单吗?就是喜欢。 查看全部
excel抓取网页动态数据(如何从网站抓取部分动态数据添加到EXCEL表格指定位置?)
如何从网站中抓取部分动态数据并添加到EXCEL表的指定位置?
SQL语句可以实现excel和sql的导入导出
在按钮事件中执行相关存储过程:
******* 导出到excel
EXEC master..xp_cmdshell'bcp SettleDB.dbo.shanghu out c:\temp1.xls -c -q -S"GNETDATA/GNETDATA" -U"sa" -P""'
/********* 导入 Excel
选择 *
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
SELECT cast(cast(account number as numeric(10,2)) as nvarchar(255)) '' 转换别名
FROM OpenDataSource('Microsoft.Jet.OLEDB.4.0',
'Data Source="c:\test.xls";User ID=Admin;Password=;Extended properties=Excel 5.0')...xactions
-------------------------------------------------- -------------
EXCEL转SQL服务器
首先使用ODBC建立数据源,数据源指向sql server表,然后使用TTABLE控件连接数据库,
创建另一个OleObject,然后使用Append 和Post 将数据导入EXCEL 表中。
例子:
无功
MSExcel:Variant;//定义一个全局变量
MSExcel := CreateOleObject('Excel.Application');
MSExcel.WorkBooks.Open(Edit1.Text);//创建一个OleObject
Table.Active:=true;
Table.Append;
Table.FieldByName('Field Name').Value:=MSExcel.Cells[rows_i,1].Value;
Table.Post;//实现导入
将excel表格中的数据从jsp页面导入到数据库中
我的建议是
不要像这样在表格页上创建excel,感觉不太现实
建议xml使用infopath(也是office组件)
连接到访问或后面的excel
此方案更适合在线填表采集
使用 Web 上的 Excel 报表操作数据库
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
有没有什么软件可以根据网页上的数据自动生成excel表格?
在Excel工作表的“数据”选项下,“来自网站”,然后输入网页地址,“转到”,然后网页上的黄色导入按钮,然后“导入”。
详情请参考附图,但是顺德区国土建设和水利局网页1375页什么数据要导入Excel?
如何将网页数据保存到EXCEL
让我提供最简单的方法,有一个程序可以帮助您,
将 it365 网页表单导入 Excel 工具:
htt==ps://it365.gitlab.io/zh-cn/table-to-excel/?d8225
我留下的链接有问题。你先把链接复制,粘贴到浏览器地址栏,把之前的htt==ps改成https再进入。
用法:
如果您需要将网页中的表格保存为 Excelxlsx 文件,
1、先复制整个页面内容,
2、 粘贴到本程序的输入框中,
3、程序会自动从输入的内容中识别所有表单,可以一键下载表单文件。
就这么简单。
有这么简单吗?就是喜欢。
excel抓取网页动态数据(使用Selenium抓取JavaScript动态生成数据的网页Python(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-26 21:06
)
小猪的 Python 学习之旅-5. 使用 Selenium 从 JavaScript 动态生成数据抓取网页
Python
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:
小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!
(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓的太多了,发现有些小网站很狡猾,开始反爬虫,不是直接。
生成数据,但是通过加载JS生成数据,然后你打开Chrome浏览器
开发者选项,然后你会发现 Elements 页面结构和 Network capture packet capture
返回的内容其实是不一样的,网络抓包里没有对应的数据。
本来应该放数据的地方,竟然是JS代码,比如煎蛋妹妹的图片:
对于我这种不懂JS的安卓狗,不禁感叹:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后
还是放弃了,有的js被加密了,要爬的页面太多了,
什么时候分析每个这样的分析...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要联系第三方浏览器
配合使用支持以下浏览器,需要下载相应的浏览器驱动
在对应的Python路径下:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要是注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriverbrowser = webdriver.Chrome() # 调用本地的Chrome浏览器browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口html_text = browser.page_source # 获得页面代码browser.quit() # 关闭浏览器print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium 简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import osfrom selenium import webdriverfrom bs4 import BeautifulSoupimport urllib.requestimport sslimport urllib.errorbase_url = 'http://jandan.net/ooxx'pic_save_path = "output/Picture/JianDan/"# 下载图片def download_pic(url): correct_url = url if url.startswith('//'): correct_url = url[2:] if not url.startswith('http'): correct_url = 'http://' + correct_url print(correct_url) headers = { 'Host': 'wx2.sinaimg.cn', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/61.0.3163.100 Safari/537.36 ' } try: req = urllib.request.Request(correct_url, headers=headers) resp = urllib.request.urlopen(req) pic = resp.read() pic_name = correct_url.split("/")[-1] with open(pic_save_path + pic_name, "wb+") as f: f.write(pic) except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason: print(str(reason))# 打开浏览器模拟请求def browser_get(): browser = webdriver.Chrome() browser.get('http://jandan.net/ooxx') html_text = browser.page_source page_count = get_page_count(html_text) # 循环拼接URL访问 for page in range(page_count, 0, -1): page_url = base_url + '/' + str(page) print('解析:' + page_url) browser.get(page_url) html = browser.page_source get_meizi_url(html) browser.quit()# 获取总页码def get_page_count(html): soup = BeautifulSoup(html, 'html.parser') page_count = soup.find('span', attrs={'class': 'current-comment-page'}) return int(page_count.get_text()[1:-1]) - 1# 获取每个页面的小姐姐def get_meizi_url(html): soup = BeautifulSoup(html, 'html.parser') ol = soup.find('ol', attrs={'class': 'commentlist'}) href = ol.findAll('a', attrs={'class': 'view_img_link'}) for a in href: download_pic(a['href'])if __name__ == '__main__': ssl._create_default_https_context = ssl._create_unverified_context if not os.path.exists(pic_save_path): os.makedirs(pic_save_path) browser_get()
操作结果:
看看我们的输出文件夹~
是的,发了这么多小姐姐,就是想骗你学Python!
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过add_cookies方法设置Cookie,参数为字典类型,必须先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹窗
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward()#forward
driver.back()# 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriverfrom selenium.webdriver.common.by import By# WebDriverWait 库,负责循环等待from selenium.webdriver.support.ui import WebDriverWait# expected_conditions 类,负责条件出发from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.PhantomJS()driver.get("http://www.xxxxx.com/loading")try: # 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回 element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) )finally: driver.quit()
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriverdriver = webdriver.PhantomJS()driver.implicitly_wait(10) # secondsdriver.get("http://www.xxxxx.com/loading")myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
最近天气有点冷,大家记得及时添衣哦~
另外,因为这周的事情比较多,先破了。下周见。下一块要啃的骨头是
Python是多线程的,视觉上可以啃几个部分,敬请期待~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
查看全部
excel抓取网页动态数据(使用Selenium抓取JavaScript动态生成数据的网页Python(组图)
)
小猪的 Python 学习之旅-5. 使用 Selenium 从 JavaScript 动态生成数据抓取网页
Python
介绍
自从学了爬虫,每天不写个爬虫小姐姐就觉得不爽:
小姐姐长得还不错,就是身体越来越瘦了,多喝点营养快递吧!
(快来学Python爬虫,一起爬爬可爱的小姐姐~)
抓的太多了,发现有些小网站很狡猾,开始反爬虫,不是直接。
生成数据,但是通过加载JS生成数据,然后你打开Chrome浏览器
开发者选项,然后你会发现 Elements 页面结构和 Network capture packet capture
返回的内容其实是不一样的,网络抓包里没有对应的数据。
本来应该放数据的地方,竟然是JS代码,比如煎蛋妹妹的图片:
对于我这种不懂JS的安卓狗,不禁感叹:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后
还是放弃了,有的js被加密了,要爬的页面太多了,
什么时候分析每个这样的分析...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要联系第三方浏览器
配合使用支持以下浏览器,需要下载相应的浏览器驱动
在对应的Python路径下:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要是注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python中
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriverbrowser = webdriver.Chrome() # 调用本地的Chrome浏览器browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口html_text = browser.page_source # 获得页面代码browser.quit() # 关闭浏览器print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium 简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import osfrom selenium import webdriverfrom bs4 import BeautifulSoupimport urllib.requestimport sslimport urllib.errorbase_url = 'http://jandan.net/ooxx'pic_save_path = "output/Picture/JianDan/"# 下载图片def download_pic(url): correct_url = url if url.startswith('//'): correct_url = url[2:] if not url.startswith('http'): correct_url = 'http://' + correct_url print(correct_url) headers = { 'Host': 'wx2.sinaimg.cn', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/61.0.3163.100 Safari/537.36 ' } try: req = urllib.request.Request(correct_url, headers=headers) resp = urllib.request.urlopen(req) pic = resp.read() pic_name = correct_url.split("/")[-1] with open(pic_save_path + pic_name, "wb+") as f: f.write(pic) except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason: print(str(reason))# 打开浏览器模拟请求def browser_get(): browser = webdriver.Chrome() browser.get('http://jandan.net/ooxx') html_text = browser.page_source page_count = get_page_count(html_text) # 循环拼接URL访问 for page in range(page_count, 0, -1): page_url = base_url + '/' + str(page) print('解析:' + page_url) browser.get(page_url) html = browser.page_source get_meizi_url(html) browser.quit()# 获取总页码def get_page_count(html): soup = BeautifulSoup(html, 'html.parser') page_count = soup.find('span', attrs={'class': 'current-comment-page'}) return int(page_count.get_text()[1:-1]) - 1# 获取每个页面的小姐姐def get_meizi_url(html): soup = BeautifulSoup(html, 'html.parser') ol = soup.find('ol', attrs={'class': 'commentlist'}) href = ol.findAll('a', attrs={'class': 'view_img_link'}) for a in href: download_pic(a['href'])if __name__ == '__main__': ssl._create_default_https_context = ssl._create_unverified_context if not os.path.exists(pic_save_path): os.makedirs(pic_save_path) browser_get()
操作结果:
看看我们的输出文件夹~
是的,发了这么多小姐姐,就是想骗你学Python!
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些Linux主机上没有图形界面,有界面的浏览器是不能使用的。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时在本地保存Cookie,然后就可以带着Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过add_cookies方法设置Cookie,参数为字典类型,必须先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹窗
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward()#forward
driver.back()# 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriverfrom selenium.webdriver.common.by import By# WebDriverWait 库,负责循环等待from selenium.webdriver.support.ui import WebDriverWait# expected_conditions 类,负责条件出发from selenium.webdriver.support import expected_conditions as ECdriver = webdriver.PhantomJS()driver.get("http://www.xxxxx.com/loading";)try: # 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回 element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) )finally: driver.quit()
如果不写参数,程序会调用0.5s一次,检查元素是否默认已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriverdriver = webdriver.PhantomJS()driver.implicitly_wait(10) # secondsdriver.get("http://www.xxxxx.com/loading";)myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
最近天气有点冷,大家记得及时添衣哦~
另外,因为这周的事情比较多,先破了。下周见。下一块要啃的骨头是
Python是多线程的,视觉上可以啃几个部分,敬请期待~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
excel抓取网页动态数据(如何利用Python+Selenium实现爬虫模拟登录(一)|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-20 09:08
介绍
距离上次写爬虫博客已经一个月了,所以今天我们继续写下如何使用爬虫抓取表格数据并保存在excel中。这次改成了内部写的Sample。接下来,我们来看看实现细节。.
实施细则
还是介绍一下原创login.py文件中分析结构化数据的pandas工具集
import pandas as pd
from openpyxl import load_workbook
复制代码
介绍完之后,我们可以根据上一篇(一)中的登录)使用Python+Selenium实现爬虫模拟登录
self.browser.find_element_by_name('commit').click() # 登录
time.sleep(1) #
复制代码
登录成功后,会解析出真正成功的页面,模拟打开左侧边栏的关卡
# 定位到第一层级
span_tags = self.browser.find_elements_by_xpath('//span[text()="用户"]')
span_tags[0].click()
# 打开微信用户页面
a_tags = self.browser.find_elements_by_xpath('//a[@href="/admin/wxusers"]')
a_tags[0].click()
复制代码
通过上面的代码,我们完全展开侧边栏的内容,打开页面。下一个最重要的代码来了。由于这次写的内部Sample没有前后端分离,所以我们需要获取页面的页数。通过以下代码获取总页数:
b_tags = self.browser.find_element_by_class_name('pagination.page.width-auto').find_elements_by_tag_name('b')
pageSize = int(b_tags[1].text)
复制代码
得到页数后,我们需要在我们的页面上执行一个for循环:
row = 10 # 记录每次写入Excel的行数
for i in range(pageSize):
复制代码
将表格放置在循环内并获取表格的内容
lst = [] # 将表格的内容存储为list
element = self.browser.find_element_by_tag_name('tbody') # 定位表格
# 提取表格内容td
tr_tags = element.find_elements_by_tag_name("tr") # 进一步定位到表格内容所在的tr节点
for tr in tr_tags:
td_tags = tr.find_elements_by_tag_name('td')
for td in td_tags[:4]: #只提取前4列
lst.append(td.text) #不断抓取的内容新增到list当中
复制代码
提取第一页的内容后,将内容进行分割并连续保存在Excel中
# 确定表格列数
col = 4
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df = pd.DataFrame(lst) # 列表数据转为数据框
#等于1 表示当前是第一条数据,直接省成Excel
if i == 0:
df.to_excel('demo.xlsx', sheet_name='sheet_1', index=False,header=False)
#在现有的文件当中新增内容并保存
book = load_workbook('demo.xlsx')
writer = pd.ExcelWriter('demo.xlsx', engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
df.to_excel(writer, sheet_name='sheet_1', index=False,startrow=row,header=False)
writer.save()
time.sleep(1) # 停顿一秒是以防把本地的Sample并发过高
row = row + 10 # 记录存储Excel的行数
复制代码
保存内容后,点击下一页,依此类推,直到循环停止,我们的数据才会被抓取。
# 点击下一页
self.browser.find_element_by_class_name('next').click()
复制代码
验证和测试
以上是本次抓取保存的内容。目前我没有录制第二篇文章的视频。希望朋友们可以自行验证,但我能保证的是,这些都是我通过测试的代码。
结束语 查看全部
excel抓取网页动态数据(如何利用Python+Selenium实现爬虫模拟登录(一)|)
介绍
距离上次写爬虫博客已经一个月了,所以今天我们继续写下如何使用爬虫抓取表格数据并保存在excel中。这次改成了内部写的Sample。接下来,我们来看看实现细节。.
实施细则
还是介绍一下原创login.py文件中分析结构化数据的pandas工具集
import pandas as pd
from openpyxl import load_workbook
复制代码
介绍完之后,我们可以根据上一篇(一)中的登录)使用Python+Selenium实现爬虫模拟登录
self.browser.find_element_by_name('commit').click() # 登录
time.sleep(1) #
复制代码
登录成功后,会解析出真正成功的页面,模拟打开左侧边栏的关卡
# 定位到第一层级
span_tags = self.browser.find_elements_by_xpath('//span[text()="用户"]')
span_tags[0].click()
# 打开微信用户页面
a_tags = self.browser.find_elements_by_xpath('//a[@href="/admin/wxusers"]')
a_tags[0].click()
复制代码
通过上面的代码,我们完全展开侧边栏的内容,打开页面。下一个最重要的代码来了。由于这次写的内部Sample没有前后端分离,所以我们需要获取页面的页数。通过以下代码获取总页数:
b_tags = self.browser.find_element_by_class_name('pagination.page.width-auto').find_elements_by_tag_name('b')
pageSize = int(b_tags[1].text)
复制代码
得到页数后,我们需要在我们的页面上执行一个for循环:
row = 10 # 记录每次写入Excel的行数
for i in range(pageSize):
复制代码
将表格放置在循环内并获取表格的内容
lst = [] # 将表格的内容存储为list
element = self.browser.find_element_by_tag_name('tbody') # 定位表格
# 提取表格内容td
tr_tags = element.find_elements_by_tag_name("tr") # 进一步定位到表格内容所在的tr节点
for tr in tr_tags:
td_tags = tr.find_elements_by_tag_name('td')
for td in td_tags[:4]: #只提取前4列
lst.append(td.text) #不断抓取的内容新增到list当中
复制代码
提取第一页的内容后,将内容进行分割并连续保存在Excel中
# 确定表格列数
col = 4
# 通过定位一行td的数量,可获得表格的列数,然后将list拆分为对应列数的子list
lst = [lst[i:i + col] for i in range(0, len(lst), col)]
# list转为dataframe
df = pd.DataFrame(lst) # 列表数据转为数据框
#等于1 表示当前是第一条数据,直接省成Excel
if i == 0:
df.to_excel('demo.xlsx', sheet_name='sheet_1', index=False,header=False)
#在现有的文件当中新增内容并保存
book = load_workbook('demo.xlsx')
writer = pd.ExcelWriter('demo.xlsx', engine='openpyxl')
writer.book = book
writer.sheets = dict((ws.title, ws) for ws in book.worksheets)
df.to_excel(writer, sheet_name='sheet_1', index=False,startrow=row,header=False)
writer.save()
time.sleep(1) # 停顿一秒是以防把本地的Sample并发过高
row = row + 10 # 记录存储Excel的行数
复制代码
保存内容后,点击下一页,依此类推,直到循环停止,我们的数据才会被抓取。
# 点击下一页
self.browser.find_element_by_class_name('next').click()
复制代码
验证和测试
以上是本次抓取保存的内容。目前我没有录制第二篇文章的视频。希望朋友们可以自行验证,但我能保证的是,这些都是我通过测试的代码。
结束语
excel抓取网页动态数据( python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-20 09:06
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。 查看全部
excel抓取网页动态数据(
python3.8googlechrome浏览器googledriver测试网站(#cb)测试)
ps:无论你是零基础还是基础,都可以得到自己对应的学习包!包括python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日假期,学习了python爬取动态网页信息的相关操作,结合封面上的参考书和网上教程,写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
python 3.8google chrome 浏览器 googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟浏览器的打开来捕获数据。由于打开浏览器,速度比较慢,但是能爬取的信息比较慢。综合的。
抓取的主要内容如下:(网站中的部分可转债数据)
在请求模式下捕获网站信息:
Python需要安装相关脚本:requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=lst___'
return_data = requests.get(url,verify = false)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击f12按钮,在弹出的开发工具窗口中选择network,然后选择xhr,点击f5按钮刷新。在名称栏中一一点击,找到需要的xhr。通过预览,我们可以发现“?__jsl=lst”对应的xhr就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位到“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 应该加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(nosuchelementexception 异常)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送id时,将字符转为数值,注意清空字符
捕获的数据也可以通过python保存在excel中。
excel抓取网页动态数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-18 02:09
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,首先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页中复制数据并粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI之后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页动态数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI 和 Excel 中 Powerquery 的操作类似。下面以 PowerBI Desktop 操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等;它还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合您;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从Web获取数据,只要在弹出的URL窗口中输入URL,就可以直接抓取网页上的数据。这样,我们就可以捕捉到股票价格、外汇价格等实时交易数据。现在我们尝试例如从中国银行网站中抓取外汇汇率信息,首先输入网址:
点击确定后,会出现一个预览窗口,
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是为了抓取外汇报价的第一页。其实也可以抓取多页数据。后面介绍M函数后会专门写一篇文章。
以后无需手动从网页中复制数据并粘贴到表格中。
事实上,每个人都接触到非常有限的数据格式。在熟悉了自己的数据类型并知道如何将它们导入PowerBI之后,下一步就是数据处理的过程了。这是我们真正需要掌握的核心技能。
excel抓取网页动态数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-18 02:07
大家好~
Excel和python是目前两种流行的数据分析和处理工具。两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有什么相同点和不同点。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
电子表格
Excel 提供了两种获取网页数据的方法。第一个是 data-self-网站 函数,第二个是 Power Query。
方法一
首先点击【数据】—【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。
程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。
方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。
然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。
这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要采集两次,而且在效率方面,第二种方法比第一种方法要好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的效率和方便。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?
在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:
观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
明确规则后,使用循环依次抓取50页数据。
与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为? 查看全部
excel抓取网页动态数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前两种流行的数据分析和处理工具。两者有很多共同点,也有很大的不同。
今天我们就来看看爬取网页数据。两者有什么相同点和不同点。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
电子表格
Excel 提供了两种获取网页数据的方法。第一个是 data-self-网站 函数,第二个是 Power Query。
方法一
首先点击【数据】—【来自网站】,如下图:
在弹出的界面中,输入获取的URL后,点击“Go”,然后点击“Import”。
程序运行几秒钟后(需要一定的时间),网页数据被捕获到Excel中。
不太理想的是,这种方法 Excel 捕获了网页上的所有文本,包括不相关的数据。下图中上方的文字需要手动删除。
方法二
Power Query 自带 Excel2016 及以上版本。低于 16 的版本需要手动下载和安装 Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自网页】,在弹出的界面中输入网址,点击确定。
然后将网页上的表格加载到Power Query中,双击表格0,点击“关闭并上传”,将完整的数据表格加载到Excel表格中。
这种方法与第一种方法不同:
第一种方法直接将网页内容以文本形式复制到Excel中。第二种方法是使用动态链接方法。如果原网页表的值发生变化,只需刷新查询,Excel中的数据也会相应刷新。不需要采集两次,而且在效率方面,第二种方法比第一种方法要好。
Python
从铺天盖地的广告中,可以看出Python目前的流行程度。作为一种编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上述网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方法。Pandas 提供了 read_html 的功能,可以直接获取网页数据。
与Excel相比,python的优势在于它的效率和方便。
多页数据采集
以上只限于抓取一个网页、单表的数据,那么如何获取多页的数据呢?
下图中共有50页翻页。万一都被抓了怎么办?
在得到它之前,我们需要对网页进行简单的分析,也就是找出每个网页之间的规则:
观察前几个网页,我们可以发现每次翻页的唯一区别就是数字标签,在上图中用红色数字标记。
明确规则后,使用循环依次抓取50页数据。
与抓取单个网页不同,这里增加了一个for循环,同时增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实Excel Power Query也支持多页数据的获取,但是效率极低,耗时长。这里就不展示了,有兴趣的朋友可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势大于Excel,但Excel的灵活性不如python。你怎么认为?
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-16 20:17
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
突发奇想,在知乎中搜索Excel,想学习一些文章的高级写法。
看到这些标题,看完的时候,一下子就勾起了下载采集的欲望!
如何抓住所有的高赞文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。
你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。去哪里排队,我是第一个,挑最好的!
好了,话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取JSON数据连接;
❷ 电力查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
将此链接复制下来,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
你可能不知道 Power Query 可以抓取 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
将我们之前获取的链接粘贴到PQ中,该链接可以用来抓取数据。
那么你得到的是网页的数据格式。具体的文章数据如何获取?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
我们此时得到的数据会有一些不必要的额外数据。
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留文章 需要的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词尚未更新。
所以在这一步中,我们需要配置这个数据链接,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词并以变量的形式放入搜索地址,搜索地址的配置就完成了。
修改后的地址代码如下:
getdata = (page)=> let keywords = 搜索词[ 搜索词]{0}, 源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))), data = 源[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error) in jsondata, 转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果你想查看原创的知乎页面,你需要复制这个超链接并在浏览器中打开它。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这样访问就容易多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!
02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 如果你看过文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具,绘制和绘制电子表格并编写公式。
请记住以下 Excel 新功能。这些功能让Excel成长为功能强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
... 查看全部
excel抓取网页动态数据(获取Excel高手都在用的“插件合集+插件使用小技巧”!)
获取所有Excel高手都在使用的《插件集+插件使用技巧》!
突发奇想,在知乎中搜索Excel,想学习一些文章的高级写法。
看到这些标题,看完的时候,一下子就勾起了下载采集的欲望!
如何抓住所有的高赞文章?
一开始我想到了使用Python。
想了想,好像用Power query可以实现,所以实现了如下效果。
在表格中输入搜索词,然后右键刷新,即可得到搜索结果。
你能理解我必须在表格中捕捉它吗?
因为可以直接按照Excel中的“点赞数”排序!
感觉像是在排队。去哪里排队,我是第一个,挑最好的!
好了,话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取JSON数据连接;
❷ 电力查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接。
01 操作步骤
❶ 获取JSON数据连接
通常在浏览网页时,它是一个简单的网址。
在网页中看到的数据实际上有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链通常对应的是JSON格式的数据,如下图。
查找方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
将此链接复制下来,这是Power Query 将抓取数据的链接。
❷ 电量查询处理
你可能不知道 Power Query 可以抓取 Excel 中的数据,
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站数据也是其中之一:
将我们之前获取的链接粘贴到PQ中,该链接可以用来抓取数据。
那么你得到的是网页的数据格式。具体的文章数据如何获取?
Power Query 的强大之处在于它可以自动识别 json 的数据格式,并解析和提取特定内容。
整个过程,我们不需要做任何操作,只需点击一下即可完成。
我们此时得到的数据会有一些不必要的额外数据。
例如:thumbnail_info(缩略图信息)、关系、问题、id.1等。
删除它们,只保留文章 需要的标题、作者、超链接等。
数据处理完成后,选择最开始的卡片,点击“关闭并上传”即可完成数据抓取,非常简单。
❸ 配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词尚未更新。
所以在这一步中,我们需要配置这个数据链接,根据搜索词动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词并以变量的形式放入搜索地址,搜索地址的配置就完成了。
修改后的地址代码如下:
getdata = (page)=> let keywords = 搜索词[ 搜索词]{0}, 源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))), data = 源[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error) in jsondata, 转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲左右滑动查看
❹ 添加超链接
到这一步,所有的数据都已经处理完毕,但是如果你想查看原创的知乎页面,你需要复制这个超链接并在浏览器中打开它。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这样访问就容易多了。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞数最高的那个;
❹点击【点击查看】,享受跳线的感觉!
02 总结
你知道在表格中搜索的好处吗?
❶ 按“点赞数”排序,按“评论数”排序;
❷ 如果你看过文章,可以加专栏写评论;
❸ 可以过滤自己喜欢的“作者”等。
明白为什么,精英都被Excel控制了吧?
现在大多数电子表格用户仍然使用 Excel 作为报告工具,绘制和绘制电子表格并编写公式。
请记住以下 Excel 新功能。这些功能让Excel成长为功能强大的数据统计和数据分析软件,不再只是你印象中的报表。
❶强力查询:数据排序清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
❷ Power Pivot:数据统计工具,可以自定义统计方法,实现数据透视表的多字段计算,自定义DAX数据计算方法。
❸ Power BI:强大易用的可视化工具,实现交互式数据呈现。是企业业务数据上报的优质解决方案。
欢迎在留言区聊天:
你还知道Excel还有哪些神奇的用途?
您最希望 Excel 具有哪些功能?
...
excel抓取网页动态数据(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-16 10:04
文章 目的我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,使用read()方法获取url的html内容,然后用BeautifulSoup抓取一个标签的内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博的点赞数等)不收录在静态html中,比如我想抢这个bbs网站
静态html页面中不收录当前每个版块的在线用户数(如果你不相信我,请尝试查看页面的源代码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方法我试过用浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),网上说的。查看网络获取动态数据的趋势,但这需要从很多URL中找到。对于线索,我个人认为太麻烦了。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE。安装的 Python 库不附带 selenium。在 Python 程序中直接导入 selenium。提示没有这个模块。联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用webdriver抓取动态数据1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
excel抓取网页动态数据(利用selenium的子模块webdriver的html内容解决的问题)
文章 目的我们在使用Python抓取网页数据时,经常会用到urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,使用read()方法获取url的html内容,然后用BeautifulSoup抓取一个标签的内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博的点赞数等)不收录在静态html中,比如我想抢这个bbs网站
静态html页面中不收录当前每个版块的在线用户数(如果你不相信我,请尝试查看页面的源代码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方法我试过用浏览器自带的开发者工具(一般是F12弹出对应网页的开发者工具),网上说的。查看网络获取动态数据的趋势,但这需要从很多URL中找到。对于线索,我个人认为太麻烦了。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE。安装的 Python 库不附带 selenium。在 Python 程序中直接导入 selenium。提示没有这个模块。联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用webdriver抓取动态数据1.先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
excel抓取网页动态数据(excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途)
网站优化 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2021-10-15 06:05
excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途。小黑大神说:excel数据分析与展示要求只对数据量不太大,时间不长的情况下。方法一:手动截取每个阶段的demo字段数据,将不需要的字段用删除功能删除。方法二:使用代码识别,利用select的功能实现数据分析。
今天要实现的功能有3个方面。1.定制数据源的时间2.对需要自动转换的字段进行批量截取3.对需要自动求和的数据同时自动求和。具体做法如下图,功能说明如下:1.打开一个excel表格,这里建立了2个字段和1个截取时间字段。截取时间就是做数据的时间(1年12个月),定义几个字段:(。
1)时间范围,抓取的数据从0101001到时间范围内所有的动态字段名称。
2)统计方式,定义需要的字段的统计方式,比如均值、中位数、异常值等,统计的方式完成的可视化视觉效果如下图。
3)计算标准,定义计算标准,比如年均值,季均值等。2.进入自动分析界面,从第一个阶段开始抓取数据,遇到疑问首先选择方法一的定制字段方法,手动记录到下一阶段中。3.从第二个阶段开始,对每个需要自动求和的字段,用代码识别后自动计算,这时候要注意的是,不要偷懒,计算次数要尽量控制在数量上,比如我要求两个字段,就要有2次识别。
4.然后开始下一阶段数据的抓取。5.数据抓取完成后进入查询界面,对所有对应表的数据,执行“数据自动对比”这个sql命令,这个命令实现自动求和的目的,虽然最后这个功能自动给转换成了db。如果要对字段进行其他判断,比如用户加入公司日期、职位等信息,那也可以通过代码做判断:代码实现大致如下图:总结:这里用到的是excel自动化功能,对于本功能有需要的朋友,可以根据自己的需要定制个性化功能,将制作过程逐步完善。作者:黄万博笔记。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途)
excel抓取网页动态数据,实现数据自动转换自动求和,可以适用于demo、数据分析展示等用途。小黑大神说:excel数据分析与展示要求只对数据量不太大,时间不长的情况下。方法一:手动截取每个阶段的demo字段数据,将不需要的字段用删除功能删除。方法二:使用代码识别,利用select的功能实现数据分析。
今天要实现的功能有3个方面。1.定制数据源的时间2.对需要自动转换的字段进行批量截取3.对需要自动求和的数据同时自动求和。具体做法如下图,功能说明如下:1.打开一个excel表格,这里建立了2个字段和1个截取时间字段。截取时间就是做数据的时间(1年12个月),定义几个字段:(。
1)时间范围,抓取的数据从0101001到时间范围内所有的动态字段名称。
2)统计方式,定义需要的字段的统计方式,比如均值、中位数、异常值等,统计的方式完成的可视化视觉效果如下图。
3)计算标准,定义计算标准,比如年均值,季均值等。2.进入自动分析界面,从第一个阶段开始抓取数据,遇到疑问首先选择方法一的定制字段方法,手动记录到下一阶段中。3.从第二个阶段开始,对每个需要自动求和的字段,用代码识别后自动计算,这时候要注意的是,不要偷懒,计算次数要尽量控制在数量上,比如我要求两个字段,就要有2次识别。
4.然后开始下一阶段数据的抓取。5.数据抓取完成后进入查询界面,对所有对应表的数据,执行“数据自动对比”这个sql命令,这个命令实现自动求和的目的,虽然最后这个功能自动给转换成了db。如果要对字段进行其他判断,比如用户加入公司日期、职位等信息,那也可以通过代码做判断:代码实现大致如下图:总结:这里用到的是excel自动化功能,对于本功能有需要的朋友,可以根据自己的需要定制个性化功能,将制作过程逐步完善。作者:黄万博笔记。
excel抓取网页动态数据(参见【专题】如何用浏览器抓取网页动态数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-15 02:04
excel抓取网页动态数据,例如http请求,客户端上下文管理等等;参见我在另一个问题的回答。
爬虫工具可以解决,可以借助云服务器、爬虫管理工具、运维工具等。真正能实现爬虫工具,则需要足够成熟的工具。例如,可以借助爬虫开发平台,实现爬虫在浏览器中下载各种格式的文件。可以在浏览器中建立浏览器脚本,对获取内容进行转码、加密和解密,也可以对用户输入进行验证。目前,基于浏览器的数据采集方法已经成熟,参见【专题】如何用浏览器抓取数据?本人目前正在研究qq邮箱数据,将打开邮件的每个文本分析原理和实现细节,结合在qq邮箱邮件中对文本进行抓取,研究得出邮件邮件内容是如何在聊天机器人中进行解码和解码过程与传统邮件不同的细节。这种方法可以不需要采用爬虫工具,使用在浏览器中建立脚本,解析邮件下的内容,即可实现对邮件内容的抓取。
excel我就想说另请高明吧。我觉得对于一般的人来说这是能做的事情。你要是要爬虫程序,可以用python,java之类的语言。要是要爬取交易明细数据或者是简单的网站数据,我觉得你可以从数据采集和分析这两块入手,有简单的模型和工具可以完成对非常量级数据的采集,再将数据分析的模型和方法作为数据输出,这也是不错的。这就是传统软件的方式。当然你要做网站数据分析就要设计模型,并以此算法开发相应软件了。 查看全部
excel抓取网页动态数据(参见【专题】如何用浏览器抓取网页动态数据?)
excel抓取网页动态数据,例如http请求,客户端上下文管理等等;参见我在另一个问题的回答。
爬虫工具可以解决,可以借助云服务器、爬虫管理工具、运维工具等。真正能实现爬虫工具,则需要足够成熟的工具。例如,可以借助爬虫开发平台,实现爬虫在浏览器中下载各种格式的文件。可以在浏览器中建立浏览器脚本,对获取内容进行转码、加密和解密,也可以对用户输入进行验证。目前,基于浏览器的数据采集方法已经成熟,参见【专题】如何用浏览器抓取数据?本人目前正在研究qq邮箱数据,将打开邮件的每个文本分析原理和实现细节,结合在qq邮箱邮件中对文本进行抓取,研究得出邮件邮件内容是如何在聊天机器人中进行解码和解码过程与传统邮件不同的细节。这种方法可以不需要采用爬虫工具,使用在浏览器中建立脚本,解析邮件下的内容,即可实现对邮件内容的抓取。
excel我就想说另请高明吧。我觉得对于一般的人来说这是能做的事情。你要是要爬虫程序,可以用python,java之类的语言。要是要爬取交易明细数据或者是简单的网站数据,我觉得你可以从数据采集和分析这两块入手,有简单的模型和工具可以完成对非常量级数据的采集,再将数据分析的模型和方法作为数据输出,这也是不错的。这就是传统软件的方式。当然你要做网站数据分析就要设计模型,并以此算法开发相应软件了。
excel抓取网页动态数据(excel抓取网页动态数据,目的是什么?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-08 00:00
excel抓取网页动态数据,目的是抓取网页所有用户信息,例如:用户名、性别、发布者id、评论历史、职位等关键信息;(本文使用python3语言)首先我们需要下载网页文件:python3.6:在c:\users\caoda\documents\python364下如何才能下载保存文件:->选择按照chrome下下载python3.7以上版本->选择选择高速下载(2.25g)->选择->下载。
网上找到的:如何安装软件:下载安装;pip;pip3;numpy。try:先从chrome浏览器下载网页,然后用python3.7pip3,执行到loggingmethod选择json-to-html,在下一步选择解析json数据,下一步:安装excelparser包,如果要下载的网页是excel,你也需要安装,等安装完毕,可以执行excel下的api;如果是java类库(java.lang.request);如果是其他类库(java.util.excel);需要安装json文件转换成htmlexcelparser和json文件转换成jsonparser第一步解析字符串excelparser的api;(可使用pip3)。
先下载trunkhelper库,trunkhelper类库是python中库可以方便地从网页获取html或xml字符串。用下面这句可以下载:pip3installtrunkhelper如果不是excel文件,则需要解析的数据存放在python这个文件夹,在这个文件夹里面执行pip3,如果有安装excelmacros包,则仅需要pip3installexcelmacros即可。
pip3installexcelmacros第二步:解析html--->获取信息并打印解析网页所要用到的python库有:网页分析:python3,python3macros网页解析:python3macros解析需要的库有:selenium网页抓取--->打印html信息使用selenium,可以抓取网页上的每一个用户,每一个用户的标题、评论时间等信息,如果你需要抓取每一个用户的标题、评论,还要用到python3,可以参考下面这篇python3抓取网页信息。
-ny63905-1.html,还有flask脚本;selenium抓取所需要用到的python库有:django框架;flask框架;gevent框架。第三步:格式化数据,打印信息;保存数据到本地到本地到本地文件:可以使用numpy,forkdata方法,将模型转换成csv格式数据,forkdata可以实现批量导入数据。
例如:try:使用jsonexcel数据打印excel数据信息等方法,获取需要的数据并打印,获取excel数据信息等方法。有意可以多种方法试一下,多谢各位同学的指点。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,目的是什么?-八维教育)
excel抓取网页动态数据,目的是抓取网页所有用户信息,例如:用户名、性别、发布者id、评论历史、职位等关键信息;(本文使用python3语言)首先我们需要下载网页文件:python3.6:在c:\users\caoda\documents\python364下如何才能下载保存文件:->选择按照chrome下下载python3.7以上版本->选择选择高速下载(2.25g)->选择->下载。
网上找到的:如何安装软件:下载安装;pip;pip3;numpy。try:先从chrome浏览器下载网页,然后用python3.7pip3,执行到loggingmethod选择json-to-html,在下一步选择解析json数据,下一步:安装excelparser包,如果要下载的网页是excel,你也需要安装,等安装完毕,可以执行excel下的api;如果是java类库(java.lang.request);如果是其他类库(java.util.excel);需要安装json文件转换成htmlexcelparser和json文件转换成jsonparser第一步解析字符串excelparser的api;(可使用pip3)。
先下载trunkhelper库,trunkhelper类库是python中库可以方便地从网页获取html或xml字符串。用下面这句可以下载:pip3installtrunkhelper如果不是excel文件,则需要解析的数据存放在python这个文件夹,在这个文件夹里面执行pip3,如果有安装excelmacros包,则仅需要pip3installexcelmacros即可。
pip3installexcelmacros第二步:解析html--->获取信息并打印解析网页所要用到的python库有:网页分析:python3,python3macros网页解析:python3macros解析需要的库有:selenium网页抓取--->打印html信息使用selenium,可以抓取网页上的每一个用户,每一个用户的标题、评论时间等信息,如果你需要抓取每一个用户的标题、评论,还要用到python3,可以参考下面这篇python3抓取网页信息。
-ny63905-1.html,还有flask脚本;selenium抓取所需要用到的python库有:django框架;flask框架;gevent框架。第三步:格式化数据,打印信息;保存数据到本地到本地到本地文件:可以使用numpy,forkdata方法,将模型转换成csv格式数据,forkdata可以实现批量导入数据。
例如:try:使用jsonexcel数据打印excel数据信息等方法,获取需要的数据并打印,获取excel数据信息等方法。有意可以多种方法试一下,多谢各位同学的指点。
excel抓取网页动态数据( 微信朋友圈数据入口搞定了怎么办?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-07 19:25
微信朋友圈数据入口搞定了怎么办?(图)
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认为全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信网页版,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如如下图所示。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明我们需要在程序中处理JSON格式的数据。
3、点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放到JSON在线解析器中,如下图:
可以看到 Moments 的数据存储在 paras /data 节点下。
接下来,我们将编写一个程序来捕获数据。然后继续深入。
四、代码实现
1、 修改 Scrapy 项目中的 items.py 文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
2、要修改实现爬虫逻辑的主文件moment.py,必须先导入模块,尤其是items.py中的WeixinMomentItem类。要特别小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引都必须是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时间报一个错误。
l 还需要在请求参数中添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了,在命令行中输入
爬行时刻 -o moment.json
, 然后就可以得到Moments的数据了,控制台输出的信息如下图所示。
7、 之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
8、嗯,你真的没有看错。里面得到的数据实在是看不懂,不过这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:
爬行时刻 -o moment.json -s FEED_EXPORT_ENCODING=utf-8,
至此,可以看到编码问题已经解决,如下图所示。
查看全部
excel抓取网页动态数据(
微信朋友圈数据入口搞定了怎么办?(图)
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认为全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入微信网页版,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
,等待生成Scrapy爬虫项目。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”标签,然后勾选“保存日志”,即保存日志,如如下图所示。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明我们需要在程序中处理JSON格式的数据。
3、点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应的是服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放到JSON在线解析器中,如下图:
可以看到 Moments 的数据存储在 paras /data 节点下。
接下来,我们将编写一个程序来捕获数据。然后继续深入。
四、代码实现
1、 修改 Scrapy 项目中的 items.py 文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
2、要修改实现爬虫逻辑的主文件moment.py,必须先导入模块,尤其是items.py中的WeixinMomentItem类。要特别小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引都必须是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时间报一个错误。
l 还需要在请求参数中添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了,在命令行中输入
爬行时刻 -o moment.json
, 然后就可以得到Moments的数据了,控制台输出的信息如下图所示。
7、 之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
8、嗯,你真的没有看错。里面得到的数据实在是看不懂,不过这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:
爬行时刻 -o moment.json -s FEED_EXPORT_ENCODING=utf-8,
至此,可以看到编码问题已经解决,如下图所示。
excel抓取网页动态数据( Python软件工具和2020最新入门到实战教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 16:20
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合的。
主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。 查看全部
excel抓取网页动态数据(
Python软件工具和2020最新入门到实战教程(上))
PS:无论你是零基础还是基础,都可以获得自己对应的学习包!包括Python软件工具和2020最新入门实战教程。加群695185429免费获取。
5月1日放假学习Python爬取动态网页信息的相关操作,结合封面参考书和网上教程写出能满足需求的代码。从我第一次接触python开始,过程就经历了很多波折。为了避免以后出现问题,我找不到相关信息来创建这篇文章。
准备工具:
Python 3.8 Google Chrome 浏览器 Googledriver
测试 网站:
1.思想集(#cb)
考试前准备:
1. 配置python运行的环境变量,参考链接()
*本次测试主要采用两种方式抓取动态网页数据,一种是requests和json解析的方式;另一种是硒的方法。requests 方法速度快,但有些元素的链接信息无法捕获;selenium 方法通过模拟打开浏览器来捕获数据。速度比较慢,因为需要打开浏览器,但是可以爬取的信息比较慢。综合的。
主要内容如下:(网站中的部分可转债数据)
以请求方式获取网站信息:
需要安装的 Python 脚本:Requests
安装方法:以管理员身份运行cmd;输入pip install requests命令,安装成功后会有提示。如果安装失败一次,安装几次
(前提相关端口没有关闭)。如果pip版本不是最新的,会提醒你更新pip版本,pip的环境变量也要设置好。设置方法参考python的设置方法。
请求获取代码如下:
import requests
import json
url='https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___'
return_data = requests.get(url,verify = False)
js=return_data.json()
for i in js['rows']:
print(i['id']+" "+i['cell']['bond_nm']+" "+i['cell']['price'])
最终结果如下:
注意两点:
找到正确的url:chrome打开头脑风暴记录网站 (#cb)。点击F12按钮,在弹出的开发工具窗口中选择network,然后选择XHR,点击F5刷新。在名称栏中一一点击,找到您需要的XHR。通过预览,我们可以发现“?__jsl=LST”对应的XHR就是我们要找的,在headers中可以找到对应的url。
json 转换请求的数据格式,方便数据查找。json格式转换后,请求的数据格式与预览的格式一致。如果要定位“国轩转债”一栏的数据,使用代码js['rows']['cell']['bond_nm']*selenium抓取网页数据:
需要安装的Python脚本:selenium(安装方法参考requests installation)
配置浏览器对应的webdriver。以chrome为例,下载chrome版本对应的驱动(地址栏输入chrome://version,回车查看chrome版本)。放在chrome安装的文件夹下,设置环境变量。
selenium爬取代码如下:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url1='https://www.jisilu.cn/data/cbnew/#cb'
bes=driver.get(url1)
time.sleep(5) #增加延时命令,等待元素加载
driver.find_element_by_tag_name("tr").click() #增加延时,等待元素加载
table_tr_list=driver.find_element_by_xpath("//*[@id='flex_cb']").find_elements_by_tag_name("tr") #后面一个element改成elements
for tr in table_tr_list:
if len(tr.get_attribute('id'))>0:
print(tr.find_element_by_xpath("//*[@id=%d]/td[1]/a"%(int(tr.get_attribute('id')))).text+" "+tr.find_element_by_xpath("//*[@id=%d]/td[2]"%(int(tr.get_attribute('id')))).text)
driver.quit()
操作结果如下:
注意三点:
1、 必须添加一个延迟命令(time.sleep(5)),否则可能会出现找不到元素的错误(NoSuchElementException)
2、 使用find_element_by_xpath时,可以在web开发者中右键复制xpath,确认元素的路径。
3、 发送ID时,将字符转为数值,注意清除空字符
捕获的数据也可以通过python保存在excel中。
excel抓取网页动态数据( 微软发布3D可视化工具GeoFlow:加载项形式运行在Excel上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-06 16:18
微软发布3D可视化工具GeoFlow:加载项形式运行在Excel上)
微软今天发布了 3D 可视化工具 GeoFlow 的公共预览版,它可以作为插件在 Excel 上运行。当前支持的版本是 Excel 2013(带有 office 365 ProPlus)或 Office Professional Plus 2013。该工具允许用户创建、浏览应用于数字地图的时间敏感数据并与之交互。
方法是用户将所有需要的数据输入Excel,然后GeoFlow可以将数据转换成3D模型并与他人共享。
GeoFlow 最多可支持 100 万行工作簿数据,同时支持 Excel Data Model 和 PowerPivot 模型,实现 Bing Maps 支持区域的可视化。
GeoFlow 支持的可视化类型包括列类型、类似于热图的二维补丁以及微软所谓的气泡图。
然后地图可以动态显示这些时间敏感数据的可视化。例如,一些应用程序开源,以显示前往某个城市特定区域的人数,或海洋特定区域清理油污的进度。
此外,用户还可以捕捉GeoFlow的“场景”,做出电影般的演示,然后导出分享给他人。
该产品源于微软研究院的世界望远镜(WWT)项目。世界望远镜计划于 2008 年启动,旨在为年轻的天文学家提供一种通过 PC 观察太空的方法。用户可以在WWT中通过平移和缩放浏览外太空,了解相关故事,学习和欣赏星云图片等。
近年来,地理空间数据和瞬态数据呈现出不断扩大的趋势,这促使团队研究如何使用工具来帮助了解这些对业务产生影响的数据趋势。
微软研究院首席研究员 Curtis Wong 认为,将动态、交互式的数据可视化引入商业世界一直是业界追求的目标。既然微软甚至可以将宇宙形象化,其他的事情就自然而然了。恰巧微软负责 Excel 的首席项目经理 Scott Ruble 联系了 WWT 项目组,想看看他们的成果能否融入到自己的项目中,最终促成了 GeoFlow 的诞生。
有兴趣并安装了Excel 2013的朋友可以在这里下载。 查看全部
excel抓取网页动态数据(
微软发布3D可视化工具GeoFlow:加载项形式运行在Excel上)
微软今天发布了 3D 可视化工具 GeoFlow 的公共预览版,它可以作为插件在 Excel 上运行。当前支持的版本是 Excel 2013(带有 office 365 ProPlus)或 Office Professional Plus 2013。该工具允许用户创建、浏览应用于数字地图的时间敏感数据并与之交互。
方法是用户将所有需要的数据输入Excel,然后GeoFlow可以将数据转换成3D模型并与他人共享。
GeoFlow 最多可支持 100 万行工作簿数据,同时支持 Excel Data Model 和 PowerPivot 模型,实现 Bing Maps 支持区域的可视化。
GeoFlow 支持的可视化类型包括列类型、类似于热图的二维补丁以及微软所谓的气泡图。
然后地图可以动态显示这些时间敏感数据的可视化。例如,一些应用程序开源,以显示前往某个城市特定区域的人数,或海洋特定区域清理油污的进度。
此外,用户还可以捕捉GeoFlow的“场景”,做出电影般的演示,然后导出分享给他人。
该产品源于微软研究院的世界望远镜(WWT)项目。世界望远镜计划于 2008 年启动,旨在为年轻的天文学家提供一种通过 PC 观察太空的方法。用户可以在WWT中通过平移和缩放浏览外太空,了解相关故事,学习和欣赏星云图片等。
近年来,地理空间数据和瞬态数据呈现出不断扩大的趋势,这促使团队研究如何使用工具来帮助了解这些对业务产生影响的数据趋势。
微软研究院首席研究员 Curtis Wong 认为,将动态、交互式的数据可视化引入商业世界一直是业界追求的目标。既然微软甚至可以将宇宙形象化,其他的事情就自然而然了。恰巧微软负责 Excel 的首席项目经理 Scott Ruble 联系了 WWT 项目组,想看看他们的成果能否融入到自己的项目中,最终促成了 GeoFlow 的诞生。
有兴趣并安装了Excel 2013的朋友可以在这里下载。

