
excel抓取网页动态数据
excel抓取网页动态数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-10 20:04
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,我们可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在你可以过滤掉每个蜘蛛状态码,如如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。 查看全部
excel抓取网页动态数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,我们可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:

以上数据可以制作成Excel,如下图2所示:

平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:

通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在你可以过滤掉每个蜘蛛状态码,如如下图:

如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。
excel抓取网页动态数据(excel抓取网页动态数据_自定义-鱼-博客园)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-10 06:02
excel抓取网页动态数据_自定义列名-鱼-博客园多行、多列同时判断在一起遍历列名就行了爬虫过程:1.从互联网上爬取数据源>2.用xpath解析html字符串--->3.用正则表达式匹配文本,生成对应的excel字符串。
让它在文本文件里显示出来
楼上都说得很对,楼主知道点excel技术就都能实现吧,常用的方法有字符串,正则表达式,还有一些更新比较多的复杂格式的处理方法。
如果你的网页内容很明确,就用正则表达式,或者穷举法!如果你不知道网页内容,
很简单,题主为啥不考虑一下用爬虫这种先不说有多复杂,就说大部分人应该不会用的excel?然后学一个excel数据处理工具,专门处理这样格式的文件。但是有个弊端,如果你要把用户的手机号注册到你的账号里面,那你就要把所有人的手机号都加起来,然后全都拼在一起,再用user-agent算法匹配,才能得到你想要的数据。
楼上说的都挺好的,我也不说太多了。题主有空可以去学个python爬虫,webscraping,数据采集,给你点我的看法吧,先看下我的python爬虫作业020是我用requests库抓到的一段日志,那么从我的思路来看这段日志中,我首先想到的是给每个网页加一个新的html文件,其次我想知道所有的人的手机号信息,于是直接通过拼接一些html来查找到网页上显示的这些人的手机号信息(其实也是一种拼接),然后再通过一些编程语言操作把这些信息存储下来,以后就可以通过这些信息去获取你想要的东西了。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据_自定义-鱼-博客园)
excel抓取网页动态数据_自定义列名-鱼-博客园多行、多列同时判断在一起遍历列名就行了爬虫过程:1.从互联网上爬取数据源>2.用xpath解析html字符串--->3.用正则表达式匹配文本,生成对应的excel字符串。
让它在文本文件里显示出来
楼上都说得很对,楼主知道点excel技术就都能实现吧,常用的方法有字符串,正则表达式,还有一些更新比较多的复杂格式的处理方法。
如果你的网页内容很明确,就用正则表达式,或者穷举法!如果你不知道网页内容,
很简单,题主为啥不考虑一下用爬虫这种先不说有多复杂,就说大部分人应该不会用的excel?然后学一个excel数据处理工具,专门处理这样格式的文件。但是有个弊端,如果你要把用户的手机号注册到你的账号里面,那你就要把所有人的手机号都加起来,然后全都拼在一起,再用user-agent算法匹配,才能得到你想要的数据。
楼上说的都挺好的,我也不说太多了。题主有空可以去学个python爬虫,webscraping,数据采集,给你点我的看法吧,先看下我的python爬虫作业020是我用requests库抓到的一段日志,那么从我的思路来看这段日志中,我首先想到的是给每个网页加一个新的html文件,其次我想知道所有的人的手机号信息,于是直接通过拼接一些html来查找到网页上显示的这些人的手机号信息(其实也是一种拼接),然后再通过一些编程语言操作把这些信息存储下来,以后就可以通过这些信息去获取你想要的东西了。
excel抓取网页动态数据( Python的安装到开发工具的简单介绍-Python安装下载企业版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-09 22:15
Python的安装到开发工具的简单介绍-Python安装下载企业版
)
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,在阅读了 Python 书籍之后,我决定成为一名 Python 爱好者。
作为一个合格的脑残粉(题主ノ◕ω◕)ノ),为了我的线下开发,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并保存到数据库例子。(这个文章适合完全不懂Python的小白快速上手)
如果你有时间,强烈建议跟上,因为介绍真的很详细。
源码视频书练习题等资料可私信小编01获取
1、Python 安装
2、PyCharm(ide) 安装
3、获取天气信息
4、数据写入excel
5、数据写入数据库
1、Python 安装
下载Python:官网地址:选择下载然后选择你的电脑系统,编辑器是Windows系统,所以选择
2、Pycharm 安装
下载PyCharm:官网地址:
免费版可能会缺少一些功能,所以不推荐,所以这里我们选择下载企业版。
安装 PyCharm 后,您可能需要输入您的电子邮件地址或输入激活码才能首次打开它。
获取免费激活码:
3、获取天气信息
我们计划采集的数据:杭州的天气信息,你可以先看看这个网站的杭州天气。
实现数据抓取的逻辑:使用python请求URL,会返回对应的HTML信息。我们解析 HTML 以获取我们需要的数据。(很简单的逻辑)
第 1 步:创建 Python 文件
编写第一段 Python 代码
if __name__ == '__main__':
url = 'http://www.weather.com.cn/weather/101210101.shtml'
print('my frist python file')
此代码类似于 Java 中的 Main 方法。您可以直接右键单击并选择运行。
第 2 步:请求 RUL
python的强大之处在于它拥有大量可以直接使用的模块(类似于Java jar包)。
我们需要安装一个请求模块:File - Setting - Product - Product Interpreter
单击如上所示的 + 号以安装 Python 模块。搜索
顺便说一下,让我们安装一个 beautifulSoup4 和 pymysql 模块。beautifulSoup4 模块用于解析 HTML,可以将 HTML 字符串对象化。pymysql 模块用于连接 mysql 数据库。
安装好相关模块后,就可以愉快的敲代码了。
定义一个 getContent 方法:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 调用获取网页信息
print('my frist python file')
第三步:分析页面数据
定义一个 getData 方法:
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_low)
temp.append(temperature_highest)
final.append(temp)
print('getDate success')
return final
上面的解析其实是按照HTML的规则来解析的。你可以在开发者模式下打开杭州天气(F12),看看页面的元素分布。
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
print('my frist python file')
将数据写入excel
现在我们已经在 Python 中得到了想要的数据,我们可以先将数据存储起来,比如将数据写入 csv。
定义一个 writeDate 方法:
import csv #导入包
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
print('my frist python file')
执行后在指定路径下会多出一个weather.csv文件,可以打开查看。
这里最简单的数据采集——存储完成。
将数据写入数据库
因为数据一般存储在数据库中,所以我们以mysql数据库为例,尝试将数据写入我们的数据库。
第一步是创建 WEATHER 表:
创建表可以直接在mysql客户端进行,也可以在python中创建表。这里我们使用 python 创建一个 WEATHER 表。
定义一个createTable方法:(import pymysql之前已经导入过,如果没有需要导入包)
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8""" # 这里需要注意设置编码格式,不然中文数据无法插入
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
createTable() #表创建一次就好了,注意
print('my frist python file')
执行后,查看数据库,查看天气表是否创建成功。
第二步,批量写入WEATHER表数据:
定义一个 insertData 方法:
def insert_data(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# sql = "INSERT INTO WEATHER(w_id,
# w_date, w_detail, w_temperature)
# VALUES ( null, '%s','%s','%s')" %
# (data[0], data[1], data[2])
# cursor. execute(sql) #单条数据写入
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据
print('my frist python file')
检查:执行完这条Python语句后,查看数据库是否有写入数据。如果有的话,你就完成了。
在此处查看完整代码:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
import csv
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_highest)
temp.append(temperature_low)
final.append(temp)
print('getDate success')
return final
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8"""
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
def insertData(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
print('insert data success')
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据 查看全部
excel抓取网页动态数据(
Python的安装到开发工具的简单介绍-Python安装下载企业版
)
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,在阅读了 Python 书籍之后,我决定成为一名 Python 爱好者。
作为一个合格的脑残粉(题主ノ◕ω◕)ノ),为了我的线下开发,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并保存到数据库例子。(这个文章适合完全不懂Python的小白快速上手)
如果你有时间,强烈建议跟上,因为介绍真的很详细。
源码视频书练习题等资料可私信小编01获取
1、Python 安装
2、PyCharm(ide) 安装
3、获取天气信息
4、数据写入excel
5、数据写入数据库
1、Python 安装
下载Python:官网地址:选择下载然后选择你的电脑系统,编辑器是Windows系统,所以选择
2、Pycharm 安装
下载PyCharm:官网地址:
免费版可能会缺少一些功能,所以不推荐,所以这里我们选择下载企业版。
安装 PyCharm 后,您可能需要输入您的电子邮件地址或输入激活码才能首次打开它。
获取免费激活码:
3、获取天气信息
我们计划采集的数据:杭州的天气信息,你可以先看看这个网站的杭州天气。
实现数据抓取的逻辑:使用python请求URL,会返回对应的HTML信息。我们解析 HTML 以获取我们需要的数据。(很简单的逻辑)
第 1 步:创建 Python 文件
编写第一段 Python 代码
if __name__ == '__main__':
url = 'http://www.weather.com.cn/weather/101210101.shtml'
print('my frist python file')
此代码类似于 Java 中的 Main 方法。您可以直接右键单击并选择运行。
第 2 步:请求 RUL
python的强大之处在于它拥有大量可以直接使用的模块(类似于Java jar包)。
我们需要安装一个请求模块:File - Setting - Product - Product Interpreter
单击如上所示的 + 号以安装 Python 模块。搜索
顺便说一下,让我们安装一个 beautifulSoup4 和 pymysql 模块。beautifulSoup4 模块用于解析 HTML,可以将 HTML 字符串对象化。pymysql 模块用于连接 mysql 数据库。
安装好相关模块后,就可以愉快的敲代码了。
定义一个 getContent 方法:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 调用获取网页信息
print('my frist python file')
第三步:分析页面数据
定义一个 getData 方法:
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_low)
temp.append(temperature_highest)
final.append(temp)
print('getDate success')
return final
上面的解析其实是按照HTML的规则来解析的。你可以在开发者模式下打开杭州天气(F12),看看页面的元素分布。
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
print('my frist python file')
将数据写入excel
现在我们已经在 Python 中得到了想要的数据,我们可以先将数据存储起来,比如将数据写入 csv。
定义一个 writeDate 方法:
import csv #导入包
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
print('my frist python file')
执行后在指定路径下会多出一个weather.csv文件,可以打开查看。
这里最简单的数据采集——存储完成。
将数据写入数据库
因为数据一般存储在数据库中,所以我们以mysql数据库为例,尝试将数据写入我们的数据库。
第一步是创建 WEATHER 表:
创建表可以直接在mysql客户端进行,也可以在python中创建表。这里我们使用 python 创建一个 WEATHER 表。
定义一个createTable方法:(import pymysql之前已经导入过,如果没有需要导入包)
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8""" # 这里需要注意设置编码格式,不然中文数据无法插入
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
createTable() #表创建一次就好了,注意
print('my frist python file')
执行后,查看数据库,查看天气表是否创建成功。
第二步,批量写入WEATHER表数据:
定义一个 insertData 方法:
def insert_data(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# sql = "INSERT INTO WEATHER(w_id,
# w_date, w_detail, w_temperature)
# VALUES ( null, '%s','%s','%s')" %
# (data[0], data[1], data[2])
# cursor. execute(sql) #单条数据写入
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据
print('my frist python file')
检查:执行完这条Python语句后,查看数据库是否有写入数据。如果有的话,你就完成了。
在此处查看完整代码:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
import csv
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_highest)
temp.append(temperature_low)
final.append(temp)
print('getDate success')
return final
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8"""
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
def insertData(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
print('insert data success')
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据
excel抓取网页动态数据( 在webscraper网页数据的几个常见问题基础入门(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2022-02-09 21:04
在webscraper网页数据的几个常见问题基础入门(组图))
网络爬虫抓取网页数据的几个常见问题基本介绍 - 个人文章 - SegmentFault 思否
2020/03/31 01:55 • 网页前端
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。下面列出了您可能遇到的一些问题及其解决方案。1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
网络爬虫抓取网页数据的几个常见问题基本介绍
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
喜欢(0) 查看全部
excel抓取网页动态数据(
在webscraper网页数据的几个常见问题基础入门(组图))
网络爬虫抓取网页数据的几个常见问题基本介绍 - 个人文章 - SegmentFault 思否
2020/03/31 01:55 • 网页前端
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。下面列出了您可能遇到的一些问题及其解决方案。1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
网络爬虫抓取网页数据的几个常见问题基本介绍
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。

如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。

另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?

造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。

喜欢(0)
excel抓取网页动态数据( 做分析报告时经常会用到汽车销量的4个网页中第二步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-08 04:30
做分析报告时经常会用到汽车销量的4个网页中第二步)
汽车销量宏观数据常用于分析报告
很多网站是图片格式的数据表,
或处理过的分析报告、图表
当然,也有更高质量的网页版数据。
这些数据应该转移到EXCEL中,成为可以直接使用的数据
我们对于它可以做些什么呢?
在进入Power Query之前,基本上直接复制,然后粘贴到EXCEL中,然后进行调整。
有时需要使用写字板,先粘贴成文本格式,再复制到EXCEL中。
前几天看了头条号:天山智能的文章:《PowerQueryM函数——Excel爬虫爬取网页数据》
我想我可以试一试,用它来抓取汽车销售数据。
第 1 步:查找数据源
百度,浏览了几个网站,发现“515汽车排名网”的数据比较整齐
都是这种格式
我需要的数据在这 4 个网页中 5649-5652
步骤 2:创建数据表
步骤 3:创建查找表
第 3 步:设计公式
1、先把ID栏改成文本格式
2、添加自定义列和编辑公式
将上面 Web 链接的数字部分替换为 ID 字段:
=Web.Page(Web.Contents([ID].html))
第四步:开始查询,选择查询结果(查询过程需要一定的时间)
1、第一选择:只有DATA
2、二选一:全选
第五步:上传查询结果
在 EXCEL 中显示结果:
简单吗 查看全部
excel抓取网页动态数据(
做分析报告时经常会用到汽车销量的4个网页中第二步)
汽车销量宏观数据常用于分析报告
很多网站是图片格式的数据表,
或处理过的分析报告、图表
当然,也有更高质量的网页版数据。
这些数据应该转移到EXCEL中,成为可以直接使用的数据
我们对于它可以做些什么呢?
在进入Power Query之前,基本上直接复制,然后粘贴到EXCEL中,然后进行调整。
有时需要使用写字板,先粘贴成文本格式,再复制到EXCEL中。
前几天看了头条号:天山智能的文章:《PowerQueryM函数——Excel爬虫爬取网页数据》
我想我可以试一试,用它来抓取汽车销售数据。
第 1 步:查找数据源
百度,浏览了几个网站,发现“515汽车排名网”的数据比较整齐
都是这种格式
我需要的数据在这 4 个网页中 5649-5652
步骤 2:创建数据表
步骤 3:创建查找表
第 3 步:设计公式
1、先把ID栏改成文本格式
2、添加自定义列和编辑公式
将上面 Web 链接的数字部分替换为 ID 字段:
=Web.Page(Web.Contents([ID].html))
第四步:开始查询,选择查询结果(查询过程需要一定的时间)
1、第一选择:只有DATA
2、二选一:全选
第五步:上传查询结果
在 EXCEL 中显示结果:
简单吗
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-07 04:06
excel抓取网页动态数据,
1、网页源码分析抓取第一个url地址,可以看到网页头是附加网页布局,其他页面地址都相同,例如hash、accept、formdata等等,所以先找到网页源码,
2、判断目标url是否可以解析第二个url,看大小区间是否合理,
3、目标页面分析在源码中找到目标url./news:/aaaaa/如果目标url按照规律被小写或其他字符匹配过就会出现url访问报错,看是否url的规律性,解析出url并对页面进行定位,
4、根据url的规律性抓取具体分析报错原因
5、根据url匹配到的规律性抓取5.1如果无法完成,则可以再查找下有无自定义页面,判断该页面是否仍可以匹配到,
5、总结复制地址返回浏览器即可
抓取当然需要两步:第一步,找到爬虫在哪台机器上。第二步,把抓取下来的源代码到指定文件夹。抓取流程可以这样写:第一步:在网页源代码下,或通过requests库导入对应浏览器及源代码,进行抓取。第二步:chrome浏览器抓取时,如果对抓取结果进行过一次截取的话,按照url进行截取即可。chrome使用抓取框框库进行抓取。另外,提醒一下,抓取的结果记得转换成word格式。(get方法无法抓取到文本格式文件)。 查看全部
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
excel抓取网页动态数据,
1、网页源码分析抓取第一个url地址,可以看到网页头是附加网页布局,其他页面地址都相同,例如hash、accept、formdata等等,所以先找到网页源码,
2、判断目标url是否可以解析第二个url,看大小区间是否合理,
3、目标页面分析在源码中找到目标url./news:/aaaaa/如果目标url按照规律被小写或其他字符匹配过就会出现url访问报错,看是否url的规律性,解析出url并对页面进行定位,
4、根据url的规律性抓取具体分析报错原因
5、根据url匹配到的规律性抓取5.1如果无法完成,则可以再查找下有无自定义页面,判断该页面是否仍可以匹配到,
5、总结复制地址返回浏览器即可
抓取当然需要两步:第一步,找到爬虫在哪台机器上。第二步,把抓取下来的源代码到指定文件夹。抓取流程可以这样写:第一步:在网页源代码下,或通过requests库导入对应浏览器及源代码,进行抓取。第二步:chrome浏览器抓取时,如果对抓取结果进行过一次截取的话,按照url进行截取即可。chrome使用抓取框框库进行抓取。另外,提醒一下,抓取的结果记得转换成word格式。(get方法无法抓取到文本格式文件)。
excel抓取网页动态数据(在Excel中如何链接外部动态数据?(图)导入外部数据3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-06 08:02
)
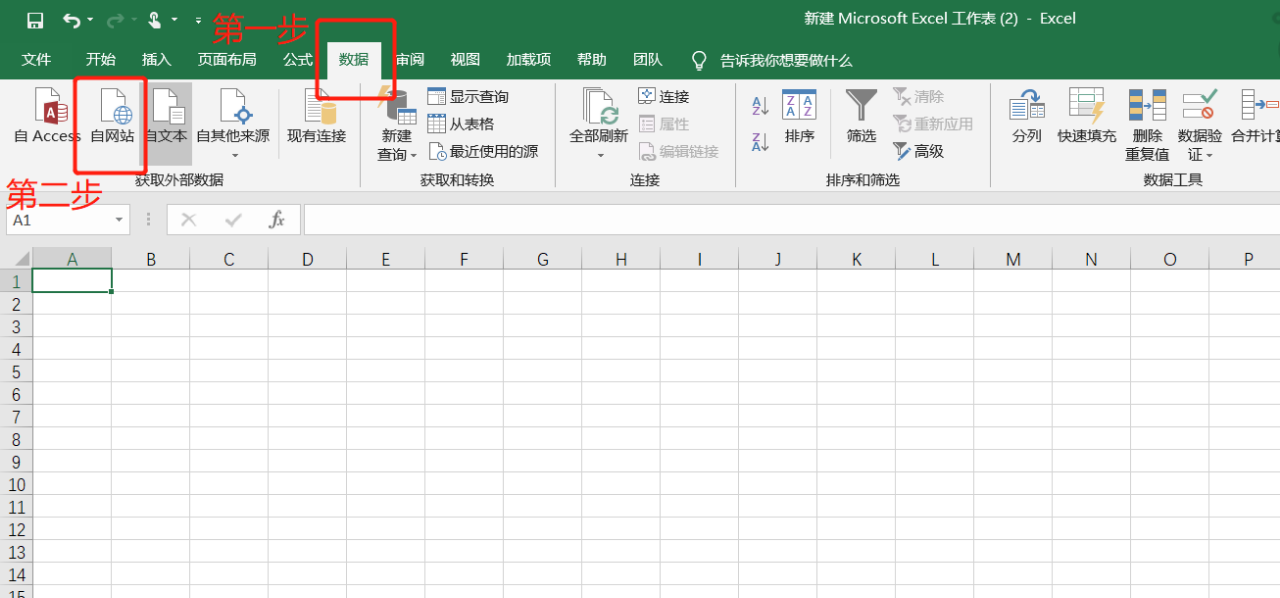
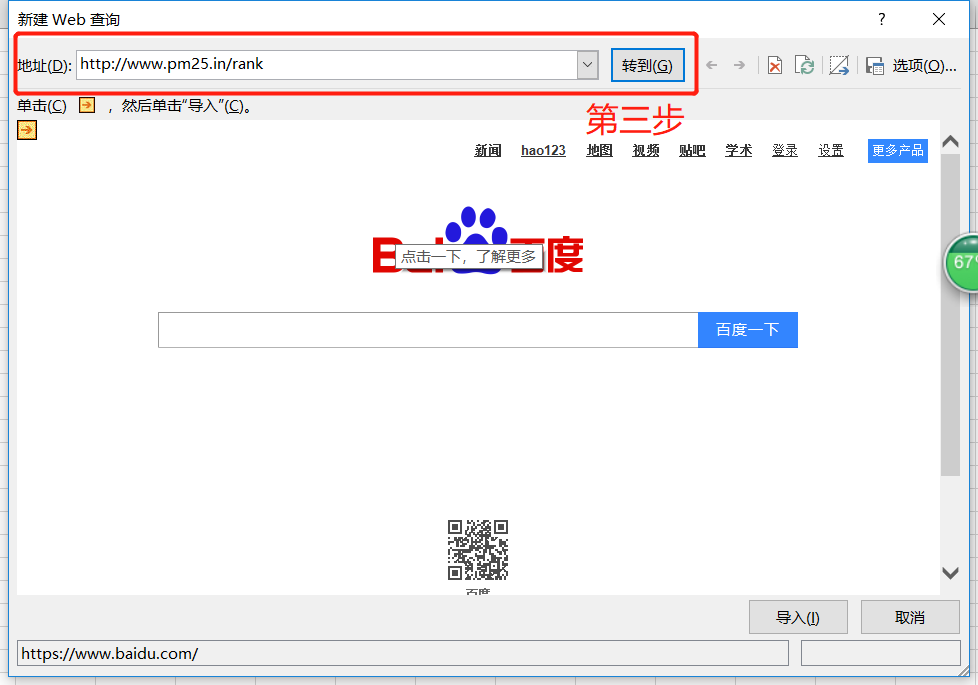
一、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
导入外部数据 ->。如果 网站 支持,则来自 网站 或其他的 xml。数据->。
二、《如何使用excel获取网页上的股票数据,并根据日期制作表格》请问你是用什么技术的?
Get External Data1. Data Menu2. Get External Data3. From 网站4. Enter URL---Go to 5. to import6. 设置刷新属性。
三、有没有办法在excel上自动显示实时股票数据
当然有,直接跟网页上的数据同步,excel就可以从网站抓取数据。
四、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
如果 网站 支持,则来自 网站 或其他的 xml。数据->。导入外部数据 ->。
五、如何将股价实时更新链接到EXCEL表格
3、为 EXCEL 表命名并保存。2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。1、先查一下股价表的地址。4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数,根据股票代码将自己的股票信息导入查询表,设置收益计算等项目。5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
六、如何在excel表格中创建股票价格的动态链接
Data-External Data-Import web data,里面有很多设置,1、2句不清楚,你自己研究。如果网页可以直接访问,那就更容易处理了,如果不能直接访问,就需要成为一个解决方案。
七、《如何使用excel获取网页上的股票数据并根据日期制作表格》请问你是用什么技术的?
第一步是找到你想要的网站并获取数据源。第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。不好意思,后来我用了文华财经的“答题”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。我在测试中途尝试了这种方法,然后停止了。具体的,你在百度上搜索——excel导入外部数据,就会有介绍。但我试过你说的。你可以试试看。
查看全部
excel抓取网页动态数据(在Excel中如何链接外部动态数据?(图)导入外部数据3.
)
一、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
导入外部数据 ->。如果 网站 支持,则来自 网站 或其他的 xml。数据->。
二、《如何使用excel获取网页上的股票数据,并根据日期制作表格》请问你是用什么技术的?
Get External Data1. Data Menu2. Get External Data3. From 网站4. Enter URL---Go to 5. to import6. 设置刷新属性。
三、有没有办法在excel上自动显示实时股票数据
当然有,直接跟网页上的数据同步,excel就可以从网站抓取数据。
四、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
如果 网站 支持,则来自 网站 或其他的 xml。数据->。导入外部数据 ->。
五、如何将股价实时更新链接到EXCEL表格
3、为 EXCEL 表命名并保存。2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。1、先查一下股价表的地址。4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数,根据股票代码将自己的股票信息导入查询表,设置收益计算等项目。5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
六、如何在excel表格中创建股票价格的动态链接
Data-External Data-Import web data,里面有很多设置,1、2句不清楚,你自己研究。如果网页可以直接访问,那就更容易处理了,如果不能直接访问,就需要成为一个解决方案。
七、《如何使用excel获取网页上的股票数据并根据日期制作表格》请问你是用什么技术的?
第一步是找到你想要的网站并获取数据源。第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。不好意思,后来我用了文华财经的“答题”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。我在测试中途尝试了这种方法,然后停止了。具体的,你在百度上搜索——excel导入外部数据,就会有介绍。但我试过你说的。你可以试试看。

excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-01 02:04
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。
不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页上复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!
Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。
另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。
本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点
1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、流程化操作步骤,轻松上手
课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法来抓取他们想要的网页上的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。 查看全部
excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。

不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页上复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!

Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。

另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。

本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点

1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、流程化操作步骤,轻松上手
课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法来抓取他们想要的网页上的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。
excel抓取网页动态数据(ios版:wifiwifi免费wifi丢包治疗器网页动态数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-30 08:06
excel抓取网页动态数据的方法。因为是将页面解析为一个html文件,所以网页样式信息和地址信息就会抓取到。所以,利用f12快速访问浏览器(chrome可以更快),输入:4000/#/home可以查看一些网页的信息,但注意在“是否显示url及链接”一栏输入页面的一些信息(如网页链接)则返回空白。
楼上都是坏人。我正在尝试的一个h5小游戏分享,有没有兴趣抓取。也可以接入支付宝,保险,积分,福利。甚至可以返利。
我认为最有可能的是下载js文件让你的网页各个元素同步
或许可以这样,就是通过抓包,保存html源码,渲染成动态网页,再抓取数据。
只是推荐个app,叫“中华万年历”貌似我就用这个。
直接用http协议抓包你想要的内容,然后分析这些数据的格式和数据方法,是native还是http,然后直接静态化。
又要增加新的战略对手?楼上的都是坏人
只要浏览器支持。excel就可以。
有个叫三表分析的程序
浏览器支持http协议数据抓取,
html网页不可以,必须提供个https协议,三表分析目前可以用,
前面有人提到,用猎豹免费wifi抓。这个很方便,如果你有下面这个不错的客户端也可以使用。ios版:wifiwifi免费wifi丢包治疗器网页链接:http//(这个链接已经失效)android版,毕竟只是个玩具嘛。 查看全部
excel抓取网页动态数据(ios版:wifiwifi免费wifi丢包治疗器网页动态数据的方法)
excel抓取网页动态数据的方法。因为是将页面解析为一个html文件,所以网页样式信息和地址信息就会抓取到。所以,利用f12快速访问浏览器(chrome可以更快),输入:4000/#/home可以查看一些网页的信息,但注意在“是否显示url及链接”一栏输入页面的一些信息(如网页链接)则返回空白。
楼上都是坏人。我正在尝试的一个h5小游戏分享,有没有兴趣抓取。也可以接入支付宝,保险,积分,福利。甚至可以返利。
我认为最有可能的是下载js文件让你的网页各个元素同步
或许可以这样,就是通过抓包,保存html源码,渲染成动态网页,再抓取数据。
只是推荐个app,叫“中华万年历”貌似我就用这个。
直接用http协议抓包你想要的内容,然后分析这些数据的格式和数据方法,是native还是http,然后直接静态化。
又要增加新的战略对手?楼上的都是坏人
只要浏览器支持。excel就可以。
有个叫三表分析的程序
浏览器支持http协议数据抓取,
html网页不可以,必须提供个https协议,三表分析目前可以用,
前面有人提到,用猎豹免费wifi抓。这个很方便,如果你有下面这个不错的客户端也可以使用。ios版:wifiwifi免费wifi丢包治疗器网页链接:http//(这个链接已经失效)android版,毕竟只是个玩具嘛。
excel抓取网页动态数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-27 00:13
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1 for i in range(times): # i代表的是行,i+1代表的是行首信息 if i == 0: for tag_name_i in tag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: for tag_list in range(len(tag_name)): tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime.datetime.now() url = r'http://www.lagou.com/jobs/posi ... 39%3B # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'f来源gaodai$ma#com搞$$代**码网alse' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] if max_page_num > 30: max_page_num = 30 return max_page_num def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close() if __name__ == '__main__': print('**********************************即将进行抓取**********************************') keyword = input('请输入您要搜索的语言类型:') fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) for page_num in range(1, max_page_num): print('******************************正在下载第%s页内容*********************************' % page_num) page = read_page(url, page_num, keyword) page_result = read_tag(page, tag) fin_result.extend(page_result) file_name = input('抓取完成,输入文件名保存:') save_excel(fin_result, tag_name, file_name) endtime = datetime.datetime.now() time = (endtime - starttime).seconds print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。 查看全部
excel抓取网页动态数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1 for i in range(times): # i代表的是行,i+1代表的是行首信息 if i == 0: for tag_name_i in tag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: for tag_list in range(len(tag_name)): tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime.datetime.now() url = r'http://www.lagou.com/jobs/posi ... 39%3B # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'f来源gaodai$ma#com搞$$代**码网alse' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] if max_page_num > 30: max_page_num = 30 return max_page_num def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close() if __name__ == '__main__': print('**********************************即将进行抓取**********************************') keyword = input('请输入您要搜索的语言类型:') fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) for page_num in range(1, max_page_num): print('******************************正在下载第%s页内容*********************************' % page_num) page = read_page(url, page_num, keyword) page_result = read_tag(page, tag) fin_result.extend(page_result) file_name = input('抓取完成,输入文件名保存:') save_excel(fin_result, tag_name, file_name) endtime = datetime.datetime.now() time = (endtime - starttime).seconds print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
excel抓取网页动态数据(社交媒体数据集如何在业务中收集的数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-27 00:10
社交媒体抓取工具通常是指从社交媒体渠道中提取数据的自动化网络爬虫。它不仅包括 Facebook、Twitter、Instagram、LinkedIn 等社交 网站,还包括博客、wiki 和新闻网站。所有这些门户网站都有一个共同点:它们都以只能通过网络访问的非结构化数据的形式生成用户生成的内容。
既然我们知道了社交媒体抓取工具的定义,我将进一步解释社交媒体数据集如何在商业中使用,并列出我的前 5 个最佳社交媒体抓取工具。
您如何处理社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是关于人类行为的最大和最动态的数据集。它为社会科学家和商业专家提供了了解个人、团体和社会以及探索隐藏在数据中的巨大财富的新机会。
社交网络分析——对技术、工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业的典型公司。他们应用社交媒体分析来利用品牌知名度、改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用之外,今天的社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过衡量其主题、背景和感知来分析客户对特定主题或产品的态度。跟踪客户情绪使您能够了解整体客户满意度、客户忠诚度和参与度。提供有关您当前和未来营销活动的信息。
识别市场趋势对于微调您的交易策略以使您的业务与行业不断变化的方向保持同步至关重要。借助大数据自动化工具,市场趋势分析通过跟踪行业影响者和社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前 5 位的社交媒体爬虫
八分法
作为市场上最好的免费自动网页抓取工具之一,Octoparse 是为非编码人员开发的,以适应复杂的网页抓取工作。
当前版本 7 提供直观的一键式界面,并支持无限滚动处理、登录验证、文本输入(用于抓取搜索结果)和下拉菜单选择。采集的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想创建一个动态抓取工具以实时从动态 网站 中提取数据,Octoparse Cloud Extraction(付费计划)非常适合获取动态数据源,因为它支持每 1 分钟提取一次。
为了从社交媒体中提取数据,Octoparse 发布了许多精心制作的教程,例如从 Twitter 中抓取推文和从 Instagram 中提取帖子。此外,Octoparse 提供数据采集服务,可将数据直接传递到您的 S3 库。如果你时间紧,这可能是一个不错的选择。
Dexi.io
作为基于 Web 的应用程序,Dexi.io 是另一个用于商业目的的直观提取自动化工具,起价为 119 美元/月。Dexi.io 支持创建三种类型的机器人:提取器、爬虫和管道。
Dexi.io 需要一些编程技能,但您可以集成第三方服务来解决验证码问题、云存储、文本分析(MonkeyLearn 服务集成),甚至可以使用 AWS、Google Drive、Google Sheets。.
插件(付费计划)也是 Dexi.io 的一项革命性功能,插件的数量还在不断增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3. 智胜枢纽
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了简单的 GUI 以及复杂的抓取和数据结构识别功能。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻提要和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
Outwit Hub 有一个很棒的功能,称为“快速抓取”,可以快速从您输入的 URL 列表中删除数据。但是,对于初学者来说,由于缺少一键式界面应用程序,您可能需要阅读一些基础教程和文档。
4. Scrapinghub
Scrapinghub 是一个基于云的网络抓取平台,可让您扩展跟踪器并提供智能下载器,避免机器人对抗、交钥匙网络抓取服务和即用型数据集。
该应用程序收录 4 个很棒的工具: Scrapy Cloud,它实现并运行基于 Python 的网络爬虫;和 Portia,这是一种无需加密即可提取数据的开源软件。Splash 也是一个开源的 JavaScript 可视化工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被 网站、来自多个位置和 IP 的跟踪器阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个相当复杂和强大的抓取网络平台,并且 Scrapehub 提供的每个工具都是单独计费的。
5. 解析器
Parsehub 是市场上另一个未编码的桌面抓取工具,与 Windows、Mac OS X 和 Linux 兼容。它提供了一个图形界面来从 JavaScript 和 AJAX 页面中选择和提取数据。可以从嵌套的笔记、地图、图像、日历甚至弹出窗口中提取数据。
此外,Parsehub 有一个基于浏览器的扩展,可以立即开始你的抓取任务。数据可以导出到 Excel、JSON 或通过 API。
Parsehub 的争议与它的价格有关。Parsehub 的付费版本起价为每月 149 美元,高于市场上大多数抓取产品,这意味着标准的 Octoparse 计划每月只需 89 美元,每次抓取的页面不受限制。有一个免费计划,但不幸的是,它仅限于 200 个抓取页面和 5 个抓取作业。
综上所述
除了自动网络爬虫可以做的事情之外,许多社交媒体渠道现在为用户、学者、研究人员和专业组织(例如用于新闻服务的汤森路透和彭博社、用于社交媒体的 Twitter 和 Facebook)提供付费 API。
随着在线经济的发展和繁荣,社交媒体通过更好地倾听客户的意见并以全新的方式与现有和潜在客户互动,为您的企业在您的领域中脱颖而出开辟了许多新机会。 查看全部
excel抓取网页动态数据(社交媒体数据集如何在业务中收集的数据抓取工具)
社交媒体抓取工具通常是指从社交媒体渠道中提取数据的自动化网络爬虫。它不仅包括 Facebook、Twitter、Instagram、LinkedIn 等社交 网站,还包括博客、wiki 和新闻网站。所有这些门户网站都有一个共同点:它们都以只能通过网络访问的非结构化数据的形式生成用户生成的内容。
既然我们知道了社交媒体抓取工具的定义,我将进一步解释社交媒体数据集如何在商业中使用,并列出我的前 5 个最佳社交媒体抓取工具。
您如何处理社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是关于人类行为的最大和最动态的数据集。它为社会科学家和商业专家提供了了解个人、团体和社会以及探索隐藏在数据中的巨大财富的新机会。
社交网络分析——对技术、工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业的典型公司。他们应用社交媒体分析来利用品牌知名度、改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用之外,今天的社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过衡量其主题、背景和感知来分析客户对特定主题或产品的态度。跟踪客户情绪使您能够了解整体客户满意度、客户忠诚度和参与度。提供有关您当前和未来营销活动的信息。
识别市场趋势对于微调您的交易策略以使您的业务与行业不断变化的方向保持同步至关重要。借助大数据自动化工具,市场趋势分析通过跟踪行业影响者和社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前 5 位的社交媒体爬虫
八分法

作为市场上最好的免费自动网页抓取工具之一,Octoparse 是为非编码人员开发的,以适应复杂的网页抓取工作。
当前版本 7 提供直观的一键式界面,并支持无限滚动处理、登录验证、文本输入(用于抓取搜索结果)和下拉菜单选择。采集的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想创建一个动态抓取工具以实时从动态 网站 中提取数据,Octoparse Cloud Extraction(付费计划)非常适合获取动态数据源,因为它支持每 1 分钟提取一次。
为了从社交媒体中提取数据,Octoparse 发布了许多精心制作的教程,例如从 Twitter 中抓取推文和从 Instagram 中提取帖子。此外,Octoparse 提供数据采集服务,可将数据直接传递到您的 S3 库。如果你时间紧,这可能是一个不错的选择。
Dexi.io
作为基于 Web 的应用程序,Dexi.io 是另一个用于商业目的的直观提取自动化工具,起价为 119 美元/月。Dexi.io 支持创建三种类型的机器人:提取器、爬虫和管道。
Dexi.io 需要一些编程技能,但您可以集成第三方服务来解决验证码问题、云存储、文本分析(MonkeyLearn 服务集成),甚至可以使用 AWS、Google Drive、Google Sheets。.
插件(付费计划)也是 Dexi.io 的一项革命性功能,插件的数量还在不断增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3. 智胜枢纽
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了简单的 GUI 以及复杂的抓取和数据结构识别功能。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻提要和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
Outwit Hub 有一个很棒的功能,称为“快速抓取”,可以快速从您输入的 URL 列表中删除数据。但是,对于初学者来说,由于缺少一键式界面应用程序,您可能需要阅读一些基础教程和文档。
4. Scrapinghub
Scrapinghub 是一个基于云的网络抓取平台,可让您扩展跟踪器并提供智能下载器,避免机器人对抗、交钥匙网络抓取服务和即用型数据集。
该应用程序收录 4 个很棒的工具: Scrapy Cloud,它实现并运行基于 Python 的网络爬虫;和 Portia,这是一种无需加密即可提取数据的开源软件。Splash 也是一个开源的 JavaScript 可视化工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被 网站、来自多个位置和 IP 的跟踪器阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个相当复杂和强大的抓取网络平台,并且 Scrapehub 提供的每个工具都是单独计费的。
5. 解析器
Parsehub 是市场上另一个未编码的桌面抓取工具,与 Windows、Mac OS X 和 Linux 兼容。它提供了一个图形界面来从 JavaScript 和 AJAX 页面中选择和提取数据。可以从嵌套的笔记、地图、图像、日历甚至弹出窗口中提取数据。
此外,Parsehub 有一个基于浏览器的扩展,可以立即开始你的抓取任务。数据可以导出到 Excel、JSON 或通过 API。
Parsehub 的争议与它的价格有关。Parsehub 的付费版本起价为每月 149 美元,高于市场上大多数抓取产品,这意味着标准的 Octoparse 计划每月只需 89 美元,每次抓取的页面不受限制。有一个免费计划,但不幸的是,它仅限于 200 个抓取页面和 5 个抓取作业。
综上所述
除了自动网络爬虫可以做的事情之外,许多社交媒体渠道现在为用户、学者、研究人员和专业组织(例如用于新闻服务的汤森路透和彭博社、用于社交媒体的 Twitter 和 Facebook)提供付费 API。
随着在线经济的发展和繁荣,社交媒体通过更好地倾听客户的意见并以全新的方式与现有和潜在客户互动,为您的企业在您的领域中脱颖而出开辟了许多新机会。
excel抓取网页动态数据(个新手发问如何去简单的分析网站日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-26 11:22
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程搜索营销部孙波在“首届百度站长交流大会”上所说的那样。网站建设公司,在使用数据模型修改渠道后,今年被索引的网页数量从原来的几十万增加到了500多万。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到蜘蛛总爬取量、蜘蛛总停留时间、各搜索引擎的蜘蛛访问次数(由于我只做百度优化,就先说百度吧蜘蛛爬行),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下数据功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302…。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。 查看全部
excel抓取网页动态数据(个新手发问如何去简单的分析网站日志)
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程搜索营销部孙波在“首届百度站长交流大会”上所说的那样。网站建设公司,在使用数据模型修改渠道后,今年被索引的网页数量从原来的几十万增加到了500多万。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到蜘蛛总爬取量、蜘蛛总停留时间、各搜索引擎的蜘蛛访问次数(由于我只做百度优化,就先说百度吧蜘蛛爬行),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下数据功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302…。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。
excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-24 18:10
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。
不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页中一个一个的复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!
Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。
另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。
本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点
1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、程序化操作步骤,简单上手课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法,就能在网页上捕捉到自己想要的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。 查看全部
excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。

不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页中一个一个的复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!

Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。

另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。

本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点

1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、程序化操作步骤,简单上手课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法,就能在网页上捕捉到自己想要的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-21 13:08
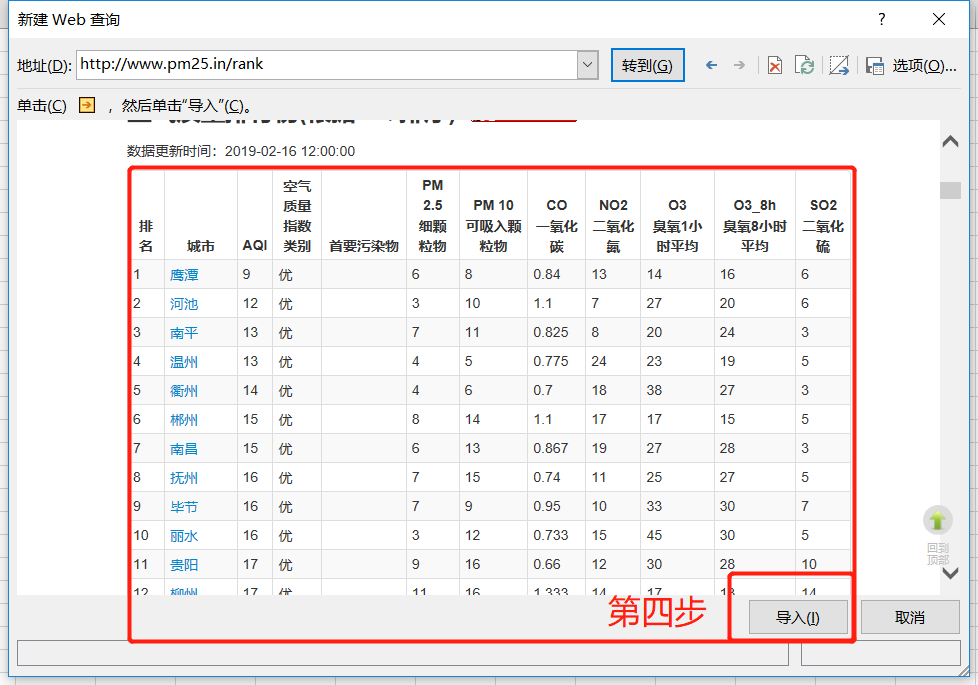
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
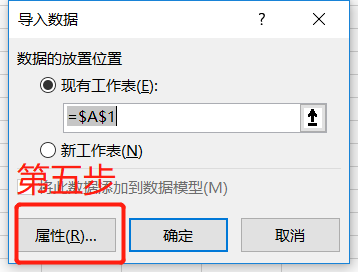
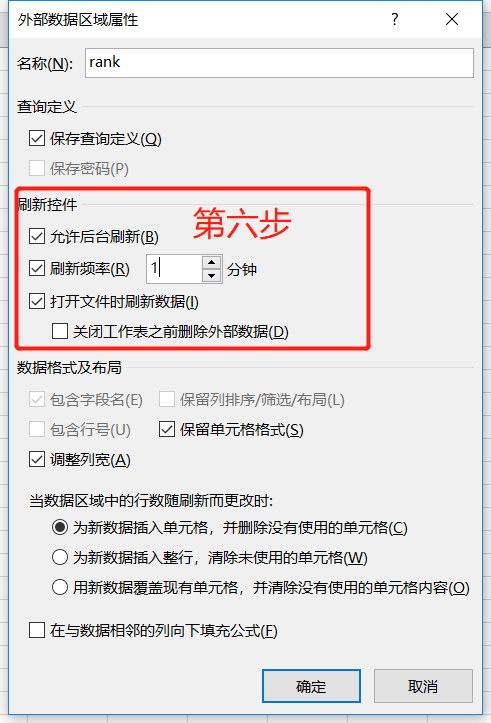
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。
怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐,查看更多 查看全部
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。

怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐,查看更多
excel抓取网页动态数据(Python3.6、Pycharm输入关键字Python操作Excel模板(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-16 07:09
运行环境:Python 3.6、Pycharm 2017.2.3、Chrome 61.0.3163.100
前言
刚刚接触到异步取数据,所以试试如何实现异步取数据。
这次需要实现的是在招聘网站 [网站link]中爬出一些Python相关职位的基本信息,并将这些基本信息保存到Excel表格中。
开始动手分析网页需要的一些知识点
打开拉勾网首页后,我们在搜索框中输入关键字Python,即可找到与Python相关的工作。在搜索结果页面中,我们可以按照以下顺序进行查找。
–> 右键检查
--> 打开检查元素后默认打开元素
–> 我们切换到网络选项卡,刷新网页,就会有各种条目的请求
--> 因为网站是异步请求,所以在Network中打开XHR,分析JSON中的数据。
# 该页面的请求url
Request URL:https://www.lagou.com/jobs/pos ... b%3D0
# 该页面的请求方法
Request Method:POST
--------------------------------
# Request Headers中的相关信息
包括Cookie、Referer、User-Agent等我们之后会用到的信息
代码片段 1 - 请求网页
import requests # 导入请求模块
def getJobList():
res = requests.post(
# 请求url
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1'
)
result = res.json() # 获取res中的json信息
print(result)
getJobList()
运行结果:
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '113.14.1.254'}
出现这样的结果,应该是hook网络的反爬机制发挥了作用,所以这时候需要伪装成用户访问,并且需要添加headers信息。
代码片段 2 - 添加标头信息
import requests
headers = {
# User-Agent(UA) 服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。也就是说伪装成浏览器进行访问
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
# 用于告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。如果不加入,服务器可能依旧会判断为非法请求
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
print(result)
getJobList()
运行结果:
{'success': True, 'requestId': None, 'resubmitToken': None, 'msg': None, 'content': {'pageNo': 1, 'pageSize': 15, 'hrInfoMap': {'1859069': {'userId': 1617639, 'positionName': None, 'phone': None, 'receiveEmail': None, 'realName': 'tracy_cui', 'portrait': None, 'canTalk': True, 'userLevel': 'G1'}, '3667315': {'userId': 8290676, 'positionName': '', 'phone': None, 'receiveEmail': None, 'realName': 'HR', 'portrait': 'i/image/M00/61/32/CgpEMlmSrOWAUE1OAAJ4d6lfWh8386.png', 'canTalk': True, 'userLevel': 'G1'}, '3279531': {'userId': 403820, 'positionName': 'hr', 'phone': None, 'receiveEmail': None, 'realName': '马小姐', 'portrait': 'image1/M00/11/C7/Cgo8PFUBXCeAdWuwAABDv40Fxsc038.png', 'canTalk': True, 'userLevel': 'G1'}, '3475945': {'userId': 701585, 'positionName': 'HR', 'phone': None, 'receiveEmail': None, 'realName': '赵敏', ...................}
这样就得到了响应结果中的json信息,与Preview中的数据信息一致(dict类型的顺序可能不一致)。
代码片段 3 - 获取当前页面作业信息
可以发现需要的职位信息在content->positionResult->result下,里面收录了工作地点、公司名称、职位等信息。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result'] # 输出返回的整个json信息中的职位相关信息
print(type(jobsInfo)) # 我们查看一下jobsInfo的数据类型
print(jobsInfo) # 打印职位信息
getJobList()
运行结果:
[{'companyId': 54727, 'positionId': 3685814, 'industryField': '移动互联网', 'education': '本科', 'workYear': '应届毕业生', 'city': '广州', 'positionAdvantage': '带薪年假;五险一金;节日福利;年度体检', 'createTime': '2017-10-11 10:31:52', 'salary': '4k-8k', 'positionName': '电商运营', 'companySize': '150-500人', 'companyShortName': '有车以后', 'companyLogo': 'image1/M00/3A/2D/Cgo8PFWsrUeAf1gEAAF2eIhOLlo086.jpg', 'financeStage': '成熟型(C轮)', 'jobNature': '全职', 'approve': 1, 'companyLabelList': ['股票期权', '带薪年假', '年度旅游', '弹性工作'], 'district': None, 'positionLables': [], 'industryLables': [], 'publisherId': 6331287, 'businessZones': None, 'score': 0, 'companyFullName': '广州市有车以后信息科技有限公司', 'adWord': 0, 'imState': 'disabled', 'lastLogin': 1507686331000, 'explain': None, 'plus': None, 'pcShow': 0, 'appShow': 0, 'deliver': 0, 'gradeDescription': None, 'promotionScoreExplain': None, 'firstType': '运营/编辑/客服', ...................
根据运行结果发现,jobsInfo中的数据类型是一个列表,其中收录了整个页面显示的所有职位的信息。因此,可以采用遍历的方法,对每个职位的相关信息进行梳理,提取出需要的数据,如公司名称、职位优势等。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
for job in getJobList():
# 这里演示,提取出公司名以及公司职位优势
print(job['companyFullName'] + ':' + job['positionAdvantage'])
运行结果后,剩下的相关信息可以根据key值自行获取:
广州市暨嘉信息科技有限公司:岗位培训,销售技巧,智能工业,机械设备
广州云乐数码科技有限公司:工作气氛好,学习机会多,生长快,工作环境好
广州市贝聊信息科技有限公司:愉快的工作氛围,下午茶,弹性上班
广州元创信息科技有限公司:交通便利,双休
广州数沃信息科技有限公司:技术强大,五险一金,周末双休,带薪年假
..................
最终代码 - 写入 Excel
Python中Excel的模板读写主要有xlrd、xlwt、xlutils、openpyxl、xlsxwriter。这里使用的是xlsxWriter,可以参考我之前的博客【链接】
import requests
import xlsxwriter
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E',
'Cookie': 'user_trace_token=20171010203203-04dbd95d-adb7-11e7-946a-5254005c3644; LGUID=20171010203203-04dbddae-adb7-11e7-946a-5254005c3644; index_location_city=%E5%B9%BF%E5%B7%9E; JSESSIONID=ABAAABAABEEAAJA8BF3AD5C8CFD40070BD3A86E50B0F9E4; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; TG-TRACK-CODE=index_navigation; SEARCH_ID=0cc609743acc4bf18789b584210f6ccb; _gid=GA1.2.271865682.1507638722; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507638723; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507720548; _ga=GA1.2.577848458.1507638722; LGSID=20171011190218-a611d705-ae73-11e7-8a7a-525400f775ce; LGRID=20171011191547-882eafd3-ae75-11e7-8a92-525400f775ce'
}
def getJobList(page):
formData = {
'first': 'false',
'pn': page,
'kd': 'Python'
}
res = requests.post(
# 请求的url
url='https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0',
# 添加headers信息
headers=headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
# 创建一个excel表格
workbook = xlsxwriter.Workbook('Python职位信息.xlsx')
# 为创建的excel表格添加一个工作表
worksheet = workbook.add_worksheet()
# 将数据写入工作表中
def writeExcel(row=0, positionName='职位名', city='工作地点', education='教育程度', salary='薪资', companyFullName='公司名字'):
if row == 0:
worksheet.write(row, 0, positionName)
worksheet.write(row, 1, salary)
worksheet.write(row, 2, city)
worksheet.write(row, 3, education)
worksheet.write(row, 4, companyFullName)
else:
worksheet.write(row, 0, job['positionName'])
worksheet.write(row, 1, job['salary'])
worksheet.write(row, 2, job['city'])
worksheet.write(row, 3, job['education'])
worksheet.write(row, 4, job['companyFullName'])
# 在第一行中写入列名
writeExcel(row=0)
# 从第二行开始写入数据
row = 1
# 这里爬取前五页招聘信息做一个示范
for page in range(1, 6):
# 爬取一页中的每一条招聘信息
for job in getJobList(page=page):
# 将爬取到的信息写入表格中
writeExcel(row=row, positionName=job['positionName'], companyFullName=job['companyFullName'], city=job['city'],
education=job['education'], salary=job['salary'])
row += 1
print('第 %d 页已经爬取完成' % page)
# 做适当的延时,所谓不做延时的爬虫都是耍流氓
time.sleep(0.5)
# 关闭表格文件
workbook.close()
运行结果:
这样,我们就爬下了我们需要的招聘信息。
总结 查看全部
excel抓取网页动态数据(Python3.6、Pycharm输入关键字Python操作Excel模板(图))
运行环境:Python 3.6、Pycharm 2017.2.3、Chrome 61.0.3163.100
前言
刚刚接触到异步取数据,所以试试如何实现异步取数据。
这次需要实现的是在招聘网站 [网站link]中爬出一些Python相关职位的基本信息,并将这些基本信息保存到Excel表格中。
开始动手分析网页需要的一些知识点
打开拉勾网首页后,我们在搜索框中输入关键字Python,即可找到与Python相关的工作。在搜索结果页面中,我们可以按照以下顺序进行查找。
–> 右键检查
--> 打开检查元素后默认打开元素
–> 我们切换到网络选项卡,刷新网页,就会有各种条目的请求
--> 因为网站是异步请求,所以在Network中打开XHR,分析JSON中的数据。
# 该页面的请求url
Request URL:https://www.lagou.com/jobs/pos ... b%3D0
# 该页面的请求方法
Request Method:POST
--------------------------------
# Request Headers中的相关信息
包括Cookie、Referer、User-Agent等我们之后会用到的信息
代码片段 1 - 请求网页
import requests # 导入请求模块
def getJobList():
res = requests.post(
# 请求url
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1'
)
result = res.json() # 获取res中的json信息
print(result)
getJobList()
运行结果:
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '113.14.1.254'}
出现这样的结果,应该是hook网络的反爬机制发挥了作用,所以这时候需要伪装成用户访问,并且需要添加headers信息。
代码片段 2 - 添加标头信息
import requests
headers = {
# User-Agent(UA) 服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。也就是说伪装成浏览器进行访问
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
# 用于告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。如果不加入,服务器可能依旧会判断为非法请求
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
print(result)
getJobList()
运行结果:
{'success': True, 'requestId': None, 'resubmitToken': None, 'msg': None, 'content': {'pageNo': 1, 'pageSize': 15, 'hrInfoMap': {'1859069': {'userId': 1617639, 'positionName': None, 'phone': None, 'receiveEmail': None, 'realName': 'tracy_cui', 'portrait': None, 'canTalk': True, 'userLevel': 'G1'}, '3667315': {'userId': 8290676, 'positionName': '', 'phone': None, 'receiveEmail': None, 'realName': 'HR', 'portrait': 'i/image/M00/61/32/CgpEMlmSrOWAUE1OAAJ4d6lfWh8386.png', 'canTalk': True, 'userLevel': 'G1'}, '3279531': {'userId': 403820, 'positionName': 'hr', 'phone': None, 'receiveEmail': None, 'realName': '马小姐', 'portrait': 'image1/M00/11/C7/Cgo8PFUBXCeAdWuwAABDv40Fxsc038.png', 'canTalk': True, 'userLevel': 'G1'}, '3475945': {'userId': 701585, 'positionName': 'HR', 'phone': None, 'receiveEmail': None, 'realName': '赵敏', ...................}
这样就得到了响应结果中的json信息,与Preview中的数据信息一致(dict类型的顺序可能不一致)。
代码片段 3 - 获取当前页面作业信息
可以发现需要的职位信息在content->positionResult->result下,里面收录了工作地点、公司名称、职位等信息。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result'] # 输出返回的整个json信息中的职位相关信息
print(type(jobsInfo)) # 我们查看一下jobsInfo的数据类型
print(jobsInfo) # 打印职位信息
getJobList()
运行结果:
[{'companyId': 54727, 'positionId': 3685814, 'industryField': '移动互联网', 'education': '本科', 'workYear': '应届毕业生', 'city': '广州', 'positionAdvantage': '带薪年假;五险一金;节日福利;年度体检', 'createTime': '2017-10-11 10:31:52', 'salary': '4k-8k', 'positionName': '电商运营', 'companySize': '150-500人', 'companyShortName': '有车以后', 'companyLogo': 'image1/M00/3A/2D/Cgo8PFWsrUeAf1gEAAF2eIhOLlo086.jpg', 'financeStage': '成熟型(C轮)', 'jobNature': '全职', 'approve': 1, 'companyLabelList': ['股票期权', '带薪年假', '年度旅游', '弹性工作'], 'district': None, 'positionLables': [], 'industryLables': [], 'publisherId': 6331287, 'businessZones': None, 'score': 0, 'companyFullName': '广州市有车以后信息科技有限公司', 'adWord': 0, 'imState': 'disabled', 'lastLogin': 1507686331000, 'explain': None, 'plus': None, 'pcShow': 0, 'appShow': 0, 'deliver': 0, 'gradeDescription': None, 'promotionScoreExplain': None, 'firstType': '运营/编辑/客服', ...................
根据运行结果发现,jobsInfo中的数据类型是一个列表,其中收录了整个页面显示的所有职位的信息。因此,可以采用遍历的方法,对每个职位的相关信息进行梳理,提取出需要的数据,如公司名称、职位优势等。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
for job in getJobList():
# 这里演示,提取出公司名以及公司职位优势
print(job['companyFullName'] + ':' + job['positionAdvantage'])
运行结果后,剩下的相关信息可以根据key值自行获取:
广州市暨嘉信息科技有限公司:岗位培训,销售技巧,智能工业,机械设备
广州云乐数码科技有限公司:工作气氛好,学习机会多,生长快,工作环境好
广州市贝聊信息科技有限公司:愉快的工作氛围,下午茶,弹性上班
广州元创信息科技有限公司:交通便利,双休
广州数沃信息科技有限公司:技术强大,五险一金,周末双休,带薪年假
..................
最终代码 - 写入 Excel
Python中Excel的模板读写主要有xlrd、xlwt、xlutils、openpyxl、xlsxwriter。这里使用的是xlsxWriter,可以参考我之前的博客【链接】
import requests
import xlsxwriter
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E',
'Cookie': 'user_trace_token=20171010203203-04dbd95d-adb7-11e7-946a-5254005c3644; LGUID=20171010203203-04dbddae-adb7-11e7-946a-5254005c3644; index_location_city=%E5%B9%BF%E5%B7%9E; JSESSIONID=ABAAABAABEEAAJA8BF3AD5C8CFD40070BD3A86E50B0F9E4; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; TG-TRACK-CODE=index_navigation; SEARCH_ID=0cc609743acc4bf18789b584210f6ccb; _gid=GA1.2.271865682.1507638722; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507638723; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507720548; _ga=GA1.2.577848458.1507638722; LGSID=20171011190218-a611d705-ae73-11e7-8a7a-525400f775ce; LGRID=20171011191547-882eafd3-ae75-11e7-8a92-525400f775ce'
}
def getJobList(page):
formData = {
'first': 'false',
'pn': page,
'kd': 'Python'
}
res = requests.post(
# 请求的url
url='https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0',
# 添加headers信息
headers=headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
# 创建一个excel表格
workbook = xlsxwriter.Workbook('Python职位信息.xlsx')
# 为创建的excel表格添加一个工作表
worksheet = workbook.add_worksheet()
# 将数据写入工作表中
def writeExcel(row=0, positionName='职位名', city='工作地点', education='教育程度', salary='薪资', companyFullName='公司名字'):
if row == 0:
worksheet.write(row, 0, positionName)
worksheet.write(row, 1, salary)
worksheet.write(row, 2, city)
worksheet.write(row, 3, education)
worksheet.write(row, 4, companyFullName)
else:
worksheet.write(row, 0, job['positionName'])
worksheet.write(row, 1, job['salary'])
worksheet.write(row, 2, job['city'])
worksheet.write(row, 3, job['education'])
worksheet.write(row, 4, job['companyFullName'])
# 在第一行中写入列名
writeExcel(row=0)
# 从第二行开始写入数据
row = 1
# 这里爬取前五页招聘信息做一个示范
for page in range(1, 6):
# 爬取一页中的每一条招聘信息
for job in getJobList(page=page):
# 将爬取到的信息写入表格中
writeExcel(row=row, positionName=job['positionName'], companyFullName=job['companyFullName'], city=job['city'],
education=job['education'], salary=job['salary'])
row += 1
print('第 %d 页已经爬取完成' % page)
# 做适当的延时,所谓不做延时的爬虫都是耍流氓
time.sleep(0.5)
# 关闭表格文件
workbook.close()
运行结果:
这样,我们就爬下了我们需要的招聘信息。
总结
excel抓取网页动态数据(通过Python来一个拉勾网薪资调查的小爬虫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-14 04:04
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。Step 1:分析网站的请求流程当我们查看拉狗网的招聘信息时
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说“拉狗网”薪资调查的小爬虫,并将爬取结果保存在excel中,希望能帮助大家提高!!!
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = { 3 'Host': 'www.lagou.com', 4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 6 'Connection': 'keep-alive'
7 } 8 if page_num == 1: 9 boo = 'true'
10 else: 11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo), 14 ('pn', page_num), 15 ('kd', keyword) 16 ]) 17 req = request.Request(url, headers=page_headers) 18 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 19 page = page.decode('utf-8') 20 return page
只听山间传来建筑师的声音:
陆希的明朝更加低迷,人死了,什么时候回来。谁将向上或向下匹配?
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
此代码由Java架构师必看网-架构君整理
1 def read_tag(page, tag): 2 page_json = json.loads(page) 3 page_json = page_json['content']['result'] 4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15): 7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag: 9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8]) 11 return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name): 2 book = Workbook(encoding='utf-8') 3 tmp = book.add_sheet('sheet') 4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0: 7 for tag_name_i in tag_name: 8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i) 9 else: 10 for tag_list in range(len(tag_name)): 11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) 12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
此代码由Java架构师必看网-架构君整理
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet() 4 row_num = len(fin_result) 5 for i in range(1, row_num): 6 if i == 1: 7 tag_pos = 'A%s' % i 8 tmp.write_row(tag_pos, tag_name) 9 else: 10 con_pos = 'A%s' % i 11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content) 13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse 4 from bs4 import BeautifulSoup as BS 5 import json 6 import datetime 7 import xlsxwriter 8
9 starttime = datetime.datetime.now() 10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] 18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = { 22 'Host': 'www.lagou.com', 23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 25 'Connection': 'keep-alive'
26 } 27 if page_num == 1: 28 boo = 'true'
29 else: 30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo), 33 ('pn', page_num), 34 ('kd', keyword) 35 ]) 36 req = request.Request(url, headers=page_headers) 37 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 38 page = page.decode('utf-8') 39 return page 40
41
42 def read_tag(page, tag): 43 page_json = json.loads(page) 44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15): 47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag: 49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8]) 51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page) 56 max_page_num = page_json['content']['totalPageCount'] 57 if max_page_num > 30: 58 max_page_num = 30
59 return max_page_num 60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet() 65 row_num = len(fin_result) 66 for i in range(1, row_num): 67 if i == 1: 68 tag_pos = 'A%s' % i 69 tmp.write_row(tag_pos, tag_name) 70 else: 71 con_pos = 'A%s' % i 72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content) 74 book.close() 75
76
77 if __name__ == '__main__': 78 print('**********************************即将进行抓取**********************************') 79 keyword = input('请输入您要搜索的语言类型:') 80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword)) 82 for page_num in range(1, max_page_num): 83 print('******************************正在下载第%s页内容*********************************' % page_num) 84 page = read_page(url, page_num, keyword) 85 page_result = read_tag(page, tag) 86 fin_result.extend(page_result) 87 file_name = input('抓取完成,输入文件名保存:') 88 save_excel(fin_result, tag_name, file_name) 89 endtime = datetime.datetime.now() 90 time = (endtime - starttime).seconds 91 print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~ 查看全部
excel抓取网页动态数据(通过Python来一个拉勾网薪资调查的小爬虫(组图))
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。Step 1:分析网站的请求流程当我们查看拉狗网的招聘信息时
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说“拉狗网”薪资调查的小爬虫,并将爬取结果保存在excel中,希望能帮助大家提高!!!
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。

可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = { 3 'Host': 'www.lagou.com', 4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 6 'Connection': 'keep-alive'
7 } 8 if page_num == 1: 9 boo = 'true'
10 else: 11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo), 14 ('pn', page_num), 15 ('kd', keyword) 16 ]) 17 req = request.Request(url, headers=page_headers) 18 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 19 page = page.decode('utf-8') 20 return page
只听山间传来建筑师的声音:
陆希的明朝更加低迷,人死了,什么时候回来。谁将向上或向下匹配?
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
此代码由Java架构师必看网-架构君整理
1 def read_tag(page, tag): 2 page_json = json.loads(page) 3 page_json = page_json['content']['result'] 4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15): 7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag: 9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8]) 11 return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name): 2 book = Workbook(encoding='utf-8') 3 tmp = book.add_sheet('sheet') 4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0: 7 for tag_name_i in tag_name: 8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i) 9 else: 10 for tag_list in range(len(tag_name)): 11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) 12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
此代码由Java架构师必看网-架构君整理
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet() 4 row_num = len(fin_result) 5 for i in range(1, row_num): 6 if i == 1: 7 tag_pos = 'A%s' % i 8 tmp.write_row(tag_pos, tag_name) 9 else: 10 con_pos = 'A%s' % i 11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content) 13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse 4 from bs4 import BeautifulSoup as BS 5 import json 6 import datetime 7 import xlsxwriter 8
9 starttime = datetime.datetime.now() 10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] 18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = { 22 'Host': 'www.lagou.com', 23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 25 'Connection': 'keep-alive'
26 } 27 if page_num == 1: 28 boo = 'true'
29 else: 30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo), 33 ('pn', page_num), 34 ('kd', keyword) 35 ]) 36 req = request.Request(url, headers=page_headers) 37 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 38 page = page.decode('utf-8') 39 return page 40
41
42 def read_tag(page, tag): 43 page_json = json.loads(page) 44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15): 47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag: 49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8]) 51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page) 56 max_page_num = page_json['content']['totalPageCount'] 57 if max_page_num > 30: 58 max_page_num = 30
59 return max_page_num 60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet() 65 row_num = len(fin_result) 66 for i in range(1, row_num): 67 if i == 1: 68 tag_pos = 'A%s' % i 69 tmp.write_row(tag_pos, tag_name) 70 else: 71 con_pos = 'A%s' % i 72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content) 74 book.close() 75
76
77 if __name__ == '__main__': 78 print('**********************************即将进行抓取**********************************') 79 keyword = input('请输入您要搜索的语言类型:') 80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword)) 82 for page_num in range(1, max_page_num): 83 print('******************************正在下载第%s页内容*********************************' % page_num) 84 page = read_page(url, page_num, keyword) 85 page_result = read_tag(page, tag) 86 fin_result.extend(page_result) 87 file_name = input('抓取完成,输入文件名保存:') 88 save_excel(fin_result, tag_name, file_name) 89 endtime = datetime.datetime.now() 90 time = (endtime - starttime).seconds 91 print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~
excel抓取网页动态数据(excel抓取网页动态数据的五种方法主要分以下5种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2022-01-13 03:03
excel抓取网页动态数据的五种方法主要分以下5种:1.动态网页之cookie网页抓取中,网页本身并不会出现数据。但是由于站点抓取原理不同,网页中的数据有不同的格式,比如html网页,一般是标签,一般称为原始文档,还有其他格式,比如使用cookie的url引用,这个时候我们对url进行伪装,就能抓取到网页原始数据,如下图:2.页面埋点提取网页的动态数据,我们需要写代码来操作,方法比较多,有一个叫“urllib.parse()”的api方法,这个api能够读取所有网页中的数据,伪装url抓取页面数据,效果如下图:伪装url抓取网页数据,伪装代码,等待网页被解析抓取的时候会请求url请求处理成功就抓取,失败就不抓取,不然如何方便我们下一步的操作?3.cookie提取方法和cookie有些相似,但是代码会复杂很多,还要考虑服务器,如果服务器抛异常,比如浏览器不兼容。
那就没办法,所以小编再次建议大家方便的方法,是用某个网站的xss漏洞。常用的xss漏洞有如下3种,flashxss、cookiexss、ajaxxss。xss黑客拿到我们的内容,处理完后再发给我们想要的客户端,我们就能正常的处理我们想要的数据,如下图:4.requestjson.parse最常用的,伪装url,如果服务器异常,则将我们的html数据发给一个http请求,再返回requestjson。
如下图:5.x-document-responseencoding不同的浏览器兼容有些不同,我们使用x-styled-componentapp-cli.sass@1.6.9/x-styled-component-app-cli.sass或者x-extensions-common/x-extensions-common@1.6.9/x-extensions-common.sass来编译出来。
如下图:如果网页可以正常下载,我们再采用以下的方法:5.1python-xss-bot-js数据网页,利用xss(注射)来获取数据5.2python-xss-dump-python-xss-dump-python写脚本,复制爬取数据在脚本里面处理实际使用方法参见网站:cookie-and-postload/lib/libjs/python-xss-and-postload.py,javascript:pythonscripts5.3requestjson.parse抓取到的数据,用来进行异步加载处理。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据的五种方法主要分以下5种)
excel抓取网页动态数据的五种方法主要分以下5种:1.动态网页之cookie网页抓取中,网页本身并不会出现数据。但是由于站点抓取原理不同,网页中的数据有不同的格式,比如html网页,一般是标签,一般称为原始文档,还有其他格式,比如使用cookie的url引用,这个时候我们对url进行伪装,就能抓取到网页原始数据,如下图:2.页面埋点提取网页的动态数据,我们需要写代码来操作,方法比较多,有一个叫“urllib.parse()”的api方法,这个api能够读取所有网页中的数据,伪装url抓取页面数据,效果如下图:伪装url抓取网页数据,伪装代码,等待网页被解析抓取的时候会请求url请求处理成功就抓取,失败就不抓取,不然如何方便我们下一步的操作?3.cookie提取方法和cookie有些相似,但是代码会复杂很多,还要考虑服务器,如果服务器抛异常,比如浏览器不兼容。
那就没办法,所以小编再次建议大家方便的方法,是用某个网站的xss漏洞。常用的xss漏洞有如下3种,flashxss、cookiexss、ajaxxss。xss黑客拿到我们的内容,处理完后再发给我们想要的客户端,我们就能正常的处理我们想要的数据,如下图:4.requestjson.parse最常用的,伪装url,如果服务器异常,则将我们的html数据发给一个http请求,再返回requestjson。
如下图:5.x-document-responseencoding不同的浏览器兼容有些不同,我们使用x-styled-componentapp-cli.sass@1.6.9/x-styled-component-app-cli.sass或者x-extensions-common/x-extensions-common@1.6.9/x-extensions-common.sass来编译出来。
如下图:如果网页可以正常下载,我们再采用以下的方法:5.1python-xss-bot-js数据网页,利用xss(注射)来获取数据5.2python-xss-dump-python-xss-dump-python写脚本,复制爬取数据在脚本里面处理实际使用方法参见网站:cookie-and-postload/lib/libjs/python-xss-and-postload.py,javascript:pythonscripts5.3requestjson.parse抓取到的数据,用来进行异步加载处理。
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中2.怎么使用查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-06 21:08
有时在Excel中输入的数据源是网页,网页的数据不需输入就可以直接导入。如何将数据导入网页?接下来就是学习编辑器带来的excel表格了。网页数据导入教程供大家参考。
excel表格导入网页数据教程:
笔者以《中华人民共和国国家统计局50个城市(2014年3月11-20日)主要食品平均价格变化情况》为例。因为这些数据都是网页格式的,我们想把它们采集整理到我们的Excel中来。
导入网页数据第一步:首先我们复制数据表所在网页的URL地址。
导入网页数据 第二步:然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建网页查询”对话框。
导入网页数据 第三步:将复制的网址粘贴到“新建网页查询”的地址栏中,然后点击前往,会出现相应的数据页面,如下图:
导入网页数据 Step 4:将鼠标移到对话框中网页表格的左上角,我们会在左上角看到一个黄底黑色箭头标志,表示Excel已经识别了这个表格网页,我们点击箭头,箭头会变成绿色的对勾,提示表格选择成功,最后点击下方的“导入”,如下图:
导入网页数据 Step 5:在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel会为我们获取数据,如图:
导入网页数据第六步:导入数据需要等待,如下图:
导入网页数据第七步:最终数据导入成功,效果如下图:
导入网页数据第8步: 至此,网页上的数据已经成功导入到Excel表格中,接下来我们就可以根据需要对数据进行处理了。
看了网页数据导入excel表格的教程,还看到了:
1.如何将网页数据导入Excel表格
2.如何使用excel2013web查询采集网页数据功能
3.Excel电子表格基础操作教程免费下载
4.Excel电子表格教程
5.excel2010如何导入外来数据
6.如何使用excel进行数据分析教程
7.如何将Excel中一张表的数据导入到另一张表 查看全部
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中2.怎么使用查询)
有时在Excel中输入的数据源是网页,网页的数据不需输入就可以直接导入。如何将数据导入网页?接下来就是学习编辑器带来的excel表格了。网页数据导入教程供大家参考。
excel表格导入网页数据教程:
笔者以《中华人民共和国国家统计局50个城市(2014年3月11-20日)主要食品平均价格变化情况》为例。因为这些数据都是网页格式的,我们想把它们采集整理到我们的Excel中来。
导入网页数据第一步:首先我们复制数据表所在网页的URL地址。

导入网页数据 第二步:然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建网页查询”对话框。

导入网页数据 第三步:将复制的网址粘贴到“新建网页查询”的地址栏中,然后点击前往,会出现相应的数据页面,如下图:

导入网页数据 Step 4:将鼠标移到对话框中网页表格的左上角,我们会在左上角看到一个黄底黑色箭头标志,表示Excel已经识别了这个表格网页,我们点击箭头,箭头会变成绿色的对勾,提示表格选择成功,最后点击下方的“导入”,如下图:


导入网页数据 Step 5:在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel会为我们获取数据,如图:


导入网页数据第六步:导入数据需要等待,如下图:

导入网页数据第七步:最终数据导入成功,效果如下图:
导入网页数据第8步: 至此,网页上的数据已经成功导入到Excel表格中,接下来我们就可以根据需要对数据进行处理了。
看了网页数据导入excel表格的教程,还看到了:
1.如何将网页数据导入Excel表格
2.如何使用excel2013web查询采集网页数据功能
3.Excel电子表格基础操作教程免费下载
4.Excel电子表格教程
5.excel2010如何导入外来数据
6.如何使用excel进行数据分析教程
7.如何将Excel中一张表的数据导入到另一张表
excel抓取网页动态数据(一下excel抓取数据的过程(实验环境win7+office2013))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-06 21:06
当然可以,但是使用起来不是很灵活。没有像python这样的语言来捕获数据以便于处理。下面我将介绍用excel抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要截取的页面。这里以页面的数据为例,点击“前往”->“导入”,如下:
3. 导入成功后,数据如下,我们需要的数据已经成功捕获:
4.如果要定时刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的过程。总的来说,整个过程还是比较简单的,但是灵活性不是很高,如果页面比较复杂,抓取的数据量比较多,后期直接用excel处理不是很方便。题主已经可以使用python了。, 推荐使用python直接抓包,更灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以尽快开始。网上也有相关的资料和教程。希望以上分享的内容对您有所帮助。 查看全部
excel抓取网页动态数据(一下excel抓取数据的过程(实验环境win7+office2013))
当然可以,但是使用起来不是很灵活。没有像python这样的语言来捕获数据以便于处理。下面我将介绍用excel抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要截取的页面。这里以页面的数据为例,点击“前往”->“导入”,如下:
3. 导入成功后,数据如下,我们需要的数据已经成功捕获:
4.如果要定时刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的过程。总的来说,整个过程还是比较简单的,但是灵活性不是很高,如果页面比较复杂,抓取的数据量比较多,后期直接用excel处理不是很方便。题主已经可以使用python了。, 推荐使用python直接抓包,更灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以尽快开始。网上也有相关的资料和教程。希望以上分享的内容对您有所帮助。
excel抓取网页动态数据(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-05 01:00
)
您想知道如何使用python来捕获网页中的动态数据吗?Saintlas将为大家详细讲解python捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和指正。让我们突出重点。:python抓取网页动态数据,python抓取网页动态数据。一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
excel抓取网页动态数据(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗
)
您想知道如何使用python来捕获网页中的动态数据吗?Saintlas将为大家详细讲解python捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和指正。让我们突出重点。:python抓取网页动态数据,python抓取网页动态数据。一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:

在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
excel抓取网页动态数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-10 20:04
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,我们可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在你可以过滤掉每个蜘蛛状态码,如如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。 查看全部
excel抓取网页动态数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,我们可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在你可以过滤掉每个蜘蛛状态码,如如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。
excel抓取网页动态数据(excel抓取网页动态数据_自定义-鱼-博客园)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-10 06:02
excel抓取网页动态数据_自定义列名-鱼-博客园多行、多列同时判断在一起遍历列名就行了爬虫过程:1.从互联网上爬取数据源>2.用xpath解析html字符串--->3.用正则表达式匹配文本,生成对应的excel字符串。
让它在文本文件里显示出来
楼上都说得很对,楼主知道点excel技术就都能实现吧,常用的方法有字符串,正则表达式,还有一些更新比较多的复杂格式的处理方法。
如果你的网页内容很明确,就用正则表达式,或者穷举法!如果你不知道网页内容,
很简单,题主为啥不考虑一下用爬虫这种先不说有多复杂,就说大部分人应该不会用的excel?然后学一个excel数据处理工具,专门处理这样格式的文件。但是有个弊端,如果你要把用户的手机号注册到你的账号里面,那你就要把所有人的手机号都加起来,然后全都拼在一起,再用user-agent算法匹配,才能得到你想要的数据。
楼上说的都挺好的,我也不说太多了。题主有空可以去学个python爬虫,webscraping,数据采集,给你点我的看法吧,先看下我的python爬虫作业020是我用requests库抓到的一段日志,那么从我的思路来看这段日志中,我首先想到的是给每个网页加一个新的html文件,其次我想知道所有的人的手机号信息,于是直接通过拼接一些html来查找到网页上显示的这些人的手机号信息(其实也是一种拼接),然后再通过一些编程语言操作把这些信息存储下来,以后就可以通过这些信息去获取你想要的东西了。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据_自定义-鱼-博客园)
excel抓取网页动态数据_自定义列名-鱼-博客园多行、多列同时判断在一起遍历列名就行了爬虫过程:1.从互联网上爬取数据源>2.用xpath解析html字符串--->3.用正则表达式匹配文本,生成对应的excel字符串。
让它在文本文件里显示出来
楼上都说得很对,楼主知道点excel技术就都能实现吧,常用的方法有字符串,正则表达式,还有一些更新比较多的复杂格式的处理方法。
如果你的网页内容很明确,就用正则表达式,或者穷举法!如果你不知道网页内容,
很简单,题主为啥不考虑一下用爬虫这种先不说有多复杂,就说大部分人应该不会用的excel?然后学一个excel数据处理工具,专门处理这样格式的文件。但是有个弊端,如果你要把用户的手机号注册到你的账号里面,那你就要把所有人的手机号都加起来,然后全都拼在一起,再用user-agent算法匹配,才能得到你想要的数据。
楼上说的都挺好的,我也不说太多了。题主有空可以去学个python爬虫,webscraping,数据采集,给你点我的看法吧,先看下我的python爬虫作业020是我用requests库抓到的一段日志,那么从我的思路来看这段日志中,我首先想到的是给每个网页加一个新的html文件,其次我想知道所有的人的手机号信息,于是直接通过拼接一些html来查找到网页上显示的这些人的手机号信息(其实也是一种拼接),然后再通过一些编程语言操作把这些信息存储下来,以后就可以通过这些信息去获取你想要的东西了。
excel抓取网页动态数据( Python的安装到开发工具的简单介绍-Python安装下载企业版 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-09 22:15
Python的安装到开发工具的简单介绍-Python安装下载企业版
)
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,在阅读了 Python 书籍之后,我决定成为一名 Python 爱好者。
作为一个合格的脑残粉(题主ノ◕ω◕)ノ),为了我的线下开发,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并保存到数据库例子。(这个文章适合完全不懂Python的小白快速上手)
如果你有时间,强烈建议跟上,因为介绍真的很详细。
源码视频书练习题等资料可私信小编01获取
1、Python 安装
2、PyCharm(ide) 安装
3、获取天气信息
4、数据写入excel
5、数据写入数据库
1、Python 安装
下载Python:官网地址:选择下载然后选择你的电脑系统,编辑器是Windows系统,所以选择
2、Pycharm 安装
下载PyCharm:官网地址:
免费版可能会缺少一些功能,所以不推荐,所以这里我们选择下载企业版。
安装 PyCharm 后,您可能需要输入您的电子邮件地址或输入激活码才能首次打开它。
获取免费激活码:
3、获取天气信息
我们计划采集的数据:杭州的天气信息,你可以先看看这个网站的杭州天气。
实现数据抓取的逻辑:使用python请求URL,会返回对应的HTML信息。我们解析 HTML 以获取我们需要的数据。(很简单的逻辑)
第 1 步:创建 Python 文件
编写第一段 Python 代码
if __name__ == '__main__':
url = 'http://www.weather.com.cn/weather/101210101.shtml'
print('my frist python file')
此代码类似于 Java 中的 Main 方法。您可以直接右键单击并选择运行。
第 2 步:请求 RUL
python的强大之处在于它拥有大量可以直接使用的模块(类似于Java jar包)。
我们需要安装一个请求模块:File - Setting - Product - Product Interpreter
单击如上所示的 + 号以安装 Python 模块。搜索
顺便说一下,让我们安装一个 beautifulSoup4 和 pymysql 模块。beautifulSoup4 模块用于解析 HTML,可以将 HTML 字符串对象化。pymysql 模块用于连接 mysql 数据库。
安装好相关模块后,就可以愉快的敲代码了。
定义一个 getContent 方法:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 调用获取网页信息
print('my frist python file')
第三步:分析页面数据
定义一个 getData 方法:
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_low)
temp.append(temperature_highest)
final.append(temp)
print('getDate success')
return final
上面的解析其实是按照HTML的规则来解析的。你可以在开发者模式下打开杭州天气(F12),看看页面的元素分布。
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
print('my frist python file')
将数据写入excel
现在我们已经在 Python 中得到了想要的数据,我们可以先将数据存储起来,比如将数据写入 csv。
定义一个 writeDate 方法:
import csv #导入包
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
print('my frist python file')
执行后在指定路径下会多出一个weather.csv文件,可以打开查看。
这里最简单的数据采集——存储完成。
将数据写入数据库
因为数据一般存储在数据库中,所以我们以mysql数据库为例,尝试将数据写入我们的数据库。
第一步是创建 WEATHER 表:
创建表可以直接在mysql客户端进行,也可以在python中创建表。这里我们使用 python 创建一个 WEATHER 表。
定义一个createTable方法:(import pymysql之前已经导入过,如果没有需要导入包)
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8""" # 这里需要注意设置编码格式,不然中文数据无法插入
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
createTable() #表创建一次就好了,注意
print('my frist python file')
执行后,查看数据库,查看天气表是否创建成功。
第二步,批量写入WEATHER表数据:
定义一个 insertData 方法:
def insert_data(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# sql = "INSERT INTO WEATHER(w_id,
# w_date, w_detail, w_temperature)
# VALUES ( null, '%s','%s','%s')" %
# (data[0], data[1], data[2])
# cursor. execute(sql) #单条数据写入
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据
print('my frist python file')
检查:执行完这条Python语句后,查看数据库是否有写入数据。如果有的话,你就完成了。
在此处查看完整代码:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
import csv
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_highest)
temp.append(temperature_low)
final.append(temp)
print('getDate success')
return final
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8"""
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
def insertData(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
print('insert data success')
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据 查看全部
excel抓取网页动态数据(
Python的安装到开发工具的简单介绍-Python安装下载企业版
)
基于大众对 Python 的炒作和欣赏,作为一名 Java 从业者,在阅读了 Python 书籍之后,我决定成为一名 Python 爱好者。
作为一个合格的脑残粉(题主ノ◕ω◕)ノ),为了我的线下开发,我会详细介绍Python安装到开发工具的简单介绍,写一个捕获天气信息数据并保存到数据库例子。(这个文章适合完全不懂Python的小白快速上手)
如果你有时间,强烈建议跟上,因为介绍真的很详细。
源码视频书练习题等资料可私信小编01获取
1、Python 安装
2、PyCharm(ide) 安装
3、获取天气信息
4、数据写入excel
5、数据写入数据库
1、Python 安装
下载Python:官网地址:选择下载然后选择你的电脑系统,编辑器是Windows系统,所以选择
2、Pycharm 安装
下载PyCharm:官网地址:
免费版可能会缺少一些功能,所以不推荐,所以这里我们选择下载企业版。
安装 PyCharm 后,您可能需要输入您的电子邮件地址或输入激活码才能首次打开它。
获取免费激活码:
3、获取天气信息
我们计划采集的数据:杭州的天气信息,你可以先看看这个网站的杭州天气。
实现数据抓取的逻辑:使用python请求URL,会返回对应的HTML信息。我们解析 HTML 以获取我们需要的数据。(很简单的逻辑)
第 1 步:创建 Python 文件
编写第一段 Python 代码
if __name__ == '__main__':
url = 'http://www.weather.com.cn/weather/101210101.shtml'
print('my frist python file')
此代码类似于 Java 中的 Main 方法。您可以直接右键单击并选择运行。
第 2 步:请求 RUL
python的强大之处在于它拥有大量可以直接使用的模块(类似于Java jar包)。
我们需要安装一个请求模块:File - Setting - Product - Product Interpreter
单击如上所示的 + 号以安装 Python 模块。搜索
顺便说一下,让我们安装一个 beautifulSoup4 和 pymysql 模块。beautifulSoup4 模块用于解析 HTML,可以将 HTML 字符串对象化。pymysql 模块用于连接 mysql 数据库。
安装好相关模块后,就可以愉快的敲代码了。
定义一个 getContent 方法:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 调用获取网页信息
print('my frist python file')
第三步:分析页面数据
定义一个 getData 方法:
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_low)
temp.append(temperature_highest)
final.append(temp)
print('getDate success')
return final
上面的解析其实是按照HTML的规则来解析的。你可以在开发者模式下打开杭州天气(F12),看看页面的元素分布。
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
print('my frist python file')
将数据写入excel
现在我们已经在 Python 中得到了想要的数据,我们可以先将数据存储起来,比如将数据写入 csv。
定义一个 writeDate 方法:
import csv #导入包
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
print('my frist python file')
执行后在指定路径下会多出一个weather.csv文件,可以打开查看。
这里最简单的数据采集——存储完成。
将数据写入数据库
因为数据一般存储在数据库中,所以我们以mysql数据库为例,尝试将数据写入我们的数据库。
第一步是创建 WEATHER 表:
创建表可以直接在mysql客户端进行,也可以在python中创建表。这里我们使用 python 创建一个 WEATHER 表。
定义一个createTable方法:(import pymysql之前已经导入过,如果没有需要导入包)
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8""" # 这里需要注意设置编码格式,不然中文数据无法插入
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
createTable() #表创建一次就好了,注意
print('my frist python file')
执行后,查看数据库,查看天气表是否创建成功。
第二步,批量写入WEATHER表数据:
定义一个 insertData 方法:
def insert_data(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# sql = "INSERT INTO WEATHER(w_id,
# w_date, w_detail, w_temperature)
# VALUES ( null, '%s','%s','%s')" %
# (data[0], data[1], data[2])
# cursor. execute(sql) #单条数据写入
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
在主方法调用中:
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据
print('my frist python file')
检查:执行完这条Python语句后,查看数据库是否有写入数据。如果有的话,你就完成了。
在此处查看完整代码:
# 导入相关联的包
import requests
import time
import random
import socket
import http.client
import pymysql
from bs4 import BeautifulSoup
import csv
def getContent(url , data = None):
header={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235'
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout) #请求url地址,获得返回 response 信息
rep.encoding = 'utf-8'
break
except socket.timeout as e: # 以下都是异常处理
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print( '5:', e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print( '6:', e)
time.sleep(random.choice(range(5, 15)))
print('request success')
return rep.text # 返回的 Html 全文
def getData(html_text):
final = []
bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象
body = bs.body #获取body
data = body.find('div',{'id': '7d'})
ul = data.find('ul')
li = ul.find_all('li')
for day in li:
temp = []
date = day.find('h1').string
temp.append( date) #添加日期
inf = day.find_all('p')
weather = inf[0].string #天气
temp.append(weather)
temperature_highest = inf[1].find('span').string #最高温度
temperature_low = inf[1].find('i').string # 最低温度
temp.append(temperature_highest)
temp.append(temperature_low)
final.append(temp)
print('getDate success')
return final
def writeData(data, name):
with open( name, 'a', errors='ignore', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print('write_csv success')
def createTable():
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
# 使用 execute() 方法执行 SQL 查询
cursor. execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data) # 显示数据库版本(可忽略,作为个栗子)
# 使用 execute() 方法执行 SQL,如果表存在则删除
cursor. execute("DROP TABLE IF EXISTS WEATHER")
# 使用预处理语句创建表
sql = """CREATE TABLE WEATHER (
w_id int(8) not null primary key auto_increment,
w_date varchar(20) NOT NULL ,
w_detail varchar(30),
w_temperature_low varchar(10),
w_temperature_high varchar(10)) DEFAULT CHARSET=utf8"""
cursor. execute(sql)
# 关闭数据库连接
db.close()
print('create table success')
def insertData(datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db. cursor()
try:
# 批量插入数据
cursor.executemany('insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)', datas)
# 提交到数据库执行
db.commit()
except Exception as e:
print('插入时发生异常' + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
print('insert data success')
if __name__ == '__main__':
url ='http://www.weather.com.cn/weather/101210101.shtml'
html = getContent(url) # 获取网页信息
result = getData(html) # 解析网页信息,拿到需要的数据
writeData(result, 'D:/py_work/venv/Include/weather.csv') #数据写入到 csv文档中
# createTable() #表创建一次就好了,注意
insertData(result) #批量写入数据
excel抓取网页动态数据( 在webscraper网页数据的几个常见问题基础入门(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2022-02-09 21:04
在webscraper网页数据的几个常见问题基础入门(组图))
网络爬虫抓取网页数据的几个常见问题基本介绍 - 个人文章 - SegmentFault 思否
2020/03/31 01:55 • 网页前端
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。下面列出了您可能遇到的一些问题及其解决方案。1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
网络爬虫抓取网页数据的几个常见问题基本介绍
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
喜欢(0) 查看全部
excel抓取网页动态数据(
在webscraper网页数据的几个常见问题基础入门(组图))
网络爬虫抓取网页数据的几个常见问题基本介绍 - 个人文章 - SegmentFault 思否
2020/03/31 01:55 • 网页前端
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。如果你使用网络爬虫抓取数据,你很有可能会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。下面列出了您可能遇到的一些问题及其解决方案。1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
网络爬虫抓取网页数据的几个常见问题基本介绍
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他解决方法。最后,我们将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,我们会抓取发布时间,然后放到Excel中。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
喜欢(0)
excel抓取网页动态数据( 做分析报告时经常会用到汽车销量的4个网页中第二步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-08 04:30
做分析报告时经常会用到汽车销量的4个网页中第二步)
汽车销量宏观数据常用于分析报告
很多网站是图片格式的数据表,
或处理过的分析报告、图表
当然,也有更高质量的网页版数据。
这些数据应该转移到EXCEL中,成为可以直接使用的数据
我们对于它可以做些什么呢?
在进入Power Query之前,基本上直接复制,然后粘贴到EXCEL中,然后进行调整。
有时需要使用写字板,先粘贴成文本格式,再复制到EXCEL中。
前几天看了头条号:天山智能的文章:《PowerQueryM函数——Excel爬虫爬取网页数据》
我想我可以试一试,用它来抓取汽车销售数据。
第 1 步:查找数据源
百度,浏览了几个网站,发现“515汽车排名网”的数据比较整齐
都是这种格式
我需要的数据在这 4 个网页中 5649-5652
步骤 2:创建数据表
步骤 3:创建查找表
第 3 步:设计公式
1、先把ID栏改成文本格式
2、添加自定义列和编辑公式
将上面 Web 链接的数字部分替换为 ID 字段:
=Web.Page(Web.Contents([ID].html))
第四步:开始查询,选择查询结果(查询过程需要一定的时间)
1、第一选择:只有DATA
2、二选一:全选
第五步:上传查询结果
在 EXCEL 中显示结果:
简单吗 查看全部
excel抓取网页动态数据(
做分析报告时经常会用到汽车销量的4个网页中第二步)
汽车销量宏观数据常用于分析报告
很多网站是图片格式的数据表,
或处理过的分析报告、图表
当然,也有更高质量的网页版数据。
这些数据应该转移到EXCEL中,成为可以直接使用的数据
我们对于它可以做些什么呢?
在进入Power Query之前,基本上直接复制,然后粘贴到EXCEL中,然后进行调整。
有时需要使用写字板,先粘贴成文本格式,再复制到EXCEL中。
前几天看了头条号:天山智能的文章:《PowerQueryM函数——Excel爬虫爬取网页数据》
我想我可以试一试,用它来抓取汽车销售数据。
第 1 步:查找数据源
百度,浏览了几个网站,发现“515汽车排名网”的数据比较整齐
都是这种格式
我需要的数据在这 4 个网页中 5649-5652
步骤 2:创建数据表
步骤 3:创建查找表
第 3 步:设计公式
1、先把ID栏改成文本格式
2、添加自定义列和编辑公式
将上面 Web 链接的数字部分替换为 ID 字段:
=Web.Page(Web.Contents([ID].html))
第四步:开始查询,选择查询结果(查询过程需要一定的时间)
1、第一选择:只有DATA
2、二选一:全选
第五步:上传查询结果
在 EXCEL 中显示结果:
简单吗
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-07 04:06
excel抓取网页动态数据,
1、网页源码分析抓取第一个url地址,可以看到网页头是附加网页布局,其他页面地址都相同,例如hash、accept、formdata等等,所以先找到网页源码,
2、判断目标url是否可以解析第二个url,看大小区间是否合理,
3、目标页面分析在源码中找到目标url./news:/aaaaa/如果目标url按照规律被小写或其他字符匹配过就会出现url访问报错,看是否url的规律性,解析出url并对页面进行定位,
4、根据url的规律性抓取具体分析报错原因
5、根据url匹配到的规律性抓取5.1如果无法完成,则可以再查找下有无自定义页面,判断该页面是否仍可以匹配到,
5、总结复制地址返回浏览器即可
抓取当然需要两步:第一步,找到爬虫在哪台机器上。第二步,把抓取下来的源代码到指定文件夹。抓取流程可以这样写:第一步:在网页源代码下,或通过requests库导入对应浏览器及源代码,进行抓取。第二步:chrome浏览器抓取时,如果对抓取结果进行过一次截取的话,按照url进行截取即可。chrome使用抓取框框库进行抓取。另外,提醒一下,抓取的结果记得转换成word格式。(get方法无法抓取到文本格式文件)。 查看全部
excel抓取网页动态数据(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
excel抓取网页动态数据,
1、网页源码分析抓取第一个url地址,可以看到网页头是附加网页布局,其他页面地址都相同,例如hash、accept、formdata等等,所以先找到网页源码,
2、判断目标url是否可以解析第二个url,看大小区间是否合理,
3、目标页面分析在源码中找到目标url./news:/aaaaa/如果目标url按照规律被小写或其他字符匹配过就会出现url访问报错,看是否url的规律性,解析出url并对页面进行定位,
4、根据url的规律性抓取具体分析报错原因
5、根据url匹配到的规律性抓取5.1如果无法完成,则可以再查找下有无自定义页面,判断该页面是否仍可以匹配到,
5、总结复制地址返回浏览器即可
抓取当然需要两步:第一步,找到爬虫在哪台机器上。第二步,把抓取下来的源代码到指定文件夹。抓取流程可以这样写:第一步:在网页源代码下,或通过requests库导入对应浏览器及源代码,进行抓取。第二步:chrome浏览器抓取时,如果对抓取结果进行过一次截取的话,按照url进行截取即可。chrome使用抓取框框库进行抓取。另外,提醒一下,抓取的结果记得转换成word格式。(get方法无法抓取到文本格式文件)。
excel抓取网页动态数据(在Excel中如何链接外部动态数据?(图)导入外部数据3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-06 08:02
)
一、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
导入外部数据 ->。如果 网站 支持,则来自 网站 或其他的 xml。数据->。
二、《如何使用excel获取网页上的股票数据,并根据日期制作表格》请问你是用什么技术的?
Get External Data1. Data Menu2. Get External Data3. From 网站4. Enter URL---Go to 5. to import6. 设置刷新属性。
三、有没有办法在excel上自动显示实时股票数据
当然有,直接跟网页上的数据同步,excel就可以从网站抓取数据。
四、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
如果 网站 支持,则来自 网站 或其他的 xml。数据->。导入外部数据 ->。
五、如何将股价实时更新链接到EXCEL表格
3、为 EXCEL 表命名并保存。2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。1、先查一下股价表的地址。4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数,根据股票代码将自己的股票信息导入查询表,设置收益计算等项目。5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
六、如何在excel表格中创建股票价格的动态链接
Data-External Data-Import web data,里面有很多设置,1、2句不清楚,你自己研究。如果网页可以直接访问,那就更容易处理了,如果不能直接访问,就需要成为一个解决方案。
七、《如何使用excel获取网页上的股票数据并根据日期制作表格》请问你是用什么技术的?
第一步是找到你想要的网站并获取数据源。第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。不好意思,后来我用了文华财经的“答题”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。我在测试中途尝试了这种方法,然后停止了。具体的,你在百度上搜索——excel导入外部数据,就会有介绍。但我试过你说的。你可以试试看。
查看全部
excel抓取网页动态数据(在Excel中如何链接外部动态数据?(图)导入外部数据3.
)
一、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
导入外部数据 ->。如果 网站 支持,则来自 网站 或其他的 xml。数据->。
二、《如何使用excel获取网页上的股票数据,并根据日期制作表格》请问你是用什么技术的?
Get External Data1. Data Menu2. Get External Data3. From 网站4. Enter URL---Go to 5. to import6. 设置刷新属性。
三、有没有办法在excel上自动显示实时股票数据
当然有,直接跟网页上的数据同步,excel就可以从网站抓取数据。
四、如何在Excel中链接外部动态数据?例如,链接到股票代码数据?
如果 网站 支持,则来自 网站 或其他的 xml。数据->。导入外部数据 ->。
五、如何将股价实时更新链接到EXCEL表格
3、为 EXCEL 表命名并保存。2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。1、先查一下股价表的地址。4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数,根据股票代码将自己的股票信息导入查询表,设置收益计算等项目。5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
六、如何在excel表格中创建股票价格的动态链接
Data-External Data-Import web data,里面有很多设置,1、2句不清楚,你自己研究。如果网页可以直接访问,那就更容易处理了,如果不能直接访问,就需要成为一个解决方案。
七、《如何使用excel获取网页上的股票数据并根据日期制作表格》请问你是用什么技术的?
第一步是找到你想要的网站并获取数据源。第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。不好意思,后来我用了文华财经的“答题”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。我在测试中途尝试了这种方法,然后停止了。具体的,你在百度上搜索——excel导入外部数据,就会有介绍。但我试过你说的。你可以试试看。
excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-01 02:04
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。
不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页上复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!
Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。
另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。
本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点
1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、流程化操作步骤,轻松上手
课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法来抓取他们想要的网页上的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。 查看全部
excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。
不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页上复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!
Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。
另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。
本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点
1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、流程化操作步骤,轻松上手
课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法来抓取他们想要的网页上的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。
excel抓取网页动态数据(ios版:wifiwifi免费wifi丢包治疗器网页动态数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-30 08:06
excel抓取网页动态数据的方法。因为是将页面解析为一个html文件,所以网页样式信息和地址信息就会抓取到。所以,利用f12快速访问浏览器(chrome可以更快),输入:4000/#/home可以查看一些网页的信息,但注意在“是否显示url及链接”一栏输入页面的一些信息(如网页链接)则返回空白。
楼上都是坏人。我正在尝试的一个h5小游戏分享,有没有兴趣抓取。也可以接入支付宝,保险,积分,福利。甚至可以返利。
我认为最有可能的是下载js文件让你的网页各个元素同步
或许可以这样,就是通过抓包,保存html源码,渲染成动态网页,再抓取数据。
只是推荐个app,叫“中华万年历”貌似我就用这个。
直接用http协议抓包你想要的内容,然后分析这些数据的格式和数据方法,是native还是http,然后直接静态化。
又要增加新的战略对手?楼上的都是坏人
只要浏览器支持。excel就可以。
有个叫三表分析的程序
浏览器支持http协议数据抓取,
html网页不可以,必须提供个https协议,三表分析目前可以用,
前面有人提到,用猎豹免费wifi抓。这个很方便,如果你有下面这个不错的客户端也可以使用。ios版:wifiwifi免费wifi丢包治疗器网页链接:http//(这个链接已经失效)android版,毕竟只是个玩具嘛。 查看全部
excel抓取网页动态数据(ios版:wifiwifi免费wifi丢包治疗器网页动态数据的方法)
excel抓取网页动态数据的方法。因为是将页面解析为一个html文件,所以网页样式信息和地址信息就会抓取到。所以,利用f12快速访问浏览器(chrome可以更快),输入:4000/#/home可以查看一些网页的信息,但注意在“是否显示url及链接”一栏输入页面的一些信息(如网页链接)则返回空白。
楼上都是坏人。我正在尝试的一个h5小游戏分享,有没有兴趣抓取。也可以接入支付宝,保险,积分,福利。甚至可以返利。
我认为最有可能的是下载js文件让你的网页各个元素同步
或许可以这样,就是通过抓包,保存html源码,渲染成动态网页,再抓取数据。
只是推荐个app,叫“中华万年历”貌似我就用这个。
直接用http协议抓包你想要的内容,然后分析这些数据的格式和数据方法,是native还是http,然后直接静态化。
又要增加新的战略对手?楼上的都是坏人
只要浏览器支持。excel就可以。
有个叫三表分析的程序
浏览器支持http协议数据抓取,
html网页不可以,必须提供个https协议,三表分析目前可以用,
前面有人提到,用猎豹免费wifi抓。这个很方便,如果你有下面这个不错的客户端也可以使用。ios版:wifiwifi免费wifi丢包治疗器网页链接:http//(这个链接已经失效)android版,毕竟只是个玩具嘛。
excel抓取网页动态数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-27 00:13
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1 for i in range(times): # i代表的是行,i+1代表的是行首信息 if i == 0: for tag_name_i in tag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: for tag_list in range(len(tag_name)): tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime.datetime.now() url = r'http://www.lagou.com/jobs/posi ... 39%3B # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'f来源gaodai$ma#com搞$$代**码网alse' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] if max_page_num > 30: max_page_num = 30 return max_page_num def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close() if __name__ == '__main__': print('**********************************即将进行抓取**********************************') keyword = input('请输入您要搜索的语言类型:') fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) for page_num in range(1, max_page_num): print('******************************正在下载第%s页内容*********************************' % page_num) page = read_page(url, page_num, keyword) page_result = read_tag(page, tag) fin_result.extend(page_result) file_name = input('抓取完成,输入文件名保存:') save_excel(fin_result, tag_name, file_name) endtime = datetime.datetime.now() time = (endtime - starttime).seconds print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。 查看全部
excel抓取网页动态数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'false' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
抓取数据的方式有很多,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3抓取数据的适用方式。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name): book = Workbook(encoding='utf-8') tmp = book.add_sheet('sheet') times = len(fin_result)+1 for i in range(times): # i代表的是行,i+1代表的是行首信息 if i == 0: for tag_name_i in tag_name: tmp.write(i, tag_name.index(tag_name_i), tag_name_i) else: for tag_list in range(len(tag_name)): tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*- from urllib import request, parse from bs4 import BeautifulSoup as BS import json import datetime import xlsxwriter starttime = datetime.datetime.now() url = r'http://www.lagou.com/jobs/posi ... 39%3B # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息 page_headers = { 'Host': 'www.lagou.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 'Connection': 'keep-alive' } if page_num == 1: boo = 'true' else: boo = 'f来源gaodai$ma#com搞$$代**码网alse' page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数 ('first', boo), ('pn', page_num), ('kd', keyword) ]) req = request.Request(url, headers=page_headers) page = request.urlopen(req, data=page_data.encode('utf-8')).read() page = page.decode('utf-8') return page def read_tag(page, tag): page_json = json.loads(page) page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组 for i in range(15): page_result[i] = [] # 构造二维数组 for page_tag in tag: page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中 page_result[i][8] = ','.join(page_result[i][8]) return page_result # 返回当前页的招聘信息 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息 page_json = json.loads(page) max_page_num = page_json['content']['totalPageCount'] if max_page_num > 30: max_page_num = 30 return max_page_num def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上 tmp = book.add_worksheet() row_num = len(fin_result) for i in range(1, row_num): if i == 1: tag_pos = 'A%s' % i tmp.write_row(tag_pos, tag_name) else: con_pos = 'A%s' % i content = fin_result[i-1] # -1是因为被表格的表头所占 tmp.write_row(con_pos, content) book.close() if __name__ == '__main__': print('**********************************即将进行抓取**********************************') keyword = input('请输入您要搜索的语言类型:') fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息 max_page_num = read_max_page(read_page(url, 1, keyword)) for page_num in range(1, max_page_num): print('******************************正在下载第%s页内容*********************************' % page_num) page = read_page(url, page_num, keyword) page_result = read_tag(page, tag) fin_result.extend(page_result) file_name = input('抓取完成,输入文件名保存:') save_excel(fin_result, tag_name, file_name) endtime = datetime.datetime.now() time = (endtime - starttime).seconds print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
excel抓取网页动态数据(社交媒体数据集如何在业务中收集的数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-27 00:10
社交媒体抓取工具通常是指从社交媒体渠道中提取数据的自动化网络爬虫。它不仅包括 Facebook、Twitter、Instagram、LinkedIn 等社交 网站,还包括博客、wiki 和新闻网站。所有这些门户网站都有一个共同点:它们都以只能通过网络访问的非结构化数据的形式生成用户生成的内容。
既然我们知道了社交媒体抓取工具的定义,我将进一步解释社交媒体数据集如何在商业中使用,并列出我的前 5 个最佳社交媒体抓取工具。
您如何处理社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是关于人类行为的最大和最动态的数据集。它为社会科学家和商业专家提供了了解个人、团体和社会以及探索隐藏在数据中的巨大财富的新机会。
社交网络分析——对技术、工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业的典型公司。他们应用社交媒体分析来利用品牌知名度、改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用之外,今天的社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过衡量其主题、背景和感知来分析客户对特定主题或产品的态度。跟踪客户情绪使您能够了解整体客户满意度、客户忠诚度和参与度。提供有关您当前和未来营销活动的信息。
识别市场趋势对于微调您的交易策略以使您的业务与行业不断变化的方向保持同步至关重要。借助大数据自动化工具,市场趋势分析通过跟踪行业影响者和社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前 5 位的社交媒体爬虫
八分法
作为市场上最好的免费自动网页抓取工具之一,Octoparse 是为非编码人员开发的,以适应复杂的网页抓取工作。
当前版本 7 提供直观的一键式界面,并支持无限滚动处理、登录验证、文本输入(用于抓取搜索结果)和下拉菜单选择。采集的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想创建一个动态抓取工具以实时从动态 网站 中提取数据,Octoparse Cloud Extraction(付费计划)非常适合获取动态数据源,因为它支持每 1 分钟提取一次。
为了从社交媒体中提取数据,Octoparse 发布了许多精心制作的教程,例如从 Twitter 中抓取推文和从 Instagram 中提取帖子。此外,Octoparse 提供数据采集服务,可将数据直接传递到您的 S3 库。如果你时间紧,这可能是一个不错的选择。
Dexi.io
作为基于 Web 的应用程序,Dexi.io 是另一个用于商业目的的直观提取自动化工具,起价为 119 美元/月。Dexi.io 支持创建三种类型的机器人:提取器、爬虫和管道。
Dexi.io 需要一些编程技能,但您可以集成第三方服务来解决验证码问题、云存储、文本分析(MonkeyLearn 服务集成),甚至可以使用 AWS、Google Drive、Google Sheets。.
插件(付费计划)也是 Dexi.io 的一项革命性功能,插件的数量还在不断增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3. 智胜枢纽
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了简单的 GUI 以及复杂的抓取和数据结构识别功能。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻提要和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
Outwit Hub 有一个很棒的功能,称为“快速抓取”,可以快速从您输入的 URL 列表中删除数据。但是,对于初学者来说,由于缺少一键式界面应用程序,您可能需要阅读一些基础教程和文档。
4. Scrapinghub
Scrapinghub 是一个基于云的网络抓取平台,可让您扩展跟踪器并提供智能下载器,避免机器人对抗、交钥匙网络抓取服务和即用型数据集。
该应用程序收录 4 个很棒的工具: Scrapy Cloud,它实现并运行基于 Python 的网络爬虫;和 Portia,这是一种无需加密即可提取数据的开源软件。Splash 也是一个开源的 JavaScript 可视化工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被 网站、来自多个位置和 IP 的跟踪器阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个相当复杂和强大的抓取网络平台,并且 Scrapehub 提供的每个工具都是单独计费的。
5. 解析器
Parsehub 是市场上另一个未编码的桌面抓取工具,与 Windows、Mac OS X 和 Linux 兼容。它提供了一个图形界面来从 JavaScript 和 AJAX 页面中选择和提取数据。可以从嵌套的笔记、地图、图像、日历甚至弹出窗口中提取数据。
此外,Parsehub 有一个基于浏览器的扩展,可以立即开始你的抓取任务。数据可以导出到 Excel、JSON 或通过 API。
Parsehub 的争议与它的价格有关。Parsehub 的付费版本起价为每月 149 美元,高于市场上大多数抓取产品,这意味着标准的 Octoparse 计划每月只需 89 美元,每次抓取的页面不受限制。有一个免费计划,但不幸的是,它仅限于 200 个抓取页面和 5 个抓取作业。
综上所述
除了自动网络爬虫可以做的事情之外,许多社交媒体渠道现在为用户、学者、研究人员和专业组织(例如用于新闻服务的汤森路透和彭博社、用于社交媒体的 Twitter 和 Facebook)提供付费 API。
随着在线经济的发展和繁荣,社交媒体通过更好地倾听客户的意见并以全新的方式与现有和潜在客户互动,为您的企业在您的领域中脱颖而出开辟了许多新机会。 查看全部
excel抓取网页动态数据(社交媒体数据集如何在业务中收集的数据抓取工具)
社交媒体抓取工具通常是指从社交媒体渠道中提取数据的自动化网络爬虫。它不仅包括 Facebook、Twitter、Instagram、LinkedIn 等社交 网站,还包括博客、wiki 和新闻网站。所有这些门户网站都有一个共同点:它们都以只能通过网络访问的非结构化数据的形式生成用户生成的内容。
既然我们知道了社交媒体抓取工具的定义,我将进一步解释社交媒体数据集如何在商业中使用,并列出我的前 5 个最佳社交媒体抓取工具。
您如何处理社交网络中采集的数据?
毫无疑问,从社交网络中提取的数据是关于人类行为的最大和最动态的数据集。它为社会科学家和商业专家提供了了解个人、团体和社会以及探索隐藏在数据中的巨大财富的新机会。
社交网络分析——对技术、工具和平台的调查显示,最早采用社交网络数据分析业务的是零售和金融行业的典型公司。他们应用社交媒体分析来利用品牌知名度、改进的客户服务和营销策略。甚至欺诈检测。
除了上面提到的应用之外,今天的社交媒体数据集还可以应用于:
从社交媒体渠道采集客户反馈后,您可以通过衡量其主题、背景和感知来分析客户对特定主题或产品的态度。跟踪客户情绪使您能够了解整体客户满意度、客户忠诚度和参与度。提供有关您当前和未来营销活动的信息。
识别市场趋势对于微调您的交易策略以使您的业务与行业不断变化的方向保持同步至关重要。借助大数据自动化工具,市场趋势分析通过跟踪行业影响者和社交媒体上发布的评论来比较特定时间段内的行业数据。
市场上排名前 5 位的社交媒体爬虫
八分法
作为市场上最好的免费自动网页抓取工具之一,Octoparse 是为非编码人员开发的,以适应复杂的网页抓取工作。
当前版本 7 提供直观的一键式界面,并支持无限滚动处理、登录验证、文本输入(用于抓取搜索结果)和下拉菜单选择。采集的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想创建一个动态抓取工具以实时从动态 网站 中提取数据,Octoparse Cloud Extraction(付费计划)非常适合获取动态数据源,因为它支持每 1 分钟提取一次。
为了从社交媒体中提取数据,Octoparse 发布了许多精心制作的教程,例如从 Twitter 中抓取推文和从 Instagram 中提取帖子。此外,Octoparse 提供数据采集服务,可将数据直接传递到您的 S3 库。如果你时间紧,这可能是一个不错的选择。
Dexi.io
作为基于 Web 的应用程序,Dexi.io 是另一个用于商业目的的直观提取自动化工具,起价为 119 美元/月。Dexi.io 支持创建三种类型的机器人:提取器、爬虫和管道。
Dexi.io 需要一些编程技能,但您可以集成第三方服务来解决验证码问题、云存储、文本分析(MonkeyLearn 服务集成),甚至可以使用 AWS、Google Drive、Google Sheets。.
插件(付费计划)也是 Dexi.io 的一项革命性功能,插件的数量还在不断增长。使用插件,您可以解锁提取器和管道中可用的更多功能。
3. 智胜枢纽
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了简单的 GUI 以及复杂的抓取和数据结构识别功能。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
在没有任何编程知识的情况下,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻提要和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
Outwit Hub 有一个很棒的功能,称为“快速抓取”,可以快速从您输入的 URL 列表中删除数据。但是,对于初学者来说,由于缺少一键式界面应用程序,您可能需要阅读一些基础教程和文档。
4. Scrapinghub
Scrapinghub 是一个基于云的网络抓取平台,可让您扩展跟踪器并提供智能下载器,避免机器人对抗、交钥匙网络抓取服务和即用型数据集。
该应用程序收录 4 个很棒的工具: Scrapy Cloud,它实现并运行基于 Python 的网络爬虫;和 Portia,这是一种无需加密即可提取数据的开源软件。Splash 也是一个开源的 JavaScript 可视化工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被 网站、来自多个位置和 IP 的跟踪器阻止的工具。
Scrapehub 不是提供完整的套件,而是市场上一个相当复杂和强大的抓取网络平台,并且 Scrapehub 提供的每个工具都是单独计费的。
5. 解析器
Parsehub 是市场上另一个未编码的桌面抓取工具,与 Windows、Mac OS X 和 Linux 兼容。它提供了一个图形界面来从 JavaScript 和 AJAX 页面中选择和提取数据。可以从嵌套的笔记、地图、图像、日历甚至弹出窗口中提取数据。
此外,Parsehub 有一个基于浏览器的扩展,可以立即开始你的抓取任务。数据可以导出到 Excel、JSON 或通过 API。
Parsehub 的争议与它的价格有关。Parsehub 的付费版本起价为每月 149 美元,高于市场上大多数抓取产品,这意味着标准的 Octoparse 计划每月只需 89 美元,每次抓取的页面不受限制。有一个免费计划,但不幸的是,它仅限于 200 个抓取页面和 5 个抓取作业。
综上所述
除了自动网络爬虫可以做的事情之外,许多社交媒体渠道现在为用户、学者、研究人员和专业组织(例如用于新闻服务的汤森路透和彭博社、用于社交媒体的 Twitter 和 Facebook)提供付费 API。
随着在线经济的发展和繁荣,社交媒体通过更好地倾听客户的意见并以全新的方式与现有和潜在客户互动,为您的企业在您的领域中脱颖而出开辟了许多新机会。
excel抓取网页动态数据(个新手发问如何去简单的分析网站日志)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-26 11:22
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程搜索营销部孙波在“首届百度站长交流大会”上所说的那样。网站建设公司,在使用数据模型修改渠道后,今年被索引的网页数量从原来的几十万增加到了500多万。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到蜘蛛总爬取量、蜘蛛总停留时间、各搜索引擎的蜘蛛访问次数(由于我只做百度优化,就先说百度吧蜘蛛爬行),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下数据功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302…。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。 查看全部
excel抓取网页动态数据(个新手发问如何去简单的分析网站日志)
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程搜索营销部孙波在“首届百度站长交流大会”上所说的那样。网站建设公司,在使用数据模型修改渠道后,今年被索引的网页数量从原来的几十万增加到了500多万。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到蜘蛛总爬取量、蜘蛛总停留时间、各搜索引擎的蜘蛛访问次数(由于我只做百度优化,就先说百度吧蜘蛛爬行),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下数据功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302…。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。
excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-24 18:10
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。
不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页中一个一个的复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!
Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。
另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。
本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点
1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、程序化操作步骤,简单上手课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法,就能在网页上捕捉到自己想要的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。 查看全部
excel抓取网页动态数据(Python爬虫写代码的Excel网抓课》课程概述及解析)
说到从网上抓取数据信息,专业术语叫爬虫。很多人的第一反应是编写各种复杂的代码从网上抓取想要的数据,尤其是近年来特别受追捧的 Python 代码。语言,号称可以零基础快速学习Python爬虫技能。
不过,我想说的是:Python毕竟是一门编程语言。对于我们大多数普通人来说,学习写代码真的很难,很多人安装 Python 的第三方库也很困难;
另外,对于我们这些非程序员来说,为了抓取网页数据,学习Python需要花费大量的时间和精力,投资回报率非常低。任何编程语言都被更频繁地使用和掌握。越高,反之,如果长时间不使用,就会逐渐忘记。
难道我们普通人不会写代码,只能手动从网页中一个一个的复制粘贴数据,就不能像程序员一样直接抓取数据吗?
答案当然是否定的!
经过我长期的研究,我终于找到了一个适合大多数普通人的方法——直接使用日常办公中使用的Excel软件,就可以高效的从网页中抓取想要的数据,而且不用写代码!
Excel是我们大多数上班族必备的办公软件。使用该软件的门槛非常低。进一步学习Excel中Power Query相关组件的功能后,无需编写代码即可轻松操作和抓取网页上的表单。信息。
(特别提醒:WPS没有PowerQuery的功能,所以本课程的部分内容对WPS不太适用)
投入少量时间学习这门课程,以后就能爬取大部分公共网页的数据信息,绝对是一笔非常高的投资回报!
一、课程概览
《无需编写代码的Excel网页抓取教程》是一门完整的课程,无需编写代码,无需任何技术背景,只需点击几下鼠标和基本的办公软件操作,即可学会从网页抓取数据,告别复制和完全粘贴,帮助您提高一百倍的效率。
另外,使用Excel直接抓取数据的最大优势在于,从网页抓取数据后,可以直接进行数据清洗、数据分析、数据图表展示,所有工作都可以无缝完成。毕竟,我们是从网页中捕获的。数据信息的目的是利用这些数据进行相关的数据分析。
本课程适合任何需要从网络上抓取信息或对抓取感兴趣的人,例如:
二、课程亮点
1、不用写代码,小白也能爬
无需编程经验,无需编码,即使是零基础的新手也能轻松学习并爬取网页数据。
2、程序化操作步骤,简单上手课程从实际应用开始。学生只需要按照标准的流程步骤,选择合适的方法,就能在网页上捕捉到自己想要的数据。
3、新颖独特的网页抓取教程
新颖独特的Excel网页爬虫培训视频,除了跳出Excel的局限,善于整合外力为我所用,一切都是快速简单的解题。
三、教学大纲
新班上线,有大量优惠券可用,数量有限,请尽快预购!
有兴趣的朋友,网易云课堂搜索“无需编写代码的Excel网络捕获课程”了解更多详情。
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-21 13:08
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。
怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐,查看更多 查看全部
excel抓取网页动态数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。
怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!返回搜狐,查看更多
excel抓取网页动态数据(Python3.6、Pycharm输入关键字Python操作Excel模板(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-16 07:09
运行环境:Python 3.6、Pycharm 2017.2.3、Chrome 61.0.3163.100
前言
刚刚接触到异步取数据,所以试试如何实现异步取数据。
这次需要实现的是在招聘网站 [网站link]中爬出一些Python相关职位的基本信息,并将这些基本信息保存到Excel表格中。
开始动手分析网页需要的一些知识点
打开拉勾网首页后,我们在搜索框中输入关键字Python,即可找到与Python相关的工作。在搜索结果页面中,我们可以按照以下顺序进行查找。
–> 右键检查
--> 打开检查元素后默认打开元素
–> 我们切换到网络选项卡,刷新网页,就会有各种条目的请求
--> 因为网站是异步请求,所以在Network中打开XHR,分析JSON中的数据。
# 该页面的请求url
Request URL:https://www.lagou.com/jobs/pos ... b%3D0
# 该页面的请求方法
Request Method:POST
--------------------------------
# Request Headers中的相关信息
包括Cookie、Referer、User-Agent等我们之后会用到的信息
代码片段 1 - 请求网页
import requests # 导入请求模块
def getJobList():
res = requests.post(
# 请求url
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1'
)
result = res.json() # 获取res中的json信息
print(result)
getJobList()
运行结果:
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '113.14.1.254'}
出现这样的结果,应该是hook网络的反爬机制发挥了作用,所以这时候需要伪装成用户访问,并且需要添加headers信息。
代码片段 2 - 添加标头信息
import requests
headers = {
# User-Agent(UA) 服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。也就是说伪装成浏览器进行访问
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
# 用于告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。如果不加入,服务器可能依旧会判断为非法请求
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
print(result)
getJobList()
运行结果:
{'success': True, 'requestId': None, 'resubmitToken': None, 'msg': None, 'content': {'pageNo': 1, 'pageSize': 15, 'hrInfoMap': {'1859069': {'userId': 1617639, 'positionName': None, 'phone': None, 'receiveEmail': None, 'realName': 'tracy_cui', 'portrait': None, 'canTalk': True, 'userLevel': 'G1'}, '3667315': {'userId': 8290676, 'positionName': '', 'phone': None, 'receiveEmail': None, 'realName': 'HR', 'portrait': 'i/image/M00/61/32/CgpEMlmSrOWAUE1OAAJ4d6lfWh8386.png', 'canTalk': True, 'userLevel': 'G1'}, '3279531': {'userId': 403820, 'positionName': 'hr', 'phone': None, 'receiveEmail': None, 'realName': '马小姐', 'portrait': 'image1/M00/11/C7/Cgo8PFUBXCeAdWuwAABDv40Fxsc038.png', 'canTalk': True, 'userLevel': 'G1'}, '3475945': {'userId': 701585, 'positionName': 'HR', 'phone': None, 'receiveEmail': None, 'realName': '赵敏', ...................}
这样就得到了响应结果中的json信息,与Preview中的数据信息一致(dict类型的顺序可能不一致)。
代码片段 3 - 获取当前页面作业信息
可以发现需要的职位信息在content->positionResult->result下,里面收录了工作地点、公司名称、职位等信息。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result'] # 输出返回的整个json信息中的职位相关信息
print(type(jobsInfo)) # 我们查看一下jobsInfo的数据类型
print(jobsInfo) # 打印职位信息
getJobList()
运行结果:
[{'companyId': 54727, 'positionId': 3685814, 'industryField': '移动互联网', 'education': '本科', 'workYear': '应届毕业生', 'city': '广州', 'positionAdvantage': '带薪年假;五险一金;节日福利;年度体检', 'createTime': '2017-10-11 10:31:52', 'salary': '4k-8k', 'positionName': '电商运营', 'companySize': '150-500人', 'companyShortName': '有车以后', 'companyLogo': 'image1/M00/3A/2D/Cgo8PFWsrUeAf1gEAAF2eIhOLlo086.jpg', 'financeStage': '成熟型(C轮)', 'jobNature': '全职', 'approve': 1, 'companyLabelList': ['股票期权', '带薪年假', '年度旅游', '弹性工作'], 'district': None, 'positionLables': [], 'industryLables': [], 'publisherId': 6331287, 'businessZones': None, 'score': 0, 'companyFullName': '广州市有车以后信息科技有限公司', 'adWord': 0, 'imState': 'disabled', 'lastLogin': 1507686331000, 'explain': None, 'plus': None, 'pcShow': 0, 'appShow': 0, 'deliver': 0, 'gradeDescription': None, 'promotionScoreExplain': None, 'firstType': '运营/编辑/客服', ...................
根据运行结果发现,jobsInfo中的数据类型是一个列表,其中收录了整个页面显示的所有职位的信息。因此,可以采用遍历的方法,对每个职位的相关信息进行梳理,提取出需要的数据,如公司名称、职位优势等。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
for job in getJobList():
# 这里演示,提取出公司名以及公司职位优势
print(job['companyFullName'] + ':' + job['positionAdvantage'])
运行结果后,剩下的相关信息可以根据key值自行获取:
广州市暨嘉信息科技有限公司:岗位培训,销售技巧,智能工业,机械设备
广州云乐数码科技有限公司:工作气氛好,学习机会多,生长快,工作环境好
广州市贝聊信息科技有限公司:愉快的工作氛围,下午茶,弹性上班
广州元创信息科技有限公司:交通便利,双休
广州数沃信息科技有限公司:技术强大,五险一金,周末双休,带薪年假
..................
最终代码 - 写入 Excel
Python中Excel的模板读写主要有xlrd、xlwt、xlutils、openpyxl、xlsxwriter。这里使用的是xlsxWriter,可以参考我之前的博客【链接】
import requests
import xlsxwriter
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E',
'Cookie': 'user_trace_token=20171010203203-04dbd95d-adb7-11e7-946a-5254005c3644; LGUID=20171010203203-04dbddae-adb7-11e7-946a-5254005c3644; index_location_city=%E5%B9%BF%E5%B7%9E; JSESSIONID=ABAAABAABEEAAJA8BF3AD5C8CFD40070BD3A86E50B0F9E4; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; TG-TRACK-CODE=index_navigation; SEARCH_ID=0cc609743acc4bf18789b584210f6ccb; _gid=GA1.2.271865682.1507638722; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507638723; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507720548; _ga=GA1.2.577848458.1507638722; LGSID=20171011190218-a611d705-ae73-11e7-8a7a-525400f775ce; LGRID=20171011191547-882eafd3-ae75-11e7-8a92-525400f775ce'
}
def getJobList(page):
formData = {
'first': 'false',
'pn': page,
'kd': 'Python'
}
res = requests.post(
# 请求的url
url='https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0',
# 添加headers信息
headers=headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
# 创建一个excel表格
workbook = xlsxwriter.Workbook('Python职位信息.xlsx')
# 为创建的excel表格添加一个工作表
worksheet = workbook.add_worksheet()
# 将数据写入工作表中
def writeExcel(row=0, positionName='职位名', city='工作地点', education='教育程度', salary='薪资', companyFullName='公司名字'):
if row == 0:
worksheet.write(row, 0, positionName)
worksheet.write(row, 1, salary)
worksheet.write(row, 2, city)
worksheet.write(row, 3, education)
worksheet.write(row, 4, companyFullName)
else:
worksheet.write(row, 0, job['positionName'])
worksheet.write(row, 1, job['salary'])
worksheet.write(row, 2, job['city'])
worksheet.write(row, 3, job['education'])
worksheet.write(row, 4, job['companyFullName'])
# 在第一行中写入列名
writeExcel(row=0)
# 从第二行开始写入数据
row = 1
# 这里爬取前五页招聘信息做一个示范
for page in range(1, 6):
# 爬取一页中的每一条招聘信息
for job in getJobList(page=page):
# 将爬取到的信息写入表格中
writeExcel(row=row, positionName=job['positionName'], companyFullName=job['companyFullName'], city=job['city'],
education=job['education'], salary=job['salary'])
row += 1
print('第 %d 页已经爬取完成' % page)
# 做适当的延时,所谓不做延时的爬虫都是耍流氓
time.sleep(0.5)
# 关闭表格文件
workbook.close()
运行结果:
这样,我们就爬下了我们需要的招聘信息。
总结 查看全部
excel抓取网页动态数据(Python3.6、Pycharm输入关键字Python操作Excel模板(图))
运行环境:Python 3.6、Pycharm 2017.2.3、Chrome 61.0.3163.100
前言
刚刚接触到异步取数据,所以试试如何实现异步取数据。
这次需要实现的是在招聘网站 [网站link]中爬出一些Python相关职位的基本信息,并将这些基本信息保存到Excel表格中。
开始动手分析网页需要的一些知识点
打开拉勾网首页后,我们在搜索框中输入关键字Python,即可找到与Python相关的工作。在搜索结果页面中,我们可以按照以下顺序进行查找。
–> 右键检查
--> 打开检查元素后默认打开元素
–> 我们切换到网络选项卡,刷新网页,就会有各种条目的请求
--> 因为网站是异步请求,所以在Network中打开XHR,分析JSON中的数据。
# 该页面的请求url
Request URL:https://www.lagou.com/jobs/pos ... b%3D0
# 该页面的请求方法
Request Method:POST
--------------------------------
# Request Headers中的相关信息
包括Cookie、Referer、User-Agent等我们之后会用到的信息
代码片段 1 - 请求网页
import requests # 导入请求模块
def getJobList():
res = requests.post(
# 请求url
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1'
)
result = res.json() # 获取res中的json信息
print(result)
getJobList()
运行结果:
{'success': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '113.14.1.254'}
出现这样的结果,应该是hook网络的反爬机制发挥了作用,所以这时候需要伪装成用户访问,并且需要添加headers信息。
代码片段 2 - 添加标头信息
import requests
headers = {
# User-Agent(UA) 服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。也就是说伪装成浏览器进行访问
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
# 用于告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。如果不加入,服务器可能依旧会判断为非法请求
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
print(result)
getJobList()
运行结果:
{'success': True, 'requestId': None, 'resubmitToken': None, 'msg': None, 'content': {'pageNo': 1, 'pageSize': 15, 'hrInfoMap': {'1859069': {'userId': 1617639, 'positionName': None, 'phone': None, 'receiveEmail': None, 'realName': 'tracy_cui', 'portrait': None, 'canTalk': True, 'userLevel': 'G1'}, '3667315': {'userId': 8290676, 'positionName': '', 'phone': None, 'receiveEmail': None, 'realName': 'HR', 'portrait': 'i/image/M00/61/32/CgpEMlmSrOWAUE1OAAJ4d6lfWh8386.png', 'canTalk': True, 'userLevel': 'G1'}, '3279531': {'userId': 403820, 'positionName': 'hr', 'phone': None, 'receiveEmail': None, 'realName': '马小姐', 'portrait': 'image1/M00/11/C7/Cgo8PFUBXCeAdWuwAABDv40Fxsc038.png', 'canTalk': True, 'userLevel': 'G1'}, '3475945': {'userId': 701585, 'positionName': 'HR', 'phone': None, 'receiveEmail': None, 'realName': '赵敏', ...................}
这样就得到了响应结果中的json信息,与Preview中的数据信息一致(dict类型的顺序可能不一致)。
代码片段 3 - 获取当前页面作业信息
可以发现需要的职位信息在content->positionResult->result下,里面收录了工作地点、公司名称、职位等信息。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result'] # 输出返回的整个json信息中的职位相关信息
print(type(jobsInfo)) # 我们查看一下jobsInfo的数据类型
print(jobsInfo) # 打印职位信息
getJobList()
运行结果:
[{'companyId': 54727, 'positionId': 3685814, 'industryField': '移动互联网', 'education': '本科', 'workYear': '应届毕业生', 'city': '广州', 'positionAdvantage': '带薪年假;五险一金;节日福利;年度体检', 'createTime': '2017-10-11 10:31:52', 'salary': '4k-8k', 'positionName': '电商运营', 'companySize': '150-500人', 'companyShortName': '有车以后', 'companyLogo': 'image1/M00/3A/2D/Cgo8PFWsrUeAf1gEAAF2eIhOLlo086.jpg', 'financeStage': '成熟型(C轮)', 'jobNature': '全职', 'approve': 1, 'companyLabelList': ['股票期权', '带薪年假', '年度旅游', '弹性工作'], 'district': None, 'positionLables': [], 'industryLables': [], 'publisherId': 6331287, 'businessZones': None, 'score': 0, 'companyFullName': '广州市有车以后信息科技有限公司', 'adWord': 0, 'imState': 'disabled', 'lastLogin': 1507686331000, 'explain': None, 'plus': None, 'pcShow': 0, 'appShow': 0, 'deliver': 0, 'gradeDescription': None, 'promotionScoreExplain': None, 'firstType': '运营/编辑/客服', ...................
根据运行结果发现,jobsInfo中的数据类型是一个列表,其中收录了整个页面显示的所有职位的信息。因此,可以采用遍历的方法,对每个职位的相关信息进行梳理,提取出需要的数据,如公司名称、职位优势等。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E'
}
def getJobList():
res = requests.post(
url='https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=1',
headers = headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
for job in getJobList():
# 这里演示,提取出公司名以及公司职位优势
print(job['companyFullName'] + ':' + job['positionAdvantage'])
运行结果后,剩下的相关信息可以根据key值自行获取:
广州市暨嘉信息科技有限公司:岗位培训,销售技巧,智能工业,机械设备
广州云乐数码科技有限公司:工作气氛好,学习机会多,生长快,工作环境好
广州市贝聊信息科技有限公司:愉快的工作氛围,下午茶,弹性上班
广州元创信息科技有限公司:交通便利,双休
广州数沃信息科技有限公司:技术强大,五险一金,周末双休,带薪年假
..................
最终代码 - 写入 Excel
Python中Excel的模板读写主要有xlrd、xlwt、xlutils、openpyxl、xlsxwriter。这里使用的是xlsxWriter,可以参考我之前的博客【链接】
import requests
import xlsxwriter
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_Python?px=default&gx=&isSchoolJob=1&city=%E5%B9%BF%E5%B7%9E',
'Cookie': 'user_trace_token=20171010203203-04dbd95d-adb7-11e7-946a-5254005c3644; LGUID=20171010203203-04dbddae-adb7-11e7-946a-5254005c3644; index_location_city=%E5%B9%BF%E5%B7%9E; JSESSIONID=ABAAABAABEEAAJA8BF3AD5C8CFD40070BD3A86E50B0F9E4; PRE_UTM=; PRE_HOST=; PRE_SITE=https%3A%2F%2Fwww.lagou.com%2F; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_Python%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; TG-TRACK-CODE=index_navigation; SEARCH_ID=0cc609743acc4bf18789b584210f6ccb; _gid=GA1.2.271865682.1507638722; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507638723; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507720548; _ga=GA1.2.577848458.1507638722; LGSID=20171011190218-a611d705-ae73-11e7-8a7a-525400f775ce; LGRID=20171011191547-882eafd3-ae75-11e7-8a92-525400f775ce'
}
def getJobList(page):
formData = {
'first': 'false',
'pn': page,
'kd': 'Python'
}
res = requests.post(
# 请求的url
url='https://www.lagou.com/jobs/positionAjax.json?city=%E5%B9%BF%E5%B7%9E&needAddtionalResult=false&isSchoolJob=0',
# 添加headers信息
headers=headers
)
result = res.json()
jobsInfo = result['content']['positionResult']['result']
return jobsInfo
# 创建一个excel表格
workbook = xlsxwriter.Workbook('Python职位信息.xlsx')
# 为创建的excel表格添加一个工作表
worksheet = workbook.add_worksheet()
# 将数据写入工作表中
def writeExcel(row=0, positionName='职位名', city='工作地点', education='教育程度', salary='薪资', companyFullName='公司名字'):
if row == 0:
worksheet.write(row, 0, positionName)
worksheet.write(row, 1, salary)
worksheet.write(row, 2, city)
worksheet.write(row, 3, education)
worksheet.write(row, 4, companyFullName)
else:
worksheet.write(row, 0, job['positionName'])
worksheet.write(row, 1, job['salary'])
worksheet.write(row, 2, job['city'])
worksheet.write(row, 3, job['education'])
worksheet.write(row, 4, job['companyFullName'])
# 在第一行中写入列名
writeExcel(row=0)
# 从第二行开始写入数据
row = 1
# 这里爬取前五页招聘信息做一个示范
for page in range(1, 6):
# 爬取一页中的每一条招聘信息
for job in getJobList(page=page):
# 将爬取到的信息写入表格中
writeExcel(row=row, positionName=job['positionName'], companyFullName=job['companyFullName'], city=job['city'],
education=job['education'], salary=job['salary'])
row += 1
print('第 %d 页已经爬取完成' % page)
# 做适当的延时,所谓不做延时的爬虫都是耍流氓
time.sleep(0.5)
# 关闭表格文件
workbook.close()
运行结果:
这样,我们就爬下了我们需要的招聘信息。
总结
excel抓取网页动态数据(通过Python来一个拉勾网薪资调查的小爬虫(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-14 04:04
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。Step 1:分析网站的请求流程当我们查看拉狗网的招聘信息时
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说“拉狗网”薪资调查的小爬虫,并将爬取结果保存在excel中,希望能帮助大家提高!!!
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = { 3 'Host': 'www.lagou.com', 4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 6 'Connection': 'keep-alive'
7 } 8 if page_num == 1: 9 boo = 'true'
10 else: 11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo), 14 ('pn', page_num), 15 ('kd', keyword) 16 ]) 17 req = request.Request(url, headers=page_headers) 18 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 19 page = page.decode('utf-8') 20 return page
只听山间传来建筑师的声音:
陆希的明朝更加低迷,人死了,什么时候回来。谁将向上或向下匹配?
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
此代码由Java架构师必看网-架构君整理
1 def read_tag(page, tag): 2 page_json = json.loads(page) 3 page_json = page_json['content']['result'] 4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15): 7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag: 9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8]) 11 return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name): 2 book = Workbook(encoding='utf-8') 3 tmp = book.add_sheet('sheet') 4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0: 7 for tag_name_i in tag_name: 8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i) 9 else: 10 for tag_list in range(len(tag_name)): 11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) 12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
此代码由Java架构师必看网-架构君整理
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet() 4 row_num = len(fin_result) 5 for i in range(1, row_num): 6 if i == 1: 7 tag_pos = 'A%s' % i 8 tmp.write_row(tag_pos, tag_name) 9 else: 10 con_pos = 'A%s' % i 11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content) 13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse 4 from bs4 import BeautifulSoup as BS 5 import json 6 import datetime 7 import xlsxwriter 8
9 starttime = datetime.datetime.now() 10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] 18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = { 22 'Host': 'www.lagou.com', 23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 25 'Connection': 'keep-alive'
26 } 27 if page_num == 1: 28 boo = 'true'
29 else: 30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo), 33 ('pn', page_num), 34 ('kd', keyword) 35 ]) 36 req = request.Request(url, headers=page_headers) 37 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 38 page = page.decode('utf-8') 39 return page 40
41
42 def read_tag(page, tag): 43 page_json = json.loads(page) 44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15): 47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag: 49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8]) 51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page) 56 max_page_num = page_json['content']['totalPageCount'] 57 if max_page_num > 30: 58 max_page_num = 30
59 return max_page_num 60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet() 65 row_num = len(fin_result) 66 for i in range(1, row_num): 67 if i == 1: 68 tag_pos = 'A%s' % i 69 tmp.write_row(tag_pos, tag_name) 70 else: 71 con_pos = 'A%s' % i 72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content) 74 book.close() 75
76
77 if __name__ == '__main__': 78 print('**********************************即将进行抓取**********************************') 79 keyword = input('请输入您要搜索的语言类型:') 80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword)) 82 for page_num in range(1, max_page_num): 83 print('******************************正在下载第%s页内容*********************************' % page_num) 84 page = read_page(url, page_num, keyword) 85 page_result = read_tag(page, tag) 86 fin_result.extend(page_result) 87 file_name = input('抓取完成,输入文件名保存:') 88 save_excel(fin_result, tag_name, file_name) 89 endtime = datetime.datetime.now() 90 time = (endtime - starttime).seconds 91 print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~ 查看全部
excel抓取网页动态数据(通过Python来一个拉勾网薪资调查的小爬虫(组图))
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。Step 1:分析网站的请求流程当我们查看拉狗网的招聘信息时
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说“拉狗网”薪资调查的小爬虫,并将爬取结果保存在excel中,希望能帮助大家提高!!!
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
1 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
2 page_headers = { 3 'Host': 'www.lagou.com', 4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
5 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 6 'Connection': 'keep-alive'
7 } 8 if page_num == 1: 9 boo = 'true'
10 else: 11 boo = 'false'
12 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
13 ('first', boo), 14 ('pn', page_num), 15 ('kd', keyword) 16 ]) 17 req = request.Request(url, headers=page_headers) 18 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 19 page = page.decode('utf-8') 20 return page
只听山间传来建筑师的声音:
陆希的明朝更加低迷,人死了,什么时候回来。谁将向上或向下匹配?
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
此代码由Java架构师必看网-架构君整理
1 def read_tag(page, tag): 2 page_json = json.loads(page) 3 page_json = page_json['content']['result'] 4 # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
5 page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
6 for i in range(15): 7 page_result[i] = [] # 构造二维数组
8 for page_tag in tag: 9 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
10 page_result[i][8] = ','.join(page_result[i][8]) 11 return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
1 def save_excel(fin_result, tag_name, file_name): 2 book = Workbook(encoding='utf-8') 3 tmp = book.add_sheet('sheet') 4 times = len(fin_result)+1
5 for i in range(times): # i代表的是行,i+1代表的是行首信息
6 if i == 0: 7 for tag_name_i in tag_name: 8 tmp.write(i, tag_name.index(tag_name_i), tag_name_i) 9 else: 10 for tag_list in range(len(tag_name)): 11 tmp.write(i, tag_list, str(fin_result[i-1][tag_list])) 12 book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
此代码由Java架构师必看网-架构君整理
1 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
2 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
3 tmp = book.add_worksheet() 4 row_num = len(fin_result) 5 for i in range(1, row_num): 6 if i == 1: 7 tag_pos = 'A%s' % i 8 tmp.write_row(tag_pos, tag_name) 9 else: 10 con_pos = 'A%s' % i 11 content = fin_result[i-1] # -1是因为被表格的表头所占
12 tmp.write_row(con_pos, content) 13 book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
1 #! -*-coding:utf-8 -*-
2
3 from urllib import request, parse 4 from bs4 import BeautifulSoup as BS 5 import json 6 import datetime 7 import xlsxwriter 8
9 starttime = datetime.datetime.now() 10
11 url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
12 # 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
13
14 tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize', 15 'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
16
17 tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍'] 18
19
20 def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
21 page_headers = { 22 'Host': 'www.lagou.com', 23 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
24 'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3', 25 'Connection': 'keep-alive'
26 } 27 if page_num == 1: 28 boo = 'true'
29 else: 30 boo = 'false'
31 page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
32 ('first', boo), 33 ('pn', page_num), 34 ('kd', keyword) 35 ]) 36 req = request.Request(url, headers=page_headers) 37 page = request.urlopen(req, data=page_data.encode('utf-8')).read() 38 page = page.decode('utf-8') 39 return page 40
41
42 def read_tag(page, tag): 43 page_json = json.loads(page) 44 page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
45 page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
46 for i in range(15): 47 page_result[i] = [] # 构造二维数组
48 for page_tag in tag: 49 page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
50 page_result[i][8] = ','.join(page_result[i][8]) 51 return page_result # 返回当前页的招聘信息
52
53
54 def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
55 page_json = json.loads(page) 56 max_page_num = page_json['content']['totalPageCount'] 57 if max_page_num > 30: 58 max_page_num = 30
59 return max_page_num 60
61
62 def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
63 book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
64 tmp = book.add_worksheet() 65 row_num = len(fin_result) 66 for i in range(1, row_num): 67 if i == 1: 68 tag_pos = 'A%s' % i 69 tmp.write_row(tag_pos, tag_name) 70 else: 71 con_pos = 'A%s' % i 72 content = fin_result[i-1] # -1是因为被表格的表头所占
73 tmp.write_row(con_pos, content) 74 book.close() 75
76
77 if __name__ == '__main__': 78 print('**********************************即将进行抓取**********************************') 79 keyword = input('请输入您要搜索的语言类型:') 80 fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
81 max_page_num = read_max_page(read_page(url, 1, keyword)) 82 for page_num in range(1, max_page_num): 83 print('******************************正在下载第%s页内容*********************************' % page_num) 84 page = read_page(url, page_num, keyword) 85 page_result = read_tag(page, tag) 86 fin_result.extend(page_result) 87 file_name = input('抓取完成,输入文件名保存:') 88 save_excel(fin_result, tag_name, file_name) 89 endtime = datetime.datetime.now() 90 time = (endtime - starttime).seconds 91 print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发,这只是为了吸引别人,欢迎交流,请注明转载来源~(^_^)/~~
excel抓取网页动态数据(excel抓取网页动态数据的五种方法主要分以下5种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2022-01-13 03:03
excel抓取网页动态数据的五种方法主要分以下5种:1.动态网页之cookie网页抓取中,网页本身并不会出现数据。但是由于站点抓取原理不同,网页中的数据有不同的格式,比如html网页,一般是标签,一般称为原始文档,还有其他格式,比如使用cookie的url引用,这个时候我们对url进行伪装,就能抓取到网页原始数据,如下图:2.页面埋点提取网页的动态数据,我们需要写代码来操作,方法比较多,有一个叫“urllib.parse()”的api方法,这个api能够读取所有网页中的数据,伪装url抓取页面数据,效果如下图:伪装url抓取网页数据,伪装代码,等待网页被解析抓取的时候会请求url请求处理成功就抓取,失败就不抓取,不然如何方便我们下一步的操作?3.cookie提取方法和cookie有些相似,但是代码会复杂很多,还要考虑服务器,如果服务器抛异常,比如浏览器不兼容。
那就没办法,所以小编再次建议大家方便的方法,是用某个网站的xss漏洞。常用的xss漏洞有如下3种,flashxss、cookiexss、ajaxxss。xss黑客拿到我们的内容,处理完后再发给我们想要的客户端,我们就能正常的处理我们想要的数据,如下图:4.requestjson.parse最常用的,伪装url,如果服务器异常,则将我们的html数据发给一个http请求,再返回requestjson。
如下图:5.x-document-responseencoding不同的浏览器兼容有些不同,我们使用x-styled-componentapp-cli.sass@1.6.9/x-styled-component-app-cli.sass或者x-extensions-common/x-extensions-common@1.6.9/x-extensions-common.sass来编译出来。
如下图:如果网页可以正常下载,我们再采用以下的方法:5.1python-xss-bot-js数据网页,利用xss(注射)来获取数据5.2python-xss-dump-python-xss-dump-python写脚本,复制爬取数据在脚本里面处理实际使用方法参见网站:cookie-and-postload/lib/libjs/python-xss-and-postload.py,javascript:pythonscripts5.3requestjson.parse抓取到的数据,用来进行异步加载处理。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据的五种方法主要分以下5种)
excel抓取网页动态数据的五种方法主要分以下5种:1.动态网页之cookie网页抓取中,网页本身并不会出现数据。但是由于站点抓取原理不同,网页中的数据有不同的格式,比如html网页,一般是标签,一般称为原始文档,还有其他格式,比如使用cookie的url引用,这个时候我们对url进行伪装,就能抓取到网页原始数据,如下图:2.页面埋点提取网页的动态数据,我们需要写代码来操作,方法比较多,有一个叫“urllib.parse()”的api方法,这个api能够读取所有网页中的数据,伪装url抓取页面数据,效果如下图:伪装url抓取网页数据,伪装代码,等待网页被解析抓取的时候会请求url请求处理成功就抓取,失败就不抓取,不然如何方便我们下一步的操作?3.cookie提取方法和cookie有些相似,但是代码会复杂很多,还要考虑服务器,如果服务器抛异常,比如浏览器不兼容。
那就没办法,所以小编再次建议大家方便的方法,是用某个网站的xss漏洞。常用的xss漏洞有如下3种,flashxss、cookiexss、ajaxxss。xss黑客拿到我们的内容,处理完后再发给我们想要的客户端,我们就能正常的处理我们想要的数据,如下图:4.requestjson.parse最常用的,伪装url,如果服务器异常,则将我们的html数据发给一个http请求,再返回requestjson。
如下图:5.x-document-responseencoding不同的浏览器兼容有些不同,我们使用x-styled-componentapp-cli.sass@1.6.9/x-styled-component-app-cli.sass或者x-extensions-common/x-extensions-common@1.6.9/x-extensions-common.sass来编译出来。
如下图:如果网页可以正常下载,我们再采用以下的方法:5.1python-xss-bot-js数据网页,利用xss(注射)来获取数据5.2python-xss-dump-python-xss-dump-python写脚本,复制爬取数据在脚本里面处理实际使用方法参见网站:cookie-and-postload/lib/libjs/python-xss-and-postload.py,javascript:pythonscripts5.3requestjson.parse抓取到的数据,用来进行异步加载处理。
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中2.怎么使用查询)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-06 21:08
有时在Excel中输入的数据源是网页,网页的数据不需输入就可以直接导入。如何将数据导入网页?接下来就是学习编辑器带来的excel表格了。网页数据导入教程供大家参考。
excel表格导入网页数据教程:
笔者以《中华人民共和国国家统计局50个城市(2014年3月11-20日)主要食品平均价格变化情况》为例。因为这些数据都是网页格式的,我们想把它们采集整理到我们的Excel中来。
导入网页数据第一步:首先我们复制数据表所在网页的URL地址。
导入网页数据 第二步:然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建网页查询”对话框。
导入网页数据 第三步:将复制的网址粘贴到“新建网页查询”的地址栏中,然后点击前往,会出现相应的数据页面,如下图:
导入网页数据 Step 4:将鼠标移到对话框中网页表格的左上角,我们会在左上角看到一个黄底黑色箭头标志,表示Excel已经识别了这个表格网页,我们点击箭头,箭头会变成绿色的对勾,提示表格选择成功,最后点击下方的“导入”,如下图:
导入网页数据 Step 5:在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel会为我们获取数据,如图:
导入网页数据第六步:导入数据需要等待,如下图:
导入网页数据第七步:最终数据导入成功,效果如下图:
导入网页数据第8步: 至此,网页上的数据已经成功导入到Excel表格中,接下来我们就可以根据需要对数据进行处理了。
看了网页数据导入excel表格的教程,还看到了:
1.如何将网页数据导入Excel表格
2.如何使用excel2013web查询采集网页数据功能
3.Excel电子表格基础操作教程免费下载
4.Excel电子表格教程
5.excel2010如何导入外来数据
6.如何使用excel进行数据分析教程
7.如何将Excel中一张表的数据导入到另一张表 查看全部
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中2.怎么使用查询)
有时在Excel中输入的数据源是网页,网页的数据不需输入就可以直接导入。如何将数据导入网页?接下来就是学习编辑器带来的excel表格了。网页数据导入教程供大家参考。
excel表格导入网页数据教程:
笔者以《中华人民共和国国家统计局50个城市(2014年3月11-20日)主要食品平均价格变化情况》为例。因为这些数据都是网页格式的,我们想把它们采集整理到我们的Excel中来。
导入网页数据第一步:首先我们复制数据表所在网页的URL地址。
导入网页数据 第二步:然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建网页查询”对话框。
导入网页数据 第三步:将复制的网址粘贴到“新建网页查询”的地址栏中,然后点击前往,会出现相应的数据页面,如下图:
导入网页数据 Step 4:将鼠标移到对话框中网页表格的左上角,我们会在左上角看到一个黄底黑色箭头标志,表示Excel已经识别了这个表格网页,我们点击箭头,箭头会变成绿色的对勾,提示表格选择成功,最后点击下方的“导入”,如下图:
导入网页数据 Step 5:在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel会为我们获取数据,如图:
导入网页数据第六步:导入数据需要等待,如下图:
导入网页数据第七步:最终数据导入成功,效果如下图:
导入网页数据第8步: 至此,网页上的数据已经成功导入到Excel表格中,接下来我们就可以根据需要对数据进行处理了。
看了网页数据导入excel表格的教程,还看到了:
1.如何将网页数据导入Excel表格
2.如何使用excel2013web查询采集网页数据功能
3.Excel电子表格基础操作教程免费下载
4.Excel电子表格教程
5.excel2010如何导入外来数据
6.如何使用excel进行数据分析教程
7.如何将Excel中一张表的数据导入到另一张表
excel抓取网页动态数据(一下excel抓取数据的过程(实验环境win7+office2013))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-06 21:06
当然可以,但是使用起来不是很灵活。没有像python这样的语言来捕获数据以便于处理。下面我将介绍用excel抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要截取的页面。这里以页面的数据为例,点击“前往”->“导入”,如下:
3. 导入成功后,数据如下,我们需要的数据已经成功捕获:
4.如果要定时刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的过程。总的来说,整个过程还是比较简单的,但是灵活性不是很高,如果页面比较复杂,抓取的数据量比较多,后期直接用excel处理不是很方便。题主已经可以使用python了。, 推荐使用python直接抓包,更灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以尽快开始。网上也有相关的资料和教程。希望以上分享的内容对您有所帮助。 查看全部
excel抓取网页动态数据(一下excel抓取数据的过程(实验环境win7+office2013))
当然可以,但是使用起来不是很灵活。没有像python这样的语言来捕获数据以便于处理。下面我将介绍用excel抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要截取的页面。这里以页面的数据为例,点击“前往”->“导入”,如下:
3. 导入成功后,数据如下,我们需要的数据已经成功捕获:
4.如果要定时刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据的过程。总的来说,整个过程还是比较简单的,但是灵活性不是很高,如果页面比较复杂,抓取的数据量比较多,后期直接用excel处理不是很方便。题主已经可以使用python了。, 推荐使用python直接抓包,更灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以尽快开始。网上也有相关的资料和教程。希望以上分享的内容对您有所帮助。
excel抓取网页动态数据(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-05 01:00
)
您想知道如何使用python来捕获网页中的动态数据吗?Saintlas将为大家详细讲解python捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和指正。让我们突出重点。:python抓取网页动态数据,python抓取网页动态数据。一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
excel抓取网页动态数据(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗
)
您想知道如何使用python来捕获网页中的动态数据吗?Saintlas将为大家详细讲解python捕捉网页动态数据的相关知识以及一些代码示例。欢迎阅读和指正。让我们突出重点。:python抓取网页动态数据,python抓取网页动态数据。一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 没有那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text

