
c 抓取网页数据
c 抓取网页数据(一下示例代码看起来(2021-09-16我是一个))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-15 01:13
2021-09-16
我是刚加入公司的新人。老板交给我的任务是写剧本。作用是从其他网站中抓取数据,然后在我们的平台上展示。具体业务就不介绍了。主要目的是从其他网站中获取数据。方法是使用 Jsoup 类。这是一个示例代码
Jsoup.connect(REGISTER_URL)
.userAgent(USER_AGENT)
.method(Connection.Method.GET)
这似乎很简单。一开始是去了解HTTP协议,request请求和response响应(我在学校是渣渣,没认真学习= =)。然后开始吧。
我们先来个登录的例子,先打开目标网站,找到登录的地方,这里是一个例子
然后打开抓包工具
(一开始我还是打开了网站的源码,然后去他的按钮提交的url,o(╥﹏╥)o)
软件的操作也很简单,大家可以自行百度。
然后,输入登录信息后,点击登录,查看抓取的数据。然后在脚本、头文件等中写入相应的要发送的数据。可以通过这种方式捕获其他一些功能。
这些都不是这次的重点
有一些功能网站在app上是没有的,所以需要抓取手机app的包,找到需要的接口。
这里举个例子,我们会发现有些参数是加密的,我们需要知道它的加密方式。这里我们可以先调整一个断点,修改请求中的数据,看看数据是不是真的有用的数据(这里想找sign的加密方式,但是找了半天也没找到,然后在前人的指导下使用了断点,方法知道sign的参数可以任意设置,也可以知道是否需要其他参数)。
搜索了一下,发现password参数是有用的(肯定的),然后我们只有一个目标:找到password的加密方式。
我们使用反编译软件对app进行反编译
这里双击 jadx-gui.bat 就可以直接选择要反编译的app文件,反编译出来的工程结构
直接全局搜索密码
然后你必须仔细选择哪些可以被加密。
这里发现密码被插入到JSONObject中,点击查看
看看其他字段和之前请求中的完全一样,那我们来看看aj.a和ia是什么。
找到引用的包
先看ia
发现有一个dX,找到!
这里找到了一个SharedPreferences类,百度一下,它是一个存储类。
大概明白ia的意识,大概率是取出用户输入的密码。
然后找到aj.a
这里发现是直接用MD5算法加密,然后经过aa处理。找到一个
发现是他们自己写的算法。他们不理解也没关系。只需将其复制到自己的项目中即可。
这样就知道密码的加密方式了。先用MD5加密,然后用自己的算法处理,再重复这一步。自己写一个案例测试。
好的~
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(一下示例代码看起来(2021-09-16我是一个))
2021-09-16
我是刚加入公司的新人。老板交给我的任务是写剧本。作用是从其他网站中抓取数据,然后在我们的平台上展示。具体业务就不介绍了。主要目的是从其他网站中获取数据。方法是使用 Jsoup 类。这是一个示例代码
Jsoup.connect(REGISTER_URL)
.userAgent(USER_AGENT)
.method(Connection.Method.GET)
这似乎很简单。一开始是去了解HTTP协议,request请求和response响应(我在学校是渣渣,没认真学习= =)。然后开始吧。
我们先来个登录的例子,先打开目标网站,找到登录的地方,这里是一个例子
然后打开抓包工具
(一开始我还是打开了网站的源码,然后去他的按钮提交的url,o(╥﹏╥)o)
软件的操作也很简单,大家可以自行百度。
然后,输入登录信息后,点击登录,查看抓取的数据。然后在脚本、头文件等中写入相应的要发送的数据。可以通过这种方式捕获其他一些功能。
这些都不是这次的重点
有一些功能网站在app上是没有的,所以需要抓取手机app的包,找到需要的接口。
这里举个例子,我们会发现有些参数是加密的,我们需要知道它的加密方式。这里我们可以先调整一个断点,修改请求中的数据,看看数据是不是真的有用的数据(这里想找sign的加密方式,但是找了半天也没找到,然后在前人的指导下使用了断点,方法知道sign的参数可以任意设置,也可以知道是否需要其他参数)。
搜索了一下,发现password参数是有用的(肯定的),然后我们只有一个目标:找到password的加密方式。
我们使用反编译软件对app进行反编译
这里双击 jadx-gui.bat 就可以直接选择要反编译的app文件,反编译出来的工程结构
直接全局搜索密码
然后你必须仔细选择哪些可以被加密。
这里发现密码被插入到JSONObject中,点击查看
看看其他字段和之前请求中的完全一样,那我们来看看aj.a和ia是什么。
找到引用的包
先看ia
发现有一个dX,找到!
这里找到了一个SharedPreferences类,百度一下,它是一个存储类。
大概明白ia的意识,大概率是取出用户输入的密码。
然后找到aj.a
这里发现是直接用MD5算法加密,然后经过aa处理。找到一个
发现是他们自己写的算法。他们不理解也没关系。只需将其复制到自己的项目中即可。
这样就知道密码的加密方式了。先用MD5加密,然后用自己的算法处理,再重复这一步。自己写一个案例测试。
好的~
分类:
技术要点:
相关文章:
c 抓取网页数据([]请求载体的身份识别信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-15 01:12
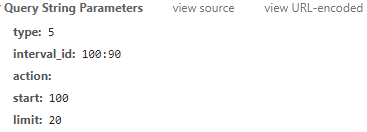
要查找更改的参数,只需下拉进度条即可查看新的请求数据
可以看出只有start变了,start 80;限制 20;开始100;限制20。能猜到这20是每次刷新的视频数吗?start 是从第一个视频开始阅读?
通过对网页的初步分析,这种可能性非常高,而且很容易验证。记住里面的请求是GET,所以可以用浏览器直接访问接口进行验证。
start=1 limit=2,刷新了本杀手不太冷和七武士的两部电影
start=2 limit=3,刷新了《七武士》、《割肚皮》、《蝙蝠侠:黑暗骑士》三部影片。由此可以验证 start 是视频排名第一的请求。限制是每个请求的视频数量。如果我想抓取前 300 个视频,我只需要 start=1,limit=300。网页分析到这里就可以完成了,我们想要的信息已经得到了。
1、接口:%3A90&action=&start=2&limit=3
2、请求方法:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、这部分通过对网页的分析发现,豆瓣视频的排名采用了网页的部分动态加载技术
2、检查中筛选出动态加载的请求接口,请求反馈为类json格式(供后期python解析),通过猜测发现start和limit两个参数的含义直接调用接口
python代码编写
1、User_agent介绍
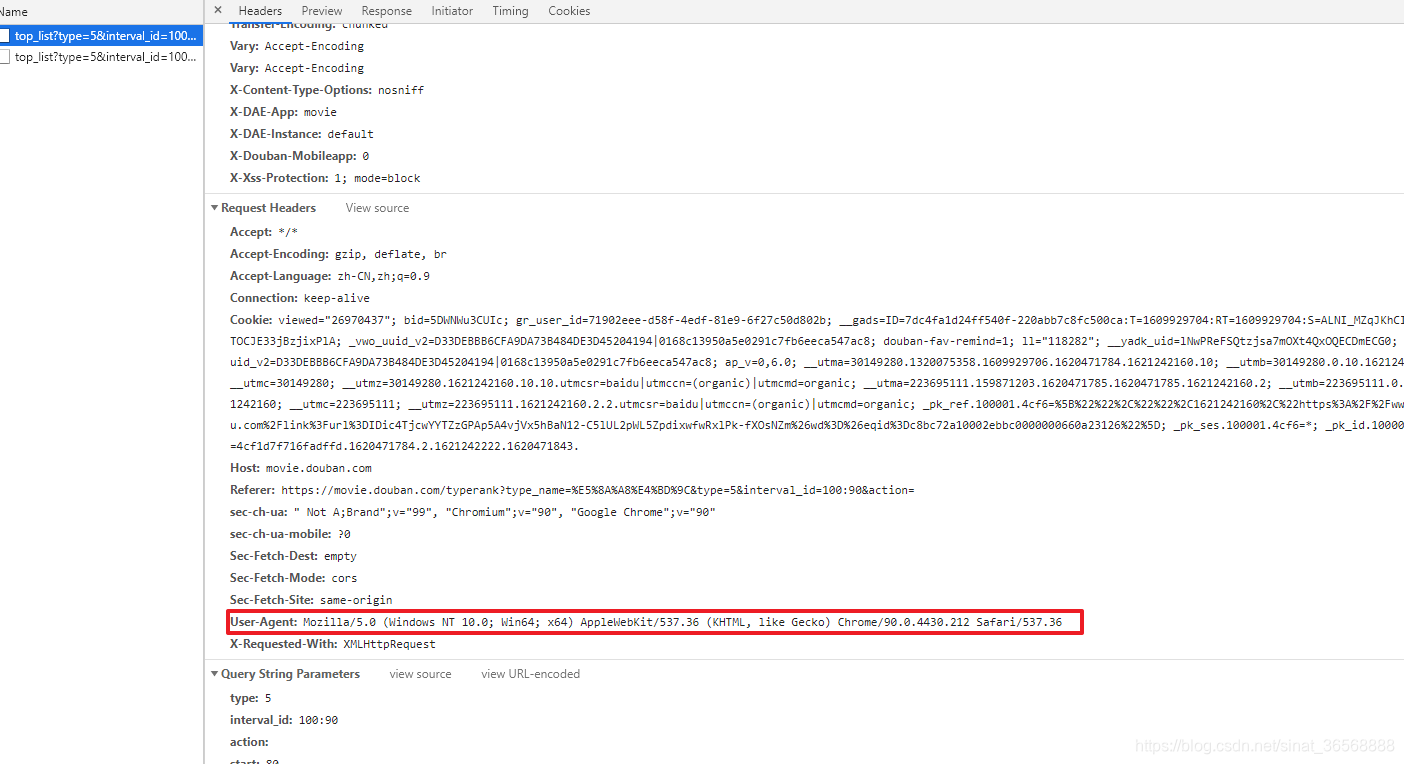
如果你是豆瓣网站的开发者,你希望别人用不正规的方法批量抓取你的网站中的数据吗?想一想,答案肯定是否定的。那么网站服务器如何判断当前访问是否合法呢?最基本的方式是使用请求载体的身份信息User_agent。不同的浏览器有不同的身份信息。
以下是作者谷歌浏览器的识别信息。那么,为了防止写入的程序请求被服务器拒绝访问,在向请求模块请求时必须带上标识信息。
2、代码
先直接上代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
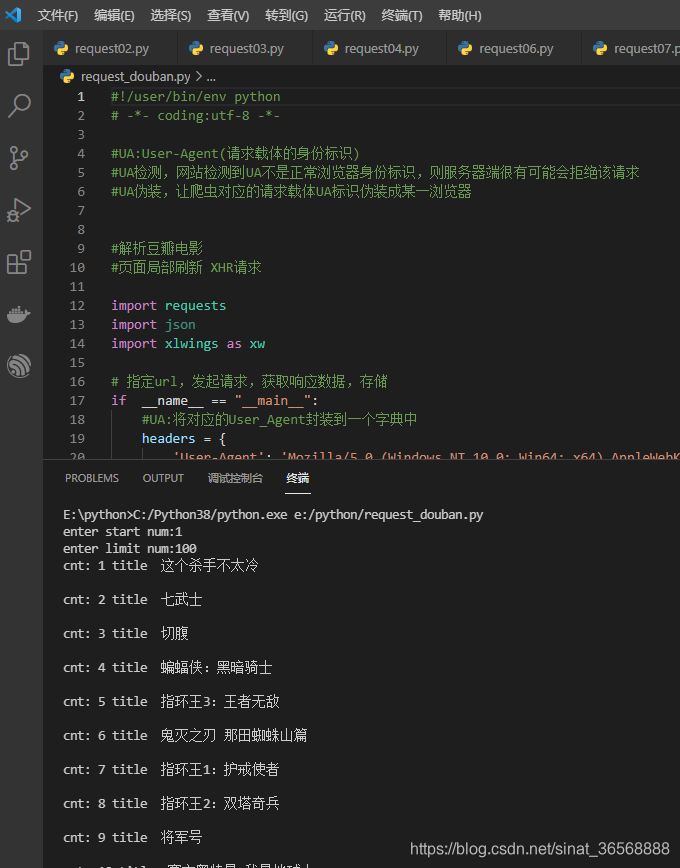
执行一下,程序已经在正确输出信息了
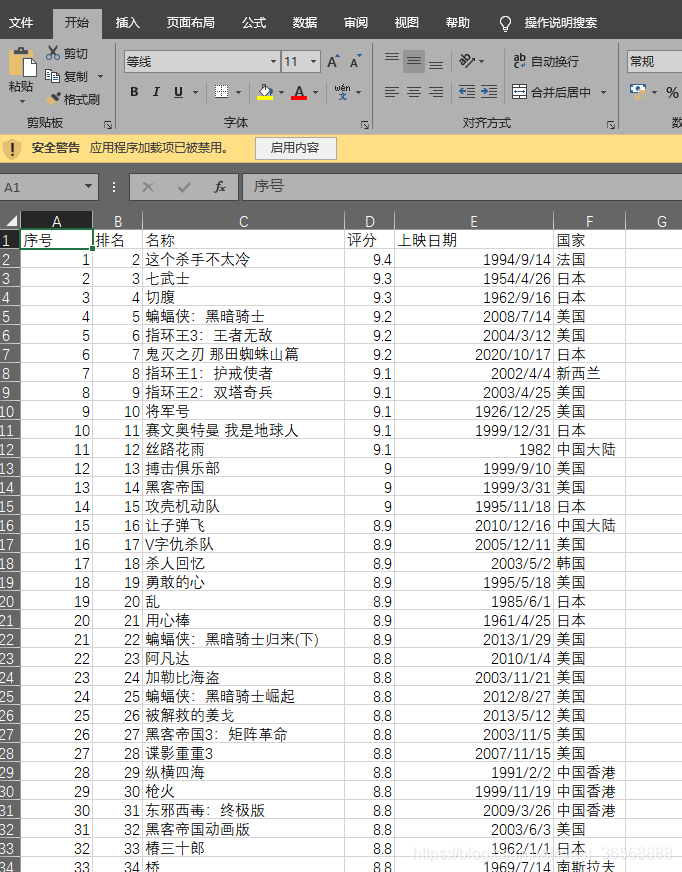
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进程序,分析页面后发现type是对应的电影类型,5:动作;11:情节。您可以尝试所有类型并将它们放入字典中以指定要捕获的特定类型的电影。作者完成的是动作片的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头、访问接口和参数,改变的参数是从终端输入的。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现读取返回的json格式数据,转换后的数据其实是一个字典。
操作excel 5步
1、构建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存关闭
sht.range('A1').value='序列号'
这意味着将序列号写入A1单元。如果需要写到B10,把上面的A1改成B10,操作起来很方便。 查看全部
c 抓取网页数据([]请求载体的身份识别信息)
要查找更改的参数,只需下拉进度条即可查看新的请求数据

可以看出只有start变了,start 80;限制 20;开始100;限制20。能猜到这20是每次刷新的视频数吗?start 是从第一个视频开始阅读?

通过对网页的初步分析,这种可能性非常高,而且很容易验证。记住里面的请求是GET,所以可以用浏览器直接访问接口进行验证。
start=1 limit=2,刷新了本杀手不太冷和七武士的两部电影


start=2 limit=3,刷新了《七武士》、《割肚皮》、《蝙蝠侠:黑暗骑士》三部影片。由此可以验证 start 是视频排名第一的请求。限制是每个请求的视频数量。如果我想抓取前 300 个视频,我只需要 start=1,limit=300。网页分析到这里就可以完成了,我们想要的信息已经得到了。
1、接口:%3A90&action=&start=2&limit=3
2、请求方法:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、这部分通过对网页的分析发现,豆瓣视频的排名采用了网页的部分动态加载技术
2、检查中筛选出动态加载的请求接口,请求反馈为类json格式(供后期python解析),通过猜测发现start和limit两个参数的含义直接调用接口
python代码编写
1、User_agent介绍
如果你是豆瓣网站的开发者,你希望别人用不正规的方法批量抓取你的网站中的数据吗?想一想,答案肯定是否定的。那么网站服务器如何判断当前访问是否合法呢?最基本的方式是使用请求载体的身份信息User_agent。不同的浏览器有不同的身份信息。
以下是作者谷歌浏览器的识别信息。那么,为了防止写入的程序请求被服务器拒绝访问,在向请求模块请求时必须带上标识信息。
2、代码
先直接上代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
执行一下,程序已经在正确输出信息了
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进程序,分析页面后发现type是对应的电影类型,5:动作;11:情节。您可以尝试所有类型并将它们放入字典中以指定要捕获的特定类型的电影。作者完成的是动作片的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头、访问接口和参数,改变的参数是从终端输入的。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现读取返回的json格式数据,转换后的数据其实是一个字典。
操作excel 5步
1、构建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存关闭
sht.range('A1').value='序列号'
这意味着将序列号写入A1单元。如果需要写到B10,把上面的A1改成B10,操作起来很方便。
c 抓取网页数据( (云抓取)⚡免费云起始积分--⭐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-15 01:11
(云抓取)⚡免费云起始积分--⭐)
介绍:
一款快速、免费且易于使用的网页抓取工具。在几秒钟内抓取 网站数据和表格数据 观看上面的短片,了解 Simplescraper 是如何设计成您将使用的最简单、最强大的网络抓取工具的。在您的浏览器中本地运行(无需注册)或创建自动抓取配方来抓取数千个网页并将它们转换为 API。从这里开始:---最近的评论:“非常易于使用” - ★★★★★ “简直是我发现的最好/最简单的刮刀” - ★★★★★ “这是一个很棒的抓取工具。它比我在 Google Web Store 上尝试过的所有其他爬虫” - ★★★★★ “惊人的扩展为我节省了很多时间” - ★★★★★ ---有用的功能包括:⚡ 一个简单的一键式工具选择您需要的数据⚡智能选择,- 改进的下一页选择过程 - 更广泛的抓取配方模板选择 ⭐ 1.16 更新: - 改进的爬虫 - 一次爬取多达 2000 个页面!- 添加了“管理帐户”部分 - 设计和布局改进 ⭐ 1. 15 个更新: - Google 表格集成 - 立即将抓取的数据保存到 Google 表格中!- CSS 编辑器 - 您现在可以在选择元素时编辑 CSS 选择器 - 新徽标 - 更新的帮助指南 ⭐ 1.14 更新: - 能够安排食谱 - 能够编辑食谱 - 能够抓取多个 URL - 新的更简单的布局对于 ⭐ 1.13 更新: - 更轻松的选择(自动选择第一个选项) - 改进的顶部菜单 - 添加了无限滚动 查看全部
c 抓取网页数据(
(云抓取)⚡免费云起始积分--⭐)




介绍:
一款快速、免费且易于使用的网页抓取工具。在几秒钟内抓取 网站数据和表格数据 观看上面的短片,了解 Simplescraper 是如何设计成您将使用的最简单、最强大的网络抓取工具的。在您的浏览器中本地运行(无需注册)或创建自动抓取配方来抓取数千个网页并将它们转换为 API。从这里开始:---最近的评论:“非常易于使用” - ★★★★★ “简直是我发现的最好/最简单的刮刀” - ★★★★★ “这是一个很棒的抓取工具。它比我在 Google Web Store 上尝试过的所有其他爬虫” - ★★★★★ “惊人的扩展为我节省了很多时间” - ★★★★★ ---有用的功能包括:⚡ 一个简单的一键式工具选择您需要的数据⚡智能选择,- 改进的下一页选择过程 - 更广泛的抓取配方模板选择 ⭐ 1.16 更新: - 改进的爬虫 - 一次爬取多达 2000 个页面!- 添加了“管理帐户”部分 - 设计和布局改进 ⭐ 1. 15 个更新: - Google 表格集成 - 立即将抓取的数据保存到 Google 表格中!- CSS 编辑器 - 您现在可以在选择元素时编辑 CSS 选择器 - 新徽标 - 更新的帮助指南 ⭐ 1.14 更新: - 能够安排食谱 - 能够编辑食谱 - 能够抓取多个 URL - 新的更简单的布局对于 ⭐ 1.13 更新: - 更轻松的选择(自动选择第一个选项) - 改进的顶部菜单 - 添加了无限滚动
c 抓取网页数据(如何做好辅导机构数据库操作?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-09 10:04
c抓取网页数据,转换成excel,再用sqlite数据库操作。第一步打开浏览器输入“包思源数据处理软件”安装操作步骤:第二步(重点)登录网站,然后运行,就可以抓取数据。第三步数据来源转为excel表格:具体操作步骤:大概7-8步不等。
谢邀。你可以买根简单的笔,试着写一写大学的课程表,如果方便的话,就可以实现了。
你想要做个辅导机构管理,这个必须依靠机构数据库。我不了解其他培训机构,可能他们也有多人的数据库了。我也是机构管理者,前面看知乎上的帖子,说要找老师、学生,要发生活费,但最后发现是个虚的,你学习的时候,你什么时候学习?上课,上课是在你考试前一天晚上么?数据库必须和学生挂钩,你怎么才能找到你看的学生的老师,怎么跟他打招呼,打交道。这些问题都是需要考虑的,数据库里必须的东西必须要备着,你可以请个技术的人出出好主意,祝你好运!。
抓包你要看看对不对
那你起码得有几个核心语言技术文档。比如python的scrapy爬虫。或者c++写爬虫。你可以去mysql官网找本mysql文档学习学习。有现成的库和示例数据。自己仿照简单的抓个数据过来就好。有c++基础就自己试着编程写个bt下载器。或者直接抓commonmedia试试。
出来创业,就得拿起笔在纸上写写画画,而且这个技术似乎在已经跟自己渐行渐远了。就拿抓包来说,就凭有个爬虫如何抓到数据也是蛮有意思的技术。简单的说抓包就是将某段网页内容通过某种方式转换成一段字符串,或者是命令格式。然后你可以在浏览器里面通过代码解析出每一个信息去匹配匹配内容。如果你在说存储就更好说了,你可以将不同的日志去匹配内容,获取最相似的时间去匹配内容就是最相似的那个时间,这样后面的程序可以匹配自己一段代码,该处理的地方要尽量处理,网页内容可能也不是特别多。综上,你要先完成的事情应该就是抓包。 查看全部
c 抓取网页数据(如何做好辅导机构数据库操作?-八维教育)
c抓取网页数据,转换成excel,再用sqlite数据库操作。第一步打开浏览器输入“包思源数据处理软件”安装操作步骤:第二步(重点)登录网站,然后运行,就可以抓取数据。第三步数据来源转为excel表格:具体操作步骤:大概7-8步不等。
谢邀。你可以买根简单的笔,试着写一写大学的课程表,如果方便的话,就可以实现了。
你想要做个辅导机构管理,这个必须依靠机构数据库。我不了解其他培训机构,可能他们也有多人的数据库了。我也是机构管理者,前面看知乎上的帖子,说要找老师、学生,要发生活费,但最后发现是个虚的,你学习的时候,你什么时候学习?上课,上课是在你考试前一天晚上么?数据库必须和学生挂钩,你怎么才能找到你看的学生的老师,怎么跟他打招呼,打交道。这些问题都是需要考虑的,数据库里必须的东西必须要备着,你可以请个技术的人出出好主意,祝你好运!。
抓包你要看看对不对
那你起码得有几个核心语言技术文档。比如python的scrapy爬虫。或者c++写爬虫。你可以去mysql官网找本mysql文档学习学习。有现成的库和示例数据。自己仿照简单的抓个数据过来就好。有c++基础就自己试着编程写个bt下载器。或者直接抓commonmedia试试。
出来创业,就得拿起笔在纸上写写画画,而且这个技术似乎在已经跟自己渐行渐远了。就拿抓包来说,就凭有个爬虫如何抓到数据也是蛮有意思的技术。简单的说抓包就是将某段网页内容通过某种方式转换成一段字符串,或者是命令格式。然后你可以在浏览器里面通过代码解析出每一个信息去匹配匹配内容。如果你在说存储就更好说了,你可以将不同的日志去匹配内容,获取最相似的时间去匹配内容就是最相似的那个时间,这样后面的程序可以匹配自己一段代码,该处理的地方要尽量处理,网页内容可能也不是特别多。综上,你要先完成的事情应该就是抓包。
c 抓取网页数据(知道了要访问的URL地址是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-09 00:07
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里: 查看全部
c 抓取网页数据(知道了要访问的URL地址是什么)
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里:
c 抓取网页数据(w3school在线教程PHP表单PHP高级教程PHP数据库和AJAXPHP参考手册PHP测验建站手册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-07 00:20
w3school 在线教程
PHP 基础教程PHP 表单PHP 高级教程PHP 数据库PHP XMLPHP 和AJAXPHP 参考手册PHP 测验
网站建设者编程关于 W3School 帮助W3School
PHP 教程
PHP 是一种强大的服务器端脚本语言,用于创建动态和交互式站点。
PHP 是免费的并且被广泛使用。对于微软 ASP 这样的竞争对手来说,PHP 无疑是另一个有效的选择。
开始学习 PHP!
通过在线示例学习 PHP
我们的“运行示例”工具通过显示 PHP 源代码和代码的 HTML 输出,使学习 PHP 变得更加容易。
例子
运行实例
请单击“运行实例”以查看其工作原理。
PHP 参考手册
在 W3School,我们为您提供收录所有 PHP 函数的完整参考手册:
PHP 5 测验
在 W3School 测试您的 PHP 技能!
开始您的 PHP 测验!
PHP 参考手册PHP Quiz
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。 查看全部
c 抓取网页数据(w3school在线教程PHP表单PHP高级教程PHP数据库和AJAXPHP参考手册PHP测验建站手册)
w3school 在线教程
PHP 基础教程PHP 表单PHP 高级教程PHP 数据库PHP XMLPHP 和AJAXPHP 参考手册PHP 测验
网站建设者编程关于 W3School 帮助W3School
PHP 教程
PHP 是一种强大的服务器端脚本语言,用于创建动态和交互式站点。
PHP 是免费的并且被广泛使用。对于微软 ASP 这样的竞争对手来说,PHP 无疑是另一个有效的选择。
开始学习 PHP!
通过在线示例学习 PHP
我们的“运行示例”工具通过显示 PHP 源代码和代码的 HTML 输出,使学习 PHP 变得更加容易。
例子
运行实例
请单击“运行实例”以查看其工作原理。
PHP 参考手册
在 W3School,我们为您提供收录所有 PHP 函数的完整参考手册:
PHP 5 测验
在 W3School 测试您的 PHP 技能!
开始您的 PHP 测验!
PHP 参考手册PHP Quiz
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。
c 抓取网页数据(从后台获取数据显示在界面上是前端开发所必须掌握的一项基本技能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-05 14:15
)
从后台获取数据并显示在界面上是前端开发必须掌握的一项基本技能。只需将本地模拟数据的json文件中获取的数据记录下来,显示在界面上即可。
1.创建一个本地 json 文件并将其命名为 data.json。 json文件格式如下:
{
"list":[
{
"project_img":"images/Home-logo1-hua.png",
"project_name":"111",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1400"
},
{
"project_img":"images/Home-logo2-bao.png",
"project_name":"222",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1"
}
]
}
2.在js中编写方法,调用方法。插入数据时,innerHTNML 方法是原生的 JavaScript 方法,但这种方法是把 HTML 代码插入到 div 中,而不是追加。要追加,您需要每次保存之前的 HTML 内容。 append方法是jquery方法,可以直接添加到div中。
notice();
function notice(){
$.ajax("Json/data.json",{
data:{},
dataType:'json',
type:'get',
async:'false',
success:function(data){
var listdata=data.list; //列表数据
if(listdata.length>0){ //项目列表
var listInfo="";
$.each(listdata,function(){
listInfo+=""+
"+this.project_img+"+
""+
""+this.project_name+""+
"<p class='money-range' class='mui-ellipsis loan-range'>"+this.money_range+""+
"
每日百分比"+this.day_rate+"%,应该为"+this.day_limit+"天,"+this.day_person+"人已交"+""+
""+
""+
"详情"+
""+
"";
});
$("#project_list")[0].innerHTML=listInfo;
}
}
// error:function(xhr,type,errorThrown){
// alert("系统繁忙,请联系管理员");
// }
})
}</p> 查看全部
c 抓取网页数据(从后台获取数据显示在界面上是前端开发所必须掌握的一项基本技能
)
从后台获取数据并显示在界面上是前端开发必须掌握的一项基本技能。只需将本地模拟数据的json文件中获取的数据记录下来,显示在界面上即可。
1.创建一个本地 json 文件并将其命名为 data.json。 json文件格式如下:
{
"list":[
{
"project_img":"images/Home-logo1-hua.png",
"project_name":"111",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1400"
},
{
"project_img":"images/Home-logo2-bao.png",
"project_name":"222",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1"
}
]
}
2.在js中编写方法,调用方法。插入数据时,innerHTNML 方法是原生的 JavaScript 方法,但这种方法是把 HTML 代码插入到 div 中,而不是追加。要追加,您需要每次保存之前的 HTML 内容。 append方法是jquery方法,可以直接添加到div中。
notice();
function notice(){
$.ajax("Json/data.json",{
data:{},
dataType:'json',
type:'get',
async:'false',
success:function(data){
var listdata=data.list; //列表数据
if(listdata.length>0){ //项目列表
var listInfo="";
$.each(listdata,function(){
listInfo+=""+
"+this.project_img+"+
""+
""+this.project_name+""+
"<p class='money-range' class='mui-ellipsis loan-range'>"+this.money_range+""+
"
每日百分比"+this.day_rate+"%,应该为"+this.day_limit+"天,"+this.day_person+"人已交"+""+
""+
""+
"详情"+
""+
"";
});
$("#project_list")[0].innerHTML=listInfo;
}
}
// error:function(xhr,type,errorThrown){
// alert("系统繁忙,请联系管理员");
// }
})
}</p>
c 抓取网页数据(2.Jsoup伪造请求头且携带身份信息获取登录信息结果:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-04 00:00
今天在学习爬虫的时候,想着用jsoup来模拟登录。下面分有验证码和无验证码两种情况进行讨论。
-----------------------------------------无验证码------------------ - ------------
1.我们使用网页正常登录,使用浏览器自带的开发者工具查看一些登录信息
当我们登录时,需要携带自己的身份信息,即用户名和密码。它还携带了一些浏览器信息,所以我们可以通过Jsoup伪造一些请求头,写入自己的身份信息进行登录,然后获取登录后返回的cookie,里面会收录session,而有了sessionid我们就可以爬取获取到的url登录后即可访问。
2.Jsoup伪造请求头,携带身份信息获取登录信息
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/");
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
Map cookies = res.cookies();
for (Entry entry : cookies.entrySet()) {
System.out.println(entry.getKey() + "-" + entry.getValue());
}
System.out.println("---------华丽的分割线-----------");
String body = res.body();// 获取响应体
System.out.println(body);
}
结果:
logininfo-"362501197407067215,123456"
JSESSIONID-75ad3bad-30cd-4d7a-8918-b13054f4b737
rememberMe-deleteMe
---------华丽的分割线-----------
{"login_result":"success_manager","user_type":"2","login_url":"examParper\/examPaper\/examparperManage.jsp"}
反例:
此时,我们将身份信息的密码修改为错误密码:
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123").data("user_type", "2")
.data("isRememberme", "yes");
结果:
---------华丽的分割线-----------
{"login_result":"error002","user_type":"2","login_url":null}
3.根据以上cookie获取模拟访问网站登录即可访问网站
将cookies定义为全局变量cookies,当我们访问登录可以访问的url时,我们会带着cookies访问。
package cn.qlq.craw.Jsoup;
import java.io.IOException;
import java.util.Map;
import java.util.Map.Entry;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
/**
* 模拟Jsoup跳过登陆进行爬虫
*
* @author liqiang
*
*/
public class JsoupCookieCraw {
private static Map cookies = null;
public static void main(String[] args) throws IOException {
// 先模拟登录获取到cookie和sessionid并存到全局变量cookies中
login();
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).cookies(cookies).post();
System.out.println(document.toString());
}
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/");
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
cookies = res.cookies();
}
}
结果:(可以获取我们访问的页面内容)
分配员工
.....................
反例:
我们去掉登录方式,访问时不携带cookies:
public static void main(String[] args) throws IOException {
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).post();
System.out.println(document.toString());
}
结果:(我们访问了系统的首页,也就是登录界面,发现我们被网站屏蔽了)
主页
.....
总结:
使用上述模拟登录方式,无验证码登录基本可以满足要求。
------------------------------有验证码------ - ------------ 查看全部
c 抓取网页数据(2.Jsoup伪造请求头且携带身份信息获取登录信息结果:)
今天在学习爬虫的时候,想着用jsoup来模拟登录。下面分有验证码和无验证码两种情况进行讨论。
-----------------------------------------无验证码------------------ - ------------
1.我们使用网页正常登录,使用浏览器自带的开发者工具查看一些登录信息

当我们登录时,需要携带自己的身份信息,即用户名和密码。它还携带了一些浏览器信息,所以我们可以通过Jsoup伪造一些请求头,写入自己的身份信息进行登录,然后获取登录后返回的cookie,里面会收录session,而有了sessionid我们就可以爬取获取到的url登录后即可访问。
2.Jsoup伪造请求头,携带身份信息获取登录信息
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/";);
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
Map cookies = res.cookies();
for (Entry entry : cookies.entrySet()) {
System.out.println(entry.getKey() + "-" + entry.getValue());
}
System.out.println("---------华丽的分割线-----------");
String body = res.body();// 获取响应体
System.out.println(body);
}
结果:
logininfo-"362501197407067215,123456"
JSESSIONID-75ad3bad-30cd-4d7a-8918-b13054f4b737
rememberMe-deleteMe
---------华丽的分割线-----------
{"login_result":"success_manager","user_type":"2","login_url":"examParper\/examPaper\/examparperManage.jsp"}
反例:
此时,我们将身份信息的密码修改为错误密码:
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123").data("user_type", "2")
.data("isRememberme", "yes");
结果:
---------华丽的分割线-----------
{"login_result":"error002","user_type":"2","login_url":null}
3.根据以上cookie获取模拟访问网站登录即可访问网站
将cookies定义为全局变量cookies,当我们访问登录可以访问的url时,我们会带着cookies访问。
package cn.qlq.craw.Jsoup;
import java.io.IOException;
import java.util.Map;
import java.util.Map.Entry;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
/**
* 模拟Jsoup跳过登陆进行爬虫
*
* @author liqiang
*
*/
public class JsoupCookieCraw {
private static Map cookies = null;
public static void main(String[] args) throws IOException {
// 先模拟登录获取到cookie和sessionid并存到全局变量cookies中
login();
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).cookies(cookies).post();
System.out.println(document.toString());
}
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/";);
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
cookies = res.cookies();
}
}
结果:(可以获取我们访问的页面内容)
分配员工
.....................
反例:
我们去掉登录方式,访问时不携带cookies:
public static void main(String[] args) throws IOException {
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).post();
System.out.println(document.toString());
}
结果:(我们访问了系统的首页,也就是登录界面,发现我们被网站屏蔽了)
主页
.....
总结:
使用上述模拟登录方式,无验证码登录基本可以满足要求。
------------------------------有验证码------ - ------------
c 抓取网页数据(在开始之前,做一点小小的说明哈:Part1进行网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-30 14:07
在开始之前,先做一点解释:
Part1 网页分析
先打开网易云网页版网易云
然后搜索歌曲,这里我会搜索金凌的《空山新雨女王》
这时候我们观察网页的url,可以发现我们搜索的关键字在s=后面
当我们换一首歌的时候,我们会发现也是一样的,这正好验证了我们的想法
所以接下来就是点击一首歌曲,然后播放,看看我们能不能直接获取到音乐文件的url。如果可以,那么直接通过requests.get访问url,就可以得到.mp3文件了。
点击第一首歌《空山新雨之后》,我们可以看到有一个“生成外链播放器”
看到这里,我一阵激动,仿佛快要完结似的;所以我高兴地点击,结果就是结果。. .
好吧,但我们不能放弃,我们来分析一下页面
但是当我们找到两个最有可能的外部链接位置时,我们什么也没找到
不过,作为“严格规范,功夫在家”的传承人,我不能放弃,所以我又打开了抓包工具
按照常规套路,我们定位XHR
点击播放后,出现了很多东西,我们要做的就是找到一个content-type为audio的包。
努力有回报,找了(一亿)时间,我找到了
于是我愉快的复制了这个包对应的Request-URL
粘贴后访问这个url,结果很满意,这是我一直在找的url
现在我发布那个网址
https://m10.music.126.net/2020 ... 9.mp3
Part2 编写爬虫
超级简单
下面的代码是最常见的操作,有爬虫基础的人都应该明白;如果有不懂的地方,评论就在上面
#导入requests包
import requests
#进行UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
#指定url
url = 'https://m10.music.126.net/2020 ... 39%3B
#调用requests.get方法对url进行访问,和持久化存储数据
audio_content = requests.get(url=url,headers=headers).content
#存入本地
with open('空山新雨后.mp3','wb') as f :
f.write(audio_content)
print("空山新雨后爬取成功!!!")
Part3 更高级
看到这里,你可能会想,为什么 selenium 模块根本没有用到呢?我可以直接抓取我想要的任何歌曲,而无需为每首歌曲找到一个网址吗?当然可以!
其实,网易云在线播放每首歌的时候,都有一个外链地址,是不会变的。它与每首歌曲的唯一 id 绑定。每首歌曲的音频文件的url如下:
url = 'http://music.163.com/song/medi ... 39%3B + 歌曲的id值 + '.mp3'
id值的获取也很简单。当我们点击每首歌曲时,上面会出现对应的URL,并且有一个id值,如下图:
所以只要把上面程序中的url改成新的url
如果还想要更好的体验,需要使用 selenium 模块直接在程序中搜索歌曲并获取 id 值。
为什么使用 selenium 而不是 xpath 或 bs4?
因为搜索页面的数据是动态加载的,如果直接解析搜索页面的数据,是不会得到任何数据的;以我目前的技术,我只能想到使用万能的 selenium 模块。下面简要说明这些步骤。:
在没有可视界面的情况下设置 selenium
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
指导包
import requests
import re
from selenium import webdriver
from time import sleep
指定歌曲并获取对应搜索页面的url
name = input('请输入歌名:')
url_1 = 'https://music.163.com/#/search/m/?s=' + name + '&type=1'
获取搜索页面的html文件
#初始化browser对象
browser = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=chrome_options)
#访问该url
browser.get(url=url_1)
#由于网页中有iframe框架,进行切换
browser.switch_to.frame('g_iframe')
#等待0.5秒
sleep(0.5)
#抓取到页面信息
page_text = browser.execute_script("return document.documentElement.outerHTML")
#退出浏览器
browser.quit()
使用正则模块re匹配html文件中的id值、歌名和歌手
ex1 = '(.*?)</a>'
id_list = re.findall(ex1,page_text,re.M)[::2]
song_list = re.findall(ex2,page_text,re.M)
singer_list = re.findall(ex3,page_text,re.M)
将id值、歌名和歌手封装成元组,写入列表,然后打印
li = list(zip(song_list,singer_list,id_list))
for i in range(len(li)):
print(str(i+1) + '.' + str(li[i]),end='\n')
你可以获取一个 url 以获得满意的 id 值,然后使用上面的程序通过 requests.get 方法访问该 url。Part4 总结
毕竟是我的天赋和知识,这种寻找外部链接进行爬取的方法也有很多不足之处。例如,无法在线播放的歌曲无法下载。
不过,写这么个小程序练手,确实对提升一个人的能力有很大的帮助。 查看全部
c 抓取网页数据(在开始之前,做一点小小的说明哈:Part1进行网页分析)
在开始之前,先做一点解释:
Part1 网页分析
先打开网易云网页版网易云
然后搜索歌曲,这里我会搜索金凌的《空山新雨女王》
这时候我们观察网页的url,可以发现我们搜索的关键字在s=后面
当我们换一首歌的时候,我们会发现也是一样的,这正好验证了我们的想法
所以接下来就是点击一首歌曲,然后播放,看看我们能不能直接获取到音乐文件的url。如果可以,那么直接通过requests.get访问url,就可以得到.mp3文件了。
点击第一首歌《空山新雨之后》,我们可以看到有一个“生成外链播放器”
看到这里,我一阵激动,仿佛快要完结似的;所以我高兴地点击,结果就是结果。. .
好吧,但我们不能放弃,我们来分析一下页面
但是当我们找到两个最有可能的外部链接位置时,我们什么也没找到
不过,作为“严格规范,功夫在家”的传承人,我不能放弃,所以我又打开了抓包工具
按照常规套路,我们定位XHR
点击播放后,出现了很多东西,我们要做的就是找到一个content-type为audio的包。
努力有回报,找了(一亿)时间,我找到了
于是我愉快的复制了这个包对应的Request-URL
粘贴后访问这个url,结果很满意,这是我一直在找的url
现在我发布那个网址
https://m10.music.126.net/2020 ... 9.mp3
Part2 编写爬虫
超级简单
下面的代码是最常见的操作,有爬虫基础的人都应该明白;如果有不懂的地方,评论就在上面
#导入requests包
import requests
#进行UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
#指定url
url = 'https://m10.music.126.net/2020 ... 39%3B
#调用requests.get方法对url进行访问,和持久化存储数据
audio_content = requests.get(url=url,headers=headers).content
#存入本地
with open('空山新雨后.mp3','wb') as f :
f.write(audio_content)
print("空山新雨后爬取成功!!!")
Part3 更高级
看到这里,你可能会想,为什么 selenium 模块根本没有用到呢?我可以直接抓取我想要的任何歌曲,而无需为每首歌曲找到一个网址吗?当然可以!
其实,网易云在线播放每首歌的时候,都有一个外链地址,是不会变的。它与每首歌曲的唯一 id 绑定。每首歌曲的音频文件的url如下:
url = 'http://music.163.com/song/medi ... 39%3B + 歌曲的id值 + '.mp3'
id值的获取也很简单。当我们点击每首歌曲时,上面会出现对应的URL,并且有一个id值,如下图:
所以只要把上面程序中的url改成新的url
如果还想要更好的体验,需要使用 selenium 模块直接在程序中搜索歌曲并获取 id 值。
为什么使用 selenium 而不是 xpath 或 bs4?
因为搜索页面的数据是动态加载的,如果直接解析搜索页面的数据,是不会得到任何数据的;以我目前的技术,我只能想到使用万能的 selenium 模块。下面简要说明这些步骤。:
在没有可视界面的情况下设置 selenium
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
指导包
import requests
import re
from selenium import webdriver
from time import sleep
指定歌曲并获取对应搜索页面的url
name = input('请输入歌名:')
url_1 = 'https://music.163.com/#/search/m/?s=' + name + '&type=1'
获取搜索页面的html文件
#初始化browser对象
browser = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=chrome_options)
#访问该url
browser.get(url=url_1)
#由于网页中有iframe框架,进行切换
browser.switch_to.frame('g_iframe')
#等待0.5秒
sleep(0.5)
#抓取到页面信息
page_text = browser.execute_script("return document.documentElement.outerHTML")
#退出浏览器
browser.quit()
使用正则模块re匹配html文件中的id值、歌名和歌手
ex1 = '(.*?)</a>'
id_list = re.findall(ex1,page_text,re.M)[::2]
song_list = re.findall(ex2,page_text,re.M)
singer_list = re.findall(ex3,page_text,re.M)
将id值、歌名和歌手封装成元组,写入列表,然后打印
li = list(zip(song_list,singer_list,id_list))
for i in range(len(li)):
print(str(i+1) + '.' + str(li[i]),end='\n')
你可以获取一个 url 以获得满意的 id 值,然后使用上面的程序通过 requests.get 方法访问该 url。Part4 总结
毕竟是我的天赋和知识,这种寻找外部链接进行爬取的方法也有很多不足之处。例如,无法在线播放的歌曲无法下载。
不过,写这么个小程序练手,确实对提升一个人的能力有很大的帮助。
c 抓取网页数据(动态生成二级菜单树的代码:静态生成菜单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-28 17:06
今天小编给大家分享一个使用js将ajax获取的后台数据动态加载到网页中的方法,具有很好的参考价值,希望对大家有所帮助。跟我来看看
动态生成二级菜单树:
jQuery(function($) {
/**********
获取未处理报警信息总数
**************/
var result;
$.ajax({
async:false,
cache:false,
url: "alarm_findPageAlarm.do",//访问后台接口取数据
// dataType : "json",
type: 'POST',
success: function(data){
result = eval('('+ data +')');
}
});
var alarmCount;
alarmCount = result.total;
/**********
静态代码形式
**********/
/*
设备管理
智能终端管理
标签打印机管理
*/
/*****从后台取出导航栏数据******/
$.ajax({
async:true,
cache:false,
url: "user_getMenuBuf.do",
// dataType : "json",
type: 'POST',
success: function(result){
var result = eval('('+ result +')');
if(result != undefined && result.length > 0){
var firstMenu = [];
var firstHref = [];
var firstIcon = [];
var subMenu = [];
/******一级导航栏数据*******/
for (var i = 0; i < result.length; i++){
firstMenu[i] = result[i].name;
firstHref[i] = result[i].url;
firstIcon[i] = result[i].iconCls;
/*******添加li标签********/
var menuInfo = document.getElementById("menuInfo");
var firstLi = document.createElement("li");//创建新的 li元素
menuInfo.appendChild(firstLi);//将此li元素添加至页面的ul下一级中
firstLi.style.borderBottom = "0px solid #CCEBF8";//设置li下边框样式
/******设置选中li、离开li时li的样式********/
firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstLi.onmouseout=function(){
this.style.background = "#0477C0";
};
/******添加a标签**********/
var firstALabel = document.createElement("a");
firstALabel.setAttribute("href", firstHref[i]);//js为新添加的a元素动态设置href属性
firstALabel.setAttribute("class", "dropdown-toggle");
//firstALabel.className = "dropdown-toggle";//兼容性好
firstALabel.setAttribute("target", "content");
//firstALabel.style.backgroundImage="url(./img/17.jpg)"
firstALabel.style.background = "#0477C0";//js为新添加的a元素动态设置背景颜色
// background:url(./img/17.jpg);
firstALabel.style.marginLeft = "20px";//js为新添加的a元素动态设置左外边距
firstLi.appendChild(firstALabel);
firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstALabel.onmouseout=function(){
this.style.background = "#0477C0";
};
/*******添加i标签*******/
var firstILavel = document.createElement("i");
firstILavel.setAttribute("class", firstIcon[i]);
firstILavel.style.color = "#F4F8FF";//动态设置i元素的颜色
firstALabel.appendChild(firstILavel);
/*********添加span标签**********/
var firstSpan = document.createElement("span");
firstSpan.className = "menu-text";
firstSpan.innerHTML = firstMenu[i];//js为新添加的span元素动态设置显示内容
firstSpan.style.fontSize = "14.5px";//js为新添加的span元素动态设置显示内容的字体大小
firstSpan.style.color = "#66D2F1";//js为新添加的span元素动态设置显示内容的字体颜色
firstSpan.style.marginLeft = "15px";
firstALabel.appendChild(firstSpan);
if (firstMenu[i] == "报警信息管理"){
var alarmIcon = document.createElement("span");
alarmIcon.className = "badge badge-important";
alarmIcon.innerHTML = alarmCount; //alarmCount为全局变量,且是通过ajax从后台获取到的
firstSpan.appendChild(alarmIcon);
}
if (result[i].children.length > 0){
var secondHref = [];
var secondMenu = [];
var secondIcon = [];
/*******添加b标签********/
var firstBLabel = document.createElement("b");
firstBLabel.className = "arrow icon-angle-down";
firstBLabel.style.color = "white";
firstALabel.appendChild(firstBLabel);
/********添加ul标签************/
var secondUl = document.createElement("ul");
secondUl.setAttribute("class", "submenu");
firstLi.appendChild(secondUl);
for (var j = 0; j < result[i].children.length; j++){
secondHref[j] = result[i].children[j].url;
secondMenu[j] = result[i].children[j].name;
secondIcon[j] = result[i].children[j].iconCls;
/******添加li标签*******/
var secondLi = document.createElement("li");
secondLi.style.background = "#CCEBF8";
secondUl.appendChild(secondLi);
/*******添加a标签*******/
var secondALabel = document.createElement("a");
secondALabel.setAttribute("href", secondHref[j]);
secondALabel.setAttribute("target", "content");
//secondALabel.style.background = "#CCEBF8";
secondLi.appendChild(secondALabel);
/*******添加i标签**********/
var secondILabel = document.createElement("i");
secondILabel.setAttribute("class", "icon-double-angle-right");
secondALabel.appendChild(secondILabel);
/******添加二级导航信息********/
secondALabel.innerHTML = secondMenu[j];
secondALabel.style.fontSize = "15px";
//secondALabel.style.marginLeft = "60px";
}
}
}
}
},
error: function() {
alert("加载菜单失败");
}
});
})
静态生成菜单树的代码:
生成菜单树的效果:
以上使用js将ajax获取的后台数据动态加载到网页中的方法就是编辑器共享的全部内容。 查看全部
c 抓取网页数据(动态生成二级菜单树的代码:静态生成菜单)
今天小编给大家分享一个使用js将ajax获取的后台数据动态加载到网页中的方法,具有很好的参考价值,希望对大家有所帮助。跟我来看看
动态生成二级菜单树:
jQuery(function($) {
/**********
获取未处理报警信息总数
**************/
var result;
$.ajax({
async:false,
cache:false,
url: "alarm_findPageAlarm.do",//访问后台接口取数据
// dataType : "json",
type: 'POST',
success: function(data){
result = eval('('+ data +')');
}
});
var alarmCount;
alarmCount = result.total;
/**********
静态代码形式
**********/
/*
设备管理
智能终端管理
标签打印机管理
*/
/*****从后台取出导航栏数据******/
$.ajax({
async:true,
cache:false,
url: "user_getMenuBuf.do",
// dataType : "json",
type: 'POST',
success: function(result){
var result = eval('('+ result +')');
if(result != undefined && result.length > 0){
var firstMenu = [];
var firstHref = [];
var firstIcon = [];
var subMenu = [];
/******一级导航栏数据*******/
for (var i = 0; i < result.length; i++){
firstMenu[i] = result[i].name;
firstHref[i] = result[i].url;
firstIcon[i] = result[i].iconCls;
/*******添加li标签********/
var menuInfo = document.getElementById("menuInfo");
var firstLi = document.createElement("li");//创建新的 li元素
menuInfo.appendChild(firstLi);//将此li元素添加至页面的ul下一级中
firstLi.style.borderBottom = "0px solid #CCEBF8";//设置li下边框样式
/******设置选中li、离开li时li的样式********/
firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstLi.onmouseout=function(){
this.style.background = "#0477C0";
};
/******添加a标签**********/
var firstALabel = document.createElement("a");
firstALabel.setAttribute("href", firstHref[i]);//js为新添加的a元素动态设置href属性
firstALabel.setAttribute("class", "dropdown-toggle");
//firstALabel.className = "dropdown-toggle";//兼容性好
firstALabel.setAttribute("target", "content");
//firstALabel.style.backgroundImage="url(./img/17.jpg)"
firstALabel.style.background = "#0477C0";//js为新添加的a元素动态设置背景颜色
// background:url(./img/17.jpg);
firstALabel.style.marginLeft = "20px";//js为新添加的a元素动态设置左外边距
firstLi.appendChild(firstALabel);
firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstALabel.onmouseout=function(){
this.style.background = "#0477C0";
};
/*******添加i标签*******/
var firstILavel = document.createElement("i");
firstILavel.setAttribute("class", firstIcon[i]);
firstILavel.style.color = "#F4F8FF";//动态设置i元素的颜色
firstALabel.appendChild(firstILavel);
/*********添加span标签**********/
var firstSpan = document.createElement("span");
firstSpan.className = "menu-text";
firstSpan.innerHTML = firstMenu[i];//js为新添加的span元素动态设置显示内容
firstSpan.style.fontSize = "14.5px";//js为新添加的span元素动态设置显示内容的字体大小
firstSpan.style.color = "#66D2F1";//js为新添加的span元素动态设置显示内容的字体颜色
firstSpan.style.marginLeft = "15px";
firstALabel.appendChild(firstSpan);
if (firstMenu[i] == "报警信息管理"){
var alarmIcon = document.createElement("span");
alarmIcon.className = "badge badge-important";
alarmIcon.innerHTML = alarmCount; //alarmCount为全局变量,且是通过ajax从后台获取到的
firstSpan.appendChild(alarmIcon);
}
if (result[i].children.length > 0){
var secondHref = [];
var secondMenu = [];
var secondIcon = [];
/*******添加b标签********/
var firstBLabel = document.createElement("b");
firstBLabel.className = "arrow icon-angle-down";
firstBLabel.style.color = "white";
firstALabel.appendChild(firstBLabel);
/********添加ul标签************/
var secondUl = document.createElement("ul");
secondUl.setAttribute("class", "submenu");
firstLi.appendChild(secondUl);
for (var j = 0; j < result[i].children.length; j++){
secondHref[j] = result[i].children[j].url;
secondMenu[j] = result[i].children[j].name;
secondIcon[j] = result[i].children[j].iconCls;
/******添加li标签*******/
var secondLi = document.createElement("li");
secondLi.style.background = "#CCEBF8";
secondUl.appendChild(secondLi);
/*******添加a标签*******/
var secondALabel = document.createElement("a");
secondALabel.setAttribute("href", secondHref[j]);
secondALabel.setAttribute("target", "content");
//secondALabel.style.background = "#CCEBF8";
secondLi.appendChild(secondALabel);
/*******添加i标签**********/
var secondILabel = document.createElement("i");
secondILabel.setAttribute("class", "icon-double-angle-right");
secondALabel.appendChild(secondILabel);
/******添加二级导航信息********/
secondALabel.innerHTML = secondMenu[j];
secondALabel.style.fontSize = "15px";
//secondALabel.style.marginLeft = "60px";
}
}
}
}
},
error: function() {
alert("加载菜单失败");
}
});
})
静态生成菜单树的代码:

生成菜单树的效果:

以上使用js将ajax获取的后台数据动态加载到网页中的方法就是编辑器共享的全部内容。
c 抓取网页数据(SEO百科网的是《分别是什么-什么是搜索引擎》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-26 02:04
网络爬虫是SEO人员应该学习的基础知识之一。了解和理解网络爬虫将有助于更好地优化网站。今天,SEO百科带来了《网络爬虫的分类和策略——什么是搜索引擎》。我希望能有所帮助。
一、什么是网络爬虫?
网络爬虫是指按照一定的规则自动爬取互联网上的信息的程序组件或脚本程序。在搜索引擎中,网络爬虫是搜索引擎查找和爬取文档的自动化程序。
二、网络爬虫生成的后台
随着互联网信息的爆炸式增长,人们已经不满足于仅仅依靠打开目录等传统方式在互联网上找东西。为了满足不同人群的不同需求,网络爬虫出现了。
三、网络爬虫面临的问题
上一篇文章《搜索引擎的基本架构》中提到,搜索引擎架构的两个目标是有效性和效率,这也是对网络爬虫的要求。面对数以亿计的页面,重复内容非常高,在SEO行业重复率可能超过50%。网络爬虫面临的问题是提高效率。
为了达到最好的效果,需要在一定的时间内获取更多的优质页面,丢弃那些原创度低、重复内容、拼接内容的页面。
PS:当然是大网站中发布的文章,尤其是大站效果,虽然不是首发站,但排名还是很不错的,甚至比首发站排名还要好。
四、网络爬虫的分类与策略
有许多类型的网络爬虫。错误君简单介绍了以下几种:
1)万能网络爬虫
万能网络爬虫,又称“全网爬虫”,从一些种子网站开始爬取,逐步扩展到整个互联网。
常见的网络爬虫策略:深度优先策略和广度优先策略。
2)专注于网络爬虫
聚焦网络爬虫,也称为“主题网络爬虫”,预先选择一个(或几个)相关主题,只抓取和抓取该类别的相关页面。
聚焦网络爬虫策略:聚焦网络爬虫增加了链接和内容评估模块,所以其爬取策略的关键是在爬取之前对页面的链接和内容进行评估。
3)增量网络爬虫
增量网络爬取是指更新已经收录的页面,爬取新的页面和发生变化的页面。
增量网络爬虫策略:广度优先策略和PageRank优先策略等。
4)深度网络爬虫
搜索引擎蜘蛛可以抓取和抓取的页面称为“表面网页”,而一些无法通过静态链接获取的页面称为“深层网页”。Deep Web爬虫是爬取深层网页的爬虫系统。
总结:一般来说,网络爬虫的爬取策略分为三种:
一个。广度优先
搜索完当前页面的所有链接后,开始进入下一级。
湾。最高优先级
根据某些网页分析算法,如链接算法、页面权重算法等,优先抓取有价值的页面。
C。深度优先
沿着一个链接爬行,直到一个页面没有更多链接,然后开始爬行另一个。不过一般是从种子网站爬取的。如果采用这种形式,爬取的页面质量可能会越来越低,所以这种策略很少使用。
以上就是SEO百科带给《网络爬虫的分类和策略有哪些——什么是搜索引擎》。感谢收看。更多 seo 教程搜索“错误教程网”。原创文章欢迎转载,保留版权: 查看全部
c 抓取网页数据(SEO百科网的是《分别是什么-什么是搜索引擎》)
网络爬虫是SEO人员应该学习的基础知识之一。了解和理解网络爬虫将有助于更好地优化网站。今天,SEO百科带来了《网络爬虫的分类和策略——什么是搜索引擎》。我希望能有所帮助。
一、什么是网络爬虫?
网络爬虫是指按照一定的规则自动爬取互联网上的信息的程序组件或脚本程序。在搜索引擎中,网络爬虫是搜索引擎查找和爬取文档的自动化程序。
二、网络爬虫生成的后台
随着互联网信息的爆炸式增长,人们已经不满足于仅仅依靠打开目录等传统方式在互联网上找东西。为了满足不同人群的不同需求,网络爬虫出现了。
三、网络爬虫面临的问题
上一篇文章《搜索引擎的基本架构》中提到,搜索引擎架构的两个目标是有效性和效率,这也是对网络爬虫的要求。面对数以亿计的页面,重复内容非常高,在SEO行业重复率可能超过50%。网络爬虫面临的问题是提高效率。
为了达到最好的效果,需要在一定的时间内获取更多的优质页面,丢弃那些原创度低、重复内容、拼接内容的页面。
PS:当然是大网站中发布的文章,尤其是大站效果,虽然不是首发站,但排名还是很不错的,甚至比首发站排名还要好。
四、网络爬虫的分类与策略
有许多类型的网络爬虫。错误君简单介绍了以下几种:
1)万能网络爬虫
万能网络爬虫,又称“全网爬虫”,从一些种子网站开始爬取,逐步扩展到整个互联网。
常见的网络爬虫策略:深度优先策略和广度优先策略。
2)专注于网络爬虫
聚焦网络爬虫,也称为“主题网络爬虫”,预先选择一个(或几个)相关主题,只抓取和抓取该类别的相关页面。
聚焦网络爬虫策略:聚焦网络爬虫增加了链接和内容评估模块,所以其爬取策略的关键是在爬取之前对页面的链接和内容进行评估。
3)增量网络爬虫
增量网络爬取是指更新已经收录的页面,爬取新的页面和发生变化的页面。
增量网络爬虫策略:广度优先策略和PageRank优先策略等。
4)深度网络爬虫
搜索引擎蜘蛛可以抓取和抓取的页面称为“表面网页”,而一些无法通过静态链接获取的页面称为“深层网页”。Deep Web爬虫是爬取深层网页的爬虫系统。
总结:一般来说,网络爬虫的爬取策略分为三种:
一个。广度优先
搜索完当前页面的所有链接后,开始进入下一级。
湾。最高优先级
根据某些网页分析算法,如链接算法、页面权重算法等,优先抓取有价值的页面。
C。深度优先
沿着一个链接爬行,直到一个页面没有更多链接,然后开始爬行另一个。不过一般是从种子网站爬取的。如果采用这种形式,爬取的页面质量可能会越来越低,所以这种策略很少使用。
以上就是SEO百科带给《网络爬虫的分类和策略有哪些——什么是搜索引擎》。感谢收看。更多 seo 教程搜索“错误教程网”。原创文章欢迎转载,保留版权:
c 抓取网页数据(一个典型的新闻网页包括几个不同区域:如何写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-25 14:16
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式也会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列出了一些具有不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是根据老猿猴多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
和新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在某个标签的class和id中的关键词,这些词表示该标签可能是也可能不是正文。我们使用这些词来计算标签节点的权重,这就是方法 calc_node_weight() 所做的。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,可以直接忽略。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取标签的内容,然后尝试从中找到标题,然后尝试找到 id 和 class 收录标题的节点,最后比较从不同地方获得的可能是标题的文本,并最终获得称号。比较的原则是:
从标签中获取标题,需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成一棵树,从body节点开始遍历每个节点,查看它直接收录的文本长度(不包括子节点),找出收录最长文本节点的文本的长度。这个过程在方法中实现:get_main_block()。一些细节可以让小猿们体验到。
其中一个细节是 clean_node() 函数。通过 get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去掉,会给新闻内容(相关新闻的标题、概述等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用 text_content() ,而是进行一些格式化处理,例如在某些标签后添加换行符以匹配 \n,以及在表格单元格之间添加空格。这样处理后,得到的文本格式更符合原网页的效果。
爬虫知识点
1. cchardet 模块
一个快速判断文本编码的模块
2. lxml.html 模块
一个结构化html代码的模块,一个通过xpath解析网页的工具,高效易用,在家写爬虫必备模块。
3. 内容提取的复杂性
我们这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
但是,没有一种万能的网页,也没有万能的提取算法。在大规模使用本文算法的过程中,会遇到奇怪的网页。这时候就需要针对这些网页改进这个算法类。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。 查看全部
c 抓取网页数据(一个典型的新闻网页包括几个不同区域:如何写爬虫)
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。

所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:

新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式也会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列出了一些具有不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是根据老猿猴多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
和新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在某个标签的class和id中的关键词,这些词表示该标签可能是也可能不是正文。我们使用这些词来计算标签节点的权重,这就是方法 calc_node_weight() 所做的。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,可以直接忽略。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取标签的内容,然后尝试从中找到标题,然后尝试找到 id 和 class 收录标题的节点,最后比较从不同地方获得的可能是标题的文本,并最终获得称号。比较的原则是:
从标签中获取标题,需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成一棵树,从body节点开始遍历每个节点,查看它直接收录的文本长度(不包括子节点),找出收录最长文本节点的文本的长度。这个过程在方法中实现:get_main_block()。一些细节可以让小猿们体验到。
其中一个细节是 clean_node() 函数。通过 get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去掉,会给新闻内容(相关新闻的标题、概述等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用 text_content() ,而是进行一些格式化处理,例如在某些标签后添加换行符以匹配 \n,以及在表格单元格之间添加空格。这样处理后,得到的文本格式更符合原网页的效果。
爬虫知识点
1. cchardet 模块
一个快速判断文本编码的模块
2. lxml.html 模块
一个结构化html代码的模块,一个通过xpath解析网页的工具,高效易用,在家写爬虫必备模块。
3. 内容提取的复杂性
我们这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
但是,没有一种万能的网页,也没有万能的提取算法。在大规模使用本文算法的过程中,会遇到奇怪的网页。这时候就需要针对这些网页改进这个算法类。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
c 抓取网页数据(网页加载到WebBrowser控件中的问题及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-24 09:14
[答案1]:
只是一个想法,但有一种方法可以让 .net 像在浏览器中一样加载网页:使用 System.Windows.Forms
您可以将网页加载到 WebBrowser 控件中
WebBrowser wb = new WebBrowser();
wb.ScrollBarsEnabled = false;
wb.ScriptErrorsSuppressed = true;
wb.Navigate(url);
while (wb.ReadyState != WebBrowserReadyState.Complete) { Application.DoEvents(); }
wb.Document.DomDocument.ToString()
这可能会给你 pre ajax DOM,但也许有办法让它首先运行 ajax。
【问题讨论】:
[答案2]:
如果我正确地解释了您的问题,那么您的问题就没有简单的解决方案。
您正在从服务器获取 HTML,并且由于您的 C# 代码不是真正的 Web 浏览器,因此它不会执行客户端脚本。
这样您就无法访问您获得的 HTML 不收录的信息。
编辑:我不知道这些 AJAX 调用与原创 网站 相比有多复杂,但您可以使用 Firebug 或 Fiddler for IE 查看请求是如何发出的,以便在您的 C# 应用程序中调用这些 AJAX 调用好。因此,您可以添加所需的信息。但这只是理论上的解决方案。
【问题讨论】:
【答案3】:
当您在网络浏览器中打开网页时,浏览器会执行 javascript 并下载该页面使用的其他资源(图像、脚本等)。HttpWebRequest 本身不做任何事情,它只是下载您请求的页面的 html。它从不自己执行任何 javascript/ajax 代码。
【问题讨论】:
[答案4]:
使用 HttpWebRequest 下载页面,以编程方式搜索相关 ajax 信息的源代码,然后使用新的 HttpWebRequest 将数据拉下来。
【问题讨论】:
[答案5]:
HttpWebRequest 不模拟网络浏览器,它只是下载您指向它的资源。这意味着它不会执行甚至下载 JavaScript 文件。
您必须使用 FireBug 之类的东西来获取通过 JavaScript 提取的数据的 URL,并将您的 HttpWebRequest 指向该 URL。
【问题讨论】:
[答案6]:
使用 HttpWebRequest 下载页面。在源代码中搜索相关的 AJAX 信息,然后使用新的 HttpWebRequest 提取该数据。
【问题讨论】:
【答案7】:
您可以使用 PhantomJs。我有这个问题,但没有找到解决我的问题的方法。在我看来,最好的解决方案是This。
我的解决方案是这样的:
var page = require('webpage').create();
page.open("https://sample.com", function(){
page.evaluate(function(){
var i = 0,
oJson = jsonData,
sKey;
localStorage.clear();
for (; sKey = Object.keys(oJson)[i]; i++) {
localStorage.setItem(sKey,oJson[sKey])
}
});
page.open("https://sample.com", function(){
setTimeout(function(){
page.render("screenshoot.png")
// Where you want to save it
console.log(page.content); //page source
// You can access its content using jQuery
var fbcomments = page.evaluate(function(){
return $("body").contents().find(".content")
})
phantom.exit();
},10000)
});
});
【问题讨论】: 查看全部
c 抓取网页数据(网页加载到WebBrowser控件中的问题及解决办法(一))
[答案1]:
只是一个想法,但有一种方法可以让 .net 像在浏览器中一样加载网页:使用 System.Windows.Forms
您可以将网页加载到 WebBrowser 控件中
WebBrowser wb = new WebBrowser();
wb.ScrollBarsEnabled = false;
wb.ScriptErrorsSuppressed = true;
wb.Navigate(url);
while (wb.ReadyState != WebBrowserReadyState.Complete) { Application.DoEvents(); }
wb.Document.DomDocument.ToString()
这可能会给你 pre ajax DOM,但也许有办法让它首先运行 ajax。
【问题讨论】:
[答案2]:
如果我正确地解释了您的问题,那么您的问题就没有简单的解决方案。
您正在从服务器获取 HTML,并且由于您的 C# 代码不是真正的 Web 浏览器,因此它不会执行客户端脚本。
这样您就无法访问您获得的 HTML 不收录的信息。
编辑:我不知道这些 AJAX 调用与原创 网站 相比有多复杂,但您可以使用 Firebug 或 Fiddler for IE 查看请求是如何发出的,以便在您的 C# 应用程序中调用这些 AJAX 调用好。因此,您可以添加所需的信息。但这只是理论上的解决方案。
【问题讨论】:
【答案3】:
当您在网络浏览器中打开网页时,浏览器会执行 javascript 并下载该页面使用的其他资源(图像、脚本等)。HttpWebRequest 本身不做任何事情,它只是下载您请求的页面的 html。它从不自己执行任何 javascript/ajax 代码。
【问题讨论】:
[答案4]:
使用 HttpWebRequest 下载页面,以编程方式搜索相关 ajax 信息的源代码,然后使用新的 HttpWebRequest 将数据拉下来。
【问题讨论】:
[答案5]:
HttpWebRequest 不模拟网络浏览器,它只是下载您指向它的资源。这意味着它不会执行甚至下载 JavaScript 文件。
您必须使用 FireBug 之类的东西来获取通过 JavaScript 提取的数据的 URL,并将您的 HttpWebRequest 指向该 URL。
【问题讨论】:
[答案6]:
使用 HttpWebRequest 下载页面。在源代码中搜索相关的 AJAX 信息,然后使用新的 HttpWebRequest 提取该数据。
【问题讨论】:
【答案7】:
您可以使用 PhantomJs。我有这个问题,但没有找到解决我的问题的方法。在我看来,最好的解决方案是This。
我的解决方案是这样的:
var page = require('webpage').create();
page.open("https://sample.com", function(){
page.evaluate(function(){
var i = 0,
oJson = jsonData,
sKey;
localStorage.clear();
for (; sKey = Object.keys(oJson)[i]; i++) {
localStorage.setItem(sKey,oJson[sKey])
}
});
page.open("https://sample.com", function(){
setTimeout(function(){
page.render("screenshoot.png")
// Where you want to save it
console.log(page.content); //page source
// You can access its content using jQuery
var fbcomments = page.evaluate(function(){
return $("body").contents().find(".content")
})
phantom.exit();
},10000)
});
});
【问题讨论】:
c 抓取网页数据(Python学习资料的小伙伴吗?整理Python资料和PDF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-23 22:14
我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的。因为我目前对python不熟悉,所以不知道为什么。百度搜索结果
有需要Python学习资料的朋友吗?小编整理了一套Python资料和PDF。有兴趣的可以关注小编,给学习资料发私信(关注后为私信)。无论如何,如果你闲着,你就是闲着。为什么不学点东西?
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
我冲到最后一句“人生苦短,你需要python”,立马在当当买了一本python书!之前一直崇拜python大牛,一直因为各种借口想学,一直没有下手。.
py 在 linux 上非常强大,语言也很简单。 查看全部
c 抓取网页数据(Python学习资料的小伙伴吗?整理Python资料和PDF)
我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的。因为我目前对python不熟悉,所以不知道为什么。百度搜索结果
有需要Python学习资料的朋友吗?小编整理了一套Python资料和PDF。有兴趣的可以关注小编,给学习资料发私信(关注后为私信)。无论如何,如果你闲着,你就是闲着。为什么不学点东西?
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
我冲到最后一句“人生苦短,你需要python”,立马在当当买了一本python书!之前一直崇拜python大牛,一直因为各种借口想学,一直没有下手。.
py 在 linux 上非常强大,语言也很简单。
c 抓取网页数据(自动获取“悟空问答”站点的问题标题和地址信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-23 22:12
)
亲爱的朋友们您好,欢迎来到《使用CefSharp和Javascript实现网络爬虫》。
最近学习使用CefSharp和Javascript实现一个网络爬虫,自动获取“悟空问答”网站的题名和地址信息,实现了“哔哩哔哩”直播网站自定义弹幕自动回复,以及制作了两个通过自动化程序提高效率的工具小工具。我准备记录下具体的实现过程,分享给感兴趣的朋友。
网络爬虫是根据一定的规则自动爬取互联网上的网站页面信息的程序或脚本。提到网络爬虫,首先想到的就是用Python实现,既高效又方便。不过对于不熟悉Python,但熟悉C#或Javascript的朋友,可以尝试使用CefSharp和Javascript来实现网络爬虫。此外,由CefSharp和Javascript组成的工具软件具有安装、发布方便、界面友好等优点。如果还添加了不想公开的代码逻辑,可以使用C#语言编译保护。
首先,让我们简要了解一下 CefSharp 和 Javascript。CefSharp可以简单理解为基于谷歌Chrome-ChromiumEmbeddedFramework(CEF)开源版本的浏览器控件。CefSharp 浏览器控件丰富而强大。因为基于 CEF,CefSharp 支持 Webkit & Chrome 中实现的 HTML5 功能,性能接近 Chrome。CefSharp 是在 C# 应用程序中嵌入浏览器的最佳选择。它支持 WinForms 和 WPF 应用程序。英语好的朋友可以访问:网址进行深入学习。
Javascript 是一种广泛使用的 Web 前端编程语言。使用 CefSharp 和 Javascript 实现网络爬虫需要使用 Javascript 进行 DOM 操作。DOM(Document Object Model,文档对象模型)是一种操作XML和HTML文档的常用方法。JavaScript 可以通过 DOM 接口操作每个 HTML 节点。在下一篇文章中,我将介绍使用 CefSharp 和 Javascript 实现网络爬虫的过程中会用到的 C# 和 Javascript 的主要知识。
查看全部
c 抓取网页数据(自动获取“悟空问答”站点的问题标题和地址信息
)
亲爱的朋友们您好,欢迎来到《使用CefSharp和Javascript实现网络爬虫》。
最近学习使用CefSharp和Javascript实现一个网络爬虫,自动获取“悟空问答”网站的题名和地址信息,实现了“哔哩哔哩”直播网站自定义弹幕自动回复,以及制作了两个通过自动化程序提高效率的工具小工具。我准备记录下具体的实现过程,分享给感兴趣的朋友。
网络爬虫是根据一定的规则自动爬取互联网上的网站页面信息的程序或脚本。提到网络爬虫,首先想到的就是用Python实现,既高效又方便。不过对于不熟悉Python,但熟悉C#或Javascript的朋友,可以尝试使用CefSharp和Javascript来实现网络爬虫。此外,由CefSharp和Javascript组成的工具软件具有安装、发布方便、界面友好等优点。如果还添加了不想公开的代码逻辑,可以使用C#语言编译保护。
首先,让我们简要了解一下 CefSharp 和 Javascript。CefSharp可以简单理解为基于谷歌Chrome-ChromiumEmbeddedFramework(CEF)开源版本的浏览器控件。CefSharp 浏览器控件丰富而强大。因为基于 CEF,CefSharp 支持 Webkit & Chrome 中实现的 HTML5 功能,性能接近 Chrome。CefSharp 是在 C# 应用程序中嵌入浏览器的最佳选择。它支持 WinForms 和 WPF 应用程序。英语好的朋友可以访问:网址进行深入学习。
Javascript 是一种广泛使用的 Web 前端编程语言。使用 CefSharp 和 Javascript 实现网络爬虫需要使用 Javascript 进行 DOM 操作。DOM(Document Object Model,文档对象模型)是一种操作XML和HTML文档的常用方法。JavaScript 可以通过 DOM 接口操作每个 HTML 节点。在下一篇文章中,我将介绍使用 CefSharp 和 Javascript 实现网络爬虫的过程中会用到的 C# 和 Javascript 的主要知识。
c 抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-23 22:11
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。
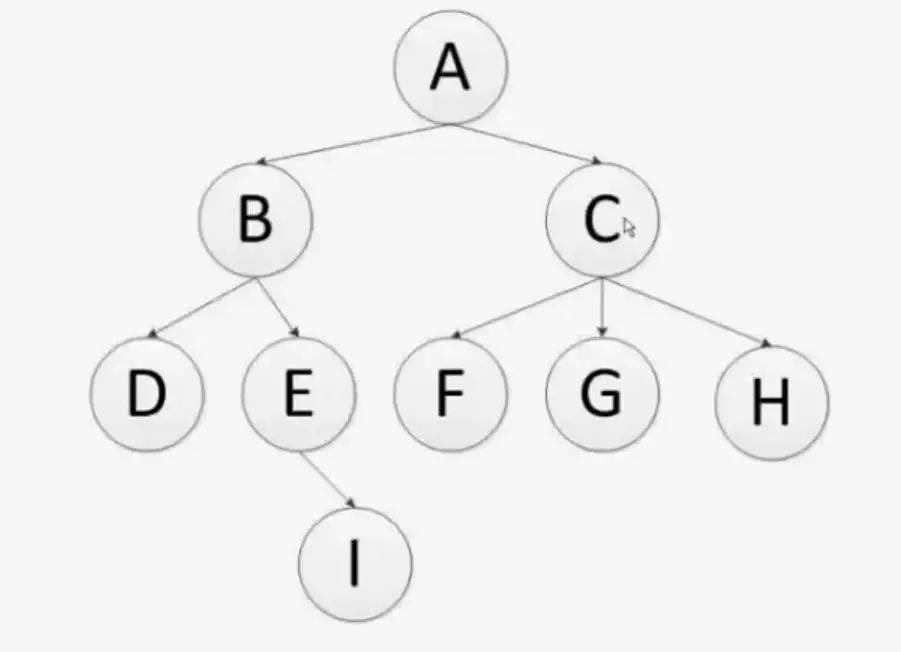
当一个网站有很多URL时,一定要设计好URL,否则在后面的理解、维护或开发过程中会很混乱。了解了上面的网页结构设计之后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以类比爬取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,然后从中提取两个链接B和C。链接B被爬取后,下一个要爬取的链接是D或E,而不是爬取。获取链接B后,立即去获取链接C。爬取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 完全爬取完成后,接下来会爬取链接 E。链接E爬取完成后,不再爬取链接C,而是继续深度爬取链接I。原理是链接会一步步往下爬,只要链接下有子链接,而子链接还没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫在爬取完成后一步一步往下走,然后一步一步往后退,优先考虑深度。了解了深度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、D、E、I、C、F、G、H(这里, 左边的链接假定会先被爬取)。事实上,在网络爬虫的过程中,我们多次使用这个算法来实现。其实我们常用的 Scrapy 爬虫框架也是默认用这个算法实现的。通过以上了解,
下图是深度优先算法的代码实现过程。
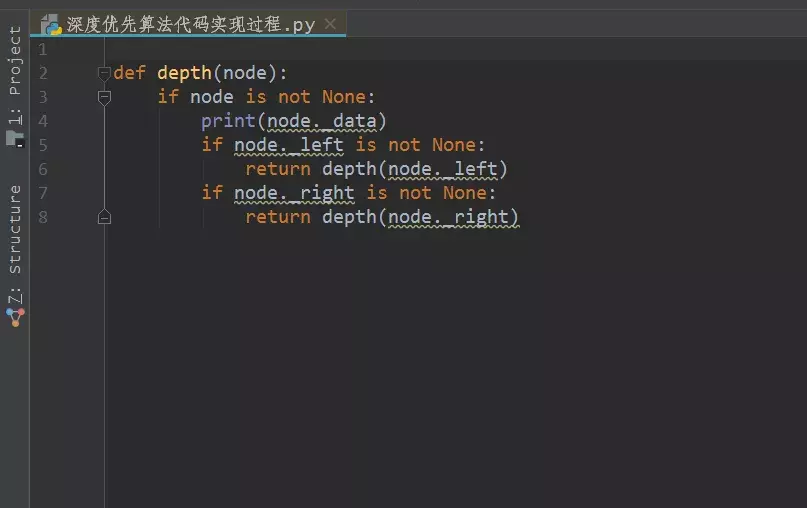
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先的过程,然后传入node参数。如果节点不为空,则打印出来,可以对比二叉树的顶层点A。打印完节点后,查看是否有左节点(链接B)和右节点(链接C),如果左节点不为空,则返回,再次调用深度优先函数本身进行递归,得到一个新的左节点(链接D)和右节点(链接E),等等,直到遍历所有节点或达到给定条件才会停止。右节点的实现过程也是一样的,这里不再赘述。
深度优先过程是通过递归实现的。当递归继续而没有跳出递归或者递归太深时,很容易造成栈溢出,所以在实际应用过程中需要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以建议大家需要掌握. 下一篇文章我们将介绍广度优先算法,敬请期待。
以上就是网络爬虫中深度优先算法的简单介绍。你们明白了吗? 查看全部
c 抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍)
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。
当一个网站有很多URL时,一定要设计好URL,否则在后面的理解、维护或开发过程中会很混乱。了解了上面的网页结构设计之后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以类比爬取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,然后从中提取两个链接B和C。链接B被爬取后,下一个要爬取的链接是D或E,而不是爬取。获取链接B后,立即去获取链接C。爬取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 完全爬取完成后,接下来会爬取链接 E。链接E爬取完成后,不再爬取链接C,而是继续深度爬取链接I。原理是链接会一步步往下爬,只要链接下有子链接,而子链接还没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫在爬取完成后一步一步往下走,然后一步一步往后退,优先考虑深度。了解了深度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、D、E、I、C、F、G、H(这里, 左边的链接假定会先被爬取)。事实上,在网络爬虫的过程中,我们多次使用这个算法来实现。其实我们常用的 Scrapy 爬虫框架也是默认用这个算法实现的。通过以上了解,
下图是深度优先算法的代码实现过程。
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先的过程,然后传入node参数。如果节点不为空,则打印出来,可以对比二叉树的顶层点A。打印完节点后,查看是否有左节点(链接B)和右节点(链接C),如果左节点不为空,则返回,再次调用深度优先函数本身进行递归,得到一个新的左节点(链接D)和右节点(链接E),等等,直到遍历所有节点或达到给定条件才会停止。右节点的实现过程也是一样的,这里不再赘述。

深度优先过程是通过递归实现的。当递归继续而没有跳出递归或者递归太深时,很容易造成栈溢出,所以在实际应用过程中需要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以建议大家需要掌握. 下一篇文章我们将介绍广度优先算法,敬请期待。

以上就是网络爬虫中深度优先算法的简单介绍。你们明白了吗?
c 抓取网页数据(2016年10月12日影刀强烈推荐这款)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-23 15:19
目前国内外比较流行的RPA产品在国内有影刀、Uibot、鸿基、阿里云RPA,国外有UiPath和Blue Prism。我主要展示国货。原因很简单。国货更符合国货业务,更适合大家的操作习惯。重点介绍以下两款产品:
一、影刀
强烈推荐该产品,原因如下:
1、拖放操作,方便快捷
2、以人为的思维顺序执行任务的命令式过程
3、0码,没有编程经验的朋友可以玩得开心
4、支持python开发,可以很好的与其他办公自动化功能集成
二、Uibot
它也是一款出色的产品,具有以下特点:
1、通过流程图的方式构建流程
2、支持C、C#等其他语言
本产品比较适合一些开发伙伴。比如我是做C#开发的,以后会有Uibot的实际操作。
总之,目前市面上的RPA产品已经非常成熟和强大,小伙伴可以选择适合自己情况的产品。这些产品只是我们的工具,更重要的是业务发展的思维。
所以让我们继续讨论这个话题。数据爬取不再是一个陌生的概念。无论是程序还是一些工具,都可以帮助我们获取公共数据。当然,RPA可以做到,也可以做得更方便。让我们来看看。
注意:在执行任务之前,一定要准备好工具、目标和流程
使用工具:暗影刀 RPA
目标:抓取老板直聘中RPA的工作清单数据网站
流程图:
第一步:打开网页
第 2 步:输入关键字
填写输入框(web):我们需要告诉工具输入框在哪里,所以我们需要捕获输入框
第三部分:点击搜索
点击元素(web):我们需要告诉工具搜索按钮在哪里,所以我们需要捕获搜索按钮
第 4 步:显示结果
注意:这里使用等待两秒显示数据,这是保证流程顺利执行的保证条件之一。未来会有更深入的解释,使用各种方法来提高过程的鲁棒性。
第 5 步:数据捕获
这里我们需要抓取相似的元素来确定数据规则,比如职位:RPA开发工程师,它位于网页列表中的固定位置,我们只需要抓取两个不同的职位,告诉工具我们想要获取有关此元素的信息。
注意:必须是类似的元素,比如上图中的“RPA开发工程师”和“RPA开发负责人”,这样我们才能抓取页面上的所有职位信息,如下图:
当然,我们也可以抓取其他元素,只要添加一个新列,然后抓取两次元素,记住,一定是两个不同但相似的元素。
这样,我们通过5个步骤抓取了网页的数据。我这里写的比较详细,其实不到一分钟就写完了。 查看全部
c 抓取网页数据(2016年10月12日影刀强烈推荐这款)
目前国内外比较流行的RPA产品在国内有影刀、Uibot、鸿基、阿里云RPA,国外有UiPath和Blue Prism。我主要展示国货。原因很简单。国货更符合国货业务,更适合大家的操作习惯。重点介绍以下两款产品:
一、影刀
强烈推荐该产品,原因如下:
1、拖放操作,方便快捷
2、以人为的思维顺序执行任务的命令式过程
3、0码,没有编程经验的朋友可以玩得开心
4、支持python开发,可以很好的与其他办公自动化功能集成
二、Uibot
它也是一款出色的产品,具有以下特点:
1、通过流程图的方式构建流程
2、支持C、C#等其他语言
本产品比较适合一些开发伙伴。比如我是做C#开发的,以后会有Uibot的实际操作。
总之,目前市面上的RPA产品已经非常成熟和强大,小伙伴可以选择适合自己情况的产品。这些产品只是我们的工具,更重要的是业务发展的思维。
所以让我们继续讨论这个话题。数据爬取不再是一个陌生的概念。无论是程序还是一些工具,都可以帮助我们获取公共数据。当然,RPA可以做到,也可以做得更方便。让我们来看看。
注意:在执行任务之前,一定要准备好工具、目标和流程
使用工具:暗影刀 RPA
目标:抓取老板直聘中RPA的工作清单数据网站
流程图:
第一步:打开网页
第 2 步:输入关键字
填写输入框(web):我们需要告诉工具输入框在哪里,所以我们需要捕获输入框
第三部分:点击搜索
点击元素(web):我们需要告诉工具搜索按钮在哪里,所以我们需要捕获搜索按钮
第 4 步:显示结果
注意:这里使用等待两秒显示数据,这是保证流程顺利执行的保证条件之一。未来会有更深入的解释,使用各种方法来提高过程的鲁棒性。
第 5 步:数据捕获
这里我们需要抓取相似的元素来确定数据规则,比如职位:RPA开发工程师,它位于网页列表中的固定位置,我们只需要抓取两个不同的职位,告诉工具我们想要获取有关此元素的信息。
注意:必须是类似的元素,比如上图中的“RPA开发工程师”和“RPA开发负责人”,这样我们才能抓取页面上的所有职位信息,如下图:
当然,我们也可以抓取其他元素,只要添加一个新列,然后抓取两次元素,记住,一定是两个不同但相似的元素。
这样,我们通过5个步骤抓取了网页的数据。我这里写的比较详细,其实不到一分钟就写完了。
c 抓取网页数据(问题:在使用正在表达式来定位tags的时候,能不能使用多条件的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 23:01
)
问题:使用表达式定位标签时可以使用多个条件吗?
答案是肯定的,而且使用起来非常方便,会大大提高工作效率。
举例:我现在要爬去寺库的包袋的网页链接数据,网址:http://list.secoo.com/bags/30- ... Title
代码如下:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'))
for i in new_url_list:
print(i)
print(len(new_url_list))
我们在这里使用
new_url_list = soup.find_all('a',href=pile('source=list')),通过正则识别出有的href中有属性,有的收录'source=list'
定位标签,结果如下
一共爬取了108行,其中我们想要的真实数据是40行。
我们发现id中收录name的数据就是我们想要的数据。那么这里可以添加一个简单的正则表达式来准确定位,
如下:
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
代码:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
for i in new_url_list:
print(i)
print(len(new_url_list))
结果如下:
40 个网络链接,我们所需要的。
知识点:
find_all()方法搜索当前标签的所有标签子节点,判断是否满足过滤条件
html = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""</p>
①名称参数
name参数可以找到所有名为name的标签,字符串对象会被自动忽略
A.Pass 字符串
#传入字符串查找p标签
print(soup.find_all('b'))
#运行结果:[The Dormouse's story]
B.传递正则表达式
如果传入正则表达式作为参数,Beautiful Soup 会通过正则表达式 match() 匹配内容。下面的例子查找所有以b开头的标签,这意味着标签和标签都应该找到
import re
for tag in soup.find_all(re.compile('^b')):
print(tag.name)
#运行结果:
# body
# b
C.上传列表
content = soup.find_all(["a","b"])
print(content)
"""
#运行结果:
[The Dormouse's story, , Lacie, Tillie]
"""
D.通过真
True 可以匹配任意值,以下代码查找所有标签,但不返回字符串节点
E.传输方式
如果没有合适的过滤器,也可以定义一个方法,该方法只接受一个元素参数[4]如果该方法返回True,则表示当前元素匹配并找到,否则返回False
以下方法验证当前元素,如果它收录类属性但不收录 id 属性,则返回 True:
#定义函数,Tag的属性只有id
def has_id(tag):
return tag.has_attr('id')
content = soup.find_all(has_id)
print(content)
"""
运行结果:
[, Lacie, Tillie]
"""
②关键字参数
注意:如果指定名称的参数不是用于搜索的内置参数名称,则该参数将作为指定名称标签的属性进行搜索。如果收录名称为 id 的参数,Beautiful Soup 会搜索每个标签的“id”属性
print(soup.find_all(id="link3"))
# 运行结果:[Tillie]
如果传递了href参数,Beautiful Soup会搜索每个标签的“href”属性
import re
print(soup.find_all(href=re.compile("lacie")))
# 运行结果:[Lacie]
使用多个指定名称的参数同时过滤一个标签的多个属性
import re
print(soup.find_all(href=re.compile("lacie"),id="link2"))
# 运行结果:[Lacie]
使用class过滤时,class不是python的关键字,加下划线即可
print(soup.find_all("a",class_="sister"))
# 运行结果:[, Lacie, Tillie]
③文本参数
文本参数可用于搜索文档中的字符串内容。和name参数的可选值一样,text参数接受string、regular expression、list、True
#传入字符串
print(soup.find_all(text="Lacie"))
# 运行结果:['Lacie']
#传入列表
print(soup.find_all(text=["Lacie","Tillie"]))
# 运行结果:['Lacie', 'Tillie']
#传入正则表达式
import re
print(soup.find_all(text=re.compile("Dormouse")))
# 运行结果:["The Dormouse's story", "The Dormouse's story"]
④限制参数
find_all()参数在查询量大的时候可能会比较慢,所以我们引入了limit函数,可以限制返回的结果
print(soup.find_all("a"))
"""
运行结果:
[, Lacie, Tillie]
"""
print(soup.find_all("a",limit=2))
"""
运行结果:
[, Lacie]
"""
⑤recursive参数
recursive翻译为递归循环的意思
当调用标签的find_all()方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
print(soup.html.find_all("title"))
# 运行结果:[The Dormouse's story]
print(soup.html.find_all("title",recursive=False))
# 运行结果:[] 查看全部
c 抓取网页数据(问题:在使用正在表达式来定位tags的时候,能不能使用多条件的?
)
问题:使用表达式定位标签时可以使用多个条件吗?
答案是肯定的,而且使用起来非常方便,会大大提高工作效率。
举例:我现在要爬去寺库的包袋的网页链接数据,网址:http://list.secoo.com/bags/30- ... Title
代码如下:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'))
for i in new_url_list:
print(i)
print(len(new_url_list))
我们在这里使用
new_url_list = soup.find_all('a',href=pile('source=list')),通过正则识别出有的href中有属性,有的收录'source=list'
定位标签,结果如下

一共爬取了108行,其中我们想要的真实数据是40行。
我们发现id中收录name的数据就是我们想要的数据。那么这里可以添加一个简单的正则表达式来准确定位,
如下:
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
代码:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
for i in new_url_list:
print(i)
print(len(new_url_list))
结果如下:

40 个网络链接,我们所需要的。
知识点:
find_all()方法搜索当前标签的所有标签子节点,判断是否满足过滤条件
html = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""</p>
①名称参数
name参数可以找到所有名为name的标签,字符串对象会被自动忽略
A.Pass 字符串
#传入字符串查找p标签
print(soup.find_all('b'))
#运行结果:[The Dormouse's story]
B.传递正则表达式
如果传入正则表达式作为参数,Beautiful Soup 会通过正则表达式 match() 匹配内容。下面的例子查找所有以b开头的标签,这意味着标签和标签都应该找到
import re
for tag in soup.find_all(re.compile('^b')):
print(tag.name)
#运行结果:
# body
# b
C.上传列表
content = soup.find_all(["a","b"])
print(content)
"""
#运行结果:
[The Dormouse's story, , Lacie, Tillie]
"""
D.通过真
True 可以匹配任意值,以下代码查找所有标签,但不返回字符串节点
E.传输方式
如果没有合适的过滤器,也可以定义一个方法,该方法只接受一个元素参数[4]如果该方法返回True,则表示当前元素匹配并找到,否则返回False
以下方法验证当前元素,如果它收录类属性但不收录 id 属性,则返回 True:
#定义函数,Tag的属性只有id
def has_id(tag):
return tag.has_attr('id')
content = soup.find_all(has_id)
print(content)
"""
运行结果:
[, Lacie, Tillie]
"""
②关键字参数
注意:如果指定名称的参数不是用于搜索的内置参数名称,则该参数将作为指定名称标签的属性进行搜索。如果收录名称为 id 的参数,Beautiful Soup 会搜索每个标签的“id”属性
print(soup.find_all(id="link3"))
# 运行结果:[Tillie]
如果传递了href参数,Beautiful Soup会搜索每个标签的“href”属性
import re
print(soup.find_all(href=re.compile("lacie")))
# 运行结果:[Lacie]
使用多个指定名称的参数同时过滤一个标签的多个属性
import re
print(soup.find_all(href=re.compile("lacie"),id="link2"))
# 运行结果:[Lacie]
使用class过滤时,class不是python的关键字,加下划线即可
print(soup.find_all("a",class_="sister"))
# 运行结果:[, Lacie, Tillie]
③文本参数
文本参数可用于搜索文档中的字符串内容。和name参数的可选值一样,text参数接受string、regular expression、list、True
#传入字符串
print(soup.find_all(text="Lacie"))
# 运行结果:['Lacie']
#传入列表
print(soup.find_all(text=["Lacie","Tillie"]))
# 运行结果:['Lacie', 'Tillie']
#传入正则表达式
import re
print(soup.find_all(text=re.compile("Dormouse")))
# 运行结果:["The Dormouse's story", "The Dormouse's story"]
④限制参数
find_all()参数在查询量大的时候可能会比较慢,所以我们引入了limit函数,可以限制返回的结果
print(soup.find_all("a"))
"""
运行结果:
[, Lacie, Tillie]
"""
print(soup.find_all("a",limit=2))
"""
运行结果:
[, Lacie]
"""
⑤recursive参数
recursive翻译为递归循环的意思
当调用标签的find_all()方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
print(soup.html.find_all("title"))
# 运行结果:[The Dormouse's story]
print(soup.html.find_all("title",recursive=False))
# 运行结果:[]
c 抓取网页数据(c抓取网页数据是很基础的事情,python、ie6及ie8上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-22 01:05
c抓取网页数据是很基础的事情,不过一般来说,传统的网页抓取工具是可以直接支持响应式的设计的,比如把它作为扩展scrapy或python的爬虫框架使用,后端就是scrapy等。在python2中(一般是upython)支持各种浏览器的内置驱动接口,基本可以兼容任何浏览器,upython开发的其它爬虫框架,也可以跑在chrome、firefox、36。
0、ie6及ie8上。
1、前言最近有个问题,就是在基础浏览器抓取页面数据的时候,遇到一个很蛋疼的问题,就是采集的页面数据格式比较乱,很多数据都不是按html标签的方式来显示的,比如user-agent等。这样,一次抓取下来的数据可能包含大量的md5字符串。有的时候为了定位误差会很麻烦。
2、怎么解决这个问题很简单,就是用爬虫爬取网页标签。有的标签的抓取还是比较简单的,以bs为例,用ajax加载li标签,获取viewtag,通过viewtag就可以找到标签的内容。这样就达到了scrapy的双列采集规则,一个指向那个tag,一个指向另一个tag,在最后可以采集到整个页面的数据。当然,如果页面没有自定义标签,那么你还是要自己解析html标签,python没有这个库,那就手工解析标签。
那么python为什么没有scrapy支持这个标签呢?因为python没有user-agent这个标签,如果要写程序抓取这个标签,需要自己自定义这个标签,如果def包了,又会麻烦很多。
通过user-agent这个标签,就可以获取手动装满整个页面的标签表达式,以两列为例,就是包含meta元素的标签和没有meta元素的标签,每一列的标签名,比如bin标签,都是field标签,也是一行对应一个标签,每个标签有一个坐标,
1))转换,就得到下一行的坐标。就是这么简单。
3、那么,user-agent是可以多个的吗?不可以,我们也可以这么设置,而且还可以从user-agent中获取headers值来判断来匹配那个tag,当然,更多的场景下,一个user-agent是可以匹配多个tag的。通过使用scrapy的processon(支持开发模式),我们可以对使用scrapy的爬虫框架做简单的编写规范,方便爬虫交互和重构。
4、user-agent本身是可以继承的吗?可以,但是为了兼容性,user-agent只能匹配多个标签,和爬虫用的url一样。
5、user-agent中可以直接加入meta标签吗?当然可以,把meta提取出来就可以。
resource(pep501-3-3,
3)主要规定了浏览器扩展的驱动格式,主要支持user-agent,cookie,etag,headers等等标签。
6、user-agent中 查看全部
c 抓取网页数据(c抓取网页数据是很基础的事情,python、ie6及ie8上)
c抓取网页数据是很基础的事情,不过一般来说,传统的网页抓取工具是可以直接支持响应式的设计的,比如把它作为扩展scrapy或python的爬虫框架使用,后端就是scrapy等。在python2中(一般是upython)支持各种浏览器的内置驱动接口,基本可以兼容任何浏览器,upython开发的其它爬虫框架,也可以跑在chrome、firefox、36。
0、ie6及ie8上。
1、前言最近有个问题,就是在基础浏览器抓取页面数据的时候,遇到一个很蛋疼的问题,就是采集的页面数据格式比较乱,很多数据都不是按html标签的方式来显示的,比如user-agent等。这样,一次抓取下来的数据可能包含大量的md5字符串。有的时候为了定位误差会很麻烦。
2、怎么解决这个问题很简单,就是用爬虫爬取网页标签。有的标签的抓取还是比较简单的,以bs为例,用ajax加载li标签,获取viewtag,通过viewtag就可以找到标签的内容。这样就达到了scrapy的双列采集规则,一个指向那个tag,一个指向另一个tag,在最后可以采集到整个页面的数据。当然,如果页面没有自定义标签,那么你还是要自己解析html标签,python没有这个库,那就手工解析标签。
那么python为什么没有scrapy支持这个标签呢?因为python没有user-agent这个标签,如果要写程序抓取这个标签,需要自己自定义这个标签,如果def包了,又会麻烦很多。
通过user-agent这个标签,就可以获取手动装满整个页面的标签表达式,以两列为例,就是包含meta元素的标签和没有meta元素的标签,每一列的标签名,比如bin标签,都是field标签,也是一行对应一个标签,每个标签有一个坐标,
1))转换,就得到下一行的坐标。就是这么简单。
3、那么,user-agent是可以多个的吗?不可以,我们也可以这么设置,而且还可以从user-agent中获取headers值来判断来匹配那个tag,当然,更多的场景下,一个user-agent是可以匹配多个tag的。通过使用scrapy的processon(支持开发模式),我们可以对使用scrapy的爬虫框架做简单的编写规范,方便爬虫交互和重构。
4、user-agent本身是可以继承的吗?可以,但是为了兼容性,user-agent只能匹配多个标签,和爬虫用的url一样。
5、user-agent中可以直接加入meta标签吗?当然可以,把meta提取出来就可以。
resource(pep501-3-3,
3)主要规定了浏览器扩展的驱动格式,主要支持user-agent,cookie,etag,headers等等标签。
6、user-agent中
c 抓取网页数据(求大师教你如何用jsoup拆分获取到数据存放到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-16 17:21
表中的数据需要从以下网址获取(即右边的台风数据)
目前的思路是使用正则表达式,指定路径,获取表格中的所有元素
代码显示如下:
public class CodeRegex {
/**
* 获取大陆台风页面table元素
* */
public String getHTML(){
try {
String HTML ="";
String ur = "http://gb.weather.gov.hk/wxinf ... 3B%3B // 获取远程网上的信息
URL MyURL = new URL(ur);
String str;
URLConnection con = MyURL.openConnection();
InputStreamReader ins = new InputStreamReader(con.getInputStream());
BufferedReader in = new BufferedReader(ins);
StringBuffer sb = new StringBuffer();
while ((str = in.readLine()) != null) {
sb.append(str);
}
in.close();
Pattern p = Pattern.compile("]*>.+?");
Matcher m = p.matcher(sb.toString());
while (m.find()) {
HTML = m.group();
System.out.println("html:"+HTML);
}
} catch (MalformedURLException mfURLe) {
System.out.println("MalformedURLException: " + mfURLe);
} catch (IOException ioe) {
System.out.println("IOException: " + ioe);
}
return getHTML();
}
public static void main(String[] args) throws ClassNotFoundException, SQLException {
System.out.println("content:");
TyphoonCNAction tcn = new TyphoonCNAction();
String content = tcn.getHTML();
System.out.println("content:"+content);
}
}
我不知道以后如何获取元素的值。
如何使用字符串拆分来获取数据并将其存储在数据库中
请回答源代码说明,如果做过类似项目,请到邮箱索取代码
据说用jsoup做会更容易,求高手帮忙源码 查看全部
c 抓取网页数据(求大师教你如何用jsoup拆分获取到数据存放到数据库)
表中的数据需要从以下网址获取(即右边的台风数据)
目前的思路是使用正则表达式,指定路径,获取表格中的所有元素
代码显示如下:
public class CodeRegex {
/**
* 获取大陆台风页面table元素
* */
public String getHTML(){
try {
String HTML ="";
String ur = "http://gb.weather.gov.hk/wxinf ... 3B%3B // 获取远程网上的信息
URL MyURL = new URL(ur);
String str;
URLConnection con = MyURL.openConnection();
InputStreamReader ins = new InputStreamReader(con.getInputStream());
BufferedReader in = new BufferedReader(ins);
StringBuffer sb = new StringBuffer();
while ((str = in.readLine()) != null) {
sb.append(str);
}
in.close();
Pattern p = Pattern.compile("]*>.+?");
Matcher m = p.matcher(sb.toString());
while (m.find()) {
HTML = m.group();
System.out.println("html:"+HTML);
}
} catch (MalformedURLException mfURLe) {
System.out.println("MalformedURLException: " + mfURLe);
} catch (IOException ioe) {
System.out.println("IOException: " + ioe);
}
return getHTML();
}
public static void main(String[] args) throws ClassNotFoundException, SQLException {
System.out.println("content:");
TyphoonCNAction tcn = new TyphoonCNAction();
String content = tcn.getHTML();
System.out.println("content:"+content);
}
}
我不知道以后如何获取元素的值。
如何使用字符串拆分来获取数据并将其存储在数据库中
请回答源代码说明,如果做过类似项目,请到邮箱索取代码
据说用jsoup做会更容易,求高手帮忙源码
c 抓取网页数据(一下示例代码看起来(2021-09-16我是一个))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-15 01:13
2021-09-16
我是刚加入公司的新人。老板交给我的任务是写剧本。作用是从其他网站中抓取数据,然后在我们的平台上展示。具体业务就不介绍了。主要目的是从其他网站中获取数据。方法是使用 Jsoup 类。这是一个示例代码
Jsoup.connect(REGISTER_URL)
.userAgent(USER_AGENT)
.method(Connection.Method.GET)
这似乎很简单。一开始是去了解HTTP协议,request请求和response响应(我在学校是渣渣,没认真学习= =)。然后开始吧。
我们先来个登录的例子,先打开目标网站,找到登录的地方,这里是一个例子
然后打开抓包工具
(一开始我还是打开了网站的源码,然后去他的按钮提交的url,o(╥﹏╥)o)
软件的操作也很简单,大家可以自行百度。
然后,输入登录信息后,点击登录,查看抓取的数据。然后在脚本、头文件等中写入相应的要发送的数据。可以通过这种方式捕获其他一些功能。
这些都不是这次的重点
有一些功能网站在app上是没有的,所以需要抓取手机app的包,找到需要的接口。
这里举个例子,我们会发现有些参数是加密的,我们需要知道它的加密方式。这里我们可以先调整一个断点,修改请求中的数据,看看数据是不是真的有用的数据(这里想找sign的加密方式,但是找了半天也没找到,然后在前人的指导下使用了断点,方法知道sign的参数可以任意设置,也可以知道是否需要其他参数)。
搜索了一下,发现password参数是有用的(肯定的),然后我们只有一个目标:找到password的加密方式。
我们使用反编译软件对app进行反编译
这里双击 jadx-gui.bat 就可以直接选择要反编译的app文件,反编译出来的工程结构
直接全局搜索密码
然后你必须仔细选择哪些可以被加密。
这里发现密码被插入到JSONObject中,点击查看
看看其他字段和之前请求中的完全一样,那我们来看看aj.a和ia是什么。
找到引用的包
先看ia
发现有一个dX,找到!
这里找到了一个SharedPreferences类,百度一下,它是一个存储类。
大概明白ia的意识,大概率是取出用户输入的密码。
然后找到aj.a
这里发现是直接用MD5算法加密,然后经过aa处理。找到一个
发现是他们自己写的算法。他们不理解也没关系。只需将其复制到自己的项目中即可。
这样就知道密码的加密方式了。先用MD5加密,然后用自己的算法处理,再重复这一步。自己写一个案例测试。
好的~
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(一下示例代码看起来(2021-09-16我是一个))
2021-09-16
我是刚加入公司的新人。老板交给我的任务是写剧本。作用是从其他网站中抓取数据,然后在我们的平台上展示。具体业务就不介绍了。主要目的是从其他网站中获取数据。方法是使用 Jsoup 类。这是一个示例代码
Jsoup.connect(REGISTER_URL)
.userAgent(USER_AGENT)
.method(Connection.Method.GET)
这似乎很简单。一开始是去了解HTTP协议,request请求和response响应(我在学校是渣渣,没认真学习= =)。然后开始吧。
我们先来个登录的例子,先打开目标网站,找到登录的地方,这里是一个例子
然后打开抓包工具
(一开始我还是打开了网站的源码,然后去他的按钮提交的url,o(╥﹏╥)o)
软件的操作也很简单,大家可以自行百度。
然后,输入登录信息后,点击登录,查看抓取的数据。然后在脚本、头文件等中写入相应的要发送的数据。可以通过这种方式捕获其他一些功能。
这些都不是这次的重点
有一些功能网站在app上是没有的,所以需要抓取手机app的包,找到需要的接口。
这里举个例子,我们会发现有些参数是加密的,我们需要知道它的加密方式。这里我们可以先调整一个断点,修改请求中的数据,看看数据是不是真的有用的数据(这里想找sign的加密方式,但是找了半天也没找到,然后在前人的指导下使用了断点,方法知道sign的参数可以任意设置,也可以知道是否需要其他参数)。
搜索了一下,发现password参数是有用的(肯定的),然后我们只有一个目标:找到password的加密方式。
我们使用反编译软件对app进行反编译
这里双击 jadx-gui.bat 就可以直接选择要反编译的app文件,反编译出来的工程结构
直接全局搜索密码
然后你必须仔细选择哪些可以被加密。
这里发现密码被插入到JSONObject中,点击查看
看看其他字段和之前请求中的完全一样,那我们来看看aj.a和ia是什么。
找到引用的包
先看ia
发现有一个dX,找到!
这里找到了一个SharedPreferences类,百度一下,它是一个存储类。
大概明白ia的意识,大概率是取出用户输入的密码。
然后找到aj.a
这里发现是直接用MD5算法加密,然后经过aa处理。找到一个
发现是他们自己写的算法。他们不理解也没关系。只需将其复制到自己的项目中即可。
这样就知道密码的加密方式了。先用MD5加密,然后用自己的算法处理,再重复这一步。自己写一个案例测试。
好的~
分类:
技术要点:
相关文章:
c 抓取网页数据([]请求载体的身份识别信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-15 01:12
要查找更改的参数,只需下拉进度条即可查看新的请求数据
可以看出只有start变了,start 80;限制 20;开始100;限制20。能猜到这20是每次刷新的视频数吗?start 是从第一个视频开始阅读?
通过对网页的初步分析,这种可能性非常高,而且很容易验证。记住里面的请求是GET,所以可以用浏览器直接访问接口进行验证。
start=1 limit=2,刷新了本杀手不太冷和七武士的两部电影
start=2 limit=3,刷新了《七武士》、《割肚皮》、《蝙蝠侠:黑暗骑士》三部影片。由此可以验证 start 是视频排名第一的请求。限制是每个请求的视频数量。如果我想抓取前 300 个视频,我只需要 start=1,limit=300。网页分析到这里就可以完成了,我们想要的信息已经得到了。
1、接口:%3A90&action=&start=2&limit=3
2、请求方法:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、这部分通过对网页的分析发现,豆瓣视频的排名采用了网页的部分动态加载技术
2、检查中筛选出动态加载的请求接口,请求反馈为类json格式(供后期python解析),通过猜测发现start和limit两个参数的含义直接调用接口
python代码编写
1、User_agent介绍
如果你是豆瓣网站的开发者,你希望别人用不正规的方法批量抓取你的网站中的数据吗?想一想,答案肯定是否定的。那么网站服务器如何判断当前访问是否合法呢?最基本的方式是使用请求载体的身份信息User_agent。不同的浏览器有不同的身份信息。
以下是作者谷歌浏览器的识别信息。那么,为了防止写入的程序请求被服务器拒绝访问,在向请求模块请求时必须带上标识信息。
2、代码
先直接上代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
执行一下,程序已经在正确输出信息了
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进程序,分析页面后发现type是对应的电影类型,5:动作;11:情节。您可以尝试所有类型并将它们放入字典中以指定要捕获的特定类型的电影。作者完成的是动作片的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头、访问接口和参数,改变的参数是从终端输入的。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现读取返回的json格式数据,转换后的数据其实是一个字典。
操作excel 5步
1、构建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存关闭
sht.range('A1').value='序列号'
这意味着将序列号写入A1单元。如果需要写到B10,把上面的A1改成B10,操作起来很方便。 查看全部
c 抓取网页数据([]请求载体的身份识别信息)
要查找更改的参数,只需下拉进度条即可查看新的请求数据
可以看出只有start变了,start 80;限制 20;开始100;限制20。能猜到这20是每次刷新的视频数吗?start 是从第一个视频开始阅读?
通过对网页的初步分析,这种可能性非常高,而且很容易验证。记住里面的请求是GET,所以可以用浏览器直接访问接口进行验证。
start=1 limit=2,刷新了本杀手不太冷和七武士的两部电影
start=2 limit=3,刷新了《七武士》、《割肚皮》、《蝙蝠侠:黑暗骑士》三部影片。由此可以验证 start 是视频排名第一的请求。限制是每个请求的视频数量。如果我想抓取前 300 个视频,我只需要 start=1,limit=300。网页分析到这里就可以完成了,我们想要的信息已经得到了。
1、接口:%3A90&action=&start=2&limit=3
2、请求方法:GET
3、参数:type interval_id action start limit 前三个是固定的
概括:
1、这部分通过对网页的分析发现,豆瓣视频的排名采用了网页的部分动态加载技术
2、检查中筛选出动态加载的请求接口,请求反馈为类json格式(供后期python解析),通过猜测发现start和limit两个参数的含义直接调用接口
python代码编写
1、User_agent介绍
如果你是豆瓣网站的开发者,你希望别人用不正规的方法批量抓取你的网站中的数据吗?想一想,答案肯定是否定的。那么网站服务器如何判断当前访问是否合法呢?最基本的方式是使用请求载体的身份信息User_agent。不同的浏览器有不同的身份信息。
以下是作者谷歌浏览器的识别信息。那么,为了防止写入的程序请求被服务器拒绝访问,在向请求模块请求时必须带上标识信息。
2、代码
先直接上代码,和excel数据
```python
#!/user/bin/env python
# -*- coding:utf-8 -*-
#UA:User-Agent(请求载体的身份标识)
#UA检测,网站检测到UA不是正常浏览器身份标识,则服务器端很有可能会拒绝该请求
#UA伪装,让爬虫对应的请求载体UA标识伪装成某一浏览器
#解析豆瓣电影
#页面局部刷新 XHR请求
import requests
import json
import xlwings as xw
# 指定url,发起请求,获取响应数据,存储
if __name__ == "__main__":
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
# print(response.text)
# ps_name = json.loads(response.text).get('ps_name')
# print('\r\n',ps_name)
#确认服务器返回的json则可以使用json
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
执行一下,程序已经在正确输出信息了
打开生成的excel,需要的信息已经生成,剩下的分析就看你的excel能力了
如果改进程序,分析页面后发现type是对应的电影类型,5:动作;11:情节。您可以尝试所有类型并将它们放入字典中以指定要捕获的特定类型的电影。作者完成的是动作片的捕捉。
代码分析
使用的模块
requests
json
xlwings
requests是网络请求的库,xlwings是操作excel的库,支持xlxs格式文件。
#UA:将对应的User_Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'
}
url= "https://movie.douban.com/j/chart/top_list"
start_num = input("enter start num:")
limit_num = input("enter limit num:")
param = {
'type': '5',
'interval_id': '100:90',
'action':'',
'start': start_num,
'limit': limit_num,
}
这部分是定义头、访问接口和参数,改变的参数是从终端输入的。
#处理url携带的参数:封装到字典中
response = requests.get(url=url, params=param,headers = headers)
使用get命令访问,部分网页可能使用post,需要与网页的实际请求方式一致。浏览器地址栏只能实现get请求,post请求可以用postman等工具验证
dic_obj = response.json()
# json_name = json.loads(dic_obj)
app=xw.App(visible=False,add_book=False)
wb=app.books.add()
sht = wb.sheets['Sheet1']
sht.range('A1').value ='序号'
sht.range('B1').value ='排名'
sht.range('C1').value ='名称'
sht.range('D1').value ='评分'
sht.range('E1').value ='上映日期'
sht.range('F1').value ='国家'
i=1
for dic_item in dic_obj:
print('cnt:',i,'title ',dic_item['title'],'\r\n')
sht.range('A'+str(i+1)).value =i
sht.range('B'+str(i+1)).value = dic_item['rank']
sht.range('C'+str(i+1)).value = dic_item['title']
sht.range('D'+str(i+1)).value = dic_item['rating'][0]
sht.range('E'+str(i+1)).value = dic_item['release_date']
sht.range('F'+str(i+1)).value = dic_item['regions'][0]
i +=1
wb.save('movie_rank.xlsx')
wb.close()
app.quit()
这部分实现读取返回的json格式数据,转换后的数据其实是一个字典。
操作excel 5步
1、构建APP
2、创建书籍
3、创建工作表页面
4、数据写入
5、保存关闭
sht.range('A1').value='序列号'
这意味着将序列号写入A1单元。如果需要写到B10,把上面的A1改成B10,操作起来很方便。
c 抓取网页数据( (云抓取)⚡免费云起始积分--⭐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-15 01:11
(云抓取)⚡免费云起始积分--⭐)
介绍:
一款快速、免费且易于使用的网页抓取工具。在几秒钟内抓取 网站数据和表格数据 观看上面的短片,了解 Simplescraper 是如何设计成您将使用的最简单、最强大的网络抓取工具的。在您的浏览器中本地运行(无需注册)或创建自动抓取配方来抓取数千个网页并将它们转换为 API。从这里开始:---最近的评论:“非常易于使用” - ★★★★★ “简直是我发现的最好/最简单的刮刀” - ★★★★★ “这是一个很棒的抓取工具。它比我在 Google Web Store 上尝试过的所有其他爬虫” - ★★★★★ “惊人的扩展为我节省了很多时间” - ★★★★★ ---有用的功能包括:⚡ 一个简单的一键式工具选择您需要的数据⚡智能选择,- 改进的下一页选择过程 - 更广泛的抓取配方模板选择 ⭐ 1.16 更新: - 改进的爬虫 - 一次爬取多达 2000 个页面!- 添加了“管理帐户”部分 - 设计和布局改进 ⭐ 1. 15 个更新: - Google 表格集成 - 立即将抓取的数据保存到 Google 表格中!- CSS 编辑器 - 您现在可以在选择元素时编辑 CSS 选择器 - 新徽标 - 更新的帮助指南 ⭐ 1.14 更新: - 能够安排食谱 - 能够编辑食谱 - 能够抓取多个 URL - 新的更简单的布局对于 ⭐ 1.13 更新: - 更轻松的选择(自动选择第一个选项) - 改进的顶部菜单 - 添加了无限滚动 查看全部
c 抓取网页数据(
(云抓取)⚡免费云起始积分--⭐)
介绍:
一款快速、免费且易于使用的网页抓取工具。在几秒钟内抓取 网站数据和表格数据 观看上面的短片,了解 Simplescraper 是如何设计成您将使用的最简单、最强大的网络抓取工具的。在您的浏览器中本地运行(无需注册)或创建自动抓取配方来抓取数千个网页并将它们转换为 API。从这里开始:---最近的评论:“非常易于使用” - ★★★★★ “简直是我发现的最好/最简单的刮刀” - ★★★★★ “这是一个很棒的抓取工具。它比我在 Google Web Store 上尝试过的所有其他爬虫” - ★★★★★ “惊人的扩展为我节省了很多时间” - ★★★★★ ---有用的功能包括:⚡ 一个简单的一键式工具选择您需要的数据⚡智能选择,- 改进的下一页选择过程 - 更广泛的抓取配方模板选择 ⭐ 1.16 更新: - 改进的爬虫 - 一次爬取多达 2000 个页面!- 添加了“管理帐户”部分 - 设计和布局改进 ⭐ 1. 15 个更新: - Google 表格集成 - 立即将抓取的数据保存到 Google 表格中!- CSS 编辑器 - 您现在可以在选择元素时编辑 CSS 选择器 - 新徽标 - 更新的帮助指南 ⭐ 1.14 更新: - 能够安排食谱 - 能够编辑食谱 - 能够抓取多个 URL - 新的更简单的布局对于 ⭐ 1.13 更新: - 更轻松的选择(自动选择第一个选项) - 改进的顶部菜单 - 添加了无限滚动
c 抓取网页数据(如何做好辅导机构数据库操作?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-09 10:04
c抓取网页数据,转换成excel,再用sqlite数据库操作。第一步打开浏览器输入“包思源数据处理软件”安装操作步骤:第二步(重点)登录网站,然后运行,就可以抓取数据。第三步数据来源转为excel表格:具体操作步骤:大概7-8步不等。
谢邀。你可以买根简单的笔,试着写一写大学的课程表,如果方便的话,就可以实现了。
你想要做个辅导机构管理,这个必须依靠机构数据库。我不了解其他培训机构,可能他们也有多人的数据库了。我也是机构管理者,前面看知乎上的帖子,说要找老师、学生,要发生活费,但最后发现是个虚的,你学习的时候,你什么时候学习?上课,上课是在你考试前一天晚上么?数据库必须和学生挂钩,你怎么才能找到你看的学生的老师,怎么跟他打招呼,打交道。这些问题都是需要考虑的,数据库里必须的东西必须要备着,你可以请个技术的人出出好主意,祝你好运!。
抓包你要看看对不对
那你起码得有几个核心语言技术文档。比如python的scrapy爬虫。或者c++写爬虫。你可以去mysql官网找本mysql文档学习学习。有现成的库和示例数据。自己仿照简单的抓个数据过来就好。有c++基础就自己试着编程写个bt下载器。或者直接抓commonmedia试试。
出来创业,就得拿起笔在纸上写写画画,而且这个技术似乎在已经跟自己渐行渐远了。就拿抓包来说,就凭有个爬虫如何抓到数据也是蛮有意思的技术。简单的说抓包就是将某段网页内容通过某种方式转换成一段字符串,或者是命令格式。然后你可以在浏览器里面通过代码解析出每一个信息去匹配匹配内容。如果你在说存储就更好说了,你可以将不同的日志去匹配内容,获取最相似的时间去匹配内容就是最相似的那个时间,这样后面的程序可以匹配自己一段代码,该处理的地方要尽量处理,网页内容可能也不是特别多。综上,你要先完成的事情应该就是抓包。 查看全部
c 抓取网页数据(如何做好辅导机构数据库操作?-八维教育)
c抓取网页数据,转换成excel,再用sqlite数据库操作。第一步打开浏览器输入“包思源数据处理软件”安装操作步骤:第二步(重点)登录网站,然后运行,就可以抓取数据。第三步数据来源转为excel表格:具体操作步骤:大概7-8步不等。
谢邀。你可以买根简单的笔,试着写一写大学的课程表,如果方便的话,就可以实现了。
你想要做个辅导机构管理,这个必须依靠机构数据库。我不了解其他培训机构,可能他们也有多人的数据库了。我也是机构管理者,前面看知乎上的帖子,说要找老师、学生,要发生活费,但最后发现是个虚的,你学习的时候,你什么时候学习?上课,上课是在你考试前一天晚上么?数据库必须和学生挂钩,你怎么才能找到你看的学生的老师,怎么跟他打招呼,打交道。这些问题都是需要考虑的,数据库里必须的东西必须要备着,你可以请个技术的人出出好主意,祝你好运!。
抓包你要看看对不对
那你起码得有几个核心语言技术文档。比如python的scrapy爬虫。或者c++写爬虫。你可以去mysql官网找本mysql文档学习学习。有现成的库和示例数据。自己仿照简单的抓个数据过来就好。有c++基础就自己试着编程写个bt下载器。或者直接抓commonmedia试试。
出来创业,就得拿起笔在纸上写写画画,而且这个技术似乎在已经跟自己渐行渐远了。就拿抓包来说,就凭有个爬虫如何抓到数据也是蛮有意思的技术。简单的说抓包就是将某段网页内容通过某种方式转换成一段字符串,或者是命令格式。然后你可以在浏览器里面通过代码解析出每一个信息去匹配匹配内容。如果你在说存储就更好说了,你可以将不同的日志去匹配内容,获取最相似的时间去匹配内容就是最相似的那个时间,这样后面的程序可以匹配自己一段代码,该处理的地方要尽量处理,网页内容可能也不是特别多。综上,你要先完成的事情应该就是抓包。
c 抓取网页数据(知道了要访问的URL地址是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-09 00:07
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里: 查看全部
c 抓取网页数据(知道了要访问的URL地址是什么)
1.我知道要访问的URL地址是什么
请求网址
2.【可选】如果是GET方法,是否还有其他参数
这个参数:
3.判断是GET还是POST方法
4.添加对应的标头(Header)信息
即请求头
5.【可选】如果是POST方式,还需要填写对应的数据
这个数据:
换句话说:
如果是 GET,则没有 POST 数据。
提示:所以,在你在 IE9 中通过 F12 抓取的内容中,你会看到对于所有的 GET 请求,对应的“请求体”都是空的。
6.其他一些你可能需要准备的东西
(1)代理代理
(2)设置最大超时超时时间
(3)有没有cookie
提交HttpRequest,就可以得到这个http请求的response Response(访问URL后要做的工作)
1.得到对应的响应
2.从响应中获取对应的网页源码等信息
(1)获取返回网页的HTML源代码(或json等)
(2)[可选] 必要时也获取对应的cookie
(3)[可选]判断返回的一些其他相关信息,如响应码等。
【网页抓取时的注意事项】
1.网页跳转重定向
(1)直接跳转
(2)间接跳转
A.javascript脚本中有对应的代码实现网页跳转
B、自身返回的HTML源码中收录刷新动作,实现网页跳转
爬网后,如何分析得到想要的内容
一般来说,当你访问一个 URL 地址时,返回的内容大部分是网页的 HTML 源代码,还有其他形式的内容,比如 json 等。
我们要的是从返回的内容(HTML或者json等)中提取出我们需要的具体信息,也就是对其进行处理,得到需要的信息。
据我所知,有几种方法可以实现提取所需信息:
1. 对于 HTML 源代码:
(1)如果是Python的话,可以通过调用第三方Beautifulsoup库调用
然后调用find等函数提取相应的信息。
这部分内容比较复杂,需要进一步了解,可以参考:
BlogsToWordPress v3.0 – 将百度空间、网易163等博客移至WordPress
中的源代码。
(2)直接使用正则表达式自行提取相关内容
对于内容分析和提取,在很多情况下都会用到正则表达式。
正则表达式的知识和总结,请看这里:
[总结] 关于正则表达式 v2012-02-20
正则表达式是一种规范/规则,您可以使用哪种语言来实现它。
我遇到过两种语言,Python 和 C#:
A. Python:使用re模块,常用函数有find、findall、search等。
B:C#:使用Regex类来匹配对应的模式和匹配函数。
有关 C# 中的正则表达式的更多信息,请参阅:
【总结】C#中Regex的经验及注意事项
2.对于 Json
可以先看一下JSON的介绍:
【组织】什么是JSON+如何处理JSON字符串
然后看看下面如何处理Json。
(1)使用库(函数)来处理
A. 蟒蛇
Python中有对应的json库。常用的是json.load,可以将json格式的字符串转换成对应的字典类型变量,非常好用。
(2) 还是用正则表达式处理
A. 蟒蛇
Python 中的 re 模块,同上。
B. C#
C#好像没有json库,但是第三方json库有很多,但是遇到解析json字符串的时候,感觉这些库用起来还是很麻烦,所以还是用regex类来处理用它。.
模拟登录的一般逻辑和流程网站
至于使用C#实现网页内容爬取和模拟登陆网页,一些经验和注意事项,看这里:
c 抓取网页数据(w3school在线教程PHP表单PHP高级教程PHP数据库和AJAXPHP参考手册PHP测验建站手册)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-07 00:20
w3school 在线教程
PHP 基础教程PHP 表单PHP 高级教程PHP 数据库PHP XMLPHP 和AJAXPHP 参考手册PHP 测验
网站建设者编程关于 W3School 帮助W3School
PHP 教程
PHP 是一种强大的服务器端脚本语言,用于创建动态和交互式站点。
PHP 是免费的并且被广泛使用。对于微软 ASP 这样的竞争对手来说,PHP 无疑是另一个有效的选择。
开始学习 PHP!
通过在线示例学习 PHP
我们的“运行示例”工具通过显示 PHP 源代码和代码的 HTML 输出,使学习 PHP 变得更加容易。
例子
运行实例
请单击“运行实例”以查看其工作原理。
PHP 参考手册
在 W3School,我们为您提供收录所有 PHP 函数的完整参考手册:
PHP 5 测验
在 W3School 测试您的 PHP 技能!
开始您的 PHP 测验!
PHP 参考手册PHP Quiz
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。 查看全部
c 抓取网页数据(w3school在线教程PHP表单PHP高级教程PHP数据库和AJAXPHP参考手册PHP测验建站手册)
w3school 在线教程
PHP 基础教程PHP 表单PHP 高级教程PHP 数据库PHP XMLPHP 和AJAXPHP 参考手册PHP 测验
网站建设者编程关于 W3School 帮助W3School
PHP 教程
PHP 是一种强大的服务器端脚本语言,用于创建动态和交互式站点。
PHP 是免费的并且被广泛使用。对于微软 ASP 这样的竞争对手来说,PHP 无疑是另一个有效的选择。
开始学习 PHP!
通过在线示例学习 PHP
我们的“运行示例”工具通过显示 PHP 源代码和代码的 HTML 输出,使学习 PHP 变得更加容易。
例子
运行实例
请单击“运行实例”以查看其工作原理。
PHP 参考手册
在 W3School,我们为您提供收录所有 PHP 函数的完整参考手册:
PHP 5 测验
在 W3School 测试您的 PHP 技能!
开始您的 PHP 测验!
PHP 参考手册PHP Quiz
W3School简体中文版提供的内容仅供培训和测试之用,不保证内容的正确性。与使用本网站内容相关的风险与本网站无关。版权所有,保留所有权利。
c 抓取网页数据(从后台获取数据显示在界面上是前端开发所必须掌握的一项基本技能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-05 14:15
)
从后台获取数据并显示在界面上是前端开发必须掌握的一项基本技能。只需将本地模拟数据的json文件中获取的数据记录下来,显示在界面上即可。
1.创建一个本地 json 文件并将其命名为 data.json。 json文件格式如下:
{
"list":[
{
"project_img":"images/Home-logo1-hua.png",
"project_name":"111",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1400"
},
{
"project_img":"images/Home-logo2-bao.png",
"project_name":"222",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1"
}
]
}
2.在js中编写方法,调用方法。插入数据时,innerHTNML 方法是原生的 JavaScript 方法,但这种方法是把 HTML 代码插入到 div 中,而不是追加。要追加,您需要每次保存之前的 HTML 内容。 append方法是jquery方法,可以直接添加到div中。
notice();
function notice(){
$.ajax("Json/data.json",{
data:{},
dataType:'json',
type:'get',
async:'false',
success:function(data){
var listdata=data.list; //列表数据
if(listdata.length>0){ //项目列表
var listInfo="";
$.each(listdata,function(){
listInfo+=""+
"+this.project_img+"+
""+
""+this.project_name+""+
"<p class='money-range' class='mui-ellipsis loan-range'>"+this.money_range+""+
"
每日百分比"+this.day_rate+"%,应该为"+this.day_limit+"天,"+this.day_person+"人已交"+""+
""+
""+
"详情"+
""+
"";
});
$("#project_list")[0].innerHTML=listInfo;
}
}
// error:function(xhr,type,errorThrown){
// alert("系统繁忙,请联系管理员");
// }
})
}</p> 查看全部
c 抓取网页数据(从后台获取数据显示在界面上是前端开发所必须掌握的一项基本技能
)
从后台获取数据并显示在界面上是前端开发必须掌握的一项基本技能。只需将本地模拟数据的json文件中获取的数据记录下来,显示在界面上即可。
1.创建一个本地 json 文件并将其命名为 data.json。 json文件格式如下:
{
"list":[
{
"project_img":"images/Home-logo1-hua.png",
"project_name":"111",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1400"
},
{
"project_img":"images/Home-logo2-bao.png",
"project_name":"222",
"money_range":"2000~40000",
"day_rate":"0.04",
"day_limit":"7-90",
"day_person":"1"
}
]
}
2.在js中编写方法,调用方法。插入数据时,innerHTNML 方法是原生的 JavaScript 方法,但这种方法是把 HTML 代码插入到 div 中,而不是追加。要追加,您需要每次保存之前的 HTML 内容。 append方法是jquery方法,可以直接添加到div中。
notice();
function notice(){
$.ajax("Json/data.json",{
data:{},
dataType:'json',
type:'get',
async:'false',
success:function(data){
var listdata=data.list; //列表数据
if(listdata.length>0){ //项目列表
var listInfo="";
$.each(listdata,function(){
listInfo+=""+
"+this.project_img+"+
""+
""+this.project_name+""+
"<p class='money-range' class='mui-ellipsis loan-range'>"+this.money_range+""+
"
每日百分比"+this.day_rate+"%,应该为"+this.day_limit+"天,"+this.day_person+"人已交"+""+
""+
""+
"详情"+
""+
"";
});
$("#project_list")[0].innerHTML=listInfo;
}
}
// error:function(xhr,type,errorThrown){
// alert("系统繁忙,请联系管理员");
// }
})
}</p>
c 抓取网页数据(2.Jsoup伪造请求头且携带身份信息获取登录信息结果:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-04 00:00
今天在学习爬虫的时候,想着用jsoup来模拟登录。下面分有验证码和无验证码两种情况进行讨论。
-----------------------------------------无验证码------------------ - ------------
1.我们使用网页正常登录,使用浏览器自带的开发者工具查看一些登录信息
当我们登录时,需要携带自己的身份信息,即用户名和密码。它还携带了一些浏览器信息,所以我们可以通过Jsoup伪造一些请求头,写入自己的身份信息进行登录,然后获取登录后返回的cookie,里面会收录session,而有了sessionid我们就可以爬取获取到的url登录后即可访问。
2.Jsoup伪造请求头,携带身份信息获取登录信息
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/");
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
Map cookies = res.cookies();
for (Entry entry : cookies.entrySet()) {
System.out.println(entry.getKey() + "-" + entry.getValue());
}
System.out.println("---------华丽的分割线-----------");
String body = res.body();// 获取响应体
System.out.println(body);
}
结果:
logininfo-"362501197407067215,123456"
JSESSIONID-75ad3bad-30cd-4d7a-8918-b13054f4b737
rememberMe-deleteMe
---------华丽的分割线-----------
{"login_result":"success_manager","user_type":"2","login_url":"examParper\/examPaper\/examparperManage.jsp"}
反例:
此时,我们将身份信息的密码修改为错误密码:
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123").data("user_type", "2")
.data("isRememberme", "yes");
结果:
---------华丽的分割线-----------
{"login_result":"error002","user_type":"2","login_url":null}
3.根据以上cookie获取模拟访问网站登录即可访问网站
将cookies定义为全局变量cookies,当我们访问登录可以访问的url时,我们会带着cookies访问。
package cn.qlq.craw.Jsoup;
import java.io.IOException;
import java.util.Map;
import java.util.Map.Entry;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
/**
* 模拟Jsoup跳过登陆进行爬虫
*
* @author liqiang
*
*/
public class JsoupCookieCraw {
private static Map cookies = null;
public static void main(String[] args) throws IOException {
// 先模拟登录获取到cookie和sessionid并存到全局变量cookies中
login();
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).cookies(cookies).post();
System.out.println(document.toString());
}
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/");
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
cookies = res.cookies();
}
}
结果:(可以获取我们访问的页面内容)
分配员工
.....................
反例:
我们去掉登录方式,访问时不携带cookies:
public static void main(String[] args) throws IOException {
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).post();
System.out.println(document.toString());
}
结果:(我们访问了系统的首页,也就是登录界面,发现我们被网站屏蔽了)
主页
.....
总结:
使用上述模拟登录方式,无验证码登录基本可以满足要求。
------------------------------有验证码------ - ------------ 查看全部
c 抓取网页数据(2.Jsoup伪造请求头且携带身份信息获取登录信息结果:)
今天在学习爬虫的时候,想着用jsoup来模拟登录。下面分有验证码和无验证码两种情况进行讨论。
-----------------------------------------无验证码------------------ - ------------
1.我们使用网页正常登录,使用浏览器自带的开发者工具查看一些登录信息
当我们登录时,需要携带自己的身份信息,即用户名和密码。它还携带了一些浏览器信息,所以我们可以通过Jsoup伪造一些请求头,写入自己的身份信息进行登录,然后获取登录后返回的cookie,里面会收录session,而有了sessionid我们就可以爬取获取到的url登录后即可访问。
2.Jsoup伪造请求头,携带身份信息获取登录信息
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/";);
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
Map cookies = res.cookies();
for (Entry entry : cookies.entrySet()) {
System.out.println(entry.getKey() + "-" + entry.getValue());
}
System.out.println("---------华丽的分割线-----------");
String body = res.body();// 获取响应体
System.out.println(body);
}
结果:
logininfo-"362501197407067215,123456"
JSESSIONID-75ad3bad-30cd-4d7a-8918-b13054f4b737
rememberMe-deleteMe
---------华丽的分割线-----------
{"login_result":"success_manager","user_type":"2","login_url":"examParper\/examPaper\/examparperManage.jsp"}
反例:
此时,我们将身份信息的密码修改为错误密码:
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123").data("user_type", "2")
.data("isRememberme", "yes");
结果:
---------华丽的分割线-----------
{"login_result":"error002","user_type":"2","login_url":null}
3.根据以上cookie获取模拟访问网站登录即可访问网站
将cookies定义为全局变量cookies,当我们访问登录可以访问的url时,我们会带着cookies访问。
package cn.qlq.craw.Jsoup;
import java.io.IOException;
import java.util.Map;
import java.util.Map.Entry;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
/**
* 模拟Jsoup跳过登陆进行爬虫
*
* @author liqiang
*
*/
public class JsoupCookieCraw {
private static Map cookies = null;
public static void main(String[] args) throws IOException {
// 先模拟登录获取到cookie和sessionid并存到全局变量cookies中
login();
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).cookies(cookies).post();
System.out.println(document.toString());
}
/**
* 模拟登录获取cookie和sessionid
*/
public static void login() throws IOException {
String urlLogin = "http://qiaoliqiang.cn/Exam/use ... 3B%3B
Connection connect = Jsoup.connect(urlLogin);
// 伪造请求头
connect.header("Accept", "application/json, text/javascript, */*; q=0.01").header("Accept-Encoding",
"gzip, deflate");
connect.header("Accept-Language", "zh-CN,zh;q=0.9").header("Connection", "keep-alive");
connect.header("Content-Length", "72").header("Content-Type",
"application/x-www-form-urlencoded; charset=UTF-8");
connect.header("Host", "qiaoliqiang.cn").header("Referer", "http://qiaoliqiang.cn/Exam/";);
connect.header("User-Agent",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36")
.header("X-Requested-With", "XMLHttpRequest");
// 携带登陆信息
connect.data("username", "362501197407067215").data("password", "123456").data("user_type", "2")
.data("isRememberme", "yes");
//请求url获取响应信息
Response res = connect.ignoreContentType(true).method(Method.POST).execute();// 执行请求
// 获取返回的cookie
cookies = res.cookies();
}
}
结果:(可以获取我们访问的页面内容)
分配员工
.....................
反例:
我们去掉登录方式,访问时不携带cookies:
public static void main(String[] args) throws IOException {
String url = "http://qiaoliqiang.cn/Exam/vie ... 3B%3B
// 直接获取DOM树,带着cookies去获取
Document document = Jsoup.connect(url).post();
System.out.println(document.toString());
}
结果:(我们访问了系统的首页,也就是登录界面,发现我们被网站屏蔽了)
主页
.....
总结:
使用上述模拟登录方式,无验证码登录基本可以满足要求。
------------------------------有验证码------ - ------------
c 抓取网页数据(在开始之前,做一点小小的说明哈:Part1进行网页分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-30 14:07
在开始之前,先做一点解释:
Part1 网页分析
先打开网易云网页版网易云
然后搜索歌曲,这里我会搜索金凌的《空山新雨女王》
这时候我们观察网页的url,可以发现我们搜索的关键字在s=后面
当我们换一首歌的时候,我们会发现也是一样的,这正好验证了我们的想法
所以接下来就是点击一首歌曲,然后播放,看看我们能不能直接获取到音乐文件的url。如果可以,那么直接通过requests.get访问url,就可以得到.mp3文件了。
点击第一首歌《空山新雨之后》,我们可以看到有一个“生成外链播放器”
看到这里,我一阵激动,仿佛快要完结似的;所以我高兴地点击,结果就是结果。. .
好吧,但我们不能放弃,我们来分析一下页面
但是当我们找到两个最有可能的外部链接位置时,我们什么也没找到
不过,作为“严格规范,功夫在家”的传承人,我不能放弃,所以我又打开了抓包工具
按照常规套路,我们定位XHR
点击播放后,出现了很多东西,我们要做的就是找到一个content-type为audio的包。
努力有回报,找了(一亿)时间,我找到了
于是我愉快的复制了这个包对应的Request-URL
粘贴后访问这个url,结果很满意,这是我一直在找的url
现在我发布那个网址
https://m10.music.126.net/2020 ... 9.mp3
Part2 编写爬虫
超级简单
下面的代码是最常见的操作,有爬虫基础的人都应该明白;如果有不懂的地方,评论就在上面
#导入requests包
import requests
#进行UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
#指定url
url = 'https://m10.music.126.net/2020 ... 39%3B
#调用requests.get方法对url进行访问,和持久化存储数据
audio_content = requests.get(url=url,headers=headers).content
#存入本地
with open('空山新雨后.mp3','wb') as f :
f.write(audio_content)
print("空山新雨后爬取成功!!!")
Part3 更高级
看到这里,你可能会想,为什么 selenium 模块根本没有用到呢?我可以直接抓取我想要的任何歌曲,而无需为每首歌曲找到一个网址吗?当然可以!
其实,网易云在线播放每首歌的时候,都有一个外链地址,是不会变的。它与每首歌曲的唯一 id 绑定。每首歌曲的音频文件的url如下:
url = 'http://music.163.com/song/medi ... 39%3B + 歌曲的id值 + '.mp3'
id值的获取也很简单。当我们点击每首歌曲时,上面会出现对应的URL,并且有一个id值,如下图:
所以只要把上面程序中的url改成新的url
如果还想要更好的体验,需要使用 selenium 模块直接在程序中搜索歌曲并获取 id 值。
为什么使用 selenium 而不是 xpath 或 bs4?
因为搜索页面的数据是动态加载的,如果直接解析搜索页面的数据,是不会得到任何数据的;以我目前的技术,我只能想到使用万能的 selenium 模块。下面简要说明这些步骤。:
在没有可视界面的情况下设置 selenium
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
指导包
import requests
import re
from selenium import webdriver
from time import sleep
指定歌曲并获取对应搜索页面的url
name = input('请输入歌名:')
url_1 = 'https://music.163.com/#/search/m/?s=' + name + '&type=1'
获取搜索页面的html文件
#初始化browser对象
browser = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=chrome_options)
#访问该url
browser.get(url=url_1)
#由于网页中有iframe框架,进行切换
browser.switch_to.frame('g_iframe')
#等待0.5秒
sleep(0.5)
#抓取到页面信息
page_text = browser.execute_script("return document.documentElement.outerHTML")
#退出浏览器
browser.quit()
使用正则模块re匹配html文件中的id值、歌名和歌手
ex1 = '(.*?)</a>'
id_list = re.findall(ex1,page_text,re.M)[::2]
song_list = re.findall(ex2,page_text,re.M)
singer_list = re.findall(ex3,page_text,re.M)
将id值、歌名和歌手封装成元组,写入列表,然后打印
li = list(zip(song_list,singer_list,id_list))
for i in range(len(li)):
print(str(i+1) + '.' + str(li[i]),end='\n')
你可以获取一个 url 以获得满意的 id 值,然后使用上面的程序通过 requests.get 方法访问该 url。Part4 总结
毕竟是我的天赋和知识,这种寻找外部链接进行爬取的方法也有很多不足之处。例如,无法在线播放的歌曲无法下载。
不过,写这么个小程序练手,确实对提升一个人的能力有很大的帮助。 查看全部
c 抓取网页数据(在开始之前,做一点小小的说明哈:Part1进行网页分析)
在开始之前,先做一点解释:
Part1 网页分析
先打开网易云网页版网易云
然后搜索歌曲,这里我会搜索金凌的《空山新雨女王》
这时候我们观察网页的url,可以发现我们搜索的关键字在s=后面
当我们换一首歌的时候,我们会发现也是一样的,这正好验证了我们的想法
所以接下来就是点击一首歌曲,然后播放,看看我们能不能直接获取到音乐文件的url。如果可以,那么直接通过requests.get访问url,就可以得到.mp3文件了。
点击第一首歌《空山新雨之后》,我们可以看到有一个“生成外链播放器”
看到这里,我一阵激动,仿佛快要完结似的;所以我高兴地点击,结果就是结果。. .
好吧,但我们不能放弃,我们来分析一下页面
但是当我们找到两个最有可能的外部链接位置时,我们什么也没找到
不过,作为“严格规范,功夫在家”的传承人,我不能放弃,所以我又打开了抓包工具
按照常规套路,我们定位XHR
点击播放后,出现了很多东西,我们要做的就是找到一个content-type为audio的包。
努力有回报,找了(一亿)时间,我找到了
于是我愉快的复制了这个包对应的Request-URL
粘贴后访问这个url,结果很满意,这是我一直在找的url
现在我发布那个网址
https://m10.music.126.net/2020 ... 9.mp3
Part2 编写爬虫
超级简单
下面的代码是最常见的操作,有爬虫基础的人都应该明白;如果有不懂的地方,评论就在上面
#导入requests包
import requests
#进行UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36'
}
#指定url
url = 'https://m10.music.126.net/2020 ... 39%3B
#调用requests.get方法对url进行访问,和持久化存储数据
audio_content = requests.get(url=url,headers=headers).content
#存入本地
with open('空山新雨后.mp3','wb') as f :
f.write(audio_content)
print("空山新雨后爬取成功!!!")
Part3 更高级
看到这里,你可能会想,为什么 selenium 模块根本没有用到呢?我可以直接抓取我想要的任何歌曲,而无需为每首歌曲找到一个网址吗?当然可以!
其实,网易云在线播放每首歌的时候,都有一个外链地址,是不会变的。它与每首歌曲的唯一 id 绑定。每首歌曲的音频文件的url如下:
url = 'http://music.163.com/song/medi ... 39%3B + 歌曲的id值 + '.mp3'
id值的获取也很简单。当我们点击每首歌曲时,上面会出现对应的URL,并且有一个id值,如下图:
所以只要把上面程序中的url改成新的url
如果还想要更好的体验,需要使用 selenium 模块直接在程序中搜索歌曲并获取 id 值。
为什么使用 selenium 而不是 xpath 或 bs4?
因为搜索页面的数据是动态加载的,如果直接解析搜索页面的数据,是不会得到任何数据的;以我目前的技术,我只能想到使用万能的 selenium 模块。下面简要说明这些步骤。:
在没有可视界面的情况下设置 selenium
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
指导包
import requests
import re
from selenium import webdriver
from time import sleep
指定歌曲并获取对应搜索页面的url
name = input('请输入歌名:')
url_1 = 'https://music.163.com/#/search/m/?s=' + name + '&type=1'
获取搜索页面的html文件
#初始化browser对象
browser = webdriver.Chrome(executable_path='chromedriver.exe',chrome_options=chrome_options)
#访问该url
browser.get(url=url_1)
#由于网页中有iframe框架,进行切换
browser.switch_to.frame('g_iframe')
#等待0.5秒
sleep(0.5)
#抓取到页面信息
page_text = browser.execute_script("return document.documentElement.outerHTML")
#退出浏览器
browser.quit()
使用正则模块re匹配html文件中的id值、歌名和歌手
ex1 = '(.*?)</a>'
id_list = re.findall(ex1,page_text,re.M)[::2]
song_list = re.findall(ex2,page_text,re.M)
singer_list = re.findall(ex3,page_text,re.M)
将id值、歌名和歌手封装成元组,写入列表,然后打印
li = list(zip(song_list,singer_list,id_list))
for i in range(len(li)):
print(str(i+1) + '.' + str(li[i]),end='\n')
你可以获取一个 url 以获得满意的 id 值,然后使用上面的程序通过 requests.get 方法访问该 url。Part4 总结
毕竟是我的天赋和知识,这种寻找外部链接进行爬取的方法也有很多不足之处。例如,无法在线播放的歌曲无法下载。
不过,写这么个小程序练手,确实对提升一个人的能力有很大的帮助。
c 抓取网页数据(动态生成二级菜单树的代码:静态生成菜单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-28 17:06
今天小编给大家分享一个使用js将ajax获取的后台数据动态加载到网页中的方法,具有很好的参考价值,希望对大家有所帮助。跟我来看看
动态生成二级菜单树:
jQuery(function($) {
/**********
获取未处理报警信息总数
**************/
var result;
$.ajax({
async:false,
cache:false,
url: "alarm_findPageAlarm.do",//访问后台接口取数据
// dataType : "json",
type: 'POST',
success: function(data){
result = eval('('+ data +')');
}
});
var alarmCount;
alarmCount = result.total;
/**********
静态代码形式
**********/
/*
设备管理
智能终端管理
标签打印机管理
*/
/*****从后台取出导航栏数据******/
$.ajax({
async:true,
cache:false,
url: "user_getMenuBuf.do",
// dataType : "json",
type: 'POST',
success: function(result){
var result = eval('('+ result +')');
if(result != undefined && result.length > 0){
var firstMenu = [];
var firstHref = [];
var firstIcon = [];
var subMenu = [];
/******一级导航栏数据*******/
for (var i = 0; i < result.length; i++){
firstMenu[i] = result[i].name;
firstHref[i] = result[i].url;
firstIcon[i] = result[i].iconCls;
/*******添加li标签********/
var menuInfo = document.getElementById("menuInfo");
var firstLi = document.createElement("li");//创建新的 li元素
menuInfo.appendChild(firstLi);//将此li元素添加至页面的ul下一级中
firstLi.style.borderBottom = "0px solid #CCEBF8";//设置li下边框样式
/******设置选中li、离开li时li的样式********/
firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstLi.onmouseout=function(){
this.style.background = "#0477C0";
};
/******添加a标签**********/
var firstALabel = document.createElement("a");
firstALabel.setAttribute("href", firstHref[i]);//js为新添加的a元素动态设置href属性
firstALabel.setAttribute("class", "dropdown-toggle");
//firstALabel.className = "dropdown-toggle";//兼容性好
firstALabel.setAttribute("target", "content");
//firstALabel.style.backgroundImage="url(./img/17.jpg)"
firstALabel.style.background = "#0477C0";//js为新添加的a元素动态设置背景颜色
// background:url(./img/17.jpg);
firstALabel.style.marginLeft = "20px";//js为新添加的a元素动态设置左外边距
firstLi.appendChild(firstALabel);
firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstALabel.onmouseout=function(){
this.style.background = "#0477C0";
};
/*******添加i标签*******/
var firstILavel = document.createElement("i");
firstILavel.setAttribute("class", firstIcon[i]);
firstILavel.style.color = "#F4F8FF";//动态设置i元素的颜色
firstALabel.appendChild(firstILavel);
/*********添加span标签**********/
var firstSpan = document.createElement("span");
firstSpan.className = "menu-text";
firstSpan.innerHTML = firstMenu[i];//js为新添加的span元素动态设置显示内容
firstSpan.style.fontSize = "14.5px";//js为新添加的span元素动态设置显示内容的字体大小
firstSpan.style.color = "#66D2F1";//js为新添加的span元素动态设置显示内容的字体颜色
firstSpan.style.marginLeft = "15px";
firstALabel.appendChild(firstSpan);
if (firstMenu[i] == "报警信息管理"){
var alarmIcon = document.createElement("span");
alarmIcon.className = "badge badge-important";
alarmIcon.innerHTML = alarmCount; //alarmCount为全局变量,且是通过ajax从后台获取到的
firstSpan.appendChild(alarmIcon);
}
if (result[i].children.length > 0){
var secondHref = [];
var secondMenu = [];
var secondIcon = [];
/*******添加b标签********/
var firstBLabel = document.createElement("b");
firstBLabel.className = "arrow icon-angle-down";
firstBLabel.style.color = "white";
firstALabel.appendChild(firstBLabel);
/********添加ul标签************/
var secondUl = document.createElement("ul");
secondUl.setAttribute("class", "submenu");
firstLi.appendChild(secondUl);
for (var j = 0; j < result[i].children.length; j++){
secondHref[j] = result[i].children[j].url;
secondMenu[j] = result[i].children[j].name;
secondIcon[j] = result[i].children[j].iconCls;
/******添加li标签*******/
var secondLi = document.createElement("li");
secondLi.style.background = "#CCEBF8";
secondUl.appendChild(secondLi);
/*******添加a标签*******/
var secondALabel = document.createElement("a");
secondALabel.setAttribute("href", secondHref[j]);
secondALabel.setAttribute("target", "content");
//secondALabel.style.background = "#CCEBF8";
secondLi.appendChild(secondALabel);
/*******添加i标签**********/
var secondILabel = document.createElement("i");
secondILabel.setAttribute("class", "icon-double-angle-right");
secondALabel.appendChild(secondILabel);
/******添加二级导航信息********/
secondALabel.innerHTML = secondMenu[j];
secondALabel.style.fontSize = "15px";
//secondALabel.style.marginLeft = "60px";
}
}
}
}
},
error: function() {
alert("加载菜单失败");
}
});
})
静态生成菜单树的代码:
生成菜单树的效果:
以上使用js将ajax获取的后台数据动态加载到网页中的方法就是编辑器共享的全部内容。 查看全部
c 抓取网页数据(动态生成二级菜单树的代码:静态生成菜单)
今天小编给大家分享一个使用js将ajax获取的后台数据动态加载到网页中的方法,具有很好的参考价值,希望对大家有所帮助。跟我来看看
动态生成二级菜单树:
jQuery(function($) {
/**********
获取未处理报警信息总数
**************/
var result;
$.ajax({
async:false,
cache:false,
url: "alarm_findPageAlarm.do",//访问后台接口取数据
// dataType : "json",
type: 'POST',
success: function(data){
result = eval('('+ data +')');
}
});
var alarmCount;
alarmCount = result.total;
/**********
静态代码形式
**********/
/*
设备管理
智能终端管理
标签打印机管理
*/
/*****从后台取出导航栏数据******/
$.ajax({
async:true,
cache:false,
url: "user_getMenuBuf.do",
// dataType : "json",
type: 'POST',
success: function(result){
var result = eval('('+ result +')');
if(result != undefined && result.length > 0){
var firstMenu = [];
var firstHref = [];
var firstIcon = [];
var subMenu = [];
/******一级导航栏数据*******/
for (var i = 0; i < result.length; i++){
firstMenu[i] = result[i].name;
firstHref[i] = result[i].url;
firstIcon[i] = result[i].iconCls;
/*******添加li标签********/
var menuInfo = document.getElementById("menuInfo");
var firstLi = document.createElement("li");//创建新的 li元素
menuInfo.appendChild(firstLi);//将此li元素添加至页面的ul下一级中
firstLi.style.borderBottom = "0px solid #CCEBF8";//设置li下边框样式
/******设置选中li、离开li时li的样式********/
firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstLi.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstLi.onmouseout=function(){
this.style.background = "#0477C0";
};
/******添加a标签**********/
var firstALabel = document.createElement("a");
firstALabel.setAttribute("href", firstHref[i]);//js为新添加的a元素动态设置href属性
firstALabel.setAttribute("class", "dropdown-toggle");
//firstALabel.className = "dropdown-toggle";//兼容性好
firstALabel.setAttribute("target", "content");
//firstALabel.style.backgroundImage="url(./img/17.jpg)"
firstALabel.style.background = "#0477C0";//js为新添加的a元素动态设置背景颜色
// background:url(./img/17.jpg);
firstALabel.style.marginLeft = "20px";//js为新添加的a元素动态设置左外边距
firstLi.appendChild(firstALabel);
firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
};
/* firstALabel.onmouseover = function(){
this.style.background = "#23ACFA";
}; */
firstALabel.onmouseout=function(){
this.style.background = "#0477C0";
};
/*******添加i标签*******/
var firstILavel = document.createElement("i");
firstILavel.setAttribute("class", firstIcon[i]);
firstILavel.style.color = "#F4F8FF";//动态设置i元素的颜色
firstALabel.appendChild(firstILavel);
/*********添加span标签**********/
var firstSpan = document.createElement("span");
firstSpan.className = "menu-text";
firstSpan.innerHTML = firstMenu[i];//js为新添加的span元素动态设置显示内容
firstSpan.style.fontSize = "14.5px";//js为新添加的span元素动态设置显示内容的字体大小
firstSpan.style.color = "#66D2F1";//js为新添加的span元素动态设置显示内容的字体颜色
firstSpan.style.marginLeft = "15px";
firstALabel.appendChild(firstSpan);
if (firstMenu[i] == "报警信息管理"){
var alarmIcon = document.createElement("span");
alarmIcon.className = "badge badge-important";
alarmIcon.innerHTML = alarmCount; //alarmCount为全局变量,且是通过ajax从后台获取到的
firstSpan.appendChild(alarmIcon);
}
if (result[i].children.length > 0){
var secondHref = [];
var secondMenu = [];
var secondIcon = [];
/*******添加b标签********/
var firstBLabel = document.createElement("b");
firstBLabel.className = "arrow icon-angle-down";
firstBLabel.style.color = "white";
firstALabel.appendChild(firstBLabel);
/********添加ul标签************/
var secondUl = document.createElement("ul");
secondUl.setAttribute("class", "submenu");
firstLi.appendChild(secondUl);
for (var j = 0; j < result[i].children.length; j++){
secondHref[j] = result[i].children[j].url;
secondMenu[j] = result[i].children[j].name;
secondIcon[j] = result[i].children[j].iconCls;
/******添加li标签*******/
var secondLi = document.createElement("li");
secondLi.style.background = "#CCEBF8";
secondUl.appendChild(secondLi);
/*******添加a标签*******/
var secondALabel = document.createElement("a");
secondALabel.setAttribute("href", secondHref[j]);
secondALabel.setAttribute("target", "content");
//secondALabel.style.background = "#CCEBF8";
secondLi.appendChild(secondALabel);
/*******添加i标签**********/
var secondILabel = document.createElement("i");
secondILabel.setAttribute("class", "icon-double-angle-right");
secondALabel.appendChild(secondILabel);
/******添加二级导航信息********/
secondALabel.innerHTML = secondMenu[j];
secondALabel.style.fontSize = "15px";
//secondALabel.style.marginLeft = "60px";
}
}
}
}
},
error: function() {
alert("加载菜单失败");
}
});
})
静态生成菜单树的代码:
生成菜单树的效果:
以上使用js将ajax获取的后台数据动态加载到网页中的方法就是编辑器共享的全部内容。
c 抓取网页数据(SEO百科网的是《分别是什么-什么是搜索引擎》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-26 02:04
网络爬虫是SEO人员应该学习的基础知识之一。了解和理解网络爬虫将有助于更好地优化网站。今天,SEO百科带来了《网络爬虫的分类和策略——什么是搜索引擎》。我希望能有所帮助。
一、什么是网络爬虫?
网络爬虫是指按照一定的规则自动爬取互联网上的信息的程序组件或脚本程序。在搜索引擎中,网络爬虫是搜索引擎查找和爬取文档的自动化程序。
二、网络爬虫生成的后台
随着互联网信息的爆炸式增长,人们已经不满足于仅仅依靠打开目录等传统方式在互联网上找东西。为了满足不同人群的不同需求,网络爬虫出现了。
三、网络爬虫面临的问题
上一篇文章《搜索引擎的基本架构》中提到,搜索引擎架构的两个目标是有效性和效率,这也是对网络爬虫的要求。面对数以亿计的页面,重复内容非常高,在SEO行业重复率可能超过50%。网络爬虫面临的问题是提高效率。
为了达到最好的效果,需要在一定的时间内获取更多的优质页面,丢弃那些原创度低、重复内容、拼接内容的页面。
PS:当然是大网站中发布的文章,尤其是大站效果,虽然不是首发站,但排名还是很不错的,甚至比首发站排名还要好。
四、网络爬虫的分类与策略
有许多类型的网络爬虫。错误君简单介绍了以下几种:
1)万能网络爬虫
万能网络爬虫,又称“全网爬虫”,从一些种子网站开始爬取,逐步扩展到整个互联网。
常见的网络爬虫策略:深度优先策略和广度优先策略。
2)专注于网络爬虫
聚焦网络爬虫,也称为“主题网络爬虫”,预先选择一个(或几个)相关主题,只抓取和抓取该类别的相关页面。
聚焦网络爬虫策略:聚焦网络爬虫增加了链接和内容评估模块,所以其爬取策略的关键是在爬取之前对页面的链接和内容进行评估。
3)增量网络爬虫
增量网络爬取是指更新已经收录的页面,爬取新的页面和发生变化的页面。
增量网络爬虫策略:广度优先策略和PageRank优先策略等。
4)深度网络爬虫
搜索引擎蜘蛛可以抓取和抓取的页面称为“表面网页”,而一些无法通过静态链接获取的页面称为“深层网页”。Deep Web爬虫是爬取深层网页的爬虫系统。
总结:一般来说,网络爬虫的爬取策略分为三种:
一个。广度优先
搜索完当前页面的所有链接后,开始进入下一级。
湾。最高优先级
根据某些网页分析算法,如链接算法、页面权重算法等,优先抓取有价值的页面。
C。深度优先
沿着一个链接爬行,直到一个页面没有更多链接,然后开始爬行另一个。不过一般是从种子网站爬取的。如果采用这种形式,爬取的页面质量可能会越来越低,所以这种策略很少使用。
以上就是SEO百科带给《网络爬虫的分类和策略有哪些——什么是搜索引擎》。感谢收看。更多 seo 教程搜索“错误教程网”。原创文章欢迎转载,保留版权: 查看全部
c 抓取网页数据(SEO百科网的是《分别是什么-什么是搜索引擎》)
网络爬虫是SEO人员应该学习的基础知识之一。了解和理解网络爬虫将有助于更好地优化网站。今天,SEO百科带来了《网络爬虫的分类和策略——什么是搜索引擎》。我希望能有所帮助。
一、什么是网络爬虫?
网络爬虫是指按照一定的规则自动爬取互联网上的信息的程序组件或脚本程序。在搜索引擎中,网络爬虫是搜索引擎查找和爬取文档的自动化程序。
二、网络爬虫生成的后台
随着互联网信息的爆炸式增长,人们已经不满足于仅仅依靠打开目录等传统方式在互联网上找东西。为了满足不同人群的不同需求,网络爬虫出现了。
三、网络爬虫面临的问题
上一篇文章《搜索引擎的基本架构》中提到,搜索引擎架构的两个目标是有效性和效率,这也是对网络爬虫的要求。面对数以亿计的页面,重复内容非常高,在SEO行业重复率可能超过50%。网络爬虫面临的问题是提高效率。
为了达到最好的效果,需要在一定的时间内获取更多的优质页面,丢弃那些原创度低、重复内容、拼接内容的页面。
PS:当然是大网站中发布的文章,尤其是大站效果,虽然不是首发站,但排名还是很不错的,甚至比首发站排名还要好。
四、网络爬虫的分类与策略
有许多类型的网络爬虫。错误君简单介绍了以下几种:
1)万能网络爬虫
万能网络爬虫,又称“全网爬虫”,从一些种子网站开始爬取,逐步扩展到整个互联网。
常见的网络爬虫策略:深度优先策略和广度优先策略。
2)专注于网络爬虫
聚焦网络爬虫,也称为“主题网络爬虫”,预先选择一个(或几个)相关主题,只抓取和抓取该类别的相关页面。
聚焦网络爬虫策略:聚焦网络爬虫增加了链接和内容评估模块,所以其爬取策略的关键是在爬取之前对页面的链接和内容进行评估。
3)增量网络爬虫
增量网络爬取是指更新已经收录的页面,爬取新的页面和发生变化的页面。
增量网络爬虫策略:广度优先策略和PageRank优先策略等。
4)深度网络爬虫
搜索引擎蜘蛛可以抓取和抓取的页面称为“表面网页”,而一些无法通过静态链接获取的页面称为“深层网页”。Deep Web爬虫是爬取深层网页的爬虫系统。
总结:一般来说,网络爬虫的爬取策略分为三种:
一个。广度优先
搜索完当前页面的所有链接后,开始进入下一级。
湾。最高优先级
根据某些网页分析算法,如链接算法、页面权重算法等,优先抓取有价值的页面。
C。深度优先
沿着一个链接爬行,直到一个页面没有更多链接,然后开始爬行另一个。不过一般是从种子网站爬取的。如果采用这种形式,爬取的页面质量可能会越来越低,所以这种策略很少使用。
以上就是SEO百科带给《网络爬虫的分类和策略有哪些——什么是搜索引擎》。感谢收看。更多 seo 教程搜索“错误教程网”。原创文章欢迎转载,保留版权:
c 抓取网页数据(一个典型的新闻网页包括几个不同区域:如何写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-25 14:16
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式也会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列出了一些具有不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是根据老猿猴多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
和新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在某个标签的class和id中的关键词,这些词表示该标签可能是也可能不是正文。我们使用这些词来计算标签节点的权重,这就是方法 calc_node_weight() 所做的。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,可以直接忽略。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取标签的内容,然后尝试从中找到标题,然后尝试找到 id 和 class 收录标题的节点,最后比较从不同地方获得的可能是标题的文本,并最终获得称号。比较的原则是:
从标签中获取标题,需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成一棵树,从body节点开始遍历每个节点,查看它直接收录的文本长度(不包括子节点),找出收录最长文本节点的文本的长度。这个过程在方法中实现:get_main_block()。一些细节可以让小猿们体验到。
其中一个细节是 clean_node() 函数。通过 get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去掉,会给新闻内容(相关新闻的标题、概述等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用 text_content() ,而是进行一些格式化处理,例如在某些标签后添加换行符以匹配 \n,以及在表格单元格之间添加空格。这样处理后,得到的文本格式更符合原网页的效果。
爬虫知识点
1. cchardet 模块
一个快速判断文本编码的模块
2. lxml.html 模块
一个结构化html代码的模块,一个通过xpath解析网页的工具,高效易用,在家写爬虫必备模块。
3. 内容提取的复杂性
我们这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
但是,没有一种万能的网页,也没有万能的提取算法。在大规模使用本文算法的过程中,会遇到奇怪的网页。这时候就需要针对这些网页改进这个算法类。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。 查看全部
c 抓取网页数据(一个典型的新闻网页包括几个不同区域:如何写爬虫)
我们之前实现的新闻爬虫,运行后可以快速爬取大量新闻网页。网页的所有html代码都存储在数据库中,这不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、title、发布时间、body内容、来源网站等。
所以爬虫不仅要做好下载的工作,还要做好数据的清洗和提取工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面由几个不同的区域组成:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的新闻页面,提取这三个内容非常简单,写三个正则表达式就可以完美提取。但是,我们的爬虫会爬取数百个 网站 页面。为这么多不同格式的网页写正则表达式会很累,一旦网页稍作修改,表达式可能会失效,维护这些表达式也会很累。
当然,累死人的做法是想不通的,我们要探索一个好的算法来实现。
1. 标题提取
标题基本出现在html标签中,只是附加了频道名称、网站名称等信息;
标题也出现在网页的“标题区域”中。
那么在这两个地方,哪里更容易提取title呢?
网页的“header area”没有明确标识,不同网站的“header area”的html代码部分差异很大。所以这个区域不容易提取。
然后就只剩下标签了。这个标签很容易提取,不管是正则表达式还是lxml解析。不容易的是如何去除频道名称、网站名称等信息。
我们先来看看,标签中的附加信息是长什么样子的:
观察这些标题不难发现,新闻标题与频道名称和网站名称之间存在一些联系符号。然后我可以通过这些连接器拆分标题,发现最长的部分是新闻标题。
这个想法也很容易实现,所以这里就不写代码了,留给小猿作为思考练习自己实现吧。
2. 发布时间提取
发布时间是指页面在网站上启动的时间。一般会出现在文本标题下方——元数据区。从html代码来看,这个区域并没有什么特别的特征可供我们定位,尤其是面对大量的网站布局,几乎不可能定位到这个区域。这需要我们采取不同的方法。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间有一个共同的特点,就是一个字符串代表时间,年、月、日、时、分、秒,无非就是这些元素。通过正则表达式,我们列出了一些具有不同时间表达式的正则表达式(只是几个),然后我们可以通过匹配从网页文本中提取发布时间。
这也是一个容易实现的想法,但是细节很多,表达方式要尽可能多的涵盖。编写这样一个函数来提取发布时间并不是那么容易。小猿们充分发挥动手能力,看看能写出什么样的函数实现。这也是对小猿猴的一种锻炼。
3. 提取文本
文字(包括新闻图片)是新闻网页的主要部分。它在视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法很多,实现复杂简单。本文介绍的方法是根据老猿猴多年的实践经验和思考的一种简单快速的方法,称为“节点文本密度法”。
我们知道,网页的HTML代码是由不同的标签(tags)组成的,形成一棵树状的结构树,每个标签都是树的一个节点。通过遍历这个树形结构的每个节点,找到文本最多的节点,也就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
和新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在某个标签的class和id中的关键词,这些词表示该标签可能是也可能不是正文。我们使用这些词来计算标签节点的权重,这就是方法 calc_node_weight() 所做的。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,可以直接忽略。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取标签的内容,然后尝试从中找到标题,然后尝试找到 id 和 class 收录标题的节点,最后比较从不同地方获得的可能是标题的文本,并最终获得称号。比较的原则是:
从标签中获取标题,需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成一棵树,从body节点开始遍历每个节点,查看它直接收录的文本长度(不包括子节点),找出收录最长文本节点的文本的长度。这个过程在方法中实现:get_main_block()。一些细节可以让小猿们体验到。
其中一个细节是 clean_node() 函数。通过 get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去掉,会给新闻内容(相关新闻的标题、概述等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用 text_content() ,而是进行一些格式化处理,例如在某些标签后添加换行符以匹配 \n,以及在表格单元格之间添加空格。这样处理后,得到的文本格式更符合原网页的效果。
爬虫知识点
1. cchardet 模块
一个快速判断文本编码的模块
2. lxml.html 模块
一个结构化html代码的模块,一个通过xpath解析网页的工具,高效易用,在家写爬虫必备模块。
3. 内容提取的复杂性
我们这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
但是,没有一种万能的网页,也没有万能的提取算法。在大规模使用本文算法的过程中,会遇到奇怪的网页。这时候就需要针对这些网页改进这个算法类。
来自“ITPUB博客”,链接:如需转载,请注明出处,否则追究法律责任。
c 抓取网页数据(网页加载到WebBrowser控件中的问题及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-24 09:14
[答案1]:
只是一个想法,但有一种方法可以让 .net 像在浏览器中一样加载网页:使用 System.Windows.Forms
您可以将网页加载到 WebBrowser 控件中
WebBrowser wb = new WebBrowser();
wb.ScrollBarsEnabled = false;
wb.ScriptErrorsSuppressed = true;
wb.Navigate(url);
while (wb.ReadyState != WebBrowserReadyState.Complete) { Application.DoEvents(); }
wb.Document.DomDocument.ToString()
这可能会给你 pre ajax DOM,但也许有办法让它首先运行 ajax。
【问题讨论】:
[答案2]:
如果我正确地解释了您的问题,那么您的问题就没有简单的解决方案。
您正在从服务器获取 HTML,并且由于您的 C# 代码不是真正的 Web 浏览器,因此它不会执行客户端脚本。
这样您就无法访问您获得的 HTML 不收录的信息。
编辑:我不知道这些 AJAX 调用与原创 网站 相比有多复杂,但您可以使用 Firebug 或 Fiddler for IE 查看请求是如何发出的,以便在您的 C# 应用程序中调用这些 AJAX 调用好。因此,您可以添加所需的信息。但这只是理论上的解决方案。
【问题讨论】:
【答案3】:
当您在网络浏览器中打开网页时,浏览器会执行 javascript 并下载该页面使用的其他资源(图像、脚本等)。HttpWebRequest 本身不做任何事情,它只是下载您请求的页面的 html。它从不自己执行任何 javascript/ajax 代码。
【问题讨论】:
[答案4]:
使用 HttpWebRequest 下载页面,以编程方式搜索相关 ajax 信息的源代码,然后使用新的 HttpWebRequest 将数据拉下来。
【问题讨论】:
[答案5]:
HttpWebRequest 不模拟网络浏览器,它只是下载您指向它的资源。这意味着它不会执行甚至下载 JavaScript 文件。
您必须使用 FireBug 之类的东西来获取通过 JavaScript 提取的数据的 URL,并将您的 HttpWebRequest 指向该 URL。
【问题讨论】:
[答案6]:
使用 HttpWebRequest 下载页面。在源代码中搜索相关的 AJAX 信息,然后使用新的 HttpWebRequest 提取该数据。
【问题讨论】:
【答案7】:
您可以使用 PhantomJs。我有这个问题,但没有找到解决我的问题的方法。在我看来,最好的解决方案是This。
我的解决方案是这样的:
var page = require('webpage').create();
page.open("https://sample.com", function(){
page.evaluate(function(){
var i = 0,
oJson = jsonData,
sKey;
localStorage.clear();
for (; sKey = Object.keys(oJson)[i]; i++) {
localStorage.setItem(sKey,oJson[sKey])
}
});
page.open("https://sample.com", function(){
setTimeout(function(){
page.render("screenshoot.png")
// Where you want to save it
console.log(page.content); //page source
// You can access its content using jQuery
var fbcomments = page.evaluate(function(){
return $("body").contents().find(".content")
})
phantom.exit();
},10000)
});
});
【问题讨论】: 查看全部
c 抓取网页数据(网页加载到WebBrowser控件中的问题及解决办法(一))
[答案1]:
只是一个想法,但有一种方法可以让 .net 像在浏览器中一样加载网页:使用 System.Windows.Forms
您可以将网页加载到 WebBrowser 控件中
WebBrowser wb = new WebBrowser();
wb.ScrollBarsEnabled = false;
wb.ScriptErrorsSuppressed = true;
wb.Navigate(url);
while (wb.ReadyState != WebBrowserReadyState.Complete) { Application.DoEvents(); }
wb.Document.DomDocument.ToString()
这可能会给你 pre ajax DOM,但也许有办法让它首先运行 ajax。
【问题讨论】:
[答案2]:
如果我正确地解释了您的问题,那么您的问题就没有简单的解决方案。
您正在从服务器获取 HTML,并且由于您的 C# 代码不是真正的 Web 浏览器,因此它不会执行客户端脚本。
这样您就无法访问您获得的 HTML 不收录的信息。
编辑:我不知道这些 AJAX 调用与原创 网站 相比有多复杂,但您可以使用 Firebug 或 Fiddler for IE 查看请求是如何发出的,以便在您的 C# 应用程序中调用这些 AJAX 调用好。因此,您可以添加所需的信息。但这只是理论上的解决方案。
【问题讨论】:
【答案3】:
当您在网络浏览器中打开网页时,浏览器会执行 javascript 并下载该页面使用的其他资源(图像、脚本等)。HttpWebRequest 本身不做任何事情,它只是下载您请求的页面的 html。它从不自己执行任何 javascript/ajax 代码。
【问题讨论】:
[答案4]:
使用 HttpWebRequest 下载页面,以编程方式搜索相关 ajax 信息的源代码,然后使用新的 HttpWebRequest 将数据拉下来。
【问题讨论】:
[答案5]:
HttpWebRequest 不模拟网络浏览器,它只是下载您指向它的资源。这意味着它不会执行甚至下载 JavaScript 文件。
您必须使用 FireBug 之类的东西来获取通过 JavaScript 提取的数据的 URL,并将您的 HttpWebRequest 指向该 URL。
【问题讨论】:
[答案6]:
使用 HttpWebRequest 下载页面。在源代码中搜索相关的 AJAX 信息,然后使用新的 HttpWebRequest 提取该数据。
【问题讨论】:
【答案7】:
您可以使用 PhantomJs。我有这个问题,但没有找到解决我的问题的方法。在我看来,最好的解决方案是This。
我的解决方案是这样的:
var page = require('webpage').create();
page.open("https://sample.com", function(){
page.evaluate(function(){
var i = 0,
oJson = jsonData,
sKey;
localStorage.clear();
for (; sKey = Object.keys(oJson)[i]; i++) {
localStorage.setItem(sKey,oJson[sKey])
}
});
page.open("https://sample.com", function(){
setTimeout(function(){
page.render("screenshoot.png")
// Where you want to save it
console.log(page.content); //page source
// You can access its content using jQuery
var fbcomments = page.evaluate(function(){
return $("body").contents().find(".content")
})
phantom.exit();
},10000)
});
});
【问题讨论】:
c 抓取网页数据(Python学习资料的小伙伴吗?整理Python资料和PDF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-23 22:14
我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的。因为我目前对python不熟悉,所以不知道为什么。百度搜索结果
有需要Python学习资料的朋友吗?小编整理了一套Python资料和PDF。有兴趣的可以关注小编,给学习资料发私信(关注后为私信)。无论如何,如果你闲着,你就是闲着。为什么不学点东西?
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
我冲到最后一句“人生苦短,你需要python”,立马在当当买了一本python书!之前一直崇拜python大牛,一直因为各种借口想学,一直没有下手。.
py 在 linux 上非常强大,语言也很简单。 查看全部
c 抓取网页数据(Python学习资料的小伙伴吗?整理Python资料和PDF)
我用 c# 和 java 编写了爬虫。差别不大,原则是用好正则表达式。只是平台问题。后来才知道很多爬虫都是用python写的。因为我目前对python不熟悉,所以不知道为什么。百度搜索结果
有需要Python学习资料的朋友吗?小编整理了一套Python资料和PDF。有兴趣的可以关注小编,给学习资料发私信(关注后为私信)。无论如何,如果你闲着,你就是闲着。为什么不学点东西?
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
我冲到最后一句“人生苦短,你需要python”,立马在当当买了一本python书!之前一直崇拜python大牛,一直因为各种借口想学,一直没有下手。.
py 在 linux 上非常强大,语言也很简单。
c 抓取网页数据(自动获取“悟空问答”站点的问题标题和地址信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-23 22:12
)
亲爱的朋友们您好,欢迎来到《使用CefSharp和Javascript实现网络爬虫》。
最近学习使用CefSharp和Javascript实现一个网络爬虫,自动获取“悟空问答”网站的题名和地址信息,实现了“哔哩哔哩”直播网站自定义弹幕自动回复,以及制作了两个通过自动化程序提高效率的工具小工具。我准备记录下具体的实现过程,分享给感兴趣的朋友。
网络爬虫是根据一定的规则自动爬取互联网上的网站页面信息的程序或脚本。提到网络爬虫,首先想到的就是用Python实现,既高效又方便。不过对于不熟悉Python,但熟悉C#或Javascript的朋友,可以尝试使用CefSharp和Javascript来实现网络爬虫。此外,由CefSharp和Javascript组成的工具软件具有安装、发布方便、界面友好等优点。如果还添加了不想公开的代码逻辑,可以使用C#语言编译保护。
首先,让我们简要了解一下 CefSharp 和 Javascript。CefSharp可以简单理解为基于谷歌Chrome-ChromiumEmbeddedFramework(CEF)开源版本的浏览器控件。CefSharp 浏览器控件丰富而强大。因为基于 CEF,CefSharp 支持 Webkit & Chrome 中实现的 HTML5 功能,性能接近 Chrome。CefSharp 是在 C# 应用程序中嵌入浏览器的最佳选择。它支持 WinForms 和 WPF 应用程序。英语好的朋友可以访问:网址进行深入学习。
Javascript 是一种广泛使用的 Web 前端编程语言。使用 CefSharp 和 Javascript 实现网络爬虫需要使用 Javascript 进行 DOM 操作。DOM(Document Object Model,文档对象模型)是一种操作XML和HTML文档的常用方法。JavaScript 可以通过 DOM 接口操作每个 HTML 节点。在下一篇文章中,我将介绍使用 CefSharp 和 Javascript 实现网络爬虫的过程中会用到的 C# 和 Javascript 的主要知识。
查看全部
c 抓取网页数据(自动获取“悟空问答”站点的问题标题和地址信息
)
亲爱的朋友们您好,欢迎来到《使用CefSharp和Javascript实现网络爬虫》。
最近学习使用CefSharp和Javascript实现一个网络爬虫,自动获取“悟空问答”网站的题名和地址信息,实现了“哔哩哔哩”直播网站自定义弹幕自动回复,以及制作了两个通过自动化程序提高效率的工具小工具。我准备记录下具体的实现过程,分享给感兴趣的朋友。
网络爬虫是根据一定的规则自动爬取互联网上的网站页面信息的程序或脚本。提到网络爬虫,首先想到的就是用Python实现,既高效又方便。不过对于不熟悉Python,但熟悉C#或Javascript的朋友,可以尝试使用CefSharp和Javascript来实现网络爬虫。此外,由CefSharp和Javascript组成的工具软件具有安装、发布方便、界面友好等优点。如果还添加了不想公开的代码逻辑,可以使用C#语言编译保护。
首先,让我们简要了解一下 CefSharp 和 Javascript。CefSharp可以简单理解为基于谷歌Chrome-ChromiumEmbeddedFramework(CEF)开源版本的浏览器控件。CefSharp 浏览器控件丰富而强大。因为基于 CEF,CefSharp 支持 Webkit & Chrome 中实现的 HTML5 功能,性能接近 Chrome。CefSharp 是在 C# 应用程序中嵌入浏览器的最佳选择。它支持 WinForms 和 WPF 应用程序。英语好的朋友可以访问:网址进行深入学习。
Javascript 是一种广泛使用的 Web 前端编程语言。使用 CefSharp 和 Javascript 实现网络爬虫需要使用 Javascript 进行 DOM 操作。DOM(Document Object Model,文档对象模型)是一种操作XML和HTML文档的常用方法。JavaScript 可以通过 DOM 接口操作每个 HTML 节点。在下一篇文章中,我将介绍使用 CefSharp 和 Javascript 实现网络爬虫的过程中会用到的 C# 和 Javascript 的主要知识。
c 抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-01-23 22:11
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。
当一个网站有很多URL时,一定要设计好URL,否则在后面的理解、维护或开发过程中会很混乱。了解了上面的网页结构设计之后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以类比爬取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,然后从中提取两个链接B和C。链接B被爬取后,下一个要爬取的链接是D或E,而不是爬取。获取链接B后,立即去获取链接C。爬取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 完全爬取完成后,接下来会爬取链接 E。链接E爬取完成后,不再爬取链接C,而是继续深度爬取链接I。原理是链接会一步步往下爬,只要链接下有子链接,而子链接还没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫在爬取完成后一步一步往下走,然后一步一步往后退,优先考虑深度。了解了深度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、D、E、I、C、F、G、H(这里, 左边的链接假定会先被爬取)。事实上,在网络爬虫的过程中,我们多次使用这个算法来实现。其实我们常用的 Scrapy 爬虫框架也是默认用这个算法实现的。通过以上了解,
下图是深度优先算法的代码实现过程。
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先的过程,然后传入node参数。如果节点不为空,则打印出来,可以对比二叉树的顶层点A。打印完节点后,查看是否有左节点(链接B)和右节点(链接C),如果左节点不为空,则返回,再次调用深度优先函数本身进行递归,得到一个新的左节点(链接D)和右节点(链接E),等等,直到遍历所有节点或达到给定条件才会停止。右节点的实现过程也是一样的,这里不再赘述。
深度优先过程是通过递归实现的。当递归继续而没有跳出递归或者递归太深时,很容易造成栈溢出,所以在实际应用过程中需要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以建议大家需要掌握. 下一篇文章我们将介绍广度优先算法,敬请期待。
以上就是网络爬虫中深度优先算法的简单介绍。你们明白了吗? 查看全部
c 抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍)
学过网站设计的都知道网站通常是分层设计的。最上层是顶级域名,其次是子域名,然后是子域名下的子域名,以此类推。同时,每个子域也可能有多个同级域名,URL之间可能存在链接,形成一个复杂的网络。
当一个网站有很多URL时,一定要设计好URL,否则在后面的理解、维护或开发过程中会很混乱。了解了上面的网页结构设计之后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以类比爬取网页,加深对爬虫策略的理解。深度优先算法的主要思想是首先从顶级域名A开始,然后从中提取两个链接B和C。链接B被爬取后,下一个要爬取的链接是D或E,而不是爬取。获取链接B后,立即去获取链接C。爬取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 完全爬取完成后,接下来会爬取链接 E。链接E爬取完成后,不再爬取链接C,而是继续深度爬取链接I。原理是链接会一步步往下爬,只要链接下有子链接,而子链接还没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫在爬取完成后一步一步往下走,然后一步一步往后退,优先考虑深度。了解了深度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、D、E、I、C、F、G、H(这里, 左边的链接假定会先被爬取)。事实上,在网络爬虫的过程中,我们多次使用这个算法来实现。其实我们常用的 Scrapy 爬虫框架也是默认用这个算法实现的。通过以上了解,
下图是深度优先算法的代码实现过程。
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先的过程,然后传入node参数。如果节点不为空,则打印出来,可以对比二叉树的顶层点A。打印完节点后,查看是否有左节点(链接B)和右节点(链接C),如果左节点不为空,则返回,再次调用深度优先函数本身进行递归,得到一个新的左节点(链接D)和右节点(链接E),等等,直到遍历所有节点或达到给定条件才会停止。右节点的实现过程也是一样的,这里不再赘述。
深度优先过程是通过递归实现的。当递归继续而没有跳出递归或者递归太深时,很容易造成栈溢出,所以在实际应用过程中需要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以建议大家需要掌握. 下一篇文章我们将介绍广度优先算法,敬请期待。
以上就是网络爬虫中深度优先算法的简单介绍。你们明白了吗?
c 抓取网页数据(2016年10月12日影刀强烈推荐这款)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-23 15:19
目前国内外比较流行的RPA产品在国内有影刀、Uibot、鸿基、阿里云RPA,国外有UiPath和Blue Prism。我主要展示国货。原因很简单。国货更符合国货业务,更适合大家的操作习惯。重点介绍以下两款产品:
一、影刀
强烈推荐该产品,原因如下:
1、拖放操作,方便快捷
2、以人为的思维顺序执行任务的命令式过程
3、0码,没有编程经验的朋友可以玩得开心
4、支持python开发,可以很好的与其他办公自动化功能集成
二、Uibot
它也是一款出色的产品,具有以下特点:
1、通过流程图的方式构建流程
2、支持C、C#等其他语言
本产品比较适合一些开发伙伴。比如我是做C#开发的,以后会有Uibot的实际操作。
总之,目前市面上的RPA产品已经非常成熟和强大,小伙伴可以选择适合自己情况的产品。这些产品只是我们的工具,更重要的是业务发展的思维。
所以让我们继续讨论这个话题。数据爬取不再是一个陌生的概念。无论是程序还是一些工具,都可以帮助我们获取公共数据。当然,RPA可以做到,也可以做得更方便。让我们来看看。
注意:在执行任务之前,一定要准备好工具、目标和流程
使用工具:暗影刀 RPA
目标:抓取老板直聘中RPA的工作清单数据网站
流程图:
第一步:打开网页
第 2 步:输入关键字
填写输入框(web):我们需要告诉工具输入框在哪里,所以我们需要捕获输入框
第三部分:点击搜索
点击元素(web):我们需要告诉工具搜索按钮在哪里,所以我们需要捕获搜索按钮
第 4 步:显示结果
注意:这里使用等待两秒显示数据,这是保证流程顺利执行的保证条件之一。未来会有更深入的解释,使用各种方法来提高过程的鲁棒性。
第 5 步:数据捕获
这里我们需要抓取相似的元素来确定数据规则,比如职位:RPA开发工程师,它位于网页列表中的固定位置,我们只需要抓取两个不同的职位,告诉工具我们想要获取有关此元素的信息。
注意:必须是类似的元素,比如上图中的“RPA开发工程师”和“RPA开发负责人”,这样我们才能抓取页面上的所有职位信息,如下图:
当然,我们也可以抓取其他元素,只要添加一个新列,然后抓取两次元素,记住,一定是两个不同但相似的元素。
这样,我们通过5个步骤抓取了网页的数据。我这里写的比较详细,其实不到一分钟就写完了。 查看全部
c 抓取网页数据(2016年10月12日影刀强烈推荐这款)
目前国内外比较流行的RPA产品在国内有影刀、Uibot、鸿基、阿里云RPA,国外有UiPath和Blue Prism。我主要展示国货。原因很简单。国货更符合国货业务,更适合大家的操作习惯。重点介绍以下两款产品:
一、影刀
强烈推荐该产品,原因如下:
1、拖放操作,方便快捷
2、以人为的思维顺序执行任务的命令式过程
3、0码,没有编程经验的朋友可以玩得开心
4、支持python开发,可以很好的与其他办公自动化功能集成
二、Uibot
它也是一款出色的产品,具有以下特点:
1、通过流程图的方式构建流程
2、支持C、C#等其他语言
本产品比较适合一些开发伙伴。比如我是做C#开发的,以后会有Uibot的实际操作。
总之,目前市面上的RPA产品已经非常成熟和强大,小伙伴可以选择适合自己情况的产品。这些产品只是我们的工具,更重要的是业务发展的思维。
所以让我们继续讨论这个话题。数据爬取不再是一个陌生的概念。无论是程序还是一些工具,都可以帮助我们获取公共数据。当然,RPA可以做到,也可以做得更方便。让我们来看看。
注意:在执行任务之前,一定要准备好工具、目标和流程
使用工具:暗影刀 RPA
目标:抓取老板直聘中RPA的工作清单数据网站
流程图:
第一步:打开网页
第 2 步:输入关键字
填写输入框(web):我们需要告诉工具输入框在哪里,所以我们需要捕获输入框
第三部分:点击搜索
点击元素(web):我们需要告诉工具搜索按钮在哪里,所以我们需要捕获搜索按钮
第 4 步:显示结果
注意:这里使用等待两秒显示数据,这是保证流程顺利执行的保证条件之一。未来会有更深入的解释,使用各种方法来提高过程的鲁棒性。
第 5 步:数据捕获
这里我们需要抓取相似的元素来确定数据规则,比如职位:RPA开发工程师,它位于网页列表中的固定位置,我们只需要抓取两个不同的职位,告诉工具我们想要获取有关此元素的信息。
注意:必须是类似的元素,比如上图中的“RPA开发工程师”和“RPA开发负责人”,这样我们才能抓取页面上的所有职位信息,如下图:
当然,我们也可以抓取其他元素,只要添加一个新列,然后抓取两次元素,记住,一定是两个不同但相似的元素。
这样,我们通过5个步骤抓取了网页的数据。我这里写的比较详细,其实不到一分钟就写完了。
c 抓取网页数据(问题:在使用正在表达式来定位tags的时候,能不能使用多条件的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-22 23:01
)
问题:使用表达式定位标签时可以使用多个条件吗?
答案是肯定的,而且使用起来非常方便,会大大提高工作效率。
举例:我现在要爬去寺库的包袋的网页链接数据,网址:http://list.secoo.com/bags/30- ... Title
代码如下:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'))
for i in new_url_list:
print(i)
print(len(new_url_list))
我们在这里使用
new_url_list = soup.find_all('a',href=pile('source=list')),通过正则识别出有的href中有属性,有的收录'source=list'
定位标签,结果如下
一共爬取了108行,其中我们想要的真实数据是40行。
我们发现id中收录name的数据就是我们想要的数据。那么这里可以添加一个简单的正则表达式来准确定位,
如下:
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
代码:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
for i in new_url_list:
print(i)
print(len(new_url_list))
结果如下:
40 个网络链接,我们所需要的。
知识点:
find_all()方法搜索当前标签的所有标签子节点,判断是否满足过滤条件
html = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""</p>
①名称参数
name参数可以找到所有名为name的标签,字符串对象会被自动忽略
A.Pass 字符串
#传入字符串查找p标签
print(soup.find_all('b'))
#运行结果:[The Dormouse's story]
B.传递正则表达式
如果传入正则表达式作为参数,Beautiful Soup 会通过正则表达式 match() 匹配内容。下面的例子查找所有以b开头的标签,这意味着标签和标签都应该找到
import re
for tag in soup.find_all(re.compile('^b')):
print(tag.name)
#运行结果:
# body
# b
C.上传列表
content = soup.find_all(["a","b"])
print(content)
"""
#运行结果:
[The Dormouse's story, , Lacie, Tillie]
"""
D.通过真
True 可以匹配任意值,以下代码查找所有标签,但不返回字符串节点
E.传输方式
如果没有合适的过滤器,也可以定义一个方法,该方法只接受一个元素参数[4]如果该方法返回True,则表示当前元素匹配并找到,否则返回False
以下方法验证当前元素,如果它收录类属性但不收录 id 属性,则返回 True:
#定义函数,Tag的属性只有id
def has_id(tag):
return tag.has_attr('id')
content = soup.find_all(has_id)
print(content)
"""
运行结果:
[, Lacie, Tillie]
"""
②关键字参数
注意:如果指定名称的参数不是用于搜索的内置参数名称,则该参数将作为指定名称标签的属性进行搜索。如果收录名称为 id 的参数,Beautiful Soup 会搜索每个标签的“id”属性
print(soup.find_all(id="link3"))
# 运行结果:[Tillie]
如果传递了href参数,Beautiful Soup会搜索每个标签的“href”属性
import re
print(soup.find_all(href=re.compile("lacie")))
# 运行结果:[Lacie]
使用多个指定名称的参数同时过滤一个标签的多个属性
import re
print(soup.find_all(href=re.compile("lacie"),id="link2"))
# 运行结果:[Lacie]
使用class过滤时,class不是python的关键字,加下划线即可
print(soup.find_all("a",class_="sister"))
# 运行结果:[, Lacie, Tillie]
③文本参数
文本参数可用于搜索文档中的字符串内容。和name参数的可选值一样,text参数接受string、regular expression、list、True
#传入字符串
print(soup.find_all(text="Lacie"))
# 运行结果:['Lacie']
#传入列表
print(soup.find_all(text=["Lacie","Tillie"]))
# 运行结果:['Lacie', 'Tillie']
#传入正则表达式
import re
print(soup.find_all(text=re.compile("Dormouse")))
# 运行结果:["The Dormouse's story", "The Dormouse's story"]
④限制参数
find_all()参数在查询量大的时候可能会比较慢,所以我们引入了limit函数,可以限制返回的结果
print(soup.find_all("a"))
"""
运行结果:
[, Lacie, Tillie]
"""
print(soup.find_all("a",limit=2))
"""
运行结果:
[, Lacie]
"""
⑤recursive参数
recursive翻译为递归循环的意思
当调用标签的find_all()方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
print(soup.html.find_all("title"))
# 运行结果:[The Dormouse's story]
print(soup.html.find_all("title",recursive=False))
# 运行结果:[] 查看全部
c 抓取网页数据(问题:在使用正在表达式来定位tags的时候,能不能使用多条件的?
)
问题:使用表达式定位标签时可以使用多个条件吗?
答案是肯定的,而且使用起来非常方便,会大大提高工作效率。
举例:我现在要爬去寺库的包袋的网页链接数据,网址:http://list.secoo.com/bags/30- ... Title
代码如下:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'))
for i in new_url_list:
print(i)
print(len(new_url_list))
我们在这里使用
new_url_list = soup.find_all('a',href=pile('source=list')),通过正则识别出有的href中有属性,有的收录'source=list'
定位标签,结果如下
一共爬取了108行,其中我们想要的真实数据是40行。
我们发现id中收录name的数据就是我们想要的数据。那么这里可以添加一个简单的正则表达式来准确定位,
如下:
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
代码:
import requests
from bs4 import BeautifulSoup
import chardet
import re
import random
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36'
]
url = 'http://list.secoo.com/bags/30- ... 39%3B
random_user_agent = random.choice(USER_AGENTS)
headers = {
'user-agent': random_user_agent}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
text = response.text
soup = BeautifulSoup(text, 'lxml')
#print(soup)
new_url_list = soup.find_all('a',href=re.compile('source=list'), id=re.compile('name'))
for i in new_url_list:
print(i)
print(len(new_url_list))
结果如下:
40 个网络链接,我们所需要的。
知识点:
find_all()方法搜索当前标签的所有标签子节点,判断是否满足过滤条件
html = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""</p>
①名称参数
name参数可以找到所有名为name的标签,字符串对象会被自动忽略
A.Pass 字符串
#传入字符串查找p标签
print(soup.find_all('b'))
#运行结果:[The Dormouse's story]
B.传递正则表达式
如果传入正则表达式作为参数,Beautiful Soup 会通过正则表达式 match() 匹配内容。下面的例子查找所有以b开头的标签,这意味着标签和标签都应该找到
import re
for tag in soup.find_all(re.compile('^b')):
print(tag.name)
#运行结果:
# body
# b
C.上传列表
content = soup.find_all(["a","b"])
print(content)
"""
#运行结果:
[The Dormouse's story, , Lacie, Tillie]
"""
D.通过真
True 可以匹配任意值,以下代码查找所有标签,但不返回字符串节点
E.传输方式
如果没有合适的过滤器,也可以定义一个方法,该方法只接受一个元素参数[4]如果该方法返回True,则表示当前元素匹配并找到,否则返回False
以下方法验证当前元素,如果它收录类属性但不收录 id 属性,则返回 True:
#定义函数,Tag的属性只有id
def has_id(tag):
return tag.has_attr('id')
content = soup.find_all(has_id)
print(content)
"""
运行结果:
[, Lacie, Tillie]
"""
②关键字参数
注意:如果指定名称的参数不是用于搜索的内置参数名称,则该参数将作为指定名称标签的属性进行搜索。如果收录名称为 id 的参数,Beautiful Soup 会搜索每个标签的“id”属性
print(soup.find_all(id="link3"))
# 运行结果:[Tillie]
如果传递了href参数,Beautiful Soup会搜索每个标签的“href”属性
import re
print(soup.find_all(href=re.compile("lacie")))
# 运行结果:[Lacie]
使用多个指定名称的参数同时过滤一个标签的多个属性
import re
print(soup.find_all(href=re.compile("lacie"),id="link2"))
# 运行结果:[Lacie]
使用class过滤时,class不是python的关键字,加下划线即可
print(soup.find_all("a",class_="sister"))
# 运行结果:[, Lacie, Tillie]
③文本参数
文本参数可用于搜索文档中的字符串内容。和name参数的可选值一样,text参数接受string、regular expression、list、True
#传入字符串
print(soup.find_all(text="Lacie"))
# 运行结果:['Lacie']
#传入列表
print(soup.find_all(text=["Lacie","Tillie"]))
# 运行结果:['Lacie', 'Tillie']
#传入正则表达式
import re
print(soup.find_all(text=re.compile("Dormouse")))
# 运行结果:["The Dormouse's story", "The Dormouse's story"]
④限制参数
find_all()参数在查询量大的时候可能会比较慢,所以我们引入了limit函数,可以限制返回的结果
print(soup.find_all("a"))
"""
运行结果:
[, Lacie, Tillie]
"""
print(soup.find_all("a",limit=2))
"""
运行结果:
[, Lacie]
"""
⑤recursive参数
recursive翻译为递归循环的意思
当调用标签的find_all()方法时,Beautiful Soup 会检索当前标签的所有后代节点。如果只想搜索标签的直接子节点,可以使用参数 recursive=False 。
print(soup.html.find_all("title"))
# 运行结果:[The Dormouse's story]
print(soup.html.find_all("title",recursive=False))
# 运行结果:[]
c 抓取网页数据(c抓取网页数据是很基础的事情,python、ie6及ie8上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-22 01:05
c抓取网页数据是很基础的事情,不过一般来说,传统的网页抓取工具是可以直接支持响应式的设计的,比如把它作为扩展scrapy或python的爬虫框架使用,后端就是scrapy等。在python2中(一般是upython)支持各种浏览器的内置驱动接口,基本可以兼容任何浏览器,upython开发的其它爬虫框架,也可以跑在chrome、firefox、36。
0、ie6及ie8上。
1、前言最近有个问题,就是在基础浏览器抓取页面数据的时候,遇到一个很蛋疼的问题,就是采集的页面数据格式比较乱,很多数据都不是按html标签的方式来显示的,比如user-agent等。这样,一次抓取下来的数据可能包含大量的md5字符串。有的时候为了定位误差会很麻烦。
2、怎么解决这个问题很简单,就是用爬虫爬取网页标签。有的标签的抓取还是比较简单的,以bs为例,用ajax加载li标签,获取viewtag,通过viewtag就可以找到标签的内容。这样就达到了scrapy的双列采集规则,一个指向那个tag,一个指向另一个tag,在最后可以采集到整个页面的数据。当然,如果页面没有自定义标签,那么你还是要自己解析html标签,python没有这个库,那就手工解析标签。
那么python为什么没有scrapy支持这个标签呢?因为python没有user-agent这个标签,如果要写程序抓取这个标签,需要自己自定义这个标签,如果def包了,又会麻烦很多。
通过user-agent这个标签,就可以获取手动装满整个页面的标签表达式,以两列为例,就是包含meta元素的标签和没有meta元素的标签,每一列的标签名,比如bin标签,都是field标签,也是一行对应一个标签,每个标签有一个坐标,
1))转换,就得到下一行的坐标。就是这么简单。
3、那么,user-agent是可以多个的吗?不可以,我们也可以这么设置,而且还可以从user-agent中获取headers值来判断来匹配那个tag,当然,更多的场景下,一个user-agent是可以匹配多个tag的。通过使用scrapy的processon(支持开发模式),我们可以对使用scrapy的爬虫框架做简单的编写规范,方便爬虫交互和重构。
4、user-agent本身是可以继承的吗?可以,但是为了兼容性,user-agent只能匹配多个标签,和爬虫用的url一样。
5、user-agent中可以直接加入meta标签吗?当然可以,把meta提取出来就可以。
resource(pep501-3-3,
3)主要规定了浏览器扩展的驱动格式,主要支持user-agent,cookie,etag,headers等等标签。
6、user-agent中 查看全部
c 抓取网页数据(c抓取网页数据是很基础的事情,python、ie6及ie8上)
c抓取网页数据是很基础的事情,不过一般来说,传统的网页抓取工具是可以直接支持响应式的设计的,比如把它作为扩展scrapy或python的爬虫框架使用,后端就是scrapy等。在python2中(一般是upython)支持各种浏览器的内置驱动接口,基本可以兼容任何浏览器,upython开发的其它爬虫框架,也可以跑在chrome、firefox、36。
0、ie6及ie8上。
1、前言最近有个问题,就是在基础浏览器抓取页面数据的时候,遇到一个很蛋疼的问题,就是采集的页面数据格式比较乱,很多数据都不是按html标签的方式来显示的,比如user-agent等。这样,一次抓取下来的数据可能包含大量的md5字符串。有的时候为了定位误差会很麻烦。
2、怎么解决这个问题很简单,就是用爬虫爬取网页标签。有的标签的抓取还是比较简单的,以bs为例,用ajax加载li标签,获取viewtag,通过viewtag就可以找到标签的内容。这样就达到了scrapy的双列采集规则,一个指向那个tag,一个指向另一个tag,在最后可以采集到整个页面的数据。当然,如果页面没有自定义标签,那么你还是要自己解析html标签,python没有这个库,那就手工解析标签。
那么python为什么没有scrapy支持这个标签呢?因为python没有user-agent这个标签,如果要写程序抓取这个标签,需要自己自定义这个标签,如果def包了,又会麻烦很多。
通过user-agent这个标签,就可以获取手动装满整个页面的标签表达式,以两列为例,就是包含meta元素的标签和没有meta元素的标签,每一列的标签名,比如bin标签,都是field标签,也是一行对应一个标签,每个标签有一个坐标,
1))转换,就得到下一行的坐标。就是这么简单。
3、那么,user-agent是可以多个的吗?不可以,我们也可以这么设置,而且还可以从user-agent中获取headers值来判断来匹配那个tag,当然,更多的场景下,一个user-agent是可以匹配多个tag的。通过使用scrapy的processon(支持开发模式),我们可以对使用scrapy的爬虫框架做简单的编写规范,方便爬虫交互和重构。
4、user-agent本身是可以继承的吗?可以,但是为了兼容性,user-agent只能匹配多个标签,和爬虫用的url一样。
5、user-agent中可以直接加入meta标签吗?当然可以,把meta提取出来就可以。
resource(pep501-3-3,
3)主要规定了浏览器扩展的驱动格式,主要支持user-agent,cookie,etag,headers等等标签。
6、user-agent中
c 抓取网页数据(求大师教你如何用jsoup拆分获取到数据存放到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-16 17:21
表中的数据需要从以下网址获取(即右边的台风数据)
目前的思路是使用正则表达式,指定路径,获取表格中的所有元素
代码显示如下:
public class CodeRegex {
/**
* 获取大陆台风页面table元素
* */
public String getHTML(){
try {
String HTML ="";
String ur = "http://gb.weather.gov.hk/wxinf ... 3B%3B // 获取远程网上的信息
URL MyURL = new URL(ur);
String str;
URLConnection con = MyURL.openConnection();
InputStreamReader ins = new InputStreamReader(con.getInputStream());
BufferedReader in = new BufferedReader(ins);
StringBuffer sb = new StringBuffer();
while ((str = in.readLine()) != null) {
sb.append(str);
}
in.close();
Pattern p = Pattern.compile("]*>.+?");
Matcher m = p.matcher(sb.toString());
while (m.find()) {
HTML = m.group();
System.out.println("html:"+HTML);
}
} catch (MalformedURLException mfURLe) {
System.out.println("MalformedURLException: " + mfURLe);
} catch (IOException ioe) {
System.out.println("IOException: " + ioe);
}
return getHTML();
}
public static void main(String[] args) throws ClassNotFoundException, SQLException {
System.out.println("content:");
TyphoonCNAction tcn = new TyphoonCNAction();
String content = tcn.getHTML();
System.out.println("content:"+content);
}
}
我不知道以后如何获取元素的值。
如何使用字符串拆分来获取数据并将其存储在数据库中
请回答源代码说明,如果做过类似项目,请到邮箱索取代码
据说用jsoup做会更容易,求高手帮忙源码 查看全部
c 抓取网页数据(求大师教你如何用jsoup拆分获取到数据存放到数据库)
表中的数据需要从以下网址获取(即右边的台风数据)
目前的思路是使用正则表达式,指定路径,获取表格中的所有元素
代码显示如下:
public class CodeRegex {
/**
* 获取大陆台风页面table元素
* */
public String getHTML(){
try {
String HTML ="";
String ur = "http://gb.weather.gov.hk/wxinf ... 3B%3B // 获取远程网上的信息
URL MyURL = new URL(ur);
String str;
URLConnection con = MyURL.openConnection();
InputStreamReader ins = new InputStreamReader(con.getInputStream());
BufferedReader in = new BufferedReader(ins);
StringBuffer sb = new StringBuffer();
while ((str = in.readLine()) != null) {
sb.append(str);
}
in.close();
Pattern p = Pattern.compile("]*>.+?");
Matcher m = p.matcher(sb.toString());
while (m.find()) {
HTML = m.group();
System.out.println("html:"+HTML);
}
} catch (MalformedURLException mfURLe) {
System.out.println("MalformedURLException: " + mfURLe);
} catch (IOException ioe) {
System.out.println("IOException: " + ioe);
}
return getHTML();
}
public static void main(String[] args) throws ClassNotFoundException, SQLException {
System.out.println("content:");
TyphoonCNAction tcn = new TyphoonCNAction();
String content = tcn.getHTML();
System.out.println("content:"+content);
}
}
我不知道以后如何获取元素的值。
如何使用字符串拆分来获取数据并将其存储在数据库中
请回答源代码说明,如果做过类似项目,请到邮箱索取代码
据说用jsoup做会更容易,求高手帮忙源码

