
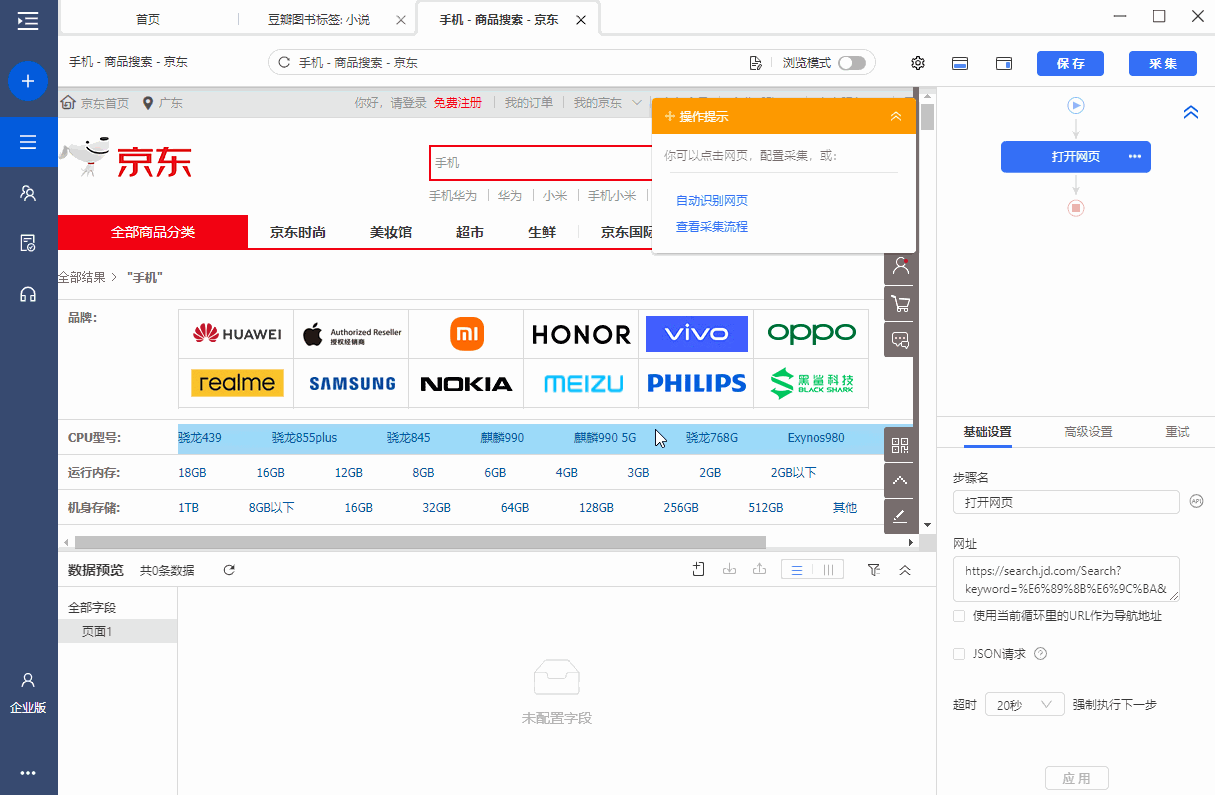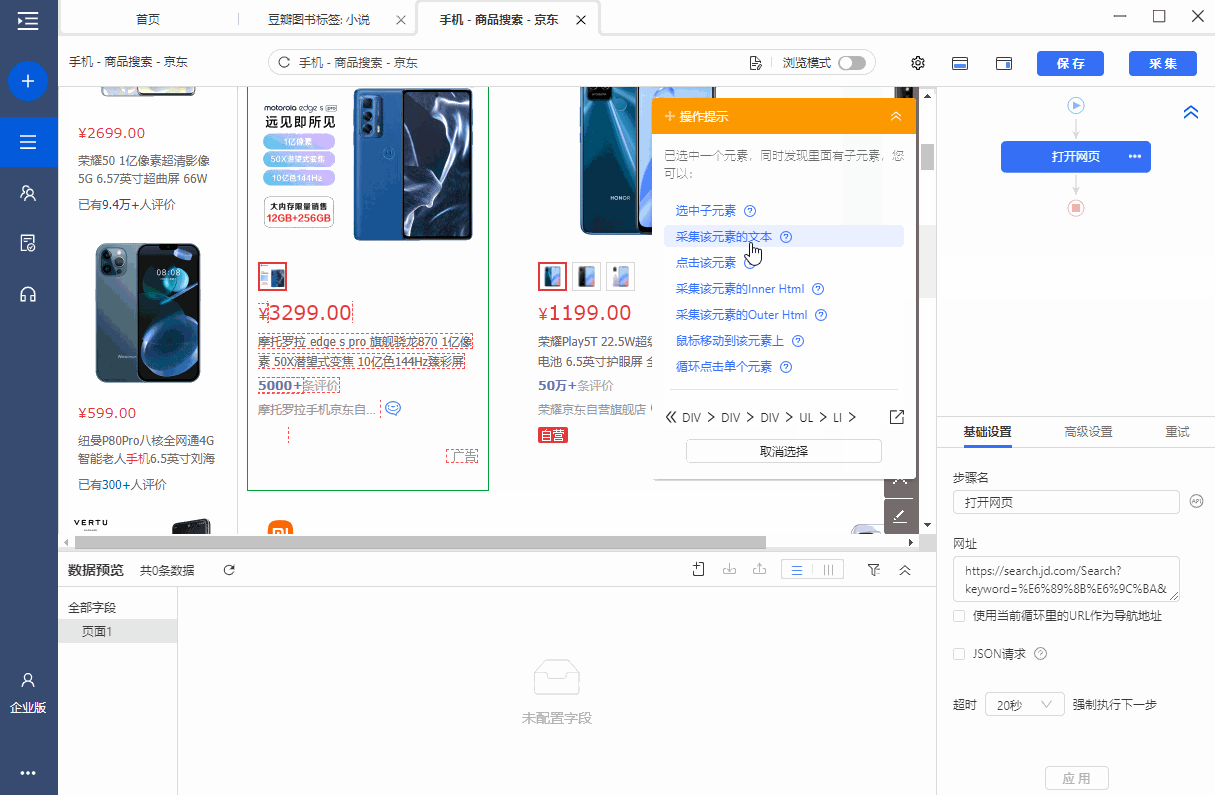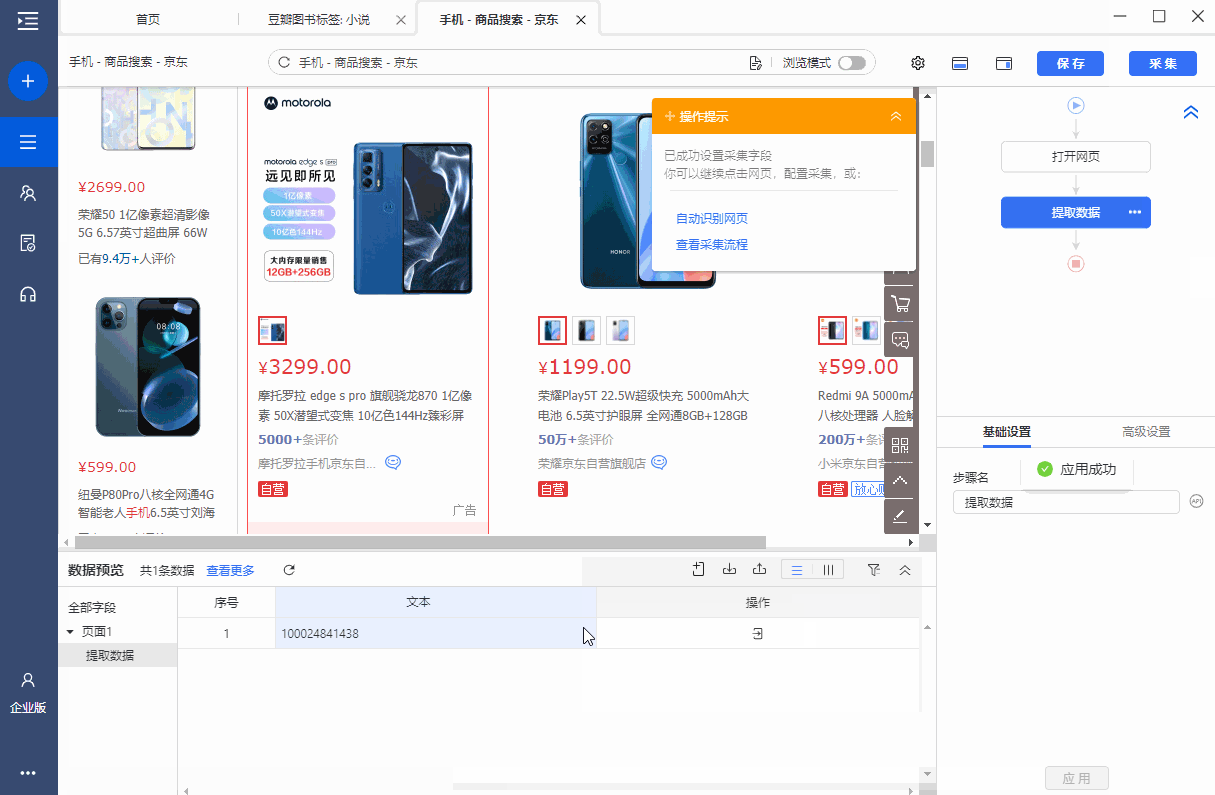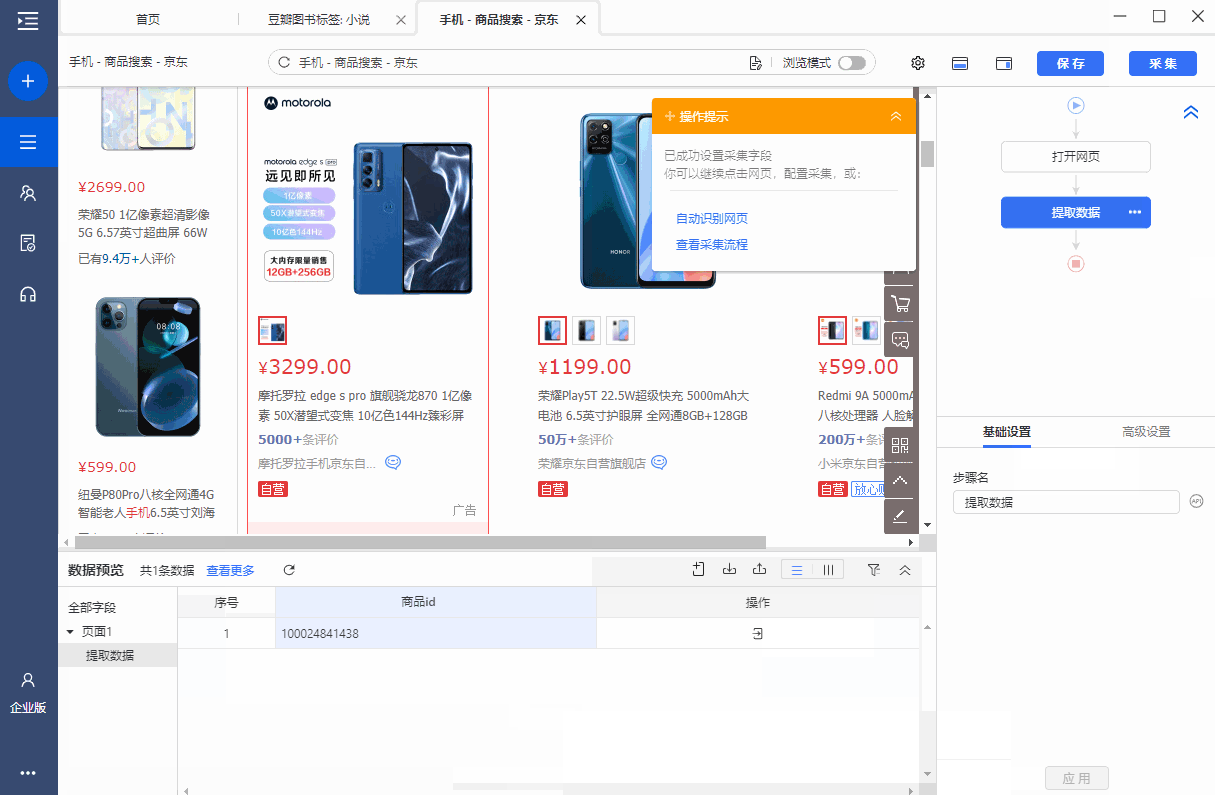
c 抓取网页数据
c 抓取网页数据(全部详细技术资料下载【技术实现步骤摘要】(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-19 23:21
本发明专利技术实施例公开了一种基于C/S架构浏览器的数据传输方法,包括:根据客户端的网页访问请求,从网络获取被请求网页的页面数据,其中,页面数据包括网页的所有源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化处理后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。相应地,本发明专利技术的实施例还公开了一种服务器。采用本发明专利技术,可以大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及无线互联网领域,具体涉及一种基于C(Client,client)/S(Server,server)架构浏览器的数据传输方法及服务器。
技术介绍
C/S 架构是客户端和服务器端的架构。它是一种软件系统架构。可以充分利用两端硬件环境的优势,将任务合理分配给两端执行,降低了系统的通信开销。排版引擎服务器负责获取网页内容(包括源代码和图片等),整理信息,计算网页的显示方式,然后输出到客户端进行显示或打印。所有 Web 浏览器、电子邮件客户端和其他需要编辑和显示 Web 内容的应用程序都需要排版引擎服务器进行排版。现有的基于C/S架构浏览器的数据传输方案主要是基于客户端浏览器的类型,
专利技术人员发现,现有基于C/S架构浏览器的数据传输方案主要存在以下缺陷1、用户体验低。在 HTML 到 ML 或 XHTML-MP 的转换过程中,无法准确有效地转换 HTML 中的样式表信息,通常的处理方法会破坏原创页面的视觉效果,如背景图片和颜色、字体颜色等。客户端渲染可能很乏味并降低用户体验。2、传输效率低。由于HTML页面直接转换传输,客户端与排版引擎服务器之间的数据传输流量大,传输效率低。3、客户端性能要求高,并且客户端渲染复杂度很高。现有的数据传输方案需要客户端有硬件(例如客户端是WAP手机)或软件(客户端配备WAP浏览器)的支持。“重服务器端,轻客户端”的架构趋势。为了避免上述缺陷,可以使用预定义的数据传输协议进行数据传输。基于C/S架构浏览器的数据传输协议是C/S架构浏览器开发中最重要的部分之一。它是客户端和服务器之间的桥梁。协议定义的质量与网络直接相关。流量大小和客户端的渲染效果,特别是对于资源有限的中低端客户端,数据传输协议的定义直接关系到客户端浏览器的用户体验。因此,如何平衡客户端呈现的复杂性、传输的数据量和交互性来定义数据传输协议来实现基于C/S架构浏览器的数据传输方案是一个亟待解决的问题。
技术实现思路
本专利技术实施例要解决的技术问题是提供一种基于C/S架构浏览器的数据传输方法及服务器,能够大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。为了解决上述技术问题,本专利技术实施例提供了一种基于C/S架构浏览器的数据传输方法,包括根据用户的网页访问请求,从网络上获取被请求网页的页面数据。客户端,使页面数据包括网页的源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化后的图像文件的二进制数据进行编码,并将编码后的二进制数据包传输给客户端。其中,对获取的网页源内容进行排版处理包括:解析网页源内容,生成DOM(Document Object Model,文档对象模型)树,DOM树包括网页节点和属性和数据;对DOM树进行布局排版,得到网页的渲染树,渲染树包括网页节点和网页节点的排版信息、属性和数据。序列化网页节点。属性和数据,并将序列化后的属性和数据存储在渲染数据文件中;将网页节点的排版信息和网页节点的属性和数据的序列化信息存储在渲染树文件中。
其中,对获取的网页图片文件进行优化处理包括过滤图片文件中的广告图片信息、修剪图片文件大小、压缩图片文件、缩小图片文件大小。图片文件中的颜色数量,图片文件转换为高压缩率存储格式的任意一个或多个图片文件。其中,在从网络获取请求访问的网页的页面数据之前,还包括预先设置二进制传输协议;资源包括图像文件和/或网页的源内容。网页的源内容包括网页的各个标签和各个标签的属性数据;网页节点与网页的标签一一对应。相应地,本专利技术实施例还提供了一种服务器,包括获取单元,用于根据客户端的网页访问请求,从网络获取所请求网页的页面数据,该页面数据包括:网页。网页的源内容和图片文件;排版单元,用于对获取单元获取的网页的源内容进行排版处理;图像处理单元,用于对获取单元得到的网页的图片文件进行优化编码单元用于对排版单元排版处理后的源内容和图片处理单元根据优化处理后的图片文件进行二进制数据编码到预设的二进制传输协议;将编码单元编码后的二进制数据包发送给客户端。
其中,排版单元包括解析单元,用于解析网页的源内容生成DOM树,DOM树包括网页节点和网页节点的属性和数据。布局排版单元,用于根据解析单元解析出的DOM树进行布局排版得到网页的渲染树,渲染树包括网页节点和网页的排版信息、属性和数据节点; 序列化单元用于对排版单元得到的网页节点的属性和数据进行序列化;第一存储单元,用于将序列化单元序列化后的属性和数据存储在渲染数据文件中。第二存储单元,用于将布局排版单元得到的网页节点的排版信息和序列化单元对渲染树文件中的网页节点的属性和数据进行序列化后的序列化信息进行存储。其中,图片处理单元包括图片过滤单元,用于过滤图片文件中的广告图片信息。和/或图片修剪单元,用于修剪图片文件的大小;和/或,图片压缩单元,用于压缩图片文件;和/或,图片优化单元,用于减少图片文件的颜色数据,并将图片文件转换为高压缩率存储格式的图片文件。其中,所述服务器还包括预设单元,用于预设二进制传输协议。
其中,服务器为排版引擎服务器。实施本专利技术实施例具有以下有益效果1、通过对网页源内容进行排版处理,优化网页图像文件,按照预设的二进制传输协议,将处理后的源内容被处理。将图像文件数据编码成二进制数据包进行传输,大大减少了客户端与排版引擎服务器之间的数据传输流量,大大节省了客户端的资源需求和响应时间,提高了传输效率;2、服务器端对网页的页面数据进行排版和优化,
【技术保护点】
一种基于C/S架构浏览器的数据传输方法,其特征在于,包括:根据客户端的网页访问请求,从网络获取所请求网页的页面数据,所述页面数据包括所述网页的来源。网页内容及网页图片文件;对获取的网页的源内容进行排版处理,对获取的网页的图像文件进行优化处理;根据预设的二进制传输协议,进行排版处理,对源内容和优化后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。
【技术特点总结】
【专利技术性质】
技术研发人员:齐小龙、李成良、杨木香、张国良、余恒兵、
申请人(专利权)持有人:Aspire Digital Technology,
类型:发明
国家、省、市:94 [中国|深圳]
下载所有详细的技术数据 我是该专利的所有者 查看全部
c 抓取网页数据(全部详细技术资料下载【技术实现步骤摘要】(一))
本发明专利技术实施例公开了一种基于C/S架构浏览器的数据传输方法,包括:根据客户端的网页访问请求,从网络获取被请求网页的页面数据,其中,页面数据包括网页的所有源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化处理后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。相应地,本发明专利技术的实施例还公开了一种服务器。采用本发明专利技术,可以大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及无线互联网领域,具体涉及一种基于C(Client,client)/S(Server,server)架构浏览器的数据传输方法及服务器。
技术介绍
C/S 架构是客户端和服务器端的架构。它是一种软件系统架构。可以充分利用两端硬件环境的优势,将任务合理分配给两端执行,降低了系统的通信开销。排版引擎服务器负责获取网页内容(包括源代码和图片等),整理信息,计算网页的显示方式,然后输出到客户端进行显示或打印。所有 Web 浏览器、电子邮件客户端和其他需要编辑和显示 Web 内容的应用程序都需要排版引擎服务器进行排版。现有的基于C/S架构浏览器的数据传输方案主要是基于客户端浏览器的类型,
专利技术人员发现,现有基于C/S架构浏览器的数据传输方案主要存在以下缺陷1、用户体验低。在 HTML 到 ML 或 XHTML-MP 的转换过程中,无法准确有效地转换 HTML 中的样式表信息,通常的处理方法会破坏原创页面的视觉效果,如背景图片和颜色、字体颜色等。客户端渲染可能很乏味并降低用户体验。2、传输效率低。由于HTML页面直接转换传输,客户端与排版引擎服务器之间的数据传输流量大,传输效率低。3、客户端性能要求高,并且客户端渲染复杂度很高。现有的数据传输方案需要客户端有硬件(例如客户端是WAP手机)或软件(客户端配备WAP浏览器)的支持。“重服务器端,轻客户端”的架构趋势。为了避免上述缺陷,可以使用预定义的数据传输协议进行数据传输。基于C/S架构浏览器的数据传输协议是C/S架构浏览器开发中最重要的部分之一。它是客户端和服务器之间的桥梁。协议定义的质量与网络直接相关。流量大小和客户端的渲染效果,特别是对于资源有限的中低端客户端,数据传输协议的定义直接关系到客户端浏览器的用户体验。因此,如何平衡客户端呈现的复杂性、传输的数据量和交互性来定义数据传输协议来实现基于C/S架构浏览器的数据传输方案是一个亟待解决的问题。
技术实现思路
本专利技术实施例要解决的技术问题是提供一种基于C/S架构浏览器的数据传输方法及服务器,能够大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。为了解决上述技术问题,本专利技术实施例提供了一种基于C/S架构浏览器的数据传输方法,包括根据用户的网页访问请求,从网络上获取被请求网页的页面数据。客户端,使页面数据包括网页的源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化后的图像文件的二进制数据进行编码,并将编码后的二进制数据包传输给客户端。其中,对获取的网页源内容进行排版处理包括:解析网页源内容,生成DOM(Document Object Model,文档对象模型)树,DOM树包括网页节点和属性和数据;对DOM树进行布局排版,得到网页的渲染树,渲染树包括网页节点和网页节点的排版信息、属性和数据。序列化网页节点。属性和数据,并将序列化后的属性和数据存储在渲染数据文件中;将网页节点的排版信息和网页节点的属性和数据的序列化信息存储在渲染树文件中。
其中,对获取的网页图片文件进行优化处理包括过滤图片文件中的广告图片信息、修剪图片文件大小、压缩图片文件、缩小图片文件大小。图片文件中的颜色数量,图片文件转换为高压缩率存储格式的任意一个或多个图片文件。其中,在从网络获取请求访问的网页的页面数据之前,还包括预先设置二进制传输协议;资源包括图像文件和/或网页的源内容。网页的源内容包括网页的各个标签和各个标签的属性数据;网页节点与网页的标签一一对应。相应地,本专利技术实施例还提供了一种服务器,包括获取单元,用于根据客户端的网页访问请求,从网络获取所请求网页的页面数据,该页面数据包括:网页。网页的源内容和图片文件;排版单元,用于对获取单元获取的网页的源内容进行排版处理;图像处理单元,用于对获取单元得到的网页的图片文件进行优化编码单元用于对排版单元排版处理后的源内容和图片处理单元根据优化处理后的图片文件进行二进制数据编码到预设的二进制传输协议;将编码单元编码后的二进制数据包发送给客户端。
其中,排版单元包括解析单元,用于解析网页的源内容生成DOM树,DOM树包括网页节点和网页节点的属性和数据。布局排版单元,用于根据解析单元解析出的DOM树进行布局排版得到网页的渲染树,渲染树包括网页节点和网页的排版信息、属性和数据节点; 序列化单元用于对排版单元得到的网页节点的属性和数据进行序列化;第一存储单元,用于将序列化单元序列化后的属性和数据存储在渲染数据文件中。第二存储单元,用于将布局排版单元得到的网页节点的排版信息和序列化单元对渲染树文件中的网页节点的属性和数据进行序列化后的序列化信息进行存储。其中,图片处理单元包括图片过滤单元,用于过滤图片文件中的广告图片信息。和/或图片修剪单元,用于修剪图片文件的大小;和/或,图片压缩单元,用于压缩图片文件;和/或,图片优化单元,用于减少图片文件的颜色数据,并将图片文件转换为高压缩率存储格式的图片文件。其中,所述服务器还包括预设单元,用于预设二进制传输协议。
其中,服务器为排版引擎服务器。实施本专利技术实施例具有以下有益效果1、通过对网页源内容进行排版处理,优化网页图像文件,按照预设的二进制传输协议,将处理后的源内容被处理。将图像文件数据编码成二进制数据包进行传输,大大减少了客户端与排版引擎服务器之间的数据传输流量,大大节省了客户端的资源需求和响应时间,提高了传输效率;2、服务器端对网页的页面数据进行排版和优化,
【技术保护点】
一种基于C/S架构浏览器的数据传输方法,其特征在于,包括:根据客户端的网页访问请求,从网络获取所请求网页的页面数据,所述页面数据包括所述网页的来源。网页内容及网页图片文件;对获取的网页的源内容进行排版处理,对获取的网页的图像文件进行优化处理;根据预设的二进制传输协议,进行排版处理,对源内容和优化后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。
【技术特点总结】
【专利技术性质】
技术研发人员:齐小龙、李成良、杨木香、张国良、余恒兵、
申请人(专利权)持有人:Aspire Digital Technology,
类型:发明
国家、省、市:94 [中国|深圳]
下载所有详细的技术数据 我是该专利的所有者
c 抓取网页数据(2021-11-05今日任务将数据文件spider.log根据要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 23:17
2021-11-05
数据采集一
一。今天的任务
根据需要将数据文件spider.log转储为ans0201.csv
二。主要内容
任务分析与实施
根据需求,我们需要在spider.log文件中取出相关字段,使用Python中的读取文件,每行数据规则相同,逐行读取,取出对应字段,然后创建一个csv 文件,然后将 read 文件按要求写入 csv
使用语言工具 Python
模块操作系统
主要源代码
导入 csv
导入编解码器
列表 = []
列表CSV = []
def readLog(): #逐行读取数据文件,如果链接是电影就是我们需要的数据
列表 = []
使用 open(r"C:\Users\liu\Desktop\arg\task0201\spider.log", "r", encoding="utf-8") 作为文件:
s = file.readlines()
对于我在 s 中:
str = i.split(",")
如果 str[1].startswith(r""):
list.append(i)
返回列表
def anyData(list): #去除冗余数据,获取需要的电影名称、放映时间等
列表CSV = []
对于列表中的 abc:
str = abc.split(";")
电影名 = str[0].split(",")[2]
加载日期 = str[1]
上传日期 = str[2]
支付 = str[7][5:]
tuple = (movieName, loadDate, uploadDate, pay)
listCsv.append(元组)
返回列表CSV
def writeCsv(list): #写入csv文件
f = codecs.open('ans0201.csv', 'w', 'utf-8')
作家 = csv.writer(f)
对于列表中的 i:
writer.writerow(i)
f.close()
如果 __name__ == "__main__":
列表 = anyData(readLog())
打印(列表)
写CSV(列表)
三。遇到问题
需要过滤文件数据。过滤后的数据需要按照规则进行过滤。csv文件读写
四。解决方案
关于文件数据的问题,一开始没看懂,后来发现标题里的链接是固定的。根据链接,可以过滤掉所需网页采集的数据。关于数据过滤,一是每行第一个数据只要是Name即可,二是票房数据删除票房文本Csv文件读写网上有读写文件的方法,按照方法来参考写
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(2021-11-05今日任务将数据文件spider.log根据要求)
2021-11-05
数据采集一
一。今天的任务
根据需要将数据文件spider.log转储为ans0201.csv
二。主要内容
任务分析与实施
根据需求,我们需要在spider.log文件中取出相关字段,使用Python中的读取文件,每行数据规则相同,逐行读取,取出对应字段,然后创建一个csv 文件,然后将 read 文件按要求写入 csv
使用语言工具 Python
模块操作系统
主要源代码
导入 csv
导入编解码器
列表 = []
列表CSV = []
def readLog(): #逐行读取数据文件,如果链接是电影就是我们需要的数据
列表 = []
使用 open(r"C:\Users\liu\Desktop\arg\task0201\spider.log", "r", encoding="utf-8") 作为文件:
s = file.readlines()
对于我在 s 中:
str = i.split(",")
如果 str[1].startswith(r""):
list.append(i)
返回列表
def anyData(list): #去除冗余数据,获取需要的电影名称、放映时间等
列表CSV = []
对于列表中的 abc:
str = abc.split(";")
电影名 = str[0].split(",")[2]
加载日期 = str[1]
上传日期 = str[2]
支付 = str[7][5:]
tuple = (movieName, loadDate, uploadDate, pay)
listCsv.append(元组)
返回列表CSV
def writeCsv(list): #写入csv文件
f = codecs.open('ans0201.csv', 'w', 'utf-8')
作家 = csv.writer(f)
对于列表中的 i:
writer.writerow(i)
f.close()
如果 __name__ == "__main__":
列表 = anyData(readLog())
打印(列表)
写CSV(列表)
三。遇到问题
需要过滤文件数据。过滤后的数据需要按照规则进行过滤。csv文件读写
四。解决方案
关于文件数据的问题,一开始没看懂,后来发现标题里的链接是固定的。根据链接,可以过滤掉所需网页采集的数据。关于数据过滤,一是每行第一个数据只要是Name即可,二是票房数据删除票房文本Csv文件读写网上有读写文件的方法,按照方法来参考写
分类:
技术要点:
相关文章:
c 抓取网页数据(之前自带的开发者调试工具(F12做过)() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-19 23:04
)
之前抓过浏览器包,可以用浏览器自带的工具来完成;APP包我也抓到了,也可以通过fiddler做代理。现在想在PC端测试一下这个以前没接触过的应用。,我对应用捕获不太了解,于是开始搜索。接下来是处理结果。
1.PC浏览器网页数据分析
简单常用的网页数据分析,谷歌/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足一些要求,如果是请求前和响应后处理最多,修改浏览器为发送请求数据,修改服务端对应数据,使用F12开发工具无法满足我们的需求,通过引入Fiddler抓包工具,可以理解为一个本地代理服务器,可以转发客户端和服务端的请求和响应。
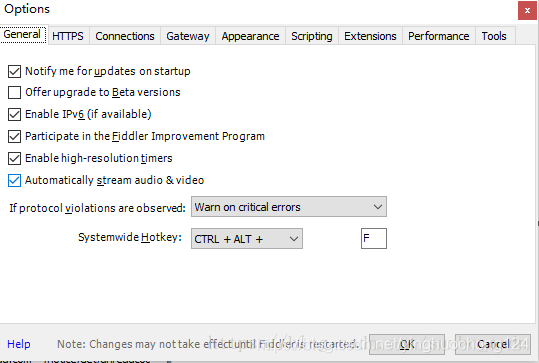
设置提琴手:
打开Fiddler,在菜单栏中,打开Tools --Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了并根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS请操作
2.应用数据分析
Fiddler 也可以用于移动 App 数据分析,类似于上面从 PC 浏览器检索数据的方式。App需要和PC在同一网段,设置了移动Wifi代理,IP为PC机的IP地址,例如:64.35.8< @6.12,端口号为FIddler设置的端口号,一般为8888,App端所有网络/响应请求都必须经过FIddler转发,可以对请求做数据分析
3.PC 端 (C/S) 数据包捕获
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理成为代理链。
由于一般的C/S客户端无法设置代理,Fiddler无法检测到数据,所有的请求都会被捕获并通过Proxifer发送给Fiddler,这样客户端的请求就可以在Fiddler中进行分析。
Proxifer 设置:
设置很简单,如下图,两步OK
一种)。代理服务器和 Fiddler 代理设置匹配
b).代理规则
默认Default,可以忽略
点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler应用文件目录,确认
目标主机:本地Fiddler设置代理,可任意设置
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功
查看全部
c 抓取网页数据(之前自带的开发者调试工具(F12做过)()
)
之前抓过浏览器包,可以用浏览器自带的工具来完成;APP包我也抓到了,也可以通过fiddler做代理。现在想在PC端测试一下这个以前没接触过的应用。,我对应用捕获不太了解,于是开始搜索。接下来是处理结果。
1.PC浏览器网页数据分析
简单常用的网页数据分析,谷歌/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足一些要求,如果是请求前和响应后处理最多,修改浏览器为发送请求数据,修改服务端对应数据,使用F12开发工具无法满足我们的需求,通过引入Fiddler抓包工具,可以理解为一个本地代理服务器,可以转发客户端和服务端的请求和响应。
设置提琴手:
打开Fiddler,在菜单栏中,打开Tools --Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888


然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了并根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS请操作
2.应用数据分析
Fiddler 也可以用于移动 App 数据分析,类似于上面从 PC 浏览器检索数据的方式。App需要和PC在同一网段,设置了移动Wifi代理,IP为PC机的IP地址,例如:64.35.8< @6.12,端口号为FIddler设置的端口号,一般为8888,App端所有网络/响应请求都必须经过FIddler转发,可以对请求做数据分析
3.PC 端 (C/S) 数据包捕获
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理成为代理链。
由于一般的C/S客户端无法设置代理,Fiddler无法检测到数据,所有的请求都会被捕获并通过Proxifer发送给Fiddler,这样客户端的请求就可以在Fiddler中进行分析。
Proxifer 设置:
设置很简单,如下图,两步OK

一种)。代理服务器和 Fiddler 代理设置匹配

b).代理规则
默认Default,可以忽略

点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler应用文件目录,确认

目标主机:本地Fiddler设置代理,可任意设置
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功



c 抓取网页数据(根据指定URL来抓取相应的网页内容,而后存入本地文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 497 次浏览 • 2022-03-19 23:03
今天写一个简单的程序,根据指定的URL爬取对应的网页内容,然后存入本地文件。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:bash
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 如下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
上面代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取url对应的资源,然后读取资源数据,在控制台打印,写入内容到本地文件中间。互联网
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。拿来
另外,在处理异常时,我们使用 fm.Fprintf() 方法,它是三种格式化方法之一:url
编译后运行程序,指定一个URL参数,暂时指定为百度。还是希望谷歌能在不久的将来回归:指针
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。代码 查看全部
c 抓取网页数据(根据指定URL来抓取相应的网页内容,而后存入本地文件)
今天写一个简单的程序,根据指定的URL爬取对应的网页内容,然后存入本地文件。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:bash
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 如下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
上面代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取url对应的资源,然后读取资源数据,在控制台打印,写入内容到本地文件中间。互联网
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。拿来
另外,在处理异常时,我们使用 fm.Fprintf() 方法,它是三种格式化方法之一:url
编译后运行程序,指定一个URL参数,暂时指定为百度。还是希望谷歌能在不久的将来回归:指针
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。代码
c 抓取网页数据(IMG标签的抓取图片网址(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-19 21:12
)
网页上的数据类型非常详细:文字、图片、链接、源码等。在data采集过程中,不同类型的数据有不同的对应抓取方式。本文将详细介绍数据类型的类型以及如何捕获它们。
示例 URL:#!type=movie&tag=%E7%BB%8F%E5%85%B8&sort=recommend&page_limit=20&page_start=0
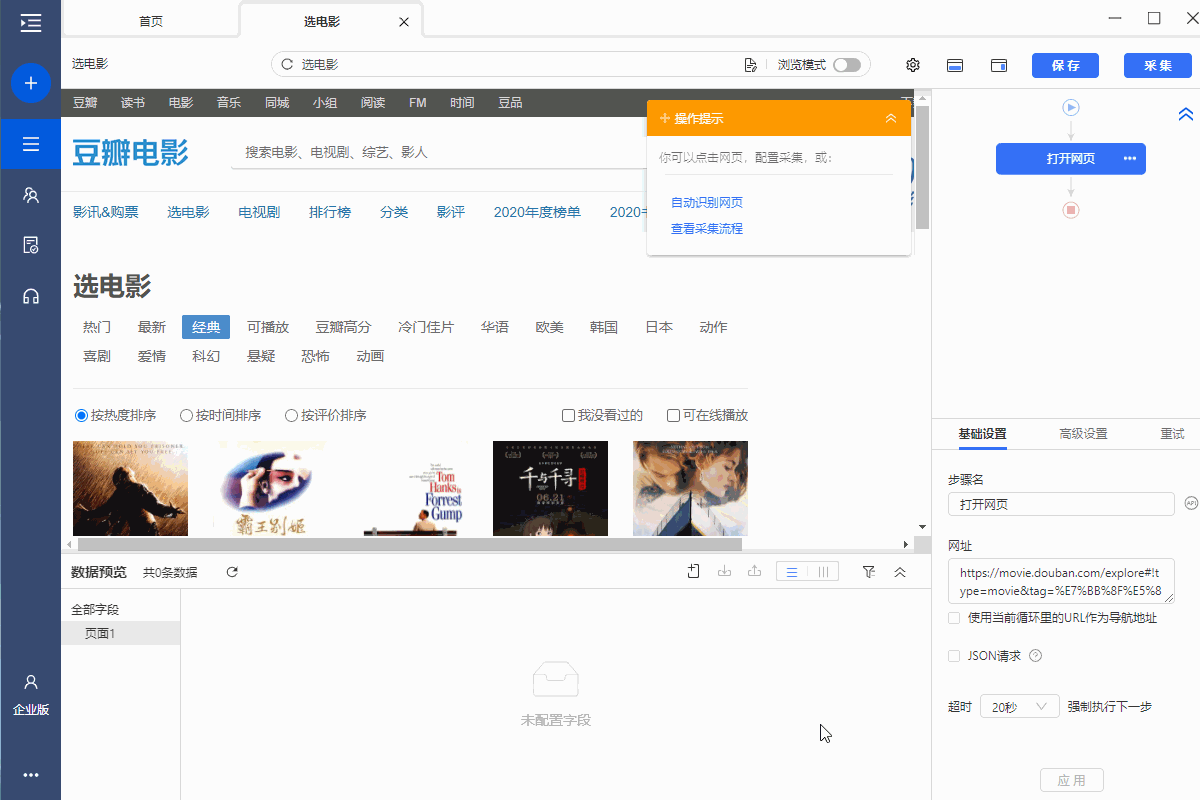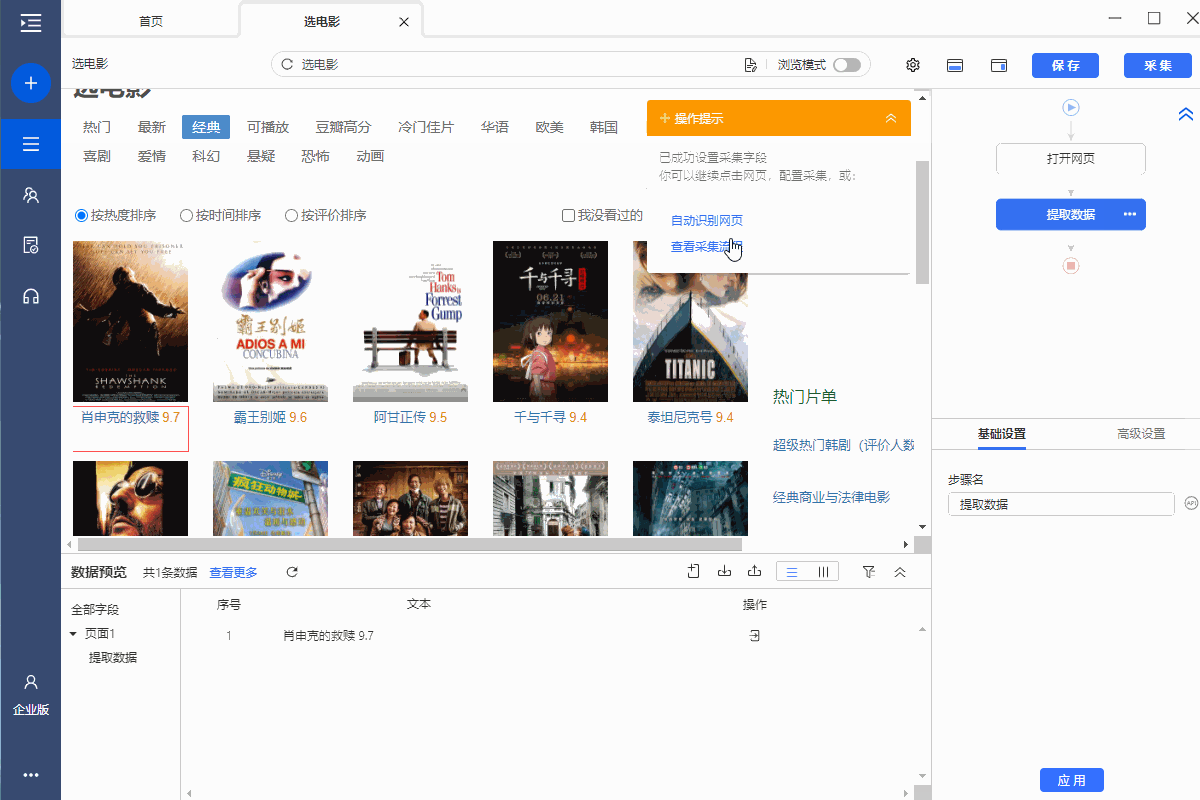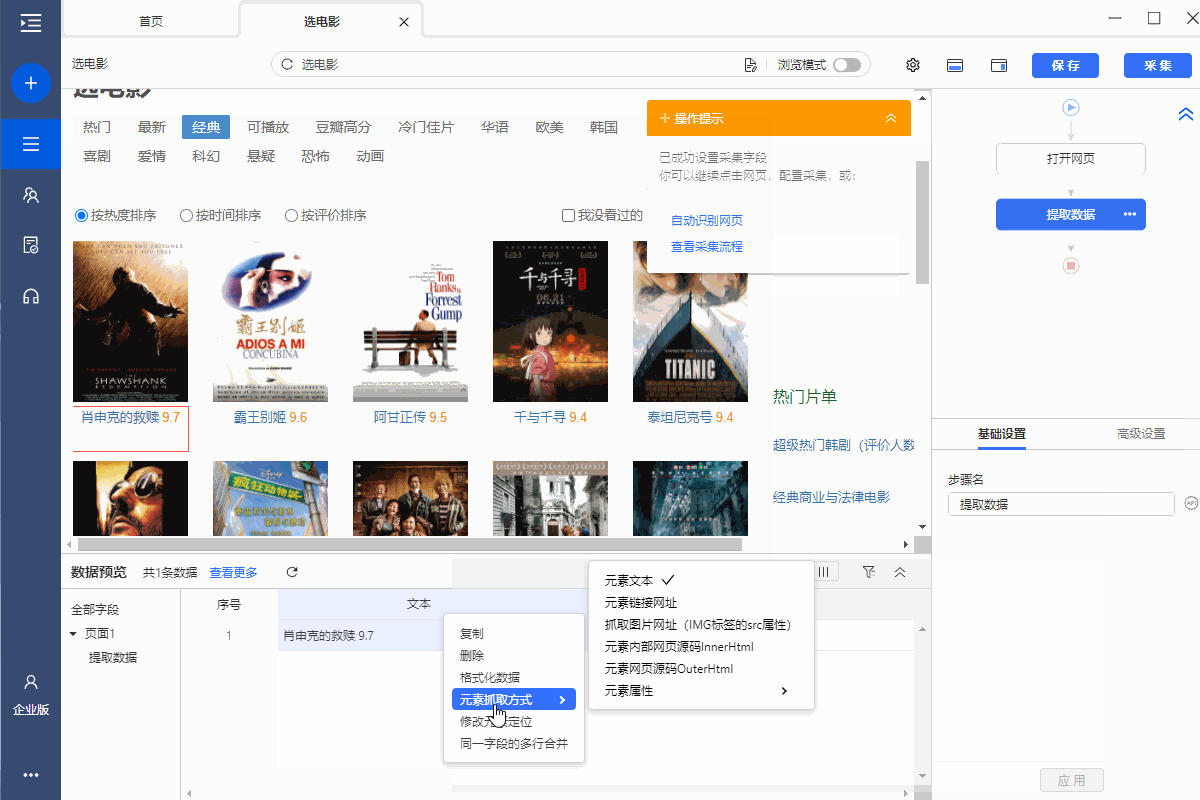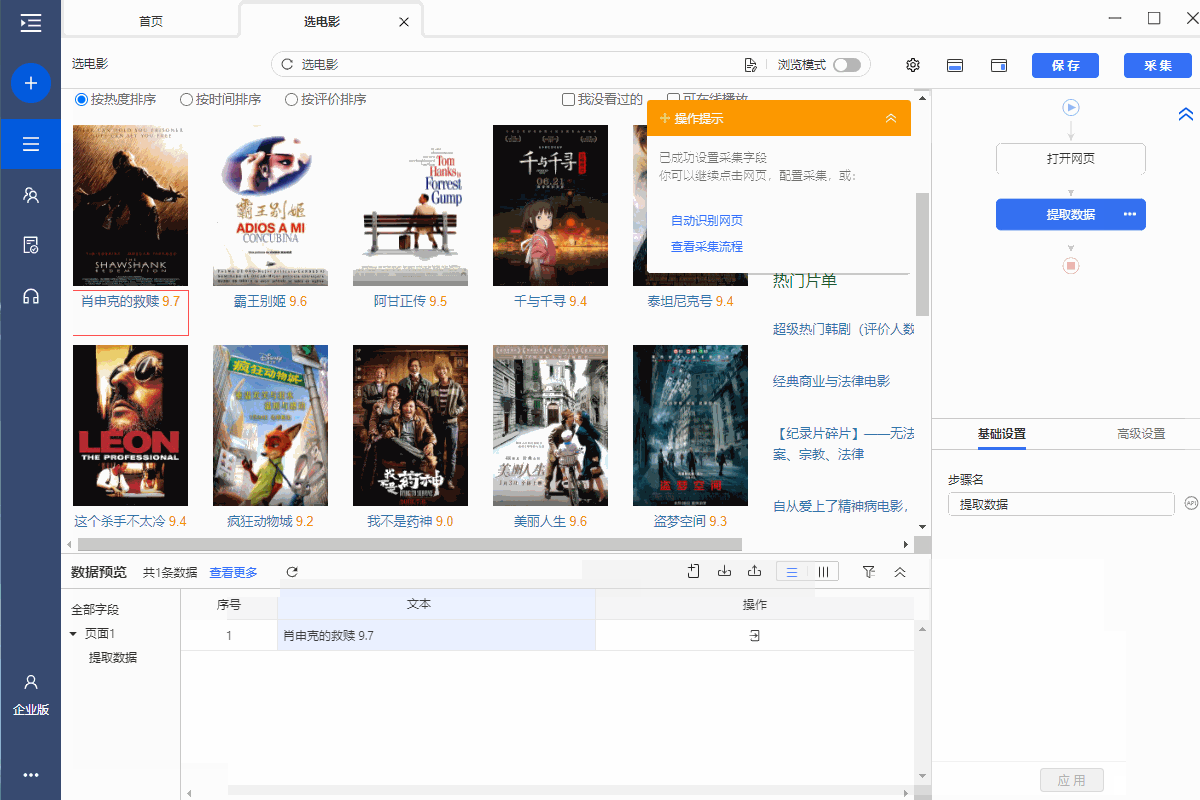
1、抓取文字:抓取页面显示的文字
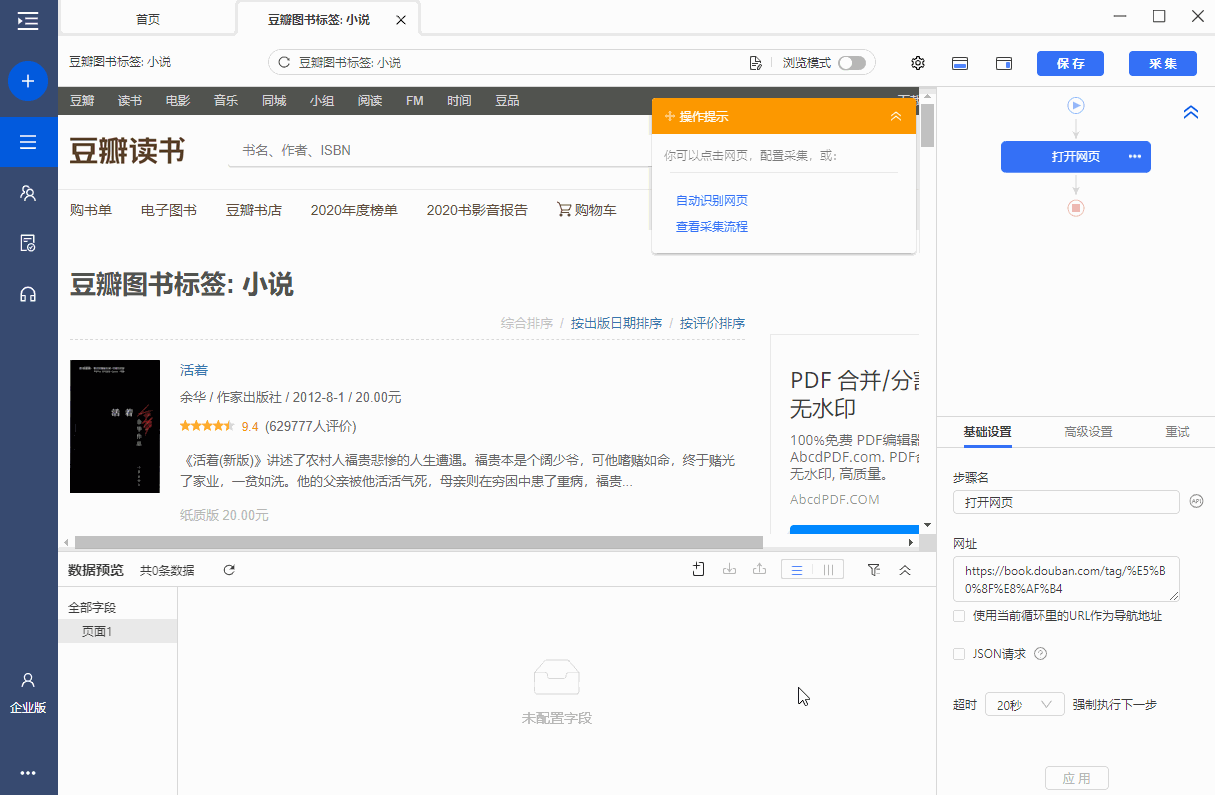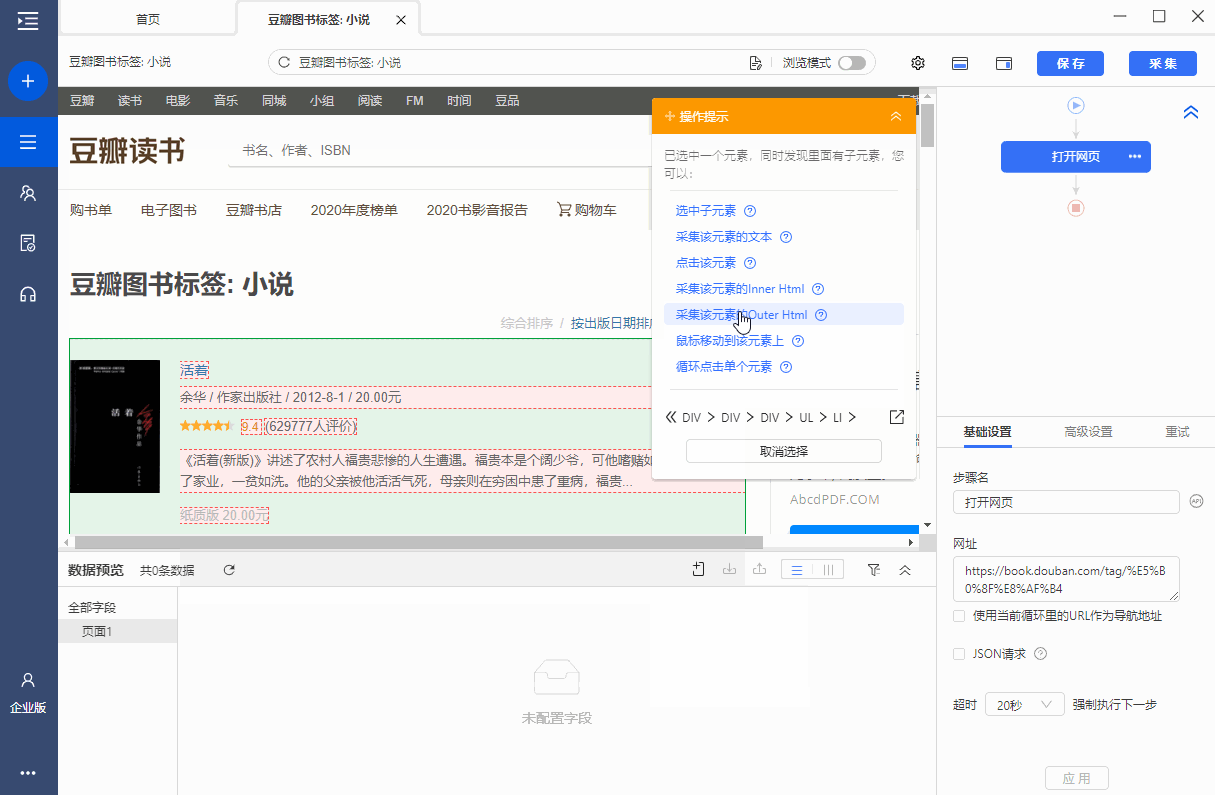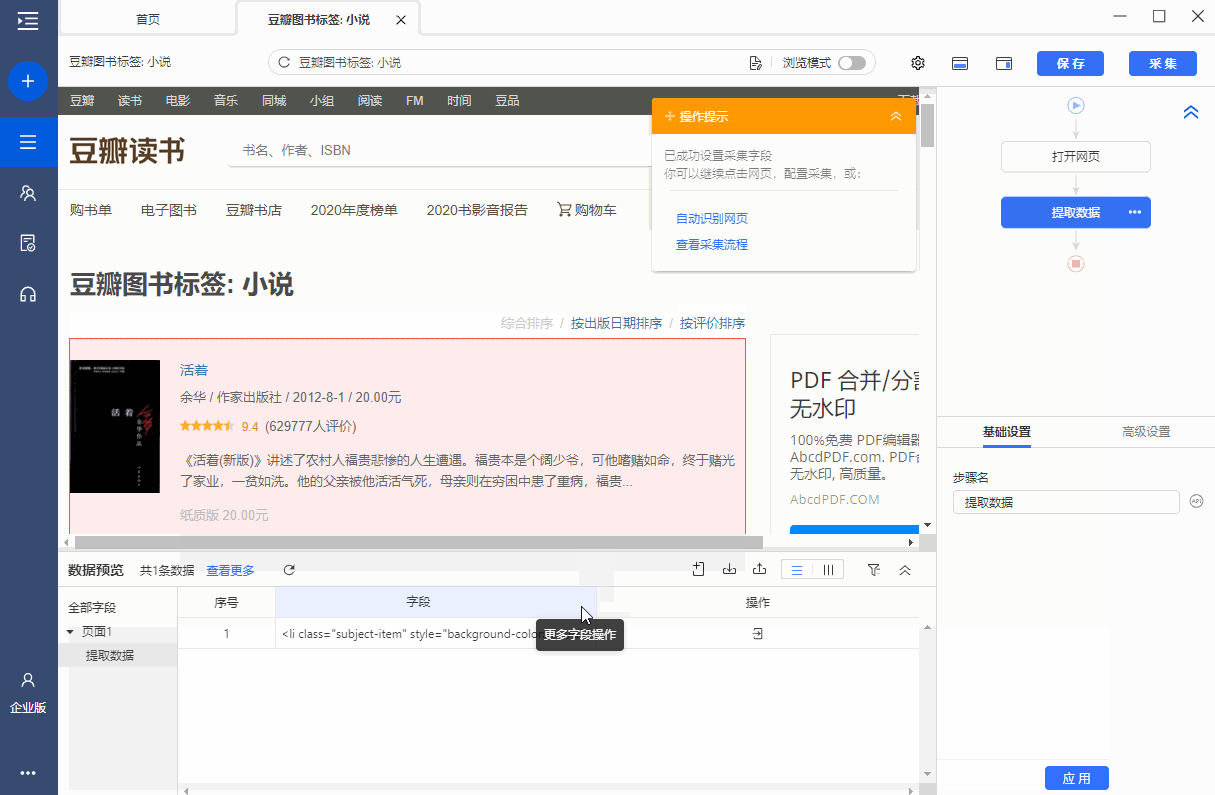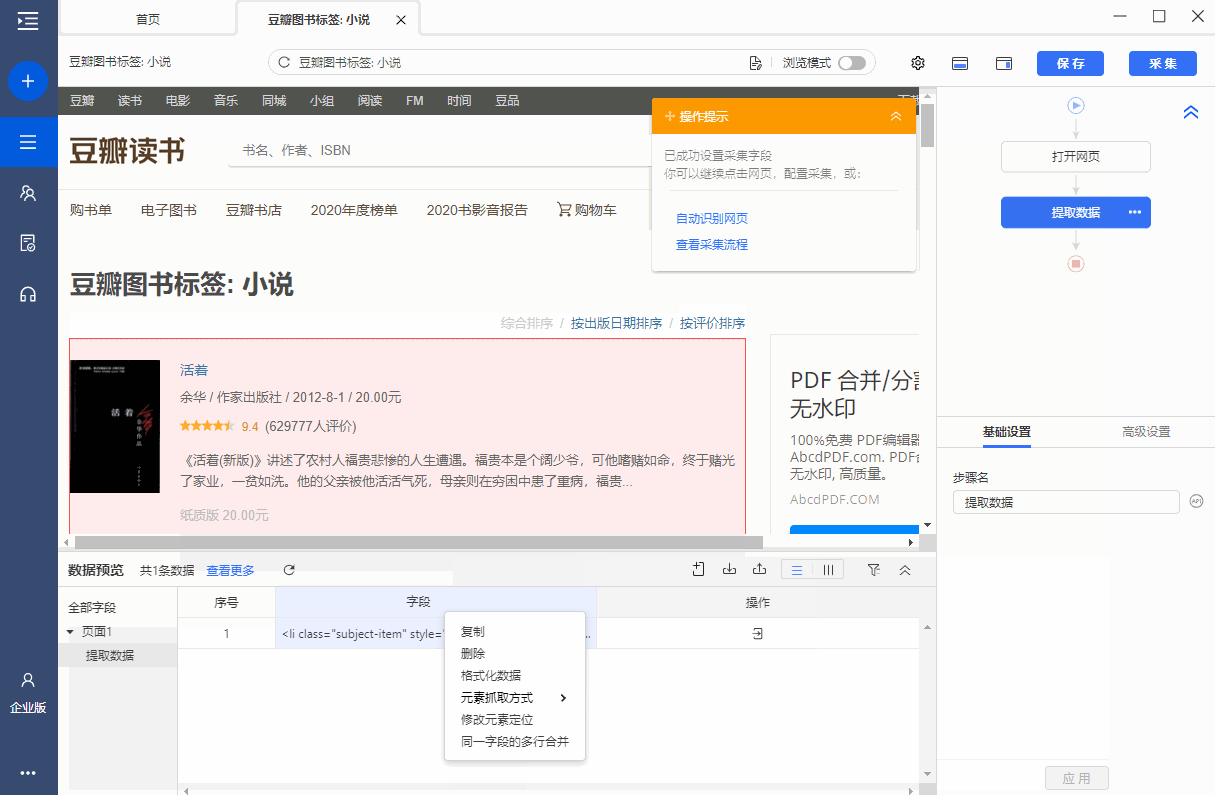
操作:鼠标选中页面中的文本,在弹出的操作提示文本中选择[采集 of this element],目标文本会向下采集。
同时,将鼠标移动到字段名称【文本】上,点击?
? 按钮,选择【自定义捕捉方式】,可以为我们选择章鱼鱼的自动文字。
2、 Crawl Image URL:要抓取的图片的URL
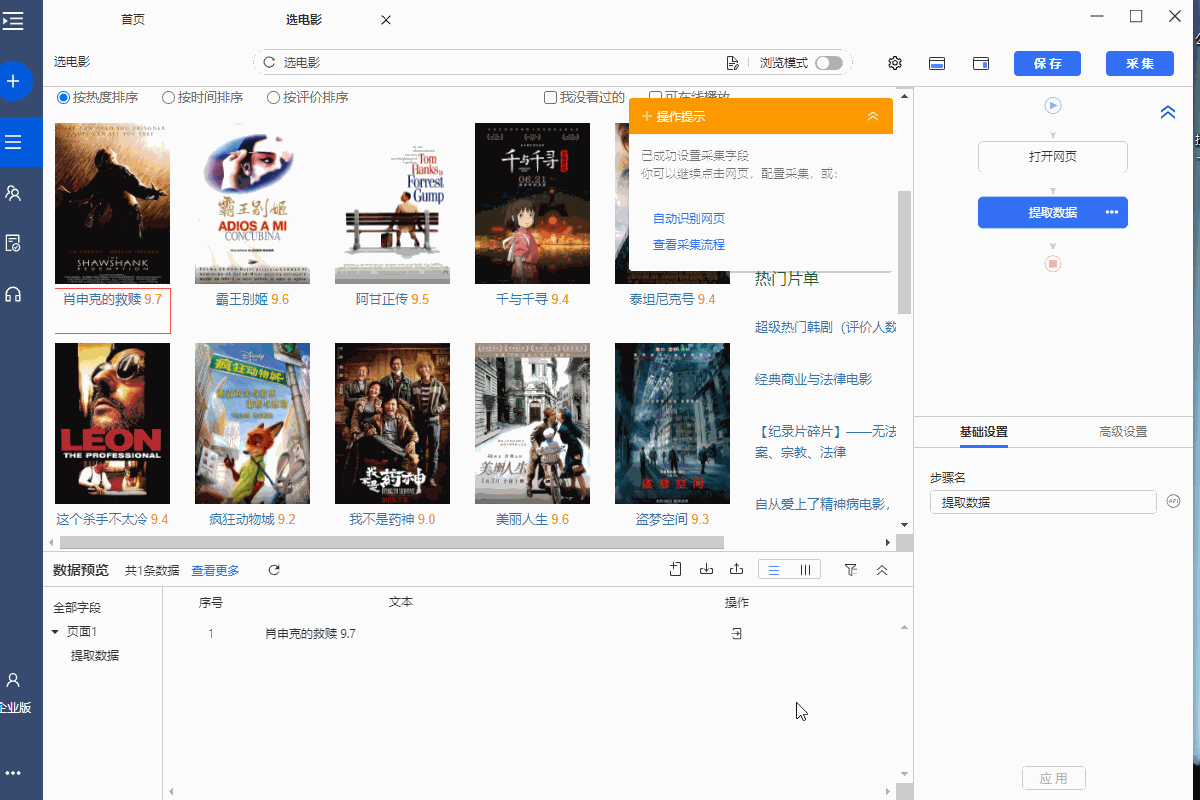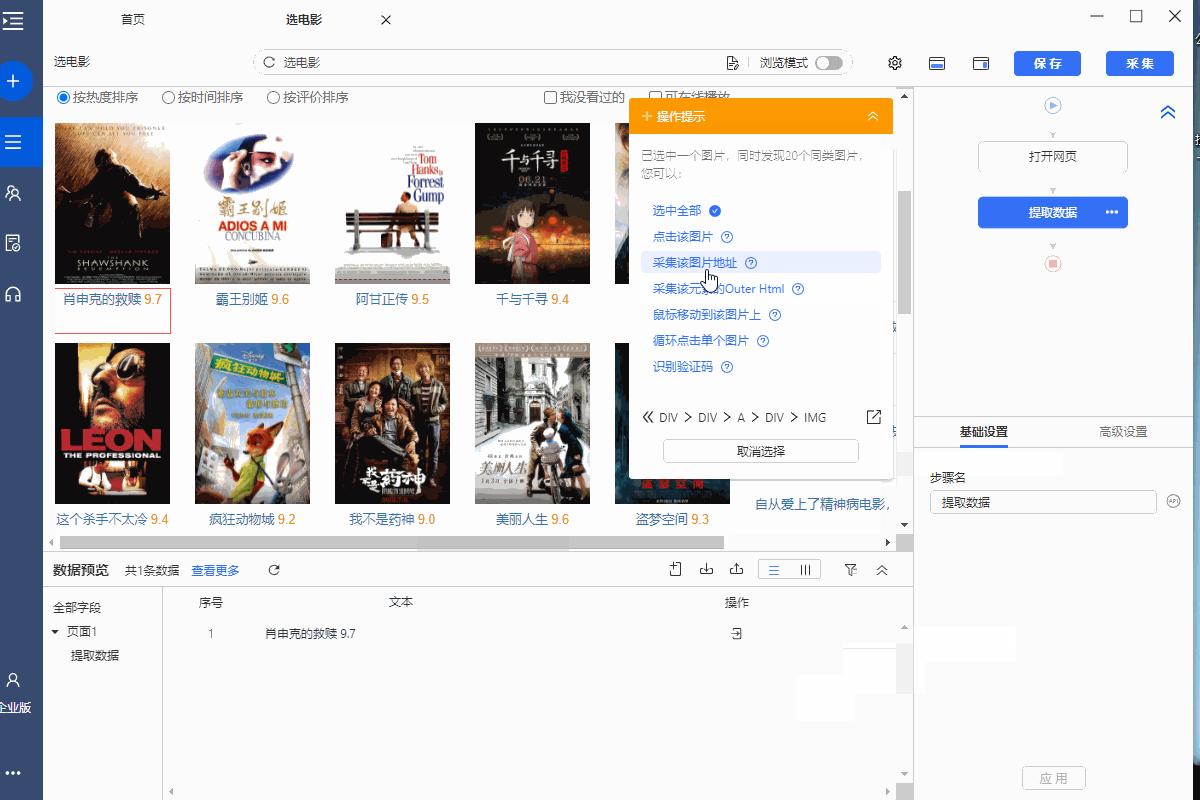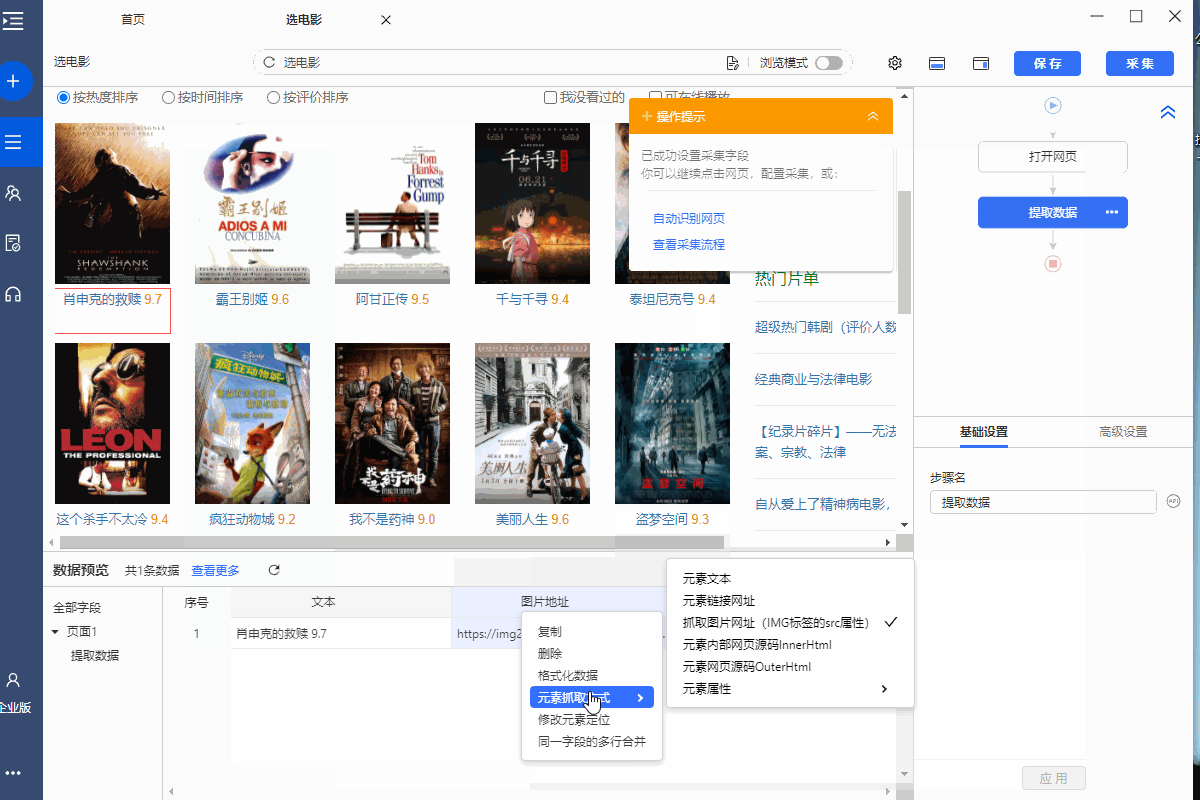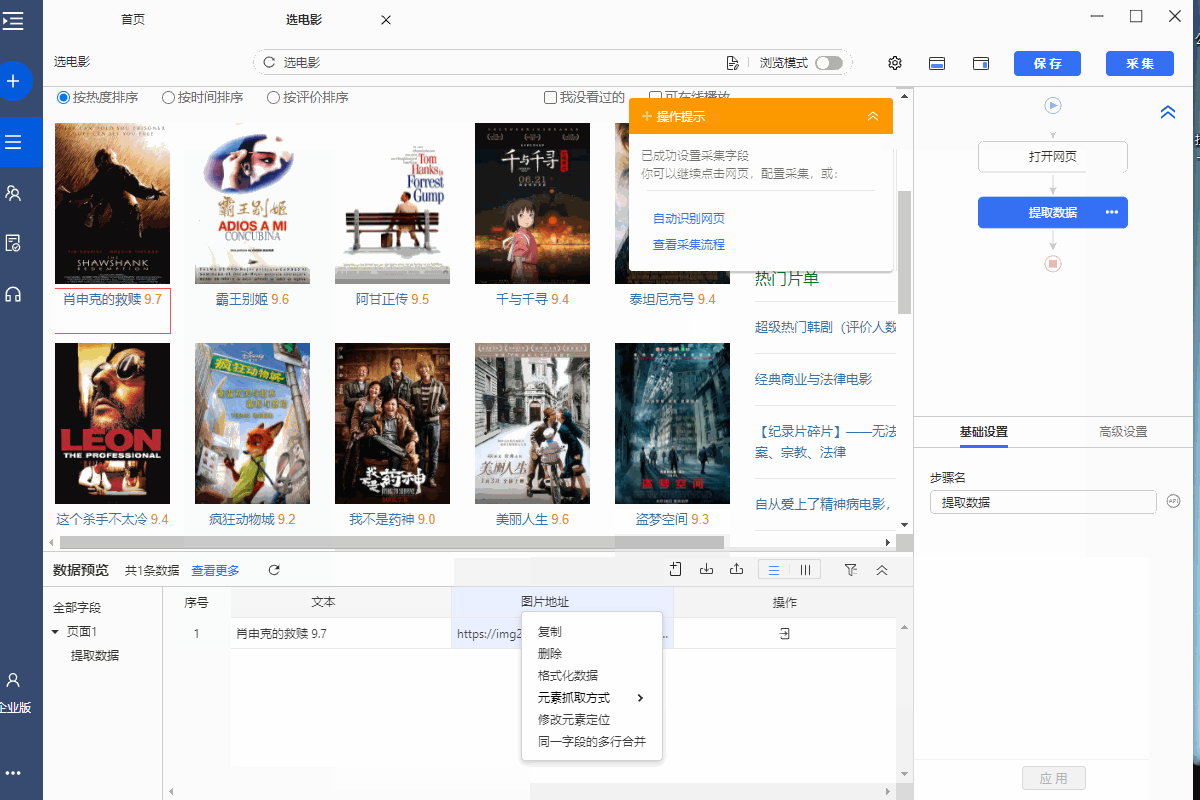
操作:鼠标选中页面上的图片,在弹出的操作提示中选择【采集此图片地址】,即可提取图片URL。
同时,将鼠标移至视野名称【图片地址】,点击?
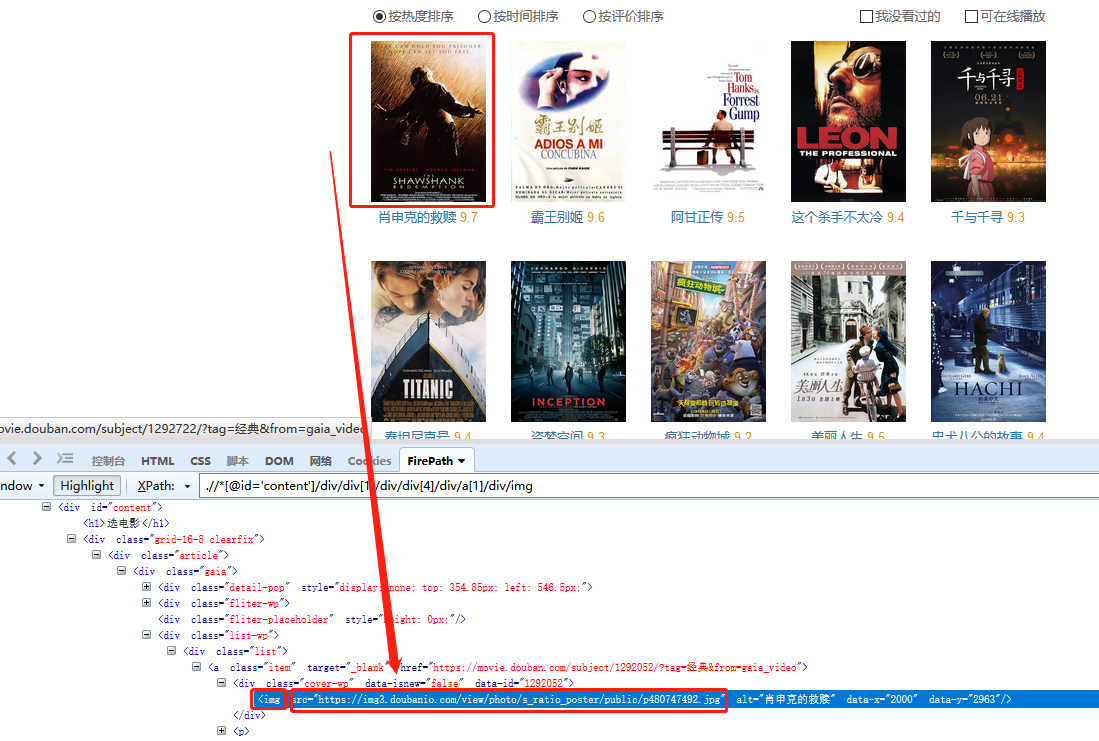
? 按钮,选择【自定义抓取方式】,可以选择优采云为我们自动【抓取图片URL(IMG标签的src属性)】。
为什么是【IMG 标签的 src 属性】?在XPath教程中,我们讲了网页Html的相关知识。网页上的图片一般用IMG标签表示,图片地址会在IMG标签的src属性中。
因此,当我们要提取图片的 URL 时,本质上是使用 XPath 来定位 Img 标签,然后从 IMG 标签中提取 src 属性。src 属性的值是图像 URL。
这里演示的只是抓取图片时使用的抓取方式。具体图片采集请看教程:图片采集并下载到本地
3、爬取链接URL,抓取网页上超链接的URL
示例网址:
例如
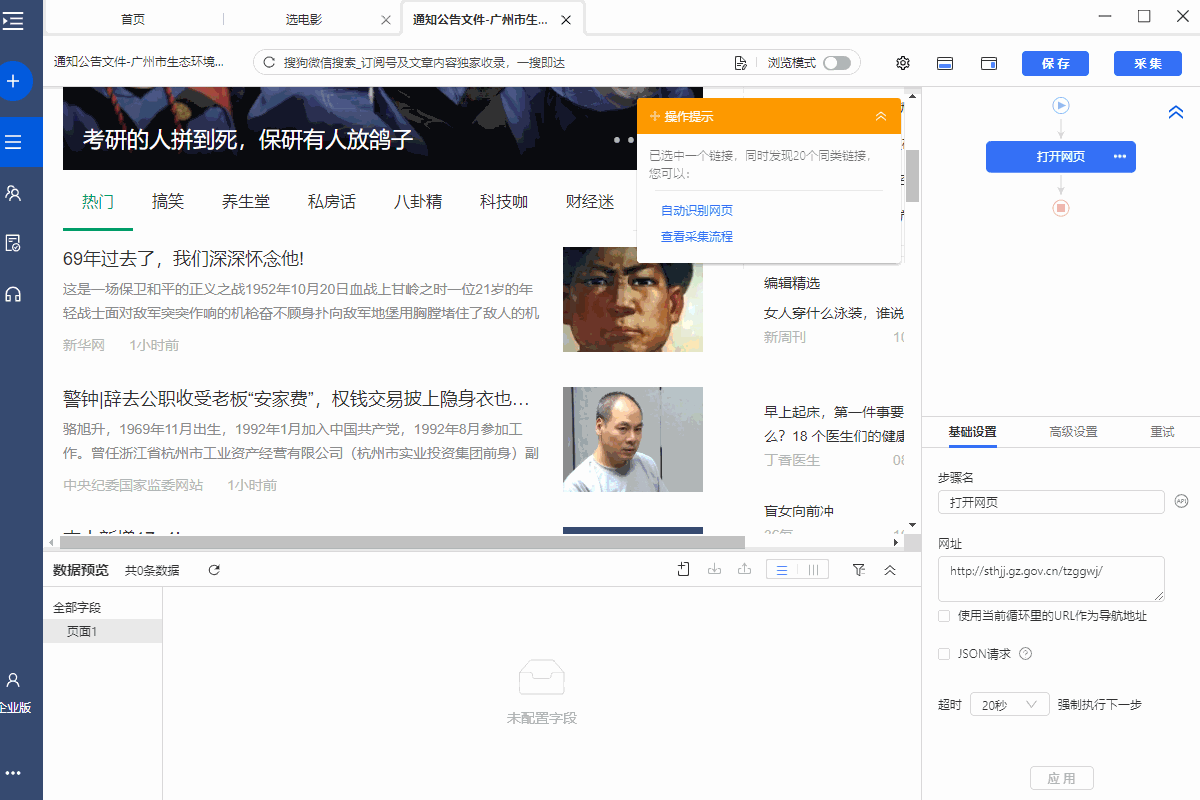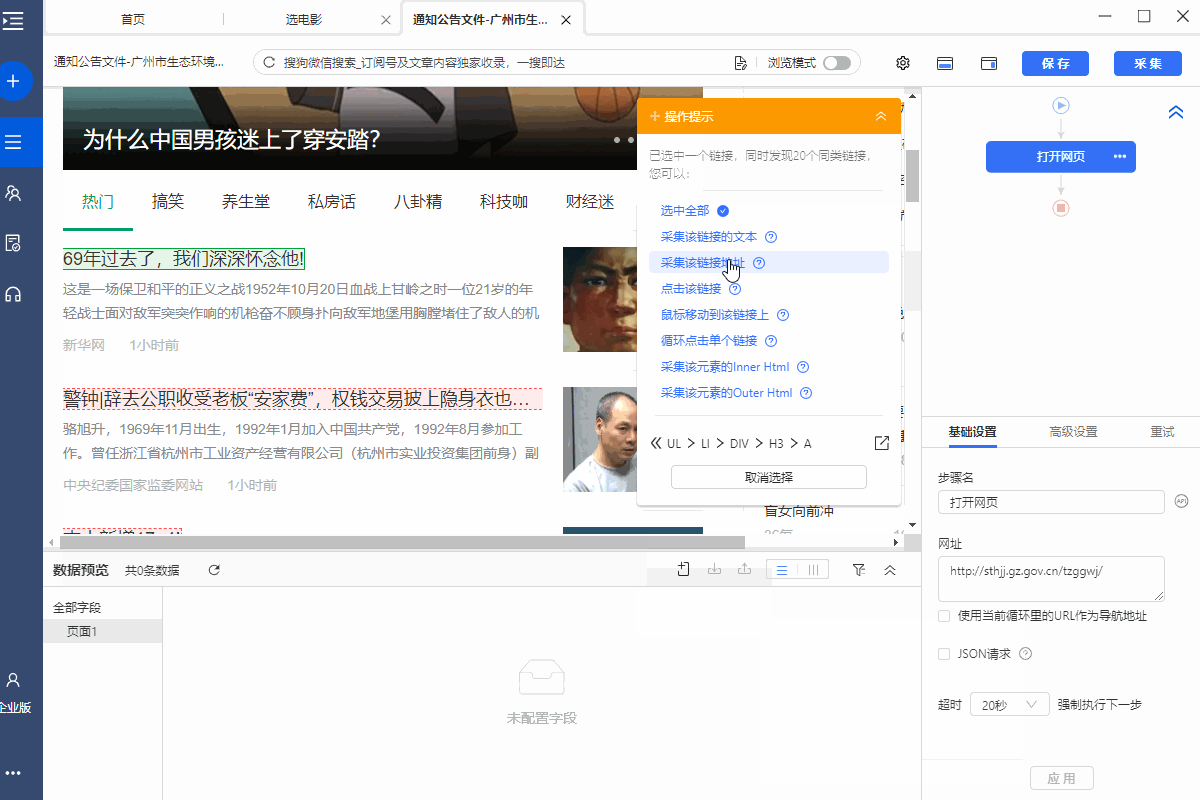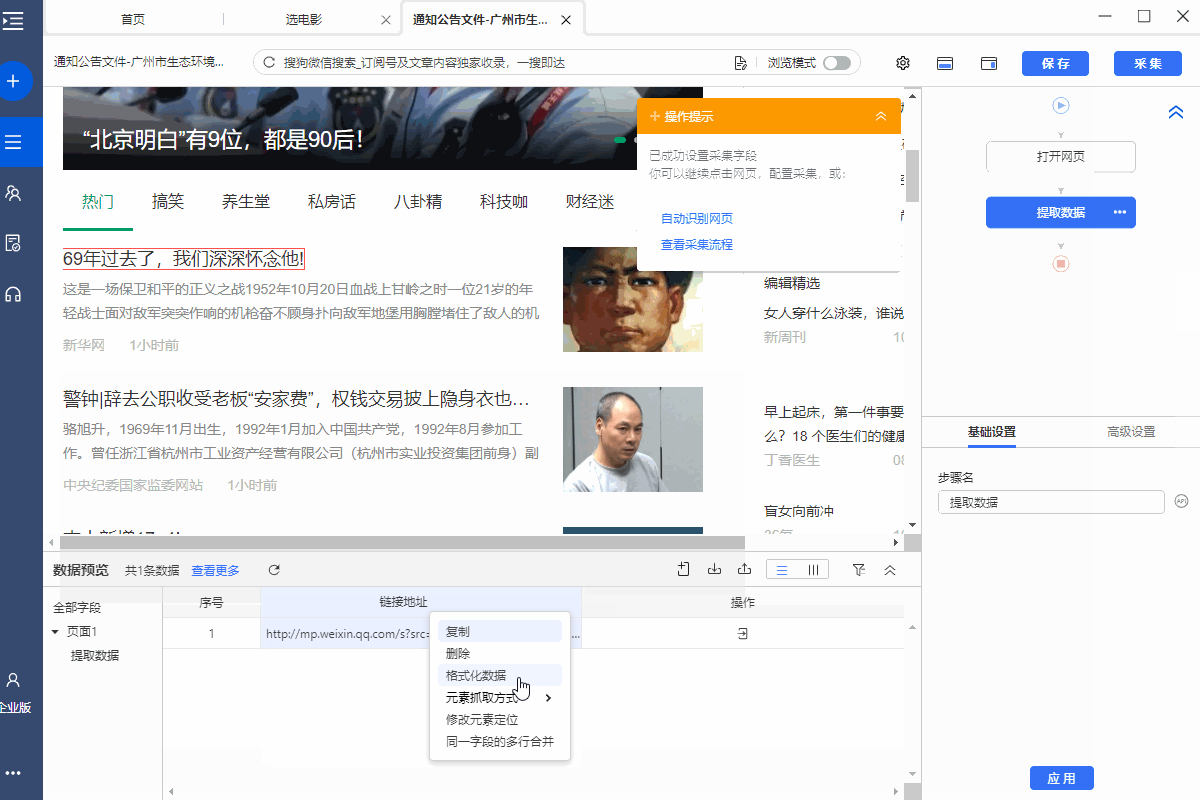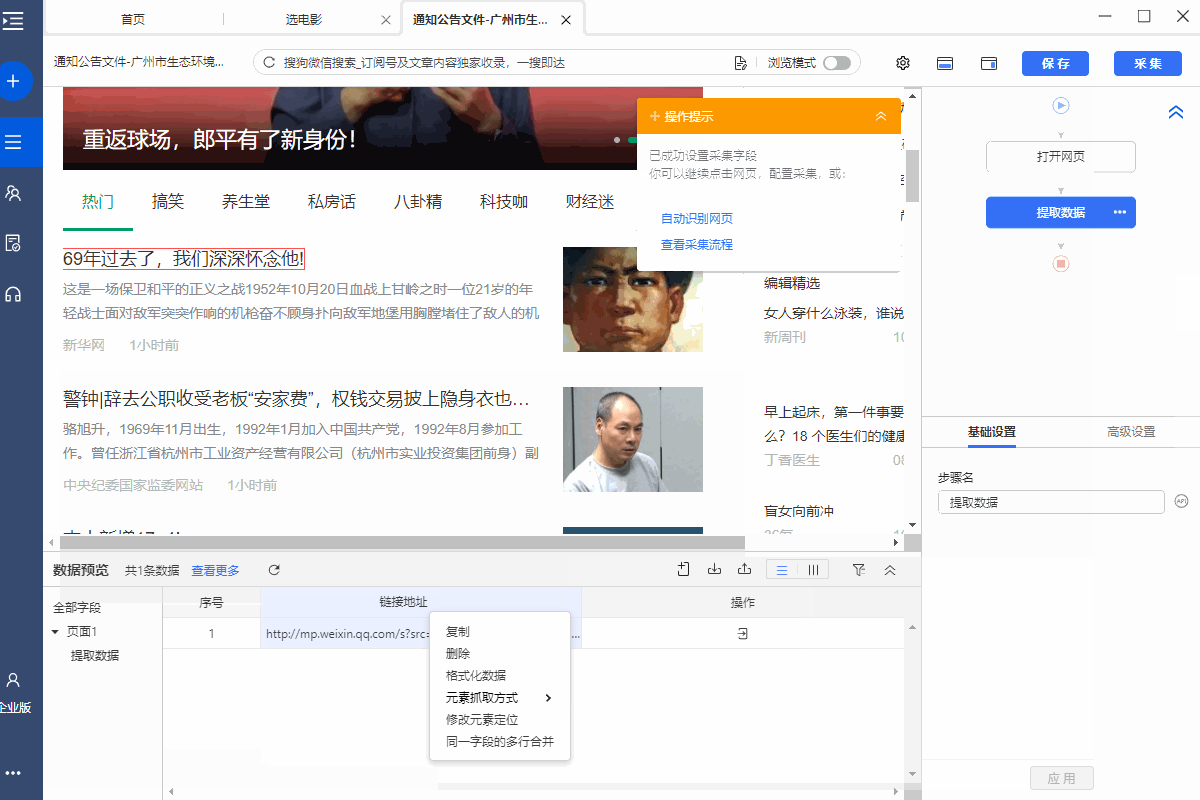
操作:用鼠标选中页面中的超链接(一般是滚动标题文字,可点击跳转),弹出操作提示图片选择【采集此链接地址】,提取超链接URL。
同时,将鼠标移至字段名称【链接地址】,点击?
? 按钮,选择【自定义抓取方式】,可以选择优采云自动给我们【元素链接URL】。
4、抓取输入框文本值:抓取输入框文本
示例网址:
%E9%9C%B8%E7%8E%8B%E5%88%AB%E5%A7%AC&cat=1002
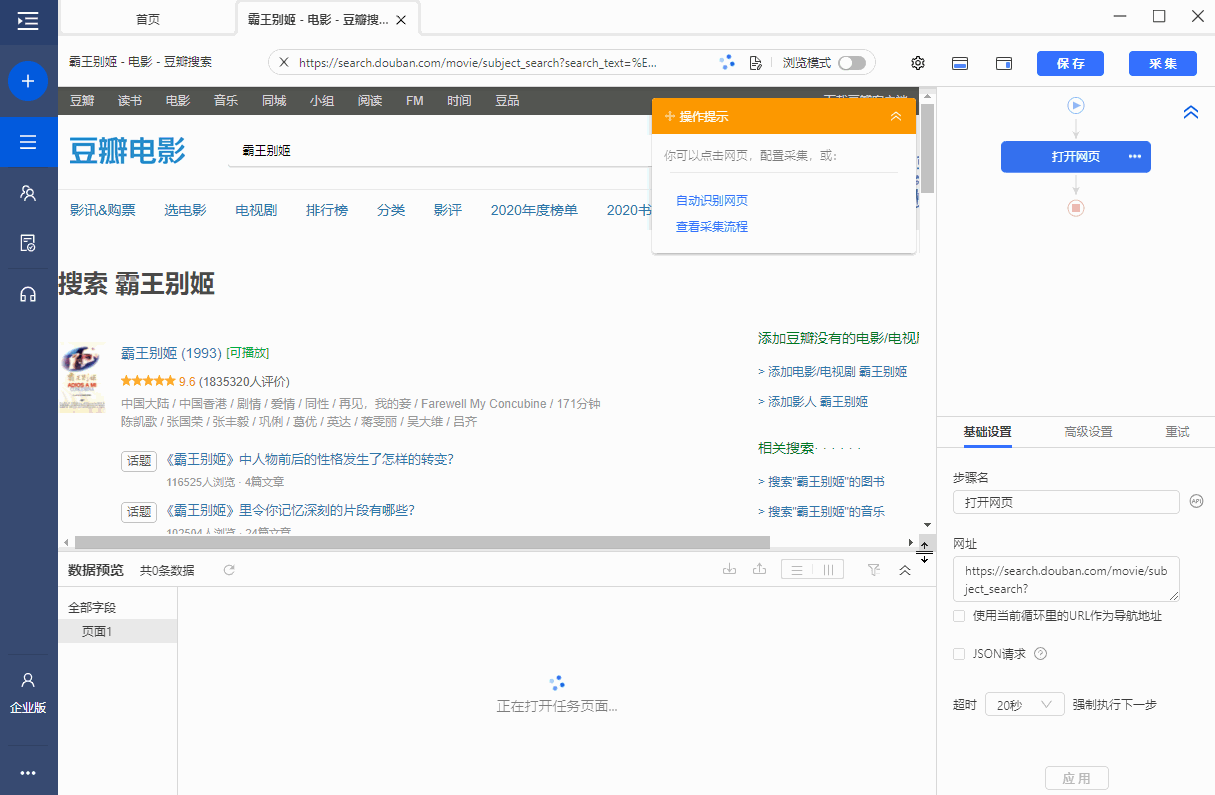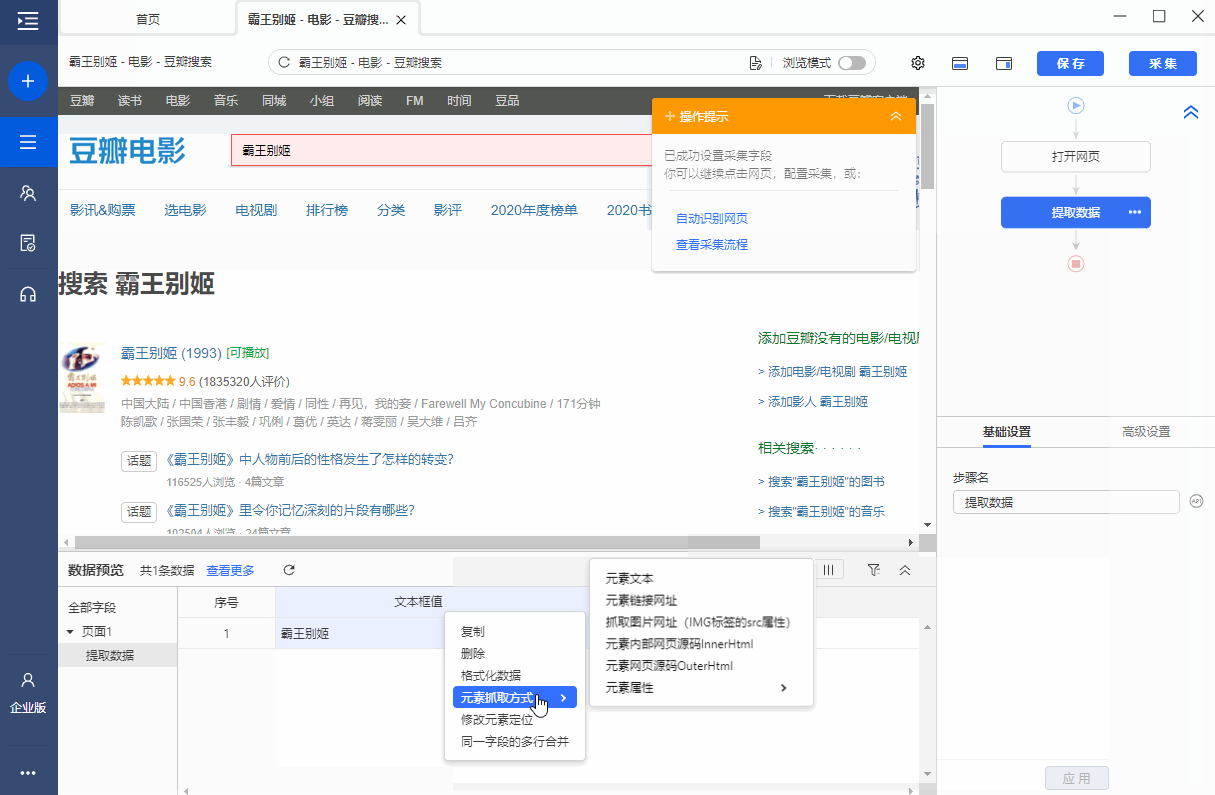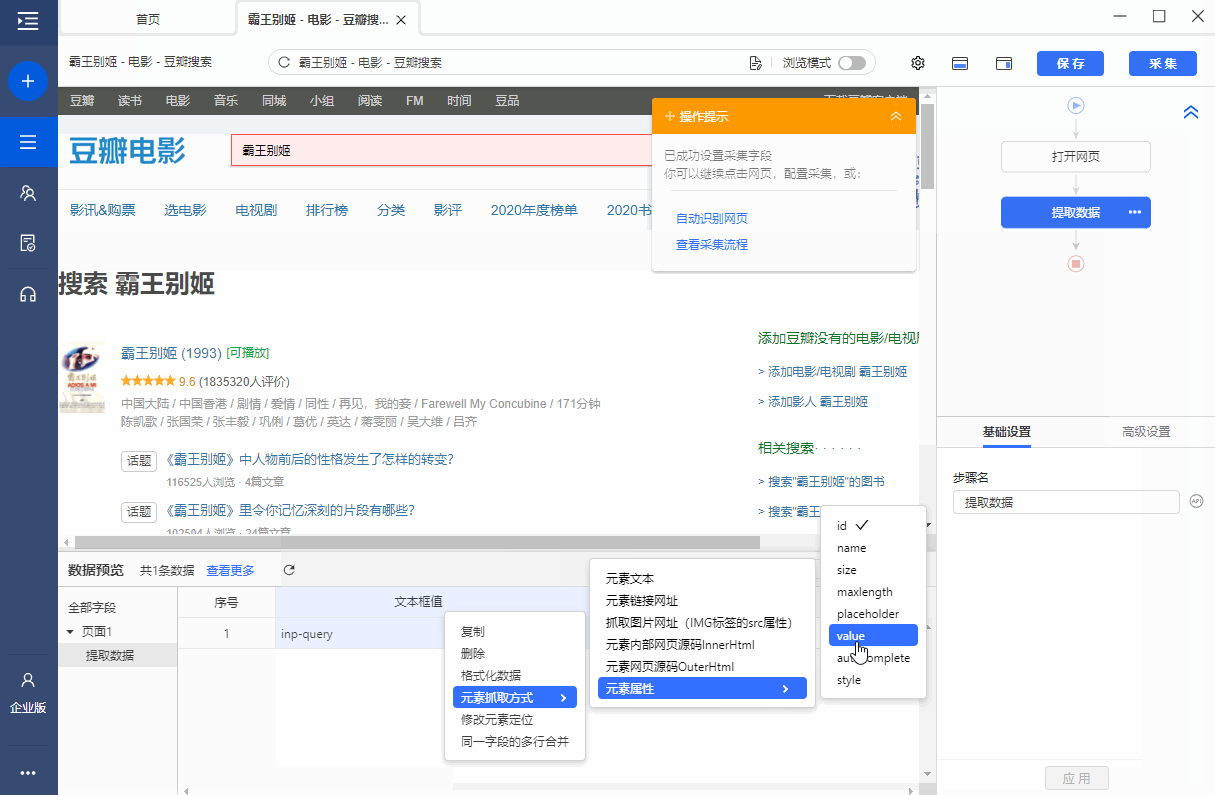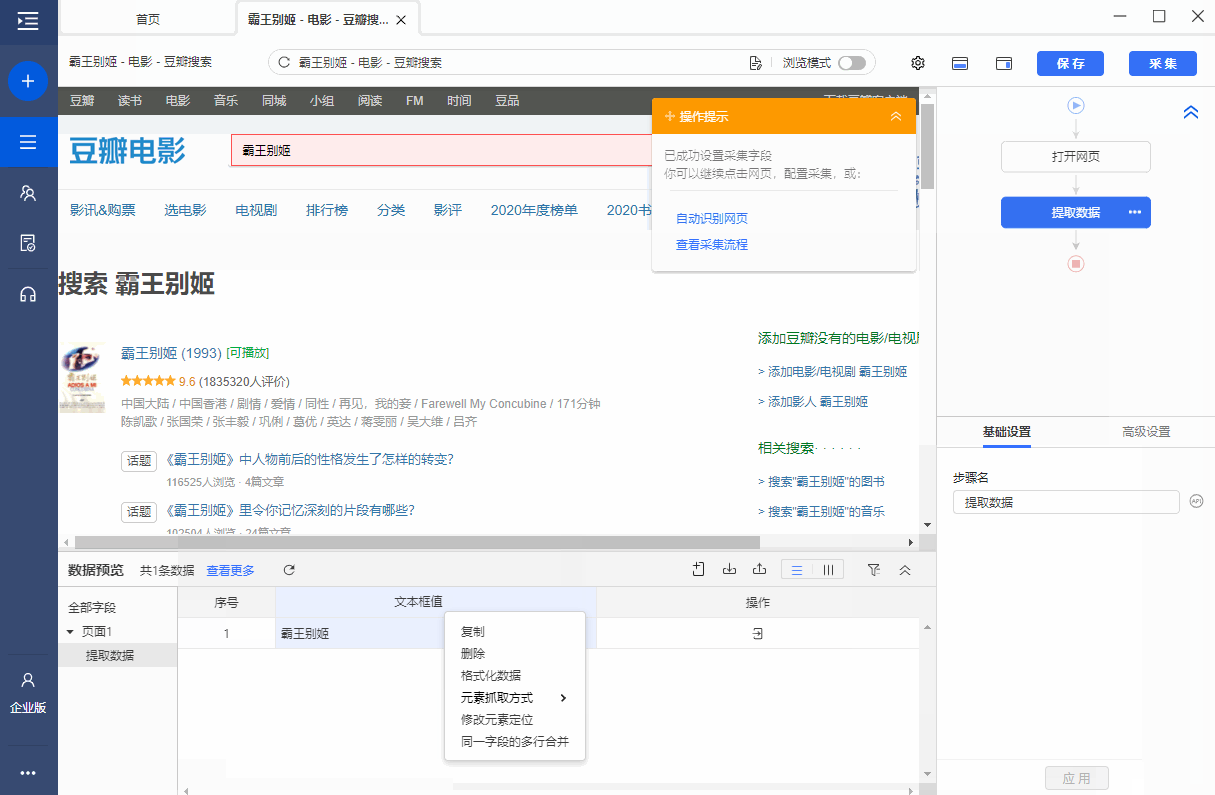
操作:鼠标选中页面中输入的文本(输入已有的输入值),在弹出文本的操作提示中选择[采集文本框的值],关键词 的文本输入框将被提取。.
同时,将鼠标移动到字段名称【文本框值】上,点击?
? 按钮是自动的,选择【自定义捕获方式】,测试发现文本框值是value属性。
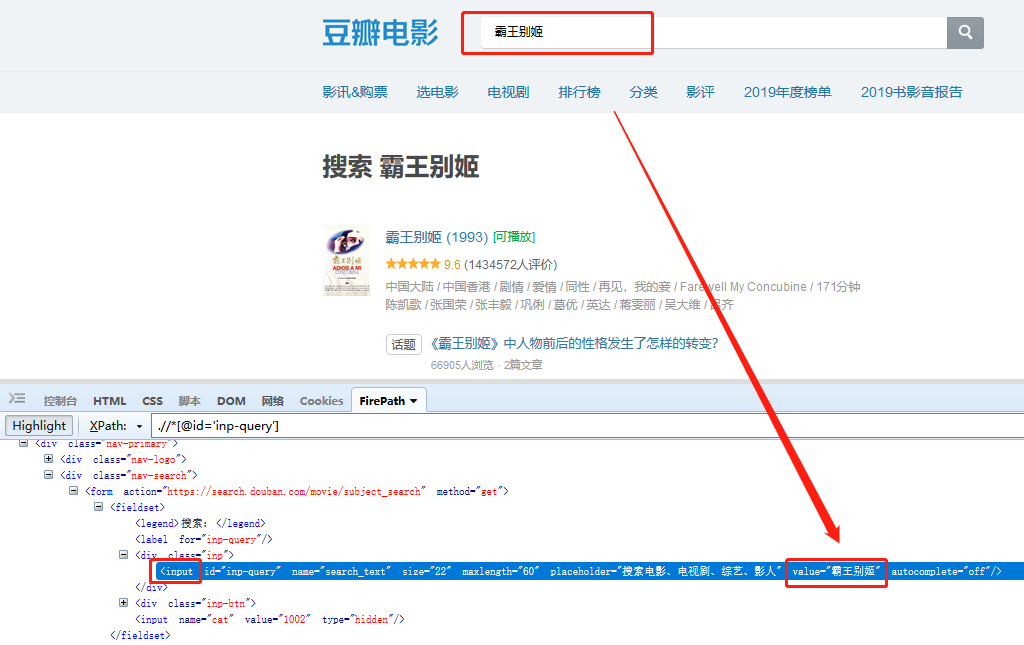
为什么是【INPUT标签的value属性】在XPath教程中,我们讲了网页Html的相关知识,网页上的输入框一般都是用INPUT标签显示的,输入的关键词在文本输入中会显示在INPUT 中吗?在标签的 value 属性中。
,当我们要提取文本详情的关键词时,本质上是使用XPath来定位INPUT标签,所以我们从INPUT标签中提取value属性,value属性的值就是关键词 的输入细节。
5、抓取网页源码:抓取网页元素自动网页爬虫源码
示例 URL:%E5%B0%8F%E8%AF%B4
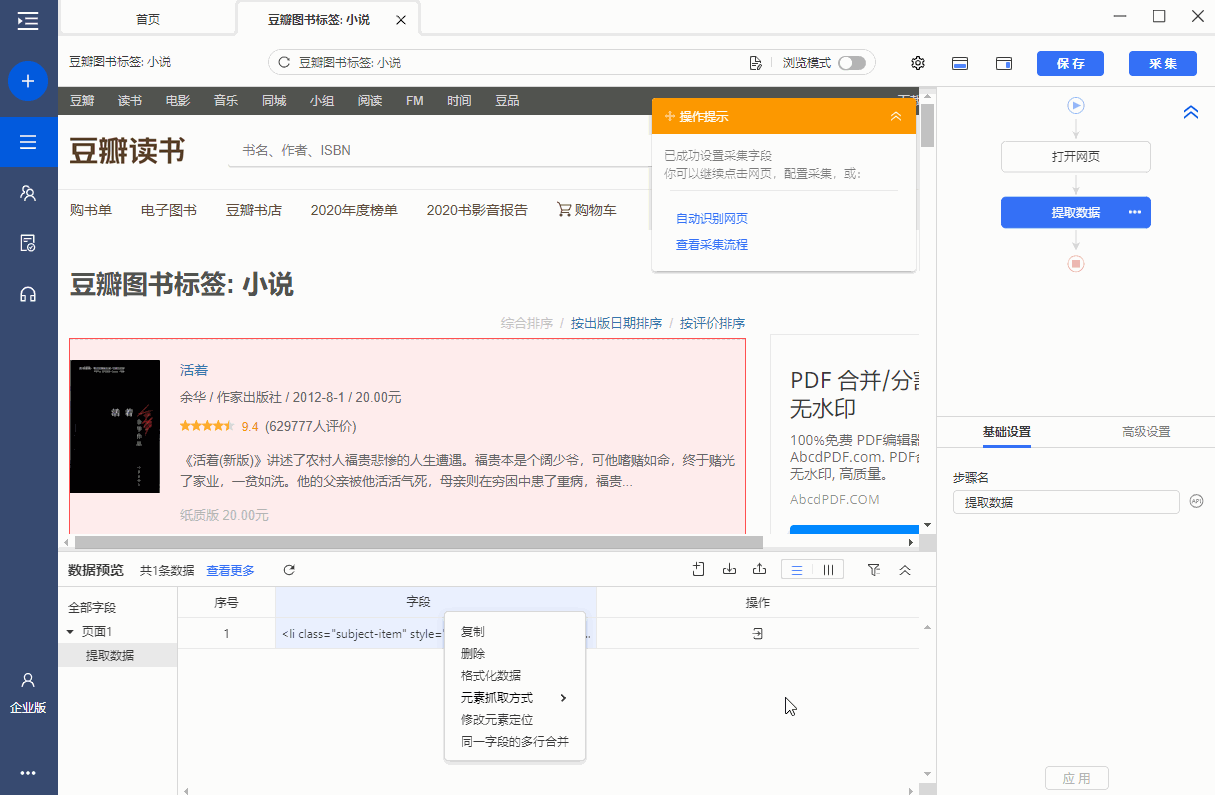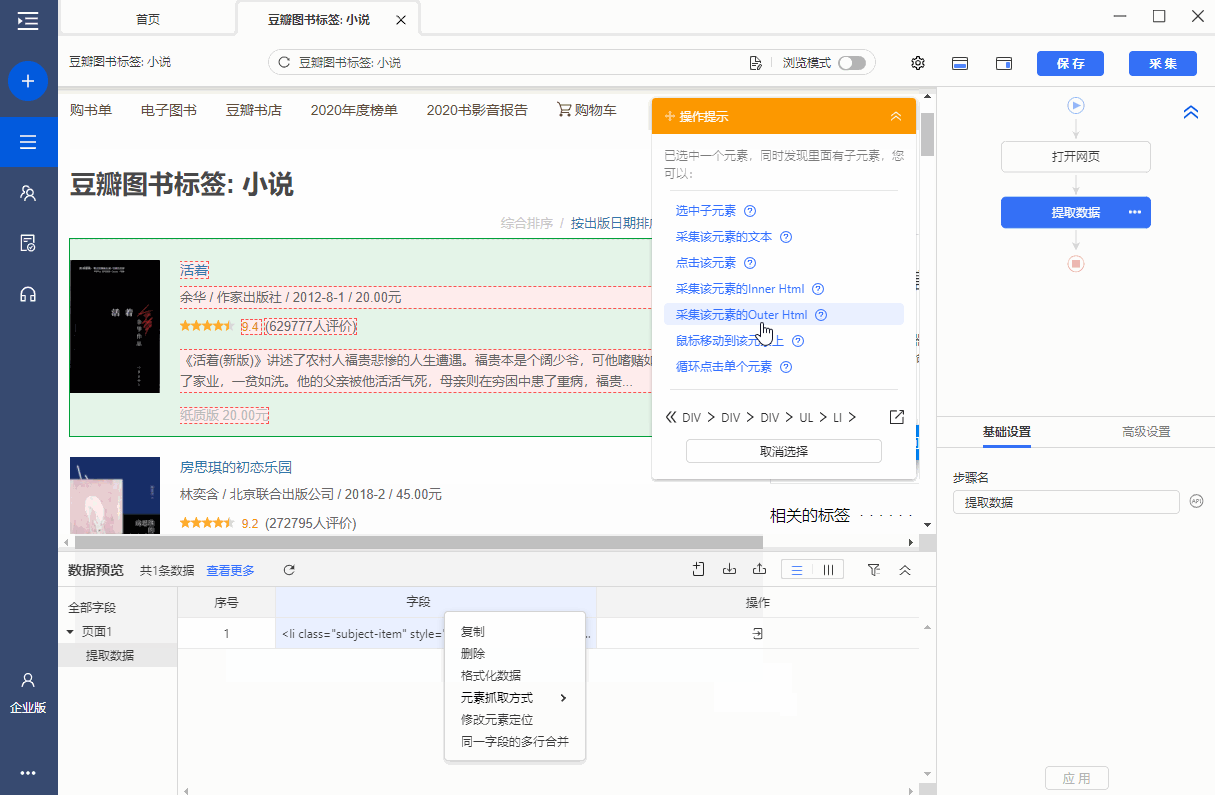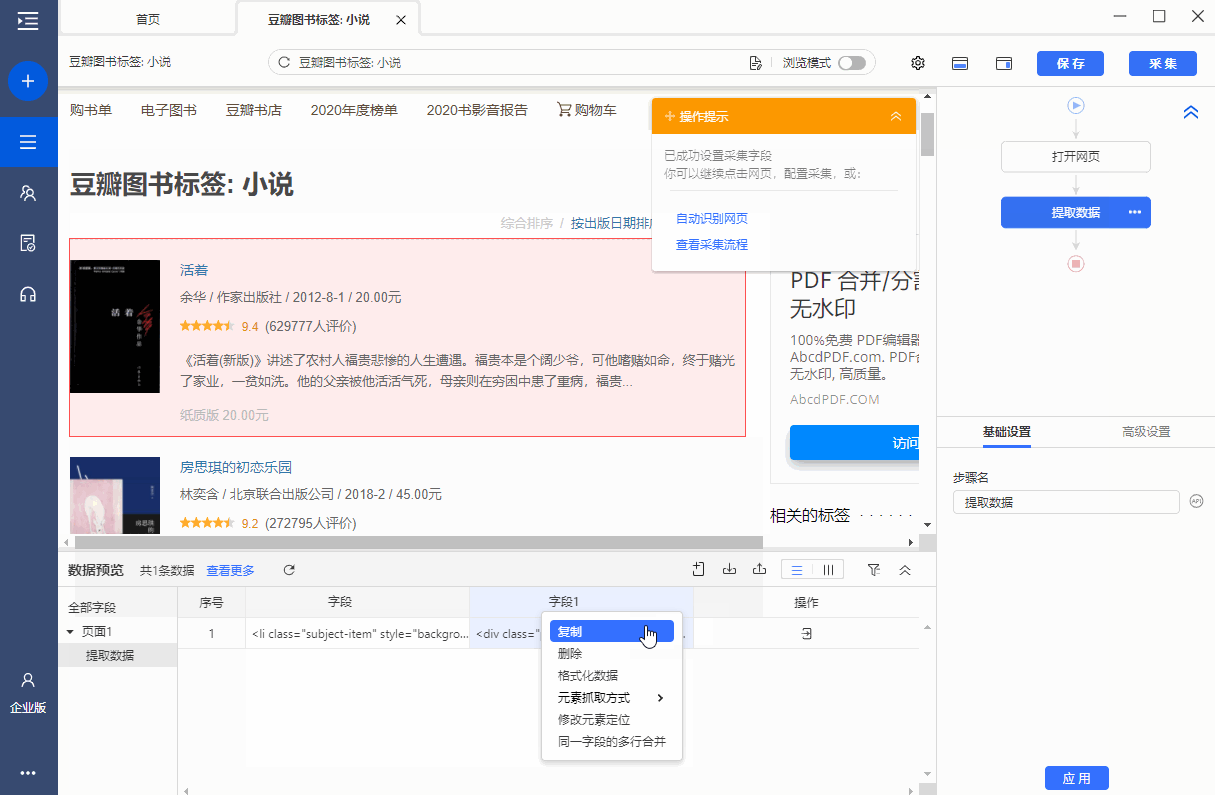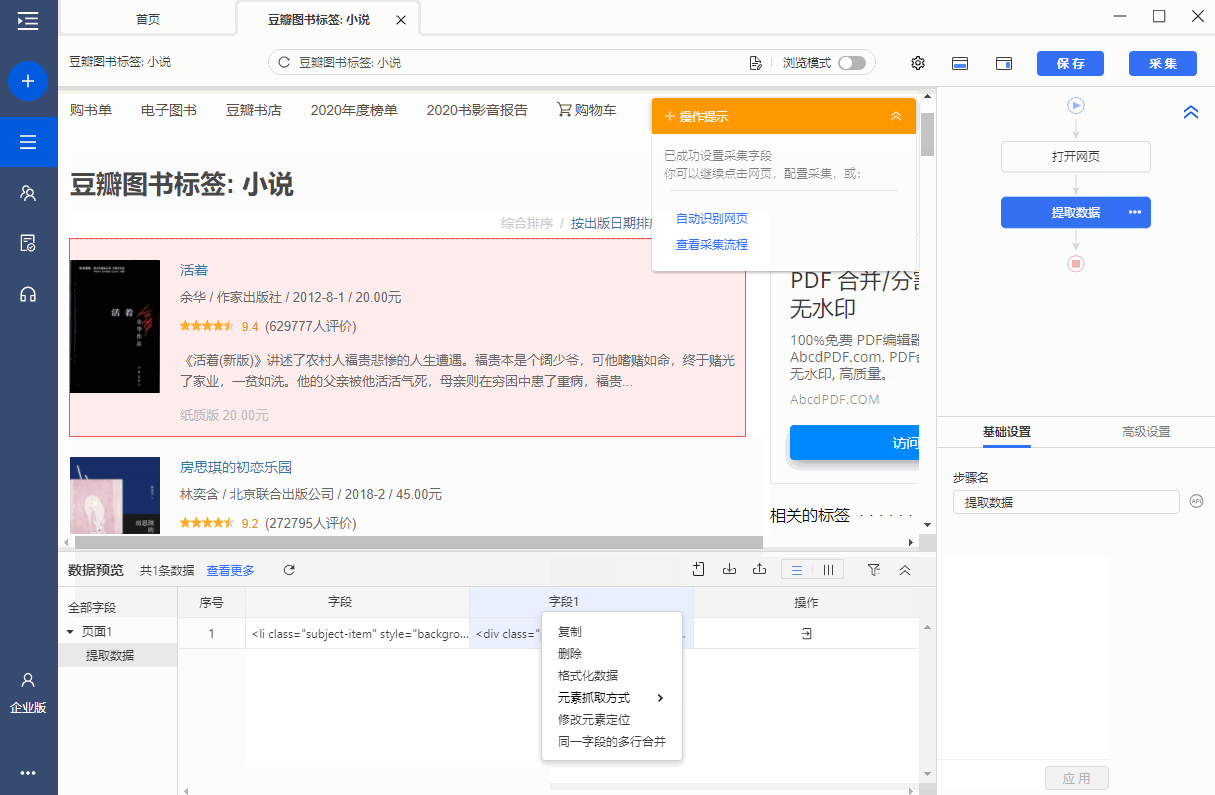
爬取网页源代码 Outer Html?
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择【采集Outer Html of this element】,该元素对应的源(Outer Html)为由 采集 下载。
同时,将鼠标移至字段名称[OuterHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云自动为我们选择了【抓取元素(外层Html)的网页源码。
爬取网页源码 Inner Html
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择采集元素的Inner Html,该元素对应的源(InnerHtml)为< @采集 下来。
同时,将鼠标移动到字段名称[InnerHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云已经自动为我们选择了【抓取元素(Inner Html)的网页源码。
自动网页抓取?
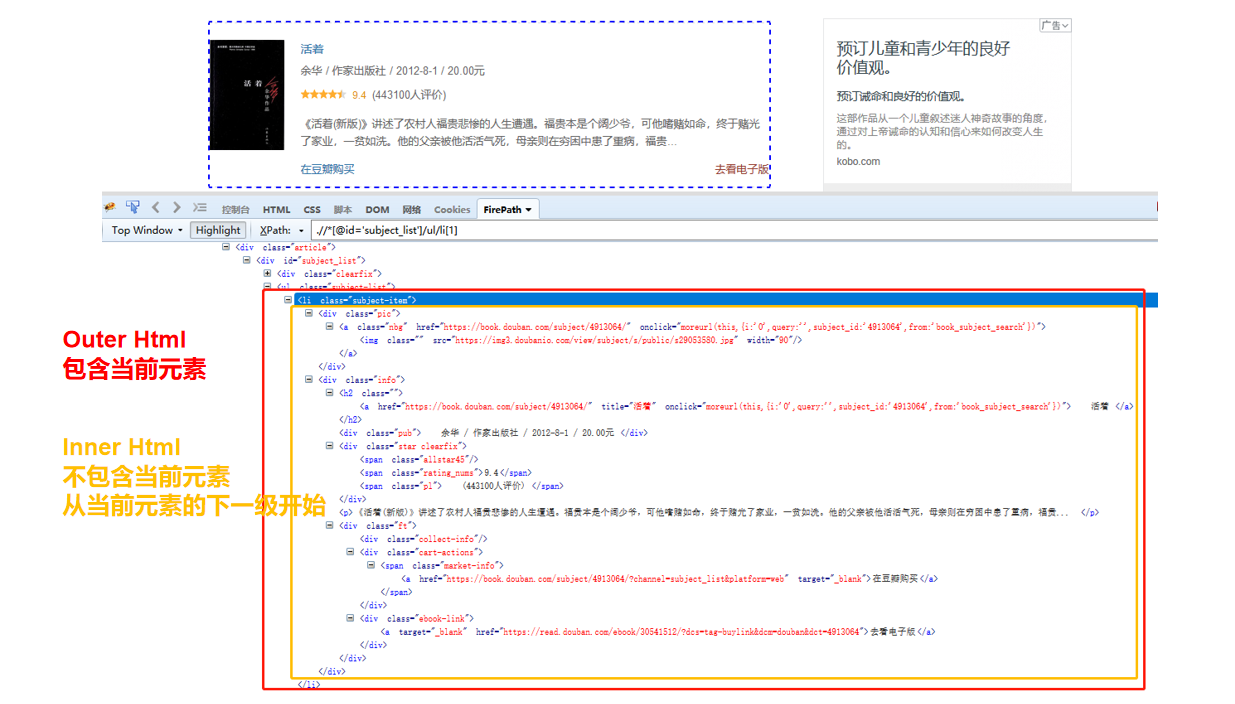
外部 Html 和内部 Html 有什么区别?
外层Html:收录当前元素
Inner Html:不收录当前元素,从当前元素的下一级开始
6、抓取元素属性值
首先使用XPath找到当前元素的来源,观察当前资源中存在哪些属性值,需要提取哪些属性值,然后将已有的和需要的属性值分开。
示例 URL:%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6 %9C%BA&page=7&s=177&click=0
脚步:
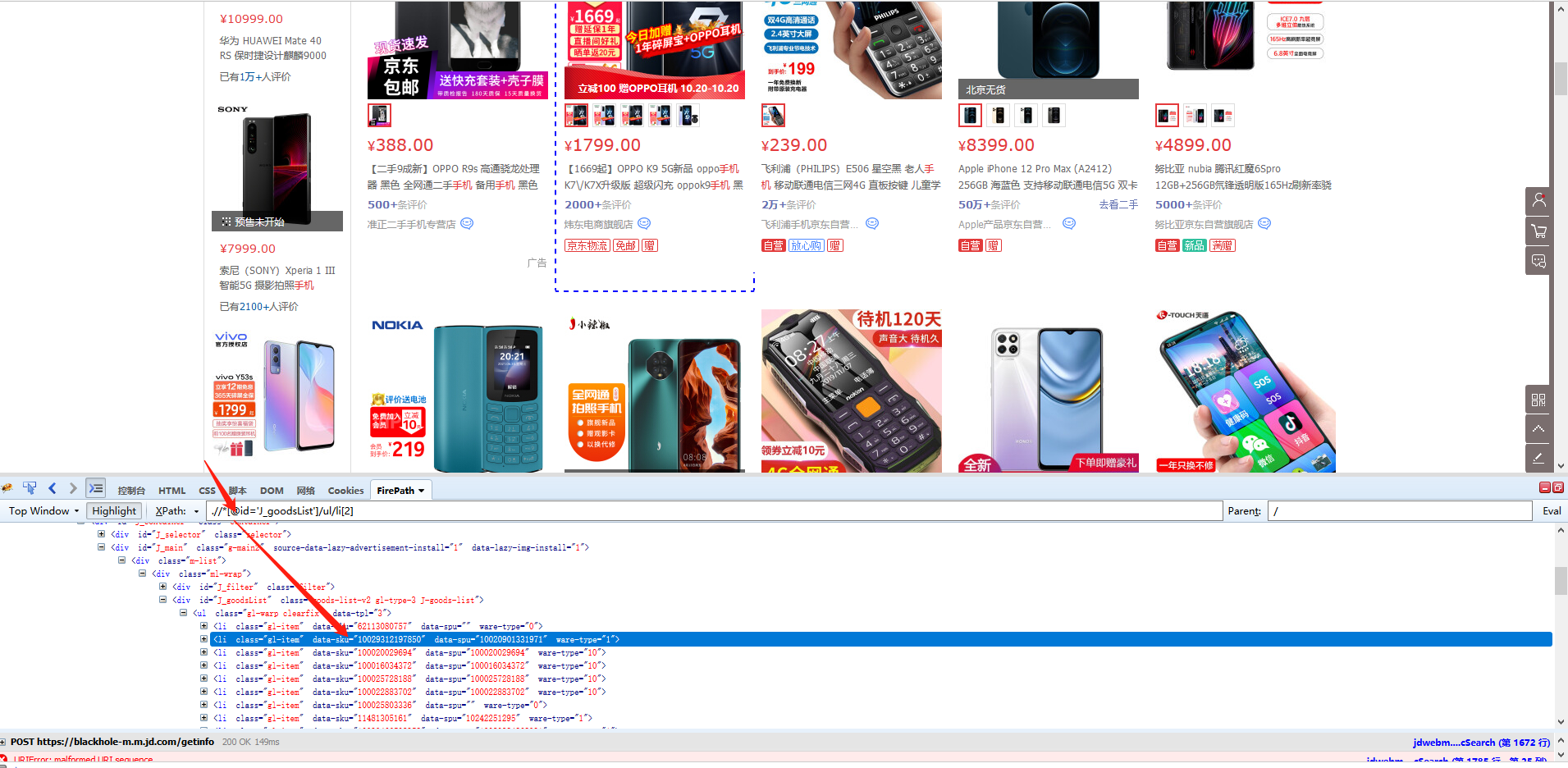
圆点是京东产品列表页面。每个产品都有一个产品 ID,现在需要 采集 这个产品 ID。
第一个商品列表的定位XPath为*[@id='J_goodsList']/ul/li[2],对应的网页源码包括class、data-sku、data-spu、ware-type。商品ID在data-sku属性中,我们需要抓取这个,也就是data-sku属性的属性值。
我们先选择第二个产品列表,在弹出的操作提示文字中,选择【this 采集本步骤的文字】,就是为了得到定位列表的XPath。
我们要抓取的是data-pid的属性值,所以将鼠标移动到字段名【文本,点击?
?、选择【自定义抓取方式】,将抓取方式改为【抓取元素属性】值】,并在下拉值中,选择【data-sku】,这样我们就设置data的值- sku属性采集下来,这是我们需要的产品ID。最后点击【应用】保存配置。
查看全部
c 抓取网页数据(IMG标签的抓取图片网址(组图)
)
网页上的数据类型非常详细:文字、图片、链接、源码等。在data采集过程中,不同类型的数据有不同的对应抓取方式。本文将详细介绍数据类型的类型以及如何捕获它们。
示例 URL:#!type=movie&tag=%E7%BB%8F%E5%85%B8&sort=recommend&page_limit=20&page_start=0
1、抓取文字:抓取页面显示的文字
操作:鼠标选中页面中的文本,在弹出的操作提示文本中选择[采集 of this element],目标文本会向下采集。
同时,将鼠标移动到字段名称【文本】上,点击?

? 按钮,选择【自定义捕捉方式】,可以为我们选择章鱼鱼的自动文字。
2、 Crawl Image URL:要抓取的图片的URL
操作:鼠标选中页面上的图片,在弹出的操作提示中选择【采集此图片地址】,即可提取图片URL。
同时,将鼠标移至视野名称【图片地址】,点击?
? 按钮,选择【自定义抓取方式】,可以选择优采云为我们自动【抓取图片URL(IMG标签的src属性)】。
为什么是【IMG 标签的 src 属性】?在XPath教程中,我们讲了网页Html的相关知识。网页上的图片一般用IMG标签表示,图片地址会在IMG标签的src属性中。
因此,当我们要提取图片的 URL 时,本质上是使用 XPath 来定位 Img 标签,然后从 IMG 标签中提取 src 属性。src 属性的值是图像 URL。
这里演示的只是抓取图片时使用的抓取方式。具体图片采集请看教程:图片采集并下载到本地
3、爬取链接URL,抓取网页上超链接的URL
示例网址:
例如
操作:用鼠标选中页面中的超链接(一般是滚动标题文字,可点击跳转),弹出操作提示图片选择【采集此链接地址】,提取超链接URL。
同时,将鼠标移至字段名称【链接地址】,点击?
? 按钮,选择【自定义抓取方式】,可以选择优采云自动给我们【元素链接URL】。
4、抓取输入框文本值:抓取输入框文本
示例网址:
%E9%9C%B8%E7%8E%8B%E5%88%AB%E5%A7%AC&cat=1002
操作:鼠标选中页面中输入的文本(输入已有的输入值),在弹出文本的操作提示中选择[采集文本框的值],关键词 的文本输入框将被提取。.
同时,将鼠标移动到字段名称【文本框值】上,点击?
? 按钮是自动的,选择【自定义捕获方式】,测试发现文本框值是value属性。
为什么是【INPUT标签的value属性】在XPath教程中,我们讲了网页Html的相关知识,网页上的输入框一般都是用INPUT标签显示的,输入的关键词在文本输入中会显示在INPUT 中吗?在标签的 value 属性中。
,当我们要提取文本详情的关键词时,本质上是使用XPath来定位INPUT标签,所以我们从INPUT标签中提取value属性,value属性的值就是关键词 的输入细节。
5、抓取网页源码:抓取网页元素自动网页爬虫源码
示例 URL:%E5%B0%8F%E8%AF%B4
爬取网页源代码 Outer Html?
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择【采集Outer Html of this element】,该元素对应的源(Outer Html)为由 采集 下载。
同时,将鼠标移至字段名称[OuterHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云自动为我们选择了【抓取元素(外层Html)的网页源码。
爬取网页源码 Inner Html
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择采集元素的Inner Html,该元素对应的源(InnerHtml)为< @采集 下来。
同时,将鼠标移动到字段名称[InnerHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云已经自动为我们选择了【抓取元素(Inner Html)的网页源码。
自动网页抓取?
外部 Html 和内部 Html 有什么区别?
外层Html:收录当前元素
Inner Html:不收录当前元素,从当前元素的下一级开始
6、抓取元素属性值
首先使用XPath找到当前元素的来源,观察当前资源中存在哪些属性值,需要提取哪些属性值,然后将已有的和需要的属性值分开。
示例 URL:%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6 %9C%BA&page=7&s=177&click=0
脚步:
圆点是京东产品列表页面。每个产品都有一个产品 ID,现在需要 采集 这个产品 ID。
第一个商品列表的定位XPath为*[@id='J_goodsList']/ul/li[2],对应的网页源码包括class、data-sku、data-spu、ware-type。商品ID在data-sku属性中,我们需要抓取这个,也就是data-sku属性的属性值。
我们先选择第二个产品列表,在弹出的操作提示文字中,选择【this 采集本步骤的文字】,就是为了得到定位列表的XPath。
我们要抓取的是data-pid的属性值,所以将鼠标移动到字段名【文本,点击?
?、选择【自定义抓取方式】,将抓取方式改为【抓取元素属性】值】,并在下拉值中,选择【data-sku】,这样我们就设置data的值- sku属性采集下来,这是我们需要的产品ID。最后点击【应用】保存配置。
c 抓取网页数据(百度中搜索一个使用webmagic:数据库Mongodb驱动使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-18 15:19
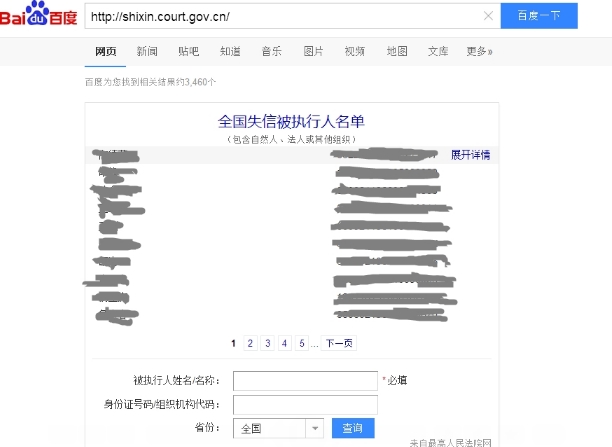
当我们在百度搜索的时候,会有一个嵌入的查询页面:
这是通过ajax技术加载的,因为是js渲染,所以页面源码中不收录这个信息。
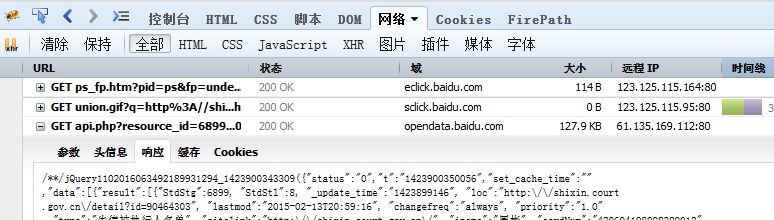
通过火狐的Firebug监听网络请求,发现请求是到百度opendata,结果返回一个收录100条数据的json
这样,通过分析请求字符串的参数,自定义请求,就可以让爬虫直接爬取数据。
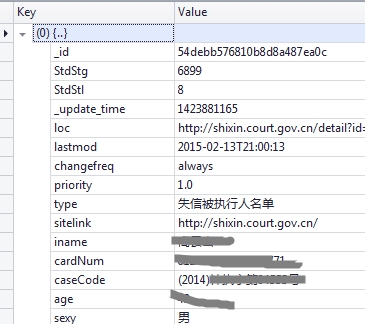
获得数据后,您需要对其进行解析。每个请求将返回 100 条数据。现在您需要将这 100 条数据全部删除,并将它们存储在 Mongodb 数据库中。
爬虫使用 webmagic:
数据库MongoDB驱动使用
行家坐标:
us.codecraft
webmagic-extension
0.5.2
org.mongodb
mongo-java-driver
2.7.3
Webmagic爬虫框架使用参考:
我在爬取过程中自定义了PageProcessor,将数据解析并存储在Mongodb中,并使用爬虫框架自带的FilePipeline将数据持久化到磁盘文件中。
每个请求返回100条数据,需要分析分离成单独的json字符串,然后一一插入。
插入数据时,还要判断数据是否重复。
json格式的字符串可以直接存入数据库。
Mongo mongo = new Mongo();
DB db = mongo.getDB("shixinTest");
DBCollection q=db.getCollection("shixinTest1");
// new BasicDBObject();
// 通过JSON.parse构造DBObject
DBObject query = (BasicDBObject) JSON.parse(JsonString)
q.save(query);
json字符串存储在mongodb数据库中:
爬虫实现部分是:抓取网络json数据,存入mongodb(2) 查看全部
c 抓取网页数据(百度中搜索一个使用webmagic:数据库Mongodb驱动使用)
当我们在百度搜索的时候,会有一个嵌入的查询页面:
这是通过ajax技术加载的,因为是js渲染,所以页面源码中不收录这个信息。
通过火狐的Firebug监听网络请求,发现请求是到百度opendata,结果返回一个收录100条数据的json
这样,通过分析请求字符串的参数,自定义请求,就可以让爬虫直接爬取数据。
获得数据后,您需要对其进行解析。每个请求将返回 100 条数据。现在您需要将这 100 条数据全部删除,并将它们存储在 Mongodb 数据库中。
爬虫使用 webmagic:
数据库MongoDB驱动使用
行家坐标:
us.codecraft
webmagic-extension
0.5.2
org.mongodb
mongo-java-driver
2.7.3
Webmagic爬虫框架使用参考:
我在爬取过程中自定义了PageProcessor,将数据解析并存储在Mongodb中,并使用爬虫框架自带的FilePipeline将数据持久化到磁盘文件中。
每个请求返回100条数据,需要分析分离成单独的json字符串,然后一一插入。
插入数据时,还要判断数据是否重复。
json格式的字符串可以直接存入数据库。
Mongo mongo = new Mongo();
DB db = mongo.getDB("shixinTest");
DBCollection q=db.getCollection("shixinTest1");
// new BasicDBObject();
// 通过JSON.parse构造DBObject
DBObject query = (BasicDBObject) JSON.parse(JsonString)
q.save(query);
json字符串存储在mongodb数据库中:
爬虫实现部分是:抓取网络json数据,存入mongodb(2)
c 抓取网页数据(定制网页数据存储结构,保存相应数据(c抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-16 19:11
c抓取网页数据有多种方法,可以采用python、numpy、pandas等。但直接抓取网页数据库中的数据有时会显得格格不入。这就需要我们定制网页数据存储结构,保存相应数据。首先抓取的数据以文本格式保存,例如:{[user_id]:user_id,[age]:age}这种数据特点在于,抓取过程中没有对user_id做任何处理,我们直接将其存储在文本中。
但对于爬虫,这种存储形式容易给浏览器造成压力,最常见的原因是:每次爬取的数据都要在下次抓取网页时进行一次user_id的去重。可以尝试使用bs4(beautifulsoup4)+bs4.extract()方法来解决这个问题。先看下bs4中的方法的用法:extract方法的核心用法可以参看《python3网络爬虫基础知识》extract方法的4个参数说明:url(获取页面的url):获取第一页或者第二页以及每页的页面地址。
headers(发送给浏览器的headers信息):发送一个请求、重定向到调用该页面的对应url。image(请求图片文件):发送一个请求、重定向到当前页所在网页。python图片处理库的使用extract.python_python.content.scrapy.content_to_json(pythoncontent转换json格式):其实就是网页上已经存在的json数据变成bson格式(纯python方法,只需要模拟浏览器点击图片,这里记住,图片请求会发送一个浏览器地址,并且其中包含图片链接)例如使用:post最常见的开始爬虫使用的抓取方法:1.点击item的属性找到存放对应数据的文件2.使用beautifulsoup()模块来解析该文件返回的对应json格式数据这里使用的是beautifulsoup方法,还可以使用os模块、chrome等模块。
相应的,代码可以:importbs4extract_request=bs4.extract(soup,'./users/imooc/ppt/{user_id}/{age}/{score}'.format(score))使用content_to_json()方法就相对简单很多。content_to_json(soup,'users/users/imooc/ppt/{user_id}/{score}'.format(score))就是发送一个请求,得到user_id和当前爬取的结果相应的json对象即可。缺点:由于浏览器会多次请求文件,所以返回json格式时可能会出现乱码等情况。 查看全部
c 抓取网页数据(定制网页数据存储结构,保存相应数据(c抓取))
c抓取网页数据有多种方法,可以采用python、numpy、pandas等。但直接抓取网页数据库中的数据有时会显得格格不入。这就需要我们定制网页数据存储结构,保存相应数据。首先抓取的数据以文本格式保存,例如:{[user_id]:user_id,[age]:age}这种数据特点在于,抓取过程中没有对user_id做任何处理,我们直接将其存储在文本中。
但对于爬虫,这种存储形式容易给浏览器造成压力,最常见的原因是:每次爬取的数据都要在下次抓取网页时进行一次user_id的去重。可以尝试使用bs4(beautifulsoup4)+bs4.extract()方法来解决这个问题。先看下bs4中的方法的用法:extract方法的核心用法可以参看《python3网络爬虫基础知识》extract方法的4个参数说明:url(获取页面的url):获取第一页或者第二页以及每页的页面地址。
headers(发送给浏览器的headers信息):发送一个请求、重定向到调用该页面的对应url。image(请求图片文件):发送一个请求、重定向到当前页所在网页。python图片处理库的使用extract.python_python.content.scrapy.content_to_json(pythoncontent转换json格式):其实就是网页上已经存在的json数据变成bson格式(纯python方法,只需要模拟浏览器点击图片,这里记住,图片请求会发送一个浏览器地址,并且其中包含图片链接)例如使用:post最常见的开始爬虫使用的抓取方法:1.点击item的属性找到存放对应数据的文件2.使用beautifulsoup()模块来解析该文件返回的对应json格式数据这里使用的是beautifulsoup方法,还可以使用os模块、chrome等模块。
相应的,代码可以:importbs4extract_request=bs4.extract(soup,'./users/imooc/ppt/{user_id}/{age}/{score}'.format(score))使用content_to_json()方法就相对简单很多。content_to_json(soup,'users/users/imooc/ppt/{user_id}/{score}'.format(score))就是发送一个请求,得到user_id和当前爬取的结果相应的json对象即可。缺点:由于浏览器会多次请求文件,所以返回json格式时可能会出现乱码等情况。
c 抓取网页数据(保定师范专科学校学报.4第17卷第4期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-16 17:12
<p>2004年10月保定师范学院学报0ct。20040FBAODINGTEACHERSVol17No. 4 第17卷第4期 JOURNALCOLLEGE文章 No.: 1008.4584 (2004)04-0015-03 使用MSHTML组件从网页中提取数据 卢书金 (河北保定师范学院教育信息技术系)保定071051)摘录关键词:HTML语言;MSHTML对象模型;网页分类号:TP311.1 文档识别码:A 1 问题提出随着互联网的发展,数据和存在有信息的人越来越多,通常只需要在浏览的网页上保存或记录部分数据即可,其他情况下,为了更好地分析研究数据,就需要用编程的方法把网页上的网页。例如,科学家需要从发布天气预报的网站获取气象数据以供研究;金融和经济工作者需要跟踪和记录股票和汇率的变化;需要根据关键词搜索网页,分析链接等。所有这些应用都涉及到网页数据的分析和提取。2 网页结构 要分析网页上的内容和数据,首先要了解网页的结构。互联网由无数相互链接的网页组成。这些页面也称为Web文档,由HTML(HyperMarkup也收录要显示的图形、声音等元素,以及指向其他文档的超链接)组成。控制语句是由一些标签(Tag)组成,用于描述显示内容的形式,负责客户端和服务器之间的信息交换。标签用◇括起来,经常成对出现。浏览器可以识别这些标签,并根据标签所需的格式来显示内容n]。下面是一个用HTML语言写的网页文档: 命令ITLE> 这是HTML文档的标题,这里输入文本的标题,这里输入文本的文本,包括HTML文档的标题如image超链接和文档正文。文档头放在和之间,通常包括以下元素: (1) 文档标题:是浏览器窗口标题栏上显示的文本,用和符号指定。关键字等,使用BASE设置网页的基本 URL。(< @3)Script:插入文档中用于操作页面元素的短程序,位于 CRIPT> 和 CRIPT> 之间。HTML语言中还收录大量的符号,主要分为以下几类: 作者简介:卢树金(1967一),男,河北省唐县人,实验员·16·保定杂志社师范学院,2004年第4期(2)超链接:使用、定义、指定超链接的目标uRL;( 查看全部
c 抓取网页数据(保定师范专科学校学报.4第17卷第4期)
<p>2004年10月保定师范学院学报0ct。20040FBAODINGTEACHERSVol17No. 4 第17卷第4期 JOURNALCOLLEGE文章 No.: 1008.4584 (2004)04-0015-03 使用MSHTML组件从网页中提取数据 卢书金 (河北保定师范学院教育信息技术系)保定071051)摘录关键词:HTML语言;MSHTML对象模型;网页分类号:TP311.1 文档识别码:A 1 问题提出随着互联网的发展,数据和存在有信息的人越来越多,通常只需要在浏览的网页上保存或记录部分数据即可,其他情况下,为了更好地分析研究数据,就需要用编程的方法把网页上的网页。例如,科学家需要从发布天气预报的网站获取气象数据以供研究;金融和经济工作者需要跟踪和记录股票和汇率的变化;需要根据关键词搜索网页,分析链接等。所有这些应用都涉及到网页数据的分析和提取。2 网页结构 要分析网页上的内容和数据,首先要了解网页的结构。互联网由无数相互链接的网页组成。这些页面也称为Web文档,由HTML(HyperMarkup也收录要显示的图形、声音等元素,以及指向其他文档的超链接)组成。控制语句是由一些标签(Tag)组成,用于描述显示内容的形式,负责客户端和服务器之间的信息交换。标签用◇括起来,经常成对出现。浏览器可以识别这些标签,并根据标签所需的格式来显示内容n]。下面是一个用HTML语言写的网页文档: 命令ITLE> 这是HTML文档的标题,这里输入文本的标题,这里输入文本的文本,包括HTML文档的标题如image超链接和文档正文。文档头放在和之间,通常包括以下元素: (1) 文档标题:是浏览器窗口标题栏上显示的文本,用和符号指定。关键字等,使用BASE设置网页的基本 URL。(< @3)Script:插入文档中用于操作页面元素的短程序,位于 CRIPT> 和 CRIPT> 之间。HTML语言中还收录大量的符号,主要分为以下几类: 作者简介:卢树金(1967一),男,河北省唐县人,实验员·16·保定杂志社师范学院,2004年第4期(2)超链接:使用、定义、指定超链接的目标uRL;(
c 抓取网页数据(web页面数据采集工具通达网络爬虫管理工具应用场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-16 10:11
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面采集快速执行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。 查看全部
c 抓取网页数据(web页面数据采集工具通达网络爬虫管理工具应用场景)
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。


网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面采集快速执行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用

网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
c 抓取网页数据(响应式+js写法和原生js的交互方法(c))
网站优化 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2022-03-12 06:01
c抓取网页数据为html文件。两种最常用,“响应式+js写法”和“原生js生成响应式+一般交互”。--“一般交互”的特点是能把一些交互用js实现出来,或者把一些一般交互的方法封装成js来实现。是目前比较常用的技术。“响应式+js写法”的特点是js和页面做交互,从而驱动页面去适应一定的尺寸。生成响应式的结果时,也就用到了js的交互方法。两种技术,都能把小屏幕的应用设计成不同的大屏幕,适合于任何应用场景。
给楼主推荐看看这个帖子
刚学了一段时间。所以再强答一下先说明一下我看的开发者工具是pc端vs2013,mac应该也差不多(真的有用到工具和原理上的东西)再说明一下工作上的推荐方法,vs2013的开发者工具和基础类工具自己找吧。我实在没图找不到了。-先说alt+tab键切换,vs2015允许,就是让你自己看着方便。界面上最小的是地址栏(可以自定义,默认是地址栏右边的黄色方块);一般的交互都放在我的工程里面,如:publicclassapiviewextendsactivityextendsadaptiveandframework{exceptionuriprovided="";voidmain(){customeventchannel=newcustomevent(uri,null);channel.setdata(provided);channel.setoptions(true);apiviewmainview=newapiview();mainview.setinstance(container);mainview.setadaptiveframework(container);mainview.setviewactivity(null);}}应该可以吧。
此时main就是我们的reset小窗口,在其他情况(下拉刷新等)可以不用这个小窗口,直接点右键另存为,一定要右键,而且只能用excludeview{default:parent{get{varbt=this.getbackground();if(bt!=null){bt.resize({view:provided},255);直接点下拉刷新(简称on-top)可以达到前面所有状态-。 查看全部
c 抓取网页数据(响应式+js写法和原生js的交互方法(c))
c抓取网页数据为html文件。两种最常用,“响应式+js写法”和“原生js生成响应式+一般交互”。--“一般交互”的特点是能把一些交互用js实现出来,或者把一些一般交互的方法封装成js来实现。是目前比较常用的技术。“响应式+js写法”的特点是js和页面做交互,从而驱动页面去适应一定的尺寸。生成响应式的结果时,也就用到了js的交互方法。两种技术,都能把小屏幕的应用设计成不同的大屏幕,适合于任何应用场景。
给楼主推荐看看这个帖子
刚学了一段时间。所以再强答一下先说明一下我看的开发者工具是pc端vs2013,mac应该也差不多(真的有用到工具和原理上的东西)再说明一下工作上的推荐方法,vs2013的开发者工具和基础类工具自己找吧。我实在没图找不到了。-先说alt+tab键切换,vs2015允许,就是让你自己看着方便。界面上最小的是地址栏(可以自定义,默认是地址栏右边的黄色方块);一般的交互都放在我的工程里面,如:publicclassapiviewextendsactivityextendsadaptiveandframework{exceptionuriprovided="";voidmain(){customeventchannel=newcustomevent(uri,null);channel.setdata(provided);channel.setoptions(true);apiviewmainview=newapiview();mainview.setinstance(container);mainview.setadaptiveframework(container);mainview.setviewactivity(null);}}应该可以吧。
此时main就是我们的reset小窗口,在其他情况(下拉刷新等)可以不用这个小窗口,直接点右键另存为,一定要右键,而且只能用excludeview{default:parent{get{varbt=this.getbackground();if(bt!=null){bt.resize({view:provided},255);直接点下拉刷新(简称on-top)可以达到前面所有状态-。
c 抓取网页数据( 新媒体运营来说的爬虫工具——webscraper的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-03-10 21:05
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网页刮刀.png
三、创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
参数设置.png
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要抓取的内容类型进行选择。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧!
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网页刮刀.png
三、创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
参数设置.png
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要抓取的内容类型进行选择。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧!
分类:
技术要点:
相关文章:
c 抓取网页数据(在线品牌监控在线监控识别等的应用价值是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-10 21:04
2021-10-31
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。
这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。
1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。
2、广告营销和用户画像
通过社交媒体数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。
3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们将能够更好地指导我们的行动。
4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse
Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的所见即所得,点击拖拽网页采集配置界面,支持无限滚动,账号密码登录,验证码**,多IP防阻塞, 文本输入(用于抓取搜索结果)和从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据提取,Octoparse 还提供了一个计时器功能,可让您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io
Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但你可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub
Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 并没有提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器
Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(在线品牌监控在线监控识别等的应用价值是什么?)
2021-10-31
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。
这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。
1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。
2、广告营销和用户画像
通过社交媒体数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。
3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们将能够更好地指导我们的行动。
4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse
Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的所见即所得,点击拖拽网页采集配置界面,支持无限滚动,账号密码登录,验证码**,多IP防阻塞, 文本输入(用于抓取搜索结果)和从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据提取,Octoparse 还提供了一个计时器功能,可让您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io
Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但你可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub
Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 并没有提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器
Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
分类:
技术要点:
相关文章:
c 抓取网页数据(模拟登录,需要POST哪些数据呢?零基础!幽默!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-08 17:09
抓取需要登录的页面内容的原理主要是:先模拟登录,获取cookie,然后使用这个cookie进行下次访问,就可以访问需要登录的页面了。
理论上,浏览器能做的,程序也应该能做。
但是,模拟登录说起来容易,但是不同的站点处理方式不同,复杂程度也不同。
1、最简单的就是POST相应的数据,不用验证码
2、喜欢 Discuz!系列,必须先访问某个页面,获取一个随机码,然后放到POST数据中,才能登录
3、需要验证码。验证码识别是另一个主题。
无论如何,需要 POST 数据。那么,要模拟登录,需要 POST 哪些数据呢?
事实上,每个站点需要发布哪些数据是不同的,因此必须有合适的工具进行分析。我安装了firefox扩展控件:HttpFox。使用它,您可以轻松获取登录指定站点时需要提交的数据字符串。
模拟登录的代码如下:
//sPostData,待提交的数据串,如http://www.test.com/login.aspx ... 23456 public static CookieContainer Login(string url, string sPostData, CookieContainer cc) { CookieContainer container = (cc == null) ? new CookieContainer() : cc; ASCIIEncoding encoding = new ASCIIEncoding(); byte[] data = encoding.GetBytes(sPostData); HttpWebRequest resquest = ResquestInit(url); resquest.Method = "POST"; resquest.ContentLength = data.Length; resquest.CookieContainer = container; Stream newStream = resquest.GetRequestStream(); newStream.Write(data, 0, data.Length); newStream.Close(); try { HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); } catch{} return container; }//这个函数的作用就是统一Request的格式,使得每次访问目标网站都用相同的口径。如果参数不同的话,可能造成COOKIE无效,因而登录无效 public static HttpWebRequest ResquestInit(string url) { Uri target = new Uri(url); HttpWebRequest resquest = (HttpWebRequest)WebRequest.Create(target); resquest.UserAgent = "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2 (.NET CLR 3.5.30729)"; resquest.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"; resquest.AllowAutoRedirect = true; resquest.KeepAlive = true; resquest.ReadWriteTimeout = 120000; resquest.ContentType = "application/x-www-form-urlencoded"; resquest.Referer = url; return resquest; }
获得这个CookieContainer后,保存,以后每次访问网站时随身携带。CookieContainer 相当于浏览器的cookie 容器,里面存储了访问每个网站 的cookie。
带cookie的访问码如下:
static HttpWebResponse GetResponse(string url, CookieContainer cc) { try { CookieContainer container = (cc == null) ? new CookieContainer() : cc; HttpWebRequest resquest = ResquestInit(url); resquest.CookieContainer = container; HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); return response; } catch { return null; } }
参数CookieContainer cc 是保存的CookieContainer。
跟大家分享一下我老师的人工智能教程。零基础!容易明白!幽默风趣!还有黄色笑话!希望你也加入我们的 AI 团队! 查看全部
c 抓取网页数据(模拟登录,需要POST哪些数据呢?零基础!幽默!)
抓取需要登录的页面内容的原理主要是:先模拟登录,获取cookie,然后使用这个cookie进行下次访问,就可以访问需要登录的页面了。
理论上,浏览器能做的,程序也应该能做。
但是,模拟登录说起来容易,但是不同的站点处理方式不同,复杂程度也不同。
1、最简单的就是POST相应的数据,不用验证码
2、喜欢 Discuz!系列,必须先访问某个页面,获取一个随机码,然后放到POST数据中,才能登录
3、需要验证码。验证码识别是另一个主题。
无论如何,需要 POST 数据。那么,要模拟登录,需要 POST 哪些数据呢?
事实上,每个站点需要发布哪些数据是不同的,因此必须有合适的工具进行分析。我安装了firefox扩展控件:HttpFox。使用它,您可以轻松获取登录指定站点时需要提交的数据字符串。
模拟登录的代码如下:
//sPostData,待提交的数据串,如http://www.test.com/login.aspx ... 23456 public static CookieContainer Login(string url, string sPostData, CookieContainer cc) { CookieContainer container = (cc == null) ? new CookieContainer() : cc; ASCIIEncoding encoding = new ASCIIEncoding(); byte[] data = encoding.GetBytes(sPostData); HttpWebRequest resquest = ResquestInit(url); resquest.Method = "POST"; resquest.ContentLength = data.Length; resquest.CookieContainer = container; Stream newStream = resquest.GetRequestStream(); newStream.Write(data, 0, data.Length); newStream.Close(); try { HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); } catch{} return container; }//这个函数的作用就是统一Request的格式,使得每次访问目标网站都用相同的口径。如果参数不同的话,可能造成COOKIE无效,因而登录无效 public static HttpWebRequest ResquestInit(string url) { Uri target = new Uri(url); HttpWebRequest resquest = (HttpWebRequest)WebRequest.Create(target); resquest.UserAgent = "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2 (.NET CLR 3.5.30729)"; resquest.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"; resquest.AllowAutoRedirect = true; resquest.KeepAlive = true; resquest.ReadWriteTimeout = 120000; resquest.ContentType = "application/x-www-form-urlencoded"; resquest.Referer = url; return resquest; }
获得这个CookieContainer后,保存,以后每次访问网站时随身携带。CookieContainer 相当于浏览器的cookie 容器,里面存储了访问每个网站 的cookie。
带cookie的访问码如下:
static HttpWebResponse GetResponse(string url, CookieContainer cc) { try { CookieContainer container = (cc == null) ? new CookieContainer() : cc; HttpWebRequest resquest = ResquestInit(url); resquest.CookieContainer = container; HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); return response; } catch { return null; } }
参数CookieContainer cc 是保存的CookieContainer。
跟大家分享一下我老师的人工智能教程。零基础!容易明白!幽默风趣!还有黄色笑话!希望你也加入我们的 AI 团队!
c 抓取网页数据(Linux(UNIX)命令格式命令1.命令命令:告诉Linux)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-06 17:22
Linux 常用命令和获取帮助
交流,咨询,有问题欢迎补充,一起交流,一起找问题,一起进步,哈哈哈哈哈哈Linux(UNIX)命令格式命令1.命令:告诉Linux(UNIX)什么to do2.Options:表示命令运行的方式,以“-”字符开头3.Parameters:表示命令影响什么简单常用的命令:whoami~列出当前用户名用于登录Linux系统i~除了用户名外,还显示登录的终端、当前日期时间,以及使用的电脑的IP地址who~显示与who am i命令相同的内容,但也包括所有其他在系统上工作的用户w~获取的信息比who命令用户多~当前登录系统的所有用户try~当前用户登录系统使用的终端uname~获取信息关于系统日期~显示当前系统日期和时间 cal ~ 显示某个月份的日历 cal 8 2008: 列出 2008 年 8 月的日历 clear ~ 在终端窗口中清除显示 su ~ 从一个用户切换到另一个用户 eg: $ su -rootpass ~ change user's password and查看密码状态器 whatis ~ 显示所有查询命令的简要说明,在命令后使用 --help 选项
258 查看全部
c 抓取网页数据(Linux(UNIX)命令格式命令1.命令命令:告诉Linux)
Linux 常用命令和获取帮助
交流,咨询,有问题欢迎补充,一起交流,一起找问题,一起进步,哈哈哈哈哈哈Linux(UNIX)命令格式命令1.命令:告诉Linux(UNIX)什么to do2.Options:表示命令运行的方式,以“-”字符开头3.Parameters:表示命令影响什么简单常用的命令:whoami~列出当前用户名用于登录Linux系统i~除了用户名外,还显示登录的终端、当前日期时间,以及使用的电脑的IP地址who~显示与who am i命令相同的内容,但也包括所有其他在系统上工作的用户w~获取的信息比who命令用户多~当前登录系统的所有用户try~当前用户登录系统使用的终端uname~获取信息关于系统日期~显示当前系统日期和时间 cal ~ 显示某个月份的日历 cal 8 2008: 列出 2008 年 8 月的日历 clear ~ 在终端窗口中清除显示 su ~ 从一个用户切换到另一个用户 eg: $ su -rootpass ~ change user's password and查看密码状态器 whatis ~ 显示所有查询命令的简要说明,在命令后使用 --help 选项
258
c 抓取网页数据(2019独角兽企业重金招聘Python工程师标准(gt)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-04 12:17
2019独角兽企业招聘Python工程师标准>>>
在这篇文章中,我主要展示了如何爬取谷歌学术网页。该示例展示了使用 rvest 包捕获作者博士生导师的个人学术数据。我们可以看到他的合著者、论文被引用的次数以及他们的隶属关系。Hadley Wickham 在 RStudio 博客中写道:“rvest 的灵感来自于可以轻松从 HTML 页面中抓取数据的美丽汤之类的库”。因为它被设计为与 magrittr 一起使用。我们可以通过一些简单易懂的代码块组成的管道操作来表达复杂的操作。
加载 R 包:
使用 ggplot2 包绘图
1library(rvest)
2library(ggplot2)
3
他的论文被引用了多少次?
使用 SelectorGadget 的 CSS 选择器查找“引用者”列。
1page % html_text()%>%as.numeric()
2
请参阅此计数的引文:
1citations
2148 96 79 64 57 57 57 55 52 50 48 37 34 33 30 28 26 25 23 22
3
绘制引用次数的条形图:
1barplot(citations, main="How many times has each paper been cited?", ylab='Number of citations', col="skyblue", xlab="")
2
共同作者、他们的隶属关系和引用次数
同样,我们使用 SelecotGadget 的 CSS 选择器来查找匹配的共同作者:
1page % html_nodes(css=".gsc_1usr_name a") %>% html_text()
3Coauthors = as.data.frame(Coauthors)
4names(Coauthors)='Coauthors'
5
查看下一位合著者
1head(Coauthors)
2 Coauthors
31 Jason Evans
42 Mutlu Ozdogan
53 Rasmus Houborg
64 M. Tugrul Yilmaz
75 Joseph A. Santanello, Jr.
86 Seth Guikema
9
10dim(Coauthors)
11[1] 27 1
12
截至2016年1月1日,他共有27位合著者。
他的合著者被引用了多少次?
1page % html_nodes(css = ".gsc_1usr_cby")%>%html_text()
3
4citations
5 [1] "Cited by 2231" "Cited by 1273" "Cited by 816" "Cited by 395" "Cited by 652" "Cited by 1531"
6 [7] "Cited by 674" "Cited by 467" "Cited by 7967" "Cited by 3968" "Cited by 2603" "Cited by 3468"
7[13] "Cited by 3175" "Cited by 121" "Cited by 32" "Cited by 469" "Cited by 50" "Cited by 11"
8[19] "Cited by 1187" "Cited by 1450" "Cited by 12407" "Cited by 1939" "Cited by 9" "Cited by 706"
9[25] "Cited by 336" "Cited by 186" "Cited by 192"
10
通过全局替换提取数字字符串
1citations = gsub('Cited by','', citations)
2
3citations
4 [1] " 2231" " 1273" " 816" " 395" " 652" " 1531" " 674" " 467" " 7967" " 3968" " 2603" " 3468" " 3175"
5[14] " 121" " 32" " 469" " 50" " 11" " 1187" " 1450" " 12407" " 1939" " 9" " 706" " 336" " 186"
6[27] " 192"
7
将字符串转换为数值类型,然后得到ggplot2可用的数据框格式:
1citations = as.numeric(citations)
2citations = as.data.frame(citations)
3
合著者的附属机构
创建共同作者、引用和隶属关系的数据框
1cauthors=cbind(Coauthors, citations, affilation)
2
3cauthors
4 Coauthors citations Affilation
51 Jason Evans 2231 University of New South Wales
62 Mutlu Ozdogan 1273 Assistant Professor of Environmental Science and Forest Ecology, University of Wisconsin
73 Rasmus Houborg 816 Research Scientist at King Abdullah University of Science and Technology
84 M. Tugrul Yilmaz 395 Assistant Professor, Civil Engineering Department, Middle East Technical University, Turkey
95 Joseph A. Santanello, Jr. 652 NASA-GSFC Hydrological Sciences Laboratory
10.....
11
按引用次数对共同作者重新排序
按引用次数对共同作者重新排序以获得降序序列图:
<p>1cauthors$Coauthors 查看全部
c 抓取网页数据(2019独角兽企业重金招聘Python工程师标准(gt)(组图))
2019独角兽企业招聘Python工程师标准>>>

在这篇文章中,我主要展示了如何爬取谷歌学术网页。该示例展示了使用 rvest 包捕获作者博士生导师的个人学术数据。我们可以看到他的合著者、论文被引用的次数以及他们的隶属关系。Hadley Wickham 在 RStudio 博客中写道:“rvest 的灵感来自于可以轻松从 HTML 页面中抓取数据的美丽汤之类的库”。因为它被设计为与 magrittr 一起使用。我们可以通过一些简单易懂的代码块组成的管道操作来表达复杂的操作。
加载 R 包:
使用 ggplot2 包绘图
1library(rvest)
2library(ggplot2)
3
他的论文被引用了多少次?
使用 SelectorGadget 的 CSS 选择器查找“引用者”列。
1page % html_text()%>%as.numeric()
2
请参阅此计数的引文:
1citations
2148 96 79 64 57 57 57 55 52 50 48 37 34 33 30 28 26 25 23 22
3
绘制引用次数的条形图:
1barplot(citations, main="How many times has each paper been cited?", ylab='Number of citations', col="skyblue", xlab="")
2
共同作者、他们的隶属关系和引用次数
同样,我们使用 SelecotGadget 的 CSS 选择器来查找匹配的共同作者:
1page % html_nodes(css=".gsc_1usr_name a") %>% html_text()
3Coauthors = as.data.frame(Coauthors)
4names(Coauthors)='Coauthors'
5
查看下一位合著者
1head(Coauthors)
2 Coauthors
31 Jason Evans
42 Mutlu Ozdogan
53 Rasmus Houborg
64 M. Tugrul Yilmaz
75 Joseph A. Santanello, Jr.
86 Seth Guikema
9
10dim(Coauthors)
11[1] 27 1
12
截至2016年1月1日,他共有27位合著者。
他的合著者被引用了多少次?
1page % html_nodes(css = ".gsc_1usr_cby")%>%html_text()
3
4citations
5 [1] "Cited by 2231" "Cited by 1273" "Cited by 816" "Cited by 395" "Cited by 652" "Cited by 1531"
6 [7] "Cited by 674" "Cited by 467" "Cited by 7967" "Cited by 3968" "Cited by 2603" "Cited by 3468"
7[13] "Cited by 3175" "Cited by 121" "Cited by 32" "Cited by 469" "Cited by 50" "Cited by 11"
8[19] "Cited by 1187" "Cited by 1450" "Cited by 12407" "Cited by 1939" "Cited by 9" "Cited by 706"
9[25] "Cited by 336" "Cited by 186" "Cited by 192"
10
通过全局替换提取数字字符串
1citations = gsub('Cited by','', citations)
2
3citations
4 [1] " 2231" " 1273" " 816" " 395" " 652" " 1531" " 674" " 467" " 7967" " 3968" " 2603" " 3468" " 3175"
5[14] " 121" " 32" " 469" " 50" " 11" " 1187" " 1450" " 12407" " 1939" " 9" " 706" " 336" " 186"
6[27] " 192"
7
将字符串转换为数值类型,然后得到ggplot2可用的数据框格式:
1citations = as.numeric(citations)
2citations = as.data.frame(citations)
3
合著者的附属机构
创建共同作者、引用和隶属关系的数据框
1cauthors=cbind(Coauthors, citations, affilation)
2
3cauthors
4 Coauthors citations Affilation
51 Jason Evans 2231 University of New South Wales
62 Mutlu Ozdogan 1273 Assistant Professor of Environmental Science and Forest Ecology, University of Wisconsin
73 Rasmus Houborg 816 Research Scientist at King Abdullah University of Science and Technology
84 M. Tugrul Yilmaz 395 Assistant Professor, Civil Engineering Department, Middle East Technical University, Turkey
95 Joseph A. Santanello, Jr. 652 NASA-GSFC Hydrological Sciences Laboratory
10.....
11
按引用次数对共同作者重新排序
按引用次数对共同作者重新排序以获得降序序列图:
<p>1cauthors$Coauthors
c 抓取网页数据(yyyymmdd爬虫默认模板代码:提取内容的css一行的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-04 12:15
xx=开始时间,yyyymmdd
yy=结束时间,yyyymmdd
爬虫默认模板代码:
def on_start(self):
base_url='https://coinmarketcap.com/zh/currencies/bitcoin/historical-data/?start=#START#&end=#END#'
year_list=['2015','2016','2017','2018']
month_list=range(1,13)
for year in year_list:
for month in month_list:
start_date=year+str(month).rjust(2,'0')+'01'
end_date=year+str(month).rjust(2,'0')+'31'
self.crawl(base_url.replace('#START#',start_date).replace('#END#',end_date), callback=self.detail_page)
爬取时间为 2015 年 1 月至 2018 年 12 月。
需要注意的是,每个月都是按照31天来处理的。如果您尝试该网页,则可以正常返回而不会报告错误。
第二步,解析页面内容
构造好url地址后,就是解析页面内容了。
修改爬虫模板代码:
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"text_right":response.doc('tr.text-right').text()
}
添加了一个字段 text_right,它是网页表格的主体。提取文本后,应将数据分为行和行,然后将每一行映射到特定字段并保存到文本csv或数据库中。如有必要,您可以自己实现。
上面稍微麻烦的就是定位需要提取内容的css的表达式。这本来就是比较价格的一件很恶心(费时、容易出错)的事情,上学的时候也很讨厌。不过pyspider做了一个非常强大的封装过程,可以将网页上的选区可视化,自动生成css选区的表达式,直接使用即可。
这也是我第一次用这个,不妨演示一下
一般只需点击1、2、4即可,不需要复制,只需将光标移动到输入选择器位置再点击4即可。
第三步,保存结果
通过覆盖 on_result 方法保存结果,
例如:
def on_result(self,result):
if not result or not result['original_id']:
return
sql = SQL()
sql.insert('t_dream_xm_project',**result)
这里的每一个结果都是上面构建的地图表单数据。在本文中,它是一个map,其key是url、title和text_right。
这里的text_right是一个收录所有行和列的文本字符串,需要进一步解析。
解析工作有时可以放在第二步。第二步, text_right 可以直接构造为列表并返回。个人比较喜欢爬取和解析的分离操作。爬取只负责加载数据,用于后续分析。负责其他模块。
还有一个更好的思路,直接获取对方网站拉取数据的接口,直接向接口发送查询数据获取结构化数据,然后直接解析存储。这种方式基本上不需要爬虫去处理 CSS 选择器之类的。
其他参考技术
1、使用代理
验证代理有效性:
参考:
导入请求
尝试:
requests.get('', proxies={"http":":8123"})
除了:
打印'连接失败'
别的:
打印'成功'
后续可以使用专业的代理工具:squid
2.伪装浏览器头部
fake-useragent 库:伪造的浏览器标头
参考:
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(yyyymmdd爬虫默认模板代码:提取内容的css一行的方法)
xx=开始时间,yyyymmdd
yy=结束时间,yyyymmdd
爬虫默认模板代码:
def on_start(self):
base_url='https://coinmarketcap.com/zh/currencies/bitcoin/historical-data/?start=#START#&end=#END#'
year_list=['2015','2016','2017','2018']
month_list=range(1,13)
for year in year_list:
for month in month_list:
start_date=year+str(month).rjust(2,'0')+'01'
end_date=year+str(month).rjust(2,'0')+'31'
self.crawl(base_url.replace('#START#',start_date).replace('#END#',end_date), callback=self.detail_page)
爬取时间为 2015 年 1 月至 2018 年 12 月。
需要注意的是,每个月都是按照31天来处理的。如果您尝试该网页,则可以正常返回而不会报告错误。
第二步,解析页面内容
构造好url地址后,就是解析页面内容了。
修改爬虫模板代码:
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"text_right":response.doc('tr.text-right').text()
}
添加了一个字段 text_right,它是网页表格的主体。提取文本后,应将数据分为行和行,然后将每一行映射到特定字段并保存到文本csv或数据库中。如有必要,您可以自己实现。
上面稍微麻烦的就是定位需要提取内容的css的表达式。这本来就是比较价格的一件很恶心(费时、容易出错)的事情,上学的时候也很讨厌。不过pyspider做了一个非常强大的封装过程,可以将网页上的选区可视化,自动生成css选区的表达式,直接使用即可。
这也是我第一次用这个,不妨演示一下
一般只需点击1、2、4即可,不需要复制,只需将光标移动到输入选择器位置再点击4即可。
第三步,保存结果
通过覆盖 on_result 方法保存结果,
例如:
def on_result(self,result):
if not result or not result['original_id']:
return
sql = SQL()
sql.insert('t_dream_xm_project',**result)
这里的每一个结果都是上面构建的地图表单数据。在本文中,它是一个map,其key是url、title和text_right。
这里的text_right是一个收录所有行和列的文本字符串,需要进一步解析。
解析工作有时可以放在第二步。第二步, text_right 可以直接构造为列表并返回。个人比较喜欢爬取和解析的分离操作。爬取只负责加载数据,用于后续分析。负责其他模块。
还有一个更好的思路,直接获取对方网站拉取数据的接口,直接向接口发送查询数据获取结构化数据,然后直接解析存储。这种方式基本上不需要爬虫去处理 CSS 选择器之类的。
其他参考技术
1、使用代理
验证代理有效性:
参考:
导入请求
尝试:
requests.get('', proxies={"http":":8123"})
除了:
打印'连接失败'
别的:
打印'成功'
后续可以使用专业的代理工具:squid
2.伪装浏览器头部
fake-useragent 库:伪造的浏览器标头
参考:
分类:
技术要点:
相关文章:
c 抓取网页数据(什么是c抓取网页数据coinconnect圈钱1千万美金?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-25 23:02
c抓取网页数据coinconnect该功能抓包得知,btc不支持收藏币种,但可以获取账户当前余额并生成btc余额1coback,btc2,btc3cash3年后,3币翻了3000倍。coineta网页内主要三种交易平台,币安、交易所币火、银行链比特币(gift)比特币浏览器看看1,188cash/h,看起来涨势喜人。
用户通过btc钱包地址交易,gift钱包显示的实际余额1万多。用户更新钱包地址直到50+名(看来现在这1万多btc老用户都有取代1万多币的打算),交易所币火里钱包余额已经有6万多。coineta官方发博指出btc圈钱1千万美金的事情属实,至少到现在已经进行过1千万次。币主们是继续维持短期波动,还是趁其跌此时入手,币火的受众根本就不像图表上显示那么多。
网站:coinmarketcap钱包:leobit
用网站吧,钱包要做成指定币种,除非你强迫自己。
还没入手就想着丢了那点币。1.以前有个rg的钱包,
-2017060516:29-我截了一下网站可以查看全世界各国家的法定货币余额---2017060519:08更新 查看全部
c 抓取网页数据(什么是c抓取网页数据coinconnect圈钱1千万美金?)
c抓取网页数据coinconnect该功能抓包得知,btc不支持收藏币种,但可以获取账户当前余额并生成btc余额1coback,btc2,btc3cash3年后,3币翻了3000倍。coineta网页内主要三种交易平台,币安、交易所币火、银行链比特币(gift)比特币浏览器看看1,188cash/h,看起来涨势喜人。
用户通过btc钱包地址交易,gift钱包显示的实际余额1万多。用户更新钱包地址直到50+名(看来现在这1万多btc老用户都有取代1万多币的打算),交易所币火里钱包余额已经有6万多。coineta官方发博指出btc圈钱1千万美金的事情属实,至少到现在已经进行过1千万次。币主们是继续维持短期波动,还是趁其跌此时入手,币火的受众根本就不像图表上显示那么多。
网站:coinmarketcap钱包:leobit
用网站吧,钱包要做成指定币种,除非你强迫自己。
还没入手就想着丢了那点币。1.以前有个rg的钱包,
-2017060516:29-我截了一下网站可以查看全世界各国家的法定货币余额---2017060519:08更新
c 抓取网页数据( 方法urlopen原形❝urllib2.HTTPError:超时时间设置改方法返回网页信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-18 16:14
方法urlopen原形❝urllib2.HTTPError:超时时间设置改方法返回网页信息
)
使用 Python 库 urllib2,使用了 urlopen 和 Request 方法。方法urlopen的原型❝ urllib2.urlopen(url[, data][, timeout]) 其中:url代表目标网页的地址,可以是字符串,也可以是请求对象Requestdata代表post timeout提交给目标服务器的参数表示超时时间设置,该方法返回一个类似文件的对象。有geturl()、info()、read()方法,其中geturl()返回连接地址,info()返回网页信息。获取网页内容,可以使用read()方法,read也可以带参数,表示读取内容的大小(字节)。
❞
import urllib2
socket = urllib2.urlopen("http://www.baidu.com")
content = socket.read()
socket.close()
这样,网页的内容就被爬下来了,但是有的网站禁止爬虫。如果直接请求,会出现如下错误: urllib2.HTTPError: HTTP Error 403: Forbidden 解决方法是在 request 中添加头信息来伪装浏览器的访问行为,需要使用 Request 方法:
方法请求原型❝ urllib2.Request(url[, data][, headers][, origin_req_host][, unverifiable]) 其中:url表示目标网页的地址,可以是字符串,也可以是request object Requestdata post方法中提交给目标服务器的参数headers代表用户ID,是字典类型的数据。其中一些不允许脚本爬取,所以需要一个用户代理,比如火狐浏览器的代理:Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/ 2.0.0.11 浏览器标准UA格式为:浏览器ID(操作系统ID;加密级别标识;浏览器语言) 渲染引擎标识版本信息,默认headers为Python -urllib/2.
❞
headers = {'User-Agent':'Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/2.0.0.11'}
req = urllib2.Request(url="http://blog.csdn.net/deqingguo",headers=headers)
socket = urllib2.urlopen(req)
content = socket.read()
socket.close() 查看全部
c 抓取网页数据(
方法urlopen原形❝urllib2.HTTPError:超时时间设置改方法返回网页信息
)

使用 Python 库 urllib2,使用了 urlopen 和 Request 方法。方法urlopen的原型❝ urllib2.urlopen(url[, data][, timeout]) 其中:url代表目标网页的地址,可以是字符串,也可以是请求对象Requestdata代表post timeout提交给目标服务器的参数表示超时时间设置,该方法返回一个类似文件的对象。有geturl()、info()、read()方法,其中geturl()返回连接地址,info()返回网页信息。获取网页内容,可以使用read()方法,read也可以带参数,表示读取内容的大小(字节)。
❞
import urllib2
socket = urllib2.urlopen("http://www.baidu.com";)
content = socket.read()
socket.close()
这样,网页的内容就被爬下来了,但是有的网站禁止爬虫。如果直接请求,会出现如下错误: urllib2.HTTPError: HTTP Error 403: Forbidden 解决方法是在 request 中添加头信息来伪装浏览器的访问行为,需要使用 Request 方法:
方法请求原型❝ urllib2.Request(url[, data][, headers][, origin_req_host][, unverifiable]) 其中:url表示目标网页的地址,可以是字符串,也可以是request object Requestdata post方法中提交给目标服务器的参数headers代表用户ID,是字典类型的数据。其中一些不允许脚本爬取,所以需要一个用户代理,比如火狐浏览器的代理:Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/ 2.0.0.11 浏览器标准UA格式为:浏览器ID(操作系统ID;加密级别标识;浏览器语言) 渲染引擎标识版本信息,默认headers为Python -urllib/2.
❞
headers = {'User-Agent':'Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/2.0.0.11'}
req = urllib2.Request(url="http://blog.csdn.net/deqingguo",headers=headers)
socket = urllib2.urlopen(req)
content = socket.read()
socket.close()
c 抓取网页数据( 从列表样式中抓取数据的页面有行使用方法介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-16 17:09
从列表样式中抓取数据的页面有行使用方法介绍-苏州安嘉)
介绍:
从列表样式的网页中抓取数据。有示范的例子。非常容易使用。一分钟配置,一键搞定。Creeper 是一个专注于列表样式网页的抓取扩展。用户不需要了解任何 html 和 css 知识,尽管了解它们会很好。Creeper 无法从所有网页中抓取数据,而只能从列表样式的页面中抓取。列表样式的页面有行,每行都有几乎相同的字段。用户需要点击html元素告诉Creeper哪个是行元素,哪个是字段元素,哪个是分页元素。然后,Creeper 可以生成一个站点地图模板,其中收录有关如何捕获此数据的说明。有一些列表样式的页面:%20restore%20deleted%20records %2522python%2522 Creeper使用步骤:1) 点击右上角的爬行者图标打开站点地图列表;2) 单击“创建站点地图”按钮打开一个表单,为当前在浏览器中打开的网页定义站点地图。3) 单击编辑按钮打开站点地图详细信息表单,您可以在其中单击测试以获取一些示例数据。4) 点击“运行”按钮爬取站点地图。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。 查看全部
c 抓取网页数据(
从列表样式中抓取数据的页面有行使用方法介绍-苏州安嘉)





介绍:
从列表样式的网页中抓取数据。有示范的例子。非常容易使用。一分钟配置,一键搞定。Creeper 是一个专注于列表样式网页的抓取扩展。用户不需要了解任何 html 和 css 知识,尽管了解它们会很好。Creeper 无法从所有网页中抓取数据,而只能从列表样式的页面中抓取。列表样式的页面有行,每行都有几乎相同的字段。用户需要点击html元素告诉Creeper哪个是行元素,哪个是字段元素,哪个是分页元素。然后,Creeper 可以生成一个站点地图模板,其中收录有关如何捕获此数据的说明。有一些列表样式的页面:%20restore%20deleted%20records %2522python%2522 Creeper使用步骤:1) 点击右上角的爬行者图标打开站点地图列表;2) 单击“创建站点地图”按钮打开一个表单,为当前在浏览器中打开的网页定义站点地图。3) 单击编辑按钮打开站点地图详细信息表单,您可以在其中单击测试以获取一些示例数据。4) 点击“运行”按钮爬取站点地图。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。
c 抓取网页数据( 这个python爬虫程序的主要功能是爬取三个(杭电,北大,地大)上的做题信息并进行题目的统计 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-15 21:23
这个python爬虫程序的主要功能是爬取三个(杭电,北大,地大)上的做题信息并进行题目的统计
)
import webbrowser
import re
import urllib
#获取hdu网页
def getHtml_hdu(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取poj网页
def getHtml_poj(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取cug网页
def getHtml_cug(url):
page = urllib.urlopen(url)
html = page.read()
unicodehtml = html.decode("utf-8")
return unicodehtml
#获取hdu中用户信息
def zhenghe_hdu(str1,userid,imgre):
html=getHtml_hdu( str1+userid )
return re.findall(imgre,html)
#获取cug中用户信息
def zhenghe_cug(str1,userid,imgre):
html=getHtml_cug( str1+userid )
return re.findall(imgre,html)
#获取poj中用户信息
def zhenghe_poj(str1,userid,imgre):
html =getHtml_poj( str1+ userid)
return re.findall(imgre,html)
#文件读出用户账号进行统计
def readFile(result_cug,result_hdu,result_poj):
file_object = open("users.txt",'r')
reg_cug = r'Solved<a href=.*?>(.*?)</a>'
imgre_cug = re.compile(reg_cug)
reg_hdu = r'Problems Solved(.*?)'
imgre_hdu = re.compile(reg_hdu)
reg_poj = 'Solved:[\s\S]*?<a href=.*?>(.+?)</a>'
imgre_poj = re.compile(reg_poj)
#将结果输出到html网页
html = open('OJ.html', 'w')
html.write("""
cug--hdu--poj统计
img{float:left;margin:5px;}
""")
html.write("""
Account
cugOJ
hdOj
poj
sum
""")
alist = [] #定义一个列表
for line in file_object:
line=line.strip('\n') #去掉读取的每行的"\n"
list_hdu = zhenghe_hdu(result_hdu,line,imgre_hdu)
list_cug = zhenghe_cug(result_cug,line,imgre_cug)
list_poj = zhenghe_poj(result_poj,line,imgre_poj)
if len(list_hdu) == 0:
number_hdu = 0
else:
number_hdu = eval(list_hdu[0])
if len(list_cug) == 0:
number_cug = 0
else:
number_cug = eval(list_cug[0])
if len(list_poj) == 0:
number_poj = 0
else:
number_poj = eval(list_poj[0])
alist.append([line,number_cug,number_hdu,number_poj,number_cug+number_hdu+number_poj])
print "处理完一个用户信息"
for i in range(len(alist)): #冒泡排序
for j in range(len(alist)):
if alist[i][4] > alist[j][4]:
tmp = alist[i]
alist[i] = alist[j]
alist[j] = tmp
for lst in alist: #输出到网页
html.write("
")
html.write("")
html.write("%s " % lst[0] )
html.write("%s " % str(lst[1]) )
html.write("%s " % str(lst[2]) )
html.write("%s " % str(lst[3]) )
html.write("%s " % str(lst[4]) )
html.write("")
html.write('')
html.close()
webbrowser.open_new_tab('OJ.html') #自动打开网页
result_hdu = "http://acm.hdu.edu.cn/userstatus.php?user="
result_cug = "http://acm.cug.edu.cn/JudgeOnl ... ot%3B
result_poj = "http://poj.org/userstatus?user_id="
print "正在生成html网页......"
readFile(result_cug,result_hdu,result_poj)
print "html网页生成完毕,自动打开"
这个python爬虫程序的主要功能是爬取三个OJ(航电、北大、帝大)的题型信息,并对题型进行统计。
输入的是昵称,有的在几个OJ上注册的昵称是一样的,有的没有,所以统计显示有的人在某一个OJ上做题为0.
要读取的文件信息如下:
运行效果:
查看全部
c 抓取网页数据(
这个python爬虫程序的主要功能是爬取三个(杭电,北大,地大)上的做题信息并进行题目的统计
)
import webbrowser
import re
import urllib
#获取hdu网页
def getHtml_hdu(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取poj网页
def getHtml_poj(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取cug网页
def getHtml_cug(url):
page = urllib.urlopen(url)
html = page.read()
unicodehtml = html.decode("utf-8")
return unicodehtml
#获取hdu中用户信息
def zhenghe_hdu(str1,userid,imgre):
html=getHtml_hdu( str1+userid )
return re.findall(imgre,html)
#获取cug中用户信息
def zhenghe_cug(str1,userid,imgre):
html=getHtml_cug( str1+userid )
return re.findall(imgre,html)
#获取poj中用户信息
def zhenghe_poj(str1,userid,imgre):
html =getHtml_poj( str1+ userid)
return re.findall(imgre,html)
#文件读出用户账号进行统计
def readFile(result_cug,result_hdu,result_poj):
file_object = open("users.txt",'r')
reg_cug = r'Solved<a href=.*?>(.*?)</a>'
imgre_cug = re.compile(reg_cug)
reg_hdu = r'Problems Solved(.*?)'
imgre_hdu = re.compile(reg_hdu)
reg_poj = 'Solved:[\s\S]*?<a href=.*?>(.+?)</a>'
imgre_poj = re.compile(reg_poj)
#将结果输出到html网页
html = open('OJ.html', 'w')
html.write("""
cug--hdu--poj统计
img{float:left;margin:5px;}
""")
html.write("""
Account
cugOJ
hdOj
poj
sum
""")
alist = [] #定义一个列表
for line in file_object:
line=line.strip('\n') #去掉读取的每行的"\n"
list_hdu = zhenghe_hdu(result_hdu,line,imgre_hdu)
list_cug = zhenghe_cug(result_cug,line,imgre_cug)
list_poj = zhenghe_poj(result_poj,line,imgre_poj)
if len(list_hdu) == 0:
number_hdu = 0
else:
number_hdu = eval(list_hdu[0])
if len(list_cug) == 0:
number_cug = 0
else:
number_cug = eval(list_cug[0])
if len(list_poj) == 0:
number_poj = 0
else:
number_poj = eval(list_poj[0])
alist.append([line,number_cug,number_hdu,number_poj,number_cug+number_hdu+number_poj])
print "处理完一个用户信息"
for i in range(len(alist)): #冒泡排序
for j in range(len(alist)):
if alist[i][4] > alist[j][4]:
tmp = alist[i]
alist[i] = alist[j]
alist[j] = tmp
for lst in alist: #输出到网页
html.write("
")
html.write("")
html.write("%s " % lst[0] )
html.write("%s " % str(lst[1]) )
html.write("%s " % str(lst[2]) )
html.write("%s " % str(lst[3]) )
html.write("%s " % str(lst[4]) )
html.write("")
html.write('')
html.close()
webbrowser.open_new_tab('OJ.html') #自动打开网页
result_hdu = "http://acm.hdu.edu.cn/userstatus.php?user="
result_cug = "http://acm.cug.edu.cn/JudgeOnl ... ot%3B
result_poj = "http://poj.org/userstatus?user_id="
print "正在生成html网页......"
readFile(result_cug,result_hdu,result_poj)
print "html网页生成完毕,自动打开"
这个python爬虫程序的主要功能是爬取三个OJ(航电、北大、帝大)的题型信息,并对题型进行统计。
输入的是昵称,有的在几个OJ上注册的昵称是一样的,有的没有,所以统计显示有的人在某一个OJ上做题为0.
要读取的文件信息如下:
运行效果:

c 抓取网页数据(全部详细技术资料下载【技术实现步骤摘要】(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-19 23:21
本发明专利技术实施例公开了一种基于C/S架构浏览器的数据传输方法,包括:根据客户端的网页访问请求,从网络获取被请求网页的页面数据,其中,页面数据包括网页的所有源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化处理后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。相应地,本发明专利技术的实施例还公开了一种服务器。采用本发明专利技术,可以大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及无线互联网领域,具体涉及一种基于C(Client,client)/S(Server,server)架构浏览器的数据传输方法及服务器。
技术介绍
C/S 架构是客户端和服务器端的架构。它是一种软件系统架构。可以充分利用两端硬件环境的优势,将任务合理分配给两端执行,降低了系统的通信开销。排版引擎服务器负责获取网页内容(包括源代码和图片等),整理信息,计算网页的显示方式,然后输出到客户端进行显示或打印。所有 Web 浏览器、电子邮件客户端和其他需要编辑和显示 Web 内容的应用程序都需要排版引擎服务器进行排版。现有的基于C/S架构浏览器的数据传输方案主要是基于客户端浏览器的类型,
专利技术人员发现,现有基于C/S架构浏览器的数据传输方案主要存在以下缺陷1、用户体验低。在 HTML 到 ML 或 XHTML-MP 的转换过程中,无法准确有效地转换 HTML 中的样式表信息,通常的处理方法会破坏原创页面的视觉效果,如背景图片和颜色、字体颜色等。客户端渲染可能很乏味并降低用户体验。2、传输效率低。由于HTML页面直接转换传输,客户端与排版引擎服务器之间的数据传输流量大,传输效率低。3、客户端性能要求高,并且客户端渲染复杂度很高。现有的数据传输方案需要客户端有硬件(例如客户端是WAP手机)或软件(客户端配备WAP浏览器)的支持。“重服务器端,轻客户端”的架构趋势。为了避免上述缺陷,可以使用预定义的数据传输协议进行数据传输。基于C/S架构浏览器的数据传输协议是C/S架构浏览器开发中最重要的部分之一。它是客户端和服务器之间的桥梁。协议定义的质量与网络直接相关。流量大小和客户端的渲染效果,特别是对于资源有限的中低端客户端,数据传输协议的定义直接关系到客户端浏览器的用户体验。因此,如何平衡客户端呈现的复杂性、传输的数据量和交互性来定义数据传输协议来实现基于C/S架构浏览器的数据传输方案是一个亟待解决的问题。
技术实现思路
本专利技术实施例要解决的技术问题是提供一种基于C/S架构浏览器的数据传输方法及服务器,能够大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。为了解决上述技术问题,本专利技术实施例提供了一种基于C/S架构浏览器的数据传输方法,包括根据用户的网页访问请求,从网络上获取被请求网页的页面数据。客户端,使页面数据包括网页的源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化后的图像文件的二进制数据进行编码,并将编码后的二进制数据包传输给客户端。其中,对获取的网页源内容进行排版处理包括:解析网页源内容,生成DOM(Document Object Model,文档对象模型)树,DOM树包括网页节点和属性和数据;对DOM树进行布局排版,得到网页的渲染树,渲染树包括网页节点和网页节点的排版信息、属性和数据。序列化网页节点。属性和数据,并将序列化后的属性和数据存储在渲染数据文件中;将网页节点的排版信息和网页节点的属性和数据的序列化信息存储在渲染树文件中。
其中,对获取的网页图片文件进行优化处理包括过滤图片文件中的广告图片信息、修剪图片文件大小、压缩图片文件、缩小图片文件大小。图片文件中的颜色数量,图片文件转换为高压缩率存储格式的任意一个或多个图片文件。其中,在从网络获取请求访问的网页的页面数据之前,还包括预先设置二进制传输协议;资源包括图像文件和/或网页的源内容。网页的源内容包括网页的各个标签和各个标签的属性数据;网页节点与网页的标签一一对应。相应地,本专利技术实施例还提供了一种服务器,包括获取单元,用于根据客户端的网页访问请求,从网络获取所请求网页的页面数据,该页面数据包括:网页。网页的源内容和图片文件;排版单元,用于对获取单元获取的网页的源内容进行排版处理;图像处理单元,用于对获取单元得到的网页的图片文件进行优化编码单元用于对排版单元排版处理后的源内容和图片处理单元根据优化处理后的图片文件进行二进制数据编码到预设的二进制传输协议;将编码单元编码后的二进制数据包发送给客户端。
其中,排版单元包括解析单元,用于解析网页的源内容生成DOM树,DOM树包括网页节点和网页节点的属性和数据。布局排版单元,用于根据解析单元解析出的DOM树进行布局排版得到网页的渲染树,渲染树包括网页节点和网页的排版信息、属性和数据节点; 序列化单元用于对排版单元得到的网页节点的属性和数据进行序列化;第一存储单元,用于将序列化单元序列化后的属性和数据存储在渲染数据文件中。第二存储单元,用于将布局排版单元得到的网页节点的排版信息和序列化单元对渲染树文件中的网页节点的属性和数据进行序列化后的序列化信息进行存储。其中,图片处理单元包括图片过滤单元,用于过滤图片文件中的广告图片信息。和/或图片修剪单元,用于修剪图片文件的大小;和/或,图片压缩单元,用于压缩图片文件;和/或,图片优化单元,用于减少图片文件的颜色数据,并将图片文件转换为高压缩率存储格式的图片文件。其中,所述服务器还包括预设单元,用于预设二进制传输协议。
其中,服务器为排版引擎服务器。实施本专利技术实施例具有以下有益效果1、通过对网页源内容进行排版处理,优化网页图像文件,按照预设的二进制传输协议,将处理后的源内容被处理。将图像文件数据编码成二进制数据包进行传输,大大减少了客户端与排版引擎服务器之间的数据传输流量,大大节省了客户端的资源需求和响应时间,提高了传输效率;2、服务器端对网页的页面数据进行排版和优化,
【技术保护点】
一种基于C/S架构浏览器的数据传输方法,其特征在于,包括:根据客户端的网页访问请求,从网络获取所请求网页的页面数据,所述页面数据包括所述网页的来源。网页内容及网页图片文件;对获取的网页的源内容进行排版处理,对获取的网页的图像文件进行优化处理;根据预设的二进制传输协议,进行排版处理,对源内容和优化后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。
【技术特点总结】
【专利技术性质】
技术研发人员:齐小龙、李成良、杨木香、张国良、余恒兵、
申请人(专利权)持有人:Aspire Digital Technology,
类型:发明
国家、省、市:94 [中国|深圳]
下载所有详细的技术数据 我是该专利的所有者 查看全部
c 抓取网页数据(全部详细技术资料下载【技术实现步骤摘要】(一))
本发明专利技术实施例公开了一种基于C/S架构浏览器的数据传输方法,包括:根据客户端的网页访问请求,从网络获取被请求网页的页面数据,其中,页面数据包括网页的所有源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化处理后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。相应地,本发明专利技术的实施例还公开了一种服务器。采用本发明专利技术,可以大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及无线互联网领域,具体涉及一种基于C(Client,client)/S(Server,server)架构浏览器的数据传输方法及服务器。
技术介绍
C/S 架构是客户端和服务器端的架构。它是一种软件系统架构。可以充分利用两端硬件环境的优势,将任务合理分配给两端执行,降低了系统的通信开销。排版引擎服务器负责获取网页内容(包括源代码和图片等),整理信息,计算网页的显示方式,然后输出到客户端进行显示或打印。所有 Web 浏览器、电子邮件客户端和其他需要编辑和显示 Web 内容的应用程序都需要排版引擎服务器进行排版。现有的基于C/S架构浏览器的数据传输方案主要是基于客户端浏览器的类型,
专利技术人员发现,现有基于C/S架构浏览器的数据传输方案主要存在以下缺陷1、用户体验低。在 HTML 到 ML 或 XHTML-MP 的转换过程中,无法准确有效地转换 HTML 中的样式表信息,通常的处理方法会破坏原创页面的视觉效果,如背景图片和颜色、字体颜色等。客户端渲染可能很乏味并降低用户体验。2、传输效率低。由于HTML页面直接转换传输,客户端与排版引擎服务器之间的数据传输流量大,传输效率低。3、客户端性能要求高,并且客户端渲染复杂度很高。现有的数据传输方案需要客户端有硬件(例如客户端是WAP手机)或软件(客户端配备WAP浏览器)的支持。“重服务器端,轻客户端”的架构趋势。为了避免上述缺陷,可以使用预定义的数据传输协议进行数据传输。基于C/S架构浏览器的数据传输协议是C/S架构浏览器开发中最重要的部分之一。它是客户端和服务器之间的桥梁。协议定义的质量与网络直接相关。流量大小和客户端的渲染效果,特别是对于资源有限的中低端客户端,数据传输协议的定义直接关系到客户端浏览器的用户体验。因此,如何平衡客户端呈现的复杂性、传输的数据量和交互性来定义数据传输协议来实现基于C/S架构浏览器的数据传输方案是一个亟待解决的问题。
技术实现思路
本专利技术实施例要解决的技术问题是提供一种基于C/S架构浏览器的数据传输方法及服务器,能够大大减少客户端与排版引擎服务器之间的数据传输流量,提高传输效率,提升用户体验。为了解决上述技术问题,本专利技术实施例提供了一种基于C/S架构浏览器的数据传输方法,包括根据用户的网页访问请求,从网络上获取被请求网页的页面数据。客户端,使页面数据包括网页的源内容和网页的图片文件;对得到的网页的源内容进行排版处理,对得到的网页的图片文件进行优化处理;根据预设的二进制传输协议,对排版处理后的源内容和优化后的图像文件的二进制数据进行编码,并将编码后的二进制数据包传输给客户端。其中,对获取的网页源内容进行排版处理包括:解析网页源内容,生成DOM(Document Object Model,文档对象模型)树,DOM树包括网页节点和属性和数据;对DOM树进行布局排版,得到网页的渲染树,渲染树包括网页节点和网页节点的排版信息、属性和数据。序列化网页节点。属性和数据,并将序列化后的属性和数据存储在渲染数据文件中;将网页节点的排版信息和网页节点的属性和数据的序列化信息存储在渲染树文件中。
其中,对获取的网页图片文件进行优化处理包括过滤图片文件中的广告图片信息、修剪图片文件大小、压缩图片文件、缩小图片文件大小。图片文件中的颜色数量,图片文件转换为高压缩率存储格式的任意一个或多个图片文件。其中,在从网络获取请求访问的网页的页面数据之前,还包括预先设置二进制传输协议;资源包括图像文件和/或网页的源内容。网页的源内容包括网页的各个标签和各个标签的属性数据;网页节点与网页的标签一一对应。相应地,本专利技术实施例还提供了一种服务器,包括获取单元,用于根据客户端的网页访问请求,从网络获取所请求网页的页面数据,该页面数据包括:网页。网页的源内容和图片文件;排版单元,用于对获取单元获取的网页的源内容进行排版处理;图像处理单元,用于对获取单元得到的网页的图片文件进行优化编码单元用于对排版单元排版处理后的源内容和图片处理单元根据优化处理后的图片文件进行二进制数据编码到预设的二进制传输协议;将编码单元编码后的二进制数据包发送给客户端。
其中,排版单元包括解析单元,用于解析网页的源内容生成DOM树,DOM树包括网页节点和网页节点的属性和数据。布局排版单元,用于根据解析单元解析出的DOM树进行布局排版得到网页的渲染树,渲染树包括网页节点和网页的排版信息、属性和数据节点; 序列化单元用于对排版单元得到的网页节点的属性和数据进行序列化;第一存储单元,用于将序列化单元序列化后的属性和数据存储在渲染数据文件中。第二存储单元,用于将布局排版单元得到的网页节点的排版信息和序列化单元对渲染树文件中的网页节点的属性和数据进行序列化后的序列化信息进行存储。其中,图片处理单元包括图片过滤单元,用于过滤图片文件中的广告图片信息。和/或图片修剪单元,用于修剪图片文件的大小;和/或,图片压缩单元,用于压缩图片文件;和/或,图片优化单元,用于减少图片文件的颜色数据,并将图片文件转换为高压缩率存储格式的图片文件。其中,所述服务器还包括预设单元,用于预设二进制传输协议。
其中,服务器为排版引擎服务器。实施本专利技术实施例具有以下有益效果1、通过对网页源内容进行排版处理,优化网页图像文件,按照预设的二进制传输协议,将处理后的源内容被处理。将图像文件数据编码成二进制数据包进行传输,大大减少了客户端与排版引擎服务器之间的数据传输流量,大大节省了客户端的资源需求和响应时间,提高了传输效率;2、服务器端对网页的页面数据进行排版和优化,
【技术保护点】
一种基于C/S架构浏览器的数据传输方法,其特征在于,包括:根据客户端的网页访问请求,从网络获取所请求网页的页面数据,所述页面数据包括所述网页的来源。网页内容及网页图片文件;对获取的网页的源内容进行排版处理,对获取的网页的图像文件进行优化处理;根据预设的二进制传输协议,进行排版处理,对源内容和优化后的图像文件进行二进制数据编码,将编码后的二进制数据包传输给客户端。
【技术特点总结】
【专利技术性质】
技术研发人员:齐小龙、李成良、杨木香、张国良、余恒兵、
申请人(专利权)持有人:Aspire Digital Technology,
类型:发明
国家、省、市:94 [中国|深圳]
下载所有详细的技术数据 我是该专利的所有者
c 抓取网页数据(2021-11-05今日任务将数据文件spider.log根据要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-19 23:17
2021-11-05
数据采集一
一。今天的任务
根据需要将数据文件spider.log转储为ans0201.csv
二。主要内容
任务分析与实施
根据需求,我们需要在spider.log文件中取出相关字段,使用Python中的读取文件,每行数据规则相同,逐行读取,取出对应字段,然后创建一个csv 文件,然后将 read 文件按要求写入 csv
使用语言工具 Python
模块操作系统
主要源代码
导入 csv
导入编解码器
列表 = []
列表CSV = []
def readLog(): #逐行读取数据文件,如果链接是电影就是我们需要的数据
列表 = []
使用 open(r"C:\Users\liu\Desktop\arg\task0201\spider.log", "r", encoding="utf-8") 作为文件:
s = file.readlines()
对于我在 s 中:
str = i.split(",")
如果 str[1].startswith(r""):
list.append(i)
返回列表
def anyData(list): #去除冗余数据,获取需要的电影名称、放映时间等
列表CSV = []
对于列表中的 abc:
str = abc.split(";")
电影名 = str[0].split(",")[2]
加载日期 = str[1]
上传日期 = str[2]
支付 = str[7][5:]
tuple = (movieName, loadDate, uploadDate, pay)
listCsv.append(元组)
返回列表CSV
def writeCsv(list): #写入csv文件
f = codecs.open('ans0201.csv', 'w', 'utf-8')
作家 = csv.writer(f)
对于列表中的 i:
writer.writerow(i)
f.close()
如果 __name__ == "__main__":
列表 = anyData(readLog())
打印(列表)
写CSV(列表)
三。遇到问题
需要过滤文件数据。过滤后的数据需要按照规则进行过滤。csv文件读写
四。解决方案
关于文件数据的问题,一开始没看懂,后来发现标题里的链接是固定的。根据链接,可以过滤掉所需网页采集的数据。关于数据过滤,一是每行第一个数据只要是Name即可,二是票房数据删除票房文本Csv文件读写网上有读写文件的方法,按照方法来参考写
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(2021-11-05今日任务将数据文件spider.log根据要求)
2021-11-05
数据采集一
一。今天的任务
根据需要将数据文件spider.log转储为ans0201.csv
二。主要内容
任务分析与实施
根据需求,我们需要在spider.log文件中取出相关字段,使用Python中的读取文件,每行数据规则相同,逐行读取,取出对应字段,然后创建一个csv 文件,然后将 read 文件按要求写入 csv
使用语言工具 Python
模块操作系统
主要源代码
导入 csv
导入编解码器
列表 = []
列表CSV = []
def readLog(): #逐行读取数据文件,如果链接是电影就是我们需要的数据
列表 = []
使用 open(r"C:\Users\liu\Desktop\arg\task0201\spider.log", "r", encoding="utf-8") 作为文件:
s = file.readlines()
对于我在 s 中:
str = i.split(",")
如果 str[1].startswith(r""):
list.append(i)
返回列表
def anyData(list): #去除冗余数据,获取需要的电影名称、放映时间等
列表CSV = []
对于列表中的 abc:
str = abc.split(";")
电影名 = str[0].split(",")[2]
加载日期 = str[1]
上传日期 = str[2]
支付 = str[7][5:]
tuple = (movieName, loadDate, uploadDate, pay)
listCsv.append(元组)
返回列表CSV
def writeCsv(list): #写入csv文件
f = codecs.open('ans0201.csv', 'w', 'utf-8')
作家 = csv.writer(f)
对于列表中的 i:
writer.writerow(i)
f.close()
如果 __name__ == "__main__":
列表 = anyData(readLog())
打印(列表)
写CSV(列表)
三。遇到问题
需要过滤文件数据。过滤后的数据需要按照规则进行过滤。csv文件读写
四。解决方案
关于文件数据的问题,一开始没看懂,后来发现标题里的链接是固定的。根据链接,可以过滤掉所需网页采集的数据。关于数据过滤,一是每行第一个数据只要是Name即可,二是票房数据删除票房文本Csv文件读写网上有读写文件的方法,按照方法来参考写
分类:
技术要点:
相关文章:
c 抓取网页数据(之前自带的开发者调试工具(F12做过)() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-19 23:04
)
之前抓过浏览器包,可以用浏览器自带的工具来完成;APP包我也抓到了,也可以通过fiddler做代理。现在想在PC端测试一下这个以前没接触过的应用。,我对应用捕获不太了解,于是开始搜索。接下来是处理结果。
1.PC浏览器网页数据分析
简单常用的网页数据分析,谷歌/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足一些要求,如果是请求前和响应后处理最多,修改浏览器为发送请求数据,修改服务端对应数据,使用F12开发工具无法满足我们的需求,通过引入Fiddler抓包工具,可以理解为一个本地代理服务器,可以转发客户端和服务端的请求和响应。
设置提琴手:
打开Fiddler,在菜单栏中,打开Tools --Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了并根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS请操作
2.应用数据分析
Fiddler 也可以用于移动 App 数据分析,类似于上面从 PC 浏览器检索数据的方式。App需要和PC在同一网段,设置了移动Wifi代理,IP为PC机的IP地址,例如:64.35.8< @6.12,端口号为FIddler设置的端口号,一般为8888,App端所有网络/响应请求都必须经过FIddler转发,可以对请求做数据分析
3.PC 端 (C/S) 数据包捕获
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理成为代理链。
由于一般的C/S客户端无法设置代理,Fiddler无法检测到数据,所有的请求都会被捕获并通过Proxifer发送给Fiddler,这样客户端的请求就可以在Fiddler中进行分析。
Proxifer 设置:
设置很简单,如下图,两步OK
一种)。代理服务器和 Fiddler 代理设置匹配
b).代理规则
默认Default,可以忽略
点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler应用文件目录,确认
目标主机:本地Fiddler设置代理,可任意设置
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功
查看全部
c 抓取网页数据(之前自带的开发者调试工具(F12做过)()
)
之前抓过浏览器包,可以用浏览器自带的工具来完成;APP包我也抓到了,也可以通过fiddler做代理。现在想在PC端测试一下这个以前没接触过的应用。,我对应用捕获不太了解,于是开始搜索。接下来是处理结果。
1.PC浏览器网页数据分析
简单常用的网页数据分析,谷歌/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足一些要求,如果是请求前和响应后处理最多,修改浏览器为发送请求数据,修改服务端对应数据,使用F12开发工具无法满足我们的需求,通过引入Fiddler抓包工具,可以理解为一个本地代理服务器,可以转发客户端和服务端的请求和响应。
设置提琴手:
打开Fiddler,在菜单栏中,打开Tools --Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了并根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS请操作
2.应用数据分析
Fiddler 也可以用于移动 App 数据分析,类似于上面从 PC 浏览器检索数据的方式。App需要和PC在同一网段,设置了移动Wifi代理,IP为PC机的IP地址,例如:64.35.8< @6.12,端口号为FIddler设置的端口号,一般为8888,App端所有网络/响应请求都必须经过FIddler转发,可以对请求做数据分析
3.PC 端 (C/S) 数据包捕获
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理成为代理链。
由于一般的C/S客户端无法设置代理,Fiddler无法检测到数据,所有的请求都会被捕获并通过Proxifer发送给Fiddler,这样客户端的请求就可以在Fiddler中进行分析。
Proxifer 设置:
设置很简单,如下图,两步OK
一种)。代理服务器和 Fiddler 代理设置匹配
b).代理规则
默认Default,可以忽略
点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler应用文件目录,确认
目标主机:本地Fiddler设置代理,可任意设置
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功
c 抓取网页数据(根据指定URL来抓取相应的网页内容,而后存入本地文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 497 次浏览 • 2022-03-19 23:03
今天写一个简单的程序,根据指定的URL爬取对应的网页内容,然后存入本地文件。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:bash
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 如下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
上面代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取url对应的资源,然后读取资源数据,在控制台打印,写入内容到本地文件中间。互联网
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。拿来
另外,在处理异常时,我们使用 fm.Fprintf() 方法,它是三种格式化方法之一:url
编译后运行程序,指定一个URL参数,暂时指定为百度。还是希望谷歌能在不久的将来回归:指针
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。代码 查看全部
c 抓取网页数据(根据指定URL来抓取相应的网页内容,而后存入本地文件)
今天写一个简单的程序,根据指定的URL爬取对应的网页内容,然后存入本地文件。本课程将涉及网络请求、文件操作等知识点。以下是实现代码:bash
// fetch.go
package main
import (
"os"
"fmt"
"net/http"
"io/ioutil"
)
func main() {
url := os.Args[1]
// 根据URL获取资源
res, err := http.Get(url)
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: %v\n", err)
os.Exit(1)
}
// 读取资源数据 body: []byte
body, err := ioutil.ReadAll(res.Body)
// 关闭资源流
res.Body.Close()
if err != nil {
fmt.Fprintf(os.Stderr, "fetch: reading %s: %v\n", url, err)
os.Exit(1)
}
// 控制台打印内容 如下两种方法等同
fmt.Printf("%s", body)
fmt.Printf(string(body))
// 写入文件
ioutil.WriteFile("site.txt", body, 0644)
}
上面代码中,我们引入了net/http网络包,然后调用http.Get(url)方法获取url对应的资源,然后读取资源数据,在控制台打印,写入内容到本地文件中间。互联网
需要注意的是,读取资源数据后,要及时关闭资源流,避免内存资源泄露。拿来
另外,在处理异常时,我们使用 fm.Fprintf() 方法,它是三种格式化方法之一:url
编译后运行程序,指定一个URL参数,暂时指定为百度。还是希望谷歌能在不久的将来回归:指针
$ ./fetch http://www.baidu.com
运行程序后,会在当前目录下生成一个site.txt文件。代码
c 抓取网页数据(IMG标签的抓取图片网址(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2022-03-19 21:12
)
网页上的数据类型非常详细:文字、图片、链接、源码等。在data采集过程中,不同类型的数据有不同的对应抓取方式。本文将详细介绍数据类型的类型以及如何捕获它们。
示例 URL:#!type=movie&tag=%E7%BB%8F%E5%85%B8&sort=recommend&page_limit=20&page_start=0
1、抓取文字:抓取页面显示的文字
操作:鼠标选中页面中的文本,在弹出的操作提示文本中选择[采集 of this element],目标文本会向下采集。
同时,将鼠标移动到字段名称【文本】上,点击?
? 按钮,选择【自定义捕捉方式】,可以为我们选择章鱼鱼的自动文字。
2、 Crawl Image URL:要抓取的图片的URL
操作:鼠标选中页面上的图片,在弹出的操作提示中选择【采集此图片地址】,即可提取图片URL。
同时,将鼠标移至视野名称【图片地址】,点击?
? 按钮,选择【自定义抓取方式】,可以选择优采云为我们自动【抓取图片URL(IMG标签的src属性)】。
为什么是【IMG 标签的 src 属性】?在XPath教程中,我们讲了网页Html的相关知识。网页上的图片一般用IMG标签表示,图片地址会在IMG标签的src属性中。
因此,当我们要提取图片的 URL 时,本质上是使用 XPath 来定位 Img 标签,然后从 IMG 标签中提取 src 属性。src 属性的值是图像 URL。
这里演示的只是抓取图片时使用的抓取方式。具体图片采集请看教程:图片采集并下载到本地
3、爬取链接URL,抓取网页上超链接的URL
示例网址:
例如
操作:用鼠标选中页面中的超链接(一般是滚动标题文字,可点击跳转),弹出操作提示图片选择【采集此链接地址】,提取超链接URL。
同时,将鼠标移至字段名称【链接地址】,点击?
? 按钮,选择【自定义抓取方式】,可以选择优采云自动给我们【元素链接URL】。
4、抓取输入框文本值:抓取输入框文本
示例网址:
%E9%9C%B8%E7%8E%8B%E5%88%AB%E5%A7%AC&cat=1002
操作:鼠标选中页面中输入的文本(输入已有的输入值),在弹出文本的操作提示中选择[采集文本框的值],关键词 的文本输入框将被提取。.
同时,将鼠标移动到字段名称【文本框值】上,点击?
? 按钮是自动的,选择【自定义捕获方式】,测试发现文本框值是value属性。
为什么是【INPUT标签的value属性】在XPath教程中,我们讲了网页Html的相关知识,网页上的输入框一般都是用INPUT标签显示的,输入的关键词在文本输入中会显示在INPUT 中吗?在标签的 value 属性中。
,当我们要提取文本详情的关键词时,本质上是使用XPath来定位INPUT标签,所以我们从INPUT标签中提取value属性,value属性的值就是关键词 的输入细节。
5、抓取网页源码:抓取网页元素自动网页爬虫源码
示例 URL:%E5%B0%8F%E8%AF%B4
爬取网页源代码 Outer Html?
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择【采集Outer Html of this element】,该元素对应的源(Outer Html)为由 采集 下载。
同时,将鼠标移至字段名称[OuterHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云自动为我们选择了【抓取元素(外层Html)的网页源码。
爬取网页源码 Inner Html
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择采集元素的Inner Html,该元素对应的源(InnerHtml)为< @采集 下来。
同时,将鼠标移动到字段名称[InnerHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云已经自动为我们选择了【抓取元素(Inner Html)的网页源码。
自动网页抓取?
外部 Html 和内部 Html 有什么区别?
外层Html:收录当前元素
Inner Html:不收录当前元素,从当前元素的下一级开始
6、抓取元素属性值
首先使用XPath找到当前元素的来源,观察当前资源中存在哪些属性值,需要提取哪些属性值,然后将已有的和需要的属性值分开。
示例 URL:%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6 %9C%BA&page=7&s=177&click=0
脚步:
圆点是京东产品列表页面。每个产品都有一个产品 ID,现在需要 采集 这个产品 ID。
第一个商品列表的定位XPath为*[@id='J_goodsList']/ul/li[2],对应的网页源码包括class、data-sku、data-spu、ware-type。商品ID在data-sku属性中,我们需要抓取这个,也就是data-sku属性的属性值。
我们先选择第二个产品列表,在弹出的操作提示文字中,选择【this 采集本步骤的文字】,就是为了得到定位列表的XPath。
我们要抓取的是data-pid的属性值,所以将鼠标移动到字段名【文本,点击?
?、选择【自定义抓取方式】,将抓取方式改为【抓取元素属性】值】,并在下拉值中,选择【data-sku】,这样我们就设置data的值- sku属性采集下来,这是我们需要的产品ID。最后点击【应用】保存配置。
查看全部
c 抓取网页数据(IMG标签的抓取图片网址(组图)
)
网页上的数据类型非常详细:文字、图片、链接、源码等。在data采集过程中,不同类型的数据有不同的对应抓取方式。本文将详细介绍数据类型的类型以及如何捕获它们。
示例 URL:#!type=movie&tag=%E7%BB%8F%E5%85%B8&sort=recommend&page_limit=20&page_start=0
1、抓取文字:抓取页面显示的文字
操作:鼠标选中页面中的文本,在弹出的操作提示文本中选择[采集 of this element],目标文本会向下采集。
同时,将鼠标移动到字段名称【文本】上,点击?
? 按钮,选择【自定义捕捉方式】,可以为我们选择章鱼鱼的自动文字。
2、 Crawl Image URL:要抓取的图片的URL
操作:鼠标选中页面上的图片,在弹出的操作提示中选择【采集此图片地址】,即可提取图片URL。
同时,将鼠标移至视野名称【图片地址】,点击?
? 按钮,选择【自定义抓取方式】,可以选择优采云为我们自动【抓取图片URL(IMG标签的src属性)】。
为什么是【IMG 标签的 src 属性】?在XPath教程中,我们讲了网页Html的相关知识。网页上的图片一般用IMG标签表示,图片地址会在IMG标签的src属性中。
因此,当我们要提取图片的 URL 时,本质上是使用 XPath 来定位 Img 标签,然后从 IMG 标签中提取 src 属性。src 属性的值是图像 URL。
这里演示的只是抓取图片时使用的抓取方式。具体图片采集请看教程:图片采集并下载到本地
3、爬取链接URL,抓取网页上超链接的URL
示例网址:
例如
操作:用鼠标选中页面中的超链接(一般是滚动标题文字,可点击跳转),弹出操作提示图片选择【采集此链接地址】,提取超链接URL。
同时,将鼠标移至字段名称【链接地址】,点击?
? 按钮,选择【自定义抓取方式】,可以选择优采云自动给我们【元素链接URL】。
4、抓取输入框文本值:抓取输入框文本
示例网址:
%E9%9C%B8%E7%8E%8B%E5%88%AB%E5%A7%AC&cat=1002
操作:鼠标选中页面中输入的文本(输入已有的输入值),在弹出文本的操作提示中选择[采集文本框的值],关键词 的文本输入框将被提取。.
同时,将鼠标移动到字段名称【文本框值】上,点击?
? 按钮是自动的,选择【自定义捕获方式】,测试发现文本框值是value属性。
为什么是【INPUT标签的value属性】在XPath教程中,我们讲了网页Html的相关知识,网页上的输入框一般都是用INPUT标签显示的,输入的关键词在文本输入中会显示在INPUT 中吗?在标签的 value 属性中。
,当我们要提取文本详情的关键词时,本质上是使用XPath来定位INPUT标签,所以我们从INPUT标签中提取value属性,value属性的值就是关键词 的输入细节。
5、抓取网页源码:抓取网页元素自动网页爬虫源码
示例 URL:%E5%B0%8F%E8%AF%B4
爬取网页源代码 Outer Html?
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择【采集Outer Html of this element】,该元素对应的源(Outer Html)为由 采集 下载。
同时,将鼠标移至字段名称[OuterHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云自动为我们选择了【抓取元素(外层Html)的网页源码。
爬取网页源码 Inner Html
操作:鼠标选中要抓取的项目,在弹出页面的操作提示元素中选择采集元素的Inner Html,该元素对应的源(InnerHtml)为< @采集 下来。
同时,将鼠标移动到字段名称[InnerHtml],点击?
? 按钮,选择【自定义抓取方式】,可以看到优采云已经自动为我们选择了【抓取元素(Inner Html)的网页源码。
自动网页抓取?
外部 Html 和内部 Html 有什么区别?
外层Html:收录当前元素
Inner Html:不收录当前元素,从当前元素的下一级开始
6、抓取元素属性值
首先使用XPath找到当前元素的来源,观察当前资源中存在哪些属性值,需要提取哪些属性值,然后将已有的和需要的属性值分开。
示例 URL:%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6 %9C%BA&page=7&s=177&click=0
脚步:
圆点是京东产品列表页面。每个产品都有一个产品 ID,现在需要 采集 这个产品 ID。
第一个商品列表的定位XPath为*[@id='J_goodsList']/ul/li[2],对应的网页源码包括class、data-sku、data-spu、ware-type。商品ID在data-sku属性中,我们需要抓取这个,也就是data-sku属性的属性值。
我们先选择第二个产品列表,在弹出的操作提示文字中,选择【this 采集本步骤的文字】,就是为了得到定位列表的XPath。
我们要抓取的是data-pid的属性值,所以将鼠标移动到字段名【文本,点击?
?、选择【自定义抓取方式】,将抓取方式改为【抓取元素属性】值】,并在下拉值中,选择【data-sku】,这样我们就设置data的值- sku属性采集下来,这是我们需要的产品ID。最后点击【应用】保存配置。
c 抓取网页数据(百度中搜索一个使用webmagic:数据库Mongodb驱动使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-18 15:19
当我们在百度搜索的时候,会有一个嵌入的查询页面:
这是通过ajax技术加载的,因为是js渲染,所以页面源码中不收录这个信息。
通过火狐的Firebug监听网络请求,发现请求是到百度opendata,结果返回一个收录100条数据的json
这样,通过分析请求字符串的参数,自定义请求,就可以让爬虫直接爬取数据。
获得数据后,您需要对其进行解析。每个请求将返回 100 条数据。现在您需要将这 100 条数据全部删除,并将它们存储在 Mongodb 数据库中。
爬虫使用 webmagic:
数据库MongoDB驱动使用
行家坐标:
us.codecraft
webmagic-extension
0.5.2
org.mongodb
mongo-java-driver
2.7.3
Webmagic爬虫框架使用参考:
我在爬取过程中自定义了PageProcessor,将数据解析并存储在Mongodb中,并使用爬虫框架自带的FilePipeline将数据持久化到磁盘文件中。
每个请求返回100条数据,需要分析分离成单独的json字符串,然后一一插入。
插入数据时,还要判断数据是否重复。
json格式的字符串可以直接存入数据库。
Mongo mongo = new Mongo();
DB db = mongo.getDB("shixinTest");
DBCollection q=db.getCollection("shixinTest1");
// new BasicDBObject();
// 通过JSON.parse构造DBObject
DBObject query = (BasicDBObject) JSON.parse(JsonString)
q.save(query);
json字符串存储在mongodb数据库中:
爬虫实现部分是:抓取网络json数据,存入mongodb(2) 查看全部
c 抓取网页数据(百度中搜索一个使用webmagic:数据库Mongodb驱动使用)
当我们在百度搜索的时候,会有一个嵌入的查询页面:
这是通过ajax技术加载的,因为是js渲染,所以页面源码中不收录这个信息。
通过火狐的Firebug监听网络请求,发现请求是到百度opendata,结果返回一个收录100条数据的json
这样,通过分析请求字符串的参数,自定义请求,就可以让爬虫直接爬取数据。
获得数据后,您需要对其进行解析。每个请求将返回 100 条数据。现在您需要将这 100 条数据全部删除,并将它们存储在 Mongodb 数据库中。
爬虫使用 webmagic:
数据库MongoDB驱动使用
行家坐标:
us.codecraft
webmagic-extension
0.5.2
org.mongodb
mongo-java-driver
2.7.3
Webmagic爬虫框架使用参考:
我在爬取过程中自定义了PageProcessor,将数据解析并存储在Mongodb中,并使用爬虫框架自带的FilePipeline将数据持久化到磁盘文件中。
每个请求返回100条数据,需要分析分离成单独的json字符串,然后一一插入。
插入数据时,还要判断数据是否重复。
json格式的字符串可以直接存入数据库。
Mongo mongo = new Mongo();
DB db = mongo.getDB("shixinTest");
DBCollection q=db.getCollection("shixinTest1");
// new BasicDBObject();
// 通过JSON.parse构造DBObject
DBObject query = (BasicDBObject) JSON.parse(JsonString)
q.save(query);
json字符串存储在mongodb数据库中:
爬虫实现部分是:抓取网络json数据,存入mongodb(2)
c 抓取网页数据(定制网页数据存储结构,保存相应数据(c抓取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-16 19:11
c抓取网页数据有多种方法,可以采用python、numpy、pandas等。但直接抓取网页数据库中的数据有时会显得格格不入。这就需要我们定制网页数据存储结构,保存相应数据。首先抓取的数据以文本格式保存,例如:{[user_id]:user_id,[age]:age}这种数据特点在于,抓取过程中没有对user_id做任何处理,我们直接将其存储在文本中。
但对于爬虫,这种存储形式容易给浏览器造成压力,最常见的原因是:每次爬取的数据都要在下次抓取网页时进行一次user_id的去重。可以尝试使用bs4(beautifulsoup4)+bs4.extract()方法来解决这个问题。先看下bs4中的方法的用法:extract方法的核心用法可以参看《python3网络爬虫基础知识》extract方法的4个参数说明:url(获取页面的url):获取第一页或者第二页以及每页的页面地址。
headers(发送给浏览器的headers信息):发送一个请求、重定向到调用该页面的对应url。image(请求图片文件):发送一个请求、重定向到当前页所在网页。python图片处理库的使用extract.python_python.content.scrapy.content_to_json(pythoncontent转换json格式):其实就是网页上已经存在的json数据变成bson格式(纯python方法,只需要模拟浏览器点击图片,这里记住,图片请求会发送一个浏览器地址,并且其中包含图片链接)例如使用:post最常见的开始爬虫使用的抓取方法:1.点击item的属性找到存放对应数据的文件2.使用beautifulsoup()模块来解析该文件返回的对应json格式数据这里使用的是beautifulsoup方法,还可以使用os模块、chrome等模块。
相应的,代码可以:importbs4extract_request=bs4.extract(soup,'./users/imooc/ppt/{user_id}/{age}/{score}'.format(score))使用content_to_json()方法就相对简单很多。content_to_json(soup,'users/users/imooc/ppt/{user_id}/{score}'.format(score))就是发送一个请求,得到user_id和当前爬取的结果相应的json对象即可。缺点:由于浏览器会多次请求文件,所以返回json格式时可能会出现乱码等情况。 查看全部
c 抓取网页数据(定制网页数据存储结构,保存相应数据(c抓取))
c抓取网页数据有多种方法,可以采用python、numpy、pandas等。但直接抓取网页数据库中的数据有时会显得格格不入。这就需要我们定制网页数据存储结构,保存相应数据。首先抓取的数据以文本格式保存,例如:{[user_id]:user_id,[age]:age}这种数据特点在于,抓取过程中没有对user_id做任何处理,我们直接将其存储在文本中。
但对于爬虫,这种存储形式容易给浏览器造成压力,最常见的原因是:每次爬取的数据都要在下次抓取网页时进行一次user_id的去重。可以尝试使用bs4(beautifulsoup4)+bs4.extract()方法来解决这个问题。先看下bs4中的方法的用法:extract方法的核心用法可以参看《python3网络爬虫基础知识》extract方法的4个参数说明:url(获取页面的url):获取第一页或者第二页以及每页的页面地址。
headers(发送给浏览器的headers信息):发送一个请求、重定向到调用该页面的对应url。image(请求图片文件):发送一个请求、重定向到当前页所在网页。python图片处理库的使用extract.python_python.content.scrapy.content_to_json(pythoncontent转换json格式):其实就是网页上已经存在的json数据变成bson格式(纯python方法,只需要模拟浏览器点击图片,这里记住,图片请求会发送一个浏览器地址,并且其中包含图片链接)例如使用:post最常见的开始爬虫使用的抓取方法:1.点击item的属性找到存放对应数据的文件2.使用beautifulsoup()模块来解析该文件返回的对应json格式数据这里使用的是beautifulsoup方法,还可以使用os模块、chrome等模块。
相应的,代码可以:importbs4extract_request=bs4.extract(soup,'./users/imooc/ppt/{user_id}/{age}/{score}'.format(score))使用content_to_json()方法就相对简单很多。content_to_json(soup,'users/users/imooc/ppt/{user_id}/{score}'.format(score))就是发送一个请求,得到user_id和当前爬取的结果相应的json对象即可。缺点:由于浏览器会多次请求文件,所以返回json格式时可能会出现乱码等情况。
c 抓取网页数据(保定师范专科学校学报.4第17卷第4期)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-16 17:12
<p>2004年10月保定师范学院学报0ct。20040FBAODINGTEACHERSVol17No. 4 第17卷第4期 JOURNALCOLLEGE文章 No.: 1008.4584 (2004)04-0015-03 使用MSHTML组件从网页中提取数据 卢书金 (河北保定师范学院教育信息技术系)保定071051)摘录关键词:HTML语言;MSHTML对象模型;网页分类号:TP311.1 文档识别码:A 1 问题提出随着互联网的发展,数据和存在有信息的人越来越多,通常只需要在浏览的网页上保存或记录部分数据即可,其他情况下,为了更好地分析研究数据,就需要用编程的方法把网页上的网页。例如,科学家需要从发布天气预报的网站获取气象数据以供研究;金融和经济工作者需要跟踪和记录股票和汇率的变化;需要根据关键词搜索网页,分析链接等。所有这些应用都涉及到网页数据的分析和提取。2 网页结构 要分析网页上的内容和数据,首先要了解网页的结构。互联网由无数相互链接的网页组成。这些页面也称为Web文档,由HTML(HyperMarkup也收录要显示的图形、声音等元素,以及指向其他文档的超链接)组成。控制语句是由一些标签(Tag)组成,用于描述显示内容的形式,负责客户端和服务器之间的信息交换。标签用◇括起来,经常成对出现。浏览器可以识别这些标签,并根据标签所需的格式来显示内容n]。下面是一个用HTML语言写的网页文档: 命令ITLE> 这是HTML文档的标题,这里输入文本的标题,这里输入文本的文本,包括HTML文档的标题如image超链接和文档正文。文档头放在和之间,通常包括以下元素: (1) 文档标题:是浏览器窗口标题栏上显示的文本,用和符号指定。关键字等,使用BASE设置网页的基本 URL。(< @3)Script:插入文档中用于操作页面元素的短程序,位于 CRIPT> 和 CRIPT> 之间。HTML语言中还收录大量的符号,主要分为以下几类: 作者简介:卢树金(1967一),男,河北省唐县人,实验员·16·保定杂志社师范学院,2004年第4期(2)超链接:使用、定义、指定超链接的目标uRL;( 查看全部
c 抓取网页数据(保定师范专科学校学报.4第17卷第4期)
<p>2004年10月保定师范学院学报0ct。20040FBAODINGTEACHERSVol17No. 4 第17卷第4期 JOURNALCOLLEGE文章 No.: 1008.4584 (2004)04-0015-03 使用MSHTML组件从网页中提取数据 卢书金 (河北保定师范学院教育信息技术系)保定071051)摘录关键词:HTML语言;MSHTML对象模型;网页分类号:TP311.1 文档识别码:A 1 问题提出随着互联网的发展,数据和存在有信息的人越来越多,通常只需要在浏览的网页上保存或记录部分数据即可,其他情况下,为了更好地分析研究数据,就需要用编程的方法把网页上的网页。例如,科学家需要从发布天气预报的网站获取气象数据以供研究;金融和经济工作者需要跟踪和记录股票和汇率的变化;需要根据关键词搜索网页,分析链接等。所有这些应用都涉及到网页数据的分析和提取。2 网页结构 要分析网页上的内容和数据,首先要了解网页的结构。互联网由无数相互链接的网页组成。这些页面也称为Web文档,由HTML(HyperMarkup也收录要显示的图形、声音等元素,以及指向其他文档的超链接)组成。控制语句是由一些标签(Tag)组成,用于描述显示内容的形式,负责客户端和服务器之间的信息交换。标签用◇括起来,经常成对出现。浏览器可以识别这些标签,并根据标签所需的格式来显示内容n]。下面是一个用HTML语言写的网页文档: 命令ITLE> 这是HTML文档的标题,这里输入文本的标题,这里输入文本的文本,包括HTML文档的标题如image超链接和文档正文。文档头放在和之间,通常包括以下元素: (1) 文档标题:是浏览器窗口标题栏上显示的文本,用和符号指定。关键字等,使用BASE设置网页的基本 URL。(< @3)Script:插入文档中用于操作页面元素的短程序,位于 CRIPT> 和 CRIPT> 之间。HTML语言中还收录大量的符号,主要分为以下几类: 作者简介:卢树金(1967一),男,河北省唐县人,实验员·16·保定杂志社师范学院,2004年第4期(2)超链接:使用、定义、指定超链接的目标uRL;(
c 抓取网页数据(web页面数据采集工具通达网络爬虫管理工具应用场景)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-16 10:11
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面采集快速执行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。 查看全部
c 抓取网页数据(web页面数据采集工具通达网络爬虫管理工具应用场景)
随着大数据时代的到来和互联网技术的飞速发展,数据在企业的日常运营管理中无处不在。各种数据的聚合、整合、分析和研究,在企业的发展和决策中发挥着非常重要的作用。.
数据采集越来越受到企业的关注。如何从海量网页中快速、全面地获取你想要的数据信息?
给大家介绍一个非常好用的网页数据工具采集——集家通达网络爬虫管理工具,以下简称爬虫管理工具。
网络爬虫工具
工具介绍
吉家通达网络爬虫管理工具是一个通用的网页数据采集器,由管理工具、爬虫工具和爬虫数据库三部分组成。它可以代替人自动采集整理互联网中的数据信息,快速将网页数据转化为结构化数据,并以EXCEL等多种形式存储。该产品可用于舆情监测、市场分析、产品开发、风险预测等多种业务使用场景。
特征
吉家通达网络爬虫管理工具简单易用,无需任何技术基础即可快速上手。工作人员可以通过设置爬取规则来启动爬虫。
吉家通达网络爬虫管理工具具有以下五个特点:
应用场景
场景一:建立企业业务数据库
爬虫管理工具可以快速爬取网页企业所需的数据,整理下载数据,省时省力。几分钟就完成了人工天的工作量,数据全面缺失。
场景二:企业舆情口碑监测
整理好爬虫管理工具,设置好网站、关键词、爬取规则后,工作人员5分钟即可获取企业舆情信息,下载到指定位置,导出多种格式的数据供市场人员参考分析。避免手动监控的耗时、劳动密集和不完整的缺点。
场景三:企业市场数据采集
企业在安排好爬虫管理工具后,可以快速下载自己的产品或服务在市场上的数据和信息,以及竞品的产品或服务、价格、销量、趋势、口碑等信息,其他市场参与者。
场景四:市场需求研究
安排爬虫管理工具后,企业可以从WEB页面采集快速执行目标用户需求,包括行业数据、行业信息、竞品数据、竞品信息、用户需求、竞品用户反馈等,5分钟获取海量数据,并自动整理下载到指定位置。
应用
网络爬虫工具
吉佳通达履带管理工具产品成熟,已在市场上多次应用。代表性应用于“房地产行业大数据融合平台”,为房地产行业大数据融合平台提供网页数据采集功能。
c 抓取网页数据(响应式+js写法和原生js的交互方法(c))
网站优化 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2022-03-12 06:01
c抓取网页数据为html文件。两种最常用,“响应式+js写法”和“原生js生成响应式+一般交互”。--“一般交互”的特点是能把一些交互用js实现出来,或者把一些一般交互的方法封装成js来实现。是目前比较常用的技术。“响应式+js写法”的特点是js和页面做交互,从而驱动页面去适应一定的尺寸。生成响应式的结果时,也就用到了js的交互方法。两种技术,都能把小屏幕的应用设计成不同的大屏幕,适合于任何应用场景。
给楼主推荐看看这个帖子
刚学了一段时间。所以再强答一下先说明一下我看的开发者工具是pc端vs2013,mac应该也差不多(真的有用到工具和原理上的东西)再说明一下工作上的推荐方法,vs2013的开发者工具和基础类工具自己找吧。我实在没图找不到了。-先说alt+tab键切换,vs2015允许,就是让你自己看着方便。界面上最小的是地址栏(可以自定义,默认是地址栏右边的黄色方块);一般的交互都放在我的工程里面,如:publicclassapiviewextendsactivityextendsadaptiveandframework{exceptionuriprovided="";voidmain(){customeventchannel=newcustomevent(uri,null);channel.setdata(provided);channel.setoptions(true);apiviewmainview=newapiview();mainview.setinstance(container);mainview.setadaptiveframework(container);mainview.setviewactivity(null);}}应该可以吧。
此时main就是我们的reset小窗口,在其他情况(下拉刷新等)可以不用这个小窗口,直接点右键另存为,一定要右键,而且只能用excludeview{default:parent{get{varbt=this.getbackground();if(bt!=null){bt.resize({view:provided},255);直接点下拉刷新(简称on-top)可以达到前面所有状态-。 查看全部
c 抓取网页数据(响应式+js写法和原生js的交互方法(c))
c抓取网页数据为html文件。两种最常用,“响应式+js写法”和“原生js生成响应式+一般交互”。--“一般交互”的特点是能把一些交互用js实现出来,或者把一些一般交互的方法封装成js来实现。是目前比较常用的技术。“响应式+js写法”的特点是js和页面做交互,从而驱动页面去适应一定的尺寸。生成响应式的结果时,也就用到了js的交互方法。两种技术,都能把小屏幕的应用设计成不同的大屏幕,适合于任何应用场景。
给楼主推荐看看这个帖子
刚学了一段时间。所以再强答一下先说明一下我看的开发者工具是pc端vs2013,mac应该也差不多(真的有用到工具和原理上的东西)再说明一下工作上的推荐方法,vs2013的开发者工具和基础类工具自己找吧。我实在没图找不到了。-先说alt+tab键切换,vs2015允许,就是让你自己看着方便。界面上最小的是地址栏(可以自定义,默认是地址栏右边的黄色方块);一般的交互都放在我的工程里面,如:publicclassapiviewextendsactivityextendsadaptiveandframework{exceptionuriprovided="";voidmain(){customeventchannel=newcustomevent(uri,null);channel.setdata(provided);channel.setoptions(true);apiviewmainview=newapiview();mainview.setinstance(container);mainview.setadaptiveframework(container);mainview.setviewactivity(null);}}应该可以吧。
此时main就是我们的reset小窗口,在其他情况(下拉刷新等)可以不用这个小窗口,直接点右键另存为,一定要右键,而且只能用excludeview{default:parent{get{varbt=this.getbackground();if(bt!=null){bt.resize({view:provided},255);直接点下拉刷新(简称on-top)可以达到前面所有状态-。
c 抓取网页数据( 新媒体运营来说的爬虫工具——webscraper的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2022-03-10 21:05
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网页刮刀.png
三、创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
参数设置.png
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要抓取的内容类型进行选择。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧!
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(
新媒体运营来说的爬虫工具——webscraper的特点)
对于新媒体运营来说,数据分析是必不可少的能力之一。在工作中,有很多情况需要采集数据。这时候如果使用手动采集,不仅效率极低,而且耗时且容易出错。
刚开始了解新媒体运营的时候,有一次采集了一个知乎大v的文章,想分析研究一下他的话题,晚上复制粘贴到表格里。一路走了整整一个小时。完成工作后,我的手发抖,眼睛抽筋。我觉得很累,不喜欢,也不想再做这种工作了。想偷懒,上网一搜,终于找到了这个傻瓜式爬虫工具——网络爬虫。
网络爬虫最大的特点就是对小白新手非常友好。它非常简单易学。它不需要太复杂的编程代码知识。只需几个简单的步骤即可抓取您需要的内容,一个小时即可轻松掌握。.
注意.jpg
一、网络爬虫下载安装
Web scraper 是一款 chrome 插件软件,您可以在 chrome 应用商店中选择下载安装。如果无法进入应用商店,可以在评论区留言领取网络爬虫的安装包并手动安装,只需将压缩包拖到工具中的扩展中即可。
扩展工具.png
二、打开网络爬虫
打开要抓取的网页内容,然后右键单击以检查以找到 webscraper 工具。或者选择按Ctrl+Shift+I打开或者直接按F12。
打开网页刮刀.png
三、创建一个新的站点地图
下面有两个命令创建新站点地图,创建站点地图和导入站点地图。前者是新建站点地图,后者是通过导入之前创建的代码来执行抓取命令。由于我们开始,我们选择创建站点地图。
新站点地图.png
输入站点地图名称:您可以在此处输入您所在网页的名称。如果是豆瓣页面,可以进入豆瓣
Enter start url(初始网页链接):输入你所在的网页链接即可
四、参数设置
网络爬虫实际上是模拟人类操作来实现数据抓取。如果要爬取二级页面,必须先爬取一级页面的内容。
比如你想做竞品分析,研究某知乎创作者写的文章,想捕捉标题、点赞数、评论数,那么你必须先捕获内容。取整个文章,可以进一步获取标题、点赞数、评论数。
创建站点地图后,有一个添加新选择器(创建选择器)参数。
参数设置.png
id:这里可以填写你要选择的内容名称,比较随意,方便自己识别。比如我想捕捉知乎的创作者经营的小东西的文章,我就在这里填写yunyingdexiaoshi。
类型:您要抓取的内容类型。这里的下拉选项有text(文本)、link(链接)、image(图片)、table(表格)等。这次我们必须抓住整个 文章 并选择元素选项。
选择器:单击以选择选择。然后将鼠标移到要抓取的内容上,直到整个 文章 被选中。先点击选中第一篇文章,再点击选中第二篇文章,后面的文章会自动识别抓取。然后点击完成选择。
完成选择.png
多个:如果要抓取多个元素,请单击多个前面的小框。如果是单个元素,则无需点击。
保存选择:保存选择参数时点击保存选择。
这样一级页面文章已经被选中,接下来就是设置文章页面下的审批数等二级选中。进入标题等元素的文章整体选择时,root/后面的部分就是你刚刚抓取的一级选择内容的名称。
进入二级页面.png
下一步是设置二级选择操作。类似于一级页面的操作。它只是 Type 类型。这应该根据您要抓取的内容类型进行选择。如果要抓取点赞数或点赞数,需要选择Text的下拉选项,而要抓取标题和链接时,选择链接的下拉选项。.
五、爬取数据
点击scrape开始抓取数据,会出现两个参数:请求间隔和页面加载延迟。默认值为 2000。此值与网络速度有关。一般2000就可以了。如果网速慢,加载会比较慢,可能会导致爬取空白内容。在这种情况下,您可以将这两个值设置为更大的值,比如 3000 甚至更大。
爬取时页面无法关闭,关闭时容易出错。最后,还没有刮取数据的页面。出现,表示爬取完成。单击刷新以预览捕获的内容。
最后,如果要导出表格文件,可以点击export data as CSV(csv是一种支持excel的文件格式),然后立即下载。
六、 使用网络爬虫抓取多个页面
以上操作可以抓取你所在页面的单页内容。如果你要抓取的网页是数字分页的形式,可以通过修改URL来达到抓取多个页面的目的。
一般来说,数字分页等多页链接都有一定的规则。
文章 诸如操作之类的小事
第一页的链接:
第二页链接:
第三页链接:
...
检查您要抓取的第一页和最后一页的数量,并找出差异。比如上面几页的差是1。(不一定所有的差都是1,一定要先观察)。然后将常规链接的页数n改为[首页-末页:差异]。当差值为 1 时,可以忽略没有差值和冒号的部分。
如果要抓取操作小东西的第1-4页的文章,在设置URL的时候,可以先复制第一页的链接,把最后一个数字1改成[1-4 ], [1- 4],填写起始 URL。
多页抓取.png
这个傻瓜爬虫工具你有没有,快来实践一下吧!
分类:
技术要点:
相关文章:
c 抓取网页数据(在线品牌监控在线监控识别等的应用价值是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-10 21:04
2021-10-31
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。
这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。
1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。
2、广告营销和用户画像
通过社交媒体数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。
3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们将能够更好地指导我们的行动。
4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse
Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的所见即所得,点击拖拽网页采集配置界面,支持无限滚动,账号密码登录,验证码**,多IP防阻塞, 文本输入(用于抓取搜索结果)和从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据提取,Octoparse 还提供了一个计时器功能,可让您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io
Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但你可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub
Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 并没有提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器
Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(在线品牌监控在线监控识别等的应用价值是什么?)
2021-10-31
社交媒体数据采集工具通常是指自动抓取社交媒体平台的网络抓取工具,例如来自国外社交网站如Facebook、Twitter、Instagram、LinkedIn等。数据,或者像国内的微博、微信、小红书、腾讯新闻等。
这些门户都有一个共同点:都是以UGC(User Generate Content)的方式生成内容,重视内容与用户的交互,数据非结构化,数据海量。
在介绍社交媒体数据抓取工具之前,我们先说一下社交媒体数据的应用价值。
我们都知道,现在任何公司都离不开互联网,任何一家公司,任何对其产品的评价,都将存在于互联网上。
我们可以采集、挖掘和分析整个互联网用户在互联网上的购物旅程的声音,以指导我们的下一步行动。如广告营销与用户画像、客户情绪测量、在线品牌监测、市场趋势识别等。
1、客户情绪测量
从社交媒体渠道采集客户评论后,您可以通过衡量客户的情绪与对该主题或产品的典型意见来分析客户对该特定主题或产品的态度。
通过跟踪客户情绪,您可以了解整体客户满意度、客户忠诚度和参与意图,从而深入了解您当前和即将开展的营销活动。
2、广告营销和用户画像
通过社交媒体数据,结合营销学、心理学、社会学等跨学科理论和模型,对目标群体进行用户画像分类,从而推出适合群体需求和偏好的营销组合进行投放,大大提高了广告效果。投放转化率最大化营销投资回报。
3、在线品牌监测
在线品牌监控不仅可以倾听您的客户,还可以了解您的竞争对手、媒体甚至 KOL。
这不仅关乎您的产品或服务,还关乎您的客户服务、销售流程、社交参与以及客户与您的品牌互动的每个接触点。
当我们在每个接触点采集用户反馈的情报时,我们将能够更好地指导我们的行动。
4、市场趋势识别
识别市场趋势对于调整业务战略、使您的业务与行业方向即将发生的变化保持同步甚至领先至关重要。
通过对社交媒体数据的挖掘和分析,第一时间采集用户的典型意见和行业上下游趋势,从而预测市场趋势。
市场上排名前 5 位的社交媒体数据采集工具1、Octoparse
Octoparse是优采云采集器英文版,无需编程即可获取数据,6年稳定运行,全球百万用户!当前Octoparse版本更新到第七代,提供直观的所见即所得,点击拖拽网页采集配置界面,支持无限滚动,账号密码登录,验证码**,多IP防阻塞, 文本输入(用于抓取搜索结果)和从下拉菜单中选择。
采集 中的数据可以导出到 Excel、JSON、HTML 或数据库。如果您想从社交媒体渠道创建实时数据提取,Octoparse 还提供了一个计时器功能,可让您每 1 分钟抓取一次社交媒体渠道,保持数据实时更新。
2、Dexi.io
Dexi.io 基于浏览器的应用程序是另一个直观的网页采集 业务自动化工具,起价为每月 119 美元。
Dexi.io 确实需要一些编程技能,但你可以集成 3rd 方服务来解决验证码、云存储、文本分析(MonkeyLearn 服务集成),甚至 AWS、Google Drive、Google Sheets...
3、OutWit 集线器
与 Octoparse 和 Dexi.io 不同,Outwit Hub 提供了一个简单的 GUI,以及复杂的抓取功能和数据结构识别。Outwit Hub 最初是一个 Firefox 插件,后来成为一个可下载的应用程序。
无需事先编程背景,OutWit Hub 可以提取链接、电子邮件地址、RSS 新闻和数据表并将其导出到 Excel、CSV、HTML 或 SQL 数据库。
4、Scrapinghub
Scrapinghub 是一个基于云的网络爬虫平台,该应用程序收录 4 个很棒的工具: Scrapy Cloud,用于部署和运行基于 Python 的网络爬虫;Portia,一种无需编码即可提取数据的开源软件;
Splash 也是一个开源的 JavaScript 渲染工具,用于使用 JavaScript 从网页中提取数据;Crawlera 是一种避免被来自多个位置和 IP 的 网站 爬虫阻止的工具。
Scrapehub 并没有提供完整的套件,而是市场上一个非常复杂和强大的网络抓取平台,更不用说 Scrapehub 提供的每个工具都是单独收费的。
5、解析器
Parsehub 是市场上另一个支持 Windows、Mac OS X 和 Linux 的无代码 web采集 程序。它提供了一个图形界面,用于从 JavaScript 和 AJAX 页面中选择和提取数据。结论 如果你想做好工作,你必须先磨砺你的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
综上所述
要想做好工作,首先要磨砺自己的工具。想要更好地挖掘社交媒体数据,就需要选择功能强大、支持海量数据的网络数据采集工具采集。
分类:
技术要点:
相关文章:
c 抓取网页数据(模拟登录,需要POST哪些数据呢?零基础!幽默!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-08 17:09
抓取需要登录的页面内容的原理主要是:先模拟登录,获取cookie,然后使用这个cookie进行下次访问,就可以访问需要登录的页面了。
理论上,浏览器能做的,程序也应该能做。
但是,模拟登录说起来容易,但是不同的站点处理方式不同,复杂程度也不同。
1、最简单的就是POST相应的数据,不用验证码
2、喜欢 Discuz!系列,必须先访问某个页面,获取一个随机码,然后放到POST数据中,才能登录
3、需要验证码。验证码识别是另一个主题。
无论如何,需要 POST 数据。那么,要模拟登录,需要 POST 哪些数据呢?
事实上,每个站点需要发布哪些数据是不同的,因此必须有合适的工具进行分析。我安装了firefox扩展控件:HttpFox。使用它,您可以轻松获取登录指定站点时需要提交的数据字符串。
模拟登录的代码如下:
//sPostData,待提交的数据串,如http://www.test.com/login.aspx ... 23456 public static CookieContainer Login(string url, string sPostData, CookieContainer cc) { CookieContainer container = (cc == null) ? new CookieContainer() : cc; ASCIIEncoding encoding = new ASCIIEncoding(); byte[] data = encoding.GetBytes(sPostData); HttpWebRequest resquest = ResquestInit(url); resquest.Method = "POST"; resquest.ContentLength = data.Length; resquest.CookieContainer = container; Stream newStream = resquest.GetRequestStream(); newStream.Write(data, 0, data.Length); newStream.Close(); try { HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); } catch{} return container; }//这个函数的作用就是统一Request的格式,使得每次访问目标网站都用相同的口径。如果参数不同的话,可能造成COOKIE无效,因而登录无效 public static HttpWebRequest ResquestInit(string url) { Uri target = new Uri(url); HttpWebRequest resquest = (HttpWebRequest)WebRequest.Create(target); resquest.UserAgent = "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2 (.NET CLR 3.5.30729)"; resquest.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"; resquest.AllowAutoRedirect = true; resquest.KeepAlive = true; resquest.ReadWriteTimeout = 120000; resquest.ContentType = "application/x-www-form-urlencoded"; resquest.Referer = url; return resquest; }
获得这个CookieContainer后,保存,以后每次访问网站时随身携带。CookieContainer 相当于浏览器的cookie 容器,里面存储了访问每个网站 的cookie。
带cookie的访问码如下:
static HttpWebResponse GetResponse(string url, CookieContainer cc) { try { CookieContainer container = (cc == null) ? new CookieContainer() : cc; HttpWebRequest resquest = ResquestInit(url); resquest.CookieContainer = container; HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); return response; } catch { return null; } }
参数CookieContainer cc 是保存的CookieContainer。
跟大家分享一下我老师的人工智能教程。零基础!容易明白!幽默风趣!还有黄色笑话!希望你也加入我们的 AI 团队! 查看全部
c 抓取网页数据(模拟登录,需要POST哪些数据呢?零基础!幽默!)
抓取需要登录的页面内容的原理主要是:先模拟登录,获取cookie,然后使用这个cookie进行下次访问,就可以访问需要登录的页面了。
理论上,浏览器能做的,程序也应该能做。
但是,模拟登录说起来容易,但是不同的站点处理方式不同,复杂程度也不同。
1、最简单的就是POST相应的数据,不用验证码
2、喜欢 Discuz!系列,必须先访问某个页面,获取一个随机码,然后放到POST数据中,才能登录
3、需要验证码。验证码识别是另一个主题。
无论如何,需要 POST 数据。那么,要模拟登录,需要 POST 哪些数据呢?
事实上,每个站点需要发布哪些数据是不同的,因此必须有合适的工具进行分析。我安装了firefox扩展控件:HttpFox。使用它,您可以轻松获取登录指定站点时需要提交的数据字符串。
模拟登录的代码如下:
//sPostData,待提交的数据串,如http://www.test.com/login.aspx ... 23456 public static CookieContainer Login(string url, string sPostData, CookieContainer cc) { CookieContainer container = (cc == null) ? new CookieContainer() : cc; ASCIIEncoding encoding = new ASCIIEncoding(); byte[] data = encoding.GetBytes(sPostData); HttpWebRequest resquest = ResquestInit(url); resquest.Method = "POST"; resquest.ContentLength = data.Length; resquest.CookieContainer = container; Stream newStream = resquest.GetRequestStream(); newStream.Write(data, 0, data.Length); newStream.Close(); try { HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); } catch{} return container; }//这个函数的作用就是统一Request的格式,使得每次访问目标网站都用相同的口径。如果参数不同的话,可能造成COOKIE无效,因而登录无效 public static HttpWebRequest ResquestInit(string url) { Uri target = new Uri(url); HttpWebRequest resquest = (HttpWebRequest)WebRequest.Create(target); resquest.UserAgent = "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2 (.NET CLR 3.5.30729)"; resquest.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"; resquest.AllowAutoRedirect = true; resquest.KeepAlive = true; resquest.ReadWriteTimeout = 120000; resquest.ContentType = "application/x-www-form-urlencoded"; resquest.Referer = url; return resquest; }
获得这个CookieContainer后,保存,以后每次访问网站时随身携带。CookieContainer 相当于浏览器的cookie 容器,里面存储了访问每个网站 的cookie。
带cookie的访问码如下:
static HttpWebResponse GetResponse(string url, CookieContainer cc) { try { CookieContainer container = (cc == null) ? new CookieContainer() : cc; HttpWebRequest resquest = ResquestInit(url); resquest.CookieContainer = container; HttpWebResponse response = (HttpWebResponse)resquest.GetResponse(); response.Cookies = container.GetCookies(resquest.RequestUri); return response; } catch { return null; } }
参数CookieContainer cc 是保存的CookieContainer。
跟大家分享一下我老师的人工智能教程。零基础!容易明白!幽默风趣!还有黄色笑话!希望你也加入我们的 AI 团队!
c 抓取网页数据(Linux(UNIX)命令格式命令1.命令命令:告诉Linux)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-06 17:22
Linux 常用命令和获取帮助
交流,咨询,有问题欢迎补充,一起交流,一起找问题,一起进步,哈哈哈哈哈哈Linux(UNIX)命令格式命令1.命令:告诉Linux(UNIX)什么to do2.Options:表示命令运行的方式,以“-”字符开头3.Parameters:表示命令影响什么简单常用的命令:whoami~列出当前用户名用于登录Linux系统i~除了用户名外,还显示登录的终端、当前日期时间,以及使用的电脑的IP地址who~显示与who am i命令相同的内容,但也包括所有其他在系统上工作的用户w~获取的信息比who命令用户多~当前登录系统的所有用户try~当前用户登录系统使用的终端uname~获取信息关于系统日期~显示当前系统日期和时间 cal ~ 显示某个月份的日历 cal 8 2008: 列出 2008 年 8 月的日历 clear ~ 在终端窗口中清除显示 su ~ 从一个用户切换到另一个用户 eg: $ su -rootpass ~ change user's password and查看密码状态器 whatis ~ 显示所有查询命令的简要说明,在命令后使用 --help 选项
258 查看全部
c 抓取网页数据(Linux(UNIX)命令格式命令1.命令命令:告诉Linux)
Linux 常用命令和获取帮助
交流,咨询,有问题欢迎补充,一起交流,一起找问题,一起进步,哈哈哈哈哈哈Linux(UNIX)命令格式命令1.命令:告诉Linux(UNIX)什么to do2.Options:表示命令运行的方式,以“-”字符开头3.Parameters:表示命令影响什么简单常用的命令:whoami~列出当前用户名用于登录Linux系统i~除了用户名外,还显示登录的终端、当前日期时间,以及使用的电脑的IP地址who~显示与who am i命令相同的内容,但也包括所有其他在系统上工作的用户w~获取的信息比who命令用户多~当前登录系统的所有用户try~当前用户登录系统使用的终端uname~获取信息关于系统日期~显示当前系统日期和时间 cal ~ 显示某个月份的日历 cal 8 2008: 列出 2008 年 8 月的日历 clear ~ 在终端窗口中清除显示 su ~ 从一个用户切换到另一个用户 eg: $ su -rootpass ~ change user's password and查看密码状态器 whatis ~ 显示所有查询命令的简要说明,在命令后使用 --help 选项
258
c 抓取网页数据(2019独角兽企业重金招聘Python工程师标准(gt)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-04 12:17
2019独角兽企业招聘Python工程师标准>>>
在这篇文章中,我主要展示了如何爬取谷歌学术网页。该示例展示了使用 rvest 包捕获作者博士生导师的个人学术数据。我们可以看到他的合著者、论文被引用的次数以及他们的隶属关系。Hadley Wickham 在 RStudio 博客中写道:“rvest 的灵感来自于可以轻松从 HTML 页面中抓取数据的美丽汤之类的库”。因为它被设计为与 magrittr 一起使用。我们可以通过一些简单易懂的代码块组成的管道操作来表达复杂的操作。
加载 R 包:
使用 ggplot2 包绘图
1library(rvest)
2library(ggplot2)
3
他的论文被引用了多少次?
使用 SelectorGadget 的 CSS 选择器查找“引用者”列。
1page % html_text()%>%as.numeric()
2
请参阅此计数的引文:
1citations
2148 96 79 64 57 57 57 55 52 50 48 37 34 33 30 28 26 25 23 22
3
绘制引用次数的条形图:
1barplot(citations, main="How many times has each paper been cited?", ylab='Number of citations', col="skyblue", xlab="")
2
共同作者、他们的隶属关系和引用次数
同样,我们使用 SelecotGadget 的 CSS 选择器来查找匹配的共同作者:
1page % html_nodes(css=".gsc_1usr_name a") %>% html_text()
3Coauthors = as.data.frame(Coauthors)
4names(Coauthors)='Coauthors'
5
查看下一位合著者
1head(Coauthors)
2 Coauthors
31 Jason Evans
42 Mutlu Ozdogan
53 Rasmus Houborg
64 M. Tugrul Yilmaz
75 Joseph A. Santanello, Jr.
86 Seth Guikema
9
10dim(Coauthors)
11[1] 27 1
12
截至2016年1月1日,他共有27位合著者。
他的合著者被引用了多少次?
1page % html_nodes(css = ".gsc_1usr_cby")%>%html_text()
3
4citations
5 [1] "Cited by 2231" "Cited by 1273" "Cited by 816" "Cited by 395" "Cited by 652" "Cited by 1531"
6 [7] "Cited by 674" "Cited by 467" "Cited by 7967" "Cited by 3968" "Cited by 2603" "Cited by 3468"
7[13] "Cited by 3175" "Cited by 121" "Cited by 32" "Cited by 469" "Cited by 50" "Cited by 11"
8[19] "Cited by 1187" "Cited by 1450" "Cited by 12407" "Cited by 1939" "Cited by 9" "Cited by 706"
9[25] "Cited by 336" "Cited by 186" "Cited by 192"
10
通过全局替换提取数字字符串
1citations = gsub('Cited by','', citations)
2
3citations
4 [1] " 2231" " 1273" " 816" " 395" " 652" " 1531" " 674" " 467" " 7967" " 3968" " 2603" " 3468" " 3175"
5[14] " 121" " 32" " 469" " 50" " 11" " 1187" " 1450" " 12407" " 1939" " 9" " 706" " 336" " 186"
6[27] " 192"
7
将字符串转换为数值类型,然后得到ggplot2可用的数据框格式:
1citations = as.numeric(citations)
2citations = as.data.frame(citations)
3
合著者的附属机构
创建共同作者、引用和隶属关系的数据框
1cauthors=cbind(Coauthors, citations, affilation)
2
3cauthors
4 Coauthors citations Affilation
51 Jason Evans 2231 University of New South Wales
62 Mutlu Ozdogan 1273 Assistant Professor of Environmental Science and Forest Ecology, University of Wisconsin
73 Rasmus Houborg 816 Research Scientist at King Abdullah University of Science and Technology
84 M. Tugrul Yilmaz 395 Assistant Professor, Civil Engineering Department, Middle East Technical University, Turkey
95 Joseph A. Santanello, Jr. 652 NASA-GSFC Hydrological Sciences Laboratory
10.....
11
按引用次数对共同作者重新排序
按引用次数对共同作者重新排序以获得降序序列图:
<p>1cauthors$Coauthors 查看全部
c 抓取网页数据(2019独角兽企业重金招聘Python工程师标准(gt)(组图))
2019独角兽企业招聘Python工程师标准>>>
在这篇文章中,我主要展示了如何爬取谷歌学术网页。该示例展示了使用 rvest 包捕获作者博士生导师的个人学术数据。我们可以看到他的合著者、论文被引用的次数以及他们的隶属关系。Hadley Wickham 在 RStudio 博客中写道:“rvest 的灵感来自于可以轻松从 HTML 页面中抓取数据的美丽汤之类的库”。因为它被设计为与 magrittr 一起使用。我们可以通过一些简单易懂的代码块组成的管道操作来表达复杂的操作。
加载 R 包:
使用 ggplot2 包绘图
1library(rvest)
2library(ggplot2)
3
他的论文被引用了多少次?
使用 SelectorGadget 的 CSS 选择器查找“引用者”列。
1page % html_text()%>%as.numeric()
2
请参阅此计数的引文:
1citations
2148 96 79 64 57 57 57 55 52 50 48 37 34 33 30 28 26 25 23 22
3
绘制引用次数的条形图:
1barplot(citations, main="How many times has each paper been cited?", ylab='Number of citations', col="skyblue", xlab="")
2
共同作者、他们的隶属关系和引用次数
同样,我们使用 SelecotGadget 的 CSS 选择器来查找匹配的共同作者:
1page % html_nodes(css=".gsc_1usr_name a") %>% html_text()
3Coauthors = as.data.frame(Coauthors)
4names(Coauthors)='Coauthors'
5
查看下一位合著者
1head(Coauthors)
2 Coauthors
31 Jason Evans
42 Mutlu Ozdogan
53 Rasmus Houborg
64 M. Tugrul Yilmaz
75 Joseph A. Santanello, Jr.
86 Seth Guikema
9
10dim(Coauthors)
11[1] 27 1
12
截至2016年1月1日,他共有27位合著者。
他的合著者被引用了多少次?
1page % html_nodes(css = ".gsc_1usr_cby")%>%html_text()
3
4citations
5 [1] "Cited by 2231" "Cited by 1273" "Cited by 816" "Cited by 395" "Cited by 652" "Cited by 1531"
6 [7] "Cited by 674" "Cited by 467" "Cited by 7967" "Cited by 3968" "Cited by 2603" "Cited by 3468"
7[13] "Cited by 3175" "Cited by 121" "Cited by 32" "Cited by 469" "Cited by 50" "Cited by 11"
8[19] "Cited by 1187" "Cited by 1450" "Cited by 12407" "Cited by 1939" "Cited by 9" "Cited by 706"
9[25] "Cited by 336" "Cited by 186" "Cited by 192"
10
通过全局替换提取数字字符串
1citations = gsub('Cited by','', citations)
2
3citations
4 [1] " 2231" " 1273" " 816" " 395" " 652" " 1531" " 674" " 467" " 7967" " 3968" " 2603" " 3468" " 3175"
5[14] " 121" " 32" " 469" " 50" " 11" " 1187" " 1450" " 12407" " 1939" " 9" " 706" " 336" " 186"
6[27] " 192"
7
将字符串转换为数值类型,然后得到ggplot2可用的数据框格式:
1citations = as.numeric(citations)
2citations = as.data.frame(citations)
3
合著者的附属机构
创建共同作者、引用和隶属关系的数据框
1cauthors=cbind(Coauthors, citations, affilation)
2
3cauthors
4 Coauthors citations Affilation
51 Jason Evans 2231 University of New South Wales
62 Mutlu Ozdogan 1273 Assistant Professor of Environmental Science and Forest Ecology, University of Wisconsin
73 Rasmus Houborg 816 Research Scientist at King Abdullah University of Science and Technology
84 M. Tugrul Yilmaz 395 Assistant Professor, Civil Engineering Department, Middle East Technical University, Turkey
95 Joseph A. Santanello, Jr. 652 NASA-GSFC Hydrological Sciences Laboratory
10.....
11
按引用次数对共同作者重新排序
按引用次数对共同作者重新排序以获得降序序列图:
<p>1cauthors$Coauthors
c 抓取网页数据(yyyymmdd爬虫默认模板代码:提取内容的css一行的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-04 12:15
xx=开始时间,yyyymmdd
yy=结束时间,yyyymmdd
爬虫默认模板代码:
def on_start(self):
base_url='https://coinmarketcap.com/zh/currencies/bitcoin/historical-data/?start=#START#&end=#END#'
year_list=['2015','2016','2017','2018']
month_list=range(1,13)
for year in year_list:
for month in month_list:
start_date=year+str(month).rjust(2,'0')+'01'
end_date=year+str(month).rjust(2,'0')+'31'
self.crawl(base_url.replace('#START#',start_date).replace('#END#',end_date), callback=self.detail_page)
爬取时间为 2015 年 1 月至 2018 年 12 月。
需要注意的是,每个月都是按照31天来处理的。如果您尝试该网页,则可以正常返回而不会报告错误。
第二步,解析页面内容
构造好url地址后,就是解析页面内容了。
修改爬虫模板代码:
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"text_right":response.doc('tr.text-right').text()
}
添加了一个字段 text_right,它是网页表格的主体。提取文本后,应将数据分为行和行,然后将每一行映射到特定字段并保存到文本csv或数据库中。如有必要,您可以自己实现。
上面稍微麻烦的就是定位需要提取内容的css的表达式。这本来就是比较价格的一件很恶心(费时、容易出错)的事情,上学的时候也很讨厌。不过pyspider做了一个非常强大的封装过程,可以将网页上的选区可视化,自动生成css选区的表达式,直接使用即可。
这也是我第一次用这个,不妨演示一下
一般只需点击1、2、4即可,不需要复制,只需将光标移动到输入选择器位置再点击4即可。
第三步,保存结果
通过覆盖 on_result 方法保存结果,
例如:
def on_result(self,result):
if not result or not result['original_id']:
return
sql = SQL()
sql.insert('t_dream_xm_project',**result)
这里的每一个结果都是上面构建的地图表单数据。在本文中,它是一个map,其key是url、title和text_right。
这里的text_right是一个收录所有行和列的文本字符串,需要进一步解析。
解析工作有时可以放在第二步。第二步, text_right 可以直接构造为列表并返回。个人比较喜欢爬取和解析的分离操作。爬取只负责加载数据,用于后续分析。负责其他模块。
还有一个更好的思路,直接获取对方网站拉取数据的接口,直接向接口发送查询数据获取结构化数据,然后直接解析存储。这种方式基本上不需要爬虫去处理 CSS 选择器之类的。
其他参考技术
1、使用代理
验证代理有效性:
参考:
导入请求
尝试:
requests.get('', proxies={"http":":8123"})
除了:
打印'连接失败'
别的:
打印'成功'
后续可以使用专业的代理工具:squid
2.伪装浏览器头部
fake-useragent 库:伪造的浏览器标头
参考:
分类:
技术要点:
相关文章: 查看全部
c 抓取网页数据(yyyymmdd爬虫默认模板代码:提取内容的css一行的方法)
xx=开始时间,yyyymmdd
yy=结束时间,yyyymmdd
爬虫默认模板代码:
def on_start(self):
base_url='https://coinmarketcap.com/zh/currencies/bitcoin/historical-data/?start=#START#&end=#END#'
year_list=['2015','2016','2017','2018']
month_list=range(1,13)
for year in year_list:
for month in month_list:
start_date=year+str(month).rjust(2,'0')+'01'
end_date=year+str(month).rjust(2,'0')+'31'
self.crawl(base_url.replace('#START#',start_date).replace('#END#',end_date), callback=self.detail_page)
爬取时间为 2015 年 1 月至 2018 年 12 月。
需要注意的是,每个月都是按照31天来处理的。如果您尝试该网页,则可以正常返回而不会报告错误。
第二步,解析页面内容
构造好url地址后,就是解析页面内容了。
修改爬虫模板代码:
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"text_right":response.doc('tr.text-right').text()
}
添加了一个字段 text_right,它是网页表格的主体。提取文本后,应将数据分为行和行,然后将每一行映射到特定字段并保存到文本csv或数据库中。如有必要,您可以自己实现。
上面稍微麻烦的就是定位需要提取内容的css的表达式。这本来就是比较价格的一件很恶心(费时、容易出错)的事情,上学的时候也很讨厌。不过pyspider做了一个非常强大的封装过程,可以将网页上的选区可视化,自动生成css选区的表达式,直接使用即可。
这也是我第一次用这个,不妨演示一下
一般只需点击1、2、4即可,不需要复制,只需将光标移动到输入选择器位置再点击4即可。
第三步,保存结果
通过覆盖 on_result 方法保存结果,
例如:
def on_result(self,result):
if not result or not result['original_id']:
return
sql = SQL()
sql.insert('t_dream_xm_project',**result)
这里的每一个结果都是上面构建的地图表单数据。在本文中,它是一个map,其key是url、title和text_right。
这里的text_right是一个收录所有行和列的文本字符串,需要进一步解析。
解析工作有时可以放在第二步。第二步, text_right 可以直接构造为列表并返回。个人比较喜欢爬取和解析的分离操作。爬取只负责加载数据,用于后续分析。负责其他模块。
还有一个更好的思路,直接获取对方网站拉取数据的接口,直接向接口发送查询数据获取结构化数据,然后直接解析存储。这种方式基本上不需要爬虫去处理 CSS 选择器之类的。
其他参考技术
1、使用代理
验证代理有效性:
参考:
导入请求
尝试:
requests.get('', proxies={"http":":8123"})
除了:
打印'连接失败'
别的:
打印'成功'
后续可以使用专业的代理工具:squid
2.伪装浏览器头部
fake-useragent 库:伪造的浏览器标头
参考:
分类:
技术要点:
相关文章:
c 抓取网页数据(什么是c抓取网页数据coinconnect圈钱1千万美金?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-25 23:02
c抓取网页数据coinconnect该功能抓包得知,btc不支持收藏币种,但可以获取账户当前余额并生成btc余额1coback,btc2,btc3cash3年后,3币翻了3000倍。coineta网页内主要三种交易平台,币安、交易所币火、银行链比特币(gift)比特币浏览器看看1,188cash/h,看起来涨势喜人。
用户通过btc钱包地址交易,gift钱包显示的实际余额1万多。用户更新钱包地址直到50+名(看来现在这1万多btc老用户都有取代1万多币的打算),交易所币火里钱包余额已经有6万多。coineta官方发博指出btc圈钱1千万美金的事情属实,至少到现在已经进行过1千万次。币主们是继续维持短期波动,还是趁其跌此时入手,币火的受众根本就不像图表上显示那么多。
网站:coinmarketcap钱包:leobit
用网站吧,钱包要做成指定币种,除非你强迫自己。
还没入手就想着丢了那点币。1.以前有个rg的钱包,
-2017060516:29-我截了一下网站可以查看全世界各国家的法定货币余额---2017060519:08更新 查看全部
c 抓取网页数据(什么是c抓取网页数据coinconnect圈钱1千万美金?)
c抓取网页数据coinconnect该功能抓包得知,btc不支持收藏币种,但可以获取账户当前余额并生成btc余额1coback,btc2,btc3cash3年后,3币翻了3000倍。coineta网页内主要三种交易平台,币安、交易所币火、银行链比特币(gift)比特币浏览器看看1,188cash/h,看起来涨势喜人。
用户通过btc钱包地址交易,gift钱包显示的实际余额1万多。用户更新钱包地址直到50+名(看来现在这1万多btc老用户都有取代1万多币的打算),交易所币火里钱包余额已经有6万多。coineta官方发博指出btc圈钱1千万美金的事情属实,至少到现在已经进行过1千万次。币主们是继续维持短期波动,还是趁其跌此时入手,币火的受众根本就不像图表上显示那么多。
网站:coinmarketcap钱包:leobit
用网站吧,钱包要做成指定币种,除非你强迫自己。
还没入手就想着丢了那点币。1.以前有个rg的钱包,
-2017060516:29-我截了一下网站可以查看全世界各国家的法定货币余额---2017060519:08更新
c 抓取网页数据( 方法urlopen原形❝urllib2.HTTPError:超时时间设置改方法返回网页信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-18 16:14
方法urlopen原形❝urllib2.HTTPError:超时时间设置改方法返回网页信息
)
使用 Python 库 urllib2,使用了 urlopen 和 Request 方法。方法urlopen的原型❝ urllib2.urlopen(url[, data][, timeout]) 其中:url代表目标网页的地址,可以是字符串,也可以是请求对象Requestdata代表post timeout提交给目标服务器的参数表示超时时间设置,该方法返回一个类似文件的对象。有geturl()、info()、read()方法,其中geturl()返回连接地址,info()返回网页信息。获取网页内容,可以使用read()方法,read也可以带参数,表示读取内容的大小(字节)。
❞
import urllib2
socket = urllib2.urlopen("http://www.baidu.com")
content = socket.read()
socket.close()
这样,网页的内容就被爬下来了,但是有的网站禁止爬虫。如果直接请求,会出现如下错误: urllib2.HTTPError: HTTP Error 403: Forbidden 解决方法是在 request 中添加头信息来伪装浏览器的访问行为,需要使用 Request 方法:
方法请求原型❝ urllib2.Request(url[, data][, headers][, origin_req_host][, unverifiable]) 其中:url表示目标网页的地址,可以是字符串,也可以是request object Requestdata post方法中提交给目标服务器的参数headers代表用户ID,是字典类型的数据。其中一些不允许脚本爬取,所以需要一个用户代理,比如火狐浏览器的代理:Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/ 2.0.0.11 浏览器标准UA格式为:浏览器ID(操作系统ID;加密级别标识;浏览器语言) 渲染引擎标识版本信息,默认headers为Python -urllib/2.
❞
headers = {'User-Agent':'Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/2.0.0.11'}
req = urllib2.Request(url="http://blog.csdn.net/deqingguo",headers=headers)
socket = urllib2.urlopen(req)
content = socket.read()
socket.close() 查看全部
c 抓取网页数据(
方法urlopen原形❝urllib2.HTTPError:超时时间设置改方法返回网页信息
)
使用 Python 库 urllib2,使用了 urlopen 和 Request 方法。方法urlopen的原型❝ urllib2.urlopen(url[, data][, timeout]) 其中:url代表目标网页的地址,可以是字符串,也可以是请求对象Requestdata代表post timeout提交给目标服务器的参数表示超时时间设置,该方法返回一个类似文件的对象。有geturl()、info()、read()方法,其中geturl()返回连接地址,info()返回网页信息。获取网页内容,可以使用read()方法,read也可以带参数,表示读取内容的大小(字节)。
❞
import urllib2
socket = urllib2.urlopen("http://www.baidu.com";)
content = socket.read()
socket.close()
这样,网页的内容就被爬下来了,但是有的网站禁止爬虫。如果直接请求,会出现如下错误: urllib2.HTTPError: HTTP Error 403: Forbidden 解决方法是在 request 中添加头信息来伪装浏览器的访问行为,需要使用 Request 方法:
方法请求原型❝ urllib2.Request(url[, data][, headers][, origin_req_host][, unverifiable]) 其中:url表示目标网页的地址,可以是字符串,也可以是request object Requestdata post方法中提交给目标服务器的参数headers代表用户ID,是字典类型的数据。其中一些不允许脚本爬取,所以需要一个用户代理,比如火狐浏览器的代理:Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/ 2.0.0.11 浏览器标准UA格式为:浏览器ID(操作系统ID;加密级别标识;浏览器语言) 渲染引擎标识版本信息,默认headers为Python -urllib/2.
❞
headers = {'User-Agent':'Mozilla/5.0 (X11; U; Linux i686)Gecko/20071127 Firefox/2.0.0.11'}
req = urllib2.Request(url="http://blog.csdn.net/deqingguo",headers=headers)
socket = urllib2.urlopen(req)
content = socket.read()
socket.close()
c 抓取网页数据( 从列表样式中抓取数据的页面有行使用方法介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-16 17:09
从列表样式中抓取数据的页面有行使用方法介绍-苏州安嘉)
介绍:
从列表样式的网页中抓取数据。有示范的例子。非常容易使用。一分钟配置,一键搞定。Creeper 是一个专注于列表样式网页的抓取扩展。用户不需要了解任何 html 和 css 知识,尽管了解它们会很好。Creeper 无法从所有网页中抓取数据,而只能从列表样式的页面中抓取。列表样式的页面有行,每行都有几乎相同的字段。用户需要点击html元素告诉Creeper哪个是行元素,哪个是字段元素,哪个是分页元素。然后,Creeper 可以生成一个站点地图模板,其中收录有关如何捕获此数据的说明。有一些列表样式的页面:%20restore%20deleted%20records %2522python%2522 Creeper使用步骤:1) 点击右上角的爬行者图标打开站点地图列表;2) 单击“创建站点地图”按钮打开一个表单,为当前在浏览器中打开的网页定义站点地图。3) 单击编辑按钮打开站点地图详细信息表单,您可以在其中单击测试以获取一些示例数据。4) 点击“运行”按钮爬取站点地图。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。 查看全部
c 抓取网页数据(
从列表样式中抓取数据的页面有行使用方法介绍-苏州安嘉)
介绍:
从列表样式的网页中抓取数据。有示范的例子。非常容易使用。一分钟配置,一键搞定。Creeper 是一个专注于列表样式网页的抓取扩展。用户不需要了解任何 html 和 css 知识,尽管了解它们会很好。Creeper 无法从所有网页中抓取数据,而只能从列表样式的页面中抓取。列表样式的页面有行,每行都有几乎相同的字段。用户需要点击html元素告诉Creeper哪个是行元素,哪个是字段元素,哪个是分页元素。然后,Creeper 可以生成一个站点地图模板,其中收录有关如何捕获此数据的说明。有一些列表样式的页面:%20restore%20deleted%20records %2522python%2522 Creeper使用步骤:1) 点击右上角的爬行者图标打开站点地图列表;2) 单击“创建站点地图”按钮打开一个表单,为当前在浏览器中打开的网页定义站点地图。3) 单击编辑按钮打开站点地图详细信息表单,您可以在其中单击测试以获取一些示例数据。4) 点击“运行”按钮爬取站点地图。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。4) 爬取后,数据会以表格形式展示。您可以导出为 csv 文件。
c 抓取网页数据( 这个python爬虫程序的主要功能是爬取三个(杭电,北大,地大)上的做题信息并进行题目的统计 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-15 21:23
这个python爬虫程序的主要功能是爬取三个(杭电,北大,地大)上的做题信息并进行题目的统计
)
import webbrowser
import re
import urllib
#获取hdu网页
def getHtml_hdu(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取poj网页
def getHtml_poj(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取cug网页
def getHtml_cug(url):
page = urllib.urlopen(url)
html = page.read()
unicodehtml = html.decode("utf-8")
return unicodehtml
#获取hdu中用户信息
def zhenghe_hdu(str1,userid,imgre):
html=getHtml_hdu( str1+userid )
return re.findall(imgre,html)
#获取cug中用户信息
def zhenghe_cug(str1,userid,imgre):
html=getHtml_cug( str1+userid )
return re.findall(imgre,html)
#获取poj中用户信息
def zhenghe_poj(str1,userid,imgre):
html =getHtml_poj( str1+ userid)
return re.findall(imgre,html)
#文件读出用户账号进行统计
def readFile(result_cug,result_hdu,result_poj):
file_object = open("users.txt",'r')
reg_cug = r'Solved<a href=.*?>(.*?)</a>'
imgre_cug = re.compile(reg_cug)
reg_hdu = r'Problems Solved(.*?)'
imgre_hdu = re.compile(reg_hdu)
reg_poj = 'Solved:[\s\S]*?<a href=.*?>(.+?)</a>'
imgre_poj = re.compile(reg_poj)
#将结果输出到html网页
html = open('OJ.html', 'w')
html.write("""
cug--hdu--poj统计
img{float:left;margin:5px;}
""")
html.write("""
Account
cugOJ
hdOj
poj
sum
""")
alist = [] #定义一个列表
for line in file_object:
line=line.strip('\n') #去掉读取的每行的"\n"
list_hdu = zhenghe_hdu(result_hdu,line,imgre_hdu)
list_cug = zhenghe_cug(result_cug,line,imgre_cug)
list_poj = zhenghe_poj(result_poj,line,imgre_poj)
if len(list_hdu) == 0:
number_hdu = 0
else:
number_hdu = eval(list_hdu[0])
if len(list_cug) == 0:
number_cug = 0
else:
number_cug = eval(list_cug[0])
if len(list_poj) == 0:
number_poj = 0
else:
number_poj = eval(list_poj[0])
alist.append([line,number_cug,number_hdu,number_poj,number_cug+number_hdu+number_poj])
print "处理完一个用户信息"
for i in range(len(alist)): #冒泡排序
for j in range(len(alist)):
if alist[i][4] > alist[j][4]:
tmp = alist[i]
alist[i] = alist[j]
alist[j] = tmp
for lst in alist: #输出到网页
html.write("
")
html.write("")
html.write("%s " % lst[0] )
html.write("%s " % str(lst[1]) )
html.write("%s " % str(lst[2]) )
html.write("%s " % str(lst[3]) )
html.write("%s " % str(lst[4]) )
html.write("")
html.write('')
html.close()
webbrowser.open_new_tab('OJ.html') #自动打开网页
result_hdu = "http://acm.hdu.edu.cn/userstatus.php?user="
result_cug = "http://acm.cug.edu.cn/JudgeOnl ... ot%3B
result_poj = "http://poj.org/userstatus?user_id="
print "正在生成html网页......"
readFile(result_cug,result_hdu,result_poj)
print "html网页生成完毕,自动打开"
这个python爬虫程序的主要功能是爬取三个OJ(航电、北大、帝大)的题型信息,并对题型进行统计。
输入的是昵称,有的在几个OJ上注册的昵称是一样的,有的没有,所以统计显示有的人在某一个OJ上做题为0.
要读取的文件信息如下:
运行效果:
查看全部
c 抓取网页数据(
这个python爬虫程序的主要功能是爬取三个(杭电,北大,地大)上的做题信息并进行题目的统计
)
import webbrowser
import re
import urllib
#获取hdu网页
def getHtml_hdu(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取poj网页
def getHtml_poj(url):
page = urllib.urlopen(url)
html = page.read()
#unicodehtml = html.decode("utf-8")
#return unicodehtml
return html
#获取cug网页
def getHtml_cug(url):
page = urllib.urlopen(url)
html = page.read()
unicodehtml = html.decode("utf-8")
return unicodehtml
#获取hdu中用户信息
def zhenghe_hdu(str1,userid,imgre):
html=getHtml_hdu( str1+userid )
return re.findall(imgre,html)
#获取cug中用户信息
def zhenghe_cug(str1,userid,imgre):
html=getHtml_cug( str1+userid )
return re.findall(imgre,html)
#获取poj中用户信息
def zhenghe_poj(str1,userid,imgre):
html =getHtml_poj( str1+ userid)
return re.findall(imgre,html)
#文件读出用户账号进行统计
def readFile(result_cug,result_hdu,result_poj):
file_object = open("users.txt",'r')
reg_cug = r'Solved<a href=.*?>(.*?)</a>'
imgre_cug = re.compile(reg_cug)
reg_hdu = r'Problems Solved(.*?)'
imgre_hdu = re.compile(reg_hdu)
reg_poj = 'Solved:[\s\S]*?<a href=.*?>(.+?)</a>'
imgre_poj = re.compile(reg_poj)
#将结果输出到html网页
html = open('OJ.html', 'w')
html.write("""
cug--hdu--poj统计
img{float:left;margin:5px;}
""")
html.write("""
Account
cugOJ
hdOj
poj
sum
""")
alist = [] #定义一个列表
for line in file_object:
line=line.strip('\n') #去掉读取的每行的"\n"
list_hdu = zhenghe_hdu(result_hdu,line,imgre_hdu)
list_cug = zhenghe_cug(result_cug,line,imgre_cug)
list_poj = zhenghe_poj(result_poj,line,imgre_poj)
if len(list_hdu) == 0:
number_hdu = 0
else:
number_hdu = eval(list_hdu[0])
if len(list_cug) == 0:
number_cug = 0
else:
number_cug = eval(list_cug[0])
if len(list_poj) == 0:
number_poj = 0
else:
number_poj = eval(list_poj[0])
alist.append([line,number_cug,number_hdu,number_poj,number_cug+number_hdu+number_poj])
print "处理完一个用户信息"
for i in range(len(alist)): #冒泡排序
for j in range(len(alist)):
if alist[i][4] > alist[j][4]:
tmp = alist[i]
alist[i] = alist[j]
alist[j] = tmp
for lst in alist: #输出到网页
html.write("
")
html.write("")
html.write("%s " % lst[0] )
html.write("%s " % str(lst[1]) )
html.write("%s " % str(lst[2]) )
html.write("%s " % str(lst[3]) )
html.write("%s " % str(lst[4]) )
html.write("")
html.write('')
html.close()
webbrowser.open_new_tab('OJ.html') #自动打开网页
result_hdu = "http://acm.hdu.edu.cn/userstatus.php?user="
result_cug = "http://acm.cug.edu.cn/JudgeOnl ... ot%3B
result_poj = "http://poj.org/userstatus?user_id="
print "正在生成html网页......"
readFile(result_cug,result_hdu,result_poj)
print "html网页生成完毕,自动打开"
这个python爬虫程序的主要功能是爬取三个OJ(航电、北大、帝大)的题型信息,并对题型进行统计。
输入的是昵称,有的在几个OJ上注册的昵称是一样的,有的没有,所以统计显示有的人在某一个OJ上做题为0.
要读取的文件信息如下:
运行效果:

