
c 抓取网页数据
c 抓取网页数据(Python静态网页抓取学习过程及一点简单的分析保存方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-12 05:38
Python 静态网页抓取
最近学习了使用Python爬虫爬取静态网页,做一点简单的分析保存。以下是整个学习过程:
实践要求的目的
访问豆瓣电影Top250网站,抓取所有电影的片名、导演、主演、上映年份、电影分级和评分。并将结果保存到 Excel。
爬取过程 爬取网页
使用Python中的requests库,可以直接爬取网页源代码。
我们首先使用DOS来安装requests
pip install --user requests
根据百度上的pip安装教程,使用pip安装时,直接输入pip install +(库名),但无法安装成功。根据内置提示,添加--user即可成功安装。
在 Python 中导入请求后,使用库函数 get 直接获取网页的源代码。
link = 'https://movie.douban.com/top250'
r = requests.get(link,headers,timeout=20)
在获取函数中:
让我们仔细看看最后两个参数。
请求标头为我们提供有关请求、响应或其他发送实体的信息。如果没有请求头或者请求头没有正确对应网页,那么我们抓取的结果可能是错误的。
如何找到网页的请求头?
我们进入豆瓣电影top250的网页,按f12进入开发者模式;
单击网络并刷新界面。
点击网页名称,然后点击Headers,我们可以在其中找到请求头的内容,并按照如下格式保存在Python中。
headers ={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Host':'movie.douban.com'}
说完请求头,再来说说响应时间的设置。
因为有时候爬虫会遇到服务端长时间不响应不返回的情况,那么爬虫就会等待,我们设置一个无响应返回的时间,如果时间截止点还没有返回回应。
接下来我们会发现上面的链接只有25部电影,总共250部电影分布在10个页面上;我们点击第二页,发现URL变了:;第三页:;再多一页,在链接的最后一个数字上加 25。
我们可以设置一个for循环来不断更新爬取的网页。
for i in range (0,10):
link = 'https://movie.douban.com/top250?start=' + str(i*25)
r = requests.get(link,headers=headers,timeout=20)
至此,我们可以检查上述过程是否正确,是否爬取成功。
我们打印出每一页的响应状态码。
print('Page',i,' ',r.status_code)
当状态码为200时,爬取成功。
分析网页
经过上面的过程,我们就可以得到网页的HTML代码了,但是我们不需要这么多东西,我们需要分析并从中提取出我们想要的东西。
我们需要使用第三方库bs4中的BeautifulSoup;
通过 pip 安装和导入,方法同上。
pip install --user bs4
from bs4 import BeautifulSoup #导入
BeautifulSoup 可以自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。BeautifulSoup可以将html解析成对象进行处理,并将所有页面转换成字典或数组,相比正则表达式可以大大简化处理过程。
我们创建一个 BeautifulSoup 对象汤来解析网页。
soup = BeautifulSoup(r.text,"lxml")
这里的lxml是Python解析HTML页面的库,是BeautifulSoup解析的固定搭配之一。(这里如果代码报错,可能是因为没有安装lxml库,用pip安装就行了。)
我们先通过浏览器的开发者模式观察发现
电影名称保存在 div 标签下的 class="hd" 中,我们需要的其他信息保存在 div 标签下的 class="bd" 中。
我们首先讨论电影标题的提取。其余项目基本类似。
我们直接使用soup中的find_all函数。汤里有两个函数,一个是find,一个是find_all。find函数返回第一个满足搜索条件的结果,find_all返回所有结果。这里我们根据需要使用 find_all。,并将结果保存到列表中。
div_list1 = soup.find_all('div',class_='hd')
这里会打印列表,并截取第一个“肖申克的救赎”的结果,即div_list[0]。同时,我们将对比豆瓣网页源代码的形式。我们可以提取名称。
电影名称存储在标签 a 下方的第一个跨度标签中。使用循环将所有电影的名称保存在第一页上。
for each in div_list1:
#中文名
movie_name = each.a.span.text.strip()
movies_name.append(movie_name)
这里 movies_name 是一个收录所有电影名称的列表。
这样我们就保存了整个 top250 电影的名称。让我们输出它来检查。
后续其他项目的流程基本相同。
我们将 find_all 函数中的第二个参数替换为:class="bd" 并将其保存在一个列表中。
问题来了。我们需要的内容不是保存在a和span中,而是保存在一个标签p中。如果我们直接用p替换a,跳过span部分,报错!,怎么办?
我们需要用另一个函数来替换它:contents,contents可以输出p下面的所有内容,并返回一个列表。我们现在可以在这个列表中找到我们需要的东西。
我还是先输出吗
div_list2=soup.find_all('div',class_='bd')
的结果。(为了方便观察,我们直接用断点+单步调试的方法查看结果)
我们需要从 div_list2 的第二项开始,所以循环应该从 div_list2[1] 开始。
只有 each.p.contents 中的第一项和第三项是我们需要的,所以我们列表的底部确定为 contents[0] 和 contents[2]。
我们先谈谈内容[0]。我们通过strip函数和split函数对字符串进行处理,去掉一些杂项。
movie = each.p.contents[0].strip().split('\xa0')
当当,结果出来了。
当我们输出所有结果时,发现有问题。错误!或者是数组越界的错,为什么是这个时候?显然第一个提取成功了,第二个也成功了。
再来看看豆瓣的网站
最后,它并没有显示全部。也就是说,后面的一部电影导演太多,或者名字太长的时候,主角就变成了“……”,无法展现。最重要的是上面movie返回的list长度从4变成了4。 2、当我们尝试使用上面的
actor = movie[3]
,自然会报错。
如何解决这个问题?
这个问题我其实还没有从根本上解决,因为这是豆瓣网页的问题,不能添加html中没有的词,除非我点击每个电影链接查看,但是这250个的具体细节movies 链接之间没有直接关联,也许有办法提取新的URL,从而重新爬取新的URL,然后分析,然后得到。从这个方向思考,似乎太麻烦了。
包括以上,有人可能会怀疑我提取了中文电影名,为什么不提取英文名和港台名。这里挖了一个小坑。有兴趣的可以尝试提取英文名和港台名。
当然,也有可能是我的水平不够,不知道有什么厉害的方法。
这里我们直接使用if判断语句根据电影的长度来判断。
if len(movie)==4:
movie_dir = movie[0][4:]
movie_actor = movie[3][4:]
else:
movie_dir = movie[0][4:]
movie_actor = '...'
其余部分没有坑。按照上述步骤,您可以提取电影的发行年份、国家、分类和评级。此处不再赘述。
保存数据
所有数据都被提取和分析,并保存在movies_name、movies_dir、movies_actor、movies_time、movies_nation、movies_class、movies_grade的列表中。接下来就是如何保存到Excel中了,方便我们进行进一步的工作。
为了保存到 excel,我们使用与 Python 和 Excel 关联的库 xlwt。
xlrd和xlwt这两个库在Python文件操作中与Excel关联,分别对应Excel的读写。写在这里,使用 xlwt。可以直接通过pip安装。
直接使用xlwt的功能:
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('豆瓣top250')
xlwt.Workbook(encoding = 'utf-8') - 创建一个 utf-8 编码的 Excel 工作表。
add_sheet('Douban top250') - 在sheet中创建一个名为“Douban top250”的工作簿。
一旦建立,下一步就是写入数据。只需使用一个功能。
worksheet.write(r,c,str)
其中,r代表行,c代表列,str代表内容。
只需依次存储我们列表的内容。
最后,保存 Excel:
保存(文件名)
filename 是保存文件的路径。
统计结果(部分)
完整代码下载 查看全部
c 抓取网页数据(Python静态网页抓取学习过程及一点简单的分析保存方法)
Python 静态网页抓取
最近学习了使用Python爬虫爬取静态网页,做一点简单的分析保存。以下是整个学习过程:
实践要求的目的
访问豆瓣电影Top250网站,抓取所有电影的片名、导演、主演、上映年份、电影分级和评分。并将结果保存到 Excel。
爬取过程 爬取网页
使用Python中的requests库,可以直接爬取网页源代码。
我们首先使用DOS来安装requests
pip install --user requests
根据百度上的pip安装教程,使用pip安装时,直接输入pip install +(库名),但无法安装成功。根据内置提示,添加--user即可成功安装。
在 Python 中导入请求后,使用库函数 get 直接获取网页的源代码。
link = 'https://movie.douban.com/top250'
r = requests.get(link,headers,timeout=20)
在获取函数中:
让我们仔细看看最后两个参数。
请求标头为我们提供有关请求、响应或其他发送实体的信息。如果没有请求头或者请求头没有正确对应网页,那么我们抓取的结果可能是错误的。
如何找到网页的请求头?
我们进入豆瓣电影top250的网页,按f12进入开发者模式;

单击网络并刷新界面。

点击网页名称,然后点击Headers,我们可以在其中找到请求头的内容,并按照如下格式保存在Python中。
headers ={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Host':'movie.douban.com'}
说完请求头,再来说说响应时间的设置。
因为有时候爬虫会遇到服务端长时间不响应不返回的情况,那么爬虫就会等待,我们设置一个无响应返回的时间,如果时间截止点还没有返回回应。
接下来我们会发现上面的链接只有25部电影,总共250部电影分布在10个页面上;我们点击第二页,发现URL变了:;第三页:;再多一页,在链接的最后一个数字上加 25。
我们可以设置一个for循环来不断更新爬取的网页。
for i in range (0,10):
link = 'https://movie.douban.com/top250?start=' + str(i*25)
r = requests.get(link,headers=headers,timeout=20)
至此,我们可以检查上述过程是否正确,是否爬取成功。
我们打印出每一页的响应状态码。
print('Page',i,' ',r.status_code)

当状态码为200时,爬取成功。
分析网页
经过上面的过程,我们就可以得到网页的HTML代码了,但是我们不需要这么多东西,我们需要分析并从中提取出我们想要的东西。
我们需要使用第三方库bs4中的BeautifulSoup;
通过 pip 安装和导入,方法同上。
pip install --user bs4
from bs4 import BeautifulSoup #导入
BeautifulSoup 可以自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。BeautifulSoup可以将html解析成对象进行处理,并将所有页面转换成字典或数组,相比正则表达式可以大大简化处理过程。
我们创建一个 BeautifulSoup 对象汤来解析网页。
soup = BeautifulSoup(r.text,"lxml")
这里的lxml是Python解析HTML页面的库,是BeautifulSoup解析的固定搭配之一。(这里如果代码报错,可能是因为没有安装lxml库,用pip安装就行了。)
我们先通过浏览器的开发者模式观察发现

电影名称保存在 div 标签下的 class="hd" 中,我们需要的其他信息保存在 div 标签下的 class="bd" 中。
我们首先讨论电影标题的提取。其余项目基本类似。
我们直接使用soup中的find_all函数。汤里有两个函数,一个是find,一个是find_all。find函数返回第一个满足搜索条件的结果,find_all返回所有结果。这里我们根据需要使用 find_all。,并将结果保存到列表中。
div_list1 = soup.find_all('div',class_='hd')

这里会打印列表,并截取第一个“肖申克的救赎”的结果,即div_list[0]。同时,我们将对比豆瓣网页源代码的形式。我们可以提取名称。
电影名称存储在标签 a 下方的第一个跨度标签中。使用循环将所有电影的名称保存在第一页上。
for each in div_list1:
#中文名
movie_name = each.a.span.text.strip()
movies_name.append(movie_name)
这里 movies_name 是一个收录所有电影名称的列表。
这样我们就保存了整个 top250 电影的名称。让我们输出它来检查。

后续其他项目的流程基本相同。
我们将 find_all 函数中的第二个参数替换为:class="bd" 并将其保存在一个列表中。
问题来了。我们需要的内容不是保存在a和span中,而是保存在一个标签p中。如果我们直接用p替换a,跳过span部分,报错!,怎么办?
我们需要用另一个函数来替换它:contents,contents可以输出p下面的所有内容,并返回一个列表。我们现在可以在这个列表中找到我们需要的东西。
我还是先输出吗
div_list2=soup.find_all('div',class_='bd')
的结果。(为了方便观察,我们直接用断点+单步调试的方法查看结果)

我们需要从 div_list2 的第二项开始,所以循环应该从 div_list2[1] 开始。

只有 each.p.contents 中的第一项和第三项是我们需要的,所以我们列表的底部确定为 contents[0] 和 contents[2]。
我们先谈谈内容[0]。我们通过strip函数和split函数对字符串进行处理,去掉一些杂项。
movie = each.p.contents[0].strip().split('\xa0')

当当,结果出来了。
当我们输出所有结果时,发现有问题。错误!或者是数组越界的错,为什么是这个时候?显然第一个提取成功了,第二个也成功了。
再来看看豆瓣的网站

最后,它并没有显示全部。也就是说,后面的一部电影导演太多,或者名字太长的时候,主角就变成了“……”,无法展现。最重要的是上面movie返回的list长度从4变成了4。 2、当我们尝试使用上面的
actor = movie[3]
,自然会报错。
如何解决这个问题?
这个问题我其实还没有从根本上解决,因为这是豆瓣网页的问题,不能添加html中没有的词,除非我点击每个电影链接查看,但是这250个的具体细节movies 链接之间没有直接关联,也许有办法提取新的URL,从而重新爬取新的URL,然后分析,然后得到。从这个方向思考,似乎太麻烦了。
包括以上,有人可能会怀疑我提取了中文电影名,为什么不提取英文名和港台名。这里挖了一个小坑。有兴趣的可以尝试提取英文名和港台名。
当然,也有可能是我的水平不够,不知道有什么厉害的方法。
这里我们直接使用if判断语句根据电影的长度来判断。
if len(movie)==4:
movie_dir = movie[0][4:]
movie_actor = movie[3][4:]
else:
movie_dir = movie[0][4:]
movie_actor = '...'
其余部分没有坑。按照上述步骤,您可以提取电影的发行年份、国家、分类和评级。此处不再赘述。
保存数据
所有数据都被提取和分析,并保存在movies_name、movies_dir、movies_actor、movies_time、movies_nation、movies_class、movies_grade的列表中。接下来就是如何保存到Excel中了,方便我们进行进一步的工作。
为了保存到 excel,我们使用与 Python 和 Excel 关联的库 xlwt。
xlrd和xlwt这两个库在Python文件操作中与Excel关联,分别对应Excel的读写。写在这里,使用 xlwt。可以直接通过pip安装。
直接使用xlwt的功能:
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('豆瓣top250')
xlwt.Workbook(encoding = 'utf-8') - 创建一个 utf-8 编码的 Excel 工作表。
add_sheet('Douban top250') - 在sheet中创建一个名为“Douban top250”的工作簿。
一旦建立,下一步就是写入数据。只需使用一个功能。
worksheet.write(r,c,str)
其中,r代表行,c代表列,str代表内容。
只需依次存储我们列表的内容。
最后,保存 Excel:
保存(文件名)
filename 是保存文件的路径。
统计结果(部分)

完整代码下载
c 抓取网页数据(怎样优化好你的网站,从而受到蜘蛛喜欢,排在)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-10 21:15
如何优化你的网站,从而被蜘蛛点赞,排在主流搜索的前几页,是站长们不懈的追求。
关键词,即代码中关键词与页面标题和元描述之间的关键词,要慎重选择。
A. baidu关键词优化技巧。
经验表明 关键词 太有用了。你为什么这么说?许多人在代码中列出了大量的单词。而且,百度老板只对前三四个字感冒,也会造成被K怀疑作弊的风险,字数也是有限制的。一般字数不超过20字。超出的单词将不会收录在搜索结果中。白农。
B. GOOGLE关键词优化技巧。
GOOGLE和百度一样,对关键词的字数、标题和描述有同样的限制和注意点。如果你不明白,请看上面。
但仅限谷歌
所以标题和描述的内容应该是优化网站的重点内容,包括关键词的选择,字数,那些关键词顶,怎么匹配长尾,增加更有可能被搜索引擎抓取的访问次数。
禁忌是不要过多地重复列表关键词。在标题和描述中,尽量使句子流畅。不要简单地把关键词一一排好。实践证明,像句子这样的描述更受欢迎。欢迎蜘蛛。
C. 让蜘蛛顺利爬取你的网页
也就是说,想办法让搜索引擎蜘蛛在你的网站中畅行无阻,顺利找到你的网页。
体验网站地图,比如网站xml格式的地图,把网站地图的地址写到你的robots.txt中,很有效,新站提交地图给gg后,两三个小时后,gg蜘蛛就会到你的车站,就像110报警一样。
D. 如何让搜索引擎蜘蛛经常来你的网站
和打110很像。如果你经常报警,他们会很快,很勤奋,但如果你什么都没发生,或者你让他空着,他会少来一次,甚至一个月一次。:
1.经常更新你的内容来吸引搜索引擎蜘蛛,这样你就不用白跑了。
2、为了保证内容的质量,尽量不要和别人重复太多,也就是给蜘蛛们新鲜好吃的东西吃。
3、去一些知名的,高权限的网站建立友好的链接,发帖,吸引蜘蛛来。
4、经常查看日志网站,研究蜘蛛频繁出现的次数和列,以便采取相应的动作让蜘蛛更喜欢,增加内容,整列等。 查看全部
c 抓取网页数据(怎样优化好你的网站,从而受到蜘蛛喜欢,排在)
如何优化你的网站,从而被蜘蛛点赞,排在主流搜索的前几页,是站长们不懈的追求。
关键词,即代码中关键词与页面标题和元描述之间的关键词,要慎重选择。
A. baidu关键词优化技巧。
经验表明 关键词 太有用了。你为什么这么说?许多人在代码中列出了大量的单词。而且,百度老板只对前三四个字感冒,也会造成被K怀疑作弊的风险,字数也是有限制的。一般字数不超过20字。超出的单词将不会收录在搜索结果中。白农。
B. GOOGLE关键词优化技巧。
GOOGLE和百度一样,对关键词的字数、标题和描述有同样的限制和注意点。如果你不明白,请看上面。
但仅限谷歌
所以标题和描述的内容应该是优化网站的重点内容,包括关键词的选择,字数,那些关键词顶,怎么匹配长尾,增加更有可能被搜索引擎抓取的访问次数。
禁忌是不要过多地重复列表关键词。在标题和描述中,尽量使句子流畅。不要简单地把关键词一一排好。实践证明,像句子这样的描述更受欢迎。欢迎蜘蛛。
C. 让蜘蛛顺利爬取你的网页
也就是说,想办法让搜索引擎蜘蛛在你的网站中畅行无阻,顺利找到你的网页。
体验网站地图,比如网站xml格式的地图,把网站地图的地址写到你的robots.txt中,很有效,新站提交地图给gg后,两三个小时后,gg蜘蛛就会到你的车站,就像110报警一样。
D. 如何让搜索引擎蜘蛛经常来你的网站
和打110很像。如果你经常报警,他们会很快,很勤奋,但如果你什么都没发生,或者你让他空着,他会少来一次,甚至一个月一次。:
1.经常更新你的内容来吸引搜索引擎蜘蛛,这样你就不用白跑了。
2、为了保证内容的质量,尽量不要和别人重复太多,也就是给蜘蛛们新鲜好吃的东西吃。
3、去一些知名的,高权限的网站建立友好的链接,发帖,吸引蜘蛛来。
4、经常查看日志网站,研究蜘蛛频繁出现的次数和列,以便采取相应的动作让蜘蛛更喜欢,增加内容,整列等。
c 抓取网页数据(写入值到word二、spider爬取标题进行写入三、爬去代码并将代码进行装换遇到问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-10 16:20
)
一、将值写入word 二、蜘蛛爬取标题供写三、爬取代码并替换代码遇到的问题:
在代码块中,每个字符都用一个 span 包裹
这个方法可以直接获取代码的值,可以用它来获取代码思路一、直接模仿代码进行在线替换,写操作思路二、使用文件操作技术获取替换的代码,然后使用脚本将其复制并粘贴到word文档中。 Ideas三、通过拼接直接得到的span标签的值,将拼接后的值传入word(select)中,最后使用etree执行代码块。解析项目遇到的工具:
(etree)
(查询)
代码:
import requests
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
from lxml import etree
from docx import Document
from docx.shared import Inches
url="https://www.runoob.com/cprogra ... ot%3B
def geu_page(url):
try:
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode("utf-8")
except Exception as e:
for i in range(3):
print(url,e)
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode('utf-8')
def getdata(url1):
html1 = geu_page(url1)
doc = pq(html1) # 解析html文件
datas = etree.HTML(html1)
data = datas.xpath('//div[@class="hl-main"]/span/text()')
code = ''.join(data)
title = doc('#content > p:nth-child(3)').text() # 其中doc(使用的是selector选择器)
content = doc('#content > p:nth-child(4)').text()
# 对url进行切割获取下标
begin = url1.find("example")
end = url1.find(".html")
index = url1[begin + 7:end]
print("开始写入第"+index+"个实例")
write_to_word(code,title,content,head=index)
def write_to_word(code,title,content,head):
# 标题
document.add_heading("C语言实例"+str(head), level=0)
# 文本: 题目
document.add_paragraph(title)
# 文本: 程序分析
document.add_paragraph(content)
# 代码: 代码
document.add_paragraph(code)
# 结果: result
document = Document()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx')
ent()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx') 查看全部
c 抓取网页数据(写入值到word二、spider爬取标题进行写入三、爬去代码并将代码进行装换遇到问题
)
一、将值写入word 二、蜘蛛爬取标题供写三、爬取代码并替换代码遇到的问题:

在代码块中,每个字符都用一个 span 包裹

这个方法可以直接获取代码的值,可以用它来获取代码思路一、直接模仿代码进行在线替换,写操作思路二、使用文件操作技术获取替换的代码,然后使用脚本将其复制并粘贴到word文档中。 Ideas三、通过拼接直接得到的span标签的值,将拼接后的值传入word(select)中,最后使用etree执行代码块。解析项目遇到的工具:


(etree)
(查询)
代码:
import requests
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
from lxml import etree
from docx import Document
from docx.shared import Inches
url="https://www.runoob.com/cprogra ... ot%3B
def geu_page(url):
try:
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode("utf-8")
except Exception as e:
for i in range(3):
print(url,e)
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode('utf-8')
def getdata(url1):
html1 = geu_page(url1)
doc = pq(html1) # 解析html文件
datas = etree.HTML(html1)
data = datas.xpath('//div[@class="hl-main"]/span/text()')
code = ''.join(data)
title = doc('#content > p:nth-child(3)').text() # 其中doc(使用的是selector选择器)
content = doc('#content > p:nth-child(4)').text()
# 对url进行切割获取下标
begin = url1.find("example")
end = url1.find(".html")
index = url1[begin + 7:end]
print("开始写入第"+index+"个实例")
write_to_word(code,title,content,head=index)
def write_to_word(code,title,content,head):
# 标题
document.add_heading("C语言实例"+str(head), level=0)
# 文本: 题目
document.add_paragraph(title)
# 文本: 程序分析
document.add_paragraph(content)
# 代码: 代码
document.add_paragraph(code)
# 结果: result
document = Document()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx')
ent()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx')
c 抓取网页数据(SpringBoot的一个好处(就是)的好处 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-09 20:43
)
Spring Boot 的一个优点是前端页面的参数可以通过注解方便的获取,然后通过一系列处理将参数传入后端数据库。如果某件事一段时间不写下来,几乎就忘记了,感觉自己的记忆力越来越差。这里简单总结一下,大致可以分为以下几类:
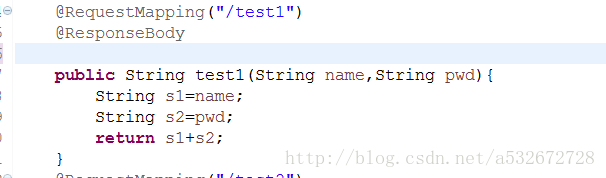
1.指定前端url请求参数名与方法名相同,如下图,这个方法简单的说就是url请求格式中的参数需要对应的参数名方法,比如这样一个url请求:8080/0919/test1?name=xxx&pwd=yyy,给指定的控制器类添加Controller注解,同时指定RequestMapping注解。当请求路径参数与方法参数匹配时,会自动注入
启动主程序,访问浏览器出现下图,说明注入参数成功。这个方法一般是一个get请求。
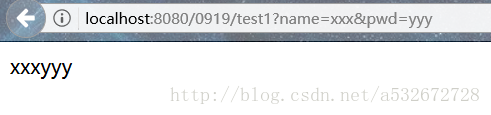
2.第二种方式是通过HttpServletRequest获取前端页面参数。代码如下图所示。简单来说就是调用请求的getParameter方法获取参数。例如访问路径类似这样:8080/0919/test2?firstName =zhang&lastName=san
启动主程序,访问浏览器出现下图,说明注入参数成功。该方法也可以获取表单参数。通常,get 和 post 请求都可以使用。
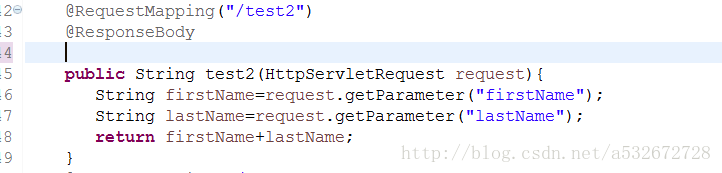
3.第三种方式是创建一个JavaBean对象来封装表单参数或者请求url路径中的参数。具体代码如下图所示
对应的JavaBean对象如下
简单来说,表单参数作为一个JavaBean类的属性,通过将方法参数设置为一个JavaBean对象,然后在方法中通过调用该对象的get方法来获取表单传递的参数,例如,访问路径是这样的: 8080/0919 /test3?firstName=zhang&lastName=san 启动主程序,在浏览器访问看到下图,说明注入参数成功,如果有多个form可以考虑这个方法要求的参数
4.第四种方式是通过PathVariable注解绑定请求路径的参数。参考代码如下
这种情况简单的表现为url中动态绑定的形式,然后通过PathVariable将方法中指定的参数绑定到请求url中的参数到方法参数中。这里没有指定PathVariable注解的具体值。可以根据请求路径中动态变量的顺序和注解的顺序进行注入。如果要指定注入,可以指定 PathVariable 注解的值与特定注入的动态变量的名称相同。比如请求路径是这样的:8080/0919/test4/111/222
启动主程序并在浏览器中访问它。出现下图说明注入参数成功。
5.第五种方式是通过RequestParam注解获取。具体代码如下
该方法将请求路径上的参数以url路径的形式绑定到方法的参数上。简而言之,将实参值赋给对应的形参。与上述方法不同的是,前者是动态url模板注入,这里是常见的url请求注入。比如访问路径是这样的:8080/0919/test5?aaa=111&bbb=4444
启动主程序,访问请求,浏览器出现如下提示,说明注入参数成功。这里可以通过指定RequestParam的值来指定url请求路径参数来指定具体注入哪个方法参数,但是一般来说两者同名更方便。
6.第六种方法是通过ModelAttribute方法注入参数。具体代码如下
这个方法一般显示在页面上,所以这里有两个页面用于测试 test2.jsp 和 test3.jsp 进行测试
简单来说就是通过ModelAttribute注解将请求参数封装到指定的JavaBean对象中,接受表单参数的对象通过value值赋值。在这里,s被赋值给了一个名为kkk的变量,然后你可以在jsp页面上使用这个变量名来使用el表达式来获取表单传递过来的参数。这里的测试路径是:8080/0919/kkk,访问浏览器进行测试,见下图
点击提交,出现下图,说明表单参数被后台成功接受并在首页输出。这种方法一般在输出首页时使用。
查看全部
c 抓取网页数据(SpringBoot的一个好处(就是)的好处
)
Spring Boot 的一个优点是前端页面的参数可以通过注解方便的获取,然后通过一系列处理将参数传入后端数据库。如果某件事一段时间不写下来,几乎就忘记了,感觉自己的记忆力越来越差。这里简单总结一下,大致可以分为以下几类:
1.指定前端url请求参数名与方法名相同,如下图,这个方法简单的说就是url请求格式中的参数需要对应的参数名方法,比如这样一个url请求:8080/0919/test1?name=xxx&pwd=yyy,给指定的控制器类添加Controller注解,同时指定RequestMapping注解。当请求路径参数与方法参数匹配时,会自动注入
启动主程序,访问浏览器出现下图,说明注入参数成功。这个方法一般是一个get请求。
2.第二种方式是通过HttpServletRequest获取前端页面参数。代码如下图所示。简单来说就是调用请求的getParameter方法获取参数。例如访问路径类似这样:8080/0919/test2?firstName =zhang&lastName=san
启动主程序,访问浏览器出现下图,说明注入参数成功。该方法也可以获取表单参数。通常,get 和 post 请求都可以使用。

3.第三种方式是创建一个JavaBean对象来封装表单参数或者请求url路径中的参数。具体代码如下图所示
对应的JavaBean对象如下
简单来说,表单参数作为一个JavaBean类的属性,通过将方法参数设置为一个JavaBean对象,然后在方法中通过调用该对象的get方法来获取表单传递的参数,例如,访问路径是这样的: 8080/0919 /test3?firstName=zhang&lastName=san 启动主程序,在浏览器访问看到下图,说明注入参数成功,如果有多个form可以考虑这个方法要求的参数

4.第四种方式是通过PathVariable注解绑定请求路径的参数。参考代码如下

这种情况简单的表现为url中动态绑定的形式,然后通过PathVariable将方法中指定的参数绑定到请求url中的参数到方法参数中。这里没有指定PathVariable注解的具体值。可以根据请求路径中动态变量的顺序和注解的顺序进行注入。如果要指定注入,可以指定 PathVariable 注解的值与特定注入的动态变量的名称相同。比如请求路径是这样的:8080/0919/test4/111/222
启动主程序并在浏览器中访问它。出现下图说明注入参数成功。

5.第五种方式是通过RequestParam注解获取。具体代码如下

该方法将请求路径上的参数以url路径的形式绑定到方法的参数上。简而言之,将实参值赋给对应的形参。与上述方法不同的是,前者是动态url模板注入,这里是常见的url请求注入。比如访问路径是这样的:8080/0919/test5?aaa=111&bbb=4444
启动主程序,访问请求,浏览器出现如下提示,说明注入参数成功。这里可以通过指定RequestParam的值来指定url请求路径参数来指定具体注入哪个方法参数,但是一般来说两者同名更方便。

6.第六种方法是通过ModelAttribute方法注入参数。具体代码如下

这个方法一般显示在页面上,所以这里有两个页面用于测试 test2.jsp 和 test3.jsp 进行测试

简单来说就是通过ModelAttribute注解将请求参数封装到指定的JavaBean对象中,接受表单参数的对象通过value值赋值。在这里,s被赋值给了一个名为kkk的变量,然后你可以在jsp页面上使用这个变量名来使用el表达式来获取表单传递过来的参数。这里的测试路径是:8080/0919/kkk,访问浏览器进行测试,见下图
点击提交,出现下图,说明表单参数被后台成功接受并在首页输出。这种方法一般在输出首页时使用。
c 抓取网页数据(2017年上海事业单位招聘考试每日一练())
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-09 18:39
买菜 D、刷卡消费6、使用VB编程语言编程处理信息的一般过程分为四个步骤。“分析问题”之后的下一步是(设计算法B,编写程序C,调试运行D,得到答案 data.jpgB, data.mpgC , data.wavD, data.html 王丹老师的教案保存数据B、代码C、文件D、符号输入网站的IP地址即可打开。可能的原因有(网卡故障B、域名解析错误C、网线问题D、浏览器故障10、分析信息支持解决问题,是()信息识别时效性B、权威性C、多样性D、适用性11、网络上的视频可以多人同时在线观看,
中国红十字会号召全国人民为无钱治疗的白血病儿童捐款。你判断这个信息的依据是 A、信息的多样性、信息的及时性 C、信息的权威性 D、信息共享 18、当王明收到同学聚会的邀请卡时,同学聚会就结束了,王明错过了团聚时间,也见不到同学了。及时性B、可共享性C、真实性D、载体依赖2 -10ACCBD11-15CBACC16-20DCAB21、一个完整的数据库管理系统表必须用()来表示数据记录B、数据C、文件D、字段的关系22、在下面对搜索引擎的描述中,错误是(A.搜索引擎一般使用“关键字”
发送消息可以包括文本、语言、图像、图形。C. 不可能携带计算机病毒。D. 同一条消息可以发送给多个收件人。30、数据库管理系统中数据信息的操作(A、高速、低效B、快速、高效C、慢速、高效D、慢速、低效31、@ > 为了呈现学生成绩的变化趋势,在制作Excel图表时,应该选择(A,柱形图B,条形图C,折线图D,饼图3 2、下面是视频文件(A、data.jpgB、data.mpgC、data.mp3D、data.html33、MP3歌曲的组织形式为(A、文件B、声音C、声波D、符号34、@ > 域名系统中,顶级域名GOV代表(A、教育机构B、
A.键盘 B、ModemC、鼠标 A.推动科技进步 B.给人们带来麻烦 C.创造人类新文明 D.加速产业转型 39、信息安全危害的两大来源是计算机病毒和网络黑客,其中网络黑客指(A、计算机编程高手 B、cookies的发布者 C、网络的非法入侵者 D、垃圾邮件的制造者 40、创建数据库并在数据库管理系统 与表的关系在建立数据库的过程中(操作。A、分析信息特征 B、确定特征之间的关系 C、创建数据库结构 D、编辑数据库 21-25DBAAB26-30BDACB31- 35CBABA36-40CDBCC 真或假 4 @1、计算机管理大量信息的方式比手动管理的方式效率更高(42、IP电话使用分组数据交换技术(43、保存网页时,可以插入页面中的图片直接保存在页面上,不需要单独保存,但是声音文件不能直接保存在网页上,必须单独保存(45、人类探索的使用火星上的机器人是人工智能的典型应用。( )46、在Word中使用“打印预览”命令查看文章在纸上打印的实际效果。(49、创建的网页可以通过FTP软件上传。(52、一个可以建立一个或多个不同网站的web服务器。(53、每个 IP 地址由 32 个十进制数字组成。
(56、Word中设置阿拉伯数字文字字体大小时,数字越大,文字越大。(57、OS模型不是分层架构。(58、将域名转换为IP地址166.111.4.100的过程称为域名解析。()59、赵天祥用photoshop的软件帮助魏老师将审稿材料手稿制作成word文档。(60、交互性是多媒体作品的重要特点之一。()61、在Word中编辑文档时,可以使用“文件页面设置”命令设置纸张大小。 查看全部
c 抓取网页数据(2017年上海事业单位招聘考试每日一练())
买菜 D、刷卡消费6、使用VB编程语言编程处理信息的一般过程分为四个步骤。“分析问题”之后的下一步是(设计算法B,编写程序C,调试运行D,得到答案 data.jpgB, data.mpgC , data.wavD, data.html 王丹老师的教案保存数据B、代码C、文件D、符号输入网站的IP地址即可打开。可能的原因有(网卡故障B、域名解析错误C、网线问题D、浏览器故障10、分析信息支持解决问题,是()信息识别时效性B、权威性C、多样性D、适用性11、网络上的视频可以多人同时在线观看,
中国红十字会号召全国人民为无钱治疗的白血病儿童捐款。你判断这个信息的依据是 A、信息的多样性、信息的及时性 C、信息的权威性 D、信息共享 18、当王明收到同学聚会的邀请卡时,同学聚会就结束了,王明错过了团聚时间,也见不到同学了。及时性B、可共享性C、真实性D、载体依赖2 -10ACCBD11-15CBACC16-20DCAB21、一个完整的数据库管理系统表必须用()来表示数据记录B、数据C、文件D、字段的关系22、在下面对搜索引擎的描述中,错误是(A.搜索引擎一般使用“关键字”
发送消息可以包括文本、语言、图像、图形。C. 不可能携带计算机病毒。D. 同一条消息可以发送给多个收件人。30、数据库管理系统中数据信息的操作(A、高速、低效B、快速、高效C、慢速、高效D、慢速、低效31、@ > 为了呈现学生成绩的变化趋势,在制作Excel图表时,应该选择(A,柱形图B,条形图C,折线图D,饼图3 2、下面是视频文件(A、data.jpgB、data.mpgC、data.mp3D、data.html33、MP3歌曲的组织形式为(A、文件B、声音C、声波D、符号34、@ > 域名系统中,顶级域名GOV代表(A、教育机构B、
A.键盘 B、ModemC、鼠标 A.推动科技进步 B.给人们带来麻烦 C.创造人类新文明 D.加速产业转型 39、信息安全危害的两大来源是计算机病毒和网络黑客,其中网络黑客指(A、计算机编程高手 B、cookies的发布者 C、网络的非法入侵者 D、垃圾邮件的制造者 40、创建数据库并在数据库管理系统 与表的关系在建立数据库的过程中(操作。A、分析信息特征 B、确定特征之间的关系 C、创建数据库结构 D、编辑数据库 21-25DBAAB26-30BDACB31- 35CBABA36-40CDBCC 真或假 4 @1、计算机管理大量信息的方式比手动管理的方式效率更高(42、IP电话使用分组数据交换技术(43、保存网页时,可以插入页面中的图片直接保存在页面上,不需要单独保存,但是声音文件不能直接保存在网页上,必须单独保存(45、人类探索的使用火星上的机器人是人工智能的典型应用。( )46、在Word中使用“打印预览”命令查看文章在纸上打印的实际效果。(49、创建的网页可以通过FTP软件上传。(52、一个可以建立一个或多个不同网站的web服务器。(53、每个 IP 地址由 32 个十进制数字组成。
(56、Word中设置阿拉伯数字文字字体大小时,数字越大,文字越大。(57、OS模型不是分层架构。(58、将域名转换为IP地址166.111.4.100的过程称为域名解析。()59、赵天祥用photoshop的软件帮助魏老师将审稿材料手稿制作成word文档。(60、交互性是多媒体作品的重要特点之一。()61、在Word中编辑文档时,可以使用“文件页面设置”命令设置纸张大小。
c 抓取网页数据(0x1工具准备工欲善其事必先利其器,爬取语料的根基基于python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-09 07:15
0x1 工具准备
要想把工作做好,首先要磨砺自己的工具。爬取语料库的基础是python。
我们基于python3开发,主要使用以下模块:requests、lxml、json。
各模块功能简介
01|要求
requests 是一个 Python 第三方库,特别方便处理 URL 资源。它的官方文档有一个很大的口号:HTTP for Humans(为人类使用HTTP而生)。对比python自带的urllib体验,笔者认为requests的体验比urllib高一个数量级。
让我们做一个简单的比较:
网址库:
1import urllib2
2import urllib
3
4URL_GET = "https://api.douban.com/v2/event/list"
5#构建请求参数
6params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
7
8#发送请求
9response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
10#Response Headers
11print(response.info())
12#Response Code
13print(response.getcode())
14#Response Body
15print(response.read())
复制代码
要求:
1import requests
2
3URL_GET = "https://api.douban.com/v2/event/list"
4#构建请求参数
5params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
6
7#发送请求
8response = requests.get(URL_GET,params=params)
9#Response Headers
10print(response.headers)
11#Response Code
12print(response.status_code)
13#Response Body
14print(response.text)复制代码
我们可以发现这两个库有一些区别:
1. 参数的构造:urllib需要对参数进行urlencode,比较麻烦;请求不需要额外的编码,非常简洁。
2. 请求发送:urllib需要额外将url参数构造成符合要求的形式;requests 简洁很多,直接获取对应的链接和参数。
3. 连接方式:查看返回数据的头部信息中的“连接”。使用 urllib 库时,“connection”:“close”表示每次请求结束时关闭socket通道,requests库使用urllib3,多个请求复用一个socket,“connection”:“keep-alive”,表示多个请求使用一个连接,消耗资源较少
4. 编码方式:requests库的编码方式Accept-Encoding比较全,这里就不举例了
综上所述,使用requests更加简洁易懂,极大的方便了我们的开发。
02|lxml
BeautifulSoup 是一个库,XPath 是一种技术,python 中使用最多的 XPath 库是 lxml。
当我们得到请求返回的页面时,我们如何得到我们想要的数据呢?此时,lxml 是一个强大的 HTML/XML 解析工具。Python从来不缺解析库,那我们为什么要在众多库中选择lxml呢?我们选择另一个知名的 HTML 解析库 BeautifulSoup 进行对比。
让我们做一个简单的比较:
美丽汤:
1from bs4 import BeautifulSoup #导入库
2# 假设html是需要被解析的html
3
4#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
5soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
6#查找所有的h4标签
7links = soup.find_all("h4")
复制代码
lxml:
1from lxml import etree
2# 假设html是需要被解析的html
3
4#将html传入etree 的构造方法,得到一个文档的对象
5root = etree.HTML(html)
6#查找所有的h4标签
7links = root.xpath("//h4")
复制代码
我们可以发现这两个库有一些区别:
1.解析html:BeautifulSoup的解析方式和JQ类似。API 非常人性化,支持 css 选择器;lxml语法有一定的学习成本
2. 性能:BeautifulSoup 是基于 DOM 的,它会加载整个文档并解析整个 DOM 树,所以时间和内存开销会大很多;而lxml只会在本地遍历,而lxml是用c写的,而BeautifulSoup是用python写的,明显的表现就是lxml>>BeautifulSoup。
综上所述,使用 BeautifulSoup 更加简洁易用。lxml虽然有一定的学习成本,但总体来说简单易懂。最重要的是它是基于C编写的,速度要快得多。对于笔者的强迫症,自然就选择lxml了。
03|json
Python 自带了自己的 json 库,对于基本的 json 处理来说已经足够了。但是如果你想更懒一点,可以使用第三方的json库,常见的有demjson和simplejson。
这两个库,无论是导入模块速度,还是编解码速度,都比simplejson好,simplejson的兼容性更好。所以如果你想使用square库,你可以使用simplejson。
0x2 确定语料来源
武器准备好后,下一步就是确定爬行方向。
以电竞语料为例,现在我们来爬取电竞相关的语料。熟悉的电竞平台有企鹅电竞、企鹅电竞和企鹅电竞(斜视),所以我们使用企鹅电竞上的比赛直播作为数据源进行爬取。
我们登陆企鹅电竞官网,进入游戏列表页面。我们可以发现页面上有很多游戏。手动写这些游戏名显然是无利可图的,于是我们开始了爬虫的第一步:游戏列表爬取。
1import requests
2from lxml import etree
3
4# 更新游戏列表
5def _updateGameList():
6 # 发送HTTP请求时的HEAD信息,用于伪装为浏览器
7 heads = {
8 'Connection': 'Keep-Alive',
9 'Accept': 'text/html, application/xhtml+xml, */*',
10 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
11 'Accept-Encoding': 'gzip, deflate',
12 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
13 }
14 # 需要爬取的游戏列表页
15 url = 'https://egame.qq.com/gamelist'
16
17 # 不压缩html,最大链接时间为10妙
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码utf-8
20 res.encoding = 'utf-8'
21 # 将html构建为Xpath模式
22 root = etree.HTML(res.content)
23 # 使用Xpath语法,获取游戏名
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出爬到的游戏名
26 print(gameList)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于线块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页分词查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们把这两个标签和其中收录的文本组合成一个标签窗口(比如I am h1中的“I am h1”就是标签窗口的内容),取出文本的标签窗口。.
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于线块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时块长为引入判断。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
以这个网页为例:网页的文本区域从145行到182行。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1# 假设content为已经拿到的html
2
3# Ctext取周围k行(k max_text_len and (not boolstart)):
38 # Cblock下面3个都不为0,认为是正文
39 if (Ctext_len[i + 1] != 0 or Ctext_len[i + 2] != 0 or Ctext_len[i + 3] != 0):
40 boolstart = True
41 start = i
42 continue
43 if (boolstart):
44 # Cblock下面3个中有0,则结束
45 if (Ctext_len[i] == 0 or Ctext_len[i + 1] == 0):
46 end = i
47 boolend = True
48 tmp = []
49
50 # 判断下面还有没有正文
51 if(boolend):
52 for ii in range(start, end + 1):
53 if(len(lines[ii]) < 5):
54 continue
55 tmp.append(lines[ii] + "n")
56 str = "".join(list(tmp))
57 # 去掉版权信息
58 if ("Copyright" in str or "版权所有" in str):
59 continue
60 main_text.append(str)
61 boolstart = boolend = False
62# 返回主内容
63result = "".join(list(main_text))
复制代码
0x4 结语
至此,我们可以获得任意内容的文章语料库,但这仅仅是开始。获得这些语料后,我们还需要一次清洗、分割、标记等,才能得到实际可以使用的语料。 查看全部
c 抓取网页数据(0x1工具准备工欲善其事必先利其器,爬取语料的根基基于python)
0x1 工具准备
要想把工作做好,首先要磨砺自己的工具。爬取语料库的基础是python。
我们基于python3开发,主要使用以下模块:requests、lxml、json。
各模块功能简介
01|要求
requests 是一个 Python 第三方库,特别方便处理 URL 资源。它的官方文档有一个很大的口号:HTTP for Humans(为人类使用HTTP而生)。对比python自带的urllib体验,笔者认为requests的体验比urllib高一个数量级。
让我们做一个简单的比较:
网址库:
1import urllib2
2import urllib
3
4URL_GET = "https://api.douban.com/v2/event/list"
5#构建请求参数
6params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
7
8#发送请求
9response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
10#Response Headers
11print(response.info())
12#Response Code
13print(response.getcode())
14#Response Body
15print(response.read())
复制代码
要求:
1import requests
2
3URL_GET = "https://api.douban.com/v2/event/list"
4#构建请求参数
5params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
6
7#发送请求
8response = requests.get(URL_GET,params=params)
9#Response Headers
10print(response.headers)
11#Response Code
12print(response.status_code)
13#Response Body
14print(response.text)复制代码
我们可以发现这两个库有一些区别:
1. 参数的构造:urllib需要对参数进行urlencode,比较麻烦;请求不需要额外的编码,非常简洁。
2. 请求发送:urllib需要额外将url参数构造成符合要求的形式;requests 简洁很多,直接获取对应的链接和参数。
3. 连接方式:查看返回数据的头部信息中的“连接”。使用 urllib 库时,“connection”:“close”表示每次请求结束时关闭socket通道,requests库使用urllib3,多个请求复用一个socket,“connection”:“keep-alive”,表示多个请求使用一个连接,消耗资源较少
4. 编码方式:requests库的编码方式Accept-Encoding比较全,这里就不举例了
综上所述,使用requests更加简洁易懂,极大的方便了我们的开发。
02|lxml
BeautifulSoup 是一个库,XPath 是一种技术,python 中使用最多的 XPath 库是 lxml。
当我们得到请求返回的页面时,我们如何得到我们想要的数据呢?此时,lxml 是一个强大的 HTML/XML 解析工具。Python从来不缺解析库,那我们为什么要在众多库中选择lxml呢?我们选择另一个知名的 HTML 解析库 BeautifulSoup 进行对比。
让我们做一个简单的比较:
美丽汤:
1from bs4 import BeautifulSoup #导入库
2# 假设html是需要被解析的html
3
4#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
5soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
6#查找所有的h4标签
7links = soup.find_all("h4")
复制代码
lxml:
1from lxml import etree
2# 假设html是需要被解析的html
3
4#将html传入etree 的构造方法,得到一个文档的对象
5root = etree.HTML(html)
6#查找所有的h4标签
7links = root.xpath("//h4")
复制代码
我们可以发现这两个库有一些区别:
1.解析html:BeautifulSoup的解析方式和JQ类似。API 非常人性化,支持 css 选择器;lxml语法有一定的学习成本
2. 性能:BeautifulSoup 是基于 DOM 的,它会加载整个文档并解析整个 DOM 树,所以时间和内存开销会大很多;而lxml只会在本地遍历,而lxml是用c写的,而BeautifulSoup是用python写的,明显的表现就是lxml>>BeautifulSoup。
综上所述,使用 BeautifulSoup 更加简洁易用。lxml虽然有一定的学习成本,但总体来说简单易懂。最重要的是它是基于C编写的,速度要快得多。对于笔者的强迫症,自然就选择lxml了。
03|json
Python 自带了自己的 json 库,对于基本的 json 处理来说已经足够了。但是如果你想更懒一点,可以使用第三方的json库,常见的有demjson和simplejson。
这两个库,无论是导入模块速度,还是编解码速度,都比simplejson好,simplejson的兼容性更好。所以如果你想使用square库,你可以使用simplejson。
0x2 确定语料来源
武器准备好后,下一步就是确定爬行方向。
以电竞语料为例,现在我们来爬取电竞相关的语料。熟悉的电竞平台有企鹅电竞、企鹅电竞和企鹅电竞(斜视),所以我们使用企鹅电竞上的比赛直播作为数据源进行爬取。
我们登陆企鹅电竞官网,进入游戏列表页面。我们可以发现页面上有很多游戏。手动写这些游戏名显然是无利可图的,于是我们开始了爬虫的第一步:游戏列表爬取。
1import requests
2from lxml import etree
3
4# 更新游戏列表
5def _updateGameList():
6 # 发送HTTP请求时的HEAD信息,用于伪装为浏览器
7 heads = {
8 'Connection': 'Keep-Alive',
9 'Accept': 'text/html, application/xhtml+xml, */*',
10 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
11 'Accept-Encoding': 'gzip, deflate',
12 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
13 }
14 # 需要爬取的游戏列表页
15 url = 'https://egame.qq.com/gamelist'
16
17 # 不压缩html,最大链接时间为10妙
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码utf-8
20 res.encoding = 'utf-8'
21 # 将html构建为Xpath模式
22 root = etree.HTML(res.content)
23 # 使用Xpath语法,获取游戏名
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出爬到的游戏名
26 print(gameList)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于线块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页分词查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们把这两个标签和其中收录的文本组合成一个标签窗口(比如I am h1中的“I am h1”就是标签窗口的内容),取出文本的标签窗口。.
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于线块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时块长为引入判断。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
以这个网页为例:网页的文本区域从145行到182行。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1# 假设content为已经拿到的html
2
3# Ctext取周围k行(k max_text_len and (not boolstart)):
38 # Cblock下面3个都不为0,认为是正文
39 if (Ctext_len[i + 1] != 0 or Ctext_len[i + 2] != 0 or Ctext_len[i + 3] != 0):
40 boolstart = True
41 start = i
42 continue
43 if (boolstart):
44 # Cblock下面3个中有0,则结束
45 if (Ctext_len[i] == 0 or Ctext_len[i + 1] == 0):
46 end = i
47 boolend = True
48 tmp = []
49
50 # 判断下面还有没有正文
51 if(boolend):
52 for ii in range(start, end + 1):
53 if(len(lines[ii]) < 5):
54 continue
55 tmp.append(lines[ii] + "n")
56 str = "".join(list(tmp))
57 # 去掉版权信息
58 if ("Copyright" in str or "版权所有" in str):
59 continue
60 main_text.append(str)
61 boolstart = boolend = False
62# 返回主内容
63result = "".join(list(main_text))
复制代码
0x4 结语
至此,我们可以获得任意内容的文章语料库,但这仅仅是开始。获得这些语料后,我们还需要一次清洗、分割、标记等,才能得到实际可以使用的语料。
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2022-04-06 18:15
开场白:为了写爬虫,抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。让我们记录三种常见的情况。以下抓包方法
1.PC浏览器网页抓取
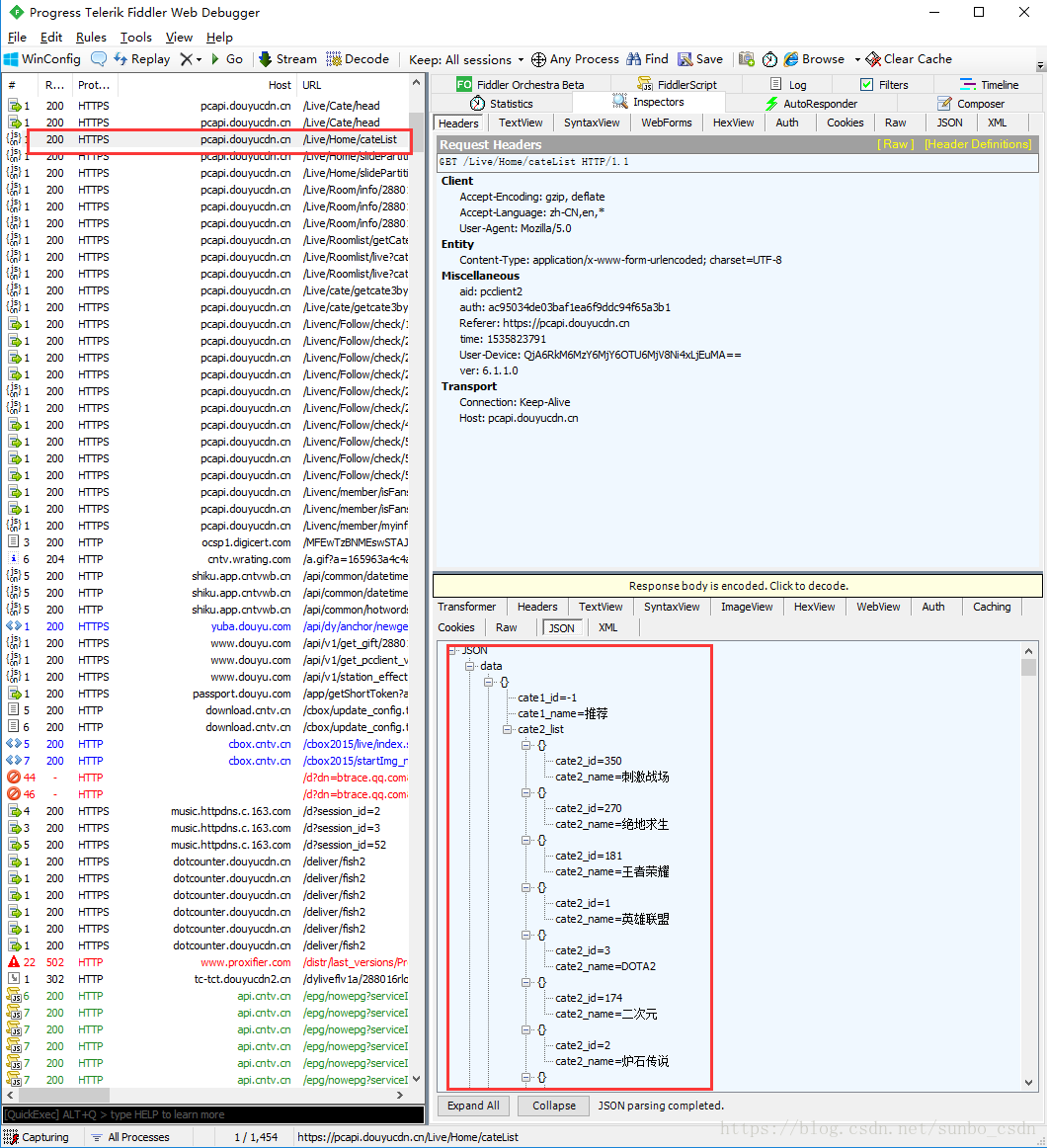
网络板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足部分需求,如果是请求前和响应后处理最多),比如修改请求浏览器发送的数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为一个本地代理服务器,实现转发客户端和服务器的请求和响应
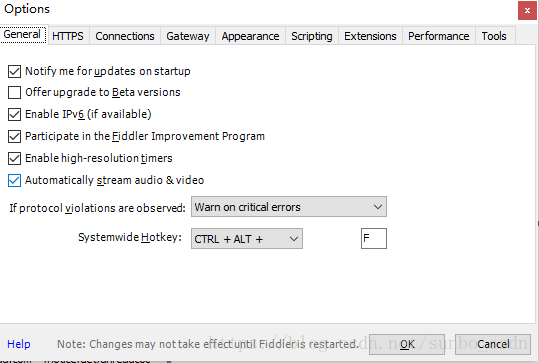
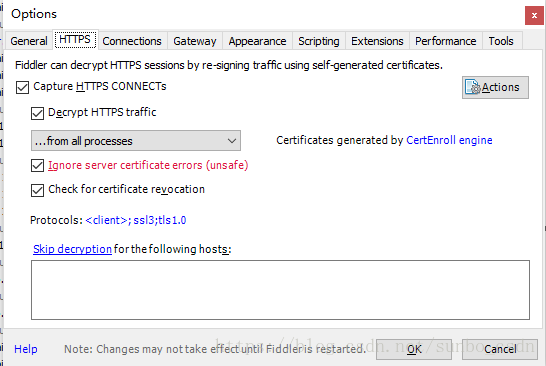
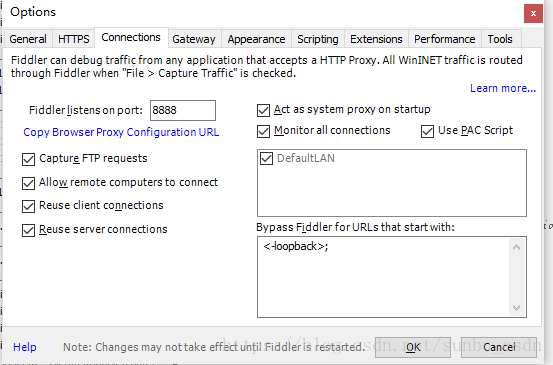
设置 Fiddler:
打开Fiddler,在菜单栏中,打开Tools –Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在手机app上使用Fiddler抓包也很简单。它类似于上面的PC浏览器。移动终端和PC应该在同一个局域网内。手机Wifi应该设置为代理。IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般为8888,这样手机上所有的网络/响应请求都必须被FIddler捕获并发送,这样我们才能针对某些链接进行分析
3.PC客户端(C/S)抓包
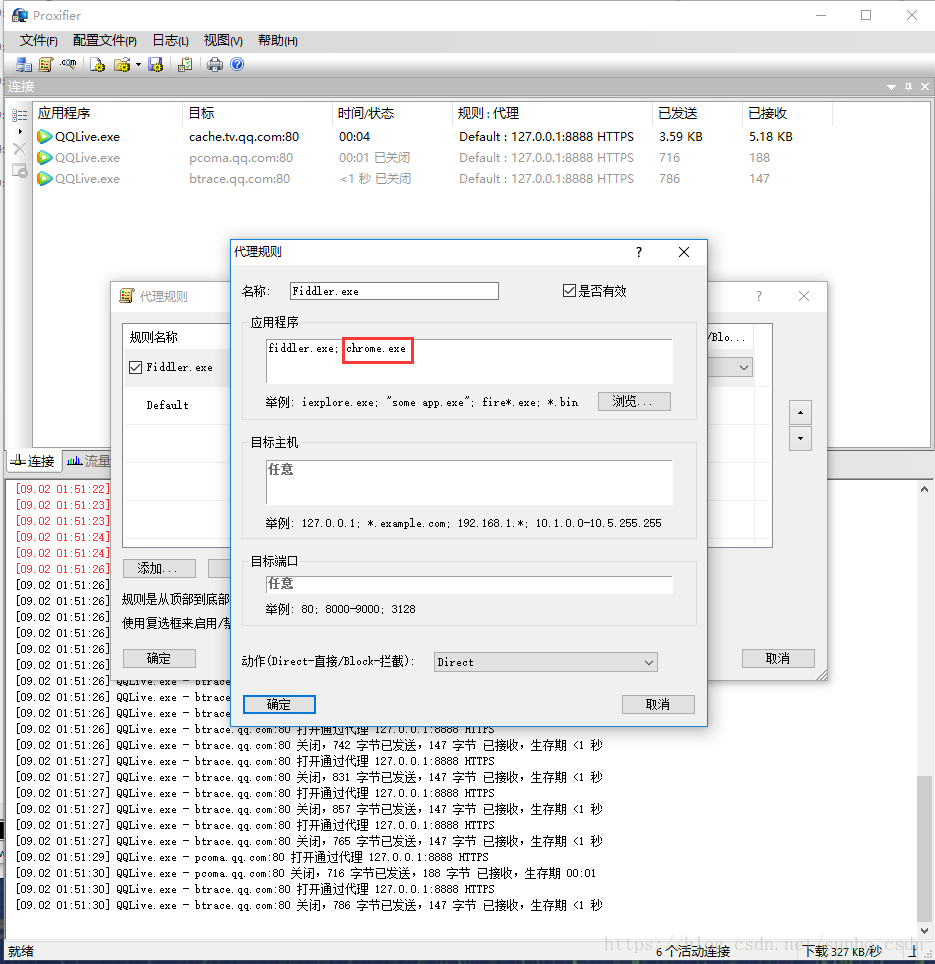
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理或代理链。
由于一般C/S客户端无法设置代理,FIddler无法检测到数据。我们可以使用 Proxifer 捕获所有请求并将其发送给 Fiddler,这样我们就可以在 Fiddler 中分析客户端请求。
Proxifer 设置:
设置很简单,如下图,两步就OK了
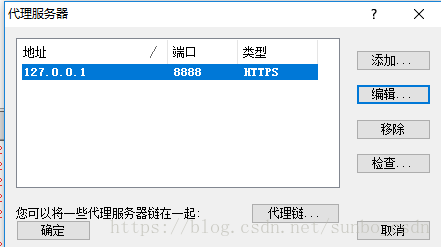
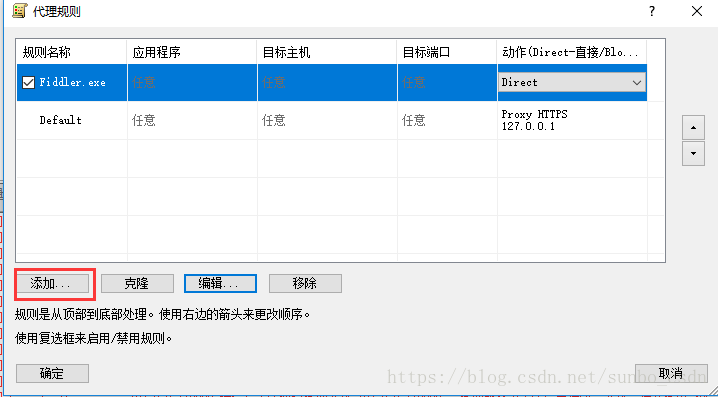
一种)。设置代理服务器以匹配 Fiddler 代理设置
b).设置代理规则
默认Default,我们可以忽略
点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地Fiddler设置的代理,可以任意设置
目的港:任意
行动:直接
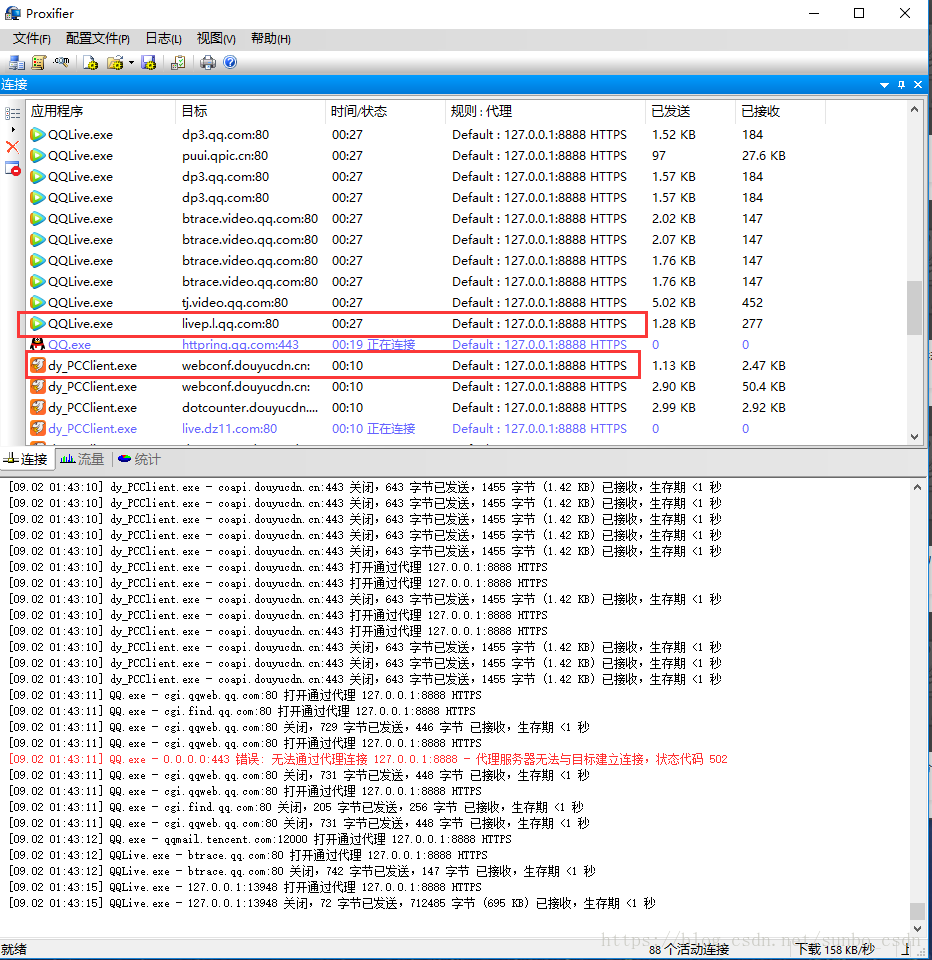
到这里设置就完成了,我们可以打开腾讯视频视频客户端,在Fiddler和Proxifer中看到数据
4.计算机上的所有C/S客户端都可以抓包
这时候,当 Proxifer 打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器可执行程序文件,确认后即可上网
转载地址: 查看全部
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?)
开场白:为了写爬虫,抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。让我们记录三种常见的情况。以下抓包方法
1.PC浏览器网页抓取
网络板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足部分需求,如果是请求前和响应后处理最多),比如修改请求浏览器发送的数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为一个本地代理服务器,实现转发客户端和服务器的请求和响应
设置 Fiddler:
打开Fiddler,在菜单栏中,打开Tools –Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在手机app上使用Fiddler抓包也很简单。它类似于上面的PC浏览器。移动终端和PC应该在同一个局域网内。手机Wifi应该设置为代理。IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般为8888,这样手机上所有的网络/响应请求都必须被FIddler捕获并发送,这样我们才能针对某些链接进行分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理或代理链。
由于一般C/S客户端无法设置代理,FIddler无法检测到数据。我们可以使用 Proxifer 捕获所有请求并将其发送给 Fiddler,这样我们就可以在 Fiddler 中分析客户端请求。
Proxifer 设置:
设置很简单,如下图,两步就OK了

一种)。设置代理服务器以匹配 Fiddler 代理设置
b).设置代理规则
默认Default,我们可以忽略
点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地Fiddler设置的代理,可以任意设置
目的港:任意
行动:直接
到这里设置就完成了,我们可以打开腾讯视频视频客户端,在Fiddler和Proxifer中看到数据
4.计算机上的所有C/S客户端都可以抓包
这时候,当 Proxifer 打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器可执行程序文件,确认后即可上网
转载地址:
c 抓取网页数据(浅谈网络爬虫中广度优先算法的介绍及其代码实现过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-06 13:15
前几天分享了深度优先算法在网络爬虫中的介绍及其代码实现过程。还没来得及上车的可以点这个文章——关于深度优先算法和网络爬虫的简单代码。今天给大家分享一下网络爬虫中广度优先算法的介绍及其代码实现过程。
广度优先算法和深度优先算法正好相反。这里我们继续以上图中的二叉树为例。广度优先算法的主要思想是从顶级域名A开始,然后从中提取两个链接B和C。链接B爬完之后,下一个要爬的链接是链接B的同级链接C,而不是说爬完链接B之后,马上下去爬取子链接C或者D。爬完C之后,再回到继续爬取兄弟链接 B 下的子链接 D 或 E,然后返回爬取 C 链接下的兄弟链接 F、G、H,以此类推。
从表面上看,广度优先算法是一种分层爬取的策略。先抓取第一层的节点,再抓取第二层的节点,再依次抓取第三层的节点,以此类推,直到抓取完成或达到预定的抓取条件。可以认为广度优先算法是一种根据层次结构的遍历方法,因此也称为广度优先算法。了解了广度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、C、D、E、F、G、H、I(这里, 左边的链接假定会先被爬取)。通过以上了解,
下图是广度优先算法的代码实现过程。
首先传入一个顶层节点节点(链接A),然后判断该节点是否不为空。如果它是空的,它将被退回。如果不为空,则将其放入队列列表中,然后开始循环。使用pop()方法将队列列表中的元素移除(此时只有节点A),然后打印节点的数据。打印完节点后,看看是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则获取一个新的左节点(链接B)并将其放入队列列表中。之后程序继续执行,右节点的执行过程也是一样的。这时会得到正确的节点(链接C),也将其放入队列列表中。此时,队列列表中的元素有链接B和链接C,然后再次进行新一轮的循环。这样,我们就实现了广度优先算法中分层抓取链接的过程。这个逻辑比深度优先算法简单。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法。也是面试过程中很常见的面试题,所以建议大家需要掌握。
以上就是网络爬虫中广度优先算法的简单介绍。你们明白了吗? 查看全部
c 抓取网页数据(浅谈网络爬虫中广度优先算法的介绍及其代码实现过程)
前几天分享了深度优先算法在网络爬虫中的介绍及其代码实现过程。还没来得及上车的可以点这个文章——关于深度优先算法和网络爬虫的简单代码。今天给大家分享一下网络爬虫中广度优先算法的介绍及其代码实现过程。
广度优先算法和深度优先算法正好相反。这里我们继续以上图中的二叉树为例。广度优先算法的主要思想是从顶级域名A开始,然后从中提取两个链接B和C。链接B爬完之后,下一个要爬的链接是链接B的同级链接C,而不是说爬完链接B之后,马上下去爬取子链接C或者D。爬完C之后,再回到继续爬取兄弟链接 B 下的子链接 D 或 E,然后返回爬取 C 链接下的兄弟链接 F、G、H,以此类推。
从表面上看,广度优先算法是一种分层爬取的策略。先抓取第一层的节点,再抓取第二层的节点,再依次抓取第三层的节点,以此类推,直到抓取完成或达到预定的抓取条件。可以认为广度优先算法是一种根据层次结构的遍历方法,因此也称为广度优先算法。了解了广度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、C、D、E、F、G、H、I(这里, 左边的链接假定会先被爬取)。通过以上了解,
下图是广度优先算法的代码实现过程。
首先传入一个顶层节点节点(链接A),然后判断该节点是否不为空。如果它是空的,它将被退回。如果不为空,则将其放入队列列表中,然后开始循环。使用pop()方法将队列列表中的元素移除(此时只有节点A),然后打印节点的数据。打印完节点后,看看是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则获取一个新的左节点(链接B)并将其放入队列列表中。之后程序继续执行,右节点的执行过程也是一样的。这时会得到正确的节点(链接C),也将其放入队列列表中。此时,队列列表中的元素有链接B和链接C,然后再次进行新一轮的循环。这样,我们就实现了广度优先算法中分层抓取链接的过程。这个逻辑比深度优先算法简单。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法。也是面试过程中很常见的面试题,所以建议大家需要掌握。
以上就是网络爬虫中广度优先算法的简单介绍。你们明白了吗?
c 抓取网页数据( 网页信息提取的方式从网页中提取信息有一些方法? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2022-04-05 06:19
网页信息提取的方式从网页中提取信息有一些方法?
)
关于转载授权
编译|丁学煌年程序笔记|奚雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求呈指数级增长,其重要性也越来越明显。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并不是所有的 网站 都提供 API。有的网站不愿意让读者以结构化的方式获取大量信息,有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?好吧,我们需要通过网络抓取来获取数据。
当然还有其他的,比如RSS提要等,但由于使用限制,我不会在这里讨论它们。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转化为结构化数据(数据库或电子表格)。
网页抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
需要使用非编程方式提取网页数据的读者,可以去import.io看看。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用两个 Python 模块来抓取数据:
Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
·BeautifulSoup:这是一个从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。如:
·机械化
·刮痕
·scrapy
基础 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
此语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html 文件写在 和 标签之间
3.html文档的可见部分写在和标签之间
4.html头使用
标记定义
5.html段落使用
标签定义
其他有用的 HTML 标签是:
1.html 链接是使用标签“This is a test ”定义的
2.html表格使用定义,row用row表示,row的第二个元素在标签里,不在
分为数据
3.htmlList 以
)
如上图,你会注意到
标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。让我们看一下代码:
最后,我们dataframe里面的数据如下:
同样,可以使用 BeautifulSoup 执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但是为什么我不能只使用正则表达式呢?
现在,如果你知道一个正则表达式,你可能会认为你可以用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比用正则表达式编写的代码更强大。使用正则表达式编写的代码必须随着页面的变化而变化。尽管 BeautifulSoup 在某些情况下需要调整,但相对而言,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结语
在本文中,我们使用了两个 Python 库 BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。上海长海医院硕士研究生黄念对生物医学大数据挖掘及其应用非常感兴趣,愿意通过这个平台结识更多的朋友。熊芬 熊芬是北京邮电大学无线信号处理专业的研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。. 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
查看全部
c 抓取网页数据(
网页信息提取的方式从网页中提取信息有一些方法?
)

关于转载授权
编译|丁学煌年程序笔记|奚雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求呈指数级增长,其重要性也越来越明显。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并不是所有的 网站 都提供 API。有的网站不愿意让读者以结构化的方式获取大量信息,有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?好吧,我们需要通过网络抓取来获取数据。
当然还有其他的,比如RSS提要等,但由于使用限制,我不会在这里讨论它们。

什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转化为结构化数据(数据库或电子表格)。
网页抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
需要使用非编程方式提取网页数据的读者,可以去import.io看看。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用两个 Python 模块来抓取数据:
Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
·BeautifulSoup:这是一个从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。如:
·机械化
·刮痕
·scrapy
基础 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:

此语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html 文件写在 和 标签之间
3.html文档的可见部分写在和标签之间
4.html头使用
标记定义
5.html段落使用
标签定义
其他有用的 HTML 标签是:
1.html 链接是使用标签“This is a test ”定义的
2.html表格使用定义,row用row表示,row的第二个元素在标签里,不在
分为数据

3.htmlList 以
)

如上图,你会注意到
标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。让我们看一下代码:




最后,我们dataframe里面的数据如下:

同样,可以使用 BeautifulSoup 执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但是为什么我不能只使用正则表达式呢?
现在,如果你知道一个正则表达式,你可能会认为你可以用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比用正则表达式编写的代码更强大。使用正则表达式编写的代码必须随着页面的变化而变化。尽管 BeautifulSoup 在某些情况下需要调整,但相对而言,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结语
在本文中,我们使用了两个 Python 库 BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。上海长海医院硕士研究生黄念对生物医学大数据挖掘及其应用非常感兴趣,愿意通过这个平台结识更多的朋友。熊芬 熊芬是北京邮电大学无线信号处理专业的研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。. 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。

c 抓取网页数据( 路上在将图像发送到模型之前模型接收带有车牌的输入 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-03 08:18
路上在将图像发送到模型之前模型接收带有车牌的输入
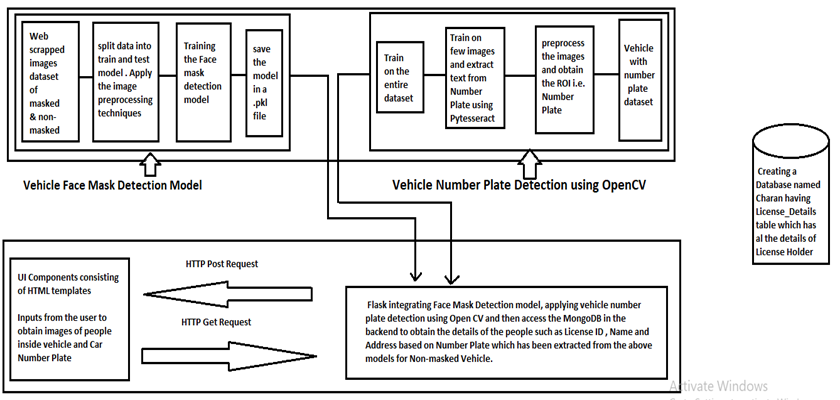
)
<p data-darkmode-bgcolor="rgb(36, 36, 36)" data-darkmode-color="rgb(143, 155, 171)" data-style="margin: 0em 0.5em; padding: 0px 0.5em; text-align: center; color: rgb(62, 71, 83); text-transform: none; text-indent: 0px; letter-spacing: 0.54px; clear: both; font-size: 16px; font-style: normal; font-variant: normal; font-weight: 400; text-decoration: none; word-spacing: 0px; white-space: normal; min-height: 1em; max-width: 100%; box-sizing: border-box; orphans: 2; -webkit-text-stroke-width: 0px; overflow-wrap: break-word; background-color: rgb(255, 255, 255);" style="margin: 0em 0.5em;padding-right: 0.5em;padding-left: 0.5em;font-variant-ligatures: no-common-ligatures no-discretionary-ligatures no-historical-ligatures no-contextual;font-variant-numeric: normal;font-variant-east-asian: normal;white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;widows: 1;text-align: center;color: rgb(62, 71, 83);letter-spacing: 0.54px;visibility: visible;">点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达</p>
介绍
我们知道,在当前形势下,我们正在逐步稳步战胜疫情,而且情况每天都在好转。然而,众所周知,即使在疫苗接种开始之后,彻底根除病毒也需要很多年。所以,为了安全起见,在接下来的几年里,我们所有人可能都会习惯戴口罩。就交通违法行为而言,政府仍然对不戴口罩上路的人进行严格的罚款。创建一个可以跟踪所有交通违法者详细信息并提高公民意识和纪律的系统是一种非常有用的方法。该系统还可以通过另外创建一个仪表板监控程序来改进,以跟踪违反该交通规则的人的增加或减少,在给定的时期内收取罚款,并确定主要违规者。工作范围作为代码实现的一部分,我们计划设计一个模型,将图像分类为有掩码和没有掩码的掩码。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构
网络抓取图像
该项目从识别要使用的数据集的问题开始。在我们的项目中,网上冲浪几乎没有为我们提供可用于我们项目的现有数据集。因此,我们决定应用网络抓取来采集带口罩和不带口罩的图像。我们使用 Beautiful Soap 和 Requests 库从 网站 下载图像并将它们保存到收录带和不带掩码的驱动程序的单独文件夹中。我们从以下 URL 中提取了数据,这些 URL 由蒙版和未蒙版图像组成。link url1 = link url2 = 下面是一段代码,用于演示网络上的图像抓取。
from bs4 import *
import requests as rq
import os
url1 = 'https://www.gettyimages.in/photos/driving-mask?page='
url2 = '&phrase=driving%20mask&sort=mostpopular'
url_list=[]
Links = []
for i in range(1,56):
full_url = url1+str(i)+url2
url_list.append(full_url)
for lst in url_list:
r2 = rq.get(lst)
soup = BeautifulSoup(r2.text, 'html.parser')
x=soup.select('img[src^="https://media.gettyimages.com/photos/"]')
for img in x:
Links.append(img['src'])
print(len(Links))
for index, img_link in enumerate(Links):
if i =0.5:
result = 'The person is Masked'
else:
result = 'The Person is Non Masked'
print(result)
return render_template('Show.html',result=result)
下面是作为上传图像文件的一部分向用户显示的 HTML 模板。
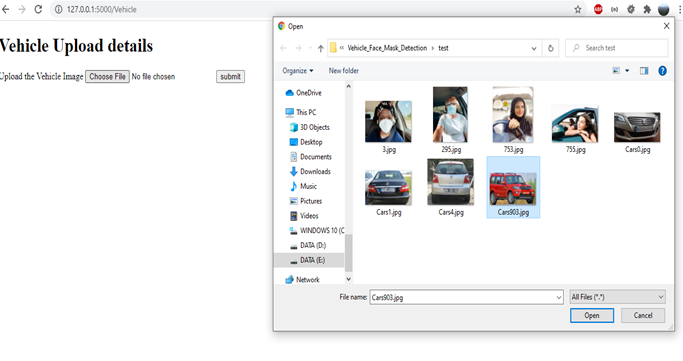
下面是一个 Html 模板,当 POST 方法在处理图像后发送结果时显示,显示驾驶员是否戴着口罩。
接下来,我们上传车辆的图像,该图像已被识别为未戴口罩的驾驶员。车辆图像通过图像预处理阶段再次处理,模型尝试从车牌中的车牌框中提取文本。
@app.route('/Vehicle', methods=['POST'])
def table2():
uploaded_file = request.files['file']
result=''
if uploaded_file.filename != '':
path='static/car'
filename = uploaded_file.filename
uploaded_file.save(os.path.join(path, filename))
img_path = os.path.join(path, filename)
print(img_path)
img = cv2.imread(img_path,cv2.IMREAD_COLOR)
img = cv2.resize(img, (600,400) )
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 13, 15, 15)
edged = cv2.Canny(gray, 30, 200)
contours = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:10]
screenCnt = None
for c in contours:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
if screenCnt is None:
detected = 0
print ("No contour detected")
else:
detected = 1
if detected == 1:
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
mask = np.zeros(gray.shape,np.uint8)
new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)
new_image = cv2.bitwise_and(img,img,mask=mask)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
Cropped = gray[topx:bottomx+1, topy:bottomy+1]
text = pytesseract.image_to_string(Cropped, config='--psm 11')
print("Detected license plate Number is:",text)
#text='GJW-1-15-A-1138'
print('"{}"'.format(text))
re.sub(r'[^\x00-\x7f]',r'', text)
text = text.replace("\n", " ")
text = re.sub('[\W_]+', '', text)
print(text)
print('"{}"'.format(text))
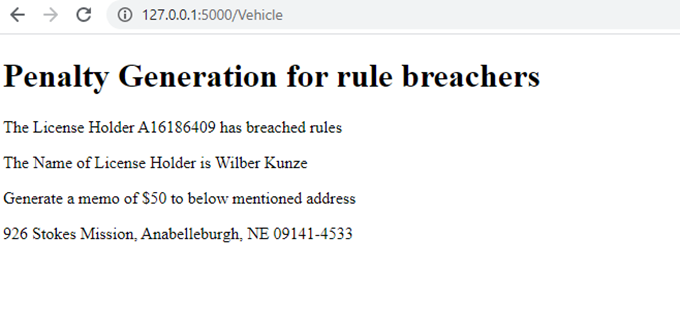
query1 = {"Number Plate": text}
print("0")
for doc in collection.find(query1):
doc1 = doc
Name=doc1['Name']
Address=doc1['Address']
License=doc1['License Number']
return render_template('Penalty.html',Name=Name,Address=Address,License=License)
下面是车辆图像上传页面,它接受用户输入并处理车辆图像以获得车牌号文本。
提取车牌号文本后,我们需要使用车牌来查找车牌持有人的详细信息,接下来我们将连接到 MongoDB 创建的名为 License_Details 的表。一旦我们有了车牌号、姓名、地址和其他详细信息,我们就可以生成罚款并将其显示在 HTML 模板页面上。
在未来的工作中,掩模模型的测试准确率与训练准确率相比要低得多。因此,未知数据集的误分类非常高。此外,我们需要努力提高基于 OpenCV 的车牌提取的准确性,因为错误的感兴趣区域可能会导致提取空车牌文本。此外,前端可以进一步改进,使其更具吸引力。参考
1.面罩检测器
2.面部识别与面膜应用和神经网络
3.在智能城市网络中使用口罩检测限制 COVID-19 的自动化系统:
4.自动车牌检测系统检测远车牌
5.自动车牌识别系统 (ANPR):一项调查
6.COVID-19:具有 OpenCV、Keras/TensorFlow 和深度学习的面罩检测器
7.OpenCV:使用 Python 的自动车牌/车牌识别 (ANPR)
8.
9.
10.使用OpenCV Python的车牌识别
11.车牌号检测
12.Github 链接
个人微信(如果没有备注不拉群!)请注明:地区+学校/企业+研究方向+昵称
<p style="padding-right: 0.5em;padding-left: 0.5em;letter-spacing: 0.544px;white-space: pre-wrap;background-color: rgb(254, 254, 254);"></p> 查看全部
c 抓取网页数据(
路上在将图像发送到模型之前模型接收带有车牌的输入
)
<p data-darkmode-bgcolor="rgb(36, 36, 36)" data-darkmode-color="rgb(143, 155, 171)" data-style="margin: 0em 0.5em; padding: 0px 0.5em; text-align: center; color: rgb(62, 71, 83); text-transform: none; text-indent: 0px; letter-spacing: 0.54px; clear: both; font-size: 16px; font-style: normal; font-variant: normal; font-weight: 400; text-decoration: none; word-spacing: 0px; white-space: normal; min-height: 1em; max-width: 100%; box-sizing: border-box; orphans: 2; -webkit-text-stroke-width: 0px; overflow-wrap: break-word; background-color: rgb(255, 255, 255);" style="margin: 0em 0.5em;padding-right: 0.5em;padding-left: 0.5em;font-variant-ligatures: no-common-ligatures no-discretionary-ligatures no-historical-ligatures no-contextual;font-variant-numeric: normal;font-variant-east-asian: normal;white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;widows: 1;text-align: center;color: rgb(62, 71, 83);letter-spacing: 0.54px;visibility: visible;">点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达</p>

介绍
我们知道,在当前形势下,我们正在逐步稳步战胜疫情,而且情况每天都在好转。然而,众所周知,即使在疫苗接种开始之后,彻底根除病毒也需要很多年。所以,为了安全起见,在接下来的几年里,我们所有人可能都会习惯戴口罩。就交通违法行为而言,政府仍然对不戴口罩上路的人进行严格的罚款。创建一个可以跟踪所有交通违法者详细信息并提高公民意识和纪律的系统是一种非常有用的方法。该系统还可以通过另外创建一个仪表板监控程序来改进,以跟踪违反该交通规则的人的增加或减少,在给定的时期内收取罚款,并确定主要违规者。工作范围作为代码实现的一部分,我们计划设计一个模型,将图像分类为有掩码和没有掩码的掩码。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构
网络抓取图像

该项目从识别要使用的数据集的问题开始。在我们的项目中,网上冲浪几乎没有为我们提供可用于我们项目的现有数据集。因此,我们决定应用网络抓取来采集带口罩和不带口罩的图像。我们使用 Beautiful Soap 和 Requests 库从 网站 下载图像并将它们保存到收录带和不带掩码的驱动程序的单独文件夹中。我们从以下 URL 中提取了数据,这些 URL 由蒙版和未蒙版图像组成。link url1 = link url2 = 下面是一段代码,用于演示网络上的图像抓取。
from bs4 import *
import requests as rq
import os
url1 = 'https://www.gettyimages.in/photos/driving-mask?page='
url2 = '&phrase=driving%20mask&sort=mostpopular'
url_list=[]
Links = []
for i in range(1,56):
full_url = url1+str(i)+url2
url_list.append(full_url)
for lst in url_list:
r2 = rq.get(lst)
soup = BeautifulSoup(r2.text, 'html.parser')
x=soup.select('img[src^="https://media.gettyimages.com/photos/"]')
for img in x:
Links.append(img['src'])
print(len(Links))
for index, img_link in enumerate(Links):
if i =0.5:
result = 'The person is Masked'
else:
result = 'The Person is Non Masked'
print(result)
return render_template('Show.html',result=result)
下面是作为上传图像文件的一部分向用户显示的 HTML 模板。
下面是一个 Html 模板,当 POST 方法在处理图像后发送结果时显示,显示驾驶员是否戴着口罩。
接下来,我们上传车辆的图像,该图像已被识别为未戴口罩的驾驶员。车辆图像通过图像预处理阶段再次处理,模型尝试从车牌中的车牌框中提取文本。
@app.route('/Vehicle', methods=['POST'])
def table2():
uploaded_file = request.files['file']
result=''
if uploaded_file.filename != '':
path='static/car'
filename = uploaded_file.filename
uploaded_file.save(os.path.join(path, filename))
img_path = os.path.join(path, filename)
print(img_path)
img = cv2.imread(img_path,cv2.IMREAD_COLOR)
img = cv2.resize(img, (600,400) )
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 13, 15, 15)
edged = cv2.Canny(gray, 30, 200)
contours = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:10]
screenCnt = None
for c in contours:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
if screenCnt is None:
detected = 0
print ("No contour detected")
else:
detected = 1
if detected == 1:
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
mask = np.zeros(gray.shape,np.uint8)
new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)
new_image = cv2.bitwise_and(img,img,mask=mask)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
Cropped = gray[topx:bottomx+1, topy:bottomy+1]
text = pytesseract.image_to_string(Cropped, config='--psm 11')
print("Detected license plate Number is:",text)
#text='GJW-1-15-A-1138'
print('"{}"'.format(text))
re.sub(r'[^\x00-\x7f]',r'', text)
text = text.replace("\n", " ")
text = re.sub('[\W_]+', '', text)
print(text)
print('"{}"'.format(text))
query1 = {"Number Plate": text}
print("0")
for doc in collection.find(query1):
doc1 = doc
Name=doc1['Name']
Address=doc1['Address']
License=doc1['License Number']
return render_template('Penalty.html',Name=Name,Address=Address,License=License)
下面是车辆图像上传页面,它接受用户输入并处理车辆图像以获得车牌号文本。
提取车牌号文本后,我们需要使用车牌来查找车牌持有人的详细信息,接下来我们将连接到 MongoDB 创建的名为 License_Details 的表。一旦我们有了车牌号、姓名、地址和其他详细信息,我们就可以生成罚款并将其显示在 HTML 模板页面上。
在未来的工作中,掩模模型的测试准确率与训练准确率相比要低得多。因此,未知数据集的误分类非常高。此外,我们需要努力提高基于 OpenCV 的车牌提取的准确性,因为错误的感兴趣区域可能会导致提取空车牌文本。此外,前端可以进一步改进,使其更具吸引力。参考
1.面罩检测器
2.面部识别与面膜应用和神经网络
3.在智能城市网络中使用口罩检测限制 COVID-19 的自动化系统:
4.自动车牌检测系统检测远车牌
5.自动车牌识别系统 (ANPR):一项调查
6.COVID-19:具有 OpenCV、Keras/TensorFlow 和深度学习的面罩检测器
7.OpenCV:使用 Python 的自动车牌/车牌识别 (ANPR)
8.
9.
10.使用OpenCV Python的车牌识别
11.车牌号检测
12.Github 链接
个人微信(如果没有备注不拉群!)请注明:地区+学校/企业+研究方向+昵称
<p style="padding-right: 0.5em;padding-left: 0.5em;letter-spacing: 0.544px;white-space: pre-wrap;background-color: rgb(254, 254, 254);">
 </p>
</p> c 抓取网页数据( 谷歌都行的手机号码归属地查询的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-02 17:13
谷歌都行的手机号码归属地查询的
)
【转载】提供网页抓取hao123手机号归属地示例-苏飞-Perky Su-博客园。
我有一段时间没有写博客了。最近工作压力很大。你在忙什么?最近装了win7操作系统,感觉很不错。我也体验过IE9。其中的开发人员工具非常有用。
说到这里,你可以用火狐的谷歌。在这个例子中,我主要使用IE9自带的来分析hao123手机号码归属地查询的问题。
让我们看看下面的图片
在hao123的这个界面中,我们只需要输入一个手机号码,无论是中国移动、中国联通还是电信,点击查询,就可以直接查询到归属地、号码类型,比如在线。
网站很多,我就以这个为例,那我们如何把这些信息放在我们自己的网站上呢?
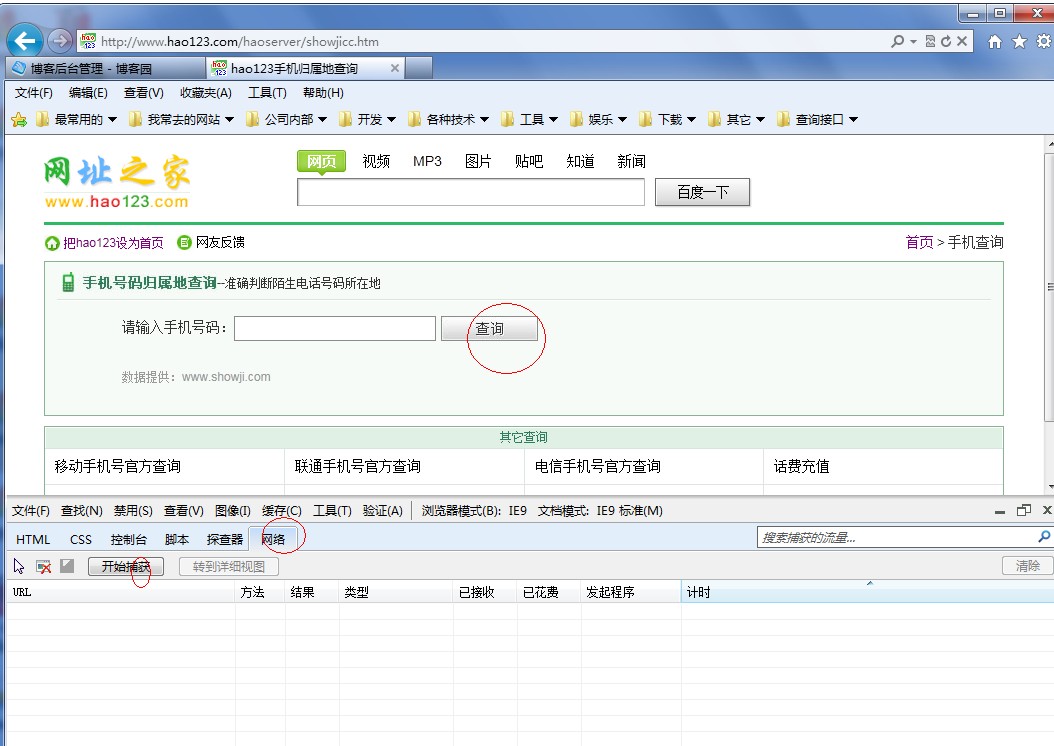
我们先来分析一下。它实际上非常方便。我们在IE9下打开这个界面然后进入工具-开发者工具,或者直接安装f12。
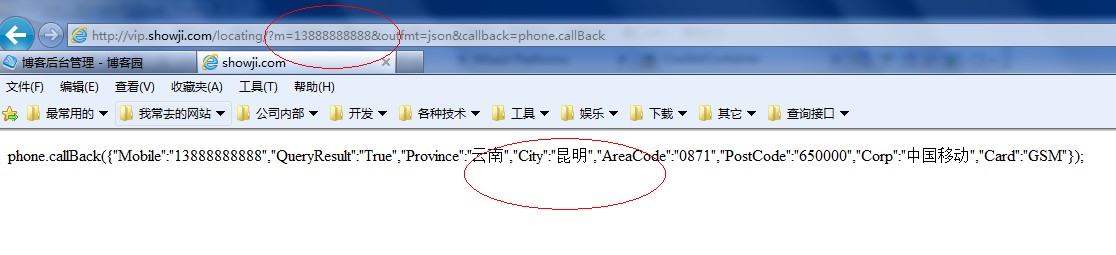
我们先点击网络然后点击开始抓包,这次我们再次点击查询按钮看看会发生什么
有两个完整的吗?第一个显然是加载我们输入的号码的归属信息,而第一个是加载一张图片,这对我们没有任何用处。我不在乎这里,现在我们
我们点击第一种方法,看看捕获了什么
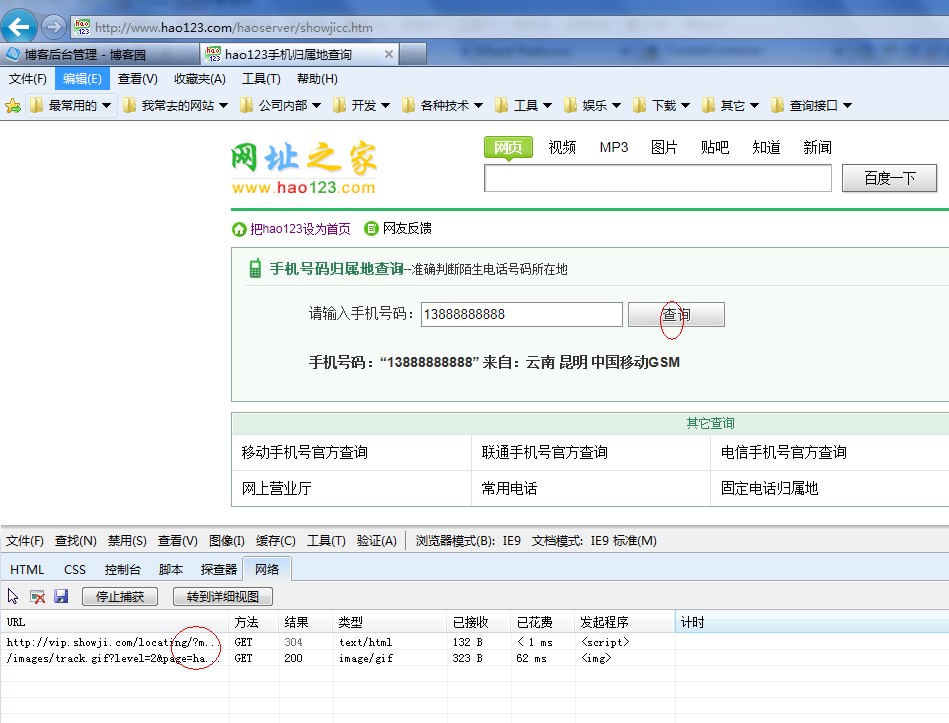
URL显然是一个GET请求,只要请求这个地址,就可以得到如下结果
phone.callBack({"Mobile":"","QueryResult":"True","Province":"云南","City":"昆明","AreaCode":"0871","PostCode":"650000 ","企业":"中国移动","卡":"GSM"});
使用手机号、省、市,以及邮编、号码类型等信息。如果我们这样看,我们可以直接把这个区域复制到地址栏中,然后我们来看看效果。
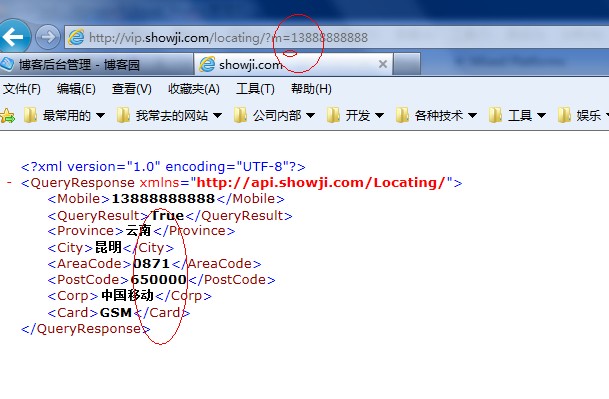
果然是我们想要的,别着急,其他的可以更简单,我们来看看这个网址
如果我删除以下 RUles 编号并仅保留这些编号会怎样?
直接放到地址栏试试效果
哦,太神奇了,我得到的是一个xml文件
这就像我们调用WebServices一样简单,我们只需要编写一个程序来请求这个地址就可以得到我们想要的效果。
随便新建一个项目,一起看看
我就不一步一步分析了,你可以直接看我的代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Net;
using System.IO;
using System.Security.Cryptography.X509Certificates;
using System.Net.Security;
using System.Security.Cryptography;
using System.Xml;
namespace ccbText
{
public partial class Form2 : Form
{
public Form2()
{
InitializeComponent();
}
private void Form2_Load(object sender, EventArgs e)
{
}
这个方法在这里没有用到,大家可以做为参考
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
// 获取对应HTTP请求的响应
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("utf-8"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
}
///
/// 好123查询,符合下列规则也可使用
/// 返回xml
/// 需要顺序的节点:
/// QueryResult(查询结果状态True,False)
/// Province(所属省份)
/// City(所属地区)
/// Corp(服务商)
/// Card(卡类型 GSM)
/// AreaCode(区号)
/// PostCode(邮编)
///
///
///
///
public static string[] GetInfoByxml(string url, string mobileNum)
{
try
{
XmlDocument xml = new XmlDocument();
// xml.LoadXml("
15890636739True
河南郑州0371
450000中国移动GSM");
xml.Load(string.Format(url, mobileNum));
XmlNamespaceManager xmlNm = new XmlNamespaceManager(xml.NameTable);
xmlNm.AddNamespace("content", "http://api.showji.com/Locating/");
XmlNodeList nodes = xml.SelectNodes("//content:QueryResult|//content:Mobile|//content:Province|//content:City|//content:Corp|//content:Card|//content:AreaCode|//content:PostCode", xmlNm);
if (nodes.Count == 8)
{
if ("True".Equals(nodes[1].InnerText))
{
return new string[] { nodes[0].InnerText, nodes[2].InnerText + nodes[3].InnerText, nodes[6].InnerText + nodes[7].InnerText, nodes[4].InnerText, nodes[5].InnerText };
}
}
return new string[] { "FALSE" };
}
catch
{
return new string[] { "FALSE" };
}
}
//调用方法查询数据
private void button1_Click(object sender, EventArgs e)
{
foreach (string item in GetInfoByxml(" http://vip.showji.com/locating/?m={0}", txtMobile.Text.Trim()))
{
richTextBox1.Text += "__" + item;
}
}
}
}
运行一下看看效果
我用 Winfrom 做测试,如果你想用 Asp。net也是一样,把我的方法复制到你网页的cs代码中就OK了。
好了,我们的分析到此结束。
这里我再添加一个调用网站的方法,带证书到大空
因为证书文件要通过证书文件进行验证,所以我们直接让他在本地回调验证。在这种情况下,我们需要重写方法。我们来看看回调方法。
//回调验证证书问题
public bool CheckValidationResult(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{ // 总是接受
return true;
}
其他的很简单,只要在我们上面的方法GetUrltoHtml()中添加几行代码,修改后的方法
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
ServicePointManager.ServerCertificateValidationCallback = new System.Net.Security.RemoteCertificateValidationCallback(CheckValidationResult);//验证
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8; .NET4.0C; .NET4.0E)";
request.Method = "GET";
request.Accept = "*/*";
//创建证书文件
X509Certificate objx509 = new X509Certificate(Application.StartupPath + "\\123.cer");
//添加到请求里
request.ClientCertificates.Add(objx509);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取对应HTTP请求的响应
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("GBK"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
} 查看全部
c 抓取网页数据(
谷歌都行的手机号码归属地查询的
)


【转载】提供网页抓取hao123手机号归属地示例-苏飞-Perky Su-博客园。
我有一段时间没有写博客了。最近工作压力很大。你在忙什么?最近装了win7操作系统,感觉很不错。我也体验过IE9。其中的开发人员工具非常有用。
说到这里,你可以用火狐的谷歌。在这个例子中,我主要使用IE9自带的来分析hao123手机号码归属地查询的问题。
让我们看看下面的图片

在hao123的这个界面中,我们只需要输入一个手机号码,无论是中国移动、中国联通还是电信,点击查询,就可以直接查询到归属地、号码类型,比如在线。
网站很多,我就以这个为例,那我们如何把这些信息放在我们自己的网站上呢?
我们先来分析一下。它实际上非常方便。我们在IE9下打开这个界面然后进入工具-开发者工具,或者直接安装f12。
我们先点击网络然后点击开始抓包,这次我们再次点击查询按钮看看会发生什么
有两个完整的吗?第一个显然是加载我们输入的号码的归属信息,而第一个是加载一张图片,这对我们没有任何用处。我不在乎这里,现在我们
我们点击第一种方法,看看捕获了什么

URL显然是一个GET请求,只要请求这个地址,就可以得到如下结果
phone.callBack({"Mobile":"","QueryResult":"True","Province":"云南","City":"昆明","AreaCode":"0871","PostCode":"650000 ","企业":"中国移动","卡":"GSM"});
使用手机号、省、市,以及邮编、号码类型等信息。如果我们这样看,我们可以直接把这个区域复制到地址栏中,然后我们来看看效果。
果然是我们想要的,别着急,其他的可以更简单,我们来看看这个网址
如果我删除以下 RUles 编号并仅保留这些编号会怎样?
直接放到地址栏试试效果
哦,太神奇了,我得到的是一个xml文件
这就像我们调用WebServices一样简单,我们只需要编写一个程序来请求这个地址就可以得到我们想要的效果。
随便新建一个项目,一起看看
我就不一步一步分析了,你可以直接看我的代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Net;
using System.IO;
using System.Security.Cryptography.X509Certificates;
using System.Net.Security;
using System.Security.Cryptography;
using System.Xml;
namespace ccbText
{
public partial class Form2 : Form
{
public Form2()
{
InitializeComponent();
}
private void Form2_Load(object sender, EventArgs e)
{
}
这个方法在这里没有用到,大家可以做为参考
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
// 获取对应HTTP请求的响应
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("utf-8"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
}
///
/// 好123查询,符合下列规则也可使用
/// 返回xml
/// 需要顺序的节点:
/// QueryResult(查询结果状态True,False)
/// Province(所属省份)
/// City(所属地区)
/// Corp(服务商)
/// Card(卡类型 GSM)
/// AreaCode(区号)
/// PostCode(邮编)
///
///
///
///
public static string[] GetInfoByxml(string url, string mobileNum)
{
try
{
XmlDocument xml = new XmlDocument();
// xml.LoadXml("
15890636739True
河南郑州0371
450000中国移动GSM");
xml.Load(string.Format(url, mobileNum));
XmlNamespaceManager xmlNm = new XmlNamespaceManager(xml.NameTable);
xmlNm.AddNamespace("content", "http://api.showji.com/Locating/";);
XmlNodeList nodes = xml.SelectNodes("//content:QueryResult|//content:Mobile|//content:Province|//content:City|//content:Corp|//content:Card|//content:AreaCode|//content:PostCode", xmlNm);
if (nodes.Count == 8)
{
if ("True".Equals(nodes[1].InnerText))
{
return new string[] { nodes[0].InnerText, nodes[2].InnerText + nodes[3].InnerText, nodes[6].InnerText + nodes[7].InnerText, nodes[4].InnerText, nodes[5].InnerText };
}
}
return new string[] { "FALSE" };
}
catch
{
return new string[] { "FALSE" };
}
}
//调用方法查询数据
private void button1_Click(object sender, EventArgs e)
{
foreach (string item in GetInfoByxml(" http://vip.showji.com/locating/?m={0}", txtMobile.Text.Trim()))
{
richTextBox1.Text += "__" + item;
}
}
}
}
运行一下看看效果

我用 Winfrom 做测试,如果你想用 Asp。net也是一样,把我的方法复制到你网页的cs代码中就OK了。
好了,我们的分析到此结束。
这里我再添加一个调用网站的方法,带证书到大空
因为证书文件要通过证书文件进行验证,所以我们直接让他在本地回调验证。在这种情况下,我们需要重写方法。我们来看看回调方法。
//回调验证证书问题
public bool CheckValidationResult(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{ // 总是接受
return true;
}
其他的很简单,只要在我们上面的方法GetUrltoHtml()中添加几行代码,修改后的方法
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
ServicePointManager.ServerCertificateValidationCallback = new System.Net.Security.RemoteCertificateValidationCallback(CheckValidationResult);//验证
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8; .NET4.0C; .NET4.0E)";
request.Method = "GET";
request.Accept = "*/*";
//创建证书文件
X509Certificate objx509 = new X509Certificate(Application.StartupPath + "\\123.cer");
//添加到请求里
request.ClientCertificates.Add(objx509);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取对应HTTP请求的响应
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("GBK"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
}
c 抓取网页数据(Python爬虫世界里必不可少的神兵利器-页面解析和数据提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-30 15:14
页面解析和数据提取javascript
一般来说,对于我们来说,需要爬取的是一个网站或者一个应用的内容,以提取有用的价值。内容通常分为两部分,非结构化数据和结构化数据。php
非结构化数据处理文本、电话号码、电子邮件地址HTML 文档结构化数据处理JSON 文档XML 文档为什么要学习正则表达式
其实爬虫主要有四个步骤: css
清除目标(知道要在哪个范围内搜索或网站) 爬取(爬取网站的所有内容) 获取(删除对我们无用的数据) 处理数据(根据以我们想要的方式存储和使用)
我们实际上省略了步骤 3,即昨天案例中的“采取”步骤。由于我们下载的数据都是网页,数据庞大而混乱,而且大部分是我们不关心的,所以我们需要根据自己的需要进行过滤和匹配。html
所以对于文本过滤或者规则匹配来说,最厉害的就是正则表达式,它是Python爬虫世界里不可或缺的利器。爪哇
什么是正则表达式
正则表达式也称为正则表达式,一般用于检索和替换符合某种模式(规则)的文本。节点
正则表达式是一个字符串操作的逻辑公式,就是用一些预先定义好的特定字符和这些特定字符的组合组成一个“规则字符串”,而这个“规则字符串”用来表达A过滤逻辑字符串。Python
给定一个正则表达式和另一个字符串,我们可以实现以下目标: 程序员
正则表达式匹配规则
Python的re模块
在 Python 中,我们可以通过内置的 re 模块来使用正则表达式。网络
需要注意的一点是正则表达式使用特殊字符的转义,所以如果我们想使用原创字符串,只需添加一个 r 前缀,例如:正则表达式
r'chuanzhiboke\t\.\tpython'
使用 re 模块的通常步骤如下:
使用compile()函数将正则表达式的字符串形式编译成Pattern对象
通过Pattern对象提供的一系列方法,对文本进行匹配查找,得到匹配结果,就是一个Match对象。
最后,使用 Match 对象提供的属性和方法来获取信息,并根据需要执行其余操作。编译函数
compile函数用于编译正则表达式并生成Pattern对象,通常以如下形式使用:
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
上面,我们已经将一个正则表达式编译成一个 Pattern 对象。接下来,我们可以使用pattern的一系列方法来匹配文本。
Pattern 对象的一些常用方法是:
匹配方法
match方法用于查找字符串的头部(也可以指定起始位置),是一个匹配,只要找到一个匹配的结果,就会返回,而不是查找所有的匹配结果。它通常以下列形式使用:
match(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。所以,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
上面,匹配成功时返回一个 Match 对象,其中:
让我们看另一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print m # 匹配成功,返回一个 Match 对象
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last): File "", line 1, in IndexError: no such group
-------------------------------------------------- -------------------------------------------------- -- 搜索方法
search 方法用于查找字符串中的任何位置。这也是一场比赛。只要找到匹配结果,就会返回,而不是查找所有匹配结果。它通常以下列形式使用:
搜索(字符串[,pos[,endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
让我们看一个例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里若是使用 match 方法则不匹配
>>> m
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
>>> m.group()
'34'
>>> m.span()
(13, 15)
让我们看另一个例子:
# -*- coding: utf-8 -*-
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 没法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 得到分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span()
结果:
matching string: 123456
position: (6, 12)
-------------------------------------------------- -------------------------------------------------- -- findall 方法
以上匹配和搜索方式都是一次性匹配,只要找到匹配结果,就会返回。但是,大多数时候,我们需要搜索整个字符串来获得所有匹配的结果。
findall 方法可以按以下形式使用:
findall(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
findall 将所有匹配的子字符串作为一个列表返回,如果没有匹配则返回一个空列表。
看一下这个例子:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print result1
print result2
结果:
['123456', '789']
['1', '2']
我们先来看一个栗子:
# re_test.py
import re
#re模块提供一个方法叫compile模块,提供咱们输入一个匹配的规则
#而后返回一个pattern实例,咱们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*')
#经过partten.findall()方法就可以所有匹配到咱们获得的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall 以 列表形式 返回所有能匹配的子串给result
for item in result:
print item
运行结果:
123.141593
3.15
-------------------------------------------------- -------------------------------------------------- -- 查找器方法
finditer 方法的行为类似于 findall 的行为,同样会搜索整个字符串并获取所有匹配的结果。但它返回一个迭代器,该迭代器按顺序访问每个匹配结果(Match 对象)。
看一下这个例子:
# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print type(result_iter1)
print type(result_iter2)
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span())
print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
结果:
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
-------------------------------------------------- -------------------------------------------------- -- 分割方法
split 方法根据可以匹配的子字符串将字符串拆分后返回一个列表。它可以以下列形式使用:
split(string[, maxsplit])
其中,maxsplit 用于指定最大拆分次数,而不是指定所有拆分。
看一下这个例子:
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
结果:
['a', 'b', 'c', 'd']
-------------------------------------------------- -------------------------------------------------- -- 子方法
sub 方法用于替换。它以下列形式使用:
sub(repl, string[, count])
其中,repl 可以是字符串,也可以是函数:
看一下这个例子:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456'
print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组
def func(m):
return 'hi' + ' ' + m.group(2)
print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
-------------------------------------------------- -------------------------------------------------- -- 匹配中文
在某些情况下,我们希望匹配文本中的汉字。需要注意的一点是,中文的unicode编码范围主要在[u4e00-u9fa5],这主要是因为这个范围不完整,比如不包括全角(中文)标点,但是,在大多数情况下。
假设现在要提取字符串title = u'hello, hello, world'中的中文,可以这样:
import re
title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print result
请注意,我们为正则表达式添加了两个前缀 ur,其中 r 表示使用原创字符串,u 表示它是 unicode 字符串。
结果:
[u'\u4f60\u597d', u'\u4e16\u754c']
注意:贪心模式和非贪心模式贪心模式:在整个表达式匹配成功的前提下,尽量匹配(*);非贪心模式:在整个表达式匹配成功的前提下,尽量少匹配(?);Python 中的量词默认是贪婪的。示例 1:源字符串:abbbc 示例 2:源字符串:aa
测试1
bb
测试2
抄送
这是贪婪模式。匹配到第一个“
",整个表达式都可以匹配成功,但是因为使用了贪心模式,所以还是要尝试向右匹配,看是否有更长的子串可以匹配成功。匹配到第二个" 查看全部
c 抓取网页数据(Python爬虫世界里必不可少的神兵利器-页面解析和数据提取)
页面解析和数据提取javascript
一般来说,对于我们来说,需要爬取的是一个网站或者一个应用的内容,以提取有用的价值。内容通常分为两部分,非结构化数据和结构化数据。php
非结构化数据处理文本、电话号码、电子邮件地址HTML 文档结构化数据处理JSON 文档XML 文档为什么要学习正则表达式
其实爬虫主要有四个步骤: css
清除目标(知道要在哪个范围内搜索或网站) 爬取(爬取网站的所有内容) 获取(删除对我们无用的数据) 处理数据(根据以我们想要的方式存储和使用)
我们实际上省略了步骤 3,即昨天案例中的“采取”步骤。由于我们下载的数据都是网页,数据庞大而混乱,而且大部分是我们不关心的,所以我们需要根据自己的需要进行过滤和匹配。html
所以对于文本过滤或者规则匹配来说,最厉害的就是正则表达式,它是Python爬虫世界里不可或缺的利器。爪哇
什么是正则表达式
正则表达式也称为正则表达式,一般用于检索和替换符合某种模式(规则)的文本。节点
正则表达式是一个字符串操作的逻辑公式,就是用一些预先定义好的特定字符和这些特定字符的组合组成一个“规则字符串”,而这个“规则字符串”用来表达A过滤逻辑字符串。Python
给定一个正则表达式和另一个字符串,我们可以实现以下目标: 程序员

正则表达式匹配规则
Python的re模块
在 Python 中,我们可以通过内置的 re 模块来使用正则表达式。网络
需要注意的一点是正则表达式使用特殊字符的转义,所以如果我们想使用原创字符串,只需添加一个 r 前缀,例如:正则表达式
r'chuanzhiboke\t\.\tpython'
使用 re 模块的通常步骤如下:
使用compile()函数将正则表达式的字符串形式编译成Pattern对象
通过Pattern对象提供的一系列方法,对文本进行匹配查找,得到匹配结果,就是一个Match对象。
最后,使用 Match 对象提供的属性和方法来获取信息,并根据需要执行其余操作。编译函数
compile函数用于编译正则表达式并生成Pattern对象,通常以如下形式使用:
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
上面,我们已经将一个正则表达式编译成一个 Pattern 对象。接下来,我们可以使用pattern的一系列方法来匹配文本。
Pattern 对象的一些常用方法是:
匹配方法
match方法用于查找字符串的头部(也可以指定起始位置),是一个匹配,只要找到一个匹配的结果,就会返回,而不是查找所有的匹配结果。它通常以下列形式使用:
match(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。所以,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
上面,匹配成功时返回一个 Match 对象,其中:
让我们看另一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print m # 匹配成功,返回一个 Match 对象
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last): File "", line 1, in IndexError: no such group
-------------------------------------------------- -------------------------------------------------- -- 搜索方法
search 方法用于查找字符串中的任何位置。这也是一场比赛。只要找到匹配结果,就会返回,而不是查找所有匹配结果。它通常以下列形式使用:
搜索(字符串[,pos[,endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
让我们看一个例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里若是使用 match 方法则不匹配
>>> m
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
>>> m.group()
'34'
>>> m.span()
(13, 15)
让我们看另一个例子:
# -*- coding: utf-8 -*-
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 没法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 得到分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span()
结果:
matching string: 123456
position: (6, 12)
-------------------------------------------------- -------------------------------------------------- -- findall 方法
以上匹配和搜索方式都是一次性匹配,只要找到匹配结果,就会返回。但是,大多数时候,我们需要搜索整个字符串来获得所有匹配的结果。
findall 方法可以按以下形式使用:
findall(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
findall 将所有匹配的子字符串作为一个列表返回,如果没有匹配则返回一个空列表。
看一下这个例子:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print result1
print result2
结果:
['123456', '789']
['1', '2']
我们先来看一个栗子:
# re_test.py
import re
#re模块提供一个方法叫compile模块,提供咱们输入一个匹配的规则
#而后返回一个pattern实例,咱们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*')
#经过partten.findall()方法就可以所有匹配到咱们获得的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall 以 列表形式 返回所有能匹配的子串给result
for item in result:
print item
运行结果:
123.141593
3.15
-------------------------------------------------- -------------------------------------------------- -- 查找器方法
finditer 方法的行为类似于 findall 的行为,同样会搜索整个字符串并获取所有匹配的结果。但它返回一个迭代器,该迭代器按顺序访问每个匹配结果(Match 对象)。
看一下这个例子:
# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print type(result_iter1)
print type(result_iter2)
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span())
print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
结果:
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
-------------------------------------------------- -------------------------------------------------- -- 分割方法
split 方法根据可以匹配的子字符串将字符串拆分后返回一个列表。它可以以下列形式使用:
split(string[, maxsplit])
其中,maxsplit 用于指定最大拆分次数,而不是指定所有拆分。
看一下这个例子:
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
结果:
['a', 'b', 'c', 'd']
-------------------------------------------------- -------------------------------------------------- -- 子方法
sub 方法用于替换。它以下列形式使用:
sub(repl, string[, count])
其中,repl 可以是字符串,也可以是函数:
看一下这个例子:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456'
print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组
def func(m):
return 'hi' + ' ' + m.group(2)
print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
-------------------------------------------------- -------------------------------------------------- -- 匹配中文
在某些情况下,我们希望匹配文本中的汉字。需要注意的一点是,中文的unicode编码范围主要在[u4e00-u9fa5],这主要是因为这个范围不完整,比如不包括全角(中文)标点,但是,在大多数情况下。
假设现在要提取字符串title = u'hello, hello, world'中的中文,可以这样:
import re
title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print result
请注意,我们为正则表达式添加了两个前缀 ur,其中 r 表示使用原创字符串,u 表示它是 unicode 字符串。
结果:
[u'\u4f60\u597d', u'\u4e16\u754c']
注意:贪心模式和非贪心模式贪心模式:在整个表达式匹配成功的前提下,尽量匹配(*);非贪心模式:在整个表达式匹配成功的前提下,尽量少匹配(?);Python 中的量词默认是贪婪的。示例 1:源字符串:abbbc 示例 2:源字符串:aa
测试1
bb
测试2
抄送
这是贪婪模式。匹配到第一个“
",整个表达式都可以匹配成功,但是因为使用了贪心模式,所以还是要尝试向右匹配,看是否有更长的子串可以匹配成功。匹配到第二个"
c 抓取网页数据(京东云专有云安全白皮书-自然语言处理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-30 15:10
下载链接
相关链接 有关京东云数据安全的更多信息,以及查看和下载京东云数据安全白皮书PDF版本,请访问以下链接。京东云数据安全白皮书
下载链接
相关链接 更多专有云安全信息,以及查看和下载京东云专有云安全白皮书PDF版,请访问以下链接。京东云专有云安全白皮书
【人工智能-自然语言处理】语言模型填空
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】闲聊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
插入规则
2、在弹窗中编辑插入规则,点击确定完成操作。请注意,插入操作会在单击插入按钮的规则之前插入更高优先级的规则。比如用户需要在优先级1和2的规则之间插入,点击优先级2规则的插入按钮。插入完成后,新插入的规则的优先级为2,规则原创优先级为 2 及以后的优先级。等级 +1 自动。
【人工智能-自然语言处理】句法分析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】评论意见抽取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本分类
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址解析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本流畅度
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】智能分诊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】机器翻译
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】草题
进入京东云控制台总览页面,您可以根据实际需要进行配置。
Oracle企业链云平台
企业建链云平台封装了区块链底层技术,将复杂的区块链系统拆分成完全独立的模块,为建链者提供全面的建链解决方案,通过图形界面产品实现标准化制造。连锁,简单,无门槛,高效低成本。
Oracle数据链上云平台
数据上传云平台让政府、企业和开发者更轻松地实现适合自身业务场景的数据上传。
【人工智能-自然语言处理】IP风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】定制智能写作
进入京东云控制台总览页面,您可以根据实际需要进行配置。
网站记录号超链接设置
·备案号已链接工信部网站,点击跳转到工信部查询确认备案信息页面。
10多个sku链接进行产品直播
商品直播链接 查看全部
c 抓取网页数据(京东云专有云安全白皮书-自然语言处理(组图))
下载链接
相关链接 有关京东云数据安全的更多信息,以及查看和下载京东云数据安全白皮书PDF版本,请访问以下链接。京东云数据安全白皮书
下载链接
相关链接 更多专有云安全信息,以及查看和下载京东云专有云安全白皮书PDF版,请访问以下链接。京东云专有云安全白皮书
【人工智能-自然语言处理】语言模型填空
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】闲聊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
插入规则
2、在弹窗中编辑插入规则,点击确定完成操作。请注意,插入操作会在单击插入按钮的规则之前插入更高优先级的规则。比如用户需要在优先级1和2的规则之间插入,点击优先级2规则的插入按钮。插入完成后,新插入的规则的优先级为2,规则原创优先级为 2 及以后的优先级。等级 +1 自动。
【人工智能-自然语言处理】句法分析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】评论意见抽取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本分类
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址解析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本流畅度
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】智能分诊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】机器翻译
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】草题
进入京东云控制台总览页面,您可以根据实际需要进行配置。
Oracle企业链云平台
企业建链云平台封装了区块链底层技术,将复杂的区块链系统拆分成完全独立的模块,为建链者提供全面的建链解决方案,通过图形界面产品实现标准化制造。连锁,简单,无门槛,高效低成本。
Oracle数据链上云平台
数据上传云平台让政府、企业和开发者更轻松地实现适合自身业务场景的数据上传。
【人工智能-自然语言处理】IP风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】定制智能写作
进入京东云控制台总览页面,您可以根据实际需要进行配置。
网站记录号超链接设置
·备案号已链接工信部网站,点击跳转到工信部查询确认备案信息页面。
10多个sku链接进行产品直播
商品直播链接
c 抓取网页数据(python爬取js执行后输出的信息-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-29 12:12
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页的文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url))# 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url)#请求页面会打开浏览器窗口
html_text=driver.page_source
driver.quit()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))# 会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序=webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content=driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索我们之前的文章或者继续浏览下面的相关文章希望大家以后多多支持! 查看全部
c 抓取网页数据(python爬取js执行后输出的信息-苏州安嘉)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页的文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url))# 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url)#请求页面会打开浏览器窗口
html_text=driver.page_source
driver.quit()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))# 会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序=webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content=driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索我们之前的文章或者继续浏览下面的相关文章希望大家以后多多支持!
c 抓取网页数据( 执行后cookie信息就被存到了(.txt))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-28 01:14
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
执行后cookie信息保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站都会监控你的cookie信息来判断你是否按照规则访问了他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、模仿浏览器
有些 网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器端会认为是使用IE8.0访问的
7、假引用(热链接)
很多服务器会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。这是一个小偷
curl 中的内置选项:-e 允许我们设置引用者
# curl -e "www.linux.com" http://mail.linux.com
这将使服务器认为您来自单击链接
8、下载文件
8.1:使用 curl 下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称在本地保存文件
8.2:循环下载
有时候下载的图片可能和前面部分名字一样,但是最后一个尾部名字不一样
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样,hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这样就可以查看dodo1.JPG的内容了
8.5: 通过 ftp 下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6: 显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点处恢复上传。curl也可以通过内置选项达到同样的效果:-C
如果在下载dodo1.JPG的过程中突然断线,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会将文件 dodo1.JPG 上传到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
12、通过 -L 选项重定向
默认情况下,CURL 不发送 HTTP Location 标头(重定向)。当请求的页面移动到另一个站点时,会发送一个 HTTP Loaction 标头作为请求,并将请求重定向到新地址。
例如:访问时,地址会自动重定向到.hk。
1 curl http://www.google.com
2
3
4
5 302 Moved
6
7
8 302 Moved
9 The document has moved
10 <A HREF=span style="color: rgba(128, 0, 0, 1)""span style="color: rgba(128, 0, 0, 1)"http://www.google.com.hk/url%3 ... Aspan style="color: rgba(128, 0, 0, 1)"">here</A>.
11
12
上面的输出显示请求的存档已移至。可以使用 -L 选项强制重定向
1 # 让curl使用地址重定向,此时会查询google.com.hk站点
2 curl -L http://www.google.com
补充恢复:通过使用-C选项,可以对大文件使用恢复功能,如:
1 # 当文件在下载完成之前结束该进程
2 $ curl -O http://www.gnu.org/software/ge ... .html
3 ############## 20.1%
4
5 # 通过添加-C选项继续对该文件进行下载,已经下载过的文件不会被重新下载
6 curl -C - -O http://www.gnu.org/software/ge ... .html
7 ############### 21.1%
使用 CURL 进行网络限速
通过 --limit-rate 选项限制 CURL 的最大网络使用量
1 # 下载速度最大不会超过1000B/second
2
3 curl --limit-rate 1000B -O http://www.gnu.org/software/ge ... .html
下载指定时间内修改过的文件
下载文件时,可以判断文件的最后修改日期。如果文件在指定日期内被修改过,则下载,否则不下载。
此功能可以通过使用 -z 选项来实现:
1 # 若yy.html文件在2011/12/21之后有过更新才会进行下载
2 curl -z 21-Dec-11 http://www.example.com/yy.html
卷曲授权
访问需要授权的页面时,可以通过 -u 选项提供用户名和密码进行授权
1 curl -u username:password URL
2
3 # 通常的做法是在命令行只输入用户名,之后会提示输入密码,这样可以保证在查看历史记录时不会将密码泄露
4 curl -u username URL
从 FTP 服务器下载文件
CURL 还支持 FTP 下载。如果在 url 中指定了文件路径,而不是指定要下载的特定文件名,则 CURL 将列出目录中的所有文件名,而不是下载目录中的所有文件。
1 # 列出public_html下的所有文件夹和文件
2 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/
3
4 # 下载xss.php文件
5 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/xss.php
上传文件到 FTP 服务器
使用 -T 选项将指定的本地文件上传到 FTP 服务器
# 将myfile.txt文件上传到服务器
curl -u ftpuser:ftppass -T myfile.txt ftp://ftp.testserver.com
# 同时上传多个文件
curl -u ftpuser:ftppass -T "{file1,file2}" ftp://ftp.testserver.com
# 从标准输入获取内容保存到服务器指定的文件中
curl -u ftpuser:ftppass -T - ftp://ftp.testserver.com/myfile_1.txt
获取更多信息
使用 -v 和 -trace 获取更多链接信息
在字典中查找单词
1 # 查询bash单词的含义
2 curl dict://dict.org/d:bash
3
4 # 列出所有可用词典
5 curl dict://dict.org/show:db
6
7 # 在foldoc词典中查询bash单词的含义
8 curl dict://dict.org/d:bash:foldoc
为 CURL 设置代理
-x 选项可以向 CURL 添加代理功能
1 # 指定代理主机和端口
2 curl -x proxysever.test.com:3128 http://google.co.in
其他网站组织
网站cookie 信息的存储和使用
1 # 将网站的cookies信息保存到sugarcookies文件中
2 curl -D sugarcookies http://localhost/sugarcrm/index.php
3
4 # 使用上次保存的cookie信息
5 curl -b sugarcookies http://localhost/sugarcrm/index.php
传递请求数据
curl 默认使用 GET 方法请求数据,这种方式直接通过 URL 传递数据
可以使用 --data/-d 方法指定使用 POST 传递数据
1 # GET
2 curl -u username https://api.github.com/user%3F ... XXXXX
3
4 # POST
5 curl -u username --data "param1=value1¶m2=value" https://api.github.com
6
7 # 也可以指定一个文件,将该文件中的内容当作数据传递给服务器端
8 curl --data @filename https://github.api.com/authorizations
注意:默认情况下,如果过去通过 POST 传递的数据中存在特殊字符,则需要先将特殊字符转义到服务器。如果该值收录空格,则需要先将空格转换为 %20。如:
1 curl -d "value%201" http://hostname.com
在 CURL 的新版本中,提供了一个新选项 --data-urlencode,通过该选项提供的参数将自动转义特殊字符。
1 curl --data-urlencode "value 1" http://hostname.com
除了使用 GET 和 POST 协议之外,还可以使用 -X 选项指定其他协议,例如:
1 curl -I -X DELETE https://api.github.cim
上传文件
1 curl --form "fileupload=@filename.txt" http://hostname/resource
获取请求头信息
curl --head http://www.example.com
返回数据:
HTTP/1.1 200 OK
Content-Encoding: gzip
Accept-Ranges: bytes
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Tue, 23 Oct 2018 11:29:23 GMT
Etag: "1541025663+gzip"
Expires: Tue, 30 Oct 2018 11:29:23 GMT
Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
Server: ECS (dca/532C)
X-Cache: HIT
Content-Length: 606
其他参数(翻译为转载here):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
官方文档: 查看全部
c 抓取网页数据(
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
执行后cookie信息保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站都会监控你的cookie信息来判断你是否按照规则访问了他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、模仿浏览器
有些 网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器端会认为是使用IE8.0访问的
7、假引用(热链接)
很多服务器会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。这是一个小偷
curl 中的内置选项:-e 允许我们设置引用者
# curl -e "www.linux.com" http://mail.linux.com
这将使服务器认为您来自单击链接
8、下载文件
8.1:使用 curl 下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称在本地保存文件
8.2:循环下载
有时候下载的图片可能和前面部分名字一样,但是最后一个尾部名字不一样
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样,hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这样就可以查看dodo1.JPG的内容了
8.5: 通过 ftp 下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6: 显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点处恢复上传。curl也可以通过内置选项达到同样的效果:-C
如果在下载dodo1.JPG的过程中突然断线,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会将文件 dodo1.JPG 上传到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
12、通过 -L 选项重定向
默认情况下,CURL 不发送 HTTP Location 标头(重定向)。当请求的页面移动到另一个站点时,会发送一个 HTTP Loaction 标头作为请求,并将请求重定向到新地址。
例如:访问时,地址会自动重定向到.hk。

1 curl http://www.google.com
2
3
4
5 302 Moved
6
7
8 302 Moved
9 The document has moved
10 <A HREF=span style="color: rgba(128, 0, 0, 1)""span style="color: rgba(128, 0, 0, 1)"http://www.google.com.hk/url%3 ... Aspan style="color: rgba(128, 0, 0, 1)"">here</A>.
11
12
上面的输出显示请求的存档已移至。可以使用 -L 选项强制重定向
1 # 让curl使用地址重定向,此时会查询google.com.hk站点
2 curl -L http://www.google.com
补充恢复:通过使用-C选项,可以对大文件使用恢复功能,如:
1 # 当文件在下载完成之前结束该进程
2 $ curl -O http://www.gnu.org/software/ge ... .html
3 ############## 20.1%
4
5 # 通过添加-C选项继续对该文件进行下载,已经下载过的文件不会被重新下载
6 curl -C - -O http://www.gnu.org/software/ge ... .html
7 ############### 21.1%
使用 CURL 进行网络限速
通过 --limit-rate 选项限制 CURL 的最大网络使用量
1 # 下载速度最大不会超过1000B/second
2
3 curl --limit-rate 1000B -O http://www.gnu.org/software/ge ... .html
下载指定时间内修改过的文件
下载文件时,可以判断文件的最后修改日期。如果文件在指定日期内被修改过,则下载,否则不下载。
此功能可以通过使用 -z 选项来实现:
1 # 若yy.html文件在2011/12/21之后有过更新才会进行下载
2 curl -z 21-Dec-11 http://www.example.com/yy.html
卷曲授权
访问需要授权的页面时,可以通过 -u 选项提供用户名和密码进行授权
1 curl -u username:password URL
2
3 # 通常的做法是在命令行只输入用户名,之后会提示输入密码,这样可以保证在查看历史记录时不会将密码泄露
4 curl -u username URL
从 FTP 服务器下载文件
CURL 还支持 FTP 下载。如果在 url 中指定了文件路径,而不是指定要下载的特定文件名,则 CURL 将列出目录中的所有文件名,而不是下载目录中的所有文件。
1 # 列出public_html下的所有文件夹和文件
2 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/
3
4 # 下载xss.php文件
5 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/xss.php
上传文件到 FTP 服务器
使用 -T 选项将指定的本地文件上传到 FTP 服务器
# 将myfile.txt文件上传到服务器
curl -u ftpuser:ftppass -T myfile.txt ftp://ftp.testserver.com
# 同时上传多个文件
curl -u ftpuser:ftppass -T "{file1,file2}" ftp://ftp.testserver.com
# 从标准输入获取内容保存到服务器指定的文件中
curl -u ftpuser:ftppass -T - ftp://ftp.testserver.com/myfile_1.txt
获取更多信息
使用 -v 和 -trace 获取更多链接信息
在字典中查找单词
1 # 查询bash单词的含义
2 curl dict://dict.org/d:bash
3
4 # 列出所有可用词典
5 curl dict://dict.org/show:db
6
7 # 在foldoc词典中查询bash单词的含义
8 curl dict://dict.org/d:bash:foldoc
为 CURL 设置代理
-x 选项可以向 CURL 添加代理功能
1 # 指定代理主机和端口
2 curl -x proxysever.test.com:3128 http://google.co.in
其他网站组织
网站cookie 信息的存储和使用
1 # 将网站的cookies信息保存到sugarcookies文件中
2 curl -D sugarcookies http://localhost/sugarcrm/index.php
3
4 # 使用上次保存的cookie信息
5 curl -b sugarcookies http://localhost/sugarcrm/index.php
传递请求数据
curl 默认使用 GET 方法请求数据,这种方式直接通过 URL 传递数据
可以使用 --data/-d 方法指定使用 POST 传递数据
1 # GET
2 curl -u username https://api.github.com/user%3F ... XXXXX
3
4 # POST
5 curl -u username --data "param1=value1¶m2=value" https://api.github.com
6
7 # 也可以指定一个文件,将该文件中的内容当作数据传递给服务器端
8 curl --data @filename https://github.api.com/authorizations
注意:默认情况下,如果过去通过 POST 传递的数据中存在特殊字符,则需要先将特殊字符转义到服务器。如果该值收录空格,则需要先将空格转换为 %20。如:
1 curl -d "value%201" http://hostname.com
在 CURL 的新版本中,提供了一个新选项 --data-urlencode,通过该选项提供的参数将自动转义特殊字符。
1 curl --data-urlencode "value 1" http://hostname.com
除了使用 GET 和 POST 协议之外,还可以使用 -X 选项指定其他协议,例如:
1 curl -I -X DELETE https://api.github.cim
上传文件
1 curl --form "fileupload=@filename.txt" http://hostname/resource
获取请求头信息
curl --head http://www.example.com
返回数据:
HTTP/1.1 200 OK
Content-Encoding: gzip
Accept-Ranges: bytes
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Tue, 23 Oct 2018 11:29:23 GMT
Etag: "1541025663+gzip"
Expires: Tue, 30 Oct 2018 11:29:23 GMT
Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
Server: ECS (dca/532C)
X-Cache: HIT
Content-Length: 606
其他参数(翻译为转载here):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
官方文档:
c 抓取网页数据(记录思路如下:记录SQL中的注释(使用--进行注释))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-25 11:12
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</ 查看全部
c 抓取网页数据(记录思路如下:记录SQL中的注释(使用--进行注释))
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</
c 抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-23 01:10
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓取地址栏url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网! 查看全部
c 抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。

1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓取地址栏url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:

或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。

在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。

查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。

根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:

注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网!
c 抓取网页数据( 如何使用网页监听获取想要的数据?解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-20 19:21
如何使用网页监听获取想要的数据?解决办法)
使用网络监听命令获取数据
在网页抓取数据时,如果有些图表数据无法抓取,元素变化频繁,或者网页有广告影响操作,可以考虑使用网页监控来获取想要的数据。
脚步
① 打开要采集数据的网页,在网页上按F12打开开发者模式。
② 按 Ctrl + R 重新加载网页。
③ 等待所需数据加载完毕,激活网络选项卡上的搜索框,输入所需数据,然后按 Enter。
④ 如图
如果找不到目标数据,尝试其他可能的数据搜索,减少关键词的数量,或者依次在请求列表中搜索数据。
⑤ 开始监控数据,获取网页对象-开始监控请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果) - 停止监听网页请求。
可能数据很多,建议不要打印,先写入文本文件
⑥打开写入的文件,按Crtl+F查看是否找到想要的数据。
⑦使用命令获取网页请求的结果是一个收录目标url数据的字典。响应中的数据收录在循环项字典的键 ["body"] 中。body 是一个字符串,它被转换成一个 json 对象。可以提取数据。
为了方便观察结构,可以先把body的数据拿出来粘贴,会自动转换成便于观察的格式。
粘贴到格式化工具后,在列表goodsDetailList中找到想要的数据:
所以按照下面的逻辑取对应的数据:
流程执行结果:
问题没有解决?去社区提问 保留所有权利,由 Gitbook 提供支持 查看全部
c 抓取网页数据(
如何使用网页监听获取想要的数据?解决办法)
使用网络监听命令获取数据
在网页抓取数据时,如果有些图表数据无法抓取,元素变化频繁,或者网页有广告影响操作,可以考虑使用网页监控来获取想要的数据。
脚步
① 打开要采集数据的网页,在网页上按F12打开开发者模式。
② 按 Ctrl + R 重新加载网页。
③ 等待所需数据加载完毕,激活网络选项卡上的搜索框,输入所需数据,然后按 Enter。

④ 如图

如果找不到目标数据,尝试其他可能的数据搜索,减少关键词的数量,或者依次在请求列表中搜索数据。
⑤ 开始监控数据,获取网页对象-开始监控请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果) - 停止监听网页请求。
可能数据很多,建议不要打印,先写入文本文件


⑥打开写入的文件,按Crtl+F查看是否找到想要的数据。
⑦使用命令获取网页请求的结果是一个收录目标url数据的字典。响应中的数据收录在循环项字典的键 ["body"] 中。body 是一个字符串,它被转换成一个 json 对象。可以提取数据。
为了方便观察结构,可以先把body的数据拿出来粘贴,会自动转换成便于观察的格式。

粘贴到格式化工具后,在列表goodsDetailList中找到想要的数据:


所以按照下面的逻辑取对应的数据:

流程执行结果:

问题没有解决?去社区提问 保留所有权利,由 Gitbook 提供支持
c 抓取网页数据(【天学网:】25#输出爬到的游戏名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-20 15:27
7 头 = {
8“连接”:“保持活动”,
9 '接受':'文本/html,应用程序/xhtml+xml,*/*',
10 '接受语言': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3 ',
11 '接受编码':'gzip,放气',
12 '用户代理': 'Mozilla/6.1 (Windows NT 6.3; WOW64; 三叉戟/7.0; rv:11.0)像壁虎'
13 }
14 # 待爬取的游戏列表页面
15 网址 = '#39;
16
17 # 不压缩html,最大链接时间为10秒
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码为 utf-8
20 res.encoding = 'utf-8'
21 # 将 html 构建为 Xpath 模式
22 根 = etree.HTML(res.content)
23 # 使用Xpath语法获取游戏名称
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出你爬到的游戏名称
26 打印(游戏列表)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于行块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页切分查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们将两个标签和其中收录的文本组合成一个标签窗口(如
I am h1中的“I am h1”是标记窗口的内容),取出标记窗口的文本。
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于行块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时引入块长法官。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1#假设内容是已经获取到的html
2
3# Ctext取周围的k行(k
4blocksWidth = 3
5#每个Cblock的长度
6Ctext_len = []
7#Ctext
8lines = content.split('n')
9#删除空格
10for i in range(len(lines)):
11 如果行[i] == ' ' 或行[i] == 'n':
12 行 [i] = ''
13#计算纵坐标,每个Ctext的长度
14for i in range(0, len(lines) - blocksWidth):
15 个字数 = 0
16 for j in range(i, i + blocksWidth):
17 行[j] = 行[j].replace("\s", "")
18 wordsNum += len(lines[j])
19 Ctext_len.append(wordsNum)
20#开始标志
21开始=-1
22#结束标记
23 结束 = -1
24#是否开始打标
25boolstart=假
26#是否结束标记
27布尔=假
28#行块长度阈值
29max_text_len = 88
30# 文章主要内容
31main_text = []
32# Ctext 没有分段
33if 长度(Ctext_len)
34返回'没有身体'
35for i in range(len(Ctext_len) - 3):
36 # 如果高于这个阈值
37 if(Ctext_len[i] > max_text_len and (not boolstart)):
38 # Cblock下面三个不为0,认为是文本
39 if (Ctext_len[i + 1] != 0 或 Ctext_len[i + 2] != 0 或 Ctext_len[i + 3] != 0):
40 布尔启动 = 真
41 开始 = 我
42 继续
43 如果(布尔启动):
44 # 如果Cblock后面3个有0,则结束
45 if (Ctext_len[i] == 0 或 Ctext_len[i + 1] == 0):
46 结束 = 我
47布尔=真
48 tmp = []
49
50 # 判断下面是否有文字
51 如果(布尔值):
52 for ii in range(start, end + 1):
53 if(len(行[ii])
54 继续
55 tmp.append(行[ii] + "n")
56 str = "".join(列表(tmp)) 查看全部
c 抓取网页数据(【天学网:】25#输出爬到的游戏名)
7 头 = {
8“连接”:“保持活动”,
9 '接受':'文本/html,应用程序/xhtml+xml,*/*',
10 '接受语言': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3 ',
11 '接受编码':'gzip,放气',
12 '用户代理': 'Mozilla/6.1 (Windows NT 6.3; WOW64; 三叉戟/7.0; rv:11.0)像壁虎'
13 }
14 # 待爬取的游戏列表页面
15 网址 = '#39;
16
17 # 不压缩html,最大链接时间为10秒
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码为 utf-8
20 res.encoding = 'utf-8'
21 # 将 html 构建为 Xpath 模式
22 根 = etree.HTML(res.content)
23 # 使用Xpath语法获取游戏名称
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出你爬到的游戏名称
26 打印(游戏列表)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于行块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页切分查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们将两个标签和其中收录的文本组合成一个标签窗口(如
I am h1中的“I am h1”是标记窗口的内容),取出标记窗口的文本。
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于行块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时引入块长法官。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1#假设内容是已经获取到的html
2
3# Ctext取周围的k行(k
4blocksWidth = 3
5#每个Cblock的长度
6Ctext_len = []
7#Ctext
8lines = content.split('n')
9#删除空格
10for i in range(len(lines)):
11 如果行[i] == ' ' 或行[i] == 'n':
12 行 [i] = ''
13#计算纵坐标,每个Ctext的长度
14for i in range(0, len(lines) - blocksWidth):
15 个字数 = 0
16 for j in range(i, i + blocksWidth):
17 行[j] = 行[j].replace("\s", "")
18 wordsNum += len(lines[j])
19 Ctext_len.append(wordsNum)
20#开始标志
21开始=-1
22#结束标记
23 结束 = -1
24#是否开始打标
25boolstart=假
26#是否结束标记
27布尔=假
28#行块长度阈值
29max_text_len = 88
30# 文章主要内容
31main_text = []
32# Ctext 没有分段
33if 长度(Ctext_len)
34返回'没有身体'
35for i in range(len(Ctext_len) - 3):
36 # 如果高于这个阈值
37 if(Ctext_len[i] > max_text_len and (not boolstart)):
38 # Cblock下面三个不为0,认为是文本
39 if (Ctext_len[i + 1] != 0 或 Ctext_len[i + 2] != 0 或 Ctext_len[i + 3] != 0):
40 布尔启动 = 真
41 开始 = 我
42 继续
43 如果(布尔启动):
44 # 如果Cblock后面3个有0,则结束
45 if (Ctext_len[i] == 0 或 Ctext_len[i + 1] == 0):
46 结束 = 我
47布尔=真
48 tmp = []
49
50 # 判断下面是否有文字
51 如果(布尔值):
52 for ii in range(start, end + 1):
53 if(len(行[ii])
54 继续
55 tmp.append(行[ii] + "n")
56 str = "".join(列表(tmp))
c 抓取网页数据( Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-20 05:06
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化和聚焦核心业务的需要,使得各种翻译业务的利润越来越高。云翻译平台Smartling是一家完整的全球翻译公司,承接所有可以翻译的事情,包括企业文件。,网页,应用程序,小到一个图标都包括在内。Smartling 刚刚完成了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投,Venrock、US Venture Partners、IDG Ventures、First Round Capital 和 Felicis Ventures 无一例外地追加投资。
Smartling将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API开放为企业用户本地化语言提供数据监控服务网站。比如某公司的网页翻译成中文后,用户可以通过Smartling的dashboard网站@网站看到中文版产生的流量等数据。
上传需要翻译的文件类型后,用户可以选择专业、众包或Smartling内部员工将其翻译成多种语言。整个业务流程对用户可见可控,用户可以根据需要选择合适的翻译。各种设置,例如资源甚至翻译的风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供了跨平台优化。
Smartling 声称其服务可以将翻译管理成本降低多达 90%,Smartling 保证当日送达。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling的客户包括电子商务、旅游相关行业相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是其客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频: 查看全部
c 抓取网页数据(
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化和聚焦核心业务的需要,使得各种翻译业务的利润越来越高。云翻译平台Smartling是一家完整的全球翻译公司,承接所有可以翻译的事情,包括企业文件。,网页,应用程序,小到一个图标都包括在内。Smartling 刚刚完成了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投,Venrock、US Venture Partners、IDG Ventures、First Round Capital 和 Felicis Ventures 无一例外地追加投资。
Smartling将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API开放为企业用户本地化语言提供数据监控服务网站。比如某公司的网页翻译成中文后,用户可以通过Smartling的dashboard网站@网站看到中文版产生的流量等数据。
上传需要翻译的文件类型后,用户可以选择专业、众包或Smartling内部员工将其翻译成多种语言。整个业务流程对用户可见可控,用户可以根据需要选择合适的翻译。各种设置,例如资源甚至翻译的风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供了跨平台优化。
Smartling 声称其服务可以将翻译管理成本降低多达 90%,Smartling 保证当日送达。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling的客户包括电子商务、旅游相关行业相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是其客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频:
c 抓取网页数据(Python静态网页抓取学习过程及一点简单的分析保存方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-04-12 05:38
Python 静态网页抓取
最近学习了使用Python爬虫爬取静态网页,做一点简单的分析保存。以下是整个学习过程:
实践要求的目的
访问豆瓣电影Top250网站,抓取所有电影的片名、导演、主演、上映年份、电影分级和评分。并将结果保存到 Excel。
爬取过程 爬取网页
使用Python中的requests库,可以直接爬取网页源代码。
我们首先使用DOS来安装requests
pip install --user requests
根据百度上的pip安装教程,使用pip安装时,直接输入pip install +(库名),但无法安装成功。根据内置提示,添加--user即可成功安装。
在 Python 中导入请求后,使用库函数 get 直接获取网页的源代码。
link = 'https://movie.douban.com/top250'
r = requests.get(link,headers,timeout=20)
在获取函数中:
让我们仔细看看最后两个参数。
请求标头为我们提供有关请求、响应或其他发送实体的信息。如果没有请求头或者请求头没有正确对应网页,那么我们抓取的结果可能是错误的。
如何找到网页的请求头?
我们进入豆瓣电影top250的网页,按f12进入开发者模式;
单击网络并刷新界面。
点击网页名称,然后点击Headers,我们可以在其中找到请求头的内容,并按照如下格式保存在Python中。
headers ={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Host':'movie.douban.com'}
说完请求头,再来说说响应时间的设置。
因为有时候爬虫会遇到服务端长时间不响应不返回的情况,那么爬虫就会等待,我们设置一个无响应返回的时间,如果时间截止点还没有返回回应。
接下来我们会发现上面的链接只有25部电影,总共250部电影分布在10个页面上;我们点击第二页,发现URL变了:;第三页:;再多一页,在链接的最后一个数字上加 25。
我们可以设置一个for循环来不断更新爬取的网页。
for i in range (0,10):
link = 'https://movie.douban.com/top250?start=' + str(i*25)
r = requests.get(link,headers=headers,timeout=20)
至此,我们可以检查上述过程是否正确,是否爬取成功。
我们打印出每一页的响应状态码。
print('Page',i,' ',r.status_code)
当状态码为200时,爬取成功。
分析网页
经过上面的过程,我们就可以得到网页的HTML代码了,但是我们不需要这么多东西,我们需要分析并从中提取出我们想要的东西。
我们需要使用第三方库bs4中的BeautifulSoup;
通过 pip 安装和导入,方法同上。
pip install --user bs4
from bs4 import BeautifulSoup #导入
BeautifulSoup 可以自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。BeautifulSoup可以将html解析成对象进行处理,并将所有页面转换成字典或数组,相比正则表达式可以大大简化处理过程。
我们创建一个 BeautifulSoup 对象汤来解析网页。
soup = BeautifulSoup(r.text,"lxml")
这里的lxml是Python解析HTML页面的库,是BeautifulSoup解析的固定搭配之一。(这里如果代码报错,可能是因为没有安装lxml库,用pip安装就行了。)
我们先通过浏览器的开发者模式观察发现
电影名称保存在 div 标签下的 class="hd" 中,我们需要的其他信息保存在 div 标签下的 class="bd" 中。
我们首先讨论电影标题的提取。其余项目基本类似。
我们直接使用soup中的find_all函数。汤里有两个函数,一个是find,一个是find_all。find函数返回第一个满足搜索条件的结果,find_all返回所有结果。这里我们根据需要使用 find_all。,并将结果保存到列表中。
div_list1 = soup.find_all('div',class_='hd')
这里会打印列表,并截取第一个“肖申克的救赎”的结果,即div_list[0]。同时,我们将对比豆瓣网页源代码的形式。我们可以提取名称。
电影名称存储在标签 a 下方的第一个跨度标签中。使用循环将所有电影的名称保存在第一页上。
for each in div_list1:
#中文名
movie_name = each.a.span.text.strip()
movies_name.append(movie_name)
这里 movies_name 是一个收录所有电影名称的列表。
这样我们就保存了整个 top250 电影的名称。让我们输出它来检查。
后续其他项目的流程基本相同。
我们将 find_all 函数中的第二个参数替换为:class="bd" 并将其保存在一个列表中。
问题来了。我们需要的内容不是保存在a和span中,而是保存在一个标签p中。如果我们直接用p替换a,跳过span部分,报错!,怎么办?
我们需要用另一个函数来替换它:contents,contents可以输出p下面的所有内容,并返回一个列表。我们现在可以在这个列表中找到我们需要的东西。
我还是先输出吗
div_list2=soup.find_all('div',class_='bd')
的结果。(为了方便观察,我们直接用断点+单步调试的方法查看结果)
我们需要从 div_list2 的第二项开始,所以循环应该从 div_list2[1] 开始。
只有 each.p.contents 中的第一项和第三项是我们需要的,所以我们列表的底部确定为 contents[0] 和 contents[2]。
我们先谈谈内容[0]。我们通过strip函数和split函数对字符串进行处理,去掉一些杂项。
movie = each.p.contents[0].strip().split('\xa0')
当当,结果出来了。
当我们输出所有结果时,发现有问题。错误!或者是数组越界的错,为什么是这个时候?显然第一个提取成功了,第二个也成功了。
再来看看豆瓣的网站
最后,它并没有显示全部。也就是说,后面的一部电影导演太多,或者名字太长的时候,主角就变成了“……”,无法展现。最重要的是上面movie返回的list长度从4变成了4。 2、当我们尝试使用上面的
actor = movie[3]
,自然会报错。
如何解决这个问题?
这个问题我其实还没有从根本上解决,因为这是豆瓣网页的问题,不能添加html中没有的词,除非我点击每个电影链接查看,但是这250个的具体细节movies 链接之间没有直接关联,也许有办法提取新的URL,从而重新爬取新的URL,然后分析,然后得到。从这个方向思考,似乎太麻烦了。
包括以上,有人可能会怀疑我提取了中文电影名,为什么不提取英文名和港台名。这里挖了一个小坑。有兴趣的可以尝试提取英文名和港台名。
当然,也有可能是我的水平不够,不知道有什么厉害的方法。
这里我们直接使用if判断语句根据电影的长度来判断。
if len(movie)==4:
movie_dir = movie[0][4:]
movie_actor = movie[3][4:]
else:
movie_dir = movie[0][4:]
movie_actor = '...'
其余部分没有坑。按照上述步骤,您可以提取电影的发行年份、国家、分类和评级。此处不再赘述。
保存数据
所有数据都被提取和分析,并保存在movies_name、movies_dir、movies_actor、movies_time、movies_nation、movies_class、movies_grade的列表中。接下来就是如何保存到Excel中了,方便我们进行进一步的工作。
为了保存到 excel,我们使用与 Python 和 Excel 关联的库 xlwt。
xlrd和xlwt这两个库在Python文件操作中与Excel关联,分别对应Excel的读写。写在这里,使用 xlwt。可以直接通过pip安装。
直接使用xlwt的功能:
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('豆瓣top250')
xlwt.Workbook(encoding = 'utf-8') - 创建一个 utf-8 编码的 Excel 工作表。
add_sheet('Douban top250') - 在sheet中创建一个名为“Douban top250”的工作簿。
一旦建立,下一步就是写入数据。只需使用一个功能。
worksheet.write(r,c,str)
其中,r代表行,c代表列,str代表内容。
只需依次存储我们列表的内容。
最后,保存 Excel:
保存(文件名)
filename 是保存文件的路径。
统计结果(部分)
完整代码下载 查看全部
c 抓取网页数据(Python静态网页抓取学习过程及一点简单的分析保存方法)
Python 静态网页抓取
最近学习了使用Python爬虫爬取静态网页,做一点简单的分析保存。以下是整个学习过程:
实践要求的目的
访问豆瓣电影Top250网站,抓取所有电影的片名、导演、主演、上映年份、电影分级和评分。并将结果保存到 Excel。
爬取过程 爬取网页
使用Python中的requests库,可以直接爬取网页源代码。
我们首先使用DOS来安装requests
pip install --user requests
根据百度上的pip安装教程,使用pip安装时,直接输入pip install +(库名),但无法安装成功。根据内置提示,添加--user即可成功安装。
在 Python 中导入请求后,使用库函数 get 直接获取网页的源代码。
link = 'https://movie.douban.com/top250'
r = requests.get(link,headers,timeout=20)
在获取函数中:
让我们仔细看看最后两个参数。
请求标头为我们提供有关请求、响应或其他发送实体的信息。如果没有请求头或者请求头没有正确对应网页,那么我们抓取的结果可能是错误的。
如何找到网页的请求头?
我们进入豆瓣电影top250的网页,按f12进入开发者模式;
单击网络并刷新界面。
点击网页名称,然后点击Headers,我们可以在其中找到请求头的内容,并按照如下格式保存在Python中。
headers ={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Host':'movie.douban.com'}
说完请求头,再来说说响应时间的设置。
因为有时候爬虫会遇到服务端长时间不响应不返回的情况,那么爬虫就会等待,我们设置一个无响应返回的时间,如果时间截止点还没有返回回应。
接下来我们会发现上面的链接只有25部电影,总共250部电影分布在10个页面上;我们点击第二页,发现URL变了:;第三页:;再多一页,在链接的最后一个数字上加 25。
我们可以设置一个for循环来不断更新爬取的网页。
for i in range (0,10):
link = 'https://movie.douban.com/top250?start=' + str(i*25)
r = requests.get(link,headers=headers,timeout=20)
至此,我们可以检查上述过程是否正确,是否爬取成功。
我们打印出每一页的响应状态码。
print('Page',i,' ',r.status_code)
当状态码为200时,爬取成功。
分析网页
经过上面的过程,我们就可以得到网页的HTML代码了,但是我们不需要这么多东西,我们需要分析并从中提取出我们想要的东西。
我们需要使用第三方库bs4中的BeautifulSoup;
通过 pip 安装和导入,方法同上。
pip install --user bs4
from bs4 import BeautifulSoup #导入
BeautifulSoup 可以自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。BeautifulSoup可以将html解析成对象进行处理,并将所有页面转换成字典或数组,相比正则表达式可以大大简化处理过程。
我们创建一个 BeautifulSoup 对象汤来解析网页。
soup = BeautifulSoup(r.text,"lxml")
这里的lxml是Python解析HTML页面的库,是BeautifulSoup解析的固定搭配之一。(这里如果代码报错,可能是因为没有安装lxml库,用pip安装就行了。)
我们先通过浏览器的开发者模式观察发现
电影名称保存在 div 标签下的 class="hd" 中,我们需要的其他信息保存在 div 标签下的 class="bd" 中。
我们首先讨论电影标题的提取。其余项目基本类似。
我们直接使用soup中的find_all函数。汤里有两个函数,一个是find,一个是find_all。find函数返回第一个满足搜索条件的结果,find_all返回所有结果。这里我们根据需要使用 find_all。,并将结果保存到列表中。
div_list1 = soup.find_all('div',class_='hd')
这里会打印列表,并截取第一个“肖申克的救赎”的结果,即div_list[0]。同时,我们将对比豆瓣网页源代码的形式。我们可以提取名称。
电影名称存储在标签 a 下方的第一个跨度标签中。使用循环将所有电影的名称保存在第一页上。
for each in div_list1:
#中文名
movie_name = each.a.span.text.strip()
movies_name.append(movie_name)
这里 movies_name 是一个收录所有电影名称的列表。
这样我们就保存了整个 top250 电影的名称。让我们输出它来检查。
后续其他项目的流程基本相同。
我们将 find_all 函数中的第二个参数替换为:class="bd" 并将其保存在一个列表中。
问题来了。我们需要的内容不是保存在a和span中,而是保存在一个标签p中。如果我们直接用p替换a,跳过span部分,报错!,怎么办?
我们需要用另一个函数来替换它:contents,contents可以输出p下面的所有内容,并返回一个列表。我们现在可以在这个列表中找到我们需要的东西。
我还是先输出吗
div_list2=soup.find_all('div',class_='bd')
的结果。(为了方便观察,我们直接用断点+单步调试的方法查看结果)
我们需要从 div_list2 的第二项开始,所以循环应该从 div_list2[1] 开始。
只有 each.p.contents 中的第一项和第三项是我们需要的,所以我们列表的底部确定为 contents[0] 和 contents[2]。
我们先谈谈内容[0]。我们通过strip函数和split函数对字符串进行处理,去掉一些杂项。
movie = each.p.contents[0].strip().split('\xa0')
当当,结果出来了。
当我们输出所有结果时,发现有问题。错误!或者是数组越界的错,为什么是这个时候?显然第一个提取成功了,第二个也成功了。
再来看看豆瓣的网站
最后,它并没有显示全部。也就是说,后面的一部电影导演太多,或者名字太长的时候,主角就变成了“……”,无法展现。最重要的是上面movie返回的list长度从4变成了4。 2、当我们尝试使用上面的
actor = movie[3]
,自然会报错。
如何解决这个问题?
这个问题我其实还没有从根本上解决,因为这是豆瓣网页的问题,不能添加html中没有的词,除非我点击每个电影链接查看,但是这250个的具体细节movies 链接之间没有直接关联,也许有办法提取新的URL,从而重新爬取新的URL,然后分析,然后得到。从这个方向思考,似乎太麻烦了。
包括以上,有人可能会怀疑我提取了中文电影名,为什么不提取英文名和港台名。这里挖了一个小坑。有兴趣的可以尝试提取英文名和港台名。
当然,也有可能是我的水平不够,不知道有什么厉害的方法。
这里我们直接使用if判断语句根据电影的长度来判断。
if len(movie)==4:
movie_dir = movie[0][4:]
movie_actor = movie[3][4:]
else:
movie_dir = movie[0][4:]
movie_actor = '...'
其余部分没有坑。按照上述步骤,您可以提取电影的发行年份、国家、分类和评级。此处不再赘述。
保存数据
所有数据都被提取和分析,并保存在movies_name、movies_dir、movies_actor、movies_time、movies_nation、movies_class、movies_grade的列表中。接下来就是如何保存到Excel中了,方便我们进行进一步的工作。
为了保存到 excel,我们使用与 Python 和 Excel 关联的库 xlwt。
xlrd和xlwt这两个库在Python文件操作中与Excel关联,分别对应Excel的读写。写在这里,使用 xlwt。可以直接通过pip安装。
直接使用xlwt的功能:
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('豆瓣top250')
xlwt.Workbook(encoding = 'utf-8') - 创建一个 utf-8 编码的 Excel 工作表。
add_sheet('Douban top250') - 在sheet中创建一个名为“Douban top250”的工作簿。
一旦建立,下一步就是写入数据。只需使用一个功能。
worksheet.write(r,c,str)
其中,r代表行,c代表列,str代表内容。
只需依次存储我们列表的内容。
最后,保存 Excel:
保存(文件名)
filename 是保存文件的路径。
统计结果(部分)
完整代码下载
c 抓取网页数据(怎样优化好你的网站,从而受到蜘蛛喜欢,排在)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-10 21:15
如何优化你的网站,从而被蜘蛛点赞,排在主流搜索的前几页,是站长们不懈的追求。
关键词,即代码中关键词与页面标题和元描述之间的关键词,要慎重选择。
A. baidu关键词优化技巧。
经验表明 关键词 太有用了。你为什么这么说?许多人在代码中列出了大量的单词。而且,百度老板只对前三四个字感冒,也会造成被K怀疑作弊的风险,字数也是有限制的。一般字数不超过20字。超出的单词将不会收录在搜索结果中。白农。
B. GOOGLE关键词优化技巧。
GOOGLE和百度一样,对关键词的字数、标题和描述有同样的限制和注意点。如果你不明白,请看上面。
但仅限谷歌
所以标题和描述的内容应该是优化网站的重点内容,包括关键词的选择,字数,那些关键词顶,怎么匹配长尾,增加更有可能被搜索引擎抓取的访问次数。
禁忌是不要过多地重复列表关键词。在标题和描述中,尽量使句子流畅。不要简单地把关键词一一排好。实践证明,像句子这样的描述更受欢迎。欢迎蜘蛛。
C. 让蜘蛛顺利爬取你的网页
也就是说,想办法让搜索引擎蜘蛛在你的网站中畅行无阻,顺利找到你的网页。
体验网站地图,比如网站xml格式的地图,把网站地图的地址写到你的robots.txt中,很有效,新站提交地图给gg后,两三个小时后,gg蜘蛛就会到你的车站,就像110报警一样。
D. 如何让搜索引擎蜘蛛经常来你的网站
和打110很像。如果你经常报警,他们会很快,很勤奋,但如果你什么都没发生,或者你让他空着,他会少来一次,甚至一个月一次。:
1.经常更新你的内容来吸引搜索引擎蜘蛛,这样你就不用白跑了。
2、为了保证内容的质量,尽量不要和别人重复太多,也就是给蜘蛛们新鲜好吃的东西吃。
3、去一些知名的,高权限的网站建立友好的链接,发帖,吸引蜘蛛来。
4、经常查看日志网站,研究蜘蛛频繁出现的次数和列,以便采取相应的动作让蜘蛛更喜欢,增加内容,整列等。 查看全部
c 抓取网页数据(怎样优化好你的网站,从而受到蜘蛛喜欢,排在)
如何优化你的网站,从而被蜘蛛点赞,排在主流搜索的前几页,是站长们不懈的追求。
关键词,即代码中关键词与页面标题和元描述之间的关键词,要慎重选择。
A. baidu关键词优化技巧。
经验表明 关键词 太有用了。你为什么这么说?许多人在代码中列出了大量的单词。而且,百度老板只对前三四个字感冒,也会造成被K怀疑作弊的风险,字数也是有限制的。一般字数不超过20字。超出的单词将不会收录在搜索结果中。白农。
B. GOOGLE关键词优化技巧。
GOOGLE和百度一样,对关键词的字数、标题和描述有同样的限制和注意点。如果你不明白,请看上面。
但仅限谷歌
所以标题和描述的内容应该是优化网站的重点内容,包括关键词的选择,字数,那些关键词顶,怎么匹配长尾,增加更有可能被搜索引擎抓取的访问次数。
禁忌是不要过多地重复列表关键词。在标题和描述中,尽量使句子流畅。不要简单地把关键词一一排好。实践证明,像句子这样的描述更受欢迎。欢迎蜘蛛。
C. 让蜘蛛顺利爬取你的网页
也就是说,想办法让搜索引擎蜘蛛在你的网站中畅行无阻,顺利找到你的网页。
体验网站地图,比如网站xml格式的地图,把网站地图的地址写到你的robots.txt中,很有效,新站提交地图给gg后,两三个小时后,gg蜘蛛就会到你的车站,就像110报警一样。
D. 如何让搜索引擎蜘蛛经常来你的网站
和打110很像。如果你经常报警,他们会很快,很勤奋,但如果你什么都没发生,或者你让他空着,他会少来一次,甚至一个月一次。:
1.经常更新你的内容来吸引搜索引擎蜘蛛,这样你就不用白跑了。
2、为了保证内容的质量,尽量不要和别人重复太多,也就是给蜘蛛们新鲜好吃的东西吃。
3、去一些知名的,高权限的网站建立友好的链接,发帖,吸引蜘蛛来。
4、经常查看日志网站,研究蜘蛛频繁出现的次数和列,以便采取相应的动作让蜘蛛更喜欢,增加内容,整列等。
c 抓取网页数据(写入值到word二、spider爬取标题进行写入三、爬去代码并将代码进行装换遇到问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-10 16:20
)
一、将值写入word 二、蜘蛛爬取标题供写三、爬取代码并替换代码遇到的问题:
在代码块中,每个字符都用一个 span 包裹
这个方法可以直接获取代码的值,可以用它来获取代码思路一、直接模仿代码进行在线替换,写操作思路二、使用文件操作技术获取替换的代码,然后使用脚本将其复制并粘贴到word文档中。 Ideas三、通过拼接直接得到的span标签的值,将拼接后的值传入word(select)中,最后使用etree执行代码块。解析项目遇到的工具:
(etree)
(查询)
代码:
import requests
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
from lxml import etree
from docx import Document
from docx.shared import Inches
url="https://www.runoob.com/cprogra ... ot%3B
def geu_page(url):
try:
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode("utf-8")
except Exception as e:
for i in range(3):
print(url,e)
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode('utf-8')
def getdata(url1):
html1 = geu_page(url1)
doc = pq(html1) # 解析html文件
datas = etree.HTML(html1)
data = datas.xpath('//div[@class="hl-main"]/span/text()')
code = ''.join(data)
title = doc('#content > p:nth-child(3)').text() # 其中doc(使用的是selector选择器)
content = doc('#content > p:nth-child(4)').text()
# 对url进行切割获取下标
begin = url1.find("example")
end = url1.find(".html")
index = url1[begin + 7:end]
print("开始写入第"+index+"个实例")
write_to_word(code,title,content,head=index)
def write_to_word(code,title,content,head):
# 标题
document.add_heading("C语言实例"+str(head), level=0)
# 文本: 题目
document.add_paragraph(title)
# 文本: 程序分析
document.add_paragraph(content)
# 代码: 代码
document.add_paragraph(code)
# 结果: result
document = Document()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx')
ent()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx') 查看全部
c 抓取网页数据(写入值到word二、spider爬取标题进行写入三、爬去代码并将代码进行装换遇到问题
)
一、将值写入word 二、蜘蛛爬取标题供写三、爬取代码并替换代码遇到的问题:
在代码块中,每个字符都用一个 span 包裹
这个方法可以直接获取代码的值,可以用它来获取代码思路一、直接模仿代码进行在线替换,写操作思路二、使用文件操作技术获取替换的代码,然后使用脚本将其复制并粘贴到word文档中。 Ideas三、通过拼接直接得到的span标签的值,将拼接后的值传入word(select)中,最后使用etree执行代码块。解析项目遇到的工具:
(etree)
(查询)
代码:
import requests
from bs4 import BeautifulSoup
from pyquery import PyQuery as pq
from lxml import etree
from docx import Document
from docx.shared import Inches
url="https://www.runoob.com/cprogra ... ot%3B
def geu_page(url):
try:
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode("utf-8")
except Exception as e:
for i in range(3):
print(url,e)
res = requests.get(url,timeout=4)
res.encoding = 'utf-8'
if res.status_code == 200:
html = res.text
return html.encode('utf-8')
def getdata(url1):
html1 = geu_page(url1)
doc = pq(html1) # 解析html文件
datas = etree.HTML(html1)
data = datas.xpath('//div[@class="hl-main"]/span/text()')
code = ''.join(data)
title = doc('#content > p:nth-child(3)').text() # 其中doc(使用的是selector选择器)
content = doc('#content > p:nth-child(4)').text()
# 对url进行切割获取下标
begin = url1.find("example")
end = url1.find(".html")
index = url1[begin + 7:end]
print("开始写入第"+index+"个实例")
write_to_word(code,title,content,head=index)
def write_to_word(code,title,content,head):
# 标题
document.add_heading("C语言实例"+str(head), level=0)
# 文本: 题目
document.add_paragraph(title)
# 文本: 程序分析
document.add_paragraph(content)
# 代码: 代码
document.add_paragraph(code)
# 结果: result
document = Document()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx')
ent()
for i in range(1,101):
url1=url+str(i)+".html"
getdata(url1)
document.save('C 语言经典100例.docx')
c 抓取网页数据(SpringBoot的一个好处(就是)的好处 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-09 20:43
)
Spring Boot 的一个优点是前端页面的参数可以通过注解方便的获取,然后通过一系列处理将参数传入后端数据库。如果某件事一段时间不写下来,几乎就忘记了,感觉自己的记忆力越来越差。这里简单总结一下,大致可以分为以下几类:
1.指定前端url请求参数名与方法名相同,如下图,这个方法简单的说就是url请求格式中的参数需要对应的参数名方法,比如这样一个url请求:8080/0919/test1?name=xxx&pwd=yyy,给指定的控制器类添加Controller注解,同时指定RequestMapping注解。当请求路径参数与方法参数匹配时,会自动注入
启动主程序,访问浏览器出现下图,说明注入参数成功。这个方法一般是一个get请求。
2.第二种方式是通过HttpServletRequest获取前端页面参数。代码如下图所示。简单来说就是调用请求的getParameter方法获取参数。例如访问路径类似这样:8080/0919/test2?firstName =zhang&lastName=san
启动主程序,访问浏览器出现下图,说明注入参数成功。该方法也可以获取表单参数。通常,get 和 post 请求都可以使用。
3.第三种方式是创建一个JavaBean对象来封装表单参数或者请求url路径中的参数。具体代码如下图所示
对应的JavaBean对象如下
简单来说,表单参数作为一个JavaBean类的属性,通过将方法参数设置为一个JavaBean对象,然后在方法中通过调用该对象的get方法来获取表单传递的参数,例如,访问路径是这样的: 8080/0919 /test3?firstName=zhang&lastName=san 启动主程序,在浏览器访问看到下图,说明注入参数成功,如果有多个form可以考虑这个方法要求的参数
4.第四种方式是通过PathVariable注解绑定请求路径的参数。参考代码如下
这种情况简单的表现为url中动态绑定的形式,然后通过PathVariable将方法中指定的参数绑定到请求url中的参数到方法参数中。这里没有指定PathVariable注解的具体值。可以根据请求路径中动态变量的顺序和注解的顺序进行注入。如果要指定注入,可以指定 PathVariable 注解的值与特定注入的动态变量的名称相同。比如请求路径是这样的:8080/0919/test4/111/222
启动主程序并在浏览器中访问它。出现下图说明注入参数成功。
5.第五种方式是通过RequestParam注解获取。具体代码如下
该方法将请求路径上的参数以url路径的形式绑定到方法的参数上。简而言之,将实参值赋给对应的形参。与上述方法不同的是,前者是动态url模板注入,这里是常见的url请求注入。比如访问路径是这样的:8080/0919/test5?aaa=111&bbb=4444
启动主程序,访问请求,浏览器出现如下提示,说明注入参数成功。这里可以通过指定RequestParam的值来指定url请求路径参数来指定具体注入哪个方法参数,但是一般来说两者同名更方便。
6.第六种方法是通过ModelAttribute方法注入参数。具体代码如下
这个方法一般显示在页面上,所以这里有两个页面用于测试 test2.jsp 和 test3.jsp 进行测试
简单来说就是通过ModelAttribute注解将请求参数封装到指定的JavaBean对象中,接受表单参数的对象通过value值赋值。在这里,s被赋值给了一个名为kkk的变量,然后你可以在jsp页面上使用这个变量名来使用el表达式来获取表单传递过来的参数。这里的测试路径是:8080/0919/kkk,访问浏览器进行测试,见下图
点击提交,出现下图,说明表单参数被后台成功接受并在首页输出。这种方法一般在输出首页时使用。
查看全部
c 抓取网页数据(SpringBoot的一个好处(就是)的好处
)
Spring Boot 的一个优点是前端页面的参数可以通过注解方便的获取,然后通过一系列处理将参数传入后端数据库。如果某件事一段时间不写下来,几乎就忘记了,感觉自己的记忆力越来越差。这里简单总结一下,大致可以分为以下几类:
1.指定前端url请求参数名与方法名相同,如下图,这个方法简单的说就是url请求格式中的参数需要对应的参数名方法,比如这样一个url请求:8080/0919/test1?name=xxx&pwd=yyy,给指定的控制器类添加Controller注解,同时指定RequestMapping注解。当请求路径参数与方法参数匹配时,会自动注入
启动主程序,访问浏览器出现下图,说明注入参数成功。这个方法一般是一个get请求。
2.第二种方式是通过HttpServletRequest获取前端页面参数。代码如下图所示。简单来说就是调用请求的getParameter方法获取参数。例如访问路径类似这样:8080/0919/test2?firstName =zhang&lastName=san
启动主程序,访问浏览器出现下图,说明注入参数成功。该方法也可以获取表单参数。通常,get 和 post 请求都可以使用。
3.第三种方式是创建一个JavaBean对象来封装表单参数或者请求url路径中的参数。具体代码如下图所示
对应的JavaBean对象如下
简单来说,表单参数作为一个JavaBean类的属性,通过将方法参数设置为一个JavaBean对象,然后在方法中通过调用该对象的get方法来获取表单传递的参数,例如,访问路径是这样的: 8080/0919 /test3?firstName=zhang&lastName=san 启动主程序,在浏览器访问看到下图,说明注入参数成功,如果有多个form可以考虑这个方法要求的参数
4.第四种方式是通过PathVariable注解绑定请求路径的参数。参考代码如下
这种情况简单的表现为url中动态绑定的形式,然后通过PathVariable将方法中指定的参数绑定到请求url中的参数到方法参数中。这里没有指定PathVariable注解的具体值。可以根据请求路径中动态变量的顺序和注解的顺序进行注入。如果要指定注入,可以指定 PathVariable 注解的值与特定注入的动态变量的名称相同。比如请求路径是这样的:8080/0919/test4/111/222
启动主程序并在浏览器中访问它。出现下图说明注入参数成功。
5.第五种方式是通过RequestParam注解获取。具体代码如下
该方法将请求路径上的参数以url路径的形式绑定到方法的参数上。简而言之,将实参值赋给对应的形参。与上述方法不同的是,前者是动态url模板注入,这里是常见的url请求注入。比如访问路径是这样的:8080/0919/test5?aaa=111&bbb=4444
启动主程序,访问请求,浏览器出现如下提示,说明注入参数成功。这里可以通过指定RequestParam的值来指定url请求路径参数来指定具体注入哪个方法参数,但是一般来说两者同名更方便。
6.第六种方法是通过ModelAttribute方法注入参数。具体代码如下
这个方法一般显示在页面上,所以这里有两个页面用于测试 test2.jsp 和 test3.jsp 进行测试
简单来说就是通过ModelAttribute注解将请求参数封装到指定的JavaBean对象中,接受表单参数的对象通过value值赋值。在这里,s被赋值给了一个名为kkk的变量,然后你可以在jsp页面上使用这个变量名来使用el表达式来获取表单传递过来的参数。这里的测试路径是:8080/0919/kkk,访问浏览器进行测试,见下图
点击提交,出现下图,说明表单参数被后台成功接受并在首页输出。这种方法一般在输出首页时使用。
c 抓取网页数据(2017年上海事业单位招聘考试每日一练())
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-09 18:39
买菜 D、刷卡消费6、使用VB编程语言编程处理信息的一般过程分为四个步骤。“分析问题”之后的下一步是(设计算法B,编写程序C,调试运行D,得到答案 data.jpgB, data.mpgC , data.wavD, data.html 王丹老师的教案保存数据B、代码C、文件D、符号输入网站的IP地址即可打开。可能的原因有(网卡故障B、域名解析错误C、网线问题D、浏览器故障10、分析信息支持解决问题,是()信息识别时效性B、权威性C、多样性D、适用性11、网络上的视频可以多人同时在线观看,
中国红十字会号召全国人民为无钱治疗的白血病儿童捐款。你判断这个信息的依据是 A、信息的多样性、信息的及时性 C、信息的权威性 D、信息共享 18、当王明收到同学聚会的邀请卡时,同学聚会就结束了,王明错过了团聚时间,也见不到同学了。及时性B、可共享性C、真实性D、载体依赖2 -10ACCBD11-15CBACC16-20DCAB21、一个完整的数据库管理系统表必须用()来表示数据记录B、数据C、文件D、字段的关系22、在下面对搜索引擎的描述中,错误是(A.搜索引擎一般使用“关键字”
发送消息可以包括文本、语言、图像、图形。C. 不可能携带计算机病毒。D. 同一条消息可以发送给多个收件人。30、数据库管理系统中数据信息的操作(A、高速、低效B、快速、高效C、慢速、高效D、慢速、低效31、@ > 为了呈现学生成绩的变化趋势,在制作Excel图表时,应该选择(A,柱形图B,条形图C,折线图D,饼图3 2、下面是视频文件(A、data.jpgB、data.mpgC、data.mp3D、data.html33、MP3歌曲的组织形式为(A、文件B、声音C、声波D、符号34、@ > 域名系统中,顶级域名GOV代表(A、教育机构B、
A.键盘 B、ModemC、鼠标 A.推动科技进步 B.给人们带来麻烦 C.创造人类新文明 D.加速产业转型 39、信息安全危害的两大来源是计算机病毒和网络黑客,其中网络黑客指(A、计算机编程高手 B、cookies的发布者 C、网络的非法入侵者 D、垃圾邮件的制造者 40、创建数据库并在数据库管理系统 与表的关系在建立数据库的过程中(操作。A、分析信息特征 B、确定特征之间的关系 C、创建数据库结构 D、编辑数据库 21-25DBAAB26-30BDACB31- 35CBABA36-40CDBCC 真或假 4 @1、计算机管理大量信息的方式比手动管理的方式效率更高(42、IP电话使用分组数据交换技术(43、保存网页时,可以插入页面中的图片直接保存在页面上,不需要单独保存,但是声音文件不能直接保存在网页上,必须单独保存(45、人类探索的使用火星上的机器人是人工智能的典型应用。( )46、在Word中使用“打印预览”命令查看文章在纸上打印的实际效果。(49、创建的网页可以通过FTP软件上传。(52、一个可以建立一个或多个不同网站的web服务器。(53、每个 IP 地址由 32 个十进制数字组成。
(56、Word中设置阿拉伯数字文字字体大小时,数字越大,文字越大。(57、OS模型不是分层架构。(58、将域名转换为IP地址166.111.4.100的过程称为域名解析。()59、赵天祥用photoshop的软件帮助魏老师将审稿材料手稿制作成word文档。(60、交互性是多媒体作品的重要特点之一。()61、在Word中编辑文档时,可以使用“文件页面设置”命令设置纸张大小。 查看全部
c 抓取网页数据(2017年上海事业单位招聘考试每日一练())
买菜 D、刷卡消费6、使用VB编程语言编程处理信息的一般过程分为四个步骤。“分析问题”之后的下一步是(设计算法B,编写程序C,调试运行D,得到答案 data.jpgB, data.mpgC , data.wavD, data.html 王丹老师的教案保存数据B、代码C、文件D、符号输入网站的IP地址即可打开。可能的原因有(网卡故障B、域名解析错误C、网线问题D、浏览器故障10、分析信息支持解决问题,是()信息识别时效性B、权威性C、多样性D、适用性11、网络上的视频可以多人同时在线观看,
中国红十字会号召全国人民为无钱治疗的白血病儿童捐款。你判断这个信息的依据是 A、信息的多样性、信息的及时性 C、信息的权威性 D、信息共享 18、当王明收到同学聚会的邀请卡时,同学聚会就结束了,王明错过了团聚时间,也见不到同学了。及时性B、可共享性C、真实性D、载体依赖2 -10ACCBD11-15CBACC16-20DCAB21、一个完整的数据库管理系统表必须用()来表示数据记录B、数据C、文件D、字段的关系22、在下面对搜索引擎的描述中,错误是(A.搜索引擎一般使用“关键字”
发送消息可以包括文本、语言、图像、图形。C. 不可能携带计算机病毒。D. 同一条消息可以发送给多个收件人。30、数据库管理系统中数据信息的操作(A、高速、低效B、快速、高效C、慢速、高效D、慢速、低效31、@ > 为了呈现学生成绩的变化趋势,在制作Excel图表时,应该选择(A,柱形图B,条形图C,折线图D,饼图3 2、下面是视频文件(A、data.jpgB、data.mpgC、data.mp3D、data.html33、MP3歌曲的组织形式为(A、文件B、声音C、声波D、符号34、@ > 域名系统中,顶级域名GOV代表(A、教育机构B、
A.键盘 B、ModemC、鼠标 A.推动科技进步 B.给人们带来麻烦 C.创造人类新文明 D.加速产业转型 39、信息安全危害的两大来源是计算机病毒和网络黑客,其中网络黑客指(A、计算机编程高手 B、cookies的发布者 C、网络的非法入侵者 D、垃圾邮件的制造者 40、创建数据库并在数据库管理系统 与表的关系在建立数据库的过程中(操作。A、分析信息特征 B、确定特征之间的关系 C、创建数据库结构 D、编辑数据库 21-25DBAAB26-30BDACB31- 35CBABA36-40CDBCC 真或假 4 @1、计算机管理大量信息的方式比手动管理的方式效率更高(42、IP电话使用分组数据交换技术(43、保存网页时,可以插入页面中的图片直接保存在页面上,不需要单独保存,但是声音文件不能直接保存在网页上,必须单独保存(45、人类探索的使用火星上的机器人是人工智能的典型应用。( )46、在Word中使用“打印预览”命令查看文章在纸上打印的实际效果。(49、创建的网页可以通过FTP软件上传。(52、一个可以建立一个或多个不同网站的web服务器。(53、每个 IP 地址由 32 个十进制数字组成。
(56、Word中设置阿拉伯数字文字字体大小时,数字越大,文字越大。(57、OS模型不是分层架构。(58、将域名转换为IP地址166.111.4.100的过程称为域名解析。()59、赵天祥用photoshop的软件帮助魏老师将审稿材料手稿制作成word文档。(60、交互性是多媒体作品的重要特点之一。()61、在Word中编辑文档时,可以使用“文件页面设置”命令设置纸张大小。
c 抓取网页数据(0x1工具准备工欲善其事必先利其器,爬取语料的根基基于python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-09 07:15
0x1 工具准备
要想把工作做好,首先要磨砺自己的工具。爬取语料库的基础是python。
我们基于python3开发,主要使用以下模块:requests、lxml、json。
各模块功能简介
01|要求
requests 是一个 Python 第三方库,特别方便处理 URL 资源。它的官方文档有一个很大的口号:HTTP for Humans(为人类使用HTTP而生)。对比python自带的urllib体验,笔者认为requests的体验比urllib高一个数量级。
让我们做一个简单的比较:
网址库:
1import urllib2
2import urllib
3
4URL_GET = "https://api.douban.com/v2/event/list"
5#构建请求参数
6params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
7
8#发送请求
9response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
10#Response Headers
11print(response.info())
12#Response Code
13print(response.getcode())
14#Response Body
15print(response.read())
复制代码
要求:
1import requests
2
3URL_GET = "https://api.douban.com/v2/event/list"
4#构建请求参数
5params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
6
7#发送请求
8response = requests.get(URL_GET,params=params)
9#Response Headers
10print(response.headers)
11#Response Code
12print(response.status_code)
13#Response Body
14print(response.text)复制代码
我们可以发现这两个库有一些区别:
1. 参数的构造:urllib需要对参数进行urlencode,比较麻烦;请求不需要额外的编码,非常简洁。
2. 请求发送:urllib需要额外将url参数构造成符合要求的形式;requests 简洁很多,直接获取对应的链接和参数。
3. 连接方式:查看返回数据的头部信息中的“连接”。使用 urllib 库时,“connection”:“close”表示每次请求结束时关闭socket通道,requests库使用urllib3,多个请求复用一个socket,“connection”:“keep-alive”,表示多个请求使用一个连接,消耗资源较少
4. 编码方式:requests库的编码方式Accept-Encoding比较全,这里就不举例了
综上所述,使用requests更加简洁易懂,极大的方便了我们的开发。
02|lxml
BeautifulSoup 是一个库,XPath 是一种技术,python 中使用最多的 XPath 库是 lxml。
当我们得到请求返回的页面时,我们如何得到我们想要的数据呢?此时,lxml 是一个强大的 HTML/XML 解析工具。Python从来不缺解析库,那我们为什么要在众多库中选择lxml呢?我们选择另一个知名的 HTML 解析库 BeautifulSoup 进行对比。
让我们做一个简单的比较:
美丽汤:
1from bs4 import BeautifulSoup #导入库
2# 假设html是需要被解析的html
3
4#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
5soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
6#查找所有的h4标签
7links = soup.find_all("h4")
复制代码
lxml:
1from lxml import etree
2# 假设html是需要被解析的html
3
4#将html传入etree 的构造方法,得到一个文档的对象
5root = etree.HTML(html)
6#查找所有的h4标签
7links = root.xpath("//h4")
复制代码
我们可以发现这两个库有一些区别:
1.解析html:BeautifulSoup的解析方式和JQ类似。API 非常人性化,支持 css 选择器;lxml语法有一定的学习成本
2. 性能:BeautifulSoup 是基于 DOM 的,它会加载整个文档并解析整个 DOM 树,所以时间和内存开销会大很多;而lxml只会在本地遍历,而lxml是用c写的,而BeautifulSoup是用python写的,明显的表现就是lxml>>BeautifulSoup。
综上所述,使用 BeautifulSoup 更加简洁易用。lxml虽然有一定的学习成本,但总体来说简单易懂。最重要的是它是基于C编写的,速度要快得多。对于笔者的强迫症,自然就选择lxml了。
03|json
Python 自带了自己的 json 库,对于基本的 json 处理来说已经足够了。但是如果你想更懒一点,可以使用第三方的json库,常见的有demjson和simplejson。
这两个库,无论是导入模块速度,还是编解码速度,都比simplejson好,simplejson的兼容性更好。所以如果你想使用square库,你可以使用simplejson。
0x2 确定语料来源
武器准备好后,下一步就是确定爬行方向。
以电竞语料为例,现在我们来爬取电竞相关的语料。熟悉的电竞平台有企鹅电竞、企鹅电竞和企鹅电竞(斜视),所以我们使用企鹅电竞上的比赛直播作为数据源进行爬取。
我们登陆企鹅电竞官网,进入游戏列表页面。我们可以发现页面上有很多游戏。手动写这些游戏名显然是无利可图的,于是我们开始了爬虫的第一步:游戏列表爬取。
1import requests
2from lxml import etree
3
4# 更新游戏列表
5def _updateGameList():
6 # 发送HTTP请求时的HEAD信息,用于伪装为浏览器
7 heads = {
8 'Connection': 'Keep-Alive',
9 'Accept': 'text/html, application/xhtml+xml, */*',
10 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
11 'Accept-Encoding': 'gzip, deflate',
12 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
13 }
14 # 需要爬取的游戏列表页
15 url = 'https://egame.qq.com/gamelist'
16
17 # 不压缩html,最大链接时间为10妙
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码utf-8
20 res.encoding = 'utf-8'
21 # 将html构建为Xpath模式
22 root = etree.HTML(res.content)
23 # 使用Xpath语法,获取游戏名
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出爬到的游戏名
26 print(gameList)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于线块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页分词查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们把这两个标签和其中收录的文本组合成一个标签窗口(比如I am h1中的“I am h1”就是标签窗口的内容),取出文本的标签窗口。.
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于线块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时块长为引入判断。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
以这个网页为例:网页的文本区域从145行到182行。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1# 假设content为已经拿到的html
2
3# Ctext取周围k行(k max_text_len and (not boolstart)):
38 # Cblock下面3个都不为0,认为是正文
39 if (Ctext_len[i + 1] != 0 or Ctext_len[i + 2] != 0 or Ctext_len[i + 3] != 0):
40 boolstart = True
41 start = i
42 continue
43 if (boolstart):
44 # Cblock下面3个中有0,则结束
45 if (Ctext_len[i] == 0 or Ctext_len[i + 1] == 0):
46 end = i
47 boolend = True
48 tmp = []
49
50 # 判断下面还有没有正文
51 if(boolend):
52 for ii in range(start, end + 1):
53 if(len(lines[ii]) < 5):
54 continue
55 tmp.append(lines[ii] + "n")
56 str = "".join(list(tmp))
57 # 去掉版权信息
58 if ("Copyright" in str or "版权所有" in str):
59 continue
60 main_text.append(str)
61 boolstart = boolend = False
62# 返回主内容
63result = "".join(list(main_text))
复制代码
0x4 结语
至此,我们可以获得任意内容的文章语料库,但这仅仅是开始。获得这些语料后,我们还需要一次清洗、分割、标记等,才能得到实际可以使用的语料。 查看全部
c 抓取网页数据(0x1工具准备工欲善其事必先利其器,爬取语料的根基基于python)
0x1 工具准备
要想把工作做好,首先要磨砺自己的工具。爬取语料库的基础是python。
我们基于python3开发,主要使用以下模块:requests、lxml、json。
各模块功能简介
01|要求
requests 是一个 Python 第三方库,特别方便处理 URL 资源。它的官方文档有一个很大的口号:HTTP for Humans(为人类使用HTTP而生)。对比python自带的urllib体验,笔者认为requests的体验比urllib高一个数量级。
让我们做一个简单的比较:
网址库:
1import urllib2
2import urllib
3
4URL_GET = "https://api.douban.com/v2/event/list"
5#构建请求参数
6params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
7
8#发送请求
9response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
10#Response Headers
11print(response.info())
12#Response Code
13print(response.getcode())
14#Response Body
15print(response.read())
复制代码
要求:
1import requests
2
3URL_GET = "https://api.douban.com/v2/event/list"
4#构建请求参数
5params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
6
7#发送请求
8response = requests.get(URL_GET,params=params)
9#Response Headers
10print(response.headers)
11#Response Code
12print(response.status_code)
13#Response Body
14print(response.text)复制代码
我们可以发现这两个库有一些区别:
1. 参数的构造:urllib需要对参数进行urlencode,比较麻烦;请求不需要额外的编码,非常简洁。
2. 请求发送:urllib需要额外将url参数构造成符合要求的形式;requests 简洁很多,直接获取对应的链接和参数。
3. 连接方式:查看返回数据的头部信息中的“连接”。使用 urllib 库时,“connection”:“close”表示每次请求结束时关闭socket通道,requests库使用urllib3,多个请求复用一个socket,“connection”:“keep-alive”,表示多个请求使用一个连接,消耗资源较少
4. 编码方式:requests库的编码方式Accept-Encoding比较全,这里就不举例了
综上所述,使用requests更加简洁易懂,极大的方便了我们的开发。
02|lxml
BeautifulSoup 是一个库,XPath 是一种技术,python 中使用最多的 XPath 库是 lxml。
当我们得到请求返回的页面时,我们如何得到我们想要的数据呢?此时,lxml 是一个强大的 HTML/XML 解析工具。Python从来不缺解析库,那我们为什么要在众多库中选择lxml呢?我们选择另一个知名的 HTML 解析库 BeautifulSoup 进行对比。
让我们做一个简单的比较:
美丽汤:
1from bs4 import BeautifulSoup #导入库
2# 假设html是需要被解析的html
3
4#将html传入BeautifulSoup 的构造方法,得到一个文档的对象
5soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
6#查找所有的h4标签
7links = soup.find_all("h4")
复制代码
lxml:
1from lxml import etree
2# 假设html是需要被解析的html
3
4#将html传入etree 的构造方法,得到一个文档的对象
5root = etree.HTML(html)
6#查找所有的h4标签
7links = root.xpath("//h4")
复制代码
我们可以发现这两个库有一些区别:
1.解析html:BeautifulSoup的解析方式和JQ类似。API 非常人性化,支持 css 选择器;lxml语法有一定的学习成本
2. 性能:BeautifulSoup 是基于 DOM 的,它会加载整个文档并解析整个 DOM 树,所以时间和内存开销会大很多;而lxml只会在本地遍历,而lxml是用c写的,而BeautifulSoup是用python写的,明显的表现就是lxml>>BeautifulSoup。
综上所述,使用 BeautifulSoup 更加简洁易用。lxml虽然有一定的学习成本,但总体来说简单易懂。最重要的是它是基于C编写的,速度要快得多。对于笔者的强迫症,自然就选择lxml了。
03|json
Python 自带了自己的 json 库,对于基本的 json 处理来说已经足够了。但是如果你想更懒一点,可以使用第三方的json库,常见的有demjson和simplejson。
这两个库,无论是导入模块速度,还是编解码速度,都比simplejson好,simplejson的兼容性更好。所以如果你想使用square库,你可以使用simplejson。
0x2 确定语料来源
武器准备好后,下一步就是确定爬行方向。
以电竞语料为例,现在我们来爬取电竞相关的语料。熟悉的电竞平台有企鹅电竞、企鹅电竞和企鹅电竞(斜视),所以我们使用企鹅电竞上的比赛直播作为数据源进行爬取。
我们登陆企鹅电竞官网,进入游戏列表页面。我们可以发现页面上有很多游戏。手动写这些游戏名显然是无利可图的,于是我们开始了爬虫的第一步:游戏列表爬取。
1import requests
2from lxml import etree
3
4# 更新游戏列表
5def _updateGameList():
6 # 发送HTTP请求时的HEAD信息,用于伪装为浏览器
7 heads = {
8 'Connection': 'Keep-Alive',
9 'Accept': 'text/html, application/xhtml+xml, */*',
10 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
11 'Accept-Encoding': 'gzip, deflate',
12 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
13 }
14 # 需要爬取的游戏列表页
15 url = 'https://egame.qq.com/gamelist'
16
17 # 不压缩html,最大链接时间为10妙
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码utf-8
20 res.encoding = 'utf-8'
21 # 将html构建为Xpath模式
22 root = etree.HTML(res.content)
23 # 使用Xpath语法,获取游戏名
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出爬到的游戏名
26 print(gameList)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于线块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页分词查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们把这两个标签和其中收录的文本组合成一个标签窗口(比如I am h1中的“I am h1”就是标签窗口的内容),取出文本的标签窗口。.
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于线块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时块长为引入判断。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
以这个网页为例:网页的文本区域从145行到182行。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1# 假设content为已经拿到的html
2
3# Ctext取周围k行(k max_text_len and (not boolstart)):
38 # Cblock下面3个都不为0,认为是正文
39 if (Ctext_len[i + 1] != 0 or Ctext_len[i + 2] != 0 or Ctext_len[i + 3] != 0):
40 boolstart = True
41 start = i
42 continue
43 if (boolstart):
44 # Cblock下面3个中有0,则结束
45 if (Ctext_len[i] == 0 or Ctext_len[i + 1] == 0):
46 end = i
47 boolend = True
48 tmp = []
49
50 # 判断下面还有没有正文
51 if(boolend):
52 for ii in range(start, end + 1):
53 if(len(lines[ii]) < 5):
54 continue
55 tmp.append(lines[ii] + "n")
56 str = "".join(list(tmp))
57 # 去掉版权信息
58 if ("Copyright" in str or "版权所有" in str):
59 continue
60 main_text.append(str)
61 boolstart = boolend = False
62# 返回主内容
63result = "".join(list(main_text))
复制代码
0x4 结语
至此,我们可以获得任意内容的文章语料库,但这仅仅是开始。获得这些语料后,我们还需要一次清洗、分割、标记等,才能得到实际可以使用的语料。
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2022-04-06 18:15
开场白:为了写爬虫,抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。让我们记录三种常见的情况。以下抓包方法
1.PC浏览器网页抓取
网络板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足部分需求,如果是请求前和响应后处理最多),比如修改请求浏览器发送的数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为一个本地代理服务器,实现转发客户端和服务器的请求和响应
设置 Fiddler:
打开Fiddler,在菜单栏中,打开Tools –Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在手机app上使用Fiddler抓包也很简单。它类似于上面的PC浏览器。移动终端和PC应该在同一个局域网内。手机Wifi应该设置为代理。IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般为8888,这样手机上所有的网络/响应请求都必须被FIddler捕获并发送,这样我们才能针对某些链接进行分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理或代理链。
由于一般C/S客户端无法设置代理,FIddler无法检测到数据。我们可以使用 Proxifer 捕获所有请求并将其发送给 Fiddler,这样我们就可以在 Fiddler 中分析客户端请求。
Proxifer 设置:
设置很简单,如下图,两步就OK了
一种)。设置代理服务器以匹配 Fiddler 代理设置
b).设置代理规则
默认Default,我们可以忽略
点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地Fiddler设置的代理,可以任意设置
目的港:任意
行动:直接
到这里设置就完成了,我们可以打开腾讯视频视频客户端,在Fiddler和Proxifer中看到数据
4.计算机上的所有C/S客户端都可以抓包
这时候,当 Proxifer 打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器可执行程序文件,确认后即可上网
转载地址: 查看全部
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?)
开场白:为了写爬虫,抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。让我们记录三种常见的情况。以下抓包方法
1.PC浏览器网页抓取
网络板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12)可以满足部分需求,如果是请求前和响应后处理最多),比如修改请求浏览器发送的数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为一个本地代理服务器,实现转发客户端和服务器的请求和响应
设置 Fiddler:
打开Fiddler,在菜单栏中,打开Tools –Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在手机app上使用Fiddler抓包也很简单。它类似于上面的PC浏览器。移动终端和PC应该在同一个局域网内。手机Wifi应该设置为代理。IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般为8888,这样手机上所有的网络/响应请求都必须被FIddler捕获并发送,这样我们才能针对某些链接进行分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer的帮助
Proxifier 是一个非常强大的 socks5 客户端,它允许不支持通过代理服务器工作的网络程序通过 HTTPS 或 SOCKS 代理或代理链。
由于一般C/S客户端无法设置代理,FIddler无法检测到数据。我们可以使用 Proxifer 捕获所有请求并将其发送给 Fiddler,这样我们就可以在 Fiddler 中分析客户端请求。
Proxifer 设置:
设置很简单,如下图,两步就OK了
一种)。设置代理服务器以匹配 Fiddler 代理设置
b).设置代理规则
默认Default,我们可以忽略
点击添加
名称:提琴手.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地Fiddler设置的代理,可以任意设置
目的港:任意
行动:直接
到这里设置就完成了,我们可以打开腾讯视频视频客户端,在Fiddler和Proxifer中看到数据
4.计算机上的所有C/S客户端都可以抓包
这时候,当 Proxifer 打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器可执行程序文件,确认后即可上网
转载地址:
c 抓取网页数据(浅谈网络爬虫中广度优先算法的介绍及其代码实现过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-04-06 13:15
前几天分享了深度优先算法在网络爬虫中的介绍及其代码实现过程。还没来得及上车的可以点这个文章——关于深度优先算法和网络爬虫的简单代码。今天给大家分享一下网络爬虫中广度优先算法的介绍及其代码实现过程。
广度优先算法和深度优先算法正好相反。这里我们继续以上图中的二叉树为例。广度优先算法的主要思想是从顶级域名A开始,然后从中提取两个链接B和C。链接B爬完之后,下一个要爬的链接是链接B的同级链接C,而不是说爬完链接B之后,马上下去爬取子链接C或者D。爬完C之后,再回到继续爬取兄弟链接 B 下的子链接 D 或 E,然后返回爬取 C 链接下的兄弟链接 F、G、H,以此类推。
从表面上看,广度优先算法是一种分层爬取的策略。先抓取第一层的节点,再抓取第二层的节点,再依次抓取第三层的节点,以此类推,直到抓取完成或达到预定的抓取条件。可以认为广度优先算法是一种根据层次结构的遍历方法,因此也称为广度优先算法。了解了广度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、C、D、E、F、G、H、I(这里, 左边的链接假定会先被爬取)。通过以上了解,
下图是广度优先算法的代码实现过程。
首先传入一个顶层节点节点(链接A),然后判断该节点是否不为空。如果它是空的,它将被退回。如果不为空,则将其放入队列列表中,然后开始循环。使用pop()方法将队列列表中的元素移除(此时只有节点A),然后打印节点的数据。打印完节点后,看看是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则获取一个新的左节点(链接B)并将其放入队列列表中。之后程序继续执行,右节点的执行过程也是一样的。这时会得到正确的节点(链接C),也将其放入队列列表中。此时,队列列表中的元素有链接B和链接C,然后再次进行新一轮的循环。这样,我们就实现了广度优先算法中分层抓取链接的过程。这个逻辑比深度优先算法简单。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法。也是面试过程中很常见的面试题,所以建议大家需要掌握。
以上就是网络爬虫中广度优先算法的简单介绍。你们明白了吗? 查看全部
c 抓取网页数据(浅谈网络爬虫中广度优先算法的介绍及其代码实现过程)
前几天分享了深度优先算法在网络爬虫中的介绍及其代码实现过程。还没来得及上车的可以点这个文章——关于深度优先算法和网络爬虫的简单代码。今天给大家分享一下网络爬虫中广度优先算法的介绍及其代码实现过程。
广度优先算法和深度优先算法正好相反。这里我们继续以上图中的二叉树为例。广度优先算法的主要思想是从顶级域名A开始,然后从中提取两个链接B和C。链接B爬完之后,下一个要爬的链接是链接B的同级链接C,而不是说爬完链接B之后,马上下去爬取子链接C或者D。爬完C之后,再回到继续爬取兄弟链接 B 下的子链接 D 或 E,然后返回爬取 C 链接下的兄弟链接 F、G、H,以此类推。
从表面上看,广度优先算法是一种分层爬取的策略。先抓取第一层的节点,再抓取第二层的节点,再依次抓取第三层的节点,以此类推,直到抓取完成或达到预定的抓取条件。可以认为广度优先算法是一种根据层次结构的遍历方法,因此也称为广度优先算法。了解了广度优先算法后,再看上图,可以看到二叉树呈现的爬取链接的顺序是:A、B、C、D、E、F、G、H、I(这里, 左边的链接假定会先被爬取)。通过以上了解,
下图是广度优先算法的代码实现过程。
首先传入一个顶层节点节点(链接A),然后判断该节点是否不为空。如果它是空的,它将被退回。如果不为空,则将其放入队列列表中,然后开始循环。使用pop()方法将队列列表中的元素移除(此时只有节点A),然后打印节点的数据。打印完节点后,看看是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则获取一个新的左节点(链接B)并将其放入队列列表中。之后程序继续执行,右节点的执行过程也是一样的。这时会得到正确的节点(链接C),也将其放入队列列表中。此时,队列列表中的元素有链接B和链接C,然后再次进行新一轮的循环。这样,我们就实现了广度优先算法中分层抓取链接的过程。这个逻辑比深度优先算法简单。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法。也是面试过程中很常见的面试题,所以建议大家需要掌握。
以上就是网络爬虫中广度优先算法的简单介绍。你们明白了吗?
c 抓取网页数据( 网页信息提取的方式从网页中提取信息有一些方法? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 371 次浏览 • 2022-04-05 06:19
网页信息提取的方式从网页中提取信息有一些方法?
)
关于转载授权
编译|丁学煌年程序笔记|奚雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求呈指数级增长,其重要性也越来越明显。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并不是所有的 网站 都提供 API。有的网站不愿意让读者以结构化的方式获取大量信息,有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?好吧,我们需要通过网络抓取来获取数据。
当然还有其他的,比如RSS提要等,但由于使用限制,我不会在这里讨论它们。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转化为结构化数据(数据库或电子表格)。
网页抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
需要使用非编程方式提取网页数据的读者,可以去import.io看看。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用两个 Python 模块来抓取数据:
Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
·BeautifulSoup:这是一个从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。如:
·机械化
·刮痕
·scrapy
基础 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
此语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html 文件写在 和 标签之间
3.html文档的可见部分写在和标签之间
4.html头使用
标记定义
5.html段落使用
标签定义
其他有用的 HTML 标签是:
1.html 链接是使用标签“This is a test ”定义的
2.html表格使用定义,row用row表示,row的第二个元素在标签里,不在
分为数据
3.htmlList 以
)
如上图,你会注意到
标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。让我们看一下代码:
最后,我们dataframe里面的数据如下:
同样,可以使用 BeautifulSoup 执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但是为什么我不能只使用正则表达式呢?
现在,如果你知道一个正则表达式,你可能会认为你可以用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比用正则表达式编写的代码更强大。使用正则表达式编写的代码必须随着页面的变化而变化。尽管 BeautifulSoup 在某些情况下需要调整,但相对而言,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结语
在本文中,我们使用了两个 Python 库 BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。上海长海医院硕士研究生黄念对生物医学大数据挖掘及其应用非常感兴趣,愿意通过这个平台结识更多的朋友。熊芬 熊芬是北京邮电大学无线信号处理专业的研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。. 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
查看全部
c 抓取网页数据(
网页信息提取的方式从网页中提取信息有一些方法?
)
关于转载授权
编译|丁学煌年程序笔记|奚雄芬校对|姚嘉玲
介绍
从网页中提取信息的需求呈指数级增长,其重要性也越来越明显。每隔几周,我自己就想从网上获取一些信息。例如,上周我们考虑建立一个关于各种数据科学在线课程的受欢迎程度和意见指数。我们不仅需要识别新课程,还需要获取课程评论,总结它们并建立一些指标。这是一个问题或产品,其功效更多地取决于网络抓取和信息提取(数据集)技术,而不是我们过去使用的数据聚合技术。
如何从网页中提取信息
有几种方法可以从网页中提取信息。使用 API 可能被认为是从 网站 中提取信息的最佳方式。几乎所有的大型网站,如 Twitter、Facebook、Google、Twitter、StackOverflow 都提供 API 以更结构化的方式访问这些 网站 数据。如果可以直接通过 API 获取所需信息,这种方法几乎总是比网络抓取更好。因为如果可以从数据提供者那里获取结构化数据,为什么还要构建自己的引擎来提取相同的数据呢?
不幸的是,并不是所有的 网站 都提供 API。有的网站不愿意让读者以结构化的方式获取大量信息,有的网站由于缺乏相关的技术知识而无法提供API。在这样的情况下,应该怎么办?好吧,我们需要通过网络抓取来获取数据。
当然还有其他的,比如RSS提要等,但由于使用限制,我不会在这里讨论它们。
什么是网页抓取?
网页抓取是一种用于从 网站 获取信息的计算机软件技术。该技术主要侧重于将网络上的非结构化数据(HTML 格式)转化为结构化数据(数据库或电子表格)。
网页抓取可以通过不同的方式实现,从 Google Docs 到几乎任何编程语言。我会选择使用 Python,因为它的易用性和丰富的生态系统。Python 中的 BeautifulSoup 库可以协助完成这项任务。在本文中,我将向您展示使用 Python 编程语言学习网络抓取的最简单方法。
需要使用非编程方式提取网页数据的读者,可以去import.io看看。有基于GUI的驱动来运行网页抓取的基本操作,电脑爱好者可以继续阅读这篇文章!
网页抓取所需的库
我们都知道 Python 是一种开源编程语言。您也许可以找到许多库来实现一个功能。因此,找出最好的库是非常有必要的。我倾向于使用 BeautifulSoup(一个 Python 库),因为它易于使用且直观。准确地说,我使用两个 Python 模块来抓取数据:
Urllib2:它是一个用于获取 URL 的 Python 模块。它定义了实现 URL 操作(基本、摘要式身份验证、重定向、cookie 等)的函数和类。有关详细信息,请参阅文档页面。
·BeautifulSoup:这是一个从网页中提取信息的神奇工具。您可以使用它从网页中提取表格、列表、段落,还可以添加过滤器。在本文中,我们将使用最新版本 BeautifulSoup 4。安装说明可以在其文档页面上找到。
BeautifulSoup 不能帮助我们获取网页,这就是我使用 urllib2 和 BeautifulSoup 库的原因。除了 BeautifulSoup,Python 还有其他抓取 HTML 的方法。如:
·机械化
·刮痕
·scrapy
基础 - 熟悉 HTML(标签)
在进行网页抓取时,我们需要处理 html 标签。因此,我们首先要搞清楚标签。如果您已经了解 HTML 的基础知识,则可以跳过本节。以下是 HTML 的基本语法:
此语法的各种标签解释如下:
1.:html 文档必须以类型声明开头
2.html 文件写在 和 标签之间
3.html文档的可见部分写在和标签之间
4.html头使用
标记定义
5.html段落使用
标签定义
其他有用的 HTML 标签是:
1.html 链接是使用标签“This is a test ”定义的
2.html表格使用定义,row用row表示,row的第二个元素在标签里,不在
分为数据
3.htmlList 以
)
如上图,你会注意到
标签内。所以我们需要注意这一点。现在要访问每个元素的值,我们将为每个元素使用“find(text=True)”选项。让我们看一下代码:
最后,我们dataframe里面的数据如下:
同样,可以使用 BeautifulSoup 执行各种其他类型的网页抓取。这将简化从网页手动采集数据的工作。另请参阅其他属性,例如 .parent、.contents、.descendants 和 .next_sibling、.prev_sibling 以及标签名称浏览的各种属性。这些将帮助您有效地抓取网络。
但是为什么我不能只使用正则表达式呢?
现在,如果你知道一个正则表达式,你可能会认为你可以用它来编写代码来做同样的事情。当然,我也遇到过这个问题。我使用 BeautifulSoup 和正则表达式来做同样的事情,发现:
BeautifulSoup 中的代码比用正则表达式编写的代码更强大。使用正则表达式编写的代码必须随着页面的变化而变化。尽管 BeautifulSoup 在某些情况下需要调整,但相对而言,BeautifulSoup 更好。
正则表达式比 BeautifulSoup 快得多,在相同结果下比 BeautifulSoup 快 100 倍。
所以它归结为代码的速度和健壮性之间的比较,这里没有一刀切的赢家。如果您要查找的信息可以通过简单的正则表达式语句获取,那么您应该选择使用它们。对于几乎所有复杂的工作,我通常比正则表达式更推荐 BeautifulSoup。
结语
在本文中,我们使用了两个 Python 库 BeautifulSoup 和 urllib2。我们还学习了 HTML 的基础知识,并通过解决一个问题逐步实现了网页抓取。我建议您练习并使用它从网页中采集数据。
译者简介 丁雪,华中师范大学信息科学硕士,从事用户行为与个性化服务研究。关注大数据的发展,希望从事互联网和咨询行业的相关工作。上海长海医院硕士研究生黄念对生物医学大数据挖掘及其应用非常感兴趣,愿意通过这个平台结识更多的朋友。熊芬 熊芬是北京邮电大学无线信号处理专业的研究生。主要研究图信号处理,对基于社交网络的图数据挖掘感兴趣。他希望通过这个平台结识更多从事大数据的人,结交更多志同道合的人。. 家庭主妇姚嘉玲对数据分析处理非常感兴趣。她正在努力学习,希望能和你多交流。
c 抓取网页数据( 路上在将图像发送到模型之前模型接收带有车牌的输入 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-03 08:18
路上在将图像发送到模型之前模型接收带有车牌的输入
)
<p data-darkmode-bgcolor="rgb(36, 36, 36)" data-darkmode-color="rgb(143, 155, 171)" data-style="margin: 0em 0.5em; padding: 0px 0.5em; text-align: center; color: rgb(62, 71, 83); text-transform: none; text-indent: 0px; letter-spacing: 0.54px; clear: both; font-size: 16px; font-style: normal; font-variant: normal; font-weight: 400; text-decoration: none; word-spacing: 0px; white-space: normal; min-height: 1em; max-width: 100%; box-sizing: border-box; orphans: 2; -webkit-text-stroke-width: 0px; overflow-wrap: break-word; background-color: rgb(255, 255, 255);" style="margin: 0em 0.5em;padding-right: 0.5em;padding-left: 0.5em;font-variant-ligatures: no-common-ligatures no-discretionary-ligatures no-historical-ligatures no-contextual;font-variant-numeric: normal;font-variant-east-asian: normal;white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;widows: 1;text-align: center;color: rgb(62, 71, 83);letter-spacing: 0.54px;visibility: visible;">点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达</p>
介绍
我们知道,在当前形势下,我们正在逐步稳步战胜疫情,而且情况每天都在好转。然而,众所周知,即使在疫苗接种开始之后,彻底根除病毒也需要很多年。所以,为了安全起见,在接下来的几年里,我们所有人可能都会习惯戴口罩。就交通违法行为而言,政府仍然对不戴口罩上路的人进行严格的罚款。创建一个可以跟踪所有交通违法者详细信息并提高公民意识和纪律的系统是一种非常有用的方法。该系统还可以通过另外创建一个仪表板监控程序来改进,以跟踪违反该交通规则的人的增加或减少,在给定的时期内收取罚款,并确定主要违规者。工作范围作为代码实现的一部分,我们计划设计一个模型,将图像分类为有掩码和没有掩码的掩码。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构
网络抓取图像
该项目从识别要使用的数据集的问题开始。在我们的项目中,网上冲浪几乎没有为我们提供可用于我们项目的现有数据集。因此,我们决定应用网络抓取来采集带口罩和不带口罩的图像。我们使用 Beautiful Soap 和 Requests 库从 网站 下载图像并将它们保存到收录带和不带掩码的驱动程序的单独文件夹中。我们从以下 URL 中提取了数据,这些 URL 由蒙版和未蒙版图像组成。link url1 = link url2 = 下面是一段代码,用于演示网络上的图像抓取。
from bs4 import *
import requests as rq
import os
url1 = 'https://www.gettyimages.in/photos/driving-mask?page='
url2 = '&phrase=driving%20mask&sort=mostpopular'
url_list=[]
Links = []
for i in range(1,56):
full_url = url1+str(i)+url2
url_list.append(full_url)
for lst in url_list:
r2 = rq.get(lst)
soup = BeautifulSoup(r2.text, 'html.parser')
x=soup.select('img[src^="https://media.gettyimages.com/photos/"]')
for img in x:
Links.append(img['src'])
print(len(Links))
for index, img_link in enumerate(Links):
if i =0.5:
result = 'The person is Masked'
else:
result = 'The Person is Non Masked'
print(result)
return render_template('Show.html',result=result)
下面是作为上传图像文件的一部分向用户显示的 HTML 模板。
下面是一个 Html 模板,当 POST 方法在处理图像后发送结果时显示,显示驾驶员是否戴着口罩。
接下来,我们上传车辆的图像,该图像已被识别为未戴口罩的驾驶员。车辆图像通过图像预处理阶段再次处理,模型尝试从车牌中的车牌框中提取文本。
@app.route('/Vehicle', methods=['POST'])
def table2():
uploaded_file = request.files['file']
result=''
if uploaded_file.filename != '':
path='static/car'
filename = uploaded_file.filename
uploaded_file.save(os.path.join(path, filename))
img_path = os.path.join(path, filename)
print(img_path)
img = cv2.imread(img_path,cv2.IMREAD_COLOR)
img = cv2.resize(img, (600,400) )
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 13, 15, 15)
edged = cv2.Canny(gray, 30, 200)
contours = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:10]
screenCnt = None
for c in contours:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
if screenCnt is None:
detected = 0
print ("No contour detected")
else:
detected = 1
if detected == 1:
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
mask = np.zeros(gray.shape,np.uint8)
new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)
new_image = cv2.bitwise_and(img,img,mask=mask)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
Cropped = gray[topx:bottomx+1, topy:bottomy+1]
text = pytesseract.image_to_string(Cropped, config='--psm 11')
print("Detected license plate Number is:",text)
#text='GJW-1-15-A-1138'
print('"{}"'.format(text))
re.sub(r'[^\x00-\x7f]',r'', text)
text = text.replace("\n", " ")
text = re.sub('[\W_]+', '', text)
print(text)
print('"{}"'.format(text))
query1 = {"Number Plate": text}
print("0")
for doc in collection.find(query1):
doc1 = doc
Name=doc1['Name']
Address=doc1['Address']
License=doc1['License Number']
return render_template('Penalty.html',Name=Name,Address=Address,License=License)
下面是车辆图像上传页面,它接受用户输入并处理车辆图像以获得车牌号文本。
提取车牌号文本后,我们需要使用车牌来查找车牌持有人的详细信息,接下来我们将连接到 MongoDB 创建的名为 License_Details 的表。一旦我们有了车牌号、姓名、地址和其他详细信息,我们就可以生成罚款并将其显示在 HTML 模板页面上。
在未来的工作中,掩模模型的测试准确率与训练准确率相比要低得多。因此,未知数据集的误分类非常高。此外,我们需要努力提高基于 OpenCV 的车牌提取的准确性,因为错误的感兴趣区域可能会导致提取空车牌文本。此外,前端可以进一步改进,使其更具吸引力。参考
1.面罩检测器
2.面部识别与面膜应用和神经网络
3.在智能城市网络中使用口罩检测限制 COVID-19 的自动化系统:
4.自动车牌检测系统检测远车牌
5.自动车牌识别系统 (ANPR):一项调查
6.COVID-19:具有 OpenCV、Keras/TensorFlow 和深度学习的面罩检测器
7.OpenCV:使用 Python 的自动车牌/车牌识别 (ANPR)
8.
9.
10.使用OpenCV Python的车牌识别
11.车牌号检测
12.Github 链接
个人微信(如果没有备注不拉群!)请注明:地区+学校/企业+研究方向+昵称
<p style="padding-right: 0.5em;padding-left: 0.5em;letter-spacing: 0.544px;white-space: pre-wrap;background-color: rgb(254, 254, 254);"></p> 查看全部
c 抓取网页数据(
路上在将图像发送到模型之前模型接收带有车牌的输入
)
<p data-darkmode-bgcolor="rgb(36, 36, 36)" data-darkmode-color="rgb(143, 155, 171)" data-style="margin: 0em 0.5em; padding: 0px 0.5em; text-align: center; color: rgb(62, 71, 83); text-transform: none; text-indent: 0px; letter-spacing: 0.54px; clear: both; font-size: 16px; font-style: normal; font-variant: normal; font-weight: 400; text-decoration: none; word-spacing: 0px; white-space: normal; min-height: 1em; max-width: 100%; box-sizing: border-box; orphans: 2; -webkit-text-stroke-width: 0px; overflow-wrap: break-word; background-color: rgb(255, 255, 255);" style="margin: 0em 0.5em;padding-right: 0.5em;padding-left: 0.5em;font-variant-ligatures: no-common-ligatures no-discretionary-ligatures no-historical-ligatures no-contextual;font-variant-numeric: normal;font-variant-east-asian: normal;white-space: normal;font-family: -apple-system-font, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;font-size: 16px;widows: 1;text-align: center;color: rgb(62, 71, 83);letter-spacing: 0.54px;visibility: visible;">点击下方“AI算法与图像处理”,关注一下
重磅干货,第一时间送达</p>
介绍
我们知道,在当前形势下,我们正在逐步稳步战胜疫情,而且情况每天都在好转。然而,众所周知,即使在疫苗接种开始之后,彻底根除病毒也需要很多年。所以,为了安全起见,在接下来的几年里,我们所有人可能都会习惯戴口罩。就交通违法行为而言,政府仍然对不戴口罩上路的人进行严格的罚款。创建一个可以跟踪所有交通违法者详细信息并提高公民意识和纪律的系统是一种非常有用的方法。该系统还可以通过另外创建一个仪表板监控程序来改进,以跟踪违反该交通规则的人的增加或减少,在给定的时期内收取罚款,并确定主要违规者。工作范围作为代码实现的一部分,我们计划设计一个模型,将图像分类为有掩码和没有掩码的掩码。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 我们计划设计一个模型,将图像分类为带口罩和不带口罩的口罩。对于获得的属于无遮罩类别的图像,我们获取车牌图像并尝试提取车辆细节。车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构 车牌识别是使用第二个模型完成的,该模型接收带有车牌作为汽车图像的输入。完成车辆 ID 后,我们会将详细信息传递到一个虚拟数据库,其中收录车牌持有人的数据以及车辆的详细信息。根据数据验证,我们将生成罚款,将直接发送到罪犯的家庭地址。软件架构
网络抓取图像
该项目从识别要使用的数据集的问题开始。在我们的项目中,网上冲浪几乎没有为我们提供可用于我们项目的现有数据集。因此,我们决定应用网络抓取来采集带口罩和不带口罩的图像。我们使用 Beautiful Soap 和 Requests 库从 网站 下载图像并将它们保存到收录带和不带掩码的驱动程序的单独文件夹中。我们从以下 URL 中提取了数据,这些 URL 由蒙版和未蒙版图像组成。link url1 = link url2 = 下面是一段代码,用于演示网络上的图像抓取。
from bs4 import *
import requests as rq
import os
url1 = 'https://www.gettyimages.in/photos/driving-mask?page='
url2 = '&phrase=driving%20mask&sort=mostpopular'
url_list=[]
Links = []
for i in range(1,56):
full_url = url1+str(i)+url2
url_list.append(full_url)
for lst in url_list:
r2 = rq.get(lst)
soup = BeautifulSoup(r2.text, 'html.parser')
x=soup.select('img[src^="https://media.gettyimages.com/photos/"]')
for img in x:
Links.append(img['src'])
print(len(Links))
for index, img_link in enumerate(Links):
if i =0.5:
result = 'The person is Masked'
else:
result = 'The Person is Non Masked'
print(result)
return render_template('Show.html',result=result)
下面是作为上传图像文件的一部分向用户显示的 HTML 模板。
下面是一个 Html 模板,当 POST 方法在处理图像后发送结果时显示,显示驾驶员是否戴着口罩。
接下来,我们上传车辆的图像,该图像已被识别为未戴口罩的驾驶员。车辆图像通过图像预处理阶段再次处理,模型尝试从车牌中的车牌框中提取文本。
@app.route('/Vehicle', methods=['POST'])
def table2():
uploaded_file = request.files['file']
result=''
if uploaded_file.filename != '':
path='static/car'
filename = uploaded_file.filename
uploaded_file.save(os.path.join(path, filename))
img_path = os.path.join(path, filename)
print(img_path)
img = cv2.imread(img_path,cv2.IMREAD_COLOR)
img = cv2.resize(img, (600,400) )
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.bilateralFilter(gray, 13, 15, 15)
edged = cv2.Canny(gray, 30, 200)
contours = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = imutils.grab_contours(contours)
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:10]
screenCnt = None
for c in contours:
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
if len(approx) == 4:
screenCnt = approx
break
if screenCnt is None:
detected = 0
print ("No contour detected")
else:
detected = 1
if detected == 1:
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
mask = np.zeros(gray.shape,np.uint8)
new_image = cv2.drawContours(mask,[screenCnt],0,255,-1,)
new_image = cv2.bitwise_and(img,img,mask=mask)
(x, y) = np.where(mask == 255)
(topx, topy) = (np.min(x), np.min(y))
(bottomx, bottomy) = (np.max(x), np.max(y))
Cropped = gray[topx:bottomx+1, topy:bottomy+1]
text = pytesseract.image_to_string(Cropped, config='--psm 11')
print("Detected license plate Number is:",text)
#text='GJW-1-15-A-1138'
print('"{}"'.format(text))
re.sub(r'[^\x00-\x7f]',r'', text)
text = text.replace("\n", " ")
text = re.sub('[\W_]+', '', text)
print(text)
print('"{}"'.format(text))
query1 = {"Number Plate": text}
print("0")
for doc in collection.find(query1):
doc1 = doc
Name=doc1['Name']
Address=doc1['Address']
License=doc1['License Number']
return render_template('Penalty.html',Name=Name,Address=Address,License=License)
下面是车辆图像上传页面,它接受用户输入并处理车辆图像以获得车牌号文本。
提取车牌号文本后,我们需要使用车牌来查找车牌持有人的详细信息,接下来我们将连接到 MongoDB 创建的名为 License_Details 的表。一旦我们有了车牌号、姓名、地址和其他详细信息,我们就可以生成罚款并将其显示在 HTML 模板页面上。
在未来的工作中,掩模模型的测试准确率与训练准确率相比要低得多。因此,未知数据集的误分类非常高。此外,我们需要努力提高基于 OpenCV 的车牌提取的准确性,因为错误的感兴趣区域可能会导致提取空车牌文本。此外,前端可以进一步改进,使其更具吸引力。参考
1.面罩检测器
2.面部识别与面膜应用和神经网络
3.在智能城市网络中使用口罩检测限制 COVID-19 的自动化系统:
4.自动车牌检测系统检测远车牌
5.自动车牌识别系统 (ANPR):一项调查
6.COVID-19:具有 OpenCV、Keras/TensorFlow 和深度学习的面罩检测器
7.OpenCV:使用 Python 的自动车牌/车牌识别 (ANPR)
8.
9.
10.使用OpenCV Python的车牌识别
11.车牌号检测
12.Github 链接
个人微信(如果没有备注不拉群!)请注明:地区+学校/企业+研究方向+昵称
<p style="padding-right: 0.5em;padding-left: 0.5em;letter-spacing: 0.544px;white-space: pre-wrap;background-color: rgb(254, 254, 254);">
</p> c 抓取网页数据( 谷歌都行的手机号码归属地查询的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-02 17:13
谷歌都行的手机号码归属地查询的
)
【转载】提供网页抓取hao123手机号归属地示例-苏飞-Perky Su-博客园。
我有一段时间没有写博客了。最近工作压力很大。你在忙什么?最近装了win7操作系统,感觉很不错。我也体验过IE9。其中的开发人员工具非常有用。
说到这里,你可以用火狐的谷歌。在这个例子中,我主要使用IE9自带的来分析hao123手机号码归属地查询的问题。
让我们看看下面的图片
在hao123的这个界面中,我们只需要输入一个手机号码,无论是中国移动、中国联通还是电信,点击查询,就可以直接查询到归属地、号码类型,比如在线。
网站很多,我就以这个为例,那我们如何把这些信息放在我们自己的网站上呢?
我们先来分析一下。它实际上非常方便。我们在IE9下打开这个界面然后进入工具-开发者工具,或者直接安装f12。
我们先点击网络然后点击开始抓包,这次我们再次点击查询按钮看看会发生什么
有两个完整的吗?第一个显然是加载我们输入的号码的归属信息,而第一个是加载一张图片,这对我们没有任何用处。我不在乎这里,现在我们
我们点击第一种方法,看看捕获了什么
URL显然是一个GET请求,只要请求这个地址,就可以得到如下结果
phone.callBack({"Mobile":"","QueryResult":"True","Province":"云南","City":"昆明","AreaCode":"0871","PostCode":"650000 ","企业":"中国移动","卡":"GSM"});
使用手机号、省、市,以及邮编、号码类型等信息。如果我们这样看,我们可以直接把这个区域复制到地址栏中,然后我们来看看效果。
果然是我们想要的,别着急,其他的可以更简单,我们来看看这个网址
如果我删除以下 RUles 编号并仅保留这些编号会怎样?
直接放到地址栏试试效果
哦,太神奇了,我得到的是一个xml文件
这就像我们调用WebServices一样简单,我们只需要编写一个程序来请求这个地址就可以得到我们想要的效果。
随便新建一个项目,一起看看
我就不一步一步分析了,你可以直接看我的代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Net;
using System.IO;
using System.Security.Cryptography.X509Certificates;
using System.Net.Security;
using System.Security.Cryptography;
using System.Xml;
namespace ccbText
{
public partial class Form2 : Form
{
public Form2()
{
InitializeComponent();
}
private void Form2_Load(object sender, EventArgs e)
{
}
这个方法在这里没有用到,大家可以做为参考
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
// 获取对应HTTP请求的响应
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("utf-8"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
}
///
/// 好123查询,符合下列规则也可使用
/// 返回xml
/// 需要顺序的节点:
/// QueryResult(查询结果状态True,False)
/// Province(所属省份)
/// City(所属地区)
/// Corp(服务商)
/// Card(卡类型 GSM)
/// AreaCode(区号)
/// PostCode(邮编)
///
///
///
///
public static string[] GetInfoByxml(string url, string mobileNum)
{
try
{
XmlDocument xml = new XmlDocument();
// xml.LoadXml("
15890636739True
河南郑州0371
450000中国移动GSM");
xml.Load(string.Format(url, mobileNum));
XmlNamespaceManager xmlNm = new XmlNamespaceManager(xml.NameTable);
xmlNm.AddNamespace("content", "http://api.showji.com/Locating/");
XmlNodeList nodes = xml.SelectNodes("//content:QueryResult|//content:Mobile|//content:Province|//content:City|//content:Corp|//content:Card|//content:AreaCode|//content:PostCode", xmlNm);
if (nodes.Count == 8)
{
if ("True".Equals(nodes[1].InnerText))
{
return new string[] { nodes[0].InnerText, nodes[2].InnerText + nodes[3].InnerText, nodes[6].InnerText + nodes[7].InnerText, nodes[4].InnerText, nodes[5].InnerText };
}
}
return new string[] { "FALSE" };
}
catch
{
return new string[] { "FALSE" };
}
}
//调用方法查询数据
private void button1_Click(object sender, EventArgs e)
{
foreach (string item in GetInfoByxml(" http://vip.showji.com/locating/?m={0}", txtMobile.Text.Trim()))
{
richTextBox1.Text += "__" + item;
}
}
}
}
运行一下看看效果
我用 Winfrom 做测试,如果你想用 Asp。net也是一样,把我的方法复制到你网页的cs代码中就OK了。
好了,我们的分析到此结束。
这里我再添加一个调用网站的方法,带证书到大空
因为证书文件要通过证书文件进行验证,所以我们直接让他在本地回调验证。在这种情况下,我们需要重写方法。我们来看看回调方法。
//回调验证证书问题
public bool CheckValidationResult(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{ // 总是接受
return true;
}
其他的很简单,只要在我们上面的方法GetUrltoHtml()中添加几行代码,修改后的方法
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
ServicePointManager.ServerCertificateValidationCallback = new System.Net.Security.RemoteCertificateValidationCallback(CheckValidationResult);//验证
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8; .NET4.0C; .NET4.0E)";
request.Method = "GET";
request.Accept = "*/*";
//创建证书文件
X509Certificate objx509 = new X509Certificate(Application.StartupPath + "\\123.cer");
//添加到请求里
request.ClientCertificates.Add(objx509);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取对应HTTP请求的响应
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("GBK"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
} 查看全部
c 抓取网页数据(
谷歌都行的手机号码归属地查询的
)
【转载】提供网页抓取hao123手机号归属地示例-苏飞-Perky Su-博客园。
我有一段时间没有写博客了。最近工作压力很大。你在忙什么?最近装了win7操作系统,感觉很不错。我也体验过IE9。其中的开发人员工具非常有用。
说到这里,你可以用火狐的谷歌。在这个例子中,我主要使用IE9自带的来分析hao123手机号码归属地查询的问题。
让我们看看下面的图片
在hao123的这个界面中,我们只需要输入一个手机号码,无论是中国移动、中国联通还是电信,点击查询,就可以直接查询到归属地、号码类型,比如在线。
网站很多,我就以这个为例,那我们如何把这些信息放在我们自己的网站上呢?
我们先来分析一下。它实际上非常方便。我们在IE9下打开这个界面然后进入工具-开发者工具,或者直接安装f12。
我们先点击网络然后点击开始抓包,这次我们再次点击查询按钮看看会发生什么
有两个完整的吗?第一个显然是加载我们输入的号码的归属信息,而第一个是加载一张图片,这对我们没有任何用处。我不在乎这里,现在我们
我们点击第一种方法,看看捕获了什么
URL显然是一个GET请求,只要请求这个地址,就可以得到如下结果
phone.callBack({"Mobile":"","QueryResult":"True","Province":"云南","City":"昆明","AreaCode":"0871","PostCode":"650000 ","企业":"中国移动","卡":"GSM"});
使用手机号、省、市,以及邮编、号码类型等信息。如果我们这样看,我们可以直接把这个区域复制到地址栏中,然后我们来看看效果。
果然是我们想要的,别着急,其他的可以更简单,我们来看看这个网址
如果我删除以下 RUles 编号并仅保留这些编号会怎样?
直接放到地址栏试试效果
哦,太神奇了,我得到的是一个xml文件
这就像我们调用WebServices一样简单,我们只需要编写一个程序来请求这个地址就可以得到我们想要的效果。
随便新建一个项目,一起看看
我就不一步一步分析了,你可以直接看我的代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Net;
using System.IO;
using System.Security.Cryptography.X509Certificates;
using System.Net.Security;
using System.Security.Cryptography;
using System.Xml;
namespace ccbText
{
public partial class Form2 : Form
{
public Form2()
{
InitializeComponent();
}
private void Form2_Load(object sender, EventArgs e)
{
}
这个方法在这里没有用到,大家可以做为参考
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
// 获取对应HTTP请求的响应
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("utf-8"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
}
///
/// 好123查询,符合下列规则也可使用
/// 返回xml
/// 需要顺序的节点:
/// QueryResult(查询结果状态True,False)
/// Province(所属省份)
/// City(所属地区)
/// Corp(服务商)
/// Card(卡类型 GSM)
/// AreaCode(区号)
/// PostCode(邮编)
///
///
///
///
public static string[] GetInfoByxml(string url, string mobileNum)
{
try
{
XmlDocument xml = new XmlDocument();
// xml.LoadXml("
15890636739True
河南郑州0371
450000中国移动GSM");
xml.Load(string.Format(url, mobileNum));
XmlNamespaceManager xmlNm = new XmlNamespaceManager(xml.NameTable);
xmlNm.AddNamespace("content", "http://api.showji.com/Locating/";);
XmlNodeList nodes = xml.SelectNodes("//content:QueryResult|//content:Mobile|//content:Province|//content:City|//content:Corp|//content:Card|//content:AreaCode|//content:PostCode", xmlNm);
if (nodes.Count == 8)
{
if ("True".Equals(nodes[1].InnerText))
{
return new string[] { nodes[0].InnerText, nodes[2].InnerText + nodes[3].InnerText, nodes[6].InnerText + nodes[7].InnerText, nodes[4].InnerText, nodes[5].InnerText };
}
}
return new string[] { "FALSE" };
}
catch
{
return new string[] { "FALSE" };
}
}
//调用方法查询数据
private void button1_Click(object sender, EventArgs e)
{
foreach (string item in GetInfoByxml(" http://vip.showji.com/locating/?m={0}", txtMobile.Text.Trim()))
{
richTextBox1.Text += "__" + item;
}
}
}
}
运行一下看看效果
我用 Winfrom 做测试,如果你想用 Asp。net也是一样,把我的方法复制到你网页的cs代码中就OK了。
好了,我们的分析到此结束。
这里我再添加一个调用网站的方法,带证书到大空
因为证书文件要通过证书文件进行验证,所以我们直接让他在本地回调验证。在这种情况下,我们需要重写方法。我们来看看回调方法。
//回调验证证书问题
public bool CheckValidationResult(object sender, X509Certificate certificate, X509Chain chain, SslPolicyErrors errors)
{ // 总是接受
return true;
}
其他的很简单,只要在我们上面的方法GetUrltoHtml()中添加几行代码,修改后的方法
///
/// 传入URL返回网页的html代码
///
///
URL ///
public string GetUrltoHtml(string Url)
{
StringBuilder content = new StringBuilder();
try
{
// 与指定URL创建HTTP请求
ServicePointManager.ServerCertificateValidationCallback = new System.Net.Security.RemoteCertificateValidationCallback(CheckValidationResult);//验证
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Url);
request.KeepAlive = false;
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8; .NET4.0C; .NET4.0E)";
request.Method = "GET";
request.Accept = "*/*";
//创建证书文件
X509Certificate objx509 = new X509Certificate(Application.StartupPath + "\\123.cer");
//添加到请求里
request.ClientCertificates.Add(objx509);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
// 获取对应HTTP请求的响应
// 获取响应流
Stream responseStream = response.GetResponseStream();
// 对接响应流(以"GBK"字符集)
StreamReader sReader = new StreamReader(responseStream, Encoding.GetEncoding("GBK"));
// 开始读取数据
Char[] sReaderBuffer = new Char[256];
int count = sReader.Read(sReaderBuffer, 0, 256);
while (count > 0)
{
String tempStr = new String(sReaderBuffer, 0, count);
content.Append(tempStr);
count = sReader.Read(sReaderBuffer, 0, 256);
}
// 读取结束
sReader.Close();
}
catch (Exception)
{
content = new StringBuilder("Runtime Error");
}
return content.ToString();
}
c 抓取网页数据(Python爬虫世界里必不可少的神兵利器-页面解析和数据提取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-30 15:14
页面解析和数据提取javascript
一般来说,对于我们来说,需要爬取的是一个网站或者一个应用的内容,以提取有用的价值。内容通常分为两部分,非结构化数据和结构化数据。php
非结构化数据处理文本、电话号码、电子邮件地址HTML 文档结构化数据处理JSON 文档XML 文档为什么要学习正则表达式
其实爬虫主要有四个步骤: css
清除目标(知道要在哪个范围内搜索或网站) 爬取(爬取网站的所有内容) 获取(删除对我们无用的数据) 处理数据(根据以我们想要的方式存储和使用)
我们实际上省略了步骤 3,即昨天案例中的“采取”步骤。由于我们下载的数据都是网页,数据庞大而混乱,而且大部分是我们不关心的,所以我们需要根据自己的需要进行过滤和匹配。html
所以对于文本过滤或者规则匹配来说,最厉害的就是正则表达式,它是Python爬虫世界里不可或缺的利器。爪哇
什么是正则表达式
正则表达式也称为正则表达式,一般用于检索和替换符合某种模式(规则)的文本。节点
正则表达式是一个字符串操作的逻辑公式,就是用一些预先定义好的特定字符和这些特定字符的组合组成一个“规则字符串”,而这个“规则字符串”用来表达A过滤逻辑字符串。Python
给定一个正则表达式和另一个字符串,我们可以实现以下目标: 程序员
正则表达式匹配规则
Python的re模块
在 Python 中,我们可以通过内置的 re 模块来使用正则表达式。网络
需要注意的一点是正则表达式使用特殊字符的转义,所以如果我们想使用原创字符串,只需添加一个 r 前缀,例如:正则表达式
r'chuanzhiboke\t\.\tpython'
使用 re 模块的通常步骤如下:
使用compile()函数将正则表达式的字符串形式编译成Pattern对象
通过Pattern对象提供的一系列方法,对文本进行匹配查找,得到匹配结果,就是一个Match对象。
最后,使用 Match 对象提供的属性和方法来获取信息,并根据需要执行其余操作。编译函数
compile函数用于编译正则表达式并生成Pattern对象,通常以如下形式使用:
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
上面,我们已经将一个正则表达式编译成一个 Pattern 对象。接下来,我们可以使用pattern的一系列方法来匹配文本。
Pattern 对象的一些常用方法是:
匹配方法
match方法用于查找字符串的头部(也可以指定起始位置),是一个匹配,只要找到一个匹配的结果,就会返回,而不是查找所有的匹配结果。它通常以下列形式使用:
match(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。所以,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
上面,匹配成功时返回一个 Match 对象,其中:
让我们看另一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print m # 匹配成功,返回一个 Match 对象
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last): File "", line 1, in IndexError: no such group
-------------------------------------------------- -------------------------------------------------- -- 搜索方法
search 方法用于查找字符串中的任何位置。这也是一场比赛。只要找到匹配结果,就会返回,而不是查找所有匹配结果。它通常以下列形式使用:
搜索(字符串[,pos[,endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
让我们看一个例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里若是使用 match 方法则不匹配
>>> m
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
>>> m.group()
'34'
>>> m.span()
(13, 15)
让我们看另一个例子:
# -*- coding: utf-8 -*-
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 没法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 得到分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span()
结果:
matching string: 123456
position: (6, 12)
-------------------------------------------------- -------------------------------------------------- -- findall 方法
以上匹配和搜索方式都是一次性匹配,只要找到匹配结果,就会返回。但是,大多数时候,我们需要搜索整个字符串来获得所有匹配的结果。
findall 方法可以按以下形式使用:
findall(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
findall 将所有匹配的子字符串作为一个列表返回,如果没有匹配则返回一个空列表。
看一下这个例子:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print result1
print result2
结果:
['123456', '789']
['1', '2']
我们先来看一个栗子:
# re_test.py
import re
#re模块提供一个方法叫compile模块,提供咱们输入一个匹配的规则
#而后返回一个pattern实例,咱们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*')
#经过partten.findall()方法就可以所有匹配到咱们获得的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall 以 列表形式 返回所有能匹配的子串给result
for item in result:
print item
运行结果:
123.141593
3.15
-------------------------------------------------- -------------------------------------------------- -- 查找器方法
finditer 方法的行为类似于 findall 的行为,同样会搜索整个字符串并获取所有匹配的结果。但它返回一个迭代器,该迭代器按顺序访问每个匹配结果(Match 对象)。
看一下这个例子:
# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print type(result_iter1)
print type(result_iter2)
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span())
print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
结果:
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
-------------------------------------------------- -------------------------------------------------- -- 分割方法
split 方法根据可以匹配的子字符串将字符串拆分后返回一个列表。它可以以下列形式使用:
split(string[, maxsplit])
其中,maxsplit 用于指定最大拆分次数,而不是指定所有拆分。
看一下这个例子:
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
结果:
['a', 'b', 'c', 'd']
-------------------------------------------------- -------------------------------------------------- -- 子方法
sub 方法用于替换。它以下列形式使用:
sub(repl, string[, count])
其中,repl 可以是字符串,也可以是函数:
看一下这个例子:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456'
print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组
def func(m):
return 'hi' + ' ' + m.group(2)
print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
-------------------------------------------------- -------------------------------------------------- -- 匹配中文
在某些情况下,我们希望匹配文本中的汉字。需要注意的一点是,中文的unicode编码范围主要在[u4e00-u9fa5],这主要是因为这个范围不完整,比如不包括全角(中文)标点,但是,在大多数情况下。
假设现在要提取字符串title = u'hello, hello, world'中的中文,可以这样:
import re
title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print result
请注意,我们为正则表达式添加了两个前缀 ur,其中 r 表示使用原创字符串,u 表示它是 unicode 字符串。
结果:
[u'\u4f60\u597d', u'\u4e16\u754c']
注意:贪心模式和非贪心模式贪心模式:在整个表达式匹配成功的前提下,尽量匹配(*);非贪心模式:在整个表达式匹配成功的前提下,尽量少匹配(?);Python 中的量词默认是贪婪的。示例 1:源字符串:abbbc 示例 2:源字符串:aa
测试1
bb
测试2
抄送
这是贪婪模式。匹配到第一个“
",整个表达式都可以匹配成功,但是因为使用了贪心模式,所以还是要尝试向右匹配,看是否有更长的子串可以匹配成功。匹配到第二个" 查看全部
c 抓取网页数据(Python爬虫世界里必不可少的神兵利器-页面解析和数据提取)
页面解析和数据提取javascript
一般来说,对于我们来说,需要爬取的是一个网站或者一个应用的内容,以提取有用的价值。内容通常分为两部分,非结构化数据和结构化数据。php
非结构化数据处理文本、电话号码、电子邮件地址HTML 文档结构化数据处理JSON 文档XML 文档为什么要学习正则表达式
其实爬虫主要有四个步骤: css
清除目标(知道要在哪个范围内搜索或网站) 爬取(爬取网站的所有内容) 获取(删除对我们无用的数据) 处理数据(根据以我们想要的方式存储和使用)
我们实际上省略了步骤 3,即昨天案例中的“采取”步骤。由于我们下载的数据都是网页,数据庞大而混乱,而且大部分是我们不关心的,所以我们需要根据自己的需要进行过滤和匹配。html
所以对于文本过滤或者规则匹配来说,最厉害的就是正则表达式,它是Python爬虫世界里不可或缺的利器。爪哇
什么是正则表达式
正则表达式也称为正则表达式,一般用于检索和替换符合某种模式(规则)的文本。节点
正则表达式是一个字符串操作的逻辑公式,就是用一些预先定义好的特定字符和这些特定字符的组合组成一个“规则字符串”,而这个“规则字符串”用来表达A过滤逻辑字符串。Python
给定一个正则表达式和另一个字符串,我们可以实现以下目标: 程序员
正则表达式匹配规则
Python的re模块
在 Python 中,我们可以通过内置的 re 模块来使用正则表达式。网络
需要注意的一点是正则表达式使用特殊字符的转义,所以如果我们想使用原创字符串,只需添加一个 r 前缀,例如:正则表达式
r'chuanzhiboke\t\.\tpython'
使用 re 模块的通常步骤如下:
使用compile()函数将正则表达式的字符串形式编译成Pattern对象
通过Pattern对象提供的一系列方法,对文本进行匹配查找,得到匹配结果,就是一个Match对象。
最后,使用 Match 对象提供的属性和方法来获取信息,并根据需要执行其余操作。编译函数
compile函数用于编译正则表达式并生成Pattern对象,通常以如下形式使用:
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
上面,我们已经将一个正则表达式编译成一个 Pattern 对象。接下来,我们可以使用pattern的一系列方法来匹配文本。
Pattern 对象的一些常用方法是:
匹配方法
match方法用于查找字符串的头部(也可以指定起始位置),是一个匹配,只要找到一个匹配的结果,就会返回,而不是查找所有的匹配结果。它通常以下列形式使用:
match(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。所以,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
上面,匹配成功时返回一个 Match 对象,其中:
让我们看另一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print m # 匹配成功,返回一个 Match 对象
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last): File "", line 1, in IndexError: no such group
-------------------------------------------------- -------------------------------------------------- -- 搜索方法
search 方法用于查找字符串中的任何位置。这也是一场比赛。只要找到匹配结果,就会返回,而不是查找所有匹配结果。它通常以下列形式使用:
搜索(字符串[,pos[,endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配,则返回 None。
让我们看一个例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里若是使用 match 方法则不匹配
>>> m
>>> m.group()
'12'
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
>>> m.group()
'34'
>>> m.span()
(13, 15)
让我们看另一个例子:
# -*- coding: utf-8 -*-
import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 没法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 得到分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span()
结果:
matching string: 123456
position: (6, 12)
-------------------------------------------------- -------------------------------------------------- -- findall 方法
以上匹配和搜索方式都是一次性匹配,只要找到匹配结果,就会返回。但是,大多数时候,我们需要搜索整个字符串来获得所有匹配的结果。
findall 方法可以按以下形式使用:
findall(string[, pos[, endpos]])
其中,string为要匹配的字符串,pos和endpos为可选参数,指定字符串的起止位置,默认值分别为0和len(字符串长度)。
findall 将所有匹配的子字符串作为一个列表返回,如果没有匹配则返回一个空列表。
看一下这个例子:
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10)
print result1
print result2
结果:
['123456', '789']
['1', '2']
我们先来看一个栗子:
# re_test.py
import re
#re模块提供一个方法叫compile模块,提供咱们输入一个匹配的规则
#而后返回一个pattern实例,咱们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*')
#经过partten.findall()方法就可以所有匹配到咱们获得的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15")
#findall 以 列表形式 返回所有能匹配的子串给result
for item in result:
print item
运行结果:
123.141593
3.15
-------------------------------------------------- -------------------------------------------------- -- 查找器方法
finditer 方法的行为类似于 findall 的行为,同样会搜索整个字符串并获取所有匹配的结果。但它返回一个迭代器,该迭代器按顺序访问每个匹配结果(Match 对象)。
看一下这个例子:
# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print type(result_iter1)
print type(result_iter2)
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span())
print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
结果:
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
-------------------------------------------------- -------------------------------------------------- -- 分割方法
split 方法根据可以匹配的子字符串将字符串拆分后返回一个列表。它可以以下列形式使用:
split(string[, maxsplit])
其中,maxsplit 用于指定最大拆分次数,而不是指定所有拆分。
看一下这个例子:
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
结果:
['a', 'b', 'c', 'd']
-------------------------------------------------- -------------------------------------------------- -- 子方法
sub 方法用于替换。它以下列形式使用:
sub(repl, string[, count])
其中,repl 可以是字符串,也可以是函数:
看一下这个例子:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456'
print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组
def func(m):
return 'hi' + ' ' + m.group(2)
print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
-------------------------------------------------- -------------------------------------------------- -- 匹配中文
在某些情况下,我们希望匹配文本中的汉字。需要注意的一点是,中文的unicode编码范围主要在[u4e00-u9fa5],这主要是因为这个范围不完整,比如不包括全角(中文)标点,但是,在大多数情况下。
假设现在要提取字符串title = u'hello, hello, world'中的中文,可以这样:
import re
title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print result
请注意,我们为正则表达式添加了两个前缀 ur,其中 r 表示使用原创字符串,u 表示它是 unicode 字符串。
结果:
[u'\u4f60\u597d', u'\u4e16\u754c']
注意:贪心模式和非贪心模式贪心模式:在整个表达式匹配成功的前提下,尽量匹配(*);非贪心模式:在整个表达式匹配成功的前提下,尽量少匹配(?);Python 中的量词默认是贪婪的。示例 1:源字符串:abbbc 示例 2:源字符串:aa
测试1
bb
测试2
抄送
这是贪婪模式。匹配到第一个“
",整个表达式都可以匹配成功,但是因为使用了贪心模式,所以还是要尝试向右匹配,看是否有更长的子串可以匹配成功。匹配到第二个"
c 抓取网页数据(京东云专有云安全白皮书-自然语言处理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-30 15:10
下载链接
相关链接 有关京东云数据安全的更多信息,以及查看和下载京东云数据安全白皮书PDF版本,请访问以下链接。京东云数据安全白皮书
下载链接
相关链接 更多专有云安全信息,以及查看和下载京东云专有云安全白皮书PDF版,请访问以下链接。京东云专有云安全白皮书
【人工智能-自然语言处理】语言模型填空
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】闲聊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
插入规则
2、在弹窗中编辑插入规则,点击确定完成操作。请注意,插入操作会在单击插入按钮的规则之前插入更高优先级的规则。比如用户需要在优先级1和2的规则之间插入,点击优先级2规则的插入按钮。插入完成后,新插入的规则的优先级为2,规则原创优先级为 2 及以后的优先级。等级 +1 自动。
【人工智能-自然语言处理】句法分析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】评论意见抽取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本分类
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址解析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本流畅度
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】智能分诊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】机器翻译
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】草题
进入京东云控制台总览页面,您可以根据实际需要进行配置。
Oracle企业链云平台
企业建链云平台封装了区块链底层技术,将复杂的区块链系统拆分成完全独立的模块,为建链者提供全面的建链解决方案,通过图形界面产品实现标准化制造。连锁,简单,无门槛,高效低成本。
Oracle数据链上云平台
数据上传云平台让政府、企业和开发者更轻松地实现适合自身业务场景的数据上传。
【人工智能-自然语言处理】IP风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】定制智能写作
进入京东云控制台总览页面,您可以根据实际需要进行配置。
网站记录号超链接设置
·备案号已链接工信部网站,点击跳转到工信部查询确认备案信息页面。
10多个sku链接进行产品直播
商品直播链接 查看全部
c 抓取网页数据(京东云专有云安全白皮书-自然语言处理(组图))
下载链接
相关链接 有关京东云数据安全的更多信息,以及查看和下载京东云数据安全白皮书PDF版本,请访问以下链接。京东云数据安全白皮书
下载链接
相关链接 更多专有云安全信息,以及查看和下载京东云专有云安全白皮书PDF版,请访问以下链接。京东云专有云安全白皮书
【人工智能-自然语言处理】语言模型填空
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】闲聊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
插入规则
2、在弹窗中编辑插入规则,点击确定完成操作。请注意,插入操作会在单击插入按钮的规则之前插入更高优先级的规则。比如用户需要在优先级1和2的规则之间插入,点击优先级2规则的插入按钮。插入完成后,新插入的规则的优先级为2,规则原创优先级为 2 及以后的优先级。等级 +1 自动。
【人工智能-自然语言处理】句法分析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】评论意见抽取
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本分类
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址解析
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】文本流畅度
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】智能分诊
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】机器翻译
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】草题
进入京东云控制台总览页面,您可以根据实际需要进行配置。
Oracle企业链云平台
企业建链云平台封装了区块链底层技术,将复杂的区块链系统拆分成完全独立的模块,为建链者提供全面的建链解决方案,通过图形界面产品实现标准化制造。连锁,简单,无门槛,高效低成本。
Oracle数据链上云平台
数据上传云平台让政府、企业和开发者更轻松地实现适合自身业务场景的数据上传。
【人工智能-自然语言处理】IP风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】地址风险识别
进入京东云控制台总览页面,您可以根据实际需要进行配置。
【人工智能-自然语言处理】定制智能写作
进入京东云控制台总览页面,您可以根据实际需要进行配置。
网站记录号超链接设置
·备案号已链接工信部网站,点击跳转到工信部查询确认备案信息页面。
10多个sku链接进行产品直播
商品直播链接
c 抓取网页数据(python爬取js执行后输出的信息-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-29 12:12
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页的文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url))# 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url)#请求页面会打开浏览器窗口
html_text=driver.page_source
driver.quit()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))# 会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序=webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content=driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索我们之前的文章或者继续浏览下面的相关文章希望大家以后多多支持! 查看全部
c 抓取网页数据(python爬取js执行后输出的信息-苏州安嘉)
Python 有很多库可以让我们轻松编写网络爬虫,爬取特定页面,获取有价值的信息!但很多情况下,爬虫获取到的页面只是静态页面,也就是网页的源代码,就像在浏览器上“查看网页源代码”一样。一些动态的东西,比如执行javascript脚本产生的信息,是无法捕获的。这里有一些解决方案可以用于python爬取js执行后输出的信息。
1、两个基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本由浏览器执行并返回信息。因此,在js执行后捕获页面最直接的方法之一就是使用python来模拟浏览器的行为。WebKit是一个开源的浏览器引擎,python提供了很多库来调用这个引擎,dryscrape就是其中之一,它调用webkit引擎来处理收录js的网页等等!
进口干刮
#使用dryscrape库动态抓取页面
defget_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url)#请求页面
response=session_req.body()#网页的文本
#打印(响应)
返回响应
get_text_line(get_url_dynamic(url))# 会输出一个文本
这也适用于其他收录js的网页!虽然可以满足爬取动态页面的要求,但是缺点还是很明显:慢!它太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完毕后,加载js文件,让js执行,返回执行的页面。应该慢一点!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(可以用它写浏览器)、pyjamas等,听说也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium是一个web测试框架,允许调用本地浏览器引擎发送网页请求,因此也可以实现爬取页面的需求。
# 使用 selenium webdriver 有效,但会实时打开浏览器窗口
defget_url_dynamic2(url):
driver=webdriver.Firefox()#调用本地Firefox浏览器,Chrom甚至Ie也可以
driver.get(url)#请求页面会打开浏览器窗口
html_text=driver.page_source
driver.quit()
#printhtml_text
返回html_text
get_text_line(get_url_dynamic2(url))# 会输出一个文本
这也是一个临时解决方案!类似selenium的框架也有风车,感觉稍微复杂一点,就不细说了!
2、selenium的安装和使用
2.1 selenium 的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2.firefox 47及以上版本需要下载第三方驱动,即geckodriver
还需要一些特殊操作:
1. 下载geckodriverckod地址:
Mozilla/geckodriver
2. 解压后将geckodriverckod存放在/usr/local/bin/路径下:
sudomv~/Downloads/geckodriver/usr/local/bin/
2.2 硒的使用
1. 运行错误:
驱动程序=webdriver.chrome()
TypeError:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 由
content=driver.find_element_by_class_name('content')
定位元素时,此方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
值=内容.文本
这是文章关于python如何爬取动态网站的介绍。更多关于python如何爬取动态网站的信息,请搜索我们之前的文章或者继续浏览下面的相关文章希望大家以后多多支持!
c 抓取网页数据( 执行后cookie信息就被存到了(.txt))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-28 01:14
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
执行后cookie信息保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站都会监控你的cookie信息来判断你是否按照规则访问了他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、模仿浏览器
有些 网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器端会认为是使用IE8.0访问的
7、假引用(热链接)
很多服务器会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。这是一个小偷
curl 中的内置选项:-e 允许我们设置引用者
# curl -e "www.linux.com" http://mail.linux.com
这将使服务器认为您来自单击链接
8、下载文件
8.1:使用 curl 下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称在本地保存文件
8.2:循环下载
有时候下载的图片可能和前面部分名字一样,但是最后一个尾部名字不一样
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样,hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这样就可以查看dodo1.JPG的内容了
8.5: 通过 ftp 下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6: 显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点处恢复上传。curl也可以通过内置选项达到同样的效果:-C
如果在下载dodo1.JPG的过程中突然断线,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会将文件 dodo1.JPG 上传到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
12、通过 -L 选项重定向
默认情况下,CURL 不发送 HTTP Location 标头(重定向)。当请求的页面移动到另一个站点时,会发送一个 HTTP Loaction 标头作为请求,并将请求重定向到新地址。
例如:访问时,地址会自动重定向到.hk。
1 curl http://www.google.com
2
3
4
5 302 Moved
6
7
8 302 Moved
9 The document has moved
10 <A HREF=span style="color: rgba(128, 0, 0, 1)""span style="color: rgba(128, 0, 0, 1)"http://www.google.com.hk/url%3 ... Aspan style="color: rgba(128, 0, 0, 1)"">here</A>.
11
12
上面的输出显示请求的存档已移至。可以使用 -L 选项强制重定向
1 # 让curl使用地址重定向,此时会查询google.com.hk站点
2 curl -L http://www.google.com
补充恢复:通过使用-C选项,可以对大文件使用恢复功能,如:
1 # 当文件在下载完成之前结束该进程
2 $ curl -O http://www.gnu.org/software/ge ... .html
3 ############## 20.1%
4
5 # 通过添加-C选项继续对该文件进行下载,已经下载过的文件不会被重新下载
6 curl -C - -O http://www.gnu.org/software/ge ... .html
7 ############### 21.1%
使用 CURL 进行网络限速
通过 --limit-rate 选项限制 CURL 的最大网络使用量
1 # 下载速度最大不会超过1000B/second
2
3 curl --limit-rate 1000B -O http://www.gnu.org/software/ge ... .html
下载指定时间内修改过的文件
下载文件时,可以判断文件的最后修改日期。如果文件在指定日期内被修改过,则下载,否则不下载。
此功能可以通过使用 -z 选项来实现:
1 # 若yy.html文件在2011/12/21之后有过更新才会进行下载
2 curl -z 21-Dec-11 http://www.example.com/yy.html
卷曲授权
访问需要授权的页面时,可以通过 -u 选项提供用户名和密码进行授权
1 curl -u username:password URL
2
3 # 通常的做法是在命令行只输入用户名,之后会提示输入密码,这样可以保证在查看历史记录时不会将密码泄露
4 curl -u username URL
从 FTP 服务器下载文件
CURL 还支持 FTP 下载。如果在 url 中指定了文件路径,而不是指定要下载的特定文件名,则 CURL 将列出目录中的所有文件名,而不是下载目录中的所有文件。
1 # 列出public_html下的所有文件夹和文件
2 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/
3
4 # 下载xss.php文件
5 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/xss.php
上传文件到 FTP 服务器
使用 -T 选项将指定的本地文件上传到 FTP 服务器
# 将myfile.txt文件上传到服务器
curl -u ftpuser:ftppass -T myfile.txt ftp://ftp.testserver.com
# 同时上传多个文件
curl -u ftpuser:ftppass -T "{file1,file2}" ftp://ftp.testserver.com
# 从标准输入获取内容保存到服务器指定的文件中
curl -u ftpuser:ftppass -T - ftp://ftp.testserver.com/myfile_1.txt
获取更多信息
使用 -v 和 -trace 获取更多链接信息
在字典中查找单词
1 # 查询bash单词的含义
2 curl dict://dict.org/d:bash
3
4 # 列出所有可用词典
5 curl dict://dict.org/show:db
6
7 # 在foldoc词典中查询bash单词的含义
8 curl dict://dict.org/d:bash:foldoc
为 CURL 设置代理
-x 选项可以向 CURL 添加代理功能
1 # 指定代理主机和端口
2 curl -x proxysever.test.com:3128 http://google.co.in
其他网站组织
网站cookie 信息的存储和使用
1 # 将网站的cookies信息保存到sugarcookies文件中
2 curl -D sugarcookies http://localhost/sugarcrm/index.php
3
4 # 使用上次保存的cookie信息
5 curl -b sugarcookies http://localhost/sugarcrm/index.php
传递请求数据
curl 默认使用 GET 方法请求数据,这种方式直接通过 URL 传递数据
可以使用 --data/-d 方法指定使用 POST 传递数据
1 # GET
2 curl -u username https://api.github.com/user%3F ... XXXXX
3
4 # POST
5 curl -u username --data "param1=value1¶m2=value" https://api.github.com
6
7 # 也可以指定一个文件,将该文件中的内容当作数据传递给服务器端
8 curl --data @filename https://github.api.com/authorizations
注意:默认情况下,如果过去通过 POST 传递的数据中存在特殊字符,则需要先将特殊字符转义到服务器。如果该值收录空格,则需要先将空格转换为 %20。如:
1 curl -d "value%201" http://hostname.com
在 CURL 的新版本中,提供了一个新选项 --data-urlencode,通过该选项提供的参数将自动转义特殊字符。
1 curl --data-urlencode "value 1" http://hostname.com
除了使用 GET 和 POST 协议之外,还可以使用 -X 选项指定其他协议,例如:
1 curl -I -X DELETE https://api.github.cim
上传文件
1 curl --form "fileupload=@filename.txt" http://hostname/resource
获取请求头信息
curl --head http://www.example.com
返回数据:
HTTP/1.1 200 OK
Content-Encoding: gzip
Accept-Ranges: bytes
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Tue, 23 Oct 2018 11:29:23 GMT
Etag: "1541025663+gzip"
Expires: Tue, 30 Oct 2018 11:29:23 GMT
Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
Server: ECS (dca/532C)
X-Cache: HIT
Content-Length: 606
其他参数(翻译为转载here):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
官方文档: 查看全部
c 抓取网页数据(
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
执行后cookie信息保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站都会监控你的cookie信息来判断你是否按照规则访问了他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、模仿浏览器
有些 网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器端会认为是使用IE8.0访问的
7、假引用(热链接)
很多服务器会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。这是一个小偷
curl 中的内置选项:-e 允许我们设置引用者
# curl -e "www.linux.com" http://mail.linux.com
这将使服务器认为您来自单击链接
8、下载文件
8.1:使用 curl 下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称在本地保存文件
8.2:循环下载
有时候下载的图片可能和前面部分名字一样,但是最后一个尾部名字不一样
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样,hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这样就可以查看dodo1.JPG的内容了
8.5: 通过 ftp 下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6: 显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点处恢复上传。curl也可以通过内置选项达到同样的效果:-C
如果在下载dodo1.JPG的过程中突然断线,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会将文件 dodo1.JPG 上传到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
12、通过 -L 选项重定向
默认情况下,CURL 不发送 HTTP Location 标头(重定向)。当请求的页面移动到另一个站点时,会发送一个 HTTP Loaction 标头作为请求,并将请求重定向到新地址。
例如:访问时,地址会自动重定向到.hk。
1 curl http://www.google.com
2
3
4
5 302 Moved
6
7
8 302 Moved
9 The document has moved
10 <A HREF=span style="color: rgba(128, 0, 0, 1)""span style="color: rgba(128, 0, 0, 1)"http://www.google.com.hk/url%3 ... Aspan style="color: rgba(128, 0, 0, 1)"">here</A>.
11
12
上面的输出显示请求的存档已移至。可以使用 -L 选项强制重定向
1 # 让curl使用地址重定向,此时会查询google.com.hk站点
2 curl -L http://www.google.com
补充恢复:通过使用-C选项,可以对大文件使用恢复功能,如:
1 # 当文件在下载完成之前结束该进程
2 $ curl -O http://www.gnu.org/software/ge ... .html
3 ############## 20.1%
4
5 # 通过添加-C选项继续对该文件进行下载,已经下载过的文件不会被重新下载
6 curl -C - -O http://www.gnu.org/software/ge ... .html
7 ############### 21.1%
使用 CURL 进行网络限速
通过 --limit-rate 选项限制 CURL 的最大网络使用量
1 # 下载速度最大不会超过1000B/second
2
3 curl --limit-rate 1000B -O http://www.gnu.org/software/ge ... .html
下载指定时间内修改过的文件
下载文件时,可以判断文件的最后修改日期。如果文件在指定日期内被修改过,则下载,否则不下载。
此功能可以通过使用 -z 选项来实现:
1 # 若yy.html文件在2011/12/21之后有过更新才会进行下载
2 curl -z 21-Dec-11 http://www.example.com/yy.html
卷曲授权
访问需要授权的页面时,可以通过 -u 选项提供用户名和密码进行授权
1 curl -u username:password URL
2
3 # 通常的做法是在命令行只输入用户名,之后会提示输入密码,这样可以保证在查看历史记录时不会将密码泄露
4 curl -u username URL
从 FTP 服务器下载文件
CURL 还支持 FTP 下载。如果在 url 中指定了文件路径,而不是指定要下载的特定文件名,则 CURL 将列出目录中的所有文件名,而不是下载目录中的所有文件。
1 # 列出public_html下的所有文件夹和文件
2 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/
3
4 # 下载xss.php文件
5 curl -u ftpuser:ftppass -O ftp://ftp_server/public_html/xss.php
上传文件到 FTP 服务器
使用 -T 选项将指定的本地文件上传到 FTP 服务器
# 将myfile.txt文件上传到服务器
curl -u ftpuser:ftppass -T myfile.txt ftp://ftp.testserver.com
# 同时上传多个文件
curl -u ftpuser:ftppass -T "{file1,file2}" ftp://ftp.testserver.com
# 从标准输入获取内容保存到服务器指定的文件中
curl -u ftpuser:ftppass -T - ftp://ftp.testserver.com/myfile_1.txt
获取更多信息
使用 -v 和 -trace 获取更多链接信息
在字典中查找单词
1 # 查询bash单词的含义
2 curl dict://dict.org/d:bash
3
4 # 列出所有可用词典
5 curl dict://dict.org/show:db
6
7 # 在foldoc词典中查询bash单词的含义
8 curl dict://dict.org/d:bash:foldoc
为 CURL 设置代理
-x 选项可以向 CURL 添加代理功能
1 # 指定代理主机和端口
2 curl -x proxysever.test.com:3128 http://google.co.in
其他网站组织
网站cookie 信息的存储和使用
1 # 将网站的cookies信息保存到sugarcookies文件中
2 curl -D sugarcookies http://localhost/sugarcrm/index.php
3
4 # 使用上次保存的cookie信息
5 curl -b sugarcookies http://localhost/sugarcrm/index.php
传递请求数据
curl 默认使用 GET 方法请求数据,这种方式直接通过 URL 传递数据
可以使用 --data/-d 方法指定使用 POST 传递数据
1 # GET
2 curl -u username https://api.github.com/user%3F ... XXXXX
3
4 # POST
5 curl -u username --data "param1=value1¶m2=value" https://api.github.com
6
7 # 也可以指定一个文件,将该文件中的内容当作数据传递给服务器端
8 curl --data @filename https://github.api.com/authorizations
注意:默认情况下,如果过去通过 POST 传递的数据中存在特殊字符,则需要先将特殊字符转义到服务器。如果该值收录空格,则需要先将空格转换为 %20。如:
1 curl -d "value%201" http://hostname.com
在 CURL 的新版本中,提供了一个新选项 --data-urlencode,通过该选项提供的参数将自动转义特殊字符。
1 curl --data-urlencode "value 1" http://hostname.com
除了使用 GET 和 POST 协议之外,还可以使用 -X 选项指定其他协议,例如:
1 curl -I -X DELETE https://api.github.cim
上传文件
1 curl --form "fileupload=@filename.txt" http://hostname/resource
获取请求头信息
curl --head http://www.example.com
返回数据:
HTTP/1.1 200 OK
Content-Encoding: gzip
Accept-Ranges: bytes
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Tue, 23 Oct 2018 11:29:23 GMT
Etag: "1541025663+gzip"
Expires: Tue, 30 Oct 2018 11:29:23 GMT
Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
Server: ECS (dca/532C)
X-Cache: HIT
Content-Length: 606
其他参数(翻译为转载here):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
官方文档:
c 抓取网页数据(记录思路如下:记录SQL中的注释(使用--进行注释))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-25 11:12
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</ 查看全部
c 抓取网页数据(记录思路如下:记录SQL中的注释(使用--进行注释))
【原需求】
该公司的用户手册是SGML的源代码。文档中有一些 SQL 语句。目前,我想验证这些SQL是否可以复制和执行。
【对策】
使用手动副本验证太慢。
所以想抓取相关内容,然后直接使用工具执行,手动查看执行结果。
经分析,源码部分一般受and标签约束,所以针对这两个标签进行shell要抓取的具体内容。
录音思路如下:
1、 先在 SQL 中处理注释(使用--for comments 类似于 C 语言中的#)
2、去掉文本空间进行序列处理,使用上面的标签进行拆分,然后在拆分后取偶数位置的值(不解释)
3、标签中的内容可以通过第二步获取,标签中的特殊字符需要处理
<p>#!/bin/bash
path='/home/ckdu/sgml_qsruan/sgml'
for file in `ls /home/qs/sgml/*.sgml`
do
cat ${file} |sed 's/−/-/g'|awk -F'--' '{print $1}'> ${file}.tmp
cat ${file}.tmp | awk '{printf("%s",$0)}' |awk -F "()|()|()|()" '{for(i=2;i/g'|sed 's///g'|sed 's///g'|sed 's/&&/\&/g'|sed 's/</
c 抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-23 01:10
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓取地址栏url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网! 查看全部
c 抓取网页数据(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓取地址栏url对应的数据包,在数据包的响应标签中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
这是文章关于Python如何实现对网页中动态加载的数据的爬取的介绍。更多关于使用Python从网页抓取动态数据的信息,请在自学编程网前搜索文章或文章。继续浏览以下相关文章希望大家以后多多支持自学编程网!
c 抓取网页数据( 如何使用网页监听获取想要的数据?解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-20 19:21
如何使用网页监听获取想要的数据?解决办法)
使用网络监听命令获取数据
在网页抓取数据时,如果有些图表数据无法抓取,元素变化频繁,或者网页有广告影响操作,可以考虑使用网页监控来获取想要的数据。
脚步
① 打开要采集数据的网页,在网页上按F12打开开发者模式。
② 按 Ctrl + R 重新加载网页。
③ 等待所需数据加载完毕,激活网络选项卡上的搜索框,输入所需数据,然后按 Enter。
④ 如图
如果找不到目标数据,尝试其他可能的数据搜索,减少关键词的数量,或者依次在请求列表中搜索数据。
⑤ 开始监控数据,获取网页对象-开始监控请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果) - 停止监听网页请求。
可能数据很多,建议不要打印,先写入文本文件
⑥打开写入的文件,按Crtl+F查看是否找到想要的数据。
⑦使用命令获取网页请求的结果是一个收录目标url数据的字典。响应中的数据收录在循环项字典的键 ["body"] 中。body 是一个字符串,它被转换成一个 json 对象。可以提取数据。
为了方便观察结构,可以先把body的数据拿出来粘贴,会自动转换成便于观察的格式。
粘贴到格式化工具后,在列表goodsDetailList中找到想要的数据:
所以按照下面的逻辑取对应的数据:
流程执行结果:
问题没有解决?去社区提问 保留所有权利,由 Gitbook 提供支持 查看全部
c 抓取网页数据(
如何使用网页监听获取想要的数据?解决办法)
使用网络监听命令获取数据
在网页抓取数据时,如果有些图表数据无法抓取,元素变化频繁,或者网页有广告影响操作,可以考虑使用网页监控来获取想要的数据。
脚步
① 打开要采集数据的网页,在网页上按F12打开开发者模式。
② 按 Ctrl + R 重新加载网页。
③ 等待所需数据加载完毕,激活网络选项卡上的搜索框,输入所需数据,然后按 Enter。
④ 如图
如果找不到目标数据,尝试其他可能的数据搜索,减少关键词的数量,或者依次在请求列表中搜索数据。
⑤ 开始监控数据,获取网页对象-开始监控请求-跳转到新的URL(重新加载)-延迟执行(等待加载完成)-获取网页监控结果(获取第一步获取的URL的监控结果) - 停止监听网页请求。
可能数据很多,建议不要打印,先写入文本文件
⑥打开写入的文件,按Crtl+F查看是否找到想要的数据。
⑦使用命令获取网页请求的结果是一个收录目标url数据的字典。响应中的数据收录在循环项字典的键 ["body"] 中。body 是一个字符串,它被转换成一个 json 对象。可以提取数据。
为了方便观察结构,可以先把body的数据拿出来粘贴,会自动转换成便于观察的格式。
粘贴到格式化工具后,在列表goodsDetailList中找到想要的数据:
所以按照下面的逻辑取对应的数据:
流程执行结果:
问题没有解决?去社区提问 保留所有权利,由 Gitbook 提供支持
c 抓取网页数据(【天学网:】25#输出爬到的游戏名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-20 15:27
7 头 = {
8“连接”:“保持活动”,
9 '接受':'文本/html,应用程序/xhtml+xml,*/*',
10 '接受语言': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3 ',
11 '接受编码':'gzip,放气',
12 '用户代理': 'Mozilla/6.1 (Windows NT 6.3; WOW64; 三叉戟/7.0; rv:11.0)像壁虎'
13 }
14 # 待爬取的游戏列表页面
15 网址 = '#39;
16
17 # 不压缩html,最大链接时间为10秒
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码为 utf-8
20 res.encoding = 'utf-8'
21 # 将 html 构建为 Xpath 模式
22 根 = etree.HTML(res.content)
23 # 使用Xpath语法获取游戏名称
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出你爬到的游戏名称
26 打印(游戏列表)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于行块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页切分查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们将两个标签和其中收录的文本组合成一个标签窗口(如
I am h1中的“I am h1”是标记窗口的内容),取出标记窗口的文本。
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于行块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时引入块长法官。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1#假设内容是已经获取到的html
2
3# Ctext取周围的k行(k
4blocksWidth = 3
5#每个Cblock的长度
6Ctext_len = []
7#Ctext
8lines = content.split('n')
9#删除空格
10for i in range(len(lines)):
11 如果行[i] == ' ' 或行[i] == 'n':
12 行 [i] = ''
13#计算纵坐标,每个Ctext的长度
14for i in range(0, len(lines) - blocksWidth):
15 个字数 = 0
16 for j in range(i, i + blocksWidth):
17 行[j] = 行[j].replace("\s", "")
18 wordsNum += len(lines[j])
19 Ctext_len.append(wordsNum)
20#开始标志
21开始=-1
22#结束标记
23 结束 = -1
24#是否开始打标
25boolstart=假
26#是否结束标记
27布尔=假
28#行块长度阈值
29max_text_len = 88
30# 文章主要内容
31main_text = []
32# Ctext 没有分段
33if 长度(Ctext_len)
34返回'没有身体'
35for i in range(len(Ctext_len) - 3):
36 # 如果高于这个阈值
37 if(Ctext_len[i] > max_text_len and (not boolstart)):
38 # Cblock下面三个不为0,认为是文本
39 if (Ctext_len[i + 1] != 0 或 Ctext_len[i + 2] != 0 或 Ctext_len[i + 3] != 0):
40 布尔启动 = 真
41 开始 = 我
42 继续
43 如果(布尔启动):
44 # 如果Cblock后面3个有0,则结束
45 if (Ctext_len[i] == 0 或 Ctext_len[i + 1] == 0):
46 结束 = 我
47布尔=真
48 tmp = []
49
50 # 判断下面是否有文字
51 如果(布尔值):
52 for ii in range(start, end + 1):
53 if(len(行[ii])
54 继续
55 tmp.append(行[ii] + "n")
56 str = "".join(列表(tmp)) 查看全部
c 抓取网页数据(【天学网:】25#输出爬到的游戏名)
7 头 = {
8“连接”:“保持活动”,
9 '接受':'文本/html,应用程序/xhtml+xml,*/*',
10 '接受语言': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3 ',
11 '接受编码':'gzip,放气',
12 '用户代理': 'Mozilla/6.1 (Windows NT 6.3; WOW64; 三叉戟/7.0; rv:11.0)像壁虎'
13 }
14 # 待爬取的游戏列表页面
15 网址 = '#39;
16
17 # 不压缩html,最大链接时间为10秒
18 res = requests.get(url, headers=heads, verify=False, timeout=10)
19 # 为防止出错,编码为 utf-8
20 res.encoding = 'utf-8'
21 # 将 html 构建为 Xpath 模式
22 根 = etree.HTML(res.content)
23 # 使用Xpath语法获取游戏名称
24 gameList = root.xpath("//ul[@class='livelist-mod']//li//p//text()")
25 # 输出你爬到的游戏名称
26 打印(游戏列表)
复制代码
我们拿到这几十个游戏名之后,接下来就是爬取这几十个游戏的语料库了。这时问题来了,我们要从哪个网站爬取这几十个游戏攻略,taptap?多玩?17173?分析了这些网站,发现这些网站只有一些文章热门游戏的语料库,一些冷门或者低热度的游戏,比如《灵魂芯片》、《奇迹》: Awakening”、“Death iscoming”等,在这些网站上很难找到大量的文章语料库,如图:
我们可以发现,《奇迹:觉醒》和《灵魂碎片》的文章语料特别少,数量达不到我们的要求。那么有没有更通用的资源站,拥有极其丰富的文章语料库,可以满足我们的需求。
其实静下心来想想,我们每天都在用这个资源站,那就是百度。我们在百度新闻上搜索了相关游戏,得到了搜索结果列表。这些列表的链接网页内容几乎都与搜索结果有很强的相关性,从而可以轻松解决数据源不足的问题。但是这时候又出现了一个新的问题,也是一个比较难解决的问题——如何爬取任意网页的文章的内容?
因为不同的网站有不同的页面结构,我们无法预测会爬到哪些网站数据,也不可能为每个网站爬虫写一组数据,工作量是难以想象的!但我们不能简单粗暴地爬下页面中的所有单词。使用这样的语料库进行训练无疑是一场噩梦!
与每个网站角力,查询资料和思考后,终于找到了一个更通用的解决方案。让我告诉你作者的想法。
0x3 网站 的任何 文章 语料库爬取
01|提取方法
1)基于Dom树文本提取
2)根据网页切分查找文本块
3)基于标记窗口的文本提取
4)基于数据挖掘或机器学习
5)基于行块分布函数的文本提取
02|萃取原理
看到这些类型你是不是有点疑惑,它们是怎么提取出来的呢?让作者慢慢来。
1)基于Dom树的文本提取:
该方法主要是通过比较标准的HTML构建Dom树,然后base cabinet遍历Dom,比较识别各种非文本信息,包括广告、链接和非重要节点信息。非文字信息提取出来后,剩下的自然就是文字信息了。
但是这种方法有两个问题
① 尤其依赖于HTML良好的结构。如果我们爬取一个不是按照 W3c 规范编写的网页,这种方法就不是很适合了。
②树的建立和遍历的时间复杂度和空间复杂度都很高,树的遍历方式也会因为HTML标签的不同而有不同的差异。
2) 根据网页切分查找文本块:
一种方法是在 HTML 标记中使用分隔线以及一些视觉信息(例如文本颜色、字体大小、文本信息等)。
这种方法有一个问题:
①不同的网站HTML样式差别很大,没有办法统一分割,无法保证通用性。
3) 基于标记窗口的文本提取:
首先普及一个概念——标签窗口,我们将两个标签和其中收录的文本组合成一个标签窗口(如
I am h1中的“I am h1”是标记窗口的内容),取出标记窗口的文本。
该方法首先获取 文章 标题和 HTML 中的所有标记窗口,然后对其进行分词。然后计算标记窗口中标题序列和文本序列之间的单词距离L。如果 L 小于阈值,则标记窗口中的文本被认为是文本。
这种方法虽然看起来不错,但实际上存在问题:
① 页面中的所有文字都需要切分,效率不高。
②词距的阈值难以确定,不同的文章阈值不同。
4)基于数据挖掘或机器学习
使用大数据进行训练,让机器提取正文。
这种方法固然优秀,但是在训练之前需要html和body数据。我们不会在这里讨论它。
5)基于行块分布函数的文本提取
对于任何网页,它的正文和标签总是混合在一起的。该方法的核心有亮点:①文本区域的密度;②线块的长度;网页的文本区域一定是文本信息分布最密集的区域之一,而且这个区域可能是最大的(长评论信息、短文本),所以同时引入块长法官。
实施思路:
①我们先去掉HTML标签,只留下所有的文字,去掉标签后留下所有空白的位置信息,我们称之为Ctext;
②对每个Ctext取周围的k行(k
③ 去除Cblock中所有的空白字符,文本的总长度称为Clen;
④ 以Ctext为横坐标,每行Clen为纵坐标,建立坐标系。
从上图可以看出,正确的文本区域是分布函数图上所有收录最高值且连续的区域。该区域通常收录一个膨胀点和一个坍落点。因此,网页文本提取问题转化为线块分布函数上的两个边界点,膨胀点和下降点。这两个边界点所收录的区域收录当前网页的最大行块长度,并且是连续的。.
经过大量实验,证明该方法对中文网页的文本提取具有较高的准确率。这种算法的优点是行块功能不依赖于HTML代码,与HTML标签无关。实现简单,准确率高。
主要逻辑代码如下:
1#假设内容是已经获取到的html
2
3# Ctext取周围的k行(k
4blocksWidth = 3
5#每个Cblock的长度
6Ctext_len = []
7#Ctext
8lines = content.split('n')
9#删除空格
10for i in range(len(lines)):
11 如果行[i] == ' ' 或行[i] == 'n':
12 行 [i] = ''
13#计算纵坐标,每个Ctext的长度
14for i in range(0, len(lines) - blocksWidth):
15 个字数 = 0
16 for j in range(i, i + blocksWidth):
17 行[j] = 行[j].replace("\s", "")
18 wordsNum += len(lines[j])
19 Ctext_len.append(wordsNum)
20#开始标志
21开始=-1
22#结束标记
23 结束 = -1
24#是否开始打标
25boolstart=假
26#是否结束标记
27布尔=假
28#行块长度阈值
29max_text_len = 88
30# 文章主要内容
31main_text = []
32# Ctext 没有分段
33if 长度(Ctext_len)
34返回'没有身体'
35for i in range(len(Ctext_len) - 3):
36 # 如果高于这个阈值
37 if(Ctext_len[i] > max_text_len and (not boolstart)):
38 # Cblock下面三个不为0,认为是文本
39 if (Ctext_len[i + 1] != 0 或 Ctext_len[i + 2] != 0 或 Ctext_len[i + 3] != 0):
40 布尔启动 = 真
41 开始 = 我
42 继续
43 如果(布尔启动):
44 # 如果Cblock后面3个有0,则结束
45 if (Ctext_len[i] == 0 或 Ctext_len[i + 1] == 0):
46 结束 = 我
47布尔=真
48 tmp = []
49
50 # 判断下面是否有文字
51 如果(布尔值):
52 for ii in range(start, end + 1):
53 if(len(行[ii])
54 继续
55 tmp.append(行[ii] + "n")
56 str = "".join(列表(tmp))
c 抓取网页数据( Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-20 05:06
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化和聚焦核心业务的需要,使得各种翻译业务的利润越来越高。云翻译平台Smartling是一家完整的全球翻译公司,承接所有可以翻译的事情,包括企业文件。,网页,应用程序,小到一个图标都包括在内。Smartling 刚刚完成了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投,Venrock、US Venture Partners、IDG Ventures、First Round Capital 和 Felicis Ventures 无一例外地追加投资。
Smartling将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API开放为企业用户本地化语言提供数据监控服务网站。比如某公司的网页翻译成中文后,用户可以通过Smartling的dashboard网站@网站看到中文版产生的流量等数据。
上传需要翻译的文件类型后,用户可以选择专业、众包或Smartling内部员工将其翻译成多种语言。整个业务流程对用户可见可控,用户可以根据需要选择合适的翻译。各种设置,例如资源甚至翻译的风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供了跨平台优化。
Smartling 声称其服务可以将翻译管理成本降低多达 90%,Smartling 保证当日送达。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling的客户包括电子商务、旅游相关行业相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是其客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频: 查看全部
c 抓取网页数据(
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化和聚焦核心业务的需要,使得各种翻译业务的利润越来越高。云翻译平台Smartling是一家完整的全球翻译公司,承接所有可以翻译的事情,包括企业文件。,网页,应用程序,小到一个图标都包括在内。Smartling 刚刚完成了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投,Venrock、US Venture Partners、IDG Ventures、First Round Capital 和 Felicis Ventures 无一例外地追加投资。
Smartling将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API开放为企业用户本地化语言提供数据监控服务网站。比如某公司的网页翻译成中文后,用户可以通过Smartling的dashboard网站@网站看到中文版产生的流量等数据。
上传需要翻译的文件类型后,用户可以选择专业、众包或Smartling内部员工将其翻译成多种语言。整个业务流程对用户可见可控,用户可以根据需要选择合适的翻译。各种设置,例如资源甚至翻译的风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供了跨平台优化。
Smartling 声称其服务可以将翻译管理成本降低多达 90%,Smartling 保证当日送达。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling的客户包括电子商务、旅游相关行业相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是其客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频:

