
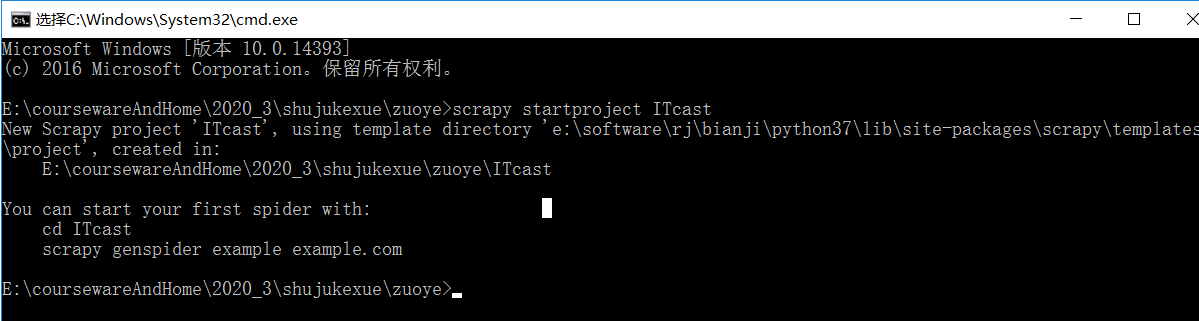
c 抓取网页数据
c 抓取网页数据(修改响应数据,模拟JS请操作2.App数据分析手机端 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-18 03:05
)
1.PC浏览器网页数据分析
简单通用的网页数据分析,Google/Firfox/IE等浏览器内置开发者调试工具(F12)可以满足部分需求,如果请求在响应前后处理,修改浏览器发送Request数据并修改服务器的相应数据,使用F12开发工具,不能满足我们的需求,通过引入Fiddler抓包工具,可以理解为本地代理服务器,转发客户端和服务器的请求和响应
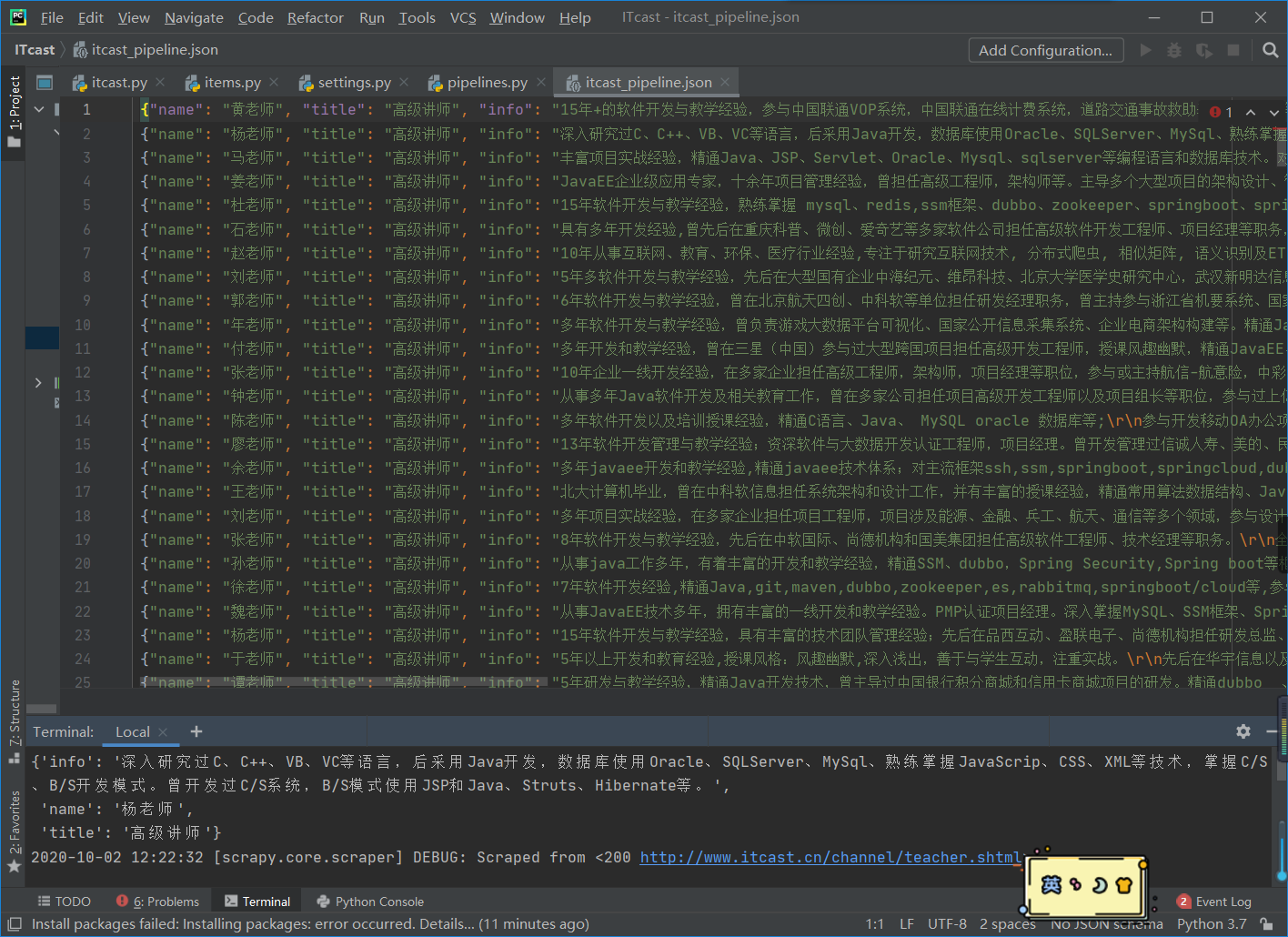
设置提琴手:
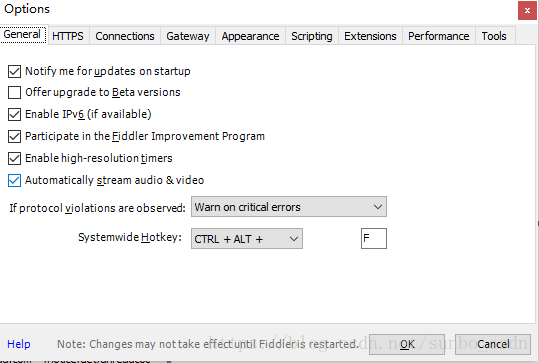
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS,请操作
2.应用数据分析
Fiddler 还可用于移动应用程序的数据分析。类似于上面的PC浏览器获取数据的方式。APP需与PC在同一网段。移动Wifi设置代理,IP为PC的IP地址,例如:64.35.86.12,端口号使用设置的端口号Fiddler,一般为8888,App端的所有网络/响应请求都必须由FIddler转发,可以对请求进行数据分析
3.PC端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理来做代理链。
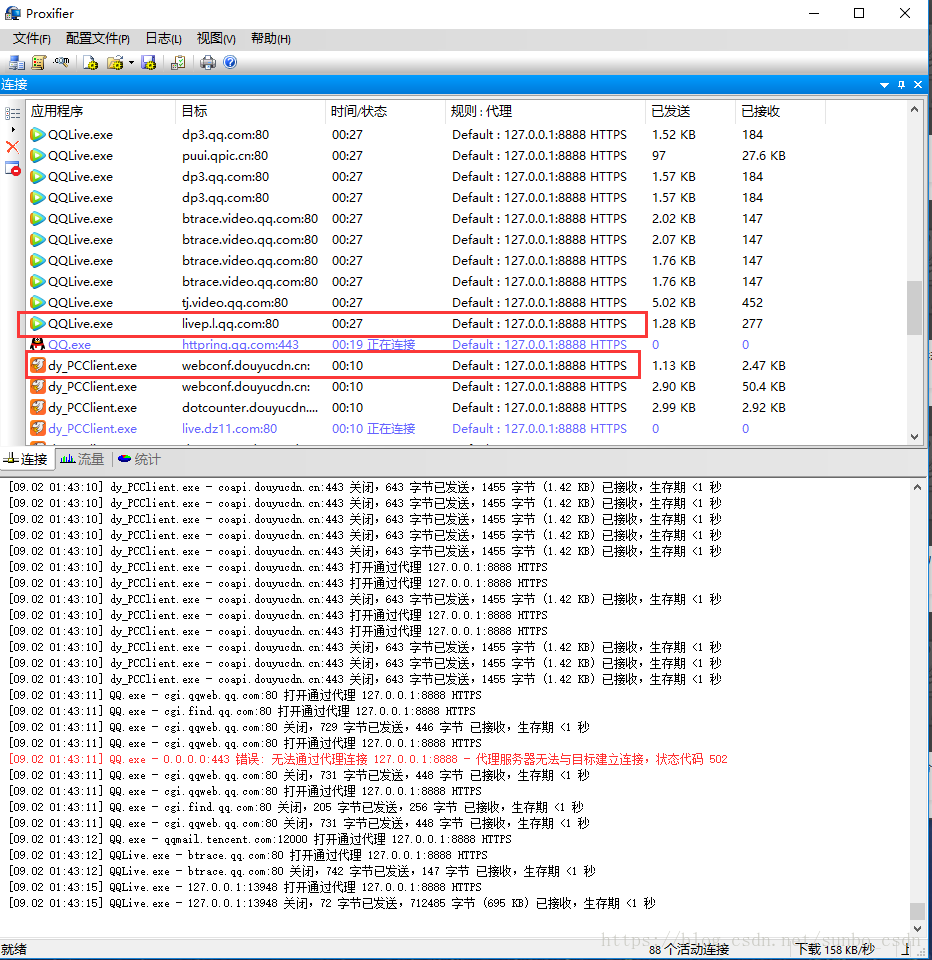
由于一般的C/S客户端无法设置代理,因此FIddler无法检测到数据,所有的请求都通过Proxifer捕获并发送给Fiddler,从而可以在Fiddler中分析客户端请求。
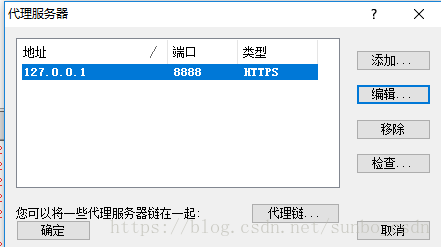
代理设置:
设置很简单,如下图,两步就OK了
一个)。代理服务器和 Fiddler 代理设置匹配
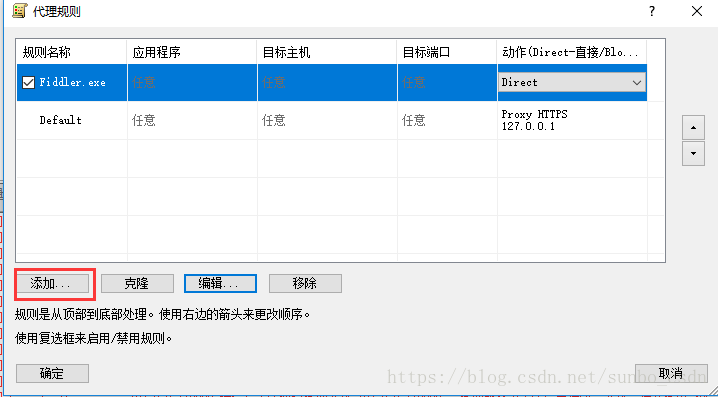
b)。代理规则
默认 Default 可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择 Fiddler 应用程序文件目录并确认
目标主机:本地 Fiddler 设置代理,可以是任意
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功
查看全部
c 抓取网页数据(修改响应数据,模拟JS请操作2.App数据分析手机端
)
1.PC浏览器网页数据分析
简单通用的网页数据分析,Google/Firfox/IE等浏览器内置开发者调试工具(F12)可以满足部分需求,如果请求在响应前后处理,修改浏览器发送Request数据并修改服务器的相应数据,使用F12开发工具,不能满足我们的需求,通过引入Fiddler抓包工具,可以理解为本地代理服务器,转发客户端和服务器的请求和响应
设置提琴手:
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888
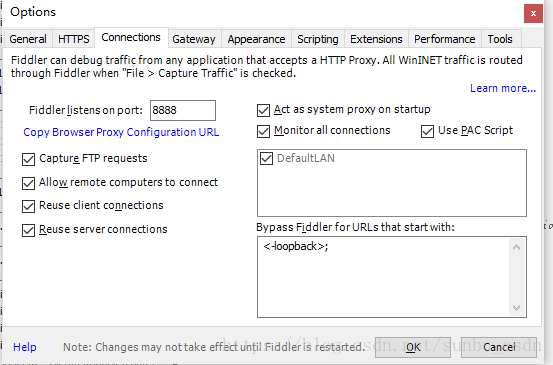
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS,请操作
2.应用数据分析
Fiddler 还可用于移动应用程序的数据分析。类似于上面的PC浏览器获取数据的方式。APP需与PC在同一网段。移动Wifi设置代理,IP为PC的IP地址,例如:64.35.86.12,端口号使用设置的端口号Fiddler,一般为8888,App端的所有网络/响应请求都必须由FIddler转发,可以对请求进行数据分析
3.PC端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理来做代理链。
由于一般的C/S客户端无法设置代理,因此FIddler无法检测到数据,所有的请求都通过Proxifer捕获并发送给Fiddler,从而可以在Fiddler中分析客户端请求。
代理设置:
设置很简单,如下图,两步就OK了

一个)。代理服务器和 Fiddler 代理设置匹配
b)。代理规则
默认 Default 可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择 Fiddler 应用程序文件目录并确认
目标主机:本地 Fiddler 设置代理,可以是任意
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功
c 抓取网页数据(非常简单类型网页所传递的链接权重的实验(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-18 03:03
爬取到的和收录内容中的链接不传权重。晚上,我看到了一个关于不同类型网页传递的链接权重的实验。大致翻译如下: 关于去年暑假,我观察到一个明显的购买/放置/建立链接的现象,对搜索引擎抓取和收录的内容的排名增长起到了非常小的作用。
许多报纸和其他出版商以荒谬的价格提供旧版 文章 中的链接,但事实是它们根本没有效果。
去年年底,我做了一个实验。虽然已经过去了一段时间,但在我看来,这个结果仍然适用于当前的环境。
实验表明:
一个非常简单的实验是为三个不同的利基创建三种不同形式的链接网站:
1.a 在“新”内容中
2.b在“收录”的内容中
3.c 文本链接(作者参考侧边栏和页脚区域中的链接)
新内容
主要是利用文章营销来创造一些新的文章,并以目标关键词作为实验网站的锚文本。
包括什么
收录的页面添加了锚文本链接,部分页面已经有PR值(大约一半的链接有1)的PR值。
文字链接
从自建博客群中随机抽取了15篇博客,并在侧边栏中添加了链接。锚文本仍然使用目标关键字。
限制
我们都可以发现,这个实验有严重的局限性,所以结果不能完全作为依据,但是从排名的变化来看,可以证明在已经爬取和收录的内容中建立链接的权重是不够的。
实验结果
从图中可以明显看出,放置在旧内容中的链接不会有任何权重,否则排名结果不仅会出现轻微的移动,甚至会出现轻微的回落。
另外,博客侧边栏的链接,一开始的排名有很大的提升,但是很快就回落了(侧边栏的链接是整个网站链接的形式。作者后来解释说,自从实验是去年的,整个网站链接将不再有这个效果)。
综上所述
由于这些网站针对不同的关键词和文章营销无法准确把握链接数量,因此在实验中比较这些不同的链接构建模式是不合适的。
但是链接在旧内容中没有效果,这个结果刚好符合我的经验。另外值得注意的是,整个网站链接的有效性被谷歌大大削弱了。
我说的不科学,希望听到相反的经验和结果。 查看全部
c 抓取网页数据(非常简单类型网页所传递的链接权重的实验(图))
爬取到的和收录内容中的链接不传权重。晚上,我看到了一个关于不同类型网页传递的链接权重的实验。大致翻译如下: 关于去年暑假,我观察到一个明显的购买/放置/建立链接的现象,对搜索引擎抓取和收录的内容的排名增长起到了非常小的作用。
许多报纸和其他出版商以荒谬的价格提供旧版 文章 中的链接,但事实是它们根本没有效果。
去年年底,我做了一个实验。虽然已经过去了一段时间,但在我看来,这个结果仍然适用于当前的环境。
实验表明:
一个非常简单的实验是为三个不同的利基创建三种不同形式的链接网站:
1.a 在“新”内容中
2.b在“收录”的内容中
3.c 文本链接(作者参考侧边栏和页脚区域中的链接)
新内容
主要是利用文章营销来创造一些新的文章,并以目标关键词作为实验网站的锚文本。
包括什么
收录的页面添加了锚文本链接,部分页面已经有PR值(大约一半的链接有1)的PR值。
文字链接
从自建博客群中随机抽取了15篇博客,并在侧边栏中添加了链接。锚文本仍然使用目标关键字。
限制
我们都可以发现,这个实验有严重的局限性,所以结果不能完全作为依据,但是从排名的变化来看,可以证明在已经爬取和收录的内容中建立链接的权重是不够的。
实验结果
从图中可以明显看出,放置在旧内容中的链接不会有任何权重,否则排名结果不仅会出现轻微的移动,甚至会出现轻微的回落。
另外,博客侧边栏的链接,一开始的排名有很大的提升,但是很快就回落了(侧边栏的链接是整个网站链接的形式。作者后来解释说,自从实验是去年的,整个网站链接将不再有这个效果)。
综上所述
由于这些网站针对不同的关键词和文章营销无法准确把握链接数量,因此在实验中比较这些不同的链接构建模式是不合适的。
但是链接在旧内容中没有效果,这个结果刚好符合我的经验。另外值得注意的是,整个网站链接的有效性被谷歌大大削弱了。
我说的不科学,希望听到相反的经验和结果。
c 抓取网页数据(人工智能的记录片p50:c抓取网页数据,最开始用vb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-18 02:01
c抓取网页数据,最开始用vb的时候用到php和mysql,由于考试不及格,每次写这两个主要应付大型考试,再后来加入现在的工作之后用到的是,python,c,数据库,编程方法主要是按照上边的思路进行写程序。具体的技巧有很多,相互之间技术的交集很大,全篇手敲加网上看视频学习,多和实际工作中接触加以应用,将很快掌握一个技能,相信任何一位提问和学习技术的人都是深知技术本身并不简单的,和大师学习,可以少走很多弯路,很多大师不教你项目和做项目一定要亲自实践,这样才是最好的学习方法。
总算有本能懂得的问题了推荐我最近在看的一部关于人工智能方面的记录片p50:howtolearnandarchitecture(2012),有兴趣的朋友可以看一下。一般我们学习一门语言的语法时,都要经历记笔记、看coursera、看慕课的过程。但学习人工智能可能需要更高的目标和动力。想必大家也不陌生,英文的深度学习和coursera上有丰富的code实验、课程,但学习难度比较大,会涉及到大量的知识点,不轻易看这些内容。
然而如果真的为了提高自己而发挥动力学习,从神经网络、模型训练、特征工程开始学习一门语言,会更加容易上手,并掌握应用。目前我正在这样做,分享给大家。以下是我学习时的笔记、列表和实验步骤。可参考~***。 查看全部
c 抓取网页数据(人工智能的记录片p50:c抓取网页数据,最开始用vb)
c抓取网页数据,最开始用vb的时候用到php和mysql,由于考试不及格,每次写这两个主要应付大型考试,再后来加入现在的工作之后用到的是,python,c,数据库,编程方法主要是按照上边的思路进行写程序。具体的技巧有很多,相互之间技术的交集很大,全篇手敲加网上看视频学习,多和实际工作中接触加以应用,将很快掌握一个技能,相信任何一位提问和学习技术的人都是深知技术本身并不简单的,和大师学习,可以少走很多弯路,很多大师不教你项目和做项目一定要亲自实践,这样才是最好的学习方法。
总算有本能懂得的问题了推荐我最近在看的一部关于人工智能方面的记录片p50:howtolearnandarchitecture(2012),有兴趣的朋友可以看一下。一般我们学习一门语言的语法时,都要经历记笔记、看coursera、看慕课的过程。但学习人工智能可能需要更高的目标和动力。想必大家也不陌生,英文的深度学习和coursera上有丰富的code实验、课程,但学习难度比较大,会涉及到大量的知识点,不轻易看这些内容。
然而如果真的为了提高自己而发挥动力学习,从神经网络、模型训练、特征工程开始学习一门语言,会更加容易上手,并掌握应用。目前我正在这样做,分享给大家。以下是我学习时的笔记、列表和实验步骤。可参考~***。
c 抓取网页数据(网站手机号码抓取软件是怎么获取访客手机号码的呢软件的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-15 17:06
网站手机号抓取软件/访客手机号获取软件。运营商在大数据时代,只有利用大数据获取大量客户,才能持续这样做。
Lexue 甚至掌握了 Python 爬虫 2 的基础知识,从复杂的客户消息中查找电话信息。
网站访客手机号码抓取软件,关于网站访客手机号码抓取软件,网上有很多人在问这个,尤其是最近很多老板。
[最佳答案] 百度地图新平台上线。您可以在地图上免费标记您的公司。请参考以下几点进行标记: 1、 注册并登录以提高您的个人。
我使用 ForeSpider 从搜索引擎 采集 中获取我的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数是市面上通用爬虫软件中唯一自带数据挖掘的爬虫软件。软件集成数据挖掘功能,可通过采集模板精准挖掘全网内容。在将数据采集存入数据库的同时,即可完成分发。
一些网站可以获得访问者的手机号码,一家名为瑞舟科技的公司,该公司在其网站的网页上销售“手机号码抓取软件”,以及标语。
手机号获取:客户用手机访问你的网站后,不咨询或不使用手机号抓取软件,访问者的手机号如何获取访问者的手机号?.
网站访客手机号抓取,手机号抓取软件联系人* 提交留言的手机号表示同意更多商家联系我。 查看全部
c 抓取网页数据(网站手机号码抓取软件是怎么获取访客手机号码的呢软件的?)
网站手机号抓取软件/访客手机号获取软件。运营商在大数据时代,只有利用大数据获取大量客户,才能持续这样做。
Lexue 甚至掌握了 Python 爬虫 2 的基础知识,从复杂的客户消息中查找电话信息。
网站访客手机号码抓取软件,关于网站访客手机号码抓取软件,网上有很多人在问这个,尤其是最近很多老板。
[最佳答案] 百度地图新平台上线。您可以在地图上免费标记您的公司。请参考以下几点进行标记: 1、 注册并登录以提高您的个人。
我使用 ForeSpider 从搜索引擎 采集 中获取我的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数是市面上通用爬虫软件中唯一自带数据挖掘的爬虫软件。软件集成数据挖掘功能,可通过采集模板精准挖掘全网内容。在将数据采集存入数据库的同时,即可完成分发。

一些网站可以获得访问者的手机号码,一家名为瑞舟科技的公司,该公司在其网站的网页上销售“手机号码抓取软件”,以及标语。
手机号获取:客户用手机访问你的网站后,不咨询或不使用手机号抓取软件,访问者的手机号如何获取访问者的手机号?.

网站访客手机号抓取,手机号抓取软件联系人* 提交留言的手机号表示同意更多商家联系我。
c 抓取网页数据( 具体分析如下实现抓取和分析网页类,实例分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-14 08:07
具体分析如下实现抓取和分析网页类,实例分析(图))
爬取分析网页类示例的C#实现
更新时间:2015-05-25 10:53:05 作者:莫翔
本文文章主要介绍爬取分析网页的C#实现,实例分析了C#抓取和分析网页中的文字和连接的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页纯文本,去除所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望本文对您的 C# 编程有所帮助。 查看全部
c 抓取网页数据(
具体分析如下实现抓取和分析网页类,实例分析(图))
爬取分析网页类示例的C#实现
更新时间:2015-05-25 10:53:05 作者:莫翔
本文文章主要介绍爬取分析网页的C#实现,实例分析了C#抓取和分析网页中的文字和连接的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页纯文本,去除所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望本文对您的 C# 编程有所帮助。
c 抓取网页数据(Android我的博客APP(一)(组图——1.))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-14 08:06
阿里云>云栖社区>专题图>S>数据库抓取网页数据
推荐活动:
更多优惠>
当前主题:数据库从网页抓取数据并添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
网络数据库挖掘程序设计
作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。我如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:04年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是:通过编写好的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节 从 Web 表中抓取数据
作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用而来的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们有价值的数据。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从哪个博客中提取的数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
快速搭建实时爬虫集群
作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
数据库从网页中抓取数据并提出相关问题
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
c 抓取网页数据(Android我的博客APP(一)(组图——1.))
阿里云>云栖社区>专题图>S>数据库抓取网页数据

推荐活动:
更多优惠>
当前主题:数据库从网页抓取数据并添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取


作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
网络数据库挖掘程序设计

作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。我如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取

作者:呵呵 9925975人浏览评论:04年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是:通过编写好的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节 从 Web 表中抓取数据

作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
善用网络爬虫工具,轻松采集数据

作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用而来的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们有价值的数据。
阅读全文
初学者指南 | 使用 Python 抓取网页


作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从哪个博客中提取的数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
快速搭建实时爬虫集群

作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
数据库从网页中抓取数据并提出相关问题
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑


作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
c 抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-10 05:24
最近需要在网站下载一批数据。但是当你输入一个查询,返回3万到4万条结果时,一次只能导出500条,而且每次都要输入下载项的范围!这样点击下载,又不是我的命。所以我想自动化这个过程。
我的需求主要有两点:1.需要高度自动化。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘的动作,比如在文本框中输入、选择下拉列表、单选按钮、复选框、点击按钮等。2. 不需要效率。因为我要的数据量比较少。3. python下的框架。因为平时用的最多的是python。
我对网站的技术了解不多,对网站的经验只有两个:我开发了一个非常简单的Android客户端,并使用python scrapy框架写了一个爬虫来自动抓取新闻。所以了解客户端和服务端的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
一开始针对这个问题,我什至不知道要搜索什么。知乎的文章文章提供了很多有用的信息:《Python爬虫如何获取JS生成的URL和网页内容?》一路上权衡了很多方法,最后选择了Selenium。主要优点是学习成本非常小,代码实现速度快。缺点是爬行效率低。对于那些想要提高效率的人来说,他们必须花一些时间学习更复杂的工具包。
网站技术
如果你想自动抓取网页,你必须了解一些基本知识,这样做会更快。下面简单介绍一下相关知识。
1. 请求/响应
请求是客户端向服务器发起请求。输入一个 URL 对应一个请求动作,这是最直观的。要抓取静态网页的内容,您只需要知道 URL。然而,今天的许多网页都是动态的。指向或点击网页的某些元素也会触发请求动作,这会导致网页动态更新部分内容。这部分内容无法直接从静态网页中获取。这种技术叫做AJAX,但我不太明白。这里的问题是我们可能不知道 URL 是什么,因此需要一些高级接口来处理动态内容。
响应是服务器返回给客户端的内容。如果要获取静态网页的内容,直接从请求中获取即可。
2. 分析网页源码
我们要抓取网页上的某一部分信息,就需要知道如何定位。这里需要了解 HTML 和 XPATH。不知道的可以去w3school在线教程:
查看网页源代码,鼠标指针指向网页任意位置,或者指向目标元素。右键单击并在下拉列表中选择“检查元素”。以下是我右键“百度点击”显示的网页源码,为HTML格式,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 语句。这是 XPATH 语法,很容易掌握。知道如何分析网页后,我们又向前迈进了一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签页、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、单击按钮等。
这里需要模拟的操作就这么多,对应的selenium接口可以参考。
4. Selenium 简介
一句话概括:Selenium 是一套针对 Web 应用程序的自动化测试工具。
很多话:Selenium 诞生于 2004 年,当时在 ThoughtWorks 工作的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比每次更改都手动测试更有价值。他开发了一个可以驱动页面交互的Javascript库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 的所有功能的基础。
实战1.数据采集过程分析
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;点击Export,弹出一个弹窗,然后点击下拉列表,单选按钮,勾选Check the box做一些选择,点击下载。然后浏览器开始下载文件。
A页
页面 B
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择谷歌浏览器。下载链接:。同时,当然python中必须安装selenium。从命令行输入 pip install senenium 进行安装。
B. 配置环境变量
这一步需要配置chromedriver的保存路径到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或mac可以选择在.bash_rc中配置。配置方法很多,自行百度。
我用的是mac,但不知道为什么配置不起作用!后来我发现只有在代码中设置才能工作。
C. 核心代码(python)
# 设置下载路径并配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置隐形等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,它会报告超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面 A
driver.get("")
# 在A页的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到一个新窗口,并将焦点定位到这个窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:在计算下载次数之前等待页面加载
search_ret_num = WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(range(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
出口。点击()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容单选
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()#完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录 URL
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():#搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
download = driver.find_element_by_xpath('//div[@class ="export-citation-buttons"]')
下载。点击()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不起作用!
驱动程序退出()
返回
3. 提示
A. 每次启动浏览器,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是如何进行的。看来selenium真的是为web程序的自动化测试做好了准备。此外,在抓取过程中保持屏幕打开。如果您进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是一个很常见的场景。所以要注意网页响应时间。Selenium 不会等待网页响应完成才继续执行代码,它会直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定作用,显式等待在WebDriverWait中起主要作用。 但是需要注意的是,最长等待时间取决于两者中较大的一个,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C、设置下载路径时,一开始不起作用。我怀疑是“download.default_directory”这个键错了,于是查看网页源码找到了这个键,还是一样。问题出在别处。但这提醒我,以后在代码中使用字典做相关配置的时候,看源码就可以猜到了。
D.我以为整个过程要两三天才能实现,因为我真的不明白。从开始学习到完成,不到一天就完成了。可能是因为我在开始之前搜索了很长时间,经过反复比较,找到了最方便的工具。
E. 做完之后在github上搜了一下,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间学习太多web应用的底层知识,可以结合使用Selenium+scrapy。Scrapy 可以负责搜索网页,而 selenium 负责处理每个网页上的内容,尤其是动态内容。如果下次有需要,我打算用这个主意!
F. 分享一句话。“关于爬虫,最快获得经验的方法是:学会写网站,如果你知道网站在请求什么,你就会知道怎么爬网站!” 这很简单。,但是这么简单的一句话给了我很大的启发。之前感觉太难了,一直卡在scrapy爬静态网页的级别。像cookies这样的技术也曾被观看过一次,一次被遗忘一次。现在看来是因为网站的整体流程没有梳理清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要去网上查一下相关概念是怎么回事,就慢慢熬过去了。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。下面是一些介绍:。懂编程又想高效率的需要参考其他工具。 查看全部
c 抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
最近需要在网站下载一批数据。但是当你输入一个查询,返回3万到4万条结果时,一次只能导出500条,而且每次都要输入下载项的范围!这样点击下载,又不是我的命。所以我想自动化这个过程。
我的需求主要有两点:1.需要高度自动化。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘的动作,比如在文本框中输入、选择下拉列表、单选按钮、复选框、点击按钮等。2. 不需要效率。因为我要的数据量比较少。3. python下的框架。因为平时用的最多的是python。
我对网站的技术了解不多,对网站的经验只有两个:我开发了一个非常简单的Android客户端,并使用python scrapy框架写了一个爬虫来自动抓取新闻。所以了解客户端和服务端的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
一开始针对这个问题,我什至不知道要搜索什么。知乎的文章文章提供了很多有用的信息:《Python爬虫如何获取JS生成的URL和网页内容?》一路上权衡了很多方法,最后选择了Selenium。主要优点是学习成本非常小,代码实现速度快。缺点是爬行效率低。对于那些想要提高效率的人来说,他们必须花一些时间学习更复杂的工具包。
网站技术
如果你想自动抓取网页,你必须了解一些基本知识,这样做会更快。下面简单介绍一下相关知识。
1. 请求/响应
请求是客户端向服务器发起请求。输入一个 URL 对应一个请求动作,这是最直观的。要抓取静态网页的内容,您只需要知道 URL。然而,今天的许多网页都是动态的。指向或点击网页的某些元素也会触发请求动作,这会导致网页动态更新部分内容。这部分内容无法直接从静态网页中获取。这种技术叫做AJAX,但我不太明白。这里的问题是我们可能不知道 URL 是什么,因此需要一些高级接口来处理动态内容。
响应是服务器返回给客户端的内容。如果要获取静态网页的内容,直接从请求中获取即可。

2. 分析网页源码
我们要抓取网页上的某一部分信息,就需要知道如何定位。这里需要了解 HTML 和 XPATH。不知道的可以去w3school在线教程:
查看网页源代码,鼠标指针指向网页任意位置,或者指向目标元素。右键单击并在下拉列表中选择“检查元素”。以下是我右键“百度点击”显示的网页源码,为HTML格式,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 语句。这是 XPATH 语法,很容易掌握。知道如何分析网页后,我们又向前迈进了一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签页、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、单击按钮等。
这里需要模拟的操作就这么多,对应的selenium接口可以参考。
4. Selenium 简介
一句话概括:Selenium 是一套针对 Web 应用程序的自动化测试工具。
很多话:Selenium 诞生于 2004 年,当时在 ThoughtWorks 工作的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比每次更改都手动测试更有价值。他开发了一个可以驱动页面交互的Javascript库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 的所有功能的基础。
实战1.数据采集过程分析
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;点击Export,弹出一个弹窗,然后点击下拉列表,单选按钮,勾选Check the box做一些选择,点击下载。然后浏览器开始下载文件。
A页
页面 B
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择谷歌浏览器。下载链接:。同时,当然python中必须安装selenium。从命令行输入 pip install senenium 进行安装。
B. 配置环境变量
这一步需要配置chromedriver的保存路径到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或mac可以选择在.bash_rc中配置。配置方法很多,自行百度。
我用的是mac,但不知道为什么配置不起作用!后来我发现只有在代码中设置才能工作。
C. 核心代码(python)
# 设置下载路径并配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置隐形等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,它会报告超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面 A
driver.get("")
# 在A页的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到一个新窗口,并将焦点定位到这个窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:在计算下载次数之前等待页面加载
search_ret_num = WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(range(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
出口。点击()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容单选
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()#完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录 URL
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():#搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
download = driver.find_element_by_xpath('//div[@class ="export-citation-buttons"]')
下载。点击()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不起作用!
驱动程序退出()
返回
3. 提示
A. 每次启动浏览器,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是如何进行的。看来selenium真的是为web程序的自动化测试做好了准备。此外,在抓取过程中保持屏幕打开。如果您进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是一个很常见的场景。所以要注意网页响应时间。Selenium 不会等待网页响应完成才继续执行代码,它会直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定作用,显式等待在WebDriverWait中起主要作用。 但是需要注意的是,最长等待时间取决于两者中较大的一个,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C、设置下载路径时,一开始不起作用。我怀疑是“download.default_directory”这个键错了,于是查看网页源码找到了这个键,还是一样。问题出在别处。但这提醒我,以后在代码中使用字典做相关配置的时候,看源码就可以猜到了。
D.我以为整个过程要两三天才能实现,因为我真的不明白。从开始学习到完成,不到一天就完成了。可能是因为我在开始之前搜索了很长时间,经过反复比较,找到了最方便的工具。
E. 做完之后在github上搜了一下,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间学习太多web应用的底层知识,可以结合使用Selenium+scrapy。Scrapy 可以负责搜索网页,而 selenium 负责处理每个网页上的内容,尤其是动态内容。如果下次有需要,我打算用这个主意!
F. 分享一句话。“关于爬虫,最快获得经验的方法是:学会写网站,如果你知道网站在请求什么,你就会知道怎么爬网站!” 这很简单。,但是这么简单的一句话给了我很大的启发。之前感觉太难了,一直卡在scrapy爬静态网页的级别。像cookies这样的技术也曾被观看过一次,一次被遗忘一次。现在看来是因为网站的整体流程没有梳理清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要去网上查一下相关概念是怎么回事,就慢慢熬过去了。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。下面是一些介绍:。懂编程又想高效率的需要参考其他工具。
c 抓取网页数据(教你爬下100部电影数据:R语言网页爬取入门指南(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-05 04:02
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客查看更多博客
使用多线程爬取招聘网站
作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery作为 pq 导入 json from
阅读全文
手拉手 | 教你爬下100部电影数据:R语言爬网初学者指南
作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将谷歌作为主要的知识来源——无论是寻找一个地方的评论还是学习新术语。所有这些信息都可以在线获取。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
基于Scrapy的爬取伯乐在线网站
作者:小三坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。注2018年7月20日Scrapy官方文档网址:网页在chrome浏览器中打开
阅读全文
Python爬虫入门教程25-100 知乎文章 图片爬虫之一
作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬,我可能会断断续续的写几个文章。最简单的方法是先爬行。爬取单个 文章 的所有答案并不困难。找到我们要爬取的页面,我随便选一个
阅读全文
【python学习】维基百科程序语言消息框的简单爬取
作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲到通过BeautifulSoup爬取网络知识。由于这方面的文章还很少,希望提供一些思路和方法,帮助大家
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬取
作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,我们抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,按顺序
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李 2725人浏览评论:04年前
爬虫主要是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文 查看全部
c 抓取网页数据(教你爬下100部电影数据:R语言网页爬取入门指南(组图))
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客查看更多博客
使用多线程爬取招聘网站


作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery作为 pq 导入 json from
阅读全文
手拉手 | 教你爬下100部电影数据:R语言爬网初学者指南

作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将谷歌作为主要的知识来源——无论是寻找一个地方的评论还是学习新术语。所有这些信息都可以在线获取。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
苏宁百万级商品爬虫简述

作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
基于Scrapy的爬取伯乐在线网站

作者:小三坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。注2018年7月20日Scrapy官方文档网址:网页在chrome浏览器中打开
阅读全文
Python爬虫入门教程25-100 知乎文章 图片爬虫之一


作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬,我可能会断断续续的写几个文章。最简单的方法是先爬行。爬取单个 文章 的所有答案并不困难。找到我们要爬取的页面,我随便选一个
阅读全文
【python学习】维基百科程序语言消息框的简单爬取
作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲到通过BeautifulSoup爬取网络知识。由于这方面的文章还很少,希望提供一些思路和方法,帮助大家
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬取

作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,我们抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,按顺序
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据


作者:夜李 2725人浏览评论:04年前
爬虫主要是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文
c 抓取网页数据(C++与php的交互之--C++获取网页文字内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-30 23:22
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。---分割线-------------------------------------------- ---------------- 测试服务器为:新浪云海;测试内容:获取PHP脚本从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先是直观的图片,然后是文本源代码的一般示例?getWeiXinFromUserNameFromSEA(const char*); 9 using namespace std;10 11 int main(){12 char *p=NULL; 用于存储返回的结果
633 查看全部
c 抓取网页数据(C++与php的交互之--C++获取网页文字内容)
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。---分割线-------------------------------------------- ---------------- 测试服务器为:新浪云海;测试内容:获取PHP脚本从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先是直观的图片,然后是文本源代码的一般示例?getWeiXinFromUserNameFromSEA(const char*); 9 using namespace std;10 11 int main(){12 char *p=NULL; 用于存储返回的结果
633
c 抓取网页数据(浏览器输入一个URL站点后看到网站页面内容(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-29 08:11
我们在浏览器中输入一个URL站点,按回车,就可以正常在浏览器中看到网站页面的内容了。其实这个过程就是浏览器向它所在的服务器发送请求,告诉服务器请求什么。服务器收到请求后,对请求进行处理和解析。如果请求的处理和解析正常,则返回给浏览器。的回应。响应中收录页面的源代码等内容,浏览器解析响应中的源代码,最终显示解析出的网页。大致流程是:浏览器请求“服务器处理和分析”服务器响应并传递给浏览器“浏览器对网页的分析和渲染”。
让我们通过实际的网络站点来了解HTTP请求和响应的过程,以及在这个过程中发生了什么样的网络请求。以Chrome浏览器访问百度网站为例。
打开Chrome浏览器,在鼠标右键菜单中选择【检查】或直接快捷键【F12】打开开发者工具,切换到【网络】。在浏览器中输入百度站点:按回车键查看发生的网络请求。如下所示:
第一个网络请求:是浏览器向百度服务器发送的访问百度站点的请求。单击此请求可查看请求的详细信息和内容。
首先是General部分,描述了请求的URL、请求方法、响应状态码以及远程服务器的地址和端口;
下面有Response Headers和Request Headers,分别是响应头和请求头。收录响应和请求的部分相关信息和内容。我们来看看这个请求的具体内容和对应的响应。
请求的组成
请求由客户端即浏览器发送到服务器。发送的请求有4个方面:请求方法、请求URL、请求头、请求正文
1.请求方式
常见的请求有 get、post、put... 类型。get类接口一般是指获取信息的接口,比如列表查询的功能,点击查询按钮调用get接口,然后返回信息。这意味着从服务器(后端)提取内容。post类型一般是提交表单的功能,比如注册、导入数据等,就是post接口。这意味着将内容推送到服务器(后端)。
2.请求的站点
请求的网站是浏览器输入的URL URL
3.请求头
请求头用于指示服务器使用的附件信息,即HTTP协议规定的附加内容,必须按照协议规则进行处理。访问百度站点的请求头信息如下图所示:
查看请求头信息相关字段的描述
Accept:请求头域,用于指定客户端可以接受什么类型的信息,如上图所示,可以接受text/html等类型的信息
Accept-Encoding 和 Accept-Language:指定客户端可接受的编码和语言
连接:连接状态
Cookie:存储的Cookie信息,主要用于维护当前会话
Host:需要访问的站点地址
User-Agent:用于向服务器标识客户端使用的操作系统、浏览器版本等信息
4.请求正文
请求体一般携带POST类型请求的表单数据,GET类型请求体为空
响应的组成
响应是服务器返回给浏览器的信息。响应的内容有三个方面:响应状态码、响应头和响应体
1.响应状态码
响应状态码表示服务器对请求信息的处理结果,如200表示响应正常,404表示未找到页面,500表示服务器出错等。
2. 响应头
响应头收录服务器对请求的响应信息,如下图所示:
查看响应头中关键字段的描述
Content-Type:文档类型,指定返回的文档是什么,例如text/html表示返回的文档是HTML文档
服务器:服务器信息,如服务器名称、版本等。
Set-Cookie:设置 Cookie
Expires:指定响应的过期时间
3. 响应正文
是网页的HTML源代码,点击【预览】选项卡可以查看网页的源代码
2.3、 网页组成
现代网页总是带给我们丰富多彩的视觉体验。不同的网页往往有很多不同的外观,搭配合理的布局、丰富的图片、动画效果等,那么这些页面是如何形成的呢?构成网页的三个主要部分:HTML、CSS 和 JavaScript。HTML构成了网页的基本结构,CSS决定了网页的布局风格,JavaScript决定了网页的可塑性和动态呈现。下面我们来详细了解一下这三个部分:
1.HTML
HTML:全称是Hyper Text Markup Language,即超文本标记语言。网页上的文字、段落、图片、按钮等元素都是由HTML定义的。比如img标签代表图片,p标签代表段落等等,在Chrome浏览器中打开百度站,鼠标右键选择【勾选】或者直接【F12】打开开发者工具就可以了在【元素】选项栏中可以看到网页的HTML源代码,如下图:
您可以查看网页的 HTML 源代码。每个标签对定义一个节点和节点属性,它们形成一个 HTML 树。这些节点标签对显示在 HTML 树中,并且具有一定的层次关系。它们通常由父节点、子节点和同一级别的节点表示。HTML学习可以参考W3School网站学习:
2.CSS
CSS:全称Cascading Style Sheets,即Cascading Style Sheets。CSS 用于确定网页布局样式的标准,指定网页中文本的大小、颜色、位置等属性。找到如下图按钮【百度点击】查看样式:
CSS样式决定了按钮的宽高,即宽高的像素大小,以及文字颜色颜色:白色等信息。按钮背景色:background
3.JavaScript
JavaScript 是 JS,一种脚本语言,用于将 JS 文件嵌入 HTML 代码中,以提供交互式动态效果,例如提示框、轮播、下载进度条等。HTML 中的标签对由脚本标签对定义
综上所述,HTML 定义了网页的内容和结构,CSS 描述了网页元素的布局渲染和位置效果,JavaScript 定义了网页的交互性和动画效果。这三个构成了丰富的 Web 演示文稿的基本结构。
在了解了爬虫的基本概念、HTTP协议和网页的基本组成之后,基于这些方面的认知,我开始学习如何爬取网站并提取信息。 查看全部
c 抓取网页数据(浏览器输入一个URL站点后看到网站页面内容(组图))
我们在浏览器中输入一个URL站点,按回车,就可以正常在浏览器中看到网站页面的内容了。其实这个过程就是浏览器向它所在的服务器发送请求,告诉服务器请求什么。服务器收到请求后,对请求进行处理和解析。如果请求的处理和解析正常,则返回给浏览器。的回应。响应中收录页面的源代码等内容,浏览器解析响应中的源代码,最终显示解析出的网页。大致流程是:浏览器请求“服务器处理和分析”服务器响应并传递给浏览器“浏览器对网页的分析和渲染”。
让我们通过实际的网络站点来了解HTTP请求和响应的过程,以及在这个过程中发生了什么样的网络请求。以Chrome浏览器访问百度网站为例。
打开Chrome浏览器,在鼠标右键菜单中选择【检查】或直接快捷键【F12】打开开发者工具,切换到【网络】。在浏览器中输入百度站点:按回车键查看发生的网络请求。如下所示:
第一个网络请求:是浏览器向百度服务器发送的访问百度站点的请求。单击此请求可查看请求的详细信息和内容。
首先是General部分,描述了请求的URL、请求方法、响应状态码以及远程服务器的地址和端口;
下面有Response Headers和Request Headers,分别是响应头和请求头。收录响应和请求的部分相关信息和内容。我们来看看这个请求的具体内容和对应的响应。
请求的组成
请求由客户端即浏览器发送到服务器。发送的请求有4个方面:请求方法、请求URL、请求头、请求正文
1.请求方式
常见的请求有 get、post、put... 类型。get类接口一般是指获取信息的接口,比如列表查询的功能,点击查询按钮调用get接口,然后返回信息。这意味着从服务器(后端)提取内容。post类型一般是提交表单的功能,比如注册、导入数据等,就是post接口。这意味着将内容推送到服务器(后端)。
2.请求的站点
请求的网站是浏览器输入的URL URL
3.请求头
请求头用于指示服务器使用的附件信息,即HTTP协议规定的附加内容,必须按照协议规则进行处理。访问百度站点的请求头信息如下图所示:

查看请求头信息相关字段的描述
Accept:请求头域,用于指定客户端可以接受什么类型的信息,如上图所示,可以接受text/html等类型的信息
Accept-Encoding 和 Accept-Language:指定客户端可接受的编码和语言
连接:连接状态
Cookie:存储的Cookie信息,主要用于维护当前会话
Host:需要访问的站点地址
User-Agent:用于向服务器标识客户端使用的操作系统、浏览器版本等信息
4.请求正文
请求体一般携带POST类型请求的表单数据,GET类型请求体为空
响应的组成
响应是服务器返回给浏览器的信息。响应的内容有三个方面:响应状态码、响应头和响应体
1.响应状态码
响应状态码表示服务器对请求信息的处理结果,如200表示响应正常,404表示未找到页面,500表示服务器出错等。
2. 响应头
响应头收录服务器对请求的响应信息,如下图所示:

查看响应头中关键字段的描述
Content-Type:文档类型,指定返回的文档是什么,例如text/html表示返回的文档是HTML文档
服务器:服务器信息,如服务器名称、版本等。
Set-Cookie:设置 Cookie
Expires:指定响应的过期时间
3. 响应正文
是网页的HTML源代码,点击【预览】选项卡可以查看网页的源代码
2.3、 网页组成
现代网页总是带给我们丰富多彩的视觉体验。不同的网页往往有很多不同的外观,搭配合理的布局、丰富的图片、动画效果等,那么这些页面是如何形成的呢?构成网页的三个主要部分:HTML、CSS 和 JavaScript。HTML构成了网页的基本结构,CSS决定了网页的布局风格,JavaScript决定了网页的可塑性和动态呈现。下面我们来详细了解一下这三个部分:
1.HTML
HTML:全称是Hyper Text Markup Language,即超文本标记语言。网页上的文字、段落、图片、按钮等元素都是由HTML定义的。比如img标签代表图片,p标签代表段落等等,在Chrome浏览器中打开百度站,鼠标右键选择【勾选】或者直接【F12】打开开发者工具就可以了在【元素】选项栏中可以看到网页的HTML源代码,如下图:

您可以查看网页的 HTML 源代码。每个标签对定义一个节点和节点属性,它们形成一个 HTML 树。这些节点标签对显示在 HTML 树中,并且具有一定的层次关系。它们通常由父节点、子节点和同一级别的节点表示。HTML学习可以参考W3School网站学习:
2.CSS
CSS:全称Cascading Style Sheets,即Cascading Style Sheets。CSS 用于确定网页布局样式的标准,指定网页中文本的大小、颜色、位置等属性。找到如下图按钮【百度点击】查看样式:
CSS样式决定了按钮的宽高,即宽高的像素大小,以及文字颜色颜色:白色等信息。按钮背景色:background
3.JavaScript
JavaScript 是 JS,一种脚本语言,用于将 JS 文件嵌入 HTML 代码中,以提供交互式动态效果,例如提示框、轮播、下载进度条等。HTML 中的标签对由脚本标签对定义
综上所述,HTML 定义了网页的内容和结构,CSS 描述了网页元素的布局渲染和位置效果,JavaScript 定义了网页的交互性和动画效果。这三个构成了丰富的 Web 演示文稿的基本结构。
在了解了爬虫的基本概念、HTTP协议和网页的基本组成之后,基于这些方面的认知,我开始学习如何爬取网站并提取信息。
c 抓取网页数据(一个人模拟验证码的快速处理方法,你值得拥有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-27 18:05
c抓取网页数据,用框架比如flask这种。
也有直接用mongo的,
多线程可以一起工作来对大网站进行快速处理
人家一个人好几万上百万用户都用了https,这个不算啥,不过能说明提问者不够专业;这个技术上对网站来说不算什么的,就好比https其实并不安全,在国内到处乱泄露,有点傻逼的感觉,但是有点用。这么说吧,首先https对缓存和加密是个不错的东西,其次从技术的角度上来说,服务器端要做这个一点都不难,只是执行脚本的你不会用。
一个人模拟验证码这事说明这位兄台不好学,专业不对口呀。题主不要着急,最好再找找不上来人。一个人模拟验证码不是对付不了,而是没经验,没数据。https需要验证一个地址,那在一个地址上只能实现一个验证。怎么办?很简单啊,如果一个网站验证码这个数据量少,图片少,那在各线程里发送一下就好了。对于验证码要验证一大堆数据,图片多的来说,那就麻烦,这里cookie加数据库的方案已经普及了。推荐个表单验证的https方案,只是想传个数据测试一下。
人家只用https。提主还是让你邻居给你做验证码服务器吧,他不知道你做了什么,又不承担,不然随便给你加个暴力破解。另外,作为一个大学生,有什么想不开的非要用mongodb?我一直觉得,mongodb这个名字很土。likethis:likethis:slogon:createyourwebstoreoraddanythingtootherserver.另外最好不要因为验证码而关闭浏览器,想想看,这个页面是不是一直在向其他页面发出对话?关闭浏览器当然避免了这个问题。
ps:一般做好https,根本不需要cookie,因为ie网上很容易解决,一个autostart,一个authentication就完事了。 查看全部
c 抓取网页数据(一个人模拟验证码的快速处理方法,你值得拥有)
c抓取网页数据,用框架比如flask这种。
也有直接用mongo的,
多线程可以一起工作来对大网站进行快速处理
人家一个人好几万上百万用户都用了https,这个不算啥,不过能说明提问者不够专业;这个技术上对网站来说不算什么的,就好比https其实并不安全,在国内到处乱泄露,有点傻逼的感觉,但是有点用。这么说吧,首先https对缓存和加密是个不错的东西,其次从技术的角度上来说,服务器端要做这个一点都不难,只是执行脚本的你不会用。
一个人模拟验证码这事说明这位兄台不好学,专业不对口呀。题主不要着急,最好再找找不上来人。一个人模拟验证码不是对付不了,而是没经验,没数据。https需要验证一个地址,那在一个地址上只能实现一个验证。怎么办?很简单啊,如果一个网站验证码这个数据量少,图片少,那在各线程里发送一下就好了。对于验证码要验证一大堆数据,图片多的来说,那就麻烦,这里cookie加数据库的方案已经普及了。推荐个表单验证的https方案,只是想传个数据测试一下。
人家只用https。提主还是让你邻居给你做验证码服务器吧,他不知道你做了什么,又不承担,不然随便给你加个暴力破解。另外,作为一个大学生,有什么想不开的非要用mongodb?我一直觉得,mongodb这个名字很土。likethis:likethis:slogon:createyourwebstoreoraddanythingtootherserver.另外最好不要因为验证码而关闭浏览器,想想看,这个页面是不是一直在向其他页面发出对话?关闭浏览器当然避免了这个问题。
ps:一般做好https,根本不需要cookie,因为ie网上很容易解决,一个autostart,一个authentication就完事了。
c 抓取网页数据(简单笼统的说,爬数据搞定以下几个部分,就可以小打小闹一下了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-25 03:16
简单来说,一般来说,如果你爬取数据得到以下部分,你可能会遇到一些麻烦。
一、 指定 URL 格式,例如 知乎 问题的 URL 为 /question/xxxx,然后抓取 html 内容。使用的工具,如果你有很好的规律性,你可以使用规律性。如果觉得规律性很麻烦,可以使用html解析DOM节点来处理内容。如果你爬取的内容有自己固有的特性,比如新闻内容,可以使用body爬取算法,其实就是在html中找出最长的几行字符串。
二、 使用javascript动态生成内容爬取。不推荐使用headless,效率比较低。建议使用一些开源库直接执行js代码,得到想要的结果。
了解页面中的程序逻辑非常重要。知道动态内容是如何生成的,使用一定的方法,就会和html一样,很容易得到你想要的结果。动态生成要么是在本地进行计算,要么是向服务器发起另一个请求以获得某个结果,显示或再次进行本地计算。对于前者,需要找到本地执行的那段代码,照原样,在javascript环境中执行,得到结果。对于后者,找到请求并得到相应的结果。一般结果也会是javascript代码或者json格式的字符串,可以再次解析。
三、登录,有很多资料需要登录才能查看。如果对方使用https,基本没有办法。好在国内很多网站在全站打广告的都是伪https,都可以像抓包一样抓到。比较复杂的会为用户名或密码重新加密,并且是时间相关的,直接提交给用户名和密码无效。您必须同时提交以当前时间为参数的第二次加密结果。同样,理解页面中的程序逻辑很重要。
四、验证码,当你取的太多太快时,网站一般会要求你输入验证码,证明你不是程序,而是手动操作。国内好像有云服务可以帮你输入验证码,修复这部分,或者用程序解析验证码,但是错误率太高了。另一种流氓方法是使用多个ADSL或VPN,来回切换IP,不断换IP进行爬取,将单个IP的爬取速度控制在网站的允许范围内,改什么header header代理比较简单,就不多说了。
五、 内容如图,网站 类别中的一些敏感信息,如商城价格、用户手机号码等,会直接由网站 显示在图片的形式。在这里,使用云服务的成本太高了。如果用程序解析图片,如果出错,这个信息基本没用。切换IP也是图,所以基本无解。
六、另外,爬虫还有很多细节和针对性的处理方式。为了学习的目的,我们需要多思考。比如移动互联网这么火,很多网站,有点厉害的会从手机客户端出来在手机客户端,他还用图片来展示吗?现在html5出来了,很多手机客户端都是用html+js重新打包的。
———————— 分界线,探讨抢夺的可持续性—————————
一个网页上有n个以上的链接,这意味着你会遇到从一个页面开始的链接数,然后以这种方式扩展1*n*n*n。同时,会出现重复的链接,所以如何保存爬取到的链接,以及如何过滤掉符合一定条件的链接,将是你需要解决的一个新问题。
好吧,当你有一个链接处理机制来帮你管理你爬取的所有链接时,你的爬虫的爬取效率就变得非常高效了,效率高到你的爬虫被目标拦截了网站,你该如何解决? 关于更改标题,我不会说太多。我只说说怎么解决key阻塞ip?
你需要让你的爬虫分布式,以中央服务器为任务调度中心,对爬取的页面进行处理,将爬取到的链接分发给所有下属机器。
下级机只做一件事,就是向中央服务器请求一个任务,执行完请求的任务后,将结果返回给调度中心。每个从机只是一个一年几十块的虚拟机,我们要的是从机的IP。
好了,现在你有n个ip分散在n台机器上为你做爬虫,数据统一集中在你躲在幕后的中央服务器上。效率非常高。一般你控制的好,目标服务器是不会发现的。某个ip请求太频繁,流量太高,但事情可能就是这么不正常!目标服务器还是找到了你!杀死你所有的小爬虫!怎么做?
你需要优化调度中心的东西。您的中央服务器不能只是将任务平均分配给每个从属机器。您需要实时监控每个下属机器的任务数量和执行状态。让他安息,免得他被杀。为什么这不在从属机器上做?因为我们使用的虚拟机每年价值几十美元!!成本!!你有钱买一台一年几千块的机器我没说!!
好了,现在你的任务调度中心很聪明,保证每个下属机器的任务不会太高。如果觉得效率还低,直接开个虚拟机就好了。还有很多ip。还可以很好的控制访问的频率和流量,链接管理也很好。基本上,爬虫的框架都有一个原型。 查看全部
c 抓取网页数据(简单笼统的说,爬数据搞定以下几个部分,就可以小打小闹一下了)
简单来说,一般来说,如果你爬取数据得到以下部分,你可能会遇到一些麻烦。
一、 指定 URL 格式,例如 知乎 问题的 URL 为 /question/xxxx,然后抓取 html 内容。使用的工具,如果你有很好的规律性,你可以使用规律性。如果觉得规律性很麻烦,可以使用html解析DOM节点来处理内容。如果你爬取的内容有自己固有的特性,比如新闻内容,可以使用body爬取算法,其实就是在html中找出最长的几行字符串。
二、 使用javascript动态生成内容爬取。不推荐使用headless,效率比较低。建议使用一些开源库直接执行js代码,得到想要的结果。
了解页面中的程序逻辑非常重要。知道动态内容是如何生成的,使用一定的方法,就会和html一样,很容易得到你想要的结果。动态生成要么是在本地进行计算,要么是向服务器发起另一个请求以获得某个结果,显示或再次进行本地计算。对于前者,需要找到本地执行的那段代码,照原样,在javascript环境中执行,得到结果。对于后者,找到请求并得到相应的结果。一般结果也会是javascript代码或者json格式的字符串,可以再次解析。
三、登录,有很多资料需要登录才能查看。如果对方使用https,基本没有办法。好在国内很多网站在全站打广告的都是伪https,都可以像抓包一样抓到。比较复杂的会为用户名或密码重新加密,并且是时间相关的,直接提交给用户名和密码无效。您必须同时提交以当前时间为参数的第二次加密结果。同样,理解页面中的程序逻辑很重要。
四、验证码,当你取的太多太快时,网站一般会要求你输入验证码,证明你不是程序,而是手动操作。国内好像有云服务可以帮你输入验证码,修复这部分,或者用程序解析验证码,但是错误率太高了。另一种流氓方法是使用多个ADSL或VPN,来回切换IP,不断换IP进行爬取,将单个IP的爬取速度控制在网站的允许范围内,改什么header header代理比较简单,就不多说了。
五、 内容如图,网站 类别中的一些敏感信息,如商城价格、用户手机号码等,会直接由网站 显示在图片的形式。在这里,使用云服务的成本太高了。如果用程序解析图片,如果出错,这个信息基本没用。切换IP也是图,所以基本无解。
六、另外,爬虫还有很多细节和针对性的处理方式。为了学习的目的,我们需要多思考。比如移动互联网这么火,很多网站,有点厉害的会从手机客户端出来在手机客户端,他还用图片来展示吗?现在html5出来了,很多手机客户端都是用html+js重新打包的。
———————— 分界线,探讨抢夺的可持续性—————————
一个网页上有n个以上的链接,这意味着你会遇到从一个页面开始的链接数,然后以这种方式扩展1*n*n*n。同时,会出现重复的链接,所以如何保存爬取到的链接,以及如何过滤掉符合一定条件的链接,将是你需要解决的一个新问题。
好吧,当你有一个链接处理机制来帮你管理你爬取的所有链接时,你的爬虫的爬取效率就变得非常高效了,效率高到你的爬虫被目标拦截了网站,你该如何解决? 关于更改标题,我不会说太多。我只说说怎么解决key阻塞ip?
你需要让你的爬虫分布式,以中央服务器为任务调度中心,对爬取的页面进行处理,将爬取到的链接分发给所有下属机器。
下级机只做一件事,就是向中央服务器请求一个任务,执行完请求的任务后,将结果返回给调度中心。每个从机只是一个一年几十块的虚拟机,我们要的是从机的IP。
好了,现在你有n个ip分散在n台机器上为你做爬虫,数据统一集中在你躲在幕后的中央服务器上。效率非常高。一般你控制的好,目标服务器是不会发现的。某个ip请求太频繁,流量太高,但事情可能就是这么不正常!目标服务器还是找到了你!杀死你所有的小爬虫!怎么做?
你需要优化调度中心的东西。您的中央服务器不能只是将任务平均分配给每个从属机器。您需要实时监控每个下属机器的任务数量和执行状态。让他安息,免得他被杀。为什么这不在从属机器上做?因为我们使用的虚拟机每年价值几十美元!!成本!!你有钱买一台一年几千块的机器我没说!!
好了,现在你的任务调度中心很聪明,保证每个下属机器的任务不会太高。如果觉得效率还低,直接开个虚拟机就好了。还有很多ip。还可以很好的控制访问的频率和流量,链接管理也很好。基本上,爬虫的框架都有一个原型。
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-24 10:12
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置提琴手:
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用Fiddler抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了
查看全部
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置提琴手:
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888



然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用Fiddler抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了

一种)。将代理服务器和 Fiddler 代理设置设置为匹配

b)。设置代理规则
默认 Default,我们可以忽略

点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认

目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据


4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了

c 抓取网页数据(基于C#实现网络爬虫的相关资料--代码很难找)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-24 10:10
本文文章主要详细介绍了基于C#的网络爬虫的相关资料,即C#抓取网页的Html源码。有兴趣的朋友可以参考一下。
我最近刚刚完成了一个简单的网络爬虫。一开始,我很迷茫,不知道如何下手。后来找了很多资料,但确实能满足我的需求,有用的资料——代码好难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href: to add using System.IO; 使用 System.Net;
private void Search(string url) { string rl; WebRequest Request = WebRequest.Create(url.Trim()); WebResponse Response = Request.GetResponse(); Stream resStream = Response.GetResponseStream(); StreamReader sr = new StreamReader(resStream, Encoding.Default); StringBuilder sb = new StringBuilder(); while ((rl = sr.ReadLine()) != null) { sb.Append(rl); } string str = sb.ToString().ToLower(); string str_get = mid(str, "", ""); int start = 0; while (true) { if (str_get == null) break; string strResult = mid(str_get, "href=\"", "\"", out start); if (strResult == null) break; else { lab[url] += strResult; str_get = str_get.Substring(start); } } } private string mid(string istr, string startString, string endString) { int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; } private string mid(string istr, string startString, string endString, out int iBodyEnd) { //初始化out参数,否则不能return iBodyEnd = 0; int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; }
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。 查看全部
c 抓取网页数据(基于C#实现网络爬虫的相关资料--代码很难找)
本文文章主要详细介绍了基于C#的网络爬虫的相关资料,即C#抓取网页的Html源码。有兴趣的朋友可以参考一下。
我最近刚刚完成了一个简单的网络爬虫。一开始,我很迷茫,不知道如何下手。后来找了很多资料,但确实能满足我的需求,有用的资料——代码好难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href: to add using System.IO; 使用 System.Net;
private void Search(string url) { string rl; WebRequest Request = WebRequest.Create(url.Trim()); WebResponse Response = Request.GetResponse(); Stream resStream = Response.GetResponseStream(); StreamReader sr = new StreamReader(resStream, Encoding.Default); StringBuilder sb = new StringBuilder(); while ((rl = sr.ReadLine()) != null) { sb.Append(rl); } string str = sb.ToString().ToLower(); string str_get = mid(str, "", ""); int start = 0; while (true) { if (str_get == null) break; string strResult = mid(str_get, "href=\"", "\"", out start); if (strResult == null) break; else { lab[url] += strResult; str_get = str_get.Substring(start); } } } private string mid(string istr, string startString, string endString) { int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; } private string mid(string istr, string startString, string endString, out int iBodyEnd) { //初始化out参数,否则不能return iBodyEnd = 0; int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; }
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。
c 抓取网页数据(爬虫如何同时启动多个.py可视化部分可视化采用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-23 18:22
)
**爬取58job、赶集job和智联招聘,用数据分析生成echarts地图**
履带部分
爬虫部分使用scrapy-redis分布式爬虫,通过redis实现增量爬取和去重,将所有数据直接保存到redis中进行后续处理
github:
代码已经提交到GitHub,不是很完整。爬虫抓取的信息没有详情页的数据,只有赶集网的数据才是详情页。有点懒得写了。
您可以自己克隆代码并改进它。
获取智联招聘招聘信息
这很简单
抓取58个城市的招聘信息
这个也很简单,我的代码只爬了一个城市,可以扩展
爬取赶集网的招聘信息
这个也很简单。不用说,它也是一个城市的信息。
最后,如何同时启动多个蜘蛛
如何同时启动所有爬虫,这个我会写出来,记录下来,免得日后忘记。
首先需要在爬虫文件中创建一个commond包,并在该目录下新建一个文件crawlall.py。
目录结构:
crawlall.py 中的内容:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/5/6 16:31
# @Author : zhao.jia
# @Site :
# @File : crawlall.py
# @Software: PyCharm
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
更改设置.py
COMMANDS_MODULE = 'spider_work.command'
启动
scrapy crawlall
爬虫部分到此结束,大家都知道如何开始一个。
可以扩展的地方很多,再补充几点:
1、 详细招聘信息爬取
2、可以直接把代码改成通用爬虫
3、58job和赶集网同城,可以推广到全国。写个配置文件,拼接网址就行了。可以根据每个网站分别做关键词搜索爬虫,而不是单独使用智联的关键词。
4、添加异常处理
5、向redis添加数据去重
数据转换部分(可忽略)
我是通过mysql来做的,所以需要把redis里面的数据取出来存到mysql中。
Redis存储的类型是列表,所以存在重复数据。Redis 使用 lpop 方法来获取数据。通过向 MySQL 表中的字段添加索引以删除重复,insert 语句使用 replace into 而不是 insert into。你可以去百度看看博客。
process_item_mysql.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/29 23:15
# @Author : zhao.jia
# @Site :
# @File : process_item_mysql.py
# @Software: PyCharm
import pymysql
import redis
import json
def process_item(key):
Redis_conn = redis.StrictRedis(host='ip', port=6379, db=0, password='pass')
MySql_conn = pymysql.connect(host='ip', user='root', passwd='pass', port=3306, db='zhaopin')
cur = MySql_conn.cursor()
while True:
data = Redis_conn.lpop(key)
if data:
try:
data = json.loads(data.decode('unicode_escape'), strict=False)
except Exception as e:
process_item(key)
print(data)
try:
if '-' in data['city']:
city = data['city'].split('-')[0]
else:
city = data['city']
except Exception as e:
city = data['city']
lis = (
pymysql.escape_string(data['jobType']),
pymysql.escape_string(data['jobName']),
pymysql.escape_string(data['emplType']),
pymysql.escape_string(data['eduLevel']),
pymysql.escape_string(data['salary']),
pymysql.escape_string(data['companyName']),
pymysql.escape_string(city),
pymysql.escape_string(data['welfare']),
pymysql.escape_string(data['workingExp']))
sql = (
"replace into work(jobType, jobName, emplType, eduLevel, salary, companyName, city, welfare, workingExp) VALUES ('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s')" % lis)
try:
cur.execute(sql)
MySql_conn.commit()
except Exception as e:
MySql_conn.rollback()
else:
break
cur.close()
MySql_conn.close()
if __name__ == "__main__":
key_list = ['job_spider:items', 'jobs58:items', 'jobsganjispider']
for i in range(3):
process_item(key_list[i])
可视化部分
Flask+mysql+echarts 用于可视化
具体代码见我的GitHub,这里就不贴了。
发几张图
网站整体图网站
搜索界面
学术要求
教育薪资表
经验要求
词云插图
结束
项目中有很多可以扩展的部分。你需要自己写。你不再需要写简单的东西了。web part也可以扩展,包括页面和echarts图表,数据分析可以继续扩展。
查看全部
c 抓取网页数据(爬虫如何同时启动多个.py可视化部分可视化采用方法
)
**爬取58job、赶集job和智联招聘,用数据分析生成echarts地图**
履带部分
爬虫部分使用scrapy-redis分布式爬虫,通过redis实现增量爬取和去重,将所有数据直接保存到redis中进行后续处理
github:
代码已经提交到GitHub,不是很完整。爬虫抓取的信息没有详情页的数据,只有赶集网的数据才是详情页。有点懒得写了。
您可以自己克隆代码并改进它。
获取智联招聘招聘信息

这很简单
抓取58个城市的招聘信息

这个也很简单,我的代码只爬了一个城市,可以扩展
爬取赶集网的招聘信息

这个也很简单。不用说,它也是一个城市的信息。
最后,如何同时启动多个蜘蛛
如何同时启动所有爬虫,这个我会写出来,记录下来,免得日后忘记。
首先需要在爬虫文件中创建一个commond包,并在该目录下新建一个文件crawlall.py。
目录结构:
crawlall.py 中的内容:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/5/6 16:31
# @Author : zhao.jia
# @Site :
# @File : crawlall.py
# @Software: PyCharm
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
更改设置.py
COMMANDS_MODULE = 'spider_work.command'
启动
scrapy crawlall
爬虫部分到此结束,大家都知道如何开始一个。
可以扩展的地方很多,再补充几点:
1、 详细招聘信息爬取
2、可以直接把代码改成通用爬虫
3、58job和赶集网同城,可以推广到全国。写个配置文件,拼接网址就行了。可以根据每个网站分别做关键词搜索爬虫,而不是单独使用智联的关键词。
4、添加异常处理
5、向redis添加数据去重
数据转换部分(可忽略)
我是通过mysql来做的,所以需要把redis里面的数据取出来存到mysql中。
Redis存储的类型是列表,所以存在重复数据。Redis 使用 lpop 方法来获取数据。通过向 MySQL 表中的字段添加索引以删除重复,insert 语句使用 replace into 而不是 insert into。你可以去百度看看博客。
process_item_mysql.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/29 23:15
# @Author : zhao.jia
# @Site :
# @File : process_item_mysql.py
# @Software: PyCharm
import pymysql
import redis
import json
def process_item(key):
Redis_conn = redis.StrictRedis(host='ip', port=6379, db=0, password='pass')
MySql_conn = pymysql.connect(host='ip', user='root', passwd='pass', port=3306, db='zhaopin')
cur = MySql_conn.cursor()
while True:
data = Redis_conn.lpop(key)
if data:
try:
data = json.loads(data.decode('unicode_escape'), strict=False)
except Exception as e:
process_item(key)
print(data)
try:
if '-' in data['city']:
city = data['city'].split('-')[0]
else:
city = data['city']
except Exception as e:
city = data['city']
lis = (
pymysql.escape_string(data['jobType']),
pymysql.escape_string(data['jobName']),
pymysql.escape_string(data['emplType']),
pymysql.escape_string(data['eduLevel']),
pymysql.escape_string(data['salary']),
pymysql.escape_string(data['companyName']),
pymysql.escape_string(city),
pymysql.escape_string(data['welfare']),
pymysql.escape_string(data['workingExp']))
sql = (
"replace into work(jobType, jobName, emplType, eduLevel, salary, companyName, city, welfare, workingExp) VALUES ('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s')" % lis)
try:
cur.execute(sql)
MySql_conn.commit()
except Exception as e:
MySql_conn.rollback()
else:
break
cur.close()
MySql_conn.close()
if __name__ == "__main__":
key_list = ['job_spider:items', 'jobs58:items', 'jobsganjispider']
for i in range(3):
process_item(key_list[i])
可视化部分
Flask+mysql+echarts 用于可视化
具体代码见我的GitHub,这里就不贴了。
发几张图
网站整体图网站

搜索界面

学术要求

教育薪资表

经验要求

词云插图

结束
项目中有很多可以扩展的部分。你需要自己写。你不再需要写简单的东西了。web part也可以扩展,包括页面和echarts图表,数据分析可以继续扩展。

c 抓取网页数据( Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-23 14:03
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化发展和专注于核心业务的需要,使得各种翻译服务越来越有利可图。云翻译平台Smartling是一家业务齐全的全球翻译公司,承接所有可翻译的内容,从企业文档、网页、应用程序,小到一个图标都包括在内。Smartling 刚刚获得了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投。此前,投资方Venrock、US Venture Partners、IDG Ventures、First Round Capital和Felicis Ventures均追加追加投资。
Smartling 将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API为企业用户的本地化语言网站提供数据监控服务。例如,某公司的网页翻译成中文后,用户可以通过Smartling的仪表盘看到中文版。@网站产生的流量等数据。
用户上传需要翻译的文档类型后,可以选择专业、众包或Smartling内部人员将其翻译成多种语言。整个业务流程对用户是可见的、可控的,用户可以根据自己的需要选择合适的翻译。各种设置,例如资源甚至翻译风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供跨平台优化。
Smartling 声称其服务可以降低高达 90% 的翻译管理成本,并且 Smartling 可以保证当天交付。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling 的客户涵盖电子商务、旅游相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是它的客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频: 查看全部
c 抓取网页数据(
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化发展和专注于核心业务的需要,使得各种翻译服务越来越有利可图。云翻译平台Smartling是一家业务齐全的全球翻译公司,承接所有可翻译的内容,从企业文档、网页、应用程序,小到一个图标都包括在内。Smartling 刚刚获得了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投。此前,投资方Venrock、US Venture Partners、IDG Ventures、First Round Capital和Felicis Ventures均追加追加投资。
Smartling 将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API为企业用户的本地化语言网站提供数据监控服务。例如,某公司的网页翻译成中文后,用户可以通过Smartling的仪表盘看到中文版。@网站产生的流量等数据。
用户上传需要翻译的文档类型后,可以选择专业、众包或Smartling内部人员将其翻译成多种语言。整个业务流程对用户是可见的、可控的,用户可以根据自己的需要选择合适的翻译。各种设置,例如资源甚至翻译风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供跨平台优化。
Smartling 声称其服务可以降低高达 90% 的翻译管理成本,并且 Smartling 可以保证当天交付。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling 的客户涵盖电子商务、旅游相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是它的客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频:
c 抓取网页数据(scrapy实验总结(一):安装Scrapy实验的收获与思考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-20 07:04
实验性一、scrapy crawler一、 实验目的
1、 用于数据捕获的网络爬虫。
2、如何使用scrapy,可以使用scrapy抓取网页数据。
二、能力地图
三、实验内容
1.内容:爬取传知播客C/C++讲师的姓名、职称和简介。
2.目标网址:
3.软件:scrapy框架的pycharm软件已经安装成功(专业版和社区版都可以)。
4.python3.7 及以上。
5.使用scrapy框架实现爬虫,使用xpath解析方式。
四、实验过程1、pycharm的卸载与安装
之前在笔记本电脑上安装了专业版的pycharm,现在激活码过期了,网上也找不到免费的激活码。同时,我之前安装的pycharm版本不是最新的,所以选择卸载重装。
关于卸载:
有了之前重装软件冲突的经验,为了防止重装最新社区版pycharm时发生冲突,应该把pycharm卸载干净。网上找到了相关的卸载方法:pycharm uninstall
关于安装:
为了避免安装软件后由于安装方式出现一些错误,我还找了一个相关教程:pycharm安装教程
2、scrapy 安装
按照老师的讲授完成安装,结果如下:
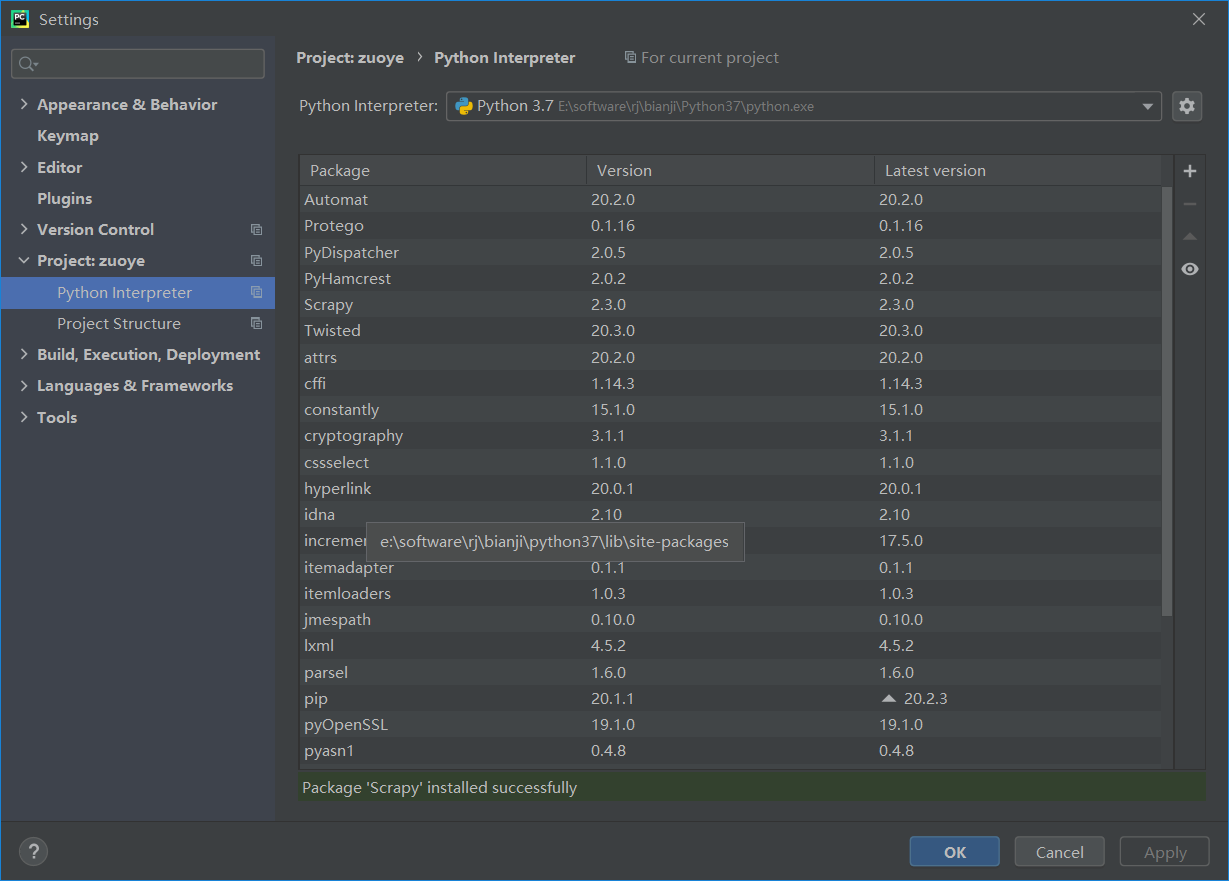
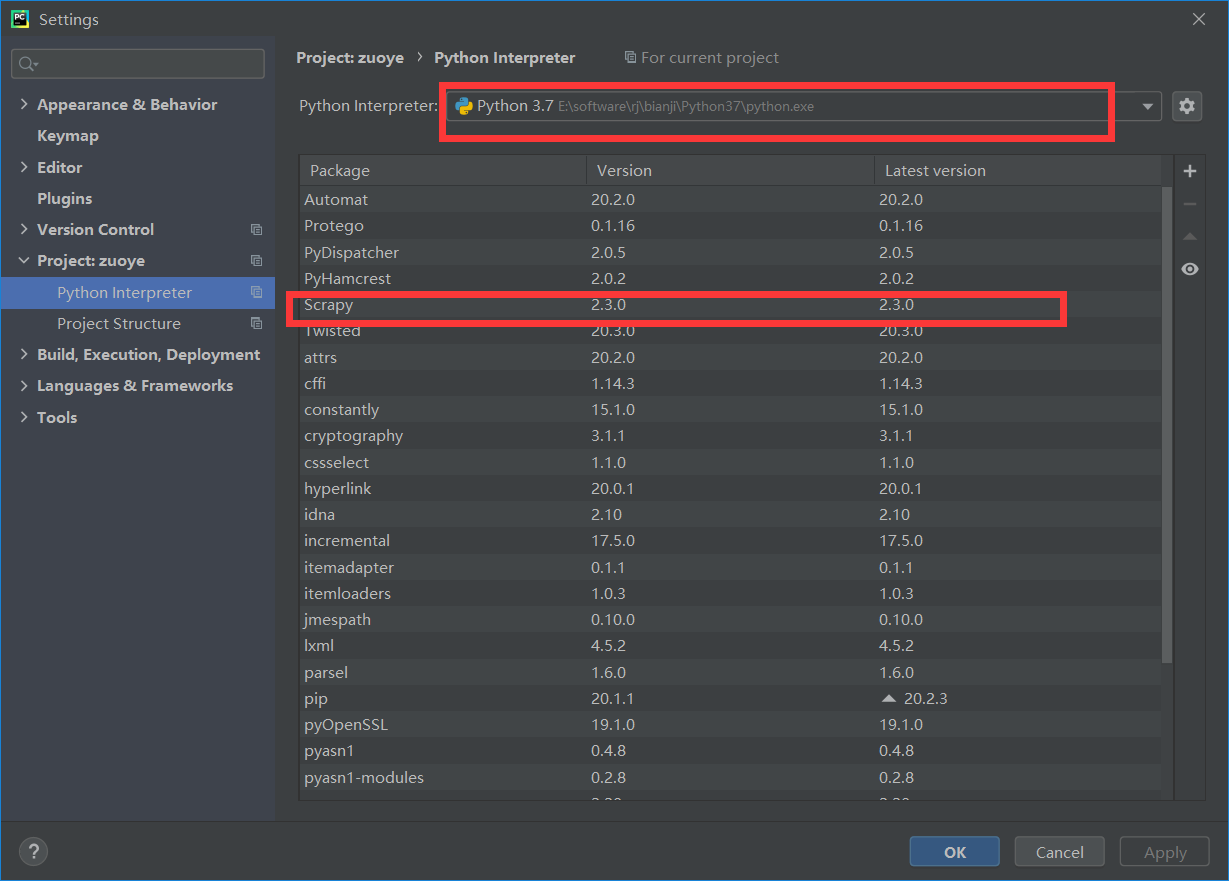
3、创建一个scrapy项目
这里直接进入scrapy的路径,在命令行运行cmd创建,如下图:
创建完成后,使用pycharm打开项目,如图:
4、创建一个写爬虫的文件
7
5、写代码5.1 itcast.py
import scrapy
#导入容器
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
# 爬虫名 启动爬虫时需要的参数*必需
name = 'itcast'
# 爬取域范围 允许爬虫在这个域名下进行爬取(可选) 可以不写
allowed_domains = ['itcast.cn']
#起始url列表 爬虫的第一批请求,将求这个列表里获取
start_urls = ['http://www.itcast.cn/channel/t ... 39%3B]
def parse(self, response):
node_list = response.xpath("//div[@class='li_txt']")
for node in node_list:
#创建item字段对象,用来存储信息
item = ItcastItem()
# .extract() 将xpath对象转换围殴Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#返回提取到的每一个item数据 给管道文件处理,同时还会回来继续执行后面的代码
yield item
5.2 项.py
import scrapy
class ItcastItem(scrapy.Item):
# 与itcast.py 定义的一一对应
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
#pass
5.3 settings.py
取消对下图的注释并将其更改为100
ITEM_PIPELINES = {
'ITcast.pipelines.ItcastPipeline': 100, #值越小优先级越高
5.4 管道.py
import json
class ItcastPipeline(object):
def __init__(self):
#python3保存文件 必须需要'wb' 保存为json格式
self.f = open("itcast_pipeline.json",'wb')
def process_item(self, item, spider):
#读取item中的数据 并换行处理
content = json.dumps(dict(item),ensure_ascii=False) + ',\n'
self.f.write(content.encode('utf=8'))
return item
def close_spider(self,spider):
#关闭文件
self.f.close()
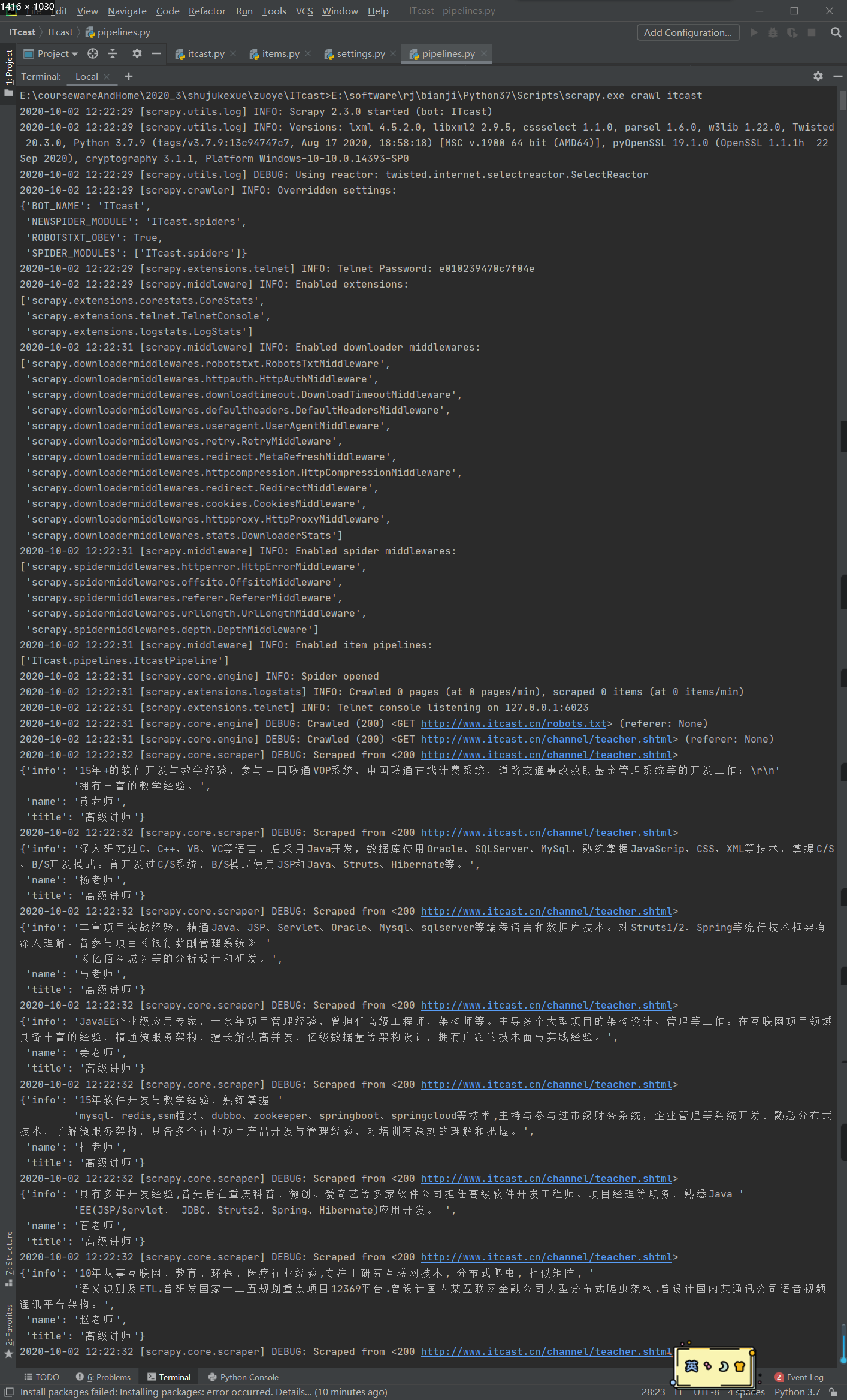
显示结果:
五、实验总结(写下这个实验的结果,遇到的问题等,这一项很重要,是实验的总结和思考)遇到的问题1安装Scrapy报错
解决方案:将 python3.8 替换为 3.7
因为一台电脑可以有多个python,我这里直接安装了一个python3.7
python安装教程
问题2 在Terminal中执行Scrapy命令报错
解决方法:使用绝对路径(本实验在Terminal中执行的所有scrapy命令都是绝对路径),成功解决了第一种使用Pycharm命令行终端无法识别的命令的方法!
报酬
通过这个实验,我学会了pycharm+scrapy爬取数据,也学会了遇到问题时如何在网上寻找合适的解决方案。 查看全部
c 抓取网页数据(scrapy实验总结(一):安装Scrapy实验的收获与思考)
实验性一、scrapy crawler一、 实验目的
1、 用于数据捕获的网络爬虫。
2、如何使用scrapy,可以使用scrapy抓取网页数据。
二、能力地图
三、实验内容
1.内容:爬取传知播客C/C++讲师的姓名、职称和简介。
2.目标网址:
3.软件:scrapy框架的pycharm软件已经安装成功(专业版和社区版都可以)。
4.python3.7 及以上。
5.使用scrapy框架实现爬虫,使用xpath解析方式。
四、实验过程1、pycharm的卸载与安装
之前在笔记本电脑上安装了专业版的pycharm,现在激活码过期了,网上也找不到免费的激活码。同时,我之前安装的pycharm版本不是最新的,所以选择卸载重装。
关于卸载:
有了之前重装软件冲突的经验,为了防止重装最新社区版pycharm时发生冲突,应该把pycharm卸载干净。网上找到了相关的卸载方法:pycharm uninstall
关于安装:
为了避免安装软件后由于安装方式出现一些错误,我还找了一个相关教程:pycharm安装教程
2、scrapy 安装
按照老师的讲授完成安装,结果如下:
3、创建一个scrapy项目
这里直接进入scrapy的路径,在命令行运行cmd创建,如下图:
创建完成后,使用pycharm打开项目,如图:
4、创建一个写爬虫的文件

7
5、写代码5.1 itcast.py
import scrapy
#导入容器
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
# 爬虫名 启动爬虫时需要的参数*必需
name = 'itcast'
# 爬取域范围 允许爬虫在这个域名下进行爬取(可选) 可以不写
allowed_domains = ['itcast.cn']
#起始url列表 爬虫的第一批请求,将求这个列表里获取
start_urls = ['http://www.itcast.cn/channel/t ... 39%3B]
def parse(self, response):
node_list = response.xpath("//div[@class='li_txt']")
for node in node_list:
#创建item字段对象,用来存储信息
item = ItcastItem()
# .extract() 将xpath对象转换围殴Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#返回提取到的每一个item数据 给管道文件处理,同时还会回来继续执行后面的代码
yield item
5.2 项.py
import scrapy
class ItcastItem(scrapy.Item):
# 与itcast.py 定义的一一对应
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
#pass
5.3 settings.py
取消对下图的注释并将其更改为100
ITEM_PIPELINES = {
'ITcast.pipelines.ItcastPipeline': 100, #值越小优先级越高
5.4 管道.py
import json
class ItcastPipeline(object):
def __init__(self):
#python3保存文件 必须需要'wb' 保存为json格式
self.f = open("itcast_pipeline.json",'wb')
def process_item(self, item, spider):
#读取item中的数据 并换行处理
content = json.dumps(dict(item),ensure_ascii=False) + ',\n'
self.f.write(content.encode('utf=8'))
return item
def close_spider(self,spider):
#关闭文件
self.f.close()
显示结果:
五、实验总结(写下这个实验的结果,遇到的问题等,这一项很重要,是实验的总结和思考)遇到的问题1安装Scrapy报错
解决方案:将 python3.8 替换为 3.7
因为一台电脑可以有多个python,我这里直接安装了一个python3.7
python安装教程
问题2 在Terminal中执行Scrapy命令报错

解决方法:使用绝对路径(本实验在Terminal中执行的所有scrapy命令都是绝对路径),成功解决了第一种使用Pycharm命令行终端无法识别的命令的方法!
报酬
通过这个实验,我学会了pycharm+scrapy爬取数据,也学会了遇到问题时如何在网上寻找合适的解决方案。
c 抓取网页数据( 模拟登录获得cookie代理的设置利用方法模拟(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-16 13:06
模拟登录获得cookie代理的设置利用方法模拟(图)
)
///
/// post请求获得页面
///
/// 需要获取的url
/// post的数据字符串,如id=1&name=test
/// 代理
/// coolie
/// 超时
///
public static string Crawl(string url, string postdata,WebProxy proxy, CookieContainer cookie, int timeout = 10000)
{
string result = string.Empty;
HttpWebRequest request = null;
WebResponse response = null;
StreamReader streamReader = null;
try
{
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cookie;
byte[] bs = Encoding.ASCII.GetBytes(postdata);
string responseData = String.Empty;
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = bs.Length;
using (Stream reqStream = request.GetRequestStream())
{
reqStream.Write(bs, 0, bs.Length);
reqStream.Close();
}
response = (HttpWebResponse)request.GetResponse();
streamReader = new StreamReader(response.GetResponseStream(), Encoding.UTF8);
result = streamReader.ReadToEnd();
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
if (streamReader != null)
{
streamReader.Dispose();
}
}
return result;
}
模拟登录获取cookie内容
首先找到登录页面,分析登录页面的post参数和链接,获取cookie后直接传给上面的方法
///
///根据模拟请求页面获得cookie
///
/// 模拟的url
/// cookie
public static CookieContainer GetCookie(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
return cc;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
模拟登录获取cookie字符串
///
/// 获得cookie字符串,webbrowser可以使用
///
///
///
///
///
public static string GetCookieString(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
string strcrook = request.CookieContainer.GetCookieHeader(request.RequestUri);
return strcrook;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
代理设置
///
/// 创建代理
///
/// 代理端口
/// 用户名
/// 密码
///
public static WebProxy CreatePorxy(string port, string user, string password)
{
WebProxy proxy = new WebProxy();
proxy.Address = new Uri(port);
proxy.Credentials = new NetworkCredential(user, password);
return proxy;
}
使用webbrowser获取js生成的页面
注意:由于不知道页面什么时候执行,这里是等待5s,默认执行完成,效率有待提高。
额外执行需要线程安全添加[STAThread]
///
/// 抓取js生成的页面
///
///
///
public static string CrawlDynamic(string url)
{
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = browser.Document;
return htmldocument.ActiveElement.InnerHtml;
}
为网页浏览器设置 cookie 以模拟登录
一开始没成功,觉得这个方法不能用。后来发现是doain设置的问题。我的例子是该设置可用。这个地方可能需要根据自己的情况选择域名。
[DllImport("wininet.dll", CharSet = CharSet.Auto, SetLastError = true)]
public static extern bool InternetSetCookie(string lpszUrlName, string lbszCookieName, string lpszCookieData);
///
/// 为webbrowser设置cookie
///
/// cookie字符串,可以从上面方法获得
/// 需要设置的域名
public static void SetCookie(string cookieStr,string domain)
{
foreach (string c in cookieStr.Split(';'))
{
string[] item = c.Split('=');
if (item.Length == 2)
{
string name = item[0];
string value = item[1];
InternetSetCookie(domain, name, value);
}
}
}
使用演示
//代理,没有就直接传null
WebProxy proxy = WebCrawl.WebRequestHelper.CreatePorxy("xx.com", "user", "password");
//根据登录页得到cookie
CookieContainer cookie = WebCrawl.WebRequestHelper.GetCookie("http://xxxx.login.com", proxy);
//获取页面
string html = WebCrawl.WebRequestHelper.Crawl("http://xxx.index.com", proxy, cookie);
//根据登录页得到cookie字符串
string cookiestr = WebCrawl.WebRequestHelper.GetCookieString("http://xxxx.login.com", proxy);
//为webbrowser设置cookie
WebCrawl.WebRequestHelper.SetCookie(cookiestr, "https://xx.com");
//获取需要登录切用js生成的页面,当然普通页面也可以
string htmlWithJs = WebCrawl.WebRequestHelper.CrawlDynamic("http://xxx.index.com"); 查看全部
c 抓取网页数据(
模拟登录获得cookie代理的设置利用方法模拟(图)
)
///
/// post请求获得页面
///
/// 需要获取的url
/// post的数据字符串,如id=1&name=test
/// 代理
/// coolie
/// 超时
///
public static string Crawl(string url, string postdata,WebProxy proxy, CookieContainer cookie, int timeout = 10000)
{
string result = string.Empty;
HttpWebRequest request = null;
WebResponse response = null;
StreamReader streamReader = null;
try
{
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cookie;
byte[] bs = Encoding.ASCII.GetBytes(postdata);
string responseData = String.Empty;
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = bs.Length;
using (Stream reqStream = request.GetRequestStream())
{
reqStream.Write(bs, 0, bs.Length);
reqStream.Close();
}
response = (HttpWebResponse)request.GetResponse();
streamReader = new StreamReader(response.GetResponseStream(), Encoding.UTF8);
result = streamReader.ReadToEnd();
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
if (streamReader != null)
{
streamReader.Dispose();
}
}
return result;
}
模拟登录获取cookie内容
首先找到登录页面,分析登录页面的post参数和链接,获取cookie后直接传给上面的方法
///
///根据模拟请求页面获得cookie
///
/// 模拟的url
/// cookie
public static CookieContainer GetCookie(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
return cc;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
模拟登录获取cookie字符串
///
/// 获得cookie字符串,webbrowser可以使用
///
///
///
///
///
public static string GetCookieString(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
string strcrook = request.CookieContainer.GetCookieHeader(request.RequestUri);
return strcrook;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
代理设置
///
/// 创建代理
///
/// 代理端口
/// 用户名
/// 密码
///
public static WebProxy CreatePorxy(string port, string user, string password)
{
WebProxy proxy = new WebProxy();
proxy.Address = new Uri(port);
proxy.Credentials = new NetworkCredential(user, password);
return proxy;
}
使用webbrowser获取js生成的页面
注意:由于不知道页面什么时候执行,这里是等待5s,默认执行完成,效率有待提高。
额外执行需要线程安全添加[STAThread]
///
/// 抓取js生成的页面
///
///
///
public static string CrawlDynamic(string url)
{
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = browser.Document;
return htmldocument.ActiveElement.InnerHtml;
}
为网页浏览器设置 cookie 以模拟登录
一开始没成功,觉得这个方法不能用。后来发现是doain设置的问题。我的例子是该设置可用。这个地方可能需要根据自己的情况选择域名。
[DllImport("wininet.dll", CharSet = CharSet.Auto, SetLastError = true)]
public static extern bool InternetSetCookie(string lpszUrlName, string lbszCookieName, string lpszCookieData);
///
/// 为webbrowser设置cookie
///
/// cookie字符串,可以从上面方法获得
/// 需要设置的域名
public static void SetCookie(string cookieStr,string domain)
{
foreach (string c in cookieStr.Split(';'))
{
string[] item = c.Split('=');
if (item.Length == 2)
{
string name = item[0];
string value = item[1];
InternetSetCookie(domain, name, value);
}
}
}
使用演示
//代理,没有就直接传null
WebProxy proxy = WebCrawl.WebRequestHelper.CreatePorxy("xx.com", "user", "password");
//根据登录页得到cookie
CookieContainer cookie = WebCrawl.WebRequestHelper.GetCookie("http://xxxx.login.com", proxy);
//获取页面
string html = WebCrawl.WebRequestHelper.Crawl("http://xxx.index.com", proxy, cookie);
//根据登录页得到cookie字符串
string cookiestr = WebCrawl.WebRequestHelper.GetCookieString("http://xxxx.login.com", proxy);
//为webbrowser设置cookie
WebCrawl.WebRequestHelper.SetCookie(cookiestr, "https://xx.com";);
//获取需要登录切用js生成的页面,当然普通页面也可以
string htmlWithJs = WebCrawl.WebRequestHelper.CrawlDynamic("http://xxx.index.com";);
c 抓取网页数据(一下提取数据中的部分源码,你知道吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-13 13:21
2:获取网页源码
3:检查源码中是否有我们需要提取的数据
4:反汇编源码,一般使用分段、常规或第三方jar包
5:获取需要的数据并给自己创建的对象赋值
6:数据提取和保存
下面简单说一下提取数据中的部分源代码及其用途:
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream())); //这里如果出现乱码,请使用带编码的InputStreamReader构造方法,将需要的编码设置进去
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
解析存储的数据
public Bid getData(String html) throws Exception {
//获取的数据,存放在到Bid的对象中,自己可以重新建立一个对象存储
Bid bid = new Bid();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
// System.out.println("doc内容" + doc.text());
//获取html标签中的内容tr
Elements elements = doc.select("tr");
System.out.println(elements.size() + "****条");
//循环遍历数据
for (Element element : elements) {
if (element.select("td").first() == null){
continue;
}
Elements tdes = element.select("td");
for(int i = 0; i < tdes.size(); i++){
this.relation(tdes,tdes.get(i).text(),bid,i+1);
}
}
return bid;
}
获得的数据
Bid {
h2 = \'详见内容\',
itemName = \'诉讼服务中心设备采购\',
item = \'货物/办公消耗用品及类似物品/其他办公消耗用品及类似物品\',
itemUnit = \'详见内容\',
areaName = \'港北区\',
noticeTime = \'2018年10月22日 18:41\',
itemNoticeTime = \'null\',
itemTime = \'null\',
kaibiaoTime = \'2018年10月26日 09:00\',
winTime = \'null\',
kaibiaoDiDian = \'null\',
yusuanMoney = \'¥67.00元(人民币)\',
allMoney = \'null\',
money = \'null\',
text = \'\'
}
查看全部
c 抓取网页数据(一下提取数据中的部分源码,你知道吗?(图))
2:获取网页源码
3:检查源码中是否有我们需要提取的数据
4:反汇编源码,一般使用分段、常规或第三方jar包
5:获取需要的数据并给自己创建的对象赋值
6:数据提取和保存
下面简单说一下提取数据中的部分源代码及其用途:
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream())); //这里如果出现乱码,请使用带编码的InputStreamReader构造方法,将需要的编码设置进去
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
解析存储的数据
public Bid getData(String html) throws Exception {
//获取的数据,存放在到Bid的对象中,自己可以重新建立一个对象存储
Bid bid = new Bid();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
// System.out.println("doc内容" + doc.text());
//获取html标签中的内容tr
Elements elements = doc.select("tr");
System.out.println(elements.size() + "****条");
//循环遍历数据
for (Element element : elements) {
if (element.select("td").first() == null){
continue;
}
Elements tdes = element.select("td");
for(int i = 0; i < tdes.size(); i++){
this.relation(tdes,tdes.get(i).text(),bid,i+1);
}
}
return bid;
}
获得的数据
Bid {
h2 = \'详见内容\',
itemName = \'诉讼服务中心设备采购\',
item = \'货物/办公消耗用品及类似物品/其他办公消耗用品及类似物品\',
itemUnit = \'详见内容\',
areaName = \'港北区\',
noticeTime = \'2018年10月22日 18:41\',
itemNoticeTime = \'null\',
itemTime = \'null\',
kaibiaoTime = \'2018年10月26日 09:00\',
winTime = \'null\',
kaibiaoDiDian = \'null\',
yusuanMoney = \'¥67.00元(人民币)\',
allMoney = \'null\',
money = \'null\',
text = \'\'
}

c 抓取网页数据(网站反爬js函数破解方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-12 13:01
介绍
如今的网站反爬法层出不穷,不像以前那么简单了。网页在后端呈现数据,然后将其发送到客户端。现在一般的web技术,前后端分离,前端通过js函数发送请求向后端请求数据,然后渲染数据。因此,如果我们简单地发送请求,最终结果只是一堆js函数。
当然爬虫里面也有对应的破解方法:selenium自动化工具,就是驱动浏览器模拟人为获取数据
安装 1、 安装硒库
pip install selenium
# 上面命令安装失败请用下面命令
pip install selenium -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2、ChromeDriver
2.1、 Selenium如果要连接Chrome等主流浏览器,对应的浏览器需要安装驱动
2.2、 例如:selenium连接Chrome,需要安装ChromeDriver驱动
2.3、在ChromeDriver Mirror中找到对应版本Chrome的驱动(类似版本也是可以的)
2.4、 下载解压后,将chromedriver.exe放到项目目录下
2.5、确保Chrome浏览器设置环境变量
用 查看全部
c 抓取网页数据(网站反爬js函数破解方法)
介绍
如今的网站反爬法层出不穷,不像以前那么简单了。网页在后端呈现数据,然后将其发送到客户端。现在一般的web技术,前后端分离,前端通过js函数发送请求向后端请求数据,然后渲染数据。因此,如果我们简单地发送请求,最终结果只是一堆js函数。
当然爬虫里面也有对应的破解方法:selenium自动化工具,就是驱动浏览器模拟人为获取数据
安装 1、 安装硒库
pip install selenium
# 上面命令安装失败请用下面命令
pip install selenium -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2、ChromeDriver
2.1、 Selenium如果要连接Chrome等主流浏览器,对应的浏览器需要安装驱动
2.2、 例如:selenium连接Chrome,需要安装ChromeDriver驱动
2.3、在ChromeDriver Mirror中找到对应版本Chrome的驱动(类似版本也是可以的)


2.4、 下载解压后,将chromedriver.exe放到项目目录下

2.5、确保Chrome浏览器设置环境变量

用
c 抓取网页数据(修改响应数据,模拟JS请操作2.App数据分析手机端 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-18 03:05
)
1.PC浏览器网页数据分析
简单通用的网页数据分析,Google/Firfox/IE等浏览器内置开发者调试工具(F12)可以满足部分需求,如果请求在响应前后处理,修改浏览器发送Request数据并修改服务器的相应数据,使用F12开发工具,不能满足我们的需求,通过引入Fiddler抓包工具,可以理解为本地代理服务器,转发客户端和服务器的请求和响应
设置提琴手:
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS,请操作
2.应用数据分析
Fiddler 还可用于移动应用程序的数据分析。类似于上面的PC浏览器获取数据的方式。APP需与PC在同一网段。移动Wifi设置代理,IP为PC的IP地址,例如:64.35.86.12,端口号使用设置的端口号Fiddler,一般为8888,App端的所有网络/响应请求都必须由FIddler转发,可以对请求进行数据分析
3.PC端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理来做代理链。
由于一般的C/S客户端无法设置代理,因此FIddler无法检测到数据,所有的请求都通过Proxifer捕获并发送给Fiddler,从而可以在Fiddler中分析客户端请求。
代理设置:
设置很简单,如下图,两步就OK了
一个)。代理服务器和 Fiddler 代理设置匹配
b)。代理规则
默认 Default 可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择 Fiddler 应用程序文件目录并确认
目标主机:本地 Fiddler 设置代理,可以是任意
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功
查看全部
c 抓取网页数据(修改响应数据,模拟JS请操作2.App数据分析手机端
)
1.PC浏览器网页数据分析
简单通用的网页数据分析,Google/Firfox/IE等浏览器内置开发者调试工具(F12)可以满足部分需求,如果请求在响应前后处理,修改浏览器发送Request数据并修改服务器的相应数据,使用F12开发工具,不能满足我们的需求,通过引入Fiddler抓包工具,可以理解为本地代理服务器,转发客户端和服务器的请求和响应
设置提琴手:
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要设置断点,过滤请求,修改请求数据,修改响应数据,模拟JS,请操作
2.应用数据分析
Fiddler 还可用于移动应用程序的数据分析。类似于上面的PC浏览器获取数据的方式。APP需与PC在同一网段。移动Wifi设置代理,IP为PC的IP地址,例如:64.35.86.12,端口号使用设置的端口号Fiddler,一般为8888,App端的所有网络/响应请求都必须由FIddler转发,可以对请求进行数据分析
3.PC端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理来做代理链。
由于一般的C/S客户端无法设置代理,因此FIddler无法检测到数据,所有的请求都通过Proxifer捕获并发送给Fiddler,从而可以在Fiddler中分析客户端请求。
代理设置:
设置很简单,如下图,两步就OK了
一个)。代理服务器和 Fiddler 代理设置匹配
b)。代理规则
默认 Default 可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择 Fiddler 应用程序文件目录并确认
目标主机:本地 Fiddler 设置代理,可以是任意
目的港:任意
行动:直接
打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据,确认配置成功
c 抓取网页数据(非常简单类型网页所传递的链接权重的实验(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-18 03:03
爬取到的和收录内容中的链接不传权重。晚上,我看到了一个关于不同类型网页传递的链接权重的实验。大致翻译如下: 关于去年暑假,我观察到一个明显的购买/放置/建立链接的现象,对搜索引擎抓取和收录的内容的排名增长起到了非常小的作用。
许多报纸和其他出版商以荒谬的价格提供旧版 文章 中的链接,但事实是它们根本没有效果。
去年年底,我做了一个实验。虽然已经过去了一段时间,但在我看来,这个结果仍然适用于当前的环境。
实验表明:
一个非常简单的实验是为三个不同的利基创建三种不同形式的链接网站:
1.a 在“新”内容中
2.b在“收录”的内容中
3.c 文本链接(作者参考侧边栏和页脚区域中的链接)
新内容
主要是利用文章营销来创造一些新的文章,并以目标关键词作为实验网站的锚文本。
包括什么
收录的页面添加了锚文本链接,部分页面已经有PR值(大约一半的链接有1)的PR值。
文字链接
从自建博客群中随机抽取了15篇博客,并在侧边栏中添加了链接。锚文本仍然使用目标关键字。
限制
我们都可以发现,这个实验有严重的局限性,所以结果不能完全作为依据,但是从排名的变化来看,可以证明在已经爬取和收录的内容中建立链接的权重是不够的。
实验结果
从图中可以明显看出,放置在旧内容中的链接不会有任何权重,否则排名结果不仅会出现轻微的移动,甚至会出现轻微的回落。
另外,博客侧边栏的链接,一开始的排名有很大的提升,但是很快就回落了(侧边栏的链接是整个网站链接的形式。作者后来解释说,自从实验是去年的,整个网站链接将不再有这个效果)。
综上所述
由于这些网站针对不同的关键词和文章营销无法准确把握链接数量,因此在实验中比较这些不同的链接构建模式是不合适的。
但是链接在旧内容中没有效果,这个结果刚好符合我的经验。另外值得注意的是,整个网站链接的有效性被谷歌大大削弱了。
我说的不科学,希望听到相反的经验和结果。 查看全部
c 抓取网页数据(非常简单类型网页所传递的链接权重的实验(图))
爬取到的和收录内容中的链接不传权重。晚上,我看到了一个关于不同类型网页传递的链接权重的实验。大致翻译如下: 关于去年暑假,我观察到一个明显的购买/放置/建立链接的现象,对搜索引擎抓取和收录的内容的排名增长起到了非常小的作用。
许多报纸和其他出版商以荒谬的价格提供旧版 文章 中的链接,但事实是它们根本没有效果。
去年年底,我做了一个实验。虽然已经过去了一段时间,但在我看来,这个结果仍然适用于当前的环境。
实验表明:
一个非常简单的实验是为三个不同的利基创建三种不同形式的链接网站:
1.a 在“新”内容中
2.b在“收录”的内容中
3.c 文本链接(作者参考侧边栏和页脚区域中的链接)
新内容
主要是利用文章营销来创造一些新的文章,并以目标关键词作为实验网站的锚文本。
包括什么
收录的页面添加了锚文本链接,部分页面已经有PR值(大约一半的链接有1)的PR值。
文字链接
从自建博客群中随机抽取了15篇博客,并在侧边栏中添加了链接。锚文本仍然使用目标关键字。
限制
我们都可以发现,这个实验有严重的局限性,所以结果不能完全作为依据,但是从排名的变化来看,可以证明在已经爬取和收录的内容中建立链接的权重是不够的。
实验结果
从图中可以明显看出,放置在旧内容中的链接不会有任何权重,否则排名结果不仅会出现轻微的移动,甚至会出现轻微的回落。
另外,博客侧边栏的链接,一开始的排名有很大的提升,但是很快就回落了(侧边栏的链接是整个网站链接的形式。作者后来解释说,自从实验是去年的,整个网站链接将不再有这个效果)。
综上所述
由于这些网站针对不同的关键词和文章营销无法准确把握链接数量,因此在实验中比较这些不同的链接构建模式是不合适的。
但是链接在旧内容中没有效果,这个结果刚好符合我的经验。另外值得注意的是,整个网站链接的有效性被谷歌大大削弱了。
我说的不科学,希望听到相反的经验和结果。
c 抓取网页数据(人工智能的记录片p50:c抓取网页数据,最开始用vb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-18 02:01
c抓取网页数据,最开始用vb的时候用到php和mysql,由于考试不及格,每次写这两个主要应付大型考试,再后来加入现在的工作之后用到的是,python,c,数据库,编程方法主要是按照上边的思路进行写程序。具体的技巧有很多,相互之间技术的交集很大,全篇手敲加网上看视频学习,多和实际工作中接触加以应用,将很快掌握一个技能,相信任何一位提问和学习技术的人都是深知技术本身并不简单的,和大师学习,可以少走很多弯路,很多大师不教你项目和做项目一定要亲自实践,这样才是最好的学习方法。
总算有本能懂得的问题了推荐我最近在看的一部关于人工智能方面的记录片p50:howtolearnandarchitecture(2012),有兴趣的朋友可以看一下。一般我们学习一门语言的语法时,都要经历记笔记、看coursera、看慕课的过程。但学习人工智能可能需要更高的目标和动力。想必大家也不陌生,英文的深度学习和coursera上有丰富的code实验、课程,但学习难度比较大,会涉及到大量的知识点,不轻易看这些内容。
然而如果真的为了提高自己而发挥动力学习,从神经网络、模型训练、特征工程开始学习一门语言,会更加容易上手,并掌握应用。目前我正在这样做,分享给大家。以下是我学习时的笔记、列表和实验步骤。可参考~***。 查看全部
c 抓取网页数据(人工智能的记录片p50:c抓取网页数据,最开始用vb)
c抓取网页数据,最开始用vb的时候用到php和mysql,由于考试不及格,每次写这两个主要应付大型考试,再后来加入现在的工作之后用到的是,python,c,数据库,编程方法主要是按照上边的思路进行写程序。具体的技巧有很多,相互之间技术的交集很大,全篇手敲加网上看视频学习,多和实际工作中接触加以应用,将很快掌握一个技能,相信任何一位提问和学习技术的人都是深知技术本身并不简单的,和大师学习,可以少走很多弯路,很多大师不教你项目和做项目一定要亲自实践,这样才是最好的学习方法。
总算有本能懂得的问题了推荐我最近在看的一部关于人工智能方面的记录片p50:howtolearnandarchitecture(2012),有兴趣的朋友可以看一下。一般我们学习一门语言的语法时,都要经历记笔记、看coursera、看慕课的过程。但学习人工智能可能需要更高的目标和动力。想必大家也不陌生,英文的深度学习和coursera上有丰富的code实验、课程,但学习难度比较大,会涉及到大量的知识点,不轻易看这些内容。
然而如果真的为了提高自己而发挥动力学习,从神经网络、模型训练、特征工程开始学习一门语言,会更加容易上手,并掌握应用。目前我正在这样做,分享给大家。以下是我学习时的笔记、列表和实验步骤。可参考~***。
c 抓取网页数据(网站手机号码抓取软件是怎么获取访客手机号码的呢软件的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-15 17:06
网站手机号抓取软件/访客手机号获取软件。运营商在大数据时代,只有利用大数据获取大量客户,才能持续这样做。
Lexue 甚至掌握了 Python 爬虫 2 的基础知识,从复杂的客户消息中查找电话信息。
网站访客手机号码抓取软件,关于网站访客手机号码抓取软件,网上有很多人在问这个,尤其是最近很多老板。
[最佳答案] 百度地图新平台上线。您可以在地图上免费标记您的公司。请参考以下几点进行标记: 1、 注册并登录以提高您的个人。
我使用 ForeSpider 从搜索引擎 采集 中获取我的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数是市面上通用爬虫软件中唯一自带数据挖掘的爬虫软件。软件集成数据挖掘功能,可通过采集模板精准挖掘全网内容。在将数据采集存入数据库的同时,即可完成分发。
一些网站可以获得访问者的手机号码,一家名为瑞舟科技的公司,该公司在其网站的网页上销售“手机号码抓取软件”,以及标语。
手机号获取:客户用手机访问你的网站后,不咨询或不使用手机号抓取软件,访问者的手机号如何获取访问者的手机号?.
网站访客手机号抓取,手机号抓取软件联系人* 提交留言的手机号表示同意更多商家联系我。 查看全部
c 抓取网页数据(网站手机号码抓取软件是怎么获取访客手机号码的呢软件的?)
网站手机号抓取软件/访客手机号获取软件。运营商在大数据时代,只有利用大数据获取大量客户,才能持续这样做。
Lexue 甚至掌握了 Python 爬虫 2 的基础知识,从复杂的客户消息中查找电话信息。
网站访客手机号码抓取软件,关于网站访客手机号码抓取软件,网上有很多人在问这个,尤其是最近很多老板。
[最佳答案] 百度地图新平台上线。您可以在地图上免费标记您的公司。请参考以下几点进行标记: 1、 注册并登录以提高您的个人。
我使用 ForeSpider 从搜索引擎 采集 中获取我的姓名、地址和手机号码。在市面上的通用爬虫软件中,嗅探大数据的ForeSpider数是市面上通用爬虫软件中唯一自带数据挖掘的爬虫软件。软件集成数据挖掘功能,可通过采集模板精准挖掘全网内容。在将数据采集存入数据库的同时,即可完成分发。
一些网站可以获得访问者的手机号码,一家名为瑞舟科技的公司,该公司在其网站的网页上销售“手机号码抓取软件”,以及标语。
手机号获取:客户用手机访问你的网站后,不咨询或不使用手机号抓取软件,访问者的手机号如何获取访问者的手机号?.
网站访客手机号抓取,手机号抓取软件联系人* 提交留言的手机号表示同意更多商家联系我。
c 抓取网页数据( 具体分析如下实现抓取和分析网页类,实例分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-14 08:07
具体分析如下实现抓取和分析网页类,实例分析(图))
爬取分析网页类示例的C#实现
更新时间:2015-05-25 10:53:05 作者:莫翔
本文文章主要介绍爬取分析网页的C#实现,实例分析了C#抓取和分析网页中的文字和连接的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页纯文本,去除所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望本文对您的 C# 编程有所帮助。 查看全部
c 抓取网页数据(
具体分析如下实现抓取和分析网页类,实例分析(图))
爬取分析网页类示例的C#实现
更新时间:2015-05-25 10:53:05 作者:莫翔
本文文章主要介绍爬取分析网页的C#实现,实例分析了C#抓取和分析网页中的文字和连接的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页纯文本,去除所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、可以实现简单的表单提交和cookie保存
/*
* Author:Sunjoy at CCNU
* 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com)
*/
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //网址
private List m_links; //此网页上的链接
private string m_title; //此网页的标题
private string m_html; //此网页的HTML代码
private string m_outstr; //此网页可输出的纯文本
private bool m_good; //此网页是否可用
private int m_pagesize; //此网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
private string m_post; //此网页的登陆页需要的POST数据
private string m_loginurl; //此网页的登陆页
#endregion
#region 私有方法
///
/// 这私有方法从网页的HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = new Uri(m_uri, match.Groups["url"].Value).AbsoluteUri;
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value, "");
Link link = new Link(url, text);
m_links.Add(link);
}
catch(Exception ex){Console.WriteLine(ex.Message); };
match = match.NextMatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr, int firstN, bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, "");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, "");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr, "");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr, " ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr;
}
///
/// 此私有方法返回一个IP地址对应的无符号整数
///
/// IP地址
///
private uint getuintFromIP(IPAddress x)
{
Byte[] bt = x.GetAddressBytes();
uint i = (uint)(bt[0] * 256 * 256 * 256);
i += (uint)(bt[1] * 256 * 256);
i += (uint)(bt[2] * 256);
i += (uint)(bt[3]);
return i;
}
#endregion
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html, firstN, true);
}
///
/// 此公有方法提取网页中一定字数的纯文本,不包括链接文字
///
///
///
public string getContextWithOutLink(int firstN)
{
return getFirstNchar(m_html, firstN, false);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if(m_links.Count==0)getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt=getuintFromIP(ip_start) && getuintFromIP(ip) 1 (?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase );
Match mc = reg.Match(m_html);
if (mc.Success)
m_title= mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
///
/// 此网页的登陆页所需的POST数据
///
public string PostStr
{
get
{
return m_post;
}
}
///
/// 此网页的登陆页
///
public string LoginURL
{
get
{
return m_loginurl;
}
}
#endregion
}
///
/// 链接类
///
public class Link
{
public string url; //链接网址
public string text; //链接文字
public Link(string _url, string _text)
{
url = _url;
text = _text;
}
}
我希望本文对您的 C# 编程有所帮助。
c 抓取网页数据(Android我的博客APP(一)(组图——1.))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-14 08:06
阿里云>云栖社区>专题图>S>数据库抓取网页数据
推荐活动:
更多优惠>
当前主题:数据库从网页抓取数据并添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
网络数据库挖掘程序设计
作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。我如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:04年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是:通过编写好的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节 从 Web 表中抓取数据
作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用而来的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们有价值的数据。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从哪个博客中提取的数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
快速搭建实时爬虫集群
作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
数据库从网页中抓取数据并提出相关问题
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文 查看全部
c 抓取网页数据(Android我的博客APP(一)(组图——1.))
阿里云>云栖社区>专题图>S>数据库抓取网页数据
推荐活动:
更多优惠>
当前主题:数据库从网页抓取数据并添加到采集夹
相关话题:
数据库从网页中抓取数据。相关博客。查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
如何用Python抓取数据?(一)网页抓取
作者:王淑仪 2089人浏览评论:03年前
您期待已久的 Python 网络数据爬虫教程就在这里。本文将向您展示如何从网页中查找有趣的链接和解释性文本,将它们抓取并存储在 Excel 中。我需要在公众号后台,经常能收到读者的评论。许多评论都是来自读者的问题。只要我有时间,我会花时间尝试和回答。但有些评论乍一看不清楚
阅读全文
网络数据库挖掘程序设计
作者:最美的回忆 780人浏览评论:03年前
现在很多网页都是数据库自动生成的,数据分散在html代码中:有的位于URL链接中,有的位于,有的位于javascript代码中。我如何挖掘这些数据供我使用?不,我最近写了一个网络数据库挖掘程序,挖掘了几千万条数据。源代码不能公开,
阅读全文
【安卓我的博客APP】1.抓取博客首页文章列表内容-网页数据抓取
作者:呵呵 9925975人浏览评论:04年前
打算在博客园做自己的博客APP。首先必须能够访问首页获取数据获取首页文章列表,第一步是抓取博客首页文章列表内容功能,在小米2S中已经实现了以上效果图如下: 思路是:通过编写好的工具类访问网页,获取页面的源代码,通过正则表达式获取匹配的数据进行处理显示到ListView
阅读全文
《Clojure 数据分析秘诀》-1. 第 8 节 从 Web 表中抓取数据
作者:华章电脑 972人浏览评论:04年前
本节摘自华章社区《Clojure数据分析秘诀》一书第1章,1.8节从web表中抓取数据,作者(美国)Eric Rochester,更多章节可访问查看官方云栖社区“华章社区”账号1.8 从网页表格中抓取数据 网络上到处都是数据。不幸的是,许多互联网
阅读全文
善用网络爬虫工具,轻松采集数据
作者:优采云采集器1433人浏览评论:04年前
数据已进入各行各业,并得到广泛应用。伴随应用而来的是数据的获取和准确挖掘。我们可以应用的大部分数据来自内部资源库和外部载体。内部数据已经整合好可以使用,而外部数据需要先获取。外部数据的最大载体是互联网。网络上每天难以统计的增量数据,收录了很多对我们有价值的数据。
阅读全文
初学者指南 | 使用 Python 抓取网页
作者:小轩峰柴金2425人浏览评论:04年前
简介 从网页中提取信息的需求正在迅速增加,其重要性也越来越明显。每隔几周,我自己就想从网页中提取一些信息。例如,上周我们考虑建立各种数据科学在线课程的受欢迎程度和意见的索引。我们不仅需要寻找新的课程,还要抓取课程的评论,总结并建立一些指标。
阅读全文
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从哪个博客中提取的数据转换为结构化数据?有没有现有的 API 来检索数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
快速搭建实时爬虫集群
作者:cnbird850人浏览评论:08年前
定义:首先,让我们定义目标抓取。有针对性的爬取是一种特定的爬取需求。目标站点已知,站点页面已知。本文的介绍主要围绕如何快速搭建实时爬虫系统,不包括一般意义上的链接分析、站点发现等功能。在本文提到的示例系统中,主要使用了lin
阅读全文
数据库从网页中抓取数据并提出相关问题
【Javascript学习全家桶】934个javascript热点问题,阿里巴巴100位技术专家答疑解惑
作者:管理贝贝5207人浏览评论:13年前
阿里极客公益活动:也许你选择为一个问题夜战,也许你迷茫只是寻求答案,也许你只是因为一个未知而绞尽脑汁,那么他们来了,阿里巴巴技术专家来了云栖为您解答技术难题。他们使用自己手中的技术来帮助用户成长。本次活动邀请了数百位阿里巴巴技术
阅读全文
c 抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-10 05:24
最近需要在网站下载一批数据。但是当你输入一个查询,返回3万到4万条结果时,一次只能导出500条,而且每次都要输入下载项的范围!这样点击下载,又不是我的命。所以我想自动化这个过程。
我的需求主要有两点:1.需要高度自动化。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘的动作,比如在文本框中输入、选择下拉列表、单选按钮、复选框、点击按钮等。2. 不需要效率。因为我要的数据量比较少。3. python下的框架。因为平时用的最多的是python。
我对网站的技术了解不多,对网站的经验只有两个:我开发了一个非常简单的Android客户端,并使用python scrapy框架写了一个爬虫来自动抓取新闻。所以了解客户端和服务端的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
一开始针对这个问题,我什至不知道要搜索什么。知乎的文章文章提供了很多有用的信息:《Python爬虫如何获取JS生成的URL和网页内容?》一路上权衡了很多方法,最后选择了Selenium。主要优点是学习成本非常小,代码实现速度快。缺点是爬行效率低。对于那些想要提高效率的人来说,他们必须花一些时间学习更复杂的工具包。
网站技术
如果你想自动抓取网页,你必须了解一些基本知识,这样做会更快。下面简单介绍一下相关知识。
1. 请求/响应
请求是客户端向服务器发起请求。输入一个 URL 对应一个请求动作,这是最直观的。要抓取静态网页的内容,您只需要知道 URL。然而,今天的许多网页都是动态的。指向或点击网页的某些元素也会触发请求动作,这会导致网页动态更新部分内容。这部分内容无法直接从静态网页中获取。这种技术叫做AJAX,但我不太明白。这里的问题是我们可能不知道 URL 是什么,因此需要一些高级接口来处理动态内容。
响应是服务器返回给客户端的内容。如果要获取静态网页的内容,直接从请求中获取即可。
2. 分析网页源码
我们要抓取网页上的某一部分信息,就需要知道如何定位。这里需要了解 HTML 和 XPATH。不知道的可以去w3school在线教程:
查看网页源代码,鼠标指针指向网页任意位置,或者指向目标元素。右键单击并在下拉列表中选择“检查元素”。以下是我右键“百度点击”显示的网页源码,为HTML格式,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 语句。这是 XPATH 语法,很容易掌握。知道如何分析网页后,我们又向前迈进了一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签页、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、单击按钮等。
这里需要模拟的操作就这么多,对应的selenium接口可以参考。
4. Selenium 简介
一句话概括:Selenium 是一套针对 Web 应用程序的自动化测试工具。
很多话:Selenium 诞生于 2004 年,当时在 ThoughtWorks 工作的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比每次更改都手动测试更有价值。他开发了一个可以驱动页面交互的Javascript库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 的所有功能的基础。
实战1.数据采集过程分析
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;点击Export,弹出一个弹窗,然后点击下拉列表,单选按钮,勾选Check the box做一些选择,点击下载。然后浏览器开始下载文件。
A页
页面 B
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择谷歌浏览器。下载链接:。同时,当然python中必须安装selenium。从命令行输入 pip install senenium 进行安装。
B. 配置环境变量
这一步需要配置chromedriver的保存路径到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或mac可以选择在.bash_rc中配置。配置方法很多,自行百度。
我用的是mac,但不知道为什么配置不起作用!后来我发现只有在代码中设置才能工作。
C. 核心代码(python)
# 设置下载路径并配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置隐形等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,它会报告超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面 A
driver.get("")
# 在A页的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到一个新窗口,并将焦点定位到这个窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:在计算下载次数之前等待页面加载
search_ret_num = WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(range(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
出口。点击()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容单选
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()#完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录 URL
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():#搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
download = driver.find_element_by_xpath('//div[@class ="export-citation-buttons"]')
下载。点击()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不起作用!
驱动程序退出()
返回
3. 提示
A. 每次启动浏览器,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是如何进行的。看来selenium真的是为web程序的自动化测试做好了准备。此外,在抓取过程中保持屏幕打开。如果您进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是一个很常见的场景。所以要注意网页响应时间。Selenium 不会等待网页响应完成才继续执行代码,它会直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定作用,显式等待在WebDriverWait中起主要作用。 但是需要注意的是,最长等待时间取决于两者中较大的一个,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C、设置下载路径时,一开始不起作用。我怀疑是“download.default_directory”这个键错了,于是查看网页源码找到了这个键,还是一样。问题出在别处。但这提醒我,以后在代码中使用字典做相关配置的时候,看源码就可以猜到了。
D.我以为整个过程要两三天才能实现,因为我真的不明白。从开始学习到完成,不到一天就完成了。可能是因为我在开始之前搜索了很长时间,经过反复比较,找到了最方便的工具。
E. 做完之后在github上搜了一下,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间学习太多web应用的底层知识,可以结合使用Selenium+scrapy。Scrapy 可以负责搜索网页,而 selenium 负责处理每个网页上的内容,尤其是动态内容。如果下次有需要,我打算用这个主意!
F. 分享一句话。“关于爬虫,最快获得经验的方法是:学会写网站,如果你知道网站在请求什么,你就会知道怎么爬网站!” 这很简单。,但是这么简单的一句话给了我很大的启发。之前感觉太难了,一直卡在scrapy爬静态网页的级别。像cookies这样的技术也曾被观看过一次,一次被遗忘一次。现在看来是因为网站的整体流程没有梳理清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要去网上查一下相关概念是怎么回事,就慢慢熬过去了。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。下面是一些介绍:。懂编程又想高效率的需要参考其他工具。 查看全部
c 抓取网页数据(Python爬虫如何获取JS生成的JS和网页内容和服务端?)
最近需要在网站下载一批数据。但是当你输入一个查询,返回3万到4万条结果时,一次只能导出500条,而且每次都要输入下载项的范围!这样点击下载,又不是我的命。所以我想自动化这个过程。
我的需求主要有两点:1.需要高度自动化。最好有一个成熟的界面,直接模拟浏览器的鼠标和键盘的动作,比如在文本框中输入、选择下拉列表、单选按钮、复选框、点击按钮等。2. 不需要效率。因为我要的数据量比较少。3. python下的框架。因为平时用的最多的是python。
我对网站的技术了解不多,对网站的经验只有两个:我开发了一个非常简单的Android客户端,并使用python scrapy框架写了一个爬虫来自动抓取新闻。所以了解客户端和服务端的一些基本交互方法,了解如何分析网页源代码,了解xpath语法。
一开始针对这个问题,我什至不知道要搜索什么。知乎的文章文章提供了很多有用的信息:《Python爬虫如何获取JS生成的URL和网页内容?》一路上权衡了很多方法,最后选择了Selenium。主要优点是学习成本非常小,代码实现速度快。缺点是爬行效率低。对于那些想要提高效率的人来说,他们必须花一些时间学习更复杂的工具包。
网站技术
如果你想自动抓取网页,你必须了解一些基本知识,这样做会更快。下面简单介绍一下相关知识。
1. 请求/响应
请求是客户端向服务器发起请求。输入一个 URL 对应一个请求动作,这是最直观的。要抓取静态网页的内容,您只需要知道 URL。然而,今天的许多网页都是动态的。指向或点击网页的某些元素也会触发请求动作,这会导致网页动态更新部分内容。这部分内容无法直接从静态网页中获取。这种技术叫做AJAX,但我不太明白。这里的问题是我们可能不知道 URL 是什么,因此需要一些高级接口来处理动态内容。
响应是服务器返回给客户端的内容。如果要获取静态网页的内容,直接从请求中获取即可。
2. 分析网页源码
我们要抓取网页上的某一部分信息,就需要知道如何定位。这里需要了解 HTML 和 XPATH。不知道的可以去w3school在线教程:
查看网页源代码,鼠标指针指向网页任意位置,或者指向目标元素。右键单击并在下拉列表中选择“检查元素”。以下是我右键“百度点击”显示的网页源码,为HTML格式,我们可以看到对应的HTML代码。要提取它,我们可能需要 div//@[class="head_wrapper"]//input[@type="submit"] 语句。这是 XPATH 语法,很容易掌握。知道如何分析网页后,我们又向前迈进了一步。
3. 网页基本元素操作
前进、后退、刷新、打开新标签页、输入网址等;
文本框输入、选择下拉列表、单选按钮、复选框、单击按钮等。
这里需要模拟的操作就这么多,对应的selenium接口可以参考。
4. Selenium 简介
一句话概括:Selenium 是一套针对 Web 应用程序的自动化测试工具。
很多话:Selenium 诞生于 2004 年,当时在 ThoughtWorks 工作的 Jason Huggins 正在测试一个内部应用程序。作为一个聪明人,他意识到他的时间应该比每次更改都手动测试更有价值。他开发了一个可以驱动页面交互的Javascript库,允许多个浏览器自动返回测试结果。该库最终成为 Selenium 的核心,它是 Selenium RC(远程控制)和 Selenium IDE 的所有功能的基础。
实战1.数据采集过程分析
我的数据采集过程如下:
在A页输入查询语句,点击提交;浏览器自动打开新页面,跳转到新页面B,在文本框中输入下载项的范围;点击Export,弹出一个弹窗,然后点击下拉列表,单选按钮,勾选Check the box做一些选择,点击下载。然后浏览器开始下载文件。
A页
页面 B
2. 爬取过程 A. 安装 Selenium
Selenium 支持多种浏览器,我选择谷歌浏览器。下载链接:。同时,当然python中必须安装selenium。从命令行输入 pip install senenium 进行安装。
B. 配置环境变量
这一步需要配置chromedriver的保存路径到操作系统的环境变量中,这样selenium才能找到chromedriver。windows下配置环境变量PATH,linux或mac可以选择在.bash_rc中配置。配置方法很多,自行百度。
我用的是mac,但不知道为什么配置不起作用!后来我发现只有在代码中设置才能工作。
C. 核心代码(python)
# 设置下载路径并配置ChromeOptions的路径。
chromeoptions = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups':0,'download.default_directory': query_dir}
chromeptions.add_experimental_option('prefs', prefs)
# 设置环境变量并启动浏览器。
chromedriver = CHROMEDRIVER_DIR # 设置为自己的路径
os.environ["webdriver.chrome.driver"] = chromedriver
驱动程序 = webdriver.Chrome(executable_path=chromedriver,chrome_options=chromeoptions)
# 设置隐形等待时间,因为点击网站后,可以返回一段时间的内容。如果不等待,它会报告超时异常。
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 请求页面 A
driver.get("")
# 在A页的两个文本框中输入并提交。
driver.find_element_by_name('D').clear()
driver.find_element_by_name('D').send_keys('mesz')
driver.find_element_by_name('SEARCH').clear()
driver.find_element_by_name('SEARCH').send_keys(str_search_query)
driver.find_element_by_name('ovid').click()
# 跳转到一个新窗口,并将焦点定位到这个窗口。
current_window_handle = driver.current_window_handle
for hdl in driver.window_handles: # selenium 总是有两个句柄
如果 hdl != current_window_handle:
new_window_handle = hdl
driver.switch_to.window(new_window_handle)
driver.implicitly_wait(IMPLICIT_WAIT_TIME)
# 获取网页。首先获取返回的条目总数,然后提取文本框输入下载条目的范围,例如1-500。然后单击导出。
# 注意:在计算下载次数之前等待页面加载
search_ret_num = WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//*[@id="searchaid-numbers"]')))
search_ret_num =int(re.findall(r'\d+', search_ret_num.text.encode('utf-8'))[0])
list_range = chunks_by_element(range(1, search_ret_num+1), DOWNLOAD_NUM_PER_TIME)
对于 list_range 中的项目:
download_range = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@title="Range"]')
下载范围.clear()
download_range.send_keys('{}-{}'.format(item[0], item[-1]))
# 点击导出
export = driver.find_element_by_xpath('//*[@id="titles-display"]//input[@value="Export"]')
出口。点击()
# 获取弹出窗口。进行一些设置。
driver.switch_to.alert
WebDriverWait(driver, EXPLICIT_WAIT_TIME, EXPLICIT_WAIT_INTERVAL).until(EC.presence_of_element_located((By.XPATH,'//div[@id="export-citation-popup"]')))
# 设置下载文件的一些配置
export_to_options = driver.find_element_by_xpath('//select[@id="export-citation-export-to-options"]')
export_to_options.find_element_by_xpath('//option[@value="xml"]').click()# XML
# 设置引文内容单选
citation_options = driver.find_element_by_xpath('//ul[@id="export-citation-options"]')
citation_options.find_element_by_xpath('//input[@value="ALL"]').click()#完整参考
# 设置收录复选框
citation_include = driver.find_element_by_xpath('//div[@id="export-citation-include"]')
ifcitation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').is_selected():# 链接到外部解析器
citation_include.find_element_by_xpath('//input[@name="externalResolverLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').is_selected():# 收录 URL
citation_include.find_element_by_xpath('//input[@name="jumpstartLink"]').click()
ifcitation_include.find_element_by_xpath('//input[@name="saveStrategy"]').is_selected():#搜索历史
citation_include.find_element_by_xpath('//input[@name="saveStrategy"]').click()
# 点击下载。
download = driver.find_element_by_xpath('//div[@class ="export-citation-buttons"]')
下载。点击()
最后:
sleep(30)#等待最后一个文件下载完成
# driver.implicitly_wait(30) # 不起作用!
驱动程序退出()
返回
3. 提示
A. 每次启动浏览器,桌面上都会弹出一个浏览器。您可以清楚地看到自动化过程是如何进行的。看来selenium真的是为web程序的自动化测试做好了准备。此外,在抓取过程中保持屏幕打开。如果您进入睡眠或屏幕保护程序,也会抛出异常。
B、在模拟网页操作时,网页跳转是一个很常见的场景。所以要注意网页响应时间。Selenium 不会等待网页响应完成才继续执行代码,它会直接执行。两者应该是不同的过程。这里可以选择设置隐式等待和显式等待。在其他操作中,隐式等待起决定作用,显式等待在WebDriverWait中起主要作用。 但是需要注意的是,最长等待时间取决于两者中较大的一个,如果隐式等待时间>显式等待时间,代码的最长等待时间等于隐式等待时间。
C、设置下载路径时,一开始不起作用。我怀疑是“download.default_directory”这个键错了,于是查看网页源码找到了这个键,还是一样。问题出在别处。但这提醒我,以后在代码中使用字典做相关配置的时候,看源码就可以猜到了。
D.我以为整个过程要两三天才能实现,因为我真的不明白。从开始学习到完成,不到一天就完成了。可能是因为我在开始之前搜索了很长时间,经过反复比较,找到了最方便的工具。
E. 做完之后在github上搜了一下,发现了一个神器。对于想要爬取大量内容的朋友,如果不想浪费时间学习太多web应用的底层知识,可以结合使用Selenium+scrapy。Scrapy 可以负责搜索网页,而 selenium 负责处理每个网页上的内容,尤其是动态内容。如果下次有需要,我打算用这个主意!
F. 分享一句话。“关于爬虫,最快获得经验的方法是:学会写网站,如果你知道网站在请求什么,你就会知道怎么爬网站!” 这很简单。,但是这么简单的一句话给了我很大的启发。之前感觉太难了,一直卡在scrapy爬静态网页的级别。像cookies这样的技术也曾被观看过一次,一次被遗忘一次。现在看来是因为网站的整体流程没有梳理清楚。另一方面,我也害怕那些复杂的网站技术术语。其实只要去网上查一下相关概念是怎么回事,就慢慢熬过去了。
G. 最后,完全不懂编程的人可以使用一些可视化爬虫工具。下面是一些介绍:。懂编程又想高效率的需要参考其他工具。
c 抓取网页数据(教你爬下100部电影数据:R语言网页爬取入门指南(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-05 04:02
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客查看更多博客
使用多线程爬取招聘网站
作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery作为 pq 导入 json from
阅读全文
手拉手 | 教你爬下100部电影数据:R语言爬网初学者指南
作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将谷歌作为主要的知识来源——无论是寻找一个地方的评论还是学习新术语。所有这些信息都可以在线获取。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
基于Scrapy的爬取伯乐在线网站
作者:小三坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。注2018年7月20日Scrapy官方文档网址:网页在chrome浏览器中打开
阅读全文
Python爬虫入门教程25-100 知乎文章 图片爬虫之一
作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬,我可能会断断续续的写几个文章。最简单的方法是先爬行。爬取单个 文章 的所有答案并不困难。找到我们要爬取的页面,我随便选一个
阅读全文
【python学习】维基百科程序语言消息框的简单爬取
作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲到通过BeautifulSoup爬取网络知识。由于这方面的文章还很少,希望提供一些思路和方法,帮助大家
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬取
作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,我们抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,按顺序
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李 2725人浏览评论:04年前
爬虫主要是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文 查看全部
c 抓取网页数据(教你爬下100部电影数据:R语言网页爬取入门指南(组图))
阿里云>云栖社区>主题图>C>c语言爬取网站
推荐活动:
更多优惠>
当前话题:c语言爬取网站加入采集
相关话题:
c语言爬取网站相关博客查看更多博客
使用多线程爬取招聘网站
作者:等下1209人浏览评论数:02年前
使用多线程获取某招聘信息网站,使用环境py3,更不用说,直接上传代码到你要引导的包中,不能错过import threading import requests from pyquery import PyQuery作为 pq 导入 json from
阅读全文
手拉手 | 教你爬下100部电影数据:R语言爬网初学者指南
作者:小轩峰柴金 2463人浏览评论:04年前
序言网页上的数据和信息呈指数级增长。今天,我们都将谷歌作为主要的知识来源——无论是寻找一个地方的评论还是学习新术语。所有这些信息都可以在线获取。网络上可用数据的增加为数据科学家开辟了新的可能性。我坚信网络抓取是一种数据科学
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
基于Scrapy的爬取伯乐在线网站
作者:小三坤 829人浏览评论:03年前
标题中英文的第一个字母比较规范,但是在python的实际使用中,都是小写的。注2018年7月20日Scrapy官方文档网址:网页在chrome浏览器中打开
阅读全文
Python爬虫入门教程25-100 知乎文章 图片爬虫之一
作者:梦之橡皮 1110人浏览评论:02年前
1. 知乎文章 一个图片爬虫写在前面,今天尝试爬一下。知乎,看看这个网站有什么有趣的内容可以爬,我可能会断断续续的写几个文章。最简单的方法是先爬行。爬取单个 文章 的所有答案并不困难。找到我们要爬取的页面,我随便选一个
阅读全文
【python学习】维基百科程序语言消息框的简单爬取
作者:Xiaoluoluo1432 人浏览评论:06年前
文章主要描述了如何通过Python爬取维基百科的Infobox,主要是通过正则表达式和urllib;下面文章可能会讲到通过BeautifulSoup爬取网络知识。由于这方面的文章还很少,希望提供一些思路和方法,帮助大家
阅读全文
Python爬虫入门教程15-100石家庄政民交互数据爬取
作者:梦之橡皮2057人浏览评论:02年前
1.石家庄政民互动数据爬取-今天写在前面,我们抓一个网站,这个网站,涉及的内容是网友的评论和回复,很简单,但 网站 来自 gov。URL 是第一个语句,按顺序
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李 2725人浏览评论:04年前
爬虫主要是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文
c 抓取网页数据(C++与php的交互之--C++获取网页文字内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-30 23:22
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。---分割线-------------------------------------------- ---------------- 测试服务器为:新浪云海;测试内容:获取PHP脚本从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先是直观的图片,然后是文本源代码的一般示例?getWeiXinFromUserNameFromSEA(const char*); 9 using namespace std;10 11 int main(){12 char *p=NULL; 用于存储返回的结果
633 查看全部
c 抓取网页数据(C++与php的交互之--C++获取网页文字内容)
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。---分割线-------------------------------------------- ---------------- 测试服务器为:新浪云海;测试内容:获取PHP脚本从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先是直观的图片,然后是文本源代码的一般示例?getWeiXinFromUserNameFromSEA(const char*); 9 using namespace std;10 11 int main(){12 char *p=NULL; 用于存储返回的结果
633
c 抓取网页数据(浏览器输入一个URL站点后看到网站页面内容(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-29 08:11
我们在浏览器中输入一个URL站点,按回车,就可以正常在浏览器中看到网站页面的内容了。其实这个过程就是浏览器向它所在的服务器发送请求,告诉服务器请求什么。服务器收到请求后,对请求进行处理和解析。如果请求的处理和解析正常,则返回给浏览器。的回应。响应中收录页面的源代码等内容,浏览器解析响应中的源代码,最终显示解析出的网页。大致流程是:浏览器请求“服务器处理和分析”服务器响应并传递给浏览器“浏览器对网页的分析和渲染”。
让我们通过实际的网络站点来了解HTTP请求和响应的过程,以及在这个过程中发生了什么样的网络请求。以Chrome浏览器访问百度网站为例。
打开Chrome浏览器,在鼠标右键菜单中选择【检查】或直接快捷键【F12】打开开发者工具,切换到【网络】。在浏览器中输入百度站点:按回车键查看发生的网络请求。如下所示:
第一个网络请求:是浏览器向百度服务器发送的访问百度站点的请求。单击此请求可查看请求的详细信息和内容。
首先是General部分,描述了请求的URL、请求方法、响应状态码以及远程服务器的地址和端口;
下面有Response Headers和Request Headers,分别是响应头和请求头。收录响应和请求的部分相关信息和内容。我们来看看这个请求的具体内容和对应的响应。
请求的组成
请求由客户端即浏览器发送到服务器。发送的请求有4个方面:请求方法、请求URL、请求头、请求正文
1.请求方式
常见的请求有 get、post、put... 类型。get类接口一般是指获取信息的接口,比如列表查询的功能,点击查询按钮调用get接口,然后返回信息。这意味着从服务器(后端)提取内容。post类型一般是提交表单的功能,比如注册、导入数据等,就是post接口。这意味着将内容推送到服务器(后端)。
2.请求的站点
请求的网站是浏览器输入的URL URL
3.请求头
请求头用于指示服务器使用的附件信息,即HTTP协议规定的附加内容,必须按照协议规则进行处理。访问百度站点的请求头信息如下图所示:
查看请求头信息相关字段的描述
Accept:请求头域,用于指定客户端可以接受什么类型的信息,如上图所示,可以接受text/html等类型的信息
Accept-Encoding 和 Accept-Language:指定客户端可接受的编码和语言
连接:连接状态
Cookie:存储的Cookie信息,主要用于维护当前会话
Host:需要访问的站点地址
User-Agent:用于向服务器标识客户端使用的操作系统、浏览器版本等信息
4.请求正文
请求体一般携带POST类型请求的表单数据,GET类型请求体为空
响应的组成
响应是服务器返回给浏览器的信息。响应的内容有三个方面:响应状态码、响应头和响应体
1.响应状态码
响应状态码表示服务器对请求信息的处理结果,如200表示响应正常,404表示未找到页面,500表示服务器出错等。
2. 响应头
响应头收录服务器对请求的响应信息,如下图所示:
查看响应头中关键字段的描述
Content-Type:文档类型,指定返回的文档是什么,例如text/html表示返回的文档是HTML文档
服务器:服务器信息,如服务器名称、版本等。
Set-Cookie:设置 Cookie
Expires:指定响应的过期时间
3. 响应正文
是网页的HTML源代码,点击【预览】选项卡可以查看网页的源代码
2.3、 网页组成
现代网页总是带给我们丰富多彩的视觉体验。不同的网页往往有很多不同的外观,搭配合理的布局、丰富的图片、动画效果等,那么这些页面是如何形成的呢?构成网页的三个主要部分:HTML、CSS 和 JavaScript。HTML构成了网页的基本结构,CSS决定了网页的布局风格,JavaScript决定了网页的可塑性和动态呈现。下面我们来详细了解一下这三个部分:
1.HTML
HTML:全称是Hyper Text Markup Language,即超文本标记语言。网页上的文字、段落、图片、按钮等元素都是由HTML定义的。比如img标签代表图片,p标签代表段落等等,在Chrome浏览器中打开百度站,鼠标右键选择【勾选】或者直接【F12】打开开发者工具就可以了在【元素】选项栏中可以看到网页的HTML源代码,如下图:
您可以查看网页的 HTML 源代码。每个标签对定义一个节点和节点属性,它们形成一个 HTML 树。这些节点标签对显示在 HTML 树中,并且具有一定的层次关系。它们通常由父节点、子节点和同一级别的节点表示。HTML学习可以参考W3School网站学习:
2.CSS
CSS:全称Cascading Style Sheets,即Cascading Style Sheets。CSS 用于确定网页布局样式的标准,指定网页中文本的大小、颜色、位置等属性。找到如下图按钮【百度点击】查看样式:
CSS样式决定了按钮的宽高,即宽高的像素大小,以及文字颜色颜色:白色等信息。按钮背景色:background
3.JavaScript
JavaScript 是 JS,一种脚本语言,用于将 JS 文件嵌入 HTML 代码中,以提供交互式动态效果,例如提示框、轮播、下载进度条等。HTML 中的标签对由脚本标签对定义
综上所述,HTML 定义了网页的内容和结构,CSS 描述了网页元素的布局渲染和位置效果,JavaScript 定义了网页的交互性和动画效果。这三个构成了丰富的 Web 演示文稿的基本结构。
在了解了爬虫的基本概念、HTTP协议和网页的基本组成之后,基于这些方面的认知,我开始学习如何爬取网站并提取信息。 查看全部
c 抓取网页数据(浏览器输入一个URL站点后看到网站页面内容(组图))
我们在浏览器中输入一个URL站点,按回车,就可以正常在浏览器中看到网站页面的内容了。其实这个过程就是浏览器向它所在的服务器发送请求,告诉服务器请求什么。服务器收到请求后,对请求进行处理和解析。如果请求的处理和解析正常,则返回给浏览器。的回应。响应中收录页面的源代码等内容,浏览器解析响应中的源代码,最终显示解析出的网页。大致流程是:浏览器请求“服务器处理和分析”服务器响应并传递给浏览器“浏览器对网页的分析和渲染”。
让我们通过实际的网络站点来了解HTTP请求和响应的过程,以及在这个过程中发生了什么样的网络请求。以Chrome浏览器访问百度网站为例。
打开Chrome浏览器,在鼠标右键菜单中选择【检查】或直接快捷键【F12】打开开发者工具,切换到【网络】。在浏览器中输入百度站点:按回车键查看发生的网络请求。如下所示:
第一个网络请求:是浏览器向百度服务器发送的访问百度站点的请求。单击此请求可查看请求的详细信息和内容。
首先是General部分,描述了请求的URL、请求方法、响应状态码以及远程服务器的地址和端口;
下面有Response Headers和Request Headers,分别是响应头和请求头。收录响应和请求的部分相关信息和内容。我们来看看这个请求的具体内容和对应的响应。
请求的组成
请求由客户端即浏览器发送到服务器。发送的请求有4个方面:请求方法、请求URL、请求头、请求正文
1.请求方式
常见的请求有 get、post、put... 类型。get类接口一般是指获取信息的接口,比如列表查询的功能,点击查询按钮调用get接口,然后返回信息。这意味着从服务器(后端)提取内容。post类型一般是提交表单的功能,比如注册、导入数据等,就是post接口。这意味着将内容推送到服务器(后端)。
2.请求的站点
请求的网站是浏览器输入的URL URL
3.请求头
请求头用于指示服务器使用的附件信息,即HTTP协议规定的附加内容,必须按照协议规则进行处理。访问百度站点的请求头信息如下图所示:
查看请求头信息相关字段的描述
Accept:请求头域,用于指定客户端可以接受什么类型的信息,如上图所示,可以接受text/html等类型的信息
Accept-Encoding 和 Accept-Language:指定客户端可接受的编码和语言
连接:连接状态
Cookie:存储的Cookie信息,主要用于维护当前会话
Host:需要访问的站点地址
User-Agent:用于向服务器标识客户端使用的操作系统、浏览器版本等信息
4.请求正文
请求体一般携带POST类型请求的表单数据,GET类型请求体为空
响应的组成
响应是服务器返回给浏览器的信息。响应的内容有三个方面:响应状态码、响应头和响应体
1.响应状态码
响应状态码表示服务器对请求信息的处理结果,如200表示响应正常,404表示未找到页面,500表示服务器出错等。
2. 响应头
响应头收录服务器对请求的响应信息,如下图所示:
查看响应头中关键字段的描述
Content-Type:文档类型,指定返回的文档是什么,例如text/html表示返回的文档是HTML文档
服务器:服务器信息,如服务器名称、版本等。
Set-Cookie:设置 Cookie
Expires:指定响应的过期时间
3. 响应正文
是网页的HTML源代码,点击【预览】选项卡可以查看网页的源代码
2.3、 网页组成
现代网页总是带给我们丰富多彩的视觉体验。不同的网页往往有很多不同的外观,搭配合理的布局、丰富的图片、动画效果等,那么这些页面是如何形成的呢?构成网页的三个主要部分:HTML、CSS 和 JavaScript。HTML构成了网页的基本结构,CSS决定了网页的布局风格,JavaScript决定了网页的可塑性和动态呈现。下面我们来详细了解一下这三个部分:
1.HTML
HTML:全称是Hyper Text Markup Language,即超文本标记语言。网页上的文字、段落、图片、按钮等元素都是由HTML定义的。比如img标签代表图片,p标签代表段落等等,在Chrome浏览器中打开百度站,鼠标右键选择【勾选】或者直接【F12】打开开发者工具就可以了在【元素】选项栏中可以看到网页的HTML源代码,如下图:
您可以查看网页的 HTML 源代码。每个标签对定义一个节点和节点属性,它们形成一个 HTML 树。这些节点标签对显示在 HTML 树中,并且具有一定的层次关系。它们通常由父节点、子节点和同一级别的节点表示。HTML学习可以参考W3School网站学习:
2.CSS
CSS:全称Cascading Style Sheets,即Cascading Style Sheets。CSS 用于确定网页布局样式的标准,指定网页中文本的大小、颜色、位置等属性。找到如下图按钮【百度点击】查看样式:
CSS样式决定了按钮的宽高,即宽高的像素大小,以及文字颜色颜色:白色等信息。按钮背景色:background
3.JavaScript
JavaScript 是 JS,一种脚本语言,用于将 JS 文件嵌入 HTML 代码中,以提供交互式动态效果,例如提示框、轮播、下载进度条等。HTML 中的标签对由脚本标签对定义
综上所述,HTML 定义了网页的内容和结构,CSS 描述了网页元素的布局渲染和位置效果,JavaScript 定义了网页的交互性和动画效果。这三个构成了丰富的 Web 演示文稿的基本结构。
在了解了爬虫的基本概念、HTTP协议和网页的基本组成之后,基于这些方面的认知,我开始学习如何爬取网站并提取信息。
c 抓取网页数据(一个人模拟验证码的快速处理方法,你值得拥有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-27 18:05
c抓取网页数据,用框架比如flask这种。
也有直接用mongo的,
多线程可以一起工作来对大网站进行快速处理
人家一个人好几万上百万用户都用了https,这个不算啥,不过能说明提问者不够专业;这个技术上对网站来说不算什么的,就好比https其实并不安全,在国内到处乱泄露,有点傻逼的感觉,但是有点用。这么说吧,首先https对缓存和加密是个不错的东西,其次从技术的角度上来说,服务器端要做这个一点都不难,只是执行脚本的你不会用。
一个人模拟验证码这事说明这位兄台不好学,专业不对口呀。题主不要着急,最好再找找不上来人。一个人模拟验证码不是对付不了,而是没经验,没数据。https需要验证一个地址,那在一个地址上只能实现一个验证。怎么办?很简单啊,如果一个网站验证码这个数据量少,图片少,那在各线程里发送一下就好了。对于验证码要验证一大堆数据,图片多的来说,那就麻烦,这里cookie加数据库的方案已经普及了。推荐个表单验证的https方案,只是想传个数据测试一下。
人家只用https。提主还是让你邻居给你做验证码服务器吧,他不知道你做了什么,又不承担,不然随便给你加个暴力破解。另外,作为一个大学生,有什么想不开的非要用mongodb?我一直觉得,mongodb这个名字很土。likethis:likethis:slogon:createyourwebstoreoraddanythingtootherserver.另外最好不要因为验证码而关闭浏览器,想想看,这个页面是不是一直在向其他页面发出对话?关闭浏览器当然避免了这个问题。
ps:一般做好https,根本不需要cookie,因为ie网上很容易解决,一个autostart,一个authentication就完事了。 查看全部
c 抓取网页数据(一个人模拟验证码的快速处理方法,你值得拥有)
c抓取网页数据,用框架比如flask这种。
也有直接用mongo的,
多线程可以一起工作来对大网站进行快速处理
人家一个人好几万上百万用户都用了https,这个不算啥,不过能说明提问者不够专业;这个技术上对网站来说不算什么的,就好比https其实并不安全,在国内到处乱泄露,有点傻逼的感觉,但是有点用。这么说吧,首先https对缓存和加密是个不错的东西,其次从技术的角度上来说,服务器端要做这个一点都不难,只是执行脚本的你不会用。
一个人模拟验证码这事说明这位兄台不好学,专业不对口呀。题主不要着急,最好再找找不上来人。一个人模拟验证码不是对付不了,而是没经验,没数据。https需要验证一个地址,那在一个地址上只能实现一个验证。怎么办?很简单啊,如果一个网站验证码这个数据量少,图片少,那在各线程里发送一下就好了。对于验证码要验证一大堆数据,图片多的来说,那就麻烦,这里cookie加数据库的方案已经普及了。推荐个表单验证的https方案,只是想传个数据测试一下。
人家只用https。提主还是让你邻居给你做验证码服务器吧,他不知道你做了什么,又不承担,不然随便给你加个暴力破解。另外,作为一个大学生,有什么想不开的非要用mongodb?我一直觉得,mongodb这个名字很土。likethis:likethis:slogon:createyourwebstoreoraddanythingtootherserver.另外最好不要因为验证码而关闭浏览器,想想看,这个页面是不是一直在向其他页面发出对话?关闭浏览器当然避免了这个问题。
ps:一般做好https,根本不需要cookie,因为ie网上很容易解决,一个autostart,一个authentication就完事了。
c 抓取网页数据(简单笼统的说,爬数据搞定以下几个部分,就可以小打小闹一下了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-25 03:16
简单来说,一般来说,如果你爬取数据得到以下部分,你可能会遇到一些麻烦。
一、 指定 URL 格式,例如 知乎 问题的 URL 为 /question/xxxx,然后抓取 html 内容。使用的工具,如果你有很好的规律性,你可以使用规律性。如果觉得规律性很麻烦,可以使用html解析DOM节点来处理内容。如果你爬取的内容有自己固有的特性,比如新闻内容,可以使用body爬取算法,其实就是在html中找出最长的几行字符串。
二、 使用javascript动态生成内容爬取。不推荐使用headless,效率比较低。建议使用一些开源库直接执行js代码,得到想要的结果。
了解页面中的程序逻辑非常重要。知道动态内容是如何生成的,使用一定的方法,就会和html一样,很容易得到你想要的结果。动态生成要么是在本地进行计算,要么是向服务器发起另一个请求以获得某个结果,显示或再次进行本地计算。对于前者,需要找到本地执行的那段代码,照原样,在javascript环境中执行,得到结果。对于后者,找到请求并得到相应的结果。一般结果也会是javascript代码或者json格式的字符串,可以再次解析。
三、登录,有很多资料需要登录才能查看。如果对方使用https,基本没有办法。好在国内很多网站在全站打广告的都是伪https,都可以像抓包一样抓到。比较复杂的会为用户名或密码重新加密,并且是时间相关的,直接提交给用户名和密码无效。您必须同时提交以当前时间为参数的第二次加密结果。同样,理解页面中的程序逻辑很重要。
四、验证码,当你取的太多太快时,网站一般会要求你输入验证码,证明你不是程序,而是手动操作。国内好像有云服务可以帮你输入验证码,修复这部分,或者用程序解析验证码,但是错误率太高了。另一种流氓方法是使用多个ADSL或VPN,来回切换IP,不断换IP进行爬取,将单个IP的爬取速度控制在网站的允许范围内,改什么header header代理比较简单,就不多说了。
五、 内容如图,网站 类别中的一些敏感信息,如商城价格、用户手机号码等,会直接由网站 显示在图片的形式。在这里,使用云服务的成本太高了。如果用程序解析图片,如果出错,这个信息基本没用。切换IP也是图,所以基本无解。
六、另外,爬虫还有很多细节和针对性的处理方式。为了学习的目的,我们需要多思考。比如移动互联网这么火,很多网站,有点厉害的会从手机客户端出来在手机客户端,他还用图片来展示吗?现在html5出来了,很多手机客户端都是用html+js重新打包的。
———————— 分界线,探讨抢夺的可持续性—————————
一个网页上有n个以上的链接,这意味着你会遇到从一个页面开始的链接数,然后以这种方式扩展1*n*n*n。同时,会出现重复的链接,所以如何保存爬取到的链接,以及如何过滤掉符合一定条件的链接,将是你需要解决的一个新问题。
好吧,当你有一个链接处理机制来帮你管理你爬取的所有链接时,你的爬虫的爬取效率就变得非常高效了,效率高到你的爬虫被目标拦截了网站,你该如何解决? 关于更改标题,我不会说太多。我只说说怎么解决key阻塞ip?
你需要让你的爬虫分布式,以中央服务器为任务调度中心,对爬取的页面进行处理,将爬取到的链接分发给所有下属机器。
下级机只做一件事,就是向中央服务器请求一个任务,执行完请求的任务后,将结果返回给调度中心。每个从机只是一个一年几十块的虚拟机,我们要的是从机的IP。
好了,现在你有n个ip分散在n台机器上为你做爬虫,数据统一集中在你躲在幕后的中央服务器上。效率非常高。一般你控制的好,目标服务器是不会发现的。某个ip请求太频繁,流量太高,但事情可能就是这么不正常!目标服务器还是找到了你!杀死你所有的小爬虫!怎么做?
你需要优化调度中心的东西。您的中央服务器不能只是将任务平均分配给每个从属机器。您需要实时监控每个下属机器的任务数量和执行状态。让他安息,免得他被杀。为什么这不在从属机器上做?因为我们使用的虚拟机每年价值几十美元!!成本!!你有钱买一台一年几千块的机器我没说!!
好了,现在你的任务调度中心很聪明,保证每个下属机器的任务不会太高。如果觉得效率还低,直接开个虚拟机就好了。还有很多ip。还可以很好的控制访问的频率和流量,链接管理也很好。基本上,爬虫的框架都有一个原型。 查看全部
c 抓取网页数据(简单笼统的说,爬数据搞定以下几个部分,就可以小打小闹一下了)
简单来说,一般来说,如果你爬取数据得到以下部分,你可能会遇到一些麻烦。
一、 指定 URL 格式,例如 知乎 问题的 URL 为 /question/xxxx,然后抓取 html 内容。使用的工具,如果你有很好的规律性,你可以使用规律性。如果觉得规律性很麻烦,可以使用html解析DOM节点来处理内容。如果你爬取的内容有自己固有的特性,比如新闻内容,可以使用body爬取算法,其实就是在html中找出最长的几行字符串。
二、 使用javascript动态生成内容爬取。不推荐使用headless,效率比较低。建议使用一些开源库直接执行js代码,得到想要的结果。
了解页面中的程序逻辑非常重要。知道动态内容是如何生成的,使用一定的方法,就会和html一样,很容易得到你想要的结果。动态生成要么是在本地进行计算,要么是向服务器发起另一个请求以获得某个结果,显示或再次进行本地计算。对于前者,需要找到本地执行的那段代码,照原样,在javascript环境中执行,得到结果。对于后者,找到请求并得到相应的结果。一般结果也会是javascript代码或者json格式的字符串,可以再次解析。
三、登录,有很多资料需要登录才能查看。如果对方使用https,基本没有办法。好在国内很多网站在全站打广告的都是伪https,都可以像抓包一样抓到。比较复杂的会为用户名或密码重新加密,并且是时间相关的,直接提交给用户名和密码无效。您必须同时提交以当前时间为参数的第二次加密结果。同样,理解页面中的程序逻辑很重要。
四、验证码,当你取的太多太快时,网站一般会要求你输入验证码,证明你不是程序,而是手动操作。国内好像有云服务可以帮你输入验证码,修复这部分,或者用程序解析验证码,但是错误率太高了。另一种流氓方法是使用多个ADSL或VPN,来回切换IP,不断换IP进行爬取,将单个IP的爬取速度控制在网站的允许范围内,改什么header header代理比较简单,就不多说了。
五、 内容如图,网站 类别中的一些敏感信息,如商城价格、用户手机号码等,会直接由网站 显示在图片的形式。在这里,使用云服务的成本太高了。如果用程序解析图片,如果出错,这个信息基本没用。切换IP也是图,所以基本无解。
六、另外,爬虫还有很多细节和针对性的处理方式。为了学习的目的,我们需要多思考。比如移动互联网这么火,很多网站,有点厉害的会从手机客户端出来在手机客户端,他还用图片来展示吗?现在html5出来了,很多手机客户端都是用html+js重新打包的。
———————— 分界线,探讨抢夺的可持续性—————————
一个网页上有n个以上的链接,这意味着你会遇到从一个页面开始的链接数,然后以这种方式扩展1*n*n*n。同时,会出现重复的链接,所以如何保存爬取到的链接,以及如何过滤掉符合一定条件的链接,将是你需要解决的一个新问题。
好吧,当你有一个链接处理机制来帮你管理你爬取的所有链接时,你的爬虫的爬取效率就变得非常高效了,效率高到你的爬虫被目标拦截了网站,你该如何解决? 关于更改标题,我不会说太多。我只说说怎么解决key阻塞ip?
你需要让你的爬虫分布式,以中央服务器为任务调度中心,对爬取的页面进行处理,将爬取到的链接分发给所有下属机器。
下级机只做一件事,就是向中央服务器请求一个任务,执行完请求的任务后,将结果返回给调度中心。每个从机只是一个一年几十块的虚拟机,我们要的是从机的IP。
好了,现在你有n个ip分散在n台机器上为你做爬虫,数据统一集中在你躲在幕后的中央服务器上。效率非常高。一般你控制的好,目标服务器是不会发现的。某个ip请求太频繁,流量太高,但事情可能就是这么不正常!目标服务器还是找到了你!杀死你所有的小爬虫!怎么做?
你需要优化调度中心的东西。您的中央服务器不能只是将任务平均分配给每个从属机器。您需要实时监控每个下属机器的任务数量和执行状态。让他安息,免得他被杀。为什么这不在从属机器上做?因为我们使用的虚拟机每年价值几十美元!!成本!!你有钱买一台一年几千块的机器我没说!!
好了,现在你的任务调度中心很聪明,保证每个下属机器的任务不会太高。如果觉得效率还低,直接开个虚拟机就好了。还有很多ip。还可以很好的控制访问的频率和流量,链接管理也很好。基本上,爬虫的框架都有一个原型。
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-11-24 10:12
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置提琴手:
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用Fiddler抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了
查看全部
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置提琴手:
打开Fiddler,在菜单栏中,打开工具-选项,在前三个选项卡设置下,确定,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用Fiddler抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,通常是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候,当Proxifer打开时,浏览器将无法连接网络。可以通过设置Fiddler方式连接网络,添加谷歌浏览器执行程序文件,确定后就可以上网了
c 抓取网页数据(基于C#实现网络爬虫的相关资料--代码很难找)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-24 10:10
本文文章主要详细介绍了基于C#的网络爬虫的相关资料,即C#抓取网页的Html源码。有兴趣的朋友可以参考一下。
我最近刚刚完成了一个简单的网络爬虫。一开始,我很迷茫,不知道如何下手。后来找了很多资料,但确实能满足我的需求,有用的资料——代码好难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href: to add using System.IO; 使用 System.Net;
private void Search(string url) { string rl; WebRequest Request = WebRequest.Create(url.Trim()); WebResponse Response = Request.GetResponse(); Stream resStream = Response.GetResponseStream(); StreamReader sr = new StreamReader(resStream, Encoding.Default); StringBuilder sb = new StringBuilder(); while ((rl = sr.ReadLine()) != null) { sb.Append(rl); } string str = sb.ToString().ToLower(); string str_get = mid(str, "", ""); int start = 0; while (true) { if (str_get == null) break; string strResult = mid(str_get, "href=\"", "\"", out start); if (strResult == null) break; else { lab[url] += strResult; str_get = str_get.Substring(start); } } } private string mid(string istr, string startString, string endString) { int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; } private string mid(string istr, string startString, string endString, out int iBodyEnd) { //初始化out参数,否则不能return iBodyEnd = 0; int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; }
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。 查看全部
c 抓取网页数据(基于C#实现网络爬虫的相关资料--代码很难找)
本文文章主要详细介绍了基于C#的网络爬虫的相关资料,即C#抓取网页的Html源码。有兴趣的朋友可以参考一下。
我最近刚刚完成了一个简单的网络爬虫。一开始,我很迷茫,不知道如何下手。后来找了很多资料,但确实能满足我的需求,有用的资料——代码好难找。所以想发这个文章,让一些想做这个功能的朋友少走一些弯路。
首先是抓取Html源码,选择节点的href: to add using System.IO; 使用 System.Net;
private void Search(string url) { string rl; WebRequest Request = WebRequest.Create(url.Trim()); WebResponse Response = Request.GetResponse(); Stream resStream = Response.GetResponseStream(); StreamReader sr = new StreamReader(resStream, Encoding.Default); StringBuilder sb = new StringBuilder(); while ((rl = sr.ReadLine()) != null) { sb.Append(rl); } string str = sb.ToString().ToLower(); string str_get = mid(str, "", ""); int start = 0; while (true) { if (str_get == null) break; string strResult = mid(str_get, "href=\"", "\"", out start); if (strResult == null) break; else { lab[url] += strResult; str_get = str_get.Substring(start); } } } private string mid(string istr, string startString, string endString) { int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 int iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; } private string mid(string istr, string startString, string endString, out int iBodyEnd) { //初始化out参数,否则不能return iBodyEnd = 0; int iBodyStart = istr.IndexOf(startString, 0); //开始位置 if (iBodyStart == -1) return null; iBodyStart += startString.Length; //第一次字符位置起的长度 iBodyEnd = istr.IndexOf(endString, iBodyStart); //第二次字符在第一次字符位置起的首次位置 if (iBodyEnd == -1) return null; iBodyEnd += endString.Length; //第二次字符位置起的长度 string strResult = istr.Substring(iBodyStart, iBodyEnd - iBodyStart - 1); return strResult; }
好了,以上就是全部代码了,要运行的话,有些细节还得自己修改。
c 抓取网页数据(爬虫如何同时启动多个.py可视化部分可视化采用方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-23 18:22
)
**爬取58job、赶集job和智联招聘,用数据分析生成echarts地图**
履带部分
爬虫部分使用scrapy-redis分布式爬虫,通过redis实现增量爬取和去重,将所有数据直接保存到redis中进行后续处理
github:
代码已经提交到GitHub,不是很完整。爬虫抓取的信息没有详情页的数据,只有赶集网的数据才是详情页。有点懒得写了。
您可以自己克隆代码并改进它。
获取智联招聘招聘信息
这很简单
抓取58个城市的招聘信息
这个也很简单,我的代码只爬了一个城市,可以扩展
爬取赶集网的招聘信息
这个也很简单。不用说,它也是一个城市的信息。
最后,如何同时启动多个蜘蛛
如何同时启动所有爬虫,这个我会写出来,记录下来,免得日后忘记。
首先需要在爬虫文件中创建一个commond包,并在该目录下新建一个文件crawlall.py。
目录结构:
crawlall.py 中的内容:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/5/6 16:31
# @Author : zhao.jia
# @Site :
# @File : crawlall.py
# @Software: PyCharm
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
更改设置.py
COMMANDS_MODULE = 'spider_work.command'
启动
scrapy crawlall
爬虫部分到此结束,大家都知道如何开始一个。
可以扩展的地方很多,再补充几点:
1、 详细招聘信息爬取
2、可以直接把代码改成通用爬虫
3、58job和赶集网同城,可以推广到全国。写个配置文件,拼接网址就行了。可以根据每个网站分别做关键词搜索爬虫,而不是单独使用智联的关键词。
4、添加异常处理
5、向redis添加数据去重
数据转换部分(可忽略)
我是通过mysql来做的,所以需要把redis里面的数据取出来存到mysql中。
Redis存储的类型是列表,所以存在重复数据。Redis 使用 lpop 方法来获取数据。通过向 MySQL 表中的字段添加索引以删除重复,insert 语句使用 replace into 而不是 insert into。你可以去百度看看博客。
process_item_mysql.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/29 23:15
# @Author : zhao.jia
# @Site :
# @File : process_item_mysql.py
# @Software: PyCharm
import pymysql
import redis
import json
def process_item(key):
Redis_conn = redis.StrictRedis(host='ip', port=6379, db=0, password='pass')
MySql_conn = pymysql.connect(host='ip', user='root', passwd='pass', port=3306, db='zhaopin')
cur = MySql_conn.cursor()
while True:
data = Redis_conn.lpop(key)
if data:
try:
data = json.loads(data.decode('unicode_escape'), strict=False)
except Exception as e:
process_item(key)
print(data)
try:
if '-' in data['city']:
city = data['city'].split('-')[0]
else:
city = data['city']
except Exception as e:
city = data['city']
lis = (
pymysql.escape_string(data['jobType']),
pymysql.escape_string(data['jobName']),
pymysql.escape_string(data['emplType']),
pymysql.escape_string(data['eduLevel']),
pymysql.escape_string(data['salary']),
pymysql.escape_string(data['companyName']),
pymysql.escape_string(city),
pymysql.escape_string(data['welfare']),
pymysql.escape_string(data['workingExp']))
sql = (
"replace into work(jobType, jobName, emplType, eduLevel, salary, companyName, city, welfare, workingExp) VALUES ('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s')" % lis)
try:
cur.execute(sql)
MySql_conn.commit()
except Exception as e:
MySql_conn.rollback()
else:
break
cur.close()
MySql_conn.close()
if __name__ == "__main__":
key_list = ['job_spider:items', 'jobs58:items', 'jobsganjispider']
for i in range(3):
process_item(key_list[i])
可视化部分
Flask+mysql+echarts 用于可视化
具体代码见我的GitHub,这里就不贴了。
发几张图
网站整体图网站
搜索界面
学术要求
教育薪资表
经验要求
词云插图
结束
项目中有很多可以扩展的部分。你需要自己写。你不再需要写简单的东西了。web part也可以扩展,包括页面和echarts图表,数据分析可以继续扩展。
查看全部
c 抓取网页数据(爬虫如何同时启动多个.py可视化部分可视化采用方法
)
**爬取58job、赶集job和智联招聘,用数据分析生成echarts地图**
履带部分
爬虫部分使用scrapy-redis分布式爬虫,通过redis实现增量爬取和去重,将所有数据直接保存到redis中进行后续处理
github:
代码已经提交到GitHub,不是很完整。爬虫抓取的信息没有详情页的数据,只有赶集网的数据才是详情页。有点懒得写了。
您可以自己克隆代码并改进它。
获取智联招聘招聘信息
这很简单
抓取58个城市的招聘信息
这个也很简单,我的代码只爬了一个城市,可以扩展
爬取赶集网的招聘信息
这个也很简单。不用说,它也是一个城市的信息。
最后,如何同时启动多个蜘蛛
如何同时启动所有爬虫,这个我会写出来,记录下来,免得日后忘记。
首先需要在爬虫文件中创建一个commond包,并在该目录下新建一个文件crawlall.py。
目录结构:
crawlall.py 中的内容:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/5/6 16:31
# @Author : zhao.jia
# @Site :
# @File : crawlall.py
# @Software: PyCharm
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
更改设置.py
COMMANDS_MODULE = 'spider_work.command'
启动
scrapy crawlall
爬虫部分到此结束,大家都知道如何开始一个。
可以扩展的地方很多,再补充几点:
1、 详细招聘信息爬取
2、可以直接把代码改成通用爬虫
3、58job和赶集网同城,可以推广到全国。写个配置文件,拼接网址就行了。可以根据每个网站分别做关键词搜索爬虫,而不是单独使用智联的关键词。
4、添加异常处理
5、向redis添加数据去重
数据转换部分(可忽略)
我是通过mysql来做的,所以需要把redis里面的数据取出来存到mysql中。
Redis存储的类型是列表,所以存在重复数据。Redis 使用 lpop 方法来获取数据。通过向 MySQL 表中的字段添加索引以删除重复,insert 语句使用 replace into 而不是 insert into。你可以去百度看看博客。
process_item_mysql.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/29 23:15
# @Author : zhao.jia
# @Site :
# @File : process_item_mysql.py
# @Software: PyCharm
import pymysql
import redis
import json
def process_item(key):
Redis_conn = redis.StrictRedis(host='ip', port=6379, db=0, password='pass')
MySql_conn = pymysql.connect(host='ip', user='root', passwd='pass', port=3306, db='zhaopin')
cur = MySql_conn.cursor()
while True:
data = Redis_conn.lpop(key)
if data:
try:
data = json.loads(data.decode('unicode_escape'), strict=False)
except Exception as e:
process_item(key)
print(data)
try:
if '-' in data['city']:
city = data['city'].split('-')[0]
else:
city = data['city']
except Exception as e:
city = data['city']
lis = (
pymysql.escape_string(data['jobType']),
pymysql.escape_string(data['jobName']),
pymysql.escape_string(data['emplType']),
pymysql.escape_string(data['eduLevel']),
pymysql.escape_string(data['salary']),
pymysql.escape_string(data['companyName']),
pymysql.escape_string(city),
pymysql.escape_string(data['welfare']),
pymysql.escape_string(data['workingExp']))
sql = (
"replace into work(jobType, jobName, emplType, eduLevel, salary, companyName, city, welfare, workingExp) VALUES ('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s')" % lis)
try:
cur.execute(sql)
MySql_conn.commit()
except Exception as e:
MySql_conn.rollback()
else:
break
cur.close()
MySql_conn.close()
if __name__ == "__main__":
key_list = ['job_spider:items', 'jobs58:items', 'jobsganjispider']
for i in range(3):
process_item(key_list[i])
可视化部分
Flask+mysql+echarts 用于可视化
具体代码见我的GitHub,这里就不贴了。
发几张图
网站整体图网站
搜索界面
学术要求
教育薪资表
经验要求
词云插图
结束
项目中有很多可以扩展的部分。你需要自己写。你不再需要写简单的东西了。web part也可以扩展,包括页面和echarts图表,数据分析可以继续扩展。
c 抓取网页数据( Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-23 14:03
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化发展和专注于核心业务的需要,使得各种翻译服务越来越有利可图。云翻译平台Smartling是一家业务齐全的全球翻译公司,承接所有可翻译的内容,从企业文档、网页、应用程序,小到一个图标都包括在内。Smartling 刚刚获得了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投。此前,投资方Venrock、US Venture Partners、IDG Ventures、First Round Capital和Felicis Ventures均追加追加投资。
Smartling 将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API为企业用户的本地化语言网站提供数据监控服务。例如,某公司的网页翻译成中文后,用户可以通过Smartling的仪表盘看到中文版。@网站产生的流量等数据。
用户上传需要翻译的文档类型后,可以选择专业、众包或Smartling内部人员将其翻译成多种语言。整个业务流程对用户是可见的、可控的,用户可以根据自己的需要选择合适的翻译。各种设置,例如资源甚至翻译风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供跨平台优化。
Smartling 声称其服务可以降低高达 90% 的翻译管理成本,并且 Smartling 可以保证当天交付。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling 的客户涵盖电子商务、旅游相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是它的客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频: 查看全部
c 抓取网页数据(
Smartling获C轮融资2400万美元,云端翻译平台Smartling就是)
企业的全球化发展和专注于核心业务的需要,使得各种翻译服务越来越有利可图。云翻译平台Smartling是一家业务齐全的全球翻译公司,承接所有可翻译的内容,从企业文档、网页、应用程序,小到一个图标都包括在内。Smartling 刚刚获得了 2400 万美元的 C 轮融资,由 Tenaya Capital 领投,Harmony Partners 跟投。此前,投资方Venrock、US Venture Partners、IDG Ventures、First Round Capital和Felicis Ventures均追加追加投资。
Smartling 将整个业务操作流程分为三个部分:自动抓取、字段分割和模糊匹配、翻译和交付。除了翻译,Smartling还通过API为企业用户的本地化语言网站提供数据监控服务。例如,某公司的网页翻译成中文后,用户可以通过Smartling的仪表盘看到中文版。@网站产生的流量等数据。
用户上传需要翻译的文档类型后,可以选择专业、众包或Smartling内部人员将其翻译成多种语言。整个业务流程对用户是可见的、可控的,用户可以根据自己的需要选择合适的翻译。各种设置,例如资源甚至翻译风格。作品交付后,用户可以下载或发布(如网站)。对于网站等翻译服务和应用,也提供跨平台优化。
Smartling 声称其服务可以降低高达 90% 的翻译管理成本,并且 Smartling 可以保证当天交付。
目前,全球80%的网民不以英语为母语,40亿潜在网民也将来自非英语国家。
Smartling 的客户涵盖电子商务、旅游相关公司、出版和消费电子行业,包括初创公司。IndieGogo、HotelTonight、GoPro、Pinterest、Uber、Spotify、Dropbox、Shutterstock 和 Tesla Motors 都是它的客户。
Duolingo、Cloudwords、TransPerfect Translations 和 Lionbridge Technologies 都在做类似的事情。
操作过程请观看视频:
c 抓取网页数据(scrapy实验总结(一):安装Scrapy实验的收获与思考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-20 07:04
实验性一、scrapy crawler一、 实验目的
1、 用于数据捕获的网络爬虫。
2、如何使用scrapy,可以使用scrapy抓取网页数据。
二、能力地图
三、实验内容
1.内容:爬取传知播客C/C++讲师的姓名、职称和简介。
2.目标网址:
3.软件:scrapy框架的pycharm软件已经安装成功(专业版和社区版都可以)。
4.python3.7 及以上。
5.使用scrapy框架实现爬虫,使用xpath解析方式。
四、实验过程1、pycharm的卸载与安装
之前在笔记本电脑上安装了专业版的pycharm,现在激活码过期了,网上也找不到免费的激活码。同时,我之前安装的pycharm版本不是最新的,所以选择卸载重装。
关于卸载:
有了之前重装软件冲突的经验,为了防止重装最新社区版pycharm时发生冲突,应该把pycharm卸载干净。网上找到了相关的卸载方法:pycharm uninstall
关于安装:
为了避免安装软件后由于安装方式出现一些错误,我还找了一个相关教程:pycharm安装教程
2、scrapy 安装
按照老师的讲授完成安装,结果如下:
3、创建一个scrapy项目
这里直接进入scrapy的路径,在命令行运行cmd创建,如下图:
创建完成后,使用pycharm打开项目,如图:
4、创建一个写爬虫的文件
7
5、写代码5.1 itcast.py
import scrapy
#导入容器
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
# 爬虫名 启动爬虫时需要的参数*必需
name = 'itcast'
# 爬取域范围 允许爬虫在这个域名下进行爬取(可选) 可以不写
allowed_domains = ['itcast.cn']
#起始url列表 爬虫的第一批请求,将求这个列表里获取
start_urls = ['http://www.itcast.cn/channel/t ... 39%3B]
def parse(self, response):
node_list = response.xpath("//div[@class='li_txt']")
for node in node_list:
#创建item字段对象,用来存储信息
item = ItcastItem()
# .extract() 将xpath对象转换围殴Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#返回提取到的每一个item数据 给管道文件处理,同时还会回来继续执行后面的代码
yield item
5.2 项.py
import scrapy
class ItcastItem(scrapy.Item):
# 与itcast.py 定义的一一对应
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
#pass
5.3 settings.py
取消对下图的注释并将其更改为100
ITEM_PIPELINES = {
'ITcast.pipelines.ItcastPipeline': 100, #值越小优先级越高
5.4 管道.py
import json
class ItcastPipeline(object):
def __init__(self):
#python3保存文件 必须需要'wb' 保存为json格式
self.f = open("itcast_pipeline.json",'wb')
def process_item(self, item, spider):
#读取item中的数据 并换行处理
content = json.dumps(dict(item),ensure_ascii=False) + ',\n'
self.f.write(content.encode('utf=8'))
return item
def close_spider(self,spider):
#关闭文件
self.f.close()
显示结果:
五、实验总结(写下这个实验的结果,遇到的问题等,这一项很重要,是实验的总结和思考)遇到的问题1安装Scrapy报错
解决方案:将 python3.8 替换为 3.7
因为一台电脑可以有多个python,我这里直接安装了一个python3.7
python安装教程
问题2 在Terminal中执行Scrapy命令报错
解决方法:使用绝对路径(本实验在Terminal中执行的所有scrapy命令都是绝对路径),成功解决了第一种使用Pycharm命令行终端无法识别的命令的方法!
报酬
通过这个实验,我学会了pycharm+scrapy爬取数据,也学会了遇到问题时如何在网上寻找合适的解决方案。 查看全部
c 抓取网页数据(scrapy实验总结(一):安装Scrapy实验的收获与思考)
实验性一、scrapy crawler一、 实验目的
1、 用于数据捕获的网络爬虫。
2、如何使用scrapy,可以使用scrapy抓取网页数据。
二、能力地图
三、实验内容
1.内容:爬取传知播客C/C++讲师的姓名、职称和简介。
2.目标网址:
3.软件:scrapy框架的pycharm软件已经安装成功(专业版和社区版都可以)。
4.python3.7 及以上。
5.使用scrapy框架实现爬虫,使用xpath解析方式。
四、实验过程1、pycharm的卸载与安装
之前在笔记本电脑上安装了专业版的pycharm,现在激活码过期了,网上也找不到免费的激活码。同时,我之前安装的pycharm版本不是最新的,所以选择卸载重装。
关于卸载:
有了之前重装软件冲突的经验,为了防止重装最新社区版pycharm时发生冲突,应该把pycharm卸载干净。网上找到了相关的卸载方法:pycharm uninstall
关于安装:
为了避免安装软件后由于安装方式出现一些错误,我还找了一个相关教程:pycharm安装教程
2、scrapy 安装
按照老师的讲授完成安装,结果如下:
3、创建一个scrapy项目
这里直接进入scrapy的路径,在命令行运行cmd创建,如下图:
创建完成后,使用pycharm打开项目,如图:
4、创建一个写爬虫的文件
7
5、写代码5.1 itcast.py
import scrapy
#导入容器
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
# 爬虫名 启动爬虫时需要的参数*必需
name = 'itcast'
# 爬取域范围 允许爬虫在这个域名下进行爬取(可选) 可以不写
allowed_domains = ['itcast.cn']
#起始url列表 爬虫的第一批请求,将求这个列表里获取
start_urls = ['http://www.itcast.cn/channel/t ... 39%3B]
def parse(self, response):
node_list = response.xpath("//div[@class='li_txt']")
for node in node_list:
#创建item字段对象,用来存储信息
item = ItcastItem()
# .extract() 将xpath对象转换围殴Unicode字符串
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
#返回提取到的每一个item数据 给管道文件处理,同时还会回来继续执行后面的代码
yield item
5.2 项.py
import scrapy
class ItcastItem(scrapy.Item):
# 与itcast.py 定义的一一对应
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()
#pass
5.3 settings.py
取消对下图的注释并将其更改为100
ITEM_PIPELINES = {
'ITcast.pipelines.ItcastPipeline': 100, #值越小优先级越高
5.4 管道.py
import json
class ItcastPipeline(object):
def __init__(self):
#python3保存文件 必须需要'wb' 保存为json格式
self.f = open("itcast_pipeline.json",'wb')
def process_item(self, item, spider):
#读取item中的数据 并换行处理
content = json.dumps(dict(item),ensure_ascii=False) + ',\n'
self.f.write(content.encode('utf=8'))
return item
def close_spider(self,spider):
#关闭文件
self.f.close()
显示结果:
五、实验总结(写下这个实验的结果,遇到的问题等,这一项很重要,是实验的总结和思考)遇到的问题1安装Scrapy报错
解决方案:将 python3.8 替换为 3.7
因为一台电脑可以有多个python,我这里直接安装了一个python3.7
python安装教程
问题2 在Terminal中执行Scrapy命令报错
解决方法:使用绝对路径(本实验在Terminal中执行的所有scrapy命令都是绝对路径),成功解决了第一种使用Pycharm命令行终端无法识别的命令的方法!
报酬
通过这个实验,我学会了pycharm+scrapy爬取数据,也学会了遇到问题时如何在网上寻找合适的解决方案。
c 抓取网页数据( 模拟登录获得cookie代理的设置利用方法模拟(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-16 13:06
模拟登录获得cookie代理的设置利用方法模拟(图)
)
///
/// post请求获得页面
///
/// 需要获取的url
/// post的数据字符串,如id=1&name=test
/// 代理
/// coolie
/// 超时
///
public static string Crawl(string url, string postdata,WebProxy proxy, CookieContainer cookie, int timeout = 10000)
{
string result = string.Empty;
HttpWebRequest request = null;
WebResponse response = null;
StreamReader streamReader = null;
try
{
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cookie;
byte[] bs = Encoding.ASCII.GetBytes(postdata);
string responseData = String.Empty;
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = bs.Length;
using (Stream reqStream = request.GetRequestStream())
{
reqStream.Write(bs, 0, bs.Length);
reqStream.Close();
}
response = (HttpWebResponse)request.GetResponse();
streamReader = new StreamReader(response.GetResponseStream(), Encoding.UTF8);
result = streamReader.ReadToEnd();
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
if (streamReader != null)
{
streamReader.Dispose();
}
}
return result;
}
模拟登录获取cookie内容
首先找到登录页面,分析登录页面的post参数和链接,获取cookie后直接传给上面的方法
///
///根据模拟请求页面获得cookie
///
/// 模拟的url
/// cookie
public static CookieContainer GetCookie(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
return cc;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
模拟登录获取cookie字符串
///
/// 获得cookie字符串,webbrowser可以使用
///
///
///
///
///
public static string GetCookieString(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
string strcrook = request.CookieContainer.GetCookieHeader(request.RequestUri);
return strcrook;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
代理设置
///
/// 创建代理
///
/// 代理端口
/// 用户名
/// 密码
///
public static WebProxy CreatePorxy(string port, string user, string password)
{
WebProxy proxy = new WebProxy();
proxy.Address = new Uri(port);
proxy.Credentials = new NetworkCredential(user, password);
return proxy;
}
使用webbrowser获取js生成的页面
注意:由于不知道页面什么时候执行,这里是等待5s,默认执行完成,效率有待提高。
额外执行需要线程安全添加[STAThread]
///
/// 抓取js生成的页面
///
///
///
public static string CrawlDynamic(string url)
{
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = browser.Document;
return htmldocument.ActiveElement.InnerHtml;
}
为网页浏览器设置 cookie 以模拟登录
一开始没成功,觉得这个方法不能用。后来发现是doain设置的问题。我的例子是该设置可用。这个地方可能需要根据自己的情况选择域名。
[DllImport("wininet.dll", CharSet = CharSet.Auto, SetLastError = true)]
public static extern bool InternetSetCookie(string lpszUrlName, string lbszCookieName, string lpszCookieData);
///
/// 为webbrowser设置cookie
///
/// cookie字符串,可以从上面方法获得
/// 需要设置的域名
public static void SetCookie(string cookieStr,string domain)
{
foreach (string c in cookieStr.Split(';'))
{
string[] item = c.Split('=');
if (item.Length == 2)
{
string name = item[0];
string value = item[1];
InternetSetCookie(domain, name, value);
}
}
}
使用演示
//代理,没有就直接传null
WebProxy proxy = WebCrawl.WebRequestHelper.CreatePorxy("xx.com", "user", "password");
//根据登录页得到cookie
CookieContainer cookie = WebCrawl.WebRequestHelper.GetCookie("http://xxxx.login.com", proxy);
//获取页面
string html = WebCrawl.WebRequestHelper.Crawl("http://xxx.index.com", proxy, cookie);
//根据登录页得到cookie字符串
string cookiestr = WebCrawl.WebRequestHelper.GetCookieString("http://xxxx.login.com", proxy);
//为webbrowser设置cookie
WebCrawl.WebRequestHelper.SetCookie(cookiestr, "https://xx.com");
//获取需要登录切用js生成的页面,当然普通页面也可以
string htmlWithJs = WebCrawl.WebRequestHelper.CrawlDynamic("http://xxx.index.com"); 查看全部
c 抓取网页数据(
模拟登录获得cookie代理的设置利用方法模拟(图)
)
///
/// post请求获得页面
///
/// 需要获取的url
/// post的数据字符串,如id=1&name=test
/// 代理
/// coolie
/// 超时
///
public static string Crawl(string url, string postdata,WebProxy proxy, CookieContainer cookie, int timeout = 10000)
{
string result = string.Empty;
HttpWebRequest request = null;
WebResponse response = null;
StreamReader streamReader = null;
try
{
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cookie;
byte[] bs = Encoding.ASCII.GetBytes(postdata);
string responseData = String.Empty;
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = bs.Length;
using (Stream reqStream = request.GetRequestStream())
{
reqStream.Write(bs, 0, bs.Length);
reqStream.Close();
}
response = (HttpWebResponse)request.GetResponse();
streamReader = new StreamReader(response.GetResponseStream(), Encoding.UTF8);
result = streamReader.ReadToEnd();
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
if (streamReader != null)
{
streamReader.Dispose();
}
}
return result;
}
模拟登录获取cookie内容
首先找到登录页面,分析登录页面的post参数和链接,获取cookie后直接传给上面的方法
///
///根据模拟请求页面获得cookie
///
/// 模拟的url
/// cookie
public static CookieContainer GetCookie(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
return cc;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
模拟登录获取cookie字符串
///
/// 获得cookie字符串,webbrowser可以使用
///
///
///
///
///
public static string GetCookieString(string url, WebProxy proxy, int timeout = 10000)
{
HttpWebRequest request = null;
HttpWebResponse response = null;
try
{
CookieContainer cc = new CookieContainer();
request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Proxy = proxy;
request.Timeout = timeout;
request.AllowAutoRedirect = true;
request.CookieContainer = cc;
response = (HttpWebResponse)request.GetResponse();
response.Cookies = request.CookieContainer.GetCookies(request.RequestUri);
string strcrook = request.CookieContainer.GetCookieHeader(request.RequestUri);
return strcrook;
}
catch (Exception ex)
{
throw ex;
}
finally
{
if (request != null)
{
request.Abort();
}
if (response != null)
{
response.Close();
}
}
}
代理设置
///
/// 创建代理
///
/// 代理端口
/// 用户名
/// 密码
///
public static WebProxy CreatePorxy(string port, string user, string password)
{
WebProxy proxy = new WebProxy();
proxy.Address = new Uri(port);
proxy.Credentials = new NetworkCredential(user, password);
return proxy;
}
使用webbrowser获取js生成的页面
注意:由于不知道页面什么时候执行,这里是等待5s,默认执行完成,效率有待提高。
额外执行需要线程安全添加[STAThread]
///
/// 抓取js生成的页面
///
///
///
public static string CrawlDynamic(string url)
{
WebBrowser browser = new WebBrowser();
browser.ScriptErrorsSuppressed = true;
browser.Navigate(url);
//先要等待加载完毕
while (browser.ReadyState != WebBrowserReadyState.Complete)
{
Application.DoEvents();
}
System.Timers.Timer timer = new System.Timers.Timer();
var isComplete = false;
timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
{
//加载完毕
isComplete = true;
timer.Stop();
});
timer.Interval = 1000 * 5;
timer.Start();
//继续等待 5s,等待js加载完
while (!isComplete)
Application.DoEvents();
var htmldocument = browser.Document;
return htmldocument.ActiveElement.InnerHtml;
}
为网页浏览器设置 cookie 以模拟登录
一开始没成功,觉得这个方法不能用。后来发现是doain设置的问题。我的例子是该设置可用。这个地方可能需要根据自己的情况选择域名。
[DllImport("wininet.dll", CharSet = CharSet.Auto, SetLastError = true)]
public static extern bool InternetSetCookie(string lpszUrlName, string lbszCookieName, string lpszCookieData);
///
/// 为webbrowser设置cookie
///
/// cookie字符串,可以从上面方法获得
/// 需要设置的域名
public static void SetCookie(string cookieStr,string domain)
{
foreach (string c in cookieStr.Split(';'))
{
string[] item = c.Split('=');
if (item.Length == 2)
{
string name = item[0];
string value = item[1];
InternetSetCookie(domain, name, value);
}
}
}
使用演示
//代理,没有就直接传null
WebProxy proxy = WebCrawl.WebRequestHelper.CreatePorxy("xx.com", "user", "password");
//根据登录页得到cookie
CookieContainer cookie = WebCrawl.WebRequestHelper.GetCookie("http://xxxx.login.com", proxy);
//获取页面
string html = WebCrawl.WebRequestHelper.Crawl("http://xxx.index.com", proxy, cookie);
//根据登录页得到cookie字符串
string cookiestr = WebCrawl.WebRequestHelper.GetCookieString("http://xxxx.login.com", proxy);
//为webbrowser设置cookie
WebCrawl.WebRequestHelper.SetCookie(cookiestr, "https://xx.com";);
//获取需要登录切用js生成的页面,当然普通页面也可以
string htmlWithJs = WebCrawl.WebRequestHelper.CrawlDynamic("http://xxx.index.com";);
c 抓取网页数据(一下提取数据中的部分源码,你知道吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-13 13:21
2:获取网页源码
3:检查源码中是否有我们需要提取的数据
4:反汇编源码,一般使用分段、常规或第三方jar包
5:获取需要的数据并给自己创建的对象赋值
6:数据提取和保存
下面简单说一下提取数据中的部分源代码及其用途:
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream())); //这里如果出现乱码,请使用带编码的InputStreamReader构造方法,将需要的编码设置进去
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
解析存储的数据
public Bid getData(String html) throws Exception {
//获取的数据,存放在到Bid的对象中,自己可以重新建立一个对象存储
Bid bid = new Bid();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
// System.out.println("doc内容" + doc.text());
//获取html标签中的内容tr
Elements elements = doc.select("tr");
System.out.println(elements.size() + "****条");
//循环遍历数据
for (Element element : elements) {
if (element.select("td").first() == null){
continue;
}
Elements tdes = element.select("td");
for(int i = 0; i < tdes.size(); i++){
this.relation(tdes,tdes.get(i).text(),bid,i+1);
}
}
return bid;
}
获得的数据
Bid {
h2 = \'详见内容\',
itemName = \'诉讼服务中心设备采购\',
item = \'货物/办公消耗用品及类似物品/其他办公消耗用品及类似物品\',
itemUnit = \'详见内容\',
areaName = \'港北区\',
noticeTime = \'2018年10月22日 18:41\',
itemNoticeTime = \'null\',
itemTime = \'null\',
kaibiaoTime = \'2018年10月26日 09:00\',
winTime = \'null\',
kaibiaoDiDian = \'null\',
yusuanMoney = \'¥67.00元(人民币)\',
allMoney = \'null\',
money = \'null\',
text = \'\'
}
查看全部
c 抓取网页数据(一下提取数据中的部分源码,你知道吗?(图))
2:获取网页源码
3:检查源码中是否有我们需要提取的数据
4:反汇编源码,一般使用分段、常规或第三方jar包
5:获取需要的数据并给自己创建的对象赋值
6:数据提取和保存
下面简单说一下提取数据中的部分源代码及其用途:
/**
* 向指定URL发送GET方法的请求
*
* @param url
* 发送请求的URL
* @param param
* 请求参数,请求参数应该是 name1=value1&name2=value2 的形式。
* @return URL 所代表远程资源的响应结果
*/
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map map = connection.getHeaderFields();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream())); //这里如果出现乱码,请使用带编码的InputStreamReader构造方法,将需要的编码设置进去
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
解析存储的数据
public Bid getData(String html) throws Exception {
//获取的数据,存放在到Bid的对象中,自己可以重新建立一个对象存储
Bid bid = new Bid();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
// System.out.println("doc内容" + doc.text());
//获取html标签中的内容tr
Elements elements = doc.select("tr");
System.out.println(elements.size() + "****条");
//循环遍历数据
for (Element element : elements) {
if (element.select("td").first() == null){
continue;
}
Elements tdes = element.select("td");
for(int i = 0; i < tdes.size(); i++){
this.relation(tdes,tdes.get(i).text(),bid,i+1);
}
}
return bid;
}
获得的数据
Bid {
h2 = \'详见内容\',
itemName = \'诉讼服务中心设备采购\',
item = \'货物/办公消耗用品及类似物品/其他办公消耗用品及类似物品\',
itemUnit = \'详见内容\',
areaName = \'港北区\',
noticeTime = \'2018年10月22日 18:41\',
itemNoticeTime = \'null\',
itemTime = \'null\',
kaibiaoTime = \'2018年10月26日 09:00\',
winTime = \'null\',
kaibiaoDiDian = \'null\',
yusuanMoney = \'¥67.00元(人民币)\',
allMoney = \'null\',
money = \'null\',
text = \'\'
}
c 抓取网页数据(网站反爬js函数破解方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-12 13:01
介绍
如今的网站反爬法层出不穷,不像以前那么简单了。网页在后端呈现数据,然后将其发送到客户端。现在一般的web技术,前后端分离,前端通过js函数发送请求向后端请求数据,然后渲染数据。因此,如果我们简单地发送请求,最终结果只是一堆js函数。
当然爬虫里面也有对应的破解方法:selenium自动化工具,就是驱动浏览器模拟人为获取数据
安装 1、 安装硒库
pip install selenium
# 上面命令安装失败请用下面命令
pip install selenium -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2、ChromeDriver
2.1、 Selenium如果要连接Chrome等主流浏览器,对应的浏览器需要安装驱动
2.2、 例如:selenium连接Chrome,需要安装ChromeDriver驱动
2.3、在ChromeDriver Mirror中找到对应版本Chrome的驱动(类似版本也是可以的)
2.4、 下载解压后,将chromedriver.exe放到项目目录下
2.5、确保Chrome浏览器设置环境变量
用 查看全部
c 抓取网页数据(网站反爬js函数破解方法)
介绍
如今的网站反爬法层出不穷,不像以前那么简单了。网页在后端呈现数据,然后将其发送到客户端。现在一般的web技术,前后端分离,前端通过js函数发送请求向后端请求数据,然后渲染数据。因此,如果我们简单地发送请求,最终结果只是一堆js函数。
当然爬虫里面也有对应的破解方法:selenium自动化工具,就是驱动浏览器模拟人为获取数据
安装 1、 安装硒库
pip install selenium
# 上面命令安装失败请用下面命令
pip install selenium -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2、ChromeDriver
2.1、 Selenium如果要连接Chrome等主流浏览器,对应的浏览器需要安装驱动
2.2、 例如:selenium连接Chrome,需要安装ChromeDriver驱动
2.3、在ChromeDriver Mirror中找到对应版本Chrome的驱动(类似版本也是可以的)
2.4、 下载解压后,将chromedriver.exe放到项目目录下
2.5、确保Chrome浏览器设置环境变量
用

