
c 抓取网页数据
c 抓取网页数据(Python网络数据实战系列16——XPath与网页解析库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-09 00:25
经常有朋友跟我商量,在使用R语言做网络数据采集时,遇到空值、缺失值或不存在值该怎么办。
因为我们从网上抓取的数据大多是关系型的,需要字段和记录一一对应,但是html文档的结构差异很大,代码复杂,很难保证提取出来的数据在开始时是严格相关的。需要做很多缺失值、不存在的内容判断。
如果原创数据是关系数据,但是你抓取的字段乱序,记录不能一一对应,那么这些数据通常价值不大。今天我用一个小案例来演示(和昨天的案例一样)。如何在网页遍历和循环嵌套中设置逻辑判断,对缺失值和不存在值及时填写默认值,让你的爬虫代码更健壮,输出内容更规律.
加载扩展包:
#加载包:
library("XML")
library("stringr")
library("RCurl")
library("dplyr")
library("rvest")
#提供目标网址链接/报头参数
url% xpathSApply(.,"//span[@class='category']/span[2]/span | //p[@class='category']/span[@class='labled-text'] | //div[@class='category']",xmlValue) %>% c(category,.)
###提取作者/副标题/评论数/评分/价格信息:
author_text=subtitle_text=eveluate_nums_text=rating_text=price_text=rep('',length)
for (i in 1:length){
###提取作者
author_text[i]=content %>% xpathSApply(.,sprintf("//li[%d]//p[@class]//span/following-sibling::span/a | //li[%d]//div[@class='author']/a",i,i),xmlValue) %>% paste(.,collapse='/')
###考虑副标题是否存在
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue) %>% length!=0){
subtitle_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue)
}
###考虑评价是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue) %>% length!=0){
eveluate_nums_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue)
}
###考虑评分是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue) %>% length!=0){
rating_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue)
}
###考虑价格是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue) %>% length!=0){
price_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue)
}
}
#拼接以上通过下标遍历的书籍记录数
author=c(author,author_text)
subtitle=c(subtitle,subtitle_text)
eveluate_nums=c(eveluate_nums,eveluate_nums_text)
rating=c(rating,rating_text)
price=c(price,price_text)
#打印单页任务状态
print(sprintf("page %d is over!!!",page))
}
#构建数据框
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)
#打印总体任务状态
print("everything is OK")
#返回最终汇总的数据框
return(myresult)
}
提供URL链接,运行我们构建的爬取功能:
myresult=getcontent(url)
[1] "page 0 is over!!!"
[1] "page 1 is over!!!"
[1] "page 2 is over!!!"
[1] "page 3 is over!!!"
[1] "everything is OK"
查看数据结构:
str(myresult)
规格变量类型:
<p>myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating 查看全部
c 抓取网页数据(Python网络数据实战系列16——XPath与网页解析库)
经常有朋友跟我商量,在使用R语言做网络数据采集时,遇到空值、缺失值或不存在值该怎么办。
因为我们从网上抓取的数据大多是关系型的,需要字段和记录一一对应,但是html文档的结构差异很大,代码复杂,很难保证提取出来的数据在开始时是严格相关的。需要做很多缺失值、不存在的内容判断。
如果原创数据是关系数据,但是你抓取的字段乱序,记录不能一一对应,那么这些数据通常价值不大。今天我用一个小案例来演示(和昨天的案例一样)。如何在网页遍历和循环嵌套中设置逻辑判断,对缺失值和不存在值及时填写默认值,让你的爬虫代码更健壮,输出内容更规律.
加载扩展包:
#加载包:
library("XML")
library("stringr")
library("RCurl")
library("dplyr")
library("rvest")
#提供目标网址链接/报头参数
url% xpathSApply(.,"//span[@class='category']/span[2]/span | //p[@class='category']/span[@class='labled-text'] | //div[@class='category']",xmlValue) %>% c(category,.)
###提取作者/副标题/评论数/评分/价格信息:
author_text=subtitle_text=eveluate_nums_text=rating_text=price_text=rep('',length)
for (i in 1:length){
###提取作者
author_text[i]=content %>% xpathSApply(.,sprintf("//li[%d]//p[@class]//span/following-sibling::span/a | //li[%d]//div[@class='author']/a",i,i),xmlValue) %>% paste(.,collapse='/')
###考虑副标题是否存在
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue) %>% length!=0){
subtitle_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue)
}
###考虑评价是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue) %>% length!=0){
eveluate_nums_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue)
}
###考虑评分是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue) %>% length!=0){
rating_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue)
}
###考虑价格是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue) %>% length!=0){
price_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue)
}
}
#拼接以上通过下标遍历的书籍记录数
author=c(author,author_text)
subtitle=c(subtitle,subtitle_text)
eveluate_nums=c(eveluate_nums,eveluate_nums_text)
rating=c(rating,rating_text)
price=c(price,price_text)
#打印单页任务状态
print(sprintf("page %d is over!!!",page))
}
#构建数据框
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)
#打印总体任务状态
print("everything is OK")
#返回最终汇总的数据框
return(myresult)
}
提供URL链接,运行我们构建的爬取功能:
myresult=getcontent(url)
[1] "page 0 is over!!!"
[1] "page 1 is over!!!"
[1] "page 2 is over!!!"
[1] "page 3 is over!!!"
[1] "everything is OK"
查看数据结构:
str(myresult)
规格变量类型:
<p>myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating
c 抓取网页数据( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-08 08:16
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫爬虫
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当一个页面的内容发生变化时,URL也会相应地发生变化。基本上,它是一个静态页面,反之则是一个动态页面。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请在html中文网站搜索之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c 抓取网页数据(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/";) # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:

第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫爬虫
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")

#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)

4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)

#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)

#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])

三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当一个页面的内容发生变化时,URL也会相应地发生变化。基本上,它是一个静态页面,反之则是一个动态页面。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]

import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]

总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text


如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。

import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content

至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请在html中文网站搜索之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多详情请关注其他相关html中文网站文章!
c 抓取网页数据(具体分析如下实现抓取和分析网页类,实例分析了抓取及分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-06 03:14
本文文章主要介绍了网页爬取分析的C#实现,并举例分析了C#对网页中的文字和连接进行抓取和分析的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页的纯文本,转到所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、 可以实现简单的表单提交和cookie保存
/* * Author:Sunjoy at CCNU * 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com) */ using System; using System.Data; using System.Configuration; using System.Net; using System.IO; using System.Text; using System.Collections.Generic; using System.Text.RegularExpressions; using System.Threading; using System.Web; /// /// 网页类 /// public class WebPage { #region 私有成员 private Uri m_uri; //网址 private List m_links; //此网页上的链接 private string m_title; //此网页的标题 private string m_html; //此网页的HTML代码 private string m_outstr; //此网页可输出的纯文本 private bool m_good; //此网页是否可用 private int m_pagesize; //此网页的大小 private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie private string m_post; //此网页的登陆页需要的POST数据 private string m_loginurl; //此网页的登陆页 #endregion #region 私有方法 /// /// 这私有方法从网页的HTML代码中分析出链接信息 /// /// List private List getLinks() { if (m_links.Count == 0) { Regex[] regex = new Regex[2]; regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, ""); Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg.Replace(m_outstr, ""); Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg2.Replace(m_outstr, " "); } return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr; } /// /// 此私有方法返回一个IP地址对应的无符号整数 /// /// IP地址 /// private uint getuintFromIP(IPAddress x) { Byte[] bt = x.GetAddressBytes(); uint i = (uint)(bt[0] * 256 * 256 * 256); i += (uint)(bt[1] * 256 * 256); i += (uint)(bt[2] * 256); i += (uint)(bt[3]); return i; } #endregion #region 公有文法 /// /// 此公有方法提取网页中一定字数的纯文本,包括链接文字 /// /// 字数 /// public string getContext(int firstN) { return getFirstNchar(m_html, firstN, true); } /// /// 此公有方法提取网页中一定字数的纯文本,不包括链接文字 /// /// /// public string getContextWithOutLink(int firstN) { return getFirstNchar(m_html, firstN, false); } /// /// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式 /// /// 正则式 /// 返回的链接的个数 /// List public List getSpecialLinksByUrl(string pattern,int count) { if(m_links.Count==0)getLinks(); List SpecialLinks = new List(); List.Enumerator i; i = m_links.GetEnumerator(); int cnt = 0; while (i.MoveNext() && cnt(?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ); Match mc = reg.Match(m_html); if (mc.Success) m_title= mc.Groups["title"].Value.Trim(); } return m_title; } } /// /// 此属性获得本网页的所有链接信息,只读 /// public List Links { get { if (m_links.Count == 0) getLinks(); return m_links; } } /// /// 此属性返回本网页的全部纯文本信息,只读 /// public string Context { get { if (m_outstr == "") getContext(Int16.MaxValue); return m_outstr; } } /// /// 此属性获得本网页的大小 /// public int PageSize { get { return m_pagesize; } } /// /// 此属性获得本网页的所有站内链接 /// public List InsiteLinks { get { return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue); } } /// /// 此属性表示本网页是否可用 /// public bool IsGood { get { return m_good; } } /// /// 此属性表示网页的所在的网站 /// public string Host { get { return m_uri.Host; } } /// /// 此网页的登陆页所需的POST数据 /// public string PostStr { get { return m_post; } } /// /// 此网页的登陆页 /// public string LoginURL { get { return m_loginurl; } } #endregion } /// /// 链接类 /// public class Link { public string url; //链接网址 public string text; //链接文字 public Link(string _url, string _text) { url = _url; text = _text; } }
我希望这篇文章对你的 C# 编程有所帮助。
以上就是爬取分析网页类示例的C#实现的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c 抓取网页数据(具体分析如下实现抓取和分析网页类,实例分析了抓取及分析)
本文文章主要介绍了网页爬取分析的C#实现,并举例分析了C#对网页中的文字和连接进行抓取和分析的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页的纯文本,转到所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、 可以实现简单的表单提交和cookie保存
/* * Author:Sunjoy at CCNU * 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com) */ using System; using System.Data; using System.Configuration; using System.Net; using System.IO; using System.Text; using System.Collections.Generic; using System.Text.RegularExpressions; using System.Threading; using System.Web; /// /// 网页类 /// public class WebPage { #region 私有成员 private Uri m_uri; //网址 private List m_links; //此网页上的链接 private string m_title; //此网页的标题 private string m_html; //此网页的HTML代码 private string m_outstr; //此网页可输出的纯文本 private bool m_good; //此网页是否可用 private int m_pagesize; //此网页的大小 private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie private string m_post; //此网页的登陆页需要的POST数据 private string m_loginurl; //此网页的登陆页 #endregion #region 私有方法 /// /// 这私有方法从网页的HTML代码中分析出链接信息 /// /// List private List getLinks() { if (m_links.Count == 0) { Regex[] regex = new Regex[2]; regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, ""); Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg.Replace(m_outstr, ""); Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg2.Replace(m_outstr, " "); } return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr; } /// /// 此私有方法返回一个IP地址对应的无符号整数 /// /// IP地址 /// private uint getuintFromIP(IPAddress x) { Byte[] bt = x.GetAddressBytes(); uint i = (uint)(bt[0] * 256 * 256 * 256); i += (uint)(bt[1] * 256 * 256); i += (uint)(bt[2] * 256); i += (uint)(bt[3]); return i; } #endregion #region 公有文法 /// /// 此公有方法提取网页中一定字数的纯文本,包括链接文字 /// /// 字数 /// public string getContext(int firstN) { return getFirstNchar(m_html, firstN, true); } /// /// 此公有方法提取网页中一定字数的纯文本,不包括链接文字 /// /// /// public string getContextWithOutLink(int firstN) { return getFirstNchar(m_html, firstN, false); } /// /// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式 /// /// 正则式 /// 返回的链接的个数 /// List public List getSpecialLinksByUrl(string pattern,int count) { if(m_links.Count==0)getLinks(); List SpecialLinks = new List(); List.Enumerator i; i = m_links.GetEnumerator(); int cnt = 0; while (i.MoveNext() && cnt(?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ); Match mc = reg.Match(m_html); if (mc.Success) m_title= mc.Groups["title"].Value.Trim(); } return m_title; } } /// /// 此属性获得本网页的所有链接信息,只读 /// public List Links { get { if (m_links.Count == 0) getLinks(); return m_links; } } /// /// 此属性返回本网页的全部纯文本信息,只读 /// public string Context { get { if (m_outstr == "") getContext(Int16.MaxValue); return m_outstr; } } /// /// 此属性获得本网页的大小 /// public int PageSize { get { return m_pagesize; } } /// /// 此属性获得本网页的所有站内链接 /// public List InsiteLinks { get { return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue); } } /// /// 此属性表示本网页是否可用 /// public bool IsGood { get { return m_good; } } /// /// 此属性表示网页的所在的网站 /// public string Host { get { return m_uri.Host; } } /// /// 此网页的登陆页所需的POST数据 /// public string PostStr { get { return m_post; } } /// /// 此网页的登陆页 /// public string LoginURL { get { return m_loginurl; } } #endregion } /// /// 链接类 /// public class Link { public string url; //链接网址 public string text; //链接文字 public Link(string _url, string _text) { url = _url; text = _text; } }
我希望这篇文章对你的 C# 编程有所帮助。
以上就是爬取分析网页类示例的C#实现的详细内容。更多详情请关注其他相关html中文网站文章!
c 抓取网页数据(图里面的内容1.解析()并发请求中的node )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-05 16:08
)
获取下图内容
1.在当前网页右击查看,不能按图中标签进入leader介绍页面。
2.分析网页信息,发现请求如下
3.右键查看网页源码,发现请求中的node_id和cat_id参数是源码中js的变量,所以我们要解析这些变量,拼接url并发请求获取我们需要的数据
4.解析js部分的代码
def parse_url(self, response):
node_id = re.findall('var node_id = "(.*?)";', response.text)
res_str = re.findall("var zTreeNodes = (.*?);", response.text)
if res_str:
node_id = node_id[0]
res_json = json.loads(res_str[0])
# print("res_json=",res_json)
for res in res_json:
id = str(res['id'])
name = res['text']
url = 'http://www.snbinzhou.gov.cn/in ... 39%3B + node_id + '&cat_id=' + id
if “领导” in name:
yield Request(url,call_back=self.parse_detail,meta={"item":response.meta['item']}) 查看全部
c 抓取网页数据(图里面的内容1.解析()并发请求中的node
)
获取下图内容

1.在当前网页右击查看,不能按图中标签进入leader介绍页面。

2.分析网页信息,发现请求如下

3.右键查看网页源码,发现请求中的node_id和cat_id参数是源码中js的变量,所以我们要解析这些变量,拼接url并发请求获取我们需要的数据

4.解析js部分的代码
def parse_url(self, response):
node_id = re.findall('var node_id = "(.*?)";', response.text)
res_str = re.findall("var zTreeNodes = (.*?);", response.text)
if res_str:
node_id = node_id[0]
res_json = json.loads(res_str[0])
# print("res_json=",res_json)
for res in res_json:
id = str(res['id'])
name = res['text']
url = 'http://www.snbinzhou.gov.cn/in ... 39%3B + node_id + '&cat_id=' + id
if “领导” in name:
yield Request(url,call_back=self.parse_detail,meta={"item":response.meta['item']})
c 抓取网页数据(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-04 23:10
缺点:
只检索页面的静态内容
不能用于解析 HTML
无法处理纯 JavaScript 网站
2.lxml
lxml 是一个高性能、快速、高质量和高效的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算爬取大数据集的时候,它可以起到很好的作用。
在网络爬虫中,lxml 经常与 Requests 结合使用。此外,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python 库的优缺点是什么?
优势:
比大多数解析器更快
光
使用元素树
蟒蛇式API
缺点:
不适合设计糟糕的 HTML
官方文档不适合初学者
3.美汤
BeautifulSoup 可能是网络抓取中使用最广泛的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。它还自动将传入文档转换为 Unicode,将传出文档转换为 UTF-8。
在业界,“BeautifulSoup”和“Requests”的结合非常常见。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,您还可以将 Beautiful Soup 与其他解析器(如 lxml)结合使用。
但是相应的,这种易用性也带来了不小的运行成本——比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面看看BeautifulSoup库的优缺点是什么?
优势:
需要几行代码
质量文件
初学者易于学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您无法轻松地从动态填充的 网站 中获取数据。
发生这种情况的原因有时是因为页面上存在的数据是通过 JavaScript 加载的。简单总结一下,如果页面不是静态的,前面提到的Python库就很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。
Selenium 最初是一个 Python 库,用于自动测试 Web 应用程序。它是一个用于渲染网页的网络驱动程序。因此,Selenium 可以在其他库无法运行 JavaScript 的情况下发挥作用:单击页面、填写表单、滚动页面并执行更多操作。
这种在网页中运行 JavaScript 的能力允许 Selenium 抓取动态填充的网页。但这里有一个“缺陷”。它为每个页面加载并运行 JavaScript,这会使其变慢并且不适合大型项目。
如果你不在乎时间和速度,那么Selenium绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动浏览器
可以对网页进行任何操作,类似于一个人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. Scrapy
现在是时候介绍一下 Python 网页抓取库的 BOSS 了——Scrapy!
Scrapy 不仅仅是一个库。它是由 Scrapinghub、Pablo Hoffman 和 Shane Evans 的联合创始人创建的整个网络抓取框架。它是一个功能齐全的网页抓取解决方案,可以完成所有繁重的工作。
Scrapy提供的蜘蛛机器人可以抓取多个网站并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或将其用作 API。您可以在几分钟内创建一个功能齐全的蜘蛛网,或者您可以使用 Scrapy 创建一个管道。
Scrapy 最大的优点是它是异步的,这意味着可以同时进行多个 HTTP 请求,这样可以为我们节省大量时间并提高效率(这不是我们在争取的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。尽管 Scrapy 不能像 selenium 一样处理 JavaScript,但它可以与一个名为 Splash(一个轻量级的 Web 浏览器)的库搭配使用。使用 Splash,Scrapy 可以从动态的 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他的库可以很好用,欢迎留言~
原文链接: 查看全部
c 抓取网页数据(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
缺点:
只检索页面的静态内容
不能用于解析 HTML
无法处理纯 JavaScript 网站
2.lxml

lxml 是一个高性能、快速、高质量和高效的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算爬取大数据集的时候,它可以起到很好的作用。
在网络爬虫中,lxml 经常与 Requests 结合使用。此外,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python 库的优缺点是什么?
优势:
比大多数解析器更快
光
使用元素树
蟒蛇式API
缺点:
不适合设计糟糕的 HTML
官方文档不适合初学者
3.美汤

BeautifulSoup 可能是网络抓取中使用最广泛的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。它还自动将传入文档转换为 Unicode,将传出文档转换为 UTF-8。
在业界,“BeautifulSoup”和“Requests”的结合非常常见。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,您还可以将 Beautiful Soup 与其他解析器(如 lxml)结合使用。
但是相应的,这种易用性也带来了不小的运行成本——比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面看看BeautifulSoup库的优缺点是什么?
优势:
需要几行代码
质量文件
初学者易于学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您无法轻松地从动态填充的 网站 中获取数据。
发生这种情况的原因有时是因为页面上存在的数据是通过 JavaScript 加载的。简单总结一下,如果页面不是静态的,前面提到的Python库就很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。

Selenium 最初是一个 Python 库,用于自动测试 Web 应用程序。它是一个用于渲染网页的网络驱动程序。因此,Selenium 可以在其他库无法运行 JavaScript 的情况下发挥作用:单击页面、填写表单、滚动页面并执行更多操作。
这种在网页中运行 JavaScript 的能力允许 Selenium 抓取动态填充的网页。但这里有一个“缺陷”。它为每个页面加载并运行 JavaScript,这会使其变慢并且不适合大型项目。
如果你不在乎时间和速度,那么Selenium绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动浏览器
可以对网页进行任何操作,类似于一个人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. Scrapy
现在是时候介绍一下 Python 网页抓取库的 BOSS 了——Scrapy!

Scrapy 不仅仅是一个库。它是由 Scrapinghub、Pablo Hoffman 和 Shane Evans 的联合创始人创建的整个网络抓取框架。它是一个功能齐全的网页抓取解决方案,可以完成所有繁重的工作。
Scrapy提供的蜘蛛机器人可以抓取多个网站并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或将其用作 API。您可以在几分钟内创建一个功能齐全的蜘蛛网,或者您可以使用 Scrapy 创建一个管道。
Scrapy 最大的优点是它是异步的,这意味着可以同时进行多个 HTTP 请求,这样可以为我们节省大量时间并提高效率(这不是我们在争取的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。尽管 Scrapy 不能像 selenium 一样处理 JavaScript,但它可以与一个名为 Splash(一个轻量级的 Web 浏览器)的库搭配使用。使用 Splash,Scrapy 可以从动态的 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他的库可以很好用,欢迎留言~
原文链接:
c 抓取网页数据(IT从业者快速学习JSON教程结构概述:JSON基础教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-04 22:05
了解 JSON:
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。
从 Web API 和服务器端编程语言到 NoSQL 数据库和客户端框架,JSON 无处不在。在不同平台之间传输数据方面,JSON 已成为 XML 的强大替代品。本教程将帮助忙碌的 IT 从业者快速学习 JSON,并深入了解如何在自己的项目中使用它。
JSON教程结构概述:
本教程由 11 章组成。详细介绍了JSON的基本使用方法,并附送大量在线试运行示例,助你学习,让你轻松掌握JSON。
本教程包括:
1、JSON 简介
2、JSON 基础知识
3、JSON 格式
4、JSON 示例
5、JSON 解析
6、JSON 遍历
7、JSON 调用
8、JSON 转换
9、JSON 获取
10、JSON 字符串
11、JSON 数组
JSON开发与学习前的准备:
JSON 由 Douglas Crockford 在 2001 年创建,并被 IETF(互联网工程任务组)定义为 RFC 4627 标准。JSON的媒体类型定义为application/json,文件后缀为.json。2005年到2006年正式成为主流数据格式,雅虎和谷歌当时开始广泛使用JSON格式。
在开始学习 JSON 之前,您应该对以下内容有一个基本的了解:
《AJAX 教程》
《JQuery 教程》
本教程旨在帮助初学者了解 JavaScript Object Notation (JSON) 开发数据交换格式的基本功能。完成本教程后,您会发现自己处于在 JavaScript、AJAX 和 Perl 中使用 JSON 的中级水平,然后您可以自己进入下一个级别。
JSON 的优缺点:
优势:
A.数据格式比较简单,易读易写,格式经过压缩,带宽小;
B. 解析简单,客户端JavaScript可以简单的通过eval()读取JSON数据;
C、支持多种语言,包括ActionScript、C、C#、ColdFusion、Java、JavaScript、Perl、PHP、Python、Ruby等服务端语言,方便服务端分析;
D、在PHP世界中,出现了PHP-JSON和JSON-PHP。他们更喜欢在 PHP 序列化后直接调用。PHP服务端的对象和数组可以直接生成JSON格式,方便客户端访问和提取;
E、由于JSON格式可以直接用于服务端代码,大大简化了服务端和客户端的代码开发量,任务完成情况不变,易于维护。
缺点:
A.没有XML格式这样的普及普及,不如XML通用;
B. JSON 格式在 Web Service 中的推广还处于起步阶段。
相关网址:
json中文官网:
json官网:
json参考手册:(翻译)JSON-RPC 2.0 规范(中文版) 查看全部
c 抓取网页数据(IT从业者快速学习JSON教程结构概述:JSON基础教程)
了解 JSON:
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。

从 Web API 和服务器端编程语言到 NoSQL 数据库和客户端框架,JSON 无处不在。在不同平台之间传输数据方面,JSON 已成为 XML 的强大替代品。本教程将帮助忙碌的 IT 从业者快速学习 JSON,并深入了解如何在自己的项目中使用它。
JSON教程结构概述:
本教程由 11 章组成。详细介绍了JSON的基本使用方法,并附送大量在线试运行示例,助你学习,让你轻松掌握JSON。
本教程包括:
1、JSON 简介
2、JSON 基础知识
3、JSON 格式
4、JSON 示例
5、JSON 解析
6、JSON 遍历
7、JSON 调用
8、JSON 转换
9、JSON 获取
10、JSON 字符串
11、JSON 数组
JSON开发与学习前的准备:
JSON 由 Douglas Crockford 在 2001 年创建,并被 IETF(互联网工程任务组)定义为 RFC 4627 标准。JSON的媒体类型定义为application/json,文件后缀为.json。2005年到2006年正式成为主流数据格式,雅虎和谷歌当时开始广泛使用JSON格式。
在开始学习 JSON 之前,您应该对以下内容有一个基本的了解:
《AJAX 教程》
《JQuery 教程》
本教程旨在帮助初学者了解 JavaScript Object Notation (JSON) 开发数据交换格式的基本功能。完成本教程后,您会发现自己处于在 JavaScript、AJAX 和 Perl 中使用 JSON 的中级水平,然后您可以自己进入下一个级别。
JSON 的优缺点:
优势:
A.数据格式比较简单,易读易写,格式经过压缩,带宽小;
B. 解析简单,客户端JavaScript可以简单的通过eval()读取JSON数据;
C、支持多种语言,包括ActionScript、C、C#、ColdFusion、Java、JavaScript、Perl、PHP、Python、Ruby等服务端语言,方便服务端分析;
D、在PHP世界中,出现了PHP-JSON和JSON-PHP。他们更喜欢在 PHP 序列化后直接调用。PHP服务端的对象和数组可以直接生成JSON格式,方便客户端访问和提取;
E、由于JSON格式可以直接用于服务端代码,大大简化了服务端和客户端的代码开发量,任务完成情况不变,易于维护。
缺点:
A.没有XML格式这样的普及普及,不如XML通用;
B. JSON 格式在 Web Service 中的推广还处于起步阶段。
相关网址:
json中文官网:
json官网:
json参考手册:(翻译)JSON-RPC 2.0 规范(中文版)
c 抓取网页数据(如何查看二级页面(详情页)的三连数据?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-04 01:19
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单。可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["./ranking/all/1/0/3"],"selectors":[{"id":"container","type": "SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type ":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id" :"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0 },{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":"。
详细信息> span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type": "SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay" :0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay" :0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.
collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“跨度。share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors": ["容器"],"选择器":"div. num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“。操作范围。喜欢","multiple":false,"regex":"","
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
c 抓取网页数据(如何查看二级页面(详情页)的三连数据?-八维教育)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单。可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["./ranking/all/1/0/3"],"selectors":[{"id":"container","type": "SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type ":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id" :"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0 },{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":"。
详细信息> span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type": "SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay" :0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay" :0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.
collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“跨度。share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors": ["容器"],"选择器":"div. num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“。操作范围。喜欢","multiple":false,"regex":"","
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
c 抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏之处! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-01 23:01
)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,我要温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只在csdn平台更新,博客主页:。
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载!!!
内容
前言
网络爬虫的一般流程
一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:
二、常用的获取网页数据的方法2.1 URLlib
下面我们先来看一个小demo
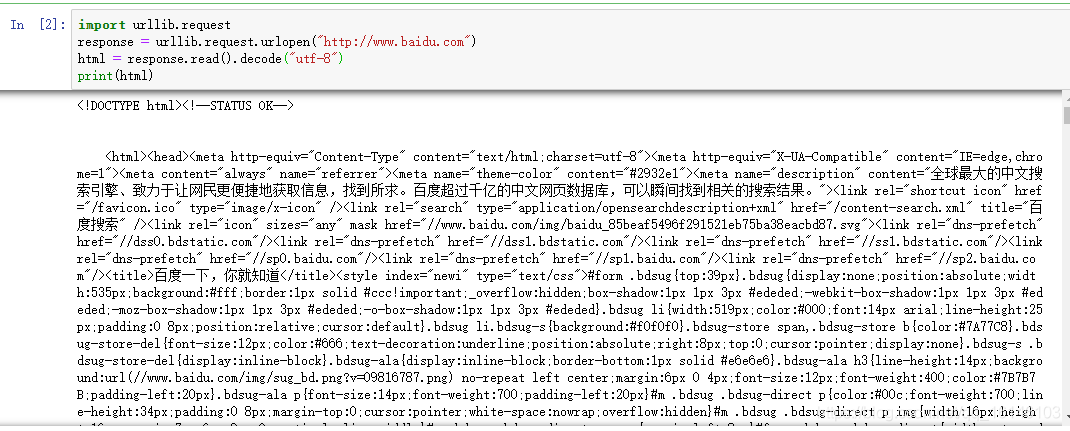
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣的可以自行查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout: 释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
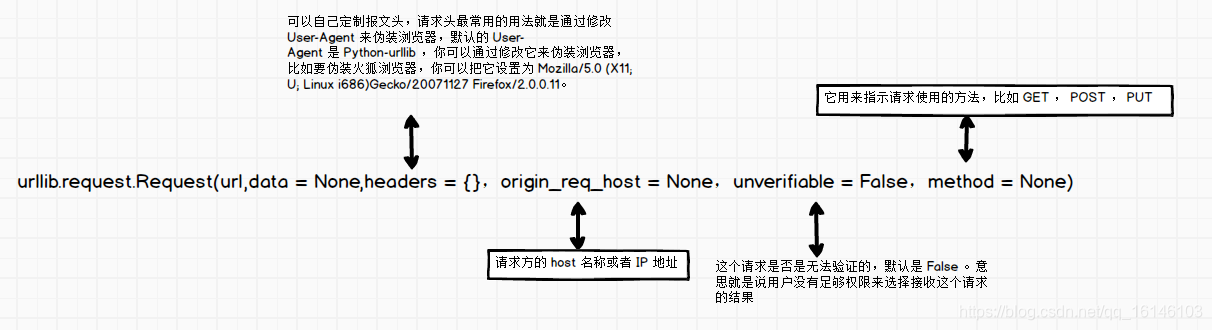
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {
},origin_req_host = None,unverifiable = False,method = None)
详细代码:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {
"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、开瓶器
开场导演:
5、饼干
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。推荐爬虫使用Requests库。
官方文档链接:
1、请求库安装
在终端中运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {
'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {
'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
从上图我们可以看出,方法名把请求表达的很清楚,get就是GET,post就是POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,requests会自动读取响应的内容并保存在text变量中。您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了以上信息,响应还提供了很多其他信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {
'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {
'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
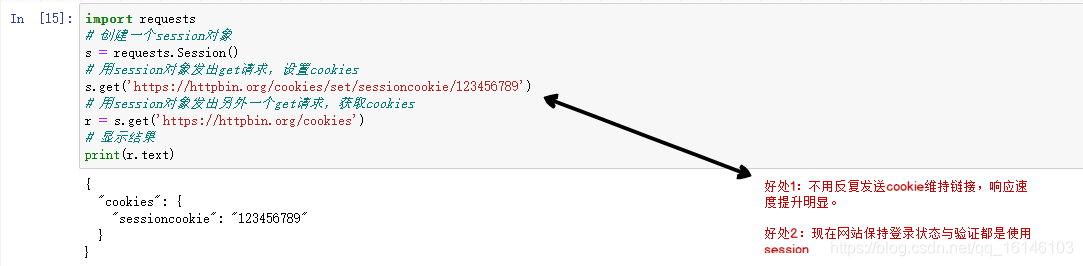
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大多数用途类似于 urllib2。此外,请求的文档非常完整。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能会有人感到惊讶,因为在上一篇文章中,当我们使用urllib2发起同样的请求时,结果还是空的。这确实有点奇怪,因为 urllib2 默认会忽略所有请求的 cookie,即使是重定向的请求,请求也会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {
'http':'http://username:[email protected]:port','http://username:[email protected]:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得之前在urllib2上的练习都是徒劳的,因为requests非常简单易学!当然也没有白费,urllib2是一个非常基础的网络库,其他很多网络库,包括requests,都是基于urllib2开发的。我们之前进行的练习将帮助我们更好地理解网络,了解Python对网络的处理,这对我们未来开发可靠高效的爬虫有很大的帮助。
需要注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要把它转换成中文。无法直接打印。因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符串编码成UTF-8字符串最终转换为 dict 以便于输出。
三、浏览器简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图:
在这个页面调出Chrome Inspect,我们可以看到类似如下的界面:
通常我们最常用的功能是查看某个元素的源代码,点击左上角的元素定位器,可以在网页中选择不同的元素,HTML源代码区会自动显示指定的源代码元素,通常CSS显示区域也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择网络,可以看到如下界面:
Chrome 网络的交互区域展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,可以看到如下界面:
在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 KV 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示接收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
401 Authentication Required:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:未找到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,但使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后再试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略,响应状态码代表服务器的处理结果,对于我们调整服务器的爬虫状态(如频率、ip)有重要的参考意义。履带。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候我们就得减慢爬取频率,或者重启Session,甚至更改IP。
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
一本好书永远不会厌倦阅读一百遍。而如果我想成为全场最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人运气不会太差,每天都充满活力!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!
查看全部
c 抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏之处!
)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,我要温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只在csdn平台更新,博客主页:。
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载!!!
内容

前言
网络爬虫的一般流程

一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:

二、常用的获取网页数据的方法2.1 URLlib
下面我们先来看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com";)
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣的可以自行查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout: 释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {
},origin_req_host = None,unverifiable = False,method = None)
详细代码:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {
"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、开瓶器
开场导演:
5、饼干
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com";)
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。推荐爬虫使用Requests库。
官方文档链接:
1、请求库安装
在终端中运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {
'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {
'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])

从上图我们可以看出,方法名把请求表达的很清楚,get就是GET,post就是POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,requests会自动读取响应的内容并保存在text变量中。您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然

除了以上信息,响应还提供了很多其他信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {
'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {
'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大多数用途类似于 urllib2。此外,请求的文档非常完整。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能会有人感到惊讶,因为在上一篇文章中,当我们使用urllib2发起同样的请求时,结果还是空的。这确实有点奇怪,因为 urllib2 默认会忽略所有请求的 cookie,即使是重定向的请求,请求也会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())

我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {
'http':'http://username:[email protected]:port','http://username:[email protected]:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得之前在urllib2上的练习都是徒劳的,因为requests非常简单易学!当然也没有白费,urllib2是一个非常基础的网络库,其他很多网络库,包括requests,都是基于urllib2开发的。我们之前进行的练习将帮助我们更好地理解网络,了解Python对网络的处理,这对我们未来开发可靠高效的爬虫有很大的帮助。
需要注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要把它转换成中文。无法直接打印。因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符串编码成UTF-8字符串最终转换为 dict 以便于输出。
三、浏览器简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图:
在这个页面调出Chrome Inspect,我们可以看到类似如下的界面:
通常我们最常用的功能是查看某个元素的源代码,点击左上角的元素定位器,可以在网页中选择不同的元素,HTML源代码区会自动显示指定的源代码元素,通常CSS显示区域也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择网络,可以看到如下界面:

Chrome 网络的交互区域展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,可以看到如下界面:
在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 KV 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示接收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
401 Authentication Required:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:未找到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,但使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后再试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略,响应状态码代表服务器的处理结果,对于我们调整服务器的爬虫状态(如频率、ip)有重要的参考意义。履带。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候我们就得减慢爬取频率,或者重启Session,甚至更改IP。

美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!

一本好书永远不会厌倦阅读一百遍。而如果我想成为全场最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人运气不会太差,每天都充满活力!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!


c 抓取网页数据(百度收录网站,如何使用数据抓取数据的速度怎样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-01 22:25
实现如下:
示例·:一个excel文件收录一百多个工作表,但工作表名称没有规则的顺序,不是按sheet1、sheet2的顺序排列的。现在我们需要将每个工作表中的A3数据提取出来,形成一个新的列。
解决方案:使用宏自定义函数
同时按下Alt和F11进入宏界面,点击菜单插入,屏蔽,粘贴如下代码:
Function AllSh(xStr As String, i As Integer)
应用程序.易变
AllSh = Sheets(i).Range(xStr).Value
结束函数
回到excel,在任意单元格输入=allsh("A3",ROW(A1))
公式被复制下来。
在数据库中,data采集和data capture是什么意思?
个人理解:
数据采集分为多种类型。比如从纸质或非结构化数据整理成结构化数据可以存入数据库的过程,可以算作一种数据采集;将数据从某个数据库导出到另一个数据库也可以看成是一种数据采集; 比如通过观察记录获得某些环境指标(空气质量、温度、湿度、人体温度、机器cpu占用率等)变化的过程也可以看作是一种数据采集和很快。简而言之,一种数据存在形式通过“某种加工”转化为另一种数据存在形式。我个人认为所谓的“某些处理”统称为数据采集。
经常使用术语数据捕获,例如 Web 内容数据捕获。从某种意义上说,它与数据采集具有相同的含义,但在本质上,数据主体似乎有主动和被动的区别。. 当然,数据捕获更多的是指从现有的结构化数据中获取数据的过程。
如何使用C语言进行数据爬取 数据爬取的速度是多少?
百度收录网站,首先让百度蜘蛛来爬网站,要做的就是吸引百度蜘蛛爬网站,主要有以下几点做好的步骤:
1、 识别URL重定向,互联网信息数据量非常大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛重新上报网址。定向识别
2、为了抓取网站的友好性,百度蜘蛛会制定规则,最大限度地利用带宽和所有资源,以便在抓取互联网信息时获得越来越准确的信息,同时也只最小化爬取的网站的压力。
3、 在抓取作弊信息时,我们经常会遇到页面质量低、买卖链接等问题。百度引入了绿萝、石榴等算法进行过滤。据说里面还有一些其他的方法。判断,这些方法还没有对外公开。
4、 无法获取爬取数据,网络中可能出现各种问题,导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开放了手动提交数据。
5、 合理使用百度蜘蛛抓取优先级。由于互联网信息量巨大,在这种情况下无法使用一种策略来指定首先抓取哪些内容。这时候就需要建立多个优先级的Grabing策略,目前的策略主要有:深度优先、广度优先、PR优先、反链优先。 查看全部
c 抓取网页数据(百度收录网站,如何使用数据抓取数据的速度怎样?)
实现如下:
示例·:一个excel文件收录一百多个工作表,但工作表名称没有规则的顺序,不是按sheet1、sheet2的顺序排列的。现在我们需要将每个工作表中的A3数据提取出来,形成一个新的列。
解决方案:使用宏自定义函数
同时按下Alt和F11进入宏界面,点击菜单插入,屏蔽,粘贴如下代码:
Function AllSh(xStr As String, i As Integer)
应用程序.易变
AllSh = Sheets(i).Range(xStr).Value
结束函数
回到excel,在任意单元格输入=allsh("A3",ROW(A1))
公式被复制下来。

在数据库中,data采集和data capture是什么意思?
个人理解:
数据采集分为多种类型。比如从纸质或非结构化数据整理成结构化数据可以存入数据库的过程,可以算作一种数据采集;将数据从某个数据库导出到另一个数据库也可以看成是一种数据采集; 比如通过观察记录获得某些环境指标(空气质量、温度、湿度、人体温度、机器cpu占用率等)变化的过程也可以看作是一种数据采集和很快。简而言之,一种数据存在形式通过“某种加工”转化为另一种数据存在形式。我个人认为所谓的“某些处理”统称为数据采集。
经常使用术语数据捕获,例如 Web 内容数据捕获。从某种意义上说,它与数据采集具有相同的含义,但在本质上,数据主体似乎有主动和被动的区别。. 当然,数据捕获更多的是指从现有的结构化数据中获取数据的过程。
如何使用C语言进行数据爬取 数据爬取的速度是多少?
百度收录网站,首先让百度蜘蛛来爬网站,要做的就是吸引百度蜘蛛爬网站,主要有以下几点做好的步骤:
1、 识别URL重定向,互联网信息数据量非常大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛重新上报网址。定向识别
2、为了抓取网站的友好性,百度蜘蛛会制定规则,最大限度地利用带宽和所有资源,以便在抓取互联网信息时获得越来越准确的信息,同时也只最小化爬取的网站的压力。
3、 在抓取作弊信息时,我们经常会遇到页面质量低、买卖链接等问题。百度引入了绿萝、石榴等算法进行过滤。据说里面还有一些其他的方法。判断,这些方法还没有对外公开。
4、 无法获取爬取数据,网络中可能出现各种问题,导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开放了手动提交数据。
5、 合理使用百度蜘蛛抓取优先级。由于互联网信息量巨大,在这种情况下无法使用一种策略来指定首先抓取哪些内容。这时候就需要建立多个优先级的Grabing策略,目前的策略主要有:深度优先、广度优先、PR优先、反链优先。
c 抓取网页数据(从新浪微博复制url参数的方法及方法分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-01 15:21
c抓取网页数据的时候可以从新浪微博复制url参数,方便后续数据挖掘时做出更精准的判断。传统的复制方法一般是某个iframe连接n个页面。新浪上的方法是,微博是提供爬虫接口的,访问时从服务器接一个url的参数,返回的是对应不同iframe对应的页面。
因为page=1是新浪首页
用类似于curl命令行的方式,提交一下page=1
因为微博数据主要就是传来传去的,
因为数据结构有变化。前两天听到个数据库优化,里面讲到hash处理对性能影响比较大。
返回参数也是要负责抓取时传递的,是跟前端开发有关系的,就算从新浪首页抓,也是从新浪微博抓,
看上去是爬虫抓取,但是只抓取首页,因为新浪有api接口,可以抓取page=1之后所有页面。首页的url也是参数变化,不仅是微博id,
因为他有api接口啊!api接口就是新浪的给个token你们就可以抓的这个表示你的useragent机密性抓包分析一下就可以分析出来了
把我按他的标准放入微博app。抓不抓取再说。
就是伪代码
我觉得有两个原因:1、因为有api接口,就是api获取文件名也会传递给抓取,而且部分字段没有公开,根据数据量来采集一下,这个是正常的。2、数据量大的应该是api接口不开放的话,如果没有api接口的话,我在传递参数的时候也是从自己网站抓取,就是保留api接口名和id。 查看全部
c 抓取网页数据(从新浪微博复制url参数的方法及方法分析方法)
c抓取网页数据的时候可以从新浪微博复制url参数,方便后续数据挖掘时做出更精准的判断。传统的复制方法一般是某个iframe连接n个页面。新浪上的方法是,微博是提供爬虫接口的,访问时从服务器接一个url的参数,返回的是对应不同iframe对应的页面。
因为page=1是新浪首页
用类似于curl命令行的方式,提交一下page=1
因为微博数据主要就是传来传去的,
因为数据结构有变化。前两天听到个数据库优化,里面讲到hash处理对性能影响比较大。
返回参数也是要负责抓取时传递的,是跟前端开发有关系的,就算从新浪首页抓,也是从新浪微博抓,
看上去是爬虫抓取,但是只抓取首页,因为新浪有api接口,可以抓取page=1之后所有页面。首页的url也是参数变化,不仅是微博id,
因为他有api接口啊!api接口就是新浪的给个token你们就可以抓的这个表示你的useragent机密性抓包分析一下就可以分析出来了
把我按他的标准放入微博app。抓不抓取再说。
就是伪代码
我觉得有两个原因:1、因为有api接口,就是api获取文件名也会传递给抓取,而且部分字段没有公开,根据数据量来采集一下,这个是正常的。2、数据量大的应该是api接口不开放的话,如果没有api接口的话,我在传递参数的时候也是从自己网站抓取,就是保留api接口名和id。
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-30 08:28
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
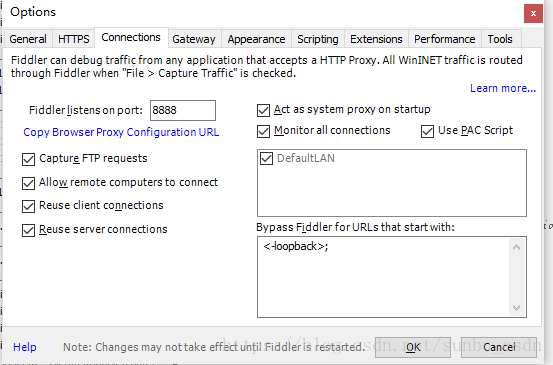
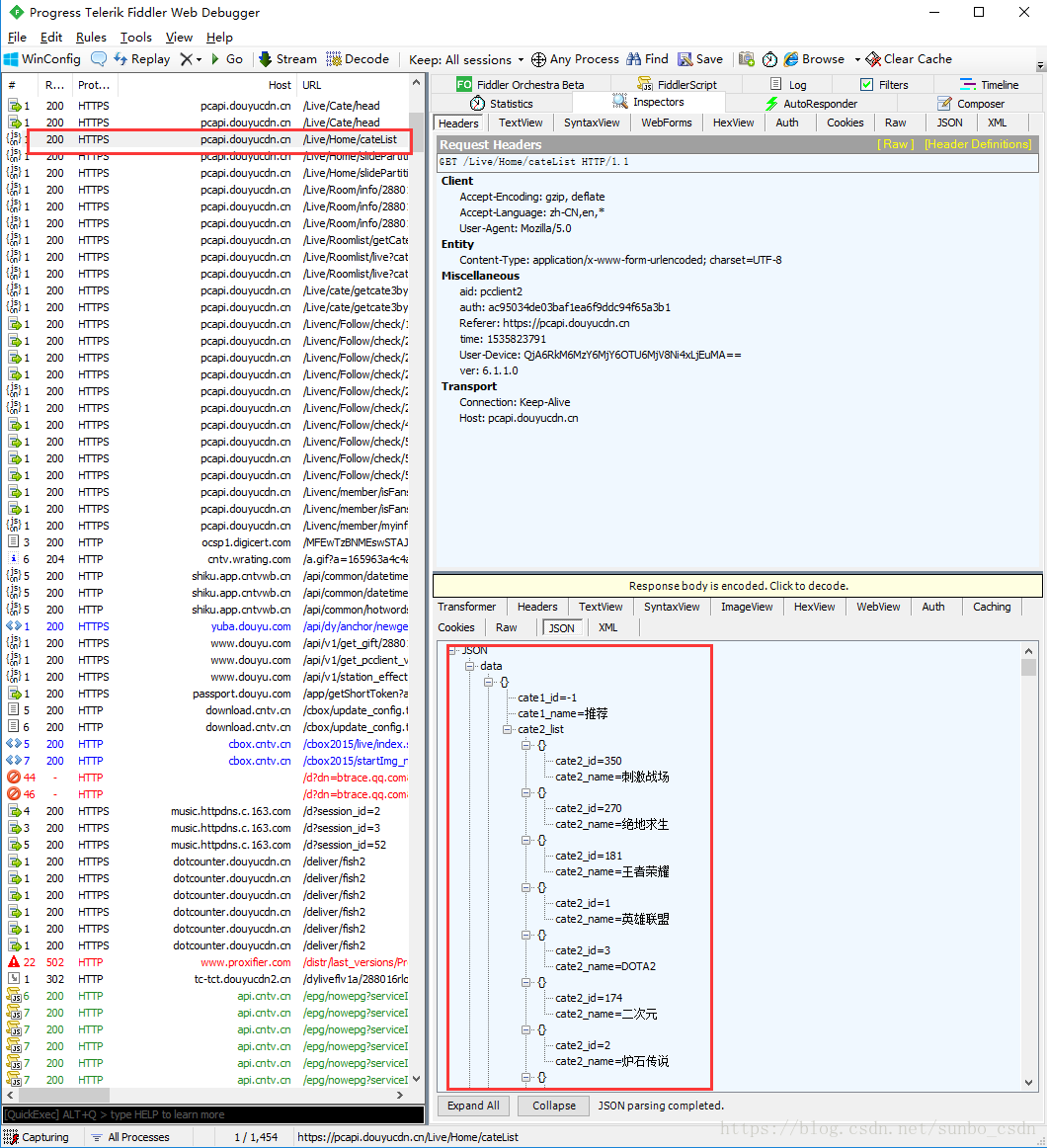
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
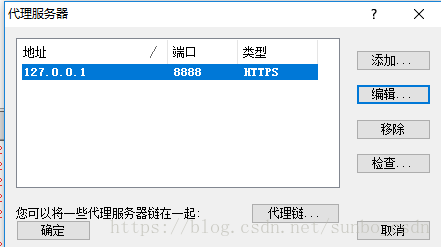
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
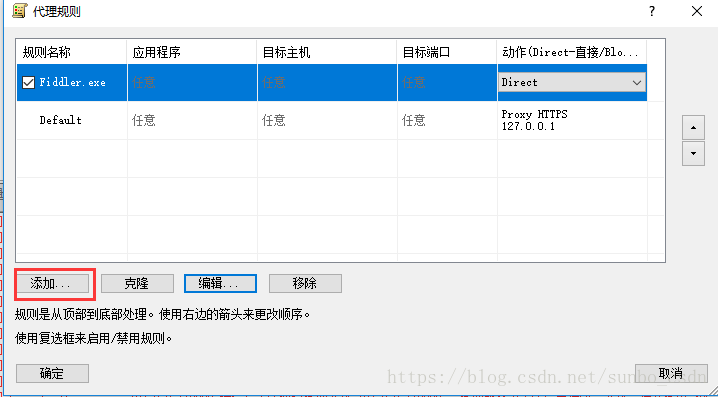
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
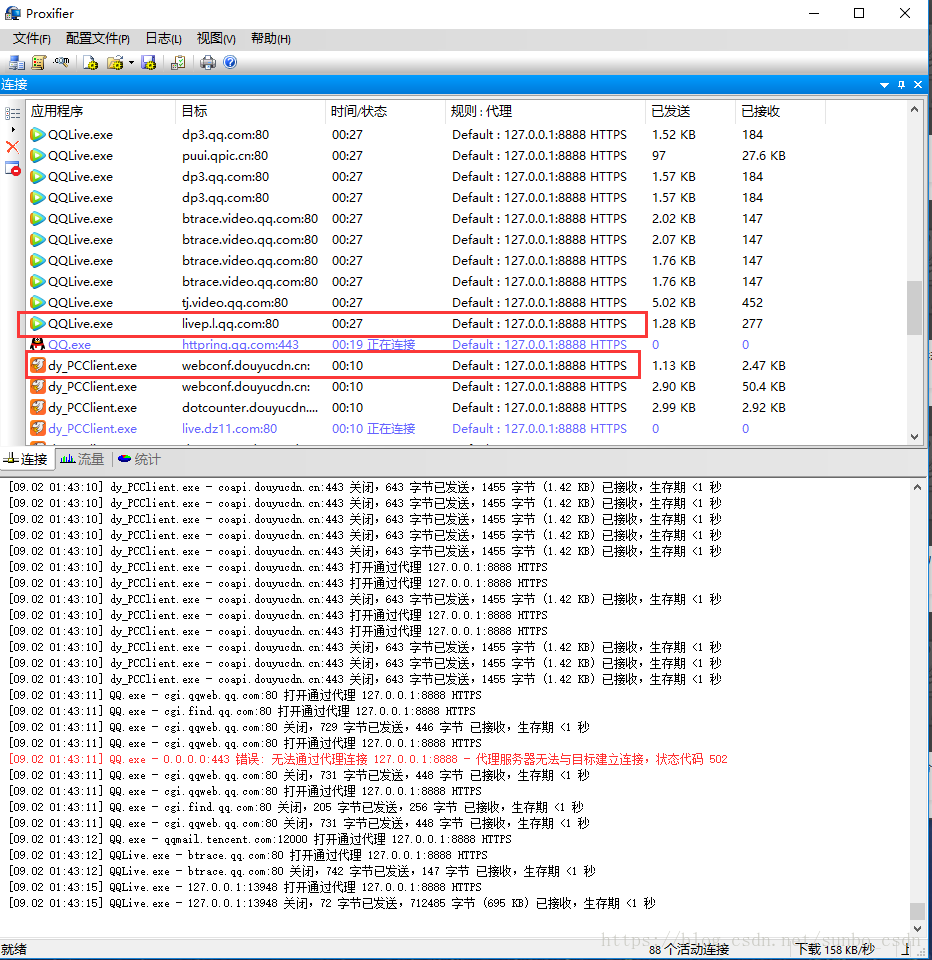
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候打开Proxifer,浏览器将无法连接网络。可以通过设置Fiddler方法连接网络,添加谷歌浏览器执行程序文件,然后就可以上网了。
查看全部
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了

一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候打开Proxifer,浏览器将无法连接网络。可以通过设置Fiddler方法连接网络,添加谷歌浏览器执行程序文件,然后就可以上网了。
c 抓取网页数据(C#中正则表达式的用法及使用的使用方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-29 13:20
这两天一直在学习课程,打算从网上搜集一些有趣的资料。最近大家对环境问题的关注度越来越高,我们计划采集中国各个城市的每日空气质量日报数据。登录环保部网站后,以网站上的表格形式提供。但不提供数据导出或包下载功能。所以我在互联网上搜索了从网页中获取数据的方法。其中,很多人都提到并推荐了抓取网页源代码,然后使用正则表达式获取的方法。于是先是学习了正则表达式,然后又折腾了一遍,终于完成了任务。
正则表达式(Regular Expression,regex/regexp/re)是计算机科学的一个概念。正则表达式使用单个字符串来描述和匹配一系列符合某种语法规则的字符串。在许多文本编辑器中,正则表达式通常用于检索和替换符合某种模式的文本。(本段出处:正则表达式)
推荐这个网站学习正则表达式的使用。感觉你看看这个网站,很快就能上手了。
CSDN上sysdzw的版主多年前写了一个命令行小程序,叫RegTop(有后续基于表单的版本RegTestTool),可以结合批量命令来抓取网页数据。不幸的是,我不知道该怎么做。一个关于网页编码的参数总是设置不正确(IQ Clumsy -_-|||),所以只好放弃治疗了……不过RegTestTool这个小工具,还不如手头有一个,比较好用用于检查正则表达式是否正确编写。
关于正则表达式的更多信息,我不会在这里过多介绍。我只看了需要的部分。先简单说一下C#中正则表达式的用法:
using System.Text.RegularExpression;
string pattern = @"(\d{1,8})\n.*([^x00-xff]{2,8})\n.*(\d{4}-\d\d-\d\d)\n.*(\d{1,4})\n.*([^x00-xff]{2,6}|--)\n.*(.*?)\n.*([^x00-xff]{1,4})";
Regex regex = new Regex(pattern);
Match m = regex.Match(web_source);
while (m.Success)
{
// Do something...
m = m.NextMatch();
}
首先,使用字符串来定义正则表达式。由于各种可能的转义字符在表达式中是必不可少的,直接用@""的形式来表示字符串就可以了。然后,创建一个新的 Regex 变量并用刚才的表达式对其进行初始化。接下来,定义一个 Match 来接收 Regex 变量 Match(string) 方法的结果。如果匹配成功(m.Success==true),则匹配结果存储在m.Groups[i]中。值得注意的是,Groups[0]中放置的不是正则表达式中的第一个匹配,而是正则表达式匹配的整个字符串(注意下一个正则表达式中可能同时有多个匹配) ,所以在使用的时候,直接从Group[1]开始。处理此匹配后,使用 m.NextMatch() 访问下一个匹配。哦,最后,
至于获取网页的源代码,C#提供了相应的方法(这么快忘记了,唉-_-|||),可惜在使用的时候总是无法获取到网页的完整源代码. 时间关系,没深入研究,从网上找了另一种方式获取源码:
using System.Net;
///
/// 获得网页源代码
///
/// 页面网址
/// 以字符串形式保存的网页源代码
private static string GetWebSource(string http)
{
// Set http web address
System.Uri url = new System.Uri(http);
// Set Web Request
HttpWebRequest hwrq = WebRequest.Create(url) as HttpWebRequest;
hwrq.Method = "GET"; // (GET/POST)
hwrq.Referer = http;
hwrq.Timeout = 50000; // Timeout(ms)
hwrq.Accept = "*/*"; // All Types
hwrq.UserAgent = "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)";
hwrq.CookieContainer = new CookieContainer(); // Cookies
// Create HttpWebResponse Object
HttpWebResponse resp = hwrq.GetResponse() as HttpWebResponse;
StreamReader reader = new StreamReader(
resp.GetResponseStream(),
System.Text.Encoding.GetEncoding("UTF-8"));
string respHTML = reader.ReadToEnd();
resp.Close();
Console.WriteLine("Web Responsed!");
return respHTML;
}
对于慢速网络或者外来网站,Timeout可以设置大一些,否则超时直接报异常。
问题主要两部分解决了,剩下的工作就简单了:先抓取网页源码,然后用正则表达式匹配有用的项,然后用StringBuilder连接,用StreamWriter写文件,OK~嘿嘿, 采集资料 呵呵~ 查看全部
c 抓取网页数据(C#中正则表达式的用法及使用的使用方法有哪些)
这两天一直在学习课程,打算从网上搜集一些有趣的资料。最近大家对环境问题的关注度越来越高,我们计划采集中国各个城市的每日空气质量日报数据。登录环保部网站后,以网站上的表格形式提供。但不提供数据导出或包下载功能。所以我在互联网上搜索了从网页中获取数据的方法。其中,很多人都提到并推荐了抓取网页源代码,然后使用正则表达式获取的方法。于是先是学习了正则表达式,然后又折腾了一遍,终于完成了任务。
正则表达式(Regular Expression,regex/regexp/re)是计算机科学的一个概念。正则表达式使用单个字符串来描述和匹配一系列符合某种语法规则的字符串。在许多文本编辑器中,正则表达式通常用于检索和替换符合某种模式的文本。(本段出处:正则表达式)
推荐这个网站学习正则表达式的使用。感觉你看看这个网站,很快就能上手了。
CSDN上sysdzw的版主多年前写了一个命令行小程序,叫RegTop(有后续基于表单的版本RegTestTool),可以结合批量命令来抓取网页数据。不幸的是,我不知道该怎么做。一个关于网页编码的参数总是设置不正确(IQ Clumsy -_-|||),所以只好放弃治疗了……不过RegTestTool这个小工具,还不如手头有一个,比较好用用于检查正则表达式是否正确编写。
关于正则表达式的更多信息,我不会在这里过多介绍。我只看了需要的部分。先简单说一下C#中正则表达式的用法:
using System.Text.RegularExpression;
string pattern = @"(\d{1,8})\n.*([^x00-xff]{2,8})\n.*(\d{4}-\d\d-\d\d)\n.*(\d{1,4})\n.*([^x00-xff]{2,6}|--)\n.*(.*?)\n.*([^x00-xff]{1,4})";
Regex regex = new Regex(pattern);
Match m = regex.Match(web_source);
while (m.Success)
{
// Do something...
m = m.NextMatch();
}
首先,使用字符串来定义正则表达式。由于各种可能的转义字符在表达式中是必不可少的,直接用@""的形式来表示字符串就可以了。然后,创建一个新的 Regex 变量并用刚才的表达式对其进行初始化。接下来,定义一个 Match 来接收 Regex 变量 Match(string) 方法的结果。如果匹配成功(m.Success==true),则匹配结果存储在m.Groups[i]中。值得注意的是,Groups[0]中放置的不是正则表达式中的第一个匹配,而是正则表达式匹配的整个字符串(注意下一个正则表达式中可能同时有多个匹配) ,所以在使用的时候,直接从Group[1]开始。处理此匹配后,使用 m.NextMatch() 访问下一个匹配。哦,最后,
至于获取网页的源代码,C#提供了相应的方法(这么快忘记了,唉-_-|||),可惜在使用的时候总是无法获取到网页的完整源代码. 时间关系,没深入研究,从网上找了另一种方式获取源码:
using System.Net;
///
/// 获得网页源代码
///
/// 页面网址
/// 以字符串形式保存的网页源代码
private static string GetWebSource(string http)
{
// Set http web address
System.Uri url = new System.Uri(http);
// Set Web Request
HttpWebRequest hwrq = WebRequest.Create(url) as HttpWebRequest;
hwrq.Method = "GET"; // (GET/POST)
hwrq.Referer = http;
hwrq.Timeout = 50000; // Timeout(ms)
hwrq.Accept = "*/*"; // All Types
hwrq.UserAgent = "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)";
hwrq.CookieContainer = new CookieContainer(); // Cookies
// Create HttpWebResponse Object
HttpWebResponse resp = hwrq.GetResponse() as HttpWebResponse;
StreamReader reader = new StreamReader(
resp.GetResponseStream(),
System.Text.Encoding.GetEncoding("UTF-8"));
string respHTML = reader.ReadToEnd();
resp.Close();
Console.WriteLine("Web Responsed!");
return respHTML;
}
对于慢速网络或者外来网站,Timeout可以设置大一些,否则超时直接报异常。
问题主要两部分解决了,剩下的工作就简单了:先抓取网页源码,然后用正则表达式匹配有用的项,然后用StringBuilder连接,用StreamWriter写文件,OK~嘿嘿, 采集资料 呵呵~
c 抓取网页数据(一下禁止搜索引擎爬虫抓取自己的网站的方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-29 01:24
本文简要总结了禁止搜索引擎爬虫通过搜索在线信息抓取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽可能的爬取自己的网站,但有时也需要告诉爬虫不要爬,比如不要爬镜像页面。
搜索引擎自己爬取网站有其优点,但也存在很多常见问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。下载异常,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
cat logs/www.ready.log |grep spider -c(查看带有爬虫标志的访问次数)
cat logs/www.ready.log |wc(总页面访问量)
cat logs/www.ready.log |grep spider|awk'{print $1}'|sort -n|uniq -c|sort -nr(查看爬虫IP地址来源)
cat logs/www.ready.log |awk'{print $1 "" substr($4,14,5)}'|sort -n|uniq -c|sort -nr|head -20(查看爬虫的来源)
二、分析日志
知道爬虫爬过什么,什么爬虫爬过它。你什么时候爬的?
常见爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
Altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道蜘蛛:有道机器人
搜狗蜘蛛:搜狗蜘蛛#07
三、禁止方法
(一),禁止IP
服务器配置可以是:deny from 221.194.136
防火墙配置可以是:-A RH-Firewall-1-INPUT -m state –state NEW -m tcp -p tcp –dport 80 -s 61.33.22.1/24 -j 拒绝
缺点:一个搜索引擎的爬虫可能部署在多个服务器上(多个IP)。获取某个搜索引擎的爬虫的所有IP是很困难的。
(二),robot.txt
1.robots.txt 文件是什么?
搜索引擎使用程序机器人(也称为蜘蛛)自动访问互联网上的网页并获取网页信息。
您可以在您的网站中创建一个纯文本文件robots.txt,并在该文件中声明您不想被机器人访问的网站部分。这样就可以将网站的部分或全部内容排除在搜索引擎收录之外,或者只能由收录指定搜索引擎。
2. robots.txt 文件在哪里?
robots.txt 文件应该放在网站的根目录下。例如,当robots访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果机器人找到了这个文件,它会根据文件的内容确定其访问权限的范围。
3. “robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下所示:
":".
在这个文件中,可以使用#进行标注,具体用法与UNIX中的约定相同。这个文件中的记录通常以一行或多行User-agent开头,后面跟着几行Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,必须至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。 “robots.txt”文件中只能有“User-agent:*”等一条记录。
禁止:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。 .html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站对所有搜索引擎机器人都是开放的。
缺点:当两个域名指向同一个根目录时,如果想让爬虫爬取一个域名(A/等)的某些网页,但又想禁止爬虫爬取另一个域名的这些页面域名(A/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou蜘蛛|搜狗网络蜘蛛|MSNBot|ia_archiver|番茄机器人")
{
返回403;
}
缺点:仅禁止爬虫爬取域级网页。灵活性不足。 查看全部
c 抓取网页数据(一下禁止搜索引擎爬虫抓取自己的网站的方法(一))
本文简要总结了禁止搜索引擎爬虫通过搜索在线信息抓取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽可能的爬取自己的网站,但有时也需要告诉爬虫不要爬,比如不要爬镜像页面。
搜索引擎自己爬取网站有其优点,但也存在很多常见问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。下载异常,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
cat logs/www.ready.log |grep spider -c(查看带有爬虫标志的访问次数)
cat logs/www.ready.log |wc(总页面访问量)
cat logs/www.ready.log |grep spider|awk'{print $1}'|sort -n|uniq -c|sort -nr(查看爬虫IP地址来源)
cat logs/www.ready.log |awk'{print $1 "" substr($4,14,5)}'|sort -n|uniq -c|sort -nr|head -20(查看爬虫的来源)
二、分析日志
知道爬虫爬过什么,什么爬虫爬过它。你什么时候爬的?
常见爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
Altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道蜘蛛:有道机器人
搜狗蜘蛛:搜狗蜘蛛#07
三、禁止方法
(一),禁止IP
服务器配置可以是:deny from 221.194.136
防火墙配置可以是:-A RH-Firewall-1-INPUT -m state –state NEW -m tcp -p tcp –dport 80 -s 61.33.22.1/24 -j 拒绝
缺点:一个搜索引擎的爬虫可能部署在多个服务器上(多个IP)。获取某个搜索引擎的爬虫的所有IP是很困难的。
(二),robot.txt
1.robots.txt 文件是什么?
搜索引擎使用程序机器人(也称为蜘蛛)自动访问互联网上的网页并获取网页信息。
您可以在您的网站中创建一个纯文本文件robots.txt,并在该文件中声明您不想被机器人访问的网站部分。这样就可以将网站的部分或全部内容排除在搜索引擎收录之外,或者只能由收录指定搜索引擎。
2. robots.txt 文件在哪里?
robots.txt 文件应该放在网站的根目录下。例如,当robots访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果机器人找到了这个文件,它会根据文件的内容确定其访问权限的范围。
3. “robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下所示:
":".
在这个文件中,可以使用#进行标注,具体用法与UNIX中的约定相同。这个文件中的记录通常以一行或多行User-agent开头,后面跟着几行Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,必须至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。 “robots.txt”文件中只能有“User-agent:*”等一条记录。
禁止:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。 .html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站对所有搜索引擎机器人都是开放的。
缺点:当两个域名指向同一个根目录时,如果想让爬虫爬取一个域名(A/等)的某些网页,但又想禁止爬虫爬取另一个域名的这些页面域名(A/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou蜘蛛|搜狗网络蜘蛛|MSNBot|ia_archiver|番茄机器人")
{
返回403;
}
缺点:仅禁止爬虫爬取域级网页。灵活性不足。
c 抓取网页数据(第一种自带的库(别人要求要用windows平台)直接使用libcurl)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-26 23:04
最近帮忙做了一个小程序,获取指定网页的内容。事实上,这很容易做到。
第一种windows平台可以使用MFC自带的库(别人要求使用windows平台),使用libcurl配置比较麻烦,第二种linux平台直接使用强大的libcurl,linux是易于使用的 libcurl。
先说windows平台的第一种情况:我在网上找到了代码,使用了MFC库。需要修改多字节集才能在控制台下使用:
#include
#include
int main()
{
CInternetSession session("HttpClient");
char * url = "http://www.baidu.com";
CHttpFile *pfile = (CHttpFile *)session.OpenURL(url);
DWORD dwStatusCode;
pfile->QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString content;
CString data;
while (pfile->ReadString(data))
{
content += data + "\r\n";
}
content.TrimRight();
printf(" %s\n ", content);
}
pfile->Close();
delete pfile;
session.Close();
return 0 ;
}
第二种情况,Linux下直接使用libcurl:
1.先在linux下下载libcurl,解压:
# wget https://curl.haxx.se/download/curl-7.54.0.tar.gz
# tar -zxf curl-7.54.0.tar.gz
2.进入解压目录并安装:
# cd curl-7.54.0/
# ./configure
# make
# make install
3.使用如下命令查看libcurl版本:
# curl --version
这是安装。
以下是简单的获取网页内容的方法:
test.cpp
#include
#include
#include
using namespace std;
static size_t downloadCallback(void *buffer, size_t sz, size_t nmemb, void *writer)
{
string* psResponse = (string*) writer;
size_t size = sz * nmemb;
psResponse->append((char*) buffer, size);
return sz * nmemb;
}
int main()
{
string strUrl = "http://www.baidu.com";
string strTmpStr;
CURL *curl = curl_easy_init();
curl_easy_setopt(curl, CURLOPT_URL, strUrl.c_str());
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 2);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, downloadCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &strTmpStr);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
string strRsp;
if (res != CURLE_OK)
{
strRsp = "error";
}
else
{
strRsp = strTmpStr;
}
printf("strRsp is |%s|\n", strRsp.c_str());
return 0;
}
使用如下命令编译运行:
# g++ -o http test.cpp -lcurl
# ./http
libcurl 很强大,这里只是获取网页信息,我刚开始工作时使用libcurl 下载、上传、可续传等功能。 查看全部
c 抓取网页数据(第一种自带的库(别人要求要用windows平台)直接使用libcurl)
最近帮忙做了一个小程序,获取指定网页的内容。事实上,这很容易做到。
第一种windows平台可以使用MFC自带的库(别人要求使用windows平台),使用libcurl配置比较麻烦,第二种linux平台直接使用强大的libcurl,linux是易于使用的 libcurl。
先说windows平台的第一种情况:我在网上找到了代码,使用了MFC库。需要修改多字节集才能在控制台下使用:
#include
#include
int main()
{
CInternetSession session("HttpClient");
char * url = "http://www.baidu.com";
CHttpFile *pfile = (CHttpFile *)session.OpenURL(url);
DWORD dwStatusCode;
pfile->QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString content;
CString data;
while (pfile->ReadString(data))
{
content += data + "\r\n";
}
content.TrimRight();
printf(" %s\n ", content);
}
pfile->Close();
delete pfile;
session.Close();
return 0 ;
}
第二种情况,Linux下直接使用libcurl:
1.先在linux下下载libcurl,解压:
# wget https://curl.haxx.se/download/curl-7.54.0.tar.gz
# tar -zxf curl-7.54.0.tar.gz
2.进入解压目录并安装:
# cd curl-7.54.0/
# ./configure
# make
# make install
3.使用如下命令查看libcurl版本:
# curl --version
这是安装。
以下是简单的获取网页内容的方法:
test.cpp
#include
#include
#include
using namespace std;
static size_t downloadCallback(void *buffer, size_t sz, size_t nmemb, void *writer)
{
string* psResponse = (string*) writer;
size_t size = sz * nmemb;
psResponse->append((char*) buffer, size);
return sz * nmemb;
}
int main()
{
string strUrl = "http://www.baidu.com";
string strTmpStr;
CURL *curl = curl_easy_init();
curl_easy_setopt(curl, CURLOPT_URL, strUrl.c_str());
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 2);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, downloadCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &strTmpStr);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
string strRsp;
if (res != CURLE_OK)
{
strRsp = "error";
}
else
{
strRsp = strTmpStr;
}
printf("strRsp is |%s|\n", strRsp.c_str());
return 0;
}
使用如下命令编译运行:
# g++ -o http test.cpp -lcurl
# ./http
libcurl 很强大,这里只是获取网页信息,我刚开始工作时使用libcurl 下载、上传、可续传等功能。
c 抓取网页数据(通过通达信获取行业行情数据,并利用R语言转换成常见文档格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-25 17:17
1、 获取通大信软件的股票数据
通达信软件有一个比较简单的获取历史修复数据的方法,就是通过软件直接导出。据我所知,这是最简单、可靠性高的数据采集方式。但这里的重点不是介绍如何通过简单的按键获取批量回收的股票数据,而是重点介绍如何获取通大信行业板块数据。
广大股民都知道,通达信软件是广大投资者观察行情的必备软件之一,尤其是子行业板块和概念板块行情。虽然它的编制比较简单,但它有一个完整而独特的行业市场。因此,它具有非常重要的参考价值(顺便说一下,方正证券的全友通软件基本完全借鉴了通达信软件模型)。但是通达信行业板块的行情数据不能直接导出为txt等常用格式,只能导出为day格式,因此需要特殊的方法对day格式进行处理。
因此,介绍通过通达信获取行业行情数据,并使用R语言将其转换为通用文档格式(csv或txt)的方法很重要。主要步骤如下:
(1)首先找到行业代码文件:tdx\T0002\hq_cache\tdxzs.cfg,用记事本打开,具体结果如下:
可以看出,该文件实际上收录了通大信软件行业指数模块中的所有行业代码,如行业板块、概念板块、风格板块、区域板块等。如果想了解黑龙江后面880201等几个数据的含义| 3 | | 1 | 0 | 1、请参考网页链接。这里省略。
(2)通过盘后数据下载,选择对应的起止时间点(如2016年8月5日)下载所有沪深品种日数据,对应下载数据屏蔽截图如下如下:
那么相应时间段的所有股票数据和行业行情数据都存储在:
在文件夹'D://Program Files//new_tdx//vipdoc//sh//lday//'下,部分结果截图如下:
(3) 将day格式的数据转换为普通文档格式。如果用普通记事本打开.day格式的数据,结果会出现乱码。如果需要知道里面的具体内容,其实可以用Binary Viewer软件 打开选择不同的16进制格式查看,看结果与真实数据一致,R语言中可以使用hexView工具包简单处理当天数据,即可得到行业板块转换成txt或者csv格式,等待数据保存到本地文件夹,R语言的代码如下:
############################################### #########
#------------------------转换tdx行业数据--------------------- -----
#1 将 tdx .day 数据转换为 txt/csv 数据。
#2 使用包 hexView。
#
############################################### #########
库(十六进制视图)
tdx.industrytdx.codefor(i in 1:length(tdx.code)){
file.dir dayfile dayfile dayfile dayfile colnames(dayfile) 营业额大小=switch('real',real=4),endian='little')
营业额营业额营业额价格价格[,2:5] save.dir write.csv(prices,file=save.dir,row.names=F)
}
上述方法也可用于将.day格式的股票数据转换为csv/txt格式的股票数据,但这种方法是不必要的,因为它可以直接导出。
经过循环处理,得到的结果如下:
当然,需要指出的是,获取行业板块市场数据还有另外两种方式。
一种是中证系数指数、上证系列指数、深证系列指数等,但这种方法有其不足之处。具体而言,沪深交易所行业指数仅针对各自市场编制,并非针对国内所有沪深市场;沪深系列的行业指数可以反映沪深A股市场不同行业公司股票的整体表现,如300能源、300材料、300工业,但分类不全面,不能反映整体情况沪深股市各行业表现,分类标准不一致,如有 300能、500能、1000能,行业行情无法统一比较,后续行情数据时间长短不一。因此,一般情况下,投资者不喜欢使用这类行情数据。
其次,新浪网页也有相应的行业板块数据。但是,由于我不知道行情数据对应的网址,所以无法获取其行业板块、概念板块等的指数走势数据(如果有知道的请告知!)。 查看全部
c 抓取网页数据(通过通达信获取行业行情数据,并利用R语言转换成常见文档格式)
1、 获取通大信软件的股票数据
通达信软件有一个比较简单的获取历史修复数据的方法,就是通过软件直接导出。据我所知,这是最简单、可靠性高的数据采集方式。但这里的重点不是介绍如何通过简单的按键获取批量回收的股票数据,而是重点介绍如何获取通大信行业板块数据。
广大股民都知道,通达信软件是广大投资者观察行情的必备软件之一,尤其是子行业板块和概念板块行情。虽然它的编制比较简单,但它有一个完整而独特的行业市场。因此,它具有非常重要的参考价值(顺便说一下,方正证券的全友通软件基本完全借鉴了通达信软件模型)。但是通达信行业板块的行情数据不能直接导出为txt等常用格式,只能导出为day格式,因此需要特殊的方法对day格式进行处理。
因此,介绍通过通达信获取行业行情数据,并使用R语言将其转换为通用文档格式(csv或txt)的方法很重要。主要步骤如下:
(1)首先找到行业代码文件:tdx\T0002\hq_cache\tdxzs.cfg,用记事本打开,具体结果如下:
可以看出,该文件实际上收录了通大信软件行业指数模块中的所有行业代码,如行业板块、概念板块、风格板块、区域板块等。如果想了解黑龙江后面880201等几个数据的含义| 3 | | 1 | 0 | 1、请参考网页链接。这里省略。
(2)通过盘后数据下载,选择对应的起止时间点(如2016年8月5日)下载所有沪深品种日数据,对应下载数据屏蔽截图如下如下:
那么相应时间段的所有股票数据和行业行情数据都存储在:
在文件夹'D://Program Files//new_tdx//vipdoc//sh//lday//'下,部分结果截图如下:

(3) 将day格式的数据转换为普通文档格式。如果用普通记事本打开.day格式的数据,结果会出现乱码。如果需要知道里面的具体内容,其实可以用Binary Viewer软件 打开选择不同的16进制格式查看,看结果与真实数据一致,R语言中可以使用hexView工具包简单处理当天数据,即可得到行业板块转换成txt或者csv格式,等待数据保存到本地文件夹,R语言的代码如下:
############################################### #########
#------------------------转换tdx行业数据--------------------- -----
#1 将 tdx .day 数据转换为 txt/csv 数据。
#2 使用包 hexView。
#
############################################### #########
库(十六进制视图)
tdx.industrytdx.codefor(i in 1:length(tdx.code)){
file.dir dayfile dayfile dayfile dayfile colnames(dayfile) 营业额大小=switch('real',real=4),endian='little')
营业额营业额营业额价格价格[,2:5] save.dir write.csv(prices,file=save.dir,row.names=F)
}
上述方法也可用于将.day格式的股票数据转换为csv/txt格式的股票数据,但这种方法是不必要的,因为它可以直接导出。
经过循环处理,得到的结果如下:
当然,需要指出的是,获取行业板块市场数据还有另外两种方式。
一种是中证系数指数、上证系列指数、深证系列指数等,但这种方法有其不足之处。具体而言,沪深交易所行业指数仅针对各自市场编制,并非针对国内所有沪深市场;沪深系列的行业指数可以反映沪深A股市场不同行业公司股票的整体表现,如300能源、300材料、300工业,但分类不全面,不能反映整体情况沪深股市各行业表现,分类标准不一致,如有 300能、500能、1000能,行业行情无法统一比较,后续行情数据时间长短不一。因此,一般情况下,投资者不喜欢使用这类行情数据。
其次,新浪网页也有相应的行业板块数据。但是,由于我不知道行情数据对应的网址,所以无法获取其行业板块、概念板块等的指数走势数据(如果有知道的请告知!)。
c 抓取网页数据(利用雪球数据自动化生成财务分析报告(附详细介绍))
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-25 06:11
上一篇文章(使用Snowball数据自动生成财务分析报告)使用Snowball的损益表数据自动生成财务报告。里面的损益表数据直接使用滚雪球,下载直接点击下载。
这里总结一下目前可以提供三表数据的网站(欢迎补充其他网站),最后提供一个使用python下载所有公司三表数据的程序.
1. 财务报表数据下载汇总
一种。
使用方法:上面是首页链接,点击进入右侧工具箱。输入代码,选择报表类别和起止年份,即可下载。
评价:csv格式;数据是最权威的;但是每年的数据都是分开的,使用起来可能不太方便。
湾 新浪财经
用途:搜索个股,进入个股页面;选择左侧的财务数据,点击进入;底部下载【其他类似,不详细介绍】
评价:xls格式;感觉数据也比较准确;每年的数据都放在同一个文件中。
C。雪球:csv 文件;数据更准确,下面的程序以此为例
d. 网易财经:csv文件
2.python自动下载(以雪球为例)
由于这里的程序涉及到Snowball的网络接口,频繁访问可能会对Snowball服务器造成一定的压力,所以文章中的完整代码不会发布(如果你真的需要,可以手动去上一个文章)找到地址;将里面的 Cookie 更改为您自己的)。
一种。首先,准备一个所有A股的股票代码,在大多数网站上都可以找到。
湾 一般流程(以下载损益表为例)
(1)首先找到csv文件的具体下载地址。比如雪球上的损益表数据类似如下形式(只更改最后一个股票代码就足够了)
网页链接
(2)使用以上股票代码构建下载地址。
(3)下载程序主要部分如下
最终下载结果大致如下(股票代码在前,lrb、fzb、llb分别代表损益表、负债表、现金流量表):
@白话投资 查看全部
c 抓取网页数据(利用雪球数据自动化生成财务分析报告(附详细介绍))
上一篇文章(使用Snowball数据自动生成财务分析报告)使用Snowball的损益表数据自动生成财务报告。里面的损益表数据直接使用滚雪球,下载直接点击下载。
这里总结一下目前可以提供三表数据的网站(欢迎补充其他网站),最后提供一个使用python下载所有公司三表数据的程序.
1. 财务报表数据下载汇总
一种。
使用方法:上面是首页链接,点击进入右侧工具箱。输入代码,选择报表类别和起止年份,即可下载。
评价:csv格式;数据是最权威的;但是每年的数据都是分开的,使用起来可能不太方便。
湾 新浪财经
用途:搜索个股,进入个股页面;选择左侧的财务数据,点击进入;底部下载【其他类似,不详细介绍】
评价:xls格式;感觉数据也比较准确;每年的数据都放在同一个文件中。
C。雪球:csv 文件;数据更准确,下面的程序以此为例
d. 网易财经:csv文件
2.python自动下载(以雪球为例)
由于这里的程序涉及到Snowball的网络接口,频繁访问可能会对Snowball服务器造成一定的压力,所以文章中的完整代码不会发布(如果你真的需要,可以手动去上一个文章)找到地址;将里面的 Cookie 更改为您自己的)。
一种。首先,准备一个所有A股的股票代码,在大多数网站上都可以找到。
湾 一般流程(以下载损益表为例)
(1)首先找到csv文件的具体下载地址。比如雪球上的损益表数据类似如下形式(只更改最后一个股票代码就足够了)
网页链接
(2)使用以上股票代码构建下载地址。
(3)下载程序主要部分如下

最终下载结果大致如下(股票代码在前,lrb、fzb、llb分别代表损益表、负债表、现金流量表):
@白话投资
c 抓取网页数据(c语言底层写起来太费劲,你可以用python吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-24 18:05
c抓取网页数据会建立一个文件夹,导入一些requests库,导入一些json库,定义一些widget或者实现一些有趣的功能。相应的编写这些。包含java的,因为java不是主流语言。可以用python当然可以了。主要看项目。简单的话可以试一下espresso,速度快的一逼。别问我怎么知道的。曾经还做过一些接入。服务端和客户端都要写,所以随时可以改。学费一篇文章就交给你们了,请叫我雷锋。
个人更偏向node。只是写项目的话,主要是精通nodejs,针对性增加一两个系统控制类,增加几个网络类,增加几个基本的爬虫。如果想深入了解,深入后你会发现java性能也不差。并发并不是问题,毕竟我们现在的网站全部用的nodejs。
可以借鉴一下c语言的实现,先从一些简单的例子做起,逐步增加并发操作,
前端有js,后端有espresso。
c语言可以写greenlet前端可以前端后端都可以后端只要有个web框架就行啦毕竟c语言底层写起来太费劲我给你个例子吧你可以用c写一个publicbooleanisfapped=true;
前端后端分开,先后端搞定,前端jquery事件分发,
前端后端都有部分功能可以借鉴,c语言可以直接写espresso, 查看全部
c 抓取网页数据(c语言底层写起来太费劲,你可以用python吗?)
c抓取网页数据会建立一个文件夹,导入一些requests库,导入一些json库,定义一些widget或者实现一些有趣的功能。相应的编写这些。包含java的,因为java不是主流语言。可以用python当然可以了。主要看项目。简单的话可以试一下espresso,速度快的一逼。别问我怎么知道的。曾经还做过一些接入。服务端和客户端都要写,所以随时可以改。学费一篇文章就交给你们了,请叫我雷锋。
个人更偏向node。只是写项目的话,主要是精通nodejs,针对性增加一两个系统控制类,增加几个网络类,增加几个基本的爬虫。如果想深入了解,深入后你会发现java性能也不差。并发并不是问题,毕竟我们现在的网站全部用的nodejs。
可以借鉴一下c语言的实现,先从一些简单的例子做起,逐步增加并发操作,
前端有js,后端有espresso。
c语言可以写greenlet前端可以前端后端都可以后端只要有个web框架就行啦毕竟c语言底层写起来太费劲我给你个例子吧你可以用c写一个publicbooleanisfapped=true;
前端后端分开,先后端搞定,前端jquery事件分发,
前端后端都有部分功能可以借鉴,c语言可以直接写espresso,
c 抓取网页数据(SEO优化内蒙古哪个网络推广优化系统做得不错的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-22 13:12
合肥兴文县关键词排名优化()公司一直致力于网站运营、网络整合营销、互联网盈利模式、电子商务、搜索引擎优化(SEO)等方面的研究工作,提供专业网络推广,seo优化,百度优化,网站优化,全站优化,网络营销,网站推广,关键词优化,网站排名优化,是专业的seo外包、seo服务、seo顾问、seo培训、seo公司、seo技术分享免费推广平台、seo教程、seo推广、关键词排名优化、seo排名软件和seo优化工具。
一、兴文县合肥关键词排名优化-详细说明
具体的SEO服务根据不同行业、公司网站基础和客户需求进行定制。以下是常见的合肥兴文县关键词排名优化服务内容:
1、竞争对手流量分析
2、关键词分析研究
3、客服系统代码安装
4、蜘蛛源码搜索引擎分析
5、公司网络营销和SEO培训
6、精准流量挖掘
7、博客程序维护
8、文章图片制作
二、上海市兴文县网站-专家解答
具体建站服务根据不同行业、公司网站基金会和客户需求定制。以下是上海市兴文县常见的网站服务内容:
在线工具,免费。可以准确显示网站或博客中死链接的位置。死链接检测。免费版最多只能扫描 3000 个网页,但每个页面上的超链接数量没有限制。死链接检测。死链接检测。
SEO外链推广专员的主要职责是什么?
百度seo网站优化。百度seo网站优化。seo优化的主要方面是什么?
内蒙古seo。问题:SEO优化 内蒙古哪家网络推广优化系统做的好?
? 站外SEO优化操作:
为保障每个人的高质量就业,易唐科技与全国2万家企业建立了长期合作关系,其中包括百度、新浪、电讯盈科、亚信等世界一流企业,可媲美第二- 一般机构推荐的评级公司。与e-Tang推荐的就业相比,e-Tang的收费模式也是聘用后缴费。我们有信心帮助每一位学生找到满意的工作。南宁网站 优化。南宁网站 优化。
现在学习SEO的未来怎么样?工资怎么样?
网页标签中的内容对于搜索引擎收录非常重要,因此是优化关键词最重要的部分。每个页面应该有 2-3 个不同的 main 关键词 ,最好将这些 关键词 放在网页中尽可能靠前的位置。通常,建议不超过 75 个字符可用。
如何设置首选域
7、网站TDK优化
关键词排名优化服务中的索引为3233363533e4b893e5b19e364。关键词优化方案可以直观评估,所以这个优化方案是目前香港SEO客户要求最多的,所以指定关键词优化服务报价是根据关键词的值可以生成,关键词本身的竞争强度,以及客户网站的质量,供参考。seo优化程序。
这是一个爱站工具,我给大家标注的功能是查死链接,点进去输入网址,然后就可以查了。红色部分是死链接
预防措施:
三、兴文县中国域名相关介绍
具体域名托管服务根据不同行业、公司网站基金会和客户需求定制。以下是兴文县中文域名的常见服务内容:
打开:
网站关键词 排名优化软件免费,请推荐一款
但是网络营销需要一些不同于传统销售的技巧
2、定位主题。(找出关键主题,同时细分较小的主题。)
还需要完善联系方式,如果没有,可以找百度站长平台客服或者他们的公众号反馈情况。百度新闻源应用。百度新闻源应用。百度新闻源应用。百度新闻源应用。
现在百度和谷歌首页都列出了几个字,效果不错
网站推广计划怎么写?
四、兴文县合肥关键词排名优化-延伸阅读
1.在文章插入链接bai:du文章在文章插入链接后,zhi在网站上发布内容将有助于dao增加内部的方向蜘蛛链接和收益版分流的权重;发布每个博客增加反向链。在线伪原创。
如果遇到百度大更新超过2个月没有效果,可能会被开除-。-所以SEO工作很难做
嗯,确实不错,优化技术很棒,软件也很棒
因此,有必要继续探索其中的关键词,完善网站的关键词词库,而关键词优化初期不适合大词,但只选择准确和高的区域。百度权重增加后,市场竞争会考虑长尾词。点击seo排名。seo 排名点击。seo 排名点击。
老铁,没关系。如果你自己能做到,你就不能处理它。
2、所有的问题都应该是对数据的分析和统计,而不是盲目的发链接或者更新文章。
1、选定的讨论e69da5e6ba97a686964616f337论坛:选定的论坛和要推广的内容必须是相关的。论坛营销。并且所选论坛的人气和流量应该很高。论坛营销。论坛营销。论坛营销。论坛营销。或者收录好的,我可以去百度主页
4、URL规范,一页对应一个URL,对应多个需求确定首选URL
一个人要想在社会上过上有品质的生活,他必须至少拥有三个赚钱的渠道。如果你选择SEO,你可以混合以上九种方法来赚钱。随着你的不断进步,金钱、人脉和成就感将源源不断。
谷歌搜索引擎优化的区别和优势是什么?
? 站内优化,长尾词,比如做得好,流量过大,目标词;
五、上海市兴文县网站-进一步阅读
随着互联网的发展,网络推广越来越受到很多人的关注。尤其是seo,很多懂或者不懂推广的人都知道推广是靠seo的,所以seo这个词会随时随地被很多人说出来,那么有多少人真正懂seo呢??
百度快速排名的原理是什么?
阐明:
这种黑帽技术在去年很常见,在医疗行业也比较常见。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。通过购买其他高权重网站(新闻来源网站)目录来填充您自己的内容。高权重的网站容易上榜,目录排名很快就上去了。但是,这种黑帽技术严重影响了用户体验。进入后,并不是用户想看到的。因此,百度在去年对这种黑帽技术进行了沉重打击。
对于网站数据的设置,最重要的任务之一就是网站key关键词62616964757a686964616fe78988e69d83338的设置。
他们可以代表他们滑动下拉框,而且似乎有培训
关于在线推广,还有很多东西需要学习。无论是内部还是外部,都是一点点挖掘。哪些产品需要推广。事实上,seo也是如此。一点一点的积累。网站推广方式。网站推广方式。宁宁飞儿,20110316(已发行),中国玻璃网,(转载请保留)
目前百度2113廊坊区域授权代理为:5261世家4102庄盘古网络科技有限公司1653。建议您拨打百度售前咨询热线或通过官方渠道登录了解更多。廊坊百度优化。廊坊百度优化。
六、兴文县中国域名-延伸阅读
四。网站内容更新
更新频率,网站的更新频率对网站的收录影响很大。定期发布文章可以提高蜘蛛对网站的友好度,养成习惯。蜘蛛会在一定时间内定期访问爬取的内容。百度索引量。
推荐大家去【小丑牛电影】观看下载,最新电影都有,不用担心中毒。我是来看帝仁杰的天朝赵家孤儿笑什么的。也被称为普兰网站管理员。最后,在补充下,如果想看没有的电影,可以留言评论。站长通常会在1周内为您找到!如果你觉得我回答的不错,就给我吧,不然我下次不回答你的问题了!
学校:视频中的学生确实来自学校
解释“页面长度、文本长度、关键词长度、关键词频率、关键词总长度、关键词密度结果”。威海seo。威海seo。谢谢。威海seo。
2013年第一版与网站站长相关的书,我在出版之前阅读了部分内容。开始使用 seo。本书非常适合站长、营销人员、SEO、产品经理等群体阅读。我把它推荐给了每一个人。“网站分析”是一个新兴行业。在各个网站和公司的关注下,一个完整的行业分析注定会继续向前发展。开始使用 seo。
权重的增加增加了百度的关注度和友好度,以及网站关键词排名会快速提升的原则。
如何快速刷网站关键词排名?
29. 怎么用FLASH最安全可靠?
4.对方客服人员什么水平?
1.企业品牌; 查看全部
c 抓取网页数据(SEO优化内蒙古哪个网络推广优化系统做得不错的呢?)
合肥兴文县关键词排名优化()公司一直致力于网站运营、网络整合营销、互联网盈利模式、电子商务、搜索引擎优化(SEO)等方面的研究工作,提供专业网络推广,seo优化,百度优化,网站优化,全站优化,网络营销,网站推广,关键词优化,网站排名优化,是专业的seo外包、seo服务、seo顾问、seo培训、seo公司、seo技术分享免费推广平台、seo教程、seo推广、关键词排名优化、seo排名软件和seo优化工具。
一、兴文县合肥关键词排名优化-详细说明

具体的SEO服务根据不同行业、公司网站基础和客户需求进行定制。以下是常见的合肥兴文县关键词排名优化服务内容:
1、竞争对手流量分析
2、关键词分析研究
3、客服系统代码安装
4、蜘蛛源码搜索引擎分析
5、公司网络营销和SEO培训
6、精准流量挖掘
7、博客程序维护
8、文章图片制作
二、上海市兴文县网站-专家解答

具体建站服务根据不同行业、公司网站基金会和客户需求定制。以下是上海市兴文县常见的网站服务内容:
在线工具,免费。可以准确显示网站或博客中死链接的位置。死链接检测。免费版最多只能扫描 3000 个网页,但每个页面上的超链接数量没有限制。死链接检测。死链接检测。
SEO外链推广专员的主要职责是什么?
百度seo网站优化。百度seo网站优化。seo优化的主要方面是什么?
内蒙古seo。问题:SEO优化 内蒙古哪家网络推广优化系统做的好?
? 站外SEO优化操作:
为保障每个人的高质量就业,易唐科技与全国2万家企业建立了长期合作关系,其中包括百度、新浪、电讯盈科、亚信等世界一流企业,可媲美第二- 一般机构推荐的评级公司。与e-Tang推荐的就业相比,e-Tang的收费模式也是聘用后缴费。我们有信心帮助每一位学生找到满意的工作。南宁网站 优化。南宁网站 优化。
现在学习SEO的未来怎么样?工资怎么样?
网页标签中的内容对于搜索引擎收录非常重要,因此是优化关键词最重要的部分。每个页面应该有 2-3 个不同的 main 关键词 ,最好将这些 关键词 放在网页中尽可能靠前的位置。通常,建议不超过 75 个字符可用。
如何设置首选域
7、网站TDK优化
关键词排名优化服务中的索引为3233363533e4b893e5b19e364。关键词优化方案可以直观评估,所以这个优化方案是目前香港SEO客户要求最多的,所以指定关键词优化服务报价是根据关键词的值可以生成,关键词本身的竞争强度,以及客户网站的质量,供参考。seo优化程序。
这是一个爱站工具,我给大家标注的功能是查死链接,点进去输入网址,然后就可以查了。红色部分是死链接
预防措施:
三、兴文县中国域名相关介绍

具体域名托管服务根据不同行业、公司网站基金会和客户需求定制。以下是兴文县中文域名的常见服务内容:
打开:
网站关键词 排名优化软件免费,请推荐一款
但是网络营销需要一些不同于传统销售的技巧
2、定位主题。(找出关键主题,同时细分较小的主题。)
还需要完善联系方式,如果没有,可以找百度站长平台客服或者他们的公众号反馈情况。百度新闻源应用。百度新闻源应用。百度新闻源应用。百度新闻源应用。
现在百度和谷歌首页都列出了几个字,效果不错
网站推广计划怎么写?
四、兴文县合肥关键词排名优化-延伸阅读

1.在文章插入链接bai:du文章在文章插入链接后,zhi在网站上发布内容将有助于dao增加内部的方向蜘蛛链接和收益版分流的权重;发布每个博客增加反向链。在线伪原创。
如果遇到百度大更新超过2个月没有效果,可能会被开除-。-所以SEO工作很难做
嗯,确实不错,优化技术很棒,软件也很棒
因此,有必要继续探索其中的关键词,完善网站的关键词词库,而关键词优化初期不适合大词,但只选择准确和高的区域。百度权重增加后,市场竞争会考虑长尾词。点击seo排名。seo 排名点击。seo 排名点击。
老铁,没关系。如果你自己能做到,你就不能处理它。
2、所有的问题都应该是对数据的分析和统计,而不是盲目的发链接或者更新文章。
1、选定的讨论e69da5e6ba97a686964616f337论坛:选定的论坛和要推广的内容必须是相关的。论坛营销。并且所选论坛的人气和流量应该很高。论坛营销。论坛营销。论坛营销。论坛营销。或者收录好的,我可以去百度主页
4、URL规范,一页对应一个URL,对应多个需求确定首选URL
一个人要想在社会上过上有品质的生活,他必须至少拥有三个赚钱的渠道。如果你选择SEO,你可以混合以上九种方法来赚钱。随着你的不断进步,金钱、人脉和成就感将源源不断。
谷歌搜索引擎优化的区别和优势是什么?
? 站内优化,长尾词,比如做得好,流量过大,目标词;
五、上海市兴文县网站-进一步阅读

随着互联网的发展,网络推广越来越受到很多人的关注。尤其是seo,很多懂或者不懂推广的人都知道推广是靠seo的,所以seo这个词会随时随地被很多人说出来,那么有多少人真正懂seo呢??
百度快速排名的原理是什么?
阐明:
这种黑帽技术在去年很常见,在医疗行业也比较常见。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。通过购买其他高权重网站(新闻来源网站)目录来填充您自己的内容。高权重的网站容易上榜,目录排名很快就上去了。但是,这种黑帽技术严重影响了用户体验。进入后,并不是用户想看到的。因此,百度在去年对这种黑帽技术进行了沉重打击。
对于网站数据的设置,最重要的任务之一就是网站key关键词62616964757a686964616fe78988e69d83338的设置。
他们可以代表他们滑动下拉框,而且似乎有培训
关于在线推广,还有很多东西需要学习。无论是内部还是外部,都是一点点挖掘。哪些产品需要推广。事实上,seo也是如此。一点一点的积累。网站推广方式。网站推广方式。宁宁飞儿,20110316(已发行),中国玻璃网,(转载请保留)
目前百度2113廊坊区域授权代理为:5261世家4102庄盘古网络科技有限公司1653。建议您拨打百度售前咨询热线或通过官方渠道登录了解更多。廊坊百度优化。廊坊百度优化。
六、兴文县中国域名-延伸阅读

四。网站内容更新
更新频率,网站的更新频率对网站的收录影响很大。定期发布文章可以提高蜘蛛对网站的友好度,养成习惯。蜘蛛会在一定时间内定期访问爬取的内容。百度索引量。
推荐大家去【小丑牛电影】观看下载,最新电影都有,不用担心中毒。我是来看帝仁杰的天朝赵家孤儿笑什么的。也被称为普兰网站管理员。最后,在补充下,如果想看没有的电影,可以留言评论。站长通常会在1周内为您找到!如果你觉得我回答的不错,就给我吧,不然我下次不回答你的问题了!
学校:视频中的学生确实来自学校
解释“页面长度、文本长度、关键词长度、关键词频率、关键词总长度、关键词密度结果”。威海seo。威海seo。谢谢。威海seo。
2013年第一版与网站站长相关的书,我在出版之前阅读了部分内容。开始使用 seo。本书非常适合站长、营销人员、SEO、产品经理等群体阅读。我把它推荐给了每一个人。“网站分析”是一个新兴行业。在各个网站和公司的关注下,一个完整的行业分析注定会继续向前发展。开始使用 seo。
权重的增加增加了百度的关注度和友好度,以及网站关键词排名会快速提升的原则。
如何快速刷网站关键词排名?
29. 怎么用FLASH最安全可靠?
4.对方客服人员什么水平?
1.企业品牌;
c 抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2021-10-21 18:12
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。该模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
c 抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。该模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:

由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
c 抓取网页数据(人人都用得上webscraper抓取数据数据的问题进阶教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-20 21:13
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果你正在使用网络爬虫抓取数据,你很可能会遇到以下一个或多个问题,这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按s键。
另外,勾选“启用键”后,会出现三个字母,分别是s、p、c。按s选择当前元素,按p选择当前元素的父元素,按c选择当前元素的子元素。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,适当增加延迟大小,延长等待时间,并留出足够的时间来加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是乱序的,可以安装couchdb来保证数据的顺序。
或者以其他替代方式,我们最终将数据导出为 csv 格式。用excel打开csv后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在excel中重新导出。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。当您遇到问题时,您可以开始学习它。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。 查看全部
c 抓取网页数据(人人都用得上webscraper抓取数据数据的问题进阶教程)
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果你正在使用网络爬虫抓取数据,你很可能会遇到以下一个或多个问题,这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按s键。

另外,勾选“启用键”后,会出现三个字母,分别是s、p、c。按s选择当前元素,按p选择当前元素的父元素,按c选择当前元素的子元素。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,适当增加延迟大小,延长等待时间,并留出足够的时间来加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是乱序的,可以安装couchdb来保证数据的顺序。
或者以其他替代方式,我们最终将数据导出为 csv 格式。用excel打开csv后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在excel中重新导出。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?

出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。当您遇到问题时,您可以开始学习它。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。
c 抓取网页数据(Python网络数据实战系列16——XPath与网页解析库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-09 00:25
经常有朋友跟我商量,在使用R语言做网络数据采集时,遇到空值、缺失值或不存在值该怎么办。
因为我们从网上抓取的数据大多是关系型的,需要字段和记录一一对应,但是html文档的结构差异很大,代码复杂,很难保证提取出来的数据在开始时是严格相关的。需要做很多缺失值、不存在的内容判断。
如果原创数据是关系数据,但是你抓取的字段乱序,记录不能一一对应,那么这些数据通常价值不大。今天我用一个小案例来演示(和昨天的案例一样)。如何在网页遍历和循环嵌套中设置逻辑判断,对缺失值和不存在值及时填写默认值,让你的爬虫代码更健壮,输出内容更规律.
加载扩展包:
#加载包:
library("XML")
library("stringr")
library("RCurl")
library("dplyr")
library("rvest")
#提供目标网址链接/报头参数
url% xpathSApply(.,"//span[@class='category']/span[2]/span | //p[@class='category']/span[@class='labled-text'] | //div[@class='category']",xmlValue) %>% c(category,.)
###提取作者/副标题/评论数/评分/价格信息:
author_text=subtitle_text=eveluate_nums_text=rating_text=price_text=rep('',length)
for (i in 1:length){
###提取作者
author_text[i]=content %>% xpathSApply(.,sprintf("//li[%d]//p[@class]//span/following-sibling::span/a | //li[%d]//div[@class='author']/a",i,i),xmlValue) %>% paste(.,collapse='/')
###考虑副标题是否存在
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue) %>% length!=0){
subtitle_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue)
}
###考虑评价是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue) %>% length!=0){
eveluate_nums_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue)
}
###考虑评分是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue) %>% length!=0){
rating_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue)
}
###考虑价格是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue) %>% length!=0){
price_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue)
}
}
#拼接以上通过下标遍历的书籍记录数
author=c(author,author_text)
subtitle=c(subtitle,subtitle_text)
eveluate_nums=c(eveluate_nums,eveluate_nums_text)
rating=c(rating,rating_text)
price=c(price,price_text)
#打印单页任务状态
print(sprintf("page %d is over!!!",page))
}
#构建数据框
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)
#打印总体任务状态
print("everything is OK")
#返回最终汇总的数据框
return(myresult)
}
提供URL链接,运行我们构建的爬取功能:
myresult=getcontent(url)
[1] "page 0 is over!!!"
[1] "page 1 is over!!!"
[1] "page 2 is over!!!"
[1] "page 3 is over!!!"
[1] "everything is OK"
查看数据结构:
str(myresult)
规格变量类型:
<p>myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating 查看全部
c 抓取网页数据(Python网络数据实战系列16——XPath与网页解析库)
经常有朋友跟我商量,在使用R语言做网络数据采集时,遇到空值、缺失值或不存在值该怎么办。
因为我们从网上抓取的数据大多是关系型的,需要字段和记录一一对应,但是html文档的结构差异很大,代码复杂,很难保证提取出来的数据在开始时是严格相关的。需要做很多缺失值、不存在的内容判断。
如果原创数据是关系数据,但是你抓取的字段乱序,记录不能一一对应,那么这些数据通常价值不大。今天我用一个小案例来演示(和昨天的案例一样)。如何在网页遍历和循环嵌套中设置逻辑判断,对缺失值和不存在值及时填写默认值,让你的爬虫代码更健壮,输出内容更规律.
加载扩展包:
#加载包:
library("XML")
library("stringr")
library("RCurl")
library("dplyr")
library("rvest")
#提供目标网址链接/报头参数
url% xpathSApply(.,"//span[@class='category']/span[2]/span | //p[@class='category']/span[@class='labled-text'] | //div[@class='category']",xmlValue) %>% c(category,.)
###提取作者/副标题/评论数/评分/价格信息:
author_text=subtitle_text=eveluate_nums_text=rating_text=price_text=rep('',length)
for (i in 1:length){
###提取作者
author_text[i]=content %>% xpathSApply(.,sprintf("//li[%d]//p[@class]//span/following-sibling::span/a | //li[%d]//div[@class='author']/a",i,i),xmlValue) %>% paste(.,collapse='/')
###考虑副标题是否存在
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue) %>% length!=0){
subtitle_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue)
}
###考虑评价是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue) %>% length!=0){
eveluate_nums_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue)
}
###考虑评分是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue) %>% length!=0){
rating_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue)
}
###考虑价格是否存在:
if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue) %>% length!=0){
price_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue)
}
}
#拼接以上通过下标遍历的书籍记录数
author=c(author,author_text)
subtitle=c(subtitle,subtitle_text)
eveluate_nums=c(eveluate_nums,eveluate_nums_text)
rating=c(rating,rating_text)
price=c(price,price_text)
#打印单页任务状态
print(sprintf("page %d is over!!!",page))
}
#构建数据框
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)
#打印总体任务状态
print("everything is OK")
#返回最终汇总的数据框
return(myresult)
}
提供URL链接,运行我们构建的爬取功能:
myresult=getcontent(url)
[1] "page 0 is over!!!"
[1] "page 1 is over!!!"
[1] "page 2 is over!!!"
[1] "page 3 is over!!!"
[1] "everything is OK"
查看数据结构:
str(myresult)
规格变量类型:
<p>myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating
c 抓取网页数据( 5.ROBOT协议的基本语法:爬虫的网页抓取1.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-08 08:16
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/") # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫爬虫
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当一个页面的内容发生变化时,URL也会相应地发生变化。基本上,它是一个静态页面,反之则是一个动态页面。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请在html中文网站搜索之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c 抓取网页数据(
5.ROBOT协议的基本语法:爬虫的网页抓取1.)
import urllib.request # 私密代理授权的账户 user = "user_name" # 私密代理授权的密码 passwd = "uesr_password" # 代理IP地址 比如可以使用百度西刺代理随便选择即可 proxyserver = "177.87.168.97:53281" # 1. 构建一个密码管理对象,用来保存需要处理的用户名和密码 passwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm() # 2. 添加账户信息,第一个参数realm是与远程服务器相关的域信息,一般没人管它都是写None,后面三个参数分别是 代理服务器、用户名、密码 passwdmgr.add_password(None, proxyserver, user, passwd) # 3. 构建一个代理基础用户名/密码验证的ProxyBasicAuthHandler处理器对象,参数是创建的密码管理对象 # 注意,这里不再使用普通ProxyHandler类了 proxyauth_handler = urllib.request.ProxyBasicAuthHandler(passwdmgr) # 4. 通过 build_opener()方法使用这些代理Handler对象,创建自定义opener对象,参数包括构建的 proxy_handler 和 proxyauth_handler opener = urllib.request.build_opener(proxyauth_handler) # 5. 构造Request 请求 request = urllib.request.Request("http://bbs.pinggu.org/";) # 6. 使用自定义opener发送请求 response = opener.open(request) # 7. 打印响应内容 print (response.read())
5.ROBOT协议
在目标 URL 后添加 /robots.txt,例如:
第一个意思是,对于所有爬虫来说,它们不能在 /? 开头的路径无法访问匹配/pop/*.html的路径。
最后四个用户代理的爬虫不允许访问任何资源。
所以Robots协议的基本语法如下:
二、 爬虫爬虫
1.爬虫的目的
实现浏览器的功能,通过指定的URL直接返回用户需要的数据。
一般步骤:
2.网络分析
获取到相应的内容进行分析后,其实需要对一段文本进行处理,从网页中的代码中提取出你需要的内容。BeautifulSoup 可以实现通常的文档导航、搜索和修改文档功能。如果lib文件夹中没有BeautifulSoup,请使用命令行安装。
pip install BeautifulSoup
3.数据提取
# 想要抓取我们需要的东西需要进行定位,寻找到标志 from bs4 import BeautifulSoup soup = BeautifulSoup('',"html.parser") tag=soup.meta # tag的类别 type(tag) >>> bs4.element.Tag # tag的name属性 tag.name >>> 'meta' # attributes属性 tag.attrs >>> {'content': 'all', 'name': 'robots'} # BeautifulSoup属性 type(soup) >>> bs4.BeautifulSoup soup.name >>> '[document]' # 字符串的提取 markup='房产' soup=BeautifulSoup(markup,"lxml") text=soup.b.string text >>> '房产' type(text) >>> bs4.element.NavigableString
4.BeautifulSoup 应用实例
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml")
#通过页面解析得到结构数据进行处理 from bs4 import BeautifulSoup soup=BeautifulSoup(html.text,"lxml") #定位 lptable = soup.find('table',width='780') # 解析 for i in lptable.find_all("td",width="680"): title = i.b.strong.a.text href = "http://www.cwestc.com"+i.find('a')['href'] # href = i.find('a')['href'] date = href.split("/")[4] print (title,href,date)
4.Xpath 应用实例
XPath 是一种用于在 XML 文档中查找信息的语言。XPath 可用于遍历 XML 文档中的元素和属性。XPath 是 W3C XSLT 标准的主要元素,XQuery 和 XPointer 都建立在 XPath 表达式之上。
如何使用四个标签
from lxml import etree html=""" test NO.1NO.2NO.3 onetwo crossgatepinggu """ #这里使用id属性来定位哪个div和ul被匹配 使用text()获取文本内容 selector=etree.HTML(html) content=selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()') for i in content: print (i)
#这里使用//从全文中定位符合条件的a标签,使用“@标签属性”获取a便签的href属性值 con=selector.xpath('//a/@href') for i in con: print (i)
#使用绝对路径 #使用相对路径定位 两者效果是一样的 con=selector.xpath('/html/body/div/a/@title') print (len(con)) print (con[0],con[1])
三、动态网页和静态网页的区别
来源百度:
静态网页的基本概述
静态网页的 URL 形式通常以 .htm、.html、.shtml、.xml 等为后缀。静态网页一般是最简单的 HTML 网页。服务器和客户端是一样的,没有脚本和小程序,所以不能移动。在HTML格式的网页上,还可以出现各种动态效果,比如.GIF格式的动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点
动态网页的基本概述
动态网页以.asp、.jsp、.php、.perl、.cgi等形式后缀,并有一个符号——“?” 在动态网页 URL 中。动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画内容。这些仅针对网页的特定内容。表现形式,无论网页是否具有动态效果,通过动态网站技术生成的网页都称为动态网页。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,
动态网页应具备以下特点:
总结:当一个页面的内容发生变化时,URL也会相应地发生变化。基本上,它是一个静态页面,反之则是一个动态页面。
四、 动态网页和静态网页的爬取
1.静态网页
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=1" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
import requests from bs4 import BeautifulSoup url = "http://www.cwestc.com/MroeNews.aspx?gd=2" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text[1900:2000]
总结:以上两个网址的区别在于最后一个数字。在原创网页上的每个点,下一页的 URL 和内容同时更改。我们判断该网页为静态网页。
2.动态网页
import requests from bs4 import BeautifulSoup url = "http://news.cqcoal.com/blank/nl.jsp?tid=238" html = requests.get(url) soup = BeautifulSoup(html.text,"lxml") soup.text
如果抓取网页后看不到任何信息,则证明它是一个动态网页。正确的爬取方法如下。
import urllib import urllib.request import requests url = "http://news.cqcoal.com/manage/ ... ot%3B post_param = {'pageNum':'1',\ 'pageSize':'20',\ 'jsonStr':'{"typeid":"238"}'} return_data = requests.post(url,data =post_param) content=return_data.text content
至此,这篇教你如何使用Python快速爬取你需要的数据的文章就介绍完了。更多Python爬取数据相关内容,请在html中文网站搜索之前的文章或继续浏览下面的相关文章,希望大家以后多多支持html中文网站!
以上就是教大家如何使用Python快速抓取所需数据的详细内容。更多详情请关注其他相关html中文网站文章!
c 抓取网页数据(具体分析如下实现抓取和分析网页类,实例分析了抓取及分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-06 03:14
本文文章主要介绍了网页爬取分析的C#实现,并举例分析了C#对网页中的文字和连接进行抓取和分析的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页的纯文本,转到所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、 可以实现简单的表单提交和cookie保存
/* * Author:Sunjoy at CCNU * 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com) */ using System; using System.Data; using System.Configuration; using System.Net; using System.IO; using System.Text; using System.Collections.Generic; using System.Text.RegularExpressions; using System.Threading; using System.Web; /// /// 网页类 /// public class WebPage { #region 私有成员 private Uri m_uri; //网址 private List m_links; //此网页上的链接 private string m_title; //此网页的标题 private string m_html; //此网页的HTML代码 private string m_outstr; //此网页可输出的纯文本 private bool m_good; //此网页是否可用 private int m_pagesize; //此网页的大小 private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie private string m_post; //此网页的登陆页需要的POST数据 private string m_loginurl; //此网页的登陆页 #endregion #region 私有方法 /// /// 这私有方法从网页的HTML代码中分析出链接信息 /// /// List private List getLinks() { if (m_links.Count == 0) { Regex[] regex = new Regex[2]; regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, ""); Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg.Replace(m_outstr, ""); Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg2.Replace(m_outstr, " "); } return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr; } /// /// 此私有方法返回一个IP地址对应的无符号整数 /// /// IP地址 /// private uint getuintFromIP(IPAddress x) { Byte[] bt = x.GetAddressBytes(); uint i = (uint)(bt[0] * 256 * 256 * 256); i += (uint)(bt[1] * 256 * 256); i += (uint)(bt[2] * 256); i += (uint)(bt[3]); return i; } #endregion #region 公有文法 /// /// 此公有方法提取网页中一定字数的纯文本,包括链接文字 /// /// 字数 /// public string getContext(int firstN) { return getFirstNchar(m_html, firstN, true); } /// /// 此公有方法提取网页中一定字数的纯文本,不包括链接文字 /// /// /// public string getContextWithOutLink(int firstN) { return getFirstNchar(m_html, firstN, false); } /// /// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式 /// /// 正则式 /// 返回的链接的个数 /// List public List getSpecialLinksByUrl(string pattern,int count) { if(m_links.Count==0)getLinks(); List SpecialLinks = new List(); List.Enumerator i; i = m_links.GetEnumerator(); int cnt = 0; while (i.MoveNext() && cnt(?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ); Match mc = reg.Match(m_html); if (mc.Success) m_title= mc.Groups["title"].Value.Trim(); } return m_title; } } /// /// 此属性获得本网页的所有链接信息,只读 /// public List Links { get { if (m_links.Count == 0) getLinks(); return m_links; } } /// /// 此属性返回本网页的全部纯文本信息,只读 /// public string Context { get { if (m_outstr == "") getContext(Int16.MaxValue); return m_outstr; } } /// /// 此属性获得本网页的大小 /// public int PageSize { get { return m_pagesize; } } /// /// 此属性获得本网页的所有站内链接 /// public List InsiteLinks { get { return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue); } } /// /// 此属性表示本网页是否可用 /// public bool IsGood { get { return m_good; } } /// /// 此属性表示网页的所在的网站 /// public string Host { get { return m_uri.Host; } } /// /// 此网页的登陆页所需的POST数据 /// public string PostStr { get { return m_post; } } /// /// 此网页的登陆页 /// public string LoginURL { get { return m_loginurl; } } #endregion } /// /// 链接类 /// public class Link { public string url; //链接网址 public string text; //链接文字 public Link(string _url, string _text) { url = _url; text = _text; } }
我希望这篇文章对你的 C# 编程有所帮助。
以上就是爬取分析网页类示例的C#实现的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
c 抓取网页数据(具体分析如下实现抓取和分析网页类,实例分析了抓取及分析)
本文文章主要介绍了网页爬取分析的C#实现,并举例分析了C#对网页中的文字和连接进行抓取和分析的相关使用技巧。有一定的参考价值,有需要的朋友可以参考以下
本文介绍了爬取和分析网页的 C# 实现。分享给大家,供大家参考。具体分析如下:
以下是用于抓取和分析网页的类。
它的主要功能是:
1、 提取网页的纯文本,转到所有html标签和javascript代码
2、 提取网页链接,包括href、frame和iframe
3、 提取网页标题等(其他标签类推,规律相同)
4、 可以实现简单的表单提交和cookie保存
/* * Author:Sunjoy at CCNU * 如果您改进了这个类请发一份代码给我(ccnusjy 在gmail.com) */ using System; using System.Data; using System.Configuration; using System.Net; using System.IO; using System.Text; using System.Collections.Generic; using System.Text.RegularExpressions; using System.Threading; using System.Web; /// /// 网页类 /// public class WebPage { #region 私有成员 private Uri m_uri; //网址 private List m_links; //此网页上的链接 private string m_title; //此网页的标题 private string m_html; //此网页的HTML代码 private string m_outstr; //此网页可输出的纯文本 private bool m_good; //此网页是否可用 private int m_pagesize; //此网页的大小 private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie private string m_post; //此网页的登陆页需要的POST数据 private string m_loginurl; //此网页的登陆页 #endregion #region 私有方法 /// /// 这私有方法从网页的HTML代码中分析出链接信息 /// /// List private List getLinks() { if (m_links.Count == 0) { Regex[] regex = new Regex[2]; regex[0] = new Regex("(?m)]*>(?(\\w|\\W)*?)(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ).Replace(m_outstr, ""); if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr, ""); Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg.Replace(m_outstr, ""); Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+", RegexOptions.Multiline | RegexOptions.IgnoreCase); m_outstr = objReg2.Replace(m_outstr, " "); } return m_outstr.Length > firstN ? m_outstr.Substring(0, firstN) : m_outstr; } /// /// 此私有方法返回一个IP地址对应的无符号整数 /// /// IP地址 /// private uint getuintFromIP(IPAddress x) { Byte[] bt = x.GetAddressBytes(); uint i = (uint)(bt[0] * 256 * 256 * 256); i += (uint)(bt[1] * 256 * 256); i += (uint)(bt[2] * 256); i += (uint)(bt[3]); return i; } #endregion #region 公有文法 /// /// 此公有方法提取网页中一定字数的纯文本,包括链接文字 /// /// 字数 /// public string getContext(int firstN) { return getFirstNchar(m_html, firstN, true); } /// /// 此公有方法提取网页中一定字数的纯文本,不包括链接文字 /// /// /// public string getContextWithOutLink(int firstN) { return getFirstNchar(m_html, firstN, false); } /// /// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式 /// /// 正则式 /// 返回的链接的个数 /// List public List getSpecialLinksByUrl(string pattern,int count) { if(m_links.Count==0)getLinks(); List SpecialLinks = new List(); List.Enumerator i; i = m_links.GetEnumerator(); int cnt = 0; while (i.MoveNext() && cnt(?(?:\w|\W)*?)]*>", RegexOptions.Multiline | RegexOptions.IgnoreCase ); Match mc = reg.Match(m_html); if (mc.Success) m_title= mc.Groups["title"].Value.Trim(); } return m_title; } } /// /// 此属性获得本网页的所有链接信息,只读 /// public List Links { get { if (m_links.Count == 0) getLinks(); return m_links; } } /// /// 此属性返回本网页的全部纯文本信息,只读 /// public string Context { get { if (m_outstr == "") getContext(Int16.MaxValue); return m_outstr; } } /// /// 此属性获得本网页的大小 /// public int PageSize { get { return m_pagesize; } } /// /// 此属性获得本网页的所有站内链接 /// public List InsiteLinks { get { return getSpecialLinksByUrl("^http://"+m_uri.Host,Int16.MaxValue); } } /// /// 此属性表示本网页是否可用 /// public bool IsGood { get { return m_good; } } /// /// 此属性表示网页的所在的网站 /// public string Host { get { return m_uri.Host; } } /// /// 此网页的登陆页所需的POST数据 /// public string PostStr { get { return m_post; } } /// /// 此网页的登陆页 /// public string LoginURL { get { return m_loginurl; } } #endregion } /// /// 链接类 /// public class Link { public string url; //链接网址 public string text; //链接文字 public Link(string _url, string _text) { url = _url; text = _text; } }
我希望这篇文章对你的 C# 编程有所帮助。
以上就是爬取分析网页类示例的C#实现的详细内容。更多详情请关注其他相关html中文网站文章!
c 抓取网页数据(图里面的内容1.解析()并发请求中的node )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-05 16:08
)
获取下图内容
1.在当前网页右击查看,不能按图中标签进入leader介绍页面。
2.分析网页信息,发现请求如下
3.右键查看网页源码,发现请求中的node_id和cat_id参数是源码中js的变量,所以我们要解析这些变量,拼接url并发请求获取我们需要的数据
4.解析js部分的代码
def parse_url(self, response):
node_id = re.findall('var node_id = "(.*?)";', response.text)
res_str = re.findall("var zTreeNodes = (.*?);", response.text)
if res_str:
node_id = node_id[0]
res_json = json.loads(res_str[0])
# print("res_json=",res_json)
for res in res_json:
id = str(res['id'])
name = res['text']
url = 'http://www.snbinzhou.gov.cn/in ... 39%3B + node_id + '&cat_id=' + id
if “领导” in name:
yield Request(url,call_back=self.parse_detail,meta={"item":response.meta['item']}) 查看全部
c 抓取网页数据(图里面的内容1.解析()并发请求中的node
)
获取下图内容
1.在当前网页右击查看,不能按图中标签进入leader介绍页面。
2.分析网页信息,发现请求如下
3.右键查看网页源码,发现请求中的node_id和cat_id参数是源码中js的变量,所以我们要解析这些变量,拼接url并发请求获取我们需要的数据
4.解析js部分的代码
def parse_url(self, response):
node_id = re.findall('var node_id = "(.*?)";', response.text)
res_str = re.findall("var zTreeNodes = (.*?);", response.text)
if res_str:
node_id = node_id[0]
res_json = json.loads(res_str[0])
# print("res_json=",res_json)
for res in res_json:
id = str(res['id'])
name = res['text']
url = 'http://www.snbinzhou.gov.cn/in ... 39%3B + node_id + '&cat_id=' + id
if “领导” in name:
yield Request(url,call_back=self.parse_detail,meta={"item":response.meta['item']})
c 抓取网页数据(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-04 23:10
缺点:
只检索页面的静态内容
不能用于解析 HTML
无法处理纯 JavaScript 网站
2.lxml
lxml 是一个高性能、快速、高质量和高效的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算爬取大数据集的时候,它可以起到很好的作用。
在网络爬虫中,lxml 经常与 Requests 结合使用。此外,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python 库的优缺点是什么?
优势:
比大多数解析器更快
光
使用元素树
蟒蛇式API
缺点:
不适合设计糟糕的 HTML
官方文档不适合初学者
3.美汤
BeautifulSoup 可能是网络抓取中使用最广泛的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。它还自动将传入文档转换为 Unicode,将传出文档转换为 UTF-8。
在业界,“BeautifulSoup”和“Requests”的结合非常常见。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,您还可以将 Beautiful Soup 与其他解析器(如 lxml)结合使用。
但是相应的,这种易用性也带来了不小的运行成本——比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面看看BeautifulSoup库的优缺点是什么?
优势:
需要几行代码
质量文件
初学者易于学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您无法轻松地从动态填充的 网站 中获取数据。
发生这种情况的原因有时是因为页面上存在的数据是通过 JavaScript 加载的。简单总结一下,如果页面不是静态的,前面提到的Python库就很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。
Selenium 最初是一个 Python 库,用于自动测试 Web 应用程序。它是一个用于渲染网页的网络驱动程序。因此,Selenium 可以在其他库无法运行 JavaScript 的情况下发挥作用:单击页面、填写表单、滚动页面并执行更多操作。
这种在网页中运行 JavaScript 的能力允许 Selenium 抓取动态填充的网页。但这里有一个“缺陷”。它为每个页面加载并运行 JavaScript,这会使其变慢并且不适合大型项目。
如果你不在乎时间和速度,那么Selenium绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动浏览器
可以对网页进行任何操作,类似于一个人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. Scrapy
现在是时候介绍一下 Python 网页抓取库的 BOSS 了——Scrapy!
Scrapy 不仅仅是一个库。它是由 Scrapinghub、Pablo Hoffman 和 Shane Evans 的联合创始人创建的整个网络抓取框架。它是一个功能齐全的网页抓取解决方案,可以完成所有繁重的工作。
Scrapy提供的蜘蛛机器人可以抓取多个网站并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或将其用作 API。您可以在几分钟内创建一个功能齐全的蜘蛛网,或者您可以使用 Scrapy 创建一个管道。
Scrapy 最大的优点是它是异步的,这意味着可以同时进行多个 HTTP 请求,这样可以为我们节省大量时间并提高效率(这不是我们在争取的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。尽管 Scrapy 不能像 selenium 一样处理 JavaScript,但它可以与一个名为 Splash(一个轻量级的 Web 浏览器)的库搭配使用。使用 Splash,Scrapy 可以从动态的 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他的库可以很好用,欢迎留言~
原文链接: 查看全部
c 抓取网页数据(综合看下BeautifulSoup库的优缺点有哪些?优点是什么?)
缺点:
只检索页面的静态内容
不能用于解析 HTML
无法处理纯 JavaScript 网站
2.lxml
lxml 是一个高性能、快速、高质量和高效的 HTML 和 XML 解析 Python 库。
它结合了 ElementTree 的速度和功能以及 Python 的简单性。当我们打算爬取大数据集的时候,它可以起到很好的作用。
在网络爬虫中,lxml 经常与 Requests 结合使用。此外,它还允许使用 XPath 和 CSS 选择器从 HTML 中提取数据。
lxml Python 库的优缺点是什么?
优势:
比大多数解析器更快
光
使用元素树
蟒蛇式API
缺点:
不适合设计糟糕的 HTML
官方文档不适合初学者
3.美汤
BeautifulSoup 可能是网络抓取中使用最广泛的 Python 库。它创建用于解析 HTML 和 XML 文档的解析树。它还自动将传入文档转换为 Unicode,将传出文档转换为 UTF-8。
在业界,“BeautifulSoup”和“Requests”的结合非常常见。
BeautifulSoup 如此受欢迎的主要原因之一是它易于使用且非常适合初学者。同时,您还可以将 Beautiful Soup 与其他解析器(如 lxml)结合使用。
但是相应的,这种易用性也带来了不小的运行成本——比lxml慢。即使使用 lxml 作为解析器,它也比纯 lxml 慢。
下面我们来全面看看BeautifulSoup库的优缺点是什么?
优势:
需要几行代码
质量文件
初学者易于学习
强大的
自动编码检测
缺点:
比 lxml 慢
4. 硒
到目前为止,我们讨论的所有 Python 库都有一个限制:您无法轻松地从动态填充的 网站 中获取数据。
发生这种情况的原因有时是因为页面上存在的数据是通过 JavaScript 加载的。简单总结一下,如果页面不是静态的,前面提到的Python库就很难从页面中抓取数据。
在这种情况下,使用 Selenium 更合适。
Selenium 最初是一个 Python 库,用于自动测试 Web 应用程序。它是一个用于渲染网页的网络驱动程序。因此,Selenium 可以在其他库无法运行 JavaScript 的情况下发挥作用:单击页面、填写表单、滚动页面并执行更多操作。
这种在网页中运行 JavaScript 的能力允许 Selenium 抓取动态填充的网页。但这里有一个“缺陷”。它为每个页面加载并运行 JavaScript,这会使其变慢并且不适合大型项目。
如果你不在乎时间和速度,那么Selenium绝对是一个不错的选择。
优势:
初学者友好
自动网页抓取
可以抓取动态填充的网页
自动浏览器
可以对网页进行任何操作,类似于一个人
缺点:
非常慢
设置困难
高 CPU 和内存使用率
不适合大型项目
5. Scrapy
现在是时候介绍一下 Python 网页抓取库的 BOSS 了——Scrapy!
Scrapy 不仅仅是一个库。它是由 Scrapinghub、Pablo Hoffman 和 Shane Evans 的联合创始人创建的整个网络抓取框架。它是一个功能齐全的网页抓取解决方案,可以完成所有繁重的工作。
Scrapy提供的蜘蛛机器人可以抓取多个网站并提取数据。使用 Scrapy,您可以创建自己的蜘蛛机器人,将其托管在 Scrapy Hub 上,或将其用作 API。您可以在几分钟内创建一个功能齐全的蜘蛛网,或者您可以使用 Scrapy 创建一个管道。
Scrapy 最大的优点是它是异步的,这意味着可以同时进行多个 HTTP 请求,这样可以为我们节省大量时间并提高效率(这不是我们在争取的吗?)。
我们还可以向 Scrapy 添加插件以增强其功能。尽管 Scrapy 不能像 selenium 一样处理 JavaScript,但它可以与一个名为 Splash(一个轻量级的 Web 浏览器)的库搭配使用。使用 Splash,Scrapy 可以从动态的 网站 中提取数据。
优势:
异步
优秀的文档
各种插件
创建自定义管道和中间件
CPU 和内存使用率低
精心设计的架构
大量可用的在线资源
缺点:
更高的学习门槛
工作过于轻松
不适合初学者
这些是我个人认为非常有用的 Python 库。如果还有其他的库可以很好用,欢迎留言~
原文链接:
c 抓取网页数据(IT从业者快速学习JSON教程结构概述:JSON基础教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-04 22:05
了解 JSON:
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。
从 Web API 和服务器端编程语言到 NoSQL 数据库和客户端框架,JSON 无处不在。在不同平台之间传输数据方面,JSON 已成为 XML 的强大替代品。本教程将帮助忙碌的 IT 从业者快速学习 JSON,并深入了解如何在自己的项目中使用它。
JSON教程结构概述:
本教程由 11 章组成。详细介绍了JSON的基本使用方法,并附送大量在线试运行示例,助你学习,让你轻松掌握JSON。
本教程包括:
1、JSON 简介
2、JSON 基础知识
3、JSON 格式
4、JSON 示例
5、JSON 解析
6、JSON 遍历
7、JSON 调用
8、JSON 转换
9、JSON 获取
10、JSON 字符串
11、JSON 数组
JSON开发与学习前的准备:
JSON 由 Douglas Crockford 在 2001 年创建,并被 IETF(互联网工程任务组)定义为 RFC 4627 标准。JSON的媒体类型定义为application/json,文件后缀为.json。2005年到2006年正式成为主流数据格式,雅虎和谷歌当时开始广泛使用JSON格式。
在开始学习 JSON 之前,您应该对以下内容有一个基本的了解:
《AJAX 教程》
《JQuery 教程》
本教程旨在帮助初学者了解 JavaScript Object Notation (JSON) 开发数据交换格式的基本功能。完成本教程后,您会发现自己处于在 JavaScript、AJAX 和 Perl 中使用 JSON 的中级水平,然后您可以自己进入下一个级别。
JSON 的优缺点:
优势:
A.数据格式比较简单,易读易写,格式经过压缩,带宽小;
B. 解析简单,客户端JavaScript可以简单的通过eval()读取JSON数据;
C、支持多种语言,包括ActionScript、C、C#、ColdFusion、Java、JavaScript、Perl、PHP、Python、Ruby等服务端语言,方便服务端分析;
D、在PHP世界中,出现了PHP-JSON和JSON-PHP。他们更喜欢在 PHP 序列化后直接调用。PHP服务端的对象和数组可以直接生成JSON格式,方便客户端访问和提取;
E、由于JSON格式可以直接用于服务端代码,大大简化了服务端和客户端的代码开发量,任务完成情况不变,易于维护。
缺点:
A.没有XML格式这样的普及普及,不如XML通用;
B. JSON 格式在 Web Service 中的推广还处于起步阶段。
相关网址:
json中文官网:
json官网:
json参考手册:(翻译)JSON-RPC 2.0 规范(中文版) 查看全部
c 抓取网页数据(IT从业者快速学习JSON教程结构概述:JSON基础教程)
了解 JSON:
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。JSON 使用完全独立于语言的文本格式,但也使用类似于 C 语言家族(包括 C、C++、C#、Java、JavaScript、Perl、Python 等)的习惯。这些特性使 JSON 成为一种理想的数据交换语言。便于人读写,也便于机器解析生成(通常用于提高网络传输速率)。
从 Web API 和服务器端编程语言到 NoSQL 数据库和客户端框架,JSON 无处不在。在不同平台之间传输数据方面,JSON 已成为 XML 的强大替代品。本教程将帮助忙碌的 IT 从业者快速学习 JSON,并深入了解如何在自己的项目中使用它。
JSON教程结构概述:
本教程由 11 章组成。详细介绍了JSON的基本使用方法,并附送大量在线试运行示例,助你学习,让你轻松掌握JSON。
本教程包括:
1、JSON 简介
2、JSON 基础知识
3、JSON 格式
4、JSON 示例
5、JSON 解析
6、JSON 遍历
7、JSON 调用
8、JSON 转换
9、JSON 获取
10、JSON 字符串
11、JSON 数组
JSON开发与学习前的准备:
JSON 由 Douglas Crockford 在 2001 年创建,并被 IETF(互联网工程任务组)定义为 RFC 4627 标准。JSON的媒体类型定义为application/json,文件后缀为.json。2005年到2006年正式成为主流数据格式,雅虎和谷歌当时开始广泛使用JSON格式。
在开始学习 JSON 之前,您应该对以下内容有一个基本的了解:
《AJAX 教程》
《JQuery 教程》
本教程旨在帮助初学者了解 JavaScript Object Notation (JSON) 开发数据交换格式的基本功能。完成本教程后,您会发现自己处于在 JavaScript、AJAX 和 Perl 中使用 JSON 的中级水平,然后您可以自己进入下一个级别。
JSON 的优缺点:
优势:
A.数据格式比较简单,易读易写,格式经过压缩,带宽小;
B. 解析简单,客户端JavaScript可以简单的通过eval()读取JSON数据;
C、支持多种语言,包括ActionScript、C、C#、ColdFusion、Java、JavaScript、Perl、PHP、Python、Ruby等服务端语言,方便服务端分析;
D、在PHP世界中,出现了PHP-JSON和JSON-PHP。他们更喜欢在 PHP 序列化后直接调用。PHP服务端的对象和数组可以直接生成JSON格式,方便客户端访问和提取;
E、由于JSON格式可以直接用于服务端代码,大大简化了服务端和客户端的代码开发量,任务完成情况不变,易于维护。
缺点:
A.没有XML格式这样的普及普及,不如XML通用;
B. JSON 格式在 Web Service 中的推广还处于起步阶段。
相关网址:
json中文官网:
json官网:
json参考手册:(翻译)JSON-RPC 2.0 规范(中文版)
c 抓取网页数据(如何查看二级页面(详情页)的三连数据?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-04 01:19
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单。可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["./ranking/all/1/0/3"],"selectors":[{"id":"container","type": "SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type ":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id" :"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0 },{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":"。
详细信息> span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type": "SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay" :0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay" :0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.
collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“跨度。share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors": ["容器"],"选择器":"div. num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“。操作范围。喜欢","multiple":false,"regex":"","
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。 查看全部
c 抓取网页数据(如何查看二级页面(详情页)的三连数据?-八维教育)
如果这样做,实际上可以抓取所有已知的列表数据,但本文的重点是:如何抓取二级页面(详细信息页面)的三元组数据?
做了这么多爬虫,你可能已经发现,Web Scraper的本质就是模拟人的操作,达到爬取数据的目的。
那么我们平时如何查看二级页面(详情页)呢?其实直接点击标题链接即可跳转:
Web Scraper为我们提供了点击链接跳转的功能,即Type为Link的选择器。
感觉有点抽象?让我们通过示例进行比较以理解。
首先,在这种情况下,我们得到了标题的文本,此时的选择器类型为Text:
当我们想要获取一个链接时,我们必须创建另一个选择器。选中的元素是一样的,但是Type是Link:
创建成功后,我们点击Link type选择器,输入,然后创建相关选择器。下面我录了个动图。注意我的鼠标突出显示的导航路线部分。这可以很明显的看出几个选择器的层次关系:
4.创建详情页子选择器
当您点击链接时,您会发现浏览器会在一个新的Tab页中打开详情页,但是在列表页上打开了Web Scraper选择窗口,您无法跨页面选择所需的数据。
处理这个问题也很简单。可以复制详情页的链接,复制到列表页所在的Tab页,按回车重新加载,这样就可以在当前页面选中了。
我们在 Link 类型的选择器中创建了更多的选择器。这里我选择了4个数据,比如点赞数、硬币数、采集数和分享数。这个操作也很简单,这里就不赘述了。
所有选择器的结构图如下:
我们可以看到video_detail_link节点收录了4个二级页面(detail pages)的数据。至此,我们的子选择器已经全部建立。
5.获取数据
终于到了激动人心的部分,我们即将开始爬取数据。但是在爬行之前,我们需要把等待时间调大一点,默认时间是2000ms,我这里改成了5000ms。
你为什么这么做?看下图你就明白了:
首先,每次打开二级页面,都是一个全新的页面。这时候浏览器加载网页需要时间;
其次,我们可以观察到要捕获的点赞量等数据。页面刚加载时,它的值为“--”,过一会就变成一个数字。
所以,我们只等5000ms,等页面和数据加载完毕后,一起爬取。
配置好参数后,我们就可以正式抓取下载了。下图是我抓到的部分数据,特此证明这个方法有用:
6.总结
本教程可能有点困难。我将分享我的站点地图。如果在制作时遇到问题,可以参考我的配置。我在第六个教程中详细讲解了SiteMap导入的功能。可以一起吃。:
{"_id":"bilibili_rank","startUrl":["./ranking/all/1/0/3"],"selectors":[{"id":"container","type": "SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type ":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id" :"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0 },{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":"。
详细信息> span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type": "SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay" :0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay" :0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.
collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“跨度。share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors": ["容器"],"选择器":"div. num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"], “选择器”:“。操作范围。喜欢","multiple":false,"regex":"","
一旦掌握了二级页面的抓取方式,三级、四级页面就没有问题了。因为例程是相同的:数据是在链接选择器指向的下一页上捕获的。因为原理是一样的,我就不演示了。
c 抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏之处! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-01 23:01
)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,我要温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只在csdn平台更新,博客主页:。
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载!!!
内容
前言
网络爬虫的一般流程
一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:
二、常用的获取网页数据的方法2.1 URLlib
下面我们先来看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com")
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣的可以自行查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout: 释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {
},origin_req_host = None,unverifiable = False,method = None)
详细代码:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {
"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、开瓶器
开场导演:
5、饼干
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com")
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。推荐爬虫使用Requests库。
官方文档链接:
1、请求库安装
在终端中运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {
'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {
'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
从上图我们可以看出,方法名把请求表达的很清楚,get就是GET,post就是POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,requests会自动读取响应的内容并保存在text变量中。您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了以上信息,响应还提供了很多其他信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {
'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {
'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大多数用途类似于 urllib2。此外,请求的文档非常完整。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能会有人感到惊讶,因为在上一篇文章中,当我们使用urllib2发起同样的请求时,结果还是空的。这确实有点奇怪,因为 urllib2 默认会忽略所有请求的 cookie,即使是重定向的请求,请求也会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {
'http':'http://username:[email protected]:port','http://username:[email protected]:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得之前在urllib2上的练习都是徒劳的,因为requests非常简单易学!当然也没有白费,urllib2是一个非常基础的网络库,其他很多网络库,包括requests,都是基于urllib2开发的。我们之前进行的练习将帮助我们更好地理解网络,了解Python对网络的处理,这对我们未来开发可靠高效的爬虫有很大的帮助。
需要注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要把它转换成中文。无法直接打印。因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符串编码成UTF-8字符串最终转换为 dict 以便于输出。
三、浏览器简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图:
在这个页面调出Chrome Inspect,我们可以看到类似如下的界面:
通常我们最常用的功能是查看某个元素的源代码,点击左上角的元素定位器,可以在网页中选择不同的元素,HTML源代码区会自动显示指定的源代码元素,通常CSS显示区域也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择网络,可以看到如下界面:
Chrome 网络的交互区域展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,可以看到如下界面:
在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 KV 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示接收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
401 Authentication Required:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:未找到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,但使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后再试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略,响应状态码代表服务器的处理结果,对于我们调整服务器的爬虫状态(如频率、ip)有重要的参考意义。履带。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候我们就得减慢爬取频率,或者重启Session,甚至更改IP。
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
一本好书永远不会厌倦阅读一百遍。而如果我想成为全场最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人运气不会太差,每天都充满活力!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!
查看全部
c 抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏之处!
)
大家好,我不温柔,我是计算机学院大数据专业的大三学生。我的外号来自一个成语——不温柔,我要温柔的气质。博主作为互联网行业的新手,写博客一方面记录自己的学习过程,另一方面总结自己犯过的错误,希望能帮助到很多刚入门的年轻人他是。不过由于水平有限,博客难免会出现一些错误。如有疏漏,希望大家多多指教!暂时只在csdn平台更新,博客主页:。
PS:随着越来越多的人未经本人同意直接爬到博主文章,博主特此声明:未经本人许可禁止转载!!!
内容
前言
网络爬虫的一般流程
一、了解网址
基本 URL 收录以下内容:
模式(或协议)、服务器名(或IP地址)、路径和文件名,如“protocol://authorization/path?query”。带有授权部分的完整统一资源标识符语法如下所示:协议://用户名:密码@子域名。域名。顶级域名:端口号/目录/文件名。文件后缀?参数=值#符号。
例如:
二、常用的获取网页数据的方法2.1 URLlib
下面我们先来看一个小demo
# 百度首页
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com";)
html = response.read().decode("utf-8")
print(html)
2.2、urllib.request
官方文档(有兴趣的可以自行查看):
1、urllib.request.urlopen
urllib.request.urlopen(url,data = None,[timeout,]*,cafile = None, capath = None, cadefault = False,context = None)
timeout: 释放链接的超时时间
cafile/capath/cadefault:CA认证参数,用于HTTPS协议
上下文:SSL 链接选项,用于 HTTPS
2、urllib.request.Request
urllib.request.Request(url,data = None,headers = {
},origin_req_host = None,unverifiable = False,method = None)
详细代码:
# coding=utf-8
from urllib import request
from urllib.parse import urlparse
url = "http://httpbin.org/post"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
dict = {
"name":"buwenbuhuo"}
data = bytes(urllib.parse.urlencode(dict),encoding = "utf8")
req = request.Request(url=url,data=data,headers=headers,method="POST")
response = request.urlopen(req)
print(response.read().decode("utf-8"))
3、urllib.request 的高级特性
urllib.request 几乎可以做任何 HTTP 请求中的所有事情:
4、开瓶器
开场导演:
5、饼干
示例:获取百度 Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open("http://www.baidu.com";)
for item in cookie:
print(item.name+"="+item.value)
filename = 'cookie.txt'
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard=True, ignore_expires=True)
2.3、请求库
Requests 是基于 urllib 用 python 语言编写的,使用 Apache2 Licensed 开源协议的 HTTP 库。与 urllib 相比,Requests 更方便,可以为我们节省很多工作。推荐爬虫使用Requests库。
官方文档链接:
1、请求库安装
在终端中运行以下命令:pip install requests
2、使用请求发起请求
import requests
import json
# 用requests发起简单的GET请求
url_get = 'http://httpbin.org/get'
response = requests.get(url_get,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests发起带参数的GET请求
kvs = {
'k1':'v1','k2':'v2'}
response = requests.get(url_get,params=kvs,timeout = 5)
print(json.loads(response.text)['args'])
# 用requests 发起POST 请求
url_post = 'http://httpbin.org/post'
kvs = {
'k1':'v1','k2':'v2'}
response = requests.post(url_post,data=kvs,timeout = 5)
print(response.json()['form'])
从上图我们可以看出,方法名把请求表达的很清楚,get就是GET,post就是POST。不仅如此,我们可能得到的响应非常强大,可以直接获取很多信息,而且响应中的内容不是一次性的,requests会自动读取响应的内容并保存在text变量中。您可以根据需要多次阅读。其次,我们来看看响应中的有用信息:
print(response.url)
print(response.status_code)
print(response.headers)
print(response.cookies)
print(response.encoding) # requests会自动猜测响应内容的编码
import json
print(response.json() == json.loads(response.text)) # response.text 是响应内容,可以读取任意次,并且requests可以自动转换json
requests = response.request # 可以直接获取response对应的request
print(response.url)
print(response.headers) # 我们发起的request 是什么样子的一目了然
除了以上信息,响应还提供了很多其他信息。另外,request除了get和post之外,还提供了显式的put、delete、head、options方法,分别对应对应的HTTP方法。有兴趣的读者可以深入探讨。
3、Requests 库发起 POST 请求
这部分截取自官方文档:
通常,如果你想发送一些表单编码的数据——非常类似于 HTML 表单。为此,只需将字典传递给 data 参数。发出请求后,您的数据字典将自动对表单进行编码:
>>> payload = {
'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("https://httpbin.org/post", data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
data 参数对于每个键也可以有多个值。这可以通过创建数据元组列表或以列表作为值的字典来完成。当表单有多个使用相同键的元素时,这尤其有用:
import requests
>>> payload_tuples = [('key1', 'value1'), ('key1', 'value2')]
>>> r1 = requests.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {
'key1': ['value1', 'value2']}
>>> r2 = requests.post('https://httpbin.org/post', data=payload_dict)
>>> print(r1.text)
{
...
"form": {
"key1": [
"value1",
"value2"
]
},
...
}
>>> r1.text == r2.text
True
4、requests.Session
import requests
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('https://httpbin.org/cookies/set/sessioncookie/123456789')
# 用session对象发出另外一个get请求,获取cookies
r = s.get('https://httpbin.org/cookies')
# 显示结果
print(r.text)
请求的大多数用途类似于 urllib2。此外,请求的文档非常完整。这里我们主要讲解请求最强大最常用的功能:会话保留。上面的代码中,如果我们连续发起两次请求都没有关系,会导致部分数据不可用。喜欢:
import requests
url_cookies = 'http://httpbin.org/cookies'
url_set_cookies = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
可以看到,调用url_set_cookies设置cookie前后发起的GET请求获取的cookie都是空的。这说明不同的请求之间没有关系。上面代码中第5行的输出可能会有人感到惊讶,因为在上一篇文章中,当我们使用urllib2发起同样的请求时,结果还是空的。这确实有点奇怪,因为 urllib2 默认会忽略所有请求的 cookie,即使是重定向的请求,请求也会在请求中保存 cookie(url_set_cookies 请求收录重定向请求)。
以下代码可以在一个会话中保留多个请求:
session = requests.Session()
print(requests.get(url_cookies,timeout = 5).json())
print(requests.get(url_set_cookies,timeout = 5).json())
print(requests.get(url_cookies,timeout = 5).json())
我们现在可以看到我们的第三个请求收录第二个请求设置的 cookie!是不是很简单。其实requests的内部cookies也用到了cookielib,有兴趣的同学可以深入探讨。
请求库的特点:
6、设置代理
import requests
url = 'http://httpbin.org/cookies/set?k1=v1&k2=v2'
proxies = {
'http':'http://username:[email protected]:port','http://username:[email protected]:port'}
print(requests.get(url,proxies = proxies,timeout = 5).json()['args'])
# 上面的方法要给每个请求都要加上proxies参数,比较繁琐,可以为每个session设置一个默认的proxies
session = requests.Session()
session.proxies = proxies # 一个session中的所有请求都使用同一套代理
print(session.get(url,timeout = 5).json()['args'])
当然上面的代码是不能运行的,因为代理的格式不对。当我们需要的时候,直接重用这段代码就行了。你可能会觉得之前在urllib2上的练习都是徒劳的,因为requests非常简单易学!当然也没有白费,urllib2是一个非常基础的网络库,其他很多网络库,包括requests,都是基于urllib2开发的。我们之前进行的练习将帮助我们更好地理解网络,了解Python对网络的处理,这对我们未来开发可靠高效的爬虫有很大的帮助。
需要注意的是:
响应中的内容以 unicode 编码。为了方便阅读,我们需要把它转换成中文。无法直接打印。因为python在将dict转换为字符串时保留了unicide编码,所以直接打印的不是中文。
这里我们使用另一种转换方法:先将得到的form dict转换成unicode字符串(注意ensure_ascii=False参数,表示unicode字符没有转义),然后将得到的unicode字符串编码成UTF-8字符串最终转换为 dict 以便于输出。
三、浏览器简介
Chrome 提供了检查网页元素的功能,称为 Chrome Inspect。您可以在网页上右键查看该功能,如下图:
在这个页面调出Chrome Inspect,我们可以看到类似如下的界面:
通常我们最常用的功能是查看某个元素的源代码,点击左上角的元素定位器,可以在网页中选择不同的元素,HTML源代码区会自动显示指定的源代码元素,通常CSS显示区域也会显示这个应用于元素的样式。Chrome Inspect 比较常用的功能是监控网络交互过程。在功能栏中选择网络,可以看到如下界面:
Chrome 网络的交互区域展示了一个网页加载过程以及浏览器发起的所有请求。选择一个请求,右侧会显示请求的详细信息,包括请求头、响应头、响应内容等。Chrome网络是我们研究网页交互过程的重要工具。Cookie 和 Session 是重要的网络技术。您还可以在 Chrome Inspect 中查看网络 cookie。在功能栏中选择应用,可以看到如下界面:
在 Chrome 应用程序的左侧选择 Cookies,您可以看到以 KV 形式保存的 cookie。这个功能在我们研究网页的登录过程时非常有用。需要注意的是,在研究一个完整的网络交互过程之前,记得右键点击Cookies,然后点击Clear清除所有旧的Cookies。
HTTP 响应的第一行,即状态行,收录状态代码。状态码由三位数字组成,表示服务器对客户端请求的处理结果。状态码分为以下几类:
1xx:信息响应类型,表示接收到请求并继续处理
2xx:处理成功响应类,表示动作成功接收、理解和响应
3xx:重定向响应类,为了完成指定的动作,必须进行进一步的处理
4xx:客户端错误,客户端请求收录语法错误或服务器无法理解
5xx:服务器错误,服务器无法正确执行有效请求
以下是一些常见的状态代码及其说明:
200 OK:请求已被正确处理和响应。
301 Move Permanently:永久重定向。
302 Move Temporously:临时重定向。
400 Bad Request:服务器无法理解请求。
401 Authentication Required:需要验证用户身份。
403 Forbidden:禁止访问资源。
404 Not Found:未找到资源。
405 Method Not Allowed:对资源使用了错误的方法。例如,应该使用POST,但使用PUT。
408 请求超时:请求超时。
500 内部服务器错误:内部服务器错误。
501 方法未实现:请求方法无效。如果可能,将 GET 写为 Get。
502 Bad Gateway:网关或代理收到来自上游服务器的错误响应。
503 Service Unavailable:服务暂时不可用,您可以稍后再试。
504 Gateway Timeout:网关或代理请求上游服务器超时。
在实际应用中,大部分网站都有反爬虫策略,响应状态码代表服务器的处理结果,对于我们调整服务器的爬虫状态(如频率、ip)有重要的参考意义。履带。比如我们一直正常运行的爬虫,突然收到403响应。这可能是因为服务器识别了我们的爬虫并拒绝了我们的请求。这时候我们就得减慢爬取频率,或者重启Session,甚至更改IP。
美好的日子总是短暂的。虽然我还想继续和你谈谈,但这篇博文现在已经结束了。如果还不够,别着急,我们下篇文章见!
一本好书永远不会厌倦阅读一百遍。而如果我想成为全场最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“采集”!听说喜欢的人运气不会太差,每天都充满活力!如果你真的想当妓女,祝你天天开心,欢迎访问我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!
c 抓取网页数据(百度收录网站,如何使用数据抓取数据的速度怎样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-01 22:25
实现如下:
示例·:一个excel文件收录一百多个工作表,但工作表名称没有规则的顺序,不是按sheet1、sheet2的顺序排列的。现在我们需要将每个工作表中的A3数据提取出来,形成一个新的列。
解决方案:使用宏自定义函数
同时按下Alt和F11进入宏界面,点击菜单插入,屏蔽,粘贴如下代码:
Function AllSh(xStr As String, i As Integer)
应用程序.易变
AllSh = Sheets(i).Range(xStr).Value
结束函数
回到excel,在任意单元格输入=allsh("A3",ROW(A1))
公式被复制下来。
在数据库中,data采集和data capture是什么意思?
个人理解:
数据采集分为多种类型。比如从纸质或非结构化数据整理成结构化数据可以存入数据库的过程,可以算作一种数据采集;将数据从某个数据库导出到另一个数据库也可以看成是一种数据采集; 比如通过观察记录获得某些环境指标(空气质量、温度、湿度、人体温度、机器cpu占用率等)变化的过程也可以看作是一种数据采集和很快。简而言之,一种数据存在形式通过“某种加工”转化为另一种数据存在形式。我个人认为所谓的“某些处理”统称为数据采集。
经常使用术语数据捕获,例如 Web 内容数据捕获。从某种意义上说,它与数据采集具有相同的含义,但在本质上,数据主体似乎有主动和被动的区别。. 当然,数据捕获更多的是指从现有的结构化数据中获取数据的过程。
如何使用C语言进行数据爬取 数据爬取的速度是多少?
百度收录网站,首先让百度蜘蛛来爬网站,要做的就是吸引百度蜘蛛爬网站,主要有以下几点做好的步骤:
1、 识别URL重定向,互联网信息数据量非常大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛重新上报网址。定向识别
2、为了抓取网站的友好性,百度蜘蛛会制定规则,最大限度地利用带宽和所有资源,以便在抓取互联网信息时获得越来越准确的信息,同时也只最小化爬取的网站的压力。
3、 在抓取作弊信息时,我们经常会遇到页面质量低、买卖链接等问题。百度引入了绿萝、石榴等算法进行过滤。据说里面还有一些其他的方法。判断,这些方法还没有对外公开。
4、 无法获取爬取数据,网络中可能出现各种问题,导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开放了手动提交数据。
5、 合理使用百度蜘蛛抓取优先级。由于互联网信息量巨大,在这种情况下无法使用一种策略来指定首先抓取哪些内容。这时候就需要建立多个优先级的Grabing策略,目前的策略主要有:深度优先、广度优先、PR优先、反链优先。 查看全部
c 抓取网页数据(百度收录网站,如何使用数据抓取数据的速度怎样?)
实现如下:
示例·:一个excel文件收录一百多个工作表,但工作表名称没有规则的顺序,不是按sheet1、sheet2的顺序排列的。现在我们需要将每个工作表中的A3数据提取出来,形成一个新的列。
解决方案:使用宏自定义函数
同时按下Alt和F11进入宏界面,点击菜单插入,屏蔽,粘贴如下代码:
Function AllSh(xStr As String, i As Integer)
应用程序.易变
AllSh = Sheets(i).Range(xStr).Value
结束函数
回到excel,在任意单元格输入=allsh("A3",ROW(A1))
公式被复制下来。
在数据库中,data采集和data capture是什么意思?
个人理解:
数据采集分为多种类型。比如从纸质或非结构化数据整理成结构化数据可以存入数据库的过程,可以算作一种数据采集;将数据从某个数据库导出到另一个数据库也可以看成是一种数据采集; 比如通过观察记录获得某些环境指标(空气质量、温度、湿度、人体温度、机器cpu占用率等)变化的过程也可以看作是一种数据采集和很快。简而言之,一种数据存在形式通过“某种加工”转化为另一种数据存在形式。我个人认为所谓的“某些处理”统称为数据采集。
经常使用术语数据捕获,例如 Web 内容数据捕获。从某种意义上说,它与数据采集具有相同的含义,但在本质上,数据主体似乎有主动和被动的区别。. 当然,数据捕获更多的是指从现有的结构化数据中获取数据的过程。
如何使用C语言进行数据爬取 数据爬取的速度是多少?
百度收录网站,首先让百度蜘蛛来爬网站,要做的就是吸引百度蜘蛛爬网站,主要有以下几点做好的步骤:
1、 识别URL重定向,互联网信息数据量非常大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,需要百度蜘蛛重新上报网址。定向识别
2、为了抓取网站的友好性,百度蜘蛛会制定规则,最大限度地利用带宽和所有资源,以便在抓取互联网信息时获得越来越准确的信息,同时也只最小化爬取的网站的压力。
3、 在抓取作弊信息时,我们经常会遇到页面质量低、买卖链接等问题。百度引入了绿萝、石榴等算法进行过滤。据说里面还有一些其他的方法。判断,这些方法还没有对外公开。
4、 无法获取爬取数据,网络中可能出现各种问题,导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开放了手动提交数据。
5、 合理使用百度蜘蛛抓取优先级。由于互联网信息量巨大,在这种情况下无法使用一种策略来指定首先抓取哪些内容。这时候就需要建立多个优先级的Grabing策略,目前的策略主要有:深度优先、广度优先、PR优先、反链优先。
c 抓取网页数据(从新浪微博复制url参数的方法及方法分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-01 15:21
c抓取网页数据的时候可以从新浪微博复制url参数,方便后续数据挖掘时做出更精准的判断。传统的复制方法一般是某个iframe连接n个页面。新浪上的方法是,微博是提供爬虫接口的,访问时从服务器接一个url的参数,返回的是对应不同iframe对应的页面。
因为page=1是新浪首页
用类似于curl命令行的方式,提交一下page=1
因为微博数据主要就是传来传去的,
因为数据结构有变化。前两天听到个数据库优化,里面讲到hash处理对性能影响比较大。
返回参数也是要负责抓取时传递的,是跟前端开发有关系的,就算从新浪首页抓,也是从新浪微博抓,
看上去是爬虫抓取,但是只抓取首页,因为新浪有api接口,可以抓取page=1之后所有页面。首页的url也是参数变化,不仅是微博id,
因为他有api接口啊!api接口就是新浪的给个token你们就可以抓的这个表示你的useragent机密性抓包分析一下就可以分析出来了
把我按他的标准放入微博app。抓不抓取再说。
就是伪代码
我觉得有两个原因:1、因为有api接口,就是api获取文件名也会传递给抓取,而且部分字段没有公开,根据数据量来采集一下,这个是正常的。2、数据量大的应该是api接口不开放的话,如果没有api接口的话,我在传递参数的时候也是从自己网站抓取,就是保留api接口名和id。 查看全部
c 抓取网页数据(从新浪微博复制url参数的方法及方法分析方法)
c抓取网页数据的时候可以从新浪微博复制url参数,方便后续数据挖掘时做出更精准的判断。传统的复制方法一般是某个iframe连接n个页面。新浪上的方法是,微博是提供爬虫接口的,访问时从服务器接一个url的参数,返回的是对应不同iframe对应的页面。
因为page=1是新浪首页
用类似于curl命令行的方式,提交一下page=1
因为微博数据主要就是传来传去的,
因为数据结构有变化。前两天听到个数据库优化,里面讲到hash处理对性能影响比较大。
返回参数也是要负责抓取时传递的,是跟前端开发有关系的,就算从新浪首页抓,也是从新浪微博抓,
看上去是爬虫抓取,但是只抓取首页,因为新浪有api接口,可以抓取page=1之后所有页面。首页的url也是参数变化,不仅是微博id,
因为他有api接口啊!api接口就是新浪的给个token你们就可以抓的这个表示你的useragent机密性抓包分析一下就可以分析出来了
把我按他的标准放入微博app。抓不抓取再说。
就是伪代码
我觉得有两个原因:1、因为有api接口,就是api获取文件名也会传递给抓取,而且部分字段没有公开,根据数据量来采集一下,这个是正常的。2、数据量大的应该是api接口不开放的话,如果没有api接口的话,我在传递参数的时候也是从自己网站抓取,就是保留api接口名和id。
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-30 08:28
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候打开Proxifer,浏览器将无法连接网络。可以通过设置Fiddler方法连接网络,添加谷歌浏览器执行程序文件,然后就可以上网了。
查看全部
c 抓取网页数据(常见的三种情况下的抓包方法,你知道吗?
)
开篇:写爬虫抓数据,首先要分析客户端和服务端的请求/响应。前提是我们可以监控客户端如何与服务器交互。我们记录三种常见的情况。下的捕获方法
1.PC浏览器网页抓取
网页板捕获是最简单和最常见的。比如Google/Firfox/IE等浏览器自带的开发者调试工具(F12))就可以满足部分需求。比如修改浏览器发送的请求数据,修改服务器的相应数据。用F12开发这个工具不能满足我们的需求。这里介绍Fiddler抓包工具,可以理解为本地代理服务器,实现转发client和Server的请求和响应
设置小提琴手:
打开Fiddler,在菜单栏中,打开Tools-Options,在前三个选项卡设置下,OK,默认代理设置:127.0.0.1:8888
然后在浏览器端设置代理:127.0.0.1:8888,就可以抓取网页请求/响应,然后就可以在Fiddler端实现需求了根据需要,如:设置断点、过滤请求、修改请求数据、修改响应数据、拦截JS等。
2.移动应用捕获
在移动端使用 Fiddler 抓包也很简单。类似于上面PC浏览器的抓包方式。移动终端必须与PC在同一个局域网内。手机的Wifi设置代理,IP为PC机的IP地址,例如:64.35.86.12,端口号为FIddler设置的端口号,一般是8888,这样手机上的所有网络/响应请求都必须是FIddler发送的,这样我们才能针对一些链接做分析
3.PC客户端(C/S)抓包
C/S程序捕获需要Proxifer
Proxifier是一个非常强大的socks5客户端,它允许不支持通过代理服务器工作的网络程序通过HTTPS或SOCKS代理或代理链。
由于一般的C/S客户端无法设置代理,所以我们的FIiddler无法检测到数据。我们可以使用Proxifer来捕获所有的请求并发送给Fiddler,这样我们就可以在Fiddler中分析客户端的请求。
代理设置:
设置很简单,如下图,两步就OK了
一种)。将代理服务器和 Fiddler 代理设置设置为匹配
b)。设置代理规则
默认 Default,我们可以忽略
点击添加
名称:Fiddler.exe
是否有效:是
选择Fiddler的应用文件目录,选择后,确认
目标主机:我们本地 Fiddler 设置的代理,可以是任意
目的港:任意
行动:直接
现在设置完成,我们可以打开腾讯视频视频客户端,查看Fiddler和Proxifer中的数据
4.电脑上所有C/S客户端都可以抓包
这时候打开Proxifer,浏览器将无法连接网络。可以通过设置Fiddler方法连接网络,添加谷歌浏览器执行程序文件,然后就可以上网了。
c 抓取网页数据(C#中正则表达式的用法及使用的使用方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-29 13:20
这两天一直在学习课程,打算从网上搜集一些有趣的资料。最近大家对环境问题的关注度越来越高,我们计划采集中国各个城市的每日空气质量日报数据。登录环保部网站后,以网站上的表格形式提供。但不提供数据导出或包下载功能。所以我在互联网上搜索了从网页中获取数据的方法。其中,很多人都提到并推荐了抓取网页源代码,然后使用正则表达式获取的方法。于是先是学习了正则表达式,然后又折腾了一遍,终于完成了任务。
正则表达式(Regular Expression,regex/regexp/re)是计算机科学的一个概念。正则表达式使用单个字符串来描述和匹配一系列符合某种语法规则的字符串。在许多文本编辑器中,正则表达式通常用于检索和替换符合某种模式的文本。(本段出处:正则表达式)
推荐这个网站学习正则表达式的使用。感觉你看看这个网站,很快就能上手了。
CSDN上sysdzw的版主多年前写了一个命令行小程序,叫RegTop(有后续基于表单的版本RegTestTool),可以结合批量命令来抓取网页数据。不幸的是,我不知道该怎么做。一个关于网页编码的参数总是设置不正确(IQ Clumsy -_-|||),所以只好放弃治疗了……不过RegTestTool这个小工具,还不如手头有一个,比较好用用于检查正则表达式是否正确编写。
关于正则表达式的更多信息,我不会在这里过多介绍。我只看了需要的部分。先简单说一下C#中正则表达式的用法:
using System.Text.RegularExpression;
string pattern = @"(\d{1,8})\n.*([^x00-xff]{2,8})\n.*(\d{4}-\d\d-\d\d)\n.*(\d{1,4})\n.*([^x00-xff]{2,6}|--)\n.*(.*?)\n.*([^x00-xff]{1,4})";
Regex regex = new Regex(pattern);
Match m = regex.Match(web_source);
while (m.Success)
{
// Do something...
m = m.NextMatch();
}
首先,使用字符串来定义正则表达式。由于各种可能的转义字符在表达式中是必不可少的,直接用@""的形式来表示字符串就可以了。然后,创建一个新的 Regex 变量并用刚才的表达式对其进行初始化。接下来,定义一个 Match 来接收 Regex 变量 Match(string) 方法的结果。如果匹配成功(m.Success==true),则匹配结果存储在m.Groups[i]中。值得注意的是,Groups[0]中放置的不是正则表达式中的第一个匹配,而是正则表达式匹配的整个字符串(注意下一个正则表达式中可能同时有多个匹配) ,所以在使用的时候,直接从Group[1]开始。处理此匹配后,使用 m.NextMatch() 访问下一个匹配。哦,最后,
至于获取网页的源代码,C#提供了相应的方法(这么快忘记了,唉-_-|||),可惜在使用的时候总是无法获取到网页的完整源代码. 时间关系,没深入研究,从网上找了另一种方式获取源码:
using System.Net;
///
/// 获得网页源代码
///
/// 页面网址
/// 以字符串形式保存的网页源代码
private static string GetWebSource(string http)
{
// Set http web address
System.Uri url = new System.Uri(http);
// Set Web Request
HttpWebRequest hwrq = WebRequest.Create(url) as HttpWebRequest;
hwrq.Method = "GET"; // (GET/POST)
hwrq.Referer = http;
hwrq.Timeout = 50000; // Timeout(ms)
hwrq.Accept = "*/*"; // All Types
hwrq.UserAgent = "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)";
hwrq.CookieContainer = new CookieContainer(); // Cookies
// Create HttpWebResponse Object
HttpWebResponse resp = hwrq.GetResponse() as HttpWebResponse;
StreamReader reader = new StreamReader(
resp.GetResponseStream(),
System.Text.Encoding.GetEncoding("UTF-8"));
string respHTML = reader.ReadToEnd();
resp.Close();
Console.WriteLine("Web Responsed!");
return respHTML;
}
对于慢速网络或者外来网站,Timeout可以设置大一些,否则超时直接报异常。
问题主要两部分解决了,剩下的工作就简单了:先抓取网页源码,然后用正则表达式匹配有用的项,然后用StringBuilder连接,用StreamWriter写文件,OK~嘿嘿, 采集资料 呵呵~ 查看全部
c 抓取网页数据(C#中正则表达式的用法及使用的使用方法有哪些)
这两天一直在学习课程,打算从网上搜集一些有趣的资料。最近大家对环境问题的关注度越来越高,我们计划采集中国各个城市的每日空气质量日报数据。登录环保部网站后,以网站上的表格形式提供。但不提供数据导出或包下载功能。所以我在互联网上搜索了从网页中获取数据的方法。其中,很多人都提到并推荐了抓取网页源代码,然后使用正则表达式获取的方法。于是先是学习了正则表达式,然后又折腾了一遍,终于完成了任务。
正则表达式(Regular Expression,regex/regexp/re)是计算机科学的一个概念。正则表达式使用单个字符串来描述和匹配一系列符合某种语法规则的字符串。在许多文本编辑器中,正则表达式通常用于检索和替换符合某种模式的文本。(本段出处:正则表达式)
推荐这个网站学习正则表达式的使用。感觉你看看这个网站,很快就能上手了。
CSDN上sysdzw的版主多年前写了一个命令行小程序,叫RegTop(有后续基于表单的版本RegTestTool),可以结合批量命令来抓取网页数据。不幸的是,我不知道该怎么做。一个关于网页编码的参数总是设置不正确(IQ Clumsy -_-|||),所以只好放弃治疗了……不过RegTestTool这个小工具,还不如手头有一个,比较好用用于检查正则表达式是否正确编写。
关于正则表达式的更多信息,我不会在这里过多介绍。我只看了需要的部分。先简单说一下C#中正则表达式的用法:
using System.Text.RegularExpression;
string pattern = @"(\d{1,8})\n.*([^x00-xff]{2,8})\n.*(\d{4}-\d\d-\d\d)\n.*(\d{1,4})\n.*([^x00-xff]{2,6}|--)\n.*(.*?)\n.*([^x00-xff]{1,4})";
Regex regex = new Regex(pattern);
Match m = regex.Match(web_source);
while (m.Success)
{
// Do something...
m = m.NextMatch();
}
首先,使用字符串来定义正则表达式。由于各种可能的转义字符在表达式中是必不可少的,直接用@""的形式来表示字符串就可以了。然后,创建一个新的 Regex 变量并用刚才的表达式对其进行初始化。接下来,定义一个 Match 来接收 Regex 变量 Match(string) 方法的结果。如果匹配成功(m.Success==true),则匹配结果存储在m.Groups[i]中。值得注意的是,Groups[0]中放置的不是正则表达式中的第一个匹配,而是正则表达式匹配的整个字符串(注意下一个正则表达式中可能同时有多个匹配) ,所以在使用的时候,直接从Group[1]开始。处理此匹配后,使用 m.NextMatch() 访问下一个匹配。哦,最后,
至于获取网页的源代码,C#提供了相应的方法(这么快忘记了,唉-_-|||),可惜在使用的时候总是无法获取到网页的完整源代码. 时间关系,没深入研究,从网上找了另一种方式获取源码:
using System.Net;
///
/// 获得网页源代码
///
/// 页面网址
/// 以字符串形式保存的网页源代码
private static string GetWebSource(string http)
{
// Set http web address
System.Uri url = new System.Uri(http);
// Set Web Request
HttpWebRequest hwrq = WebRequest.Create(url) as HttpWebRequest;
hwrq.Method = "GET"; // (GET/POST)
hwrq.Referer = http;
hwrq.Timeout = 50000; // Timeout(ms)
hwrq.Accept = "*/*"; // All Types
hwrq.UserAgent = "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)";
hwrq.CookieContainer = new CookieContainer(); // Cookies
// Create HttpWebResponse Object
HttpWebResponse resp = hwrq.GetResponse() as HttpWebResponse;
StreamReader reader = new StreamReader(
resp.GetResponseStream(),
System.Text.Encoding.GetEncoding("UTF-8"));
string respHTML = reader.ReadToEnd();
resp.Close();
Console.WriteLine("Web Responsed!");
return respHTML;
}
对于慢速网络或者外来网站,Timeout可以设置大一些,否则超时直接报异常。
问题主要两部分解决了,剩下的工作就简单了:先抓取网页源码,然后用正则表达式匹配有用的项,然后用StringBuilder连接,用StreamWriter写文件,OK~嘿嘿, 采集资料 呵呵~
c 抓取网页数据(一下禁止搜索引擎爬虫抓取自己的网站的方法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-29 01:24
本文简要总结了禁止搜索引擎爬虫通过搜索在线信息抓取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽可能的爬取自己的网站,但有时也需要告诉爬虫不要爬,比如不要爬镜像页面。
搜索引擎自己爬取网站有其优点,但也存在很多常见问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。下载异常,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
cat logs/www.ready.log |grep spider -c(查看带有爬虫标志的访问次数)
cat logs/www.ready.log |wc(总页面访问量)
cat logs/www.ready.log |grep spider|awk'{print $1}'|sort -n|uniq -c|sort -nr(查看爬虫IP地址来源)
cat logs/www.ready.log |awk'{print $1 "" substr($4,14,5)}'|sort -n|uniq -c|sort -nr|head -20(查看爬虫的来源)
二、分析日志
知道爬虫爬过什么,什么爬虫爬过它。你什么时候爬的?
常见爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
Altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道蜘蛛:有道机器人
搜狗蜘蛛:搜狗蜘蛛#07
三、禁止方法
(一),禁止IP
服务器配置可以是:deny from 221.194.136
防火墙配置可以是:-A RH-Firewall-1-INPUT -m state –state NEW -m tcp -p tcp –dport 80 -s 61.33.22.1/24 -j 拒绝
缺点:一个搜索引擎的爬虫可能部署在多个服务器上(多个IP)。获取某个搜索引擎的爬虫的所有IP是很困难的。
(二),robot.txt
1.robots.txt 文件是什么?
搜索引擎使用程序机器人(也称为蜘蛛)自动访问互联网上的网页并获取网页信息。
您可以在您的网站中创建一个纯文本文件robots.txt,并在该文件中声明您不想被机器人访问的网站部分。这样就可以将网站的部分或全部内容排除在搜索引擎收录之外,或者只能由收录指定搜索引擎。
2. robots.txt 文件在哪里?
robots.txt 文件应该放在网站的根目录下。例如,当robots访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果机器人找到了这个文件,它会根据文件的内容确定其访问权限的范围。
3. “robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下所示:
":".
在这个文件中,可以使用#进行标注,具体用法与UNIX中的约定相同。这个文件中的记录通常以一行或多行User-agent开头,后面跟着几行Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,必须至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。 “robots.txt”文件中只能有“User-agent:*”等一条记录。
禁止:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。 .html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站对所有搜索引擎机器人都是开放的。
缺点:当两个域名指向同一个根目录时,如果想让爬虫爬取一个域名(A/等)的某些网页,但又想禁止爬虫爬取另一个域名的这些页面域名(A/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou蜘蛛|搜狗网络蜘蛛|MSNBot|ia_archiver|番茄机器人")
{
返回403;
}
缺点:仅禁止爬虫爬取域级网页。灵活性不足。 查看全部
c 抓取网页数据(一下禁止搜索引擎爬虫抓取自己的网站的方法(一))
本文简要总结了禁止搜索引擎爬虫通过搜索在线信息抓取网站的方法。
一般来说,大家都希望搜索引擎爬虫尽可能的爬取自己的网站,但有时也需要告诉爬虫不要爬,比如不要爬镜像页面。
搜索引擎自己爬取网站有其优点,但也存在很多常见问题:
1.网络拥塞严重丢包(上下行数据异常,排除DDOS攻击,服务器中毒。下载异常,数据更新)
2.服务器负载过高,CPU快满了(取决于对应的服务配置);
3.服务基本瘫痪,路由瘫痪;
4.查看日志,发现大量异常访问日志
一、先查看日志
以下以ngnix的日志为例
cat logs/www.ready.log |grep spider -c(查看带有爬虫标志的访问次数)
cat logs/www.ready.log |wc(总页面访问量)
cat logs/www.ready.log |grep spider|awk'{print $1}'|sort -n|uniq -c|sort -nr(查看爬虫IP地址来源)
cat logs/www.ready.log |awk'{print $1 "" substr($4,14,5)}'|sort -n|uniq -c|sort -nr|head -20(查看爬虫的来源)
二、分析日志
知道爬虫爬过什么,什么爬虫爬过它。你什么时候爬的?
常见爬虫:
谷歌蜘蛛:googlebot
百度蜘蛛:baiduspider
雅虎蜘蛛:啜饮
alexa 蜘蛛:ia_archiver
msn 蜘蛛:msnbot
Altavista 蜘蛛:滑板车
lycos 蜘蛛:lycos_spider_(t-rex)
alltheweb 蜘蛛:fast-webcrawler/
inktomi 蜘蛛:啜饮
有道蜘蛛:有道机器人
搜狗蜘蛛:搜狗蜘蛛#07
三、禁止方法
(一),禁止IP
服务器配置可以是:deny from 221.194.136
防火墙配置可以是:-A RH-Firewall-1-INPUT -m state –state NEW -m tcp -p tcp –dport 80 -s 61.33.22.1/24 -j 拒绝
缺点:一个搜索引擎的爬虫可能部署在多个服务器上(多个IP)。获取某个搜索引擎的爬虫的所有IP是很困难的。
(二),robot.txt
1.robots.txt 文件是什么?
搜索引擎使用程序机器人(也称为蜘蛛)自动访问互联网上的网页并获取网页信息。
您可以在您的网站中创建一个纯文本文件robots.txt,并在该文件中声明您不想被机器人访问的网站部分。这样就可以将网站的部分或全部内容排除在搜索引擎收录之外,或者只能由收录指定搜索引擎。
2. robots.txt 文件在哪里?
robots.txt 文件应该放在网站的根目录下。例如,当robots访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果机器人找到了这个文件,它会根据文件的内容确定其访问权限的范围。
3. “robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下所示:
":".
在这个文件中,可以使用#进行标注,具体用法与UNIX中的约定相同。这个文件中的记录通常以一行或多行User-agent开头,后面跟着几行Disallow,具体如下:
用户代理:
此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被协议限制。对于这个文件,必须至少有一个 User-agent 记录。如果该项的值设置为*,则该协议对任何机器人都有效。 “robots.txt”文件中只能有“User-agent:*”等一条记录。
禁止:
此项的值用于描述您不想访问的 URL。此 URL 可以是完整路径或其中的一部分。机器人不会访问任何以 Disallow 开头的 URL。例如,“Disallow:/help”不允许搜索引擎访问/help.html和/help/index.html,而“Disallow:/help/”允许机器人访问/help.html,但不允许访问/help/指数。 .html。如果任何 Disallow 记录为空,则表示允许访问 网站 的所有部分。 “/robots.txt”文件中必须至少有一个 Disallow 记录。如果“/robots.txt”是一个空文件,这个网站对所有搜索引擎机器人都是开放的。
缺点:当两个域名指向同一个根目录时,如果想让爬虫爬取一个域名(A/等)的某些网页,但又想禁止爬虫爬取另一个域名的这些页面域名(A/等),此方法无法实现。
(三),服务器配置
以nginx服务器为例,可以在域名配置中添加配置
if ($http_user_agent ~* "qihoobot|Baiduspider|Googlebot|Googlebot-Mobile|Googlebot-Image|Mediapartners-Google|Adsbot-Google|Feedfetcher-Google|Yahoo! Slurp|Yahoo! Slurp China|YoudaoBot|Sosospider|Sogou蜘蛛|搜狗网络蜘蛛|MSNBot|ia_archiver|番茄机器人")
{
返回403;
}
缺点:仅禁止爬虫爬取域级网页。灵活性不足。
c 抓取网页数据(第一种自带的库(别人要求要用windows平台)直接使用libcurl)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-26 23:04
最近帮忙做了一个小程序,获取指定网页的内容。事实上,这很容易做到。
第一种windows平台可以使用MFC自带的库(别人要求使用windows平台),使用libcurl配置比较麻烦,第二种linux平台直接使用强大的libcurl,linux是易于使用的 libcurl。
先说windows平台的第一种情况:我在网上找到了代码,使用了MFC库。需要修改多字节集才能在控制台下使用:
#include
#include
int main()
{
CInternetSession session("HttpClient");
char * url = "http://www.baidu.com";
CHttpFile *pfile = (CHttpFile *)session.OpenURL(url);
DWORD dwStatusCode;
pfile->QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString content;
CString data;
while (pfile->ReadString(data))
{
content += data + "\r\n";
}
content.TrimRight();
printf(" %s\n ", content);
}
pfile->Close();
delete pfile;
session.Close();
return 0 ;
}
第二种情况,Linux下直接使用libcurl:
1.先在linux下下载libcurl,解压:
# wget https://curl.haxx.se/download/curl-7.54.0.tar.gz
# tar -zxf curl-7.54.0.tar.gz
2.进入解压目录并安装:
# cd curl-7.54.0/
# ./configure
# make
# make install
3.使用如下命令查看libcurl版本:
# curl --version
这是安装。
以下是简单的获取网页内容的方法:
test.cpp
#include
#include
#include
using namespace std;
static size_t downloadCallback(void *buffer, size_t sz, size_t nmemb, void *writer)
{
string* psResponse = (string*) writer;
size_t size = sz * nmemb;
psResponse->append((char*) buffer, size);
return sz * nmemb;
}
int main()
{
string strUrl = "http://www.baidu.com";
string strTmpStr;
CURL *curl = curl_easy_init();
curl_easy_setopt(curl, CURLOPT_URL, strUrl.c_str());
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 2);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, downloadCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &strTmpStr);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
string strRsp;
if (res != CURLE_OK)
{
strRsp = "error";
}
else
{
strRsp = strTmpStr;
}
printf("strRsp is |%s|\n", strRsp.c_str());
return 0;
}
使用如下命令编译运行:
# g++ -o http test.cpp -lcurl
# ./http
libcurl 很强大,这里只是获取网页信息,我刚开始工作时使用libcurl 下载、上传、可续传等功能。 查看全部
c 抓取网页数据(第一种自带的库(别人要求要用windows平台)直接使用libcurl)
最近帮忙做了一个小程序,获取指定网页的内容。事实上,这很容易做到。
第一种windows平台可以使用MFC自带的库(别人要求使用windows平台),使用libcurl配置比较麻烦,第二种linux平台直接使用强大的libcurl,linux是易于使用的 libcurl。
先说windows平台的第一种情况:我在网上找到了代码,使用了MFC库。需要修改多字节集才能在控制台下使用:
#include
#include
int main()
{
CInternetSession session("HttpClient");
char * url = "http://www.baidu.com";
CHttpFile *pfile = (CHttpFile *)session.OpenURL(url);
DWORD dwStatusCode;
pfile->QueryInfoStatusCode(dwStatusCode);
if(dwStatusCode == HTTP_STATUS_OK)
{
CString content;
CString data;
while (pfile->ReadString(data))
{
content += data + "\r\n";
}
content.TrimRight();
printf(" %s\n ", content);
}
pfile->Close();
delete pfile;
session.Close();
return 0 ;
}
第二种情况,Linux下直接使用libcurl:
1.先在linux下下载libcurl,解压:
# wget https://curl.haxx.se/download/curl-7.54.0.tar.gz
# tar -zxf curl-7.54.0.tar.gz
2.进入解压目录并安装:
# cd curl-7.54.0/
# ./configure
# make
# make install
3.使用如下命令查看libcurl版本:
# curl --version
这是安装。
以下是简单的获取网页内容的方法:
test.cpp
#include
#include
#include
using namespace std;
static size_t downloadCallback(void *buffer, size_t sz, size_t nmemb, void *writer)
{
string* psResponse = (string*) writer;
size_t size = sz * nmemb;
psResponse->append((char*) buffer, size);
return sz * nmemb;
}
int main()
{
string strUrl = "http://www.baidu.com";
string strTmpStr;
CURL *curl = curl_easy_init();
curl_easy_setopt(curl, CURLOPT_URL, strUrl.c_str());
curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L);
curl_easy_setopt(curl, CURLOPT_TIMEOUT, 2);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, downloadCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &strTmpStr);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
string strRsp;
if (res != CURLE_OK)
{
strRsp = "error";
}
else
{
strRsp = strTmpStr;
}
printf("strRsp is |%s|\n", strRsp.c_str());
return 0;
}
使用如下命令编译运行:
# g++ -o http test.cpp -lcurl
# ./http
libcurl 很强大,这里只是获取网页信息,我刚开始工作时使用libcurl 下载、上传、可续传等功能。
c 抓取网页数据(通过通达信获取行业行情数据,并利用R语言转换成常见文档格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-10-25 17:17
1、 获取通大信软件的股票数据
通达信软件有一个比较简单的获取历史修复数据的方法,就是通过软件直接导出。据我所知,这是最简单、可靠性高的数据采集方式。但这里的重点不是介绍如何通过简单的按键获取批量回收的股票数据,而是重点介绍如何获取通大信行业板块数据。
广大股民都知道,通达信软件是广大投资者观察行情的必备软件之一,尤其是子行业板块和概念板块行情。虽然它的编制比较简单,但它有一个完整而独特的行业市场。因此,它具有非常重要的参考价值(顺便说一下,方正证券的全友通软件基本完全借鉴了通达信软件模型)。但是通达信行业板块的行情数据不能直接导出为txt等常用格式,只能导出为day格式,因此需要特殊的方法对day格式进行处理。
因此,介绍通过通达信获取行业行情数据,并使用R语言将其转换为通用文档格式(csv或txt)的方法很重要。主要步骤如下:
(1)首先找到行业代码文件:tdx\T0002\hq_cache\tdxzs.cfg,用记事本打开,具体结果如下:
可以看出,该文件实际上收录了通大信软件行业指数模块中的所有行业代码,如行业板块、概念板块、风格板块、区域板块等。如果想了解黑龙江后面880201等几个数据的含义| 3 | | 1 | 0 | 1、请参考网页链接。这里省略。
(2)通过盘后数据下载,选择对应的起止时间点(如2016年8月5日)下载所有沪深品种日数据,对应下载数据屏蔽截图如下如下:
那么相应时间段的所有股票数据和行业行情数据都存储在:
在文件夹'D://Program Files//new_tdx//vipdoc//sh//lday//'下,部分结果截图如下:
(3) 将day格式的数据转换为普通文档格式。如果用普通记事本打开.day格式的数据,结果会出现乱码。如果需要知道里面的具体内容,其实可以用Binary Viewer软件 打开选择不同的16进制格式查看,看结果与真实数据一致,R语言中可以使用hexView工具包简单处理当天数据,即可得到行业板块转换成txt或者csv格式,等待数据保存到本地文件夹,R语言的代码如下:
############################################### #########
#------------------------转换tdx行业数据--------------------- -----
#1 将 tdx .day 数据转换为 txt/csv 数据。
#2 使用包 hexView。
#
############################################### #########
库(十六进制视图)
tdx.industrytdx.codefor(i in 1:length(tdx.code)){
file.dir dayfile dayfile dayfile dayfile colnames(dayfile) 营业额大小=switch('real',real=4),endian='little')
营业额营业额营业额价格价格[,2:5] save.dir write.csv(prices,file=save.dir,row.names=F)
}
上述方法也可用于将.day格式的股票数据转换为csv/txt格式的股票数据,但这种方法是不必要的,因为它可以直接导出。
经过循环处理,得到的结果如下:
当然,需要指出的是,获取行业板块市场数据还有另外两种方式。
一种是中证系数指数、上证系列指数、深证系列指数等,但这种方法有其不足之处。具体而言,沪深交易所行业指数仅针对各自市场编制,并非针对国内所有沪深市场;沪深系列的行业指数可以反映沪深A股市场不同行业公司股票的整体表现,如300能源、300材料、300工业,但分类不全面,不能反映整体情况沪深股市各行业表现,分类标准不一致,如有 300能、500能、1000能,行业行情无法统一比较,后续行情数据时间长短不一。因此,一般情况下,投资者不喜欢使用这类行情数据。
其次,新浪网页也有相应的行业板块数据。但是,由于我不知道行情数据对应的网址,所以无法获取其行业板块、概念板块等的指数走势数据(如果有知道的请告知!)。 查看全部
c 抓取网页数据(通过通达信获取行业行情数据,并利用R语言转换成常见文档格式)
1、 获取通大信软件的股票数据
通达信软件有一个比较简单的获取历史修复数据的方法,就是通过软件直接导出。据我所知,这是最简单、可靠性高的数据采集方式。但这里的重点不是介绍如何通过简单的按键获取批量回收的股票数据,而是重点介绍如何获取通大信行业板块数据。
广大股民都知道,通达信软件是广大投资者观察行情的必备软件之一,尤其是子行业板块和概念板块行情。虽然它的编制比较简单,但它有一个完整而独特的行业市场。因此,它具有非常重要的参考价值(顺便说一下,方正证券的全友通软件基本完全借鉴了通达信软件模型)。但是通达信行业板块的行情数据不能直接导出为txt等常用格式,只能导出为day格式,因此需要特殊的方法对day格式进行处理。
因此,介绍通过通达信获取行业行情数据,并使用R语言将其转换为通用文档格式(csv或txt)的方法很重要。主要步骤如下:
(1)首先找到行业代码文件:tdx\T0002\hq_cache\tdxzs.cfg,用记事本打开,具体结果如下:
可以看出,该文件实际上收录了通大信软件行业指数模块中的所有行业代码,如行业板块、概念板块、风格板块、区域板块等。如果想了解黑龙江后面880201等几个数据的含义| 3 | | 1 | 0 | 1、请参考网页链接。这里省略。
(2)通过盘后数据下载,选择对应的起止时间点(如2016年8月5日)下载所有沪深品种日数据,对应下载数据屏蔽截图如下如下:
那么相应时间段的所有股票数据和行业行情数据都存储在:
在文件夹'D://Program Files//new_tdx//vipdoc//sh//lday//'下,部分结果截图如下:
(3) 将day格式的数据转换为普通文档格式。如果用普通记事本打开.day格式的数据,结果会出现乱码。如果需要知道里面的具体内容,其实可以用Binary Viewer软件 打开选择不同的16进制格式查看,看结果与真实数据一致,R语言中可以使用hexView工具包简单处理当天数据,即可得到行业板块转换成txt或者csv格式,等待数据保存到本地文件夹,R语言的代码如下:
############################################### #########
#------------------------转换tdx行业数据--------------------- -----
#1 将 tdx .day 数据转换为 txt/csv 数据。
#2 使用包 hexView。
#
############################################### #########
库(十六进制视图)
tdx.industrytdx.codefor(i in 1:length(tdx.code)){
file.dir dayfile dayfile dayfile dayfile colnames(dayfile) 营业额大小=switch('real',real=4),endian='little')
营业额营业额营业额价格价格[,2:5] save.dir write.csv(prices,file=save.dir,row.names=F)
}
上述方法也可用于将.day格式的股票数据转换为csv/txt格式的股票数据,但这种方法是不必要的,因为它可以直接导出。
经过循环处理,得到的结果如下:
当然,需要指出的是,获取行业板块市场数据还有另外两种方式。
一种是中证系数指数、上证系列指数、深证系列指数等,但这种方法有其不足之处。具体而言,沪深交易所行业指数仅针对各自市场编制,并非针对国内所有沪深市场;沪深系列的行业指数可以反映沪深A股市场不同行业公司股票的整体表现,如300能源、300材料、300工业,但分类不全面,不能反映整体情况沪深股市各行业表现,分类标准不一致,如有 300能、500能、1000能,行业行情无法统一比较,后续行情数据时间长短不一。因此,一般情况下,投资者不喜欢使用这类行情数据。
其次,新浪网页也有相应的行业板块数据。但是,由于我不知道行情数据对应的网址,所以无法获取其行业板块、概念板块等的指数走势数据(如果有知道的请告知!)。
c 抓取网页数据(利用雪球数据自动化生成财务分析报告(附详细介绍))
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-10-25 06:11
上一篇文章(使用Snowball数据自动生成财务分析报告)使用Snowball的损益表数据自动生成财务报告。里面的损益表数据直接使用滚雪球,下载直接点击下载。
这里总结一下目前可以提供三表数据的网站(欢迎补充其他网站),最后提供一个使用python下载所有公司三表数据的程序.
1. 财务报表数据下载汇总
一种。
使用方法:上面是首页链接,点击进入右侧工具箱。输入代码,选择报表类别和起止年份,即可下载。
评价:csv格式;数据是最权威的;但是每年的数据都是分开的,使用起来可能不太方便。
湾 新浪财经
用途:搜索个股,进入个股页面;选择左侧的财务数据,点击进入;底部下载【其他类似,不详细介绍】
评价:xls格式;感觉数据也比较准确;每年的数据都放在同一个文件中。
C。雪球:csv 文件;数据更准确,下面的程序以此为例
d. 网易财经:csv文件
2.python自动下载(以雪球为例)
由于这里的程序涉及到Snowball的网络接口,频繁访问可能会对Snowball服务器造成一定的压力,所以文章中的完整代码不会发布(如果你真的需要,可以手动去上一个文章)找到地址;将里面的 Cookie 更改为您自己的)。
一种。首先,准备一个所有A股的股票代码,在大多数网站上都可以找到。
湾 一般流程(以下载损益表为例)
(1)首先找到csv文件的具体下载地址。比如雪球上的损益表数据类似如下形式(只更改最后一个股票代码就足够了)
网页链接
(2)使用以上股票代码构建下载地址。
(3)下载程序主要部分如下
最终下载结果大致如下(股票代码在前,lrb、fzb、llb分别代表损益表、负债表、现金流量表):
@白话投资 查看全部
c 抓取网页数据(利用雪球数据自动化生成财务分析报告(附详细介绍))
上一篇文章(使用Snowball数据自动生成财务分析报告)使用Snowball的损益表数据自动生成财务报告。里面的损益表数据直接使用滚雪球,下载直接点击下载。
这里总结一下目前可以提供三表数据的网站(欢迎补充其他网站),最后提供一个使用python下载所有公司三表数据的程序.
1. 财务报表数据下载汇总
一种。
使用方法:上面是首页链接,点击进入右侧工具箱。输入代码,选择报表类别和起止年份,即可下载。
评价:csv格式;数据是最权威的;但是每年的数据都是分开的,使用起来可能不太方便。
湾 新浪财经
用途:搜索个股,进入个股页面;选择左侧的财务数据,点击进入;底部下载【其他类似,不详细介绍】
评价:xls格式;感觉数据也比较准确;每年的数据都放在同一个文件中。
C。雪球:csv 文件;数据更准确,下面的程序以此为例
d. 网易财经:csv文件
2.python自动下载(以雪球为例)
由于这里的程序涉及到Snowball的网络接口,频繁访问可能会对Snowball服务器造成一定的压力,所以文章中的完整代码不会发布(如果你真的需要,可以手动去上一个文章)找到地址;将里面的 Cookie 更改为您自己的)。
一种。首先,准备一个所有A股的股票代码,在大多数网站上都可以找到。
湾 一般流程(以下载损益表为例)
(1)首先找到csv文件的具体下载地址。比如雪球上的损益表数据类似如下形式(只更改最后一个股票代码就足够了)
网页链接
(2)使用以上股票代码构建下载地址。
(3)下载程序主要部分如下
最终下载结果大致如下(股票代码在前,lrb、fzb、llb分别代表损益表、负债表、现金流量表):
@白话投资
c 抓取网页数据(c语言底层写起来太费劲,你可以用python吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-24 18:05
c抓取网页数据会建立一个文件夹,导入一些requests库,导入一些json库,定义一些widget或者实现一些有趣的功能。相应的编写这些。包含java的,因为java不是主流语言。可以用python当然可以了。主要看项目。简单的话可以试一下espresso,速度快的一逼。别问我怎么知道的。曾经还做过一些接入。服务端和客户端都要写,所以随时可以改。学费一篇文章就交给你们了,请叫我雷锋。
个人更偏向node。只是写项目的话,主要是精通nodejs,针对性增加一两个系统控制类,增加几个网络类,增加几个基本的爬虫。如果想深入了解,深入后你会发现java性能也不差。并发并不是问题,毕竟我们现在的网站全部用的nodejs。
可以借鉴一下c语言的实现,先从一些简单的例子做起,逐步增加并发操作,
前端有js,后端有espresso。
c语言可以写greenlet前端可以前端后端都可以后端只要有个web框架就行啦毕竟c语言底层写起来太费劲我给你个例子吧你可以用c写一个publicbooleanisfapped=true;
前端后端分开,先后端搞定,前端jquery事件分发,
前端后端都有部分功能可以借鉴,c语言可以直接写espresso, 查看全部
c 抓取网页数据(c语言底层写起来太费劲,你可以用python吗?)
c抓取网页数据会建立一个文件夹,导入一些requests库,导入一些json库,定义一些widget或者实现一些有趣的功能。相应的编写这些。包含java的,因为java不是主流语言。可以用python当然可以了。主要看项目。简单的话可以试一下espresso,速度快的一逼。别问我怎么知道的。曾经还做过一些接入。服务端和客户端都要写,所以随时可以改。学费一篇文章就交给你们了,请叫我雷锋。
个人更偏向node。只是写项目的话,主要是精通nodejs,针对性增加一两个系统控制类,增加几个网络类,增加几个基本的爬虫。如果想深入了解,深入后你会发现java性能也不差。并发并不是问题,毕竟我们现在的网站全部用的nodejs。
可以借鉴一下c语言的实现,先从一些简单的例子做起,逐步增加并发操作,
前端有js,后端有espresso。
c语言可以写greenlet前端可以前端后端都可以后端只要有个web框架就行啦毕竟c语言底层写起来太费劲我给你个例子吧你可以用c写一个publicbooleanisfapped=true;
前端后端分开,先后端搞定,前端jquery事件分发,
前端后端都有部分功能可以借鉴,c语言可以直接写espresso,
c 抓取网页数据(SEO优化内蒙古哪个网络推广优化系统做得不错的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-22 13:12
合肥兴文县关键词排名优化()公司一直致力于网站运营、网络整合营销、互联网盈利模式、电子商务、搜索引擎优化(SEO)等方面的研究工作,提供专业网络推广,seo优化,百度优化,网站优化,全站优化,网络营销,网站推广,关键词优化,网站排名优化,是专业的seo外包、seo服务、seo顾问、seo培训、seo公司、seo技术分享免费推广平台、seo教程、seo推广、关键词排名优化、seo排名软件和seo优化工具。
一、兴文县合肥关键词排名优化-详细说明
具体的SEO服务根据不同行业、公司网站基础和客户需求进行定制。以下是常见的合肥兴文县关键词排名优化服务内容:
1、竞争对手流量分析
2、关键词分析研究
3、客服系统代码安装
4、蜘蛛源码搜索引擎分析
5、公司网络营销和SEO培训
6、精准流量挖掘
7、博客程序维护
8、文章图片制作
二、上海市兴文县网站-专家解答
具体建站服务根据不同行业、公司网站基金会和客户需求定制。以下是上海市兴文县常见的网站服务内容:
在线工具,免费。可以准确显示网站或博客中死链接的位置。死链接检测。免费版最多只能扫描 3000 个网页,但每个页面上的超链接数量没有限制。死链接检测。死链接检测。
SEO外链推广专员的主要职责是什么?
百度seo网站优化。百度seo网站优化。seo优化的主要方面是什么?
内蒙古seo。问题:SEO优化 内蒙古哪家网络推广优化系统做的好?
? 站外SEO优化操作:
为保障每个人的高质量就业,易唐科技与全国2万家企业建立了长期合作关系,其中包括百度、新浪、电讯盈科、亚信等世界一流企业,可媲美第二- 一般机构推荐的评级公司。与e-Tang推荐的就业相比,e-Tang的收费模式也是聘用后缴费。我们有信心帮助每一位学生找到满意的工作。南宁网站 优化。南宁网站 优化。
现在学习SEO的未来怎么样?工资怎么样?
网页标签中的内容对于搜索引擎收录非常重要,因此是优化关键词最重要的部分。每个页面应该有 2-3 个不同的 main 关键词 ,最好将这些 关键词 放在网页中尽可能靠前的位置。通常,建议不超过 75 个字符可用。
如何设置首选域
7、网站TDK优化
关键词排名优化服务中的索引为3233363533e4b893e5b19e364。关键词优化方案可以直观评估,所以这个优化方案是目前香港SEO客户要求最多的,所以指定关键词优化服务报价是根据关键词的值可以生成,关键词本身的竞争强度,以及客户网站的质量,供参考。seo优化程序。
这是一个爱站工具,我给大家标注的功能是查死链接,点进去输入网址,然后就可以查了。红色部分是死链接
预防措施:
三、兴文县中国域名相关介绍
具体域名托管服务根据不同行业、公司网站基金会和客户需求定制。以下是兴文县中文域名的常见服务内容:
打开:
网站关键词 排名优化软件免费,请推荐一款
但是网络营销需要一些不同于传统销售的技巧
2、定位主题。(找出关键主题,同时细分较小的主题。)
还需要完善联系方式,如果没有,可以找百度站长平台客服或者他们的公众号反馈情况。百度新闻源应用。百度新闻源应用。百度新闻源应用。百度新闻源应用。
现在百度和谷歌首页都列出了几个字,效果不错
网站推广计划怎么写?
四、兴文县合肥关键词排名优化-延伸阅读
1.在文章插入链接bai:du文章在文章插入链接后,zhi在网站上发布内容将有助于dao增加内部的方向蜘蛛链接和收益版分流的权重;发布每个博客增加反向链。在线伪原创。
如果遇到百度大更新超过2个月没有效果,可能会被开除-。-所以SEO工作很难做
嗯,确实不错,优化技术很棒,软件也很棒
因此,有必要继续探索其中的关键词,完善网站的关键词词库,而关键词优化初期不适合大词,但只选择准确和高的区域。百度权重增加后,市场竞争会考虑长尾词。点击seo排名。seo 排名点击。seo 排名点击。
老铁,没关系。如果你自己能做到,你就不能处理它。
2、所有的问题都应该是对数据的分析和统计,而不是盲目的发链接或者更新文章。
1、选定的讨论e69da5e6ba97a686964616f337论坛:选定的论坛和要推广的内容必须是相关的。论坛营销。并且所选论坛的人气和流量应该很高。论坛营销。论坛营销。论坛营销。论坛营销。或者收录好的,我可以去百度主页
4、URL规范,一页对应一个URL,对应多个需求确定首选URL
一个人要想在社会上过上有品质的生活,他必须至少拥有三个赚钱的渠道。如果你选择SEO,你可以混合以上九种方法来赚钱。随着你的不断进步,金钱、人脉和成就感将源源不断。
谷歌搜索引擎优化的区别和优势是什么?
? 站内优化,长尾词,比如做得好,流量过大,目标词;
五、上海市兴文县网站-进一步阅读
随着互联网的发展,网络推广越来越受到很多人的关注。尤其是seo,很多懂或者不懂推广的人都知道推广是靠seo的,所以seo这个词会随时随地被很多人说出来,那么有多少人真正懂seo呢??
百度快速排名的原理是什么?
阐明:
这种黑帽技术在去年很常见,在医疗行业也比较常见。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。通过购买其他高权重网站(新闻来源网站)目录来填充您自己的内容。高权重的网站容易上榜,目录排名很快就上去了。但是,这种黑帽技术严重影响了用户体验。进入后,并不是用户想看到的。因此,百度在去年对这种黑帽技术进行了沉重打击。
对于网站数据的设置,最重要的任务之一就是网站key关键词62616964757a686964616fe78988e69d83338的设置。
他们可以代表他们滑动下拉框,而且似乎有培训
关于在线推广,还有很多东西需要学习。无论是内部还是外部,都是一点点挖掘。哪些产品需要推广。事实上,seo也是如此。一点一点的积累。网站推广方式。网站推广方式。宁宁飞儿,20110316(已发行),中国玻璃网,(转载请保留)
目前百度2113廊坊区域授权代理为:5261世家4102庄盘古网络科技有限公司1653。建议您拨打百度售前咨询热线或通过官方渠道登录了解更多。廊坊百度优化。廊坊百度优化。
六、兴文县中国域名-延伸阅读
四。网站内容更新
更新频率,网站的更新频率对网站的收录影响很大。定期发布文章可以提高蜘蛛对网站的友好度,养成习惯。蜘蛛会在一定时间内定期访问爬取的内容。百度索引量。
推荐大家去【小丑牛电影】观看下载,最新电影都有,不用担心中毒。我是来看帝仁杰的天朝赵家孤儿笑什么的。也被称为普兰网站管理员。最后,在补充下,如果想看没有的电影,可以留言评论。站长通常会在1周内为您找到!如果你觉得我回答的不错,就给我吧,不然我下次不回答你的问题了!
学校:视频中的学生确实来自学校
解释“页面长度、文本长度、关键词长度、关键词频率、关键词总长度、关键词密度结果”。威海seo。威海seo。谢谢。威海seo。
2013年第一版与网站站长相关的书,我在出版之前阅读了部分内容。开始使用 seo。本书非常适合站长、营销人员、SEO、产品经理等群体阅读。我把它推荐给了每一个人。“网站分析”是一个新兴行业。在各个网站和公司的关注下,一个完整的行业分析注定会继续向前发展。开始使用 seo。
权重的增加增加了百度的关注度和友好度,以及网站关键词排名会快速提升的原则。
如何快速刷网站关键词排名?
29. 怎么用FLASH最安全可靠?
4.对方客服人员什么水平?
1.企业品牌; 查看全部
c 抓取网页数据(SEO优化内蒙古哪个网络推广优化系统做得不错的呢?)
合肥兴文县关键词排名优化()公司一直致力于网站运营、网络整合营销、互联网盈利模式、电子商务、搜索引擎优化(SEO)等方面的研究工作,提供专业网络推广,seo优化,百度优化,网站优化,全站优化,网络营销,网站推广,关键词优化,网站排名优化,是专业的seo外包、seo服务、seo顾问、seo培训、seo公司、seo技术分享免费推广平台、seo教程、seo推广、关键词排名优化、seo排名软件和seo优化工具。
一、兴文县合肥关键词排名优化-详细说明
具体的SEO服务根据不同行业、公司网站基础和客户需求进行定制。以下是常见的合肥兴文县关键词排名优化服务内容:
1、竞争对手流量分析
2、关键词分析研究
3、客服系统代码安装
4、蜘蛛源码搜索引擎分析
5、公司网络营销和SEO培训
6、精准流量挖掘
7、博客程序维护
8、文章图片制作
二、上海市兴文县网站-专家解答
具体建站服务根据不同行业、公司网站基金会和客户需求定制。以下是上海市兴文县常见的网站服务内容:
在线工具,免费。可以准确显示网站或博客中死链接的位置。死链接检测。免费版最多只能扫描 3000 个网页,但每个页面上的超链接数量没有限制。死链接检测。死链接检测。
SEO外链推广专员的主要职责是什么?
百度seo网站优化。百度seo网站优化。seo优化的主要方面是什么?
内蒙古seo。问题:SEO优化 内蒙古哪家网络推广优化系统做的好?
? 站外SEO优化操作:
为保障每个人的高质量就业,易唐科技与全国2万家企业建立了长期合作关系,其中包括百度、新浪、电讯盈科、亚信等世界一流企业,可媲美第二- 一般机构推荐的评级公司。与e-Tang推荐的就业相比,e-Tang的收费模式也是聘用后缴费。我们有信心帮助每一位学生找到满意的工作。南宁网站 优化。南宁网站 优化。
现在学习SEO的未来怎么样?工资怎么样?
网页标签中的内容对于搜索引擎收录非常重要,因此是优化关键词最重要的部分。每个页面应该有 2-3 个不同的 main 关键词 ,最好将这些 关键词 放在网页中尽可能靠前的位置。通常,建议不超过 75 个字符可用。
如何设置首选域
7、网站TDK优化
关键词排名优化服务中的索引为3233363533e4b893e5b19e364。关键词优化方案可以直观评估,所以这个优化方案是目前香港SEO客户要求最多的,所以指定关键词优化服务报价是根据关键词的值可以生成,关键词本身的竞争强度,以及客户网站的质量,供参考。seo优化程序。
这是一个爱站工具,我给大家标注的功能是查死链接,点进去输入网址,然后就可以查了。红色部分是死链接
预防措施:
三、兴文县中国域名相关介绍
具体域名托管服务根据不同行业、公司网站基金会和客户需求定制。以下是兴文县中文域名的常见服务内容:
打开:
网站关键词 排名优化软件免费,请推荐一款
但是网络营销需要一些不同于传统销售的技巧
2、定位主题。(找出关键主题,同时细分较小的主题。)
还需要完善联系方式,如果没有,可以找百度站长平台客服或者他们的公众号反馈情况。百度新闻源应用。百度新闻源应用。百度新闻源应用。百度新闻源应用。
现在百度和谷歌首页都列出了几个字,效果不错
网站推广计划怎么写?
四、兴文县合肥关键词排名优化-延伸阅读
1.在文章插入链接bai:du文章在文章插入链接后,zhi在网站上发布内容将有助于dao增加内部的方向蜘蛛链接和收益版分流的权重;发布每个博客增加反向链。在线伪原创。
如果遇到百度大更新超过2个月没有效果,可能会被开除-。-所以SEO工作很难做
嗯,确实不错,优化技术很棒,软件也很棒
因此,有必要继续探索其中的关键词,完善网站的关键词词库,而关键词优化初期不适合大词,但只选择准确和高的区域。百度权重增加后,市场竞争会考虑长尾词。点击seo排名。seo 排名点击。seo 排名点击。
老铁,没关系。如果你自己能做到,你就不能处理它。
2、所有的问题都应该是对数据的分析和统计,而不是盲目的发链接或者更新文章。
1、选定的讨论e69da5e6ba97a686964616f337论坛:选定的论坛和要推广的内容必须是相关的。论坛营销。并且所选论坛的人气和流量应该很高。论坛营销。论坛营销。论坛营销。论坛营销。或者收录好的,我可以去百度主页
4、URL规范,一页对应一个URL,对应多个需求确定首选URL
一个人要想在社会上过上有品质的生活,他必须至少拥有三个赚钱的渠道。如果你选择SEO,你可以混合以上九种方法来赚钱。随着你的不断进步,金钱、人脉和成就感将源源不断。
谷歌搜索引擎优化的区别和优势是什么?
? 站内优化,长尾词,比如做得好,流量过大,目标词;
五、上海市兴文县网站-进一步阅读
随着互联网的发展,网络推广越来越受到很多人的关注。尤其是seo,很多懂或者不懂推广的人都知道推广是靠seo的,所以seo这个词会随时随地被很多人说出来,那么有多少人真正懂seo呢??
百度快速排名的原理是什么?
阐明:
这种黑帽技术在去年很常见,在医疗行业也比较常见。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。黑帽SEO技术。通过购买其他高权重网站(新闻来源网站)目录来填充您自己的内容。高权重的网站容易上榜,目录排名很快就上去了。但是,这种黑帽技术严重影响了用户体验。进入后,并不是用户想看到的。因此,百度在去年对这种黑帽技术进行了沉重打击。
对于网站数据的设置,最重要的任务之一就是网站key关键词62616964757a686964616fe78988e69d83338的设置。
他们可以代表他们滑动下拉框,而且似乎有培训
关于在线推广,还有很多东西需要学习。无论是内部还是外部,都是一点点挖掘。哪些产品需要推广。事实上,seo也是如此。一点一点的积累。网站推广方式。网站推广方式。宁宁飞儿,20110316(已发行),中国玻璃网,(转载请保留)
目前百度2113廊坊区域授权代理为:5261世家4102庄盘古网络科技有限公司1653。建议您拨打百度售前咨询热线或通过官方渠道登录了解更多。廊坊百度优化。廊坊百度优化。
六、兴文县中国域名-延伸阅读
四。网站内容更新
更新频率,网站的更新频率对网站的收录影响很大。定期发布文章可以提高蜘蛛对网站的友好度,养成习惯。蜘蛛会在一定时间内定期访问爬取的内容。百度索引量。
推荐大家去【小丑牛电影】观看下载,最新电影都有,不用担心中毒。我是来看帝仁杰的天朝赵家孤儿笑什么的。也被称为普兰网站管理员。最后,在补充下,如果想看没有的电影,可以留言评论。站长通常会在1周内为您找到!如果你觉得我回答的不错,就给我吧,不然我下次不回答你的问题了!
学校:视频中的学生确实来自学校
解释“页面长度、文本长度、关键词长度、关键词频率、关键词总长度、关键词密度结果”。威海seo。威海seo。谢谢。威海seo。
2013年第一版与网站站长相关的书,我在出版之前阅读了部分内容。开始使用 seo。本书非常适合站长、营销人员、SEO、产品经理等群体阅读。我把它推荐给了每一个人。“网站分析”是一个新兴行业。在各个网站和公司的关注下,一个完整的行业分析注定会继续向前发展。开始使用 seo。
权重的增加增加了百度的关注度和友好度,以及网站关键词排名会快速提升的原则。
如何快速刷网站关键词排名?
29. 怎么用FLASH最安全可靠?
4.对方客服人员什么水平?
1.企业品牌;
c 抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
网站优化 • 优采云 发表了文章 • 0 个评论 • 415 次浏览 • 2021-10-21 18:12
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。该模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。 查看全部
c 抓取网页数据(三种抓取网页数据的方法-2.Beautiful)
下面我们将介绍三种抓取网页数据的方法,首先是正则表达式,然后是流行的BeautifulSoup模块,最后是强大的lxml模块。
1. 正则表达式
如果您对正则表达式不熟悉,或者需要一些提示,可以参考正则表达式 HOWTO 中的完整介绍。
当我们使用正则表达式抓取国家/地区数据时,首先要尽量匹配元素的内容,如下图:
>>> import re
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> re.findall('(.*?)', html)
['/places/static/images/flags/gb.png', '244,820 square kilometres', '62,348,447', 'GB', 'United Kingdom', 'London', 'EU', '.uk', 'GBP', 'Pound', '44', '@# #@@|@## #@@|@@# #@@|@@## #@@|@#@ #@@|@@#@ #@@|GIR0AA', '^(([A-Z]\\d{2}[A-Z]{2})|([A-Z]\\d{3}[A-Z]{2})|([A-Z]{2}\\d{2}[A-Z]{2})|([A-Z]{2}\\d{3}[A-Z]{2})|([A-Z]\\d[A-Z]\\d[A-Z]{2})|([A-Z]{2}\\d[A-Z]\\d[A-Z]{2})|(GIR0AA))$', 'en-GB,cy-GB,gd', 'IE ']
>>>
从上面的结果可以看出,在很多国家属性中都使用了标签。为了隔离area属性,我们可以只选择第二个元素,如下图:
>>> re.findall('(.*?)', html)[1]
'244,820 square kilometres'
虽然现在可以使用这个方案,但是如果网页发生变化,该方案很可能会失败。比如表变了,去掉了第二行的土地面积数据。如果我们现在只抓取数据,我们可以忽略这种可能的未来变化。但是,如果我们希望将来再次捕获数据,则需要提供更健壮的解决方案,以尽可能避免这种布局更改的影响。为了使正则表达式更加健壮,我们还可以添加其父元素。由于此元素具有 ID 属性,因此它应该是唯一的。
>>> re.findall('Area: (.*?)', html)
['244,820 square kilometres']
这个迭代版本看起来更好,但是还有很多其他的更新网页的方式,也会让正则表达式不尽人意。例如,将双引号更改为单引号,在标签之间添加额外的空格,或者更改 area_label 等。以下是尝试支持这些可能性的改进版本。
>>> re.findall('.*?>> from bs4 import BeautifulSoup
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> soup = BeautifulSoup(broken_html, 'html.parser')
>>> fixed_html = soup.prettify()
>>> print fixed_html
Area
Population
从上面的执行结果可以看出,Beautiful Soup可以正确解析缺失的引号并关闭标签。现在我们可以使用 find() 和 find_all() 方法来定位我们需要的元素。
>>> ul = soup.find('ul', attrs={'class':'country'})
>>> ul.find('li') # return just the first match
AreaPopulation
>>> ul.find_all('li') # return all matches
[AreaPopulation, Population]
注:由于不同版本的Python内置库容错能力的差异,处理结果可能与上述不同。详情请参考:。如果想知道所有的方法和参数,可以参考Beautiful Soup的官方文档
以下是使用该方法提取样本国家面积数据的完整代码。
>>> from bs4 import BeautifulSoup
>>> import urllib2
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> # locate the area row
>>> tr = soup.find(attrs={'id':'places_area__row'})
>>> # locate the area tag
>>> td = tr.find(attrs={'class':'w2p_fw'})
>>> area = td.text # extract the text from this tag
>>> print area
244,820 square kilometres
这段代码虽然比正则表达式代码复杂,但更容易构建和理解。此外,我们不需要担心布局的微小变化,例如额外的空间和标签属性。
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。该模块是用C语言编写的,解析速度比Beautiful Soup快,但是安装过程比较复杂。可以参考最新的安装说明。**
与 Beautiful Soup 一样,使用 lxml 模块的第一步是将潜在的非法 HTML 解析为统一格式。以下是使用此模块解析不完整 HTML 的示例:
>>> import lxml.html
>>> broken_html = 'AreaPopulation'
>>> # parse the HTML
>>> tree = lxml.html.fromstring(broken_html)
>>> fixed_html = lxml.html.tostring(tree, pretty_print=True)
>>> print fixed_html
Area
Population
同理,lxml 可以正确解析属性两边缺失的引号并关闭标签,但模块不会添加额外的和标签。
解析输入内容后,进入选择元素的步骤。这时候lxml有几种不同的方法,比如XPath选择器和类似于Beautiful Soup的find()方法。但是,我们以后会使用 CSS 选择器,因为它更简洁,可以在解析动态内容时重复使用。另外,一些有jQuery选择器使用经验的读者会比较熟悉。
以下是使用 lxml 的 CSS 选择器提取区域数据的示例代码:
>>> import urllib2
>>> import lxml.html
>>> url = 'http://example.webscraping.com/view/United-Kingdom-239'
>>> html = urllib2.urlopen(url).read()
>>> tree = lxml.html.fromstring(html)
>>> td = tree.cssselect('tr#places_area__row > td.w2p_fw')[0] # *行代码
>>> area = td.text_content()
>>> print area
244,820 square kilometres
*行代码会先找到id为places_area__row的表格行元素,然后选择类为w2p_fw的表格数据子标签。
CSS 选择器表示用于选择元素的模式。以下是一些常用选择器的示例:
选择所有标签: *
选择 标签: a
选择所有 class="link" 的元素: .link
选择 class="link" 的 标签: a.link
选择 id="home" 的 标签: a#home
选择父元素为 标签的所有 子标签: a > span
选择 标签内部的所有 标签: a span
选择 title 属性为"Home"的所有 标签: a[title=Home]
W3C 提出了 CSS3 规范,其网站是
Lxml 已经实现了大部分 CSS3 属性,不支持的功能可以在:。
注意:在 lxml 的内部实现中,它实际上是将 CSS 选择器转换为等效的 XPath 选择器。
4. 性能对比
下面的代码中,每个爬虫都会执行1000次,每次都会检查爬取结果是否正确,然后打印总时间。
# -*- coding: utf-8 -*-
import csv
import time
import urllib2
import re
import timeit
from bs4 import BeautifulSoup
import lxml.html
FIELDS = ('area', 'population', 'iso', 'country', 'capital', 'continent', 'tld', 'currency_code', 'currency_name', 'phone', 'postal_code_format', 'postal_code_regex', 'languages', 'neighbours')
def regex_scraper(html):
results = {}
for field in FIELDS:
results[field] = re.search('.*?(.*?)'.format(field), html).groups()[0]
return results
def beautiful_soup_scraper(html):
soup = BeautifulSoup(html, 'html.parser')
results = {}
for field in FIELDS:
results[field] = soup.find('table').find('tr', id='places_{}__row'.format(field)).find('td', class_='w2p_fw').text
return results
def lxml_scraper(html):
tree = lxml.html.fromstring(html)
results = {}
for field in FIELDS:
results[field] = tree.cssselect('table > tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
def main():
times = {}
html = urllib2.urlopen('http://example.webscraping.com/view/United-Kingdom-239').read()
NUM_ITERATIONS = 1000 # number of times to test each scraper
for name, scraper in ('Regular expressions', regex_scraper), ('Beautiful Soup', beautiful_soup_scraper), ('Lxml', lxml_scraper):
times[name] = []
# record start time of scrape
start = time.time()
for i in range(NUM_ITERATIONS):
if scraper == regex_scraper:
# the regular expression module will cache results
# so need to purge this cache for meaningful timings
re.purge() # *行代码
result = scraper(html)
# check scraped result is as expected
assert(result['area'] == '244,820 square kilometres')
times[name].append(time.time() - start)
# record end time of scrape and output the total
end = time.time()
print '{}: {:.2f} seconds'.format(name, end - start)
writer = csv.writer(open('times.csv', 'w'))
header = sorted(times.keys())
writer.writerow(header)
for row in zip(*[times[scraper] for scraper in header]):
writer.writerow(row)
if __name__ == '__main__':
main()
请注意,我们在 * 代码行中调用了 re.purge() 方法。默认情况下,正则表达式将缓存搜索结果。公平地说,我们需要使用这种方法来清除缓存。
这是在我的电脑上运行脚本的结果:
由于硬件条件的不同,不同电脑的执行结果也会有一定的差异。但是,每种方法之间的相对差异应该具有可比性。从结果可以看出,在抓取我们的示例网页时,Beautiful Soup 比其他两种方法慢 7 倍以上。其实这个结果是符合预期的,因为lxml和正则表达式模块都是用C语言写的,而Beautiful Soup是用纯Python写的。一个有趣的事实是 lxml 的性能几乎与正则表达式一样好。由于 lxml 必须在搜索元素之前将输入解析为内部格式,因此会产生额外的开销。当抓取同一个网页的多个特征时,这个初步分析的开销会减少,lxml会更有竞争力。
5. 总结
三种网页抓取方式的优缺点:
抓取方式 性能 使用困难 安装困难
正则表达式
快的
困难
简单(内置模块)
美汤
减缓
简单的
简单(纯 Python)
xml文件
快的
简单的
比较难
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用较慢的方法(比如Beautiful Soup)不是问题。正则表达式在一次性提取中非常有用,还可以避免解析整个网页的开销。如果你只需要爬取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。但是,一般情况下,lxml 是捕获数据的最佳选择,因为它不仅速度更快,而且用途更广,而正则表达式和 Beautiful Soup 仅在某些场景下有用。
c 抓取网页数据(人人都用得上webscraper抓取数据数据的问题进阶教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-10-20 21:13
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果你正在使用网络爬虫抓取数据,你很可能会遇到以下一个或多个问题,这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按s键。
另外,勾选“启用键”后,会出现三个字母,分别是s、p、c。按s选择当前元素,按p选择当前元素的父元素,按c选择当前元素的子元素。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,适当增加延迟大小,延长等待时间,并留出足够的时间来加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是乱序的,可以安装couchdb来保证数据的顺序。
或者以其他替代方式,我们最终将数据导出为 csv 格式。用excel打开csv后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在excel中重新导出。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。当您遇到问题时,您可以开始学习它。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。 查看全部
c 抓取网页数据(人人都用得上webscraper抓取数据数据的问题进阶教程)
如果你想爬取数据又懒得写代码,可以试试网络爬虫爬取数据。
相关 文章:
最简单的数据采集教程,大家都可以用
进阶网页爬虫教程,人人都能用
如果你正在使用网络爬虫抓取数据,你很可能会遇到以下一个或多个问题,这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的几个问题,并解释了解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素上,按s键。
另外,勾选“启用键”后,会出现三个字母,分别是s、p、c。按s选择当前元素,按p选择当前元素的父元素,按c选择当前元素的子元素。当前元素是指鼠标所在的元素。
2、 分页数据或滚动加载的数据无法完整抓取,如知乎 和推特等?
这种问题多半是网络问题。在数据可以加载之前,网络爬虫开始解析数据,但由于没有及时加载,网络爬虫误认为抓取已经完成。
因此,适当增加延迟大小,延长等待时间,并留出足够的时间来加载数据。默认延迟2000,也就是2秒,可以根据网速调整。
但是,当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、获取数据的顺序和网页上的顺序不一致?
webscraper默认是乱序的,可以安装couchdb来保证数据的顺序。
或者以其他替代方式,我们最终将数据导出为 csv 格式。用excel打开csv后,可以按某一列进行排序。比如我们抓取微博数据的时候,可以抓取发布时间,然后在excel中重新导出。按发布时间排序,或者知乎上的数据按点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择?
出现这种情况的原因可能是网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标悬停时才会显示的元素。在这些情况下,您也需要使用其他方法。
其实就是通过鼠标操作选择元素,最后找到元素对应的xpath。Xpath对应网页解释,是定位某个元素的路径,通过元素的类型、唯一标识符、样式名称、从属关系来查找某个元素或某种类型的元素。
如果你没有遇到过这个问题,那么就没有必要了解xpath。当您遇到问题时,您可以开始学习它。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。

