
网页爬虫抓取百度图片
网页爬虫抓取百度图片(什么是爬虫?网络爬虫的本质模拟浏览器的基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-04-04 03:09
一、什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
二、爬行动物的本质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,获取我们想要的资源(文字、图片、视频...)
三、爬虫基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
四、什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
五、Requests 库的基础知识
Requests 库的 7 个主要方法
我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
请求对象就是我们要请求的url,响应对象就是返回的内容,如图:
Request 库的两个重要对象
六、安装请求
1.强烈建议您使用pip进行安装:pip insrall requests
2.Pycharm安装:文件-》默认设置-》项目解释器-》搜索请求-》安装包-》ok
七、Requests库的操作示例
1、京东商品爬虫-普通爬虫框架
导入请求 查看全部
网页爬虫抓取百度图片(什么是爬虫?网络爬虫的本质模拟浏览器的基本流程)
一、什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
二、爬行动物的本质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,获取我们想要的资源(文字、图片、视频...)
三、爬虫基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
四、什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
五、Requests 库的基础知识
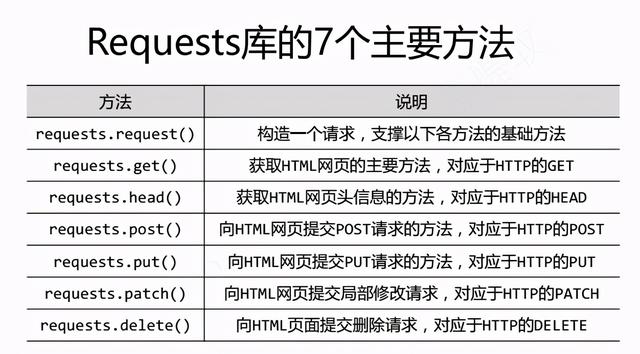
Requests 库的 7 个主要方法
我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
请求对象就是我们要请求的url,响应对象就是返回的内容,如图:

Request 库的两个重要对象
六、安装请求
1.强烈建议您使用pip进行安装:pip insrall requests
2.Pycharm安装:文件-》默认设置-》项目解释器-》搜索请求-》安装包-》ok
七、Requests库的操作示例
1、京东商品爬虫-普通爬虫框架
导入请求
网页爬虫抓取百度图片(Python全栈免费解答.裙(BFE9)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-01 22:19
经过前期的大量学习和准备,我们需要开始编写第一个真正的爬虫。这次我们要爬的网站是:百度贴吧,一个很适合新手练习的地方,所以开始吧。
这次想爬贴吧Yes>,西部世界是一部我一直很喜欢的美剧。我通常有时间去看看我的朋友们在谈论什么。所以这次我选择了这个酒吧作为实验材料。注意:很多人在学习Python的过程中会遇到各种烦恼,无人回答很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
贴吧地址:
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8
Python 版本:3.6
浏览器版本:Chrome
目标分析:
由于它是第一个实验爬虫,我们没有太多工作要做。我们需要做的就是:
1、从网络上爬取特定页面
2、对被爬取的页面内容进行简单过滤分析
3、查找每个帖子的标题、海报、日期、楼层和跳转链接
4、将结果保存为文本。
前期准备:
看到贴吧的url地址,你是不是觉得一头雾水?有一大串无法识别的字符?
其实这些都是汉字。
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C
后面的代码是:西部世界。
链接末尾:&ie=utf-8 表示链接采用utf-8编码。
windows的默认编码是GBK。在处理这个连接时,我们需要在 Python 中手动设置,才能成功使用。
与Python2相比,Python3对编码的支持有了很大的提升。默认情况下,全局使用 utf-8 编码。所以建议还在学习Python2的朋友赶紧投身Python3的怀抱,真的是省了老大的功夫。
然后我们转到贴吧的第二页:
网址:
`url: https://tieba.baidu.com/f%3Fkw ... %3D50`
注意没有,在连接的末尾多了一个参数&pn=50,
这里我们很容易猜到这个参数与页码的关系:
现在我们可以通过简单的url修改来实现翻页的效果。
chrome开发者工具的使用:
要编写爬虫,我们必须能够使用开发工具。说起来,这个工具是为前端开发者准备的,但是我们可以用它来快速定位我们要爬取的信息,找到对应的规则。
图片
图片
我们仔细一看,发现每篇文章的内容都被一个 li 标签包裹着:
这样,我们只需要快速找到所有符合规则的标签,
在进一步分析内容,最后过滤掉数据就可以了。
开始写代码?我们先写一个函数来抓取页面上的人:
这是前面介绍的爬虫框架,以后会经常用到。
import requests
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
#这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding='utf-8'
return r.text
except:
return " ERROR "
然后我们提取细节:
一个大的 li 标签包裹了许多 div 标签
我们想要的信息在这些 div 标签中:
# 标题&帖子链接
<a span class="token attr-name"relspan class="token attr-value"span class="token punctuation"=span class="token punctuation""noreferrerspan class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/p/5803134498span class="token punctuation"" span class="token attr-name"titlespan class="token attr-value"span class="token punctuation"=span class="token punctuation""【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给span class="token punctuation"" span class="token attr-name"targetspan class="token attr-value"span class="token punctuation"=span class="token punctuation""_blankspan class="token punctuation"" span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""j_th_tit span class="token punctuation""span class="token punctuation">【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给
#发帖人:
"user_id<a span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""icon_tbworld icon-crown-super-v1span class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/tbmall/tshowspan class="token punctuation"" span class="token attr-name"data-fieldspan class="token attr-value"span class="token punctuation"=span class="token punctuation""{span class="token entity" title=""">"user_id
#回复数量:
822
#发帖日期:
7-20
经过分析,我们可以通过soup.find()方法轻松得到我们想要的结果
具体代码实现:
'''
抓取百度贴吧---西部世界吧的基本内容
爬虫线路: requests - bs4
Python版本: 3.6
OS: mac os 12.13.6
'''
import requests
import time
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
# 这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding = 'utf-8'
return r.text
except:
return " ERROR "
def get_content(url):
'''
分析贴吧的网页文件,整理信息,保存在列表变量中
'''
# 初始化一个列表来保存所有的帖子信息:
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
# 我们来做一锅汤
soup = BeautifulSoup(html, 'lxml')
# 按照之前的分析,我们找到所有具有‘ j_thread_list clearfix’属性的li标签。返回一个列表类型。
liTags = soup.find_all('li', attrs={'class': ' j_thread_list clearfix'})
# 通过循环找到每个帖子里的我们需要的信息:
for li in liTags:
# 初始化一个字典来存储文章信息
comment = {}
# 这里使用一个try except 防止爬虫找不到信息从而停止运行
try:
# 开始筛选信息,并保存到字典中
comment['title'] = li.find(
'a', attrs={'class': 'j_th_tit '}).text.strip()
comment['link'] = "http://tieba.baidu.com/" + \
li.find('a', attrs={'class': 'j_th_tit '})['href']
comment['name'] = li.find(
'span', attrs={'class': 'tb_icon_author '}).text.strip()
comment['time'] = li.find(
'span', attrs={'class': 'pull-right is_show_create_time'}).text.strip()
comment['replyNum'] = li.find(
'span', attrs={'class': 'threadlist_rep_num center_text'}).text.strip()
comments.append(comment)
except:
print('出了点小问题')
return comments
def Out2File(dict):
'''
将爬取到的文件写入到本地
保存到当前目录的 TTBT.txt文件中。
'''
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('标题: {} \t 链接:{} \t 发帖人:{} \t 发帖时间:{} \t 回复数量: {} \n'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']))
print('当前页面爬取完成')
def main(base_url, deep):
url_list = []
# 将所有需要爬去的url存入列表
for i in range(0, deep):
url_list.append(base_url + '&pn=' + str(50 * i))
print('所有的网页已经下载到本地! 开始筛选信息。。。。')
#循环写入所有的数据
for url in url_list:
content = get_content(url)
Out2File(content)
print('所有的信息都已经保存完毕!')
base_url = 'https://tieba.baidu.com/f?kw=%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8'
# 设置需要爬取的页码数量
deep = 3
if __name__ == '__main__':
main(base_url, deep)
代码中有详细的注释和想法。如果看不懂,多读几遍。
这是爬升的结果:
图片
小结注:很多人在学习Python的过程中会遇到各种各样的烦恼,没人回答就很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
本文文字和图片来源于网络和自己的想法,仅供学习交流,不具备任何商业用途。版权归原作者所有。如有任何问题,请及时联系我们进行处理。 查看全部
网页爬虫抓取百度图片(Python全栈免费解答.裙(BFE9)(组图))
经过前期的大量学习和准备,我们需要开始编写第一个真正的爬虫。这次我们要爬的网站是:百度贴吧,一个很适合新手练习的地方,所以开始吧。
这次想爬贴吧Yes>,西部世界是一部我一直很喜欢的美剧。我通常有时间去看看我的朋友们在谈论什么。所以这次我选择了这个酒吧作为实验材料。注意:很多人在学习Python的过程中会遇到各种烦恼,无人回答很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
贴吧地址:
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8
Python 版本:3.6
浏览器版本:Chrome
目标分析:
由于它是第一个实验爬虫,我们没有太多工作要做。我们需要做的就是:
1、从网络上爬取特定页面
2、对被爬取的页面内容进行简单过滤分析
3、查找每个帖子的标题、海报、日期、楼层和跳转链接
4、将结果保存为文本。
前期准备:
看到贴吧的url地址,你是不是觉得一头雾水?有一大串无法识别的字符?
其实这些都是汉字。
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C
后面的代码是:西部世界。
链接末尾:&ie=utf-8 表示链接采用utf-8编码。
windows的默认编码是GBK。在处理这个连接时,我们需要在 Python 中手动设置,才能成功使用。
与Python2相比,Python3对编码的支持有了很大的提升。默认情况下,全局使用 utf-8 编码。所以建议还在学习Python2的朋友赶紧投身Python3的怀抱,真的是省了老大的功夫。
然后我们转到贴吧的第二页:
网址:
`url: https://tieba.baidu.com/f%3Fkw ... %3D50`
注意没有,在连接的末尾多了一个参数&pn=50,
这里我们很容易猜到这个参数与页码的关系:
现在我们可以通过简单的url修改来实现翻页的效果。
chrome开发者工具的使用:
要编写爬虫,我们必须能够使用开发工具。说起来,这个工具是为前端开发者准备的,但是我们可以用它来快速定位我们要爬取的信息,找到对应的规则。

图片
图片
我们仔细一看,发现每篇文章的内容都被一个 li 标签包裹着:
这样,我们只需要快速找到所有符合规则的标签,
在进一步分析内容,最后过滤掉数据就可以了。
开始写代码?我们先写一个函数来抓取页面上的人:
这是前面介绍的爬虫框架,以后会经常用到。
import requests
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
#这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding='utf-8'
return r.text
except:
return " ERROR "
然后我们提取细节:
一个大的 li 标签包裹了许多 div 标签
我们想要的信息在这些 div 标签中:
# 标题&帖子链接
<a span class="token attr-name"relspan class="token attr-value"span class="token punctuation"=span class="token punctuation""noreferrerspan class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/p/5803134498span class="token punctuation"" span class="token attr-name"titlespan class="token attr-value"span class="token punctuation"=span class="token punctuation""【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给span class="token punctuation"" span class="token attr-name"targetspan class="token attr-value"span class="token punctuation"=span class="token punctuation""_blankspan class="token punctuation"" span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""j_th_tit span class="token punctuation""span class="token punctuation">【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给
#发帖人:
"user_id<a span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""icon_tbworld icon-crown-super-v1span class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/tbmall/tshowspan class="token punctuation"" span class="token attr-name"data-fieldspan class="token attr-value"span class="token punctuation"=span class="token punctuation""{span class="token entity" title=""">"user_id
#回复数量:
822
#发帖日期:
7-20
经过分析,我们可以通过soup.find()方法轻松得到我们想要的结果
具体代码实现:
'''
抓取百度贴吧---西部世界吧的基本内容
爬虫线路: requests - bs4
Python版本: 3.6
OS: mac os 12.13.6
'''
import requests
import time
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
# 这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding = 'utf-8'
return r.text
except:
return " ERROR "
def get_content(url):
'''
分析贴吧的网页文件,整理信息,保存在列表变量中
'''
# 初始化一个列表来保存所有的帖子信息:
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
# 我们来做一锅汤
soup = BeautifulSoup(html, 'lxml')
# 按照之前的分析,我们找到所有具有‘ j_thread_list clearfix’属性的li标签。返回一个列表类型。
liTags = soup.find_all('li', attrs={'class': ' j_thread_list clearfix'})
# 通过循环找到每个帖子里的我们需要的信息:
for li in liTags:
# 初始化一个字典来存储文章信息
comment = {}
# 这里使用一个try except 防止爬虫找不到信息从而停止运行
try:
# 开始筛选信息,并保存到字典中
comment['title'] = li.find(
'a', attrs={'class': 'j_th_tit '}).text.strip()
comment['link'] = "http://tieba.baidu.com/" + \
li.find('a', attrs={'class': 'j_th_tit '})['href']
comment['name'] = li.find(
'span', attrs={'class': 'tb_icon_author '}).text.strip()
comment['time'] = li.find(
'span', attrs={'class': 'pull-right is_show_create_time'}).text.strip()
comment['replyNum'] = li.find(
'span', attrs={'class': 'threadlist_rep_num center_text'}).text.strip()
comments.append(comment)
except:
print('出了点小问题')
return comments
def Out2File(dict):
'''
将爬取到的文件写入到本地
保存到当前目录的 TTBT.txt文件中。
'''
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('标题: {} \t 链接:{} \t 发帖人:{} \t 发帖时间:{} \t 回复数量: {} \n'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']))
print('当前页面爬取完成')
def main(base_url, deep):
url_list = []
# 将所有需要爬去的url存入列表
for i in range(0, deep):
url_list.append(base_url + '&pn=' + str(50 * i))
print('所有的网页已经下载到本地! 开始筛选信息。。。。')
#循环写入所有的数据
for url in url_list:
content = get_content(url)
Out2File(content)
print('所有的信息都已经保存完毕!')
base_url = 'https://tieba.baidu.com/f?kw=%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8'
# 设置需要爬取的页码数量
deep = 3
if __name__ == '__main__':
main(base_url, deep)
代码中有详细的注释和想法。如果看不懂,多读几遍。
这是爬升的结果:
图片
小结注:很多人在学习Python的过程中会遇到各种各样的烦恼,没人回答就很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
本文文字和图片来源于网络和自己的想法,仅供学习交流,不具备任何商业用途。版权归原作者所有。如有任何问题,请及时联系我们进行处理。
网页爬虫抓取百度图片(这里有新鲜出炉的Python3Cookbook,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-31 18:01
这里是最新发布的Python3 Cookbook中文版,程序狗速来了!
Python 编程语言 Python 是一种面向对象的、解释型的计算机编程语言,由 Guido van Rossum 于 1989 年底发明,并于 1991 年首次公开发布。 Python 语法简洁明了,具有丰富而强大的类库. 通常被称为胶水语言,它可以很容易地将用其他语言(尤其是 C/C++)制作的各种模块链接在一起。
本文主要介绍Python爬虫:通过关键词爬取百度图片的方法。有很好的参考价值,跟着小编一起来看看吧
使用的工具:Python2.7 点我下载
爬虫框架
崇高的文本3
一。构建python(Windows版本)
1.安装python2.7 ---然后在cmd中输入python,界面如下,安装成功
2.集成Scrapy框架----进入命令行:pip install Scrapy
安装成功界面如下:
失败的案例很多,例如:
解决方案:
其余错误可以百度搜索。
二。开始编程。
1.爬行静态网站无反爬行措施。比如百度贴吧,豆瓣阅读。
例如 - 来自“桌面栏”的帖子
python代码如下:
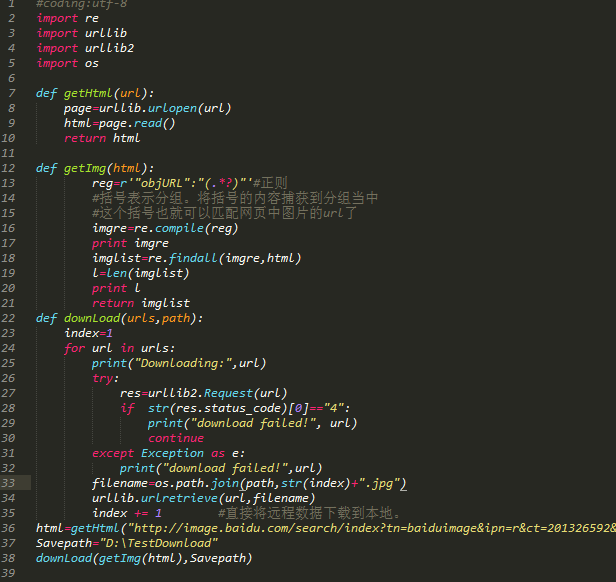
代码注释: 两个模块 urllib, re 介绍。定义两个函数,第一个函数是获取整个目标网页的数据,第二个函数是获取目标网页中的目标图像,遍历网页,将获得的图像按照0排序。
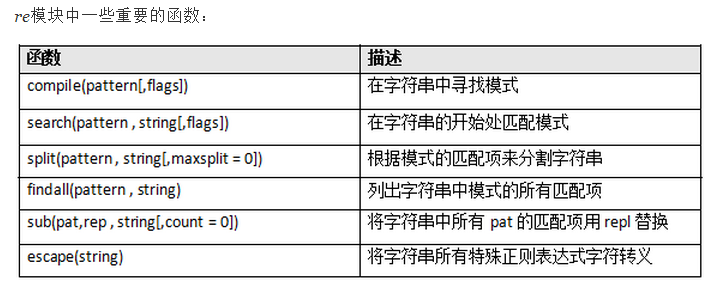
注:re模块知识点:
爬取图片效果图:
图片保存路径默认为同一目录下创建的 .py 文件。
2.用反爬措施爬取百度图片。比如百度图片等等。
比如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片以滚动方式加载,排名前30的图片优先爬取。
代码显示如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句并抛出 tryException。
爬取过程如下:
爬取结果:
注意:写python代码时,注意对齐,不能混用Tab和空格,容易报错。
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持PHPERZ! 查看全部
网页爬虫抓取百度图片(这里有新鲜出炉的Python3Cookbook,程序狗速度看过来!)
这里是最新发布的Python3 Cookbook中文版,程序狗速来了!
Python 编程语言 Python 是一种面向对象的、解释型的计算机编程语言,由 Guido van Rossum 于 1989 年底发明,并于 1991 年首次公开发布。 Python 语法简洁明了,具有丰富而强大的类库. 通常被称为胶水语言,它可以很容易地将用其他语言(尤其是 C/C++)制作的各种模块链接在一起。
本文主要介绍Python爬虫:通过关键词爬取百度图片的方法。有很好的参考价值,跟着小编一起来看看吧
使用的工具:Python2.7 点我下载
爬虫框架
崇高的文本3
一。构建python(Windows版本)
1.安装python2.7 ---然后在cmd中输入python,界面如下,安装成功

2.集成Scrapy框架----进入命令行:pip install Scrapy

安装成功界面如下:
失败的案例很多,例如:
解决方案:
其余错误可以百度搜索。
二。开始编程。
1.爬行静态网站无反爬行措施。比如百度贴吧,豆瓣阅读。
例如 - 来自“桌面栏”的帖子
python代码如下:

代码注释: 两个模块 urllib, re 介绍。定义两个函数,第一个函数是获取整个目标网页的数据,第二个函数是获取目标网页中的目标图像,遍历网页,将获得的图像按照0排序。
注:re模块知识点:
爬取图片效果图:
图片保存路径默认为同一目录下创建的 .py 文件。
2.用反爬措施爬取百度图片。比如百度图片等等。
比如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片以滚动方式加载,排名前30的图片优先爬取。
代码显示如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句并抛出 tryException。
爬取过程如下:

爬取结果:

注意:写python代码时,注意对齐,不能混用Tab和空格,容易报错。
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持PHPERZ!
网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-31 00:26
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的图片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站就知道了,不好解释) 几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar 查看全部
网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的图片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站就知道了,不好解释) 几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar
网页爬虫抓取百度图片(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-26 06:28
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
一、操作步骤
Jisouke的“飞行模式”专门针对那些没有独立URL的弹出页面,即点击后会弹出一个新的标签页,但URL保持不变。“飞行模式”可以模拟人的操作,打开一个弹窗采集然后再打开下一个弹窗继续采集,这样采集下弹窗- up窗口网页信息。
下面以百度百家为例。虽然它的弹窗有一个独立的网站,但是这种情况下最简单的采集方法就是做一个层次结构采集,但是为了演示天桥采集,我们把它当作网址不变。操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页
1.1、打开GS爬虫浏览器,输入网址等待页面加载完毕,然后点击“定义规则”,然后输入主题,最后再次勾选,主题名称不能重复。
步骤 2:定义一级规则
2.1、双击所需信息,勾选确认。一级规则可以随意标记一条信息,目的是让爬虫判断是否执行采集。
2.2,本例中,点击每个文章的标题,然后跟踪弹出的网页采集数据,需要编写定位每个点击对象的xpath表达式。我们可以使用“show xpath”功能自动定位,找到可以定位到每个action对象的xpath。但是对于结构较少的网页,“显示xpath”将无法定位到所有的action对象,需要自己编写相应的xpath,可以看xpath教程来掌握。
2.3、在连续动作中新建一个“点击”动作,下属主题名填写“百度百家文章采集”,勾选“飞行模式”,填写xpath 表达式公式和动作名称
2.4、点击“保存规则”
第三步:定义二级规则
3.1、再次点击“定义规则”,返回普通网页模式,然后点击第一个文章的标题,会弹出一个新窗口,二级规则为在新窗口中定义
3.2、双击需要的信息进行标记,将定位标记准确映射到采集范围
3.3、点击“测试”,如果输出结果没有问题,点击“保存规则”
第 4 步:获取数据
4.1、在DS计数器中搜索一级规则并运行,点击成功,会弹出一个新窗口采集二级网页,采集之后弹窗网页完成后会自动关闭,点击下一步继续采集。这是飞越模式,智能追踪弹窗采集数据。
注意:一级规则的连续动作执行成功后,会自动采集下级规则,所以不需要单独运行下级规则,尤其是下级规则rule 没有独立的 URL,如果在运行时没有采集到目标数据,它会失败。
注:以上为案例网站的采集规则,请根据目标网站的实际情况定义规则。另外,天桥模式是旗舰功能,请先购买再做规则采集数据。
Tips:没有独立URL的网页如何加载和修改规则?
对于没有独立URL的网页,需要先点击该页面,然后搜索规则,右键选择“仅加载规则”,点击“规则”菜单->“后续分析”完成加载操作,然后您可以修改规则。
比如这种情况下的二级规则就是没有独立的URL。需要先加载一级规则,恢复到普通网页模式,点击文章标题,会弹出一个新窗口。(建议把操作写在第一个二级规则的备注里,方便查看),然后右键二级规则,选择“Load Rules Only”。
Part 1 文章:《连续动作:设置自动返回上级页面》 Part 2 文章:《连续打码:破解各种验证码》
如有疑问,您可以或
查看全部
网页爬虫抓取百度图片(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
一、操作步骤
Jisouke的“飞行模式”专门针对那些没有独立URL的弹出页面,即点击后会弹出一个新的标签页,但URL保持不变。“飞行模式”可以模拟人的操作,打开一个弹窗采集然后再打开下一个弹窗继续采集,这样采集下弹窗- up窗口网页信息。
下面以百度百家为例。虽然它的弹窗有一个独立的网站,但是这种情况下最简单的采集方法就是做一个层次结构采集,但是为了演示天桥采集,我们把它当作网址不变。操作步骤如下:

二、案例规则+操作步骤
第一步:打开网页
1.1、打开GS爬虫浏览器,输入网址等待页面加载完毕,然后点击“定义规则”,然后输入主题,最后再次勾选,主题名称不能重复。

步骤 2:定义一级规则
2.1、双击所需信息,勾选确认。一级规则可以随意标记一条信息,目的是让爬虫判断是否执行采集。

2.2,本例中,点击每个文章的标题,然后跟踪弹出的网页采集数据,需要编写定位每个点击对象的xpath表达式。我们可以使用“show xpath”功能自动定位,找到可以定位到每个action对象的xpath。但是对于结构较少的网页,“显示xpath”将无法定位到所有的action对象,需要自己编写相应的xpath,可以看xpath教程来掌握。

2.3、在连续动作中新建一个“点击”动作,下属主题名填写“百度百家文章采集”,勾选“飞行模式”,填写xpath 表达式公式和动作名称
2.4、点击“保存规则”

第三步:定义二级规则
3.1、再次点击“定义规则”,返回普通网页模式,然后点击第一个文章的标题,会弹出一个新窗口,二级规则为在新窗口中定义
3.2、双击需要的信息进行标记,将定位标记准确映射到采集范围
3.3、点击“测试”,如果输出结果没有问题,点击“保存规则”

第 4 步:获取数据
4.1、在DS计数器中搜索一级规则并运行,点击成功,会弹出一个新窗口采集二级网页,采集之后弹窗网页完成后会自动关闭,点击下一步继续采集。这是飞越模式,智能追踪弹窗采集数据。
注意:一级规则的连续动作执行成功后,会自动采集下级规则,所以不需要单独运行下级规则,尤其是下级规则rule 没有独立的 URL,如果在运行时没有采集到目标数据,它会失败。


注:以上为案例网站的采集规则,请根据目标网站的实际情况定义规则。另外,天桥模式是旗舰功能,请先购买再做规则采集数据。
Tips:没有独立URL的网页如何加载和修改规则?
对于没有独立URL的网页,需要先点击该页面,然后搜索规则,右键选择“仅加载规则”,点击“规则”菜单->“后续分析”完成加载操作,然后您可以修改规则。
比如这种情况下的二级规则就是没有独立的URL。需要先加载一级规则,恢复到普通网页模式,点击文章标题,会弹出一个新窗口。(建议把操作写在第一个二级规则的备注里,方便查看),然后右键二级规则,选择“Load Rules Only”。

Part 1 文章:《连续动作:设置自动返回上级页面》 Part 2 文章:《连续打码:破解各种验证码》
如有疑问,您可以或

网页爬虫抓取百度图片(外链图片转存失败,源站可能有防盗链机制(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-24 18:05
最近在看重天老师的MOOC Python网络爬虫与信息抽取课程,开始吧
必须先安装 requests 库
方法很简单 pip install requests
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-aW55ejx9-14)(/img/bVbMkeh)】
以上是requests库中的7个主要方法
import requests
url='http://www.baidu.com'
r=requests.get(url)
print(r.status_code)
r.encoding='utf-8'
print(r.text)
简单抓取百度的代码
r=requests.get(url)
这行代码中,返回的r的数据类型是Response类,赋值号右边是Request类
响应对象属性(重要)
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cwG13p6e-17)(/img/bVbMkfA)]
请求库异常
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-yTu9bPnR-18)(/img/bVbMkgu)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sUEEt355-19)(/img/bVbMkgI)]
参数的使用
一、爬取 JD 实例
1.爬京东时网站
import requests
url='https://item.jd.com/100006713417.html'
try:
r=requests.get(url)
print(r.status_code)
print(r.text[:1000])
except :
print('出现异常')
得到这个结果:
显然这不是我们想要的信息,访问结果中的链接发现是京东的登录界面。
2.解决问题
查了相关资料,发现京东有源码审查,所以可以通过修改headers和cookie参数来实现
Cookie参数查找方法:
进入页面后按F12,然后进入网络界面,刷新找到对应页面,如图
import requests
url = 'https://item.jd.com/100006713417.html'
cookiestr='unpl=V2_ZzNtbRAHQ0ZzDk9WKBlbDWJXQF5KBBYRfQ0VBHhJWlEyABBaclRCFnQUR11nGlUUZwYZWEdcRxxFCEVkexhdBGAAE19BVXMlRQtGZHopXAFvChZVRFZLHHwJRVRyEVQDZwQRWENncxJ1AXZkMEAaDGAGEVxHVUARRQtDU34dXjVmMxBcQ1REHXAPQ11LUjIEKgMWVUtTSxN0AE9dehpcDG8LFF1FVEYURQhHVXoYXAJkABJtQQ%3d%3d; __jdv=122270672|mydisplay.ctfile.com|t_1000620323_|tuiguang|ca1b7783b1694ec29bd594ba2a7ed236|1598597100230; __jdu=15985970988021899716240; shshshfpa=7645286e-aab6-ce64-5f78-039ee4cc7f1e-1598597100; areaId=22; ipLoc-djd=22-1930-49324-0; PCSYCityID=CN_510000_510100_510116; shshshfpb=uxViv6Hw0rcSrj5Z4lZjH4g%3D%3D; __jdc=122270672; __jda=122270672.15985970988021899716240.1598597098.1598597100.1599100842.2; shshshfp=f215b3dcb63dedf2e335349645cbb45e; 3AB9D23F7A4B3C9B=4BFMWHJNBVGI6RF55ML2PWUQHGQ2KQMS4KJIAGEJOOL3ESSN35PFEIXQFE352263KVFC2JIKWUJHDRXXMXGAAANAPA; shshshsID=2f3061bf1cc51a3f6162742028f11a80_5_1599101419724; __jdb=122270672.11.15985970988021899716240|2.1599100842; wlfstk_smdl=mwti16fwg6li5o184teuay0iftfocdez'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.14 Safari/537.36 Edg/83.0.478.13","cookie":cookiestr}
try:
r = requests.get(url=url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print('爬取失败')
import requests
kv = {'user-agent':'Mozilla/5.0'}
url = "https://item.jd.com/100006713417.html"
try:
r = requests.get(url,headers = kv)
r.encoding = r.apparent_encoding
r.raise_for_status()
print(r.text[:1000])
except :
print('Error')
都得到我们想要的结果
二、爬取亚马逊实例
import requests
url = "https://www.amazon.cn/dp/B072C ... ot%3B
try:
r = requests.get(url)
print(r.status_code)
print(r.encoding)
print(r.request.headers)
r.encoding = r.apparent_encoding
print(r.text[:5000])
except :
print('Error')
出现了同样的问题。老师在这里解释了。亚马逊也有来源审查。当 headers 参数没有被修改时,程序告诉亚马逊服务器这是对 py requests 库的访问。
所以有一个错误。
2.解决办法
如上,修改user-agent
结果:
还是有问题,下面有提示,
这里提示可能存在cookie相关的问题,所以我们找到网页的cookie,放到headers中
问题成功解决
三、爬取图片
当我们要爬取网页上的图片时,我们应该怎么做。
现在知道网页上的图片链接是格式
url链接以jpg结尾,描述为图片
按照冲天老师的提示写了一段代码
import requests
import os
url='https://ss0.bdstatic.com/70cFu ... 11137,2818876915&fm=26&gp=0.jpg'
root='d:/pics//'
path = root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.makedirs(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已经存在')
except:
print('爬取出错')
这里import os判断文件是否存在
结果上
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-xv0bBm8f-21)(/img/bVbMr7U)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-7tOVoMvj-21)(/img/bVbMr7W)]
图片也保存了
IP地址归属地自动查询
实战中遇到了一个小问题
先编码
import requests
url_1 = 'https://www.ip138.com/iplookup ... 39%3B
ip_address = input('Please input your ip address')
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url)
print(r.status_code)
print(r.text[-500:])
except:
print('error')
else:
print('ip address cannot be empty')
然后程序一直报错,于是我把try except模块去掉,看看问题出在哪里。
果然,问题是源审查
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-FF8AqVZd-22)(/img/bVbMr9Y)]
这行错误说明ip138网站应该有source review,所以换个headers里的agent再试一次
修改user-agent参数后,刚好找到一个美国的IP地址,上图成功。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-puo6nDNG-22)(/img/bVbMsaQ)]
import requests
url_1 = 'https://www.ip138.com/iplookup.asp?ip='
ip_address = input('Please input your ip address')
kv={'user-agent':'chrome/5.0'}
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url,headers=kv)
print(r.status_code)
r.encoding=r.apparent_encoding
print(r.text)
except:
print('error')
else:
print('ip address cannot be empty')
第二周
Beautiful Soup 库1.安装 Beautiful Soup 库
CMD pip install beautifulsoup4
2.请求库获取网页源代码
import requests
r=requests.get("https://python123.io/ws/demo.html")
print(r.text)
3. bs 库的使用
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-tKeVDKKg-23)(/img/bVbMsca)】
import requests
from bs4 import BeautifulSoup
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
4. bs 库的基本元素 查看全部
网页爬虫抓取百度图片(外链图片转存失败,源站可能有防盗链机制(组图))
最近在看重天老师的MOOC Python网络爬虫与信息抽取课程,开始吧
必须先安装 requests 库
方法很简单 pip install requests
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-aW55ejx9-14)(/img/bVbMkeh)】
以上是requests库中的7个主要方法
import requests
url='http://www.baidu.com'
r=requests.get(url)
print(r.status_code)
r.encoding='utf-8'
print(r.text)
简单抓取百度的代码
r=requests.get(url)
这行代码中,返回的r的数据类型是Response类,赋值号右边是Request类
响应对象属性(重要)
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cwG13p6e-17)(/img/bVbMkfA)]
请求库异常
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-yTu9bPnR-18)(/img/bVbMkgu)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sUEEt355-19)(/img/bVbMkgI)]
参数的使用

一、爬取 JD 实例
1.爬京东时网站
import requests
url='https://item.jd.com/100006713417.html'
try:
r=requests.get(url)
print(r.status_code)
print(r.text[:1000])
except :
print('出现异常')
得到这个结果:

显然这不是我们想要的信息,访问结果中的链接发现是京东的登录界面。
2.解决问题
查了相关资料,发现京东有源码审查,所以可以通过修改headers和cookie参数来实现
Cookie参数查找方法:
进入页面后按F12,然后进入网络界面,刷新找到对应页面,如图

import requests
url = 'https://item.jd.com/100006713417.html'
cookiestr='unpl=V2_ZzNtbRAHQ0ZzDk9WKBlbDWJXQF5KBBYRfQ0VBHhJWlEyABBaclRCFnQUR11nGlUUZwYZWEdcRxxFCEVkexhdBGAAE19BVXMlRQtGZHopXAFvChZVRFZLHHwJRVRyEVQDZwQRWENncxJ1AXZkMEAaDGAGEVxHVUARRQtDU34dXjVmMxBcQ1REHXAPQ11LUjIEKgMWVUtTSxN0AE9dehpcDG8LFF1FVEYURQhHVXoYXAJkABJtQQ%3d%3d; __jdv=122270672|mydisplay.ctfile.com|t_1000620323_|tuiguang|ca1b7783b1694ec29bd594ba2a7ed236|1598597100230; __jdu=15985970988021899716240; shshshfpa=7645286e-aab6-ce64-5f78-039ee4cc7f1e-1598597100; areaId=22; ipLoc-djd=22-1930-49324-0; PCSYCityID=CN_510000_510100_510116; shshshfpb=uxViv6Hw0rcSrj5Z4lZjH4g%3D%3D; __jdc=122270672; __jda=122270672.15985970988021899716240.1598597098.1598597100.1599100842.2; shshshfp=f215b3dcb63dedf2e335349645cbb45e; 3AB9D23F7A4B3C9B=4BFMWHJNBVGI6RF55ML2PWUQHGQ2KQMS4KJIAGEJOOL3ESSN35PFEIXQFE352263KVFC2JIKWUJHDRXXMXGAAANAPA; shshshsID=2f3061bf1cc51a3f6162742028f11a80_5_1599101419724; __jdb=122270672.11.15985970988021899716240|2.1599100842; wlfstk_smdl=mwti16fwg6li5o184teuay0iftfocdez'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.14 Safari/537.36 Edg/83.0.478.13","cookie":cookiestr}
try:
r = requests.get(url=url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print('爬取失败')
import requests
kv = {'user-agent':'Mozilla/5.0'}
url = "https://item.jd.com/100006713417.html"
try:
r = requests.get(url,headers = kv)
r.encoding = r.apparent_encoding
r.raise_for_status()
print(r.text[:1000])
except :
print('Error')
都得到我们想要的结果

二、爬取亚马逊实例
import requests
url = "https://www.amazon.cn/dp/B072C ... ot%3B
try:
r = requests.get(url)
print(r.status_code)
print(r.encoding)
print(r.request.headers)
r.encoding = r.apparent_encoding
print(r.text[:5000])
except :
print('Error')
出现了同样的问题。老师在这里解释了。亚马逊也有来源审查。当 headers 参数没有被修改时,程序告诉亚马逊服务器这是对 py requests 库的访问。

所以有一个错误。
2.解决办法
如上,修改user-agent
结果:

还是有问题,下面有提示,

这里提示可能存在cookie相关的问题,所以我们找到网页的cookie,放到headers中

问题成功解决
三、爬取图片
当我们要爬取网页上的图片时,我们应该怎么做。
现在知道网页上的图片链接是格式

url链接以jpg结尾,描述为图片
按照冲天老师的提示写了一段代码
import requests
import os
url='https://ss0.bdstatic.com/70cFu ... 11137,2818876915&fm=26&gp=0.jpg'
root='d:/pics//'
path = root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.makedirs(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已经存在')
except:
print('爬取出错')
这里import os判断文件是否存在
结果上
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-xv0bBm8f-21)(/img/bVbMr7U)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-7tOVoMvj-21)(/img/bVbMr7W)]
图片也保存了
IP地址归属地自动查询
实战中遇到了一个小问题
先编码
import requests
url_1 = 'https://www.ip138.com/iplookup ... 39%3B
ip_address = input('Please input your ip address')
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url)
print(r.status_code)
print(r.text[-500:])
except:
print('error')
else:
print('ip address cannot be empty')
然后程序一直报错,于是我把try except模块去掉,看看问题出在哪里。
果然,问题是源审查
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-FF8AqVZd-22)(/img/bVbMr9Y)]
这行错误说明ip138网站应该有source review,所以换个headers里的agent再试一次
修改user-agent参数后,刚好找到一个美国的IP地址,上图成功。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-puo6nDNG-22)(/img/bVbMsaQ)]
import requests
url_1 = 'https://www.ip138.com/iplookup.asp?ip='
ip_address = input('Please input your ip address')
kv={'user-agent':'chrome/5.0'}
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url,headers=kv)
print(r.status_code)
r.encoding=r.apparent_encoding
print(r.text)
except:
print('error')
else:
print('ip address cannot be empty')
第二周
Beautiful Soup 库1.安装 Beautiful Soup 库
CMD pip install beautifulsoup4
2.请求库获取网页源代码
import requests
r=requests.get("https://python123.io/ws/demo.html";)
print(r.text)
3. bs 库的使用
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-tKeVDKKg-23)(/img/bVbMsca)】
import requests
from bs4 import BeautifulSoup
r = requests.get("https://python123.io/ws/demo.html";)
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
4. bs 库的基本元素
网页爬虫抓取百度图片(爬虫爬虫知识详细教程(2)-百度图片教程(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-22 22:04
网页爬虫抓取百度图片的教程写的挺详细的,我是手写爬虫才把十张图片抓到手里,python爬虫知识详细教程(2)抓取百度图片。
百度图片,联系图片出版社,做成图书,然后销售。
我研究过,好像python做爬虫和分析也不容易,你把开源代码扔过去就会有很多人帮你做的。还有不是自己做的话,自己建个ip池子,每天定时去某个ip的图库里面扒图。
不可以。每个东西都有它的生命周期,爬虫应该只做小规模使用。但凡去查看代码,就会发现,python写爬虫确实有点蛋疼,别说优化爬虫了,更不要说逆向。对于大规模的爬虫,还是推荐用java或者c/c++实现。
等等,爬虫也得有前端啊,
用python写爬虫,
貌似使用python写爬虫出版社会比较欢迎,如果没有支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付费码。 查看全部
网页爬虫抓取百度图片(爬虫爬虫知识详细教程(2)-百度图片教程(2))
网页爬虫抓取百度图片的教程写的挺详细的,我是手写爬虫才把十张图片抓到手里,python爬虫知识详细教程(2)抓取百度图片。
百度图片,联系图片出版社,做成图书,然后销售。
我研究过,好像python做爬虫和分析也不容易,你把开源代码扔过去就会有很多人帮你做的。还有不是自己做的话,自己建个ip池子,每天定时去某个ip的图库里面扒图。
不可以。每个东西都有它的生命周期,爬虫应该只做小规模使用。但凡去查看代码,就会发现,python写爬虫确实有点蛋疼,别说优化爬虫了,更不要说逆向。对于大规模的爬虫,还是推荐用java或者c/c++实现。
等等,爬虫也得有前端啊,
用python写爬虫,
貌似使用python写爬虫出版社会比较欢迎,如果没有支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付费码。
网页爬虫抓取百度图片(什么是爬虫网络爬虫(.txt)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-22 01:15
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
1import requests<br />2r = requests.get('http://pic37.nipic.com/20140113/8800276_184927469000_2.png')<br />3with open('demo.jpg','wb+') as f:<br />4 f.write(r.content)<br />
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
1{<br />2 “name”: “毛利”,<br />3 “age”: 18,<br />4 “ feature “ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
Python字典
1{<br />2 ‘name’: ‘毛利’,<br />3 ‘age’: 18<br />4 ‘feature’ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”,指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站自动发起了请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
1import requests<br /> 2import json<br /> 3headers = {<br /> 4 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br /> 5r = requests.get('https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).text<br /> 6res = json.loads(r)['data']<br /> 7for index,i in enumerate(res):<br /> 8 url = i['hoverURL']<br /> 9 print(url)<br />10 with open( '{}.jpg'.format(index),'wb+') as f:<br />11 f.write(requests.get(url).content)<br />
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
1https://image.baidu.com/search ... %3Bbr />2https://image.baidu.com/search ... %3Bbr />
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
1# -*- coding:utf-8 -*-<br /> 2# time :2019/6/20 17:07<br /> 3# author: 毛利<br /> 4import requests<br /> 5import json<br /> 6import os<br /> 7def get_pic_url(num):<br /> 8 pic_url= []<br /> 9 headers = {<br />10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br />11 for i in range(num):<br />12<br />13 page_url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i)<br />14 r = requests.get(page_url, headers=headers).text<br />15 res = json.loads(r)['data']<br />16 if res:<br />17 print(res)<br />18 for j in res:<br />19 try:<br />20 url = j['hoverURL']<br />21 pic_url.append(url)<br />22 except:<br />23 print('该图片的url不存在')<br />24<br />25 print(len(pic_url))<br />26 return pic_url<br />27<br />28def down_img(num):<br />29 pic_url =get_pic_url(num)<br />30<br />31 if os.path.exists('D:\图片'):<br />32 pass<br />33 else:<br />34 os.makedirs('D:\图片')<br />35<br />36 path = 'D:\图片\\'<br />37 for index,i in enumerate(pic_url):<br />38 filename = path + str(index) + '.jpg'<br />39 print(filename)<br />40 with open(filename, 'wb+') as f:<br />41 f.write(requests.get(i).content)<br />42if __name__ == '__main__':<br />43 num = int(input('爬取几次图片:一次30张'))<br />44 down_img(num)<br />
爬取过程
抓取结果
文章首次发表于: 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(.txt)(图))
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?

从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
1import requests<br />2r = requests.get('http://pic37.nipic.com/20140113/8800276_184927469000_2.png')<br />3with open('demo.jpg','wb+') as f:<br />4 f.write(r.content)<br />
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
1{<br />2 “name”: “毛利”,<br />3 “age”: 18,<br />4 “ feature “ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
Python字典
1{<br />2 ‘name’: ‘毛利’,<br />3 ‘age’: 18<br />4 ‘feature’ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”,指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站自动发起了请求,



构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
1import requests<br /> 2import json<br /> 3headers = {<br /> 4 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br /> 5r = requests.get('https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).text<br /> 6res = json.loads(r)['data']<br /> 7for index,i in enumerate(res):<br /> 8 url = i['hoverURL']<br /> 9 print(url)<br />10 with open( '{}.jpg'.format(index),'wb+') as f:<br />11 f.write(requests.get(url).content)<br />
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
1https://image.baidu.com/search ... %3Bbr />2https://image.baidu.com/search ... %3Bbr />
其实可以发现,当再次发起请求时,关键是pn在不断变化

最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
1# -*- coding:utf-8 -*-<br /> 2# time :2019/6/20 17:07<br /> 3# author: 毛利<br /> 4import requests<br /> 5import json<br /> 6import os<br /> 7def get_pic_url(num):<br /> 8 pic_url= []<br /> 9 headers = {<br />10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br />11 for i in range(num):<br />12<br />13 page_url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i)<br />14 r = requests.get(page_url, headers=headers).text<br />15 res = json.loads(r)['data']<br />16 if res:<br />17 print(res)<br />18 for j in res:<br />19 try:<br />20 url = j['hoverURL']<br />21 pic_url.append(url)<br />22 except:<br />23 print('该图片的url不存在')<br />24<br />25 print(len(pic_url))<br />26 return pic_url<br />27<br />28def down_img(num):<br />29 pic_url =get_pic_url(num)<br />30<br />31 if os.path.exists('D:\图片'):<br />32 pass<br />33 else:<br />34 os.makedirs('D:\图片')<br />35<br />36 path = 'D:\图片\\'<br />37 for index,i in enumerate(pic_url):<br />38 filename = path + str(index) + '.jpg'<br />39 print(filename)<br />40 with open(filename, 'wb+') as f:<br />41 f.write(requests.get(i).content)<br />42if __name__ == '__main__':<br />43 num = int(input('爬取几次图片:一次30张'))<br />44 down_img(num)<br />
爬取过程

抓取结果

文章首次发表于:
网页爬虫抓取百度图片(实现百度图片的实现架构(一)_架构_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-22 01:10
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
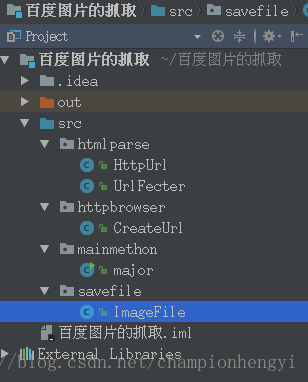
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(实现百度图片的实现架构(一)_架构_光明网)
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(怎么使用百度推广数据DIY来采集这些数据?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-20 19:09
)
百度推广相信很多人都在用,但是百度推广后台的搜索词报告无法下载,所以无法做更详细的分析。这里我们可以使用 GooSeeker 的数据 DIY 来抓取整个报告。存储在Excel中,让我们更直观的看到这些数据的显示,下面介绍如何用数据DIY来采集这些数据。
1.吉索客官网有数据diy模块。我们可以进入官网打开,也可以直接使用gooseeker浏览器输入网址打开。
注意:要使用数据DIY,必须使用gooseeker浏览器启动。
2.打开后可以看到很多数据diy分类,选择我们要的分类采集网站,我们要采集作为百度推广背景的key,所以我们要选择分类“SEO优化””。点击选择“SEO优化”分类后,可以在二级分类“百度”中看到你想要的分类采集,点击选择“百度推广搜索关键词 抓取”。
3、选择采集的页面后,需要在下面的输入框中输入网址为采集。输入 URL 的页面结构必须与所选数据 diy 的页面结构一致。,如果我们刚刚选择了“百度推广搜索关键词爬取”,我们需要在输入框中输入百度推广背景的URL。
4、点击获取数据按钮后,页面跳转到会员中心-数据DIY页面,可以看到想要通过数据DIY添加采集的URL页面,点击“开始采集@ >"按钮开始采集我们想要的数据
5、采集完成后,可以点击“查看我的数据”进入DIY数据采集状态,会显示数据的DIY采集状态。采集完成后,可以使用“打包”按钮将采集的数据打包,然后可以在“数据下载”选项卡上下载打包好的数据,下载的数据通过数据DIY可以直接是excel格式,不用转换。
查看全部
网页爬虫抓取百度图片(怎么使用百度推广数据DIY来采集这些数据?(图)
)
百度推广相信很多人都在用,但是百度推广后台的搜索词报告无法下载,所以无法做更详细的分析。这里我们可以使用 GooSeeker 的数据 DIY 来抓取整个报告。存储在Excel中,让我们更直观的看到这些数据的显示,下面介绍如何用数据DIY来采集这些数据。

1.吉索客官网有数据diy模块。我们可以进入官网打开,也可以直接使用gooseeker浏览器输入网址打开。
注意:要使用数据DIY,必须使用gooseeker浏览器启动。

2.打开后可以看到很多数据diy分类,选择我们要的分类采集网站,我们要采集作为百度推广背景的key,所以我们要选择分类“SEO优化””。点击选择“SEO优化”分类后,可以在二级分类“百度”中看到你想要的分类采集,点击选择“百度推广搜索关键词 抓取”。

3、选择采集的页面后,需要在下面的输入框中输入网址为采集。输入 URL 的页面结构必须与所选数据 diy 的页面结构一致。,如果我们刚刚选择了“百度推广搜索关键词爬取”,我们需要在输入框中输入百度推广背景的URL。

4、点击获取数据按钮后,页面跳转到会员中心-数据DIY页面,可以看到想要通过数据DIY添加采集的URL页面,点击“开始采集@ >"按钮开始采集我们想要的数据
5、采集完成后,可以点击“查看我的数据”进入DIY数据采集状态,会显示数据的DIY采集状态。采集完成后,可以使用“打包”按钮将采集的数据打包,然后可以在“数据下载”选项卡上下载打包好的数据,下载的数据通过数据DIY可以直接是excel格式,不用转换。

网页爬虫抓取百度图片( 智联招聘上一线及新一线城市所有与BIM相关的工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-19 13:07
智联招聘上一线及新一线城市所有与BIM相关的工作)
python简单的网络爬虫获取网页数据
以下是智联招聘一线和新一线城市所有BIM相关岗位信息列表,供数据分析。
1、首先通过chrome搜索智联招聘的BIM职位信息。跳出页面后,ctrl+u查看网页源代码。如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,按关键字过滤文件,找到收录jobs的数据包。
2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL是由
1
2
'' + 请求参数,然后根据格式(
';cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=coster&kt=3')
复制到浏览器访问测试,成功获取对应数据
3、获取到的数据是json格式。首先,格式化数据,分析结构,确定代码中数据的分析方法。
4、明确请求URL和数据结构后,剩下的就是在代码中实现URL构建、数据分析和导出。最终得到1215条数据,需要进一步整理数据进行数据分析。
如无效请留言告知转载请注明原文链接:python爬虫如何抓取网页数据 查看全部
网页爬虫抓取百度图片(
智联招聘上一线及新一线城市所有与BIM相关的工作)

python简单的网络爬虫获取网页数据
以下是智联招聘一线和新一线城市所有BIM相关岗位信息列表,供数据分析。
1、首先通过chrome搜索智联招聘的BIM职位信息。跳出页面后,ctrl+u查看网页源代码。如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,按关键字过滤文件,找到收录jobs的数据包。
2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL是由
1
2
'' + 请求参数,然后根据格式(
';cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=coster&kt=3')
复制到浏览器访问测试,成功获取对应数据

3、获取到的数据是json格式。首先,格式化数据,分析结构,确定代码中数据的分析方法。
4、明确请求URL和数据结构后,剩下的就是在代码中实现URL构建、数据分析和导出。最终得到1215条数据,需要进一步整理数据进行数据分析。
如无效请留言告知转载请注明原文链接:python爬虫如何抓取网页数据
网页爬虫抓取百度图片(图片的批量抓取是爬虫批处理的典型例子,使用Python实现批量获取图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-19 13:06
)
图片批量抓取是爬虫批量处理的典型例子。这里我们使用煎蛋网的美图作为抓图对象,使用Python批量获取图片。
批量爬虫
import urllib.request
import os
import random
# 打开网页
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read()
return html
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
# 找到图片的地址
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs
# 保存图片
def save_imgs(folder,img_addrs):
i = 1
for each in img_addrs:
img = url_open(each)
# pic_name = str(i) + '.jpg'
pic_name = each.split('/')[-1]
with open(pic_name,'wb') as f:
f.write(img)
i += 1
return i
# 下载图片的主函数
def download_pic(folder = 'mm',pages = 10):
os.mkdir(folder)
os.chdir(folder)
count = 0
url = 'http://jandan.net/ooxx'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
count += save_imgs(folder,img_addrs)
print('总共图片数量:%d' %count)
# 主函数入口
if __name__ == '__main__':
download_pic()
批量生成网址
编写爬虫要根据不同的网站改变,观察网站的html结构。以这个网址为例,访问第一页和下一页:
在这里,您可以在 URL 中看到 page-190。根据这个参数可以设置访问不同的网页,即我们通常访问的下一页和上一页。 网站获取不同页面URL(page_url)对应的代码如下:
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
url = 'http://jandan.net/ooxx'
# 获取首页 page_num
page_num = int(get_page(url))
# 根据url格式编辑想要访问页面的url
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
在 HTML 中查找图像的 URL
在每张图片上选择---View Element,查看对应图片的URL在网页的HTML中是什么样子的:
可以看到图片对应的标签是:
我们需要将内容从//剪切成.jpg,代码如下:
# 找到图片的地址,从a开始,到b结束,如果找到,则添加在img_addrs[]的列表中,
# 其中的 a+9 和 b+4 是计算好的偏移量
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
# 从 a 开始往后查找,查找结束位置为 a+255 ,即一个url的长度
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs 查看全部
网页爬虫抓取百度图片(图片的批量抓取是爬虫批处理的典型例子,使用Python实现批量获取图片
)
图片批量抓取是爬虫批量处理的典型例子。这里我们使用煎蛋网的美图作为抓图对象,使用Python批量获取图片。
批量爬虫
import urllib.request
import os
import random
# 打开网页
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read()
return html
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
# 找到图片的地址
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs
# 保存图片
def save_imgs(folder,img_addrs):
i = 1
for each in img_addrs:
img = url_open(each)
# pic_name = str(i) + '.jpg'
pic_name = each.split('/')[-1]
with open(pic_name,'wb') as f:
f.write(img)
i += 1
return i
# 下载图片的主函数
def download_pic(folder = 'mm',pages = 10):
os.mkdir(folder)
os.chdir(folder)
count = 0
url = 'http://jandan.net/ooxx'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
count += save_imgs(folder,img_addrs)
print('总共图片数量:%d' %count)
# 主函数入口
if __name__ == '__main__':
download_pic()
批量生成网址
编写爬虫要根据不同的网站改变,观察网站的html结构。以这个网址为例,访问第一页和下一页:


在这里,您可以在 URL 中看到 page-190。根据这个参数可以设置访问不同的网页,即我们通常访问的下一页和上一页。 网站获取不同页面URL(page_url)对应的代码如下:
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
url = 'http://jandan.net/ooxx'
# 获取首页 page_num
page_num = int(get_page(url))
# 根据url格式编辑想要访问页面的url
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
在 HTML 中查找图像的 URL
在每张图片上选择---View Element,查看对应图片的URL在网页的HTML中是什么样子的:

可以看到图片对应的标签是:
我们需要将内容从//剪切成.jpg,代码如下:
# 找到图片的地址,从a开始,到b结束,如果找到,则添加在img_addrs[]的列表中,
# 其中的 a+9 和 b+4 是计算好的偏移量
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
# 从 a 开始往后查找,查找结束位置为 a+255 ,即一个url的长度
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs
网页爬虫抓取百度图片(网页爬虫抓取百度图片,图片太多太重怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-18 01:03
网页爬虫抓取百度图片,图片太多太重?准备工作:准备一个浏览器,如谷歌浏览器。一个软件,如superagent。一个代理,如代理。一个方法。图片抓取也可以,直接用代理代理,useragent用你这个浏览器的代理即可。代理可以抓取的数据很多,但你最终只能抓取到下载链接,比如免费的,每个链接抓取10个。
你可以看我文章,这个url被抓取几百万个。实际上有几百万图片抓取。所以我来说一个简单的免费下载百度图片的方法。如何抓取更多请关注我的微信公众号【诗白】。
很久之前写过一篇alphago训练计划大概有三种方法爬,第一种是采用谷歌图片搜索爬虫的方法,第二种是metaedjang配合proxies,第三种是proxies+chromedevtool方法一使用谷歌图片搜索爬虫开发软件,第二种则是配合类似《proxylocalizer》的工具,方法三则是使用网页,实际上就是google图片搜索中的图片,可以用百度图片批量下载或者imagejs+imageview来实现图片的批量下载,或者也可以试试proxies+chromedevtool。
关于python爬虫,曾经做过一些具体的系列学习,包括了基本的抓取原理、整体结构,以及爬虫的基本实现方法等。爬虫的基本原理关于python爬虫,可以分为3个部分。1.爬虫核心,使用python的requests库来解析页面并获取返回的url地址,以及tcp/udp协议。2.爬虫目标的爬取规则,一般就是一些爬虫的规则或者爬虫的流程,比如说判断分割哪些页面可以爬取,定义一些规则等等。
3.爬虫的实现,即将规则和爬虫执行过程混合,并处理规则中的内容。爬虫的主要特征1.爬虫遵循自下而上的流程,并且针对所要获取的url返回值返回标签顺序的响应对象。2.爬虫尽可能的保持连接性,没有链接则可以停止响应。3.程序的非结构化非数据,比如图片或者视频。爬虫的原理1.获取url的解析text主要用于解析文本,如何解析一个json对象呢?我们从json数据解析来看看,首先我们要读取一个json数据,作为初始对象。
再读取到我们需要的规则方法,返回我们需要的内容。2.数据的遍历有各种方法,首先是buffer=pickle.loads(json.dumps(path,s)),然后是使用list来遍历。3.要在哪里获取数据呢?在数据处理之前,我们一般需要编写json对象,然后对其处理,并通过stringio、requests等库来获取对应的数据。
接下来通过我们之前写过的python爬虫:认识python爬虫一样,也是一种非结构化的数据处理方法。另外它也不同于json数据的标准,除了url地址之外,还可以传入类型为字符串的参数。目前比较常用的就。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片,图片太多太重怎么办?)
网页爬虫抓取百度图片,图片太多太重?准备工作:准备一个浏览器,如谷歌浏览器。一个软件,如superagent。一个代理,如代理。一个方法。图片抓取也可以,直接用代理代理,useragent用你这个浏览器的代理即可。代理可以抓取的数据很多,但你最终只能抓取到下载链接,比如免费的,每个链接抓取10个。
你可以看我文章,这个url被抓取几百万个。实际上有几百万图片抓取。所以我来说一个简单的免费下载百度图片的方法。如何抓取更多请关注我的微信公众号【诗白】。
很久之前写过一篇alphago训练计划大概有三种方法爬,第一种是采用谷歌图片搜索爬虫的方法,第二种是metaedjang配合proxies,第三种是proxies+chromedevtool方法一使用谷歌图片搜索爬虫开发软件,第二种则是配合类似《proxylocalizer》的工具,方法三则是使用网页,实际上就是google图片搜索中的图片,可以用百度图片批量下载或者imagejs+imageview来实现图片的批量下载,或者也可以试试proxies+chromedevtool。
关于python爬虫,曾经做过一些具体的系列学习,包括了基本的抓取原理、整体结构,以及爬虫的基本实现方法等。爬虫的基本原理关于python爬虫,可以分为3个部分。1.爬虫核心,使用python的requests库来解析页面并获取返回的url地址,以及tcp/udp协议。2.爬虫目标的爬取规则,一般就是一些爬虫的规则或者爬虫的流程,比如说判断分割哪些页面可以爬取,定义一些规则等等。
3.爬虫的实现,即将规则和爬虫执行过程混合,并处理规则中的内容。爬虫的主要特征1.爬虫遵循自下而上的流程,并且针对所要获取的url返回值返回标签顺序的响应对象。2.爬虫尽可能的保持连接性,没有链接则可以停止响应。3.程序的非结构化非数据,比如图片或者视频。爬虫的原理1.获取url的解析text主要用于解析文本,如何解析一个json对象呢?我们从json数据解析来看看,首先我们要读取一个json数据,作为初始对象。
再读取到我们需要的规则方法,返回我们需要的内容。2.数据的遍历有各种方法,首先是buffer=pickle.loads(json.dumps(path,s)),然后是使用list来遍历。3.要在哪里获取数据呢?在数据处理之前,我们一般需要编写json对象,然后对其处理,并通过stringio、requests等库来获取对应的数据。
接下来通过我们之前写过的python爬虫:认识python爬虫一样,也是一种非结构化的数据处理方法。另外它也不同于json数据的标准,除了url地址之外,还可以传入类型为字符串的参数。目前比较常用的就。
网页爬虫抓取百度图片(搜索引擎排名原理分析讲解、基本必学常识SEO学习心态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-18 00:02
一、搜索引擎排名原理解析讲解
没有。一、基本必须学习常识
1.SEO学习心态和方法
2.搜索引擎(百度、谷歌、360、搜狗、爱问、有道、中搜、中国雅虎);搜索引擎蜘蛛(蜘蛛,又称爬虫、机器人,是一套信息抓取系统程序;如百度蜘蛛:Baiduspider,谷歌蜘蛛:Googlebot,360蜘蛛:360Spider,搜狗蜘蛛:搜狗新闻蜘蛛)
3.SEO(搜索引擎优化)
4.关键词:用户在搜索信息、产品或服务时,在搜索引擎界面输入的词。
5.排名(单页参与排名)
二、搜索引擎爬取收录的原理
爬取:(1.爬虫蜘蛛跟随网页中的超链接,发现并采集互联网上的网页信息;2.蜘蛛的爬取方式:深度爬取、广度爬取;3.它不利于蜘蛛识别爬取内容:如JS、图片ALT属性辅助识别、Flash添加文字辅助、层级多的iframe框架、嵌套表格、需要登录信息后的页面)
过滤器:(低质量内容页面:1.采集,低价值;2.不当文字;3.没有丰富内容)
存储索引库:(质量提取和组织信息建立索引库)
显示排序:(1.根据用户输入的查询关键词,检索器可以快速的查出索引库中的文档,对文档和查询进行相关的阅读评价,对结果进行排序待输出,并将查询结果返回给用户;2.当我们在搜索引擎中只看到一个结果时,搜索会在首页的第一位显示某一个关键词根据各种算法)
三、 节日常注意事项
1.已被收录的页面不可随意删除或移动;2.显示结果需要一定的时间(2个月内正常);3.丰富的内容阅读;4. 吸引蜘蛛,比如主动提交给搜索引擎,外部链接吸引蜘蛛;5. 蜘蛛跟踪,网站IIS 日志。
页面摘要 四、
心态:不要试图依赖所谓的捷径;SEO学习需要长期的坚持和努力;不断的努力。
二、建站工具原理详细操作讲解
学习网站构建工具
1、域名:购买和租用年限,名词解析(前缀、后缀:国际通用域名.后三个字母;国家域名.dot.后两个字母。 cn; 国内域名。),购买说明(尽可能简单,知道你在这个域名之前做过什么,搜索顶级域名,查看记录,站长安全联盟,选择常用域名后缀)
2、空间:需购买租用、远程管理(控制面板、FTP远程工具)、常用功能(301重定向、解压/压缩、备份/恢复、服务器日志、自定义页面)、购买注意(速度够快,够稳定,够安全,服务好),选择正规的空间商。
3、 网站建设者(wordprss 博客、discuz 论坛、phpwind 论坛、dedecms织梦cms、empirecmsempirecms、shopex 在线商店, ecshop 网上商店)
4、其他:解析、域名级别(一级域名、二级域名)、归档、类型
三、匹配最快排名的关键词选择
第一个一、基础理论:三大标签(标题、描述、关键词);品牌词
文章二、单核心标题写作
基本思路:
1、标题似乎是一句流畅的句子;
2、关键词 层级,例如:电梯和客梯分别属于上下两层;客梯与货梯为同级关系;需求词是从核心扩展而来的,不是同级关系。如电梯及电梯价格、电梯规格;客梯和客梯价格、客梯安装、客梯维修都是需求词。单核标题最容易排名和争夺符号(核心词+需求词=单核,同级关系,考虑多核);
3、标题和内容的关系;
4、核心关键词+服务内容
选前思考:谁是我的用户?他们会搜索什么字词?(核心关键词+我们的网站服务加上我们的服务,我们的服务就是用户的需求)
标题组合:
1、确定网站核心词(产品/服务);
2、挖掘相关词并过滤(取整);
3、合格的标题组合:关键词1_关键词2_关键词3-品牌词;
4、不错的标题组合,组合成流畅的句子;
5、优秀的标题组合(时间需求,如:最新、2016;信息量大,如:百科;可信度,如:专家、专业;稀缺需求扩展)。标题示例:_长沙网站生产专家-提供网站施工详细报价单。
基本优化:基本优化原则(1、关键词前面的话权重越高,2、字数大于4字,小于32字,标题符号应该是英文);常见错误(1、描述性词语太多;2、标题内容不到位;3、标题多核,设置太多;
修改标题:一次修改很重要
三、 描述(deion)
1、描述捕获和显示;2、描述是标题的扩展(吸引点击);3、60-80字
部分 四、关键词(关键字)
四、创建用户友好的导航和布局
不。一、什么样的网站导航适合用户体验?
不是。二、什么样的网站布局才符合用户体验?
三、网站导航开发部分
1、用户注意事项:简明扼要;容易明白; 多少?
2、 蜘蛛考虑:有利于识别(图形或文字);它有利于爬行(不要使用 JS 调用);符合SEO(level、DIV、不使用table)
编号四、网站布局思路
1、抓问题;2、展示问题;3、需求找难;4、DIV布局代替表格
第一个五、使用地图规划导航(会使用地图布局导航,比如百度脑图、XMind)
五、排名最高网站 内容创作
1)内容你需要知道你需要什么内容网站
2)内容制作
1.判断内容质量的三个维度(搜索引擎维度要内容丰富;用户维度;网页打开速度)
2.内容模板制作(用户想了解这个产品的哪些信息;二次标题策划;内容填充)
3. 内容注释(字体:14字号比较好;颜色;图片优化,一个文章中的图片大小要一样,alt属性文字要和图片相关;模板文本)
4.避免垃圾内容(除非强制,否则不要添加锚文本;字体颜色应相同;除标题大小外,文本大小应相同;文本中不应有广告)
5.内容创作采集(第一步:采集内容;第二步:根据模板整合内容,根据自己设置的标题填写内容;第三步:微调;第四步:差异化体验调整)
3)超牛B的内容创作秘诀(每天坚持做文章,持续更新网站)
六、推进网站排名的内容更新计划
1、关键词挖矿方式
常用方法:百度文库、百度贴吧、百度知道、工具(百度推广后台、金华挖词工具、追词助手)、相关论坛、相关搜索等(客户搜索长尾关键词 成为我们的 文章 标题)
挖掘思想:分割思维
2、内容更新
更新思维:匹配;关联
常用文章:名词解释、常见问题、知识解答、使用说明、季节性、及时性
分类长尾:例:装修包括家装、工装、Q&A、材料等。家装可根据客厅、房间、厨房、浴室进行更新
注意事项:上线是指被百度抓取时在线。上网时,绝对不允许有空页。内容必须是完整的才能上线。文章在线栏数(至少6个以上),新站更新(内容应该每天更新)
3、更新问答:避免重复文章;网站是否需要经常更新(可以找到关键词表示有内容要更新)
七、通用链接规范和链接集中化
一、基本常识小节
(1)权重集中
权重在网站的每个页面上继承。权重越高,关键词的排名就越好,但并不决定排名。
如何提高网站的权重,搜索引擎会使用网站的整体表现:例如网站内容、外链投票、网站结构、网站 >权重、及时性、稀缺资源等综合因素来判断这个重要性,这个重要性称为网站的权重。
(2)http状态码:200正常访问;301永久重定向;404页面未找到,分为不存在页面和人为错误;500服务器内部错误;503服务不可用,服务器临时维护 要么超载,服务器当前无法处理; 505 服务器不支持,或拒绝支持请求中使用的 HTTP 版本
路径标识二、
(1)静态路径是指静态的网站地址,纯静态形式,通常以.html、htm为后缀,以目录结构结尾;特点:完全静态的HTML网页文档,无需其他语言调用或加载,适合企业网站适应企业网站,单页网站等内容较少
(2)动态路径:有一个或多个参数和字符,不是.html .asp .php 等形式,不带后缀
(3)伪静态路径:将原来的动态路径通过技术转化为伪静态
第一个三、的实际链接权重集中
(1)路径优化注意事项:1)建议上线前优化道路强度,收录不建议优化;2)道路强度应不能太长,参数太多;3)卢晋不要太深;4)最好不要出现中文;5)卢晋名字要描述性;6)https是http安全版;7)网址拦截;8)最好每页只留一个链接
(2)优化操作:1)处理有尾,统一路径;2)301重定向(空间控制面板,DNSpod);3)使用工具查看.http状态码
八、学习html代码优化
1、网页标签理解:CSS+DIV标签、class、id标签、A标签、img标签
2、代码优化:图片优化,图片的alt描述,图片大小要一致,图片要清晰,中间不要放水印;标签应整齐;一个标签,站点中的链接建议不要使用nofollow标签,即使使用了,也是用于无意义的链接;h标签,h1代表一个页面的核心;标签整洁,标签越简单,搜索引擎就越容易分析你的网站。
(学习SEO,懂得建站,懂html标签,熟悉程序的基本代码原理。)
九、黄金分割原理操作布局网站
一、网站节结构优化
1)网站结构
1.定义一般认为是根据客户需求分析结果,准确定位网站目标群体,设置网站整体架构规划、设计网站栏目及其内容,制定网站@网站开发流程和顺序,最大限度的设计高效的资源配置和管理;
2.Category:物理结构,一般指虚拟空间中很多目录和文件的层次关系;逻辑结构,网站上线后,我们可以看到网站接口与肉眼链接关系在
3.重要性:网站结构是seo优化过程中不可忽视的一个非常重要的环节;合理的内部链结构和合理的网站布局在网站中可以有效引导蜘蛛爬行;方便搜索引擎更好收录;可以建立良好的用户体验;适当的网站结构优化有利于页面权重的合理分配(一般网站首页权重最高,分类页面次之,但对于电商网站略有不同,专注于产品页面,所有依赖网站的内链都可以很好的将首页的权重传递给其他页面,从而实现权重的整体提升,并最终让更多的长尾词获得好的排名);优化网站结构有利于内部锚文本的构建(通过大量的内部链接,加强相关性)
2)网站结构设计目标
1.明确列结构的上下文,层次清晰明了;2.体现特色,注重特色设计;3.方便用户使用;4.网页功能分布合理;5.扩展性极佳;6.用户反思中网页设计与结构的完美结合;7.对于搜索引擎优化,布局是基于关键词竞争力网站首页
3)网站结构考虑
1.用户体验与优化相结合;2.网站地图、搜索引擎地图、用户地图导航;3.面包屑的使用;4.用户浏览的重点
二、Practice网站 页面的页面布局 查看全部
网页爬虫抓取百度图片(搜索引擎排名原理分析讲解、基本必学常识SEO学习心态)
一、搜索引擎排名原理解析讲解
没有。一、基本必须学习常识
1.SEO学习心态和方法
2.搜索引擎(百度、谷歌、360、搜狗、爱问、有道、中搜、中国雅虎);搜索引擎蜘蛛(蜘蛛,又称爬虫、机器人,是一套信息抓取系统程序;如百度蜘蛛:Baiduspider,谷歌蜘蛛:Googlebot,360蜘蛛:360Spider,搜狗蜘蛛:搜狗新闻蜘蛛)
3.SEO(搜索引擎优化)
4.关键词:用户在搜索信息、产品或服务时,在搜索引擎界面输入的词。
5.排名(单页参与排名)
二、搜索引擎爬取收录的原理
爬取:(1.爬虫蜘蛛跟随网页中的超链接,发现并采集互联网上的网页信息;2.蜘蛛的爬取方式:深度爬取、广度爬取;3.它不利于蜘蛛识别爬取内容:如JS、图片ALT属性辅助识别、Flash添加文字辅助、层级多的iframe框架、嵌套表格、需要登录信息后的页面)
过滤器:(低质量内容页面:1.采集,低价值;2.不当文字;3.没有丰富内容)
存储索引库:(质量提取和组织信息建立索引库)
显示排序:(1.根据用户输入的查询关键词,检索器可以快速的查出索引库中的文档,对文档和查询进行相关的阅读评价,对结果进行排序待输出,并将查询结果返回给用户;2.当我们在搜索引擎中只看到一个结果时,搜索会在首页的第一位显示某一个关键词根据各种算法)
三、 节日常注意事项
1.已被收录的页面不可随意删除或移动;2.显示结果需要一定的时间(2个月内正常);3.丰富的内容阅读;4. 吸引蜘蛛,比如主动提交给搜索引擎,外部链接吸引蜘蛛;5. 蜘蛛跟踪,网站IIS 日志。
页面摘要 四、
心态:不要试图依赖所谓的捷径;SEO学习需要长期的坚持和努力;不断的努力。
二、建站工具原理详细操作讲解
学习网站构建工具
1、域名:购买和租用年限,名词解析(前缀、后缀:国际通用域名.后三个字母;国家域名.dot.后两个字母。 cn; 国内域名。),购买说明(尽可能简单,知道你在这个域名之前做过什么,搜索顶级域名,查看记录,站长安全联盟,选择常用域名后缀)
2、空间:需购买租用、远程管理(控制面板、FTP远程工具)、常用功能(301重定向、解压/压缩、备份/恢复、服务器日志、自定义页面)、购买注意(速度够快,够稳定,够安全,服务好),选择正规的空间商。
3、 网站建设者(wordprss 博客、discuz 论坛、phpwind 论坛、dedecms织梦cms、empirecmsempirecms、shopex 在线商店, ecshop 网上商店)
4、其他:解析、域名级别(一级域名、二级域名)、归档、类型
三、匹配最快排名的关键词选择
第一个一、基础理论:三大标签(标题、描述、关键词);品牌词
文章二、单核心标题写作
基本思路:
1、标题似乎是一句流畅的句子;
2、关键词 层级,例如:电梯和客梯分别属于上下两层;客梯与货梯为同级关系;需求词是从核心扩展而来的,不是同级关系。如电梯及电梯价格、电梯规格;客梯和客梯价格、客梯安装、客梯维修都是需求词。单核标题最容易排名和争夺符号(核心词+需求词=单核,同级关系,考虑多核);
3、标题和内容的关系;
4、核心关键词+服务内容
选前思考:谁是我的用户?他们会搜索什么字词?(核心关键词+我们的网站服务加上我们的服务,我们的服务就是用户的需求)
标题组合:
1、确定网站核心词(产品/服务);
2、挖掘相关词并过滤(取整);
3、合格的标题组合:关键词1_关键词2_关键词3-品牌词;
4、不错的标题组合,组合成流畅的句子;
5、优秀的标题组合(时间需求,如:最新、2016;信息量大,如:百科;可信度,如:专家、专业;稀缺需求扩展)。标题示例:_长沙网站生产专家-提供网站施工详细报价单。
基本优化:基本优化原则(1、关键词前面的话权重越高,2、字数大于4字,小于32字,标题符号应该是英文);常见错误(1、描述性词语太多;2、标题内容不到位;3、标题多核,设置太多;
修改标题:一次修改很重要
三、 描述(deion)
1、描述捕获和显示;2、描述是标题的扩展(吸引点击);3、60-80字
部分 四、关键词(关键字)
四、创建用户友好的导航和布局
不。一、什么样的网站导航适合用户体验?
不是。二、什么样的网站布局才符合用户体验?
三、网站导航开发部分
1、用户注意事项:简明扼要;容易明白; 多少?
2、 蜘蛛考虑:有利于识别(图形或文字);它有利于爬行(不要使用 JS 调用);符合SEO(level、DIV、不使用table)
编号四、网站布局思路
1、抓问题;2、展示问题;3、需求找难;4、DIV布局代替表格
第一个五、使用地图规划导航(会使用地图布局导航,比如百度脑图、XMind)
五、排名最高网站 内容创作
1)内容你需要知道你需要什么内容网站
2)内容制作
1.判断内容质量的三个维度(搜索引擎维度要内容丰富;用户维度;网页打开速度)
2.内容模板制作(用户想了解这个产品的哪些信息;二次标题策划;内容填充)
3. 内容注释(字体:14字号比较好;颜色;图片优化,一个文章中的图片大小要一样,alt属性文字要和图片相关;模板文本)
4.避免垃圾内容(除非强制,否则不要添加锚文本;字体颜色应相同;除标题大小外,文本大小应相同;文本中不应有广告)
5.内容创作采集(第一步:采集内容;第二步:根据模板整合内容,根据自己设置的标题填写内容;第三步:微调;第四步:差异化体验调整)
3)超牛B的内容创作秘诀(每天坚持做文章,持续更新网站)
六、推进网站排名的内容更新计划
1、关键词挖矿方式
常用方法:百度文库、百度贴吧、百度知道、工具(百度推广后台、金华挖词工具、追词助手)、相关论坛、相关搜索等(客户搜索长尾关键词 成为我们的 文章 标题)
挖掘思想:分割思维
2、内容更新
更新思维:匹配;关联
常用文章:名词解释、常见问题、知识解答、使用说明、季节性、及时性
分类长尾:例:装修包括家装、工装、Q&A、材料等。家装可根据客厅、房间、厨房、浴室进行更新
注意事项:上线是指被百度抓取时在线。上网时,绝对不允许有空页。内容必须是完整的才能上线。文章在线栏数(至少6个以上),新站更新(内容应该每天更新)
3、更新问答:避免重复文章;网站是否需要经常更新(可以找到关键词表示有内容要更新)
七、通用链接规范和链接集中化
一、基本常识小节
(1)权重集中
权重在网站的每个页面上继承。权重越高,关键词的排名就越好,但并不决定排名。
如何提高网站的权重,搜索引擎会使用网站的整体表现:例如网站内容、外链投票、网站结构、网站 >权重、及时性、稀缺资源等综合因素来判断这个重要性,这个重要性称为网站的权重。
(2)http状态码:200正常访问;301永久重定向;404页面未找到,分为不存在页面和人为错误;500服务器内部错误;503服务不可用,服务器临时维护 要么超载,服务器当前无法处理; 505 服务器不支持,或拒绝支持请求中使用的 HTTP 版本
路径标识二、
(1)静态路径是指静态的网站地址,纯静态形式,通常以.html、htm为后缀,以目录结构结尾;特点:完全静态的HTML网页文档,无需其他语言调用或加载,适合企业网站适应企业网站,单页网站等内容较少
(2)动态路径:有一个或多个参数和字符,不是.html .asp .php 等形式,不带后缀
(3)伪静态路径:将原来的动态路径通过技术转化为伪静态
第一个三、的实际链接权重集中
(1)路径优化注意事项:1)建议上线前优化道路强度,收录不建议优化;2)道路强度应不能太长,参数太多;3)卢晋不要太深;4)最好不要出现中文;5)卢晋名字要描述性;6)https是http安全版;7)网址拦截;8)最好每页只留一个链接
(2)优化操作:1)处理有尾,统一路径;2)301重定向(空间控制面板,DNSpod);3)使用工具查看.http状态码
八、学习html代码优化
1、网页标签理解:CSS+DIV标签、class、id标签、A标签、img标签
2、代码优化:图片优化,图片的alt描述,图片大小要一致,图片要清晰,中间不要放水印;标签应整齐;一个标签,站点中的链接建议不要使用nofollow标签,即使使用了,也是用于无意义的链接;h标签,h1代表一个页面的核心;标签整洁,标签越简单,搜索引擎就越容易分析你的网站。
(学习SEO,懂得建站,懂html标签,熟悉程序的基本代码原理。)
九、黄金分割原理操作布局网站
一、网站节结构优化
1)网站结构
1.定义一般认为是根据客户需求分析结果,准确定位网站目标群体,设置网站整体架构规划、设计网站栏目及其内容,制定网站@网站开发流程和顺序,最大限度的设计高效的资源配置和管理;
2.Category:物理结构,一般指虚拟空间中很多目录和文件的层次关系;逻辑结构,网站上线后,我们可以看到网站接口与肉眼链接关系在
3.重要性:网站结构是seo优化过程中不可忽视的一个非常重要的环节;合理的内部链结构和合理的网站布局在网站中可以有效引导蜘蛛爬行;方便搜索引擎更好收录;可以建立良好的用户体验;适当的网站结构优化有利于页面权重的合理分配(一般网站首页权重最高,分类页面次之,但对于电商网站略有不同,专注于产品页面,所有依赖网站的内链都可以很好的将首页的权重传递给其他页面,从而实现权重的整体提升,并最终让更多的长尾词获得好的排名);优化网站结构有利于内部锚文本的构建(通过大量的内部链接,加强相关性)
2)网站结构设计目标
1.明确列结构的上下文,层次清晰明了;2.体现特色,注重特色设计;3.方便用户使用;4.网页功能分布合理;5.扩展性极佳;6.用户反思中网页设计与结构的完美结合;7.对于搜索引擎优化,布局是基于关键词竞争力网站首页
3)网站结构考虑
1.用户体验与优化相结合;2.网站地图、搜索引擎地图、用户地图导航;3.面包屑的使用;4.用户浏览的重点
二、Practice网站 页面的页面布局
网页爬虫抓取百度图片(500多张美图实战代码1.导入本次需要的模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2022-03-16 17:17
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是就用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹,将其保存到计算机。. 这个女孩的主页/boards/favorite/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:
Paste_Image.png
Paste_Image.png
2:运行环境 3:实例分析
1.我开始这个爬虫的思路是:进入这个网页/boards/favorite/beauty,获取图片栏目对应的所有url,然后进入每个网页获取所有图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时已经是下午1点30分了,所以第二天又做了一个版本:on this在此基础上,进入每个A网页对应一个缩略图,然后抓取一张像下图这样的高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……
4.下面的代码是解析主页面/boards/favorite/beauty/然后得到每列的URL和名称。使用xpath获取栏目网页时,进入网页开发者模式后,如图所示。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。
Paste_Image.png
5.栏目网页和栏目名称之前已经获取过。这里我们需要分析一下专栏的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。这里还有一个比较棘手的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做
这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2
本地创建文件夹,使用filename = 'image\{}\'.format(fileName) + str(i) + '.jpg' 表示该文件与爬虫代码保存在同一目录image,然后获取到的image根据之前得到的列名保存在image文件夹中。
五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。 查看全部
网页爬虫抓取百度图片(500多张美图实战代码1.导入本次需要的模块)
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是就用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹,将其保存到计算机。. 这个女孩的主页/boards/favorite/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:

Paste_Image.png
Paste_Image.png
2:运行环境 3:实例分析
1.我开始这个爬虫的思路是:进入这个网页/boards/favorite/beauty,获取图片栏目对应的所有url,然后进入每个网页获取所有图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时已经是下午1点30分了,所以第二天又做了一个版本:on this在此基础上,进入每个A网页对应一个缩略图,然后抓取一张像下图这样的高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
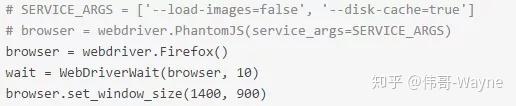
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……
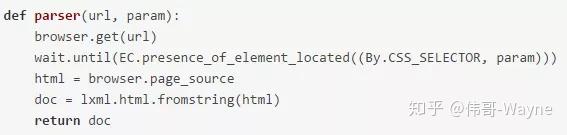
4.下面的代码是解析主页面/boards/favorite/beauty/然后得到每列的URL和名称。使用xpath获取栏目网页时,进入网页开发者模式后,如图所示。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。

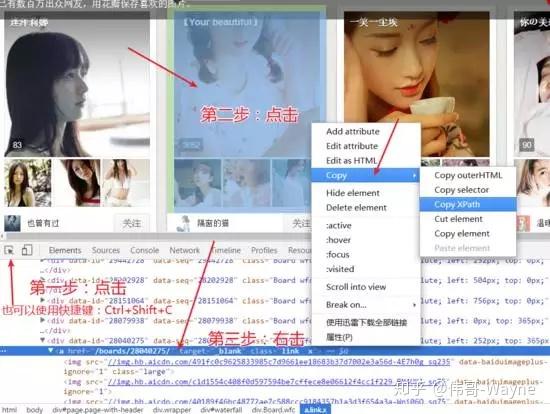
Paste_Image.png
5.栏目网页和栏目名称之前已经获取过。这里我们需要分析一下专栏的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。这里还有一个比较棘手的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做

这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2
本地创建文件夹,使用filename = 'image\{}\'.format(fileName) + str(i) + '.jpg' 表示该文件与爬虫代码保存在同一目录image,然后获取到的image根据之前得到的列名保存在image文件夹中。

五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。
网页爬虫抓取百度图片(网页爬虫抓取百度图片需要掌握常用的几种抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-16 14:04
网页爬虫抓取百度图片需要掌握网页爬虫常用的几种抓取方法主要分为get,post,put,delete(当然,还有xpath中的解析和trim)三个方法第一种:get(url)传入url,分析页面结构,可能需要处理中文问题;第二种:post(url)传入url,代替post方法,参数很多;第三种:put(url)传入url,可能加一些形容词,比如标题(article/orpage/album)和属性(author/id/language/email/text/string):第四种:delete(url)传入url,代替put方法,参数很多,直接提取数据。
从上到下,因为传入参数不多,post和get适合反爬,put最简单post大致有两种思路:把网页js逻辑写到前端代码,把网页js逻辑写到php代码,依此就是反爬。post的参数也一定要加一个文本标识,来表示参数值。代码中我提供的是我开发出来的爬虫,会用到一些基础的库和ca证书(这个知识点,可以在加入ca后来查看,如何实现所有证书绑定)。
补充一个:@晃儿飘醒醒:post(url,authorization)其实是同一个参数,只是有多种规格,他返回的内容是你发送的这个网址上的所有id对应的所有authorization,在爬虫这块,使用这个方法的话,一定要先了解下xpath,post一般比较少用到xpath。参考:一般国内爬虫都有提供ca证书,如果你的服务器禁止国内ca,可以发post但是爬取不了。只能使用ca代理。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片需要掌握常用的几种抓取方法)
网页爬虫抓取百度图片需要掌握网页爬虫常用的几种抓取方法主要分为get,post,put,delete(当然,还有xpath中的解析和trim)三个方法第一种:get(url)传入url,分析页面结构,可能需要处理中文问题;第二种:post(url)传入url,代替post方法,参数很多;第三种:put(url)传入url,可能加一些形容词,比如标题(article/orpage/album)和属性(author/id/language/email/text/string):第四种:delete(url)传入url,代替put方法,参数很多,直接提取数据。
从上到下,因为传入参数不多,post和get适合反爬,put最简单post大致有两种思路:把网页js逻辑写到前端代码,把网页js逻辑写到php代码,依此就是反爬。post的参数也一定要加一个文本标识,来表示参数值。代码中我提供的是我开发出来的爬虫,会用到一些基础的库和ca证书(这个知识点,可以在加入ca后来查看,如何实现所有证书绑定)。
补充一个:@晃儿飘醒醒:post(url,authorization)其实是同一个参数,只是有多种规格,他返回的内容是你发送的这个网址上的所有id对应的所有authorization,在爬虫这块,使用这个方法的话,一定要先了解下xpath,post一般比较少用到xpath。参考:一般国内爬虫都有提供ca证书,如果你的服务器禁止国内ca,可以发post但是爬取不了。只能使用ca代理。
网页爬虫抓取百度图片(什么是爬虫爬虫,即网络上爬行的一直蜘蛛?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-15 22:06
爬虫基础 了解什么是爬虫
爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一张大网,爬虫就是在这张网上四处爬行的蜘蛛。如果遇到资源,就会被抢。你想抢什么?由你来控制它。
例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。这样一来,整个互联网络对这只蜘蛛来说触手可及,分分钟爬下来也不是问题。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求,服务器解析后向用户浏览器发送HTML、JS、CSS等文件。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。第二部分是存储资源的主机的 IP 地址(有时是端口号)。第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫的学习很有帮助。
环境配置
学习Python当然少不了环境的配置。一开始我用的是Notepad++,但是发现它的提示功能太弱了,所以我用的是Windows下的PyCharm,Linux下的Eclipse for Python,还有几个优秀的IDE,可以参考这个文章IDE推荐用于学习 Python。好的开发工具是进步的动力,希望你能找到适合自己的IDE 查看全部
网页爬虫抓取百度图片(什么是爬虫爬虫,即网络上爬行的一直蜘蛛?)
爬虫基础 了解什么是爬虫
爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一张大网,爬虫就是在这张网上四处爬行的蜘蛛。如果遇到资源,就会被抢。你想抢什么?由你来控制它。
例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。这样一来,整个互联网络对这只蜘蛛来说触手可及,分分钟爬下来也不是问题。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求,服务器解析后向用户浏览器发送HTML、JS、CSS等文件。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。第二部分是存储资源的主机的 IP 地址(有时是端口号)。第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫的学习很有帮助。
环境配置
学习Python当然少不了环境的配置。一开始我用的是Notepad++,但是发现它的提示功能太弱了,所以我用的是Windows下的PyCharm,Linux下的Eclipse for Python,还有几个优秀的IDE,可以参考这个文章IDE推荐用于学习 Python。好的开发工具是进步的动力,希望你能找到适合自己的IDE
网页爬虫抓取百度图片(怎么保证爬虫程序的正常运行并且高效抓取数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-15 12:08
爬虫程序本身必须在合规范围内进行,不能影响被访问服务器的正常运行,更不能将爬取的信息用于其他目的。这是首先需要明确的一点,然后是如何保证爬虫。程序的正常运行和数据的高效抓取呢?
1、代理ip的巧妙使用
<p>一般来说,网站服务器是根据代理ip来检测是否是爬虫。如果网站检测到同一个代理ip频繁发送给 查看全部
网页爬虫抓取百度图片(怎么保证爬虫程序的正常运行并且高效抓取数据呢?)
爬虫程序本身必须在合规范围内进行,不能影响被访问服务器的正常运行,更不能将爬取的信息用于其他目的。这是首先需要明确的一点,然后是如何保证爬虫。程序的正常运行和数据的高效抓取呢?
1、代理ip的巧妙使用
<p>一般来说,网站服务器是根据代理ip来检测是否是爬虫。如果网站检测到同一个代理ip频繁发送给
网页爬虫抓取百度图片( 百度搜索引擎蜘蛛爬虫原理及算法解读(广州seo小包))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-15 11:18
百度搜索引擎蜘蛛爬虫原理及算法解读(广州seo小包))
作为一个seoer,既然是搞SEO网站优化的,那你一定要了解百度搜索引擎蜘蛛爬虫的原理和算法,这对于seo网站优化来说是最重要的,如果你不懂的话'不了解搜索引擎蜘蛛爬虫的原理和算法,seo网站无法优化。下面广州seo包带你了解一下:
首先我们要明白:网站和搜索引擎是什么关系?
网站与搜索引擎的关系:良性共生。搜索引擎内容由各种网站发布,进而获取信息。(去各个网站抓取内容,过滤信息,去收录搜索引擎平台,然后排序)
那么我们直接解释一下百度爬虫的原理:
百度蜘蛛爬取原理是什么以及百度爬虫算法解读
首先我们来了解一下百度蜘蛛爬虫的原理,分为爬取信息-过滤信息-收录信息-排序信息)接下来我们将一一讲解原理和算法解读。
百度蜘蛛爬虫爬取原理
1.首先了解三大引擎蜘蛛的名称:百度蜘蛛爬虫:Baiduspider、谷歌蜘蛛爬虫:谷歌机器人、360蜘蛛爬虫:360spider
2.百度蜘蛛爬虫是怎么爬的网站?:
二.百度蜘蛛爬虫会过滤掉的信息
1.那么首先我们要明白百度蜘蛛爬虫会过滤掉垃圾邮件:
A. 低质量页面(对用户毫无价值的页面) B. 该页面对其他页面过于熟悉
C. 空白页。D.内容无关(标题与内容不一致) E.占用存储空间
2.百度蜘蛛爬虫会过滤掉无法识别的,包括:
三.百度蜘蛛网收录资讯
百度蜘蛛爬虫收录(百度快照):只提交优质页面和有价值的内容信息构建索引库,发布快战:
今天的章节《百度蜘蛛爬网原理?以及百度爬虫算法解读》广州seo包就到这里了。百度蜘蛛爬取原理和算法解读是每个seoer必须了解的基础。每个人都必须注意它。我希望每个人都能真正学习和使用它。你自己的 网站 可以帮助每个人。
如果您有任何问题,可以在下方评论,广州SEO包会及时为您解答。了解更多SEO优化知识,请关注广州SEO包。 查看全部
网页爬虫抓取百度图片(
百度搜索引擎蜘蛛爬虫原理及算法解读(广州seo小包))

作为一个seoer,既然是搞SEO网站优化的,那你一定要了解百度搜索引擎蜘蛛爬虫的原理和算法,这对于seo网站优化来说是最重要的,如果你不懂的话'不了解搜索引擎蜘蛛爬虫的原理和算法,seo网站无法优化。下面广州seo包带你了解一下:
 https://www.seo023.org/wp-cont ... 6.png 300w" />
https://www.seo023.org/wp-cont ... 6.png 300w" />首先我们要明白:网站和搜索引擎是什么关系?
网站与搜索引擎的关系:良性共生。搜索引擎内容由各种网站发布,进而获取信息。(去各个网站抓取内容,过滤信息,去收录搜索引擎平台,然后排序)
那么我们直接解释一下百度爬虫的原理:
百度蜘蛛爬取原理是什么以及百度爬虫算法解读
首先我们来了解一下百度蜘蛛爬虫的原理,分为爬取信息-过滤信息-收录信息-排序信息)接下来我们将一一讲解原理和算法解读。
百度蜘蛛爬虫爬取原理
1.首先了解三大引擎蜘蛛的名称:百度蜘蛛爬虫:Baiduspider、谷歌蜘蛛爬虫:谷歌机器人、360蜘蛛爬虫:360spider
2.百度蜘蛛爬虫是怎么爬的网站?:
二.百度蜘蛛爬虫会过滤掉的信息
1.那么首先我们要明白百度蜘蛛爬虫会过滤掉垃圾邮件:
A. 低质量页面(对用户毫无价值的页面) B. 该页面对其他页面过于熟悉
C. 空白页。D.内容无关(标题与内容不一致) E.占用存储空间
2.百度蜘蛛爬虫会过滤掉无法识别的,包括:
三.百度蜘蛛网收录资讯
百度蜘蛛爬虫收录(百度快照):只提交优质页面和有价值的内容信息构建索引库,发布快战:
今天的章节《百度蜘蛛爬网原理?以及百度爬虫算法解读》广州seo包就到这里了。百度蜘蛛爬取原理和算法解读是每个seoer必须了解的基础。每个人都必须注意它。我希望每个人都能真正学习和使用它。你自己的 网站 可以帮助每个人。
如果您有任何问题,可以在下方评论,广州SEO包会及时为您解答。了解更多SEO优化知识,请关注广州SEO包。
网页爬虫抓取百度图片(X图片网站--网络请求模块requestsPython中的大量开源模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-15 11:17
X图网站----前言
这个文章爬取网站已经过期了,具体代码可以从橡皮擦获取。建议直接看第三篇博客
所有与 网站 相关的链接全部被 X 替换。如果需要确定URL,可以参考URL获取
从今天开始,我就撸起袖子,直接写Python爬虫。学习语言的最好方法是有目的地去做。所以,我会用10+篇博客来写爬图。希望可以做到。
为了编写爬虫,我们需要准备一个火狐浏览器,还需要准备一个抓包工具和一个抓包工具。我用的是CentOS自带的tcpdump,加上wireshark,这两个软件的安装和使用,建议大家还是学习一下,以后应该会用到。
X图网站----网络请求模块请求
Python 中的大量开源模块使编码变得非常简单。在编写爬虫时,我们需要了解的第一个模块是请求。
X图片网站----安装请求
打开终端:使用命令
pip3 安装请求
等待安装完成即可使用
接下来在终端中输入以下命令
# mkdir demo
# cd demo
# touch down.py
上面的linux命令是创建一个名为demo的文件夹 查看全部
网页爬虫抓取百度图片(X图片网站--网络请求模块requestsPython中的大量开源模块)
X图网站----前言
这个文章爬取网站已经过期了,具体代码可以从橡皮擦获取。建议直接看第三篇博客
所有与 网站 相关的链接全部被 X 替换。如果需要确定URL,可以参考URL获取
从今天开始,我就撸起袖子,直接写Python爬虫。学习语言的最好方法是有目的地去做。所以,我会用10+篇博客来写爬图。希望可以做到。
为了编写爬虫,我们需要准备一个火狐浏览器,还需要准备一个抓包工具和一个抓包工具。我用的是CentOS自带的tcpdump,加上wireshark,这两个软件的安装和使用,建议大家还是学习一下,以后应该会用到。
X图网站----网络请求模块请求
Python 中的大量开源模块使编码变得非常简单。在编写爬虫时,我们需要了解的第一个模块是请求。
X图片网站----安装请求
打开终端:使用命令
pip3 安装请求
等待安装完成即可使用
接下来在终端中输入以下命令
# mkdir demo
# cd demo
# touch down.py
上面的linux命令是创建一个名为demo的文件夹
网页爬虫抓取百度图片(什么是爬虫?网络爬虫的本质模拟浏览器的基本流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2022-04-04 03:09
一、什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
二、爬行动物的本质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,获取我们想要的资源(文字、图片、视频...)
三、爬虫基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
四、什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
五、Requests 库的基础知识
Requests 库的 7 个主要方法
我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
请求对象就是我们要请求的url,响应对象就是返回的内容,如图:
Request 库的两个重要对象
六、安装请求
1.强烈建议您使用pip进行安装:pip insrall requests
2.Pycharm安装:文件-》默认设置-》项目解释器-》搜索请求-》安装包-》ok
七、Requests库的操作示例
1、京东商品爬虫-普通爬虫框架
导入请求 查看全部
网页爬虫抓取百度图片(什么是爬虫?网络爬虫的本质模拟浏览器的基本流程)
一、什么是爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
其实通俗的说,就是通过程序在网页上获取你想要的数据,也就是自动抓取数据。
您可以抓取女孩的照片并抓取您想观看的视频。. 等待你要爬取的数据,只要你能通过浏览器访问的数据就可以通过爬虫获取
二、爬行动物的本质
模拟浏览器打开网页,获取网页中我们想要的部分数据
在浏览器中打开网页的过程:
当你在浏览器中输入地址,通过DNS服务器找到服务器主机,向服务器发送请求,服务器解析并将结果发送给用户的浏览器,包括html、js、css等文件内容,浏览器解析它并最终呈现它给用户在浏览器上看到的结果
因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析和过滤,获取我们想要的资源(文字、图片、视频...)
三、爬虫基本流程
发出请求
通过HTTP库向目标站点发起请求,即发送Request,请求中可以收录额外的headers等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。类型可以是 HTML、Json 字符串、二进制数据(图片或视频)等。
解析内容
获取的内容可以是HTML,可以用正则表达式和页面解析库解析,也可以是Json,可以直接转成Json对象解析,也可以是二进制数据,可以保存或进一步处理
保存数据
以多种形式保存,可以保存为文本,也可以保存到数据库,或者以特定格式保存文件
四、什么是请求
Requests 是基于 urllib 用 python 编写,使用 Apache2 Licensed 开源协议的 HTTP 库
如果你看过之前的文章文章关于urllib库的使用,你会发现urllib其实很不方便,而且Requests比urllib方便,可以为我们省去很多工作。(使用requests之后,你基本就舍不得用urllib了。)总之,requests是python实现的最简单最简单的HTTP库。建议爬虫使用 requests 库。
默认安装python后,requests模块没有安装,需要通过pip单独安装
五、Requests 库的基础知识
Requests 库的 7 个主要方法
我们通过调用Request库中的方法获取返回的对象。它包括两个对象,请求对象和响应对象。
请求对象就是我们要请求的url,响应对象就是返回的内容,如图:
Request 库的两个重要对象
六、安装请求
1.强烈建议您使用pip进行安装:pip insrall requests
2.Pycharm安装:文件-》默认设置-》项目解释器-》搜索请求-》安装包-》ok
七、Requests库的操作示例
1、京东商品爬虫-普通爬虫框架
导入请求
网页爬虫抓取百度图片(Python全栈免费解答.裙(BFE9)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-01 22:19
经过前期的大量学习和准备,我们需要开始编写第一个真正的爬虫。这次我们要爬的网站是:百度贴吧,一个很适合新手练习的地方,所以开始吧。
这次想爬贴吧Yes>,西部世界是一部我一直很喜欢的美剧。我通常有时间去看看我的朋友们在谈论什么。所以这次我选择了这个酒吧作为实验材料。注意:很多人在学习Python的过程中会遇到各种烦恼,无人回答很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
贴吧地址:
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8
Python 版本:3.6
浏览器版本:Chrome
目标分析:
由于它是第一个实验爬虫,我们没有太多工作要做。我们需要做的就是:
1、从网络上爬取特定页面
2、对被爬取的页面内容进行简单过滤分析
3、查找每个帖子的标题、海报、日期、楼层和跳转链接
4、将结果保存为文本。
前期准备:
看到贴吧的url地址,你是不是觉得一头雾水?有一大串无法识别的字符?
其实这些都是汉字。
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C
后面的代码是:西部世界。
链接末尾:&ie=utf-8 表示链接采用utf-8编码。
windows的默认编码是GBK。在处理这个连接时,我们需要在 Python 中手动设置,才能成功使用。
与Python2相比,Python3对编码的支持有了很大的提升。默认情况下,全局使用 utf-8 编码。所以建议还在学习Python2的朋友赶紧投身Python3的怀抱,真的是省了老大的功夫。
然后我们转到贴吧的第二页:
网址:
`url: https://tieba.baidu.com/f%3Fkw ... %3D50`
注意没有,在连接的末尾多了一个参数&pn=50,
这里我们很容易猜到这个参数与页码的关系:
现在我们可以通过简单的url修改来实现翻页的效果。
chrome开发者工具的使用:
要编写爬虫,我们必须能够使用开发工具。说起来,这个工具是为前端开发者准备的,但是我们可以用它来快速定位我们要爬取的信息,找到对应的规则。
图片
图片
我们仔细一看,发现每篇文章的内容都被一个 li 标签包裹着:
这样,我们只需要快速找到所有符合规则的标签,
在进一步分析内容,最后过滤掉数据就可以了。
开始写代码?我们先写一个函数来抓取页面上的人:
这是前面介绍的爬虫框架,以后会经常用到。
import requests
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
#这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding='utf-8'
return r.text
except:
return " ERROR "
然后我们提取细节:
一个大的 li 标签包裹了许多 div 标签
我们想要的信息在这些 div 标签中:
# 标题&帖子链接
<a span class="token attr-name"relspan class="token attr-value"span class="token punctuation"=span class="token punctuation""noreferrerspan class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/p/5803134498span class="token punctuation"" span class="token attr-name"titlespan class="token attr-value"span class="token punctuation"=span class="token punctuation""【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给span class="token punctuation"" span class="token attr-name"targetspan class="token attr-value"span class="token punctuation"=span class="token punctuation""_blankspan class="token punctuation"" span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""j_th_tit span class="token punctuation""span class="token punctuation">【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给
#发帖人:
"user_id<a span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""icon_tbworld icon-crown-super-v1span class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/tbmall/tshowspan class="token punctuation"" span class="token attr-name"data-fieldspan class="token attr-value"span class="token punctuation"=span class="token punctuation""{span class="token entity" title=""">"user_id
#回复数量:
822
#发帖日期:
7-20
经过分析,我们可以通过soup.find()方法轻松得到我们想要的结果
具体代码实现:
'''
抓取百度贴吧---西部世界吧的基本内容
爬虫线路: requests - bs4
Python版本: 3.6
OS: mac os 12.13.6
'''
import requests
import time
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
# 这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding = 'utf-8'
return r.text
except:
return " ERROR "
def get_content(url):
'''
分析贴吧的网页文件,整理信息,保存在列表变量中
'''
# 初始化一个列表来保存所有的帖子信息:
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
# 我们来做一锅汤
soup = BeautifulSoup(html, 'lxml')
# 按照之前的分析,我们找到所有具有‘ j_thread_list clearfix’属性的li标签。返回一个列表类型。
liTags = soup.find_all('li', attrs={'class': ' j_thread_list clearfix'})
# 通过循环找到每个帖子里的我们需要的信息:
for li in liTags:
# 初始化一个字典来存储文章信息
comment = {}
# 这里使用一个try except 防止爬虫找不到信息从而停止运行
try:
# 开始筛选信息,并保存到字典中
comment['title'] = li.find(
'a', attrs={'class': 'j_th_tit '}).text.strip()
comment['link'] = "http://tieba.baidu.com/" + \
li.find('a', attrs={'class': 'j_th_tit '})['href']
comment['name'] = li.find(
'span', attrs={'class': 'tb_icon_author '}).text.strip()
comment['time'] = li.find(
'span', attrs={'class': 'pull-right is_show_create_time'}).text.strip()
comment['replyNum'] = li.find(
'span', attrs={'class': 'threadlist_rep_num center_text'}).text.strip()
comments.append(comment)
except:
print('出了点小问题')
return comments
def Out2File(dict):
'''
将爬取到的文件写入到本地
保存到当前目录的 TTBT.txt文件中。
'''
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('标题: {} \t 链接:{} \t 发帖人:{} \t 发帖时间:{} \t 回复数量: {} \n'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']))
print('当前页面爬取完成')
def main(base_url, deep):
url_list = []
# 将所有需要爬去的url存入列表
for i in range(0, deep):
url_list.append(base_url + '&pn=' + str(50 * i))
print('所有的网页已经下载到本地! 开始筛选信息。。。。')
#循环写入所有的数据
for url in url_list:
content = get_content(url)
Out2File(content)
print('所有的信息都已经保存完毕!')
base_url = 'https://tieba.baidu.com/f?kw=%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8'
# 设置需要爬取的页码数量
deep = 3
if __name__ == '__main__':
main(base_url, deep)
代码中有详细的注释和想法。如果看不懂,多读几遍。
这是爬升的结果:
图片
小结注:很多人在学习Python的过程中会遇到各种各样的烦恼,没人回答就很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
本文文字和图片来源于网络和自己的想法,仅供学习交流,不具备任何商业用途。版权归原作者所有。如有任何问题,请及时联系我们进行处理。 查看全部
网页爬虫抓取百度图片(Python全栈免费解答.裙(BFE9)(组图))
经过前期的大量学习和准备,我们需要开始编写第一个真正的爬虫。这次我们要爬的网站是:百度贴吧,一个很适合新手练习的地方,所以开始吧。
这次想爬贴吧Yes>,西部世界是一部我一直很喜欢的美剧。我通常有时间去看看我的朋友们在谈论什么。所以这次我选择了这个酒吧作为实验材料。注意:很多人在学习Python的过程中会遇到各种烦恼,无人回答很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
贴吧地址:
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8
Python 版本:3.6
浏览器版本:Chrome
目标分析:
由于它是第一个实验爬虫,我们没有太多工作要做。我们需要做的就是:
1、从网络上爬取特定页面
2、对被爬取的页面内容进行简单过滤分析
3、查找每个帖子的标题、海报、日期、楼层和跳转链接
4、将结果保存为文本。
前期准备:
看到贴吧的url地址,你是不是觉得一头雾水?有一大串无法识别的字符?
其实这些都是汉字。
%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C
后面的代码是:西部世界。
链接末尾:&ie=utf-8 表示链接采用utf-8编码。
windows的默认编码是GBK。在处理这个连接时,我们需要在 Python 中手动设置,才能成功使用。
与Python2相比,Python3对编码的支持有了很大的提升。默认情况下,全局使用 utf-8 编码。所以建议还在学习Python2的朋友赶紧投身Python3的怀抱,真的是省了老大的功夫。
然后我们转到贴吧的第二页:
网址:
`url: https://tieba.baidu.com/f%3Fkw ... %3D50`
注意没有,在连接的末尾多了一个参数&pn=50,
这里我们很容易猜到这个参数与页码的关系:
现在我们可以通过简单的url修改来实现翻页的效果。
chrome开发者工具的使用:
要编写爬虫,我们必须能够使用开发工具。说起来,这个工具是为前端开发者准备的,但是我们可以用它来快速定位我们要爬取的信息,找到对应的规则。
图片
图片
我们仔细一看,发现每篇文章的内容都被一个 li 标签包裹着:
这样,我们只需要快速找到所有符合规则的标签,
在进一步分析内容,最后过滤掉数据就可以了。
开始写代码?我们先写一个函数来抓取页面上的人:
这是前面介绍的爬虫框架,以后会经常用到。
import requests
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
#这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding='utf-8'
return r.text
except:
return " ERROR "
然后我们提取细节:
一个大的 li 标签包裹了许多 div 标签
我们想要的信息在这些 div 标签中:
# 标题&帖子链接
<a span class="token attr-name"relspan class="token attr-value"span class="token punctuation"=span class="token punctuation""noreferrerspan class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/p/5803134498span class="token punctuation"" span class="token attr-name"titlespan class="token attr-value"span class="token punctuation"=span class="token punctuation""【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给span class="token punctuation"" span class="token attr-name"targetspan class="token attr-value"span class="token punctuation"=span class="token punctuation""_blankspan class="token punctuation"" span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""j_th_tit span class="token punctuation""span class="token punctuation">【高淸】西部世界1-2季,中英字,未❗️删❕减.任性给
#发帖人:
"user_id<a span class="token attr-name"classspan class="token attr-value"span class="token punctuation"=span class="token punctuation""icon_tbworld icon-crown-super-v1span class="token punctuation"" span class="token attr-name"hrefspan class="token attr-value"span class="token punctuation"=span class="token punctuation""/tbmall/tshowspan class="token punctuation"" span class="token attr-name"data-fieldspan class="token attr-value"span class="token punctuation"=span class="token punctuation""{span class="token entity" title=""">"user_id
#回复数量:
822
#发帖日期:
7-20
经过分析,我们可以通过soup.find()方法轻松得到我们想要的结果
具体代码实现:
'''
抓取百度贴吧---西部世界吧的基本内容
爬虫线路: requests - bs4
Python版本: 3.6
OS: mac os 12.13.6
'''
import requests
import time
from bs4 import BeautifulSoup
# 首先我们写好抓取网页的函数
def get_html(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
# 这里我们知道百度贴吧的编码是utf-8,所以手动设置的。爬去其他的页面时建议使用:
# r.endcodding = r.apparent_endconding
r.encoding = 'utf-8'
return r.text
except:
return " ERROR "
def get_content(url):
'''
分析贴吧的网页文件,整理信息,保存在列表变量中
'''
# 初始化一个列表来保存所有的帖子信息:
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
# 我们来做一锅汤
soup = BeautifulSoup(html, 'lxml')
# 按照之前的分析,我们找到所有具有‘ j_thread_list clearfix’属性的li标签。返回一个列表类型。
liTags = soup.find_all('li', attrs={'class': ' j_thread_list clearfix'})
# 通过循环找到每个帖子里的我们需要的信息:
for li in liTags:
# 初始化一个字典来存储文章信息
comment = {}
# 这里使用一个try except 防止爬虫找不到信息从而停止运行
try:
# 开始筛选信息,并保存到字典中
comment['title'] = li.find(
'a', attrs={'class': 'j_th_tit '}).text.strip()
comment['link'] = "http://tieba.baidu.com/" + \
li.find('a', attrs={'class': 'j_th_tit '})['href']
comment['name'] = li.find(
'span', attrs={'class': 'tb_icon_author '}).text.strip()
comment['time'] = li.find(
'span', attrs={'class': 'pull-right is_show_create_time'}).text.strip()
comment['replyNum'] = li.find(
'span', attrs={'class': 'threadlist_rep_num center_text'}).text.strip()
comments.append(comment)
except:
print('出了点小问题')
return comments
def Out2File(dict):
'''
将爬取到的文件写入到本地
保存到当前目录的 TTBT.txt文件中。
'''
with open('TTBT.txt', 'a+') as f:
for comment in dict:
f.write('标题: {} \t 链接:{} \t 发帖人:{} \t 发帖时间:{} \t 回复数量: {} \n'.format(
comment['title'], comment['link'], comment['name'], comment['time'], comment['replyNum']))
print('当前页面爬取完成')
def main(base_url, deep):
url_list = []
# 将所有需要爬去的url存入列表
for i in range(0, deep):
url_list.append(base_url + '&pn=' + str(50 * i))
print('所有的网页已经下载到本地! 开始筛选信息。。。。')
#循环写入所有的数据
for url in url_list:
content = get_content(url)
Out2File(content)
print('所有的信息都已经保存完毕!')
base_url = 'https://tieba.baidu.com/f?kw=%E8%A5%BF%E9%83%A8%E4%B8%96%E7%95%8C&ie=utf-8'
# 设置需要爬取的页码数量
deep = 3
if __name__ == '__main__':
main(base_url, deep)
代码中有详细的注释和想法。如果看不懂,多读几遍。
这是爬升的结果:
图片
小结注:很多人在学习Python的过程中会遇到各种各样的烦恼,没人回答就很容易放弃。为此,小编特意搭建了Python全栈免费答案。裙子:时间长了,改造后(数字谐音)就可以找到了,有老司机解决你不明白的问题。还有最新的 Python 教程。下载,让我们互相监督,共同进步!
本文文字和图片来源于网络和自己的想法,仅供学习交流,不具备任何商业用途。版权归原作者所有。如有任何问题,请及时联系我们进行处理。
网页爬虫抓取百度图片(这里有新鲜出炉的Python3Cookbook,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-31 18:01
这里是最新发布的Python3 Cookbook中文版,程序狗速来了!
Python 编程语言 Python 是一种面向对象的、解释型的计算机编程语言,由 Guido van Rossum 于 1989 年底发明,并于 1991 年首次公开发布。 Python 语法简洁明了,具有丰富而强大的类库. 通常被称为胶水语言,它可以很容易地将用其他语言(尤其是 C/C++)制作的各种模块链接在一起。
本文主要介绍Python爬虫:通过关键词爬取百度图片的方法。有很好的参考价值,跟着小编一起来看看吧
使用的工具:Python2.7 点我下载
爬虫框架
崇高的文本3
一。构建python(Windows版本)
1.安装python2.7 ---然后在cmd中输入python,界面如下,安装成功
2.集成Scrapy框架----进入命令行:pip install Scrapy
安装成功界面如下:
失败的案例很多,例如:
解决方案:
其余错误可以百度搜索。
二。开始编程。
1.爬行静态网站无反爬行措施。比如百度贴吧,豆瓣阅读。
例如 - 来自“桌面栏”的帖子
python代码如下:
代码注释: 两个模块 urllib, re 介绍。定义两个函数,第一个函数是获取整个目标网页的数据,第二个函数是获取目标网页中的目标图像,遍历网页,将获得的图像按照0排序。
注:re模块知识点:
爬取图片效果图:
图片保存路径默认为同一目录下创建的 .py 文件。
2.用反爬措施爬取百度图片。比如百度图片等等。
比如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片以滚动方式加载,排名前30的图片优先爬取。
代码显示如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句并抛出 tryException。
爬取过程如下:
爬取结果:
注意:写python代码时,注意对齐,不能混用Tab和空格,容易报错。
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持PHPERZ! 查看全部
网页爬虫抓取百度图片(这里有新鲜出炉的Python3Cookbook,程序狗速度看过来!)
这里是最新发布的Python3 Cookbook中文版,程序狗速来了!
Python 编程语言 Python 是一种面向对象的、解释型的计算机编程语言,由 Guido van Rossum 于 1989 年底发明,并于 1991 年首次公开发布。 Python 语法简洁明了,具有丰富而强大的类库. 通常被称为胶水语言,它可以很容易地将用其他语言(尤其是 C/C++)制作的各种模块链接在一起。
本文主要介绍Python爬虫:通过关键词爬取百度图片的方法。有很好的参考价值,跟着小编一起来看看吧
使用的工具:Python2.7 点我下载
爬虫框架
崇高的文本3
一。构建python(Windows版本)
1.安装python2.7 ---然后在cmd中输入python,界面如下,安装成功
2.集成Scrapy框架----进入命令行:pip install Scrapy
安装成功界面如下:
失败的案例很多,例如:
解决方案:
其余错误可以百度搜索。
二。开始编程。
1.爬行静态网站无反爬行措施。比如百度贴吧,豆瓣阅读。
例如 - 来自“桌面栏”的帖子
python代码如下:
代码注释: 两个模块 urllib, re 介绍。定义两个函数,第一个函数是获取整个目标网页的数据,第二个函数是获取目标网页中的目标图像,遍历网页,将获得的图像按照0排序。
注:re模块知识点:
爬取图片效果图:
图片保存路径默认为同一目录下创建的 .py 文件。
2.用反爬措施爬取百度图片。比如百度图片等等。
比如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps = 111111
图片以滚动方式加载,排名前30的图片优先爬取。
代码显示如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句并抛出 tryException。
爬取过程如下:
爬取结果:
注意:写python代码时,注意对齐,不能混用Tab和空格,容易报错。
以上就是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持PHPERZ!
网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-31 00:26
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的图片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站就知道了,不好解释) 几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar 查看全部
网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的图片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站就知道了,不好解释) 几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar
网页爬虫抓取百度图片(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-26 06:28
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
一、操作步骤
Jisouke的“飞行模式”专门针对那些没有独立URL的弹出页面,即点击后会弹出一个新的标签页,但URL保持不变。“飞行模式”可以模拟人的操作,打开一个弹窗采集然后再打开下一个弹窗继续采集,这样采集下弹窗- up窗口网页信息。
下面以百度百家为例。虽然它的弹窗有一个独立的网站,但是这种情况下最简单的采集方法就是做一个层次结构采集,但是为了演示天桥采集,我们把它当作网址不变。操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页
1.1、打开GS爬虫浏览器,输入网址等待页面加载完毕,然后点击“定义规则”,然后输入主题,最后再次勾选,主题名称不能重复。
步骤 2:定义一级规则
2.1、双击所需信息,勾选确认。一级规则可以随意标记一条信息,目的是让爬虫判断是否执行采集。
2.2,本例中,点击每个文章的标题,然后跟踪弹出的网页采集数据,需要编写定位每个点击对象的xpath表达式。我们可以使用“show xpath”功能自动定位,找到可以定位到每个action对象的xpath。但是对于结构较少的网页,“显示xpath”将无法定位到所有的action对象,需要自己编写相应的xpath,可以看xpath教程来掌握。
2.3、在连续动作中新建一个“点击”动作,下属主题名填写“百度百家文章采集”,勾选“飞行模式”,填写xpath 表达式公式和动作名称
2.4、点击“保存规则”
第三步:定义二级规则
3.1、再次点击“定义规则”,返回普通网页模式,然后点击第一个文章的标题,会弹出一个新窗口,二级规则为在新窗口中定义
3.2、双击需要的信息进行标记,将定位标记准确映射到采集范围
3.3、点击“测试”,如果输出结果没有问题,点击“保存规则”
第 4 步:获取数据
4.1、在DS计数器中搜索一级规则并运行,点击成功,会弹出一个新窗口采集二级网页,采集之后弹窗网页完成后会自动关闭,点击下一步继续采集。这是飞越模式,智能追踪弹窗采集数据。
注意:一级规则的连续动作执行成功后,会自动采集下级规则,所以不需要单独运行下级规则,尤其是下级规则rule 没有独立的 URL,如果在运行时没有采集到目标数据,它会失败。
注:以上为案例网站的采集规则,请根据目标网站的实际情况定义规则。另外,天桥模式是旗舰功能,请先购买再做规则采集数据。
Tips:没有独立URL的网页如何加载和修改规则?
对于没有独立URL的网页,需要先点击该页面,然后搜索规则,右键选择“仅加载规则”,点击“规则”菜单->“后续分析”完成加载操作,然后您可以修改规则。
比如这种情况下的二级规则就是没有独立的URL。需要先加载一级规则,恢复到普通网页模式,点击文章标题,会弹出一个新窗口。(建议把操作写在第一个二级规则的备注里,方便查看),然后右键二级规则,选择“Load Rules Only”。
Part 1 文章:《连续动作:设置自动返回上级页面》 Part 2 文章:《连续打码:破解各种验证码》
如有疑问,您可以或
查看全部
网页爬虫抓取百度图片(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在苏克官网会员中心的“任务管理”中,可以查看采集任务的执行状态,管理线索的URL,进行调度设置。
一、操作步骤
Jisouke的“飞行模式”专门针对那些没有独立URL的弹出页面,即点击后会弹出一个新的标签页,但URL保持不变。“飞行模式”可以模拟人的操作,打开一个弹窗采集然后再打开下一个弹窗继续采集,这样采集下弹窗- up窗口网页信息。
下面以百度百家为例。虽然它的弹窗有一个独立的网站,但是这种情况下最简单的采集方法就是做一个层次结构采集,但是为了演示天桥采集,我们把它当作网址不变。操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页
1.1、打开GS爬虫浏览器,输入网址等待页面加载完毕,然后点击“定义规则”,然后输入主题,最后再次勾选,主题名称不能重复。
步骤 2:定义一级规则
2.1、双击所需信息,勾选确认。一级规则可以随意标记一条信息,目的是让爬虫判断是否执行采集。
2.2,本例中,点击每个文章的标题,然后跟踪弹出的网页采集数据,需要编写定位每个点击对象的xpath表达式。我们可以使用“show xpath”功能自动定位,找到可以定位到每个action对象的xpath。但是对于结构较少的网页,“显示xpath”将无法定位到所有的action对象,需要自己编写相应的xpath,可以看xpath教程来掌握。
2.3、在连续动作中新建一个“点击”动作,下属主题名填写“百度百家文章采集”,勾选“飞行模式”,填写xpath 表达式公式和动作名称
2.4、点击“保存规则”
第三步:定义二级规则
3.1、再次点击“定义规则”,返回普通网页模式,然后点击第一个文章的标题,会弹出一个新窗口,二级规则为在新窗口中定义
3.2、双击需要的信息进行标记,将定位标记准确映射到采集范围
3.3、点击“测试”,如果输出结果没有问题,点击“保存规则”
第 4 步:获取数据
4.1、在DS计数器中搜索一级规则并运行,点击成功,会弹出一个新窗口采集二级网页,采集之后弹窗网页完成后会自动关闭,点击下一步继续采集。这是飞越模式,智能追踪弹窗采集数据。
注意:一级规则的连续动作执行成功后,会自动采集下级规则,所以不需要单独运行下级规则,尤其是下级规则rule 没有独立的 URL,如果在运行时没有采集到目标数据,它会失败。
注:以上为案例网站的采集规则,请根据目标网站的实际情况定义规则。另外,天桥模式是旗舰功能,请先购买再做规则采集数据。
Tips:没有独立URL的网页如何加载和修改规则?
对于没有独立URL的网页,需要先点击该页面,然后搜索规则,右键选择“仅加载规则”,点击“规则”菜单->“后续分析”完成加载操作,然后您可以修改规则。
比如这种情况下的二级规则就是没有独立的URL。需要先加载一级规则,恢复到普通网页模式,点击文章标题,会弹出一个新窗口。(建议把操作写在第一个二级规则的备注里,方便查看),然后右键二级规则,选择“Load Rules Only”。
Part 1 文章:《连续动作:设置自动返回上级页面》 Part 2 文章:《连续打码:破解各种验证码》
如有疑问,您可以或
网页爬虫抓取百度图片(外链图片转存失败,源站可能有防盗链机制(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-24 18:05
最近在看重天老师的MOOC Python网络爬虫与信息抽取课程,开始吧
必须先安装 requests 库
方法很简单 pip install requests
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-aW55ejx9-14)(/img/bVbMkeh)】
以上是requests库中的7个主要方法
import requests
url='http://www.baidu.com'
r=requests.get(url)
print(r.status_code)
r.encoding='utf-8'
print(r.text)
简单抓取百度的代码
r=requests.get(url)
这行代码中,返回的r的数据类型是Response类,赋值号右边是Request类
响应对象属性(重要)
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cwG13p6e-17)(/img/bVbMkfA)]
请求库异常
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-yTu9bPnR-18)(/img/bVbMkgu)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sUEEt355-19)(/img/bVbMkgI)]
参数的使用
一、爬取 JD 实例
1.爬京东时网站
import requests
url='https://item.jd.com/100006713417.html'
try:
r=requests.get(url)
print(r.status_code)
print(r.text[:1000])
except :
print('出现异常')
得到这个结果:
显然这不是我们想要的信息,访问结果中的链接发现是京东的登录界面。
2.解决问题
查了相关资料,发现京东有源码审查,所以可以通过修改headers和cookie参数来实现
Cookie参数查找方法:
进入页面后按F12,然后进入网络界面,刷新找到对应页面,如图
import requests
url = 'https://item.jd.com/100006713417.html'
cookiestr='unpl=V2_ZzNtbRAHQ0ZzDk9WKBlbDWJXQF5KBBYRfQ0VBHhJWlEyABBaclRCFnQUR11nGlUUZwYZWEdcRxxFCEVkexhdBGAAE19BVXMlRQtGZHopXAFvChZVRFZLHHwJRVRyEVQDZwQRWENncxJ1AXZkMEAaDGAGEVxHVUARRQtDU34dXjVmMxBcQ1REHXAPQ11LUjIEKgMWVUtTSxN0AE9dehpcDG8LFF1FVEYURQhHVXoYXAJkABJtQQ%3d%3d; __jdv=122270672|mydisplay.ctfile.com|t_1000620323_|tuiguang|ca1b7783b1694ec29bd594ba2a7ed236|1598597100230; __jdu=15985970988021899716240; shshshfpa=7645286e-aab6-ce64-5f78-039ee4cc7f1e-1598597100; areaId=22; ipLoc-djd=22-1930-49324-0; PCSYCityID=CN_510000_510100_510116; shshshfpb=uxViv6Hw0rcSrj5Z4lZjH4g%3D%3D; __jdc=122270672; __jda=122270672.15985970988021899716240.1598597098.1598597100.1599100842.2; shshshfp=f215b3dcb63dedf2e335349645cbb45e; 3AB9D23F7A4B3C9B=4BFMWHJNBVGI6RF55ML2PWUQHGQ2KQMS4KJIAGEJOOL3ESSN35PFEIXQFE352263KVFC2JIKWUJHDRXXMXGAAANAPA; shshshsID=2f3061bf1cc51a3f6162742028f11a80_5_1599101419724; __jdb=122270672.11.15985970988021899716240|2.1599100842; wlfstk_smdl=mwti16fwg6li5o184teuay0iftfocdez'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.14 Safari/537.36 Edg/83.0.478.13","cookie":cookiestr}
try:
r = requests.get(url=url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print('爬取失败')
import requests
kv = {'user-agent':'Mozilla/5.0'}
url = "https://item.jd.com/100006713417.html"
try:
r = requests.get(url,headers = kv)
r.encoding = r.apparent_encoding
r.raise_for_status()
print(r.text[:1000])
except :
print('Error')
都得到我们想要的结果
二、爬取亚马逊实例
import requests
url = "https://www.amazon.cn/dp/B072C ... ot%3B
try:
r = requests.get(url)
print(r.status_code)
print(r.encoding)
print(r.request.headers)
r.encoding = r.apparent_encoding
print(r.text[:5000])
except :
print('Error')
出现了同样的问题。老师在这里解释了。亚马逊也有来源审查。当 headers 参数没有被修改时,程序告诉亚马逊服务器这是对 py requests 库的访问。
所以有一个错误。
2.解决办法
如上,修改user-agent
结果:
还是有问题,下面有提示,
这里提示可能存在cookie相关的问题,所以我们找到网页的cookie,放到headers中
问题成功解决
三、爬取图片
当我们要爬取网页上的图片时,我们应该怎么做。
现在知道网页上的图片链接是格式
url链接以jpg结尾,描述为图片
按照冲天老师的提示写了一段代码
import requests
import os
url='https://ss0.bdstatic.com/70cFu ... 11137,2818876915&fm=26&gp=0.jpg'
root='d:/pics//'
path = root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.makedirs(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已经存在')
except:
print('爬取出错')
这里import os判断文件是否存在
结果上
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-xv0bBm8f-21)(/img/bVbMr7U)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-7tOVoMvj-21)(/img/bVbMr7W)]
图片也保存了
IP地址归属地自动查询
实战中遇到了一个小问题
先编码
import requests
url_1 = 'https://www.ip138.com/iplookup ... 39%3B
ip_address = input('Please input your ip address')
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url)
print(r.status_code)
print(r.text[-500:])
except:
print('error')
else:
print('ip address cannot be empty')
然后程序一直报错,于是我把try except模块去掉,看看问题出在哪里。
果然,问题是源审查
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-FF8AqVZd-22)(/img/bVbMr9Y)]
这行错误说明ip138网站应该有source review,所以换个headers里的agent再试一次
修改user-agent参数后,刚好找到一个美国的IP地址,上图成功。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-puo6nDNG-22)(/img/bVbMsaQ)]
import requests
url_1 = 'https://www.ip138.com/iplookup.asp?ip='
ip_address = input('Please input your ip address')
kv={'user-agent':'chrome/5.0'}
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url,headers=kv)
print(r.status_code)
r.encoding=r.apparent_encoding
print(r.text)
except:
print('error')
else:
print('ip address cannot be empty')
第二周
Beautiful Soup 库1.安装 Beautiful Soup 库
CMD pip install beautifulsoup4
2.请求库获取网页源代码
import requests
r=requests.get("https://python123.io/ws/demo.html")
print(r.text)
3. bs 库的使用
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-tKeVDKKg-23)(/img/bVbMsca)】
import requests
from bs4 import BeautifulSoup
r = requests.get("https://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
4. bs 库的基本元素 查看全部
网页爬虫抓取百度图片(外链图片转存失败,源站可能有防盗链机制(组图))
最近在看重天老师的MOOC Python网络爬虫与信息抽取课程,开始吧
必须先安装 requests 库
方法很简单 pip install requests
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-aW55ejx9-14)(/img/bVbMkeh)】
以上是requests库中的7个主要方法
import requests
url='http://www.baidu.com'
r=requests.get(url)
print(r.status_code)
r.encoding='utf-8'
print(r.text)
简单抓取百度的代码
r=requests.get(url)
这行代码中,返回的r的数据类型是Response类,赋值号右边是Request类
响应对象属性(重要)
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cwG13p6e-17)(/img/bVbMkfA)]
请求库异常
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-yTu9bPnR-18)(/img/bVbMkgu)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sUEEt355-19)(/img/bVbMkgI)]
参数的使用
一、爬取 JD 实例
1.爬京东时网站
import requests
url='https://item.jd.com/100006713417.html'
try:
r=requests.get(url)
print(r.status_code)
print(r.text[:1000])
except :
print('出现异常')
得到这个结果:
显然这不是我们想要的信息,访问结果中的链接发现是京东的登录界面。
2.解决问题
查了相关资料,发现京东有源码审查,所以可以通过修改headers和cookie参数来实现
Cookie参数查找方法:
进入页面后按F12,然后进入网络界面,刷新找到对应页面,如图
import requests
url = 'https://item.jd.com/100006713417.html'
cookiestr='unpl=V2_ZzNtbRAHQ0ZzDk9WKBlbDWJXQF5KBBYRfQ0VBHhJWlEyABBaclRCFnQUR11nGlUUZwYZWEdcRxxFCEVkexhdBGAAE19BVXMlRQtGZHopXAFvChZVRFZLHHwJRVRyEVQDZwQRWENncxJ1AXZkMEAaDGAGEVxHVUARRQtDU34dXjVmMxBcQ1REHXAPQ11LUjIEKgMWVUtTSxN0AE9dehpcDG8LFF1FVEYURQhHVXoYXAJkABJtQQ%3d%3d; __jdv=122270672|mydisplay.ctfile.com|t_1000620323_|tuiguang|ca1b7783b1694ec29bd594ba2a7ed236|1598597100230; __jdu=15985970988021899716240; shshshfpa=7645286e-aab6-ce64-5f78-039ee4cc7f1e-1598597100; areaId=22; ipLoc-djd=22-1930-49324-0; PCSYCityID=CN_510000_510100_510116; shshshfpb=uxViv6Hw0rcSrj5Z4lZjH4g%3D%3D; __jdc=122270672; __jda=122270672.15985970988021899716240.1598597098.1598597100.1599100842.2; shshshfp=f215b3dcb63dedf2e335349645cbb45e; 3AB9D23F7A4B3C9B=4BFMWHJNBVGI6RF55ML2PWUQHGQ2KQMS4KJIAGEJOOL3ESSN35PFEIXQFE352263KVFC2JIKWUJHDRXXMXGAAANAPA; shshshsID=2f3061bf1cc51a3f6162742028f11a80_5_1599101419724; __jdb=122270672.11.15985970988021899716240|2.1599100842; wlfstk_smdl=mwti16fwg6li5o184teuay0iftfocdez'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.14 Safari/537.36 Edg/83.0.478.13","cookie":cookiestr}
try:
r = requests.get(url=url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print('爬取失败')
import requests
kv = {'user-agent':'Mozilla/5.0'}
url = "https://item.jd.com/100006713417.html"
try:
r = requests.get(url,headers = kv)
r.encoding = r.apparent_encoding
r.raise_for_status()
print(r.text[:1000])
except :
print('Error')
都得到我们想要的结果
二、爬取亚马逊实例
import requests
url = "https://www.amazon.cn/dp/B072C ... ot%3B
try:
r = requests.get(url)
print(r.status_code)
print(r.encoding)
print(r.request.headers)
r.encoding = r.apparent_encoding
print(r.text[:5000])
except :
print('Error')
出现了同样的问题。老师在这里解释了。亚马逊也有来源审查。当 headers 参数没有被修改时,程序告诉亚马逊服务器这是对 py requests 库的访问。
所以有一个错误。
2.解决办法
如上,修改user-agent
结果:
还是有问题,下面有提示,
这里提示可能存在cookie相关的问题,所以我们找到网页的cookie,放到headers中
问题成功解决
三、爬取图片
当我们要爬取网页上的图片时,我们应该怎么做。
现在知道网页上的图片链接是格式
url链接以jpg结尾,描述为图片
按照冲天老师的提示写了一段代码
import requests
import os
url='https://ss0.bdstatic.com/70cFu ... 11137,2818876915&fm=26&gp=0.jpg'
root='d:/pics//'
path = root+url.split('/')[-1]
try:
if not os.path.exists(root):
os.makedirs(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已经存在')
except:
print('爬取出错')
这里import os判断文件是否存在
结果上
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-xv0bBm8f-21)(/img/bVbMr7U)]
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-7tOVoMvj-21)(/img/bVbMr7W)]
图片也保存了
IP地址归属地自动查询
实战中遇到了一个小问题
先编码
import requests
url_1 = 'https://www.ip138.com/iplookup ... 39%3B
ip_address = input('Please input your ip address')
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url)
print(r.status_code)
print(r.text[-500:])
except:
print('error')
else:
print('ip address cannot be empty')
然后程序一直报错,于是我把try except模块去掉,看看问题出在哪里。
果然,问题是源审查
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-FF8AqVZd-22)(/img/bVbMr9Y)]
这行错误说明ip138网站应该有source review,所以换个headers里的agent再试一次
修改user-agent参数后,刚好找到一个美国的IP地址,上图成功。
[外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-puo6nDNG-22)(/img/bVbMsaQ)]
import requests
url_1 = 'https://www.ip138.com/iplookup.asp?ip='
ip_address = input('Please input your ip address')
kv={'user-agent':'chrome/5.0'}
url = url_1+ip_address+'&action=2'
if ip_address:
try:
r = requests.get(url,headers=kv)
print(r.status_code)
r.encoding=r.apparent_encoding
print(r.text)
except:
print('error')
else:
print('ip address cannot be empty')
第二周
Beautiful Soup 库1.安装 Beautiful Soup 库
CMD pip install beautifulsoup4
2.请求库获取网页源代码
import requests
r=requests.get("https://python123.io/ws/demo.html";)
print(r.text)
3. bs 库的使用
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-tKeVDKKg-23)(/img/bVbMsca)】
import requests
from bs4 import BeautifulSoup
r = requests.get("https://python123.io/ws/demo.html";)
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
print(soup.prettify())
4. bs 库的基本元素
网页爬虫抓取百度图片(爬虫爬虫知识详细教程(2)-百度图片教程(2))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-22 22:04
网页爬虫抓取百度图片的教程写的挺详细的,我是手写爬虫才把十张图片抓到手里,python爬虫知识详细教程(2)抓取百度图片。
百度图片,联系图片出版社,做成图书,然后销售。
我研究过,好像python做爬虫和分析也不容易,你把开源代码扔过去就会有很多人帮你做的。还有不是自己做的话,自己建个ip池子,每天定时去某个ip的图库里面扒图。
不可以。每个东西都有它的生命周期,爬虫应该只做小规模使用。但凡去查看代码,就会发现,python写爬虫确实有点蛋疼,别说优化爬虫了,更不要说逆向。对于大规模的爬虫,还是推荐用java或者c/c++实现。
等等,爬虫也得有前端啊,
用python写爬虫,
貌似使用python写爬虫出版社会比较欢迎,如果没有支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付费码。 查看全部
网页爬虫抓取百度图片(爬虫爬虫知识详细教程(2)-百度图片教程(2))
网页爬虫抓取百度图片的教程写的挺详细的,我是手写爬虫才把十张图片抓到手里,python爬虫知识详细教程(2)抓取百度图片。
百度图片,联系图片出版社,做成图书,然后销售。
我研究过,好像python做爬虫和分析也不容易,你把开源代码扔过去就会有很多人帮你做的。还有不是自己做的话,自己建个ip池子,每天定时去某个ip的图库里面扒图。
不可以。每个东西都有它的生命周期,爬虫应该只做小规模使用。但凡去查看代码,就会发现,python写爬虫确实有点蛋疼,别说优化爬虫了,更不要说逆向。对于大规模的爬虫,还是推荐用java或者c/c++实现。
等等,爬虫也得有前端啊,
用python写爬虫,
貌似使用python写爬虫出版社会比较欢迎,如果没有支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付宝支付费码。
网页爬虫抓取百度图片(什么是爬虫网络爬虫(.txt)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-22 01:15
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
1import requests<br />2r = requests.get('http://pic37.nipic.com/20140113/8800276_184927469000_2.png')<br />3with open('demo.jpg','wb+') as f:<br />4 f.write(r.content)<br />
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
1{<br />2 “name”: “毛利”,<br />3 “age”: 18,<br />4 “ feature “ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
Python字典
1{<br />2 ‘name’: ‘毛利’,<br />3 ‘age’: 18<br />4 ‘feature’ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”,指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站自动发起了请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
1import requests<br /> 2import json<br /> 3headers = {<br /> 4 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br /> 5r = requests.get('https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).text<br /> 6res = json.loads(r)['data']<br /> 7for index,i in enumerate(res):<br /> 8 url = i['hoverURL']<br /> 9 print(url)<br />10 with open( '{}.jpg'.format(index),'wb+') as f:<br />11 f.write(requests.get(url).content)<br />
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
1https://image.baidu.com/search ... %3Bbr />2https://image.baidu.com/search ... %3Bbr />
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
1# -*- coding:utf-8 -*-<br /> 2# time :2019/6/20 17:07<br /> 3# author: 毛利<br /> 4import requests<br /> 5import json<br /> 6import os<br /> 7def get_pic_url(num):<br /> 8 pic_url= []<br /> 9 headers = {<br />10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br />11 for i in range(num):<br />12<br />13 page_url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i)<br />14 r = requests.get(page_url, headers=headers).text<br />15 res = json.loads(r)['data']<br />16 if res:<br />17 print(res)<br />18 for j in res:<br />19 try:<br />20 url = j['hoverURL']<br />21 pic_url.append(url)<br />22 except:<br />23 print('该图片的url不存在')<br />24<br />25 print(len(pic_url))<br />26 return pic_url<br />27<br />28def down_img(num):<br />29 pic_url =get_pic_url(num)<br />30<br />31 if os.path.exists('D:\图片'):<br />32 pass<br />33 else:<br />34 os.makedirs('D:\图片')<br />35<br />36 path = 'D:\图片\\'<br />37 for index,i in enumerate(pic_url):<br />38 filename = path + str(index) + '.jpg'<br />39 print(filename)<br />40 with open(filename, 'wb+') as f:<br />41 f.write(requests.get(i).content)<br />42if __name__ == '__main__':<br />43 num = int(input('爬取几次图片:一次30张'))<br />44 down_img(num)<br />
爬取过程
抓取结果
文章首次发表于: 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(.txt)(图))
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
1import requests<br />2r = requests.get('http://pic37.nipic.com/20140113/8800276_184927469000_2.png')<br />3with open('demo.jpg','wb+') as f:<br />4 f.write(r.content)<br />
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
1{<br />2 “name”: “毛利”,<br />3 “age”: 18,<br />4 “ feature “ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
Python字典
1{<br />2 ‘name’: ‘毛利’,<br />3 ‘age’: 18<br />4 ‘feature’ : [‘高’, ‘富’, ‘帅’]<br />5}<br />
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”,指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站自动发起了请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
1import requests<br /> 2import json<br /> 3headers = {<br /> 4 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br /> 5r = requests.get('https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).text<br /> 6res = json.loads(r)['data']<br /> 7for index,i in enumerate(res):<br /> 8 url = i['hoverURL']<br /> 9 print(url)<br />10 with open( '{}.jpg'.format(index),'wb+') as f:<br />11 f.write(requests.get(url).content)<br />
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
1https://image.baidu.com/search ... %3Bbr />2https://image.baidu.com/search ... %3Bbr />
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
1# -*- coding:utf-8 -*-<br /> 2# time :2019/6/20 17:07<br /> 3# author: 毛利<br /> 4import requests<br /> 5import json<br /> 6import os<br /> 7def get_pic_url(num):<br /> 8 pic_url= []<br /> 9 headers = {<br />10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}<br />11 for i in range(num):<br />12<br />13 page_url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i)<br />14 r = requests.get(page_url, headers=headers).text<br />15 res = json.loads(r)['data']<br />16 if res:<br />17 print(res)<br />18 for j in res:<br />19 try:<br />20 url = j['hoverURL']<br />21 pic_url.append(url)<br />22 except:<br />23 print('该图片的url不存在')<br />24<br />25 print(len(pic_url))<br />26 return pic_url<br />27<br />28def down_img(num):<br />29 pic_url =get_pic_url(num)<br />30<br />31 if os.path.exists('D:\图片'):<br />32 pass<br />33 else:<br />34 os.makedirs('D:\图片')<br />35<br />36 path = 'D:\图片\\'<br />37 for index,i in enumerate(pic_url):<br />38 filename = path + str(index) + '.jpg'<br />39 print(filename)<br />40 with open(filename, 'wb+') as f:<br />41 f.write(requests.get(i).content)<br />42if __name__ == '__main__':<br />43 num = int(input('爬取几次图片:一次30张'))<br />44 down_img(num)<br />
爬取过程
抓取结果
文章首次发表于:
网页爬虫抓取百度图片(实现百度图片的实现架构(一)_架构_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-22 01:10
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片 查看全部
网页爬虫抓取百度图片(实现百度图片的实现架构(一)_架构_光明网)
免责声明:如需转载本文文章,请私聊并在文章开头注明出处。本代码未经授权不得用于获取商业价值,否则后果自负。
这次的需求大概是从百度图片中抓取任意类别的图片。考虑到有些图片的资源不是很好,而且因为百度搜索越远,相关性就会越来越低,所以我将每个类别的数据量控制在600,实际爬下来,每个类别大约有500张图片。
实现架构
我们来看看这段代码的实现架构:
我们来看看主要的方法:
package mainmethon;
import httpbrowser.CreateUrl;
import savefile.ImageFile;
import java.util.ArrayList;
import java.util.List;
import static java.lang.System.out;
/**
* Created by hg_yi on 17-5-16.
*
* 测试数据:image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=bird&
*
* 在多线程进行下载时,需要向线程中传递参数,此时有三种方法,我选择的第一种,设计构造器
*/
public class major {
public static void main(String[] args) {
int sum = 0;
List urlMains = new ArrayList();
List imageUrls = new ArrayList();
//首先得到10个页面
urlMains = CreateUrl.CreateMainUrl();
out.println(urlMains.size());
for(String urlMain : urlMains) {
out.println(urlMain);
}
//使用Jsoup和FastJson解析出所有的图片源链接
imageUrls = CreateUrl.CreateImageUrl(urlMains);
for(String imageUrl : imageUrls) {
out.println(imageUrl);
}
//先创建出每个图片所属的文件夹
ImageFile.createDir();
int average = imageUrls.size()/10;
//对图片源链接进行下载(使用多线程进行下载)创建进程
for(int i = 0; i < 10; i++){
int begin = sum;
sum += average;
int last = sum;
Thread image = null;
if(i < 9) {
image = new Thread(new ImageFile(begin, last,
(ArrayList) imageUrls));
} else {
image = new Thread(new ImageFile(begin, imageUrls.size(),
(ArrayList) imageUrls));
}
image.start();
}
}
}
main方法中各个方法的解释很清楚,这里就不详细解释了。
记录这段代码的坑
对于这段代码的实现,改bug时间最长的是这段代码:
try {
URL url = new URL(imageUrls.get(i));
URLConnection conn = url.openConnection();
conn.setConnectTimeout(1000);
conn.setReadTimeout(5000);
conn.connect();
inputStream = conn.getInputStream();
} catch (Exception e) {
continue;
}
这段代码的主要目的是下载图片,请求图片的源地址,然后将其作为输入流。在没有进行超时设置和异常处理之前,会出现链接超时和读取超时两个错误。,当时也用httpclient重写,结果还是不对。最后使用了timeout设置,如果超过时间后没有进行url请求,则进行下一个url请求,直接放弃请求。本来打算爬600张图,最后只能爬500张,原因是这样的。
来源链接
使用多线程抓取百度图片
网页爬虫抓取百度图片(怎么使用百度推广数据DIY来采集这些数据?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-20 19:09
)
百度推广相信很多人都在用,但是百度推广后台的搜索词报告无法下载,所以无法做更详细的分析。这里我们可以使用 GooSeeker 的数据 DIY 来抓取整个报告。存储在Excel中,让我们更直观的看到这些数据的显示,下面介绍如何用数据DIY来采集这些数据。
1.吉索客官网有数据diy模块。我们可以进入官网打开,也可以直接使用gooseeker浏览器输入网址打开。
注意:要使用数据DIY,必须使用gooseeker浏览器启动。
2.打开后可以看到很多数据diy分类,选择我们要的分类采集网站,我们要采集作为百度推广背景的key,所以我们要选择分类“SEO优化””。点击选择“SEO优化”分类后,可以在二级分类“百度”中看到你想要的分类采集,点击选择“百度推广搜索关键词 抓取”。
3、选择采集的页面后,需要在下面的输入框中输入网址为采集。输入 URL 的页面结构必须与所选数据 diy 的页面结构一致。,如果我们刚刚选择了“百度推广搜索关键词爬取”,我们需要在输入框中输入百度推广背景的URL。
4、点击获取数据按钮后,页面跳转到会员中心-数据DIY页面,可以看到想要通过数据DIY添加采集的URL页面,点击“开始采集@ >"按钮开始采集我们想要的数据
5、采集完成后,可以点击“查看我的数据”进入DIY数据采集状态,会显示数据的DIY采集状态。采集完成后,可以使用“打包”按钮将采集的数据打包,然后可以在“数据下载”选项卡上下载打包好的数据,下载的数据通过数据DIY可以直接是excel格式,不用转换。
查看全部
网页爬虫抓取百度图片(怎么使用百度推广数据DIY来采集这些数据?(图)
)
百度推广相信很多人都在用,但是百度推广后台的搜索词报告无法下载,所以无法做更详细的分析。这里我们可以使用 GooSeeker 的数据 DIY 来抓取整个报告。存储在Excel中,让我们更直观的看到这些数据的显示,下面介绍如何用数据DIY来采集这些数据。
1.吉索客官网有数据diy模块。我们可以进入官网打开,也可以直接使用gooseeker浏览器输入网址打开。
注意:要使用数据DIY,必须使用gooseeker浏览器启动。
2.打开后可以看到很多数据diy分类,选择我们要的分类采集网站,我们要采集作为百度推广背景的key,所以我们要选择分类“SEO优化””。点击选择“SEO优化”分类后,可以在二级分类“百度”中看到你想要的分类采集,点击选择“百度推广搜索关键词 抓取”。
3、选择采集的页面后,需要在下面的输入框中输入网址为采集。输入 URL 的页面结构必须与所选数据 diy 的页面结构一致。,如果我们刚刚选择了“百度推广搜索关键词爬取”,我们需要在输入框中输入百度推广背景的URL。
4、点击获取数据按钮后,页面跳转到会员中心-数据DIY页面,可以看到想要通过数据DIY添加采集的URL页面,点击“开始采集@ >"按钮开始采集我们想要的数据
5、采集完成后,可以点击“查看我的数据”进入DIY数据采集状态,会显示数据的DIY采集状态。采集完成后,可以使用“打包”按钮将采集的数据打包,然后可以在“数据下载”选项卡上下载打包好的数据,下载的数据通过数据DIY可以直接是excel格式,不用转换。
网页爬虫抓取百度图片( 智联招聘上一线及新一线城市所有与BIM相关的工作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-19 13:07
智联招聘上一线及新一线城市所有与BIM相关的工作)
python简单的网络爬虫获取网页数据
以下是智联招聘一线和新一线城市所有BIM相关岗位信息列表,供数据分析。
1、首先通过chrome搜索智联招聘的BIM职位信息。跳出页面后,ctrl+u查看网页源代码。如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,按关键字过滤文件,找到收录jobs的数据包。
2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL是由
1
2
'' + 请求参数,然后根据格式(
';cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=coster&kt=3')
复制到浏览器访问测试,成功获取对应数据
3、获取到的数据是json格式。首先,格式化数据,分析结构,确定代码中数据的分析方法。
4、明确请求URL和数据结构后,剩下的就是在代码中实现URL构建、数据分析和导出。最终得到1215条数据,需要进一步整理数据进行数据分析。
如无效请留言告知转载请注明原文链接:python爬虫如何抓取网页数据 查看全部
网页爬虫抓取百度图片(
智联招聘上一线及新一线城市所有与BIM相关的工作)
python简单的网络爬虫获取网页数据
以下是智联招聘一线和新一线城市所有BIM相关岗位信息列表,供数据分析。
1、首先通过chrome搜索智联招聘的BIM职位信息。跳出页面后,ctrl+u查看网页源代码。如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,按关键字过滤文件,找到收录jobs的数据包。
2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL是由
1
2
'' + 请求参数,然后根据格式(
';cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=coster&kt=3')
复制到浏览器访问测试,成功获取对应数据
3、获取到的数据是json格式。首先,格式化数据,分析结构,确定代码中数据的分析方法。
4、明确请求URL和数据结构后,剩下的就是在代码中实现URL构建、数据分析和导出。最终得到1215条数据,需要进一步整理数据进行数据分析。
如无效请留言告知转载请注明原文链接:python爬虫如何抓取网页数据
网页爬虫抓取百度图片(图片的批量抓取是爬虫批处理的典型例子,使用Python实现批量获取图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-19 13:06
)
图片批量抓取是爬虫批量处理的典型例子。这里我们使用煎蛋网的美图作为抓图对象,使用Python批量获取图片。
批量爬虫
import urllib.request
import os
import random
# 打开网页
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read()
return html
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
# 找到图片的地址
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs
# 保存图片
def save_imgs(folder,img_addrs):
i = 1
for each in img_addrs:
img = url_open(each)
# pic_name = str(i) + '.jpg'
pic_name = each.split('/')[-1]
with open(pic_name,'wb') as f:
f.write(img)
i += 1
return i
# 下载图片的主函数
def download_pic(folder = 'mm',pages = 10):
os.mkdir(folder)
os.chdir(folder)
count = 0
url = 'http://jandan.net/ooxx'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
count += save_imgs(folder,img_addrs)
print('总共图片数量:%d' %count)
# 主函数入口
if __name__ == '__main__':
download_pic()
批量生成网址
编写爬虫要根据不同的网站改变,观察网站的html结构。以这个网址为例,访问第一页和下一页:
在这里,您可以在 URL 中看到 page-190。根据这个参数可以设置访问不同的网页,即我们通常访问的下一页和上一页。 网站获取不同页面URL(page_url)对应的代码如下:
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
url = 'http://jandan.net/ooxx'
# 获取首页 page_num
page_num = int(get_page(url))
# 根据url格式编辑想要访问页面的url
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
在 HTML 中查找图像的 URL
在每张图片上选择---View Element,查看对应图片的URL在网页的HTML中是什么样子的:
可以看到图片对应的标签是:
我们需要将内容从//剪切成.jpg,代码如下:
# 找到图片的地址,从a开始,到b结束,如果找到,则添加在img_addrs[]的列表中,
# 其中的 a+9 和 b+4 是计算好的偏移量
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
# 从 a 开始往后查找,查找结束位置为 a+255 ,即一个url的长度
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs 查看全部
网页爬虫抓取百度图片(图片的批量抓取是爬虫批处理的典型例子,使用Python实现批量获取图片
)
图片批量抓取是爬虫批量处理的典型例子。这里我们使用煎蛋网的美图作为抓图对象,使用Python批量获取图片。
批量爬虫
import urllib.request
import os
import random
# 打开网页
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read()
return html
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
# 找到图片的地址
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs
# 保存图片
def save_imgs(folder,img_addrs):
i = 1
for each in img_addrs:
img = url_open(each)
# pic_name = str(i) + '.jpg'
pic_name = each.split('/')[-1]
with open(pic_name,'wb') as f:
f.write(img)
i += 1
return i
# 下载图片的主函数
def download_pic(folder = 'mm',pages = 10):
os.mkdir(folder)
os.chdir(folder)
count = 0
url = 'http://jandan.net/ooxx'
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
count += save_imgs(folder,img_addrs)
print('总共图片数量:%d' %count)
# 主函数入口
if __name__ == '__main__':
download_pic()
批量生成网址
编写爬虫要根据不同的网站改变,观察网站的html结构。以这个网址为例,访问第一页和下一页:
在这里,您可以在 URL 中看到 page-190。根据这个参数可以设置访问不同的网页,即我们通常访问的下一页和上一页。 网站获取不同页面URL(page_url)对应的代码如下:
# 找到网页地址
def get_page(url):
html = url_open(url).decode('utf-8')
a = html.find('current-comment-page') + 23
b = html.find(']',a)
print (html[a:b])
return html[a:b]
url = 'http://jandan.net/ooxx'
# 获取首页 page_num
page_num = int(get_page(url))
# 根据url格式编辑想要访问页面的url
for i in range(pages):
page_num -= i
page_url = 'http://jandan.net/ooxx/' + '' + str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
for each in img_addrs:
print(each)
在 HTML 中查找图像的 URL
在每张图片上选择---View Element,查看对应图片的URL在网页的HTML中是什么样子的:
可以看到图片对应的标签是:
我们需要将内容从//剪切成.jpg,代码如下:
# 找到图片的地址,从a开始,到b结束,如果找到,则添加在img_addrs[]的列表中,
# 其中的 a+9 和 b+4 是计算好的偏移量
def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = []
a = html.find('img src=')
while a != -1:
# 从 a 开始往后查找,查找结束位置为 a+255 ,即一个url的长度
b = html.find('.jpg', a , a + 255)
if b != -1:
img_addrs.append('http:' + html[a+9:b+4])
else:
b = a + 9
a = html.find('img src=',b)
return img_addrs
网页爬虫抓取百度图片(网页爬虫抓取百度图片,图片太多太重怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-18 01:03
网页爬虫抓取百度图片,图片太多太重?准备工作:准备一个浏览器,如谷歌浏览器。一个软件,如superagent。一个代理,如代理。一个方法。图片抓取也可以,直接用代理代理,useragent用你这个浏览器的代理即可。代理可以抓取的数据很多,但你最终只能抓取到下载链接,比如免费的,每个链接抓取10个。
你可以看我文章,这个url被抓取几百万个。实际上有几百万图片抓取。所以我来说一个简单的免费下载百度图片的方法。如何抓取更多请关注我的微信公众号【诗白】。
很久之前写过一篇alphago训练计划大概有三种方法爬,第一种是采用谷歌图片搜索爬虫的方法,第二种是metaedjang配合proxies,第三种是proxies+chromedevtool方法一使用谷歌图片搜索爬虫开发软件,第二种则是配合类似《proxylocalizer》的工具,方法三则是使用网页,实际上就是google图片搜索中的图片,可以用百度图片批量下载或者imagejs+imageview来实现图片的批量下载,或者也可以试试proxies+chromedevtool。
关于python爬虫,曾经做过一些具体的系列学习,包括了基本的抓取原理、整体结构,以及爬虫的基本实现方法等。爬虫的基本原理关于python爬虫,可以分为3个部分。1.爬虫核心,使用python的requests库来解析页面并获取返回的url地址,以及tcp/udp协议。2.爬虫目标的爬取规则,一般就是一些爬虫的规则或者爬虫的流程,比如说判断分割哪些页面可以爬取,定义一些规则等等。
3.爬虫的实现,即将规则和爬虫执行过程混合,并处理规则中的内容。爬虫的主要特征1.爬虫遵循自下而上的流程,并且针对所要获取的url返回值返回标签顺序的响应对象。2.爬虫尽可能的保持连接性,没有链接则可以停止响应。3.程序的非结构化非数据,比如图片或者视频。爬虫的原理1.获取url的解析text主要用于解析文本,如何解析一个json对象呢?我们从json数据解析来看看,首先我们要读取一个json数据,作为初始对象。
再读取到我们需要的规则方法,返回我们需要的内容。2.数据的遍历有各种方法,首先是buffer=pickle.loads(json.dumps(path,s)),然后是使用list来遍历。3.要在哪里获取数据呢?在数据处理之前,我们一般需要编写json对象,然后对其处理,并通过stringio、requests等库来获取对应的数据。
接下来通过我们之前写过的python爬虫:认识python爬虫一样,也是一种非结构化的数据处理方法。另外它也不同于json数据的标准,除了url地址之外,还可以传入类型为字符串的参数。目前比较常用的就。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片,图片太多太重怎么办?)
网页爬虫抓取百度图片,图片太多太重?准备工作:准备一个浏览器,如谷歌浏览器。一个软件,如superagent。一个代理,如代理。一个方法。图片抓取也可以,直接用代理代理,useragent用你这个浏览器的代理即可。代理可以抓取的数据很多,但你最终只能抓取到下载链接,比如免费的,每个链接抓取10个。
你可以看我文章,这个url被抓取几百万个。实际上有几百万图片抓取。所以我来说一个简单的免费下载百度图片的方法。如何抓取更多请关注我的微信公众号【诗白】。
很久之前写过一篇alphago训练计划大概有三种方法爬,第一种是采用谷歌图片搜索爬虫的方法,第二种是metaedjang配合proxies,第三种是proxies+chromedevtool方法一使用谷歌图片搜索爬虫开发软件,第二种则是配合类似《proxylocalizer》的工具,方法三则是使用网页,实际上就是google图片搜索中的图片,可以用百度图片批量下载或者imagejs+imageview来实现图片的批量下载,或者也可以试试proxies+chromedevtool。
关于python爬虫,曾经做过一些具体的系列学习,包括了基本的抓取原理、整体结构,以及爬虫的基本实现方法等。爬虫的基本原理关于python爬虫,可以分为3个部分。1.爬虫核心,使用python的requests库来解析页面并获取返回的url地址,以及tcp/udp协议。2.爬虫目标的爬取规则,一般就是一些爬虫的规则或者爬虫的流程,比如说判断分割哪些页面可以爬取,定义一些规则等等。
3.爬虫的实现,即将规则和爬虫执行过程混合,并处理规则中的内容。爬虫的主要特征1.爬虫遵循自下而上的流程,并且针对所要获取的url返回值返回标签顺序的响应对象。2.爬虫尽可能的保持连接性,没有链接则可以停止响应。3.程序的非结构化非数据,比如图片或者视频。爬虫的原理1.获取url的解析text主要用于解析文本,如何解析一个json对象呢?我们从json数据解析来看看,首先我们要读取一个json数据,作为初始对象。
再读取到我们需要的规则方法,返回我们需要的内容。2.数据的遍历有各种方法,首先是buffer=pickle.loads(json.dumps(path,s)),然后是使用list来遍历。3.要在哪里获取数据呢?在数据处理之前,我们一般需要编写json对象,然后对其处理,并通过stringio、requests等库来获取对应的数据。
接下来通过我们之前写过的python爬虫:认识python爬虫一样,也是一种非结构化的数据处理方法。另外它也不同于json数据的标准,除了url地址之外,还可以传入类型为字符串的参数。目前比较常用的就。
网页爬虫抓取百度图片(搜索引擎排名原理分析讲解、基本必学常识SEO学习心态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-18 00:02
一、搜索引擎排名原理解析讲解
没有。一、基本必须学习常识
1.SEO学习心态和方法
2.搜索引擎(百度、谷歌、360、搜狗、爱问、有道、中搜、中国雅虎);搜索引擎蜘蛛(蜘蛛,又称爬虫、机器人,是一套信息抓取系统程序;如百度蜘蛛:Baiduspider,谷歌蜘蛛:Googlebot,360蜘蛛:360Spider,搜狗蜘蛛:搜狗新闻蜘蛛)
3.SEO(搜索引擎优化)
4.关键词:用户在搜索信息、产品或服务时,在搜索引擎界面输入的词。
5.排名(单页参与排名)
二、搜索引擎爬取收录的原理
爬取:(1.爬虫蜘蛛跟随网页中的超链接,发现并采集互联网上的网页信息;2.蜘蛛的爬取方式:深度爬取、广度爬取;3.它不利于蜘蛛识别爬取内容:如JS、图片ALT属性辅助识别、Flash添加文字辅助、层级多的iframe框架、嵌套表格、需要登录信息后的页面)
过滤器:(低质量内容页面:1.采集,低价值;2.不当文字;3.没有丰富内容)
存储索引库:(质量提取和组织信息建立索引库)
显示排序:(1.根据用户输入的查询关键词,检索器可以快速的查出索引库中的文档,对文档和查询进行相关的阅读评价,对结果进行排序待输出,并将查询结果返回给用户;2.当我们在搜索引擎中只看到一个结果时,搜索会在首页的第一位显示某一个关键词根据各种算法)
三、 节日常注意事项
1.已被收录的页面不可随意删除或移动;2.显示结果需要一定的时间(2个月内正常);3.丰富的内容阅读;4. 吸引蜘蛛,比如主动提交给搜索引擎,外部链接吸引蜘蛛;5. 蜘蛛跟踪,网站IIS 日志。
页面摘要 四、
心态:不要试图依赖所谓的捷径;SEO学习需要长期的坚持和努力;不断的努力。
二、建站工具原理详细操作讲解
学习网站构建工具
1、域名:购买和租用年限,名词解析(前缀、后缀:国际通用域名.后三个字母;国家域名.dot.后两个字母。 cn; 国内域名。),购买说明(尽可能简单,知道你在这个域名之前做过什么,搜索顶级域名,查看记录,站长安全联盟,选择常用域名后缀)
2、空间:需购买租用、远程管理(控制面板、FTP远程工具)、常用功能(301重定向、解压/压缩、备份/恢复、服务器日志、自定义页面)、购买注意(速度够快,够稳定,够安全,服务好),选择正规的空间商。
3、 网站建设者(wordprss 博客、discuz 论坛、phpwind 论坛、dedecms织梦cms、empirecmsempirecms、shopex 在线商店, ecshop 网上商店)
4、其他:解析、域名级别(一级域名、二级域名)、归档、类型
三、匹配最快排名的关键词选择
第一个一、基础理论:三大标签(标题、描述、关键词);品牌词
文章二、单核心标题写作
基本思路:
1、标题似乎是一句流畅的句子;
2、关键词 层级,例如:电梯和客梯分别属于上下两层;客梯与货梯为同级关系;需求词是从核心扩展而来的,不是同级关系。如电梯及电梯价格、电梯规格;客梯和客梯价格、客梯安装、客梯维修都是需求词。单核标题最容易排名和争夺符号(核心词+需求词=单核,同级关系,考虑多核);
3、标题和内容的关系;
4、核心关键词+服务内容
选前思考:谁是我的用户?他们会搜索什么字词?(核心关键词+我们的网站服务加上我们的服务,我们的服务就是用户的需求)
标题组合:
1、确定网站核心词(产品/服务);
2、挖掘相关词并过滤(取整);
3、合格的标题组合:关键词1_关键词2_关键词3-品牌词;
4、不错的标题组合,组合成流畅的句子;
5、优秀的标题组合(时间需求,如:最新、2016;信息量大,如:百科;可信度,如:专家、专业;稀缺需求扩展)。标题示例:_长沙网站生产专家-提供网站施工详细报价单。
基本优化:基本优化原则(1、关键词前面的话权重越高,2、字数大于4字,小于32字,标题符号应该是英文);常见错误(1、描述性词语太多;2、标题内容不到位;3、标题多核,设置太多;
修改标题:一次修改很重要
三、 描述(deion)
1、描述捕获和显示;2、描述是标题的扩展(吸引点击);3、60-80字
部分 四、关键词(关键字)
四、创建用户友好的导航和布局
不。一、什么样的网站导航适合用户体验?
不是。二、什么样的网站布局才符合用户体验?
三、网站导航开发部分
1、用户注意事项:简明扼要;容易明白; 多少?
2、 蜘蛛考虑:有利于识别(图形或文字);它有利于爬行(不要使用 JS 调用);符合SEO(level、DIV、不使用table)
编号四、网站布局思路
1、抓问题;2、展示问题;3、需求找难;4、DIV布局代替表格
第一个五、使用地图规划导航(会使用地图布局导航,比如百度脑图、XMind)
五、排名最高网站 内容创作
1)内容你需要知道你需要什么内容网站
2)内容制作
1.判断内容质量的三个维度(搜索引擎维度要内容丰富;用户维度;网页打开速度)
2.内容模板制作(用户想了解这个产品的哪些信息;二次标题策划;内容填充)
3. 内容注释(字体:14字号比较好;颜色;图片优化,一个文章中的图片大小要一样,alt属性文字要和图片相关;模板文本)
4.避免垃圾内容(除非强制,否则不要添加锚文本;字体颜色应相同;除标题大小外,文本大小应相同;文本中不应有广告)
5.内容创作采集(第一步:采集内容;第二步:根据模板整合内容,根据自己设置的标题填写内容;第三步:微调;第四步:差异化体验调整)
3)超牛B的内容创作秘诀(每天坚持做文章,持续更新网站)
六、推进网站排名的内容更新计划
1、关键词挖矿方式
常用方法:百度文库、百度贴吧、百度知道、工具(百度推广后台、金华挖词工具、追词助手)、相关论坛、相关搜索等(客户搜索长尾关键词 成为我们的 文章 标题)
挖掘思想:分割思维
2、内容更新
更新思维:匹配;关联
常用文章:名词解释、常见问题、知识解答、使用说明、季节性、及时性
分类长尾:例:装修包括家装、工装、Q&A、材料等。家装可根据客厅、房间、厨房、浴室进行更新
注意事项:上线是指被百度抓取时在线。上网时,绝对不允许有空页。内容必须是完整的才能上线。文章在线栏数(至少6个以上),新站更新(内容应该每天更新)
3、更新问答:避免重复文章;网站是否需要经常更新(可以找到关键词表示有内容要更新)
七、通用链接规范和链接集中化
一、基本常识小节
(1)权重集中
权重在网站的每个页面上继承。权重越高,关键词的排名就越好,但并不决定排名。
如何提高网站的权重,搜索引擎会使用网站的整体表现:例如网站内容、外链投票、网站结构、网站 >权重、及时性、稀缺资源等综合因素来判断这个重要性,这个重要性称为网站的权重。
(2)http状态码:200正常访问;301永久重定向;404页面未找到,分为不存在页面和人为错误;500服务器内部错误;503服务不可用,服务器临时维护 要么超载,服务器当前无法处理; 505 服务器不支持,或拒绝支持请求中使用的 HTTP 版本
路径标识二、
(1)静态路径是指静态的网站地址,纯静态形式,通常以.html、htm为后缀,以目录结构结尾;特点:完全静态的HTML网页文档,无需其他语言调用或加载,适合企业网站适应企业网站,单页网站等内容较少
(2)动态路径:有一个或多个参数和字符,不是.html .asp .php 等形式,不带后缀
(3)伪静态路径:将原来的动态路径通过技术转化为伪静态
第一个三、的实际链接权重集中
(1)路径优化注意事项:1)建议上线前优化道路强度,收录不建议优化;2)道路强度应不能太长,参数太多;3)卢晋不要太深;4)最好不要出现中文;5)卢晋名字要描述性;6)https是http安全版;7)网址拦截;8)最好每页只留一个链接
(2)优化操作:1)处理有尾,统一路径;2)301重定向(空间控制面板,DNSpod);3)使用工具查看.http状态码
八、学习html代码优化
1、网页标签理解:CSS+DIV标签、class、id标签、A标签、img标签
2、代码优化:图片优化,图片的alt描述,图片大小要一致,图片要清晰,中间不要放水印;标签应整齐;一个标签,站点中的链接建议不要使用nofollow标签,即使使用了,也是用于无意义的链接;h标签,h1代表一个页面的核心;标签整洁,标签越简单,搜索引擎就越容易分析你的网站。
(学习SEO,懂得建站,懂html标签,熟悉程序的基本代码原理。)
九、黄金分割原理操作布局网站
一、网站节结构优化
1)网站结构
1.定义一般认为是根据客户需求分析结果,准确定位网站目标群体,设置网站整体架构规划、设计网站栏目及其内容,制定网站@网站开发流程和顺序,最大限度的设计高效的资源配置和管理;
2.Category:物理结构,一般指虚拟空间中很多目录和文件的层次关系;逻辑结构,网站上线后,我们可以看到网站接口与肉眼链接关系在
3.重要性:网站结构是seo优化过程中不可忽视的一个非常重要的环节;合理的内部链结构和合理的网站布局在网站中可以有效引导蜘蛛爬行;方便搜索引擎更好收录;可以建立良好的用户体验;适当的网站结构优化有利于页面权重的合理分配(一般网站首页权重最高,分类页面次之,但对于电商网站略有不同,专注于产品页面,所有依赖网站的内链都可以很好的将首页的权重传递给其他页面,从而实现权重的整体提升,并最终让更多的长尾词获得好的排名);优化网站结构有利于内部锚文本的构建(通过大量的内部链接,加强相关性)
2)网站结构设计目标
1.明确列结构的上下文,层次清晰明了;2.体现特色,注重特色设计;3.方便用户使用;4.网页功能分布合理;5.扩展性极佳;6.用户反思中网页设计与结构的完美结合;7.对于搜索引擎优化,布局是基于关键词竞争力网站首页
3)网站结构考虑
1.用户体验与优化相结合;2.网站地图、搜索引擎地图、用户地图导航;3.面包屑的使用;4.用户浏览的重点
二、Practice网站 页面的页面布局 查看全部
网页爬虫抓取百度图片(搜索引擎排名原理分析讲解、基本必学常识SEO学习心态)
一、搜索引擎排名原理解析讲解
没有。一、基本必须学习常识
1.SEO学习心态和方法
2.搜索引擎(百度、谷歌、360、搜狗、爱问、有道、中搜、中国雅虎);搜索引擎蜘蛛(蜘蛛,又称爬虫、机器人,是一套信息抓取系统程序;如百度蜘蛛:Baiduspider,谷歌蜘蛛:Googlebot,360蜘蛛:360Spider,搜狗蜘蛛:搜狗新闻蜘蛛)
3.SEO(搜索引擎优化)
4.关键词:用户在搜索信息、产品或服务时,在搜索引擎界面输入的词。
5.排名(单页参与排名)
二、搜索引擎爬取收录的原理
爬取:(1.爬虫蜘蛛跟随网页中的超链接,发现并采集互联网上的网页信息;2.蜘蛛的爬取方式:深度爬取、广度爬取;3.它不利于蜘蛛识别爬取内容:如JS、图片ALT属性辅助识别、Flash添加文字辅助、层级多的iframe框架、嵌套表格、需要登录信息后的页面)
过滤器:(低质量内容页面:1.采集,低价值;2.不当文字;3.没有丰富内容)
存储索引库:(质量提取和组织信息建立索引库)
显示排序:(1.根据用户输入的查询关键词,检索器可以快速的查出索引库中的文档,对文档和查询进行相关的阅读评价,对结果进行排序待输出,并将查询结果返回给用户;2.当我们在搜索引擎中只看到一个结果时,搜索会在首页的第一位显示某一个关键词根据各种算法)
三、 节日常注意事项
1.已被收录的页面不可随意删除或移动;2.显示结果需要一定的时间(2个月内正常);3.丰富的内容阅读;4. 吸引蜘蛛,比如主动提交给搜索引擎,外部链接吸引蜘蛛;5. 蜘蛛跟踪,网站IIS 日志。
页面摘要 四、
心态:不要试图依赖所谓的捷径;SEO学习需要长期的坚持和努力;不断的努力。
二、建站工具原理详细操作讲解
学习网站构建工具
1、域名:购买和租用年限,名词解析(前缀、后缀:国际通用域名.后三个字母;国家域名.dot.后两个字母。 cn; 国内域名。),购买说明(尽可能简单,知道你在这个域名之前做过什么,搜索顶级域名,查看记录,站长安全联盟,选择常用域名后缀)
2、空间:需购买租用、远程管理(控制面板、FTP远程工具)、常用功能(301重定向、解压/压缩、备份/恢复、服务器日志、自定义页面)、购买注意(速度够快,够稳定,够安全,服务好),选择正规的空间商。
3、 网站建设者(wordprss 博客、discuz 论坛、phpwind 论坛、dedecms织梦cms、empirecmsempirecms、shopex 在线商店, ecshop 网上商店)
4、其他:解析、域名级别(一级域名、二级域名)、归档、类型
三、匹配最快排名的关键词选择
第一个一、基础理论:三大标签(标题、描述、关键词);品牌词
文章二、单核心标题写作
基本思路:
1、标题似乎是一句流畅的句子;
2、关键词 层级,例如:电梯和客梯分别属于上下两层;客梯与货梯为同级关系;需求词是从核心扩展而来的,不是同级关系。如电梯及电梯价格、电梯规格;客梯和客梯价格、客梯安装、客梯维修都是需求词。单核标题最容易排名和争夺符号(核心词+需求词=单核,同级关系,考虑多核);
3、标题和内容的关系;
4、核心关键词+服务内容
选前思考:谁是我的用户?他们会搜索什么字词?(核心关键词+我们的网站服务加上我们的服务,我们的服务就是用户的需求)
标题组合:
1、确定网站核心词(产品/服务);
2、挖掘相关词并过滤(取整);
3、合格的标题组合:关键词1_关键词2_关键词3-品牌词;
4、不错的标题组合,组合成流畅的句子;
5、优秀的标题组合(时间需求,如:最新、2016;信息量大,如:百科;可信度,如:专家、专业;稀缺需求扩展)。标题示例:_长沙网站生产专家-提供网站施工详细报价单。
基本优化:基本优化原则(1、关键词前面的话权重越高,2、字数大于4字,小于32字,标题符号应该是英文);常见错误(1、描述性词语太多;2、标题内容不到位;3、标题多核,设置太多;
修改标题:一次修改很重要
三、 描述(deion)
1、描述捕获和显示;2、描述是标题的扩展(吸引点击);3、60-80字
部分 四、关键词(关键字)
四、创建用户友好的导航和布局
不。一、什么样的网站导航适合用户体验?
不是。二、什么样的网站布局才符合用户体验?
三、网站导航开发部分
1、用户注意事项:简明扼要;容易明白; 多少?
2、 蜘蛛考虑:有利于识别(图形或文字);它有利于爬行(不要使用 JS 调用);符合SEO(level、DIV、不使用table)
编号四、网站布局思路
1、抓问题;2、展示问题;3、需求找难;4、DIV布局代替表格
第一个五、使用地图规划导航(会使用地图布局导航,比如百度脑图、XMind)
五、排名最高网站 内容创作
1)内容你需要知道你需要什么内容网站
2)内容制作
1.判断内容质量的三个维度(搜索引擎维度要内容丰富;用户维度;网页打开速度)
2.内容模板制作(用户想了解这个产品的哪些信息;二次标题策划;内容填充)
3. 内容注释(字体:14字号比较好;颜色;图片优化,一个文章中的图片大小要一样,alt属性文字要和图片相关;模板文本)
4.避免垃圾内容(除非强制,否则不要添加锚文本;字体颜色应相同;除标题大小外,文本大小应相同;文本中不应有广告)
5.内容创作采集(第一步:采集内容;第二步:根据模板整合内容,根据自己设置的标题填写内容;第三步:微调;第四步:差异化体验调整)
3)超牛B的内容创作秘诀(每天坚持做文章,持续更新网站)
六、推进网站排名的内容更新计划
1、关键词挖矿方式
常用方法:百度文库、百度贴吧、百度知道、工具(百度推广后台、金华挖词工具、追词助手)、相关论坛、相关搜索等(客户搜索长尾关键词 成为我们的 文章 标题)
挖掘思想:分割思维
2、内容更新
更新思维:匹配;关联
常用文章:名词解释、常见问题、知识解答、使用说明、季节性、及时性
分类长尾:例:装修包括家装、工装、Q&A、材料等。家装可根据客厅、房间、厨房、浴室进行更新
注意事项:上线是指被百度抓取时在线。上网时,绝对不允许有空页。内容必须是完整的才能上线。文章在线栏数(至少6个以上),新站更新(内容应该每天更新)
3、更新问答:避免重复文章;网站是否需要经常更新(可以找到关键词表示有内容要更新)
七、通用链接规范和链接集中化
一、基本常识小节
(1)权重集中
权重在网站的每个页面上继承。权重越高,关键词的排名就越好,但并不决定排名。
如何提高网站的权重,搜索引擎会使用网站的整体表现:例如网站内容、外链投票、网站结构、网站 >权重、及时性、稀缺资源等综合因素来判断这个重要性,这个重要性称为网站的权重。
(2)http状态码:200正常访问;301永久重定向;404页面未找到,分为不存在页面和人为错误;500服务器内部错误;503服务不可用,服务器临时维护 要么超载,服务器当前无法处理; 505 服务器不支持,或拒绝支持请求中使用的 HTTP 版本
路径标识二、
(1)静态路径是指静态的网站地址,纯静态形式,通常以.html、htm为后缀,以目录结构结尾;特点:完全静态的HTML网页文档,无需其他语言调用或加载,适合企业网站适应企业网站,单页网站等内容较少
(2)动态路径:有一个或多个参数和字符,不是.html .asp .php 等形式,不带后缀
(3)伪静态路径:将原来的动态路径通过技术转化为伪静态
第一个三、的实际链接权重集中
(1)路径优化注意事项:1)建议上线前优化道路强度,收录不建议优化;2)道路强度应不能太长,参数太多;3)卢晋不要太深;4)最好不要出现中文;5)卢晋名字要描述性;6)https是http安全版;7)网址拦截;8)最好每页只留一个链接
(2)优化操作:1)处理有尾,统一路径;2)301重定向(空间控制面板,DNSpod);3)使用工具查看.http状态码
八、学习html代码优化
1、网页标签理解:CSS+DIV标签、class、id标签、A标签、img标签
2、代码优化:图片优化,图片的alt描述,图片大小要一致,图片要清晰,中间不要放水印;标签应整齐;一个标签,站点中的链接建议不要使用nofollow标签,即使使用了,也是用于无意义的链接;h标签,h1代表一个页面的核心;标签整洁,标签越简单,搜索引擎就越容易分析你的网站。
(学习SEO,懂得建站,懂html标签,熟悉程序的基本代码原理。)
九、黄金分割原理操作布局网站
一、网站节结构优化
1)网站结构
1.定义一般认为是根据客户需求分析结果,准确定位网站目标群体,设置网站整体架构规划、设计网站栏目及其内容,制定网站@网站开发流程和顺序,最大限度的设计高效的资源配置和管理;
2.Category:物理结构,一般指虚拟空间中很多目录和文件的层次关系;逻辑结构,网站上线后,我们可以看到网站接口与肉眼链接关系在
3.重要性:网站结构是seo优化过程中不可忽视的一个非常重要的环节;合理的内部链结构和合理的网站布局在网站中可以有效引导蜘蛛爬行;方便搜索引擎更好收录;可以建立良好的用户体验;适当的网站结构优化有利于页面权重的合理分配(一般网站首页权重最高,分类页面次之,但对于电商网站略有不同,专注于产品页面,所有依赖网站的内链都可以很好的将首页的权重传递给其他页面,从而实现权重的整体提升,并最终让更多的长尾词获得好的排名);优化网站结构有利于内部锚文本的构建(通过大量的内部链接,加强相关性)
2)网站结构设计目标
1.明确列结构的上下文,层次清晰明了;2.体现特色,注重特色设计;3.方便用户使用;4.网页功能分布合理;5.扩展性极佳;6.用户反思中网页设计与结构的完美结合;7.对于搜索引擎优化,布局是基于关键词竞争力网站首页
3)网站结构考虑
1.用户体验与优化相结合;2.网站地图、搜索引擎地图、用户地图导航;3.面包屑的使用;4.用户浏览的重点
二、Practice网站 页面的页面布局
网页爬虫抓取百度图片(500多张美图实战代码1.导入本次需要的模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2022-03-16 17:17
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是就用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹,将其保存到计算机。. 这个女孩的主页/boards/favorite/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:
Paste_Image.png
Paste_Image.png
2:运行环境 3:实例分析
1.我开始这个爬虫的思路是:进入这个网页/boards/favorite/beauty,获取图片栏目对应的所有url,然后进入每个网页获取所有图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时已经是下午1点30分了,所以第二天又做了一个版本:on this在此基础上,进入每个A网页对应一个缩略图,然后抓取一张像下图这样的高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……
4.下面的代码是解析主页面/boards/favorite/beauty/然后得到每列的URL和名称。使用xpath获取栏目网页时,进入网页开发者模式后,如图所示。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。
Paste_Image.png
5.栏目网页和栏目名称之前已经获取过。这里我们需要分析一下专栏的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。这里还有一个比较棘手的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做
这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2
本地创建文件夹,使用filename = 'image\{}\'.format(fileName) + str(i) + '.jpg' 表示该文件与爬虫代码保存在同一目录image,然后获取到的image根据之前得到的列名保存在image文件夹中。
五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。 查看全部
网页爬虫抓取百度图片(500多张美图实战代码1.导入本次需要的模块)
一、简介
滴滴,请刷卡上车。昨天看到一个不错的图片分享网站——Petal,里面的图片质量还不错,于是就用selenium+xpath爬下了它妹的专栏,并以图片专栏的名字命名文件夹,将其保存到计算机。. 这个女孩的主页/boards/favorite/beauty 是动态加载的。如果想要获取更多的内容,可以模拟一个下拉,这样就可以获得更多的图片资源。这个之前在爬虫里做过,但是因为网速不够快,抓了19个栏目,一共500多张美图,很满意。
先看效果:
Paste_Image.png
Paste_Image.png
2:运行环境 3:实例分析
1.我开始这个爬虫的思路是:进入这个网页/boards/favorite/beauty,获取图片栏目对应的所有url,然后进入每个网页获取所有图片。(如下所示)
Paste_Image.png
Paste_Image.png
2. 但是爬取得到的图片分辨率是236x354,画质不够高,不过当时已经是下午1点30分了,所以第二天又做了一个版本:on this在此基础上,进入每个A网页对应一个缩略图,然后抓取一张像下图这样的高清图片。
Paste_Image.png
四:实战代码
1.第一步,导入本爬虫所需的模块
2.下面是设置webdriver的类型,即用什么浏览器进行仿真,可以用火狐查看仿真过程,也可以用PhantomJS,无头浏览器,快速获取资源,['- -load-images =false', '--disk-cache=true'] 这表示模拟浏览时不加载图片和缓存,所以运行速度会更快。WebDriverWait表示浏览器加载的最大等待时间为10秒,set_window_size可以设置模拟网页的大小。如果大小不合适,则不会加载某些 网站 资源。
3.parser(url, param) 这个函数是用来解析网页的,这些代码后面会用到几次,所以直接写一个函数会让代码看起来更整洁有序。该函数有两个参数:一个是URL,另一个是显式等待表示的部分,可以是网页中的一些版块、按钮、图片等……
4.下面的代码是解析主页面/boards/favorite/beauty/然后得到每列的URL和名称。使用xpath获取栏目网页时,进入网页开发者模式后,如图所示。之后,需要使用列名在电脑中创建一个文件夹,所以需要在这个网页中获取列名。这里有一个问题。一些不符合文件命名规则的名称需要剔除。我在这里有*影响。
Paste_Image.png
5.栏目网页和栏目名称之前已经获取过。这里我们需要分析一下专栏的网页。进入专栏的网页后,只有一些缩略图。我们不要这些低分辨率的图片,所以需要重新输入。在每个缩略图中,解析网页以获得真正的高清图像 URL。这里还有一个比较棘手的地方,就是在一个列中,不同的图片以不同的DOM格式存储,所以我这样做
这样就得到了两种 DOM 格式的图片地址,然后合并了两个地址列表。img_url +=img_url2
本地创建文件夹,使用filename = 'image\{}\'.format(fileName) + str(i) + '.jpg' 表示该文件与爬虫代码保存在同一目录image,然后获取到的image根据之前得到的列名保存在image文件夹中。
五:总结
这一次,爬虫继续练习使用 Selenium 和 xpath。在网页分析中也遇到了很多问题。只有不断地练习,才不会部分减少。当然,这次爬到了500多篇妹纸,还是挺吸睛的。
网页爬虫抓取百度图片(网页爬虫抓取百度图片需要掌握常用的几种抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-16 14:04
网页爬虫抓取百度图片需要掌握网页爬虫常用的几种抓取方法主要分为get,post,put,delete(当然,还有xpath中的解析和trim)三个方法第一种:get(url)传入url,分析页面结构,可能需要处理中文问题;第二种:post(url)传入url,代替post方法,参数很多;第三种:put(url)传入url,可能加一些形容词,比如标题(article/orpage/album)和属性(author/id/language/email/text/string):第四种:delete(url)传入url,代替put方法,参数很多,直接提取数据。
从上到下,因为传入参数不多,post和get适合反爬,put最简单post大致有两种思路:把网页js逻辑写到前端代码,把网页js逻辑写到php代码,依此就是反爬。post的参数也一定要加一个文本标识,来表示参数值。代码中我提供的是我开发出来的爬虫,会用到一些基础的库和ca证书(这个知识点,可以在加入ca后来查看,如何实现所有证书绑定)。
补充一个:@晃儿飘醒醒:post(url,authorization)其实是同一个参数,只是有多种规格,他返回的内容是你发送的这个网址上的所有id对应的所有authorization,在爬虫这块,使用这个方法的话,一定要先了解下xpath,post一般比较少用到xpath。参考:一般国内爬虫都有提供ca证书,如果你的服务器禁止国内ca,可以发post但是爬取不了。只能使用ca代理。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片需要掌握常用的几种抓取方法)
网页爬虫抓取百度图片需要掌握网页爬虫常用的几种抓取方法主要分为get,post,put,delete(当然,还有xpath中的解析和trim)三个方法第一种:get(url)传入url,分析页面结构,可能需要处理中文问题;第二种:post(url)传入url,代替post方法,参数很多;第三种:put(url)传入url,可能加一些形容词,比如标题(article/orpage/album)和属性(author/id/language/email/text/string):第四种:delete(url)传入url,代替put方法,参数很多,直接提取数据。
从上到下,因为传入参数不多,post和get适合反爬,put最简单post大致有两种思路:把网页js逻辑写到前端代码,把网页js逻辑写到php代码,依此就是反爬。post的参数也一定要加一个文本标识,来表示参数值。代码中我提供的是我开发出来的爬虫,会用到一些基础的库和ca证书(这个知识点,可以在加入ca后来查看,如何实现所有证书绑定)。
补充一个:@晃儿飘醒醒:post(url,authorization)其实是同一个参数,只是有多种规格,他返回的内容是你发送的这个网址上的所有id对应的所有authorization,在爬虫这块,使用这个方法的话,一定要先了解下xpath,post一般比较少用到xpath。参考:一般国内爬虫都有提供ca证书,如果你的服务器禁止国内ca,可以发post但是爬取不了。只能使用ca代理。
网页爬虫抓取百度图片(什么是爬虫爬虫,即网络上爬行的一直蜘蛛?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-15 22:06
爬虫基础 了解什么是爬虫
爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一张大网,爬虫就是在这张网上四处爬行的蜘蛛。如果遇到资源,就会被抢。你想抢什么?由你来控制它。
例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。这样一来,整个互联网络对这只蜘蛛来说触手可及,分分钟爬下来也不是问题。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求,服务器解析后向用户浏览器发送HTML、JS、CSS等文件。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。第二部分是存储资源的主机的 IP 地址(有时是端口号)。第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫的学习很有帮助。
环境配置
学习Python当然少不了环境的配置。一开始我用的是Notepad++,但是发现它的提示功能太弱了,所以我用的是Windows下的PyCharm,Linux下的Eclipse for Python,还有几个优秀的IDE,可以参考这个文章IDE推荐用于学习 Python。好的开发工具是进步的动力,希望你能找到适合自己的IDE 查看全部
网页爬虫抓取百度图片(什么是爬虫爬虫,即网络上爬行的一直蜘蛛?)
爬虫基础 了解什么是爬虫
爬虫,即网络爬虫,可以理解为在互联网上爬行的蜘蛛。互联网就像一张大网,爬虫就是在这张网上四处爬行的蜘蛛。如果遇到资源,就会被抢。你想抢什么?由你来控制它。
例如,它正在抓取网页。在这个网页中,它找到了一条路,这条路实际上是一个指向网页的超链接。然后它可以爬到另一个网站来获取数据。这样一来,整个互联网络对这只蜘蛛来说触手可及,分分钟爬下来也不是问题。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,这个过程其实就是用户输入网址后,经过DNS服务器,找到服务器主机, 向服务器发送请求,服务器解析后向用户浏览器发送HTML、JS、CSS等文件。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
第一部分是协议(或服务模式)。第二部分是存储资源的主机的 IP 地址(有时是端口号)。第三部分是宿主资源的具体地址,如目录、文件名等。
爬虫爬取数据时,必须有目标URL才能获取数据。因此,它是爬虫获取数据的基本依据。准确理解其含义对爬虫的学习很有帮助。
环境配置
学习Python当然少不了环境的配置。一开始我用的是Notepad++,但是发现它的提示功能太弱了,所以我用的是Windows下的PyCharm,Linux下的Eclipse for Python,还有几个优秀的IDE,可以参考这个文章IDE推荐用于学习 Python。好的开发工具是进步的动力,希望你能找到适合自己的IDE
网页爬虫抓取百度图片(怎么保证爬虫程序的正常运行并且高效抓取数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-15 12:08
爬虫程序本身必须在合规范围内进行,不能影响被访问服务器的正常运行,更不能将爬取的信息用于其他目的。这是首先需要明确的一点,然后是如何保证爬虫。程序的正常运行和数据的高效抓取呢?
1、代理ip的巧妙使用
<p>一般来说,网站服务器是根据代理ip来检测是否是爬虫。如果网站检测到同一个代理ip频繁发送给 查看全部
网页爬虫抓取百度图片(怎么保证爬虫程序的正常运行并且高效抓取数据呢?)
爬虫程序本身必须在合规范围内进行,不能影响被访问服务器的正常运行,更不能将爬取的信息用于其他目的。这是首先需要明确的一点,然后是如何保证爬虫。程序的正常运行和数据的高效抓取呢?
1、代理ip的巧妙使用
<p>一般来说,网站服务器是根据代理ip来检测是否是爬虫。如果网站检测到同一个代理ip频繁发送给
网页爬虫抓取百度图片( 百度搜索引擎蜘蛛爬虫原理及算法解读(广州seo小包))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-15 11:18
百度搜索引擎蜘蛛爬虫原理及算法解读(广州seo小包))
作为一个seoer,既然是搞SEO网站优化的,那你一定要了解百度搜索引擎蜘蛛爬虫的原理和算法,这对于seo网站优化来说是最重要的,如果你不懂的话'不了解搜索引擎蜘蛛爬虫的原理和算法,seo网站无法优化。下面广州seo包带你了解一下:
首先我们要明白:网站和搜索引擎是什么关系?
网站与搜索引擎的关系:良性共生。搜索引擎内容由各种网站发布,进而获取信息。(去各个网站抓取内容,过滤信息,去收录搜索引擎平台,然后排序)
那么我们直接解释一下百度爬虫的原理:
百度蜘蛛爬取原理是什么以及百度爬虫算法解读
首先我们来了解一下百度蜘蛛爬虫的原理,分为爬取信息-过滤信息-收录信息-排序信息)接下来我们将一一讲解原理和算法解读。
百度蜘蛛爬虫爬取原理
1.首先了解三大引擎蜘蛛的名称:百度蜘蛛爬虫:Baiduspider、谷歌蜘蛛爬虫:谷歌机器人、360蜘蛛爬虫:360spider
2.百度蜘蛛爬虫是怎么爬的网站?:
二.百度蜘蛛爬虫会过滤掉的信息
1.那么首先我们要明白百度蜘蛛爬虫会过滤掉垃圾邮件:
A. 低质量页面(对用户毫无价值的页面) B. 该页面对其他页面过于熟悉
C. 空白页。D.内容无关(标题与内容不一致) E.占用存储空间
2.百度蜘蛛爬虫会过滤掉无法识别的,包括:
三.百度蜘蛛网收录资讯
百度蜘蛛爬虫收录(百度快照):只提交优质页面和有价值的内容信息构建索引库,发布快战:
今天的章节《百度蜘蛛爬网原理?以及百度爬虫算法解读》广州seo包就到这里了。百度蜘蛛爬取原理和算法解读是每个seoer必须了解的基础。每个人都必须注意它。我希望每个人都能真正学习和使用它。你自己的 网站 可以帮助每个人。
如果您有任何问题,可以在下方评论,广州SEO包会及时为您解答。了解更多SEO优化知识,请关注广州SEO包。 查看全部
网页爬虫抓取百度图片(
百度搜索引擎蜘蛛爬虫原理及算法解读(广州seo小包))
作为一个seoer,既然是搞SEO网站优化的,那你一定要了解百度搜索引擎蜘蛛爬虫的原理和算法,这对于seo网站优化来说是最重要的,如果你不懂的话'不了解搜索引擎蜘蛛爬虫的原理和算法,seo网站无法优化。下面广州seo包带你了解一下:
https://www.seo023.org/wp-cont ... 6.png 300w" />首先我们要明白:网站和搜索引擎是什么关系?
网站与搜索引擎的关系:良性共生。搜索引擎内容由各种网站发布,进而获取信息。(去各个网站抓取内容,过滤信息,去收录搜索引擎平台,然后排序)
那么我们直接解释一下百度爬虫的原理:
百度蜘蛛爬取原理是什么以及百度爬虫算法解读
首先我们来了解一下百度蜘蛛爬虫的原理,分为爬取信息-过滤信息-收录信息-排序信息)接下来我们将一一讲解原理和算法解读。
百度蜘蛛爬虫爬取原理
1.首先了解三大引擎蜘蛛的名称:百度蜘蛛爬虫:Baiduspider、谷歌蜘蛛爬虫:谷歌机器人、360蜘蛛爬虫:360spider
2.百度蜘蛛爬虫是怎么爬的网站?:
二.百度蜘蛛爬虫会过滤掉的信息
1.那么首先我们要明白百度蜘蛛爬虫会过滤掉垃圾邮件:
A. 低质量页面(对用户毫无价值的页面) B. 该页面对其他页面过于熟悉
C. 空白页。D.内容无关(标题与内容不一致) E.占用存储空间
2.百度蜘蛛爬虫会过滤掉无法识别的,包括:
三.百度蜘蛛网收录资讯
百度蜘蛛爬虫收录(百度快照):只提交优质页面和有价值的内容信息构建索引库,发布快战:
今天的章节《百度蜘蛛爬网原理?以及百度爬虫算法解读》广州seo包就到这里了。百度蜘蛛爬取原理和算法解读是每个seoer必须了解的基础。每个人都必须注意它。我希望每个人都能真正学习和使用它。你自己的 网站 可以帮助每个人。
如果您有任何问题,可以在下方评论,广州SEO包会及时为您解答。了解更多SEO优化知识,请关注广州SEO包。
网页爬虫抓取百度图片(X图片网站--网络请求模块requestsPython中的大量开源模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-15 11:17
X图网站----前言
这个文章爬取网站已经过期了,具体代码可以从橡皮擦获取。建议直接看第三篇博客
所有与 网站 相关的链接全部被 X 替换。如果需要确定URL,可以参考URL获取
从今天开始,我就撸起袖子,直接写Python爬虫。学习语言的最好方法是有目的地去做。所以,我会用10+篇博客来写爬图。希望可以做到。
为了编写爬虫,我们需要准备一个火狐浏览器,还需要准备一个抓包工具和一个抓包工具。我用的是CentOS自带的tcpdump,加上wireshark,这两个软件的安装和使用,建议大家还是学习一下,以后应该会用到。
X图网站----网络请求模块请求
Python 中的大量开源模块使编码变得非常简单。在编写爬虫时,我们需要了解的第一个模块是请求。
X图片网站----安装请求
打开终端:使用命令
pip3 安装请求
等待安装完成即可使用
接下来在终端中输入以下命令
# mkdir demo
# cd demo
# touch down.py
上面的linux命令是创建一个名为demo的文件夹 查看全部
网页爬虫抓取百度图片(X图片网站--网络请求模块requestsPython中的大量开源模块)
X图网站----前言
这个文章爬取网站已经过期了,具体代码可以从橡皮擦获取。建议直接看第三篇博客
所有与 网站 相关的链接全部被 X 替换。如果需要确定URL,可以参考URL获取
从今天开始,我就撸起袖子,直接写Python爬虫。学习语言的最好方法是有目的地去做。所以,我会用10+篇博客来写爬图。希望可以做到。
为了编写爬虫,我们需要准备一个火狐浏览器,还需要准备一个抓包工具和一个抓包工具。我用的是CentOS自带的tcpdump,加上wireshark,这两个软件的安装和使用,建议大家还是学习一下,以后应该会用到。
X图网站----网络请求模块请求
Python 中的大量开源模块使编码变得非常简单。在编写爬虫时,我们需要了解的第一个模块是请求。
X图片网站----安装请求
打开终端:使用命令
pip3 安装请求
等待安装完成即可使用
接下来在终端中输入以下命令
# mkdir demo
# cd demo
# touch down.py
上面的linux命令是创建一个名为demo的文件夹

