
网页爬虫抓取百度图片
网页爬虫抓取百度图片( 网站怎么做SEO关键词-如何分类网站优化关键词、方法和优化技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-26 15:18
网站怎么做SEO关键词-如何分类网站优化关键词、方法和优化技巧)
百度 收录 请求 - 为什么百度没有索引您的 网站
网站添加阿里妈妈广告导致百度收录少或没有收录!如果一定要改程序,建议你彻底关闭网站1个月后再重新上传你的程序,这样百度会认为你是新站点,网站会容易很多@收录。因为cn域名比较便宜,很多人用cn域名做垃圾邮件网站,影响百度很多cn自有网页收录少或没有收录!...
网站如何做SEO关键词-如何分类网站优化关键词,方法和优化技巧!
今天就和大家聊聊网站、网站关键词分类优化中最重要的一项。那么接下来就讲讲网站优化关键词的分类方法、优化技巧!那么网站关键词怎么分类呢?4、brands关键词:一般设置在每页标题的最后,是网站关键词的唯一性,也是常见的建立品牌的方式品牌。2、根据网站优化:关键词大致可以分为核心词、需求词、品牌词。网站关键词有哪些优化技巧...
什么是 SEO 内部链接和外部链接 - 外部链接和内部链接有什么区别?
什么是外部链接?例如,百度是一个常见的外部链接。什么是内部链接?面比较重要,可以先抓收录。有了内部链接和外部链接的解释,您已经知道了外部链接和内部链接的区别。垃圾网站你也投票,那你的投票权就会越来越小。做外链和内链需要注意什么?所以一个好的网站必须有很多外部链接。没有投票,所以你在论坛上发帖是没有用的。快速增长或快速...
SEO优化的优势——SEO优化和SEM竞价的优缺点和区别
PPC的优缺点:搜索引擎优化的优缺点:1、价格低,网站维持排名一年的成本可能只做一到两个月,竞价是比较便宜很多。3、手机、MP3等难以区分和竞争关键词,排名难优化,时间长,价格高,太难的话不适合优化。通过对以上优缺点的总结和分析,网站优化的整体效果远胜于竞品排名,价格也优于竞品…… 查看全部
网页爬虫抓取百度图片(
网站怎么做SEO关键词-如何分类网站优化关键词、方法和优化技巧)

百度 收录 请求 - 为什么百度没有索引您的 网站
网站添加阿里妈妈广告导致百度收录少或没有收录!如果一定要改程序,建议你彻底关闭网站1个月后再重新上传你的程序,这样百度会认为你是新站点,网站会容易很多@收录。因为cn域名比较便宜,很多人用cn域名做垃圾邮件网站,影响百度很多cn自有网页收录少或没有收录!...

网站如何做SEO关键词-如何分类网站优化关键词,方法和优化技巧!
今天就和大家聊聊网站、网站关键词分类优化中最重要的一项。那么接下来就讲讲网站优化关键词的分类方法、优化技巧!那么网站关键词怎么分类呢?4、brands关键词:一般设置在每页标题的最后,是网站关键词的唯一性,也是常见的建立品牌的方式品牌。2、根据网站优化:关键词大致可以分为核心词、需求词、品牌词。网站关键词有哪些优化技巧...
什么是 SEO 内部链接和外部链接 - 外部链接和内部链接有什么区别?
什么是外部链接?例如,百度是一个常见的外部链接。什么是内部链接?面比较重要,可以先抓收录。有了内部链接和外部链接的解释,您已经知道了外部链接和内部链接的区别。垃圾网站你也投票,那你的投票权就会越来越小。做外链和内链需要注意什么?所以一个好的网站必须有很多外部链接。没有投票,所以你在论坛上发帖是没有用的。快速增长或快速...

SEO优化的优势——SEO优化和SEM竞价的优缺点和区别
PPC的优缺点:搜索引擎优化的优缺点:1、价格低,网站维持排名一年的成本可能只做一到两个月,竞价是比较便宜很多。3、手机、MP3等难以区分和竞争关键词,排名难优化,时间长,价格高,太难的话不适合优化。通过对以上优缺点的总结和分析,网站优化的整体效果远胜于竞品排名,价格也优于竞品……
网页爬虫抓取百度图片(爬虫项目学习之爬取地址特点通过右键的分析方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2022-02-26 10:23
1、总结
目的:学习爬虫项目,使用requests方法爬取百度贴吧美容吧每篇帖子的图片,并保存在本地。
方法:首先通过requests请求美容吧网页的内容;二、通过xpath方法清理数据,获取每个post的url地址;再次请求每个帖子的地址,从每个帖子地址爬取图片链接;最后,请求图像数据并将数据以二进制格式保存在本地。
2、网页分析
如下图,这是本次爬取的目标网站,百度美吧,要求:爬取每个帖子里的图片,保存到本地。爬取网站首先需要分析网站的特征。需要分析的内容包括:网站页面的特征、post url地址的特征、图片链接地址的获取方式。以下是我需要分析的内容:
2.1 美容吧网页特色
美容棒:%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0
观察可以看出kw为搜索内容,pn为页码,第一页为0,第二页为50,所以页码的公式为pn=(页数-1)*50。
2.2 Post url 地址功能
通过右键-勾选,可以查看网页的源代码信息,从中我们可以定位到每个帖子的代码,如下图:
可以看到,点击“我真的很漂亮”的帖子,定位到代码,可见帖子的url地址在这段代码中;然后点击href =p/6593341944,发现跳转到帖子“我真的很漂亮”太漂亮了,此时的url地址是:,所以可以发现帖子的地址主要是由两部分组成:+href的内容,所以我们只需要爬取href =p/6593341944的内容,然后拼接,就可以得到每个帖子的地址。
通过xpath_help工具,写: //div[@class="threadlist_title pull_left j_th_tit "]/a/@href 得到每个url地址的一部分。
2.3 获取帖子的图片链接
获取每个帖子的链接,通过类似操作找到帖子中图片的链接地址,如下图定位到图片的链接
同理,通过xpath_help匹配图片链接,代码为://img[@class="BDE_Image"]/@src
3、程序代码:
# -*- 编码:utf-8 -*-import requestsfrom lxml import etreeimport os#爬虫类BtcSpider(object):def __init__(self):#爬取美女图片#解析:美妆吧url地址,pn值决定页码, pn = 0 第一页, pn = 50 第二页...self.url = '%E7%BE%8E%E5%A5%B3&ie=utf-8&pn={}'self.headers = { ' User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',}os.makedirs('美颜图片',exist_ok=True)self.dir = '美颜图片\\'#发送请求def get_response(self,url):response = requests.get(url,headers = self.headers)data = response.textreturn data#发送请求获取网页数据,数据以二进制内容形式读取 def get_data(self,url) :data = requests.get(url,headers = self.headers).contentreturn data#parse data, 封装 xpathdef get_xpath(self,html,pattern):#build tree p = etree.HTML(html)#解析网页内容,获取url_listsresult = p.xpath(pattern)return result#下载图片 &def download_src(self,url):html = self.get_response(url)html = html.replace ("
内容 查看全部
网页爬虫抓取百度图片(爬虫项目学习之爬取地址特点通过右键的分析方法(图))
1、总结
目的:学习爬虫项目,使用requests方法爬取百度贴吧美容吧每篇帖子的图片,并保存在本地。
方法:首先通过requests请求美容吧网页的内容;二、通过xpath方法清理数据,获取每个post的url地址;再次请求每个帖子的地址,从每个帖子地址爬取图片链接;最后,请求图像数据并将数据以二进制格式保存在本地。
2、网页分析
如下图,这是本次爬取的目标网站,百度美吧,要求:爬取每个帖子里的图片,保存到本地。爬取网站首先需要分析网站的特征。需要分析的内容包括:网站页面的特征、post url地址的特征、图片链接地址的获取方式。以下是我需要分析的内容:
2.1 美容吧网页特色
美容棒:%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0
观察可以看出kw为搜索内容,pn为页码,第一页为0,第二页为50,所以页码的公式为pn=(页数-1)*50。
2.2 Post url 地址功能
通过右键-勾选,可以查看网页的源代码信息,从中我们可以定位到每个帖子的代码,如下图:
可以看到,点击“我真的很漂亮”的帖子,定位到代码,可见帖子的url地址在这段代码中;然后点击href =p/6593341944,发现跳转到帖子“我真的很漂亮”太漂亮了,此时的url地址是:,所以可以发现帖子的地址主要是由两部分组成:+href的内容,所以我们只需要爬取href =p/6593341944的内容,然后拼接,就可以得到每个帖子的地址。
通过xpath_help工具,写: //div[@class="threadlist_title pull_left j_th_tit "]/a/@href 得到每个url地址的一部分。
2.3 获取帖子的图片链接
获取每个帖子的链接,通过类似操作找到帖子中图片的链接地址,如下图定位到图片的链接
同理,通过xpath_help匹配图片链接,代码为://img[@class="BDE_Image"]/@src
3、程序代码:
# -*- 编码:utf-8 -*-import requestsfrom lxml import etreeimport os#爬虫类BtcSpider(object):def __init__(self):#爬取美女图片#解析:美妆吧url地址,pn值决定页码, pn = 0 第一页, pn = 50 第二页...self.url = '%E7%BE%8E%E5%A5%B3&ie=utf-8&pn={}'self.headers = { ' User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',}os.makedirs('美颜图片',exist_ok=True)self.dir = '美颜图片\\'#发送请求def get_response(self,url):response = requests.get(url,headers = self.headers)data = response.textreturn data#发送请求获取网页数据,数据以二进制内容形式读取 def get_data(self,url) :data = requests.get(url,headers = self.headers).contentreturn data#parse data, 封装 xpathdef get_xpath(self,html,pattern):#build tree p = etree.HTML(html)#解析网页内容,获取url_listsresult = p.xpath(pattern)return result#下载图片 &def download_src(self,url):html = self.get_response(url)html = html.replace ("
内容
网页爬虫抓取百度图片( 爬虫通用爬虫技术框架爬虫系统的诞生蜘蛛爬虫系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-25 19:13
爬虫通用爬虫技术框架爬虫系统的诞生蜘蛛爬虫系统)
干货全流程| 入门级爬虫技术原理,这就够了
爬虫系统的诞生
蜘蛛爬虫
一般搜索引擎的处理对象是互联网页面。目前,互联网页面数量已达100亿。因此,搜索引擎面临的第一个问题就是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地。互联网网页的镜像备份在本地形成。
网络爬虫可以发挥这样的作用,完成这项艰巨的任务。它是搜索引擎系统中一个非常关键和基本的组件。本文主要介绍网络爬虫相关的技术。虽然爬虫经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,它们也面临着一些新的挑战。
通用爬虫技术框架
爬虫系统首先从互联网页面中精心挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子放入待爬取的URL队列中。爬虫依次读取要爬取的URL,通过DNS Parse传递URL,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载网页。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载网页的URL放入爬取队列,记录爬虫系统已经下载的网页URL,避免系统重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在下载的URL队列中进行检查。如果发现该链接没有被爬取,则将其放在待爬取的URL队列的末尾。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。
常见爬虫架构
以上是一般爬虫的整体流程。从宏观上看,动态爬取过程中的爬虫与互联网上所有网页的关系可以概括为以下五个部分:
下载网页的绑定:爬虫从互联网上下载到本地索引的网页的集合。
过期网页组合:由于网页数量较多,爬虫完成一轮完整的爬取需要较长时间。在爬取过程中,很多下载的网页可能已经更新,导致过期。原因是互联网上的网页处于不断动态变化的过程中,很容易产生本地网页内容与真实互联网的不一致。
待下载网页集合:URL队列中待爬取的网页,这些网页即将被爬虫下载。
已知网页集合:这些网页没有被爬虫下载,也没有出现在待爬取的URL队列中。通过已经爬取的网页或者待爬取的URL队列中的网页,总是可以通过链接关系找到它们。稍后会被爬虫抓取和索引。
未知网页的集合:一些网页无法被爬虫抓取,这些网页构成了未知网页的组合。实际上,这部分页面占比很高。
互联网页面划分
从理解爬虫的角度来看,以上对互联网页面的划分有助于深入理解搜索引擎爬虫面临的主要任务和挑战。绝大多数爬虫系统都遵循上述流程,但并非所有爬虫系统都如此一致。根据具体的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫系统可以分为以下三种。
批处理式爬虫:批处理式爬虫的抓取范围和目标比较明确。当爬虫达到这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容发生变化是常有的事,增量爬虫需要及时反映这种变化,所以在不断的爬取过程,他们要么是在爬取新的网页,要么是在更新现有的网页。常见的商业搜索引擎爬虫基本属于这一类。
垂直爬虫:垂直爬虫专注于属于特定行业的特定主题或网页。比如健康网站,你只需要从互联网页面中找到健康相关的页面内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,下载后不可能屏蔽所有的互联网页面,这样会造成资源的过度浪费。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关,尽量不使用。爬取不相关的页面以达到节省资源的目的。垂直搜索网站或垂直行业网站往往需要这种爬虫。
好的爬行动物的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是用爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实用的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫多线程运行,以多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会部署在全球、不同区域,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议来告知爬虫哪些内容不是。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaimage-package">
索引网页与互联网网页
爬取的本地网页很可能发生了变化,或者被删除,或者内容发生了变化,因为爬虫完成一轮爬取需要很长时间,所以部分爬取的网页肯定是过期的。因此,网页库中的过期数据越少,网页的新鲜度就越好,对提升用户体验大有裨益。如果新颖性不好,搜索结果全是过时数据,或者网页被删除,用户的内心感受可想而知。
尽管 Internet 上有很多网页,但每个网页都有很大的不同。例如,腾讯和网易新闻的网页与作弊网页一样重要。如果搜索引擎抓取的网页大部分都是比较重要的网页,就可以说明他们在抓取网页的重要性方面做得很好。你在这方面做得越好,搜索引擎就会越准确。
通过以上三个标准的分析,爬虫开发的目标可以简单描述为:在资源有限的情况下,由于搜索引擎只能爬取互联网上现有网页的一部分,所以更重要的部分应尽可能选择。要索引的页面;对于已经爬取的页面,尽快更新内容,使被索引页面的内容与互联网上对应页面的内容同步更新;网页。三个“尽可能”基本明确了爬虫系统提升用户体验的目标。
为了满足这三个质量标准,大型商业搜索引擎开发了多套针对性强的爬虫系统。以谷歌为例,至少有两种不同的爬虫系统,一种叫做Fresh Bot,主要考虑网页的新鲜度。对于内容更新频繁的网页,目前更新周期可以达到秒级;另一组称为 Deep Crawl Bot,主要针对更新不频繁、更新周期为几天的网页抓取。此外,谷歌在开发暗网爬虫系统方面也投入了大量精力。以后有时间讲解暗网系统。
谷歌的两个爬虫系统
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 解密爬虫爬取更新网页的策略方法
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
网页爬虫抓取百度图片(
爬虫通用爬虫技术框架爬虫系统的诞生蜘蛛爬虫系统)
干货全流程| 入门级爬虫技术原理,这就够了
爬虫系统的诞生

蜘蛛爬虫
一般搜索引擎的处理对象是互联网页面。目前,互联网页面数量已达100亿。因此,搜索引擎面临的第一个问题就是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地。互联网网页的镜像备份在本地形成。
网络爬虫可以发挥这样的作用,完成这项艰巨的任务。它是搜索引擎系统中一个非常关键和基本的组件。本文主要介绍网络爬虫相关的技术。虽然爬虫经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,它们也面临着一些新的挑战。
通用爬虫技术框架
爬虫系统首先从互联网页面中精心挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子放入待爬取的URL队列中。爬虫依次读取要爬取的URL,通过DNS Parse传递URL,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载网页。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载网页的URL放入爬取队列,记录爬虫系统已经下载的网页URL,避免系统重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在下载的URL队列中进行检查。如果发现该链接没有被爬取,则将其放在待爬取的URL队列的末尾。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。

常见爬虫架构
以上是一般爬虫的整体流程。从宏观上看,动态爬取过程中的爬虫与互联网上所有网页的关系可以概括为以下五个部分:
下载网页的绑定:爬虫从互联网上下载到本地索引的网页的集合。
过期网页组合:由于网页数量较多,爬虫完成一轮完整的爬取需要较长时间。在爬取过程中,很多下载的网页可能已经更新,导致过期。原因是互联网上的网页处于不断动态变化的过程中,很容易产生本地网页内容与真实互联网的不一致。
待下载网页集合:URL队列中待爬取的网页,这些网页即将被爬虫下载。
已知网页集合:这些网页没有被爬虫下载,也没有出现在待爬取的URL队列中。通过已经爬取的网页或者待爬取的URL队列中的网页,总是可以通过链接关系找到它们。稍后会被爬虫抓取和索引。
未知网页的集合:一些网页无法被爬虫抓取,这些网页构成了未知网页的组合。实际上,这部分页面占比很高。
互联网页面划分
从理解爬虫的角度来看,以上对互联网页面的划分有助于深入理解搜索引擎爬虫面临的主要任务和挑战。绝大多数爬虫系统都遵循上述流程,但并非所有爬虫系统都如此一致。根据具体的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫系统可以分为以下三种。
批处理式爬虫:批处理式爬虫的抓取范围和目标比较明确。当爬虫达到这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容发生变化是常有的事,增量爬虫需要及时反映这种变化,所以在不断的爬取过程,他们要么是在爬取新的网页,要么是在更新现有的网页。常见的商业搜索引擎爬虫基本属于这一类。
垂直爬虫:垂直爬虫专注于属于特定行业的特定主题或网页。比如健康网站,你只需要从互联网页面中找到健康相关的页面内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,下载后不可能屏蔽所有的互联网页面,这样会造成资源的过度浪费。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关,尽量不使用。爬取不相关的页面以达到节省资源的目的。垂直搜索网站或垂直行业网站往往需要这种爬虫。
好的爬行动物的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是用爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实用的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫多线程运行,以多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会部署在全球、不同区域,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议来告知爬虫哪些内容不是。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaimage-package">
索引网页与互联网网页
爬取的本地网页很可能发生了变化,或者被删除,或者内容发生了变化,因为爬虫完成一轮爬取需要很长时间,所以部分爬取的网页肯定是过期的。因此,网页库中的过期数据越少,网页的新鲜度就越好,对提升用户体验大有裨益。如果新颖性不好,搜索结果全是过时数据,或者网页被删除,用户的内心感受可想而知。
尽管 Internet 上有很多网页,但每个网页都有很大的不同。例如,腾讯和网易新闻的网页与作弊网页一样重要。如果搜索引擎抓取的网页大部分都是比较重要的网页,就可以说明他们在抓取网页的重要性方面做得很好。你在这方面做得越好,搜索引擎就会越准确。
通过以上三个标准的分析,爬虫开发的目标可以简单描述为:在资源有限的情况下,由于搜索引擎只能爬取互联网上现有网页的一部分,所以更重要的部分应尽可能选择。要索引的页面;对于已经爬取的页面,尽快更新内容,使被索引页面的内容与互联网上对应页面的内容同步更新;网页。三个“尽可能”基本明确了爬虫系统提升用户体验的目标。
为了满足这三个质量标准,大型商业搜索引擎开发了多套针对性强的爬虫系统。以谷歌为例,至少有两种不同的爬虫系统,一种叫做Fresh Bot,主要考虑网页的新鲜度。对于内容更新频繁的网页,目前更新周期可以达到秒级;另一组称为 Deep Crawl Bot,主要针对更新不频繁、更新周期为几天的网页抓取。此外,谷歌在开发暗网爬虫系统方面也投入了大量精力。以后有时间讲解暗网系统。
谷歌的两个爬虫系统
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 解密爬虫爬取更新网页的策略方法
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-23 23:21
我也是刚开始学python爬虫技术,后来想在网上找一些教程看看。谁知道,一搜,大部分都是用python2写的。新手一般喜欢安装新版本。于是我也写了一个简单的python3爬虫,爬取贴吧的图片。事不宜迟,让我们开始吧。
首先,让我们谈谈知识。
一、什么是爬虫?
采集网页上的数据
二、学习爬虫的作用是什么?
做案例研究,做数据分析,分析网页结构......
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、爬虫思路:
1. 打开网页并获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----获取不到想要的内容/请求失败/IP容易被封....等
*解决方案:伪装 - 不要告诉 网站 我是一个脚本,告诉它我是一个浏览器。(添加任意浏览器的头信息,伪装成浏览器),既然是简单的例子,那我们就不搞这些刁钻的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 功能:查找所有相同的对象。
这里的解析器可能有问题,我们就不多说了。有问题的学生有一堆解决方案。
3. 保存图片地址并下载图片
*一种。使用urllib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,那么一定要写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人不明白。
有一件事要提:您可以在没有常客的情况下使用 BeautifulSoup;爬虫使用正则、Bs4 和 xpath。只需选择三个中的一个。当然,它也可以组合使用,以及其他类型。
爬取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725") #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束。
参考地址:
(ps:我也是python新手,文章如有错误请多多包涵) 查看全部
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
我也是刚开始学python爬虫技术,后来想在网上找一些教程看看。谁知道,一搜,大部分都是用python2写的。新手一般喜欢安装新版本。于是我也写了一个简单的python3爬虫,爬取贴吧的图片。事不宜迟,让我们开始吧。
首先,让我们谈谈知识。
一、什么是爬虫?
采集网页上的数据
二、学习爬虫的作用是什么?
做案例研究,做数据分析,分析网页结构......
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、爬虫思路:
1. 打开网页并获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----获取不到想要的内容/请求失败/IP容易被封....等
*解决方案:伪装 - 不要告诉 网站 我是一个脚本,告诉它我是一个浏览器。(添加任意浏览器的头信息,伪装成浏览器),既然是简单的例子,那我们就不搞这些刁钻的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 功能:查找所有相同的对象。
这里的解析器可能有问题,我们就不多说了。有问题的学生有一堆解决方案。
3. 保存图片地址并下载图片
*一种。使用urllib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,那么一定要写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人不明白。
有一件事要提:您可以在没有常客的情况下使用 BeautifulSoup;爬虫使用正则、Bs4 和 xpath。只需选择三个中的一个。当然,它也可以组合使用,以及其他类型。
爬取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725";) #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:

好了,教程到此结束。
参考地址:
(ps:我也是python新手,文章如有错误请多多包涵)
网页爬虫抓取百度图片(润森什么是爬虫网络爬虫(又被称为网页蜘蛛) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-23 19:12
)
大家好,我是润森
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
"
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
"
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requestsr = requests.get('http://pic37.nipic.com/2014011 ... %2339;)with open('demo.jpg','wb+') as f:f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
"
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
"
json是js的对象,就是访问数据
JSON字符串
{ “name”: “毛利”, “age”: 18, “ feature “ : [‘高’, ‘富’, ‘帅’]}
Python字典
{ ‘name’: ‘毛利’, ‘age’: 18 ‘feature’ : [‘高’, ‘富’, ‘帅’]}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
"
在python中导入json,传递json.loads(s) --> 将json数据转换成python数据(字典)
ajax的使用
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
"
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
分析图片url链接的位置
同时找到ajax请求对应的url
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requestsimport jsonheaders = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}r = requests.get('https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).textres = json.loads(r)['data']for index,i in enumerate(res): url = i['hoverURL'] print(url) with open( '{}.jpg'.format(index),'wb+') as f: f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
"
首先分析不同json发起的请求
https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1561022599355=https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
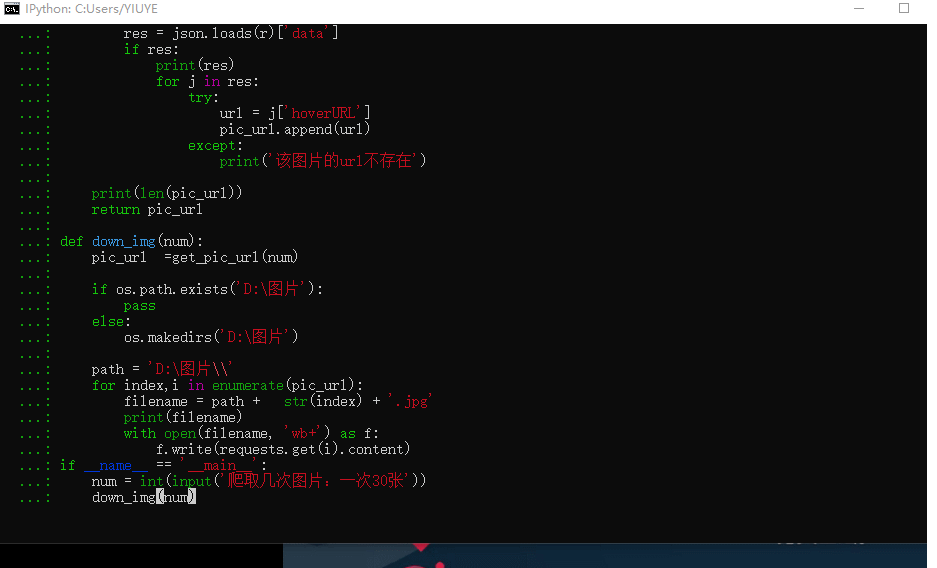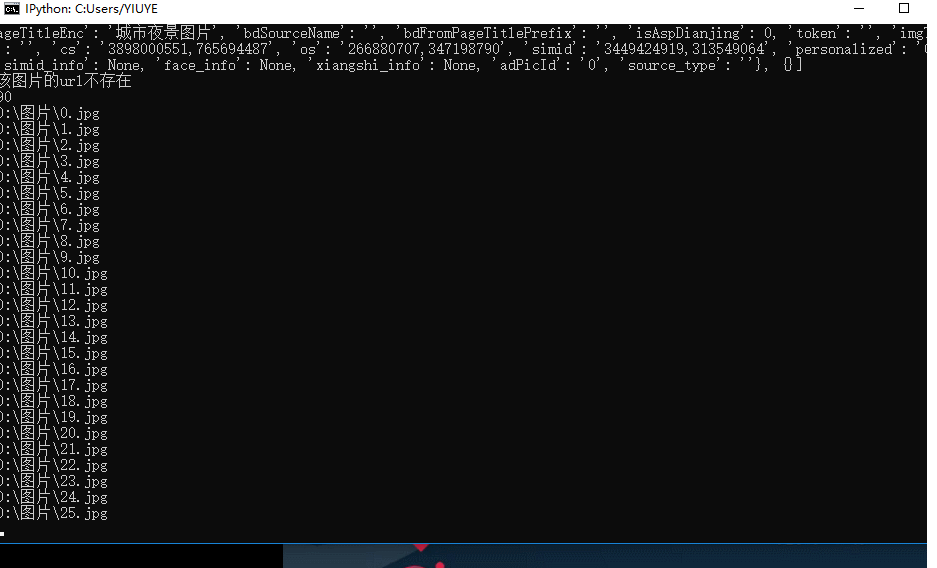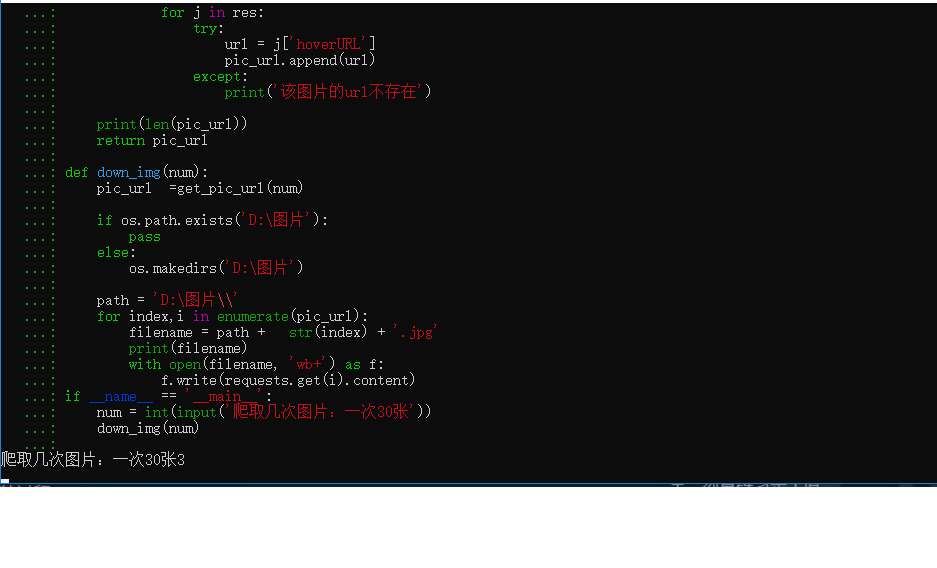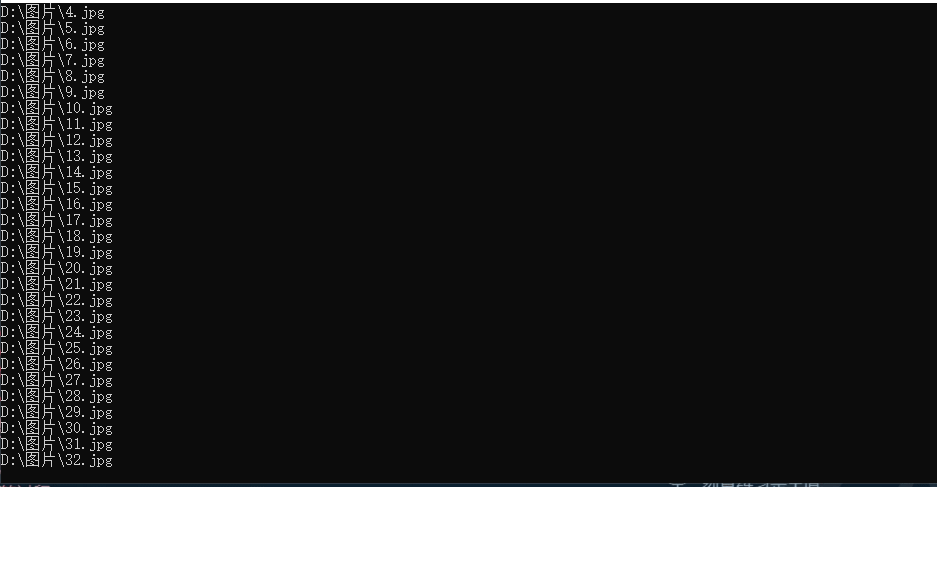
# -*- coding:utf-8 -*-# time :2019/6/20 17:07# author: 毛利import requestsimport jsonimport osdef get_pic_url(num): pic_url= [] headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'} for i in range(num): page_url = 'https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i) r = requests.get(page_url, headers=headers).text res = json.loads(r)['data'] if res: print(res) for j in res: try: url = j['hoverURL'] pic_url.append(url) except: print('该图片的url不存在') print(len(pic_url)) return pic_urldef down_img(num): pic_url =get_pic_url(num) if os.path.exists('D:图片'): pass else: os.makedirs('D:图片') path = 'D:图片' for index,i in enumerate(pic_url): filename = path + str(index) + '.jpg' print(filename) with open(filename, 'wb+') as f: f.write(requests.get(i).content)if __name__ == '__main__': num = int(input('爬取几次图片:一次30张')) down_img(num)
查看全部
网页爬虫抓取百度图片(润森什么是爬虫网络爬虫(又被称为网页蜘蛛)
)
大家好,我是润森
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
"
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
"
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requestsr = requests.get('http://pic37.nipic.com/2014011 ... %2339;)with open('demo.jpg','wb+') as f:f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
"
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
"
json是js的对象,就是访问数据
JSON字符串
{ “name”: “毛利”, “age”: 18, “ feature “ : [‘高’, ‘富’, ‘帅’]}
Python字典
{ ‘name’: ‘毛利’, ‘age’: 18 ‘feature’ : [‘高’, ‘富’, ‘帅’]}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
"
在python中导入json,传递json.loads(s) --> 将json数据转换成python数据(字典)
ajax的使用
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
"
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,

分析图片url链接的位置

同时找到ajax请求对应的url

构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requestsimport jsonheaders = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}r = requests.get('https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).textres = json.loads(r)['data']for index,i in enumerate(res): url = i['hoverURL'] print(url) with open( '{}.jpg'.format(index),'wb+') as f: f.write(requests.get(url).content)

一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
"
首先分析不同json发起的请求
https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1561022599355=https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=
其实可以发现,当再次发起请求时,关键是pn在不断变化

最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-# time :2019/6/20 17:07# author: 毛利import requestsimport jsonimport osdef get_pic_url(num): pic_url= [] headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'} for i in range(num): page_url = 'https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i) r = requests.get(page_url, headers=headers).text res = json.loads(r)['data'] if res: print(res) for j in res: try: url = j['hoverURL'] pic_url.append(url) except: print('该图片的url不存在') print(len(pic_url)) return pic_urldef down_img(num): pic_url =get_pic_url(num) if os.path.exists('D:图片'): pass else: os.makedirs('D:图片') path = 'D:图片' for index,i in enumerate(pic_url): filename = path + str(index) + '.jpg' print(filename) with open(filename, 'wb+') as f: f.write(requests.get(i).content)if __name__ == '__main__': num = int(input('爬取几次图片:一次30张')) down_img(num)

网页爬虫抓取百度图片(百度爬虫抓取量其实简单就是百度对站点一天网页的数量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-23 05:10
影响百度爬虫网站爬取量的因素有哪些?百度爬虫的爬取量实际上是百度爬虫在一天内爬取一个网站的页面数。在这里,新网小编就为大家介绍一下影响百度爬虫网站爬取量的因素。
其中之一就是本站生成新的网页,对于中小型网站可以在同一天完成。大的 网站 可能无法完成它们。百度收录有5W,那么百度会给一个时间段,比如30天,然后平均出来,每天去这个网站抢5W/30这样一个数字,但是具体金额,百度有自己的一套算法公式可以计算。
影响百度抓取量的因素。
1.网站安全
对于中小型网站来说,安全技术比较薄弱,被黑客篡改的现象非常普遍。通常,有几种常见的被黑客入侵的情况。一是主域被黑,二是标题被篡改,二是页面有很多外部链接。一般主域被黑了就是劫持了,就是主域被301重定向到指定的网站,如果你在百度上跳转后发现一些垃圾站,那么你的站点就抢量里面会减少。
2.内容质量
如果爬取了10万个页面,只创建了100个,爬取量就会下降,因为百度会认为爬取的页面比例很低,所以没必要多爬取,所以“最好是短于浪费”,尤其是在建网站的时候,一定要注意质量,不要采集一些内容,这是一个潜在的隐患。
3.网站响应能力
① 网页大小会影响爬取。百度推荐网页大小在1M以内。当然,它类似于新浪所说的大型门户网站。
②代码质量、机器性能和带宽,这个不多说,后面作者会单独拿出文章解释,请实时关注“营销专家”。
4.同一ip上的主域数
百度爬取是基于ip的。比如一个ip每天爬1000w个页面,这个站点有40W个站点,那么平均每个站点的爬取次数会很分散。很少。
相信大家都知道哪些因素会影响百度爬虫对网站的抓取量。提醒大家,在选择服务商的时候,要检查一下同一个ip上是否有大网站。如果有大站点的话,可能分配的爬取量会很小,因为流量会流向大站点。
_创新互联,为您提供面包屑导航、网站导航、网站策划、搜索引擎优化、网站、网站制作 查看全部
网页爬虫抓取百度图片(百度爬虫抓取量其实简单就是百度对站点一天网页的数量)
影响百度爬虫网站爬取量的因素有哪些?百度爬虫的爬取量实际上是百度爬虫在一天内爬取一个网站的页面数。在这里,新网小编就为大家介绍一下影响百度爬虫网站爬取量的因素。
其中之一就是本站生成新的网页,对于中小型网站可以在同一天完成。大的 网站 可能无法完成它们。百度收录有5W,那么百度会给一个时间段,比如30天,然后平均出来,每天去这个网站抢5W/30这样一个数字,但是具体金额,百度有自己的一套算法公式可以计算。
影响百度抓取量的因素。
1.网站安全
对于中小型网站来说,安全技术比较薄弱,被黑客篡改的现象非常普遍。通常,有几种常见的被黑客入侵的情况。一是主域被黑,二是标题被篡改,二是页面有很多外部链接。一般主域被黑了就是劫持了,就是主域被301重定向到指定的网站,如果你在百度上跳转后发现一些垃圾站,那么你的站点就抢量里面会减少。
2.内容质量
如果爬取了10万个页面,只创建了100个,爬取量就会下降,因为百度会认为爬取的页面比例很低,所以没必要多爬取,所以“最好是短于浪费”,尤其是在建网站的时候,一定要注意质量,不要采集一些内容,这是一个潜在的隐患。
3.网站响应能力
① 网页大小会影响爬取。百度推荐网页大小在1M以内。当然,它类似于新浪所说的大型门户网站。
②代码质量、机器性能和带宽,这个不多说,后面作者会单独拿出文章解释,请实时关注“营销专家”。
4.同一ip上的主域数
百度爬取是基于ip的。比如一个ip每天爬1000w个页面,这个站点有40W个站点,那么平均每个站点的爬取次数会很分散。很少。
相信大家都知道哪些因素会影响百度爬虫对网站的抓取量。提醒大家,在选择服务商的时候,要检查一下同一个ip上是否有大网站。如果有大站点的话,可能分配的爬取量会很小,因为流量会流向大站点。
_创新互联,为您提供面包屑导航、网站导航、网站策划、搜索引擎优化、网站、网站制作
网页爬虫抓取百度图片(为什么使用爬虫为什么我们需要使用千磨风?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2022-02-22 15:11
关键词:爬虫简介
千辛万苦,千锤百炼,任尔南北风,东风西风。本期文章主要讲第55天:爬虫相关知识介绍,希望对大家有所帮助。
由先欢
作为程序员,相信大家对“爬虫”这个词并不陌生。人们经常在周围提到这个词。在不知道的人眼里,他们会认为这项技术非常高端和神秘。别着急,我们的爬虫系列就带你揭开它的神秘面纱,探寻它的真面目。
什么是爬行动物
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗地说,我们把互联网比作一个大蜘蛛网,每个站点资源都比作蜘蛛网上的一个节点。爬虫就像一只蜘蛛,按照设计好的路线和规则在这张蜘蛛网上寻找目标节点。,获取资源。
为什么要使用爬虫
为什么我们需要使用爬虫?
你可以想象一个场景:你很崇拜一个微博名人,你对他的微博很着迷,你想把他微博上十年的每一句话都提取出来,做成名人语录。你在这个时候做什么?手动转到 Ctrl+C 和 Ctrl+V?这种方法确实是正确的。数据量少的时候我们可以这样做,但是数据量上千的时候还需要这样做吗?
再想象一个场景:你想做一个新闻聚合网站,你需要每天定时去几条新闻网站获取最新消息,我们称之为RSS订阅。你定期去每个订阅网站复制新闻吗?恐怕个人很难做到这一点。
在以上两种场景下,使用爬虫技术可以轻松解决问题。因此,我们可以看到爬虫技术主要可以帮我们做两种事情:一是数据获取需求,主要是针对特定规则下的大量数据的获取;另一个是自动化需求,主要用于类似信息的聚合、搜索等。
爬行动物的分类
从爬取对象的角度,爬虫可以分为通用爬虫和专注爬虫。
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web,主要针对搜索引擎和大型Web服务商采集数据。此类网络爬虫的爬取范围和数量巨大,对爬取速度和存储空间的要求比较高,对爬取页面的顺序要求比较低。比如我们常见的百度和谷歌搜索。我们进入关键词,他们会从全网找到关键词相关的网页,并按照一定的顺序呈现给我们。
Focused Crawler 是指有选择地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,聚焦爬虫只需要爬取特定的网页,爬取的广度会小很多。比如我们需要爬取东方财富网的基金数据,只需要制定规则爬取东方财富网的页面即可。
通俗的说,万能爬虫类似于蜘蛛,需要寻找特定的食物,但是它不知道蜘蛛网的哪个节点有它,所以只能从一个节点开始,到时候再看这个节点遇到它,如果有食物就拿食物,如果这个节点表示某个节点有食物,那么它会按照指示寻找下一个节点。网络爬虫的重点是蜘蛛知道哪个节点有食物,它只需要规划一条路线到达那个节点就可以得到食物。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,类似下图:
这个过程其实就是用户输入URL后,经过DNS服务器,找到服务器主机,向服务器发送请求。服务器解析后,将html、js、css等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
由于爬虫的目标是获取资源,而资源存储在某个主机上,所以爬虫在爬取数据时必须有一个目标URL来获取数据。因此,它是爬虫获取数据的基本依据。准确理解它的含义,对于爬虫的学习很有帮助。
爬虫的过程
我们下一章主要讨论焦点爬虫。焦点爬虫的工作流程如下:
从这个爬虫的过程中,你应该可以想到学习爬虫需要学习的关键步骤。首先,我们需要像浏览器一样请求一个URL来获取主机的资源,所以正确请求和获取内容的方法是我们研究的重点。我们获取资源后(即请求URL后得到的响应内容),需要解析响应内容,为我们获取有价值的数据。这里的分析方法是学习的重点。我们拿到数据后,接下来需要存储数据,数据的存储方式也很重要。
因此,我们所学的爬虫技术其实可以概括为三个基本问题:请求、解析和存储。如果掌握了这三个问题的相应解决方案,爬虫技术就掌握了。在学习爬虫的过程中,大家都会关注这三个问题,不会走弯路。
总结
本节介绍爬虫的基本概念,以便您对爬虫有一个大致的了解,以便在后续章节中学习。开胃菜吃完了,下一节就要开始饕餮盛宴了,你准备好了吗?
文中示例代码: 查看全部
网页爬虫抓取百度图片(为什么使用爬虫为什么我们需要使用千磨风?(上))
关键词:爬虫简介
千辛万苦,千锤百炼,任尔南北风,东风西风。本期文章主要讲第55天:爬虫相关知识介绍,希望对大家有所帮助。
由先欢
作为程序员,相信大家对“爬虫”这个词并不陌生。人们经常在周围提到这个词。在不知道的人眼里,他们会认为这项技术非常高端和神秘。别着急,我们的爬虫系列就带你揭开它的神秘面纱,探寻它的真面目。
什么是爬行动物
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗地说,我们把互联网比作一个大蜘蛛网,每个站点资源都比作蜘蛛网上的一个节点。爬虫就像一只蜘蛛,按照设计好的路线和规则在这张蜘蛛网上寻找目标节点。,获取资源。
为什么要使用爬虫
为什么我们需要使用爬虫?
你可以想象一个场景:你很崇拜一个微博名人,你对他的微博很着迷,你想把他微博上十年的每一句话都提取出来,做成名人语录。你在这个时候做什么?手动转到 Ctrl+C 和 Ctrl+V?这种方法确实是正确的。数据量少的时候我们可以这样做,但是数据量上千的时候还需要这样做吗?
再想象一个场景:你想做一个新闻聚合网站,你需要每天定时去几条新闻网站获取最新消息,我们称之为RSS订阅。你定期去每个订阅网站复制新闻吗?恐怕个人很难做到这一点。
在以上两种场景下,使用爬虫技术可以轻松解决问题。因此,我们可以看到爬虫技术主要可以帮我们做两种事情:一是数据获取需求,主要是针对特定规则下的大量数据的获取;另一个是自动化需求,主要用于类似信息的聚合、搜索等。
爬行动物的分类
从爬取对象的角度,爬虫可以分为通用爬虫和专注爬虫。
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web,主要针对搜索引擎和大型Web服务商采集数据。此类网络爬虫的爬取范围和数量巨大,对爬取速度和存储空间的要求比较高,对爬取页面的顺序要求比较低。比如我们常见的百度和谷歌搜索。我们进入关键词,他们会从全网找到关键词相关的网页,并按照一定的顺序呈现给我们。
Focused Crawler 是指有选择地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,聚焦爬虫只需要爬取特定的网页,爬取的广度会小很多。比如我们需要爬取东方财富网的基金数据,只需要制定规则爬取东方财富网的页面即可。
通俗的说,万能爬虫类似于蜘蛛,需要寻找特定的食物,但是它不知道蜘蛛网的哪个节点有它,所以只能从一个节点开始,到时候再看这个节点遇到它,如果有食物就拿食物,如果这个节点表示某个节点有食物,那么它会按照指示寻找下一个节点。网络爬虫的重点是蜘蛛知道哪个节点有食物,它只需要规划一条路线到达那个节点就可以得到食物。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,类似下图:

这个过程其实就是用户输入URL后,经过DNS服务器,找到服务器主机,向服务器发送请求。服务器解析后,将html、js、css等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
由于爬虫的目标是获取资源,而资源存储在某个主机上,所以爬虫在爬取数据时必须有一个目标URL来获取数据。因此,它是爬虫获取数据的基本依据。准确理解它的含义,对于爬虫的学习很有帮助。
爬虫的过程
我们下一章主要讨论焦点爬虫。焦点爬虫的工作流程如下:

从这个爬虫的过程中,你应该可以想到学习爬虫需要学习的关键步骤。首先,我们需要像浏览器一样请求一个URL来获取主机的资源,所以正确请求和获取内容的方法是我们研究的重点。我们获取资源后(即请求URL后得到的响应内容),需要解析响应内容,为我们获取有价值的数据。这里的分析方法是学习的重点。我们拿到数据后,接下来需要存储数据,数据的存储方式也很重要。
因此,我们所学的爬虫技术其实可以概括为三个基本问题:请求、解析和存储。如果掌握了这三个问题的相应解决方案,爬虫技术就掌握了。在学习爬虫的过程中,大家都会关注这三个问题,不会走弯路。
总结
本节介绍爬虫的基本概念,以便您对爬虫有一个大致的了解,以便在后续章节中学习。开胃菜吃完了,下一节就要开始饕餮盛宴了,你准备好了吗?
文中示例代码:
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一时间解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-22 15:07
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看
在当今社会,如何有效地提取和利用信息已成为一个巨大的挑战。基于这个巨大的市场需求,履带技术应运而生,这也是为什么对履带工程师的需求与日俱增的原因。那么Python网络爬虫需要掌握哪些核心技术呢?以小编推出的《Python网络爬虫解析》课程为例,内容涉及Scrapy框架、分布式爬虫等核心技术。下面一起来看看Python网络爬虫的具体学习内容吧!
Python网络爬虫课程简介:
为了让具备Python基础的人适合工作需要,小编推出了全面、系统、简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了一个爬虫框架。学习完内容后,您将能够全面掌握爬取和解析网页的各种技术,还可以掌握爬虫的一些扩展知识,如并发下载、识别图片文本、抓取动态内容等。并且每个人都可以掌握爬虫框架的使用,比如Scrapy,从而创建自己的网络爬虫项目,胜任Python网络爬虫工程师相关的工作。
Python网络爬虫知识大纲:
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、什么是爬虫、爬虫的目的、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫的实现原理、爬取网页的详细过程、通用爬虫中网页的分类、通用爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有一定的了解,以后会针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍网页请求的原理,包括浏览网页的过程、HTTP网络请求的原理、HTTP抓包工具Fiddler。
第 4 部分
介绍了两个用于抓取 Web 数据的库:urllib 和 requests。首先介绍了urllib库的基本使用,包括使用urllib传输数据,添加具体的header,设置代理服务器,超时设置,常见的网络异常,然后介绍一个更加人性化的requests库,结合百度< @贴吧的案例说明了如何使用urllib库爬取网页数据。大家应该能熟练掌握这两个库的使用,反复使用多练习。另外,可以参考官网提供的文档进行深入研究。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了封装这些技术的Python模块或库的基本使用,包括re模块、lxml库、bs4库、json模块、并结合腾讯社招网站的案例,分别讲解如何使用re模块、lxml库和bs4库来解析网页数据,以便更好地区分这些技术之间的差异。在实际工作中,可以根据具体情况选择合理的技术来使用。
第 6 部分
主要讲解并发下载,包括多线程爬虫进程分析,使用queue模块实现多线程爬取,协程实现并发爬取。结合尴尬百科的案例,分别使用了单线程、多线程、协程三种技术。获取网页数据,分析三者的表现。
第 7 部分
介绍围绕抓取动态内容,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登陆的案例,在项目中解释了项目如何应用 selenium 和 PhantomJS 技术。
第 8 部分
主要讲解图像识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、标准格式文本处理、验证码处理等,结合一个识别本地验证码图片的小程序,讲解如何使用 pytesseract 识别图像中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储在数据库等,并结合豆瓣电影的案例讲解如何抓取,从 网站 一步一步地解析和存储电影信息。
第 10 部分
主要是对爬虫框架Scrapy的初步讲解,包括常用爬虫框架介绍、Scrapy框架结构、运行流程、安装、基本操作等。
第 11 部分
首先介绍Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并用一个例子来巩固。然后,详细介绍了 Scrapy 框架的一些核心组件,包括 Spiders、Item Pipeline 和 Settings。最后结合斗鱼App爬虫的案例,讲解了如何使用。Scrapy 框架捕获移动应用程序的数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括先了解爬虫类CrawlSpider,CrawlSpider类的工作原理,通过Rule类确定爬取规则,通过LinkExtractor类提取链接,以及开发了一个CrawlSpider类来爬取腾讯招聘网站的案例,并将这部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括完整的架构、运行流程、主要组件、Scrapy-Redis的基本使用、如何搭建Scrapy-Redis开发环境等,并结合百度百科案例使用这些知识点。
以上就是成为Python网络爬虫需要掌握的核心技术。你想通了吗?其实,做一个网络爬虫并不难。只要掌握科学的学习方法,将理论基础与实践经验相结合,就能快速掌握爬虫的核心技术。 查看全部
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一时间解决?(图))
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看
在当今社会,如何有效地提取和利用信息已成为一个巨大的挑战。基于这个巨大的市场需求,履带技术应运而生,这也是为什么对履带工程师的需求与日俱增的原因。那么Python网络爬虫需要掌握哪些核心技术呢?以小编推出的《Python网络爬虫解析》课程为例,内容涉及Scrapy框架、分布式爬虫等核心技术。下面一起来看看Python网络爬虫的具体学习内容吧!
Python网络爬虫课程简介:
为了让具备Python基础的人适合工作需要,小编推出了全面、系统、简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了一个爬虫框架。学习完内容后,您将能够全面掌握爬取和解析网页的各种技术,还可以掌握爬虫的一些扩展知识,如并发下载、识别图片文本、抓取动态内容等。并且每个人都可以掌握爬虫框架的使用,比如Scrapy,从而创建自己的网络爬虫项目,胜任Python网络爬虫工程师相关的工作。
Python网络爬虫知识大纲:
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、什么是爬虫、爬虫的目的、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫的实现原理、爬取网页的详细过程、通用爬虫中网页的分类、通用爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有一定的了解,以后会针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍网页请求的原理,包括浏览网页的过程、HTTP网络请求的原理、HTTP抓包工具Fiddler。
第 4 部分
介绍了两个用于抓取 Web 数据的库:urllib 和 requests。首先介绍了urllib库的基本使用,包括使用urllib传输数据,添加具体的header,设置代理服务器,超时设置,常见的网络异常,然后介绍一个更加人性化的requests库,结合百度< @贴吧的案例说明了如何使用urllib库爬取网页数据。大家应该能熟练掌握这两个库的使用,反复使用多练习。另外,可以参考官网提供的文档进行深入研究。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了封装这些技术的Python模块或库的基本使用,包括re模块、lxml库、bs4库、json模块、并结合腾讯社招网站的案例,分别讲解如何使用re模块、lxml库和bs4库来解析网页数据,以便更好地区分这些技术之间的差异。在实际工作中,可以根据具体情况选择合理的技术来使用。
第 6 部分
主要讲解并发下载,包括多线程爬虫进程分析,使用queue模块实现多线程爬取,协程实现并发爬取。结合尴尬百科的案例,分别使用了单线程、多线程、协程三种技术。获取网页数据,分析三者的表现。
第 7 部分
介绍围绕抓取动态内容,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登陆的案例,在项目中解释了项目如何应用 selenium 和 PhantomJS 技术。
第 8 部分
主要讲解图像识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、标准格式文本处理、验证码处理等,结合一个识别本地验证码图片的小程序,讲解如何使用 pytesseract 识别图像中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储在数据库等,并结合豆瓣电影的案例讲解如何抓取,从 网站 一步一步地解析和存储电影信息。
第 10 部分
主要是对爬虫框架Scrapy的初步讲解,包括常用爬虫框架介绍、Scrapy框架结构、运行流程、安装、基本操作等。
第 11 部分
首先介绍Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并用一个例子来巩固。然后,详细介绍了 Scrapy 框架的一些核心组件,包括 Spiders、Item Pipeline 和 Settings。最后结合斗鱼App爬虫的案例,讲解了如何使用。Scrapy 框架捕获移动应用程序的数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括先了解爬虫类CrawlSpider,CrawlSpider类的工作原理,通过Rule类确定爬取规则,通过LinkExtractor类提取链接,以及开发了一个CrawlSpider类来爬取腾讯招聘网站的案例,并将这部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括完整的架构、运行流程、主要组件、Scrapy-Redis的基本使用、如何搭建Scrapy-Redis开发环境等,并结合百度百科案例使用这些知识点。
以上就是成为Python网络爬虫需要掌握的核心技术。你想通了吗?其实,做一个网络爬虫并不难。只要掌握科学的学习方法,将理论基础与实践经验相结合,就能快速掌握爬虫的核心技术。
网页爬虫抓取百度图片( 一个特别小的爬虫案例!微信推文中的图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-22 05:05
一个特别小的爬虫案例!微信推文中的图片
)
大家好,今天给大家分享一个非常小的爬虫案例!
在微信推文中抓取图片!!!!
有人说,这有什么用,,,,万一有人的推特是把一个PPT的内容以图片的形式放上去,你想把它弄下来,那就是爬。
欢迎关注哔哩哔哩UP主:《我的儿子Q》。
坚持不懈,努力工作;你和我在一起!为战斗而生!
相信大家都听说过爬虫技术。一旦你学会了这项技术,你将成为资源老板。这条推文将在以下两个方面展开:
1、爬虫科学
2、微信推文中的图片
爬行动物科学的定义
近年来,爬虫这个词广为流传,还有一个新兴的职位——爬虫工程师。那么什么是爬行动物?
下面是百度百科的解释:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
大概还是不明白。
其实通俗的说,就是在网络上根据自己的需要,通过相应的技术手段来获取我们需要的数据信息。这个过程称为爬行。
该网站是API。. .
我们说网络上的每一个网站都被视为一个API,也就是一个接口,通过它我们可以获取信息和数据。一个网站叫做 URL,这个 URL 就是我们爬取的 API。
爬虫无非就是以下几个流程:
1、了解网页
2、获取网页内容
3、解析网页并选择需要的内容
4、保存你想要的
两个机器人协议
在爬取之前,你需要知道一些事情:
1、服务器上的数据是专有的。
2、网络爬虫数据牟利存在法律风险。
3、爬虫可能会丢失个人数据。
许多公司还对爬虫进行了一些预防设置。一般会判断你的访问来源,并尝试判断你是被人访问还是被机器访问,从而做出必要的限制。
robots协议,也称为robots.txt,是大家都认同的爬虫协议。说白了,就是爬虫的道德标准。很多公司会在它的一些网站上设置robots协议,这个协议会告诉你哪些内容网站允许你抓取,哪些内容不允许抓取。该协议是 网站 根目录中的 robots.txt 文件。京东的机器人协议如下。
首先,我将向大家解释这些的目的。也希望大家都能做一个合法的爬虫,遵守网络道德,做社会主义的接班人。不过普通的小爬虫是允许的,大家可以大胆尝试。
三爬虫框架
目前爬虫已经有比较成熟的框架和比较成熟的第三方库供大家使用。
上面给出了两个更成熟的爬虫库。下面我们简单介绍一下Requests的使用。
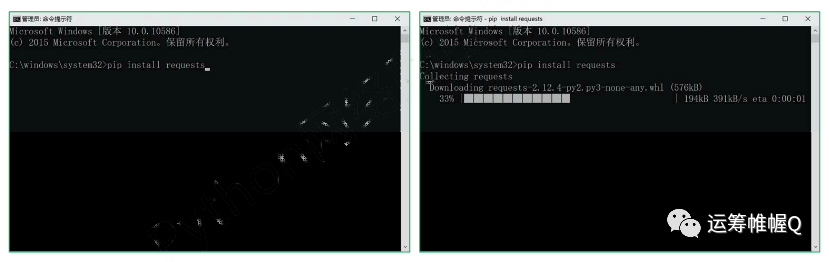
首先,您需要安装此库。库的安装方法很简单。在 Windows 系统上,以管理员身份运行 cmd 并执行 pip install 请求。
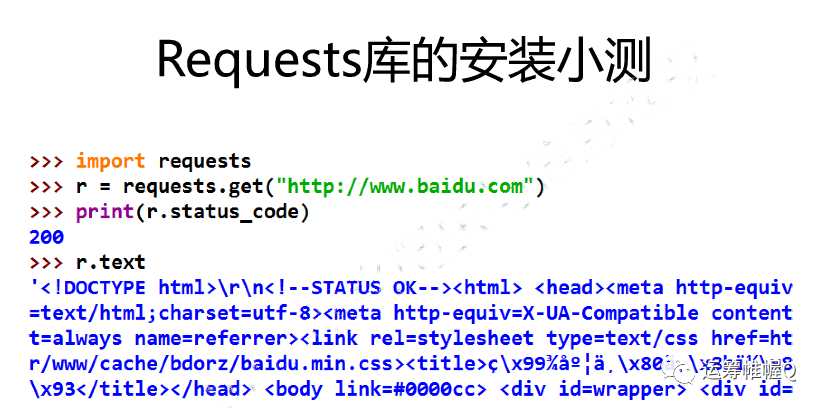
安装好之后就可以测试了。
爬虫的框架如下:
import requests # 导入requests库def Get_Url_text(URL): # 定义获取相应链接文本的函数 try:# 这里是异常处理机制 r = requests.get(url, timeout=30) # 访问这个链接,并返回一个名为r的对象 r.raise_for_status() # 返回访问的状态,若为200,即为访问成功 r.encoding = r.apparent_encoding # 将网页的编码和头文件的编码改为一致 except: return "产生异常"if __name__ = "main": url = "https://www.Baidu.com" print(Get_Url_text(url))
四个Requests库的一些常用方法
requests库的七种常用方法
这里有两个对象,一个是访问的url,一个是返回的响应对象,也就是前面代码中的r对象,其中也有返回对象的一些属性。如下表所示。
微信推文爬取图片示例
简单说一下这里使用的python自带的urllib中的request。但是整体的爬取思路是一样的。还用到了其他一些库,大家可以自行理解。代码和解释如下所示。
import urllib.requestimport re # 正则表达式库import osimport urllib# 根据给定的网址来获取网页详细信息,得到的html就是网页的源代码def getHtml(url): page = urllib.request.urlopen(url) html = page.read() return html.decode('UTF-8')def getImg(html): reg = r' src="(.+?)" ' # 括号里面就是我们要取得的图片网址 imgre = re.compile(reg) imglist = imgre.findall(html) # 表示在整个网页中过滤出所有图片的地址,放在imglist中 x = 0 path = 'D:\\python_project\\GRASP_pic_from_wechat\\pic' # 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建 if not os.path.isdir(path): os.makedirs(path) paths = path + '\\' # 保存在test路径下 for imgurl in imglist: urllib.request.urlretrieve(imgurl, '{0}{1}.jpg'.format(paths, x)) # 打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串 x = x + 1 return imglisthtml = getHtml("https://mp.weixin.qq.com/s/z8p ... 6quot;) # 获取该网址网页详细信息,得到的html就是网页的源代码print(getImg(html)) # 从网页源代码中分析并下载保存图片
好了,今天的内容就到此结束,希望对大家有所帮助,欢迎点赞转发!!
发送封面:
查看全部
网页爬虫抓取百度图片(
一个特别小的爬虫案例!微信推文中的图片
)

大家好,今天给大家分享一个非常小的爬虫案例!
在微信推文中抓取图片!!!!
有人说,这有什么用,,,,万一有人的推特是把一个PPT的内容以图片的形式放上去,你想把它弄下来,那就是爬。
欢迎关注哔哩哔哩UP主:《我的儿子Q》。
坚持不懈,努力工作;你和我在一起!为战斗而生!
相信大家都听说过爬虫技术。一旦你学会了这项技术,你将成为资源老板。这条推文将在以下两个方面展开:
1、爬虫科学
2、微信推文中的图片

爬行动物科学的定义
近年来,爬虫这个词广为流传,还有一个新兴的职位——爬虫工程师。那么什么是爬行动物?
下面是百度百科的解释:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
大概还是不明白。

其实通俗的说,就是在网络上根据自己的需要,通过相应的技术手段来获取我们需要的数据信息。这个过程称为爬行。
该网站是API。. .
我们说网络上的每一个网站都被视为一个API,也就是一个接口,通过它我们可以获取信息和数据。一个网站叫做 URL,这个 URL 就是我们爬取的 API。
爬虫无非就是以下几个流程:
1、了解网页
2、获取网页内容
3、解析网页并选择需要的内容
4、保存你想要的
两个机器人协议
在爬取之前,你需要知道一些事情:
1、服务器上的数据是专有的。
2、网络爬虫数据牟利存在法律风险。
3、爬虫可能会丢失个人数据。
许多公司还对爬虫进行了一些预防设置。一般会判断你的访问来源,并尝试判断你是被人访问还是被机器访问,从而做出必要的限制。
robots协议,也称为robots.txt,是大家都认同的爬虫协议。说白了,就是爬虫的道德标准。很多公司会在它的一些网站上设置robots协议,这个协议会告诉你哪些内容网站允许你抓取,哪些内容不允许抓取。该协议是 网站 根目录中的 robots.txt 文件。京东的机器人协议如下。

首先,我将向大家解释这些的目的。也希望大家都能做一个合法的爬虫,遵守网络道德,做社会主义的接班人。不过普通的小爬虫是允许的,大家可以大胆尝试。

三爬虫框架
目前爬虫已经有比较成熟的框架和比较成熟的第三方库供大家使用。

上面给出了两个更成熟的爬虫库。下面我们简单介绍一下Requests的使用。
首先,您需要安装此库。库的安装方法很简单。在 Windows 系统上,以管理员身份运行 cmd 并执行 pip install 请求。
安装好之后就可以测试了。
爬虫的框架如下:
import requests # 导入requests库def Get_Url_text(URL): # 定义获取相应链接文本的函数 try:# 这里是异常处理机制 r = requests.get(url, timeout=30) # 访问这个链接,并返回一个名为r的对象 r.raise_for_status() # 返回访问的状态,若为200,即为访问成功 r.encoding = r.apparent_encoding # 将网页的编码和头文件的编码改为一致 except: return "产生异常"if __name__ = "main": url = "https://www.Baidu.com" print(Get_Url_text(url))
四个Requests库的一些常用方法
requests库的七种常用方法
这里有两个对象,一个是访问的url,一个是返回的响应对象,也就是前面代码中的r对象,其中也有返回对象的一些属性。如下表所示。

微信推文爬取图片示例
简单说一下这里使用的python自带的urllib中的request。但是整体的爬取思路是一样的。还用到了其他一些库,大家可以自行理解。代码和解释如下所示。
import urllib.requestimport re # 正则表达式库import osimport urllib# 根据给定的网址来获取网页详细信息,得到的html就是网页的源代码def getHtml(url): page = urllib.request.urlopen(url) html = page.read() return html.decode('UTF-8')def getImg(html): reg = r' src="(.+?)" ' # 括号里面就是我们要取得的图片网址 imgre = re.compile(reg) imglist = imgre.findall(html) # 表示在整个网页中过滤出所有图片的地址,放在imglist中 x = 0 path = 'D:\\python_project\\GRASP_pic_from_wechat\\pic' # 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建 if not os.path.isdir(path): os.makedirs(path) paths = path + '\\' # 保存在test路径下 for imgurl in imglist: urllib.request.urlretrieve(imgurl, '{0}{1}.jpg'.format(paths, x)) # 打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串 x = x + 1 return imglisthtml = getHtml("https://mp.weixin.qq.com/s/z8p ... 6quot;) # 获取该网址网页详细信息,得到的html就是网页的源代码print(getImg(html)) # 从网页源代码中分析并下载保存图片
好了,今天的内容就到此结束,希望对大家有所帮助,欢迎点赞转发!!
发送封面:


网页爬虫抓取百度图片(Python爬虫之旅学习文章目录()-乐题库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-20 04:15
)
Python爬虫学习
文章目录
前言
写个项目书找资料真是大手笔,训练模型采集图片更烦人。我也复习了自己的python,于是开始了python爬虫的旅程,这样以后可以更方便的找资料。
一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫是一段代码,可以自动从 Internet 上找到我需要的一些信息。例如,如果我想搜索一些信息,我可以搜索全世界。使用爬虫,我们可以通过关键字过滤我们需要的内容。或者你想看高收视率的电影。这时候也可以使用爬虫来查找一些收视率高的电影。
爬行动物的矛和盾
1、防爬机制
2、反反爬策略
3、robots.txt(君子协议)
二、打开一个小爬虫
使用软件 Pycharm
爬虫:通过编写程序获取互联网资源
要求:使用程序模拟浏览器。输入从中获取资源或内容的 URL
1、导入urlopen包
from urllib.request import urlopen
2、打开一个 URL 并获得响应
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read()) #打印信息
前面有个b',代表字节,我们需要把字节转成字符串
3、解码
查看charest等号后面的内容,通过resp.read.decode()解码
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read().decode("utf-8")) #打印解码信息
4、保存到文件
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
with open("mybaidu.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")
这次信息保存在html文件中
5、打开
这时,百度就会打开。
上面是我们搜索打开百度的网址,下面的网址明显不一样
它的本质是一样的,你可以查看网页的源代码,你会发现源代码是一样的,上面也有提到
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
还能爬CCTV
from urllib.request import urlopen #导入urlopen
url = "http://v.cctv.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
#print(resp.read().decode("utf-8"))
with open("my2.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")
查看全部
网页爬虫抓取百度图片(Python爬虫之旅学习文章目录()-乐题库
)
Python爬虫学习
文章目录
前言
写个项目书找资料真是大手笔,训练模型采集图片更烦人。我也复习了自己的python,于是开始了python爬虫的旅程,这样以后可以更方便的找资料。
一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫是一段代码,可以自动从 Internet 上找到我需要的一些信息。例如,如果我想搜索一些信息,我可以搜索全世界。使用爬虫,我们可以通过关键字过滤我们需要的内容。或者你想看高收视率的电影。这时候也可以使用爬虫来查找一些收视率高的电影。
爬行动物的矛和盾
1、防爬机制
2、反反爬策略
3、robots.txt(君子协议)
二、打开一个小爬虫
使用软件 Pycharm
爬虫:通过编写程序获取互联网资源
要求:使用程序模拟浏览器。输入从中获取资源或内容的 URL
1、导入urlopen包
from urllib.request import urlopen
2、打开一个 URL 并获得响应
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read()) #打印信息

前面有个b',代表字节,我们需要把字节转成字符串
3、解码
查看charest等号后面的内容,通过resp.read.decode()解码
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read().decode("utf-8")) #打印解码信息

4、保存到文件
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
with open("mybaidu.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")

这次信息保存在html文件中
5、打开

这时,百度就会打开。

上面是我们搜索打开百度的网址,下面的网址明显不一样

它的本质是一样的,你可以查看网页的源代码,你会发现源代码是一样的,上面也有提到
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
还能爬CCTV
from urllib.request import urlopen #导入urlopen
url = "http://v.cctv.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
#print(resp.read().decode("utf-8"))
with open("my2.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")

网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2022-02-19 21:14
)
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... %2339;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 39%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人)
)
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?

从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... %2339;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,



构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 39%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化

最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-19 21:10
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬取过程
抓取结果
文章首次发表于: 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬取过程
抓取结果
文章首次发表于:
网页爬虫抓取百度图片(Python这把利器,开启网络爬虫之路(1)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2022-02-19 11:21
摘要:获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。本文使用的版本是python3.6,用于抓取深圳大学首页的图片信息和百度股票网某只股票的日K和月K数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
【欢迎关注、点赞、采集、私信、交流】一起学习进步
获取网页源代码 获取百度图片网页
通过在百度图片上随机搜索关键词,可以得到网页地址并分析其规律性。发现可以通过修改地址末尾的word字段来搜索任意关键字的图片。因此,我们通过自定义word字段,将自定义word字段添加到固有的URL格式中来获取要爬取的网页地址,并使用requests模块中的get函数将网页的源代码下载到记忆。
如:
param={"word":"深圳大学"}
r=requests.get('/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=47_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width= &height=&face=0&istype=2&ie=utf-8&',params=param)
1.2 百度股票数据采集
百度互联互通的信息在网页上以动画的形式展示,例如:
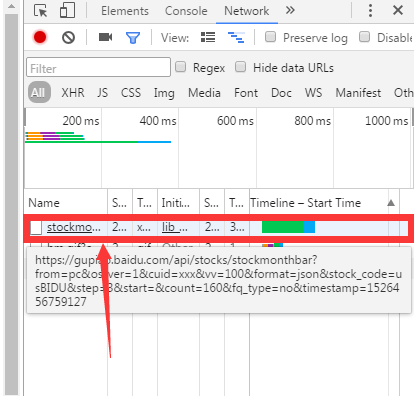
从这种显示数据的方式来看,直接从网页中获取所需的数据基本上是不可能的。因此,我们在巡视中打开网络查找动画中的数据源,如:
我们发现当月K按钮被点击时,地址出现在网络中。因此,当我们打开地址时,发现正是我们需要的数据。通过实验发现,地址中的数据会根据时间的变化自动更新。因此,复制地址,解析地址,得到要爬取的数据。
提取所需内容
2.1 从百度图片中提取图片地址
在解析网页的时候,我们发现所有页面的图片地址都在thumb:字段后面,所以我们可以使用re模块中的findall函数来匹配地址,如:
img_links=re.findall('"thumbURL":"(.*?)",',html)
获取到地址后,同样的方法可以使用requests.get将图片信息下载到内存中。
2.2 提取百度股票信息
解析之前得到的数据,发现其内容是以每个日期为单位记录的格式,而且非常有规律,如:{"errorNo":0,"errorMsg":"SUCCESS","mashData" :[ {"date":20180515,"kline":{"open":220.83999633789,"high":271.98001098633,"low":213.55599975586, "close":271.92001342773,"volume":39366713,"amount":0,"ccl":null,"preClose":272.26000976562,"netChangeRatio":-0. 201},
因此,同样的方式,通过requests.get,我们可以得到我们需要的每一条信息,比如获取零钱:
monthnetchangeratio=re.findall('"netChangeRatio":(.*?)}',html)
爬取结果整理
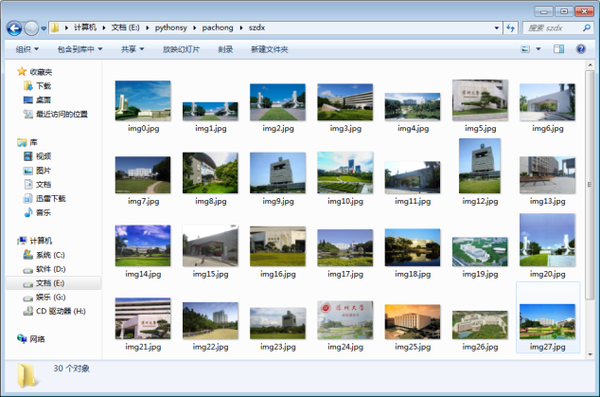
3.1 百度图片下载:
首先,创建一个保存图片的文件夹:os.makedirs('./szdx/',exist_ok=True)
获取到所有图片的地址后,可以通过设置循环来一张一张下载图片:
对于 img_links 中的链接:
picurl=链接
pic=requests.get(picurl)
打开 ('./szdx/img'+str(j)+'.jpg','wb') 作为 f:
对于 pic.iter_content(chunk_size=32):
f.write(块)
f.close()
j=j+1#这里的j是为了防止在给每张图片命名的时候重复命名。
3.2百度股票信息整理
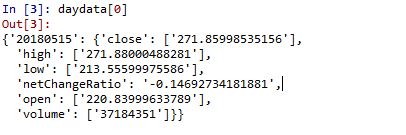
在实验中,我们使用字典来存储股票信息,方便按日期顺序检索股票信息:
月数据={}
我=0
对于 d 日期:
数据={}
数据tmp={}
datatmp['open']=re.findall(d+',"kline":{"open":(.*?),"high"',html)
...(中间信息提取过程省略)
我=我+1
图为每日K数据的第一个日期信息。
总结
通过这个实验练习,我们熟悉了网页的构成和数据爬取的基本原理。更重要的是,通过编程练习,我们发现了许多新的编程技能,并在实践中不断提高这些编程技能。经过小组讨论,确定了数据的来源,掌握了各种函数的使用方法,掌握了数据的最终存储形式,最终完成了实验。 查看全部
网页爬虫抓取百度图片(Python这把利器,开启网络爬虫之路(1)(组图))
摘要:获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。本文使用的版本是python3.6,用于抓取深圳大学首页的图片信息和百度股票网某只股票的日K和月K数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
【欢迎关注、点赞、采集、私信、交流】一起学习进步
获取网页源代码 获取百度图片网页
通过在百度图片上随机搜索关键词,可以得到网页地址并分析其规律性。发现可以通过修改地址末尾的word字段来搜索任意关键字的图片。因此,我们通过自定义word字段,将自定义word字段添加到固有的URL格式中来获取要爬取的网页地址,并使用requests模块中的get函数将网页的源代码下载到记忆。
如:
param={"word":"深圳大学"}
r=requests.get('/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=47_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width= &height=&face=0&istype=2&ie=utf-8&',params=param)
1.2 百度股票数据采集
百度互联互通的信息在网页上以动画的形式展示,例如:
从这种显示数据的方式来看,直接从网页中获取所需的数据基本上是不可能的。因此,我们在巡视中打开网络查找动画中的数据源,如:
我们发现当月K按钮被点击时,地址出现在网络中。因此,当我们打开地址时,发现正是我们需要的数据。通过实验发现,地址中的数据会根据时间的变化自动更新。因此,复制地址,解析地址,得到要爬取的数据。
提取所需内容
2.1 从百度图片中提取图片地址
在解析网页的时候,我们发现所有页面的图片地址都在thumb:字段后面,所以我们可以使用re模块中的findall函数来匹配地址,如:
img_links=re.findall('"thumbURL":"(.*?)",',html)
获取到地址后,同样的方法可以使用requests.get将图片信息下载到内存中。
2.2 提取百度股票信息
解析之前得到的数据,发现其内容是以每个日期为单位记录的格式,而且非常有规律,如:{"errorNo":0,"errorMsg":"SUCCESS","mashData" :[ {"date":20180515,"kline":{"open":220.83999633789,"high":271.98001098633,"low":213.55599975586, "close":271.92001342773,"volume":39366713,"amount":0,"ccl":null,"preClose":272.26000976562,"netChangeRatio":-0. 201},
因此,同样的方式,通过requests.get,我们可以得到我们需要的每一条信息,比如获取零钱:
monthnetchangeratio=re.findall('"netChangeRatio":(.*?)}',html)
爬取结果整理
3.1 百度图片下载:
首先,创建一个保存图片的文件夹:os.makedirs('./szdx/',exist_ok=True)
获取到所有图片的地址后,可以通过设置循环来一张一张下载图片:
对于 img_links 中的链接:
picurl=链接
pic=requests.get(picurl)
打开 ('./szdx/img'+str(j)+'.jpg','wb') 作为 f:
对于 pic.iter_content(chunk_size=32):
f.write(块)
f.close()
j=j+1#这里的j是为了防止在给每张图片命名的时候重复命名。
3.2百度股票信息整理
在实验中,我们使用字典来存储股票信息,方便按日期顺序检索股票信息:
月数据={}
我=0
对于 d 日期:
数据={}
数据tmp={}
datatmp['open']=re.findall(d+',"kline":{"open":(.*?),"high"',html)
...(中间信息提取过程省略)
我=我+1
图为每日K数据的第一个日期信息。
总结
通过这个实验练习,我们熟悉了网页的构成和数据爬取的基本原理。更重要的是,通过编程练习,我们发现了许多新的编程技能,并在实践中不断提高这些编程技能。经过小组讨论,确定了数据的来源,掌握了各种函数的使用方法,掌握了数据的最终存储形式,最终完成了实验。
网页爬虫抓取百度图片(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-18 11:06
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表重复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序import urllib.request # python自带的爬操作url的库import re # 正则表达式# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue passif __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)。如何设计正则表达式需要可以根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具import urllib # python自带的爬操作url的库# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载:%s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。 查看全部
网页爬虫抓取百度图片(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表重复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序import urllib.request # python自带的爬操作url的库import re # 正则表达式# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue passif __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)。如何设计正则表达式需要可以根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具import urllib # python自带的爬操作url的库# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载:%s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。
网页爬虫抓取百度图片(通用网络爬虫和聚焦爬虫(一):百度图片爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-17 17:21
通用爬虫和焦点爬虫
根据使用场景,网络爬虫可以分为通用爬虫和专注爬虫。
万能网络爬虫:是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,它从互联网上采集网页和采集信息,这些网页信息用于构建一个为搜索引擎提供支持的索引,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以其性能的好坏直接影响到搜索引擎的效果。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份。
聚焦爬虫:是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于,焦点爬虫在实现网络爬虫时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息。也就是一般意义上的爬行动物。
百度图片爬取
需求分析,至少要实现两个功能:一是搜索图片,二是自动下载
分析网页(注意:不用的参数可以删除不影响页面加载)源码,用F12
编写正则表达式或其他解析器代码
本地存储数据
正式写python爬虫代码
页面分析非常重要。不同的需求对应不同的URL,不同的URL的源码明显不同。因此,掌握如何分析页面是爬虫成功的第一步。本页源码分析如下图所示:
import os
import re
import requests
from colorama import Fore
def download_image(url, keyword):
"""
下载图片
:param url: 百度图片的网址
:return: Bool
"""
# 1. 向服务器发起HTTP请求
response = requests.get(url)
# 2. 获取服务器端的响应信息
# 响应信息: status_code, text, url
data = response.text # 获取页面源码
# 3. 编写正则表达式,获取图片的网址
# data = ...[{"ObjURL":"http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg",....}]...
# 需要获取到的是: http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg
# 正则的语法: .代表除了\n之外的任意字符, *代表前一个字符出现0次或者无数次. ?代表非贪婪模式
pattern = r'"objURL":"(.*?)"'
# 4. 根据正则表达式寻找符合条件的图片网址.
image_urls = re.findall(pattern, data)
# 5. 根据图片网址下载猫的图片到本地
index = 1
for image_url in image_urls:
print(image_url) # 'xxxx.jpg xxxx.png'
# response.text 返回 unicode 的文本信息, response.text 返回 bytes 类型的信息
try:
response = requests.get(image_url) # 向每一个图片的url发起HTTP请求
except Exception as e:
print(Fore.RED + "[-] 下载失败: %s" % (image_url))
else:
old_image_filename = image_url.split('/')[-1]
if old_image_filename:
# 获取图片的后缀
image_format = old_image_filename.split('.')[-1]
# 处理 url 为...jpeg?imageview&thumbnail=550x0 结尾(传参)的情况
if '?' in image_format:
image_format = image_format.split('?')[0]
else:
image_format = 'jpg'
# 生成图片的存储目录
keyword = keyword.split(' ', '-')
if not os.path.exists(keyword):
os.mkdir(keyword)
image_filename = os.path.join(keyword, str(index) + '.' + image_format)
# 保存图片
with open(image_filename, 'wb') as f:
f.write(response.content)
print(Fore.BLUE + "[+] 保存图片%s.jpg成功" % (index))
index += 1
if __name__ == '__main__':
keyword = input("请输入批量下载图片的关键字: ")
url = 'http://image.baidu.com/search/index?tn=baiduimage&word=' + keyword
print(Fore.BLUE + '[+] 正在请求网址: %s' % (url))
download_image(url, keyword)
结果:
常见问题:
为什么只有30张图片,百度有30多张图片
百度图片是响应式的,下拉的时候会不断的加载新的图片,也就是说浏览器中的页面是通过JS处理数据的结果,Ajax爬虫的内容这里不再详述。
搜索页面下点击单张图片的url与程序中获取的ObjURL不一致
这可能是百度缓存处理的结果。每张图片本质上都是“外网”,不是百度,所以在程序中,选择向实际存储图片的url发起HTTP请求。 查看全部
网页爬虫抓取百度图片(通用网络爬虫和聚焦爬虫(一):百度图片爬取)
通用爬虫和焦点爬虫
根据使用场景,网络爬虫可以分为通用爬虫和专注爬虫。
万能网络爬虫:是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,它从互联网上采集网页和采集信息,这些网页信息用于构建一个为搜索引擎提供支持的索引,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以其性能的好坏直接影响到搜索引擎的效果。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份。

聚焦爬虫:是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于,焦点爬虫在实现网络爬虫时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息。也就是一般意义上的爬行动物。
百度图片爬取
需求分析,至少要实现两个功能:一是搜索图片,二是自动下载
分析网页(注意:不用的参数可以删除不影响页面加载)源码,用F12
编写正则表达式或其他解析器代码
本地存储数据
正式写python爬虫代码
页面分析非常重要。不同的需求对应不同的URL,不同的URL的源码明显不同。因此,掌握如何分析页面是爬虫成功的第一步。本页源码分析如下图所示:

import os
import re
import requests
from colorama import Fore
def download_image(url, keyword):
"""
下载图片
:param url: 百度图片的网址
:return: Bool
"""
# 1. 向服务器发起HTTP请求
response = requests.get(url)
# 2. 获取服务器端的响应信息
# 响应信息: status_code, text, url
data = response.text # 获取页面源码
# 3. 编写正则表达式,获取图片的网址
# data = ...[{"ObjURL":"http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg",....}]...
# 需要获取到的是: http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg
# 正则的语法: .代表除了\n之外的任意字符, *代表前一个字符出现0次或者无数次. ?代表非贪婪模式
pattern = r'"objURL":"(.*?)"'
# 4. 根据正则表达式寻找符合条件的图片网址.
image_urls = re.findall(pattern, data)
# 5. 根据图片网址下载猫的图片到本地
index = 1
for image_url in image_urls:
print(image_url) # 'xxxx.jpg xxxx.png'
# response.text 返回 unicode 的文本信息, response.text 返回 bytes 类型的信息
try:
response = requests.get(image_url) # 向每一个图片的url发起HTTP请求
except Exception as e:
print(Fore.RED + "[-] 下载失败: %s" % (image_url))
else:
old_image_filename = image_url.split('/')[-1]
if old_image_filename:
# 获取图片的后缀
image_format = old_image_filename.split('.')[-1]
# 处理 url 为...jpeg?imageview&thumbnail=550x0 结尾(传参)的情况
if '?' in image_format:
image_format = image_format.split('?')[0]
else:
image_format = 'jpg'
# 生成图片的存储目录
keyword = keyword.split(' ', '-')
if not os.path.exists(keyword):
os.mkdir(keyword)
image_filename = os.path.join(keyword, str(index) + '.' + image_format)
# 保存图片
with open(image_filename, 'wb') as f:
f.write(response.content)
print(Fore.BLUE + "[+] 保存图片%s.jpg成功" % (index))
index += 1
if __name__ == '__main__':
keyword = input("请输入批量下载图片的关键字: ")
url = 'http://image.baidu.com/search/index?tn=baiduimage&word=' + keyword
print(Fore.BLUE + '[+] 正在请求网址: %s' % (url))
download_image(url, keyword)
结果:

常见问题:
为什么只有30张图片,百度有30多张图片
百度图片是响应式的,下拉的时候会不断的加载新的图片,也就是说浏览器中的页面是通过JS处理数据的结果,Ajax爬虫的内容这里不再详述。
搜索页面下点击单张图片的url与程序中获取的ObjURL不一致
这可能是百度缓存处理的结果。每张图片本质上都是“外网”,不是百度,所以在程序中,选择向实际存储图片的url发起HTTP请求。
网页爬虫抓取百度图片(fildder抓包来分析这些新闻网址等信息隐藏在那个地方 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-16 05:21
)
先分析
打开网站后,再打开源码,发现之前的一些新闻头条在源码中可以找到,而下面的头条在源码中找不到
这时候我们就需要使用fildder抓包来分析这些新闻的URL以及隐藏在那个地方的其他信息
这些有我们正在寻找的信息
我们复制网址在浏览器中打开发现不是我们要找的源信息
复制这个url找到我们的源码,比较两个url的区别
t只是一个时间戳,我们将第二个URL改为
&ajax=json
我们可以通过上面的网址访问源代码
我们受到下面蓝色网址的启发,只需要通过以上网址的拼接来获取我们的源代码
1、首先定义我们要爬取哪些字段。这是在 items 中定义的
import scrapy
class BaidunewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
"""1定义爬取的东西"""
title=scrapy.Field()
link=scrapy.Field()
content=scrapy.Field()
2、编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from baidunews.items import BaidunewsItem
from scrapy.http import Request
import re
class NewsSpider(scrapy.Spider):
name = 'news'
allowed_domains = ['news.baidu.com']
start_urls = ['http://news.baidu.com/widget%3 ... 39%3B]
all_id = ['LocalNews', 'civilnews', 'InternationalNews', 'EnterNews', 'SportNews', 'FinanceNews', 'TechNews',
'MilitaryNews', 'InternetNews', 'DiscoveryNews', 'LadyNews', 'HealthNews', 'PicWall']
all_url = []
for i in range(len(all_id)):
current_id = all_id[i]
current_url = 'http://news.baidu.com/widget?id=' + current_id + '&ajax=json'
all_url.append(current_url)
"""得到某个栏目块的url"""
def parse(self, response):
for i in range(0, len(self.all_url)):
print("第" + str(i) + "个栏目")
yield Request(self.all_url[i], callback=self.next)
"""某个模块下面的所有的新闻的url"""
def next(self, response):
data = response.body.decode('utf-8', 'ignore')
# print(self.all_url)
partten1 = '"url":"(.*?)"'
partten2 = '"m_url":"(.*?)"'
url1 = re.compile(partten1, re.S).findall(data)
url2 = re.compile(partten2, re.S).findall(data)
if (len(url1) != 0):
url = url1
else:
url = url2
# print(url)
# print("===========================")
for i in range(0, len(url)):
thisurl = re.sub(r"\\\/", '/', url[i])
# print(thisurl)
yield Request(thisurl, callback=self.next2,dont_filter=True) # thisurl是返回的值,回调函数调next2去处理,
def next2(self, response):
item = BaidunewsItem()
item['link'] = response.url
item['title'] = response.xpath("/html/head/title/text()").extract()
item['content'] = response.body
yield item
这里总结几点
1、代码中yieldRequest()中的第一个参数是yield生成器返回的值,第二个callback=XXX是接下来要调用的参数
2、yield Request(thisurl, callback=self.next2,dont_filter=True) 如果不加dont_filter=True,则无法获取返回项
3 教我的大佬解释说,allowed_domains = [''] 我们里面这个参数是设置成在URL中收录这个来获取我们想要的信息,比如current_url = '#39; + current_id + '&ajax=json ' 而且我们的每个栏目块下都没有一条新闻。只有加上上面dont_filter=True的参数才能返回我们的item信息
3、我们可以编写管道来查看一些返回的项目
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
class BaidunewsPipeline(object):
def process_item(self, item, spider):
# print("===========================")
print(item["title"].decode('utf-8')+item['link']+item['content'])
return item
4 我们还需要在执行代码之前在设置中注册
# -*- coding: utf-8 -*-
# Scrapy settings for baidunews project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
BOT_NAME = 'baidunews'
SPIDER_MODULES = ['baidunews.spiders']
NEWSPIDER_MODULE = 'baidunews.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'baidunews (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/late ... delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
#SPIDER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
#DOWNLOADER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/late ... .html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/late ... .html
#注册pipeline
ITEM_PIPELINES = {
'baidunews.pipelines.BaidunewsPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/late ... .html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/late ... tings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5然后我们就可以在命令行窗口成功执行scrapy爬取新闻了
6 下面是我们的目录结构
查看全部
网页爬虫抓取百度图片(fildder抓包来分析这些新闻网址等信息隐藏在那个地方
)
先分析

打开网站后,再打开源码,发现之前的一些新闻头条在源码中可以找到,而下面的头条在源码中找不到
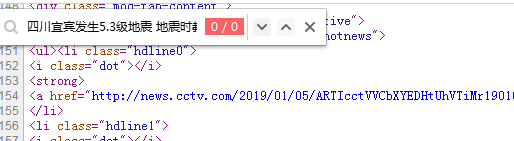
这时候我们就需要使用fildder抓包来分析这些新闻的URL以及隐藏在那个地方的其他信息

这些有我们正在寻找的信息

我们复制网址在浏览器中打开发现不是我们要找的源信息

复制这个url找到我们的源码,比较两个url的区别
t只是一个时间戳,我们将第二个URL改为
&ajax=json
我们可以通过上面的网址访问源代码
我们受到下面蓝色网址的启发,只需要通过以上网址的拼接来获取我们的源代码
1、首先定义我们要爬取哪些字段。这是在 items 中定义的
import scrapy
class BaidunewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
"""1定义爬取的东西"""
title=scrapy.Field()
link=scrapy.Field()
content=scrapy.Field()
2、编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from baidunews.items import BaidunewsItem
from scrapy.http import Request
import re
class NewsSpider(scrapy.Spider):
name = 'news'
allowed_domains = ['news.baidu.com']
start_urls = ['http://news.baidu.com/widget%3 ... 39%3B]
all_id = ['LocalNews', 'civilnews', 'InternationalNews', 'EnterNews', 'SportNews', 'FinanceNews', 'TechNews',
'MilitaryNews', 'InternetNews', 'DiscoveryNews', 'LadyNews', 'HealthNews', 'PicWall']
all_url = []
for i in range(len(all_id)):
current_id = all_id[i]
current_url = 'http://news.baidu.com/widget?id=' + current_id + '&ajax=json'
all_url.append(current_url)
"""得到某个栏目块的url"""
def parse(self, response):
for i in range(0, len(self.all_url)):
print("第" + str(i) + "个栏目")
yield Request(self.all_url[i], callback=self.next)
"""某个模块下面的所有的新闻的url"""
def next(self, response):
data = response.body.decode('utf-8', 'ignore')
# print(self.all_url)
partten1 = '"url":"(.*?)"'
partten2 = '"m_url":"(.*?)"'
url1 = re.compile(partten1, re.S).findall(data)
url2 = re.compile(partten2, re.S).findall(data)
if (len(url1) != 0):
url = url1
else:
url = url2
# print(url)
# print("===========================")
for i in range(0, len(url)):
thisurl = re.sub(r"\\\/", '/', url[i])
# print(thisurl)
yield Request(thisurl, callback=self.next2,dont_filter=True) # thisurl是返回的值,回调函数调next2去处理,
def next2(self, response):
item = BaidunewsItem()
item['link'] = response.url
item['title'] = response.xpath("/html/head/title/text()").extract()
item['content'] = response.body
yield item
这里总结几点
1、代码中yieldRequest()中的第一个参数是yield生成器返回的值,第二个callback=XXX是接下来要调用的参数
2、yield Request(thisurl, callback=self.next2,dont_filter=True) 如果不加dont_filter=True,则无法获取返回项
3 教我的大佬解释说,allowed_domains = [''] 我们里面这个参数是设置成在URL中收录这个来获取我们想要的信息,比如current_url = '#39; + current_id + '&ajax=json ' 而且我们的每个栏目块下都没有一条新闻。只有加上上面dont_filter=True的参数才能返回我们的item信息
3、我们可以编写管道来查看一些返回的项目
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
class BaidunewsPipeline(object):
def process_item(self, item, spider):
# print("===========================")
print(item["title"].decode('utf-8')+item['link']+item['content'])
return item
4 我们还需要在执行代码之前在设置中注册
# -*- coding: utf-8 -*-
# Scrapy settings for baidunews project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
BOT_NAME = 'baidunews'
SPIDER_MODULES = ['baidunews.spiders']
NEWSPIDER_MODULE = 'baidunews.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'baidunews (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/late ... delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
#SPIDER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
#DOWNLOADER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/late ... .html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/late ... .html
#注册pipeline
ITEM_PIPELINES = {
'baidunews.pipelines.BaidunewsPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/late ... .html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/late ... tings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5然后我们就可以在命令行窗口成功执行scrapy爬取新闻了
6 下面是我们的目录结构

网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-16 05:20
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,但是请求方法比较简单
不要忘记爬虫的基本思想:
1.指定要爬取的链接,然后爬取网站源码
2.提取你想要的内容,比如如果要爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签方法
3.循环获取要爬取的内容列表并保存文件
这里的代码和我博客前几章的代码(图片爬虫系列一)的区别是:
1.reques库用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀名
3.保存图片时不使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
注意我们之所以判断图片链接是否以“https://”开头,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一个图片,然后点击html所在的代码。 ,按住鼠标,可以看到绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图:
查看全部
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生)
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,但是请求方法比较简单
不要忘记爬虫的基本思想:
1.指定要爬取的链接,然后爬取网站源码
2.提取你想要的内容,比如如果要爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签方法
3.循环获取要爬取的内容列表并保存文件
这里的代码和我博客前几章的代码(图片爬虫系列一)的区别是:
1.reques库用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀名
3.保存图片时不使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
注意我们之所以判断图片链接是否以“https://”开头,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一个图片,然后点击html所在的代码。 ,按住鼠标,可以看到绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图:
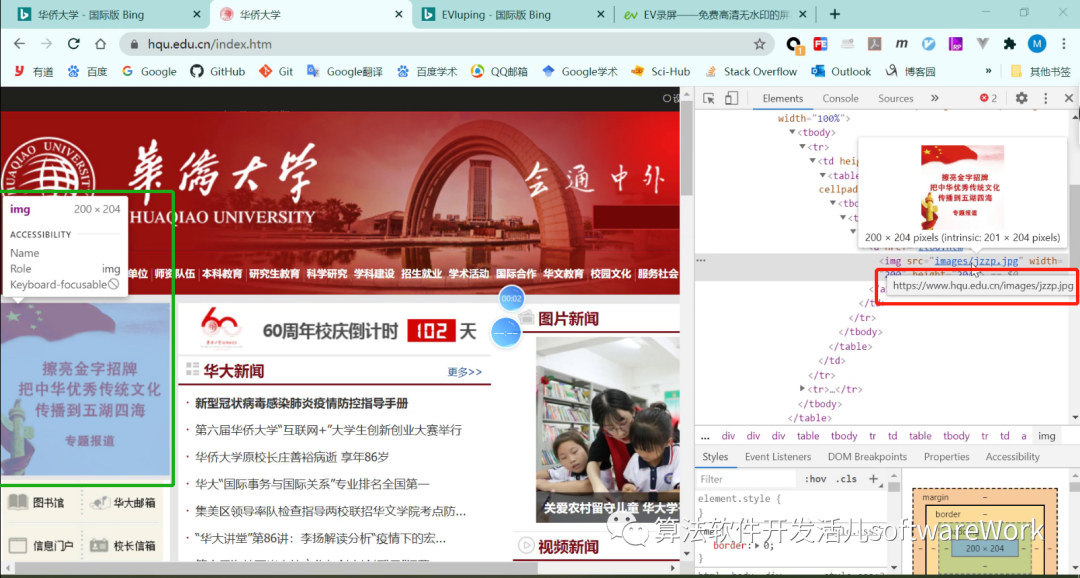
网页爬虫抓取百度图片(#第一次学习爬虫后,自己编码抓取图片' )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-16 05:11
)
#第一次学爬虫后,自己编码和抓图
##下面介绍主要流程
先打开一个你要抓图的网页,我以''为例|
url = 'https://www.quanjing.com/creat ... 39%3B
2.然后阅读网页的源码,我们可以在源码中找到我们要抓取的图片对应的链接|
这里可能有人文,网页的源代码在哪里?
答:右键找到网页源代码,或者直接F12
html = urllib.request.urlopen(url).read().decode('utf-8')
运行后,我们可以看到链接抓取成功,都是以列表的形式抓取的:
3.下面使用 urllib.request.urlretrieve(url, 'target address')
要从对应链接下载图片,首先要把上面得到的字符串形式转换成不带“”的链接
html1 = i.replace('"','')``
4.批量下载到本地
```python
for i in page_list:
html1 = i.replace('"','')
print(html1)
global x
urllib.request.urlretrieve(html1, 'image\%s.jpg' % x)
x+=1
这里保存到py文件对应目录下的image文件中
查看全部
网页爬虫抓取百度图片(#第一次学习爬虫后,自己编码抓取图片'
)
#第一次学爬虫后,自己编码和抓图
##下面介绍主要流程
先打开一个你要抓图的网页,我以''为例|
url = 'https://www.quanjing.com/creat ... 39%3B
2.然后阅读网页的源码,我们可以在源码中找到我们要抓取的图片对应的链接|
这里可能有人文,网页的源代码在哪里?
答:右键找到网页源代码,或者直接F12
html = urllib.request.urlopen(url).read().decode('utf-8')
运行后,我们可以看到链接抓取成功,都是以列表的形式抓取的:

3.下面使用 urllib.request.urlretrieve(url, 'target address')
要从对应链接下载图片,首先要把上面得到的字符串形式转换成不带“”的链接
html1 = i.replace('"','')``
4.批量下载到本地
```python
for i in page_list:
html1 = i.replace('"','')
print(html1)
global x
urllib.request.urlretrieve(html1, 'image\%s.jpg' % x)
x+=1
这里保存到py文件对应目录下的image文件中

网页爬虫抓取百度图片(在python学习之路(10):爬虫进阶,使用python爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-14 08:11
python学习之路(一0):高级爬虫,用python爬取你喜欢的小说
在这个 文章 中,我们使用 BeautifulSoup 爬取了一本小说。这是学习BeautifulSoup后写的第一个小程序,但是感觉自己对BeautifulSoup的使用不够熟练,所以再写一个爬虫。增强 BeautifulSoup 的使用。
本次抓取微信公众号的文章标题、文章摘要、文章网址、文章封面图片网址、公众号名称等信息。
python学习之路(12):连接Mysql数据库及简单的增删改查查询回滚操作)
在这个文章中,我们谈到了mysql的使用,所以这次我们将抓取的数据存储在数据库中。
我们不应该忘记我们以前学过的知识。我们应该把以前学过的东西都应用到现在的学习中,这样可以让我们复习旧知识,更牢牢地掌握知识点。
微信文章捕获的地址为:
这是搜狗微信的搜索页面,里面的文章每隔几个小时就会更新一次。所以在这里抓取 文章 是相当全面的。
想法
1、 研究网页结构
2、 使用 BeautifulSoup 解析我们需要的信息
3、 将解析后的信息存入mysql数据库
学习网络结构
研究网页的结构,当然是右键->检查元素
但是很快我发现了一个问题,每个页面只有20篇微信文章文章,要查看更多,我必须点击“加载更多”按钮。首先想了一下能不能用python来点击,但是网上找的方法太深奥了,对python的学习还没有深入,所以决定换一种方式。
懂一点JS的人都知道,如果是做“加载更多”之类的功能,就必须使用AJAX向服务器请求新的数据,所以在我点击“加载更多”按钮后,我使用了浏览器的网络看到这个请求。
我猜这一定是请求新数据的接口,我们打开看看
哈哈,这个页面也是微信文章的页面,简单多了,大大降低了我们分析的难度。
并且发现了另一种模式。此 URL 以 1.html 结尾。
如果我把它改成 2.html
哈哈,神奇的发现改成2.html还是可以访问的,所以我大胆猜测,这应该是页数的意思。
我在上面的 URL 中发现的另一个有趣的事情是有一个 PC_0。
所以我决定把它改成 pc_1 试试看。
还能访问,看到这边的信息让我觉得这是不是文章的另一类。
在审查了元素之后,这证实了我的怀疑。
经过以上研究,以下地址
可以得出两个结论:
1、后面的1.html是页数,不同的数字代表不同的页数。
2、 后面pc_0中的0代表分类,不同的数字代表不同的类型。
有了这两个结论,我们写一个抓微信文章的代码就简单多了。
这个文章就写到这里了,后面我会根据这个文章得到的结论来谈抓数据,因为我在研究这个网页的时候也在写这个文章。我也写了代码。这个文章会先解释一下研究一个网页的思路。等我把代码写好整理后,分享给大家。 查看全部
网页爬虫抓取百度图片(在python学习之路(10):爬虫进阶,使用python爬取)
python学习之路(一0):高级爬虫,用python爬取你喜欢的小说
在这个 文章 中,我们使用 BeautifulSoup 爬取了一本小说。这是学习BeautifulSoup后写的第一个小程序,但是感觉自己对BeautifulSoup的使用不够熟练,所以再写一个爬虫。增强 BeautifulSoup 的使用。
本次抓取微信公众号的文章标题、文章摘要、文章网址、文章封面图片网址、公众号名称等信息。
python学习之路(12):连接Mysql数据库及简单的增删改查查询回滚操作)
在这个文章中,我们谈到了mysql的使用,所以这次我们将抓取的数据存储在数据库中。
我们不应该忘记我们以前学过的知识。我们应该把以前学过的东西都应用到现在的学习中,这样可以让我们复习旧知识,更牢牢地掌握知识点。
微信文章捕获的地址为:
这是搜狗微信的搜索页面,里面的文章每隔几个小时就会更新一次。所以在这里抓取 文章 是相当全面的。
想法
1、 研究网页结构
2、 使用 BeautifulSoup 解析我们需要的信息
3、 将解析后的信息存入mysql数据库
学习网络结构
研究网页的结构,当然是右键->检查元素
但是很快我发现了一个问题,每个页面只有20篇微信文章文章,要查看更多,我必须点击“加载更多”按钮。首先想了一下能不能用python来点击,但是网上找的方法太深奥了,对python的学习还没有深入,所以决定换一种方式。
懂一点JS的人都知道,如果是做“加载更多”之类的功能,就必须使用AJAX向服务器请求新的数据,所以在我点击“加载更多”按钮后,我使用了浏览器的网络看到这个请求。
我猜这一定是请求新数据的接口,我们打开看看
哈哈,这个页面也是微信文章的页面,简单多了,大大降低了我们分析的难度。
并且发现了另一种模式。此 URL 以 1.html 结尾。
如果我把它改成 2.html
哈哈,神奇的发现改成2.html还是可以访问的,所以我大胆猜测,这应该是页数的意思。
我在上面的 URL 中发现的另一个有趣的事情是有一个 PC_0。
所以我决定把它改成 pc_1 试试看。
还能访问,看到这边的信息让我觉得这是不是文章的另一类。
在审查了元素之后,这证实了我的怀疑。
经过以上研究,以下地址
可以得出两个结论:
1、后面的1.html是页数,不同的数字代表不同的页数。
2、 后面pc_0中的0代表分类,不同的数字代表不同的类型。
有了这两个结论,我们写一个抓微信文章的代码就简单多了。
这个文章就写到这里了,后面我会根据这个文章得到的结论来谈抓数据,因为我在研究这个网页的时候也在写这个文章。我也写了代码。这个文章会先解释一下研究一个网页的思路。等我把代码写好整理后,分享给大家。
网页爬虫抓取百度图片(用Jsoup解析img标签并提取里面的title和data-original属性 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-08 00:14
)
大家好,我是小北。
在普通的群聊中,有时会遇到那种欺负人。如果你不同意,你会开始谈论阴阳并发送各种表情符号。但是,你的微信表情总是一点点,不够个性,上网去百度太麻烦了。本文文章根据emoji中的关键词网站下载emoji到本地,让黑帮远离你。
本文使用java的OKHttp框架作为爬虫抓取“post emoji”网站()的表情包,使用Jsoup框架解析抓取到的网页。
马文
OKHttp是一个优秀的网络请求框架,可以请求http、https、get()、post()、put()等请求方法。Jsoup是一个解析网页的框架,可以像JS一样使用。
com.squareup.okhttp3
okhttp
4.9.3
org.jsoup
jsoup
1.14.3
思路分析
打开网站,搜索关键字[Loading Force]的表情包,打开F12控制面板,可以看到每个表情包都收录在div元素中,翻的时候可以读取url地址这一页。可以看到第一页最后一个数字是1,第二页是2,第三页是3。这个很容易做到,只需要改变数字即可。
String url = String.format("https://fabiaoqing.com/search/ ... ot%3B, "装逼", 1);
public Request buildRequest(String url) {
Request request = new Request.Builder()
.url(url)
.build();
return request;
}
public Response getResponse( Request request) {
Response response = null;
try {
OkHttpClient client = new OkHttpClient();
response = client.newCall(request).execute();
System.out.println(response.body().string());
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
继续查看网页源码,表情图片隐藏在div层下的img表情中,使用Jsoup解析img标签,提取里面的title和data-original属性,作为文件名和内容图片。
Map map = new HashMap();
Document document = Jsoup.parse(html);
Elements elements = document.getElementsByClass("ui image bqppsearch lazy");
for (Element element : elements) {
Attributes attributes = element.attributes();
String key = attributes.get("title").replaceAll("\\n", "").replaceAll("[/\\\\\\\\:*?|\\\"]", "");
String value = attributes.get("data-original");
map.put(key, value);
} 查看全部
网页爬虫抓取百度图片(用Jsoup解析img标签并提取里面的title和data-original属性
)
大家好,我是小北。

在普通的群聊中,有时会遇到那种欺负人。如果你不同意,你会开始谈论阴阳并发送各种表情符号。但是,你的微信表情总是一点点,不够个性,上网去百度太麻烦了。本文文章根据emoji中的关键词网站下载emoji到本地,让黑帮远离你。
本文使用java的OKHttp框架作为爬虫抓取“post emoji”网站()的表情包,使用Jsoup框架解析抓取到的网页。
马文
OKHttp是一个优秀的网络请求框架,可以请求http、https、get()、post()、put()等请求方法。Jsoup是一个解析网页的框架,可以像JS一样使用。
com.squareup.okhttp3
okhttp
4.9.3
org.jsoup
jsoup
1.14.3
思路分析
打开网站,搜索关键字[Loading Force]的表情包,打开F12控制面板,可以看到每个表情包都收录在div元素中,翻的时候可以读取url地址这一页。可以看到第一页最后一个数字是1,第二页是2,第三页是3。这个很容易做到,只需要改变数字即可。
String url = String.format("https://fabiaoqing.com/search/ ... ot%3B, "装逼", 1);
public Request buildRequest(String url) {
Request request = new Request.Builder()
.url(url)
.build();
return request;
}
public Response getResponse( Request request) {
Response response = null;
try {
OkHttpClient client = new OkHttpClient();
response = client.newCall(request).execute();
System.out.println(response.body().string());
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
继续查看网页源码,表情图片隐藏在div层下的img表情中,使用Jsoup解析img标签,提取里面的title和data-original属性,作为文件名和内容图片。

Map map = new HashMap();
Document document = Jsoup.parse(html);
Elements elements = document.getElementsByClass("ui image bqppsearch lazy");
for (Element element : elements) {
Attributes attributes = element.attributes();
String key = attributes.get("title").replaceAll("\\n", "").replaceAll("[/\\\\\\\\:*?|\\\"]", "");
String value = attributes.get("data-original");
map.put(key, value);
}
网页爬虫抓取百度图片( 网站怎么做SEO关键词-如何分类网站优化关键词、方法和优化技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-26 15:18
网站怎么做SEO关键词-如何分类网站优化关键词、方法和优化技巧)
百度 收录 请求 - 为什么百度没有索引您的 网站
网站添加阿里妈妈广告导致百度收录少或没有收录!如果一定要改程序,建议你彻底关闭网站1个月后再重新上传你的程序,这样百度会认为你是新站点,网站会容易很多@收录。因为cn域名比较便宜,很多人用cn域名做垃圾邮件网站,影响百度很多cn自有网页收录少或没有收录!...
网站如何做SEO关键词-如何分类网站优化关键词,方法和优化技巧!
今天就和大家聊聊网站、网站关键词分类优化中最重要的一项。那么接下来就讲讲网站优化关键词的分类方法、优化技巧!那么网站关键词怎么分类呢?4、brands关键词:一般设置在每页标题的最后,是网站关键词的唯一性,也是常见的建立品牌的方式品牌。2、根据网站优化:关键词大致可以分为核心词、需求词、品牌词。网站关键词有哪些优化技巧...
什么是 SEO 内部链接和外部链接 - 外部链接和内部链接有什么区别?
什么是外部链接?例如,百度是一个常见的外部链接。什么是内部链接?面比较重要,可以先抓收录。有了内部链接和外部链接的解释,您已经知道了外部链接和内部链接的区别。垃圾网站你也投票,那你的投票权就会越来越小。做外链和内链需要注意什么?所以一个好的网站必须有很多外部链接。没有投票,所以你在论坛上发帖是没有用的。快速增长或快速...
SEO优化的优势——SEO优化和SEM竞价的优缺点和区别
PPC的优缺点:搜索引擎优化的优缺点:1、价格低,网站维持排名一年的成本可能只做一到两个月,竞价是比较便宜很多。3、手机、MP3等难以区分和竞争关键词,排名难优化,时间长,价格高,太难的话不适合优化。通过对以上优缺点的总结和分析,网站优化的整体效果远胜于竞品排名,价格也优于竞品…… 查看全部
网页爬虫抓取百度图片(
网站怎么做SEO关键词-如何分类网站优化关键词、方法和优化技巧)
百度 收录 请求 - 为什么百度没有索引您的 网站
网站添加阿里妈妈广告导致百度收录少或没有收录!如果一定要改程序,建议你彻底关闭网站1个月后再重新上传你的程序,这样百度会认为你是新站点,网站会容易很多@收录。因为cn域名比较便宜,很多人用cn域名做垃圾邮件网站,影响百度很多cn自有网页收录少或没有收录!...
网站如何做SEO关键词-如何分类网站优化关键词,方法和优化技巧!
今天就和大家聊聊网站、网站关键词分类优化中最重要的一项。那么接下来就讲讲网站优化关键词的分类方法、优化技巧!那么网站关键词怎么分类呢?4、brands关键词:一般设置在每页标题的最后,是网站关键词的唯一性,也是常见的建立品牌的方式品牌。2、根据网站优化:关键词大致可以分为核心词、需求词、品牌词。网站关键词有哪些优化技巧...
什么是 SEO 内部链接和外部链接 - 外部链接和内部链接有什么区别?
什么是外部链接?例如,百度是一个常见的外部链接。什么是内部链接?面比较重要,可以先抓收录。有了内部链接和外部链接的解释,您已经知道了外部链接和内部链接的区别。垃圾网站你也投票,那你的投票权就会越来越小。做外链和内链需要注意什么?所以一个好的网站必须有很多外部链接。没有投票,所以你在论坛上发帖是没有用的。快速增长或快速...
SEO优化的优势——SEO优化和SEM竞价的优缺点和区别
PPC的优缺点:搜索引擎优化的优缺点:1、价格低,网站维持排名一年的成本可能只做一到两个月,竞价是比较便宜很多。3、手机、MP3等难以区分和竞争关键词,排名难优化,时间长,价格高,太难的话不适合优化。通过对以上优缺点的总结和分析,网站优化的整体效果远胜于竞品排名,价格也优于竞品……
网页爬虫抓取百度图片(爬虫项目学习之爬取地址特点通过右键的分析方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2022-02-26 10:23
1、总结
目的:学习爬虫项目,使用requests方法爬取百度贴吧美容吧每篇帖子的图片,并保存在本地。
方法:首先通过requests请求美容吧网页的内容;二、通过xpath方法清理数据,获取每个post的url地址;再次请求每个帖子的地址,从每个帖子地址爬取图片链接;最后,请求图像数据并将数据以二进制格式保存在本地。
2、网页分析
如下图,这是本次爬取的目标网站,百度美吧,要求:爬取每个帖子里的图片,保存到本地。爬取网站首先需要分析网站的特征。需要分析的内容包括:网站页面的特征、post url地址的特征、图片链接地址的获取方式。以下是我需要分析的内容:
2.1 美容吧网页特色
美容棒:%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0
观察可以看出kw为搜索内容,pn为页码,第一页为0,第二页为50,所以页码的公式为pn=(页数-1)*50。
2.2 Post url 地址功能
通过右键-勾选,可以查看网页的源代码信息,从中我们可以定位到每个帖子的代码,如下图:
可以看到,点击“我真的很漂亮”的帖子,定位到代码,可见帖子的url地址在这段代码中;然后点击href =p/6593341944,发现跳转到帖子“我真的很漂亮”太漂亮了,此时的url地址是:,所以可以发现帖子的地址主要是由两部分组成:+href的内容,所以我们只需要爬取href =p/6593341944的内容,然后拼接,就可以得到每个帖子的地址。
通过xpath_help工具,写: //div[@class="threadlist_title pull_left j_th_tit "]/a/@href 得到每个url地址的一部分。
2.3 获取帖子的图片链接
获取每个帖子的链接,通过类似操作找到帖子中图片的链接地址,如下图定位到图片的链接
同理,通过xpath_help匹配图片链接,代码为://img[@class="BDE_Image"]/@src
3、程序代码:
# -*- 编码:utf-8 -*-import requestsfrom lxml import etreeimport os#爬虫类BtcSpider(object):def __init__(self):#爬取美女图片#解析:美妆吧url地址,pn值决定页码, pn = 0 第一页, pn = 50 第二页...self.url = '%E7%BE%8E%E5%A5%B3&ie=utf-8&pn={}'self.headers = { ' User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',}os.makedirs('美颜图片',exist_ok=True)self.dir = '美颜图片\\'#发送请求def get_response(self,url):response = requests.get(url,headers = self.headers)data = response.textreturn data#发送请求获取网页数据,数据以二进制内容形式读取 def get_data(self,url) :data = requests.get(url,headers = self.headers).contentreturn data#parse data, 封装 xpathdef get_xpath(self,html,pattern):#build tree p = etree.HTML(html)#解析网页内容,获取url_listsresult = p.xpath(pattern)return result#下载图片 &def download_src(self,url):html = self.get_response(url)html = html.replace ("
内容 查看全部
网页爬虫抓取百度图片(爬虫项目学习之爬取地址特点通过右键的分析方法(图))
1、总结
目的:学习爬虫项目,使用requests方法爬取百度贴吧美容吧每篇帖子的图片,并保存在本地。
方法:首先通过requests请求美容吧网页的内容;二、通过xpath方法清理数据,获取每个post的url地址;再次请求每个帖子的地址,从每个帖子地址爬取图片链接;最后,请求图像数据并将数据以二进制格式保存在本地。
2、网页分析
如下图,这是本次爬取的目标网站,百度美吧,要求:爬取每个帖子里的图片,保存到本地。爬取网站首先需要分析网站的特征。需要分析的内容包括:网站页面的特征、post url地址的特征、图片链接地址的获取方式。以下是我需要分析的内容:
2.1 美容吧网页特色
美容棒:%E7%BE%8E%E5%A5%B3&ie=utf-8&pn=0
观察可以看出kw为搜索内容,pn为页码,第一页为0,第二页为50,所以页码的公式为pn=(页数-1)*50。
2.2 Post url 地址功能
通过右键-勾选,可以查看网页的源代码信息,从中我们可以定位到每个帖子的代码,如下图:
可以看到,点击“我真的很漂亮”的帖子,定位到代码,可见帖子的url地址在这段代码中;然后点击href =p/6593341944,发现跳转到帖子“我真的很漂亮”太漂亮了,此时的url地址是:,所以可以发现帖子的地址主要是由两部分组成:+href的内容,所以我们只需要爬取href =p/6593341944的内容,然后拼接,就可以得到每个帖子的地址。
通过xpath_help工具,写: //div[@class="threadlist_title pull_left j_th_tit "]/a/@href 得到每个url地址的一部分。
2.3 获取帖子的图片链接
获取每个帖子的链接,通过类似操作找到帖子中图片的链接地址,如下图定位到图片的链接
同理,通过xpath_help匹配图片链接,代码为://img[@class="BDE_Image"]/@src
3、程序代码:
# -*- 编码:utf-8 -*-import requestsfrom lxml import etreeimport os#爬虫类BtcSpider(object):def __init__(self):#爬取美女图片#解析:美妆吧url地址,pn值决定页码, pn = 0 第一页, pn = 50 第二页...self.url = '%E7%BE%8E%E5%A5%B3&ie=utf-8&pn={}'self.headers = { ' User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',}os.makedirs('美颜图片',exist_ok=True)self.dir = '美颜图片\\'#发送请求def get_response(self,url):response = requests.get(url,headers = self.headers)data = response.textreturn data#发送请求获取网页数据,数据以二进制内容形式读取 def get_data(self,url) :data = requests.get(url,headers = self.headers).contentreturn data#parse data, 封装 xpathdef get_xpath(self,html,pattern):#build tree p = etree.HTML(html)#解析网页内容,获取url_listsresult = p.xpath(pattern)return result#下载图片 &def download_src(self,url):html = self.get_response(url)html = html.replace ("
内容
网页爬虫抓取百度图片( 爬虫通用爬虫技术框架爬虫系统的诞生蜘蛛爬虫系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-25 19:13
爬虫通用爬虫技术框架爬虫系统的诞生蜘蛛爬虫系统)
干货全流程| 入门级爬虫技术原理,这就够了
爬虫系统的诞生
蜘蛛爬虫
一般搜索引擎的处理对象是互联网页面。目前,互联网页面数量已达100亿。因此,搜索引擎面临的第一个问题就是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地。互联网网页的镜像备份在本地形成。
网络爬虫可以发挥这样的作用,完成这项艰巨的任务。它是搜索引擎系统中一个非常关键和基本的组件。本文主要介绍网络爬虫相关的技术。虽然爬虫经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,它们也面临着一些新的挑战。
通用爬虫技术框架
爬虫系统首先从互联网页面中精心挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子放入待爬取的URL队列中。爬虫依次读取要爬取的URL,通过DNS Parse传递URL,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载网页。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载网页的URL放入爬取队列,记录爬虫系统已经下载的网页URL,避免系统重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在下载的URL队列中进行检查。如果发现该链接没有被爬取,则将其放在待爬取的URL队列的末尾。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。
常见爬虫架构
以上是一般爬虫的整体流程。从宏观上看,动态爬取过程中的爬虫与互联网上所有网页的关系可以概括为以下五个部分:
下载网页的绑定:爬虫从互联网上下载到本地索引的网页的集合。
过期网页组合:由于网页数量较多,爬虫完成一轮完整的爬取需要较长时间。在爬取过程中,很多下载的网页可能已经更新,导致过期。原因是互联网上的网页处于不断动态变化的过程中,很容易产生本地网页内容与真实互联网的不一致。
待下载网页集合:URL队列中待爬取的网页,这些网页即将被爬虫下载。
已知网页集合:这些网页没有被爬虫下载,也没有出现在待爬取的URL队列中。通过已经爬取的网页或者待爬取的URL队列中的网页,总是可以通过链接关系找到它们。稍后会被爬虫抓取和索引。
未知网页的集合:一些网页无法被爬虫抓取,这些网页构成了未知网页的组合。实际上,这部分页面占比很高。
互联网页面划分
从理解爬虫的角度来看,以上对互联网页面的划分有助于深入理解搜索引擎爬虫面临的主要任务和挑战。绝大多数爬虫系统都遵循上述流程,但并非所有爬虫系统都如此一致。根据具体的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫系统可以分为以下三种。
批处理式爬虫:批处理式爬虫的抓取范围和目标比较明确。当爬虫达到这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容发生变化是常有的事,增量爬虫需要及时反映这种变化,所以在不断的爬取过程,他们要么是在爬取新的网页,要么是在更新现有的网页。常见的商业搜索引擎爬虫基本属于这一类。
垂直爬虫:垂直爬虫专注于属于特定行业的特定主题或网页。比如健康网站,你只需要从互联网页面中找到健康相关的页面内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,下载后不可能屏蔽所有的互联网页面,这样会造成资源的过度浪费。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关,尽量不使用。爬取不相关的页面以达到节省资源的目的。垂直搜索网站或垂直行业网站往往需要这种爬虫。
好的爬行动物的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是用爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实用的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫多线程运行,以多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会部署在全球、不同区域,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议来告知爬虫哪些内容不是。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaimage-package">
索引网页与互联网网页
爬取的本地网页很可能发生了变化,或者被删除,或者内容发生了变化,因为爬虫完成一轮爬取需要很长时间,所以部分爬取的网页肯定是过期的。因此,网页库中的过期数据越少,网页的新鲜度就越好,对提升用户体验大有裨益。如果新颖性不好,搜索结果全是过时数据,或者网页被删除,用户的内心感受可想而知。
尽管 Internet 上有很多网页,但每个网页都有很大的不同。例如,腾讯和网易新闻的网页与作弊网页一样重要。如果搜索引擎抓取的网页大部分都是比较重要的网页,就可以说明他们在抓取网页的重要性方面做得很好。你在这方面做得越好,搜索引擎就会越准确。
通过以上三个标准的分析,爬虫开发的目标可以简单描述为:在资源有限的情况下,由于搜索引擎只能爬取互联网上现有网页的一部分,所以更重要的部分应尽可能选择。要索引的页面;对于已经爬取的页面,尽快更新内容,使被索引页面的内容与互联网上对应页面的内容同步更新;网页。三个“尽可能”基本明确了爬虫系统提升用户体验的目标。
为了满足这三个质量标准,大型商业搜索引擎开发了多套针对性强的爬虫系统。以谷歌为例,至少有两种不同的爬虫系统,一种叫做Fresh Bot,主要考虑网页的新鲜度。对于内容更新频繁的网页,目前更新周期可以达到秒级;另一组称为 Deep Crawl Bot,主要针对更新不频繁、更新周期为几天的网页抓取。此外,谷歌在开发暗网爬虫系统方面也投入了大量精力。以后有时间讲解暗网系统。
谷歌的两个爬虫系统
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 解密爬虫爬取更新网页的策略方法
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
网页爬虫抓取百度图片(
爬虫通用爬虫技术框架爬虫系统的诞生蜘蛛爬虫系统)
干货全流程| 入门级爬虫技术原理,这就够了
爬虫系统的诞生
蜘蛛爬虫
一般搜索引擎的处理对象是互联网页面。目前,互联网页面数量已达100亿。因此,搜索引擎面临的第一个问题就是:如何设计一个高效的下载系统,将如此海量的网页数据传输到本地。互联网网页的镜像备份在本地形成。
网络爬虫可以发挥这样的作用,完成这项艰巨的任务。它是搜索引擎系统中一个非常关键和基本的组件。本文主要介绍网络爬虫相关的技术。虽然爬虫经过几十年的发展,在整体框架上已经比较成熟,但随着互联网的不断发展,它们也面临着一些新的挑战。
通用爬虫技术框架
爬虫系统首先从互联网页面中精心挑选一些网页,将这些网页的链接地址作为种子URL,将这些种子放入待爬取的URL队列中。爬虫依次读取要爬取的URL,通过DNS Parse传递URL,将链接地址转换为网站服务器对应的IP地址。然后把它和网页的相对路径名交给网页下载器,网页下载器负责下载网页。对于下载到本地的网页,一方面是存储在页库中,等待索引等后续处理;另一方面,将下载网页的URL放入爬取队列,记录爬虫系统已经下载的网页URL,避免系统重复爬取。对于刚刚下载的网页,提取其中收录的所有链接信息,并在下载的URL队列中进行检查。如果发现该链接没有被爬取,则将其放在待爬取的URL队列的末尾。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。该 URL 对应的网页将在爬取计划中下载。这样就形成了一个循环,直到待爬取的URL队列为空,这意味着爬虫系统已经对所有可以爬取的网页进行了爬取,此时完成了一个完整的爬取过程。
常见爬虫架构
以上是一般爬虫的整体流程。从宏观上看,动态爬取过程中的爬虫与互联网上所有网页的关系可以概括为以下五个部分:
下载网页的绑定:爬虫从互联网上下载到本地索引的网页的集合。
过期网页组合:由于网页数量较多,爬虫完成一轮完整的爬取需要较长时间。在爬取过程中,很多下载的网页可能已经更新,导致过期。原因是互联网上的网页处于不断动态变化的过程中,很容易产生本地网页内容与真实互联网的不一致。
待下载网页集合:URL队列中待爬取的网页,这些网页即将被爬虫下载。
已知网页集合:这些网页没有被爬虫下载,也没有出现在待爬取的URL队列中。通过已经爬取的网页或者待爬取的URL队列中的网页,总是可以通过链接关系找到它们。稍后会被爬虫抓取和索引。
未知网页的集合:一些网页无法被爬虫抓取,这些网页构成了未知网页的组合。实际上,这部分页面占比很高。
互联网页面划分
从理解爬虫的角度来看,以上对互联网页面的划分有助于深入理解搜索引擎爬虫面临的主要任务和挑战。绝大多数爬虫系统都遵循上述流程,但并非所有爬虫系统都如此一致。根据具体的应用,爬虫系统在很多方面都有所不同。一般来说,爬虫系统可以分为以下三种。
批处理式爬虫:批处理式爬虫的抓取范围和目标比较明确。当爬虫达到这个设定的目标时,它会停止爬取过程。至于具体的目标,可能不一样,可能是设置爬取一定数量的网页,也可能是设置爬取时间等等,都不一样。
增量爬虫:与批量爬虫不同,增量爬虫会不断地爬取。抓取到的网页要定期更新,因为互联网网页在不断变化,新网页、网页被删除或网页内容发生变化是常有的事,增量爬虫需要及时反映这种变化,所以在不断的爬取过程,他们要么是在爬取新的网页,要么是在更新现有的网页。常见的商业搜索引擎爬虫基本属于这一类。
垂直爬虫:垂直爬虫专注于属于特定行业的特定主题或网页。比如健康网站,你只需要从互联网页面中找到健康相关的页面内容,其他行业的内容是没有的。考虑范围。垂直爬虫最大的特点和难点之一是如何识别网页内容是否属于指定行业或主题。从节省系统资源的角度来看,下载后不可能屏蔽所有的互联网页面,这样会造成资源的过度浪费。爬虫往往需要在爬取阶段动态识别某个URL是否与主题相关,尽量不使用。爬取不相关的页面以达到节省资源的目的。垂直搜索网站或垂直行业网站往往需要这种爬虫。
好的爬行动物的特征
一个优秀爬虫的特性可能针对不同的应用有不同的实现方式,但是一个实用的爬虫应该具备以下特性。
01高性能
互联网上的网页数量非常庞大。因此,爬虫的性能非常重要。这里的性能主要是指爬虫下载网页的爬取速度。常用的评价方法是用爬虫每秒可以下载的网页数量作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越高。
为了提高爬虫的性能,设计时程序访问磁盘的操作方式和具体实现时数据结构的选择至关重要。例如,对于待爬取的URL队列和已爬取的URL队列,由于URL的数量非常多,不同实现方式的性能非常重要。性能差异很大,所以高效的数据结构对爬虫性能影响很大。
02 可扩展性
即使单个爬虫的性能很高,将所有网页下载到本地仍然需要很长时间。为了尽可能地缩短爬取周期,爬虫系统应该具有良好的可扩展性,即很容易增加 Crawl 的服务器和爬虫的数量来实现这一点。
目前实用的大型网络爬虫必须以分布式方式运行,即多台服务器专门进行爬虫,每台服务器部署多个爬虫,每个爬虫多线程运行,以多种方式增加并发。对于大型搜索引擎服务商来说,数据中心也可能会部署在全球、不同区域,爬虫也被分配到不同的数据中心,这对于提升爬虫系统的整体性能非常有帮助。
03 鲁棒性
当爬虫想要访问各种类型的网站服务器时,可能会遇到很多异常情况,比如网页的HTML编码不规则,被爬取的服务器突然崩溃,甚至出现爬虫陷阱。爬虫能够正确处理各种异常情况是非常重要的,否则它可能会时不时停止工作,这是难以忍受的。
从另一个角度来说,假设爬虫程序在爬取过程中死掉了,或者爬虫所在的服务器宕机了,一个健壮的爬虫应该可以做到。当爬虫再次启动时,它可以恢复之前爬取的内容和数据结构。不必每次都从头开始做所有的工作,这也是爬虫健壮性的体现。
04友善
爬虫的友好性有两层含义:一是保护网站的部分隐私,二是减少被爬取的网站的网络负载。爬虫爬取的对象是各种类型的网站。对于网站的拥有者来说,有些内容不想被所有人搜索到,所以需要设置一个协议来告知爬虫哪些内容不是。允许爬行。目前,实现这一目标的主流方法有两种:爬虫禁止协议和网页禁止标记。
爬虫禁止协议是指网站的拥有者生成的指定文件robot.txt,放在网站服务器的根目录下。该文件表示网站中哪些目录下面的网页不允许被爬虫爬取。在爬取网站的网页之前,友好的爬虫必须先读取robot.txt文件,并且不会下载被禁止爬取的网页。
网页禁止标签一般在网页的HTML代码中通过添加metaimage-package">
索引网页与互联网网页
爬取的本地网页很可能发生了变化,或者被删除,或者内容发生了变化,因为爬虫完成一轮爬取需要很长时间,所以部分爬取的网页肯定是过期的。因此,网页库中的过期数据越少,网页的新鲜度就越好,对提升用户体验大有裨益。如果新颖性不好,搜索结果全是过时数据,或者网页被删除,用户的内心感受可想而知。
尽管 Internet 上有很多网页,但每个网页都有很大的不同。例如,腾讯和网易新闻的网页与作弊网页一样重要。如果搜索引擎抓取的网页大部分都是比较重要的网页,就可以说明他们在抓取网页的重要性方面做得很好。你在这方面做得越好,搜索引擎就会越准确。
通过以上三个标准的分析,爬虫开发的目标可以简单描述为:在资源有限的情况下,由于搜索引擎只能爬取互联网上现有网页的一部分,所以更重要的部分应尽可能选择。要索引的页面;对于已经爬取的页面,尽快更新内容,使被索引页面的内容与互联网上对应页面的内容同步更新;网页。三个“尽可能”基本明确了爬虫系统提升用户体验的目标。
为了满足这三个质量标准,大型商业搜索引擎开发了多套针对性强的爬虫系统。以谷歌为例,至少有两种不同的爬虫系统,一种叫做Fresh Bot,主要考虑网页的新鲜度。对于内容更新频繁的网页,目前更新周期可以达到秒级;另一组称为 Deep Crawl Bot,主要针对更新不频繁、更新周期为几天的网页抓取。此外,谷歌在开发暗网爬虫系统方面也投入了大量精力。以后有时间讲解暗网系统。
谷歌的两个爬虫系统
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 解密爬虫爬取更新网页的策略方法
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-23 23:21
我也是刚开始学python爬虫技术,后来想在网上找一些教程看看。谁知道,一搜,大部分都是用python2写的。新手一般喜欢安装新版本。于是我也写了一个简单的python3爬虫,爬取贴吧的图片。事不宜迟,让我们开始吧。
首先,让我们谈谈知识。
一、什么是爬虫?
采集网页上的数据
二、学习爬虫的作用是什么?
做案例研究,做数据分析,分析网页结构......
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、爬虫思路:
1. 打开网页并获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----获取不到想要的内容/请求失败/IP容易被封....等
*解决方案:伪装 - 不要告诉 网站 我是一个脚本,告诉它我是一个浏览器。(添加任意浏览器的头信息,伪装成浏览器),既然是简单的例子,那我们就不搞这些刁钻的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 功能:查找所有相同的对象。
这里的解析器可能有问题,我们就不多说了。有问题的学生有一堆解决方案。
3. 保存图片地址并下载图片
*一种。使用urllib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,那么一定要写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人不明白。
有一件事要提:您可以在没有常客的情况下使用 BeautifulSoup;爬虫使用正则、Bs4 和 xpath。只需选择三个中的一个。当然,它也可以组合使用,以及其他类型。
爬取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725") #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束。
参考地址:
(ps:我也是python新手,文章如有错误请多多包涵) 查看全部
网页爬虫抓取百度图片(刚刚开始python3简单的爬虫,爬虫一下贴吧的图片吧。)
我也是刚开始学python爬虫技术,后来想在网上找一些教程看看。谁知道,一搜,大部分都是用python2写的。新手一般喜欢安装新版本。于是我也写了一个简单的python3爬虫,爬取贴吧的图片。事不宜迟,让我们开始吧。
首先,让我们谈谈知识。
一、什么是爬虫?
采集网页上的数据
二、学习爬虫的作用是什么?
做案例研究,做数据分析,分析网页结构......
三、爬虫环境
要求:python3x pycharm
模块:urllib、urllib2、bs4、re
四、爬虫思路:
1. 打开网页并获取源代码。
*由于多人同时爬取某个网站,会造成数据冗余和网站崩溃,所以部分网站被禁止爬取,会返回403 access denied错误信息。----获取不到想要的内容/请求失败/IP容易被封....等
*解决方案:伪装 - 不要告诉 网站 我是一个脚本,告诉它我是一个浏览器。(添加任意浏览器的头信息,伪装成浏览器),既然是简单的例子,那我们就不搞这些刁钻的操作了。
2. 获取图片
*查找功能:只查找第一个目标,查询一次
*Find_all 功能:查找所有相同的对象。
这里的解析器可能有问题,我们就不多说了。有问题的学生有一堆解决方案。
3. 保存图片地址并下载图片
*一种。使用urllib---urlretrieve下载(保存位置:如果和*.py文件保存在同一个地方,那么只需要文件夹名,如果在别处,那么一定要写绝对路径。)
算了,废话不多说,既然是简单的例子,那我就直接贴代码了。相信没有多少人不明白。
有一件事要提:您可以在没有常客的情况下使用 BeautifulSoup;爬虫使用正则、Bs4 和 xpath。只需选择三个中的一个。当然,它也可以组合使用,以及其他类型。
爬取地址:
百度贴吧的壁纸图片。
代码显示如下:
import urllib.request
import re
import os
import urllib
#!/usr/bin/python3
import re
import os
import urllib.request
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg) #转换成一个正则对象
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
print("====图片的地址=====",imglist)
x = 0 #声明一个变量赋值
path = r'H:/python lianxi/zout_pc5/test' #设置保存地址
if not os.path.isdir(path):
os.makedirs(path) # 将图片保存到文件夹,没有则创建
paths = path+'/'
print(paths)
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist,下载图片保存在本地,
x = x + 1
print('图片已开始下载,注意查看文件夹')
return imglist
html = getHtml("http://tieba.baidu.com/p/3840085725";) #获取该网址网页的源代码
print(getImg(html)) #从网页源代码中分析并下载保存图片
最终效果如下:
好了,教程到此结束。
参考地址:
(ps:我也是python新手,文章如有错误请多多包涵)
网页爬虫抓取百度图片(润森什么是爬虫网络爬虫(又被称为网页蜘蛛) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-23 19:12
)
大家好,我是润森
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
"
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
"
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requestsr = requests.get('http://pic37.nipic.com/2014011 ... %2339;)with open('demo.jpg','wb+') as f:f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
"
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
"
json是js的对象,就是访问数据
JSON字符串
{ “name”: “毛利”, “age”: 18, “ feature “ : [‘高’, ‘富’, ‘帅’]}
Python字典
{ ‘name’: ‘毛利’, ‘age’: 18 ‘feature’ : [‘高’, ‘富’, ‘帅’]}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
"
在python中导入json,传递json.loads(s) --> 将json数据转换成python数据(字典)
ajax的使用
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
"
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
分析图片url链接的位置
同时找到ajax请求对应的url
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requestsimport jsonheaders = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}r = requests.get('https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).textres = json.loads(r)['data']for index,i in enumerate(res): url = i['hoverURL'] print(url) with open( '{}.jpg'.format(index),'wb+') as f: f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
"
首先分析不同json发起的请求
https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1561022599355=https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-# time :2019/6/20 17:07# author: 毛利import requestsimport jsonimport osdef get_pic_url(num): pic_url= [] headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'} for i in range(num): page_url = 'https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i) r = requests.get(page_url, headers=headers).text res = json.loads(r)['data'] if res: print(res) for j in res: try: url = j['hoverURL'] pic_url.append(url) except: print('该图片的url不存在') print(len(pic_url)) return pic_urldef down_img(num): pic_url =get_pic_url(num) if os.path.exists('D:图片'): pass else: os.makedirs('D:图片') path = 'D:图片' for index,i in enumerate(pic_url): filename = path + str(index) + '.jpg' print(filename) with open(filename, 'wb+') as f: f.write(requests.get(i).content)if __name__ == '__main__': num = int(input('爬取几次图片:一次30张')) down_img(num)
查看全部
网页爬虫抓取百度图片(润森什么是爬虫网络爬虫(又被称为网页蜘蛛)
)
大家好,我是润森
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站通过Robots Protocol,告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 系统附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的基本术语,指的是用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
"
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
"
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requestsr = requests.get('http://pic37.nipic.com/2014011 ... %2339;)with open('demo.jpg','wb+') as f:f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
"
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
"
json是js的对象,就是访问数据
JSON字符串
{ “name”: “毛利”, “age”: 18, “ feature “ : [‘高’, ‘富’, ‘帅’]}
Python字典
{ ‘name’: ‘毛利’, ‘age’: 18 ‘feature’ : [‘高’, ‘富’, ‘帅’]}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
"
在python中导入json,传递json.loads(s) --> 将json数据转换成python数据(字典)
ajax的使用
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
"
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
分析图片url链接的位置
同时找到ajax请求对应的url
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requestsimport jsonheaders = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}r = requests.get('https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=',headers = headers).textres = json.loads(r)['data']for index,i in enumerate(res): url = i['hoverURL'] print(url) with open( '{}.jpg'.format(index),'wb+') as f: f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
"
首先分析不同json发起的请求
https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1561022599355=https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1561022599290=
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-# time :2019/6/20 17:07# author: 毛利import requestsimport jsonimport osdef get_pic_url(num): pic_url= [] headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'} for i in range(num): page_url = 'https://image.baidu.com/search ... st%3D©right=&word=%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1561022599290='.format(30*i) r = requests.get(page_url, headers=headers).text res = json.loads(r)['data'] if res: print(res) for j in res: try: url = j['hoverURL'] pic_url.append(url) except: print('该图片的url不存在') print(len(pic_url)) return pic_urldef down_img(num): pic_url =get_pic_url(num) if os.path.exists('D:图片'): pass else: os.makedirs('D:图片') path = 'D:图片' for index,i in enumerate(pic_url): filename = path + str(index) + '.jpg' print(filename) with open(filename, 'wb+') as f: f.write(requests.get(i).content)if __name__ == '__main__': num = int(input('爬取几次图片:一次30张')) down_img(num)
网页爬虫抓取百度图片(百度爬虫抓取量其实简单就是百度对站点一天网页的数量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-23 05:10
影响百度爬虫网站爬取量的因素有哪些?百度爬虫的爬取量实际上是百度爬虫在一天内爬取一个网站的页面数。在这里,新网小编就为大家介绍一下影响百度爬虫网站爬取量的因素。
其中之一就是本站生成新的网页,对于中小型网站可以在同一天完成。大的 网站 可能无法完成它们。百度收录有5W,那么百度会给一个时间段,比如30天,然后平均出来,每天去这个网站抢5W/30这样一个数字,但是具体金额,百度有自己的一套算法公式可以计算。
影响百度抓取量的因素。
1.网站安全
对于中小型网站来说,安全技术比较薄弱,被黑客篡改的现象非常普遍。通常,有几种常见的被黑客入侵的情况。一是主域被黑,二是标题被篡改,二是页面有很多外部链接。一般主域被黑了就是劫持了,就是主域被301重定向到指定的网站,如果你在百度上跳转后发现一些垃圾站,那么你的站点就抢量里面会减少。
2.内容质量
如果爬取了10万个页面,只创建了100个,爬取量就会下降,因为百度会认为爬取的页面比例很低,所以没必要多爬取,所以“最好是短于浪费”,尤其是在建网站的时候,一定要注意质量,不要采集一些内容,这是一个潜在的隐患。
3.网站响应能力
① 网页大小会影响爬取。百度推荐网页大小在1M以内。当然,它类似于新浪所说的大型门户网站。
②代码质量、机器性能和带宽,这个不多说,后面作者会单独拿出文章解释,请实时关注“营销专家”。
4.同一ip上的主域数
百度爬取是基于ip的。比如一个ip每天爬1000w个页面,这个站点有40W个站点,那么平均每个站点的爬取次数会很分散。很少。
相信大家都知道哪些因素会影响百度爬虫对网站的抓取量。提醒大家,在选择服务商的时候,要检查一下同一个ip上是否有大网站。如果有大站点的话,可能分配的爬取量会很小,因为流量会流向大站点。
_创新互联,为您提供面包屑导航、网站导航、网站策划、搜索引擎优化、网站、网站制作 查看全部
网页爬虫抓取百度图片(百度爬虫抓取量其实简单就是百度对站点一天网页的数量)
影响百度爬虫网站爬取量的因素有哪些?百度爬虫的爬取量实际上是百度爬虫在一天内爬取一个网站的页面数。在这里,新网小编就为大家介绍一下影响百度爬虫网站爬取量的因素。
其中之一就是本站生成新的网页,对于中小型网站可以在同一天完成。大的 网站 可能无法完成它们。百度收录有5W,那么百度会给一个时间段,比如30天,然后平均出来,每天去这个网站抢5W/30这样一个数字,但是具体金额,百度有自己的一套算法公式可以计算。
影响百度抓取量的因素。
1.网站安全
对于中小型网站来说,安全技术比较薄弱,被黑客篡改的现象非常普遍。通常,有几种常见的被黑客入侵的情况。一是主域被黑,二是标题被篡改,二是页面有很多外部链接。一般主域被黑了就是劫持了,就是主域被301重定向到指定的网站,如果你在百度上跳转后发现一些垃圾站,那么你的站点就抢量里面会减少。
2.内容质量
如果爬取了10万个页面,只创建了100个,爬取量就会下降,因为百度会认为爬取的页面比例很低,所以没必要多爬取,所以“最好是短于浪费”,尤其是在建网站的时候,一定要注意质量,不要采集一些内容,这是一个潜在的隐患。
3.网站响应能力
① 网页大小会影响爬取。百度推荐网页大小在1M以内。当然,它类似于新浪所说的大型门户网站。
②代码质量、机器性能和带宽,这个不多说,后面作者会单独拿出文章解释,请实时关注“营销专家”。
4.同一ip上的主域数
百度爬取是基于ip的。比如一个ip每天爬1000w个页面,这个站点有40W个站点,那么平均每个站点的爬取次数会很分散。很少。
相信大家都知道哪些因素会影响百度爬虫对网站的抓取量。提醒大家,在选择服务商的时候,要检查一下同一个ip上是否有大网站。如果有大站点的话,可能分配的爬取量会很小,因为流量会流向大站点。
_创新互联,为您提供面包屑导航、网站导航、网站策划、搜索引擎优化、网站、网站制作
网页爬虫抓取百度图片(为什么使用爬虫为什么我们需要使用千磨风?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2022-02-22 15:11
关键词:爬虫简介
千辛万苦,千锤百炼,任尔南北风,东风西风。本期文章主要讲第55天:爬虫相关知识介绍,希望对大家有所帮助。
由先欢
作为程序员,相信大家对“爬虫”这个词并不陌生。人们经常在周围提到这个词。在不知道的人眼里,他们会认为这项技术非常高端和神秘。别着急,我们的爬虫系列就带你揭开它的神秘面纱,探寻它的真面目。
什么是爬行动物
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗地说,我们把互联网比作一个大蜘蛛网,每个站点资源都比作蜘蛛网上的一个节点。爬虫就像一只蜘蛛,按照设计好的路线和规则在这张蜘蛛网上寻找目标节点。,获取资源。
为什么要使用爬虫
为什么我们需要使用爬虫?
你可以想象一个场景:你很崇拜一个微博名人,你对他的微博很着迷,你想把他微博上十年的每一句话都提取出来,做成名人语录。你在这个时候做什么?手动转到 Ctrl+C 和 Ctrl+V?这种方法确实是正确的。数据量少的时候我们可以这样做,但是数据量上千的时候还需要这样做吗?
再想象一个场景:你想做一个新闻聚合网站,你需要每天定时去几条新闻网站获取最新消息,我们称之为RSS订阅。你定期去每个订阅网站复制新闻吗?恐怕个人很难做到这一点。
在以上两种场景下,使用爬虫技术可以轻松解决问题。因此,我们可以看到爬虫技术主要可以帮我们做两种事情:一是数据获取需求,主要是针对特定规则下的大量数据的获取;另一个是自动化需求,主要用于类似信息的聚合、搜索等。
爬行动物的分类
从爬取对象的角度,爬虫可以分为通用爬虫和专注爬虫。
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web,主要针对搜索引擎和大型Web服务商采集数据。此类网络爬虫的爬取范围和数量巨大,对爬取速度和存储空间的要求比较高,对爬取页面的顺序要求比较低。比如我们常见的百度和谷歌搜索。我们进入关键词,他们会从全网找到关键词相关的网页,并按照一定的顺序呈现给我们。
Focused Crawler 是指有选择地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,聚焦爬虫只需要爬取特定的网页,爬取的广度会小很多。比如我们需要爬取东方财富网的基金数据,只需要制定规则爬取东方财富网的页面即可。
通俗的说,万能爬虫类似于蜘蛛,需要寻找特定的食物,但是它不知道蜘蛛网的哪个节点有它,所以只能从一个节点开始,到时候再看这个节点遇到它,如果有食物就拿食物,如果这个节点表示某个节点有食物,那么它会按照指示寻找下一个节点。网络爬虫的重点是蜘蛛知道哪个节点有食物,它只需要规划一条路线到达那个节点就可以得到食物。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,类似下图:
这个过程其实就是用户输入URL后,经过DNS服务器,找到服务器主机,向服务器发送请求。服务器解析后,将html、js、css等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
由于爬虫的目标是获取资源,而资源存储在某个主机上,所以爬虫在爬取数据时必须有一个目标URL来获取数据。因此,它是爬虫获取数据的基本依据。准确理解它的含义,对于爬虫的学习很有帮助。
爬虫的过程
我们下一章主要讨论焦点爬虫。焦点爬虫的工作流程如下:
从这个爬虫的过程中,你应该可以想到学习爬虫需要学习的关键步骤。首先,我们需要像浏览器一样请求一个URL来获取主机的资源,所以正确请求和获取内容的方法是我们研究的重点。我们获取资源后(即请求URL后得到的响应内容),需要解析响应内容,为我们获取有价值的数据。这里的分析方法是学习的重点。我们拿到数据后,接下来需要存储数据,数据的存储方式也很重要。
因此,我们所学的爬虫技术其实可以概括为三个基本问题:请求、解析和存储。如果掌握了这三个问题的相应解决方案,爬虫技术就掌握了。在学习爬虫的过程中,大家都会关注这三个问题,不会走弯路。
总结
本节介绍爬虫的基本概念,以便您对爬虫有一个大致的了解,以便在后续章节中学习。开胃菜吃完了,下一节就要开始饕餮盛宴了,你准备好了吗?
文中示例代码: 查看全部
网页爬虫抓取百度图片(为什么使用爬虫为什么我们需要使用千磨风?(上))
关键词:爬虫简介
千辛万苦,千锤百炼,任尔南北风,东风西风。本期文章主要讲第55天:爬虫相关知识介绍,希望对大家有所帮助。
由先欢
作为程序员,相信大家对“爬虫”这个词并不陌生。人们经常在周围提到这个词。在不知道的人眼里,他们会认为这项技术非常高端和神秘。别着急,我们的爬虫系列就带你揭开它的神秘面纱,探寻它的真面目。
什么是爬行动物
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
通俗地说,我们把互联网比作一个大蜘蛛网,每个站点资源都比作蜘蛛网上的一个节点。爬虫就像一只蜘蛛,按照设计好的路线和规则在这张蜘蛛网上寻找目标节点。,获取资源。
为什么要使用爬虫
为什么我们需要使用爬虫?
你可以想象一个场景:你很崇拜一个微博名人,你对他的微博很着迷,你想把他微博上十年的每一句话都提取出来,做成名人语录。你在这个时候做什么?手动转到 Ctrl+C 和 Ctrl+V?这种方法确实是正确的。数据量少的时候我们可以这样做,但是数据量上千的时候还需要这样做吗?
再想象一个场景:你想做一个新闻聚合网站,你需要每天定时去几条新闻网站获取最新消息,我们称之为RSS订阅。你定期去每个订阅网站复制新闻吗?恐怕个人很难做到这一点。
在以上两种场景下,使用爬虫技术可以轻松解决问题。因此,我们可以看到爬虫技术主要可以帮我们做两种事情:一是数据获取需求,主要是针对特定规则下的大量数据的获取;另一个是自动化需求,主要用于类似信息的聚合、搜索等。
爬行动物的分类
从爬取对象的角度,爬虫可以分为通用爬虫和专注爬虫。
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web,主要针对搜索引擎和大型Web服务商采集数据。此类网络爬虫的爬取范围和数量巨大,对爬取速度和存储空间的要求比较高,对爬取页面的顺序要求比较低。比如我们常见的百度和谷歌搜索。我们进入关键词,他们会从全网找到关键词相关的网页,并按照一定的顺序呈现给我们。
Focused Crawler 是指有选择地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,聚焦爬虫只需要爬取特定的网页,爬取的广度会小很多。比如我们需要爬取东方财富网的基金数据,只需要制定规则爬取东方财富网的页面即可。
通俗的说,万能爬虫类似于蜘蛛,需要寻找特定的食物,但是它不知道蜘蛛网的哪个节点有它,所以只能从一个节点开始,到时候再看这个节点遇到它,如果有食物就拿食物,如果这个节点表示某个节点有食物,那么它会按照指示寻找下一个节点。网络爬虫的重点是蜘蛛知道哪个节点有食物,它只需要规划一条路线到达那个节点就可以得到食物。
浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到几张图片和百度搜索框,类似下图:
这个过程其实就是用户输入URL后,经过DNS服务器,找到服务器主机,向服务器发送请求。服务器解析后,将html、js、css等文件发送到用户的浏览器。浏览器解析后,用户可以看到各种图片。
因此,用户看到的网页本质上是由 HTML 代码组成的,爬虫爬取这些内容。通过对这些HTML代码进行分析和过滤,实现图片、文字等资源的获取。
网址的含义
URL,即Uniform Resource Locator,也就是我们所说的网站,Uniform Resource Locator是对可以从互联网上获取的资源的位置和访问方式的简明表示,是互联网上标准资源的地址. Internet 上的每个文件都有一个唯一的 URL,其中收录指示文件位置以及浏览器应该如何处理它的信息。
URL的格式由三部分组成:
由于爬虫的目标是获取资源,而资源存储在某个主机上,所以爬虫在爬取数据时必须有一个目标URL来获取数据。因此,它是爬虫获取数据的基本依据。准确理解它的含义,对于爬虫的学习很有帮助。
爬虫的过程
我们下一章主要讨论焦点爬虫。焦点爬虫的工作流程如下:
从这个爬虫的过程中,你应该可以想到学习爬虫需要学习的关键步骤。首先,我们需要像浏览器一样请求一个URL来获取主机的资源,所以正确请求和获取内容的方法是我们研究的重点。我们获取资源后(即请求URL后得到的响应内容),需要解析响应内容,为我们获取有价值的数据。这里的分析方法是学习的重点。我们拿到数据后,接下来需要存储数据,数据的存储方式也很重要。
因此,我们所学的爬虫技术其实可以概括为三个基本问题:请求、解析和存储。如果掌握了这三个问题的相应解决方案,爬虫技术就掌握了。在学习爬虫的过程中,大家都会关注这三个问题,不会走弯路。
总结
本节介绍爬虫的基本概念,以便您对爬虫有一个大致的了解,以便在后续章节中学习。开胃菜吃完了,下一节就要开始饕餮盛宴了,你准备好了吗?
文中示例代码:
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一时间解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-22 15:07
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看
在当今社会,如何有效地提取和利用信息已成为一个巨大的挑战。基于这个巨大的市场需求,履带技术应运而生,这也是为什么对履带工程师的需求与日俱增的原因。那么Python网络爬虫需要掌握哪些核心技术呢?以小编推出的《Python网络爬虫解析》课程为例,内容涉及Scrapy框架、分布式爬虫等核心技术。下面一起来看看Python网络爬虫的具体学习内容吧!
Python网络爬虫课程简介:
为了让具备Python基础的人适合工作需要,小编推出了全面、系统、简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了一个爬虫框架。学习完内容后,您将能够全面掌握爬取和解析网页的各种技术,还可以掌握爬虫的一些扩展知识,如并发下载、识别图片文本、抓取动态内容等。并且每个人都可以掌握爬虫框架的使用,比如Scrapy,从而创建自己的网络爬虫项目,胜任Python网络爬虫工程师相关的工作。
Python网络爬虫知识大纲:
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、什么是爬虫、爬虫的目的、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫的实现原理、爬取网页的详细过程、通用爬虫中网页的分类、通用爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有一定的了解,以后会针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍网页请求的原理,包括浏览网页的过程、HTTP网络请求的原理、HTTP抓包工具Fiddler。
第 4 部分
介绍了两个用于抓取 Web 数据的库:urllib 和 requests。首先介绍了urllib库的基本使用,包括使用urllib传输数据,添加具体的header,设置代理服务器,超时设置,常见的网络异常,然后介绍一个更加人性化的requests库,结合百度< @贴吧的案例说明了如何使用urllib库爬取网页数据。大家应该能熟练掌握这两个库的使用,反复使用多练习。另外,可以参考官网提供的文档进行深入研究。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了封装这些技术的Python模块或库的基本使用,包括re模块、lxml库、bs4库、json模块、并结合腾讯社招网站的案例,分别讲解如何使用re模块、lxml库和bs4库来解析网页数据,以便更好地区分这些技术之间的差异。在实际工作中,可以根据具体情况选择合理的技术来使用。
第 6 部分
主要讲解并发下载,包括多线程爬虫进程分析,使用queue模块实现多线程爬取,协程实现并发爬取。结合尴尬百科的案例,分别使用了单线程、多线程、协程三种技术。获取网页数据,分析三者的表现。
第 7 部分
介绍围绕抓取动态内容,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登陆的案例,在项目中解释了项目如何应用 selenium 和 PhantomJS 技术。
第 8 部分
主要讲解图像识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、标准格式文本处理、验证码处理等,结合一个识别本地验证码图片的小程序,讲解如何使用 pytesseract 识别图像中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储在数据库等,并结合豆瓣电影的案例讲解如何抓取,从 网站 一步一步地解析和存储电影信息。
第 10 部分
主要是对爬虫框架Scrapy的初步讲解,包括常用爬虫框架介绍、Scrapy框架结构、运行流程、安装、基本操作等。
第 11 部分
首先介绍Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并用一个例子来巩固。然后,详细介绍了 Scrapy 框架的一些核心组件,包括 Spiders、Item Pipeline 和 Settings。最后结合斗鱼App爬虫的案例,讲解了如何使用。Scrapy 框架捕获移动应用程序的数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括先了解爬虫类CrawlSpider,CrawlSpider类的工作原理,通过Rule类确定爬取规则,通过LinkExtractor类提取链接,以及开发了一个CrawlSpider类来爬取腾讯招聘网站的案例,并将这部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括完整的架构、运行流程、主要组件、Scrapy-Redis的基本使用、如何搭建Scrapy-Redis开发环境等,并结合百度百科案例使用这些知识点。
以上就是成为Python网络爬虫需要掌握的核心技术。你想通了吗?其实,做一个网络爬虫并不难。只要掌握科学的学习方法,将理论基础与实践经验相结合,就能快速掌握爬虫的核心技术。 查看全部
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一时间解决?(图))
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看
在当今社会,如何有效地提取和利用信息已成为一个巨大的挑战。基于这个巨大的市场需求,履带技术应运而生,这也是为什么对履带工程师的需求与日俱增的原因。那么Python网络爬虫需要掌握哪些核心技术呢?以小编推出的《Python网络爬虫解析》课程为例,内容涉及Scrapy框架、分布式爬虫等核心技术。下面一起来看看Python网络爬虫的具体学习内容吧!
Python网络爬虫课程简介:
为了让具备Python基础的人适合工作需要,小编推出了全面、系统、简单的Python网络爬虫入门课程,不仅讲解了学习网络爬虫必备的基础知识,还增加了一个爬虫框架。学习完内容后,您将能够全面掌握爬取和解析网页的各种技术,还可以掌握爬虫的一些扩展知识,如并发下载、识别图片文本、抓取动态内容等。并且每个人都可以掌握爬虫框架的使用,比如Scrapy,从而创建自己的网络爬虫项目,胜任Python网络爬虫工程师相关的工作。
Python网络爬虫知识大纲:
第1部分
主要是带领大家了解网络爬虫,包括爬虫的背景、什么是爬虫、爬虫的目的、爬虫的分类等。
第2部分
主要讲解爬虫的实现原理和技术,包括爬虫的实现原理、爬取网页的详细过程、通用爬虫中网页的分类、通用爬虫相关的网站文件、反爬虫响应策略,以及为什么选择 Python 爬虫等。希望读者能够了解爬虫是如何爬取网页的,对爬取过程中出现的一些问题有一定的了解,以后会针对这些问题提供一些合理的解决方案。
第 3 部分
主要介绍网页请求的原理,包括浏览网页的过程、HTTP网络请求的原理、HTTP抓包工具Fiddler。
第 4 部分
介绍了两个用于抓取 Web 数据的库:urllib 和 requests。首先介绍了urllib库的基本使用,包括使用urllib传输数据,添加具体的header,设置代理服务器,超时设置,常见的网络异常,然后介绍一个更加人性化的requests库,结合百度< @贴吧的案例说明了如何使用urllib库爬取网页数据。大家应该能熟练掌握这两个库的使用,反复使用多练习。另外,可以参考官网提供的文档进行深入研究。
第 5 部分
主要介绍了几种解析网页数据的技术,包括正则表达式、XPath、Beautiful Soup和JSONPath,并讲解了封装这些技术的Python模块或库的基本使用,包括re模块、lxml库、bs4库、json模块、并结合腾讯社招网站的案例,分别讲解如何使用re模块、lxml库和bs4库来解析网页数据,以便更好地区分这些技术之间的差异。在实际工作中,可以根据具体情况选择合理的技术来使用。
第 6 部分
主要讲解并发下载,包括多线程爬虫进程分析,使用queue模块实现多线程爬取,协程实现并发爬取。结合尴尬百科的案例,分别使用了单线程、多线程、协程三种技术。获取网页数据,分析三者的表现。
第 7 部分
介绍围绕抓取动态内容,包括动态网页介绍,selenium和PhantomJS概述,selenium和PhantomJS的安装和配置,selenium和PhantomJS的基本使用,结合模拟豆瓣网站登陆的案例,在项目中解释了项目如何应用 selenium 和 PhantomJS 技术。
第 8 部分
主要讲解图像识别和文字处理,包括Tesseract引擎、pytesseract和PIL库的下载安装、标准格式文本处理、验证码处理等,结合一个识别本地验证码图片的小程序,讲解如何使用 pytesseract 识别图像中的验证码。
第 9 部分
主要介绍爬虫数据的存储,包括数据存储的介绍、MongoDB数据库的介绍、使用PyMongo库存储在数据库等,并结合豆瓣电影的案例讲解如何抓取,从 网站 一步一步地解析和存储电影信息。
第 10 部分
主要是对爬虫框架Scrapy的初步讲解,包括常用爬虫框架介绍、Scrapy框架结构、运行流程、安装、基本操作等。
第 11 部分
首先介绍Scrapy终端和核心组件。首先介绍了Scrapy终端的启动和使用,并用一个例子来巩固。然后,详细介绍了 Scrapy 框架的一些核心组件,包括 Spiders、Item Pipeline 和 Settings。最后结合斗鱼App爬虫的案例,讲解了如何使用。Scrapy 框架捕获移动应用程序的数据。
第 12 部分
继续介绍自动爬取网页的爬虫CrawlSpider的知识,包括先了解爬虫类CrawlSpider,CrawlSpider类的工作原理,通过Rule类确定爬取规则,通过LinkExtractor类提取链接,以及开发了一个CrawlSpider类来爬取腾讯招聘网站的案例,并将这部分的知识点应用到案例中。
第 13 部分
围绕Scrapy-Redis分布式爬虫进行讲解,包括完整的架构、运行流程、主要组件、Scrapy-Redis的基本使用、如何搭建Scrapy-Redis开发环境等,并结合百度百科案例使用这些知识点。
以上就是成为Python网络爬虫需要掌握的核心技术。你想通了吗?其实,做一个网络爬虫并不难。只要掌握科学的学习方法,将理论基础与实践经验相结合,就能快速掌握爬虫的核心技术。
网页爬虫抓取百度图片( 一个特别小的爬虫案例!微信推文中的图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-22 05:05
一个特别小的爬虫案例!微信推文中的图片
)
大家好,今天给大家分享一个非常小的爬虫案例!
在微信推文中抓取图片!!!!
有人说,这有什么用,,,,万一有人的推特是把一个PPT的内容以图片的形式放上去,你想把它弄下来,那就是爬。
欢迎关注哔哩哔哩UP主:《我的儿子Q》。
坚持不懈,努力工作;你和我在一起!为战斗而生!
相信大家都听说过爬虫技术。一旦你学会了这项技术,你将成为资源老板。这条推文将在以下两个方面展开:
1、爬虫科学
2、微信推文中的图片
爬行动物科学的定义
近年来,爬虫这个词广为流传,还有一个新兴的职位——爬虫工程师。那么什么是爬行动物?
下面是百度百科的解释:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
大概还是不明白。
其实通俗的说,就是在网络上根据自己的需要,通过相应的技术手段来获取我们需要的数据信息。这个过程称为爬行。
该网站是API。. .
我们说网络上的每一个网站都被视为一个API,也就是一个接口,通过它我们可以获取信息和数据。一个网站叫做 URL,这个 URL 就是我们爬取的 API。
爬虫无非就是以下几个流程:
1、了解网页
2、获取网页内容
3、解析网页并选择需要的内容
4、保存你想要的
两个机器人协议
在爬取之前,你需要知道一些事情:
1、服务器上的数据是专有的。
2、网络爬虫数据牟利存在法律风险。
3、爬虫可能会丢失个人数据。
许多公司还对爬虫进行了一些预防设置。一般会判断你的访问来源,并尝试判断你是被人访问还是被机器访问,从而做出必要的限制。
robots协议,也称为robots.txt,是大家都认同的爬虫协议。说白了,就是爬虫的道德标准。很多公司会在它的一些网站上设置robots协议,这个协议会告诉你哪些内容网站允许你抓取,哪些内容不允许抓取。该协议是 网站 根目录中的 robots.txt 文件。京东的机器人协议如下。
首先,我将向大家解释这些的目的。也希望大家都能做一个合法的爬虫,遵守网络道德,做社会主义的接班人。不过普通的小爬虫是允许的,大家可以大胆尝试。
三爬虫框架
目前爬虫已经有比较成熟的框架和比较成熟的第三方库供大家使用。
上面给出了两个更成熟的爬虫库。下面我们简单介绍一下Requests的使用。
首先,您需要安装此库。库的安装方法很简单。在 Windows 系统上,以管理员身份运行 cmd 并执行 pip install 请求。
安装好之后就可以测试了。
爬虫的框架如下:
import requests # 导入requests库def Get_Url_text(URL): # 定义获取相应链接文本的函数 try:# 这里是异常处理机制 r = requests.get(url, timeout=30) # 访问这个链接,并返回一个名为r的对象 r.raise_for_status() # 返回访问的状态,若为200,即为访问成功 r.encoding = r.apparent_encoding # 将网页的编码和头文件的编码改为一致 except: return "产生异常"if __name__ = "main": url = "https://www.Baidu.com" print(Get_Url_text(url))
四个Requests库的一些常用方法
requests库的七种常用方法
这里有两个对象,一个是访问的url,一个是返回的响应对象,也就是前面代码中的r对象,其中也有返回对象的一些属性。如下表所示。
微信推文爬取图片示例
简单说一下这里使用的python自带的urllib中的request。但是整体的爬取思路是一样的。还用到了其他一些库,大家可以自行理解。代码和解释如下所示。
import urllib.requestimport re # 正则表达式库import osimport urllib# 根据给定的网址来获取网页详细信息,得到的html就是网页的源代码def getHtml(url): page = urllib.request.urlopen(url) html = page.read() return html.decode('UTF-8')def getImg(html): reg = r' src="(.+?)" ' # 括号里面就是我们要取得的图片网址 imgre = re.compile(reg) imglist = imgre.findall(html) # 表示在整个网页中过滤出所有图片的地址,放在imglist中 x = 0 path = 'D:\\python_project\\GRASP_pic_from_wechat\\pic' # 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建 if not os.path.isdir(path): os.makedirs(path) paths = path + '\\' # 保存在test路径下 for imgurl in imglist: urllib.request.urlretrieve(imgurl, '{0}{1}.jpg'.format(paths, x)) # 打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串 x = x + 1 return imglisthtml = getHtml("https://mp.weixin.qq.com/s/z8p ... 6quot;) # 获取该网址网页详细信息,得到的html就是网页的源代码print(getImg(html)) # 从网页源代码中分析并下载保存图片
好了,今天的内容就到此结束,希望对大家有所帮助,欢迎点赞转发!!
发送封面:
查看全部
网页爬虫抓取百度图片(
一个特别小的爬虫案例!微信推文中的图片
)
大家好,今天给大家分享一个非常小的爬虫案例!
在微信推文中抓取图片!!!!
有人说,这有什么用,,,,万一有人的推特是把一个PPT的内容以图片的形式放上去,你想把它弄下来,那就是爬。
欢迎关注哔哩哔哩UP主:《我的儿子Q》。
坚持不懈,努力工作;你和我在一起!为战斗而生!
相信大家都听说过爬虫技术。一旦你学会了这项技术,你将成为资源老板。这条推文将在以下两个方面展开:
1、爬虫科学
2、微信推文中的图片
爬行动物科学的定义
近年来,爬虫这个词广为流传,还有一个新兴的职位——爬虫工程师。那么什么是爬行动物?
下面是百度百科的解释:
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
大概还是不明白。
其实通俗的说,就是在网络上根据自己的需要,通过相应的技术手段来获取我们需要的数据信息。这个过程称为爬行。
该网站是API。. .
我们说网络上的每一个网站都被视为一个API,也就是一个接口,通过它我们可以获取信息和数据。一个网站叫做 URL,这个 URL 就是我们爬取的 API。
爬虫无非就是以下几个流程:
1、了解网页
2、获取网页内容
3、解析网页并选择需要的内容
4、保存你想要的
两个机器人协议
在爬取之前,你需要知道一些事情:
1、服务器上的数据是专有的。
2、网络爬虫数据牟利存在法律风险。
3、爬虫可能会丢失个人数据。
许多公司还对爬虫进行了一些预防设置。一般会判断你的访问来源,并尝试判断你是被人访问还是被机器访问,从而做出必要的限制。
robots协议,也称为robots.txt,是大家都认同的爬虫协议。说白了,就是爬虫的道德标准。很多公司会在它的一些网站上设置robots协议,这个协议会告诉你哪些内容网站允许你抓取,哪些内容不允许抓取。该协议是 网站 根目录中的 robots.txt 文件。京东的机器人协议如下。
首先,我将向大家解释这些的目的。也希望大家都能做一个合法的爬虫,遵守网络道德,做社会主义的接班人。不过普通的小爬虫是允许的,大家可以大胆尝试。
三爬虫框架
目前爬虫已经有比较成熟的框架和比较成熟的第三方库供大家使用。
上面给出了两个更成熟的爬虫库。下面我们简单介绍一下Requests的使用。
首先,您需要安装此库。库的安装方法很简单。在 Windows 系统上,以管理员身份运行 cmd 并执行 pip install 请求。
安装好之后就可以测试了。
爬虫的框架如下:
import requests # 导入requests库def Get_Url_text(URL): # 定义获取相应链接文本的函数 try:# 这里是异常处理机制 r = requests.get(url, timeout=30) # 访问这个链接,并返回一个名为r的对象 r.raise_for_status() # 返回访问的状态,若为200,即为访问成功 r.encoding = r.apparent_encoding # 将网页的编码和头文件的编码改为一致 except: return "产生异常"if __name__ = "main": url = "https://www.Baidu.com" print(Get_Url_text(url))
四个Requests库的一些常用方法
requests库的七种常用方法
这里有两个对象,一个是访问的url,一个是返回的响应对象,也就是前面代码中的r对象,其中也有返回对象的一些属性。如下表所示。
微信推文爬取图片示例
简单说一下这里使用的python自带的urllib中的request。但是整体的爬取思路是一样的。还用到了其他一些库,大家可以自行理解。代码和解释如下所示。
import urllib.requestimport re # 正则表达式库import osimport urllib# 根据给定的网址来获取网页详细信息,得到的html就是网页的源代码def getHtml(url): page = urllib.request.urlopen(url) html = page.read() return html.decode('UTF-8')def getImg(html): reg = r' src="(.+?)" ' # 括号里面就是我们要取得的图片网址 imgre = re.compile(reg) imglist = imgre.findall(html) # 表示在整个网页中过滤出所有图片的地址,放在imglist中 x = 0 path = 'D:\\python_project\\GRASP_pic_from_wechat\\pic' # 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建 if not os.path.isdir(path): os.makedirs(path) paths = path + '\\' # 保存在test路径下 for imgurl in imglist: urllib.request.urlretrieve(imgurl, '{0}{1}.jpg'.format(paths, x)) # 打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串 x = x + 1 return imglisthtml = getHtml("https://mp.weixin.qq.com/s/z8p ... 6quot;) # 获取该网址网页详细信息,得到的html就是网页的源代码print(getImg(html)) # 从网页源代码中分析并下载保存图片
好了,今天的内容就到此结束,希望对大家有所帮助,欢迎点赞转发!!
发送封面:
网页爬虫抓取百度图片(Python爬虫之旅学习文章目录()-乐题库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-20 04:15
)
Python爬虫学习
文章目录
前言
写个项目书找资料真是大手笔,训练模型采集图片更烦人。我也复习了自己的python,于是开始了python爬虫的旅程,这样以后可以更方便的找资料。
一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫是一段代码,可以自动从 Internet 上找到我需要的一些信息。例如,如果我想搜索一些信息,我可以搜索全世界。使用爬虫,我们可以通过关键字过滤我们需要的内容。或者你想看高收视率的电影。这时候也可以使用爬虫来查找一些收视率高的电影。
爬行动物的矛和盾
1、防爬机制
2、反反爬策略
3、robots.txt(君子协议)
二、打开一个小爬虫
使用软件 Pycharm
爬虫:通过编写程序获取互联网资源
要求:使用程序模拟浏览器。输入从中获取资源或内容的 URL
1、导入urlopen包
from urllib.request import urlopen
2、打开一个 URL 并获得响应
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read()) #打印信息
前面有个b',代表字节,我们需要把字节转成字符串
3、解码
查看charest等号后面的内容,通过resp.read.decode()解码
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read().decode("utf-8")) #打印解码信息
4、保存到文件
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
with open("mybaidu.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")
这次信息保存在html文件中
5、打开
这时,百度就会打开。
上面是我们搜索打开百度的网址,下面的网址明显不一样
它的本质是一样的,你可以查看网页的源代码,你会发现源代码是一样的,上面也有提到
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
还能爬CCTV
from urllib.request import urlopen #导入urlopen
url = "http://v.cctv.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
#print(resp.read().decode("utf-8"))
with open("my2.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")
查看全部
网页爬虫抓取百度图片(Python爬虫之旅学习文章目录()-乐题库
)
Python爬虫学习
文章目录
前言
写个项目书找资料真是大手笔,训练模型采集图片更烦人。我也复习了自己的python,于是开始了python爬虫的旅程,这样以后可以更方便的找资料。
一、什么是爬虫
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫是一段代码,可以自动从 Internet 上找到我需要的一些信息。例如,如果我想搜索一些信息,我可以搜索全世界。使用爬虫,我们可以通过关键字过滤我们需要的内容。或者你想看高收视率的电影。这时候也可以使用爬虫来查找一些收视率高的电影。
爬行动物的矛和盾
1、防爬机制
2、反反爬策略
3、robots.txt(君子协议)
二、打开一个小爬虫
使用软件 Pycharm
爬虫:通过编写程序获取互联网资源
要求:使用程序模拟浏览器。输入从中获取资源或内容的 URL
1、导入urlopen包
from urllib.request import urlopen
2、打开一个 URL 并获得响应
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read()) #打印信息
前面有个b',代表字节,我们需要把字节转成字符串
3、解码
查看charest等号后面的内容,通过resp.read.decode()解码
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
print(resp.read().decode("utf-8")) #打印解码信息
4、保存到文件
from urllib.request import urlopen #导入urlopen
url = "http://www.baidu.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
with open("mybaidu.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")
这次信息保存在html文件中
5、打开
这时,百度就会打开。
上面是我们搜索打开百度的网址,下面的网址明显不一样
它的本质是一样的,你可以查看网页的源代码,你会发现源代码是一样的,上面也有提到
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
还能爬CCTV
from urllib.request import urlopen #导入urlopen
url = "http://v.cctv.com/" #要爬取的网址
resp = urlopen(url) #打开网址并返回响应
#print(resp.read().decode("utf-8"))
with open("my2.html",mode="w",encoding='utf-8') as f: #创建html文件并保存 ,encoding设置编码
f.write(resp.read().decode("utf-8")) #读取网页的页面源代码
print("文件保存完成")
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2022-02-19 21:14
)
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... %2339;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 39%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人)
)
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... %2339;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 39%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-19 21:10
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬取过程
抓取结果
文章首次发表于: 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。(来源:百度百科)
爬虫协议
Robots Protocol(也称Crawler Protocol、Robot Protocol等)的全称是“Robots Exclusion Protocol”。网站 通过 Robots Protocol 告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。
robots.txt 文件是一个文本文件,可以使用任何常见的文本编辑器(例如 Windows 附带的记事本)创建和编辑。robots.txt 是协议,而不是命令。robots.txt 是搜索引擎在访问 网站 时查看的第一个文件。robots.txt 文件告诉蜘蛛可以查看服务器上的哪些文件。(来源:百度百科)
爬虫百度图片
目标:爬取百度图片并存入电脑
首先,数据是公开的吗?可以下载吗?
从图中可以看出,百度的图片是完全可以下载的,说明图片可以爬取
首先,了解什么是图片?
有形的东西,我们看,是图片、照片、拓片等的统称。绘画是技术制图的一个基本术语,是指用点、线、符号、文字和数字来描述的一种形式。事物的几何特征、形状、位置和大小。随着数字采集技术和信号处理理论的发展,越来越多的图片以数字形式存储。
那么图片需要在哪里呢?
图片保存在云服务器的数据库中
每张图片都有对应的url,通过requests模块发起请求,以文件的wb+方式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是谁写代码是为了爬图,还是直接下载比较好。爬虫的目的是达到批量下载的目的,这才是真正的爬虫
先了解json
JSON(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。
json是js的对象,就是访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在python中,不能直接通过键值对获取值,所以不得不说python中的字典
在python中导入json,通过json.loads(s)将json数据转成python数据(字典) -->
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
图片是通过ajax方式加载的,也就是我下拉的时候会自动加载图片,因为网站会自动发起请求,
构造ajax url请求将json转成字典,通过取字典的键值对的值获取图片对应的url
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个json有30张图片,所以通过发出json请求,我们可以爬到30张,但是还是不够。
首先分析不同json发起的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
其实可以发现,当再次发起请求时,关键是pn在不断变化
最后封装代码,一个list定义producer用来存储不断生成的图片url,另一个list定义consumer用来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬取过程
抓取结果
文章首次发表于:
网页爬虫抓取百度图片(Python这把利器,开启网络爬虫之路(1)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 203 次浏览 • 2022-02-19 11:21
摘要:获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。本文使用的版本是python3.6,用于抓取深圳大学首页的图片信息和百度股票网某只股票的日K和月K数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
【欢迎关注、点赞、采集、私信、交流】一起学习进步
获取网页源代码 获取百度图片网页
通过在百度图片上随机搜索关键词,可以得到网页地址并分析其规律性。发现可以通过修改地址末尾的word字段来搜索任意关键字的图片。因此,我们通过自定义word字段,将自定义word字段添加到固有的URL格式中来获取要爬取的网页地址,并使用requests模块中的get函数将网页的源代码下载到记忆。
如:
param={"word":"深圳大学"}
r=requests.get('/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=47_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width= &height=&face=0&istype=2&ie=utf-8&',params=param)
1.2 百度股票数据采集
百度互联互通的信息在网页上以动画的形式展示,例如:
从这种显示数据的方式来看,直接从网页中获取所需的数据基本上是不可能的。因此,我们在巡视中打开网络查找动画中的数据源,如:
我们发现当月K按钮被点击时,地址出现在网络中。因此,当我们打开地址时,发现正是我们需要的数据。通过实验发现,地址中的数据会根据时间的变化自动更新。因此,复制地址,解析地址,得到要爬取的数据。
提取所需内容
2.1 从百度图片中提取图片地址
在解析网页的时候,我们发现所有页面的图片地址都在thumb:字段后面,所以我们可以使用re模块中的findall函数来匹配地址,如:
img_links=re.findall('"thumbURL":"(.*?)",',html)
获取到地址后,同样的方法可以使用requests.get将图片信息下载到内存中。
2.2 提取百度股票信息
解析之前得到的数据,发现其内容是以每个日期为单位记录的格式,而且非常有规律,如:{"errorNo":0,"errorMsg":"SUCCESS","mashData" :[ {"date":20180515,"kline":{"open":220.83999633789,"high":271.98001098633,"low":213.55599975586, "close":271.92001342773,"volume":39366713,"amount":0,"ccl":null,"preClose":272.26000976562,"netChangeRatio":-0. 201},
因此,同样的方式,通过requests.get,我们可以得到我们需要的每一条信息,比如获取零钱:
monthnetchangeratio=re.findall('"netChangeRatio":(.*?)}',html)
爬取结果整理
3.1 百度图片下载:
首先,创建一个保存图片的文件夹:os.makedirs('./szdx/',exist_ok=True)
获取到所有图片的地址后,可以通过设置循环来一张一张下载图片:
对于 img_links 中的链接:
picurl=链接
pic=requests.get(picurl)
打开 ('./szdx/img'+str(j)+'.jpg','wb') 作为 f:
对于 pic.iter_content(chunk_size=32):
f.write(块)
f.close()
j=j+1#这里的j是为了防止在给每张图片命名的时候重复命名。
3.2百度股票信息整理
在实验中,我们使用字典来存储股票信息,方便按日期顺序检索股票信息:
月数据={}
我=0
对于 d 日期:
数据={}
数据tmp={}
datatmp['open']=re.findall(d+',"kline":{"open":(.*?),"high"',html)
...(中间信息提取过程省略)
我=我+1
图为每日K数据的第一个日期信息。
总结
通过这个实验练习,我们熟悉了网页的构成和数据爬取的基本原理。更重要的是,通过编程练习,我们发现了许多新的编程技能,并在实践中不断提高这些编程技能。经过小组讨论,确定了数据的来源,掌握了各种函数的使用方法,掌握了数据的最终存储形式,最终完成了实验。 查看全部
网页爬虫抓取百度图片(Python这把利器,开启网络爬虫之路(1)(组图))
摘要:获取数据是数据分析的重要组成部分,网络爬虫是获取数据的重要渠道之一。鉴于此,我拿起了 Python 作为武器,开始了爬网之路。本文使用的版本是python3.6,用于抓取深圳大学首页的图片信息和百度股票网某只股票的日K和月K数据。程序主要分为三个部分:网页源代码的获取、所需内容的提取、所得结果的排列。
【欢迎关注、点赞、采集、私信、交流】一起学习进步
获取网页源代码 获取百度图片网页
通过在百度图片上随机搜索关键词,可以得到网页地址并分析其规律性。发现可以通过修改地址末尾的word字段来搜索任意关键字的图片。因此,我们通过自定义word字段,将自定义word字段添加到固有的URL格式中来获取要爬取的网页地址,并使用requests模块中的get函数将网页的源代码下载到记忆。
如:
param={"word":"深圳大学"}
r=requests.get('/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=47_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width= &height=&face=0&istype=2&ie=utf-8&',params=param)
1.2 百度股票数据采集
百度互联互通的信息在网页上以动画的形式展示,例如:
从这种显示数据的方式来看,直接从网页中获取所需的数据基本上是不可能的。因此,我们在巡视中打开网络查找动画中的数据源,如:
我们发现当月K按钮被点击时,地址出现在网络中。因此,当我们打开地址时,发现正是我们需要的数据。通过实验发现,地址中的数据会根据时间的变化自动更新。因此,复制地址,解析地址,得到要爬取的数据。
提取所需内容
2.1 从百度图片中提取图片地址
在解析网页的时候,我们发现所有页面的图片地址都在thumb:字段后面,所以我们可以使用re模块中的findall函数来匹配地址,如:
img_links=re.findall('"thumbURL":"(.*?)",',html)
获取到地址后,同样的方法可以使用requests.get将图片信息下载到内存中。
2.2 提取百度股票信息
解析之前得到的数据,发现其内容是以每个日期为单位记录的格式,而且非常有规律,如:{"errorNo":0,"errorMsg":"SUCCESS","mashData" :[ {"date":20180515,"kline":{"open":220.83999633789,"high":271.98001098633,"low":213.55599975586, "close":271.92001342773,"volume":39366713,"amount":0,"ccl":null,"preClose":272.26000976562,"netChangeRatio":-0. 201},
因此,同样的方式,通过requests.get,我们可以得到我们需要的每一条信息,比如获取零钱:
monthnetchangeratio=re.findall('"netChangeRatio":(.*?)}',html)
爬取结果整理
3.1 百度图片下载:
首先,创建一个保存图片的文件夹:os.makedirs('./szdx/',exist_ok=True)
获取到所有图片的地址后,可以通过设置循环来一张一张下载图片:
对于 img_links 中的链接:
picurl=链接
pic=requests.get(picurl)
打开 ('./szdx/img'+str(j)+'.jpg','wb') 作为 f:
对于 pic.iter_content(chunk_size=32):
f.write(块)
f.close()
j=j+1#这里的j是为了防止在给每张图片命名的时候重复命名。
3.2百度股票信息整理
在实验中,我们使用字典来存储股票信息,方便按日期顺序检索股票信息:
月数据={}
我=0
对于 d 日期:
数据={}
数据tmp={}
datatmp['open']=re.findall(d+',"kline":{"open":(.*?),"high"',html)
...(中间信息提取过程省略)
我=我+1
图为每日K数据的第一个日期信息。
总结
通过这个实验练习,我们熟悉了网页的构成和数据爬取的基本原理。更重要的是,通过编程练习,我们发现了许多新的编程技能,并在实践中不断提高这些编程技能。经过小组讨论,确定了数据的来源,掌握了各种函数的使用方法,掌握了数据的最终存储形式,最终完成了实验。
网页爬虫抓取百度图片(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-18 11:06
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表重复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序import urllib.request # python自带的爬操作url的库import re # 正则表达式# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue passif __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)。如何设计正则表达式需要可以根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具import urllib # python自带的爬操作url的库# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载:%s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。 查看全部
网页爬虫抓取百度图片(Python项目案例开发从入门到实战(清华大学出版社郑秋生夏敏捷主编))
来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生夏敏捷主编)爬虫应用-抓百度图片
爬取指定网页中的图片,需要经过以下三个步骤:
(1)指定网站的链接,抓取网站的源码(如果用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2)设置正则表达式来匹配你要抓取的内容
(3)设置循环列表重复抓取和保存内容
下面介绍两种方法来实现指定网页中图片的抓取
(1)方法一:使用正则表达式过滤抓取到的html内容字符串
# 第一个简单的爬取图片的程序import urllib.request # python自带的爬操作url的库import re # 正则表达式# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # [^\s]*? 表示最小匹配, 两个括号表示列表中有两个元组 # imageList = re.findall(r'(https:[^\s]*?(png))"', page) imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page) x = 0 # 循环列表 for imageUrl in imageList: try: print('正在下载: %s' % imageUrl[0]) # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(imageUrl[0], image_save_path) x = x + 1 except: continue passif __name__ == '__main__': # 指定要爬取的网站 url = "https://www.cnblogs.com/ttweix ... ot%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page) # print(page)
注意代码中需要修改的是imageList = re.findall(r'(https:[^\s]*?(jpg|png|gif))"', page)。如何设计正则表达式需要可以根据你要抓取的内容设置,我的设计来源如下:
可以看到,因为这个网页上的图片都是png格式的,所以也可以写成imageList = re.findall(r'(https:[^\s]*?(png))"', page) .
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具import urllib # python自带的爬操作url的库# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求 headers = { 'User-Agent': 'Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N) \ AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36' } # 将headers头部添加到url,模拟浏览器访问 url = urllib.request.Request(url, headers=headers) # 将url页面的源代码保存成字符串 page = urllib.request.urlopen(url).read() # 字符串转码 page = page.decode('UTF-8') return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImage(page): # 按照html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 格式化输出DOM树的内容 print(soup.prettify()) # 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是 imgList = soup.find_all('img') x = 0 # 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片 for imgUrl in imgList[1:]: print('正在下载:%s ' % imgUrl.get('src')) # 得到scr的内容,这里返回的就是Url字符串链接,如'https://img2020.cnblogs.com/bl ... 39%3B image_url = imgUrl.get('src') # 这个image文件夹需要先创建好才能看到结果 image_save_path = './image/%d.png' % x # 下载图片并且保存到指定文件夹中 urllib.request.urlretrieve(image_url, image_save_path) x = x + 1if __name__ == '__main__': # 指定要爬取的网站 url = 'https://www.cnblogs.com/ttweix ... 39%3B # 得到该网站的源代码 page = getHtmlCode(url) # 爬取该网站的图片并且保存 getImage(page)
这两种方法各有优缺点。我认为它们可以灵活地组合使用。例如,使用方法2中指定标签的方法来缩小要查找的内容的范围,然后使用正则表达式匹配所需的内容。这样做更简洁明了。
网页爬虫抓取百度图片(通用网络爬虫和聚焦爬虫(一):百度图片爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-17 17:21
通用爬虫和焦点爬虫
根据使用场景,网络爬虫可以分为通用爬虫和专注爬虫。
万能网络爬虫:是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,它从互联网上采集网页和采集信息,这些网页信息用于构建一个为搜索引擎提供支持的索引,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以其性能的好坏直接影响到搜索引擎的效果。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份。
聚焦爬虫:是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于,焦点爬虫在实现网络爬虫时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息。也就是一般意义上的爬行动物。
百度图片爬取
需求分析,至少要实现两个功能:一是搜索图片,二是自动下载
分析网页(注意:不用的参数可以删除不影响页面加载)源码,用F12
编写正则表达式或其他解析器代码
本地存储数据
正式写python爬虫代码
页面分析非常重要。不同的需求对应不同的URL,不同的URL的源码明显不同。因此,掌握如何分析页面是爬虫成功的第一步。本页源码分析如下图所示:
import os
import re
import requests
from colorama import Fore
def download_image(url, keyword):
"""
下载图片
:param url: 百度图片的网址
:return: Bool
"""
# 1. 向服务器发起HTTP请求
response = requests.get(url)
# 2. 获取服务器端的响应信息
# 响应信息: status_code, text, url
data = response.text # 获取页面源码
# 3. 编写正则表达式,获取图片的网址
# data = ...[{"ObjURL":"http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg",....}]...
# 需要获取到的是: http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg
# 正则的语法: .代表除了\n之外的任意字符, *代表前一个字符出现0次或者无数次. ?代表非贪婪模式
pattern = r'"objURL":"(.*?)"'
# 4. 根据正则表达式寻找符合条件的图片网址.
image_urls = re.findall(pattern, data)
# 5. 根据图片网址下载猫的图片到本地
index = 1
for image_url in image_urls:
print(image_url) # 'xxxx.jpg xxxx.png'
# response.text 返回 unicode 的文本信息, response.text 返回 bytes 类型的信息
try:
response = requests.get(image_url) # 向每一个图片的url发起HTTP请求
except Exception as e:
print(Fore.RED + "[-] 下载失败: %s" % (image_url))
else:
old_image_filename = image_url.split('/')[-1]
if old_image_filename:
# 获取图片的后缀
image_format = old_image_filename.split('.')[-1]
# 处理 url 为...jpeg?imageview&thumbnail=550x0 结尾(传参)的情况
if '?' in image_format:
image_format = image_format.split('?')[0]
else:
image_format = 'jpg'
# 生成图片的存储目录
keyword = keyword.split(' ', '-')
if not os.path.exists(keyword):
os.mkdir(keyword)
image_filename = os.path.join(keyword, str(index) + '.' + image_format)
# 保存图片
with open(image_filename, 'wb') as f:
f.write(response.content)
print(Fore.BLUE + "[+] 保存图片%s.jpg成功" % (index))
index += 1
if __name__ == '__main__':
keyword = input("请输入批量下载图片的关键字: ")
url = 'http://image.baidu.com/search/index?tn=baiduimage&word=' + keyword
print(Fore.BLUE + '[+] 正在请求网址: %s' % (url))
download_image(url, keyword)
结果:
常见问题:
为什么只有30张图片,百度有30多张图片
百度图片是响应式的,下拉的时候会不断的加载新的图片,也就是说浏览器中的页面是通过JS处理数据的结果,Ajax爬虫的内容这里不再详述。
搜索页面下点击单张图片的url与程序中获取的ObjURL不一致
这可能是百度缓存处理的结果。每张图片本质上都是“外网”,不是百度,所以在程序中,选择向实际存储图片的url发起HTTP请求。 查看全部
网页爬虫抓取百度图片(通用网络爬虫和聚焦爬虫(一):百度图片爬取)
通用爬虫和焦点爬虫
根据使用场景,网络爬虫可以分为通用爬虫和专注爬虫。
万能网络爬虫:是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分,它从互联网上采集网页和采集信息,这些网页信息用于构建一个为搜索引擎提供支持的索引,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以其性能的好坏直接影响到搜索引擎的效果。主要目的是将互联网上的网页下载到本地,形成互联网内容的镜像备份。
聚焦爬虫:是一种“面向特定主题需求”的网络爬虫程序。它与一般搜索引擎爬虫的区别在于,焦点爬虫在实现网络爬虫时会对内容进行处理和过滤,并尽量保证只爬取与需求相关的内容。网页信息。也就是一般意义上的爬行动物。
百度图片爬取
需求分析,至少要实现两个功能:一是搜索图片,二是自动下载
分析网页(注意:不用的参数可以删除不影响页面加载)源码,用F12
编写正则表达式或其他解析器代码
本地存储数据
正式写python爬虫代码
页面分析非常重要。不同的需求对应不同的URL,不同的URL的源码明显不同。因此,掌握如何分析页面是爬虫成功的第一步。本页源码分析如下图所示:
import os
import re
import requests
from colorama import Fore
def download_image(url, keyword):
"""
下载图片
:param url: 百度图片的网址
:return: Bool
"""
# 1. 向服务器发起HTTP请求
response = requests.get(url)
# 2. 获取服务器端的响应信息
# 响应信息: status_code, text, url
data = response.text # 获取页面源码
# 3. 编写正则表达式,获取图片的网址
# data = ...[{"ObjURL":"http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg",....}]...
# 需要获取到的是: http:\/\/images.freeimages.com\/images\/large-previews\/3bc\/calico-cat-outside-1561133.jpg
# 正则的语法: .代表除了\n之外的任意字符, *代表前一个字符出现0次或者无数次. ?代表非贪婪模式
pattern = r'"objURL":"(.*?)"'
# 4. 根据正则表达式寻找符合条件的图片网址.
image_urls = re.findall(pattern, data)
# 5. 根据图片网址下载猫的图片到本地
index = 1
for image_url in image_urls:
print(image_url) # 'xxxx.jpg xxxx.png'
# response.text 返回 unicode 的文本信息, response.text 返回 bytes 类型的信息
try:
response = requests.get(image_url) # 向每一个图片的url发起HTTP请求
except Exception as e:
print(Fore.RED + "[-] 下载失败: %s" % (image_url))
else:
old_image_filename = image_url.split('/')[-1]
if old_image_filename:
# 获取图片的后缀
image_format = old_image_filename.split('.')[-1]
# 处理 url 为...jpeg?imageview&thumbnail=550x0 结尾(传参)的情况
if '?' in image_format:
image_format = image_format.split('?')[0]
else:
image_format = 'jpg'
# 生成图片的存储目录
keyword = keyword.split(' ', '-')
if not os.path.exists(keyword):
os.mkdir(keyword)
image_filename = os.path.join(keyword, str(index) + '.' + image_format)
# 保存图片
with open(image_filename, 'wb') as f:
f.write(response.content)
print(Fore.BLUE + "[+] 保存图片%s.jpg成功" % (index))
index += 1
if __name__ == '__main__':
keyword = input("请输入批量下载图片的关键字: ")
url = 'http://image.baidu.com/search/index?tn=baiduimage&word=' + keyword
print(Fore.BLUE + '[+] 正在请求网址: %s' % (url))
download_image(url, keyword)
结果:
常见问题:
为什么只有30张图片,百度有30多张图片
百度图片是响应式的,下拉的时候会不断的加载新的图片,也就是说浏览器中的页面是通过JS处理数据的结果,Ajax爬虫的内容这里不再详述。
搜索页面下点击单张图片的url与程序中获取的ObjURL不一致
这可能是百度缓存处理的结果。每张图片本质上都是“外网”,不是百度,所以在程序中,选择向实际存储图片的url发起HTTP请求。
网页爬虫抓取百度图片(fildder抓包来分析这些新闻网址等信息隐藏在那个地方 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-16 05:21
)
先分析
打开网站后,再打开源码,发现之前的一些新闻头条在源码中可以找到,而下面的头条在源码中找不到
这时候我们就需要使用fildder抓包来分析这些新闻的URL以及隐藏在那个地方的其他信息
这些有我们正在寻找的信息
我们复制网址在浏览器中打开发现不是我们要找的源信息
复制这个url找到我们的源码,比较两个url的区别
t只是一个时间戳,我们将第二个URL改为
&ajax=json
我们可以通过上面的网址访问源代码
我们受到下面蓝色网址的启发,只需要通过以上网址的拼接来获取我们的源代码
1、首先定义我们要爬取哪些字段。这是在 items 中定义的
import scrapy
class BaidunewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
"""1定义爬取的东西"""
title=scrapy.Field()
link=scrapy.Field()
content=scrapy.Field()
2、编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from baidunews.items import BaidunewsItem
from scrapy.http import Request
import re
class NewsSpider(scrapy.Spider):
name = 'news'
allowed_domains = ['news.baidu.com']
start_urls = ['http://news.baidu.com/widget%3 ... 39%3B]
all_id = ['LocalNews', 'civilnews', 'InternationalNews', 'EnterNews', 'SportNews', 'FinanceNews', 'TechNews',
'MilitaryNews', 'InternetNews', 'DiscoveryNews', 'LadyNews', 'HealthNews', 'PicWall']
all_url = []
for i in range(len(all_id)):
current_id = all_id[i]
current_url = 'http://news.baidu.com/widget?id=' + current_id + '&ajax=json'
all_url.append(current_url)
"""得到某个栏目块的url"""
def parse(self, response):
for i in range(0, len(self.all_url)):
print("第" + str(i) + "个栏目")
yield Request(self.all_url[i], callback=self.next)
"""某个模块下面的所有的新闻的url"""
def next(self, response):
data = response.body.decode('utf-8', 'ignore')
# print(self.all_url)
partten1 = '"url":"(.*?)"'
partten2 = '"m_url":"(.*?)"'
url1 = re.compile(partten1, re.S).findall(data)
url2 = re.compile(partten2, re.S).findall(data)
if (len(url1) != 0):
url = url1
else:
url = url2
# print(url)
# print("===========================")
for i in range(0, len(url)):
thisurl = re.sub(r"\\\/", '/', url[i])
# print(thisurl)
yield Request(thisurl, callback=self.next2,dont_filter=True) # thisurl是返回的值,回调函数调next2去处理,
def next2(self, response):
item = BaidunewsItem()
item['link'] = response.url
item['title'] = response.xpath("/html/head/title/text()").extract()
item['content'] = response.body
yield item
这里总结几点
1、代码中yieldRequest()中的第一个参数是yield生成器返回的值,第二个callback=XXX是接下来要调用的参数
2、yield Request(thisurl, callback=self.next2,dont_filter=True) 如果不加dont_filter=True,则无法获取返回项
3 教我的大佬解释说,allowed_domains = [''] 我们里面这个参数是设置成在URL中收录这个来获取我们想要的信息,比如current_url = '#39; + current_id + '&ajax=json ' 而且我们的每个栏目块下都没有一条新闻。只有加上上面dont_filter=True的参数才能返回我们的item信息
3、我们可以编写管道来查看一些返回的项目
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
class BaidunewsPipeline(object):
def process_item(self, item, spider):
# print("===========================")
print(item["title"].decode('utf-8')+item['link']+item['content'])
return item
4 我们还需要在执行代码之前在设置中注册
# -*- coding: utf-8 -*-
# Scrapy settings for baidunews project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
BOT_NAME = 'baidunews'
SPIDER_MODULES = ['baidunews.spiders']
NEWSPIDER_MODULE = 'baidunews.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'baidunews (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/late ... delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
#SPIDER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
#DOWNLOADER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/late ... .html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/late ... .html
#注册pipeline
ITEM_PIPELINES = {
'baidunews.pipelines.BaidunewsPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/late ... .html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/late ... tings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5然后我们就可以在命令行窗口成功执行scrapy爬取新闻了
6 下面是我们的目录结构
查看全部
网页爬虫抓取百度图片(fildder抓包来分析这些新闻网址等信息隐藏在那个地方
)
先分析
打开网站后,再打开源码,发现之前的一些新闻头条在源码中可以找到,而下面的头条在源码中找不到
这时候我们就需要使用fildder抓包来分析这些新闻的URL以及隐藏在那个地方的其他信息
这些有我们正在寻找的信息
我们复制网址在浏览器中打开发现不是我们要找的源信息
复制这个url找到我们的源码,比较两个url的区别
t只是一个时间戳,我们将第二个URL改为
&ajax=json
我们可以通过上面的网址访问源代码
我们受到下面蓝色网址的启发,只需要通过以上网址的拼接来获取我们的源代码
1、首先定义我们要爬取哪些字段。这是在 items 中定义的
import scrapy
class BaidunewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
"""1定义爬取的东西"""
title=scrapy.Field()
link=scrapy.Field()
content=scrapy.Field()
2、编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from baidunews.items import BaidunewsItem
from scrapy.http import Request
import re
class NewsSpider(scrapy.Spider):
name = 'news'
allowed_domains = ['news.baidu.com']
start_urls = ['http://news.baidu.com/widget%3 ... 39%3B]
all_id = ['LocalNews', 'civilnews', 'InternationalNews', 'EnterNews', 'SportNews', 'FinanceNews', 'TechNews',
'MilitaryNews', 'InternetNews', 'DiscoveryNews', 'LadyNews', 'HealthNews', 'PicWall']
all_url = []
for i in range(len(all_id)):
current_id = all_id[i]
current_url = 'http://news.baidu.com/widget?id=' + current_id + '&ajax=json'
all_url.append(current_url)
"""得到某个栏目块的url"""
def parse(self, response):
for i in range(0, len(self.all_url)):
print("第" + str(i) + "个栏目")
yield Request(self.all_url[i], callback=self.next)
"""某个模块下面的所有的新闻的url"""
def next(self, response):
data = response.body.decode('utf-8', 'ignore')
# print(self.all_url)
partten1 = '"url":"(.*?)"'
partten2 = '"m_url":"(.*?)"'
url1 = re.compile(partten1, re.S).findall(data)
url2 = re.compile(partten2, re.S).findall(data)
if (len(url1) != 0):
url = url1
else:
url = url2
# print(url)
# print("===========================")
for i in range(0, len(url)):
thisurl = re.sub(r"\\\/", '/', url[i])
# print(thisurl)
yield Request(thisurl, callback=self.next2,dont_filter=True) # thisurl是返回的值,回调函数调next2去处理,
def next2(self, response):
item = BaidunewsItem()
item['link'] = response.url
item['title'] = response.xpath("/html/head/title/text()").extract()
item['content'] = response.body
yield item
这里总结几点
1、代码中yieldRequest()中的第一个参数是yield生成器返回的值,第二个callback=XXX是接下来要调用的参数
2、yield Request(thisurl, callback=self.next2,dont_filter=True) 如果不加dont_filter=True,则无法获取返回项
3 教我的大佬解释说,allowed_domains = [''] 我们里面这个参数是设置成在URL中收录这个来获取我们想要的信息,比如current_url = '#39; + current_id + '&ajax=json ' 而且我们的每个栏目块下都没有一条新闻。只有加上上面dont_filter=True的参数才能返回我们的item信息
3、我们可以编写管道来查看一些返回的项目
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/late ... .html
class BaidunewsPipeline(object):
def process_item(self, item, spider):
# print("===========================")
print(item["title"].decode('utf-8')+item['link']+item['content'])
return item
4 我们还需要在执行代码之前在设置中注册
# -*- coding: utf-8 -*-
# Scrapy settings for baidunews project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
# https://doc.scrapy.org/en/late ... .html
BOT_NAME = 'baidunews'
SPIDER_MODULES = ['baidunews.spiders']
NEWSPIDER_MODULE = 'baidunews.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'baidunews (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/late ... delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/late ... .html
#SPIDER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/late ... .html
#DOWNLOADER_MIDDLEWARES = {
# 'baidunews.middlewares.BaidunewsDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/late ... .html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/late ... .html
#注册pipeline
ITEM_PIPELINES = {
'baidunews.pipelines.BaidunewsPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/late ... .html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/late ... tings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5然后我们就可以在命令行窗口成功执行scrapy爬取新闻了
6 下面是我们的目录结构
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-16 05:20
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,但是请求方法比较简单
不要忘记爬虫的基本思想:
1.指定要爬取的链接,然后爬取网站源码
2.提取你想要的内容,比如如果要爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签方法
3.循环获取要爬取的内容列表并保存文件
这里的代码和我博客前几章的代码(图片爬虫系列一)的区别是:
1.reques库用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀名
3.保存图片时不使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
注意我们之所以判断图片链接是否以“https://”开头,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一个图片,然后点击html所在的代码。 ,按住鼠标,可以看到绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图:
查看全部
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生)
)
来自《Python项目案例开发从入门到实战》(清华大学出版社,郑秋生,夏九杰主编)爬虫应用——抓取百度图片
本文使用请求库抓取某网站的图片。前面的博客章节介绍了如何使用 urllib 库来爬取网页。本文主要使用请求库来抓取网页内容。使用方法 基本一样,但是请求方法比较简单
不要忘记爬虫的基本思想:
1.指定要爬取的链接,然后爬取网站源码
2.提取你想要的内容,比如如果要爬取图片信息,可以选择用正则表达式过滤或者使用提取
标签方法
3.循环获取要爬取的内容列表并保存文件
这里的代码和我博客前几章的代码(图片爬虫系列一)的区别是:
1.reques库用于提取网页
2.保存图片时,后缀不固定使用png或jpg,而是图片本身的后缀名
3.保存图片时不使用urllib.request.urlretrieve函数,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
注意我们之所以判断图片链接是否以“https://”开头,主要是因为我们需要一个完整的绝对路径来下载图片,而这个需要看网页原代码,选择一个图片,然后点击html所在的代码。 ,按住鼠标,可以看到绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图:
网页爬虫抓取百度图片(#第一次学习爬虫后,自己编码抓取图片' )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-16 05:11
)
#第一次学爬虫后,自己编码和抓图
##下面介绍主要流程
先打开一个你要抓图的网页,我以''为例|
url = 'https://www.quanjing.com/creat ... 39%3B
2.然后阅读网页的源码,我们可以在源码中找到我们要抓取的图片对应的链接|
这里可能有人文,网页的源代码在哪里?
答:右键找到网页源代码,或者直接F12
html = urllib.request.urlopen(url).read().decode('utf-8')
运行后,我们可以看到链接抓取成功,都是以列表的形式抓取的:
3.下面使用 urllib.request.urlretrieve(url, 'target address')
要从对应链接下载图片,首先要把上面得到的字符串形式转换成不带“”的链接
html1 = i.replace('"','')``
4.批量下载到本地
```python
for i in page_list:
html1 = i.replace('"','')
print(html1)
global x
urllib.request.urlretrieve(html1, 'image\%s.jpg' % x)
x+=1
这里保存到py文件对应目录下的image文件中
查看全部
网页爬虫抓取百度图片(#第一次学习爬虫后,自己编码抓取图片'
)
#第一次学爬虫后,自己编码和抓图
##下面介绍主要流程
先打开一个你要抓图的网页,我以''为例|
url = 'https://www.quanjing.com/creat ... 39%3B
2.然后阅读网页的源码,我们可以在源码中找到我们要抓取的图片对应的链接|
这里可能有人文,网页的源代码在哪里?
答:右键找到网页源代码,或者直接F12
html = urllib.request.urlopen(url).read().decode('utf-8')
运行后,我们可以看到链接抓取成功,都是以列表的形式抓取的:
3.下面使用 urllib.request.urlretrieve(url, 'target address')
要从对应链接下载图片,首先要把上面得到的字符串形式转换成不带“”的链接
html1 = i.replace('"','')``
4.批量下载到本地
```python
for i in page_list:
html1 = i.replace('"','')
print(html1)
global x
urllib.request.urlretrieve(html1, 'image\%s.jpg' % x)
x+=1
这里保存到py文件对应目录下的image文件中
网页爬虫抓取百度图片(在python学习之路(10):爬虫进阶,使用python爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-14 08:11
python学习之路(一0):高级爬虫,用python爬取你喜欢的小说
在这个 文章 中,我们使用 BeautifulSoup 爬取了一本小说。这是学习BeautifulSoup后写的第一个小程序,但是感觉自己对BeautifulSoup的使用不够熟练,所以再写一个爬虫。增强 BeautifulSoup 的使用。
本次抓取微信公众号的文章标题、文章摘要、文章网址、文章封面图片网址、公众号名称等信息。
python学习之路(12):连接Mysql数据库及简单的增删改查查询回滚操作)
在这个文章中,我们谈到了mysql的使用,所以这次我们将抓取的数据存储在数据库中。
我们不应该忘记我们以前学过的知识。我们应该把以前学过的东西都应用到现在的学习中,这样可以让我们复习旧知识,更牢牢地掌握知识点。
微信文章捕获的地址为:
这是搜狗微信的搜索页面,里面的文章每隔几个小时就会更新一次。所以在这里抓取 文章 是相当全面的。
想法
1、 研究网页结构
2、 使用 BeautifulSoup 解析我们需要的信息
3、 将解析后的信息存入mysql数据库
学习网络结构
研究网页的结构,当然是右键->检查元素
但是很快我发现了一个问题,每个页面只有20篇微信文章文章,要查看更多,我必须点击“加载更多”按钮。首先想了一下能不能用python来点击,但是网上找的方法太深奥了,对python的学习还没有深入,所以决定换一种方式。
懂一点JS的人都知道,如果是做“加载更多”之类的功能,就必须使用AJAX向服务器请求新的数据,所以在我点击“加载更多”按钮后,我使用了浏览器的网络看到这个请求。
我猜这一定是请求新数据的接口,我们打开看看
哈哈,这个页面也是微信文章的页面,简单多了,大大降低了我们分析的难度。
并且发现了另一种模式。此 URL 以 1.html 结尾。
如果我把它改成 2.html
哈哈,神奇的发现改成2.html还是可以访问的,所以我大胆猜测,这应该是页数的意思。
我在上面的 URL 中发现的另一个有趣的事情是有一个 PC_0。
所以我决定把它改成 pc_1 试试看。
还能访问,看到这边的信息让我觉得这是不是文章的另一类。
在审查了元素之后,这证实了我的怀疑。
经过以上研究,以下地址
可以得出两个结论:
1、后面的1.html是页数,不同的数字代表不同的页数。
2、 后面pc_0中的0代表分类,不同的数字代表不同的类型。
有了这两个结论,我们写一个抓微信文章的代码就简单多了。
这个文章就写到这里了,后面我会根据这个文章得到的结论来谈抓数据,因为我在研究这个网页的时候也在写这个文章。我也写了代码。这个文章会先解释一下研究一个网页的思路。等我把代码写好整理后,分享给大家。 查看全部
网页爬虫抓取百度图片(在python学习之路(10):爬虫进阶,使用python爬取)
python学习之路(一0):高级爬虫,用python爬取你喜欢的小说
在这个 文章 中,我们使用 BeautifulSoup 爬取了一本小说。这是学习BeautifulSoup后写的第一个小程序,但是感觉自己对BeautifulSoup的使用不够熟练,所以再写一个爬虫。增强 BeautifulSoup 的使用。
本次抓取微信公众号的文章标题、文章摘要、文章网址、文章封面图片网址、公众号名称等信息。
python学习之路(12):连接Mysql数据库及简单的增删改查查询回滚操作)
在这个文章中,我们谈到了mysql的使用,所以这次我们将抓取的数据存储在数据库中。
我们不应该忘记我们以前学过的知识。我们应该把以前学过的东西都应用到现在的学习中,这样可以让我们复习旧知识,更牢牢地掌握知识点。
微信文章捕获的地址为:
这是搜狗微信的搜索页面,里面的文章每隔几个小时就会更新一次。所以在这里抓取 文章 是相当全面的。
想法
1、 研究网页结构
2、 使用 BeautifulSoup 解析我们需要的信息
3、 将解析后的信息存入mysql数据库
学习网络结构
研究网页的结构,当然是右键->检查元素
但是很快我发现了一个问题,每个页面只有20篇微信文章文章,要查看更多,我必须点击“加载更多”按钮。首先想了一下能不能用python来点击,但是网上找的方法太深奥了,对python的学习还没有深入,所以决定换一种方式。
懂一点JS的人都知道,如果是做“加载更多”之类的功能,就必须使用AJAX向服务器请求新的数据,所以在我点击“加载更多”按钮后,我使用了浏览器的网络看到这个请求。
我猜这一定是请求新数据的接口,我们打开看看
哈哈,这个页面也是微信文章的页面,简单多了,大大降低了我们分析的难度。
并且发现了另一种模式。此 URL 以 1.html 结尾。
如果我把它改成 2.html
哈哈,神奇的发现改成2.html还是可以访问的,所以我大胆猜测,这应该是页数的意思。
我在上面的 URL 中发现的另一个有趣的事情是有一个 PC_0。
所以我决定把它改成 pc_1 试试看。
还能访问,看到这边的信息让我觉得这是不是文章的另一类。
在审查了元素之后,这证实了我的怀疑。
经过以上研究,以下地址
可以得出两个结论:
1、后面的1.html是页数,不同的数字代表不同的页数。
2、 后面pc_0中的0代表分类,不同的数字代表不同的类型。
有了这两个结论,我们写一个抓微信文章的代码就简单多了。
这个文章就写到这里了,后面我会根据这个文章得到的结论来谈抓数据,因为我在研究这个网页的时候也在写这个文章。我也写了代码。这个文章会先解释一下研究一个网页的思路。等我把代码写好整理后,分享给大家。
网页爬虫抓取百度图片(用Jsoup解析img标签并提取里面的title和data-original属性 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-08 00:14
)
大家好,我是小北。
在普通的群聊中,有时会遇到那种欺负人。如果你不同意,你会开始谈论阴阳并发送各种表情符号。但是,你的微信表情总是一点点,不够个性,上网去百度太麻烦了。本文文章根据emoji中的关键词网站下载emoji到本地,让黑帮远离你。
本文使用java的OKHttp框架作为爬虫抓取“post emoji”网站()的表情包,使用Jsoup框架解析抓取到的网页。
马文
OKHttp是一个优秀的网络请求框架,可以请求http、https、get()、post()、put()等请求方法。Jsoup是一个解析网页的框架,可以像JS一样使用。
com.squareup.okhttp3
okhttp
4.9.3
org.jsoup
jsoup
1.14.3
思路分析
打开网站,搜索关键字[Loading Force]的表情包,打开F12控制面板,可以看到每个表情包都收录在div元素中,翻的时候可以读取url地址这一页。可以看到第一页最后一个数字是1,第二页是2,第三页是3。这个很容易做到,只需要改变数字即可。
String url = String.format("https://fabiaoqing.com/search/ ... ot%3B, "装逼", 1);
public Request buildRequest(String url) {
Request request = new Request.Builder()
.url(url)
.build();
return request;
}
public Response getResponse( Request request) {
Response response = null;
try {
OkHttpClient client = new OkHttpClient();
response = client.newCall(request).execute();
System.out.println(response.body().string());
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
继续查看网页源码,表情图片隐藏在div层下的img表情中,使用Jsoup解析img标签,提取里面的title和data-original属性,作为文件名和内容图片。
Map map = new HashMap();
Document document = Jsoup.parse(html);
Elements elements = document.getElementsByClass("ui image bqppsearch lazy");
for (Element element : elements) {
Attributes attributes = element.attributes();
String key = attributes.get("title").replaceAll("\\n", "").replaceAll("[/\\\\\\\\:*?|\\\"]", "");
String value = attributes.get("data-original");
map.put(key, value);
} 查看全部
网页爬虫抓取百度图片(用Jsoup解析img标签并提取里面的title和data-original属性
)
大家好,我是小北。
在普通的群聊中,有时会遇到那种欺负人。如果你不同意,你会开始谈论阴阳并发送各种表情符号。但是,你的微信表情总是一点点,不够个性,上网去百度太麻烦了。本文文章根据emoji中的关键词网站下载emoji到本地,让黑帮远离你。
本文使用java的OKHttp框架作为爬虫抓取“post emoji”网站()的表情包,使用Jsoup框架解析抓取到的网页。
马文
OKHttp是一个优秀的网络请求框架,可以请求http、https、get()、post()、put()等请求方法。Jsoup是一个解析网页的框架,可以像JS一样使用。
com.squareup.okhttp3
okhttp
4.9.3
org.jsoup
jsoup
1.14.3
思路分析
打开网站,搜索关键字[Loading Force]的表情包,打开F12控制面板,可以看到每个表情包都收录在div元素中,翻的时候可以读取url地址这一页。可以看到第一页最后一个数字是1,第二页是2,第三页是3。这个很容易做到,只需要改变数字即可。
String url = String.format("https://fabiaoqing.com/search/ ... ot%3B, "装逼", 1);
public Request buildRequest(String url) {
Request request = new Request.Builder()
.url(url)
.build();
return request;
}
public Response getResponse( Request request) {
Response response = null;
try {
OkHttpClient client = new OkHttpClient();
response = client.newCall(request).execute();
System.out.println(response.body().string());
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
继续查看网页源码,表情图片隐藏在div层下的img表情中,使用Jsoup解析img标签,提取里面的title和data-original属性,作为文件名和内容图片。
Map map = new HashMap();
Document document = Jsoup.parse(html);
Elements elements = document.getElementsByClass("ui image bqppsearch lazy");
for (Element element : elements) {
Attributes attributes = element.attributes();
String key = attributes.get("title").replaceAll("\\n", "").replaceAll("[/\\\\\\\\:*?|\\\"]", "");
String value = attributes.get("data-original");
map.put(key, value);
}

