
网页爬虫抓取百度图片
网页爬虫抓取百度图片(网络爬虫爬取百度图片猫的图片为案例演示(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-15 00:00
)
网络爬虫主要分为4大板块:
分析具有明确目标的网页结构,
在网页中查找信息的地址,
抓取信息,
保存信息
以下以网络爬虫抓取百度图片猫的图片为例进行演示
项目案例:
爬取百度所有狗图片网站
步骤分析:第一步:明确目标,我们将百度的狗图片作为目标爬取,分析网页结构
1、输入以下网址
^00_1583X672&word=狗
2、选择下一页时,只有pn和gsm值发生了变化。
到目前为止,我所知道的是:pn参数代表页数; word参数自然是关键词,需要转换编码格式。
gsm 的值,随意更改似乎没有任何作用。有句话说gsm:代表pn的十六进制值
3、可以拼接出页面请求的URL,代码如下
import sys
import urllib
import requests
def getPage(keyword, page, n):
page = page * n
keyword = urllib.parse.quote(keyword, safe='/')
url_begin = "http://image.baidu.com/search/ ... ot%3B
url = url_begin + keyword + "&pn=" + str(page) + "&gsm=" + str(hex(page)) + "&ct=&ic=0&lm=-1&width=0&height=0"
return url
第二步:在网页中查找图片地址
1、右键查看网页源代码,分析JSON数据可以看到objURL字段代表原图的下载路径
2、根据URL地址,获取图片地址的代码为:
def get_onepage_urls(onepageurl):
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
return pic_urls
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
return pic_urls
三、爬取图片并保存
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = 'data2/'+str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
四、调用函数
if __name__ == '__main__':
keyword = '狗' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
page_begin = 0
page_number = 30
image_number = 3
all_pic_urls = []
while 1:
if page_begin > image_number:
break
print("第%d次请求数据", [page_begin])
url = getPage(keyword, page_begin, page_number)
onepage_urls = get_onepage_urls(url)
page_begin += 1
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
查看全部
网页爬虫抓取百度图片(网络爬虫爬取百度图片猫的图片为案例演示(图)
)
网络爬虫主要分为4大板块:
分析具有明确目标的网页结构,
在网页中查找信息的地址,
抓取信息,
保存信息
以下以网络爬虫抓取百度图片猫的图片为例进行演示
项目案例:
爬取百度所有狗图片网站
步骤分析:第一步:明确目标,我们将百度的狗图片作为目标爬取,分析网页结构
1、输入以下网址
^00_1583X672&word=狗

2、选择下一页时,只有pn和gsm值发生了变化。


到目前为止,我所知道的是:pn参数代表页数; word参数自然是关键词,需要转换编码格式。
gsm 的值,随意更改似乎没有任何作用。有句话说gsm:代表pn的十六进制值
3、可以拼接出页面请求的URL,代码如下
import sys
import urllib
import requests
def getPage(keyword, page, n):
page = page * n
keyword = urllib.parse.quote(keyword, safe='/')
url_begin = "http://image.baidu.com/search/ ... ot%3B
url = url_begin + keyword + "&pn=" + str(page) + "&gsm=" + str(hex(page)) + "&ct=&ic=0&lm=-1&width=0&height=0"
return url
第二步:在网页中查找图片地址
1、右键查看网页源代码,分析JSON数据可以看到objURL字段代表原图的下载路径

2、根据URL地址,获取图片地址的代码为:
def get_onepage_urls(onepageurl):
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
return pic_urls
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
return pic_urls
三、爬取图片并保存
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = 'data2/'+str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
四、调用函数
if __name__ == '__main__':
keyword = '狗' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
page_begin = 0
page_number = 30
image_number = 3
all_pic_urls = []
while 1:
if page_begin > image_number:
break
print("第%d次请求数据", [page_begin])
url = getPage(keyword, page_begin, page_number)
onepage_urls = get_onepage_urls(url)
page_begin += 1
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))


网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-12 03:11
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的照片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站你懂的,很难解释)几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar 查看全部
网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的照片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站你懂的,很难解释)几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar
网页爬虫抓取百度图片(Python视频写了一个爬虫程序,实现简单的网页图片下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-12 03:11
一、介绍
我学习 Python 已经有一段时间了。听说Python爬虫很厉害。我现在才学到这个。跟着小龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的网址使用了反爬虫算法。所以无法爬取想要的图片,所以,只做爬虫笔记。仅供学习参考【捂脸】。 . . .
终于:我把jpg格式改成gif了,还是能爬到一个很差的gif图:
第一张图片是反爬机制的图片占位符,完全没有内容 查看全部
网页爬虫抓取百度图片(Python视频写了一个爬虫程序,实现简单的网页图片下载)
一、介绍
我学习 Python 已经有一段时间了。听说Python爬虫很厉害。我现在才学到这个。跟着小龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的网址使用了反爬虫算法。所以无法爬取想要的图片,所以,只做爬虫笔记。仅供学习参考【捂脸】。 . . .
终于:我把jpg格式改成gif了,还是能爬到一个很差的gif图:

第一张图片是反爬机制的图片占位符,完全没有内容
网页爬虫抓取百度图片(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-10 04:21
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-
import urllib.request
req = urllib.request.urlopen('https://www.amazon.com')
print(req.code)
复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requests
url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'
web_header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': '你的cookie值',
'TE': 'Trailers'}
r = requests.get(url,headers=web_header)
print(r.status_code)
复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium
复制代码
在代码中引入 selenium 并设置相关参数
import os
from requests.api import options
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#selenium配置参数
options = Options()
#配置无头参数,即不打开浏览器
options.add_argument('--headless')
#配置Chrome浏览器的selenium驱动
chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
#将参数设置+浏览器驱动组合
browser = webdriver.Chrome(chromedriver,chrome_options=options)
复制代码
测试访问
url = "https://www.amazon.com"
print(url)
#通过selenium来访问亚马逊
browser.get(url)
复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件
fw=open('E:/amzon.html','w',encoding='utf-8')
fw.write(str(browser.page_source))
browser.close()
fw.close()
复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。 查看全部
网页爬虫抓取百度图片(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等

反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-
import urllib.request
req = urllib.request.urlopen('https://www.amazon.com')
print(req.code)
复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。

以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200

分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问

代码如下↓ ↓ ↓
import requests
url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'
web_header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': '你的cookie值',
'TE': 'Trailers'}
r = requests.get(url,headers=web_header)
print(r.status_code)
复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。

我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium
复制代码
在代码中引入 selenium 并设置相关参数
import os
from requests.api import options
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#selenium配置参数
options = Options()
#配置无头参数,即不打开浏览器
options.add_argument('--headless')
#配置Chrome浏览器的selenium驱动
chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
#将参数设置+浏览器驱动组合
browser = webdriver.Chrome(chromedriver,chrome_options=options)
复制代码
测试访问
url = "https://www.amazon.com"
print(url)
#通过selenium来访问亚马逊
browser.get(url)
复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件
fw=open('E:/amzon.html','w',encoding='utf-8')
fw.write(str(browser.page_source))
browser.close()
fw.close()
复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页

结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。
网页爬虫抓取百度图片(网络爬虫技术(Webcrawler)的工作流程及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-09 15:11
网络爬虫技术
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们被广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。 查看全部
网页爬虫抓取百度图片(网络爬虫技术(Webcrawler)的工作流程及注意事项)
网络爬虫技术
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们被广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
网页爬虫抓取百度图片( 爬取百度贴吧了百度你还真是鸡贼鼠标向下滚动)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-07 10:07
爬取百度贴吧了百度你还真是鸡贼鼠标向下滚动)
测试爬取百度贴吧图片
定义爬取百度斗图首页每篇文章URL的爬取规则对象
1 /**
2 * 斗图吧贴子的url
3 */
4 SpiderFunction doutubaTieZiUrl = spider -> {
5 // 文本爬取对象
6 TextSpider textSpider = (TextSpider) spider;
7 // 文本爬取规则 定位元素
8 textSpider.setReg("div:t_concleafix>*>a>href>*");
9 return textSpider.getData().getResult().stream()
10 // 爬取后的数据处理 因为可能存在相同引用的连接所以使用Set容器去重
11 .filter(url -> (!"#".equals(url)) && (!url.contains("?")) && (url.contains("/p/")))
12 .map(url -> url.startsWith("http") ? url : "https://tieba.baidu.com" + url
13 ).collect(Collectors.toSet());
14 };
15
16
在搜索爬虫规则的过程中,发现百度贴吧帖子列表页面的所有内容都被注释掉了,所以需要修改文字规则拦截部分的代码
过滤评论部分需要处理
编写一个爬取规则对象,爬取每篇文章的页数
1 /**
2 * 百度贴吧贴子的每页的url
3 */
4 SpiderFunction doutubaTieZiPageUrl = spider -> {
5 Set urls = new HashSet();
6 String page = spider.getUrl();
7 TextSpider textSpider = (TextSpider) spider;
8 // 定位总页数位置
9 textSpider.setReg("li:l_reply_num>1>span>2");
10 List result = textSpider.getData().getResult();
11 // 循环生成某个贴子的所有页面的url
12 if (Lists.isValuable(result)) {
13 String endNum = result.get(0);
14 if (endNum.matches("^[0-9]+$")) {
15 for (int i = 1; i {
5 TextSpider textSpider = (TextSpider) spider;
6 textSpider.setReg("div:p_content>*>img>src>*");
7 return textSpider.getData().getResult().stream()
8 .map(url -> url.startsWith("http") ? url : spider.getUrl() + url)
9 .filter(SpiderCommonUtils::isImgUrl)
10 .collect(Collectors.toSet());
11 };
12
13
获取豆瓣的代码
1 /**
2 * 抓取斗图吧图片
3 */
4 @Test
5 public void testP(){
6 //String doutu = "https://tieba.baidu.com/f%3Fkw ... 3B%3B
7 for (int i = 0; i {
56 if (jsonMap.containsKey(tag)) {
57 result.addAll(getDataList(jsonMap.get(tag).toString(),endTag));
58 }
59 });
60 }
61 }else{
62 JSON json = JSONUtil.parse(source);
63 if (json instanceof JSONObject) {
64 if (((JSONObject) json).containsKey(reg)) {
65 result.add(((JSONObject) json).get(reg).toString());
66 }
67 } else if (json instanceof JSONArray) {
68 ((JSONArray) json).toList(Map.class).stream().forEach(jsonMap -> {
69 if (jsonMap.containsKey(reg)) {
70 result.add(jsonMap.get(reg).toString());
71 }
72 });
73 }
74 }
75 return result;
76 }
77}
78
79
编写爬取规则对象
1 /**
2 * 百度搜图的图片url
3 */
4 SpiderFunction baiDuSouImgUrl = spider -> {
5 AjaxSpider ajaxSpider = (AjaxSpider) spider;
6 return ajaxSpider.getData().getDataList("data.hoverURL");
7 };
8
9
爬取代码
<p>1 /**
2 * 抓取百度图片搜索
3 */
4 @Test
5 public void testPt(){
6 String image = "https://image.baidu.com/search/acjson?";
7 //搜索的关键字
8 String queryWords = "米老鼠";
9 // 参数
10 Map parms = new HashMap();
11 parms.put("tn", "resultjson_com");
12 parms.put("ipn", "rj");
13 parms.put("ct", "201326592");
14 parms.put("is", "");
15 parms.put("fp", "result");
16 parms.put("queryWord", queryWords);
17 parms.put("cl", "2");
18 parms.put("lm", "-1");
19 parms.put("ie", "utf-8");
20 parms.put("oe", "utf-8");
21 parms.put("adpicid", "");
22 parms.put("st", "-1");
23 parms.put("z", "");
24 parms.put("ic", "0");
25 parms.put("hd", "");
26 parms.put("latest", "");
27 parms.put("copyright", "");
28 parms.put("word", queryWords);
29 parms.put("s", "");
30 parms.put("se", "");
31 parms.put("tab", "");
32 parms.put("width", "");
33 parms.put("height", "");
34 parms.put("face", "0");
35 parms.put("istype", "2");
36 parms.put("qc", "");
37 parms.put("nc", "1");
38 parms.put("fr", "");
39 parms.put("expermode", "");
40 parms.put("rn", "30");
41 parms.put("gsm", "");
42 parms.put(String.valueOf(System.currentTimeMillis()),"");
43 for (int i = 0; i 查看全部
网页爬虫抓取百度图片(
爬取百度贴吧了百度你还真是鸡贼鼠标向下滚动)
测试爬取百度贴吧图片
定义爬取百度斗图首页每篇文章URL的爬取规则对象
1 /**
2 * 斗图吧贴子的url
3 */
4 SpiderFunction doutubaTieZiUrl = spider -> {
5 // 文本爬取对象
6 TextSpider textSpider = (TextSpider) spider;
7 // 文本爬取规则 定位元素
8 textSpider.setReg("div:t_concleafix>*>a>href>*");
9 return textSpider.getData().getResult().stream()
10 // 爬取后的数据处理 因为可能存在相同引用的连接所以使用Set容器去重
11 .filter(url -> (!"#".equals(url)) && (!url.contains("?")) && (url.contains("/p/")))
12 .map(url -> url.startsWith("http") ? url : "https://tieba.baidu.com" + url
13 ).collect(Collectors.toSet());
14 };
15
16
在搜索爬虫规则的过程中,发现百度贴吧帖子列表页面的所有内容都被注释掉了,所以需要修改文字规则拦截部分的代码

过滤评论部分需要处理
编写一个爬取规则对象,爬取每篇文章的页数
1 /**
2 * 百度贴吧贴子的每页的url
3 */
4 SpiderFunction doutubaTieZiPageUrl = spider -> {
5 Set urls = new HashSet();
6 String page = spider.getUrl();
7 TextSpider textSpider = (TextSpider) spider;
8 // 定位总页数位置
9 textSpider.setReg("li:l_reply_num>1>span>2");
10 List result = textSpider.getData().getResult();
11 // 循环生成某个贴子的所有页面的url
12 if (Lists.isValuable(result)) {
13 String endNum = result.get(0);
14 if (endNum.matches("^[0-9]+$")) {
15 for (int i = 1; i {
5 TextSpider textSpider = (TextSpider) spider;
6 textSpider.setReg("div:p_content>*>img>src>*");
7 return textSpider.getData().getResult().stream()
8 .map(url -> url.startsWith("http") ? url : spider.getUrl() + url)
9 .filter(SpiderCommonUtils::isImgUrl)
10 .collect(Collectors.toSet());
11 };
12
13
获取豆瓣的代码
1 /**
2 * 抓取斗图吧图片
3 */
4 @Test
5 public void testP(){
6 //String doutu = "https://tieba.baidu.com/f%3Fkw ... 3B%3B
7 for (int i = 0; i {
56 if (jsonMap.containsKey(tag)) {
57 result.addAll(getDataList(jsonMap.get(tag).toString(),endTag));
58 }
59 });
60 }
61 }else{
62 JSON json = JSONUtil.parse(source);
63 if (json instanceof JSONObject) {
64 if (((JSONObject) json).containsKey(reg)) {
65 result.add(((JSONObject) json).get(reg).toString());
66 }
67 } else if (json instanceof JSONArray) {
68 ((JSONArray) json).toList(Map.class).stream().forEach(jsonMap -> {
69 if (jsonMap.containsKey(reg)) {
70 result.add(jsonMap.get(reg).toString());
71 }
72 });
73 }
74 }
75 return result;
76 }
77}
78
79
编写爬取规则对象
1 /**
2 * 百度搜图的图片url
3 */
4 SpiderFunction baiDuSouImgUrl = spider -> {
5 AjaxSpider ajaxSpider = (AjaxSpider) spider;
6 return ajaxSpider.getData().getDataList("data.hoverURL");
7 };
8
9
爬取代码
<p>1 /**
2 * 抓取百度图片搜索
3 */
4 @Test
5 public void testPt(){
6 String image = "https://image.baidu.com/search/acjson?";
7 //搜索的关键字
8 String queryWords = "米老鼠";
9 // 参数
10 Map parms = new HashMap();
11 parms.put("tn", "resultjson_com");
12 parms.put("ipn", "rj");
13 parms.put("ct", "201326592");
14 parms.put("is", "");
15 parms.put("fp", "result");
16 parms.put("queryWord", queryWords);
17 parms.put("cl", "2");
18 parms.put("lm", "-1");
19 parms.put("ie", "utf-8");
20 parms.put("oe", "utf-8");
21 parms.put("adpicid", "");
22 parms.put("st", "-1");
23 parms.put("z", "");
24 parms.put("ic", "0");
25 parms.put("hd", "");
26 parms.put("latest", "");
27 parms.put("copyright", "");
28 parms.put("word", queryWords);
29 parms.put("s", "");
30 parms.put("se", "");
31 parms.put("tab", "");
32 parms.put("width", "");
33 parms.put("height", "");
34 parms.put("face", "0");
35 parms.put("istype", "2");
36 parms.put("qc", "");
37 parms.put("nc", "1");
38 parms.put("fr", "");
39 parms.put("expermode", "");
40 parms.put("rn", "30");
41 parms.put("gsm", "");
42 parms.put(String.valueOf(System.currentTimeMillis()),"");
43 for (int i = 0; i
网页爬虫抓取百度图片(Python爬虫抓取csdn博客+C和Ctrl+V)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-06 06:12
Python爬虫csdn博客
昨晚为了把某csdn大佬的博文全部下载保存,写了一个爬虫自动抓取文章保存为txt文本,当然也可以保存为html网页。这样Ctrl+C和Ctrl+V都可以用,很方便,抓取其他网站也差不多。
为了解析爬取的网页,使用了第三方模块BeautifulSoup。这个模块对于解析 html 文件非常有用。当然也可以使用正则表达式自己解析,但是比较麻烦。
由于csdn网站的robots.txt文件显示禁止任何爬虫,所以爬虫必须伪装成浏览器,不能频繁爬取。如果他们睡一会儿,他们就会被封锁。 ,但可以使用代理ip。
<p>#-*- encoding: utf-8 -*-
'''
Created on 2014-09-18 21:10:39
@author: Mangoer
@email: 2395528746@qq.com
'''
import urllib2
import re
from bs4 import BeautifulSoup
import random
import time
class CSDN_Blog_Spider:
def __init__(self,url):
print '\n'
print('已启动网络爬虫。。。')
print '网页地址: ' + url
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
# use proxy ip
# ips_list = ['60.220.204.2:63000','123.150.92.91:80','121.248.150.107:8080','61.185.21.175:8080','222.216.109.114:3128','118.144.54.190:8118',
# '1.50.235.82:80','203.80.144.4:80']
# ip = random.choice(ips_list)
# print '使用的代理ip地址: ' + ip
# proxy_support = urllib2.ProxyHandler({'http':'http://'+ip})
# opener = urllib2.build_opener(proxy_support)
# urllib2.install_opener(opener)
agent = random.choice(user_agents)
req = urllib2.Request(url)
req.add_header('User-Agent',agent)
req.add_header('Host','blog.csdn.net')
req.add_header('Accept','*/*')
req.add_header('Referer','http://blog.csdn.net/mangoer_ys?viewmode=list')
req.add_header('GET',url)
html = urllib2.urlopen(req)
page = html.read().decode('gbk','ignore').encode('utf-8')
self.page = page
self.title = self.getTitle()
self.content = self.getContent()
self.saveFile()
def printInfo(self):
print('文章标题是: '+self.title + '\n')
print('内容已经存储到out.txt文件中!')
def getTitle(self):
rex = re.compile('(.*?)',re.DOTALL)
match = rex.search(self.page)
if match:
return match.group(1)
return 'NO TITLE'
def getContent(self):
bs = BeautifulSoup(self.page)
html_content_list = bs.findAll('div',{'id':'article_content','class':'article_content'})
html_content = str(html_content_list[0])
rex_p = re.compile(r'(?:.*?)>(.*?) 查看全部
网页爬虫抓取百度图片(Python爬虫抓取csdn博客+C和Ctrl+V)
Python爬虫csdn博客
昨晚为了把某csdn大佬的博文全部下载保存,写了一个爬虫自动抓取文章保存为txt文本,当然也可以保存为html网页。这样Ctrl+C和Ctrl+V都可以用,很方便,抓取其他网站也差不多。
为了解析爬取的网页,使用了第三方模块BeautifulSoup。这个模块对于解析 html 文件非常有用。当然也可以使用正则表达式自己解析,但是比较麻烦。
由于csdn网站的robots.txt文件显示禁止任何爬虫,所以爬虫必须伪装成浏览器,不能频繁爬取。如果他们睡一会儿,他们就会被封锁。 ,但可以使用代理ip。
<p>#-*- encoding: utf-8 -*-
'''
Created on 2014-09-18 21:10:39
@author: Mangoer
@email: 2395528746@qq.com
'''
import urllib2
import re
from bs4 import BeautifulSoup
import random
import time
class CSDN_Blog_Spider:
def __init__(self,url):
print '\n'
print('已启动网络爬虫。。。')
print '网页地址: ' + url
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
# use proxy ip
# ips_list = ['60.220.204.2:63000','123.150.92.91:80','121.248.150.107:8080','61.185.21.175:8080','222.216.109.114:3128','118.144.54.190:8118',
# '1.50.235.82:80','203.80.144.4:80']
# ip = random.choice(ips_list)
# print '使用的代理ip地址: ' + ip
# proxy_support = urllib2.ProxyHandler({'http':'http://'+ip})
# opener = urllib2.build_opener(proxy_support)
# urllib2.install_opener(opener)
agent = random.choice(user_agents)
req = urllib2.Request(url)
req.add_header('User-Agent',agent)
req.add_header('Host','blog.csdn.net')
req.add_header('Accept','*/*')
req.add_header('Referer','http://blog.csdn.net/mangoer_ys?viewmode=list')
req.add_header('GET',url)
html = urllib2.urlopen(req)
page = html.read().decode('gbk','ignore').encode('utf-8')
self.page = page
self.title = self.getTitle()
self.content = self.getContent()
self.saveFile()
def printInfo(self):
print('文章标题是: '+self.title + '\n')
print('内容已经存储到out.txt文件中!')
def getTitle(self):
rex = re.compile('(.*?)',re.DOTALL)
match = rex.search(self.page)
if match:
return match.group(1)
return 'NO TITLE'
def getContent(self):
bs = BeautifulSoup(self.page)
html_content_list = bs.findAll('div',{'id':'article_content','class':'article_content'})
html_content = str(html_content_list[0])
rex_p = re.compile(r'(?:.*?)>(.*?)
网页爬虫抓取百度图片(简要的实现Python爬虫爬取百度贴吧页面上的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-05 22:07
Python爬虫爬取百度贴吧页面图片的简单实现,下面这个网页就是本博客要爬取的网页,当然你看到的只是图片的一部分,也就是要爬取的页面被爬行,
下图是最终爬取的图片:
接下来简单说一下爬取的全过程:
首先,你需要一个好的编程工具。博主使用的是他们觉得更容易使用的 Pycharm 工具。这是Pycharm官网下载的下载地址。您可以根据自己的电脑配置下载。是的,网上还有很多,可以参考。
下一步是编写爬虫代码。先不说代码:
<p>import urllib.request
import re
import os
''' 这是需要引入的三个文件包 '''
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'mozilla/5.0 (windows nt 6.3; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/65.0.3325.181 safari/537.36')
'''User_Ahent是爬虫所需要模拟浏览器访问所需要的一些标识信息,如浏览器类型,操作系统等'''
page = urllib.request.urlopen(req)
html = page.read().decode('utf-8')
return html
def get_img(html):
p = r' 查看全部
网页爬虫抓取百度图片(简要的实现Python爬虫爬取百度贴吧页面上的图片)
Python爬虫爬取百度贴吧页面图片的简单实现,下面这个网页就是本博客要爬取的网页,当然你看到的只是图片的一部分,也就是要爬取的页面被爬行,
下图是最终爬取的图片:
接下来简单说一下爬取的全过程:
首先,你需要一个好的编程工具。博主使用的是他们觉得更容易使用的 Pycharm 工具。这是Pycharm官网下载的下载地址。您可以根据自己的电脑配置下载。是的,网上还有很多,可以参考。
下一步是编写爬虫代码。先不说代码:
<p>import urllib.request
import re
import os
''' 这是需要引入的三个文件包 '''
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'mozilla/5.0 (windows nt 6.3; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/65.0.3325.181 safari/537.36')
'''User_Ahent是爬虫所需要模拟浏览器访问所需要的一些标识信息,如浏览器类型,操作系统等'''
page = urllib.request.urlopen(req)
html = page.read().decode('utf-8')
return html
def get_img(html):
p = r'
网页爬虫抓取百度图片(【干货】网页的壁纸都爬取了,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-05 04:12
前言
我想每个人都更喜欢漂亮的照片!不要隐瞒任何事情,每个人都知道对美丽的热爱。小编最近也比较无聊,就去爬壁纸、图片等。所以我添加了一些代码来抓取整个网页的所有壁纸。
目录 1:概述
在电脑上,创建一个文件夹,用来存放爬到对方桌面的图片
这个文件夹下有25个文件夹,对应分类
每个分类文件夹下有几个文件夹,对应页码
在页码文件夹下,存放图片文件
目录二:环境准备
在终端中分别输入以下 pip 命令进行安装
python -m pip install beautifulsoup4
python -m pip install lxml
python -m pip install requests
内容三:分析页面结构
4k类别下的壁纸是网站收入的重要资源,我们对4k壁纸有需求,所以不抓取
我用审美类下的壁纸来讲解下如何爬取图片
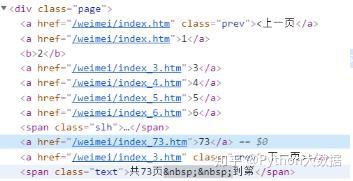
1.一共73页,除了最后一页,每页18张图片
但是在代码中,我们最好需要自动获取总页码,嗯,对方桌面壁纸网站的结构真的很舒服,基本上每个页码的html结构都差不多
CSS选择器:div.page a,定位到包裹页数的a标签,只有6个
并且每页第三张图片是同一个广告,需要在代码中过滤掉
每个分页的超链接清晰:/weimei/index_x.htm
x 正是页面的页码
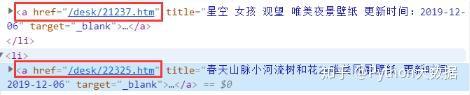
注意:您在类别下看到的图片是低分辨率的缩略图;要得到分辨率为1920×1080的图片,需要进行两次跳转
下图是一个例子
在分类页面中,我们可以直接获取图片的url,但遗憾的是,它的分辨率并不理想;
通过检查,很明显类别页面中显示的每个图像都指向另一个超链接
CSS选择器:div#main div.list ul li a,定位到包裹图片的a标签
点击图片,第一次跳转,跳转到新链接,页面显示如下内容:
CSS选择器:div#main div.endpage div.pic div.pic-down a,找到包裹图片的a标签
点击按钮下载壁纸(1920×1080),第二次跳转,转向新链接,最终达到目的,链接中显示的图片分辨率为1920×1080
几经周折,终于为我找到了图片的1920×1080高清图
CSS选择器:div#main table a img,定位图片的img标签
经过我自己的爬虫检查,很少有图片因为很多碎片问题而无法下载,还有少数图片是因为网站虽然提供了1920×1080分辨率的下载按钮,但还是给了其他决议。
目录4:代码分析
第一步:设置全局变量
index = 'http://www.netbian.com' # 网站根地址
interval = 10 # 爬取图片的间隔时间
firstDir = 'D:/zgh/Pictures/netbian' # 总路径
classificationDict = {} # 存放网站分类子页面的信息
第二步:获取页面过滤后的内容列表
def screen(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers()) # 随机获取一个headers
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)
第三步:获取所有类别的 URL
# 将分类子页面信息存放在字典中
def init_classification():
url = index
select = '#header > div.head > ul > li:nth-child(1) > div > a'
classifications = screen(url, select)
for c in classifications:
href = c.get('href') # 获取的是相对地址
text = c.string # 获取分类名
if(text == '4k壁纸'): # 4k壁纸,因权限问题无法爬取,直接跳过
continue
secondDir = firstDir + '/' + text # 分类目录
url = index + href # 分类子页面url
global classificationDict
classificationDict[text] = {
'path': secondDir,
'url': url
}
在接下来的代码中,我将使用审美类别下的壁纸来讲解如何通过两次跳转链接爬取高清图片
第四步:获取分类页面下所有页面的url
大多数类别的分页大于等于6页,可以直接使用上面定义的screen函数,select定义为div.page a,然后screen函数返回的列表中的第六个元素可以得到最后一个我们需要的页码
但是,有些类别的页数少于 6 页,例如:
您需要重写一个过滤器函数以通过兄弟元素获取它
# 获取页码
def screenPage(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers())
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)[0].next_sibling.text
获取分类页面下所有分页的url
url = 'http://www.netbian.com/weimei/'
select = '#main > div.page > span.slh'
pageIndex = screenPage(secondUrl, select)
lastPagenum = int(pageIndex) # 获取最后一页的页码
for i in range(lastPagenum):
if i == 0:
url = 'http://www.netbian.com/weimei/index.htm'
else:
url = 'http://www.netbian.com/weimei/ ... 39%3B %(i+1)
由于网站的HTML结构非常清晰,代码写起来也很简单
第五步:获取分页下图片指向的URL
通过查看可以看到获取到的url是相对地址,需要转换成绝对地址
select = 'div#main div.list ul li a'
imgUrls = screen(url, select)
这两行代码得到的列表中的值是这样的:
星空 女孩 观望 唯美夜景壁纸
第 6 步:找到 1920 × 1080 分辨率的图像
# 定位到 1920 1080 分辨率图片
def handleImgs(links, path):
for link in links:
href = link.get('href')
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
# 第一次跳转
if('http://' in href): # 有极个别图片不提供正确的相对地址
url = href
else:
url = index + href
select = 'div#main div.endpage div.pic div.pic-down a'
link = screen(url, select)
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
href = link[0].get('href')
# 第二次跳转
url = index + href
# 获取到图片了
select = 'div#main table a img'
link = screen(url, select)
if(link == []):
print(url + " 该图片需要登录才能爬取,爬取失败")
continue
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
print(name) # 输出下载图片的文件名
src = link[0].get('src')
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
print()
download(src, name, path)
time.sleep(interval)
第 7 步:下载图像
# 下载操作
def download(src, name, path):
if(isinstance(src, str)):
response = requests.get(src)
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
with open(path,'wb') as pic:
for chunk in response.iter_content(128):
pic.write(chunk)
目录五:代码容错
1:过滤图片广告
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
二:第一次跳转到页面,没有我们需要的链接
对方壁纸网站,给第一个跳转页面的链接一个相对地址
但是很少有图片直接给出绝对地址,并且给出类别URL,所以需要分两步处理
if('http://' in href):
url = href
else:
url = index + href
...
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
以下是第二次跳转页面遇到的问题
三:由于权限问题无法爬取图片
if(link == []):
print(url + "该图片需要登录才能爬取,爬取失败")
continue
四:获取img的alt作为下载的图片文件的文件名,名称中带有\t或者文件名中不允许出现的特殊字符:
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
五:获取img的alt作为下载的图片文件的文件名,名称重复
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
六:图片链接404
例如
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
目录 6:完整代码
最后
动动你的小手发财,给小编一份关心是小编最大的动力,谢谢! 查看全部
网页爬虫抓取百度图片(【干货】网页的壁纸都爬取了,你知道吗?)
前言
我想每个人都更喜欢漂亮的照片!不要隐瞒任何事情,每个人都知道对美丽的热爱。小编最近也比较无聊,就去爬壁纸、图片等。所以我添加了一些代码来抓取整个网页的所有壁纸。
目录 1:概述
在电脑上,创建一个文件夹,用来存放爬到对方桌面的图片

这个文件夹下有25个文件夹,对应分类
每个分类文件夹下有几个文件夹,对应页码

在页码文件夹下,存放图片文件
目录二:环境准备
在终端中分别输入以下 pip 命令进行安装
python -m pip install beautifulsoup4
python -m pip install lxml
python -m pip install requests
内容三:分析页面结构
4k类别下的壁纸是网站收入的重要资源,我们对4k壁纸有需求,所以不抓取

我用审美类下的壁纸来讲解下如何爬取图片

1.一共73页,除了最后一页,每页18张图片

但是在代码中,我们最好需要自动获取总页码,嗯,对方桌面壁纸网站的结构真的很舒服,基本上每个页码的html结构都差不多
CSS选择器:div.page a,定位到包裹页数的a标签,只有6个
并且每页第三张图片是同一个广告,需要在代码中过滤掉
每个分页的超链接清晰:/weimei/index_x.htm
x 正是页面的页码
注意:您在类别下看到的图片是低分辨率的缩略图;要得到分辨率为1920×1080的图片,需要进行两次跳转
下图是一个例子

在分类页面中,我们可以直接获取图片的url,但遗憾的是,它的分辨率并不理想;
通过检查,很明显类别页面中显示的每个图像都指向另一个超链接

CSS选择器:div#main div.list ul li a,定位到包裹图片的a标签
点击图片,第一次跳转,跳转到新链接,页面显示如下内容:

CSS选择器:div#main div.endpage div.pic div.pic-down a,找到包裹图片的a标签
点击按钮下载壁纸(1920×1080),第二次跳转,转向新链接,最终达到目的,链接中显示的图片分辨率为1920×1080
几经周折,终于为我找到了图片的1920×1080高清图
CSS选择器:div#main table a img,定位图片的img标签
经过我自己的爬虫检查,很少有图片因为很多碎片问题而无法下载,还有少数图片是因为网站虽然提供了1920×1080分辨率的下载按钮,但还是给了其他决议。
目录4:代码分析
第一步:设置全局变量
index = 'http://www.netbian.com' # 网站根地址
interval = 10 # 爬取图片的间隔时间
firstDir = 'D:/zgh/Pictures/netbian' # 总路径
classificationDict = {} # 存放网站分类子页面的信息
第二步:获取页面过滤后的内容列表
def screen(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers()) # 随机获取一个headers
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)

第三步:获取所有类别的 URL
# 将分类子页面信息存放在字典中
def init_classification():
url = index
select = '#header > div.head > ul > li:nth-child(1) > div > a'
classifications = screen(url, select)
for c in classifications:
href = c.get('href') # 获取的是相对地址
text = c.string # 获取分类名
if(text == '4k壁纸'): # 4k壁纸,因权限问题无法爬取,直接跳过
continue
secondDir = firstDir + '/' + text # 分类目录
url = index + href # 分类子页面url
global classificationDict
classificationDict[text] = {
'path': secondDir,
'url': url
}
在接下来的代码中,我将使用审美类别下的壁纸来讲解如何通过两次跳转链接爬取高清图片
第四步:获取分类页面下所有页面的url
大多数类别的分页大于等于6页,可以直接使用上面定义的screen函数,select定义为div.page a,然后screen函数返回的列表中的第六个元素可以得到最后一个我们需要的页码
但是,有些类别的页数少于 6 页,例如:

您需要重写一个过滤器函数以通过兄弟元素获取它
# 获取页码
def screenPage(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers())
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)[0].next_sibling.text
获取分类页面下所有分页的url
url = 'http://www.netbian.com/weimei/'
select = '#main > div.page > span.slh'
pageIndex = screenPage(secondUrl, select)
lastPagenum = int(pageIndex) # 获取最后一页的页码
for i in range(lastPagenum):
if i == 0:
url = 'http://www.netbian.com/weimei/index.htm'
else:
url = 'http://www.netbian.com/weimei/ ... 39%3B %(i+1)
由于网站的HTML结构非常清晰,代码写起来也很简单
第五步:获取分页下图片指向的URL
通过查看可以看到获取到的url是相对地址,需要转换成绝对地址
select = 'div#main div.list ul li a'
imgUrls = screen(url, select)
这两行代码得到的列表中的值是这样的:
 星空 女孩 观望 唯美夜景壁纸
星空 女孩 观望 唯美夜景壁纸第 6 步:找到 1920 × 1080 分辨率的图像
# 定位到 1920 1080 分辨率图片
def handleImgs(links, path):
for link in links:
href = link.get('href')
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
# 第一次跳转
if('http://' in href): # 有极个别图片不提供正确的相对地址
url = href
else:
url = index + href
select = 'div#main div.endpage div.pic div.pic-down a'
link = screen(url, select)
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
href = link[0].get('href')
# 第二次跳转
url = index + href
# 获取到图片了
select = 'div#main table a img'
link = screen(url, select)
if(link == []):
print(url + " 该图片需要登录才能爬取,爬取失败")
continue
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
print(name) # 输出下载图片的文件名
src = link[0].get('src')
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
print()
download(src, name, path)
time.sleep(interval)
第 7 步:下载图像
# 下载操作
def download(src, name, path):
if(isinstance(src, str)):
response = requests.get(src)
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
with open(path,'wb') as pic:
for chunk in response.iter_content(128):
pic.write(chunk)
目录五:代码容错
1:过滤图片广告
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
二:第一次跳转到页面,没有我们需要的链接
对方壁纸网站,给第一个跳转页面的链接一个相对地址
但是很少有图片直接给出绝对地址,并且给出类别URL,所以需要分两步处理
if('http://' in href):
url = href
else:
url = index + href
...
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
以下是第二次跳转页面遇到的问题
三:由于权限问题无法爬取图片
if(link == []):
print(url + "该图片需要登录才能爬取,爬取失败")
continue
四:获取img的alt作为下载的图片文件的文件名,名称中带有\t或者文件名中不允许出现的特殊字符:

name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
五:获取img的alt作为下载的图片文件的文件名,名称重复
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
六:图片链接404
例如

if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
目录 6:完整代码
最后
动动你的小手发财,给小编一份关心是小编最大的动力,谢谢!
网页爬虫抓取百度图片(猫评论信息和图片下载的二合一升级版() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-04 19:07
)
之前我做过天猫评论信息抓取,还有评论图片下载,但是那一次我把所有的信息都存到数据库里,然后从数据库中提取图片信息下载。这次我做了信息爬取和图片下载二合一升级版。
这一次,我们瞄准的是京东nike自营店。
链接是:
老办法,按F12打开流量监控,点击网络中的js,然后在众多信息中找到存放评论信息的链接,如下:
我找到的最后一个链接如下所示:
打开链接后发现也是json格式的,很简单
先用urllib.request打开链接,然后用json加载json文件,代码如下:
url='https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
jsondata = re.search(r'\{.*\}', html).group()
data = json.loads(jsondata)
这里使用正则是因为打开html后发现是这样的:
我们需要的json格式文件放在那个()里面。
得到json格式的数据后,需要对数据进行过滤。我把用户名和评论等一些信息放入数据库,图片立即下载
先写一个循环遍历当前url中的所有评论内容,部分代码如下:
for i in range(0, len(data['comments'])):
id = data['comments'][i]['nickname']
# 用户名
content = data['comments'][i]['content']
# 评论
time = data['comments'][i]['creationTime']
# 评论日期
type = data['comments'][i]['referenceName']
# 型号及颜色
在爬取图片链接下载的时候,因为有些评论没有图片,所以需要判断key是否存在。
if('images' in data['comments'][i].keys()):
如果存在,请获取图片链接,完成链接并下载:
pics = data['comments'][i]['images'][k]['imgUrl']
a='http:'+pics
urllib.request.urlretrieve(a, 'D:\jd_pics/' + str(z)+'_'+str(i+1) + '_' + 'pic' + '_' + str(k) + '.jpg')
# 买家秀,命名规则:第几页第几条评论的第几个图片
对于后续审稿的爬取,大体思路同上,这里不再赘述。
最后就是考虑循环抓取了,只要写个循环就可以了
for j in range(0,150):
url='https://sclub.jd.com/comment/p ... 2Bstr(j)+'&pageSize=10&isShadowSku=0&fold=1'
我在这里尝试抓取前150页评论的内容,因为我要边抓取边下载图片,所以需要很长时间。我花了大约25分钟,终于在数据库中得到了1000条信息
和本地1216图片
呵呵~这不对,150页每页10条信息,总数应该是1500!为什么我的数据库中只有 1000 个条目?
我去百度了一下,一位前辈是这样解释的:
“在 MySQL 中,每个数据库最多可以创建 20 亿个表,一个表允许定义 1024 列,每行最大长度为 8092 字节(不包括文本和图像类型的长度)。
当表定义为 varchar、nvarchar 或 varbinary 类型列时,如果插入表中的数据行超过 8092 字节,则 Transact-SQL 语句将失败并生成错误消息。
SQL对每张表的行数没有直接限制,但受数据库存储空间的限制。
每个数据库的最大空间是1048516TB,所以一个表的最大可用空间是1048516TB减去数据库类系统表和其他数据库对象占用的空间。"
也就是说,一个数据库的容量肯定是够用的,那剩下的 500 条记录到哪里去了呢?
找了半天,发现navicat for mysql有分页功能,自动帮我分页
oh~傻哭自己
我是学生,刚开始学习python爬虫。如果本文和代码有漏洞,还望各位大神赐教,谢谢!
查看全部
网页爬虫抓取百度图片(猫评论信息和图片下载的二合一升级版()
)
之前我做过天猫评论信息抓取,还有评论图片下载,但是那一次我把所有的信息都存到数据库里,然后从数据库中提取图片信息下载。这次我做了信息爬取和图片下载二合一升级版。
这一次,我们瞄准的是京东nike自营店。
链接是:
老办法,按F12打开流量监控,点击网络中的js,然后在众多信息中找到存放评论信息的链接,如下:

我找到的最后一个链接如下所示:
打开链接后发现也是json格式的,很简单
先用urllib.request打开链接,然后用json加载json文件,代码如下:
url='https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
jsondata = re.search(r'\{.*\}', html).group()
data = json.loads(jsondata)
这里使用正则是因为打开html后发现是这样的:

我们需要的json格式文件放在那个()里面。
得到json格式的数据后,需要对数据进行过滤。我把用户名和评论等一些信息放入数据库,图片立即下载
先写一个循环遍历当前url中的所有评论内容,部分代码如下:
for i in range(0, len(data['comments'])):
id = data['comments'][i]['nickname']
# 用户名
content = data['comments'][i]['content']
# 评论
time = data['comments'][i]['creationTime']
# 评论日期
type = data['comments'][i]['referenceName']
# 型号及颜色
在爬取图片链接下载的时候,因为有些评论没有图片,所以需要判断key是否存在。
if('images' in data['comments'][i].keys()):
如果存在,请获取图片链接,完成链接并下载:
pics = data['comments'][i]['images'][k]['imgUrl']
a='http:'+pics
urllib.request.urlretrieve(a, 'D:\jd_pics/' + str(z)+'_'+str(i+1) + '_' + 'pic' + '_' + str(k) + '.jpg')
# 买家秀,命名规则:第几页第几条评论的第几个图片
对于后续审稿的爬取,大体思路同上,这里不再赘述。
最后就是考虑循环抓取了,只要写个循环就可以了
for j in range(0,150):
url='https://sclub.jd.com/comment/p ... 2Bstr(j)+'&pageSize=10&isShadowSku=0&fold=1'
我在这里尝试抓取前150页评论的内容,因为我要边抓取边下载图片,所以需要很长时间。我花了大约25分钟,终于在数据库中得到了1000条信息

和本地1216图片

呵呵~这不对,150页每页10条信息,总数应该是1500!为什么我的数据库中只有 1000 个条目?

我去百度了一下,一位前辈是这样解释的:
“在 MySQL 中,每个数据库最多可以创建 20 亿个表,一个表允许定义 1024 列,每行最大长度为 8092 字节(不包括文本和图像类型的长度)。
当表定义为 varchar、nvarchar 或 varbinary 类型列时,如果插入表中的数据行超过 8092 字节,则 Transact-SQL 语句将失败并生成错误消息。
SQL对每张表的行数没有直接限制,但受数据库存储空间的限制。
每个数据库的最大空间是1048516TB,所以一个表的最大可用空间是1048516TB减去数据库类系统表和其他数据库对象占用的空间。"
也就是说,一个数据库的容量肯定是够用的,那剩下的 500 条记录到哪里去了呢?
找了半天,发现navicat for mysql有分页功能,自动帮我分页


oh~傻哭自己


我是学生,刚开始学习python爬虫。如果本文和代码有漏洞,还望各位大神赐教,谢谢!

网页爬虫抓取百度图片(大数据技术被用于各行各业,一切都是有不同的处理方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-04 07:17
大数据技术现在应用在各行各业,回归、SVM、神经网络、文本分析……各种真棒的模拟和预测,但没有数据,一切都是空谈!许多人使用爬虫来采集网页信息。问题是爬下来的数据有什么用。这取决于个人的能力。对于同样的数据,不同的人会有不同的处理方式,会导致不同的结果。下面为您介绍一些典型的应用场景:
1、电子商务网站的产品数据
爬取了某个行业的产品信息,包括品牌、价格、销量、规格型号等。然后分析该行业的畅销品牌、畅销品类、价格趋势、行业前景等。信息量还是很大的。
2、微博/BBS舆情数据
针对某个话题,从微博和论坛中抓取相关信息,挖掘该话题的一些有趣的舆情信息。事实上,利用爬虫进行舆情监测是比较成熟的,很多大公司都有相关的监测部门。但是微博的反爬机制比较麻烦,部分数据采集不完整。
3、新闻正文
新闻文字其实是一种舆论,但比微博上的文字更正式。在百度新闻上爬取某个关键词的信息,每周梳理几条关键词,可以掌握行业动态。
4、学术信息
抓取一些关于学术网站 的信息以供学习和研究。比如在CNKI上,如果你输入一个关键词,比如大数据,就会出现很多与大数据相关的文献。
点击进入,会有每个文档的基本信息、摘要等信息。如果你是研究人员或学生,点击并一一记录下来太费时间了。写一个爬虫,你可以按照标准格式爬取所有的数据,然后阅读和进一步分析就会方便很多。. 使用 GooSeeker 爬虫可以轻松地采集 批量下载此类网页。 查看全部
网页爬虫抓取百度图片(大数据技术被用于各行各业,一切都是有不同的处理方式)
大数据技术现在应用在各行各业,回归、SVM、神经网络、文本分析……各种真棒的模拟和预测,但没有数据,一切都是空谈!许多人使用爬虫来采集网页信息。问题是爬下来的数据有什么用。这取决于个人的能力。对于同样的数据,不同的人会有不同的处理方式,会导致不同的结果。下面为您介绍一些典型的应用场景:
1、电子商务网站的产品数据
爬取了某个行业的产品信息,包括品牌、价格、销量、规格型号等。然后分析该行业的畅销品牌、畅销品类、价格趋势、行业前景等。信息量还是很大的。
2、微博/BBS舆情数据
针对某个话题,从微博和论坛中抓取相关信息,挖掘该话题的一些有趣的舆情信息。事实上,利用爬虫进行舆情监测是比较成熟的,很多大公司都有相关的监测部门。但是微博的反爬机制比较麻烦,部分数据采集不完整。
3、新闻正文
新闻文字其实是一种舆论,但比微博上的文字更正式。在百度新闻上爬取某个关键词的信息,每周梳理几条关键词,可以掌握行业动态。
4、学术信息
抓取一些关于学术网站 的信息以供学习和研究。比如在CNKI上,如果你输入一个关键词,比如大数据,就会出现很多与大数据相关的文献。
点击进入,会有每个文档的基本信息、摘要等信息。如果你是研究人员或学生,点击并一一记录下来太费时间了。写一个爬虫,你可以按照标准格式爬取所有的数据,然后阅读和进一步分析就会方便很多。. 使用 GooSeeker 爬虫可以轻松地采集 批量下载此类网页。
网页爬虫抓取百度图片(网站一般如何实现图片懒技术呢?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-03 14:05
关键词:
逆流而上,用力撑着它,一分一毫的懈怠,它就退却了万千搜索。本文章主要介绍了python网络爬虫的图片懒加载技术selenium和PhantomJS相关的知识,希望对大家有所帮助。
一.什么是图片延迟加载?
- 案例研究:抓取站长素材中的图片数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘)
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
运行结果观察我们可以得到图片的名字,但是得到的链接是空的。检查后发现xpath表达式没有问题。是什么原因?
- 图片延迟加载概念:
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在被请求的时候会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端的配合,图片只有出现在浏览器当前窗口时才加载,减少首屏图片请求次数的技术称为“图片懒加载” ”。
- 网站一般如何实现延迟图片加载技术?
在网页的源码中,首先在img标签中使用了一个“伪属性”(通常是src2,original...)来存储真实的图片链接,而不是直接存储在src属性中。当图片出现在页面可视区域时,伪属性会被动态替换为src属性,完成图片的加载。
- 站长素材案例后续分析:仔细观察页面结构后发现,网页中图片的链接存放在伪属性src2中
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘2) #src2伪属性
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
二.硒
- 什么是硒?
它是 Python 的第三方库。外部提供的界面可以操作浏览器,然后让浏览器完成自动操作。
- 环境建设
1.安装硒:pip install selenium
2.获取浏览器驱动(以谷歌浏览器为例)
2.1 谷歌浏览器驱动下载地址:
2.2 下载的驱动必须和浏览器版本一致。可以根据提供的版本映射表进行映射
- 效果展示:可以运行以下代码观看效果
from selenium import webdriver
from time import sleep
# 后面是你的浏览器驱动位置,记得前面加r‘‘,‘r‘是防止字符转义的
driver = webdriver.Chrome(r‘驱动程序路径‘)
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text(‘设置‘)[0].click()
sleep(2)
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text(‘搜索设置‘)[0].click()
sleep(2)
# 选中每页显示50条
m = driver.find_element_by_id(‘nr‘)
sleep(2)
m.find_element_by_xpath(‘//*[@id="nr"]/option[3]‘).click()
m.find_element_by_xpath(‘.//option[3]‘).click()
sleep(2)
# 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2)
# 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to_alert().accept()
sleep(2)
# 找到百度的输入框,并输入 美女
driver.find_element_by_id(‘kw‘).send_keys(‘美女‘)
sleep(2)
# 点击搜索按钮
driver.find_element_by_id(‘su‘).click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text(‘美女_百度图片‘)[0].click()
sleep(3)
# 关闭浏览器
driver.quit()
- 代码操作:
#导包
from selenium import webdriver
#创建浏览器对象,通过该对象可以操作浏览器
browser = webdriver.Chrome(‘驱动路径‘)
#使用浏览器发起指定请求
browser.get(url)
#使用下面的方法,查找指定的元素进行操作即可
find_element_by_id 根据id找节点
find_elements_by_name 根据name找
find_elements_by_xpath 根据xpath查找
find_elements_by_tag_name 根据标签名找
find_elements_by_class_name 根据class名字查找
三.幻影JS
PhantomJS 是一款非界面浏览器,其自动化操作过程与上述谷歌浏览器的操作一致。由于没有界面,为了能够展示自动化的操作过程,PhantomJS为用户提供了截图功能,使用save_screenshot函数实现。
-案子:
from selenium import webdriver
import time
# phantomjs路径
path = r‘PhantomJS驱动路径‘
browser = webdriver.PhantomJS(path)
# 打开百度
url = ‘http://www.baidu.com/‘
browser.get(url)
time.sleep(3)
browser.save_screenshot(r‘phantomjsaidu.png‘)
# 查找input输入框
my_input = browser.find_element_by_id(‘kw‘)
# 往框里面写文字
my_input.send_keys(‘美女‘)
time.sleep(3)
#截屏
browser.save_screenshot(r‘phantomjsmeinv.png‘)
# 查找搜索按钮
button = browser.find_elements_by_class_name(‘s_btn‘)[0]
button.click()
time.sleep(3)
browser.save_screenshot(r‘phantomjsshow.png‘)
time.sleep(3)
browser.quit()
【重点】selenium+phantomjs是爬虫的终极解决方案:网站上的一些内容信息是通过动态加载js形成的,所以使用普通爬虫程序无法回到动态加载的js内容。例如,豆瓣电影中的电影信息是通过下拉操作动态加载更多电影信息的。
综合操作:
- 要求:尽可能多地在豆瓣上爬取电影信息
from selenium import webdriver
from time import sleep
import time
if __name__ == ‘__main__‘:
url = ‘https://movie.douban.com/typer ... on%3D‘
# 发起请求前,可以让url表示的页面动态加载出更多的数据
path = r‘C:UsersAdministratorDesktop爬虫授课day05ziliaophantomjs-2.1.1-windowsinphantomjs.exe‘
# 创建无界面的浏览器对象
bro = webdriver.PhantomJS(path)
# 发起url请求
bro.get(url)
time.sleep(3)
# 截图
bro.save_screenshot(‘1.png‘)
# 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息))
js = ‘document.body.scrollTop=2000‘
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(4)
bro.save_screenshot(‘2.png‘)
time.sleep(2)
# 使用爬虫程序爬去当前url中的内容
html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html)
with open(‘./source.html‘, ‘w‘, encoding=‘utf-8‘) as fp:
fp.write(html_source)
bro.quit()
四.谷歌无头浏览器
由于 PhantomJs 最近已经停止更新和维护,建议大家使用谷歌的无头浏览器,这是一款没有界面的谷歌浏览器。
1 from selenium import webdriver
2 from selenium.webdriver.chrome.options import Options
3 import time
4
5 # 创建一个参数对象,用来控制chrome以无界面模式打开
6 chrome_options = Options()
7 chrome_options.add_argument(‘--headless‘)
8 chrome_options.add_argument(‘--disable-gpu‘)
9 # 驱动路径
10 path = r‘C:UsersBLiDesktop1801day05ziliaochromedriver.exe‘
11
12 # 创建浏览器对象
13 browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options)
14
15 # 上网
16 url = ‘http://www.baidu.com/‘
17 browser.get(url)
18 time.sleep(3)
19
20 browser.save_screenshot(‘baidu.png‘)
21
22 browser.quit()
至此,这篇关于Python网络爬虫selenium和PhantomJS的懒加载技术的文章就讲完了。如果您的问题无法解决,请参考以下文章: 查看全部
网页爬虫抓取百度图片(网站一般如何实现图片懒技术呢?-八维教育)
关键词:
逆流而上,用力撑着它,一分一毫的懈怠,它就退却了万千搜索。本文章主要介绍了python网络爬虫的图片懒加载技术selenium和PhantomJS相关的知识,希望对大家有所帮助。
一.什么是图片延迟加载?
- 案例研究:抓取站长素材中的图片数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘)
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
运行结果观察我们可以得到图片的名字,但是得到的链接是空的。检查后发现xpath表达式没有问题。是什么原因?
- 图片延迟加载概念:
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在被请求的时候会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端的配合,图片只有出现在浏览器当前窗口时才加载,减少首屏图片请求次数的技术称为“图片懒加载” ”。
- 网站一般如何实现延迟图片加载技术?
在网页的源码中,首先在img标签中使用了一个“伪属性”(通常是src2,original...)来存储真实的图片链接,而不是直接存储在src属性中。当图片出现在页面可视区域时,伪属性会被动态替换为src属性,完成图片的加载。
- 站长素材案例后续分析:仔细观察页面结构后发现,网页中图片的链接存放在伪属性src2中
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘2) #src2伪属性
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
二.硒
- 什么是硒?
它是 Python 的第三方库。外部提供的界面可以操作浏览器,然后让浏览器完成自动操作。
- 环境建设
1.安装硒:pip install selenium
2.获取浏览器驱动(以谷歌浏览器为例)
2.1 谷歌浏览器驱动下载地址:
2.2 下载的驱动必须和浏览器版本一致。可以根据提供的版本映射表进行映射
- 效果展示:可以运行以下代码观看效果
from selenium import webdriver
from time import sleep
# 后面是你的浏览器驱动位置,记得前面加r‘‘,‘r‘是防止字符转义的
driver = webdriver.Chrome(r‘驱动程序路径‘)
# 用get打开百度页面
driver.get("http://www.baidu.com";)
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text(‘设置‘)[0].click()
sleep(2)
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text(‘搜索设置‘)[0].click()
sleep(2)
# 选中每页显示50条
m = driver.find_element_by_id(‘nr‘)
sleep(2)
m.find_element_by_xpath(‘//*[@id="nr"]/option[3]‘).click()
m.find_element_by_xpath(‘.//option[3]‘).click()
sleep(2)
# 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2)
# 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to_alert().accept()
sleep(2)
# 找到百度的输入框,并输入 美女
driver.find_element_by_id(‘kw‘).send_keys(‘美女‘)
sleep(2)
# 点击搜索按钮
driver.find_element_by_id(‘su‘).click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text(‘美女_百度图片‘)[0].click()
sleep(3)
# 关闭浏览器
driver.quit()
- 代码操作:
#导包
from selenium import webdriver
#创建浏览器对象,通过该对象可以操作浏览器
browser = webdriver.Chrome(‘驱动路径‘)
#使用浏览器发起指定请求
browser.get(url)
#使用下面的方法,查找指定的元素进行操作即可
find_element_by_id 根据id找节点
find_elements_by_name 根据name找
find_elements_by_xpath 根据xpath查找
find_elements_by_tag_name 根据标签名找
find_elements_by_class_name 根据class名字查找
三.幻影JS
PhantomJS 是一款非界面浏览器,其自动化操作过程与上述谷歌浏览器的操作一致。由于没有界面,为了能够展示自动化的操作过程,PhantomJS为用户提供了截图功能,使用save_screenshot函数实现。
-案子:
from selenium import webdriver
import time
# phantomjs路径
path = r‘PhantomJS驱动路径‘
browser = webdriver.PhantomJS(path)
# 打开百度
url = ‘http://www.baidu.com/‘
browser.get(url)
time.sleep(3)
browser.save_screenshot(r‘phantomjsaidu.png‘)
# 查找input输入框
my_input = browser.find_element_by_id(‘kw‘)
# 往框里面写文字
my_input.send_keys(‘美女‘)
time.sleep(3)
#截屏
browser.save_screenshot(r‘phantomjsmeinv.png‘)
# 查找搜索按钮
button = browser.find_elements_by_class_name(‘s_btn‘)[0]
button.click()
time.sleep(3)
browser.save_screenshot(r‘phantomjsshow.png‘)
time.sleep(3)
browser.quit()
【重点】selenium+phantomjs是爬虫的终极解决方案:网站上的一些内容信息是通过动态加载js形成的,所以使用普通爬虫程序无法回到动态加载的js内容。例如,豆瓣电影中的电影信息是通过下拉操作动态加载更多电影信息的。
综合操作:
- 要求:尽可能多地在豆瓣上爬取电影信息
from selenium import webdriver
from time import sleep
import time
if __name__ == ‘__main__‘:
url = ‘https://movie.douban.com/typer ... on%3D‘
# 发起请求前,可以让url表示的页面动态加载出更多的数据
path = r‘C:UsersAdministratorDesktop爬虫授课day05ziliaophantomjs-2.1.1-windowsinphantomjs.exe‘
# 创建无界面的浏览器对象
bro = webdriver.PhantomJS(path)
# 发起url请求
bro.get(url)
time.sleep(3)
# 截图
bro.save_screenshot(‘1.png‘)
# 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息))
js = ‘document.body.scrollTop=2000‘
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(4)
bro.save_screenshot(‘2.png‘)
time.sleep(2)
# 使用爬虫程序爬去当前url中的内容
html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html)
with open(‘./source.html‘, ‘w‘, encoding=‘utf-8‘) as fp:
fp.write(html_source)
bro.quit()
四.谷歌无头浏览器
由于 PhantomJs 最近已经停止更新和维护,建议大家使用谷歌的无头浏览器,这是一款没有界面的谷歌浏览器。
1 from selenium import webdriver
2 from selenium.webdriver.chrome.options import Options
3 import time
4
5 # 创建一个参数对象,用来控制chrome以无界面模式打开
6 chrome_options = Options()
7 chrome_options.add_argument(‘--headless‘)
8 chrome_options.add_argument(‘--disable-gpu‘)
9 # 驱动路径
10 path = r‘C:UsersBLiDesktop1801day05ziliaochromedriver.exe‘
11
12 # 创建浏览器对象
13 browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options)
14
15 # 上网
16 url = ‘http://www.baidu.com/‘
17 browser.get(url)
18 time.sleep(3)
19
20 browser.save_screenshot(‘baidu.png‘)
21
22 browser.quit()
至此,这篇关于Python网络爬虫selenium和PhantomJS的懒加载技术的文章就讲完了。如果您的问题无法解决,请参考以下文章:
网页爬虫抓取百度图片(为什么用Python写爬虫程序:爬虫前奏)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-03 14:01
爬行动物前奏
爬虫实例:
搜索引擎(百度、谷歌、360搜索等)。
伯乐在线。
慧慧购物助理。
数据分析与研究(数据冰山知乎栏目)。
抢票软件等
什么是网络爬虫:
通俗理解:爬虫是模拟人类请求行为的程序网站。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
专业介绍:百度百科。
通用爬虫和焦点爬虫:
万能爬虫:万能爬虫是搜索引擎爬虫系统(百度、谷歌、搜狗等)的重要组成部分。主要是将互联网上的网页下载到本地,形成互联网内容的镜像备份。
Focused crawler:是一种针对特定需求的网络爬虫程序。它与一般爬虫的区别在于:聚焦爬虫在实现网页爬虫时会对内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。.
为什么要用 Python 编写爬虫程序:
PHP:PHP是世界上最好的语言,但他不是天生就干这个的,而且对多线程、异步支持、并发处理能力弱等问题也不是很好。爬虫是一个工具程序,对速度和效率的要求很高。
Java:生态非常完整,是Python爬虫最大的竞争对手。但是Java语言本身很笨重,代码量很大。重构的成本比较高,任何修改都会导致代码的大量变化。爬虫经常需要修改 采集 代码。
C/C++:运行效率无敌。但学习和发展成本很高。写一个小爬虫可能需要半天以上的时间。
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。
准备工具:
Python3.6 开发环境。
Pycharm 2017 专业版。
虚拟环境。虚拟环境/虚拟环境包装器。 查看全部
网页爬虫抓取百度图片(为什么用Python写爬虫程序:爬虫前奏)
爬行动物前奏
爬虫实例:
搜索引擎(百度、谷歌、360搜索等)。
伯乐在线。
慧慧购物助理。
数据分析与研究(数据冰山知乎栏目)。
抢票软件等
什么是网络爬虫:
通俗理解:爬虫是模拟人类请求行为的程序网站。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
专业介绍:百度百科。
通用爬虫和焦点爬虫:
万能爬虫:万能爬虫是搜索引擎爬虫系统(百度、谷歌、搜狗等)的重要组成部分。主要是将互联网上的网页下载到本地,形成互联网内容的镜像备份。
Focused crawler:是一种针对特定需求的网络爬虫程序。它与一般爬虫的区别在于:聚焦爬虫在实现网页爬虫时会对内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。.
为什么要用 Python 编写爬虫程序:
PHP:PHP是世界上最好的语言,但他不是天生就干这个的,而且对多线程、异步支持、并发处理能力弱等问题也不是很好。爬虫是一个工具程序,对速度和效率的要求很高。
Java:生态非常完整,是Python爬虫最大的竞争对手。但是Java语言本身很笨重,代码量很大。重构的成本比较高,任何修改都会导致代码的大量变化。爬虫经常需要修改 采集 代码。
C/C++:运行效率无敌。但学习和发展成本很高。写一个小爬虫可能需要半天以上的时间。
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。
准备工具:
Python3.6 开发环境。
Pycharm 2017 专业版。
虚拟环境。虚拟环境/虚拟环境包装器。
网页爬虫抓取百度图片(Pythonampamp//amp管理员;管理员管理员(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-03 08:04
python爬虫BeautifulSoup快速抓取网站图片 Python / Admin 发表于 1 个月前 80
本文介绍BeautifulSoup模块的使用方法和注意事项,帮助您快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的朋友,快点学习吧。关注公众号获取爬虫教程。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接,翻页操作
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第 3 步:编写代码以实现需求
1、导入模块
导入我们需要使用的所有模块。
2、获取列表的标题,以及链接
3、获取类别列表标题、链接和翻页。
4、获取详细图片并保存
知识点总结
学习本文,可以掌握知识点。
1、掌握 BeautifulSoup
区分find和find_all的用法:find,查找第一个返回字符串,find_all查找全部,返回一个列表
区分get和get_text的用法:get获取标签中的属性,get_text获取标签包围的文本。
2、掌握正则,re.findall的使用
3、掌握字符串切片的方式 str[0,-5] 截取第一个文本到倒数第五个文本。
4、掌握创建文件夹的方法os.mkdir(name)
5、掌握with open(f, w) as f的用法:
6、掌握requests模块的get请求方法。 查看全部
网页爬虫抓取百度图片(Pythonampamp//amp管理员;管理员管理员(组图))
python爬虫BeautifulSoup快速抓取网站图片 Python / Admin 发表于 1 个月前 80
本文介绍BeautifulSoup模块的使用方法和注意事项,帮助您快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的朋友,快点学习吧。关注公众号获取爬虫教程。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接,翻页操作
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第 3 步:编写代码以实现需求
1、导入模块
导入我们需要使用的所有模块。
2、获取列表的标题,以及链接
3、获取类别列表标题、链接和翻页。
4、获取详细图片并保存
知识点总结
学习本文,可以掌握知识点。
1、掌握 BeautifulSoup
区分find和find_all的用法:find,查找第一个返回字符串,find_all查找全部,返回一个列表
区分get和get_text的用法:get获取标签中的属性,get_text获取标签包围的文本。
2、掌握正则,re.findall的使用
3、掌握字符串切片的方式 str[0,-5] 截取第一个文本到倒数第五个文本。
4、掌握创建文件夹的方法os.mkdir(name)
5、掌握with open(f, w) as f的用法:
6、掌握requests模块的get请求方法。
网页爬虫抓取百度图片(爬取今日头条图集,老司机以街拍为例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-02 15:09
今天,我们来爬取今日头条图集。老司机以街拍为例。
操作平台:Windows
Python版本:Python3.6
IDE:崇高文本
其他工具:Chrome浏览器
1、网页分析
从打开今日头条首页,搜索“街拍”,有“综合”、“视频”、“图集”和“用户”四个标签,我们依次点击几个标签,虽然页面变了,但是address bar 的 URL 没有变化,说明页面内容是动态加载的。
按“F12”调出开发者工具,刷新页面,然后分析开发者工具:
①:点击网络
②:选择XHR
③:找到以“?offset=”开头的项目并点击,右侧会出现详细信息
④:点击右侧的“页眉”标签
⑤:查看请求方式和请求地址
⑥:这里是请求的参数
接下来点击 Preview 选项卡查看返回的数据:
返回的数据格式为json,展开“data”字段,展开第一项,查找“title”,可以看到和网页上第一个图集的title一样,说明找到了正确的地方。
继续分析,在“data”的第一项中有一个“image_detail”字段。展开可以看到 6 个项目,每个项目都有一个 url。乍一看,它是图像 URL。我不知道这是否是我们正在寻找的。复制到浏览器打开确实和第一个缩略图一样,那么这6张图都是图集的吗?
点击网页的第一个图集,可以看到确实只有6张图片,和返回的json数据中的图片是一致的。
分析完了吗?我们看看页面除了图片,文字和相关推荐占了这么多内容,图片有点小,我们在图片上右击选择“在新标签页打开图片”,注意地址栏:
你发现其中的奥秘了吗?图片地址“large”变成了“origin”,分别保存两张图片,对比大小,origin比large大很多,这就是我们需要的,至此,网页解析完成,接下来开始编写代码。
2、代码
requests 库用于抓取。由于前面的分析很详细,代码不再单独讲解。请看评论。
#-*- 编码:utf-8 -*-
导入操作系统
重新进口
导入json
导入请求
从 urllib.parse 导入 urlencode
def get_one_page(偏移量,关键字):
'''
获取网页html内容并返回
'''
段 = {
'offset': offset, # 搜索结果项从哪里开始
'format': 'json', # 返回数据格式
'keyword': 关键字,#要搜索的关键字
'autoload': 'true', # 自动加载
'count': 20, # 每次加载结果的项数
'cur_tab': 3, # 当前标签页索引,3为“Atlas”
'from': 'gallery' # 来源,“画廊”
}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)铬/63.0.3239.132 Safari/537.36'}
网址 = '#39; + urlencode(段落)
尝试:
# 获取网页内容并以json格式返回数据
响应 = requests.get(url, headers=headers)
# 通过状态码判断获取是否成功
如果 response.status_code == 200:
返回响应.文本
返回无
除了请求异常:
返回无
def parse_one_page(html):
'''
解析出群组图片的URL,返回网页中所有图集的标题和图片地址
'''
网址 = []
数据 = json.loads(html)
如果 data.keys() 中的数据和“数据”:
对于 data.get('data') 中的项目:
page_urls = []
标题 = item.get('title')
image_detail = item.get('image_detail')
对于我在范围内(len(image_detail)):
# 获取大图地址
url = image_detail[i]['url']
# 替换URL获取原创高清图片
url = url.replace('大', '原点')
page_urls.append(url)
urls.append({'title': 标题,'url_list': page_urls})
返回网址
def save_image_file(url, 路径):
'''
保存图像文件
'''
ir = requests.get(url)
如果 ir.status_code == 200:
使用 open(path, 'wb') 作为 f:
f.write(ir.content)
f.close()
def main(偏移量,字):
html = get_one_page(偏移量,字)
网址 = parse_one_page(html)
# 如果图片文件夹不存在则创建
root_path = 单词
如果不是 os.path.exists(root_path):
os.mkdir(root_path)
对于我在范围内(len(urls)):
print('---正在下载 %s'%urls[i]['title'])
文件夹 = root_path + '/' + urls[i]['title']
如果不是 os.path.exists(文件夹):
尝试:
os.mkdir(文件夹)
NotADirectoryError 除外:
继续
除了 OSError:
继续
url_list = urls[i]['url_list']
对于范围内的 j(len(url_list)):
路径 = 文件夹 + '/index_' + str("d"%j) + '.jpg'
如果不是 os.path.exists(path):
save_image_file(urls[i]['url_list'][j], 路径)
如果 __name__ == '__main__':
# 抓2000个图集,基本上包括所有图集
对于我在范围内(100):
main(i*20, '街拍')
您可以根据自己的喜好替换关键词来下载您喜欢的图集。 查看全部
网页爬虫抓取百度图片(爬取今日头条图集,老司机以街拍为例(组图))
今天,我们来爬取今日头条图集。老司机以街拍为例。
操作平台:Windows
Python版本:Python3.6
IDE:崇高文本
其他工具:Chrome浏览器
1、网页分析
从打开今日头条首页,搜索“街拍”,有“综合”、“视频”、“图集”和“用户”四个标签,我们依次点击几个标签,虽然页面变了,但是address bar 的 URL 没有变化,说明页面内容是动态加载的。
按“F12”调出开发者工具,刷新页面,然后分析开发者工具:
①:点击网络
②:选择XHR
③:找到以“?offset=”开头的项目并点击,右侧会出现详细信息
④:点击右侧的“页眉”标签
⑤:查看请求方式和请求地址
⑥:这里是请求的参数
接下来点击 Preview 选项卡查看返回的数据:
返回的数据格式为json,展开“data”字段,展开第一项,查找“title”,可以看到和网页上第一个图集的title一样,说明找到了正确的地方。
继续分析,在“data”的第一项中有一个“image_detail”字段。展开可以看到 6 个项目,每个项目都有一个 url。乍一看,它是图像 URL。我不知道这是否是我们正在寻找的。复制到浏览器打开确实和第一个缩略图一样,那么这6张图都是图集的吗?
点击网页的第一个图集,可以看到确实只有6张图片,和返回的json数据中的图片是一致的。
分析完了吗?我们看看页面除了图片,文字和相关推荐占了这么多内容,图片有点小,我们在图片上右击选择“在新标签页打开图片”,注意地址栏:
你发现其中的奥秘了吗?图片地址“large”变成了“origin”,分别保存两张图片,对比大小,origin比large大很多,这就是我们需要的,至此,网页解析完成,接下来开始编写代码。
2、代码
requests 库用于抓取。由于前面的分析很详细,代码不再单独讲解。请看评论。
#-*- 编码:utf-8 -*-
导入操作系统
重新进口
导入json
导入请求
从 urllib.parse 导入 urlencode
def get_one_page(偏移量,关键字):
'''
获取网页html内容并返回
'''
段 = {
'offset': offset, # 搜索结果项从哪里开始
'format': 'json', # 返回数据格式
'keyword': 关键字,#要搜索的关键字
'autoload': 'true', # 自动加载
'count': 20, # 每次加载结果的项数
'cur_tab': 3, # 当前标签页索引,3为“Atlas”
'from': 'gallery' # 来源,“画廊”
}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)铬/63.0.3239.132 Safari/537.36'}
网址 = '#39; + urlencode(段落)
尝试:
# 获取网页内容并以json格式返回数据
响应 = requests.get(url, headers=headers)
# 通过状态码判断获取是否成功
如果 response.status_code == 200:
返回响应.文本
返回无
除了请求异常:
返回无
def parse_one_page(html):
'''
解析出群组图片的URL,返回网页中所有图集的标题和图片地址
'''
网址 = []
数据 = json.loads(html)
如果 data.keys() 中的数据和“数据”:
对于 data.get('data') 中的项目:
page_urls = []
标题 = item.get('title')
image_detail = item.get('image_detail')
对于我在范围内(len(image_detail)):
# 获取大图地址
url = image_detail[i]['url']
# 替换URL获取原创高清图片
url = url.replace('大', '原点')
page_urls.append(url)
urls.append({'title': 标题,'url_list': page_urls})
返回网址
def save_image_file(url, 路径):
'''
保存图像文件
'''
ir = requests.get(url)
如果 ir.status_code == 200:
使用 open(path, 'wb') 作为 f:
f.write(ir.content)
f.close()
def main(偏移量,字):
html = get_one_page(偏移量,字)
网址 = parse_one_page(html)
# 如果图片文件夹不存在则创建
root_path = 单词
如果不是 os.path.exists(root_path):
os.mkdir(root_path)
对于我在范围内(len(urls)):
print('---正在下载 %s'%urls[i]['title'])
文件夹 = root_path + '/' + urls[i]['title']
如果不是 os.path.exists(文件夹):
尝试:
os.mkdir(文件夹)
NotADirectoryError 除外:
继续
除了 OSError:
继续
url_list = urls[i]['url_list']
对于范围内的 j(len(url_list)):
路径 = 文件夹 + '/index_' + str("d"%j) + '.jpg'
如果不是 os.path.exists(path):
save_image_file(urls[i]['url_list'][j], 路径)
如果 __name__ == '__main__':
# 抓2000个图集,基本上包括所有图集
对于我在范围内(100):
main(i*20, '街拍')
您可以根据自己的喜好替换关键词来下载您喜欢的图集。
网页爬虫抓取百度图片(百度资源平台官方直播一节公开课工作原理及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-01 20:04
大家好,今天百度资源平台正式开课了,主要给大家讲一个网站抓取和收录的原理,这里我为大家做了详细的笔记(一个字不漏),看完后它,可以说做收录基本上问题不大。
百度爬虫的工作原理
首先,百度的爬虫会与网站的首页进行交互。拿到网站的首页后,会理解页面,理解它的收录(类型,值计算),其次,会把网站的所有超链接都提取到首页。如下图所示,首页上的超链接称为“反向链接”。当下一轮爬取发生时,爬虫会继续与这些超链接页面交互,获取页面进行细化,一层一层的继续爬取。一层抓取,构成抓取环。
编辑搜索图片,请点击输入图片描述(最多18个字符)
爬取友好度优化
1、网址规范:
任何资源都是通过 URL 抓取的。URL是相对于网站的门牌号的,所以URL的规划很重要。尤其如上图所示,在“待爬取URL”的环境下,爬虫在首页时,并不知道URL长什么样。
优秀的网址的特点是主流、简洁,可以不做一些非主流的风格,让人看起来很直观的网址。
好的 URL 示例:
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图,第一个链接是百度知道的链接。整个链接分为三个部分。第一段是网站的站点,第二段是资源类型,第三段是资源的ID。这是一个非常简单且具有爬虫外观的高质量 URL。
如上图所示,第三段比百度知道的多一段。首先第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录,最后一个段是内容ID网站。像这样的 URL 也符合标准。
不友好的 URL 示例:
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址收录字符,而这个网址中收录文章的标题,导致网址过长。, 与简单 URL 相比,长 URL 并不占优势。百度站长平台规则明确规定网址不能超过256字节。个人建议URL长度控制在100字节100字符以内。足够的资源来显示 URL。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,该网址收录统计参数,可能导致重复爬取,浪费站点权限。因此,不能使用参数。如果必须使用参数,也可以保留必要的参数。参数字符可以使用常规的连接符,如“?”、“&”,避免使用非主流的连接符。
2、合理发现链接:
爬虫从首页开始逐层爬取,所以需要做好首页与资源页的URL关系。这样,爬行相对来说比较省力。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大多数移动台都不太关注发现链接的关系,因此爬虫无法爬取内容页面。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这两个站点是移动网站常用的建站方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大部分做Feed流的网站后台数据很多,用户会不断刷新新的内容,但是无论你刷新多少次,可能也只能刷新1%左右内容。爬虫相当于一个用户。爬虫不可能以这种方式爬取网站的所有内容,所以有些页面不会被爬取。就算你有100万的内容,也可能只能抢到1-200万。
只有搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫是不可能输入关键词再爬的,所以爬虫之后只能爬到首页,没有回链,自然爬行和 收录 不会是理想的。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页面抓取你的网站最新资源。另外,新发布的资源要实时发布。索引页已同步。很多纯静态的网页都更新了内容,但是首页(索引页)还没有出来。这将导致搜索引擎无法通过索引页面抓取最新的资源。第三点是后链(最新文章的URL)需要直接暴露在源码中,方便搜索引擎抓取。最后,索引页越多越好,几个优质的索引页就够了,比如长城,基本上只用首页作为索引页。
最后,这里有一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新资源。这里有两点需要注意。
Q:是不是提交的资源越多越好?
A:收录效果的核心永远是内容的质量。如果大量提交低质量、超标的资源,就会造成惩罚性打击。
问:为什么我提交了一个普通的 收录 却没有被抓到?
A:资源提交只能加速资源发现,不能保证短时间内爬取。当然,百度表示,算法不断优化,让优质内容被更快抓取。
3、访问友好性:
爬虫需要和网站交互,保证网站的稳定性,爬虫才能正常爬取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议将加载时间控制在2S以内,这样无论是用户还是爬虫都会更喜欢打开速度更快的网站,二是避免不必要的跳转,虽然这是很少见的部分,但是有还是网站多级跳转,所以对于爬虫来说,多级跳转的同时断线的可能性很大。常见的做法是先不带www的域名跳转到带WWW的域名,再用带WWW的域名跳转到https,最后换一个新站点。在这种情况下,有三个或四个级别的跳跃。如果有类似网站的修改,建议直接跳转到新域名。
标准http返回码:我们常见的301/302的正确使用,以及404的正确使用,主要是常规问题,用常规方法解决,比如遇到无效资源,那就用404来做,不要t 使用一些特殊的返回状态码。
访问稳定性优化:一是尽量选择国内规模较大的DNS服务,保证网站的稳定性。对于域名的DNS来说,阿里云其实是比较稳定可靠的,那么二是谨慎使用技术手段,阻止爬取。如果有特定资源不想在百度上展示,可以使用机器人屏蔽。比如网站的后台链接大多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是防止防火墙误拦截爬虫爬取,所以建议可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的情况下。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫的数量会相应增加。这次会导致您的服务器出现故障吗?打开压力太大,这个问题需要站长注意。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这三个例子是第三方防火墙拦截的一种状态。普通用户打开这个状态,搜索引擎爬取的时候也是这个状态,所以如果遇到CC或者DDOS,我们在打开防火墙之前,必须先释放搜索引擎的UA。
4、识别百度爬虫
对于一些网站,可能有针对用户的特殊优化,可能有网站想区分用户和爬虫进行优化,所以这时候就需要识别百度爬虫了。
编辑搜索图片,请点击输入图片描述(最多18个字符)
首先,通过一个简单的方法,我们可以通过百度的UA来识别百度爬虫。目前百度PC、手机、小程序是三种不同的UA。然后,通过简单的识别方法,就有了第三方UA。爬虫模拟百度爬虫,所以你认不出来。那么这时候我们就可以通过双向DNS解析认证来区分了。详情请参考《简单两步:教你快速识别百度蜘蛛》。
提问时间
问:新网站会有抓取限制吗?
A:对于任何新站点,都没有抓取限制,但是从去年开始,我们就开始提供对新站点的支持,让你的网站,首先是收录上百度。然后做一个价值判断,那么如何让百度知道你是新站点,有两个捷径,一是去百度资源平台提交,二是去工信部ICP备案,我们可以从工信部得到,从ICP备案的数据,备案后,我们知道有人建了一个新站点,这样我们就可以为新站点提供基础的流量支持。
Q:蜘蛛抓取的配额会针对每个站点进行调整。多久会调整一次?
A:确实会有调整。对于新资源,会与你的抓取频率有关,而对于旧资源,会与你的内容质量有关。如果新资源的质量发生变化,那么爬取频率也会发生变化。网站@如果>的规模发生变化,爬取的频率也会发生变化。如果有大改版,那么爬取的频率也会相对变化。
Q:网站降级可以恢复吗?
A:网站降级恢复的前提是,我们会重新评估网站,检查网站是否已整改,如果有整改,是否404已制作并提交给资源 如果平台完全符合要求,搜索引擎将在评估后恢复不违反规则的网站。
问:新网站是否有评估期?
A:对我们来说,没有评估期这回事。正如我们前面提到的,它可能支持一个新站点的流量。假设一个新站点经过1-2个月的流量支持,发现网站继续保持这个状态,那么不会有大的调整。当我们发现网站的质量有明显提升时,我们也会相应的提升百度排名。
Q:百度对待国外服务器和国内服务器有区别吗?
A:从战略上看,没有严格的区分。不过很多国外服务器在中国部分地区封杀了,从国外服务器网站备案来看,国内服务器有优势。
Q:新站点的旧域名是不是更有优势?
A:如果说旧域名和新网站是同一个内容,在初期确实有一定的优势,但也只是初期,内容的好坏还要看后期. 需要特别注意的是,如果老域名行业和你的新网站的内容无关,即使是所谓的高权限老域名也会适得其反。百度会觉得,今天做那个明天做,效果还不如新建一个域名。
Q:蜘蛛有重量吗,比如220、116等高重量蜘蛛?
答:蜘蛛没有重量。网站 的排名主要取决于 网站 的质量。 查看全部
网页爬虫抓取百度图片(百度资源平台官方直播一节公开课工作原理及解决办法(一))
大家好,今天百度资源平台正式开课了,主要给大家讲一个网站抓取和收录的原理,这里我为大家做了详细的笔记(一个字不漏),看完后它,可以说做收录基本上问题不大。
百度爬虫的工作原理
首先,百度的爬虫会与网站的首页进行交互。拿到网站的首页后,会理解页面,理解它的收录(类型,值计算),其次,会把网站的所有超链接都提取到首页。如下图所示,首页上的超链接称为“反向链接”。当下一轮爬取发生时,爬虫会继续与这些超链接页面交互,获取页面进行细化,一层一层的继续爬取。一层抓取,构成抓取环。
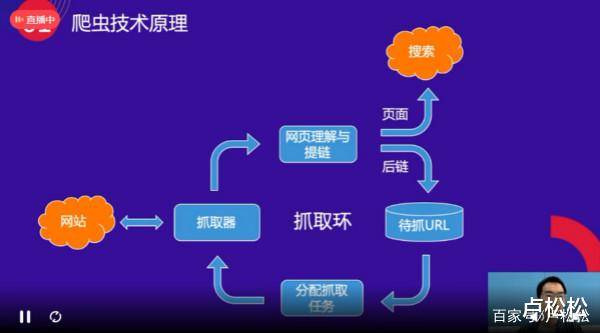
编辑搜索图片,请点击输入图片描述(最多18个字符)
爬取友好度优化
1、网址规范:
任何资源都是通过 URL 抓取的。URL是相对于网站的门牌号的,所以URL的规划很重要。尤其如上图所示,在“待爬取URL”的环境下,爬虫在首页时,并不知道URL长什么样。
优秀的网址的特点是主流、简洁,可以不做一些非主流的风格,让人看起来很直观的网址。
好的 URL 示例:

编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图,第一个链接是百度知道的链接。整个链接分为三个部分。第一段是网站的站点,第二段是资源类型,第三段是资源的ID。这是一个非常简单且具有爬虫外观的高质量 URL。
如上图所示,第三段比百度知道的多一段。首先第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录,最后一个段是内容ID网站。像这样的 URL 也符合标准。
不友好的 URL 示例:

编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址收录字符,而这个网址中收录文章的标题,导致网址过长。, 与简单 URL 相比,长 URL 并不占优势。百度站长平台规则明确规定网址不能超过256字节。个人建议URL长度控制在100字节100字符以内。足够的资源来显示 URL。

编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,该网址收录统计参数,可能导致重复爬取,浪费站点权限。因此,不能使用参数。如果必须使用参数,也可以保留必要的参数。参数字符可以使用常规的连接符,如“?”、“&”,避免使用非主流的连接符。
2、合理发现链接:
爬虫从首页开始逐层爬取,所以需要做好首页与资源页的URL关系。这样,爬行相对来说比较省力。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大多数移动台都不太关注发现链接的关系,因此爬虫无法爬取内容页面。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这两个站点是移动网站常用的建站方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大部分做Feed流的网站后台数据很多,用户会不断刷新新的内容,但是无论你刷新多少次,可能也只能刷新1%左右内容。爬虫相当于一个用户。爬虫不可能以这种方式爬取网站的所有内容,所以有些页面不会被爬取。就算你有100万的内容,也可能只能抢到1-200万。
只有搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫是不可能输入关键词再爬的,所以爬虫之后只能爬到首页,没有回链,自然爬行和 收录 不会是理想的。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页面抓取你的网站最新资源。另外,新发布的资源要实时发布。索引页已同步。很多纯静态的网页都更新了内容,但是首页(索引页)还没有出来。这将导致搜索引擎无法通过索引页面抓取最新的资源。第三点是后链(最新文章的URL)需要直接暴露在源码中,方便搜索引擎抓取。最后,索引页越多越好,几个优质的索引页就够了,比如长城,基本上只用首页作为索引页。
最后,这里有一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新资源。这里有两点需要注意。
Q:是不是提交的资源越多越好?
A:收录效果的核心永远是内容的质量。如果大量提交低质量、超标的资源,就会造成惩罚性打击。
问:为什么我提交了一个普通的 收录 却没有被抓到?
A:资源提交只能加速资源发现,不能保证短时间内爬取。当然,百度表示,算法不断优化,让优质内容被更快抓取。
3、访问友好性:
爬虫需要和网站交互,保证网站的稳定性,爬虫才能正常爬取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议将加载时间控制在2S以内,这样无论是用户还是爬虫都会更喜欢打开速度更快的网站,二是避免不必要的跳转,虽然这是很少见的部分,但是有还是网站多级跳转,所以对于爬虫来说,多级跳转的同时断线的可能性很大。常见的做法是先不带www的域名跳转到带WWW的域名,再用带WWW的域名跳转到https,最后换一个新站点。在这种情况下,有三个或四个级别的跳跃。如果有类似网站的修改,建议直接跳转到新域名。
标准http返回码:我们常见的301/302的正确使用,以及404的正确使用,主要是常规问题,用常规方法解决,比如遇到无效资源,那就用404来做,不要t 使用一些特殊的返回状态码。
访问稳定性优化:一是尽量选择国内规模较大的DNS服务,保证网站的稳定性。对于域名的DNS来说,阿里云其实是比较稳定可靠的,那么二是谨慎使用技术手段,阻止爬取。如果有特定资源不想在百度上展示,可以使用机器人屏蔽。比如网站的后台链接大多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是防止防火墙误拦截爬虫爬取,所以建议可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的情况下。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫的数量会相应增加。这次会导致您的服务器出现故障吗?打开压力太大,这个问题需要站长注意。
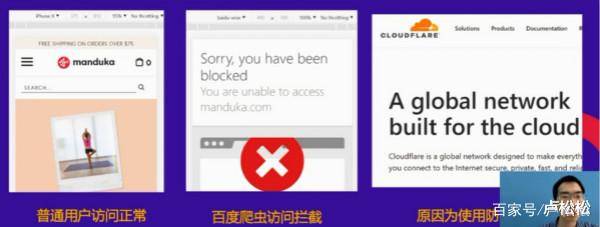
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这三个例子是第三方防火墙拦截的一种状态。普通用户打开这个状态,搜索引擎爬取的时候也是这个状态,所以如果遇到CC或者DDOS,我们在打开防火墙之前,必须先释放搜索引擎的UA。
4、识别百度爬虫
对于一些网站,可能有针对用户的特殊优化,可能有网站想区分用户和爬虫进行优化,所以这时候就需要识别百度爬虫了。

编辑搜索图片,请点击输入图片描述(最多18个字符)
首先,通过一个简单的方法,我们可以通过百度的UA来识别百度爬虫。目前百度PC、手机、小程序是三种不同的UA。然后,通过简单的识别方法,就有了第三方UA。爬虫模拟百度爬虫,所以你认不出来。那么这时候我们就可以通过双向DNS解析认证来区分了。详情请参考《简单两步:教你快速识别百度蜘蛛》。
提问时间
问:新网站会有抓取限制吗?
A:对于任何新站点,都没有抓取限制,但是从去年开始,我们就开始提供对新站点的支持,让你的网站,首先是收录上百度。然后做一个价值判断,那么如何让百度知道你是新站点,有两个捷径,一是去百度资源平台提交,二是去工信部ICP备案,我们可以从工信部得到,从ICP备案的数据,备案后,我们知道有人建了一个新站点,这样我们就可以为新站点提供基础的流量支持。
Q:蜘蛛抓取的配额会针对每个站点进行调整。多久会调整一次?
A:确实会有调整。对于新资源,会与你的抓取频率有关,而对于旧资源,会与你的内容质量有关。如果新资源的质量发生变化,那么爬取频率也会发生变化。网站@如果>的规模发生变化,爬取的频率也会发生变化。如果有大改版,那么爬取的频率也会相对变化。
Q:网站降级可以恢复吗?
A:网站降级恢复的前提是,我们会重新评估网站,检查网站是否已整改,如果有整改,是否404已制作并提交给资源 如果平台完全符合要求,搜索引擎将在评估后恢复不违反规则的网站。
问:新网站是否有评估期?
A:对我们来说,没有评估期这回事。正如我们前面提到的,它可能支持一个新站点的流量。假设一个新站点经过1-2个月的流量支持,发现网站继续保持这个状态,那么不会有大的调整。当我们发现网站的质量有明显提升时,我们也会相应的提升百度排名。
Q:百度对待国外服务器和国内服务器有区别吗?
A:从战略上看,没有严格的区分。不过很多国外服务器在中国部分地区封杀了,从国外服务器网站备案来看,国内服务器有优势。
Q:新站点的旧域名是不是更有优势?
A:如果说旧域名和新网站是同一个内容,在初期确实有一定的优势,但也只是初期,内容的好坏还要看后期. 需要特别注意的是,如果老域名行业和你的新网站的内容无关,即使是所谓的高权限老域名也会适得其反。百度会觉得,今天做那个明天做,效果还不如新建一个域名。
Q:蜘蛛有重量吗,比如220、116等高重量蜘蛛?
答:蜘蛛没有重量。网站 的排名主要取决于 网站 的质量。
网页爬虫抓取百度图片(项目招商找A5快速获取精准代理名单说到SEO)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-01 13:16
项目投资找A5快速获取精准代理商名单
说到SEO,没有人不熟悉。SEO中文翻译为Search Engine Optimization,是指通过优化网站来提高网站的关键词排名,从而增加公司产品的曝光率。
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
确定几个关键词对网站流量的提升会有很大的好处,但必须与网站和产品高度相关。同时,您可以分析竞争对手的关键词,从而了解自己和他人。当然,必须有一个核心关键词,如果你做的是网站服务,那么你的核心关键词可以是:网站SEO,网站优化;如果是其他产品,可以根据自己的产品或服务范围进行定位,比如:减肥、保湿、汽车保养等……
那么长尾 关键词 是什么?顾名思义,它实际上是一个比较长的关键词。长尾关键词的搜索量比较小,在企业文章、软文中可以适当出现。
需要注意的是,关键词的密度不能出现太多,但也不能太小。一般3%~6%比较合适。同样,文章关键词的文章最好不要出现太多,最好在3~5左右。
外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
我们经常看到很多网站的地方都会有友情链接,但是随着百度算法的调整,友情链接的作用已经很小了。目前通过软文和图片传播链接的方法是最科学的方法,尤其是通过高质量的软文允许他人转载传播网站的外部链接,即目前最好的。大大地。
如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果想让你的网站更多的页面是收录,首先要让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
如果你尝试了很多,仍然没有被爬虫爬取,可以看看工程师给出的两个建议:
1、不建议本站使用js生成主要内容。如果js渲染不正确,可能会导致页面内容读取错误,导致爬虫无法抓取页面。
2、许多网站都将针对爬虫进行优化。建议页面长度在128k以内,不要太长。
SEO是用户最感兴趣的搜索服务,最具有潜在的商业价值。这是一项长期的工作,不能急于求成。在这个互联网竞争的环境下,你应该比你的竞争对手多做一点。才有可能获得质的飞跃!
原文由好推建站提供:网站转载时须以链接形式注明作者、原文出处及本声明。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网页爬虫抓取百度图片(项目招商找A5快速获取精准代理名单说到SEO)
项目投资找A5快速获取精准代理商名单
说到SEO,没有人不熟悉。SEO中文翻译为Search Engine Optimization,是指通过优化网站来提高网站的关键词排名,从而增加公司产品的曝光率。
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
确定几个关键词对网站流量的提升会有很大的好处,但必须与网站和产品高度相关。同时,您可以分析竞争对手的关键词,从而了解自己和他人。当然,必须有一个核心关键词,如果你做的是网站服务,那么你的核心关键词可以是:网站SEO,网站优化;如果是其他产品,可以根据自己的产品或服务范围进行定位,比如:减肥、保湿、汽车保养等……
那么长尾 关键词 是什么?顾名思义,它实际上是一个比较长的关键词。长尾关键词的搜索量比较小,在企业文章、软文中可以适当出现。
需要注意的是,关键词的密度不能出现太多,但也不能太小。一般3%~6%比较合适。同样,文章关键词的文章最好不要出现太多,最好在3~5左右。
外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
我们经常看到很多网站的地方都会有友情链接,但是随着百度算法的调整,友情链接的作用已经很小了。目前通过软文和图片传播链接的方法是最科学的方法,尤其是通过高质量的软文允许他人转载传播网站的外部链接,即目前最好的。大大地。
如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果想让你的网站更多的页面是收录,首先要让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
如果你尝试了很多,仍然没有被爬虫爬取,可以看看工程师给出的两个建议:
1、不建议本站使用js生成主要内容。如果js渲染不正确,可能会导致页面内容读取错误,导致爬虫无法抓取页面。
2、许多网站都将针对爬虫进行优化。建议页面长度在128k以内,不要太长。
SEO是用户最感兴趣的搜索服务,最具有潜在的商业价值。这是一项长期的工作,不能急于求成。在这个互联网竞争的环境下,你应该比你的竞争对手多做一点。才有可能获得质的飞跃!
原文由好推建站提供:网站转载时须以链接形式注明作者、原文出处及本声明。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网页爬虫抓取百度图片(soup爬虫学习方法总结(一):SQL语句create数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-02-28 08:09
获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。响应的内容可能包括 HTML、Json 字符串、二进制数据(如图片和视频)等。
解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库进行解析;可能是Json,可以直接转成Json对象解析;它可能是二进制数据,可以保存或进一步处理。
保存数据:数据分析完成后保存。既可以存储为文本文件,也可以存储在数据库中。
四、Python 爬虫实例
爬行动物的定义、功能、原理等信息前面已经介绍过了。相信很多小伙伴已经开始对爬虫产生了兴趣,准备尝试一下。现在,我们来“干货”,直接贴一个简单的Python爬虫代码:
1.前期准备:安装Python环境,安装PYCHARM软件,安装MYSQL数据库,新建数据库考试,考试中建表屋,用于存储爬虫结果【SQL语句:create table house(price varchar ( 88),unit varchar(88),area varchar(88));]
2.爬虫的目标:爬取链家租赁网首页(url:)中所有房源的价格、单位、面积,然后将爬虫结构存入数据库。
3.爬虫源码:如下
import requests #请求URL页面内容
from bs4 import BeautifulSoup #获取页面元素
import pymysql #链接数据库
导入时间#time函数
import lxml #解析库(支持HTML\XML解析,支持XPATH解析)
#get_page 功能:通过requests的get方法获取url链接的内容,然后整合成BeautifulSoup可以处理的格式
def get_page(url):
响应 = requests.get(url)
汤= BeautifulSoup(response.text,'lxml')
回汤
#get_links函数的作用:获取listing页面上的所有出租链接
def get_links(link_url):
汤 = get_page(link_url)
links_div = soup.find_all('div',class_="pic-panel")
links=[div.a.get('href') for div in links_div]
返回链接
#get_house_info的作用是获取一个出租页面的信息:价格、单位、面积等。
def get_house_info(house_url):
汤=get_page(house_url)
价格 =soup.find('span',class_='total').text
unit = soup.find('span',class_='unit').text.strip()
area = 'test' #这里area字段我们自定义一个测试进行测试
信息 = {
“价格”:价格,
“单位”:单位,
“区域”:区域
}
返回信息
#数据库配置信息写入字典
数据库 = {
'主机': '127.0.0.1',
'数据库':'考试',
“用户”:“根”,
“密码”:“根”,
'字符集':'utf8mb4'}
#链接数据库
def get_db(设置):
返回 pymysql.connect(**设置)
#将爬虫获取的数据插入数据库
定义插入(分贝,房子):
值 = "'{}',"*2 + "'{}'"
sql_values=values.format(house['price'],house['unit'],house['area'])
sql="""
插入房屋(价格,单位,面积)值({})
""".format(sql_values)
游标 = db.cursor()
cursor.execute(sql)
mit()
#主程序流程:1.连接数据库2.获取每个listing信息的URL列表3.FOR循环从第一个URL开始获取具体信息(价格等)列表的4. 一一插入数据库
db = get_db(数据库)
链接 = get_links('#39;)
对于链接中的链接:
时间.sleep(2)
房子=get_house_info(链接)
插入(分贝,房子)
首先,“要想做好工作,必须先利其器”。用 Python 编写爬虫程序也是如此。在编写爬虫的过程中,需要导入各种库文件。正是这些及其有用的库文件帮助我们完成了爬虫。对于大部分工作,我们只需要调用相关的接口函数即可。导入格式为导入库文件名。这里需要注意的是,要在PYCHARM中安装库文件,可以将光标放在库文件名上同时按ctrl+alt键安装库文件,也可以是通过命令行安装(pip安装库文件名),如果安装失败或者没有安装,后续爬虫肯定会报错。在这段代码中,程序前五行导入相关库文件:requests用于请求URL页面内容;BeautifulSoup 用于解析页面元素;pymysql用于连接数据库;time 收录各种时间函数;lxml是一个解析库,用于解析HTML、XML格式文件,也支持XPATH解析。
其次,我们从代码末尾的主程序来看整个爬虫流程:
通过 get_db 函数连接到数据库。深入get_db函数,可以看到是通过调用
Pymysql的connect函数用于实现数据库的连接。这里的**seting是Python采集关键字参数的一种方式。我们将数据库的连接信息写入一个字典DataBase,并将字典中的信息传递给connect实现。参考。
使用get_links函数获取链家首页所有房源的链接。所有列表的链接都以列表的形式存储在 Links 中。get_links函数首先通过requests请求获取链家首页的内容,然后通过BeautyfuSoup的接口对内容的格式进行整理,转化为自己可以处理的格式。最后通过电泳find_all函数找到所有收录图片的div样式,然后用for循环获取所有div样式中收录的超链接标签(a)的内容(即href属性的内容),所有超链接存储在列表链接中。
通过 FOR 循环,遍历 links 中的所有链接(例如,其中一个链接是:)
使用与2)相同的方法,通过find函数定位元素,获取3)中链接中的价格、单位、地区信息,并将这些信息写入字典Info。
调用insert函数,将链接中获取的Info信息写入到数据库的house表中。深入insert函数可知,它通过数据库游标函数cursor()执行一条SQL语句,然后数据库执行commit操作,实现响应功能。SQL 语句在这里以一种特殊的方式编写。
给格式化函数格式化,这是为了方便函数的复用。
最后运行爬虫代码,可以看到链家首页所有房源信息都写入了数据中。(注:test是我手动指定的测试字符串)
后记:其实Python爬虫并不难。在熟悉了整个爬取过程之后,需要注意一些细节,比如如何获取页面元素,如何构造SQL语句等等。遇到问题不要慌张,可以通过查看IDE的提示一一排除bug,最终得到我们期望的结构。
最后:
可以获取我的个人V:atstudy-js,可以免费获取10G软件测试工程师面试合集文档。并免费分享对应的视频学习教程!,包括基础知识、Linux要领、Mysql数据库、抓包工具、接口测试工具、高级测试——Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架,性能测试等
这些测试数据应该是做【软件测试】的朋友最全面最完整的准备仓库了。这个仓库也陪我走过了最艰难的旅程,希望也能帮到你! 查看全部
网页爬虫抓取百度图片(soup爬虫学习方法总结(一):SQL语句create数据)
获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。响应的内容可能包括 HTML、Json 字符串、二进制数据(如图片和视频)等。
解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库进行解析;可能是Json,可以直接转成Json对象解析;它可能是二进制数据,可以保存或进一步处理。
保存数据:数据分析完成后保存。既可以存储为文本文件,也可以存储在数据库中。
四、Python 爬虫实例
爬行动物的定义、功能、原理等信息前面已经介绍过了。相信很多小伙伴已经开始对爬虫产生了兴趣,准备尝试一下。现在,我们来“干货”,直接贴一个简单的Python爬虫代码:
1.前期准备:安装Python环境,安装PYCHARM软件,安装MYSQL数据库,新建数据库考试,考试中建表屋,用于存储爬虫结果【SQL语句:create table house(price varchar ( 88),unit varchar(88),area varchar(88));]
2.爬虫的目标:爬取链家租赁网首页(url:)中所有房源的价格、单位、面积,然后将爬虫结构存入数据库。
3.爬虫源码:如下
import requests #请求URL页面内容
from bs4 import BeautifulSoup #获取页面元素
import pymysql #链接数据库
导入时间#time函数
import lxml #解析库(支持HTML\XML解析,支持XPATH解析)
#get_page 功能:通过requests的get方法获取url链接的内容,然后整合成BeautifulSoup可以处理的格式
def get_page(url):
响应 = requests.get(url)
汤= BeautifulSoup(response.text,'lxml')
回汤
#get_links函数的作用:获取listing页面上的所有出租链接
def get_links(link_url):
汤 = get_page(link_url)
links_div = soup.find_all('div',class_="pic-panel")
links=[div.a.get('href') for div in links_div]
返回链接
#get_house_info的作用是获取一个出租页面的信息:价格、单位、面积等。
def get_house_info(house_url):
汤=get_page(house_url)
价格 =soup.find('span',class_='total').text
unit = soup.find('span',class_='unit').text.strip()
area = 'test' #这里area字段我们自定义一个测试进行测试
信息 = {
“价格”:价格,
“单位”:单位,
“区域”:区域
}
返回信息
#数据库配置信息写入字典
数据库 = {
'主机': '127.0.0.1',
'数据库':'考试',
“用户”:“根”,
“密码”:“根”,
'字符集':'utf8mb4'}
#链接数据库
def get_db(设置):
返回 pymysql.connect(**设置)
#将爬虫获取的数据插入数据库
定义插入(分贝,房子):
值 = "'{}',"*2 + "'{}'"
sql_values=values.format(house['price'],house['unit'],house['area'])
sql="""
插入房屋(价格,单位,面积)值({})
""".format(sql_values)
游标 = db.cursor()
cursor.execute(sql)
mit()
#主程序流程:1.连接数据库2.获取每个listing信息的URL列表3.FOR循环从第一个URL开始获取具体信息(价格等)列表的4. 一一插入数据库
db = get_db(数据库)
链接 = get_links('#39;)
对于链接中的链接:
时间.sleep(2)
房子=get_house_info(链接)
插入(分贝,房子)
首先,“要想做好工作,必须先利其器”。用 Python 编写爬虫程序也是如此。在编写爬虫的过程中,需要导入各种库文件。正是这些及其有用的库文件帮助我们完成了爬虫。对于大部分工作,我们只需要调用相关的接口函数即可。导入格式为导入库文件名。这里需要注意的是,要在PYCHARM中安装库文件,可以将光标放在库文件名上同时按ctrl+alt键安装库文件,也可以是通过命令行安装(pip安装库文件名),如果安装失败或者没有安装,后续爬虫肯定会报错。在这段代码中,程序前五行导入相关库文件:requests用于请求URL页面内容;BeautifulSoup 用于解析页面元素;pymysql用于连接数据库;time 收录各种时间函数;lxml是一个解析库,用于解析HTML、XML格式文件,也支持XPATH解析。
其次,我们从代码末尾的主程序来看整个爬虫流程:
通过 get_db 函数连接到数据库。深入get_db函数,可以看到是通过调用
Pymysql的connect函数用于实现数据库的连接。这里的**seting是Python采集关键字参数的一种方式。我们将数据库的连接信息写入一个字典DataBase,并将字典中的信息传递给connect实现。参考。
使用get_links函数获取链家首页所有房源的链接。所有列表的链接都以列表的形式存储在 Links 中。get_links函数首先通过requests请求获取链家首页的内容,然后通过BeautyfuSoup的接口对内容的格式进行整理,转化为自己可以处理的格式。最后通过电泳find_all函数找到所有收录图片的div样式,然后用for循环获取所有div样式中收录的超链接标签(a)的内容(即href属性的内容),所有超链接存储在列表链接中。
通过 FOR 循环,遍历 links 中的所有链接(例如,其中一个链接是:)
使用与2)相同的方法,通过find函数定位元素,获取3)中链接中的价格、单位、地区信息,并将这些信息写入字典Info。
调用insert函数,将链接中获取的Info信息写入到数据库的house表中。深入insert函数可知,它通过数据库游标函数cursor()执行一条SQL语句,然后数据库执行commit操作,实现响应功能。SQL 语句在这里以一种特殊的方式编写。
给格式化函数格式化,这是为了方便函数的复用。
最后运行爬虫代码,可以看到链家首页所有房源信息都写入了数据中。(注:test是我手动指定的测试字符串)

后记:其实Python爬虫并不难。在熟悉了整个爬取过程之后,需要注意一些细节,比如如何获取页面元素,如何构造SQL语句等等。遇到问题不要慌张,可以通过查看IDE的提示一一排除bug,最终得到我们期望的结构。
最后:
可以获取我的个人V:atstudy-js,可以免费获取10G软件测试工程师面试合集文档。并免费分享对应的视频学习教程!,包括基础知识、Linux要领、Mysql数据库、抓包工具、接口测试工具、高级测试——Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架,性能测试等
这些测试数据应该是做【软件测试】的朋友最全面最完整的准备仓库了。这个仓库也陪我走过了最艰难的旅程,希望也能帮到你!
网页爬虫抓取百度图片(网页爬虫抓取百度图片试试?页面加载有点慢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-26 19:04
网页爬虫抓取百度图片试试?页面加载有点慢,不知道能不能用requests抓取下来。
哈哈~个人更推荐使用flask相对于python自带的那些功能它基本上都有对于web爬虫我更喜欢flask,用起来也简单而且python本身没有这方面的框架,还是跟着别人学吧上面那个写爬虫的写的的很清楚,
首先你要确定你是想要抓取哪些图片网站的图片。网站上的爬虫是不是有对图片url地址进行针对性地查找,然后发现该网站上已经有图片。一般的爬虫能力没有那么强大。推荐用蜘蛛程序爬下来,进行一个下载工作。或者图片搜索工具对图片信息进行爬取。
据我所知微信公众号图文消息的接口不能爬取图片,你可以选择把那个接口转换成抓取类,直接抓取。
我目前用了两个微信公众号的接口,一个搜,一个推。其中公众号搜是图片接口,可以抓取其它地方的,比如说我的知乎。
建议使用像flask这种pythonweb框架,
额,我刚接触爬虫没多久,目前采用图片链接去抓取微信文章的图片,刚开始学,
可以用户工具箱
我也试了各种方式都没成功好烦人
实在不行就编写个爬虫程序
这些微信公众号都会放一些免费图片的链接供爬取,但是仅限原创文章。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片试试?页面加载有点慢)
网页爬虫抓取百度图片试试?页面加载有点慢,不知道能不能用requests抓取下来。
哈哈~个人更推荐使用flask相对于python自带的那些功能它基本上都有对于web爬虫我更喜欢flask,用起来也简单而且python本身没有这方面的框架,还是跟着别人学吧上面那个写爬虫的写的的很清楚,
首先你要确定你是想要抓取哪些图片网站的图片。网站上的爬虫是不是有对图片url地址进行针对性地查找,然后发现该网站上已经有图片。一般的爬虫能力没有那么强大。推荐用蜘蛛程序爬下来,进行一个下载工作。或者图片搜索工具对图片信息进行爬取。
据我所知微信公众号图文消息的接口不能爬取图片,你可以选择把那个接口转换成抓取类,直接抓取。
我目前用了两个微信公众号的接口,一个搜,一个推。其中公众号搜是图片接口,可以抓取其它地方的,比如说我的知乎。
建议使用像flask这种pythonweb框架,
额,我刚接触爬虫没多久,目前采用图片链接去抓取微信文章的图片,刚开始学,
可以用户工具箱
我也试了各种方式都没成功好烦人
实在不行就编写个爬虫程序
这些微信公众号都会放一些免费图片的链接供爬取,但是仅限原创文章。
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一第一时间解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-26 15:20
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看
1. 概述
本文主要实现一个简单的爬虫,目的是从百度贴吧页面下载图片。下载图片的步骤如下:
(1)获取网页的html文本内容;
(2)分析html中图片的html标签特征,使用正则解析得到所有图片url链接的列表;
(3)根据图片的url链接列表将图片下载到本地文件夹。
2. urllib+re 实现
<p>1#!/usr/bin/python
2# coding:utf-8
3# 实现一个简单的爬虫,爬取百度贴吧图片
4import urllib
5import re
6# 根据url获取网页html内容
7def getHtmlContent(url):
8 page = urllib.urlopen(url)
9
10return page.read()
11# 从html中解析出所有jpg图片的url
12# 百度贴吧html中jpg图片的url格式为:XXX.jpg
13def getJPGs(html):
14# 解析jpg图片url的正则
15 jpgReg = re.compile(r' 查看全部
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一第一时间解决?(图))
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看

1. 概述
本文主要实现一个简单的爬虫,目的是从百度贴吧页面下载图片。下载图片的步骤如下:
(1)获取网页的html文本内容;
(2)分析html中图片的html标签特征,使用正则解析得到所有图片url链接的列表;
(3)根据图片的url链接列表将图片下载到本地文件夹。
2. urllib+re 实现
<p>1#!/usr/bin/python
2# coding:utf-8
3# 实现一个简单的爬虫,爬取百度贴吧图片
4import urllib
5import re
6# 根据url获取网页html内容
7def getHtmlContent(url):
8 page = urllib.urlopen(url)
9
10return page.read()
11# 从html中解析出所有jpg图片的url
12# 百度贴吧html中jpg图片的url格式为:XXX.jpg
13def getJPGs(html):
14# 解析jpg图片url的正则
15 jpgReg = re.compile(r'
网页爬虫抓取百度图片(网络爬虫爬取百度图片猫的图片为案例演示(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-15 00:00
)
网络爬虫主要分为4大板块:
分析具有明确目标的网页结构,
在网页中查找信息的地址,
抓取信息,
保存信息
以下以网络爬虫抓取百度图片猫的图片为例进行演示
项目案例:
爬取百度所有狗图片网站
步骤分析:第一步:明确目标,我们将百度的狗图片作为目标爬取,分析网页结构
1、输入以下网址
^00_1583X672&word=狗
2、选择下一页时,只有pn和gsm值发生了变化。
到目前为止,我所知道的是:pn参数代表页数; word参数自然是关键词,需要转换编码格式。
gsm 的值,随意更改似乎没有任何作用。有句话说gsm:代表pn的十六进制值
3、可以拼接出页面请求的URL,代码如下
import sys
import urllib
import requests
def getPage(keyword, page, n):
page = page * n
keyword = urllib.parse.quote(keyword, safe='/')
url_begin = "http://image.baidu.com/search/ ... ot%3B
url = url_begin + keyword + "&pn=" + str(page) + "&gsm=" + str(hex(page)) + "&ct=&ic=0&lm=-1&width=0&height=0"
return url
第二步:在网页中查找图片地址
1、右键查看网页源代码,分析JSON数据可以看到objURL字段代表原图的下载路径
2、根据URL地址,获取图片地址的代码为:
def get_onepage_urls(onepageurl):
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
return pic_urls
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
return pic_urls
三、爬取图片并保存
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = 'data2/'+str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
四、调用函数
if __name__ == '__main__':
keyword = '狗' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
page_begin = 0
page_number = 30
image_number = 3
all_pic_urls = []
while 1:
if page_begin > image_number:
break
print("第%d次请求数据", [page_begin])
url = getPage(keyword, page_begin, page_number)
onepage_urls = get_onepage_urls(url)
page_begin += 1
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
查看全部
网页爬虫抓取百度图片(网络爬虫爬取百度图片猫的图片为案例演示(图)
)
网络爬虫主要分为4大板块:
分析具有明确目标的网页结构,
在网页中查找信息的地址,
抓取信息,
保存信息
以下以网络爬虫抓取百度图片猫的图片为例进行演示
项目案例:
爬取百度所有狗图片网站
步骤分析:第一步:明确目标,我们将百度的狗图片作为目标爬取,分析网页结构
1、输入以下网址
^00_1583X672&word=狗
2、选择下一页时,只有pn和gsm值发生了变化。
到目前为止,我所知道的是:pn参数代表页数; word参数自然是关键词,需要转换编码格式。
gsm 的值,随意更改似乎没有任何作用。有句话说gsm:代表pn的十六进制值
3、可以拼接出页面请求的URL,代码如下
import sys
import urllib
import requests
def getPage(keyword, page, n):
page = page * n
keyword = urllib.parse.quote(keyword, safe='/')
url_begin = "http://image.baidu.com/search/ ... ot%3B
url = url_begin + keyword + "&pn=" + str(page) + "&gsm=" + str(hex(page)) + "&ct=&ic=0&lm=-1&width=0&height=0"
return url
第二步:在网页中查找图片地址
1、右键查看网页源代码,分析JSON数据可以看到objURL字段代表原图的下载路径
2、根据URL地址,获取图片地址的代码为:
def get_onepage_urls(onepageurl):
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
return pic_urls
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
return pic_urls
三、爬取图片并保存
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = 'data2/'+str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
四、调用函数
if __name__ == '__main__':
keyword = '狗' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
page_begin = 0
page_number = 30
image_number = 3
all_pic_urls = []
while 1:
if page_begin > image_number:
break
print("第%d次请求数据", [page_begin])
url = getPage(keyword, page_begin, page_number)
onepage_urls = get_onepage_urls(url)
page_begin += 1
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-12 03:11
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的照片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站你懂的,很难解释)几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar 查看全部
网页爬虫抓取百度图片(怎么老是静不下心来心来搞定一方面的技术,再学点其他的东西)
我对xmfdsh真的很感兴趣,为什么不能静下心来搞定一个方面的技术,然后再学习其他的东西,一步一步来,好吧,我又要去学习网络爬虫了,这是一个简单的版本,参考网上很多资料,用C#写的,专门抓图,可以抓一些需要cookies的网站,所以功能还是挺全的,xmfdsh才研究了三天,所以有仍有很大的改进空间。我会慢慢改进的。我将在本文末尾附上整个项目。献给喜欢学习C#的朋友。让我慢慢说:
#region 访问数据 + Request(int index)
///
/// 访问数据
///
private void Request(int index)
{
try
{
int depth;
string url = "";
//lock锁住Dictionary,因为Dictionary多线程会出错
lock (_locker)
{
//查看是否还存在未下载的链接
if (UnDownLoad.Count 0)
{
MemoryStream ms = new System.IO.MemoryStream(rs.Data, 0, read);
BinaryReader reader = new BinaryReader(ms);
byte[] buffer = new byte[32 * 1024];
while ((read = reader.Read(buffer, 0, buffer.Length)) > 0)
{
rs.memoryStream.Write(buffer, 0, read);
}
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
else
{
read = responseStream.EndRead(ar);
if (read > 0)
{
//创建内存流
MemoryStream ms = new MemoryStream(rs.Data, 0, read);
StreamReader reader = new StreamReader(ms, Encoding.GetEncoding("gb2312"));
string str = reader.ReadToEnd();
//添加到末尾
rs.Html.Append(str);
//递归 再次请求数据
var result = responseStream.BeginRead(rs.Data, 0, rs.BufferSize, new AsyncCallback(ReceivedData), rs);
return;
}
}
if (url.Contains(".jpg") || url.Contains(".png"))
{
//images = rs.Images;
SaveContents(rs.memoryStream.GetBuffer(), url);
}
else
{
html = rs.Html.ToString();
//保存
SaveContents(html, url);
//获取页面的链接
}
}
catch (Exception ex)
{
_reqsBusy[rs.Index] = false;
DispatchWork();
}
List links = GetLinks(html,url);
//得到过滤后的链接,并保存到未下载集合
AddUrls(links, depth + 1);
_reqsBusy[index] = false;
DispatchWork();
}
#endregion
这就是数据的处理,这是这里的重点。其实不难判断是不是图片。如果是图片,把图片存起来,因为在目前的网络爬虫还不够先进的情况下,爬取图片比较实用有趣。(不要急着找出哪个网站有很多女孩的照片),如果不是图片,我们认为是正常的html页面,然后阅读html代码,如果有链接http或 href,它将被添加到下载链接。当然,对于我们阅读的链接,我们已经限制了一些js或者一些css(不要阅读这样的东西)。
private void SaveContents(byte[] images, string url)
{
if (images.Count() < 1024*30)
return;
if (url.Contains(".jpg"))
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".jpg", images);
Console.WriteLine("图片保存成功" + url);
}
else
{
File.WriteAllBytes(@"d:\网络爬虫图片\" + _index++ + ".png", images);
Console.WriteLine("图片保存成功" + url);
}
}
#region 提取页面链接 + List GetLinks(string html)
///
/// 提取页面链接
///
///
///
private List GetLinks(string html,string url)
{
//匹配http链接
const string pattern2 = @"http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List links = new List();
for (int i = 0; i < m2.Count; i++)
{
//这个原因是w3school的网址,但里面的东西明显不是我们想要的
if (m2[i].ToString().Contains("www.w3.org"))
continue;
links.Add(m2[i].ToString());
}
//匹配href里面的链接,并加到主网址上(学网站的你懂的)
const string pattern = @"href=([""'])?(?[^'""]+)\1[^>]*";
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
// List links = new List();
for (int i = 0; i < m.Count; i++)
{
string href1 = m[i].ToString().Replace("href=", "");
href1 = href1.Replace("\"", "");
//找到符合的,添加到主网址(一开始输入的网址)里面去
string href = RootUrl + href1;
if (m[i].ToString().Contains("www.w3.org"))
continue;
links.Add(href);
}
return links;
}
#endregion
提取页面链接的方法,当阅读发现这是html代码时,继续解释里面的代码,找到里面的url链接,这正是拥有网络爬虫功能的方法(不然会很无聊只提取这个页面),这里当然应该提取http链接,href中的字是因为。. . . (学网站你懂的,很难解释)几乎所有的图片都放在里面,文章,所以上面有href之类的代码要处理。
#region 添加url到 UnDownLoad 集合 + AddUrls(List urls, int depth)
///
/// 添加url到 UnDownLoad 集合
///
///
///
private void AddUrls(List urls, int depth)
{
lock (_locker)
{
if (depth >= MAXDEPTH)
{
//深度过大
return;
}
foreach (string url in urls)
{
string cleanUrl = url.Trim();
int end = cleanUrl.IndexOf(' ');
if (end > 0)
{
cleanUrl = cleanUrl.Substring(0, end);
}
if (UrlAvailable(cleanUrl))
{
UnDownLoad.Add(cleanUrl, depth);
}
}
}
}
#endregion
#region 开始捕获 + DispatchWork()
///
/// 开始捕获
///
private void DispatchWork()
{
for (int i = 0; i < _reqCount; i++)
{
if (!_reqsBusy[i])
{
Request(i);
Thread.Sleep(1000);
}
}
}
#endregion
此功能是为了使这些错误起作用。_reqCount 的值在开头设置。事实上,视觉上的理解就是你发布的 bug 的数量。在这个程序中,我默认放了20个,可以随时修改。对于一些需要cookies的网站,就是通过访问开头输入的URL,当然也可以使用HttpWebRequest辅助类,cookies = request.CookieContainer; //保存cookie,以后访问后续URL时添加就行 request.CookieContainer = cookies; //饼干尝试。对于 网站 只能通过应用 cookie 访问,不需要根网页,就像不需要百度图片的 URL,但如果访问里面的图片很突然,cookie会附上,所以这个问题也解决了。xmfdsh 发现这个程序中还有一些网站不能抓图。当捕捉到一定数量的照片时它会停止。具体原因不明,以后慢慢完善。
附上源码:%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB.rar
网页爬虫抓取百度图片(Python视频写了一个爬虫程序,实现简单的网页图片下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-12 03:11
一、介绍
我学习 Python 已经有一段时间了。听说Python爬虫很厉害。我现在才学到这个。跟着小龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的网址使用了反爬虫算法。所以无法爬取想要的图片,所以,只做爬虫笔记。仅供学习参考【捂脸】。 . . .
终于:我把jpg格式改成gif了,还是能爬到一个很差的gif图:
第一张图片是反爬机制的图片占位符,完全没有内容 查看全部
网页爬虫抓取百度图片(Python视频写了一个爬虫程序,实现简单的网页图片下载)
一、介绍
我学习 Python 已经有一段时间了。听说Python爬虫很厉害。我现在才学到这个。跟着小龟的Python视频写了一个爬虫程序,可以实现简单的网页图片下载。
二、代码
__author__ = "JentZhang"
import urllib.request
import os
import random
import re
def url_open(url):
'''
打开网页
:param url:
:return:
'''
req = urllib.request.Request(url)
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')
# 应用代理
'''
proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]
proxy = random.choice(proxyies)
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
urllib.request.install_opener(opener)
'''
response = urllib.request.urlopen(url)
html = response.read()
return html
def save_img(folder, img_addrs):
'''
保存图片
:param folder: 要保存的文件夹
:param img_addrs: 图片地址(列表)
:return:
'''
# 创建文件夹用来存放图片
if not os.path.exists(folder):
os.mkdir(folder)
os.chdir(folder)
for each in img_addrs:
filename = each.split('/')[-1]
try:
with open(filename, 'wb') as f:
img = url_open("http:" + each)
f.write(img)
except urllib.error.HTTPError as e:
# print(e.reason)
pass
print('完毕!')
def find_imgs(url):
'''
获取全部的图片链接
:param url: 连接地址
:return: 图片地址的列表
'''
html = url_open(url).decode("utf-8")
img_addrs = re.findall(r'src="(.+?\.gif)', html)
return img_addrs
def get_page(url):
'''
获取当前一共有多少页的图片
:param url: 网页地址
:return:
'''
html = url_open(url).decode('utf-8')
a = html.find("current-comment-page") + 23
b = html.find("]", a)
return html[a:b]
def download_mm(url="http://jandan.net/ooxx/", folder="OOXX", pages=1):
'''
主程序(下载图片)
:param folder:默认存放的文件夹
:param pages: 下载的页数
:return:
'''
page_num = int(get_page(url))
for i in range(pages):
page_num -= i
page_url = url + "page-" + str(page_num) + "#comments"
img_addrs = find_imgs(page_url)
save_img(folder, img_addrs)
if __name__ == "__main__":
download_mm()
三、总结
因为代码中访问的网址使用了反爬虫算法。所以无法爬取想要的图片,所以,只做爬虫笔记。仅供学习参考【捂脸】。 . . .
终于:我把jpg格式改成gif了,还是能爬到一个很差的gif图:
第一张图片是反爬机制的图片占位符,完全没有内容
网页爬虫抓取百度图片(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-10 04:21
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-
import urllib.request
req = urllib.request.urlopen('https://www.amazon.com')
print(req.code)
复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requests
url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'
web_header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': '你的cookie值',
'TE': 'Trailers'}
r = requests.get(url,headers=web_header)
print(r.status_code)
复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium
复制代码
在代码中引入 selenium 并设置相关参数
import os
from requests.api import options
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#selenium配置参数
options = Options()
#配置无头参数,即不打开浏览器
options.add_argument('--headless')
#配置Chrome浏览器的selenium驱动
chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
#将参数设置+浏览器驱动组合
browser = webdriver.Chrome(chromedriver,chrome_options=options)
复制代码
测试访问
url = "https://www.amazon.com"
print(url)
#通过selenium来访问亚马逊
browser.get(url)
复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件
fw=open('E:/amzon.html','w',encoding='utf-8')
fw.write(str(browser.page_source))
browser.close()
fw.close()
复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。 查看全部
网页爬虫抓取百度图片(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-
import urllib.request
req = urllib.request.urlopen('https://www.amazon.com')
print(req.code)
复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requests
url='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'
web_header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'Cookie': '你的cookie值',
'TE': 'Trailers'}
r = requests.get(url,headers=web_header)
print(r.status_code)
复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium
复制代码
在代码中引入 selenium 并设置相关参数
import os
from requests.api import options
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#selenium配置参数
options = Options()
#配置无头参数,即不打开浏览器
options.add_argument('--headless')
#配置Chrome浏览器的selenium驱动
chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
#将参数设置+浏览器驱动组合
browser = webdriver.Chrome(chromedriver,chrome_options=options)
复制代码
测试访问
url = "https://www.amazon.com"
print(url)
#通过selenium来访问亚马逊
browser.get(url)
复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件
fw=open('E:/amzon.html','w',encoding='utf-8')
fw.write(str(browser.page_source))
browser.close()
fw.close()
复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。
网页爬虫抓取百度图片(网络爬虫技术(Webcrawler)的工作流程及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-09 15:11
网络爬虫技术
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们被广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。 查看全部
网页爬虫抓取百度图片(网络爬虫技术(Webcrawler)的工作流程及注意事项)
网络爬虫技术
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们被广泛应用于互联网搜索引擎或其他类似的网站,并且可以自动采集所有它可以访问的页面的内容来获取或更新这些网站的内容和检索方式. 从功能上来说,爬虫一般分为数据采集、处理、存储三部分。
传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。
焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
网页爬虫抓取百度图片( 爬取百度贴吧了百度你还真是鸡贼鼠标向下滚动)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-07 10:07
爬取百度贴吧了百度你还真是鸡贼鼠标向下滚动)
测试爬取百度贴吧图片
定义爬取百度斗图首页每篇文章URL的爬取规则对象
1 /**
2 * 斗图吧贴子的url
3 */
4 SpiderFunction doutubaTieZiUrl = spider -> {
5 // 文本爬取对象
6 TextSpider textSpider = (TextSpider) spider;
7 // 文本爬取规则 定位元素
8 textSpider.setReg("div:t_concleafix>*>a>href>*");
9 return textSpider.getData().getResult().stream()
10 // 爬取后的数据处理 因为可能存在相同引用的连接所以使用Set容器去重
11 .filter(url -> (!"#".equals(url)) && (!url.contains("?")) && (url.contains("/p/")))
12 .map(url -> url.startsWith("http") ? url : "https://tieba.baidu.com" + url
13 ).collect(Collectors.toSet());
14 };
15
16
在搜索爬虫规则的过程中,发现百度贴吧帖子列表页面的所有内容都被注释掉了,所以需要修改文字规则拦截部分的代码
过滤评论部分需要处理
编写一个爬取规则对象,爬取每篇文章的页数
1 /**
2 * 百度贴吧贴子的每页的url
3 */
4 SpiderFunction doutubaTieZiPageUrl = spider -> {
5 Set urls = new HashSet();
6 String page = spider.getUrl();
7 TextSpider textSpider = (TextSpider) spider;
8 // 定位总页数位置
9 textSpider.setReg("li:l_reply_num>1>span>2");
10 List result = textSpider.getData().getResult();
11 // 循环生成某个贴子的所有页面的url
12 if (Lists.isValuable(result)) {
13 String endNum = result.get(0);
14 if (endNum.matches("^[0-9]+$")) {
15 for (int i = 1; i {
5 TextSpider textSpider = (TextSpider) spider;
6 textSpider.setReg("div:p_content>*>img>src>*");
7 return textSpider.getData().getResult().stream()
8 .map(url -> url.startsWith("http") ? url : spider.getUrl() + url)
9 .filter(SpiderCommonUtils::isImgUrl)
10 .collect(Collectors.toSet());
11 };
12
13
获取豆瓣的代码
1 /**
2 * 抓取斗图吧图片
3 */
4 @Test
5 public void testP(){
6 //String doutu = "https://tieba.baidu.com/f%3Fkw ... 3B%3B
7 for (int i = 0; i {
56 if (jsonMap.containsKey(tag)) {
57 result.addAll(getDataList(jsonMap.get(tag).toString(),endTag));
58 }
59 });
60 }
61 }else{
62 JSON json = JSONUtil.parse(source);
63 if (json instanceof JSONObject) {
64 if (((JSONObject) json).containsKey(reg)) {
65 result.add(((JSONObject) json).get(reg).toString());
66 }
67 } else if (json instanceof JSONArray) {
68 ((JSONArray) json).toList(Map.class).stream().forEach(jsonMap -> {
69 if (jsonMap.containsKey(reg)) {
70 result.add(jsonMap.get(reg).toString());
71 }
72 });
73 }
74 }
75 return result;
76 }
77}
78
79
编写爬取规则对象
1 /**
2 * 百度搜图的图片url
3 */
4 SpiderFunction baiDuSouImgUrl = spider -> {
5 AjaxSpider ajaxSpider = (AjaxSpider) spider;
6 return ajaxSpider.getData().getDataList("data.hoverURL");
7 };
8
9
爬取代码
<p>1 /**
2 * 抓取百度图片搜索
3 */
4 @Test
5 public void testPt(){
6 String image = "https://image.baidu.com/search/acjson?";
7 //搜索的关键字
8 String queryWords = "米老鼠";
9 // 参数
10 Map parms = new HashMap();
11 parms.put("tn", "resultjson_com");
12 parms.put("ipn", "rj");
13 parms.put("ct", "201326592");
14 parms.put("is", "");
15 parms.put("fp", "result");
16 parms.put("queryWord", queryWords);
17 parms.put("cl", "2");
18 parms.put("lm", "-1");
19 parms.put("ie", "utf-8");
20 parms.put("oe", "utf-8");
21 parms.put("adpicid", "");
22 parms.put("st", "-1");
23 parms.put("z", "");
24 parms.put("ic", "0");
25 parms.put("hd", "");
26 parms.put("latest", "");
27 parms.put("copyright", "");
28 parms.put("word", queryWords);
29 parms.put("s", "");
30 parms.put("se", "");
31 parms.put("tab", "");
32 parms.put("width", "");
33 parms.put("height", "");
34 parms.put("face", "0");
35 parms.put("istype", "2");
36 parms.put("qc", "");
37 parms.put("nc", "1");
38 parms.put("fr", "");
39 parms.put("expermode", "");
40 parms.put("rn", "30");
41 parms.put("gsm", "");
42 parms.put(String.valueOf(System.currentTimeMillis()),"");
43 for (int i = 0; i 查看全部
网页爬虫抓取百度图片(
爬取百度贴吧了百度你还真是鸡贼鼠标向下滚动)
测试爬取百度贴吧图片
定义爬取百度斗图首页每篇文章URL的爬取规则对象
1 /**
2 * 斗图吧贴子的url
3 */
4 SpiderFunction doutubaTieZiUrl = spider -> {
5 // 文本爬取对象
6 TextSpider textSpider = (TextSpider) spider;
7 // 文本爬取规则 定位元素
8 textSpider.setReg("div:t_concleafix>*>a>href>*");
9 return textSpider.getData().getResult().stream()
10 // 爬取后的数据处理 因为可能存在相同引用的连接所以使用Set容器去重
11 .filter(url -> (!"#".equals(url)) && (!url.contains("?")) && (url.contains("/p/")))
12 .map(url -> url.startsWith("http") ? url : "https://tieba.baidu.com" + url
13 ).collect(Collectors.toSet());
14 };
15
16
在搜索爬虫规则的过程中,发现百度贴吧帖子列表页面的所有内容都被注释掉了,所以需要修改文字规则拦截部分的代码
过滤评论部分需要处理
编写一个爬取规则对象,爬取每篇文章的页数
1 /**
2 * 百度贴吧贴子的每页的url
3 */
4 SpiderFunction doutubaTieZiPageUrl = spider -> {
5 Set urls = new HashSet();
6 String page = spider.getUrl();
7 TextSpider textSpider = (TextSpider) spider;
8 // 定位总页数位置
9 textSpider.setReg("li:l_reply_num>1>span>2");
10 List result = textSpider.getData().getResult();
11 // 循环生成某个贴子的所有页面的url
12 if (Lists.isValuable(result)) {
13 String endNum = result.get(0);
14 if (endNum.matches("^[0-9]+$")) {
15 for (int i = 1; i {
5 TextSpider textSpider = (TextSpider) spider;
6 textSpider.setReg("div:p_content>*>img>src>*");
7 return textSpider.getData().getResult().stream()
8 .map(url -> url.startsWith("http") ? url : spider.getUrl() + url)
9 .filter(SpiderCommonUtils::isImgUrl)
10 .collect(Collectors.toSet());
11 };
12
13
获取豆瓣的代码
1 /**
2 * 抓取斗图吧图片
3 */
4 @Test
5 public void testP(){
6 //String doutu = "https://tieba.baidu.com/f%3Fkw ... 3B%3B
7 for (int i = 0; i {
56 if (jsonMap.containsKey(tag)) {
57 result.addAll(getDataList(jsonMap.get(tag).toString(),endTag));
58 }
59 });
60 }
61 }else{
62 JSON json = JSONUtil.parse(source);
63 if (json instanceof JSONObject) {
64 if (((JSONObject) json).containsKey(reg)) {
65 result.add(((JSONObject) json).get(reg).toString());
66 }
67 } else if (json instanceof JSONArray) {
68 ((JSONArray) json).toList(Map.class).stream().forEach(jsonMap -> {
69 if (jsonMap.containsKey(reg)) {
70 result.add(jsonMap.get(reg).toString());
71 }
72 });
73 }
74 }
75 return result;
76 }
77}
78
79
编写爬取规则对象
1 /**
2 * 百度搜图的图片url
3 */
4 SpiderFunction baiDuSouImgUrl = spider -> {
5 AjaxSpider ajaxSpider = (AjaxSpider) spider;
6 return ajaxSpider.getData().getDataList("data.hoverURL");
7 };
8
9
爬取代码
<p>1 /**
2 * 抓取百度图片搜索
3 */
4 @Test
5 public void testPt(){
6 String image = "https://image.baidu.com/search/acjson?";
7 //搜索的关键字
8 String queryWords = "米老鼠";
9 // 参数
10 Map parms = new HashMap();
11 parms.put("tn", "resultjson_com");
12 parms.put("ipn", "rj");
13 parms.put("ct", "201326592");
14 parms.put("is", "");
15 parms.put("fp", "result");
16 parms.put("queryWord", queryWords);
17 parms.put("cl", "2");
18 parms.put("lm", "-1");
19 parms.put("ie", "utf-8");
20 parms.put("oe", "utf-8");
21 parms.put("adpicid", "");
22 parms.put("st", "-1");
23 parms.put("z", "");
24 parms.put("ic", "0");
25 parms.put("hd", "");
26 parms.put("latest", "");
27 parms.put("copyright", "");
28 parms.put("word", queryWords);
29 parms.put("s", "");
30 parms.put("se", "");
31 parms.put("tab", "");
32 parms.put("width", "");
33 parms.put("height", "");
34 parms.put("face", "0");
35 parms.put("istype", "2");
36 parms.put("qc", "");
37 parms.put("nc", "1");
38 parms.put("fr", "");
39 parms.put("expermode", "");
40 parms.put("rn", "30");
41 parms.put("gsm", "");
42 parms.put(String.valueOf(System.currentTimeMillis()),"");
43 for (int i = 0; i
网页爬虫抓取百度图片(Python爬虫抓取csdn博客+C和Ctrl+V)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-06 06:12
Python爬虫csdn博客
昨晚为了把某csdn大佬的博文全部下载保存,写了一个爬虫自动抓取文章保存为txt文本,当然也可以保存为html网页。这样Ctrl+C和Ctrl+V都可以用,很方便,抓取其他网站也差不多。
为了解析爬取的网页,使用了第三方模块BeautifulSoup。这个模块对于解析 html 文件非常有用。当然也可以使用正则表达式自己解析,但是比较麻烦。
由于csdn网站的robots.txt文件显示禁止任何爬虫,所以爬虫必须伪装成浏览器,不能频繁爬取。如果他们睡一会儿,他们就会被封锁。 ,但可以使用代理ip。
<p>#-*- encoding: utf-8 -*-
'''
Created on 2014-09-18 21:10:39
@author: Mangoer
@email: 2395528746@qq.com
'''
import urllib2
import re
from bs4 import BeautifulSoup
import random
import time
class CSDN_Blog_Spider:
def __init__(self,url):
print '\n'
print('已启动网络爬虫。。。')
print '网页地址: ' + url
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
# use proxy ip
# ips_list = ['60.220.204.2:63000','123.150.92.91:80','121.248.150.107:8080','61.185.21.175:8080','222.216.109.114:3128','118.144.54.190:8118',
# '1.50.235.82:80','203.80.144.4:80']
# ip = random.choice(ips_list)
# print '使用的代理ip地址: ' + ip
# proxy_support = urllib2.ProxyHandler({'http':'http://'+ip})
# opener = urllib2.build_opener(proxy_support)
# urllib2.install_opener(opener)
agent = random.choice(user_agents)
req = urllib2.Request(url)
req.add_header('User-Agent',agent)
req.add_header('Host','blog.csdn.net')
req.add_header('Accept','*/*')
req.add_header('Referer','http://blog.csdn.net/mangoer_ys?viewmode=list')
req.add_header('GET',url)
html = urllib2.urlopen(req)
page = html.read().decode('gbk','ignore').encode('utf-8')
self.page = page
self.title = self.getTitle()
self.content = self.getContent()
self.saveFile()
def printInfo(self):
print('文章标题是: '+self.title + '\n')
print('内容已经存储到out.txt文件中!')
def getTitle(self):
rex = re.compile('(.*?)',re.DOTALL)
match = rex.search(self.page)
if match:
return match.group(1)
return 'NO TITLE'
def getContent(self):
bs = BeautifulSoup(self.page)
html_content_list = bs.findAll('div',{'id':'article_content','class':'article_content'})
html_content = str(html_content_list[0])
rex_p = re.compile(r'(?:.*?)>(.*?) 查看全部
网页爬虫抓取百度图片(Python爬虫抓取csdn博客+C和Ctrl+V)
Python爬虫csdn博客
昨晚为了把某csdn大佬的博文全部下载保存,写了一个爬虫自动抓取文章保存为txt文本,当然也可以保存为html网页。这样Ctrl+C和Ctrl+V都可以用,很方便,抓取其他网站也差不多。
为了解析爬取的网页,使用了第三方模块BeautifulSoup。这个模块对于解析 html 文件非常有用。当然也可以使用正则表达式自己解析,但是比较麻烦。
由于csdn网站的robots.txt文件显示禁止任何爬虫,所以爬虫必须伪装成浏览器,不能频繁爬取。如果他们睡一会儿,他们就会被封锁。 ,但可以使用代理ip。
<p>#-*- encoding: utf-8 -*-
'''
Created on 2014-09-18 21:10:39
@author: Mangoer
@email: 2395528746@qq.com
'''
import urllib2
import re
from bs4 import BeautifulSoup
import random
import time
class CSDN_Blog_Spider:
def __init__(self,url):
print '\n'
print('已启动网络爬虫。。。')
print '网页地址: ' + url
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
# use proxy ip
# ips_list = ['60.220.204.2:63000','123.150.92.91:80','121.248.150.107:8080','61.185.21.175:8080','222.216.109.114:3128','118.144.54.190:8118',
# '1.50.235.82:80','203.80.144.4:80']
# ip = random.choice(ips_list)
# print '使用的代理ip地址: ' + ip
# proxy_support = urllib2.ProxyHandler({'http':'http://'+ip})
# opener = urllib2.build_opener(proxy_support)
# urllib2.install_opener(opener)
agent = random.choice(user_agents)
req = urllib2.Request(url)
req.add_header('User-Agent',agent)
req.add_header('Host','blog.csdn.net')
req.add_header('Accept','*/*')
req.add_header('Referer','http://blog.csdn.net/mangoer_ys?viewmode=list')
req.add_header('GET',url)
html = urllib2.urlopen(req)
page = html.read().decode('gbk','ignore').encode('utf-8')
self.page = page
self.title = self.getTitle()
self.content = self.getContent()
self.saveFile()
def printInfo(self):
print('文章标题是: '+self.title + '\n')
print('内容已经存储到out.txt文件中!')
def getTitle(self):
rex = re.compile('(.*?)',re.DOTALL)
match = rex.search(self.page)
if match:
return match.group(1)
return 'NO TITLE'
def getContent(self):
bs = BeautifulSoup(self.page)
html_content_list = bs.findAll('div',{'id':'article_content','class':'article_content'})
html_content = str(html_content_list[0])
rex_p = re.compile(r'(?:.*?)>(.*?)
网页爬虫抓取百度图片(简要的实现Python爬虫爬取百度贴吧页面上的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-05 22:07
Python爬虫爬取百度贴吧页面图片的简单实现,下面这个网页就是本博客要爬取的网页,当然你看到的只是图片的一部分,也就是要爬取的页面被爬行,
下图是最终爬取的图片:
接下来简单说一下爬取的全过程:
首先,你需要一个好的编程工具。博主使用的是他们觉得更容易使用的 Pycharm 工具。这是Pycharm官网下载的下载地址。您可以根据自己的电脑配置下载。是的,网上还有很多,可以参考。
下一步是编写爬虫代码。先不说代码:
<p>import urllib.request
import re
import os
''' 这是需要引入的三个文件包 '''
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'mozilla/5.0 (windows nt 6.3; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/65.0.3325.181 safari/537.36')
'''User_Ahent是爬虫所需要模拟浏览器访问所需要的一些标识信息,如浏览器类型,操作系统等'''
page = urllib.request.urlopen(req)
html = page.read().decode('utf-8')
return html
def get_img(html):
p = r' 查看全部
网页爬虫抓取百度图片(简要的实现Python爬虫爬取百度贴吧页面上的图片)
Python爬虫爬取百度贴吧页面图片的简单实现,下面这个网页就是本博客要爬取的网页,当然你看到的只是图片的一部分,也就是要爬取的页面被爬行,
下图是最终爬取的图片:
接下来简单说一下爬取的全过程:
首先,你需要一个好的编程工具。博主使用的是他们觉得更容易使用的 Pycharm 工具。这是Pycharm官网下载的下载地址。您可以根据自己的电脑配置下载。是的,网上还有很多,可以参考。
下一步是编写爬虫代码。先不说代码:
<p>import urllib.request
import re
import os
''' 这是需要引入的三个文件包 '''
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'mozilla/5.0 (windows nt 6.3; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/65.0.3325.181 safari/537.36')
'''User_Ahent是爬虫所需要模拟浏览器访问所需要的一些标识信息,如浏览器类型,操作系统等'''
page = urllib.request.urlopen(req)
html = page.read().decode('utf-8')
return html
def get_img(html):
p = r'
网页爬虫抓取百度图片(【干货】网页的壁纸都爬取了,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-05 04:12
前言
我想每个人都更喜欢漂亮的照片!不要隐瞒任何事情,每个人都知道对美丽的热爱。小编最近也比较无聊,就去爬壁纸、图片等。所以我添加了一些代码来抓取整个网页的所有壁纸。
目录 1:概述
在电脑上,创建一个文件夹,用来存放爬到对方桌面的图片
这个文件夹下有25个文件夹,对应分类
每个分类文件夹下有几个文件夹,对应页码
在页码文件夹下,存放图片文件
目录二:环境准备
在终端中分别输入以下 pip 命令进行安装
python -m pip install beautifulsoup4
python -m pip install lxml
python -m pip install requests
内容三:分析页面结构
4k类别下的壁纸是网站收入的重要资源,我们对4k壁纸有需求,所以不抓取
我用审美类下的壁纸来讲解下如何爬取图片
1.一共73页,除了最后一页,每页18张图片
但是在代码中,我们最好需要自动获取总页码,嗯,对方桌面壁纸网站的结构真的很舒服,基本上每个页码的html结构都差不多
CSS选择器:div.page a,定位到包裹页数的a标签,只有6个
并且每页第三张图片是同一个广告,需要在代码中过滤掉
每个分页的超链接清晰:/weimei/index_x.htm
x 正是页面的页码
注意:您在类别下看到的图片是低分辨率的缩略图;要得到分辨率为1920×1080的图片,需要进行两次跳转
下图是一个例子
在分类页面中,我们可以直接获取图片的url,但遗憾的是,它的分辨率并不理想;
通过检查,很明显类别页面中显示的每个图像都指向另一个超链接
CSS选择器:div#main div.list ul li a,定位到包裹图片的a标签
点击图片,第一次跳转,跳转到新链接,页面显示如下内容:
CSS选择器:div#main div.endpage div.pic div.pic-down a,找到包裹图片的a标签
点击按钮下载壁纸(1920×1080),第二次跳转,转向新链接,最终达到目的,链接中显示的图片分辨率为1920×1080
几经周折,终于为我找到了图片的1920×1080高清图
CSS选择器:div#main table a img,定位图片的img标签
经过我自己的爬虫检查,很少有图片因为很多碎片问题而无法下载,还有少数图片是因为网站虽然提供了1920×1080分辨率的下载按钮,但还是给了其他决议。
目录4:代码分析
第一步:设置全局变量
index = 'http://www.netbian.com' # 网站根地址
interval = 10 # 爬取图片的间隔时间
firstDir = 'D:/zgh/Pictures/netbian' # 总路径
classificationDict = {} # 存放网站分类子页面的信息
第二步:获取页面过滤后的内容列表
def screen(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers()) # 随机获取一个headers
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)
第三步:获取所有类别的 URL
# 将分类子页面信息存放在字典中
def init_classification():
url = index
select = '#header > div.head > ul > li:nth-child(1) > div > a'
classifications = screen(url, select)
for c in classifications:
href = c.get('href') # 获取的是相对地址
text = c.string # 获取分类名
if(text == '4k壁纸'): # 4k壁纸,因权限问题无法爬取,直接跳过
continue
secondDir = firstDir + '/' + text # 分类目录
url = index + href # 分类子页面url
global classificationDict
classificationDict[text] = {
'path': secondDir,
'url': url
}
在接下来的代码中,我将使用审美类别下的壁纸来讲解如何通过两次跳转链接爬取高清图片
第四步:获取分类页面下所有页面的url
大多数类别的分页大于等于6页,可以直接使用上面定义的screen函数,select定义为div.page a,然后screen函数返回的列表中的第六个元素可以得到最后一个我们需要的页码
但是,有些类别的页数少于 6 页,例如:
您需要重写一个过滤器函数以通过兄弟元素获取它
# 获取页码
def screenPage(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers())
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)[0].next_sibling.text
获取分类页面下所有分页的url
url = 'http://www.netbian.com/weimei/'
select = '#main > div.page > span.slh'
pageIndex = screenPage(secondUrl, select)
lastPagenum = int(pageIndex) # 获取最后一页的页码
for i in range(lastPagenum):
if i == 0:
url = 'http://www.netbian.com/weimei/index.htm'
else:
url = 'http://www.netbian.com/weimei/ ... 39%3B %(i+1)
由于网站的HTML结构非常清晰,代码写起来也很简单
第五步:获取分页下图片指向的URL
通过查看可以看到获取到的url是相对地址,需要转换成绝对地址
select = 'div#main div.list ul li a'
imgUrls = screen(url, select)
这两行代码得到的列表中的值是这样的:
星空 女孩 观望 唯美夜景壁纸
第 6 步:找到 1920 × 1080 分辨率的图像
# 定位到 1920 1080 分辨率图片
def handleImgs(links, path):
for link in links:
href = link.get('href')
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
# 第一次跳转
if('http://' in href): # 有极个别图片不提供正确的相对地址
url = href
else:
url = index + href
select = 'div#main div.endpage div.pic div.pic-down a'
link = screen(url, select)
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
href = link[0].get('href')
# 第二次跳转
url = index + href
# 获取到图片了
select = 'div#main table a img'
link = screen(url, select)
if(link == []):
print(url + " 该图片需要登录才能爬取,爬取失败")
continue
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
print(name) # 输出下载图片的文件名
src = link[0].get('src')
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
print()
download(src, name, path)
time.sleep(interval)
第 7 步:下载图像
# 下载操作
def download(src, name, path):
if(isinstance(src, str)):
response = requests.get(src)
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
with open(path,'wb') as pic:
for chunk in response.iter_content(128):
pic.write(chunk)
目录五:代码容错
1:过滤图片广告
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
二:第一次跳转到页面,没有我们需要的链接
对方壁纸网站,给第一个跳转页面的链接一个相对地址
但是很少有图片直接给出绝对地址,并且给出类别URL,所以需要分两步处理
if('http://' in href):
url = href
else:
url = index + href
...
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
以下是第二次跳转页面遇到的问题
三:由于权限问题无法爬取图片
if(link == []):
print(url + "该图片需要登录才能爬取,爬取失败")
continue
四:获取img的alt作为下载的图片文件的文件名,名称中带有\t或者文件名中不允许出现的特殊字符:
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
五:获取img的alt作为下载的图片文件的文件名,名称重复
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
六:图片链接404
例如
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
目录 6:完整代码
最后
动动你的小手发财,给小编一份关心是小编最大的动力,谢谢! 查看全部
网页爬虫抓取百度图片(【干货】网页的壁纸都爬取了,你知道吗?)
前言
我想每个人都更喜欢漂亮的照片!不要隐瞒任何事情,每个人都知道对美丽的热爱。小编最近也比较无聊,就去爬壁纸、图片等。所以我添加了一些代码来抓取整个网页的所有壁纸。
目录 1:概述
在电脑上,创建一个文件夹,用来存放爬到对方桌面的图片
这个文件夹下有25个文件夹,对应分类
每个分类文件夹下有几个文件夹,对应页码
在页码文件夹下,存放图片文件
目录二:环境准备
在终端中分别输入以下 pip 命令进行安装
python -m pip install beautifulsoup4
python -m pip install lxml
python -m pip install requests
内容三:分析页面结构
4k类别下的壁纸是网站收入的重要资源,我们对4k壁纸有需求,所以不抓取
我用审美类下的壁纸来讲解下如何爬取图片
1.一共73页,除了最后一页,每页18张图片
但是在代码中,我们最好需要自动获取总页码,嗯,对方桌面壁纸网站的结构真的很舒服,基本上每个页码的html结构都差不多
CSS选择器:div.page a,定位到包裹页数的a标签,只有6个
并且每页第三张图片是同一个广告,需要在代码中过滤掉
每个分页的超链接清晰:/weimei/index_x.htm
x 正是页面的页码
注意:您在类别下看到的图片是低分辨率的缩略图;要得到分辨率为1920×1080的图片,需要进行两次跳转
下图是一个例子
在分类页面中,我们可以直接获取图片的url,但遗憾的是,它的分辨率并不理想;
通过检查,很明显类别页面中显示的每个图像都指向另一个超链接
CSS选择器:div#main div.list ul li a,定位到包裹图片的a标签
点击图片,第一次跳转,跳转到新链接,页面显示如下内容:
CSS选择器:div#main div.endpage div.pic div.pic-down a,找到包裹图片的a标签
点击按钮下载壁纸(1920×1080),第二次跳转,转向新链接,最终达到目的,链接中显示的图片分辨率为1920×1080
几经周折,终于为我找到了图片的1920×1080高清图
CSS选择器:div#main table a img,定位图片的img标签
经过我自己的爬虫检查,很少有图片因为很多碎片问题而无法下载,还有少数图片是因为网站虽然提供了1920×1080分辨率的下载按钮,但还是给了其他决议。
目录4:代码分析
第一步:设置全局变量
index = 'http://www.netbian.com' # 网站根地址
interval = 10 # 爬取图片的间隔时间
firstDir = 'D:/zgh/Pictures/netbian' # 总路径
classificationDict = {} # 存放网站分类子页面的信息
第二步:获取页面过滤后的内容列表
def screen(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers()) # 随机获取一个headers
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)
第三步:获取所有类别的 URL
# 将分类子页面信息存放在字典中
def init_classification():
url = index
select = '#header > div.head > ul > li:nth-child(1) > div > a'
classifications = screen(url, select)
for c in classifications:
href = c.get('href') # 获取的是相对地址
text = c.string # 获取分类名
if(text == '4k壁纸'): # 4k壁纸,因权限问题无法爬取,直接跳过
continue
secondDir = firstDir + '/' + text # 分类目录
url = index + href # 分类子页面url
global classificationDict
classificationDict[text] = {
'path': secondDir,
'url': url
}
在接下来的代码中,我将使用审美类别下的壁纸来讲解如何通过两次跳转链接爬取高清图片
第四步:获取分类页面下所有页面的url
大多数类别的分页大于等于6页,可以直接使用上面定义的screen函数,select定义为div.page a,然后screen函数返回的列表中的第六个元素可以得到最后一个我们需要的页码
但是,有些类别的页数少于 6 页,例如:
您需要重写一个过滤器函数以通过兄弟元素获取它
# 获取页码
def screenPage(url, select):
html = requests.get(url = url, headers = UserAgent.get_headers())
html.encoding = 'gbk'
html = html.text
soup = BeautifulSoup(html, 'lxml')
return soup.select(select)[0].next_sibling.text
获取分类页面下所有分页的url
url = 'http://www.netbian.com/weimei/'
select = '#main > div.page > span.slh'
pageIndex = screenPage(secondUrl, select)
lastPagenum = int(pageIndex) # 获取最后一页的页码
for i in range(lastPagenum):
if i == 0:
url = 'http://www.netbian.com/weimei/index.htm'
else:
url = 'http://www.netbian.com/weimei/ ... 39%3B %(i+1)
由于网站的HTML结构非常清晰,代码写起来也很简单
第五步:获取分页下图片指向的URL
通过查看可以看到获取到的url是相对地址,需要转换成绝对地址
select = 'div#main div.list ul li a'
imgUrls = screen(url, select)
这两行代码得到的列表中的值是这样的:
星空 女孩 观望 唯美夜景壁纸第 6 步:找到 1920 × 1080 分辨率的图像
# 定位到 1920 1080 分辨率图片
def handleImgs(links, path):
for link in links:
href = link.get('href')
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
# 第一次跳转
if('http://' in href): # 有极个别图片不提供正确的相对地址
url = href
else:
url = index + href
select = 'div#main div.endpage div.pic div.pic-down a'
link = screen(url, select)
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
href = link[0].get('href')
# 第二次跳转
url = index + href
# 获取到图片了
select = 'div#main table a img'
link = screen(url, select)
if(link == []):
print(url + " 该图片需要登录才能爬取,爬取失败")
continue
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
print(name) # 输出下载图片的文件名
src = link[0].get('src')
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
print()
download(src, name, path)
time.sleep(interval)
第 7 步:下载图像
# 下载操作
def download(src, name, path):
if(isinstance(src, str)):
response = requests.get(src)
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
with open(path,'wb') as pic:
for chunk in response.iter_content(128):
pic.write(chunk)
目录五:代码容错
1:过滤图片广告
if(href == 'http://pic.netbian.com/'): # 过滤图片广告
continue
二:第一次跳转到页面,没有我们需要的链接
对方壁纸网站,给第一个跳转页面的链接一个相对地址
但是很少有图片直接给出绝对地址,并且给出类别URL,所以需要分两步处理
if('http://' in href):
url = href
else:
url = index + href
...
if(link == []):
print(url + ' 无此图片,爬取失败')
continue
以下是第二次跳转页面遇到的问题
三:由于权限问题无法爬取图片
if(link == []):
print(url + "该图片需要登录才能爬取,爬取失败")
continue
四:获取img的alt作为下载的图片文件的文件名,名称中带有\t或者文件名中不允许出现的特殊字符:
name = link[0].get('alt').replace('\t', '').replace('|', '').replace(':', '').replace('\\', '').replace('/', '').replace('*', '').replace('?', '').replace('"', '').replace('', '')
五:获取img的alt作为下载的图片文件的文件名,名称重复
path = path + '/' + name + '.jpg'
while(os.path.exists(path)): # 若文件名重复
path = path.split(".")[0] + str(random.randint(2, 17)) + '.' + path.split(".")[1]
六:图片链接404
例如
if(requests.get(src).status_code == 404):
print(url + ' 该图片下载链接404,爬取失败')
print()
continue
目录 6:完整代码
最后
动动你的小手发财,给小编一份关心是小编最大的动力,谢谢!
网页爬虫抓取百度图片(猫评论信息和图片下载的二合一升级版() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-04 19:07
)
之前我做过天猫评论信息抓取,还有评论图片下载,但是那一次我把所有的信息都存到数据库里,然后从数据库中提取图片信息下载。这次我做了信息爬取和图片下载二合一升级版。
这一次,我们瞄准的是京东nike自营店。
链接是:
老办法,按F12打开流量监控,点击网络中的js,然后在众多信息中找到存放评论信息的链接,如下:
我找到的最后一个链接如下所示:
打开链接后发现也是json格式的,很简单
先用urllib.request打开链接,然后用json加载json文件,代码如下:
url='https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
jsondata = re.search(r'\{.*\}', html).group()
data = json.loads(jsondata)
这里使用正则是因为打开html后发现是这样的:
我们需要的json格式文件放在那个()里面。
得到json格式的数据后,需要对数据进行过滤。我把用户名和评论等一些信息放入数据库,图片立即下载
先写一个循环遍历当前url中的所有评论内容,部分代码如下:
for i in range(0, len(data['comments'])):
id = data['comments'][i]['nickname']
# 用户名
content = data['comments'][i]['content']
# 评论
time = data['comments'][i]['creationTime']
# 评论日期
type = data['comments'][i]['referenceName']
# 型号及颜色
在爬取图片链接下载的时候,因为有些评论没有图片,所以需要判断key是否存在。
if('images' in data['comments'][i].keys()):
如果存在,请获取图片链接,完成链接并下载:
pics = data['comments'][i]['images'][k]['imgUrl']
a='http:'+pics
urllib.request.urlretrieve(a, 'D:\jd_pics/' + str(z)+'_'+str(i+1) + '_' + 'pic' + '_' + str(k) + '.jpg')
# 买家秀,命名规则:第几页第几条评论的第几个图片
对于后续审稿的爬取,大体思路同上,这里不再赘述。
最后就是考虑循环抓取了,只要写个循环就可以了
for j in range(0,150):
url='https://sclub.jd.com/comment/p ... 2Bstr(j)+'&pageSize=10&isShadowSku=0&fold=1'
我在这里尝试抓取前150页评论的内容,因为我要边抓取边下载图片,所以需要很长时间。我花了大约25分钟,终于在数据库中得到了1000条信息
和本地1216图片
呵呵~这不对,150页每页10条信息,总数应该是1500!为什么我的数据库中只有 1000 个条目?
我去百度了一下,一位前辈是这样解释的:
“在 MySQL 中,每个数据库最多可以创建 20 亿个表,一个表允许定义 1024 列,每行最大长度为 8092 字节(不包括文本和图像类型的长度)。
当表定义为 varchar、nvarchar 或 varbinary 类型列时,如果插入表中的数据行超过 8092 字节,则 Transact-SQL 语句将失败并生成错误消息。
SQL对每张表的行数没有直接限制,但受数据库存储空间的限制。
每个数据库的最大空间是1048516TB,所以一个表的最大可用空间是1048516TB减去数据库类系统表和其他数据库对象占用的空间。"
也就是说,一个数据库的容量肯定是够用的,那剩下的 500 条记录到哪里去了呢?
找了半天,发现navicat for mysql有分页功能,自动帮我分页
oh~傻哭自己
我是学生,刚开始学习python爬虫。如果本文和代码有漏洞,还望各位大神赐教,谢谢!
查看全部
网页爬虫抓取百度图片(猫评论信息和图片下载的二合一升级版()
)
之前我做过天猫评论信息抓取,还有评论图片下载,但是那一次我把所有的信息都存到数据库里,然后从数据库中提取图片信息下载。这次我做了信息爬取和图片下载二合一升级版。
这一次,我们瞄准的是京东nike自营店。
链接是:
老办法,按F12打开流量监控,点击网络中的js,然后在众多信息中找到存放评论信息的链接,如下:
我找到的最后一个链接如下所示:
打开链接后发现也是json格式的,很简单
先用urllib.request打开链接,然后用json加载json文件,代码如下:
url='https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
jsondata = re.search(r'\{.*\}', html).group()
data = json.loads(jsondata)
这里使用正则是因为打开html后发现是这样的:
我们需要的json格式文件放在那个()里面。
得到json格式的数据后,需要对数据进行过滤。我把用户名和评论等一些信息放入数据库,图片立即下载
先写一个循环遍历当前url中的所有评论内容,部分代码如下:
for i in range(0, len(data['comments'])):
id = data['comments'][i]['nickname']
# 用户名
content = data['comments'][i]['content']
# 评论
time = data['comments'][i]['creationTime']
# 评论日期
type = data['comments'][i]['referenceName']
# 型号及颜色
在爬取图片链接下载的时候,因为有些评论没有图片,所以需要判断key是否存在。
if('images' in data['comments'][i].keys()):
如果存在,请获取图片链接,完成链接并下载:
pics = data['comments'][i]['images'][k]['imgUrl']
a='http:'+pics
urllib.request.urlretrieve(a, 'D:\jd_pics/' + str(z)+'_'+str(i+1) + '_' + 'pic' + '_' + str(k) + '.jpg')
# 买家秀,命名规则:第几页第几条评论的第几个图片
对于后续审稿的爬取,大体思路同上,这里不再赘述。
最后就是考虑循环抓取了,只要写个循环就可以了
for j in range(0,150):
url='https://sclub.jd.com/comment/p ... 2Bstr(j)+'&pageSize=10&isShadowSku=0&fold=1'
我在这里尝试抓取前150页评论的内容,因为我要边抓取边下载图片,所以需要很长时间。我花了大约25分钟,终于在数据库中得到了1000条信息
和本地1216图片
呵呵~这不对,150页每页10条信息,总数应该是1500!为什么我的数据库中只有 1000 个条目?
我去百度了一下,一位前辈是这样解释的:
“在 MySQL 中,每个数据库最多可以创建 20 亿个表,一个表允许定义 1024 列,每行最大长度为 8092 字节(不包括文本和图像类型的长度)。
当表定义为 varchar、nvarchar 或 varbinary 类型列时,如果插入表中的数据行超过 8092 字节,则 Transact-SQL 语句将失败并生成错误消息。
SQL对每张表的行数没有直接限制,但受数据库存储空间的限制。
每个数据库的最大空间是1048516TB,所以一个表的最大可用空间是1048516TB减去数据库类系统表和其他数据库对象占用的空间。"
也就是说,一个数据库的容量肯定是够用的,那剩下的 500 条记录到哪里去了呢?
找了半天,发现navicat for mysql有分页功能,自动帮我分页
oh~傻哭自己
我是学生,刚开始学习python爬虫。如果本文和代码有漏洞,还望各位大神赐教,谢谢!
网页爬虫抓取百度图片(大数据技术被用于各行各业,一切都是有不同的处理方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-04 07:17
大数据技术现在应用在各行各业,回归、SVM、神经网络、文本分析……各种真棒的模拟和预测,但没有数据,一切都是空谈!许多人使用爬虫来采集网页信息。问题是爬下来的数据有什么用。这取决于个人的能力。对于同样的数据,不同的人会有不同的处理方式,会导致不同的结果。下面为您介绍一些典型的应用场景:
1、电子商务网站的产品数据
爬取了某个行业的产品信息,包括品牌、价格、销量、规格型号等。然后分析该行业的畅销品牌、畅销品类、价格趋势、行业前景等。信息量还是很大的。
2、微博/BBS舆情数据
针对某个话题,从微博和论坛中抓取相关信息,挖掘该话题的一些有趣的舆情信息。事实上,利用爬虫进行舆情监测是比较成熟的,很多大公司都有相关的监测部门。但是微博的反爬机制比较麻烦,部分数据采集不完整。
3、新闻正文
新闻文字其实是一种舆论,但比微博上的文字更正式。在百度新闻上爬取某个关键词的信息,每周梳理几条关键词,可以掌握行业动态。
4、学术信息
抓取一些关于学术网站 的信息以供学习和研究。比如在CNKI上,如果你输入一个关键词,比如大数据,就会出现很多与大数据相关的文献。
点击进入,会有每个文档的基本信息、摘要等信息。如果你是研究人员或学生,点击并一一记录下来太费时间了。写一个爬虫,你可以按照标准格式爬取所有的数据,然后阅读和进一步分析就会方便很多。. 使用 GooSeeker 爬虫可以轻松地采集 批量下载此类网页。 查看全部
网页爬虫抓取百度图片(大数据技术被用于各行各业,一切都是有不同的处理方式)
大数据技术现在应用在各行各业,回归、SVM、神经网络、文本分析……各种真棒的模拟和预测,但没有数据,一切都是空谈!许多人使用爬虫来采集网页信息。问题是爬下来的数据有什么用。这取决于个人的能力。对于同样的数据,不同的人会有不同的处理方式,会导致不同的结果。下面为您介绍一些典型的应用场景:
1、电子商务网站的产品数据
爬取了某个行业的产品信息,包括品牌、价格、销量、规格型号等。然后分析该行业的畅销品牌、畅销品类、价格趋势、行业前景等。信息量还是很大的。
2、微博/BBS舆情数据
针对某个话题,从微博和论坛中抓取相关信息,挖掘该话题的一些有趣的舆情信息。事实上,利用爬虫进行舆情监测是比较成熟的,很多大公司都有相关的监测部门。但是微博的反爬机制比较麻烦,部分数据采集不完整。
3、新闻正文
新闻文字其实是一种舆论,但比微博上的文字更正式。在百度新闻上爬取某个关键词的信息,每周梳理几条关键词,可以掌握行业动态。
4、学术信息
抓取一些关于学术网站 的信息以供学习和研究。比如在CNKI上,如果你输入一个关键词,比如大数据,就会出现很多与大数据相关的文献。
点击进入,会有每个文档的基本信息、摘要等信息。如果你是研究人员或学生,点击并一一记录下来太费时间了。写一个爬虫,你可以按照标准格式爬取所有的数据,然后阅读和进一步分析就会方便很多。. 使用 GooSeeker 爬虫可以轻松地采集 批量下载此类网页。
网页爬虫抓取百度图片(网站一般如何实现图片懒技术呢?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-03 14:05
关键词:
逆流而上,用力撑着它,一分一毫的懈怠,它就退却了万千搜索。本文章主要介绍了python网络爬虫的图片懒加载技术selenium和PhantomJS相关的知识,希望对大家有所帮助。
一.什么是图片延迟加载?
- 案例研究:抓取站长素材中的图片数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘)
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
运行结果观察我们可以得到图片的名字,但是得到的链接是空的。检查后发现xpath表达式没有问题。是什么原因?
- 图片延迟加载概念:
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在被请求的时候会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端的配合,图片只有出现在浏览器当前窗口时才加载,减少首屏图片请求次数的技术称为“图片懒加载” ”。
- 网站一般如何实现延迟图片加载技术?
在网页的源码中,首先在img标签中使用了一个“伪属性”(通常是src2,original...)来存储真实的图片链接,而不是直接存储在src属性中。当图片出现在页面可视区域时,伪属性会被动态替换为src属性,完成图片的加载。
- 站长素材案例后续分析:仔细观察页面结构后发现,网页中图片的链接存放在伪属性src2中
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘2) #src2伪属性
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
二.硒
- 什么是硒?
它是 Python 的第三方库。外部提供的界面可以操作浏览器,然后让浏览器完成自动操作。
- 环境建设
1.安装硒:pip install selenium
2.获取浏览器驱动(以谷歌浏览器为例)
2.1 谷歌浏览器驱动下载地址:
2.2 下载的驱动必须和浏览器版本一致。可以根据提供的版本映射表进行映射
- 效果展示:可以运行以下代码观看效果
from selenium import webdriver
from time import sleep
# 后面是你的浏览器驱动位置,记得前面加r‘‘,‘r‘是防止字符转义的
driver = webdriver.Chrome(r‘驱动程序路径‘)
# 用get打开百度页面
driver.get("http://www.baidu.com")
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text(‘设置‘)[0].click()
sleep(2)
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text(‘搜索设置‘)[0].click()
sleep(2)
# 选中每页显示50条
m = driver.find_element_by_id(‘nr‘)
sleep(2)
m.find_element_by_xpath(‘//*[@id="nr"]/option[3]‘).click()
m.find_element_by_xpath(‘.//option[3]‘).click()
sleep(2)
# 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2)
# 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to_alert().accept()
sleep(2)
# 找到百度的输入框,并输入 美女
driver.find_element_by_id(‘kw‘).send_keys(‘美女‘)
sleep(2)
# 点击搜索按钮
driver.find_element_by_id(‘su‘).click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text(‘美女_百度图片‘)[0].click()
sleep(3)
# 关闭浏览器
driver.quit()
- 代码操作:
#导包
from selenium import webdriver
#创建浏览器对象,通过该对象可以操作浏览器
browser = webdriver.Chrome(‘驱动路径‘)
#使用浏览器发起指定请求
browser.get(url)
#使用下面的方法,查找指定的元素进行操作即可
find_element_by_id 根据id找节点
find_elements_by_name 根据name找
find_elements_by_xpath 根据xpath查找
find_elements_by_tag_name 根据标签名找
find_elements_by_class_name 根据class名字查找
三.幻影JS
PhantomJS 是一款非界面浏览器,其自动化操作过程与上述谷歌浏览器的操作一致。由于没有界面,为了能够展示自动化的操作过程,PhantomJS为用户提供了截图功能,使用save_screenshot函数实现。
-案子:
from selenium import webdriver
import time
# phantomjs路径
path = r‘PhantomJS驱动路径‘
browser = webdriver.PhantomJS(path)
# 打开百度
url = ‘http://www.baidu.com/‘
browser.get(url)
time.sleep(3)
browser.save_screenshot(r‘phantomjsaidu.png‘)
# 查找input输入框
my_input = browser.find_element_by_id(‘kw‘)
# 往框里面写文字
my_input.send_keys(‘美女‘)
time.sleep(3)
#截屏
browser.save_screenshot(r‘phantomjsmeinv.png‘)
# 查找搜索按钮
button = browser.find_elements_by_class_name(‘s_btn‘)[0]
button.click()
time.sleep(3)
browser.save_screenshot(r‘phantomjsshow.png‘)
time.sleep(3)
browser.quit()
【重点】selenium+phantomjs是爬虫的终极解决方案:网站上的一些内容信息是通过动态加载js形成的,所以使用普通爬虫程序无法回到动态加载的js内容。例如,豆瓣电影中的电影信息是通过下拉操作动态加载更多电影信息的。
综合操作:
- 要求:尽可能多地在豆瓣上爬取电影信息
from selenium import webdriver
from time import sleep
import time
if __name__ == ‘__main__‘:
url = ‘https://movie.douban.com/typer ... on%3D‘
# 发起请求前,可以让url表示的页面动态加载出更多的数据
path = r‘C:UsersAdministratorDesktop爬虫授课day05ziliaophantomjs-2.1.1-windowsinphantomjs.exe‘
# 创建无界面的浏览器对象
bro = webdriver.PhantomJS(path)
# 发起url请求
bro.get(url)
time.sleep(3)
# 截图
bro.save_screenshot(‘1.png‘)
# 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息))
js = ‘document.body.scrollTop=2000‘
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(4)
bro.save_screenshot(‘2.png‘)
time.sleep(2)
# 使用爬虫程序爬去当前url中的内容
html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html)
with open(‘./source.html‘, ‘w‘, encoding=‘utf-8‘) as fp:
fp.write(html_source)
bro.quit()
四.谷歌无头浏览器
由于 PhantomJs 最近已经停止更新和维护,建议大家使用谷歌的无头浏览器,这是一款没有界面的谷歌浏览器。
1 from selenium import webdriver
2 from selenium.webdriver.chrome.options import Options
3 import time
4
5 # 创建一个参数对象,用来控制chrome以无界面模式打开
6 chrome_options = Options()
7 chrome_options.add_argument(‘--headless‘)
8 chrome_options.add_argument(‘--disable-gpu‘)
9 # 驱动路径
10 path = r‘C:UsersBLiDesktop1801day05ziliaochromedriver.exe‘
11
12 # 创建浏览器对象
13 browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options)
14
15 # 上网
16 url = ‘http://www.baidu.com/‘
17 browser.get(url)
18 time.sleep(3)
19
20 browser.save_screenshot(‘baidu.png‘)
21
22 browser.quit()
至此,这篇关于Python网络爬虫selenium和PhantomJS的懒加载技术的文章就讲完了。如果您的问题无法解决,请参考以下文章: 查看全部
网页爬虫抓取百度图片(网站一般如何实现图片懒技术呢?-八维教育)
关键词:
逆流而上,用力撑着它,一分一毫的懈怠,它就退却了万千搜索。本文章主要介绍了python网络爬虫的图片懒加载技术selenium和PhantomJS相关的知识,希望对大家有所帮助。
一.什么是图片延迟加载?
- 案例研究:抓取站长素材中的图片数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘)
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
运行结果观察我们可以得到图片的名字,但是得到的链接是空的。检查后发现xpath表达式没有问题。是什么原因?
- 图片延迟加载概念:
图片延迟加载是一种网页优化技术。图片作为一种网络资源,在被请求的时候会占用网络资源,一次加载整个页面的所有图片会大大增加页面首屏的加载时间。为了解决这个问题,通过前后端的配合,图片只有出现在浏览器当前窗口时才加载,减少首屏图片请求次数的技术称为“图片懒加载” ”。
- 网站一般如何实现延迟图片加载技术?
在网页的源码中,首先在img标签中使用了一个“伪属性”(通常是src2,original...)来存储真实的图片链接,而不是直接存储在src属性中。当图片出现在页面可视区域时,伪属性会被动态替换为src属性,完成图片的加载。
- 站长素材案例后续分析:仔细观察页面结构后发现,网页中图片的链接存放在伪属性src2中
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
if __name__ == "__main__":
url = ‘http://sc.chinaz.com/tupian/gudianmeinvtupian.html‘
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘,
}
#获取页面文本数据
response = requests.get(url=url,headers=headers)
response.encoding = ‘utf-8‘
page_text = response.text
#解析页面数据(获取页面中的图片链接)
#创建etree对象
tree = etree.HTML(page_text)
div_list = tree.xpath(‘//div[@id="container"]/div‘)
#解析获取图片地址和图片的名称
for div in div_list:
image_url = div.xpath(‘.//img/@src‘2) #src2伪属性
image_name = div.xpath(‘.//img/@alt‘)
print(image_url) #打印图片链接
print(image_name)#打印图片名称
二.硒
- 什么是硒?
它是 Python 的第三方库。外部提供的界面可以操作浏览器,然后让浏览器完成自动操作。
- 环境建设
1.安装硒:pip install selenium
2.获取浏览器驱动(以谷歌浏览器为例)
2.1 谷歌浏览器驱动下载地址:
2.2 下载的驱动必须和浏览器版本一致。可以根据提供的版本映射表进行映射
- 效果展示:可以运行以下代码观看效果
from selenium import webdriver
from time import sleep
# 后面是你的浏览器驱动位置,记得前面加r‘‘,‘r‘是防止字符转义的
driver = webdriver.Chrome(r‘驱动程序路径‘)
# 用get打开百度页面
driver.get("http://www.baidu.com";)
# 查找页面的“设置”选项,并进行点击
driver.find_elements_by_link_text(‘设置‘)[0].click()
sleep(2)
# # 打开设置后找到“搜索设置”选项,设置为每页显示50条
driver.find_elements_by_link_text(‘搜索设置‘)[0].click()
sleep(2)
# 选中每页显示50条
m = driver.find_element_by_id(‘nr‘)
sleep(2)
m.find_element_by_xpath(‘//*[@id="nr"]/option[3]‘).click()
m.find_element_by_xpath(‘.//option[3]‘).click()
sleep(2)
# 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(2)
# 处理弹出的警告页面 确定accept() 和 取消dismiss()
driver.switch_to_alert().accept()
sleep(2)
# 找到百度的输入框,并输入 美女
driver.find_element_by_id(‘kw‘).send_keys(‘美女‘)
sleep(2)
# 点击搜索按钮
driver.find_element_by_id(‘su‘).click()
sleep(2)
# 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面
driver.find_elements_by_link_text(‘美女_百度图片‘)[0].click()
sleep(3)
# 关闭浏览器
driver.quit()
- 代码操作:
#导包
from selenium import webdriver
#创建浏览器对象,通过该对象可以操作浏览器
browser = webdriver.Chrome(‘驱动路径‘)
#使用浏览器发起指定请求
browser.get(url)
#使用下面的方法,查找指定的元素进行操作即可
find_element_by_id 根据id找节点
find_elements_by_name 根据name找
find_elements_by_xpath 根据xpath查找
find_elements_by_tag_name 根据标签名找
find_elements_by_class_name 根据class名字查找
三.幻影JS
PhantomJS 是一款非界面浏览器,其自动化操作过程与上述谷歌浏览器的操作一致。由于没有界面,为了能够展示自动化的操作过程,PhantomJS为用户提供了截图功能,使用save_screenshot函数实现。
-案子:
from selenium import webdriver
import time
# phantomjs路径
path = r‘PhantomJS驱动路径‘
browser = webdriver.PhantomJS(path)
# 打开百度
url = ‘http://www.baidu.com/‘
browser.get(url)
time.sleep(3)
browser.save_screenshot(r‘phantomjsaidu.png‘)
# 查找input输入框
my_input = browser.find_element_by_id(‘kw‘)
# 往框里面写文字
my_input.send_keys(‘美女‘)
time.sleep(3)
#截屏
browser.save_screenshot(r‘phantomjsmeinv.png‘)
# 查找搜索按钮
button = browser.find_elements_by_class_name(‘s_btn‘)[0]
button.click()
time.sleep(3)
browser.save_screenshot(r‘phantomjsshow.png‘)
time.sleep(3)
browser.quit()
【重点】selenium+phantomjs是爬虫的终极解决方案:网站上的一些内容信息是通过动态加载js形成的,所以使用普通爬虫程序无法回到动态加载的js内容。例如,豆瓣电影中的电影信息是通过下拉操作动态加载更多电影信息的。
综合操作:
- 要求:尽可能多地在豆瓣上爬取电影信息
from selenium import webdriver
from time import sleep
import time
if __name__ == ‘__main__‘:
url = ‘https://movie.douban.com/typer ... on%3D‘
# 发起请求前,可以让url表示的页面动态加载出更多的数据
path = r‘C:UsersAdministratorDesktop爬虫授课day05ziliaophantomjs-2.1.1-windowsinphantomjs.exe‘
# 创建无界面的浏览器对象
bro = webdriver.PhantomJS(path)
# 发起url请求
bro.get(url)
time.sleep(3)
# 截图
bro.save_screenshot(‘1.png‘)
# 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息))
js = ‘document.body.scrollTop=2000‘
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(4)
bro.save_screenshot(‘2.png‘)
time.sleep(2)
# 使用爬虫程序爬去当前url中的内容
html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html)
with open(‘./source.html‘, ‘w‘, encoding=‘utf-8‘) as fp:
fp.write(html_source)
bro.quit()
四.谷歌无头浏览器
由于 PhantomJs 最近已经停止更新和维护,建议大家使用谷歌的无头浏览器,这是一款没有界面的谷歌浏览器。
1 from selenium import webdriver
2 from selenium.webdriver.chrome.options import Options
3 import time
4
5 # 创建一个参数对象,用来控制chrome以无界面模式打开
6 chrome_options = Options()
7 chrome_options.add_argument(‘--headless‘)
8 chrome_options.add_argument(‘--disable-gpu‘)
9 # 驱动路径
10 path = r‘C:UsersBLiDesktop1801day05ziliaochromedriver.exe‘
11
12 # 创建浏览器对象
13 browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options)
14
15 # 上网
16 url = ‘http://www.baidu.com/‘
17 browser.get(url)
18 time.sleep(3)
19
20 browser.save_screenshot(‘baidu.png‘)
21
22 browser.quit()
至此,这篇关于Python网络爬虫selenium和PhantomJS的懒加载技术的文章就讲完了。如果您的问题无法解决,请参考以下文章:
网页爬虫抓取百度图片(为什么用Python写爬虫程序:爬虫前奏)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-03 14:01
爬行动物前奏
爬虫实例:
搜索引擎(百度、谷歌、360搜索等)。
伯乐在线。
慧慧购物助理。
数据分析与研究(数据冰山知乎栏目)。
抢票软件等
什么是网络爬虫:
通俗理解:爬虫是模拟人类请求行为的程序网站。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
专业介绍:百度百科。
通用爬虫和焦点爬虫:
万能爬虫:万能爬虫是搜索引擎爬虫系统(百度、谷歌、搜狗等)的重要组成部分。主要是将互联网上的网页下载到本地,形成互联网内容的镜像备份。
Focused crawler:是一种针对特定需求的网络爬虫程序。它与一般爬虫的区别在于:聚焦爬虫在实现网页爬虫时会对内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。.
为什么要用 Python 编写爬虫程序:
PHP:PHP是世界上最好的语言,但他不是天生就干这个的,而且对多线程、异步支持、并发处理能力弱等问题也不是很好。爬虫是一个工具程序,对速度和效率的要求很高。
Java:生态非常完整,是Python爬虫最大的竞争对手。但是Java语言本身很笨重,代码量很大。重构的成本比较高,任何修改都会导致代码的大量变化。爬虫经常需要修改 采集 代码。
C/C++:运行效率无敌。但学习和发展成本很高。写一个小爬虫可能需要半天以上的时间。
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。
准备工具:
Python3.6 开发环境。
Pycharm 2017 专业版。
虚拟环境。虚拟环境/虚拟环境包装器。 查看全部
网页爬虫抓取百度图片(为什么用Python写爬虫程序:爬虫前奏)
爬行动物前奏
爬虫实例:
搜索引擎(百度、谷歌、360搜索等)。
伯乐在线。
慧慧购物助理。
数据分析与研究(数据冰山知乎栏目)。
抢票软件等
什么是网络爬虫:
通俗理解:爬虫是模拟人类请求行为的程序网站。它可以自动请求网页,获取数据,然后使用一定的规则来提取有价值的数据。
专业介绍:百度百科。
通用爬虫和焦点爬虫:
万能爬虫:万能爬虫是搜索引擎爬虫系统(百度、谷歌、搜狗等)的重要组成部分。主要是将互联网上的网页下载到本地,形成互联网内容的镜像备份。
Focused crawler:是一种针对特定需求的网络爬虫程序。它与一般爬虫的区别在于:聚焦爬虫在实现网页爬虫时会对内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。.
为什么要用 Python 编写爬虫程序:
PHP:PHP是世界上最好的语言,但他不是天生就干这个的,而且对多线程、异步支持、并发处理能力弱等问题也不是很好。爬虫是一个工具程序,对速度和效率的要求很高。
Java:生态非常完整,是Python爬虫最大的竞争对手。但是Java语言本身很笨重,代码量很大。重构的成本比较高,任何修改都会导致代码的大量变化。爬虫经常需要修改 采集 代码。
C/C++:运行效率无敌。但学习和发展成本很高。写一个小爬虫可能需要半天以上的时间。
Python:语法优美,代码简洁,开发效率高,支持的模块多。相关的HTTP请求模块和HTML解析模块非常丰富。还有 Scrapy 和 Scrapy-redis 框架,让我们开发爬虫变得非常容易。
准备工具:
Python3.6 开发环境。
Pycharm 2017 专业版。
虚拟环境。虚拟环境/虚拟环境包装器。
网页爬虫抓取百度图片(Pythonampamp//amp管理员;管理员管理员(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-03 08:04
python爬虫BeautifulSoup快速抓取网站图片 Python / Admin 发表于 1 个月前 80
本文介绍BeautifulSoup模块的使用方法和注意事项,帮助您快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的朋友,快点学习吧。关注公众号获取爬虫教程。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接,翻页操作
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第 3 步:编写代码以实现需求
1、导入模块
导入我们需要使用的所有模块。
2、获取列表的标题,以及链接
3、获取类别列表标题、链接和翻页。
4、获取详细图片并保存
知识点总结
学习本文,可以掌握知识点。
1、掌握 BeautifulSoup
区分find和find_all的用法:find,查找第一个返回字符串,find_all查找全部,返回一个列表
区分get和get_text的用法:get获取标签中的属性,get_text获取标签包围的文本。
2、掌握正则,re.findall的使用
3、掌握字符串切片的方式 str[0,-5] 截取第一个文本到倒数第五个文本。
4、掌握创建文件夹的方法os.mkdir(name)
5、掌握with open(f, w) as f的用法:
6、掌握requests模块的get请求方法。 查看全部
网页爬虫抓取百度图片(Pythonampamp//amp管理员;管理员管理员(组图))
python爬虫BeautifulSoup快速抓取网站图片 Python / Admin 发表于 1 个月前 80
本文介绍BeautifulSoup模块的使用方法和注意事项,帮助您快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的朋友,快点学习吧。关注公众号获取爬虫教程。
第一步:了解需求
在开始写作之前,我们需要知道我们将要做什么?做爬行动物。
抢什么?抓取 网站 图像。
去哪里抢?图片之家
可以用这个网站练手,页面比较简单。
第 2 步:分析 网站 因素
我们知道需要抓取哪些网站数据,那么我们来分析一下网站是如何提供数据的。
根据分析,所有页面看起来都一样,所以我们选择一张照片给大家演示一下。
1、获取列表的标题以及链接
进一步研究页面数据,每个页面下面都有一个列表,然后通过列表的标题进入下一层。然后在这个页面上我们需要获取列表标题。
2、获取图片列表,以及链接,翻页操作
3、获取图片详情,所有图片
然后点击继续研究,发现还有更多图片。
分析完毕,我们来写代码。
流程图如下:
第 3 步:编写代码以实现需求
1、导入模块
导入我们需要使用的所有模块。
2、获取列表的标题,以及链接
3、获取类别列表标题、链接和翻页。
4、获取详细图片并保存
知识点总结
学习本文,可以掌握知识点。
1、掌握 BeautifulSoup
区分find和find_all的用法:find,查找第一个返回字符串,find_all查找全部,返回一个列表
区分get和get_text的用法:get获取标签中的属性,get_text获取标签包围的文本。
2、掌握正则,re.findall的使用
3、掌握字符串切片的方式 str[0,-5] 截取第一个文本到倒数第五个文本。
4、掌握创建文件夹的方法os.mkdir(name)
5、掌握with open(f, w) as f的用法:
6、掌握requests模块的get请求方法。
网页爬虫抓取百度图片(爬取今日头条图集,老司机以街拍为例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-02 15:09
今天,我们来爬取今日头条图集。老司机以街拍为例。
操作平台:Windows
Python版本:Python3.6
IDE:崇高文本
其他工具:Chrome浏览器
1、网页分析
从打开今日头条首页,搜索“街拍”,有“综合”、“视频”、“图集”和“用户”四个标签,我们依次点击几个标签,虽然页面变了,但是address bar 的 URL 没有变化,说明页面内容是动态加载的。
按“F12”调出开发者工具,刷新页面,然后分析开发者工具:
①:点击网络
②:选择XHR
③:找到以“?offset=”开头的项目并点击,右侧会出现详细信息
④:点击右侧的“页眉”标签
⑤:查看请求方式和请求地址
⑥:这里是请求的参数
接下来点击 Preview 选项卡查看返回的数据:
返回的数据格式为json,展开“data”字段,展开第一项,查找“title”,可以看到和网页上第一个图集的title一样,说明找到了正确的地方。
继续分析,在“data”的第一项中有一个“image_detail”字段。展开可以看到 6 个项目,每个项目都有一个 url。乍一看,它是图像 URL。我不知道这是否是我们正在寻找的。复制到浏览器打开确实和第一个缩略图一样,那么这6张图都是图集的吗?
点击网页的第一个图集,可以看到确实只有6张图片,和返回的json数据中的图片是一致的。
分析完了吗?我们看看页面除了图片,文字和相关推荐占了这么多内容,图片有点小,我们在图片上右击选择“在新标签页打开图片”,注意地址栏:
你发现其中的奥秘了吗?图片地址“large”变成了“origin”,分别保存两张图片,对比大小,origin比large大很多,这就是我们需要的,至此,网页解析完成,接下来开始编写代码。
2、代码
requests 库用于抓取。由于前面的分析很详细,代码不再单独讲解。请看评论。
#-*- 编码:utf-8 -*-
导入操作系统
重新进口
导入json
导入请求
从 urllib.parse 导入 urlencode
def get_one_page(偏移量,关键字):
'''
获取网页html内容并返回
'''
段 = {
'offset': offset, # 搜索结果项从哪里开始
'format': 'json', # 返回数据格式
'keyword': 关键字,#要搜索的关键字
'autoload': 'true', # 自动加载
'count': 20, # 每次加载结果的项数
'cur_tab': 3, # 当前标签页索引,3为“Atlas”
'from': 'gallery' # 来源,“画廊”
}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)铬/63.0.3239.132 Safari/537.36'}
网址 = '#39; + urlencode(段落)
尝试:
# 获取网页内容并以json格式返回数据
响应 = requests.get(url, headers=headers)
# 通过状态码判断获取是否成功
如果 response.status_code == 200:
返回响应.文本
返回无
除了请求异常:
返回无
def parse_one_page(html):
'''
解析出群组图片的URL,返回网页中所有图集的标题和图片地址
'''
网址 = []
数据 = json.loads(html)
如果 data.keys() 中的数据和“数据”:
对于 data.get('data') 中的项目:
page_urls = []
标题 = item.get('title')
image_detail = item.get('image_detail')
对于我在范围内(len(image_detail)):
# 获取大图地址
url = image_detail[i]['url']
# 替换URL获取原创高清图片
url = url.replace('大', '原点')
page_urls.append(url)
urls.append({'title': 标题,'url_list': page_urls})
返回网址
def save_image_file(url, 路径):
'''
保存图像文件
'''
ir = requests.get(url)
如果 ir.status_code == 200:
使用 open(path, 'wb') 作为 f:
f.write(ir.content)
f.close()
def main(偏移量,字):
html = get_one_page(偏移量,字)
网址 = parse_one_page(html)
# 如果图片文件夹不存在则创建
root_path = 单词
如果不是 os.path.exists(root_path):
os.mkdir(root_path)
对于我在范围内(len(urls)):
print('---正在下载 %s'%urls[i]['title'])
文件夹 = root_path + '/' + urls[i]['title']
如果不是 os.path.exists(文件夹):
尝试:
os.mkdir(文件夹)
NotADirectoryError 除外:
继续
除了 OSError:
继续
url_list = urls[i]['url_list']
对于范围内的 j(len(url_list)):
路径 = 文件夹 + '/index_' + str("d"%j) + '.jpg'
如果不是 os.path.exists(path):
save_image_file(urls[i]['url_list'][j], 路径)
如果 __name__ == '__main__':
# 抓2000个图集,基本上包括所有图集
对于我在范围内(100):
main(i*20, '街拍')
您可以根据自己的喜好替换关键词来下载您喜欢的图集。 查看全部
网页爬虫抓取百度图片(爬取今日头条图集,老司机以街拍为例(组图))
今天,我们来爬取今日头条图集。老司机以街拍为例。
操作平台:Windows
Python版本:Python3.6
IDE:崇高文本
其他工具:Chrome浏览器
1、网页分析
从打开今日头条首页,搜索“街拍”,有“综合”、“视频”、“图集”和“用户”四个标签,我们依次点击几个标签,虽然页面变了,但是address bar 的 URL 没有变化,说明页面内容是动态加载的。
按“F12”调出开发者工具,刷新页面,然后分析开发者工具:
①:点击网络
②:选择XHR
③:找到以“?offset=”开头的项目并点击,右侧会出现详细信息
④:点击右侧的“页眉”标签
⑤:查看请求方式和请求地址
⑥:这里是请求的参数
接下来点击 Preview 选项卡查看返回的数据:
返回的数据格式为json,展开“data”字段,展开第一项,查找“title”,可以看到和网页上第一个图集的title一样,说明找到了正确的地方。
继续分析,在“data”的第一项中有一个“image_detail”字段。展开可以看到 6 个项目,每个项目都有一个 url。乍一看,它是图像 URL。我不知道这是否是我们正在寻找的。复制到浏览器打开确实和第一个缩略图一样,那么这6张图都是图集的吗?
点击网页的第一个图集,可以看到确实只有6张图片,和返回的json数据中的图片是一致的。
分析完了吗?我们看看页面除了图片,文字和相关推荐占了这么多内容,图片有点小,我们在图片上右击选择“在新标签页打开图片”,注意地址栏:
你发现其中的奥秘了吗?图片地址“large”变成了“origin”,分别保存两张图片,对比大小,origin比large大很多,这就是我们需要的,至此,网页解析完成,接下来开始编写代码。
2、代码
requests 库用于抓取。由于前面的分析很详细,代码不再单独讲解。请看评论。
#-*- 编码:utf-8 -*-
导入操作系统
重新进口
导入json
导入请求
从 urllib.parse 导入 urlencode
def get_one_page(偏移量,关键字):
'''
获取网页html内容并返回
'''
段 = {
'offset': offset, # 搜索结果项从哪里开始
'format': 'json', # 返回数据格式
'keyword': 关键字,#要搜索的关键字
'autoload': 'true', # 自动加载
'count': 20, # 每次加载结果的项数
'cur_tab': 3, # 当前标签页索引,3为“Atlas”
'from': 'gallery' # 来源,“画廊”
}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, 像 Gecko)铬/63.0.3239.132 Safari/537.36'}
网址 = '#39; + urlencode(段落)
尝试:
# 获取网页内容并以json格式返回数据
响应 = requests.get(url, headers=headers)
# 通过状态码判断获取是否成功
如果 response.status_code == 200:
返回响应.文本
返回无
除了请求异常:
返回无
def parse_one_page(html):
'''
解析出群组图片的URL,返回网页中所有图集的标题和图片地址
'''
网址 = []
数据 = json.loads(html)
如果 data.keys() 中的数据和“数据”:
对于 data.get('data') 中的项目:
page_urls = []
标题 = item.get('title')
image_detail = item.get('image_detail')
对于我在范围内(len(image_detail)):
# 获取大图地址
url = image_detail[i]['url']
# 替换URL获取原创高清图片
url = url.replace('大', '原点')
page_urls.append(url)
urls.append({'title': 标题,'url_list': page_urls})
返回网址
def save_image_file(url, 路径):
'''
保存图像文件
'''
ir = requests.get(url)
如果 ir.status_code == 200:
使用 open(path, 'wb') 作为 f:
f.write(ir.content)
f.close()
def main(偏移量,字):
html = get_one_page(偏移量,字)
网址 = parse_one_page(html)
# 如果图片文件夹不存在则创建
root_path = 单词
如果不是 os.path.exists(root_path):
os.mkdir(root_path)
对于我在范围内(len(urls)):
print('---正在下载 %s'%urls[i]['title'])
文件夹 = root_path + '/' + urls[i]['title']
如果不是 os.path.exists(文件夹):
尝试:
os.mkdir(文件夹)
NotADirectoryError 除外:
继续
除了 OSError:
继续
url_list = urls[i]['url_list']
对于范围内的 j(len(url_list)):
路径 = 文件夹 + '/index_' + str("d"%j) + '.jpg'
如果不是 os.path.exists(path):
save_image_file(urls[i]['url_list'][j], 路径)
如果 __name__ == '__main__':
# 抓2000个图集,基本上包括所有图集
对于我在范围内(100):
main(i*20, '街拍')
您可以根据自己的喜好替换关键词来下载您喜欢的图集。
网页爬虫抓取百度图片(百度资源平台官方直播一节公开课工作原理及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-01 20:04
大家好,今天百度资源平台正式开课了,主要给大家讲一个网站抓取和收录的原理,这里我为大家做了详细的笔记(一个字不漏),看完后它,可以说做收录基本上问题不大。
百度爬虫的工作原理
首先,百度的爬虫会与网站的首页进行交互。拿到网站的首页后,会理解页面,理解它的收录(类型,值计算),其次,会把网站的所有超链接都提取到首页。如下图所示,首页上的超链接称为“反向链接”。当下一轮爬取发生时,爬虫会继续与这些超链接页面交互,获取页面进行细化,一层一层的继续爬取。一层抓取,构成抓取环。
编辑搜索图片,请点击输入图片描述(最多18个字符)
爬取友好度优化
1、网址规范:
任何资源都是通过 URL 抓取的。URL是相对于网站的门牌号的,所以URL的规划很重要。尤其如上图所示,在“待爬取URL”的环境下,爬虫在首页时,并不知道URL长什么样。
优秀的网址的特点是主流、简洁,可以不做一些非主流的风格,让人看起来很直观的网址。
好的 URL 示例:
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图,第一个链接是百度知道的链接。整个链接分为三个部分。第一段是网站的站点,第二段是资源类型,第三段是资源的ID。这是一个非常简单且具有爬虫外观的高质量 URL。
如上图所示,第三段比百度知道的多一段。首先第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录,最后一个段是内容ID网站。像这样的 URL 也符合标准。
不友好的 URL 示例:
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址收录字符,而这个网址中收录文章的标题,导致网址过长。, 与简单 URL 相比,长 URL 并不占优势。百度站长平台规则明确规定网址不能超过256字节。个人建议URL长度控制在100字节100字符以内。足够的资源来显示 URL。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,该网址收录统计参数,可能导致重复爬取,浪费站点权限。因此,不能使用参数。如果必须使用参数,也可以保留必要的参数。参数字符可以使用常规的连接符,如“?”、“&”,避免使用非主流的连接符。
2、合理发现链接:
爬虫从首页开始逐层爬取,所以需要做好首页与资源页的URL关系。这样,爬行相对来说比较省力。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大多数移动台都不太关注发现链接的关系,因此爬虫无法爬取内容页面。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这两个站点是移动网站常用的建站方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大部分做Feed流的网站后台数据很多,用户会不断刷新新的内容,但是无论你刷新多少次,可能也只能刷新1%左右内容。爬虫相当于一个用户。爬虫不可能以这种方式爬取网站的所有内容,所以有些页面不会被爬取。就算你有100万的内容,也可能只能抢到1-200万。
只有搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫是不可能输入关键词再爬的,所以爬虫之后只能爬到首页,没有回链,自然爬行和 收录 不会是理想的。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页面抓取你的网站最新资源。另外,新发布的资源要实时发布。索引页已同步。很多纯静态的网页都更新了内容,但是首页(索引页)还没有出来。这将导致搜索引擎无法通过索引页面抓取最新的资源。第三点是后链(最新文章的URL)需要直接暴露在源码中,方便搜索引擎抓取。最后,索引页越多越好,几个优质的索引页就够了,比如长城,基本上只用首页作为索引页。
最后,这里有一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新资源。这里有两点需要注意。
Q:是不是提交的资源越多越好?
A:收录效果的核心永远是内容的质量。如果大量提交低质量、超标的资源,就会造成惩罚性打击。
问:为什么我提交了一个普通的 收录 却没有被抓到?
A:资源提交只能加速资源发现,不能保证短时间内爬取。当然,百度表示,算法不断优化,让优质内容被更快抓取。
3、访问友好性:
爬虫需要和网站交互,保证网站的稳定性,爬虫才能正常爬取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议将加载时间控制在2S以内,这样无论是用户还是爬虫都会更喜欢打开速度更快的网站,二是避免不必要的跳转,虽然这是很少见的部分,但是有还是网站多级跳转,所以对于爬虫来说,多级跳转的同时断线的可能性很大。常见的做法是先不带www的域名跳转到带WWW的域名,再用带WWW的域名跳转到https,最后换一个新站点。在这种情况下,有三个或四个级别的跳跃。如果有类似网站的修改,建议直接跳转到新域名。
标准http返回码:我们常见的301/302的正确使用,以及404的正确使用,主要是常规问题,用常规方法解决,比如遇到无效资源,那就用404来做,不要t 使用一些特殊的返回状态码。
访问稳定性优化:一是尽量选择国内规模较大的DNS服务,保证网站的稳定性。对于域名的DNS来说,阿里云其实是比较稳定可靠的,那么二是谨慎使用技术手段,阻止爬取。如果有特定资源不想在百度上展示,可以使用机器人屏蔽。比如网站的后台链接大多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是防止防火墙误拦截爬虫爬取,所以建议可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的情况下。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫的数量会相应增加。这次会导致您的服务器出现故障吗?打开压力太大,这个问题需要站长注意。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这三个例子是第三方防火墙拦截的一种状态。普通用户打开这个状态,搜索引擎爬取的时候也是这个状态,所以如果遇到CC或者DDOS,我们在打开防火墙之前,必须先释放搜索引擎的UA。
4、识别百度爬虫
对于一些网站,可能有针对用户的特殊优化,可能有网站想区分用户和爬虫进行优化,所以这时候就需要识别百度爬虫了。
编辑搜索图片,请点击输入图片描述(最多18个字符)
首先,通过一个简单的方法,我们可以通过百度的UA来识别百度爬虫。目前百度PC、手机、小程序是三种不同的UA。然后,通过简单的识别方法,就有了第三方UA。爬虫模拟百度爬虫,所以你认不出来。那么这时候我们就可以通过双向DNS解析认证来区分了。详情请参考《简单两步:教你快速识别百度蜘蛛》。
提问时间
问:新网站会有抓取限制吗?
A:对于任何新站点,都没有抓取限制,但是从去年开始,我们就开始提供对新站点的支持,让你的网站,首先是收录上百度。然后做一个价值判断,那么如何让百度知道你是新站点,有两个捷径,一是去百度资源平台提交,二是去工信部ICP备案,我们可以从工信部得到,从ICP备案的数据,备案后,我们知道有人建了一个新站点,这样我们就可以为新站点提供基础的流量支持。
Q:蜘蛛抓取的配额会针对每个站点进行调整。多久会调整一次?
A:确实会有调整。对于新资源,会与你的抓取频率有关,而对于旧资源,会与你的内容质量有关。如果新资源的质量发生变化,那么爬取频率也会发生变化。网站@如果>的规模发生变化,爬取的频率也会发生变化。如果有大改版,那么爬取的频率也会相对变化。
Q:网站降级可以恢复吗?
A:网站降级恢复的前提是,我们会重新评估网站,检查网站是否已整改,如果有整改,是否404已制作并提交给资源 如果平台完全符合要求,搜索引擎将在评估后恢复不违反规则的网站。
问:新网站是否有评估期?
A:对我们来说,没有评估期这回事。正如我们前面提到的,它可能支持一个新站点的流量。假设一个新站点经过1-2个月的流量支持,发现网站继续保持这个状态,那么不会有大的调整。当我们发现网站的质量有明显提升时,我们也会相应的提升百度排名。
Q:百度对待国外服务器和国内服务器有区别吗?
A:从战略上看,没有严格的区分。不过很多国外服务器在中国部分地区封杀了,从国外服务器网站备案来看,国内服务器有优势。
Q:新站点的旧域名是不是更有优势?
A:如果说旧域名和新网站是同一个内容,在初期确实有一定的优势,但也只是初期,内容的好坏还要看后期. 需要特别注意的是,如果老域名行业和你的新网站的内容无关,即使是所谓的高权限老域名也会适得其反。百度会觉得,今天做那个明天做,效果还不如新建一个域名。
Q:蜘蛛有重量吗,比如220、116等高重量蜘蛛?
答:蜘蛛没有重量。网站 的排名主要取决于 网站 的质量。 查看全部
网页爬虫抓取百度图片(百度资源平台官方直播一节公开课工作原理及解决办法(一))
大家好,今天百度资源平台正式开课了,主要给大家讲一个网站抓取和收录的原理,这里我为大家做了详细的笔记(一个字不漏),看完后它,可以说做收录基本上问题不大。
百度爬虫的工作原理
首先,百度的爬虫会与网站的首页进行交互。拿到网站的首页后,会理解页面,理解它的收录(类型,值计算),其次,会把网站的所有超链接都提取到首页。如下图所示,首页上的超链接称为“反向链接”。当下一轮爬取发生时,爬虫会继续与这些超链接页面交互,获取页面进行细化,一层一层的继续爬取。一层抓取,构成抓取环。
编辑搜索图片,请点击输入图片描述(最多18个字符)
爬取友好度优化
1、网址规范:
任何资源都是通过 URL 抓取的。URL是相对于网站的门牌号的,所以URL的规划很重要。尤其如上图所示,在“待爬取URL”的环境下,爬虫在首页时,并不知道URL长什么样。
优秀的网址的特点是主流、简洁,可以不做一些非主流的风格,让人看起来很直观的网址。
好的 URL 示例:
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图,第一个链接是百度知道的链接。整个链接分为三个部分。第一段是网站的站点,第二段是资源类型,第三段是资源的ID。这是一个非常简单且具有爬虫外观的高质量 URL。
如上图所示,第三段比百度知道的多一段。首先第一段是网站的站点,第二段是站点的一级目录,第三段是站点的二级目录,最后一个段是内容ID网站。像这样的 URL 也符合标准。
不友好的 URL 示例:
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这种链接乍一看很长很复杂。有经验的站长可以看到,这种网址收录字符,而这个网址中收录文章的标题,导致网址过长。, 与简单 URL 相比,长 URL 并不占优势。百度站长平台规则明确规定网址不能超过256字节。个人建议URL长度控制在100字节100字符以内。足够的资源来显示 URL。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,该网址收录统计参数,可能导致重复爬取,浪费站点权限。因此,不能使用参数。如果必须使用参数,也可以保留必要的参数。参数字符可以使用常规的连接符,如“?”、“&”,避免使用非主流的连接符。
2、合理发现链接:
爬虫从首页开始逐层爬取,所以需要做好首页与资源页的URL关系。这样,爬行相对来说比较省力。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,从首页到具体内容的超链接路径关系称为发现链接。目前大多数移动台都不太关注发现链接的关系,因此爬虫无法爬取内容页面。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这两个站点是移动网站常用的建站方式。从链接发现的角度来看,这两类网站并不友好。
Feed流推荐:大部分做Feed流的网站后台数据很多,用户会不断刷新新的内容,但是无论你刷新多少次,可能也只能刷新1%左右内容。爬虫相当于一个用户。爬虫不可能以这种方式爬取网站的所有内容,所以有些页面不会被爬取。就算你有100万的内容,也可能只能抢到1-200万。
只有搜索条目:如上图所示,首页只有一个搜索框。用户需要输入关键词才能找到对应的内容,但是爬虫是不可能输入关键词再爬的,所以爬虫之后只能爬到首页,没有回链,自然爬行和 收录 不会是理想的。
解决方法:索引页下的内容按发布时间倒序排列。这样做的好处是搜索引擎可以通过索引页面抓取你的网站最新资源。另外,新发布的资源要实时发布。索引页已同步。很多纯静态的网页都更新了内容,但是首页(索引页)还没有出来。这将导致搜索引擎无法通过索引页面抓取最新的资源。第三点是后链(最新文章的URL)需要直接暴露在源码中,方便搜索引擎抓取。最后,索引页越多越好,几个优质的索引页就够了,比如长城,基本上只用首页作为索引页。
最后,这里有一个更高效的解决方案,就是直接通过百度站长资源平台主动提交资源,让搜索引擎绕过索引页,直接抓取最新资源。这里有两点需要注意。
Q:是不是提交的资源越多越好?
A:收录效果的核心永远是内容的质量。如果大量提交低质量、超标的资源,就会造成惩罚性打击。
问:为什么我提交了一个普通的 收录 却没有被抓到?
A:资源提交只能加速资源发现,不能保证短时间内爬取。当然,百度表示,算法不断优化,让优质内容被更快抓取。
3、访问友好性:
爬虫需要和网站交互,保证网站的稳定性,爬虫才能正常爬取。那么访问友好性主要包括以下几个方面。
访问速度优化:建议将加载时间控制在2S以内,这样无论是用户还是爬虫都会更喜欢打开速度更快的网站,二是避免不必要的跳转,虽然这是很少见的部分,但是有还是网站多级跳转,所以对于爬虫来说,多级跳转的同时断线的可能性很大。常见的做法是先不带www的域名跳转到带WWW的域名,再用带WWW的域名跳转到https,最后换一个新站点。在这种情况下,有三个或四个级别的跳跃。如果有类似网站的修改,建议直接跳转到新域名。
标准http返回码:我们常见的301/302的正确使用,以及404的正确使用,主要是常规问题,用常规方法解决,比如遇到无效资源,那就用404来做,不要t 使用一些特殊的返回状态码。
访问稳定性优化:一是尽量选择国内规模较大的DNS服务,保证网站的稳定性。对于域名的DNS来说,阿里云其实是比较稳定可靠的,那么二是谨慎使用技术手段,阻止爬取。如果有特定资源不想在百度上展示,可以使用机器人屏蔽。比如网站的后台链接大多被机器人屏蔽。如果爬取频率过高,导致服务器压力过大,影响用户正常访问,可以通过资源平台的工具降低爬取频率。二是防止防火墙误拦截爬虫爬取,所以建议可以将搜索引擎的UA加入白名单。最后一点是服务器的稳定性,尤其是在短时间内提交大量优质资源的情况下。这时候一定要注意服务器的稳定性,因为当你提交大量资源时,爬虫的数量会相应增加。这次会导致您的服务器出现故障吗?打开压力太大,这个问题需要站长注意。
编辑搜索图片,请点击输入图片描述(最多18个字符)
如上图所示,这三个例子是第三方防火墙拦截的一种状态。普通用户打开这个状态,搜索引擎爬取的时候也是这个状态,所以如果遇到CC或者DDOS,我们在打开防火墙之前,必须先释放搜索引擎的UA。
4、识别百度爬虫
对于一些网站,可能有针对用户的特殊优化,可能有网站想区分用户和爬虫进行优化,所以这时候就需要识别百度爬虫了。
编辑搜索图片,请点击输入图片描述(最多18个字符)
首先,通过一个简单的方法,我们可以通过百度的UA来识别百度爬虫。目前百度PC、手机、小程序是三种不同的UA。然后,通过简单的识别方法,就有了第三方UA。爬虫模拟百度爬虫,所以你认不出来。那么这时候我们就可以通过双向DNS解析认证来区分了。详情请参考《简单两步:教你快速识别百度蜘蛛》。
提问时间
问:新网站会有抓取限制吗?
A:对于任何新站点,都没有抓取限制,但是从去年开始,我们就开始提供对新站点的支持,让你的网站,首先是收录上百度。然后做一个价值判断,那么如何让百度知道你是新站点,有两个捷径,一是去百度资源平台提交,二是去工信部ICP备案,我们可以从工信部得到,从ICP备案的数据,备案后,我们知道有人建了一个新站点,这样我们就可以为新站点提供基础的流量支持。
Q:蜘蛛抓取的配额会针对每个站点进行调整。多久会调整一次?
A:确实会有调整。对于新资源,会与你的抓取频率有关,而对于旧资源,会与你的内容质量有关。如果新资源的质量发生变化,那么爬取频率也会发生变化。网站@如果>的规模发生变化,爬取的频率也会发生变化。如果有大改版,那么爬取的频率也会相对变化。
Q:网站降级可以恢复吗?
A:网站降级恢复的前提是,我们会重新评估网站,检查网站是否已整改,如果有整改,是否404已制作并提交给资源 如果平台完全符合要求,搜索引擎将在评估后恢复不违反规则的网站。
问:新网站是否有评估期?
A:对我们来说,没有评估期这回事。正如我们前面提到的,它可能支持一个新站点的流量。假设一个新站点经过1-2个月的流量支持,发现网站继续保持这个状态,那么不会有大的调整。当我们发现网站的质量有明显提升时,我们也会相应的提升百度排名。
Q:百度对待国外服务器和国内服务器有区别吗?
A:从战略上看,没有严格的区分。不过很多国外服务器在中国部分地区封杀了,从国外服务器网站备案来看,国内服务器有优势。
Q:新站点的旧域名是不是更有优势?
A:如果说旧域名和新网站是同一个内容,在初期确实有一定的优势,但也只是初期,内容的好坏还要看后期. 需要特别注意的是,如果老域名行业和你的新网站的内容无关,即使是所谓的高权限老域名也会适得其反。百度会觉得,今天做那个明天做,效果还不如新建一个域名。
Q:蜘蛛有重量吗,比如220、116等高重量蜘蛛?
答:蜘蛛没有重量。网站 的排名主要取决于 网站 的质量。
网页爬虫抓取百度图片(项目招商找A5快速获取精准代理名单说到SEO)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-01 13:16
项目投资找A5快速获取精准代理商名单
说到SEO,没有人不熟悉。SEO中文翻译为Search Engine Optimization,是指通过优化网站来提高网站的关键词排名,从而增加公司产品的曝光率。
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
确定几个关键词对网站流量的提升会有很大的好处,但必须与网站和产品高度相关。同时,您可以分析竞争对手的关键词,从而了解自己和他人。当然,必须有一个核心关键词,如果你做的是网站服务,那么你的核心关键词可以是:网站SEO,网站优化;如果是其他产品,可以根据自己的产品或服务范围进行定位,比如:减肥、保湿、汽车保养等……
那么长尾 关键词 是什么?顾名思义,它实际上是一个比较长的关键词。长尾关键词的搜索量比较小,在企业文章、软文中可以适当出现。
需要注意的是,关键词的密度不能出现太多,但也不能太小。一般3%~6%比较合适。同样,文章关键词的文章最好不要出现太多,最好在3~5左右。
外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
我们经常看到很多网站的地方都会有友情链接,但是随着百度算法的调整,友情链接的作用已经很小了。目前通过软文和图片传播链接的方法是最科学的方法,尤其是通过高质量的软文允许他人转载传播网站的外部链接,即目前最好的。大大地。
如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果想让你的网站更多的页面是收录,首先要让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
如果你尝试了很多,仍然没有被爬虫爬取,可以看看工程师给出的两个建议:
1、不建议本站使用js生成主要内容。如果js渲染不正确,可能会导致页面内容读取错误,导致爬虫无法抓取页面。
2、许多网站都将针对爬虫进行优化。建议页面长度在128k以内,不要太长。
SEO是用户最感兴趣的搜索服务,最具有潜在的商业价值。这是一项长期的工作,不能急于求成。在这个互联网竞争的环境下,你应该比你的竞争对手多做一点。才有可能获得质的飞跃!
原文由好推建站提供:网站转载时须以链接形式注明作者、原文出处及本声明。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机! 查看全部
网页爬虫抓取百度图片(项目招商找A5快速获取精准代理名单说到SEO)
项目投资找A5快速获取精准代理商名单
说到SEO,没有人不熟悉。SEO中文翻译为Search Engine Optimization,是指通过优化网站来提高网站的关键词排名,从而增加公司产品的曝光率。
在这个互联网时代,很多人在购买新品之前都会上网查询信息,看看哪些品牌的口碑和评价更好。这个时候,排名靠前的产品将占据绝对优势。据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果自然排名的首页找到自己需要的信息。
可见,目前,SEO对于企业和产品有着不可替代的意义。
关键词 是重中之重
我们经常听到人们谈论关键词,但关键词的具体用途是什么?关键词是SEO的核心,也是网站在搜索引擎中排名的重要因素。
确定几个关键词对网站流量的提升会有很大的好处,但必须与网站和产品高度相关。同时,您可以分析竞争对手的关键词,从而了解自己和他人。当然,必须有一个核心关键词,如果你做的是网站服务,那么你的核心关键词可以是:网站SEO,网站优化;如果是其他产品,可以根据自己的产品或服务范围进行定位,比如:减肥、保湿、汽车保养等……
那么长尾 关键词 是什么?顾名思义,它实际上是一个比较长的关键词。长尾关键词的搜索量比较小,在企业文章、软文中可以适当出现。
需要注意的是,关键词的密度不能出现太多,但也不能太小。一般3%~6%比较合适。同样,文章关键词的文章最好不要出现太多,最好在3~5左右。
外部链接也会影响权重
入链也是网站优化的一个很重要的过程,可以间接影响网站在搜索引擎中的权重。目前常用的链接分为:锚文本链接、超链接、纯文本链接和图片链接。
我们经常看到很多网站的地方都会有友情链接,但是随着百度算法的调整,友情链接的作用已经很小了。目前通过软文和图片传播链接的方法是最科学的方法,尤其是通过高质量的软文允许他人转载传播网站的外部链接,即目前最好的。大大地。
如何被爬虫爬取?
爬虫是一个自动提取网页的程序,比如百度的蜘蛛等。如果想让你的网站更多的页面是收录,首先要让网页被爬虫抓取.
如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,优质内容是爬虫喜欢抓取的目标,尤其是原创内容。
如果你尝试了很多,仍然没有被爬虫爬取,可以看看工程师给出的两个建议:
1、不建议本站使用js生成主要内容。如果js渲染不正确,可能会导致页面内容读取错误,导致爬虫无法抓取页面。
2、许多网站都将针对爬虫进行优化。建议页面长度在128k以内,不要太长。
SEO是用户最感兴趣的搜索服务,最具有潜在的商业价值。这是一项长期的工作,不能急于求成。在这个互联网竞争的环境下,你应该比你的竞争对手多做一点。才有可能获得质的飞跃!
原文由好推建站提供:网站转载时须以链接形式注明作者、原文出处及本声明。
申请创业报告,分享创业好点子。点击这里一起讨论新的商机!
网页爬虫抓取百度图片(soup爬虫学习方法总结(一):SQL语句create数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-02-28 08:09
获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。响应的内容可能包括 HTML、Json 字符串、二进制数据(如图片和视频)等。
解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库进行解析;可能是Json,可以直接转成Json对象解析;它可能是二进制数据,可以保存或进一步处理。
保存数据:数据分析完成后保存。既可以存储为文本文件,也可以存储在数据库中。
四、Python 爬虫实例
爬行动物的定义、功能、原理等信息前面已经介绍过了。相信很多小伙伴已经开始对爬虫产生了兴趣,准备尝试一下。现在,我们来“干货”,直接贴一个简单的Python爬虫代码:
1.前期准备:安装Python环境,安装PYCHARM软件,安装MYSQL数据库,新建数据库考试,考试中建表屋,用于存储爬虫结果【SQL语句:create table house(price varchar ( 88),unit varchar(88),area varchar(88));]
2.爬虫的目标:爬取链家租赁网首页(url:)中所有房源的价格、单位、面积,然后将爬虫结构存入数据库。
3.爬虫源码:如下
import requests #请求URL页面内容
from bs4 import BeautifulSoup #获取页面元素
import pymysql #链接数据库
导入时间#time函数
import lxml #解析库(支持HTML\XML解析,支持XPATH解析)
#get_page 功能:通过requests的get方法获取url链接的内容,然后整合成BeautifulSoup可以处理的格式
def get_page(url):
响应 = requests.get(url)
汤= BeautifulSoup(response.text,'lxml')
回汤
#get_links函数的作用:获取listing页面上的所有出租链接
def get_links(link_url):
汤 = get_page(link_url)
links_div = soup.find_all('div',class_="pic-panel")
links=[div.a.get('href') for div in links_div]
返回链接
#get_house_info的作用是获取一个出租页面的信息:价格、单位、面积等。
def get_house_info(house_url):
汤=get_page(house_url)
价格 =soup.find('span',class_='total').text
unit = soup.find('span',class_='unit').text.strip()
area = 'test' #这里area字段我们自定义一个测试进行测试
信息 = {
“价格”:价格,
“单位”:单位,
“区域”:区域
}
返回信息
#数据库配置信息写入字典
数据库 = {
'主机': '127.0.0.1',
'数据库':'考试',
“用户”:“根”,
“密码”:“根”,
'字符集':'utf8mb4'}
#链接数据库
def get_db(设置):
返回 pymysql.connect(**设置)
#将爬虫获取的数据插入数据库
定义插入(分贝,房子):
值 = "'{}',"*2 + "'{}'"
sql_values=values.format(house['price'],house['unit'],house['area'])
sql="""
插入房屋(价格,单位,面积)值({})
""".format(sql_values)
游标 = db.cursor()
cursor.execute(sql)
mit()
#主程序流程:1.连接数据库2.获取每个listing信息的URL列表3.FOR循环从第一个URL开始获取具体信息(价格等)列表的4. 一一插入数据库
db = get_db(数据库)
链接 = get_links('#39;)
对于链接中的链接:
时间.sleep(2)
房子=get_house_info(链接)
插入(分贝,房子)
首先,“要想做好工作,必须先利其器”。用 Python 编写爬虫程序也是如此。在编写爬虫的过程中,需要导入各种库文件。正是这些及其有用的库文件帮助我们完成了爬虫。对于大部分工作,我们只需要调用相关的接口函数即可。导入格式为导入库文件名。这里需要注意的是,要在PYCHARM中安装库文件,可以将光标放在库文件名上同时按ctrl+alt键安装库文件,也可以是通过命令行安装(pip安装库文件名),如果安装失败或者没有安装,后续爬虫肯定会报错。在这段代码中,程序前五行导入相关库文件:requests用于请求URL页面内容;BeautifulSoup 用于解析页面元素;pymysql用于连接数据库;time 收录各种时间函数;lxml是一个解析库,用于解析HTML、XML格式文件,也支持XPATH解析。
其次,我们从代码末尾的主程序来看整个爬虫流程:
通过 get_db 函数连接到数据库。深入get_db函数,可以看到是通过调用
Pymysql的connect函数用于实现数据库的连接。这里的**seting是Python采集关键字参数的一种方式。我们将数据库的连接信息写入一个字典DataBase,并将字典中的信息传递给connect实现。参考。
使用get_links函数获取链家首页所有房源的链接。所有列表的链接都以列表的形式存储在 Links 中。get_links函数首先通过requests请求获取链家首页的内容,然后通过BeautyfuSoup的接口对内容的格式进行整理,转化为自己可以处理的格式。最后通过电泳find_all函数找到所有收录图片的div样式,然后用for循环获取所有div样式中收录的超链接标签(a)的内容(即href属性的内容),所有超链接存储在列表链接中。
通过 FOR 循环,遍历 links 中的所有链接(例如,其中一个链接是:)
使用与2)相同的方法,通过find函数定位元素,获取3)中链接中的价格、单位、地区信息,并将这些信息写入字典Info。
调用insert函数,将链接中获取的Info信息写入到数据库的house表中。深入insert函数可知,它通过数据库游标函数cursor()执行一条SQL语句,然后数据库执行commit操作,实现响应功能。SQL 语句在这里以一种特殊的方式编写。
给格式化函数格式化,这是为了方便函数的复用。
最后运行爬虫代码,可以看到链家首页所有房源信息都写入了数据中。(注:test是我手动指定的测试字符串)
后记:其实Python爬虫并不难。在熟悉了整个爬取过程之后,需要注意一些细节,比如如何获取页面元素,如何构造SQL语句等等。遇到问题不要慌张,可以通过查看IDE的提示一一排除bug,最终得到我们期望的结构。
最后:
可以获取我的个人V:atstudy-js,可以免费获取10G软件测试工程师面试合集文档。并免费分享对应的视频学习教程!,包括基础知识、Linux要领、Mysql数据库、抓包工具、接口测试工具、高级测试——Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架,性能测试等
这些测试数据应该是做【软件测试】的朋友最全面最完整的准备仓库了。这个仓库也陪我走过了最艰难的旅程,希望也能帮到你! 查看全部
网页爬虫抓取百度图片(soup爬虫学习方法总结(一):SQL语句create数据)
获取响应内容:如果服务器能正常响应,就会得到一个Response。Response的内容就是要获取的页面的内容。响应的内容可能包括 HTML、Json 字符串、二进制数据(如图片和视频)等。
解析内容:获取的内容可能是HTML,可以用正则表达式和网页解析库进行解析;可能是Json,可以直接转成Json对象解析;它可能是二进制数据,可以保存或进一步处理。
保存数据:数据分析完成后保存。既可以存储为文本文件,也可以存储在数据库中。
四、Python 爬虫实例
爬行动物的定义、功能、原理等信息前面已经介绍过了。相信很多小伙伴已经开始对爬虫产生了兴趣,准备尝试一下。现在,我们来“干货”,直接贴一个简单的Python爬虫代码:
1.前期准备:安装Python环境,安装PYCHARM软件,安装MYSQL数据库,新建数据库考试,考试中建表屋,用于存储爬虫结果【SQL语句:create table house(price varchar ( 88),unit varchar(88),area varchar(88));]
2.爬虫的目标:爬取链家租赁网首页(url:)中所有房源的价格、单位、面积,然后将爬虫结构存入数据库。
3.爬虫源码:如下
import requests #请求URL页面内容
from bs4 import BeautifulSoup #获取页面元素
import pymysql #链接数据库
导入时间#time函数
import lxml #解析库(支持HTML\XML解析,支持XPATH解析)
#get_page 功能:通过requests的get方法获取url链接的内容,然后整合成BeautifulSoup可以处理的格式
def get_page(url):
响应 = requests.get(url)
汤= BeautifulSoup(response.text,'lxml')
回汤
#get_links函数的作用:获取listing页面上的所有出租链接
def get_links(link_url):
汤 = get_page(link_url)
links_div = soup.find_all('div',class_="pic-panel")
links=[div.a.get('href') for div in links_div]
返回链接
#get_house_info的作用是获取一个出租页面的信息:价格、单位、面积等。
def get_house_info(house_url):
汤=get_page(house_url)
价格 =soup.find('span',class_='total').text
unit = soup.find('span',class_='unit').text.strip()
area = 'test' #这里area字段我们自定义一个测试进行测试
信息 = {
“价格”:价格,
“单位”:单位,
“区域”:区域
}
返回信息
#数据库配置信息写入字典
数据库 = {
'主机': '127.0.0.1',
'数据库':'考试',
“用户”:“根”,
“密码”:“根”,
'字符集':'utf8mb4'}
#链接数据库
def get_db(设置):
返回 pymysql.connect(**设置)
#将爬虫获取的数据插入数据库
定义插入(分贝,房子):
值 = "'{}',"*2 + "'{}'"
sql_values=values.format(house['price'],house['unit'],house['area'])
sql="""
插入房屋(价格,单位,面积)值({})
""".format(sql_values)
游标 = db.cursor()
cursor.execute(sql)
mit()
#主程序流程:1.连接数据库2.获取每个listing信息的URL列表3.FOR循环从第一个URL开始获取具体信息(价格等)列表的4. 一一插入数据库
db = get_db(数据库)
链接 = get_links('#39;)
对于链接中的链接:
时间.sleep(2)
房子=get_house_info(链接)
插入(分贝,房子)
首先,“要想做好工作,必须先利其器”。用 Python 编写爬虫程序也是如此。在编写爬虫的过程中,需要导入各种库文件。正是这些及其有用的库文件帮助我们完成了爬虫。对于大部分工作,我们只需要调用相关的接口函数即可。导入格式为导入库文件名。这里需要注意的是,要在PYCHARM中安装库文件,可以将光标放在库文件名上同时按ctrl+alt键安装库文件,也可以是通过命令行安装(pip安装库文件名),如果安装失败或者没有安装,后续爬虫肯定会报错。在这段代码中,程序前五行导入相关库文件:requests用于请求URL页面内容;BeautifulSoup 用于解析页面元素;pymysql用于连接数据库;time 收录各种时间函数;lxml是一个解析库,用于解析HTML、XML格式文件,也支持XPATH解析。
其次,我们从代码末尾的主程序来看整个爬虫流程:
通过 get_db 函数连接到数据库。深入get_db函数,可以看到是通过调用
Pymysql的connect函数用于实现数据库的连接。这里的**seting是Python采集关键字参数的一种方式。我们将数据库的连接信息写入一个字典DataBase,并将字典中的信息传递给connect实现。参考。
使用get_links函数获取链家首页所有房源的链接。所有列表的链接都以列表的形式存储在 Links 中。get_links函数首先通过requests请求获取链家首页的内容,然后通过BeautyfuSoup的接口对内容的格式进行整理,转化为自己可以处理的格式。最后通过电泳find_all函数找到所有收录图片的div样式,然后用for循环获取所有div样式中收录的超链接标签(a)的内容(即href属性的内容),所有超链接存储在列表链接中。
通过 FOR 循环,遍历 links 中的所有链接(例如,其中一个链接是:)
使用与2)相同的方法,通过find函数定位元素,获取3)中链接中的价格、单位、地区信息,并将这些信息写入字典Info。
调用insert函数,将链接中获取的Info信息写入到数据库的house表中。深入insert函数可知,它通过数据库游标函数cursor()执行一条SQL语句,然后数据库执行commit操作,实现响应功能。SQL 语句在这里以一种特殊的方式编写。
给格式化函数格式化,这是为了方便函数的复用。
最后运行爬虫代码,可以看到链家首页所有房源信息都写入了数据中。(注:test是我手动指定的测试字符串)
后记:其实Python爬虫并不难。在熟悉了整个爬取过程之后,需要注意一些细节,比如如何获取页面元素,如何构造SQL语句等等。遇到问题不要慌张,可以通过查看IDE的提示一一排除bug,最终得到我们期望的结构。
最后:
可以获取我的个人V:atstudy-js,可以免费获取10G软件测试工程师面试合集文档。并免费分享对应的视频学习教程!,包括基础知识、Linux要领、Mysql数据库、抓包工具、接口测试工具、高级测试——Python编程、Web自动化测试、APP自动化测试、接口自动化测试、测试高级持续集成、测试架构开发测试框架,性能测试等
这些测试数据应该是做【软件测试】的朋友最全面最完整的准备仓库了。这个仓库也陪我走过了最艰难的旅程,希望也能帮到你!
网页爬虫抓取百度图片(网页爬虫抓取百度图片试试?页面加载有点慢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-26 19:04
网页爬虫抓取百度图片试试?页面加载有点慢,不知道能不能用requests抓取下来。
哈哈~个人更推荐使用flask相对于python自带的那些功能它基本上都有对于web爬虫我更喜欢flask,用起来也简单而且python本身没有这方面的框架,还是跟着别人学吧上面那个写爬虫的写的的很清楚,
首先你要确定你是想要抓取哪些图片网站的图片。网站上的爬虫是不是有对图片url地址进行针对性地查找,然后发现该网站上已经有图片。一般的爬虫能力没有那么强大。推荐用蜘蛛程序爬下来,进行一个下载工作。或者图片搜索工具对图片信息进行爬取。
据我所知微信公众号图文消息的接口不能爬取图片,你可以选择把那个接口转换成抓取类,直接抓取。
我目前用了两个微信公众号的接口,一个搜,一个推。其中公众号搜是图片接口,可以抓取其它地方的,比如说我的知乎。
建议使用像flask这种pythonweb框架,
额,我刚接触爬虫没多久,目前采用图片链接去抓取微信文章的图片,刚开始学,
可以用户工具箱
我也试了各种方式都没成功好烦人
实在不行就编写个爬虫程序
这些微信公众号都会放一些免费图片的链接供爬取,但是仅限原创文章。 查看全部
网页爬虫抓取百度图片(网页爬虫抓取百度图片试试?页面加载有点慢)
网页爬虫抓取百度图片试试?页面加载有点慢,不知道能不能用requests抓取下来。
哈哈~个人更推荐使用flask相对于python自带的那些功能它基本上都有对于web爬虫我更喜欢flask,用起来也简单而且python本身没有这方面的框架,还是跟着别人学吧上面那个写爬虫的写的的很清楚,
首先你要确定你是想要抓取哪些图片网站的图片。网站上的爬虫是不是有对图片url地址进行针对性地查找,然后发现该网站上已经有图片。一般的爬虫能力没有那么强大。推荐用蜘蛛程序爬下来,进行一个下载工作。或者图片搜索工具对图片信息进行爬取。
据我所知微信公众号图文消息的接口不能爬取图片,你可以选择把那个接口转换成抓取类,直接抓取。
我目前用了两个微信公众号的接口,一个搜,一个推。其中公众号搜是图片接口,可以抓取其它地方的,比如说我的知乎。
建议使用像flask这种pythonweb框架,
额,我刚接触爬虫没多久,目前采用图片链接去抓取微信文章的图片,刚开始学,
可以用户工具箱
我也试了各种方式都没成功好烦人
实在不行就编写个爬虫程序
这些微信公众号都会放一些免费图片的链接供爬取,但是仅限原创文章。
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一第一时间解决?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-26 15:20
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看
1. 概述
本文主要实现一个简单的爬虫,目的是从百度贴吧页面下载图片。下载图片的步骤如下:
(1)获取网页的html文本内容;
(2)分析html中图片的html标签特征,使用正则解析得到所有图片url链接的列表;
(3)根据图片的url链接列表将图片下载到本地文件夹。
2. urllib+re 实现
<p>1#!/usr/bin/python
2# coding:utf-8
3# 实现一个简单的爬虫,爬取百度贴吧图片
4import urllib
5import re
6# 根据url获取网页html内容
7def getHtmlContent(url):
8 page = urllib.urlopen(url)
9
10return page.read()
11# 从html中解析出所有jpg图片的url
12# 百度贴吧html中jpg图片的url格式为:XXX.jpg
13def getJPGs(html):
14# 解析jpg图片url的正则
15 jpgReg = re.compile(r' 查看全部
网页爬虫抓取百度图片(想要学习Python?有问题得不到第一第一时间解决?(图))
想学 Python?遇到无法第一时间解决的问题?来这里看看“1039649593”满足你的需求,资料已经上传到文件中,你可以自己下载!还有大量2020最新的python学习资料。
点击查看
1. 概述
本文主要实现一个简单的爬虫,目的是从百度贴吧页面下载图片。下载图片的步骤如下:
(1)获取网页的html文本内容;
(2)分析html中图片的html标签特征,使用正则解析得到所有图片url链接的列表;
(3)根据图片的url链接列表将图片下载到本地文件夹。
2. urllib+re 实现
<p>1#!/usr/bin/python
2# coding:utf-8
3# 实现一个简单的爬虫,爬取百度贴吧图片
4import urllib
5import re
6# 根据url获取网页html内容
7def getHtmlContent(url):
8 page = urllib.urlopen(url)
9
10return page.read()
11# 从html中解析出所有jpg图片的url
12# 百度贴吧html中jpg图片的url格式为:XXX.jpg
13def getJPGs(html):
14# 解析jpg图片url的正则
15 jpgReg = re.compile(r'

