
网页爬虫抓取百度图片
网页爬虫抓取百度图片(一种全新的方式来获取图片素材,你想要的这里全都有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-30 18:10
你还去网站搜什么图?
你还在寻找百度图片等图片素材网站吗?
今天给大家分享一个全新的图片素材获取方式。你想要的这里都有!
是新浪微博!新一代的超级流量门户,甚至现在很多人都用它作为替代百度搜索的工具。以前是找杜娘找东西,现在是搜微博。
比如某个宅男想看清纯少女的照片,越多越好。他会这样搜索:
然后,他会逐页阅读和欣赏这些吸引眼球的图片,并在遇到喜欢的人时将大图片下载到本地保存。
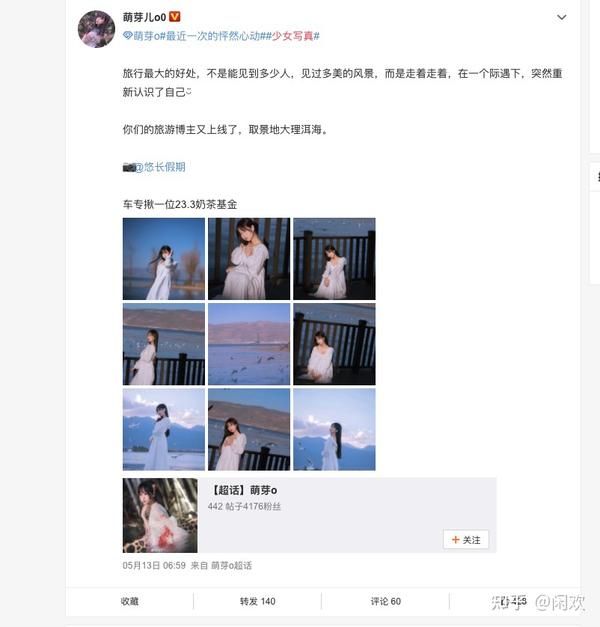
作为一个python程序员,我懒得像这样一页一页地翻页。喜欢全部下载下来慢慢欣赏,爆了硬盘!类似于以下内容:
这种简单的问题让我们为pythoner写爬虫那么容易,何乐而不为呢?让我直接与你分享。
分析目标网站
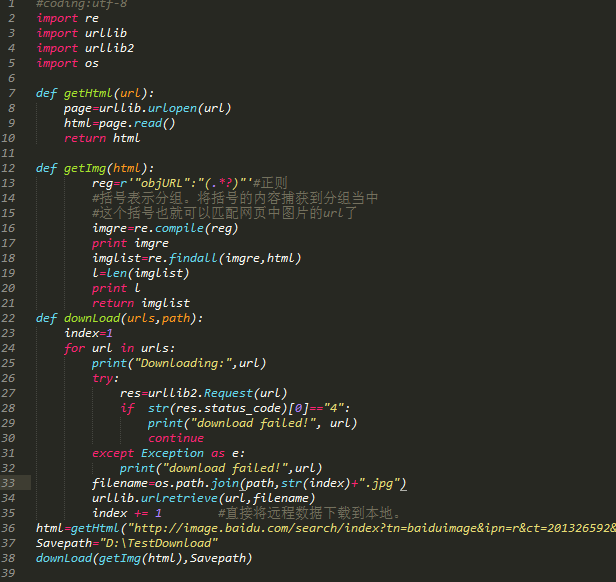
微博的搜索结果是分页的,所以我们的思路肯定是分页处理,逐页解析。
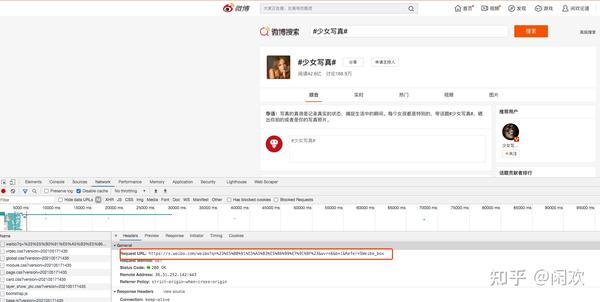
我们先来看看搜索结果:
我们点击“搜索”按钮后,很容易找到搜索请求。此处网页显示了第一页的结果。
然后我们点击“Next”,我们可以发现请求变成了如下:
细心的话,可能一眼就发现在请求后多了一个page参数,指的是页码。这很容易。我们只需要改变页码就可以请求对应页面的内容。
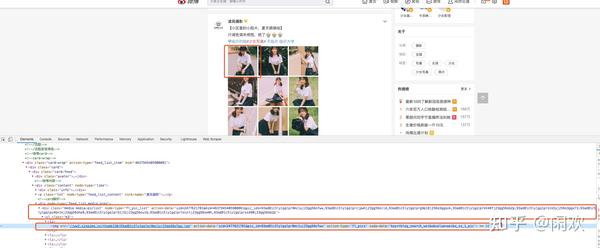
由于此请求返回一个 HTML 页面,因此我们需要在此页面上努力找到指向图像的链接。我们随便用页面元素检查来定位一张图片,会看到如下效果:
我们可以看到这个div里面的action-data是一个集合,下面li里面img的action-data是单张图片的数据。
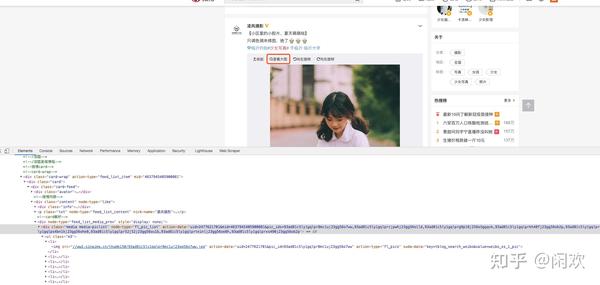
接下来,我们点击“查看大图”按钮,浏览器会跳转到一个新页面,页面内容为大图。
从请求的 URL 往下看,我发现了这个:
我把这个网址复制到浏览器请求中,发现这正是我们需要的大图。我们也可以很容易的看到这个URL的特点,就是最后我们在上面的action-data中添加了pic_id。
这样,我们的思路就很清晰了,下面是获取一页图片的思路:
获取页面内容;在页面内容中找到图片ID;拼接查看大图的URL,请求获取图片;将图像写入本地。代码代码
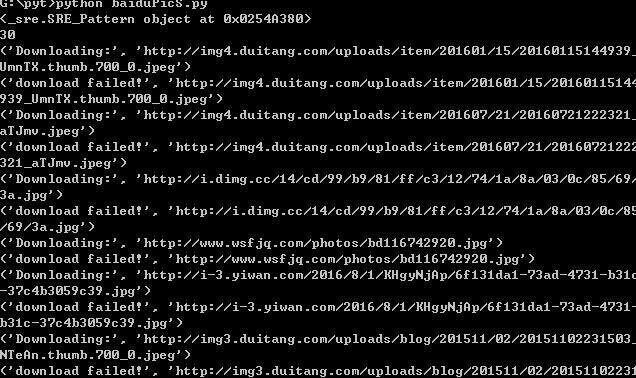
思路很清晰,需要代码code来验证。由于代码比较简单,我就一次性给大家展示一下。
import requests
import re
import os
import time
cookie = {
'Cookie': 'your cookie'
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4144.2 Safari/537.36'
}
get_order = input('是否启动程序? yes or no: ')
number = 1
store_path = 'your path'
while True:
if get_order != 'no':
print('抓取中......') # 下面的链接填写微博搜索的链接
url = f'https://s.weibo.com/weibo%3Fq% ... ge%3D{number}'
response = requests.get(url, cookies=cookie)
result = response.text
print(result)
detail = re.findall('data="uid=(.*?)&mid=(.*?)&pic_ids=(.*?)">', result)
for part in detail:
uid = part[0]
mid = part[1]
pids = part[2]
for picid in pids.split(','):
url_x = f'https://wx1.sinaimg.cn/large/%s.jpg'%picid # 这里就是大图链接了
response_photo = requests.get(url_x, headers=header)
file_name = url_x[-10:]
if not os.path.exists(store_path+uid):
os.mkdir(store_path+uid)
with open(store_path+uid + '/' + file_name, 'ab') as f: # 保存文件
f.write(response_photo.content)
time.sleep(0.5)
print('获取完毕')
get_order = input('是否继续获取下一页? Y:yes N:no: ')
if get_order != 'no':
number += 1
else:
print('程序结束')
break
else:
print('程序结束')
break
我这里采用了逐页断点的形式,方便调试。如果你想一次得到所有页面的图片,你可以把这些输入判断去掉,一次性全部运行。代码中的cookie和图片存储路径需要替换为你本地的。
运行后的结果如下:
我按照微博把图片分到文件夹里。如果觉得不直观,想把所有图片都放在一个目录下,可以去掉这一层文件夹。
总结
本文介绍如何通过一个简单的爬虫获取微博图片搜索结果。代码量相当少,但是对一些人来说是很有帮助的,省时省力。还可以展开,除了图片,还可以获取其他搜索内容,比如微博文字、视频、购物链接等。 查看全部
网页爬虫抓取百度图片(一种全新的方式来获取图片素材,你想要的这里全都有)
你还去网站搜什么图?
你还在寻找百度图片等图片素材网站吗?
今天给大家分享一个全新的图片素材获取方式。你想要的这里都有!
是新浪微博!新一代的超级流量门户,甚至现在很多人都用它作为替代百度搜索的工具。以前是找杜娘找东西,现在是搜微博。
比如某个宅男想看清纯少女的照片,越多越好。他会这样搜索:
然后,他会逐页阅读和欣赏这些吸引眼球的图片,并在遇到喜欢的人时将大图片下载到本地保存。
作为一个python程序员,我懒得像这样一页一页地翻页。喜欢全部下载下来慢慢欣赏,爆了硬盘!类似于以下内容:
这种简单的问题让我们为pythoner写爬虫那么容易,何乐而不为呢?让我直接与你分享。
分析目标网站
微博的搜索结果是分页的,所以我们的思路肯定是分页处理,逐页解析。
我们先来看看搜索结果:
我们点击“搜索”按钮后,很容易找到搜索请求。此处网页显示了第一页的结果。
然后我们点击“Next”,我们可以发现请求变成了如下:
细心的话,可能一眼就发现在请求后多了一个page参数,指的是页码。这很容易。我们只需要改变页码就可以请求对应页面的内容。
由于此请求返回一个 HTML 页面,因此我们需要在此页面上努力找到指向图像的链接。我们随便用页面元素检查来定位一张图片,会看到如下效果:
我们可以看到这个div里面的action-data是一个集合,下面li里面img的action-data是单张图片的数据。
接下来,我们点击“查看大图”按钮,浏览器会跳转到一个新页面,页面内容为大图。
从请求的 URL 往下看,我发现了这个:
我把这个网址复制到浏览器请求中,发现这正是我们需要的大图。我们也可以很容易的看到这个URL的特点,就是最后我们在上面的action-data中添加了pic_id。
这样,我们的思路就很清晰了,下面是获取一页图片的思路:
获取页面内容;在页面内容中找到图片ID;拼接查看大图的URL,请求获取图片;将图像写入本地。代码代码
思路很清晰,需要代码code来验证。由于代码比较简单,我就一次性给大家展示一下。
import requests
import re
import os
import time
cookie = {
'Cookie': 'your cookie'
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4144.2 Safari/537.36'
}
get_order = input('是否启动程序? yes or no: ')
number = 1
store_path = 'your path'
while True:
if get_order != 'no':
print('抓取中......') # 下面的链接填写微博搜索的链接
url = f'https://s.weibo.com/weibo%3Fq% ... ge%3D{number}'
response = requests.get(url, cookies=cookie)
result = response.text
print(result)
detail = re.findall('data="uid=(.*?)&mid=(.*?)&pic_ids=(.*?)">', result)
for part in detail:
uid = part[0]
mid = part[1]
pids = part[2]
for picid in pids.split(','):
url_x = f'https://wx1.sinaimg.cn/large/%s.jpg'%picid # 这里就是大图链接了
response_photo = requests.get(url_x, headers=header)
file_name = url_x[-10:]
if not os.path.exists(store_path+uid):
os.mkdir(store_path+uid)
with open(store_path+uid + '/' + file_name, 'ab') as f: # 保存文件
f.write(response_photo.content)
time.sleep(0.5)
print('获取完毕')
get_order = input('是否继续获取下一页? Y:yes N:no: ')
if get_order != 'no':
number += 1
else:
print('程序结束')
break
else:
print('程序结束')
break
我这里采用了逐页断点的形式,方便调试。如果你想一次得到所有页面的图片,你可以把这些输入判断去掉,一次性全部运行。代码中的cookie和图片存储路径需要替换为你本地的。
运行后的结果如下:
我按照微博把图片分到文件夹里。如果觉得不直观,想把所有图片都放在一个目录下,可以去掉这一层文件夹。
总结
本文介绍如何通过一个简单的爬虫获取微博图片搜索结果。代码量相当少,但是对一些人来说是很有帮助的,省时省力。还可以展开,除了图片,还可以获取其他搜索内容,比如微博文字、视频、购物链接等。
网页爬虫抓取百度图片(,文中示例代码介绍-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-30 17:20
本文文章主要介绍Python3简单爬虫抓取网页图片代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考。
网上有很多用python2编写的爬虫抓取网页图片的例子,但是不适合新手(新手使用python3环境,不兼容python2),
于是写了一个简单的例子,用Python3语法抓取网页图片。希望能帮到你,也希望你能批评指正。
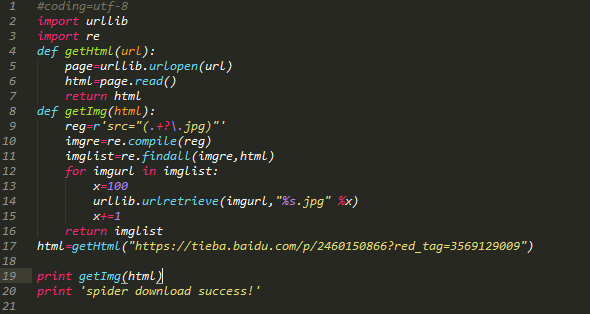
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
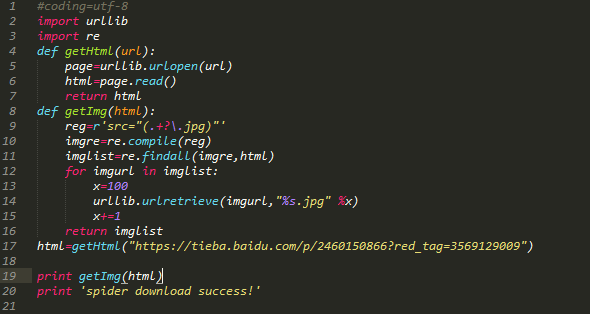
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
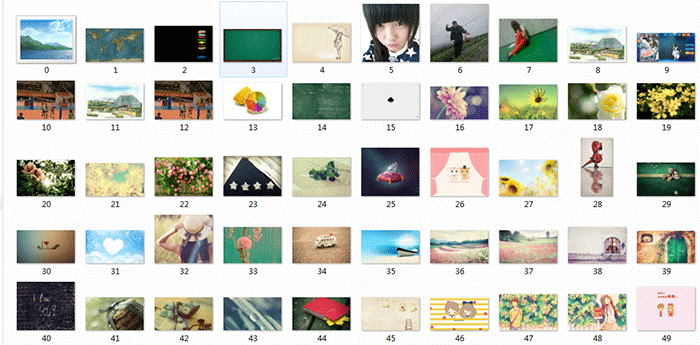
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页爬虫抓取百度图片(,文中示例代码介绍-上海怡健医学())
本文文章主要介绍Python3简单爬虫抓取网页图片代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考。
网上有很多用python2编写的爬虫抓取网页图片的例子,但是不适合新手(新手使用python3环境,不兼容python2),
于是写了一个简单的例子,用Python3语法抓取网页图片。希望能帮到你,也希望你能批评指正。
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-30 02:11
)
这篇文章是针对初学者的,我会用最简单的案例来告诉你如何开始使用python爬虫!
开始使用Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫其实叫做Web Data采集,比较容易理解。
就是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。
总结为四个主要步骤:
根据url获取HTML数据解析HTML,获取目标信息存储数据重复第一步
这将涉及很多内容,例如数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全和图像处理。但是对于初学者来说,没必要掌握那么多。
二、python学多少
如果你不懂python,你需要学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。学习起来会很枯燥,但并不难。
刚开始,你甚至不需要学习python类、多线程、模块等高难度内容。找本初学者的教材或者网上教程,花十几天的时间,可以对python的基础有三到四点的了解,这时候就可以玩爬虫了!
当然,前提是你这十天一定要认真打好代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等核心东西一定要熟透心手.
教材选择比较多。个人推荐python官方文档和python简明教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面提到爬虫想要爬取的数据隐藏在网页的HTML中,有点间接!
维基百科这样解释 HTML
超文本标记语言(英文:Hyper Text Markup Language,简称 HTML)是一种用于创建网页的标准标记语言。HTML 是一项基本技术,经常与 CSS 和许多 网站 一起使用来设计网页、Web 应用程序和移动应用程序的用户界面 [3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视化网页。HTML 描述了 网站 的结构和语义以及线索的呈现,使其成为标记语言而不是编程语言。
综上所述,HTML 是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并呈现为我们看到的网页。
这就是为什么我们先爬取 HTML,然后解析数据,因为数据隐藏在 HTML 中。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则即可,这里是一个大致的介绍。
HTML 标签包括几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如和。
在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,括在尖括号中,例如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间。
四、了解python网络爬虫的基本原理
在编写python爬虫程序时,只需要做以下两件事:
对于这两件事,python有相应的库可以帮你做,你只需要知道如何使用它们即可。
五、 使用python库抓取百度首页标题和图片
首先,发送HTML数据请求,可以使用python内置库urllib,它有一个urlopen函数,可以根据url获取HTML文件。这里,尝试获取百度首页的HTML内容""
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/")
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看效果:
部分截取输出html内容
我们来看看真正的百度主页的html是什么样子的。如果您使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:
在 Google Chrome 中查看 HTML
通过对比你就会知道,刚才通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的python库BeautifulSoup作为解析上面已经得到的HTML的工具。
BeautifulSoup 是第三方库,需要安装使用。只需在命令行上使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据即可:
比如我想得到百度首页的标题“我点击百度就知道了”,怎么办?
这个title被两个label困住了,一个是primary label,一个是secondary label,所以从label里面取出信息就行了。
# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
看看结果:
到此,百度主页的标题就提取成功了。
如果我想下载百度首页标志图片怎么办?
第一步是获取网页的所有图片标签和网址。这个可以使用BeautifulSoup的findAll方法,可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll("img")来获取所有的图片信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
看看结果:
打印所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有一张百度首页logo的图片,图片的类(元素类名)为index-logo-src。
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:
获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
最终图像保存在'logo.png'
六、结论
本文以抓取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识,还有很多优秀的python爬虫库和框架有待以后学习。
当然,如果你掌握了本文讨论的知识点,你就已经开始使用python爬虫了。来吧,男孩!
这里有一个方便大家的python学习交流群:196872581免费领取学习路线、大纲、课程等资料
查看全部
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫
)
这篇文章是针对初学者的,我会用最简单的案例来告诉你如何开始使用python爬虫!
开始使用Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫其实叫做Web Data采集,比较容易理解。
就是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。
总结为四个主要步骤:
根据url获取HTML数据解析HTML,获取目标信息存储数据重复第一步
这将涉及很多内容,例如数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全和图像处理。但是对于初学者来说,没必要掌握那么多。
二、python学多少
如果你不懂python,你需要学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。学习起来会很枯燥,但并不难。
刚开始,你甚至不需要学习python类、多线程、模块等高难度内容。找本初学者的教材或者网上教程,花十几天的时间,可以对python的基础有三到四点的了解,这时候就可以玩爬虫了!
当然,前提是你这十天一定要认真打好代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等核心东西一定要熟透心手.
教材选择比较多。个人推荐python官方文档和python简明教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面提到爬虫想要爬取的数据隐藏在网页的HTML中,有点间接!
维基百科这样解释 HTML
超文本标记语言(英文:Hyper Text Markup Language,简称 HTML)是一种用于创建网页的标准标记语言。HTML 是一项基本技术,经常与 CSS 和许多 网站 一起使用来设计网页、Web 应用程序和移动应用程序的用户界面 [3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视化网页。HTML 描述了 网站 的结构和语义以及线索的呈现,使其成为标记语言而不是编程语言。
综上所述,HTML 是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并呈现为我们看到的网页。
这就是为什么我们先爬取 HTML,然后解析数据,因为数据隐藏在 HTML 中。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则即可,这里是一个大致的介绍。
HTML 标签包括几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如和。
在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,括在尖括号中,例如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间。
四、了解python网络爬虫的基本原理
在编写python爬虫程序时,只需要做以下两件事:
对于这两件事,python有相应的库可以帮你做,你只需要知道如何使用它们即可。
五、 使用python库抓取百度首页标题和图片
首先,发送HTML数据请求,可以使用python内置库urllib,它有一个urlopen函数,可以根据url获取HTML文件。这里,尝试获取百度首页的HTML内容""
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/";)
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看效果:

部分截取输出html内容
我们来看看真正的百度主页的html是什么样子的。如果您使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:

在 Google Chrome 中查看 HTML
通过对比你就会知道,刚才通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的python库BeautifulSoup作为解析上面已经得到的HTML的工具。
BeautifulSoup 是第三方库,需要安装使用。只需在命令行上使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据即可:

比如我想得到百度首页的标题“我点击百度就知道了”,怎么办?
这个title被两个label困住了,一个是primary label,一个是secondary label,所以从label里面取出信息就行了。

# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
看看结果:

到此,百度主页的标题就提取成功了。
如果我想下载百度首页标志图片怎么办?
第一步是获取网页的所有图片标签和网址。这个可以使用BeautifulSoup的findAll方法,可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll("img")来获取所有的图片信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
看看结果:

打印所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有一张百度首页logo的图片,图片的类(元素类名)为index-logo-src。
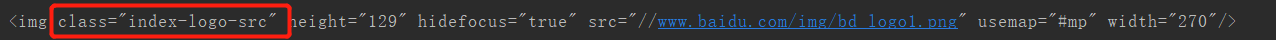
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:

获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
最终图像保存在'logo.png'

六、结论
本文以抓取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识,还有很多优秀的python爬虫库和框架有待以后学习。
当然,如果你掌握了本文讨论的知识点,你就已经开始使用python爬虫了。来吧,男孩!
这里有一个方便大家的python学习交流群:196872581免费领取学习路线、大纲、课程等资料

网页爬虫抓取百度图片(爬虫记录自己练习爬虫的始末,这次用下载图片展示主流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-29 03:27
爬虫笔记 [01]
一、前言
记录下自己爬虫练习的开始和结束,这次用下载的图片来展示主要过程。
二、 爬虫逻辑理解
网页上的几乎所有内容都在服务器上。在网上查东西时,类似于对服务器说:“我想看滑雪的照片”。服务器首先听到您的喊叫声,然后嗡嗡作响。开始向您发送带有代码的服务器滑雪图片和网页。数据当然是二进制的,所以你需要把数据编码成人类可以理解的东西。最后显示出你想要的图片,你可以下载保存到电脑中。
整个过程就是有人要东西,服务器听到有人要东西,服务器把东西发给你,你通过各种方式调出具体的内容。
三、 爬图
爬虫需要导入requests库,用于向服务器请求内容(发送请求)。os 库用于目录和文件操作,这是一个非常基础的操作。
# 导入使用的库
import requests
import os
在百度贴吧上找到了一张滑雪的图片,想下载。直接另存为很方便,不能手动存成1000张。
一、右键复制图片地址
# 图片地址存到变量中
imurl = 'http://tiebapic.baidu.com/forum/w%3D580%3B/sign=\ac30c67119f41bd5da53e8fc61e180cb/78310a55b319ebc4666b57c39526cffc1e17165c.jpg'
然后我们需要找到一个叫做“请求头”的东西,理解为个人名字,服务器需要知道是谁在请求这个东西,而user-agent主要收录浏览器的信息。因为爬虫是模拟成年人用电脑搜索内容的方式,如果user-agent不是浏览器的名字,很可能就是爬虫,会被拦截。
# 从浏览器中复制下来后,要用字典类型包起来,键值都是字符串类型
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
# 这里就是做一个向服务器要内容的请求,对应的连接和伪装的浏览器名字。
# imr是服务器对你请求的回答(响应),包含了图片数据在内的一些信息
imr = requests.get(url = imurl, headers = headers)
# 观察状态码,就是看服务器到底有没有理你,理你了就代表请求成功
# 如果是状态码是200,就代表服务器理你了
print(imr.status_code)
最终结论取决于编码是什么。如果编码不同,最终的信息就会乱七八糟。
# 一般utf8是正确的编码,常规操作是imr.encoding = imr.apparent_encoding
print(imr.encoding)
print(imr.apparent_coding)
# 查看当前操作目录,做一个新目录出来
cwd = os.getcwd()
print(cwd)
newpath = os.mkdir(cwd + '/spider')
path_photo = cwd + '/spider/snowboarding.png'
# 图片是二进制,所以用wb的模式进行写入
with open(pathn_photo, 'wb') as im:
im.write(imr.content)
最后我们下载了图片 查看全部
网页爬虫抓取百度图片(爬虫记录自己练习爬虫的始末,这次用下载图片展示主流程)
爬虫笔记 [01]
一、前言
记录下自己爬虫练习的开始和结束,这次用下载的图片来展示主要过程。
二、 爬虫逻辑理解
网页上的几乎所有内容都在服务器上。在网上查东西时,类似于对服务器说:“我想看滑雪的照片”。服务器首先听到您的喊叫声,然后嗡嗡作响。开始向您发送带有代码的服务器滑雪图片和网页。数据当然是二进制的,所以你需要把数据编码成人类可以理解的东西。最后显示出你想要的图片,你可以下载保存到电脑中。
整个过程就是有人要东西,服务器听到有人要东西,服务器把东西发给你,你通过各种方式调出具体的内容。
三、 爬图
爬虫需要导入requests库,用于向服务器请求内容(发送请求)。os 库用于目录和文件操作,这是一个非常基础的操作。
# 导入使用的库
import requests
import os
在百度贴吧上找到了一张滑雪的图片,想下载。直接另存为很方便,不能手动存成1000张。

一、右键复制图片地址

# 图片地址存到变量中
imurl = 'http://tiebapic.baidu.com/forum/w%3D580%3B/sign=\ac30c67119f41bd5da53e8fc61e180cb/78310a55b319ebc4666b57c39526cffc1e17165c.jpg'
然后我们需要找到一个叫做“请求头”的东西,理解为个人名字,服务器需要知道是谁在请求这个东西,而user-agent主要收录浏览器的信息。因为爬虫是模拟成年人用电脑搜索内容的方式,如果user-agent不是浏览器的名字,很可能就是爬虫,会被拦截。

# 从浏览器中复制下来后,要用字典类型包起来,键值都是字符串类型
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
# 这里就是做一个向服务器要内容的请求,对应的连接和伪装的浏览器名字。
# imr是服务器对你请求的回答(响应),包含了图片数据在内的一些信息
imr = requests.get(url = imurl, headers = headers)
# 观察状态码,就是看服务器到底有没有理你,理你了就代表请求成功
# 如果是状态码是200,就代表服务器理你了
print(imr.status_code)

最终结论取决于编码是什么。如果编码不同,最终的信息就会乱七八糟。
# 一般utf8是正确的编码,常规操作是imr.encoding = imr.apparent_encoding
print(imr.encoding)
print(imr.apparent_coding)
# 查看当前操作目录,做一个新目录出来
cwd = os.getcwd()
print(cwd)
newpath = os.mkdir(cwd + '/spider')
path_photo = cwd + '/spider/snowboarding.png'
# 图片是二进制,所以用wb的模式进行写入
with open(pathn_photo, 'wb') as im:
im.write(imr.content)
最后我们下载了图片
网页爬虫抓取百度图片( 上海海事大学‘发现链接变成第一个项目(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-29 03:26
上海海事大学‘发现链接变成第一个项目(组图))
爬虫训练项目1_爬行百度贴吧
前言
这是我开始学习爬虫时的第一个手工练习项目。在B站看到了一些教学视频,觉得挺有意思的,就决定跟上。
1、找到对方的c位置(确定要爬取的目标)
要抓取网页,首先需要知道网页的 url
首先用浏览器打开贴吧网页。
搜索“上海海事大学”
发现链接变为上海海事大学&fr=search
点击到第二页,再次观察url,发现多了一个pn=50的参数
尝试将pn=50改为pn=0,发现刚才访问的是第一页的内容。
于是找到规则,第一页pn=0,第二页pn=50,
那么第三页应该是pn=100,依此类推
至于另一个参数:ie=utf-8,可以删除
所以,我们需要访问的链接格式是
——&Pn=——
2、发起进攻(发送请求)
上一步我们已经知道要爬取的url
现在你需要发送请求
至于如何发送请求
我们需要安装一个库:请求库
pip 安装请求
然后导入这个库
import requests
然后开始构造url并存入列表
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
复制浏览器logo,放在headers中(有的网站会根据浏览器logo判断是否是爬虫,所以加个logo防止一)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
然后发送请求并保存页面
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
3、 攻击敌方水晶(完整代码)
"""
获取贴吧内容
"""
import requests
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
然后在pycharm中打开保存的网页并运行
和浏览器搜索到的网页一模一样
胜利
至此,你已经基本完成了学习爬虫的第一步
以后学爬的时候会慢慢更新其他的训练项目 查看全部
网页爬虫抓取百度图片(
上海海事大学‘发现链接变成第一个项目(组图))
爬虫训练项目1_爬行百度贴吧
前言
这是我开始学习爬虫时的第一个手工练习项目。在B站看到了一些教学视频,觉得挺有意思的,就决定跟上。

1、找到对方的c位置(确定要爬取的目标)
要抓取网页,首先需要知道网页的 url
首先用浏览器打开贴吧网页。

搜索“上海海事大学”
发现链接变为上海海事大学&fr=search

点击到第二页,再次观察url,发现多了一个pn=50的参数

尝试将pn=50改为pn=0,发现刚才访问的是第一页的内容。
于是找到规则,第一页pn=0,第二页pn=50,
那么第三页应该是pn=100,依此类推
至于另一个参数:ie=utf-8,可以删除
所以,我们需要访问的链接格式是
——&Pn=——
2、发起进攻(发送请求)
上一步我们已经知道要爬取的url
现在你需要发送请求
至于如何发送请求
我们需要安装一个库:请求库
pip 安装请求
然后导入这个库
import requests
然后开始构造url并存入列表
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
复制浏览器logo,放在headers中(有的网站会根据浏览器logo判断是否是爬虫,所以加个logo防止一)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}

然后发送请求并保存页面
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
3、 攻击敌方水晶(完整代码)
"""
获取贴吧内容
"""
import requests
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
然后在pycharm中打开保存的网页并运行


和浏览器搜索到的网页一模一样
胜利
至此,你已经基本完成了学习爬虫的第一步
以后学爬的时候会慢慢更新其他的训练项目
网页爬虫抓取百度图片(廖雪峰老师的python处理和复杂芜杂的网络框架给整崩溃了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-25 04:10
说些什么
其实一直对python这个语言很感兴趣,但是之前一直在做图像处理相关的事情,所以没怎么关注这种不能触及底层内存处理的语言,但是最近才真正用上通过 C++ 字符。字符串处理和复杂的网络框架崩溃了,看到大家都说python很好玩,所以趁着最近没事的时候学习了python。
昨天关注了廖雪峰老师的python教程(推荐基础教程)。看了基本的数据结构和逻辑后,我决定直接从一个实际的小项目来实践。最好的语言方式),所以就选择了一个比较简单的python爬虫项目来练习。
写爬虫最重要的就是了解我们平时访问的网页是什么。其实我们平时访问的网页源代码是一个字符串文件(当然也可以说是二进制文件)
每次我们在浏览器上输入一个网址,比如这个网址,浏览器会帮我们访问远程服务器,并根据绑定的ip地址发送请求,远程服务器会发送这个网页的源代码直接打包发送给我们的浏览器(html文件格式),然后我们的浏览器会解析这个字符串文件,比如通过div格式化和渲染网页,h1、h2 layouts 显示,继续发送请求给远程服务器为img这些资源获取图片,然后在网页上填写。
什么是爬虫
怎么说呢,爬虫,简单来说就是模拟浏览器获取一个网页的源代码。至于你用源代码做什么,没关系。
说的更复杂一点,爬虫其实就是对所有网页数据处理的综合,比如:自动抓取网页源代码,分析网页数据,获取关键数据并保存,或者自动下载需要的网页图片、音频,和视频。
那么当我们在写一个pythonm爬虫的时候,我们在写什么呢?
当我们需要爬虫的时候,一般会遇到比较复杂的数据需求。这个要求对于手工作业来说是非常复杂的。仅此要求就可以由爬虫轻松解决。
那么首先确定我们的需求,我们需要这个爬虫做什么?
比如我们认为一个教学网站的数据很有趣,但是它的格式太复杂,或者需要频繁翻页,不能通过复制粘贴轻易获取,爬虫就会起作用。
总之,我们以一个爬虫的例子来说明。
爬取百度图片ps:python版-Python 3.7.0
第一个爬虫当然不能选择太复杂的东西,涉及到很多复杂的网络规则,所以我们来爬一些网站,简单的让爬虫去爬。
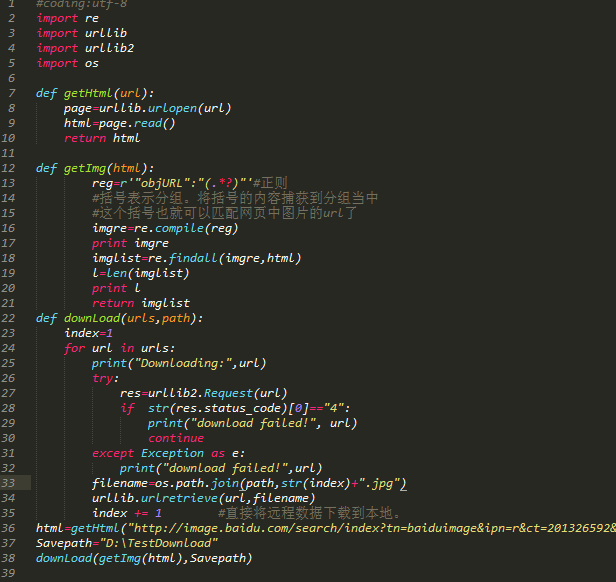
比如抓取下载关键词下的某百度图片的图片数据。
1、建立需求
暂时确定以上需求,然后开始写真正的爬虫代码
2、 观察网页源码
首先打开百度图片,随意搜索一个关键词。比如这次我会用我最喜欢的动漫角色栗山未来来测试
右键查看网页源码,可以看到每张图片的原创地址都是以一个简单的“objURL”开头,以一个小逗号结尾,如下:
基于此,我们可以确定爬虫应该如何运行。很简单——从网页源码中提取这些url并下载\(^o^)/~
3、获取网页源码
其实这一步我是不想写的,只是担心看了我博客刚学python的朋友可能会出错,所以说一下。
首先,我们需要在python中导入网络库urllib。因为我们需要用到的urlopen和read方法在我的python版本中,直接引用urllib会出错,所以一般使用这个import:import urllib.request
提取网页源代码的整个方法如下:
import urllib.request
def get_html(httpUrl):
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
我们可以将这个方法打包成一个py文件,然后直接在其他py文件中导入这个方法,然后直接使用我们写的get_html方法。
然后将上面得到的二进制文件解码成普通字符串:
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
4、提取图片地址
从网页的源代码中提取关键数据时,实际上是字符串匹配。如果这样估计C++累死我了,当然我也写过类似的,甚至更复杂的,真的是痛苦的回忆。
这里推荐一个比较简单的字符串搜索和匹配程序-正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE)
当然,如何使用正则表达式我就不多说了。你可以自己搜索每个视频网站,看个大概就够了,或者直接看这里——正则表达式基础
了解正则表达式的基本逻辑就可以了。
进入正题,上面的步骤已经分析到每张图片的原创地址开头都有一个很简单的“objURL”,所以我们正则化的关键就是把“objURL”后面的地址取出来。这个很简单,我直接把写好的正则表达式拿出来:
reg=r'"objURL":"(.*?)",'
ps:字符串前的r主要是为了防止转义字符丢失导致的字符丢失
这个规律的作用如下:
匹配任何以 "objURL":" 开头并以 ", 结尾的字符串
然后简单地编译这个正则(记得导入 re 包):
import re
reg=r'"objURL":"(.*?)",'
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
然后使用上面编译的正则表达式解析第三步得到的字符串,如下:
pic_list = reg_compile.findall(html_str)
上面的 pic_list 是一个简单的列表
输出列表中的数据:
for pic in pic_list:
print(pic)
输出如下:
http://b-ssl.duitang.com/uploa ... .jpeg
http://b-ssl.duitang.com/uploa ... .jpeg
http://cdnq.duitang.com/upload ... .jpeg
http://wxpic.7399.com/nqvaoZto ... cpNpu
http://i1.hdslb.com/bfs/archiv ... 0.jpg
http://wxpic.7399.com/nqvaoZto ... cpNpu
可以清楚的看到,有些地址不是图片地址。这可以说是我正则化的问题,但也无伤大雅(其实我也懒得改了)。一点判断就可以完美解决(由于所有图片地址都以g结尾,比如png、jpg、jpeg^_^)
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
完美解,w(゚Д゚)w
ps:哈哈哈,这里当然是玩笑了,大家记得想好办法改正,算是小测试,毕竟真的是无害的。
5、下载图片
下载图片也很简单。正如我开头所说的,图片实际上是存在于远程服务器上的图片文件。只要服务器允许,我们可以很容易的通过GET请求得到这张图片。毕竟,浏览器也会这样做。,至于你得到的,没人管它是用来实际填网页还是给自己用。
python中下载图片的方式有很多种,如下三种
(以下代码不是我写的,不知道版本对不对,如有错误请自行百度。第一种在我的版本中没有问题):
def urllib_download(url):
from urllib.request import urlretrieve
urlretrieve(url, '1.png')
def request_download(url):
import requests
r = requests.get(url)
with open('1.png', 'wb') as f:
f.write(r.content)
def chunk_download(url):
import requests
r = requests.get(url, stream=True)
with open('1.png', 'wb') as f:
for chunk in r.iter_content(chunk_size=32):
f.write(chunk)
所以我们只需要下载上面列表中的每个图片网址。我选择了上面的第一个。这是urllib.request中存在的一个方法,定义如下:
urllib.request.urlretrieve(url, filename, reporthook, data)
参数说明:
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
然后一个简单的循环下载就可以了:
def download_pic(pic_adr,x):
urllib.request.urlretrieve(pic_adr, '%s.jpg' %x)
# './images/%s.jpg',这里也可以自己选择创建一个文件吧所有图片放进去,而不是直接放在当前目录下
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
download_pic(pic,x)
x += 1
当然需要为每张图片选择一个本地名称,只需将名称增加1234即可。
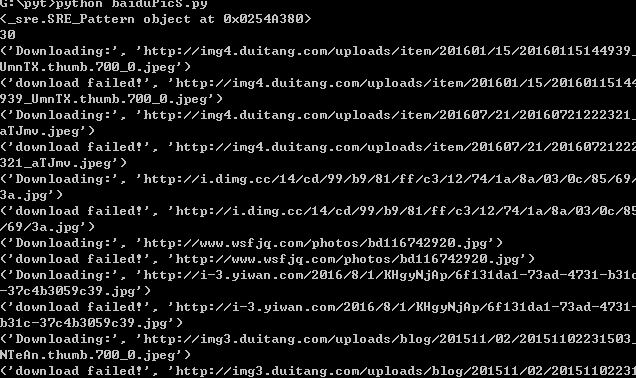
这样,我们就结束了整个爬取过程。执行后效果如下:
可以看到,效果还是不错的。毕竟,只要把它放在那里,让它自己下载。还可以考虑如何翻页的效果。事实上,这很简单。我就讲实现一个变化。关键词的效果提醒大家(其实是因为我有点懒,不想写了)
6、更改搜索关键词
看百度搜索页面的网址:
观察这个网址,我们很容易发现原来最后一个关键字是关键词。复制就改了,但是复制之后就不简单了:
http://image.baidu.com/search/ ... %25A5
为什么word变成%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5
这么一堆东西?
很简单,因为url是ASCII码,而这里我们用的是中文,只要稍微操作一下就可以转:
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
urllib.parse.quote 是解码后的代码,在最后加上关键字就OK了。
简单,这个简单的python爬虫就完成了。.
虽然还是想自己写字符串识别,但是regular真的好用。建议多学习一些常规的骚技能。
就这样。
如需修改,请自行复制完整代码并进行更改。下载多个页面也是很简单的操作,就不多说了,还是可以加多线程,代理,动态ip。无论如何,这就是我的第一个爬虫。
完整源码(百度图片爬虫)
import urllib
import time
from urllib.request import urlretrieve
import re
import urllib.request
def get_html(httpUrl):#获取网页源码
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
def get_keyword_urllist(keyword):#爬取当前关键词下的图片地址
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
pic_list = reg_compile.findall(html_str)
return pic_list
keyword="栗山未来"#自己修改,或者自己写个input或者一个txt自己读就完事了,甚至你写一个配置表,把爬取数量、爬取关键词、爬取图片大小都写好都可以
pic_list=get_keyword_urllist(keyword)
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
name = keyword+str(x)
time.sleep(0.01)
urllib.request.urlretrieve(pic, './images/%s.jpg' %name)
x += 1
如果不行,请检查收录的模板是否正确或版本是否正确。
重点
最后运行上面的源码,应该会发现虽然可以下载,但是下载速度太慢了。解决它需要几秒钟,但如果它更慢,则可能需要十秒钟以上。
针对这种情况,我重写了上面的代码,加入了多线程处理,将爬取时间缩短到1s以内。我是直接上传到我的github上的,大家可以自己下载。
快速爬取百度图片-爬虫1.0版 查看全部
网页爬虫抓取百度图片(廖雪峰老师的python处理和复杂芜杂的网络框架给整崩溃了)
说些什么
其实一直对python这个语言很感兴趣,但是之前一直在做图像处理相关的事情,所以没怎么关注这种不能触及底层内存处理的语言,但是最近才真正用上通过 C++ 字符。字符串处理和复杂的网络框架崩溃了,看到大家都说python很好玩,所以趁着最近没事的时候学习了python。
昨天关注了廖雪峰老师的python教程(推荐基础教程)。看了基本的数据结构和逻辑后,我决定直接从一个实际的小项目来实践。最好的语言方式),所以就选择了一个比较简单的python爬虫项目来练习。
写爬虫最重要的就是了解我们平时访问的网页是什么。其实我们平时访问的网页源代码是一个字符串文件(当然也可以说是二进制文件)
每次我们在浏览器上输入一个网址,比如这个网址,浏览器会帮我们访问远程服务器,并根据绑定的ip地址发送请求,远程服务器会发送这个网页的源代码直接打包发送给我们的浏览器(html文件格式),然后我们的浏览器会解析这个字符串文件,比如通过div格式化和渲染网页,h1、h2 layouts 显示,继续发送请求给远程服务器为img这些资源获取图片,然后在网页上填写。
什么是爬虫
怎么说呢,爬虫,简单来说就是模拟浏览器获取一个网页的源代码。至于你用源代码做什么,没关系。
说的更复杂一点,爬虫其实就是对所有网页数据处理的综合,比如:自动抓取网页源代码,分析网页数据,获取关键数据并保存,或者自动下载需要的网页图片、音频,和视频。
那么当我们在写一个pythonm爬虫的时候,我们在写什么呢?
当我们需要爬虫的时候,一般会遇到比较复杂的数据需求。这个要求对于手工作业来说是非常复杂的。仅此要求就可以由爬虫轻松解决。
那么首先确定我们的需求,我们需要这个爬虫做什么?
比如我们认为一个教学网站的数据很有趣,但是它的格式太复杂,或者需要频繁翻页,不能通过复制粘贴轻易获取,爬虫就会起作用。
总之,我们以一个爬虫的例子来说明。
爬取百度图片ps:python版-Python 3.7.0
第一个爬虫当然不能选择太复杂的东西,涉及到很多复杂的网络规则,所以我们来爬一些网站,简单的让爬虫去爬。
比如抓取下载关键词下的某百度图片的图片数据。
1、建立需求
暂时确定以上需求,然后开始写真正的爬虫代码
2、 观察网页源码
首先打开百度图片,随意搜索一个关键词。比如这次我会用我最喜欢的动漫角色栗山未来来测试
右键查看网页源码,可以看到每张图片的原创地址都是以一个简单的“objURL”开头,以一个小逗号结尾,如下:

基于此,我们可以确定爬虫应该如何运行。很简单——从网页源码中提取这些url并下载\(^o^)/~
3、获取网页源码
其实这一步我是不想写的,只是担心看了我博客刚学python的朋友可能会出错,所以说一下。
首先,我们需要在python中导入网络库urllib。因为我们需要用到的urlopen和read方法在我的python版本中,直接引用urllib会出错,所以一般使用这个import:import urllib.request
提取网页源代码的整个方法如下:
import urllib.request
def get_html(httpUrl):
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
我们可以将这个方法打包成一个py文件,然后直接在其他py文件中导入这个方法,然后直接使用我们写的get_html方法。
然后将上面得到的二进制文件解码成普通字符串:
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
4、提取图片地址
从网页的源代码中提取关键数据时,实际上是字符串匹配。如果这样估计C++累死我了,当然我也写过类似的,甚至更复杂的,真的是痛苦的回忆。
这里推荐一个比较简单的字符串搜索和匹配程序-正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE)
当然,如何使用正则表达式我就不多说了。你可以自己搜索每个视频网站,看个大概就够了,或者直接看这里——正则表达式基础
了解正则表达式的基本逻辑就可以了。
进入正题,上面的步骤已经分析到每张图片的原创地址开头都有一个很简单的“objURL”,所以我们正则化的关键就是把“objURL”后面的地址取出来。这个很简单,我直接把写好的正则表达式拿出来:
reg=r'"objURL":"(.*?)",'
ps:字符串前的r主要是为了防止转义字符丢失导致的字符丢失
这个规律的作用如下:
匹配任何以 "objURL":" 开头并以 ", 结尾的字符串
然后简单地编译这个正则(记得导入 re 包):
import re
reg=r'"objURL":"(.*?)",'
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
然后使用上面编译的正则表达式解析第三步得到的字符串,如下:
pic_list = reg_compile.findall(html_str)
上面的 pic_list 是一个简单的列表
输出列表中的数据:
for pic in pic_list:
print(pic)
输出如下:
http://b-ssl.duitang.com/uploa ... .jpeg
http://b-ssl.duitang.com/uploa ... .jpeg
http://cdnq.duitang.com/upload ... .jpeg
http://wxpic.7399.com/nqvaoZto ... cpNpu
http://i1.hdslb.com/bfs/archiv ... 0.jpg
http://wxpic.7399.com/nqvaoZto ... cpNpu
可以清楚的看到,有些地址不是图片地址。这可以说是我正则化的问题,但也无伤大雅(其实我也懒得改了)。一点判断就可以完美解决(由于所有图片地址都以g结尾,比如png、jpg、jpeg^_^)
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
完美解,w(゚Д゚)w
ps:哈哈哈,这里当然是玩笑了,大家记得想好办法改正,算是小测试,毕竟真的是无害的。
5、下载图片
下载图片也很简单。正如我开头所说的,图片实际上是存在于远程服务器上的图片文件。只要服务器允许,我们可以很容易的通过GET请求得到这张图片。毕竟,浏览器也会这样做。,至于你得到的,没人管它是用来实际填网页还是给自己用。
python中下载图片的方式有很多种,如下三种
(以下代码不是我写的,不知道版本对不对,如有错误请自行百度。第一种在我的版本中没有问题):
def urllib_download(url):
from urllib.request import urlretrieve
urlretrieve(url, '1.png')
def request_download(url):
import requests
r = requests.get(url)
with open('1.png', 'wb') as f:
f.write(r.content)
def chunk_download(url):
import requests
r = requests.get(url, stream=True)
with open('1.png', 'wb') as f:
for chunk in r.iter_content(chunk_size=32):
f.write(chunk)
所以我们只需要下载上面列表中的每个图片网址。我选择了上面的第一个。这是urllib.request中存在的一个方法,定义如下:
urllib.request.urlretrieve(url, filename, reporthook, data)
参数说明:
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
然后一个简单的循环下载就可以了:
def download_pic(pic_adr,x):
urllib.request.urlretrieve(pic_adr, '%s.jpg' %x)
# './images/%s.jpg',这里也可以自己选择创建一个文件吧所有图片放进去,而不是直接放在当前目录下
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
download_pic(pic,x)
x += 1
当然需要为每张图片选择一个本地名称,只需将名称增加1234即可。
这样,我们就结束了整个爬取过程。执行后效果如下:

可以看到,效果还是不错的。毕竟,只要把它放在那里,让它自己下载。还可以考虑如何翻页的效果。事实上,这很简单。我就讲实现一个变化。关键词的效果提醒大家(其实是因为我有点懒,不想写了)
6、更改搜索关键词
看百度搜索页面的网址:

观察这个网址,我们很容易发现原来最后一个关键字是关键词。复制就改了,但是复制之后就不简单了:
http://image.baidu.com/search/ ... %25A5
为什么word变成%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5
这么一堆东西?
很简单,因为url是ASCII码,而这里我们用的是中文,只要稍微操作一下就可以转:
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
urllib.parse.quote 是解码后的代码,在最后加上关键字就OK了。
简单,这个简单的python爬虫就完成了。.
虽然还是想自己写字符串识别,但是regular真的好用。建议多学习一些常规的骚技能。
就这样。
如需修改,请自行复制完整代码并进行更改。下载多个页面也是很简单的操作,就不多说了,还是可以加多线程,代理,动态ip。无论如何,这就是我的第一个爬虫。
完整源码(百度图片爬虫)
import urllib
import time
from urllib.request import urlretrieve
import re
import urllib.request
def get_html(httpUrl):#获取网页源码
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
def get_keyword_urllist(keyword):#爬取当前关键词下的图片地址
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
pic_list = reg_compile.findall(html_str)
return pic_list
keyword="栗山未来"#自己修改,或者自己写个input或者一个txt自己读就完事了,甚至你写一个配置表,把爬取数量、爬取关键词、爬取图片大小都写好都可以
pic_list=get_keyword_urllist(keyword)
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
name = keyword+str(x)
time.sleep(0.01)
urllib.request.urlretrieve(pic, './images/%s.jpg' %name)
x += 1
如果不行,请检查收录的模板是否正确或版本是否正确。
重点
最后运行上面的源码,应该会发现虽然可以下载,但是下载速度太慢了。解决它需要几秒钟,但如果它更慢,则可能需要十秒钟以上。
针对这种情况,我重写了上面的代码,加入了多线程处理,将爬取时间缩短到1s以内。我是直接上传到我的github上的,大家可以自己下载。
快速爬取百度图片-爬虫1.0版
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-19 20:02
对于网站webmaster来说,反爬虫是一项非常重要的工作——没有人想让爬虫占据超过一半的宽带
只有百度爬虫是个例外。对于站长来说,一篇文章文章被百度收录证明得越快,其优化效果就越显著
那么百度爬虫的捕获规则是什么呢?让我们今天来看看
一、高质量连续内容更新
用户和百度爬虫都对枯燥的内容非常感兴趣,能够持续更新并确保更新内容质量的网站当然比那些多年不更新或更新原创内容的网站更具吸引力
二、高质量外链
这是网站提高排名的重要一步。对于百度来说,大流量网站的权重必须高于小流量网站的权重。如果我们的网站外链是一个流量大的门户网站网站的话,通常这个门户网站网站在百度也会有很高的权重,也就是说,它间接提高了我们自己的网站曝光率,增加了百度爬虫抓取其网站内容的可能性
三、优质内链
在构建爬虫捕获矩阵(或“Web”)时,除了延伸的高质量外链,我们网站内链的质量也决定了百度爬虫收录的可能性和速度@文章. 百度爬虫将跟随网站导航和网站内页锚文本连接进入网站内页。简明的导航允许爬虫更快地找到内部页面的锚文本。这样,百度不仅可以接收目标页面的内容,还可以收录接收路径上的所有页面
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录a文章of网站吸引了大量流量,但大量前来访问网站的用户由于网站空间不足而无法打开网页,甚至无法打开百度爬虫,无疑会降低百度对该网站的权重分布@ 查看全部
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
对于网站webmaster来说,反爬虫是一项非常重要的工作——没有人想让爬虫占据超过一半的宽带
只有百度爬虫是个例外。对于站长来说,一篇文章文章被百度收录证明得越快,其优化效果就越显著
那么百度爬虫的捕获规则是什么呢?让我们今天来看看

一、高质量连续内容更新
用户和百度爬虫都对枯燥的内容非常感兴趣,能够持续更新并确保更新内容质量的网站当然比那些多年不更新或更新原创内容的网站更具吸引力
二、高质量外链
这是网站提高排名的重要一步。对于百度来说,大流量网站的权重必须高于小流量网站的权重。如果我们的网站外链是一个流量大的门户网站网站的话,通常这个门户网站网站在百度也会有很高的权重,也就是说,它间接提高了我们自己的网站曝光率,增加了百度爬虫抓取其网站内容的可能性
三、优质内链
在构建爬虫捕获矩阵(或“Web”)时,除了延伸的高质量外链,我们网站内链的质量也决定了百度爬虫收录的可能性和速度@文章. 百度爬虫将跟随网站导航和网站内页锚文本连接进入网站内页。简明的导航允许爬虫更快地找到内部页面的锚文本。这样,百度不仅可以接收目标页面的内容,还可以收录接收路径上的所有页面
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录a文章of网站吸引了大量流量,但大量前来访问网站的用户由于网站空间不足而无法打开网页,甚至无法打开百度爬虫,无疑会降低百度对该网站的权重分布@
网页爬虫抓取百度图片( java开发修真院,初学者不再的数据有什么用和搜索引擎结合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-19 19:26
java开发修真院,初学者不再的数据有什么用和搜索引擎结合)
1.什么是爬行动物
爬虫,也被称为网络爬虫,是一个自动程序或脚本运行在互联网上获取数据
2.爬行动物解决了什么问题
爬虫解决了获取数据的问题
3.crawler抓取的数据有什么用途
结合搜索引擎,对数据进行分析,提取有价值的信息,得到数据的商业价值
4.爬行动物的简单分类
通用爬虫:百度抓取互联网上所有数据的爬虫称为通用爬虫
垂直爬虫:为数据分析而爬虫特定数据的爬虫称为垂直爬虫
摘要:在互联网上,大多数都是垂直爬虫,也就是说,通过值爬虫来获取一定范围内的数据
首先,以百度主页为例,通过HTTP get获取百度主页的内容
百度页面源代码
临时要求:
获取百度徽标中的大熊爪图片链接
一.enclosure-get方法
经营成果:
index.html
是的,这是我们的第一个常规代码
通过这种方式,捕获图片的链接必须很方便
我们将常规匹配封装到一个函数中,然后修改代码如下:
只要抓住SRC=“XXXXXX”字符串,就可以抓住整个SRC链接,因此可以使用一个简单的正则语句:SRC=\“(.+?)\”
完整代码如下:
“我们相信,每个人都可以成为java开发的伟大之神。从现在开始,找一位师兄来介绍你。在学习的过程中,你将不再迷茫。这是java开发学院,初学者可以在这里转行到互联网行业。”
"我是一名从事开发多年的老java程序员。我辞职了,目前正在学习自己的java私人定制课程。今年年初,我花了一个月的时间整理了一个最适合2019年学习的java learning dry产品。我整理了从最基本的javase到spring等各种框架给每个Java合作伙伴。如果你想得到它,你可以关注我的头条新闻,并在给我的私人信件中发布:Java,你可以免费得到它 查看全部
网页爬虫抓取百度图片(
java开发修真院,初学者不再的数据有什么用和搜索引擎结合)

1.什么是爬行动物
爬虫,也被称为网络爬虫,是一个自动程序或脚本运行在互联网上获取数据
2.爬行动物解决了什么问题
爬虫解决了获取数据的问题
3.crawler抓取的数据有什么用途
结合搜索引擎,对数据进行分析,提取有价值的信息,得到数据的商业价值
4.爬行动物的简单分类
通用爬虫:百度抓取互联网上所有数据的爬虫称为通用爬虫
垂直爬虫:为数据分析而爬虫特定数据的爬虫称为垂直爬虫
摘要:在互联网上,大多数都是垂直爬虫,也就是说,通过值爬虫来获取一定范围内的数据

首先,以百度主页为例,通过HTTP get获取百度主页的内容



百度页面源代码
临时要求:
获取百度徽标中的大熊爪图片链接
一.enclosure-get方法



经营成果:
index.html
是的,这是我们的第一个常规代码
通过这种方式,捕获图片的链接必须很方便
我们将常规匹配封装到一个函数中,然后修改代码如下:


只要抓住SRC=“XXXXXX”字符串,就可以抓住整个SRC链接,因此可以使用一个简单的正则语句:SRC=\“(.+?)\”
完整代码如下:


“我们相信,每个人都可以成为java开发的伟大之神。从现在开始,找一位师兄来介绍你。在学习的过程中,你将不再迷茫。这是java开发学院,初学者可以在这里转行到互联网行业。”
"我是一名从事开发多年的老java程序员。我辞职了,目前正在学习自己的java私人定制课程。今年年初,我花了一个月的时间整理了一个最适合2019年学习的java learning dry产品。我整理了从最基本的javase到spring等各种框架给每个Java合作伙伴。如果你想得到它,你可以关注我的头条新闻,并在给我的私人信件中发布:Java,你可以免费得到它
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-17 19:09
)
Python项目中的爬虫应用案例开发从入门到实战(清华大学出版社郑秋生、夏雅捷主编)-抓拍百度图片
本文使用请求库对网站图片进行爬网。前几章中的博客介绍了如何使用urllib库抓取网页。本文主要利用请求库对网页内容进行抓取。使用方法基本相同,但请求方法相对简单
不要忘记爬行动物的基本概念:
1.指定要抓取的链接,然后抓取网站源代码
2.提取您想要的内容。例如,如果要对图像信息进行爬网,可以选择使用正则表达式过滤或使用提取
标记法
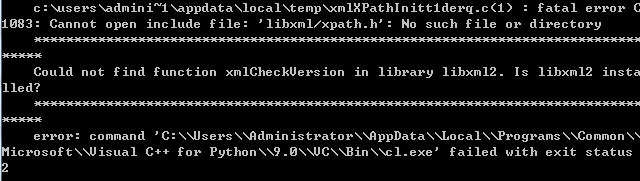
3.cycle获取要爬网的内容列表并保存文件
这里的代码与我的博客(photo crawler series一))前几章的区别在于:
1.提取网页使用请求库
2.保存图片时,后缀不是PNG或JPG,而是图片本身的后缀
3.不使用urllib.request.urlretrieve函数保存图片,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
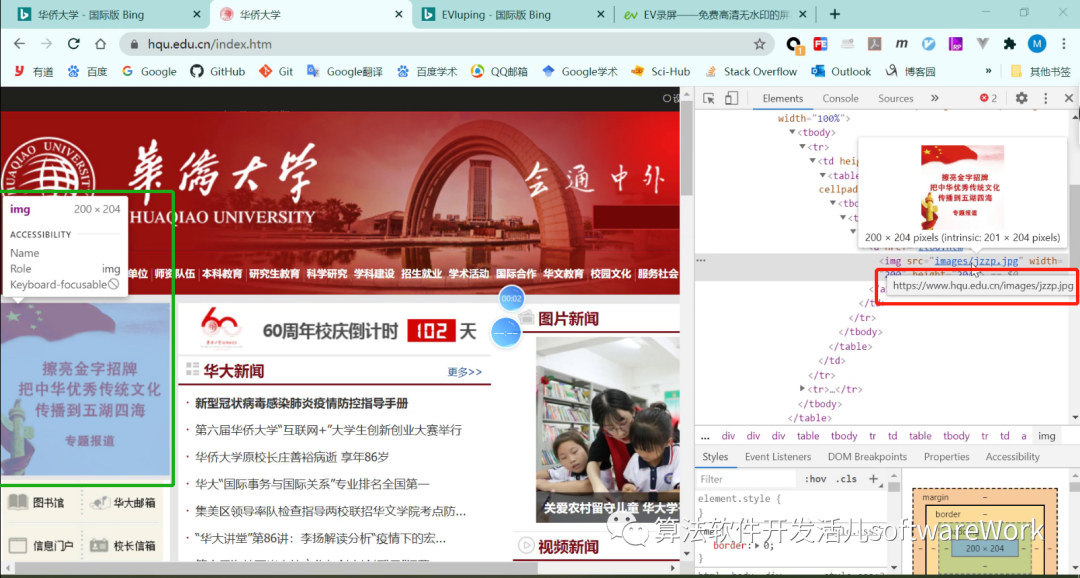
请注意,为什么在开始时判断图片链接是否来自“HTTPS://”,主要是因为我们需要完整的绝对路径来下载图片,并且我们需要查看原创网页代码。选择图片,点击html所在的代码,按住鼠标查看绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图所示:
查看全部
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生)
)
Python项目中的爬虫应用案例开发从入门到实战(清华大学出版社郑秋生、夏雅捷主编)-抓拍百度图片
本文使用请求库对网站图片进行爬网。前几章中的博客介绍了如何使用urllib库抓取网页。本文主要利用请求库对网页内容进行抓取。使用方法基本相同,但请求方法相对简单
不要忘记爬行动物的基本概念:
1.指定要抓取的链接,然后抓取网站源代码
2.提取您想要的内容。例如,如果要对图像信息进行爬网,可以选择使用正则表达式过滤或使用提取
标记法
3.cycle获取要爬网的内容列表并保存文件
这里的代码与我的博客(photo crawler series一))前几章的区别在于:
1.提取网页使用请求库
2.保存图片时,后缀不是PNG或JPG,而是图片本身的后缀
3.不使用urllib.request.urlretrieve函数保存图片,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
请注意,为什么在开始时判断图片链接是否来自“HTTPS://”,主要是因为我们需要完整的绝对路径来下载图片,并且我们需要查看原创网页代码。选择图片,点击html所在的代码,按住鼠标查看绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图所示:
网页爬虫抓取百度图片(《百度热点新闻上》第6期 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-17 19:06
)
在百度热点新闻中,前6条在strong>A下抓取,后30条在各子栏目(国内、国际、本地、娱乐、体育等)下抓取,抓取的特征值为标签下的mon值,C=栏目名称,PN=各栏目下的新闻条数,12个项目显示在一个类别下(8个本地新闻项目),只需查看原创网页即可
完整代码如下所示
import requests
from bs4 import BeautifulSoup
import time
url='http://news.baidu.com/'
res=requests.get(url)
soup = BeautifulSoup(res.text,'lxml')
print('百度新闻python爬虫抓取')
print('头条热点新闻')
sel_a =soup.select('strong a')
for i in range(0,5):
print(sel_a[i].get_text())
print(sel_a[i].get('href'))
print('热点新闻')
titles_b=[]
titlew=""
for i in range(1,31):
sel_b=soup.find_all('a',mon="ct=1&a=2&c=top&pn="+str(i))
titles_b.append(sel_b[0])
for i in range(0,30):
print(titles_b[i].get_text())
print(titles_b[i].get('href'))
titlew=titlew + titles_b[i].get_text() + "\n"
# 获取当前时间
now = time.strftime('%Y-%m-%d', time.localtime(time.time()))
# 输出到文件
with open('news' + now + '.txt', 'a', encoding='utf-8') as file:
file.write(titlew) #只输出标题
在浏览过程中,您可以直接将网页下载到本地进行调试。代码如下:
with open('本地文件路径',encoding='utf-8') as f:
# print(f.read())
soup = BeautifulSoup(f,'lxml') 查看全部
网页爬虫抓取百度图片(《百度热点新闻上》第6期
)
在百度热点新闻中,前6条在strong>A下抓取,后30条在各子栏目(国内、国际、本地、娱乐、体育等)下抓取,抓取的特征值为标签下的mon值,C=栏目名称,PN=各栏目下的新闻条数,12个项目显示在一个类别下(8个本地新闻项目),只需查看原创网页即可
完整代码如下所示
import requests
from bs4 import BeautifulSoup
import time
url='http://news.baidu.com/'
res=requests.get(url)
soup = BeautifulSoup(res.text,'lxml')
print('百度新闻python爬虫抓取')
print('头条热点新闻')
sel_a =soup.select('strong a')
for i in range(0,5):
print(sel_a[i].get_text())
print(sel_a[i].get('href'))
print('热点新闻')
titles_b=[]
titlew=""
for i in range(1,31):
sel_b=soup.find_all('a',mon="ct=1&a=2&c=top&pn="+str(i))
titles_b.append(sel_b[0])
for i in range(0,30):
print(titles_b[i].get_text())
print(titles_b[i].get('href'))
titlew=titlew + titles_b[i].get_text() + "\n"
# 获取当前时间
now = time.strftime('%Y-%m-%d', time.localtime(time.time()))
# 输出到文件
with open('news' + now + '.txt', 'a', encoding='utf-8') as file:
file.write(titlew) #只输出标题
在浏览过程中,您可以直接将网页下载到本地进行调试。代码如下:
with open('本地文件路径',encoding='utf-8') as f:
# print(f.read())
soup = BeautifulSoup(f,'lxml')
网页爬虫抓取百度图片(用python访问直接Fobbiden!真小气qwq最后还是乖乖去爬zol上的壁纸)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-17 12:14
根据老师的指导,我昨天开始自学爬虫入门
虽然我意识到了一个相对简单的小爬虫,但我还是很兴奋。我真的很高兴第一次意识到这一点
起初,我想爬上pexel的墙纸,但我发现对方的网页不知道设置了什么。无论如何,有一个反爬虫机制,我使用Python直接访问fobbiden!多么小气的qwq
最后,我爬上了ZOL的墙纸
之前:
当设计一个爬虫项目时,我们应该首先阐明手动浏览页面以获取大脑中图片的步骤
一般来说,当我们批量在线打开壁纸时,一般操作如下:
1、打开墙纸页
2、单击墙纸贴图(打开指定墙纸的页面)
3、选择分辨率(我们想下载高清图片)
4、save图片
在实际操作中,我们实现了以下步骤来访问网页地址:打开网页的壁纸→ 单击墙纸贴图打开指定页面→ 选择分辨率,单击打开最终保存的目标图像的网页→ 保存图像
在抓取过程中,我们尝试通过模拟浏览器的操作来打开网页,一步一步地获取并访问网页,最后获取目标图像的下载地址,将图像下载并保存到指定路径
*为了在这些中间过程中构建网页的某些特定过滤条件,有必要打开指定页面的源代码,观察并找到收录有目的链接的标记
具体实施项目和说明
这里我只是想得到一些指定的图片,所以我首先搜索了“昌门有喜”的网页,打开了一个搜索结果页面,发现这个页面上还收录了其他相同类型的壁纸链接,所以我从一开始就将我第一次访问的目的地地址设置为这个搜索结果页面
目标结果页面的屏幕截图:
图中的下标为“1/29”和“2/29”是相同类型的其他目标壁纸。通过单击这些图片,我们可以打开一个新的目标下载图片页面
这里我们看一下网页的源代码
图的黄色底部是这些类似墙纸的目标地址(访问时需要添加前缀“”)
现在我们可以尝试实现构建爬虫程序:
打开指定的页面→ 过滤并获取所有昌门优喜壁纸的目标下载页面链接
代码如下:
1 from urllib import request,error
2 import re
3
4 url = "http://desk.zol.com.cn/bizhi/561_5496_2.html"
5
6 try:
7 response = request.urlopen(url)# 打开页面
8 html = response.read() #此时是byte类型
9 html = str(html) # 转换成字符串
10
11 pattern = re.compile(r'.*?</a>')
12 imglist = re.findall(pattern,html) # 匹配<a>标签中的href地址
13 truelist = []
14 for item in imglist:
15 if re.match(r'^\/bizhi\/561_',item): # 观察到所有目的地址下载页面前缀都是/bizhi/561_,通过match函数进行筛选
16 truelist.append(item)# 筛选掉其他无关的页面(把真的目标页面加到truelist列表中)
17 except error.HTTPError as e:
18 print(e.reason)
19 except error.URLError as e:
20 print(e.reason)
21 except:
22 pass
在获得地址后,我们可以获得地址→ 打开指定的页面→ 选择分辨率→ 获取目标下载地址→ 保存到本地指定路径
在测试期间,我输出了在信任列表的前一步中保存的内容
您可以看到只保存了一个后缀。我们需要在访问时添加指定的前缀
实施代码(见***代码):
<p> 1 # 对于每一张地址,抓取其地址并且下载到本地
2 x=0
3 for wallpaperpage in truelist:
4 try:
5 # print(wallpaperpage)
6 url1 = "http://desk.zol.com.cn" + wallpaperpage
7 response1 = request.urlopen(url1) # 打开壁纸的页面,相当于在浏览器中单击壁纸名
8 html1 = response1.read()
9 html1 = str(html1)
10 pattern1 = re.compile(r'.*</a>')
11 urllist = re.findall(pattern1,html1) #匹配<a>标签中的id为1920 * 1080的地址,相当于在浏览器中选择1920*1080分辨率
12 html2 = str(request.urlopen("http://desk.zol.com.cn"+urllist[0]).read()) # 打开网页
13
14 pattern2 = re.compile(r' 查看全部
网页爬虫抓取百度图片(用python访问直接Fobbiden!真小气qwq最后还是乖乖去爬zol上的壁纸)
根据老师的指导,我昨天开始自学爬虫入门
虽然我意识到了一个相对简单的小爬虫,但我还是很兴奋。我真的很高兴第一次意识到这一点
起初,我想爬上pexel的墙纸,但我发现对方的网页不知道设置了什么。无论如何,有一个反爬虫机制,我使用Python直接访问fobbiden!多么小气的qwq
最后,我爬上了ZOL的墙纸
之前:
当设计一个爬虫项目时,我们应该首先阐明手动浏览页面以获取大脑中图片的步骤
一般来说,当我们批量在线打开壁纸时,一般操作如下:
1、打开墙纸页
2、单击墙纸贴图(打开指定墙纸的页面)
3、选择分辨率(我们想下载高清图片)
4、save图片
在实际操作中,我们实现了以下步骤来访问网页地址:打开网页的壁纸→ 单击墙纸贴图打开指定页面→ 选择分辨率,单击打开最终保存的目标图像的网页→ 保存图像
在抓取过程中,我们尝试通过模拟浏览器的操作来打开网页,一步一步地获取并访问网页,最后获取目标图像的下载地址,将图像下载并保存到指定路径
*为了在这些中间过程中构建网页的某些特定过滤条件,有必要打开指定页面的源代码,观察并找到收录有目的链接的标记
具体实施项目和说明
这里我只是想得到一些指定的图片,所以我首先搜索了“昌门有喜”的网页,打开了一个搜索结果页面,发现这个页面上还收录了其他相同类型的壁纸链接,所以我从一开始就将我第一次访问的目的地地址设置为这个搜索结果页面
目标结果页面的屏幕截图:

图中的下标为“1/29”和“2/29”是相同类型的其他目标壁纸。通过单击这些图片,我们可以打开一个新的目标下载图片页面
这里我们看一下网页的源代码

图的黄色底部是这些类似墙纸的目标地址(访问时需要添加前缀“”)
现在我们可以尝试实现构建爬虫程序:
打开指定的页面→ 过滤并获取所有昌门优喜壁纸的目标下载页面链接
代码如下:
1 from urllib import request,error
2 import re
3
4 url = "http://desk.zol.com.cn/bizhi/561_5496_2.html"
5
6 try:
7 response = request.urlopen(url)# 打开页面
8 html = response.read() #此时是byte类型
9 html = str(html) # 转换成字符串
10
11 pattern = re.compile(r'.*?</a>')
12 imglist = re.findall(pattern,html) # 匹配<a>标签中的href地址
13 truelist = []
14 for item in imglist:
15 if re.match(r'^\/bizhi\/561_',item): # 观察到所有目的地址下载页面前缀都是/bizhi/561_,通过match函数进行筛选
16 truelist.append(item)# 筛选掉其他无关的页面(把真的目标页面加到truelist列表中)
17 except error.HTTPError as e:
18 print(e.reason)
19 except error.URLError as e:
20 print(e.reason)
21 except:
22 pass
在获得地址后,我们可以获得地址→ 打开指定的页面→ 选择分辨率→ 获取目标下载地址→ 保存到本地指定路径
在测试期间,我输出了在信任列表的前一步中保存的内容

您可以看到只保存了一个后缀。我们需要在访问时添加指定的前缀
实施代码(见***代码):
<p> 1 # 对于每一张地址,抓取其地址并且下载到本地
2 x=0
3 for wallpaperpage in truelist:
4 try:
5 # print(wallpaperpage)
6 url1 = "http://desk.zol.com.cn" + wallpaperpage
7 response1 = request.urlopen(url1) # 打开壁纸的页面,相当于在浏览器中单击壁纸名
8 html1 = response1.read()
9 html1 = str(html1)
10 pattern1 = re.compile(r'.*</a>')
11 urllist = re.findall(pattern1,html1) #匹配<a>标签中的id为1920 * 1080的地址,相当于在浏览器中选择1920*1080分辨率
12 html2 = str(request.urlopen("http://desk.zol.com.cn"+urllist[0]).read()) # 打开网页
13
14 pattern2 = re.compile(r'
网页爬虫抓取百度图片(本次做的爬虫实例比较简单,晚上回来的时间用来码代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-16 06:16
)
最近,我在互联网上看到了文章爬虫的引入。我觉得很有趣。搬家总比搬家好。晚上回来的时间只是用来编码的~~
网络爬虫:根据一定的规则对网页上的信息进行爬网,通常先爬网到一些URL,然后将这些URL放入队列中进行反复搜索。我不知道是DFS还是BFS。我在这里不研究算法,因为爬虫示例相对简单。我实现了一个java小程序来抓取百度页面的徽标
事实上,爬虫的作用远远大于此。此示例仅供介绍性参考
首先,让我们分析一下,在本例中,抓取图片的过程只不过是以下步骤:
1.访问百度主页获取网页返回的信息
2.get有用信息(这里是网页的源代码或所有图片的URL)
3.访问所有图片的URL
4.可以以流的形式本地存储
通过以上步骤,很容易编写一个简单的爬虫程序。下面是代码中带有注释的代码
<p>import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Bug {
String url = "http://www.baidu.com";//待爬取的URL
//获取url页面的源码;
public String ClimbBug() throws IOException{
URL accessurl = new URL(url);
HttpURLConnection conn = (HttpURLConnection) accessurl.openConnection();
conn.connect();//连接
InputStream is = null;
if(conn.getResponseCode()==200){//判断状态吗是否为200,正常的话获取返回信息
byte[] b=new byte[4096];
is = conn.getInputStream();
StringBuilder sb = new StringBuilder();
int len=0;
while((len=is.read(b))!=-1){
sb.append(new String(b,0,len,"UTF-8"));
}
return sb.toString();//返回百度页面源代码,这里跟网页上右键查看源代码的效果一致
}
return "Error";
}
//获取图片页面URL
public List regex() throws IOException{
System.out.println(new Bug().ClimbBug());
String regex = "src[\\s\\S]*?>";//匹配所有图片的URL
List list = new ArrayList();
Matcher p = Pattern.compile(regex).matcher(new Bug().ClimbBug());
while(p.find()){
list.add(p.group());
}//匹配到放入我们的URLlist
return list;
}
//下载图片到本地或者结合数据库做其他想做的操作;
public void download(List list) throws IOException{
InputStream is =null;
OutputStream os =null;
for (int i=0;i 查看全部
网页爬虫抓取百度图片(本次做的爬虫实例比较简单,晚上回来的时间用来码代码
)
最近,我在互联网上看到了文章爬虫的引入。我觉得很有趣。搬家总比搬家好。晚上回来的时间只是用来编码的~~
网络爬虫:根据一定的规则对网页上的信息进行爬网,通常先爬网到一些URL,然后将这些URL放入队列中进行反复搜索。我不知道是DFS还是BFS。我在这里不研究算法,因为爬虫示例相对简单。我实现了一个java小程序来抓取百度页面的徽标
事实上,爬虫的作用远远大于此。此示例仅供介绍性参考
首先,让我们分析一下,在本例中,抓取图片的过程只不过是以下步骤:
1.访问百度主页获取网页返回的信息
2.get有用信息(这里是网页的源代码或所有图片的URL)
3.访问所有图片的URL
4.可以以流的形式本地存储
通过以上步骤,很容易编写一个简单的爬虫程序。下面是代码中带有注释的代码
<p>import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Bug {
String url = "http://www.baidu.com";//待爬取的URL
//获取url页面的源码;
public String ClimbBug() throws IOException{
URL accessurl = new URL(url);
HttpURLConnection conn = (HttpURLConnection) accessurl.openConnection();
conn.connect();//连接
InputStream is = null;
if(conn.getResponseCode()==200){//判断状态吗是否为200,正常的话获取返回信息
byte[] b=new byte[4096];
is = conn.getInputStream();
StringBuilder sb = new StringBuilder();
int len=0;
while((len=is.read(b))!=-1){
sb.append(new String(b,0,len,"UTF-8"));
}
return sb.toString();//返回百度页面源代码,这里跟网页上右键查看源代码的效果一致
}
return "Error";
}
//获取图片页面URL
public List regex() throws IOException{
System.out.println(new Bug().ClimbBug());
String regex = "src[\\s\\S]*?>";//匹配所有图片的URL
List list = new ArrayList();
Matcher p = Pattern.compile(regex).matcher(new Bug().ClimbBug());
while(p.find()){
list.add(p.group());
}//匹配到放入我们的URLlist
return list;
}
//下载图片到本地或者结合数据库做其他想做的操作;
public void download(List list) throws IOException{
InputStream is =null;
OutputStream os =null;
for (int i=0;i
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-16 06:14
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。(来源:百度百科全书)
爬虫协议
robots协议(也称为crawler协议、robot协议等)的全称为“robots exclusion protocol”,网站通过该协议,robots协议告诉搜索引擎哪些页面可以爬网,哪些页面不能爬网
robots.txt文件是一个文本文件。您可以使用任何通用文本编辑器(如Windows系统附带的记事本)创建和编辑它。Robots.txt是一个协议,不是命令。Robots.txt是在搜索引擎中访问网站时查看的第一个文件。txt文件告诉爬行器可以在服务器上查看哪些文件。(来源:百度百科全书)
爬虫百度图片
目标:抓取百度图片并保存在电脑上
首先,数据是公开的吗?我可以下载吗
从图中可以看出,百度图片完全可以下载,说明图片可以爬网
首先,了解图片是什么
我们看到的正式事物统称为图片、照片、拓片等。图形是技术制图中的一个基本术语,指用点、线、符号、文字和数字来描述事物的几何特征、形状、位置和大小的一种形式。随着数字采集技术和信号处理理论的发展,越来越多的图像以数字形式存储
那照片在哪里
映像保存在ECS数据库中
每张图片都有一个对应的URL。请求通过请求模块启动,并以文件的WB+模式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是任何编写代码来爬升图片的人都可以直接下载。爬虫的目的是实现批量下载的目的,这才是真正的爬虫
首先,了解JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于ECMAScript(由欧洲计算机协会制定的JS规范)的子集,并使用完全独立于编程语言的文本格式来存储和表示数据。简洁清晰的层次结构使JSON成为理想的数据交换语言
JSON是JS的对象,用于访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在Python中,不能通过键值对直接获取值,因此我必须讨论Python中的字典
在Python中导入JSON,并通过JSON将JSON数据转换为Python数据(字典)。装载量-->
Ajax,即“异步JavaScript和XML”,是指一种用于创建交互式网页应用程序的网页开发技术
图片是通过Ajax方法加载的,也就是说,当我下拉时,图片会自动加载,因为网站会自动启动请求
构造Ajax的URL请求,将JSON转换成字典,通过字典的键值对得到图片对应的URL
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个JSON中有30张图片,因此我们可以通过启动JSON请求来提升多达30张图片,但这还不够
首先,分析在不同JSON中启动的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
事实上,可以发现,当请求再次启动时,关键是PN不断变化
最后,封装代码。一个列表定义生产者来存储不断生成的图片的URL,另一个列表定义消费者来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬行过程
爬网结果
文章开始于: 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。(来源:百度百科全书)
爬虫协议
robots协议(也称为crawler协议、robot协议等)的全称为“robots exclusion protocol”,网站通过该协议,robots协议告诉搜索引擎哪些页面可以爬网,哪些页面不能爬网
robots.txt文件是一个文本文件。您可以使用任何通用文本编辑器(如Windows系统附带的记事本)创建和编辑它。Robots.txt是一个协议,不是命令。Robots.txt是在搜索引擎中访问网站时查看的第一个文件。txt文件告诉爬行器可以在服务器上查看哪些文件。(来源:百度百科全书)
爬虫百度图片
目标:抓取百度图片并保存在电脑上
首先,数据是公开的吗?我可以下载吗
从图中可以看出,百度图片完全可以下载,说明图片可以爬网
首先,了解图片是什么
我们看到的正式事物统称为图片、照片、拓片等。图形是技术制图中的一个基本术语,指用点、线、符号、文字和数字来描述事物的几何特征、形状、位置和大小的一种形式。随着数字采集技术和信号处理理论的发展,越来越多的图像以数字形式存储
那照片在哪里
映像保存在ECS数据库中
每张图片都有一个对应的URL。请求通过请求模块启动,并以文件的WB+模式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是任何编写代码来爬升图片的人都可以直接下载。爬虫的目的是实现批量下载的目的,这才是真正的爬虫
首先,了解JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于ECMAScript(由欧洲计算机协会制定的JS规范)的子集,并使用完全独立于编程语言的文本格式来存储和表示数据。简洁清晰的层次结构使JSON成为理想的数据交换语言
JSON是JS的对象,用于访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在Python中,不能通过键值对直接获取值,因此我必须讨论Python中的字典
在Python中导入JSON,并通过JSON将JSON数据转换为Python数据(字典)。装载量-->
Ajax,即“异步JavaScript和XML”,是指一种用于创建交互式网页应用程序的网页开发技术
图片是通过Ajax方法加载的,也就是说,当我下拉时,图片会自动加载,因为网站会自动启动请求
构造Ajax的URL请求,将JSON转换成字典,通过字典的键值对得到图片对应的URL
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个JSON中有30张图片,因此我们可以通过启动JSON请求来提升多达30张图片,但这还不够
首先,分析在不同JSON中启动的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
事实上,可以发现,当请求再次启动时,关键是PN不断变化
最后,封装代码。一个列表定义生产者来存储不断生成的图片的URL,另一个列表定义消费者来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬行过程
爬网结果
文章开始于:
网页爬虫抓取百度图片( ,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-16 06:11
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
Java中使用爬虫捕获网站网页内容的方法
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了用Java-crawler捕获网站网页内容的方法,并结合实例分析了Java-crawler的两种实现技巧,具有一定的参考价值。有需要的朋友可以参考
本文描述了在Java中使用爬虫捕获网站网页内容的方法。与您分享,供您参考。详情如下:
最近,我在用java学习爬行技术。哈哈,我进门和你分享了我的经历
提供以下两种方法。一种是使用Apache提供的包。另一个是使用Java提供的包
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
网页爬虫抓取百度图片(
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
Java中使用爬虫捕获网站网页内容的方法
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了用Java-crawler捕获网站网页内容的方法,并结合实例分析了Java-crawler的两种实现技巧,具有一定的参考价值。有需要的朋友可以参考
本文描述了在Java中使用爬虫捕获网站网页内容的方法。与您分享,供您参考。详情如下:
最近,我在用java学习爬行技术。哈哈,我进门和你分享了我的经历
提供以下两种方法。一种是使用Apache提供的包。另一个是使用Java提供的包
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站().7点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2021-09-10 11:07
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功
2.Integrated Scrapy framework----进入命令行:pip install Scrapy
安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持服务器之家!
原文链接: 查看全部
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站().7点)
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功

2.Integrated Scrapy framework----进入命令行:pip install Scrapy

安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:

注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持服务器之家!
原文链接:
网页爬虫抓取百度图片( 2017年02月17日09:58:cong框架sublimetext3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-10 11:06
2017年02月17日09:58:cong框架sublimetext3)
Python爬虫:通过关键词抓取百度图片
更新时间:2017年2月17日09:58:19 作者:WC-cong
本文主要介绍Python爬虫:通过关键字爬取百度图片的方法。有很好的参考价值,下面小编一起来看看吧
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功
2.Integrated Scrapy framework----进入命令行:pip install Scrapy
安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家! 查看全部
网页爬虫抓取百度图片(
2017年02月17日09:58:cong框架sublimetext3)
Python爬虫:通过关键词抓取百度图片
更新时间:2017年2月17日09:58:19 作者:WC-cong
本文主要介绍Python爬虫:通过关键字爬取百度图片的方法。有很好的参考价值,下面小编一起来看看吧
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功

2.Integrated Scrapy framework----进入命令行:pip install Scrapy

安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:

爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:

注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家!
网页爬虫抓取百度图片(一种全新的方式来获取图片素材,你想要的这里全都有)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-30 18:10
你还去网站搜什么图?
你还在寻找百度图片等图片素材网站吗?
今天给大家分享一个全新的图片素材获取方式。你想要的这里都有!
是新浪微博!新一代的超级流量门户,甚至现在很多人都用它作为替代百度搜索的工具。以前是找杜娘找东西,现在是搜微博。
比如某个宅男想看清纯少女的照片,越多越好。他会这样搜索:
然后,他会逐页阅读和欣赏这些吸引眼球的图片,并在遇到喜欢的人时将大图片下载到本地保存。
作为一个python程序员,我懒得像这样一页一页地翻页。喜欢全部下载下来慢慢欣赏,爆了硬盘!类似于以下内容:
这种简单的问题让我们为pythoner写爬虫那么容易,何乐而不为呢?让我直接与你分享。
分析目标网站
微博的搜索结果是分页的,所以我们的思路肯定是分页处理,逐页解析。
我们先来看看搜索结果:
我们点击“搜索”按钮后,很容易找到搜索请求。此处网页显示了第一页的结果。
然后我们点击“Next”,我们可以发现请求变成了如下:
细心的话,可能一眼就发现在请求后多了一个page参数,指的是页码。这很容易。我们只需要改变页码就可以请求对应页面的内容。
由于此请求返回一个 HTML 页面,因此我们需要在此页面上努力找到指向图像的链接。我们随便用页面元素检查来定位一张图片,会看到如下效果:
我们可以看到这个div里面的action-data是一个集合,下面li里面img的action-data是单张图片的数据。
接下来,我们点击“查看大图”按钮,浏览器会跳转到一个新页面,页面内容为大图。
从请求的 URL 往下看,我发现了这个:
我把这个网址复制到浏览器请求中,发现这正是我们需要的大图。我们也可以很容易的看到这个URL的特点,就是最后我们在上面的action-data中添加了pic_id。
这样,我们的思路就很清晰了,下面是获取一页图片的思路:
获取页面内容;在页面内容中找到图片ID;拼接查看大图的URL,请求获取图片;将图像写入本地。代码代码
思路很清晰,需要代码code来验证。由于代码比较简单,我就一次性给大家展示一下。
import requests
import re
import os
import time
cookie = {
'Cookie': 'your cookie'
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4144.2 Safari/537.36'
}
get_order = input('是否启动程序? yes or no: ')
number = 1
store_path = 'your path'
while True:
if get_order != 'no':
print('抓取中......') # 下面的链接填写微博搜索的链接
url = f'https://s.weibo.com/weibo%3Fq% ... ge%3D{number}'
response = requests.get(url, cookies=cookie)
result = response.text
print(result)
detail = re.findall('data="uid=(.*?)&mid=(.*?)&pic_ids=(.*?)">', result)
for part in detail:
uid = part[0]
mid = part[1]
pids = part[2]
for picid in pids.split(','):
url_x = f'https://wx1.sinaimg.cn/large/%s.jpg'%picid # 这里就是大图链接了
response_photo = requests.get(url_x, headers=header)
file_name = url_x[-10:]
if not os.path.exists(store_path+uid):
os.mkdir(store_path+uid)
with open(store_path+uid + '/' + file_name, 'ab') as f: # 保存文件
f.write(response_photo.content)
time.sleep(0.5)
print('获取完毕')
get_order = input('是否继续获取下一页? Y:yes N:no: ')
if get_order != 'no':
number += 1
else:
print('程序结束')
break
else:
print('程序结束')
break
我这里采用了逐页断点的形式,方便调试。如果你想一次得到所有页面的图片,你可以把这些输入判断去掉,一次性全部运行。代码中的cookie和图片存储路径需要替换为你本地的。
运行后的结果如下:
我按照微博把图片分到文件夹里。如果觉得不直观,想把所有图片都放在一个目录下,可以去掉这一层文件夹。
总结
本文介绍如何通过一个简单的爬虫获取微博图片搜索结果。代码量相当少,但是对一些人来说是很有帮助的,省时省力。还可以展开,除了图片,还可以获取其他搜索内容,比如微博文字、视频、购物链接等。 查看全部
网页爬虫抓取百度图片(一种全新的方式来获取图片素材,你想要的这里全都有)
你还去网站搜什么图?
你还在寻找百度图片等图片素材网站吗?
今天给大家分享一个全新的图片素材获取方式。你想要的这里都有!
是新浪微博!新一代的超级流量门户,甚至现在很多人都用它作为替代百度搜索的工具。以前是找杜娘找东西,现在是搜微博。
比如某个宅男想看清纯少女的照片,越多越好。他会这样搜索:
然后,他会逐页阅读和欣赏这些吸引眼球的图片,并在遇到喜欢的人时将大图片下载到本地保存。
作为一个python程序员,我懒得像这样一页一页地翻页。喜欢全部下载下来慢慢欣赏,爆了硬盘!类似于以下内容:
这种简单的问题让我们为pythoner写爬虫那么容易,何乐而不为呢?让我直接与你分享。
分析目标网站
微博的搜索结果是分页的,所以我们的思路肯定是分页处理,逐页解析。
我们先来看看搜索结果:
我们点击“搜索”按钮后,很容易找到搜索请求。此处网页显示了第一页的结果。
然后我们点击“Next”,我们可以发现请求变成了如下:
细心的话,可能一眼就发现在请求后多了一个page参数,指的是页码。这很容易。我们只需要改变页码就可以请求对应页面的内容。
由于此请求返回一个 HTML 页面,因此我们需要在此页面上努力找到指向图像的链接。我们随便用页面元素检查来定位一张图片,会看到如下效果:
我们可以看到这个div里面的action-data是一个集合,下面li里面img的action-data是单张图片的数据。
接下来,我们点击“查看大图”按钮,浏览器会跳转到一个新页面,页面内容为大图。
从请求的 URL 往下看,我发现了这个:
我把这个网址复制到浏览器请求中,发现这正是我们需要的大图。我们也可以很容易的看到这个URL的特点,就是最后我们在上面的action-data中添加了pic_id。
这样,我们的思路就很清晰了,下面是获取一页图片的思路:
获取页面内容;在页面内容中找到图片ID;拼接查看大图的URL,请求获取图片;将图像写入本地。代码代码
思路很清晰,需要代码code来验证。由于代码比较简单,我就一次性给大家展示一下。
import requests
import re
import os
import time
cookie = {
'Cookie': 'your cookie'
}
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4144.2 Safari/537.36'
}
get_order = input('是否启动程序? yes or no: ')
number = 1
store_path = 'your path'
while True:
if get_order != 'no':
print('抓取中......') # 下面的链接填写微博搜索的链接
url = f'https://s.weibo.com/weibo%3Fq% ... ge%3D{number}'
response = requests.get(url, cookies=cookie)
result = response.text
print(result)
detail = re.findall('data="uid=(.*?)&mid=(.*?)&pic_ids=(.*?)">', result)
for part in detail:
uid = part[0]
mid = part[1]
pids = part[2]
for picid in pids.split(','):
url_x = f'https://wx1.sinaimg.cn/large/%s.jpg'%picid # 这里就是大图链接了
response_photo = requests.get(url_x, headers=header)
file_name = url_x[-10:]
if not os.path.exists(store_path+uid):
os.mkdir(store_path+uid)
with open(store_path+uid + '/' + file_name, 'ab') as f: # 保存文件
f.write(response_photo.content)
time.sleep(0.5)
print('获取完毕')
get_order = input('是否继续获取下一页? Y:yes N:no: ')
if get_order != 'no':
number += 1
else:
print('程序结束')
break
else:
print('程序结束')
break
我这里采用了逐页断点的形式,方便调试。如果你想一次得到所有页面的图片,你可以把这些输入判断去掉,一次性全部运行。代码中的cookie和图片存储路径需要替换为你本地的。
运行后的结果如下:
我按照微博把图片分到文件夹里。如果觉得不直观,想把所有图片都放在一个目录下,可以去掉这一层文件夹。
总结
本文介绍如何通过一个简单的爬虫获取微博图片搜索结果。代码量相当少,但是对一些人来说是很有帮助的,省时省力。还可以展开,除了图片,还可以获取其他搜索内容,比如微博文字、视频、购物链接等。
网页爬虫抓取百度图片(,文中示例代码介绍-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-30 17:20
本文文章主要介绍Python3简单爬虫抓取网页图片代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考。
网上有很多用python2编写的爬虫抓取网页图片的例子,但是不适合新手(新手使用python3环境,不兼容python2),
于是写了一个简单的例子,用Python3语法抓取网页图片。希望能帮到你,也希望你能批评指正。
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
网页爬虫抓取百度图片(,文中示例代码介绍-上海怡健医学())
本文文章主要介绍Python3简单爬虫抓取网页图片代码示例。文章通过示例代码介绍了非常详细的例子。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考。
网上有很多用python2编写的爬虫抓取网页图片的例子,但是不适合新手(新手使用python3环境,不兼容python2),
于是写了一个简单的例子,用Python3语法抓取网页图片。希望能帮到你,也希望你能批评指正。
import urllib.request
import re
import os
import urllib
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html.decode('UTF-8')
def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html)#表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
path = 'D:\\test'
# 将图片保存到D:\\test文件夹中,如果没有test文件夹则创建
if not os.path.isdir(path):
os.makedirs(path)
paths = path+'\\' #保存在test路径下
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图片网址,并下载图片保存在本地,format格式化字符串
x = x + 1
return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866";)#获取该网址网页详细信息,得到的html就是网页的源代码
print (getImg(html)) #从网页源代码中分析并下载保存图片
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2021-09-30 02:11
)
这篇文章是针对初学者的,我会用最简单的案例来告诉你如何开始使用python爬虫!
开始使用Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫其实叫做Web Data采集,比较容易理解。
就是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。
总结为四个主要步骤:
根据url获取HTML数据解析HTML,获取目标信息存储数据重复第一步
这将涉及很多内容,例如数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全和图像处理。但是对于初学者来说,没必要掌握那么多。
二、python学多少
如果你不懂python,你需要学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。学习起来会很枯燥,但并不难。
刚开始,你甚至不需要学习python类、多线程、模块等高难度内容。找本初学者的教材或者网上教程,花十几天的时间,可以对python的基础有三到四点的了解,这时候就可以玩爬虫了!
当然,前提是你这十天一定要认真打好代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等核心东西一定要熟透心手.
教材选择比较多。个人推荐python官方文档和python简明教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面提到爬虫想要爬取的数据隐藏在网页的HTML中,有点间接!
维基百科这样解释 HTML
超文本标记语言(英文:Hyper Text Markup Language,简称 HTML)是一种用于创建网页的标准标记语言。HTML 是一项基本技术,经常与 CSS 和许多 网站 一起使用来设计网页、Web 应用程序和移动应用程序的用户界面 [3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视化网页。HTML 描述了 网站 的结构和语义以及线索的呈现,使其成为标记语言而不是编程语言。
综上所述,HTML 是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并呈现为我们看到的网页。
这就是为什么我们先爬取 HTML,然后解析数据,因为数据隐藏在 HTML 中。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则即可,这里是一个大致的介绍。
HTML 标签包括几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如和。
在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,括在尖括号中,例如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间。
四、了解python网络爬虫的基本原理
在编写python爬虫程序时,只需要做以下两件事:
对于这两件事,python有相应的库可以帮你做,你只需要知道如何使用它们即可。
五、 使用python库抓取百度首页标题和图片
首先,发送HTML数据请求,可以使用python内置库urllib,它有一个urlopen函数,可以根据url获取HTML文件。这里,尝试获取百度首页的HTML内容""
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/")
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看效果:
部分截取输出html内容
我们来看看真正的百度主页的html是什么样子的。如果您使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:
在 Google Chrome 中查看 HTML
通过对比你就会知道,刚才通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的python库BeautifulSoup作为解析上面已经得到的HTML的工具。
BeautifulSoup 是第三方库,需要安装使用。只需在命令行上使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据即可:
比如我想得到百度首页的标题“我点击百度就知道了”,怎么办?
这个title被两个label困住了,一个是primary label,一个是secondary label,所以从label里面取出信息就行了。
# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
看看结果:
到此,百度主页的标题就提取成功了。
如果我想下载百度首页标志图片怎么办?
第一步是获取网页的所有图片标签和网址。这个可以使用BeautifulSoup的findAll方法,可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll("img")来获取所有的图片信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
看看结果:
打印所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有一张百度首页logo的图片,图片的类(元素类名)为index-logo-src。
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:
获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
最终图像保存在'logo.png'
六、结论
本文以抓取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识,还有很多优秀的python爬虫库和框架有待以后学习。
当然,如果你掌握了本文讨论的知识点,你就已经开始使用python爬虫了。来吧,男孩!
这里有一个方便大家的python学习交流群:196872581免费领取学习路线、大纲、课程等资料
查看全部
网页爬虫抓取百度图片(本文针对初学者,我会用最简单的案例告诉你如何入门python爬虫
)
这篇文章是针对初学者的,我会用最简单的案例来告诉你如何开始使用python爬虫!
开始使用Python爬虫,首先需要解决四个问题
一、你应该知道什么是爬虫吧?
网络爬虫其实叫做Web Data采集,比较容易理解。
就是通过编程向Web服务器请求数据(HTML形式),然后解析HTML,提取出你想要的数据。
总结为四个主要步骤:
根据url获取HTML数据解析HTML,获取目标信息存储数据重复第一步
这将涉及很多内容,例如数据库、Web 服务器、HTTP 协议、HTML、数据科学、网络安全和图像处理。但是对于初学者来说,没必要掌握那么多。
二、python学多少
如果你不懂python,你需要学习python,一种非常简单的语言(相对于其他语言)。
编程语言的基本语法无非是数据类型、数据结构、运算符、逻辑结构、函数、文件IO、错误处理。学习起来会很枯燥,但并不难。
刚开始,你甚至不需要学习python类、多线程、模块等高难度内容。找本初学者的教材或者网上教程,花十几天的时间,可以对python的基础有三到四点的了解,这时候就可以玩爬虫了!
当然,前提是你这十天一定要认真打好代码,反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等核心东西一定要熟透心手.
教材选择比较多。个人推荐python官方文档和python简明教程。前者更系统,后者更简洁。
三、为什么你需要了解 HTML
前面提到爬虫想要爬取的数据隐藏在网页的HTML中,有点间接!
维基百科这样解释 HTML
超文本标记语言(英文:Hyper Text Markup Language,简称 HTML)是一种用于创建网页的标准标记语言。HTML 是一项基本技术,经常与 CSS 和许多 网站 一起使用来设计网页、Web 应用程序和移动应用程序的用户界面 [3]。Web 浏览器可以读取 HTML 文件并将它们呈现为可视化网页。HTML 描述了 网站 的结构和语义以及线索的呈现,使其成为标记语言而不是编程语言。
综上所述,HTML 是一种用于创建网页的标记语言,嵌入了文本、图像等数据,可以被浏览器读取并呈现为我们看到的网页。
这就是为什么我们先爬取 HTML,然后解析数据,因为数据隐藏在 HTML 中。
学习HTML并不难,它不是一门编程语言,你只需要熟悉它的标记规则即可,这里是一个大致的介绍。
HTML 标签包括几个关键部分,例如标签(及其属性)、基于字符的数据类型、字符引用和实体引用。
HTML 标签是最常见的,通常成对出现,例如和。
在成对出现的标签中,第一个标签是开始标签,第二个标签是结束标签。两个标签之间是元素的内容(文本、图像等)。有些标签没有内容,是空元素,例如。
下面是一个经典的 Hello World 程序示例:
This is a title
<p>Hello world!
</p>
HTML 文档由嵌套的 HTML 元素组成。它们由 HTML 标记表示,括在尖括号中,例如 [56]
通常,一个元素由一对标签表示:“开始标签”和“结束标签”。如果元素收录文本内容,则将其放置在这些标签之间。
四、了解python网络爬虫的基本原理
在编写python爬虫程序时,只需要做以下两件事:
对于这两件事,python有相应的库可以帮你做,你只需要知道如何使用它们即可。
五、 使用python库抓取百度首页标题和图片
首先,发送HTML数据请求,可以使用python内置库urllib,它有一个urlopen函数,可以根据url获取HTML文件。这里,尝试获取百度首页的HTML内容""
# 导入urllib库的urlopen函数
from urllib.request import urlopen
# 发出请求,获取html
html = urlopen("https://www.baidu.com/";)
# 获取的html内容是字节,将其转化为字符串
html_text = bytes.decode(html.read())
# 打印html内容
print(html_text)
看效果:
部分截取输出html内容
我们来看看真正的百度主页的html是什么样子的。如果您使用的是谷歌浏览器,在百度首页打开设置>更多工具>开发者工具,点击元素,可以看到:
在 Google Chrome 中查看 HTML
通过对比你就会知道,刚才通过python程序得到的HTML和网页是一样的!
获取到HTML后,下一步就是解析HTML,因为你想要的文字、图片、视频都隐藏在HTML中,需要通过某种方式提取出需要的数据。
Python 还提供了许多强大的库来帮助您解析 HTML。这里使用了著名的python库BeautifulSoup作为解析上面已经得到的HTML的工具。
BeautifulSoup 是第三方库,需要安装使用。只需在命令行上使用 pip 安装它:
pip install bs4
BeautifulSoup 会将 HTML 内容转换为结构化内容,您只需要从结构化标签中提取数据即可:
比如我想得到百度首页的标题“我点击百度就知道了”,怎么办?
这个title被两个label困住了,一个是primary label,一个是secondary label,所以从label里面取出信息就行了。
# 导入urlopen函数
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 打印标题
print(title)
看看结果:
到此,百度主页的标题就提取成功了。
如果我想下载百度首页标志图片怎么办?
第一步是获取网页的所有图片标签和网址。这个可以使用BeautifulSoup的findAll方法,可以提取标签中收录的信息。
一般来说,HTML中所有的图片信息都会在“img”标签中,所以我们可以通过findAll("img")来获取所有的图片信息。
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 使用find_all函数获取所有图片的信息
pic_info = obj.find_all('img')
# 分别打印每个图片的信息
for i in pic_info:
print(i)
看看结果:
打印所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有一张百度首页logo的图片,图片的类(元素类名)为index-logo-src。
[//www.baidu.com/img/bd_logo1.png, //www.baidu.com/img/baidu_jgylogo3.gif]
可以看到图片的链接地址在src属性中。我们需要获取图片的链接地址:
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)
结果:
获取地址后,可以使用urllib.urlretrieve函数下载logo图片
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/";)
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
最终图像保存在'logo.png'
六、结论
本文以抓取百度首页标题和logo图片为例,讲解python爬虫的基本原理以及相关python库的使用。这是比较基础的爬虫知识,还有很多优秀的python爬虫库和框架有待以后学习。
当然,如果你掌握了本文讨论的知识点,你就已经开始使用python爬虫了。来吧,男孩!
这里有一个方便大家的python学习交流群:196872581免费领取学习路线、大纲、课程等资料
网页爬虫抓取百度图片(爬虫记录自己练习爬虫的始末,这次用下载图片展示主流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-29 03:27
爬虫笔记 [01]
一、前言
记录下自己爬虫练习的开始和结束,这次用下载的图片来展示主要过程。
二、 爬虫逻辑理解
网页上的几乎所有内容都在服务器上。在网上查东西时,类似于对服务器说:“我想看滑雪的照片”。服务器首先听到您的喊叫声,然后嗡嗡作响。开始向您发送带有代码的服务器滑雪图片和网页。数据当然是二进制的,所以你需要把数据编码成人类可以理解的东西。最后显示出你想要的图片,你可以下载保存到电脑中。
整个过程就是有人要东西,服务器听到有人要东西,服务器把东西发给你,你通过各种方式调出具体的内容。
三、 爬图
爬虫需要导入requests库,用于向服务器请求内容(发送请求)。os 库用于目录和文件操作,这是一个非常基础的操作。
# 导入使用的库
import requests
import os
在百度贴吧上找到了一张滑雪的图片,想下载。直接另存为很方便,不能手动存成1000张。
一、右键复制图片地址
# 图片地址存到变量中
imurl = 'http://tiebapic.baidu.com/forum/w%3D580%3B/sign=\ac30c67119f41bd5da53e8fc61e180cb/78310a55b319ebc4666b57c39526cffc1e17165c.jpg'
然后我们需要找到一个叫做“请求头”的东西,理解为个人名字,服务器需要知道是谁在请求这个东西,而user-agent主要收录浏览器的信息。因为爬虫是模拟成年人用电脑搜索内容的方式,如果user-agent不是浏览器的名字,很可能就是爬虫,会被拦截。
# 从浏览器中复制下来后,要用字典类型包起来,键值都是字符串类型
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
# 这里就是做一个向服务器要内容的请求,对应的连接和伪装的浏览器名字。
# imr是服务器对你请求的回答(响应),包含了图片数据在内的一些信息
imr = requests.get(url = imurl, headers = headers)
# 观察状态码,就是看服务器到底有没有理你,理你了就代表请求成功
# 如果是状态码是200,就代表服务器理你了
print(imr.status_code)
最终结论取决于编码是什么。如果编码不同,最终的信息就会乱七八糟。
# 一般utf8是正确的编码,常规操作是imr.encoding = imr.apparent_encoding
print(imr.encoding)
print(imr.apparent_coding)
# 查看当前操作目录,做一个新目录出来
cwd = os.getcwd()
print(cwd)
newpath = os.mkdir(cwd + '/spider')
path_photo = cwd + '/spider/snowboarding.png'
# 图片是二进制,所以用wb的模式进行写入
with open(pathn_photo, 'wb') as im:
im.write(imr.content)
最后我们下载了图片 查看全部
网页爬虫抓取百度图片(爬虫记录自己练习爬虫的始末,这次用下载图片展示主流程)
爬虫笔记 [01]
一、前言
记录下自己爬虫练习的开始和结束,这次用下载的图片来展示主要过程。
二、 爬虫逻辑理解
网页上的几乎所有内容都在服务器上。在网上查东西时,类似于对服务器说:“我想看滑雪的照片”。服务器首先听到您的喊叫声,然后嗡嗡作响。开始向您发送带有代码的服务器滑雪图片和网页。数据当然是二进制的,所以你需要把数据编码成人类可以理解的东西。最后显示出你想要的图片,你可以下载保存到电脑中。
整个过程就是有人要东西,服务器听到有人要东西,服务器把东西发给你,你通过各种方式调出具体的内容。
三、 爬图
爬虫需要导入requests库,用于向服务器请求内容(发送请求)。os 库用于目录和文件操作,这是一个非常基础的操作。
# 导入使用的库
import requests
import os
在百度贴吧上找到了一张滑雪的图片,想下载。直接另存为很方便,不能手动存成1000张。
一、右键复制图片地址
# 图片地址存到变量中
imurl = 'http://tiebapic.baidu.com/forum/w%3D580%3B/sign=\ac30c67119f41bd5da53e8fc61e180cb/78310a55b319ebc4666b57c39526cffc1e17165c.jpg'
然后我们需要找到一个叫做“请求头”的东西,理解为个人名字,服务器需要知道是谁在请求这个东西,而user-agent主要收录浏览器的信息。因为爬虫是模拟成年人用电脑搜索内容的方式,如果user-agent不是浏览器的名字,很可能就是爬虫,会被拦截。
# 从浏览器中复制下来后,要用字典类型包起来,键值都是字符串类型
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
# 这里就是做一个向服务器要内容的请求,对应的连接和伪装的浏览器名字。
# imr是服务器对你请求的回答(响应),包含了图片数据在内的一些信息
imr = requests.get(url = imurl, headers = headers)
# 观察状态码,就是看服务器到底有没有理你,理你了就代表请求成功
# 如果是状态码是200,就代表服务器理你了
print(imr.status_code)
最终结论取决于编码是什么。如果编码不同,最终的信息就会乱七八糟。
# 一般utf8是正确的编码,常规操作是imr.encoding = imr.apparent_encoding
print(imr.encoding)
print(imr.apparent_coding)
# 查看当前操作目录,做一个新目录出来
cwd = os.getcwd()
print(cwd)
newpath = os.mkdir(cwd + '/spider')
path_photo = cwd + '/spider/snowboarding.png'
# 图片是二进制,所以用wb的模式进行写入
with open(pathn_photo, 'wb') as im:
im.write(imr.content)
最后我们下载了图片
网页爬虫抓取百度图片( 上海海事大学‘发现链接变成第一个项目(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-29 03:26
上海海事大学‘发现链接变成第一个项目(组图))
爬虫训练项目1_爬行百度贴吧
前言
这是我开始学习爬虫时的第一个手工练习项目。在B站看到了一些教学视频,觉得挺有意思的,就决定跟上。
1、找到对方的c位置(确定要爬取的目标)
要抓取网页,首先需要知道网页的 url
首先用浏览器打开贴吧网页。
搜索“上海海事大学”
发现链接变为上海海事大学&fr=search
点击到第二页,再次观察url,发现多了一个pn=50的参数
尝试将pn=50改为pn=0,发现刚才访问的是第一页的内容。
于是找到规则,第一页pn=0,第二页pn=50,
那么第三页应该是pn=100,依此类推
至于另一个参数:ie=utf-8,可以删除
所以,我们需要访问的链接格式是
——&Pn=——
2、发起进攻(发送请求)
上一步我们已经知道要爬取的url
现在你需要发送请求
至于如何发送请求
我们需要安装一个库:请求库
pip 安装请求
然后导入这个库
import requests
然后开始构造url并存入列表
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
复制浏览器logo,放在headers中(有的网站会根据浏览器logo判断是否是爬虫,所以加个logo防止一)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
然后发送请求并保存页面
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
3、 攻击敌方水晶(完整代码)
"""
获取贴吧内容
"""
import requests
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
然后在pycharm中打开保存的网页并运行
和浏览器搜索到的网页一模一样
胜利
至此,你已经基本完成了学习爬虫的第一步
以后学爬的时候会慢慢更新其他的训练项目 查看全部
网页爬虫抓取百度图片(
上海海事大学‘发现链接变成第一个项目(组图))
爬虫训练项目1_爬行百度贴吧
前言
这是我开始学习爬虫时的第一个手工练习项目。在B站看到了一些教学视频,觉得挺有意思的,就决定跟上。
1、找到对方的c位置(确定要爬取的目标)
要抓取网页,首先需要知道网页的 url
首先用浏览器打开贴吧网页。
搜索“上海海事大学”
发现链接变为上海海事大学&fr=search
点击到第二页,再次观察url,发现多了一个pn=50的参数
尝试将pn=50改为pn=0,发现刚才访问的是第一页的内容。
于是找到规则,第一页pn=0,第二页pn=50,
那么第三页应该是pn=100,依此类推
至于另一个参数:ie=utf-8,可以删除
所以,我们需要访问的链接格式是
——&Pn=——
2、发起进攻(发送请求)
上一步我们已经知道要爬取的url
现在你需要发送请求
至于如何发送请求
我们需要安装一个库:请求库
pip 安装请求
然后导入这个库
import requests
然后开始构造url并存入列表
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
复制浏览器logo,放在headers中(有的网站会根据浏览器logo判断是否是爬虫,所以加个logo防止一)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
然后发送请求并保存页面
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
3、 攻击敌方水晶(完整代码)
"""
获取贴吧内容
"""
import requests
url = 'https://tieba.baidu.com/f?kw={}&pn={}'
text = input("请输入贴吧的名字:")
num = int(input('输入要爬取的页数:'))
url_list = [url.format(text, i * 50) for i in range(num)]
print(url_list)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'}
for item_url in url_list:
response = requests.get(item_url, headers=headers)
file_name = '贴吧_' + text + '第{}页'.format(url_list.index(item_url) + 1) + '.html'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(response.content.decode())
然后在pycharm中打开保存的网页并运行
和浏览器搜索到的网页一模一样
胜利
至此,你已经基本完成了学习爬虫的第一步
以后学爬的时候会慢慢更新其他的训练项目
网页爬虫抓取百度图片(廖雪峰老师的python处理和复杂芜杂的网络框架给整崩溃了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-25 04:10
说些什么
其实一直对python这个语言很感兴趣,但是之前一直在做图像处理相关的事情,所以没怎么关注这种不能触及底层内存处理的语言,但是最近才真正用上通过 C++ 字符。字符串处理和复杂的网络框架崩溃了,看到大家都说python很好玩,所以趁着最近没事的时候学习了python。
昨天关注了廖雪峰老师的python教程(推荐基础教程)。看了基本的数据结构和逻辑后,我决定直接从一个实际的小项目来实践。最好的语言方式),所以就选择了一个比较简单的python爬虫项目来练习。
写爬虫最重要的就是了解我们平时访问的网页是什么。其实我们平时访问的网页源代码是一个字符串文件(当然也可以说是二进制文件)
每次我们在浏览器上输入一个网址,比如这个网址,浏览器会帮我们访问远程服务器,并根据绑定的ip地址发送请求,远程服务器会发送这个网页的源代码直接打包发送给我们的浏览器(html文件格式),然后我们的浏览器会解析这个字符串文件,比如通过div格式化和渲染网页,h1、h2 layouts 显示,继续发送请求给远程服务器为img这些资源获取图片,然后在网页上填写。
什么是爬虫
怎么说呢,爬虫,简单来说就是模拟浏览器获取一个网页的源代码。至于你用源代码做什么,没关系。
说的更复杂一点,爬虫其实就是对所有网页数据处理的综合,比如:自动抓取网页源代码,分析网页数据,获取关键数据并保存,或者自动下载需要的网页图片、音频,和视频。
那么当我们在写一个pythonm爬虫的时候,我们在写什么呢?
当我们需要爬虫的时候,一般会遇到比较复杂的数据需求。这个要求对于手工作业来说是非常复杂的。仅此要求就可以由爬虫轻松解决。
那么首先确定我们的需求,我们需要这个爬虫做什么?
比如我们认为一个教学网站的数据很有趣,但是它的格式太复杂,或者需要频繁翻页,不能通过复制粘贴轻易获取,爬虫就会起作用。
总之,我们以一个爬虫的例子来说明。
爬取百度图片ps:python版-Python 3.7.0
第一个爬虫当然不能选择太复杂的东西,涉及到很多复杂的网络规则,所以我们来爬一些网站,简单的让爬虫去爬。
比如抓取下载关键词下的某百度图片的图片数据。
1、建立需求
暂时确定以上需求,然后开始写真正的爬虫代码
2、 观察网页源码
首先打开百度图片,随意搜索一个关键词。比如这次我会用我最喜欢的动漫角色栗山未来来测试
右键查看网页源码,可以看到每张图片的原创地址都是以一个简单的“objURL”开头,以一个小逗号结尾,如下:
基于此,我们可以确定爬虫应该如何运行。很简单——从网页源码中提取这些url并下载\(^o^)/~
3、获取网页源码
其实这一步我是不想写的,只是担心看了我博客刚学python的朋友可能会出错,所以说一下。
首先,我们需要在python中导入网络库urllib。因为我们需要用到的urlopen和read方法在我的python版本中,直接引用urllib会出错,所以一般使用这个import:import urllib.request
提取网页源代码的整个方法如下:
import urllib.request
def get_html(httpUrl):
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
我们可以将这个方法打包成一个py文件,然后直接在其他py文件中导入这个方法,然后直接使用我们写的get_html方法。
然后将上面得到的二进制文件解码成普通字符串:
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
4、提取图片地址
从网页的源代码中提取关键数据时,实际上是字符串匹配。如果这样估计C++累死我了,当然我也写过类似的,甚至更复杂的,真的是痛苦的回忆。
这里推荐一个比较简单的字符串搜索和匹配程序-正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE)
当然,如何使用正则表达式我就不多说了。你可以自己搜索每个视频网站,看个大概就够了,或者直接看这里——正则表达式基础
了解正则表达式的基本逻辑就可以了。
进入正题,上面的步骤已经分析到每张图片的原创地址开头都有一个很简单的“objURL”,所以我们正则化的关键就是把“objURL”后面的地址取出来。这个很简单,我直接把写好的正则表达式拿出来:
reg=r'"objURL":"(.*?)",'
ps:字符串前的r主要是为了防止转义字符丢失导致的字符丢失
这个规律的作用如下:
匹配任何以 "objURL":" 开头并以 ", 结尾的字符串
然后简单地编译这个正则(记得导入 re 包):
import re
reg=r'"objURL":"(.*?)",'
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
然后使用上面编译的正则表达式解析第三步得到的字符串,如下:
pic_list = reg_compile.findall(html_str)
上面的 pic_list 是一个简单的列表
输出列表中的数据:
for pic in pic_list:
print(pic)
输出如下:
http://b-ssl.duitang.com/uploa ... .jpeg
http://b-ssl.duitang.com/uploa ... .jpeg
http://cdnq.duitang.com/upload ... .jpeg
http://wxpic.7399.com/nqvaoZto ... cpNpu
http://i1.hdslb.com/bfs/archiv ... 0.jpg
http://wxpic.7399.com/nqvaoZto ... cpNpu
可以清楚的看到,有些地址不是图片地址。这可以说是我正则化的问题,但也无伤大雅(其实我也懒得改了)。一点判断就可以完美解决(由于所有图片地址都以g结尾,比如png、jpg、jpeg^_^)
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
完美解,w(゚Д゚)w
ps:哈哈哈,这里当然是玩笑了,大家记得想好办法改正,算是小测试,毕竟真的是无害的。
5、下载图片
下载图片也很简单。正如我开头所说的,图片实际上是存在于远程服务器上的图片文件。只要服务器允许,我们可以很容易的通过GET请求得到这张图片。毕竟,浏览器也会这样做。,至于你得到的,没人管它是用来实际填网页还是给自己用。
python中下载图片的方式有很多种,如下三种
(以下代码不是我写的,不知道版本对不对,如有错误请自行百度。第一种在我的版本中没有问题):
def urllib_download(url):
from urllib.request import urlretrieve
urlretrieve(url, '1.png')
def request_download(url):
import requests
r = requests.get(url)
with open('1.png', 'wb') as f:
f.write(r.content)
def chunk_download(url):
import requests
r = requests.get(url, stream=True)
with open('1.png', 'wb') as f:
for chunk in r.iter_content(chunk_size=32):
f.write(chunk)
所以我们只需要下载上面列表中的每个图片网址。我选择了上面的第一个。这是urllib.request中存在的一个方法,定义如下:
urllib.request.urlretrieve(url, filename, reporthook, data)
参数说明:
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
然后一个简单的循环下载就可以了:
def download_pic(pic_adr,x):
urllib.request.urlretrieve(pic_adr, '%s.jpg' %x)
# './images/%s.jpg',这里也可以自己选择创建一个文件吧所有图片放进去,而不是直接放在当前目录下
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
download_pic(pic,x)
x += 1
当然需要为每张图片选择一个本地名称,只需将名称增加1234即可。
这样,我们就结束了整个爬取过程。执行后效果如下:
可以看到,效果还是不错的。毕竟,只要把它放在那里,让它自己下载。还可以考虑如何翻页的效果。事实上,这很简单。我就讲实现一个变化。关键词的效果提醒大家(其实是因为我有点懒,不想写了)
6、更改搜索关键词
看百度搜索页面的网址:
观察这个网址,我们很容易发现原来最后一个关键字是关键词。复制就改了,但是复制之后就不简单了:
http://image.baidu.com/search/ ... %25A5
为什么word变成%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5
这么一堆东西?
很简单,因为url是ASCII码,而这里我们用的是中文,只要稍微操作一下就可以转:
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
urllib.parse.quote 是解码后的代码,在最后加上关键字就OK了。
简单,这个简单的python爬虫就完成了。.
虽然还是想自己写字符串识别,但是regular真的好用。建议多学习一些常规的骚技能。
就这样。
如需修改,请自行复制完整代码并进行更改。下载多个页面也是很简单的操作,就不多说了,还是可以加多线程,代理,动态ip。无论如何,这就是我的第一个爬虫。
完整源码(百度图片爬虫)
import urllib
import time
from urllib.request import urlretrieve
import re
import urllib.request
def get_html(httpUrl):#获取网页源码
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
def get_keyword_urllist(keyword):#爬取当前关键词下的图片地址
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
pic_list = reg_compile.findall(html_str)
return pic_list
keyword="栗山未来"#自己修改,或者自己写个input或者一个txt自己读就完事了,甚至你写一个配置表,把爬取数量、爬取关键词、爬取图片大小都写好都可以
pic_list=get_keyword_urllist(keyword)
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
name = keyword+str(x)
time.sleep(0.01)
urllib.request.urlretrieve(pic, './images/%s.jpg' %name)
x += 1
如果不行,请检查收录的模板是否正确或版本是否正确。
重点
最后运行上面的源码,应该会发现虽然可以下载,但是下载速度太慢了。解决它需要几秒钟,但如果它更慢,则可能需要十秒钟以上。
针对这种情况,我重写了上面的代码,加入了多线程处理,将爬取时间缩短到1s以内。我是直接上传到我的github上的,大家可以自己下载。
快速爬取百度图片-爬虫1.0版 查看全部
网页爬虫抓取百度图片(廖雪峰老师的python处理和复杂芜杂的网络框架给整崩溃了)
说些什么
其实一直对python这个语言很感兴趣,但是之前一直在做图像处理相关的事情,所以没怎么关注这种不能触及底层内存处理的语言,但是最近才真正用上通过 C++ 字符。字符串处理和复杂的网络框架崩溃了,看到大家都说python很好玩,所以趁着最近没事的时候学习了python。
昨天关注了廖雪峰老师的python教程(推荐基础教程)。看了基本的数据结构和逻辑后,我决定直接从一个实际的小项目来实践。最好的语言方式),所以就选择了一个比较简单的python爬虫项目来练习。
写爬虫最重要的就是了解我们平时访问的网页是什么。其实我们平时访问的网页源代码是一个字符串文件(当然也可以说是二进制文件)
每次我们在浏览器上输入一个网址,比如这个网址,浏览器会帮我们访问远程服务器,并根据绑定的ip地址发送请求,远程服务器会发送这个网页的源代码直接打包发送给我们的浏览器(html文件格式),然后我们的浏览器会解析这个字符串文件,比如通过div格式化和渲染网页,h1、h2 layouts 显示,继续发送请求给远程服务器为img这些资源获取图片,然后在网页上填写。
什么是爬虫
怎么说呢,爬虫,简单来说就是模拟浏览器获取一个网页的源代码。至于你用源代码做什么,没关系。
说的更复杂一点,爬虫其实就是对所有网页数据处理的综合,比如:自动抓取网页源代码,分析网页数据,获取关键数据并保存,或者自动下载需要的网页图片、音频,和视频。
那么当我们在写一个pythonm爬虫的时候,我们在写什么呢?
当我们需要爬虫的时候,一般会遇到比较复杂的数据需求。这个要求对于手工作业来说是非常复杂的。仅此要求就可以由爬虫轻松解决。
那么首先确定我们的需求,我们需要这个爬虫做什么?
比如我们认为一个教学网站的数据很有趣,但是它的格式太复杂,或者需要频繁翻页,不能通过复制粘贴轻易获取,爬虫就会起作用。
总之,我们以一个爬虫的例子来说明。
爬取百度图片ps:python版-Python 3.7.0
第一个爬虫当然不能选择太复杂的东西,涉及到很多复杂的网络规则,所以我们来爬一些网站,简单的让爬虫去爬。
比如抓取下载关键词下的某百度图片的图片数据。
1、建立需求
暂时确定以上需求,然后开始写真正的爬虫代码
2、 观察网页源码
首先打开百度图片,随意搜索一个关键词。比如这次我会用我最喜欢的动漫角色栗山未来来测试
右键查看网页源码,可以看到每张图片的原创地址都是以一个简单的“objURL”开头,以一个小逗号结尾,如下:
基于此,我们可以确定爬虫应该如何运行。很简单——从网页源码中提取这些url并下载\(^o^)/~
3、获取网页源码
其实这一步我是不想写的,只是担心看了我博客刚学python的朋友可能会出错,所以说一下。
首先,我们需要在python中导入网络库urllib。因为我们需要用到的urlopen和read方法在我的python版本中,直接引用urllib会出错,所以一般使用这个import:import urllib.request
提取网页源代码的整个方法如下:
import urllib.request
def get_html(httpUrl):
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
我们可以将这个方法打包成一个py文件,然后直接在其他py文件中导入这个方法,然后直接使用我们写的get_html方法。
然后将上面得到的二进制文件解码成普通字符串:
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
4、提取图片地址
从网页的源代码中提取关键数据时,实际上是字符串匹配。如果这样估计C++累死我了,当然我也写过类似的,甚至更复杂的,真的是痛苦的回忆。
这里推荐一个比较简单的字符串搜索和匹配程序-正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE)
当然,如何使用正则表达式我就不多说了。你可以自己搜索每个视频网站,看个大概就够了,或者直接看这里——正则表达式基础
了解正则表达式的基本逻辑就可以了。
进入正题,上面的步骤已经分析到每张图片的原创地址开头都有一个很简单的“objURL”,所以我们正则化的关键就是把“objURL”后面的地址取出来。这个很简单,我直接把写好的正则表达式拿出来:
reg=r'"objURL":"(.*?)",'
ps:字符串前的r主要是为了防止转义字符丢失导致的字符丢失
这个规律的作用如下:
匹配任何以 "objURL":" 开头并以 ", 结尾的字符串
然后简单地编译这个正则(记得导入 re 包):
import re
reg=r'"objURL":"(.*?)",'
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
然后使用上面编译的正则表达式解析第三步得到的字符串,如下:
pic_list = reg_compile.findall(html_str)
上面的 pic_list 是一个简单的列表
输出列表中的数据:
for pic in pic_list:
print(pic)
输出如下:
http://b-ssl.duitang.com/uploa ... .jpeg
http://b-ssl.duitang.com/uploa ... .jpeg
http://cdnq.duitang.com/upload ... .jpeg
http://wxpic.7399.com/nqvaoZto ... cpNpu
http://i1.hdslb.com/bfs/archiv ... 0.jpg
http://wxpic.7399.com/nqvaoZto ... cpNpu
可以清楚的看到,有些地址不是图片地址。这可以说是我正则化的问题,但也无伤大雅(其实我也懒得改了)。一点判断就可以完美解决(由于所有图片地址都以g结尾,比如png、jpg、jpeg^_^)
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
完美解,w(゚Д゚)w
ps:哈哈哈,这里当然是玩笑了,大家记得想好办法改正,算是小测试,毕竟真的是无害的。
5、下载图片
下载图片也很简单。正如我开头所说的,图片实际上是存在于远程服务器上的图片文件。只要服务器允许,我们可以很容易的通过GET请求得到这张图片。毕竟,浏览器也会这样做。,至于你得到的,没人管它是用来实际填网页还是给自己用。
python中下载图片的方式有很多种,如下三种
(以下代码不是我写的,不知道版本对不对,如有错误请自行百度。第一种在我的版本中没有问题):
def urllib_download(url):
from urllib.request import urlretrieve
urlretrieve(url, '1.png')
def request_download(url):
import requests
r = requests.get(url)
with open('1.png', 'wb') as f:
f.write(r.content)
def chunk_download(url):
import requests
r = requests.get(url, stream=True)
with open('1.png', 'wb') as f:
for chunk in r.iter_content(chunk_size=32):
f.write(chunk)
所以我们只需要下载上面列表中的每个图片网址。我选择了上面的第一个。这是urllib.request中存在的一个方法,定义如下:
urllib.request.urlretrieve(url, filename, reporthook, data)
参数说明:
url:外部或者本地url
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度。
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
然后一个简单的循环下载就可以了:
def download_pic(pic_adr,x):
urllib.request.urlretrieve(pic_adr, '%s.jpg' %x)
# './images/%s.jpg',这里也可以自己选择创建一个文件吧所有图片放进去,而不是直接放在当前目录下
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
download_pic(pic,x)
x += 1
当然需要为每张图片选择一个本地名称,只需将名称增加1234即可。
这样,我们就结束了整个爬取过程。执行后效果如下:
可以看到,效果还是不错的。毕竟,只要把它放在那里,让它自己下载。还可以考虑如何翻页的效果。事实上,这很简单。我就讲实现一个变化。关键词的效果提醒大家(其实是因为我有点懒,不想写了)
6、更改搜索关键词
看百度搜索页面的网址:
观察这个网址,我们很容易发现原来最后一个关键字是关键词。复制就改了,但是复制之后就不简单了:
http://image.baidu.com/search/ ... %25A5
为什么word变成%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5
这么一堆东西?
很简单,因为url是ASCII码,而这里我们用的是中文,只要稍微操作一下就可以转:
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
urllib.parse.quote 是解码后的代码,在最后加上关键字就OK了。
简单,这个简单的python爬虫就完成了。.
虽然还是想自己写字符串识别,但是regular真的好用。建议多学习一些常规的骚技能。
就这样。
如需修改,请自行复制完整代码并进行更改。下载多个页面也是很简单的操作,就不多说了,还是可以加多线程,代理,动态ip。无论如何,这就是我的第一个爬虫。
完整源码(百度图片爬虫)
import urllib
import time
from urllib.request import urlretrieve
import re
import urllib.request
def get_html(httpUrl):#获取网页源码
page = urllib.request.urlopen( httpUrl )#打开网页
htmlCode = page.read( )#读取网页
return htmlCode
def get_keyword_urllist(keyword):#爬取当前关键词下的图片地址
keyword=urllib.parse.quote(keyword)
search_url="http://image.baidu.com/search/ ... ot%3B
search_url=search_url+keyword #加上关键字
html_code=get_html(search_url)
html_str=html_code.decode(encoding = "utf-8")#将二进制码解码为utf-8编码,即str
reg_str = r'"objURL":"(.*?)",' #正则表达式
reg_compile = re.compile(reg_str)
pic_list = reg_compile.findall(html_str)
return pic_list
keyword="栗山未来"#自己修改,或者自己写个input或者一个txt自己读就完事了,甚至你写一个配置表,把爬取数量、爬取关键词、爬取图片大小都写好都可以
pic_list=get_keyword_urllist(keyword)
x=0
for pic in pic_list:
if pic[len(pic)-1]=='g':
print(pic)
name = keyword+str(x)
time.sleep(0.01)
urllib.request.urlretrieve(pic, './images/%s.jpg' %name)
x += 1
如果不行,请检查收录的模板是否正确或版本是否正确。
重点
最后运行上面的源码,应该会发现虽然可以下载,但是下载速度太慢了。解决它需要几秒钟,但如果它更慢,则可能需要十秒钟以上。
针对这种情况,我重写了上面的代码,加入了多线程处理,将爬取时间缩短到1s以内。我是直接上传到我的github上的,大家可以自己下载。
快速爬取百度图片-爬虫1.0版
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-19 20:02
对于网站webmaster来说,反爬虫是一项非常重要的工作——没有人想让爬虫占据超过一半的宽带
只有百度爬虫是个例外。对于站长来说,一篇文章文章被百度收录证明得越快,其优化效果就越显著
那么百度爬虫的捕获规则是什么呢?让我们今天来看看
一、高质量连续内容更新
用户和百度爬虫都对枯燥的内容非常感兴趣,能够持续更新并确保更新内容质量的网站当然比那些多年不更新或更新原创内容的网站更具吸引力
二、高质量外链
这是网站提高排名的重要一步。对于百度来说,大流量网站的权重必须高于小流量网站的权重。如果我们的网站外链是一个流量大的门户网站网站的话,通常这个门户网站网站在百度也会有很高的权重,也就是说,它间接提高了我们自己的网站曝光率,增加了百度爬虫抓取其网站内容的可能性
三、优质内链
在构建爬虫捕获矩阵(或“Web”)时,除了延伸的高质量外链,我们网站内链的质量也决定了百度爬虫收录的可能性和速度@文章. 百度爬虫将跟随网站导航和网站内页锚文本连接进入网站内页。简明的导航允许爬虫更快地找到内部页面的锚文本。这样,百度不仅可以接收目标页面的内容,还可以收录接收路径上的所有页面
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录a文章of网站吸引了大量流量,但大量前来访问网站的用户由于网站空间不足而无法打开网页,甚至无法打开百度爬虫,无疑会降低百度对该网站的权重分布@ 查看全部
网页爬虫抓取百度图片(百度爬虫的抓取规则是怎么样的的吗??)
对于网站webmaster来说,反爬虫是一项非常重要的工作——没有人想让爬虫占据超过一半的宽带
只有百度爬虫是个例外。对于站长来说,一篇文章文章被百度收录证明得越快,其优化效果就越显著
那么百度爬虫的捕获规则是什么呢?让我们今天来看看
一、高质量连续内容更新
用户和百度爬虫都对枯燥的内容非常感兴趣,能够持续更新并确保更新内容质量的网站当然比那些多年不更新或更新原创内容的网站更具吸引力
二、高质量外链
这是网站提高排名的重要一步。对于百度来说,大流量网站的权重必须高于小流量网站的权重。如果我们的网站外链是一个流量大的门户网站网站的话,通常这个门户网站网站在百度也会有很高的权重,也就是说,它间接提高了我们自己的网站曝光率,增加了百度爬虫抓取其网站内容的可能性
三、优质内链
在构建爬虫捕获矩阵(或“Web”)时,除了延伸的高质量外链,我们网站内链的质量也决定了百度爬虫收录的可能性和速度@文章. 百度爬虫将跟随网站导航和网站内页锚文本连接进入网站内页。简明的导航允许爬虫更快地找到内部页面的锚文本。这样,百度不仅可以接收目标页面的内容,还可以收录接收路径上的所有页面
四、高品质网站空间
这里的“高质量”不仅在于网站空间的稳定性,还在于网站空间足够大,可以让百度爬虫自由进出。如果百度收录a文章of网站吸引了大量流量,但大量前来访问网站的用户由于网站空间不足而无法打开网页,甚至无法打开百度爬虫,无疑会降低百度对该网站的权重分布@
网页爬虫抓取百度图片( java开发修真院,初学者不再的数据有什么用和搜索引擎结合)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-19 19:26
java开发修真院,初学者不再的数据有什么用和搜索引擎结合)
1.什么是爬行动物
爬虫,也被称为网络爬虫,是一个自动程序或脚本运行在互联网上获取数据
2.爬行动物解决了什么问题
爬虫解决了获取数据的问题
3.crawler抓取的数据有什么用途
结合搜索引擎,对数据进行分析,提取有价值的信息,得到数据的商业价值
4.爬行动物的简单分类
通用爬虫:百度抓取互联网上所有数据的爬虫称为通用爬虫
垂直爬虫:为数据分析而爬虫特定数据的爬虫称为垂直爬虫
摘要:在互联网上,大多数都是垂直爬虫,也就是说,通过值爬虫来获取一定范围内的数据
首先,以百度主页为例,通过HTTP get获取百度主页的内容
百度页面源代码
临时要求:
获取百度徽标中的大熊爪图片链接
一.enclosure-get方法
经营成果:
index.html
是的,这是我们的第一个常规代码
通过这种方式,捕获图片的链接必须很方便
我们将常规匹配封装到一个函数中,然后修改代码如下:
只要抓住SRC=“XXXXXX”字符串,就可以抓住整个SRC链接,因此可以使用一个简单的正则语句:SRC=\“(.+?)\”
完整代码如下:
“我们相信,每个人都可以成为java开发的伟大之神。从现在开始,找一位师兄来介绍你。在学习的过程中,你将不再迷茫。这是java开发学院,初学者可以在这里转行到互联网行业。”
"我是一名从事开发多年的老java程序员。我辞职了,目前正在学习自己的java私人定制课程。今年年初,我花了一个月的时间整理了一个最适合2019年学习的java learning dry产品。我整理了从最基本的javase到spring等各种框架给每个Java合作伙伴。如果你想得到它,你可以关注我的头条新闻,并在给我的私人信件中发布:Java,你可以免费得到它 查看全部
网页爬虫抓取百度图片(
java开发修真院,初学者不再的数据有什么用和搜索引擎结合)
1.什么是爬行动物
爬虫,也被称为网络爬虫,是一个自动程序或脚本运行在互联网上获取数据
2.爬行动物解决了什么问题
爬虫解决了获取数据的问题
3.crawler抓取的数据有什么用途
结合搜索引擎,对数据进行分析,提取有价值的信息,得到数据的商业价值
4.爬行动物的简单分类
通用爬虫:百度抓取互联网上所有数据的爬虫称为通用爬虫
垂直爬虫:为数据分析而爬虫特定数据的爬虫称为垂直爬虫
摘要:在互联网上,大多数都是垂直爬虫,也就是说,通过值爬虫来获取一定范围内的数据
首先,以百度主页为例,通过HTTP get获取百度主页的内容
百度页面源代码
临时要求:
获取百度徽标中的大熊爪图片链接
一.enclosure-get方法
经营成果:
index.html
是的,这是我们的第一个常规代码
通过这种方式,捕获图片的链接必须很方便
我们将常规匹配封装到一个函数中,然后修改代码如下:
只要抓住SRC=“XXXXXX”字符串,就可以抓住整个SRC链接,因此可以使用一个简单的正则语句:SRC=\“(.+?)\”
完整代码如下:
“我们相信,每个人都可以成为java开发的伟大之神。从现在开始,找一位师兄来介绍你。在学习的过程中,你将不再迷茫。这是java开发学院,初学者可以在这里转行到互联网行业。”
"我是一名从事开发多年的老java程序员。我辞职了,目前正在学习自己的java私人定制课程。今年年初,我花了一个月的时间整理了一个最适合2019年学习的java learning dry产品。我整理了从最基本的javase到spring等各种框架给每个Java合作伙伴。如果你想得到它,你可以关注我的头条新闻,并在给我的私人信件中发布:Java,你可以免费得到它
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-09-17 19:09
)
Python项目中的爬虫应用案例开发从入门到实战(清华大学出版社郑秋生、夏雅捷主编)-抓拍百度图片
本文使用请求库对网站图片进行爬网。前几章中的博客介绍了如何使用urllib库抓取网页。本文主要利用请求库对网页内容进行抓取。使用方法基本相同,但请求方法相对简单
不要忘记爬行动物的基本概念:
1.指定要抓取的链接,然后抓取网站源代码
2.提取您想要的内容。例如,如果要对图像信息进行爬网,可以选择使用正则表达式过滤或使用提取
标记法
3.cycle获取要爬网的内容列表并保存文件
这里的代码与我的博客(photo crawler series一))前几章的区别在于:
1.提取网页使用请求库
2.保存图片时,后缀不是PNG或JPG,而是图片本身的后缀
3.不使用urllib.request.urlretrieve函数保存图片,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
请注意,为什么在开始时判断图片链接是否来自“HTTPS://”,主要是因为我们需要完整的绝对路径来下载图片,并且我们需要查看原创网页代码。选择图片,点击html所在的代码,按住鼠标查看绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图所示:
查看全部
网页爬虫抓取百度图片(来自《Python项目案例开发从入门到实战》(清华大学出版社郑秋生)
)
Python项目中的爬虫应用案例开发从入门到实战(清华大学出版社郑秋生、夏雅捷主编)-抓拍百度图片
本文使用请求库对网站图片进行爬网。前几章中的博客介绍了如何使用urllib库抓取网页。本文主要利用请求库对网页内容进行抓取。使用方法基本相同,但请求方法相对简单
不要忘记爬行动物的基本概念:
1.指定要抓取的链接,然后抓取网站源代码
2.提取您想要的内容。例如,如果要对图像信息进行爬网,可以选择使用正则表达式过滤或使用提取
标记法
3.cycle获取要爬网的内容列表并保存文件
这里的代码与我的博客(photo crawler series一))前几章的区别在于:
1.提取网页使用请求库
2.保存图片时,后缀不是PNG或JPG,而是图片本身的后缀
3.不使用urllib.request.urlretrieve函数保存图片,而是使用文件读写操作保存图片
具体代码如下图所示:
# 使用requests、bs4库下载华侨大学主页上的所有图片import osimport requestsfrom bs4 import BeautifulSoupimport shutilfrom pathlib import Path # 关于文件路径操作的库,这里主要为了得到图片后缀名# 该方法传入url,返回url的html的源代码def getHtmlCode(url): # 伪装请求的头部来隐藏自己 headers = { 'User-Agent': 'MMozilla/5.0(Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } # 获取网页 r = requests.get(url, headers=headers) # 指定网页解析的编码格式 r.encoding = 'UTF-8' # 获取url页面的源代码字符串文本 page = r.text return page# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机def getImg(page, localPath): # 判断文件夹是否存在,存在则删除,最后都要重新新的文件夹 if os.path.exists(localPath): shutil.rmtree(localPath) os.mkdir(localPath) # 按照Html格式解析页面 soup = BeautifulSoup(page, 'html.parser') # 返回的是一个包含所有img标签的列表 imgList = soup.find_all('img') x = 0 # 循环url列表 for imgUrl in imgList: try: # 得到img标签中的src具体内容 imgUrl_src = imgUrl.get('src') # 排除 src='' 的情况 if imgUrl_src != '': print('正在下载第 %d : %s 张图片' % (x+1, imgUrl_src)) # 判断图片是否是从绝对路径https开始,具体为什么这样操作可以看下图所示 if "https://" not in imgUrl_src: m = 'https://www.hqu.edu.cn/' + imgUrl_src print('正在下载:%s' % m) # 获取图片 ir = requests.get(m) else: ir = requests.get(imgUrl_src) # 设置Path变量,为了使用Pahtlib库中的方法提取后缀名 p = Path(imgUrl_src) # 得到后缀,返回的是如 '.jpg' p_suffix = p.suffix # 用write()方法写入本地文件中,存储的后缀名用原始的后缀名称 open(localPath + str(x) + p_suffix, 'wb').write(ir.content) x = x + 1 except: continueif __name__ == '__main__': # 指定爬取图片链接 url = 'https://www.hqu.edu.cn/index.htm' # 指定存储图片路径 localPath = './img/' # 得到网页源代码 page = getHtmlCode(url) # 保存图片 getImg(page, localPath)
请注意,为什么在开始时判断图片链接是否来自“HTTPS://”,主要是因为我们需要完整的绝对路径来下载图片,并且我们需要查看原创网页代码。选择图片,点击html所在的代码,按住鼠标查看绝对路径,然后根据绝对路径设置要添加的缺失部分,如下图所示:
网页爬虫抓取百度图片(《百度热点新闻上》第6期 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-17 19:06
)
在百度热点新闻中,前6条在strong>A下抓取,后30条在各子栏目(国内、国际、本地、娱乐、体育等)下抓取,抓取的特征值为标签下的mon值,C=栏目名称,PN=各栏目下的新闻条数,12个项目显示在一个类别下(8个本地新闻项目),只需查看原创网页即可
完整代码如下所示
import requests
from bs4 import BeautifulSoup
import time
url='http://news.baidu.com/'
res=requests.get(url)
soup = BeautifulSoup(res.text,'lxml')
print('百度新闻python爬虫抓取')
print('头条热点新闻')
sel_a =soup.select('strong a')
for i in range(0,5):
print(sel_a[i].get_text())
print(sel_a[i].get('href'))
print('热点新闻')
titles_b=[]
titlew=""
for i in range(1,31):
sel_b=soup.find_all('a',mon="ct=1&a=2&c=top&pn="+str(i))
titles_b.append(sel_b[0])
for i in range(0,30):
print(titles_b[i].get_text())
print(titles_b[i].get('href'))
titlew=titlew + titles_b[i].get_text() + "\n"
# 获取当前时间
now = time.strftime('%Y-%m-%d', time.localtime(time.time()))
# 输出到文件
with open('news' + now + '.txt', 'a', encoding='utf-8') as file:
file.write(titlew) #只输出标题
在浏览过程中,您可以直接将网页下载到本地进行调试。代码如下:
with open('本地文件路径',encoding='utf-8') as f:
# print(f.read())
soup = BeautifulSoup(f,'lxml') 查看全部
网页爬虫抓取百度图片(《百度热点新闻上》第6期
)
在百度热点新闻中,前6条在strong>A下抓取,后30条在各子栏目(国内、国际、本地、娱乐、体育等)下抓取,抓取的特征值为标签下的mon值,C=栏目名称,PN=各栏目下的新闻条数,12个项目显示在一个类别下(8个本地新闻项目),只需查看原创网页即可
完整代码如下所示
import requests
from bs4 import BeautifulSoup
import time
url='http://news.baidu.com/'
res=requests.get(url)
soup = BeautifulSoup(res.text,'lxml')
print('百度新闻python爬虫抓取')
print('头条热点新闻')
sel_a =soup.select('strong a')
for i in range(0,5):
print(sel_a[i].get_text())
print(sel_a[i].get('href'))
print('热点新闻')
titles_b=[]
titlew=""
for i in range(1,31):
sel_b=soup.find_all('a',mon="ct=1&a=2&c=top&pn="+str(i))
titles_b.append(sel_b[0])
for i in range(0,30):
print(titles_b[i].get_text())
print(titles_b[i].get('href'))
titlew=titlew + titles_b[i].get_text() + "\n"
# 获取当前时间
now = time.strftime('%Y-%m-%d', time.localtime(time.time()))
# 输出到文件
with open('news' + now + '.txt', 'a', encoding='utf-8') as file:
file.write(titlew) #只输出标题
在浏览过程中,您可以直接将网页下载到本地进行调试。代码如下:
with open('本地文件路径',encoding='utf-8') as f:
# print(f.read())
soup = BeautifulSoup(f,'lxml')
网页爬虫抓取百度图片(用python访问直接Fobbiden!真小气qwq最后还是乖乖去爬zol上的壁纸)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-17 12:14
根据老师的指导,我昨天开始自学爬虫入门
虽然我意识到了一个相对简单的小爬虫,但我还是很兴奋。我真的很高兴第一次意识到这一点
起初,我想爬上pexel的墙纸,但我发现对方的网页不知道设置了什么。无论如何,有一个反爬虫机制,我使用Python直接访问fobbiden!多么小气的qwq
最后,我爬上了ZOL的墙纸
之前:
当设计一个爬虫项目时,我们应该首先阐明手动浏览页面以获取大脑中图片的步骤
一般来说,当我们批量在线打开壁纸时,一般操作如下:
1、打开墙纸页
2、单击墙纸贴图(打开指定墙纸的页面)
3、选择分辨率(我们想下载高清图片)
4、save图片
在实际操作中,我们实现了以下步骤来访问网页地址:打开网页的壁纸→ 单击墙纸贴图打开指定页面→ 选择分辨率,单击打开最终保存的目标图像的网页→ 保存图像
在抓取过程中,我们尝试通过模拟浏览器的操作来打开网页,一步一步地获取并访问网页,最后获取目标图像的下载地址,将图像下载并保存到指定路径
*为了在这些中间过程中构建网页的某些特定过滤条件,有必要打开指定页面的源代码,观察并找到收录有目的链接的标记
具体实施项目和说明
这里我只是想得到一些指定的图片,所以我首先搜索了“昌门有喜”的网页,打开了一个搜索结果页面,发现这个页面上还收录了其他相同类型的壁纸链接,所以我从一开始就将我第一次访问的目的地地址设置为这个搜索结果页面
目标结果页面的屏幕截图:
图中的下标为“1/29”和“2/29”是相同类型的其他目标壁纸。通过单击这些图片,我们可以打开一个新的目标下载图片页面
这里我们看一下网页的源代码
图的黄色底部是这些类似墙纸的目标地址(访问时需要添加前缀“”)
现在我们可以尝试实现构建爬虫程序:
打开指定的页面→ 过滤并获取所有昌门优喜壁纸的目标下载页面链接
代码如下:
1 from urllib import request,error
2 import re
3
4 url = "http://desk.zol.com.cn/bizhi/561_5496_2.html"
5
6 try:
7 response = request.urlopen(url)# 打开页面
8 html = response.read() #此时是byte类型
9 html = str(html) # 转换成字符串
10
11 pattern = re.compile(r'.*?</a>')
12 imglist = re.findall(pattern,html) # 匹配<a>标签中的href地址
13 truelist = []
14 for item in imglist:
15 if re.match(r'^\/bizhi\/561_',item): # 观察到所有目的地址下载页面前缀都是/bizhi/561_,通过match函数进行筛选
16 truelist.append(item)# 筛选掉其他无关的页面(把真的目标页面加到truelist列表中)
17 except error.HTTPError as e:
18 print(e.reason)
19 except error.URLError as e:
20 print(e.reason)
21 except:
22 pass
在获得地址后,我们可以获得地址→ 打开指定的页面→ 选择分辨率→ 获取目标下载地址→ 保存到本地指定路径
在测试期间,我输出了在信任列表的前一步中保存的内容
您可以看到只保存了一个后缀。我们需要在访问时添加指定的前缀
实施代码(见***代码):
<p> 1 # 对于每一张地址,抓取其地址并且下载到本地
2 x=0
3 for wallpaperpage in truelist:
4 try:
5 # print(wallpaperpage)
6 url1 = "http://desk.zol.com.cn" + wallpaperpage
7 response1 = request.urlopen(url1) # 打开壁纸的页面,相当于在浏览器中单击壁纸名
8 html1 = response1.read()
9 html1 = str(html1)
10 pattern1 = re.compile(r'.*</a>')
11 urllist = re.findall(pattern1,html1) #匹配<a>标签中的id为1920 * 1080的地址,相当于在浏览器中选择1920*1080分辨率
12 html2 = str(request.urlopen("http://desk.zol.com.cn"+urllist[0]).read()) # 打开网页
13
14 pattern2 = re.compile(r' 查看全部
网页爬虫抓取百度图片(用python访问直接Fobbiden!真小气qwq最后还是乖乖去爬zol上的壁纸)
根据老师的指导,我昨天开始自学爬虫入门
虽然我意识到了一个相对简单的小爬虫,但我还是很兴奋。我真的很高兴第一次意识到这一点
起初,我想爬上pexel的墙纸,但我发现对方的网页不知道设置了什么。无论如何,有一个反爬虫机制,我使用Python直接访问fobbiden!多么小气的qwq
最后,我爬上了ZOL的墙纸
之前:
当设计一个爬虫项目时,我们应该首先阐明手动浏览页面以获取大脑中图片的步骤
一般来说,当我们批量在线打开壁纸时,一般操作如下:
1、打开墙纸页
2、单击墙纸贴图(打开指定墙纸的页面)
3、选择分辨率(我们想下载高清图片)
4、save图片
在实际操作中,我们实现了以下步骤来访问网页地址:打开网页的壁纸→ 单击墙纸贴图打开指定页面→ 选择分辨率,单击打开最终保存的目标图像的网页→ 保存图像
在抓取过程中,我们尝试通过模拟浏览器的操作来打开网页,一步一步地获取并访问网页,最后获取目标图像的下载地址,将图像下载并保存到指定路径
*为了在这些中间过程中构建网页的某些特定过滤条件,有必要打开指定页面的源代码,观察并找到收录有目的链接的标记
具体实施项目和说明
这里我只是想得到一些指定的图片,所以我首先搜索了“昌门有喜”的网页,打开了一个搜索结果页面,发现这个页面上还收录了其他相同类型的壁纸链接,所以我从一开始就将我第一次访问的目的地地址设置为这个搜索结果页面
目标结果页面的屏幕截图:
图中的下标为“1/29”和“2/29”是相同类型的其他目标壁纸。通过单击这些图片,我们可以打开一个新的目标下载图片页面
这里我们看一下网页的源代码
图的黄色底部是这些类似墙纸的目标地址(访问时需要添加前缀“”)
现在我们可以尝试实现构建爬虫程序:
打开指定的页面→ 过滤并获取所有昌门优喜壁纸的目标下载页面链接
代码如下:
1 from urllib import request,error
2 import re
3
4 url = "http://desk.zol.com.cn/bizhi/561_5496_2.html"
5
6 try:
7 response = request.urlopen(url)# 打开页面
8 html = response.read() #此时是byte类型
9 html = str(html) # 转换成字符串
10
11 pattern = re.compile(r'.*?</a>')
12 imglist = re.findall(pattern,html) # 匹配<a>标签中的href地址
13 truelist = []
14 for item in imglist:
15 if re.match(r'^\/bizhi\/561_',item): # 观察到所有目的地址下载页面前缀都是/bizhi/561_,通过match函数进行筛选
16 truelist.append(item)# 筛选掉其他无关的页面(把真的目标页面加到truelist列表中)
17 except error.HTTPError as e:
18 print(e.reason)
19 except error.URLError as e:
20 print(e.reason)
21 except:
22 pass
在获得地址后,我们可以获得地址→ 打开指定的页面→ 选择分辨率→ 获取目标下载地址→ 保存到本地指定路径
在测试期间,我输出了在信任列表的前一步中保存的内容
您可以看到只保存了一个后缀。我们需要在访问时添加指定的前缀
实施代码(见***代码):
<p> 1 # 对于每一张地址,抓取其地址并且下载到本地
2 x=0
3 for wallpaperpage in truelist:
4 try:
5 # print(wallpaperpage)
6 url1 = "http://desk.zol.com.cn" + wallpaperpage
7 response1 = request.urlopen(url1) # 打开壁纸的页面,相当于在浏览器中单击壁纸名
8 html1 = response1.read()
9 html1 = str(html1)
10 pattern1 = re.compile(r'.*</a>')
11 urllist = re.findall(pattern1,html1) #匹配<a>标签中的id为1920 * 1080的地址,相当于在浏览器中选择1920*1080分辨率
12 html2 = str(request.urlopen("http://desk.zol.com.cn"+urllist[0]).read()) # 打开网页
13
14 pattern2 = re.compile(r'
网页爬虫抓取百度图片(本次做的爬虫实例比较简单,晚上回来的时间用来码代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-16 06:16
)
最近,我在互联网上看到了文章爬虫的引入。我觉得很有趣。搬家总比搬家好。晚上回来的时间只是用来编码的~~
网络爬虫:根据一定的规则对网页上的信息进行爬网,通常先爬网到一些URL,然后将这些URL放入队列中进行反复搜索。我不知道是DFS还是BFS。我在这里不研究算法,因为爬虫示例相对简单。我实现了一个java小程序来抓取百度页面的徽标
事实上,爬虫的作用远远大于此。此示例仅供介绍性参考
首先,让我们分析一下,在本例中,抓取图片的过程只不过是以下步骤:
1.访问百度主页获取网页返回的信息
2.get有用信息(这里是网页的源代码或所有图片的URL)
3.访问所有图片的URL
4.可以以流的形式本地存储
通过以上步骤,很容易编写一个简单的爬虫程序。下面是代码中带有注释的代码
<p>import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Bug {
String url = "http://www.baidu.com";//待爬取的URL
//获取url页面的源码;
public String ClimbBug() throws IOException{
URL accessurl = new URL(url);
HttpURLConnection conn = (HttpURLConnection) accessurl.openConnection();
conn.connect();//连接
InputStream is = null;
if(conn.getResponseCode()==200){//判断状态吗是否为200,正常的话获取返回信息
byte[] b=new byte[4096];
is = conn.getInputStream();
StringBuilder sb = new StringBuilder();
int len=0;
while((len=is.read(b))!=-1){
sb.append(new String(b,0,len,"UTF-8"));
}
return sb.toString();//返回百度页面源代码,这里跟网页上右键查看源代码的效果一致
}
return "Error";
}
//获取图片页面URL
public List regex() throws IOException{
System.out.println(new Bug().ClimbBug());
String regex = "src[\\s\\S]*?>";//匹配所有图片的URL
List list = new ArrayList();
Matcher p = Pattern.compile(regex).matcher(new Bug().ClimbBug());
while(p.find()){
list.add(p.group());
}//匹配到放入我们的URLlist
return list;
}
//下载图片到本地或者结合数据库做其他想做的操作;
public void download(List list) throws IOException{
InputStream is =null;
OutputStream os =null;
for (int i=0;i 查看全部
网页爬虫抓取百度图片(本次做的爬虫实例比较简单,晚上回来的时间用来码代码
)
最近,我在互联网上看到了文章爬虫的引入。我觉得很有趣。搬家总比搬家好。晚上回来的时间只是用来编码的~~
网络爬虫:根据一定的规则对网页上的信息进行爬网,通常先爬网到一些URL,然后将这些URL放入队列中进行反复搜索。我不知道是DFS还是BFS。我在这里不研究算法,因为爬虫示例相对简单。我实现了一个java小程序来抓取百度页面的徽标
事实上,爬虫的作用远远大于此。此示例仅供介绍性参考
首先,让我们分析一下,在本例中,抓取图片的过程只不过是以下步骤:
1.访问百度主页获取网页返回的信息
2.get有用信息(这里是网页的源代码或所有图片的URL)
3.访问所有图片的URL
4.可以以流的形式本地存储
通过以上步骤,很容易编写一个简单的爬虫程序。下面是代码中带有注释的代码
<p>import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Bug {
String url = "http://www.baidu.com";//待爬取的URL
//获取url页面的源码;
public String ClimbBug() throws IOException{
URL accessurl = new URL(url);
HttpURLConnection conn = (HttpURLConnection) accessurl.openConnection();
conn.connect();//连接
InputStream is = null;
if(conn.getResponseCode()==200){//判断状态吗是否为200,正常的话获取返回信息
byte[] b=new byte[4096];
is = conn.getInputStream();
StringBuilder sb = new StringBuilder();
int len=0;
while((len=is.read(b))!=-1){
sb.append(new String(b,0,len,"UTF-8"));
}
return sb.toString();//返回百度页面源代码,这里跟网页上右键查看源代码的效果一致
}
return "Error";
}
//获取图片页面URL
public List regex() throws IOException{
System.out.println(new Bug().ClimbBug());
String regex = "src[\\s\\S]*?>";//匹配所有图片的URL
List list = new ArrayList();
Matcher p = Pattern.compile(regex).matcher(new Bug().ClimbBug());
while(p.find()){
list.add(p.group());
}//匹配到放入我们的URLlist
return list;
}
//下载图片到本地或者结合数据库做其他想做的操作;
public void download(List list) throws IOException{
InputStream is =null;
OutputStream os =null;
for (int i=0;i
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-16 06:14
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。(来源:百度百科全书)
爬虫协议
robots协议(也称为crawler协议、robot协议等)的全称为“robots exclusion protocol”,网站通过该协议,robots协议告诉搜索引擎哪些页面可以爬网,哪些页面不能爬网
robots.txt文件是一个文本文件。您可以使用任何通用文本编辑器(如Windows系统附带的记事本)创建和编辑它。Robots.txt是一个协议,不是命令。Robots.txt是在搜索引擎中访问网站时查看的第一个文件。txt文件告诉爬行器可以在服务器上查看哪些文件。(来源:百度百科全书)
爬虫百度图片
目标:抓取百度图片并保存在电脑上
首先,数据是公开的吗?我可以下载吗
从图中可以看出,百度图片完全可以下载,说明图片可以爬网
首先,了解图片是什么
我们看到的正式事物统称为图片、照片、拓片等。图形是技术制图中的一个基本术语,指用点、线、符号、文字和数字来描述事物的几何特征、形状、位置和大小的一种形式。随着数字采集技术和信号处理理论的发展,越来越多的图像以数字形式存储
那照片在哪里
映像保存在ECS数据库中
每张图片都有一个对应的URL。请求通过请求模块启动,并以文件的WB+模式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是任何编写代码来爬升图片的人都可以直接下载。爬虫的目的是实现批量下载的目的,这才是真正的爬虫
首先,了解JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于ECMAScript(由欧洲计算机协会制定的JS规范)的子集,并使用完全独立于编程语言的文本格式来存储和表示数据。简洁清晰的层次结构使JSON成为理想的数据交换语言
JSON是JS的对象,用于访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在Python中,不能通过键值对直接获取值,因此我必须讨论Python中的字典
在Python中导入JSON,并通过JSON将JSON数据转换为Python数据(字典)。装载量-->
Ajax,即“异步JavaScript和XML”,是指一种用于创建交互式网页应用程序的网页开发技术
图片是通过Ajax方法加载的,也就是说,当我下拉时,图片会自动加载,因为网站会自动启动请求
构造Ajax的URL请求,将JSON转换成字典,通过字典的键值对得到图片对应的URL
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个JSON中有30张图片,因此我们可以通过启动JSON请求来提升多达30张图片,但这还不够
首先,分析在不同JSON中启动的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
事实上,可以发现,当请求再次启动时,关键是PN不断变化
最后,封装代码。一个列表定义生产者来存储不断生成的图片的URL,另一个列表定义消费者来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬行过程
爬网结果
文章开始于: 查看全部
网页爬虫抓取百度图片(什么是爬虫网络爬虫(又被称为网页蜘蛛,网络机器人))
什么是爬行动物
网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中更常被称为网络追踪器)是一种程序或脚本,根据特定规则自动获取万维网信息。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。(来源:百度百科全书)
爬虫协议
robots协议(也称为crawler协议、robot协议等)的全称为“robots exclusion protocol”,网站通过该协议,robots协议告诉搜索引擎哪些页面可以爬网,哪些页面不能爬网
robots.txt文件是一个文本文件。您可以使用任何通用文本编辑器(如Windows系统附带的记事本)创建和编辑它。Robots.txt是一个协议,不是命令。Robots.txt是在搜索引擎中访问网站时查看的第一个文件。txt文件告诉爬行器可以在服务器上查看哪些文件。(来源:百度百科全书)
爬虫百度图片
目标:抓取百度图片并保存在电脑上
首先,数据是公开的吗?我可以下载吗
从图中可以看出,百度图片完全可以下载,说明图片可以爬网
首先,了解图片是什么
我们看到的正式事物统称为图片、照片、拓片等。图形是技术制图中的一个基本术语,指用点、线、符号、文字和数字来描述事物的几何特征、形状、位置和大小的一种形式。随着数字采集技术和信号处理理论的发展,越来越多的图像以数字形式存储
那照片在哪里
映像保存在ECS数据库中
每张图片都有一个对应的URL。请求通过请求模块启动,并以文件的WB+模式保存
import requests
r = requests.get('http://pic37.nipic.com/2014011 ... 23x27;)
with open('demo.jpg','wb+') as f:
f.write(r.content)
但是任何编写代码来爬升图片的人都可以直接下载。爬虫的目的是实现批量下载的目的,这才是真正的爬虫
首先,了解JSON
JSON(JavaScript对象表示法)是一种轻量级数据交换格式。它基于ECMAScript(由欧洲计算机协会制定的JS规范)的子集,并使用完全独立于编程语言的文本格式来存储和表示数据。简洁清晰的层次结构使JSON成为理想的数据交换语言
JSON是JS的对象,用于访问数据
JSON字符串
{
“name”: “毛利”,
“age”: 18,
“ feature “ : [‘高’, ‘富’, ‘帅’]
}
Python字典
{
‘name’: ‘毛利’,
‘age’: 18
‘feature’ : [‘高’, ‘富’, ‘帅’]
}
但是在Python中,不能通过键值对直接获取值,因此我必须讨论Python中的字典
在Python中导入JSON,并通过JSON将JSON数据转换为Python数据(字典)。装载量-->
Ajax,即“异步JavaScript和XML”,是指一种用于创建交互式网页应用程序的网页开发技术
图片是通过Ajax方法加载的,也就是说,当我下拉时,图片会自动加载,因为网站会自动启动请求
构造Ajax的URL请求,将JSON转换成字典,通过字典的键值对得到图片对应的URL
import requests
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://image.baidu.com/search ... 27%3B,headers = headers).text
res = json.loads(r)['data']
for index,i in enumerate(res):
url = i['hoverURL']
print(url)
with open( '{}.jpg'.format(index),'wb+') as f:
f.write(requests.get(url).content)
一个JSON中有30张图片,因此我们可以通过启动JSON请求来提升多达30张图片,但这还不够
首先,分析在不同JSON中启动的请求
https://image.baidu.com/search ... 55%3D
https://image.baidu.com/search ... 90%3D
事实上,可以发现,当请求再次启动时,关键是PN不断变化
最后,封装代码。一个列表定义生产者来存储不断生成的图片的URL,另一个列表定义消费者来保存图片
# -*- coding:utf-8 -*-
# time :2019/6/20 17:07
# author: 毛利
import requests
import json
import os
def get_pic_url(num):
pic_url= []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
for i in range(num):
page_url = 'https://image.baidu.com/search ... pn%3D{}&rn=30&gsm=1e&1561022599290='.format(30*i)
r = requests.get(page_url, headers=headers).text
res = json.loads(r)['data']
if res:
print(res)
for j in res:
try:
url = j['hoverURL']
pic_url.append(url)
except:
print('该图片的url不存在')
print(len(pic_url))
return pic_url
def down_img(num):
pic_url =get_pic_url(num)
if os.path.exists('D:\图片'):
pass
else:
os.makedirs('D:\图片')
path = 'D:\图片\\'
for index,i in enumerate(pic_url):
filename = path + str(index) + '.jpg'
print(filename)
with open(filename, 'wb+') as f:
f.write(requests.get(i).content)
if __name__ == '__main__':
num = int(input('爬取几次图片:一次30张'))
down_img(num)
爬行过程
爬网结果
文章开始于:
网页爬虫抓取百度图片( ,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-16 06:11
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
Java中使用爬虫捕获网站网页内容的方法
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了用Java-crawler捕获网站网页内容的方法,并结合实例分析了Java-crawler的两种实现技巧,具有一定的参考价值。有需要的朋友可以参考
本文描述了在Java中使用爬虫捕获网站网页内容的方法。与您分享,供您参考。详情如下:
最近,我在用java学习爬行技术。哈哈,我进门和你分享了我的经历
提供以下两种方法。一种是使用Apache提供的包。另一个是使用Java提供的包
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength 查看全部
网页爬虫抓取百度图片(
,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
Java中使用爬虫捕获网站网页内容的方法
更新时间:2015年7月24日09:36:05作者:fzhlee
本文文章主要介绍了用Java-crawler捕获网站网页内容的方法,并结合实例分析了Java-crawler的两种实现技巧,具有一定的参考价值。有需要的朋友可以参考
本文描述了在Java中使用爬虫捕获网站网页内容的方法。与您分享,供您参考。详情如下:
最近,我在用java学习爬行技术。哈哈,我进门和你分享了我的经历
提供以下两种方法。一种是使用Apache提供的包。另一个是使用Java提供的包
代码如下:
<p>
// 第一种方法
//这种方法是用apache提供的包,简单方便
//但是要用到以下包:commons-codec-1.4.jar
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null;
String keyword = null;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes("ISO-8859-1"), "gb2312");
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll("//&[a-zA-Z]{1,10};", "")
.replaceAll("]*>", "");//去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
// 第二种方法
// 这种方法是JAVA自带的URL来抓取网站内容
public String getPageContent(String strUrl, String strPostRequest,
int maxLength) {
// 读取结果网页
StringBuffer buffer = new StringBuffer();
System.setProperty("sun.net.client.defaultConnectTimeout", "5000");
System.setProperty("sun.net.client.defaultReadTimeout", "5000");
try {
URL newUrl = new URL(strUrl);
HttpURLConnection hConnect = (HttpURLConnection) newUrl
.openConnection();
// POST方式的额外数据
if (strPostRequest.length() > 0) {
hConnect.setDoOutput(true);
OutputStreamWriter out = new OutputStreamWriter(hConnect
.getOutputStream());
out.write(strPostRequest);
out.flush();
out.close();
}
// 读取内容
BufferedReader rd = new BufferedReader(new InputStreamReader(
hConnect.getInputStream()));
int ch;
for (int length = 0; (ch = rd.read()) > -1
&& (maxLength
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站().7点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2021-09-10 11:07
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功
2.Integrated Scrapy framework----进入命令行:pip install Scrapy
安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持服务器之家!
原文链接: 查看全部
网页爬虫抓取百度图片(爬取爬虫爬虫措施的静态网站().7点)
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功
2.Integrated Scrapy framework----进入命令行:pip install Scrapy
安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助,也希望多多支持服务器之家!
原文链接:
网页爬虫抓取百度图片( 2017年02月17日09:58:cong框架sublimetext3)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-10 11:06
2017年02月17日09:58:cong框架sublimetext3)
Python爬虫:通过关键词抓取百度图片
更新时间:2017年2月17日09:58:19 作者:WC-cong
本文主要介绍Python爬虫:通过关键字爬取百度图片的方法。有很好的参考价值,下面小编一起来看看吧
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功
2.Integrated Scrapy framework----进入命令行:pip install Scrapy
安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家! 查看全部
网页爬虫抓取百度图片(
2017年02月17日09:58:cong框架sublimetext3)
Python爬虫:通过关键词抓取百度图片
更新时间:2017年2月17日09:58:19 作者:WC-cong
本文主要介绍Python爬虫:通过关键字爬取百度图片的方法。有很好的参考价值,下面小编一起来看看吧
使用工具:Python2.7点我下载
Scrapy 框架
sublime text3
一个。构建python(Windows版)
1.Install python2.7 --- 然后在cmd中输入python,界面如下,安装成功
2.Integrated Scrapy framework----进入命令行:pip install Scrapy
安装成功界面如下:
失败有很多,例如:
解决方案:
其他错误可以百度搜索。
两个。开始编程。
1.Crawl static 网站 没有反爬虫措施。比如百度贴吧、豆瓣书树。
例如-“桌面栏”中的帖子
python代码如下:
代码注释:引入两个模块urllib。定义了两个函数。第一个功能是获取整个目标网页的数据,第二个功能是获取目标网页中的目标图片,遍历网页,开始按照0对获取的图片进行排序。
注:re模块知识点:
爬行图片效果图:
默认情况下,图片保存路径与创建的.py在同一个目录文件中。
2. 用反爬虫措施抓取百度图片。比如百度图片等等。
例如关键字搜索“表情包”%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos= 0&hs =2&xthttps=111111
图片滚动加载,前30张图片先爬取。
代码如下:
代码注释:导入4个模块,os模块用于指定保存路径。前两个功能同上。第三个函数使用 if 语句和 tryException。
抓取过程如下:
抓取结果:
注意:写python代码时注意对齐,不能混用Tab和空格,容易报错。
以上是本文的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。同时也希望大家多多支持脚本之家!

