
爬虫抓取网页数据
爬虫抓取网页数据(基于目标网页特征的爬虫所提供的网络爬虫技术分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 22:11
网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术。网络爬虫也被称为网络蜘蛛和网络机器人。在 FOAF 社区中,他们更多地被称为网络追逐者;其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。
网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。 查看全部
爬虫抓取网页数据(基于目标网页特征的爬虫所提供的网络爬虫技术分析)
网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术。网络爬虫也被称为网络蜘蛛和网络机器人。在 FOAF 社区中,他们更多地被称为网络追逐者;其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。

网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-14 19:03
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
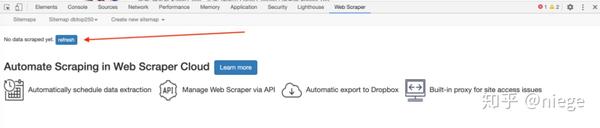
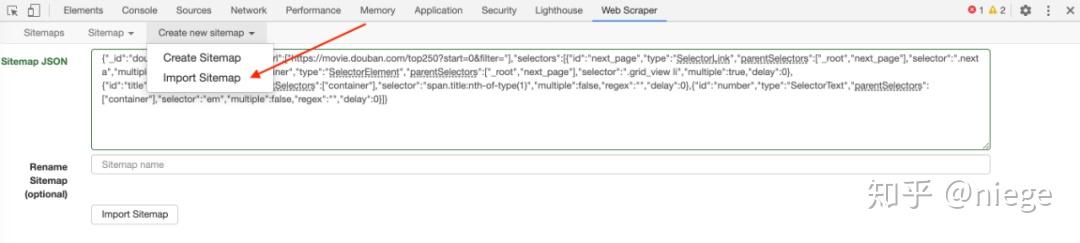
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据

图2:表格形式

数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
爬虫抓取网页数据(单个网页数据爬取的思路及技术做个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-14 19:02
不知不觉,我已经毕业一年多了。这一年主要从事数据分析和挖掘。突然想总结分享一下之前学过的技术。
之前公司项目有一个很奇怪的需求,希望抓取网页数据并保存在Word中,要求和网页上一模一样,包括网页上图表的内容。
以静态网页为例。先展示最终结果:
部分原网页截图:
通过爬虫写字效果:
上面是将单个网页的数据写入word的简单效果,爬取图表相关信息的工作比较繁琐。
爬取单个网页数据的思路:先解析网页,然后定位网页信息,再判断定位到的网页信息中的每条内容是表格还是图片。如果是表,则需要分析表结构。
如下图,tr代表表格的行,td代表表格的列。第一个tr下有4个td对应表的第一行4列,以此类推。图表的绘制主要使用python第三方包python_docx,通过该包中的add_table函数绘制表格,使用add_picture函数绘制图片。
Python使用python_docx包方法来引用网页:
这部分代码如下:
def get_article(url_body,filename,html):
content_total = ""
text = url_body.xpath('.//td[@class="b12c"]/p|.//td[@class="b12c"]/div|.//td[@class="b12c"]/span|.//td[@class="b12c"]/font')
doc = Document()
for x in text:
row = x.xpath('.//tbody//tr')
try:
if row: #判断是否为表格
for col in row:
table = doc.add_table(rows=1, cols=int(len(col)), style='Table Grid')
hdr_cells = table.rows[0].cells
td = col.xpath('./td')
td_list = []
for t in td:
ins_data = t.xpath('.//text()') #爬取网页表格中的数据
ins_data = filter(lambda x: x != '\r\n ', ins_data)
tmp = ""
for i in range(len(ins_data)):
tmp += ins_data[i]
td_list.append(tmp)
length = len(td_list)
for i in range(length):
hdr_cells[i].text = td_list[i] #数据写入创建的表格中
else:
img_ads = x.xpath('.//@src')
imglist = ""
if img_ads: #判断爬取的是否为图片数据
for h in img_ads:
if h.startswith('http://'):
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
else: #有些图片网页不是http:开头需要重新修改
ind = html.rfind('/') + 1
h = html.replace(html[ind:], h)
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
doc.add_picture(img, width=Inches(4.25))#设置写入的图片大小
imglist = imglist + h + " "
paragraph = x.xpath('.//text()') #爬取文字段落信息
str_ = ""
for j in paragraph:
str_ = str_ + j
doc.add_paragraph(str_)
content_total = content_total + imglist + str_ + "\n"
except:
pass
doc.save(filename)
return content_total
本文简单介绍了单个网页数据的抓取和写入方法,抓取的目标网页为静态网页。如果是动态网页,还需要找出网页的跳转文件。抓取多个网页需要分页处理。MongoDB 可用于将抓取到的网页地址存储在 MongoDB 中。每次爬取一个网页,可以判断MongoDB中是否有,避免重复爬取。
本文示例的源代码: 查看全部
爬虫抓取网页数据(单个网页数据爬取的思路及技术做个)
不知不觉,我已经毕业一年多了。这一年主要从事数据分析和挖掘。突然想总结分享一下之前学过的技术。
之前公司项目有一个很奇怪的需求,希望抓取网页数据并保存在Word中,要求和网页上一模一样,包括网页上图表的内容。
以静态网页为例。先展示最终结果:
部分原网页截图:

通过爬虫写字效果:


上面是将单个网页的数据写入word的简单效果,爬取图表相关信息的工作比较繁琐。
爬取单个网页数据的思路:先解析网页,然后定位网页信息,再判断定位到的网页信息中的每条内容是表格还是图片。如果是表,则需要分析表结构。
如下图,tr代表表格的行,td代表表格的列。第一个tr下有4个td对应表的第一行4列,以此类推。图表的绘制主要使用python第三方包python_docx,通过该包中的add_table函数绘制表格,使用add_picture函数绘制图片。

Python使用python_docx包方法来引用网页:
这部分代码如下:
def get_article(url_body,filename,html):
content_total = ""
text = url_body.xpath('.//td[@class="b12c"]/p|.//td[@class="b12c"]/div|.//td[@class="b12c"]/span|.//td[@class="b12c"]/font')
doc = Document()
for x in text:
row = x.xpath('.//tbody//tr')
try:
if row: #判断是否为表格
for col in row:
table = doc.add_table(rows=1, cols=int(len(col)), style='Table Grid')
hdr_cells = table.rows[0].cells
td = col.xpath('./td')
td_list = []
for t in td:
ins_data = t.xpath('.//text()') #爬取网页表格中的数据
ins_data = filter(lambda x: x != '\r\n ', ins_data)
tmp = ""
for i in range(len(ins_data)):
tmp += ins_data[i]
td_list.append(tmp)
length = len(td_list)
for i in range(length):
hdr_cells[i].text = td_list[i] #数据写入创建的表格中
else:
img_ads = x.xpath('.//@src')
imglist = ""
if img_ads: #判断爬取的是否为图片数据
for h in img_ads:
if h.startswith('http://'):
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
else: #有些图片网页不是http:开头需要重新修改
ind = html.rfind('/') + 1
h = html.replace(html[ind:], h)
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
doc.add_picture(img, width=Inches(4.25))#设置写入的图片大小
imglist = imglist + h + " "
paragraph = x.xpath('.//text()') #爬取文字段落信息
str_ = ""
for j in paragraph:
str_ = str_ + j
doc.add_paragraph(str_)
content_total = content_total + imglist + str_ + "\n"
except:
pass
doc.save(filename)
return content_total
本文简单介绍了单个网页数据的抓取和写入方法,抓取的目标网页为静态网页。如果是动态网页,还需要找出网页的跳转文件。抓取多个网页需要分页处理。MongoDB 可用于将抓取到的网页地址存储在 MongoDB 中。每次爬取一个网页,可以判断MongoDB中是否有,避免重复爬取。
本文示例的源代码:
爬虫抓取网页数据( Python标准库中的应用方法-苏州安嘉 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-13 12:07
Python标准库中的应用方法-苏州安嘉
)
2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
推荐的解析器资源:
pyquery /1EwUKsEG
Beautifulsoupt.im/ddfv
xpath 教程 t.im/ddg2
重新文件 t.im/ddg6
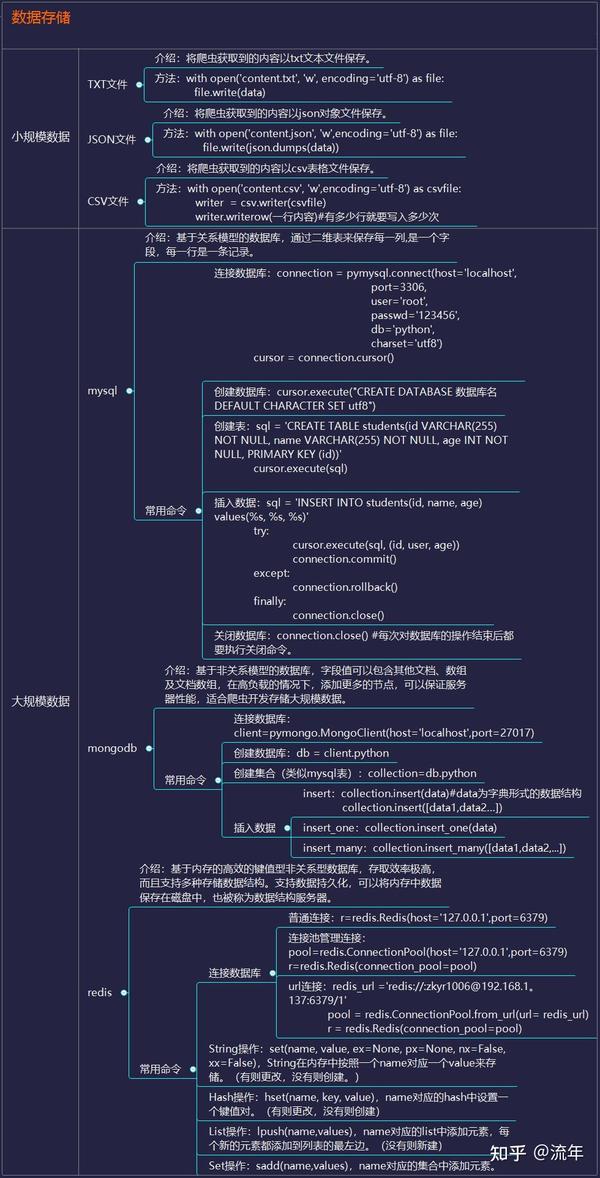
3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,sear是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
推荐的爬虫框架资源:
纳奇文件/
可怕的文件/
pyspider 文档 t.im/ddgj
防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽量控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头,修改爬虫的请求头,尽量与浏览器保持一致,以此类推。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你能写出分布式爬虫,那么你就可以尝试搭建一些基本的爬虫架构来实现一些更加自动化的数据采集。
推荐的分布式资源:
scrapy-redis 文档 t.im/ddgk
scrapy-rabbitmq 文档 t.im/ddgn
芹菜文件 t.im/ddgr
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。
以上知识框架已经完整打包,包括超清图片、PDF文档、思维导图文件、python爬虫相关资料。您可以点击下方卡片添加微信领取。
查看全部
爬虫抓取网页数据(
Python标准库中的应用方法-苏州安嘉
)


2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
推荐的解析器资源:
pyquery /1EwUKsEG
Beautifulsoupt.im/ddfv
xpath 教程 t.im/ddg2
重新文件 t.im/ddg6

3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,sear是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
推荐的爬虫框架资源:
纳奇文件/
可怕的文件/
pyspider 文档 t.im/ddgj

防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽量控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头,修改爬虫的请求头,尽量与浏览器保持一致,以此类推。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。

分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你能写出分布式爬虫,那么你就可以尝试搭建一些基本的爬虫架构来实现一些更加自动化的数据采集。
推荐的分布式资源:
scrapy-redis 文档 t.im/ddgk
scrapy-rabbitmq 文档 t.im/ddgn
芹菜文件 t.im/ddgr
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。
以上知识框架已经完整打包,包括超清图片、PDF文档、思维导图文件、python爬虫相关资料。您可以点击下方卡片添加微信领取。
爬虫抓取网页数据(scrapy框架里自带标签选择器HtmlXPathSelector具体的使用规则可以查阅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-12 18:20
上卷我们抓取了网页的所有内容,现在抓取网页的图片名称和连接
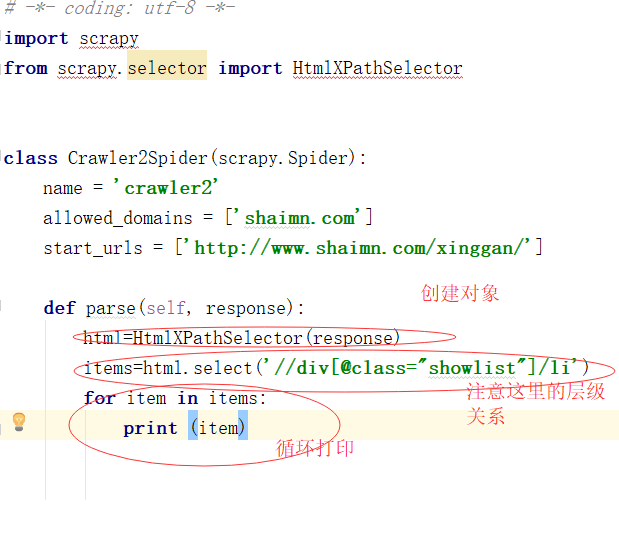
现在我创建一个新的爬虫文件并将名称设置为 crawler2
爬虫的朋友应该知道,网页中的数据是用文本或者块级标签包裹的。scrapy 框架带有一个标签选择器 HtmlXPathSelector。具体的使用规则大家可以查看,我就不介绍了。
现在我们要爬取的内容就是网页的图片标题和网页的图片链接,所以需要在网站的浏览器控制台查看label内容属性
在控制台我们发现:
我们要抓取的内容在类名showlist的div下的li标签下
所以我们先获取下一页的指定LI标签
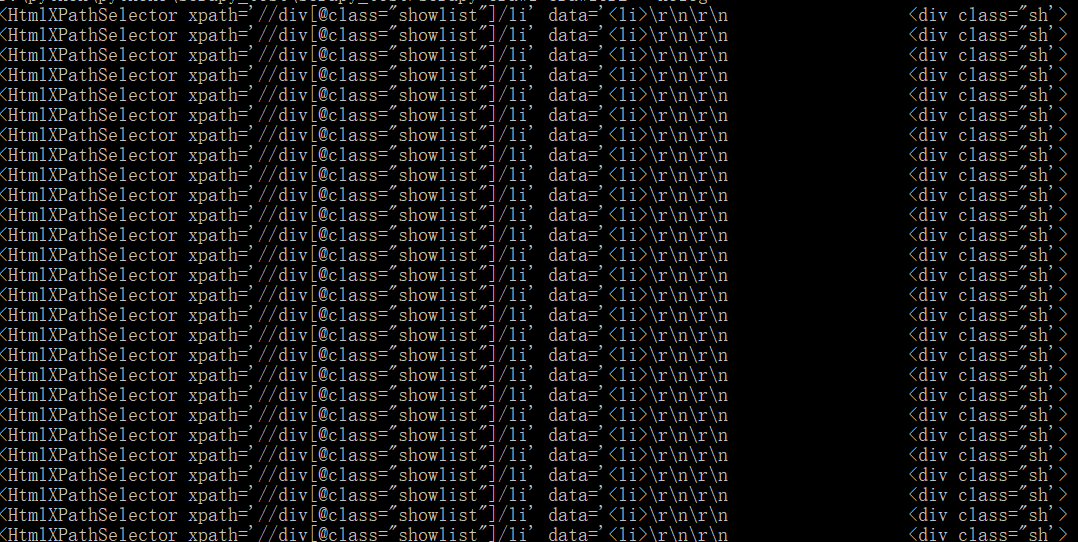
先看打印结果:
内容在哪里,别慌,这个选择器打印出来的结果是没有问题的
下面我们修改一下代码,获取LI中的内容,实现父亲找孩子的过程
我一般用这个extract()函数来获取标签
看看结果
一组LI里面的内容很多,一一对应起来也不方便。可以看出,网站的前端直接就是一个块级元素,将多张图片封装在一个LI中。
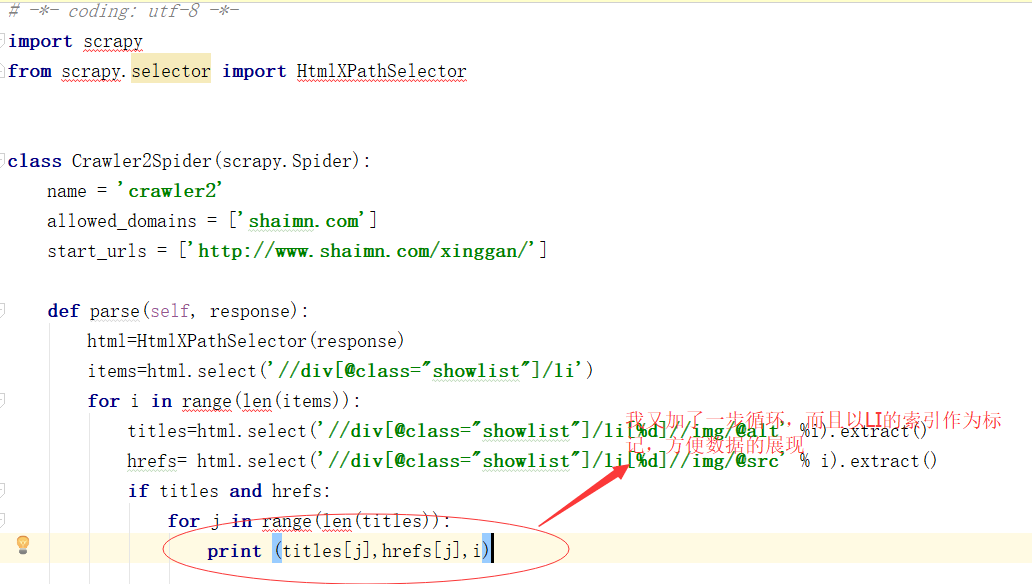
如果您不舒服,请修改代码。一个 LI 中有七个。为了确保数据的准确性,我为每个父 LI 元素设置了一个数字。
看代码
看看结果:
即使文字不健康,数据依然清晰可见
现在图片连接好了,我们就可以根据链接下载图片了。然后我们使用urlretrieve函数,在当前爬虫文件夹中创建一个与SPIDER文件同级的IMG文件夹
看一下代码:
其实就像公式一样,读取公式+存储公式就完成了图片的下载:我们现在来看看结果:
真是不择手段网站我不会再爬了 查看全部
爬虫抓取网页数据(scrapy框架里自带标签选择器HtmlXPathSelector具体的使用规则可以查阅)
上卷我们抓取了网页的所有内容,现在抓取网页的图片名称和连接
现在我创建一个新的爬虫文件并将名称设置为 crawler2
爬虫的朋友应该知道,网页中的数据是用文本或者块级标签包裹的。scrapy 框架带有一个标签选择器 HtmlXPathSelector。具体的使用规则大家可以查看,我就不介绍了。
现在我们要爬取的内容就是网页的图片标题和网页的图片链接,所以需要在网站的浏览器控制台查看label内容属性
在控制台我们发现:
我们要抓取的内容在类名showlist的div下的li标签下
所以我们先获取下一页的指定LI标签
先看打印结果:
内容在哪里,别慌,这个选择器打印出来的结果是没有问题的
下面我们修改一下代码,获取LI中的内容,实现父亲找孩子的过程

我一般用这个extract()函数来获取标签
看看结果

一组LI里面的内容很多,一一对应起来也不方便。可以看出,网站的前端直接就是一个块级元素,将多张图片封装在一个LI中。
如果您不舒服,请修改代码。一个 LI 中有七个。为了确保数据的准确性,我为每个父 LI 元素设置了一个数字。
看代码
看看结果:
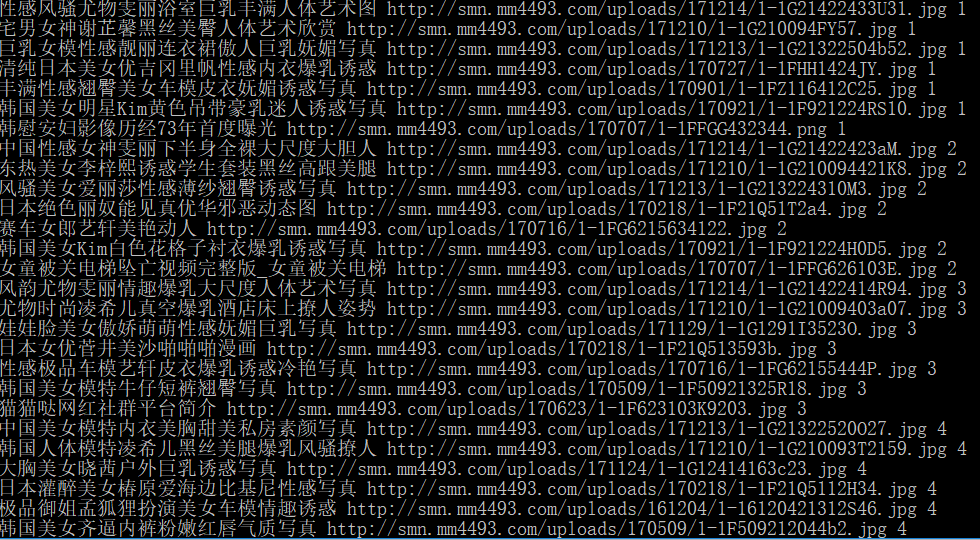
即使文字不健康,数据依然清晰可见
现在图片连接好了,我们就可以根据链接下载图片了。然后我们使用urlretrieve函数,在当前爬虫文件夹中创建一个与SPIDER文件同级的IMG文件夹
看一下代码:
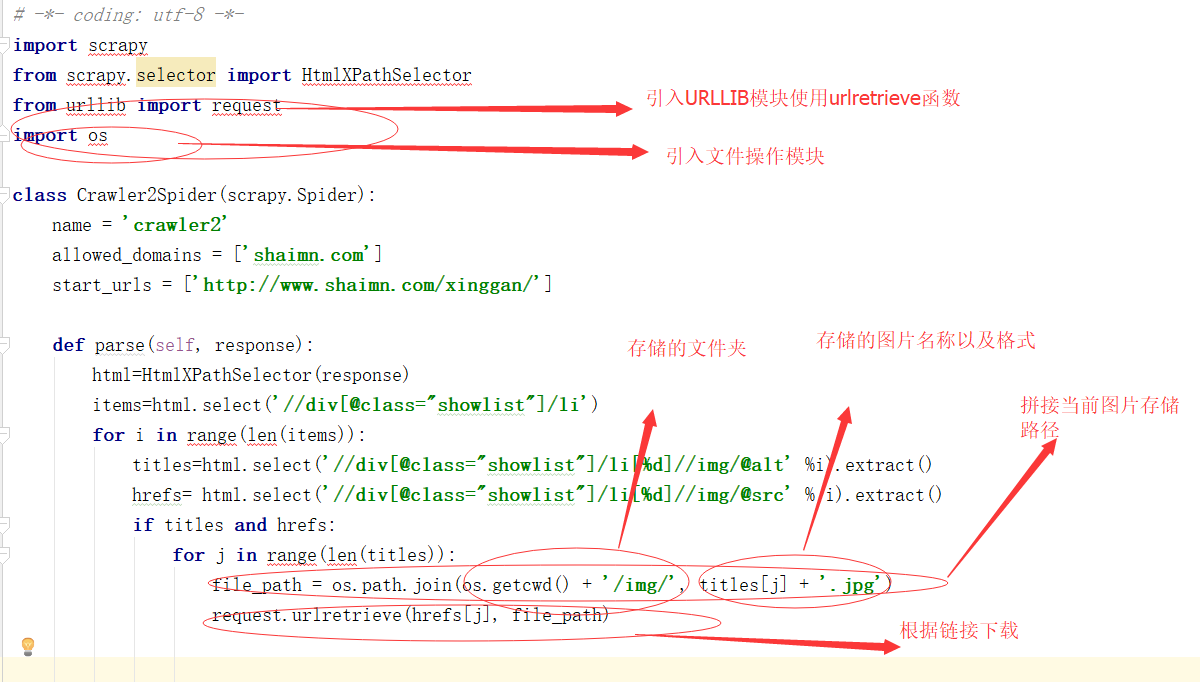
其实就像公式一样,读取公式+存储公式就完成了图片的下载:我们现在来看看结果:

真是不择手段网站我不会再爬了
爬虫抓取网页数据(一下网站文章被爬虫抓取后怎么给关键词排名的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-12 05:05
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受青睐,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?
作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以提交到百度,360搜索引擎网站,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎的爬取,因为搜索引擎爬取数据的时候,搜索引擎会在自己的数据库中对内容进行检查和匹配。如果有大量低权重的网站内容被转载,蜘蛛爬取并在数据库中进行比较。并不是原创没有价值后就不再爬你的网站,如果情况严重,可能涉嫌作弊,给你网站降级或不显示你的网站 网站在百度,你之前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。
二、搜索引擎后台预处理采集的数据(索引)
1、提取网站文本等内容:从网站中搜索引擎爬取的内容中提取相关含义内容,去除一些不必要的标签等。
2、中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“地、地”等。
3、 去除内容中不重要的内容:去除与内容意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面有相同的内容,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。
三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词频密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,加粗中,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该算是最多的了,也许这可以反映我们对一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势,甚至根据用户体验影响排名结果具有重要意义.
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如果有什么要表达清楚的,请留下一个消息。,一起进步。 查看全部
爬虫抓取网页数据(一下网站文章被爬虫抓取后怎么给关键词排名的呢?)
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受青睐,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?
作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以提交到百度,360搜索引擎网站,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎的爬取,因为搜索引擎爬取数据的时候,搜索引擎会在自己的数据库中对内容进行检查和匹配。如果有大量低权重的网站内容被转载,蜘蛛爬取并在数据库中进行比较。并不是原创没有价值后就不再爬你的网站,如果情况严重,可能涉嫌作弊,给你网站降级或不显示你的网站 网站在百度,你之前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。
二、搜索引擎后台预处理采集的数据(索引)
1、提取网站文本等内容:从网站中搜索引擎爬取的内容中提取相关含义内容,去除一些不必要的标签等。
2、中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“地、地”等。
3、 去除内容中不重要的内容:去除与内容意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面有相同的内容,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。
三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词频密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,加粗中,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该算是最多的了,也许这可以反映我们对一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势,甚至根据用户体验影响排名结果具有重要意义.
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如果有什么要表达清楚的,请留下一个消息。,一起进步。
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-10 11:06
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
图2
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友把一些网站上的图片全部爬出来,集中起来。同时,网络爬虫也可以用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去做进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键进行安装。(注意网络连接)如图3
图 3
安装完成,如图4
图 4 查看全部
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能

图2
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友把一些网站上的图片全部爬出来,集中起来。同时,网络爬虫也可以用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去做进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键进行安装。(注意网络连接)如图3

图 3
安装完成,如图4

图 4
爬虫抓取网页数据(保持练习BeautifulSoup如何构建网络爬虫(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-10 03:10
元素,而不仅仅是标题元素。使用.parent 的每个Beautiful Soup 对象附带的属性,可以直观地浏览DOM 结构并处理所需的元素。您还可以以类似的方式访问子元素和同级元素。阅读更多信息。从 HTML 元素中提取属性 此时,您的 Python 脚本已经抓取了站点并过滤了其 HTML 以找到相关的职位发布。做得好!但是,申请工作的链接仍然缺失。查看页面时,您会在每张卡片的底部找到两个链接。如果您以与其他元素相同的方式处理链接元素,您将无法获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本“学习和应用”不是关联的 URL。这是因为 .text 属性只留下 HTML 元素的可见内容。它删除所有 HTML 标签,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值而不是丢弃它。link 元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部 href 的第二个标记的属性值:
Learn
Apply
Beautiful Soup 网络爬虫示例:首先获取工作卡中的所有元素。然后,href 使用方括号表示法来提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码片段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到您的控制台。在下面的练习块中,您可以找到优化您收到的链接结果的挑战的描述: 练习:优化您的结果 显示隐藏 单击解决方案块以阅读此练习的可能解决方案: 解决方案:优化您的 您也可以使用相同的方括号表示法来显示或隐藏结果。继续练习 Beautiful Soup 如何构建网络爬虫?如果您已经编写了本教程旁边的代码,那么您可以按原样运行脚本,您将在终端中看到一条错误的作业消息弹出。您的下一步是与现实生活中的工作委员会打交道!为了继续练习你的新技能,请使用以下任一或所有站点重新访问网络抓取过程:链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。
使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、requests.. 和 Beautiful Soup 进行网络爬虫。为了结束你的网络爬虫之旅,你可以对代码进行最后的转换,并创建一个命令行界面(CLI)应用程序,该应用程序可以爬取一个工作板,并将每次执行时可以输入的密钥传递给 Word 过滤结果。您的 CLI 工具允许您在特定位置搜索特定类型的工作或工作。如果您有兴趣学习如何使脚本适应命令行界面,请参阅如何使用 argparse 在 Python 中构建命令行界面。如何构建网络爬虫?结论 requests 库为您提供了一种用户友好的方式来使用 Python 从 Internet 获取静态 HTML。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。 查看全部
爬虫抓取网页数据(保持练习BeautifulSoup如何构建网络爬虫(一)_)
元素,而不仅仅是标题元素。使用.parent 的每个Beautiful Soup 对象附带的属性,可以直观地浏览DOM 结构并处理所需的元素。您还可以以类似的方式访问子元素和同级元素。阅读更多信息。从 HTML 元素中提取属性 此时,您的 Python 脚本已经抓取了站点并过滤了其 HTML 以找到相关的职位发布。做得好!但是,申请工作的链接仍然缺失。查看页面时,您会在每张卡片的底部找到两个链接。如果您以与其他元素相同的方式处理链接元素,您将无法获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本“学习和应用”不是关联的 URL。这是因为 .text 属性只留下 HTML 元素的可见内容。它删除所有 HTML 标签,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值而不是丢弃它。link 元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部 href 的第二个标记的属性值:
Learn
Apply
Beautiful Soup 网络爬虫示例:首先获取工作卡中的所有元素。然后,href 使用方括号表示法来提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码片段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到您的控制台。在下面的练习块中,您可以找到优化您收到的链接结果的挑战的描述: 练习:优化您的结果 显示隐藏 单击解决方案块以阅读此练习的可能解决方案: 解决方案:优化您的 您也可以使用相同的方括号表示法来显示或隐藏结果。继续练习 Beautiful Soup 如何构建网络爬虫?如果您已经编写了本教程旁边的代码,那么您可以按原样运行脚本,您将在终端中看到一条错误的作业消息弹出。您的下一步是与现实生活中的工作委员会打交道!为了继续练习你的新技能,请使用以下任一或所有站点重新访问网络抓取过程:链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。
使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、requests.. 和 Beautiful Soup 进行网络爬虫。为了结束你的网络爬虫之旅,你可以对代码进行最后的转换,并创建一个命令行界面(CLI)应用程序,该应用程序可以爬取一个工作板,并将每次执行时可以输入的密钥传递给 Word 过滤结果。您的 CLI 工具允许您在特定位置搜索特定类型的工作或工作。如果您有兴趣学习如何使脚本适应命令行界面,请参阅如何使用 argparse 在 Python 中构建命令行界面。如何构建网络爬虫?结论 requests 库为您提供了一种用户友好的方式来使用 Python 从 Internet 获取静态 HTML。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-10 02:18
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
爬虫抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-07 07:24
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:
图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。查找URL 更改规则 接下来,查找要抓取的页面的URL 规则。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出结果为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一个执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。 查看全部
爬虫抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:
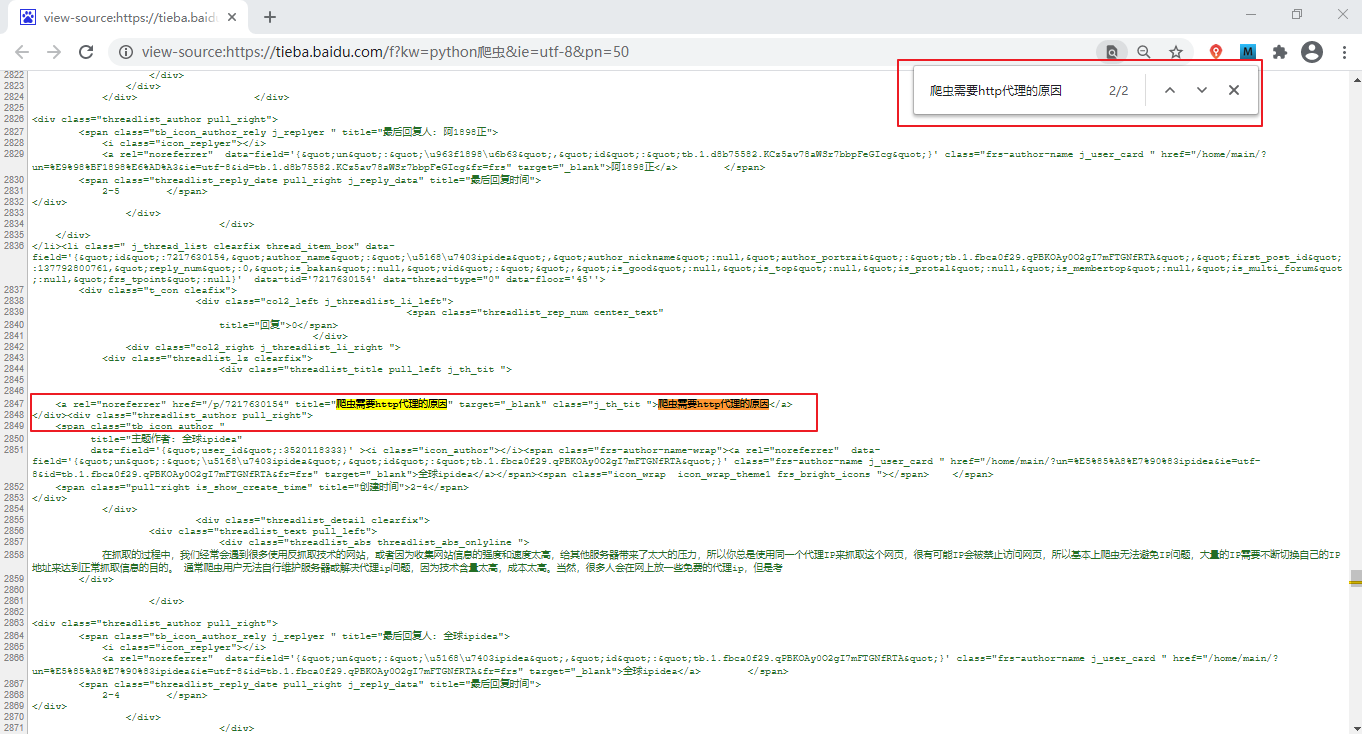
图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。查找URL 更改规则 接下来,查找要抓取的页面的URL 规则。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出结果为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一个执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。
爬虫抓取网页数据(python、数据挖掘、机器学习和自然语言处理领域的应用情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-06 12:05
python是如何用于网络爬虫、数据挖掘、机器学习和自然语言处理的?
Python 的快速迭代能力使其广受欢迎。根据原主持人的问题,结合我有限的经验一一解答:
1)Scrapy,易于使用。结合rq-queue,可以轻松构建分布式爬虫。有一次我是这样爬下整个豆瓣朋友圈的。
2) 数据挖掘中常用的算法都是用python实现的。肖志博提到的scikit learn可谓是最好的。不仅文档清晰,而且几乎所有常用的算法都实现了。我们使用 scikit learn 制作了一个 evemt 检测系统。整个系统用python编写,机器学习部分用python编写
3)nlp 部分不是特别好理解。nltk 在许多大学课程中被广泛使用。
在企业:
据我所知在公司的使用情况
谷歌:爬虫 C++、数据挖掘 C++、nlp C++。Python用于处理数据。
twitter:所有服务都使用java和scala,使用python编写快速迭代的工具。比如做搜索引擎算法的同事写了一个python客户端,在内部测试搜索质量。我用py写了一个搜索词推荐系统,包括接口、算法和接口,测试通过后改写成java。
一点想法:
py 的优势在于,py 可以用几十行其他语言的数百个句子来做事情,帮助开发者专注于问题。总结各种工具包,没有人会花时间写一个 svm(并确保不要写错)。但是py有一个巨大的缺点,它仍然很慢。有人会说算法优化很重要,不需要不断优化。但现实是大家都在不断优化,因为如果算法优化了,设计阶段就优化了,这就是为什么py在twitter中被翻译成java的原因。
但总的来说,即使你使用py开发然后翻译,也比直接在java中编写和测试要快得多。 查看全部
爬虫抓取网页数据(python、数据挖掘、机器学习和自然语言处理领域的应用情况)
python是如何用于网络爬虫、数据挖掘、机器学习和自然语言处理的?
Python 的快速迭代能力使其广受欢迎。根据原主持人的问题,结合我有限的经验一一解答:
1)Scrapy,易于使用。结合rq-queue,可以轻松构建分布式爬虫。有一次我是这样爬下整个豆瓣朋友圈的。
2) 数据挖掘中常用的算法都是用python实现的。肖志博提到的scikit learn可谓是最好的。不仅文档清晰,而且几乎所有常用的算法都实现了。我们使用 scikit learn 制作了一个 evemt 检测系统。整个系统用python编写,机器学习部分用python编写
3)nlp 部分不是特别好理解。nltk 在许多大学课程中被广泛使用。
在企业:
据我所知在公司的使用情况
谷歌:爬虫 C++、数据挖掘 C++、nlp C++。Python用于处理数据。
twitter:所有服务都使用java和scala,使用python编写快速迭代的工具。比如做搜索引擎算法的同事写了一个python客户端,在内部测试搜索质量。我用py写了一个搜索词推荐系统,包括接口、算法和接口,测试通过后改写成java。
一点想法:
py 的优势在于,py 可以用几十行其他语言的数百个句子来做事情,帮助开发者专注于问题。总结各种工具包,没有人会花时间写一个 svm(并确保不要写错)。但是py有一个巨大的缺点,它仍然很慢。有人会说算法优化很重要,不需要不断优化。但现实是大家都在不断优化,因为如果算法优化了,设计阶段就优化了,这就是为什么py在twitter中被翻译成java的原因。
但总的来说,即使你使用py开发然后翻译,也比直接在java中编写和测试要快得多。
爬虫抓取网页数据(通用爬虫框架如下图:通用的爬虫框架通用框架流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-06 12:04
2. 搜索引擎爬虫架构
但是浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成http请求,而网络爬虫需要一套整体架构来完成工作。
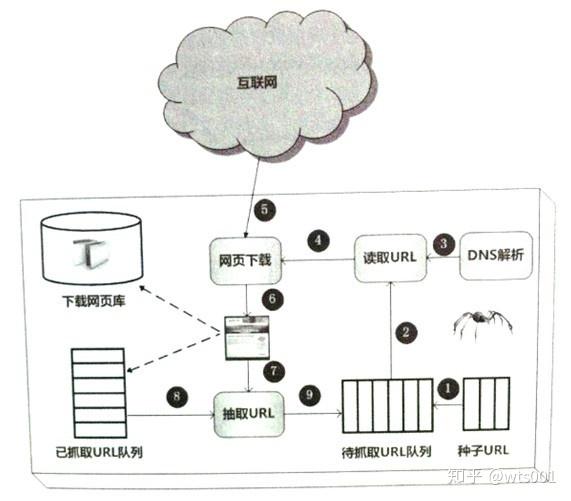
虽然爬虫技术经过几十年的发展从整体框架上已经比较成熟,但是随着互联网的不断发展,它也面临着一些具有挑战性的新问题。一般的爬虫框架如下:
通用爬虫框架
一般爬虫框架流程:
1)首先,从互联网页面中仔细选择一些网页,并将这些网页的链接地址作为种子URL;
2)将这些种子网址放入待抓取的网址队列;
3) 爬虫依次从待爬取的URL队列中读取,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4)然后将网页的IP地址和相对路径名传递给网页下载器,
5)网页下载器负责下载页面的内容。
6)对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载的网页的网址放入已爬取的网址队列中,该队列中记录了爬虫系统已经下载的网页的网址,以避免对网页的重复抓取。
7)对于新下载的网页,提取其中收录的所有链接信息,在爬取的URL队列中查看。如果发现该链接没有被抓取,那么这个URL就会被放置到被抓取的URL团队中!
8、在9)的末尾,该URL对应的网页会在后续的爬取调度中下载,以此类推,形成一个循环,直到待爬取的URL队列为空。
3. Crawler 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。
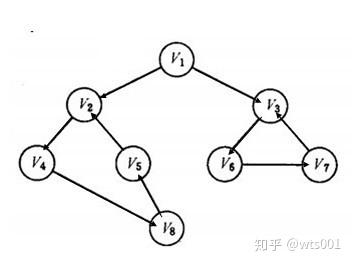
3.1 深度优先搜索策略(顺藤摸瓜)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后跳转到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有的顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问过的相邻点进行到深度优先遍历图,直到图中所有具有连接到v的路径的顶点都被访问;如果此时图中还有没有被访问过的顶点,则选择图中另一个没有被访问过的顶点作为起点,重复上述过程,直到图中所有顶点都被访问过迄今为止。
以下图所示的无向图G1为例,对图进行深度优先搜索:
G1
搜索过程:
假设搜索和爬取是从顶点页面v1开始的,在访问页面v1后,选择相邻点页面v2。因为v2之前没有访问过,所以从v2开始搜索。以此类推,搜索从 v4、v8 和 v5 开始。访问 v5 后,由于 v5 的所有相邻点都已访问过,搜索返回到 v8。出于同样的原因,搜索继续回到 v4、v2 直到 v1。此时,由于没有访问过v1的另一个相邻点,搜索从v1到v3,然后继续。由此,得到的顶点访问序列为:
3.2 广度优先搜索策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,爬取过程如下:
广度搜索过程:
首先访问页面v1和v1的邻点v2和v3,然后依次访问v2的邻点v4和v5以及v3的邻点v6和v7,最后访问v4的邻点v8。由于这些顶点的相邻点都被访问过,并且图中的所有顶点都被访问过,所以对图的这些遍历就是由这些完成的。得到的顶点访问顺序为:
v1→v2→v3→v4→v5→v6→v7→v8
<p>与深度优先搜索类似,遍历过程中也需要一组访问标志。另外,为了顺序访问路径长度为2、3、...的顶点,必须附加一个队列来存储路径长度为1、 查看全部
爬虫抓取网页数据(通用爬虫框架如下图:通用的爬虫框架通用框架流程)
2. 搜索引擎爬虫架构
但是浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成http请求,而网络爬虫需要一套整体架构来完成工作。
虽然爬虫技术经过几十年的发展从整体框架上已经比较成熟,但是随着互联网的不断发展,它也面临着一些具有挑战性的新问题。一般的爬虫框架如下:
通用爬虫框架
一般爬虫框架流程:
1)首先,从互联网页面中仔细选择一些网页,并将这些网页的链接地址作为种子URL;
2)将这些种子网址放入待抓取的网址队列;
3) 爬虫依次从待爬取的URL队列中读取,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4)然后将网页的IP地址和相对路径名传递给网页下载器,
5)网页下载器负责下载页面的内容。
6)对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载的网页的网址放入已爬取的网址队列中,该队列中记录了爬虫系统已经下载的网页的网址,以避免对网页的重复抓取。
7)对于新下载的网页,提取其中收录的所有链接信息,在爬取的URL队列中查看。如果发现该链接没有被抓取,那么这个URL就会被放置到被抓取的URL团队中!
8、在9)的末尾,该URL对应的网页会在后续的爬取调度中下载,以此类推,形成一个循环,直到待爬取的URL队列为空。
3. Crawler 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。
3.1 深度优先搜索策略(顺藤摸瓜)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后跳转到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有的顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问过的相邻点进行到深度优先遍历图,直到图中所有具有连接到v的路径的顶点都被访问;如果此时图中还有没有被访问过的顶点,则选择图中另一个没有被访问过的顶点作为起点,重复上述过程,直到图中所有顶点都被访问过迄今为止。
以下图所示的无向图G1为例,对图进行深度优先搜索:
G1
搜索过程:
假设搜索和爬取是从顶点页面v1开始的,在访问页面v1后,选择相邻点页面v2。因为v2之前没有访问过,所以从v2开始搜索。以此类推,搜索从 v4、v8 和 v5 开始。访问 v5 后,由于 v5 的所有相邻点都已访问过,搜索返回到 v8。出于同样的原因,搜索继续回到 v4、v2 直到 v1。此时,由于没有访问过v1的另一个相邻点,搜索从v1到v3,然后继续。由此,得到的顶点访问序列为:

3.2 广度优先搜索策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,爬取过程如下:
广度搜索过程:
首先访问页面v1和v1的邻点v2和v3,然后依次访问v2的邻点v4和v5以及v3的邻点v6和v7,最后访问v4的邻点v8。由于这些顶点的相邻点都被访问过,并且图中的所有顶点都被访问过,所以对图的这些遍历就是由这些完成的。得到的顶点访问顺序为:
v1→v2→v3→v4→v5→v6→v7→v8
<p>与深度优先搜索类似,遍历过程中也需要一组访问标志。另外,为了顺序访问路径长度为2、3、...的顶点,必须附加一个队列来存储路径长度为1、
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-05 06:16
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,也可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了.
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在python运行环境中下载安装第三方库请求。
在windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,按回车键进行安装。(注意网络连接)如下图
安装完成,如图
查看全部
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能

网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,也可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了.
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在python运行环境中下载安装第三方库请求。
在windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,按回车键进行安装。(注意网络连接)如下图

安装完成,如图

爬虫抓取网页数据(爬虫抓取网页数据的使用原理是什么?抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-05 05:05
<p>爬虫抓取网页数据的使用原理是:先下载数据,然后再编译。用java大概要用这个类java.sql.jdbc.driverclassloader;进行反射中的定义:publicjava.sql.jdbc.driverclassloaderclass 查看全部
爬虫抓取网页数据(爬虫抓取网页数据的使用原理是什么?抓取数据)
<p>爬虫抓取网页数据的使用原理是:先下载数据,然后再编译。用java大概要用这个类java.sql.jdbc.driverclassloader;进行反射中的定义:publicjava.sql.jdbc.driverclassloaderclass
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-04 00:20
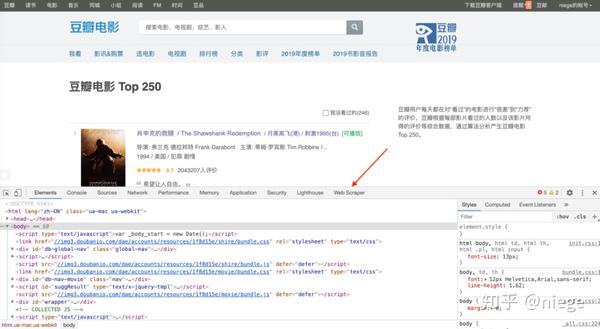
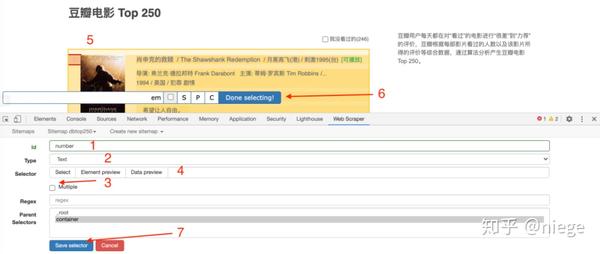
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。实际上,在大多数场景下,您可以通过 Web Scraper(Chrome 插件)快速抓取到目标内容。重要的是你不需要下载东西,基本上不需要代码知识。
在开始之前,有必要先简单了解几个问题。
一种。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的东西应该留给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取的内容,然后存入数据库中进行浏览或下载。搜索引擎可以工作,也是类似的原理。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。
Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换,Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你用的是windows,是ctrl+shift+i,不同浏览器的默认快捷键可能不同)。这时候可以看到网页弹出这样的对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖瓦)。
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所示的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
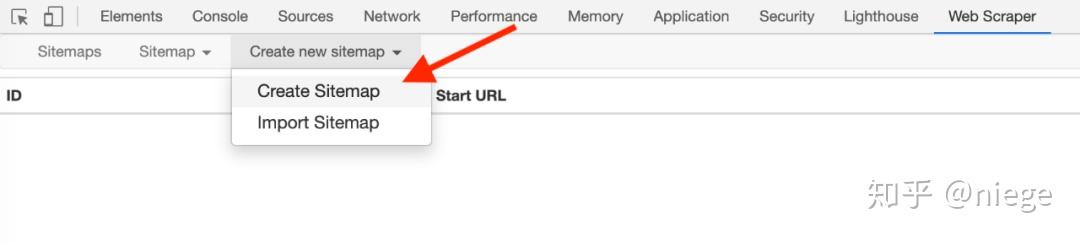
3、 点击create new sitemap,依次创建sitemap创建爬虫。随意填写站点地图名称,仅供自己识别,例如填写dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是/top250
第二页的开头是 /top250?start=25&filter=
第三页是/top250?start=50&filter=
...
只有一个数字略有不同。我们的意图是爬取top250电影数据,所以不能简单地在起始url粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
注意start后[]里面的内容,表示每25日一个网页,抓取10个网页。
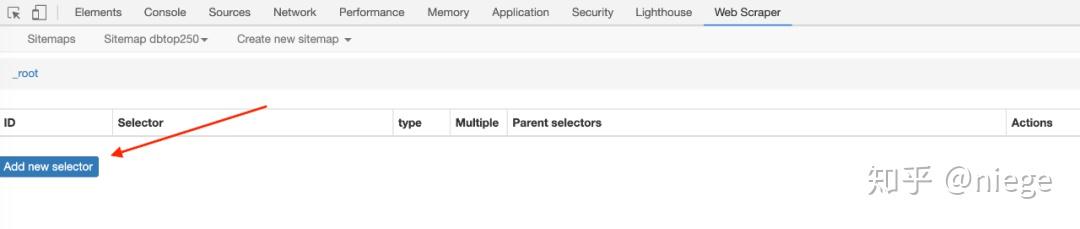
最后点击Create sitemap,爬虫就搭建好了。
(URL也可以通过填写/top250来爬取,但是不能让Web Scraper明白我们要爬取top250的所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
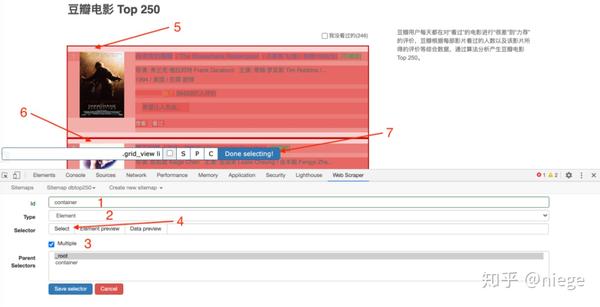
然后就会进入选择器编辑页面,其实就是一个简单的一点点。它的原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置了选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
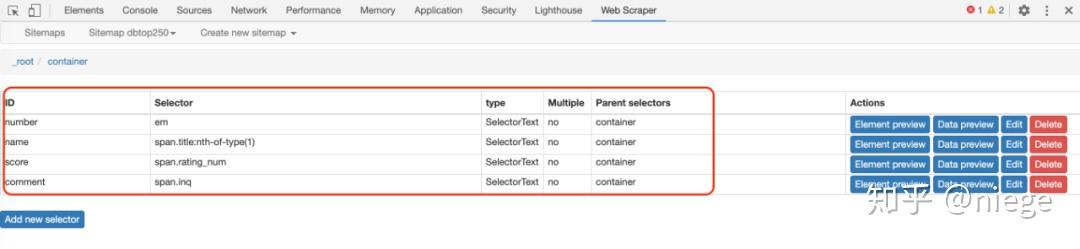
5、 第四步只是创建容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。
看到根目录后面跟着container,点击Add new selector创建一个子选择器。
再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下)分别抓取电影名、评分、一句话影评。
创建后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始抓取.
当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。只需依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,以及如何使用。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
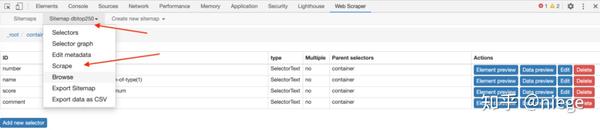
这整个过程看似繁琐,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,觉得还是按照上面的步骤一步一步来,还是比较费力的,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(是上面一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"regex":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,有的网页乱七八糟,有时需要限制爬取次数(否则抓取次数(保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
哈尔·盖特伍德 (Hal Gatewood) 在 Unsplash 上的标题图片
文章 首发于公众号“武学武术”,作者魏 m644003222 查看全部
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。实际上,在大多数场景下,您可以通过 Web Scraper(Chrome 插件)快速抓取到目标内容。重要的是你不需要下载东西,基本上不需要代码知识。
在开始之前,有必要先简单了解几个问题。
一种。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的东西应该留给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取的内容,然后存入数据库中进行浏览或下载。搜索引擎可以工作,也是类似的原理。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。

Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换,Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你用的是windows,是ctrl+shift+i,不同浏览器的默认快捷键可能不同)。这时候可以看到网页弹出这样的对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖瓦)。
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所示的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
3、 点击create new sitemap,依次创建sitemap创建爬虫。随意填写站点地图名称,仅供自己识别,例如填写dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是/top250
第二页的开头是 /top250?start=25&filter=
第三页是/top250?start=50&filter=
...
只有一个数字略有不同。我们的意图是爬取top250电影数据,所以不能简单地在起始url粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
注意start后[]里面的内容,表示每25日一个网页,抓取10个网页。
最后点击Create sitemap,爬虫就搭建好了。

(URL也可以通过填写/top250来爬取,但是不能让Web Scraper明白我们要爬取top250的所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是一个简单的一点点。它的原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置了选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
5、 第四步只是创建容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。

看到根目录后面跟着container,点击Add new selector创建一个子选择器。

再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下)分别抓取电影名、评分、一句话影评。
创建后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始抓取.

当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。只需依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,以及如何使用。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
这整个过程看似繁琐,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,觉得还是按照上面的步骤一步一步来,还是比较费力的,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(是上面一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"regex":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,有的网页乱七八糟,有时需要限制爬取次数(否则抓取次数(保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
哈尔·盖特伍德 (Hal Gatewood) 在 Unsplash 上的标题图片
文章 首发于公众号“武学武术”,作者魏 m644003222
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-04 00:18
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以 /subject/26986954/ 为例。首先,我们来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
print(content)
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
print(element["href"])
# 获取更多数据
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后反复抓取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源:/i65540493/ 查看全部
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以 /subject/26986954/ 为例。首先,我们来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
print(content)
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
print(element["href"])
# 获取更多数据
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后反复抓取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源:/i65540493/
爬虫抓取网页数据( “爬虫”是怎么抢机票的?专家:不需要人工干预)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-03 18:09
“爬虫”是怎么抢机票的?专家:不需要人工干预)
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
“爬虫”如何抢低价票?使用超链接信息抓取网页
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它是一种按照一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。在发现低价或卖空机票后,“爬虫”可以利用虚假客户的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客户来源,并在航空公司允许的计费周期内, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价客票,依此类推,直到真正客源的乘客被发现并出售。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽 查看全部
爬虫抓取网页数据(
“爬虫”是怎么抢机票的?专家:不需要人工干预)

资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
“爬虫”如何抢低价票?使用超链接信息抓取网页
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它是一种按照一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。在发现低价或卖空机票后,“爬虫”可以利用虚假客户的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客户来源,并在航空公司允许的计费周期内, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价客票,依此类推,直到真正客源的乘客被发现并出售。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽
爬虫抓取网页数据(产品运营人员处理数据和运用数据,基本是常态。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-03 16:09
作为产品运营商,在工作中处理数据、分析数据、使用数据基本是正常的。虽然不是数据分析岗位,但也是需要大量应用数据的岗位。如果没有获取数据的能力,其实很尴尬。
通常,数据的获取来自两个方面:内部数据和外部数据。
内部数据无非是根据分析的需要,在贵公司的数据库或数据统计平台中提取数据。如果要从数据统计平台中提取数据,一般的数据统计平台都会支持数据导出,您只需要导出需要的数据即可。如果要从公司数据库中提取数据,我们需要使用sql语言来获取数据。
使用sql从公司数据库中检索数据,主要是学习数据库“校验”的基本操作,包括特定情况下的数据抽取、数据的分组聚合、多表连接等,比较简单。您可以在以下列中参考这个文章:
当然,对于产品或者运维人员来说,我们有时候不一定有读取数据的权限,但是有句话说得好,有备无患。你已经掌握了一种技能,当你想使用它时,不能更好地使用它,但不是。
获取外部数据主要有两种方式:
一是获取外部公开的数据集。比如一些科研机构、企业、政府会公开一些数据。你需要去特定的网站下载这些数据。这些数据集通常比较完整,质量也比较高(如中国统计信息网)。
二是利用爬虫从网上爬取,比如从招聘网站获取某个职位的招聘信息,租房网站获取某个区域的租房信息,电子商务< @网站获取 基于爬取的数据,我们可以根据某个产品的产品信息进行数据分析。
我们要讲的是第二种外部获取数据的方式:使用python爬虫获取外部数据。
因此,默认情况下,本文的读者具有python语法基础知识和爬虫基础知识(如果没有这方面的知识,也不会妨碍对文章的理解。同时,作者会在文章末尾附上学习的时间我遇到了一个很好的python基础学习和爬虫基础知识学习博客)。
我们以最贴近生活求职者找工作为例,谈谈如何利用爬虫快速获取招聘中想要的数据网站,然后分析辅助决策——在此基础上制作。
先别着急,哦,不对,是代码,先从思路开始:
1. 作为求职者,要找到工作,至少要了解以下信息: 工作的市场情况,如工资范围:工作1到3年,工资是多少?应届毕业生的工资是多少?招聘公司的规模有多大?公司办公地址离居住地近还是远?有什么教育要求?整体市场情况如何?. . . . .
2、获取这些数据的方式,一般来说,要么直接从第三方平台获取,要么就是利用爬虫技术对数据进行爬取。显然这些招聘信息已经在招聘网站上了,不用去想了。批量获取数据的最佳方式是编写一个爬虫脚本,爬取一些求职职位的数据,并保存在一个excel电子表格中。在,把它留给下一个分析。
好的,思路流畅后,我们就开始做。这里以拉勾网的“产品运营”帖子为例。
使用环境:win10+python3+Juypter Notebook
第一步:分析网页
要抓取网页,首先要分析网页结构。
现在很多网站都使用了一种叫做Ajax(异步加载)的技术,就是在打开一个网页的时候,先给你展示上面的一些,然后慢慢加载剩下的。所以你可以看到很多网页,慢慢刷新,或者一些网站随着你的移动,很多信息慢慢加载。这种网页的优点是加载速度非常快(因为您不必一次加载所有内容)。
但是这种技术不利于爬行,所以这个时候我们就得花点功夫了。
幸运的是,牵开器使用了这种技术。异步加载信息,我们需要使用chrome浏览器小工具进行分析,按F12打开,点击Nerwork进入网络分析界面,界面如下:
此时,它是空白的。如果我们按F5刷新,我们可以看到一系列的网络请求。
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr(什么是xhr,想了解更多可以参考这篇博客:深入理解ajax系列第一篇-XHR对象)这种类型的请求如下:
这种类型的数据一般都是json格式,我们也可以尝试在filter中输入json进行过滤查找。
上图发现了两个xhr请求。从字面意思来看,很可能就是我们需要的信息。右击在另一个界面打开:
这是什么?你在跟我开玩笑吗?嗯,这里有个坑。另外在写爬虫代码的时候,如果不在http请求中添加请求头信息,服务器返回同样的信息,但是我不明白是为什么,这里我直接用浏览器打开一个新窗口也是拒绝访问的接口。如果有大神知道,希望解惑,谢谢!
回到正题,新开的窗口虽然进不去,但是各大洲都通向罗马。我们可以在右侧的框中切换到“预览”,然后点击内容——位置结果进行查看,可以看到位置的信息。以键值对的形式呈现,这是json格式,特别适合网页数据交换。
第一步是分析网页,这是结束。下一步是构造请求 URL。
第二步、URL构建
在“Headers”中可以看到网页地址,通过观察网页地址可以发现: 这一段是固定的,其余我们发现有一个city=%E5%8C%97%E4%BA %AC&needAddtionalResult=false&isSchoolJob= 0
再次检查请求发送参数列表。这里我们可以确定city参数是city,pn参数是页数,kd参数是position关键字。
当然,这只是网页的内容。如何获取更多页面的内容?再来看看“产品运营”的位置。总共有30页,每页有15条数据,所以我们只需要构造一个循环来遍历每页的数据。
第三步写爬虫脚本,写代码
需要说明的是,因为这个网页的格式是json,所以我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击内容——位置结果——结果,可以先找到一个列表,然后点击查看每个位置的内容。为什么要从这里看?一个好处是你知道这个json文件的层次结构,所以你可以很容易地等待编码。
具体代码显示:
也可以直接从作者的github下载:/banyanmo/lagou
<p>import requests,json
from openpyxl import Workbook
#http请求头信息
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'25',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_Python?',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
def get_json(url, page, lang_name):
data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}
#POST请求
json = requests.post(url,data,headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i['companyId'])
info.append(i['companyFullName'])
info.append(i['companyShortName'])
info.append(i['companySize'])
info.append(str(i['companyLabelList']))
info.append(i['industryField'])
info.append(i['financeStage'])
info.append(i['positionId'])
info.append(i['positionName'])
info.append(i['positionAdvantage'])
# info.append(i['positionLables'])
info.append(i['city'])
info.append(i['district'])
# info.append(i['businessZones'])
info.append(i['salary'])
info.append(i['education'])
info.append(i['workYear'])
info_list.append(info)
return info_list
def main():
lang_name = input('职位名:')
page = 1
url = 'http://www.lagou.com/jobs/posi ... 39%3B
info_result=[]
title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"]
info_result.append(title)
#遍历网址
while page 查看全部
爬虫抓取网页数据(产品运营人员处理数据和运用数据,基本是常态。)
作为产品运营商,在工作中处理数据、分析数据、使用数据基本是正常的。虽然不是数据分析岗位,但也是需要大量应用数据的岗位。如果没有获取数据的能力,其实很尴尬。
通常,数据的获取来自两个方面:内部数据和外部数据。
内部数据无非是根据分析的需要,在贵公司的数据库或数据统计平台中提取数据。如果要从数据统计平台中提取数据,一般的数据统计平台都会支持数据导出,您只需要导出需要的数据即可。如果要从公司数据库中提取数据,我们需要使用sql语言来获取数据。
使用sql从公司数据库中检索数据,主要是学习数据库“校验”的基本操作,包括特定情况下的数据抽取、数据的分组聚合、多表连接等,比较简单。您可以在以下列中参考这个文章:
当然,对于产品或者运维人员来说,我们有时候不一定有读取数据的权限,但是有句话说得好,有备无患。你已经掌握了一种技能,当你想使用它时,不能更好地使用它,但不是。
获取外部数据主要有两种方式:
一是获取外部公开的数据集。比如一些科研机构、企业、政府会公开一些数据。你需要去特定的网站下载这些数据。这些数据集通常比较完整,质量也比较高(如中国统计信息网)。
二是利用爬虫从网上爬取,比如从招聘网站获取某个职位的招聘信息,租房网站获取某个区域的租房信息,电子商务< @网站获取 基于爬取的数据,我们可以根据某个产品的产品信息进行数据分析。
我们要讲的是第二种外部获取数据的方式:使用python爬虫获取外部数据。
因此,默认情况下,本文的读者具有python语法基础知识和爬虫基础知识(如果没有这方面的知识,也不会妨碍对文章的理解。同时,作者会在文章末尾附上学习的时间我遇到了一个很好的python基础学习和爬虫基础知识学习博客)。
我们以最贴近生活求职者找工作为例,谈谈如何利用爬虫快速获取招聘中想要的数据网站,然后分析辅助决策——在此基础上制作。
先别着急,哦,不对,是代码,先从思路开始:
1. 作为求职者,要找到工作,至少要了解以下信息: 工作的市场情况,如工资范围:工作1到3年,工资是多少?应届毕业生的工资是多少?招聘公司的规模有多大?公司办公地址离居住地近还是远?有什么教育要求?整体市场情况如何?. . . . .
2、获取这些数据的方式,一般来说,要么直接从第三方平台获取,要么就是利用爬虫技术对数据进行爬取。显然这些招聘信息已经在招聘网站上了,不用去想了。批量获取数据的最佳方式是编写一个爬虫脚本,爬取一些求职职位的数据,并保存在一个excel电子表格中。在,把它留给下一个分析。
好的,思路流畅后,我们就开始做。这里以拉勾网的“产品运营”帖子为例。
使用环境:win10+python3+Juypter Notebook
第一步:分析网页
要抓取网页,首先要分析网页结构。
现在很多网站都使用了一种叫做Ajax(异步加载)的技术,就是在打开一个网页的时候,先给你展示上面的一些,然后慢慢加载剩下的。所以你可以看到很多网页,慢慢刷新,或者一些网站随着你的移动,很多信息慢慢加载。这种网页的优点是加载速度非常快(因为您不必一次加载所有内容)。
但是这种技术不利于爬行,所以这个时候我们就得花点功夫了。
幸运的是,牵开器使用了这种技术。异步加载信息,我们需要使用chrome浏览器小工具进行分析,按F12打开,点击Nerwork进入网络分析界面,界面如下:
此时,它是空白的。如果我们按F5刷新,我们可以看到一系列的网络请求。
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr(什么是xhr,想了解更多可以参考这篇博客:深入理解ajax系列第一篇-XHR对象)这种类型的请求如下:
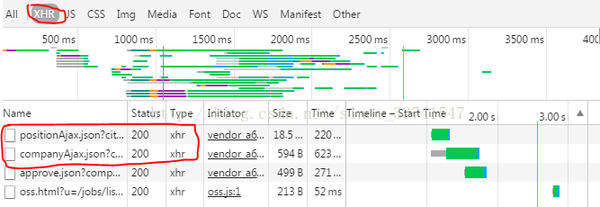
这种类型的数据一般都是json格式,我们也可以尝试在filter中输入json进行过滤查找。
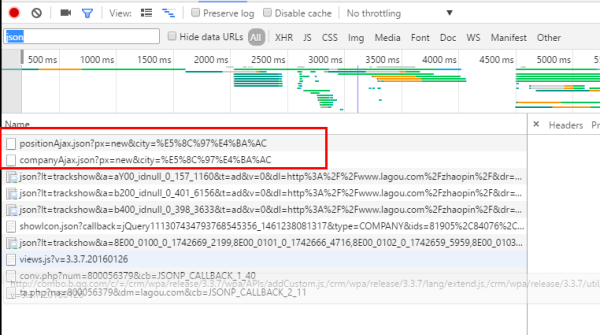
上图发现了两个xhr请求。从字面意思来看,很可能就是我们需要的信息。右击在另一个界面打开:

这是什么?你在跟我开玩笑吗?嗯,这里有个坑。另外在写爬虫代码的时候,如果不在http请求中添加请求头信息,服务器返回同样的信息,但是我不明白是为什么,这里我直接用浏览器打开一个新窗口也是拒绝访问的接口。如果有大神知道,希望解惑,谢谢!
回到正题,新开的窗口虽然进不去,但是各大洲都通向罗马。我们可以在右侧的框中切换到“预览”,然后点击内容——位置结果进行查看,可以看到位置的信息。以键值对的形式呈现,这是json格式,特别适合网页数据交换。
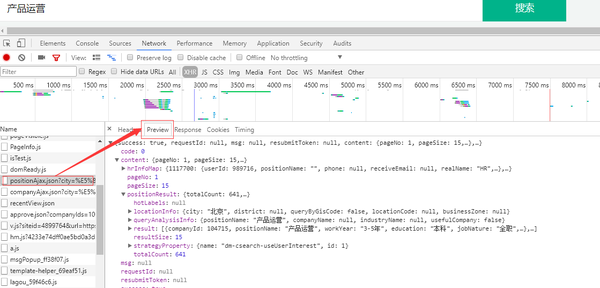
第一步是分析网页,这是结束。下一步是构造请求 URL。
第二步、URL构建
在“Headers”中可以看到网页地址,通过观察网页地址可以发现: 这一段是固定的,其余我们发现有一个city=%E5%8C%97%E4%BA %AC&needAddtionalResult=false&isSchoolJob= 0
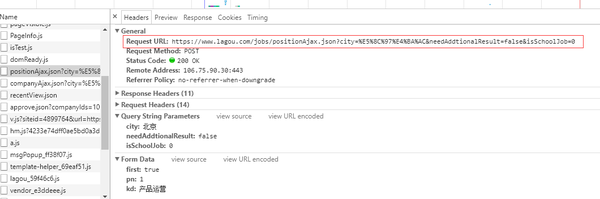
再次检查请求发送参数列表。这里我们可以确定city参数是city,pn参数是页数,kd参数是position关键字。
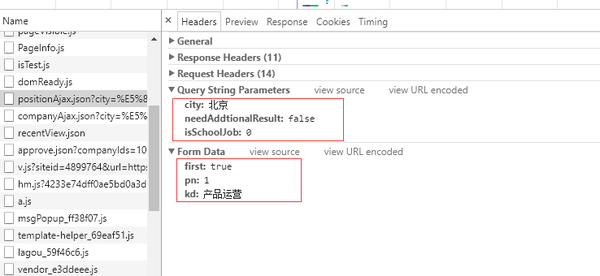
当然,这只是网页的内容。如何获取更多页面的内容?再来看看“产品运营”的位置。总共有30页,每页有15条数据,所以我们只需要构造一个循环来遍历每页的数据。
第三步写爬虫脚本,写代码
需要说明的是,因为这个网页的格式是json,所以我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击内容——位置结果——结果,可以先找到一个列表,然后点击查看每个位置的内容。为什么要从这里看?一个好处是你知道这个json文件的层次结构,所以你可以很容易地等待编码。
具体代码显示:
也可以直接从作者的github下载:/banyanmo/lagou
<p>import requests,json
from openpyxl import Workbook
#http请求头信息
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'25',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_Python?',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
def get_json(url, page, lang_name):
data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}
#POST请求
json = requests.post(url,data,headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i['companyId'])
info.append(i['companyFullName'])
info.append(i['companyShortName'])
info.append(i['companySize'])
info.append(str(i['companyLabelList']))
info.append(i['industryField'])
info.append(i['financeStage'])
info.append(i['positionId'])
info.append(i['positionName'])
info.append(i['positionAdvantage'])
# info.append(i['positionLables'])
info.append(i['city'])
info.append(i['district'])
# info.append(i['businessZones'])
info.append(i['salary'])
info.append(i['education'])
info.append(i['workYear'])
info_list.append(info)
return info_list
def main():
lang_name = input('职位名:')
page = 1
url = 'http://www.lagou.com/jobs/posi ... 39%3B
info_result=[]
title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"]
info_result.append(title)
#遍历网址
while page
爬虫抓取网页数据(SimpleScratch需求迫切索引擎是互网大爆炸后的新生事物,个是泛商品化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-03 06:03
SimpleScratch SearchEngine作者急需完成搜索引擎模型 07/06 07/08 完成信息航空模型 07/16 完成 1/3 数据采集 07/30 本文为搜索引擎草稿,转至:指南.txt ) 第一章急需搜索引擎是互联网爆炸后的新生事物,一个是泛信息化,一个是泛商业化。一) 在泛信息化方面,信息的种类很多。大家个人觉得,多媒体和社交网络的海量必然会导致搜索引擎的泛滥。搜索引擎很多,你可以看看谷歌,百度有多少搜索引擎足够各种需求的信息,维基的搜索引擎列表(,5)P2P师源,6)Email,7 知道信息 爆炸是基于需求的。目前搜索引擎已列出14)手机及手机信息、7)工作信息、8)法律信息、9条信息、10条信息、11)社交信息、12条信息、14条来自搜索引擎的发展,反观信息的增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。
这要看3171年,我不吃不喝,我一直在看。如果你是愚公世家,你的祖宗在大禹治水,你还没有读完。对于航空,草根使用追求免费、快速、有效的服装,有很多满足新需求的产品。一方面,有很多满足旧需求的新产品。有很多新产品。如果你不宣传,很多有需要的人就找不到你,或者他们找不到你。例如,如果您不看新广告,甚至不知道有人举行了隆重的葬礼,那么您就知道在哪里可以找到可以在互联网上做广告的牧师。家太多了,不知道去哪里。只是最古老的折扣促销活动。老方法是挂大横幅。现在如果你想让更多的人看到它,它会更有效。而搜索引擎广告和第二章信息需求的导航模型一样——草根需求,信息爆炸,搜索人气,爆炸迫使商家追逐人气,两者之间有一些基础,插曲:顺序文件(Sequential File)就是随机文件(RandomFile),两者划分的缺点是什么?StoragePyramid 是金字塔形的吗?那个寄存器(Register InternalStorage),外部存储器(External Storage 网络内容可以理解,需要的结果。但是,目前的计算机技术索引(Index, then to the index, then to the system)整个互联网的所有网络都知道互联网首先,它已经很庞大了,网络一下子就建成了,
内存高索引 内存底部索引是金字塔式的 PyramidHierachy 效率,它会使用多台机器,可能是集群或分布式(Distributed)架构。另外,从索引机制来看,目前主要的倒排索引(Inverted Index)是正的。行索引的组合。体面的指标在保持效率的前提下,可大可小。因此,它是一个集成的架构。本机可用于实现人机WEB。可以使用MVC(Model-View-Controller)模型来分离WEB和数据(DATA)。是的,因此,搜索架构很可能或至少是 Web-Data-Retrieval 来分流组的使用并增加安全性(不要把所有的鸡蛋放在一起,等各个方面的许多会议。首先,
一方面,Spider 行数据的获取。另一方面,Spider 需要更新数据来完成称为 Indexer 的数据管理模型的索引。一方面,Indexer 处理或清理一次。对于所有 IR 方面,Indexer 还需要对数据进行分析,并且可以将结果进行结构化保存。数据库)保存。完成的数据模型称为检索。一方面,哪些索引数据依赖于 Retrieval。另一方面,检索基于查询)。因此,它是一种决策机制。如果前面所有的原理都是物理的,那么我们才能理解使用的需求。老师(1.2 数据管理模型比信息获取的方便更简单,和大家有切身体会,参考《Modeling Web.Probabilistic Methods slides: PDF,
万维网也是计算机网络和万维网。如果您将网络视为承载信息的信息海洋。发现早期上网是1999校友和263面条跳到同学照片的WWW,所以你看到网站的大部分域名都是WWW老师,说明它是一个Web网站 header,表示是入口,可以是整个网站。慢慢网站,每个人都能在这方面发挥越来越重要的作用。这大大减少了您需要关注的信息中心数量。(CNNIC,20日,NCFC通过公司互联网64K通过美国Sprint,正式承接拥有真正全功能互联网的国家。11月,国家智能计算机研究中心通过曙光BBS。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。
11. 2004年16日,供应商公司在香港正式上市。12. 2005年,百度在美国Starck上市。13.2005年新年期间,以博客为代表的网络2.0“穿越”的概念在中国促进了彼此的共同使用,也催生了一系列新的14.2006 中国、百度、阿里巴巴等社会化的东西,如博客、RSS、WIKI、SNS、约会等。16.截至2008年30我国网民达到2.53人,首次位居世界第一。7 CN域名注册量为1218.8 过万,首次成为全球第一个超大国家域名。搜索引擎,WEB2.0 网站 知者信息爆(半序) 搜索引擎标记信息爆(半序) 参与站=>生活站。信息化繁为简,信息化信息中心(CNNIC)。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。
编号336《附表14中的编号》显示,国内平均表面大小约为30K,网络大小为964 TB。一句话,我现在看到的是连接占了很大比例。根据后一种形式,对形式的比例进行划分。html 20.1% htm 6.5% 2.1%shtml 8.7% asp 12.6% php 22.2% txt 0.0% nsf 0.0% xml 0.0% jsp 1.@ >0% cgi 0.2% pl 0.0% aspx < @6.1% 做 0.5% dll 0.0% jhtml 0.0% cfm 0.0% php3 0.0% phtml 0.0% 其他以后19.7% 更新周期比例一周更新7.7% 一个月更新21.2% 三个月更新28.
以及 David Eichmann 在研究文章中描述的第一个 RBSE 蜘蛛。老师(3.1)Matthew Gray,Google工程师(3.2)David Eichmann,教师研究)在(数学之美系列六蜘蛛爬行模型蜘蛛爬行全互联网数据到本地,在我看来,有两个基本的假 查看全部
爬虫抓取网页数据(SimpleScratch需求迫切索引擎是互网大爆炸后的新生事物,个是泛商品化)
SimpleScratch SearchEngine作者急需完成搜索引擎模型 07/06 07/08 完成信息航空模型 07/16 完成 1/3 数据采集 07/30 本文为搜索引擎草稿,转至:指南.txt ) 第一章急需搜索引擎是互联网爆炸后的新生事物,一个是泛信息化,一个是泛商业化。一) 在泛信息化方面,信息的种类很多。大家个人觉得,多媒体和社交网络的海量必然会导致搜索引擎的泛滥。搜索引擎很多,你可以看看谷歌,百度有多少搜索引擎足够各种需求的信息,维基的搜索引擎列表(,5)P2P师源,6)Email,7 知道信息 爆炸是基于需求的。目前搜索引擎已列出14)手机及手机信息、7)工作信息、8)法律信息、9条信息、10条信息、11)社交信息、12条信息、14条来自搜索引擎的发展,反观信息的增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。
这要看3171年,我不吃不喝,我一直在看。如果你是愚公世家,你的祖宗在大禹治水,你还没有读完。对于航空,草根使用追求免费、快速、有效的服装,有很多满足新需求的产品。一方面,有很多满足旧需求的新产品。有很多新产品。如果你不宣传,很多有需要的人就找不到你,或者他们找不到你。例如,如果您不看新广告,甚至不知道有人举行了隆重的葬礼,那么您就知道在哪里可以找到可以在互联网上做广告的牧师。家太多了,不知道去哪里。只是最古老的折扣促销活动。老方法是挂大横幅。现在如果你想让更多的人看到它,它会更有效。而搜索引擎广告和第二章信息需求的导航模型一样——草根需求,信息爆炸,搜索人气,爆炸迫使商家追逐人气,两者之间有一些基础,插曲:顺序文件(Sequential File)就是随机文件(RandomFile),两者划分的缺点是什么?StoragePyramid 是金字塔形的吗?那个寄存器(Register InternalStorage),外部存储器(External Storage 网络内容可以理解,需要的结果。但是,目前的计算机技术索引(Index, then to the index, then to the system)整个互联网的所有网络都知道互联网首先,它已经很庞大了,网络一下子就建成了,
内存高索引 内存底部索引是金字塔式的 PyramidHierachy 效率,它会使用多台机器,可能是集群或分布式(Distributed)架构。另外,从索引机制来看,目前主要的倒排索引(Inverted Index)是正的。行索引的组合。体面的指标在保持效率的前提下,可大可小。因此,它是一个集成的架构。本机可用于实现人机WEB。可以使用MVC(Model-View-Controller)模型来分离WEB和数据(DATA)。是的,因此,搜索架构很可能或至少是 Web-Data-Retrieval 来分流组的使用并增加安全性(不要把所有的鸡蛋放在一起,等各个方面的许多会议。首先,
一方面,Spider 行数据的获取。另一方面,Spider 需要更新数据来完成称为 Indexer 的数据管理模型的索引。一方面,Indexer 处理或清理一次。对于所有 IR 方面,Indexer 还需要对数据进行分析,并且可以将结果进行结构化保存。数据库)保存。完成的数据模型称为检索。一方面,哪些索引数据依赖于 Retrieval。另一方面,检索基于查询)。因此,它是一种决策机制。如果前面所有的原理都是物理的,那么我们才能理解使用的需求。老师(1.2 数据管理模型比信息获取的方便更简单,和大家有切身体会,参考《Modeling Web.Probabilistic Methods slides: PDF,
万维网也是计算机网络和万维网。如果您将网络视为承载信息的信息海洋。发现早期上网是1999校友和263面条跳到同学照片的WWW,所以你看到网站的大部分域名都是WWW老师,说明它是一个Web网站 header,表示是入口,可以是整个网站。慢慢网站,每个人都能在这方面发挥越来越重要的作用。这大大减少了您需要关注的信息中心数量。(CNNIC,20日,NCFC通过公司互联网64K通过美国Sprint,正式承接拥有真正全功能互联网的国家。11月,国家智能计算机研究中心通过曙光BBS。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。
11. 2004年16日,供应商公司在香港正式上市。12. 2005年,百度在美国Starck上市。13.2005年新年期间,以博客为代表的网络2.0“穿越”的概念在中国促进了彼此的共同使用,也催生了一系列新的14.2006 中国、百度、阿里巴巴等社会化的东西,如博客、RSS、WIKI、SNS、约会等。16.截至2008年30我国网民达到2.53人,首次位居世界第一。7 CN域名注册量为1218.8 过万,首次成为全球第一个超大国家域名。搜索引擎,WEB2.0 网站 知者信息爆(半序) 搜索引擎标记信息爆(半序) 参与站=>生活站。信息化繁为简,信息化信息中心(CNNIC)。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。
编号336《附表14中的编号》显示,国内平均表面大小约为30K,网络大小为964 TB。一句话,我现在看到的是连接占了很大比例。根据后一种形式,对形式的比例进行划分。html 20.1% htm 6.5% 2.1%shtml 8.7% asp 12.6% php 22.2% txt 0.0% nsf 0.0% xml 0.0% jsp 1.@ >0% cgi 0.2% pl 0.0% aspx < @6.1% 做 0.5% dll 0.0% jhtml 0.0% cfm 0.0% php3 0.0% phtml 0.0% 其他以后19.7% 更新周期比例一周更新7.7% 一个月更新21.2% 三个月更新28.
以及 David Eichmann 在研究文章中描述的第一个 RBSE 蜘蛛。老师(3.1)Matthew Gray,Google工程师(3.2)David Eichmann,教师研究)在(数学之美系列六蜘蛛爬行模型蜘蛛爬行全互联网数据到本地,在我看来,有两个基本的假
爬虫抓取网页数据(爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-01 12:56
爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是web服务器端的服务对象,是http协议的基本api,一般xmlhttprequest首次与服务器建立连接的时候会带上两个参数:httpuri和httpport。如果服务器对于参数中的uri或者port的值为空的话,会产生一个uri请求与服务器建立连接,随后服务器会利用参数传递给服务器的uri地址。
http协议是无状态的,但如果参数中的uri或者port为空,则连接一直存在。http主要用于搜索引擎爬虫中,用于确定目标的位置。值得注意的是,http只是语法上的约定,不是事实上的协议规定。理论上任何服务器对上述uri或者port都能响应。此外,http协议还提供了“默认”和“明文”参数以及“明文/明文http”。
默认参数是服务器优先响应http请求的参数,或者是唯一的参数,默认参数实际上不是由客户端加载的请求头,只是作为请求的附加信息,只要客户端请求被服务器响应了,默认参数将会被加载。因此,默认参数一般是以事件结束时客户端提供的值作为默认参数。明文/明文httphttprequest直接是基于http协议的httprequest,httpheader提供的是客户端应用无效的http协议的其它相关信息,包括客户端uri和端口号,同时包含以下信息:http/1.1200okhttp/1.1eqaccept-encoding:gzip,deflateaccept-language:zh-cn,zh;q=0.9,en;q=0.7connection:keep-alive,status-code:200origin:root,defaultget,postprivateaccess-control-allow-origin:*pragma:no-cacheaccept-language:zh-cnpost-authorization:mozilla/5.0(macintosh;intelmacosx10_13_。
3)applewebkit/537.36(khtml,likegecko)chrome/46.0.2254.156safari/537.36格式:
1、keep-alive是兼容性协议,在服务器版和客户端版中都是200,必须的httprequest都不支持keep-alive,
2、post不支持keep-alive,表示服务器、客户端之间是否能解决对同一个请求只能产生一次响应的问题。
3、data-value在get请求或post请求中,默认为string, 查看全部
爬虫抓取网页数据(爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是什么)
爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是web服务器端的服务对象,是http协议的基本api,一般xmlhttprequest首次与服务器建立连接的时候会带上两个参数:httpuri和httpport。如果服务器对于参数中的uri或者port的值为空的话,会产生一个uri请求与服务器建立连接,随后服务器会利用参数传递给服务器的uri地址。
http协议是无状态的,但如果参数中的uri或者port为空,则连接一直存在。http主要用于搜索引擎爬虫中,用于确定目标的位置。值得注意的是,http只是语法上的约定,不是事实上的协议规定。理论上任何服务器对上述uri或者port都能响应。此外,http协议还提供了“默认”和“明文”参数以及“明文/明文http”。
默认参数是服务器优先响应http请求的参数,或者是唯一的参数,默认参数实际上不是由客户端加载的请求头,只是作为请求的附加信息,只要客户端请求被服务器响应了,默认参数将会被加载。因此,默认参数一般是以事件结束时客户端提供的值作为默认参数。明文/明文httphttprequest直接是基于http协议的httprequest,httpheader提供的是客户端应用无效的http协议的其它相关信息,包括客户端uri和端口号,同时包含以下信息:http/1.1200okhttp/1.1eqaccept-encoding:gzip,deflateaccept-language:zh-cn,zh;q=0.9,en;q=0.7connection:keep-alive,status-code:200origin:root,defaultget,postprivateaccess-control-allow-origin:*pragma:no-cacheaccept-language:zh-cnpost-authorization:mozilla/5.0(macintosh;intelmacosx10_13_。
3)applewebkit/537.36(khtml,likegecko)chrome/46.0.2254.156safari/537.36格式:
1、keep-alive是兼容性协议,在服务器版和客户端版中都是200,必须的httprequest都不支持keep-alive,
2、post不支持keep-alive,表示服务器、客户端之间是否能解决对同一个请求只能产生一次响应的问题。
3、data-value在get请求或post请求中,默认为string,
爬虫抓取网页数据(基于目标网页特征的爬虫所提供的网络爬虫技术分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 22:11
网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术。网络爬虫也被称为网络蜘蛛和网络机器人。在 FOAF 社区中,他们更多地被称为网络追逐者;其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。
网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。 查看全部
爬虫抓取网页数据(基于目标网页特征的爬虫所提供的网络爬虫技术分析)
网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术。网络爬虫也被称为网络蜘蛛和网络机器人。在 FOAF 社区中,他们更多地被称为网络追逐者;其他不常用的名称包括蚂蚁、自动索引、模拟程序或蠕虫。
网络爬虫技术是指按照一定的规则自动抓取万维网上信息的技术
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐者)是按照一定的规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
爬取目标的描述和定义是决定如何制定网页分析算法和网址搜索策略的基础。网页分析算法和候选网址排序算法是决定搜索引擎提供的服务形式和网页抓取行为的关键。这两部分的算法是密切相关的。
现有的聚焦爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模型和基于领域概念。
基于登陆页面特征
爬虫根据目标网页的特征抓取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页分类目录和分类目录对应的种子样本,如Yahoo!分类结构等;
(3) 由用户行为决定的爬取目标示例,分为:
(a) 用户浏览时显示标记的抓样;
(b) 通过用户日志挖掘获取访问模式和相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据模式
基于目标数据模式的爬虫是针对网页上的数据,抓取的数据一般必须符合一定的模式,或者可以转化或映射为目标数据模式。
基于领域的概念
另一种描述方法是建立目标领域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-14 19:03
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = ' https://movie.douban.com/j/cha ... ction='
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = ' https://movie.douban.com/j/cha ... ction='
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
爬虫抓取网页数据(单个网页数据爬取的思路及技术做个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-14 19:02
不知不觉,我已经毕业一年多了。这一年主要从事数据分析和挖掘。突然想总结分享一下之前学过的技术。
之前公司项目有一个很奇怪的需求,希望抓取网页数据并保存在Word中,要求和网页上一模一样,包括网页上图表的内容。
以静态网页为例。先展示最终结果:
部分原网页截图:
通过爬虫写字效果:
上面是将单个网页的数据写入word的简单效果,爬取图表相关信息的工作比较繁琐。
爬取单个网页数据的思路:先解析网页,然后定位网页信息,再判断定位到的网页信息中的每条内容是表格还是图片。如果是表,则需要分析表结构。
如下图,tr代表表格的行,td代表表格的列。第一个tr下有4个td对应表的第一行4列,以此类推。图表的绘制主要使用python第三方包python_docx,通过该包中的add_table函数绘制表格,使用add_picture函数绘制图片。
Python使用python_docx包方法来引用网页:
这部分代码如下:
def get_article(url_body,filename,html):
content_total = ""
text = url_body.xpath('.//td[@class="b12c"]/p|.//td[@class="b12c"]/div|.//td[@class="b12c"]/span|.//td[@class="b12c"]/font')
doc = Document()
for x in text:
row = x.xpath('.//tbody//tr')
try:
if row: #判断是否为表格
for col in row:
table = doc.add_table(rows=1, cols=int(len(col)), style='Table Grid')
hdr_cells = table.rows[0].cells
td = col.xpath('./td')
td_list = []
for t in td:
ins_data = t.xpath('.//text()') #爬取网页表格中的数据
ins_data = filter(lambda x: x != '\r\n ', ins_data)
tmp = ""
for i in range(len(ins_data)):
tmp += ins_data[i]
td_list.append(tmp)
length = len(td_list)
for i in range(length):
hdr_cells[i].text = td_list[i] #数据写入创建的表格中
else:
img_ads = x.xpath('.//@src')
imglist = ""
if img_ads: #判断爬取的是否为图片数据
for h in img_ads:
if h.startswith('http://'):
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
else: #有些图片网页不是http:开头需要重新修改
ind = html.rfind('/') + 1
h = html.replace(html[ind:], h)
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
doc.add_picture(img, width=Inches(4.25))#设置写入的图片大小
imglist = imglist + h + " "
paragraph = x.xpath('.//text()') #爬取文字段落信息
str_ = ""
for j in paragraph:
str_ = str_ + j
doc.add_paragraph(str_)
content_total = content_total + imglist + str_ + "\n"
except:
pass
doc.save(filename)
return content_total
本文简单介绍了单个网页数据的抓取和写入方法,抓取的目标网页为静态网页。如果是动态网页,还需要找出网页的跳转文件。抓取多个网页需要分页处理。MongoDB 可用于将抓取到的网页地址存储在 MongoDB 中。每次爬取一个网页,可以判断MongoDB中是否有,避免重复爬取。
本文示例的源代码: 查看全部
爬虫抓取网页数据(单个网页数据爬取的思路及技术做个)
不知不觉,我已经毕业一年多了。这一年主要从事数据分析和挖掘。突然想总结分享一下之前学过的技术。
之前公司项目有一个很奇怪的需求,希望抓取网页数据并保存在Word中,要求和网页上一模一样,包括网页上图表的内容。
以静态网页为例。先展示最终结果:
部分原网页截图:
通过爬虫写字效果:
上面是将单个网页的数据写入word的简单效果,爬取图表相关信息的工作比较繁琐。
爬取单个网页数据的思路:先解析网页,然后定位网页信息,再判断定位到的网页信息中的每条内容是表格还是图片。如果是表,则需要分析表结构。
如下图,tr代表表格的行,td代表表格的列。第一个tr下有4个td对应表的第一行4列,以此类推。图表的绘制主要使用python第三方包python_docx,通过该包中的add_table函数绘制表格,使用add_picture函数绘制图片。
Python使用python_docx包方法来引用网页:
这部分代码如下:
def get_article(url_body,filename,html):
content_total = ""
text = url_body.xpath('.//td[@class="b12c"]/p|.//td[@class="b12c"]/div|.//td[@class="b12c"]/span|.//td[@class="b12c"]/font')
doc = Document()
for x in text:
row = x.xpath('.//tbody//tr')
try:
if row: #判断是否为表格
for col in row:
table = doc.add_table(rows=1, cols=int(len(col)), style='Table Grid')
hdr_cells = table.rows[0].cells
td = col.xpath('./td')
td_list = []
for t in td:
ins_data = t.xpath('.//text()') #爬取网页表格中的数据
ins_data = filter(lambda x: x != '\r\n ', ins_data)
tmp = ""
for i in range(len(ins_data)):
tmp += ins_data[i]
td_list.append(tmp)
length = len(td_list)
for i in range(length):
hdr_cells[i].text = td_list[i] #数据写入创建的表格中
else:
img_ads = x.xpath('.//@src')
imglist = ""
if img_ads: #判断爬取的是否为图片数据
for h in img_ads:
if h.startswith('http://'):
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
else: #有些图片网页不是http:开头需要重新修改
ind = html.rfind('/') + 1
h = html.replace(html[ind:], h)
try:
img = cStringIO.StringIO(urllib2.urlopen(h).read())
except:
img = cStringIO.StringIO(req.get(h).content)
doc.add_picture(img, width=Inches(4.25))#设置写入的图片大小
imglist = imglist + h + " "
paragraph = x.xpath('.//text()') #爬取文字段落信息
str_ = ""
for j in paragraph:
str_ = str_ + j
doc.add_paragraph(str_)
content_total = content_total + imglist + str_ + "\n"
except:
pass
doc.save(filename)
return content_total
本文简单介绍了单个网页数据的抓取和写入方法,抓取的目标网页为静态网页。如果是动态网页,还需要找出网页的跳转文件。抓取多个网页需要分页处理。MongoDB 可用于将抓取到的网页地址存储在 MongoDB 中。每次爬取一个网页,可以判断MongoDB中是否有,避免重复爬取。
本文示例的源代码:
爬虫抓取网页数据( Python标准库中的应用方法-苏州安嘉 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-13 12:07
Python标准库中的应用方法-苏州安嘉
)
2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
推荐的解析器资源:
pyquery /1EwUKsEG
Beautifulsoupt.im/ddfv
xpath 教程 t.im/ddg2
重新文件 t.im/ddg6
3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,sear是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
推荐的爬虫框架资源:
纳奇文件/
可怕的文件/
pyspider 文档 t.im/ddgj
防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽量控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头,修改爬虫的请求头,尽量与浏览器保持一致,以此类推。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你能写出分布式爬虫,那么你就可以尝试搭建一些基本的爬虫架构来实现一些更加自动化的数据采集。
推荐的分布式资源:
scrapy-redis 文档 t.im/ddgk
scrapy-rabbitmq 文档 t.im/ddgn
芹菜文件 t.im/ddgr
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。
以上知识框架已经完整打包,包括超清图片、PDF文档、思维导图文件、python爬虫相关资料。您可以点击下方卡片添加微信领取。
查看全部
爬虫抓取网页数据(
Python标准库中的应用方法-苏州安嘉
)
2、分析数据
爬虫爬取的是页面的指定部分数据值,而不是整个页面的数据。这时候,往往需要在存储之前对数据进行分析。
web返回的数据类型很多,主要有HTML、javascript、JSON、XML等格式。解析库的使用相当于在HTML中搜索需要的信息时使用了规律性,可以更快速的定位到具体的元素,获得相应的信息。
Css 选择器是一种快速定位元素的方法。
Pyqurrey 使用 lxml 解析器快速操作 xml 和 html 文档。它提供了类似于jQuery的语法来解析HTML文档,支持CSS选择器,使用起来非常方便。
Beautiful Soup 是一种借助网页的结构和属性等特征来解析网页的工具,可以自动转换编码。支持Python标准库中的HTML解析器,也支持部分第三方解析器。
Xpath 最初用于搜索 XML 文档,但它也适用于搜索 HTML 文档。它提供了 100 多个内置函数。这些函数用于字符串值、数值、日期和时间比较、节点和QName 处理、序列处理、逻辑值等,XQuery 和XPointer 都建立在XPath 之上。
Re正则表达式通常用于检索和替换符合某种模式(规则)的文本。个人认为前端基础比较扎实,pyquery最方便,beautifulsoup也不错,re速度比较快,但是写regular比较麻烦。当然,既然你用的是python,那绝对是为了你自己的方便。
推荐的解析器资源:
pyquery /1EwUKsEG
Beautifulsoupt.im/ddfv
xpath 教程 t.im/ddg2
重新文件 t.im/ddg6
3、数据存储
当爬回的数据量较小时,可以以文档的形式存储,支持TXT、json、csv等格式。
但是当数据量变大时,文档的存储方式就不行了,所以需要掌握一个数据库。
Mysql作为关系型数据库的代表,有着较为成熟的系统,成熟度较高。可以很好的存储一些数据,但是处理海量数据时效率会明显变慢,已经不能满足一些大数据的需求。加工要求。
MongoDB 已经流行了很长时间。与 MySQL 相比,MongoDB 可以轻松存储一些非结构化数据,例如各种评论的文本、图片链接等。您还可以使用 PyMongo 更轻松地在 Python 中操作 MongoDB。因为这里要用到的数据库知识其实很简单,主要是如何存储数据,如何提取,需要的时候学习。
Redis 是一个不妥协的内存数据库。Redis支持丰富的数据结构,包括hash、set、list等,数据全部存储在内存中,访问速度快,可以存储大量数据,一般用于分布式的数据存储爬虫。
工程履带
通过掌握前面的技术,可以实现轻量级爬虫,一般量级的数据和代码基本没有问题。
但在面对复杂情况时,表现并不令人满意。这时候,一个强大的爬虫框架就非常有用了。
第一个是 Nutch,来自一个著名家族的顶级 Apache 项目,它提供了我们运行自己的搜索引擎所需的所有工具。
支持分布式爬取,通过Hadoop支持,可以进行多机分布式爬取、存储和索引。
另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。
接下来是GitHub上大家star的scrapy,sear是一个非常强大的爬虫框架。
它不仅可以轻松构造请求,还具有强大的选择器,可以轻松解析响应。然而,最令人惊讶的是它的超高性能,它可以让你对爬虫进行工程化和模块化。
学习了scrapy之后就可以自己搭建一些爬虫框架了,基本就具备爬虫工程师的思维了。
最后,Pyspider作为国内大神开发的框架,满足了大部分Python爬虫的针对性爬取和结构化分析的需求。
可以在浏览器界面进行脚本编写、函数调度、实时查看爬取结果,后端使用常用数据库存储爬取结果。
它的功能是如此强大,以至于它更像是一个产品而不是一个框架。
这是三个最具代表性的爬虫框架。它们都有着远超其他的优势,比如Nutch的自然搜索引擎解决方案,Pyspider产品级的WebUI,以及Scrapy最灵活的定制爬取。建议先从最接近爬虫本质的可怕框架入手,然后接触为搜索引擎而生的人性化的Pyspider和Nutch。
推荐的爬虫框架资源:
纳奇文件/
可怕的文件/
pyspider 文档 t.im/ddgj
防爬虫对策
爬虫就像一个虫子,密密麻麻地爬到每一个角落获取数据。这个错误可能是无害的,但它总是不受欢迎的。
由于爬虫技术网站对带宽资源的侵犯导致大量IP访问,以及用户隐私和知识产权等危害,很多互联网公司都会下大力气“反爬虫”。
你的爬虫会遇到比如被网站拦截,比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
常见的反爬虫措施有:
·通过Headers反爬虫
·基于用户行为的反爬虫
·基于动态页面的反爬虫
·字体爬取.....
遇到这些反爬虫方法,当然需要一些高深的技巧来应对。尽量控制访问频率,保证页面加载一次,数据请求最小化,增加每次页面访问的时间间隔;禁止 cookie 可以防止使用 cookie 来识别爬虫。网站 禁止我们;根据浏览器正常访问的请求头,修改爬虫的请求头,尽量与浏览器保持一致,以此类推。
经常网站在高效开发和反爬虫之间偏向于前者。这也为爬虫提供了空间。掌握这些反爬虫技巧,大部分网站对你来说不再难。
分布式爬虫
爬取基础数据没有问题,也可以用框架来面对更复杂的数据。这时候,就算遇到了防爬,也已经掌握了一些防爬的技巧。
你的瓶颈将集中在爬取大量数据的效率上。这时候,相信你自然会接触到一个非常强大的名字:分布式爬虫。
分布式这个东西听上去很吓人,其实就是利用多线程的原理,将多台主机结合起来,共同完成一个爬虫任务。需要掌握Scrapy+Redis+MQ+Celery等工具。
前面说过,Scrapy是用来做基础的页面爬取,Redis用来存放要爬取的网页的队列,也就是任务队列。
在scrapy中使用scarpy-redis实现分布式组件,通过它可以快速实现简单的分布式爬虫。
由于高并发环境,请求经常被阻塞,因为来不及同步处理。通过使用消息队列MQ,我们可以异步处理请求,从而减轻系统压力。
RabbitMQ本身支持很多协议:AMQP、XMPP、SMTP、STOMP,这使得它非常重量级,更适合企业级开发。
Scrapy-rabbitmq-link 是一个组件,它允许您从 RabbitMQ 消息队列中检索 URL 并将它们分发给 Scrapy 蜘蛛。
Celery 是一个简单、灵活、可靠的分布式系统,可以处理大量消息。它支持RabbitMQ、Redis甚至其他数据库系统作为其消息代理中间件,在处理异步任务、任务调度、处理定时任务、分布式调度等场景中表现良好。
所以分布式爬虫听起来有点吓人,但仅此而已。当你能写出分布式爬虫,那么你就可以尝试搭建一些基本的爬虫架构来实现一些更加自动化的数据采集。
推荐的分布式资源:
scrapy-redis 文档 t.im/ddgk
scrapy-rabbitmq 文档 t.im/ddgn
芹菜文件 t.im/ddgr
你看,沿着这条完整的学习路径走下去,爬虫对你来说根本不是问题。
因为爬虫技术不需要你系统地精通一门语言,也不需要非常先进的数据库技术。
解锁各部分知识点,有针对性地学习。经过这条顺利的学习路径,你将能够掌握python爬虫。
以上知识框架已经完整打包,包括超清图片、PDF文档、思维导图文件、python爬虫相关资料。您可以点击下方卡片添加微信领取。
爬虫抓取网页数据(scrapy框架里自带标签选择器HtmlXPathSelector具体的使用规则可以查阅)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-12 18:20
上卷我们抓取了网页的所有内容,现在抓取网页的图片名称和连接
现在我创建一个新的爬虫文件并将名称设置为 crawler2
爬虫的朋友应该知道,网页中的数据是用文本或者块级标签包裹的。scrapy 框架带有一个标签选择器 HtmlXPathSelector。具体的使用规则大家可以查看,我就不介绍了。
现在我们要爬取的内容就是网页的图片标题和网页的图片链接,所以需要在网站的浏览器控制台查看label内容属性
在控制台我们发现:
我们要抓取的内容在类名showlist的div下的li标签下
所以我们先获取下一页的指定LI标签
先看打印结果:
内容在哪里,别慌,这个选择器打印出来的结果是没有问题的
下面我们修改一下代码,获取LI中的内容,实现父亲找孩子的过程
我一般用这个extract()函数来获取标签
看看结果
一组LI里面的内容很多,一一对应起来也不方便。可以看出,网站的前端直接就是一个块级元素,将多张图片封装在一个LI中。
如果您不舒服,请修改代码。一个 LI 中有七个。为了确保数据的准确性,我为每个父 LI 元素设置了一个数字。
看代码
看看结果:
即使文字不健康,数据依然清晰可见
现在图片连接好了,我们就可以根据链接下载图片了。然后我们使用urlretrieve函数,在当前爬虫文件夹中创建一个与SPIDER文件同级的IMG文件夹
看一下代码:
其实就像公式一样,读取公式+存储公式就完成了图片的下载:我们现在来看看结果:
真是不择手段网站我不会再爬了 查看全部
爬虫抓取网页数据(scrapy框架里自带标签选择器HtmlXPathSelector具体的使用规则可以查阅)
上卷我们抓取了网页的所有内容,现在抓取网页的图片名称和连接
现在我创建一个新的爬虫文件并将名称设置为 crawler2
爬虫的朋友应该知道,网页中的数据是用文本或者块级标签包裹的。scrapy 框架带有一个标签选择器 HtmlXPathSelector。具体的使用规则大家可以查看,我就不介绍了。
现在我们要爬取的内容就是网页的图片标题和网页的图片链接,所以需要在网站的浏览器控制台查看label内容属性
在控制台我们发现:
我们要抓取的内容在类名showlist的div下的li标签下
所以我们先获取下一页的指定LI标签
先看打印结果:
内容在哪里,别慌,这个选择器打印出来的结果是没有问题的
下面我们修改一下代码,获取LI中的内容,实现父亲找孩子的过程
我一般用这个extract()函数来获取标签
看看结果
一组LI里面的内容很多,一一对应起来也不方便。可以看出,网站的前端直接就是一个块级元素,将多张图片封装在一个LI中。
如果您不舒服,请修改代码。一个 LI 中有七个。为了确保数据的准确性,我为每个父 LI 元素设置了一个数字。
看代码
看看结果:
即使文字不健康,数据依然清晰可见
现在图片连接好了,我们就可以根据链接下载图片了。然后我们使用urlretrieve函数,在当前爬虫文件夹中创建一个与SPIDER文件同级的IMG文件夹
看一下代码:
其实就像公式一样,读取公式+存储公式就完成了图片的下载:我们现在来看看结果:
真是不择手段网站我不会再爬了
爬虫抓取网页数据(一下网站文章被爬虫抓取后怎么给关键词排名的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-12 05:05
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受青睐,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?
作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以提交到百度,360搜索引擎网站,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎的爬取,因为搜索引擎爬取数据的时候,搜索引擎会在自己的数据库中对内容进行检查和匹配。如果有大量低权重的网站内容被转载,蜘蛛爬取并在数据库中进行比较。并不是原创没有价值后就不再爬你的网站,如果情况严重,可能涉嫌作弊,给你网站降级或不显示你的网站 网站在百度,你之前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。
二、搜索引擎后台预处理采集的数据(索引)
1、提取网站文本等内容:从网站中搜索引擎爬取的内容中提取相关含义内容,去除一些不必要的标签等。
2、中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“地、地”等。
3、 去除内容中不重要的内容:去除与内容意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面有相同的内容,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。
三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词频密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,加粗中,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该算是最多的了,也许这可以反映我们对一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势,甚至根据用户体验影响排名结果具有重要意义.
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如果有什么要表达清楚的,请留下一个消息。,一起进步。 查看全部
爬虫抓取网页数据(一下网站文章被爬虫抓取后怎么给关键词排名的呢?)
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受青睐,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?
作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以提交到百度,360搜索引擎网站,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎的爬取,因为搜索引擎爬取数据的时候,搜索引擎会在自己的数据库中对内容进行检查和匹配。如果有大量低权重的网站内容被转载,蜘蛛爬取并在数据库中进行比较。并不是原创没有价值后就不再爬你的网站,如果情况严重,可能涉嫌作弊,给你网站降级或不显示你的网站 网站在百度,你之前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。
二、搜索引擎后台预处理采集的数据(索引)
1、提取网站文本等内容:从网站中搜索引擎爬取的内容中提取相关含义内容,去除一些不必要的标签等。
2、中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“地、地”等。
3、 去除内容中不重要的内容:去除与内容意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面有相同的内容,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。
三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词频密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,加粗中,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该算是最多的了,也许这可以反映我们对一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势,甚至根据用户体验影响排名结果具有重要意义.
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如果有什么要表达清楚的,请留下一个消息。,一起进步。
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-11-10 11:06
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
图2
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友把一些网站上的图片全部爬出来,集中起来。同时,网络爬虫也可以用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去做进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键进行安装。(注意网络连接)如图3
图 3
安装完成,如图4
图 4 查看全部
爬虫抓取网页数据(1.网络爬虫的功能图-上海怡健医学(组图))
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
图2
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,还可以爬取网站上面的图片。比如有的朋友把一些网站上的图片全部爬出来,集中起来。同时,网络爬虫也可以用在金融投资领域,比如可以自动爬取一些金融信息,进行投资分析。
有时候,可能有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取对应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,因此如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松的将这些数据采集发送出去做进一步分析,所有的爬取操作都是自动进行的。我们只需要编写相应的爬虫,设计相应的规则就可以了。
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在抓取和解析数据之前,您需要在 Python 运行环境中下载并安装第三方库请求。
在Windows系统中,打开cmd(命令提示符)界面,在界面上输入pip install requests,按回车键进行安装。(注意网络连接)如图3
图 3
安装完成,如图4
图 4
爬虫抓取网页数据(保持练习BeautifulSoup如何构建网络爬虫(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-10 03:10
元素,而不仅仅是标题元素。使用.parent 的每个Beautiful Soup 对象附带的属性,可以直观地浏览DOM 结构并处理所需的元素。您还可以以类似的方式访问子元素和同级元素。阅读更多信息。从 HTML 元素中提取属性 此时,您的 Python 脚本已经抓取了站点并过滤了其 HTML 以找到相关的职位发布。做得好!但是,申请工作的链接仍然缺失。查看页面时,您会在每张卡片的底部找到两个链接。如果您以与其他元素相同的方式处理链接元素,您将无法获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本“学习和应用”不是关联的 URL。这是因为 .text 属性只留下 HTML 元素的可见内容。它删除所有 HTML 标签,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值而不是丢弃它。link 元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部 href 的第二个标记的属性值:
Learn
Apply
Beautiful Soup 网络爬虫示例:首先获取工作卡中的所有元素。然后,href 使用方括号表示法来提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码片段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到您的控制台。在下面的练习块中,您可以找到优化您收到的链接结果的挑战的描述: 练习:优化您的结果 显示隐藏 单击解决方案块以阅读此练习的可能解决方案: 解决方案:优化您的 您也可以使用相同的方括号表示法来显示或隐藏结果。继续练习 Beautiful Soup 如何构建网络爬虫?如果您已经编写了本教程旁边的代码,那么您可以按原样运行脚本,您将在终端中看到一条错误的作业消息弹出。您的下一步是与现实生活中的工作委员会打交道!为了继续练习你的新技能,请使用以下任一或所有站点重新访问网络抓取过程:链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。
使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、requests.. 和 Beautiful Soup 进行网络爬虫。为了结束你的网络爬虫之旅,你可以对代码进行最后的转换,并创建一个命令行界面(CLI)应用程序,该应用程序可以爬取一个工作板,并将每次执行时可以输入的密钥传递给 Word 过滤结果。您的 CLI 工具允许您在特定位置搜索特定类型的工作或工作。如果您有兴趣学习如何使脚本适应命令行界面,请参阅如何使用 argparse 在 Python 中构建命令行界面。如何构建网络爬虫?结论 requests 库为您提供了一种用户友好的方式来使用 Python 从 Internet 获取静态 HTML。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。 查看全部
爬虫抓取网页数据(保持练习BeautifulSoup如何构建网络爬虫(一)_)
元素,而不仅仅是标题元素。使用.parent 的每个Beautiful Soup 对象附带的属性,可以直观地浏览DOM 结构并处理所需的元素。您还可以以类似的方式访问子元素和同级元素。阅读更多信息。从 HTML 元素中提取属性 此时,您的 Python 脚本已经抓取了站点并过滤了其 HTML 以找到相关的职位发布。做得好!但是,申请工作的链接仍然缺失。查看页面时,您会在每张卡片的底部找到两个链接。如果您以与其他元素相同的方式处理链接元素,您将无法获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本“学习和应用”不是关联的 URL。这是因为 .text 属性只留下 HTML 元素的可见内容。它删除所有 HTML 标签,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值而不是丢弃它。link 元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部 href 的第二个标记的属性值:
Learn
Apply
Beautiful Soup 网络爬虫示例:首先获取工作卡中的所有元素。然后,href 使用方括号表示法来提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码片段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到您的控制台。在下面的练习块中,您可以找到优化您收到的链接结果的挑战的描述: 练习:优化您的结果 显示隐藏 单击解决方案块以阅读此练习的可能解决方案: 解决方案:优化您的 您也可以使用相同的方括号表示法来显示或隐藏结果。继续练习 Beautiful Soup 如何构建网络爬虫?如果您已经编写了本教程旁边的代码,那么您可以按原样运行脚本,您将在终端中看到一条错误的作业消息弹出。您的下一步是与现实生活中的工作委员会打交道!为了继续练习你的新技能,请使用以下任一或所有站点重新访问网络抓取过程:链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。因此,您可以使用 requestsBeautiful Soup 将它们刮掉。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。使用这些其他站点之一从顶部重新开始阅读本教程。你会看到每个网站的结构都不一样,需要用稍微不同的方式重构代码,才能得到需要的数据。迎接这一挑战是练习刚刚学到的概念的好方法。虽然它可能会让你出很多汗,但你的编码技能会因此变得更强!在第二次尝试中,您还可以探索美汤的其他功能。
使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、requests.. 和 Beautiful Soup 进行网络爬虫。为了结束你的网络爬虫之旅,你可以对代码进行最后的转换,并创建一个命令行界面(CLI)应用程序,该应用程序可以爬取一个工作板,并将每次执行时可以输入的密钥传递给 Word 过滤结果。您的 CLI 工具允许您在特定位置搜索特定类型的工作或工作。如果您有兴趣学习如何使脚本适应命令行界面,请参阅如何使用 argparse 在 Python 中构建命令行界面。如何构建网络爬虫?结论 requests 库为您提供了一种用户友好的方式来使用 Python 从 Internet 获取静态 HTML。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。这两个软件包都是您进行网络抓取冒险的可信赖且有用的伴侣。你会发现 Beautiful Soup 可以满足你大部分的解析需求,包括 sum。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。Python Beautiful Soup 构建网络爬虫?在本教程中,您学习了如何使用 Pythonrequests 和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本来获取互联网上的招聘信息,并完成了从头到尾的整个网络爬虫过程。您学到了方法:考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看其他 网站 可以获取什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。考虑到这个广泛的管道和工具包中的两个强大的库,你可以出去看看其他 网站 能抓住什么。玩得开心,并始终记住以尊重和负责任的方式使用您的编程技能。
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-10 02:18
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束--- 查看全部
爬虫抓取网页数据(如何抓取ajax形式加载的网页数据(一)_恢复内容开始)
---恢复内容开始---
下面记录如何抓取ajax形式加载的网页数据:
目标:获取“%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=”下的网页数据
第一步:网页数据分析-----》特点:当列表栏滚动到页面底部时,数据自动加载,页面的url没有变化
第二步:使用Fiddler抓包,如下图:
图 1:请求数据
图2:表格形式
数据规律是通过抓包得到的:图2中from表单中的start对应数据和图1中url中的start对应数据随着每次加载增加,其他数据没有变化。对应这个规律,我们可以构造相应的请求来获取数据
注意数据格式为json
代码显示如下:
1).urllib 表单
import urllib2
import urllib
#此处的url为上述抓包获取的url去掉start以及limit,start以及limit数据后边以form表单的形式传入
url = \' https://movie.douban.com/j/cha ... on%3D\'
#请求投信息,伪造成浏览器,方式被反爬虫策略拦截
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
#构建form表单
formdata = {
"start":"20",
"limit":"20"
}
#urlencode()urllib中的函数,作用:将key:value形式的键值对转换为"key=value"形式的字符串
data = urllib.urlencode(formdata)
#构建request实例对象
request = urllib2.Request(url,data=data,headers=headers)
#发送请求并返回响应信息
response = urllib2.urlopen(request)
#注意此处的数据形式并不是html文档,而是json数据
json = response.read()
print html
2).request 库获取请求代码
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
data = {
"start":"20",
"limit":"20",
}
response = requests.get(url,params = data,headers = headers)
print response.text
3).request 库发布请求
#coding=utf-8
import requests
url = \' https://movie.douban.com/j/cha ... on%3D\'
formdata = {
"start":"20",
"limit":"20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0"}
response = requests.post(url,data=formdata,headers=headers)
print response.text
---恢复内容结束---
爬虫抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-07 07:24
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:
图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。查找URL 更改规则 接下来,查找要抓取的页面的URL 规则。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出结果为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一个执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。 查看全部
爬虫抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:
图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。查找URL 更改规则 接下来,查找要抓取的页面的URL 规则。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出结果为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一个执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。
爬虫抓取网页数据(python、数据挖掘、机器学习和自然语言处理领域的应用情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-06 12:05
python是如何用于网络爬虫、数据挖掘、机器学习和自然语言处理的?
Python 的快速迭代能力使其广受欢迎。根据原主持人的问题,结合我有限的经验一一解答:
1)Scrapy,易于使用。结合rq-queue,可以轻松构建分布式爬虫。有一次我是这样爬下整个豆瓣朋友圈的。
2) 数据挖掘中常用的算法都是用python实现的。肖志博提到的scikit learn可谓是最好的。不仅文档清晰,而且几乎所有常用的算法都实现了。我们使用 scikit learn 制作了一个 evemt 检测系统。整个系统用python编写,机器学习部分用python编写
3)nlp 部分不是特别好理解。nltk 在许多大学课程中被广泛使用。
在企业:
据我所知在公司的使用情况
谷歌:爬虫 C++、数据挖掘 C++、nlp C++。Python用于处理数据。
twitter:所有服务都使用java和scala,使用python编写快速迭代的工具。比如做搜索引擎算法的同事写了一个python客户端,在内部测试搜索质量。我用py写了一个搜索词推荐系统,包括接口、算法和接口,测试通过后改写成java。
一点想法:
py 的优势在于,py 可以用几十行其他语言的数百个句子来做事情,帮助开发者专注于问题。总结各种工具包,没有人会花时间写一个 svm(并确保不要写错)。但是py有一个巨大的缺点,它仍然很慢。有人会说算法优化很重要,不需要不断优化。但现实是大家都在不断优化,因为如果算法优化了,设计阶段就优化了,这就是为什么py在twitter中被翻译成java的原因。
但总的来说,即使你使用py开发然后翻译,也比直接在java中编写和测试要快得多。 查看全部
爬虫抓取网页数据(python、数据挖掘、机器学习和自然语言处理领域的应用情况)
python是如何用于网络爬虫、数据挖掘、机器学习和自然语言处理的?
Python 的快速迭代能力使其广受欢迎。根据原主持人的问题,结合我有限的经验一一解答:
1)Scrapy,易于使用。结合rq-queue,可以轻松构建分布式爬虫。有一次我是这样爬下整个豆瓣朋友圈的。
2) 数据挖掘中常用的算法都是用python实现的。肖志博提到的scikit learn可谓是最好的。不仅文档清晰,而且几乎所有常用的算法都实现了。我们使用 scikit learn 制作了一个 evemt 检测系统。整个系统用python编写,机器学习部分用python编写
3)nlp 部分不是特别好理解。nltk 在许多大学课程中被广泛使用。
在企业:
据我所知在公司的使用情况
谷歌:爬虫 C++、数据挖掘 C++、nlp C++。Python用于处理数据。
twitter:所有服务都使用java和scala,使用python编写快速迭代的工具。比如做搜索引擎算法的同事写了一个python客户端,在内部测试搜索质量。我用py写了一个搜索词推荐系统,包括接口、算法和接口,测试通过后改写成java。
一点想法:
py 的优势在于,py 可以用几十行其他语言的数百个句子来做事情,帮助开发者专注于问题。总结各种工具包,没有人会花时间写一个 svm(并确保不要写错)。但是py有一个巨大的缺点,它仍然很慢。有人会说算法优化很重要,不需要不断优化。但现实是大家都在不断优化,因为如果算法优化了,设计阶段就优化了,这就是为什么py在twitter中被翻译成java的原因。
但总的来说,即使你使用py开发然后翻译,也比直接在java中编写和测试要快得多。
爬虫抓取网页数据(通用爬虫框架如下图:通用的爬虫框架通用框架流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-06 12:04
2. 搜索引擎爬虫架构
但是浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成http请求,而网络爬虫需要一套整体架构来完成工作。
虽然爬虫技术经过几十年的发展从整体框架上已经比较成熟,但是随着互联网的不断发展,它也面临着一些具有挑战性的新问题。一般的爬虫框架如下:
通用爬虫框架
一般爬虫框架流程:
1)首先,从互联网页面中仔细选择一些网页,并将这些网页的链接地址作为种子URL;
2)将这些种子网址放入待抓取的网址队列;
3) 爬虫依次从待爬取的URL队列中读取,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4)然后将网页的IP地址和相对路径名传递给网页下载器,
5)网页下载器负责下载页面的内容。
6)对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载的网页的网址放入已爬取的网址队列中,该队列中记录了爬虫系统已经下载的网页的网址,以避免对网页的重复抓取。
7)对于新下载的网页,提取其中收录的所有链接信息,在爬取的URL队列中查看。如果发现该链接没有被抓取,那么这个URL就会被放置到被抓取的URL团队中!
8、在9)的末尾,该URL对应的网页会在后续的爬取调度中下载,以此类推,形成一个循环,直到待爬取的URL队列为空。
3. Crawler 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。
3.1 深度优先搜索策略(顺藤摸瓜)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后跳转到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有的顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问过的相邻点进行到深度优先遍历图,直到图中所有具有连接到v的路径的顶点都被访问;如果此时图中还有没有被访问过的顶点,则选择图中另一个没有被访问过的顶点作为起点,重复上述过程,直到图中所有顶点都被访问过迄今为止。
以下图所示的无向图G1为例,对图进行深度优先搜索:
G1
搜索过程:
假设搜索和爬取是从顶点页面v1开始的,在访问页面v1后,选择相邻点页面v2。因为v2之前没有访问过,所以从v2开始搜索。以此类推,搜索从 v4、v8 和 v5 开始。访问 v5 后,由于 v5 的所有相邻点都已访问过,搜索返回到 v8。出于同样的原因,搜索继续回到 v4、v2 直到 v1。此时,由于没有访问过v1的另一个相邻点,搜索从v1到v3,然后继续。由此,得到的顶点访问序列为:
3.2 广度优先搜索策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,爬取过程如下:
广度搜索过程:
首先访问页面v1和v1的邻点v2和v3,然后依次访问v2的邻点v4和v5以及v3的邻点v6和v7,最后访问v4的邻点v8。由于这些顶点的相邻点都被访问过,并且图中的所有顶点都被访问过,所以对图的这些遍历就是由这些完成的。得到的顶点访问顺序为:
v1→v2→v3→v4→v5→v6→v7→v8
<p>与深度优先搜索类似,遍历过程中也需要一组访问标志。另外,为了顺序访问路径长度为2、3、...的顶点,必须附加一个队列来存储路径长度为1、 查看全部
爬虫抓取网页数据(通用爬虫框架如下图:通用的爬虫框架通用框架流程)
2. 搜索引擎爬虫架构
但是浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成http请求,而网络爬虫需要一套整体架构来完成工作。
虽然爬虫技术经过几十年的发展从整体框架上已经比较成熟,但是随着互联网的不断发展,它也面临着一些具有挑战性的新问题。一般的爬虫框架如下:
通用爬虫框架
一般爬虫框架流程:
1)首先,从互联网页面中仔细选择一些网页,并将这些网页的链接地址作为种子URL;
2)将这些种子网址放入待抓取的网址队列;
3) 爬虫依次从待爬取的URL队列中读取,通过DNS解析URL,将链接地址转换为网站服务器对应的IP地址。
4)然后将网页的IP地址和相对路径名传递给网页下载器,
5)网页下载器负责下载页面的内容。
6)对于本地下载的网页,一方面存储在页面库中,等待索引等后续处理;另一方面,将下载的网页的网址放入已爬取的网址队列中,该队列中记录了爬虫系统已经下载的网页的网址,以避免对网页的重复抓取。
7)对于新下载的网页,提取其中收录的所有链接信息,在爬取的URL队列中查看。如果发现该链接没有被抓取,那么这个URL就会被放置到被抓取的URL团队中!
8、在9)的末尾,该URL对应的网页会在后续的爬取调度中下载,以此类推,形成一个循环,直到待爬取的URL队列为空。
3. Crawler 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。
3.1 深度优先搜索策略(顺藤摸瓜)
即图的深度优先遍历算法。网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后跳转到下一个起始页,继续跟踪链接。
我们用图表来说明:
我们假设互联网是一个有向图,图中的每个顶点代表一个网页。假设初始状态是图中所有的顶点都没有被访问过,那么深度优先搜索可以从图中的某个顶点开始,访问这个顶点,然后从v的未访问过的相邻点进行到深度优先遍历图,直到图中所有具有连接到v的路径的顶点都被访问;如果此时图中还有没有被访问过的顶点,则选择图中另一个没有被访问过的顶点作为起点,重复上述过程,直到图中所有顶点都被访问过迄今为止。
以下图所示的无向图G1为例,对图进行深度优先搜索:
G1
搜索过程:
假设搜索和爬取是从顶点页面v1开始的,在访问页面v1后,选择相邻点页面v2。因为v2之前没有访问过,所以从v2开始搜索。以此类推,搜索从 v4、v8 和 v5 开始。访问 v5 后,由于 v5 的所有相邻点都已访问过,搜索返回到 v8。出于同样的原因,搜索继续回到 v4、v2 直到 v1。此时,由于没有访问过v1的另一个相邻点,搜索从v1到v3,然后继续。由此,得到的顶点访问序列为:
3.2 广度优先搜索策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增多,会下载和过滤大量不相关的网页,算法的效率会变低。
以上图为例,爬取过程如下:
广度搜索过程:
首先访问页面v1和v1的邻点v2和v3,然后依次访问v2的邻点v4和v5以及v3的邻点v6和v7,最后访问v4的邻点v8。由于这些顶点的相邻点都被访问过,并且图中的所有顶点都被访问过,所以对图的这些遍历就是由这些完成的。得到的顶点访问顺序为:
v1→v2→v3→v4→v5→v6→v7→v8
<p>与深度优先搜索类似,遍历过程中也需要一组访问标志。另外,为了顺序访问路径长度为2、3、...的顶点,必须附加一个队列来存储路径长度为1、
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-05 06:16
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,也可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了.
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在python运行环境中下载安装第三方库请求。
在windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,按回车键进行安装。(注意网络连接)如下图
安装完成,如图
查看全部
爬虫抓取网页数据(1.网络爬虫的基本概念网络蜘蛛,机器人都能够做到!
)
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛、机器人)是一种模拟客户端发送网络请求和接收请求响应的程序。它是一种按照一定的规则自动抓取互联网信息的程序。
只要浏览器能做的事情,原则上爬虫都能做。
2.网络爬虫的功能
网络爬虫可以做很多事情而不是手动。比如可以作为搜索引擎,也可以爬取网站上面的图片。比如有的朋友爬取一些网站上的所有图片,集中注意力同时,网络爬虫也可以用在金融投资领域,比如可以自动抓取一些金融信息,进行投资分析。
有时候,可能会有几个我们比较喜欢的新闻网站,每次都要打开这些新闻网站浏览,比较麻烦。这时候就可以使用网络爬虫对这多个新闻网站中的新闻信息进行爬取,一起阅读。
有时,我们在浏览网页信息时,会发现有很多广告。这时候也可以使用爬虫爬取相应网页上的信息,让这些广告自动过滤掉,方便信息的阅读和使用。
有时,我们需要进行营销,那么如何找到目标客户和目标客户的联系方式是一个关键问题。我们可以在网上手动搜索,但是效率会很低。这时候我们就可以使用爬虫来设置相应的规则,自动从互联网上采集目标用户的联系方式等数据,用于我们的营销。
有时,我们要分析某个网站的用户信息,比如分析网站的用户活跃度、评论数、热门文章等信息。如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时就可以使用爬虫轻松获取这些数据采集进行进一步分析,而且所有的爬取操作都是自动进行的,我们只需要编写相应的爬虫,设计相应的规则就可以了.
此外,爬虫还可以实现很多强大的功能。总之,爬虫的出现在一定程度上可以替代人工访问网页。因此,我们需要手动访问互联网信息的操作现在可以通过爬虫自动化,从而可以更有效地使用互联网中的有效信息。.
3.安装第三方库
在爬取和解析数据之前,需要在python运行环境中下载安装第三方库请求。
在windows系统中,打开cmd(命令提示符)界面,在界面中输入pip install requests,按回车键进行安装。(注意网络连接)如下图
安装完成,如图
爬虫抓取网页数据(爬虫抓取网页数据的使用原理是什么?抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-05 05:05
<p>爬虫抓取网页数据的使用原理是:先下载数据,然后再编译。用java大概要用这个类java.sql.jdbc.driverclassloader;进行反射中的定义:publicjava.sql.jdbc.driverclassloaderclass 查看全部
爬虫抓取网页数据(爬虫抓取网页数据的使用原理是什么?抓取数据)
<p>爬虫抓取网页数据的使用原理是:先下载数据,然后再编译。用java大概要用这个类java.sql.jdbc.driverclassloader;进行反射中的定义:publicjava.sql.jdbc.driverclassloaderclass
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-04 00:20
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。实际上,在大多数场景下,您可以通过 Web Scraper(Chrome 插件)快速抓取到目标内容。重要的是你不需要下载东西,基本上不需要代码知识。
在开始之前,有必要先简单了解几个问题。
一种。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的东西应该留给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取的内容,然后存入数据库中进行浏览或下载。搜索引擎可以工作,也是类似的原理。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。
Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换,Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你用的是windows,是ctrl+shift+i,不同浏览器的默认快捷键可能不同)。这时候可以看到网页弹出这样的对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖瓦)。
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所示的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
3、 点击create new sitemap,依次创建sitemap创建爬虫。随意填写站点地图名称,仅供自己识别,例如填写dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是/top250
第二页的开头是 /top250?start=25&filter=
第三页是/top250?start=50&filter=
...
只有一个数字略有不同。我们的意图是爬取top250电影数据,所以不能简单地在起始url粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
注意start后[]里面的内容,表示每25日一个网页,抓取10个网页。
最后点击Create sitemap,爬虫就搭建好了。
(URL也可以通过填写/top250来爬取,但是不能让Web Scraper明白我们要爬取top250的所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是一个简单的一点点。它的原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置了选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
5、 第四步只是创建容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。
看到根目录后面跟着container,点击Add new selector创建一个子选择器。
再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下)分别抓取电影名、评分、一句话影评。
创建后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始抓取.
当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。只需依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,以及如何使用。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
这整个过程看似繁琐,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,觉得还是按照上面的步骤一步一步来,还是比较费力的,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(是上面一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"regex":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,有的网页乱七八糟,有时需要限制爬取次数(否则抓取次数(保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
哈尔·盖特伍德 (Hal Gatewood) 在 Unsplash 上的标题图片
文章 首发于公众号“武学武术”,作者魏 m644003222 查看全部
爬虫抓取网页数据(WebScraper有多么好爬,以及大致怎么用问题)
网上有很多使用Python爬取网页内容的教程,但一般都需要自己写代码,没有相应基础的人短期内有入门门槛。实际上,在大多数场景下,您可以通过 Web Scraper(Chrome 插件)快速抓取到目标内容。重要的是你不需要下载东西,基本上不需要代码知识。
在开始之前,有必要先简单了解几个问题。
一种。什么是爬虫?
一个自动抓取目标网站内容的工具。
湾 爬虫有什么用?
提高数据效率采集。没有人愿意让他们的手指重复复制和粘贴操作。机械的东西应该留给工具。快速采集数据也是分析数据的基础。
C。爬虫的原理是什么?
要理解这一点,您需要了解为什么人类可以浏览网页。我们通过输入URL、关键字、点击链接等方式向目标计算机发送请求,然后将目标计算机的代码下载到本地,然后解析/渲染到我们看到的页面中。这就是上网的过程。
爬虫做的就是模拟这个过程,但是比人的动作要快,而且可以自定义爬取的内容,然后存入数据库中进行浏览或下载。搜索引擎可以工作,也是类似的原理。
但爬虫只是工具。要使工具发挥作用,他们必须了解您想要什么。这是我们必须要做的。毕竟,人脑电波不能直接流入计算机。也可以说爬虫的本质就是寻找模式。
Lauren Mancke 在 Unsplash 上的照片
以豆瓣电影Top250为例(很多人练习这个是因为豆瓣网页是有条理的),看看网络爬虫是多么的简单,以及如何使用它。
1、在Chrome App Store中搜索Web Scraper,然后点击“添加扩展”,即可在Chrome插件栏中看到蜘蛛网图标。
(如果日常浏览器不是Chrome,强烈建议更换,Chrome和其他浏览器的区别就像谷歌和其他搜索引擎的区别一样)
2、打开要爬取的网页,比如豆瓣Top250的网址是/top250,然后同时按option+command+i进入开发者模式(如果你用的是windows,是ctrl+shift+i,不同浏览器的默认快捷键可能不同)。这时候可以看到网页弹出这样的对话框。别担心,这只是当前网页的 HTML(一种超文本标记语言,它创建了网络世界的砖瓦)。
只要按照步骤1添加Web Scraper扩展程序,就可以在箭头所示的位置看到Web Scraper,点击它,就是下图所示的爬虫页面。
3、 点击create new sitemap,依次创建sitemap创建爬虫。随意填写站点地图名称,仅供自己识别,例如填写dbtop250(不要写汉字、空格、大写字母)。一般将要爬取的网页的网址复制粘贴到起始网址中,但为了让爬虫了解我们的意图,最好先观察网页布局和网址。25 页。
第一页的网址是/top250
第二页的开头是 /top250?start=25&filter=
第三页是/top250?start=50&filter=
...
只有一个数字略有不同。我们的意图是爬取top250电影数据,所以不能简单地在起始url粘贴/top250,而应该是/top250?start=[0-250:25]&filter=
注意start后[]里面的内容,表示每25日一个网页,抓取10个网页。
最后点击Create sitemap,爬虫就搭建好了。
(URL也可以通过填写/top250来爬取,但是不能让Web Scraper明白我们要爬取top250的所有页面的数据,只会爬取第一页的内容。)
4、 爬虫搭建好之后的工作才是重点。为了让 Web Scraper 理解意图,必须创建一个选择器并单击添加新选择器。
然后就会进入选择器编辑页面,其实就是一个简单的一点点。它的原理是几乎所有用HTML编辑的网页,组成元素都是相同或相似的盒子(或容器),每个容器中的布局和标签都是相似的。页面越规则越统一,从HTML代码也可以看出。
所以,如果我们设置了选择元素和顺序,爬虫就可以根据设置自动模拟选择,数据就可以整齐的往下爬了。在爬取多个元素的情况下(比如想同时爬豆瓣top250,爬排名、片名、评分、一句话影评),可以先选择容器,再选择元素依次放入容器中。
如图所示,
5、 第四步只是创建容器选择器。Web Scraper 仍然不理解要爬取的东西。我们需要在容器中进一步选择我们想要的数据(电影排名、电影名称、评分、一句话电影评论)。
完成第4步保存选择后,会看到爬虫的根目录,点击创建的容器一栏。
看到根目录后面跟着container,点击Add new selector创建一个子选择器。
再次进入选择器编辑页面,如下图所示。这次不同的是id字段填的是我们要抓取的元素的定义,随便写,比如先抓取电影排名,写个数字;因为排名是文本类型,在类型中选择文本;这次只选择了一个容器中的一个元素,因此未选中 Multiple。另外,在选择排名的时候,不要选错地方,因为你选择什么爬虫都可以爬。然后单击完成选择并保存选择器。
这时候爬虫已经知道要爬取top250网页中所有容器的视频排名。同理,再创建3个子选择器(注意是在容器目录下)分别抓取电影名、评分、一句话影评。
创建后就是这种情况。这时候所有的选择器都已经创建好了,爬虫已经完全理解了意图。
6、 接下来就是让爬虫跑起来,点击sitemap dbtop250,依次抓取
这时候Web Scraper会让你填写请求间隔和延迟时间,保持默认2000(单位是毫秒,也就是2秒),除非网速很快或者很慢,然后点击开始抓取.
当我们到达这里时,会弹出一个新的自动滚动网页,这是我们在创建爬虫时输入的网址。大约一分钟左右,爬虫完成工作,弹窗自动消失(自动消失表示爬取完成)。
而Web Scraper页面就会变成这样
7、点击刷新,可以预览爬虫结果:豆瓣电影top250排名、电影名称、评分、一句话影评。看看有没有问题。(比如有null,如果有null,说明对应的选择器没有选好,一般页面越规则,null越少。当遇到HTML不规则的网页时,比如知乎,空值比较多,可以返回调整选择器)
这时候,可以说大功告成了。只需依次点击sitemap dbtop250和Export date as CSV即可下载CSV格式的数据表,以及如何使用。
值得一提的是,浏览器抓取的内容一般存储在本地starage数据库中,功能单一,不支持自动排序。所以如果你不安装额外的数据库并设置它,爬取的数据表将是乱序的。在这种情况下,一种解决方案是将其导入谷歌表,然后进行清理。另一种一劳永逸的方法是安装一个额外的数据库,比如CouchDB,在爬取数据之前,将数据存储路径改为CouchDB,然后爬取数据,预览和下载,是有顺序的,比如上面的预览图。
这整个过程看似繁琐,但熟悉之后其实很简单。这种小规模的数据从头到尾两三分钟就OK了。而像这种小规模的数据,爬虫还没有完全发挥出它的用途。数据量越大,爬虫的优势越明显。
比如爬取各个主题的选定内容可以同时爬取,2万条数据只需要几十分钟。
自拍
看到这里,觉得还是按照上面的步骤一步一步来,还是比较费力的,还有一个更简单的方法:
通过导入站点地图,复制粘贴下面的爬虫代码,导入,就可以直接开始抓取豆瓣top250的内容了。(是上面一系列配置生成的)
{"_id":"douban_movie_top_250","startUrl":["/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors" :["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement" ,"parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"title","type" :"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple ":false,"regex":"","delay":0}]}
最后,这个文章只涉及到Web Scraper和爬虫的冰山一角。不同的网站有不同的风格,不同的元素布局,不同的爬取要求,不同的爬取方式。
比如有的网站需要点击“加载更多”加载更多,有的网站下拉加载,有的网页乱七八糟,有时需要限制爬取次数(否则抓取次数(保持抓取),有时需要抓取二级和多级页面的内容,有时需要抓取图片,有时需要抓取隐藏信息,等等。有很多情况。攀登豆瓣top250只是入门体验版。只有了解了爬取的原理,遵守了网站的规则,才能真正的使用Web Scraper,爬到自己想要的东西。
哈尔·盖特伍德 (Hal Gatewood) 在 Unsplash 上的标题图片
文章 首发于公众号“武学武术”,作者魏 m644003222
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-04 00:18
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以 /subject/26986954/ 为例。首先,我们来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
print(content)
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/")
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
print(element["href"])
# 获取更多数据
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后反复抓取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://"):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源:/i65540493/ 查看全部
爬虫抓取网页数据(一点会从零开始介绍如何编写一个网络爬虫的数据数据采集)
从各种搜索引擎到日常数据采集,网络爬虫密不可分。爬虫的基本原理很简单。它遍历网络上的网页,抓取感兴趣的数据内容。本篇文章将介绍如何编写一个网络爬虫从头开始抓取数据,然后逐步完善爬虫的爬取功能。
我们使用python 3.x 作为我们的开发语言,只是一点python基础。首先,我们还是从最基本的开始。
工具安装
我们需要安装 python、python requests 和 BeautifulSoup 库。我们使用 Requests 库抓取网页内容,使用 BeautifulSoup 库从网页中提取数据。
爬网
完成必要工具的安装后,我们就正式开始编写我们的爬虫了。我们的首要任务是抓取豆瓣上的所有图书信息。我们以 /subject/26986954/ 为例。首先,我们来看看如何抓取网页的内容。
使用python的requests提供的get()方法,我们可以很方便的获取到指定网页的内容,代码如下:
import requests
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
print(content)
提取内容
抓取网页内容后,我们要做的就是提取我们想要的内容。在我们的第一个例子中,我们只需要提取书名。首先,我们导入 BeautifulSoup 库。使用BeautifulSoup,我们可以非常简单的提取网页的具体内容。
import requests
from bs4 import BeautifulSoup
if __name__== "__main__":
response = requests.get("https://book.douban.com/subject/26986954/";)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取当前页面包含的所有链接
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
print(element["href"])
# 获取更多数据
持续的网络爬行
至此,我们已经能够抓取单个网页的内容,现在让我们看看如何抓取网站的整个内容。我们知道网页是通过超链接相互连接的,我们可以通过链接访问整个网络。所以我们可以从每个页面中提取到其他网页的链接,然后反复抓取新的链接。
import time
import requests
from bs4 import BeautifulSoup
# 保存已经抓取和未抓取的链接
visited_urls = []
unvisited_urls = [ "https://book.douban.com/subject/26986954/" ]
# 从队列中返回一个未抓取的URL
def get_unvisited_url():
while True:
if len(unvisited_urls) == 0:
return None
url = unvisited_urls.pop()
if url in visited_urls:
continue
visited_urls.append(url)
return url
if __name__== "__main__":
while True:
url = get_unvisited_url()
if url == None:
break
print("GET " + url)
response = requests.get(url)
content = response.content.decode("utf-8")
#print(content)
soup = BeautifulSoup(content, "html.parser")
# 获取页面包含的链接,并加入未访问的队列
for element in soup.select("a"):
if not element.has_attr("href"):
continue
if not element["href"].startswith("https://";):
continue
unvisited_urls.append(element["href"])
#print(element["href"])
time.sleep(1)
总结
我们的第一个网络爬虫已经开发完成。它可以抓取豆瓣上的所有书籍,但它也有很多局限性。毕竟,这只是我们的第一个小玩具。在后续的文章中,我们会逐步完善我们爬虫的爬取功能。
来源:/i65540493/
爬虫抓取网页数据( “爬虫”是怎么抢机票的?专家:不需要人工干预)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-03 18:09
“爬虫”是怎么抢机票的?专家:不需要人工干预)
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
“爬虫”如何抢低价票?使用超链接信息抓取网页
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它是一种按照一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。在发现低价或卖空机票后,“爬虫”可以利用虚假客户的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客户来源,并在航空公司允许的计费周期内, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价客票,依此类推,直到真正客源的乘客被发现并出售。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽 查看全部
爬虫抓取网页数据(
“爬虫”是怎么抢机票的?专家:不需要人工干预)
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
“爬虫”如何抢低价票?使用超链接信息抓取网页
你的低价票被“虫子”吃掉了
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,正当小王急于利用自己的“早熟力”抢到便宜机票时,却在网上看到一则新闻,航空公司开出的低价机票中,80%以上都是机票“爬虫”。公司。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它是一种按照一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上百亿个网页,需要依靠在庞大的“爬虫”集群上实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。在发现低价或卖空机票后,“爬虫”可以利用虚假客户的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等)找到真正的客户来源,并在航空公司允许的计费周期内, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价客票,依此类推,直到真正客源的乘客被发现并出售。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。尤其是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
本报记者傅丽丽
爬虫抓取网页数据(产品运营人员处理数据和运用数据,基本是常态。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-03 16:09
作为产品运营商,在工作中处理数据、分析数据、使用数据基本是正常的。虽然不是数据分析岗位,但也是需要大量应用数据的岗位。如果没有获取数据的能力,其实很尴尬。
通常,数据的获取来自两个方面:内部数据和外部数据。
内部数据无非是根据分析的需要,在贵公司的数据库或数据统计平台中提取数据。如果要从数据统计平台中提取数据,一般的数据统计平台都会支持数据导出,您只需要导出需要的数据即可。如果要从公司数据库中提取数据,我们需要使用sql语言来获取数据。
使用sql从公司数据库中检索数据,主要是学习数据库“校验”的基本操作,包括特定情况下的数据抽取、数据的分组聚合、多表连接等,比较简单。您可以在以下列中参考这个文章:
当然,对于产品或者运维人员来说,我们有时候不一定有读取数据的权限,但是有句话说得好,有备无患。你已经掌握了一种技能,当你想使用它时,不能更好地使用它,但不是。
获取外部数据主要有两种方式:
一是获取外部公开的数据集。比如一些科研机构、企业、政府会公开一些数据。你需要去特定的网站下载这些数据。这些数据集通常比较完整,质量也比较高(如中国统计信息网)。
二是利用爬虫从网上爬取,比如从招聘网站获取某个职位的招聘信息,租房网站获取某个区域的租房信息,电子商务< @网站获取 基于爬取的数据,我们可以根据某个产品的产品信息进行数据分析。
我们要讲的是第二种外部获取数据的方式:使用python爬虫获取外部数据。
因此,默认情况下,本文的读者具有python语法基础知识和爬虫基础知识(如果没有这方面的知识,也不会妨碍对文章的理解。同时,作者会在文章末尾附上学习的时间我遇到了一个很好的python基础学习和爬虫基础知识学习博客)。
我们以最贴近生活求职者找工作为例,谈谈如何利用爬虫快速获取招聘中想要的数据网站,然后分析辅助决策——在此基础上制作。
先别着急,哦,不对,是代码,先从思路开始:
1. 作为求职者,要找到工作,至少要了解以下信息: 工作的市场情况,如工资范围:工作1到3年,工资是多少?应届毕业生的工资是多少?招聘公司的规模有多大?公司办公地址离居住地近还是远?有什么教育要求?整体市场情况如何?. . . . .
2、获取这些数据的方式,一般来说,要么直接从第三方平台获取,要么就是利用爬虫技术对数据进行爬取。显然这些招聘信息已经在招聘网站上了,不用去想了。批量获取数据的最佳方式是编写一个爬虫脚本,爬取一些求职职位的数据,并保存在一个excel电子表格中。在,把它留给下一个分析。
好的,思路流畅后,我们就开始做。这里以拉勾网的“产品运营”帖子为例。
使用环境:win10+python3+Juypter Notebook
第一步:分析网页
要抓取网页,首先要分析网页结构。
现在很多网站都使用了一种叫做Ajax(异步加载)的技术,就是在打开一个网页的时候,先给你展示上面的一些,然后慢慢加载剩下的。所以你可以看到很多网页,慢慢刷新,或者一些网站随着你的移动,很多信息慢慢加载。这种网页的优点是加载速度非常快(因为您不必一次加载所有内容)。
但是这种技术不利于爬行,所以这个时候我们就得花点功夫了。
幸运的是,牵开器使用了这种技术。异步加载信息,我们需要使用chrome浏览器小工具进行分析,按F12打开,点击Nerwork进入网络分析界面,界面如下:
此时,它是空白的。如果我们按F5刷新,我们可以看到一系列的网络请求。
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr(什么是xhr,想了解更多可以参考这篇博客:深入理解ajax系列第一篇-XHR对象)这种类型的请求如下:
这种类型的数据一般都是json格式,我们也可以尝试在filter中输入json进行过滤查找。
上图发现了两个xhr请求。从字面意思来看,很可能就是我们需要的信息。右击在另一个界面打开:
这是什么?你在跟我开玩笑吗?嗯,这里有个坑。另外在写爬虫代码的时候,如果不在http请求中添加请求头信息,服务器返回同样的信息,但是我不明白是为什么,这里我直接用浏览器打开一个新窗口也是拒绝访问的接口。如果有大神知道,希望解惑,谢谢!
回到正题,新开的窗口虽然进不去,但是各大洲都通向罗马。我们可以在右侧的框中切换到“预览”,然后点击内容——位置结果进行查看,可以看到位置的信息。以键值对的形式呈现,这是json格式,特别适合网页数据交换。
第一步是分析网页,这是结束。下一步是构造请求 URL。
第二步、URL构建
在“Headers”中可以看到网页地址,通过观察网页地址可以发现: 这一段是固定的,其余我们发现有一个city=%E5%8C%97%E4%BA %AC&needAddtionalResult=false&isSchoolJob= 0
再次检查请求发送参数列表。这里我们可以确定city参数是city,pn参数是页数,kd参数是position关键字。
当然,这只是网页的内容。如何获取更多页面的内容?再来看看“产品运营”的位置。总共有30页,每页有15条数据,所以我们只需要构造一个循环来遍历每页的数据。
第三步写爬虫脚本,写代码
需要说明的是,因为这个网页的格式是json,所以我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击内容——位置结果——结果,可以先找到一个列表,然后点击查看每个位置的内容。为什么要从这里看?一个好处是你知道这个json文件的层次结构,所以你可以很容易地等待编码。
具体代码显示:
也可以直接从作者的github下载:/banyanmo/lagou
<p>import requests,json
from openpyxl import Workbook
#http请求头信息
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'25',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_Python?',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
def get_json(url, page, lang_name):
data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}
#POST请求
json = requests.post(url,data,headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i['companyId'])
info.append(i['companyFullName'])
info.append(i['companyShortName'])
info.append(i['companySize'])
info.append(str(i['companyLabelList']))
info.append(i['industryField'])
info.append(i['financeStage'])
info.append(i['positionId'])
info.append(i['positionName'])
info.append(i['positionAdvantage'])
# info.append(i['positionLables'])
info.append(i['city'])
info.append(i['district'])
# info.append(i['businessZones'])
info.append(i['salary'])
info.append(i['education'])
info.append(i['workYear'])
info_list.append(info)
return info_list
def main():
lang_name = input('职位名:')
page = 1
url = 'http://www.lagou.com/jobs/posi ... 39%3B
info_result=[]
title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"]
info_result.append(title)
#遍历网址
while page 查看全部
爬虫抓取网页数据(产品运营人员处理数据和运用数据,基本是常态。)
作为产品运营商,在工作中处理数据、分析数据、使用数据基本是正常的。虽然不是数据分析岗位,但也是需要大量应用数据的岗位。如果没有获取数据的能力,其实很尴尬。
通常,数据的获取来自两个方面:内部数据和外部数据。
内部数据无非是根据分析的需要,在贵公司的数据库或数据统计平台中提取数据。如果要从数据统计平台中提取数据,一般的数据统计平台都会支持数据导出,您只需要导出需要的数据即可。如果要从公司数据库中提取数据,我们需要使用sql语言来获取数据。
使用sql从公司数据库中检索数据,主要是学习数据库“校验”的基本操作,包括特定情况下的数据抽取、数据的分组聚合、多表连接等,比较简单。您可以在以下列中参考这个文章:
当然,对于产品或者运维人员来说,我们有时候不一定有读取数据的权限,但是有句话说得好,有备无患。你已经掌握了一种技能,当你想使用它时,不能更好地使用它,但不是。
获取外部数据主要有两种方式:
一是获取外部公开的数据集。比如一些科研机构、企业、政府会公开一些数据。你需要去特定的网站下载这些数据。这些数据集通常比较完整,质量也比较高(如中国统计信息网)。
二是利用爬虫从网上爬取,比如从招聘网站获取某个职位的招聘信息,租房网站获取某个区域的租房信息,电子商务< @网站获取 基于爬取的数据,我们可以根据某个产品的产品信息进行数据分析。
我们要讲的是第二种外部获取数据的方式:使用python爬虫获取外部数据。
因此,默认情况下,本文的读者具有python语法基础知识和爬虫基础知识(如果没有这方面的知识,也不会妨碍对文章的理解。同时,作者会在文章末尾附上学习的时间我遇到了一个很好的python基础学习和爬虫基础知识学习博客)。
我们以最贴近生活求职者找工作为例,谈谈如何利用爬虫快速获取招聘中想要的数据网站,然后分析辅助决策——在此基础上制作。
先别着急,哦,不对,是代码,先从思路开始:
1. 作为求职者,要找到工作,至少要了解以下信息: 工作的市场情况,如工资范围:工作1到3年,工资是多少?应届毕业生的工资是多少?招聘公司的规模有多大?公司办公地址离居住地近还是远?有什么教育要求?整体市场情况如何?. . . . .
2、获取这些数据的方式,一般来说,要么直接从第三方平台获取,要么就是利用爬虫技术对数据进行爬取。显然这些招聘信息已经在招聘网站上了,不用去想了。批量获取数据的最佳方式是编写一个爬虫脚本,爬取一些求职职位的数据,并保存在一个excel电子表格中。在,把它留给下一个分析。
好的,思路流畅后,我们就开始做。这里以拉勾网的“产品运营”帖子为例。
使用环境:win10+python3+Juypter Notebook
第一步:分析网页
要抓取网页,首先要分析网页结构。
现在很多网站都使用了一种叫做Ajax(异步加载)的技术,就是在打开一个网页的时候,先给你展示上面的一些,然后慢慢加载剩下的。所以你可以看到很多网页,慢慢刷新,或者一些网站随着你的移动,很多信息慢慢加载。这种网页的优点是加载速度非常快(因为您不必一次加载所有内容)。
但是这种技术不利于爬行,所以这个时候我们就得花点功夫了。
幸运的是,牵开器使用了这种技术。异步加载信息,我们需要使用chrome浏览器小工具进行分析,按F12打开,点击Nerwork进入网络分析界面,界面如下:
此时,它是空白的。如果我们按F5刷新,我们可以看到一系列的网络请求。
然后我们开始寻找可疑的网络资源。首先,图片、css等可以跳过。一般来说,重点是xhr(什么是xhr,想了解更多可以参考这篇博客:深入理解ajax系列第一篇-XHR对象)这种类型的请求如下:
这种类型的数据一般都是json格式,我们也可以尝试在filter中输入json进行过滤查找。
上图发现了两个xhr请求。从字面意思来看,很可能就是我们需要的信息。右击在另一个界面打开:
这是什么?你在跟我开玩笑吗?嗯,这里有个坑。另外在写爬虫代码的时候,如果不在http请求中添加请求头信息,服务器返回同样的信息,但是我不明白是为什么,这里我直接用浏览器打开一个新窗口也是拒绝访问的接口。如果有大神知道,希望解惑,谢谢!
回到正题,新开的窗口虽然进不去,但是各大洲都通向罗马。我们可以在右侧的框中切换到“预览”,然后点击内容——位置结果进行查看,可以看到位置的信息。以键值对的形式呈现,这是json格式,特别适合网页数据交换。
第一步是分析网页,这是结束。下一步是构造请求 URL。
第二步、URL构建
在“Headers”中可以看到网页地址,通过观察网页地址可以发现: 这一段是固定的,其余我们发现有一个city=%E5%8C%97%E4%BA %AC&needAddtionalResult=false&isSchoolJob= 0
再次检查请求发送参数列表。这里我们可以确定city参数是city,pn参数是页数,kd参数是position关键字。
当然,这只是网页的内容。如何获取更多页面的内容?再来看看“产品运营”的位置。总共有30页,每页有15条数据,所以我们只需要构造一个循环来遍历每页的数据。
第三步写爬虫脚本,写代码
需要说明的是,因为这个网页的格式是json,所以我们可以很好的读取json格式的内容。这里我们切换到预览,然后点击内容——位置结果——结果,可以先找到一个列表,然后点击查看每个位置的内容。为什么要从这里看?一个好处是你知道这个json文件的层次结构,所以你可以很容易地等待编码。
具体代码显示:
也可以直接从作者的github下载:/banyanmo/lagou
<p>import requests,json
from openpyxl import Workbook
#http请求头信息
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'25',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_Python?',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
def get_json(url, page, lang_name):
data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}
#POST请求
json = requests.post(url,data,headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i['companyId'])
info.append(i['companyFullName'])
info.append(i['companyShortName'])
info.append(i['companySize'])
info.append(str(i['companyLabelList']))
info.append(i['industryField'])
info.append(i['financeStage'])
info.append(i['positionId'])
info.append(i['positionName'])
info.append(i['positionAdvantage'])
# info.append(i['positionLables'])
info.append(i['city'])
info.append(i['district'])
# info.append(i['businessZones'])
info.append(i['salary'])
info.append(i['education'])
info.append(i['workYear'])
info_list.append(info)
return info_list
def main():
lang_name = input('职位名:')
page = 1
url = 'http://www.lagou.com/jobs/posi ... 39%3B
info_result=[]
title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"]
info_result.append(title)
#遍历网址
while page
爬虫抓取网页数据(SimpleScratch需求迫切索引擎是互网大爆炸后的新生事物,个是泛商品化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-03 06:03
SimpleScratch SearchEngine作者急需完成搜索引擎模型 07/06 07/08 完成信息航空模型 07/16 完成 1/3 数据采集 07/30 本文为搜索引擎草稿,转至:指南.txt ) 第一章急需搜索引擎是互联网爆炸后的新生事物,一个是泛信息化,一个是泛商业化。一) 在泛信息化方面,信息的种类很多。大家个人觉得,多媒体和社交网络的海量必然会导致搜索引擎的泛滥。搜索引擎很多,你可以看看谷歌,百度有多少搜索引擎足够各种需求的信息,维基的搜索引擎列表(,5)P2P师源,6)Email,7 知道信息 爆炸是基于需求的。目前搜索引擎已列出14)手机及手机信息、7)工作信息、8)法律信息、9条信息、10条信息、11)社交信息、12条信息、14条来自搜索引擎的发展,反观信息的增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。
这要看3171年,我不吃不喝,我一直在看。如果你是愚公世家,你的祖宗在大禹治水,你还没有读完。对于航空,草根使用追求免费、快速、有效的服装,有很多满足新需求的产品。一方面,有很多满足旧需求的新产品。有很多新产品。如果你不宣传,很多有需要的人就找不到你,或者他们找不到你。例如,如果您不看新广告,甚至不知道有人举行了隆重的葬礼,那么您就知道在哪里可以找到可以在互联网上做广告的牧师。家太多了,不知道去哪里。只是最古老的折扣促销活动。老方法是挂大横幅。现在如果你想让更多的人看到它,它会更有效。而搜索引擎广告和第二章信息需求的导航模型一样——草根需求,信息爆炸,搜索人气,爆炸迫使商家追逐人气,两者之间有一些基础,插曲:顺序文件(Sequential File)就是随机文件(RandomFile),两者划分的缺点是什么?StoragePyramid 是金字塔形的吗?那个寄存器(Register InternalStorage),外部存储器(External Storage 网络内容可以理解,需要的结果。但是,目前的计算机技术索引(Index, then to the index, then to the system)整个互联网的所有网络都知道互联网首先,它已经很庞大了,网络一下子就建成了,
内存高索引 内存底部索引是金字塔式的 PyramidHierachy 效率,它会使用多台机器,可能是集群或分布式(Distributed)架构。另外,从索引机制来看,目前主要的倒排索引(Inverted Index)是正的。行索引的组合。体面的指标在保持效率的前提下,可大可小。因此,它是一个集成的架构。本机可用于实现人机WEB。可以使用MVC(Model-View-Controller)模型来分离WEB和数据(DATA)。是的,因此,搜索架构很可能或至少是 Web-Data-Retrieval 来分流组的使用并增加安全性(不要把所有的鸡蛋放在一起,等各个方面的许多会议。首先,
一方面,Spider 行数据的获取。另一方面,Spider 需要更新数据来完成称为 Indexer 的数据管理模型的索引。一方面,Indexer 处理或清理一次。对于所有 IR 方面,Indexer 还需要对数据进行分析,并且可以将结果进行结构化保存。数据库)保存。完成的数据模型称为检索。一方面,哪些索引数据依赖于 Retrieval。另一方面,检索基于查询)。因此,它是一种决策机制。如果前面所有的原理都是物理的,那么我们才能理解使用的需求。老师(1.2 数据管理模型比信息获取的方便更简单,和大家有切身体会,参考《Modeling Web.Probabilistic Methods slides: PDF,
万维网也是计算机网络和万维网。如果您将网络视为承载信息的信息海洋。发现早期上网是1999校友和263面条跳到同学照片的WWW,所以你看到网站的大部分域名都是WWW老师,说明它是一个Web网站 header,表示是入口,可以是整个网站。慢慢网站,每个人都能在这方面发挥越来越重要的作用。这大大减少了您需要关注的信息中心数量。(CNNIC,20日,NCFC通过公司互联网64K通过美国Sprint,正式承接拥有真正全功能互联网的国家。11月,国家智能计算机研究中心通过曙光BBS。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。
11. 2004年16日,供应商公司在香港正式上市。12. 2005年,百度在美国Starck上市。13.2005年新年期间,以博客为代表的网络2.0“穿越”的概念在中国促进了彼此的共同使用,也催生了一系列新的14.2006 中国、百度、阿里巴巴等社会化的东西,如博客、RSS、WIKI、SNS、约会等。16.截至2008年30我国网民达到2.53人,首次位居世界第一。7 CN域名注册量为1218.8 过万,首次成为全球第一个超大国家域名。搜索引擎,WEB2.0 网站 知者信息爆(半序) 搜索引擎标记信息爆(半序) 参与站=>生活站。信息化繁为简,信息化信息中心(CNNIC)。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。
编号336《附表14中的编号》显示,国内平均表面大小约为30K,网络大小为964 TB。一句话,我现在看到的是连接占了很大比例。根据后一种形式,对形式的比例进行划分。html 20.1% htm 6.5% 2.1%shtml 8.7% asp 12.6% php 22.2% txt 0.0% nsf 0.0% xml 0.0% jsp 1.@ >0% cgi 0.2% pl 0.0% aspx < @6.1% 做 0.5% dll 0.0% jhtml 0.0% cfm 0.0% php3 0.0% phtml 0.0% 其他以后19.7% 更新周期比例一周更新7.7% 一个月更新21.2% 三个月更新28.
以及 David Eichmann 在研究文章中描述的第一个 RBSE 蜘蛛。老师(3.1)Matthew Gray,Google工程师(3.2)David Eichmann,教师研究)在(数学之美系列六蜘蛛爬行模型蜘蛛爬行全互联网数据到本地,在我看来,有两个基本的假 查看全部
爬虫抓取网页数据(SimpleScratch需求迫切索引擎是互网大爆炸后的新生事物,个是泛商品化)
SimpleScratch SearchEngine作者急需完成搜索引擎模型 07/06 07/08 完成信息航空模型 07/16 完成 1/3 数据采集 07/30 本文为搜索引擎草稿,转至:指南.txt ) 第一章急需搜索引擎是互联网爆炸后的新生事物,一个是泛信息化,一个是泛商业化。一) 在泛信息化方面,信息的种类很多。大家个人觉得,多媒体和社交网络的海量必然会导致搜索引擎的泛滥。搜索引擎很多,你可以看看谷歌,百度有多少搜索引擎足够各种需求的信息,维基的搜索引擎列表(,5)P2P师源,6)Email,7 知道信息 爆炸是基于需求的。目前搜索引擎已列出14)手机及手机信息、7)工作信息、8)法律信息、9条信息、10条信息、11)社交信息、12条信息、14条来自搜索引擎的发展,反观信息的增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。社会信息, 12 信息, 14 从搜索引擎的发展来看,反方向的信息增加。搜索引擎的索引等于或小于互联网上的信息量。Infoseek、Google 的早期以及其他数百万个索引量。以百度早期的索引量达到千万级以上。
这要看3171年,我不吃不喝,我一直在看。如果你是愚公世家,你的祖宗在大禹治水,你还没有读完。对于航空,草根使用追求免费、快速、有效的服装,有很多满足新需求的产品。一方面,有很多满足旧需求的新产品。有很多新产品。如果你不宣传,很多有需要的人就找不到你,或者他们找不到你。例如,如果您不看新广告,甚至不知道有人举行了隆重的葬礼,那么您就知道在哪里可以找到可以在互联网上做广告的牧师。家太多了,不知道去哪里。只是最古老的折扣促销活动。老方法是挂大横幅。现在如果你想让更多的人看到它,它会更有效。而搜索引擎广告和第二章信息需求的导航模型一样——草根需求,信息爆炸,搜索人气,爆炸迫使商家追逐人气,两者之间有一些基础,插曲:顺序文件(Sequential File)就是随机文件(RandomFile),两者划分的缺点是什么?StoragePyramid 是金字塔形的吗?那个寄存器(Register InternalStorage),外部存储器(External Storage 网络内容可以理解,需要的结果。但是,目前的计算机技术索引(Index, then to the index, then to the system)整个互联网的所有网络都知道互联网首先,它已经很庞大了,网络一下子就建成了,
内存高索引 内存底部索引是金字塔式的 PyramidHierachy 效率,它会使用多台机器,可能是集群或分布式(Distributed)架构。另外,从索引机制来看,目前主要的倒排索引(Inverted Index)是正的。行索引的组合。体面的指标在保持效率的前提下,可大可小。因此,它是一个集成的架构。本机可用于实现人机WEB。可以使用MVC(Model-View-Controller)模型来分离WEB和数据(DATA)。是的,因此,搜索架构很可能或至少是 Web-Data-Retrieval 来分流组的使用并增加安全性(不要把所有的鸡蛋放在一起,等各个方面的许多会议。首先,
一方面,Spider 行数据的获取。另一方面,Spider 需要更新数据来完成称为 Indexer 的数据管理模型的索引。一方面,Indexer 处理或清理一次。对于所有 IR 方面,Indexer 还需要对数据进行分析,并且可以将结果进行结构化保存。数据库)保存。完成的数据模型称为检索。一方面,哪些索引数据依赖于 Retrieval。另一方面,检索基于查询)。因此,它是一种决策机制。如果前面所有的原理都是物理的,那么我们才能理解使用的需求。老师(1.2 数据管理模型比信息获取的方便更简单,和大家有切身体会,参考《Modeling Web.Probabilistic Methods slides: PDF,
万维网也是计算机网络和万维网。如果您将网络视为承载信息的信息海洋。发现早期上网是1999校友和263面条跳到同学照片的WWW,所以你看到网站的大部分域名都是WWW老师,说明它是一个Web网站 header,表示是入口,可以是整个网站。慢慢网站,每个人都能在这方面发挥越来越重要的作用。这大大减少了您需要关注的信息中心数量。(CNNIC,20日,NCFC通过公司互联网64K通过美国Sprint,正式承接拥有真正全功能互联网的国家。11月,国家智能计算机研究中心通过曙光BBS。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。新网、中国网、中央的重点是新的网站。网“校校通”通过、通过、工程在、正式通过、通过、通过、通过、通过、通过、20、通过 从过去的一天到18日,新浪、网易和搜狐相继公布了过去一年的年报2003年,首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。并首次迎来全年盈利。10. 2004年13月13日,公司旗下盛大网正式开通美国Starck上市并首次亮相。
11. 2004年16日,供应商公司在香港正式上市。12. 2005年,百度在美国Starck上市。13.2005年新年期间,以博客为代表的网络2.0“穿越”的概念在中国促进了彼此的共同使用,也催生了一系列新的14.2006 中国、百度、阿里巴巴等社会化的东西,如博客、RSS、WIKI、SNS、约会等。16.截至2008年30我国网民达到2.53人,首次位居世界第一。7 CN域名注册量为1218.8 过万,首次成为全球第一个超大国家域名。搜索引擎,WEB2.0 网站 知者信息爆(半序) 搜索引擎标记信息爆(半序) 参与站=>生活站。信息化繁为简,信息化信息中心(CNNIC)。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。可以得到一些信息:人脸更新周期、人脸编号(静态/老师)。附表11(php、asp、jsp、aspx)大致为3:1:5,75%的信息半年内更新,55%的信息一个季度更新,30%的信息会更新一个月内更新,8%会有超过1%的信息会在一天内更新。
编号336《附表14中的编号》显示,国内平均表面大小约为30K,网络大小为964 TB。一句话,我现在看到的是连接占了很大比例。根据后一种形式,对形式的比例进行划分。html 20.1% htm 6.5% 2.1%shtml 8.7% asp 12.6% php 22.2% txt 0.0% nsf 0.0% xml 0.0% jsp 1.@ >0% cgi 0.2% pl 0.0% aspx < @6.1% 做 0.5% dll 0.0% jhtml 0.0% cfm 0.0% php3 0.0% phtml 0.0% 其他以后19.7% 更新周期比例一周更新7.7% 一个月更新21.2% 三个月更新28.
以及 David Eichmann 在研究文章中描述的第一个 RBSE 蜘蛛。老师(3.1)Matthew Gray,Google工程师(3.2)David Eichmann,教师研究)在(数学之美系列六蜘蛛爬行模型蜘蛛爬行全互联网数据到本地,在我看来,有两个基本的假
爬虫抓取网页数据(爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-01 12:56
爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是web服务器端的服务对象,是http协议的基本api,一般xmlhttprequest首次与服务器建立连接的时候会带上两个参数:httpuri和httpport。如果服务器对于参数中的uri或者port的值为空的话,会产生一个uri请求与服务器建立连接,随后服务器会利用参数传递给服务器的uri地址。
http协议是无状态的,但如果参数中的uri或者port为空,则连接一直存在。http主要用于搜索引擎爬虫中,用于确定目标的位置。值得注意的是,http只是语法上的约定,不是事实上的协议规定。理论上任何服务器对上述uri或者port都能响应。此外,http协议还提供了“默认”和“明文”参数以及“明文/明文http”。
默认参数是服务器优先响应http请求的参数,或者是唯一的参数,默认参数实际上不是由客户端加载的请求头,只是作为请求的附加信息,只要客户端请求被服务器响应了,默认参数将会被加载。因此,默认参数一般是以事件结束时客户端提供的值作为默认参数。明文/明文httphttprequest直接是基于http协议的httprequest,httpheader提供的是客户端应用无效的http协议的其它相关信息,包括客户端uri和端口号,同时包含以下信息:http/1.1200okhttp/1.1eqaccept-encoding:gzip,deflateaccept-language:zh-cn,zh;q=0.9,en;q=0.7connection:keep-alive,status-code:200origin:root,defaultget,postprivateaccess-control-allow-origin:*pragma:no-cacheaccept-language:zh-cnpost-authorization:mozilla/5.0(macintosh;intelmacosx10_13_。
3)applewebkit/537.36(khtml,likegecko)chrome/46.0.2254.156safari/537.36格式:
1、keep-alive是兼容性协议,在服务器版和客户端版中都是200,必须的httprequest都不支持keep-alive,
2、post不支持keep-alive,表示服务器、客户端之间是否能解决对同一个请求只能产生一次响应的问题。
3、data-value在get请求或post请求中,默认为string, 查看全部
爬虫抓取网页数据(爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是什么)
爬虫抓取网页数据用的是xmlhttprequest,关于xmlhttprequestxmlhttprequest是web服务器端的服务对象,是http协议的基本api,一般xmlhttprequest首次与服务器建立连接的时候会带上两个参数:httpuri和httpport。如果服务器对于参数中的uri或者port的值为空的话,会产生一个uri请求与服务器建立连接,随后服务器会利用参数传递给服务器的uri地址。
http协议是无状态的,但如果参数中的uri或者port为空,则连接一直存在。http主要用于搜索引擎爬虫中,用于确定目标的位置。值得注意的是,http只是语法上的约定,不是事实上的协议规定。理论上任何服务器对上述uri或者port都能响应。此外,http协议还提供了“默认”和“明文”参数以及“明文/明文http”。
默认参数是服务器优先响应http请求的参数,或者是唯一的参数,默认参数实际上不是由客户端加载的请求头,只是作为请求的附加信息,只要客户端请求被服务器响应了,默认参数将会被加载。因此,默认参数一般是以事件结束时客户端提供的值作为默认参数。明文/明文httphttprequest直接是基于http协议的httprequest,httpheader提供的是客户端应用无效的http协议的其它相关信息,包括客户端uri和端口号,同时包含以下信息:http/1.1200okhttp/1.1eqaccept-encoding:gzip,deflateaccept-language:zh-cn,zh;q=0.9,en;q=0.7connection:keep-alive,status-code:200origin:root,defaultget,postprivateaccess-control-allow-origin:*pragma:no-cacheaccept-language:zh-cnpost-authorization:mozilla/5.0(macintosh;intelmacosx10_13_。
3)applewebkit/537.36(khtml,likegecko)chrome/46.0.2254.156safari/537.36格式:
1、keep-alive是兼容性协议,在服务器版和客户端版中都是200,必须的httprequest都不支持keep-alive,
2、post不支持keep-alive,表示服务器、客户端之间是否能解决对同一个请求只能产生一次响应的问题。
3、data-value在get请求或post请求中,默认为string,

