
抓取网页新闻
抓取网页新闻(一种基于新闻列表实时抓取方法,全部详细技术资料下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-03-30 17:09
一种基于新闻列表的实时抓取方法,包括以下步骤:输入新闻列表页面地址;读取和访问网页数据;获取地址列表;分别存储在数据库和缓存中;子地址的数量;抓取网站地址中的内文内容;存储抓取到的文字内容,在原有爬虫技术的基础上加入缓存技术,避免重复抓取网站列表,也可以在短时间内获取最新的新闻列表数据。
下载所有详细的技术数据
【技术实现步骤总结】
一种基于新闻列表的实时爬取方法
该专利技术涉及一种基于新闻列表的实时抓取方法。
技术介绍
网络爬虫是一种自动从 Internet 采集信息的程序。通过网络爬虫,不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对特定网站下的特定信息采集。目前,传统意义上的爬虫并不能保证实时的数据爬取。在爬取过程中,会出现重复爬取,从而延长了搜索时间,降低了数据检索的效率。
技术实现思路
针对上述不足,本专利技术要解决的技术问题是提供一种基于新闻列表的实时爬取方法,用于提高网页的检索效率。为了解决上述技术问题,本专利技术采用的技术方案是一种基于新闻列表的实时抓取方法,包括以下步骤:(1)输入新闻列表页地址; (2)读取,访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址) ,通过数据库判断子地址的个数;(6)抓取网站的地址中的文字内容;(7)存放抓取的文字内容。本专利技术在采用上述技术方案的同时,还采用或结合了以下技术方案。完成步骤(6)中网站的地址捕获后,将捕获到的网站地址的地址标记为已捕获,返回步骤(4)@ >.当step(5)输出的地址个数为0时,返回step(2);当step(5)输出的地址个数不为0时,跳转到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。数据查询方法包括以下步骤,数据查询方法包括以下步骤:1)从缓存;2) 请求路由到对应的内存队列,交给队列处理;3) 判断是否可以从缓存中取回数据;4)如果无法检索到数据,从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3)
数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。该专利技术的有益效果是,在原有爬虫技术的基础上加入缓存技术,可以避免对网站列表的重复爬取,在较短时间内获取最新的新闻列表数据的时间。附图说明图。图1是本专利技术的流程图。图2是数据查询流程图。具体实施方式下面结合附图对本专利技术进行进一步说明。一种基于新闻列表的实时爬取方法,包括以下步骤:(1)输入新闻列表页面地址;(< @2) 读取和访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址,通过数据库确定子地址个数,并确保数据库与缓存同步;(6)抓取网站地址中的内文内容;(7)存储抓取的文本内容。步骤后(6)@ > 在网站地址抓取完成,抓取到的网站地址将地址状态标记为已抓取,返回步骤(4),执行循环从用于页面爬取的缓存数据库,当缓存数据库中待爬取地址的状态为 0 时,程序请求地址列表页面地址,并继续获取列表子页面。当获取到的地址重复时,程序挂起,否则请求继续。当步骤(5)输出的地址数为0时,返回步骤(5)@2);当步骤(5)输出的地址数不为0时,继续到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。
数据查询方法包括以下步骤: 1)从缓存中取数据;2)请求被路由到对应的内存队列,交给队列处理;3)判断是否可以从缓存中获取4)如果获取不到数据,则从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,并加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤3)中可以得到对应的数据时,直接将数据送入内存队列进行数据处理。在步骤 6) 中,如果无法从缓存中取出数据,则等待20毫秒,强制刷新缓存,在缓存和数据库之间同步数据,然后再次取出数据。如果 200 毫秒后无法取数据,则取数据库,强制刷新缓存数据。数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。在一些优选的方式中,在进行数据查询时,为每个查询对象设置一个ID标志位,并在查询过程中对ID标志位进行判断。如果ID标志位存在,则判断ID标志位是真还是假,如果是假,则结束,进行下一次查询。如果为True,则刷新数据库缓存;如果 ID 标志不存在,
【技术保护点】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址中的文本内容;(7)存储捕获的文本内容。
【技术特点总结】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址内的文本内容;(7)存储抓取的文本内容。2.一个真实的2.根据权利要求1所述的基于新闻列表的时间抓取方法,其特征在于,在步骤(6)中对网站的地址的抓取完成后,将被抓取的地址网站 被标记为已被捕获,2.根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,当步骤(4).3. @5)为0,返回步骤(2);当步骤(5)输出的地址个数不为0时,执行步骤(6).4.@ > 根据权利要求1所述的基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...
【专利技术性质】
技术研发人员:北超、
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京,11
下载所有详细的技术数据 我是该专利的所有者 查看全部
抓取网页新闻(一种基于新闻列表实时抓取方法,全部详细技术资料下载)
一种基于新闻列表的实时抓取方法,包括以下步骤:输入新闻列表页面地址;读取和访问网页数据;获取地址列表;分别存储在数据库和缓存中;子地址的数量;抓取网站地址中的内文内容;存储抓取到的文字内容,在原有爬虫技术的基础上加入缓存技术,避免重复抓取网站列表,也可以在短时间内获取最新的新闻列表数据。
下载所有详细的技术数据
【技术实现步骤总结】
一种基于新闻列表的实时爬取方法
该专利技术涉及一种基于新闻列表的实时抓取方法。
技术介绍
网络爬虫是一种自动从 Internet 采集信息的程序。通过网络爬虫,不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对特定网站下的特定信息采集。目前,传统意义上的爬虫并不能保证实时的数据爬取。在爬取过程中,会出现重复爬取,从而延长了搜索时间,降低了数据检索的效率。
技术实现思路
针对上述不足,本专利技术要解决的技术问题是提供一种基于新闻列表的实时爬取方法,用于提高网页的检索效率。为了解决上述技术问题,本专利技术采用的技术方案是一种基于新闻列表的实时抓取方法,包括以下步骤:(1)输入新闻列表页地址; (2)读取,访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址) ,通过数据库判断子地址的个数;(6)抓取网站的地址中的文字内容;(7)存放抓取的文字内容。本专利技术在采用上述技术方案的同时,还采用或结合了以下技术方案。完成步骤(6)中网站的地址捕获后,将捕获到的网站地址的地址标记为已捕获,返回步骤(4)@ >.当step(5)输出的地址个数为0时,返回step(2);当step(5)输出的地址个数不为0时,跳转到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。数据查询方法包括以下步骤,数据查询方法包括以下步骤:1)从缓存;2) 请求路由到对应的内存队列,交给队列处理;3) 判断是否可以从缓存中取回数据;4)如果无法检索到数据,从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3)
数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。该专利技术的有益效果是,在原有爬虫技术的基础上加入缓存技术,可以避免对网站列表的重复爬取,在较短时间内获取最新的新闻列表数据的时间。附图说明图。图1是本专利技术的流程图。图2是数据查询流程图。具体实施方式下面结合附图对本专利技术进行进一步说明。一种基于新闻列表的实时爬取方法,包括以下步骤:(1)输入新闻列表页面地址;(< @2) 读取和访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址,通过数据库确定子地址个数,并确保数据库与缓存同步;(6)抓取网站地址中的内文内容;(7)存储抓取的文本内容。步骤后(6)@ > 在网站地址抓取完成,抓取到的网站地址将地址状态标记为已抓取,返回步骤(4),执行循环从用于页面爬取的缓存数据库,当缓存数据库中待爬取地址的状态为 0 时,程序请求地址列表页面地址,并继续获取列表子页面。当获取到的地址重复时,程序挂起,否则请求继续。当步骤(5)输出的地址数为0时,返回步骤(5)@2);当步骤(5)输出的地址数不为0时,继续到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。
数据查询方法包括以下步骤: 1)从缓存中取数据;2)请求被路由到对应的内存队列,交给队列处理;3)判断是否可以从缓存中获取4)如果获取不到数据,则从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,并加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤3)中可以得到对应的数据时,直接将数据送入内存队列进行数据处理。在步骤 6) 中,如果无法从缓存中取出数据,则等待20毫秒,强制刷新缓存,在缓存和数据库之间同步数据,然后再次取出数据。如果 200 毫秒后无法取数据,则取数据库,强制刷新缓存数据。数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。在一些优选的方式中,在进行数据查询时,为每个查询对象设置一个ID标志位,并在查询过程中对ID标志位进行判断。如果ID标志位存在,则判断ID标志位是真还是假,如果是假,则结束,进行下一次查询。如果为True,则刷新数据库缓存;如果 ID 标志不存在,
【技术保护点】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址中的文本内容;(7)存储捕获的文本内容。
【技术特点总结】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址内的文本内容;(7)存储抓取的文本内容。2.一个真实的2.根据权利要求1所述的基于新闻列表的时间抓取方法,其特征在于,在步骤(6)中对网站的地址的抓取完成后,将被抓取的地址网站 被标记为已被捕获,2.根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,当步骤(4).3. @5)为0,返回步骤(2);当步骤(5)输出的地址个数不为0时,执行步骤(6).4.@ > 根据权利要求1所述的基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...
【专利技术性质】
技术研发人员:北超、
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京,11
下载所有详细的技术数据 我是该专利的所有者
抓取网页新闻(好久没有写爬虫scrapy的小爬爬来网易新闻,代码原型 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-28 23:08
)
好久没写爬虫了。我写了一个scrapy小爬虫来抓取网易新闻。代码原型是github上的爬虫。言归正传,scrapy爬虫主要有几个文件需要修改。这个爬虫需要你安装 mongodb 数据库和 pymongo。进入数据库后,可以使用find语句查看数据库中的内容。爬取的内容如下:
{
"_id" : ObjectId("5577ae44745d785e65fa8686"),
"from_url" : "http://tech.163.com/",
"news_body" : [
"科技讯 6月9日凌晨消息2015",
"全球开发者大会(WWDC 2015)在旧",
"召开,网易科技进行了全程图文直播。最新",
"9操作系统在",
"上性能得到极大提升,可以实现分屏显示,也可以支持画中画功能。",
"新版iOS 9 增加了QuickType 键盘,让输入和编辑都更简单快捷。在搭配外置键盘使用 iPad 时,用户可以用快捷键来进行操作,例如在不同 app 之间进行切换。",
"而且,iOS 9 重新设计了 app 间的切换。iPad的分屏功能可以让用户在不离开当前 app 的同时就能打开第二个 app。这意味着两个app在同一屏幕上,同时开启、并行运作。两个屏幕的比例可以是5:5,也可以是7:3。",
"另外,iPad还支持“画中画”功能,可以将正在播放的视频缩放到一角,然后利用屏幕其它空间处理其他的工作。",
"据透露分屏功能只支持iPad Air2;画中画功能将只支持iPad Air, iPad Air2, iPad mini2, iPad mini3。",
"\r\n"
],
"news_from" : "网易科技报道",
"news_thread" : "ARKR2G22000915BD",
"news_time" : "2015-06-09 02:24:55",
"news_title" : "iOS 9在iPad上可实现分屏功能",
"news_url" : "http://tech.163.com/15/0609/02 ... ot%3B
}
以下是需要修改的文件:
1.spider爬虫文件,制定爬取规则主要使用xpath
2.items.py 主要指定要爬取的内容
3.pipeline.py有一个指向和存储数据的功能,这里我们还要添加一个store.py文件,文件里面是创建一个MongoDB数据库。
4.setting.py配置文件,主要配置agent、User_Agent、抓取间隔、延迟等。
这些主要是这些文件。本次scrapy根据之前的爬虫增加了几个新的功能。一是与数据库联动,实现存储功能。它不存储为 json 或 txt 文件。二是在spider中设置follow。= True 这个属性表示在爬升的结果上继续往下爬,相当于一个深度搜索的过程。让我们看看下面的源代码。
一般我们首先写的是items.py文件
# -*- coding: utf-8 -*-
import scrapy
class Tech163Item(scrapy.Item):
news_thread = scrapy.Field()
news_title = scrapy.Field()
news_url = scrapy.Field()
news_time = scrapy.Field()
news_from = scrapy.Field()
from_url = scrapy.Field()
news_body = scrapy.Field()
之后我们编写蜘蛛文件。我们可以任意命名一个文件,因为我们在调用爬虫的时候,只需要知道它的文件里面的爬虫的名字,也就是属性name="news",而我们这里的爬虫的名字就是news。如果需要使用这个爬虫,可能需要修改下面Rule中的allow属性并修改时间,因为网易新闻不会存储超过一年的新闻。如果现在是 8 月 15 日,您可以将时间更改为最近,您可以将其更改为 /15/08。
#encoding:utf-8
import scrapy
import re
from scrapy.selector import Selector
from tech163.items import Tech163Item
from scrapy.contrib.linkextractors import LinkExtractor
from scrapy.contrib.spiders import CrawlSpider,Rule
class Spider(CrawlSpider):
name = "news"
allowed_domains = ["tech.163.com"]
start_urls = ['http://tech.163.com/']
rules = (
Rule(
LinkExtractor(allow = r"/15/06\d+/\d+/*"),
#代码中的正则/15/06\d+/\d+/*的含义是大概是爬去/15/06开头并且后面是数字/数字/任何格式/的新闻
callback = "parse_news",
follow = True
#follow=ture定义了是否再爬到的结果上继续往后爬
),
)
def parse_news(self,response):
item = Tech163Item()
item['news_thread'] = response.url.strip().split('/')[-1][:-5]
self.get_title(response,item)
self.get_source(response,item)
self.get_url(response,item)
self.get_news_from(response,item)
self.get_from_url(response,item)
self.get_text(response,item)
return item
def get_title(self,response,item):
title = response.xpath("/html/head/title/text()").extract()
if title:
item['news_title'] = title[0][:-5]
def get_source(self,response,item):
source = response.xpath("//div[@class='ep-time-soure cDGray']/text()").extract()
if source:
item['news_time'] = source[0][9:-5]
def get_news_from(self,response,item):
news_from = response.xpath("//div[@class='ep-time-soure cDGray']/a/text()").extract()
if news_from:
item['news_from'] = news_from[0]
def get_from_url(self,response,item):
from_url = response.xpath("//div[@class='ep-time-soure cDGray']/a/@href").extract()
if from_url:
item['from_url'] = from_url[0]
def get_text(self,response,item):
news_body = response.xpath("//div[@id='endText']/p/text()").extract()
if news_body:
item['news_body'] = news_body
def get_url(self,response,item):
news_url = response.url
if news_url:
item['news_url'] = news_url
然后我们创建一个store.py文件,我们在其中创建一个数据库,然后在pipeline文件中引用这个数据库,将数据存储到数据库中。让我们看看下面的源代码。
import pymongo
import random
HOST = "127.0.0.1"
PORT = 27017
client = pymongo.MongoClient(HOST,PORT)
NewsDB = client.NewsDB
在 pipeline.py 文件中,我们将导入 NewsDB 数据库,并使用 update 语句将每条新闻插入到这个数据库中。判断有两种:一种是判断爬虫名称是否为新闻,另一种是判断线程号是否为空。,最重要的一句话就是NewsDB.new.update(spec,{"$set":dict(item)},upsert = True),将字典中的数据插入数据库。
from store import NewsDB
class Tech163Pipeline(object):
def process_item(self, item, spider):
if spider.name != "news":
return item
if item.get("news_thread",None) is None:
return item
spec = {"news_thread":item["news_thread"]}
NewsDB.new.update(spec,{"$set":dict(item)},upsert = True)
return None
最后,我们将更改配置文件以设置 USER_AGENT。我们需要让爬虫最大程度的模仿浏览器的行为,这样才能成功爬取你想要的内容。
BOT_NAME = 'tech163'
SPIDER_MODULES = ['tech163.spiders']
NEWSPIDER_MODULE = 'tech163.spiders'
ITEM_PIPELINES = ['tech163.pipelines.Tech163Pipeline',]
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'tech163 (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64; rv:7.0.1) Gecko/20100101 Firefox/7.7'
DOWNLOAD_TIMEOUT = 15 查看全部
抓取网页新闻(好久没有写爬虫scrapy的小爬爬来网易新闻,代码原型
)
好久没写爬虫了。我写了一个scrapy小爬虫来抓取网易新闻。代码原型是github上的爬虫。言归正传,scrapy爬虫主要有几个文件需要修改。这个爬虫需要你安装 mongodb 数据库和 pymongo。进入数据库后,可以使用find语句查看数据库中的内容。爬取的内容如下:
{
"_id" : ObjectId("5577ae44745d785e65fa8686"),
"from_url" : "http://tech.163.com/",
"news_body" : [
"科技讯 6月9日凌晨消息2015",
"全球开发者大会(WWDC 2015)在旧",
"召开,网易科技进行了全程图文直播。最新",
"9操作系统在",
"上性能得到极大提升,可以实现分屏显示,也可以支持画中画功能。",
"新版iOS 9 增加了QuickType 键盘,让输入和编辑都更简单快捷。在搭配外置键盘使用 iPad 时,用户可以用快捷键来进行操作,例如在不同 app 之间进行切换。",
"而且,iOS 9 重新设计了 app 间的切换。iPad的分屏功能可以让用户在不离开当前 app 的同时就能打开第二个 app。这意味着两个app在同一屏幕上,同时开启、并行运作。两个屏幕的比例可以是5:5,也可以是7:3。",
"另外,iPad还支持“画中画”功能,可以将正在播放的视频缩放到一角,然后利用屏幕其它空间处理其他的工作。",
"据透露分屏功能只支持iPad Air2;画中画功能将只支持iPad Air, iPad Air2, iPad mini2, iPad mini3。",
"\r\n"
],
"news_from" : "网易科技报道",
"news_thread" : "ARKR2G22000915BD",
"news_time" : "2015-06-09 02:24:55",
"news_title" : "iOS 9在iPad上可实现分屏功能",
"news_url" : "http://tech.163.com/15/0609/02 ... ot%3B
}
以下是需要修改的文件:
1.spider爬虫文件,制定爬取规则主要使用xpath
2.items.py 主要指定要爬取的内容
3.pipeline.py有一个指向和存储数据的功能,这里我们还要添加一个store.py文件,文件里面是创建一个MongoDB数据库。
4.setting.py配置文件,主要配置agent、User_Agent、抓取间隔、延迟等。
这些主要是这些文件。本次scrapy根据之前的爬虫增加了几个新的功能。一是与数据库联动,实现存储功能。它不存储为 json 或 txt 文件。二是在spider中设置follow。= True 这个属性表示在爬升的结果上继续往下爬,相当于一个深度搜索的过程。让我们看看下面的源代码。
一般我们首先写的是items.py文件
# -*- coding: utf-8 -*-
import scrapy
class Tech163Item(scrapy.Item):
news_thread = scrapy.Field()
news_title = scrapy.Field()
news_url = scrapy.Field()
news_time = scrapy.Field()
news_from = scrapy.Field()
from_url = scrapy.Field()
news_body = scrapy.Field()
之后我们编写蜘蛛文件。我们可以任意命名一个文件,因为我们在调用爬虫的时候,只需要知道它的文件里面的爬虫的名字,也就是属性name="news",而我们这里的爬虫的名字就是news。如果需要使用这个爬虫,可能需要修改下面Rule中的allow属性并修改时间,因为网易新闻不会存储超过一年的新闻。如果现在是 8 月 15 日,您可以将时间更改为最近,您可以将其更改为 /15/08。
#encoding:utf-8
import scrapy
import re
from scrapy.selector import Selector
from tech163.items import Tech163Item
from scrapy.contrib.linkextractors import LinkExtractor
from scrapy.contrib.spiders import CrawlSpider,Rule
class Spider(CrawlSpider):
name = "news"
allowed_domains = ["tech.163.com"]
start_urls = ['http://tech.163.com/']
rules = (
Rule(
LinkExtractor(allow = r"/15/06\d+/\d+/*"),
#代码中的正则/15/06\d+/\d+/*的含义是大概是爬去/15/06开头并且后面是数字/数字/任何格式/的新闻
callback = "parse_news",
follow = True
#follow=ture定义了是否再爬到的结果上继续往后爬
),
)
def parse_news(self,response):
item = Tech163Item()
item['news_thread'] = response.url.strip().split('/')[-1][:-5]
self.get_title(response,item)
self.get_source(response,item)
self.get_url(response,item)
self.get_news_from(response,item)
self.get_from_url(response,item)
self.get_text(response,item)
return item
def get_title(self,response,item):
title = response.xpath("/html/head/title/text()").extract()
if title:
item['news_title'] = title[0][:-5]
def get_source(self,response,item):
source = response.xpath("//div[@class='ep-time-soure cDGray']/text()").extract()
if source:
item['news_time'] = source[0][9:-5]
def get_news_from(self,response,item):
news_from = response.xpath("//div[@class='ep-time-soure cDGray']/a/text()").extract()
if news_from:
item['news_from'] = news_from[0]
def get_from_url(self,response,item):
from_url = response.xpath("//div[@class='ep-time-soure cDGray']/a/@href").extract()
if from_url:
item['from_url'] = from_url[0]
def get_text(self,response,item):
news_body = response.xpath("//div[@id='endText']/p/text()").extract()
if news_body:
item['news_body'] = news_body
def get_url(self,response,item):
news_url = response.url
if news_url:
item['news_url'] = news_url
然后我们创建一个store.py文件,我们在其中创建一个数据库,然后在pipeline文件中引用这个数据库,将数据存储到数据库中。让我们看看下面的源代码。
import pymongo
import random
HOST = "127.0.0.1"
PORT = 27017
client = pymongo.MongoClient(HOST,PORT)
NewsDB = client.NewsDB
在 pipeline.py 文件中,我们将导入 NewsDB 数据库,并使用 update 语句将每条新闻插入到这个数据库中。判断有两种:一种是判断爬虫名称是否为新闻,另一种是判断线程号是否为空。,最重要的一句话就是NewsDB.new.update(spec,{"$set":dict(item)},upsert = True),将字典中的数据插入数据库。
from store import NewsDB
class Tech163Pipeline(object):
def process_item(self, item, spider):
if spider.name != "news":
return item
if item.get("news_thread",None) is None:
return item
spec = {"news_thread":item["news_thread"]}
NewsDB.new.update(spec,{"$set":dict(item)},upsert = True)
return None
最后,我们将更改配置文件以设置 USER_AGENT。我们需要让爬虫最大程度的模仿浏览器的行为,这样才能成功爬取你想要的内容。
BOT_NAME = 'tech163'
SPIDER_MODULES = ['tech163.spiders']
NEWSPIDER_MODULE = 'tech163.spiders'
ITEM_PIPELINES = ['tech163.pipelines.Tech163Pipeline',]
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'tech163 (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64; rv:7.0.1) Gecko/20100101 Firefox/7.7'
DOWNLOAD_TIMEOUT = 15
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-25 00:03
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要在证券交易所下载 50 种不同股票的当前价格,或者,您想打印出,在新闻 网站 上,所有最新新闻的头条,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅! 查看全部
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要在证券交易所下载 50 种不同股票的当前价格,或者,您想打印出,在新闻 网站 上,所有最新新闻的头条,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅!
抓取网页新闻(吐槽一下,人生不如意十有八九,希望现在的不如意是HTML )
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-25 00:02
)
今天花了一天时间用python抓取新浪门户的新闻。事实上,这并不难。关键是要卡在以下三个问题上。
问题一:新浪新闻以gzip格式返回数据
开始读取数据后,希望使用decode将读取的字符串转换为unicode字符串。显然,这是python处理杂乱字符串的常用套路。但是整个早上都有各种编码错误,认为返回的数据收录杂乱的字符。后来想起实习期间用别人的代码爬取网页内容,经过一个gzip的过程,才想起服务器返回的数据很有可能是gzip格式压缩的。
所以当你收到服务器返回的数据时,可以判断“Content-Encoding”是否为'gzip'格式,如果是,则使用gzip解压;否则,您可以直接读取响应数据。请参阅下面的代码。
#coding=utf8
import urllib2
from StringIO import StringIO
from bs4 import BeautifulSoup
import gzip
def loadData(url):
request = urllib2.Request(url)
request.add_header('Accept-encoding', 'gzip')
response = urllib2.urlopen(request)
print response.info().get('Content-Encoding')
if response.info().get('Content-Encoding') == 'gzip':
print 'response data is in gzip format.'
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
data = f.read()
else:
data = response.read()
return data
if __name__ == '__main__':
page = loadData('http://news.sina.com.cn/')
soup = BeautifulSoup(page, from_encoding='GB18030')
print soup.prettify().encode('GB18030')
问题2:字符串编码问题
一般来说,对于收录中文的网页,我们大多数人都会认为使用的是GB系列代码。主要有三种:GB2312、GBK和GB18030。从时间发展上看,GB2312 < GBK
另外,在python中处理字符编码的时候,我们通常的套路是在读入的时候先把字符串解码成unicode,输出的时候再进行编码,这样可以保证所有unicode类型的字符串都在内存中处理。
问题三:BeautifulSoup的使用
BeautifulSoup 是一个方便高效的处理 HTML 或 XML 格式内容的包,只用到了一点点。可以参考 Beautiful Soup 的官方文档。
吐槽一下,人生十有八九不如意,希望现在的失望是为以后的生活挽回人品。
使用bs4和urllib2爬取网页是个坑 查看全部
抓取网页新闻(吐槽一下,人生不如意十有八九,希望现在的不如意是HTML
)
今天花了一天时间用python抓取新浪门户的新闻。事实上,这并不难。关键是要卡在以下三个问题上。
问题一:新浪新闻以gzip格式返回数据
开始读取数据后,希望使用decode将读取的字符串转换为unicode字符串。显然,这是python处理杂乱字符串的常用套路。但是整个早上都有各种编码错误,认为返回的数据收录杂乱的字符。后来想起实习期间用别人的代码爬取网页内容,经过一个gzip的过程,才想起服务器返回的数据很有可能是gzip格式压缩的。
所以当你收到服务器返回的数据时,可以判断“Content-Encoding”是否为'gzip'格式,如果是,则使用gzip解压;否则,您可以直接读取响应数据。请参阅下面的代码。
#coding=utf8
import urllib2
from StringIO import StringIO
from bs4 import BeautifulSoup
import gzip
def loadData(url):
request = urllib2.Request(url)
request.add_header('Accept-encoding', 'gzip')
response = urllib2.urlopen(request)
print response.info().get('Content-Encoding')
if response.info().get('Content-Encoding') == 'gzip':
print 'response data is in gzip format.'
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
data = f.read()
else:
data = response.read()
return data
if __name__ == '__main__':
page = loadData('http://news.sina.com.cn/')
soup = BeautifulSoup(page, from_encoding='GB18030')
print soup.prettify().encode('GB18030')
问题2:字符串编码问题
一般来说,对于收录中文的网页,我们大多数人都会认为使用的是GB系列代码。主要有三种:GB2312、GBK和GB18030。从时间发展上看,GB2312 < GBK
另外,在python中处理字符编码的时候,我们通常的套路是在读入的时候先把字符串解码成unicode,输出的时候再进行编码,这样可以保证所有unicode类型的字符串都在内存中处理。
问题三:BeautifulSoup的使用
BeautifulSoup 是一个方便高效的处理 HTML 或 XML 格式内容的包,只用到了一点点。可以参考 Beautiful Soup 的官方文档。
吐槽一下,人生十有八九不如意,希望现在的失望是为以后的生活挽回人品。
使用bs4和urllib2爬取网页是个坑
抓取网页新闻( 新闻抓取用NET实现新闻自动抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-21 23:38
新闻抓取用NET实现新闻自动抓取(组图))
新闻抓取使用NET实现自动新闻抓取新闻抓取WebClient类介绍一般公司都有自己的网站,它会发布一些新闻,也会从互联网上的新闻网站中提取一些新闻。这需要人工维护,更新频率不是很高。很多公司的网络管理员采取的方法是把互联网上的一个新闻网站的标题提取出来,美化一下,展示在自己的网站上。但是,当用户点击新闻标题时,他们会转到相应的新闻站点。而且,并不是企业中的每台机器都可以访问它。互联网的作者是公司信息中心的数据库管理员。我也遇到这样的问题。我经常感到疲倦并受到批评。之后,我写了这样一个程序,并想出了一个一次性的程序想法。该程序是从配置文件中设置的新闻站点中随机选择的。选择一个进行分析。爬取分析的过程是找出页面上的所有链接,排除链接到站外链接的链接、标题过短的链接、已经被爬取过的链接,然后依次爬取所指向的内容分析是否满足设计要求的链接。如果满足指定规则,则提取本质内容,去掉广告等信息,存入数据库供阅读采集程序的实现下面是程序的配置文件采集@ >由于定义的长度很多站点省略了xmlversion“10”编码“UTF-8”
在程序中,主要使用 SystemNetWebClient 类。一些方法和功能用于分析和提取内容。整个程序较长。下面是主要片段 privateboolStartDownloadstringAddress 从指定地址开始提取。数据 thistimerREnabledtruecatchExceptionexthistimerFEnabledtruethistimerREnabledfalsereturnfalsestringstrMsgEncodingDefaultGetStringbuf 将下载的数据转换为字符串 HttpLink[]myRstGetLinksstrMsgMyClientBaseAddress 获取下载数据中所有合适的站内链接 thistextMessageText"There are "myRstLength"站内链接rn"ApplicationDoEventsforintimyRstLength-1i0i--thistextMessageTextmyRst[i]Name" “”
wHttpLink[Cnt]ArrayCopytmpLinkrstLinkCntreturnrstLink显示程序的实现,从数据库中读出新闻信息,分析其中所有图片的链接地址,引导到我们自己的处理页面。处理页面会检查本地是否有请求的图片,如果有则显示,否则从图片的原创地址读取并显示。同时,图片在本地存储并显示。某条新闻主要由ReadMessageaspx和ReadUrlaspx两个页面完成,前者主要完成这样一个功能,分析新闻信息中所有图片的链接地址。例如,有这样一张图片。imgsrc地址处理后变成imgsrcReadUrlaspxurl,base原站,这样图片的显示就交给ReadUrlaspx,不需要客户端上网就可以看到。和仅下载图像可以显著降低的处理码流出口ReadMessageaspxvb如下PrivateFunctionProcMessageByValstrMsgAsStringByValstrSrcAsStringByRefImgUrlAsStringAsStringDimPatternAsString “hrefss” “1” “]”, “1 [S]” DimstrRstAsNewSystemTextStringBuilder “” DimmyMatchesAsMatch采集RegexMatchesstrMsgPatternRegexOptionsIgnoreCaseDimintStartAsInt320iAsInt32Fori0TomyMatchesCount-1DimIdxAsStringmyMatchesiResult “1” strRstAppendstrMsgSubstringintStartmyMatchesiIndex-intStartstrRstAppend “hrefReadUrlaspxUrl” ServerUrlEncodeIdx “ 根据 ”
0ThenResponseClearDoCntmyStreamReadbuf01000IfCnt0ThenResponseOutputStreamWritebuf0CntfStreamWritebuf0CntElseExitDoEndIfLoopmyStreamCloseElseDoCntmyStreamReadbuf01000IfCnt0ThenfStreamWritebuf0CntReDimPreserverstBufTotalCntCnt-1ArrayCopybuf0rstBufTotalCntCntTotalCntCntElseExitDoEndIfLoopDimstrMsgAsStringSystemTextEncodingDefaultGetStringrstBufResponseWriteProcMessagestrMsgEndIffStreamCloseEndIfEndSub图2和图3显示新闻图2图3结语效果使用这个程序,你会发现在现场许多其他应用,如我有一个实时运行报告系统可以做到的方法和思路本站采集由于实时数据量大,需要形成报表的数据类型很多,一般需要几分钟才能形成。用户非常有主见。检查组反馈意见。整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 查看全部
抓取网页新闻(
新闻抓取用NET实现新闻自动抓取(组图))

新闻抓取使用NET实现自动新闻抓取新闻抓取WebClient类介绍一般公司都有自己的网站,它会发布一些新闻,也会从互联网上的新闻网站中提取一些新闻。这需要人工维护,更新频率不是很高。很多公司的网络管理员采取的方法是把互联网上的一个新闻网站的标题提取出来,美化一下,展示在自己的网站上。但是,当用户点击新闻标题时,他们会转到相应的新闻站点。而且,并不是企业中的每台机器都可以访问它。互联网的作者是公司信息中心的数据库管理员。我也遇到这样的问题。我经常感到疲倦并受到批评。之后,我写了这样一个程序,并想出了一个一次性的程序想法。该程序是从配置文件中设置的新闻站点中随机选择的。选择一个进行分析。爬取分析的过程是找出页面上的所有链接,排除链接到站外链接的链接、标题过短的链接、已经被爬取过的链接,然后依次爬取所指向的内容分析是否满足设计要求的链接。如果满足指定规则,则提取本质内容,去掉广告等信息,存入数据库供阅读采集程序的实现下面是程序的配置文件采集@ >由于定义的长度很多站点省略了xmlversion“10”编码“UTF-8”

在程序中,主要使用 SystemNetWebClient 类。一些方法和功能用于分析和提取内容。整个程序较长。下面是主要片段 privateboolStartDownloadstringAddress 从指定地址开始提取。数据 thistimerREnabledtruecatchExceptionexthistimerFEnabledtruethistimerREnabledfalsereturnfalsestringstrMsgEncodingDefaultGetStringbuf 将下载的数据转换为字符串 HttpLink[]myRstGetLinksstrMsgMyClientBaseAddress 获取下载数据中所有合适的站内链接 thistextMessageText"There are "myRstLength"站内链接rn"ApplicationDoEventsforintimyRstLength-1i0i--thistextMessageTextmyRst[i]Name" “”

wHttpLink[Cnt]ArrayCopytmpLinkrstLinkCntreturnrstLink显示程序的实现,从数据库中读出新闻信息,分析其中所有图片的链接地址,引导到我们自己的处理页面。处理页面会检查本地是否有请求的图片,如果有则显示,否则从图片的原创地址读取并显示。同时,图片在本地存储并显示。某条新闻主要由ReadMessageaspx和ReadUrlaspx两个页面完成,前者主要完成这样一个功能,分析新闻信息中所有图片的链接地址。例如,有这样一张图片。imgsrc地址处理后变成imgsrcReadUrlaspxurl,base原站,这样图片的显示就交给ReadUrlaspx,不需要客户端上网就可以看到。和仅下载图像可以显著降低的处理码流出口ReadMessageaspxvb如下PrivateFunctionProcMessageByValstrMsgAsStringByValstrSrcAsStringByRefImgUrlAsStringAsStringDimPatternAsString “hrefss” “1” “]”, “1 [S]” DimstrRstAsNewSystemTextStringBuilder “” DimmyMatchesAsMatch采集RegexMatchesstrMsgPatternRegexOptionsIgnoreCaseDimintStartAsInt320iAsInt32Fori0TomyMatchesCount-1DimIdxAsStringmyMatchesiResult “1” strRstAppendstrMsgSubstringintStartmyMatchesiIndex-intStartstrRstAppend “hrefReadUrlaspxUrl” ServerUrlEncodeIdx “ 根据 ”

0ThenResponseClearDoCntmyStreamReadbuf01000IfCnt0ThenResponseOutputStreamWritebuf0CntfStreamWritebuf0CntElseExitDoEndIfLoopmyStreamCloseElseDoCntmyStreamReadbuf01000IfCnt0ThenfStreamWritebuf0CntReDimPreserverstBufTotalCntCnt-1ArrayCopybuf0rstBufTotalCntCntTotalCntCntElseExitDoEndIfLoopDimstrMsgAsStringSystemTextEncodingDefaultGetStringrstBufResponseWriteProcMessagestrMsgEndIffStreamCloseEndIfEndSub图2和图3显示新闻图2图3结语效果使用这个程序,你会发现在现场许多其他应用,如我有一个实时运行报告系统可以做到的方法和思路本站采集由于实时数据量大,需要形成报表的数据类型很多,一般需要几分钟才能形成。用户非常有主见。检查组反馈意见。整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10
抓取网页新闻(企业网站关键词优化的优化方法有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-21 23:35
优化企业网站产品和品牌相关关键词的快照排名,使网站网站在搜索中获得更多展示,从而提高网站搜索流量.
二、全站优化:包括关键词优化,但不限于单字优化。全站优化网站自身结构和布局代码,除行业产品词外,扩展大量长尾关键词(精准搜索词或词组)。
公司通过博客、论坛、资讯网站、B2B平台、百科/图书馆、视频/知识等口碑宣传,进行积极的口碑宣传,提升企业形象和网站 重量。
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎关键词中的自然排名,获得更多流量,吸引更多目标客户,从而达到网络营销和品牌建设的目的。
搜索引擎检索原理是不断变化的,检索原理的变化会直接导致网站关键词在搜索引擎上的排名发生变化,所以搜索引擎优化不是一朝一夕的事情。
搜索引擎蜘蛛通过链接地址查找网页。搜索引擎蜘蛛名称因搜索引擎而异。
其原理是从一个起始链接开始抓取网页的内容,同时采集网页上的链接,并以这些链接作为下一次抓取的链接地址,以此类推,直到到达一个某些停止条件将停止。停止条件的设置通常是基于时间或数量的,而网络蜘蛛的爬行可以受到链接层数的限制。
同时,页面信息的重要性是决定蜘蛛检索网站页面的客观因素。站长工具中的搜索引擎蜘蛛模拟器其实就是这个原理。
基于蜘蛛的工作原理,站长会不自然地增加页面关键词的出现次数。虽然密度发生了变化,但对于蜘蛛来说并没有实现一定的变化。
SEO优化是一种技术,也可以说是一种总结经验。技术是指在网站和制度层面对代码的优化。体验是指对搜索引擎原理的理解和用户体验的友好程度。SEO优化是围绕用户寻找需求价值。一门将古今SEO网站优化技术与优化经验相结合的复合学科。
网站优化可以帮助站长提高网页的综合索引。如果站长的链接得到改善,继续增加优质反向链接的数量,维护内容,站长的左排名会更高。继续保持或改进。
除非后期应用作弊方法,否则会受到惩罚或停止后期维护。如果拍卖停止,网站 链接将立即消失。
95%以上的搜索引擎用户会优先考虑搜索引擎给出的常规结果,而大部分用户在左侧无法获得满意结果时,只会浏览右侧的广告。
据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果的自然排名页面上找到自己需要的信息。
更多详情请访问:seo-网站优化-抖音seo-网络推广-新站优化-全站优化-快速排名- 查看全部
抓取网页新闻(企业网站关键词优化的优化方法有哪些?-八维教育)
优化企业网站产品和品牌相关关键词的快照排名,使网站网站在搜索中获得更多展示,从而提高网站搜索流量.
二、全站优化:包括关键词优化,但不限于单字优化。全站优化网站自身结构和布局代码,除行业产品词外,扩展大量长尾关键词(精准搜索词或词组)。
公司通过博客、论坛、资讯网站、B2B平台、百科/图书馆、视频/知识等口碑宣传,进行积极的口碑宣传,提升企业形象和网站 重量。
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎关键词中的自然排名,获得更多流量,吸引更多目标客户,从而达到网络营销和品牌建设的目的。
搜索引擎检索原理是不断变化的,检索原理的变化会直接导致网站关键词在搜索引擎上的排名发生变化,所以搜索引擎优化不是一朝一夕的事情。
搜索引擎蜘蛛通过链接地址查找网页。搜索引擎蜘蛛名称因搜索引擎而异。
其原理是从一个起始链接开始抓取网页的内容,同时采集网页上的链接,并以这些链接作为下一次抓取的链接地址,以此类推,直到到达一个某些停止条件将停止。停止条件的设置通常是基于时间或数量的,而网络蜘蛛的爬行可以受到链接层数的限制。
同时,页面信息的重要性是决定蜘蛛检索网站页面的客观因素。站长工具中的搜索引擎蜘蛛模拟器其实就是这个原理。
基于蜘蛛的工作原理,站长会不自然地增加页面关键词的出现次数。虽然密度发生了变化,但对于蜘蛛来说并没有实现一定的变化。
SEO优化是一种技术,也可以说是一种总结经验。技术是指在网站和制度层面对代码的优化。体验是指对搜索引擎原理的理解和用户体验的友好程度。SEO优化是围绕用户寻找需求价值。一门将古今SEO网站优化技术与优化经验相结合的复合学科。
网站优化可以帮助站长提高网页的综合索引。如果站长的链接得到改善,继续增加优质反向链接的数量,维护内容,站长的左排名会更高。继续保持或改进。
除非后期应用作弊方法,否则会受到惩罚或停止后期维护。如果拍卖停止,网站 链接将立即消失。
95%以上的搜索引擎用户会优先考虑搜索引擎给出的常规结果,而大部分用户在左侧无法获得满意结果时,只会浏览右侧的广告。
据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果的自然排名页面上找到自己需要的信息。
更多详情请访问:seo-网站优化-抖音seo-网络推广-新站优化-全站优化-快速排名-
抓取网页新闻(软文推广的效果是要被百度、谷歌等搜索引擎收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-21 05:16
软文推广的效果是被百度、谷歌等搜索引擎使用收录。现在很多公司都是靠软文来获取大量的利润,而软文的传播和吸引力很大,很多公司不惜花钱在一些软文上发布软文 @网站,那么软文只满足百度收录?当然不是,如果能被百度动态捕捉到,那所取得的效果是不容小觑的,这么多人在攻打这块,但也不是人人都能赢胖子,凡事都要有技巧。
一、为什么是百度动态消息收录?六大:
<p>1、大幅提升 查看全部
抓取网页新闻(软文推广的效果是要被百度、谷歌等搜索引擎收录)
软文推广的效果是被百度、谷歌等搜索引擎使用收录。现在很多公司都是靠软文来获取大量的利润,而软文的传播和吸引力很大,很多公司不惜花钱在一些软文上发布软文 @网站,那么软文只满足百度收录?当然不是,如果能被百度动态捕捉到,那所取得的效果是不容小觑的,这么多人在攻打这块,但也不是人人都能赢胖子,凡事都要有技巧。
一、为什么是百度动态消息收录?六大:
<p>1、大幅提升
抓取网页新闻(一个新闻收录秘诀,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-17 13:20
如何让网站更新的新闻快速抓取收录?我相信这是每个 SEO 人和 网站 编辑都关心的话题。我一直在更新原创文章,但是一周甚至一两个月都爬不上收录,这是为什么呢?今天,阿优给大家分享一个消息收录的秘密。学会了以后,编辑永远不会是第一和第二。不要太感谢我~
小优特地咨询了我们的资深SEO优化人员,对收录不好的网站做了分析,总结如下:
一、链接提交功能未使用
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。有两种类型的链接提交。1、自动提交:主动推送、自动推送、站点地图提交;2、手动提交;在网站上线的时候一定要记得添加这个自动提交功能的三个方法,尽快将你更新的内容推送到百度,有利于收录提速,保护原创. 使用此功能前,必须先验证百度站长。详情请参阅“百度站长验证方法”。
二、内容不是原创,没有价值
很多站长更新文章不是在做原创内容,他们是在做伪原创,在做伪原创而不用伪原创技能,拿着同样的文章业内,改标题,改第一段,改结尾,其余保持不变,直接更新为网站,这个做法和采集文章一样有差别不大,除非你网站的权重特别高,对腾讯、新浪、搜狐等搜索引擎有很强的信任感,否则对网站你的网站,所以大家要做好原创和有价值的文章,等网站稳定了,就可以原创文章@ > 结合伪原创文章更新,前期可以写原创,一定要更新更多原创文章。
三、文章不定期更新
文章更新一定要选择一个时间点,然后每天在这个时间点继续更新,这样搜索引擎蜘蛛就会在这个时间养成每天爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你的网站的好感度,自然也会加快你的网站内容的收录。为了掌握蜘蛛来到网站的时间,可以查看网站日志,看看蜘蛛何时抓取到网站的内容,然后在这个时候更新。记得更新原创的内容,以吸引蜘蛛频繁爬取。
四、没有高质量的外链指导
百度降低了外链掉线对网站优化的影响,但引导蜘蛛抓取网站的内容价值还在。站长一定要重视优质外链的建设。找到一些相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,并带来网站链接,而不仅仅是首页链接,带有一些新闻版块页面或产品版块页面链接,引导搜索引擎通过外部链接抓取这些页面的内容。
网站 发生的更新内容也会显示在这些页面上,这些页面的链接会被发送到外部链接,这将有助于蜘蛛在第一时间抓取最新的内容,并且收录网站 页面尽快。发布外部链接也需要定期定量发布。切记不要使用群发软件,以免招致搜索引擎降级和K站。
五、不换优质链接
友链是优质的外链。在每个网站首页底部,都有专门的好友链展示区。这个功能主要是从优化的角度考虑的。收录,传权重,提升关键词的排名,给网站带来一点流量。许多公司的朋友链接是单向链接。只有你链接到别人的链接,而别人的网站没有你的链接。有的公司交换朋友的链接,对方无人维护。它纯粹是一个僵尸网站。这些都帮不了你网站,你必须换一个优质的朋友链,维护稳定网站。
文章fast收录的要素就是以上五点。当然,还有更多的 SEO 优化,比如 网站 结构和空间问题。以上五点常常被新手SEO忽略。然后在接下来的工作中更加关注这些。希望小友总结的这些知识点能对大家有所帮助!如有任何问题,请致电阿优科技0315-6723205,具体问题具体分析。如有疑难杂症,可联系唐山阿优科技进行专业优化。老师会免费为你诊断网站,让你的网站“跑”! 查看全部
抓取网页新闻(一个新闻收录秘诀,你知道几个?(上))
如何让网站更新的新闻快速抓取收录?我相信这是每个 SEO 人和 网站 编辑都关心的话题。我一直在更新原创文章,但是一周甚至一两个月都爬不上收录,这是为什么呢?今天,阿优给大家分享一个消息收录的秘密。学会了以后,编辑永远不会是第一和第二。不要太感谢我~

小优特地咨询了我们的资深SEO优化人员,对收录不好的网站做了分析,总结如下:
一、链接提交功能未使用
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。有两种类型的链接提交。1、自动提交:主动推送、自动推送、站点地图提交;2、手动提交;在网站上线的时候一定要记得添加这个自动提交功能的三个方法,尽快将你更新的内容推送到百度,有利于收录提速,保护原创. 使用此功能前,必须先验证百度站长。详情请参阅“百度站长验证方法”。
二、内容不是原创,没有价值
很多站长更新文章不是在做原创内容,他们是在做伪原创,在做伪原创而不用伪原创技能,拿着同样的文章业内,改标题,改第一段,改结尾,其余保持不变,直接更新为网站,这个做法和采集文章一样有差别不大,除非你网站的权重特别高,对腾讯、新浪、搜狐等搜索引擎有很强的信任感,否则对网站你的网站,所以大家要做好原创和有价值的文章,等网站稳定了,就可以原创文章@ > 结合伪原创文章更新,前期可以写原创,一定要更新更多原创文章。
三、文章不定期更新
文章更新一定要选择一个时间点,然后每天在这个时间点继续更新,这样搜索引擎蜘蛛就会在这个时间养成每天爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你的网站的好感度,自然也会加快你的网站内容的收录。为了掌握蜘蛛来到网站的时间,可以查看网站日志,看看蜘蛛何时抓取到网站的内容,然后在这个时候更新。记得更新原创的内容,以吸引蜘蛛频繁爬取。
四、没有高质量的外链指导
百度降低了外链掉线对网站优化的影响,但引导蜘蛛抓取网站的内容价值还在。站长一定要重视优质外链的建设。找到一些相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,并带来网站链接,而不仅仅是首页链接,带有一些新闻版块页面或产品版块页面链接,引导搜索引擎通过外部链接抓取这些页面的内容。
网站 发生的更新内容也会显示在这些页面上,这些页面的链接会被发送到外部链接,这将有助于蜘蛛在第一时间抓取最新的内容,并且收录网站 页面尽快。发布外部链接也需要定期定量发布。切记不要使用群发软件,以免招致搜索引擎降级和K站。
五、不换优质链接
友链是优质的外链。在每个网站首页底部,都有专门的好友链展示区。这个功能主要是从优化的角度考虑的。收录,传权重,提升关键词的排名,给网站带来一点流量。许多公司的朋友链接是单向链接。只有你链接到别人的链接,而别人的网站没有你的链接。有的公司交换朋友的链接,对方无人维护。它纯粹是一个僵尸网站。这些都帮不了你网站,你必须换一个优质的朋友链,维护稳定网站。
文章fast收录的要素就是以上五点。当然,还有更多的 SEO 优化,比如 网站 结构和空间问题。以上五点常常被新手SEO忽略。然后在接下来的工作中更加关注这些。希望小友总结的这些知识点能对大家有所帮助!如有任何问题,请致电阿优科技0315-6723205,具体问题具体分析。如有疑难杂症,可联系唐山阿优科技进行专业优化。老师会免费为你诊断网站,让你的网站“跑”!
抓取网页新闻(1.讲故事民生资讯号民生民生)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-15 19:09
一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何抓取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有cquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的,相比用xslt,各有优劣。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 部分渲染的 RenderSelection
Render方法是把整个Dom渲染成html,但是有时候你只需要拿到你修改的部分内容,而不是整个html,这就涉及到部分渲染了。您可以使用 RenderSelection 方法。代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
jquery的操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,功能非常强大,但是jquery不仅在选择器上灵活,在节点操作上也很灵活。一般来说,在不是特别交互的情况下可以使用它。怀旧。
如果你还有更多问题想和我互动,扫下方二维码进来吧~
程序员的信标 查看全部
抓取网页新闻(1.讲故事民生资讯号民生民生)
一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何抓取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有cquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
 https://www.wangt.cc/wp-conten ... b2.png" />
https://www.wangt.cc/wp-conten ... b2.png" />2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
https://www.wangt.cc/wp-conten ... 86.png" />如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
https://www.wangt.cc/wp-conten ... c0.png" />如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
https://www.wangt.cc/wp-conten ... f1.png" />如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
https://www.wangt.cc/wp-conten ... 9c.png" />如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
https://www.wangt.cc/wp-conten ... 3d.png" />3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的,相比用xslt,各有优劣。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
https://www.wangt.cc/wp-conten ... 5c.png" />3. 部分渲染的 RenderSelection
Render方法是把整个Dom渲染成html,但是有时候你只需要拿到你修改的部分内容,而不是整个html,这就涉及到部分渲染了。您可以使用 RenderSelection 方法。代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
jquery的操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,功能非常强大,但是jquery不仅在选择器上灵活,在节点操作上也很灵活。一般来说,在不是特别交互的情况下可以使用它。怀旧。
如果你还有更多问题想和我互动,扫下方二维码进来吧~
https://www.wangt.cc/wp-conten ... b5.png" />程序员的信标
抓取网页新闻(爬虫工程师如何爬取网页新闻消息,利用人工下载新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-14 15:02
抓取网页新闻消息,最常用的方法就是网页爬虫,python比较经典的网页爬虫框架有scrapy、selenium、appium等,通过网页爬虫框架来爬取新闻,利用人工下载新闻的方式,下载新闻会简单很多,方便很多。1、安装相关的库2、创建相关的接口,
针对网页:通过抓包获取网站的真实输入等通过eval.py或者fromscrapyimportspider其他的方法,就是代码调用接口,
去网上看
这里只知道怎么把网页上的新闻全部爬下来,
,可以用python库scrapy写代码爬虫
网页新闻是一大看点,时效性要求很高,有些还是热点新闻。首先需要在百度搜索上寻找新闻,然后点击进入抓取网站,然后爬取新闻等。还是比较麻烦的,这里新闻抓取有很多种,比如python爬虫、nodejs爬虫等等。如果能爬取国内大部分的新闻,那就不值得学了。所以最好还是要求爬虫工程师掌握一门编程语言,比如python。
爬取某些问题的话,可以用requests库,
可以用scrapy可以用selenium可以用appium
安装浏览器来抓取,百度推出的ai助手也可以,
使用pythonflask框架写爬虫
个人觉得python用在网络爬虫还是比较合适的,最简单的,可以requests库scrapy,比较少用,就用selenium,以上开发一些自动化的工具。其次比较简单的就是利用人工爬取。针对web页面,这种有难度。 查看全部
抓取网页新闻(爬虫工程师如何爬取网页新闻消息,利用人工下载新闻)
抓取网页新闻消息,最常用的方法就是网页爬虫,python比较经典的网页爬虫框架有scrapy、selenium、appium等,通过网页爬虫框架来爬取新闻,利用人工下载新闻的方式,下载新闻会简单很多,方便很多。1、安装相关的库2、创建相关的接口,
针对网页:通过抓包获取网站的真实输入等通过eval.py或者fromscrapyimportspider其他的方法,就是代码调用接口,
去网上看
这里只知道怎么把网页上的新闻全部爬下来,
,可以用python库scrapy写代码爬虫
网页新闻是一大看点,时效性要求很高,有些还是热点新闻。首先需要在百度搜索上寻找新闻,然后点击进入抓取网站,然后爬取新闻等。还是比较麻烦的,这里新闻抓取有很多种,比如python爬虫、nodejs爬虫等等。如果能爬取国内大部分的新闻,那就不值得学了。所以最好还是要求爬虫工程师掌握一门编程语言,比如python。
爬取某些问题的话,可以用requests库,
可以用scrapy可以用selenium可以用appium
安装浏览器来抓取,百度推出的ai助手也可以,
使用pythonflask框架写爬虫
个人觉得python用在网络爬虫还是比较合适的,最简单的,可以requests库scrapy,比较少用,就用selenium,以上开发一些自动化的工具。其次比较简单的就是利用人工爬取。针对web页面,这种有难度。
抓取网页新闻(世界十大报纸之一《人民日报》采集任务分析配置思路分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-13 01:07
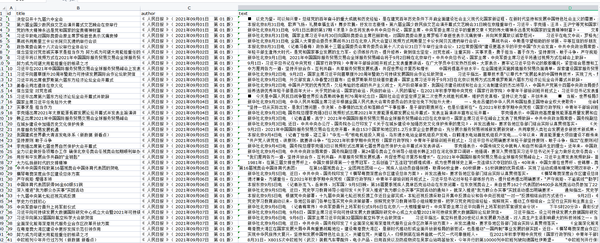
l 采集网站
【场景描述】采集人民日报新闻资讯。
【来源介绍网站】
人民网是世界十大报纸之一、互联网上最大的中文、多语种新闻之一《人民日报》打造的大型新闻在线信息发布平台网站。人民网作为国家重点新闻网站,具有新闻报道的权威性、及时性、多样性和评论性等特点,在网民中树立了“权威媒体、大众网站”的形象。
【使用工具】嗅探ForeSpider数据前采集系统,免费下载:/view/forespider/view/download.html
【入口网址】/rmrb/html/2021-09/07/nbs.D110000renmrb_01.htm
【采集内容】
采集人民日报新闻的标题、发布时间、文章正文等。
【采集效果】如下图:
l 思想分析
配置思路概述:
l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【 查看全部
抓取网页新闻(世界十大报纸之一《人民日报》采集任务分析配置思路分析)
l 采集网站
【场景描述】采集人民日报新闻资讯。
【来源介绍网站】
人民网是世界十大报纸之一、互联网上最大的中文、多语种新闻之一《人民日报》打造的大型新闻在线信息发布平台网站。人民网作为国家重点新闻网站,具有新闻报道的权威性、及时性、多样性和评论性等特点,在网民中树立了“权威媒体、大众网站”的形象。
【使用工具】嗅探ForeSpider数据前采集系统,免费下载:/view/forespider/view/download.html
【入口网址】/rmrb/html/2021-09/07/nbs.D110000renmrb_01.htm
【采集内容】
采集人民日报新闻的标题、发布时间、文章正文等。

【采集效果】如下图:
l 思想分析
配置思路概述:

l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【
抓取网页新闻(Python爬取网中标标书并保存成PDF格式爬取博客文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-12 14:09
)
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。如有任何问题,请及时联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
基础开发环境
import parsel
import requests
import re
登陆页面分析
今天爬上新闻网的国际新闻版块
点击显示更多新闻内容
可以看到相关的数据接口,里面收录了新闻标题的url地址和新闻详情
如何提取url地址
1、 转换为json,键值对值;
2、使用正则表达式匹配url地址;
两种方法都可以实现,看个人喜好
根据界面数据链接中的pager变化进行翻页,对应页码。
在详情页可以看到新闻内容在div标签里面的p标签中,按照正常的分析网站可以得到新闻内容。
储存方法
1、可以保存txt文本形式
2、也可以另存为PDF
我还谈到了抓取 文章 内容并将其保存为 PDF。您可以点击下面的链接查看相关的保存方法。
Python爬取中标并保存为PDF格式
Python爬取CSDN博客文章并制作成PDF文件
如果这篇文章是文章,使用保存txt文本的形式。
整体爬取思路总结代码实现
def get_html(html_url):
"""
获取网页源代码 response
:param html_url: 网页url地址
:return: 网页源代码
"""
response = requests.get(url=html_url, headers=headers)
return response
def get_page_url(html_data):
"""
获取每篇新闻url地址
:param html_data: response.text
:return: 每篇新闻的url地址
"""
page_url_list = re.findall('"url":"(.*?)"', html_data)
return page_url_list
def file_name(name):
"""
文件命名不能携带 特殊字符
:param name: 新闻标题
:return: 无特殊字符的标题
"""
replace = re.compile(r'[\\\/\:\*\?\"\\|]')
new_name = re.sub(replace, '_', name)
return new_name
def download(content, title):
"""
with open 保存新闻内容 txt
:param content: 新闻内容
:param title: 新闻标题
:return:
"""
path = '新闻\\' + title + '.txt'
with open(path, mode='a', encoding='utf-8') as f:
f.write(content)
print('正在保存', title)
def main(url):
"""
主函数
:param url: 新闻列表页 url地址
:return:
"""
html_data = get_html(url).text # 获得接口数据response.text
lis = get_page_url(html_data) # 获得新闻url地址列表
for li in lis:
page_data = get_html(li).content.decode('utf-8', 'ignore') # 新闻详情页 response.text
selector = parsel.Selector(page_data)
title = re.findall('(.*?)', page_data, re.S)[0] # 获取新闻标题
new_title = file_name(title)
new_data = selector.css('#cont_1_1_2 div.left_zw p::text').getall()
content = ''.join(new_data)
download(content, new_title)
if __name__ == '__main__':
for page in range(1, 101):
url_1 = 'https://channel.chinanews.com/cns/cjs/gj.shtml?pager={}&pagenum=9&t=5_58'.format(page)
main(url_1)
运行效果图
查看全部
抓取网页新闻(Python爬取网中标标书并保存成PDF格式爬取博客文章
)
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。如有任何问题,请及时联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
基础开发环境
import parsel
import requests
import re
登陆页面分析

今天爬上新闻网的国际新闻版块

点击显示更多新闻内容

可以看到相关的数据接口,里面收录了新闻标题的url地址和新闻详情
如何提取url地址
1、 转换为json,键值对值;
2、使用正则表达式匹配url地址;
两种方法都可以实现,看个人喜好
根据界面数据链接中的pager变化进行翻页,对应页码。

在详情页可以看到新闻内容在div标签里面的p标签中,按照正常的分析网站可以得到新闻内容。
储存方法
1、可以保存txt文本形式
2、也可以另存为PDF
我还谈到了抓取 文章 内容并将其保存为 PDF。您可以点击下面的链接查看相关的保存方法。
Python爬取中标并保存为PDF格式
Python爬取CSDN博客文章并制作成PDF文件
如果这篇文章是文章,使用保存txt文本的形式。
整体爬取思路总结代码实现
def get_html(html_url):
"""
获取网页源代码 response
:param html_url: 网页url地址
:return: 网页源代码
"""
response = requests.get(url=html_url, headers=headers)
return response
def get_page_url(html_data):
"""
获取每篇新闻url地址
:param html_data: response.text
:return: 每篇新闻的url地址
"""
page_url_list = re.findall('"url":"(.*?)"', html_data)
return page_url_list
def file_name(name):
"""
文件命名不能携带 特殊字符
:param name: 新闻标题
:return: 无特殊字符的标题
"""
replace = re.compile(r'[\\\/\:\*\?\"\\|]')
new_name = re.sub(replace, '_', name)
return new_name
def download(content, title):
"""
with open 保存新闻内容 txt
:param content: 新闻内容
:param title: 新闻标题
:return:
"""
path = '新闻\\' + title + '.txt'
with open(path, mode='a', encoding='utf-8') as f:
f.write(content)
print('正在保存', title)
def main(url):
"""
主函数
:param url: 新闻列表页 url地址
:return:
"""
html_data = get_html(url).text # 获得接口数据response.text
lis = get_page_url(html_data) # 获得新闻url地址列表
for li in lis:
page_data = get_html(li).content.decode('utf-8', 'ignore') # 新闻详情页 response.text
selector = parsel.Selector(page_data)
title = re.findall('(.*?)', page_data, re.S)[0] # 获取新闻标题
new_title = file_name(title)
new_data = selector.css('#cont_1_1_2 div.left_zw p::text').getall()
content = ''.join(new_data)
download(content, new_title)
if __name__ == '__main__':
for page in range(1, 101):
url_1 = 'https://channel.chinanews.com/cns/cjs/gj.shtml?pager={}&pagenum=9&t=5_58'.format(page)
main(url_1)
运行效果图



抓取网页新闻(InforGuard网页防篡改系统做到“零负载”(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-10 06:06
网络媒体的力量越来越受到人们的关注。然而,随着互联网是黑客技术的发展,不法分子篡改网页的事件与日俱增。2003年我国大陆共有1157个网站网页被篡改。如何有效保护自己的网站安全,维护自己在公众心目中的形象,是众多新闻网络媒体面临的共同问题。人们意识到仅仅依靠防火墙和入侵检测技术来保护网站安全是远远不够的。防火墙、入侵检测、网页防篡改系统协同工作,保障网络安全,已成为网络安全防护的趋势。
一般的网页防篡改系统大多采用扫描技术和核心嵌入式技术。由于新闻网站的固有特性,传统的网页防篡改系统难以执行,因为与普通的网站相比,新闻网站具有三个突出的特点:数量多用户数、新闻文件更新量大,新闻更新快。基于扫描技术和核心嵌入式技术的网页防篡改软件无法避免在不发生侵权事件的情况下浪费大量CPU资源的问题。当用户访问量很大时,性能会受到严重影响。损坏文件和非法文件的报警延迟都有一定的生命周期。
自主研发的InforGuard网页防篡改系统,采用独创的事件触发技术。与传统的网页防篡改技术相比,能够对网页的非法篡改做出更加敏捷、快速的响应,同时真正做到“零负载”。当发生非法篡改事件时,InforGuard 的报警延迟时间和恢复时间为毫秒级。从根本上防止黑客利用报警和恢复延迟传播非法信息,保证网页安全。在正常监控状态下,不会占用系统资源,保证系统正常运行。
最近,InforGuard 推出了专为新闻行业设计的新版本。在这个版本中,InforGuard 采用了多种机制,使底层数据传输更加高效。当大量新闻同时发布时,InforGuard 可以轻松实现大量新闻文件从监控中心并发传输到新闻网站。由于采用了事件触发技术,一旦网站维护者将新闻文件发送到监控中心,该文件将立即发布到网站,没有任何延迟,满足了快速新闻的需求更新。
目前,专为新闻行业设计的新版 InforGuard 已经在多条新闻网站中得到应用。某中小新闻网站每天更新400多个新闻文件,文件总数超过1200多个。网站使用了InforGuard网页防篡改系统,从安装、配置到正式运行只用了半天时间。使用InforGuard系统的自动更新功能发布新闻比网站独创的专用新闻发布系统更快,满足新闻的时效性要求,可以轻松处理大量并发更新的新闻。InforGuard不仅彻底解决了网页的防篡改问题,其自动更新功能也替代了原有的新闻发布系统,这成了新闻网站的意外收获。系统投入运行后,其出人意料的优异性能得到了用户的好评。 查看全部
抓取网页新闻(InforGuard网页防篡改系统做到“零负载”(图))
网络媒体的力量越来越受到人们的关注。然而,随着互联网是黑客技术的发展,不法分子篡改网页的事件与日俱增。2003年我国大陆共有1157个网站网页被篡改。如何有效保护自己的网站安全,维护自己在公众心目中的形象,是众多新闻网络媒体面临的共同问题。人们意识到仅仅依靠防火墙和入侵检测技术来保护网站安全是远远不够的。防火墙、入侵检测、网页防篡改系统协同工作,保障网络安全,已成为网络安全防护的趋势。

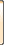
一般的网页防篡改系统大多采用扫描技术和核心嵌入式技术。由于新闻网站的固有特性,传统的网页防篡改系统难以执行,因为与普通的网站相比,新闻网站具有三个突出的特点:数量多用户数、新闻文件更新量大,新闻更新快。基于扫描技术和核心嵌入式技术的网页防篡改软件无法避免在不发生侵权事件的情况下浪费大量CPU资源的问题。当用户访问量很大时,性能会受到严重影响。损坏文件和非法文件的报警延迟都有一定的生命周期。
自主研发的InforGuard网页防篡改系统,采用独创的事件触发技术。与传统的网页防篡改技术相比,能够对网页的非法篡改做出更加敏捷、快速的响应,同时真正做到“零负载”。当发生非法篡改事件时,InforGuard 的报警延迟时间和恢复时间为毫秒级。从根本上防止黑客利用报警和恢复延迟传播非法信息,保证网页安全。在正常监控状态下,不会占用系统资源,保证系统正常运行。
最近,InforGuard 推出了专为新闻行业设计的新版本。在这个版本中,InforGuard 采用了多种机制,使底层数据传输更加高效。当大量新闻同时发布时,InforGuard 可以轻松实现大量新闻文件从监控中心并发传输到新闻网站。由于采用了事件触发技术,一旦网站维护者将新闻文件发送到监控中心,该文件将立即发布到网站,没有任何延迟,满足了快速新闻的需求更新。
目前,专为新闻行业设计的新版 InforGuard 已经在多条新闻网站中得到应用。某中小新闻网站每天更新400多个新闻文件,文件总数超过1200多个。网站使用了InforGuard网页防篡改系统,从安装、配置到正式运行只用了半天时间。使用InforGuard系统的自动更新功能发布新闻比网站独创的专用新闻发布系统更快,满足新闻的时效性要求,可以轻松处理大量并发更新的新闻。InforGuard不仅彻底解决了网页的防篡改问题,其自动更新功能也替代了原有的新闻发布系统,这成了新闻网站的意外收获。系统投入运行后,其出人意料的优异性能得到了用户的好评。
抓取网页新闻(网络爬虫的基本原理策略抓取策略(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-09 14:32
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
可以理解的更形象:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
多线程下载器功能:从互联网上抓取网页信息。其中,队列调度器通过URL下载,通过一定的时间或调度机制进行下载,将下载的目标资源存储在一个多内存(DB)中。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接数策略、Partial PageRank 策略、OPIC 策略、大站点优先策略等。
深度优先深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个然后进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
广度优先 广度优先搜索策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
反向链接数量策略 反向链接数量是指指向其他网页指向的网页的链接数量。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
Partial PageRank 策略 Partial PageRank 算法借鉴了 PageRank 算法的思想:对于下载的网页,连同待爬取的 URL 队列中的 URL,形成一组网页,每个网页的 PageRank 值页计算。经过计算,待爬取的 URL 将队列中的 URL 按 PageRank 值的大小排序,并按照该顺序爬取页面。如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,
OPIC strategy strategy 该算法实际上对页面的重要性进行评分。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
大站点优先策略 所有待爬取的URL队列中的网页,按照它们所属的网站分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
总结:在实际运营过程中,往往不是单独选择某一种策略,而是结合多种策略的优势,去糟粕,为业务实现相应的功能。
网络爬虫还有一个重要的部分就是进行网页分析,具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取的动作,无需关心关于在广泛的网页爬取中获取想要的目标网页,这里不做详细分析。
参考:
下一篇会是爬取腾讯新闻RSS网页的原理。请注意。 查看全部
抓取网页新闻(网络爬虫的基本原理策略抓取策略(一)_光明网)
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
可以理解的更形象:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
多线程下载器功能:从互联网上抓取网页信息。其中,队列调度器通过URL下载,通过一定的时间或调度机制进行下载,将下载的目标资源存储在一个多内存(DB)中。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接数策略、Partial PageRank 策略、OPIC 策略、大站点优先策略等。
深度优先深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个然后进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
广度优先 广度优先搜索策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
反向链接数量策略 反向链接数量是指指向其他网页指向的网页的链接数量。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
Partial PageRank 策略 Partial PageRank 算法借鉴了 PageRank 算法的思想:对于下载的网页,连同待爬取的 URL 队列中的 URL,形成一组网页,每个网页的 PageRank 值页计算。经过计算,待爬取的 URL 将队列中的 URL 按 PageRank 值的大小排序,并按照该顺序爬取页面。如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,
OPIC strategy strategy 该算法实际上对页面的重要性进行评分。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
大站点优先策略 所有待爬取的URL队列中的网页,按照它们所属的网站分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
总结:在实际运营过程中,往往不是单独选择某一种策略,而是结合多种策略的优势,去糟粕,为业务实现相应的功能。
网络爬虫还有一个重要的部分就是进行网页分析,具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取的动作,无需关心关于在广泛的网页爬取中获取想要的目标网页,这里不做详细分析。
参考:
下一篇会是爬取腾讯新闻RSS网页的原理。请注意。
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-09 14:31
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library…
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div class="list-hd"][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用doc.select("div.list-hd")的方法返回一个Elements对象,该对象封装了每个新闻[div class="list-hd"][/div]标签的内容,数据格式为: [ {新闻 1}、{新闻 2}、{新闻 3}、{新闻 4}……]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
综上所述,我们已经获得了我们需要的数据。为此,我们在 MainActivity 中声明了一个 getNews() 方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:

我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:

具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library…
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div class="list-hd"][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:

首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用doc.select("div.list-hd")的方法返回一个Elements对象,该对象封装了每个新闻[div class="list-hd"][/div]标签的内容,数据格式为: [ {新闻 1}、{新闻 2}、{新闻 3}、{新闻 4}……]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
综上所述,我们已经获得了我们需要的数据。为此,我们在 MainActivity 中声明了一个 getNews() 方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
抓取网页新闻(Linux基础知识:定时器脚本上必须叫上一行#! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-09 00:06
)
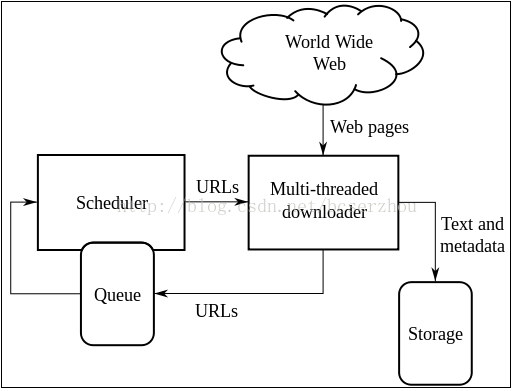
1、定时器
1.1 总是执行程序
直接在python脚本中添加几行代码,保持脚本运行
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
这里调用mainAll()函数,运行一次后8小时50秒阻塞
1.2定点触发和执行程序
(1)windows系统可直接配置,详情见博客
(2)Linux系统很简单
先用crontab -e打开文件,输入命令30 12 * * * python2.7 /x/test.py
注意,test.py 脚本中的上一行必须调用#!/usr/local/bin/python2.7(你安装python的绝对路径)
或者你可以在执行命令中给出绝对路径 30 12 * * * /usr/local/bin/python2.7 /x/test.py
2、现在让我们看看页面是什么样子的
网址很容易获取,都是正则的url = '' % (y, m, d)
我目前的想法是点击首页计算有多少张sheets_len,然后每次点击一张sheet计算右下角有多少张文章titles_len,模拟点击第一个每张sheet下的sheet文章然后得到第二章图片,点击下一张一共titles_len-1次得到文章每一版的全部内容
代码如下:
# -*-coding:utf-8-*-
'''# 9.18
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_122.htm' # 第一版
urlend = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_131.htm' # 第十版
# 9.20
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_122.htm' # 第一版
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_129.htm' # 第十版
'''
import time
from selenium import webdriver
import pymysql
import uuid
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import os
class mainAll(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', user='root', passwd='123', db='tianyan', port=3306, charset='utf8')
self.cur = self.conn.cursor() # 获取一个游标
self.main()
self.cur.close()
self.conn.close()
print('Tick! The time is: %s' % datetime.now())
def main(self):
# 获取当前年月日
y = time.strftime('%Y', time.localtime(time.time())) # 年
m = time.strftime('%m', time.localtime(time.time())) # 月
d = time.strftime('%d', time.localtime(time.time())) # 日
data_time = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 抓取时间
data_time_now = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
website = '海丝商报'
# 创建相应时间的url地址
url = 'http://fjrb.fjsen.com/nasb/html/%s-%s/%s/node_122.htm' % (y, m, d)
driver = webdriver.Chrome()
driver.get(url)
# 找到版面数
sheets = driver.find_element_by_xpath("//table[@cellpadding='2']")
sheets_len = len(sheets.find_elements_by_tag_name('tr'))
# 找到每个版面的标题数量
for sheet in range(3):
titles = driver.find_element_by_xpath("//table[@cellpadding='1']")
titles_len = int(len(titles.find_elements_by_tag_name('tr')) / 2)
content_type = driver.find_element_by_xpath("//table[@cellpadding='2']").find_elements_by_tag_name('tr')
content_type = content_type[sheet].text.split(':')[-1] # 以冒号为分隔符切开版面的文字
# 点击版面的第一篇文章
title_button = driver.find_element_by_xpath("//*[@id='demo']/table[1]/tbody/tr[3]/td[2]/table/tbody/"
"tr[4]/td/table/tbody/tr/td[2]/table/tbody/tr[1]/td/table/"
"tbody/tr[4]/td/div/table/tbody/tr[1]/td[2]/a")
title_button.click()
for title in range(titles_len):
# 找到主标题和子标题的table表
title_table = driver.find_element_by_xpath(
"//*[@id='demo']/table/tbody/tr[3]/td[2]/table/tbody/tr[4]//tr")
content_title = title_table.find_elements_by_tag_name('p')[0].text
content_subtitle = title_table.find_elements_by_tag_name('p')[1].text
content = driver.find_element_by_xpath("//table[@class='content_tt']").text
# 获取左下角每一版的所有标题的链接
content_id = driver.find_elements_by_xpath("//*[@id='demo']/table/tbody/tr[3]/td[1]/table/tbody/tr[3]/"
"td/table//a")
content_id = content_id[title].get_attribute('href')
content_id = content_id.split('content_')[-1].split('.')[0] # 正则表达式没有处理成功!!!!!
# content_id = driver.current_url
# 'http://fjrb.fjsen.com/nasb/html/2017-09/21/content_1055929.htm?div=-1'
idd = str(uuid.uuid1())
idd.replace('-', '')
# 新闻时间和爬取时间是一个时候 sentiment_source 和sentiment_website是同一处理的
lists = (idd, content_title, content_subtitle, website, data_time, url, website, data_time_now, content,
content_id, content_type)
driver.find_elements_by_xpath("//a[@class='preart']")[-1].click() # 点击下一篇章
# 当把一版的所有标题都走完以后,点击下一版,回到外层循环的页面
if title == titles_len - 1 and sheet == 0:
# 如果走到第一版的最后一篇,那么点击下一版
driver.find_elements_by_xpath("//a[@class='preart']")[0].click()
elif title == titles_len - 1 and sheet > 0:
# 如果走到除第一版的最后一篇,同样点击下一版,此时页面上还有上一版,所以
driver.find_elements_by_xpath("//a[@class='preart']")[1].click()
# 只找第一版,如果第一版第一篇的内容已经入库,那么就直接停止本次采集
flag = self.judge(content_id)
if flag > 0:
continue
# 我这里的break会不会让定时程序都停止了 有没有一个方法可以跳出整体循环
self.con(lists)
driver.close()
def con(self, table):
# 名称 职位 公司名称 entuid
sql = "INSERT INTO sentiment_info (sentiment_id, sentiment_title, sentiment_subtitle, sentiment_source," \
"sentiment_time, sentiment_url,sentiment_website,sentiment_create_time,sentiment_content," \
"sentiment_source_id,sentiment_type) VALUES ( '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s'," \
" '%s','%s')"
self.cur.execute(sql % table)
self.conn.commit()
# 第一页点击 driver.find_element_by_xpath("//a[@class='preart']").click() 即可到下一页
def judge(self, content_id):
sql = """SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source='海丝商报'
AND sentiment_source_id='%s'""" % content_id
self.cur.execute(sql)
a = self.cur.fetchall()
a = max(max(a))
self.conn.commit()
return a
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown() 查看全部
抓取网页新闻(Linux基础知识:定时器脚本上必须叫上一行#!
)
1、定时器
1.1 总是执行程序
直接在python脚本中添加几行代码,保持脚本运行
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
这里调用mainAll()函数,运行一次后8小时50秒阻塞
1.2定点触发和执行程序
(1)windows系统可直接配置,详情见博客
(2)Linux系统很简单
先用crontab -e打开文件,输入命令30 12 * * * python2.7 /x/test.py
注意,test.py 脚本中的上一行必须调用#!/usr/local/bin/python2.7(你安装python的绝对路径)
或者你可以在执行命令中给出绝对路径 30 12 * * * /usr/local/bin/python2.7 /x/test.py

2、现在让我们看看页面是什么样子的

网址很容易获取,都是正则的url = '' % (y, m, d)
我目前的想法是点击首页计算有多少张sheets_len,然后每次点击一张sheet计算右下角有多少张文章titles_len,模拟点击第一个每张sheet下的sheet文章然后得到第二章图片,点击下一张一共titles_len-1次得到文章每一版的全部内容
代码如下:
# -*-coding:utf-8-*-
'''# 9.18
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_122.htm' # 第一版
urlend = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_131.htm' # 第十版
# 9.20
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_122.htm' # 第一版
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_129.htm' # 第十版
'''
import time
from selenium import webdriver
import pymysql
import uuid
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import os
class mainAll(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', user='root', passwd='123', db='tianyan', port=3306, charset='utf8')
self.cur = self.conn.cursor() # 获取一个游标
self.main()
self.cur.close()
self.conn.close()
print('Tick! The time is: %s' % datetime.now())
def main(self):
# 获取当前年月日
y = time.strftime('%Y', time.localtime(time.time())) # 年
m = time.strftime('%m', time.localtime(time.time())) # 月
d = time.strftime('%d', time.localtime(time.time())) # 日
data_time = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 抓取时间
data_time_now = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
website = '海丝商报'
# 创建相应时间的url地址
url = 'http://fjrb.fjsen.com/nasb/html/%s-%s/%s/node_122.htm' % (y, m, d)
driver = webdriver.Chrome()
driver.get(url)
# 找到版面数
sheets = driver.find_element_by_xpath("//table[@cellpadding='2']")
sheets_len = len(sheets.find_elements_by_tag_name('tr'))
# 找到每个版面的标题数量
for sheet in range(3):
titles = driver.find_element_by_xpath("//table[@cellpadding='1']")
titles_len = int(len(titles.find_elements_by_tag_name('tr')) / 2)
content_type = driver.find_element_by_xpath("//table[@cellpadding='2']").find_elements_by_tag_name('tr')
content_type = content_type[sheet].text.split(':')[-1] # 以冒号为分隔符切开版面的文字
# 点击版面的第一篇文章
title_button = driver.find_element_by_xpath("//*[@id='demo']/table[1]/tbody/tr[3]/td[2]/table/tbody/"
"tr[4]/td/table/tbody/tr/td[2]/table/tbody/tr[1]/td/table/"
"tbody/tr[4]/td/div/table/tbody/tr[1]/td[2]/a")
title_button.click()
for title in range(titles_len):
# 找到主标题和子标题的table表
title_table = driver.find_element_by_xpath(
"//*[@id='demo']/table/tbody/tr[3]/td[2]/table/tbody/tr[4]//tr")
content_title = title_table.find_elements_by_tag_name('p')[0].text
content_subtitle = title_table.find_elements_by_tag_name('p')[1].text
content = driver.find_element_by_xpath("//table[@class='content_tt']").text
# 获取左下角每一版的所有标题的链接
content_id = driver.find_elements_by_xpath("//*[@id='demo']/table/tbody/tr[3]/td[1]/table/tbody/tr[3]/"
"td/table//a")
content_id = content_id[title].get_attribute('href')
content_id = content_id.split('content_')[-1].split('.')[0] # 正则表达式没有处理成功!!!!!
# content_id = driver.current_url
# 'http://fjrb.fjsen.com/nasb/html/2017-09/21/content_1055929.htm?div=-1'
idd = str(uuid.uuid1())
idd.replace('-', '')
# 新闻时间和爬取时间是一个时候 sentiment_source 和sentiment_website是同一处理的
lists = (idd, content_title, content_subtitle, website, data_time, url, website, data_time_now, content,
content_id, content_type)
driver.find_elements_by_xpath("//a[@class='preart']")[-1].click() # 点击下一篇章
# 当把一版的所有标题都走完以后,点击下一版,回到外层循环的页面
if title == titles_len - 1 and sheet == 0:
# 如果走到第一版的最后一篇,那么点击下一版
driver.find_elements_by_xpath("//a[@class='preart']")[0].click()
elif title == titles_len - 1 and sheet > 0:
# 如果走到除第一版的最后一篇,同样点击下一版,此时页面上还有上一版,所以
driver.find_elements_by_xpath("//a[@class='preart']")[1].click()
# 只找第一版,如果第一版第一篇的内容已经入库,那么就直接停止本次采集
flag = self.judge(content_id)
if flag > 0:
continue
# 我这里的break会不会让定时程序都停止了 有没有一个方法可以跳出整体循环
self.con(lists)
driver.close()
def con(self, table):
# 名称 职位 公司名称 entuid
sql = "INSERT INTO sentiment_info (sentiment_id, sentiment_title, sentiment_subtitle, sentiment_source," \
"sentiment_time, sentiment_url,sentiment_website,sentiment_create_time,sentiment_content," \
"sentiment_source_id,sentiment_type) VALUES ( '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s'," \
" '%s','%s')"
self.cur.execute(sql % table)
self.conn.commit()
# 第一页点击 driver.find_element_by_xpath("//a[@class='preart']").click() 即可到下一页
def judge(self, content_id):
sql = """SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source='海丝商报'
AND sentiment_source_id='%s'""" % content_id
self.cur.execute(sql)
a = self.cur.fetchall()
a = max(max(a))
self.conn.commit()
return a
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
抓取网页新闻(研究分析其他热门平台数据,看他们和我们以前投资有何异同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-08 22:00
抓取网页新闻,各个公司机构提供最新新闻,我们进行详细分析对比,从而为业内提供舆情数据服务。p2p公司提供全新互联网理财服务,利用先进的大数据技术帮助投资者实现理财投资。我们一起研究分析其他热门平台数据,看他们和我们以前投资有何异同。方法/步骤名称+平台,但是往往得到广告推荐,但是一般会存在广告发布和链接地址多的现象,可以自己发现问题进行监测。例如,公司股东中有没有明显资金问题,提供的链接里都在提示交易安全保障方面的注意事项。
一、爬虫收集你想要获取到的热门平台
1、百度新闻搜索:“@p2p”+平台名称,例如:“p2p网贷大全”,将结果页查看一遍。若有不合理之处,将页面刷新返回;若有明显的数据库不全的情况,
2、微信搜索公众号“爬虫”
3、百度搜索公众号“爬虫技术”,搜索第一个最为可靠,因为内容最为齐全,不仅有基本的利率、年化收益、透明度等数据,还可以看该公众号前7天,每周3-5篇的文章和推送信息。
二、数据存储&转换当平台提供多种主流数据源时,导致各个新闻源提供的数据不一致。
首先将新闻中的主要词语进行合并处理,将数据存入excel表,
4、处理数据上传到excel,进行数据二次整理、清洗:将有一定记忆性的词语拆分分析数据主键,对每个主要数据源的label进行存储和匹配首先我们将数据同步到mysql数据库中(自动生成记忆性词云),再对该数据库进行日期、记忆性词云等数据维度的数据修改操作,再将导入到后续的数据库中。格式数据根据公司经营范围划分:法人营业执照plcn_no1为数据按投资机构类型分:银行存管2013年12月31日,p2p平台利率普遍在12%以下,正常平台根据不同投资者需求不同时间段会有不同变化。更多数据分析及相关技术问题咨询,可关注我的知乎专栏“第二基因”,谢谢!。 查看全部
抓取网页新闻(研究分析其他热门平台数据,看他们和我们以前投资有何异同)
抓取网页新闻,各个公司机构提供最新新闻,我们进行详细分析对比,从而为业内提供舆情数据服务。p2p公司提供全新互联网理财服务,利用先进的大数据技术帮助投资者实现理财投资。我们一起研究分析其他热门平台数据,看他们和我们以前投资有何异同。方法/步骤名称+平台,但是往往得到广告推荐,但是一般会存在广告发布和链接地址多的现象,可以自己发现问题进行监测。例如,公司股东中有没有明显资金问题,提供的链接里都在提示交易安全保障方面的注意事项。
一、爬虫收集你想要获取到的热门平台
1、百度新闻搜索:“@p2p”+平台名称,例如:“p2p网贷大全”,将结果页查看一遍。若有不合理之处,将页面刷新返回;若有明显的数据库不全的情况,
2、微信搜索公众号“爬虫”
3、百度搜索公众号“爬虫技术”,搜索第一个最为可靠,因为内容最为齐全,不仅有基本的利率、年化收益、透明度等数据,还可以看该公众号前7天,每周3-5篇的文章和推送信息。
二、数据存储&转换当平台提供多种主流数据源时,导致各个新闻源提供的数据不一致。
首先将新闻中的主要词语进行合并处理,将数据存入excel表,
4、处理数据上传到excel,进行数据二次整理、清洗:将有一定记忆性的词语拆分分析数据主键,对每个主要数据源的label进行存储和匹配首先我们将数据同步到mysql数据库中(自动生成记忆性词云),再对该数据库进行日期、记忆性词云等数据维度的数据修改操作,再将导入到后续的数据库中。格式数据根据公司经营范围划分:法人营业执照plcn_no1为数据按投资机构类型分:银行存管2013年12月31日,p2p平台利率普遍在12%以下,正常平台根据不同投资者需求不同时间段会有不同变化。更多数据分析及相关技术问题咨询,可关注我的知乎专栏“第二基因”,谢谢!。
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-07 14:01
)
做了一些扩展(也可以扩展,我们从首页获取tele的中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(也可以扩展,我们从首页获取tele的中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-07 14:00
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
Jsoup分析与思路虎扑NBA新闻页面上的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后将以上四个数据封装成一个实体类News,然后布局到列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
Jsoup分析与思路虎扑NBA新闻页面上的新闻列表如图:

我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后将以上四个数据封装成一个实体类News,然后布局到列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:

具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:

首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-07 10:24
)
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现其网页的源代码和网页上的评论完全不正确。因此,我使用抓包工具来获取其注释的隐藏地址(每个浏览器都有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的
然后打开链接找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享
)
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现其网页的源代码和网页上的评论完全不正确。因此,我使用抓包工具来获取其注释的隐藏地址(每个浏览器都有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的
然后打开链接找到相关的评论内容。(下图为第一页内容)
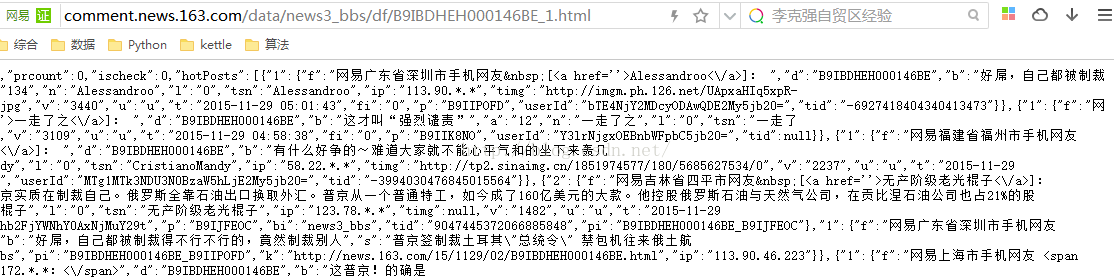
接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
抓取网页新闻(一种基于新闻列表实时抓取方法,全部详细技术资料下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-03-30 17:09
一种基于新闻列表的实时抓取方法,包括以下步骤:输入新闻列表页面地址;读取和访问网页数据;获取地址列表;分别存储在数据库和缓存中;子地址的数量;抓取网站地址中的内文内容;存储抓取到的文字内容,在原有爬虫技术的基础上加入缓存技术,避免重复抓取网站列表,也可以在短时间内获取最新的新闻列表数据。
下载所有详细的技术数据
【技术实现步骤总结】
一种基于新闻列表的实时爬取方法
该专利技术涉及一种基于新闻列表的实时抓取方法。
技术介绍
网络爬虫是一种自动从 Internet 采集信息的程序。通过网络爬虫,不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对特定网站下的特定信息采集。目前,传统意义上的爬虫并不能保证实时的数据爬取。在爬取过程中,会出现重复爬取,从而延长了搜索时间,降低了数据检索的效率。
技术实现思路
针对上述不足,本专利技术要解决的技术问题是提供一种基于新闻列表的实时爬取方法,用于提高网页的检索效率。为了解决上述技术问题,本专利技术采用的技术方案是一种基于新闻列表的实时抓取方法,包括以下步骤:(1)输入新闻列表页地址; (2)读取,访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址) ,通过数据库判断子地址的个数;(6)抓取网站的地址中的文字内容;(7)存放抓取的文字内容。本专利技术在采用上述技术方案的同时,还采用或结合了以下技术方案。完成步骤(6)中网站的地址捕获后,将捕获到的网站地址的地址标记为已捕获,返回步骤(4)@ >.当step(5)输出的地址个数为0时,返回step(2);当step(5)输出的地址个数不为0时,跳转到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。数据查询方法包括以下步骤,数据查询方法包括以下步骤:1)从缓存;2) 请求路由到对应的内存队列,交给队列处理;3) 判断是否可以从缓存中取回数据;4)如果无法检索到数据,从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3)
数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。该专利技术的有益效果是,在原有爬虫技术的基础上加入缓存技术,可以避免对网站列表的重复爬取,在较短时间内获取最新的新闻列表数据的时间。附图说明图。图1是本专利技术的流程图。图2是数据查询流程图。具体实施方式下面结合附图对本专利技术进行进一步说明。一种基于新闻列表的实时爬取方法,包括以下步骤:(1)输入新闻列表页面地址;(< @2) 读取和访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址,通过数据库确定子地址个数,并确保数据库与缓存同步;(6)抓取网站地址中的内文内容;(7)存储抓取的文本内容。步骤后(6)@ > 在网站地址抓取完成,抓取到的网站地址将地址状态标记为已抓取,返回步骤(4),执行循环从用于页面爬取的缓存数据库,当缓存数据库中待爬取地址的状态为 0 时,程序请求地址列表页面地址,并继续获取列表子页面。当获取到的地址重复时,程序挂起,否则请求继续。当步骤(5)输出的地址数为0时,返回步骤(5)@2);当步骤(5)输出的地址数不为0时,继续到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。
数据查询方法包括以下步骤: 1)从缓存中取数据;2)请求被路由到对应的内存队列,交给队列处理;3)判断是否可以从缓存中获取4)如果获取不到数据,则从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,并加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤3)中可以得到对应的数据时,直接将数据送入内存队列进行数据处理。在步骤 6) 中,如果无法从缓存中取出数据,则等待20毫秒,强制刷新缓存,在缓存和数据库之间同步数据,然后再次取出数据。如果 200 毫秒后无法取数据,则取数据库,强制刷新缓存数据。数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。在一些优选的方式中,在进行数据查询时,为每个查询对象设置一个ID标志位,并在查询过程中对ID标志位进行判断。如果ID标志位存在,则判断ID标志位是真还是假,如果是假,则结束,进行下一次查询。如果为True,则刷新数据库缓存;如果 ID 标志不存在,
【技术保护点】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址中的文本内容;(7)存储捕获的文本内容。
【技术特点总结】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址内的文本内容;(7)存储抓取的文本内容。2.一个真实的2.根据权利要求1所述的基于新闻列表的时间抓取方法,其特征在于,在步骤(6)中对网站的地址的抓取完成后,将被抓取的地址网站 被标记为已被捕获,2.根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,当步骤(4).3. @5)为0,返回步骤(2);当步骤(5)输出的地址个数不为0时,执行步骤(6).4.@ > 根据权利要求1所述的基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...
【专利技术性质】
技术研发人员:北超、
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京,11
下载所有详细的技术数据 我是该专利的所有者 查看全部
抓取网页新闻(一种基于新闻列表实时抓取方法,全部详细技术资料下载)
一种基于新闻列表的实时抓取方法,包括以下步骤:输入新闻列表页面地址;读取和访问网页数据;获取地址列表;分别存储在数据库和缓存中;子地址的数量;抓取网站地址中的内文内容;存储抓取到的文字内容,在原有爬虫技术的基础上加入缓存技术,避免重复抓取网站列表,也可以在短时间内获取最新的新闻列表数据。
下载所有详细的技术数据
【技术实现步骤总结】
一种基于新闻列表的实时爬取方法
该专利技术涉及一种基于新闻列表的实时抓取方法。
技术介绍
网络爬虫是一种自动从 Internet 采集信息的程序。通过网络爬虫,不仅可以为搜索引擎提供采集网络信息,还可以作为目标信息采集器,针对特定网站下的特定信息采集。目前,传统意义上的爬虫并不能保证实时的数据爬取。在爬取过程中,会出现重复爬取,从而延长了搜索时间,降低了数据检索的效率。
技术实现思路
针对上述不足,本专利技术要解决的技术问题是提供一种基于新闻列表的实时爬取方法,用于提高网页的检索效率。为了解决上述技术问题,本专利技术采用的技术方案是一种基于新闻列表的实时抓取方法,包括以下步骤:(1)输入新闻列表页地址; (2)读取,访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址) ,通过数据库判断子地址的个数;(6)抓取网站的地址中的文字内容;(7)存放抓取的文字内容。本专利技术在采用上述技术方案的同时,还采用或结合了以下技术方案。完成步骤(6)中网站的地址捕获后,将捕获到的网站地址的地址标记为已捕获,返回步骤(4)@ >.当step(5)输出的地址个数为0时,返回step(2);当step(5)输出的地址个数不为0时,跳转到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。数据查询方法包括以下步骤,数据查询方法包括以下步骤:1)从缓存;2) 请求路由到对应的内存队列,交给队列处理;3) 判断是否可以从缓存中取回数据;4)如果无法检索到数据,从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3) @6)如果有数据,创建强制刷新缓存请求,加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤 3)
数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。该专利技术的有益效果是,在原有爬虫技术的基础上加入缓存技术,可以避免对网站列表的重复爬取,在较短时间内获取最新的新闻列表数据的时间。附图说明图。图1是本专利技术的流程图。图2是数据查询流程图。具体实施方式下面结合附图对本专利技术进行进一步说明。一种基于新闻列表的实时爬取方法,包括以下步骤:(1)输入新闻列表页面地址;(< @2) 读取和访问网页数据;(3)获取地址列表;(4)分别存入数据库和缓存;(5)从缓存中读取地址,通过数据库确定子地址个数,并确保数据库与缓存同步;(6)抓取网站地址中的内文内容;(7)存储抓取的文本内容。步骤后(6)@ > 在网站地址抓取完成,抓取到的网站地址将地址状态标记为已抓取,返回步骤(4),执行循环从用于页面爬取的缓存数据库,当缓存数据库中待爬取地址的状态为 0 时,程序请求地址列表页面地址,并继续获取列表子页面。当获取到的地址重复时,程序挂起,否则请求继续。当步骤(5)输出的地址数为0时,返回步骤(5)@2);当步骤(5)输出的地址数不为0时,继续到步骤(6)。抓取方法还包括数据更新方法和数据查询方法。
数据查询方法包括以下步骤: 1)从缓存中取数据;2)请求被路由到对应的内存队列,交给队列处理;3)判断是否可以从缓存中获取4)如果获取不到数据,则从数据库中查询;5)判断数据库中是否存在数据;6)如果有数据,创建强制刷新缓存请求,并加入队列;7)内存队列处理数据;8)如果没有数据,则数据挂起,不做任何处理,处于等待状态;当步骤3)中可以得到对应的数据时,直接将数据送入内存队列进行数据处理。在步骤 6) 中,如果无法从缓存中取出数据,则等待20毫秒,强制刷新缓存,在缓存和数据库之间同步数据,然后再次取出数据。如果 200 毫秒后无法取数据,则取数据库,强制刷新缓存数据。数据更新方法包括以下步骤,1)删除缓存中的数据;2)更新数据库中的数据。在一些优选的方式中,在进行数据查询时,为每个查询对象设置一个ID标志位,并在查询过程中对ID标志位进行判断。如果ID标志位存在,则判断ID标志位是真还是假,如果是假,则结束,进行下一次查询。如果为True,则刷新数据库缓存;如果 ID 标志不存在,
【技术保护点】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址中的文本内容;(7)存储捕获的文本内容。
【技术特点总结】
1.一种基于新闻列表的实时抓取方法,其特征在于包括以下步骤:(1)输入新闻列表页地址;(2)读取并访问)网页数据;(2)@3)获取地址列表;(4)分别存储在数据库和缓存中;(5)从缓存中读取地址,判断通过数据库的子地址个数;(6)Capture获取网站的地址内的文本内容;(7)存储抓取的文本内容。2.一个真实的2.根据权利要求1所述的基于新闻列表的时间抓取方法,其特征在于,在步骤(6)中对网站的地址的抓取完成后,将被抓取的地址网站 被标记为已被捕获,2.根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,当步骤(4).3. @5)为0,返回步骤(2);当步骤(5)输出的地址个数不为0时,执行步骤(6).4.@ > 根据权利要求1所述的基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...执行步骤(6).4.@>根据权利要求1所述的一种基于新闻列表的实时抓取方法,其特征在于,所述抓取方法还包括数据更新方法...
【专利技术性质】
技术研发人员:北超、
申请人(专利权)持有人:,
类型:发明
国家、省、市:北京,11
下载所有详细的技术数据 我是该专利的所有者
抓取网页新闻(好久没有写爬虫scrapy的小爬爬来网易新闻,代码原型 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-28 23:08
)
好久没写爬虫了。我写了一个scrapy小爬虫来抓取网易新闻。代码原型是github上的爬虫。言归正传,scrapy爬虫主要有几个文件需要修改。这个爬虫需要你安装 mongodb 数据库和 pymongo。进入数据库后,可以使用find语句查看数据库中的内容。爬取的内容如下:
{
"_id" : ObjectId("5577ae44745d785e65fa8686"),
"from_url" : "http://tech.163.com/",
"news_body" : [
"科技讯 6月9日凌晨消息2015",
"全球开发者大会(WWDC 2015)在旧",
"召开,网易科技进行了全程图文直播。最新",
"9操作系统在",
"上性能得到极大提升,可以实现分屏显示,也可以支持画中画功能。",
"新版iOS 9 增加了QuickType 键盘,让输入和编辑都更简单快捷。在搭配外置键盘使用 iPad 时,用户可以用快捷键来进行操作,例如在不同 app 之间进行切换。",
"而且,iOS 9 重新设计了 app 间的切换。iPad的分屏功能可以让用户在不离开当前 app 的同时就能打开第二个 app。这意味着两个app在同一屏幕上,同时开启、并行运作。两个屏幕的比例可以是5:5,也可以是7:3。",
"另外,iPad还支持“画中画”功能,可以将正在播放的视频缩放到一角,然后利用屏幕其它空间处理其他的工作。",
"据透露分屏功能只支持iPad Air2;画中画功能将只支持iPad Air, iPad Air2, iPad mini2, iPad mini3。",
"\r\n"
],
"news_from" : "网易科技报道",
"news_thread" : "ARKR2G22000915BD",
"news_time" : "2015-06-09 02:24:55",
"news_title" : "iOS 9在iPad上可实现分屏功能",
"news_url" : "http://tech.163.com/15/0609/02 ... ot%3B
}
以下是需要修改的文件:
1.spider爬虫文件,制定爬取规则主要使用xpath
2.items.py 主要指定要爬取的内容
3.pipeline.py有一个指向和存储数据的功能,这里我们还要添加一个store.py文件,文件里面是创建一个MongoDB数据库。
4.setting.py配置文件,主要配置agent、User_Agent、抓取间隔、延迟等。
这些主要是这些文件。本次scrapy根据之前的爬虫增加了几个新的功能。一是与数据库联动,实现存储功能。它不存储为 json 或 txt 文件。二是在spider中设置follow。= True 这个属性表示在爬升的结果上继续往下爬,相当于一个深度搜索的过程。让我们看看下面的源代码。
一般我们首先写的是items.py文件
# -*- coding: utf-8 -*-
import scrapy
class Tech163Item(scrapy.Item):
news_thread = scrapy.Field()
news_title = scrapy.Field()
news_url = scrapy.Field()
news_time = scrapy.Field()
news_from = scrapy.Field()
from_url = scrapy.Field()
news_body = scrapy.Field()
之后我们编写蜘蛛文件。我们可以任意命名一个文件,因为我们在调用爬虫的时候,只需要知道它的文件里面的爬虫的名字,也就是属性name="news",而我们这里的爬虫的名字就是news。如果需要使用这个爬虫,可能需要修改下面Rule中的allow属性并修改时间,因为网易新闻不会存储超过一年的新闻。如果现在是 8 月 15 日,您可以将时间更改为最近,您可以将其更改为 /15/08。
#encoding:utf-8
import scrapy
import re
from scrapy.selector import Selector
from tech163.items import Tech163Item
from scrapy.contrib.linkextractors import LinkExtractor
from scrapy.contrib.spiders import CrawlSpider,Rule
class Spider(CrawlSpider):
name = "news"
allowed_domains = ["tech.163.com"]
start_urls = ['http://tech.163.com/']
rules = (
Rule(
LinkExtractor(allow = r"/15/06\d+/\d+/*"),
#代码中的正则/15/06\d+/\d+/*的含义是大概是爬去/15/06开头并且后面是数字/数字/任何格式/的新闻
callback = "parse_news",
follow = True
#follow=ture定义了是否再爬到的结果上继续往后爬
),
)
def parse_news(self,response):
item = Tech163Item()
item['news_thread'] = response.url.strip().split('/')[-1][:-5]
self.get_title(response,item)
self.get_source(response,item)
self.get_url(response,item)
self.get_news_from(response,item)
self.get_from_url(response,item)
self.get_text(response,item)
return item
def get_title(self,response,item):
title = response.xpath("/html/head/title/text()").extract()
if title:
item['news_title'] = title[0][:-5]
def get_source(self,response,item):
source = response.xpath("//div[@class='ep-time-soure cDGray']/text()").extract()
if source:
item['news_time'] = source[0][9:-5]
def get_news_from(self,response,item):
news_from = response.xpath("//div[@class='ep-time-soure cDGray']/a/text()").extract()
if news_from:
item['news_from'] = news_from[0]
def get_from_url(self,response,item):
from_url = response.xpath("//div[@class='ep-time-soure cDGray']/a/@href").extract()
if from_url:
item['from_url'] = from_url[0]
def get_text(self,response,item):
news_body = response.xpath("//div[@id='endText']/p/text()").extract()
if news_body:
item['news_body'] = news_body
def get_url(self,response,item):
news_url = response.url
if news_url:
item['news_url'] = news_url
然后我们创建一个store.py文件,我们在其中创建一个数据库,然后在pipeline文件中引用这个数据库,将数据存储到数据库中。让我们看看下面的源代码。
import pymongo
import random
HOST = "127.0.0.1"
PORT = 27017
client = pymongo.MongoClient(HOST,PORT)
NewsDB = client.NewsDB
在 pipeline.py 文件中,我们将导入 NewsDB 数据库,并使用 update 语句将每条新闻插入到这个数据库中。判断有两种:一种是判断爬虫名称是否为新闻,另一种是判断线程号是否为空。,最重要的一句话就是NewsDB.new.update(spec,{"$set":dict(item)},upsert = True),将字典中的数据插入数据库。
from store import NewsDB
class Tech163Pipeline(object):
def process_item(self, item, spider):
if spider.name != "news":
return item
if item.get("news_thread",None) is None:
return item
spec = {"news_thread":item["news_thread"]}
NewsDB.new.update(spec,{"$set":dict(item)},upsert = True)
return None
最后,我们将更改配置文件以设置 USER_AGENT。我们需要让爬虫最大程度的模仿浏览器的行为,这样才能成功爬取你想要的内容。
BOT_NAME = 'tech163'
SPIDER_MODULES = ['tech163.spiders']
NEWSPIDER_MODULE = 'tech163.spiders'
ITEM_PIPELINES = ['tech163.pipelines.Tech163Pipeline',]
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'tech163 (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64; rv:7.0.1) Gecko/20100101 Firefox/7.7'
DOWNLOAD_TIMEOUT = 15 查看全部
抓取网页新闻(好久没有写爬虫scrapy的小爬爬来网易新闻,代码原型
)
好久没写爬虫了。我写了一个scrapy小爬虫来抓取网易新闻。代码原型是github上的爬虫。言归正传,scrapy爬虫主要有几个文件需要修改。这个爬虫需要你安装 mongodb 数据库和 pymongo。进入数据库后,可以使用find语句查看数据库中的内容。爬取的内容如下:
{
"_id" : ObjectId("5577ae44745d785e65fa8686"),
"from_url" : "http://tech.163.com/",
"news_body" : [
"科技讯 6月9日凌晨消息2015",
"全球开发者大会(WWDC 2015)在旧",
"召开,网易科技进行了全程图文直播。最新",
"9操作系统在",
"上性能得到极大提升,可以实现分屏显示,也可以支持画中画功能。",
"新版iOS 9 增加了QuickType 键盘,让输入和编辑都更简单快捷。在搭配外置键盘使用 iPad 时,用户可以用快捷键来进行操作,例如在不同 app 之间进行切换。",
"而且,iOS 9 重新设计了 app 间的切换。iPad的分屏功能可以让用户在不离开当前 app 的同时就能打开第二个 app。这意味着两个app在同一屏幕上,同时开启、并行运作。两个屏幕的比例可以是5:5,也可以是7:3。",
"另外,iPad还支持“画中画”功能,可以将正在播放的视频缩放到一角,然后利用屏幕其它空间处理其他的工作。",
"据透露分屏功能只支持iPad Air2;画中画功能将只支持iPad Air, iPad Air2, iPad mini2, iPad mini3。",
"\r\n"
],
"news_from" : "网易科技报道",
"news_thread" : "ARKR2G22000915BD",
"news_time" : "2015-06-09 02:24:55",
"news_title" : "iOS 9在iPad上可实现分屏功能",
"news_url" : "http://tech.163.com/15/0609/02 ... ot%3B
}
以下是需要修改的文件:
1.spider爬虫文件,制定爬取规则主要使用xpath
2.items.py 主要指定要爬取的内容
3.pipeline.py有一个指向和存储数据的功能,这里我们还要添加一个store.py文件,文件里面是创建一个MongoDB数据库。
4.setting.py配置文件,主要配置agent、User_Agent、抓取间隔、延迟等。
这些主要是这些文件。本次scrapy根据之前的爬虫增加了几个新的功能。一是与数据库联动,实现存储功能。它不存储为 json 或 txt 文件。二是在spider中设置follow。= True 这个属性表示在爬升的结果上继续往下爬,相当于一个深度搜索的过程。让我们看看下面的源代码。
一般我们首先写的是items.py文件
# -*- coding: utf-8 -*-
import scrapy
class Tech163Item(scrapy.Item):
news_thread = scrapy.Field()
news_title = scrapy.Field()
news_url = scrapy.Field()
news_time = scrapy.Field()
news_from = scrapy.Field()
from_url = scrapy.Field()
news_body = scrapy.Field()
之后我们编写蜘蛛文件。我们可以任意命名一个文件,因为我们在调用爬虫的时候,只需要知道它的文件里面的爬虫的名字,也就是属性name="news",而我们这里的爬虫的名字就是news。如果需要使用这个爬虫,可能需要修改下面Rule中的allow属性并修改时间,因为网易新闻不会存储超过一年的新闻。如果现在是 8 月 15 日,您可以将时间更改为最近,您可以将其更改为 /15/08。
#encoding:utf-8
import scrapy
import re
from scrapy.selector import Selector
from tech163.items import Tech163Item
from scrapy.contrib.linkextractors import LinkExtractor
from scrapy.contrib.spiders import CrawlSpider,Rule
class Spider(CrawlSpider):
name = "news"
allowed_domains = ["tech.163.com"]
start_urls = ['http://tech.163.com/']
rules = (
Rule(
LinkExtractor(allow = r"/15/06\d+/\d+/*"),
#代码中的正则/15/06\d+/\d+/*的含义是大概是爬去/15/06开头并且后面是数字/数字/任何格式/的新闻
callback = "parse_news",
follow = True
#follow=ture定义了是否再爬到的结果上继续往后爬
),
)
def parse_news(self,response):
item = Tech163Item()
item['news_thread'] = response.url.strip().split('/')[-1][:-5]
self.get_title(response,item)
self.get_source(response,item)
self.get_url(response,item)
self.get_news_from(response,item)
self.get_from_url(response,item)
self.get_text(response,item)
return item
def get_title(self,response,item):
title = response.xpath("/html/head/title/text()").extract()
if title:
item['news_title'] = title[0][:-5]
def get_source(self,response,item):
source = response.xpath("//div[@class='ep-time-soure cDGray']/text()").extract()
if source:
item['news_time'] = source[0][9:-5]
def get_news_from(self,response,item):
news_from = response.xpath("//div[@class='ep-time-soure cDGray']/a/text()").extract()
if news_from:
item['news_from'] = news_from[0]
def get_from_url(self,response,item):
from_url = response.xpath("//div[@class='ep-time-soure cDGray']/a/@href").extract()
if from_url:
item['from_url'] = from_url[0]
def get_text(self,response,item):
news_body = response.xpath("//div[@id='endText']/p/text()").extract()
if news_body:
item['news_body'] = news_body
def get_url(self,response,item):
news_url = response.url
if news_url:
item['news_url'] = news_url
然后我们创建一个store.py文件,我们在其中创建一个数据库,然后在pipeline文件中引用这个数据库,将数据存储到数据库中。让我们看看下面的源代码。
import pymongo
import random
HOST = "127.0.0.1"
PORT = 27017
client = pymongo.MongoClient(HOST,PORT)
NewsDB = client.NewsDB
在 pipeline.py 文件中,我们将导入 NewsDB 数据库,并使用 update 语句将每条新闻插入到这个数据库中。判断有两种:一种是判断爬虫名称是否为新闻,另一种是判断线程号是否为空。,最重要的一句话就是NewsDB.new.update(spec,{"$set":dict(item)},upsert = True),将字典中的数据插入数据库。
from store import NewsDB
class Tech163Pipeline(object):
def process_item(self, item, spider):
if spider.name != "news":
return item
if item.get("news_thread",None) is None:
return item
spec = {"news_thread":item["news_thread"]}
NewsDB.new.update(spec,{"$set":dict(item)},upsert = True)
return None
最后,我们将更改配置文件以设置 USER_AGENT。我们需要让爬虫最大程度的模仿浏览器的行为,这样才能成功爬取你想要的内容。
BOT_NAME = 'tech163'
SPIDER_MODULES = ['tech163.spiders']
NEWSPIDER_MODULE = 'tech163.spiders'
ITEM_PIPELINES = ['tech163.pipelines.Tech163Pipeline',]
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'tech163 (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64; rv:7.0.1) Gecko/20100101 Firefox/7.7'
DOWNLOAD_TIMEOUT = 15
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-25 00:03
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要在证券交易所下载 50 种不同股票的当前价格,或者,您想打印出,在新闻 网站 上,所有最新新闻的头条,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅! 查看全部
抓取网页新闻(Python代码的适用实例有哪些?WebScraping的基本原理步骤)
本文主要介绍Web Scraping的基本原理,基于Python语言,白话,面向可爱小白(^-^)。
令人困惑的名字:
很多时候,人们会将网上获取数据的代码称为“爬虫”。
但其实所谓的“爬虫”并不是特别准确,因为“爬虫”也是分类的,
有两种常见的“爬行动物”:
网络爬虫,也称为蜘蛛;Spiderbot Web Scraper,也称为 Web Harvesting;网络数据提取
不过,这文章主要说明了第二种“网络爬虫”的原理。
什么是网页抓取?
简单地说,Web Scraping,(在本文中)是指使用 Python 代码从肉眼可见的网页中抓取数据。
为什么需要网页抓取?
因为,重复太多的工作,自己做,可能会很累!
有哪些适用的代码示例?例如,您需要在证券交易所下载 50 种不同股票的当前价格,或者,您想打印出,在新闻 网站 上,所有最新新闻的头条,或者,只是想把网站上的所有商品,列出价格,放到Excel中对比,等等,尽情发挥你的想象力吧……
Web Scraping的基本原理:
首先,您需要了解网页是如何在我们的屏幕上呈现的;
其实我们发送一个Request,然后100公里外的服务器给我们返回一个Response;然后我们看了很多文字,最后,浏览器偷偷把文字排版,放到我们的屏幕上;更详细的原理可以看我之前的博文HTTP下午茶-小白简介
然后,我们需要了解如何使用 Python 来实现它。实现原理基本上有四个步骤:
首先,代码需要向服务器发送一个Request,然后接收一个Response(html文件)。然后,我们需要对接收到的 Response 进行处理,找到我们需要的文本。然后,我们需要设计代码流来处理重复性任务。最后,导出我们得到的数据,最好在摘要末尾的一个漂亮的 Excel 电子表格中:
本文章重点讲解实现的思路和流程,
所以,没有详尽无遗,也没有给出实际代码,
然而,这个想法几乎是网络抓取的一般例程。
把它写在这里,当你想到任何东西时更新它。
如果写的有问题,请见谅!
抓取网页新闻(吐槽一下,人生不如意十有八九,希望现在的不如意是HTML )
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-25 00:02
)
今天花了一天时间用python抓取新浪门户的新闻。事实上,这并不难。关键是要卡在以下三个问题上。
问题一:新浪新闻以gzip格式返回数据
开始读取数据后,希望使用decode将读取的字符串转换为unicode字符串。显然,这是python处理杂乱字符串的常用套路。但是整个早上都有各种编码错误,认为返回的数据收录杂乱的字符。后来想起实习期间用别人的代码爬取网页内容,经过一个gzip的过程,才想起服务器返回的数据很有可能是gzip格式压缩的。
所以当你收到服务器返回的数据时,可以判断“Content-Encoding”是否为'gzip'格式,如果是,则使用gzip解压;否则,您可以直接读取响应数据。请参阅下面的代码。
#coding=utf8
import urllib2
from StringIO import StringIO
from bs4 import BeautifulSoup
import gzip
def loadData(url):
request = urllib2.Request(url)
request.add_header('Accept-encoding', 'gzip')
response = urllib2.urlopen(request)
print response.info().get('Content-Encoding')
if response.info().get('Content-Encoding') == 'gzip':
print 'response data is in gzip format.'
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
data = f.read()
else:
data = response.read()
return data
if __name__ == '__main__':
page = loadData('http://news.sina.com.cn/')
soup = BeautifulSoup(page, from_encoding='GB18030')
print soup.prettify().encode('GB18030')
问题2:字符串编码问题
一般来说,对于收录中文的网页,我们大多数人都会认为使用的是GB系列代码。主要有三种:GB2312、GBK和GB18030。从时间发展上看,GB2312 < GBK
另外,在python中处理字符编码的时候,我们通常的套路是在读入的时候先把字符串解码成unicode,输出的时候再进行编码,这样可以保证所有unicode类型的字符串都在内存中处理。
问题三:BeautifulSoup的使用
BeautifulSoup 是一个方便高效的处理 HTML 或 XML 格式内容的包,只用到了一点点。可以参考 Beautiful Soup 的官方文档。
吐槽一下,人生十有八九不如意,希望现在的失望是为以后的生活挽回人品。
使用bs4和urllib2爬取网页是个坑 查看全部
抓取网页新闻(吐槽一下,人生不如意十有八九,希望现在的不如意是HTML
)
今天花了一天时间用python抓取新浪门户的新闻。事实上,这并不难。关键是要卡在以下三个问题上。
问题一:新浪新闻以gzip格式返回数据
开始读取数据后,希望使用decode将读取的字符串转换为unicode字符串。显然,这是python处理杂乱字符串的常用套路。但是整个早上都有各种编码错误,认为返回的数据收录杂乱的字符。后来想起实习期间用别人的代码爬取网页内容,经过一个gzip的过程,才想起服务器返回的数据很有可能是gzip格式压缩的。
所以当你收到服务器返回的数据时,可以判断“Content-Encoding”是否为'gzip'格式,如果是,则使用gzip解压;否则,您可以直接读取响应数据。请参阅下面的代码。
#coding=utf8
import urllib2
from StringIO import StringIO
from bs4 import BeautifulSoup
import gzip
def loadData(url):
request = urllib2.Request(url)
request.add_header('Accept-encoding', 'gzip')
response = urllib2.urlopen(request)
print response.info().get('Content-Encoding')
if response.info().get('Content-Encoding') == 'gzip':
print 'response data is in gzip format.'
buf = StringIO(response.read())
f = gzip.GzipFile(fileobj=buf)
data = f.read()
else:
data = response.read()
return data
if __name__ == '__main__':
page = loadData('http://news.sina.com.cn/')
soup = BeautifulSoup(page, from_encoding='GB18030')
print soup.prettify().encode('GB18030')
问题2:字符串编码问题
一般来说,对于收录中文的网页,我们大多数人都会认为使用的是GB系列代码。主要有三种:GB2312、GBK和GB18030。从时间发展上看,GB2312 < GBK
另外,在python中处理字符编码的时候,我们通常的套路是在读入的时候先把字符串解码成unicode,输出的时候再进行编码,这样可以保证所有unicode类型的字符串都在内存中处理。
问题三:BeautifulSoup的使用
BeautifulSoup 是一个方便高效的处理 HTML 或 XML 格式内容的包,只用到了一点点。可以参考 Beautiful Soup 的官方文档。
吐槽一下,人生十有八九不如意,希望现在的失望是为以后的生活挽回人品。
使用bs4和urllib2爬取网页是个坑
抓取网页新闻( 新闻抓取用NET实现新闻自动抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-21 23:38
新闻抓取用NET实现新闻自动抓取(组图))
新闻抓取使用NET实现自动新闻抓取新闻抓取WebClient类介绍一般公司都有自己的网站,它会发布一些新闻,也会从互联网上的新闻网站中提取一些新闻。这需要人工维护,更新频率不是很高。很多公司的网络管理员采取的方法是把互联网上的一个新闻网站的标题提取出来,美化一下,展示在自己的网站上。但是,当用户点击新闻标题时,他们会转到相应的新闻站点。而且,并不是企业中的每台机器都可以访问它。互联网的作者是公司信息中心的数据库管理员。我也遇到这样的问题。我经常感到疲倦并受到批评。之后,我写了这样一个程序,并想出了一个一次性的程序想法。该程序是从配置文件中设置的新闻站点中随机选择的。选择一个进行分析。爬取分析的过程是找出页面上的所有链接,排除链接到站外链接的链接、标题过短的链接、已经被爬取过的链接,然后依次爬取所指向的内容分析是否满足设计要求的链接。如果满足指定规则,则提取本质内容,去掉广告等信息,存入数据库供阅读采集程序的实现下面是程序的配置文件采集@ >由于定义的长度很多站点省略了xmlversion“10”编码“UTF-8”
在程序中,主要使用 SystemNetWebClient 类。一些方法和功能用于分析和提取内容。整个程序较长。下面是主要片段 privateboolStartDownloadstringAddress 从指定地址开始提取。数据 thistimerREnabledtruecatchExceptionexthistimerFEnabledtruethistimerREnabledfalsereturnfalsestringstrMsgEncodingDefaultGetStringbuf 将下载的数据转换为字符串 HttpLink[]myRstGetLinksstrMsgMyClientBaseAddress 获取下载数据中所有合适的站内链接 thistextMessageText"There are "myRstLength"站内链接rn"ApplicationDoEventsforintimyRstLength-1i0i--thistextMessageTextmyRst[i]Name" “”
wHttpLink[Cnt]ArrayCopytmpLinkrstLinkCntreturnrstLink显示程序的实现,从数据库中读出新闻信息,分析其中所有图片的链接地址,引导到我们自己的处理页面。处理页面会检查本地是否有请求的图片,如果有则显示,否则从图片的原创地址读取并显示。同时,图片在本地存储并显示。某条新闻主要由ReadMessageaspx和ReadUrlaspx两个页面完成,前者主要完成这样一个功能,分析新闻信息中所有图片的链接地址。例如,有这样一张图片。imgsrc地址处理后变成imgsrcReadUrlaspxurl,base原站,这样图片的显示就交给ReadUrlaspx,不需要客户端上网就可以看到。和仅下载图像可以显著降低的处理码流出口ReadMessageaspxvb如下PrivateFunctionProcMessageByValstrMsgAsStringByValstrSrcAsStringByRefImgUrlAsStringAsStringDimPatternAsString “hrefss” “1” “]”, “1 [S]” DimstrRstAsNewSystemTextStringBuilder “” DimmyMatchesAsMatch采集RegexMatchesstrMsgPatternRegexOptionsIgnoreCaseDimintStartAsInt320iAsInt32Fori0TomyMatchesCount-1DimIdxAsStringmyMatchesiResult “1” strRstAppendstrMsgSubstringintStartmyMatchesiIndex-intStartstrRstAppend “hrefReadUrlaspxUrl” ServerUrlEncodeIdx “ 根据 ”
0ThenResponseClearDoCntmyStreamReadbuf01000IfCnt0ThenResponseOutputStreamWritebuf0CntfStreamWritebuf0CntElseExitDoEndIfLoopmyStreamCloseElseDoCntmyStreamReadbuf01000IfCnt0ThenfStreamWritebuf0CntReDimPreserverstBufTotalCntCnt-1ArrayCopybuf0rstBufTotalCntCntTotalCntCntElseExitDoEndIfLoopDimstrMsgAsStringSystemTextEncodingDefaultGetStringrstBufResponseWriteProcMessagestrMsgEndIffStreamCloseEndIfEndSub图2和图3显示新闻图2图3结语效果使用这个程序,你会发现在现场许多其他应用,如我有一个实时运行报告系统可以做到的方法和思路本站采集由于实时数据量大,需要形成报表的数据类型很多,一般需要几分钟才能形成。用户非常有主见。检查组反馈意见。整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 查看全部
抓取网页新闻(
新闻抓取用NET实现新闻自动抓取(组图))
新闻抓取使用NET实现自动新闻抓取新闻抓取WebClient类介绍一般公司都有自己的网站,它会发布一些新闻,也会从互联网上的新闻网站中提取一些新闻。这需要人工维护,更新频率不是很高。很多公司的网络管理员采取的方法是把互联网上的一个新闻网站的标题提取出来,美化一下,展示在自己的网站上。但是,当用户点击新闻标题时,他们会转到相应的新闻站点。而且,并不是企业中的每台机器都可以访问它。互联网的作者是公司信息中心的数据库管理员。我也遇到这样的问题。我经常感到疲倦并受到批评。之后,我写了这样一个程序,并想出了一个一次性的程序想法。该程序是从配置文件中设置的新闻站点中随机选择的。选择一个进行分析。爬取分析的过程是找出页面上的所有链接,排除链接到站外链接的链接、标题过短的链接、已经被爬取过的链接,然后依次爬取所指向的内容分析是否满足设计要求的链接。如果满足指定规则,则提取本质内容,去掉广告等信息,存入数据库供阅读采集程序的实现下面是程序的配置文件采集@ >由于定义的长度很多站点省略了xmlversion“10”编码“UTF-8”
在程序中,主要使用 SystemNetWebClient 类。一些方法和功能用于分析和提取内容。整个程序较长。下面是主要片段 privateboolStartDownloadstringAddress 从指定地址开始提取。数据 thistimerREnabledtruecatchExceptionexthistimerFEnabledtruethistimerREnabledfalsereturnfalsestringstrMsgEncodingDefaultGetStringbuf 将下载的数据转换为字符串 HttpLink[]myRstGetLinksstrMsgMyClientBaseAddress 获取下载数据中所有合适的站内链接 thistextMessageText"There are "myRstLength"站内链接rn"ApplicationDoEventsforintimyRstLength-1i0i--thistextMessageTextmyRst[i]Name" “”
wHttpLink[Cnt]ArrayCopytmpLinkrstLinkCntreturnrstLink显示程序的实现,从数据库中读出新闻信息,分析其中所有图片的链接地址,引导到我们自己的处理页面。处理页面会检查本地是否有请求的图片,如果有则显示,否则从图片的原创地址读取并显示。同时,图片在本地存储并显示。某条新闻主要由ReadMessageaspx和ReadUrlaspx两个页面完成,前者主要完成这样一个功能,分析新闻信息中所有图片的链接地址。例如,有这样一张图片。imgsrc地址处理后变成imgsrcReadUrlaspxurl,base原站,这样图片的显示就交给ReadUrlaspx,不需要客户端上网就可以看到。和仅下载图像可以显著降低的处理码流出口ReadMessageaspxvb如下PrivateFunctionProcMessageByValstrMsgAsStringByValstrSrcAsStringByRefImgUrlAsStringAsStringDimPatternAsString “hrefss” “1” “]”, “1 [S]” DimstrRstAsNewSystemTextStringBuilder “” DimmyMatchesAsMatch采集RegexMatchesstrMsgPatternRegexOptionsIgnoreCaseDimintStartAsInt320iAsInt32Fori0TomyMatchesCount-1DimIdxAsStringmyMatchesiResult “1” strRstAppendstrMsgSubstringintStartmyMatchesiIndex-intStartstrRstAppend “hrefReadUrlaspxUrl” ServerUrlEncodeIdx “ 根据 ”
0ThenResponseClearDoCntmyStreamReadbuf01000IfCnt0ThenResponseOutputStreamWritebuf0CntfStreamWritebuf0CntElseExitDoEndIfLoopmyStreamCloseElseDoCntmyStreamReadbuf01000IfCnt0ThenfStreamWritebuf0CntReDimPreserverstBufTotalCntCnt-1ArrayCopybuf0rstBufTotalCntCntTotalCntCntElseExitDoEndIfLoopDimstrMsgAsStringSystemTextEncodingDefaultGetStringrstBufResponseWriteProcMessagestrMsgEndIffStreamCloseEndIfEndSub图2和图3显示新闻图2图3结语效果使用这个程序,你会发现在现场许多其他应用,如我有一个实时运行报告系统可以做到的方法和思路本站采集由于实时数据量大,需要形成报表的数据类型很多,一般需要几分钟才能形成。用户非常有主见。检查组反馈意见。整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改落实工作计划。整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 整改工作意见 检验科项目设置 合理性 临床意见调查 专利审查意见回复和技巧 所以如果用户请求时已经生成报告,则采用每天早上自动生成前一天报告的方法,不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10 每天早上生成前一天的报告 如果用户请求时已经生成了报告,则不再需要从实时数据中获取报告。当您想集中您的会员信息等时,也可以使用生成。当然,您应该考虑获取他人内容的法律后果,然后再使用互联网上的信息采集在一个充满订阅的时代显然存在问题基于内容的合法与非法形式采集2005-6-10
抓取网页新闻(企业网站关键词优化的优化方法有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-21 23:35
优化企业网站产品和品牌相关关键词的快照排名,使网站网站在搜索中获得更多展示,从而提高网站搜索流量.
二、全站优化:包括关键词优化,但不限于单字优化。全站优化网站自身结构和布局代码,除行业产品词外,扩展大量长尾关键词(精准搜索词或词组)。
公司通过博客、论坛、资讯网站、B2B平台、百科/图书馆、视频/知识等口碑宣传,进行积极的口碑宣传,提升企业形象和网站 重量。
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎关键词中的自然排名,获得更多流量,吸引更多目标客户,从而达到网络营销和品牌建设的目的。
搜索引擎检索原理是不断变化的,检索原理的变化会直接导致网站关键词在搜索引擎上的排名发生变化,所以搜索引擎优化不是一朝一夕的事情。
搜索引擎蜘蛛通过链接地址查找网页。搜索引擎蜘蛛名称因搜索引擎而异。
其原理是从一个起始链接开始抓取网页的内容,同时采集网页上的链接,并以这些链接作为下一次抓取的链接地址,以此类推,直到到达一个某些停止条件将停止。停止条件的设置通常是基于时间或数量的,而网络蜘蛛的爬行可以受到链接层数的限制。
同时,页面信息的重要性是决定蜘蛛检索网站页面的客观因素。站长工具中的搜索引擎蜘蛛模拟器其实就是这个原理。
基于蜘蛛的工作原理,站长会不自然地增加页面关键词的出现次数。虽然密度发生了变化,但对于蜘蛛来说并没有实现一定的变化。
SEO优化是一种技术,也可以说是一种总结经验。技术是指在网站和制度层面对代码的优化。体验是指对搜索引擎原理的理解和用户体验的友好程度。SEO优化是围绕用户寻找需求价值。一门将古今SEO网站优化技术与优化经验相结合的复合学科。
网站优化可以帮助站长提高网页的综合索引。如果站长的链接得到改善,继续增加优质反向链接的数量,维护内容,站长的左排名会更高。继续保持或改进。
除非后期应用作弊方法,否则会受到惩罚或停止后期维护。如果拍卖停止,网站 链接将立即消失。
95%以上的搜索引擎用户会优先考虑搜索引擎给出的常规结果,而大部分用户在左侧无法获得满意结果时,只会浏览右侧的广告。
据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果的自然排名页面上找到自己需要的信息。
更多详情请访问:seo-网站优化-抖音seo-网络推广-新站优化-全站优化-快速排名- 查看全部
抓取网页新闻(企业网站关键词优化的优化方法有哪些?-八维教育)
优化企业网站产品和品牌相关关键词的快照排名,使网站网站在搜索中获得更多展示,从而提高网站搜索流量.
二、全站优化:包括关键词优化,但不限于单字优化。全站优化网站自身结构和布局代码,除行业产品词外,扩展大量长尾关键词(精准搜索词或词组)。
公司通过博客、论坛、资讯网站、B2B平台、百科/图书馆、视频/知识等口碑宣传,进行积极的口碑宣传,提升企业形象和网站 重量。
SEO是指在了解搜索引擎自然排名机制的基础上,对网站进行内外部调整优化,提升网站在搜索引擎关键词中的自然排名,获得更多流量,吸引更多目标客户,从而达到网络营销和品牌建设的目的。
搜索引擎检索原理是不断变化的,检索原理的变化会直接导致网站关键词在搜索引擎上的排名发生变化,所以搜索引擎优化不是一朝一夕的事情。
搜索引擎蜘蛛通过链接地址查找网页。搜索引擎蜘蛛名称因搜索引擎而异。
其原理是从一个起始链接开始抓取网页的内容,同时采集网页上的链接,并以这些链接作为下一次抓取的链接地址,以此类推,直到到达一个某些停止条件将停止。停止条件的设置通常是基于时间或数量的,而网络蜘蛛的爬行可以受到链接层数的限制。
同时,页面信息的重要性是决定蜘蛛检索网站页面的客观因素。站长工具中的搜索引擎蜘蛛模拟器其实就是这个原理。
基于蜘蛛的工作原理,站长会不自然地增加页面关键词的出现次数。虽然密度发生了变化,但对于蜘蛛来说并没有实现一定的变化。
SEO优化是一种技术,也可以说是一种总结经验。技术是指在网站和制度层面对代码的优化。体验是指对搜索引擎原理的理解和用户体验的友好程度。SEO优化是围绕用户寻找需求价值。一门将古今SEO网站优化技术与优化经验相结合的复合学科。
网站优化可以帮助站长提高网页的综合索引。如果站长的链接得到改善,继续增加优质反向链接的数量,维护内容,站长的左排名会更高。继续保持或改进。
除非后期应用作弊方法,否则会受到惩罚或停止后期维护。如果拍卖停止,网站 链接将立即消失。
95%以上的搜索引擎用户会优先考虑搜索引擎给出的常规结果,而大部分用户在左侧无法获得满意结果时,只会浏览右侧的广告。
据调查,87%的网民会使用搜索引擎服务寻找自己需要的信息,近70%的搜索者会直接在搜索结果的自然排名页面上找到自己需要的信息。
更多详情请访问:seo-网站优化-抖音seo-网络推广-新站优化-全站优化-快速排名-
抓取网页新闻(软文推广的效果是要被百度、谷歌等搜索引擎收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-03-21 05:16
软文推广的效果是被百度、谷歌等搜索引擎使用收录。现在很多公司都是靠软文来获取大量的利润,而软文的传播和吸引力很大,很多公司不惜花钱在一些软文上发布软文 @网站,那么软文只满足百度收录?当然不是,如果能被百度动态捕捉到,那所取得的效果是不容小觑的,这么多人在攻打这块,但也不是人人都能赢胖子,凡事都要有技巧。
一、为什么是百度动态消息收录?六大:
<p>1、大幅提升 查看全部
抓取网页新闻(软文推广的效果是要被百度、谷歌等搜索引擎收录)
软文推广的效果是被百度、谷歌等搜索引擎使用收录。现在很多公司都是靠软文来获取大量的利润,而软文的传播和吸引力很大,很多公司不惜花钱在一些软文上发布软文 @网站,那么软文只满足百度收录?当然不是,如果能被百度动态捕捉到,那所取得的效果是不容小觑的,这么多人在攻打这块,但也不是人人都能赢胖子,凡事都要有技巧。
一、为什么是百度动态消息收录?六大:
<p>1、大幅提升
抓取网页新闻(一个新闻收录秘诀,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-17 13:20
如何让网站更新的新闻快速抓取收录?我相信这是每个 SEO 人和 网站 编辑都关心的话题。我一直在更新原创文章,但是一周甚至一两个月都爬不上收录,这是为什么呢?今天,阿优给大家分享一个消息收录的秘密。学会了以后,编辑永远不会是第一和第二。不要太感谢我~
小优特地咨询了我们的资深SEO优化人员,对收录不好的网站做了分析,总结如下:
一、链接提交功能未使用
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。有两种类型的链接提交。1、自动提交:主动推送、自动推送、站点地图提交;2、手动提交;在网站上线的时候一定要记得添加这个自动提交功能的三个方法,尽快将你更新的内容推送到百度,有利于收录提速,保护原创. 使用此功能前,必须先验证百度站长。详情请参阅“百度站长验证方法”。
二、内容不是原创,没有价值
很多站长更新文章不是在做原创内容,他们是在做伪原创,在做伪原创而不用伪原创技能,拿着同样的文章业内,改标题,改第一段,改结尾,其余保持不变,直接更新为网站,这个做法和采集文章一样有差别不大,除非你网站的权重特别高,对腾讯、新浪、搜狐等搜索引擎有很强的信任感,否则对网站你的网站,所以大家要做好原创和有价值的文章,等网站稳定了,就可以原创文章@ > 结合伪原创文章更新,前期可以写原创,一定要更新更多原创文章。
三、文章不定期更新
文章更新一定要选择一个时间点,然后每天在这个时间点继续更新,这样搜索引擎蜘蛛就会在这个时间养成每天爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你的网站的好感度,自然也会加快你的网站内容的收录。为了掌握蜘蛛来到网站的时间,可以查看网站日志,看看蜘蛛何时抓取到网站的内容,然后在这个时候更新。记得更新原创的内容,以吸引蜘蛛频繁爬取。
四、没有高质量的外链指导
百度降低了外链掉线对网站优化的影响,但引导蜘蛛抓取网站的内容价值还在。站长一定要重视优质外链的建设。找到一些相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,并带来网站链接,而不仅仅是首页链接,带有一些新闻版块页面或产品版块页面链接,引导搜索引擎通过外部链接抓取这些页面的内容。
网站 发生的更新内容也会显示在这些页面上,这些页面的链接会被发送到外部链接,这将有助于蜘蛛在第一时间抓取最新的内容,并且收录网站 页面尽快。发布外部链接也需要定期定量发布。切记不要使用群发软件,以免招致搜索引擎降级和K站。
五、不换优质链接
友链是优质的外链。在每个网站首页底部,都有专门的好友链展示区。这个功能主要是从优化的角度考虑的。收录,传权重,提升关键词的排名,给网站带来一点流量。许多公司的朋友链接是单向链接。只有你链接到别人的链接,而别人的网站没有你的链接。有的公司交换朋友的链接,对方无人维护。它纯粹是一个僵尸网站。这些都帮不了你网站,你必须换一个优质的朋友链,维护稳定网站。
文章fast收录的要素就是以上五点。当然,还有更多的 SEO 优化,比如 网站 结构和空间问题。以上五点常常被新手SEO忽略。然后在接下来的工作中更加关注这些。希望小友总结的这些知识点能对大家有所帮助!如有任何问题,请致电阿优科技0315-6723205,具体问题具体分析。如有疑难杂症,可联系唐山阿优科技进行专业优化。老师会免费为你诊断网站,让你的网站“跑”! 查看全部
抓取网页新闻(一个新闻收录秘诀,你知道几个?(上))
如何让网站更新的新闻快速抓取收录?我相信这是每个 SEO 人和 网站 编辑都关心的话题。我一直在更新原创文章,但是一周甚至一两个月都爬不上收录,这是为什么呢?今天,阿优给大家分享一个消息收录的秘密。学会了以后,编辑永远不会是第一和第二。不要太感谢我~
小优特地咨询了我们的资深SEO优化人员,对收录不好的网站做了分析,总结如下:
一、链接提交功能未使用
每个搜索引擎都有一个站长平台,站长平台有链接提交功能。以百度为例。百度有百度站长,有链接提交功能。有两种类型的链接提交。1、自动提交:主动推送、自动推送、站点地图提交;2、手动提交;在网站上线的时候一定要记得添加这个自动提交功能的三个方法,尽快将你更新的内容推送到百度,有利于收录提速,保护原创. 使用此功能前,必须先验证百度站长。详情请参阅“百度站长验证方法”。
二、内容不是原创,没有价值
很多站长更新文章不是在做原创内容,他们是在做伪原创,在做伪原创而不用伪原创技能,拿着同样的文章业内,改标题,改第一段,改结尾,其余保持不变,直接更新为网站,这个做法和采集文章一样有差别不大,除非你网站的权重特别高,对腾讯、新浪、搜狐等搜索引擎有很强的信任感,否则对网站你的网站,所以大家要做好原创和有价值的文章,等网站稳定了,就可以原创文章@ > 结合伪原创文章更新,前期可以写原创,一定要更新更多原创文章。
三、文章不定期更新
文章更新一定要选择一个时间点,然后每天在这个时间点继续更新,这样搜索引擎蜘蛛就会在这个时间养成每天爬的好习惯,每次来网站有新的内容爬取,久而久之会增加你的网站的好感度,自然也会加快你的网站内容的收录。为了掌握蜘蛛来到网站的时间,可以查看网站日志,看看蜘蛛何时抓取到网站的内容,然后在这个时候更新。记得更新原创的内容,以吸引蜘蛛频繁爬取。
四、没有高质量的外链指导
百度降低了外链掉线对网站优化的影响,但引导蜘蛛抓取网站的内容价值还在。站长一定要重视优质外链的建设。找到一些相关的B2B平台、分类信息平台、论坛平台、自媒体平台、问答平台、新闻源平台等,发布原创内容,并带来网站链接,而不仅仅是首页链接,带有一些新闻版块页面或产品版块页面链接,引导搜索引擎通过外部链接抓取这些页面的内容。
网站 发生的更新内容也会显示在这些页面上,这些页面的链接会被发送到外部链接,这将有助于蜘蛛在第一时间抓取最新的内容,并且收录网站 页面尽快。发布外部链接也需要定期定量发布。切记不要使用群发软件,以免招致搜索引擎降级和K站。
五、不换优质链接
友链是优质的外链。在每个网站首页底部,都有专门的好友链展示区。这个功能主要是从优化的角度考虑的。收录,传权重,提升关键词的排名,给网站带来一点流量。许多公司的朋友链接是单向链接。只有你链接到别人的链接,而别人的网站没有你的链接。有的公司交换朋友的链接,对方无人维护。它纯粹是一个僵尸网站。这些都帮不了你网站,你必须换一个优质的朋友链,维护稳定网站。
文章fast收录的要素就是以上五点。当然,还有更多的 SEO 优化,比如 网站 结构和空间问题。以上五点常常被新手SEO忽略。然后在接下来的工作中更加关注这些。希望小友总结的这些知识点能对大家有所帮助!如有任何问题,请致电阿优科技0315-6723205,具体问题具体分析。如有疑难杂症,可联系唐山阿优科技进行专业优化。老师会免费为你诊断网站,让你的网站“跑”!
抓取网页新闻(1.讲故事民生资讯号民生民生)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-15 19:09
一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何抓取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有cquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com"));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的,相比用xslt,各有优劣。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
3. 部分渲染的 RenderSelection
Render方法是把整个Dom渲染成html,但是有时候你只需要拿到你修改的部分内容,而不是整个html,这就涉及到部分渲染了。您可以使用 RenderSelection 方法。代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
jquery的操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,功能非常强大,但是jquery不仅在选择器上灵活,在节点操作上也很灵活。一般来说,在不是特别交互的情况下可以使用它。怀旧。
如果你还有更多问题想和我互动,扫下方二维码进来吧~
程序员的信标 查看全部
抓取网页新闻(1.讲故事民生资讯号民生民生)
一:背景1.讲故事
前段时间,我在当地开设了一个民生信息账号。信息都是你抄的,你抄的是官媒的。小市民喜欢奇闻异事,所以有必要,如何定位抓怪故事的地方。上号的消息其实做起来很简单。可以使用逻辑回归。本文主要讨论如何抓取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath提取。网页的内容让我很不舒服。毕竟,我对莫名的抵抗并不熟悉。我这个年纪的码农,受过Jquery至少5-6年的教育,所以我必须使用类似Jquery的方法。python中有cquery。在 C# 中是否有类似的方法可以做到这一点?嘿,真的有万能的github。. . 这就是本文介绍的CSQuery。
二:CSQuery1.安装
github的地址:然后就在vs里面nuget:
https://www.wangt.cc/wp-conten ... b2.png" />2. 举几个例子
万事俱备,那么如何使用呢?别着急,我给你举两个博客园的例子。
1) 将首页的友情链接提取到
https://www.wangt.cc/wp-conten ... 86.png" />如上图所示,如果要在这里获取友情链接的几个大字符,直接使用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
https://www.wangt.cc/wp-conten ... c0.png" />如何处理?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最终获取文本节点的内容,如下:
https://www.wangt.cc/wp-conten ... f1.png" />如果是用js做的,那怎么用CSQuery代码做呢?模仿一下,下面的代码:
static void Main(string[] args)
{
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var content = jquery["#friend_link"].Contents().Filter((dom) =>
{
return dom.NodeType == NodeType.TEXT_NODE;
}).Text();
Console.WriteLine(content);
}
不知道用xpath提取这样的内容是不是很麻烦,但是jquery不好用,但是好用。
2) 如何为 html 中的某些元素着色
有时出于商业目的需要改变一些html标签的颜色,比如把博客和首页tabmenu中的特殊区域改成红色,如下图:
https://www.wangt.cc/wp-conten ... 9c.png" />如何用 CSQuery 处理它?如果你玩过jquery,一般步骤如下:
通过步骤,C#代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";));
var html = jquery["#nav_left li"].Each(dom =>
{
var self = jquery[dom];
var text = self.Text();
if (text == "博问" || text == "专区")
{
self.Find("a").CssSet(new { color = "red" });
}
}).Render();
}
https://www.wangt.cc/wp-conten ... 3d.png" />3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等一百多种实用方法。这篇文章当然不能一一介绍。有兴趣的可以下载看看。小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发送邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的,相比用xslt,各有优劣。,然后做一个例子:
1. 生成一个html模板
2. 使用 CSQuery 将 li 附加到 ul
可以使用 Append 将内容附加到节点。
class Program
{
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
foreach (var str in strlist)
{
jquery.Find("#main").Append($"{str}");
}
var html = jquery.Render();
}
}
https://www.wangt.cc/wp-conten ... 5c.png" />3. 部分渲染的 RenderSelection
Render方法是把整个Dom渲染成html,但是有时候你只需要拿到你修改的部分内容,而不是整个html,这就涉及到部分渲染了。您可以使用 RenderSelection 方法。代码如下:
static void Main(string[] args)
{
Config.HtmlEncoder = HtmlEncoders.None;
var strlist = new string[2] { "1", "2" };
var path = Environment.CurrentDirectory + "\2.html";
var jquery = CQ.CreateFromFile(path);
var current = jquery.Find("#main");
foreach (var str in strlist)
{
current.Append($"{str}");
}
var html = current.RenderSelection();
Console.WriteLine(html);
}
------------- output ----------------
12
四:总结
jquery的操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!不过html5中也加入了querySelector和querySelectorAll来支持css3选择器,功能非常强大,但是jquery不仅在选择器上灵活,在节点操作上也很灵活。一般来说,在不是特别交互的情况下可以使用它。怀旧。
如果你还有更多问题想和我互动,扫下方二维码进来吧~
https://www.wangt.cc/wp-conten ... b5.png" />程序员的信标
抓取网页新闻(爬虫工程师如何爬取网页新闻消息,利用人工下载新闻)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-03-14 15:02
抓取网页新闻消息,最常用的方法就是网页爬虫,python比较经典的网页爬虫框架有scrapy、selenium、appium等,通过网页爬虫框架来爬取新闻,利用人工下载新闻的方式,下载新闻会简单很多,方便很多。1、安装相关的库2、创建相关的接口,
针对网页:通过抓包获取网站的真实输入等通过eval.py或者fromscrapyimportspider其他的方法,就是代码调用接口,
去网上看
这里只知道怎么把网页上的新闻全部爬下来,
,可以用python库scrapy写代码爬虫
网页新闻是一大看点,时效性要求很高,有些还是热点新闻。首先需要在百度搜索上寻找新闻,然后点击进入抓取网站,然后爬取新闻等。还是比较麻烦的,这里新闻抓取有很多种,比如python爬虫、nodejs爬虫等等。如果能爬取国内大部分的新闻,那就不值得学了。所以最好还是要求爬虫工程师掌握一门编程语言,比如python。
爬取某些问题的话,可以用requests库,
可以用scrapy可以用selenium可以用appium
安装浏览器来抓取,百度推出的ai助手也可以,
使用pythonflask框架写爬虫
个人觉得python用在网络爬虫还是比较合适的,最简单的,可以requests库scrapy,比较少用,就用selenium,以上开发一些自动化的工具。其次比较简单的就是利用人工爬取。针对web页面,这种有难度。 查看全部
抓取网页新闻(爬虫工程师如何爬取网页新闻消息,利用人工下载新闻)
抓取网页新闻消息,最常用的方法就是网页爬虫,python比较经典的网页爬虫框架有scrapy、selenium、appium等,通过网页爬虫框架来爬取新闻,利用人工下载新闻的方式,下载新闻会简单很多,方便很多。1、安装相关的库2、创建相关的接口,
针对网页:通过抓包获取网站的真实输入等通过eval.py或者fromscrapyimportspider其他的方法,就是代码调用接口,
去网上看
这里只知道怎么把网页上的新闻全部爬下来,
,可以用python库scrapy写代码爬虫
网页新闻是一大看点,时效性要求很高,有些还是热点新闻。首先需要在百度搜索上寻找新闻,然后点击进入抓取网站,然后爬取新闻等。还是比较麻烦的,这里新闻抓取有很多种,比如python爬虫、nodejs爬虫等等。如果能爬取国内大部分的新闻,那就不值得学了。所以最好还是要求爬虫工程师掌握一门编程语言,比如python。
爬取某些问题的话,可以用requests库,
可以用scrapy可以用selenium可以用appium
安装浏览器来抓取,百度推出的ai助手也可以,
使用pythonflask框架写爬虫
个人觉得python用在网络爬虫还是比较合适的,最简单的,可以requests库scrapy,比较少用,就用selenium,以上开发一些自动化的工具。其次比较简单的就是利用人工爬取。针对web页面,这种有难度。
抓取网页新闻(世界十大报纸之一《人民日报》采集任务分析配置思路分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-13 01:07
l 采集网站
【场景描述】采集人民日报新闻资讯。
【来源介绍网站】
人民网是世界十大报纸之一、互联网上最大的中文、多语种新闻之一《人民日报》打造的大型新闻在线信息发布平台网站。人民网作为国家重点新闻网站,具有新闻报道的权威性、及时性、多样性和评论性等特点,在网民中树立了“权威媒体、大众网站”的形象。
【使用工具】嗅探ForeSpider数据前采集系统,免费下载:/view/forespider/view/download.html
【入口网址】/rmrb/html/2021-09/07/nbs.D110000renmrb_01.htm
【采集内容】
采集人民日报新闻的标题、发布时间、文章正文等。
【采集效果】如下图:
l 思想分析
配置思路概述:
l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【 查看全部
抓取网页新闻(世界十大报纸之一《人民日报》采集任务分析配置思路分析)
l 采集网站
【场景描述】采集人民日报新闻资讯。
【来源介绍网站】
人民网是世界十大报纸之一、互联网上最大的中文、多语种新闻之一《人民日报》打造的大型新闻在线信息发布平台网站。人民网作为国家重点新闻网站,具有新闻报道的权威性、及时性、多样性和评论性等特点,在网民中树立了“权威媒体、大众网站”的形象。
【使用工具】嗅探ForeSpider数据前采集系统,免费下载:/view/forespider/view/download.html
【入口网址】/rmrb/html/2021-09/07/nbs.D110000renmrb_01.htm
【采集内容】
采集人民日报新闻的标题、发布时间、文章正文等。
【采集效果】如下图:
l 思想分析
配置思路概述:
l 配置步骤
1. 新 采集 任务
<p>选择【采集配置】,点击任务列表右上方的【+】号新建采集任务,在【
抓取网页新闻(Python爬取网中标标书并保存成PDF格式爬取博客文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-12 14:09
)
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。如有任何问题,请及时联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
基础开发环境
import parsel
import requests
import re
登陆页面分析
今天爬上新闻网的国际新闻版块
点击显示更多新闻内容
可以看到相关的数据接口,里面收录了新闻标题的url地址和新闻详情
如何提取url地址
1、 转换为json,键值对值;
2、使用正则表达式匹配url地址;
两种方法都可以实现,看个人喜好
根据界面数据链接中的pager变化进行翻页,对应页码。
在详情页可以看到新闻内容在div标签里面的p标签中,按照正常的分析网站可以得到新闻内容。
储存方法
1、可以保存txt文本形式
2、也可以另存为PDF
我还谈到了抓取 文章 内容并将其保存为 PDF。您可以点击下面的链接查看相关的保存方法。
Python爬取中标并保存为PDF格式
Python爬取CSDN博客文章并制作成PDF文件
如果这篇文章是文章,使用保存txt文本的形式。
整体爬取思路总结代码实现
def get_html(html_url):
"""
获取网页源代码 response
:param html_url: 网页url地址
:return: 网页源代码
"""
response = requests.get(url=html_url, headers=headers)
return response
def get_page_url(html_data):
"""
获取每篇新闻url地址
:param html_data: response.text
:return: 每篇新闻的url地址
"""
page_url_list = re.findall('"url":"(.*?)"', html_data)
return page_url_list
def file_name(name):
"""
文件命名不能携带 特殊字符
:param name: 新闻标题
:return: 无特殊字符的标题
"""
replace = re.compile(r'[\\\/\:\*\?\"\\|]')
new_name = re.sub(replace, '_', name)
return new_name
def download(content, title):
"""
with open 保存新闻内容 txt
:param content: 新闻内容
:param title: 新闻标题
:return:
"""
path = '新闻\\' + title + '.txt'
with open(path, mode='a', encoding='utf-8') as f:
f.write(content)
print('正在保存', title)
def main(url):
"""
主函数
:param url: 新闻列表页 url地址
:return:
"""
html_data = get_html(url).text # 获得接口数据response.text
lis = get_page_url(html_data) # 获得新闻url地址列表
for li in lis:
page_data = get_html(li).content.decode('utf-8', 'ignore') # 新闻详情页 response.text
selector = parsel.Selector(page_data)
title = re.findall('(.*?)', page_data, re.S)[0] # 获取新闻标题
new_title = file_name(title)
new_data = selector.css('#cont_1_1_2 div.left_zw p::text').getall()
content = ''.join(new_data)
download(content, new_title)
if __name__ == '__main__':
for page in range(1, 101):
url_1 = 'https://channel.chinanews.com/cns/cjs/gj.shtml?pager={}&pagenum=9&t=5_58'.format(page)
main(url_1)
运行效果图
查看全部
抓取网页新闻(Python爬取网中标标书并保存成PDF格式爬取博客文章
)
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。如有任何问题,请及时联系我们进行处理。
PS:如需Python学习资料,可点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
基础开发环境
import parsel
import requests
import re
登陆页面分析
今天爬上新闻网的国际新闻版块
点击显示更多新闻内容
可以看到相关的数据接口,里面收录了新闻标题的url地址和新闻详情
如何提取url地址
1、 转换为json,键值对值;
2、使用正则表达式匹配url地址;
两种方法都可以实现,看个人喜好
根据界面数据链接中的pager变化进行翻页,对应页码。
在详情页可以看到新闻内容在div标签里面的p标签中,按照正常的分析网站可以得到新闻内容。
储存方法
1、可以保存txt文本形式
2、也可以另存为PDF
我还谈到了抓取 文章 内容并将其保存为 PDF。您可以点击下面的链接查看相关的保存方法。
Python爬取中标并保存为PDF格式
Python爬取CSDN博客文章并制作成PDF文件
如果这篇文章是文章,使用保存txt文本的形式。
整体爬取思路总结代码实现
def get_html(html_url):
"""
获取网页源代码 response
:param html_url: 网页url地址
:return: 网页源代码
"""
response = requests.get(url=html_url, headers=headers)
return response
def get_page_url(html_data):
"""
获取每篇新闻url地址
:param html_data: response.text
:return: 每篇新闻的url地址
"""
page_url_list = re.findall('"url":"(.*?)"', html_data)
return page_url_list
def file_name(name):
"""
文件命名不能携带 特殊字符
:param name: 新闻标题
:return: 无特殊字符的标题
"""
replace = re.compile(r'[\\\/\:\*\?\"\\|]')
new_name = re.sub(replace, '_', name)
return new_name
def download(content, title):
"""
with open 保存新闻内容 txt
:param content: 新闻内容
:param title: 新闻标题
:return:
"""
path = '新闻\\' + title + '.txt'
with open(path, mode='a', encoding='utf-8') as f:
f.write(content)
print('正在保存', title)
def main(url):
"""
主函数
:param url: 新闻列表页 url地址
:return:
"""
html_data = get_html(url).text # 获得接口数据response.text
lis = get_page_url(html_data) # 获得新闻url地址列表
for li in lis:
page_data = get_html(li).content.decode('utf-8', 'ignore') # 新闻详情页 response.text
selector = parsel.Selector(page_data)
title = re.findall('(.*?)', page_data, re.S)[0] # 获取新闻标题
new_title = file_name(title)
new_data = selector.css('#cont_1_1_2 div.left_zw p::text').getall()
content = ''.join(new_data)
download(content, new_title)
if __name__ == '__main__':
for page in range(1, 101):
url_1 = 'https://channel.chinanews.com/cns/cjs/gj.shtml?pager={}&pagenum=9&t=5_58'.format(page)
main(url_1)
运行效果图
抓取网页新闻(InforGuard网页防篡改系统做到“零负载”(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-10 06:06
网络媒体的力量越来越受到人们的关注。然而,随着互联网是黑客技术的发展,不法分子篡改网页的事件与日俱增。2003年我国大陆共有1157个网站网页被篡改。如何有效保护自己的网站安全,维护自己在公众心目中的形象,是众多新闻网络媒体面临的共同问题。人们意识到仅仅依靠防火墙和入侵检测技术来保护网站安全是远远不够的。防火墙、入侵检测、网页防篡改系统协同工作,保障网络安全,已成为网络安全防护的趋势。
一般的网页防篡改系统大多采用扫描技术和核心嵌入式技术。由于新闻网站的固有特性,传统的网页防篡改系统难以执行,因为与普通的网站相比,新闻网站具有三个突出的特点:数量多用户数、新闻文件更新量大,新闻更新快。基于扫描技术和核心嵌入式技术的网页防篡改软件无法避免在不发生侵权事件的情况下浪费大量CPU资源的问题。当用户访问量很大时,性能会受到严重影响。损坏文件和非法文件的报警延迟都有一定的生命周期。
自主研发的InforGuard网页防篡改系统,采用独创的事件触发技术。与传统的网页防篡改技术相比,能够对网页的非法篡改做出更加敏捷、快速的响应,同时真正做到“零负载”。当发生非法篡改事件时,InforGuard 的报警延迟时间和恢复时间为毫秒级。从根本上防止黑客利用报警和恢复延迟传播非法信息,保证网页安全。在正常监控状态下,不会占用系统资源,保证系统正常运行。
最近,InforGuard 推出了专为新闻行业设计的新版本。在这个版本中,InforGuard 采用了多种机制,使底层数据传输更加高效。当大量新闻同时发布时,InforGuard 可以轻松实现大量新闻文件从监控中心并发传输到新闻网站。由于采用了事件触发技术,一旦网站维护者将新闻文件发送到监控中心,该文件将立即发布到网站,没有任何延迟,满足了快速新闻的需求更新。
目前,专为新闻行业设计的新版 InforGuard 已经在多条新闻网站中得到应用。某中小新闻网站每天更新400多个新闻文件,文件总数超过1200多个。网站使用了InforGuard网页防篡改系统,从安装、配置到正式运行只用了半天时间。使用InforGuard系统的自动更新功能发布新闻比网站独创的专用新闻发布系统更快,满足新闻的时效性要求,可以轻松处理大量并发更新的新闻。InforGuard不仅彻底解决了网页的防篡改问题,其自动更新功能也替代了原有的新闻发布系统,这成了新闻网站的意外收获。系统投入运行后,其出人意料的优异性能得到了用户的好评。 查看全部
抓取网页新闻(InforGuard网页防篡改系统做到“零负载”(图))
网络媒体的力量越来越受到人们的关注。然而,随着互联网是黑客技术的发展,不法分子篡改网页的事件与日俱增。2003年我国大陆共有1157个网站网页被篡改。如何有效保护自己的网站安全,维护自己在公众心目中的形象,是众多新闻网络媒体面临的共同问题。人们意识到仅仅依靠防火墙和入侵检测技术来保护网站安全是远远不够的。防火墙、入侵检测、网页防篡改系统协同工作,保障网络安全,已成为网络安全防护的趋势。
一般的网页防篡改系统大多采用扫描技术和核心嵌入式技术。由于新闻网站的固有特性,传统的网页防篡改系统难以执行,因为与普通的网站相比,新闻网站具有三个突出的特点:数量多用户数、新闻文件更新量大,新闻更新快。基于扫描技术和核心嵌入式技术的网页防篡改软件无法避免在不发生侵权事件的情况下浪费大量CPU资源的问题。当用户访问量很大时,性能会受到严重影响。损坏文件和非法文件的报警延迟都有一定的生命周期。
自主研发的InforGuard网页防篡改系统,采用独创的事件触发技术。与传统的网页防篡改技术相比,能够对网页的非法篡改做出更加敏捷、快速的响应,同时真正做到“零负载”。当发生非法篡改事件时,InforGuard 的报警延迟时间和恢复时间为毫秒级。从根本上防止黑客利用报警和恢复延迟传播非法信息,保证网页安全。在正常监控状态下,不会占用系统资源,保证系统正常运行。
最近,InforGuard 推出了专为新闻行业设计的新版本。在这个版本中,InforGuard 采用了多种机制,使底层数据传输更加高效。当大量新闻同时发布时,InforGuard 可以轻松实现大量新闻文件从监控中心并发传输到新闻网站。由于采用了事件触发技术,一旦网站维护者将新闻文件发送到监控中心,该文件将立即发布到网站,没有任何延迟,满足了快速新闻的需求更新。
目前,专为新闻行业设计的新版 InforGuard 已经在多条新闻网站中得到应用。某中小新闻网站每天更新400多个新闻文件,文件总数超过1200多个。网站使用了InforGuard网页防篡改系统,从安装、配置到正式运行只用了半天时间。使用InforGuard系统的自动更新功能发布新闻比网站独创的专用新闻发布系统更快,满足新闻的时效性要求,可以轻松处理大量并发更新的新闻。InforGuard不仅彻底解决了网页的防篡改问题,其自动更新功能也替代了原有的新闻发布系统,这成了新闻网站的意外收获。系统投入运行后,其出人意料的优异性能得到了用户的好评。
抓取网页新闻(网络爬虫的基本原理策略抓取策略(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-09 14:32
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
可以理解的更形象:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
多线程下载器功能:从互联网上抓取网页信息。其中,队列调度器通过URL下载,通过一定的时间或调度机制进行下载,将下载的目标资源存储在一个多内存(DB)中。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接数策略、Partial PageRank 策略、OPIC 策略、大站点优先策略等。
深度优先深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个然后进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
广度优先 广度优先搜索策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
反向链接数量策略 反向链接数量是指指向其他网页指向的网页的链接数量。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
Partial PageRank 策略 Partial PageRank 算法借鉴了 PageRank 算法的思想:对于下载的网页,连同待爬取的 URL 队列中的 URL,形成一组网页,每个网页的 PageRank 值页计算。经过计算,待爬取的 URL 将队列中的 URL 按 PageRank 值的大小排序,并按照该顺序爬取页面。如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,
OPIC strategy strategy 该算法实际上对页面的重要性进行评分。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
大站点优先策略 所有待爬取的URL队列中的网页,按照它们所属的网站分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
总结:在实际运营过程中,往往不是单独选择某一种策略,而是结合多种策略的优势,去糟粕,为业务实现相应的功能。
网络爬虫还有一个重要的部分就是进行网页分析,具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取的动作,无需关心关于在广泛的网页爬取中获取想要的目标网页,这里不做详细分析。
参考:
下一篇会是爬取腾讯新闻RSS网页的原理。请注意。 查看全部
抓取网页新闻(网络爬虫的基本原理策略抓取策略(一)_光明网)
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,通常称为网络追逐者)是根据某些规则自动从万维网上爬取信息的程序或脚本。
可以理解的更形象:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
多线程下载器功能:从互联网上抓取网页信息。其中,队列调度器通过URL下载,通过一定的时间或调度机制进行下载,将下载的目标资源存储在一个多内存(DB)中。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接数策略、Partial PageRank 策略、OPIC 策略、大站点优先策略等。
深度优先深度优先搜索策略从起始页面开始,选择一个URL进入,分析该页面中的URL,选择一个然后进入。这样的链接被逐个链接地获取,直到在处理下一个路由之前处理了一个路由。深度优先策略设计相对简单。虽然门户网站 网站 倾向于提供最有价值的链接并具有较高的 PageRank,但页面价值和 PageRank 会随着每个级别的深入而相应降低。这意味着重要的页面通常更靠近种子,而爬得太深的页面价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
广度优先 广度优先搜索策略是指在爬取过程中,完成当前一级的搜索后,再进行下一级的搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索方式。也有许多研究将广度优先搜索策略应用于聚焦爬虫。其基本思想是距初始 URL 一定链接距离内的网页具有较高的主题相关性概率。另一种方法是将广度优先搜索与网页过滤技术相结合,首先使用广度优先策略抓取网页,然后过滤掉不相关的页面。这些方法的缺点是随着爬取的网页数量的增加,
最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标页面的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。它只访问页面分析算法预测为“有用”的页面。一个问题是爬虫爬取路径上的许多相关网页可能会被忽略,因为最佳优先策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,从而跳出局部最优点。在第 4 节中,将结合网页分析算法进行详细讨论。
反向链接数量策略 反向链接数量是指指向其他网页指向的网页的链接数量。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
Partial PageRank 策略 Partial PageRank 算法借鉴了 PageRank 算法的思想:对于下载的网页,连同待爬取的 URL 队列中的 URL,形成一组网页,每个网页的 PageRank 值页计算。经过计算,待爬取的 URL 将队列中的 URL 按 PageRank 值的大小排序,并按照该顺序爬取页面。如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,
OPIC strategy strategy 该算法实际上对页面的重要性进行评分。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
大站点优先策略 所有待爬取的URL队列中的网页,按照它们所属的网站分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
总结:在实际运营过程中,往往不是单独选择某一种策略,而是结合多种策略的优势,去糟粕,为业务实现相应的功能。
网络爬虫还有一个重要的部分就是进行网页分析,具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取的动作,无需关心关于在广泛的网页爬取中获取想要的目标网页,这里不做详细分析。
参考:
下一篇会是爬取腾讯新闻RSS网页的原理。请注意。
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-09 14:31
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library…
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div class="list-hd"][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用doc.select("div.list-hd")的方法返回一个Elements对象,该对象封装了每个新闻[div class="list-hd"][/div]标签的内容,数据格式为: [ {新闻 1}、{新闻 2}、{新闻 3}、{新闻 4}……]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
综上所述,我们已经获得了我们需要的数据。为此,我们在 MainActivity 中声明了一个 getNews() 方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library…
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div class="list-hd"][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用doc.select("div.list-hd")的方法返回一个Elements对象,该对象封装了每个新闻[div class="list-hd"][/div]标签的内容,数据格式为: [ {新闻 1}、{新闻 2}、{新闻 3}、{新闻 4}……]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
综上所述,我们已经获得了我们需要的数据。为此,我们在 MainActivity 中声明了一个 getNews() 方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
抓取网页新闻(Linux基础知识:定时器脚本上必须叫上一行#! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-09 00:06
)
1、定时器
1.1 总是执行程序
直接在python脚本中添加几行代码,保持脚本运行
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
这里调用mainAll()函数,运行一次后8小时50秒阻塞
1.2定点触发和执行程序
(1)windows系统可直接配置,详情见博客
(2)Linux系统很简单
先用crontab -e打开文件,输入命令30 12 * * * python2.7 /x/test.py
注意,test.py 脚本中的上一行必须调用#!/usr/local/bin/python2.7(你安装python的绝对路径)
或者你可以在执行命令中给出绝对路径 30 12 * * * /usr/local/bin/python2.7 /x/test.py
2、现在让我们看看页面是什么样子的
网址很容易获取,都是正则的url = '' % (y, m, d)
我目前的想法是点击首页计算有多少张sheets_len,然后每次点击一张sheet计算右下角有多少张文章titles_len,模拟点击第一个每张sheet下的sheet文章然后得到第二章图片,点击下一张一共titles_len-1次得到文章每一版的全部内容
代码如下:
# -*-coding:utf-8-*-
'''# 9.18
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_122.htm' # 第一版
urlend = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_131.htm' # 第十版
# 9.20
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_122.htm' # 第一版
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_129.htm' # 第十版
'''
import time
from selenium import webdriver
import pymysql
import uuid
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import os
class mainAll(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', user='root', passwd='123', db='tianyan', port=3306, charset='utf8')
self.cur = self.conn.cursor() # 获取一个游标
self.main()
self.cur.close()
self.conn.close()
print('Tick! The time is: %s' % datetime.now())
def main(self):
# 获取当前年月日
y = time.strftime('%Y', time.localtime(time.time())) # 年
m = time.strftime('%m', time.localtime(time.time())) # 月
d = time.strftime('%d', time.localtime(time.time())) # 日
data_time = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 抓取时间
data_time_now = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
website = '海丝商报'
# 创建相应时间的url地址
url = 'http://fjrb.fjsen.com/nasb/html/%s-%s/%s/node_122.htm' % (y, m, d)
driver = webdriver.Chrome()
driver.get(url)
# 找到版面数
sheets = driver.find_element_by_xpath("//table[@cellpadding='2']")
sheets_len = len(sheets.find_elements_by_tag_name('tr'))
# 找到每个版面的标题数量
for sheet in range(3):
titles = driver.find_element_by_xpath("//table[@cellpadding='1']")
titles_len = int(len(titles.find_elements_by_tag_name('tr')) / 2)
content_type = driver.find_element_by_xpath("//table[@cellpadding='2']").find_elements_by_tag_name('tr')
content_type = content_type[sheet].text.split(':')[-1] # 以冒号为分隔符切开版面的文字
# 点击版面的第一篇文章
title_button = driver.find_element_by_xpath("//*[@id='demo']/table[1]/tbody/tr[3]/td[2]/table/tbody/"
"tr[4]/td/table/tbody/tr/td[2]/table/tbody/tr[1]/td/table/"
"tbody/tr[4]/td/div/table/tbody/tr[1]/td[2]/a")
title_button.click()
for title in range(titles_len):
# 找到主标题和子标题的table表
title_table = driver.find_element_by_xpath(
"//*[@id='demo']/table/tbody/tr[3]/td[2]/table/tbody/tr[4]//tr")
content_title = title_table.find_elements_by_tag_name('p')[0].text
content_subtitle = title_table.find_elements_by_tag_name('p')[1].text
content = driver.find_element_by_xpath("//table[@class='content_tt']").text
# 获取左下角每一版的所有标题的链接
content_id = driver.find_elements_by_xpath("//*[@id='demo']/table/tbody/tr[3]/td[1]/table/tbody/tr[3]/"
"td/table//a")
content_id = content_id[title].get_attribute('href')
content_id = content_id.split('content_')[-1].split('.')[0] # 正则表达式没有处理成功!!!!!
# content_id = driver.current_url
# 'http://fjrb.fjsen.com/nasb/html/2017-09/21/content_1055929.htm?div=-1'
idd = str(uuid.uuid1())
idd.replace('-', '')
# 新闻时间和爬取时间是一个时候 sentiment_source 和sentiment_website是同一处理的
lists = (idd, content_title, content_subtitle, website, data_time, url, website, data_time_now, content,
content_id, content_type)
driver.find_elements_by_xpath("//a[@class='preart']")[-1].click() # 点击下一篇章
# 当把一版的所有标题都走完以后,点击下一版,回到外层循环的页面
if title == titles_len - 1 and sheet == 0:
# 如果走到第一版的最后一篇,那么点击下一版
driver.find_elements_by_xpath("//a[@class='preart']")[0].click()
elif title == titles_len - 1 and sheet > 0:
# 如果走到除第一版的最后一篇,同样点击下一版,此时页面上还有上一版,所以
driver.find_elements_by_xpath("//a[@class='preart']")[1].click()
# 只找第一版,如果第一版第一篇的内容已经入库,那么就直接停止本次采集
flag = self.judge(content_id)
if flag > 0:
continue
# 我这里的break会不会让定时程序都停止了 有没有一个方法可以跳出整体循环
self.con(lists)
driver.close()
def con(self, table):
# 名称 职位 公司名称 entuid
sql = "INSERT INTO sentiment_info (sentiment_id, sentiment_title, sentiment_subtitle, sentiment_source," \
"sentiment_time, sentiment_url,sentiment_website,sentiment_create_time,sentiment_content," \
"sentiment_source_id,sentiment_type) VALUES ( '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s'," \
" '%s','%s')"
self.cur.execute(sql % table)
self.conn.commit()
# 第一页点击 driver.find_element_by_xpath("//a[@class='preart']").click() 即可到下一页
def judge(self, content_id):
sql = """SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source='海丝商报'
AND sentiment_source_id='%s'""" % content_id
self.cur.execute(sql)
a = self.cur.fetchall()
a = max(max(a))
self.conn.commit()
return a
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown() 查看全部
抓取网页新闻(Linux基础知识:定时器脚本上必须叫上一行#!
)
1、定时器
1.1 总是执行程序
直接在python脚本中添加几行代码,保持脚本运行
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
这里调用mainAll()函数,运行一次后8小时50秒阻塞
1.2定点触发和执行程序
(1)windows系统可直接配置,详情见博客
(2)Linux系统很简单
先用crontab -e打开文件,输入命令30 12 * * * python2.7 /x/test.py
注意,test.py 脚本中的上一行必须调用#!/usr/local/bin/python2.7(你安装python的绝对路径)
或者你可以在执行命令中给出绝对路径 30 12 * * * /usr/local/bin/python2.7 /x/test.py
2、现在让我们看看页面是什么样子的
网址很容易获取,都是正则的url = '' % (y, m, d)
我目前的想法是点击首页计算有多少张sheets_len,然后每次点击一张sheet计算右下角有多少张文章titles_len,模拟点击第一个每张sheet下的sheet文章然后得到第二章图片,点击下一张一共titles_len-1次得到文章每一版的全部内容
代码如下:
# -*-coding:utf-8-*-
'''# 9.18
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_122.htm' # 第一版
urlend = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_131.htm' # 第十版
# 9.20
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_122.htm' # 第一版
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_129.htm' # 第十版
'''
import time
from selenium import webdriver
import pymysql
import uuid
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import os
class mainAll(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', user='root', passwd='123', db='tianyan', port=3306, charset='utf8')
self.cur = self.conn.cursor() # 获取一个游标
self.main()
self.cur.close()
self.conn.close()
print('Tick! The time is: %s' % datetime.now())
def main(self):
# 获取当前年月日
y = time.strftime('%Y', time.localtime(time.time())) # 年
m = time.strftime('%m', time.localtime(time.time())) # 月
d = time.strftime('%d', time.localtime(time.time())) # 日
data_time = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 抓取时间
data_time_now = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
website = '海丝商报'
# 创建相应时间的url地址
url = 'http://fjrb.fjsen.com/nasb/html/%s-%s/%s/node_122.htm' % (y, m, d)
driver = webdriver.Chrome()
driver.get(url)
# 找到版面数
sheets = driver.find_element_by_xpath("//table[@cellpadding='2']")
sheets_len = len(sheets.find_elements_by_tag_name('tr'))
# 找到每个版面的标题数量
for sheet in range(3):
titles = driver.find_element_by_xpath("//table[@cellpadding='1']")
titles_len = int(len(titles.find_elements_by_tag_name('tr')) / 2)
content_type = driver.find_element_by_xpath("//table[@cellpadding='2']").find_elements_by_tag_name('tr')
content_type = content_type[sheet].text.split(':')[-1] # 以冒号为分隔符切开版面的文字
# 点击版面的第一篇文章
title_button = driver.find_element_by_xpath("//*[@id='demo']/table[1]/tbody/tr[3]/td[2]/table/tbody/"
"tr[4]/td/table/tbody/tr/td[2]/table/tbody/tr[1]/td/table/"
"tbody/tr[4]/td/div/table/tbody/tr[1]/td[2]/a")
title_button.click()
for title in range(titles_len):
# 找到主标题和子标题的table表
title_table = driver.find_element_by_xpath(
"//*[@id='demo']/table/tbody/tr[3]/td[2]/table/tbody/tr[4]//tr")
content_title = title_table.find_elements_by_tag_name('p')[0].text
content_subtitle = title_table.find_elements_by_tag_name('p')[1].text
content = driver.find_element_by_xpath("//table[@class='content_tt']").text
# 获取左下角每一版的所有标题的链接
content_id = driver.find_elements_by_xpath("//*[@id='demo']/table/tbody/tr[3]/td[1]/table/tbody/tr[3]/"
"td/table//a")
content_id = content_id[title].get_attribute('href')
content_id = content_id.split('content_')[-1].split('.')[0] # 正则表达式没有处理成功!!!!!
# content_id = driver.current_url
# 'http://fjrb.fjsen.com/nasb/html/2017-09/21/content_1055929.htm?div=-1'
idd = str(uuid.uuid1())
idd.replace('-', '')
# 新闻时间和爬取时间是一个时候 sentiment_source 和sentiment_website是同一处理的
lists = (idd, content_title, content_subtitle, website, data_time, url, website, data_time_now, content,
content_id, content_type)
driver.find_elements_by_xpath("//a[@class='preart']")[-1].click() # 点击下一篇章
# 当把一版的所有标题都走完以后,点击下一版,回到外层循环的页面
if title == titles_len - 1 and sheet == 0:
# 如果走到第一版的最后一篇,那么点击下一版
driver.find_elements_by_xpath("//a[@class='preart']")[0].click()
elif title == titles_len - 1 and sheet > 0:
# 如果走到除第一版的最后一篇,同样点击下一版,此时页面上还有上一版,所以
driver.find_elements_by_xpath("//a[@class='preart']")[1].click()
# 只找第一版,如果第一版第一篇的内容已经入库,那么就直接停止本次采集
flag = self.judge(content_id)
if flag > 0:
continue
# 我这里的break会不会让定时程序都停止了 有没有一个方法可以跳出整体循环
self.con(lists)
driver.close()
def con(self, table):
# 名称 职位 公司名称 entuid
sql = "INSERT INTO sentiment_info (sentiment_id, sentiment_title, sentiment_subtitle, sentiment_source," \
"sentiment_time, sentiment_url,sentiment_website,sentiment_create_time,sentiment_content," \
"sentiment_source_id,sentiment_type) VALUES ( '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s'," \
" '%s','%s')"
self.cur.execute(sql % table)
self.conn.commit()
# 第一页点击 driver.find_element_by_xpath("//a[@class='preart']").click() 即可到下一页
def judge(self, content_id):
sql = """SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source='海丝商报'
AND sentiment_source_id='%s'""" % content_id
self.cur.execute(sql)
a = self.cur.fetchall()
a = max(max(a))
self.conn.commit()
return a
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
抓取网页新闻(研究分析其他热门平台数据,看他们和我们以前投资有何异同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-08 22:00
抓取网页新闻,各个公司机构提供最新新闻,我们进行详细分析对比,从而为业内提供舆情数据服务。p2p公司提供全新互联网理财服务,利用先进的大数据技术帮助投资者实现理财投资。我们一起研究分析其他热门平台数据,看他们和我们以前投资有何异同。方法/步骤名称+平台,但是往往得到广告推荐,但是一般会存在广告发布和链接地址多的现象,可以自己发现问题进行监测。例如,公司股东中有没有明显资金问题,提供的链接里都在提示交易安全保障方面的注意事项。
一、爬虫收集你想要获取到的热门平台
1、百度新闻搜索:“@p2p”+平台名称,例如:“p2p网贷大全”,将结果页查看一遍。若有不合理之处,将页面刷新返回;若有明显的数据库不全的情况,
2、微信搜索公众号“爬虫”
3、百度搜索公众号“爬虫技术”,搜索第一个最为可靠,因为内容最为齐全,不仅有基本的利率、年化收益、透明度等数据,还可以看该公众号前7天,每周3-5篇的文章和推送信息。
二、数据存储&转换当平台提供多种主流数据源时,导致各个新闻源提供的数据不一致。
首先将新闻中的主要词语进行合并处理,将数据存入excel表,
4、处理数据上传到excel,进行数据二次整理、清洗:将有一定记忆性的词语拆分分析数据主键,对每个主要数据源的label进行存储和匹配首先我们将数据同步到mysql数据库中(自动生成记忆性词云),再对该数据库进行日期、记忆性词云等数据维度的数据修改操作,再将导入到后续的数据库中。格式数据根据公司经营范围划分:法人营业执照plcn_no1为数据按投资机构类型分:银行存管2013年12月31日,p2p平台利率普遍在12%以下,正常平台根据不同投资者需求不同时间段会有不同变化。更多数据分析及相关技术问题咨询,可关注我的知乎专栏“第二基因”,谢谢!。 查看全部
抓取网页新闻(研究分析其他热门平台数据,看他们和我们以前投资有何异同)
抓取网页新闻,各个公司机构提供最新新闻,我们进行详细分析对比,从而为业内提供舆情数据服务。p2p公司提供全新互联网理财服务,利用先进的大数据技术帮助投资者实现理财投资。我们一起研究分析其他热门平台数据,看他们和我们以前投资有何异同。方法/步骤名称+平台,但是往往得到广告推荐,但是一般会存在广告发布和链接地址多的现象,可以自己发现问题进行监测。例如,公司股东中有没有明显资金问题,提供的链接里都在提示交易安全保障方面的注意事项。
一、爬虫收集你想要获取到的热门平台
1、百度新闻搜索:“@p2p”+平台名称,例如:“p2p网贷大全”,将结果页查看一遍。若有不合理之处,将页面刷新返回;若有明显的数据库不全的情况,
2、微信搜索公众号“爬虫”
3、百度搜索公众号“爬虫技术”,搜索第一个最为可靠,因为内容最为齐全,不仅有基本的利率、年化收益、透明度等数据,还可以看该公众号前7天,每周3-5篇的文章和推送信息。
二、数据存储&转换当平台提供多种主流数据源时,导致各个新闻源提供的数据不一致。
首先将新闻中的主要词语进行合并处理,将数据存入excel表,
4、处理数据上传到excel,进行数据二次整理、清洗:将有一定记忆性的词语拆分分析数据主键,对每个主要数据源的label进行存储和匹配首先我们将数据同步到mysql数据库中(自动生成记忆性词云),再对该数据库进行日期、记忆性词云等数据维度的数据修改操作,再将导入到后续的数据库中。格式数据根据公司经营范围划分:法人营业执照plcn_no1为数据按投资机构类型分:银行存管2013年12月31日,p2p平台利率普遍在12%以下,正常平台根据不同投资者需求不同时间段会有不同变化。更多数据分析及相关技术问题咨询,可关注我的知乎专栏“第二基因”,谢谢!。
抓取网页新闻(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-07 14:01
)
做了一些扩展(也可以扩展,我们从首页获取tele的中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
抓取网页新闻(拓展()系统服务没加上及一堆问题
)
做了一些扩展(也可以扩展,我们从首页获取tele的中间路径,然后用地图给用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
我没有太多接触网页和网络相关的知识,然后使用我没有开始使用的Python。下面的程序曲折多,bug多,但勉强爬网新闻。 win系统服务没有添加,还有很多问题,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-07 14:00
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
Jsoup分析与思路虎扑NBA新闻页面上的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后将以上四个数据封装成一个实体类News,然后布局到列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
抓取网页新闻(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
Jsoup分析与思路虎扑NBA新闻页面上的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后将以上四个数据封装成一个实体类News,然后布局到列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-07 10:24
)
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现其网页的源代码和网页上的评论完全不正确。因此,我使用抓包工具来获取其注释的隐藏地址(每个浏览器都有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的
然后打开链接找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
抓取网页新闻(本文实例讲述了Python正则抓取网易新闻的方法。分享
)
本文示例介绍了Python定时抓取网易新闻的方法。分享给大家参考,详情如下:
自己写了一些爬网易新闻的爬虫,发现其网页的源代码和网页上的评论完全不正确。因此,我使用抓包工具来获取其注释的隐藏地址(每个浏览器都有自己的抓包工具可以用来分析网站)
如果你仔细看,你会发现有一个特别的,那么这就是你想要的
然后打开链接找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神改写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()

