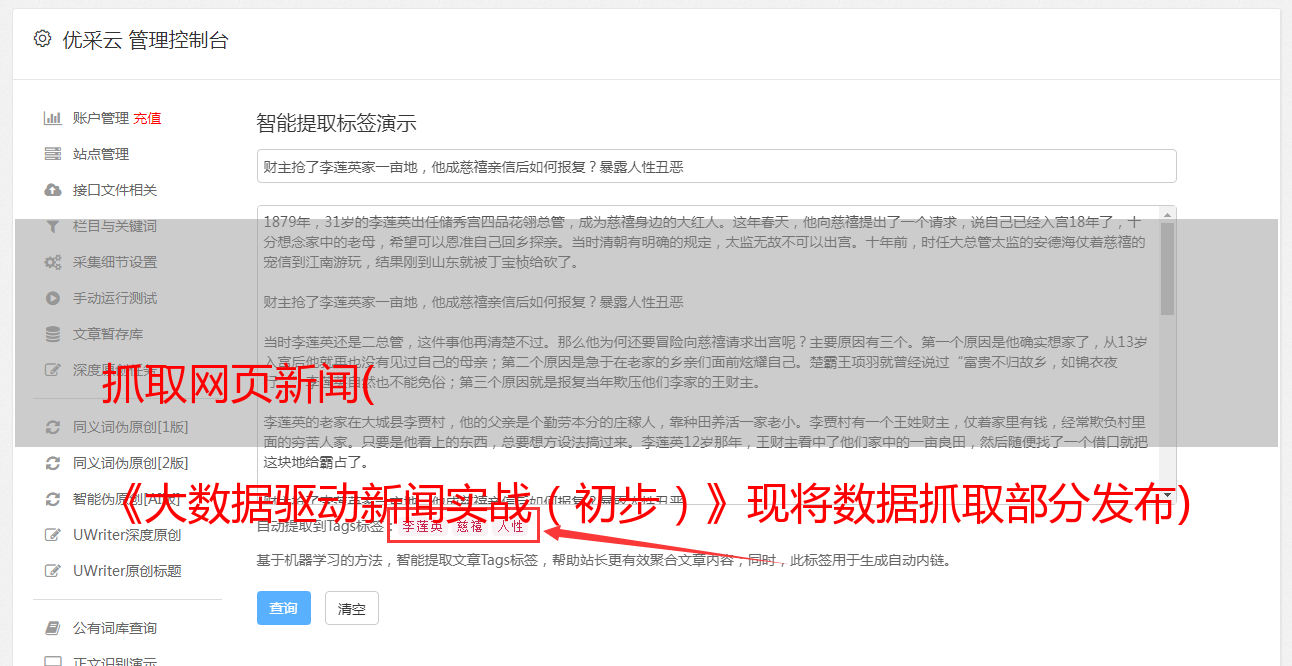
抓取网页新闻( 《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
优采云 发布时间: 2021-10-23 05:20抓取网页新闻(
《大数据驱动新闻实战(初步)》现将数据抓取部分发布)
数据新闻实战:大数据驱动的新闻数据抓取
木马童年 2018-12-9 17:20320 0
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。现将数据采集部分放出,供大家分享交流。数据采集部分分为数据源和数据采集两部分。数据来了...
《数据新闻实战实战:大数据驱动新闻的数据爬行》是部门内部传播“大数据驱动新闻实战(初稿)”的ppt演示。
现将数据采集部分放出,供大家分享交流。
数据采集部分分为数据源和数据采集两部分。
数据源主要讲数据的来源网站。
数据抓包主要讲如何抓包数据源的网络数据到本地。
网站数据源
政府网站:建议先选择政府网站。数据更权威,可长期稳定生成数据,数据量大;例如:国家质量监督检验检疫总局网站、环境保护部网站
行业垂直网站:数据更专业,整理更全面;例如:IT橘子| IT互联网公司产品数据库和商业信息服务
百度产品
百度指数:关键词指数和工业经济指数
百度预测:产业经济大数据预测
百度舆情:产业经济舆情分析
百度搜索:多条件搜索
微博指数产品
新浪微博微索引:关键词索引
微信指数产品
新上榜微信索引:关键词索引
数据抓取
网络爬虫:使用python等编程语言编写网络爬虫抓取网页信息
优点:开源、免费、操作灵活
缺点:学习编程和编写爬虫需要更多时间
采集器:使用优采云、优采云等网页采集器抓取网页信息
优点:上手非常快,无需学习编程,可导出为CSV/TXT/EXCEL等格式
缺点:超过一定数量需要付费导出,部分使用异步ajax技术的网页无法全面采集
数据采集就是这么简单,快来试试吧。

