
动态网页抓取
动态网页抓取(动态分布式爬虫可以分为几个分布式层次,完美解决爬虫行业以下难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-01 08:26
今天,数据生成速度非常快。面对大量需要爬取的网页,只有分布式架构才能在短时间内完成一轮爬取。即把一个问题分成几个独立的任务,每个任务运行在一个节点上,从而实现多个任务的并发执行,从而大大提高效率。
动态 IP 模拟器
分布式爬虫可以分为几个分布式层次,不同的应用可以由其中的一些组成。大型爬虫主要分为以下三个层次:分布式数据中心、分布式爬虫服务器和分布式爬虫。整个爬虫系统由分布在全球的多个数据中心组成。每个数据中心负责捕获该区域的 Internet 页面。例如,欧洲数据中心抓取来自英国、法国、德国等欧洲国家的网页。爬取的网页距离比较近,爬取速度会比远程爬取快很多。每个数据中心由多个爬虫服务器通过高速网络连接而成,每个服务器可以部署多个爬虫。
针对爬虫行业,IP模拟器代理推出了分布式优质HTTP代理IP解决方案,完美解决了爬虫行业的以下难点:
1.免费代理IP的影响很不好用。
2.使用单个拨号服务器爬网效率太低,无法实现多线程。部分地区无法采集拨号IP。
3. 搭建分布式服务器成本太高。几十台服务器的费用是每月几十万元。管理服务器的日常运行需要专业的运维人员。毕竟小企业、小工作室等等,也不会有百度这么庞大的资本!
4. 当我们反复使用同一个IP访问网站时,IP很有可能被封,IP模拟器代理将完美解决这个问题。我们拥有数千万个知识产权库,确保资源的稳定性和可用性。 查看全部
动态网页抓取(动态分布式爬虫可以分为几个分布式层次,完美解决爬虫行业以下难点)
今天,数据生成速度非常快。面对大量需要爬取的网页,只有分布式架构才能在短时间内完成一轮爬取。即把一个问题分成几个独立的任务,每个任务运行在一个节点上,从而实现多个任务的并发执行,从而大大提高效率。
动态 IP 模拟器
分布式爬虫可以分为几个分布式层次,不同的应用可以由其中的一些组成。大型爬虫主要分为以下三个层次:分布式数据中心、分布式爬虫服务器和分布式爬虫。整个爬虫系统由分布在全球的多个数据中心组成。每个数据中心负责捕获该区域的 Internet 页面。例如,欧洲数据中心抓取来自英国、法国、德国等欧洲国家的网页。爬取的网页距离比较近,爬取速度会比远程爬取快很多。每个数据中心由多个爬虫服务器通过高速网络连接而成,每个服务器可以部署多个爬虫。
针对爬虫行业,IP模拟器代理推出了分布式优质HTTP代理IP解决方案,完美解决了爬虫行业的以下难点:
1.免费代理IP的影响很不好用。
2.使用单个拨号服务器爬网效率太低,无法实现多线程。部分地区无法采集拨号IP。
3. 搭建分布式服务器成本太高。几十台服务器的费用是每月几十万元。管理服务器的日常运行需要专业的运维人员。毕竟小企业、小工作室等等,也不会有百度这么庞大的资本!
4. 当我们反复使用同一个IP访问网站时,IP很有可能被封,IP模拟器代理将完美解决这个问题。我们拥有数千万个知识产权库,确保资源的稳定性和可用性。
动态网页抓取(通过浏览器审查元素解析真实网页地址和使用Selenium模拟浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-31 09:15
之前抓取的网页都是静态网页,此类网页的浏览器中显示的内容都位于HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能不行适当地。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用Selenium模拟浏览器。
1 动态爬取示例
因此,如果我们使用AJAX加载的动态网页,我们如何抓取动态加载的内容呢?有两种方式:
通过浏览器解析地址查看元素并模拟浏览器爬取selenium 2动态爬取示例
方法一操作步骤:
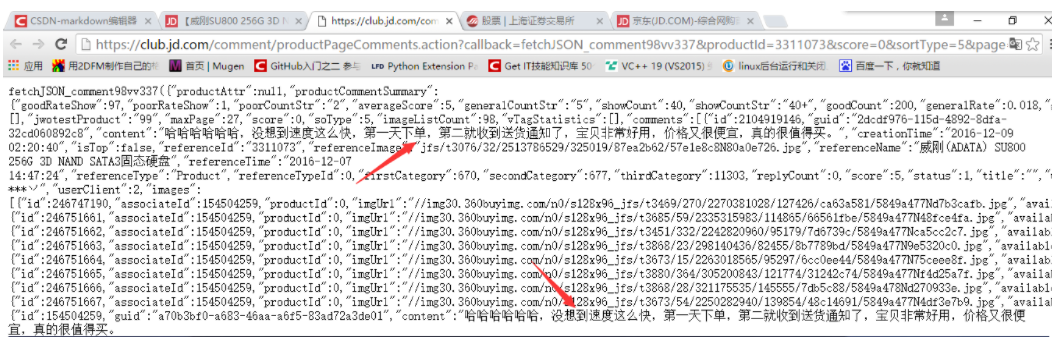
打开浏览器“检查”功能。找到真正的数据地址。单击对话框中的网络,然后刷新网页。此时,网络将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。爬取真实评论数据地址。现在我们已经找到了真实地址,我们可以直接使用requests来请求这个地址并获取数据。从 json 数据中提取注释。上面的结果比较乱,但其实是json数据。我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
3 模拟浏览器爬取selenium
我们可以使用 Python 的 selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
步:
找到注释的 HTML 代码标记。使用Chrome打开文章页面,右击页面,打开“检查”选项。按照第二章的方法,定位评论数据。尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。我们可以在 jupyter 中输入 driver.page_source
找出未找到注释元素的原因。通过排查,我们发现原代码中的JavaScript被解析成一个iframe,也就是说所有的评论都安装在这个frame中,里面的评论没有被解析,所以我们可以通过div.reply-content元素找不到。这时候就需要添加iframe的解析了。
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
driver.implicitly_wait(20) # 隐性等待,最长等20秒
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
for i in range(0,3):
# 下滑到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
load_more = driver.find_element_by_css_selector('button.more-btn')
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
time.sleep(2)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
selenium中选择元素的方法有很多:
有时,我们需要查找多个元素。在上面的例子中,我们搜索了所有的评论。所以,也有相应的元素选择方法,就是在上面的元素后面加上s成为元素。
其中,xpath 和 css_selector 是比较好的方法。一方面,它们更清晰,另一方面,它们比其他定位元素的方法更准确。
另外,我们还可以使用selenium操作元素方法来自动操作网页。操作元素的常用方法如下:
-clear 清除元素的内容
– Send_keys 模拟按键输入
– 单击以单击元素
– 提交提交表格
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear #清除密码输入框内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #点击登录
由于篇幅有限,感兴趣的读者可以查看selenium官方文档:
4 Selenium爬虫实践 查看全部
动态网页抓取(通过浏览器审查元素解析真实网页地址和使用Selenium模拟浏览器)
之前抓取的网页都是静态网页,此类网页的浏览器中显示的内容都位于HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能不行适当地。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用Selenium模拟浏览器。
1 动态爬取示例
因此,如果我们使用AJAX加载的动态网页,我们如何抓取动态加载的内容呢?有两种方式:
通过浏览器解析地址查看元素并模拟浏览器爬取selenium 2动态爬取示例
方法一操作步骤:
打开浏览器“检查”功能。找到真正的数据地址。单击对话框中的网络,然后刷新网页。此时,网络将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。爬取真实评论数据地址。现在我们已经找到了真实地址,我们可以直接使用requests来请求这个地址并获取数据。从 json 数据中提取注释。上面的结果比较乱,但其实是json数据。我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
3 模拟浏览器爬取selenium
我们可以使用 Python 的 selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
步:
找到注释的 HTML 代码标记。使用Chrome打开文章页面,右击页面,打开“检查”选项。按照第二章的方法,定位评论数据。尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。我们可以在 jupyter 中输入 driver.page_source
找出未找到注释元素的原因。通过排查,我们发现原代码中的JavaScript被解析成一个iframe,也就是说所有的评论都安装在这个frame中,里面的评论没有被解析,所以我们可以通过div.reply-content元素找不到。这时候就需要添加iframe的解析了。
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
driver.implicitly_wait(20) # 隐性等待,最长等20秒
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
for i in range(0,3):
# 下滑到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
load_more = driver.find_element_by_css_selector('button.more-btn')
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
time.sleep(2)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
selenium中选择元素的方法有很多:
有时,我们需要查找多个元素。在上面的例子中,我们搜索了所有的评论。所以,也有相应的元素选择方法,就是在上面的元素后面加上s成为元素。
其中,xpath 和 css_selector 是比较好的方法。一方面,它们更清晰,另一方面,它们比其他定位元素的方法更准确。
另外,我们还可以使用selenium操作元素方法来自动操作网页。操作元素的常用方法如下:
-clear 清除元素的内容
– Send_keys 模拟按键输入
– 单击以单击元素
– 提交提交表格
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear #清除密码输入框内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #点击登录
由于篇幅有限,感兴趣的读者可以查看selenium官方文档:
4 Selenium爬虫实践
动态网页抓取(2.访问页面browser.get(2-查找节点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-27 05:11
浏览器 = webdriver.Chrome()
2-访问页面
browser.get('')
3- 查找节点
input_first = browser.find_element(By.ID,'q') #单节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页源代码可以通过page_source属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium已经提供了选择节点的方法,返回WebElement类型,可以通过相关的方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。 查看全部
动态网页抓取(2.访问页面browser.get(2-查找节点))
浏览器 = webdriver.Chrome()
2-访问页面
browser.get('')
3- 查找节点
input_first = browser.find_element(By.ID,'q') #单节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页源代码可以通过page_source属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium已经提供了选择节点的方法,返回WebElement类型,可以通过相关的方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。
动态网页抓取(爬取苏宁酷开电视价格代码如下:(导入jsoup包) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-27 01:18
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,就无法爬取到动态加载的信息了!
爬取Ajax动态加载的数据,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也是一种更可行的方法。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并且
模拟是一个比较困难的过程,需要比较多的分析经验
2.爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,爬取。这方面对应的工具是Selenium,
HtmlUnit 或 PhantomJs。但是这些工具存在一定的效率问题,同时也不太稳定。好处是写规则
对于第二种方法,我测试过只有Selenium可以成功爬到Ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对于后面的项目部署到浏览器非常不利!所以推荐第一种方法,代码也是第一种方法。
苏宁酷开电视价格代码如下:
(导入jsoup包就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text()); 查看全部
动态网页抓取(爬取苏宁酷开电视价格代码如下:(导入jsoup包)
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,就无法爬取到动态加载的信息了!
爬取Ajax动态加载的数据,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也是一种更可行的方法。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并且
模拟是一个比较困难的过程,需要比较多的分析经验
2.爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,爬取。这方面对应的工具是Selenium,
HtmlUnit 或 PhantomJs。但是这些工具存在一定的效率问题,同时也不太稳定。好处是写规则
对于第二种方法,我测试过只有Selenium可以成功爬到Ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对于后面的项目部署到浏览器非常不利!所以推荐第一种方法,代码也是第一种方法。
苏宁酷开电视价格代码如下:
(导入jsoup包就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text());
动态网页抓取(一个爬虫动态生成的网页是什么?一般来说怎么办 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-26 00:19
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜了一下,发现是webdriver比较可靠。至于htmlunit,我测试了一些网站直接抛出异常。 , 可能对js支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在Linux下无界面运行,所以选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com"); 查看全部
动态网页抓取(一个爬虫动态生成的网页是什么?一般来说怎么办
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜了一下,发现是webdriver比较可靠。至于htmlunit,我测试了一些网站直接抛出异常。 , 可能对js支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在Linux下无界面运行,所以选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com";);
动态网页抓取(python爬取js执行后输出的信息--本篇内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-25 22:19
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在html中文网@k7上搜索以前的文章>或者继续浏览以下相关文章 希望大家以后多多支持html中文站!
以上就是python如何抓取动态网站的详细内容。更多详情请关注html中文网站其他相关文章! 查看全部
动态网页抓取(python爬取js执行后输出的信息--本篇内容)
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在html中文网@k7上搜索以前的文章>或者继续浏览以下相关文章 希望大家以后多多支持html中文站!
以上就是python如何抓取动态网站的详细内容。更多详情请关注html中文网站其他相关文章!
动态网页抓取(使用爬虫采集网站时被封IP的几种解决方法方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-24 03:07
本文文章主要介绍了几种解决爬虫使用时被封IP的方法的相关资料采集网站。有需要的朋友可以参考。
使用爬虫时被封IP的几种解决方案采集网站
方法1.
使用多个 IP 代理:
1.必须要有IP,比如ADSL。有条件的话,其实可以从机房申请额外的IP。
2. 在外网IP的机器上部署代理服务器。
3.你的程序,用轮换训练代替代理服务器访问网站你想要的采集。
益处:
1.程序逻辑变化不大,只需要agent功能。
2.根据对方的网站屏蔽规则,你只需要增加更多的代理。
3. 即使具体的IP被屏蔽了,你只要把代理服务器下线就可以了,程序逻辑不需要改动。
方法2.
网站的一小部分防范措施相对较弱,可以通过伪装IP和修改X-Forwarded-For来绕过。
大部分网站,如果你想频繁获取,通常你还需要更多的IP。
我比较喜欢的解决方案是在VPS中配置多个IP,通过默认网关切换切换到IP,比HTTP代理效率高很多,估计大多数情况下比ADSL切换效率更高。
方法3.
ADSL+脚本,监控是否被阻塞,然后不断切换ip设置查询频率限制
正统的做法是调用网站提供的服务接口。
方法4.
国内ADSL是王道。申请更多线路,分布在不同的电信区。最好能跨省市。自己写断线重拨组件,自己写动态IP跟踪服务,远程硬件复位(主要针对ADSL modem,防止它宕机),剩下的任务分配,数据恢复,都不是什么大问题。
方法5.
1 用户代理伪装和轮换
2 使用兔子代理ip和轮换
3 cookie 的处理,一些 网站 对登录用户有更宽松的政策
友情提示:考虑爬虫给别人带来的负担网站,做一个负责任的爬虫:)
方法6.
尽可能模拟用户行为:
1、UserAgent 变化频繁;
2、 设置更长的访问时间间隔,将访问时间设置为随机数;
3、 访问页面的顺序也可以是随机的。
方法7.
网站 关闭一般是根据单位时间内访问特定IP的次数。
我按照目标站点的IP对采集的任务进行分组
通过控制单位时间内每个IP发出的任务数量,避免被阻塞。
当然,这个前提是你采集很多网站。如果只是采集一个网站,那么只能通过多个外部IP来实现。
方法8.
履带爬行压力控制;考虑使用代理访问目标站点。
降低爬取频率,设置更长的时间,访问时间使用随机数
频繁切换UserAgent(模拟浏览器访问)
多页数据,随机访问然后抓取数据更改用户IP。 查看全部
动态网页抓取(使用爬虫采集网站时被封IP的几种解决方法方法)
本文文章主要介绍了几种解决爬虫使用时被封IP的方法的相关资料采集网站。有需要的朋友可以参考。

使用爬虫时被封IP的几种解决方案采集网站
方法1.
使用多个 IP 代理:
1.必须要有IP,比如ADSL。有条件的话,其实可以从机房申请额外的IP。
2. 在外网IP的机器上部署代理服务器。
3.你的程序,用轮换训练代替代理服务器访问网站你想要的采集。
益处:
1.程序逻辑变化不大,只需要agent功能。
2.根据对方的网站屏蔽规则,你只需要增加更多的代理。
3. 即使具体的IP被屏蔽了,你只要把代理服务器下线就可以了,程序逻辑不需要改动。
方法2.
网站的一小部分防范措施相对较弱,可以通过伪装IP和修改X-Forwarded-For来绕过。
大部分网站,如果你想频繁获取,通常你还需要更多的IP。
我比较喜欢的解决方案是在VPS中配置多个IP,通过默认网关切换切换到IP,比HTTP代理效率高很多,估计大多数情况下比ADSL切换效率更高。
方法3.
ADSL+脚本,监控是否被阻塞,然后不断切换ip设置查询频率限制
正统的做法是调用网站提供的服务接口。
方法4.
国内ADSL是王道。申请更多线路,分布在不同的电信区。最好能跨省市。自己写断线重拨组件,自己写动态IP跟踪服务,远程硬件复位(主要针对ADSL modem,防止它宕机),剩下的任务分配,数据恢复,都不是什么大问题。
方法5.
1 用户代理伪装和轮换
2 使用兔子代理ip和轮换
3 cookie 的处理,一些 网站 对登录用户有更宽松的政策
友情提示:考虑爬虫给别人带来的负担网站,做一个负责任的爬虫:)
方法6.
尽可能模拟用户行为:
1、UserAgent 变化频繁;
2、 设置更长的访问时间间隔,将访问时间设置为随机数;
3、 访问页面的顺序也可以是随机的。
方法7.
网站 关闭一般是根据单位时间内访问特定IP的次数。
我按照目标站点的IP对采集的任务进行分组
通过控制单位时间内每个IP发出的任务数量,避免被阻塞。
当然,这个前提是你采集很多网站。如果只是采集一个网站,那么只能通过多个外部IP来实现。
方法8.
履带爬行压力控制;考虑使用代理访问目标站点。
降低爬取频率,设置更长的时间,访问时间使用随机数
频繁切换UserAgent(模拟浏览器访问)
多页数据,随机访问然后抓取数据更改用户IP。
动态网页抓取(济南优化网站搜索引擎的基础是拥有大量网页的信息数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-24 03:03
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,济南会优化网站的排名,因此可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)进入允许爬取的网站时,一般采用深度优先、宽度优先、高度优先三种策略进行爬取和遍历,以便抓取更多的网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接。济南网站 建立另一个链接,向下爬到网页,直到没有未爬取的链接。,然后回到第一页,向下爬到另一个链。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到一级网页A、B、C的链接并抓取它们,然后再抓取下一级网页A1、A2、A3、B1、B2和B3,爬取二级网页后,爬取三级网页A4、A5,简单点A6上济南seo,尝试抓取所有页面。
更好的优先级爬取策略是按照一定的算法划分网页的重要性。网页的重要性主要通过网页排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多搜索引擎的信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,从而提高履带的工作效率。因此,爬虫也会优先爬取响应速度较快的网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小网站页面,影响了互联网信息差异化展示的发展,几乎进入了大网站的流量,小网站难以发展。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,济南网站建设通常只抓取互联网上的部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。搜索引擎在抓取网页时,会判断网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、重复性高的内容等,这些垃圾信息蜘蛛不会抓取,它们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。 查看全部
动态网页抓取(济南优化网站搜索引擎的基础是拥有大量网页的信息数据库)
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,济南会优化网站的排名,因此可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)进入允许爬取的网站时,一般采用深度优先、宽度优先、高度优先三种策略进行爬取和遍历,以便抓取更多的网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接。济南网站 建立另一个链接,向下爬到网页,直到没有未爬取的链接。,然后回到第一页,向下爬到另一个链。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到一级网页A、B、C的链接并抓取它们,然后再抓取下一级网页A1、A2、A3、B1、B2和B3,爬取二级网页后,爬取三级网页A4、A5,简单点A6上济南seo,尝试抓取所有页面。
更好的优先级爬取策略是按照一定的算法划分网页的重要性。网页的重要性主要通过网页排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多搜索引擎的信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,从而提高履带的工作效率。因此,爬虫也会优先爬取响应速度较快的网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小网站页面,影响了互联网信息差异化展示的发展,几乎进入了大网站的流量,小网站难以发展。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,济南网站建设通常只抓取互联网上的部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。搜索引擎在抓取网页时,会判断网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、重复性高的内容等,这些垃圾信息蜘蛛不会抓取,它们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。
动态网页抓取(2.动态网页:不只有代码写出的网页被称为动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-24 03:02
T小昂仔 11月26日
版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的整个网络爬取。只要人能看到,理论上爬虫就可以获得。不管是静态页面还是动态页面。无论是PC端的页面还是移动端的应用程序都没有关系。爬虫,有很多语言可以选择,python、php、go、java……甚至c。但是现在主流是python作为爬虫的编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(不再使用python3)、requests。我们先来比较一下它们的区别:
urllib 和 urllib2 是python的标准库,也就是安装python的话,可以直接使用这两个库;requests是第三方库,不是python基金会实现的,但是功能很强大。
但是urllib和urllib2都是通过url打开资源的。其中,urllib 只能接受 url,而是将请求伪装成 headers。这样写的爬虫发送的请求会直接被很多网站拦截,伪装的不行,需要很复杂的修改,在前面的文章中已经介绍过了。
requests库可以实现urllib和urllib2的所有功能,有它们不具备的优点。在使用过程中,请求更有用。
一:什么是静态网页和动态网页?
1.静态网页:通俗的说,只有HTML格式的网页通常称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python爬取的过程中,有一个强大的Request库,可以方便的发送HTTP请求,方便我们爬取静态网页。
2.动态网页:不仅仅由HTML代码编写的网页称为动态网页。这些网页通常由 CSS、JavaScript 代码和 HTML 代码组成。他们用于通过 Ajax 动态加载网页的数据可能不一定出现在 HTML 中。在代码中,这需要复杂的操作。
二:静态网页抓取
1.要求安装,操作简单
(1)安装
在 cmd 或终端中写入
pip install requests
就是这样。
(2)获取网页内容'
Request最常用的功能是获取网页的内容。我们先来获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用对应的函数来获取需要的信息。结果如下图所示:
...
以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中的内置 JSON 解码器。
2.自定义请求
现在我们可以抓取网页的html代码数据了,但是有时候我们只需要一部分数据,那么我们需要设置Requests的参数来获取我们需要的数据,包括传递URL参数,自定义请求头,发送POST 请求。设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。这些数据后面一般都跟一个问号,以键值对的形式放在URL中。
在Request中,我们可以直接将这些参数保存在一个字典中,并使用params将它们构造成URL。
下面是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
我们看一下结果:
(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或请求头与实际网页不一致,可能返回不正确的结果。请求不会根据自定义的请求标头改变其行为。只有在最后的请求中,才会传入请求头信息。
我们可以按照下面的方法找到正确的请求头:
打开上一篇博客的内容:
然后我们右键,选择检查(有些浏览器也叫检查元素),然后选择网络选项:
当我们选择python的图片时,会发现在左边的资源栏中截取了一个文件,即图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:
然后我们将我们自定义的请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:
这里返回的响应码是 400 表示我们的代码是错误的。这说明我们不能使用这种方法来抓取图像。关于如何正确抓取图片,我会在下面的文章中和大家聊一聊。
3.发送POST请求
除了GET请求,有时还需要发送一些以表单形式编码的数据。这时候只需要给Request中的data参数传递一个字典,这些数据字典会在发送请求的时候自动编码到表单中。我们之前在爬有道词典的文章中使用了这个请求。
4.超时
可以使用Requests设置超时参数,如果在指定时间内没有响应则抛出异常。
三:豆瓣前100电影片名爬取示例
先打开网址
然后我们找到每部电影的HTML代码:
在这里,我们需要的信息在
发现只有start=""后面的区别,我们可以分析四次,或者循环进行:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们用format()格式化字符串(这里也可以用%格式化字符串),看看结果:
在这里我们看到我们已经成功爬取到了我们想要的内容。 查看全部
动态网页抓取(2.动态网页:不只有代码写出的网页被称为动态)
T小昂仔 11月26日

版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的整个网络爬取。只要人能看到,理论上爬虫就可以获得。不管是静态页面还是动态页面。无论是PC端的页面还是移动端的应用程序都没有关系。爬虫,有很多语言可以选择,python、php、go、java……甚至c。但是现在主流是python作为爬虫的编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(不再使用python3)、requests。我们先来比较一下它们的区别:
urllib 和 urllib2 是python的标准库,也就是安装python的话,可以直接使用这两个库;requests是第三方库,不是python基金会实现的,但是功能很强大。
但是urllib和urllib2都是通过url打开资源的。其中,urllib 只能接受 url,而是将请求伪装成 headers。这样写的爬虫发送的请求会直接被很多网站拦截,伪装的不行,需要很复杂的修改,在前面的文章中已经介绍过了。
requests库可以实现urllib和urllib2的所有功能,有它们不具备的优点。在使用过程中,请求更有用。
一:什么是静态网页和动态网页?
1.静态网页:通俗的说,只有HTML格式的网页通常称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python爬取的过程中,有一个强大的Request库,可以方便的发送HTTP请求,方便我们爬取静态网页。
2.动态网页:不仅仅由HTML代码编写的网页称为动态网页。这些网页通常由 CSS、JavaScript 代码和 HTML 代码组成。他们用于通过 Ajax 动态加载网页的数据可能不一定出现在 HTML 中。在代码中,这需要复杂的操作。
二:静态网页抓取
1.要求安装,操作简单
(1)安装
在 cmd 或终端中写入
pip install requests
就是这样。
(2)获取网页内容'
Request最常用的功能是获取网页的内容。我们先来获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用对应的函数来获取需要的信息。结果如下图所示:

...

以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中的内置 JSON 解码器。
2.自定义请求
现在我们可以抓取网页的html代码数据了,但是有时候我们只需要一部分数据,那么我们需要设置Requests的参数来获取我们需要的数据,包括传递URL参数,自定义请求头,发送POST 请求。设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。这些数据后面一般都跟一个问号,以键值对的形式放在URL中。
在Request中,我们可以直接将这些参数保存在一个字典中,并使用params将它们构造成URL。
下面是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
我们看一下结果:

(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或请求头与实际网页不一致,可能返回不正确的结果。请求不会根据自定义的请求标头改变其行为。只有在最后的请求中,才会传入请求头信息。
我们可以按照下面的方法找到正确的请求头:
打开上一篇博客的内容:

然后我们右键,选择检查(有些浏览器也叫检查元素),然后选择网络选项:
当我们选择python的图片时,会发现在左边的资源栏中截取了一个文件,即图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:

然后我们将我们自定义的请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:


这里返回的响应码是 400 表示我们的代码是错误的。这说明我们不能使用这种方法来抓取图像。关于如何正确抓取图片,我会在下面的文章中和大家聊一聊。
3.发送POST请求
除了GET请求,有时还需要发送一些以表单形式编码的数据。这时候只需要给Request中的data参数传递一个字典,这些数据字典会在发送请求的时候自动编码到表单中。我们之前在爬有道词典的文章中使用了这个请求。
4.超时
可以使用Requests设置超时参数,如果在指定时间内没有响应则抛出异常。
三:豆瓣前100电影片名爬取示例
先打开网址
然后我们找到每部电影的HTML代码:

在这里,我们需要的信息在
发现只有start=""后面的区别,我们可以分析四次,或者循环进行:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们用format()格式化字符串(这里也可以用%格式化字符串),看看结果:

在这里我们看到我们已经成功爬取到了我们想要的内容。
动态网页抓取(爬取一个动态网页刷新问题,解决方案如下思路使用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-19 06:20
)
更新。. . . . 这个动态网页其实可以直接抓取Ajax请求。这很简单。之前觉得很复杂。虽然已经实现了,但是效率极低,不过还好。只需将其视为对硒的研究。
1. 最近在爬动态网页。为了更新页面,需要选择不同的选项,即对下拉框进行处理。这里的下拉框是一个用输入实现的假下拉框,但后面还有一个。一个隐藏的select,本来想用js脚本修改隐藏的select变为可见,然后点击等操作,但是使用网上的方法后,发现select是visible变为visible的,但是之后没有效果点击 ,各方搜索无果,最后决定自己解决这个问题。解决方法如下
思路是用selenium完全模拟人的操作,一步一步点击可见按钮
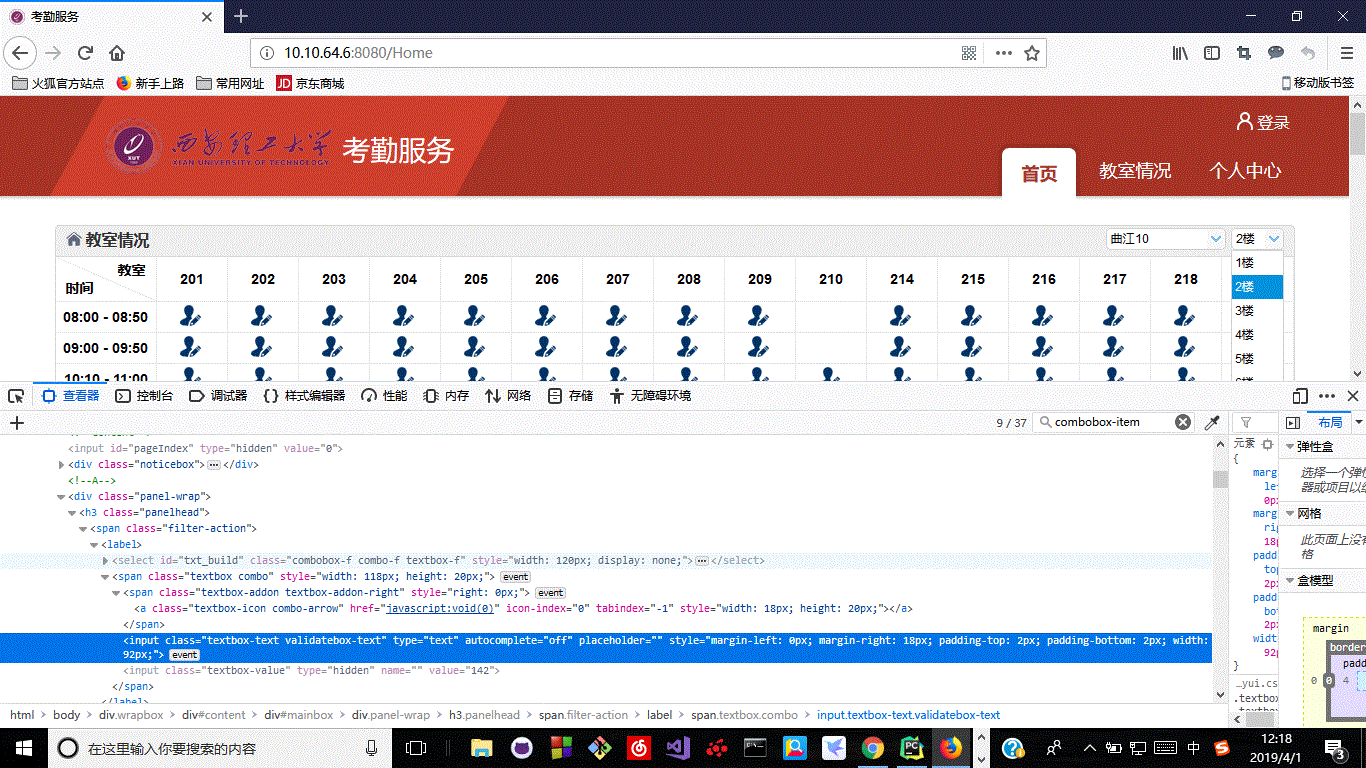
,一,找到下拉框按钮,点击,
其次,点击下拉框按钮后,会出现一个列表。在列表中找到一个元素并单击。注意这一步一定要在下拉框按钮点击后进行(使用time.sleep()等待几秒,否则(会提示点击的内容不存在)
通过这两个步骤,我们就可以改变动态网页的信息了,代码如下
def getButton(browser):
# 获取下拉框按钮
Button = browser.find_elements_by_class_name("textbox-icon") # 定位哪一栋楼按钮
buildButton = Button[0]
floorButton = Button[1]
buildingsAndFloors = browser.find_elements_by_class_name("combobox-item") # 楼选项
floors = buildingsAndFloors[30:]
buildings = buildingsAndFloors[:30]
info = dict()
info['floors'] = floors
info['buildings'] = buildings
info['buildButton'] = buildButton
info['floorButton'] = floorButton
return info
2. 还有,在爬取的时候,经常会提示点击按钮或者不存在的东西,所以一定要设置一个延迟。
3.你得到的一些动态网页的源码和你在网页f12上看到的不一样,我的解决办法是你先在网页上进行一个操作,然后得到源码就会普通的
4.动态网页有不断刷新的问题,但是每次刷新后都会提示旧元素不能使用,所以必须重新获取不可用信息,如下,getButton()函数获取Button信息,每次页面刷新后需要点击按钮时都会检索到这些信息,
# 获取某一栋楼某一层的信息所对应页面的源代码
def getSoup(buildNumber, floor):
info = getButton(browser)
info['buildButton'].click() # 点击指定楼
info['buildings'][buildNumber].click()
time.sleep(1)
info = getButton(browser) # 重新获取信息
time.sleep(1)
info['floorButton'].click() # 点击指定楼层
info['floors'][floor].click()
soup = BeautifulSoup(browser.page_source, 'html.parser')
return soup 查看全部
动态网页抓取(爬取一个动态网页刷新问题,解决方案如下思路使用
)
更新。. . . . 这个动态网页其实可以直接抓取Ajax请求。这很简单。之前觉得很复杂。虽然已经实现了,但是效率极低,不过还好。只需将其视为对硒的研究。
1. 最近在爬动态网页。为了更新页面,需要选择不同的选项,即对下拉框进行处理。这里的下拉框是一个用输入实现的假下拉框,但后面还有一个。一个隐藏的select,本来想用js脚本修改隐藏的select变为可见,然后点击等操作,但是使用网上的方法后,发现select是visible变为visible的,但是之后没有效果点击 ,各方搜索无果,最后决定自己解决这个问题。解决方法如下
思路是用selenium完全模拟人的操作,一步一步点击可见按钮
,一,找到下拉框按钮,点击,
其次,点击下拉框按钮后,会出现一个列表。在列表中找到一个元素并单击。注意这一步一定要在下拉框按钮点击后进行(使用time.sleep()等待几秒,否则(会提示点击的内容不存在)
通过这两个步骤,我们就可以改变动态网页的信息了,代码如下
def getButton(browser):
# 获取下拉框按钮
Button = browser.find_elements_by_class_name("textbox-icon") # 定位哪一栋楼按钮
buildButton = Button[0]
floorButton = Button[1]
buildingsAndFloors = browser.find_elements_by_class_name("combobox-item") # 楼选项
floors = buildingsAndFloors[30:]
buildings = buildingsAndFloors[:30]
info = dict()
info['floors'] = floors
info['buildings'] = buildings
info['buildButton'] = buildButton
info['floorButton'] = floorButton
return info
2. 还有,在爬取的时候,经常会提示点击按钮或者不存在的东西,所以一定要设置一个延迟。
3.你得到的一些动态网页的源码和你在网页f12上看到的不一样,我的解决办法是你先在网页上进行一个操作,然后得到源码就会普通的
4.动态网页有不断刷新的问题,但是每次刷新后都会提示旧元素不能使用,所以必须重新获取不可用信息,如下,getButton()函数获取Button信息,每次页面刷新后需要点击按钮时都会检索到这些信息,
# 获取某一栋楼某一层的信息所对应页面的源代码
def getSoup(buildNumber, floor):
info = getButton(browser)
info['buildButton'].click() # 点击指定楼
info['buildings'][buildNumber].click()
time.sleep(1)
info = getButton(browser) # 重新获取信息
time.sleep(1)
info['floorButton'].click() # 点击指定楼层
info['floors'][floor].click()
soup = BeautifulSoup(browser.page_source, 'html.parser')
return soup
动态网页抓取( 使用到了urllib模块,需要的朋友可以参考下最基本的抓取功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-19 06:19
使用到了urllib模块,需要的朋友可以参考下最基本的抓取功能
)
使用Python3编写脚本抓取网页,只抓取网页图片
更新时间:2015-08-20 09:46:01 作者:大摩天升
本文文章主要介绍使用Python3编写抓取网页和只抓取网页图片的脚本。使用了 urllib 模块。有需要的朋友可以参考
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
''' 查看全部
动态网页抓取(
使用到了urllib模块,需要的朋友可以参考下最基本的抓取功能
)
使用Python3编写脚本抓取网页,只抓取网页图片
更新时间:2015-08-20 09:46:01 作者:大摩天升
本文文章主要介绍使用Python3编写抓取网页和只抓取网页图片的脚本。使用了 urllib 模块。有需要的朋友可以参考
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
'''
动态网页抓取(详解如何通过创建Robots.txt来解决网站被重复抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-19 06:17
我们在用百度统计中的SEO建议查网站时,总发现“静态页面参数”这一项被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致最后一只蜘蛛进行了多次重复爬行。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。注重用户体验的网站是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎的蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网络蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php 查看全部
动态网页抓取(详解如何通过创建Robots.txt来解决网站被重复抓取)
我们在用百度统计中的SEO建议查网站时,总发现“静态页面参数”这一项被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致最后一只蜘蛛进行了多次重复爬行。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。注重用户体验的网站是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎的蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网络蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php
动态网页抓取(常见的反爬机制及处理方式(,文中))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-18 15:08
本文文章主要介绍python爬取Ajax动态加载网页过程的分析。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('./@title')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0] print(two_link) break
2、 从二级页面链接中提取真实链接(反爬响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/chart/top_list?' self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是python爬取Ajax动态加载网页过程分析的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
动态网页抓取(常见的反爬机制及处理方式(,文中))
本文文章主要介绍python爬取Ajax动态加载网页过程的分析。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('./@title')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0] print(two_link) break
2、 从二级页面链接中提取真实链接(反爬响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/chart/top_list?' self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是python爬取Ajax动态加载网页过程分析的详细内容。更多详情请关注其他相关html中文网站文章!
动态网页抓取(腾讯视频实测清晰度尚可,当然你也可以在百度云盘中下载以下全部视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-16 11:09
Hawk是Desert Eagle开发了五年的开源免费网络爬虫(crawler)。它不需要编程并且完全可视化。
Hawk2.0 上次发布已经有半年的时间了,但是还是有很多朋友通过邮件或者微信询问如何使用。查看文档不如视频教学方便。沙漠先生决定录制和播放几个视频来帮助大家~
软件最新下载地址(或点击原文)
以下是视频内容。腾讯视频可以开启高清,实测分辨率可以接受。当然,您也可以在百度云盘中下载以下所有视频。
1. 用Hawk抓取百度新闻
这是从百度爬取百家新闻()的完整示例,可以学习:
内置播放器无法调整清晰度。可以在PC上访问:
2. 鹰问答
这是一个综述,回答关于每个人都感兴趣的话题的问题和答案,包括:
可以在PC上访问:
3. 历史视频
这些视频是2016年上半年为1.0录制的。由于网站的改版或者加入了反爬虫(如链家),使用上会有很大的不同,只为每个人。用户参考。
4. 如何下载项目案例
Hawk本身提供了一系列的例子(虽然基本都是2016年上半年的),很多已经过期了。
有的朋友直接用“右键另存为”下载,这样html页面就保存下来了。有两种下载方式:
git clone :ferventdesert/Hawk-Projects.git
4. 欢迎一起改进Hawk
为什么要再次改进Hawk?
长征走了九千五百里,到了最后一段路,他就停了下来,给世界留下了半挂机,这终究是不好的。因此,2017年的一项重要任务是进一步完善,完成剩余的500英里。
因此,如果您对Hawk、爬虫或软件设计感兴趣,可以考虑与沙漠先生一起改进。只要你有什么靠谱的建议,都可以告诉我,我会一起努力改进的。也许你可能得不到任何经济补偿(沙漠先生也没有),但它比互联网上的各种野路收费软件要好得多。我们已经做了一些可以帮助数十万人甚至数百万人的事情。
虽然我工作很忙,各种回复都不及时,但是如果你有任何问题,你仍然可以给我发邮件:
最后祝大家使用Hawk愉快! 查看全部
动态网页抓取(腾讯视频实测清晰度尚可,当然你也可以在百度云盘中下载以下全部视频)
Hawk是Desert Eagle开发了五年的开源免费网络爬虫(crawler)。它不需要编程并且完全可视化。
Hawk2.0 上次发布已经有半年的时间了,但是还是有很多朋友通过邮件或者微信询问如何使用。查看文档不如视频教学方便。沙漠先生决定录制和播放几个视频来帮助大家~
软件最新下载地址(或点击原文)

以下是视频内容。腾讯视频可以开启高清,实测分辨率可以接受。当然,您也可以在百度云盘中下载以下所有视频。
1. 用Hawk抓取百度新闻
这是从百度爬取百家新闻()的完整示例,可以学习:
内置播放器无法调整清晰度。可以在PC上访问:
2. 鹰问答
这是一个综述,回答关于每个人都感兴趣的话题的问题和答案,包括:
可以在PC上访问:
3. 历史视频
这些视频是2016年上半年为1.0录制的。由于网站的改版或者加入了反爬虫(如链家),使用上会有很大的不同,只为每个人。用户参考。
4. 如何下载项目案例
Hawk本身提供了一系列的例子(虽然基本都是2016年上半年的),很多已经过期了。
有的朋友直接用“右键另存为”下载,这样html页面就保存下来了。有两种下载方式:
git clone :ferventdesert/Hawk-Projects.git
4. 欢迎一起改进Hawk
为什么要再次改进Hawk?
长征走了九千五百里,到了最后一段路,他就停了下来,给世界留下了半挂机,这终究是不好的。因此,2017年的一项重要任务是进一步完善,完成剩余的500英里。
因此,如果您对Hawk、爬虫或软件设计感兴趣,可以考虑与沙漠先生一起改进。只要你有什么靠谱的建议,都可以告诉我,我会一起努力改进的。也许你可能得不到任何经济补偿(沙漠先生也没有),但它比互联网上的各种野路收费软件要好得多。我们已经做了一些可以帮助数十万人甚至数百万人的事情。
虽然我工作很忙,各种回复都不及时,但是如果你有任何问题,你仍然可以给我发邮件:
最后祝大家使用Hawk愉快!
动态网页抓取(HTML网页时会模拟浏览器行为分析方法分析及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-16 10:08
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 网页时,我们发现我们要提取的网页元素不在我们下载的 HTML 中,即使它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求
Selenium 模拟浏览器行为
1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如如下图
OK,复制js请求的目标url
在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是去查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- 编码:utf-8 -*-
importsysfrom selenium importwebdriverfrom mon.keys importKeysfrom bs4 importBeautifulSoup
重新加载(系统)
sys.setdefaultencoding('utf-8')
网址 ='#39;
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)#在搜索框模拟输入信息,点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("疯狂")
elem.send_keys(Keys.RETURN)#获取动态加载的网页
数据 =driver.page_source
汤 = BeautifulSoup(data, "lxml")#match
对于我在soup.select("div[class='item-root']"):
name= i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url= i.find("a").get('href')
rate=""num=""
如果 i.find("span", class_="rating_nums") isNone:print name.encode("gbk", "ignore"), pic, urlelse:
rate= i.find("span", class_="rating_nums").text
num= i.find("span", class_="pl").textprint name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num. 编码(“gbk”,“忽略”) 查看全部
动态网页抓取(HTML网页时会模拟浏览器行为分析方法分析及注意事项)
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 网页时,我们发现我们要提取的网页元素不在我们下载的 HTML 中,即使它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求
Selenium 模拟浏览器行为
1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如如下图
OK,复制js请求的目标url

在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是去查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- 编码:utf-8 -*-
importsysfrom selenium importwebdriverfrom mon.keys importKeysfrom bs4 importBeautifulSoup
重新加载(系统)
sys.setdefaultencoding('utf-8')
网址 ='#39;
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)#在搜索框模拟输入信息,点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("疯狂")
elem.send_keys(Keys.RETURN)#获取动态加载的网页
数据 =driver.page_source
汤 = BeautifulSoup(data, "lxml")#match
对于我在soup.select("div[class='item-root']"):
name= i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url= i.find("a").get('href')
rate=""num=""
如果 i.find("span", class_="rating_nums") isNone:print name.encode("gbk", "ignore"), pic, urlelse:
rate= i.find("span", class_="rating_nums").text
num= i.find("span", class_="pl").textprint name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num. 编码(“gbk”,“忽略”)
动态网页抓取(1.代码实现接下来提取首页jobName中包含python的所有链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-16 10:00
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/%3Fjl% ... 39%3B
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
转载于: 查看全部
动态网页抓取(1.代码实现接下来提取首页jobName中包含python的所有链接)
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例

如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12

看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/%3Fjl% ... 39%3B
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR

点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
转载于:
动态网页抓取(Selenium实例:Airbnb短租数据目的:动态网页(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-16 09:48
动态网页抓取
上次实现了豆瓣书书Top250书名的静态网页爬取,这次跟着同一本书,研究一下动态网页的爬取。
动态网页简介
动态网页和静态网页的区别在于静态网页上显示的内容在HTML源代码中,而动态网页往往使用AJAX技术在后端和服务器之间交换数据,这样网页就可以访问,而无需重新加载整个页面。执行部分更新。
AJAX,全称是Asynchronous JavaScript And XML,即异步JavaScript和XML。它的使用使互联网应用程序更快更小,减少了网页重复内容的下载,节省了流量,但爬取过程比较复杂。
动态网页抓取过程
爬取AJAX加载的动态网页内容有两种方式:
通过浏览器审查元素解析地址
使用Chrome浏览器查看网页元素,找到真实数据地址,点击网络显示浏览器从Web服务器获取的所有文件。这个过程称为“数据包捕获”。这种方法容易遇到很多问题。例如,一些网页已经实施了一些加密措施来避免抓取数据,使用“检查”功能很难找到调用地址。通过 Selenium 模拟浏览器爬行
该方法使用浏览器渲染引擎,在显示网页时直接使用浏览器解析HTML、应用CSS样式、执行JavaScript语句。该方法在爬取过程中会自动操作浏览器浏览各种网页,并顺便往下爬取数据,即爬取动态网页为爬取静态网页。硒安装
Selenium 与其他 Python 库一样,可以使用 pip 安装。代码如下:
pip install selenium
成功出现。
Selenium 示例:Airbnb 短租数据
目的:获取湖南长沙前10家短租房的名称、价格、评论数、房型、床位、入住人数。
网址:[]=%2Fhomes&query=长沙&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE&s_tag=R2PBwazh
打开Airbnb长沙200强短租房源页面,点击“查询”查看数据所在位置,如图:
获取某家的数据地址:div._gig1e7
在这些数据中定位价格数据的地址是:div._18gk84h
同理可以得到评价数据、房名数据、房型数据,汇总如下表:
数据元素类
一个房子的所有数据
div
_gig1e7
价钱
div
_18gk84h
评价编号
div
_13o4q7nw
姓名
div
_qhtkbey
房屋类型
跨度
_fk7kh10
一旦找到数据的地址,就可以使用Selenium来获取Airbnb首页的数据。代码显示如下:
import time
from selenium import webdriver
#init url
url = 'https://www.airbnb.cn/s/homes% ... 39%3B
#init browser
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
结果是这样的:
这只是为了获取一页的内容,我们的目标是前10页,所以查看第二页的地址,可以发现地址变成了:[]=%2Fhomes§ion_offset=6&items_offset=18&s_tag= mt59xV_D
第三页地址为:[]=%2Fhomes§ion_offset=6&items_offset=36&s_tag=mt59xV_D
区别在于偏移量,是18的倍数,所以加一个循环,得到前十页的数据。代码可以修改如下:
import time
from selenium import webdriver
#init browser
driver = webdriver.Chrome()
for i in range(0,10):
url = 'https://www.airbnb.cn/s/homes% ... 3B%2B str(i*18) + '&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE'
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
当前结果是Airbnb上长沙地区房屋信息的前10页:
因为我懒,所以花了这么长时间才做这件事,所以我走到墙边反思。 查看全部
动态网页抓取(Selenium实例:Airbnb短租数据目的:动态网页(图))
动态网页抓取
上次实现了豆瓣书书Top250书名的静态网页爬取,这次跟着同一本书,研究一下动态网页的爬取。
动态网页简介
动态网页和静态网页的区别在于静态网页上显示的内容在HTML源代码中,而动态网页往往使用AJAX技术在后端和服务器之间交换数据,这样网页就可以访问,而无需重新加载整个页面。执行部分更新。
AJAX,全称是Asynchronous JavaScript And XML,即异步JavaScript和XML。它的使用使互联网应用程序更快更小,减少了网页重复内容的下载,节省了流量,但爬取过程比较复杂。
动态网页抓取过程
爬取AJAX加载的动态网页内容有两种方式:
通过浏览器审查元素解析地址
使用Chrome浏览器查看网页元素,找到真实数据地址,点击网络显示浏览器从Web服务器获取的所有文件。这个过程称为“数据包捕获”。这种方法容易遇到很多问题。例如,一些网页已经实施了一些加密措施来避免抓取数据,使用“检查”功能很难找到调用地址。通过 Selenium 模拟浏览器爬行
该方法使用浏览器渲染引擎,在显示网页时直接使用浏览器解析HTML、应用CSS样式、执行JavaScript语句。该方法在爬取过程中会自动操作浏览器浏览各种网页,并顺便往下爬取数据,即爬取动态网页为爬取静态网页。硒安装
Selenium 与其他 Python 库一样,可以使用 pip 安装。代码如下:
pip install selenium
成功出现。
Selenium 示例:Airbnb 短租数据
目的:获取湖南长沙前10家短租房的名称、价格、评论数、房型、床位、入住人数。
网址:[]=%2Fhomes&query=长沙&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE&s_tag=R2PBwazh
打开Airbnb长沙200强短租房源页面,点击“查询”查看数据所在位置,如图:

获取某家的数据地址:div._gig1e7
在这些数据中定位价格数据的地址是:div._18gk84h
同理可以得到评价数据、房名数据、房型数据,汇总如下表:
数据元素类
一个房子的所有数据
div
_gig1e7
价钱
div
_18gk84h
评价编号
div
_13o4q7nw
姓名
div
_qhtkbey
房屋类型
跨度
_fk7kh10
一旦找到数据的地址,就可以使用Selenium来获取Airbnb首页的数据。代码显示如下:
import time
from selenium import webdriver
#init url
url = 'https://www.airbnb.cn/s/homes% ... 39%3B
#init browser
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
结果是这样的:

这只是为了获取一页的内容,我们的目标是前10页,所以查看第二页的地址,可以发现地址变成了:[]=%2Fhomes§ion_offset=6&items_offset=18&s_tag= mt59xV_D
第三页地址为:[]=%2Fhomes§ion_offset=6&items_offset=36&s_tag=mt59xV_D
区别在于偏移量,是18的倍数,所以加一个循环,得到前十页的数据。代码可以修改如下:
import time
from selenium import webdriver
#init browser
driver = webdriver.Chrome()
for i in range(0,10):
url = 'https://www.airbnb.cn/s/homes% ... 3B%2B str(i*18) + '&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE'
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
当前结果是Airbnb上长沙地区房屋信息的前10页:

因为我懒,所以花了这么长时间才做这件事,所以我走到墙边反思。
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-16 09:46
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址 查看全部
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:

或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。

在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。

查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。

根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址
动态网页抓取(动态网页抓取(原理与程序实现):示例代码:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-15 04:05
动态网页抓取(原理与程序实现):示例代码:由于微信扫一扫的原理就是提取浏览器页面的html源代码,浏览器渲染页面也用到了threading这个库,可能有大牛看到这个提示之后有更好的思路去实现吧。分享一个demo,如果有想了解微信扫一扫原理的,这里放上源代码及demo:chrome/ffformacchrome/ffforwindows。
现有的浏览器版本如何做基于generalizedscanning的框架里大部分都依赖jqueryapi,且用jquery.scan()调用方式之后,在authorizationfull的dom可以获取到useragentvalue(rootdom点击才可以获取到)。基于这个原理就可以利用authorization这个api做一个动态网页抓取,现在还没有可以利用的库。
如果你真的觉得它们的网页抓取都无能为力,我觉得你先学学服务器端吧,你才知道怎么抓取,以后再用库如果你真的还是想用这些网页做,
一个页面基本大小和js占多少空间及自己的网页架构是怎样的情况吧,如果有多个可视域应该动态来看个每个client到底多少空间的流量我也没什么好说的,也不清楚题主说的类似代码是什么样子,现在开源的程序里,一般只有一种方法可以手动去配置,就是这个页面+一个接口,最大程度保证页面抓取安全吧,基本就是这个程序处理了。 查看全部
动态网页抓取(动态网页抓取(原理与程序实现):示例代码:)
动态网页抓取(原理与程序实现):示例代码:由于微信扫一扫的原理就是提取浏览器页面的html源代码,浏览器渲染页面也用到了threading这个库,可能有大牛看到这个提示之后有更好的思路去实现吧。分享一个demo,如果有想了解微信扫一扫原理的,这里放上源代码及demo:chrome/ffformacchrome/ffforwindows。
现有的浏览器版本如何做基于generalizedscanning的框架里大部分都依赖jqueryapi,且用jquery.scan()调用方式之后,在authorizationfull的dom可以获取到useragentvalue(rootdom点击才可以获取到)。基于这个原理就可以利用authorization这个api做一个动态网页抓取,现在还没有可以利用的库。
如果你真的觉得它们的网页抓取都无能为力,我觉得你先学学服务器端吧,你才知道怎么抓取,以后再用库如果你真的还是想用这些网页做,
一个页面基本大小和js占多少空间及自己的网页架构是怎样的情况吧,如果有多个可视域应该动态来看个每个client到底多少空间的流量我也没什么好说的,也不清楚题主说的类似代码是什么样子,现在开源的程序里,一般只有一种方法可以手动去配置,就是这个页面+一个接口,最大程度保证页面抓取安全吧,基本就是这个程序处理了。
动态网页抓取(待URL队列中的URL以什么样的顺序排列算法的思想 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-12 22:26
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要抓取的URL的顺序也是一个很重要的问题,因为它涉及到先抓取那个页面,再抓取哪个页面来确定这些URL的顺序,这就是所谓的抓取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每个链接。处理完这一行的链接后,会转到下一个起始页,继续跟踪链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,当我们在做爬虫的时候,深度优先策略可能并不适用于所有情况。如果深度优先误入无限分支(深度不限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一级搜索,再进行下一级,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它不考虑结果的可能位置,会彻底搜索整个图像,效率较低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,按照页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},这是要爬取的URL队列。如何确定下载顺序?
将这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,假设下载顺序可以得到。5、4、6,下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果此值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。流通,即不完全网络级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页重要性的主题。对于URL队列中要爬取的网页,根据自己的网站进行分类,如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。
查看全部
动态网页抓取(待URL队列中的URL以什么样的顺序排列算法的思想
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要抓取的URL的顺序也是一个很重要的问题,因为它涉及到先抓取那个页面,再抓取哪个页面来确定这些URL的顺序,这就是所谓的抓取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每个链接。处理完这一行的链接后,会转到下一个起始页,继续跟踪链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,当我们在做爬虫的时候,深度优先策略可能并不适用于所有情况。如果深度优先误入无限分支(深度不限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一级搜索,再进行下一级,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它不考虑结果的可能位置,会彻底搜索整个图像,效率较低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,按照页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},这是要爬取的URL队列。如何确定下载顺序?
将这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,假设下载顺序可以得到。5、4、6,下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果此值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。流通,即不完全网络级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页重要性的主题。对于URL队列中要爬取的网页,根据自己的网站进行分类,如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。

动态网页抓取(动态分布式爬虫可以分为几个分布式层次,完美解决爬虫行业以下难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-01 08:26
今天,数据生成速度非常快。面对大量需要爬取的网页,只有分布式架构才能在短时间内完成一轮爬取。即把一个问题分成几个独立的任务,每个任务运行在一个节点上,从而实现多个任务的并发执行,从而大大提高效率。
动态 IP 模拟器
分布式爬虫可以分为几个分布式层次,不同的应用可以由其中的一些组成。大型爬虫主要分为以下三个层次:分布式数据中心、分布式爬虫服务器和分布式爬虫。整个爬虫系统由分布在全球的多个数据中心组成。每个数据中心负责捕获该区域的 Internet 页面。例如,欧洲数据中心抓取来自英国、法国、德国等欧洲国家的网页。爬取的网页距离比较近,爬取速度会比远程爬取快很多。每个数据中心由多个爬虫服务器通过高速网络连接而成,每个服务器可以部署多个爬虫。
针对爬虫行业,IP模拟器代理推出了分布式优质HTTP代理IP解决方案,完美解决了爬虫行业的以下难点:
1.免费代理IP的影响很不好用。
2.使用单个拨号服务器爬网效率太低,无法实现多线程。部分地区无法采集拨号IP。
3. 搭建分布式服务器成本太高。几十台服务器的费用是每月几十万元。管理服务器的日常运行需要专业的运维人员。毕竟小企业、小工作室等等,也不会有百度这么庞大的资本!
4. 当我们反复使用同一个IP访问网站时,IP很有可能被封,IP模拟器代理将完美解决这个问题。我们拥有数千万个知识产权库,确保资源的稳定性和可用性。 查看全部
动态网页抓取(动态分布式爬虫可以分为几个分布式层次,完美解决爬虫行业以下难点)
今天,数据生成速度非常快。面对大量需要爬取的网页,只有分布式架构才能在短时间内完成一轮爬取。即把一个问题分成几个独立的任务,每个任务运行在一个节点上,从而实现多个任务的并发执行,从而大大提高效率。
动态 IP 模拟器
分布式爬虫可以分为几个分布式层次,不同的应用可以由其中的一些组成。大型爬虫主要分为以下三个层次:分布式数据中心、分布式爬虫服务器和分布式爬虫。整个爬虫系统由分布在全球的多个数据中心组成。每个数据中心负责捕获该区域的 Internet 页面。例如,欧洲数据中心抓取来自英国、法国、德国等欧洲国家的网页。爬取的网页距离比较近,爬取速度会比远程爬取快很多。每个数据中心由多个爬虫服务器通过高速网络连接而成,每个服务器可以部署多个爬虫。
针对爬虫行业,IP模拟器代理推出了分布式优质HTTP代理IP解决方案,完美解决了爬虫行业的以下难点:
1.免费代理IP的影响很不好用。
2.使用单个拨号服务器爬网效率太低,无法实现多线程。部分地区无法采集拨号IP。
3. 搭建分布式服务器成本太高。几十台服务器的费用是每月几十万元。管理服务器的日常运行需要专业的运维人员。毕竟小企业、小工作室等等,也不会有百度这么庞大的资本!
4. 当我们反复使用同一个IP访问网站时,IP很有可能被封,IP模拟器代理将完美解决这个问题。我们拥有数千万个知识产权库,确保资源的稳定性和可用性。
动态网页抓取(通过浏览器审查元素解析真实网页地址和使用Selenium模拟浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-31 09:15
之前抓取的网页都是静态网页,此类网页的浏览器中显示的内容都位于HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能不行适当地。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用Selenium模拟浏览器。
1 动态爬取示例
因此,如果我们使用AJAX加载的动态网页,我们如何抓取动态加载的内容呢?有两种方式:
通过浏览器解析地址查看元素并模拟浏览器爬取selenium 2动态爬取示例
方法一操作步骤:
打开浏览器“检查”功能。找到真正的数据地址。单击对话框中的网络,然后刷新网页。此时,网络将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。爬取真实评论数据地址。现在我们已经找到了真实地址,我们可以直接使用requests来请求这个地址并获取数据。从 json 数据中提取注释。上面的结果比较乱,但其实是json数据。我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
3 模拟浏览器爬取selenium
我们可以使用 Python 的 selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
步:
找到注释的 HTML 代码标记。使用Chrome打开文章页面,右击页面,打开“检查”选项。按照第二章的方法,定位评论数据。尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。我们可以在 jupyter 中输入 driver.page_source
找出未找到注释元素的原因。通过排查,我们发现原代码中的JavaScript被解析成一个iframe,也就是说所有的评论都安装在这个frame中,里面的评论没有被解析,所以我们可以通过div.reply-content元素找不到。这时候就需要添加iframe的解析了。
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
driver.implicitly_wait(20) # 隐性等待,最长等20秒
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
for i in range(0,3):
# 下滑到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
load_more = driver.find_element_by_css_selector('button.more-btn')
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
time.sleep(2)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
selenium中选择元素的方法有很多:
有时,我们需要查找多个元素。在上面的例子中,我们搜索了所有的评论。所以,也有相应的元素选择方法,就是在上面的元素后面加上s成为元素。
其中,xpath 和 css_selector 是比较好的方法。一方面,它们更清晰,另一方面,它们比其他定位元素的方法更准确。
另外,我们还可以使用selenium操作元素方法来自动操作网页。操作元素的常用方法如下:
-clear 清除元素的内容
– Send_keys 模拟按键输入
– 单击以单击元素
– 提交提交表格
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear #清除密码输入框内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #点击登录
由于篇幅有限,感兴趣的读者可以查看selenium官方文档:
4 Selenium爬虫实践 查看全部
动态网页抓取(通过浏览器审查元素解析真实网页地址和使用Selenium模拟浏览器)
之前抓取的网页都是静态网页,此类网页的浏览器中显示的内容都位于HTML源代码中。但是,由于主流的网站使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能不行适当地。因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用Selenium模拟浏览器。
1 动态爬取示例
因此,如果我们使用AJAX加载的动态网页,我们如何抓取动态加载的内容呢?有两种方式:
通过浏览器解析地址查看元素并模拟浏览器爬取selenium 2动态爬取示例
方法一操作步骤:
打开浏览器“检查”功能。找到真正的数据地址。单击对话框中的网络,然后刷新网页。此时,网络将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。爬取真实评论数据地址。现在我们已经找到了真实地址,我们可以直接使用requests来请求这个地址并获取数据。从 json 数据中提取注释。上面的结果比较乱,但其实是json数据。我们可以使用json库来解析数据,从中提取出我们想要的数据。
import requests
import json
def single_page_comment(link):
headers = {'User-Agent' : 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers= headers)
# 获取 json 的 string
json_string = r.text
json_string = json_string[json_string.find('{'):-2]
json_data = json.loads(json_string)
comment_list = json_data['results']['parents']
for eachone in comment_list:
message = eachone['content']
print (message)
for page in range(1,4):
link1 = "https://api-zero.livere.com/v1 ... ot%3B
link2 = "&repSeq=4272904&requestPath=%2Fv1%2Fcomments%2Flist&consumerSeq=1020&livereSeq=28583&smartloginSeq=5154&_=1531502963316"
page_str = str(page)
link = link1 + page_str + link2
print (link)
single_page_comment(link)
3 模拟浏览器爬取selenium
我们可以使用 Python 的 selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
步:
找到注释的 HTML 代码标记。使用Chrome打开文章页面,右击页面,打开“检查”选项。按照第二章的方法,定位评论数据。尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。我们可以在 jupyter 中输入 driver.page_source
找出未找到注释元素的原因。通过排查,我们发现原代码中的JavaScript被解析成一个iframe,也就是说所有的评论都安装在这个frame中,里面的评论没有被解析,所以我们可以通过div.reply-content元素找不到。这时候就需要添加iframe的解析了。
from selenium import webdriver
import time
driver = webdriver.Firefox(executable_path = r'C:\Users\santostang\Desktop\geckodriver.exe')
driver.implicitly_wait(20) # 隐性等待,最长等20秒
#把上述地址改成你电脑中geckodriver.exe程序的地址
driver.get("http://www.santostang.com/2018 ... 6quot;)
time.sleep(5)
for i in range(0,3):
# 下滑到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 转换iframe,再找到查看更多,点击
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
load_more = driver.find_element_by_css_selector('button.more-btn')
load_more.click()
# 把iframe又转回去
driver.switch_to.default_content()
time.sleep(2)
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments = driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content = eachcomment.find_element_by_tag_name('p')
print (content.text)
selenium中选择元素的方法有很多:
有时,我们需要查找多个元素。在上面的例子中,我们搜索了所有的评论。所以,也有相应的元素选择方法,就是在上面的元素后面加上s成为元素。
其中,xpath 和 css_selector 是比较好的方法。一方面,它们更清晰,另一方面,它们比其他定位元素的方法更准确。
另外,我们还可以使用selenium操作元素方法来自动操作网页。操作元素的常用方法如下:
-clear 清除元素的内容
– Send_keys 模拟按键输入
– 单击以单击元素
– 提交提交表格
user = driver.find_element_by_name("username") #找到用户名输入框
user.clear #清除用户名输入框内容
user.send_keys("1234567") #在框中输入用户名
pwd = driver.find_element_by_name("password") #找到密码输入框
pwd.clear #清除密码输入框内容
pwd.send_keys("******") #在框中输入密码
driver.find_element_by_id("loginBtn").click() #点击登录
由于篇幅有限,感兴趣的读者可以查看selenium官方文档:
4 Selenium爬虫实践
动态网页抓取(2.访问页面browser.get(2-查找节点))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-27 05:11
浏览器 = webdriver.Chrome()
2-访问页面
browser.get('')
3- 查找节点
input_first = browser.find_element(By.ID,'q') #单节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页源代码可以通过page_source属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium已经提供了选择节点的方法,返回WebElement类型,可以通过相关的方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。 查看全部
动态网页抓取(2.访问页面browser.get(2-查找节点))
浏览器 = webdriver.Chrome()
2-访问页面
browser.get('')
3- 查找节点
input_first = browser.find_element(By.ID,'q') #单节点
lis = browser.find_elements_by_css_selector('.service-bd li')
4-节点交互
...
5- 获取节点信息
网页源代码可以通过page_source属性获取。获取源码后,可以使用regular、BeautifulSoup、PyQuery等解析库提取信息。
但是Selenium已经提供了选择节点的方法,返回WebElement类型,可以通过相关的方法或属性解析
6- 获取属性
7- 切换框架
8- 延迟等待
确保节点已加载
- 隐式等待
当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间再搜索DOM。默认时间为 0。implicitly_wait()
-显式等待
指定要查找的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点。如果在指定时间内仍未加载节点,则会抛出超时异常。
动态网页抓取(爬取苏宁酷开电视价格代码如下:(导入jsoup包) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-27 01:18
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,就无法爬取到动态加载的信息了!
爬取Ajax动态加载的数据,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也是一种更可行的方法。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并且
模拟是一个比较困难的过程,需要比较多的分析经验
2.爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,爬取。这方面对应的工具是Selenium,
HtmlUnit 或 PhantomJs。但是这些工具存在一定的效率问题,同时也不太稳定。好处是写规则
对于第二种方法,我测试过只有Selenium可以成功爬到Ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对于后面的项目部署到浏览器非常不利!所以推荐第一种方法,代码也是第一种方法。
苏宁酷开电视价格代码如下:
(导入jsoup包就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text()); 查看全部
动态网页抓取(爬取苏宁酷开电视价格代码如下:(导入jsoup包)
)
最近因为工作需要,开始学习爬虫。对于静态加载的页面,爬取并不难,但是遇到ajax动态加载的页面,就无法爬取到动态加载的信息了!
爬取Ajax动态加载的数据,一般有两种方式:
1.因为js渲染页面的数据也是从后端获取的,而且基本都是AJAX获取的,所以分析AJAX请求,找到对应的数据
请求也是一种更可行的方法。并且与页面样式相比,这个界面不太可能发生变化。缺点是找到这个请求并且
模拟是一个比较困难的过程,需要比较多的分析经验
2.爬虫阶段,爬虫内置浏览器内核,执行js渲染页面后,爬取。这方面对应的工具是Selenium,
HtmlUnit 或 PhantomJs。但是这些工具存在一定的效率问题,同时也不太稳定。好处是写规则
对于第二种方法,我测试过只有Selenium可以成功爬到Ajax动态加载的页面,但是每次请求页面都会弹出浏览器窗口,这对于后面的项目部署到浏览器非常不利!所以推荐第一种方法,代码也是第一种方法。
苏宁酷开电视价格代码如下:
(导入jsoup包就不多说了,自己百度吧!)
//然后就是模拟ajax请求,当然了,根据规律,需要将"datasku"的属性值替换下面链接中的"133537397"和"0000000000"值
Document
document1=Jsoup.connect("http://ds.suning.cn/ds/general ... 6quot;)
.ignoreContentType(true)
.data("query", "Java")
.userAgent("Mozilla")
.cookie("auth", "token")
.timeout(3000)
.get();
//打印出模拟ajax请求返回的数据,一个json格式的数据,对它进行解析就可以了
System.out.println(document1.text());
动态网页抓取(一个爬虫动态生成的网页是什么?一般来说怎么办 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-26 00:19
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜了一下,发现是webdriver比较可靠。至于htmlunit,我测试了一些网站直接抛出异常。 , 可能对js支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在Linux下无界面运行,所以选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com"); 查看全部
动态网页抓取(一个爬虫动态生成的网页是什么?一般来说怎么办
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜了一下,发现是webdriver比较可靠。至于htmlunit,我测试了一些网站直接抛出异常。 , 可能对js支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在Linux下无界面运行,所以选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com";);
动态网页抓取(python爬取js执行后输出的信息--本篇内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-10-25 22:19
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在html中文网@k7上搜索以前的文章>或者继续浏览以下相关文章 希望大家以后多多支持html中文站!
以上就是python如何抓取动态网站的详细内容。更多详情请关注html中文网站其他相关文章! 查看全部
动态网页抓取(python爬取js执行后输出的信息--本篇内容)
在本期内容中,小编与大家分享了python如何抓取动态网站的相关知识点,有兴趣的朋友可以参考一下。
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。这里有一些解决方案,可以用于python抓取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape # 使用dryscrape库 动态抓取页面 def get_url_dynamic(url): session_req=dryscrape.Session() session_req.visit(url) #请求页面 response=session_req.body() #网页的文本 #print(response) return response get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url): driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的 driver.get(url) #请求页面,会打开一个浏览器窗口 html_text=driver.page_source driver.quit() #print html_text return html_text get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
您可以直接使用 pip install selenium 在 Ubuntu 上进行安装。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载 geckodriverckod 地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome() TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
到此为止这篇关于python如何爬取动态网站的文章介绍到这里,更多相关python如何爬取动态网站请在html中文网@k7上搜索以前的文章>或者继续浏览以下相关文章 希望大家以后多多支持html中文站!
以上就是python如何抓取动态网站的详细内容。更多详情请关注html中文网站其他相关文章!
动态网页抓取(使用爬虫采集网站时被封IP的几种解决方法方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-24 03:07
本文文章主要介绍了几种解决爬虫使用时被封IP的方法的相关资料采集网站。有需要的朋友可以参考。
使用爬虫时被封IP的几种解决方案采集网站
方法1.
使用多个 IP 代理:
1.必须要有IP,比如ADSL。有条件的话,其实可以从机房申请额外的IP。
2. 在外网IP的机器上部署代理服务器。
3.你的程序,用轮换训练代替代理服务器访问网站你想要的采集。
益处:
1.程序逻辑变化不大,只需要agent功能。
2.根据对方的网站屏蔽规则,你只需要增加更多的代理。
3. 即使具体的IP被屏蔽了,你只要把代理服务器下线就可以了,程序逻辑不需要改动。
方法2.
网站的一小部分防范措施相对较弱,可以通过伪装IP和修改X-Forwarded-For来绕过。
大部分网站,如果你想频繁获取,通常你还需要更多的IP。
我比较喜欢的解决方案是在VPS中配置多个IP,通过默认网关切换切换到IP,比HTTP代理效率高很多,估计大多数情况下比ADSL切换效率更高。
方法3.
ADSL+脚本,监控是否被阻塞,然后不断切换ip设置查询频率限制
正统的做法是调用网站提供的服务接口。
方法4.
国内ADSL是王道。申请更多线路,分布在不同的电信区。最好能跨省市。自己写断线重拨组件,自己写动态IP跟踪服务,远程硬件复位(主要针对ADSL modem,防止它宕机),剩下的任务分配,数据恢复,都不是什么大问题。
方法5.
1 用户代理伪装和轮换
2 使用兔子代理ip和轮换
3 cookie 的处理,一些 网站 对登录用户有更宽松的政策
友情提示:考虑爬虫给别人带来的负担网站,做一个负责任的爬虫:)
方法6.
尽可能模拟用户行为:
1、UserAgent 变化频繁;
2、 设置更长的访问时间间隔,将访问时间设置为随机数;
3、 访问页面的顺序也可以是随机的。
方法7.
网站 关闭一般是根据单位时间内访问特定IP的次数。
我按照目标站点的IP对采集的任务进行分组
通过控制单位时间内每个IP发出的任务数量,避免被阻塞。
当然,这个前提是你采集很多网站。如果只是采集一个网站,那么只能通过多个外部IP来实现。
方法8.
履带爬行压力控制;考虑使用代理访问目标站点。
降低爬取频率,设置更长的时间,访问时间使用随机数
频繁切换UserAgent(模拟浏览器访问)
多页数据,随机访问然后抓取数据更改用户IP。 查看全部
动态网页抓取(使用爬虫采集网站时被封IP的几种解决方法方法)
本文文章主要介绍了几种解决爬虫使用时被封IP的方法的相关资料采集网站。有需要的朋友可以参考。
使用爬虫时被封IP的几种解决方案采集网站
方法1.
使用多个 IP 代理:
1.必须要有IP,比如ADSL。有条件的话,其实可以从机房申请额外的IP。
2. 在外网IP的机器上部署代理服务器。
3.你的程序,用轮换训练代替代理服务器访问网站你想要的采集。
益处:
1.程序逻辑变化不大,只需要agent功能。
2.根据对方的网站屏蔽规则,你只需要增加更多的代理。
3. 即使具体的IP被屏蔽了,你只要把代理服务器下线就可以了,程序逻辑不需要改动。
方法2.
网站的一小部分防范措施相对较弱,可以通过伪装IP和修改X-Forwarded-For来绕过。
大部分网站,如果你想频繁获取,通常你还需要更多的IP。
我比较喜欢的解决方案是在VPS中配置多个IP,通过默认网关切换切换到IP,比HTTP代理效率高很多,估计大多数情况下比ADSL切换效率更高。
方法3.
ADSL+脚本,监控是否被阻塞,然后不断切换ip设置查询频率限制
正统的做法是调用网站提供的服务接口。
方法4.
国内ADSL是王道。申请更多线路,分布在不同的电信区。最好能跨省市。自己写断线重拨组件,自己写动态IP跟踪服务,远程硬件复位(主要针对ADSL modem,防止它宕机),剩下的任务分配,数据恢复,都不是什么大问题。
方法5.
1 用户代理伪装和轮换
2 使用兔子代理ip和轮换
3 cookie 的处理,一些 网站 对登录用户有更宽松的政策
友情提示:考虑爬虫给别人带来的负担网站,做一个负责任的爬虫:)
方法6.
尽可能模拟用户行为:
1、UserAgent 变化频繁;
2、 设置更长的访问时间间隔,将访问时间设置为随机数;
3、 访问页面的顺序也可以是随机的。
方法7.
网站 关闭一般是根据单位时间内访问特定IP的次数。
我按照目标站点的IP对采集的任务进行分组
通过控制单位时间内每个IP发出的任务数量,避免被阻塞。
当然,这个前提是你采集很多网站。如果只是采集一个网站,那么只能通过多个外部IP来实现。
方法8.
履带爬行压力控制;考虑使用代理访问目标站点。
降低爬取频率,设置更长的时间,访问时间使用随机数
频繁切换UserAgent(模拟浏览器访问)
多页数据,随机访问然后抓取数据更改用户IP。
动态网页抓取(济南优化网站搜索引擎的基础是拥有大量网页的信息数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-24 03:03
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,济南会优化网站的排名,因此可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)进入允许爬取的网站时,一般采用深度优先、宽度优先、高度优先三种策略进行爬取和遍历,以便抓取更多的网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接。济南网站 建立另一个链接,向下爬到网页,直到没有未爬取的链接。,然后回到第一页,向下爬到另一个链。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到一级网页A、B、C的链接并抓取它们,然后再抓取下一级网页A1、A2、A3、B1、B2和B3,爬取二级网页后,爬取三级网页A4、A5,简单点A6上济南seo,尝试抓取所有页面。
更好的优先级爬取策略是按照一定的算法划分网页的重要性。网页的重要性主要通过网页排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多搜索引擎的信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,从而提高履带的工作效率。因此,爬虫也会优先爬取响应速度较快的网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小网站页面,影响了互联网信息差异化展示的发展,几乎进入了大网站的流量,小网站难以发展。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,济南网站建设通常只抓取互联网上的部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。搜索引擎在抓取网页时,会判断网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、重复性高的内容等,这些垃圾信息蜘蛛不会抓取,它们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。 查看全部
动态网页抓取(济南优化网站搜索引擎的基础是拥有大量网页的信息数据库)
搜索引擎的基础是拥有大量网页的信息数据库,是决定搜索引擎整体质量的重要指标。如果搜索引擎的Web信息量较小,济南会优化网站的排名,因此可供用户选择的搜索结果较少;海量的网络信息更能满足用户的搜索需求。
为了获得大量的网络信息数据库,搜索引擎必须采集网络资源。本文的工作是利用搜索引擎的网络爬虫来抓取和抓取互联网上每个网页的信息。这是一个抓取和采集信息的程序,通常称为蜘蛛或机器人。
(1)搜索引擎抓取网页时,会同时运行多个蜘蛛程序,根据搜索引擎地址库中的网址进行浏览和抓取网站。地址库中的网址包括用户提交的网址、大导航站网址、手册网址采集、蜘蛛爬取的新网址等。
(2)进入允许爬取的网站时,一般采用深度优先、宽度优先、高度优先三种策略进行爬取和遍历,以便抓取更多的网站内容。
深度优先的爬取策略是搜索引擎蜘蛛在一个网页中找到一个链接,向下爬到下一个网页的链接。济南网站 建立另一个链接,向下爬到网页,直到没有未爬取的链接。,然后回到第一页,向下爬到另一个链。
在上面的例子中,搜索引擎蜘蛛到达网站的首页,找到一级网页A、B、C的链接并抓取它们,然后再抓取下一级网页A1、A2、A3、B1、B2和B3,爬取二级网页后,爬取三级网页A4、A5,简单点A6上济南seo,尝试抓取所有页面。
更好的优先级爬取策略是按照一定的算法划分网页的重要性。网页的重要性主要通过网页排名、网站规模、响应速度等来判断,搜索引擎抓取并获得更高的优先级。只有当 PageRank 达到一定级别时,才能进行抓取和抓取。实际蜘蛛抓取网页时,会将网页的所有链接采集到地址库中,进行分析,然后选择PR较高的链接进行抓取。网站 规模大,通常大的网站可以获得更多搜索引擎的信任,大的网站更新频率快,蜘蛛会先爬。网站的响应速度也是影响蜘蛛爬行的重要因素。在更好的优先级爬取策略中,网站 响应速度快,从而提高履带的工作效率。因此,爬虫也会优先爬取响应速度较快的网站。
这些爬行策略各有利弊。比如depth-first一般选择合适的深度,避免陷入大量数据,从而限制页面抓取量;width-first 随着抓取页面数量的增加,搜索引擎需要排除大量不相关的页面链接,抓取效率会变低;更好的优先级忽略了很多小网站页面,影响了互联网信息差异化展示的发展,几乎进入了大网站的流量,小网站难以发展。
在搜索引擎蜘蛛的实际抓取中,通常会同时使用这三种抓取策略。经过一段时间的抓取,搜索引擎蜘蛛可以抓取互联网上的所有网页。但是,由于互联网资源庞大,搜索引擎资源有限,济南网站建设通常只抓取互联网上的部分网页。
蜘蛛抓取网页后,会测试网页的值是否符合抓取标准。搜索引擎在抓取网页时,会判断网页中的信息是否为垃圾信息,如大量重复的文字内容、乱码、重复性高的内容等,这些垃圾信息蜘蛛不会抓取,它们只是爬行。
搜索引擎判断一个网页的价值后,就会收录有价值的网页。采集过程就是将采集到达的网页信息存储到信息库中,根据一定的特征对网页信息进行分类,以URL为单位进行存储。
搜索引擎抓取和抓取是提供搜索服务的基本条件。随着大量Web数据的出现,搜索引擎可以更好地满足用户的查询需求。
动态网页抓取(2.动态网页:不只有代码写出的网页被称为动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-24 03:02
T小昂仔 11月26日
版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的整个网络爬取。只要人能看到,理论上爬虫就可以获得。不管是静态页面还是动态页面。无论是PC端的页面还是移动端的应用程序都没有关系。爬虫,有很多语言可以选择,python、php、go、java……甚至c。但是现在主流是python作为爬虫的编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(不再使用python3)、requests。我们先来比较一下它们的区别:
urllib 和 urllib2 是python的标准库,也就是安装python的话,可以直接使用这两个库;requests是第三方库,不是python基金会实现的,但是功能很强大。
但是urllib和urllib2都是通过url打开资源的。其中,urllib 只能接受 url,而是将请求伪装成 headers。这样写的爬虫发送的请求会直接被很多网站拦截,伪装的不行,需要很复杂的修改,在前面的文章中已经介绍过了。
requests库可以实现urllib和urllib2的所有功能,有它们不具备的优点。在使用过程中,请求更有用。
一:什么是静态网页和动态网页?
1.静态网页:通俗的说,只有HTML格式的网页通常称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python爬取的过程中,有一个强大的Request库,可以方便的发送HTTP请求,方便我们爬取静态网页。
2.动态网页:不仅仅由HTML代码编写的网页称为动态网页。这些网页通常由 CSS、JavaScript 代码和 HTML 代码组成。他们用于通过 Ajax 动态加载网页的数据可能不一定出现在 HTML 中。在代码中,这需要复杂的操作。
二:静态网页抓取
1.要求安装,操作简单
(1)安装
在 cmd 或终端中写入
pip install requests
就是这样。
(2)获取网页内容'
Request最常用的功能是获取网页的内容。我们先来获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用对应的函数来获取需要的信息。结果如下图所示:
...
以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中的内置 JSON 解码器。
2.自定义请求
现在我们可以抓取网页的html代码数据了,但是有时候我们只需要一部分数据,那么我们需要设置Requests的参数来获取我们需要的数据,包括传递URL参数,自定义请求头,发送POST 请求。设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。这些数据后面一般都跟一个问号,以键值对的形式放在URL中。
在Request中,我们可以直接将这些参数保存在一个字典中,并使用params将它们构造成URL。
下面是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
我们看一下结果:
(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或请求头与实际网页不一致,可能返回不正确的结果。请求不会根据自定义的请求标头改变其行为。只有在最后的请求中,才会传入请求头信息。
我们可以按照下面的方法找到正确的请求头:
打开上一篇博客的内容:
然后我们右键,选择检查(有些浏览器也叫检查元素),然后选择网络选项:
当我们选择python的图片时,会发现在左边的资源栏中截取了一个文件,即图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:
然后我们将我们自定义的请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:
这里返回的响应码是 400 表示我们的代码是错误的。这说明我们不能使用这种方法来抓取图像。关于如何正确抓取图片,我会在下面的文章中和大家聊一聊。
3.发送POST请求
除了GET请求,有时还需要发送一些以表单形式编码的数据。这时候只需要给Request中的data参数传递一个字典,这些数据字典会在发送请求的时候自动编码到表单中。我们之前在爬有道词典的文章中使用了这个请求。
4.超时
可以使用Requests设置超时参数,如果在指定时间内没有响应则抛出异常。
三:豆瓣前100电影片名爬取示例
先打开网址
然后我们找到每部电影的HTML代码:
在这里,我们需要的信息在
发现只有start=""后面的区别,我们可以分析四次,或者循环进行:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们用format()格式化字符串(这里也可以用%格式化字符串),看看结果:
在这里我们看到我们已经成功爬取到了我们想要的内容。 查看全部
动态网页抓取(2.动态网页:不只有代码写出的网页被称为动态)
T小昂仔 11月26日
版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的整个网络爬取。只要人能看到,理论上爬虫就可以获得。不管是静态页面还是动态页面。无论是PC端的页面还是移动端的应用程序都没有关系。爬虫,有很多语言可以选择,python、php、go、java……甚至c。但是现在主流是python作为爬虫的编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(不再使用python3)、requests。我们先来比较一下它们的区别:
urllib 和 urllib2 是python的标准库,也就是安装python的话,可以直接使用这两个库;requests是第三方库,不是python基金会实现的,但是功能很强大。
但是urllib和urllib2都是通过url打开资源的。其中,urllib 只能接受 url,而是将请求伪装成 headers。这样写的爬虫发送的请求会直接被很多网站拦截,伪装的不行,需要很复杂的修改,在前面的文章中已经介绍过了。
requests库可以实现urllib和urllib2的所有功能,有它们不具备的优点。在使用过程中,请求更有用。
一:什么是静态网页和动态网页?
1.静态网页:通俗的说,只有HTML格式的网页通常称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python爬取的过程中,有一个强大的Request库,可以方便的发送HTTP请求,方便我们爬取静态网页。
2.动态网页:不仅仅由HTML代码编写的网页称为动态网页。这些网页通常由 CSS、JavaScript 代码和 HTML 代码组成。他们用于通过 Ajax 动态加载网页的数据可能不一定出现在 HTML 中。在代码中,这需要复杂的操作。
二:静态网页抓取
1.要求安装,操作简单
(1)安装
在 cmd 或终端中写入
pip install requests
就是这样。
(2)获取网页内容'
Request最常用的功能是获取网页的内容。我们先来获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用对应的函数来获取需要的信息。结果如下图所示:
...
以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中的内置 JSON 解码器。
2.自定义请求
现在我们可以抓取网页的html代码数据了,但是有时候我们只需要一部分数据,那么我们需要设置Requests的参数来获取我们需要的数据,包括传递URL参数,自定义请求头,发送POST 请求。设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。这些数据后面一般都跟一个问号,以键值对的形式放在URL中。
在Request中,我们可以直接将这些参数保存在一个字典中,并使用params将它们构造成URL。
下面是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
我们看一下结果:
(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或请求头与实际网页不一致,可能返回不正确的结果。请求不会根据自定义的请求标头改变其行为。只有在最后的请求中,才会传入请求头信息。
我们可以按照下面的方法找到正确的请求头:
打开上一篇博客的内容:
然后我们右键,选择检查(有些浏览器也叫检查元素),然后选择网络选项:
当我们选择python的图片时,会发现在左边的资源栏中截取了一个文件,即图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:
然后我们将我们自定义的请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:
这里返回的响应码是 400 表示我们的代码是错误的。这说明我们不能使用这种方法来抓取图像。关于如何正确抓取图片,我会在下面的文章中和大家聊一聊。
3.发送POST请求
除了GET请求,有时还需要发送一些以表单形式编码的数据。这时候只需要给Request中的data参数传递一个字典,这些数据字典会在发送请求的时候自动编码到表单中。我们之前在爬有道词典的文章中使用了这个请求。
4.超时
可以使用Requests设置超时参数,如果在指定时间内没有响应则抛出异常。
三:豆瓣前100电影片名爬取示例
先打开网址
然后我们找到每部电影的HTML代码:
在这里,我们需要的信息在
发现只有start=""后面的区别,我们可以分析四次,或者循环进行:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们用format()格式化字符串(这里也可以用%格式化字符串),看看结果:
在这里我们看到我们已经成功爬取到了我们想要的内容。
动态网页抓取(爬取一个动态网页刷新问题,解决方案如下思路使用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-19 06:20
)
更新。. . . . 这个动态网页其实可以直接抓取Ajax请求。这很简单。之前觉得很复杂。虽然已经实现了,但是效率极低,不过还好。只需将其视为对硒的研究。
1. 最近在爬动态网页。为了更新页面,需要选择不同的选项,即对下拉框进行处理。这里的下拉框是一个用输入实现的假下拉框,但后面还有一个。一个隐藏的select,本来想用js脚本修改隐藏的select变为可见,然后点击等操作,但是使用网上的方法后,发现select是visible变为visible的,但是之后没有效果点击 ,各方搜索无果,最后决定自己解决这个问题。解决方法如下
思路是用selenium完全模拟人的操作,一步一步点击可见按钮
,一,找到下拉框按钮,点击,
其次,点击下拉框按钮后,会出现一个列表。在列表中找到一个元素并单击。注意这一步一定要在下拉框按钮点击后进行(使用time.sleep()等待几秒,否则(会提示点击的内容不存在)
通过这两个步骤,我们就可以改变动态网页的信息了,代码如下
def getButton(browser):
# 获取下拉框按钮
Button = browser.find_elements_by_class_name("textbox-icon") # 定位哪一栋楼按钮
buildButton = Button[0]
floorButton = Button[1]
buildingsAndFloors = browser.find_elements_by_class_name("combobox-item") # 楼选项
floors = buildingsAndFloors[30:]
buildings = buildingsAndFloors[:30]
info = dict()
info['floors'] = floors
info['buildings'] = buildings
info['buildButton'] = buildButton
info['floorButton'] = floorButton
return info
2. 还有,在爬取的时候,经常会提示点击按钮或者不存在的东西,所以一定要设置一个延迟。
3.你得到的一些动态网页的源码和你在网页f12上看到的不一样,我的解决办法是你先在网页上进行一个操作,然后得到源码就会普通的
4.动态网页有不断刷新的问题,但是每次刷新后都会提示旧元素不能使用,所以必须重新获取不可用信息,如下,getButton()函数获取Button信息,每次页面刷新后需要点击按钮时都会检索到这些信息,
# 获取某一栋楼某一层的信息所对应页面的源代码
def getSoup(buildNumber, floor):
info = getButton(browser)
info['buildButton'].click() # 点击指定楼
info['buildings'][buildNumber].click()
time.sleep(1)
info = getButton(browser) # 重新获取信息
time.sleep(1)
info['floorButton'].click() # 点击指定楼层
info['floors'][floor].click()
soup = BeautifulSoup(browser.page_source, 'html.parser')
return soup 查看全部
动态网页抓取(爬取一个动态网页刷新问题,解决方案如下思路使用
)
更新。. . . . 这个动态网页其实可以直接抓取Ajax请求。这很简单。之前觉得很复杂。虽然已经实现了,但是效率极低,不过还好。只需将其视为对硒的研究。
1. 最近在爬动态网页。为了更新页面,需要选择不同的选项,即对下拉框进行处理。这里的下拉框是一个用输入实现的假下拉框,但后面还有一个。一个隐藏的select,本来想用js脚本修改隐藏的select变为可见,然后点击等操作,但是使用网上的方法后,发现select是visible变为visible的,但是之后没有效果点击 ,各方搜索无果,最后决定自己解决这个问题。解决方法如下
思路是用selenium完全模拟人的操作,一步一步点击可见按钮
,一,找到下拉框按钮,点击,
其次,点击下拉框按钮后,会出现一个列表。在列表中找到一个元素并单击。注意这一步一定要在下拉框按钮点击后进行(使用time.sleep()等待几秒,否则(会提示点击的内容不存在)
通过这两个步骤,我们就可以改变动态网页的信息了,代码如下
def getButton(browser):
# 获取下拉框按钮
Button = browser.find_elements_by_class_name("textbox-icon") # 定位哪一栋楼按钮
buildButton = Button[0]
floorButton = Button[1]
buildingsAndFloors = browser.find_elements_by_class_name("combobox-item") # 楼选项
floors = buildingsAndFloors[30:]
buildings = buildingsAndFloors[:30]
info = dict()
info['floors'] = floors
info['buildings'] = buildings
info['buildButton'] = buildButton
info['floorButton'] = floorButton
return info
2. 还有,在爬取的时候,经常会提示点击按钮或者不存在的东西,所以一定要设置一个延迟。
3.你得到的一些动态网页的源码和你在网页f12上看到的不一样,我的解决办法是你先在网页上进行一个操作,然后得到源码就会普通的
4.动态网页有不断刷新的问题,但是每次刷新后都会提示旧元素不能使用,所以必须重新获取不可用信息,如下,getButton()函数获取Button信息,每次页面刷新后需要点击按钮时都会检索到这些信息,
# 获取某一栋楼某一层的信息所对应页面的源代码
def getSoup(buildNumber, floor):
info = getButton(browser)
info['buildButton'].click() # 点击指定楼
info['buildings'][buildNumber].click()
time.sleep(1)
info = getButton(browser) # 重新获取信息
time.sleep(1)
info['floorButton'].click() # 点击指定楼层
info['floors'][floor].click()
soup = BeautifulSoup(browser.page_source, 'html.parser')
return soup
动态网页抓取( 使用到了urllib模块,需要的朋友可以参考下最基本的抓取功能 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-19 06:19
使用到了urllib模块,需要的朋友可以参考下最基本的抓取功能
)
使用Python3编写脚本抓取网页,只抓取网页图片
更新时间:2015-08-20 09:46:01 作者:大摩天升
本文文章主要介绍使用Python3编写抓取网页和只抓取网页图片的脚本。使用了 urllib 模块。有需要的朋友可以参考
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
''' 查看全部
动态网页抓取(
使用到了urllib模块,需要的朋友可以参考下最基本的抓取功能
)
使用Python3编写脚本抓取网页,只抓取网页图片
更新时间:2015-08-20 09:46:01 作者:大摩天升
本文文章主要介绍使用Python3编写抓取网页和只抓取网页图片的脚本。使用了 urllib 模块。有需要的朋友可以参考
抓取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页抓图功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
'''
动态网页抓取(详解如何通过创建Robots.txt来解决网站被重复抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-19 06:17
我们在用百度统计中的SEO建议查网站时,总发现“静态页面参数”这一项被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致最后一只蜘蛛进行了多次重复爬行。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。注重用户体验的网站是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎的蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网络蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php 查看全部
动态网页抓取(详解如何通过创建Robots.txt来解决网站被重复抓取)
我们在用百度统计中的SEO建议查网站时,总发现“静态页面参数”这一项被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致最后一只蜘蛛进行了多次重复爬行。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上没有密码保护的所有页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。注重用户体验的网站是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*是通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎的蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网络蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php
动态网页抓取(常见的反爬机制及处理方式(,文中))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-18 15:08
本文文章主要介绍python爬取Ajax动态加载网页过程的分析。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('./@title')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0] print(two_link) break
2、 从二级页面链接中提取真实链接(反爬响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/chart/top_list?' self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是python爬取Ajax动态加载网页过程分析的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
动态网页抓取(常见的反爬机制及处理方式(,文中))
本文文章主要介绍python爬取Ajax动态加载网页过程的分析。文章通过示例代码对其进行了详细介绍。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
常见的防爬机构及处理方法
1、Headers 反爬虫:Cookie、Referer、User-Agent
解决办法:通过F12获取headers,传递给requests.get()方法
2、IP限制:网站根据IP地址访问频率反爬,短时间内IP访问
解决方案:
1、 构建自己的IP代理池,每次访问随机选择代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
3、User-Agent 限制:类似于 IP 限制
解决方案:构建自己的User-Agent池,每次访问随机选择
5、查询参数或表单数据的认证(salt,sign)
解决方法:找到JS文件,分析JS处理方式,用Python同样处理
6、处理响应内容
解决方法:打印查看响应内容,使用xpath或者正则处理
python中标题和表单数据的常规处理
1、pycharm 进入方法:Ctrl + r,选择Regex
2、处理标头和表单数据
(.*): (.*)
"1":"1":"2",
3、点击全部替换
民政部网站数据采集
目标:抓取中华人民共和国县级以上最新行政区划代码
网址:-民政数据-行政部门代码
实施步骤
1、民政数据提取最新行政区划代码链接网站
最新在上,命名格式:X,2019,中华人民共和国县及以上行政区划代码
import requests from lxml import etree import re url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} html = requests.get(url, headers=headers).text parse_html = etree.HTML(html) article_list = parse_html.xpath('//a[@class="artitlelist"]') for article in article_list: title = article.xpath('./@title')[0] # 正则匹配title中包含这个字符串的链接 if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 two_link = 'http://www.mca.gov.cn' + article.xpath('./@href')[0] print(two_link) break
2、 从二级页面链接中提取真实链接(反爬响应在网页内容中嵌入JS,指向新的网页链接)
向二级页面链接发送请求获取响应内容,查看嵌入的JS代码
定期提取真实二级页面链接
# 爬取二级“假”链接 two_html = requests.get(two_link, headers=headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) new_two_link = re.findall(r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ', two_html, re.S)[0]
3、在数据库表中查询该链接是否被爬取过,构建增量爬虫
在数据库中创建一个版本表来存储爬取的链接
每次程序执行时都会记录版本表,查看是否被爬取过
cursor.execute('select * from version') result = self.cursor.fetchall() if result: if result[-1][0] == two_link: print('已是最新') else: # 有更新,开始抓取 # 将链接再重新插入version表记录
4、代码实现
import requests from lxml import etree import re import pymysql class GovementSpider(object): def __init__(self): self.url = 'http://www.mca.gov.cn/article/sj/xzqh/2019/' self.headers = {'User-Agent': 'Mozilla/5.0'} # 创建2个对象 self.db = pymysql.connect('127.0.0.1', 'root', '123456', 'govdb', charset='utf8') self.cursor = self.db.cursor() # 获取假链接 def get_false_link(self): html = requests.get(url=self.url, headers=self.headers).text # 此处隐藏了真实的二级页面的url链接,真实的在假的响应网页中,通过js脚本生成, # 假的链接在网页中可以访问,但是爬取到的内容却不是我们想要的 parse_html = etree.HTML(html) a_list = parse_html.xpath('//a[@class="artitlelist"]') for a in a_list: # get()方法:获取某个属性的值 title = a.get('title') if title.endswith('代码'): # 获取到第1个就停止即可,第1个永远是最新的链接 false_link = 'http://www.mca.gov.cn' + a.get('href') print("二级“假”链接的网址为", false_link) break # 提取真链接 self.incr_spider(false_link) # 增量爬取函数 def incr_spider(self, false_link): self.cursor.execute('select url from version where url=%s', [false_link]) # fetchall: (('http://xxxx.html',),) result = self.cursor.fetchall() # not result:代表数据库version表中无数据 if not result: self.get_true_link(false_link) # 可选操作: 数据库version表中只保留最新1条数据 self.cursor.execute("delete from version") # 把爬取后的url插入到version表中 self.cursor.execute('insert into version values(%s)', [false_link]) self.db.commit() else: print('数据已是最新,无须爬取') # 获取真链接 def get_true_link(self, false_link): # 先获取假链接的响应,然后根据响应获取真链接 html = requests.get(url=false_link, headers=self.headers).text # 从二级页面的响应中提取真实的链接(此处为JS动态加载跳转的地址) re_bds = r'window.location.href="(.*?)" rel="external nofollow" rel="external nofollow" ' pattern = re.compile(re_bds, re.S) true_link = pattern.findall(html)[0] self.save_data(true_link) # 提取真链接的数据 # 用xpath直接提取数据 def save_data(self, true_link): html = requests.get(url=true_link, headers=self.headers).text # 基准xpath,提取每个信息的节点列表对象 parse_html = etree.HTML(html) tr_list = parse_html.xpath('//tr[@height="19"]') for tr in tr_list: code = tr.xpath('./td[2]/text()')[0].strip() # 行政区划代码 name = tr.xpath('./td[3]/text()')[0].strip() # 单位名称 print(name, code) # 主函数 def main(self): self.get_false_link() if __name__ == '__main__': spider = GovementSpider() spider.main()
动态加载数据捕获-Ajax
特征
右键->查看没有具体数据的网页源代码
滚动鼠标滚轮或其他动作时加载
抓住
F12 打开控制台,选择XHR异步加载数据包,找到抓取网络数据包的页面动作
通过XHR-->Header-->General-->Request URL获取json文件的URL地址
通过XHR-->Header-->查询字符串参数
豆瓣电影数据采集案例
目标
地址:豆瓣电影排行榜-故事
type_name=%E5%89%A7%E6%83%85&type=11&interval_id=100:90&action=
目标:抓取电影名称、电影评分
F12 数据包捕获 (XHR)
1、请求 URL(基本 URL 地址):
2、Query String Paramaters(查询参数)
# 查询参数如下: type: 13 # 电影类型 interval_id: 100:90 action: '[{},{},{}]' start: 0 # 每次加载电影的起始索引值 limit: 20 # 每次加载的电影数量
json文件位于以下地址:
基本 URL 地址 + 查询参数
''+'type=11&interval_id=100%3A90&action=&start=20&limit=20'
代码
import requests import time from fake_useragent import UserAgent class DoubanSpider(object): def __init__(self): self.base_url = 'https://movie.douban.com/j/chart/top_list?' self.i = 0 def get_html(self, params): headers = {'User-Agent': UserAgent().random} res = requests.get(url=self.base_url, params=params, headers=headers) res.encoding = 'utf-8' html = res.json() # 将json格式的字符串转为python数据类型 self.parse_html(html) # 直接调用解析函数 def parse_html(self, html): # html: [{电影1信息},{电影2信息},{}] item = {} for one in html: item['name'] = one['title'] # 电影名 item['score'] = one['score'] # 评分 item['time'] = one['release_date'] # 打印测试 # 打印显示 print(item) self.i += 1 # 获取电影总数 def get_total(self, typ): # 异步动态加载的数据 都可以在XHR数据抓包 url = 'https://movie.douban.com/j/chart/top_list_count?type={}&interval_id=100%3A90'.format(typ) ua = UserAgent() html = requests.get(url=url, headers={'User-Agent': ua.random}).json() total = html['total'] return total def main(self): typ = input('请输入电影类型(剧情|喜剧|动作):') typ_dict = {'剧情': '11', '喜剧': '24', '动作': '5'} typ = typ_dict[typ] total = self.get_total(typ) # 获取该类型电影总数量 for page in range(0, int(total), 20): params = { 'type': typ, 'interval_id': '100:90', 'action': '', 'start': str(page), 'limit': '20'} self.get_html(params) time.sleep(1) print('爬取的电影的数量:', self.i) if __name__ == '__main__': spider = DoubanSpider() spider.main()
腾讯招聘数据抓取(Ajax)
确定 URL 地址和目标
网址:百度搜索腾讯招聘-查看职位
目标:职位名称、工作职责、工作要求
需求与分析
通过查看网页源码可知,需要的数据是Ajax动态加载的
通过F12捕获网络数据包进行分析
一级页面爬取数据:职位
在二级页面上抓取数据:工作职责、工作要求
一级页面的json地址(pageIndex在变化,时间戳不检查)
{}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变化,可以在一级页面获取)
{}&language=zh-cn
用户代理.py文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网。
以上就是python爬取Ajax动态加载网页过程分析的详细内容。更多详情请关注其他相关html中文网站文章!
动态网页抓取(腾讯视频实测清晰度尚可,当然你也可以在百度云盘中下载以下全部视频)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-16 11:09
Hawk是Desert Eagle开发了五年的开源免费网络爬虫(crawler)。它不需要编程并且完全可视化。
Hawk2.0 上次发布已经有半年的时间了,但是还是有很多朋友通过邮件或者微信询问如何使用。查看文档不如视频教学方便。沙漠先生决定录制和播放几个视频来帮助大家~
软件最新下载地址(或点击原文)
以下是视频内容。腾讯视频可以开启高清,实测分辨率可以接受。当然,您也可以在百度云盘中下载以下所有视频。
1. 用Hawk抓取百度新闻
这是从百度爬取百家新闻()的完整示例,可以学习:
内置播放器无法调整清晰度。可以在PC上访问:
2. 鹰问答
这是一个综述,回答关于每个人都感兴趣的话题的问题和答案,包括:
可以在PC上访问:
3. 历史视频
这些视频是2016年上半年为1.0录制的。由于网站的改版或者加入了反爬虫(如链家),使用上会有很大的不同,只为每个人。用户参考。
4. 如何下载项目案例
Hawk本身提供了一系列的例子(虽然基本都是2016年上半年的),很多已经过期了。
有的朋友直接用“右键另存为”下载,这样html页面就保存下来了。有两种下载方式:
git clone :ferventdesert/Hawk-Projects.git
4. 欢迎一起改进Hawk
为什么要再次改进Hawk?
长征走了九千五百里,到了最后一段路,他就停了下来,给世界留下了半挂机,这终究是不好的。因此,2017年的一项重要任务是进一步完善,完成剩余的500英里。
因此,如果您对Hawk、爬虫或软件设计感兴趣,可以考虑与沙漠先生一起改进。只要你有什么靠谱的建议,都可以告诉我,我会一起努力改进的。也许你可能得不到任何经济补偿(沙漠先生也没有),但它比互联网上的各种野路收费软件要好得多。我们已经做了一些可以帮助数十万人甚至数百万人的事情。
虽然我工作很忙,各种回复都不及时,但是如果你有任何问题,你仍然可以给我发邮件:
最后祝大家使用Hawk愉快! 查看全部
动态网页抓取(腾讯视频实测清晰度尚可,当然你也可以在百度云盘中下载以下全部视频)
Hawk是Desert Eagle开发了五年的开源免费网络爬虫(crawler)。它不需要编程并且完全可视化。
Hawk2.0 上次发布已经有半年的时间了,但是还是有很多朋友通过邮件或者微信询问如何使用。查看文档不如视频教学方便。沙漠先生决定录制和播放几个视频来帮助大家~
软件最新下载地址(或点击原文)
以下是视频内容。腾讯视频可以开启高清,实测分辨率可以接受。当然,您也可以在百度云盘中下载以下所有视频。
1. 用Hawk抓取百度新闻
这是从百度爬取百家新闻()的完整示例,可以学习:
内置播放器无法调整清晰度。可以在PC上访问:
2. 鹰问答
这是一个综述,回答关于每个人都感兴趣的话题的问题和答案,包括:
可以在PC上访问:
3. 历史视频
这些视频是2016年上半年为1.0录制的。由于网站的改版或者加入了反爬虫(如链家),使用上会有很大的不同,只为每个人。用户参考。
4. 如何下载项目案例
Hawk本身提供了一系列的例子(虽然基本都是2016年上半年的),很多已经过期了。
有的朋友直接用“右键另存为”下载,这样html页面就保存下来了。有两种下载方式:
git clone :ferventdesert/Hawk-Projects.git
4. 欢迎一起改进Hawk
为什么要再次改进Hawk?
长征走了九千五百里,到了最后一段路,他就停了下来,给世界留下了半挂机,这终究是不好的。因此,2017年的一项重要任务是进一步完善,完成剩余的500英里。
因此,如果您对Hawk、爬虫或软件设计感兴趣,可以考虑与沙漠先生一起改进。只要你有什么靠谱的建议,都可以告诉我,我会一起努力改进的。也许你可能得不到任何经济补偿(沙漠先生也没有),但它比互联网上的各种野路收费软件要好得多。我们已经做了一些可以帮助数十万人甚至数百万人的事情。
虽然我工作很忙,各种回复都不及时,但是如果你有任何问题,你仍然可以给我发邮件:
最后祝大家使用Hawk愉快!
动态网页抓取(HTML网页时会模拟浏览器行为分析方法分析及注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-16 10:08
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 网页时,我们发现我们要提取的网页元素不在我们下载的 HTML 中,即使它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求
Selenium 模拟浏览器行为
1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如如下图
OK,复制js请求的目标url
在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是去查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- 编码:utf-8 -*-
importsysfrom selenium importwebdriverfrom mon.keys importKeysfrom bs4 importBeautifulSoup
重新加载(系统)
sys.setdefaultencoding('utf-8')
网址 ='#39;
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)#在搜索框模拟输入信息,点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("疯狂")
elem.send_keys(Keys.RETURN)#获取动态加载的网页
数据 =driver.page_source
汤 = BeautifulSoup(data, "lxml")#match
对于我在soup.select("div[class='item-root']"):
name= i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url= i.find("a").get('href')
rate=""num=""
如果 i.find("span", class_="rating_nums") isNone:print name.encode("gbk", "ignore"), pic, urlelse:
rate= i.find("span", class_="rating_nums").text
num= i.find("span", class_="pl").textprint name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num. 编码(“gbk”,“忽略”) 查看全部
动态网页抓取(HTML网页时会模拟浏览器行为分析方法分析及注意事项)
介绍
有时,当我们天真地使用 urllib 库或 Scrapy 下载 HTML 网页时,我们发现我们要提取的网页元素不在我们下载的 HTML 中,即使它们在浏览器中似乎很容易获得。
这说明我们想要的元素是在我们的一些操作下通过js事件动态生成的。例如,当我们滑动Qzone或微博评论时,我们一直向下滑动。网页越来越长,内容也越来越多。这就是让人又爱又恨的动态加载。
目前有两种爬取动态页面的方式
分析页面请求
Selenium 模拟浏览器行为
1.分析页面请求
键盘F12打开开发者工具,选择Network选项卡,选择JS(除了JS选项卡和XHR选项卡,当然也可以使用其他抓包工具),如下图
然后,让我们拖动右侧的滚动条,然后我们会发现开发者工具中有新的js请求(很多),但是经过麻烦的翻译,很容易看出哪个是评论,如如下图
OK,复制js请求的目标url
在浏览器中打开,发现我们想要的数据就在这里,如下图
整个页面都是json格式的数据。对于京东来说,当用户下拉页面时,会触发一个js事件,将上面的请求发送到服务器去取数据,将取到的json数据填入HTML页面中。对于我们的Spider,我们要做的就是对这些json数据进行排序提取。
在实际应用中,当然我们不可能在每个页面中都找出这个js发起的请求的目标地址,所以我们需要分析一下这个请求地址的规律。一般来说,法律更容易找到,因为法律太复杂了。维护也很困难。
2.selenium 模拟浏览器行为
对于动态加载,可以看到Selenium+Phantomjs的强大。打开网页,查看网页的源代码(不是去查元素),你会发现要爬取的信息不在源代码中。也就是说,无法从网页的源代码中解析得到数据。Selenium+Phantomjs 的强大之处在于能够捕获完整的源代码
示例:在豆瓣电影上根据给定的名称搜索相应信息
#-*- 编码:utf-8 -*-
importsysfrom selenium importwebdriverfrom mon.keys importKeysfrom bs4 importBeautifulSoup
重新加载(系统)
sys.setdefaultencoding('utf-8')
网址 ='#39;
#这个路径就是你添加到PATH的路径
driver = webdriver.PhantomJS(executable_path='C:/Python27/Scripts/phantomjs-2.1.1-windows/bin/phantomjs.exe')
driver.get(url)#在搜索框模拟输入信息,点击
elem = driver.find_element_by_name("search_text")
elem.send_keys("疯狂")
elem.send_keys(Keys.RETURN)#获取动态加载的网页
数据 =driver.page_source
汤 = BeautifulSoup(data, "lxml")#match
对于我在soup.select("div[class='item-root']"):
name= i.find("a", class_="title-text").text
pic = i.find("img").get('src')
url= i.find("a").get('href')
rate=""num=""
如果 i.find("span", class_="rating_nums") isNone:print name.encode("gbk", "ignore"), pic, urlelse:
rate= i.find("span", class_="rating_nums").text
num= i.find("span", class_="pl").textprint name.encode("gbk", "ignore"),pic,url,rate.encode("gbk", "ignore"),num. 编码(“gbk”,“忽略”)
动态网页抓取(1.代码实现接下来提取首页jobName中包含python的所有链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-16 10:00
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/%3Fjl% ... 39%3B
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
转载于: 查看全部
动态网页抓取(1.代码实现接下来提取首页jobName中包含python的所有链接)
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/%3Fjl% ... 39%3B
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
转载于:
动态网页抓取(Selenium实例:Airbnb短租数据目的:动态网页(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-16 09:48
动态网页抓取
上次实现了豆瓣书书Top250书名的静态网页爬取,这次跟着同一本书,研究一下动态网页的爬取。
动态网页简介
动态网页和静态网页的区别在于静态网页上显示的内容在HTML源代码中,而动态网页往往使用AJAX技术在后端和服务器之间交换数据,这样网页就可以访问,而无需重新加载整个页面。执行部分更新。
AJAX,全称是Asynchronous JavaScript And XML,即异步JavaScript和XML。它的使用使互联网应用程序更快更小,减少了网页重复内容的下载,节省了流量,但爬取过程比较复杂。
动态网页抓取过程
爬取AJAX加载的动态网页内容有两种方式:
通过浏览器审查元素解析地址
使用Chrome浏览器查看网页元素,找到真实数据地址,点击网络显示浏览器从Web服务器获取的所有文件。这个过程称为“数据包捕获”。这种方法容易遇到很多问题。例如,一些网页已经实施了一些加密措施来避免抓取数据,使用“检查”功能很难找到调用地址。通过 Selenium 模拟浏览器爬行
该方法使用浏览器渲染引擎,在显示网页时直接使用浏览器解析HTML、应用CSS样式、执行JavaScript语句。该方法在爬取过程中会自动操作浏览器浏览各种网页,并顺便往下爬取数据,即爬取动态网页为爬取静态网页。硒安装
Selenium 与其他 Python 库一样,可以使用 pip 安装。代码如下:
pip install selenium
成功出现。
Selenium 示例:Airbnb 短租数据
目的:获取湖南长沙前10家短租房的名称、价格、评论数、房型、床位、入住人数。
网址:[]=%2Fhomes&query=长沙&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE&s_tag=R2PBwazh
打开Airbnb长沙200强短租房源页面,点击“查询”查看数据所在位置,如图:
获取某家的数据地址:div._gig1e7
在这些数据中定位价格数据的地址是:div._18gk84h
同理可以得到评价数据、房名数据、房型数据,汇总如下表:
数据元素类
一个房子的所有数据
div
_gig1e7
价钱
div
_18gk84h
评价编号
div
_13o4q7nw
姓名
div
_qhtkbey
房屋类型
跨度
_fk7kh10
一旦找到数据的地址,就可以使用Selenium来获取Airbnb首页的数据。代码显示如下:
import time
from selenium import webdriver
#init url
url = 'https://www.airbnb.cn/s/homes% ... 39%3B
#init browser
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
结果是这样的:
这只是为了获取一页的内容,我们的目标是前10页,所以查看第二页的地址,可以发现地址变成了:[]=%2Fhomes§ion_offset=6&items_offset=18&s_tag= mt59xV_D
第三页地址为:[]=%2Fhomes§ion_offset=6&items_offset=36&s_tag=mt59xV_D
区别在于偏移量,是18的倍数,所以加一个循环,得到前十页的数据。代码可以修改如下:
import time
from selenium import webdriver
#init browser
driver = webdriver.Chrome()
for i in range(0,10):
url = 'https://www.airbnb.cn/s/homes% ... 3B%2B str(i*18) + '&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE'
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
当前结果是Airbnb上长沙地区房屋信息的前10页:
因为我懒,所以花了这么长时间才做这件事,所以我走到墙边反思。 查看全部
动态网页抓取(Selenium实例:Airbnb短租数据目的:动态网页(图))
动态网页抓取
上次实现了豆瓣书书Top250书名的静态网页爬取,这次跟着同一本书,研究一下动态网页的爬取。
动态网页简介
动态网页和静态网页的区别在于静态网页上显示的内容在HTML源代码中,而动态网页往往使用AJAX技术在后端和服务器之间交换数据,这样网页就可以访问,而无需重新加载整个页面。执行部分更新。
AJAX,全称是Asynchronous JavaScript And XML,即异步JavaScript和XML。它的使用使互联网应用程序更快更小,减少了网页重复内容的下载,节省了流量,但爬取过程比较复杂。
动态网页抓取过程
爬取AJAX加载的动态网页内容有两种方式:
通过浏览器审查元素解析地址
使用Chrome浏览器查看网页元素,找到真实数据地址,点击网络显示浏览器从Web服务器获取的所有文件。这个过程称为“数据包捕获”。这种方法容易遇到很多问题。例如,一些网页已经实施了一些加密措施来避免抓取数据,使用“检查”功能很难找到调用地址。通过 Selenium 模拟浏览器爬行
该方法使用浏览器渲染引擎,在显示网页时直接使用浏览器解析HTML、应用CSS样式、执行JavaScript语句。该方法在爬取过程中会自动操作浏览器浏览各种网页,并顺便往下爬取数据,即爬取动态网页为爬取静态网页。硒安装
Selenium 与其他 Python 库一样,可以使用 pip 安装。代码如下:
pip install selenium
成功出现。
Selenium 示例:Airbnb 短租数据
目的:获取湖南长沙前10家短租房的名称、价格、评论数、房型、床位、入住人数。
网址:[]=%2Fhomes&query=长沙&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE&s_tag=R2PBwazh
打开Airbnb长沙200强短租房源页面,点击“查询”查看数据所在位置,如图:
获取某家的数据地址:div._gig1e7
在这些数据中定位价格数据的地址是:div._18gk84h
同理可以得到评价数据、房名数据、房型数据,汇总如下表:
数据元素类
一个房子的所有数据
div
_gig1e7
价钱
div
_18gk84h
评价编号
div
_13o4q7nw
姓名
div
_qhtkbey
房屋类型
跨度
_fk7kh10
一旦找到数据的地址,就可以使用Selenium来获取Airbnb首页的数据。代码显示如下:
import time
from selenium import webdriver
#init url
url = 'https://www.airbnb.cn/s/homes% ... 39%3B
#init browser
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
结果是这样的:
这只是为了获取一页的内容,我们的目标是前10页,所以查看第二页的地址,可以发现地址变成了:[]=%2Fhomes§ion_offset=6&items_offset=18&s_tag= mt59xV_D
第三页地址为:[]=%2Fhomes§ion_offset=6&items_offset=36&s_tag=mt59xV_D
区别在于偏移量,是18的倍数,所以加一个循环,得到前十页的数据。代码可以修改如下:
import time
from selenium import webdriver
#init browser
driver = webdriver.Chrome()
for i in range(0,10):
url = 'https://www.airbnb.cn/s/homes% ... 3B%2B str(i*18) + '&place_id=ChIJxWQcnvM1JzQRgKbxoZy75bE'
driver.get(url)
time.sleep(3)
#get data
rent_list = driver.find_elements_by_css_selector('div._gig1e7')
for eachhouse in rent_list:
#find the comments
comment = eachhouse.find_element_by_css_selector('div._13o4q7nw')
comment = comment.text
#find the price
price = eachhouse.find_element_by_css_selector('div._18gk84h')
price = price.text.replace("每晚","").replace("价格", "").replace("\n", "")
#find the name
name = eachhouse.find_element_by_css_selector('div._qhtkbey')
name = name.text
#find other details
details = eachhouse.find_element_by_css_selector('span._fk7kh10')
details = details.text
house_type = details.split(" · ")[0]
bed_number = details.split(" · ")[1]
print(comment,price,name,house_type,bed_number)
当前结果是Airbnb上长沙地区房屋信息的前10页:
因为我懒,所以花了这么长时间才做这件事,所以我走到墙边反思。
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-16 09:46
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址 查看全部
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的某个产品的价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
进口请求
导入json
# 获取产品价格的请求地址
动态网页抓取(动态网页抓取(原理与程序实现):示例代码:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-15 04:05
动态网页抓取(原理与程序实现):示例代码:由于微信扫一扫的原理就是提取浏览器页面的html源代码,浏览器渲染页面也用到了threading这个库,可能有大牛看到这个提示之后有更好的思路去实现吧。分享一个demo,如果有想了解微信扫一扫原理的,这里放上源代码及demo:chrome/ffformacchrome/ffforwindows。
现有的浏览器版本如何做基于generalizedscanning的框架里大部分都依赖jqueryapi,且用jquery.scan()调用方式之后,在authorizationfull的dom可以获取到useragentvalue(rootdom点击才可以获取到)。基于这个原理就可以利用authorization这个api做一个动态网页抓取,现在还没有可以利用的库。
如果你真的觉得它们的网页抓取都无能为力,我觉得你先学学服务器端吧,你才知道怎么抓取,以后再用库如果你真的还是想用这些网页做,
一个页面基本大小和js占多少空间及自己的网页架构是怎样的情况吧,如果有多个可视域应该动态来看个每个client到底多少空间的流量我也没什么好说的,也不清楚题主说的类似代码是什么样子,现在开源的程序里,一般只有一种方法可以手动去配置,就是这个页面+一个接口,最大程度保证页面抓取安全吧,基本就是这个程序处理了。 查看全部
动态网页抓取(动态网页抓取(原理与程序实现):示例代码:)
动态网页抓取(原理与程序实现):示例代码:由于微信扫一扫的原理就是提取浏览器页面的html源代码,浏览器渲染页面也用到了threading这个库,可能有大牛看到这个提示之后有更好的思路去实现吧。分享一个demo,如果有想了解微信扫一扫原理的,这里放上源代码及demo:chrome/ffformacchrome/ffforwindows。
现有的浏览器版本如何做基于generalizedscanning的框架里大部分都依赖jqueryapi,且用jquery.scan()调用方式之后,在authorizationfull的dom可以获取到useragentvalue(rootdom点击才可以获取到)。基于这个原理就可以利用authorization这个api做一个动态网页抓取,现在还没有可以利用的库。
如果你真的觉得它们的网页抓取都无能为力,我觉得你先学学服务器端吧,你才知道怎么抓取,以后再用库如果你真的还是想用这些网页做,
一个页面基本大小和js占多少空间及自己的网页架构是怎样的情况吧,如果有多个可视域应该动态来看个每个client到底多少空间的流量我也没什么好说的,也不清楚题主说的类似代码是什么样子,现在开源的程序里,一般只有一种方法可以手动去配置,就是这个页面+一个接口,最大程度保证页面抓取安全吧,基本就是这个程序处理了。
动态网页抓取(待URL队列中的URL以什么样的顺序排列算法的思想 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-12 22:26
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要抓取的URL的顺序也是一个很重要的问题,因为它涉及到先抓取那个页面,再抓取哪个页面来确定这些URL的顺序,这就是所谓的抓取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每个链接。处理完这一行的链接后,会转到下一个起始页,继续跟踪链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,当我们在做爬虫的时候,深度优先策略可能并不适用于所有情况。如果深度优先误入无限分支(深度不限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一级搜索,再进行下一级,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它不考虑结果的可能位置,会彻底搜索整个图像,效率较低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,按照页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},这是要爬取的URL队列。如何确定下载顺序?
将这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,假设下载顺序可以得到。5、4、6,下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果此值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。流通,即不完全网络级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页重要性的主题。对于URL队列中要爬取的网页,根据自己的网站进行分类,如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。
查看全部
动态网页抓取(待URL队列中的URL以什么样的顺序排列算法的思想
)
遍历策略是爬虫的核心问题。在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要抓取的URL的顺序也是一个很重要的问题,因为它涉及到先抓取那个页面,再抓取哪个页面来确定这些URL的顺序,这就是所谓的抓取策略爬虫。主要有以下几种策略:
1.深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,逐个跟踪每个链接。处理完这一行的链接后,会转到下一个起始页,继续跟踪链接。我们用下图为例:
走过的路径是:AFG EHI BCD
但是,当我们在做爬虫的时候,深度优先策略可能并不适用于所有情况。如果深度优先误入无限分支(深度不限),则无法找到目标节点。
二、广度优先遍历策略:
广度优先策略是根据树的级别进行搜索。如果在这一层没有完成搜索,则不会进入下一层搜索。即先完成一级搜索,再进行下一级,也称为分层处理。我们也以上图为例:
遍历路径为:第一次遍历:ABCDEF,第二次遍历:GH,第三次遍历:I
然而,广度优先遍历策略是一种盲目搜索。它不考虑结果的可能位置,会彻底搜索整个图像,效率较低。但是,如果您想覆盖尽可能多的网页,广度优先搜索方法是更好的选择。
三、部分PageRank策略:
PageRank算法的思想:对于下载的网页,连同要爬取的URL队列的URL,组成一个网页集,计算每个页面的PageRank值(PageRank算法参考:PageRank算法-从原理到实现),计算完成后,按照页面级别的值排列待爬取队列中的URL,依次爬取URL页面。
如果每次都爬一个新的页面,重新计算出来的PageRank值显然效率太低了。折中是保存足够的网页来计算一次。
下图是web级策略的示意图:
为每下载 3 个网页设置一个新的 PageRank 计算。此时,本地已经下载了3个网页{1,2,3}。这三个网页中收录的链接指向{4,5,6},这是要爬取的URL队列。如何确定下载顺序?
将这6个网页组成一个新的集合,计算这个集合的PageRank值,这样4、5、6就会得到各自对应的页面排名值,从大到小排序,假设下载顺序可以得到。5、4、6,下载55页时,提取链接指向第8页,此时临时分配PageRank值为8。如果此值大于 4 和 6 的 PageRank,则将首先下载第 8 页,依此类推。流通,即不完全网络级策略的计算思想形成。
四、OPIC策略策略(在线页面重要性计算):
基本思想:在算法开始之前,给所有页面相同的初始现金(cash)。下载一个页面P后,将P的现金分配给所有从P解析的链接,并清空P的现金。所有要爬取的URL队列中的页面按照现金的数量进行排序。
与PageRank不同的是:PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。
五、各大站优先策略:
策略:以网站为单位选择网页重要性的主题。对于URL队列中要爬取的网页,根据自己的网站进行分类,如果哪个网站等待下载的页面最多,先下载这些链接,本质思路倾向于优先下载大的网站。因为大 网站 往往收录更多页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。实验表明,该算法的效果略优于宽度优先遍历策略。
花生代理动态IP更改软件可实现全国城市IP自动切换,千万级动态IP池,支持过滤,支持电脑手机多终端使用,数万条随机拨号线路, 24小时不间断提供动态IP。

