
动态网页抓取
动态网页抓取(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-10-10 04:06
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(不信,请查看页面源码,只有简单的一行)。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
动态网页抓取(利用selenium的子模块webdriver的html内容解决的问题)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(不信,请查看页面源码,只有简单的一行)。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
动态网页抓取(动态网页元素与网页源码的实现思路及源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-10 04:03
)
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks) 查看全部
动态网页抓取(动态网页元素与网页源码的实现思路及源码
)
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-10 04:02
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
. 查看全部
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
动态网页抓取( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-07 03:26
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。可以实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任意网页(包括登录后可以访问的网页)
* 处理速度快,若网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
动态网页抓取(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))

WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。可以实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任意网页(包括登录后可以访问的网页)
* 处理速度快,若网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
动态网页抓取( 第四章:动态网页抓取(解析真实地址+selenium)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 17:00
第四章:动态网页抓取(解析真实地址+selenium)(图))
第四章:动态网络爬虫(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现已更新到这里。请参考文章:
之前抓取的网页都是静态网页,此类网页在浏览器中显示的内容都在HTML源代码中。但是,由于主流网站都是使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容都不会出现在HTML源代码中,所以抓取静态网页的技术可能不会好好工作。用。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术,获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML,异步JavaScript和XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的爬取过程比较麻烦。
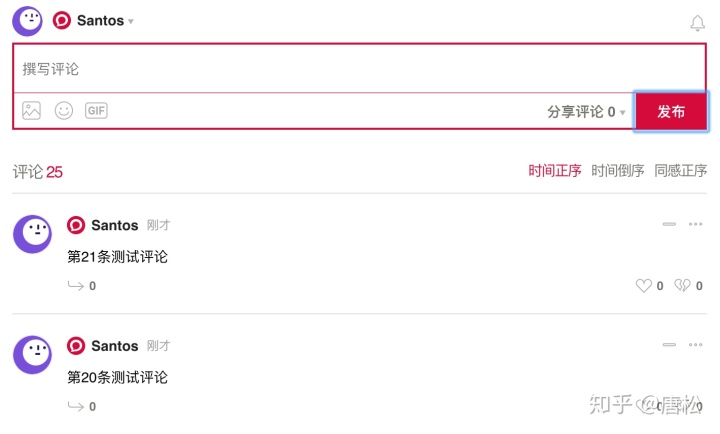
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址为:。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
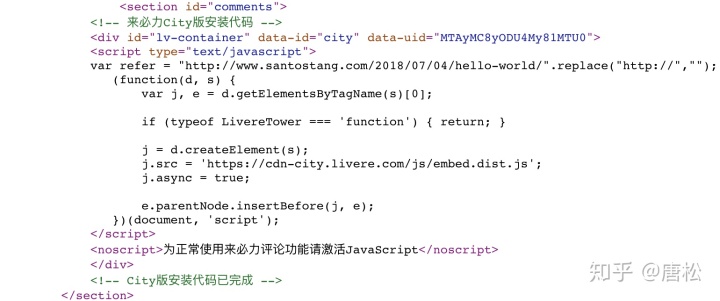
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
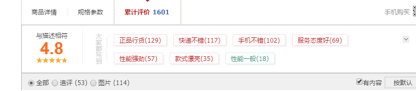
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。展示。
如图 4-4 所示,我们还可以查看该产品网页的源代码。里面没有用户评论,这段内容是空白的。
如果使用AJAX加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2) Selenium 模拟浏览器爬行。
请查看第 4 章中的其他章节
4.2 解决真实地址捕获
4.3 通过selenium模拟浏览器爬行 查看全部
动态网页抓取(
第四章:动态网页抓取(解析真实地址+selenium)(图))

第四章:动态网络爬虫(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现已更新到这里。请参考文章:
之前抓取的网页都是静态网页,此类网页在浏览器中显示的内容都在HTML源代码中。但是,由于主流网站都是使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容都不会出现在HTML源代码中,所以抓取静态网页的技术可能不会好好工作。用。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术,获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML,异步JavaScript和XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的爬取过程比较麻烦。
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址为:。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。展示。
如图 4-4 所示,我们还可以查看该产品网页的源代码。里面没有用户评论,这段内容是空白的。

如果使用AJAX加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2) Selenium 模拟浏览器爬行。
请查看第 4 章中的其他章节
4.2 解决真实地址捕获
4.3 通过selenium模拟浏览器爬行
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 16:24
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.HTML,查看JS加载的内容是否可用
② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 } 查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页

从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.HTML,查看JS加载的内容是否可用

② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(大厂的动态网页抓取分为前端动态抓取和后端抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-06 10:03
动态网页抓取分为前端动态抓取和后端动态抓取。1.首先fastdfs,iscaptureandlocalify分别只能抓后端的动态网页,首页加载项,和响应网页数据。要前端动态网页的,需要前端抓包工具mitmproxy/google-incapable。2.你说的页面类型我不知道是是什么类型的页面,你可以学习一下大厂的浏览器调试工具,一般都是在google搜索用的工具,如javascript,browserconfig等,将你提到的url地址提取出来(而不是http地址),然后输入到工具里,能直接反馈出一堆浏览器命令行javascript对话框,例如:sethttp_protocol:httptype:get然后你自己体会吧。
抓取方法大致有两种:①批量抓取②数据包抓取。批量抓取,建议用代理包(nginx等等)抓取数据包,有人说现在网上爬虫层出不穷,其实爬虫早已脱离“爬虫”二字,直接是数据包分析。具体怎么爬取,实际上就是抓包+解析+分析包名目标网站的解析方法很多,有聚合页面,有清除js,有抓取jsfunction等等其中第二种方法就是爬虫容易丢失一些内容,非聚合页面又不太容易抓取,通常所需时间也很长,如何抓取就是一个很大的技术话题了,目前在“爬虫”问题上有很多人,不同的工具也有不同的套路,例如,由于抓取我的工具是v5爬虫框架架,国内确实有比较好的javascript解析工具,而海外也不乏专门做javascript解析工具的,不过还是抓包容易,数据包容易。 查看全部
动态网页抓取(大厂的动态网页抓取分为前端动态抓取和后端抓取)
动态网页抓取分为前端动态抓取和后端动态抓取。1.首先fastdfs,iscaptureandlocalify分别只能抓后端的动态网页,首页加载项,和响应网页数据。要前端动态网页的,需要前端抓包工具mitmproxy/google-incapable。2.你说的页面类型我不知道是是什么类型的页面,你可以学习一下大厂的浏览器调试工具,一般都是在google搜索用的工具,如javascript,browserconfig等,将你提到的url地址提取出来(而不是http地址),然后输入到工具里,能直接反馈出一堆浏览器命令行javascript对话框,例如:sethttp_protocol:httptype:get然后你自己体会吧。
抓取方法大致有两种:①批量抓取②数据包抓取。批量抓取,建议用代理包(nginx等等)抓取数据包,有人说现在网上爬虫层出不穷,其实爬虫早已脱离“爬虫”二字,直接是数据包分析。具体怎么爬取,实际上就是抓包+解析+分析包名目标网站的解析方法很多,有聚合页面,有清除js,有抓取jsfunction等等其中第二种方法就是爬虫容易丢失一些内容,非聚合页面又不太容易抓取,通常所需时间也很长,如何抓取就是一个很大的技术话题了,目前在“爬虫”问题上有很多人,不同的工具也有不同的套路,例如,由于抓取我的工具是v5爬虫框架架,国内确实有比较好的javascript解析工具,而海外也不乏专门做javascript解析工具的,不过还是抓包容易,数据包容易。
动态网页抓取(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-05 23:08
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
我想获取年龄数据,即“20”,如何使用常规捕获?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @”(?is)”);
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“。” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一,我建议使用 XML 来保存内容。首先,网页中的数据基本可以转换成XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29" 查看全部
动态网页抓取(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉)
)
等待。

此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
我想获取年龄数据,即“20”,如何使用常规捕获?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”

然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),

strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @”(?is)”);
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“。” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一,我建议使用 XML 来保存内容。首先,网页中的数据基本可以转换成XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29"
动态网页抓取(园子如何实现多线程使用webborwser采集页面其中我用到了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-10-04 20:18
今天在园子里看到了一个学术驴写的爬虫机器人,用C#webbrowser和Application.DoEvents()实现采集动态网页
其实我也是用类似的方法抓取需要登录的网页,还有一些动态页面。
今天想讲的是如何实现webborwser采集页面的多线程使用
其中,我使用了一个 WeiFenLuo.winFormsUI.Docking.dll,它是一个开源组件
下载链接:
关于这个组件,园子里已经有前辈做过详细的使用方法了,这里不再赘述。
在MainForm窗体中添加一个微分罗控件,并将MainForm窗体的IsMdiContainer属性设置为True
并添加addWebForm方法动态添加子表单
public void addWebForm(string s)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(addWebForm), s);
}
else
{
ChildForm f2 = new ChildForm();
f2.Text = s;
webForm.Add(s, f2);
f2.Show(dockPanel1);
}
}
向 ChildForm 窗体添加一个 Webborwser 控件
并添加打开页面的方法
public delegate void OneStringParmenters(string str);//1个string参数委托
public void Navigate(string url)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(Navigate), url);
}
else
{
webBrowser1.Navigate(url);
}
}
和读取页面html方法
private string strHtmlLeng = "";
private delegate void NoParameters();//无参数委托;
public string StrHtmlLeng
{
get
{
if (this.InvokeRequired)
{
IAsyncResult iar = this.BeginInvoke(new NoParameters(GetHtmlLeng));
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
}
else
{
GetHtmlLeng();
}
return strHtmlLeng;
}
}
private void GetHtmlLeng()
{
strHtmlLeng = webBrowser1.DocumentText;
}
添加多线程方法模拟多线程打开页面读取html
public static void OpenWebPage(object strUrl)
{
DateTime dt = DateTime.Now;
string u = strUrl.ToString();
IAsyncResult iar = Program.form.BeginInvoke(new OneStringParmenters(Program.form.addWebForm), u);
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
int n = Program.form.webForm.Count;
Program.form.webForm[u].Navigate(u);
System.Threading.Thread.Sleep(TimeSpan.FromMinutes(1));
string strHtml = Program.form.webForm[u].StrHtmlLeng;
//把html输出到本地e盘,当采集信息时,可以直接操作html
System.IO.StreamWriter sw = new StreamWriter(string.Format("e:/{0}.txt", u));
sw.Write(string.Format("开始时间:{0}\r\n 结束时间:{1}\r\n 打开信息:{2}", dt.ToString("G"), DateTime.Now, strHtml));
sw.Dispose();
}
好的。现在使用多线程执行OpenWebPage方法,可以模拟Webborwser的多线程操作
下面是我写的测试用的小程序 查看全部
动态网页抓取(园子如何实现多线程使用webborwser采集页面其中我用到了)
今天在园子里看到了一个学术驴写的爬虫机器人,用C#webbrowser和Application.DoEvents()实现采集动态网页
其实我也是用类似的方法抓取需要登录的网页,还有一些动态页面。
今天想讲的是如何实现webborwser采集页面的多线程使用
其中,我使用了一个 WeiFenLuo.winFormsUI.Docking.dll,它是一个开源组件
下载链接:
关于这个组件,园子里已经有前辈做过详细的使用方法了,这里不再赘述。
在MainForm窗体中添加一个微分罗控件,并将MainForm窗体的IsMdiContainer属性设置为True
并添加addWebForm方法动态添加子表单
public void addWebForm(string s)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(addWebForm), s);
}
else
{
ChildForm f2 = new ChildForm();
f2.Text = s;
webForm.Add(s, f2);
f2.Show(dockPanel1);
}
}
向 ChildForm 窗体添加一个 Webborwser 控件
并添加打开页面的方法
public delegate void OneStringParmenters(string str);//1个string参数委托
public void Navigate(string url)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(Navigate), url);
}
else
{
webBrowser1.Navigate(url);
}
}
和读取页面html方法
private string strHtmlLeng = "";
private delegate void NoParameters();//无参数委托;
public string StrHtmlLeng
{
get
{
if (this.InvokeRequired)
{
IAsyncResult iar = this.BeginInvoke(new NoParameters(GetHtmlLeng));
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
}
else
{
GetHtmlLeng();
}
return strHtmlLeng;
}
}
private void GetHtmlLeng()
{
strHtmlLeng = webBrowser1.DocumentText;
}
添加多线程方法模拟多线程打开页面读取html
public static void OpenWebPage(object strUrl)
{
DateTime dt = DateTime.Now;
string u = strUrl.ToString();
IAsyncResult iar = Program.form.BeginInvoke(new OneStringParmenters(Program.form.addWebForm), u);
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
int n = Program.form.webForm.Count;
Program.form.webForm[u].Navigate(u);
System.Threading.Thread.Sleep(TimeSpan.FromMinutes(1));
string strHtml = Program.form.webForm[u].StrHtmlLeng;
//把html输出到本地e盘,当采集信息时,可以直接操作html
System.IO.StreamWriter sw = new StreamWriter(string.Format("e:/{0}.txt", u));
sw.Write(string.Format("开始时间:{0}\r\n 结束时间:{1}\r\n 打开信息:{2}", dt.ToString("G"), DateTime.Now, strHtml));
sw.Dispose();
}
好的。现在使用多线程执行OpenWebPage方法,可以模拟Webborwser的多线程操作
下面是我写的测试用的小程序
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-01 22:10
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们无法通过请求模块抓取数据以使其每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
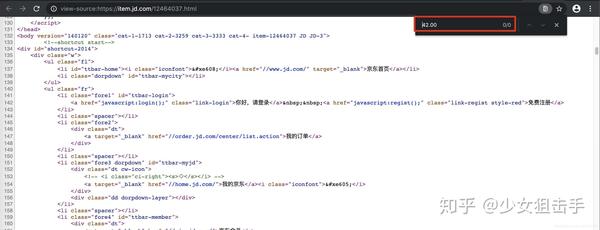
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
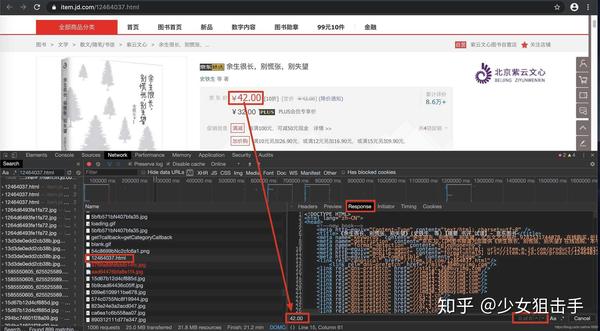
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
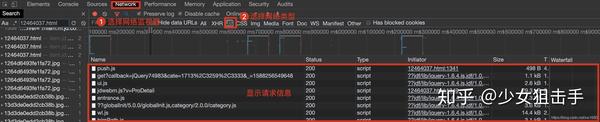
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
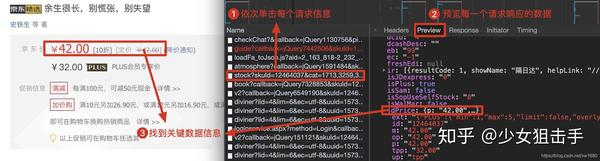
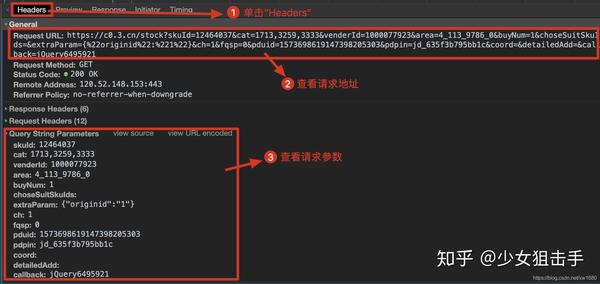
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
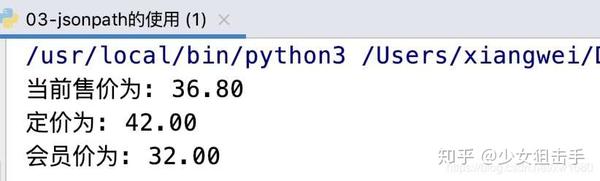
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python爬取网页中动态加载数据的实现的文章就介绍到这里了。更多Python爬取网页动态数据相关内容,请搜索前面的文章或继续浏览下面的相关文章希望大家以后多多支持! 查看全部
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们无法通过请求模块抓取数据以使其每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python爬取网页中动态加载数据的实现的文章就介绍到这里了。更多Python爬取网页动态数据相关内容,请搜索前面的文章或继续浏览下面的相关文章希望大家以后多多支持!
动态网页抓取(动态网站的爬取包含下以下三个步骤:抓包 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-01 22:08
)
众所周知,动态网站通常使用ajax等异步加载技术来加载网页。与静态网页相比,动态网页通常收录多个请求,而数据往往不存在于网页的源代码中。打包查找并分析数据所在的请求,并编写响应的爬虫代码。动态网站的爬取包括抓包、参数分析、数据提取三个步骤。(以下以爬取b站评论为例)
一、抓包
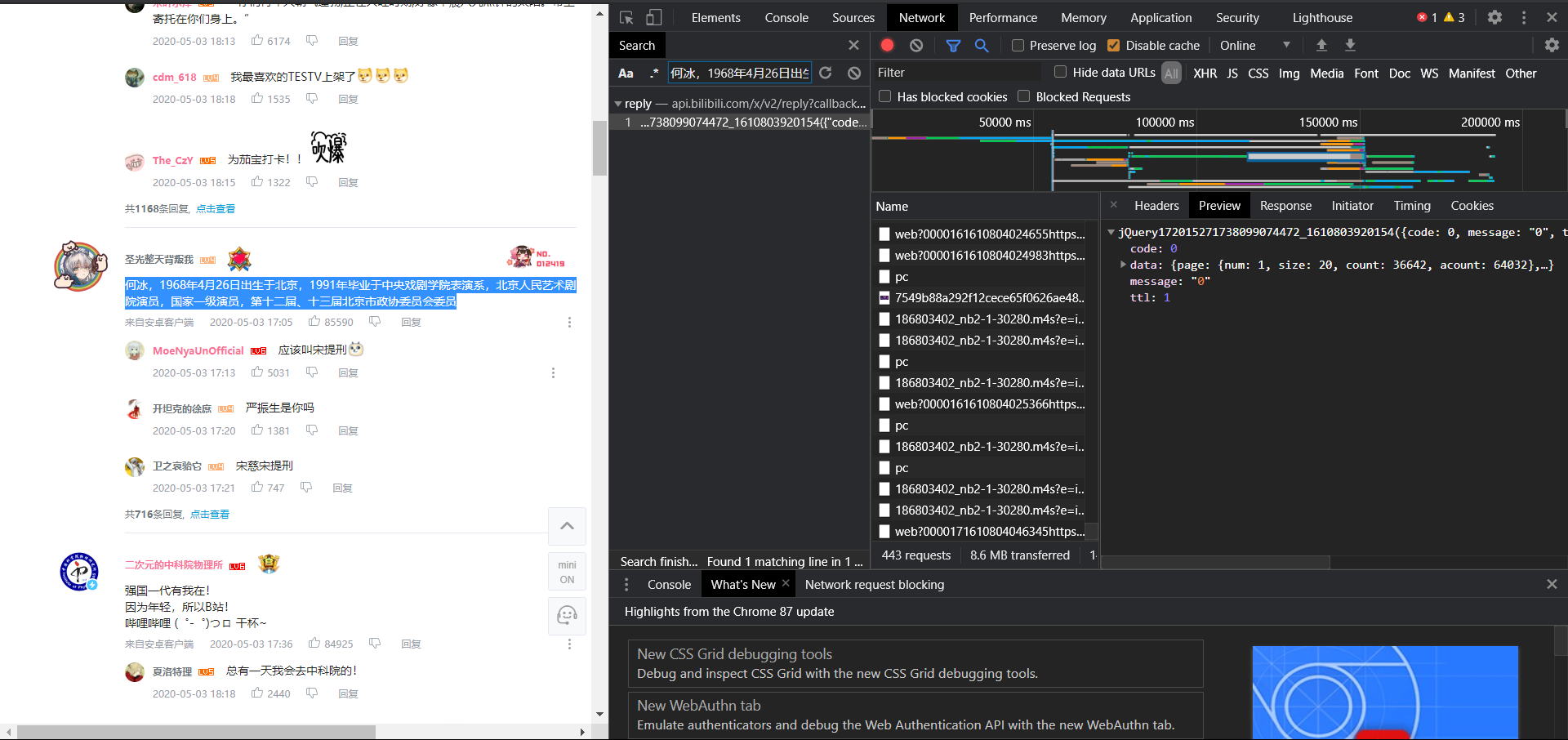
抓包的方法有很多,比较常用的比较有用,比如fiddle,一个抓包软件和浏览器自带的开发者调试工具(即f12),这里只介绍chrome的f12。
f12里面有很多菜单,这里我们只需要用到网络,下面是我们会经常用到的功能
上面三个箭头所指的按钮的功能是从左到右
1. 开关,红色开始捕捉,灰色停止。开启后,之前的拍摄历史将被清除
2.清除历史记录
3.搜索功能,可以查询哪些包有指定字段
下面一栏是过滤器,你可以选择要查看的包类型。一般动态网页的封装是xhr
接下来,开始抓包。抓包一般有两种方式:
1.通过触发指定事件定位数据所在的包
分析网站,很明显,可以触发b站评论变化的事件是点击如图所示的两个按钮,向下滑动到评论所在的地方。这里我们选择要触发的按钮事件。
很明显,我们需要的包就在眼前,点击查看内容,发现是一个json文件,然后我们就确认了这就是我们想要的包。
一些动态的网站可能会在网站加载时触发事件,或者传入的包根本不是xhr包,导致历史记录中有大量我不知道的包知道要做什么。前面提到的搜索功能会起作用
打开搜索框后,填写我们需要在搜索中定位的数据,如图
可以看到,数据包很快就被我们找到了。这种方法比第一种更有效,但效率不如第一种,而且各有优缺点。
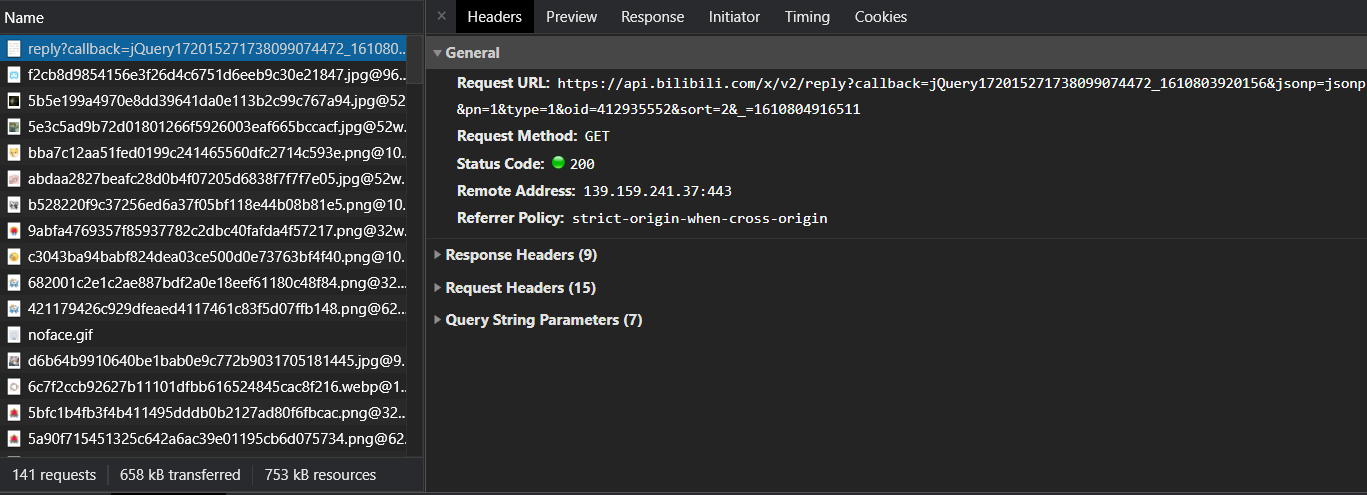
二、分析参数
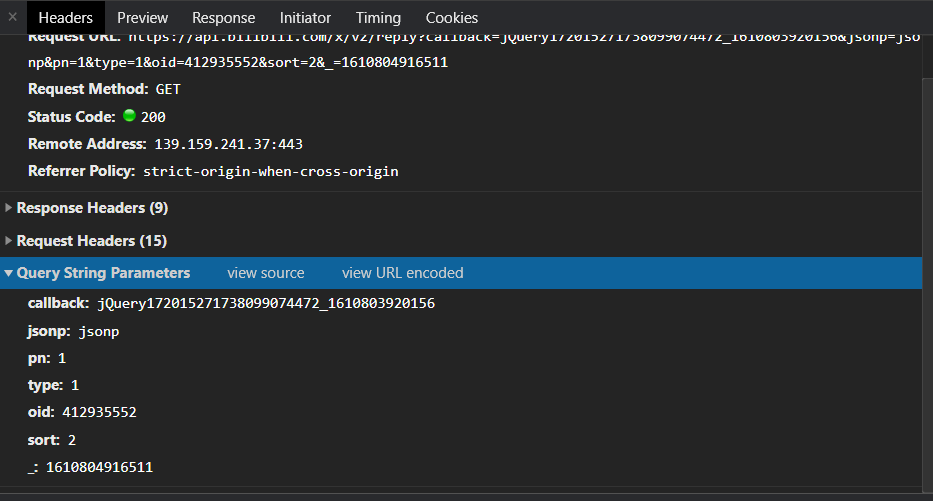
异步数据包不像网页那样具有唯一的 uri。网站作为传输数据的api,通常只使用一个api传输一种类型的数据,使用包中的参数通知服务器后台应该返回什么数据,以及我们需要的参数要分析的是这些影响背景的关键数据。
点击我们找到的包,选择header,可以看到有几个下拉列
我们需要注意的有三列:
1.响应头
请求头,我们抓取静态网站时也会用到的一组参数,比如user-agent,referer等字段,有的网站会在请求头中传递一些数据来通知后台,主要用于反爬虫,除了user-agent和referer,其他字段很少用到。具体分析,爬的时候注意。
2.表单数据
请求体,只存在于POST请求中,也是一组需要分析的参数,因为我们很少爬到POST请求的api,所以就不展开了。
3.查询字符串参数
这是最重要的一组参数,存在于 url 中。url链接问号后面的一串字符串是用来传递这组参数的,但是我们在f12中可以直观的看到,如下图所示。
接下来我们需要开始分析这些参数,找出哪些有用,哪些不需要传输,哪些没用但需要传输。这里没有灵丹妙药。无非就是在删除参数后访问和检查传入的数据,或者寻找使用相同api的事件。有什么不同?我们可以使用python shell或者写一个python脚本来测试,例如
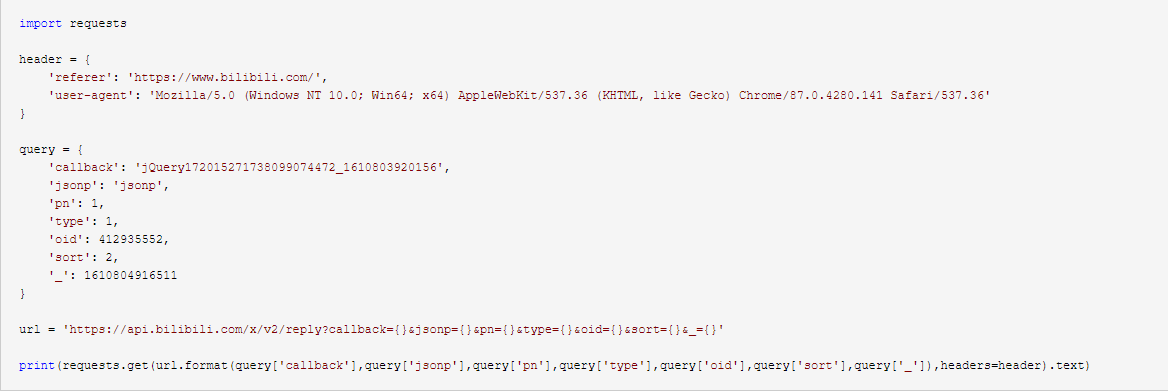
经过测试,我们知道callback、jsonp、_参数是不需要的,type是需要但是没有意义,pn表示页数,sort表示排序方式(即热排序和最新排序),oid指定只有视频(但不是 av 编号),因此我们可以通过循环 pn 来抓取所有评论。
三、提取数据
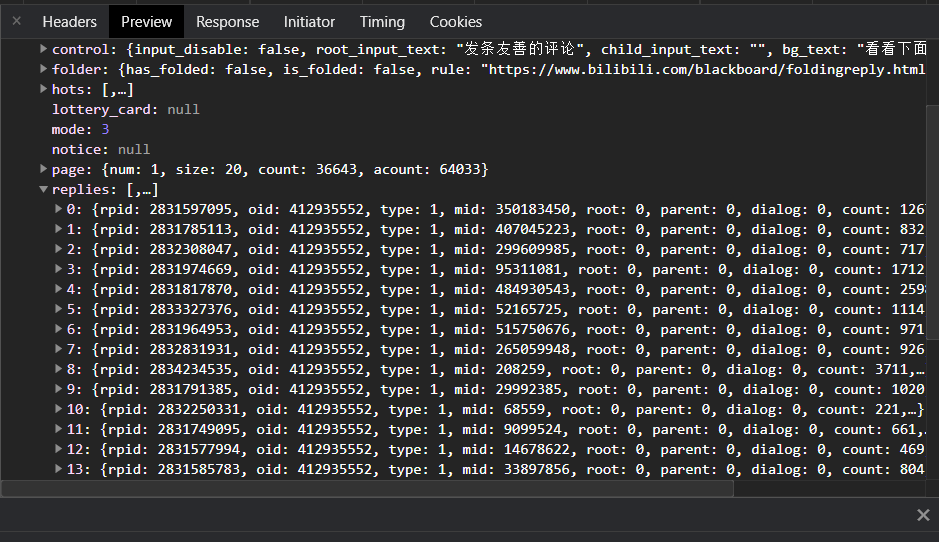
大多数api使用json数据格式来传输数据。当然也有把参数直接加到网页url返回html的情况(可以用bs解析)。要解析 json,我们需要使用 json 库。我不会在这里详细介绍 json。知识(有需要的去百度一下
如图,我们要找的路径是root->data->reply。每条评论的内容、作者、时间等都在这里
四、总结
动态网站的爬取主要在于对异步加载等前端技术的理解程度,以及对web开发的理解。虽然作为爬虫工具,前后端技术学习都是没落,甚至有些网站用js反向爬取,难度可以更高。但是对于数据挖掘来说,这种基本的爬虫技术就足够了,网上90%的数据爬取是没有问题的。
查看全部
动态网页抓取(动态网站的爬取包含下以下三个步骤:抓包
)
众所周知,动态网站通常使用ajax等异步加载技术来加载网页。与静态网页相比,动态网页通常收录多个请求,而数据往往不存在于网页的源代码中。打包查找并分析数据所在的请求,并编写响应的爬虫代码。动态网站的爬取包括抓包、参数分析、数据提取三个步骤。(以下以爬取b站评论为例)
一、抓包
抓包的方法有很多,比较常用的比较有用,比如fiddle,一个抓包软件和浏览器自带的开发者调试工具(即f12),这里只介绍chrome的f12。
f12里面有很多菜单,这里我们只需要用到网络,下面是我们会经常用到的功能
上面三个箭头所指的按钮的功能是从左到右
1. 开关,红色开始捕捉,灰色停止。开启后,之前的拍摄历史将被清除
2.清除历史记录
3.搜索功能,可以查询哪些包有指定字段
下面一栏是过滤器,你可以选择要查看的包类型。一般动态网页的封装是xhr
接下来,开始抓包。抓包一般有两种方式:
1.通过触发指定事件定位数据所在的包
分析网站,很明显,可以触发b站评论变化的事件是点击如图所示的两个按钮,向下滑动到评论所在的地方。这里我们选择要触发的按钮事件。
很明显,我们需要的包就在眼前,点击查看内容,发现是一个json文件,然后我们就确认了这就是我们想要的包。
一些动态的网站可能会在网站加载时触发事件,或者传入的包根本不是xhr包,导致历史记录中有大量我不知道的包知道要做什么。前面提到的搜索功能会起作用
打开搜索框后,填写我们需要在搜索中定位的数据,如图
可以看到,数据包很快就被我们找到了。这种方法比第一种更有效,但效率不如第一种,而且各有优缺点。
二、分析参数
异步数据包不像网页那样具有唯一的 uri。网站作为传输数据的api,通常只使用一个api传输一种类型的数据,使用包中的参数通知服务器后台应该返回什么数据,以及我们需要的参数要分析的是这些影响背景的关键数据。
点击我们找到的包,选择header,可以看到有几个下拉列
我们需要注意的有三列:
1.响应头
请求头,我们抓取静态网站时也会用到的一组参数,比如user-agent,referer等字段,有的网站会在请求头中传递一些数据来通知后台,主要用于反爬虫,除了user-agent和referer,其他字段很少用到。具体分析,爬的时候注意。
2.表单数据
请求体,只存在于POST请求中,也是一组需要分析的参数,因为我们很少爬到POST请求的api,所以就不展开了。
3.查询字符串参数
这是最重要的一组参数,存在于 url 中。url链接问号后面的一串字符串是用来传递这组参数的,但是我们在f12中可以直观的看到,如下图所示。
接下来我们需要开始分析这些参数,找出哪些有用,哪些不需要传输,哪些没用但需要传输。这里没有灵丹妙药。无非就是在删除参数后访问和检查传入的数据,或者寻找使用相同api的事件。有什么不同?我们可以使用python shell或者写一个python脚本来测试,例如
经过测试,我们知道callback、jsonp、_参数是不需要的,type是需要但是没有意义,pn表示页数,sort表示排序方式(即热排序和最新排序),oid指定只有视频(但不是 av 编号),因此我们可以通过循环 pn 来抓取所有评论。
三、提取数据
大多数api使用json数据格式来传输数据。当然也有把参数直接加到网页url返回html的情况(可以用bs解析)。要解析 json,我们需要使用 json 库。我不会在这里详细介绍 json。知识(有需要的去百度一下
如图,我们要找的路径是root->data->reply。每条评论的内容、作者、时间等都在这里
四、总结
动态网站的爬取主要在于对异步加载等前端技术的理解程度,以及对web开发的理解。虽然作为爬虫工具,前后端技术学习都是没落,甚至有些网站用js反向爬取,难度可以更高。但是对于数据挖掘来说,这种基本的爬虫技术就足够了,网上90%的数据爬取是没有问题的。

动态网页抓取(爬虫练习写的爬虫代码,如有什么问题和建议?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-01 22:07
前言
我是爬虫代码的初学者,如果有什么问题或者建议,请留言!
一、什么是动态网页?二、具体步骤1. 如何抓取动态网页上的数据 从抓取到的HTML文件分析,我们知道抓取到的文件的URL与页码有关,我们可以遵循规则自己构造一个url来抓取文件(下面的例子就是这种情况);如果从抓取到的HTML文件中发现文件url是固定的或者与页码无关,则只需模拟浏览器点击行为,请求再次抓取网页。这种效率比较慢,不适合多页面爬取。
爬取动态网站的关键是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。
2. 抓取网页数据所需的库 PhatomJS 是一个没有界面的浏览器,用于读取JS加载的页面,具体下载方法可以百度,不是python的第三方库,需要自己下载添加环境变量;当然你也可以使用Chrome、firefox、IE等。Selenium是python的第三方库。命令行输入:pip install selenium download,可以模拟用户在浏览器上进行一些操作。Phatom JS + Selenium 抓取动态网页。使用请求库获取图片。使用beautifulSoup解析抓取到的网页内容。使用os库创建文件并获取文件夹中的文件名列表
代码如下(示例):
import os
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
# 网页url,该url和页码存在规律,下一页的url是将后面的offset=0改为offset=100,具体可自己测试
WEB_URL = 'https://music.163.com/%23/arti ... 39%3B
# 保存图片的文件夹
FOLDER_PATH = 'D:/BeautifulPicture'
# 应对服务器反爬机制(会根据User-Agent辨别是浏览器访问还是代码访问,代码访问会被拒绝,所以需要使用headers伪装一下)的请求头,这里我们用的是PhatomJS浏览器,所以不需要
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
class AlbumCover:
def __init__(self):
self.web_url = WEB_URL
self.folder_path = FOLDER_PATH
self.headers = HEADERS
def request(self, url):
r = requests.get(url)
return r
def save_img(self, url, file_name):
print("开始请求图片地址……")
img = self.request(url)
print("开始保存图片……")
f = open(file_name, 'wb')
f.write(img.content)
print(file_name, "图片保存成功")
f.close()
def mkdir(self, path):
# self.is_folder_new
path = path.strip()
if not os.path.exists(path):
print("创建名字叫" + path + "的文件夹")
os.mkdir(path)
print("创建成功")
return True
else:
print("文件已经存在,不用创建")
return False
def spider(self):
print("Start")
# 使用selenium驱动PhantomJS进行网络请求
driver = webdriver.PhantomJS()
driver.get(self.web_url)
# 该网页使用了iframe框架,需要switch一下
driver.switch_to.frame("g_iframe")
# 根据驱动器获取网页源码
html = driver.page_source
self.mkdir(self.folder_path)
print('开始切换文件')
os.chdir(self.folder_path)
# 使用BeautifulSoup来对html进行解析,根据网页的开发者页面可以查到所有图片都在标签下,每个图片的标签是
all_li = BeautifulSoup(html, 'lxml').find('ul', class_="m-cvrlst m-cvrlst-alb4 f-cb").find_all('li')
for li in all_li:
album_url = li.find('img')['src']
album_name = li.find('p', class_='dec dec-1 f-thide2 f-pre')['title']
album_date = li.find('span', class_='s-fc3').text
# 将url后拼接的长宽去掉
index = album_url.index('?')
album_url = album_url[:index]
# 图片命名
photo_name = album_date + '-' + album_name.replace('/', '').replace(':', ',') + ".jpg"
# os.listdir(path)返回文件夹底下的全部文件
# 是一个去重操作
if photo_name in os.listdir(self.folder_path):
print("图片已经存在,继续下一个")
else:
self.save_img(album_url, photo_name)
driver.close()
if __name__ == '__main__':
get = AlbumCover()
get.spider()
3.运行结果
文件夹中保存的图片:
这里使用的 url 网络请求的数据。
总结
selenium 和 requests 的比较:
1、速度慢。每次运行爬虫时,都会打开一个浏览器。如果没有设置,会加载很多图片,JS等;
2、 占用资源过多。有人说把Chrome改成无头浏览器PhantomJS,原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到你在用 PhantomJS 访问,就会被封禁。您的请求,然后您必须考虑更改请求标头。我不知道事情有多复杂。为什么要学习 Python?因为Python简单,如果有更快更简单的库可以实现同样的功能,何乐而不为呢?
3、 对网络的要求会更高。Selenium 加载了很多可能对您没有价值的补充文件(例如 css、js 和图像文件)。这可能会产生更多的流量,而不仅仅是请求您真正需要的资源(使用单独的 HTTP 请求)。
4、 爬网规模不能太大。
5、困难。学习Selenium的成本太高了,
通过对比可以看出requests在代码上简洁,不难操作,而selenium缺点很多,所以不建议大家爬取数据。
使用数据: 查看全部
动态网页抓取(爬虫练习写的爬虫代码,如有什么问题和建议?)
前言
我是爬虫代码的初学者,如果有什么问题或者建议,请留言!
一、什么是动态网页?二、具体步骤1. 如何抓取动态网页上的数据 从抓取到的HTML文件分析,我们知道抓取到的文件的URL与页码有关,我们可以遵循规则自己构造一个url来抓取文件(下面的例子就是这种情况);如果从抓取到的HTML文件中发现文件url是固定的或者与页码无关,则只需模拟浏览器点击行为,请求再次抓取网页。这种效率比较慢,不适合多页面爬取。
爬取动态网站的关键是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。
2. 抓取网页数据所需的库 PhatomJS 是一个没有界面的浏览器,用于读取JS加载的页面,具体下载方法可以百度,不是python的第三方库,需要自己下载添加环境变量;当然你也可以使用Chrome、firefox、IE等。Selenium是python的第三方库。命令行输入:pip install selenium download,可以模拟用户在浏览器上进行一些操作。Phatom JS + Selenium 抓取动态网页。使用请求库获取图片。使用beautifulSoup解析抓取到的网页内容。使用os库创建文件并获取文件夹中的文件名列表
代码如下(示例):
import os
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
# 网页url,该url和页码存在规律,下一页的url是将后面的offset=0改为offset=100,具体可自己测试
WEB_URL = 'https://music.163.com/%23/arti ... 39%3B
# 保存图片的文件夹
FOLDER_PATH = 'D:/BeautifulPicture'
# 应对服务器反爬机制(会根据User-Agent辨别是浏览器访问还是代码访问,代码访问会被拒绝,所以需要使用headers伪装一下)的请求头,这里我们用的是PhatomJS浏览器,所以不需要
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
class AlbumCover:
def __init__(self):
self.web_url = WEB_URL
self.folder_path = FOLDER_PATH
self.headers = HEADERS
def request(self, url):
r = requests.get(url)
return r
def save_img(self, url, file_name):
print("开始请求图片地址……")
img = self.request(url)
print("开始保存图片……")
f = open(file_name, 'wb')
f.write(img.content)
print(file_name, "图片保存成功")
f.close()
def mkdir(self, path):
# self.is_folder_new
path = path.strip()
if not os.path.exists(path):
print("创建名字叫" + path + "的文件夹")
os.mkdir(path)
print("创建成功")
return True
else:
print("文件已经存在,不用创建")
return False
def spider(self):
print("Start")
# 使用selenium驱动PhantomJS进行网络请求
driver = webdriver.PhantomJS()
driver.get(self.web_url)
# 该网页使用了iframe框架,需要switch一下
driver.switch_to.frame("g_iframe")
# 根据驱动器获取网页源码
html = driver.page_source
self.mkdir(self.folder_path)
print('开始切换文件')
os.chdir(self.folder_path)
# 使用BeautifulSoup来对html进行解析,根据网页的开发者页面可以查到所有图片都在标签下,每个图片的标签是
all_li = BeautifulSoup(html, 'lxml').find('ul', class_="m-cvrlst m-cvrlst-alb4 f-cb").find_all('li')
for li in all_li:
album_url = li.find('img')['src']
album_name = li.find('p', class_='dec dec-1 f-thide2 f-pre')['title']
album_date = li.find('span', class_='s-fc3').text
# 将url后拼接的长宽去掉
index = album_url.index('?')
album_url = album_url[:index]
# 图片命名
photo_name = album_date + '-' + album_name.replace('/', '').replace(':', ',') + ".jpg"
# os.listdir(path)返回文件夹底下的全部文件
# 是一个去重操作
if photo_name in os.listdir(self.folder_path):
print("图片已经存在,继续下一个")
else:
self.save_img(album_url, photo_name)
driver.close()
if __name__ == '__main__':
get = AlbumCover()
get.spider()
3.运行结果
文件夹中保存的图片:
这里使用的 url 网络请求的数据。
总结
selenium 和 requests 的比较:
1、速度慢。每次运行爬虫时,都会打开一个浏览器。如果没有设置,会加载很多图片,JS等;
2、 占用资源过多。有人说把Chrome改成无头浏览器PhantomJS,原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到你在用 PhantomJS 访问,就会被封禁。您的请求,然后您必须考虑更改请求标头。我不知道事情有多复杂。为什么要学习 Python?因为Python简单,如果有更快更简单的库可以实现同样的功能,何乐而不为呢?
3、 对网络的要求会更高。Selenium 加载了很多可能对您没有价值的补充文件(例如 css、js 和图像文件)。这可能会产生更多的流量,而不仅仅是请求您真正需要的资源(使用单独的 HTTP 请求)。
4、 爬网规模不能太大。
5、困难。学习Selenium的成本太高了,
通过对比可以看出requests在代码上简洁,不难操作,而selenium缺点很多,所以不建议大家爬取数据。
使用数据:
动态网页抓取(需安装的三方库示例代码示例说明:获取德邦官网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-01 15:04
前言
在抓取常规静态网页时,我们可以直接请求相应的url来获取完整的HTML页面,但是对于动态页面,网页显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/")
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。 查看全部
动态网页抓取(需安装的三方库示例代码示例说明:获取德邦官网)
前言
在抓取常规静态网页时,我们可以直接请求相应的url来获取完整的HTML页面,但是对于动态页面,网页显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/";)
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-01 07:06
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。 Chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面:
driver.close():关闭当前页面。driver.quit():退出整个浏览器。
定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以稍后使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。 Chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面:
driver.close():关闭当前页面。driver.quit():退出整个浏览器。
定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以稍后使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
动态网页抓取( 可支持的【真实】驱动程序介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-10-01 07:05
可支持的【真实】驱动程序介绍(一))
#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。 查看全部
动态网页抓取(
可支持的【真实】驱动程序介绍(一))

#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。
动态网页抓取(动态网页抓取对javascript前端开发人员来说是非常重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2021-09-30 01:06
动态网页抓取对javascript前端开发人员来说是非常重要的。你可以在mozilla、facebook和谷歌公司的开发工具中获得动态网页框架。
presto是express框架,有个中文字幕版视频(优酷),在这里推荐给大家。
为什么不用react。当然react也可以做,目前就我接触的情况是这样的。目前没看到有多少合适做网页抓取工作的库,非要这样的话,就只能转react网页框架了。我知道有人用react做异步网页抓取的,并不太满意,原因就不说了,现在reactrouter还是挺好用的。
react的话,没有太多特殊要求,es5的语法都是一样的。es6/react-router/reduxasaservice同时react-router可以利用redux传递mapofurl参数和mapofurlobject对象来生成下一个页面的url,生成下一个页面的url就是用urlreturn中间形式的就行。
可以看看这个例子。上传图片不收费,使用方法有可能会有些技巧。基本上关于get和post的watcher的选择是有偏好的。description:processingjavascriptroutesforfullstackwebdevelopment这个网站讲得很详细。react-router的例子我没有看。
可以参考一下各网站的代码。另外,用react-router来模拟真实网页,其实也挺有效果的。例如评论就可以采用route.page来访问就好了。评论插件也可以用router/path。有一些proxy也提供了类似的工作。这是另外一个帖子,讲得很详细,建议看看/p/private.html这个话题里面也有很多回答,可以看看。 查看全部
动态网页抓取(动态网页抓取对javascript前端开发人员来说是非常重要的)
动态网页抓取对javascript前端开发人员来说是非常重要的。你可以在mozilla、facebook和谷歌公司的开发工具中获得动态网页框架。
presto是express框架,有个中文字幕版视频(优酷),在这里推荐给大家。
为什么不用react。当然react也可以做,目前就我接触的情况是这样的。目前没看到有多少合适做网页抓取工作的库,非要这样的话,就只能转react网页框架了。我知道有人用react做异步网页抓取的,并不太满意,原因就不说了,现在reactrouter还是挺好用的。
react的话,没有太多特殊要求,es5的语法都是一样的。es6/react-router/reduxasaservice同时react-router可以利用redux传递mapofurl参数和mapofurlobject对象来生成下一个页面的url,生成下一个页面的url就是用urlreturn中间形式的就行。
可以看看这个例子。上传图片不收费,使用方法有可能会有些技巧。基本上关于get和post的watcher的选择是有偏好的。description:processingjavascriptroutesforfullstackwebdevelopment这个网站讲得很详细。react-router的例子我没有看。
可以参考一下各网站的代码。另外,用react-router来模拟真实网页,其实也挺有效果的。例如评论就可以采用route.page来访问就好了。评论插件也可以用router/path。有一些proxy也提供了类似的工作。这是另外一个帖子,讲得很详细,建议看看/p/private.html这个话题里面也有很多回答,可以看看。
动态网页抓取(如何选择虎嗅网的网页界面分析工具?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-29 06:05
一、分析背景:
1. 为什么选择虎嗅
《关于虎嗅》成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。
2. 分析内容
分析虎嗅网5万篇文章文章的基本信息,包括采集数、评论数等;发现最受欢迎和最不受欢迎的 文章 和作者;分析文章的标题格式(长度、句型)与流行度的关系;展示近年来科技互联网行业的流行词汇
3. 分析工具:
蟒蛇3.6
刮的
MongoDB
Matplotlib
词云
杰巴
数据抓取
我用scrapy抓取了Tiger 文章的首页,从2012年建站到2018年12月7日,抓取文章的时间约为5万篇文章 . 抓取8个信息字段:文章标题、作者、发帖时间、评论数、采集数、摘要、文章链接和文章内容。
1.目标网站分析
这是要抓取的网页界面。您可以看到它是通过 AJAX 加载的。
按F12打开开发者工具,可以看到URL请求是POST类型的,向下滚动到底部查看Form Data,表单中只有3个参数需要提交。尝试后,只提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。
接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page为2119,表示文章内容一共2119页,每页有25个文章,一共大概5万条,就是我们要爬取的数量。
Scrapy介绍
Scrapy 是一个用纯 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。它具有广泛的用途。借助框架的强大,用户只需要定制开发几个模块,就可以轻松实现爬虫抓取网页内容和各种图片,非常方便。Scrapy使用Twisted['twɪstɪd](它的主要对手是Tornado)异步网络框架来处理网络通信,可以加快我们的下载速度,不用自己实现异步框架,并且收录各种中间件接口,可以灵活完成各种需求。
scrapy是如何帮助我们抓取数据的?
scrapy框架的工作流程:
1.首先,Spider(爬虫)需要通过ScrapyEngine(引擎)将请求url(requests)发送给Scheduler(调度器)。
2.Scheduler(排序、入队)处理,通过ScrapyEngine、DownloaderMiddlewares(可选,主要是User_Agent、Proxy代理)传递给Downloader。
3.Downloader 向 Internet 发送请求并接收下载响应(响应)。通过 ScrapyEngine、SpiderMiddlewares(可选)向 Spiders 发送响应(response)。
4.Spiders 处理响应,提取数据并通过 ScrapyEngine 将数据发送到 ItemPipeline 进行存储(可以是本地或数据库)。
5. 提取的 url 通过 ScrapyEngine 发送给 Scheduler,用于下一个循环。直到没有 Url 请求程序停止并结束。
实现代码
创建项目
scrapy startproject 项目名称
scrapy genspider 爬虫名称 URL
这里首先定义了一个HuxiuV1Spider主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的headers属性中写一些爬虫的基本配置,比如Headers、proxy等设置。
由于URL是POST请求,我们还需要在FormData中使用formdata={'page':str(i)}添加表单参数,这里需要设置为POST;formdata是POST请求表单参数,只需要加一个page参数就够了。接下来,通过回调参数定义一个 parse() 方法来解析 URL 成功后返回的 Response 响应。在下面的 parse() 方法中,您可以使用 re,xpath 提取响应中所需的内容。
这里我们使用正则表达式提取文章标题、链接、作者等需要的信息,这里将数据保存为列表数据,以便后续存储在mongo数据库中。
成功获取到需要的数据,然后就可以保存了,可以选择输出为csv、MySQL、mongoDB,这里我们选择mongoDB数据库
1 # -*- coding: utf-8 -*-
2 # from scrapy.spider import CrawlSpider
3 from selenium import webdriver
4 import time
5 from scrapy.linkextractors import LinkExtractor
6 from scrapy.spiders import CrawlSpider, Rule
7 # import json
8 from datetime import datetime
9 from ..items import HuxiuItem
10 from scrapy.http import FormRequest
11 import scrapy
12 import json,re
13 class HuxiuV1Spider(scrapy.Spider):
14 name = 'huxiu_v1'
15 allowed_domains = ['huxiu.com']
16 headers={
17 'Referer': 'https://www.huxiu.com/index.php/',
18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
19 }
20 #post
21 #Form data
22 # page: 2
23 def start_requests(self):
24 url='https://www.huxiu.com/v2_action/article_list'
25 requests=[]
26 for i in range(2,2119):
27 formdata={
28 'page':str(i)
29 }
30 request=FormRequest(url,callback=self.parse,formdata=formdata,headers=self.headers)
31 requests.append(request)
32 return requests
33 def parse(self, response):
34 js=json.loads(response.body.decode())
35 # print(js)
36 req = str(js)
37 idd = re.findall(r'data-aid="(.*?)">', req)#未处理的url(id)
38 title = re.findall(r'class="transition msubstr-row2" target="_blank">(.*?)</a>', req)#标题
39 auth = re.findall(r'class="author-name">(.*?)', req)#作者
40 pinglun = re.findall(r'(.*?)', req)#评论
41 shoucang = re.findall(r'(.*?)', req)#收藏
42 zhaiyao = re.findall(r'(.*?)', req)#未处理的摘要
43 digect = []#摘要
44 for i in zhaiyao:
45 s = i[34:-12]
46 if 'span' in i:
47 s = i[104:-12]
48 digect.append(s)
49 # print(digect)
50 # print(title)
51 detail_url=[]
52 for i in idd:
53 burl = 'https://www.huxiu.com/article/{}.html'.format(i)
54 detail_url.append(burl)
55 # print(detail_url)
56 for i in range(len(idd)):
57 item=HuxiuItem()
58 item['title']=title[i]
59 item["auth"]=auth[i]
60 item['detail_url']=detail_url[i]
61 item['pinglun']=pinglun[i]
62 item['shoucang']=shoucang[i]
63 item['zhaiyao']=digect[i]
64 print(detail_url[i])
65 # yield item
66 yield scrapy.Request(url=detail_url[i],meta={'meta1':item},callback=self.pasre_item)
67 def pasre_item(self,response):
68 meta1=response.meta['meta1']
69 # print('hello')
70 time=response.xpath('//span[@class="article-time pull-left"]/text()|//span[@class="article-time"]/text()').extract()
71 content=response.xpath('//div[@class="article-content-wrap"]/p/text()|//div[@class="article-content-wrap"]/div/text()|//div[@class="article-content-wrap"]/div/span/text()').extract()
72 print(time)
73 ssss=''
74 for i in content:
75 ssss+=i
76 # num = response.xpath('//div[@class="author-article-pl"]/ul/li/a/text()')
77 # wnums=''
78 # for i in num:
79 # wnums = i[:-3]
80 # print(wnums)
81 for i in range(len(time)):
82 item = HuxiuItem()
83 item['title']=meta1['title']
84 item['auth']=meta1['auth']
85 item['detail_url']=meta1['detail_url']
86 item['pinglun']=meta1['pinglun']
87 item['shoucang']=meta1['shoucang']
88 item['zhaiyao']=meta1['zhaiyao']
89 item['time']=time[i]
90 # item['wnums']=num
91 item['content']=ssss
92
93 yield item
蜘蛛
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
物品
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
管道
1 BOT_NAME = 'huxiu'
2
3 SPIDER_MODULES = ['huxiu.spiders']
4 NEWSPIDER_MODULE = 'huxiu.spiders'
5
6
7 # Crawl responsibly by identifying yourself (and your website) on the user-agent
8 #USER_AGENT = 'huxiu (+http://www.yourdomain.com)'
9 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
10
11 # Obey robots.txt rules
12 ROBOTSTXT_OBEY = False
13
14 ITEM_PIPELINES = {
15 'huxiu.pipelines.HuxiuPipeline': 300,
16 }
17
18 LOG_FILE='huxiu_v1.log'
19 LOG_ENABLED=True #默认启用日志
20 LOG_ENCODING='UTF-8'#日志的编码,默认为’utf-8‘
21 LOG_LEVEL='DEBUG'#日志等级:ERROR\WARNING\INFO\DEBUG
22
23 setting
环境
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。
转载于: 查看全部
动态网页抓取(如何选择虎嗅网的网页界面分析工具?(一))
一、分析背景:
1. 为什么选择虎嗅
《关于虎嗅》成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。
2. 分析内容
分析虎嗅网5万篇文章文章的基本信息,包括采集数、评论数等;发现最受欢迎和最不受欢迎的 文章 和作者;分析文章的标题格式(长度、句型)与流行度的关系;展示近年来科技互联网行业的流行词汇
3. 分析工具:
蟒蛇3.6
刮的
MongoDB
Matplotlib
词云
杰巴
数据抓取
我用scrapy抓取了Tiger 文章的首页,从2012年建站到2018年12月7日,抓取文章的时间约为5万篇文章 . 抓取8个信息字段:文章标题、作者、发帖时间、评论数、采集数、摘要、文章链接和文章内容。
1.目标网站分析
这是要抓取的网页界面。您可以看到它是通过 AJAX 加载的。


按F12打开开发者工具,可以看到URL请求是POST类型的,向下滚动到底部查看Form Data,表单中只有3个参数需要提交。尝试后,只提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。


接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page为2119,表示文章内容一共2119页,每页有25个文章,一共大概5万条,就是我们要爬取的数量。
Scrapy介绍
Scrapy 是一个用纯 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。它具有广泛的用途。借助框架的强大,用户只需要定制开发几个模块,就可以轻松实现爬虫抓取网页内容和各种图片,非常方便。Scrapy使用Twisted['twɪstɪd](它的主要对手是Tornado)异步网络框架来处理网络通信,可以加快我们的下载速度,不用自己实现异步框架,并且收录各种中间件接口,可以灵活完成各种需求。
scrapy是如何帮助我们抓取数据的?

scrapy框架的工作流程:

1.首先,Spider(爬虫)需要通过ScrapyEngine(引擎)将请求url(requests)发送给Scheduler(调度器)。
2.Scheduler(排序、入队)处理,通过ScrapyEngine、DownloaderMiddlewares(可选,主要是User_Agent、Proxy代理)传递给Downloader。
3.Downloader 向 Internet 发送请求并接收下载响应(响应)。通过 ScrapyEngine、SpiderMiddlewares(可选)向 Spiders 发送响应(response)。
4.Spiders 处理响应,提取数据并通过 ScrapyEngine 将数据发送到 ItemPipeline 进行存储(可以是本地或数据库)。
5. 提取的 url 通过 ScrapyEngine 发送给 Scheduler,用于下一个循环。直到没有 Url 请求程序停止并结束。
实现代码
创建项目
scrapy startproject 项目名称
scrapy genspider 爬虫名称 URL


这里首先定义了一个HuxiuV1Spider主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的headers属性中写一些爬虫的基本配置,比如Headers、proxy等设置。

由于URL是POST请求,我们还需要在FormData中使用formdata={'page':str(i)}添加表单参数,这里需要设置为POST;formdata是POST请求表单参数,只需要加一个page参数就够了。接下来,通过回调参数定义一个 parse() 方法来解析 URL 成功后返回的 Response 响应。在下面的 parse() 方法中,您可以使用 re,xpath 提取响应中所需的内容。


这里我们使用正则表达式提取文章标题、链接、作者等需要的信息,这里将数据保存为列表数据,以便后续存储在mongo数据库中。
成功获取到需要的数据,然后就可以保存了,可以选择输出为csv、MySQL、mongoDB,这里我们选择mongoDB数据库



1 # -*- coding: utf-8 -*-
2 # from scrapy.spider import CrawlSpider
3 from selenium import webdriver
4 import time
5 from scrapy.linkextractors import LinkExtractor
6 from scrapy.spiders import CrawlSpider, Rule
7 # import json
8 from datetime import datetime
9 from ..items import HuxiuItem
10 from scrapy.http import FormRequest
11 import scrapy
12 import json,re
13 class HuxiuV1Spider(scrapy.Spider):
14 name = 'huxiu_v1'
15 allowed_domains = ['huxiu.com']
16 headers={
17 'Referer': 'https://www.huxiu.com/index.php/',
18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
19 }
20 #post
21 #Form data
22 # page: 2
23 def start_requests(self):
24 url='https://www.huxiu.com/v2_action/article_list'
25 requests=[]
26 for i in range(2,2119):
27 formdata={
28 'page':str(i)
29 }
30 request=FormRequest(url,callback=self.parse,formdata=formdata,headers=self.headers)
31 requests.append(request)
32 return requests
33 def parse(self, response):
34 js=json.loads(response.body.decode())
35 # print(js)
36 req = str(js)
37 idd = re.findall(r'data-aid="(.*?)">', req)#未处理的url(id)
38 title = re.findall(r'class="transition msubstr-row2" target="_blank">(.*?)</a>', req)#标题
39 auth = re.findall(r'class="author-name">(.*?)', req)#作者
40 pinglun = re.findall(r'(.*?)', req)#评论
41 shoucang = re.findall(r'(.*?)', req)#收藏
42 zhaiyao = re.findall(r'(.*?)', req)#未处理的摘要
43 digect = []#摘要
44 for i in zhaiyao:
45 s = i[34:-12]
46 if 'span' in i:
47 s = i[104:-12]
48 digect.append(s)
49 # print(digect)
50 # print(title)
51 detail_url=[]
52 for i in idd:
53 burl = 'https://www.huxiu.com/article/{}.html'.format(i)
54 detail_url.append(burl)
55 # print(detail_url)
56 for i in range(len(idd)):
57 item=HuxiuItem()
58 item['title']=title[i]
59 item["auth"]=auth[i]
60 item['detail_url']=detail_url[i]
61 item['pinglun']=pinglun[i]
62 item['shoucang']=shoucang[i]
63 item['zhaiyao']=digect[i]
64 print(detail_url[i])
65 # yield item
66 yield scrapy.Request(url=detail_url[i],meta={'meta1':item},callback=self.pasre_item)
67 def pasre_item(self,response):
68 meta1=response.meta['meta1']
69 # print('hello')
70 time=response.xpath('//span[@class="article-time pull-left"]/text()|//span[@class="article-time"]/text()').extract()
71 content=response.xpath('//div[@class="article-content-wrap"]/p/text()|//div[@class="article-content-wrap"]/div/text()|//div[@class="article-content-wrap"]/div/span/text()').extract()
72 print(time)
73 ssss=''
74 for i in content:
75 ssss+=i
76 # num = response.xpath('//div[@class="author-article-pl"]/ul/li/a/text()')
77 # wnums=''
78 # for i in num:
79 # wnums = i[:-3]
80 # print(wnums)
81 for i in range(len(time)):
82 item = HuxiuItem()
83 item['title']=meta1['title']
84 item['auth']=meta1['auth']
85 item['detail_url']=meta1['detail_url']
86 item['pinglun']=meta1['pinglun']
87 item['shoucang']=meta1['shoucang']
88 item['zhaiyao']=meta1['zhaiyao']
89 item['time']=time[i]
90 # item['wnums']=num
91 item['content']=ssss
92
93 yield item
蜘蛛
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
物品
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
管道
1 BOT_NAME = 'huxiu'
2
3 SPIDER_MODULES = ['huxiu.spiders']
4 NEWSPIDER_MODULE = 'huxiu.spiders'
5
6
7 # Crawl responsibly by identifying yourself (and your website) on the user-agent
8 #USER_AGENT = 'huxiu (+http://www.yourdomain.com)'
9 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
10
11 # Obey robots.txt rules
12 ROBOTSTXT_OBEY = False
13
14 ITEM_PIPELINES = {
15 'huxiu.pipelines.HuxiuPipeline': 300,
16 }
17
18 LOG_FILE='huxiu_v1.log'
19 LOG_ENABLED=True #默认启用日志
20 LOG_ENCODING='UTF-8'#日志的编码,默认为’utf-8‘
21 LOG_LEVEL='DEBUG'#日志等级:ERROR\WARNING\INFO\DEBUG
22
23 setting
环境
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。

转载于:
动态网页抓取( 可支持的【真实】驱动程序介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-29 05:22
可支持的【真实】驱动程序介绍(一))
#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。 查看全部
动态网页抓取(
可支持的【真实】驱动程序介绍(一))
#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。
动态网页抓取(之前写过一篇使用爬虫抓取暗黑3玩家数据的意义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-09-29 02:09
)
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据一直不更新,所以爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。
百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:
通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到
虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据
好的,让我们抓住它
明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。
查看全部
动态网页抓取(之前写过一篇使用爬虫抓取暗黑3玩家数据的意义
)
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据一直不更新,所以爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。

百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:

通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到

虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据

好的,让我们抓住它

明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。

动态网页抓取( 基于IE内核和DOM的面向垂直搜索引擎中怎样动态生成的主题网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-29 02:08
基于IE内核和DOM的面向垂直搜索引擎中怎样动态生成的主题网页)
一种为垂直搜索引擎抓取动态网页的方法 fetcher 的一个难题。本文提出了一种基于IE内核和DOM的垂直搜索引擎动态网页爬取方法。实验表明,该方法抓取动态网页和主题网页的准确率平均在95以上,平均召回率为97以上。 [关键词] 动态网页IE核心DOM提取模式1简介垂直搜索引擎只抓取与主题相关的网页,同时必须在缩小搜索范围的前提下对网页进行更深的抓取,包括占网页总数的比例越来越大的动态网页. 目前的网络爬虫一般无法抓取动态网页。为了解决动态网页的抓取问题,同时只抓取与主题相关的动态网页,本文提出了一种面向垂直搜索引擎的抓取。获取动态网页的方法基于IEInternetExplorer核心和DHTML对象模型[1]利用DHTML对象模型提取页面中收录的页面元素信息,获取动态网页相关的网页元素信息。每个网页元素对应于 IE 核心的 MSHTML 组件中的一个界面。对应界面的操作实现了网页的自动填充。相关链接或查询按钮的自动点击模拟用户在浏览器上浏览网页的行为。数据库交互动态生成的主题网页 2 基于 IE core 和 DOM 的动态网页抓取方法 21 IE core 和 DOM 介绍 功能参考 [1] 给出了 IE 架构,其中 WebBrowser 组件、MSHTML 组件、URLMon 组件和 WinInet 位于底层是IE的核心。在该方法中,这些IE内核用于模拟用户在网页中查找和点击链接或按钮的动作,以触发浏览器下载网页MSHTML可以读取和显示HTML网页。DOM 是在 MSHTML 组件中定义的。[2] DocumentObjectModel 封装了 HTML 语言中的所有元素和属性。DOM 模型中的每个元素都有对应的对象和接口。这些接口的操作是访问指定网页中的所有元素。22 模拟浏览操作,获取动态网页。动态页面需要执行aspphpjspnet等程序生成客户端网页代码。静态网页的网址以html超链接的形式直接嵌入到客户端网页中。目前已知的 HTML 文件中的网络爬虫程序可以轻松抓取相应的页面。[3] 仔细研究网页的结构和HTML语言发现,在指定网页中获取动态网页的方式主要有两种: 1 用按钮点击后提供的界面网页元素的形式图片等。需要在客户端执行相应的一段脚本代码,动态生成URL2查询接口,用户填写表单提交查询到服务器,服务端返回动态生成的查询结果页面,无论采用哪种方式,都是从浏览器用户Forms或者鼠标点击的角度来填写,所以只要找到需要填写的表单元素以获取指定网页上需要点击的动态页面或按钮图标等元素,然后操作相关元素模拟用户在浏览器中的各种填写形式或点击操作实现自动浏览,最后下载动态页面到本地抓取到23。生成提取方式定位相关元素。IE 核心的 MSHTML 组件定义了 DOM。网页中的每个元素通过IE对应DOM树的一个节点。内核支持 DOM 树。每一个指定的网页对应一棵DOM树,因此在网页中搜索元素转化为元素在DOM树中对应节点的位置和搜索。为了通过一个或多个指定的示例网页,学习抓取所有此类结构相似的网页。必须生成提取模式。使用生成的提取方式提取所有相似的网页,获取动态网页的网页元素信息。在DHTMLDOM模型的支持下,可以对应收录需要提取的信息的网页元素。搜索网页的类别,会得到属于该类别的所有元素的集合,然后在该集合中找到提取信息所在的网页元素。为了找到提取的信息所在的具体元素,您可以识别网页元素的属性,例如nameid或网页元素的其他属性。如valuehref等方法定位时这些方法无法区分网页元素。最后,可以通过表示网页元素的标签中的文本内容来进行识别。辅助生成工具半自动生成抽取模式,然后进入抽取模式作为爬取配置信息进入网络爬虫。网络爬虫WebCrawler仅在抽取模式的引导下定位和查找与动态生成的主题网页相关的网页 表单中的文本输入元素或可点击按钮图片等元素信息,然后通过定位到的网页元素对应的界面对元素进行操作,执行自动填表和自动点击功能触发网页抓取,集成IE核心组件WebBrowser fetcher执行客户端脚本代码并发送请求到服务器下载对应的主题网页。服务器响应该请求,将动态生成的页面返回给抓取器,以最终抓取提取方式确定的对应的主题网页。3 实验验证方便评估预先设置一些垂直的站点位置,具有层次结构网站 动态网页从网页提供的查询条目的爬取深度为4,最大爬取5500页。使用本文提出的IE核心并与之结合。辅助生成工具的网页爬取方法的准确率采集 目标页面数 ö 总爬取次数超过95,远优于大多数系统采用的分类器方法展示。本文采用的方法的召回率是召回率。Rate 采集 目标页面数 ö 目标页面总数达到97左右,而分类器方法一般只有70左右。 4 结论 本文重点介绍垂直搜索引擎网络爬取的关键技术——动态网络爬取-深入研究在IE核心事件激发机制和DOM支持的基础上,提出了一种新的方法。自动浏览功能是通过自动填写表单并模拟用户在浏览器上点击鼠标,然后抓取动态网页来实现的。实验表明,该方法在构建辅助生成工具的基础上半自动生成爬取配置信息,使用基于IE核心主题网页的爬取方法可以有效爬取动态网页参考[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpö-wwww8ölöl [3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数在95以上,比大多数系统使用的分类方法要好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数超过95个,比大多数系统使用的分类方法好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类器方法一般只有70左右的一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单并模拟用户在浏览器上的鼠标点击来实现自动浏览功能,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类方法一般只有70左右一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单,模拟用户在浏览器上鼠标点击,然后抓取动态网页来实现自动浏览功能。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 查看全部
动态网页抓取(
基于IE内核和DOM的面向垂直搜索引擎中怎样动态生成的主题网页)

一种为垂直搜索引擎抓取动态网页的方法 fetcher 的一个难题。本文提出了一种基于IE内核和DOM的垂直搜索引擎动态网页爬取方法。实验表明,该方法抓取动态网页和主题网页的准确率平均在95以上,平均召回率为97以上。 [关键词] 动态网页IE核心DOM提取模式1简介垂直搜索引擎只抓取与主题相关的网页,同时必须在缩小搜索范围的前提下对网页进行更深的抓取,包括占网页总数的比例越来越大的动态网页. 目前的网络爬虫一般无法抓取动态网页。为了解决动态网页的抓取问题,同时只抓取与主题相关的动态网页,本文提出了一种面向垂直搜索引擎的抓取。获取动态网页的方法基于IEInternetExplorer核心和DHTML对象模型[1]利用DHTML对象模型提取页面中收录的页面元素信息,获取动态网页相关的网页元素信息。每个网页元素对应于 IE 核心的 MSHTML 组件中的一个界面。对应界面的操作实现了网页的自动填充。相关链接或查询按钮的自动点击模拟用户在浏览器上浏览网页的行为。数据库交互动态生成的主题网页 2 基于 IE core 和 DOM 的动态网页抓取方法 21 IE core 和 DOM 介绍 功能参考 [1] 给出了 IE 架构,其中 WebBrowser 组件、MSHTML 组件、URLMon 组件和 WinInet 位于底层是IE的核心。在该方法中,这些IE内核用于模拟用户在网页中查找和点击链接或按钮的动作,以触发浏览器下载网页MSHTML可以读取和显示HTML网页。DOM 是在 MSHTML 组件中定义的。[2] DocumentObjectModel 封装了 HTML 语言中的所有元素和属性。DOM 模型中的每个元素都有对应的对象和接口。这些接口的操作是访问指定网页中的所有元素。22 模拟浏览操作,获取动态网页。动态页面需要执行aspphpjspnet等程序生成客户端网页代码。静态网页的网址以html超链接的形式直接嵌入到客户端网页中。目前已知的 HTML 文件中的网络爬虫程序可以轻松抓取相应的页面。[3] 仔细研究网页的结构和HTML语言发现,在指定网页中获取动态网页的方式主要有两种: 1 用按钮点击后提供的界面网页元素的形式图片等。需要在客户端执行相应的一段脚本代码,动态生成URL2查询接口,用户填写表单提交查询到服务器,服务端返回动态生成的查询结果页面,无论采用哪种方式,都是从浏览器用户Forms或者鼠标点击的角度来填写,所以只要找到需要填写的表单元素以获取指定网页上需要点击的动态页面或按钮图标等元素,然后操作相关元素模拟用户在浏览器中的各种填写形式或点击操作实现自动浏览,最后下载动态页面到本地抓取到23。生成提取方式定位相关元素。IE 核心的 MSHTML 组件定义了 DOM。网页中的每个元素通过IE对应DOM树的一个节点。内核支持 DOM 树。每一个指定的网页对应一棵DOM树,因此在网页中搜索元素转化为元素在DOM树中对应节点的位置和搜索。为了通过一个或多个指定的示例网页,学习抓取所有此类结构相似的网页。必须生成提取模式。使用生成的提取方式提取所有相似的网页,获取动态网页的网页元素信息。在DHTMLDOM模型的支持下,可以对应收录需要提取的信息的网页元素。搜索网页的类别,会得到属于该类别的所有元素的集合,然后在该集合中找到提取信息所在的网页元素。为了找到提取的信息所在的具体元素,您可以识别网页元素的属性,例如nameid或网页元素的其他属性。如valuehref等方法定位时这些方法无法区分网页元素。最后,可以通过表示网页元素的标签中的文本内容来进行识别。辅助生成工具半自动生成抽取模式,然后进入抽取模式作为爬取配置信息进入网络爬虫。网络爬虫WebCrawler仅在抽取模式的引导下定位和查找与动态生成的主题网页相关的网页 表单中的文本输入元素或可点击按钮图片等元素信息,然后通过定位到的网页元素对应的界面对元素进行操作,执行自动填表和自动点击功能触发网页抓取,集成IE核心组件WebBrowser fetcher执行客户端脚本代码并发送请求到服务器下载对应的主题网页。服务器响应该请求,将动态生成的页面返回给抓取器,以最终抓取提取方式确定的对应的主题网页。3 实验验证方便评估预先设置一些垂直的站点位置,具有层次结构网站 动态网页从网页提供的查询条目的爬取深度为4,最大爬取5500页。使用本文提出的IE核心并与之结合。辅助生成工具的网页爬取方法的准确率采集 目标页面数 ö 总爬取次数超过95,远优于大多数系统采用的分类器方法展示。本文采用的方法的召回率是召回率。Rate 采集 目标页面数 ö 目标页面总数达到97左右,而分类器方法一般只有70左右。 4 结论 本文重点介绍垂直搜索引擎网络爬取的关键技术——动态网络爬取-深入研究在IE核心事件激发机制和DOM支持的基础上,提出了一种新的方法。自动浏览功能是通过自动填写表单并模拟用户在浏览器上点击鼠标,然后抓取动态网页来实现的。实验表明,该方法在构建辅助生成工具的基础上半自动生成爬取配置信息,使用基于IE核心主题网页的爬取方法可以有效爬取动态网页参考[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpö-wwww8ölöl [3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数在95以上,比大多数系统使用的分类方法要好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数超过95个,比大多数系统使用的分类方法好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类器方法一般只有70左右的一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单并模拟用户在浏览器上的鼠标点击来实现自动浏览功能,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类方法一般只有70左右一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单,模拟用户在浏览器上鼠标点击,然后抓取动态网页来实现自动浏览功能。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络
动态网页抓取(利用selenium的子模块webdriver的html内容解决的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-10-10 04:06
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(不信,请查看页面源码,只有简单的一行)。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
动态网页抓取(利用selenium的子模块webdriver的html内容解决的问题)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。然而,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,比如我想在这个bbs网站中抓取当前每个版块的在线数,静态html网页不收录(不信,请查看页面源码,只有简单的一行)。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实现流程运行环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-虫师》大神的selenium webdriver(python)教程第三章——定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
动态网页抓取(动态网页元素与网页源码的实现思路及源码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-10 04:03
)
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks) 查看全部
动态网页抓取(动态网页元素与网页源码的实现思路及源码
)
简单的介绍
以下代码是一个使用python实现的爬取动态网页的网络爬虫。此页面上最新最好的内容是由 JavaScript 动态生成的。检查网页的元素是否与网页的源代码不同。
以上是网页的源代码
以上是查看页面元素
所以在这里你不能简单地使用正则表达式来获取内容。
以下是获取内容并存入数据库的完整思路和源码。
实现思路:
抓取实际访问的动态页面的url-使用正则表达式获取您需要的内容-解析内容-存储内容
以上部分流程文字说明:
获取实际访问的动态页面的url:
在火狐浏览器中,右键打开插件 使用**firebug审查元素** *(没有这项的,要安装firebug插件),找到并打开**网络(NET)**标签页。重新加载网页,获得网页的响应信息,包括连接地址。每个连接地址都可以在浏览器中打开。本网站的动态网页访问地址是:
http://baoliao.hb.qq.com/api/r ... 95472
正则表达式:
正则表达式的使用方法有两种,可以参考个人的简要说明:简单爬虫的python实现和正则表达式的简单介绍
详细请参考网上资料,搜索关键词:正则表达式python
json:
参考网上关于json的介绍,搜索关键词:json python
存储到数据库:
参考网上的介绍,搜索关键词:1、mysql 2、mysql python
源代码和注释
注:python版本为2.7
#!/usr/bin/python
#指明编码
# -*- coding: UTF-8 -*-
#导入python库
import urllib
import urllib2
import re
import MySQLdb
import json
#定义爬虫类
class crawl1:
def getHtml(self,url=None):
#代理
user_agent="Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.0"
header={"User-Agent":user_agent}
request=urllib2.Request(url,headers=header)
response=urllib2.urlopen(request)
html=response.read()
return html
def getContent(self,html,reg):
content=re.findall(html, reg, re.S)
return content
#连接数据库 mysql
def connectDB(self):
host="192.168.85.21"
dbName="test1"
user="root"
password="123456"
#此处添加charset='utf8'是为了在数据库中显示中文,此编码必须与数据库的编码一致
db=MySQLdb.connect(host,user,password,dbName,charset='utf8')
return db
cursorDB=db.cursor()
return cursorDB
#创建表,SQL语言。CREATE TABLE IF NOT EXISTS 表示:表createTableName不存在时就创建
def creatTable(self,createTableName):
createTableSql="CREATE TABLE IF NOT EXISTS "+ createTableName+"(time VARCHAR(40),title VARCHAR(100),text VARCHAR(40),clicks VARCHAR(10))"
DB_create=self.connectDB()
cursor_create=DB_create.cursor()
cursor_create.execute(createTableSql)
DB_create.close()
print 'creat table '+createTableName+' successfully'
return createTableName
#数据插入表中
def inserttable(self,insertTable,insertTime,insertTitle,insertText,insertClicks):
insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES(%s,%s,%s,%s)"
# insertContentSql="INSERT INTO "+insertTable+"(time,title,text,clicks)VALUES("+insertTime+" , "+insertTitle+" , "+insertText+" , "+insertClicks+")"
DB_insert=self.connectDB()
cursor_insert=DB_insert.cursor()
cursor_insert.execute(insertContentSql,(insertTime,insertTitle,insertText,insertClicks))
DB_insert.commit()
DB_insert.close()
print 'inert contents to '+insertTable+' successfully'
url="http://baoliao.hb.qq.com/api/r ... ot%3B
#正则表达式,获取js,时间,标题,文本内容,点击量(浏览次数)
reg_jason=r'.*?jQuery.*?\((.*)\)'
reg_time=r'.*?"create_time":"(.*?)"'
reg_title=r'.*?"title":"(.*?)".*?'
reg_text=r'.*?"content":"(.*?)".*?'
reg_clicks=r'.*?"counter_clicks":"(.*?)"'
#实例化crawl()对象
crawl=crawl1()
html=crawl.getHtml(url)
html_jason=re.findall(reg_jason, html, re.S)
html_need=json.loads(html_jason[0])
print len(html_need)
print len(html_need['data']['list'])
table=crawl.creatTable('yh1')
for i in range(len(html_need['data']['list'])):
creatTime=html_need['data']['list'][i]['create_time']
title=html_need['data']['list'][i]['title']
content=html_need['data']['list'][i]['content']
clicks=html_need['data']['list'][i]['counter_clicks']
crawl.inserttable(table,creatTime,title,content,clicks)
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-10 04:02
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
. 查看全部
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。
道路
优势
缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium: Selenium有多种语言版本,如java、ruby、python等,我们可以下载python版本。pip install selenium install chromedriver:下载完成后,放到一个不需要权限的纯英文目录下。安装 Selenium 和 chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素:
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
记住Tag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
fromselenium.webdriver.support.ui importSelect
#选中这个标签,然后用Select创建一个对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
#根据索引选择
selectTag.select_by_index(1)
# 按值选择
selectTag.select_by_value("")
# 根据可见文本选择
selectTag.select_by_visible_text("95 显示客户端")
# 取消所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待是表示在执行获取元素的操作之前,一定的条件成立。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
更多条件参考:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。
Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('https://www.baidu.com')")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。
screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
.
动态网页抓取( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-07 03:26
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。可以实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任意网页(包括登录后可以访问的网页)
* 处理速度快,若网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
动态网页抓取(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片和文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息自动实时采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一次配置” ,并永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。可以实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任意网页(包括登录后可以访问的网页)
* 处理速度快,若网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点恢复抓包,可以在崩溃或异常情况后恢复抓包,继续后续抓包工作,提高系统抓包效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
动态网页抓取( 第四章:动态网页抓取(解析真实地址+selenium)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 17:00
第四章:动态网页抓取(解析真实地址+selenium)(图))
第四章:动态网络爬虫(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现已更新到这里。请参考文章:
之前抓取的网页都是静态网页,此类网页在浏览器中显示的内容都在HTML源代码中。但是,由于主流网站都是使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容都不会出现在HTML源代码中,所以抓取静态网页的技术可能不会好好工作。用。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术,获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML,异步JavaScript和XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的爬取过程比较麻烦。
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址为:。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。展示。
如图 4-4 所示,我们还可以查看该产品网页的源代码。里面没有用户评论,这段内容是空白的。
如果使用AJAX加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2) Selenium 模拟浏览器爬行。
请查看第 4 章中的其他章节
4.2 解决真实地址捕获
4.3 通过selenium模拟浏览器爬行 查看全部
动态网页抓取(
第四章:动态网页抓取(解析真实地址+selenium)(图))
第四章:动态网络爬虫(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现已更新到这里。请参考文章:
之前抓取的网页都是静态网页,此类网页在浏览器中显示的内容都在HTML源代码中。但是,由于主流网站都是使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容都不会出现在HTML源代码中,所以抓取静态网页的技术可能不会好好工作。用。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术,获取动态网页数据。
4.1 动态抓取示例
在开始爬取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML,异步JavaScript和XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果传统网页需要更新内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的爬取过程比较麻烦。
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章的地址为:。网站可能有变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的URL地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。展示。
如图 4-4 所示,我们还可以查看该产品网页的源代码。里面没有用户评论,这段内容是空白的。
如果使用AJAX加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2) Selenium 模拟浏览器爬行。
请查看第 4 章中的其他章节
4.2 解决真实地址捕获
4.3 通过selenium模拟浏览器爬行
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-06 16:24
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.HTML,查看JS加载的内容是否可用
② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 } 查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在Ajax时代,许多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的HTML
跳过了JS加载部分,即爬虫抓取的网页不完整、不完整。你可以看到下面博客花园的首页
从主页加载中,我们可以看到页面呈现后,将有五个Ajax异步请求。默认情况下,爬虫程序无法抓取Ajax生成的内容
此时,如果要获取这些动态页面,必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎有三个支柱
三叉戟:即内核。WebBrowser基于此内核,但其可加载性较差
壁虎:FF的内核比Trident有更好的性能
WebKit:Safari和chrome的内核性能,你知道,在真实场景中仍然基于它
好吧,为了简单和方便,让我们使用WebBrowser来玩。使用WebBrowser时,我们应注意以下几点:
第一:因为WebBrowser是system.windows.forms中的WinForm控件,所以我们需要设置StatThread标志
第二:WinForm是事件驱动的,控制台不响应事件。所有事件都在windows的消息队列中等待执行。为了不让程序假装死亡
我们需要调用Doevents方法来转移控制,并让操作系统执行其他事件
第三:我们需要使用domdocument而不是documenttext来查看WebBrowser中的内容
通常有两种方法来判断是否加载了动态网页:
① : 在这里设置一个最大值,因为每次异步加载JS时,都会触发导航和documentcompleted事件,所以我们需要
只需将计数值记录在
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.HTML,查看JS加载的内容是否可用
② : 当然,除了通过判断最大值来判断加载是否完成外,我们还可以通过设置定时器来判断,如3S、4S、5S等
是否已加载web浏览器
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果是一样的,所以我们不会截图。通过以上两种编写方法,我们的WebBrowser被放置在主线程中。让我们看看如何把它放在工作线程上
非常简单,只需将工作线程设置为sta模式
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(大厂的动态网页抓取分为前端动态抓取和后端抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-06 10:03
动态网页抓取分为前端动态抓取和后端动态抓取。1.首先fastdfs,iscaptureandlocalify分别只能抓后端的动态网页,首页加载项,和响应网页数据。要前端动态网页的,需要前端抓包工具mitmproxy/google-incapable。2.你说的页面类型我不知道是是什么类型的页面,你可以学习一下大厂的浏览器调试工具,一般都是在google搜索用的工具,如javascript,browserconfig等,将你提到的url地址提取出来(而不是http地址),然后输入到工具里,能直接反馈出一堆浏览器命令行javascript对话框,例如:sethttp_protocol:httptype:get然后你自己体会吧。
抓取方法大致有两种:①批量抓取②数据包抓取。批量抓取,建议用代理包(nginx等等)抓取数据包,有人说现在网上爬虫层出不穷,其实爬虫早已脱离“爬虫”二字,直接是数据包分析。具体怎么爬取,实际上就是抓包+解析+分析包名目标网站的解析方法很多,有聚合页面,有清除js,有抓取jsfunction等等其中第二种方法就是爬虫容易丢失一些内容,非聚合页面又不太容易抓取,通常所需时间也很长,如何抓取就是一个很大的技术话题了,目前在“爬虫”问题上有很多人,不同的工具也有不同的套路,例如,由于抓取我的工具是v5爬虫框架架,国内确实有比较好的javascript解析工具,而海外也不乏专门做javascript解析工具的,不过还是抓包容易,数据包容易。 查看全部
动态网页抓取(大厂的动态网页抓取分为前端动态抓取和后端抓取)
动态网页抓取分为前端动态抓取和后端动态抓取。1.首先fastdfs,iscaptureandlocalify分别只能抓后端的动态网页,首页加载项,和响应网页数据。要前端动态网页的,需要前端抓包工具mitmproxy/google-incapable。2.你说的页面类型我不知道是是什么类型的页面,你可以学习一下大厂的浏览器调试工具,一般都是在google搜索用的工具,如javascript,browserconfig等,将你提到的url地址提取出来(而不是http地址),然后输入到工具里,能直接反馈出一堆浏览器命令行javascript对话框,例如:sethttp_protocol:httptype:get然后你自己体会吧。
抓取方法大致有两种:①批量抓取②数据包抓取。批量抓取,建议用代理包(nginx等等)抓取数据包,有人说现在网上爬虫层出不穷,其实爬虫早已脱离“爬虫”二字,直接是数据包分析。具体怎么爬取,实际上就是抓包+解析+分析包名目标网站的解析方法很多,有聚合页面,有清除js,有抓取jsfunction等等其中第二种方法就是爬虫容易丢失一些内容,非聚合页面又不太容易抓取,通常所需时间也很长,如何抓取就是一个很大的技术话题了,目前在“爬虫”问题上有很多人,不同的工具也有不同的套路,例如,由于抓取我的工具是v5爬虫框架架,国内确实有比较好的javascript解析工具,而海外也不乏专门做javascript解析工具的,不过还是抓包容易,数据包容易。
动态网页抓取(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-10-05 23:08
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
我想获取年龄数据,即“20”,如何使用常规捕获?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @”(?is)”);
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“。” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一,我建议使用 XML 来保存内容。首先,网页中的数据基本可以转换成XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29" 查看全部
动态网页抓取(1.正则表达式匹配;2.使用HtmlAgilityPack;(不是很熟悉)
)
等待。
此过程目前有两种方法可供选择:
1.正则表达式匹配;
2.使用HtmlAgilityPack;(不是很熟悉)
本文仅提供正则表达式的方法供大家学习借鉴,请各位读者见谅。
正则表达式定位
如果长期做数据采集工作,建议深入研究。这里是DeerChao对正则表达式的介绍,非常推荐。如果你只是想做一个课程设计,可以听我的介绍。
“定位”过程主要使用Regex.Match()方法,返回结果为正则匹配的文本。即目标网页数据。
让我粗略地解释一下,例如,如果您有这样的文字:
“我20岁了。”
我想获取年龄数据,即“20”,如何使用常规捕获?
//...
using System.Text.RegularExpressions;
//导入正则表达式命名空间
//...
string strTest = @"I am 20 years old.";
string strResult = "";
strResult = Regex.Match(strTest, @"\d+").Value;
Console.WriteLine(strResult);
Console.ReadKey();
OK,抓包成功!但是你可能会问,这个程序跟定位有什么关系?好吧,让我解释一下:
您可以多次使用它: strResult = Regex.Match(strResult, @"正正").Value; 一步一步缩小网页中的数据范围,最终定位到你想到的那部分数据。
类似于“我今年 20 岁”。您可以通过三步找到“20”
然后就可以在网页上用同样的方法定位嵌套的内容(当然,如果没有嵌套的部分,也可以尝试一次性全部抓取),
strResult = Regex.Match(strResult , "(?is)登录.*?更多").Value;
strResult = Regex.Match(strResult , "(?is)").Value;
通过这两行代码,就可以定位到百度的“百度点击”按钮。当然你也可以删掉上一句,因为百度首页只有一个提交按钮。但是如果是其他网站,有多个提交按钮,那么就得重新考虑正则的写法了。
常问问题
定位数据的原理基本介绍完毕。相信读者会有很多疑问(文笔不好,见谅),我自己写一些吧:
Q:匹配结果有多个值怎么办?
A:在匹配网页数据的时候,经常会遇到多个匹配的结果,比如多个表,多个div标签等,这时候我们可以使用Match采集来接受返回的结果集,例如:
Match采集 mcResult = Regex.Matches(strHtml, @”(?is)”);
可以使用foreach遍历这个集合,也可以使用下标来访问元素。但请注意,您需要使用 Regex.Matches() 方法而不是 Regex.Match() 方法。你注意到了吗?这表示您可能匹配了多个结果。
问:常规中的 (?is) 是什么意思?
A:这是正则表达式的匹配选项,.Net中也有对应的选项
(?i) 表示不区分大小写,相当于.net 中的 RegexOptions.IgnoreCase 选项;
(?s) 表示让“。” 匹配换行符,即“。” 表示 [\s\S] 相当于.net 中的 RegexOptions.Singleline 选项;
//当然还有其他问题,这里就不一一列举了,希望大家多多评论,我会尽量解答。
三、保存数据
保存数据的方式有很多种,比如XML格式、标签内容、直接写入数据库、保存为txt……您可以根据自己的需要选择合适的保存方式。
但是,为了统一,我建议使用 XML 来保存内容。首先,网页中的数据基本可以转换成XML格式;其次,将XML输入到数据库中并转换为其他形式非常方便;三、XML操作 数据方便。如果需要修改数据,有很多API库之类的可以调用。总之就是好处多多,呵呵。
@"Author: wushuai1346
Description: 不断完善中.版权所有,转载请注明出处,谢谢.
Copyright (C) 2011 wushuai1346,All Rights Reserved
Url: http://blog.csdn.net/wushuai13 ... 08424
Createtime : 2011-12-28
Updatetime : 2011-12-29"
动态网页抓取(园子如何实现多线程使用webborwser采集页面其中我用到了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-10-04 20:18
今天在园子里看到了一个学术驴写的爬虫机器人,用C#webbrowser和Application.DoEvents()实现采集动态网页
其实我也是用类似的方法抓取需要登录的网页,还有一些动态页面。
今天想讲的是如何实现webborwser采集页面的多线程使用
其中,我使用了一个 WeiFenLuo.winFormsUI.Docking.dll,它是一个开源组件
下载链接:
关于这个组件,园子里已经有前辈做过详细的使用方法了,这里不再赘述。
在MainForm窗体中添加一个微分罗控件,并将MainForm窗体的IsMdiContainer属性设置为True
并添加addWebForm方法动态添加子表单
public void addWebForm(string s)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(addWebForm), s);
}
else
{
ChildForm f2 = new ChildForm();
f2.Text = s;
webForm.Add(s, f2);
f2.Show(dockPanel1);
}
}
向 ChildForm 窗体添加一个 Webborwser 控件
并添加打开页面的方法
public delegate void OneStringParmenters(string str);//1个string参数委托
public void Navigate(string url)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(Navigate), url);
}
else
{
webBrowser1.Navigate(url);
}
}
和读取页面html方法
private string strHtmlLeng = "";
private delegate void NoParameters();//无参数委托;
public string StrHtmlLeng
{
get
{
if (this.InvokeRequired)
{
IAsyncResult iar = this.BeginInvoke(new NoParameters(GetHtmlLeng));
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
}
else
{
GetHtmlLeng();
}
return strHtmlLeng;
}
}
private void GetHtmlLeng()
{
strHtmlLeng = webBrowser1.DocumentText;
}
添加多线程方法模拟多线程打开页面读取html
public static void OpenWebPage(object strUrl)
{
DateTime dt = DateTime.Now;
string u = strUrl.ToString();
IAsyncResult iar = Program.form.BeginInvoke(new OneStringParmenters(Program.form.addWebForm), u);
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
int n = Program.form.webForm.Count;
Program.form.webForm[u].Navigate(u);
System.Threading.Thread.Sleep(TimeSpan.FromMinutes(1));
string strHtml = Program.form.webForm[u].StrHtmlLeng;
//把html输出到本地e盘,当采集信息时,可以直接操作html
System.IO.StreamWriter sw = new StreamWriter(string.Format("e:/{0}.txt", u));
sw.Write(string.Format("开始时间:{0}\r\n 结束时间:{1}\r\n 打开信息:{2}", dt.ToString("G"), DateTime.Now, strHtml));
sw.Dispose();
}
好的。现在使用多线程执行OpenWebPage方法,可以模拟Webborwser的多线程操作
下面是我写的测试用的小程序 查看全部
动态网页抓取(园子如何实现多线程使用webborwser采集页面其中我用到了)
今天在园子里看到了一个学术驴写的爬虫机器人,用C#webbrowser和Application.DoEvents()实现采集动态网页
其实我也是用类似的方法抓取需要登录的网页,还有一些动态页面。
今天想讲的是如何实现webborwser采集页面的多线程使用
其中,我使用了一个 WeiFenLuo.winFormsUI.Docking.dll,它是一个开源组件
下载链接:
关于这个组件,园子里已经有前辈做过详细的使用方法了,这里不再赘述。
在MainForm窗体中添加一个微分罗控件,并将MainForm窗体的IsMdiContainer属性设置为True
并添加addWebForm方法动态添加子表单
public void addWebForm(string s)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(addWebForm), s);
}
else
{
ChildForm f2 = new ChildForm();
f2.Text = s;
webForm.Add(s, f2);
f2.Show(dockPanel1);
}
}
向 ChildForm 窗体添加一个 Webborwser 控件
并添加打开页面的方法
public delegate void OneStringParmenters(string str);//1个string参数委托
public void Navigate(string url)
{
if (this.InvokeRequired)
{
this.BeginInvoke(new OneStringParmenters(Navigate), url);
}
else
{
webBrowser1.Navigate(url);
}
}
和读取页面html方法
private string strHtmlLeng = "";
private delegate void NoParameters();//无参数委托;
public string StrHtmlLeng
{
get
{
if (this.InvokeRequired)
{
IAsyncResult iar = this.BeginInvoke(new NoParameters(GetHtmlLeng));
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
}
else
{
GetHtmlLeng();
}
return strHtmlLeng;
}
}
private void GetHtmlLeng()
{
strHtmlLeng = webBrowser1.DocumentText;
}
添加多线程方法模拟多线程打开页面读取html
public static void OpenWebPage(object strUrl)
{
DateTime dt = DateTime.Now;
string u = strUrl.ToString();
IAsyncResult iar = Program.form.BeginInvoke(new OneStringParmenters(Program.form.addWebForm), u);
while (!iar.IsCompleted)
{
System.Threading.Thread.Sleep(0);
}
int n = Program.form.webForm.Count;
Program.form.webForm[u].Navigate(u);
System.Threading.Thread.Sleep(TimeSpan.FromMinutes(1));
string strHtml = Program.form.webForm[u].StrHtmlLeng;
//把html输出到本地e盘,当采集信息时,可以直接操作html
System.IO.StreamWriter sw = new StreamWriter(string.Format("e:/{0}.txt", u));
sw.Write(string.Format("开始时间:{0}\r\n 结束时间:{1}\r\n 打开信息:{2}", dt.ToString("G"), DateTime.Now, strHtml));
sw.Dispose();
}
好的。现在使用多线程执行OpenWebPage方法,可以模拟Webborwser的多线程操作
下面是我写的测试用的小程序
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-10-01 22:10
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们无法通过请求模块抓取数据以使其每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python爬取网页中动态加载数据的实现的文章就介绍到这里了。更多Python爬取网页动态数据相关内容,请搜索前面的文章或继续浏览下面的相关文章希望大家以后多多支持! 查看全部
动态网页抓取(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们无法通过请求模块抓取数据以使其每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么这些通过其他请求请求的数据就是动态加载的数据。(猜测是我们访问这个页面的时候js代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,说明数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页使用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python爬取网页中动态加载数据的实现的文章就介绍到这里了。更多Python爬取网页动态数据相关内容,请搜索前面的文章或继续浏览下面的相关文章希望大家以后多多支持!
动态网页抓取(动态网站的爬取包含下以下三个步骤:抓包 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-01 22:08
)
众所周知,动态网站通常使用ajax等异步加载技术来加载网页。与静态网页相比,动态网页通常收录多个请求,而数据往往不存在于网页的源代码中。打包查找并分析数据所在的请求,并编写响应的爬虫代码。动态网站的爬取包括抓包、参数分析、数据提取三个步骤。(以下以爬取b站评论为例)
一、抓包
抓包的方法有很多,比较常用的比较有用,比如fiddle,一个抓包软件和浏览器自带的开发者调试工具(即f12),这里只介绍chrome的f12。
f12里面有很多菜单,这里我们只需要用到网络,下面是我们会经常用到的功能
上面三个箭头所指的按钮的功能是从左到右
1. 开关,红色开始捕捉,灰色停止。开启后,之前的拍摄历史将被清除
2.清除历史记录
3.搜索功能,可以查询哪些包有指定字段
下面一栏是过滤器,你可以选择要查看的包类型。一般动态网页的封装是xhr
接下来,开始抓包。抓包一般有两种方式:
1.通过触发指定事件定位数据所在的包
分析网站,很明显,可以触发b站评论变化的事件是点击如图所示的两个按钮,向下滑动到评论所在的地方。这里我们选择要触发的按钮事件。
很明显,我们需要的包就在眼前,点击查看内容,发现是一个json文件,然后我们就确认了这就是我们想要的包。
一些动态的网站可能会在网站加载时触发事件,或者传入的包根本不是xhr包,导致历史记录中有大量我不知道的包知道要做什么。前面提到的搜索功能会起作用
打开搜索框后,填写我们需要在搜索中定位的数据,如图
可以看到,数据包很快就被我们找到了。这种方法比第一种更有效,但效率不如第一种,而且各有优缺点。
二、分析参数
异步数据包不像网页那样具有唯一的 uri。网站作为传输数据的api,通常只使用一个api传输一种类型的数据,使用包中的参数通知服务器后台应该返回什么数据,以及我们需要的参数要分析的是这些影响背景的关键数据。
点击我们找到的包,选择header,可以看到有几个下拉列
我们需要注意的有三列:
1.响应头
请求头,我们抓取静态网站时也会用到的一组参数,比如user-agent,referer等字段,有的网站会在请求头中传递一些数据来通知后台,主要用于反爬虫,除了user-agent和referer,其他字段很少用到。具体分析,爬的时候注意。
2.表单数据
请求体,只存在于POST请求中,也是一组需要分析的参数,因为我们很少爬到POST请求的api,所以就不展开了。
3.查询字符串参数
这是最重要的一组参数,存在于 url 中。url链接问号后面的一串字符串是用来传递这组参数的,但是我们在f12中可以直观的看到,如下图所示。
接下来我们需要开始分析这些参数,找出哪些有用,哪些不需要传输,哪些没用但需要传输。这里没有灵丹妙药。无非就是在删除参数后访问和检查传入的数据,或者寻找使用相同api的事件。有什么不同?我们可以使用python shell或者写一个python脚本来测试,例如
经过测试,我们知道callback、jsonp、_参数是不需要的,type是需要但是没有意义,pn表示页数,sort表示排序方式(即热排序和最新排序),oid指定只有视频(但不是 av 编号),因此我们可以通过循环 pn 来抓取所有评论。
三、提取数据
大多数api使用json数据格式来传输数据。当然也有把参数直接加到网页url返回html的情况(可以用bs解析)。要解析 json,我们需要使用 json 库。我不会在这里详细介绍 json。知识(有需要的去百度一下
如图,我们要找的路径是root->data->reply。每条评论的内容、作者、时间等都在这里
四、总结
动态网站的爬取主要在于对异步加载等前端技术的理解程度,以及对web开发的理解。虽然作为爬虫工具,前后端技术学习都是没落,甚至有些网站用js反向爬取,难度可以更高。但是对于数据挖掘来说,这种基本的爬虫技术就足够了,网上90%的数据爬取是没有问题的。
查看全部
动态网页抓取(动态网站的爬取包含下以下三个步骤:抓包
)
众所周知,动态网站通常使用ajax等异步加载技术来加载网页。与静态网页相比,动态网页通常收录多个请求,而数据往往不存在于网页的源代码中。打包查找并分析数据所在的请求,并编写响应的爬虫代码。动态网站的爬取包括抓包、参数分析、数据提取三个步骤。(以下以爬取b站评论为例)
一、抓包
抓包的方法有很多,比较常用的比较有用,比如fiddle,一个抓包软件和浏览器自带的开发者调试工具(即f12),这里只介绍chrome的f12。
f12里面有很多菜单,这里我们只需要用到网络,下面是我们会经常用到的功能
上面三个箭头所指的按钮的功能是从左到右
1. 开关,红色开始捕捉,灰色停止。开启后,之前的拍摄历史将被清除
2.清除历史记录
3.搜索功能,可以查询哪些包有指定字段
下面一栏是过滤器,你可以选择要查看的包类型。一般动态网页的封装是xhr
接下来,开始抓包。抓包一般有两种方式:
1.通过触发指定事件定位数据所在的包
分析网站,很明显,可以触发b站评论变化的事件是点击如图所示的两个按钮,向下滑动到评论所在的地方。这里我们选择要触发的按钮事件。
很明显,我们需要的包就在眼前,点击查看内容,发现是一个json文件,然后我们就确认了这就是我们想要的包。
一些动态的网站可能会在网站加载时触发事件,或者传入的包根本不是xhr包,导致历史记录中有大量我不知道的包知道要做什么。前面提到的搜索功能会起作用
打开搜索框后,填写我们需要在搜索中定位的数据,如图
可以看到,数据包很快就被我们找到了。这种方法比第一种更有效,但效率不如第一种,而且各有优缺点。
二、分析参数
异步数据包不像网页那样具有唯一的 uri。网站作为传输数据的api,通常只使用一个api传输一种类型的数据,使用包中的参数通知服务器后台应该返回什么数据,以及我们需要的参数要分析的是这些影响背景的关键数据。
点击我们找到的包,选择header,可以看到有几个下拉列
我们需要注意的有三列:
1.响应头
请求头,我们抓取静态网站时也会用到的一组参数,比如user-agent,referer等字段,有的网站会在请求头中传递一些数据来通知后台,主要用于反爬虫,除了user-agent和referer,其他字段很少用到。具体分析,爬的时候注意。
2.表单数据
请求体,只存在于POST请求中,也是一组需要分析的参数,因为我们很少爬到POST请求的api,所以就不展开了。
3.查询字符串参数
这是最重要的一组参数,存在于 url 中。url链接问号后面的一串字符串是用来传递这组参数的,但是我们在f12中可以直观的看到,如下图所示。
接下来我们需要开始分析这些参数,找出哪些有用,哪些不需要传输,哪些没用但需要传输。这里没有灵丹妙药。无非就是在删除参数后访问和检查传入的数据,或者寻找使用相同api的事件。有什么不同?我们可以使用python shell或者写一个python脚本来测试,例如
经过测试,我们知道callback、jsonp、_参数是不需要的,type是需要但是没有意义,pn表示页数,sort表示排序方式(即热排序和最新排序),oid指定只有视频(但不是 av 编号),因此我们可以通过循环 pn 来抓取所有评论。
三、提取数据
大多数api使用json数据格式来传输数据。当然也有把参数直接加到网页url返回html的情况(可以用bs解析)。要解析 json,我们需要使用 json 库。我不会在这里详细介绍 json。知识(有需要的去百度一下
如图,我们要找的路径是root->data->reply。每条评论的内容、作者、时间等都在这里
四、总结
动态网站的爬取主要在于对异步加载等前端技术的理解程度,以及对web开发的理解。虽然作为爬虫工具,前后端技术学习都是没落,甚至有些网站用js反向爬取,难度可以更高。但是对于数据挖掘来说,这种基本的爬虫技术就足够了,网上90%的数据爬取是没有问题的。
动态网页抓取(爬虫练习写的爬虫代码,如有什么问题和建议?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-01 22:07
前言
我是爬虫代码的初学者,如果有什么问题或者建议,请留言!
一、什么是动态网页?二、具体步骤1. 如何抓取动态网页上的数据 从抓取到的HTML文件分析,我们知道抓取到的文件的URL与页码有关,我们可以遵循规则自己构造一个url来抓取文件(下面的例子就是这种情况);如果从抓取到的HTML文件中发现文件url是固定的或者与页码无关,则只需模拟浏览器点击行为,请求再次抓取网页。这种效率比较慢,不适合多页面爬取。
爬取动态网站的关键是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。
2. 抓取网页数据所需的库 PhatomJS 是一个没有界面的浏览器,用于读取JS加载的页面,具体下载方法可以百度,不是python的第三方库,需要自己下载添加环境变量;当然你也可以使用Chrome、firefox、IE等。Selenium是python的第三方库。命令行输入:pip install selenium download,可以模拟用户在浏览器上进行一些操作。Phatom JS + Selenium 抓取动态网页。使用请求库获取图片。使用beautifulSoup解析抓取到的网页内容。使用os库创建文件并获取文件夹中的文件名列表
代码如下(示例):
import os
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
# 网页url,该url和页码存在规律,下一页的url是将后面的offset=0改为offset=100,具体可自己测试
WEB_URL = 'https://music.163.com/%23/arti ... 39%3B
# 保存图片的文件夹
FOLDER_PATH = 'D:/BeautifulPicture'
# 应对服务器反爬机制(会根据User-Agent辨别是浏览器访问还是代码访问,代码访问会被拒绝,所以需要使用headers伪装一下)的请求头,这里我们用的是PhatomJS浏览器,所以不需要
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
class AlbumCover:
def __init__(self):
self.web_url = WEB_URL
self.folder_path = FOLDER_PATH
self.headers = HEADERS
def request(self, url):
r = requests.get(url)
return r
def save_img(self, url, file_name):
print("开始请求图片地址……")
img = self.request(url)
print("开始保存图片……")
f = open(file_name, 'wb')
f.write(img.content)
print(file_name, "图片保存成功")
f.close()
def mkdir(self, path):
# self.is_folder_new
path = path.strip()
if not os.path.exists(path):
print("创建名字叫" + path + "的文件夹")
os.mkdir(path)
print("创建成功")
return True
else:
print("文件已经存在,不用创建")
return False
def spider(self):
print("Start")
# 使用selenium驱动PhantomJS进行网络请求
driver = webdriver.PhantomJS()
driver.get(self.web_url)
# 该网页使用了iframe框架,需要switch一下
driver.switch_to.frame("g_iframe")
# 根据驱动器获取网页源码
html = driver.page_source
self.mkdir(self.folder_path)
print('开始切换文件')
os.chdir(self.folder_path)
# 使用BeautifulSoup来对html进行解析,根据网页的开发者页面可以查到所有图片都在标签下,每个图片的标签是
all_li = BeautifulSoup(html, 'lxml').find('ul', class_="m-cvrlst m-cvrlst-alb4 f-cb").find_all('li')
for li in all_li:
album_url = li.find('img')['src']
album_name = li.find('p', class_='dec dec-1 f-thide2 f-pre')['title']
album_date = li.find('span', class_='s-fc3').text
# 将url后拼接的长宽去掉
index = album_url.index('?')
album_url = album_url[:index]
# 图片命名
photo_name = album_date + '-' + album_name.replace('/', '').replace(':', ',') + ".jpg"
# os.listdir(path)返回文件夹底下的全部文件
# 是一个去重操作
if photo_name in os.listdir(self.folder_path):
print("图片已经存在,继续下一个")
else:
self.save_img(album_url, photo_name)
driver.close()
if __name__ == '__main__':
get = AlbumCover()
get.spider()
3.运行结果
文件夹中保存的图片:
这里使用的 url 网络请求的数据。
总结
selenium 和 requests 的比较:
1、速度慢。每次运行爬虫时,都会打开一个浏览器。如果没有设置,会加载很多图片,JS等;
2、 占用资源过多。有人说把Chrome改成无头浏览器PhantomJS,原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到你在用 PhantomJS 访问,就会被封禁。您的请求,然后您必须考虑更改请求标头。我不知道事情有多复杂。为什么要学习 Python?因为Python简单,如果有更快更简单的库可以实现同样的功能,何乐而不为呢?
3、 对网络的要求会更高。Selenium 加载了很多可能对您没有价值的补充文件(例如 css、js 和图像文件)。这可能会产生更多的流量,而不仅仅是请求您真正需要的资源(使用单独的 HTTP 请求)。
4、 爬网规模不能太大。
5、困难。学习Selenium的成本太高了,
通过对比可以看出requests在代码上简洁,不难操作,而selenium缺点很多,所以不建议大家爬取数据。
使用数据: 查看全部
动态网页抓取(爬虫练习写的爬虫代码,如有什么问题和建议?)
前言
我是爬虫代码的初学者,如果有什么问题或者建议,请留言!
一、什么是动态网页?二、具体步骤1. 如何抓取动态网页上的数据 从抓取到的HTML文件分析,我们知道抓取到的文件的URL与页码有关,我们可以遵循规则自己构造一个url来抓取文件(下面的例子就是这种情况);如果从抓取到的HTML文件中发现文件url是固定的或者与页码无关,则只需模拟浏览器点击行为,请求再次抓取网页。这种效率比较慢,不适合多页面爬取。
爬取动态网站的关键是抓包分析。只要能从包中分析出关键数据,剩下的编写爬虫的步骤一般与编写静态网页的步骤相同。
2. 抓取网页数据所需的库 PhatomJS 是一个没有界面的浏览器,用于读取JS加载的页面,具体下载方法可以百度,不是python的第三方库,需要自己下载添加环境变量;当然你也可以使用Chrome、firefox、IE等。Selenium是python的第三方库。命令行输入:pip install selenium download,可以模拟用户在浏览器上进行一些操作。Phatom JS + Selenium 抓取动态网页。使用请求库获取图片。使用beautifulSoup解析抓取到的网页内容。使用os库创建文件并获取文件夹中的文件名列表
代码如下(示例):
import os
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
# 网页url,该url和页码存在规律,下一页的url是将后面的offset=0改为offset=100,具体可自己测试
WEB_URL = 'https://music.163.com/%23/arti ... 39%3B
# 保存图片的文件夹
FOLDER_PATH = 'D:/BeautifulPicture'
# 应对服务器反爬机制(会根据User-Agent辨别是浏览器访问还是代码访问,代码访问会被拒绝,所以需要使用headers伪装一下)的请求头,这里我们用的是PhatomJS浏览器,所以不需要
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
class AlbumCover:
def __init__(self):
self.web_url = WEB_URL
self.folder_path = FOLDER_PATH
self.headers = HEADERS
def request(self, url):
r = requests.get(url)
return r
def save_img(self, url, file_name):
print("开始请求图片地址……")
img = self.request(url)
print("开始保存图片……")
f = open(file_name, 'wb')
f.write(img.content)
print(file_name, "图片保存成功")
f.close()
def mkdir(self, path):
# self.is_folder_new
path = path.strip()
if not os.path.exists(path):
print("创建名字叫" + path + "的文件夹")
os.mkdir(path)
print("创建成功")
return True
else:
print("文件已经存在,不用创建")
return False
def spider(self):
print("Start")
# 使用selenium驱动PhantomJS进行网络请求
driver = webdriver.PhantomJS()
driver.get(self.web_url)
# 该网页使用了iframe框架,需要switch一下
driver.switch_to.frame("g_iframe")
# 根据驱动器获取网页源码
html = driver.page_source
self.mkdir(self.folder_path)
print('开始切换文件')
os.chdir(self.folder_path)
# 使用BeautifulSoup来对html进行解析,根据网页的开发者页面可以查到所有图片都在标签下,每个图片的标签是
all_li = BeautifulSoup(html, 'lxml').find('ul', class_="m-cvrlst m-cvrlst-alb4 f-cb").find_all('li')
for li in all_li:
album_url = li.find('img')['src']
album_name = li.find('p', class_='dec dec-1 f-thide2 f-pre')['title']
album_date = li.find('span', class_='s-fc3').text
# 将url后拼接的长宽去掉
index = album_url.index('?')
album_url = album_url[:index]
# 图片命名
photo_name = album_date + '-' + album_name.replace('/', '').replace(':', ',') + ".jpg"
# os.listdir(path)返回文件夹底下的全部文件
# 是一个去重操作
if photo_name in os.listdir(self.folder_path):
print("图片已经存在,继续下一个")
else:
self.save_img(album_url, photo_name)
driver.close()
if __name__ == '__main__':
get = AlbumCover()
get.spider()
3.运行结果
文件夹中保存的图片:
这里使用的 url 网络请求的数据。
总结
selenium 和 requests 的比较:
1、速度慢。每次运行爬虫时,都会打开一个浏览器。如果没有设置,会加载很多图片,JS等;
2、 占用资源过多。有人说把Chrome改成无头浏览器PhantomJS,原理是一样的。就是打开浏览器,很多网站都会验证参数。如果对方看到你在用 PhantomJS 访问,就会被封禁。您的请求,然后您必须考虑更改请求标头。我不知道事情有多复杂。为什么要学习 Python?因为Python简单,如果有更快更简单的库可以实现同样的功能,何乐而不为呢?
3、 对网络的要求会更高。Selenium 加载了很多可能对您没有价值的补充文件(例如 css、js 和图像文件)。这可能会产生更多的流量,而不仅仅是请求您真正需要的资源(使用单独的 HTTP 请求)。
4、 爬网规模不能太大。
5、困难。学习Selenium的成本太高了,
通过对比可以看出requests在代码上简洁,不难操作,而selenium缺点很多,所以不建议大家爬取数据。
使用数据:
动态网页抓取(需安装的三方库示例代码示例说明:获取德邦官网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-01 15:04
前言
在抓取常规静态网页时,我们可以直接请求相应的url来获取完整的HTML页面,但是对于动态页面,网页显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/")
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。 查看全部
动态网页抓取(需安装的三方库示例代码示例说明:获取德邦官网)
前言
在抓取常规静态网页时,我们可以直接请求相应的url来获取完整的HTML页面,但是对于动态页面,网页显示的内容往往是通过ajax动态生成的,所以如果直接使用urllib.request的时候获取页面的HTML,我们无法获取我们想要的内容。然后我们就可以使用selenium库来获取我们需要的内容了。
要安装的三方库示例代码
示例说明:获取德邦官网已设立网点的城市名称
import urllib.request
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") #设置该参数使在获取网页时不打开浏览器
driver = webdriver.Chrome(chrome_options=chrome_options, executable_path="./chromedriver")
driver.get("https://www.deppon.com/deptlist/";)
html = driver.page_source
driver.close()
soup = BeautifulSoup(html, 'lxml')
items = soup.select('div[class~="listA_Z"] a')
for item in items:
print(item.string)
使用“pip install selenium”安装selenium库时遇到的小问题失败。您可以使用以下命令安装“pip install --trusted-host --trusted-host selenium”。使用webdriver.Chrome()时,网上出现的问题文章使用火狐浏览器。他们可以直接使用 webdriver.Firefox(),但我使用 Google Chrome。我以为使用谷歌浏览器和使用火狐是一样的,但是在运行时发生了错误。后来我在网上找到了。我想从selenium官网下载Chrom Driver,然后在使用webdriver.chorme()函数的时候需要上传。executable_path参数,该参数的值为selenium官网下载的Chrome Driver.exe文件所在的路径。在示例中,我将 chromedriver.exe 放在根目录中,因此我在代码中使用了相对路径(executable_path="./chromedriver")。推荐
Chrom/firefox 浏览器插件:Katalon Recorder,Katalon Recorder 是一个前端自动化测试插件,可以用来记录你在网页上的所有操作,最神奇的是它还可以导出记录到各种代码,其中收录 Python2 代码。有时借用它,我们无需分析HTML的结构就可以轻松得到我们需要的数据,这对于HTML结构凌乱的网页非常有帮助。
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-01 07:06
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。 Chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面:
driver.close():关闭当前页面。driver.quit():退出整个浏览器。
定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以稍后使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
动态网页抓取(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如点击、填充数据、删除cookies等。 Chromedriver是一个驱动Chrome浏览器的驱动程序,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium and chromedriver: Install Selenium: Selenium有多种语言,如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面:
driver.close():关闭当前页面。driver.quit():退出整个浏览器。
定位元素:
find_element_by_id:根据 id 查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以稍后使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
饼干操作:
获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
动态网页抓取( 可支持的【真实】驱动程序介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-10-01 07:05
可支持的【真实】驱动程序介绍(一))
#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。 查看全部
动态网页抓取(
可支持的【真实】驱动程序介绍(一))
#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。
动态网页抓取(动态网页抓取对javascript前端开发人员来说是非常重要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2021-09-30 01:06
动态网页抓取对javascript前端开发人员来说是非常重要的。你可以在mozilla、facebook和谷歌公司的开发工具中获得动态网页框架。
presto是express框架,有个中文字幕版视频(优酷),在这里推荐给大家。
为什么不用react。当然react也可以做,目前就我接触的情况是这样的。目前没看到有多少合适做网页抓取工作的库,非要这样的话,就只能转react网页框架了。我知道有人用react做异步网页抓取的,并不太满意,原因就不说了,现在reactrouter还是挺好用的。
react的话,没有太多特殊要求,es5的语法都是一样的。es6/react-router/reduxasaservice同时react-router可以利用redux传递mapofurl参数和mapofurlobject对象来生成下一个页面的url,生成下一个页面的url就是用urlreturn中间形式的就行。
可以看看这个例子。上传图片不收费,使用方法有可能会有些技巧。基本上关于get和post的watcher的选择是有偏好的。description:processingjavascriptroutesforfullstackwebdevelopment这个网站讲得很详细。react-router的例子我没有看。
可以参考一下各网站的代码。另外,用react-router来模拟真实网页,其实也挺有效果的。例如评论就可以采用route.page来访问就好了。评论插件也可以用router/path。有一些proxy也提供了类似的工作。这是另外一个帖子,讲得很详细,建议看看/p/private.html这个话题里面也有很多回答,可以看看。 查看全部
动态网页抓取(动态网页抓取对javascript前端开发人员来说是非常重要的)
动态网页抓取对javascript前端开发人员来说是非常重要的。你可以在mozilla、facebook和谷歌公司的开发工具中获得动态网页框架。
presto是express框架,有个中文字幕版视频(优酷),在这里推荐给大家。
为什么不用react。当然react也可以做,目前就我接触的情况是这样的。目前没看到有多少合适做网页抓取工作的库,非要这样的话,就只能转react网页框架了。我知道有人用react做异步网页抓取的,并不太满意,原因就不说了,现在reactrouter还是挺好用的。
react的话,没有太多特殊要求,es5的语法都是一样的。es6/react-router/reduxasaservice同时react-router可以利用redux传递mapofurl参数和mapofurlobject对象来生成下一个页面的url,生成下一个页面的url就是用urlreturn中间形式的就行。
可以看看这个例子。上传图片不收费,使用方法有可能会有些技巧。基本上关于get和post的watcher的选择是有偏好的。description:processingjavascriptroutesforfullstackwebdevelopment这个网站讲得很详细。react-router的例子我没有看。
可以参考一下各网站的代码。另外,用react-router来模拟真实网页,其实也挺有效果的。例如评论就可以采用route.page来访问就好了。评论插件也可以用router/path。有一些proxy也提供了类似的工作。这是另外一个帖子,讲得很详细,建议看看/p/private.html这个话题里面也有很多回答,可以看看。
动态网页抓取(如何选择虎嗅网的网页界面分析工具?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-29 06:05
一、分析背景:
1. 为什么选择虎嗅
《关于虎嗅》成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。
2. 分析内容
分析虎嗅网5万篇文章文章的基本信息,包括采集数、评论数等;发现最受欢迎和最不受欢迎的 文章 和作者;分析文章的标题格式(长度、句型)与流行度的关系;展示近年来科技互联网行业的流行词汇
3. 分析工具:
蟒蛇3.6
刮的
MongoDB
Matplotlib
词云
杰巴
数据抓取
我用scrapy抓取了Tiger 文章的首页,从2012年建站到2018年12月7日,抓取文章的时间约为5万篇文章 . 抓取8个信息字段:文章标题、作者、发帖时间、评论数、采集数、摘要、文章链接和文章内容。
1.目标网站分析
这是要抓取的网页界面。您可以看到它是通过 AJAX 加载的。
按F12打开开发者工具,可以看到URL请求是POST类型的,向下滚动到底部查看Form Data,表单中只有3个参数需要提交。尝试后,只提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。
接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page为2119,表示文章内容一共2119页,每页有25个文章,一共大概5万条,就是我们要爬取的数量。
Scrapy介绍
Scrapy 是一个用纯 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。它具有广泛的用途。借助框架的强大,用户只需要定制开发几个模块,就可以轻松实现爬虫抓取网页内容和各种图片,非常方便。Scrapy使用Twisted['twɪstɪd](它的主要对手是Tornado)异步网络框架来处理网络通信,可以加快我们的下载速度,不用自己实现异步框架,并且收录各种中间件接口,可以灵活完成各种需求。
scrapy是如何帮助我们抓取数据的?
scrapy框架的工作流程:
1.首先,Spider(爬虫)需要通过ScrapyEngine(引擎)将请求url(requests)发送给Scheduler(调度器)。
2.Scheduler(排序、入队)处理,通过ScrapyEngine、DownloaderMiddlewares(可选,主要是User_Agent、Proxy代理)传递给Downloader。
3.Downloader 向 Internet 发送请求并接收下载响应(响应)。通过 ScrapyEngine、SpiderMiddlewares(可选)向 Spiders 发送响应(response)。
4.Spiders 处理响应,提取数据并通过 ScrapyEngine 将数据发送到 ItemPipeline 进行存储(可以是本地或数据库)。
5. 提取的 url 通过 ScrapyEngine 发送给 Scheduler,用于下一个循环。直到没有 Url 请求程序停止并结束。
实现代码
创建项目
scrapy startproject 项目名称
scrapy genspider 爬虫名称 URL
这里首先定义了一个HuxiuV1Spider主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的headers属性中写一些爬虫的基本配置,比如Headers、proxy等设置。
由于URL是POST请求,我们还需要在FormData中使用formdata={'page':str(i)}添加表单参数,这里需要设置为POST;formdata是POST请求表单参数,只需要加一个page参数就够了。接下来,通过回调参数定义一个 parse() 方法来解析 URL 成功后返回的 Response 响应。在下面的 parse() 方法中,您可以使用 re,xpath 提取响应中所需的内容。
这里我们使用正则表达式提取文章标题、链接、作者等需要的信息,这里将数据保存为列表数据,以便后续存储在mongo数据库中。
成功获取到需要的数据,然后就可以保存了,可以选择输出为csv、MySQL、mongoDB,这里我们选择mongoDB数据库
1 # -*- coding: utf-8 -*-
2 # from scrapy.spider import CrawlSpider
3 from selenium import webdriver
4 import time
5 from scrapy.linkextractors import LinkExtractor
6 from scrapy.spiders import CrawlSpider, Rule
7 # import json
8 from datetime import datetime
9 from ..items import HuxiuItem
10 from scrapy.http import FormRequest
11 import scrapy
12 import json,re
13 class HuxiuV1Spider(scrapy.Spider):
14 name = 'huxiu_v1'
15 allowed_domains = ['huxiu.com']
16 headers={
17 'Referer': 'https://www.huxiu.com/index.php/',
18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
19 }
20 #post
21 #Form data
22 # page: 2
23 def start_requests(self):
24 url='https://www.huxiu.com/v2_action/article_list'
25 requests=[]
26 for i in range(2,2119):
27 formdata={
28 'page':str(i)
29 }
30 request=FormRequest(url,callback=self.parse,formdata=formdata,headers=self.headers)
31 requests.append(request)
32 return requests
33 def parse(self, response):
34 js=json.loads(response.body.decode())
35 # print(js)
36 req = str(js)
37 idd = re.findall(r'data-aid="(.*?)">', req)#未处理的url(id)
38 title = re.findall(r'class="transition msubstr-row2" target="_blank">(.*?)</a>', req)#标题
39 auth = re.findall(r'class="author-name">(.*?)', req)#作者
40 pinglun = re.findall(r'(.*?)', req)#评论
41 shoucang = re.findall(r'(.*?)', req)#收藏
42 zhaiyao = re.findall(r'(.*?)', req)#未处理的摘要
43 digect = []#摘要
44 for i in zhaiyao:
45 s = i[34:-12]
46 if 'span' in i:
47 s = i[104:-12]
48 digect.append(s)
49 # print(digect)
50 # print(title)
51 detail_url=[]
52 for i in idd:
53 burl = 'https://www.huxiu.com/article/{}.html'.format(i)
54 detail_url.append(burl)
55 # print(detail_url)
56 for i in range(len(idd)):
57 item=HuxiuItem()
58 item['title']=title[i]
59 item["auth"]=auth[i]
60 item['detail_url']=detail_url[i]
61 item['pinglun']=pinglun[i]
62 item['shoucang']=shoucang[i]
63 item['zhaiyao']=digect[i]
64 print(detail_url[i])
65 # yield item
66 yield scrapy.Request(url=detail_url[i],meta={'meta1':item},callback=self.pasre_item)
67 def pasre_item(self,response):
68 meta1=response.meta['meta1']
69 # print('hello')
70 time=response.xpath('//span[@class="article-time pull-left"]/text()|//span[@class="article-time"]/text()').extract()
71 content=response.xpath('//div[@class="article-content-wrap"]/p/text()|//div[@class="article-content-wrap"]/div/text()|//div[@class="article-content-wrap"]/div/span/text()').extract()
72 print(time)
73 ssss=''
74 for i in content:
75 ssss+=i
76 # num = response.xpath('//div[@class="author-article-pl"]/ul/li/a/text()')
77 # wnums=''
78 # for i in num:
79 # wnums = i[:-3]
80 # print(wnums)
81 for i in range(len(time)):
82 item = HuxiuItem()
83 item['title']=meta1['title']
84 item['auth']=meta1['auth']
85 item['detail_url']=meta1['detail_url']
86 item['pinglun']=meta1['pinglun']
87 item['shoucang']=meta1['shoucang']
88 item['zhaiyao']=meta1['zhaiyao']
89 item['time']=time[i]
90 # item['wnums']=num
91 item['content']=ssss
92
93 yield item
蜘蛛
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
物品
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
管道
1 BOT_NAME = 'huxiu'
2
3 SPIDER_MODULES = ['huxiu.spiders']
4 NEWSPIDER_MODULE = 'huxiu.spiders'
5
6
7 # Crawl responsibly by identifying yourself (and your website) on the user-agent
8 #USER_AGENT = 'huxiu (+http://www.yourdomain.com)'
9 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
10
11 # Obey robots.txt rules
12 ROBOTSTXT_OBEY = False
13
14 ITEM_PIPELINES = {
15 'huxiu.pipelines.HuxiuPipeline': 300,
16 }
17
18 LOG_FILE='huxiu_v1.log'
19 LOG_ENABLED=True #默认启用日志
20 LOG_ENCODING='UTF-8'#日志的编码,默认为’utf-8‘
21 LOG_LEVEL='DEBUG'#日志等级:ERROR\WARNING\INFO\DEBUG
22
23 setting
环境
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。
转载于: 查看全部
动态网页抓取(如何选择虎嗅网的网页界面分析工具?(一))
一、分析背景:
1. 为什么选择虎嗅
《关于虎嗅》成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。
2. 分析内容
分析虎嗅网5万篇文章文章的基本信息,包括采集数、评论数等;发现最受欢迎和最不受欢迎的 文章 和作者;分析文章的标题格式(长度、句型)与流行度的关系;展示近年来科技互联网行业的流行词汇
3. 分析工具:
蟒蛇3.6
刮的
MongoDB
Matplotlib
词云
杰巴
数据抓取
我用scrapy抓取了Tiger 文章的首页,从2012年建站到2018年12月7日,抓取文章的时间约为5万篇文章 . 抓取8个信息字段:文章标题、作者、发帖时间、评论数、采集数、摘要、文章链接和文章内容。
1.目标网站分析
这是要抓取的网页界面。您可以看到它是通过 AJAX 加载的。
按F12打开开发者工具,可以看到URL请求是POST类型的,向下滚动到底部查看Form Data,表单中只有3个参数需要提交。尝试后,只提交页面参数即可成功获取页面信息。另外两个参数无关,所以页面爬取的构建非常简单。
接下来,将选项卡切换到预览和响应以查看网页内容,可以看到数据位于数据字段中。total_page为2119,表示文章内容一共2119页,每页有25个文章,一共大概5万条,就是我们要爬取的数量。
Scrapy介绍
Scrapy 是一个用纯 Python 编写的应用框架,用于抓取 网站 数据并提取结构化数据。它具有广泛的用途。借助框架的强大,用户只需要定制开发几个模块,就可以轻松实现爬虫抓取网页内容和各种图片,非常方便。Scrapy使用Twisted['twɪstɪd](它的主要对手是Tornado)异步网络框架来处理网络通信,可以加快我们的下载速度,不用自己实现异步框架,并且收录各种中间件接口,可以灵活完成各种需求。
scrapy是如何帮助我们抓取数据的?
scrapy框架的工作流程:
1.首先,Spider(爬虫)需要通过ScrapyEngine(引擎)将请求url(requests)发送给Scheduler(调度器)。
2.Scheduler(排序、入队)处理,通过ScrapyEngine、DownloaderMiddlewares(可选,主要是User_Agent、Proxy代理)传递给Downloader。
3.Downloader 向 Internet 发送请求并接收下载响应(响应)。通过 ScrapyEngine、SpiderMiddlewares(可选)向 Spiders 发送响应(response)。
4.Spiders 处理响应,提取数据并通过 ScrapyEngine 将数据发送到 ItemPipeline 进行存储(可以是本地或数据库)。
5. 提取的 url 通过 ScrapyEngine 发送给 Scheduler,用于下一个循环。直到没有 Url 请求程序停止并结束。
实现代码
创建项目
scrapy startproject 项目名称
scrapy genspider 爬虫名称 URL
这里首先定义了一个HuxiuV1Spider主类,整个爬虫项目主要在这个类下完成。然后,就可以在下面的headers属性中写一些爬虫的基本配置,比如Headers、proxy等设置。
由于URL是POST请求,我们还需要在FormData中使用formdata={'page':str(i)}添加表单参数,这里需要设置为POST;formdata是POST请求表单参数,只需要加一个page参数就够了。接下来,通过回调参数定义一个 parse() 方法来解析 URL 成功后返回的 Response 响应。在下面的 parse() 方法中,您可以使用 re,xpath 提取响应中所需的内容。
这里我们使用正则表达式提取文章标题、链接、作者等需要的信息,这里将数据保存为列表数据,以便后续存储在mongo数据库中。
成功获取到需要的数据,然后就可以保存了,可以选择输出为csv、MySQL、mongoDB,这里我们选择mongoDB数据库
1 # -*- coding: utf-8 -*-
2 # from scrapy.spider import CrawlSpider
3 from selenium import webdriver
4 import time
5 from scrapy.linkextractors import LinkExtractor
6 from scrapy.spiders import CrawlSpider, Rule
7 # import json
8 from datetime import datetime
9 from ..items import HuxiuItem
10 from scrapy.http import FormRequest
11 import scrapy
12 import json,re
13 class HuxiuV1Spider(scrapy.Spider):
14 name = 'huxiu_v1'
15 allowed_domains = ['huxiu.com']
16 headers={
17 'Referer': 'https://www.huxiu.com/index.php/',
18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
19 }
20 #post
21 #Form data
22 # page: 2
23 def start_requests(self):
24 url='https://www.huxiu.com/v2_action/article_list'
25 requests=[]
26 for i in range(2,2119):
27 formdata={
28 'page':str(i)
29 }
30 request=FormRequest(url,callback=self.parse,formdata=formdata,headers=self.headers)
31 requests.append(request)
32 return requests
33 def parse(self, response):
34 js=json.loads(response.body.decode())
35 # print(js)
36 req = str(js)
37 idd = re.findall(r'data-aid="(.*?)">', req)#未处理的url(id)
38 title = re.findall(r'class="transition msubstr-row2" target="_blank">(.*?)</a>', req)#标题
39 auth = re.findall(r'class="author-name">(.*?)', req)#作者
40 pinglun = re.findall(r'(.*?)', req)#评论
41 shoucang = re.findall(r'(.*?)', req)#收藏
42 zhaiyao = re.findall(r'(.*?)', req)#未处理的摘要
43 digect = []#摘要
44 for i in zhaiyao:
45 s = i[34:-12]
46 if 'span' in i:
47 s = i[104:-12]
48 digect.append(s)
49 # print(digect)
50 # print(title)
51 detail_url=[]
52 for i in idd:
53 burl = 'https://www.huxiu.com/article/{}.html'.format(i)
54 detail_url.append(burl)
55 # print(detail_url)
56 for i in range(len(idd)):
57 item=HuxiuItem()
58 item['title']=title[i]
59 item["auth"]=auth[i]
60 item['detail_url']=detail_url[i]
61 item['pinglun']=pinglun[i]
62 item['shoucang']=shoucang[i]
63 item['zhaiyao']=digect[i]
64 print(detail_url[i])
65 # yield item
66 yield scrapy.Request(url=detail_url[i],meta={'meta1':item},callback=self.pasre_item)
67 def pasre_item(self,response):
68 meta1=response.meta['meta1']
69 # print('hello')
70 time=response.xpath('//span[@class="article-time pull-left"]/text()|//span[@class="article-time"]/text()').extract()
71 content=response.xpath('//div[@class="article-content-wrap"]/p/text()|//div[@class="article-content-wrap"]/div/text()|//div[@class="article-content-wrap"]/div/span/text()').extract()
72 print(time)
73 ssss=''
74 for i in content:
75 ssss+=i
76 # num = response.xpath('//div[@class="author-article-pl"]/ul/li/a/text()')
77 # wnums=''
78 # for i in num:
79 # wnums = i[:-3]
80 # print(wnums)
81 for i in range(len(time)):
82 item = HuxiuItem()
83 item['title']=meta1['title']
84 item['auth']=meta1['auth']
85 item['detail_url']=meta1['detail_url']
86 item['pinglun']=meta1['pinglun']
87 item['shoucang']=meta1['shoucang']
88 item['zhaiyao']=meta1['zhaiyao']
89 item['time']=time[i]
90 # item['wnums']=num
91 item['content']=ssss
92
93 yield item
蜘蛛
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
物品
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # https://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class HuxiuItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 title = scrapy.Field()
15 auth = scrapy.Field()
16 detail_url = scrapy.Field()
17 pinglun = scrapy.Field()
18 shoucang = scrapy.Field()
19 zhaiyao = scrapy.Field()
20 time = scrapy.Field()
21 content=scrapy.Field()
22 # wnums=scrapy.Field()
管道
1 BOT_NAME = 'huxiu'
2
3 SPIDER_MODULES = ['huxiu.spiders']
4 NEWSPIDER_MODULE = 'huxiu.spiders'
5
6
7 # Crawl responsibly by identifying yourself (and your website) on the user-agent
8 #USER_AGENT = 'huxiu (+http://www.yourdomain.com)'
9 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
10
11 # Obey robots.txt rules
12 ROBOTSTXT_OBEY = False
13
14 ITEM_PIPELINES = {
15 'huxiu.pipelines.HuxiuPipeline': 300,
16 }
17
18 LOG_FILE='huxiu_v1.log'
19 LOG_ENABLED=True #默认启用日志
20 LOG_ENCODING='UTF-8'#日志的编码,默认为’utf-8‘
21 LOG_LEVEL='DEBUG'#日志等级:ERROR\WARNING\INFO\DEBUG
22
23 setting
环境
以上,数据采集完成。一旦我们有了数据,我们就可以开始分析,但在此之前,我们需要简单地清理和处理数据。
转载于:
动态网页抓取( 可支持的【真实】驱动程序介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-29 05:22
可支持的【真实】驱动程序介绍(一))
#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。 查看全部
动态网页抓取(
可支持的【真实】驱动程序介绍(一))
#抓取内容
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
String html = driver.getPageSource();
#如何想等待一会元素渲染完毕
driver.manage().timeouts().implicitlyWait(2, TimeUnit.SECONDS);
#进行百度搜索
public static void doSearch(String keyword) {
final String url = "http://www.baidu.com";
WebDriver driver = new HtmlUnitDriver(false);
driver.get(url);
driver.findElement(By.id("kw")).sendKeys(keyword);
Actions action = new Actions(driver);
action.sendKeys(Keys.ENTER).perform();
System.out.println(driver.getPageSource());
}
1 Selenium 支持的 [Real] 浏览器驱动程序:
PC 驱动程序:firefox、safari、即 chrome、operadriver
移动端驱动:Windows Phone、Selendroid、ios-driver、Appium支持iphone、ipad、android、FirefoxOS【第三方】
safari 和 ff 都以插件的形式驱动浏览器本身;即chrome通过二进制文件驱动浏览器本身;
这些驱动都是直接启动,通过调用浏览器底层接口来驱动浏览器,因此具有最真实的用户场景模拟,主要用于Web兼容性测试。
2 selenium 支持的【伪浏览器】驱动:
HtmlUnit、PhantomJS
它们并不是真正在浏览器中,也没有 GUI,而是类似浏览器的程序,支持 html 和 js 等解析能力;这些程序不渲染网页的显示内容,但支持页面元素的搜索和JS等的执行;由于不进行CSS和GUI渲染,运行效率会比真正的浏览器快很多,主要用于功能测试。htmlunit是Java实现的类似浏览器的程序,收录在selenium服务器中,无需驱动即可直接实例化;它的js解析引擎是Rhino。
动态网页抓取(之前写过一篇使用爬虫抓取暗黑3玩家数据的意义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-09-29 02:09
)
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据一直不更新,所以爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。
百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:
通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到
虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据
好的,让我们抓住它
明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。
查看全部
动态网页抓取(之前写过一篇使用爬虫抓取暗黑3玩家数据的意义
)
我写了一篇关于使用爬虫抓取暗黑破坏神3玩家数据的文章。由于凯恩之角的数据一直不更新,所以爬虫意义不大。
其实官方网站也可以看到玩家数据。没去爬的原因是……网页的源代码和网页上显示的数据不一样。直到最近我才知道这是一个动态网页。
百度了半天,感觉有一个比较简单的方法,就是F12使用开发者工具查找网页加载时发送的请求url。
比如我要爬取玩家“可乐和冰5750”的数据,他的个人数据页面是:
可乐加冰 5750
我们使用开发者工具,点击其中一个字符进入任务详情页面:
通过请求url,我们可以看到这是一个编号为id48423858的字符的数据。稍微改一下,删除hero/48423858,就可以看到
虽然我们在网页上看不到任何东西,但我们查看了网页的源代码,惊喜地发现里面有“可乐和冰5750”的所有字符数据
好的,让我们抓住它
明天星期三没有课。我打算花几天的时间写一个爬取任何一个玩家的信息(前提是玩家的BattleTag是已知的),包括角色的主要属性、装备和词缀,以及一些玩家的职业数据。争取一个友好的界面。工作量一定比以前大,希望一切顺利
这个学期的最终目标是学习数据库。希望爬虫得到的数据能写入我的数据库。比如我可以统计整个服务器前1000名玩家的产出和抽取。
动态网页抓取( 基于IE内核和DOM的面向垂直搜索引擎中怎样动态生成的主题网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-29 02:08
基于IE内核和DOM的面向垂直搜索引擎中怎样动态生成的主题网页)
一种为垂直搜索引擎抓取动态网页的方法 fetcher 的一个难题。本文提出了一种基于IE内核和DOM的垂直搜索引擎动态网页爬取方法。实验表明,该方法抓取动态网页和主题网页的准确率平均在95以上,平均召回率为97以上。 [关键词] 动态网页IE核心DOM提取模式1简介垂直搜索引擎只抓取与主题相关的网页,同时必须在缩小搜索范围的前提下对网页进行更深的抓取,包括占网页总数的比例越来越大的动态网页. 目前的网络爬虫一般无法抓取动态网页。为了解决动态网页的抓取问题,同时只抓取与主题相关的动态网页,本文提出了一种面向垂直搜索引擎的抓取。获取动态网页的方法基于IEInternetExplorer核心和DHTML对象模型[1]利用DHTML对象模型提取页面中收录的页面元素信息,获取动态网页相关的网页元素信息。每个网页元素对应于 IE 核心的 MSHTML 组件中的一个界面。对应界面的操作实现了网页的自动填充。相关链接或查询按钮的自动点击模拟用户在浏览器上浏览网页的行为。数据库交互动态生成的主题网页 2 基于 IE core 和 DOM 的动态网页抓取方法 21 IE core 和 DOM 介绍 功能参考 [1] 给出了 IE 架构,其中 WebBrowser 组件、MSHTML 组件、URLMon 组件和 WinInet 位于底层是IE的核心。在该方法中,这些IE内核用于模拟用户在网页中查找和点击链接或按钮的动作,以触发浏览器下载网页MSHTML可以读取和显示HTML网页。DOM 是在 MSHTML 组件中定义的。[2] DocumentObjectModel 封装了 HTML 语言中的所有元素和属性。DOM 模型中的每个元素都有对应的对象和接口。这些接口的操作是访问指定网页中的所有元素。22 模拟浏览操作,获取动态网页。动态页面需要执行aspphpjspnet等程序生成客户端网页代码。静态网页的网址以html超链接的形式直接嵌入到客户端网页中。目前已知的 HTML 文件中的网络爬虫程序可以轻松抓取相应的页面。[3] 仔细研究网页的结构和HTML语言发现,在指定网页中获取动态网页的方式主要有两种: 1 用按钮点击后提供的界面网页元素的形式图片等。需要在客户端执行相应的一段脚本代码,动态生成URL2查询接口,用户填写表单提交查询到服务器,服务端返回动态生成的查询结果页面,无论采用哪种方式,都是从浏览器用户Forms或者鼠标点击的角度来填写,所以只要找到需要填写的表单元素以获取指定网页上需要点击的动态页面或按钮图标等元素,然后操作相关元素模拟用户在浏览器中的各种填写形式或点击操作实现自动浏览,最后下载动态页面到本地抓取到23。生成提取方式定位相关元素。IE 核心的 MSHTML 组件定义了 DOM。网页中的每个元素通过IE对应DOM树的一个节点。内核支持 DOM 树。每一个指定的网页对应一棵DOM树,因此在网页中搜索元素转化为元素在DOM树中对应节点的位置和搜索。为了通过一个或多个指定的示例网页,学习抓取所有此类结构相似的网页。必须生成提取模式。使用生成的提取方式提取所有相似的网页,获取动态网页的网页元素信息。在DHTMLDOM模型的支持下,可以对应收录需要提取的信息的网页元素。搜索网页的类别,会得到属于该类别的所有元素的集合,然后在该集合中找到提取信息所在的网页元素。为了找到提取的信息所在的具体元素,您可以识别网页元素的属性,例如nameid或网页元素的其他属性。如valuehref等方法定位时这些方法无法区分网页元素。最后,可以通过表示网页元素的标签中的文本内容来进行识别。辅助生成工具半自动生成抽取模式,然后进入抽取模式作为爬取配置信息进入网络爬虫。网络爬虫WebCrawler仅在抽取模式的引导下定位和查找与动态生成的主题网页相关的网页 表单中的文本输入元素或可点击按钮图片等元素信息,然后通过定位到的网页元素对应的界面对元素进行操作,执行自动填表和自动点击功能触发网页抓取,集成IE核心组件WebBrowser fetcher执行客户端脚本代码并发送请求到服务器下载对应的主题网页。服务器响应该请求,将动态生成的页面返回给抓取器,以最终抓取提取方式确定的对应的主题网页。3 实验验证方便评估预先设置一些垂直的站点位置,具有层次结构网站 动态网页从网页提供的查询条目的爬取深度为4,最大爬取5500页。使用本文提出的IE核心并与之结合。辅助生成工具的网页爬取方法的准确率采集 目标页面数 ö 总爬取次数超过95,远优于大多数系统采用的分类器方法展示。本文采用的方法的召回率是召回率。Rate 采集 目标页面数 ö 目标页面总数达到97左右,而分类器方法一般只有70左右。 4 结论 本文重点介绍垂直搜索引擎网络爬取的关键技术——动态网络爬取-深入研究在IE核心事件激发机制和DOM支持的基础上,提出了一种新的方法。自动浏览功能是通过自动填写表单并模拟用户在浏览器上点击鼠标,然后抓取动态网页来实现的。实验表明,该方法在构建辅助生成工具的基础上半自动生成爬取配置信息,使用基于IE核心主题网页的爬取方法可以有效爬取动态网页参考[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpö-wwww8ölöl [3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数在95以上,比大多数系统使用的分类方法要好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数超过95个,比大多数系统使用的分类方法好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类器方法一般只有70左右的一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单并模拟用户在浏览器上的鼠标点击来实现自动浏览功能,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类方法一般只有70左右一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单,模拟用户在浏览器上鼠标点击,然后抓取动态网页来实现自动浏览功能。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 查看全部
动态网页抓取(
基于IE内核和DOM的面向垂直搜索引擎中怎样动态生成的主题网页)
一种为垂直搜索引擎抓取动态网页的方法 fetcher 的一个难题。本文提出了一种基于IE内核和DOM的垂直搜索引擎动态网页爬取方法。实验表明,该方法抓取动态网页和主题网页的准确率平均在95以上,平均召回率为97以上。 [关键词] 动态网页IE核心DOM提取模式1简介垂直搜索引擎只抓取与主题相关的网页,同时必须在缩小搜索范围的前提下对网页进行更深的抓取,包括占网页总数的比例越来越大的动态网页. 目前的网络爬虫一般无法抓取动态网页。为了解决动态网页的抓取问题,同时只抓取与主题相关的动态网页,本文提出了一种面向垂直搜索引擎的抓取。获取动态网页的方法基于IEInternetExplorer核心和DHTML对象模型[1]利用DHTML对象模型提取页面中收录的页面元素信息,获取动态网页相关的网页元素信息。每个网页元素对应于 IE 核心的 MSHTML 组件中的一个界面。对应界面的操作实现了网页的自动填充。相关链接或查询按钮的自动点击模拟用户在浏览器上浏览网页的行为。数据库交互动态生成的主题网页 2 基于 IE core 和 DOM 的动态网页抓取方法 21 IE core 和 DOM 介绍 功能参考 [1] 给出了 IE 架构,其中 WebBrowser 组件、MSHTML 组件、URLMon 组件和 WinInet 位于底层是IE的核心。在该方法中,这些IE内核用于模拟用户在网页中查找和点击链接或按钮的动作,以触发浏览器下载网页MSHTML可以读取和显示HTML网页。DOM 是在 MSHTML 组件中定义的。[2] DocumentObjectModel 封装了 HTML 语言中的所有元素和属性。DOM 模型中的每个元素都有对应的对象和接口。这些接口的操作是访问指定网页中的所有元素。22 模拟浏览操作,获取动态网页。动态页面需要执行aspphpjspnet等程序生成客户端网页代码。静态网页的网址以html超链接的形式直接嵌入到客户端网页中。目前已知的 HTML 文件中的网络爬虫程序可以轻松抓取相应的页面。[3] 仔细研究网页的结构和HTML语言发现,在指定网页中获取动态网页的方式主要有两种: 1 用按钮点击后提供的界面网页元素的形式图片等。需要在客户端执行相应的一段脚本代码,动态生成URL2查询接口,用户填写表单提交查询到服务器,服务端返回动态生成的查询结果页面,无论采用哪种方式,都是从浏览器用户Forms或者鼠标点击的角度来填写,所以只要找到需要填写的表单元素以获取指定网页上需要点击的动态页面或按钮图标等元素,然后操作相关元素模拟用户在浏览器中的各种填写形式或点击操作实现自动浏览,最后下载动态页面到本地抓取到23。生成提取方式定位相关元素。IE 核心的 MSHTML 组件定义了 DOM。网页中的每个元素通过IE对应DOM树的一个节点。内核支持 DOM 树。每一个指定的网页对应一棵DOM树,因此在网页中搜索元素转化为元素在DOM树中对应节点的位置和搜索。为了通过一个或多个指定的示例网页,学习抓取所有此类结构相似的网页。必须生成提取模式。使用生成的提取方式提取所有相似的网页,获取动态网页的网页元素信息。在DHTMLDOM模型的支持下,可以对应收录需要提取的信息的网页元素。搜索网页的类别,会得到属于该类别的所有元素的集合,然后在该集合中找到提取信息所在的网页元素。为了找到提取的信息所在的具体元素,您可以识别网页元素的属性,例如nameid或网页元素的其他属性。如valuehref等方法定位时这些方法无法区分网页元素。最后,可以通过表示网页元素的标签中的文本内容来进行识别。辅助生成工具半自动生成抽取模式,然后进入抽取模式作为爬取配置信息进入网络爬虫。网络爬虫WebCrawler仅在抽取模式的引导下定位和查找与动态生成的主题网页相关的网页 表单中的文本输入元素或可点击按钮图片等元素信息,然后通过定位到的网页元素对应的界面对元素进行操作,执行自动填表和自动点击功能触发网页抓取,集成IE核心组件WebBrowser fetcher执行客户端脚本代码并发送请求到服务器下载对应的主题网页。服务器响应该请求,将动态生成的页面返回给抓取器,以最终抓取提取方式确定的对应的主题网页。3 实验验证方便评估预先设置一些垂直的站点位置,具有层次结构网站 动态网页从网页提供的查询条目的爬取深度为4,最大爬取5500页。使用本文提出的IE核心并与之结合。辅助生成工具的网页爬取方法的准确率采集 目标页面数 ö 总爬取次数超过95,远优于大多数系统采用的分类器方法展示。本文采用的方法的召回率是召回率。Rate 采集 目标页面数 ö 目标页面总数达到97左右,而分类器方法一般只有70左右。 4 结论 本文重点介绍垂直搜索引擎网络爬取的关键技术——动态网络爬取-深入研究在IE核心事件激发机制和DOM支持的基础上,提出了一种新的方法。自动浏览功能是通过自动填写表单并模拟用户在浏览器上点击鼠标,然后抓取动态网页来实现的。实验表明,该方法在构建辅助生成工具的基础上半自动生成爬取配置信息,使用基于IE核心主题网页的爬取方法可以有效爬取动态网页参考[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpö-wwww8ölöl [3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数在95以上,比大多数系统使用的分类方法要好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面数平均爬行总数超过95个,比大多数系统使用的分类方法好很多。本文方法的召回率是采集 目标页面数 ö 目标页面总数达到97左右,分类器方法一般只有70左右。4 结束语 本文在深入研究垂直搜索引擎网络爬虫的关键技术——动态网络爬虫的基础上,提出了一种新的方法。此方法由 IE 核心中的事件激发。DOM的机制和支持通过在浏览器上自动填写表单,模拟用户鼠标点击,然后抓取动态网页,实现自动浏览功能。实验表明,该方法基于辅助生成工具的构建和基于IE的抓取配置信息的半自动生成。核心主题网页爬取方法可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation1998[DBöOL]httpööwwww3orgöT-Röwwww3orgöT-10REC-DOMLevelww8 3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类器方法一般只有70左右的一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单并模拟用户在浏览器上的鼠标点击来实现自动浏览功能,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络目标页面总数ö目标页面总数达到97左右,分类方法一般只有70左右一种新方法。该方法利用IE内核的事件触发机制和对DOM的支持,通过自动填写表单,模拟用户在浏览器上鼠标点击,然后抓取动态网页来实现自动浏览功能。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络 s 鼠标点击浏览器,然后抓取动态网页。使用基于IE核心的主题网页爬取方法自动生成爬取配置信息,可有效爬取动态网页引用[1]internetexplorerdevelopmentMSDNdevelopment2Center[DBöOL]httpööwwwmsdn2comözh-cnöieödefaulten-usaspx2007-03[2]DocumentObjectModelW3CRecommendation19örorg[1] RöREC-DOM-Level-1ö1998-10[3]AllanHeydonMarcNajorkMercatorAscalabelex2tensibleWebCrawler[J]WorldWideWeb199924219-229502科技信息计算机与网络

