动态网页抓取(1.代码实现接下来提取首页jobName中包含python的所有链接)
优采云 发布时间: 2021-10-16 10:00动态网页抓取(1.代码实现接下来提取首页jobName中包含python的所有链接)
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
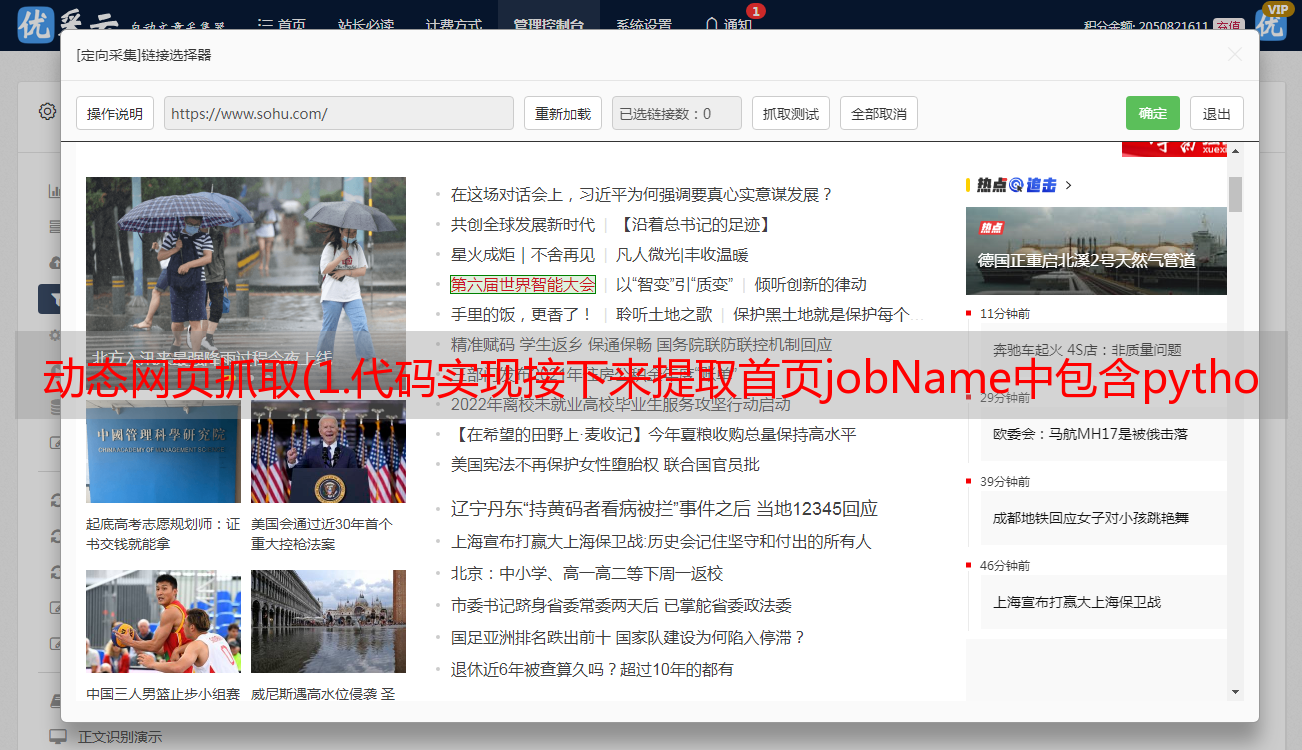
点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
转载于:

