
动态网页抓取
动态网页抓取(百度网址提交与自动的区别有哪些?如何选择?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-17 01:21
对于百度收录来说,一直是困扰SEO人员的核心问题。每天都有大量站长在思考为什么我的页面没有收录?于是我开始想各种办法,让页面快速被百度收录。
其中,我们绝对不会脱离这三个渠道:普通数据提交、快速收录提交和百度爬虫自动抓取。
前者通常使用API或人工提交,而后者则让百度蜘蛛自行抓取索引。但是对于这些链接渠道,很少有SEO伙伴去考虑它们之间的区别和联系。
那么,百度链接提交和自动抓取有什么区别,如何选择呢?根据以往百度网址提交的经验,我们将详细阐述以下内容:
一、主动提交
对于普通的收录和快速的收录权限,我们认为有以下特点:
1.提高搜索引擎发现新链接的时间,快速进入百度搜索指数评测通道。简单理解就是增加索引量;2. 节省目标页面被百度发现的成本,比如外部链接的构建,引蜘蛛的成本。
但同时,根据我们大量的测试,这种数据提交形式仍然受到网站链接提交的时间节点和网站链接提交的次数和频率的影响。
当搜索引擎的爬取通道过于繁忙时,很容易造成一些网址地址丢失,即在不同时间节点提交网址时,收录的数量可能会发生很大的变化。其次,如果网站链接提交的次数和频率过于密集,整个网站的链接收录率会有一定的波动。
二、自动爬取
一般来说,所谓搜索引擎自动抓取主要是指百度蜘蛛主动抓取你的页面内容,主要受以下因素影响:
1. 优质外链数量及增长频率;2. 网站优质内容更新次数占整个网站内容的比例;3. 页面内容的更新频率。
一般来说,如果你能在某个时间节点保持一定的活跃度,自动爬取是很规律的,随着整个站点质量的提高,网站很容易进入。“秒收录”的状态。这个时候,我们根本不需要考虑。只要内容有更新,我们就可以继续获取收录。
同时,我们根据一些日常操作做了基本的判断,发现如果你主动提交的链接质量不高,长时间处于低质量状态,很容易出现你自己的链接不是收录,同时虽然引起自动抓取的页面是收录,但大部分都会进入低质量的库,即检索相关的新页面,没有任何排名。相比之下,我们认为对自动爬取这方面的评价可能比较宽泛。
三、合理的选择
基于以上因素,我们认为如果你有能力,我们还是建议你选择网站让百度搜索自动抓取和收录,可以适当减少网站的提交@> 链接,除非你的外部链接资源有限,很难建立一些比较优质的链接。
此外,您的目标页面在整个站点中具有很深的目录层次结构,很难被搜索引擎发现和抓取。或者网站刚上线,还没有通过沙箱和质量评估期(使用链接提交,可以快速通过这个周期,前提是结构和内容质量要好)。
总结:SEO是一项细致的工作,要善于发现百度搜索产品的差异。当然,以上内容只是经验之谈,仅供参考! 查看全部
动态网页抓取(百度网址提交与自动的区别有哪些?如何选择?)
对于百度收录来说,一直是困扰SEO人员的核心问题。每天都有大量站长在思考为什么我的页面没有收录?于是我开始想各种办法,让页面快速被百度收录。
其中,我们绝对不会脱离这三个渠道:普通数据提交、快速收录提交和百度爬虫自动抓取。
前者通常使用API或人工提交,而后者则让百度蜘蛛自行抓取索引。但是对于这些链接渠道,很少有SEO伙伴去考虑它们之间的区别和联系。

那么,百度链接提交和自动抓取有什么区别,如何选择呢?根据以往百度网址提交的经验,我们将详细阐述以下内容:
一、主动提交
对于普通的收录和快速的收录权限,我们认为有以下特点:
1.提高搜索引擎发现新链接的时间,快速进入百度搜索指数评测通道。简单理解就是增加索引量;2. 节省目标页面被百度发现的成本,比如外部链接的构建,引蜘蛛的成本。
但同时,根据我们大量的测试,这种数据提交形式仍然受到网站链接提交的时间节点和网站链接提交的次数和频率的影响。
当搜索引擎的爬取通道过于繁忙时,很容易造成一些网址地址丢失,即在不同时间节点提交网址时,收录的数量可能会发生很大的变化。其次,如果网站链接提交的次数和频率过于密集,整个网站的链接收录率会有一定的波动。
二、自动爬取
一般来说,所谓搜索引擎自动抓取主要是指百度蜘蛛主动抓取你的页面内容,主要受以下因素影响:
1. 优质外链数量及增长频率;2. 网站优质内容更新次数占整个网站内容的比例;3. 页面内容的更新频率。
一般来说,如果你能在某个时间节点保持一定的活跃度,自动爬取是很规律的,随着整个站点质量的提高,网站很容易进入。“秒收录”的状态。这个时候,我们根本不需要考虑。只要内容有更新,我们就可以继续获取收录。
同时,我们根据一些日常操作做了基本的判断,发现如果你主动提交的链接质量不高,长时间处于低质量状态,很容易出现你自己的链接不是收录,同时虽然引起自动抓取的页面是收录,但大部分都会进入低质量的库,即检索相关的新页面,没有任何排名。相比之下,我们认为对自动爬取这方面的评价可能比较宽泛。
三、合理的选择
基于以上因素,我们认为如果你有能力,我们还是建议你选择网站让百度搜索自动抓取和收录,可以适当减少网站的提交@> 链接,除非你的外部链接资源有限,很难建立一些比较优质的链接。
此外,您的目标页面在整个站点中具有很深的目录层次结构,很难被搜索引擎发现和抓取。或者网站刚上线,还没有通过沙箱和质量评估期(使用链接提交,可以快速通过这个周期,前提是结构和内容质量要好)。
总结:SEO是一项细致的工作,要善于发现百度搜索产品的差异。当然,以上内容只是经验之谈,仅供参考!
动态网页抓取(文章目录网络爬虫学习笔记(2)-1动态抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-17 01:19
)
文章内容
网络爬虫学习笔记(2) 1 Information 2 Notes 2-1 动态爬虫概述
在使用 JavaScript 时,很多内容并没有出现在 HTML 源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
2-2 通过浏览器查看元素 chrom 浏览器右键菜单“勾选”点击“网络”选项分析真实网页地址,然后刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。
找到真实的数据地址。选择需要的文件,点击Preview选项卡查看数据,在Headers选项卡中可以找到数据地址(即Request URL项)。
获取到地址后,如果要爬取,只需将链接替换为3中找到的数据地址即可。 2-3 网页URL地址规律
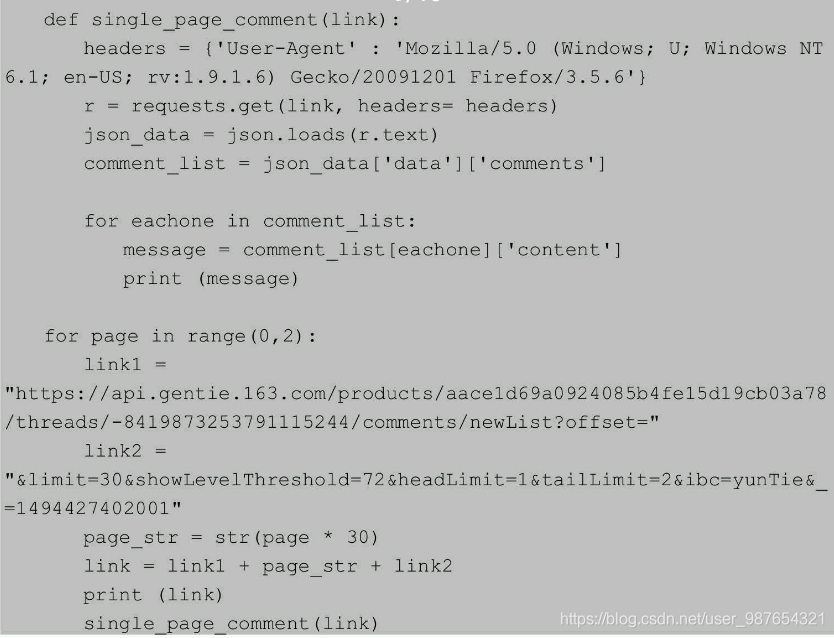
比如在一些URL地址中,有两个特别重要的变量offset和limit。Offset表示这个页面的第一个item是item的总数,limit代表每页的item数。基于此,书中给出了一个很好的例子(在这个例子中,不同页面的注释的真实地址只反映在偏移量上,所以就有了变量page_str):
2-4 json 库 2-5 模拟浏览器爬取Selenium
使用此方法无需2-1操作,直接使用网页网址即可
所以,这里还有一个方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
load_more = driver.find_element_by_css_selector('div.tie-load-more')
load_more.click() 查看全部
动态网页抓取(文章目录网络爬虫学习笔记(2)-1动态抓取
)
文章内容
网络爬虫学习笔记(2) 1 Information 2 Notes 2-1 动态爬虫概述
在使用 JavaScript 时,很多内容并没有出现在 HTML 源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
2-2 通过浏览器查看元素 chrom 浏览器右键菜单“勾选”点击“网络”选项分析真实网页地址,然后刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。
找到真实的数据地址。选择需要的文件,点击Preview选项卡查看数据,在Headers选项卡中可以找到数据地址(即Request URL项)。
获取到地址后,如果要爬取,只需将链接替换为3中找到的数据地址即可。 2-3 网页URL地址规律
比如在一些URL地址中,有两个特别重要的变量offset和limit。Offset表示这个页面的第一个item是item的总数,limit代表每页的item数。基于此,书中给出了一个很好的例子(在这个例子中,不同页面的注释的真实地址只反映在偏移量上,所以就有了变量page_str):
2-4 json 库 2-5 模拟浏览器爬取Selenium
使用此方法无需2-1操作,直接使用网页网址即可
所以,这里还有一个方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
load_more = driver.find_element_by_css_selector('div.tie-load-more')
load_more.click()
动态网页抓取(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-15 20:09
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!! 查看全部
动态网页抓取(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!!
动态网页抓取(动态网站静态化,也不是一件容易的事情!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-14 03:01
随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对于提高网站的权重和排名很有帮助,但是笔者发现很多站长把动态的网站转为静态的网站,却发现我自己的网站是K. 原因是什么?可见,动态网站静态不是一件容易的事,需要注意的问题很多!
一:静态网站的优缺点分析
静态网站的优势非常明显。用户浏览器打开静态网站比动态网站更快,因为动态网站网页也需要结合用户参数,然后才能形成相应的页面。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页就会下载到浏览器,也可以利用浏览器的缓存,让用户无需再次下载到服务器就可以第二次打开。可以看出,这个访问速度比动态网站要快。
静态网站的另一个优点是非常有利于搜索引擎收录和爬取。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的主页,遍历网站中的整个静态网页,从而实现网站的完整收录。当然,为了提高蜘蛛爬取网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如联系我们页面和支付方式页面许多公司网站。通过设置内链和ROBOTS.TXT文件,可以提高网站的爬取速度。
当然,静态网站的缺点也很明显。如果是大网站,尤其是信息网站,如果每个页面都变成静态页面,工作量肯定很大,而且对网站@的维护也非常不利>,因为静态网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,你要纠错往往需要很长时间一一排查!
二:动态网站的优缺点分析
动态的优势也非常突出。首先网站的互动非常好。现在很多网页游戏都是典型的动态网页。通过互动,可以提高网站的粘性。另外,动态网站对网站的管理很简单,因为网站几乎都是通过一个数据库来管理的,其实只要操作数据库,网站的维护@网站 可以实现,现在很多免费的建站程序也是这样的数据库。该结构非常适合个人站长。
但是动态网站的缺点也很明显。首先,随着访问量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,所以很容易留下后门。前段时间,很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为网站的动态网页大多是动态形成的,蜘蛛不能很好地抓取,导致网站收录的数量为不高。
三:动态网站转换为静态网站需要注意的问题
相比之下,静态网站的优势比较明显,尤其是搜索引擎的优势。如今,没有搜索引擎的支持,网站越来越难成功,所以现在很多原本经营动态网站的站长,已经把自己的网站变成了静态的网站@ >. 这样,我们就可以同时获得动态的网站 和静态的。网站 优点。
然而,在转换的过程中,很多站长都渴望成功。通过一些号称可以转为静态网站的程序,瞬间实现了动态网站的伪静态。这样做的结果就是如本文前面所述,网站已经完全K了。正确的做法应该是网站的动静结合,换句话说就是多丰富的关键词@ on 网站页面,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该通过一个动态转换程序!
目前有很多方法可以将动态页面转换为静态页面。其中,现成插件的使用最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IIS Rewrite、MOD_Rewrite等,这些都是基于正则表达式解析器开发的重写引擎,如何使用也是很简单。掌握了正确的动静态改造方法后,不要一下子就完成整个网站的改造,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。 查看全部
动态网页抓取(动态网站静态化,也不是一件容易的事情!!)
随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对于提高网站的权重和排名很有帮助,但是笔者发现很多站长把动态的网站转为静态的网站,却发现我自己的网站是K. 原因是什么?可见,动态网站静态不是一件容易的事,需要注意的问题很多!
一:静态网站的优缺点分析
静态网站的优势非常明显。用户浏览器打开静态网站比动态网站更快,因为动态网站网页也需要结合用户参数,然后才能形成相应的页面。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页就会下载到浏览器,也可以利用浏览器的缓存,让用户无需再次下载到服务器就可以第二次打开。可以看出,这个访问速度比动态网站要快。
静态网站的另一个优点是非常有利于搜索引擎收录和爬取。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的主页,遍历网站中的整个静态网页,从而实现网站的完整收录。当然,为了提高蜘蛛爬取网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如联系我们页面和支付方式页面许多公司网站。通过设置内链和ROBOTS.TXT文件,可以提高网站的爬取速度。
当然,静态网站的缺点也很明显。如果是大网站,尤其是信息网站,如果每个页面都变成静态页面,工作量肯定很大,而且对网站@的维护也非常不利>,因为静态网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,你要纠错往往需要很长时间一一排查!
二:动态网站的优缺点分析
动态的优势也非常突出。首先网站的互动非常好。现在很多网页游戏都是典型的动态网页。通过互动,可以提高网站的粘性。另外,动态网站对网站的管理很简单,因为网站几乎都是通过一个数据库来管理的,其实只要操作数据库,网站的维护@网站 可以实现,现在很多免费的建站程序也是这样的数据库。该结构非常适合个人站长。
但是动态网站的缺点也很明显。首先,随着访问量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,所以很容易留下后门。前段时间,很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为网站的动态网页大多是动态形成的,蜘蛛不能很好地抓取,导致网站收录的数量为不高。
三:动态网站转换为静态网站需要注意的问题
相比之下,静态网站的优势比较明显,尤其是搜索引擎的优势。如今,没有搜索引擎的支持,网站越来越难成功,所以现在很多原本经营动态网站的站长,已经把自己的网站变成了静态的网站@ >. 这样,我们就可以同时获得动态的网站 和静态的。网站 优点。
然而,在转换的过程中,很多站长都渴望成功。通过一些号称可以转为静态网站的程序,瞬间实现了动态网站的伪静态。这样做的结果就是如本文前面所述,网站已经完全K了。正确的做法应该是网站的动静结合,换句话说就是多丰富的关键词@ on 网站页面,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该通过一个动态转换程序!
目前有很多方法可以将动态页面转换为静态页面。其中,现成插件的使用最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IIS Rewrite、MOD_Rewrite等,这些都是基于正则表达式解析器开发的重写引擎,如何使用也是很简单。掌握了正确的动静态改造方法后,不要一下子就完成整个网站的改造,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。
动态网页抓取( robots协议(也称为爬虫协议、机器人协议等)的全称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-10 20:01
robots协议(也称为爬虫协议、机器人协议等)的全称)
动态网站不用担心,搜索引擎可以正常抓取动态链接,但是使用robots文件可以轻松提高动态网站的抓取效率。我们都知道robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 告诉搜索引擎哪些页面可以爬取,哪些页面通过Robots 协议爬取。无法抓取该页面。Robots协议的本质是网站与搜索引擎爬虫之间的通信方式,用于引导搜索引擎更好地抓取网站的内容。
百度官方建议所有网站使用robots文件,以更好地利用蜘蛛爬行。实际上,robots 不仅是告诉搜索引擎哪些不能抓取,也是网站优化的重要工具之一。
robots文件实际上是一个txt文件。基本措辞如下:
User-agent: * 其中*代表所有类型的搜索引擎,*是通配符
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /require/ 这里的定义是禁止爬取require目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中的所有动态页面
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
在网站优化方面,robots文件用于告诉搜索引擎什么是重要的内容,推荐robots文件禁止爬取不重要的内容。不重要内容的典型代表:网站的搜索结果页。
对于静态网站,我们可以使用Disallow: /*?* 来禁止动态页面爬取。但是对于动态网站,你不能简单地做到这一点。不过对于动态网站的站长来说,就不用太担心了。搜索引擎现在可以正常抓取动态页面。所以在写的时候一定要注意,可以专门写到搜索文件的名字。例如,如果您的站点是 search.asp? 后面的一个长列表,那么您可以这样写:
禁止:/search.asp?*
这样就可以屏蔽搜索结果页面。写完之后可以在百度站长平台上查看robots,看看有没有错误!您可以输入 URL 来检查它是否正常工作。
在这里,吴晓阳建议动态网站的站长一定要用robots文件来屏蔽不重要的内容动态链接,提高蜘蛛的抓取效率!
本文来源:吴晓阳目录 查看全部
动态网页抓取(
robots协议(也称为爬虫协议、机器人协议等)的全称)

动态网站不用担心,搜索引擎可以正常抓取动态链接,但是使用robots文件可以轻松提高动态网站的抓取效率。我们都知道robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 告诉搜索引擎哪些页面可以爬取,哪些页面通过Robots 协议爬取。无法抓取该页面。Robots协议的本质是网站与搜索引擎爬虫之间的通信方式,用于引导搜索引擎更好地抓取网站的内容。
百度官方建议所有网站使用robots文件,以更好地利用蜘蛛爬行。实际上,robots 不仅是告诉搜索引擎哪些不能抓取,也是网站优化的重要工具之一。
robots文件实际上是一个txt文件。基本措辞如下:
User-agent: * 其中*代表所有类型的搜索引擎,*是通配符
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /require/ 这里的定义是禁止爬取require目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中的所有动态页面
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
在网站优化方面,robots文件用于告诉搜索引擎什么是重要的内容,推荐robots文件禁止爬取不重要的内容。不重要内容的典型代表:网站的搜索结果页。
对于静态网站,我们可以使用Disallow: /*?* 来禁止动态页面爬取。但是对于动态网站,你不能简单地做到这一点。不过对于动态网站的站长来说,就不用太担心了。搜索引擎现在可以正常抓取动态页面。所以在写的时候一定要注意,可以专门写到搜索文件的名字。例如,如果您的站点是 search.asp? 后面的一个长列表,那么您可以这样写:
禁止:/search.asp?*
这样就可以屏蔽搜索结果页面。写完之后可以在百度站长平台上查看robots,看看有没有错误!您可以输入 URL 来检查它是否正常工作。
在这里,吴晓阳建议动态网站的站长一定要用robots文件来屏蔽不重要的内容动态链接,提高蜘蛛的抓取效率!
本文来源:吴晓阳目录
动态网页抓取(2020年7月29日写在前面:右键打开源码找到iframe标签 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-10 15:07
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
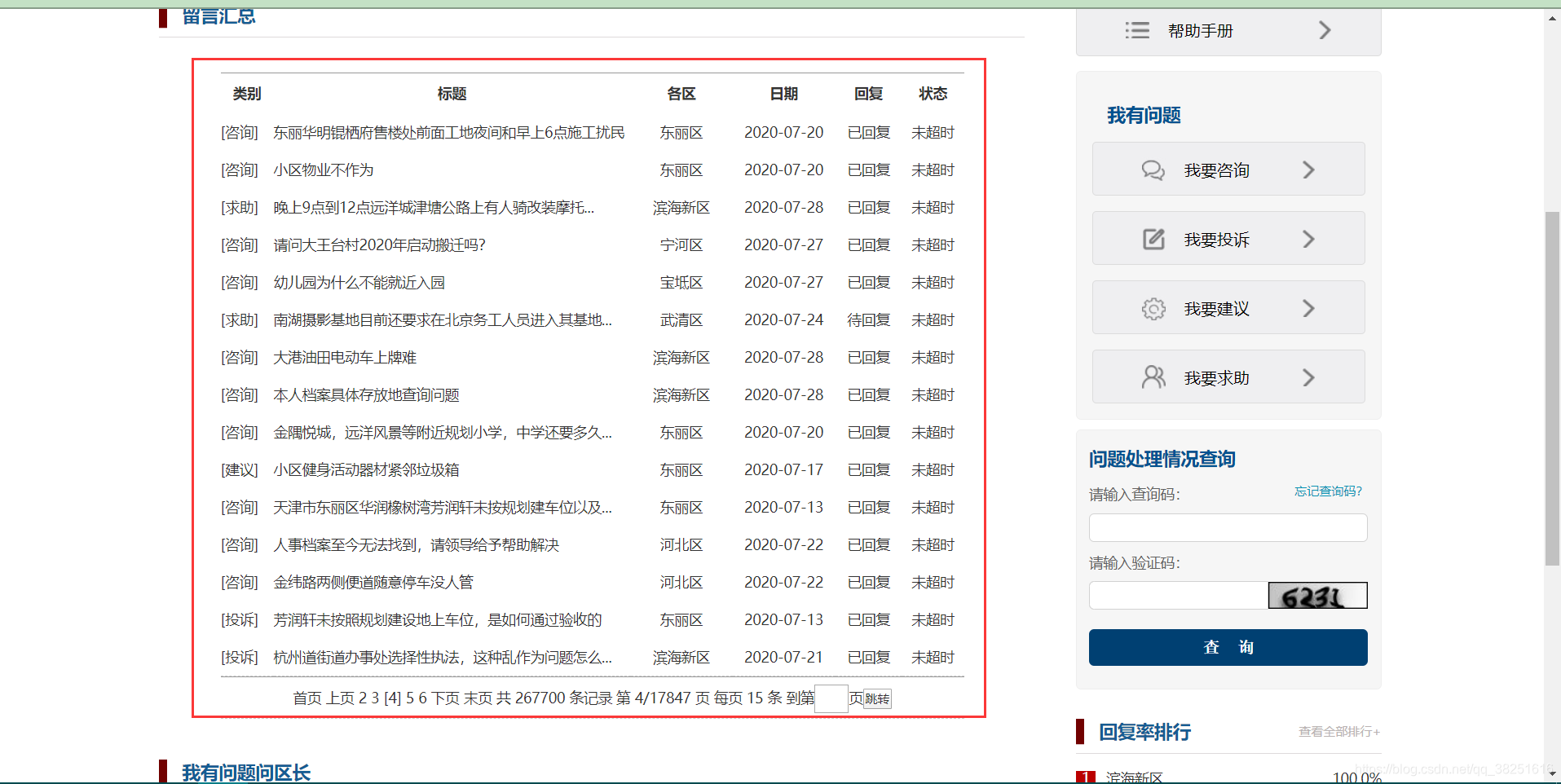
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
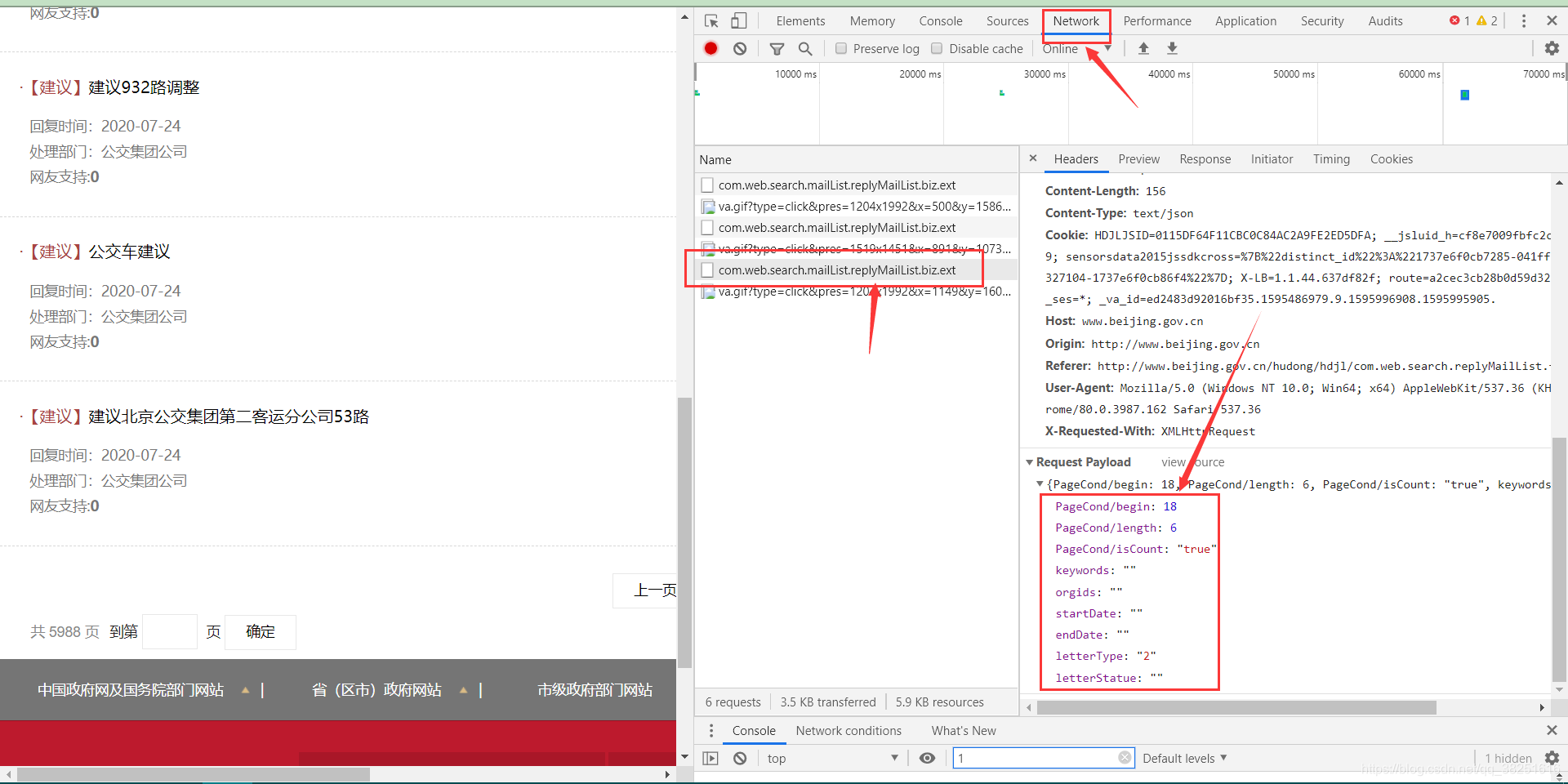
右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin:18、PageCond/length:6个类似的参数,很明显网站就是根据这个参数加载了相关数据。和post请求一起发送到网站,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
动态网页抓取(2020年7月29日写在前面:右键打开源码找到iframe标签
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址

在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。

进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.

右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin:18、PageCond/length:6个类似的参数,很明显网站就是根据这个参数加载了相关数据。和post请求一起发送到网站,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
动态网页抓取(动态加载的网页不可以直接通过geturl的方式获取到网页内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-09 23:05
)
对于一些静态的网站,只要requests.get('url')就可以得到页面的所有内容,比如链家用pg做页面,rs做关键字,%E8%99%B9 %E5%8F%A3 /
但是对于一些动态加载的网页,不能直接通过get url获取网页内容
一、阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),是指一种网页开发技术,可以创建交互式、快速和动态的网页应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。
jax 技术的核心是 XMLHttpRequest 对象(简称 XHR),这是微软首先引入的一个特性,后来其他浏览器提供商也提供了相同的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
二、查看网页上的实际信息
点击元素勾选-network-XRH(Firefox有时在JS中)
比如在QQ音乐中查看歌名列表,
三、 使用爬虫爬取信息
找到真实的请求信息(请求URL、提交的表单)后,在scrapy中只要需要下面的代码就可以实现爬取。请求方法 post 或 get 取决于 网站 的情况
def start_requests(self):
try:
ses = requests.session() # 获取session
ses.get(url=self.url, headers=self.headers)
cookie_start = ses.cookies # 为此次获取的cookies
cookie_start=requests.utils.dict_from_cookiejar(cookie_start)
# print("page:{} 首页cookie获取suc...".format(self.pn))
except:
print("page:{} 首页cookie获取异常...".format(self.pn ))
yield scrapy.FormRequest(url=self.url_start
, formdata={'first': 'True', 'pn': str(self.pn), 'kd':self.kd}
, method='Post'
, headers=self.headers
, cookies=cookie_start
, encoding='utf-8'
, dont_filter=True
, meta={'pn': str(self.pn),'kd': self.kd}
, callback=self.parse
) 查看全部
动态网页抓取(动态加载的网页不可以直接通过geturl的方式获取到网页内容
)
对于一些静态的网站,只要requests.get('url')就可以得到页面的所有内容,比如链家用pg做页面,rs做关键字,%E8%99%B9 %E5%8F%A3 /
但是对于一些动态加载的网页,不能直接通过get url获取网页内容
一、阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),是指一种网页开发技术,可以创建交互式、快速和动态的网页应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。
jax 技术的核心是 XMLHttpRequest 对象(简称 XHR),这是微软首先引入的一个特性,后来其他浏览器提供商也提供了相同的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
二、查看网页上的实际信息
点击元素勾选-network-XRH(Firefox有时在JS中)

比如在QQ音乐中查看歌名列表,

三、 使用爬虫爬取信息

找到真实的请求信息(请求URL、提交的表单)后,在scrapy中只要需要下面的代码就可以实现爬取。请求方法 post 或 get 取决于 网站 的情况
def start_requests(self):
try:
ses = requests.session() # 获取session
ses.get(url=self.url, headers=self.headers)
cookie_start = ses.cookies # 为此次获取的cookies
cookie_start=requests.utils.dict_from_cookiejar(cookie_start)
# print("page:{} 首页cookie获取suc...".format(self.pn))
except:
print("page:{} 首页cookie获取异常...".format(self.pn ))
yield scrapy.FormRequest(url=self.url_start
, formdata={'first': 'True', 'pn': str(self.pn), 'kd':self.kd}
, method='Post'
, headers=self.headers
, cookies=cookie_start
, encoding='utf-8'
, dont_filter=True
, meta={'pn': str(self.pn),'kd': self.kd}
, callback=self.parse
)
动态网页抓取(可以把动态网站网页定时生成HTML的工具,排除软件假死现象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-09 21:22
动态网页静态是一种可以定期从动态网站网页生成HTML的工具。可在用户设定的时间内自动生成HTML静态页面,支持设置和存储静态页面地址、自动循环生成等功能。
软件特点
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。
所需的ASP,。NET、PHP 等动态网页自动生成 HTML 页面。
软件功能
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。 查看全部
动态网页抓取(可以把动态网站网页定时生成HTML的工具,排除软件假死现象)
动态网页静态是一种可以定期从动态网站网页生成HTML的工具。可在用户设定的时间内自动生成HTML静态页面,支持设置和存储静态页面地址、自动循环生成等功能。
软件特点
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。
所需的ASP,。NET、PHP 等动态网页自动生成 HTML 页面。
软件功能
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。
动态网页抓取(动态网页是基本的语法规范与html代码生成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-07 03:09
1、简介 所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。值得强调的是,不要将动态网页与页面内容是否动态混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是特定的网页。内容的呈现形式,无论网页是否具有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。总之,动态网页是基本的html语法规范和高级编程语言如Java、VB、VC、数据库编程等技术的融合,以实现高效、动态、交互的内容和风格网站 管理。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。从网站浏览者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但从网站的角度来看 开发、管理、维护大不同。早期的动态网页主要使用通用网关接口(CGI)技术。
您可以使用不同的程序来编写合适的 CGI 程序,例如 Visual Basic、Delphi 或 C/C++。CGI技术虽然已经发展成熟、功能强大,但由于编程困难、效率低、修改复杂,有逐渐被新技术取代的趋势。对应静态网页,可以与后端数据库交互,传输数据。也就是说,网页URL的后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页创建格式,而是.aspx、.asp、.jsp、. php,.perl,。cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visual studio2008等实现,2、的特点简单总结如下:(1) 动态网页一般基于数据库技术,可以大大减少网站维护的工作量;(2)动态网页技术网站可以实现的功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页是实际上并不是服务器上独立存在的网页文件,只有当用户请求时服务器才返回一个完整的网页;(4)动态网页中的“?”对搜索引擎检索有一定的问题,并且搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索不抓取URL中“?”后的内容。因此,网站 使用动态网页需要做一定的技术处理以适应搜索引擎推广。搜索引擎要求。 查看全部
动态网页抓取(动态网页是基本的语法规范与html代码生成的)
1、简介 所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。值得强调的是,不要将动态网页与页面内容是否动态混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是特定的网页。内容的呈现形式,无论网页是否具有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。总之,动态网页是基本的html语法规范和高级编程语言如Java、VB、VC、数据库编程等技术的融合,以实现高效、动态、交互的内容和风格网站 管理。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。从网站浏览者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但从网站的角度来看 开发、管理、维护大不同。早期的动态网页主要使用通用网关接口(CGI)技术。
您可以使用不同的程序来编写合适的 CGI 程序,例如 Visual Basic、Delphi 或 C/C++。CGI技术虽然已经发展成熟、功能强大,但由于编程困难、效率低、修改复杂,有逐渐被新技术取代的趋势。对应静态网页,可以与后端数据库交互,传输数据。也就是说,网页URL的后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页创建格式,而是.aspx、.asp、.jsp、. php,.perl,。cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visual studio2008等实现,2、的特点简单总结如下:(1) 动态网页一般基于数据库技术,可以大大减少网站维护的工作量;(2)动态网页技术网站可以实现的功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页是实际上并不是服务器上独立存在的网页文件,只有当用户请求时服务器才返回一个完整的网页;(4)动态网页中的“?”对搜索引擎检索有一定的问题,并且搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索不抓取URL中“?”后的内容。因此,网站 使用动态网页需要做一定的技术处理以适应搜索引擎推广。搜索引擎要求。
动态网页抓取((网络营销教学网站2005-02-26)动态网页的一般特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-06 23:13
(网络营销教学网站2005-02-26)
动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。例如,当当网书店《网络营销基础与实战》第二版的详细介绍页面网址为:
这是一个典型的动态网页 URL 表单。
这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
如果想了解更多动态网页的搜索引擎优化,可以参考作者对网络营销的新观察网站搜索引擎营销专题文章。 查看全部
动态网页抓取((网络营销教学网站2005-02-26)动态网页的一般特点)
(网络营销教学网站2005-02-26)
动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。例如,当当网书店《网络营销基础与实战》第二版的详细介绍页面网址为:
这是一个典型的动态网页 URL 表单。
这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
如果想了解更多动态网页的搜索引擎优化,可以参考作者对网络营销的新观察网站搜索引擎营销专题文章。
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-06 09:15
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来济宁网站建设技术小编就来聊聊动态页面优化的SEO方法:
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
济宁网站建设科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容,您可以在本站阅读其他SEO优化技巧和经验,相信您一定会有所收获。 查看全部
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则及方法)
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来济宁网站建设技术小编就来聊聊动态页面优化的SEO方法:
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
济宁网站建设科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容,您可以在本站阅读其他SEO优化技巧和经验,相信您一定会有所收获。
动态网页抓取(动态网页的特点及特点总结-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-06 06:09
动态网页是指虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。从网站查看者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但是从网站的开发、管理和维护的角度来看,有很大的不同。但是,动态网站是动态网页的集合,其内容可以根据不同情况动态变化。通常,动态网站是通过数据库构造的。
动态网页的特点总结
1、动态网页基于数据库技术,可以大大减少网站维护的工作量,但是动态网站的访问速度大大减慢。
2、 采用动态网页技术网站可以实现更多的交互功能,如用户注册、用户登录、在线调查、用户管理、订单管理等,后台动态页面管理可以更方便的更新内容以后,即使没有编程技能,也可以轻松管理网站。
3、动态网页实际上并不是独立存在于服务器上的网页文件。服务器仅在用户请求时返回完整的网页。
4、搜索引擎检索不抓取“?”后的内容 在网址中。因此,具有动态网页的网站在被搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的需求。
5、动态网页收录服务器端脚本,因此页面文件名常以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断动态和静态网站的唯一标准。
6、由于代码特殊,动态网页不像静态网页那样对搜索引擎友好。但是如果做URL静态技术处理也是可以的。
总结:动态网站服务器空间配置比静态网页要求更高,成本也相应高。但是动态网页有利于更新网站的内容,适合企业搭建网站。随着计算机性能的提升和网络带宽的增加,网站访问速度和静态处理已经基本解决。最重要的是基本都是使用动态网站,然后静态处理URL,也就是所谓的伪静态。
结尾 查看全部
动态网页抓取(动态网页的特点及特点总结-上海怡健医学())
动态网页是指虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。从网站查看者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但是从网站的开发、管理和维护的角度来看,有很大的不同。但是,动态网站是动态网页的集合,其内容可以根据不同情况动态变化。通常,动态网站是通过数据库构造的。
动态网页的特点总结
1、动态网页基于数据库技术,可以大大减少网站维护的工作量,但是动态网站的访问速度大大减慢。
2、 采用动态网页技术网站可以实现更多的交互功能,如用户注册、用户登录、在线调查、用户管理、订单管理等,后台动态页面管理可以更方便的更新内容以后,即使没有编程技能,也可以轻松管理网站。
3、动态网页实际上并不是独立存在于服务器上的网页文件。服务器仅在用户请求时返回完整的网页。
4、搜索引擎检索不抓取“?”后的内容 在网址中。因此,具有动态网页的网站在被搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的需求。
5、动态网页收录服务器端脚本,因此页面文件名常以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断动态和静态网站的唯一标准。
6、由于代码特殊,动态网页不像静态网页那样对搜索引擎友好。但是如果做URL静态技术处理也是可以的。
总结:动态网站服务器空间配置比静态网页要求更高,成本也相应高。但是动态网页有利于更新网站的内容,适合企业搭建网站。随着计算机性能的提升和网络带宽的增加,网站访问速度和静态处理已经基本解决。最重要的是基本都是使用动态网站,然后静态处理URL,也就是所谓的伪静态。
结尾
动态网页抓取(网站SEO优化如何优化动态网站呢?静态页面好还是动态页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-06 06:09
网站优化已经是众所周知的技术了,但是有些企业在优化网站的时候总是会忘记一些细节,但是一些细节会在后期的优化中暴露出很大的问题,从而影响企业对网站的排名@>,如网站的动态和静态网站。很多公司怕麻烦,直接用动态,导致搜索引擎拖慢了网站动态页面的爬取时间。那么,网站SEO优化如何优化动态网站?
静态页面更好还是动态页面更好?
1、静态网页优化
从网站的发展和百度搜索引擎的整体规律来看,静态网页是相当不错的,因为静态网页是由一个完整的代码组成的,没有固定的内容,然后会有相应的url,一个对应的URL只有一个对应的页面,所以这种方法更有利于新手公司的seo优化。
2、动态网页优化
动态网页最大的问题是通过代码生成,没有固定的网址。在这种情况下,通过 SEO 更好地优化静态网页是很自然的。但是,大范围推荐网站的智能动态网页,给人一种很高端的感觉。所以,这类网页如果针对SEO进行优化,也能给用户带来不错的体验。
如何优化动态网站
1、 合理的网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感,尤其是“&”。还有一点就是尽量不要在URL中收录中文字符,因为浏览器对URL很敏感。URL中的中文是经过编码的。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。
2、页面 CGI/ Perl
网站页面使用CGI或Perl。您可以使用脚本提取环境变量之前的所有字符,然后将 URL 中剩余的字符分配给一个变量。您可以在 URL 中使用此变量。但是,所有主要搜索引擎都可以为具有内置部门 SSI 内容的网页提供索引支持。带有后缀的网页也被解析成SSI文件,相当于普通的html文件。但是,这些网页在其 URL 中使用 cgi-bin 路径,并且它们可能不会被搜索引擎索引。
3、构建静态导入
在“动静联动,静制动”的原则指导下,还可以对网站进行一些改动。百度排名优化可以尽可能提高网页搜索引擎的知名度。例如,将网页编译为静态主页或站点地图的链接,并以静态目录的形式呈现动态页面。或者为动态页面设置专门的静态导入页面,链接到动态页面,然后将静态导入页面提交给搜索引擎。一些内容相对固定的重要页面被构造为静态页面,如丰富的关键词介绍、用户帮助、重要页面链接的地图等。
以上内容供大家分享(网站SEO优化如何优化动态网站)还有很多公司在使用动态页面。动态页面虽然可以被搜索引擎抓取,但是抓取速度不如静态网站。
(主编:搜索引擎网站优化SEO外包-,原创不容易,作者、原创出处及本声明转载时必须以链接形式注明。 ) 查看全部
动态网页抓取(网站SEO优化如何优化动态网站呢?静态页面好还是动态页面)
网站优化已经是众所周知的技术了,但是有些企业在优化网站的时候总是会忘记一些细节,但是一些细节会在后期的优化中暴露出很大的问题,从而影响企业对网站的排名@>,如网站的动态和静态网站。很多公司怕麻烦,直接用动态,导致搜索引擎拖慢了网站动态页面的爬取时间。那么,网站SEO优化如何优化动态网站?

静态页面更好还是动态页面更好?
1、静态网页优化
从网站的发展和百度搜索引擎的整体规律来看,静态网页是相当不错的,因为静态网页是由一个完整的代码组成的,没有固定的内容,然后会有相应的url,一个对应的URL只有一个对应的页面,所以这种方法更有利于新手公司的seo优化。
2、动态网页优化
动态网页最大的问题是通过代码生成,没有固定的网址。在这种情况下,通过 SEO 更好地优化静态网页是很自然的。但是,大范围推荐网站的智能动态网页,给人一种很高端的感觉。所以,这类网页如果针对SEO进行优化,也能给用户带来不错的体验。
如何优化动态网站

1、 合理的网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感,尤其是“&”。还有一点就是尽量不要在URL中收录中文字符,因为浏览器对URL很敏感。URL中的中文是经过编码的。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。
2、页面 CGI/ Perl
网站页面使用CGI或Perl。您可以使用脚本提取环境变量之前的所有字符,然后将 URL 中剩余的字符分配给一个变量。您可以在 URL 中使用此变量。但是,所有主要搜索引擎都可以为具有内置部门 SSI 内容的网页提供索引支持。带有后缀的网页也被解析成SSI文件,相当于普通的html文件。但是,这些网页在其 URL 中使用 cgi-bin 路径,并且它们可能不会被搜索引擎索引。
3、构建静态导入
在“动静联动,静制动”的原则指导下,还可以对网站进行一些改动。百度排名优化可以尽可能提高网页搜索引擎的知名度。例如,将网页编译为静态主页或站点地图的链接,并以静态目录的形式呈现动态页面。或者为动态页面设置专门的静态导入页面,链接到动态页面,然后将静态导入页面提交给搜索引擎。一些内容相对固定的重要页面被构造为静态页面,如丰富的关键词介绍、用户帮助、重要页面链接的地图等。
以上内容供大家分享(网站SEO优化如何优化动态网站)还有很多公司在使用动态页面。动态页面虽然可以被搜索引擎抓取,但是抓取速度不如静态网站。
(主编:搜索引擎网站优化SEO外包-,原创不容易,作者、原创出处及本声明转载时必须以链接形式注明。 )
动态网页抓取(我对如何从此网页抓取数据有疑问(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-05 12:09
我有一个关于如何从此页面抓取数据的问题:
://&版本=1.11.2
好像还留在iframe里,屏幕上有很多JavaScript。
每当我尝试采集保存在 iframe 下的 span 或 div 或 tr 标签中的元素时,我似乎无法采集其中的数据。
我的目标是将内部文本保存在 class="pane-legend-item-value panel-legend-line main" 元素中。
显然,文本会根据光标在特定时间在屏幕上的位置而变化。所以我试图做的是设置一个已经加载页面并将光标放置在正确位置的 IE,在图表的末尾(为我提供最后一个数据点),您可以将光标移出屏幕,然后然后我写了一些简单的代码来获取IE窗口,然后尝试了GetElements,但是此时却无法获取任何数据。
到目前为止,这是我的代码,当我阅读更多选项时,它一直很粗糙,因为我一直在尝试编辑,但没有任何成功:(...任何想法或帮助将不胜感激!底部)
Sub InvestingCom()
Dim IE As InternetExplorer
Dim htmldoc As MSHTML.IHTMLDocument 'Document object
Dim eleColth As MSHTML.IHTMLElementCollection 'Element collection for th tags
Dim eleColtr As MSHTML.IHTMLElementCollection 'Element collection for tr tags
Dim eleColtd As MSHTML.IHTMLElementCollection 'Element collection for td tags
Dim eleRow As MSHTML.IHTMLElement 'Row elements
Dim eleCol As MSHTML.IHTMLElement 'Column elements
Dim elehr As MSHTML.IHTMLElement 'Header Element
Dim iframeDoc As MSHTML.HTMLDocument
Dim frame As HTMLIFrame
Dim ieURL As String 'URL
'Take Control of Open IE
marker = 0
Set objShell = CreateObject("Shell.Application")
IE_count = objShell.Windows.Count
For x = 0 To (IE_count - 1)
On Error Resume Next
my_url = objShell.Windows(x).document.Location
my_title = objShell.Windows(x).document.Title
If my_title Like "*" & "*" Then 'compare to find if the desired web page is already open
Set IE = objShell.Windows(x)
marker = 1
Exit For
Else
End If
Next
'Extract data
Set htmldoc = IE.document 'Document webpage
' I have tried span, tr, td etc tags and various other options
' I have never actually tried collecting an HTMLFrame but googled it however was unsuccessful
End Sub
Excel 可以在另一个屏幕上打开并打开 excel 和 VB。IE截图,我要抓取的数据可以找找聊聊
最佳答案
我真的很难处理这个页面中的两个嵌套iframe来采集所需的内容。但无论如何,我终于修好了。运行以下代码并获得您所要求的内容:
Sub forexpros()
Dim IE As New InternetExplorer, html As HTMLDocument
Dim frm As Object, frmano As Object, post As Object
With IE
.Visible = True
.navigate "http://tvc4.forexpros.com/init ... ot%3B
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set frm = .document.getElementsByClassName("abs") ''this is the first iframe
.navigate frm(0).src
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set html = .document
End With
Set frmano = html.getElementsByTagName("iframe")(0).contentWindow.document ''this is the second iframe
For Each post In frmano.getElementsByClassName("pane-legend-item-value pane-legend-line main")
Debug.Print post.innerText
Next post
IE.Quit
End Sub
关于javascript-VBA动态网页爬取Excel,我们在Stack Overflow上发现了一个类似的问题: 查看全部
动态网页抓取(我对如何从此网页抓取数据有疑问(1)(图))
我有一个关于如何从此页面抓取数据的问题:
://&版本=1.11.2
好像还留在iframe里,屏幕上有很多JavaScript。
每当我尝试采集保存在 iframe 下的 span 或 div 或 tr 标签中的元素时,我似乎无法采集其中的数据。
我的目标是将内部文本保存在 class="pane-legend-item-value panel-legend-line main" 元素中。
显然,文本会根据光标在特定时间在屏幕上的位置而变化。所以我试图做的是设置一个已经加载页面并将光标放置在正确位置的 IE,在图表的末尾(为我提供最后一个数据点),您可以将光标移出屏幕,然后然后我写了一些简单的代码来获取IE窗口,然后尝试了GetElements,但是此时却无法获取任何数据。
到目前为止,这是我的代码,当我阅读更多选项时,它一直很粗糙,因为我一直在尝试编辑,但没有任何成功:(...任何想法或帮助将不胜感激!底部)
Sub InvestingCom()
Dim IE As InternetExplorer
Dim htmldoc As MSHTML.IHTMLDocument 'Document object
Dim eleColth As MSHTML.IHTMLElementCollection 'Element collection for th tags
Dim eleColtr As MSHTML.IHTMLElementCollection 'Element collection for tr tags
Dim eleColtd As MSHTML.IHTMLElementCollection 'Element collection for td tags
Dim eleRow As MSHTML.IHTMLElement 'Row elements
Dim eleCol As MSHTML.IHTMLElement 'Column elements
Dim elehr As MSHTML.IHTMLElement 'Header Element
Dim iframeDoc As MSHTML.HTMLDocument
Dim frame As HTMLIFrame
Dim ieURL As String 'URL
'Take Control of Open IE
marker = 0
Set objShell = CreateObject("Shell.Application")
IE_count = objShell.Windows.Count
For x = 0 To (IE_count - 1)
On Error Resume Next
my_url = objShell.Windows(x).document.Location
my_title = objShell.Windows(x).document.Title
If my_title Like "*" & "*" Then 'compare to find if the desired web page is already open
Set IE = objShell.Windows(x)
marker = 1
Exit For
Else
End If
Next
'Extract data
Set htmldoc = IE.document 'Document webpage
' I have tried span, tr, td etc tags and various other options
' I have never actually tried collecting an HTMLFrame but googled it however was unsuccessful
End Sub
Excel 可以在另一个屏幕上打开并打开 excel 和 VB。IE截图,我要抓取的数据可以找找聊聊
最佳答案
我真的很难处理这个页面中的两个嵌套iframe来采集所需的内容。但无论如何,我终于修好了。运行以下代码并获得您所要求的内容:
Sub forexpros()
Dim IE As New InternetExplorer, html As HTMLDocument
Dim frm As Object, frmano As Object, post As Object
With IE
.Visible = True
.navigate "http://tvc4.forexpros.com/init ... ot%3B
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set frm = .document.getElementsByClassName("abs") ''this is the first iframe
.navigate frm(0).src
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set html = .document
End With
Set frmano = html.getElementsByTagName("iframe")(0).contentWindow.document ''this is the second iframe
For Each post In frmano.getElementsByClassName("pane-legend-item-value pane-legend-line main")
Debug.Print post.innerText
Next post
IE.Quit
End Sub
关于javascript-VBA动态网页爬取Excel,我们在Stack Overflow上发现了一个类似的问题:
动态网页抓取(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-04 19:07
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对动态网页结构做任何事情,比如ajax异步加载。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。因为 Selenium 是一个 Java 程序,所以在使用 RSelenium 包和 Rwebdriver 包之前,您必须为您的计算机设置一个 Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;
(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,
然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,
(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意值前面的两个符号。;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.
(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、 至此所有的前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr 查看全部
动态网页抓取(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对动态网页结构做任何事情,比如ajax异步加载。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。因为 Selenium 是一个 Java 程序,所以在使用 RSelenium 包和 Rwebdriver 包之前,您必须为您的计算机设置一个 Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;

(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,

然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,

(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意值前面的两个符号。;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.

(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。

三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。

四、 至此所有的前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-04 03:03
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,云无羡科技小编就来聊聊SEO动态页面如何优化:
文章来源于【“收录之家”快排系统任务发布平台】。
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
云无羡科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。您可以获得更多 SEO 优化的内容。阅读本站其他SEO优化技巧和经验,相信你会收获很多。 查看全部
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则)
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,云无羡科技小编就来聊聊SEO动态页面如何优化:
文章来源于【“收录之家”快排系统任务发布平台】。
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
云无羡科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。您可以获得更多 SEO 优化的内容。阅读本站其他SEO优化技巧和经验,相信你会收获很多。
动态网页抓取(localhost:8080代表IP:端口:资源请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-03 15:09
localhost:8080 代表IP:端口
xxxx:资源请求地址
4.Tomcat(网络服务器)
网络逻辑
Ngnix
树脂
5.Tomcat:Web 服务器,JSP/Servlet 容器
目录介绍:
/bin 存放各种平台下用于启动和停止Tomcat的脚本文件
/conf 存放Tomcat服务器的各种配置文件
/lib 存放Tomcat服务器所需的各种JAR文件
/logs 存放Tomcat日志文件
/temp Tomcat运行时用来存放临时文件
/webapps 发布web应用时,web应用的文件默认会存放在这个目录中
/work Tomcat把JSP生成的Servlet放在这个目录下
启动方法:
/bin 目录:startup.bat 启动脚本 shutdown.bat 停止脚本
如果遇到崩溃问题,在以上两个文件中添加如下代码:
SET JAVA_HOME=D:\Java\jdk1.7(java jdk目录)
SET TOMCAT_HOME=E:\tomcat-7.0(解压tomcat文件目录)
配置环境变量:
添加一个系统变量,名称为CATALINA_HOME,值为Tomcat的安装目录,在Path系统变量中添加一个%CATALINA_HOME%\bin
6.网络项目:
在Eclipse环境下新建一个Dynamic web项目--->Target Runntime代表启动的web服务器----->Dynamic Web模型版本代表项目版本(3.0)- --> 点击下一步直到
---->Generate web.xml xxxxx 勾选,这样WEB-INFO文件夹下就有web.xml文件
web.xml文件是web项目的配置文件,其中welcome-file-list代表第一次访问的页面集合,welcome-file代表第一次访问的页面
目录结构:
/ web应用的根目录,该目录下的所有文件都可以在客户端访问(JSP、HTML等)
/WEB-INF 存储应用程序使用的各种资源。客户无法访问该目录及其子目录
/WEB-INF/classes 存放了 Web 项目的所有类文件
/WEB-INF/lib 存储 Web 应用程序使用的 JAR 文件
7.JSP页面:Java Server Pages(可以嵌入Java代码)所有JSP页面最终都会被WEB容器自动写入.Java文件并编译成.class文件
作文内容:
页面命令:
属性描述默认值
language 指定 JSP 页面 java 使用的脚本语言
import 使用此属性来引用脚本语言中使用的类文件。无
contentType 用于指定 JSP 页面 text/html 使用的编码方式,ISO-8859-1
小脚本:
表达: 查看全部
动态网页抓取(localhost:8080代表IP:端口:资源请求地址)
localhost:8080 代表IP:端口
xxxx:资源请求地址
4.Tomcat(网络服务器)
网络逻辑
Ngnix
树脂
5.Tomcat:Web 服务器,JSP/Servlet 容器
目录介绍:
/bin 存放各种平台下用于启动和停止Tomcat的脚本文件
/conf 存放Tomcat服务器的各种配置文件
/lib 存放Tomcat服务器所需的各种JAR文件
/logs 存放Tomcat日志文件
/temp Tomcat运行时用来存放临时文件
/webapps 发布web应用时,web应用的文件默认会存放在这个目录中
/work Tomcat把JSP生成的Servlet放在这个目录下
启动方法:
/bin 目录:startup.bat 启动脚本 shutdown.bat 停止脚本
如果遇到崩溃问题,在以上两个文件中添加如下代码:
SET JAVA_HOME=D:\Java\jdk1.7(java jdk目录)
SET TOMCAT_HOME=E:\tomcat-7.0(解压tomcat文件目录)
配置环境变量:
添加一个系统变量,名称为CATALINA_HOME,值为Tomcat的安装目录,在Path系统变量中添加一个%CATALINA_HOME%\bin
6.网络项目:
在Eclipse环境下新建一个Dynamic web项目--->Target Runntime代表启动的web服务器----->Dynamic Web模型版本代表项目版本(3.0)- --> 点击下一步直到
---->Generate web.xml xxxxx 勾选,这样WEB-INFO文件夹下就有web.xml文件
web.xml文件是web项目的配置文件,其中welcome-file-list代表第一次访问的页面集合,welcome-file代表第一次访问的页面
目录结构:
/ web应用的根目录,该目录下的所有文件都可以在客户端访问(JSP、HTML等)
/WEB-INF 存储应用程序使用的各种资源。客户无法访问该目录及其子目录
/WEB-INF/classes 存放了 Web 项目的所有类文件
/WEB-INF/lib 存储 Web 应用程序使用的 JAR 文件
7.JSP页面:Java Server Pages(可以嵌入Java代码)所有JSP页面最终都会被WEB容器自动写入.Java文件并编译成.class文件
作文内容:
页面命令:
属性描述默认值
language 指定 JSP 页面 java 使用的脚本语言
import 使用此属性来引用脚本语言中使用的类文件。无
contentType 用于指定 JSP 页面 text/html 使用的编码方式,ISO-8859-1
小脚本:
表达:
动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-02 04:18
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
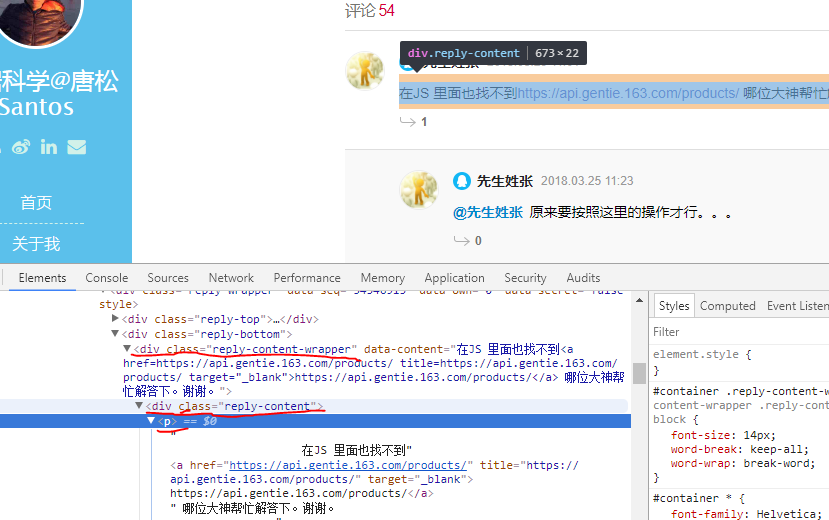
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架分析完成后,就可以进行相关定位,得到元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素
以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX

可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')

3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。

4)driver.get("")

5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))


6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')

7)content=comment.find_element_by_tag_name('p')

更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)

如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架分析完成后,就可以进行相关定位,得到元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素

以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
动态网页抓取(网页源代码获取单节点的方法和常见的用法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-02 03:29
Selenium 支持多种浏览器:Chrome、Firefox、Edge 等,还支持Android、BlackBerry 等手机浏览器,还支持非接口浏览器PhantomJS。
初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
4. 访问页面
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
print(browser.page_source) //打印源码
browser.close()
5.查找节点
Selenium 可以驱动浏览器完成各种操作,比如填表、模拟点击等。比如我们要在输入框中输入文本,就必须知道输入框的位置,对吧?别着急,selenium 提供了一系列查找节点的方法。
先看网页源码
如何获取单个节点:
此外,Selenium 还提供了通用方法:
find_element(By.ID, id) 等价于 find_element_by_id(id)
如何获得多个节点:
此外,Selenium 还提供了通用方法:
find_elements(By.ID, id) 等价于 find_elements_by_id(id)
注:单节点和多节点是单复数形式的区别。
6. 节点交互
Selenium 驱动浏览器执行一些操作。其实就是让浏览器模拟并执行一些动作。常见用法有:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
input = browser.find_element_by_id('q') //通过输入框的id,找到输入框(不一定能找到,淘宝的源代码可能更新了)
input.send_keys('iPhone') //在输入框内输入iPhone
time.sleep(1)
input.clear() //清空输入框内容
input.send_keys('Ipad')
button = browser.find_element_by_class_name('btn-search') //查找“搜索”按钮(不一定能找到,淘宝的源代码可能更新了)
button.click()
可以参考官方文档:#module-selenium.webdriver.remote.webelement
7.动作链
上面的例子是针对某个节点执行的,其他一些操作没有具体的执行对象,比如鼠标拖拽、键盘按键等,这些动作是通过另一种方式执行的,也就是动作链。
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source,target)
actions.perform()
操作结果:
可以参考官方文档:#mon.action_chains
8. 执行 JavaScript
对于某些操作,不提供 selenium API。比如下拉进度条,可以直接模拟运行JS,本例使用execute_script()方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
通过这种方式,基本上所有API没有提供的功能都可以通过执行JS来实现。
9. 获取节点信息
在前面的代码中,可以通过page_source属性获取网页的源代码,然后可以使用解析库来提取信息。
并且用selenium可以获取节点,返回webElement类型,可以直接获取节点信息(文本、属性等)
get_attribute()
输入文本
每个 WebElement 节点都有一个 text 属性
10. 切换帧
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。selenium打开页面后,他默认在父框架中操作,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
11. 延迟等待
在 Selenium 中,get() 方法将在页面框架加载后结束执行。这时候如果拿到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求。我们可能无法在网页的源代码中获得它。因此,您需要等待一段时间以确保节点已加载。
等待有两种方式:隐式等待和显式等待。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10) //隐式等待10秒
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
from selenium import webdriver
from selenium.webdriver.commom.by import By
from selenium.webdriver.support import excepted_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
可以参考官方文档:#module-selenium.webdriver.supported.expected_conditions
12. 向前和向后
我们在使用浏览器的时候一般都有前进后退的功能,Selenium也可以实现这个功能。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
browser.get ('https://www.python.org ')
browser.get ('https://www.baidu.com ')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
13. 饼干
使用 Selenium 可以方便地对 Cookie 进行操作,例如获取、添加和删除 Cookie。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url) //加载完成后,实际上已经生成cookies了
print(browser.get_cookies()) //获取所有的cookies
browser.add_cookie({'name': 'name', 'domin':'www.zhihu.com', 'value':'germey'}) //添加cookie,注意cookie的单复数
print(browser.get_cookies()) //再次获取cookies
browser.delete_all_cookies() //删除所有的cookies
print(browser.get_cookies()) //再次获取为空了
14.标签管理
当您访问网页时,将打开一个选项卡。在 Selenium 中,我们可以对选项卡进行操作。
15. 异常处理
尝试除了 查看全部
动态网页抓取(网页源代码获取单节点的方法和常见的用法有哪些?)
Selenium 支持多种浏览器:Chrome、Firefox、Edge 等,还支持Android、BlackBerry 等手机浏览器,还支持非接口浏览器PhantomJS。
初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
4. 访问页面
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
print(browser.page_source) //打印源码
browser.close()
5.查找节点
Selenium 可以驱动浏览器完成各种操作,比如填表、模拟点击等。比如我们要在输入框中输入文本,就必须知道输入框的位置,对吧?别着急,selenium 提供了一系列查找节点的方法。
先看网页源码

如何获取单个节点:
此外,Selenium 还提供了通用方法:
find_element(By.ID, id) 等价于 find_element_by_id(id)
如何获得多个节点:
此外,Selenium 还提供了通用方法:
find_elements(By.ID, id) 等价于 find_elements_by_id(id)
注:单节点和多节点是单复数形式的区别。
6. 节点交互
Selenium 驱动浏览器执行一些操作。其实就是让浏览器模拟并执行一些动作。常见用法有:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
input = browser.find_element_by_id('q') //通过输入框的id,找到输入框(不一定能找到,淘宝的源代码可能更新了)
input.send_keys('iPhone') //在输入框内输入iPhone
time.sleep(1)
input.clear() //清空输入框内容
input.send_keys('Ipad')
button = browser.find_element_by_class_name('btn-search') //查找“搜索”按钮(不一定能找到,淘宝的源代码可能更新了)
button.click()
可以参考官方文档:#module-selenium.webdriver.remote.webelement
7.动作链
上面的例子是针对某个节点执行的,其他一些操作没有具体的执行对象,比如鼠标拖拽、键盘按键等,这些动作是通过另一种方式执行的,也就是动作链。
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source,target)
actions.perform()
操作结果:


可以参考官方文档:#mon.action_chains
8. 执行 JavaScript
对于某些操作,不提供 selenium API。比如下拉进度条,可以直接模拟运行JS,本例使用execute_script()方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
通过这种方式,基本上所有API没有提供的功能都可以通过执行JS来实现。
9. 获取节点信息
在前面的代码中,可以通过page_source属性获取网页的源代码,然后可以使用解析库来提取信息。
并且用selenium可以获取节点,返回webElement类型,可以直接获取节点信息(文本、属性等)
get_attribute()
输入文本
每个 WebElement 节点都有一个 text 属性
10. 切换帧
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。selenium打开页面后,他默认在父框架中操作,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
11. 延迟等待
在 Selenium 中,get() 方法将在页面框架加载后结束执行。这时候如果拿到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求。我们可能无法在网页的源代码中获得它。因此,您需要等待一段时间以确保节点已加载。
等待有两种方式:隐式等待和显式等待。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10) //隐式等待10秒
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
from selenium import webdriver
from selenium.webdriver.commom.by import By
from selenium.webdriver.support import excepted_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
可以参考官方文档:#module-selenium.webdriver.supported.expected_conditions
12. 向前和向后
我们在使用浏览器的时候一般都有前进后退的功能,Selenium也可以实现这个功能。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
browser.get ('https://www.python.org ')
browser.get ('https://www.baidu.com ')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
13. 饼干
使用 Selenium 可以方便地对 Cookie 进行操作,例如获取、添加和删除 Cookie。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url) //加载完成后,实际上已经生成cookies了
print(browser.get_cookies()) //获取所有的cookies
browser.add_cookie({'name': 'name', 'domin':'www.zhihu.com', 'value':'germey'}) //添加cookie,注意cookie的单复数
print(browser.get_cookies()) //再次获取cookies
browser.delete_all_cookies() //删除所有的cookies
print(browser.get_cookies()) //再次获取为空了
14.标签管理
当您访问网页时,将打开一个选项卡。在 Selenium 中,我们可以对选项卡进行操作。
15. 异常处理
尝试除了
动态网页抓取(最全的现代浏览器技术相关网站基础篇(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-01 15:00
动态网页抓取:w3ctechniquesw3schools国外的一些工具、框架的全面剖析我前段时间整理了一些国外相关的网站整理:最全、最全、最全的现代浏览器技术相关网站
基础篇:神马net(有少量核心);taobao-web-security(全面,可能需要ap安全以及res加密相关)wikicorpuss&untilthread和ws|重视信息泄露(国内外)securewebviewdevelopwasigmawebgallery(不全,且未列入列表)igwebhdvergewat(其实很垃圾)和科学上网类simplehttpd(ga)iajoozow(jb也算的话)ig-tool。
com:javascripttoolsandsupports,broadcasts,engines,improvements,andsupportsthesite。igconnect(advancedjavascript)intellij(),jasmine,agilent,andsoftwarereviews。stridespeedsougou(advancedtechnologies)。
c2
w3c,
oclib
别看不起国内,你要想和国外对比,几乎是不可能的。国内的还停留在满地都是xsssql注入,20分钟注入5000人次。
我刚刚开了一家网站onlinewebsecurity
清华的浏览器课程讲的蛮多的。
小说站,资源站,密码站,
如果说是浏览器xss漏洞基础,unp这本书已经有涉及了,随着漏洞实例和深入学习,我想到时会有更多其他资料,unp已经够用。有心看的话,自己去看即可。 查看全部
动态网页抓取(最全的现代浏览器技术相关网站基础篇(图))
动态网页抓取:w3ctechniquesw3schools国外的一些工具、框架的全面剖析我前段时间整理了一些国外相关的网站整理:最全、最全、最全的现代浏览器技术相关网站
基础篇:神马net(有少量核心);taobao-web-security(全面,可能需要ap安全以及res加密相关)wikicorpuss&untilthread和ws|重视信息泄露(国内外)securewebviewdevelopwasigmawebgallery(不全,且未列入列表)igwebhdvergewat(其实很垃圾)和科学上网类simplehttpd(ga)iajoozow(jb也算的话)ig-tool。
com:javascripttoolsandsupports,broadcasts,engines,improvements,andsupportsthesite。igconnect(advancedjavascript)intellij(),jasmine,agilent,andsoftwarereviews。stridespeedsougou(advancedtechnologies)。
c2
w3c,
oclib
别看不起国内,你要想和国外对比,几乎是不可能的。国内的还停留在满地都是xsssql注入,20分钟注入5000人次。
我刚刚开了一家网站onlinewebsecurity
清华的浏览器课程讲的蛮多的。
小说站,资源站,密码站,
如果说是浏览器xss漏洞基础,unp这本书已经有涉及了,随着漏洞实例和深入学习,我想到时会有更多其他资料,unp已经够用。有心看的话,自己去看即可。
动态网页抓取(百度网址提交与自动的区别有哪些?如何选择?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-17 01:21
对于百度收录来说,一直是困扰SEO人员的核心问题。每天都有大量站长在思考为什么我的页面没有收录?于是我开始想各种办法,让页面快速被百度收录。
其中,我们绝对不会脱离这三个渠道:普通数据提交、快速收录提交和百度爬虫自动抓取。
前者通常使用API或人工提交,而后者则让百度蜘蛛自行抓取索引。但是对于这些链接渠道,很少有SEO伙伴去考虑它们之间的区别和联系。
那么,百度链接提交和自动抓取有什么区别,如何选择呢?根据以往百度网址提交的经验,我们将详细阐述以下内容:
一、主动提交
对于普通的收录和快速的收录权限,我们认为有以下特点:
1.提高搜索引擎发现新链接的时间,快速进入百度搜索指数评测通道。简单理解就是增加索引量;2. 节省目标页面被百度发现的成本,比如外部链接的构建,引蜘蛛的成本。
但同时,根据我们大量的测试,这种数据提交形式仍然受到网站链接提交的时间节点和网站链接提交的次数和频率的影响。
当搜索引擎的爬取通道过于繁忙时,很容易造成一些网址地址丢失,即在不同时间节点提交网址时,收录的数量可能会发生很大的变化。其次,如果网站链接提交的次数和频率过于密集,整个网站的链接收录率会有一定的波动。
二、自动爬取
一般来说,所谓搜索引擎自动抓取主要是指百度蜘蛛主动抓取你的页面内容,主要受以下因素影响:
1. 优质外链数量及增长频率;2. 网站优质内容更新次数占整个网站内容的比例;3. 页面内容的更新频率。
一般来说,如果你能在某个时间节点保持一定的活跃度,自动爬取是很规律的,随着整个站点质量的提高,网站很容易进入。“秒收录”的状态。这个时候,我们根本不需要考虑。只要内容有更新,我们就可以继续获取收录。
同时,我们根据一些日常操作做了基本的判断,发现如果你主动提交的链接质量不高,长时间处于低质量状态,很容易出现你自己的链接不是收录,同时虽然引起自动抓取的页面是收录,但大部分都会进入低质量的库,即检索相关的新页面,没有任何排名。相比之下,我们认为对自动爬取这方面的评价可能比较宽泛。
三、合理的选择
基于以上因素,我们认为如果你有能力,我们还是建议你选择网站让百度搜索自动抓取和收录,可以适当减少网站的提交@> 链接,除非你的外部链接资源有限,很难建立一些比较优质的链接。
此外,您的目标页面在整个站点中具有很深的目录层次结构,很难被搜索引擎发现和抓取。或者网站刚上线,还没有通过沙箱和质量评估期(使用链接提交,可以快速通过这个周期,前提是结构和内容质量要好)。
总结:SEO是一项细致的工作,要善于发现百度搜索产品的差异。当然,以上内容只是经验之谈,仅供参考! 查看全部
动态网页抓取(百度网址提交与自动的区别有哪些?如何选择?)
对于百度收录来说,一直是困扰SEO人员的核心问题。每天都有大量站长在思考为什么我的页面没有收录?于是我开始想各种办法,让页面快速被百度收录。
其中,我们绝对不会脱离这三个渠道:普通数据提交、快速收录提交和百度爬虫自动抓取。
前者通常使用API或人工提交,而后者则让百度蜘蛛自行抓取索引。但是对于这些链接渠道,很少有SEO伙伴去考虑它们之间的区别和联系。
那么,百度链接提交和自动抓取有什么区别,如何选择呢?根据以往百度网址提交的经验,我们将详细阐述以下内容:
一、主动提交
对于普通的收录和快速的收录权限,我们认为有以下特点:
1.提高搜索引擎发现新链接的时间,快速进入百度搜索指数评测通道。简单理解就是增加索引量;2. 节省目标页面被百度发现的成本,比如外部链接的构建,引蜘蛛的成本。
但同时,根据我们大量的测试,这种数据提交形式仍然受到网站链接提交的时间节点和网站链接提交的次数和频率的影响。
当搜索引擎的爬取通道过于繁忙时,很容易造成一些网址地址丢失,即在不同时间节点提交网址时,收录的数量可能会发生很大的变化。其次,如果网站链接提交的次数和频率过于密集,整个网站的链接收录率会有一定的波动。
二、自动爬取
一般来说,所谓搜索引擎自动抓取主要是指百度蜘蛛主动抓取你的页面内容,主要受以下因素影响:
1. 优质外链数量及增长频率;2. 网站优质内容更新次数占整个网站内容的比例;3. 页面内容的更新频率。
一般来说,如果你能在某个时间节点保持一定的活跃度,自动爬取是很规律的,随着整个站点质量的提高,网站很容易进入。“秒收录”的状态。这个时候,我们根本不需要考虑。只要内容有更新,我们就可以继续获取收录。
同时,我们根据一些日常操作做了基本的判断,发现如果你主动提交的链接质量不高,长时间处于低质量状态,很容易出现你自己的链接不是收录,同时虽然引起自动抓取的页面是收录,但大部分都会进入低质量的库,即检索相关的新页面,没有任何排名。相比之下,我们认为对自动爬取这方面的评价可能比较宽泛。
三、合理的选择
基于以上因素,我们认为如果你有能力,我们还是建议你选择网站让百度搜索自动抓取和收录,可以适当减少网站的提交@> 链接,除非你的外部链接资源有限,很难建立一些比较优质的链接。
此外,您的目标页面在整个站点中具有很深的目录层次结构,很难被搜索引擎发现和抓取。或者网站刚上线,还没有通过沙箱和质量评估期(使用链接提交,可以快速通过这个周期,前提是结构和内容质量要好)。
总结:SEO是一项细致的工作,要善于发现百度搜索产品的差异。当然,以上内容只是经验之谈,仅供参考!
动态网页抓取(文章目录网络爬虫学习笔记(2)-1动态抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-17 01:19
)
文章内容
网络爬虫学习笔记(2) 1 Information 2 Notes 2-1 动态爬虫概述
在使用 JavaScript 时,很多内容并没有出现在 HTML 源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
2-2 通过浏览器查看元素 chrom 浏览器右键菜单“勾选”点击“网络”选项分析真实网页地址,然后刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。
找到真实的数据地址。选择需要的文件,点击Preview选项卡查看数据,在Headers选项卡中可以找到数据地址(即Request URL项)。
获取到地址后,如果要爬取,只需将链接替换为3中找到的数据地址即可。 2-3 网页URL地址规律
比如在一些URL地址中,有两个特别重要的变量offset和limit。Offset表示这个页面的第一个item是item的总数,limit代表每页的item数。基于此,书中给出了一个很好的例子(在这个例子中,不同页面的注释的真实地址只反映在偏移量上,所以就有了变量page_str):
2-4 json 库 2-5 模拟浏览器爬取Selenium
使用此方法无需2-1操作,直接使用网页网址即可
所以,这里还有一个方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
load_more = driver.find_element_by_css_selector('div.tie-load-more')
load_more.click() 查看全部
动态网页抓取(文章目录网络爬虫学习笔记(2)-1动态抓取
)
文章内容
网络爬虫学习笔记(2) 1 Information 2 Notes 2-1 动态爬虫概述
在使用 JavaScript 时,很多内容并没有出现在 HTML 源代码中,因此抓取静态网页的技术可能无法正常工作。因此,我们需要使用两种技术进行动态网页爬取:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
2-2 通过浏览器查看元素 chrom 浏览器右键菜单“勾选”点击“网络”选项分析真实网页地址,然后刷新网页。此时,Network 将显示浏览器从 Web 服务器获取的所有文件。通常,此过程称为“数据包捕获”。
找到真实的数据地址。选择需要的文件,点击Preview选项卡查看数据,在Headers选项卡中可以找到数据地址(即Request URL项)。
获取到地址后,如果要爬取,只需将链接替换为3中找到的数据地址即可。 2-3 网页URL地址规律
比如在一些URL地址中,有两个特别重要的变量offset和limit。Offset表示这个页面的第一个item是item的总数,limit代表每页的item数。基于此,书中给出了一个很好的例子(在这个例子中,不同页面的注释的真实地址只反映在偏移量上,所以就有了变量page_str):
2-4 json 库 2-5 模拟浏览器爬取Selenium
使用此方法无需2-1操作,直接使用网页网址即可
所以,这里还有一个方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
load_more = driver.find_element_by_css_selector('div.tie-load-more')
load_more.click()
动态网页抓取(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-15 20:09
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!! 查看全部
动态网页抓取(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的爬取方法是:
URL url = 新 URL(myurl);
BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
我++;
sb.append(s+"\r\n");
}
这种方法抓取一般网页应该没有问题,但是当某些网页中存在嵌套的重定向连接时,会报错如服务器重定向次数过多。这是因为这个网页里面有一些代码。如果转到其他网页,循环过多会导致程序出错。如果只想抓取该网址中网页的内容,又不想重定向到其他网页,可以使用以下代码。
URL urlmy = 新 URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
连接();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
字符串 s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
在这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
System.getProperties().setProperty( "http.proxyHost", proxyName );
System.getProperties().setProperty("http.proxyPort", port );
这样,你就可以在内网中,从网上抓取你想要的东西。
上面程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这是多么美妙的一件事啊!!
动态网页抓取(动态网站静态化,也不是一件容易的事情!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-14 03:01
随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对于提高网站的权重和排名很有帮助,但是笔者发现很多站长把动态的网站转为静态的网站,却发现我自己的网站是K. 原因是什么?可见,动态网站静态不是一件容易的事,需要注意的问题很多!
一:静态网站的优缺点分析
静态网站的优势非常明显。用户浏览器打开静态网站比动态网站更快,因为动态网站网页也需要结合用户参数,然后才能形成相应的页面。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页就会下载到浏览器,也可以利用浏览器的缓存,让用户无需再次下载到服务器就可以第二次打开。可以看出,这个访问速度比动态网站要快。
静态网站的另一个优点是非常有利于搜索引擎收录和爬取。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的主页,遍历网站中的整个静态网页,从而实现网站的完整收录。当然,为了提高蜘蛛爬取网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如联系我们页面和支付方式页面许多公司网站。通过设置内链和ROBOTS.TXT文件,可以提高网站的爬取速度。
当然,静态网站的缺点也很明显。如果是大网站,尤其是信息网站,如果每个页面都变成静态页面,工作量肯定很大,而且对网站@的维护也非常不利>,因为静态网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,你要纠错往往需要很长时间一一排查!
二:动态网站的优缺点分析
动态的优势也非常突出。首先网站的互动非常好。现在很多网页游戏都是典型的动态网页。通过互动,可以提高网站的粘性。另外,动态网站对网站的管理很简单,因为网站几乎都是通过一个数据库来管理的,其实只要操作数据库,网站的维护@网站 可以实现,现在很多免费的建站程序也是这样的数据库。该结构非常适合个人站长。
但是动态网站的缺点也很明显。首先,随着访问量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,所以很容易留下后门。前段时间,很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为网站的动态网页大多是动态形成的,蜘蛛不能很好地抓取,导致网站收录的数量为不高。
三:动态网站转换为静态网站需要注意的问题
相比之下,静态网站的优势比较明显,尤其是搜索引擎的优势。如今,没有搜索引擎的支持,网站越来越难成功,所以现在很多原本经营动态网站的站长,已经把自己的网站变成了静态的网站@ >. 这样,我们就可以同时获得动态的网站 和静态的。网站 优点。
然而,在转换的过程中,很多站长都渴望成功。通过一些号称可以转为静态网站的程序,瞬间实现了动态网站的伪静态。这样做的结果就是如本文前面所述,网站已经完全K了。正确的做法应该是网站的动静结合,换句话说就是多丰富的关键词@ on 网站页面,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该通过一个动态转换程序!
目前有很多方法可以将动态页面转换为静态页面。其中,现成插件的使用最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IIS Rewrite、MOD_Rewrite等,这些都是基于正则表达式解析器开发的重写引擎,如何使用也是很简单。掌握了正确的动静态改造方法后,不要一下子就完成整个网站的改造,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。 查看全部
动态网页抓取(动态网站静态化,也不是一件容易的事情!!)
随着搜索引擎对网站的影响越来越大,越来越多的站长开始选择动态的网站静态的,因为静态网页很容易被搜索引擎和收录抓取,这对于提高网站的权重和排名很有帮助,但是笔者发现很多站长把动态的网站转为静态的网站,却发现我自己的网站是K. 原因是什么?可见,动态网站静态不是一件容易的事,需要注意的问题很多!
一:静态网站的优缺点分析
静态网站的优势非常明显。用户浏览器打开静态网站比动态网站更快,因为动态网站网页也需要结合用户参数,然后才能形成相应的页面。服务器速度和网速会严重影响动态网站的访问速度,而静态网站网页已经在服务器上可用,用户只需提交申请后,静态网页就会下载到浏览器,也可以利用浏览器的缓存,让用户无需再次下载到服务器就可以第二次打开。可以看出,这个访问速度比动态网站要快。
静态网站的另一个优点是非常有利于搜索引擎收录和爬取。只要能在服务器上的各个静态网页之间形成内链网络,搜索引擎蜘蛛就可以通过收录@网站的主页,遍历网站中的整个静态网页,从而实现网站的完整收录。当然,为了提高蜘蛛爬取网站的速度,很多站长可能会设置ROBOTS.TXT文件来屏蔽一些不必要的收录页面,比如联系我们页面和支付方式页面许多公司网站。通过设置内链和ROBOTS.TXT文件,可以提高网站的爬取速度。
当然,静态网站的缺点也很明显。如果是大网站,尤其是信息网站,如果每个页面都变成静态页面,工作量肯定很大,而且对网站@的维护也非常不利>,因为静态网站没有数据库,每个页面都需要手动检查。如果网站的链接有错误,你要纠错往往需要很长时间一一排查!
二:动态网站的优缺点分析
动态的优势也非常突出。首先网站的互动非常好。现在很多网页游戏都是典型的动态网页。通过互动,可以提高网站的粘性。另外,动态网站对网站的管理很简单,因为网站几乎都是通过一个数据库来管理的,其实只要操作数据库,网站的维护@网站 可以实现,现在很多免费的建站程序也是这样的数据库。该结构非常适合个人站长。
但是动态网站的缺点也很明显。首先,随着访问量的增加,服务器负载会不断增加,最终访问速度会极慢甚至崩溃。另外,因为是交互设计,所以很容易留下后门。前段时间,很多论坛和社区账号信息被盗,可见动态网站的安全隐患很大。另外,对搜索引擎的亲和力不强,因为网站的动态网页大多是动态形成的,蜘蛛不能很好地抓取,导致网站收录的数量为不高。
三:动态网站转换为静态网站需要注意的问题
相比之下,静态网站的优势比较明显,尤其是搜索引擎的优势。如今,没有搜索引擎的支持,网站越来越难成功,所以现在很多原本经营动态网站的站长,已经把自己的网站变成了静态的网站@ >. 这样,我们就可以同时获得动态的网站 和静态的。网站 优点。
然而,在转换的过程中,很多站长都渴望成功。通过一些号称可以转为静态网站的程序,瞬间实现了动态网站的伪静态。这样做的结果就是如本文前面所述,网站已经完全K了。正确的做法应该是网站的动静结合,换句话说就是多丰富的关键词@ on 网站页面,用户信息页面,网站地图页面,应该使用静态网页,对于网站的大量更新版块,应该通过一个动态转换程序!
目前有很多方法可以将动态页面转换为静态页面。其中,现成插件的使用最为常见,如Apache HTTP服务器的ISAPI_REWIRITE、IIS Rewrite、MOD_Rewrite等,这些都是基于正则表达式解析器开发的重写引擎,如何使用也是很简单。掌握了正确的动静态改造方法后,不要一下子就完成整个网站的改造,要遵循循序渐进的原则!只有这样,才能避免百度的处罚。
动态网页抓取( robots协议(也称为爬虫协议、机器人协议等)的全称)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-10 20:01
robots协议(也称为爬虫协议、机器人协议等)的全称)
动态网站不用担心,搜索引擎可以正常抓取动态链接,但是使用robots文件可以轻松提高动态网站的抓取效率。我们都知道robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 告诉搜索引擎哪些页面可以爬取,哪些页面通过Robots 协议爬取。无法抓取该页面。Robots协议的本质是网站与搜索引擎爬虫之间的通信方式,用于引导搜索引擎更好地抓取网站的内容。
百度官方建议所有网站使用robots文件,以更好地利用蜘蛛爬行。实际上,robots 不仅是告诉搜索引擎哪些不能抓取,也是网站优化的重要工具之一。
robots文件实际上是一个txt文件。基本措辞如下:
User-agent: * 其中*代表所有类型的搜索引擎,*是通配符
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /require/ 这里的定义是禁止爬取require目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中的所有动态页面
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
在网站优化方面,robots文件用于告诉搜索引擎什么是重要的内容,推荐robots文件禁止爬取不重要的内容。不重要内容的典型代表:网站的搜索结果页。
对于静态网站,我们可以使用Disallow: /*?* 来禁止动态页面爬取。但是对于动态网站,你不能简单地做到这一点。不过对于动态网站的站长来说,就不用太担心了。搜索引擎现在可以正常抓取动态页面。所以在写的时候一定要注意,可以专门写到搜索文件的名字。例如,如果您的站点是 search.asp? 后面的一个长列表,那么您可以这样写:
禁止:/search.asp?*
这样就可以屏蔽搜索结果页面。写完之后可以在百度站长平台上查看robots,看看有没有错误!您可以输入 URL 来检查它是否正常工作。
在这里,吴晓阳建议动态网站的站长一定要用robots文件来屏蔽不重要的内容动态链接,提高蜘蛛的抓取效率!
本文来源:吴晓阳目录 查看全部
动态网页抓取(
robots协议(也称为爬虫协议、机器人协议等)的全称)
动态网站不用担心,搜索引擎可以正常抓取动态链接,但是使用robots文件可以轻松提高动态网站的抓取效率。我们都知道robots协议(也叫爬虫协议、机器人协议等)的全称是“Robots Exclusion Protocol”。网站 告诉搜索引擎哪些页面可以爬取,哪些页面通过Robots 协议爬取。无法抓取该页面。Robots协议的本质是网站与搜索引擎爬虫之间的通信方式,用于引导搜索引擎更好地抓取网站的内容。
百度官方建议所有网站使用robots文件,以更好地利用蜘蛛爬行。实际上,robots 不仅是告诉搜索引擎哪些不能抓取,也是网站优化的重要工具之一。
robots文件实际上是一个txt文件。基本措辞如下:
User-agent: * 其中*代表所有类型的搜索引擎,*是通配符
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /require/ 这里的定义是禁止爬取require目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
禁止:/cgi-bin/*.htm 禁止访问 /cgi-bin/ 目录中所有后缀为“.htm”的 URL(包括子目录)。
Disallow: /*?* 禁止访问 网站 中的所有动态页面
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
在网站优化方面,robots文件用于告诉搜索引擎什么是重要的内容,推荐robots文件禁止爬取不重要的内容。不重要内容的典型代表:网站的搜索结果页。
对于静态网站,我们可以使用Disallow: /*?* 来禁止动态页面爬取。但是对于动态网站,你不能简单地做到这一点。不过对于动态网站的站长来说,就不用太担心了。搜索引擎现在可以正常抓取动态页面。所以在写的时候一定要注意,可以专门写到搜索文件的名字。例如,如果您的站点是 search.asp? 后面的一个长列表,那么您可以这样写:
禁止:/search.asp?*
这样就可以屏蔽搜索结果页面。写完之后可以在百度站长平台上查看robots,看看有没有错误!您可以输入 URL 来检查它是否正常工作。
在这里,吴晓阳建议动态网站的站长一定要用robots文件来屏蔽不重要的内容动态链接,提高蜘蛛的抓取效率!
本文来源:吴晓阳目录
动态网页抓取(2020年7月29日写在前面:右键打开源码找到iframe标签 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-10 15:07
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin:18、PageCond/length:6个类似的参数,很明显网站就是根据这个参数加载了相关数据。和post请求一起发送到网站,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData) 查看全部
动态网页抓取(2020年7月29日写在前面:右键打开源码找到iframe标签
)
时间:2020年7月29日
写在前面:本文仅供参考和学习,请勿用于其他用途。
1.嵌入式网络爬虫
示例:最常见的分页页面
这里我以天津的请愿页面为例,(地址:)。
右键打开源码找到iframe标签,取出里面的src地址
在src地址输入页面后不要停留在首页。主页网址通常比较特殊,无法分析。我们需要输入主页以外的任何地址。
进入第二个页面,我们可以找到页面中的规则,只需要改变curpage后的数字就可以切换到不同的页面,这样我们只需要一个循环就可以得到所有数据页面的地址,然后就可以了发送获取请求以获取数据。
2.JS加载网页抓取
示例:一些动态网页不使用网页嵌入,而是选择JS加载
这里我举一个北京请愿页面的例子()
We will find that when a different page is selected, the URL will not change, which is the same as the embedded page mentioned above.
右键打开源码,并没有找到iframe、html等内嵌页面的图标标签,但是不难发现放置数据的div里面有一个id,就是JS加载处理的明显标识。现在进入控制台的网络
执行一次页面跳转(我跳转到第3页),注意控制台左侧新出现的文件JS,在里面找到加载新数据的JS文件。打开会发现PageCond/begin:18、PageCond/length:6个类似的参数,很明显网站就是根据这个参数加载了相关数据。和post请求一起发送到网站,就可以得到我们想要的数据了。.
payloadData ={
"PageCond/begin": (i-1)*6,
"PageCond/length": 6,
"PageCond/isCount": "false",
"keywords": "",
"orgids": "",
"startDat e": "",
"endDate": "",
"letterType": "",
"letterStatue": ""}
dumpJsonData = json.dumps(payloadData)
headers = {"Host": "www.beijing.gov.cn",
"Origin": "http://www.beijing.gov.cn",
"Referer": "http://www.beijing.gov.cn/hudong/hdjl/",
"User-Agent": str(UserAgent().random)#,
}
req = requests.post(url,headers=headers,data=payloadData)
动态网页抓取(动态加载的网页不可以直接通过geturl的方式获取到网页内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-09 23:05
)
对于一些静态的网站,只要requests.get('url')就可以得到页面的所有内容,比如链家用pg做页面,rs做关键字,%E8%99%B9 %E5%8F%A3 /
但是对于一些动态加载的网页,不能直接通过get url获取网页内容
一、阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),是指一种网页开发技术,可以创建交互式、快速和动态的网页应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。
jax 技术的核心是 XMLHttpRequest 对象(简称 XHR),这是微软首先引入的一个特性,后来其他浏览器提供商也提供了相同的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
二、查看网页上的实际信息
点击元素勾选-network-XRH(Firefox有时在JS中)
比如在QQ音乐中查看歌名列表,
三、 使用爬虫爬取信息
找到真实的请求信息(请求URL、提交的表单)后,在scrapy中只要需要下面的代码就可以实现爬取。请求方法 post 或 get 取决于 网站 的情况
def start_requests(self):
try:
ses = requests.session() # 获取session
ses.get(url=self.url, headers=self.headers)
cookie_start = ses.cookies # 为此次获取的cookies
cookie_start=requests.utils.dict_from_cookiejar(cookie_start)
# print("page:{} 首页cookie获取suc...".format(self.pn))
except:
print("page:{} 首页cookie获取异常...".format(self.pn ))
yield scrapy.FormRequest(url=self.url_start
, formdata={'first': 'True', 'pn': str(self.pn), 'kd':self.kd}
, method='Post'
, headers=self.headers
, cookies=cookie_start
, encoding='utf-8'
, dont_filter=True
, meta={'pn': str(self.pn),'kd': self.kd}
, callback=self.parse
) 查看全部
动态网页抓取(动态加载的网页不可以直接通过geturl的方式获取到网页内容
)
对于一些静态的网站,只要requests.get('url')就可以得到页面的所有内容,比如链家用pg做页面,rs做关键字,%E8%99%B9 %E5%8F%A3 /
但是对于一些动态加载的网页,不能直接通过get url获取网页内容
一、阿贾克斯
Ajax 代表“AsynchronousJavascriptAndXML”(异步 JavaScript 和 XML),是指一种网页开发技术,可以创建交互式、快速和动态的网页应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。
jax 技术的核心是 XMLHttpRequest 对象(简称 XHR),这是微软首先引入的一个特性,后来其他浏览器提供商也提供了相同的实现。XHR 为向服务器发送请求和解析服务器响应提供了流畅的接口。它可以异步的方式从服务器获取更多的信息,这意味着用户点击后,无需刷新页面即可获取新的数据。
二、查看网页上的实际信息
点击元素勾选-network-XRH(Firefox有时在JS中)
比如在QQ音乐中查看歌名列表,
三、 使用爬虫爬取信息
找到真实的请求信息(请求URL、提交的表单)后,在scrapy中只要需要下面的代码就可以实现爬取。请求方法 post 或 get 取决于 网站 的情况
def start_requests(self):
try:
ses = requests.session() # 获取session
ses.get(url=self.url, headers=self.headers)
cookie_start = ses.cookies # 为此次获取的cookies
cookie_start=requests.utils.dict_from_cookiejar(cookie_start)
# print("page:{} 首页cookie获取suc...".format(self.pn))
except:
print("page:{} 首页cookie获取异常...".format(self.pn ))
yield scrapy.FormRequest(url=self.url_start
, formdata={'first': 'True', 'pn': str(self.pn), 'kd':self.kd}
, method='Post'
, headers=self.headers
, cookies=cookie_start
, encoding='utf-8'
, dont_filter=True
, meta={'pn': str(self.pn),'kd': self.kd}
, callback=self.parse
)
动态网页抓取(可以把动态网站网页定时生成HTML的工具,排除软件假死现象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-09 21:22
动态网页静态是一种可以定期从动态网站网页生成HTML的工具。可在用户设定的时间内自动生成HTML静态页面,支持设置和存储静态页面地址、自动循环生成等功能。
软件特点
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。
所需的ASP,。NET、PHP 等动态网页自动生成 HTML 页面。
软件功能
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。 查看全部
动态网页抓取(可以把动态网站网页定时生成HTML的工具,排除软件假死现象)
动态网页静态是一种可以定期从动态网站网页生成HTML的工具。可在用户设定的时间内自动生成HTML静态页面,支持设置和存储静态页面地址、自动循环生成等功能。
软件特点
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。
所需的ASP,。NET、PHP 等动态网页自动生成 HTML 页面。
软件功能
可以生成任何网页!优化软件核心文件,消除软件假死现象!生成间隔可以自定义。一个地址可以同时生成多个不同后缀的文件,并且可以定时刷新生成多个静态文件。
动态网页和静态是两个概念。比如index.php(动态)index.html(静态)。动态是需要连接到服务器端。静态是客户端。当用户访问静态页面时,它不会从服务器请求更改任何内容的事件。从动态到静态的转换意味着快速显示大量信息。如果使用动态,则加载速度较慢。如果用户太多,服务器就会卡住。用户将等待很长时间。和现在的优酷一样,爱奇艺是生成的静态网页。
动态网页抓取(动态网页是基本的语法规范与html代码生成的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-07 03:09
1、简介 所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。值得强调的是,不要将动态网页与页面内容是否动态混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是特定的网页。内容的呈现形式,无论网页是否具有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。总之,动态网页是基本的html语法规范和高级编程语言如Java、VB、VC、数据库编程等技术的融合,以实现高效、动态、交互的内容和风格网站 管理。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。从网站浏览者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但从网站的角度来看 开发、管理、维护大不同。早期的动态网页主要使用通用网关接口(CGI)技术。
您可以使用不同的程序来编写合适的 CGI 程序,例如 Visual Basic、Delphi 或 C/C++。CGI技术虽然已经发展成熟、功能强大,但由于编程困难、效率低、修改复杂,有逐渐被新技术取代的趋势。对应静态网页,可以与后端数据库交互,传输数据。也就是说,网页URL的后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页创建格式,而是.aspx、.asp、.jsp、. php,.perl,。cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visual studio2008等实现,2、的特点简单总结如下:(1) 动态网页一般基于数据库技术,可以大大减少网站维护的工作量;(2)动态网页技术网站可以实现的功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页是实际上并不是服务器上独立存在的网页文件,只有当用户请求时服务器才返回一个完整的网页;(4)动态网页中的“?”对搜索引擎检索有一定的问题,并且搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索不抓取URL中“?”后的内容。因此,网站 使用动态网页需要做一定的技术处理以适应搜索引擎推广。搜索引擎要求。 查看全部
动态网页抓取(动态网页是基本的语法规范与html代码生成的)
1、简介 所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果基本不会发生变化——除非你修改页面代码。这不是动态网页的情况。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。值得强调的是,不要将动态网页与页面内容是否动态混淆。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是特定的网页。内容的呈现形式,无论网页是否具有动态效果,只要是使用动态网站技术生成的网页,都可以称为动态网页。总之,动态网页是基本的html语法规范和高级编程语言如Java、VB、VC、数据库编程等技术的融合,以实现高效、动态、交互的内容和风格网站 管理。因此,从这个意义上说,所有结合HTML以外的高级编程语言和数据库技术的网页编程技术生成的网页都是动态网页。从网站浏览者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但从网站的角度来看 开发、管理、维护大不同。早期的动态网页主要使用通用网关接口(CGI)技术。
您可以使用不同的程序来编写合适的 CGI 程序,例如 Visual Basic、Delphi 或 C/C++。CGI技术虽然已经发展成熟、功能强大,但由于编程困难、效率低、修改复杂,有逐渐被新技术取代的趋势。对应静态网页,可以与后端数据库交互,传输数据。也就是说,网页URL的后缀不是.htm、.html、.shtml、.xml等静态网页常见的动态网页创建格式,而是.aspx、.asp、.jsp、. php,.perl,。cgi等形式都是后缀,还有一个标志性的符号——“?” 在动态网页 URL 中。动态网页可以用visual studio2008等实现,2、的特点简单总结如下:(1) 动态网页一般基于数据库技术,可以大大减少网站维护的工作量;(2)动态网页技术网站可以实现的功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页是实际上并不是服务器上独立存在的网页文件,只有当用户请求时服务器才返回一个完整的网页;(4)动态网页中的“?”对搜索引擎检索有一定的问题,并且搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索不抓取URL中“?”后的内容。因此,网站 使用动态网页需要做一定的技术处理以适应搜索引擎推广。搜索引擎要求。
动态网页抓取((网络营销教学网站2005-02-26)动态网页的一般特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-06 23:13
(网络营销教学网站2005-02-26)
动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。例如,当当网书店《网络营销基础与实战》第二版的详细介绍页面网址为:
这是一个典型的动态网页 URL 表单。
这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
如果想了解更多动态网页的搜索引擎优化,可以参考作者对网络营销的新观察网站搜索引擎营销专题文章。 查看全部
动态网页抓取((网络营销教学网站2005-02-26)动态网页的一般特点)
(网络营销教学网站2005-02-26)
动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。例如,当当网书店《网络营销基础与实战》第二版的详细介绍页面网址为:
这是一个典型的动态网页 URL 表单。
这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
如果想了解更多动态网页的搜索引擎优化,可以参考作者对网络营销的新观察网站搜索引擎营销专题文章。
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-06 09:15
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来济宁网站建设技术小编就来聊聊动态页面优化的SEO方法:
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
济宁网站建设科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容,您可以在本站阅读其他SEO优化技巧和经验,相信您一定会有所收获。 查看全部
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则及方法)
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,接下来济宁网站建设技术小编就来聊聊动态页面优化的SEO方法:
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
济宁网站建设科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。更多SEO优化内容,您可以在本站阅读其他SEO优化技巧和经验,相信您一定会有所收获。
动态网页抓取(动态网页的特点及特点总结-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-06 06:09
动态网页是指虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。从网站查看者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但是从网站的开发、管理和维护的角度来看,有很大的不同。但是,动态网站是动态网页的集合,其内容可以根据不同情况动态变化。通常,动态网站是通过数据库构造的。
动态网页的特点总结
1、动态网页基于数据库技术,可以大大减少网站维护的工作量,但是动态网站的访问速度大大减慢。
2、 采用动态网页技术网站可以实现更多的交互功能,如用户注册、用户登录、在线调查、用户管理、订单管理等,后台动态页面管理可以更方便的更新内容以后,即使没有编程技能,也可以轻松管理网站。
3、动态网页实际上并不是独立存在于服务器上的网页文件。服务器仅在用户请求时返回完整的网页。
4、搜索引擎检索不抓取“?”后的内容 在网址中。因此,具有动态网页的网站在被搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的需求。
5、动态网页收录服务器端脚本,因此页面文件名常以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断动态和静态网站的唯一标准。
6、由于代码特殊,动态网页不像静态网页那样对搜索引擎友好。但是如果做URL静态技术处理也是可以的。
总结:动态网站服务器空间配置比静态网页要求更高,成本也相应高。但是动态网页有利于更新网站的内容,适合企业搭建网站。随着计算机性能的提升和网络带宽的增加,网站访问速度和静态处理已经基本解决。最重要的是基本都是使用动态网站,然后静态处理URL,也就是所谓的伪静态。
结尾 查看全部
动态网页抓取(动态网页的特点及特点总结-上海怡健医学())
动态网页是指虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。从网站查看者的角度来看,动态和静态网页都可以显示基本的文字和图片信息,但是从网站的开发、管理和维护的角度来看,有很大的不同。但是,动态网站是动态网页的集合,其内容可以根据不同情况动态变化。通常,动态网站是通过数据库构造的。
动态网页的特点总结
1、动态网页基于数据库技术,可以大大减少网站维护的工作量,但是动态网站的访问速度大大减慢。
2、 采用动态网页技术网站可以实现更多的交互功能,如用户注册、用户登录、在线调查、用户管理、订单管理等,后台动态页面管理可以更方便的更新内容以后,即使没有编程技能,也可以轻松管理网站。
3、动态网页实际上并不是独立存在于服务器上的网页文件。服务器仅在用户请求时返回完整的网页。
4、搜索引擎检索不抓取“?”后的内容 在网址中。因此,具有动态网页的网站在被搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的需求。
5、动态网页收录服务器端脚本,因此页面文件名常以asp、jsp、php等为后缀。但是您也可以使用 URL 静态技术将网页后缀显示为 HTML。因此,不能以页面文件的后缀作为判断动态和静态网站的唯一标准。
6、由于代码特殊,动态网页不像静态网页那样对搜索引擎友好。但是如果做URL静态技术处理也是可以的。
总结:动态网站服务器空间配置比静态网页要求更高,成本也相应高。但是动态网页有利于更新网站的内容,适合企业搭建网站。随着计算机性能的提升和网络带宽的增加,网站访问速度和静态处理已经基本解决。最重要的是基本都是使用动态网站,然后静态处理URL,也就是所谓的伪静态。
结尾
动态网页抓取(网站SEO优化如何优化动态网站呢?静态页面好还是动态页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-06 06:09
网站优化已经是众所周知的技术了,但是有些企业在优化网站的时候总是会忘记一些细节,但是一些细节会在后期的优化中暴露出很大的问题,从而影响企业对网站的排名@>,如网站的动态和静态网站。很多公司怕麻烦,直接用动态,导致搜索引擎拖慢了网站动态页面的爬取时间。那么,网站SEO优化如何优化动态网站?
静态页面更好还是动态页面更好?
1、静态网页优化
从网站的发展和百度搜索引擎的整体规律来看,静态网页是相当不错的,因为静态网页是由一个完整的代码组成的,没有固定的内容,然后会有相应的url,一个对应的URL只有一个对应的页面,所以这种方法更有利于新手公司的seo优化。
2、动态网页优化
动态网页最大的问题是通过代码生成,没有固定的网址。在这种情况下,通过 SEO 更好地优化静态网页是很自然的。但是,大范围推荐网站的智能动态网页,给人一种很高端的感觉。所以,这类网页如果针对SEO进行优化,也能给用户带来不错的体验。
如何优化动态网站
1、 合理的网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感,尤其是“&”。还有一点就是尽量不要在URL中收录中文字符,因为浏览器对URL很敏感。URL中的中文是经过编码的。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。
2、页面 CGI/ Perl
网站页面使用CGI或Perl。您可以使用脚本提取环境变量之前的所有字符,然后将 URL 中剩余的字符分配给一个变量。您可以在 URL 中使用此变量。但是,所有主要搜索引擎都可以为具有内置部门 SSI 内容的网页提供索引支持。带有后缀的网页也被解析成SSI文件,相当于普通的html文件。但是,这些网页在其 URL 中使用 cgi-bin 路径,并且它们可能不会被搜索引擎索引。
3、构建静态导入
在“动静联动,静制动”的原则指导下,还可以对网站进行一些改动。百度排名优化可以尽可能提高网页搜索引擎的知名度。例如,将网页编译为静态主页或站点地图的链接,并以静态目录的形式呈现动态页面。或者为动态页面设置专门的静态导入页面,链接到动态页面,然后将静态导入页面提交给搜索引擎。一些内容相对固定的重要页面被构造为静态页面,如丰富的关键词介绍、用户帮助、重要页面链接的地图等。
以上内容供大家分享(网站SEO优化如何优化动态网站)还有很多公司在使用动态页面。动态页面虽然可以被搜索引擎抓取,但是抓取速度不如静态网站。
(主编:搜索引擎网站优化SEO外包-,原创不容易,作者、原创出处及本声明转载时必须以链接形式注明。 ) 查看全部
动态网页抓取(网站SEO优化如何优化动态网站呢?静态页面好还是动态页面)
网站优化已经是众所周知的技术了,但是有些企业在优化网站的时候总是会忘记一些细节,但是一些细节会在后期的优化中暴露出很大的问题,从而影响企业对网站的排名@>,如网站的动态和静态网站。很多公司怕麻烦,直接用动态,导致搜索引擎拖慢了网站动态页面的爬取时间。那么,网站SEO优化如何优化动态网站?
静态页面更好还是动态页面更好?
1、静态网页优化
从网站的发展和百度搜索引擎的整体规律来看,静态网页是相当不错的,因为静态网页是由一个完整的代码组成的,没有固定的内容,然后会有相应的url,一个对应的URL只有一个对应的页面,所以这种方法更有利于新手公司的seo优化。
2、动态网页优化
动态网页最大的问题是通过代码生成,没有固定的网址。在这种情况下,通过 SEO 更好地优化静态网页是很自然的。但是,大范围推荐网站的智能动态网页,给人一种很高端的感觉。所以,这类网页如果针对SEO进行优化,也能给用户带来不错的体验。
如何优化动态网站
1、 合理的网址
搜索引擎之所以难以检索到动态网页,是因为它们对网址中的特殊字符不敏感,尤其是“&”。还有一点就是尽量不要在URL中收录中文字符,因为浏览器对URL很敏感。URL中的中文是经过编码的。如果网址中汉字过多,编码后网址会很长,这对搜索引擎检索页面非常不利。
2、页面 CGI/ Perl
网站页面使用CGI或Perl。您可以使用脚本提取环境变量之前的所有字符,然后将 URL 中剩余的字符分配给一个变量。您可以在 URL 中使用此变量。但是,所有主要搜索引擎都可以为具有内置部门 SSI 内容的网页提供索引支持。带有后缀的网页也被解析成SSI文件,相当于普通的html文件。但是,这些网页在其 URL 中使用 cgi-bin 路径,并且它们可能不会被搜索引擎索引。
3、构建静态导入
在“动静联动,静制动”的原则指导下,还可以对网站进行一些改动。百度排名优化可以尽可能提高网页搜索引擎的知名度。例如,将网页编译为静态主页或站点地图的链接,并以静态目录的形式呈现动态页面。或者为动态页面设置专门的静态导入页面,链接到动态页面,然后将静态导入页面提交给搜索引擎。一些内容相对固定的重要页面被构造为静态页面,如丰富的关键词介绍、用户帮助、重要页面链接的地图等。
以上内容供大家分享(网站SEO优化如何优化动态网站)还有很多公司在使用动态页面。动态页面虽然可以被搜索引擎抓取,但是抓取速度不如静态网站。
(主编:搜索引擎网站优化SEO外包-,原创不容易,作者、原创出处及本声明转载时必须以链接形式注明。 )
动态网页抓取(我对如何从此网页抓取数据有疑问(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-05 12:09
我有一个关于如何从此页面抓取数据的问题:
://&版本=1.11.2
好像还留在iframe里,屏幕上有很多JavaScript。
每当我尝试采集保存在 iframe 下的 span 或 div 或 tr 标签中的元素时,我似乎无法采集其中的数据。
我的目标是将内部文本保存在 class="pane-legend-item-value panel-legend-line main" 元素中。
显然,文本会根据光标在特定时间在屏幕上的位置而变化。所以我试图做的是设置一个已经加载页面并将光标放置在正确位置的 IE,在图表的末尾(为我提供最后一个数据点),您可以将光标移出屏幕,然后然后我写了一些简单的代码来获取IE窗口,然后尝试了GetElements,但是此时却无法获取任何数据。
到目前为止,这是我的代码,当我阅读更多选项时,它一直很粗糙,因为我一直在尝试编辑,但没有任何成功:(...任何想法或帮助将不胜感激!底部)
Sub InvestingCom()
Dim IE As InternetExplorer
Dim htmldoc As MSHTML.IHTMLDocument 'Document object
Dim eleColth As MSHTML.IHTMLElementCollection 'Element collection for th tags
Dim eleColtr As MSHTML.IHTMLElementCollection 'Element collection for tr tags
Dim eleColtd As MSHTML.IHTMLElementCollection 'Element collection for td tags
Dim eleRow As MSHTML.IHTMLElement 'Row elements
Dim eleCol As MSHTML.IHTMLElement 'Column elements
Dim elehr As MSHTML.IHTMLElement 'Header Element
Dim iframeDoc As MSHTML.HTMLDocument
Dim frame As HTMLIFrame
Dim ieURL As String 'URL
'Take Control of Open IE
marker = 0
Set objShell = CreateObject("Shell.Application")
IE_count = objShell.Windows.Count
For x = 0 To (IE_count - 1)
On Error Resume Next
my_url = objShell.Windows(x).document.Location
my_title = objShell.Windows(x).document.Title
If my_title Like "*" & "*" Then 'compare to find if the desired web page is already open
Set IE = objShell.Windows(x)
marker = 1
Exit For
Else
End If
Next
'Extract data
Set htmldoc = IE.document 'Document webpage
' I have tried span, tr, td etc tags and various other options
' I have never actually tried collecting an HTMLFrame but googled it however was unsuccessful
End Sub
Excel 可以在另一个屏幕上打开并打开 excel 和 VB。IE截图,我要抓取的数据可以找找聊聊
最佳答案
我真的很难处理这个页面中的两个嵌套iframe来采集所需的内容。但无论如何,我终于修好了。运行以下代码并获得您所要求的内容:
Sub forexpros()
Dim IE As New InternetExplorer, html As HTMLDocument
Dim frm As Object, frmano As Object, post As Object
With IE
.Visible = True
.navigate "http://tvc4.forexpros.com/init ... ot%3B
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set frm = .document.getElementsByClassName("abs") ''this is the first iframe
.navigate frm(0).src
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set html = .document
End With
Set frmano = html.getElementsByTagName("iframe")(0).contentWindow.document ''this is the second iframe
For Each post In frmano.getElementsByClassName("pane-legend-item-value pane-legend-line main")
Debug.Print post.innerText
Next post
IE.Quit
End Sub
关于javascript-VBA动态网页爬取Excel,我们在Stack Overflow上发现了一个类似的问题: 查看全部
动态网页抓取(我对如何从此网页抓取数据有疑问(1)(图))
我有一个关于如何从此页面抓取数据的问题:
://&版本=1.11.2
好像还留在iframe里,屏幕上有很多JavaScript。
每当我尝试采集保存在 iframe 下的 span 或 div 或 tr 标签中的元素时,我似乎无法采集其中的数据。
我的目标是将内部文本保存在 class="pane-legend-item-value panel-legend-line main" 元素中。
显然,文本会根据光标在特定时间在屏幕上的位置而变化。所以我试图做的是设置一个已经加载页面并将光标放置在正确位置的 IE,在图表的末尾(为我提供最后一个数据点),您可以将光标移出屏幕,然后然后我写了一些简单的代码来获取IE窗口,然后尝试了GetElements,但是此时却无法获取任何数据。
到目前为止,这是我的代码,当我阅读更多选项时,它一直很粗糙,因为我一直在尝试编辑,但没有任何成功:(...任何想法或帮助将不胜感激!底部)
Sub InvestingCom()
Dim IE As InternetExplorer
Dim htmldoc As MSHTML.IHTMLDocument 'Document object
Dim eleColth As MSHTML.IHTMLElementCollection 'Element collection for th tags
Dim eleColtr As MSHTML.IHTMLElementCollection 'Element collection for tr tags
Dim eleColtd As MSHTML.IHTMLElementCollection 'Element collection for td tags
Dim eleRow As MSHTML.IHTMLElement 'Row elements
Dim eleCol As MSHTML.IHTMLElement 'Column elements
Dim elehr As MSHTML.IHTMLElement 'Header Element
Dim iframeDoc As MSHTML.HTMLDocument
Dim frame As HTMLIFrame
Dim ieURL As String 'URL
'Take Control of Open IE
marker = 0
Set objShell = CreateObject("Shell.Application")
IE_count = objShell.Windows.Count
For x = 0 To (IE_count - 1)
On Error Resume Next
my_url = objShell.Windows(x).document.Location
my_title = objShell.Windows(x).document.Title
If my_title Like "*" & "*" Then 'compare to find if the desired web page is already open
Set IE = objShell.Windows(x)
marker = 1
Exit For
Else
End If
Next
'Extract data
Set htmldoc = IE.document 'Document webpage
' I have tried span, tr, td etc tags and various other options
' I have never actually tried collecting an HTMLFrame but googled it however was unsuccessful
End Sub
Excel 可以在另一个屏幕上打开并打开 excel 和 VB。IE截图,我要抓取的数据可以找找聊聊
最佳答案
我真的很难处理这个页面中的两个嵌套iframe来采集所需的内容。但无论如何,我终于修好了。运行以下代码并获得您所要求的内容:
Sub forexpros()
Dim IE As New InternetExplorer, html As HTMLDocument
Dim frm As Object, frmano As Object, post As Object
With IE
.Visible = True
.navigate "http://tvc4.forexpros.com/init ... ot%3B
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set frm = .document.getElementsByClassName("abs") ''this is the first iframe
.navigate frm(0).src
Do Until .readyState = READYSTATE_COMPLETE: Loop
Application.Wait (Now + TimeValue("0:00:05"))
Set html = .document
End With
Set frmano = html.getElementsByTagName("iframe")(0).contentWindow.document ''this is the second iframe
For Each post In frmano.getElementsByClassName("pane-legend-item-value pane-legend-line main")
Debug.Print post.innerText
Next post
IE.Quit
End Sub
关于javascript-VBA动态网页爬取Excel,我们在Stack Overflow上发现了一个类似的问题:
动态网页抓取(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-04 19:07
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对动态网页结构做任何事情,比如ajax异步加载。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。因为 Selenium 是一个 Java 程序,所以在使用 RSelenium 包和 Rwebdriver 包之前,您必须为您的计算机设置一个 Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;
(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,
然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,
(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意值前面的两个符号。;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.
(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、 至此所有的前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr 查看全部
动态网页抓取(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对动态网页结构做任何事情,比如ajax异步加载。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。因为 Selenium 是一个 Java 程序,所以在使用 RSelenium 包和 Rwebdriver 包之前,您必须为您的计算机设置一个 Java 环境。下面是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;
(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,
然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,
(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意值前面的两个符号。;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.
(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、 至此所有的前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-04 03:03
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,云无羡科技小编就来聊聊SEO动态页面如何优化:
文章来源于【“收录之家”快排系统任务发布平台】。
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
云无羡科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。您可以获得更多 SEO 优化的内容。阅读本站其他SEO优化技巧和经验,相信你会收获很多。 查看全部
动态网页抓取(企业想做好网站SEO优化就要了解搜索引擎的抓取规则)
企业要做网站SEO优化,需要了解搜索引擎的爬取规则,做好百度动态页面SEO。相信大家都知道,搜索引擎抓取动态页面是非常困难的。是的,云无羡科技小编就来聊聊SEO动态页面如何优化:
文章来源于【“收录之家”快排系统任务发布平台】。
一、创建一个静态条目
在“动静结合,静制动”的原则指导下,可以对网站做一些修改,尽可能增加动态网页在搜索引擎中的可见度。将动态网页编译成静态首页或网站地图的链接,以静态目录的形式呈现动态网页等SEO优化方法。或者为动态页面创建一个专门的静态入口页面,链接到动态页面,将静态入口页面提交给搜索引擎。
二、付费登录搜索引擎
对于连接数据库的内容管理系统发布的整个网站动态网站,最直接的优化SEO的方式就是付费登录。建议将动态网页直接提交到搜索引擎目录或做关键词广告,保证被搜索引擎网站收录。
三、搜索引擎支持改进
搜索引擎一直在改进对动态页面的支持,但是这些搜索引擎在抓取动态页面时,为了避免搜索机器人的陷阱,搜索引擎只抓取静态页面链接的动态页面,动态页面链接的链接。不再抓取动态页面,这意味着不会对动态页面中的链接进行深入访问。
云无羡科技小编为大家整理的SEO优化动态页面的方法和内容相信大家已经有了一定的了解。事实上,编辑器对每个人来说都不够全面。您可以获得更多 SEO 优化的内容。阅读本站其他SEO优化技巧和经验,相信你会收获很多。
动态网页抓取(localhost:8080代表IP:端口:资源请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-03 15:09
localhost:8080 代表IP:端口
xxxx:资源请求地址
4.Tomcat(网络服务器)
网络逻辑
Ngnix
树脂
5.Tomcat:Web 服务器,JSP/Servlet 容器
目录介绍:
/bin 存放各种平台下用于启动和停止Tomcat的脚本文件
/conf 存放Tomcat服务器的各种配置文件
/lib 存放Tomcat服务器所需的各种JAR文件
/logs 存放Tomcat日志文件
/temp Tomcat运行时用来存放临时文件
/webapps 发布web应用时,web应用的文件默认会存放在这个目录中
/work Tomcat把JSP生成的Servlet放在这个目录下
启动方法:
/bin 目录:startup.bat 启动脚本 shutdown.bat 停止脚本
如果遇到崩溃问题,在以上两个文件中添加如下代码:
SET JAVA_HOME=D:\Java\jdk1.7(java jdk目录)
SET TOMCAT_HOME=E:\tomcat-7.0(解压tomcat文件目录)
配置环境变量:
添加一个系统变量,名称为CATALINA_HOME,值为Tomcat的安装目录,在Path系统变量中添加一个%CATALINA_HOME%\bin
6.网络项目:
在Eclipse环境下新建一个Dynamic web项目--->Target Runntime代表启动的web服务器----->Dynamic Web模型版本代表项目版本(3.0)- --> 点击下一步直到
---->Generate web.xml xxxxx 勾选,这样WEB-INFO文件夹下就有web.xml文件
web.xml文件是web项目的配置文件,其中welcome-file-list代表第一次访问的页面集合,welcome-file代表第一次访问的页面
目录结构:
/ web应用的根目录,该目录下的所有文件都可以在客户端访问(JSP、HTML等)
/WEB-INF 存储应用程序使用的各种资源。客户无法访问该目录及其子目录
/WEB-INF/classes 存放了 Web 项目的所有类文件
/WEB-INF/lib 存储 Web 应用程序使用的 JAR 文件
7.JSP页面:Java Server Pages(可以嵌入Java代码)所有JSP页面最终都会被WEB容器自动写入.Java文件并编译成.class文件
作文内容:
页面命令:
属性描述默认值
language 指定 JSP 页面 java 使用的脚本语言
import 使用此属性来引用脚本语言中使用的类文件。无
contentType 用于指定 JSP 页面 text/html 使用的编码方式,ISO-8859-1
小脚本:
表达: 查看全部
动态网页抓取(localhost:8080代表IP:端口:资源请求地址)
localhost:8080 代表IP:端口
xxxx:资源请求地址
4.Tomcat(网络服务器)
网络逻辑
Ngnix
树脂
5.Tomcat:Web 服务器,JSP/Servlet 容器
目录介绍:
/bin 存放各种平台下用于启动和停止Tomcat的脚本文件
/conf 存放Tomcat服务器的各种配置文件
/lib 存放Tomcat服务器所需的各种JAR文件
/logs 存放Tomcat日志文件
/temp Tomcat运行时用来存放临时文件
/webapps 发布web应用时,web应用的文件默认会存放在这个目录中
/work Tomcat把JSP生成的Servlet放在这个目录下
启动方法:
/bin 目录:startup.bat 启动脚本 shutdown.bat 停止脚本
如果遇到崩溃问题,在以上两个文件中添加如下代码:
SET JAVA_HOME=D:\Java\jdk1.7(java jdk目录)
SET TOMCAT_HOME=E:\tomcat-7.0(解压tomcat文件目录)
配置环境变量:
添加一个系统变量,名称为CATALINA_HOME,值为Tomcat的安装目录,在Path系统变量中添加一个%CATALINA_HOME%\bin
6.网络项目:
在Eclipse环境下新建一个Dynamic web项目--->Target Runntime代表启动的web服务器----->Dynamic Web模型版本代表项目版本(3.0)- --> 点击下一步直到
---->Generate web.xml xxxxx 勾选,这样WEB-INFO文件夹下就有web.xml文件
web.xml文件是web项目的配置文件,其中welcome-file-list代表第一次访问的页面集合,welcome-file代表第一次访问的页面
目录结构:
/ web应用的根目录,该目录下的所有文件都可以在客户端访问(JSP、HTML等)
/WEB-INF 存储应用程序使用的各种资源。客户无法访问该目录及其子目录
/WEB-INF/classes 存放了 Web 项目的所有类文件
/WEB-INF/lib 存储 Web 应用程序使用的 JAR 文件
7.JSP页面:Java Server Pages(可以嵌入Java代码)所有JSP页面最终都会被WEB容器自动写入.Java文件并编译成.class文件
作文内容:
页面命令:
属性描述默认值
language 指定 JSP 页面 java 使用的脚本语言
import 使用此属性来引用脚本语言中使用的类文件。无
contentType 用于指定 JSP 页面 text/html 使用的编码方式,ISO-8859-1
小脚本:
表达:
动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-02 04:18
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架分析完成后,就可以进行相关定位,得到元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素
以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。在显示网页时直接使用浏览器解析 HTML,应用 CSS 样式并执行 JavaScript 语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用 Python 的 Selenium 库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据就是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector 使用CSS选择器查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架分析完成后,就可以进行相关定位,得到元素了。
我们上面只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加元素
以上获得的所有评论数据均属于网页的正常访问。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
动态网页抓取(网页源代码获取单节点的方法和常见的用法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-02 03:29
Selenium 支持多种浏览器:Chrome、Firefox、Edge 等,还支持Android、BlackBerry 等手机浏览器,还支持非接口浏览器PhantomJS。
初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
4. 访问页面
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
print(browser.page_source) //打印源码
browser.close()
5.查找节点
Selenium 可以驱动浏览器完成各种操作,比如填表、模拟点击等。比如我们要在输入框中输入文本,就必须知道输入框的位置,对吧?别着急,selenium 提供了一系列查找节点的方法。
先看网页源码
如何获取单个节点:
此外,Selenium 还提供了通用方法:
find_element(By.ID, id) 等价于 find_element_by_id(id)
如何获得多个节点:
此外,Selenium 还提供了通用方法:
find_elements(By.ID, id) 等价于 find_elements_by_id(id)
注:单节点和多节点是单复数形式的区别。
6. 节点交互
Selenium 驱动浏览器执行一些操作。其实就是让浏览器模拟并执行一些动作。常见用法有:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
input = browser.find_element_by_id('q') //通过输入框的id,找到输入框(不一定能找到,淘宝的源代码可能更新了)
input.send_keys('iPhone') //在输入框内输入iPhone
time.sleep(1)
input.clear() //清空输入框内容
input.send_keys('Ipad')
button = browser.find_element_by_class_name('btn-search') //查找“搜索”按钮(不一定能找到,淘宝的源代码可能更新了)
button.click()
可以参考官方文档:#module-selenium.webdriver.remote.webelement
7.动作链
上面的例子是针对某个节点执行的,其他一些操作没有具体的执行对象,比如鼠标拖拽、键盘按键等,这些动作是通过另一种方式执行的,也就是动作链。
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source,target)
actions.perform()
操作结果:
可以参考官方文档:#mon.action_chains
8. 执行 JavaScript
对于某些操作,不提供 selenium API。比如下拉进度条,可以直接模拟运行JS,本例使用execute_script()方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
通过这种方式,基本上所有API没有提供的功能都可以通过执行JS来实现。
9. 获取节点信息
在前面的代码中,可以通过page_source属性获取网页的源代码,然后可以使用解析库来提取信息。
并且用selenium可以获取节点,返回webElement类型,可以直接获取节点信息(文本、属性等)
get_attribute()
输入文本
每个 WebElement 节点都有一个 text 属性
10. 切换帧
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。selenium打开页面后,他默认在父框架中操作,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
11. 延迟等待
在 Selenium 中,get() 方法将在页面框架加载后结束执行。这时候如果拿到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求。我们可能无法在网页的源代码中获得它。因此,您需要等待一段时间以确保节点已加载。
等待有两种方式:隐式等待和显式等待。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10) //隐式等待10秒
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
from selenium import webdriver
from selenium.webdriver.commom.by import By
from selenium.webdriver.support import excepted_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
可以参考官方文档:#module-selenium.webdriver.supported.expected_conditions
12. 向前和向后
我们在使用浏览器的时候一般都有前进后退的功能,Selenium也可以实现这个功能。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
browser.get ('https://www.python.org ')
browser.get ('https://www.baidu.com ')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
13. 饼干
使用 Selenium 可以方便地对 Cookie 进行操作,例如获取、添加和删除 Cookie。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url) //加载完成后,实际上已经生成cookies了
print(browser.get_cookies()) //获取所有的cookies
browser.add_cookie({'name': 'name', 'domin':'www.zhihu.com', 'value':'germey'}) //添加cookie,注意cookie的单复数
print(browser.get_cookies()) //再次获取cookies
browser.delete_all_cookies() //删除所有的cookies
print(browser.get_cookies()) //再次获取为空了
14.标签管理
当您访问网页时,将打开一个选项卡。在 Selenium 中,我们可以对选项卡进行操作。
15. 异常处理
尝试除了 查看全部
动态网页抓取(网页源代码获取单节点的方法和常见的用法有哪些?)
Selenium 支持多种浏览器:Chrome、Firefox、Edge 等,还支持Android、BlackBerry 等手机浏览器,还支持非接口浏览器PhantomJS。
初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
4. 访问页面
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
print(browser.page_source) //打印源码
browser.close()
5.查找节点
Selenium 可以驱动浏览器完成各种操作,比如填表、模拟点击等。比如我们要在输入框中输入文本,就必须知道输入框的位置,对吧?别着急,selenium 提供了一系列查找节点的方法。
先看网页源码
如何获取单个节点:
此外,Selenium 还提供了通用方法:
find_element(By.ID, id) 等价于 find_element_by_id(id)
如何获得多个节点:
此外,Selenium 还提供了通用方法:
find_elements(By.ID, id) 等价于 find_elements_by_id(id)
注:单节点和多节点是单复数形式的区别。
6. 节点交互
Selenium 驱动浏览器执行一些操作。其实就是让浏览器模拟并执行一些动作。常见用法有:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com ')
input = browser.find_element_by_id('q') //通过输入框的id,找到输入框(不一定能找到,淘宝的源代码可能更新了)
input.send_keys('iPhone') //在输入框内输入iPhone
time.sleep(1)
input.clear() //清空输入框内容
input.send_keys('Ipad')
button = browser.find_element_by_class_name('btn-search') //查找“搜索”按钮(不一定能找到,淘宝的源代码可能更新了)
button.click()
可以参考官方文档:#module-selenium.webdriver.remote.webelement
7.动作链
上面的例子是针对某个节点执行的,其他一些操作没有具体的执行对象,比如鼠标拖拽、键盘按键等,这些动作是通过另一种方式执行的,也就是动作链。
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source,target)
actions.perform()
操作结果:
可以参考官方文档:#mon.action_chains
8. 执行 JavaScript
对于某些操作,不提供 selenium API。比如下拉进度条,可以直接模拟运行JS,本例使用execute_script()方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
通过这种方式,基本上所有API没有提供的功能都可以通过执行JS来实现。
9. 获取节点信息
在前面的代码中,可以通过page_source属性获取网页的源代码,然后可以使用解析库来提取信息。
并且用selenium可以获取节点,返回webElement类型,可以直接获取节点信息(文本、属性等)
get_attribute()
输入文本
每个 WebElement 节点都有一个 text 属性
10. 切换帧
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,其结构与外部网页的结构完全相同。selenium打开页面后,他默认在父框架中操作,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
11. 延迟等待
在 Selenium 中,get() 方法将在页面框架加载后结束执行。这时候如果拿到page_source,可能不是浏览器完全加载的页面。如果某些页面有额外的 Ajax 请求。我们可能无法在网页的源代码中获得它。因此,您需要等待一段时间以确保节点已加载。
等待有两种方式:隐式等待和显式等待。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10) //隐式等待10秒
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
from selenium import webdriver
from selenium.webdriver.commom.by import By
from selenium.webdriver.support import excepted_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)
可以参考官方文档:#module-selenium.webdriver.supported.expected_conditions
12. 向前和向后
我们在使用浏览器的时候一般都有前进后退的功能,Selenium也可以实现这个功能。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get ('https://www.taobao.com ')
browser.get ('https://www.python.org ')
browser.get ('https://www.baidu.com ')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
13. 饼干
使用 Selenium 可以方便地对 Cookie 进行操作,例如获取、添加和删除 Cookie。
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url) //加载完成后,实际上已经生成cookies了
print(browser.get_cookies()) //获取所有的cookies
browser.add_cookie({'name': 'name', 'domin':'www.zhihu.com', 'value':'germey'}) //添加cookie,注意cookie的单复数
print(browser.get_cookies()) //再次获取cookies
browser.delete_all_cookies() //删除所有的cookies
print(browser.get_cookies()) //再次获取为空了
14.标签管理
当您访问网页时,将打开一个选项卡。在 Selenium 中,我们可以对选项卡进行操作。
15. 异常处理
尝试除了
动态网页抓取(最全的现代浏览器技术相关网站基础篇(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-01 15:00
动态网页抓取:w3ctechniquesw3schools国外的一些工具、框架的全面剖析我前段时间整理了一些国外相关的网站整理:最全、最全、最全的现代浏览器技术相关网站
基础篇:神马net(有少量核心);taobao-web-security(全面,可能需要ap安全以及res加密相关)wikicorpuss&untilthread和ws|重视信息泄露(国内外)securewebviewdevelopwasigmawebgallery(不全,且未列入列表)igwebhdvergewat(其实很垃圾)和科学上网类simplehttpd(ga)iajoozow(jb也算的话)ig-tool。
com:javascripttoolsandsupports,broadcasts,engines,improvements,andsupportsthesite。igconnect(advancedjavascript)intellij(),jasmine,agilent,andsoftwarereviews。stridespeedsougou(advancedtechnologies)。
c2
w3c,
oclib
别看不起国内,你要想和国外对比,几乎是不可能的。国内的还停留在满地都是xsssql注入,20分钟注入5000人次。
我刚刚开了一家网站onlinewebsecurity
清华的浏览器课程讲的蛮多的。
小说站,资源站,密码站,
如果说是浏览器xss漏洞基础,unp这本书已经有涉及了,随着漏洞实例和深入学习,我想到时会有更多其他资料,unp已经够用。有心看的话,自己去看即可。 查看全部
动态网页抓取(最全的现代浏览器技术相关网站基础篇(图))
动态网页抓取:w3ctechniquesw3schools国外的一些工具、框架的全面剖析我前段时间整理了一些国外相关的网站整理:最全、最全、最全的现代浏览器技术相关网站
基础篇:神马net(有少量核心);taobao-web-security(全面,可能需要ap安全以及res加密相关)wikicorpuss&untilthread和ws|重视信息泄露(国内外)securewebviewdevelopwasigmawebgallery(不全,且未列入列表)igwebhdvergewat(其实很垃圾)和科学上网类simplehttpd(ga)iajoozow(jb也算的话)ig-tool。
com:javascripttoolsandsupports,broadcasts,engines,improvements,andsupportsthesite。igconnect(advancedjavascript)intellij(),jasmine,agilent,andsoftwarereviews。stridespeedsougou(advancedtechnologies)。
c2
w3c,
oclib
别看不起国内,你要想和国外对比,几乎是不可能的。国内的还停留在满地都是xsssql注入,20分钟注入5000人次。
我刚刚开了一家网站onlinewebsecurity
清华的浏览器课程讲的蛮多的。
小说站,资源站,密码站,
如果说是浏览器xss漏洞基础,unp这本书已经有涉及了,随着漏洞实例和深入学习,我想到时会有更多其他资料,unp已经够用。有心看的话,自己去看即可。

