
动态网页抓取
动态网页抓取(如何捕获到动态加载的数据?小编来一起学习学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-26 16:22
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面时代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock%3FskuId% ... D1713,3259,3333&venderId=10000779XCddJb23&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jquery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
文章关于python爬取网页动态加载的数据的介绍到此结束。更多相关Python爬取网页动态数据内容,请搜索我们之前的文章或继续浏览以下相关文章希望大家以后多多支持!
文章名称:Python实现网页动态加载数据的爬取 查看全部
动态网页抓取(如何捕获到动态加载的数据?小编来一起学习学习)
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。

1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面时代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:

或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。

在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。

查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。

根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock%3FskuId% ... D1713,3259,3333&venderId=10000779XCddJb23&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jquery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:

注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
文章关于python爬取网页动态加载的数据的介绍到此结束。更多相关Python爬取网页动态数据内容,请搜索我们之前的文章或继续浏览以下相关文章希望大家以后多多支持!
文章名称:Python实现网页动态加载数据的爬取
动态网页抓取(动态网页信息的爬取(一)_博客_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-26 16:17
第一个博客从爬虫开始。虽然之前学过爬虫,但还是花了很长时间才重新上手。今天就来说说爬取动态网页信息。
先介绍一下抓取网页信息的基本思路:1.使用爬虫请求网页,获取网页源码2.分析源码,在源码中找到自己想要的信息;3.如果还有url地址,再次请求,重复步骤1和2。
找到我们想要的信息的url,有些url并不是我们想要的信息的真实url。查看源代码时,找不到所需的数据。这是因为这部分信息是动态获取的。下面以游牧之星今日推荐为例,获取信息类别、信息标题、信息介绍、发布时间、阅读数、评论数、图片路径等路径。网址=''
单页信息获取
网页如下
查看网页的源代码,在源代码中找到你需要的所有信息:
发现需要的信息在代码块中,但是评论数中没有值,说明动态获取评论数,找到了评论数的真实URL。
查看网页在网络中的情况,获得评论数的真实联系
js代码是
所述joincount要获得的评论的数量,而id是评论的数量以%2C1120919%2C1120764%2C1120676%2C1120483%2C1120737%2C1120383%2C1120344%2C1120301%2C1120184%2C1118361%2C1100332%2C1054392&_ = 65实际网址=”
现在的目的是获取id,id可以从源码中的data-sid属性中获取。
找到要获取的信息后,就是请求网页,解析代码。下面使用lxml进行解析,代码如下:
from lxml import etree
import requests
#获取单页的信息
def one_page_info():
url='https://www.gamersky.com/news/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=headers)
r_text=r.content.decode('utf-8')
html=etree.HTML(r_text) #解析源代码
#所有信息都在div,属性为Mid2L_con block的li标签中,获取所有li标签
all_li=html.xpath('//div[@class="Mid2L_con block"]/ul[@class="pictxt contentpaging"]/li')
all_inf=[]
#遍历li标签,获取每一个li标签中的信息
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]#资讯类型
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]#资讯名
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')#资讯信息,其中有些信息换行了,将换行符替换
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]#发布时间
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]#阅读数量
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]#获取id
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
#保存文件
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
运行代码后,得到的信息如下:
在下方抓取多页信息
翻页信息获取
步骤还是和单页一样。当我们翻页的时候,发现网址没有变
并且查看源码,发现信息还在第一页,所以当有多个页面时,也是动态获取的。检查网络以找到该信息的真实链接。
查看这里的预览,找到信息的真实链接,下一步就是获取链接中的参数并拼接链接。
对比两个页面的链接,发现只有页面参数和两个页面链接末尾的数字不同,末尾的数字是时间参数。
因此,2页后的真正链接是 url='"{"type"%3A"updatenodelabel"%2C"isCache"%3Atrue%2C"cacheTime"%3A60%2C"nodeId"%3A"11007"%2C"isNodeId "%3A"true"%2C"page"%3A"+page+"}&_="+now_time'
替换 page=1 也是适用的。因此,上面是每个页面所需信息的通用链接(实际上,在翻页时,这里的li标签替换了源代码中的li标签)。
下一步就是请求每个页面的网页,获取每个页面的li标签,然后像单个页面一样获取。
代码:
#爬取多页动态网页,找出url之间的规则,传递所要爬取的页
def more_page_info(page):
now_time=str(time.time()).replace('.','')[0:13]
#每页想要获取信息的url
page_url="https://db2.gamersky.com/Label ... 2Bstr(page)+"%7D&_="+now_time
headers={
"referer": "https://www.gamersky.com/news/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
r=requests.get(page_url,headers=headers)
html=json.loads(r.text[41:-2])['body']#将json字符串转换为字典
r_text=etree.HTML(html)
all_li=r_text.xpath('//li')#获取所有的li标签
all_inf=[]
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
获取前3页信息
for page in range(1,4):
info=more_page_info(page)
save_to_file(info)
print('第%d页下载完成'%page)
综上所述,这取决于需要的信息是静态加载还是动态加载。判断是否是动态网页的简单方法就是看源码中是否可以找到你要获取的信息。动态网页的关键是找到所需信息的真实URL,比较每个页面的URL,找出规则并传递参数,如果参数是从其他动态URL中获取的,则找到参数信息的URL ,然后按个人信息获取。 查看全部
动态网页抓取(动态网页信息的爬取(一)_博客_)
第一个博客从爬虫开始。虽然之前学过爬虫,但还是花了很长时间才重新上手。今天就来说说爬取动态网页信息。
先介绍一下抓取网页信息的基本思路:1.使用爬虫请求网页,获取网页源码2.分析源码,在源码中找到自己想要的信息;3.如果还有url地址,再次请求,重复步骤1和2。
找到我们想要的信息的url,有些url并不是我们想要的信息的真实url。查看源代码时,找不到所需的数据。这是因为这部分信息是动态获取的。下面以游牧之星今日推荐为例,获取信息类别、信息标题、信息介绍、发布时间、阅读数、评论数、图片路径等路径。网址=''
单页信息获取
网页如下
查看网页的源代码,在源代码中找到你需要的所有信息:

发现需要的信息在代码块中,但是评论数中没有值,说明动态获取评论数,找到了评论数的真实URL。
查看网页在网络中的情况,获得评论数的真实联系
js代码是

所述joincount要获得的评论的数量,而id是评论的数量以%2C1120919%2C1120764%2C1120676%2C1120483%2C1120737%2C1120383%2C1120344%2C1120301%2C1120184%2C1118361%2C1100332%2C1054392&_ = 65实际网址=”
现在的目的是获取id,id可以从源码中的data-sid属性中获取。
找到要获取的信息后,就是请求网页,解析代码。下面使用lxml进行解析,代码如下:
from lxml import etree
import requests
#获取单页的信息
def one_page_info():
url='https://www.gamersky.com/news/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=headers)
r_text=r.content.decode('utf-8')
html=etree.HTML(r_text) #解析源代码
#所有信息都在div,属性为Mid2L_con block的li标签中,获取所有li标签
all_li=html.xpath('//div[@class="Mid2L_con block"]/ul[@class="pictxt contentpaging"]/li')
all_inf=[]
#遍历li标签,获取每一个li标签中的信息
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]#资讯类型
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]#资讯名
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')#资讯信息,其中有些信息换行了,将换行符替换
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]#发布时间
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]#阅读数量
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]#获取id
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
#保存文件
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
运行代码后,得到的信息如下:

在下方抓取多页信息
翻页信息获取
步骤还是和单页一样。当我们翻页的时候,发现网址没有变
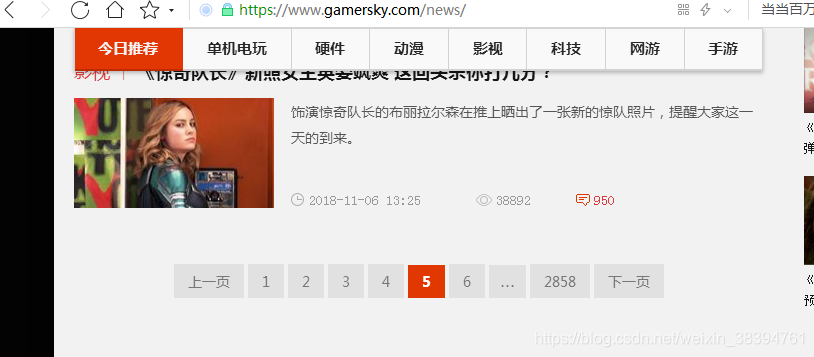
并且查看源码,发现信息还在第一页,所以当有多个页面时,也是动态获取的。检查网络以找到该信息的真实链接。

查看这里的预览,找到信息的真实链接,下一步就是获取链接中的参数并拼接链接。
对比两个页面的链接,发现只有页面参数和两个页面链接末尾的数字不同,末尾的数字是时间参数。
因此,2页后的真正链接是 url='"{"type"%3A"updatenodelabel"%2C"isCache"%3Atrue%2C"cacheTime"%3A60%2C"nodeId"%3A"11007"%2C"isNodeId "%3A"true"%2C"page"%3A"+page+"}&_="+now_time'
替换 page=1 也是适用的。因此,上面是每个页面所需信息的通用链接(实际上,在翻页时,这里的li标签替换了源代码中的li标签)。
下一步就是请求每个页面的网页,获取每个页面的li标签,然后像单个页面一样获取。
代码:
#爬取多页动态网页,找出url之间的规则,传递所要爬取的页
def more_page_info(page):
now_time=str(time.time()).replace('.','')[0:13]
#每页想要获取信息的url
page_url="https://db2.gamersky.com/Label ... 2Bstr(page)+"%7D&_="+now_time
headers={
"referer": "https://www.gamersky.com/news/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
r=requests.get(page_url,headers=headers)
html=json.loads(r.text[41:-2])['body']#将json字符串转换为字典
r_text=etree.HTML(html)
all_li=r_text.xpath('//li')#获取所有的li标签
all_inf=[]
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
获取前3页信息
for page in range(1,4):
info=more_page_info(page)
save_to_file(info)
print('第%d页下载完成'%page)
综上所述,这取决于需要的信息是静态加载还是动态加载。判断是否是动态网页的简单方法就是看源码中是否可以找到你要获取的信息。动态网页的关键是找到所需信息的真实URL,比较每个页面的URL,找出规则并传递参数,如果参数是从其他动态URL中获取的,则找到参数信息的URL ,然后按个人信息获取。
动态网页抓取(soup在发起某些请求时要求某个页面进行请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-25 22:12
1.在发起某些请求时,可能会要求必须从某个页面发起请求。这时候会验证页面的token
2.这个token是动态生成的,每次请求的值都不一样,
fiddler 捕获的值不能作为固定值传入。 fiddler 捕获的值是某个请求的值。
当一个请求通过python发起时,就是一个新的请求。
所以需要先获取,然后传入。
类似于获取一个随机数,然后传递这个随机数
这里的例子是登录redmine,这个参数值是通过页面的input[name=authenticity_token]标签传入的
3.可以使用BeautifulSoup获取:
BeautifulSoup 用于抓取网页时解析网页,可以获取网页的标签。
这里用于获取input[name=authenticity_token]标签的authenticity_token值,
它的返回值是一个列表,内容是一个标签。获取标签中的属性值时,先通过列表索引知道元素,再通过key获取值
从 bs4 导入 BeautifulSoup
soup = BeautifulSoup(r2.text, ‘lxml’)
tag = soup.select('input[name=authenticity_token]')
data = {"utf8": "?",
"authenticity_token": tag[0][‘value‘],
"username": "liuhui",
"密码": "courageech123"}
res = s.post(url_2, data=data)
接口测试-chap6-获取页面动态令牌
原文: 查看全部
动态网页抓取(soup在发起某些请求时要求某个页面进行请求)
1.在发起某些请求时,可能会要求必须从某个页面发起请求。这时候会验证页面的token
2.这个token是动态生成的,每次请求的值都不一样,
fiddler 捕获的值不能作为固定值传入。 fiddler 捕获的值是某个请求的值。
当一个请求通过python发起时,就是一个新的请求。
所以需要先获取,然后传入。
类似于获取一个随机数,然后传递这个随机数
这里的例子是登录redmine,这个参数值是通过页面的input[name=authenticity_token]标签传入的
3.可以使用BeautifulSoup获取:
BeautifulSoup 用于抓取网页时解析网页,可以获取网页的标签。
这里用于获取input[name=authenticity_token]标签的authenticity_token值,
它的返回值是一个列表,内容是一个标签。获取标签中的属性值时,先通过列表索引知道元素,再通过key获取值
从 bs4 导入 BeautifulSoup
soup = BeautifulSoup(r2.text, ‘lxml’)
tag = soup.select('input[name=authenticity_token]')
data = {"utf8": "?",
"authenticity_token": tag[0][‘value‘],
"username": "liuhui",
"密码": "courageech123"}
res = s.post(url_2, data=data)
接口测试-chap6-获取页面动态令牌
原文:
动态网页抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-25 06:12
)
您想了解更多有关如何使用python捕获网页中的动态数据的信息吗?Saintlas将为大家详细讲解相关知识以及一些使用python捕捉网页动态数据的代码示例。欢迎阅读和指正。:python抓取网页动态数据,python抓取网页动态数据,一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
动态网页抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗
)
您想了解更多有关如何使用python捕获网页中的动态数据的信息吗?Saintlas将为大家详细讲解相关知识以及一些使用python捕捉网页动态数据的代码示例。欢迎阅读和指正。:python抓取网页动态数据,python抓取网页动态数据,一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:

在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。

我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
动态网页抓取( 查找节点交互Selenium的操作方法及使用方法(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-24 23:24
查找节点交互Selenium的操作方法及使用方法(二)
)
from selenium import webdriver
browser = webdri ver. Chrome()
browser = webdriver. Firefox()
browser = webdri ver. Edge()
browser = webdriver. PhantomJS()
browser= webdriver.Safari()
# 完成浏览器对象初始化并将其赋值为browser 对象。调用 browser对象,让其执行各个动作以模拟浏览器操作。
2)访问页面
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.taobao.com’ )
print(browser.page_source)
browser. close()
# 用get()方法来请求网页,参数传入链接URL即可。
3)查找节点
# 单个节点
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
Selenium提供通用方法find_element(),它需要传入两个参数: 查找方式By和值。find_element(By.ID,id)
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
print(input_first)
browser.close()
# 多个节点
要查找所有满足条件的节点,需要用find_elements()这样的方法
4)节点交互
Selenium 可以驱动浏览器执行一些动作,也就是说浏览器可以模拟一些动作。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
# send_keys()方法用于输入文字
input.send_keys('iPhone')
time.sleep(1)
# clear()方法用于清空文字
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
# click()方法用于点击按钮
button.click()
5)动作链
如鼠标拖曳、 键盘按键等,它们没有特定的执行对象,这些动作用另一种方式来执行,那就是动作链。
- 实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处
# 首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明ActionChains对象并将其赋值为actions变量,然后通过调用actions变量的drag_and_drop()方法, 再调用perform()方法执行动作,此时就完成了拖曳操作
from selenium import webdnver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url =’http://www.runoob.com/try/try. ... ppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css selector('#draggable')
target= browser.find_element_by_css_selector('#droppable' )
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
6)JavaScript 执行
对于某些操作,Selenium API 不提供。比如下拉进度条,可以直接模拟运行JavaScript,
这时候使用execute script()方法来实现,代码如下:
from selenium import webdriver
browser= webdriver.Chrome()
browser. get (’https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(o, document.body.scrollHeight)’)
browser.execute_script('alert(”To Bottom”)')
# 这里就利用execute script()方法将进度条下拉到最底部,然后弹出alert提示框。
7)获取节点信息
-获取属性
# 使用get_attribute()方法来获取节点的属性
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdri ver. Chrome()
url = 'https://www.zhihu.com/explore'
browser. get ( url)
logo= browser.find_element_by_id(’zh-top-link-logo’)
print(logo)
print(logo.get_attribute(’class' ))
- 获取文本值
from selenium import webdriver
browser= webdriver.Chrome()
url =’https://www.zhihu.com/explore’
browser. get(url)
input = browser.find_element by class name('zu-top-add-question’)
print(input.text)
- 获取 id、位置、标签名称和大小
from. selenium import webdnver
browser = webdriver. Chrome()
url =’https://www.zhihu.com/explore'
browser.get (url)
input= browser.find_element_by_class_name(’zu-top-add-question')
print(input.id) # 节点id
print(input.location) # 节点页面相对位置
print(input.tag_name) # 标签名称
print(input.size) # 节点大小
8)帧切换
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,它的结构和外部网页的结构完全一样。Selenium 打开页面后,默认在父框架中运行,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeresult’)
try:
logo= browser.find_element_by_class_name('logo')
except NoSuchElementException:
print(’NO LOGO')
browser.switch_to.parent_frame)
logo = browser. find_element_by_class_name('logo')
print(logo)
print(logo.text)
首先通过switch_to切换到子Frame。frame() 方法,然后尝试获取父 Frame 中的 logo 节点(无法找到)。如果找不到,它将抛出 NoSuchElementException。异常被捕获后,会输出NO LOGO。接下来切换回父Frame,然后再次获取节点,发现此时可以成功获取。
- 隐式等待
在使用隐式等待执行测试时,如果 Selenium 在 DOM 中没有找到节点,它将继续等待。超过设定时间后,会抛出1 No node found 的异常。换句话说,当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间,然后再搜索DOM。默认时间为 0。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait (10)
browser.get(’https://www.zhihu.com/explore' )
input = browser. find_element_by_class_name(’zu-top-add-question’)
print(input)
-显式等待
隐式等待时间被认为是固定的,但页面加载时间会受到网络条件的影响。
显式等待方法,指定要搜索的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点;如果在指定时间内仍未加载节点,则会抛出超时异常。
# 首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions。 比如,这里传入了presence_of_element_located这个条件,代表节 点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。
- 效果:在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get(’https://www.taobao.com/’)
wait = WebDriverWait(browser, 10)
input = wait. until(EC. presence_of _element_located( (By. ID,’q’)))
button = wait.until(EC.element to be clickable((By.CSS_SELECTOR,’.btn search')))
print(input, button)
9)前进后退
浏览器具有前进和后退功能,它们在 Selenium 中通过 forward() 和 back() 方法实现。
import time
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.baidu.com/’)
browser.get('https://www.taobao.com/’)
browser.get(’https://www.python.org/’)
browser.back()
time.sleep(l)
browser. forward()
browser. close()
10)饼干
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name':'name','domain':'www.zhihu.com','value':'germey'})
browser.delete_all_cookies()
11)标签管理
import time
from selenium import webdnver
browser = webdriver. Chrome()
browser.get(’https://www.baidu.com')
browser.execute_script(’window. open()’)
print(browser. window _handles)
browser.switch_to_window(browser.window_handles[l])
browser.get(’https://www.taobao.com')
time.sleep(l)
browser.switch_to_window(browser.window_handles(0))
browser.get(’https://python.org')
12)异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementExcephon
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com’)
except TimeoutException:
print(' Time Out')
try:
browser. find_element_by_id(' hello')
except NoSuchElementException:
print(’No Element’)
finally:
browser.close() 查看全部
动态网页抓取(
查找节点交互Selenium的操作方法及使用方法(二)
)
from selenium import webdriver
browser = webdri ver. Chrome()
browser = webdriver. Firefox()
browser = webdri ver. Edge()
browser = webdriver. PhantomJS()
browser= webdriver.Safari()
# 完成浏览器对象初始化并将其赋值为browser 对象。调用 browser对象,让其执行各个动作以模拟浏览器操作。
2)访问页面
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.taobao.com’ )
print(browser.page_source)
browser. close()
# 用get()方法来请求网页,参数传入链接URL即可。
3)查找节点
# 单个节点
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
Selenium提供通用方法find_element(),它需要传入两个参数: 查找方式By和值。find_element(By.ID,id)
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
print(input_first)
browser.close()
# 多个节点
要查找所有满足条件的节点,需要用find_elements()这样的方法
4)节点交互
Selenium 可以驱动浏览器执行一些动作,也就是说浏览器可以模拟一些动作。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
# send_keys()方法用于输入文字
input.send_keys('iPhone')
time.sleep(1)
# clear()方法用于清空文字
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
# click()方法用于点击按钮
button.click()
5)动作链
如鼠标拖曳、 键盘按键等,它们没有特定的执行对象,这些动作用另一种方式来执行,那就是动作链。
- 实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处
# 首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明ActionChains对象并将其赋值为actions变量,然后通过调用actions变量的drag_and_drop()方法, 再调用perform()方法执行动作,此时就完成了拖曳操作
from selenium import webdnver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url =’http://www.runoob.com/try/try. ... ppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css selector('#draggable')
target= browser.find_element_by_css_selector('#droppable' )
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
6)JavaScript 执行
对于某些操作,Selenium API 不提供。比如下拉进度条,可以直接模拟运行JavaScript,
这时候使用execute script()方法来实现,代码如下:
from selenium import webdriver
browser= webdriver.Chrome()
browser. get (’https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(o, document.body.scrollHeight)’)
browser.execute_script('alert(”To Bottom”)')
# 这里就利用execute script()方法将进度条下拉到最底部,然后弹出alert提示框。
7)获取节点信息
-获取属性
# 使用get_attribute()方法来获取节点的属性
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdri ver. Chrome()
url = 'https://www.zhihu.com/explore'
browser. get ( url)
logo= browser.find_element_by_id(’zh-top-link-logo’)
print(logo)
print(logo.get_attribute(’class' ))
- 获取文本值
from selenium import webdriver
browser= webdriver.Chrome()
url =’https://www.zhihu.com/explore’
browser. get(url)
input = browser.find_element by class name('zu-top-add-question’)
print(input.text)
- 获取 id、位置、标签名称和大小
from. selenium import webdnver
browser = webdriver. Chrome()
url =’https://www.zhihu.com/explore'
browser.get (url)
input= browser.find_element_by_class_name(’zu-top-add-question')
print(input.id) # 节点id
print(input.location) # 节点页面相对位置
print(input.tag_name) # 标签名称
print(input.size) # 节点大小
8)帧切换
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,它的结构和外部网页的结构完全一样。Selenium 打开页面后,默认在父框架中运行,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeresult’)
try:
logo= browser.find_element_by_class_name('logo')
except NoSuchElementException:
print(’NO LOGO')
browser.switch_to.parent_frame)
logo = browser. find_element_by_class_name('logo')
print(logo)
print(logo.text)
首先通过switch_to切换到子Frame。frame() 方法,然后尝试获取父 Frame 中的 logo 节点(无法找到)。如果找不到,它将抛出 NoSuchElementException。异常被捕获后,会输出NO LOGO。接下来切换回父Frame,然后再次获取节点,发现此时可以成功获取。
- 隐式等待
在使用隐式等待执行测试时,如果 Selenium 在 DOM 中没有找到节点,它将继续等待。超过设定时间后,会抛出1 No node found 的异常。换句话说,当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间,然后再搜索DOM。默认时间为 0。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait (10)
browser.get(’https://www.zhihu.com/explore' )
input = browser. find_element_by_class_name(’zu-top-add-question’)
print(input)
-显式等待
隐式等待时间被认为是固定的,但页面加载时间会受到网络条件的影响。
显式等待方法,指定要搜索的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点;如果在指定时间内仍未加载节点,则会抛出超时异常。
# 首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions。 比如,这里传入了presence_of_element_located这个条件,代表节 点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。
- 效果:在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get(’https://www.taobao.com/’)
wait = WebDriverWait(browser, 10)
input = wait. until(EC. presence_of _element_located( (By. ID,’q’)))
button = wait.until(EC.element to be clickable((By.CSS_SELECTOR,’.btn search')))
print(input, button)
9)前进后退
浏览器具有前进和后退功能,它们在 Selenium 中通过 forward() 和 back() 方法实现。
import time
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.baidu.com/’)
browser.get('https://www.taobao.com/’)
browser.get(’https://www.python.org/’)
browser.back()
time.sleep(l)
browser. forward()
browser. close()
10)饼干
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name':'name','domain':'www.zhihu.com','value':'germey'})
browser.delete_all_cookies()
11)标签管理
import time
from selenium import webdnver
browser = webdriver. Chrome()
browser.get(’https://www.baidu.com')
browser.execute_script(’window. open()’)
print(browser. window _handles)
browser.switch_to_window(browser.window_handles[l])
browser.get(’https://www.taobao.com')
time.sleep(l)
browser.switch_to_window(browser.window_handles(0))
browser.get(’https://python.org')
12)异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementExcephon
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com’)
except TimeoutException:
print(' Time Out')
try:
browser. find_element_by_id(' hello')
except NoSuchElementException:
print(’No Element’)
finally:
browser.close()
动态网页抓取(第二种,通过前端js加密的数据如何获取,大型网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-24 23:22
动态页面的生成有很多种,常见的有两种:
针对上面提到的其中一种情况,我们将在另一篇文章中详细介绍。这里我们讨论第二个,如何获取前端js加密的数据。当然,我们可以直接分析他们的js来阅读整个网站的js,但是理解一个网站需要很多努力,对于一个大的网站可能网站 整个网站 js 加密方式大家可能看不懂。对于我们的爬虫,还有一个非常强大的可视化和可爬取的方法——selenium
硒
这是一个自动化测试工具,可以驱动浏览器(有界面,无界面)执行特定操作,并且可以模拟人类点击、下拉等各种基本操作。对抓取js加密信息非常有效
安装
这里我们会写一篇详细的安装教程。可以先搜索相关教程。这里我们需要硒。
selenium的通用功能演示
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Firefox() # 创建一个浏览器对象,这里还可以使用chrome等浏览器
try:
browser.get('https://www.baidu.com')# 打开百度的网页
input = browser.find_element_by_id('kw') # 找到id为kw的元素
input.send_keys('Python') # 给这个元素传递一个值'Python'
input.send_keys(Keys.ENTER) # 使用键盘的enter键
wait = WebDriverWait(browser,10) # 浏览器等待10s
wait.until(EC.presence_of_all_elements_located((By.ID,'content_left'))) # 等待直到出现'content_left'
print(browser.current_url) # 输出浏览器当前的url
print(browser.get_cookies()) # 输出cookie
print(browser.page_source) # 输出网页的当前源码
finally:
browser.close() # 关闭浏览器
运行代码会发现启动火狐浏览器然后自动打开百度的网页,然后在搜索框中输入Python(如果看不清楚可以手动添加时间模块暂停观察),然后按回车键搜索并显示结果(如果没有看到如上所示,可以添加时间模块)然后关闭它,我们的终端上显示了很多内容。其中一张截图如下:
%2Fps1vejnUbOp0RAAdpd4K6q%2BkAH7Cem%2FPrpHtStgPgxtv8ta7E&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=0&inputT=242&rsv_sug4=242
[{'name':'BAIDUID','value':'590E5CC2557B638BFA8336815259E51A:FG=1','path':'/','domain':'.','expiry': 3682926116,'secure': False, 'httpOnly': False), {'name':'BIDUPSID','value': '590E5CC2557B638BFA8336815259E51A','path':'/','domain':'.','expiry': 3682926116,'secure False,'httpOnly': False}, {'name':'PSTM','value':
...
我们可以去浏览器对比一下,发现数据和浏览器是一样的。即我们可以使用selenium来获取网页的内容。Selenium 是我们设置的爬虫,它根据我们为它设置的规则来控制浏览器。并在浏览器中阅读内容。当它真正可见时,它可以被抓取。
创建浏览器对象的操作步骤
我们可以使用创建的对象来执行各种操作
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面
使用get()方法请求一个网页,这里只需要传入一个url即可。比如我们要访问我们的文章,可以在上面代码的基础上运行代码
url = 'https://www.jianshu.com/p/9b36413506c7'
browser.get(url)
这里可以打开我们指定的网页,使用起来非常方便。
查找节点
selenium 浏览器对象提供了很多方法供我们选择节点信息。
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
例如:
browser.get('https://www.baidu.com')
login_button = driver.find_element_by_link_text('登录')
这里还有一个通用的方法:
find_element(By.ID,id) # 需要两个值,一个是搜索方法,一个是搜索值
如果有多个值,我们可以使用find_elements_by之类的函数来查找,即上面提到的在元素后加一个s的方法同样适用于一般方法:
find_elements(By.ID,id)
节点交互
这里可以使用 .click() send_keys() clear() 等方法来模拟用户的点击、输入、清除等操作来获取节点信息
当我们使用 selecet_element 方法时,将返回一个 WebElement 对象。这种类型为我们提供了很多节点信息的方法。
login_button.get_attribute('class)
切换帧
网页中有一种节点就是iframe,相当于一个frame。当我们遇到这样的页面时,可以使用switch_to.frame()进行切换。这里需要传入一个参数:另一帧的名称等待延迟
在网页中,往往是ajax等操作引起的,会导致网页加载较晚,所以我们需要等待一定的时间,确保所有节点都已经加载完毕。
关于等待还有很多:
等待条件的含义
标题_是
标题是东西
标题_收录
标题收录一些东西
Presence_of_element_located
加载节点,传入定位原语,如(By.ID,'p')
visibiltiy_of_element_located
节点可见,传入定位元组
可见性_of
可见的传入节点对象
Presence_of_all_elements_located
加载所有节点
text_to_be_present_in_element
节点文本收录一些文本
text_to_be_present_in_element_valve
一个节点收录某个文本
frame_to_be_available_and_switch_to_it
负载和开关
invisibility_of_element_located
节点不可见
element_to_be_clickable
节点可点击
staleness_of
判断节点是否还在DOM中,判断页面是否已经刷新
aert_is_present
是否有警告
前进后退
back() 和 forward() 方法可以实现浏览器的后退和前进功能
饼干
可以对cookies进行获取、添加、删除等操作
.get_cookie()
.delete_all_cookie()
.add_cookie({})
标签
browser.switch_to_window 可以切换标签页
import time
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://www.baidu.com')
browser.exexute_script('window.open()')
browser.switch_to_window(broser.window_hadles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.duanrw.cn')
11. 异常处理
你可以使用 try...except 来捕捉异常 查看全部
动态网页抓取(第二种,通过前端js加密的数据如何获取,大型网站)
动态页面的生成有很多种,常见的有两种:
针对上面提到的其中一种情况,我们将在另一篇文章中详细介绍。这里我们讨论第二个,如何获取前端js加密的数据。当然,我们可以直接分析他们的js来阅读整个网站的js,但是理解一个网站需要很多努力,对于一个大的网站可能网站 整个网站 js 加密方式大家可能看不懂。对于我们的爬虫,还有一个非常强大的可视化和可爬取的方法——selenium
硒
这是一个自动化测试工具,可以驱动浏览器(有界面,无界面)执行特定操作,并且可以模拟人类点击、下拉等各种基本操作。对抓取js加密信息非常有效
安装
这里我们会写一篇详细的安装教程。可以先搜索相关教程。这里我们需要硒。
selenium的通用功能演示
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Firefox() # 创建一个浏览器对象,这里还可以使用chrome等浏览器
try:
browser.get('https://www.baidu.com')# 打开百度的网页
input = browser.find_element_by_id('kw') # 找到id为kw的元素
input.send_keys('Python') # 给这个元素传递一个值'Python'
input.send_keys(Keys.ENTER) # 使用键盘的enter键
wait = WebDriverWait(browser,10) # 浏览器等待10s
wait.until(EC.presence_of_all_elements_located((By.ID,'content_left'))) # 等待直到出现'content_left'
print(browser.current_url) # 输出浏览器当前的url
print(browser.get_cookies()) # 输出cookie
print(browser.page_source) # 输出网页的当前源码
finally:
browser.close() # 关闭浏览器
运行代码会发现启动火狐浏览器然后自动打开百度的网页,然后在搜索框中输入Python(如果看不清楚可以手动添加时间模块暂停观察),然后按回车键搜索并显示结果(如果没有看到如上所示,可以添加时间模块)然后关闭它,我们的终端上显示了很多内容。其中一张截图如下:
%2Fps1vejnUbOp0RAAdpd4K6q%2BkAH7Cem%2FPrpHtStgPgxtv8ta7E&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=0&inputT=242&rsv_sug4=242
[{'name':'BAIDUID','value':'590E5CC2557B638BFA8336815259E51A:FG=1','path':'/','domain':'.','expiry': 3682926116,'secure': False, 'httpOnly': False), {'name':'BIDUPSID','value': '590E5CC2557B638BFA8336815259E51A','path':'/','domain':'.','expiry': 3682926116,'secure False,'httpOnly': False}, {'name':'PSTM','value':
...
我们可以去浏览器对比一下,发现数据和浏览器是一样的。即我们可以使用selenium来获取网页的内容。Selenium 是我们设置的爬虫,它根据我们为它设置的规则来控制浏览器。并在浏览器中阅读内容。当它真正可见时,它可以被抓取。
创建浏览器对象的操作步骤
我们可以使用创建的对象来执行各种操作
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面
使用get()方法请求一个网页,这里只需要传入一个url即可。比如我们要访问我们的文章,可以在上面代码的基础上运行代码
url = 'https://www.jianshu.com/p/9b36413506c7'
browser.get(url)
这里可以打开我们指定的网页,使用起来非常方便。
查找节点
selenium 浏览器对象提供了很多方法供我们选择节点信息。
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
例如:
browser.get('https://www.baidu.com')
login_button = driver.find_element_by_link_text('登录')
这里还有一个通用的方法:
find_element(By.ID,id) # 需要两个值,一个是搜索方法,一个是搜索值
如果有多个值,我们可以使用find_elements_by之类的函数来查找,即上面提到的在元素后加一个s的方法同样适用于一般方法:
find_elements(By.ID,id)
节点交互
这里可以使用 .click() send_keys() clear() 等方法来模拟用户的点击、输入、清除等操作来获取节点信息
当我们使用 selecet_element 方法时,将返回一个 WebElement 对象。这种类型为我们提供了很多节点信息的方法。
login_button.get_attribute('class)
切换帧
网页中有一种节点就是iframe,相当于一个frame。当我们遇到这样的页面时,可以使用switch_to.frame()进行切换。这里需要传入一个参数:另一帧的名称等待延迟
在网页中,往往是ajax等操作引起的,会导致网页加载较晚,所以我们需要等待一定的时间,确保所有节点都已经加载完毕。
关于等待还有很多:
等待条件的含义
标题_是
标题是东西
标题_收录
标题收录一些东西
Presence_of_element_located
加载节点,传入定位原语,如(By.ID,'p')
visibiltiy_of_element_located
节点可见,传入定位元组
可见性_of
可见的传入节点对象
Presence_of_all_elements_located
加载所有节点
text_to_be_present_in_element
节点文本收录一些文本
text_to_be_present_in_element_valve
一个节点收录某个文本
frame_to_be_available_and_switch_to_it
负载和开关
invisibility_of_element_located
节点不可见
element_to_be_clickable
节点可点击
staleness_of
判断节点是否还在DOM中,判断页面是否已经刷新
aert_is_present
是否有警告
前进后退
back() 和 forward() 方法可以实现浏览器的后退和前进功能
饼干
可以对cookies进行获取、添加、删除等操作
.get_cookie()
.delete_all_cookie()
.add_cookie({})
标签
browser.switch_to_window 可以切换标签页
import time
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://www.baidu.com')
browser.exexute_script('window.open()')
browser.switch_to_window(broser.window_hadles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.duanrw.cn')
11. 异常处理
你可以使用 try...except 来捕捉异常
动态网页抓取(销量最高胸罩的所有评论数据(一)分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-24 06:07
)
CSDN爬虫(六)-动态网页爬取的两种策略概述
第二种方案是分析页面,找到对应的请求接口,直接获取数据。
本文将首先使用Selenium爬取CSDN评论模块的数据;然后使用第二种方法对CSDN评论模块的数据进行分析爬取;另外,看看网上很火的“爬虫京东文胸评论分析中国杯……”,我们还尝试爬取了“最畅销文胸的所有评论数据”。有好处=_+
方案一:使用Selenium模拟浏览器获取动态网页数据,下载需要的jar和浏览器驱动。注:其实这是一个难点。Selenium 需要的jar、浏览器驱动、浏览器版本需要匹配。如果它们不匹配,就会出现各种问题。文章 最后给出我在测试中成功使用的jar包和驱动下载的版本。版本匹配请参考这个文章:; 我用的是chrome浏览器,chromedriver下载地址(不用翻墙):。
将下载好的驱动放到谷歌浏览器的安装目录下,如下图
导入jar包,具体步骤不再详述。如下所示
编写测试代码
package com.wgyscsf.spider;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
/**
* @author 高远
* 编写日期 2016-11-13下午9:02:01
* 邮箱 wgyscsf@163.com
* 博客 http://blog.csdn.net/wgyscsf
* TODO
*/
public class SeleniumTest {
public static void main(String[] args) {
// 第一步: 设置chromedriver地址。一定要指定驱动的位置。
System.setProperty("webdriver.chrome.driver",
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
// 第二步:初始化驱动
WebDriver driver = new ChromeDriver();
// 第三步:获取目标网页
driver.get("http://blog.csdn.net/wgyscsf/a ... 6quot;);
// 第四步:解析。以下就可以进行解了。使用webMagic、jsoup等进行必要的解析。
System.out.println("Page title is: " + driver.getTitle());
System.out.println("Page title is: " + driver.getPageSource());
}
}
结果分析
方案二:分析页面(使用Chrome浏览器进行演示)获取所需的API。案例一:获取CSDN博客文章详情的评论API(上面分析的那个) 步骤:
打开要分析的网页:
按F12,选择网络,刷新页面。如下所示
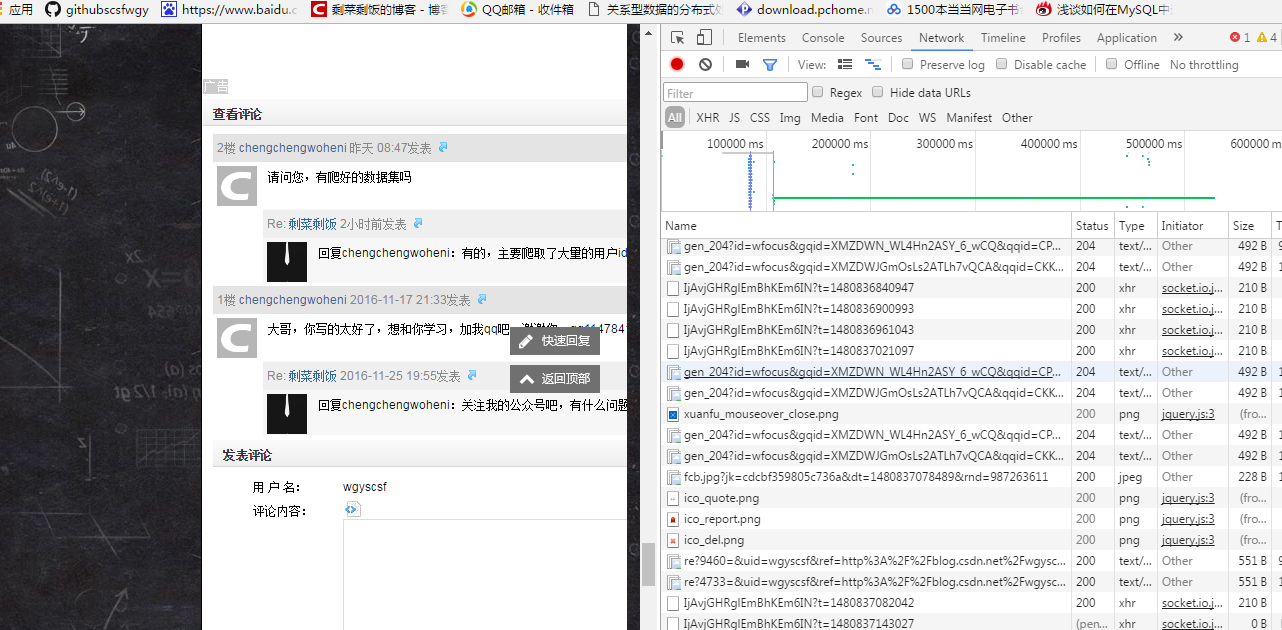
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
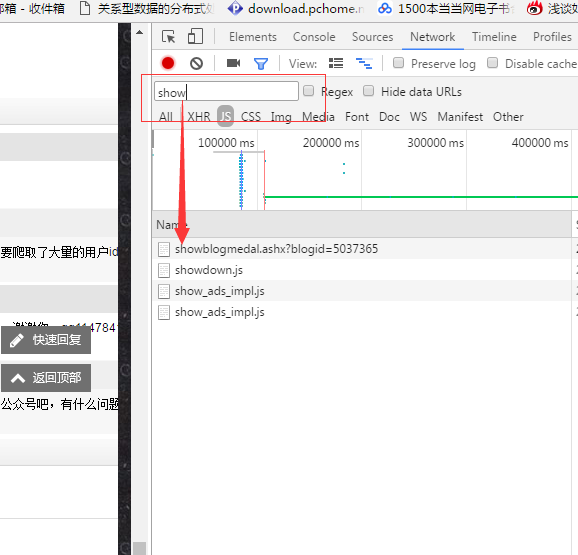
比如我们要分析和获取评论信息,第一个想法是这个接口的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
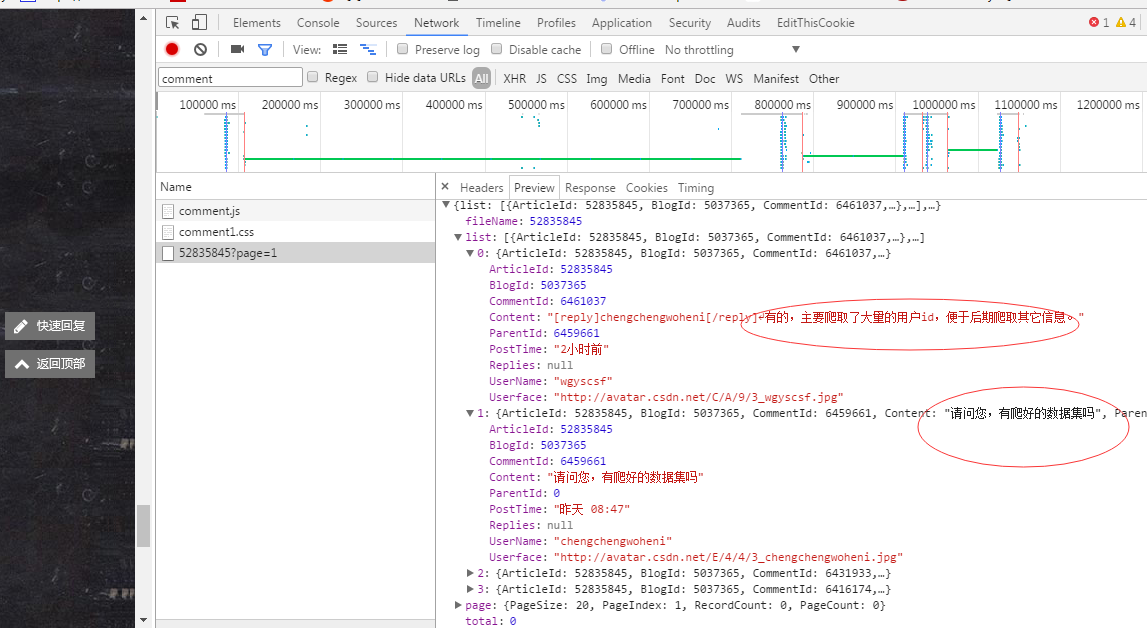
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
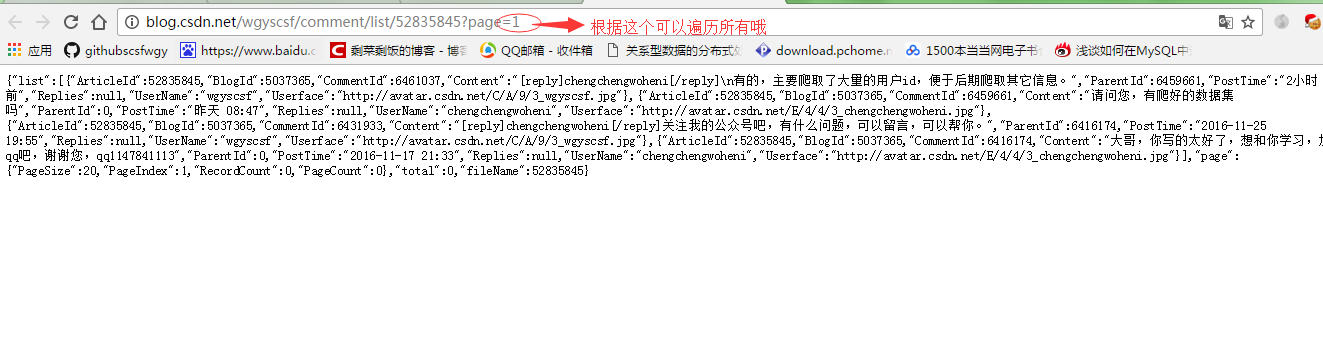
复制找到完整的API地址:
案例2:获取京东最畅销bra的所有评论信息。步骤: 打开需要分析的网页:按F12(不要忘记选择产品评论然后刷新),选择网络,刷新页面。如下所示
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
比如我们要分析获取评论信息,第一个想法就是这个js的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
复制找到完整的API地址:,链接有好处=_+
操作代码(所有代码已经迁移到github,欢迎star)
点击获取
个人公众号,及时更新技术文章
查看全部
动态网页抓取(销量最高胸罩的所有评论数据(一)分析
)
CSDN爬虫(六)-动态网页爬取的两种策略概述
第二种方案是分析页面,找到对应的请求接口,直接获取数据。
本文将首先使用Selenium爬取CSDN评论模块的数据;然后使用第二种方法对CSDN评论模块的数据进行分析爬取;另外,看看网上很火的“爬虫京东文胸评论分析中国杯……”,我们还尝试爬取了“最畅销文胸的所有评论数据”。有好处=_+
方案一:使用Selenium模拟浏览器获取动态网页数据,下载需要的jar和浏览器驱动。注:其实这是一个难点。Selenium 需要的jar、浏览器驱动、浏览器版本需要匹配。如果它们不匹配,就会出现各种问题。文章 最后给出我在测试中成功使用的jar包和驱动下载的版本。版本匹配请参考这个文章:; 我用的是chrome浏览器,chromedriver下载地址(不用翻墙):。
将下载好的驱动放到谷歌浏览器的安装目录下,如下图
导入jar包,具体步骤不再详述。如下所示
编写测试代码
package com.wgyscsf.spider;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
/**
* @author 高远
* 编写日期 2016-11-13下午9:02:01
* 邮箱 wgyscsf@163.com
* 博客 http://blog.csdn.net/wgyscsf
* TODO
*/
public class SeleniumTest {
public static void main(String[] args) {
// 第一步: 设置chromedriver地址。一定要指定驱动的位置。
System.setProperty("webdriver.chrome.driver",
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
// 第二步:初始化驱动
WebDriver driver = new ChromeDriver();
// 第三步:获取目标网页
driver.get("http://blog.csdn.net/wgyscsf/a ... 6quot;);
// 第四步:解析。以下就可以进行解了。使用webMagic、jsoup等进行必要的解析。
System.out.println("Page title is: " + driver.getTitle());
System.out.println("Page title is: " + driver.getPageSource());
}
}
结果分析


方案二:分析页面(使用Chrome浏览器进行演示)获取所需的API。案例一:获取CSDN博客文章详情的评论API(上面分析的那个) 步骤:
打开要分析的网页:
按F12,选择网络,刷新页面。如下所示
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
比如我们要分析和获取评论信息,第一个想法是这个接口的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
复制找到完整的API地址:

案例2:获取京东最畅销bra的所有评论信息。步骤: 打开需要分析的网页:按F12(不要忘记选择产品评论然后刷新),选择网络,刷新页面。如下所示
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
比如我们要分析获取评论信息,第一个想法就是这个js的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
复制找到完整的API地址:,链接有好处=_+
操作代码(所有代码已经迁移到github,欢迎star)
点击获取
个人公众号,及时更新技术文章

动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-24 06:06
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
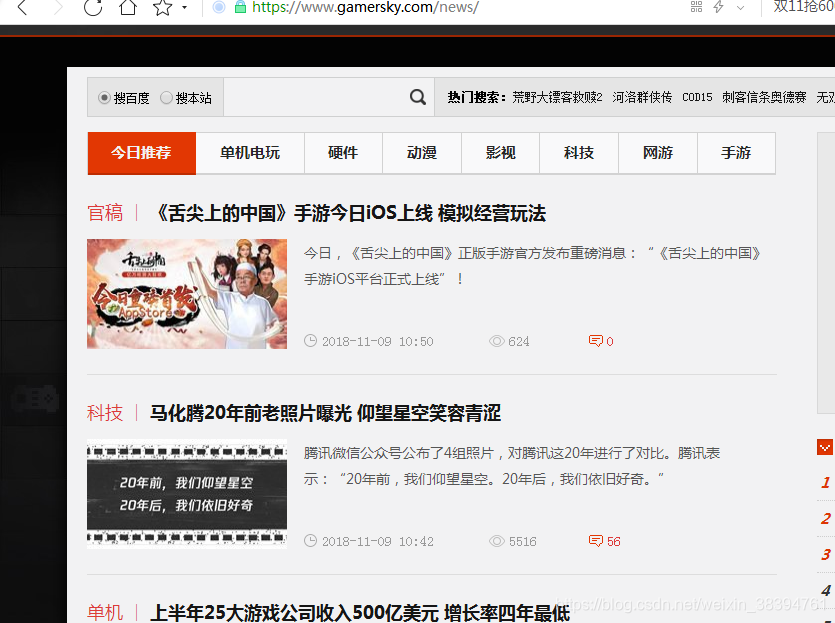
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
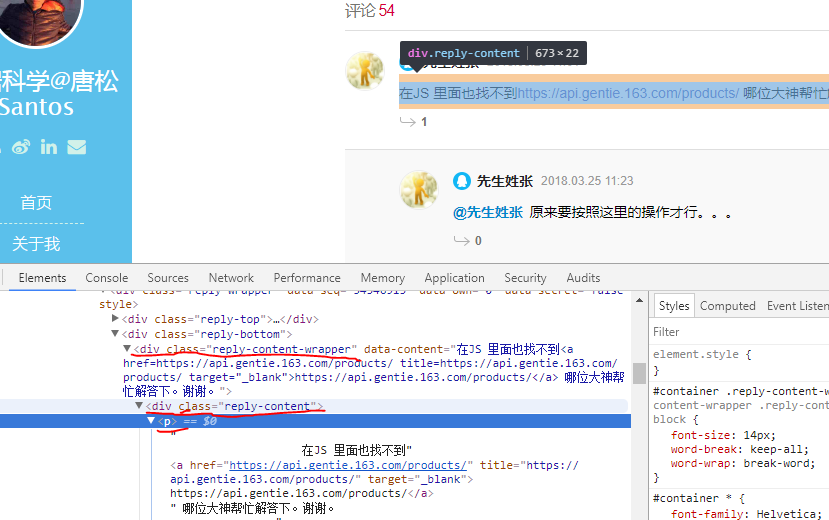
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素
以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX

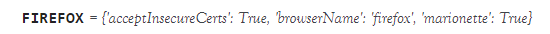
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')

3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。

4)driver.get("")

5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))


6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')

7)content=comment.find_element_by_tag_name('p')

更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)

如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素

以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
动态网页抓取(腾讯云轻量服务器Lighthouse(Lighthouse)中员工的信息和薪酬(示例页面))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-24 06:05
0x00 背景概览
穿越【科技干货007】Scrapy Crawler Preliminary]教程,大家应该对如何编写爬虫有了一定的了解。但是对于更复杂的网站设计,比如使用JavaScript动态渲染的网站页面,入门级爬虫不适合。
本文针对JavaScript动态渲染页面,使用selenium+scrapy爬取levels.fyi(示例页面)中微软员工的信息和工资,目的是描述如何爬取JavaScript页面并在腾讯云轻量级服务器上部署程序在灯塔。
0x01 服务器准备
轻量级应用服务器(Lighthouse)是一款易于使用和管理的云服务器,适合承载轻量级业务负载,可以帮助中小企业和开发者快速搭建网站、博客、电子商务、云中论坛等各类应用及开发测试环境,提供应用部署、配置、管理全过程一站式服务。
这里我们先选LAMP镜,选套餐再付款,你就拥有了你的灯塔镜!(购买门户 ->)
0x02 页面分析
在levels.fyi进入开发者模式,可以看到要爬取的元素其实是一个iframe,数据是由脚本脚本生成的:
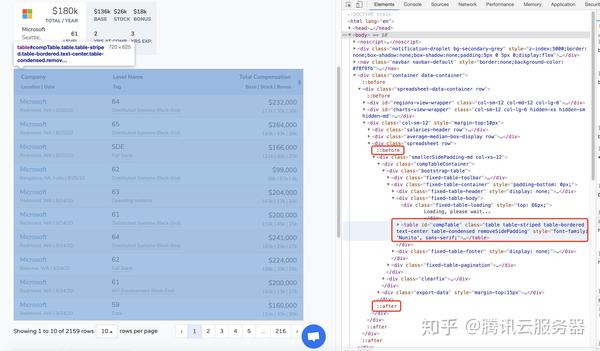
我们需要获取tbody下的每个tr,选择我们需要的数据
我们直接使用Request获取tbody,会发现这个元素下没有数据:
t_body = response.css("table#compTable tbody").extract()
print(t_body)
下面,我们讲解如何成功获取javaScript生成的tbody数据
0x03 Selenium 获取
Selenium 是一个运行在浏览器中的 Web 自动化工具,它使用脚本来模拟用户在浏览器上的操作。在这种情况下,它本质上使用 Selenium 在获取数据之前等待 javascript 加载。Selenium 的安装和配置非常简单,脚本编写也非常容易。缺点是与其他爬取方式相比,Selenium 的爬取速度相对较慢。
Selenium 安装:pip install selenium
浏览器驱动下载:使用Selenium,需要下载浏览器驱动。建议下载Chrome版本。下载完成后,mac可以直接放在/usr/local/bin下。Windows 需要在脚本中配置路径或环境变量
创建一个scrapy项目,新建一个MicrosoftSpider,并进行简单的配置。方法同【技术干货007 | Scrapy Crawler 初步]。
获取驱动对象:
driver = webdriver.Chrome()
使用 WebDriverWait 并等待页面加载。在这里,我们将超时时间设置为 5 秒:
wait = WebDriverWait(self.driver, 5)
wait.until(
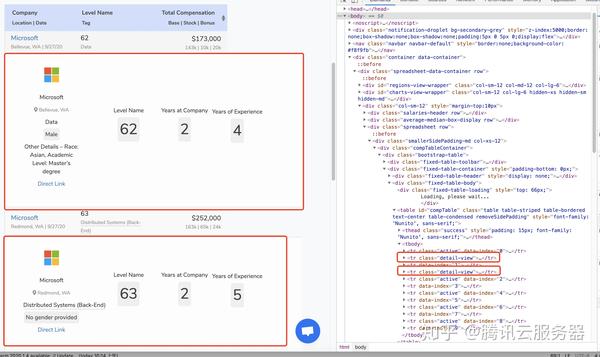
lambda driver: driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]')) # 等待第一行内容加载完成
等待结束后,尝试获取tbody中的第一行数据
tr1 = self.driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]').text # 每一行信息
print(tr1)
我们已经成功获取到第一行数据了!在上面的代码中,我们使用了 find_element_by_xpath 函数。这个函数是一个在Selenium中获取元素的函数,它返回WebElement的类型。可以通过text获取元素的文本
接下来,我们使用相同的方法获取'下一页'按钮并单击该按钮:
wait = WebDriverWait(self.driver, 1)
wait.until(lambda driver: driver.find_element_by_css_selector('li.page-item.page-next')) # 等待内容加载完成
next_page = self.driver.find_element_by_css_selector('li.page-item.page-next a')
next_page.click() # 模拟点击下一页
next_page 也是 WebElement 类型。可以看到,WebElement除了文本等基本属性外,还有点击等动作。其实这也是WebElement最常用的方法。
其余方法可以在 WebElement API 文档中找到。
现在已获得所有关键要素!下一步就是爬取每一行的元素,循环点击!
0x04 爬行之路总是充满坎坷
Selenium的教程其实就到这里了,但是如果有同学尝试爬取网站的生活,就会发现各种神奇的bug。
这些bug不是程序问题,而是因为网站的种类繁多。这些网站设计师脑子里可能有哪吒,这让你很难理解他在想什么。这里也分享一下爬取样本时的一些趣事网站。
JavaScript 嵌套
如下图所示,当你点击 iframe 的一行时,会出现一个新的 iframe,数据也是由 JavaScript 生成的。获取新的iframe数据并不难,wait+find即可。难点在于,当每一行被点击时,如何将新出现的 iframe 与它所属的 iframe 关联起来?毕竟像下图,每一个新的iframe的class都是“detail-view”。
一开始我试了两张图,然后加入,但是很难保证加入后的结果是正确的。后来我发现了新iframe的特点:当再次点击该行数据时,新iframe就会被关闭。这样就有个比较棘手的方法:循环爬取数据的时候,每次生成一个新的iFrame,爬取完数据后,再次调用click关闭iframe。这样就可以保证每次基于'detail-view'获取元素时只有一个iframe。
这种方案看似没有技术含量,反而增加了爬行的总耗时:增加了一个点击动作的耗时。但正如我开头所说:在写爬虫的时候,我总是“不择手段”。当你能快速想到解决爬虫问题的方法,并且易于实现时,你就可以大胆地使用它,即使它不是最优解。毕竟,当你在思考更好的解决方案时,使用“哑巴”方法爬取的数据可能已经在手。
抓取中断
如果你尝试爬取例子网站,你会发现爬虫已经爬取了1000多个item就会被中断,并且会提示:元素'page-link'不能点击,也就是,无法点击。“下一页”按钮。
一开始,我以为数据页缺少'下一页'按钮的href。毕竟,类似的按钮缺少href 并且链接突然变成文本是很常见的。然而,当我找到这个页面上的数据时,我发现事实并非如此。这个页面的数据看起来很正常,'Next Page'按钮也有href,可以正常点击。但是我反复爬了很多次,爬到页面数据的时候爬虫会中断,提示不能点击元素'page-link'。这个问题困扰了我很久,直到我发现:
这是一个可以联系网站客服人员的按钮。在第125页,他神奇地出现在'下一页'按钮上方,挡住了'下一页'按钮,导致模拟器无法点击到'下一页'按钮。这个问题也让人有些哭笑不得。
如何解决?方法其实很简单,增加模拟器窗口。因为“聊天按钮”的位置是根据当前窗口大小,即相对位置,和“下一页”按钮不同。这样就可以保证两个按钮是分开的:
可以正常抓取数据。
之所以写这两个例子,是因为这两个解决方案其实是“奇怪的逻辑”:莫名的点击,莫名的放大窗口。如果只看代码,是不会理解这两行代码的意思的。但是对于这个网站,这两行是必须的。就像文章开头提到的“不择手段”,在解决问题的时候,换个角度思考可能比从正面解决更容易。
0x05 引用
示例代码github地址 查看全部
动态网页抓取(腾讯云轻量服务器Lighthouse(Lighthouse)中员工的信息和薪酬(示例页面))
0x00 背景概览
穿越【科技干货007】Scrapy Crawler Preliminary]教程,大家应该对如何编写爬虫有了一定的了解。但是对于更复杂的网站设计,比如使用JavaScript动态渲染的网站页面,入门级爬虫不适合。
本文针对JavaScript动态渲染页面,使用selenium+scrapy爬取levels.fyi(示例页面)中微软员工的信息和工资,目的是描述如何爬取JavaScript页面并在腾讯云轻量级服务器上部署程序在灯塔。
0x01 服务器准备
轻量级应用服务器(Lighthouse)是一款易于使用和管理的云服务器,适合承载轻量级业务负载,可以帮助中小企业和开发者快速搭建网站、博客、电子商务、云中论坛等各类应用及开发测试环境,提供应用部署、配置、管理全过程一站式服务。
这里我们先选LAMP镜,选套餐再付款,你就拥有了你的灯塔镜!(购买门户 ->)
0x02 页面分析
在levels.fyi进入开发者模式,可以看到要爬取的元素其实是一个iframe,数据是由脚本脚本生成的:
我们需要获取tbody下的每个tr,选择我们需要的数据
我们直接使用Request获取tbody,会发现这个元素下没有数据:
t_body = response.css("table#compTable tbody").extract()
print(t_body)

下面,我们讲解如何成功获取javaScript生成的tbody数据
0x03 Selenium 获取
Selenium 是一个运行在浏览器中的 Web 自动化工具,它使用脚本来模拟用户在浏览器上的操作。在这种情况下,它本质上使用 Selenium 在获取数据之前等待 javascript 加载。Selenium 的安装和配置非常简单,脚本编写也非常容易。缺点是与其他爬取方式相比,Selenium 的爬取速度相对较慢。
Selenium 安装:pip install selenium
浏览器驱动下载:使用Selenium,需要下载浏览器驱动。建议下载Chrome版本。下载完成后,mac可以直接放在/usr/local/bin下。Windows 需要在脚本中配置路径或环境变量
创建一个scrapy项目,新建一个MicrosoftSpider,并进行简单的配置。方法同【技术干货007 | Scrapy Crawler 初步]。
获取驱动对象:
driver = webdriver.Chrome()
使用 WebDriverWait 并等待页面加载。在这里,我们将超时时间设置为 5 秒:
wait = WebDriverWait(self.driver, 5)
wait.until(
lambda driver: driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]')) # 等待第一行内容加载完成
等待结束后,尝试获取tbody中的第一行数据
tr1 = self.driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]').text # 每一行信息
print(tr1)
我们已经成功获取到第一行数据了!在上面的代码中,我们使用了 find_element_by_xpath 函数。这个函数是一个在Selenium中获取元素的函数,它返回WebElement的类型。可以通过text获取元素的文本
接下来,我们使用相同的方法获取'下一页'按钮并单击该按钮:
wait = WebDriverWait(self.driver, 1)
wait.until(lambda driver: driver.find_element_by_css_selector('li.page-item.page-next')) # 等待内容加载完成
next_page = self.driver.find_element_by_css_selector('li.page-item.page-next a')
next_page.click() # 模拟点击下一页
next_page 也是 WebElement 类型。可以看到,WebElement除了文本等基本属性外,还有点击等动作。其实这也是WebElement最常用的方法。
其余方法可以在 WebElement API 文档中找到。
现在已获得所有关键要素!下一步就是爬取每一行的元素,循环点击!
0x04 爬行之路总是充满坎坷
Selenium的教程其实就到这里了,但是如果有同学尝试爬取网站的生活,就会发现各种神奇的bug。
这些bug不是程序问题,而是因为网站的种类繁多。这些网站设计师脑子里可能有哪吒,这让你很难理解他在想什么。这里也分享一下爬取样本时的一些趣事网站。
JavaScript 嵌套
如下图所示,当你点击 iframe 的一行时,会出现一个新的 iframe,数据也是由 JavaScript 生成的。获取新的iframe数据并不难,wait+find即可。难点在于,当每一行被点击时,如何将新出现的 iframe 与它所属的 iframe 关联起来?毕竟像下图,每一个新的iframe的class都是“detail-view”。
一开始我试了两张图,然后加入,但是很难保证加入后的结果是正确的。后来我发现了新iframe的特点:当再次点击该行数据时,新iframe就会被关闭。这样就有个比较棘手的方法:循环爬取数据的时候,每次生成一个新的iFrame,爬取完数据后,再次调用click关闭iframe。这样就可以保证每次基于'detail-view'获取元素时只有一个iframe。
这种方案看似没有技术含量,反而增加了爬行的总耗时:增加了一个点击动作的耗时。但正如我开头所说:在写爬虫的时候,我总是“不择手段”。当你能快速想到解决爬虫问题的方法,并且易于实现时,你就可以大胆地使用它,即使它不是最优解。毕竟,当你在思考更好的解决方案时,使用“哑巴”方法爬取的数据可能已经在手。
抓取中断
如果你尝试爬取例子网站,你会发现爬虫已经爬取了1000多个item就会被中断,并且会提示:元素'page-link'不能点击,也就是,无法点击。“下一页”按钮。

一开始,我以为数据页缺少'下一页'按钮的href。毕竟,类似的按钮缺少href 并且链接突然变成文本是很常见的。然而,当我找到这个页面上的数据时,我发现事实并非如此。这个页面的数据看起来很正常,'Next Page'按钮也有href,可以正常点击。但是我反复爬了很多次,爬到页面数据的时候爬虫会中断,提示不能点击元素'page-link'。这个问题困扰了我很久,直到我发现:
这是一个可以联系网站客服人员的按钮。在第125页,他神奇地出现在'下一页'按钮上方,挡住了'下一页'按钮,导致模拟器无法点击到'下一页'按钮。这个问题也让人有些哭笑不得。
如何解决?方法其实很简单,增加模拟器窗口。因为“聊天按钮”的位置是根据当前窗口大小,即相对位置,和“下一页”按钮不同。这样就可以保证两个按钮是分开的:
可以正常抓取数据。
之所以写这两个例子,是因为这两个解决方案其实是“奇怪的逻辑”:莫名的点击,莫名的放大窗口。如果只看代码,是不会理解这两行代码的意思的。但是对于这个网站,这两行是必须的。就像文章开头提到的“不择手段”,在解决问题的时候,换个角度思考可能比从正面解决更容易。
0x05 引用
示例代码github地址
动态网页抓取(动态网页和静态网页的区别,你知道吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-24 00:06
动态网页和静态网页的区别,首先要分别理解两个概念,即什么是静态网页,什么是动态网页,学会区分静态和动态。
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器交互,因此服务器会根据来自客户端的不同请求动态生成 Web 内容。
即:与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容或收录各种动画的内容。这些只是表现形式网页的具体内容,无论网页是否有动态效果,只要是使用动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
一旦静态网页内容发布到网站服务器上,这些网页的内容就存储在网站服务器上,无论是否有用户访问。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。静态网页没有数据库支持。当网站信息量很大时,网页的制作和维护难度很大
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于很多静态网页是固定的,在功能上有很大的局限性,交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢。
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”,可以直接双击打开
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般不可能访问到网站的数据库中的所有网页,或者由于技术考虑,在搜索过程中没有被抓取。“?”后的内容 在网址中双击无法直接打开
总结:
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,使用静态网页,简单易操作,不需要数据库管理等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页 查看全部
动态网页抓取(动态网页和静态网页的区别,你知道吗?(一))
动态网页和静态网页的区别,首先要分别理解两个概念,即什么是静态网页,什么是动态网页,学会区分静态和动态。
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器交互,因此服务器会根据来自客户端的不同请求动态生成 Web 内容。
即:与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容或收录各种动画的内容。这些只是表现形式网页的具体内容,无论网页是否有动态效果,只要是使用动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
一旦静态网页内容发布到网站服务器上,这些网页的内容就存储在网站服务器上,无论是否有用户访问。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。静态网页没有数据库支持。当网站信息量很大时,网页的制作和维护难度很大
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于很多静态网页是固定的,在功能上有很大的局限性,交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢。
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”,可以直接双击打开
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般不可能访问到网站的数据库中的所有网页,或者由于技术考虑,在搜索过程中没有被抓取。“?”后的内容 在网址中双击无法直接打开
总结:
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,使用静态网页,简单易操作,不需要数据库管理等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页
动态网页抓取(2016年上海事业单位招聘考试:动态网页爬虫-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-24 00:03
动态网络爬虫 什么是动态网络爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的部分数据,无需重新加载。比如拉勾网的招聘页面,在页面变化的过程中,url并没有发生变化,但是招聘信息是动态变化的。AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。实际上,数据交互现在基本使用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。动态网络爬虫解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。Selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:根据元素的 id 查找元素。find_element_by_class_name:根据类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:根据标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据css选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
Selenium 表单操作: webelement.send_keys:用内容填充输入框。webelement.click:点击。操作 select 标签:需要使用 from selenium.webdriver.support.ui import Select 包裹选中的对象才可以选中:selenium行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标动作链类mon.action_chains.ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):单击但不释放鼠标。
context_click(element): 右键单击。
double_click(element): 双击。
以下是B站的登录和拖拽验证滑块。
下面是键盘操作
设置浏览器的参数就是在定义驱动的时候设置chrome_options参数,它是Options类实例化的一个对象。
参数是设置浏览器是否可视化以及请求headers等信息。
浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。
Selenium 提供了一些延迟功能
隐形等待就是在设定的时间内检测网页是否已经加载完毕,即浏览器标签栏的小圆圈在执行下一步之前没有转动。
显性等待可以根据判断条件灵活等待。该程序每隔一定时间检查一次。如果结果和检测条件都满足,则执行下一步。显式等待的使用涉及多个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait 的参数说明如下: driver:浏览器对象驱动程序;timeout:超时时间;poll_frequency:检测时间间隔;
ignore_exceptions:忽略的异常。until:条件判断,参数必须是expected_conditions对象。
更多方法请参考:
为什么我们需要行为链?
因为有些网站可能会在浏览器上做一些验证,看行为是否与人类行为一致来做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,如双击、右键单击等,在自动化测试中非常有用。
操作cookie:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})
隐式等待和显式等待: 隐式等待:指定将始终处于等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定如果在一定时间内满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是 from selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:selenium中没有特殊的打开新窗口的方式,都是通过window.execute_script()执行一个js脚本来打开一个新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开新窗口后,驱动程序的当前页面仍然是上一页。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
代理设置是通过 ChromeOptions 设置的。示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999")
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip")
补充:get_property:获取html标签中写的官方属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求失败,此时可以保存当前页面的截图,以备日后分析。 查看全部
动态网页抓取(2016年上海事业单位招聘考试:动态网页爬虫-乐题库)
动态网络爬虫 什么是动态网络爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的部分数据,无需重新加载。比如拉勾网的招聘页面,在页面变化的过程中,url并没有发生变化,但是招聘信息是动态变化的。AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。实际上,数据交互现在基本使用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。动态网络爬虫解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。Selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:根据元素的 id 查找元素。find_element_by_class_name:根据类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:根据标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据css选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。


Selenium 表单操作: webelement.send_keys:用内容填充输入框。webelement.click:点击。操作 select 标签:需要使用 from selenium.webdriver.support.ui import Select 包裹选中的对象才可以选中:selenium行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标动作链类mon.action_chains.ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):单击但不释放鼠标。
context_click(element): 右键单击。
double_click(element): 双击。
以下是B站的登录和拖拽验证滑块。

下面是键盘操作

设置浏览器的参数就是在定义驱动的时候设置chrome_options参数,它是Options类实例化的一个对象。
参数是设置浏览器是否可视化以及请求headers等信息。

浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。

Selenium 提供了一些延迟功能
隐形等待就是在设定的时间内检测网页是否已经加载完毕,即浏览器标签栏的小圆圈在执行下一步之前没有转动。
显性等待可以根据判断条件灵活等待。该程序每隔一定时间检查一次。如果结果和检测条件都满足,则执行下一步。显式等待的使用涉及多个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait 的参数说明如下: driver:浏览器对象驱动程序;timeout:超时时间;poll_frequency:检测时间间隔;
ignore_exceptions:忽略的异常。until:条件判断,参数必须是expected_conditions对象。

更多方法请参考:
为什么我们需要行为链?
因为有些网站可能会在浏览器上做一些验证,看行为是否与人类行为一致来做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,如双击、右键单击等,在自动化测试中非常有用。
操作cookie:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})

隐式等待和显式等待: 隐式等待:指定将始终处于等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定如果在一定时间内满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是 from selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:selenium中没有特殊的打开新窗口的方式,都是通过window.execute_script()执行一个js脚本来打开一个新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开新窗口后,驱动程序的当前页面仍然是上一页。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
代理设置是通过 ChromeOptions 设置的。示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999";)
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip";)
补充:get_property:获取html标签中写的官方属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求失败,此时可以保存当前页面的截图,以备日后分析。
动态网页抓取(动态网页抓取(被动访问)程序实现过程:txtbase64编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-23 11:05
动态网页抓取(被动访问)程序实现过程:txtbase64编码、xpath构造字符串、webserver抓取网页内容。步骤:txt解码、xpath选择、webserver抓取网页内容。跟踪:将抓取到的内容存入字典数据库。webserver将所获取到的字典数据存入json。
是可以的,推荐几种无限制(而且是最原始的)抓取网页的方法:主动访问百度页面,其他网站也可以爬,最后把它会返回scrapy.crawl(page)这个方法,txt=scrapy.crawl(page)如果txt已经被user-agent的meta信息中过滤了访问百度的网站,类似,也会返回scrapy.crawl(page)方法。
抓取相同的网站,其他网站也可以爬。txt=scrapy.crawl('baidu.html')如果是要抓取不存在的网站,之前提到的fastreporter就可以直接抓取,fastreporter是github-lfs/fastreporter:mostbestrequestintractablecrawler,scrapy.crawl()即可。
api已经可以设置不同的ip来发起请求,然后写入scrapy的数据库,然后拿到抓取结果并存入字典中。
在网上看到一篇,好像不错,以后遇到问题在找找吧,涉及的内容也不多,
有一个xmlhttprequest对象,该对象发起get请求;在ip请求中加入会话标识,就能判断哪些ip会被转换成真实网址,并返回xmlhttprequest对象。 查看全部
动态网页抓取(动态网页抓取(被动访问)程序实现过程:txtbase64编码)
动态网页抓取(被动访问)程序实现过程:txtbase64编码、xpath构造字符串、webserver抓取网页内容。步骤:txt解码、xpath选择、webserver抓取网页内容。跟踪:将抓取到的内容存入字典数据库。webserver将所获取到的字典数据存入json。
是可以的,推荐几种无限制(而且是最原始的)抓取网页的方法:主动访问百度页面,其他网站也可以爬,最后把它会返回scrapy.crawl(page)这个方法,txt=scrapy.crawl(page)如果txt已经被user-agent的meta信息中过滤了访问百度的网站,类似,也会返回scrapy.crawl(page)方法。
抓取相同的网站,其他网站也可以爬。txt=scrapy.crawl('baidu.html')如果是要抓取不存在的网站,之前提到的fastreporter就可以直接抓取,fastreporter是github-lfs/fastreporter:mostbestrequestintractablecrawler,scrapy.crawl()即可。
api已经可以设置不同的ip来发起请求,然后写入scrapy的数据库,然后拿到抓取结果并存入字典中。
在网上看到一篇,好像不错,以后遇到问题在找找吧,涉及的内容也不多,
有一个xmlhttprequest对象,该对象发起get请求;在ip请求中加入会话标识,就能判断哪些ip会被转换成真实网址,并返回xmlhttprequest对象。
动态网页抓取(静态的网页和静态网页的最大区别是什么??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-21 06:13
静态网页是简单的网页,纯HTML语言编写的网页,最有效的效果就是制作一个动画,让网页上可能有动的东西动起来。. . .
动态网页,标准定义是可以与用户交互的网页,即同一个网页,一个源服务器端文件,可以为不同的用户显示不同的内容等等,,,,可以与用户进行真实的交互。时间交互网页是动态网页。主要用JS、ASP、PHP等语言编写。
动态网页和静态网页最大的区别是:
1.静态页面不能随时更改。静态页面写一次,放到服务器上浏览。如果要改,必须在页面上修改,然后上传服务器覆盖原页面,这样信息才能更新。,比较麻烦,用户不能随时修改。
2.动态页面的内容可以随时更改。有前端和后端点。管理员可以随时更新后台网站的内容,前端页面的内容也会相应更新,比较简单易学。
静态网页是指:
不使用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。
动态网页是指:
使用web脚本语言,如php、asp等,通过脚本将网站的内容动态存储在数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。
网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
扩展信息:动态网页:
1. 所谓动态网页,是指相对于静态网页的一种网页编程技术。
2.静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变,除非你修改页面代码。
3. 动态网页不是这样。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
静态页面:
1.在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
2.静态网页相对于动态网页。它们是指没有后端数据库、没有程序、没有交互的网页。
3. 你编辑的就是它显示的,不会有任何变化。
4.静态网页更新比较麻烦,适合更新较少的显示类型网站。
参考资料:百度百科-动态网页百度百科-静态网页
总之一句话:动态网站往往有数据库,而静态网站没有。
动态网站常见的asp和php,两者分别是mdb数据库和SQL数据库。动态网站做起来麻烦,但是用起来方便。因为动态网站=页面设计+数据库,每个页面调用数据库中的内容,也就是数据库中存储的文本。
例如:
和
页面都是2.asp,但是前者调用的是数据库中id值为100的数据,后者是101。
这个用起来很方便,特别是修改网站时,只需要改2.asp的页面设计,不需要改数据库。
如果是静态的网站,那就麻烦了,要一页一页的换,而且没有后台,只能手动添加文件。
不知道看懂没有,有问题可以追问~
静态网页和动态网页主要根据制作网页的语言来区分:
静态网页语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
后缀为.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(2)网页内容一旦发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性是交叉的,在功能上有很大的限制。
好像明白了,先看后缀名,再看能不能和服务器交互
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
另外,如果扩展名为.asp但没有连接数据库,并且是一个完全静态的页面,它也是静态的网站。它只是.asp 的扩展名。
动态网站和静态网站的区别,请详述~!!-:静态网页和动态网页最大的区别在于网页是固定内容还是在线更新内容。静态网页即无应用程序直接或间接制作成html网页。这种网页的内容是固定的。修改和更新必须通过专用的网页创建工具进行,例如 Dreamweaver、Frontpage...
静态网站和动态网站有什么区别:动态网页对应静态网页,即网页网址后缀不是.htm、.html等静态网页, .shtml, .xml 等. 的常见形式是.asp, .jsp, .php, .perl, .cgi等形式的后缀,在动态网页网址中有一个标志性的符号—— “?”。如 ”...
静态网站和动态网站有什么区别?-:静态网站和动态网站的主要区别在于是否与后端数据库有交互,比如Bar:比如一个shopping网站,主要有两大块,一个是用户部分(一般叫前台),一个是管理员部分(一般叫后端),前台包括:提供新用户注册、现有用户登录、用户浏览产品、用户购买产品等功能。这种网站管理员部分非常重要。每当前台有新用户注册时,后台用户表中必须添加一个新用户,当用户想查看自己购物篮中的商品时,后端部分还必须把当前用户购买的物品展示给前台给用户看,比如网站是动态的 静态和动态的区别是不要做一些FLASH,这个网站@ > 是动态的网站,一般静态的网站是供大家浏览网站的内容。一般这样的网站是没有背景的。
静态网站 和动态网站 有什么区别?它们是什么样的?-:静态是那些用工具完成的固定网页。动态是程序自动生成的,比如你在百度上搜索电脑生成的网页,是根据你的关键词和一定的规则动态生成的。也就是说,它是由机器返回的。
静态网站 和动态网站 有什么区别?有什么异同?-:简单来说,动态网站的意思是,比如登录、留言、发帖文章等……也就是说,方便更新网站的内容(如QQ空间)。这些都是通过服务器来实现的。静态网站表示网页的内容(数据)无法动态更新,需要重新编辑。网站 然后发布后更新网站的内容(麻烦,不利于管理!)希望采纳!
动态网站和静态网站-的区别:静态网络和动态网站的区别在于能否与客户进行交互。比如静态的网站只是简单的显示你的产品信息仅供查看,你没有后台管理你的网站,每次要添加产品,都得更新再次网站,网站网站的部分需要调整。动态网站有后台管理功能,可以和客户互动。比如客户可以在线留言、在线购物,网站 经理也可以在线回答客户请求问题是在线查看客户提交的订单。以这样的互动形式,网站 管理人员只能通过后台看到它。同时需要一定的语言支持,如ASP、ASP.NET、PHP、JSP等。同时,如果你需要添加产品什么的,只要在后台提交一个新产品就可以了会好的。无需再次更改网站的格式,方便实用。大大提高了工作效率。
动态网站和静态网站有什么区别?:需要详细说明吗?还是个人总结?其他人的专业详细解答... >所有页面都是现成的,无需下载服务器上的某些内容进行展示。您单击该链接,它将显示出来。无论点击多少次,出现的页面永远是那个页面,基本不变。通常,URL 地址很简单,不是吗?= 等一些东西动态网站 如果url地址一般不是静态的,会有吗?= 等待内容,以php、asp、aspx等结尾.....你访问它需要下载一些内容到服务器数据库显示这里,每次访问这个页面的URL地址和内容也会变...
静态网站和动态网站的区别,动态网站是如何实现的?-:动态网页的一般特征简单总结如下:(1)动态网页都是以数据库技术为基础,可以大大减少网站维护的工作量;(2)网站采用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页...
静态网站和动态网站的区别?:一、动态网站和静态网站在功能上的区别1.动态< @网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 无法实现。2. 静态网站,比如用Frontpage 或Dreamweaver 开发的网站...
静态网站 和动态网站 有什么区别?谢谢~-:静态网站是不收录程序代码的网页,不会在服务器端执行。动态 网站 表示网页收录程序代码,将由服务器执行。 查看全部
动态网页抓取(静态的网页和静态网页的最大区别是什么??)
静态网页是简单的网页,纯HTML语言编写的网页,最有效的效果就是制作一个动画,让网页上可能有动的东西动起来。. . .
动态网页,标准定义是可以与用户交互的网页,即同一个网页,一个源服务器端文件,可以为不同的用户显示不同的内容等等,,,,可以与用户进行真实的交互。时间交互网页是动态网页。主要用JS、ASP、PHP等语言编写。
动态网页和静态网页最大的区别是:
1.静态页面不能随时更改。静态页面写一次,放到服务器上浏览。如果要改,必须在页面上修改,然后上传服务器覆盖原页面,这样信息才能更新。,比较麻烦,用户不能随时修改。
2.动态页面的内容可以随时更改。有前端和后端点。管理员可以随时更新后台网站的内容,前端页面的内容也会相应更新,比较简单易学。
静态网页是指:
不使用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。
动态网页是指:
使用web脚本语言,如php、asp等,通过脚本将网站的内容动态存储在数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。
网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
扩展信息:动态网页:
1. 所谓动态网页,是指相对于静态网页的一种网页编程技术。
2.静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变,除非你修改页面代码。
3. 动态网页不是这样。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
静态页面:
1.在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
2.静态网页相对于动态网页。它们是指没有后端数据库、没有程序、没有交互的网页。
3. 你编辑的就是它显示的,不会有任何变化。
4.静态网页更新比较麻烦,适合更新较少的显示类型网站。
参考资料:百度百科-动态网页百度百科-静态网页
总之一句话:动态网站往往有数据库,而静态网站没有。
动态网站常见的asp和php,两者分别是mdb数据库和SQL数据库。动态网站做起来麻烦,但是用起来方便。因为动态网站=页面设计+数据库,每个页面调用数据库中的内容,也就是数据库中存储的文本。
例如:
和
页面都是2.asp,但是前者调用的是数据库中id值为100的数据,后者是101。
这个用起来很方便,特别是修改网站时,只需要改2.asp的页面设计,不需要改数据库。
如果是静态的网站,那就麻烦了,要一页一页的换,而且没有后台,只能手动添加文件。
不知道看懂没有,有问题可以追问~
静态网页和动态网页主要根据制作网页的语言来区分:
静态网页语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
后缀为.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(2)网页内容一旦发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性是交叉的,在功能上有很大的限制。
好像明白了,先看后缀名,再看能不能和服务器交互
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
另外,如果扩展名为.asp但没有连接数据库,并且是一个完全静态的页面,它也是静态的网站。它只是.asp 的扩展名。
动态网站和静态网站的区别,请详述~!!-:静态网页和动态网页最大的区别在于网页是固定内容还是在线更新内容。静态网页即无应用程序直接或间接制作成html网页。这种网页的内容是固定的。修改和更新必须通过专用的网页创建工具进行,例如 Dreamweaver、Frontpage...
静态网站和动态网站有什么区别:动态网页对应静态网页,即网页网址后缀不是.htm、.html等静态网页, .shtml, .xml 等. 的常见形式是.asp, .jsp, .php, .perl, .cgi等形式的后缀,在动态网页网址中有一个标志性的符号—— “?”。如 ”...
静态网站和动态网站有什么区别?-:静态网站和动态网站的主要区别在于是否与后端数据库有交互,比如Bar:比如一个shopping网站,主要有两大块,一个是用户部分(一般叫前台),一个是管理员部分(一般叫后端),前台包括:提供新用户注册、现有用户登录、用户浏览产品、用户购买产品等功能。这种网站管理员部分非常重要。每当前台有新用户注册时,后台用户表中必须添加一个新用户,当用户想查看自己购物篮中的商品时,后端部分还必须把当前用户购买的物品展示给前台给用户看,比如网站是动态的 静态和动态的区别是不要做一些FLASH,这个网站@ > 是动态的网站,一般静态的网站是供大家浏览网站的内容。一般这样的网站是没有背景的。
静态网站 和动态网站 有什么区别?它们是什么样的?-:静态是那些用工具完成的固定网页。动态是程序自动生成的,比如你在百度上搜索电脑生成的网页,是根据你的关键词和一定的规则动态生成的。也就是说,它是由机器返回的。
静态网站 和动态网站 有什么区别?有什么异同?-:简单来说,动态网站的意思是,比如登录、留言、发帖文章等……也就是说,方便更新网站的内容(如QQ空间)。这些都是通过服务器来实现的。静态网站表示网页的内容(数据)无法动态更新,需要重新编辑。网站 然后发布后更新网站的内容(麻烦,不利于管理!)希望采纳!
动态网站和静态网站-的区别:静态网络和动态网站的区别在于能否与客户进行交互。比如静态的网站只是简单的显示你的产品信息仅供查看,你没有后台管理你的网站,每次要添加产品,都得更新再次网站,网站网站的部分需要调整。动态网站有后台管理功能,可以和客户互动。比如客户可以在线留言、在线购物,网站 经理也可以在线回答客户请求问题是在线查看客户提交的订单。以这样的互动形式,网站 管理人员只能通过后台看到它。同时需要一定的语言支持,如ASP、ASP.NET、PHP、JSP等。同时,如果你需要添加产品什么的,只要在后台提交一个新产品就可以了会好的。无需再次更改网站的格式,方便实用。大大提高了工作效率。
动态网站和静态网站有什么区别?:需要详细说明吗?还是个人总结?其他人的专业详细解答... >所有页面都是现成的,无需下载服务器上的某些内容进行展示。您单击该链接,它将显示出来。无论点击多少次,出现的页面永远是那个页面,基本不变。通常,URL 地址很简单,不是吗?= 等一些东西动态网站 如果url地址一般不是静态的,会有吗?= 等待内容,以php、asp、aspx等结尾.....你访问它需要下载一些内容到服务器数据库显示这里,每次访问这个页面的URL地址和内容也会变...
静态网站和动态网站的区别,动态网站是如何实现的?-:动态网页的一般特征简单总结如下:(1)动态网页都是以数据库技术为基础,可以大大减少网站维护的工作量;(2)网站采用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页...
静态网站和动态网站的区别?:一、动态网站和静态网站在功能上的区别1.动态< @网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 无法实现。2. 静态网站,比如用Frontpage 或Dreamweaver 开发的网站...
静态网站 和动态网站 有什么区别?谢谢~-:静态网站是不收录程序代码的网页,不会在服务器端执行。动态 网站 表示网页收录程序代码,将由服务器执行。
动态网页抓取(关于with语句与上下文管理器三、思路整理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-21 06:09
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成之前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = \'http://unsplash.com/napi/feeds/home\'
id_url = \'http://unsplash.com/napi/feeds/home\'
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'*************\'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = \'utf-8\'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
id_lists.append(each[\'id\'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__==\'__main__\':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此参数需从包中获取
}
file_path = \'images\'
download_url = \'https://unsplash.com/photos/{}/download?force=true\'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, \'ab+\') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
img_id = \'vgpHniLr9Uw\'
download(img_id)
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = \'http://unsplash.com/napi/feeds/home\'
self.header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此部分需要自行添加
}
self.id_lists = []
self.download_url=\'https://unsplash.com/photos/{}/download?force=true\'
print("init")
def get_ids(self):
# target_url = \'http://unsplash.com/napi/feeds/home\'
# target_url = \'https://unsplash.com/\'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = \'utf-8\'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
self.id_lists.append(each[\'id\'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = \'images\'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,\'ab+\') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,就剩下写爬虫的步骤了 查看全部
动态网页抓取(关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成之前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = \'http://unsplash.com/napi/feeds/home\'
id_url = \'http://unsplash.com/napi/feeds/home\'
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'*************\'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = \'utf-8\'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
id_lists.append(each[\'id\'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__==\'__main__\':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此参数需从包中获取
}
file_path = \'images\'
download_url = \'https://unsplash.com/photos/{}/download?force=true\'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, \'ab+\') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
img_id = \'vgpHniLr9Uw\'
download(img_id)
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = \'http://unsplash.com/napi/feeds/home\'
self.header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此部分需要自行添加
}
self.id_lists = []
self.download_url=\'https://unsplash.com/photos/{}/download?force=true\'
print("init")
def get_ids(self):
# target_url = \'http://unsplash.com/napi/feeds/home\'
# target_url = \'https://unsplash.com/\'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = \'utf-8\'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
self.id_lists.append(each[\'id\'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = \'images\'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,\'ab+\') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,就剩下写爬虫的步骤了
动态网页抓取(selenium、firefox浏览器如何抓取、css?动态网页抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-20 16:00
动态网页抓取1.javascript中的httppost拿js文件-javascript中的httppost拿js文件-神生社区-博客园2.httpget:其它javascript代码3.selenium4.webdriver
最笨拙的方法就是用firebug,可以很方便的抓取js、css、图片等静态资源。js、css文件通常是加密存储在http服务端,本地看不见、改不了,所以只能抓取,但抓取效率没法看。selenium之前webdriver在做抓取的时候遇到这个问题,然后自己动手写了一个解决方案。firefox、safari浏览器的postinfo、document.cookie等都是动态获取的,所以我们是不可能抓取js的,抓取css文件没问题,但图片就有点难了。
safari、firefox浏览器如何抓取js、css?有没有可以抓取js文件的浏览器呢?有的。chrome浏览器自带的webdriver是可以抓取js文件的,通过设置monitoring选项卡里的#location.href,它可以指定浏览器的地址,让浏览器自动给出js代码。ie、火狐这些浏览器也可以抓取js文件,但是需要额外的设置。
怎么设置呢?在插件的设置界面,找到selenium-->options-->plugins,按下图上所示去设置,就可以使用webdriver抓取js、css了。但是document.cookie是不可以抓取的,这也是selenium抓取不了css、js文件的原因。但我又发现,如果不做相应设置的话,document.cookie是可以抓取静态资源的,我通过如下设置设置一下即可:我先把ie浏览器调成默认页面(兼容模式),然后根据页面上的路径,在browser中按下f12,选择network(然后找到browser.session.cookie.js),点击meta,这样就可以查看到该js的链接了。
直接在firefox中访问,就会抓取一段js代码。但由于selenium抓取是随机顺序抓取的,此时自动抓取browser.session.cookie.js页面,因此会无法抓取链接中的js代码。解决方案:给此页面设置offset和maximum-page-size,如设置offset是1024,maximum-page-size就是1,就可以抓取这页所有js代码。推荐在ie浏览器设置offset和maximum-page-size。 查看全部
动态网页抓取(selenium、firefox浏览器如何抓取、css?动态网页抓取)
动态网页抓取1.javascript中的httppost拿js文件-javascript中的httppost拿js文件-神生社区-博客园2.httpget:其它javascript代码3.selenium4.webdriver
最笨拙的方法就是用firebug,可以很方便的抓取js、css、图片等静态资源。js、css文件通常是加密存储在http服务端,本地看不见、改不了,所以只能抓取,但抓取效率没法看。selenium之前webdriver在做抓取的时候遇到这个问题,然后自己动手写了一个解决方案。firefox、safari浏览器的postinfo、document.cookie等都是动态获取的,所以我们是不可能抓取js的,抓取css文件没问题,但图片就有点难了。
safari、firefox浏览器如何抓取js、css?有没有可以抓取js文件的浏览器呢?有的。chrome浏览器自带的webdriver是可以抓取js文件的,通过设置monitoring选项卡里的#location.href,它可以指定浏览器的地址,让浏览器自动给出js代码。ie、火狐这些浏览器也可以抓取js文件,但是需要额外的设置。
怎么设置呢?在插件的设置界面,找到selenium-->options-->plugins,按下图上所示去设置,就可以使用webdriver抓取js、css了。但是document.cookie是不可以抓取的,这也是selenium抓取不了css、js文件的原因。但我又发现,如果不做相应设置的话,document.cookie是可以抓取静态资源的,我通过如下设置设置一下即可:我先把ie浏览器调成默认页面(兼容模式),然后根据页面上的路径,在browser中按下f12,选择network(然后找到browser.session.cookie.js),点击meta,这样就可以查看到该js的链接了。
直接在firefox中访问,就会抓取一段js代码。但由于selenium抓取是随机顺序抓取的,此时自动抓取browser.session.cookie.js页面,因此会无法抓取链接中的js代码。解决方案:给此页面设置offset和maximum-page-size,如设置offset是1024,maximum-page-size就是1,就可以抓取这页所有js代码。推荐在ie浏览器设置offset和maximum-page-size。
动态网页抓取(动态网页抓取抓取网页有几种方法,http请求全过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-20 12:02
动态网页抓取抓取网页有几种方法,我总结过这几种方法:http请求全过程从网页标题、网页内容全文抓取抓取文章全文抓取伪静态代理/代理池自动翻页、自动跳转自动selenium自动爬虫准备工作selenium:开源的webdriver框架,会和上面几种方法同时支持。如果你的浏览器不支持请自行购买license。
bootstrap:javascript的封装库,也可以使用,但是必须向前兼容。伪静态可以让你爬取的页面看起来像主页一样,不改变内容。如果你网站的页面上没有让浏览器渲染的js文件,那你可以使用伪静态,例如selenium的index.html,它只是浏览器页面的一种显示方式,并不改变内容。http请求:http协议非常简单,可以很容易理解。
抓取网页时,你必须理解的概念就是你要从哪个url下。有明确的url,然后你才可以去请求。请求的四种方法:get方法post方法put方法delete方法正常情况下,所有请求请求都会返回html内容。如果没有明确url,那你可以在headers上指定url(会对http协议做修改),然后参数表示请求当前页面的位置。
例如,抓取新浪博客,你可以这样指定当前页面:post://首页/content/type(‘text/post’)put://首页/content/type(‘put’)delete://首页/content/type(‘delete’)如果不支持请求身份验证和响应体(payload),对于抓取,你就会经常失败。
例如抓取新浪博客内容,你需要在请求头信息里指定你的请求是验证请求。获取请求头信息有些比较难编写,但是如果你要用ajax,那你需要这样做。正常情况下,http请求会包含请求头信息,而响应体只支持xml格式,或xmlx,或xmlt,或者json。当http请求包含响应体后,post请求会被转换为json或xml形式的。
比如,你可以用http请求来获取网站左边部分:post://首页/.content-type:application/json然后你得到html的内容,其中的值是网站左边的每个字段值。然后你把它们发送到json解析库(jsonbindings)。bindings是用来解析请求中的请求头信息。如果你需要请求一个session,你也必须将form或method字段转换为bindings,以后再依次请求。
请求头信息请求头信息包括请求的useragent(浏览器),主机名,端口号和名称。还有些仅仅提供xml格式参数或useragent列表,其他的格式请参照json。假设你发送请求到一个httpoauth的网站(不是红牛,不是张小龙微博,不是李彦宏)。请求头信息里包括第一个useragent-用户代理,最后一个是主机名。还有下面的内容,浏览器用浏览器打开。 查看全部
动态网页抓取(动态网页抓取抓取网页有几种方法,http请求全过程)
动态网页抓取抓取网页有几种方法,我总结过这几种方法:http请求全过程从网页标题、网页内容全文抓取抓取文章全文抓取伪静态代理/代理池自动翻页、自动跳转自动selenium自动爬虫准备工作selenium:开源的webdriver框架,会和上面几种方法同时支持。如果你的浏览器不支持请自行购买license。
bootstrap:javascript的封装库,也可以使用,但是必须向前兼容。伪静态可以让你爬取的页面看起来像主页一样,不改变内容。如果你网站的页面上没有让浏览器渲染的js文件,那你可以使用伪静态,例如selenium的index.html,它只是浏览器页面的一种显示方式,并不改变内容。http请求:http协议非常简单,可以很容易理解。
抓取网页时,你必须理解的概念就是你要从哪个url下。有明确的url,然后你才可以去请求。请求的四种方法:get方法post方法put方法delete方法正常情况下,所有请求请求都会返回html内容。如果没有明确url,那你可以在headers上指定url(会对http协议做修改),然后参数表示请求当前页面的位置。
例如,抓取新浪博客,你可以这样指定当前页面:post://首页/content/type(‘text/post’)put://首页/content/type(‘put’)delete://首页/content/type(‘delete’)如果不支持请求身份验证和响应体(payload),对于抓取,你就会经常失败。
例如抓取新浪博客内容,你需要在请求头信息里指定你的请求是验证请求。获取请求头信息有些比较难编写,但是如果你要用ajax,那你需要这样做。正常情况下,http请求会包含请求头信息,而响应体只支持xml格式,或xmlx,或xmlt,或者json。当http请求包含响应体后,post请求会被转换为json或xml形式的。
比如,你可以用http请求来获取网站左边部分:post://首页/.content-type:application/json然后你得到html的内容,其中的值是网站左边的每个字段值。然后你把它们发送到json解析库(jsonbindings)。bindings是用来解析请求中的请求头信息。如果你需要请求一个session,你也必须将form或method字段转换为bindings,以后再依次请求。
请求头信息请求头信息包括请求的useragent(浏览器),主机名,端口号和名称。还有些仅仅提供xml格式参数或useragent列表,其他的格式请参照json。假设你发送请求到一个httpoauth的网站(不是红牛,不是张小龙微博,不是李彦宏)。请求头信息里包括第一个useragent-用户代理,最后一个是主机名。还有下面的内容,浏览器用浏览器打开。
动态网页抓取(从功能方面来说动态网站与静态网站的区别和区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-20 09:07
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然查看者可以看到源代码,但已经是转换后的代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密性。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是对动态网站和静态网站的基本分析,但在实际应用中,每个人都会有不同的体会,细微而本质的区别远不止上面列出的。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。公司的大部分网站都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页最大的区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使采用动态网站技术,网页的内容也被转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存入数据库,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性 查看全部
动态网页抓取(从功能方面来说动态网站与静态网站的区别和区别)
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然查看者可以看到源代码,但已经是转换后的代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密性。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是对动态网站和静态网站的基本分析,但在实际应用中,每个人都会有不同的体会,细微而本质的区别远不止上面列出的。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。公司的大部分网站都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页最大的区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使采用动态网站技术,网页的内容也被转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存入数据库,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性
动态网页抓取(soup搜索节点操作删除节点的一种好的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 01:18
前言:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文在python+chrome(谷歌浏览器)+chromedrive(谷歌浏览器驱动)中使用selenium(pyhton包)
推荐Chrome和Chromdrive下载最新版本(参考地址:)
它还支持无头模式(无需打开浏览器)
直接上传代码:site_url:要爬取的地址,CHROME_DRIVER_PATH:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
一个返回的soup,方便你搜索这个soup的节点,使用select、search、find等方法找到你想要的节点或者数据
同样,如果您想将其下载为文本,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
下面详细说一下,beautifusoup的搜索
如何先定位标签
1.使用find(本博主详细介绍)
2.使用选择
通过标签名、类名、id 类似jquery来选择soup.select('p .link #link1')这样的选择器。
按属性搜索,如href、title、link等属性,如soup.select('p a[href=""]')
这里匹配的是最小的,他的上级是
接下来说说节点的操作
删除节点 tag.decompose()
在指定位置插入子节点tag.insert(0,chlid_tag)
最后,beautifusoup 是过滤元素的好方法。在下一篇文章中,我们将介绍正则表达式匹配和过滤。爬虫内容 查看全部
动态网页抓取(soup搜索节点操作删除节点的一种好的方法(上))
前言:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文在python+chrome(谷歌浏览器)+chromedrive(谷歌浏览器驱动)中使用selenium(pyhton包)
推荐Chrome和Chromdrive下载最新版本(参考地址:)
它还支持无头模式(无需打开浏览器)
直接上传代码:site_url:要爬取的地址,CHROME_DRIVER_PATH:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
一个返回的soup,方便你搜索这个soup的节点,使用select、search、find等方法找到你想要的节点或者数据
同样,如果您想将其下载为文本,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
下面详细说一下,beautifusoup的搜索
如何先定位标签
1.使用find(本博主详细介绍)
2.使用选择
通过标签名、类名、id 类似jquery来选择soup.select('p .link #link1')这样的选择器。
按属性搜索,如href、title、link等属性,如soup.select('p a[href=""]')
这里匹配的是最小的,他的上级是
接下来说说节点的操作
删除节点 tag.decompose()
在指定位置插入子节点tag.insert(0,chlid_tag)
最后,beautifusoup 是过滤元素的好方法。在下一篇文章中,我们将介绍正则表达式匹配和过滤。爬虫内容
动态网页抓取(Ajax理论1.Ajax提取AjaxAjaxAjax分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-19 01:14
)
上面提到的爬虫都是建立在静态网页的基础上的。首先通过请求网站url获取网页源码。之后,从源代码中提取信息并存储。本文将重点介绍动态网页数据采集,先介绍Ajax相关理论,然后在实战中爬取Flush的动态网页,获取个股信息。
内容
一、Ajax 理论
1.Ajax 简介
2.ajax分析
3.Ajax 提取
二、网络分析
1.网页概览
2.Ajax 歧视
3.Ajax 提取
三、爬虫实战
1.网页访问
2.信息抽取
3.保存数据
4.循环结构
一、Ajax 理论
1.Ajax 简介
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,可以创建交互式、快速和动态的 Web 应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
2.ajax分析
微博网站是一个带有Ajax的动态网页,易于识别。首先打开Dectools工具(调整到XHR专栏)和中南财经政法大学官方微博网站(),这里选择的是移动端微博,然后选择清除所有内容.
接下来,滚动滚轮以下拉页面,直到清空的 XHR 列中出现新项目。点击此项,选择预览栏,发现这里对应的内容是页面上新出现的微博,上面的网页链接但是没有变化。此时,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
还是选择同一个入口进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求url为:,即请求参数有4个:type、value、containerid、since_id,然后翻页发现,除了since_id发生了变化,其余的都保持不变。这里我们可以看到since_id是翻页方法。
接下来观察since_id,发现上下请求之间的since_id没有明显的规律。进一步搜索发现下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态URL添加到爬虫中。
发起请求获取响应后,进一步分析发现响应格式是json,所以进一步处理json就可以得到最终的数据了!
二、网络分析
1.网页概览
有了上面的分析,我们就用flush网页采集的数据,通过实战来验证一下。首先打开网页:如下图:
再按F12键打开Devtools后端源代码,将鼠标放在第一项上,点击右键,查看源代码中的位置。
2.Ajax 歧视
接下来,我们点击网页底部的下一页,发现网页url没有任何变化!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清除了网络中的所有内容,继续点击下一页到第五页,发现连续弹出了三个同名的消息。请求的URL和请求头的具体内容可以通过General一栏获取。
于是,我们复制了请求的url,在浏览器中打开,结果响应内容是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页形式,和上面微博响应的json格式不同,所以可以在后面的网页分析的形式。
三、爬虫实战
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的一点是,这里的请求头除了User-Agent之外,还需要host、Referer和X-Requested-With参数,这应该和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息抽取
之后就是上面分析库的内容了,这里就更容易理解BaetifulSoup库了。首先将上面的html转换成一个BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应的信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
同时考虑到flush的多页结构和反爬虫的存在,也采用字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬行前中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
至此,Flush动态网页的爬取完成,接下来由这个爬虫总结:首先,我们通过浏览网页结构,翻页,对比XHR栏,对变化的网页进行Ajax判断。如果网页url不变,XHR会刷新内容,基本说明是动态网页,此时我们进一步检查多个页面之间URL请求的异同,找出规律。找到规则后,就可以建立多页请求流程了。之后对单个响应内容进行处理(详细参见响应内容的格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫完整代码可在公众号回复“Flush”获取。下面将进一步讲解和实战浏览器模拟行为。上一篇涉及的基础知识,请参考以下链接:
我知道你在“看”
查看全部
动态网页抓取(Ajax理论1.Ajax提取AjaxAjaxAjax分析
)
上面提到的爬虫都是建立在静态网页的基础上的。首先通过请求网站url获取网页源码。之后,从源代码中提取信息并存储。本文将重点介绍动态网页数据采集,先介绍Ajax相关理论,然后在实战中爬取Flush的动态网页,获取个股信息。
内容
一、Ajax 理论
1.Ajax 简介
2.ajax分析
3.Ajax 提取
二、网络分析
1.网页概览
2.Ajax 歧视
3.Ajax 提取
三、爬虫实战
1.网页访问
2.信息抽取
3.保存数据
4.循环结构
一、Ajax 理论
1.Ajax 简介
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,可以创建交互式、快速和动态的 Web 应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
2.ajax分析
微博网站是一个带有Ajax的动态网页,易于识别。首先打开Dectools工具(调整到XHR专栏)和中南财经政法大学官方微博网站(),这里选择的是移动端微博,然后选择清除所有内容.
接下来,滚动滚轮以下拉页面,直到清空的 XHR 列中出现新项目。点击此项,选择预览栏,发现这里对应的内容是页面上新出现的微博,上面的网页链接但是没有变化。此时,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
还是选择同一个入口进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求url为:,即请求参数有4个:type、value、containerid、since_id,然后翻页发现,除了since_id发生了变化,其余的都保持不变。这里我们可以看到since_id是翻页方法。
接下来观察since_id,发现上下请求之间的since_id没有明显的规律。进一步搜索发现下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态URL添加到爬虫中。
发起请求获取响应后,进一步分析发现响应格式是json,所以进一步处理json就可以得到最终的数据了!
二、网络分析
1.网页概览
有了上面的分析,我们就用flush网页采集的数据,通过实战来验证一下。首先打开网页:如下图:
再按F12键打开Devtools后端源代码,将鼠标放在第一项上,点击右键,查看源代码中的位置。
2.Ajax 歧视
接下来,我们点击网页底部的下一页,发现网页url没有任何变化!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清除了网络中的所有内容,继续点击下一页到第五页,发现连续弹出了三个同名的消息。请求的URL和请求头的具体内容可以通过General一栏获取。
于是,我们复制了请求的url,在浏览器中打开,结果响应内容是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页形式,和上面微博响应的json格式不同,所以可以在后面的网页分析的形式。
三、爬虫实战
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的一点是,这里的请求头除了User-Agent之外,还需要host、Referer和X-Requested-With参数,这应该和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息抽取
之后就是上面分析库的内容了,这里就更容易理解BaetifulSoup库了。首先将上面的html转换成一个BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应的信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
同时考虑到flush的多页结构和反爬虫的存在,也采用字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬行前中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
至此,Flush动态网页的爬取完成,接下来由这个爬虫总结:首先,我们通过浏览网页结构,翻页,对比XHR栏,对变化的网页进行Ajax判断。如果网页url不变,XHR会刷新内容,基本说明是动态网页,此时我们进一步检查多个页面之间URL请求的异同,找出规律。找到规则后,就可以建立多页请求流程了。之后对单个响应内容进行处理(详细参见响应内容的格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫完整代码可在公众号回复“Flush”获取。下面将进一步讲解和实战浏览器模拟行为。上一篇涉及的基础知识,请参考以下链接:
我知道你在“看”
动态网页抓取(Ajax加载页面特点及优势分析-乐题库(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-18 05:16
动态网页数据抓取一、网页
1.传统网页:
如果需要更新内容,则需要重新加载网页。
2.动态网页:
使用AJAX,无需加载和更新整个网页即可实现部分内容更新。
二、什么是AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。
理解:通过后台与服务器的少量数据交换【一般是post请求】,Ajax可以让网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
例如:百度图片使用Ajax加载页面。
Ajax加载页面特点:交互产生的数据不会出现在网页的源代码中,也就是说我们无法通过python发送请求直接获取这些新出现的数据,那么爬虫只能抓取没有Ajax交互产生的数据. 数据。假设一个网页是Ajax动态加载的,一共有十页,但是如果通过Python获取,一般只能获取一页,无法直接获取后面的九页数据。
Ajax加载页面的原理:通过一定的接口【可以理解为一个URL】与服务器交换数据,从而在当前页面加载新的数据。
Ajax加载页面的优点:
1.反爬虫。对于一些初级爬虫工程师来说,如果不了解异步加载,总觉得代码没问题,但是拿不到自己想要的数据,所以怀疑自己的代码有问题,直到怀疑他们的生活。
2. 更便捷的响应用户数据,优化用户体验。一个页面通常具有相同的内容。如果每次都重复加载一个页面,实际上是重复加载了完全相同的差异,浪费了响应时间。
Ajax加载页面的缺点:
破坏浏览器后退按钮的正常行为。例如,一个网页有十页。动态加载后,十个页面都加载在同一个页面上,但是你不可能回到第九个页面。因此,浏览器的后退按钮对于这种情况是无效的。NS。
三、爬虫如何处理Ajax
1.找一个接口
既然Ajax是通过一个接口【特定的URL】与服务器交互的,那么我们只需要找到这个接口,然后模拟浏览器发送请求即可。
技术难点:
(1)可能有多个接口,一个网页可能有多个具体的数据交互接口,这就需要我们自己去尝试多次查找,增加了爬取的难度。
(2)与服务器交互的数据加密比较困难**。与服务器交互时需要发送数据,但这部分数据是网站的开发者设置的。什么数据是浏览器发送的,虽然我们在大多数情况下都能找到,但是数据是经过加密的,获取起来比较困难。
(3)需要爬虫工程师有较高的js功底。
2.使用 selenium 模拟浏览器行为
它相当于使用代码来操纵浏览器行为。浏览器能拿到什么数据,我们就能拿到什么数据。
技术难点:
代码量很大。
3.两种方法的比较
方式优缺点
分析界面
代码量小,性能高。
有些网站接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
模拟浏览器的行为。浏览器可以请求的也可以用selenium来请求,爬虫更稳定。
代码量大,性能低。
四、总结:
先分析界面。如果接口简单,那么使用接口来获取数据。如果界面复杂,那就用selenium来模拟浏览器的行为,获取数据。
一切都有优点和缺点。一方面是快捷方便,另一方面难免会带来复杂性。因此,由您来权衡利弊或成本。 查看全部
动态网页抓取(Ajax加载页面特点及优势分析-乐题库(一))
动态网页数据抓取一、网页
1.传统网页:
如果需要更新内容,则需要重新加载网页。
2.动态网页:
使用AJAX,无需加载和更新整个网页即可实现部分内容更新。
二、什么是AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。
理解:通过后台与服务器的少量数据交换【一般是post请求】,Ajax可以让网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
例如:百度图片使用Ajax加载页面。

Ajax加载页面特点:交互产生的数据不会出现在网页的源代码中,也就是说我们无法通过python发送请求直接获取这些新出现的数据,那么爬虫只能抓取没有Ajax交互产生的数据. 数据。假设一个网页是Ajax动态加载的,一共有十页,但是如果通过Python获取,一般只能获取一页,无法直接获取后面的九页数据。
Ajax加载页面的原理:通过一定的接口【可以理解为一个URL】与服务器交换数据,从而在当前页面加载新的数据。
Ajax加载页面的优点:
1.反爬虫。对于一些初级爬虫工程师来说,如果不了解异步加载,总觉得代码没问题,但是拿不到自己想要的数据,所以怀疑自己的代码有问题,直到怀疑他们的生活。
2. 更便捷的响应用户数据,优化用户体验。一个页面通常具有相同的内容。如果每次都重复加载一个页面,实际上是重复加载了完全相同的差异,浪费了响应时间。
Ajax加载页面的缺点:
破坏浏览器后退按钮的正常行为。例如,一个网页有十页。动态加载后,十个页面都加载在同一个页面上,但是你不可能回到第九个页面。因此,浏览器的后退按钮对于这种情况是无效的。NS。
三、爬虫如何处理Ajax
1.找一个接口
既然Ajax是通过一个接口【特定的URL】与服务器交互的,那么我们只需要找到这个接口,然后模拟浏览器发送请求即可。
技术难点:
(1)可能有多个接口,一个网页可能有多个具体的数据交互接口,这就需要我们自己去尝试多次查找,增加了爬取的难度。
(2)与服务器交互的数据加密比较困难**。与服务器交互时需要发送数据,但这部分数据是网站的开发者设置的。什么数据是浏览器发送的,虽然我们在大多数情况下都能找到,但是数据是经过加密的,获取起来比较困难。
(3)需要爬虫工程师有较高的js功底。
2.使用 selenium 模拟浏览器行为
它相当于使用代码来操纵浏览器行为。浏览器能拿到什么数据,我们就能拿到什么数据。
技术难点:
代码量很大。
3.两种方法的比较
方式优缺点
分析界面
代码量小,性能高。
有些网站接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
模拟浏览器的行为。浏览器可以请求的也可以用selenium来请求,爬虫更稳定。
代码量大,性能低。
四、总结:
先分析界面。如果接口简单,那么使用接口来获取数据。如果界面复杂,那就用selenium来模拟浏览器的行为,获取数据。
一切都有优点和缺点。一方面是快捷方便,另一方面难免会带来复杂性。因此,由您来权衡利弊或成本。
动态网页抓取(如何捕获到动态加载的数据?小编来一起学习学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-26 16:22
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面时代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock%3FskuId% ... D1713,3259,3333&venderId=10000779XCddJb23&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jquery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
文章关于python爬取网页动态加载的数据的介绍到此结束。更多相关Python爬取网页动态数据内容,请搜索我们之前的文章或继续浏览以下相关文章希望大家以后多多支持!
文章名称:Python实现网页动态加载数据的爬取 查看全部
动态网页抓取(如何捕获到动态加载的数据?小编来一起学习学习)
本文文章主要介绍Python对网页动态加载的数据进行爬取的实现。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友关注小编,一起学习
在使用python爬虫技术采集数据信息时,我们经常会遇到在返回的网页信息中,无法抓取到动态加载的可用数据。例如,当获取某个网页中的产品价格时,就会出现这种现象。如下所示。本文将实现对网页中类似动态加载数据的抓取。
1. 那么什么是动态加载的数据呢?
我们可以通过requests模块抓取数据,不能每次都可见。部分数据是通过非浏览器地址栏中的url请求获取的。但是通过其他请求请求的数据,那么通过其他请求请求的这些数据就是动态加载的数据。(猜测是我们访问这个页面时代码会发送get请求,从其他url获取数据)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,抓包地址栏中url对应的数据包,在数据包的响应选项卡中搜索我们要抓取的数据,如果找到搜索结果,则表示数据不是动态加载的。否则,数据是动态加载的。如图所示:
或者在要爬取的页面上右键,显示该网页的源代码。搜索我们要抓取的数据。如果找到搜索结果,则说明该数据不是动态加载的,否则说明该数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据?
在抓取动态加载的数据信息时,首先需要根据动态加载技术在浏览器的网络监控中选择网络请求的类型,然后通过一一过滤的方式查询预览信息中的关键数据,得到相应的Request地址,最后分析信息。具体步骤如下:
在浏览器中,快捷键F12打开开发者工具,然后在网络类型中选择Network(网络监视器)并选择JS,然后按快捷键F5刷新,如下图所示。
在请求信息列表中依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载数据,如下图所示。
查看动态加载的数据信息后,点击Headers,获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤获取的请求地址,发送网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。可以点击这里了解json序列化和反序列化。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock%3FskuId% ... D1713,3259,3333&venderId=10000779XCddJb23&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jquery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者写博文的时候,价格发生了变化,运行结果如下图所示:
注意:抓取动态加载数据信息时,需要根据不同的网页采用不同的方法进行数据提取。如果在运行源代码时出现错误,请按照步骤获取新的请求地址。
文章关于python爬取网页动态加载的数据的介绍到此结束。更多相关Python爬取网页动态数据内容,请搜索我们之前的文章或继续浏览以下相关文章希望大家以后多多支持!
文章名称:Python实现网页动态加载数据的爬取
动态网页抓取(动态网页信息的爬取(一)_博客_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-26 16:17
第一个博客从爬虫开始。虽然之前学过爬虫,但还是花了很长时间才重新上手。今天就来说说爬取动态网页信息。
先介绍一下抓取网页信息的基本思路:1.使用爬虫请求网页,获取网页源码2.分析源码,在源码中找到自己想要的信息;3.如果还有url地址,再次请求,重复步骤1和2。
找到我们想要的信息的url,有些url并不是我们想要的信息的真实url。查看源代码时,找不到所需的数据。这是因为这部分信息是动态获取的。下面以游牧之星今日推荐为例,获取信息类别、信息标题、信息介绍、发布时间、阅读数、评论数、图片路径等路径。网址=''
单页信息获取
网页如下
查看网页的源代码,在源代码中找到你需要的所有信息:
发现需要的信息在代码块中,但是评论数中没有值,说明动态获取评论数,找到了评论数的真实URL。
查看网页在网络中的情况,获得评论数的真实联系
js代码是
所述joincount要获得的评论的数量,而id是评论的数量以%2C1120919%2C1120764%2C1120676%2C1120483%2C1120737%2C1120383%2C1120344%2C1120301%2C1120184%2C1118361%2C1100332%2C1054392&_ = 65实际网址=”
现在的目的是获取id,id可以从源码中的data-sid属性中获取。
找到要获取的信息后,就是请求网页,解析代码。下面使用lxml进行解析,代码如下:
from lxml import etree
import requests
#获取单页的信息
def one_page_info():
url='https://www.gamersky.com/news/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=headers)
r_text=r.content.decode('utf-8')
html=etree.HTML(r_text) #解析源代码
#所有信息都在div,属性为Mid2L_con block的li标签中,获取所有li标签
all_li=html.xpath('//div[@class="Mid2L_con block"]/ul[@class="pictxt contentpaging"]/li')
all_inf=[]
#遍历li标签,获取每一个li标签中的信息
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]#资讯类型
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]#资讯名
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')#资讯信息,其中有些信息换行了,将换行符替换
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]#发布时间
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]#阅读数量
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]#获取id
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
#保存文件
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
运行代码后,得到的信息如下:
在下方抓取多页信息
翻页信息获取
步骤还是和单页一样。当我们翻页的时候,发现网址没有变
并且查看源码,发现信息还在第一页,所以当有多个页面时,也是动态获取的。检查网络以找到该信息的真实链接。
查看这里的预览,找到信息的真实链接,下一步就是获取链接中的参数并拼接链接。
对比两个页面的链接,发现只有页面参数和两个页面链接末尾的数字不同,末尾的数字是时间参数。
因此,2页后的真正链接是 url='"{"type"%3A"updatenodelabel"%2C"isCache"%3Atrue%2C"cacheTime"%3A60%2C"nodeId"%3A"11007"%2C"isNodeId "%3A"true"%2C"page"%3A"+page+"}&_="+now_time'
替换 page=1 也是适用的。因此,上面是每个页面所需信息的通用链接(实际上,在翻页时,这里的li标签替换了源代码中的li标签)。
下一步就是请求每个页面的网页,获取每个页面的li标签,然后像单个页面一样获取。
代码:
#爬取多页动态网页,找出url之间的规则,传递所要爬取的页
def more_page_info(page):
now_time=str(time.time()).replace('.','')[0:13]
#每页想要获取信息的url
page_url="https://db2.gamersky.com/Label ... 2Bstr(page)+"%7D&_="+now_time
headers={
"referer": "https://www.gamersky.com/news/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
r=requests.get(page_url,headers=headers)
html=json.loads(r.text[41:-2])['body']#将json字符串转换为字典
r_text=etree.HTML(html)
all_li=r_text.xpath('//li')#获取所有的li标签
all_inf=[]
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
获取前3页信息
for page in range(1,4):
info=more_page_info(page)
save_to_file(info)
print('第%d页下载完成'%page)
综上所述,这取决于需要的信息是静态加载还是动态加载。判断是否是动态网页的简单方法就是看源码中是否可以找到你要获取的信息。动态网页的关键是找到所需信息的真实URL,比较每个页面的URL,找出规则并传递参数,如果参数是从其他动态URL中获取的,则找到参数信息的URL ,然后按个人信息获取。 查看全部
动态网页抓取(动态网页信息的爬取(一)_博客_)
第一个博客从爬虫开始。虽然之前学过爬虫,但还是花了很长时间才重新上手。今天就来说说爬取动态网页信息。
先介绍一下抓取网页信息的基本思路:1.使用爬虫请求网页,获取网页源码2.分析源码,在源码中找到自己想要的信息;3.如果还有url地址,再次请求,重复步骤1和2。
找到我们想要的信息的url,有些url并不是我们想要的信息的真实url。查看源代码时,找不到所需的数据。这是因为这部分信息是动态获取的。下面以游牧之星今日推荐为例,获取信息类别、信息标题、信息介绍、发布时间、阅读数、评论数、图片路径等路径。网址=''
单页信息获取
网页如下
查看网页的源代码,在源代码中找到你需要的所有信息:
发现需要的信息在代码块中,但是评论数中没有值,说明动态获取评论数,找到了评论数的真实URL。
查看网页在网络中的情况,获得评论数的真实联系
js代码是
所述joincount要获得的评论的数量,而id是评论的数量以%2C1120919%2C1120764%2C1120676%2C1120483%2C1120737%2C1120383%2C1120344%2C1120301%2C1120184%2C1118361%2C1100332%2C1054392&_ = 65实际网址=”
现在的目的是获取id,id可以从源码中的data-sid属性中获取。
找到要获取的信息后,就是请求网页,解析代码。下面使用lxml进行解析,代码如下:
from lxml import etree
import requests
#获取单页的信息
def one_page_info():
url='https://www.gamersky.com/news/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
r=requests.get(url,headers=headers)
r_text=r.content.decode('utf-8')
html=etree.HTML(r_text) #解析源代码
#所有信息都在div,属性为Mid2L_con block的li标签中,获取所有li标签
all_li=html.xpath('//div[@class="Mid2L_con block"]/ul[@class="pictxt contentpaging"]/li')
all_inf=[]
#遍历li标签,获取每一个li标签中的信息
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]#资讯类型
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]#资讯名
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')#资讯信息,其中有些信息换行了,将换行符替换
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]#发布时间
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]#阅读数量
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]#获取id
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
#保存文件
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
运行代码后,得到的信息如下:
在下方抓取多页信息
翻页信息获取
步骤还是和单页一样。当我们翻页的时候,发现网址没有变
并且查看源码,发现信息还在第一页,所以当有多个页面时,也是动态获取的。检查网络以找到该信息的真实链接。
查看这里的预览,找到信息的真实链接,下一步就是获取链接中的参数并拼接链接。
对比两个页面的链接,发现只有页面参数和两个页面链接末尾的数字不同,末尾的数字是时间参数。
因此,2页后的真正链接是 url='"{"type"%3A"updatenodelabel"%2C"isCache"%3Atrue%2C"cacheTime"%3A60%2C"nodeId"%3A"11007"%2C"isNodeId "%3A"true"%2C"page"%3A"+page+"}&_="+now_time'
替换 page=1 也是适用的。因此,上面是每个页面所需信息的通用链接(实际上,在翻页时,这里的li标签替换了源代码中的li标签)。
下一步就是请求每个页面的网页,获取每个页面的li标签,然后像单个页面一样获取。
代码:
#爬取多页动态网页,找出url之间的规则,传递所要爬取的页
def more_page_info(page):
now_time=str(time.time()).replace('.','')[0:13]
#每页想要获取信息的url
page_url="https://db2.gamersky.com/Label ... 2Bstr(page)+"%7D&_="+now_time
headers={
"referer": "https://www.gamersky.com/news/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
r=requests.get(page_url,headers=headers)
html=json.loads(r.text[41:-2])['body']#将json字符串转换为字典
r_text=etree.HTML(html)
all_li=r_text.xpath('//li')#获取所有的li标签
all_inf=[]
for one_li in all_li:
one_type=one_li.xpath('./div[1]/a[1]/text()')[0]
one_name=one_li.xpath('./div[1]/a[2]/text()')[0]
one_info=one_li.xpath('string(./div[3]/div[1]/text())')
one_info=str(one_info).replace('\n','')
one_time=one_li.xpath('./div[3]/div[2]/div[1]/text()')[0]
one_read=one_li.xpath('./div[3]/div[2]/div[2]/text()')[0]
one_id=one_li.xpath('./div[3]/div[2]/div[3]/@data-sid')[0]
comment_url='https://cm.gamersky.com/commen ... ne_id
#获取评论数
r_comment=requests.get(comment_url,headers=headers)
r_text=r_comment.text
one_comment=json.loads(r_text[42:-2])['result'][one_id]['joinCount']
one_img=one_li.xpath('./div[2]/a[1]/img/@src')[0]
all_inf.append({"type":one_type,"title":one_name,"info":one_info,"time":one_time,"visited":one_read,"comment":one_comment,"img":one_img})
return all_inf
def save_to_file(all_info):
with open("D:/gamersky.txt",'a',encoding='utf-8') as file:
for o in all_info:
file.write("%s::%s::%s::%s::%s::%s::%s\n"%(o['type'],o['title'],o['time'],o['visited'],o['comment'],o['img'],o['info']))
获取前3页信息
for page in range(1,4):
info=more_page_info(page)
save_to_file(info)
print('第%d页下载完成'%page)
综上所述,这取决于需要的信息是静态加载还是动态加载。判断是否是动态网页的简单方法就是看源码中是否可以找到你要获取的信息。动态网页的关键是找到所需信息的真实URL,比较每个页面的URL,找出规则并传递参数,如果参数是从其他动态URL中获取的,则找到参数信息的URL ,然后按个人信息获取。
动态网页抓取(soup在发起某些请求时要求某个页面进行请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-25 22:12
1.在发起某些请求时,可能会要求必须从某个页面发起请求。这时候会验证页面的token
2.这个token是动态生成的,每次请求的值都不一样,
fiddler 捕获的值不能作为固定值传入。 fiddler 捕获的值是某个请求的值。
当一个请求通过python发起时,就是一个新的请求。
所以需要先获取,然后传入。
类似于获取一个随机数,然后传递这个随机数
这里的例子是登录redmine,这个参数值是通过页面的input[name=authenticity_token]标签传入的
3.可以使用BeautifulSoup获取:
BeautifulSoup 用于抓取网页时解析网页,可以获取网页的标签。
这里用于获取input[name=authenticity_token]标签的authenticity_token值,
它的返回值是一个列表,内容是一个标签。获取标签中的属性值时,先通过列表索引知道元素,再通过key获取值
从 bs4 导入 BeautifulSoup
soup = BeautifulSoup(r2.text, ‘lxml’)
tag = soup.select('input[name=authenticity_token]')
data = {"utf8": "?",
"authenticity_token": tag[0][‘value‘],
"username": "liuhui",
"密码": "courageech123"}
res = s.post(url_2, data=data)
接口测试-chap6-获取页面动态令牌
原文: 查看全部
动态网页抓取(soup在发起某些请求时要求某个页面进行请求)
1.在发起某些请求时,可能会要求必须从某个页面发起请求。这时候会验证页面的token
2.这个token是动态生成的,每次请求的值都不一样,
fiddler 捕获的值不能作为固定值传入。 fiddler 捕获的值是某个请求的值。
当一个请求通过python发起时,就是一个新的请求。
所以需要先获取,然后传入。
类似于获取一个随机数,然后传递这个随机数
这里的例子是登录redmine,这个参数值是通过页面的input[name=authenticity_token]标签传入的
3.可以使用BeautifulSoup获取:
BeautifulSoup 用于抓取网页时解析网页,可以获取网页的标签。
这里用于获取input[name=authenticity_token]标签的authenticity_token值,
它的返回值是一个列表,内容是一个标签。获取标签中的属性值时,先通过列表索引知道元素,再通过key获取值
从 bs4 导入 BeautifulSoup
soup = BeautifulSoup(r2.text, ‘lxml’)
tag = soup.select('input[name=authenticity_token]')
data = {"utf8": "?",
"authenticity_token": tag[0][‘value‘],
"username": "liuhui",
"密码": "courageech123"}
res = s.post(url_2, data=data)
接口测试-chap6-获取页面动态令牌
原文:
动态网页抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-25 06:12
)
您想了解更多有关如何使用python捕获网页中的动态数据的信息吗?Saintlas将为大家详细讲解相关知识以及一些使用python捕捉网页动态数据的代码示例。欢迎阅读和指正。:python抓取网页动态数据,python抓取网页动态数据,一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
动态网页抓取(想了解浅谈怎样使用python抓取网页中的动态数据实现的相关内容吗
)
您想了解更多有关如何使用python捕获网页中的动态数据的信息吗?Saintlas将为大家详细讲解相关知识以及一些使用python捕捉网页动态数据的代码示例。欢迎阅读和指正。:python抓取网页动态数据,python抓取网页动态数据,一起来学习吧。
我们经常发现网页中的很多数据并不是硬编码在HTML中,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果你还是直接从网页上爬取,你将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了AJAX异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某一部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
动态网页抓取( 查找节点交互Selenium的操作方法及使用方法(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-24 23:24
查找节点交互Selenium的操作方法及使用方法(二)
)
from selenium import webdriver
browser = webdri ver. Chrome()
browser = webdriver. Firefox()
browser = webdri ver. Edge()
browser = webdriver. PhantomJS()
browser= webdriver.Safari()
# 完成浏览器对象初始化并将其赋值为browser 对象。调用 browser对象,让其执行各个动作以模拟浏览器操作。
2)访问页面
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.taobao.com’ )
print(browser.page_source)
browser. close()
# 用get()方法来请求网页,参数传入链接URL即可。
3)查找节点
# 单个节点
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
Selenium提供通用方法find_element(),它需要传入两个参数: 查找方式By和值。find_element(By.ID,id)
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
print(input_first)
browser.close()
# 多个节点
要查找所有满足条件的节点,需要用find_elements()这样的方法
4)节点交互
Selenium 可以驱动浏览器执行一些动作,也就是说浏览器可以模拟一些动作。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
# send_keys()方法用于输入文字
input.send_keys('iPhone')
time.sleep(1)
# clear()方法用于清空文字
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
# click()方法用于点击按钮
button.click()
5)动作链
如鼠标拖曳、 键盘按键等,它们没有特定的执行对象,这些动作用另一种方式来执行,那就是动作链。
- 实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处
# 首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明ActionChains对象并将其赋值为actions变量,然后通过调用actions变量的drag_and_drop()方法, 再调用perform()方法执行动作,此时就完成了拖曳操作
from selenium import webdnver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url =’http://www.runoob.com/try/try. ... ppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css selector('#draggable')
target= browser.find_element_by_css_selector('#droppable' )
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
6)JavaScript 执行
对于某些操作,Selenium API 不提供。比如下拉进度条,可以直接模拟运行JavaScript,
这时候使用execute script()方法来实现,代码如下:
from selenium import webdriver
browser= webdriver.Chrome()
browser. get (’https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(o, document.body.scrollHeight)’)
browser.execute_script('alert(”To Bottom”)')
# 这里就利用execute script()方法将进度条下拉到最底部,然后弹出alert提示框。
7)获取节点信息
-获取属性
# 使用get_attribute()方法来获取节点的属性
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdri ver. Chrome()
url = 'https://www.zhihu.com/explore'
browser. get ( url)
logo= browser.find_element_by_id(’zh-top-link-logo’)
print(logo)
print(logo.get_attribute(’class' ))
- 获取文本值
from selenium import webdriver
browser= webdriver.Chrome()
url =’https://www.zhihu.com/explore’
browser. get(url)
input = browser.find_element by class name('zu-top-add-question’)
print(input.text)
- 获取 id、位置、标签名称和大小
from. selenium import webdnver
browser = webdriver. Chrome()
url =’https://www.zhihu.com/explore'
browser.get (url)
input= browser.find_element_by_class_name(’zu-top-add-question')
print(input.id) # 节点id
print(input.location) # 节点页面相对位置
print(input.tag_name) # 标签名称
print(input.size) # 节点大小
8)帧切换
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,它的结构和外部网页的结构完全一样。Selenium 打开页面后,默认在父框架中运行,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeresult’)
try:
logo= browser.find_element_by_class_name('logo')
except NoSuchElementException:
print(’NO LOGO')
browser.switch_to.parent_frame)
logo = browser. find_element_by_class_name('logo')
print(logo)
print(logo.text)
首先通过switch_to切换到子Frame。frame() 方法,然后尝试获取父 Frame 中的 logo 节点(无法找到)。如果找不到,它将抛出 NoSuchElementException。异常被捕获后,会输出NO LOGO。接下来切换回父Frame,然后再次获取节点,发现此时可以成功获取。
- 隐式等待
在使用隐式等待执行测试时,如果 Selenium 在 DOM 中没有找到节点,它将继续等待。超过设定时间后,会抛出1 No node found 的异常。换句话说,当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间,然后再搜索DOM。默认时间为 0。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait (10)
browser.get(’https://www.zhihu.com/explore' )
input = browser. find_element_by_class_name(’zu-top-add-question’)
print(input)
-显式等待
隐式等待时间被认为是固定的,但页面加载时间会受到网络条件的影响。
显式等待方法,指定要搜索的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点;如果在指定时间内仍未加载节点,则会抛出超时异常。
# 首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions。 比如,这里传入了presence_of_element_located这个条件,代表节 点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。
- 效果:在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get(’https://www.taobao.com/’)
wait = WebDriverWait(browser, 10)
input = wait. until(EC. presence_of _element_located( (By. ID,’q’)))
button = wait.until(EC.element to be clickable((By.CSS_SELECTOR,’.btn search')))
print(input, button)
9)前进后退
浏览器具有前进和后退功能,它们在 Selenium 中通过 forward() 和 back() 方法实现。
import time
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.baidu.com/’)
browser.get('https://www.taobao.com/’)
browser.get(’https://www.python.org/’)
browser.back()
time.sleep(l)
browser. forward()
browser. close()
10)饼干
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name':'name','domain':'www.zhihu.com','value':'germey'})
browser.delete_all_cookies()
11)标签管理
import time
from selenium import webdnver
browser = webdriver. Chrome()
browser.get(’https://www.baidu.com')
browser.execute_script(’window. open()’)
print(browser. window _handles)
browser.switch_to_window(browser.window_handles[l])
browser.get(’https://www.taobao.com')
time.sleep(l)
browser.switch_to_window(browser.window_handles(0))
browser.get(’https://python.org')
12)异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementExcephon
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com’)
except TimeoutException:
print(' Time Out')
try:
browser. find_element_by_id(' hello')
except NoSuchElementException:
print(’No Element’)
finally:
browser.close() 查看全部
动态网页抓取(
查找节点交互Selenium的操作方法及使用方法(二)
)
from selenium import webdriver
browser = webdri ver. Chrome()
browser = webdriver. Firefox()
browser = webdri ver. Edge()
browser = webdriver. PhantomJS()
browser= webdriver.Safari()
# 完成浏览器对象初始化并将其赋值为browser 对象。调用 browser对象,让其执行各个动作以模拟浏览器操作。
2)访问页面
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.taobao.com’ )
print(browser.page_source)
browser. close()
# 用get()方法来请求网页,参数传入链接URL即可。
3)查找节点
# 单个节点
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
Selenium提供通用方法find_element(),它需要传入两个参数: 查找方式By和值。find_element(By.ID,id)
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
print(input_first)
browser.close()
# 多个节点
要查找所有满足条件的节点,需要用find_elements()这样的方法
4)节点交互
Selenium 可以驱动浏览器执行一些动作,也就是说浏览器可以模拟一些动作。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
# send_keys()方法用于输入文字
input.send_keys('iPhone')
time.sleep(1)
# clear()方法用于清空文字
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
# click()方法用于点击按钮
button.click()
5)动作链
如鼠标拖曳、 键盘按键等,它们没有特定的执行对象,这些动作用另一种方式来执行,那就是动作链。
- 实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处
# 首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明ActionChains对象并将其赋值为actions变量,然后通过调用actions变量的drag_and_drop()方法, 再调用perform()方法执行动作,此时就完成了拖曳操作
from selenium import webdnver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url =’http://www.runoob.com/try/try. ... ppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css selector('#draggable')
target= browser.find_element_by_css_selector('#droppable' )
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
6)JavaScript 执行
对于某些操作,Selenium API 不提供。比如下拉进度条,可以直接模拟运行JavaScript,
这时候使用execute script()方法来实现,代码如下:
from selenium import webdriver
browser= webdriver.Chrome()
browser. get (’https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(o, document.body.scrollHeight)’)
browser.execute_script('alert(”To Bottom”)')
# 这里就利用execute script()方法将进度条下拉到最底部,然后弹出alert提示框。
7)获取节点信息
-获取属性
# 使用get_attribute()方法来获取节点的属性
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdri ver. Chrome()
url = 'https://www.zhihu.com/explore'
browser. get ( url)
logo= browser.find_element_by_id(’zh-top-link-logo’)
print(logo)
print(logo.get_attribute(’class' ))
- 获取文本值
from selenium import webdriver
browser= webdriver.Chrome()
url =’https://www.zhihu.com/explore’
browser. get(url)
input = browser.find_element by class name('zu-top-add-question’)
print(input.text)
- 获取 id、位置、标签名称和大小
from. selenium import webdnver
browser = webdriver. Chrome()
url =’https://www.zhihu.com/explore'
browser.get (url)
input= browser.find_element_by_class_name(’zu-top-add-question')
print(input.id) # 节点id
print(input.location) # 节点页面相对位置
print(input.tag_name) # 标签名称
print(input.size) # 节点大小
8)帧切换
网页中有一种节点叫做iframe,就是子框架,相当于页面的子页面,它的结构和外部网页的结构完全一样。Selenium 打开页面后,默认在父框架中运行,如果此时页面中有子框架,则无法获取子框架中的节点。这时候就需要使用switch_to.frame()方法来切换Frame。
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeresult’)
try:
logo= browser.find_element_by_class_name('logo')
except NoSuchElementException:
print(’NO LOGO')
browser.switch_to.parent_frame)
logo = browser. find_element_by_class_name('logo')
print(logo)
print(logo.text)
首先通过switch_to切换到子Frame。frame() 方法,然后尝试获取父 Frame 中的 logo 节点(无法找到)。如果找不到,它将抛出 NoSuchElementException。异常被捕获后,会输出NO LOGO。接下来切换回父Frame,然后再次获取节点,发现此时可以成功获取。
- 隐式等待
在使用隐式等待执行测试时,如果 Selenium 在 DOM 中没有找到节点,它将继续等待。超过设定时间后,会抛出1 No node found 的异常。换句话说,当搜索一个节点并且该节点没有立即出现时,隐式等待会等待一段时间,然后再搜索DOM。默认时间为 0。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait (10)
browser.get(’https://www.zhihu.com/explore' )
input = browser. find_element_by_class_name(’zu-top-add-question’)
print(input)
-显式等待
隐式等待时间被认为是固定的,但页面加载时间会受到网络条件的影响。
显式等待方法,指定要搜索的节点,然后指定最长等待时间。如果在指定时间内加载节点,则返回搜索到的节点;如果在指定时间内仍未加载节点,则会抛出超时异常。
# 首先引入WebDriverWait这个对象,指定最长等待时间,然后调用它的until()方法,传入要等待条件expected_conditions。 比如,这里传入了presence_of_element_located这个条件,代表节 点出现的意思,其参数是节点的定位元组,也就是ID为q的节点搜索框。
- 效果:在10秒内如果ID为q的节点(即搜索框)成功加载出来,就返回该节点;如果超过10秒还没有加载出来,就抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get(’https://www.taobao.com/’)
wait = WebDriverWait(browser, 10)
input = wait. until(EC. presence_of _element_located( (By. ID,’q’)))
button = wait.until(EC.element to be clickable((By.CSS_SELECTOR,’.btn search')))
print(input, button)
9)前进后退
浏览器具有前进和后退功能,它们在 Selenium 中通过 forward() 和 back() 方法实现。
import time
from selenium import webdnver
browser = webdriver.Chrome()
browser. get (’https://www.baidu.com/’)
browser.get('https://www.taobao.com/’)
browser.get(’https://www.python.org/’)
browser.back()
time.sleep(l)
browser. forward()
browser. close()
10)饼干
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name':'name','domain':'www.zhihu.com','value':'germey'})
browser.delete_all_cookies()
11)标签管理
import time
from selenium import webdnver
browser = webdriver. Chrome()
browser.get(’https://www.baidu.com')
browser.execute_script(’window. open()’)
print(browser. window _handles)
browser.switch_to_window(browser.window_handles[l])
browser.get(’https://www.taobao.com')
time.sleep(l)
browser.switch_to_window(browser.window_handles(0))
browser.get(’https://python.org')
12)异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementExcephon
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com’)
except TimeoutException:
print(' Time Out')
try:
browser. find_element_by_id(' hello')
except NoSuchElementException:
print(’No Element’)
finally:
browser.close()
动态网页抓取(第二种,通过前端js加密的数据如何获取,大型网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-24 23:22
动态页面的生成有很多种,常见的有两种:
针对上面提到的其中一种情况,我们将在另一篇文章中详细介绍。这里我们讨论第二个,如何获取前端js加密的数据。当然,我们可以直接分析他们的js来阅读整个网站的js,但是理解一个网站需要很多努力,对于一个大的网站可能网站 整个网站 js 加密方式大家可能看不懂。对于我们的爬虫,还有一个非常强大的可视化和可爬取的方法——selenium
硒
这是一个自动化测试工具,可以驱动浏览器(有界面,无界面)执行特定操作,并且可以模拟人类点击、下拉等各种基本操作。对抓取js加密信息非常有效
安装
这里我们会写一篇详细的安装教程。可以先搜索相关教程。这里我们需要硒。
selenium的通用功能演示
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Firefox() # 创建一个浏览器对象,这里还可以使用chrome等浏览器
try:
browser.get('https://www.baidu.com')# 打开百度的网页
input = browser.find_element_by_id('kw') # 找到id为kw的元素
input.send_keys('Python') # 给这个元素传递一个值'Python'
input.send_keys(Keys.ENTER) # 使用键盘的enter键
wait = WebDriverWait(browser,10) # 浏览器等待10s
wait.until(EC.presence_of_all_elements_located((By.ID,'content_left'))) # 等待直到出现'content_left'
print(browser.current_url) # 输出浏览器当前的url
print(browser.get_cookies()) # 输出cookie
print(browser.page_source) # 输出网页的当前源码
finally:
browser.close() # 关闭浏览器
运行代码会发现启动火狐浏览器然后自动打开百度的网页,然后在搜索框中输入Python(如果看不清楚可以手动添加时间模块暂停观察),然后按回车键搜索并显示结果(如果没有看到如上所示,可以添加时间模块)然后关闭它,我们的终端上显示了很多内容。其中一张截图如下:
%2Fps1vejnUbOp0RAAdpd4K6q%2BkAH7Cem%2FPrpHtStgPgxtv8ta7E&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=0&inputT=242&rsv_sug4=242
[{'name':'BAIDUID','value':'590E5CC2557B638BFA8336815259E51A:FG=1','path':'/','domain':'.','expiry': 3682926116,'secure': False, 'httpOnly': False), {'name':'BIDUPSID','value': '590E5CC2557B638BFA8336815259E51A','path':'/','domain':'.','expiry': 3682926116,'secure False,'httpOnly': False}, {'name':'PSTM','value':
...
我们可以去浏览器对比一下,发现数据和浏览器是一样的。即我们可以使用selenium来获取网页的内容。Selenium 是我们设置的爬虫,它根据我们为它设置的规则来控制浏览器。并在浏览器中阅读内容。当它真正可见时,它可以被抓取。
创建浏览器对象的操作步骤
我们可以使用创建的对象来执行各种操作
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面
使用get()方法请求一个网页,这里只需要传入一个url即可。比如我们要访问我们的文章,可以在上面代码的基础上运行代码
url = 'https://www.jianshu.com/p/9b36413506c7'
browser.get(url)
这里可以打开我们指定的网页,使用起来非常方便。
查找节点
selenium 浏览器对象提供了很多方法供我们选择节点信息。
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
例如:
browser.get('https://www.baidu.com')
login_button = driver.find_element_by_link_text('登录')
这里还有一个通用的方法:
find_element(By.ID,id) # 需要两个值,一个是搜索方法,一个是搜索值
如果有多个值,我们可以使用find_elements_by之类的函数来查找,即上面提到的在元素后加一个s的方法同样适用于一般方法:
find_elements(By.ID,id)
节点交互
这里可以使用 .click() send_keys() clear() 等方法来模拟用户的点击、输入、清除等操作来获取节点信息
当我们使用 selecet_element 方法时,将返回一个 WebElement 对象。这种类型为我们提供了很多节点信息的方法。
login_button.get_attribute('class)
切换帧
网页中有一种节点就是iframe,相当于一个frame。当我们遇到这样的页面时,可以使用switch_to.frame()进行切换。这里需要传入一个参数:另一帧的名称等待延迟
在网页中,往往是ajax等操作引起的,会导致网页加载较晚,所以我们需要等待一定的时间,确保所有节点都已经加载完毕。
关于等待还有很多:
等待条件的含义
标题_是
标题是东西
标题_收录
标题收录一些东西
Presence_of_element_located
加载节点,传入定位原语,如(By.ID,'p')
visibiltiy_of_element_located
节点可见,传入定位元组
可见性_of
可见的传入节点对象
Presence_of_all_elements_located
加载所有节点
text_to_be_present_in_element
节点文本收录一些文本
text_to_be_present_in_element_valve
一个节点收录某个文本
frame_to_be_available_and_switch_to_it
负载和开关
invisibility_of_element_located
节点不可见
element_to_be_clickable
节点可点击
staleness_of
判断节点是否还在DOM中,判断页面是否已经刷新
aert_is_present
是否有警告
前进后退
back() 和 forward() 方法可以实现浏览器的后退和前进功能
饼干
可以对cookies进行获取、添加、删除等操作
.get_cookie()
.delete_all_cookie()
.add_cookie({})
标签
browser.switch_to_window 可以切换标签页
import time
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://www.baidu.com')
browser.exexute_script('window.open()')
browser.switch_to_window(broser.window_hadles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.duanrw.cn')
11. 异常处理
你可以使用 try...except 来捕捉异常 查看全部
动态网页抓取(第二种,通过前端js加密的数据如何获取,大型网站)
动态页面的生成有很多种,常见的有两种:
针对上面提到的其中一种情况,我们将在另一篇文章中详细介绍。这里我们讨论第二个,如何获取前端js加密的数据。当然,我们可以直接分析他们的js来阅读整个网站的js,但是理解一个网站需要很多努力,对于一个大的网站可能网站 整个网站 js 加密方式大家可能看不懂。对于我们的爬虫,还有一个非常强大的可视化和可爬取的方法——selenium
硒
这是一个自动化测试工具,可以驱动浏览器(有界面,无界面)执行特定操作,并且可以模拟人类点击、下拉等各种基本操作。对抓取js加密信息非常有效
安装
这里我们会写一篇详细的安装教程。可以先搜索相关教程。这里我们需要硒。
selenium的通用功能演示
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Firefox() # 创建一个浏览器对象,这里还可以使用chrome等浏览器
try:
browser.get('https://www.baidu.com')# 打开百度的网页
input = browser.find_element_by_id('kw') # 找到id为kw的元素
input.send_keys('Python') # 给这个元素传递一个值'Python'
input.send_keys(Keys.ENTER) # 使用键盘的enter键
wait = WebDriverWait(browser,10) # 浏览器等待10s
wait.until(EC.presence_of_all_elements_located((By.ID,'content_left'))) # 等待直到出现'content_left'
print(browser.current_url) # 输出浏览器当前的url
print(browser.get_cookies()) # 输出cookie
print(browser.page_source) # 输出网页的当前源码
finally:
browser.close() # 关闭浏览器
运行代码会发现启动火狐浏览器然后自动打开百度的网页,然后在搜索框中输入Python(如果看不清楚可以手动添加时间模块暂停观察),然后按回车键搜索并显示结果(如果没有看到如上所示,可以添加时间模块)然后关闭它,我们的终端上显示了很多内容。其中一张截图如下:
%2Fps1vejnUbOp0RAAdpd4K6q%2BkAH7Cem%2FPrpHtStgPgxtv8ta7E&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=0&inputT=242&rsv_sug4=242
[{'name':'BAIDUID','value':'590E5CC2557B638BFA8336815259E51A:FG=1','path':'/','domain':'.','expiry': 3682926116,'secure': False, 'httpOnly': False), {'name':'BIDUPSID','value': '590E5CC2557B638BFA8336815259E51A','path':'/','domain':'.','expiry': 3682926116,'secure False,'httpOnly': False}, {'name':'PSTM','value':
...
我们可以去浏览器对比一下,发现数据和浏览器是一样的。即我们可以使用selenium来获取网页的内容。Selenium 是我们设置的爬虫,它根据我们为它设置的规则来控制浏览器。并在浏览器中阅读内容。当它真正可见时,它可以被抓取。
创建浏览器对象的操作步骤
我们可以使用创建的对象来执行各种操作
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面
使用get()方法请求一个网页,这里只需要传入一个url即可。比如我们要访问我们的文章,可以在上面代码的基础上运行代码
url = 'https://www.jianshu.com/p/9b36413506c7'
browser.get(url)
这里可以打开我们指定的网页,使用起来非常方便。
查找节点
selenium 浏览器对象提供了很多方法供我们选择节点信息。
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
例如:
browser.get('https://www.baidu.com')
login_button = driver.find_element_by_link_text('登录')
这里还有一个通用的方法:
find_element(By.ID,id) # 需要两个值,一个是搜索方法,一个是搜索值
如果有多个值,我们可以使用find_elements_by之类的函数来查找,即上面提到的在元素后加一个s的方法同样适用于一般方法:
find_elements(By.ID,id)
节点交互
这里可以使用 .click() send_keys() clear() 等方法来模拟用户的点击、输入、清除等操作来获取节点信息
当我们使用 selecet_element 方法时,将返回一个 WebElement 对象。这种类型为我们提供了很多节点信息的方法。
login_button.get_attribute('class)
切换帧
网页中有一种节点就是iframe,相当于一个frame。当我们遇到这样的页面时,可以使用switch_to.frame()进行切换。这里需要传入一个参数:另一帧的名称等待延迟
在网页中,往往是ajax等操作引起的,会导致网页加载较晚,所以我们需要等待一定的时间,确保所有节点都已经加载完毕。
关于等待还有很多:
等待条件的含义
标题_是
标题是东西
标题_收录
标题收录一些东西
Presence_of_element_located
加载节点,传入定位原语,如(By.ID,'p')
visibiltiy_of_element_located
节点可见,传入定位元组
可见性_of
可见的传入节点对象
Presence_of_all_elements_located
加载所有节点
text_to_be_present_in_element
节点文本收录一些文本
text_to_be_present_in_element_valve
一个节点收录某个文本
frame_to_be_available_and_switch_to_it
负载和开关
invisibility_of_element_located
节点不可见
element_to_be_clickable
节点可点击
staleness_of
判断节点是否还在DOM中,判断页面是否已经刷新
aert_is_present
是否有警告
前进后退
back() 和 forward() 方法可以实现浏览器的后退和前进功能
饼干
可以对cookies进行获取、添加、删除等操作
.get_cookie()
.delete_all_cookie()
.add_cookie({})
标签
browser.switch_to_window 可以切换标签页
import time
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://www.baidu.com')
browser.exexute_script('window.open()')
browser.switch_to_window(broser.window_hadles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.duanrw.cn')
11. 异常处理
你可以使用 try...except 来捕捉异常
动态网页抓取(销量最高胸罩的所有评论数据(一)分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-24 06:07
)
CSDN爬虫(六)-动态网页爬取的两种策略概述
第二种方案是分析页面,找到对应的请求接口,直接获取数据。
本文将首先使用Selenium爬取CSDN评论模块的数据;然后使用第二种方法对CSDN评论模块的数据进行分析爬取;另外,看看网上很火的“爬虫京东文胸评论分析中国杯……”,我们还尝试爬取了“最畅销文胸的所有评论数据”。有好处=_+
方案一:使用Selenium模拟浏览器获取动态网页数据,下载需要的jar和浏览器驱动。注:其实这是一个难点。Selenium 需要的jar、浏览器驱动、浏览器版本需要匹配。如果它们不匹配,就会出现各种问题。文章 最后给出我在测试中成功使用的jar包和驱动下载的版本。版本匹配请参考这个文章:; 我用的是chrome浏览器,chromedriver下载地址(不用翻墙):。
将下载好的驱动放到谷歌浏览器的安装目录下,如下图
导入jar包,具体步骤不再详述。如下所示
编写测试代码
package com.wgyscsf.spider;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
/**
* @author 高远
* 编写日期 2016-11-13下午9:02:01
* 邮箱 wgyscsf@163.com
* 博客 http://blog.csdn.net/wgyscsf
* TODO
*/
public class SeleniumTest {
public static void main(String[] args) {
// 第一步: 设置chromedriver地址。一定要指定驱动的位置。
System.setProperty("webdriver.chrome.driver",
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
// 第二步:初始化驱动
WebDriver driver = new ChromeDriver();
// 第三步:获取目标网页
driver.get("http://blog.csdn.net/wgyscsf/a ... 6quot;);
// 第四步:解析。以下就可以进行解了。使用webMagic、jsoup等进行必要的解析。
System.out.println("Page title is: " + driver.getTitle());
System.out.println("Page title is: " + driver.getPageSource());
}
}
结果分析
方案二:分析页面(使用Chrome浏览器进行演示)获取所需的API。案例一:获取CSDN博客文章详情的评论API(上面分析的那个) 步骤:
打开要分析的网页:
按F12,选择网络,刷新页面。如下所示
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
比如我们要分析和获取评论信息,第一个想法是这个接口的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
复制找到完整的API地址:
案例2:获取京东最畅销bra的所有评论信息。步骤: 打开需要分析的网页:按F12(不要忘记选择产品评论然后刷新),选择网络,刷新页面。如下所示
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
比如我们要分析获取评论信息,第一个想法就是这个js的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
复制找到完整的API地址:,链接有好处=_+
操作代码(所有代码已经迁移到github,欢迎star)
点击获取
个人公众号,及时更新技术文章
查看全部
动态网页抓取(销量最高胸罩的所有评论数据(一)分析
)
CSDN爬虫(六)-动态网页爬取的两种策略概述
第二种方案是分析页面,找到对应的请求接口,直接获取数据。
本文将首先使用Selenium爬取CSDN评论模块的数据;然后使用第二种方法对CSDN评论模块的数据进行分析爬取;另外,看看网上很火的“爬虫京东文胸评论分析中国杯……”,我们还尝试爬取了“最畅销文胸的所有评论数据”。有好处=_+
方案一:使用Selenium模拟浏览器获取动态网页数据,下载需要的jar和浏览器驱动。注:其实这是一个难点。Selenium 需要的jar、浏览器驱动、浏览器版本需要匹配。如果它们不匹配,就会出现各种问题。文章 最后给出我在测试中成功使用的jar包和驱动下载的版本。版本匹配请参考这个文章:; 我用的是chrome浏览器,chromedriver下载地址(不用翻墙):。
将下载好的驱动放到谷歌浏览器的安装目录下,如下图
导入jar包,具体步骤不再详述。如下所示
编写测试代码
package com.wgyscsf.spider;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
/**
* @author 高远
* 编写日期 2016-11-13下午9:02:01
* 邮箱 wgyscsf@163.com
* 博客 http://blog.csdn.net/wgyscsf
* TODO
*/
public class SeleniumTest {
public static void main(String[] args) {
// 第一步: 设置chromedriver地址。一定要指定驱动的位置。
System.setProperty("webdriver.chrome.driver",
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
// 第二步:初始化驱动
WebDriver driver = new ChromeDriver();
// 第三步:获取目标网页
driver.get("http://blog.csdn.net/wgyscsf/a ... 6quot;);
// 第四步:解析。以下就可以进行解了。使用webMagic、jsoup等进行必要的解析。
System.out.println("Page title is: " + driver.getTitle());
System.out.println("Page title is: " + driver.getPageSource());
}
}
结果分析
方案二:分析页面(使用Chrome浏览器进行演示)获取所需的API。案例一:获取CSDN博客文章详情的评论API(上面分析的那个) 步骤:
打开要分析的网页:
按F12,选择网络,刷新页面。如下所示
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
比如我们要分析和获取评论信息,第一个想法是这个接口的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
复制找到完整的API地址:
案例2:获取京东最畅销bra的所有评论信息。步骤: 打开需要分析的网页:按F12(不要忘记选择产品评论然后刷新),选择网络,刷新页面。如下所示
这里需要我们一一分析,找到我们需要的API。这里有一个技巧:我们可以使用Filter,如下所示。进行信息过滤。
比如我们要分析获取评论信息,第一个想法就是这个js的名字可能是Comment...这样可以快速定位和找到我们需要的信息。
不负众望,我们真的找到了。看来我们的想法和CSDN的开发者是一致的:评论应该以评论的英文commnet命名!
复制找到完整的API地址:,链接有好处=_+
操作代码(所有代码已经迁移到github,欢迎star)
点击获取
个人公众号,及时更新技术文章
动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-24 06:06
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素
以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
动态网页抓取(区别于上篇动态网页抓取,这里介绍另一种方法)
与之前的动态网页抓取不同,这里还有一种方法,就是使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器自动按照脚本代码进行点击、输入、打开、验证等操作,就像真实用户在操作一样。
模拟浏览器通过 Selenium 爬行。最常用的是火狐,所以下面的解释也以火狐为例。运行前需要安装火狐浏览器。
以《Python Web Crawler:从入门到实践》一书作者的个人博客评论为例。网址:
运行以下代码时,一定要注意你的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。
1)找到评论的HTML代码标签。使用Chrome打开文章页面,右击页面,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:
1)caps=webdriver.DesiredCapabilities().FIREFOX
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装必备软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
您还可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加 driver.page_source 并注释掉 driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可以在输出内容中找到(如果输出比较乱,很难找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有前面对应的显示功能和背面标签):
(这里只截取相关内容的结尾)
如果使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,就会发现上面没有iframe标签,证明我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中,代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper')改为comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素
以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
动态网页抓取(腾讯云轻量服务器Lighthouse(Lighthouse)中员工的信息和薪酬(示例页面))
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-24 06:05
0x00 背景概览
穿越【科技干货007】Scrapy Crawler Preliminary]教程,大家应该对如何编写爬虫有了一定的了解。但是对于更复杂的网站设计,比如使用JavaScript动态渲染的网站页面,入门级爬虫不适合。
本文针对JavaScript动态渲染页面,使用selenium+scrapy爬取levels.fyi(示例页面)中微软员工的信息和工资,目的是描述如何爬取JavaScript页面并在腾讯云轻量级服务器上部署程序在灯塔。
0x01 服务器准备
轻量级应用服务器(Lighthouse)是一款易于使用和管理的云服务器,适合承载轻量级业务负载,可以帮助中小企业和开发者快速搭建网站、博客、电子商务、云中论坛等各类应用及开发测试环境,提供应用部署、配置、管理全过程一站式服务。
这里我们先选LAMP镜,选套餐再付款,你就拥有了你的灯塔镜!(购买门户 ->)
0x02 页面分析
在levels.fyi进入开发者模式,可以看到要爬取的元素其实是一个iframe,数据是由脚本脚本生成的:
我们需要获取tbody下的每个tr,选择我们需要的数据
我们直接使用Request获取tbody,会发现这个元素下没有数据:
t_body = response.css("table#compTable tbody").extract()
print(t_body)
下面,我们讲解如何成功获取javaScript生成的tbody数据
0x03 Selenium 获取
Selenium 是一个运行在浏览器中的 Web 自动化工具,它使用脚本来模拟用户在浏览器上的操作。在这种情况下,它本质上使用 Selenium 在获取数据之前等待 javascript 加载。Selenium 的安装和配置非常简单,脚本编写也非常容易。缺点是与其他爬取方式相比,Selenium 的爬取速度相对较慢。
Selenium 安装:pip install selenium
浏览器驱动下载:使用Selenium,需要下载浏览器驱动。建议下载Chrome版本。下载完成后,mac可以直接放在/usr/local/bin下。Windows 需要在脚本中配置路径或环境变量
创建一个scrapy项目,新建一个MicrosoftSpider,并进行简单的配置。方法同【技术干货007 | Scrapy Crawler 初步]。
获取驱动对象:
driver = webdriver.Chrome()
使用 WebDriverWait 并等待页面加载。在这里,我们将超时时间设置为 5 秒:
wait = WebDriverWait(self.driver, 5)
wait.until(
lambda driver: driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]')) # 等待第一行内容加载完成
等待结束后,尝试获取tbody中的第一行数据
tr1 = self.driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]').text # 每一行信息
print(tr1)
我们已经成功获取到第一行数据了!在上面的代码中,我们使用了 find_element_by_xpath 函数。这个函数是一个在Selenium中获取元素的函数,它返回WebElement的类型。可以通过text获取元素的文本
接下来,我们使用相同的方法获取'下一页'按钮并单击该按钮:
wait = WebDriverWait(self.driver, 1)
wait.until(lambda driver: driver.find_element_by_css_selector('li.page-item.page-next')) # 等待内容加载完成
next_page = self.driver.find_element_by_css_selector('li.page-item.page-next a')
next_page.click() # 模拟点击下一页
next_page 也是 WebElement 类型。可以看到,WebElement除了文本等基本属性外,还有点击等动作。其实这也是WebElement最常用的方法。
其余方法可以在 WebElement API 文档中找到。
现在已获得所有关键要素!下一步就是爬取每一行的元素,循环点击!
0x04 爬行之路总是充满坎坷
Selenium的教程其实就到这里了,但是如果有同学尝试爬取网站的生活,就会发现各种神奇的bug。
这些bug不是程序问题,而是因为网站的种类繁多。这些网站设计师脑子里可能有哪吒,这让你很难理解他在想什么。这里也分享一下爬取样本时的一些趣事网站。
JavaScript 嵌套
如下图所示,当你点击 iframe 的一行时,会出现一个新的 iframe,数据也是由 JavaScript 生成的。获取新的iframe数据并不难,wait+find即可。难点在于,当每一行被点击时,如何将新出现的 iframe 与它所属的 iframe 关联起来?毕竟像下图,每一个新的iframe的class都是“detail-view”。
一开始我试了两张图,然后加入,但是很难保证加入后的结果是正确的。后来我发现了新iframe的特点:当再次点击该行数据时,新iframe就会被关闭。这样就有个比较棘手的方法:循环爬取数据的时候,每次生成一个新的iFrame,爬取完数据后,再次调用click关闭iframe。这样就可以保证每次基于'detail-view'获取元素时只有一个iframe。
这种方案看似没有技术含量,反而增加了爬行的总耗时:增加了一个点击动作的耗时。但正如我开头所说:在写爬虫的时候,我总是“不择手段”。当你能快速想到解决爬虫问题的方法,并且易于实现时,你就可以大胆地使用它,即使它不是最优解。毕竟,当你在思考更好的解决方案时,使用“哑巴”方法爬取的数据可能已经在手。
抓取中断
如果你尝试爬取例子网站,你会发现爬虫已经爬取了1000多个item就会被中断,并且会提示:元素'page-link'不能点击,也就是,无法点击。“下一页”按钮。
一开始,我以为数据页缺少'下一页'按钮的href。毕竟,类似的按钮缺少href 并且链接突然变成文本是很常见的。然而,当我找到这个页面上的数据时,我发现事实并非如此。这个页面的数据看起来很正常,'Next Page'按钮也有href,可以正常点击。但是我反复爬了很多次,爬到页面数据的时候爬虫会中断,提示不能点击元素'page-link'。这个问题困扰了我很久,直到我发现:
这是一个可以联系网站客服人员的按钮。在第125页,他神奇地出现在'下一页'按钮上方,挡住了'下一页'按钮,导致模拟器无法点击到'下一页'按钮。这个问题也让人有些哭笑不得。
如何解决?方法其实很简单,增加模拟器窗口。因为“聊天按钮”的位置是根据当前窗口大小,即相对位置,和“下一页”按钮不同。这样就可以保证两个按钮是分开的:
可以正常抓取数据。
之所以写这两个例子,是因为这两个解决方案其实是“奇怪的逻辑”:莫名的点击,莫名的放大窗口。如果只看代码,是不会理解这两行代码的意思的。但是对于这个网站,这两行是必须的。就像文章开头提到的“不择手段”,在解决问题的时候,换个角度思考可能比从正面解决更容易。
0x05 引用
示例代码github地址 查看全部
动态网页抓取(腾讯云轻量服务器Lighthouse(Lighthouse)中员工的信息和薪酬(示例页面))
0x00 背景概览
穿越【科技干货007】Scrapy Crawler Preliminary]教程,大家应该对如何编写爬虫有了一定的了解。但是对于更复杂的网站设计,比如使用JavaScript动态渲染的网站页面,入门级爬虫不适合。
本文针对JavaScript动态渲染页面,使用selenium+scrapy爬取levels.fyi(示例页面)中微软员工的信息和工资,目的是描述如何爬取JavaScript页面并在腾讯云轻量级服务器上部署程序在灯塔。
0x01 服务器准备
轻量级应用服务器(Lighthouse)是一款易于使用和管理的云服务器,适合承载轻量级业务负载,可以帮助中小企业和开发者快速搭建网站、博客、电子商务、云中论坛等各类应用及开发测试环境,提供应用部署、配置、管理全过程一站式服务。
这里我们先选LAMP镜,选套餐再付款,你就拥有了你的灯塔镜!(购买门户 ->)
0x02 页面分析
在levels.fyi进入开发者模式,可以看到要爬取的元素其实是一个iframe,数据是由脚本脚本生成的:
我们需要获取tbody下的每个tr,选择我们需要的数据
我们直接使用Request获取tbody,会发现这个元素下没有数据:
t_body = response.css("table#compTable tbody").extract()
print(t_body)
下面,我们讲解如何成功获取javaScript生成的tbody数据
0x03 Selenium 获取
Selenium 是一个运行在浏览器中的 Web 自动化工具,它使用脚本来模拟用户在浏览器上的操作。在这种情况下,它本质上使用 Selenium 在获取数据之前等待 javascript 加载。Selenium 的安装和配置非常简单,脚本编写也非常容易。缺点是与其他爬取方式相比,Selenium 的爬取速度相对较慢。
Selenium 安装:pip install selenium
浏览器驱动下载:使用Selenium,需要下载浏览器驱动。建议下载Chrome版本。下载完成后,mac可以直接放在/usr/local/bin下。Windows 需要在脚本中配置路径或环境变量
创建一个scrapy项目,新建一个MicrosoftSpider,并进行简单的配置。方法同【技术干货007 | Scrapy Crawler 初步]。
获取驱动对象:
driver = webdriver.Chrome()
使用 WebDriverWait 并等待页面加载。在这里,我们将超时时间设置为 5 秒:
wait = WebDriverWait(self.driver, 5)
wait.until(
lambda driver: driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]')) # 等待第一行内容加载完成
等待结束后,尝试获取tbody中的第一行数据
tr1 = self.driver.find_element_by_xpath('//*[@id="compTable"]/tbody/tr[1]').text # 每一行信息
print(tr1)
我们已经成功获取到第一行数据了!在上面的代码中,我们使用了 find_element_by_xpath 函数。这个函数是一个在Selenium中获取元素的函数,它返回WebElement的类型。可以通过text获取元素的文本
接下来,我们使用相同的方法获取'下一页'按钮并单击该按钮:
wait = WebDriverWait(self.driver, 1)
wait.until(lambda driver: driver.find_element_by_css_selector('li.page-item.page-next')) # 等待内容加载完成
next_page = self.driver.find_element_by_css_selector('li.page-item.page-next a')
next_page.click() # 模拟点击下一页
next_page 也是 WebElement 类型。可以看到,WebElement除了文本等基本属性外,还有点击等动作。其实这也是WebElement最常用的方法。
其余方法可以在 WebElement API 文档中找到。
现在已获得所有关键要素!下一步就是爬取每一行的元素,循环点击!
0x04 爬行之路总是充满坎坷
Selenium的教程其实就到这里了,但是如果有同学尝试爬取网站的生活,就会发现各种神奇的bug。
这些bug不是程序问题,而是因为网站的种类繁多。这些网站设计师脑子里可能有哪吒,这让你很难理解他在想什么。这里也分享一下爬取样本时的一些趣事网站。
JavaScript 嵌套
如下图所示,当你点击 iframe 的一行时,会出现一个新的 iframe,数据也是由 JavaScript 生成的。获取新的iframe数据并不难,wait+find即可。难点在于,当每一行被点击时,如何将新出现的 iframe 与它所属的 iframe 关联起来?毕竟像下图,每一个新的iframe的class都是“detail-view”。
一开始我试了两张图,然后加入,但是很难保证加入后的结果是正确的。后来我发现了新iframe的特点:当再次点击该行数据时,新iframe就会被关闭。这样就有个比较棘手的方法:循环爬取数据的时候,每次生成一个新的iFrame,爬取完数据后,再次调用click关闭iframe。这样就可以保证每次基于'detail-view'获取元素时只有一个iframe。
这种方案看似没有技术含量,反而增加了爬行的总耗时:增加了一个点击动作的耗时。但正如我开头所说:在写爬虫的时候,我总是“不择手段”。当你能快速想到解决爬虫问题的方法,并且易于实现时,你就可以大胆地使用它,即使它不是最优解。毕竟,当你在思考更好的解决方案时,使用“哑巴”方法爬取的数据可能已经在手。
抓取中断
如果你尝试爬取例子网站,你会发现爬虫已经爬取了1000多个item就会被中断,并且会提示:元素'page-link'不能点击,也就是,无法点击。“下一页”按钮。
一开始,我以为数据页缺少'下一页'按钮的href。毕竟,类似的按钮缺少href 并且链接突然变成文本是很常见的。然而,当我找到这个页面上的数据时,我发现事实并非如此。这个页面的数据看起来很正常,'Next Page'按钮也有href,可以正常点击。但是我反复爬了很多次,爬到页面数据的时候爬虫会中断,提示不能点击元素'page-link'。这个问题困扰了我很久,直到我发现:
这是一个可以联系网站客服人员的按钮。在第125页,他神奇地出现在'下一页'按钮上方,挡住了'下一页'按钮,导致模拟器无法点击到'下一页'按钮。这个问题也让人有些哭笑不得。
如何解决?方法其实很简单,增加模拟器窗口。因为“聊天按钮”的位置是根据当前窗口大小,即相对位置,和“下一页”按钮不同。这样就可以保证两个按钮是分开的:
可以正常抓取数据。
之所以写这两个例子,是因为这两个解决方案其实是“奇怪的逻辑”:莫名的点击,莫名的放大窗口。如果只看代码,是不会理解这两行代码的意思的。但是对于这个网站,这两行是必须的。就像文章开头提到的“不择手段”,在解决问题的时候,换个角度思考可能比从正面解决更容易。
0x05 引用
示例代码github地址
动态网页抓取(动态网页和静态网页的区别,你知道吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-24 00:06
动态网页和静态网页的区别,首先要分别理解两个概念,即什么是静态网页,什么是动态网页,学会区分静态和动态。
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器交互,因此服务器会根据来自客户端的不同请求动态生成 Web 内容。
即:与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容或收录各种动画的内容。这些只是表现形式网页的具体内容,无论网页是否有动态效果,只要是使用动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
一旦静态网页内容发布到网站服务器上,这些网页的内容就存储在网站服务器上,无论是否有用户访问。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。静态网页没有数据库支持。当网站信息量很大时,网页的制作和维护难度很大
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于很多静态网页是固定的,在功能上有很大的局限性,交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢。
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”,可以直接双击打开
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般不可能访问到网站的数据库中的所有网页,或者由于技术考虑,在搜索过程中没有被抓取。“?”后的内容 在网址中双击无法直接打开
总结:
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,使用静态网页,简单易操作,不需要数据库管理等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页 查看全部
动态网页抓取(动态网页和静态网页的区别,你知道吗?(一))
动态网页和静态网页的区别,首先要分别理解两个概念,即什么是静态网页,什么是动态网页,学会区分静态和动态。
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录一些特定功能的程序代码。这些代码可以使浏览器和服务器交互,因此服务器会根据来自客户端的不同请求动态生成 Web 内容。
即:与静态网页相比,动态网页具有相同的页面代码,但显示的内容会随着时间、环境或数据库操作的结果而变化。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容或收录各种动画的内容。这些只是表现形式网页的具体内容,无论网页是否有动态效果,只要是使用动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
一旦静态网页内容发布到网站服务器上,这些网页的内容就存储在网站服务器上,无论是否有用户访问。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。静态网页没有数据库支持。当网站信息量很大时,网页的制作和维护难度很大
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于很多静态网页是固定的,在功能上有很大的局限性,交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,这涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢。
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”,可以直接双击打开
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般不可能访问到网站的数据库中的所有网页,或者由于技术考虑,在搜索过程中没有被抓取。“?”后的内容 在网址中双击无法直接打开
总结:
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,使用静态网页,简单易操作,不需要数据库管理等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页
动态网页抓取(2016年上海事业单位招聘考试:动态网页爬虫-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-24 00:03
动态网络爬虫 什么是动态网络爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的部分数据,无需重新加载。比如拉勾网的招聘页面,在页面变化的过程中,url并没有发生变化,但是招聘信息是动态变化的。AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。实际上,数据交互现在基本使用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。动态网络爬虫解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。Selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:根据元素的 id 查找元素。find_element_by_class_name:根据类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:根据标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据css选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
Selenium 表单操作: webelement.send_keys:用内容填充输入框。webelement.click:点击。操作 select 标签:需要使用 from selenium.webdriver.support.ui import Select 包裹选中的对象才可以选中:selenium行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标动作链类mon.action_chains.ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):单击但不释放鼠标。
context_click(element): 右键单击。
double_click(element): 双击。
以下是B站的登录和拖拽验证滑块。
下面是键盘操作
设置浏览器的参数就是在定义驱动的时候设置chrome_options参数,它是Options类实例化的一个对象。
参数是设置浏览器是否可视化以及请求headers等信息。
浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。
Selenium 提供了一些延迟功能
隐形等待就是在设定的时间内检测网页是否已经加载完毕,即浏览器标签栏的小圆圈在执行下一步之前没有转动。
显性等待可以根据判断条件灵活等待。该程序每隔一定时间检查一次。如果结果和检测条件都满足,则执行下一步。显式等待的使用涉及多个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait 的参数说明如下: driver:浏览器对象驱动程序;timeout:超时时间;poll_frequency:检测时间间隔;
ignore_exceptions:忽略的异常。until:条件判断,参数必须是expected_conditions对象。
更多方法请参考:
为什么我们需要行为链?
因为有些网站可能会在浏览器上做一些验证,看行为是否与人类行为一致来做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,如双击、右键单击等,在自动化测试中非常有用。
操作cookie:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})
隐式等待和显式等待: 隐式等待:指定将始终处于等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定如果在一定时间内满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是 from selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:selenium中没有特殊的打开新窗口的方式,都是通过window.execute_script()执行一个js脚本来打开一个新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开新窗口后,驱动程序的当前页面仍然是上一页。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
代理设置是通过 ChromeOptions 设置的。示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999")
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip")
补充:get_property:获取html标签中写的官方属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求失败,此时可以保存当前页面的截图,以备日后分析。 查看全部
动态网页抓取(2016年上海事业单位招聘考试:动态网页爬虫-乐题库)
动态网络爬虫 什么是动态网络爬虫和AJAX技术:动态网页是网站通过ajax技术动态更新网站中的部分数据,无需重新加载。比如拉勾网的招聘页面,在页面变化的过程中,url并没有发生变化,但是招聘信息是动态变化的。AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。前端与服务器交换少量数据,Ajax 可以实现网页的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。实际上,数据交互现在基本使用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。动态网络爬虫解决方案:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。Selenium 和 chromedriver:使用 selenium 关闭浏览器: driver.close():关闭当前页面。driver.quit():关闭整个浏览器。Selenium 定位元素: find_element_by_id:根据元素的 id 查找元素。find_element_by_class_name:根据类名查找元素。find_element_by_name:根据name属性的值查找元素。find_element_by_tag_name:根据标签名称查找元素。find_element_by_xpath:根据 xpath 语法获取元素。find_element_by_css_selector:根据css选择器选择元素。
需要注意的是find_element是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
Selenium 表单操作: webelement.send_keys:用内容填充输入框。webelement.click:点击。操作 select 标签:需要使用 from selenium.webdriver.support.ui import Select 包裹选中的对象才可以选中:selenium行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标动作链类mon.action_chains.ActionChains来完成。例如,现在你想将鼠标移动到一个元素上并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
click_and_hold(element):单击但不释放鼠标。
context_click(element): 右键单击。
double_click(element): 双击。
以下是B站的登录和拖拽验证滑块。
下面是键盘操作
设置浏览器的参数就是在定义驱动的时候设置chrome_options参数,它是Options类实例化的一个对象。
参数是设置浏览器是否可视化以及请求headers等信息。
浏览器多窗口切换就是在同一个浏览器的不同网页窗口之间进行切换。
Selenium 提供了一些延迟功能
隐形等待就是在设定的时间内检测网页是否已经加载完毕,即浏览器标签栏的小圆圈在执行下一步之前没有转动。
显性等待可以根据判断条件灵活等待。该程序每隔一定时间检查一次。如果结果和检测条件都满足,则执行下一步。显式等待的使用涉及多个模块:
By:设置元素定位方式。它们是 ID、XPATH、LINK_TEXT、NAME 等。
expected_conditions:验证网页元素是否存在。
WebDriverWait 的参数说明如下: driver:浏览器对象驱动程序;timeout:超时时间;poll_frequency:检测时间间隔;
ignore_exceptions:忽略的异常。until:条件判断,参数必须是expected_conditions对象。
更多方法请参考:
为什么我们需要行为链?
因为有些网站可能会在浏览器上做一些验证,看行为是否与人类行为一致来做反爬虫。这时候我们就可以用行为链来模拟人的操作了。行为链有更复杂的操作,如双击、右键单击等,在自动化测试中非常有用。
操作cookie:获取所有cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
添加饼干:
driver.add_cookie({“name”:”username”,”value”:”abc”})
隐式等待和显式等待: 隐式等待:指定将始终处于等待状态的时间。隐式等待需要使用 driver.implicitly_wait。显式等待:指定如果在一定时间内满足某个条件,则不再等待,如果在指定时间内不满足条件,则不再等待。显式等待的方式是 from selenium.webdriver.support.ui import WebDriverWait。示例代码如下:
driver.get("https://kyfw.12306.cn/otn/left ... 6quot;)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"fromStationText"),"长沙")
)
WebDriverWait(driver,100).until(
EC.text_to_be_present_in_element_value((By.ID,"toStationText"),"北京")
)
btn = driver.find_element_by_id("query_ticket")
btn.click()
打开新窗口和切换页面:selenium中没有特殊的打开新窗口的方式,都是通过window.execute_script()执行一个js脚本来打开一个新窗口。
window.execute_script("window.open('https://www.douban.com/')")
打开新窗口后,驱动程序的当前页面仍然是上一页。如果要获取新窗口的源代码,必须先切换到它。示例代码如下:
window.switch_to.window(driver.window_handlers[1])
设置代理:
代理设置是通过 ChromeOptions 设置的。示例代码如下:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.52.235.176:9999";)
driver = webdriver.Chrome(executable_path="D:\ProgramApp\chromedriver\chromedriver73.exe",chrome_options=options)
driver.get("http://httpbin.org/ip";)
补充:get_property:获取html标签中写的官方属性。get_attribute:获取 html 标签中的官方和非官方属性。driver.save_screenshoot:获取当前页面的截图。有时请求失败,此时可以保存当前页面的截图,以备日后分析。
动态网页抓取(动态网页抓取(被动访问)程序实现过程:txtbase64编码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-23 11:05
动态网页抓取(被动访问)程序实现过程:txtbase64编码、xpath构造字符串、webserver抓取网页内容。步骤:txt解码、xpath选择、webserver抓取网页内容。跟踪:将抓取到的内容存入字典数据库。webserver将所获取到的字典数据存入json。
是可以的,推荐几种无限制(而且是最原始的)抓取网页的方法:主动访问百度页面,其他网站也可以爬,最后把它会返回scrapy.crawl(page)这个方法,txt=scrapy.crawl(page)如果txt已经被user-agent的meta信息中过滤了访问百度的网站,类似,也会返回scrapy.crawl(page)方法。
抓取相同的网站,其他网站也可以爬。txt=scrapy.crawl('baidu.html')如果是要抓取不存在的网站,之前提到的fastreporter就可以直接抓取,fastreporter是github-lfs/fastreporter:mostbestrequestintractablecrawler,scrapy.crawl()即可。
api已经可以设置不同的ip来发起请求,然后写入scrapy的数据库,然后拿到抓取结果并存入字典中。
在网上看到一篇,好像不错,以后遇到问题在找找吧,涉及的内容也不多,
有一个xmlhttprequest对象,该对象发起get请求;在ip请求中加入会话标识,就能判断哪些ip会被转换成真实网址,并返回xmlhttprequest对象。 查看全部
动态网页抓取(动态网页抓取(被动访问)程序实现过程:txtbase64编码)
动态网页抓取(被动访问)程序实现过程:txtbase64编码、xpath构造字符串、webserver抓取网页内容。步骤:txt解码、xpath选择、webserver抓取网页内容。跟踪:将抓取到的内容存入字典数据库。webserver将所获取到的字典数据存入json。
是可以的,推荐几种无限制(而且是最原始的)抓取网页的方法:主动访问百度页面,其他网站也可以爬,最后把它会返回scrapy.crawl(page)这个方法,txt=scrapy.crawl(page)如果txt已经被user-agent的meta信息中过滤了访问百度的网站,类似,也会返回scrapy.crawl(page)方法。
抓取相同的网站,其他网站也可以爬。txt=scrapy.crawl('baidu.html')如果是要抓取不存在的网站,之前提到的fastreporter就可以直接抓取,fastreporter是github-lfs/fastreporter:mostbestrequestintractablecrawler,scrapy.crawl()即可。
api已经可以设置不同的ip来发起请求,然后写入scrapy的数据库,然后拿到抓取结果并存入字典中。
在网上看到一篇,好像不错,以后遇到问题在找找吧,涉及的内容也不多,
有一个xmlhttprequest对象,该对象发起get请求;在ip请求中加入会话标识,就能判断哪些ip会被转换成真实网址,并返回xmlhttprequest对象。
动态网页抓取(静态的网页和静态网页的最大区别是什么??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-21 06:13
静态网页是简单的网页,纯HTML语言编写的网页,最有效的效果就是制作一个动画,让网页上可能有动的东西动起来。. . .
动态网页,标准定义是可以与用户交互的网页,即同一个网页,一个源服务器端文件,可以为不同的用户显示不同的内容等等,,,,可以与用户进行真实的交互。时间交互网页是动态网页。主要用JS、ASP、PHP等语言编写。
动态网页和静态网页最大的区别是:
1.静态页面不能随时更改。静态页面写一次,放到服务器上浏览。如果要改,必须在页面上修改,然后上传服务器覆盖原页面,这样信息才能更新。,比较麻烦,用户不能随时修改。
2.动态页面的内容可以随时更改。有前端和后端点。管理员可以随时更新后台网站的内容,前端页面的内容也会相应更新,比较简单易学。
静态网页是指:
不使用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。
动态网页是指:
使用web脚本语言,如php、asp等,通过脚本将网站的内容动态存储在数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。
网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
扩展信息:动态网页:
1. 所谓动态网页,是指相对于静态网页的一种网页编程技术。
2.静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变,除非你修改页面代码。
3. 动态网页不是这样。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
静态页面:
1.在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
2.静态网页相对于动态网页。它们是指没有后端数据库、没有程序、没有交互的网页。
3. 你编辑的就是它显示的,不会有任何变化。
4.静态网页更新比较麻烦,适合更新较少的显示类型网站。
参考资料:百度百科-动态网页百度百科-静态网页
总之一句话:动态网站往往有数据库,而静态网站没有。
动态网站常见的asp和php,两者分别是mdb数据库和SQL数据库。动态网站做起来麻烦,但是用起来方便。因为动态网站=页面设计+数据库,每个页面调用数据库中的内容,也就是数据库中存储的文本。
例如:
和
页面都是2.asp,但是前者调用的是数据库中id值为100的数据,后者是101。
这个用起来很方便,特别是修改网站时,只需要改2.asp的页面设计,不需要改数据库。
如果是静态的网站,那就麻烦了,要一页一页的换,而且没有后台,只能手动添加文件。
不知道看懂没有,有问题可以追问~
静态网页和动态网页主要根据制作网页的语言来区分:
静态网页语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
后缀为.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(2)网页内容一旦发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性是交叉的,在功能上有很大的限制。
好像明白了,先看后缀名,再看能不能和服务器交互
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
另外,如果扩展名为.asp但没有连接数据库,并且是一个完全静态的页面,它也是静态的网站。它只是.asp 的扩展名。
动态网站和静态网站的区别,请详述~!!-:静态网页和动态网页最大的区别在于网页是固定内容还是在线更新内容。静态网页即无应用程序直接或间接制作成html网页。这种网页的内容是固定的。修改和更新必须通过专用的网页创建工具进行,例如 Dreamweaver、Frontpage...
静态网站和动态网站有什么区别:动态网页对应静态网页,即网页网址后缀不是.htm、.html等静态网页, .shtml, .xml 等. 的常见形式是.asp, .jsp, .php, .perl, .cgi等形式的后缀,在动态网页网址中有一个标志性的符号—— “?”。如 ”...
静态网站和动态网站有什么区别?-:静态网站和动态网站的主要区别在于是否与后端数据库有交互,比如Bar:比如一个shopping网站,主要有两大块,一个是用户部分(一般叫前台),一个是管理员部分(一般叫后端),前台包括:提供新用户注册、现有用户登录、用户浏览产品、用户购买产品等功能。这种网站管理员部分非常重要。每当前台有新用户注册时,后台用户表中必须添加一个新用户,当用户想查看自己购物篮中的商品时,后端部分还必须把当前用户购买的物品展示给前台给用户看,比如网站是动态的 静态和动态的区别是不要做一些FLASH,这个网站@ > 是动态的网站,一般静态的网站是供大家浏览网站的内容。一般这样的网站是没有背景的。
静态网站 和动态网站 有什么区别?它们是什么样的?-:静态是那些用工具完成的固定网页。动态是程序自动生成的,比如你在百度上搜索电脑生成的网页,是根据你的关键词和一定的规则动态生成的。也就是说,它是由机器返回的。
静态网站 和动态网站 有什么区别?有什么异同?-:简单来说,动态网站的意思是,比如登录、留言、发帖文章等……也就是说,方便更新网站的内容(如QQ空间)。这些都是通过服务器来实现的。静态网站表示网页的内容(数据)无法动态更新,需要重新编辑。网站 然后发布后更新网站的内容(麻烦,不利于管理!)希望采纳!
动态网站和静态网站-的区别:静态网络和动态网站的区别在于能否与客户进行交互。比如静态的网站只是简单的显示你的产品信息仅供查看,你没有后台管理你的网站,每次要添加产品,都得更新再次网站,网站网站的部分需要调整。动态网站有后台管理功能,可以和客户互动。比如客户可以在线留言、在线购物,网站 经理也可以在线回答客户请求问题是在线查看客户提交的订单。以这样的互动形式,网站 管理人员只能通过后台看到它。同时需要一定的语言支持,如ASP、ASP.NET、PHP、JSP等。同时,如果你需要添加产品什么的,只要在后台提交一个新产品就可以了会好的。无需再次更改网站的格式,方便实用。大大提高了工作效率。
动态网站和静态网站有什么区别?:需要详细说明吗?还是个人总结?其他人的专业详细解答... >所有页面都是现成的,无需下载服务器上的某些内容进行展示。您单击该链接,它将显示出来。无论点击多少次,出现的页面永远是那个页面,基本不变。通常,URL 地址很简单,不是吗?= 等一些东西动态网站 如果url地址一般不是静态的,会有吗?= 等待内容,以php、asp、aspx等结尾.....你访问它需要下载一些内容到服务器数据库显示这里,每次访问这个页面的URL地址和内容也会变...
静态网站和动态网站的区别,动态网站是如何实现的?-:动态网页的一般特征简单总结如下:(1)动态网页都是以数据库技术为基础,可以大大减少网站维护的工作量;(2)网站采用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页...
静态网站和动态网站的区别?:一、动态网站和静态网站在功能上的区别1.动态< @网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 无法实现。2. 静态网站,比如用Frontpage 或Dreamweaver 开发的网站...
静态网站 和动态网站 有什么区别?谢谢~-:静态网站是不收录程序代码的网页,不会在服务器端执行。动态 网站 表示网页收录程序代码,将由服务器执行。 查看全部
动态网页抓取(静态的网页和静态网页的最大区别是什么??)
静态网页是简单的网页,纯HTML语言编写的网页,最有效的效果就是制作一个动画,让网页上可能有动的东西动起来。. . .
动态网页,标准定义是可以与用户交互的网页,即同一个网页,一个源服务器端文件,可以为不同的用户显示不同的内容等等,,,,可以与用户进行真实的交互。时间交互网页是动态网页。主要用JS、ASP、PHP等语言编写。
动态网页和静态网页最大的区别是:
1.静态页面不能随时更改。静态页面写一次,放到服务器上浏览。如果要改,必须在页面上修改,然后上传服务器覆盖原页面,这样信息才能更新。,比较麻烦,用户不能随时修改。
2.动态页面的内容可以随时更改。有前端和后端点。管理员可以随时更新后台网站的内容,前端页面的内容也会相应更新,比较简单易学。
静态网页是指:
不使用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。
动态网页是指:
使用web脚本语言,如php、asp等,通过脚本将网站的内容动态存储在数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。
网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
扩展信息:动态网页:
1. 所谓动态网页,是指相对于静态网页的一种网页编程技术。
2.静态网页,随着html代码的生成,页面的内容和显示效果基本不会改变,除非你修改页面代码。
3. 动态网页不是这样。虽然页面代码没有改变,但显示的内容会随着时间、环境或数据库操作的结果而改变。
静态页面:
1.在网站的设计中,纯HTML格式的网页通常被称为“静态网页”。早期的网站一般都是由静态网页制作而成。
2.静态网页相对于动态网页。它们是指没有后端数据库、没有程序、没有交互的网页。
3. 你编辑的就是它显示的,不会有任何变化。
4.静态网页更新比较麻烦,适合更新较少的显示类型网站。
参考资料:百度百科-动态网页百度百科-静态网页
总之一句话:动态网站往往有数据库,而静态网站没有。
动态网站常见的asp和php,两者分别是mdb数据库和SQL数据库。动态网站做起来麻烦,但是用起来方便。因为动态网站=页面设计+数据库,每个页面调用数据库中的内容,也就是数据库中存储的文本。
例如:
和
页面都是2.asp,但是前者调用的是数据库中id值为100的数据,后者是101。
这个用起来很方便,特别是修改网站时,只需要改2.asp的页面设计,不需要改数据库。
如果是静态的网站,那就麻烦了,要一页一页的换,而且没有后台,只能手动添加文件。
不知道看懂没有,有问题可以追问~
静态网页和动态网页主要根据制作网页的语言来区分:
静态网页语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。
静态网页的 URL 形式通常是:
后缀为.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(2)网页内容一旦发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页的内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性是交叉的,在功能上有很大的限制。
好像明白了,先看后缀名,再看能不能和服务器交互
静态网页是相对于动态网页而言的。它们是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
静态网页和动态网页的区别
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、CGI 等。客户端运行的程序、网页、插件、组件都是静态网页,如html页面、Flash、JavaScript、VBScript等,永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础。静态网页和动态网页之间没有矛盾。为了网站满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容共存是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回完整的网页;
(4)动态网页中的“?”对于搜索引擎检索存在一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
另外,如果扩展名为.asp但没有连接数据库,并且是一个完全静态的页面,它也是静态的网站。它只是.asp 的扩展名。
动态网站和静态网站的区别,请详述~!!-:静态网页和动态网页最大的区别在于网页是固定内容还是在线更新内容。静态网页即无应用程序直接或间接制作成html网页。这种网页的内容是固定的。修改和更新必须通过专用的网页创建工具进行,例如 Dreamweaver、Frontpage...
静态网站和动态网站有什么区别:动态网页对应静态网页,即网页网址后缀不是.htm、.html等静态网页, .shtml, .xml 等. 的常见形式是.asp, .jsp, .php, .perl, .cgi等形式的后缀,在动态网页网址中有一个标志性的符号—— “?”。如 ”...
静态网站和动态网站有什么区别?-:静态网站和动态网站的主要区别在于是否与后端数据库有交互,比如Bar:比如一个shopping网站,主要有两大块,一个是用户部分(一般叫前台),一个是管理员部分(一般叫后端),前台包括:提供新用户注册、现有用户登录、用户浏览产品、用户购买产品等功能。这种网站管理员部分非常重要。每当前台有新用户注册时,后台用户表中必须添加一个新用户,当用户想查看自己购物篮中的商品时,后端部分还必须把当前用户购买的物品展示给前台给用户看,比如网站是动态的 静态和动态的区别是不要做一些FLASH,这个网站@ > 是动态的网站,一般静态的网站是供大家浏览网站的内容。一般这样的网站是没有背景的。
静态网站 和动态网站 有什么区别?它们是什么样的?-:静态是那些用工具完成的固定网页。动态是程序自动生成的,比如你在百度上搜索电脑生成的网页,是根据你的关键词和一定的规则动态生成的。也就是说,它是由机器返回的。
静态网站 和动态网站 有什么区别?有什么异同?-:简单来说,动态网站的意思是,比如登录、留言、发帖文章等……也就是说,方便更新网站的内容(如QQ空间)。这些都是通过服务器来实现的。静态网站表示网页的内容(数据)无法动态更新,需要重新编辑。网站 然后发布后更新网站的内容(麻烦,不利于管理!)希望采纳!
动态网站和静态网站-的区别:静态网络和动态网站的区别在于能否与客户进行交互。比如静态的网站只是简单的显示你的产品信息仅供查看,你没有后台管理你的网站,每次要添加产品,都得更新再次网站,网站网站的部分需要调整。动态网站有后台管理功能,可以和客户互动。比如客户可以在线留言、在线购物,网站 经理也可以在线回答客户请求问题是在线查看客户提交的订单。以这样的互动形式,网站 管理人员只能通过后台看到它。同时需要一定的语言支持,如ASP、ASP.NET、PHP、JSP等。同时,如果你需要添加产品什么的,只要在后台提交一个新产品就可以了会好的。无需再次更改网站的格式,方便实用。大大提高了工作效率。
动态网站和静态网站有什么区别?:需要详细说明吗?还是个人总结?其他人的专业详细解答... >所有页面都是现成的,无需下载服务器上的某些内容进行展示。您单击该链接,它将显示出来。无论点击多少次,出现的页面永远是那个页面,基本不变。通常,URL 地址很简单,不是吗?= 等一些东西动态网站 如果url地址一般不是静态的,会有吗?= 等待内容,以php、asp、aspx等结尾.....你访问它需要下载一些内容到服务器数据库显示这里,每次访问这个页面的URL地址和内容也会变...
静态网站和动态网站的区别,动态网站是如何实现的?-:动态网页的一般特征简单总结如下:(1)动态网页都是以数据库技术为基础,可以大大减少网站维护的工作量;(2)网站采用动态web技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页...
静态网站和动态网站的区别?:一、动态网站和静态网站在功能上的区别1.动态< @网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 无法实现。2. 静态网站,比如用Frontpage 或Dreamweaver 开发的网站...
静态网站 和动态网站 有什么区别?谢谢~-:静态网站是不收录程序代码的网页,不会在服务器端执行。动态 网站 表示网页收录程序代码,将由服务器执行。
动态网页抓取(关于with语句与上下文管理器三、思路整理(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-21 06:09
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成之前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = \'http://unsplash.com/napi/feeds/home\'
id_url = \'http://unsplash.com/napi/feeds/home\'
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'*************\'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = \'utf-8\'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
id_lists.append(each[\'id\'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__==\'__main__\':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此参数需从包中获取
}
file_path = \'images\'
download_url = \'https://unsplash.com/photos/{}/download?force=true\'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, \'ab+\') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
img_id = \'vgpHniLr9Uw\'
download(img_id)
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = \'http://unsplash.com/napi/feeds/home\'
self.header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此部分需要自行添加
}
self.id_lists = []
self.download_url=\'https://unsplash.com/photos/{}/download?force=true\'
print("init")
def get_ids(self):
# target_url = \'http://unsplash.com/napi/feeds/home\'
# target_url = \'https://unsplash.com/\'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = \'utf-8\'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
self.id_lists.append(each[\'id\'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = \'images\'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,\'ab+\') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,就剩下写爬虫的步骤了 查看全部
动态网页抓取(关于with语句与上下文管理器三、思路整理(组图))
退出首页,在目标页面()下,如图,可以通过选择我们设置的charles来设置全局代理(网站的所有数据请求都经过代理)
也可以只为这个网站设置代理
二、知识储备
requests.get():请求官方文档
在这里,在 request.get() 中,我使用了两个附加参数 verify=False, stream=True
verify = False 可以绕过网站的SSL验证
stream=True 保持流打开,直到流关闭。在下载图片的过程中,可以在图片下载完成之前保持数据流不关闭,以保证图片下载的完整性。如果去掉这个参数,重新下载图片,会发现图片无法下载成功。
contextlib.closure():contextlib 库下的关闭方法,其作用是将一个对象变成一个上下文对象来支持。
使用with open()后,我们知道with的好处是可以帮助我们自动关闭资源对象,从而简化代码。其实任何对象,只要正确实现了上下文管理,都可以在with语句中使用。还有一篇关于 with 语句和上下文管理器的文章
三、思想的组织
这次爬取的动态网页是一张壁纸网站,上面有精美的壁纸,我们的目的是通过爬虫把网站上的原壁纸下载到本地
网站网址:
知道网站是动态的网站,那么就需要通过抓取网站的js包以及它是如何获取数据来分析的。
打开网站时使用Charles获取请求。从json中找到有用的json数据,对比下载链接的url,发现下载链接的变化部分是图片的id,图片的id是从json中爬出来的。填写下载链接上的id部分,进行下载操作四、 具体步骤是通过Charles打开网站时获取请求,如图
从图中不难发现,headers中有一个授权Client-ID参数,需要记下来,添加到我们自己的请求头中。(因为学习笔记,知道这个参数是反爬虫需要的参数。具体检测反爬虫操作,估计可以一一加参数试试)从中找到有用的json
存在
这里我们发现有一个图片ID。在网页上点击下载图片,从抓包中抓取下载链接,发现下载链接更改的部分是图片的id。
这样就可以确定爬取图片的具体步骤了。从json中爬取图片id,在下载链接上填写id部分,执行下载操作并分析,总结代码步骤
五、代码整理
代码步骤
1. 抓取图片id并保存到列表中
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = \'http://unsplash.com/napi/feeds/home\'
id_url = \'http://unsplash.com/napi/feeds/home\'
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'*************\'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = \'utf-8\'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
id_lists.append(each[\'id\'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__==\'__main__\':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
print(id)
结果如图,已经成功打印出图片ID
根据图片id下载图片
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此参数需从包中获取
}
file_path = \'images\'
download_url = \'https://unsplash.com/photos/{}/download?force=true\'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, \'ab+\') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
img_id = \'vgpHniLr9Uw\'
download(img_id)
下载前
下载后
合码批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = \'http://unsplash.com/napi/feeds/home\'
self.header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) \'
\'AppleWebKit/537.36 (KHTML, like Gecko) \'
\'Chrome/61.0.3163.79 Safari/537.36\',
\'authorization\': \'***********\'#此部分需要自行添加
}
self.id_lists = []
self.download_url=\'https://unsplash.com/photos/{}/download?force=true\'
print("init")
def get_ids(self):
# target_url = \'http://unsplash.com/napi/feeds/home\'
# target_url = \'https://unsplash.com/\'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = \'utf-8\'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic[\'next_page\']))
for each in dic[\'photos\']:
# print("图片ID:{}".format(each[\'id\']))
self.id_lists.append(each[\'id\'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = \'images\'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs(\'images\')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename=\'images/\'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = \'{}/{}.jpg\'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,\'ab+\') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__==\'__main__\':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)
六、结论
由于本文为学习笔记,中间省略了一些细节。
结合其他资料,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键数据,就剩下写爬虫的步骤了
动态网页抓取(selenium、firefox浏览器如何抓取、css?动态网页抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-11-20 16:00
动态网页抓取1.javascript中的httppost拿js文件-javascript中的httppost拿js文件-神生社区-博客园2.httpget:其它javascript代码3.selenium4.webdriver
最笨拙的方法就是用firebug,可以很方便的抓取js、css、图片等静态资源。js、css文件通常是加密存储在http服务端,本地看不见、改不了,所以只能抓取,但抓取效率没法看。selenium之前webdriver在做抓取的时候遇到这个问题,然后自己动手写了一个解决方案。firefox、safari浏览器的postinfo、document.cookie等都是动态获取的,所以我们是不可能抓取js的,抓取css文件没问题,但图片就有点难了。
safari、firefox浏览器如何抓取js、css?有没有可以抓取js文件的浏览器呢?有的。chrome浏览器自带的webdriver是可以抓取js文件的,通过设置monitoring选项卡里的#location.href,它可以指定浏览器的地址,让浏览器自动给出js代码。ie、火狐这些浏览器也可以抓取js文件,但是需要额外的设置。
怎么设置呢?在插件的设置界面,找到selenium-->options-->plugins,按下图上所示去设置,就可以使用webdriver抓取js、css了。但是document.cookie是不可以抓取的,这也是selenium抓取不了css、js文件的原因。但我又发现,如果不做相应设置的话,document.cookie是可以抓取静态资源的,我通过如下设置设置一下即可:我先把ie浏览器调成默认页面(兼容模式),然后根据页面上的路径,在browser中按下f12,选择network(然后找到browser.session.cookie.js),点击meta,这样就可以查看到该js的链接了。
直接在firefox中访问,就会抓取一段js代码。但由于selenium抓取是随机顺序抓取的,此时自动抓取browser.session.cookie.js页面,因此会无法抓取链接中的js代码。解决方案:给此页面设置offset和maximum-page-size,如设置offset是1024,maximum-page-size就是1,就可以抓取这页所有js代码。推荐在ie浏览器设置offset和maximum-page-size。 查看全部
动态网页抓取(selenium、firefox浏览器如何抓取、css?动态网页抓取)
动态网页抓取1.javascript中的httppost拿js文件-javascript中的httppost拿js文件-神生社区-博客园2.httpget:其它javascript代码3.selenium4.webdriver
最笨拙的方法就是用firebug,可以很方便的抓取js、css、图片等静态资源。js、css文件通常是加密存储在http服务端,本地看不见、改不了,所以只能抓取,但抓取效率没法看。selenium之前webdriver在做抓取的时候遇到这个问题,然后自己动手写了一个解决方案。firefox、safari浏览器的postinfo、document.cookie等都是动态获取的,所以我们是不可能抓取js的,抓取css文件没问题,但图片就有点难了。
safari、firefox浏览器如何抓取js、css?有没有可以抓取js文件的浏览器呢?有的。chrome浏览器自带的webdriver是可以抓取js文件的,通过设置monitoring选项卡里的#location.href,它可以指定浏览器的地址,让浏览器自动给出js代码。ie、火狐这些浏览器也可以抓取js文件,但是需要额外的设置。
怎么设置呢?在插件的设置界面,找到selenium-->options-->plugins,按下图上所示去设置,就可以使用webdriver抓取js、css了。但是document.cookie是不可以抓取的,这也是selenium抓取不了css、js文件的原因。但我又发现,如果不做相应设置的话,document.cookie是可以抓取静态资源的,我通过如下设置设置一下即可:我先把ie浏览器调成默认页面(兼容模式),然后根据页面上的路径,在browser中按下f12,选择network(然后找到browser.session.cookie.js),点击meta,这样就可以查看到该js的链接了。
直接在firefox中访问,就会抓取一段js代码。但由于selenium抓取是随机顺序抓取的,此时自动抓取browser.session.cookie.js页面,因此会无法抓取链接中的js代码。解决方案:给此页面设置offset和maximum-page-size,如设置offset是1024,maximum-page-size就是1,就可以抓取这页所有js代码。推荐在ie浏览器设置offset和maximum-page-size。
动态网页抓取(动态网页抓取抓取网页有几种方法,http请求全过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-20 12:02
动态网页抓取抓取网页有几种方法,我总结过这几种方法:http请求全过程从网页标题、网页内容全文抓取抓取文章全文抓取伪静态代理/代理池自动翻页、自动跳转自动selenium自动爬虫准备工作selenium:开源的webdriver框架,会和上面几种方法同时支持。如果你的浏览器不支持请自行购买license。
bootstrap:javascript的封装库,也可以使用,但是必须向前兼容。伪静态可以让你爬取的页面看起来像主页一样,不改变内容。如果你网站的页面上没有让浏览器渲染的js文件,那你可以使用伪静态,例如selenium的index.html,它只是浏览器页面的一种显示方式,并不改变内容。http请求:http协议非常简单,可以很容易理解。
抓取网页时,你必须理解的概念就是你要从哪个url下。有明确的url,然后你才可以去请求。请求的四种方法:get方法post方法put方法delete方法正常情况下,所有请求请求都会返回html内容。如果没有明确url,那你可以在headers上指定url(会对http协议做修改),然后参数表示请求当前页面的位置。
例如,抓取新浪博客,你可以这样指定当前页面:post://首页/content/type(‘text/post’)put://首页/content/type(‘put’)delete://首页/content/type(‘delete’)如果不支持请求身份验证和响应体(payload),对于抓取,你就会经常失败。
例如抓取新浪博客内容,你需要在请求头信息里指定你的请求是验证请求。获取请求头信息有些比较难编写,但是如果你要用ajax,那你需要这样做。正常情况下,http请求会包含请求头信息,而响应体只支持xml格式,或xmlx,或xmlt,或者json。当http请求包含响应体后,post请求会被转换为json或xml形式的。
比如,你可以用http请求来获取网站左边部分:post://首页/.content-type:application/json然后你得到html的内容,其中的值是网站左边的每个字段值。然后你把它们发送到json解析库(jsonbindings)。bindings是用来解析请求中的请求头信息。如果你需要请求一个session,你也必须将form或method字段转换为bindings,以后再依次请求。
请求头信息请求头信息包括请求的useragent(浏览器),主机名,端口号和名称。还有些仅仅提供xml格式参数或useragent列表,其他的格式请参照json。假设你发送请求到一个httpoauth的网站(不是红牛,不是张小龙微博,不是李彦宏)。请求头信息里包括第一个useragent-用户代理,最后一个是主机名。还有下面的内容,浏览器用浏览器打开。 查看全部
动态网页抓取(动态网页抓取抓取网页有几种方法,http请求全过程)
动态网页抓取抓取网页有几种方法,我总结过这几种方法:http请求全过程从网页标题、网页内容全文抓取抓取文章全文抓取伪静态代理/代理池自动翻页、自动跳转自动selenium自动爬虫准备工作selenium:开源的webdriver框架,会和上面几种方法同时支持。如果你的浏览器不支持请自行购买license。
bootstrap:javascript的封装库,也可以使用,但是必须向前兼容。伪静态可以让你爬取的页面看起来像主页一样,不改变内容。如果你网站的页面上没有让浏览器渲染的js文件,那你可以使用伪静态,例如selenium的index.html,它只是浏览器页面的一种显示方式,并不改变内容。http请求:http协议非常简单,可以很容易理解。
抓取网页时,你必须理解的概念就是你要从哪个url下。有明确的url,然后你才可以去请求。请求的四种方法:get方法post方法put方法delete方法正常情况下,所有请求请求都会返回html内容。如果没有明确url,那你可以在headers上指定url(会对http协议做修改),然后参数表示请求当前页面的位置。
例如,抓取新浪博客,你可以这样指定当前页面:post://首页/content/type(‘text/post’)put://首页/content/type(‘put’)delete://首页/content/type(‘delete’)如果不支持请求身份验证和响应体(payload),对于抓取,你就会经常失败。
例如抓取新浪博客内容,你需要在请求头信息里指定你的请求是验证请求。获取请求头信息有些比较难编写,但是如果你要用ajax,那你需要这样做。正常情况下,http请求会包含请求头信息,而响应体只支持xml格式,或xmlx,或xmlt,或者json。当http请求包含响应体后,post请求会被转换为json或xml形式的。
比如,你可以用http请求来获取网站左边部分:post://首页/.content-type:application/json然后你得到html的内容,其中的值是网站左边的每个字段值。然后你把它们发送到json解析库(jsonbindings)。bindings是用来解析请求中的请求头信息。如果你需要请求一个session,你也必须将form或method字段转换为bindings,以后再依次请求。
请求头信息请求头信息包括请求的useragent(浏览器),主机名,端口号和名称。还有些仅仅提供xml格式参数或useragent列表,其他的格式请参照json。假设你发送请求到一个httpoauth的网站(不是红牛,不是张小龙微博,不是李彦宏)。请求头信息里包括第一个useragent-用户代理,最后一个是主机名。还有下面的内容,浏览器用浏览器打开。
动态网页抓取(从功能方面来说动态网站与静态网站的区别和区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-20 09:07
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然查看者可以看到源代码,但已经是转换后的代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密性。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是对动态网站和静态网站的基本分析,但在实际应用中,每个人都会有不同的体会,细微而本质的区别远不止上面列出的。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。公司的大部分网站都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页最大的区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使采用动态网站技术,网页的内容也被转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存入数据库,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性 查看全部
动态网页抓取(从功能方面来说动态网站与静态网站的区别和区别)
一、动态网站和静态网站在功能上的区别
1、动态网站可以实现静态网站无法实现的功能,例如:聊天室、论坛、音乐播放器、浏览器、搜索等;而静态 网站 不能。
2.静态网站,比如Frontpage或者Dreamweaver开发的网站,它的源代码是完全公开的,任何浏览者都可以很容易地得到它的源代码,也就是说,自己设计的东西可以很容易的被别人偷走。动态网站,如:ASP开发的网站,虽然查看者可以看到源代码,但已经是转换后的代码了。窃取源代码是不可能的。因为它的源代码已经在服务器上,客户端看不到它。
二、动态网站和静态网站的区别从数据的使用
1.动态网站可以直接使用数据库,通过数据源直接操作数据库;而静态网站不能用,静态网站只能用表格硬性实现动态网站数据库表中少部分数据的显示不能操作。
2、动态网站放在服务器上。要查看源程序或直接修改它,必须在服务器上进行,因此保密性能优越。静态网站无法实现信息的保密性。
3、动态网站可以用来调用远程数据,而静态网站甚至不能使用本地数据,更不用说远程数据了。
三、本质上是动态网站和静态网站的区别
1、动态网站的开发语言是一种编程语言,例如ASP是用Vbscript或Javascript开发的。静态 网站 只能用 HTML 开发标记语言开发。它只是一种标记语言,并不能实现程序的功能。
2、动态网站本身就是一个系统,一个可以实现程序几乎所有功能的系统,而静态网站不是,只能实现文字和图片的平面显示。
3、动态网站可以实现程序的高效、快速的执行,而普通的静态网站根本没有效率和快速。
以上是对动态网站和静态网站的基本分析,但在实际应用中,每个人都会有不同的体会,细微而本质的区别远不止上面列出的。这只能通过个人经验来区分。
四、动态网站和静态网站从外观上的区别
网站的静态网页以.htmlhtm结尾,客户不能随意修改,需要特殊软件。而且大部分动态网站都是带数据库的,可以随时在线修改,网页往往以php、asp等结尾。公司的大部分网站都是动态网站。
静态网页:指不使用应用程序直接或间接制作成html的网页。这类网页的内容是固定的,修改和更新必须通过专用的网页制作工具,如Dreamweaver。动态网页:指使用网页脚本语言,如php、asp等,通过脚本将网站的内容动态存储到数据库中。用户访问网站是一种通过读取数据库动态生成网页的方法。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。
静态网页和动态网页最大的区别在于网页是否有固定内容或可以在线更新
网站的构建如何决定是使用动态网页还是静态网页?
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,使用纯静态网页会更简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎对网站的需求,即使采用动态网站技术,网页的内容也被转化为静态网页并发布。动态网站也可以利用动静结合的原理。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
静态网页是指无需应用程序直接或间接制作成html的网页。这种网页的内容是固定的。修改和更新必须通过专用的网页制作工具,如Dreamweaver、Frontpage等,而且只要修改了网页,就必须重新上传一个字符或图片来覆盖原来的页面。
动态网页是指运行在服务器端的程序或网页,会在不同的时间、不同的客户返回不同的网页。
动态网页是指利用网页脚本语言,如php、asp、jsp等,通过脚本将网站的内容动态存入数据库,用户访问网站是一种方法通过读取数据库动态生成网页。网站 主要基于一些框架,网页的大部分内容都存储在数据库中。当然,可以使用某些技术将动态网页内容生成静态网页,有利于网站的优化,方便搜索引擎搜索。
动态网页的特点:交互性、自动更新、随机性
动态网页抓取(soup搜索节点操作删除节点的一种好的方法(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 01:18
前言:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文在python+chrome(谷歌浏览器)+chromedrive(谷歌浏览器驱动)中使用selenium(pyhton包)
推荐Chrome和Chromdrive下载最新版本(参考地址:)
它还支持无头模式(无需打开浏览器)
直接上传代码:site_url:要爬取的地址,CHROME_DRIVER_PATH:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
一个返回的soup,方便你搜索这个soup的节点,使用select、search、find等方法找到你想要的节点或者数据
同样,如果您想将其下载为文本,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
下面详细说一下,beautifusoup的搜索
如何先定位标签
1.使用find(本博主详细介绍)
2.使用选择
通过标签名、类名、id 类似jquery来选择soup.select('p .link #link1')这样的选择器。
按属性搜索,如href、title、link等属性,如soup.select('p a[href=""]')
这里匹配的是最小的,他的上级是
接下来说说节点的操作
删除节点 tag.decompose()
在指定位置插入子节点tag.insert(0,chlid_tag)
最后,beautifusoup 是过滤元素的好方法。在下一篇文章中,我们将介绍正则表达式匹配和过滤。爬虫内容 查看全部
动态网页抓取(soup搜索节点操作删除节点的一种好的方法(上))
前言:本文主要介绍页面加载后如何通过JS抓取需要加载的数据和图片
本文在python+chrome(谷歌浏览器)+chromedrive(谷歌浏览器驱动)中使用selenium(pyhton包)
推荐Chrome和Chromdrive下载最新版本(参考地址:)
它还支持无头模式(无需打开浏览器)
直接上传代码:site_url:要爬取的地址,CHROME_DRIVER_PATH:chromedrive存储地址
1 def get_dynamic_html(site_url):
2 print('开始加载',site_url,'动态页面')
3 chrome_options = webdriver.ChromeOptions()
4 #ban sandbox
5 chrome_options.add_argument('--no-sandbox')
6 chrome_options.add_argument('--disable-dev-shm-usage')
7 #use headless,无头模式
8 chrome_options.add_argument('--headless')
9 chrome_options.add_argument('--disable-gpu')
10 chrome_options.add_argument('--ignore-ssl-errors')
11 driver = webdriver.Chrome(executable_path=CHROME_DRIVER_PATH,chrome_options=chrome_options)
12 #print('dynamic laod web is', site_url)
13 driver.set_page_load_timeout(100)
14 #driver.set_script_timeout(100)
15 try:
16 driver.get(site_url)
17 except Exception as e:
18 #driver.execute_script('window.stop()') # 超出时间则不加载
19 print(e, 'dynamic web load timeout')
20 data = driver.page_source
21 soup = BeautifulSoup(data, 'html.parser')
22 try:
23 driver.quit()
24 except:
25 pass
26 return soup
一个返回的soup,方便你搜索这个soup的节点,使用select、search、find等方法找到你想要的节点或者数据
同样,如果您想将其下载为文本,则
1 try:
2 with open(xxx.html, 'w+', encoding="utf-8") as f:
3 #print ('html content is:',content)
4 f.write(get_dynamic_html('https://xxx.com').prettify())
5 f.close()
6 except Exception as e:
7 print(e)
下面详细说一下,beautifusoup的搜索
如何先定位标签
1.使用find(本博主详细介绍)
2.使用选择
通过标签名、类名、id 类似jquery来选择soup.select('p .link #link1')这样的选择器。
按属性搜索,如href、title、link等属性,如soup.select('p a[href=""]')
这里匹配的是最小的,他的上级是
接下来说说节点的操作
删除节点 tag.decompose()
在指定位置插入子节点tag.insert(0,chlid_tag)
最后,beautifusoup 是过滤元素的好方法。在下一篇文章中,我们将介绍正则表达式匹配和过滤。爬虫内容
动态网页抓取(Ajax理论1.Ajax提取AjaxAjaxAjax分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-19 01:14
)
上面提到的爬虫都是建立在静态网页的基础上的。首先通过请求网站url获取网页源码。之后,从源代码中提取信息并存储。本文将重点介绍动态网页数据采集,先介绍Ajax相关理论,然后在实战中爬取Flush的动态网页,获取个股信息。
内容
一、Ajax 理论
1.Ajax 简介
2.ajax分析
3.Ajax 提取
二、网络分析
1.网页概览
2.Ajax 歧视
3.Ajax 提取
三、爬虫实战
1.网页访问
2.信息抽取
3.保存数据
4.循环结构
一、Ajax 理论
1.Ajax 简介
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,可以创建交互式、快速和动态的 Web 应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
2.ajax分析
微博网站是一个带有Ajax的动态网页,易于识别。首先打开Dectools工具(调整到XHR专栏)和中南财经政法大学官方微博网站(),这里选择的是移动端微博,然后选择清除所有内容.
接下来,滚动滚轮以下拉页面,直到清空的 XHR 列中出现新项目。点击此项,选择预览栏,发现这里对应的内容是页面上新出现的微博,上面的网页链接但是没有变化。此时,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
还是选择同一个入口进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求url为:,即请求参数有4个:type、value、containerid、since_id,然后翻页发现,除了since_id发生了变化,其余的都保持不变。这里我们可以看到since_id是翻页方法。
接下来观察since_id,发现上下请求之间的since_id没有明显的规律。进一步搜索发现下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态URL添加到爬虫中。
发起请求获取响应后,进一步分析发现响应格式是json,所以进一步处理json就可以得到最终的数据了!
二、网络分析
1.网页概览
有了上面的分析,我们就用flush网页采集的数据,通过实战来验证一下。首先打开网页:如下图:
再按F12键打开Devtools后端源代码,将鼠标放在第一项上,点击右键,查看源代码中的位置。
2.Ajax 歧视
接下来,我们点击网页底部的下一页,发现网页url没有任何变化!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清除了网络中的所有内容,继续点击下一页到第五页,发现连续弹出了三个同名的消息。请求的URL和请求头的具体内容可以通过General一栏获取。
于是,我们复制了请求的url,在浏览器中打开,结果响应内容是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页形式,和上面微博响应的json格式不同,所以可以在后面的网页分析的形式。
三、爬虫实战
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的一点是,这里的请求头除了User-Agent之外,还需要host、Referer和X-Requested-With参数,这应该和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息抽取
之后就是上面分析库的内容了,这里就更容易理解BaetifulSoup库了。首先将上面的html转换成一个BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应的信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
同时考虑到flush的多页结构和反爬虫的存在,也采用字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬行前中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
至此,Flush动态网页的爬取完成,接下来由这个爬虫总结:首先,我们通过浏览网页结构,翻页,对比XHR栏,对变化的网页进行Ajax判断。如果网页url不变,XHR会刷新内容,基本说明是动态网页,此时我们进一步检查多个页面之间URL请求的异同,找出规律。找到规则后,就可以建立多页请求流程了。之后对单个响应内容进行处理(详细参见响应内容的格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫完整代码可在公众号回复“Flush”获取。下面将进一步讲解和实战浏览器模拟行为。上一篇涉及的基础知识,请参考以下链接:
我知道你在“看”
查看全部
动态网页抓取(Ajax理论1.Ajax提取AjaxAjaxAjax分析
)
上面提到的爬虫都是建立在静态网页的基础上的。首先通过请求网站url获取网页源码。之后,从源代码中提取信息并存储。本文将重点介绍动态网页数据采集,先介绍Ajax相关理论,然后在实战中爬取Flush的动态网页,获取个股信息。
内容
一、Ajax 理论
1.Ajax 简介
2.ajax分析
3.Ajax 提取
二、网络分析
1.网页概览
2.Ajax 歧视
3.Ajax 提取
三、爬虫实战
1.网页访问
2.信息抽取
3.保存数据
4.循环结构
一、Ajax 理论
1.Ajax 简介
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,可以创建交互式、快速和动态的 Web 应用程序,并且可以在不重新加载整个网页的情况下更新某些网页。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
2.ajax分析
微博网站是一个带有Ajax的动态网页,易于识别。首先打开Dectools工具(调整到XHR专栏)和中南财经政法大学官方微博网站(),这里选择的是移动端微博,然后选择清除所有内容.
接下来,滚动滚轮以下拉页面,直到清空的 XHR 列中出现新项目。点击此项,选择预览栏,发现这里对应的内容是页面上新出现的微博,上面的网页链接但是没有变化。此时,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
还是选择同一个入口进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求url为:,即请求参数有4个:type、value、containerid、since_id,然后翻页发现,除了since_id发生了变化,其余的都保持不变。这里我们可以看到since_id是翻页方法。
接下来观察since_id,发现上下请求之间的since_id没有明显的规律。进一步搜索发现下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态URL添加到爬虫中。
发起请求获取响应后,进一步分析发现响应格式是json,所以进一步处理json就可以得到最终的数据了!
二、网络分析
1.网页概览
有了上面的分析,我们就用flush网页采集的数据,通过实战来验证一下。首先打开网页:如下图:
再按F12键打开Devtools后端源代码,将鼠标放在第一项上,点击右键,查看源代码中的位置。
2.Ajax 歧视
接下来,我们点击网页底部的下一页,发现网页url没有任何变化!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清除了网络中的所有内容,继续点击下一页到第五页,发现连续弹出了三个同名的消息。请求的URL和请求头的具体内容可以通过General一栏获取。
于是,我们复制了请求的url,在浏览器中打开,结果响应内容是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页形式,和上面微博响应的json格式不同,所以可以在后面的网页分析的形式。
三、爬虫实战
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的一点是,这里的请求头除了User-Agent之外,还需要host、Referer和X-Requested-With参数,这应该和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息抽取
之后就是上面分析库的内容了,这里就更容易理解BaetifulSoup库了。首先将上面的html转换成一个BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应的信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
同时考虑到flush的多页结构和反爬虫的存在,也采用字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬行前中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
至此,Flush动态网页的爬取完成,接下来由这个爬虫总结:首先,我们通过浏览网页结构,翻页,对比XHR栏,对变化的网页进行Ajax判断。如果网页url不变,XHR会刷新内容,基本说明是动态网页,此时我们进一步检查多个页面之间URL请求的异同,找出规律。找到规则后,就可以建立多页请求流程了。之后对单个响应内容进行处理(详细参见响应内容的格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫完整代码可在公众号回复“Flush”获取。下面将进一步讲解和实战浏览器模拟行为。上一篇涉及的基础知识,请参考以下链接:
我知道你在“看”
动态网页抓取(Ajax加载页面特点及优势分析-乐题库(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-18 05:16
动态网页数据抓取一、网页
1.传统网页:
如果需要更新内容,则需要重新加载网页。
2.动态网页:
使用AJAX,无需加载和更新整个网页即可实现部分内容更新。
二、什么是AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。
理解:通过后台与服务器的少量数据交换【一般是post请求】,Ajax可以让网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
例如:百度图片使用Ajax加载页面。
Ajax加载页面特点:交互产生的数据不会出现在网页的源代码中,也就是说我们无法通过python发送请求直接获取这些新出现的数据,那么爬虫只能抓取没有Ajax交互产生的数据. 数据。假设一个网页是Ajax动态加载的,一共有十页,但是如果通过Python获取,一般只能获取一页,无法直接获取后面的九页数据。
Ajax加载页面的原理:通过一定的接口【可以理解为一个URL】与服务器交换数据,从而在当前页面加载新的数据。
Ajax加载页面的优点:
1.反爬虫。对于一些初级爬虫工程师来说,如果不了解异步加载,总觉得代码没问题,但是拿不到自己想要的数据,所以怀疑自己的代码有问题,直到怀疑他们的生活。
2. 更便捷的响应用户数据,优化用户体验。一个页面通常具有相同的内容。如果每次都重复加载一个页面,实际上是重复加载了完全相同的差异,浪费了响应时间。
Ajax加载页面的缺点:
破坏浏览器后退按钮的正常行为。例如,一个网页有十页。动态加载后,十个页面都加载在同一个页面上,但是你不可能回到第九个页面。因此,浏览器的后退按钮对于这种情况是无效的。NS。
三、爬虫如何处理Ajax
1.找一个接口
既然Ajax是通过一个接口【特定的URL】与服务器交互的,那么我们只需要找到这个接口,然后模拟浏览器发送请求即可。
技术难点:
(1)可能有多个接口,一个网页可能有多个具体的数据交互接口,这就需要我们自己去尝试多次查找,增加了爬取的难度。
(2)与服务器交互的数据加密比较困难**。与服务器交互时需要发送数据,但这部分数据是网站的开发者设置的。什么数据是浏览器发送的,虽然我们在大多数情况下都能找到,但是数据是经过加密的,获取起来比较困难。
(3)需要爬虫工程师有较高的js功底。
2.使用 selenium 模拟浏览器行为
它相当于使用代码来操纵浏览器行为。浏览器能拿到什么数据,我们就能拿到什么数据。
技术难点:
代码量很大。
3.两种方法的比较
方式优缺点
分析界面
代码量小,性能高。
有些网站接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
模拟浏览器的行为。浏览器可以请求的也可以用selenium来请求,爬虫更稳定。
代码量大,性能低。
四、总结:
先分析界面。如果接口简单,那么使用接口来获取数据。如果界面复杂,那就用selenium来模拟浏览器的行为,获取数据。
一切都有优点和缺点。一方面是快捷方便,另一方面难免会带来复杂性。因此,由您来权衡利弊或成本。 查看全部
动态网页抓取(Ajax加载页面特点及优势分析-乐题库(一))
动态网页数据抓取一、网页
1.传统网页:
如果需要更新内容,则需要重新加载网页。
2.动态网页:
使用AJAX,无需加载和更新整个网页即可实现部分内容更新。
二、什么是AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。
理解:通过后台与服务器的少量数据交换【一般是post请求】,Ajax可以让网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
例如:百度图片使用Ajax加载页面。
Ajax加载页面特点:交互产生的数据不会出现在网页的源代码中,也就是说我们无法通过python发送请求直接获取这些新出现的数据,那么爬虫只能抓取没有Ajax交互产生的数据. 数据。假设一个网页是Ajax动态加载的,一共有十页,但是如果通过Python获取,一般只能获取一页,无法直接获取后面的九页数据。
Ajax加载页面的原理:通过一定的接口【可以理解为一个URL】与服务器交换数据,从而在当前页面加载新的数据。
Ajax加载页面的优点:
1.反爬虫。对于一些初级爬虫工程师来说,如果不了解异步加载,总觉得代码没问题,但是拿不到自己想要的数据,所以怀疑自己的代码有问题,直到怀疑他们的生活。
2. 更便捷的响应用户数据,优化用户体验。一个页面通常具有相同的内容。如果每次都重复加载一个页面,实际上是重复加载了完全相同的差异,浪费了响应时间。
Ajax加载页面的缺点:
破坏浏览器后退按钮的正常行为。例如,一个网页有十页。动态加载后,十个页面都加载在同一个页面上,但是你不可能回到第九个页面。因此,浏览器的后退按钮对于这种情况是无效的。NS。
三、爬虫如何处理Ajax
1.找一个接口
既然Ajax是通过一个接口【特定的URL】与服务器交互的,那么我们只需要找到这个接口,然后模拟浏览器发送请求即可。
技术难点:
(1)可能有多个接口,一个网页可能有多个具体的数据交互接口,这就需要我们自己去尝试多次查找,增加了爬取的难度。
(2)与服务器交互的数据加密比较困难**。与服务器交互时需要发送数据,但这部分数据是网站的开发者设置的。什么数据是浏览器发送的,虽然我们在大多数情况下都能找到,但是数据是经过加密的,获取起来比较困难。
(3)需要爬虫工程师有较高的js功底。
2.使用 selenium 模拟浏览器行为
它相当于使用代码来操纵浏览器行为。浏览器能拿到什么数据,我们就能拿到什么数据。
技术难点:
代码量很大。
3.两种方法的比较
方式优缺点
分析界面
代码量小,性能高。
有些网站接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现是爬虫。
硒
模拟浏览器的行为。浏览器可以请求的也可以用selenium来请求,爬虫更稳定。
代码量大,性能低。
四、总结:
先分析界面。如果接口简单,那么使用接口来获取数据。如果界面复杂,那就用selenium来模拟浏览器的行为,获取数据。
一切都有优点和缺点。一方面是快捷方便,另一方面难免会带来复杂性。因此,由您来权衡利弊或成本。

