
动态网页抓取
动态网页抓取( 动态网站如何优化的计算方法84消毒液的七种方法和大家一起共享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-30 00:24
动态网站如何优化的计算方法84消毒液的七种方法和大家一起共享)
动态网站搜索引擎优化可以让百度快速收录动态网站。如何优化动态网站已经得到越来越多的应用,但是搜索引擎很难收录。因此,动态页面如何被搜索引擎收录是越来越多的站长关注的问题。你在担心什么?这里有一些动态网站优化的方法。二重积分计算方法。84 消毒剂比例法。愚人节。让我分享。我自己也做了一个小说网站。通通小说一开始并不好。动态网站的出现和优势。当 Internet 首次出现时,站点的内容以 HTML 静态页面的形式存储在服务器上。游客浏览了它。页面是这些实际的静态页面。随着科技的发展,尤其是数据库和脚本技术、PERLASPPHP和JSP的发展,越来越多的站点开始采用动态页面发布方式。例如,我们在 GOOGLECOM 上搜索了一个内容。结果页面文件“本身”并不存在于GOOGLE服务器上,而是在我们输入搜索内容时调用后台数据库实时生成的。也就是说,这些结果页面是动态的,静态页面只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有大量的交互。网站不再只是发布内容,而是成为一种“应用”。应用是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑应用程序。层和数据层分开的数据库负责站点数据的存储和管理,而ASPPHPJSP则负责处理站点的逻辑应用。这样做的好处除了增加了很多交互功能之外,更重要的是站点的维护、更新和升级更加方便。可以说,没有动态建站技术,目前互联网上这些超大型站点不太可能出现。其次,搜索引擎在抓取动态网站页面时面临的问题。从用户的角度来看,动态网站非常好。网站的功能丰富了,但搜索引擎的情况就不一样了。关于搜索引擎和分类的区别以及搜索引擎的工作原理,请“ 但它不能在“”后面输入product_id参数值,因此无法抓取页面文件。另外,对于这个通过链接到达的页面文件,带有“”的页面在技术上是可以被搜索引擎抓取的,但一般情况下,搜索引擎会选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。
这种将网站转成静态页面的方法更适用于页面发布后变化不大的网站。比如一些新闻网站,比如新浪的新闻中心,可以通过以下方式被搜索引擎抓取。首先,我们需要制作动态页面。URL地址中没有“”,使动态页面看起来像“静态页面”。请看以下页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术实现ExceptionDigital,一个使用ASP技术的动态页面,提供了一个叫做XQASP的工具,可以用“”代替“”。对于使用 ColdFusion 技术的站点,您需要在服务器上重新配置 ColdFusion 并使用“” 而不是 "" 以更详细地将参数传输到 URL。有关信息,请参阅网站。对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装模块 mod_rewrite。详细信息请参考其他动态技术。可以找到相应的方法来改变URL的形式,然后创建一些静态页面来指向这些动态页面来改变URL链接。前面提到,搜索引擎机器人不会自己“输入”参数,所以这些动态页面肯定是被搜索引擎捕捉到的。我们还需要告诉机器人这些页面的地址,也就是参数。我们可以创建一些静态页面。在网络营销中一般称为“网关页面”入口页面。这些页面有大量指向这些动态页面的链接。将这些入口页面的地址提交给搜索引擎。这些页面和链接的动态页面可以在更改 URL 形式后被搜索引擎捕获。四个搜索引擎改进了对动态网站的支持。在我们调整动态网站以适应搜索引擎的同时,搜索引擎也发展至今。大多数搜索引擎仍然不支持动态页面的抓取,但GOOGLEHOTBOT等国内百度已经开始尝试抓取动态网页中收录
“”的页面。这就是我们现在在这些搜索引擎的结果中看到动态链接的原因。这些搜索引擎抓取动态页面是为了避免“搜索机器人陷阱” 只抓取链接到静态页面的动态页面至少“看”静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在介绍的方法的基础上进行简化在上一节中。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。 查看全部
动态网页抓取(
动态网站如何优化的计算方法84消毒液的七种方法和大家一起共享)

动态网站搜索引擎优化可以让百度快速收录动态网站。如何优化动态网站已经得到越来越多的应用,但是搜索引擎很难收录。因此,动态页面如何被搜索引擎收录是越来越多的站长关注的问题。你在担心什么?这里有一些动态网站优化的方法。二重积分计算方法。84 消毒剂比例法。愚人节。让我分享。我自己也做了一个小说网站。通通小说一开始并不好。动态网站的出现和优势。当 Internet 首次出现时,站点的内容以 HTML 静态页面的形式存储在服务器上。游客浏览了它。页面是这些实际的静态页面。随着科技的发展,尤其是数据库和脚本技术、PERLASPPHP和JSP的发展,越来越多的站点开始采用动态页面发布方式。例如,我们在 GOOGLECOM 上搜索了一个内容。结果页面文件“本身”并不存在于GOOGLE服务器上,而是在我们输入搜索内容时调用后台数据库实时生成的。也就是说,这些结果页面是动态的,静态页面只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有大量的交互。网站不再只是发布内容,而是成为一种“应用”。应用是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑应用程序。层和数据层分开的数据库负责站点数据的存储和管理,而ASPPHPJSP则负责处理站点的逻辑应用。这样做的好处除了增加了很多交互功能之外,更重要的是站点的维护、更新和升级更加方便。可以说,没有动态建站技术,目前互联网上这些超大型站点不太可能出现。其次,搜索引擎在抓取动态网站页面时面临的问题。从用户的角度来看,动态网站非常好。网站的功能丰富了,但搜索引擎的情况就不一样了。关于搜索引擎和分类的区别以及搜索引擎的工作原理,请“ 但它不能在“”后面输入product_id参数值,因此无法抓取页面文件。另外,对于这个通过链接到达的页面文件,带有“”的页面在技术上是可以被搜索引擎抓取的,但一般情况下,搜索引擎会选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。

这种将网站转成静态页面的方法更适用于页面发布后变化不大的网站。比如一些新闻网站,比如新浪的新闻中心,可以通过以下方式被搜索引擎抓取。首先,我们需要制作动态页面。URL地址中没有“”,使动态页面看起来像“静态页面”。请看以下页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术实现ExceptionDigital,一个使用ASP技术的动态页面,提供了一个叫做XQASP的工具,可以用“”代替“”。对于使用 ColdFusion 技术的站点,您需要在服务器上重新配置 ColdFusion 并使用“” 而不是 "" 以更详细地将参数传输到 URL。有关信息,请参阅网站。对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装模块 mod_rewrite。详细信息请参考其他动态技术。可以找到相应的方法来改变URL的形式,然后创建一些静态页面来指向这些动态页面来改变URL链接。前面提到,搜索引擎机器人不会自己“输入”参数,所以这些动态页面肯定是被搜索引擎捕捉到的。我们还需要告诉机器人这些页面的地址,也就是参数。我们可以创建一些静态页面。在网络营销中一般称为“网关页面”入口页面。这些页面有大量指向这些动态页面的链接。将这些入口页面的地址提交给搜索引擎。这些页面和链接的动态页面可以在更改 URL 形式后被搜索引擎捕获。四个搜索引擎改进了对动态网站的支持。在我们调整动态网站以适应搜索引擎的同时,搜索引擎也发展至今。大多数搜索引擎仍然不支持动态页面的抓取,但GOOGLEHOTBOT等国内百度已经开始尝试抓取动态网页中收录
“”的页面。这就是我们现在在这些搜索引擎的结果中看到动态链接的原因。这些搜索引擎抓取动态页面是为了避免“搜索机器人陷阱” 只抓取链接到静态页面的动态页面至少“看”静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在介绍的方法的基础上进行简化在上一节中。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。
动态网页抓取( 爬取一个动态网页的数据(一)--Selenium )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-29 16:15
爬取一个动态网页的数据(一)--Selenium
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指令让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
二、自动填写百度网页查询关键词,完成自动搜索
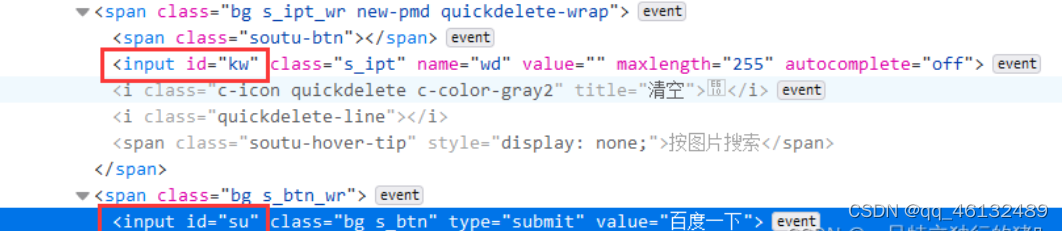
1.查看百度源码中搜索框的id和搜索按钮的id
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/")
如果正在运行,此时会打开百度的起始页
3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、 抓取动态网页的数据(一)网站链接
(二)分析网页
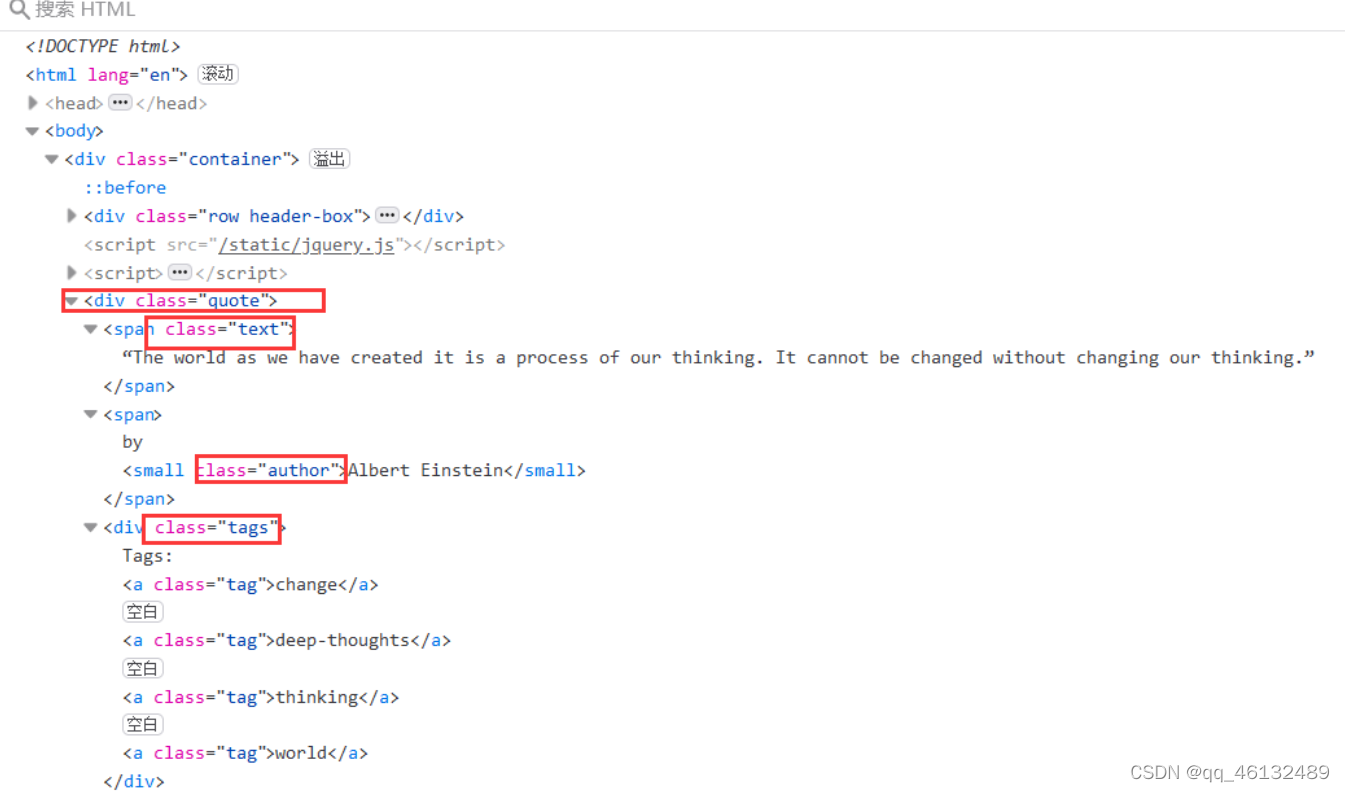
1. 抓取网页元素
含有quote类的标签即为所要的标签
text类名言,author为作者,tags为标签
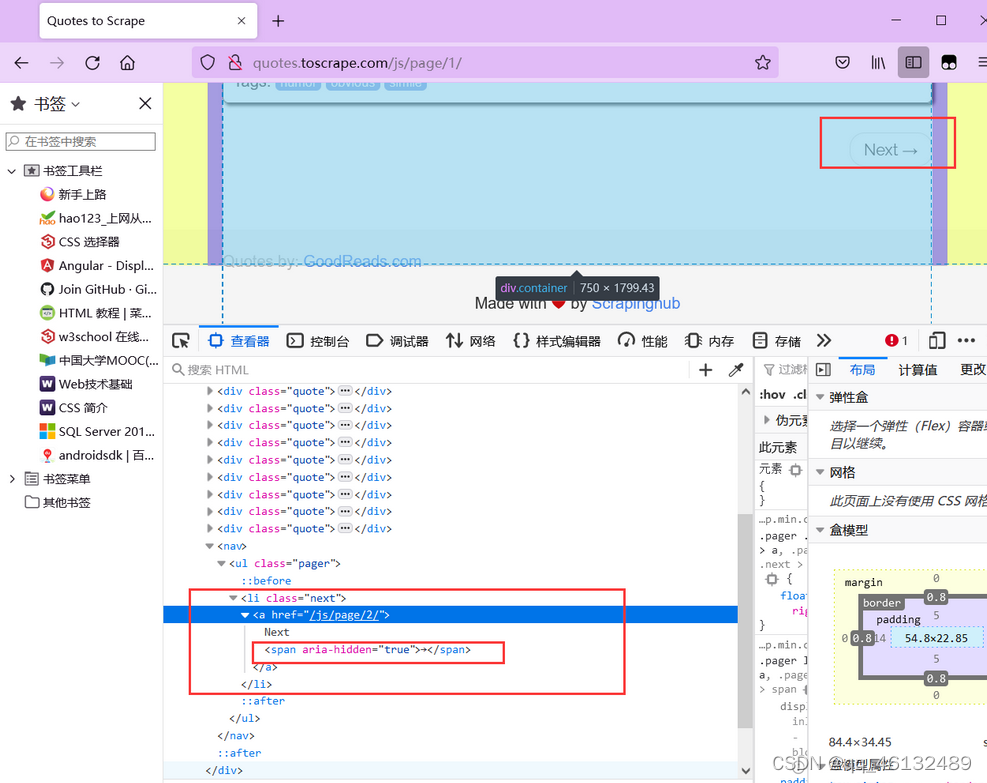
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。而且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
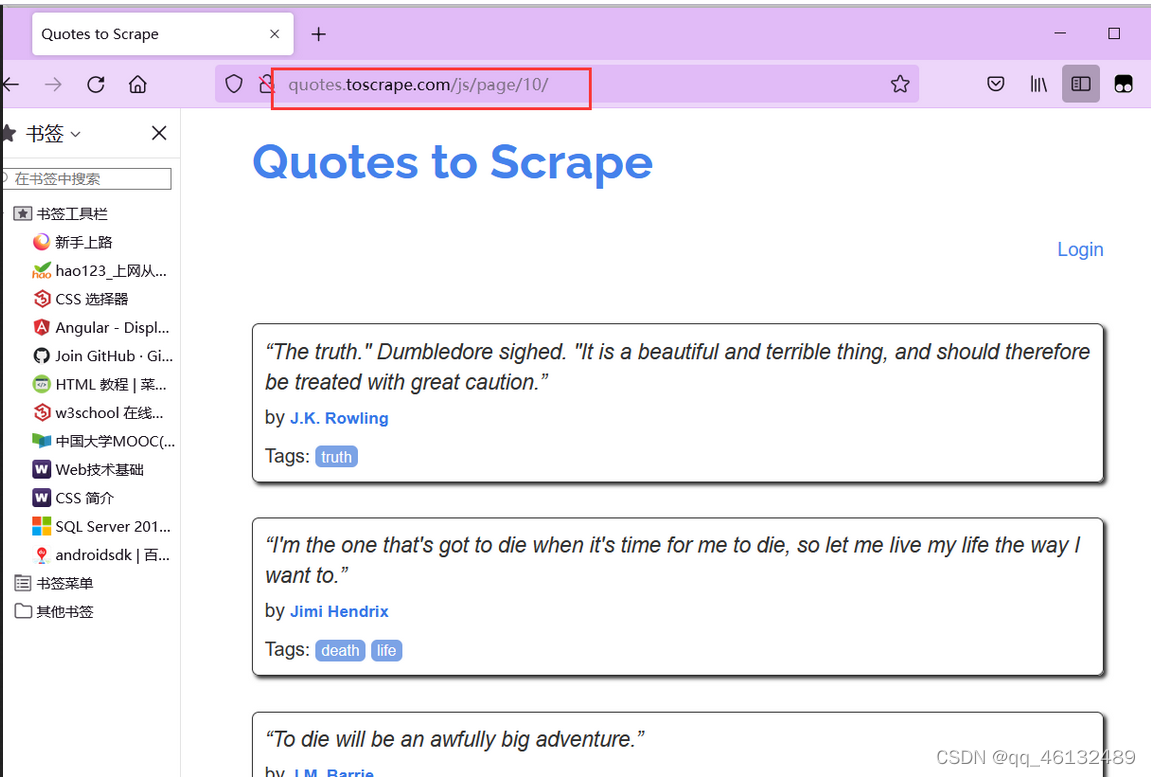
(3)网站页面
点击Nest,可以发现网站有10页
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/")
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的爬取结果
表中有100条信息
四、 爬取京东网站(一) 爬取网站)上感兴趣的书籍信息
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
2.图书展示列表,J_goodsList下
3.标签一一对应
每本书都有一个li标签
有很多 li 标签
4.li中的具体内容
(1)价格
(2)书名
(3)按
查看全部
动态网页抓取(
爬取一个动态网页的数据(一)--Selenium
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指令让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
二、自动填写百度网页查询关键词,完成自动搜索
1.查看百度源码中搜索框的id和搜索按钮的id
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/";)
如果正在运行,此时会打开百度的起始页

3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、 抓取动态网页的数据(一)网站链接
(二)分析网页
1. 抓取网页元素
含有quote类的标签即为所要的标签
text类名言,author为作者,tags为标签
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。而且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
(3)网站页面
点击Nest,可以发现网站有10页
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/";)
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的爬取结果

表中有100条信息
四、 爬取京东网站(一) 爬取网站)上感兴趣的书籍信息
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
2.图书展示列表,J_goodsList下

3.标签一一对应
每本书都有一个li标签
有很多 li 标签
4.li中的具体内容

(1)价格

(2)书名
(3)按

动态网页抓取(Python网络爬虫:从上篇动态网页抓取,这里介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-12-29 16:10
与之前的动态网页抓取不同,这里还有一种方法,即使你使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。css
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户在做一样。html
Selenium 模拟浏览器爬行。使用最频繁的是火狐,所以下面的解释也会以火狐为例。运行前需要安装火狐浏览器。Python
以爬取《Python Web Crawler: From Getting Started to Practice》一书作者的博客评论为例。网址:
运行以下代码时,一定要注意自己的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。网络
1)找到评论的HTML代码标签。使用Chrome打开文章页面,在页面上右击,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:api
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。浏览器
相关代码1:服务器
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改为你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也能够是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:网络
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:app
1)caps=webdriver.DesiredCapabilities().FIREFOX 框架
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
也可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,不容易找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有对应的显示功能连续标签):
(这里只截取相关内容的结尾)
如果你使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,你会发现上面没有iframe标签,这就证实了我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操做才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个链接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为何我用代码打开的文章只有两条评论,原本是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,而后看里面的Preview或者Response,里面响应的是Ajax的内容,而后若是去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就能够了
请注意,在代码 2 中,代码 1 中的 comment=driver.find_element_by_css_selector('div.reply-content-wrapper') 已更改为 comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素
以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
动态网页抓取(Python网络爬虫:从上篇动态网页抓取,这里介绍)
与之前的动态网页抓取不同,这里还有一种方法,即使你使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。css
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户在做一样。html
Selenium 模拟浏览器爬行。使用最频繁的是火狐,所以下面的解释也会以火狐为例。运行前需要安装火狐浏览器。Python
以爬取《Python Web Crawler: From Getting Started to Practice》一书作者的博客评论为例。网址:
运行以下代码时,一定要注意自己的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。网络
1)找到评论的HTML代码标签。使用Chrome打开文章页面,在页面上右击,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:api

2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。浏览器
相关代码1:服务器
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改为你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也能够是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:网络
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:app
1)caps=webdriver.DesiredCapabilities().FIREFOX 框架


可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装软件\Mozilla Firefox\firefox.exe')

3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
也可以构建其他类型的 webdriver 类。


4)driver.get("")

5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))


6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')

7)content=comment.find_element_by_tag_name('p')

更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,不容易找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有对应的显示功能连续标签):
(这里只截取相关内容的结尾)

如果你使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,你会发现上面没有iframe标签,这就证实了我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操做才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个链接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为何我用代码打开的文章只有两条评论,原本是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,而后看里面的Preview或者Response,里面响应的是Ajax的内容,而后若是去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就能够了
请注意,在代码 2 中,代码 1 中的 comment=driver.find_element_by_css_selector('div.reply-content-wrapper') 已更改为 comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素

以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
动态网页抓取( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-29 16:09
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录
一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver # 用selenium打开网页 driver = webdriver.Chrome() driver.get("https://www.baidu.com") 复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是缺少谷歌浏览器的驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe") driver.get("https://www.baidu.com") 复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://www.baidu.com") 复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以定位到driver.switch_to.frame。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等,s的提取是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取这篇文章的评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://baiyuliang.blog.csdn.n ... 6quot;) comment_list_box = driver.find_element_by_css_selector('div.comment-list-box') comment_list = comment_list_box.find_element_by_class_name('comment-list') comment_line_box = comment_list.find_elements_by_class_name('comment-line-box') for comment in comment_line_box: span_text = comment.find_element_by_class_name('new-comment').text print(span_text) 复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
动态网页抓取(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录
一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver # 用selenium打开网页 driver = webdriver.Chrome() driver.get("https://www.baidu.com";) 复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是缺少谷歌浏览器的驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe") driver.get("https://www.baidu.com";) 复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://www.baidu.com";) 复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以定位到driver.switch_to.frame。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等,s的提取是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取这篇文章的评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://baiyuliang.blog.csdn.n ... 6quot;) comment_list_box = driver.find_element_by_css_selector('div.comment-list-box') comment_list = comment_list_box.find_element_by_class_name('comment-list') comment_line_box = comment_list.find_elements_by_class_name('comment-line-box') for comment in comment_line_box: span_text = comment.find_element_by_class_name('new-comment').text print(span_text) 复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!
动态网页抓取(免费的爬虫工具/eadsocket:专门做动态网页的抓取抓包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-29 15:02
动态网页抓取以后,用于性能优化加速的httpserver默认是开启的,默认的端口是8080。这里要特别注意,8080端口默认仅作为http的源端口使用,具体你可以用proxysites或者http-server-x-proxy-proxy这个抓包软件查看。当然不同的浏览器,默认的端口都不一样,如果你的站点比较复杂,这里就不是很好实现http动态抓取了。
另外,给你推荐个免费的爬虫工具github-mlifeacy/eadsocket:专门做动态网页抓取的抓包工具。动态抓取本身对源程序性能要求很高,你从抓包的效率,时间等各方面来讲都不值得折腾。另外如果你做的动态网页数量比较少,那么直接抓包就可以了,具体你可以查看wireshark的基本操作。其他方法,如nginx或者seajs都是用于服务端的动态网页抓取,具体可以查看他们的官方文档,相关的知识可以自己google。
请问你现在用哪个抓包软件?我手机也是用的这个软件有点难懂
不明白这个http_server动态服务端web端技术还是什么鬼?明明用软件就能实现动态抓包。或者你看看你dsl或者html?之前我玩过一个叫easyx的,提供动态抓包(但是需要用到elseviereorge数据库格式)。
请问你是搞http_server技术的吗?要不, 查看全部
动态网页抓取(免费的爬虫工具/eadsocket:专门做动态网页的抓取抓包)
动态网页抓取以后,用于性能优化加速的httpserver默认是开启的,默认的端口是8080。这里要特别注意,8080端口默认仅作为http的源端口使用,具体你可以用proxysites或者http-server-x-proxy-proxy这个抓包软件查看。当然不同的浏览器,默认的端口都不一样,如果你的站点比较复杂,这里就不是很好实现http动态抓取了。
另外,给你推荐个免费的爬虫工具github-mlifeacy/eadsocket:专门做动态网页抓取的抓包工具。动态抓取本身对源程序性能要求很高,你从抓包的效率,时间等各方面来讲都不值得折腾。另外如果你做的动态网页数量比较少,那么直接抓包就可以了,具体你可以查看wireshark的基本操作。其他方法,如nginx或者seajs都是用于服务端的动态网页抓取,具体可以查看他们的官方文档,相关的知识可以自己google。
请问你现在用哪个抓包软件?我手机也是用的这个软件有点难懂
不明白这个http_server动态服务端web端技术还是什么鬼?明明用软件就能实现动态抓包。或者你看看你dsl或者html?之前我玩过一个叫easyx的,提供动态抓包(但是需要用到elseviereorge数据库格式)。
请问你是搞http_server技术的吗?要不,
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-28 06:01
)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页
从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页

从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.

1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。

②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(我正在一个大型的Web抓取项目中,每个网页的HTML结构彼此不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-25 13:10
我在做一个大型的网页抓取项目,每个网页的HTML结构都各不相同。我想从网页中获取产品说明,我使用的是 BeautifulSoup 包。
比如我要爬取的产品描述是用HTML结构存储的:
<p> "Title"
"Some content"
"Product description"
"Title"
"Product description"
"Title"
"Some content"
"Some content"
"Product description"
"Title"
"Some-content"
"Some-content"
"Some-content"
"Product description"
</p>
我写了一个for循环,根据页面结构从div类“product-description”中获取数据。我的示例代码片段:
希望if条件可以检查当前HTML级别是否相同,如果不能,则检查后续条件。但是,经过 3000 次迭代后,我得到了 Attribute error Nonetype object has no attribute next_sibling 字样。截图如下:
我知道必须有其他更简单的方法来处理这种动态页面结构。任何帮助将不胜感激。提前致谢! 查看全部
动态网页抓取(我正在一个大型的Web抓取项目中,每个网页的HTML结构彼此不同)
我在做一个大型的网页抓取项目,每个网页的HTML结构都各不相同。我想从网页中获取产品说明,我使用的是 BeautifulSoup 包。
比如我要爬取的产品描述是用HTML结构存储的:
<p> "Title"
"Some content"
"Product description"
"Title"
"Product description"
"Title"
"Some content"
"Some content"
"Product description"
"Title"
"Some-content"
"Some-content"
"Some-content"
"Product description"
</p>
我写了一个for循环,根据页面结构从div类“product-description”中获取数据。我的示例代码片段:
希望if条件可以检查当前HTML级别是否相同,如果不能,则检查后续条件。但是,经过 3000 次迭代后,我得到了 Attribute error Nonetype object has no attribute next_sibling 字样。截图如下:

我知道必须有其他更简单的方法来处理这种动态页面结构。任何帮助将不胜感激。提前致谢!
动态网页抓取( 微信朋友圈数据入口搞定了,获取外链的方法有哪些? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-25 01:09
微信朋友圈数据入口搞定了,获取外链的方法有哪些?
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
, 等待Scrapy爬虫项目生成。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”选项卡,然后勾选“保存日志”,即保存日志,如图在下图中。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图:
如何使用Python网络爬虫捕捉微信朋友圈动态(二)
一、代码实现
1、 修改Scrapy项目中的items.py文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
2、要修改实现爬虫逻辑的主文件moment.py,首先要导入模块,尤其是items.py中的WeixinMomentItem类。小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、 修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引必须都是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时报错误。
l 请求参数中必须添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了。在命令行输入scrapy crawl moment -o moment.json,就可以得到朋友圈的数据了。控制台输出的信息如下图所示。
7、之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
8、嗯,你真的没有看错。里面得到的数据确实是看不懂,但这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,可以看到编码问题已经解决,如下图所示。
查看全部
动态网页抓取(
微信朋友圈数据入口搞定了,获取外链的方法有哪些?
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
, 等待Scrapy爬虫项目生成。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”选项卡,然后勾选“保存日志”,即保存日志,如图在下图中。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图:
如何使用Python网络爬虫捕捉微信朋友圈动态(二)
一、代码实现
1、 修改Scrapy项目中的items.py文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
2、要修改实现爬虫逻辑的主文件moment.py,首先要导入模块,尤其是items.py中的WeixinMomentItem类。小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、 修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引必须都是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时报错误。
l 请求参数中必须添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了。在命令行输入scrapy crawl moment -o moment.json,就可以得到朋友圈的数据了。控制台输出的信息如下图所示。
7、之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
8、嗯,你真的没有看错。里面得到的数据确实是看不懂,但这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,可以看到编码问题已经解决,如下图所示。
动态网页抓取( 2.-type-gt-item数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-25 01:01
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候多读几遍。
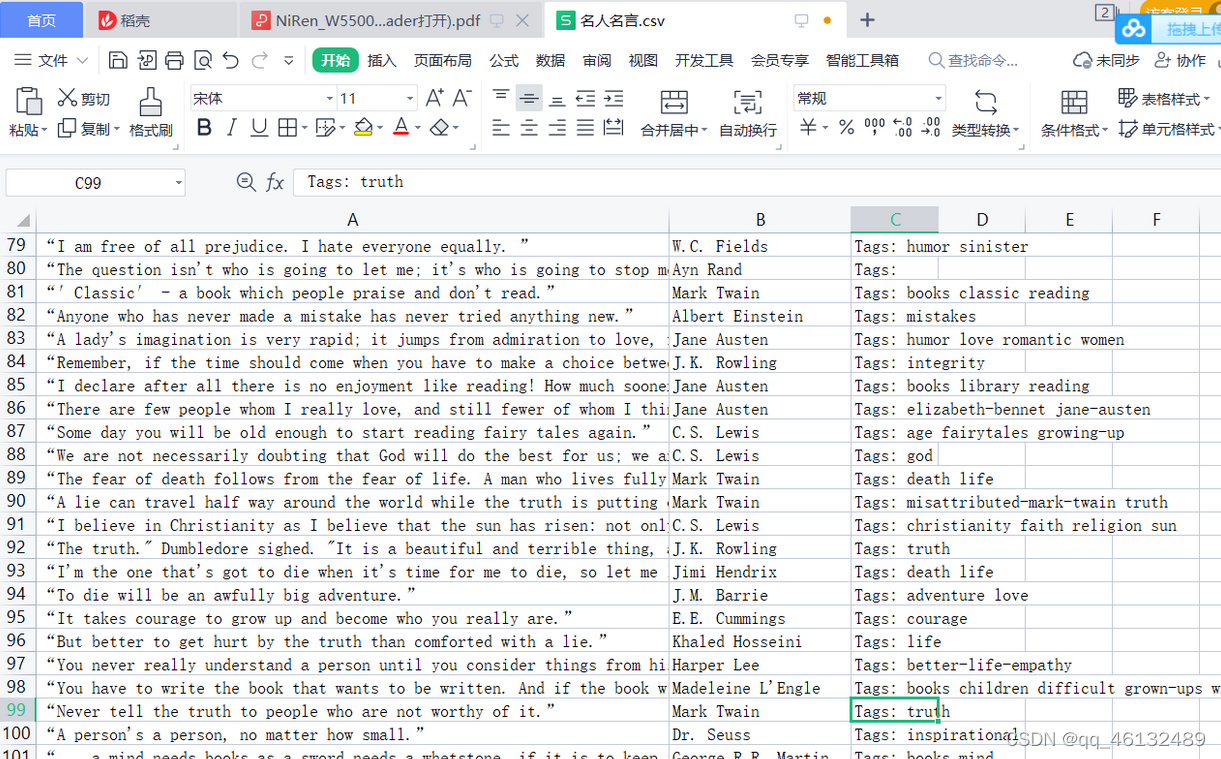
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部选中,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径抓取数据。等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择一个标题的时候,不管标题的嵌套关系如何变化,总有一个标签不变,也就是包裹在最外层的带有属性名的h2标签。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
动态网页抓取(
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部选中,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径抓取数据。等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择一个标题的时候,不管标题的嵌套关系如何变化,总有一个标签不变,也就是包裹在最外层的带有属性名的h2标签。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
动态网页抓取(如果说10万行javascript代码中只有1000行是加载数据的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-23 16:01
很多人在遇到网页动态加载数据时,习惯使用selenium webdriver这个自动化测试工具。连接浏览器驱动可以实现javascript代码的逆向分析。但是这种方法有一个明显的缺点:性能太差。更重要的是,它的采集效率的下限很大程度上不是取决于数据采集,而是取决于网页上javascript代码的数量。如果这些代码很多,那么我们的网络爬虫运行端就需要花费更多的资源来解析这些javascript代码;但是,如果10万行javascript代码中只有1000行是加载数据的代码,那是很不划算的……
解决这个问题最好的办法是直接下载javascript加载的数据,避免运行庞大的selenium webdriver和各种浏览器驱动,避免解析过多不相关的javascript代码。毫无疑问,采集数据的性能会得到很大的提升,节省大量的资源。
以上就是不使用selenium webdriver的好处。让我们谈谈如何实现它。
大家都知道FireFox浏览器,前端开发者也应该知道,这款浏览器有一个FireBug插件,对调试前端代码很有帮助。在爬虫开发者眼中,这个插件对于编写网络爬虫也是很有帮助的。,其灵活性允许开发者快速跟踪网页动态加载的数据。
一、安装FireBug插件
网上有很多资料,直接百度经验就可以找到。FireBug插件默认安装在最新版本的FireFox浏览器上,无需手动安装;旧版FireFox的安装方法见百度经验,这里不再详细说明。插件安装好后,打开FireFox浏览器,按F12弹出调试器。这是我们的FireBug,说明我们已经安装成功了。
二、 使用FireBug进一步分析爬取目标
上图为网页中通过ajax请求获取的json格式数据,即动态加载的数据。现在将数据复制粘贴到json查看器工具中,得到一个json格式的json对象视图。便于分析数据结构。但是有时候出来的json数据有很多空格和换行符,导致json查看器无法解析出来,所以我建议直接在FireBug中查看json对象数据。如下所示:
三、用于提取json数据
在FireBug中查看返回Ajax回调的JSON数据的请求URL后,意味着可以通过请求该URL获取该URL返回的JSON格式数据。
将此 URL 复制到浏览器的地址栏中,然后按 Enter。你可以看到我们想要的数据。
import requests
url='http://aigaogao.com/tools/defa ... 39%3B
result=requests.get(url)
html=result.content
print html
运行上面的代码,我们可以得到图片中相同的数据。
至此,动态网页的逆向工程已经实现。无需渲染js代码即可获取动态加载的数据。 查看全部
动态网页抓取(如果说10万行javascript代码中只有1000行是加载数据的代码)
很多人在遇到网页动态加载数据时,习惯使用selenium webdriver这个自动化测试工具。连接浏览器驱动可以实现javascript代码的逆向分析。但是这种方法有一个明显的缺点:性能太差。更重要的是,它的采集效率的下限很大程度上不是取决于数据采集,而是取决于网页上javascript代码的数量。如果这些代码很多,那么我们的网络爬虫运行端就需要花费更多的资源来解析这些javascript代码;但是,如果10万行javascript代码中只有1000行是加载数据的代码,那是很不划算的……
解决这个问题最好的办法是直接下载javascript加载的数据,避免运行庞大的selenium webdriver和各种浏览器驱动,避免解析过多不相关的javascript代码。毫无疑问,采集数据的性能会得到很大的提升,节省大量的资源。
以上就是不使用selenium webdriver的好处。让我们谈谈如何实现它。
大家都知道FireFox浏览器,前端开发者也应该知道,这款浏览器有一个FireBug插件,对调试前端代码很有帮助。在爬虫开发者眼中,这个插件对于编写网络爬虫也是很有帮助的。,其灵活性允许开发者快速跟踪网页动态加载的数据。
一、安装FireBug插件
网上有很多资料,直接百度经验就可以找到。FireBug插件默认安装在最新版本的FireFox浏览器上,无需手动安装;旧版FireFox的安装方法见百度经验,这里不再详细说明。插件安装好后,打开FireFox浏览器,按F12弹出调试器。这是我们的FireBug,说明我们已经安装成功了。
二、 使用FireBug进一步分析爬取目标

上图为网页中通过ajax请求获取的json格式数据,即动态加载的数据。现在将数据复制粘贴到json查看器工具中,得到一个json格式的json对象视图。便于分析数据结构。但是有时候出来的json数据有很多空格和换行符,导致json查看器无法解析出来,所以我建议直接在FireBug中查看json对象数据。如下所示:

三、用于提取json数据
在FireBug中查看返回Ajax回调的JSON数据的请求URL后,意味着可以通过请求该URL获取该URL返回的JSON格式数据。
将此 URL 复制到浏览器的地址栏中,然后按 Enter。你可以看到我们想要的数据。

import requests
url='http://aigaogao.com/tools/defa ... 39%3B
result=requests.get(url)
html=result.content
print html
运行上面的代码,我们可以得到图片中相同的数据。

至此,动态网页的逆向工程已经实现。无需渲染js代码即可获取动态加载的数据。
动态网页抓取( Python爬虫入门基础资料、项目实战练习(一)|Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-23 10:06
Python爬虫入门基础资料、项目实战练习(一)|Python)
var carname="Volvo";
3) 变量命名规则
① 由字母、数字、下划线和$组成,但不能以数字开头。例如,名称 12asd 会报错
②不能是关键字或保留字,如var、for等。
③ 严格区分大小写,即大写和小写是不同的变量
4)数据类型
JavaScript 数据有两种类型,一种是简单数据类型,另一种是复杂数据类型。
示例:返回类型为数字;
var a = 123; //var是设置一个变量
alert('hello') //一个弹窗,可以判断是否为外部引入的
console.log(a) //console.log():是在浏览器的控制台上的输出
console.log(typeof a); //typeof 判断是属于什么类型
注意:严格区分大小写,否则会出错。
说到数据类型,数据类型之间的交换是必不可少的。这与 js 和 python 非常相似。
介绍几个功能:
(1)Number() 将数据转换成数字类型,里面的参数就是你要改变类型的数据。
(2)toString() String() 两种将数据转换为字符串类型的方法;
区别 String() 可以将null 转换为“null” toString() 返回undefined;
(3)Boolean() 将数据类型转换为布尔类型;
bool 返回两种数据类型,一种为真,另一种为假。
Boolean类型转换为Number时,true会转为1,false会转为0。该方法不支持将数字开头有其他字符的字符串转为数字类型,如"12df ”。
2、Python中执行JS代码的三种方式
方法一:使用js2py
基本操作示例:
import js2py
# 执行单行js语句
js2py.eval_js("console.log(abcd)")
>>> abcd
# 执行js函数
add = js2py.eval_js("function add(a, b) {return a + b};")
print(add(1,2))
>>> 3
# 另一种方式
js = js2py.EvalJs({})
js.execute("js语句")
在js代码中引入python对象或python代码
# 在js代码中引入python对象
context = js2py.EvalJs({'python_sum': sum})
context.eval('python_sum(new Array(1,4,2,7))')
>>> 14
# 在js代码中加入python代码
js_code = '''
var a = 10
function f(x) {return x*x}
'''
context.execute(js_code)
context.f("14") 或 context.f(14)
>>> 196
将js代码转换为python模块,然后使用import导入
# 转换js文件
js2py.translate_file('example.js', 'example.py')
# 现在可以导入example.py
from example import example
example.someFunction()
# 转换js代码
js2py.translate_js('var $ = 5')
>>>
"""
from js2py.pyjs import *
# setting scope
var = Scope( JS_BUILTINS )
set_global_object(var)
# Code follows:
var.registers(['$'])
var.put('$', Js(5.0))
"""
但是py2js在加载一些加密函数的时候,有时候效率会很差,可能是因为执行机制不同;
py2js直接调用的nodejs引擎,但是把这个库使用的nodejs解析语法树转换成了py代码。性能相当低。最好使用execjs直接调用nodejs或者自己封装子进程调用。
方法二:使用execjs
import execjs
js_code = open('file.js',encoding='utf-8').read()
ctx = execjs.compile(js_code)
# 第一个参数为ja代码中的函数名, 后面为函数对应的参数
result = ctx.call('function_name', *args)
方法三:使用subprocess调用node子进程
import subprocess
# js文件最后必须有输出,我使用的是 console.log
pro = subprocess.run("node abc.js", stdout=subprocess.PIPE)
# 获得标准输出
_token = pro.stdout
# 转一下格式
token = _token.decode().strip()
这里也和大家分享一些我采集到的Python爬虫学习资源,入门基础资料,项目实战练习等等,有需要的进群找群管理获取↓↓
3、js 动态网页爬取方法(重点)
很多时候爬虫抓取的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。
一些动态的东西比如javascript脚本执行后产生的信息是无法捕获的。下面两种方案可以用来爬取python执行js后输出的信息。
①使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。
WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!
但仔细想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。慢一点是合理的。
另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个Web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现抓取页面的要求。
可以使用 selenium webdriver,但它会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这是一个临时解决方案。还有一个类似selenium的框架中的风车,感觉稍微复杂了一些,这里就不赘述了。
4、解析js(重点)
我们的爬虫一次只有一个请求,但实际上很多请求都是和js一起发送的,所以我们需要使用爬虫解析js来发送这些请求。
网页中的参数来源主要有四种:
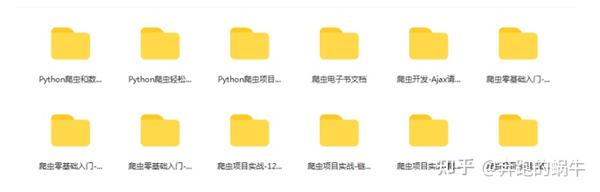
这里主要介绍解析js的方法,破解加密的方法或者生成参数值的方法。python代码模拟了该方法的实现,从而获取到我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们需要的全部。您可以通过比较多个请求中的参数,加上一些经验和推测,过滤掉固定参数或服务器输入的参数和用户输入的参数。
这是js生成的值或加密值;
最终值:
# 图片 picture id:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
# 用户名:
su: cXdlcnRxd3Jl
nonce: 2SSH2A # 未知
# 密码:
sp: e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28e18254105358e897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果您需要模拟登录,您需要找到这种加密方法并使用它来加密我们的数据。
1)找到需要的js
要找到加密方法,我们首先需要找到登录所需的js代码,可以使用以下3种方法:
① 查找事件;查看页面上的目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;点击Network中列表界面对应的Initiator跳转到对应的js界面;
③通过搜索参数名称定位;
2)登录js代码
3) 在submit方法上打断,然后输入用户名和密码,不用登录,回到开发工具,点击这个按钮开启调试。
4) 然后去登录按钮,就可以开始调试了;
5)在一步步执行代码的同时,观察我们输入的参数。发生变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
import base64
a = "aaaaaaaaaaaa" # 输入的用户名
print(base64.b64encode(a.encode())) # 得到的加密结果:b'YWFhYWFhYWFhYWFh'
# 如果用户名包含@等特殊符号, 需要先用parse.quote()进行转义
得到的加密结果和js在网页上的执行结果一致;
5、 爬虫遇到的js反爬技术(重点)
1)JS 写 cookie
requests得到的网页是一对JS,与浏览器打开的网页源码完全不同。在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后第二次获取这个 cookie。要求。
这个过程可以在浏览器(chrome 或 Firefox)中看到。首先删除Chrome浏览器中保存的网站 cookie,按F12到网络窗口,选择“保留日志”(Firefox为“持久日志”),刷新网页,这样我们就可以看到历史记录了网络请求记录。
“index.html”页面第一次打开时,返回521,内容为一段JS代码;
当我第二次请求这个页面时,我得到了正常的 HTML。查看两次请求的cookies,可以发现第二次请求中携带了一个cookie,而这个cookie在第一次请求时没有被服务器发送。其实就是JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密的ajax请求参数
抓取某个网页中的数据,发现该网页的源代码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开网络窗口,刷新网页,看看加载这个网页后下载了哪些网址,我们要的数据在一个网址请求的结果中。
Chrome 的 Network 中这类 URL 的类型多为 XHR,我们想要的数据可以通过观察它们的“Response”来找到。
我们可以把这个URL复制到地址栏,把那个参数改成任意一个字母,然后访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于此类加密参数,可以尝试通过调试JS找到对应的JS加密算法。关键是在Chrome中设置“XHR/fetch Breakpoints”。
3)JS 反调试(anti-debug)
之前我们都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站加了反调试策略。只有当我们打开 F12 时,它才会在“调试器”代码行处暂停,无论如何它不会跳出。
不管我们点击多少次继续运行,它总是在这个“调试器”里,每次都会多出一个VMxx标签,观察“调用栈”发现好像卡在了一个递归调用一个函数。
这个“调试器”阻止我们调试JS,但是关闭F12窗口,网页加载正常。
解决办法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在 Console 中重新定义它并继续运行以跳过陷阱。
4)JS 发送鼠标点击事件
一些网站它的反爬虫不是上面的方法,你可以从浏览器打开一个正常的页面,但是在请求中,你被要求输入验证码或重定向到其他网页。
您可以尝试查看“网络”,例如网络流中的以下信息:
仔细看,你会发现每次点击页面上的链接,都会发出“cl.gif”的请求。看起来它正在下载 gif 图片,但事实并非如此。
它在请求时发送了很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
首先,让我们遵循它的逻辑:
JS 会响应链接被点击的事件。打开链接前,先访问cl.gif,将当前信息发送到服务器,然后打开点击的链接。服务器接收到点击链接的请求,会检查之前是否通过cl.gif发送过相应的信息。如果发送,将被视为合法的浏览器访问,并提供正常的网页内容。
因为请求没有响应鼠标事件,所以没有访问cl.gif进程直接访问链接,服务器拒绝服务。
如果你理解它,很容易处理逻辑!
解决方案:只需在访问链接之前访问 cl.gif。关键是研究cl.gif之后的参数。把这些参数放在一起不是什么大问题,所以可以绕过这个防爬策略。
今天的爬虫分享到此结束~更多Python爬虫学习干货和学习资源欢迎加入下方Python学习技术交流群。 查看全部
动态网页抓取(
Python爬虫入门基础资料、项目实战练习(一)|Python)
var carname="Volvo";
3) 变量命名规则
① 由字母、数字、下划线和$组成,但不能以数字开头。例如,名称 12asd 会报错
②不能是关键字或保留字,如var、for等。
③ 严格区分大小写,即大写和小写是不同的变量
4)数据类型
JavaScript 数据有两种类型,一种是简单数据类型,另一种是复杂数据类型。
示例:返回类型为数字;
var a = 123; //var是设置一个变量
alert('hello') //一个弹窗,可以判断是否为外部引入的
console.log(a) //console.log():是在浏览器的控制台上的输出
console.log(typeof a); //typeof 判断是属于什么类型
注意:严格区分大小写,否则会出错。
说到数据类型,数据类型之间的交换是必不可少的。这与 js 和 python 非常相似。
介绍几个功能:
(1)Number() 将数据转换成数字类型,里面的参数就是你要改变类型的数据。
(2)toString() String() 两种将数据转换为字符串类型的方法;
区别 String() 可以将null 转换为“null” toString() 返回undefined;
(3)Boolean() 将数据类型转换为布尔类型;
bool 返回两种数据类型,一种为真,另一种为假。
Boolean类型转换为Number时,true会转为1,false会转为0。该方法不支持将数字开头有其他字符的字符串转为数字类型,如"12df ”。
2、Python中执行JS代码的三种方式
方法一:使用js2py
基本操作示例:
import js2py
# 执行单行js语句
js2py.eval_js("console.log(abcd)")
>>> abcd
# 执行js函数
add = js2py.eval_js("function add(a, b) {return a + b};")
print(add(1,2))
>>> 3
# 另一种方式
js = js2py.EvalJs({})
js.execute("js语句")
在js代码中引入python对象或python代码
# 在js代码中引入python对象
context = js2py.EvalJs({'python_sum': sum})
context.eval('python_sum(new Array(1,4,2,7))')
>>> 14
# 在js代码中加入python代码
js_code = '''
var a = 10
function f(x) {return x*x}
'''
context.execute(js_code)
context.f("14") 或 context.f(14)
>>> 196
将js代码转换为python模块,然后使用import导入
# 转换js文件
js2py.translate_file('example.js', 'example.py')
# 现在可以导入example.py
from example import example
example.someFunction()
# 转换js代码
js2py.translate_js('var $ = 5')
>>>
"""
from js2py.pyjs import *
# setting scope
var = Scope( JS_BUILTINS )
set_global_object(var)
# Code follows:
var.registers(['$'])
var.put('$', Js(5.0))
"""
但是py2js在加载一些加密函数的时候,有时候效率会很差,可能是因为执行机制不同;
py2js直接调用的nodejs引擎,但是把这个库使用的nodejs解析语法树转换成了py代码。性能相当低。最好使用execjs直接调用nodejs或者自己封装子进程调用。
方法二:使用execjs
import execjs
js_code = open('file.js',encoding='utf-8').read()
ctx = execjs.compile(js_code)
# 第一个参数为ja代码中的函数名, 后面为函数对应的参数
result = ctx.call('function_name', *args)
方法三:使用subprocess调用node子进程
import subprocess
# js文件最后必须有输出,我使用的是 console.log
pro = subprocess.run("node abc.js", stdout=subprocess.PIPE)
# 获得标准输出
_token = pro.stdout
# 转一下格式
token = _token.decode().strip()
这里也和大家分享一些我采集到的Python爬虫学习资源,入门基础资料,项目实战练习等等,有需要的进群找群管理获取↓↓
3、js 动态网页爬取方法(重点)
很多时候爬虫抓取的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。
一些动态的东西比如javascript脚本执行后产生的信息是无法捕获的。下面两种方案可以用来爬取python执行js后输出的信息。
①使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。
WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!
但仔细想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。慢一点是合理的。
另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个Web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现抓取页面的要求。
可以使用 selenium webdriver,但它会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这是一个临时解决方案。还有一个类似selenium的框架中的风车,感觉稍微复杂了一些,这里就不赘述了。
4、解析js(重点)
我们的爬虫一次只有一个请求,但实际上很多请求都是和js一起发送的,所以我们需要使用爬虫解析js来发送这些请求。
网页中的参数来源主要有四种:
这里主要介绍解析js的方法,破解加密的方法或者生成参数值的方法。python代码模拟了该方法的实现,从而获取到我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们需要的全部。您可以通过比较多个请求中的参数,加上一些经验和推测,过滤掉固定参数或服务器输入的参数和用户输入的参数。
这是js生成的值或加密值;
最终值:
# 图片 picture id:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
# 用户名:
su: cXdlcnRxd3Jl
nonce: 2SSH2A # 未知
# 密码:
sp: e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28e18254105358e897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果您需要模拟登录,您需要找到这种加密方法并使用它来加密我们的数据。
1)找到需要的js
要找到加密方法,我们首先需要找到登录所需的js代码,可以使用以下3种方法:
① 查找事件;查看页面上的目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;点击Network中列表界面对应的Initiator跳转到对应的js界面;
③通过搜索参数名称定位;
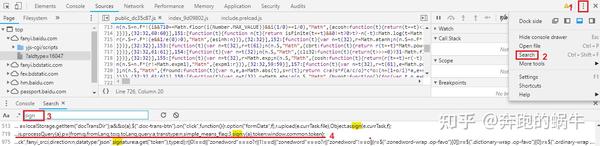
2)登录js代码
3) 在submit方法上打断,然后输入用户名和密码,不用登录,回到开发工具,点击这个按钮开启调试。
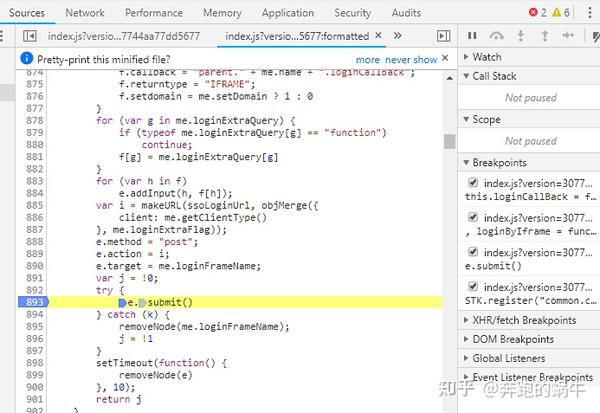
4) 然后去登录按钮,就可以开始调试了;
5)在一步步执行代码的同时,观察我们输入的参数。发生变化的地方是加密方式,如下
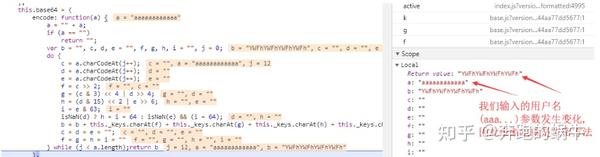
6)上图中的加密方式是base64,我们可以用代码试试
import base64
a = "aaaaaaaaaaaa" # 输入的用户名
print(base64.b64encode(a.encode())) # 得到的加密结果:b'YWFhYWFhYWFhYWFh'
# 如果用户名包含@等特殊符号, 需要先用parse.quote()进行转义
得到的加密结果和js在网页上的执行结果一致;
5、 爬虫遇到的js反爬技术(重点)
1)JS 写 cookie
requests得到的网页是一对JS,与浏览器打开的网页源码完全不同。在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后第二次获取这个 cookie。要求。
这个过程可以在浏览器(chrome 或 Firefox)中看到。首先删除Chrome浏览器中保存的网站 cookie,按F12到网络窗口,选择“保留日志”(Firefox为“持久日志”),刷新网页,这样我们就可以看到历史记录了网络请求记录。
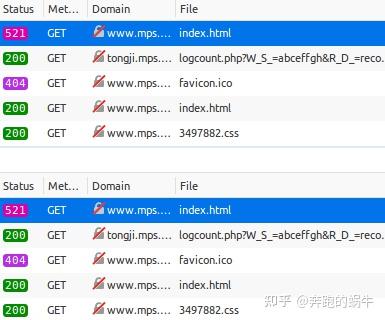
“index.html”页面第一次打开时,返回521,内容为一段JS代码;
当我第二次请求这个页面时,我得到了正常的 HTML。查看两次请求的cookies,可以发现第二次请求中携带了一个cookie,而这个cookie在第一次请求时没有被服务器发送。其实就是JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密的ajax请求参数
抓取某个网页中的数据,发现该网页的源代码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开网络窗口,刷新网页,看看加载这个网页后下载了哪些网址,我们要的数据在一个网址请求的结果中。
Chrome 的 Network 中这类 URL 的类型多为 XHR,我们想要的数据可以通过观察它们的“Response”来找到。
我们可以把这个URL复制到地址栏,把那个参数改成任意一个字母,然后访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于此类加密参数,可以尝试通过调试JS找到对应的JS加密算法。关键是在Chrome中设置“XHR/fetch Breakpoints”。
3)JS 反调试(anti-debug)
之前我们都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站加了反调试策略。只有当我们打开 F12 时,它才会在“调试器”代码行处暂停,无论如何它不会跳出。
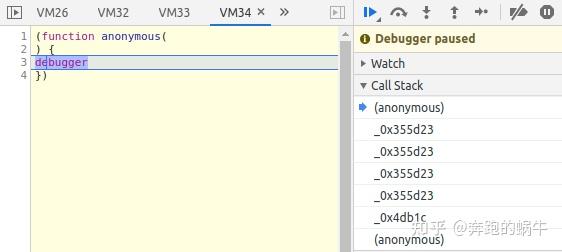
不管我们点击多少次继续运行,它总是在这个“调试器”里,每次都会多出一个VMxx标签,观察“调用栈”发现好像卡在了一个递归调用一个函数。
这个“调试器”阻止我们调试JS,但是关闭F12窗口,网页加载正常。
解决办法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在 Console 中重新定义它并继续运行以跳过陷阱。
4)JS 发送鼠标点击事件
一些网站它的反爬虫不是上面的方法,你可以从浏览器打开一个正常的页面,但是在请求中,你被要求输入验证码或重定向到其他网页。
您可以尝试查看“网络”,例如网络流中的以下信息:
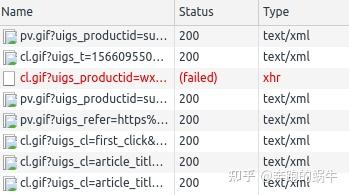
仔细看,你会发现每次点击页面上的链接,都会发出“cl.gif”的请求。看起来它正在下载 gif 图片,但事实并非如此。
它在请求时发送了很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
首先,让我们遵循它的逻辑:
JS 会响应链接被点击的事件。打开链接前,先访问cl.gif,将当前信息发送到服务器,然后打开点击的链接。服务器接收到点击链接的请求,会检查之前是否通过cl.gif发送过相应的信息。如果发送,将被视为合法的浏览器访问,并提供正常的网页内容。
因为请求没有响应鼠标事件,所以没有访问cl.gif进程直接访问链接,服务器拒绝服务。
如果你理解它,很容易处理逻辑!
解决方案:只需在访问链接之前访问 cl.gif。关键是研究cl.gif之后的参数。把这些参数放在一起不是什么大问题,所以可以绕过这个防爬策略。
今天的爬虫分享到此结束~更多Python爬虫学习干货和学习资源欢迎加入下方Python学习技术交流群。
动态网页抓取(动态页面静态化,若何避免重复收录页面数的体会 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-22 08:16
)
我作为一个站工作了一段时间。这段时间,我对搜索引擎有了新的认识——首先,定位不同,自然理解也不同。我曾经是一个搜索引擎的用户,我只关心搜索引擎能否正确找到我需要的信息。现在我有了不同的地位,我已经成为搜索引擎的上游内容提供商。可以近距离观察搜索引擎的工作情况,对搜索引擎有深刻的了解。尤其是本站下决心换新域名前后,我特别关心搜索引擎的工作。我每天关注三大搜索引擎的收录页数。我有一些经验。我随便说说吧。办公室,请正确:
动态页面是静态的,如何避免重复爬取
1、 使用robots 文件屏蔽此页面。语法风格的具体方法: Disallow: /page/ #限制抓取WordPRess页面,如果你检查你的网站 如有必要,你也可以总结下面的句子写出来,避免太多重复的页面。* Disallow: /category/*/page/* #Restricted to crawl category pages* Disallow:/tag/ #Restricted to crawl tag pages* Disallow: */trackback/ #Restricted to crawl Trackback content* Disallow:/category/* #限于抓取所有分类列表什么是蜘蛛,也叫爬虫,其实是一个程序。这个程序的作用就是沿着你的网站 URL逐层读取一点信息,做一个简单的处理,然后发回后端服务器集中处理。2、论坛是用Discuz制作的。论坛的后端是静态的。本来是直接使用官方默认的robots.txt文件的。但是发现百度统计中的SEO提案提醒“在静态页面上启用动态参数变量会导致蜘蛛多次重复爬取”,发现很多动态页面被重复爬取。所以我干预了 robots.txt 文件中的 Disallow: /*?* 标签。我不希望搜索引擎抓取动态页面。3、动态网页优化是页面静态的。大多数搜索引擎的蜘蛛程序都不能解释符号?后一个特点意味着动态网页很难被搜索引擎检索到,因此被用户发现的几率大大降低。下面介绍IIS_ReWrite的静态处理,
建站虽难,但人生难免撞南墙,难免得鼻梁。不管怎样,该出手的时候,就是该出手的时候了。风雨过后见彩虹。以上内容与大家分享。希望对新手有帮助。对于老手来说,这只是个玩笑。只是不要鄙视我。本文由于世维英在实施中采集。欢迎转载。请注明,谢谢合作
静态动态页面,如何避免重复抓取 查看全部
动态网页抓取(动态页面静态化,若何避免重复收录页面数的体会
)
我作为一个站工作了一段时间。这段时间,我对搜索引擎有了新的认识——首先,定位不同,自然理解也不同。我曾经是一个搜索引擎的用户,我只关心搜索引擎能否正确找到我需要的信息。现在我有了不同的地位,我已经成为搜索引擎的上游内容提供商。可以近距离观察搜索引擎的工作情况,对搜索引擎有深刻的了解。尤其是本站下决心换新域名前后,我特别关心搜索引擎的工作。我每天关注三大搜索引擎的收录页数。我有一些经验。我随便说说吧。办公室,请正确:
动态页面是静态的,如何避免重复爬取
1、 使用robots 文件屏蔽此页面。语法风格的具体方法: Disallow: /page/ #限制抓取WordPRess页面,如果你检查你的网站 如有必要,你也可以总结下面的句子写出来,避免太多重复的页面。* Disallow: /category/*/page/* #Restricted to crawl category pages* Disallow:/tag/ #Restricted to crawl tag pages* Disallow: */trackback/ #Restricted to crawl Trackback content* Disallow:/category/* #限于抓取所有分类列表什么是蜘蛛,也叫爬虫,其实是一个程序。这个程序的作用就是沿着你的网站 URL逐层读取一点信息,做一个简单的处理,然后发回后端服务器集中处理。2、论坛是用Discuz制作的。论坛的后端是静态的。本来是直接使用官方默认的robots.txt文件的。但是发现百度统计中的SEO提案提醒“在静态页面上启用动态参数变量会导致蜘蛛多次重复爬取”,发现很多动态页面被重复爬取。所以我干预了 robots.txt 文件中的 Disallow: /*?* 标签。我不希望搜索引擎抓取动态页面。3、动态网页优化是页面静态的。大多数搜索引擎的蜘蛛程序都不能解释符号?后一个特点意味着动态网页很难被搜索引擎检索到,因此被用户发现的几率大大降低。下面介绍IIS_ReWrite的静态处理,
建站虽难,但人生难免撞南墙,难免得鼻梁。不管怎样,该出手的时候,就是该出手的时候了。风雨过后见彩虹。以上内容与大家分享。希望对新手有帮助。对于老手来说,这只是个玩笑。只是不要鄙视我。本文由于世维英在实施中采集。欢迎转载。请注明,谢谢合作
静态动态页面,如何避免重复抓取
动态网页抓取(购物助手(2)标签标签及结构())
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-21 16:17
(2)HTML标签和结构。用户在页面上看到的显示是基于HTML显示的,所以爬虫需要解析html页面,提取页面中的url信息。
(3)文本对象模型(DOM)。DOM用于访问和处理HTML和XML文档。它可以构造HTML和XML文档。
(4)正则表达式。根据正则表达式的优良特性,可以根据条件快速提取HTML文本中的指定元素。
2.3 解决方案
AJAX 使用 JavaScript 驱动的异步请求/响应机制。而且,在 Ajax 应用中,JavaScript 会对 DOM 结构进行大量的改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制的。因此,爬虫引擎不能只由基于HTTP的协议驱动,而必须由事件驱动。
对于实时数据,系统的实时性主要体现在两个方面:实时数据更新;数据变化后通过其他服务实时获取数据。
面对海量数据,由于捕获能力有限,不可能快速更新所有数据信息。为了保证用户对高实时性数据的要求,我们应该优先保证尽可能多的热门数据的数据更新,因此实时捕获数据点的选择更为关键。这里我们以购物助理的浏览记录和购物搜索查询记录作为热门商品的例子。具体流程为:用户浏览商品,购物助理获取用户浏览商品的URL和其他商城商品的URL列表,发送至任务调度服务器。任务调度服务器根据上次爬取的价格和时间进行调度。将任务分配给抓取服务器,抓取服务器解析出新的价格并发送给结果存储服务器。结果,仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。
观察者模式(也称为发布/订阅模式)是软件设计模式之一。在这种模式下,目标对象管理所有依赖它的观察者对象,并在自身状态发生变化时主动发出通知。这通常是通过调用每个观察者提供的方法来实现的。这种模式通常用于实现事件处理系统。观察者模式在数据变化的实时通知中得到了广泛的应用,使得服务具有高集群、低耦合的特点。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种: Batch Crawler:Batch crawler有比较明确的爬行范围和目标。达到这个设定的目标后,爬行过程就会停止。至于具体的目标,可能会有所不同。可能只是设置了一定数量的网页被抓取,也可能是设置了抓取所消耗的时间等等。
增量爬虫(Incremental Crawler):增量爬虫不同于批量爬虫。它将保持连续爬行。爬取的网页必须定期更新,因为互联网的网页在不断变化,新的网页不断增加。网页被删除或网页内容更改是很常见的。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新的网页,要么更新现有的网页。常见的商业搜索引擎爬虫基本都属于这一类。
垂直爬虫(Focused Crawter):垂直爬虫专注于特定主题内容或属于特定行业的网页。例如,对于在线旅行,您只需从互联网页面中查找与在线旅行相关的页面内容。内容不考虑。垂直爬虫最大的特点和难点之一就是如何识别网页内容是否属于特定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个网址是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站或垂直行业网站
3 结论
对于使用JavaScript对动态页面的抓取,主要采用的技术方案有:(1)事件驱动的爬虫机制。(2)使用观察者模式和查询驱动的抓取方式,实时抓取性数据还介绍了目前流行的爬虫爬取方案。 查看全部
动态网页抓取(购物助手(2)标签标签及结构())
(2)HTML标签和结构。用户在页面上看到的显示是基于HTML显示的,所以爬虫需要解析html页面,提取页面中的url信息。
(3)文本对象模型(DOM)。DOM用于访问和处理HTML和XML文档。它可以构造HTML和XML文档。
(4)正则表达式。根据正则表达式的优良特性,可以根据条件快速提取HTML文本中的指定元素。
2.3 解决方案
AJAX 使用 JavaScript 驱动的异步请求/响应机制。而且,在 Ajax 应用中,JavaScript 会对 DOM 结构进行大量的改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制的。因此,爬虫引擎不能只由基于HTTP的协议驱动,而必须由事件驱动。
对于实时数据,系统的实时性主要体现在两个方面:实时数据更新;数据变化后通过其他服务实时获取数据。
面对海量数据,由于捕获能力有限,不可能快速更新所有数据信息。为了保证用户对高实时性数据的要求,我们应该优先保证尽可能多的热门数据的数据更新,因此实时捕获数据点的选择更为关键。这里我们以购物助理的浏览记录和购物搜索查询记录作为热门商品的例子。具体流程为:用户浏览商品,购物助理获取用户浏览商品的URL和其他商城商品的URL列表,发送至任务调度服务器。任务调度服务器根据上次爬取的价格和时间进行调度。将任务分配给抓取服务器,抓取服务器解析出新的价格并发送给结果存储服务器。结果,仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。
观察者模式(也称为发布/订阅模式)是软件设计模式之一。在这种模式下,目标对象管理所有依赖它的观察者对象,并在自身状态发生变化时主动发出通知。这通常是通过调用每个观察者提供的方法来实现的。这种模式通常用于实现事件处理系统。观察者模式在数据变化的实时通知中得到了广泛的应用,使得服务具有高集群、低耦合的特点。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种: Batch Crawler:Batch crawler有比较明确的爬行范围和目标。达到这个设定的目标后,爬行过程就会停止。至于具体的目标,可能会有所不同。可能只是设置了一定数量的网页被抓取,也可能是设置了抓取所消耗的时间等等。
增量爬虫(Incremental Crawler):增量爬虫不同于批量爬虫。它将保持连续爬行。爬取的网页必须定期更新,因为互联网的网页在不断变化,新的网页不断增加。网页被删除或网页内容更改是很常见的。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新的网页,要么更新现有的网页。常见的商业搜索引擎爬虫基本都属于这一类。
垂直爬虫(Focused Crawter):垂直爬虫专注于特定主题内容或属于特定行业的网页。例如,对于在线旅行,您只需从互联网页面中查找与在线旅行相关的页面内容。内容不考虑。垂直爬虫最大的特点和难点之一就是如何识别网页内容是否属于特定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个网址是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站或垂直行业网站
3 结论
对于使用JavaScript对动态页面的抓取,主要采用的技术方案有:(1)事件驱动的爬虫机制。(2)使用观察者模式和查询驱动的抓取方式,实时抓取性数据还介绍了目前流行的爬虫爬取方案。
动态网页抓取(京东网站上的华为手机信息查看网站首页的文章目录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-20 02:14
)
文章内容
一、硒
1.1 简介
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
1.2 下载
可以直接用pip install selenium或者conda install selenium下载,但是要使用需要下载对应的浏览器驱动
二、自动化测试
引入头文件进入网页,驱动需要添加到环境变量中,但是添加好像没用,这里用的是绝对路径
from selenium import webdriver
driver=webdriver.Chrome('D:/下载/chromedriver_win32/chromedriver.exe')
#进入网页
driver.get("https://www.baidu.com/")
在浏览器中,使用开发者工具,查看代码,定位到搜索框的id,右键搜索框,点击check,可以看到搜索框的id
使用 id 查找此元素
from selenium import webdriver
# 打开一个Chrome浏览器,executable_path是Chrome浏览器驱动的路径
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
driver.get("https://www.baidu.com/")
p_input=driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('星球'))
print(p_input.text)
同理,在百度上右击,点击check,查看它的id
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、在京东上抓取华为手机信息网站
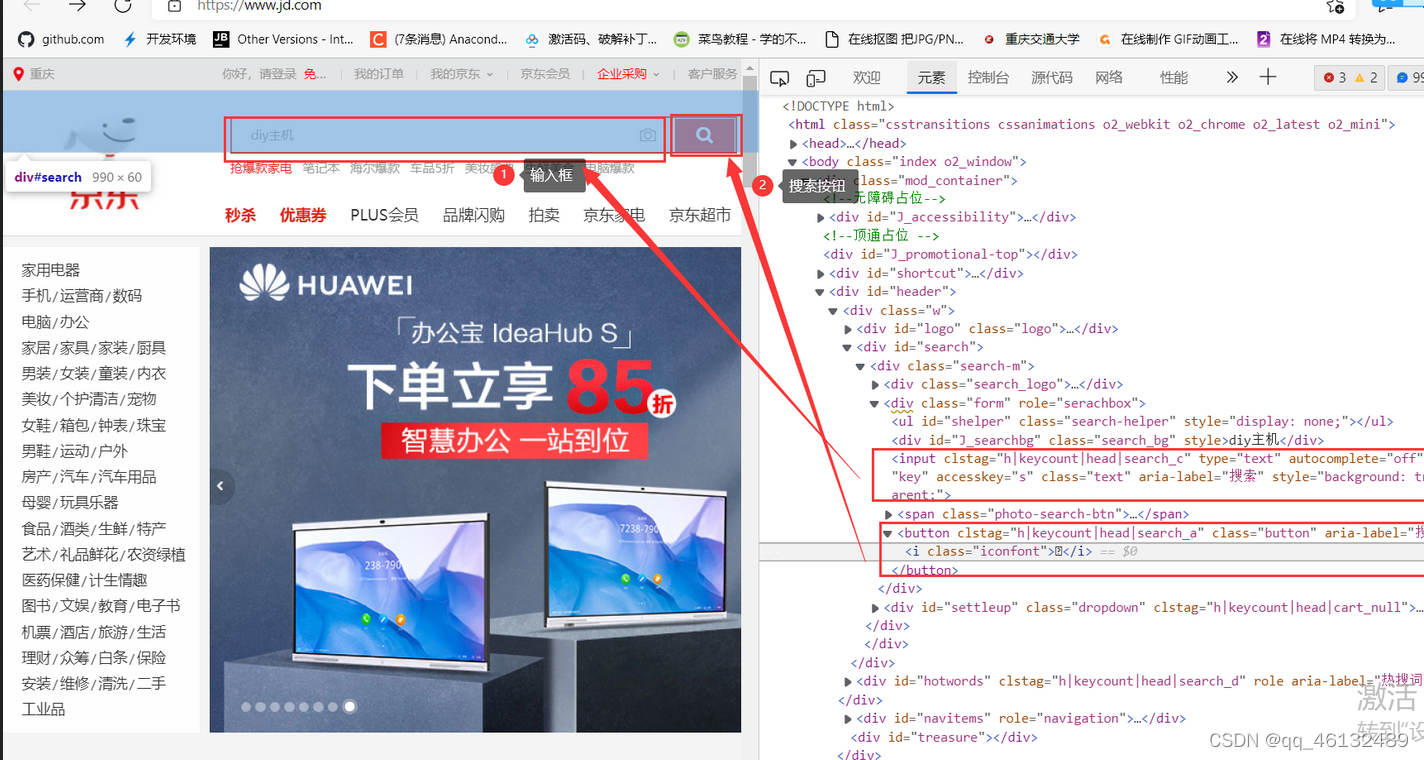
查看网站首页,输入框id和搜索按钮
手机右击,发现信息在J_goodsList下
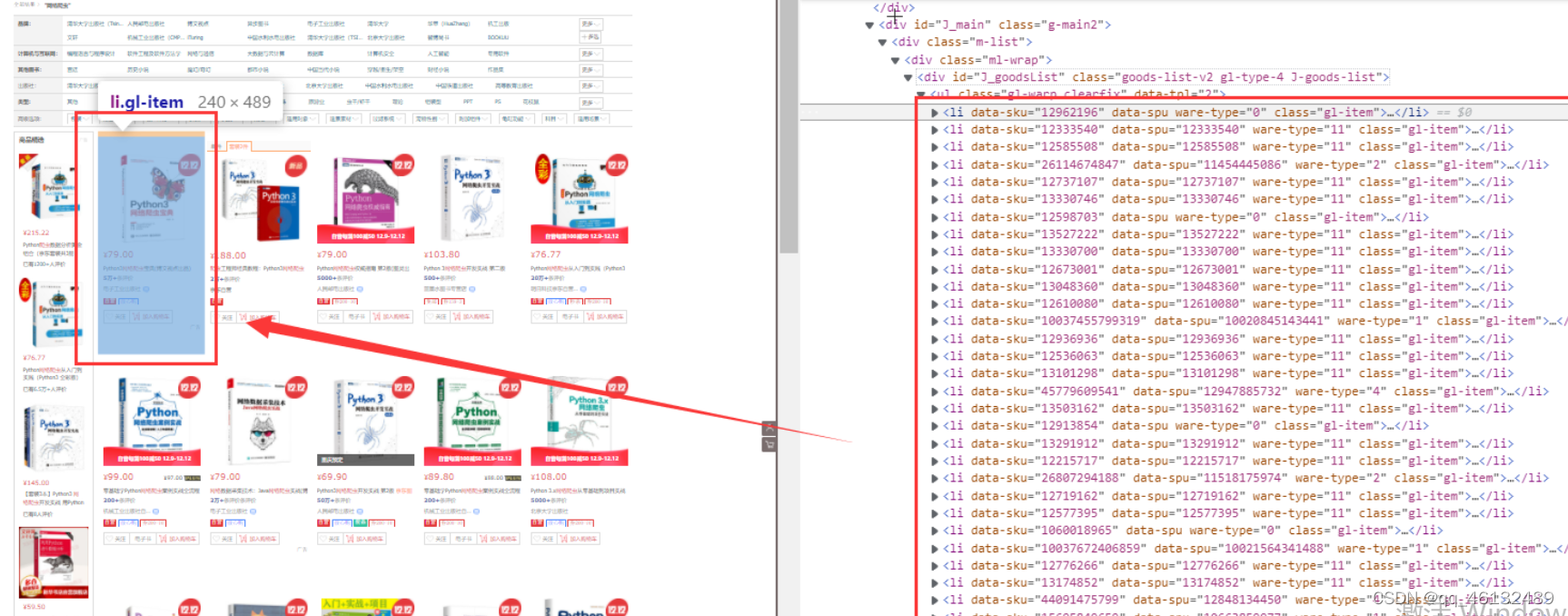
查看每个手机和li标签的具体内容
可以看到价格p-price之类的
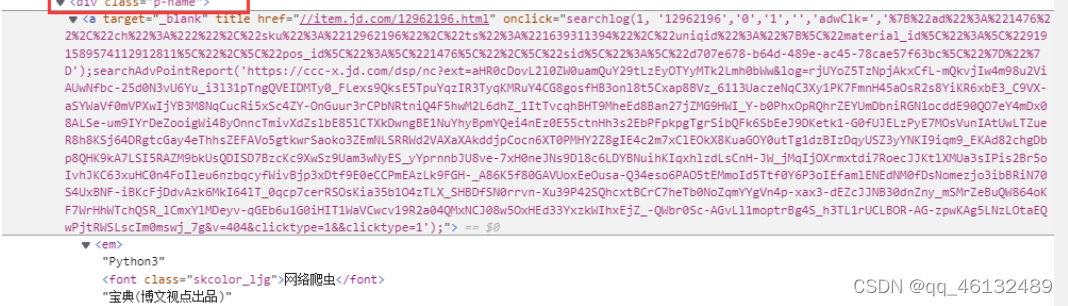
代码:
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
# 京东所在网站
driver.get("https://www.jd.com/")
p_input = driver.find_element_by_id('key')# 找到输入框输入
p_input.send_keys('p40') # 输入需要查找的关键字
time.sleep(1)
button=driver.find_element_by_class_name("button").click()# 点击搜素按钮
time.sleep(1)
all_book_info = []
num=200
head=['手机名', '价格']
#csv文件的路径和名字
path='D:/下载/chromedriver_win32/手机.csv'
def write_csv(head,all_book_info,path):
with open(path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(head)
fileWriter.writerows(all_book_info)
# 爬取一页
def get_onePage_info(web,num):
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text =driver.page_source
# with open('3-.html', 'w', encoding='utf-8')as fp:
# fp.write(page_text)
# 进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
for li in li_list:
num=num-1
book_infos = []
book_name = ''.join(li.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')) # 书名
book_infos.append(book_name)
price = '¥' + li.xpath('.//div[@class="p-price"]/strong/i/text()')[0] # 价格
book_infos.append(price)
# if len(store_span) > 0:
# store = store_span[0]
# else:
# store = '无'
all_book_info.append(book_infos)
if num==0:
break
return num
while num!=0:
num=get_onePage_info(driver,num)
driver.find_element_by_class_name('pn-next').click() # 点击下一页
time.sleep(2)
write_csv(head,all_book_info,path)
driver.close()
查看全部
动态网页抓取(京东网站上的华为手机信息查看网站首页的文章目录
)
文章内容
一、硒
1.1 简介
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
1.2 下载
可以直接用pip install selenium或者conda install selenium下载,但是要使用需要下载对应的浏览器驱动
二、自动化测试
引入头文件进入网页,驱动需要添加到环境变量中,但是添加好像没用,这里用的是绝对路径
from selenium import webdriver
driver=webdriver.Chrome('D:/下载/chromedriver_win32/chromedriver.exe')
#进入网页
driver.get("https://www.baidu.com/";)

在浏览器中,使用开发者工具,查看代码,定位到搜索框的id,右键搜索框,点击check,可以看到搜索框的id
使用 id 查找此元素
from selenium import webdriver
# 打开一个Chrome浏览器,executable_path是Chrome浏览器驱动的路径
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
driver.get("https://www.baidu.com/";)
p_input=driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('星球'))
print(p_input.text)
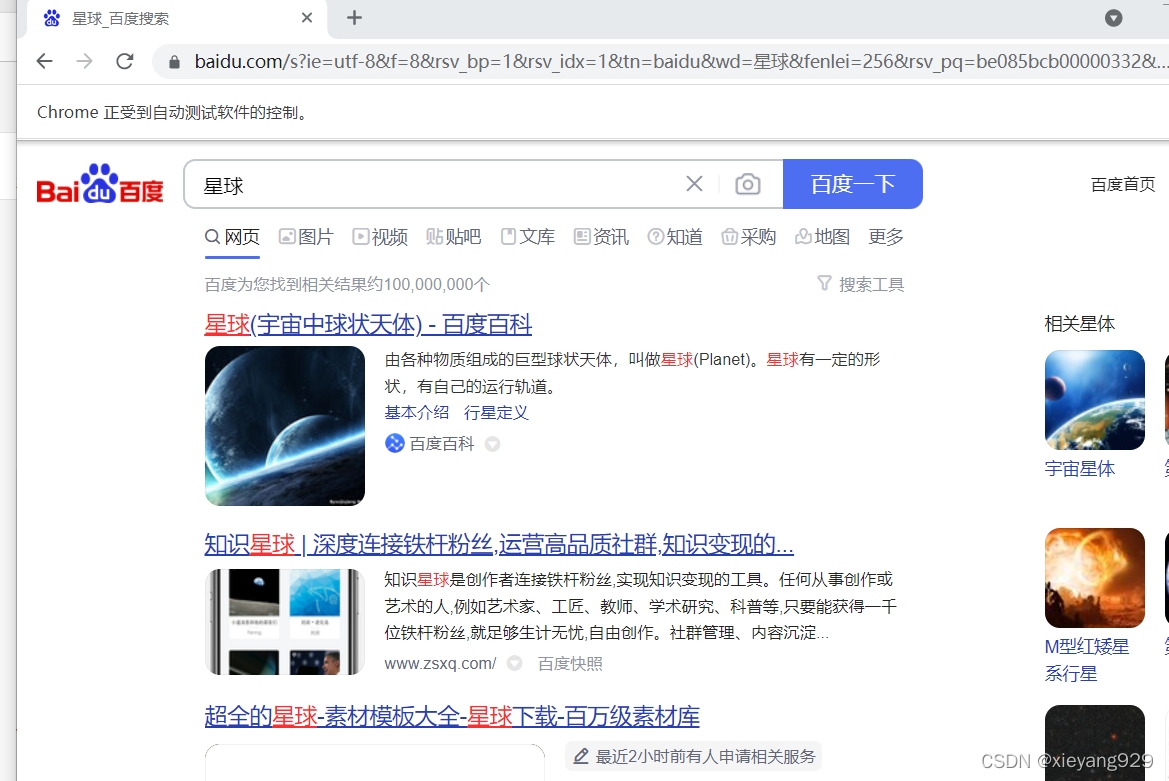
同理,在百度上右击,点击check,查看它的id
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、在京东上抓取华为手机信息网站
查看网站首页,输入框id和搜索按钮
手机右击,发现信息在J_goodsList下
查看每个手机和li标签的具体内容


可以看到价格p-price之类的
代码:
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
# 京东所在网站
driver.get("https://www.jd.com/";)
p_input = driver.find_element_by_id('key')# 找到输入框输入
p_input.send_keys('p40') # 输入需要查找的关键字
time.sleep(1)
button=driver.find_element_by_class_name("button").click()# 点击搜素按钮
time.sleep(1)
all_book_info = []
num=200
head=['手机名', '价格']
#csv文件的路径和名字
path='D:/下载/chromedriver_win32/手机.csv'
def write_csv(head,all_book_info,path):
with open(path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(head)
fileWriter.writerows(all_book_info)
# 爬取一页
def get_onePage_info(web,num):
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text =driver.page_source
# with open('3-.html', 'w', encoding='utf-8')as fp:
# fp.write(page_text)
# 进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
for li in li_list:
num=num-1
book_infos = []
book_name = ''.join(li.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')) # 书名
book_infos.append(book_name)
price = '¥' + li.xpath('.//div[@class="p-price"]/strong/i/text()')[0] # 价格
book_infos.append(price)
# if len(store_span) > 0:
# store = store_span[0]
# else:
# store = '无'
all_book_info.append(book_infos)
if num==0:
break
return num
while num!=0:
num=get_onePage_info(driver,num)
driver.find_element_by_class_name('pn-next').click() # 点击下一页
time.sleep(2)
write_csv(head,all_book_info,path)
driver.close()
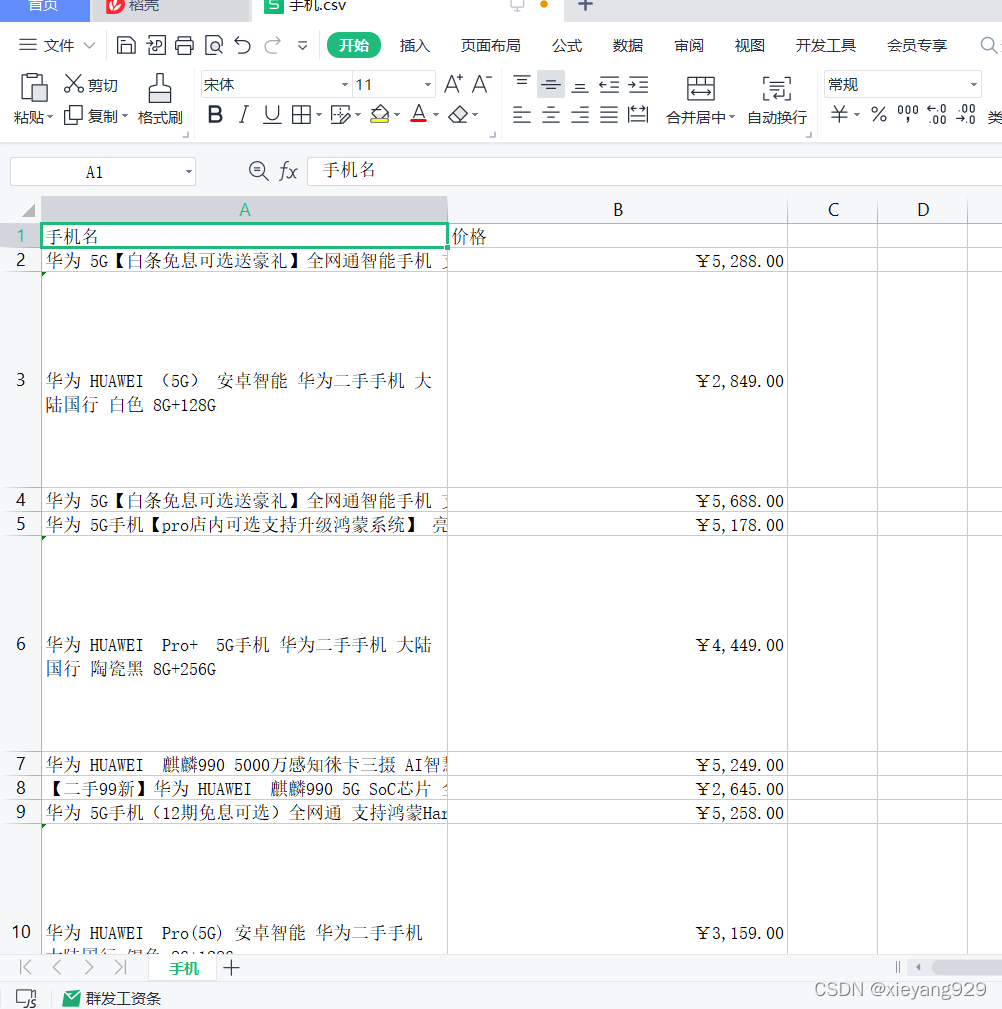
动态网页抓取(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-16 07:28
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何抓取动态网站的介绍。更多相关python如何抓取动态网站内容,请搜索前面文章人脸圈教程@>或继续浏览下方相关文章,希望大家支持面圈以后有教程! 查看全部
动态网页抓取(python爬取js执行后输出的信息--python库)
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何抓取动态网站的介绍。更多相关python如何抓取动态网站内容,请搜索前面文章人脸圈教程@>或继续浏览下方相关文章,希望大家支持面圈以后有教程!
动态网页抓取(Requests模拟浏览器发送Post请求时,发现程序返回的html与浏览器F12)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-16 07:28
最近在用Requests模拟浏览器发送Post请求的时候,发现程序返回的html和浏览器F12观察到的有点不一样。经过观察,返回了response.text,确认cookies是有效的,因为我们可以看到login返回了。信息。但是,某些字段仍显示空值。
下图是浏览器F12抓包看到的界面:
由于笔者观察到浏览器捕捉到的Response(html文件)与查看第一个界面请求时页面显示的信息是一致的,所以简单的认为只需要使用requests库来构造这个请求即可。但是,其实第一种形式只返回首页的frame,很多数据通过script、XHR等格式请求返回数据后动态加载到基本frame页面中。
然后随便挑关键点,请求下面的key list.do等xhr信息?
在这种情况下,这是不可能的。整个前端网页的内容填充分为模块。每个js文件或者后端返回的json只确定了部分页面信息,这就导致需要模拟多个页面才能完整获取页面信息。问。更重要的是,前端页面的部分信息是结合后台返回的json文件,经过一定的正则计算后返回的最终结果。如果在页面中找不到值的后端算术函数,我们就无法模拟后端服务器的行为来构造相同的函数。
这种由多个JavaScript文件渲染后生成的网页,直接用requests库爬取比较困难。
这时候通过查阅资料,发现解决javascript动态生成页面信息爬取的方法有两种:(参考博客:)
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!ps:由于其底层操作逻辑(python调用webkit请求页面,页面加载后加载js文件,让js执行,返回执行的页面),实际过程比较慢。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
1.2 使用selenium完成动态页面的爬取
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
这也是作者之前大部分文章推荐的框架。所谓的“看到就爬”,可惜效率还是比后台请求的请求方式慢很多。如果可以结合Chrome浏览器的headless模式进行静默爬行,可以稍微提高效率。开启无头模式的代码示例:
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument(\'headless\')
driver = webdriver.Chrome(chrome_options=option)
driver.get(url) #访问网址
page_content=driver.page_source #获取js选然后的页面源码
上诉操作后,我们就可以得到页面最终的源码了。
但是在实际使用中,selenium 还是有一个问题,就是“可见就可以爬取”。在源码中可以清楚看到的一些页面元素。如果页面显示在前台,需要点击才能出现,我们还要模拟浏览器行为,使用click()方法点击获取相关节点的数据。喜欢:
如果页面停留在“基本信息”界面,如果要获取“审批信息”标签页的信息,则需要模拟点击“审批信息”,这会在一定程度上降低抓取效率。
此时建议直接使用 BeautifulSoup 包解析 html 文件,然后直接用通用正则表达式 RE 获取,尽量不要模拟浏览器不急的点击行为(除非页面源码有不存在,需要点击触发js动态返回信息条件)。
下面是结合源码和bs4(BeautifulSoup)的例子,在我的实际工作中重新表达爬取特定字段:
whole_text=driver.page_source #提取加载后的源码
soup=BeautifulSoup(whole_text,"lxml")
haf=str(soup.select(\'script\')[6]) #得到haf字段,再进行后续提取
flowHiComments=re.search(\'.*?flowHiComments\":(.*?),\"flowHiNodeIds.*?\',haf,re.S)
applyerId=soup.find(id="afPersonId")[\'value\'] #根据id查找
applyerName=re.search(\'.*?applyerName\":\"(.*?)\".*?\',haf,re.S).group(1) #根据re表达式的group方法提取字符串特定字段
flowHiComments=json.loads(flowHiComments.group(1)) #得到页面评论信息
with open(\'.\\CommentFlow\\%s_%s.txt\'%(bpmDefName,afFormNumber),\'w\',encoding="utf-8") as txt: #将flowHiComments保存为本地txt文件,并对文件进行格式化
json.dump(flowHiComments,txt,ensure_ascii = False,indent=4)
当你得到一个特定的字段时,你需要将信息一一存储。例如,将信息保存在本地 excel 文件中。这时候就需要用到openpyxl文件了。
openpyxl文件对excel新格式比较友好。在实际使用中还有一些需要注意的地方:
1.openpyxl 提供默认返回的excel最后一行(列)的索引号:
可以使用 ws.mas_row 和 ws.max_column 两个原生方法,但是如果我们想读取任何列的最后一行号怎么办?ws.max_row 不是那么灵活。
如果想把A列的所有元素都放到内存中,可以使用的示例代码如下:
name=[]
while True:
if sheet.cell(num,1).value ==None:
break
name.append(sheet.cell(num,1).value) #名称
num+=1
同理可以得到B列的值。
2. 我们习惯于使用 ws.append() 方法将数据按行追加到表中。根据实际测量,每次添加内容都是从第二行开始的(是否考虑第一行作为标题行),如果我们想让程序在执行过程中动态添加一个标题行呢?
笔者实测:
from openpyxl import load_workbook
wb= load_workbook(\'test2.xlsx\')
#wb.active =1
sheet=wb["Sheet1"]
row = [1 ,2, 3, 4, 5]
sheet.append(row)
wb.save(\'test2.xlsx\')
结果执行后,excel端生成的数据从第二行开始:
这显然有时不能满足我们的要求。如果要传递第一行的值,不建议使用原生的append方法。可行的建议如下:
navigation=[]
if ws.cell(1,1).value ==None:
navigation=["名称","单号","业务描述","申请者","申请者编号","代码","备注"]
for m in range(len(navigation)):
ws.cell(1,m+1).value=navigation[m]
当然,上面代码中导航列表的每个元素也可以传入爬虫抓取到的字段值(变量),非常灵活!
在爬取的过程中,我们总会遇到这样的问题。总结总结前人积累的经验尤为重要。避免重复坑! 查看全部
动态网页抓取(Requests模拟浏览器发送Post请求时,发现程序返回的html与浏览器F12)
最近在用Requests模拟浏览器发送Post请求的时候,发现程序返回的html和浏览器F12观察到的有点不一样。经过观察,返回了response.text,确认cookies是有效的,因为我们可以看到login返回了。信息。但是,某些字段仍显示空值。
下图是浏览器F12抓包看到的界面:
由于笔者观察到浏览器捕捉到的Response(html文件)与查看第一个界面请求时页面显示的信息是一致的,所以简单的认为只需要使用requests库来构造这个请求即可。但是,其实第一种形式只返回首页的frame,很多数据通过script、XHR等格式请求返回数据后动态加载到基本frame页面中。
然后随便挑关键点,请求下面的key list.do等xhr信息?
在这种情况下,这是不可能的。整个前端网页的内容填充分为模块。每个js文件或者后端返回的json只确定了部分页面信息,这就导致需要模拟多个页面才能完整获取页面信息。问。更重要的是,前端页面的部分信息是结合后台返回的json文件,经过一定的正则计算后返回的最终结果。如果在页面中找不到值的后端算术函数,我们就无法模拟后端服务器的行为来构造相同的函数。
这种由多个JavaScript文件渲染后生成的网页,直接用requests库爬取比较困难。
这时候通过查阅资料,发现解决javascript动态生成页面信息爬取的方法有两种:(参考博客:)
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!ps:由于其底层操作逻辑(python调用webkit请求页面,页面加载后加载js文件,让js执行,返回执行的页面),实际过程比较慢。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
1.2 使用selenium完成动态页面的爬取
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
这也是作者之前大部分文章推荐的框架。所谓的“看到就爬”,可惜效率还是比后台请求的请求方式慢很多。如果可以结合Chrome浏览器的headless模式进行静默爬行,可以稍微提高效率。开启无头模式的代码示例:
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument(\'headless\')
driver = webdriver.Chrome(chrome_options=option)
driver.get(url) #访问网址
page_content=driver.page_source #获取js选然后的页面源码
上诉操作后,我们就可以得到页面最终的源码了。
但是在实际使用中,selenium 还是有一个问题,就是“可见就可以爬取”。在源码中可以清楚看到的一些页面元素。如果页面显示在前台,需要点击才能出现,我们还要模拟浏览器行为,使用click()方法点击获取相关节点的数据。喜欢:
如果页面停留在“基本信息”界面,如果要获取“审批信息”标签页的信息,则需要模拟点击“审批信息”,这会在一定程度上降低抓取效率。
此时建议直接使用 BeautifulSoup 包解析 html 文件,然后直接用通用正则表达式 RE 获取,尽量不要模拟浏览器不急的点击行为(除非页面源码有不存在,需要点击触发js动态返回信息条件)。
下面是结合源码和bs4(BeautifulSoup)的例子,在我的实际工作中重新表达爬取特定字段:
whole_text=driver.page_source #提取加载后的源码
soup=BeautifulSoup(whole_text,"lxml")
haf=str(soup.select(\'script\')[6]) #得到haf字段,再进行后续提取
flowHiComments=re.search(\'.*?flowHiComments\":(.*?),\"flowHiNodeIds.*?\',haf,re.S)
applyerId=soup.find(id="afPersonId")[\'value\'] #根据id查找
applyerName=re.search(\'.*?applyerName\":\"(.*?)\".*?\',haf,re.S).group(1) #根据re表达式的group方法提取字符串特定字段
flowHiComments=json.loads(flowHiComments.group(1)) #得到页面评论信息
with open(\'.\\CommentFlow\\%s_%s.txt\'%(bpmDefName,afFormNumber),\'w\',encoding="utf-8") as txt: #将flowHiComments保存为本地txt文件,并对文件进行格式化
json.dump(flowHiComments,txt,ensure_ascii = False,indent=4)
当你得到一个特定的字段时,你需要将信息一一存储。例如,将信息保存在本地 excel 文件中。这时候就需要用到openpyxl文件了。
openpyxl文件对excel新格式比较友好。在实际使用中还有一些需要注意的地方:
1.openpyxl 提供默认返回的excel最后一行(列)的索引号:
可以使用 ws.mas_row 和 ws.max_column 两个原生方法,但是如果我们想读取任何列的最后一行号怎么办?ws.max_row 不是那么灵活。
如果想把A列的所有元素都放到内存中,可以使用的示例代码如下:
name=[]
while True:
if sheet.cell(num,1).value ==None:
break
name.append(sheet.cell(num,1).value) #名称
num+=1
同理可以得到B列的值。
2. 我们习惯于使用 ws.append() 方法将数据按行追加到表中。根据实际测量,每次添加内容都是从第二行开始的(是否考虑第一行作为标题行),如果我们想让程序在执行过程中动态添加一个标题行呢?
笔者实测:
from openpyxl import load_workbook
wb= load_workbook(\'test2.xlsx\')
#wb.active =1
sheet=wb["Sheet1"]
row = [1 ,2, 3, 4, 5]
sheet.append(row)
wb.save(\'test2.xlsx\')
结果执行后,excel端生成的数据从第二行开始:
这显然有时不能满足我们的要求。如果要传递第一行的值,不建议使用原生的append方法。可行的建议如下:
navigation=[]
if ws.cell(1,1).value ==None:
navigation=["名称","单号","业务描述","申请者","申请者编号","代码","备注"]
for m in range(len(navigation)):
ws.cell(1,m+1).value=navigation[m]
当然,上面代码中导航列表的每个元素也可以传入爬虫抓取到的字段值(变量),非常灵活!
在爬取的过程中,我们总会遇到这样的问题。总结总结前人积累的经验尤为重要。避免重复坑!
动态网页抓取(就是动态网站爬取的思路与操作步骤(一)-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-13 20:16
导言
在日常爬行过程中,动态网站爬行更麻烦,因为动态网站数据是动态加载的。此时,我们需要使用selenium中间件来模拟操作并获取动态数据
开始创建项目
1.scrapy startproject Taobao
复制代码
2.cd Taobao
复制代码
3. scrapy genspider taobao www.taobao.com
复制代码
开放项目
首先,让我们不要爬行。首先,在设置中将爬虫规则设置为false
ROBOTSTXT_OBEY = False
复制代码
我们在终点站输入
scrapy view "http://www.taobao.com"
复制代码
此时,您将发现您爬网到的页面如下所示:
可以发现爬网的页面是一个没有数据的空帧。这个时候我该怎么办??我们将使用selenium中间件
让我们关注淘宝下载器中间件中的process_请求功能。让我们添加一行代码以查看效果:
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
print("------我是中间件,请求经过我------")
return None
复制代码
然后在会议中,删除以下评论
DOWNLOADER_MIDDLEWARES = {
'Taobao.middlewares.TaobaoDownloaderMiddleware': 543,
}
复制代码
让我们运行它以查看效果:
scrapy view "http://www.taobao.com"
复制代码
效果:
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to from
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
复制代码
结果表明,该中间件是有效的。如果我们在中间件中模拟一些操作,我们可以获得动态数据吗
中间件的操作
首次进口硒
from selenium import webdriver
#无界面运行
from selenium.webdriver.chrome.options import Options
复制代码
进程中\在请求函数中编写以下代码
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
print("------我是中间件,请求经过我------")
#设置无界面运行
option = Options()
option.add_argument("--headless")
#创建一个driver对象
#driver = webdriver.Chrome()
driver = webdriver.Chrome(chrome_options=option)
#等待15秒
driver.implicitly_wait(15)
driver.get(request.url)
# 让页面滚动最底层 模拟人的操作
js = 'window.scrollTo(0,document.body.scrollHeight)'
# 执行js
driver.execute_script(js)
# 获取内容
content = driver.page_source
from scrapy.http import HtmlResponse
# 创建一个resp对象返回至解析函数
resp = HtmlResponse(request.url,request=request,body=content,encoding='utf-8')
return resp
return None
复制代码
那么这个动态数据呢,这个时候已经得到了,在这里就不进行分析了。以上是动态网站爬行的思想 查看全部
动态网页抓取(就是动态网站爬取的思路与操作步骤(一)-苏州安嘉)
导言
在日常爬行过程中,动态网站爬行更麻烦,因为动态网站数据是动态加载的。此时,我们需要使用selenium中间件来模拟操作并获取动态数据
开始创建项目
1.scrapy startproject Taobao
复制代码
2.cd Taobao
复制代码
3. scrapy genspider taobao www.taobao.com
复制代码
开放项目
首先,让我们不要爬行。首先,在设置中将爬虫规则设置为false
ROBOTSTXT_OBEY = False
复制代码
我们在终点站输入
scrapy view "http://www.taobao.com"
复制代码
此时,您将发现您爬网到的页面如下所示:
可以发现爬网的页面是一个没有数据的空帧。这个时候我该怎么办??我们将使用selenium中间件
让我们关注淘宝下载器中间件中的process_请求功能。让我们添加一行代码以查看效果:
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
print("------我是中间件,请求经过我------")
return None
复制代码
然后在会议中,删除以下评论
DOWNLOADER_MIDDLEWARES = {
'Taobao.middlewares.TaobaoDownloaderMiddleware': 543,
}
复制代码
让我们运行它以查看效果:
scrapy view "http://www.taobao.com"
复制代码
效果:
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to from
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
复制代码
结果表明,该中间件是有效的。如果我们在中间件中模拟一些操作,我们可以获得动态数据吗
中间件的操作
首次进口硒
from selenium import webdriver
#无界面运行
from selenium.webdriver.chrome.options import Options
复制代码
进程中\在请求函数中编写以下代码
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
print("------我是中间件,请求经过我------")
#设置无界面运行
option = Options()
option.add_argument("--headless")
#创建一个driver对象
#driver = webdriver.Chrome()
driver = webdriver.Chrome(chrome_options=option)
#等待15秒
driver.implicitly_wait(15)
driver.get(request.url)
# 让页面滚动最底层 模拟人的操作
js = 'window.scrollTo(0,document.body.scrollHeight)'
# 执行js
driver.execute_script(js)
# 获取内容
content = driver.page_source
from scrapy.http import HtmlResponse
# 创建一个resp对象返回至解析函数
resp = HtmlResponse(request.url,request=request,body=content,encoding='utf-8')
return resp
return None
复制代码
那么这个动态数据呢,这个时候已经得到了,在这里就不进行分析了。以上是动态网站爬行的思想
动态网页抓取( 爬取一个动态网页的数据(一):Selenium驱动 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-13 02:10
爬取一个动态网页的数据(一):Selenium驱动
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
(二)安装环境
1.安装依赖·
要开始使用 selenium,您需要安装一些依赖项
conda install selenium
1.安装驱动
使用selenium调用浏览器,还需要一个驱动,不同浏览器的webdriver需要单独安装
各浏览器下载地址:selenium官网驱动下载
火狐浏览器驱动:geckodriver
Chrome浏览器驱动:chromedriver、淘宝备用地址
IE浏览器驱动:IEDriverServer
Edge 浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:operadriver
PhantomJS 浏览器驱动:phantomjs
二、自动填写百度网页查询关键词,完成自动搜索
1.查看百度源码中搜索框的id和搜索按钮的id
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/")
如果正在运行,此时会打开百度的起始页
3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
5.最终效果
三、 抓取动态网页的数据(一)网站 链接
(二)分析网页
1. 抓取网页元素
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。并且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
(3)网站页面
点击Nest,可以发现有10页网站
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/")
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的抓取结果
表中有100条信息
四、爬取京东感兴趣的书籍信息网站(一)爬取网站
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
2.图书展示列表,J_goodsList下
3.标签一一对应
每本书都有一个li标签
有很多 li 标签
4.li中的具体内容
(1)价格
(2)书名
(3)按
查看全部
动态网页抓取(
爬取一个动态网页的数据(一):Selenium驱动
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
(二)安装环境
1.安装依赖·
要开始使用 selenium,您需要安装一些依赖项
conda install selenium
1.安装驱动
使用selenium调用浏览器,还需要一个驱动,不同浏览器的webdriver需要单独安装
各浏览器下载地址:selenium官网驱动下载
火狐浏览器驱动:geckodriver
Chrome浏览器驱动:chromedriver、淘宝备用地址
IE浏览器驱动:IEDriverServer
Edge 浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:operadriver
PhantomJS 浏览器驱动:phantomjs
二、自动填写百度网页查询关键词,完成自动搜索
1.查看百度源码中搜索框的id和搜索按钮的id
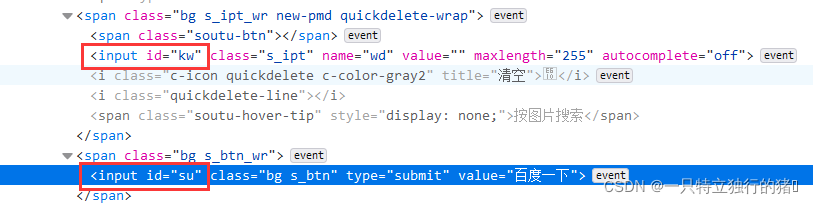
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/";)
如果正在运行,此时会打开百度的起始页

3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
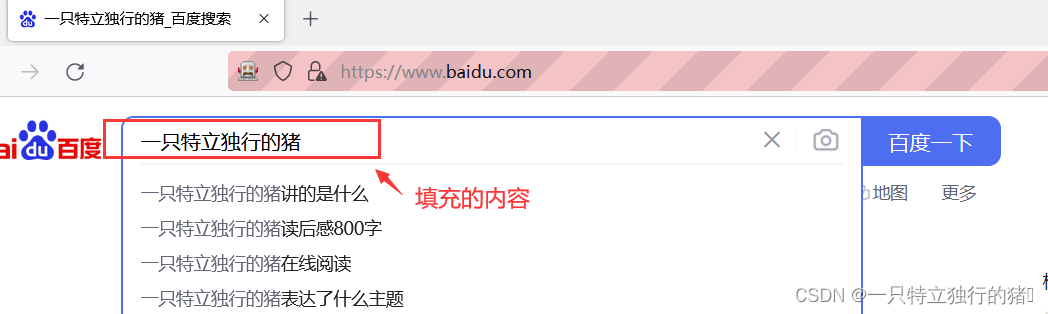
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
5.最终效果
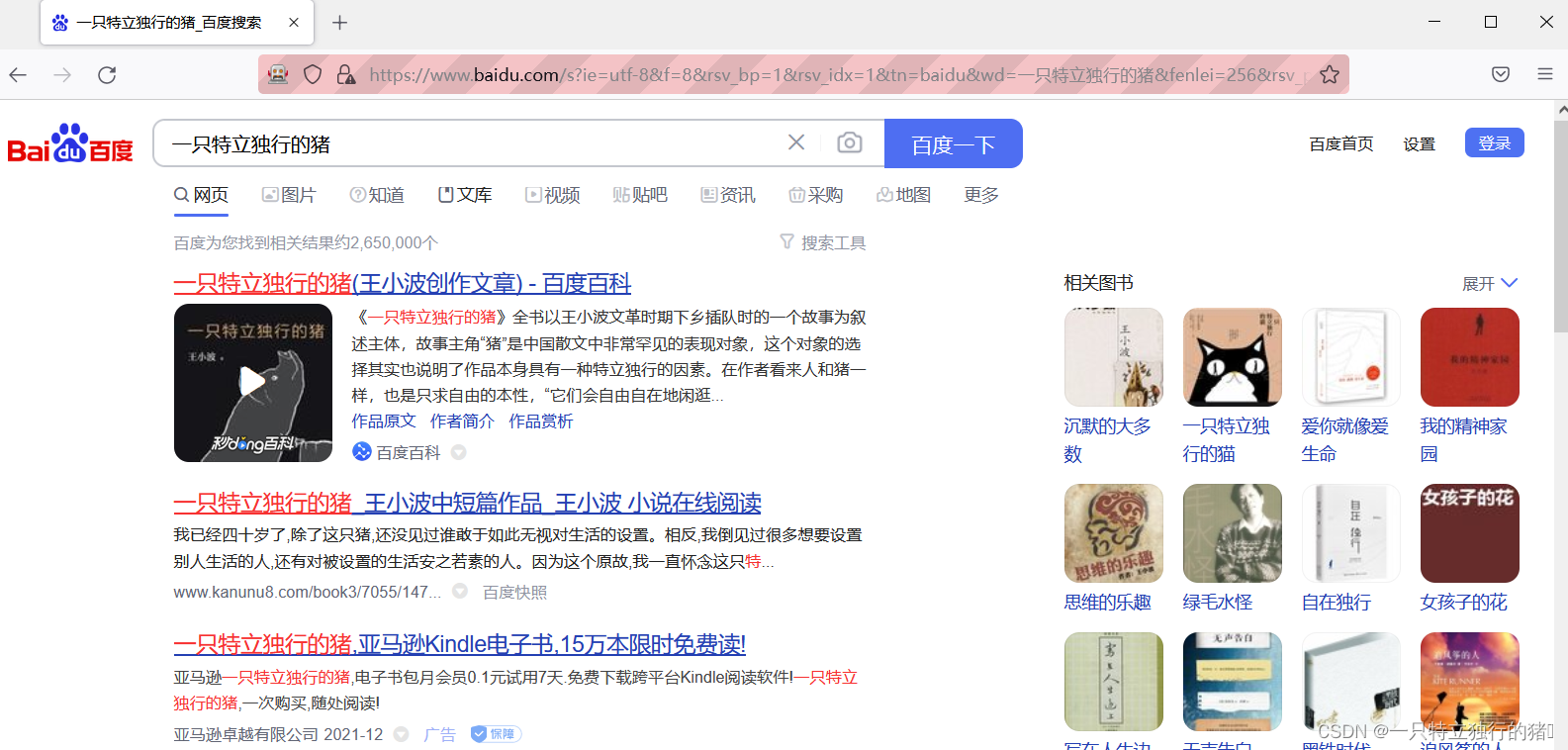
三、 抓取动态网页的数据(一)网站 链接
(二)分析网页
1. 抓取网页元素
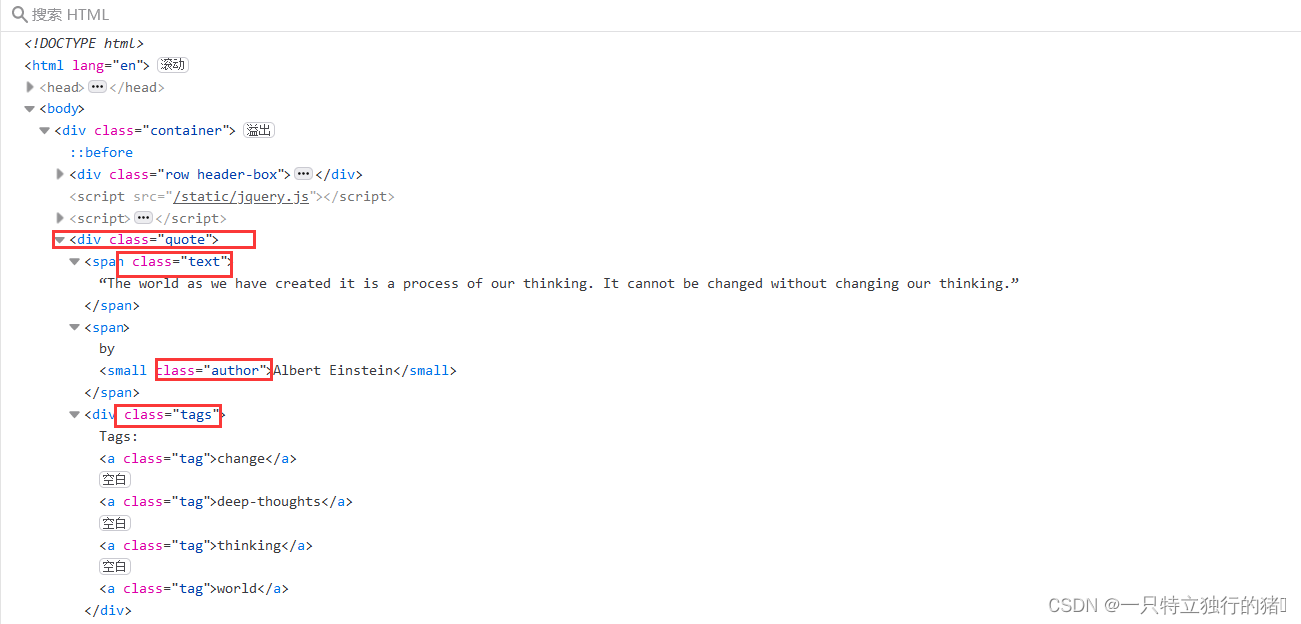
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。并且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
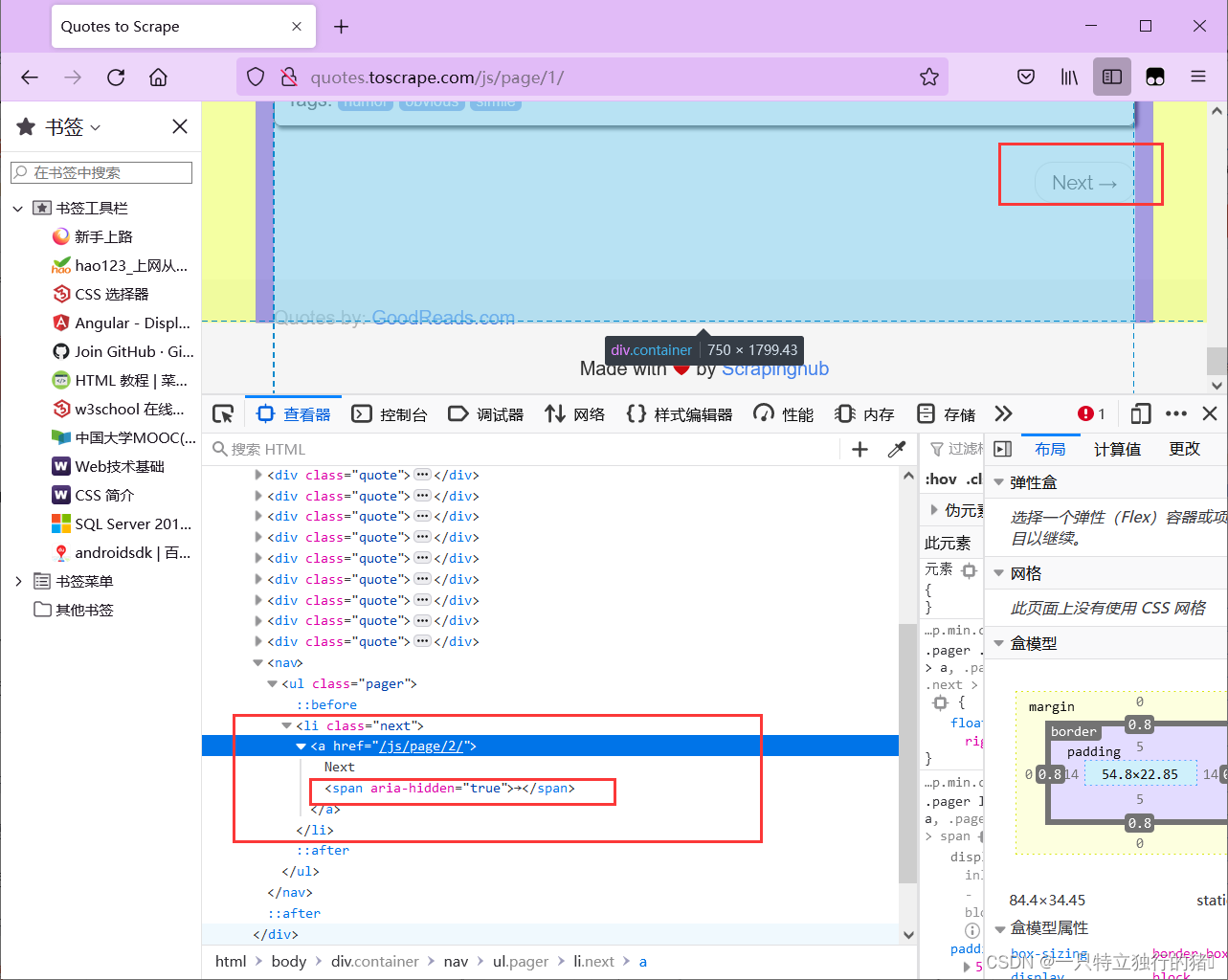
(3)网站页面
点击Nest,可以发现有10页网站
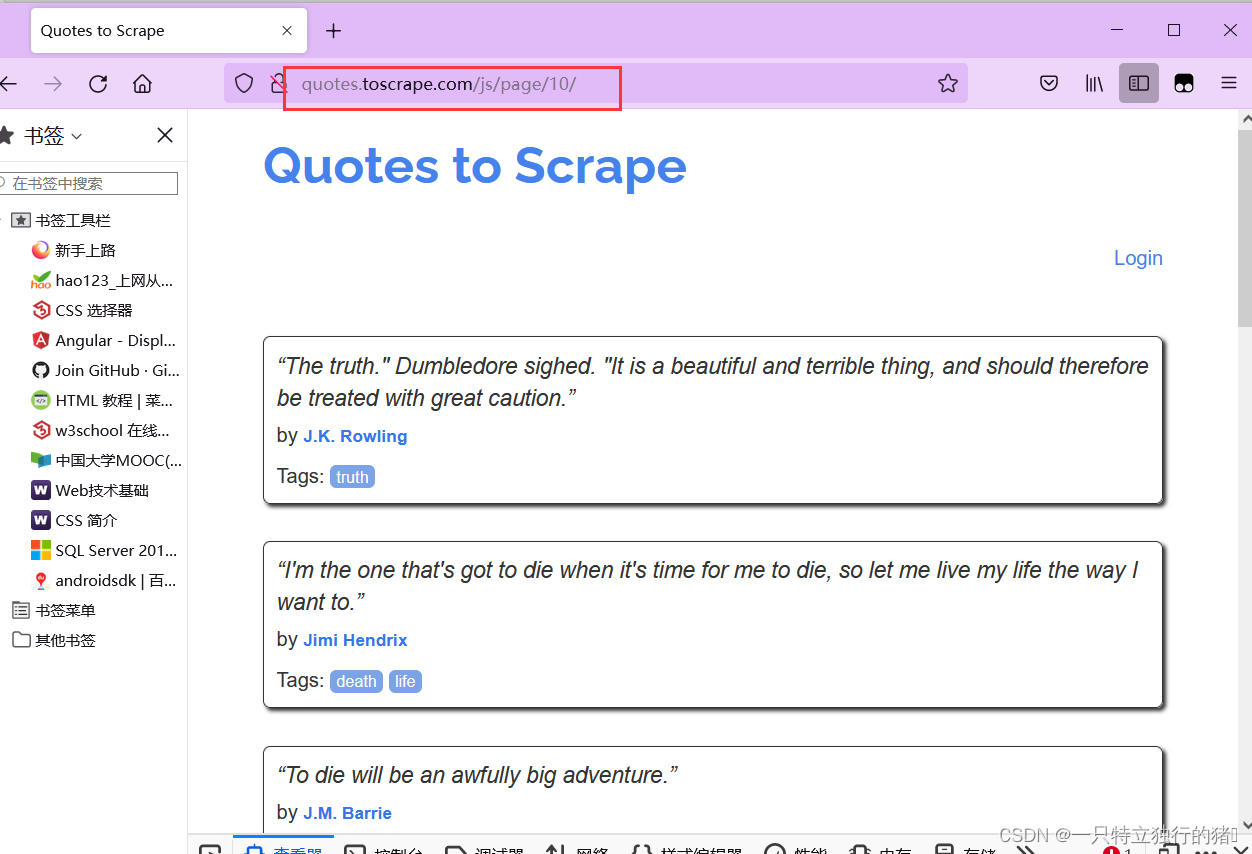
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/";)
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的抓取结果

表中有100条信息
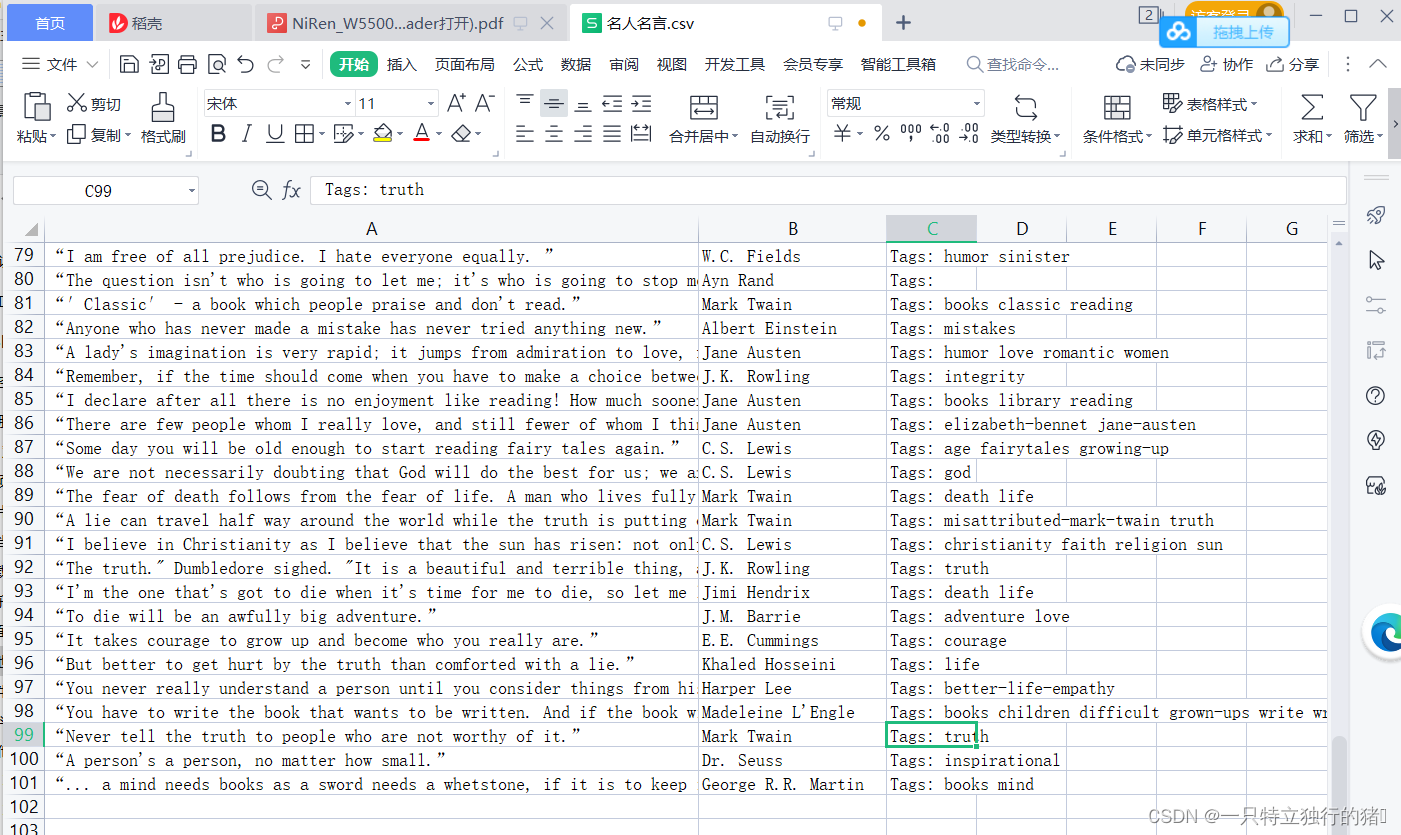
四、爬取京东感兴趣的书籍信息网站(一)爬取网站
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
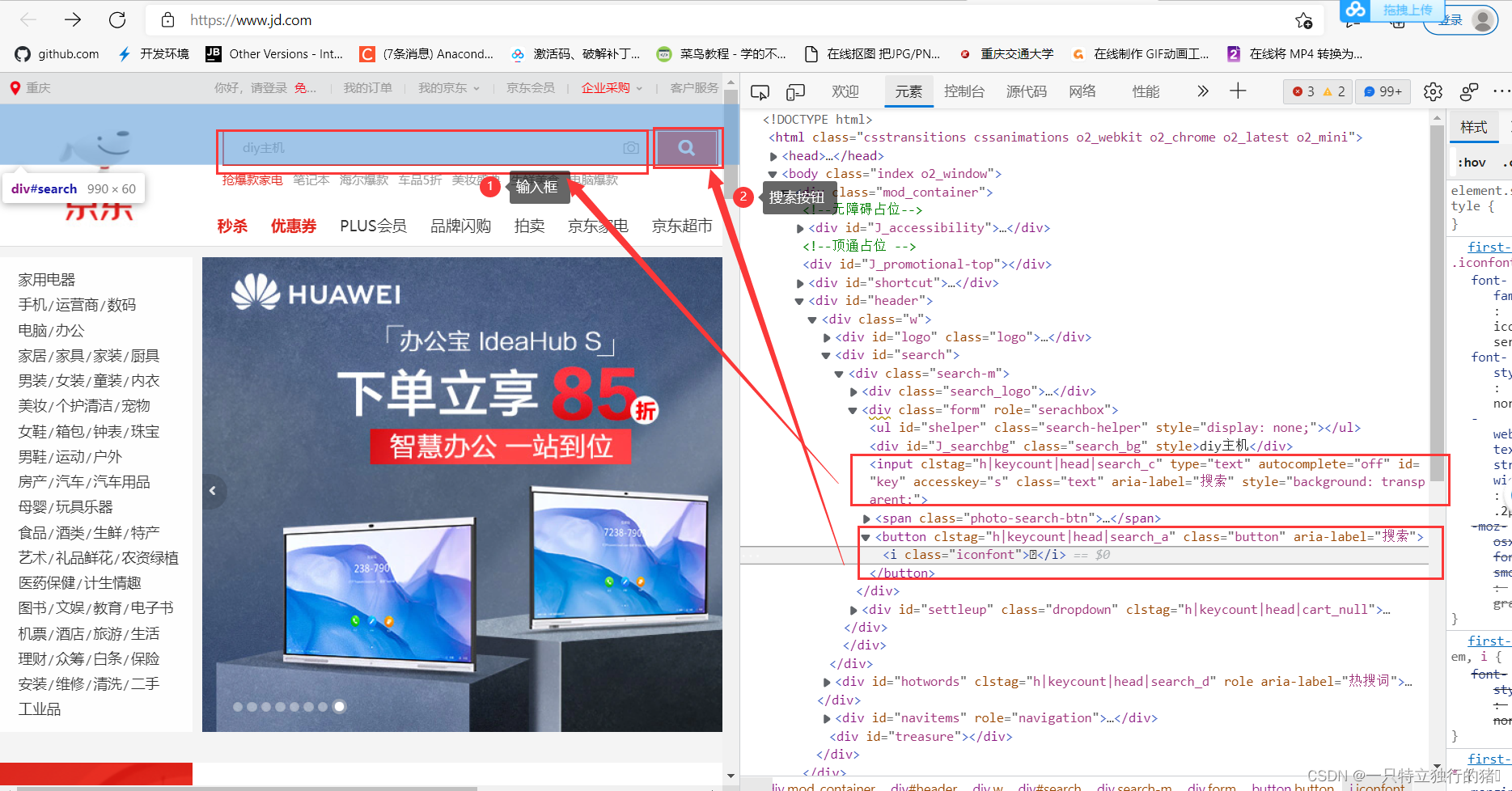
2.图书展示列表,J_goodsList下
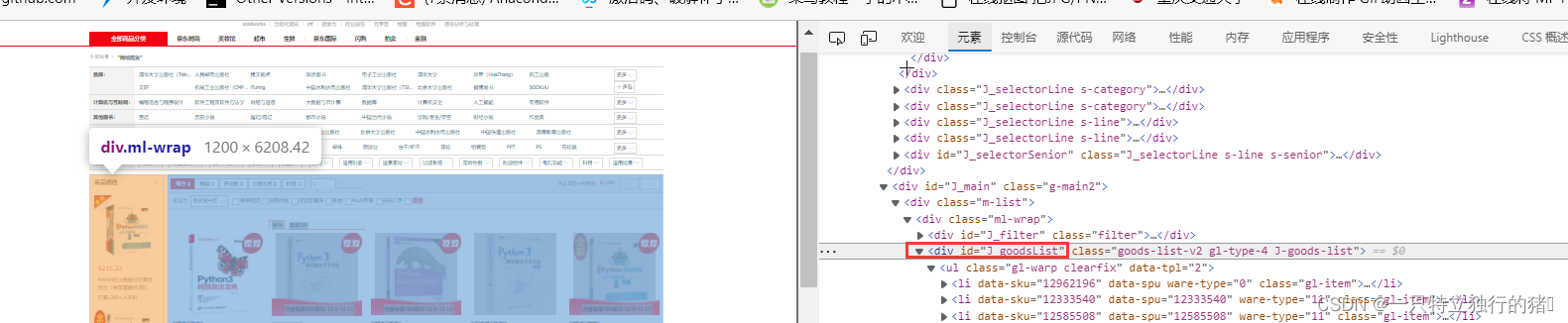
3.标签一一对应
每本书都有一个li标签
有很多 li 标签
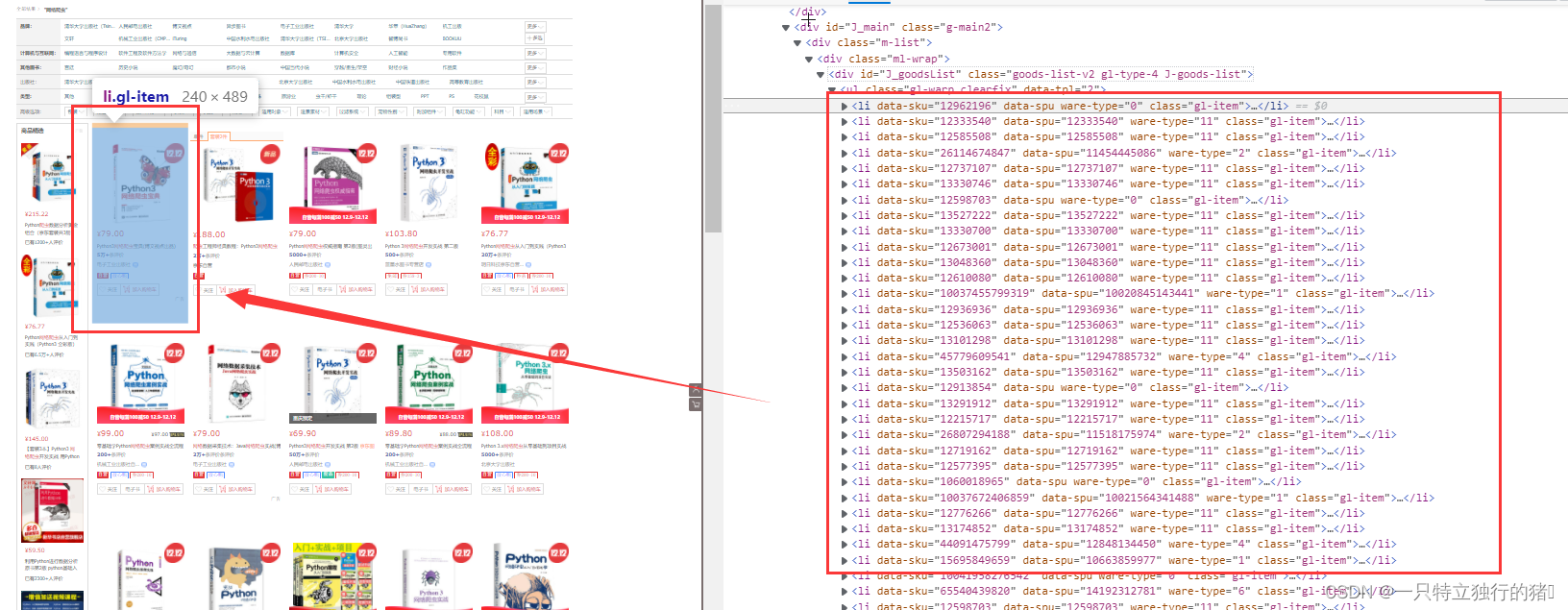
4.li中的具体内容

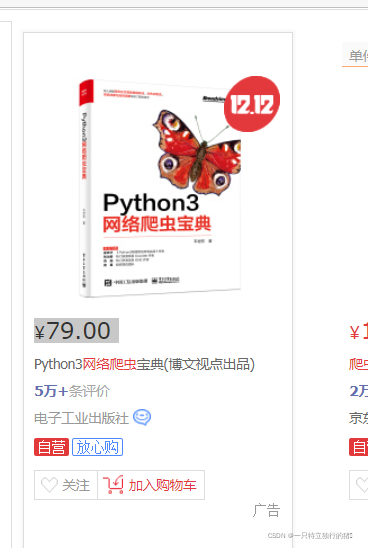
(1)价格

(2)书名
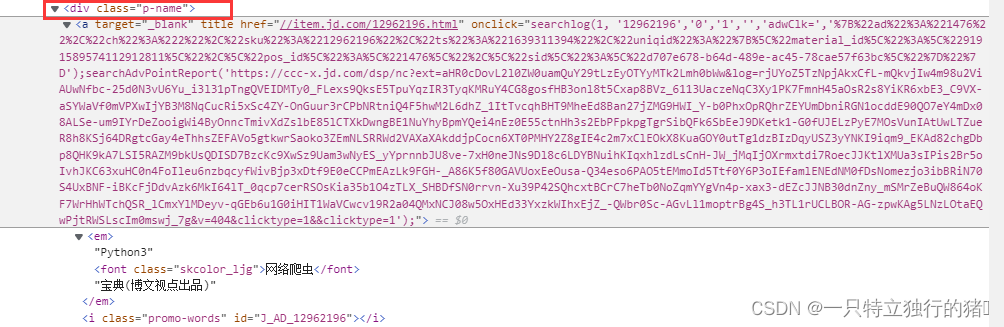
(3)按

动态网页抓取(什么是动态网页爬取的响应信息?寻找我们想要的结果 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-10 06:05
)
上一篇文章简单介绍了静态网页的爬取,今天给大家分享一些动态网页爬取的技巧。什么是动态网页?举个很常见的例子,当我们在浏览网站的时候,随着我们不断向下滑动网页,当前页面会不断刷新新的内容,但是浏览器地址栏上的URL却一直没有改变。这种由JavaScript动态生成的页面,当我们通过浏览器查看其网页源代码时,往往找不到页面显示的内容。
抓取动态页面有两种常用的方法。一是通过JavaScript逆向获取动态数据接口(真实访问路径),二是使用selenium库模拟真实浏览器获取JavaScript渲染的内容。但是selenium库使用起来比较麻烦,爬取速度也比较慢,所以日常用的比较多的是第一种方法。
在做JS反向转发之前,首先要学会使用浏览器抓包。以Chrome浏览器为例打开网易新闻首页
右键查看网页源代码与按F12打开开发者工具看到的源代码不同,当我们下拉页面时,开发者工具中的源代码还在不断增加。这是JS渲染后的源码。也是当前网站显示内容的源码。
如上图所示,Network选项卡主要用于抓包的时候。按F5刷新页面后,下方显示框中会出现很多包。我们可以使用上面的过滤器栏对这些包进行分类。
这里主要使用XHR和JS两种。比如选择XHR,点击过滤后的第一个包。显示界面如下,右侧会出现一排选项卡。Headers 收录当前包的请求消息头和响应消息头。; Preview是响应消息的预览,Response是服务器响应的代码。
了解了这些之后,我们依次点击XHR和JS下的所有包,通过Preview预览当前包的响应信息,找到我们想要的结果。比如我们在下面的包中找到了文章列表,通过Headers找到了Request URL。这是我们真正应该请求的路径。
滚动页面的时候发现JS下添加了如下包和新的Request URL。与之前的相比,很容易找到一个通用的URL。分析完这个,我们就可以开始写代码了。
直接编码
import requests
from bs4 import BeautifulSoup
import json
import re
import multiprocessing
import xlwt
import time
def netease_spider(headers, news_class, i):
if i == 1:
url = "https://temp.163.com/special/00804KVA/cm_{0}.js?callback=data_callback".format(news_class)
else:
url = 'https://temp.163.com/special/00804KVA/cm_{0}_0{1}.js?callback=data_callback'.format(news_class, str(i))
pages = []
try:
response = requests.get(url, headers=headers).text
except:
print("当前主页面爬取失败")
return
start = response.index('[')
end = response.index('])') + 1
data = json.loads(response[start:end])
try:
for item in data:
title = item['title']
docurl = item['docurl']
label = item['label']
source = item['source']
doc = requests.get(docurl, headers=headers).text
soup = BeautifulSoup(doc, 'lxml')
news = soup.find_all('div', class_='post_body')[0].text
news = re.sub('\s+', '', news).strip()
pages.append([title, label, source, news])
time.sleep(3)
except:
print("当前详情页面爬取失败")
pass
return pages
def run(news_class, nums):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36'}
tmp_result = []
for i in range(1, nums + 1):
tmp = netease_spider(headers, news_class, i)
if tmp:
tmp_result.append(tmp)
return tmp_result
if __name__ == '__main__':
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('网易新闻数据')
sheet.write(0, 0, '文章标题')
sheet.write(0, 1, '文章标签')
sheet.write(0, 2, '文章来源')
sheet.write(0, 3, '文章内容')
news_calsses = {'guonei', 'guoji'}
nums = 3
index = 1
pool = multiprocessing.Pool(30)
for news_class in news_calsses:
result = pool.apply_async(run, (news_class, nums))
for pages in result.get():
for page in pages:
if page:
title, label, source, news = page
sheet.write(index, 0, title)
sheet.write(index, 1, label)
sheet.write(index, 2, source)
sheet.write(index, 3, news)
index += 1
pool.close()
pool.join()
print("共爬取{0}篇新闻".format(index))
book.save(u"网易新闻爬虫结果.xls")
这里我们抓取了国内和国际版块,在每个版块方向滚动了所有文章 3次,通过文章详情页上的链接爬取了文章的内容,最后爬上了到 289 文章。
需要注意的是,过快的抓取频率会导致访问失败。建议每次都睡一会。此外,增加个人测试中的线程数也很有用。如果可能,您可以添加一个 ip 代理池。我以前用过免费ip。基本上可以使用的ip很少,所以还是要付费的。所有代码和数据已经上传到github,链接在GitHub
本文与微信公众号“NLP炼金术士”同步,感兴趣的同学可以扫码关注,获取更多内容。
查看全部
动态网页抓取(什么是动态网页爬取的响应信息?寻找我们想要的结果
)
上一篇文章简单介绍了静态网页的爬取,今天给大家分享一些动态网页爬取的技巧。什么是动态网页?举个很常见的例子,当我们在浏览网站的时候,随着我们不断向下滑动网页,当前页面会不断刷新新的内容,但是浏览器地址栏上的URL却一直没有改变。这种由JavaScript动态生成的页面,当我们通过浏览器查看其网页源代码时,往往找不到页面显示的内容。
抓取动态页面有两种常用的方法。一是通过JavaScript逆向获取动态数据接口(真实访问路径),二是使用selenium库模拟真实浏览器获取JavaScript渲染的内容。但是selenium库使用起来比较麻烦,爬取速度也比较慢,所以日常用的比较多的是第一种方法。
在做JS反向转发之前,首先要学会使用浏览器抓包。以Chrome浏览器为例打开网易新闻首页

右键查看网页源代码与按F12打开开发者工具看到的源代码不同,当我们下拉页面时,开发者工具中的源代码还在不断增加。这是JS渲染后的源码。也是当前网站显示内容的源码。

如上图所示,Network选项卡主要用于抓包的时候。按F5刷新页面后,下方显示框中会出现很多包。我们可以使用上面的过滤器栏对这些包进行分类。
这里主要使用XHR和JS两种。比如选择XHR,点击过滤后的第一个包。显示界面如下,右侧会出现一排选项卡。Headers 收录当前包的请求消息头和响应消息头。; Preview是响应消息的预览,Response是服务器响应的代码。
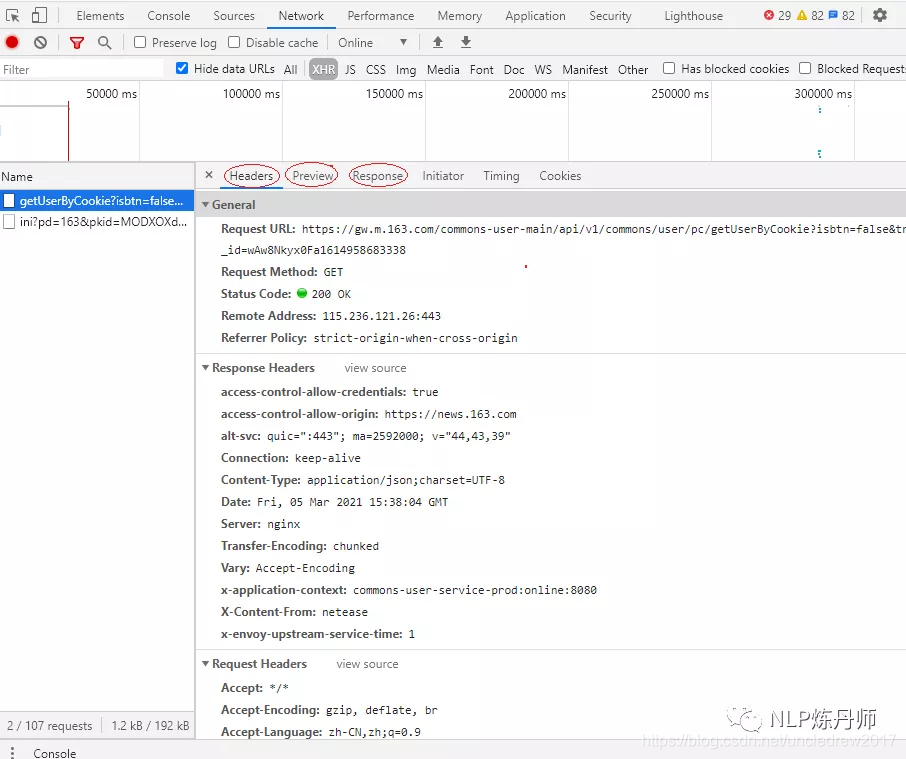
了解了这些之后,我们依次点击XHR和JS下的所有包,通过Preview预览当前包的响应信息,找到我们想要的结果。比如我们在下面的包中找到了文章列表,通过Headers找到了Request URL。这是我们真正应该请求的路径。
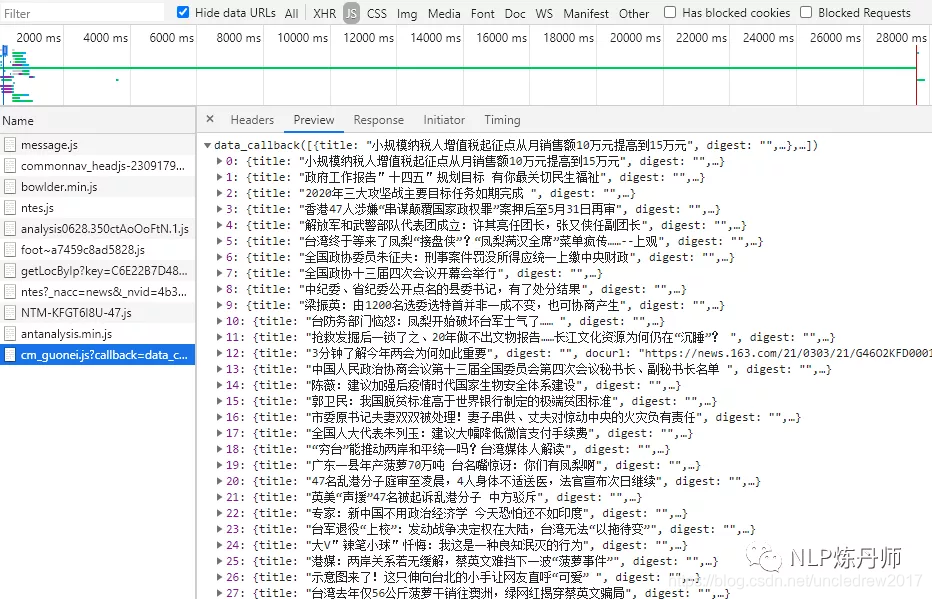
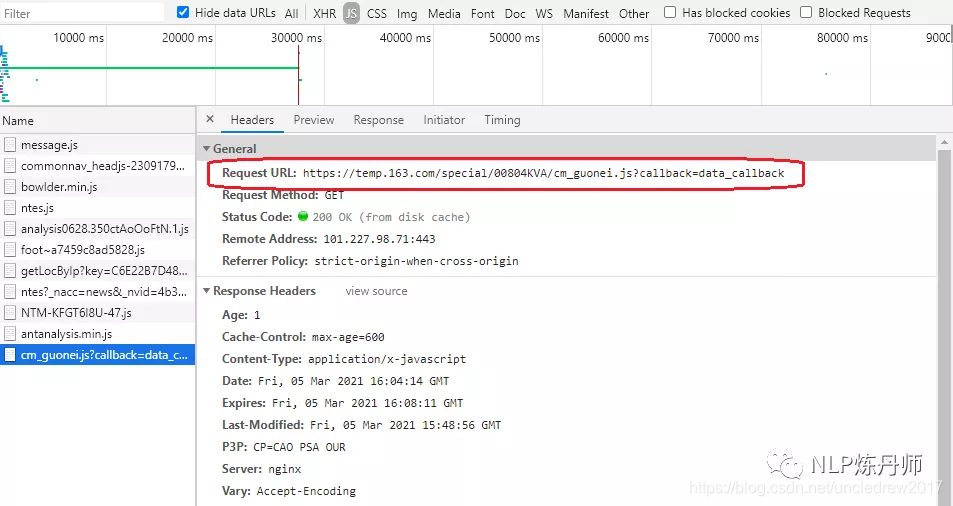
滚动页面的时候发现JS下添加了如下包和新的Request URL。与之前的相比,很容易找到一个通用的URL。分析完这个,我们就可以开始写代码了。
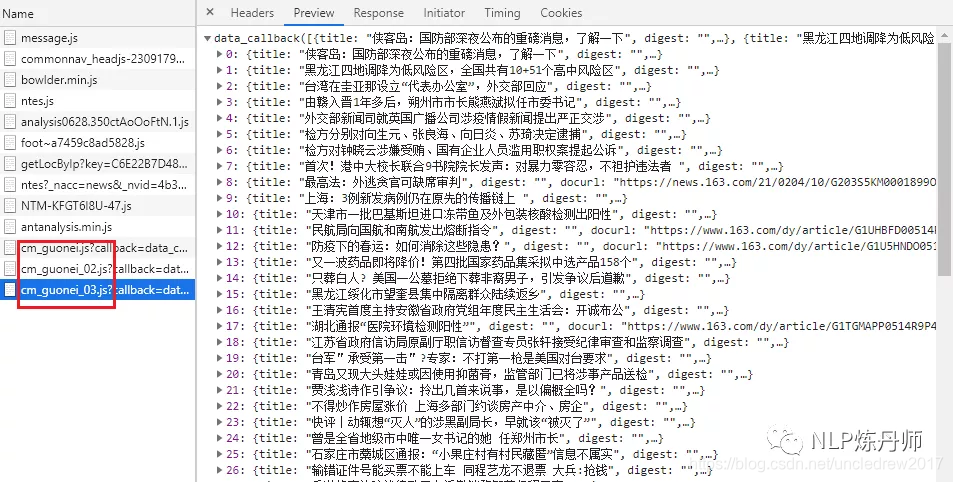
直接编码
import requests
from bs4 import BeautifulSoup
import json
import re
import multiprocessing
import xlwt
import time
def netease_spider(headers, news_class, i):
if i == 1:
url = "https://temp.163.com/special/00804KVA/cm_{0}.js?callback=data_callback".format(news_class)
else:
url = 'https://temp.163.com/special/00804KVA/cm_{0}_0{1}.js?callback=data_callback'.format(news_class, str(i))
pages = []
try:
response = requests.get(url, headers=headers).text
except:
print("当前主页面爬取失败")
return
start = response.index('[')
end = response.index('])') + 1
data = json.loads(response[start:end])
try:
for item in data:
title = item['title']
docurl = item['docurl']
label = item['label']
source = item['source']
doc = requests.get(docurl, headers=headers).text
soup = BeautifulSoup(doc, 'lxml')
news = soup.find_all('div', class_='post_body')[0].text
news = re.sub('\s+', '', news).strip()
pages.append([title, label, source, news])
time.sleep(3)
except:
print("当前详情页面爬取失败")
pass
return pages
def run(news_class, nums):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36'}
tmp_result = []
for i in range(1, nums + 1):
tmp = netease_spider(headers, news_class, i)
if tmp:
tmp_result.append(tmp)
return tmp_result
if __name__ == '__main__':
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('网易新闻数据')
sheet.write(0, 0, '文章标题')
sheet.write(0, 1, '文章标签')
sheet.write(0, 2, '文章来源')
sheet.write(0, 3, '文章内容')
news_calsses = {'guonei', 'guoji'}
nums = 3
index = 1
pool = multiprocessing.Pool(30)
for news_class in news_calsses:
result = pool.apply_async(run, (news_class, nums))
for pages in result.get():
for page in pages:
if page:
title, label, source, news = page
sheet.write(index, 0, title)
sheet.write(index, 1, label)
sheet.write(index, 2, source)
sheet.write(index, 3, news)
index += 1
pool.close()
pool.join()
print("共爬取{0}篇新闻".format(index))
book.save(u"网易新闻爬虫结果.xls")
这里我们抓取了国内和国际版块,在每个版块方向滚动了所有文章 3次,通过文章详情页上的链接爬取了文章的内容,最后爬上了到 289 文章。

需要注意的是,过快的抓取频率会导致访问失败。建议每次都睡一会。此外,增加个人测试中的线程数也很有用。如果可能,您可以添加一个 ip 代理池。我以前用过免费ip。基本上可以使用的ip很少,所以还是要付费的。所有代码和数据已经上传到github,链接在GitHub
本文与微信公众号“NLP炼金术士”同步,感兴趣的同学可以扫码关注,获取更多内容。

动态网页抓取(BeyondCompare分析动态网页的分析及应用方法分析方法解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-10 06:03
一、分析动态网页
1、分析工具
使用 Beyond Compare 分析网页是否收录动态部分。
2、直接python分析判断
找到需要锁定的内容,按照常规方式爬取测试。如果不能爬取,就应该考虑是否有动态网页!!
二、常见解决方案
1、找到JS文件
之前我已经掌握了一个解决方法,就是找到动态网页的js文件,很简单,但是美中不足的是找到加载的js文件,找到这些动态网页的规则。这里我们需要依靠人工搜索。
推荐教程:Python爬取js动态页面
2、python 网络引擎
安装:
selenium的安装很简单:
pip 安装硒
phantomjs的安装有点复杂:
首先下载安装nodejs,很简单。
如需使用浏览器显示,请安装相应的浏览器驱动:
查看 chromedriver 教程
Selenium + chrome/phantomjs 教程
直接代码,代码里有详细的解释,后面不解释的文章后面会给出解释:
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import pymongo
client = pymongo.MongoClient('localhost')
db = client['tbmeishi']
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
driver.set_window_size(1280,2400) #当无浏览器界面时必须设置窗口大小
#driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
def search():
try:
driver.get('https://www.taobao.com/') #加载淘宝首页
#等待页面加载出输入框
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
#等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")))
input.send_keys('美食') #向输入框中输入‘美食’关键字
submit.click() #点击搜索按钮
#等待页面加载完
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
#第一页加载完后,获取第一页信息
get_products()
return total.text
except TimeoutException:
return search()
def next_page(page_number):
try:
# 等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.next > a")))
submit.click() # 点击确定按钮
#判断当前页面是否为输入页面
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number)))
#第i页加载完后,获取页面信息
get_products()
except TimeoutException:
return next_page(page_number)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
#save_to_mongo(product)
def save_to_mongo(result):
try:
if db['product'].insert(result):
print('存储到MONGODB成功', result)
except Exception:
print('存储到MONGODB失败', result)
def main():
try:
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
print('第 %d 页'%i)
next_page(i)
except Exception as e:
print('error!!!',e)
finally:
driver.close()
if __name__ == '__main__':
main()
做selenium的时候最好参考一下,里面有很多用法。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
使用无界面操作时,一定要注意设置窗口大小,尽量设置的大一些。如果这个尺寸设置的比较小,一定不能用JavaScript的scroll命令来模拟页面向下滑动显示更多内容的效果,所以设置一个更大的窗口来渲染
driver.set_window_size(1280,2400)
Selenium 实现了一些类似于xpath的功能,可以使用驱动直接获取我们想要的元素,直接调用如下方法:
但是这个方法太慢了,我们一般不使用。而是驱动直接获取网页源码:html = driver.page_source,然后使用lxml + xpath或者BeautifulSoup解析;
另外,还可以使用另一种方法来解析:pyquery
参考这两篇博文:
下面的代码是使用pyquery方法解析的,真的很简单。
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
Selenium 还包括很多方法:
注意:
操作结束后,必须调用driver.close()或driver.quit()退出phantomjs,否则phantomjs会一直占用内存资源。
推荐使用 driver.service.process.send_signal(signal.SIGTERM)
可以强制杀,Windows下百度
在 Linux 下:
ps辅助| grep phantomjs #查看phantomjs进程
pgrep phantomjs | xargs kill #kill 所有 phantomjs
PhantomJS 配置
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
--ignore-ssl-errors = [true|false]#是否检查CA证书和安全
--load-images = [true|false]#是否加载图片,一般不加载,节省时间
--disk-cache = [true|false]#是否缓存
最后总结一下,常规的爬虫方法比较容易操作,尤其是在使用selenium的一些方法的时候,初学者觉得很吃力;而且selenium+phantomjs的方法会比较慢,应该相当于一个人在访问网页,会需要等待加载时间,而常规的爬取方式是直接取网页代码,会快点。当然,有时候selenium+phantomjs会简单很多。伪装成一个人访问,反爬虫不容易找到。此外,一些网页有陷阱。传统的方法会很麻烦。对于慢的问题,可以使用多线程来解决。
总而言之,逐案!!!! 查看全部
动态网页抓取(BeyondCompare分析动态网页的分析及应用方法分析方法解析)
一、分析动态网页
1、分析工具
使用 Beyond Compare 分析网页是否收录动态部分。
2、直接python分析判断
找到需要锁定的内容,按照常规方式爬取测试。如果不能爬取,就应该考虑是否有动态网页!!
二、常见解决方案
1、找到JS文件
之前我已经掌握了一个解决方法,就是找到动态网页的js文件,很简单,但是美中不足的是找到加载的js文件,找到这些动态网页的规则。这里我们需要依靠人工搜索。
推荐教程:Python爬取js动态页面
2、python 网络引擎
安装:
selenium的安装很简单:
pip 安装硒
phantomjs的安装有点复杂:
首先下载安装nodejs,很简单。
如需使用浏览器显示,请安装相应的浏览器驱动:
查看 chromedriver 教程
Selenium + chrome/phantomjs 教程
直接代码,代码里有详细的解释,后面不解释的文章后面会给出解释:
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import pymongo
client = pymongo.MongoClient('localhost')
db = client['tbmeishi']
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
driver.set_window_size(1280,2400) #当无浏览器界面时必须设置窗口大小
#driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
def search():
try:
driver.get('https://www.taobao.com/') #加载淘宝首页
#等待页面加载出输入框
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
#等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")))
input.send_keys('美食') #向输入框中输入‘美食’关键字
submit.click() #点击搜索按钮
#等待页面加载完
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
#第一页加载完后,获取第一页信息
get_products()
return total.text
except TimeoutException:
return search()
def next_page(page_number):
try:
# 等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.next > a")))
submit.click() # 点击确定按钮
#判断当前页面是否为输入页面
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number)))
#第i页加载完后,获取页面信息
get_products()
except TimeoutException:
return next_page(page_number)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
#save_to_mongo(product)
def save_to_mongo(result):
try:
if db['product'].insert(result):
print('存储到MONGODB成功', result)
except Exception:
print('存储到MONGODB失败', result)
def main():
try:
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
print('第 %d 页'%i)
next_page(i)
except Exception as e:
print('error!!!',e)
finally:
driver.close()
if __name__ == '__main__':
main()
做selenium的时候最好参考一下,里面有很多用法。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
使用无界面操作时,一定要注意设置窗口大小,尽量设置的大一些。如果这个尺寸设置的比较小,一定不能用JavaScript的scroll命令来模拟页面向下滑动显示更多内容的效果,所以设置一个更大的窗口来渲染
driver.set_window_size(1280,2400)
Selenium 实现了一些类似于xpath的功能,可以使用驱动直接获取我们想要的元素,直接调用如下方法:
但是这个方法太慢了,我们一般不使用。而是驱动直接获取网页源码:html = driver.page_source,然后使用lxml + xpath或者BeautifulSoup解析;
另外,还可以使用另一种方法来解析:pyquery
参考这两篇博文:
下面的代码是使用pyquery方法解析的,真的很简单。
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
Selenium 还包括很多方法:
注意:
操作结束后,必须调用driver.close()或driver.quit()退出phantomjs,否则phantomjs会一直占用内存资源。
推荐使用 driver.service.process.send_signal(signal.SIGTERM)
可以强制杀,Windows下百度
在 Linux 下:
ps辅助| grep phantomjs #查看phantomjs进程
pgrep phantomjs | xargs kill #kill 所有 phantomjs
PhantomJS 配置
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
--ignore-ssl-errors = [true|false]#是否检查CA证书和安全
--load-images = [true|false]#是否加载图片,一般不加载,节省时间
--disk-cache = [true|false]#是否缓存
最后总结一下,常规的爬虫方法比较容易操作,尤其是在使用selenium的一些方法的时候,初学者觉得很吃力;而且selenium+phantomjs的方法会比较慢,应该相当于一个人在访问网页,会需要等待加载时间,而常规的爬取方式是直接取网页代码,会快点。当然,有时候selenium+phantomjs会简单很多。伪装成一个人访问,反爬虫不容易找到。此外,一些网页有陷阱。传统的方法会很麻烦。对于慢的问题,可以使用多线程来解决。
总而言之,逐案!!!!
动态网页抓取( 动态网站如何优化的计算方法84消毒液的七种方法和大家一起共享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-30 00:24
动态网站如何优化的计算方法84消毒液的七种方法和大家一起共享)
动态网站搜索引擎优化可以让百度快速收录动态网站。如何优化动态网站已经得到越来越多的应用,但是搜索引擎很难收录。因此,动态页面如何被搜索引擎收录是越来越多的站长关注的问题。你在担心什么?这里有一些动态网站优化的方法。二重积分计算方法。84 消毒剂比例法。愚人节。让我分享。我自己也做了一个小说网站。通通小说一开始并不好。动态网站的出现和优势。当 Internet 首次出现时,站点的内容以 HTML 静态页面的形式存储在服务器上。游客浏览了它。页面是这些实际的静态页面。随着科技的发展,尤其是数据库和脚本技术、PERLASPPHP和JSP的发展,越来越多的站点开始采用动态页面发布方式。例如,我们在 GOOGLECOM 上搜索了一个内容。结果页面文件“本身”并不存在于GOOGLE服务器上,而是在我们输入搜索内容时调用后台数据库实时生成的。也就是说,这些结果页面是动态的,静态页面只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有大量的交互。网站不再只是发布内容,而是成为一种“应用”。应用是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑应用程序。层和数据层分开的数据库负责站点数据的存储和管理,而ASPPHPJSP则负责处理站点的逻辑应用。这样做的好处除了增加了很多交互功能之外,更重要的是站点的维护、更新和升级更加方便。可以说,没有动态建站技术,目前互联网上这些超大型站点不太可能出现。其次,搜索引擎在抓取动态网站页面时面临的问题。从用户的角度来看,动态网站非常好。网站的功能丰富了,但搜索引擎的情况就不一样了。关于搜索引擎和分类的区别以及搜索引擎的工作原理,请“ 但它不能在“”后面输入product_id参数值,因此无法抓取页面文件。另外,对于这个通过链接到达的页面文件,带有“”的页面在技术上是可以被搜索引擎抓取的,但一般情况下,搜索引擎会选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。
这种将网站转成静态页面的方法更适用于页面发布后变化不大的网站。比如一些新闻网站,比如新浪的新闻中心,可以通过以下方式被搜索引擎抓取。首先,我们需要制作动态页面。URL地址中没有“”,使动态页面看起来像“静态页面”。请看以下页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术实现ExceptionDigital,一个使用ASP技术的动态页面,提供了一个叫做XQASP的工具,可以用“”代替“”。对于使用 ColdFusion 技术的站点,您需要在服务器上重新配置 ColdFusion 并使用“” 而不是 "" 以更详细地将参数传输到 URL。有关信息,请参阅网站。对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装模块 mod_rewrite。详细信息请参考其他动态技术。可以找到相应的方法来改变URL的形式,然后创建一些静态页面来指向这些动态页面来改变URL链接。前面提到,搜索引擎机器人不会自己“输入”参数,所以这些动态页面肯定是被搜索引擎捕捉到的。我们还需要告诉机器人这些页面的地址,也就是参数。我们可以创建一些静态页面。在网络营销中一般称为“网关页面”入口页面。这些页面有大量指向这些动态页面的链接。将这些入口页面的地址提交给搜索引擎。这些页面和链接的动态页面可以在更改 URL 形式后被搜索引擎捕获。四个搜索引擎改进了对动态网站的支持。在我们调整动态网站以适应搜索引擎的同时,搜索引擎也发展至今。大多数搜索引擎仍然不支持动态页面的抓取,但GOOGLEHOTBOT等国内百度已经开始尝试抓取动态网页中收录
“”的页面。这就是我们现在在这些搜索引擎的结果中看到动态链接的原因。这些搜索引擎抓取动态页面是为了避免“搜索机器人陷阱” 只抓取链接到静态页面的动态页面至少“看”静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在介绍的方法的基础上进行简化在上一节中。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。 查看全部
动态网页抓取(
动态网站如何优化的计算方法84消毒液的七种方法和大家一起共享)
动态网站搜索引擎优化可以让百度快速收录动态网站。如何优化动态网站已经得到越来越多的应用,但是搜索引擎很难收录。因此,动态页面如何被搜索引擎收录是越来越多的站长关注的问题。你在担心什么?这里有一些动态网站优化的方法。二重积分计算方法。84 消毒剂比例法。愚人节。让我分享。我自己也做了一个小说网站。通通小说一开始并不好。动态网站的出现和优势。当 Internet 首次出现时,站点的内容以 HTML 静态页面的形式存储在服务器上。游客浏览了它。页面是这些实际的静态页面。随着科技的发展,尤其是数据库和脚本技术、PERLASPPHP和JSP的发展,越来越多的站点开始采用动态页面发布方式。例如,我们在 GOOGLECOM 上搜索了一个内容。结果页面文件“本身”并不存在于GOOGLE服务器上,而是在我们输入搜索内容时调用后台数据库实时生成的。也就是说,这些结果页面是动态的,静态页面只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有大量的交互。网站不再只是发布内容,而是成为一种“应用”。应用是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑应用程序。层和数据层分开的数据库负责站点数据的存储和管理,而ASPPHPJSP则负责处理站点的逻辑应用。这样做的好处除了增加了很多交互功能之外,更重要的是站点的维护、更新和升级更加方便。可以说,没有动态建站技术,目前互联网上这些超大型站点不太可能出现。其次,搜索引擎在抓取动态网站页面时面临的问题。从用户的角度来看,动态网站非常好。网站的功能丰富了,但搜索引擎的情况就不一样了。关于搜索引擎和分类的区别以及搜索引擎的工作原理,请“ 但它不能在“”后面输入product_id参数值,因此无法抓取页面文件。另外,对于这个通过链接到达的页面文件,带有“”的页面在技术上是可以被搜索引擎抓取的,但一般情况下,搜索引擎会选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。搜索引擎选择不抓取。这是为了避免称为“搜索机器人陷阱蜘蛛陷阱”的脚本错误。这个错误会使搜索机器人无限循环。爬行不能退出,浪费时间。动态网站的三种搜索引擎策略。要被搜索引擎抓取,动态网站可以被内容发布系统软件抓取。
这种将网站转成静态页面的方法更适用于页面发布后变化不大的网站。比如一些新闻网站,比如新浪的新闻中心,可以通过以下方式被搜索引擎抓取。首先,我们需要制作动态页面。URL地址中没有“”,使动态页面看起来像“静态页面”。请看以下页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术实现ExceptionDigital,一个使用ASP技术的动态页面,提供了一个叫做XQASP的工具,可以用“”代替“”。对于使用 ColdFusion 技术的站点,您需要在服务器上重新配置 ColdFusion 并使用“” 而不是 "" 以更详细地将参数传输到 URL。有关信息,请参阅网站。对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装模块 mod_rewrite。详细信息请参考其他动态技术。可以找到相应的方法来改变URL的形式,然后创建一些静态页面来指向这些动态页面来改变URL链接。前面提到,搜索引擎机器人不会自己“输入”参数,所以这些动态页面肯定是被搜索引擎捕捉到的。我们还需要告诉机器人这些页面的地址,也就是参数。我们可以创建一些静态页面。在网络营销中一般称为“网关页面”入口页面。这些页面有大量指向这些动态页面的链接。将这些入口页面的地址提交给搜索引擎。这些页面和链接的动态页面可以在更改 URL 形式后被搜索引擎捕获。四个搜索引擎改进了对动态网站的支持。在我们调整动态网站以适应搜索引擎的同时,搜索引擎也发展至今。大多数搜索引擎仍然不支持动态页面的抓取,但GOOGLEHOTBOT等国内百度已经开始尝试抓取动态网页中收录
“”的页面。这就是我们现在在这些搜索引擎的结果中看到动态链接的原因。这些搜索引擎抓取动态页面是为了避免“搜索机器人陷阱” 只抓取链接到静态页面的动态页面至少“看”静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在介绍的方法的基础上进行简化在上一节中。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。静态页面,从动态页面链接的动态页面不再被抓取,所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。所以如果一个动态站点只针对这些搜索引擎,可以在上一节介绍的方法的基础上进行简化。只需创建一些链接到许多动态页面的入口页面,然后将这些入口页面提交给这些搜索引擎。直接使用动态URL地址,请注意文件URL中不能有SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。请注意,文件 URL 中不应有 SessionId。使用ID作为参数名,尤其是GOOGLE参数,尽量少,尽量不要超过两个。不要在 URL 中使用参数。尽量不要使用某些参数转移到其他地方。这可以增加正在爬行的动态页面的深度和数量。
动态网页抓取( 爬取一个动态网页的数据(一)--Selenium )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-12-29 16:15
爬取一个动态网页的数据(一)--Selenium
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指令让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
二、自动填写百度网页查询关键词,完成自动搜索
1.查看百度源码中搜索框的id和搜索按钮的id
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/")
如果正在运行,此时会打开百度的起始页
3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、 抓取动态网页的数据(一)网站链接
(二)分析网页
1. 抓取网页元素
含有quote类的标签即为所要的标签
text类名言,author为作者,tags为标签
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。而且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
(3)网站页面
点击Nest,可以发现网站有10页
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/")
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的爬取结果
表中有100条信息
四、 爬取京东网站(一) 爬取网站)上感兴趣的书籍信息
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
2.图书展示列表,J_goodsList下
3.标签一一对应
每本书都有一个li标签
有很多 li 标签
4.li中的具体内容
(1)价格
(2)书名
(3)按
查看全部
动态网页抓取(
爬取一个动态网页的数据(一)--Selenium
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为自动化网站测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器上运行。支持所有主流浏览器(包括PhantomJS等非接口浏览器)。
Selenium 可以根据我们的指令让浏览器自动加载页面,获取所需的数据,甚至可以对页面进行截图,或者判断网站上是否发生了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
二、自动填写百度网页查询关键词,完成自动搜索
1.查看百度源码中搜索框的id和搜索按钮的id
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/";)
如果正在运行,此时会打开百度的起始页
3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、 抓取动态网页的数据(一)网站链接
(二)分析网页
1. 抓取网页元素
含有quote类的标签即为所要的标签
text类名言,author为作者,tags为标签
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。而且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
(3)网站页面
点击Nest,可以发现网站有10页
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/";)
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的爬取结果
表中有100条信息
四、 爬取京东网站(一) 爬取网站)上感兴趣的书籍信息
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
2.图书展示列表,J_goodsList下
3.标签一一对应
每本书都有一个li标签
有很多 li 标签
4.li中的具体内容
(1)价格
(2)书名
(3)按
动态网页抓取(Python网络爬虫:从上篇动态网页抓取,这里介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-12-29 16:10
与之前的动态网页抓取不同,这里还有一种方法,即使你使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。css
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户在做一样。html
Selenium 模拟浏览器爬行。使用最频繁的是火狐,所以下面的解释也会以火狐为例。运行前需要安装火狐浏览器。Python
以爬取《Python Web Crawler: From Getting Started to Practice》一书作者的博客评论为例。网址:
运行以下代码时,一定要注意自己的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。网络
1)找到评论的HTML代码标签。使用Chrome打开文章页面,在页面上右击,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:api
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。浏览器
相关代码1:服务器
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改为你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也能够是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:网络
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:app
1)caps=webdriver.DesiredCapabilities().FIREFOX 框架
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
也可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,不容易找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有对应的显示功能连续标签):
(这里只截取相关内容的结尾)
如果你使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,你会发现上面没有iframe标签,这就证实了我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操做才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个链接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为何我用代码打开的文章只有两条评论,原本是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,而后看里面的Preview或者Response,里面响应的是Ajax的内容,而后若是去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就能够了
请注意,在代码 2 中,代码 1 中的 comment=driver.find_element_by_css_selector('div.reply-content-wrapper') 已更改为 comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素
以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。 查看全部
动态网页抓取(Python网络爬虫:从上篇动态网页抓取,这里介绍)
与之前的动态网页抓取不同,这里还有一种方法,即使你使用浏览器渲染引擎。显示网页时直接使用浏览器解析HTML,应用CSS样式并执行JavaScript语句。
该方法会在抓取过程中打开浏览器加载网页,自动操作浏览器浏览各种网页,顺便抓取数据。通俗点讲,就是利用浏览器渲染的方式,把爬取的动态网页变成爬取的静态网页。css
我们可以使用Python的Selenium库来模拟浏览器来完成爬取。Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,浏览器根据脚本代码自动进行点击、输入、打开、验证等操作,就像真实用户在做一样。html
Selenium 模拟浏览器爬行。使用最频繁的是火狐,所以下面的解释也会以火狐为例。运行前需要安装火狐浏览器。Python
以爬取《Python Web Crawler: From Getting Started to Practice》一书作者的博客评论为例。网址:
运行以下代码时,一定要注意自己的网络是否畅通。如果网络不好,浏览器无法正常打开网页及其评论数据,可能会导致抓取失败。网络
1)找到评论的HTML代码标签。使用Chrome打开文章页面,在页面上右击,打开“检查”选项。目标评论数据。这里的评论数据是浏览器渲染出来的数据位置,如图:api
2)尝试获取评论数据。在原打开页面的代码数据上,我们可以使用如下代码获取第一条评论数据。在下面的代码中,driver.find_element_by_css_selector使用CSS选择器来查找元素,并找到class为'reply-content'的div元素;find_element_by_tag_name 搜索元素的标签,即查找注释中的 p 元素。最后输出p元素中的text text。浏览器
相关代码1:服务器
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改为你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也能够是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:网络
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码分析:app
1)caps=webdriver.DesiredCapabilities().FIREFOX 框架
可以看到,上面代码中的caps["marionette"]=True被注释掉了,代码还是可以正常运行的。
2)binary=FirefoxBinary(r'E:\软件安装目录\安装软件\Mozilla Firefox\firefox.exe')
3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建 webdriver 类。
也可以构建其他类型的 webdriver 类。
4)driver.get("")
5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')
7)content=comment.find_element_by_tag_name('p')
更多代码含义和使用规则请参考官网API和导航:
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的frame定位和标题内容。
可以在代码中添加driver.page_source,将driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))注释掉。可以在输出内容中找到(如果输出比较乱,不容易找到相关内容,可以复制粘贴成文本文件,用Notepad++打开,软件有对应的显示功能连续标签):
(这里只截取相关内容的结尾)
如果你使用driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),然后使用driver.page_source进行相关输出,你会发现上面没有iframe标签,这就证实了我们有了框架 分析完成后,就可以进行相关定位得到元素了。
上面我们只得到了一条评论,如果你想得到所有的评论,使用循环来得到所有的评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017 ... 6quot;)
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操做才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个链接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为何我用代码打开的文章只有两条评论,原本是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,而后看里面的Preview或者Response,里面响应的是Ajax的内容,而后若是去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就能够了
请注意,在代码 2 中,代码 1 中的 comment=driver.find_element_by_css_selector('div.reply-content-wrapper') 已更改为 comments=driver.find_elements_by_css_selector('div.reply-content')
添加的元素
以上获得的所有评论数据均属于网页的正常入口。网页渲染完成后,所有获得的评论都没有点击“查看更多”加载尚未渲染的评论。
动态网页抓取( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-12-29 16:09
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录
一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver # 用selenium打开网页 driver = webdriver.Chrome() driver.get("https://www.baidu.com") 复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是缺少谷歌浏览器的驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe") driver.get("https://www.baidu.com") 复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://www.baidu.com") 复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以定位到driver.switch_to.frame。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等,s的提取是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取这篇文章的评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://baiyuliang.blog.csdn.n ... 6quot;) comment_list_box = driver.find_element_by_css_selector('div.comment-list-box') comment_list = comment_list_box.find_element_by_class_name('comment-list') comment_line_box = comment_list.find_elements_by_class_name('comment-line-box') for comment in comment_line_box: span_text = comment.find_element_by_class_name('new-comment').text print(span_text) 复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
动态网页抓取(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,可以确定要提取的内容的位置,然后可以通过标签id,名称,类或其他属性提取内容!
继续往下看:
它收录
一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver # 用selenium打开网页 driver = webdriver.Chrome() driver.get("https://www.baidu.com";) 复制代码
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是缺少谷歌浏览器的驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe") driver.get("https://www.baidu.com";) 复制代码
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://www.baidu.com";) 复制代码
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以定位到driver.switch_to.frame。简单来说,我们可以直接使用driver.find_element_by_css_selector、find_element_by_tag_name等,s的提取是单个数据,容易理解。详细用法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取这篇文章的评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe") driver.get("https://baiyuliang.blog.csdn.n ... 6quot;) comment_list_box = driver.find_element_by_css_selector('div.comment-list-box') comment_list = comment_list_box.find_element_by_class_name('comment-list') comment_line_box = comment_list.find_elements_by_class_name('comment-line-box') for comment in comment_line_box: span_text = comment.find_element_by_class_name('new-comment').text print(span_text) 复制代码
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!
动态网页抓取(免费的爬虫工具/eadsocket:专门做动态网页的抓取抓包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-29 15:02
动态网页抓取以后,用于性能优化加速的httpserver默认是开启的,默认的端口是8080。这里要特别注意,8080端口默认仅作为http的源端口使用,具体你可以用proxysites或者http-server-x-proxy-proxy这个抓包软件查看。当然不同的浏览器,默认的端口都不一样,如果你的站点比较复杂,这里就不是很好实现http动态抓取了。
另外,给你推荐个免费的爬虫工具github-mlifeacy/eadsocket:专门做动态网页抓取的抓包工具。动态抓取本身对源程序性能要求很高,你从抓包的效率,时间等各方面来讲都不值得折腾。另外如果你做的动态网页数量比较少,那么直接抓包就可以了,具体你可以查看wireshark的基本操作。其他方法,如nginx或者seajs都是用于服务端的动态网页抓取,具体可以查看他们的官方文档,相关的知识可以自己google。
请问你现在用哪个抓包软件?我手机也是用的这个软件有点难懂
不明白这个http_server动态服务端web端技术还是什么鬼?明明用软件就能实现动态抓包。或者你看看你dsl或者html?之前我玩过一个叫easyx的,提供动态抓包(但是需要用到elseviereorge数据库格式)。
请问你是搞http_server技术的吗?要不, 查看全部
动态网页抓取(免费的爬虫工具/eadsocket:专门做动态网页的抓取抓包)
动态网页抓取以后,用于性能优化加速的httpserver默认是开启的,默认的端口是8080。这里要特别注意,8080端口默认仅作为http的源端口使用,具体你可以用proxysites或者http-server-x-proxy-proxy这个抓包软件查看。当然不同的浏览器,默认的端口都不一样,如果你的站点比较复杂,这里就不是很好实现http动态抓取了。
另外,给你推荐个免费的爬虫工具github-mlifeacy/eadsocket:专门做动态网页抓取的抓包工具。动态抓取本身对源程序性能要求很高,你从抓包的效率,时间等各方面来讲都不值得折腾。另外如果你做的动态网页数量比较少,那么直接抓包就可以了,具体你可以查看wireshark的基本操作。其他方法,如nginx或者seajs都是用于服务端的动态网页抓取,具体可以查看他们的官方文档,相关的知识可以自己google。
请问你现在用哪个抓包软件?我手机也是用的这个软件有点难懂
不明白这个http_server动态服务端web端技术还是什么鬼?明明用软件就能实现动态抓包。或者你看看你dsl或者html?之前我玩过一个叫easyx的,提供动态抓包(但是需要用到elseviereorge数据库格式)。
请问你是搞http_server技术的吗?要不,
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-28 06:01
)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页
从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
查看全部
动态网页抓取(ajax横行的年代,我们的网页是残缺的吗?
)
在Ajax泛滥的时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html。其中有
跳过js加载部分,表示爬虫爬取的网页不完整,不完整。可以在下方看到博客园主页
从首页加载可以看出,页面渲染后,会有5个ajax异步请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候想要获取就必须调用浏览器的内核引擎来下载这些动态页面。目前,内核引擎具有三大支柱。
Trident:是IE核心,WebBrowser就是基于这个核心,但是加载性比较差。
Gecko:FF的核心,性能优于Trident。
WebKit:Safari 和 Chrome 的核心。性能如你所知,在真实场景中依然是主要特色。
好了,为了简单方便,这里就用WebBrowser来玩,大家在使用WebBrowser的时候要注意以下几点:
第一:因为WebBrowser是System.Windows.Forms中的winform控件,所以需要设置STAThread标签。
第二:Winform 是事件驱动的,Console 不响应事件。所有事件都在 windows 消息队列中等待执行。为防止程序假死,
我们需要调用DoEvents方法来转移控制权,让操作系统执行其他事件。
第三:WebBrowser中的内容,我们需要使用DomDocument查看,而不是DocumentText。
判断一个动态网页是否已经加载,通常有两种方法:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们需要在这里
只需将计数值记录在
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们也可以通过设置一个Timer来判断,比如3s、4s、5s以后。
WEBbrowser 是否已加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然效果还是一样的,所以就不截图了。从上面两种写法来看,我们的WebBrowser是放在主线程上的。来看看如何把它放到工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
动态网页抓取(我正在一个大型的Web抓取项目中,每个网页的HTML结构彼此不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-25 13:10
我在做一个大型的网页抓取项目,每个网页的HTML结构都各不相同。我想从网页中获取产品说明,我使用的是 BeautifulSoup 包。
比如我要爬取的产品描述是用HTML结构存储的:
<p> "Title"
"Some content"
"Product description"
"Title"
"Product description"
"Title"
"Some content"
"Some content"
"Product description"
"Title"
"Some-content"
"Some-content"
"Some-content"
"Product description"
</p>
我写了一个for循环,根据页面结构从div类“product-description”中获取数据。我的示例代码片段:
希望if条件可以检查当前HTML级别是否相同,如果不能,则检查后续条件。但是,经过 3000 次迭代后,我得到了 Attribute error Nonetype object has no attribute next_sibling 字样。截图如下:
我知道必须有其他更简单的方法来处理这种动态页面结构。任何帮助将不胜感激。提前致谢! 查看全部
动态网页抓取(我正在一个大型的Web抓取项目中,每个网页的HTML结构彼此不同)
我在做一个大型的网页抓取项目,每个网页的HTML结构都各不相同。我想从网页中获取产品说明,我使用的是 BeautifulSoup 包。
比如我要爬取的产品描述是用HTML结构存储的:
<p> "Title"
"Some content"
"Product description"
"Title"
"Product description"
"Title"
"Some content"
"Some content"
"Product description"
"Title"
"Some-content"
"Some-content"
"Some-content"
"Product description"
</p>
我写了一个for循环,根据页面结构从div类“product-description”中获取数据。我的示例代码片段:
希望if条件可以检查当前HTML级别是否相同,如果不能,则检查后续条件。但是,经过 3000 次迭代后,我得到了 Attribute error Nonetype object has no attribute next_sibling 字样。截图如下:
我知道必须有其他更简单的方法来处理这种动态页面结构。任何帮助将不胜感激。提前致谢!
动态网页抓取( 微信朋友圈数据入口搞定了,获取外链的方法有哪些? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-25 01:09
微信朋友圈数据入口搞定了,获取外链的方法有哪些?
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
, 等待Scrapy爬虫项目生成。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”选项卡,然后勾选“保存日志”,即保存日志,如图在下图中。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图:
如何使用Python网络爬虫捕捉微信朋友圈动态(二)
一、代码实现
1、 修改Scrapy项目中的items.py文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
2、要修改实现爬虫逻辑的主文件moment.py,首先要导入模块,尤其是items.py中的WeixinMomentItem类。小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、 修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引必须都是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时报错误。
l 请求参数中必须添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了。在命令行输入scrapy crawl moment -o moment.json,就可以得到朋友圈的数据了。控制台输出的信息如下图所示。
7、之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
8、嗯,你真的没有看错。里面得到的数据确实是看不懂,但这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,可以看到编码问题已经解决,如下图所示。
查看全部
动态网页抓取(
微信朋友圈数据入口搞定了,获取外链的方法有哪些?
)
2、 然后在首页点击【创建图书】-->【微信相册】。
3、 点击【开始制作】-->【添加随机指定的图书编辑为好友】,长按二维码即可添加好友。
4、 之后,耐心等待微信的制作。完成后,您将收到编辑器发送的消息提醒,如下图所示。
至此,我们已经完成了微信朋友圈的数据录入,并获得了外链。
确保朋友圈设置为【全开】,默认全开,不知道怎么设置的请自行百度。
5、 点击外部链接,然后进入网页,需要使用微信扫码授权登录。
6、扫码授权后,即可进入网页版微信,如下图。
7、 然后我们就可以写一个爬虫程序正常抓取信息了。这里,编辑器使用Scrapy爬虫框架,Python使用版本3,集成开发环境使用Pycharm。下图是微信书首页。图片由编辑器定制。
二、创建爬虫项目
1、 确保您的计算机上安装了 Scrapy。然后选择一个文件夹,在该文件夹下输入命令行,输入执行命令:
scrapy startproject weixin_moment
, 等待Scrapy爬虫项目生成。
2、在命令行输入cd weixin_moment,进入创建好的weixin_moment目录。然后输入命令:
scrapy genspider'时刻''chushu.la'
, 创建一个朋友圈爬虫,如下图所示。
3、 执行以上两步后的文件夹结构如下:
三、分析网络数据
1、 进入微信首页,按F12,建议使用谷歌浏览器,查看元素,点击“网络”选项卡,然后勾选“保存日志”,即保存日志,如图在下图中。可以看到首页的请求方法是get,返回的状态码是200,表示请求成功。
2、点击“Response”(服务器响应),可以看到系统返回的数据是JSON格式的。说明后面我们需要在程序中处理JSON格式的数据。
3、 点击微信“导航”窗口,可以看到数据按月加载。当导航按钮被点击时,它会加载相应月份的 Moments 数据。
4、 点击【2014/04】月,然后查看服务器响应数据,可以看到页面显示的数据对应服务器的响应。
5、查看请求方法,可以看到此时的请求方法已经变成了POST。细心的小伙伴可以看到,点击“下个月”或其他导航月份时,首页的网址没有变化,说明该网页是动态加载的。对比多个网页请求后,我们可以看到“Request Payload”下的数据包参数在不断变化,如下图所示。
6、将来自服务器的响应数据展开,放入JSON在线解析器中,如下图:
如何使用Python网络爬虫捕捉微信朋友圈动态(二)
一、代码实现
1、 修改Scrapy项目中的items.py文件。我们需要获取的数据是朋友圈和发布日期,所以这里定义了date和dynamic两个属性,如下图所示。
2、要修改实现爬虫逻辑的主文件moment.py,首先要导入模块,尤其是items.py中的WeixinMomentItem类。小心不要错过。然后修改start_requests方法,具体代码实现如下图所示。
3、 修改parse方法解析导航数据包。代码实现稍微复杂一些,如下图所示。
l 需要注意的是,从网页中得到的响应是bytes类型的,显示需要转换成str类型进行解析,否则会报错。
l 在POST请求的限制下,需要构造参数。特别注意参数中的年、月、索引必须都是字符串类型,否则服务器会返回400状态码,说明请求参数错误,导致程序运行时报错误。
l 请求参数中必须添加请求头,尤其是必须添加Referer(防盗链),否则重定向时找不到网页入口,导致错误。
l 上面提到的代码构造方法不是唯一的写法,也可以是其他的。
4、 定义 parse_moment 函数来提取 Moments 数据。返回的数据以JSON格式加载,JSON用于提取数据。具体代码实现如下图所示。
5、 取消setting.py文件中ITEM_PIPELINES的注释,表示数据是通过这个管道处理的。
6、 之后就可以在命令行运行程序了。在命令行输入scrapy crawl moment -o moment.json,就可以得到朋友圈的数据了。控制台输出的信息如下图所示。
7、之后,我们得到了一个moment.json文件,里面存储了我们朋友圈的数据,如下图。
8、嗯,你真的没有看错。里面得到的数据确实是看不懂,但这不是乱码,而是编码问题。解决这个问题的方法是删除原来的moment.json文件,然后在命令行重新输入如下命令:scrapy crawl moment -o moment.json -s FEED_EXPORT_ENCODING=utf-8,可以看到编码问题已经解决,如下图所示。
动态网页抓取( 2.-type-gt-item数据,发现问题元素都选择好了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-25 01:01
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部选中,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径抓取数据。等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择一个标题的时候,不管标题的嵌套关系如何变化,总有一个标签不变,也就是包裹在最外层的带有属性名的h2标签。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。 查看全部
动态网页抓取(
2.-type-gt-item数据,发现问题元素都选择好了)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从经历。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们的实战培训网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据个数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素全部选中,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping 的路径抓取数据。等了十几秒结果出来后,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑。它们是网页中的骨架,提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']一个匹配规则。
首先,这是一个树结构:
<a>如何快速成为数据分析师?</a>
让我们分析一个将标题抓取为空的标题 HTML 代码。
我们可以清楚地观察到,在标题代码中,缺少名为 div 属性的标签!结果,当我们的匹配规则找不到对应的标签时,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择一个标题的时候,不管标题的嵌套关系如何变化,总有一个标签不变,也就是包裹在最外层的带有属性名的h2标签。如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper来操作呢?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape抓取数据,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎数据的时候,我们会发现滚动加载数据很快就完成了,但是匹配元素需要很多时间。
这间接说明了知乎和网站从代码的角度来说写得不好。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再增加大规模正式爬行,可以在一定程度上减少返工时间。
6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。
动态网页抓取(如果说10万行javascript代码中只有1000行是加载数据的代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-23 16:01
很多人在遇到网页动态加载数据时,习惯使用selenium webdriver这个自动化测试工具。连接浏览器驱动可以实现javascript代码的逆向分析。但是这种方法有一个明显的缺点:性能太差。更重要的是,它的采集效率的下限很大程度上不是取决于数据采集,而是取决于网页上javascript代码的数量。如果这些代码很多,那么我们的网络爬虫运行端就需要花费更多的资源来解析这些javascript代码;但是,如果10万行javascript代码中只有1000行是加载数据的代码,那是很不划算的……
解决这个问题最好的办法是直接下载javascript加载的数据,避免运行庞大的selenium webdriver和各种浏览器驱动,避免解析过多不相关的javascript代码。毫无疑问,采集数据的性能会得到很大的提升,节省大量的资源。
以上就是不使用selenium webdriver的好处。让我们谈谈如何实现它。
大家都知道FireFox浏览器,前端开发者也应该知道,这款浏览器有一个FireBug插件,对调试前端代码很有帮助。在爬虫开发者眼中,这个插件对于编写网络爬虫也是很有帮助的。,其灵活性允许开发者快速跟踪网页动态加载的数据。
一、安装FireBug插件
网上有很多资料,直接百度经验就可以找到。FireBug插件默认安装在最新版本的FireFox浏览器上,无需手动安装;旧版FireFox的安装方法见百度经验,这里不再详细说明。插件安装好后,打开FireFox浏览器,按F12弹出调试器。这是我们的FireBug,说明我们已经安装成功了。
二、 使用FireBug进一步分析爬取目标
上图为网页中通过ajax请求获取的json格式数据,即动态加载的数据。现在将数据复制粘贴到json查看器工具中,得到一个json格式的json对象视图。便于分析数据结构。但是有时候出来的json数据有很多空格和换行符,导致json查看器无法解析出来,所以我建议直接在FireBug中查看json对象数据。如下所示:
三、用于提取json数据
在FireBug中查看返回Ajax回调的JSON数据的请求URL后,意味着可以通过请求该URL获取该URL返回的JSON格式数据。
将此 URL 复制到浏览器的地址栏中,然后按 Enter。你可以看到我们想要的数据。
import requests
url='http://aigaogao.com/tools/defa ... 39%3B
result=requests.get(url)
html=result.content
print html
运行上面的代码,我们可以得到图片中相同的数据。
至此,动态网页的逆向工程已经实现。无需渲染js代码即可获取动态加载的数据。 查看全部
动态网页抓取(如果说10万行javascript代码中只有1000行是加载数据的代码)
很多人在遇到网页动态加载数据时,习惯使用selenium webdriver这个自动化测试工具。连接浏览器驱动可以实现javascript代码的逆向分析。但是这种方法有一个明显的缺点:性能太差。更重要的是,它的采集效率的下限很大程度上不是取决于数据采集,而是取决于网页上javascript代码的数量。如果这些代码很多,那么我们的网络爬虫运行端就需要花费更多的资源来解析这些javascript代码;但是,如果10万行javascript代码中只有1000行是加载数据的代码,那是很不划算的……
解决这个问题最好的办法是直接下载javascript加载的数据,避免运行庞大的selenium webdriver和各种浏览器驱动,避免解析过多不相关的javascript代码。毫无疑问,采集数据的性能会得到很大的提升,节省大量的资源。
以上就是不使用selenium webdriver的好处。让我们谈谈如何实现它。
大家都知道FireFox浏览器,前端开发者也应该知道,这款浏览器有一个FireBug插件,对调试前端代码很有帮助。在爬虫开发者眼中,这个插件对于编写网络爬虫也是很有帮助的。,其灵活性允许开发者快速跟踪网页动态加载的数据。
一、安装FireBug插件
网上有很多资料,直接百度经验就可以找到。FireBug插件默认安装在最新版本的FireFox浏览器上,无需手动安装;旧版FireFox的安装方法见百度经验,这里不再详细说明。插件安装好后,打开FireFox浏览器,按F12弹出调试器。这是我们的FireBug,说明我们已经安装成功了。
二、 使用FireBug进一步分析爬取目标
上图为网页中通过ajax请求获取的json格式数据,即动态加载的数据。现在将数据复制粘贴到json查看器工具中,得到一个json格式的json对象视图。便于分析数据结构。但是有时候出来的json数据有很多空格和换行符,导致json查看器无法解析出来,所以我建议直接在FireBug中查看json对象数据。如下所示:
三、用于提取json数据
在FireBug中查看返回Ajax回调的JSON数据的请求URL后,意味着可以通过请求该URL获取该URL返回的JSON格式数据。
将此 URL 复制到浏览器的地址栏中,然后按 Enter。你可以看到我们想要的数据。
import requests
url='http://aigaogao.com/tools/defa ... 39%3B
result=requests.get(url)
html=result.content
print html
运行上面的代码,我们可以得到图片中相同的数据。
至此,动态网页的逆向工程已经实现。无需渲染js代码即可获取动态加载的数据。
动态网页抓取( Python爬虫入门基础资料、项目实战练习(一)|Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-23 10:06
Python爬虫入门基础资料、项目实战练习(一)|Python)
var carname="Volvo";
3) 变量命名规则
① 由字母、数字、下划线和$组成,但不能以数字开头。例如,名称 12asd 会报错
②不能是关键字或保留字,如var、for等。
③ 严格区分大小写,即大写和小写是不同的变量
4)数据类型
JavaScript 数据有两种类型,一种是简单数据类型,另一种是复杂数据类型。
示例:返回类型为数字;
var a = 123; //var是设置一个变量
alert('hello') //一个弹窗,可以判断是否为外部引入的
console.log(a) //console.log():是在浏览器的控制台上的输出
console.log(typeof a); //typeof 判断是属于什么类型
注意:严格区分大小写,否则会出错。
说到数据类型,数据类型之间的交换是必不可少的。这与 js 和 python 非常相似。
介绍几个功能:
(1)Number() 将数据转换成数字类型,里面的参数就是你要改变类型的数据。
(2)toString() String() 两种将数据转换为字符串类型的方法;
区别 String() 可以将null 转换为“null” toString() 返回undefined;
(3)Boolean() 将数据类型转换为布尔类型;
bool 返回两种数据类型,一种为真,另一种为假。
Boolean类型转换为Number时,true会转为1,false会转为0。该方法不支持将数字开头有其他字符的字符串转为数字类型,如"12df ”。
2、Python中执行JS代码的三种方式
方法一:使用js2py
基本操作示例:
import js2py
# 执行单行js语句
js2py.eval_js("console.log(abcd)")
>>> abcd
# 执行js函数
add = js2py.eval_js("function add(a, b) {return a + b};")
print(add(1,2))
>>> 3
# 另一种方式
js = js2py.EvalJs({})
js.execute("js语句")
在js代码中引入python对象或python代码
# 在js代码中引入python对象
context = js2py.EvalJs({'python_sum': sum})
context.eval('python_sum(new Array(1,4,2,7))')
>>> 14
# 在js代码中加入python代码
js_code = '''
var a = 10
function f(x) {return x*x}
'''
context.execute(js_code)
context.f("14") 或 context.f(14)
>>> 196
将js代码转换为python模块,然后使用import导入
# 转换js文件
js2py.translate_file('example.js', 'example.py')
# 现在可以导入example.py
from example import example
example.someFunction()
# 转换js代码
js2py.translate_js('var $ = 5')
>>>
"""
from js2py.pyjs import *
# setting scope
var = Scope( JS_BUILTINS )
set_global_object(var)
# Code follows:
var.registers(['$'])
var.put('$', Js(5.0))
"""
但是py2js在加载一些加密函数的时候,有时候效率会很差,可能是因为执行机制不同;
py2js直接调用的nodejs引擎,但是把这个库使用的nodejs解析语法树转换成了py代码。性能相当低。最好使用execjs直接调用nodejs或者自己封装子进程调用。
方法二:使用execjs
import execjs
js_code = open('file.js',encoding='utf-8').read()
ctx = execjs.compile(js_code)
# 第一个参数为ja代码中的函数名, 后面为函数对应的参数
result = ctx.call('function_name', *args)
方法三:使用subprocess调用node子进程
import subprocess
# js文件最后必须有输出,我使用的是 console.log
pro = subprocess.run("node abc.js", stdout=subprocess.PIPE)
# 获得标准输出
_token = pro.stdout
# 转一下格式
token = _token.decode().strip()
这里也和大家分享一些我采集到的Python爬虫学习资源,入门基础资料,项目实战练习等等,有需要的进群找群管理获取↓↓
3、js 动态网页爬取方法(重点)
很多时候爬虫抓取的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。
一些动态的东西比如javascript脚本执行后产生的信息是无法捕获的。下面两种方案可以用来爬取python执行js后输出的信息。
①使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。
WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!
但仔细想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。慢一点是合理的。
另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个Web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现抓取页面的要求。
可以使用 selenium webdriver,但它会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这是一个临时解决方案。还有一个类似selenium的框架中的风车,感觉稍微复杂了一些,这里就不赘述了。
4、解析js(重点)
我们的爬虫一次只有一个请求,但实际上很多请求都是和js一起发送的,所以我们需要使用爬虫解析js来发送这些请求。
网页中的参数来源主要有四种:
这里主要介绍解析js的方法,破解加密的方法或者生成参数值的方法。python代码模拟了该方法的实现,从而获取到我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们需要的全部。您可以通过比较多个请求中的参数,加上一些经验和推测,过滤掉固定参数或服务器输入的参数和用户输入的参数。
这是js生成的值或加密值;
最终值:
# 图片 picture id:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
# 用户名:
su: cXdlcnRxd3Jl
nonce: 2SSH2A # 未知
# 密码:
sp: e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28e18254105358e897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果您需要模拟登录,您需要找到这种加密方法并使用它来加密我们的数据。
1)找到需要的js
要找到加密方法,我们首先需要找到登录所需的js代码,可以使用以下3种方法:
① 查找事件;查看页面上的目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;点击Network中列表界面对应的Initiator跳转到对应的js界面;
③通过搜索参数名称定位;
2)登录js代码
3) 在submit方法上打断,然后输入用户名和密码,不用登录,回到开发工具,点击这个按钮开启调试。
4) 然后去登录按钮,就可以开始调试了;
5)在一步步执行代码的同时,观察我们输入的参数。发生变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
import base64
a = "aaaaaaaaaaaa" # 输入的用户名
print(base64.b64encode(a.encode())) # 得到的加密结果:b'YWFhYWFhYWFhYWFh'
# 如果用户名包含@等特殊符号, 需要先用parse.quote()进行转义
得到的加密结果和js在网页上的执行结果一致;
5、 爬虫遇到的js反爬技术(重点)
1)JS 写 cookie
requests得到的网页是一对JS,与浏览器打开的网页源码完全不同。在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后第二次获取这个 cookie。要求。
这个过程可以在浏览器(chrome 或 Firefox)中看到。首先删除Chrome浏览器中保存的网站 cookie,按F12到网络窗口,选择“保留日志”(Firefox为“持久日志”),刷新网页,这样我们就可以看到历史记录了网络请求记录。
“index.html”页面第一次打开时,返回521,内容为一段JS代码;
当我第二次请求这个页面时,我得到了正常的 HTML。查看两次请求的cookies,可以发现第二次请求中携带了一个cookie,而这个cookie在第一次请求时没有被服务器发送。其实就是JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密的ajax请求参数
抓取某个网页中的数据,发现该网页的源代码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开网络窗口,刷新网页,看看加载这个网页后下载了哪些网址,我们要的数据在一个网址请求的结果中。
Chrome 的 Network 中这类 URL 的类型多为 XHR,我们想要的数据可以通过观察它们的“Response”来找到。
我们可以把这个URL复制到地址栏,把那个参数改成任意一个字母,然后访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于此类加密参数,可以尝试通过调试JS找到对应的JS加密算法。关键是在Chrome中设置“XHR/fetch Breakpoints”。
3)JS 反调试(anti-debug)
之前我们都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站加了反调试策略。只有当我们打开 F12 时,它才会在“调试器”代码行处暂停,无论如何它不会跳出。
不管我们点击多少次继续运行,它总是在这个“调试器”里,每次都会多出一个VMxx标签,观察“调用栈”发现好像卡在了一个递归调用一个函数。
这个“调试器”阻止我们调试JS,但是关闭F12窗口,网页加载正常。
解决办法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在 Console 中重新定义它并继续运行以跳过陷阱。
4)JS 发送鼠标点击事件
一些网站它的反爬虫不是上面的方法,你可以从浏览器打开一个正常的页面,但是在请求中,你被要求输入验证码或重定向到其他网页。
您可以尝试查看“网络”,例如网络流中的以下信息:
仔细看,你会发现每次点击页面上的链接,都会发出“cl.gif”的请求。看起来它正在下载 gif 图片,但事实并非如此。
它在请求时发送了很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
首先,让我们遵循它的逻辑:
JS 会响应链接被点击的事件。打开链接前,先访问cl.gif,将当前信息发送到服务器,然后打开点击的链接。服务器接收到点击链接的请求,会检查之前是否通过cl.gif发送过相应的信息。如果发送,将被视为合法的浏览器访问,并提供正常的网页内容。
因为请求没有响应鼠标事件,所以没有访问cl.gif进程直接访问链接,服务器拒绝服务。
如果你理解它,很容易处理逻辑!
解决方案:只需在访问链接之前访问 cl.gif。关键是研究cl.gif之后的参数。把这些参数放在一起不是什么大问题,所以可以绕过这个防爬策略。
今天的爬虫分享到此结束~更多Python爬虫学习干货和学习资源欢迎加入下方Python学习技术交流群。 查看全部
动态网页抓取(
Python爬虫入门基础资料、项目实战练习(一)|Python)
var carname="Volvo";
3) 变量命名规则
① 由字母、数字、下划线和$组成,但不能以数字开头。例如,名称 12asd 会报错
②不能是关键字或保留字,如var、for等。
③ 严格区分大小写,即大写和小写是不同的变量
4)数据类型
JavaScript 数据有两种类型,一种是简单数据类型,另一种是复杂数据类型。
示例:返回类型为数字;
var a = 123; //var是设置一个变量
alert('hello') //一个弹窗,可以判断是否为外部引入的
console.log(a) //console.log():是在浏览器的控制台上的输出
console.log(typeof a); //typeof 判断是属于什么类型
注意:严格区分大小写,否则会出错。
说到数据类型,数据类型之间的交换是必不可少的。这与 js 和 python 非常相似。
介绍几个功能:
(1)Number() 将数据转换成数字类型,里面的参数就是你要改变类型的数据。
(2)toString() String() 两种将数据转换为字符串类型的方法;
区别 String() 可以将null 转换为“null” toString() 返回undefined;
(3)Boolean() 将数据类型转换为布尔类型;
bool 返回两种数据类型,一种为真,另一种为假。
Boolean类型转换为Number时,true会转为1,false会转为0。该方法不支持将数字开头有其他字符的字符串转为数字类型,如"12df ”。
2、Python中执行JS代码的三种方式
方法一:使用js2py
基本操作示例:
import js2py
# 执行单行js语句
js2py.eval_js("console.log(abcd)")
>>> abcd
# 执行js函数
add = js2py.eval_js("function add(a, b) {return a + b};")
print(add(1,2))
>>> 3
# 另一种方式
js = js2py.EvalJs({})
js.execute("js语句")
在js代码中引入python对象或python代码
# 在js代码中引入python对象
context = js2py.EvalJs({'python_sum': sum})
context.eval('python_sum(new Array(1,4,2,7))')
>>> 14
# 在js代码中加入python代码
js_code = '''
var a = 10
function f(x) {return x*x}
'''
context.execute(js_code)
context.f("14") 或 context.f(14)
>>> 196
将js代码转换为python模块,然后使用import导入
# 转换js文件
js2py.translate_file('example.js', 'example.py')
# 现在可以导入example.py
from example import example
example.someFunction()
# 转换js代码
js2py.translate_js('var $ = 5')
>>>
"""
from js2py.pyjs import *
# setting scope
var = Scope( JS_BUILTINS )
set_global_object(var)
# Code follows:
var.registers(['$'])
var.put('$', Js(5.0))
"""
但是py2js在加载一些加密函数的时候,有时候效率会很差,可能是因为执行机制不同;
py2js直接调用的nodejs引擎,但是把这个库使用的nodejs解析语法树转换成了py代码。性能相当低。最好使用execjs直接调用nodejs或者自己封装子进程调用。
方法二:使用execjs
import execjs
js_code = open('file.js',encoding='utf-8').read()
ctx = execjs.compile(js_code)
# 第一个参数为ja代码中的函数名, 后面为函数对应的参数
result = ctx.call('function_name', *args)
方法三:使用subprocess调用node子进程
import subprocess
# js文件最后必须有输出,我使用的是 console.log
pro = subprocess.run("node abc.js", stdout=subprocess.PIPE)
# 获得标准输出
_token = pro.stdout
# 转一下格式
token = _token.decode().strip()
这里也和大家分享一些我采集到的Python爬虫学习资源,入门基础资料,项目实战练习等等,有需要的进群找群管理获取↓↓
3、js 动态网页爬取方法(重点)
很多时候爬虫抓取的页面只是一个静态页面,也就是网页的源代码,就像在浏览器上“查看网页的源代码”一样。
一些动态的东西比如javascript脚本执行后产生的信息是无法捕获的。下面两种方案可以用来爬取python执行js后输出的信息。
①使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。
WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页。虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!
但仔细想想也是有道理的。Python调用webkit请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。慢一点是合理的。
另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,也可以实现同样的功能。
② selenium web 测试框架
Selenium是一个Web测试框架,允许调用本地浏览器引擎发送网页请求,所以也可以实现抓取页面的要求。
可以使用 selenium webdriver,但它会实时打开浏览器窗口。
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这是一个临时解决方案。还有一个类似selenium的框架中的风车,感觉稍微复杂了一些,这里就不赘述了。
4、解析js(重点)
我们的爬虫一次只有一个请求,但实际上很多请求都是和js一起发送的,所以我们需要使用爬虫解析js来发送这些请求。
网页中的参数来源主要有四种:
这里主要介绍解析js的方法,破解加密的方法或者生成参数值的方法。python代码模拟了该方法的实现,从而获取到我们需要的请求参数。
以微博登录为例:
当我们点击登录时,我们会发送一个登录请求
登录表单中的参数不一定是我们需要的全部。您可以通过比较多个请求中的参数,加上一些经验和推测,过滤掉固定参数或服务器输入的参数和用户输入的参数。
这是js生成的值或加密值;
最终值:
# 图片 picture id:
pcid: yf-d0efa944bb243bddcf11906cda5a46dee9b8
# 用户名:
su: cXdlcnRxd3Jl
nonce: 2SSH2A # 未知
# 密码:
sp: e121946ac9273faf9c63bc0fdc5d1f84e563a4064af16f635000e49cbb2976d73734b0a8c65a6537e2e728cd123e6a34a7723c940dd2aea902fb9e7c6196e3a15ec52607fd02d5e5a28e18254105358e897996f0b9057afe2d24b491bb12ba29db3265aef533c1b57905bf02c0cee0c546f4294b0cf73a553aa1f7faf9f835e5
prelt: 148 # 未知
请求参数中的用户名和密码是加密的。如果您需要模拟登录,您需要找到这种加密方法并使用它来加密我们的数据。
1)找到需要的js
要找到加密方法,我们首先需要找到登录所需的js代码,可以使用以下3种方法:
① 查找事件;查看页面上的目标元素,在开发工具的子窗口中选择Events Listeners,找到点击事件,点击定位到js代码。
② 查找请求;点击Network中列表界面对应的Initiator跳转到对应的js界面;
③通过搜索参数名称定位;
2)登录js代码
3) 在submit方法上打断,然后输入用户名和密码,不用登录,回到开发工具,点击这个按钮开启调试。
4) 然后去登录按钮,就可以开始调试了;
5)在一步步执行代码的同时,观察我们输入的参数。发生变化的地方是加密方式,如下
6)上图中的加密方式是base64,我们可以用代码试试
import base64
a = "aaaaaaaaaaaa" # 输入的用户名
print(base64.b64encode(a.encode())) # 得到的加密结果:b'YWFhYWFhYWFhYWFh'
# 如果用户名包含@等特殊符号, 需要先用parse.quote()进行转义
得到的加密结果和js在网页上的执行结果一致;
5、 爬虫遇到的js反爬技术(重点)
1)JS 写 cookie
requests得到的网页是一对JS,与浏览器打开的网页源码完全不同。在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后第二次获取这个 cookie。要求。
这个过程可以在浏览器(chrome 或 Firefox)中看到。首先删除Chrome浏览器中保存的网站 cookie,按F12到网络窗口,选择“保留日志”(Firefox为“持久日志”),刷新网页,这样我们就可以看到历史记录了网络请求记录。
“index.html”页面第一次打开时,返回521,内容为一段JS代码;
当我第二次请求这个页面时,我得到了正常的 HTML。查看两次请求的cookies,可以发现第二次请求中携带了一个cookie,而这个cookie在第一次请求时没有被服务器发送。其实就是JS生成的。
解决方法:研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
2)JS加密的ajax请求参数
抓取某个网页中的数据,发现该网页的源代码中没有我们想要的数据。麻烦的是,数据往往是通过ajax请求获取的。
按F12打开网络窗口,刷新网页,看看加载这个网页后下载了哪些网址,我们要的数据在一个网址请求的结果中。
Chrome 的 Network 中这类 URL 的类型多为 XHR,我们想要的数据可以通过观察它们的“Response”来找到。
我们可以把这个URL复制到地址栏,把那个参数改成任意一个字母,然后访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
解决方法:对于此类加密参数,可以尝试通过调试JS找到对应的JS加密算法。关键是在Chrome中设置“XHR/fetch Breakpoints”。
3)JS 反调试(anti-debug)
之前我们都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。
不过这个方法用的太多了,网站加了反调试策略。只有当我们打开 F12 时,它才会在“调试器”代码行处暂停,无论如何它不会跳出。
不管我们点击多少次继续运行,它总是在这个“调试器”里,每次都会多出一个VMxx标签,观察“调用栈”发现好像卡在了一个递归调用一个函数。
这个“调试器”阻止我们调试JS,但是关闭F12窗口,网页加载正常。
解决办法:“反反调试”,通过“调用栈”找到让我们陷入死循环的函数,重新定义。
JS 的运行应该在设置的断点处停止。此时,该功能尚未运行。我们在 Console 中重新定义它并继续运行以跳过陷阱。
4)JS 发送鼠标点击事件
一些网站它的反爬虫不是上面的方法,你可以从浏览器打开一个正常的页面,但是在请求中,你被要求输入验证码或重定向到其他网页。
您可以尝试查看“网络”,例如网络流中的以下信息:
仔细看,你会发现每次点击页面上的链接,都会发出“cl.gif”的请求。看起来它正在下载 gif 图片,但事实并非如此。
它在请求时发送了很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
首先,让我们遵循它的逻辑:
JS 会响应链接被点击的事件。打开链接前,先访问cl.gif,将当前信息发送到服务器,然后打开点击的链接。服务器接收到点击链接的请求,会检查之前是否通过cl.gif发送过相应的信息。如果发送,将被视为合法的浏览器访问,并提供正常的网页内容。
因为请求没有响应鼠标事件,所以没有访问cl.gif进程直接访问链接,服务器拒绝服务。
如果你理解它,很容易处理逻辑!
解决方案:只需在访问链接之前访问 cl.gif。关键是研究cl.gif之后的参数。把这些参数放在一起不是什么大问题,所以可以绕过这个防爬策略。
今天的爬虫分享到此结束~更多Python爬虫学习干货和学习资源欢迎加入下方Python学习技术交流群。
动态网页抓取(动态页面静态化,若何避免重复收录页面数的体会 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-22 08:16
)
我作为一个站工作了一段时间。这段时间,我对搜索引擎有了新的认识——首先,定位不同,自然理解也不同。我曾经是一个搜索引擎的用户,我只关心搜索引擎能否正确找到我需要的信息。现在我有了不同的地位,我已经成为搜索引擎的上游内容提供商。可以近距离观察搜索引擎的工作情况,对搜索引擎有深刻的了解。尤其是本站下决心换新域名前后,我特别关心搜索引擎的工作。我每天关注三大搜索引擎的收录页数。我有一些经验。我随便说说吧。办公室,请正确:
动态页面是静态的,如何避免重复爬取
1、 使用robots 文件屏蔽此页面。语法风格的具体方法: Disallow: /page/ #限制抓取WordPRess页面,如果你检查你的网站 如有必要,你也可以总结下面的句子写出来,避免太多重复的页面。* Disallow: /category/*/page/* #Restricted to crawl category pages* Disallow:/tag/ #Restricted to crawl tag pages* Disallow: */trackback/ #Restricted to crawl Trackback content* Disallow:/category/* #限于抓取所有分类列表什么是蜘蛛,也叫爬虫,其实是一个程序。这个程序的作用就是沿着你的网站 URL逐层读取一点信息,做一个简单的处理,然后发回后端服务器集中处理。2、论坛是用Discuz制作的。论坛的后端是静态的。本来是直接使用官方默认的robots.txt文件的。但是发现百度统计中的SEO提案提醒“在静态页面上启用动态参数变量会导致蜘蛛多次重复爬取”,发现很多动态页面被重复爬取。所以我干预了 robots.txt 文件中的 Disallow: /*?* 标签。我不希望搜索引擎抓取动态页面。3、动态网页优化是页面静态的。大多数搜索引擎的蜘蛛程序都不能解释符号?后一个特点意味着动态网页很难被搜索引擎检索到,因此被用户发现的几率大大降低。下面介绍IIS_ReWrite的静态处理,
建站虽难,但人生难免撞南墙,难免得鼻梁。不管怎样,该出手的时候,就是该出手的时候了。风雨过后见彩虹。以上内容与大家分享。希望对新手有帮助。对于老手来说,这只是个玩笑。只是不要鄙视我。本文由于世维英在实施中采集。欢迎转载。请注明,谢谢合作
静态动态页面,如何避免重复抓取 查看全部
动态网页抓取(动态页面静态化,若何避免重复收录页面数的体会
)
我作为一个站工作了一段时间。这段时间,我对搜索引擎有了新的认识——首先,定位不同,自然理解也不同。我曾经是一个搜索引擎的用户,我只关心搜索引擎能否正确找到我需要的信息。现在我有了不同的地位,我已经成为搜索引擎的上游内容提供商。可以近距离观察搜索引擎的工作情况,对搜索引擎有深刻的了解。尤其是本站下决心换新域名前后,我特别关心搜索引擎的工作。我每天关注三大搜索引擎的收录页数。我有一些经验。我随便说说吧。办公室,请正确:
动态页面是静态的,如何避免重复爬取
1、 使用robots 文件屏蔽此页面。语法风格的具体方法: Disallow: /page/ #限制抓取WordPRess页面,如果你检查你的网站 如有必要,你也可以总结下面的句子写出来,避免太多重复的页面。* Disallow: /category/*/page/* #Restricted to crawl category pages* Disallow:/tag/ #Restricted to crawl tag pages* Disallow: */trackback/ #Restricted to crawl Trackback content* Disallow:/category/* #限于抓取所有分类列表什么是蜘蛛,也叫爬虫,其实是一个程序。这个程序的作用就是沿着你的网站 URL逐层读取一点信息,做一个简单的处理,然后发回后端服务器集中处理。2、论坛是用Discuz制作的。论坛的后端是静态的。本来是直接使用官方默认的robots.txt文件的。但是发现百度统计中的SEO提案提醒“在静态页面上启用动态参数变量会导致蜘蛛多次重复爬取”,发现很多动态页面被重复爬取。所以我干预了 robots.txt 文件中的 Disallow: /*?* 标签。我不希望搜索引擎抓取动态页面。3、动态网页优化是页面静态的。大多数搜索引擎的蜘蛛程序都不能解释符号?后一个特点意味着动态网页很难被搜索引擎检索到,因此被用户发现的几率大大降低。下面介绍IIS_ReWrite的静态处理,
建站虽难,但人生难免撞南墙,难免得鼻梁。不管怎样,该出手的时候,就是该出手的时候了。风雨过后见彩虹。以上内容与大家分享。希望对新手有帮助。对于老手来说,这只是个玩笑。只是不要鄙视我。本文由于世维英在实施中采集。欢迎转载。请注明,谢谢合作
静态动态页面,如何避免重复抓取
动态网页抓取(购物助手(2)标签标签及结构())
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-21 16:17
(2)HTML标签和结构。用户在页面上看到的显示是基于HTML显示的,所以爬虫需要解析html页面,提取页面中的url信息。
(3)文本对象模型(DOM)。DOM用于访问和处理HTML和XML文档。它可以构造HTML和XML文档。
(4)正则表达式。根据正则表达式的优良特性,可以根据条件快速提取HTML文本中的指定元素。
2.3 解决方案
AJAX 使用 JavaScript 驱动的异步请求/响应机制。而且,在 Ajax 应用中,JavaScript 会对 DOM 结构进行大量的改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制的。因此,爬虫引擎不能只由基于HTTP的协议驱动,而必须由事件驱动。
对于实时数据,系统的实时性主要体现在两个方面:实时数据更新;数据变化后通过其他服务实时获取数据。
面对海量数据,由于捕获能力有限,不可能快速更新所有数据信息。为了保证用户对高实时性数据的要求,我们应该优先保证尽可能多的热门数据的数据更新,因此实时捕获数据点的选择更为关键。这里我们以购物助理的浏览记录和购物搜索查询记录作为热门商品的例子。具体流程为:用户浏览商品,购物助理获取用户浏览商品的URL和其他商城商品的URL列表,发送至任务调度服务器。任务调度服务器根据上次爬取的价格和时间进行调度。将任务分配给抓取服务器,抓取服务器解析出新的价格并发送给结果存储服务器。结果,仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。
观察者模式(也称为发布/订阅模式)是软件设计模式之一。在这种模式下,目标对象管理所有依赖它的观察者对象,并在自身状态发生变化时主动发出通知。这通常是通过调用每个观察者提供的方法来实现的。这种模式通常用于实现事件处理系统。观察者模式在数据变化的实时通知中得到了广泛的应用,使得服务具有高集群、低耦合的特点。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种: Batch Crawler:Batch crawler有比较明确的爬行范围和目标。达到这个设定的目标后,爬行过程就会停止。至于具体的目标,可能会有所不同。可能只是设置了一定数量的网页被抓取,也可能是设置了抓取所消耗的时间等等。
增量爬虫(Incremental Crawler):增量爬虫不同于批量爬虫。它将保持连续爬行。爬取的网页必须定期更新,因为互联网的网页在不断变化,新的网页不断增加。网页被删除或网页内容更改是很常见的。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新的网页,要么更新现有的网页。常见的商业搜索引擎爬虫基本都属于这一类。
垂直爬虫(Focused Crawter):垂直爬虫专注于特定主题内容或属于特定行业的网页。例如,对于在线旅行,您只需从互联网页面中查找与在线旅行相关的页面内容。内容不考虑。垂直爬虫最大的特点和难点之一就是如何识别网页内容是否属于特定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个网址是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站或垂直行业网站
3 结论
对于使用JavaScript对动态页面的抓取,主要采用的技术方案有:(1)事件驱动的爬虫机制。(2)使用观察者模式和查询驱动的抓取方式,实时抓取性数据还介绍了目前流行的爬虫爬取方案。 查看全部
动态网页抓取(购物助手(2)标签标签及结构())
(2)HTML标签和结构。用户在页面上看到的显示是基于HTML显示的,所以爬虫需要解析html页面,提取页面中的url信息。
(3)文本对象模型(DOM)。DOM用于访问和处理HTML和XML文档。它可以构造HTML和XML文档。
(4)正则表达式。根据正则表达式的优良特性,可以根据条件快速提取HTML文本中的指定元素。
2.3 解决方案
AJAX 使用 JavaScript 驱动的异步请求/响应机制。而且,在 Ajax 应用中,JavaScript 会对 DOM 结构进行大量的改动,甚至页面的所有内容都是通过 JavaScript 直接从服务器读取并动态绘制的。因此,爬虫引擎不能只由基于HTTP的协议驱动,而必须由事件驱动。
对于实时数据,系统的实时性主要体现在两个方面:实时数据更新;数据变化后通过其他服务实时获取数据。
面对海量数据,由于捕获能力有限,不可能快速更新所有数据信息。为了保证用户对高实时性数据的要求,我们应该优先保证尽可能多的热门数据的数据更新,因此实时捕获数据点的选择更为关键。这里我们以购物助理的浏览记录和购物搜索查询记录作为热门商品的例子。具体流程为:用户浏览商品,购物助理获取用户浏览商品的URL和其他商城商品的URL列表,发送至任务调度服务器。任务调度服务器根据上次爬取的价格和时间进行调度。将任务分配给抓取服务器,抓取服务器解析出新的价格并发送给结果存储服务器。结果,仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。仓储服务器完成数据更新并通知其他价格事件监听器。这样就完成了整个查询驱动的实时爬取过程。这种实时爬行策略被称为“Query Triggered Crawling”(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。(QTC,简称Query Triggered Crawling)。除了实时抓取和管理所有商品的价格外,价格服务器还需要向其他服务(如降价提醒、全网比价等)提供价格变化的更新事件。如何让其他服务获取实时的商品价格变动信息?我们首先介绍观察者模式。
观察者模式(也称为发布/订阅模式)是软件设计模式之一。在这种模式下,目标对象管理所有依赖它的观察者对象,并在自身状态发生变化时主动发出通知。这通常是通过调用每个观察者提供的方法来实现的。这种模式通常用于实现事件处理系统。观察者模式在数据变化的实时通知中得到了广泛的应用,使得服务具有高集群、低耦合的特点。
根据应用的不同,爬虫系统在很多方面都有所不同。一般来说,爬虫可以分为以下三种: Batch Crawler:Batch crawler有比较明确的爬行范围和目标。达到这个设定的目标后,爬行过程就会停止。至于具体的目标,可能会有所不同。可能只是设置了一定数量的网页被抓取,也可能是设置了抓取所消耗的时间等等。
增量爬虫(Incremental Crawler):增量爬虫不同于批量爬虫。它将保持连续爬行。爬取的网页必须定期更新,因为互联网的网页在不断变化,新的网页不断增加。网页被删除或网页内容更改是很常见的。增量爬虫需要及时反映这种变化。因此,它们都在不断的爬取过程中,要么爬取新的网页,要么更新现有的网页。常见的商业搜索引擎爬虫基本都属于这一类。
垂直爬虫(Focused Crawter):垂直爬虫专注于特定主题内容或属于特定行业的网页。例如,对于在线旅行,您只需从互联网页面中查找与在线旅行相关的页面内容。内容不考虑。垂直爬虫最大的特点和难点之一就是如何识别网页内容是否属于特定的行业或主题。从节省系统资源的角度考虑,不可能把所有的网页都下载下来然后过滤。这太浪费资源了。爬虫往往需要在爬取阶段动态识别某个网址是否与主题相关。并且尽量不要去抓取不相关的页面以节省资源。垂直搜索网站或垂直行业网站
3 结论
对于使用JavaScript对动态页面的抓取,主要采用的技术方案有:(1)事件驱动的爬虫机制。(2)使用观察者模式和查询驱动的抓取方式,实时抓取性数据还介绍了目前流行的爬虫爬取方案。
动态网页抓取(京东网站上的华为手机信息查看网站首页的文章目录 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-20 02:14
)
文章内容
一、硒
1.1 简介
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
1.2 下载
可以直接用pip install selenium或者conda install selenium下载,但是要使用需要下载对应的浏览器驱动
二、自动化测试
引入头文件进入网页,驱动需要添加到环境变量中,但是添加好像没用,这里用的是绝对路径
from selenium import webdriver
driver=webdriver.Chrome('D:/下载/chromedriver_win32/chromedriver.exe')
#进入网页
driver.get("https://www.baidu.com/")
在浏览器中,使用开发者工具,查看代码,定位到搜索框的id,右键搜索框,点击check,可以看到搜索框的id
使用 id 查找此元素
from selenium import webdriver
# 打开一个Chrome浏览器,executable_path是Chrome浏览器驱动的路径
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
driver.get("https://www.baidu.com/")
p_input=driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('星球'))
print(p_input.text)
同理,在百度上右击,点击check,查看它的id
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、在京东上抓取华为手机信息网站
查看网站首页,输入框id和搜索按钮
手机右击,发现信息在J_goodsList下
查看每个手机和li标签的具体内容
可以看到价格p-price之类的
代码:
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
# 京东所在网站
driver.get("https://www.jd.com/")
p_input = driver.find_element_by_id('key')# 找到输入框输入
p_input.send_keys('p40') # 输入需要查找的关键字
time.sleep(1)
button=driver.find_element_by_class_name("button").click()# 点击搜素按钮
time.sleep(1)
all_book_info = []
num=200
head=['手机名', '价格']
#csv文件的路径和名字
path='D:/下载/chromedriver_win32/手机.csv'
def write_csv(head,all_book_info,path):
with open(path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(head)
fileWriter.writerows(all_book_info)
# 爬取一页
def get_onePage_info(web,num):
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text =driver.page_source
# with open('3-.html', 'w', encoding='utf-8')as fp:
# fp.write(page_text)
# 进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
for li in li_list:
num=num-1
book_infos = []
book_name = ''.join(li.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')) # 书名
book_infos.append(book_name)
price = '¥' + li.xpath('.//div[@class="p-price"]/strong/i/text()')[0] # 价格
book_infos.append(price)
# if len(store_span) > 0:
# store = store_span[0]
# else:
# store = '无'
all_book_info.append(book_infos)
if num==0:
break
return num
while num!=0:
num=get_onePage_info(driver,num)
driver.find_element_by_class_name('pn-next').click() # 点击下一页
time.sleep(2)
write_csv(head,all_book_info,path)
driver.close()
查看全部
动态网页抓取(京东网站上的华为手机信息查看网站首页的文章目录
)
文章内容
一、硒
1.1 简介
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
1.2 下载
可以直接用pip install selenium或者conda install selenium下载,但是要使用需要下载对应的浏览器驱动
二、自动化测试
引入头文件进入网页,驱动需要添加到环境变量中,但是添加好像没用,这里用的是绝对路径
from selenium import webdriver
driver=webdriver.Chrome('D:/下载/chromedriver_win32/chromedriver.exe')
#进入网页
driver.get("https://www.baidu.com/";)
在浏览器中,使用开发者工具,查看代码,定位到搜索框的id,右键搜索框,点击check,可以看到搜索框的id
使用 id 查找此元素
from selenium import webdriver
# 打开一个Chrome浏览器,executable_path是Chrome浏览器驱动的路径
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
driver.get("https://www.baidu.com/";)
p_input=driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('星球'))
print(p_input.text)
同理,在百度上右击,点击check,查看它的id
p_btn = driver.find_element_by_id('su')
p_btn.click()
三、在京东上抓取华为手机信息网站
查看网站首页,输入框id和搜索按钮
手机右击,发现信息在J_goodsList下
查看每个手机和li标签的具体内容
可以看到价格p-price之类的
代码:
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
driver = webdriver.Chrome(executable_path=r'D:/下载/chromedriver_win32/chromedriver.exe')
# 京东所在网站
driver.get("https://www.jd.com/";)
p_input = driver.find_element_by_id('key')# 找到输入框输入
p_input.send_keys('p40') # 输入需要查找的关键字
time.sleep(1)
button=driver.find_element_by_class_name("button").click()# 点击搜素按钮
time.sleep(1)
all_book_info = []
num=200
head=['手机名', '价格']
#csv文件的路径和名字
path='D:/下载/chromedriver_win32/手机.csv'
def write_csv(head,all_book_info,path):
with open(path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(head)
fileWriter.writerows(all_book_info)
# 爬取一页
def get_onePage_info(web,num):
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text =driver.page_source
# with open('3-.html', 'w', encoding='utf-8')as fp:
# fp.write(page_text)
# 进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
for li in li_list:
num=num-1
book_infos = []
book_name = ''.join(li.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')) # 书名
book_infos.append(book_name)
price = '¥' + li.xpath('.//div[@class="p-price"]/strong/i/text()')[0] # 价格
book_infos.append(price)
# if len(store_span) > 0:
# store = store_span[0]
# else:
# store = '无'
all_book_info.append(book_infos)
if num==0:
break
return num
while num!=0:
num=get_onePage_info(driver,num)
driver.find_element_by_class_name('pn-next').click() # 点击下一页
time.sleep(2)
write_csv(head,all_book_info,path)
driver.close()
动态网页抓取(python爬取js执行后输出的信息--python库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-12-16 07:28
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何抓取动态网站的介绍。更多相关python如何抓取动态网站内容,请搜索前面文章人脸圈教程@>或继续浏览下方相关文章,希望大家支持面圈以后有教程! 查看全部
动态网页抓取(python爬取js执行后输出的信息--python库)
Python有很多库,可以让我们轻松编写网络爬虫,抓取某些页面,获取有价值的信息!但很多情况下,爬虫抓取的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如一个javascript脚本执行后产生的信息,是无法捕捉到的。这里暂时给出一些解决方案,可以用于python爬取js执行后输出的信息。
1、两种基本解决方案
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
def get_url_dynamic2(url):
driver=webdriver.Firefox() #调用本地的火狐浏览器,Chrom 甚至 Ie 也可以的
driver.get(url) #请求页面,会打开一个浏览器窗口
html_text=driver.page_source
driver.quit()
#print html_text
return html_text
get_text_line(get_url_dynamic2(url)) #将输出一条文本
这也是临时解决办法!类似selenium的框架也有风车,感觉稍微复杂一点,就不赘述了!
2、selenium的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。由于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:
mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下:
sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
driver = webdriver.chrome()
TypeError: 'module' object is not callable
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
value = content.text
这是文章关于python如何抓取动态网站的介绍。更多相关python如何抓取动态网站内容,请搜索前面文章人脸圈教程@>或继续浏览下方相关文章,希望大家支持面圈以后有教程!
动态网页抓取(Requests模拟浏览器发送Post请求时,发现程序返回的html与浏览器F12)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-16 07:28
最近在用Requests模拟浏览器发送Post请求的时候,发现程序返回的html和浏览器F12观察到的有点不一样。经过观察,返回了response.text,确认cookies是有效的,因为我们可以看到login返回了。信息。但是,某些字段仍显示空值。
下图是浏览器F12抓包看到的界面:
由于笔者观察到浏览器捕捉到的Response(html文件)与查看第一个界面请求时页面显示的信息是一致的,所以简单的认为只需要使用requests库来构造这个请求即可。但是,其实第一种形式只返回首页的frame,很多数据通过script、XHR等格式请求返回数据后动态加载到基本frame页面中。
然后随便挑关键点,请求下面的key list.do等xhr信息?
在这种情况下,这是不可能的。整个前端网页的内容填充分为模块。每个js文件或者后端返回的json只确定了部分页面信息,这就导致需要模拟多个页面才能完整获取页面信息。问。更重要的是,前端页面的部分信息是结合后台返回的json文件,经过一定的正则计算后返回的最终结果。如果在页面中找不到值的后端算术函数,我们就无法模拟后端服务器的行为来构造相同的函数。
这种由多个JavaScript文件渲染后生成的网页,直接用requests库爬取比较困难。
这时候通过查阅资料,发现解决javascript动态生成页面信息爬取的方法有两种:(参考博客:)
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!ps:由于其底层操作逻辑(python调用webkit请求页面,页面加载后加载js文件,让js执行,返回执行的页面),实际过程比较慢。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
1.2 使用selenium完成动态页面的爬取
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
这也是作者之前大部分文章推荐的框架。所谓的“看到就爬”,可惜效率还是比后台请求的请求方式慢很多。如果可以结合Chrome浏览器的headless模式进行静默爬行,可以稍微提高效率。开启无头模式的代码示例:
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument(\'headless\')
driver = webdriver.Chrome(chrome_options=option)
driver.get(url) #访问网址
page_content=driver.page_source #获取js选然后的页面源码
上诉操作后,我们就可以得到页面最终的源码了。
但是在实际使用中,selenium 还是有一个问题,就是“可见就可以爬取”。在源码中可以清楚看到的一些页面元素。如果页面显示在前台,需要点击才能出现,我们还要模拟浏览器行为,使用click()方法点击获取相关节点的数据。喜欢:
如果页面停留在“基本信息”界面,如果要获取“审批信息”标签页的信息,则需要模拟点击“审批信息”,这会在一定程度上降低抓取效率。
此时建议直接使用 BeautifulSoup 包解析 html 文件,然后直接用通用正则表达式 RE 获取,尽量不要模拟浏览器不急的点击行为(除非页面源码有不存在,需要点击触发js动态返回信息条件)。
下面是结合源码和bs4(BeautifulSoup)的例子,在我的实际工作中重新表达爬取特定字段:
whole_text=driver.page_source #提取加载后的源码
soup=BeautifulSoup(whole_text,"lxml")
haf=str(soup.select(\'script\')[6]) #得到haf字段,再进行后续提取
flowHiComments=re.search(\'.*?flowHiComments\":(.*?),\"flowHiNodeIds.*?\',haf,re.S)
applyerId=soup.find(id="afPersonId")[\'value\'] #根据id查找
applyerName=re.search(\'.*?applyerName\":\"(.*?)\".*?\',haf,re.S).group(1) #根据re表达式的group方法提取字符串特定字段
flowHiComments=json.loads(flowHiComments.group(1)) #得到页面评论信息
with open(\'.\\CommentFlow\\%s_%s.txt\'%(bpmDefName,afFormNumber),\'w\',encoding="utf-8") as txt: #将flowHiComments保存为本地txt文件,并对文件进行格式化
json.dump(flowHiComments,txt,ensure_ascii = False,indent=4)
当你得到一个特定的字段时,你需要将信息一一存储。例如,将信息保存在本地 excel 文件中。这时候就需要用到openpyxl文件了。
openpyxl文件对excel新格式比较友好。在实际使用中还有一些需要注意的地方:
1.openpyxl 提供默认返回的excel最后一行(列)的索引号:
可以使用 ws.mas_row 和 ws.max_column 两个原生方法,但是如果我们想读取任何列的最后一行号怎么办?ws.max_row 不是那么灵活。
如果想把A列的所有元素都放到内存中,可以使用的示例代码如下:
name=[]
while True:
if sheet.cell(num,1).value ==None:
break
name.append(sheet.cell(num,1).value) #名称
num+=1
同理可以得到B列的值。
2. 我们习惯于使用 ws.append() 方法将数据按行追加到表中。根据实际测量,每次添加内容都是从第二行开始的(是否考虑第一行作为标题行),如果我们想让程序在执行过程中动态添加一个标题行呢?
笔者实测:
from openpyxl import load_workbook
wb= load_workbook(\'test2.xlsx\')
#wb.active =1
sheet=wb["Sheet1"]
row = [1 ,2, 3, 4, 5]
sheet.append(row)
wb.save(\'test2.xlsx\')
结果执行后,excel端生成的数据从第二行开始:
这显然有时不能满足我们的要求。如果要传递第一行的值,不建议使用原生的append方法。可行的建议如下:
navigation=[]
if ws.cell(1,1).value ==None:
navigation=["名称","单号","业务描述","申请者","申请者编号","代码","备注"]
for m in range(len(navigation)):
ws.cell(1,m+1).value=navigation[m]
当然,上面代码中导航列表的每个元素也可以传入爬虫抓取到的字段值(变量),非常灵活!
在爬取的过程中,我们总会遇到这样的问题。总结总结前人积累的经验尤为重要。避免重复坑! 查看全部
动态网页抓取(Requests模拟浏览器发送Post请求时,发现程序返回的html与浏览器F12)
最近在用Requests模拟浏览器发送Post请求的时候,发现程序返回的html和浏览器F12观察到的有点不一样。经过观察,返回了response.text,确认cookies是有效的,因为我们可以看到login返回了。信息。但是,某些字段仍显示空值。
下图是浏览器F12抓包看到的界面:
由于笔者观察到浏览器捕捉到的Response(html文件)与查看第一个界面请求时页面显示的信息是一致的,所以简单的认为只需要使用requests库来构造这个请求即可。但是,其实第一种形式只返回首页的frame,很多数据通过script、XHR等格式请求返回数据后动态加载到基本frame页面中。
然后随便挑关键点,请求下面的key list.do等xhr信息?
在这种情况下,这是不可能的。整个前端网页的内容填充分为模块。每个js文件或者后端返回的json只确定了部分页面信息,这就导致需要模拟多个页面才能完整获取页面信息。问。更重要的是,前端页面的部分信息是结合后台返回的json文件,经过一定的正则计算后返回的最终结果。如果在页面中找不到值的后端算术函数,我们就无法模拟后端服务器的行为来构造相同的函数。
这种由多个JavaScript文件渲染后生成的网页,直接用requests库爬取比较困难。
这时候通过查阅资料,发现解决javascript动态生成页面信息爬取的方法有两种:(参考博客:)
1.1 使用dryscrape库动态抓取页面
Node.js 脚本通过浏览器执行并返回信息。所以js执行后抓取页面最直接的方法之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!ps:由于其底层操作逻辑(python调用webkit请求页面,页面加载后加载js文件,让js执行,返回执行的页面),实际过程比较慢。
import dryscrape
# 使用dryscrape库 动态抓取页面
def get_url_dynamic(url):
session_req=dryscrape.Session()
session_req.visit(url) #请求页面
response=session_req.body() #网页的文本
#print(response)
return response
get_text_line(get_url_dynamic(url)) #将输出一条文本
1.2 使用selenium完成动态页面的爬取
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
这也是作者之前大部分文章推荐的框架。所谓的“看到就爬”,可惜效率还是比后台请求的请求方式慢很多。如果可以结合Chrome浏览器的headless模式进行静默爬行,可以稍微提高效率。开启无头模式的代码示例:
from selenium import webdriver
option = webdriver.ChromeOptions()
option.add_argument(\'headless\')
driver = webdriver.Chrome(chrome_options=option)
driver.get(url) #访问网址
page_content=driver.page_source #获取js选然后的页面源码
上诉操作后,我们就可以得到页面最终的源码了。
但是在实际使用中,selenium 还是有一个问题,就是“可见就可以爬取”。在源码中可以清楚看到的一些页面元素。如果页面显示在前台,需要点击才能出现,我们还要模拟浏览器行为,使用click()方法点击获取相关节点的数据。喜欢:
如果页面停留在“基本信息”界面,如果要获取“审批信息”标签页的信息,则需要模拟点击“审批信息”,这会在一定程度上降低抓取效率。
此时建议直接使用 BeautifulSoup 包解析 html 文件,然后直接用通用正则表达式 RE 获取,尽量不要模拟浏览器不急的点击行为(除非页面源码有不存在,需要点击触发js动态返回信息条件)。
下面是结合源码和bs4(BeautifulSoup)的例子,在我的实际工作中重新表达爬取特定字段:
whole_text=driver.page_source #提取加载后的源码
soup=BeautifulSoup(whole_text,"lxml")
haf=str(soup.select(\'script\')[6]) #得到haf字段,再进行后续提取
flowHiComments=re.search(\'.*?flowHiComments\":(.*?),\"flowHiNodeIds.*?\',haf,re.S)
applyerId=soup.find(id="afPersonId")[\'value\'] #根据id查找
applyerName=re.search(\'.*?applyerName\":\"(.*?)\".*?\',haf,re.S).group(1) #根据re表达式的group方法提取字符串特定字段
flowHiComments=json.loads(flowHiComments.group(1)) #得到页面评论信息
with open(\'.\\CommentFlow\\%s_%s.txt\'%(bpmDefName,afFormNumber),\'w\',encoding="utf-8") as txt: #将flowHiComments保存为本地txt文件,并对文件进行格式化
json.dump(flowHiComments,txt,ensure_ascii = False,indent=4)
当你得到一个特定的字段时,你需要将信息一一存储。例如,将信息保存在本地 excel 文件中。这时候就需要用到openpyxl文件了。
openpyxl文件对excel新格式比较友好。在实际使用中还有一些需要注意的地方:
1.openpyxl 提供默认返回的excel最后一行(列)的索引号:
可以使用 ws.mas_row 和 ws.max_column 两个原生方法,但是如果我们想读取任何列的最后一行号怎么办?ws.max_row 不是那么灵活。
如果想把A列的所有元素都放到内存中,可以使用的示例代码如下:
name=[]
while True:
if sheet.cell(num,1).value ==None:
break
name.append(sheet.cell(num,1).value) #名称
num+=1
同理可以得到B列的值。
2. 我们习惯于使用 ws.append() 方法将数据按行追加到表中。根据实际测量,每次添加内容都是从第二行开始的(是否考虑第一行作为标题行),如果我们想让程序在执行过程中动态添加一个标题行呢?
笔者实测:
from openpyxl import load_workbook
wb= load_workbook(\'test2.xlsx\')
#wb.active =1
sheet=wb["Sheet1"]
row = [1 ,2, 3, 4, 5]
sheet.append(row)
wb.save(\'test2.xlsx\')
结果执行后,excel端生成的数据从第二行开始:
这显然有时不能满足我们的要求。如果要传递第一行的值,不建议使用原生的append方法。可行的建议如下:
navigation=[]
if ws.cell(1,1).value ==None:
navigation=["名称","单号","业务描述","申请者","申请者编号","代码","备注"]
for m in range(len(navigation)):
ws.cell(1,m+1).value=navigation[m]
当然,上面代码中导航列表的每个元素也可以传入爬虫抓取到的字段值(变量),非常灵活!
在爬取的过程中,我们总会遇到这样的问题。总结总结前人积累的经验尤为重要。避免重复坑!
动态网页抓取(就是动态网站爬取的思路与操作步骤(一)-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-13 20:16
导言
在日常爬行过程中,动态网站爬行更麻烦,因为动态网站数据是动态加载的。此时,我们需要使用selenium中间件来模拟操作并获取动态数据
开始创建项目
1.scrapy startproject Taobao
复制代码
2.cd Taobao
复制代码
3. scrapy genspider taobao www.taobao.com
复制代码
开放项目
首先,让我们不要爬行。首先,在设置中将爬虫规则设置为false
ROBOTSTXT_OBEY = False
复制代码
我们在终点站输入
scrapy view "http://www.taobao.com"
复制代码
此时,您将发现您爬网到的页面如下所示:
可以发现爬网的页面是一个没有数据的空帧。这个时候我该怎么办??我们将使用selenium中间件
让我们关注淘宝下载器中间件中的process_请求功能。让我们添加一行代码以查看效果:
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
print("------我是中间件,请求经过我------")
return None
复制代码
然后在会议中,删除以下评论
DOWNLOADER_MIDDLEWARES = {
'Taobao.middlewares.TaobaoDownloaderMiddleware': 543,
}
复制代码
让我们运行它以查看效果:
scrapy view "http://www.taobao.com"
复制代码
效果:
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to from
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
复制代码
结果表明,该中间件是有效的。如果我们在中间件中模拟一些操作,我们可以获得动态数据吗
中间件的操作
首次进口硒
from selenium import webdriver
#无界面运行
from selenium.webdriver.chrome.options import Options
复制代码
进程中\在请求函数中编写以下代码
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
print("------我是中间件,请求经过我------")
#设置无界面运行
option = Options()
option.add_argument("--headless")
#创建一个driver对象
#driver = webdriver.Chrome()
driver = webdriver.Chrome(chrome_options=option)
#等待15秒
driver.implicitly_wait(15)
driver.get(request.url)
# 让页面滚动最底层 模拟人的操作
js = 'window.scrollTo(0,document.body.scrollHeight)'
# 执行js
driver.execute_script(js)
# 获取内容
content = driver.page_source
from scrapy.http import HtmlResponse
# 创建一个resp对象返回至解析函数
resp = HtmlResponse(request.url,request=request,body=content,encoding='utf-8')
return resp
return None
复制代码
那么这个动态数据呢,这个时候已经得到了,在这里就不进行分析了。以上是动态网站爬行的思想 查看全部
动态网页抓取(就是动态网站爬取的思路与操作步骤(一)-苏州安嘉)
导言
在日常爬行过程中,动态网站爬行更麻烦,因为动态网站数据是动态加载的。此时,我们需要使用selenium中间件来模拟操作并获取动态数据
开始创建项目
1.scrapy startproject Taobao
复制代码
2.cd Taobao
复制代码
3. scrapy genspider taobao www.taobao.com
复制代码
开放项目
首先,让我们不要爬行。首先,在设置中将爬虫规则设置为false
ROBOTSTXT_OBEY = False
复制代码
我们在终点站输入
scrapy view "http://www.taobao.com"
复制代码
此时,您将发现您爬网到的页面如下所示:
可以发现爬网的页面是一个没有数据的空帧。这个时候我该怎么办??我们将使用selenium中间件
让我们关注淘宝下载器中间件中的process_请求功能。让我们添加一行代码以查看效果:
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
print("------我是中间件,请求经过我------")
return None
复制代码
然后在会议中,删除以下评论
DOWNLOADER_MIDDLEWARES = {
'Taobao.middlewares.TaobaoDownloaderMiddleware': 543,
}
复制代码
让我们运行它以查看效果:
scrapy view "http://www.taobao.com"
复制代码
效果:
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to from
------我是中间件,请求经过我------
2018-08-29 15:38:21 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
复制代码
结果表明,该中间件是有效的。如果我们在中间件中模拟一些操作,我们可以获得动态数据吗
中间件的操作
首次进口硒
from selenium import webdriver
#无界面运行
from selenium.webdriver.chrome.options import Options
复制代码
进程中\在请求函数中编写以下代码
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
print("------我是中间件,请求经过我------")
#设置无界面运行
option = Options()
option.add_argument("--headless")
#创建一个driver对象
#driver = webdriver.Chrome()
driver = webdriver.Chrome(chrome_options=option)
#等待15秒
driver.implicitly_wait(15)
driver.get(request.url)
# 让页面滚动最底层 模拟人的操作
js = 'window.scrollTo(0,document.body.scrollHeight)'
# 执行js
driver.execute_script(js)
# 获取内容
content = driver.page_source
from scrapy.http import HtmlResponse
# 创建一个resp对象返回至解析函数
resp = HtmlResponse(request.url,request=request,body=content,encoding='utf-8')
return resp
return None
复制代码
那么这个动态数据呢,这个时候已经得到了,在这里就不进行分析了。以上是动态网站爬行的思想
动态网页抓取( 爬取一个动态网页的数据(一):Selenium驱动 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-13 02:10
爬取一个动态网页的数据(一):Selenium驱动
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
(二)安装环境
1.安装依赖·
要开始使用 selenium,您需要安装一些依赖项
conda install selenium
1.安装驱动
使用selenium调用浏览器,还需要一个驱动,不同浏览器的webdriver需要单独安装
各浏览器下载地址:selenium官网驱动下载
火狐浏览器驱动:geckodriver
Chrome浏览器驱动:chromedriver、淘宝备用地址
IE浏览器驱动:IEDriverServer
Edge 浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:operadriver
PhantomJS 浏览器驱动:phantomjs
二、自动填写百度网页查询关键词,完成自动搜索
1.查看百度源码中搜索框的id和搜索按钮的id
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/")
如果正在运行,此时会打开百度的起始页
3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
5.最终效果
三、 抓取动态网页的数据(一)网站 链接
(二)分析网页
1. 抓取网页元素
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。并且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
(3)网站页面
点击Nest,可以发现有10页网站
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/")
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的抓取结果
表中有100条信息
四、爬取京东感兴趣的书籍信息网站(一)爬取网站
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
2.图书展示列表,J_goodsList下
3.标签一一对应
每本书都有一个li标签
有很多 li 标签
4.li中的具体内容
(1)价格
(2)书名
(3)按
查看全部
动态网页抓取(
爬取一个动态网页的数据(一):Selenium驱动
)
Python+Selenium 动态网页信息抓取
一、Selenium (一)Selenium 介绍
Selenium 是一个 Web 自动化测试工具。它最初是为 网站 自动化测试而开发的。类型就像我们用来玩游戏的按钮向导。可根据指定指令自动运行。不同的是,Selenium 可以直接在浏览器中运行。它支持所有主流浏览器(包括 PhantomJS 等非接口浏览器)。
Selenium 可以让浏览器根据我们的指令自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,不支持浏览器的功能。需要配合第三方浏览器使用。但是我们有时需要让它嵌入到代码中运行,所以我们可以使用一个叫做 PhantomJS 的工具来代替真正的浏览器。
(二)安装环境
1.安装依赖·
要开始使用 selenium,您需要安装一些依赖项
conda install selenium
1.安装驱动
使用selenium调用浏览器,还需要一个驱动,不同浏览器的webdriver需要单独安装
各浏览器下载地址:selenium官网驱动下载
火狐浏览器驱动:geckodriver
Chrome浏览器驱动:chromedriver、淘宝备用地址
IE浏览器驱动:IEDriverServer
Edge 浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:operadriver
PhantomJS 浏览器驱动:phantomjs
二、自动填写百度网页查询关键词,完成自动搜索
1.查看百度源码中搜索框的id和搜索按钮的id
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/";)
如果正在运行,此时会打开百度的起始页
3.填写搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
4.模拟点击
使用另一个输入,即按钮的点击事件;或者表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
5.最终效果
三、 抓取动态网页的数据(一)网站 链接
(二)分析网页
1. 抓取网页元素
2.按钮属性
爬取一个页面后,需要翻页,即点击页面按钮。
可以发现Next按钮只有href属性,无法定位。并且第一页只有下一页按钮,后面的页面有上一页和下一页按钮,xpath无法定位,其子元素span(即箭头)在属性aria-hidden中第一页它是独一无二的。aria-hidden 属性存在于后续页面中,但 Next 的箭头始终是最后一个。
因此,您可以通过找到最后一个带有 aria-hidden 属性的 span 标签来点击跳转到下一页:
(3)网站页面
点击Nest,可以发现有10页网站
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/";)
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
2.保存的抓取结果
表中有100条信息
四、爬取京东感兴趣的书籍信息网站(一)爬取网站
京东:
(二)网络分析
1.查看网站首页、输入框和搜索按钮
2.图书展示列表,J_goodsList下
3.标签一一对应
每本书都有一个li标签
有很多 li 标签
4.li中的具体内容
(1)价格
(2)书名
(3)按
动态网页抓取(什么是动态网页爬取的响应信息?寻找我们想要的结果 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-10 06:05
)
上一篇文章简单介绍了静态网页的爬取,今天给大家分享一些动态网页爬取的技巧。什么是动态网页?举个很常见的例子,当我们在浏览网站的时候,随着我们不断向下滑动网页,当前页面会不断刷新新的内容,但是浏览器地址栏上的URL却一直没有改变。这种由JavaScript动态生成的页面,当我们通过浏览器查看其网页源代码时,往往找不到页面显示的内容。
抓取动态页面有两种常用的方法。一是通过JavaScript逆向获取动态数据接口(真实访问路径),二是使用selenium库模拟真实浏览器获取JavaScript渲染的内容。但是selenium库使用起来比较麻烦,爬取速度也比较慢,所以日常用的比较多的是第一种方法。
在做JS反向转发之前,首先要学会使用浏览器抓包。以Chrome浏览器为例打开网易新闻首页
右键查看网页源代码与按F12打开开发者工具看到的源代码不同,当我们下拉页面时,开发者工具中的源代码还在不断增加。这是JS渲染后的源码。也是当前网站显示内容的源码。
如上图所示,Network选项卡主要用于抓包的时候。按F5刷新页面后,下方显示框中会出现很多包。我们可以使用上面的过滤器栏对这些包进行分类。
这里主要使用XHR和JS两种。比如选择XHR,点击过滤后的第一个包。显示界面如下,右侧会出现一排选项卡。Headers 收录当前包的请求消息头和响应消息头。; Preview是响应消息的预览,Response是服务器响应的代码。
了解了这些之后,我们依次点击XHR和JS下的所有包,通过Preview预览当前包的响应信息,找到我们想要的结果。比如我们在下面的包中找到了文章列表,通过Headers找到了Request URL。这是我们真正应该请求的路径。
滚动页面的时候发现JS下添加了如下包和新的Request URL。与之前的相比,很容易找到一个通用的URL。分析完这个,我们就可以开始写代码了。
直接编码
import requests
from bs4 import BeautifulSoup
import json
import re
import multiprocessing
import xlwt
import time
def netease_spider(headers, news_class, i):
if i == 1:
url = "https://temp.163.com/special/00804KVA/cm_{0}.js?callback=data_callback".format(news_class)
else:
url = 'https://temp.163.com/special/00804KVA/cm_{0}_0{1}.js?callback=data_callback'.format(news_class, str(i))
pages = []
try:
response = requests.get(url, headers=headers).text
except:
print("当前主页面爬取失败")
return
start = response.index('[')
end = response.index('])') + 1
data = json.loads(response[start:end])
try:
for item in data:
title = item['title']
docurl = item['docurl']
label = item['label']
source = item['source']
doc = requests.get(docurl, headers=headers).text
soup = BeautifulSoup(doc, 'lxml')
news = soup.find_all('div', class_='post_body')[0].text
news = re.sub('\s+', '', news).strip()
pages.append([title, label, source, news])
time.sleep(3)
except:
print("当前详情页面爬取失败")
pass
return pages
def run(news_class, nums):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36'}
tmp_result = []
for i in range(1, nums + 1):
tmp = netease_spider(headers, news_class, i)
if tmp:
tmp_result.append(tmp)
return tmp_result
if __name__ == '__main__':
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('网易新闻数据')
sheet.write(0, 0, '文章标题')
sheet.write(0, 1, '文章标签')
sheet.write(0, 2, '文章来源')
sheet.write(0, 3, '文章内容')
news_calsses = {'guonei', 'guoji'}
nums = 3
index = 1
pool = multiprocessing.Pool(30)
for news_class in news_calsses:
result = pool.apply_async(run, (news_class, nums))
for pages in result.get():
for page in pages:
if page:
title, label, source, news = page
sheet.write(index, 0, title)
sheet.write(index, 1, label)
sheet.write(index, 2, source)
sheet.write(index, 3, news)
index += 1
pool.close()
pool.join()
print("共爬取{0}篇新闻".format(index))
book.save(u"网易新闻爬虫结果.xls")
这里我们抓取了国内和国际版块,在每个版块方向滚动了所有文章 3次,通过文章详情页上的链接爬取了文章的内容,最后爬上了到 289 文章。
需要注意的是,过快的抓取频率会导致访问失败。建议每次都睡一会。此外,增加个人测试中的线程数也很有用。如果可能,您可以添加一个 ip 代理池。我以前用过免费ip。基本上可以使用的ip很少,所以还是要付费的。所有代码和数据已经上传到github,链接在GitHub
本文与微信公众号“NLP炼金术士”同步,感兴趣的同学可以扫码关注,获取更多内容。
查看全部
动态网页抓取(什么是动态网页爬取的响应信息?寻找我们想要的结果
)
上一篇文章简单介绍了静态网页的爬取,今天给大家分享一些动态网页爬取的技巧。什么是动态网页?举个很常见的例子,当我们在浏览网站的时候,随着我们不断向下滑动网页,当前页面会不断刷新新的内容,但是浏览器地址栏上的URL却一直没有改变。这种由JavaScript动态生成的页面,当我们通过浏览器查看其网页源代码时,往往找不到页面显示的内容。
抓取动态页面有两种常用的方法。一是通过JavaScript逆向获取动态数据接口(真实访问路径),二是使用selenium库模拟真实浏览器获取JavaScript渲染的内容。但是selenium库使用起来比较麻烦,爬取速度也比较慢,所以日常用的比较多的是第一种方法。
在做JS反向转发之前,首先要学会使用浏览器抓包。以Chrome浏览器为例打开网易新闻首页
右键查看网页源代码与按F12打开开发者工具看到的源代码不同,当我们下拉页面时,开发者工具中的源代码还在不断增加。这是JS渲染后的源码。也是当前网站显示内容的源码。
如上图所示,Network选项卡主要用于抓包的时候。按F5刷新页面后,下方显示框中会出现很多包。我们可以使用上面的过滤器栏对这些包进行分类。
这里主要使用XHR和JS两种。比如选择XHR,点击过滤后的第一个包。显示界面如下,右侧会出现一排选项卡。Headers 收录当前包的请求消息头和响应消息头。; Preview是响应消息的预览,Response是服务器响应的代码。
了解了这些之后,我们依次点击XHR和JS下的所有包,通过Preview预览当前包的响应信息,找到我们想要的结果。比如我们在下面的包中找到了文章列表,通过Headers找到了Request URL。这是我们真正应该请求的路径。
滚动页面的时候发现JS下添加了如下包和新的Request URL。与之前的相比,很容易找到一个通用的URL。分析完这个,我们就可以开始写代码了。
直接编码
import requests
from bs4 import BeautifulSoup
import json
import re
import multiprocessing
import xlwt
import time
def netease_spider(headers, news_class, i):
if i == 1:
url = "https://temp.163.com/special/00804KVA/cm_{0}.js?callback=data_callback".format(news_class)
else:
url = 'https://temp.163.com/special/00804KVA/cm_{0}_0{1}.js?callback=data_callback'.format(news_class, str(i))
pages = []
try:
response = requests.get(url, headers=headers).text
except:
print("当前主页面爬取失败")
return
start = response.index('[')
end = response.index('])') + 1
data = json.loads(response[start:end])
try:
for item in data:
title = item['title']
docurl = item['docurl']
label = item['label']
source = item['source']
doc = requests.get(docurl, headers=headers).text
soup = BeautifulSoup(doc, 'lxml')
news = soup.find_all('div', class_='post_body')[0].text
news = re.sub('\s+', '', news).strip()
pages.append([title, label, source, news])
time.sleep(3)
except:
print("当前详情页面爬取失败")
pass
return pages
def run(news_class, nums):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36'}
tmp_result = []
for i in range(1, nums + 1):
tmp = netease_spider(headers, news_class, i)
if tmp:
tmp_result.append(tmp)
return tmp_result
if __name__ == '__main__':
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('网易新闻数据')
sheet.write(0, 0, '文章标题')
sheet.write(0, 1, '文章标签')
sheet.write(0, 2, '文章来源')
sheet.write(0, 3, '文章内容')
news_calsses = {'guonei', 'guoji'}
nums = 3
index = 1
pool = multiprocessing.Pool(30)
for news_class in news_calsses:
result = pool.apply_async(run, (news_class, nums))
for pages in result.get():
for page in pages:
if page:
title, label, source, news = page
sheet.write(index, 0, title)
sheet.write(index, 1, label)
sheet.write(index, 2, source)
sheet.write(index, 3, news)
index += 1
pool.close()
pool.join()
print("共爬取{0}篇新闻".format(index))
book.save(u"网易新闻爬虫结果.xls")
这里我们抓取了国内和国际版块,在每个版块方向滚动了所有文章 3次,通过文章详情页上的链接爬取了文章的内容,最后爬上了到 289 文章。
需要注意的是,过快的抓取频率会导致访问失败。建议每次都睡一会。此外,增加个人测试中的线程数也很有用。如果可能,您可以添加一个 ip 代理池。我以前用过免费ip。基本上可以使用的ip很少,所以还是要付费的。所有代码和数据已经上传到github,链接在GitHub
本文与微信公众号“NLP炼金术士”同步,感兴趣的同学可以扫码关注,获取更多内容。
动态网页抓取(BeyondCompare分析动态网页的分析及应用方法分析方法解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-10 06:03
一、分析动态网页
1、分析工具
使用 Beyond Compare 分析网页是否收录动态部分。
2、直接python分析判断
找到需要锁定的内容,按照常规方式爬取测试。如果不能爬取,就应该考虑是否有动态网页!!
二、常见解决方案
1、找到JS文件
之前我已经掌握了一个解决方法,就是找到动态网页的js文件,很简单,但是美中不足的是找到加载的js文件,找到这些动态网页的规则。这里我们需要依靠人工搜索。
推荐教程:Python爬取js动态页面
2、python 网络引擎
安装:
selenium的安装很简单:
pip 安装硒
phantomjs的安装有点复杂:
首先下载安装nodejs,很简单。
如需使用浏览器显示,请安装相应的浏览器驱动:
查看 chromedriver 教程
Selenium + chrome/phantomjs 教程
直接代码,代码里有详细的解释,后面不解释的文章后面会给出解释:
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import pymongo
client = pymongo.MongoClient('localhost')
db = client['tbmeishi']
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
driver.set_window_size(1280,2400) #当无浏览器界面时必须设置窗口大小
#driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
def search():
try:
driver.get('https://www.taobao.com/') #加载淘宝首页
#等待页面加载出输入框
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
#等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")))
input.send_keys('美食') #向输入框中输入‘美食’关键字
submit.click() #点击搜索按钮
#等待页面加载完
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
#第一页加载完后,获取第一页信息
get_products()
return total.text
except TimeoutException:
return search()
def next_page(page_number):
try:
# 等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.next > a")))
submit.click() # 点击确定按钮
#判断当前页面是否为输入页面
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number)))
#第i页加载完后,获取页面信息
get_products()
except TimeoutException:
return next_page(page_number)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
#save_to_mongo(product)
def save_to_mongo(result):
try:
if db['product'].insert(result):
print('存储到MONGODB成功', result)
except Exception:
print('存储到MONGODB失败', result)
def main():
try:
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
print('第 %d 页'%i)
next_page(i)
except Exception as e:
print('error!!!',e)
finally:
driver.close()
if __name__ == '__main__':
main()
做selenium的时候最好参考一下,里面有很多用法。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
使用无界面操作时,一定要注意设置窗口大小,尽量设置的大一些。如果这个尺寸设置的比较小,一定不能用JavaScript的scroll命令来模拟页面向下滑动显示更多内容的效果,所以设置一个更大的窗口来渲染
driver.set_window_size(1280,2400)
Selenium 实现了一些类似于xpath的功能,可以使用驱动直接获取我们想要的元素,直接调用如下方法:
但是这个方法太慢了,我们一般不使用。而是驱动直接获取网页源码:html = driver.page_source,然后使用lxml + xpath或者BeautifulSoup解析;
另外,还可以使用另一种方法来解析:pyquery
参考这两篇博文:
下面的代码是使用pyquery方法解析的,真的很简单。
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
Selenium 还包括很多方法:
注意:
操作结束后,必须调用driver.close()或driver.quit()退出phantomjs,否则phantomjs会一直占用内存资源。
推荐使用 driver.service.process.send_signal(signal.SIGTERM)
可以强制杀,Windows下百度
在 Linux 下:
ps辅助| grep phantomjs #查看phantomjs进程
pgrep phantomjs | xargs kill #kill 所有 phantomjs
PhantomJS 配置
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
--ignore-ssl-errors = [true|false]#是否检查CA证书和安全
--load-images = [true|false]#是否加载图片,一般不加载,节省时间
--disk-cache = [true|false]#是否缓存
最后总结一下,常规的爬虫方法比较容易操作,尤其是在使用selenium的一些方法的时候,初学者觉得很吃力;而且selenium+phantomjs的方法会比较慢,应该相当于一个人在访问网页,会需要等待加载时间,而常规的爬取方式是直接取网页代码,会快点。当然,有时候selenium+phantomjs会简单很多。伪装成一个人访问,反爬虫不容易找到。此外,一些网页有陷阱。传统的方法会很麻烦。对于慢的问题,可以使用多线程来解决。
总而言之,逐案!!!! 查看全部
动态网页抓取(BeyondCompare分析动态网页的分析及应用方法分析方法解析)
一、分析动态网页
1、分析工具
使用 Beyond Compare 分析网页是否收录动态部分。
2、直接python分析判断
找到需要锁定的内容,按照常规方式爬取测试。如果不能爬取,就应该考虑是否有动态网页!!
二、常见解决方案
1、找到JS文件
之前我已经掌握了一个解决方法,就是找到动态网页的js文件,很简单,但是美中不足的是找到加载的js文件,找到这些动态网页的规则。这里我们需要依靠人工搜索。
推荐教程:Python爬取js动态页面
2、python 网络引擎
安装:
selenium的安装很简单:
pip 安装硒
phantomjs的安装有点复杂:
首先下载安装nodejs,很简单。
如需使用浏览器显示,请安装相应的浏览器驱动:
查看 chromedriver 教程
Selenium + chrome/phantomjs 教程
直接代码,代码里有详细的解释,后面不解释的文章后面会给出解释:
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import pymongo
client = pymongo.MongoClient('localhost')
db = client['tbmeishi']
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
driver.set_window_size(1280,2400) #当无浏览器界面时必须设置窗口大小
#driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
def search():
try:
driver.get('https://www.taobao.com/') #加载淘宝首页
#等待页面加载出输入框
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
#等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")))
input.send_keys('美食') #向输入框中输入‘美食’关键字
submit.click() #点击搜索按钮
#等待页面加载完
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
#第一页加载完后,获取第一页信息
get_products()
return total.text
except TimeoutException:
return search()
def next_page(page_number):
try:
# 等待页面出现搜索按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.next > a")))
submit.click() # 点击确定按钮
#判断当前页面是否为输入页面
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'), str(page_number)))
#第i页加载完后,获取页面信息
get_products()
except TimeoutException:
return next_page(page_number)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
#save_to_mongo(product)
def save_to_mongo(result):
try:
if db['product'].insert(result):
print('存储到MONGODB成功', result)
except Exception:
print('存储到MONGODB失败', result)
def main():
try:
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
print('第 %d 页'%i)
next_page(i)
except Exception as e:
print('error!!!',e)
finally:
driver.close()
if __name__ == '__main__':
main()
做selenium的时候最好参考一下,里面有很多用法。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
使用无界面操作时,一定要注意设置窗口大小,尽量设置的大一些。如果这个尺寸设置的比较小,一定不能用JavaScript的scroll命令来模拟页面向下滑动显示更多内容的效果,所以设置一个更大的窗口来渲染
driver.set_window_size(1280,2400)
Selenium 实现了一些类似于xpath的功能,可以使用驱动直接获取我们想要的元素,直接调用如下方法:
但是这个方法太慢了,我们一般不使用。而是驱动直接获取网页源码:html = driver.page_source,然后使用lxml + xpath或者BeautifulSoup解析;
另外,还可以使用另一种方法来解析:pyquery
参考这两篇博文:
下面的代码是使用pyquery方法解析的,真的很简单。
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = driver.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
Selenium 还包括很多方法:
注意:
操作结束后,必须调用driver.close()或driver.quit()退出phantomjs,否则phantomjs会一直占用内存资源。
推荐使用 driver.service.process.send_signal(signal.SIGTERM)
可以强制杀,Windows下百度
在 Linux 下:
ps辅助| grep phantomjs #查看phantomjs进程
pgrep phantomjs | xargs kill #kill 所有 phantomjs
PhantomJS 配置
driver = webdriver.PhantomJS(service_args=['--ignore-ssl-errors=true','--load-images=false','--disk-cache=true'])
--ignore-ssl-errors = [true|false]#是否检查CA证书和安全
--load-images = [true|false]#是否加载图片,一般不加载,节省时间
--disk-cache = [true|false]#是否缓存
最后总结一下,常规的爬虫方法比较容易操作,尤其是在使用selenium的一些方法的时候,初学者觉得很吃力;而且selenium+phantomjs的方法会比较慢,应该相当于一个人在访问网页,会需要等待加载时间,而常规的爬取方式是直接取网页代码,会快点。当然,有时候selenium+phantomjs会简单很多。伪装成一个人访问,反爬虫不容易找到。此外,一些网页有陷阱。传统的方法会很麻烦。对于慢的问题,可以使用多线程来解决。
总而言之,逐案!!!!

