
js抓取网页内容
js抓取网页内容(SCRAPY学习笔记八反反爬虫技术项目实战只好V*代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-29 14:26
SCRAPY学习笔记八项反爬虫技术项目实战
我不得不V**代理,) 2:减少单个IP和设置用户的请求次数,降低单个进程的爬行速度,增加scrapy进程以提高效率。3:302跳转,scrapy本身可以辅助跳转,但是由于js检测,跳转到js警告页面。明确大体方案后,再考虑行动的过程:最大的难点不是你要抓取什么内容,而是爬虫访问时不会返回正确的信息,所以只需要测试一下就可以拿到200返回成功。在 test 阶段,可以先忽略 12 项,先实现获取。所谓cookies是指为了识别用户身份而存储在用户本地终端(Client Side)上的某些网站数据(通常是加密的)。禁止 cookie 还可以防止使用 cookie 来识别爬虫轨迹。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”改成proxy for ip,虽然不够稳定,但是数量大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。
469 查看全部
js抓取网页内容(SCRAPY学习笔记八反反爬虫技术项目实战只好V*代理)
SCRAPY学习笔记八项反爬虫技术项目实战
我不得不V**代理,) 2:减少单个IP和设置用户的请求次数,降低单个进程的爬行速度,增加scrapy进程以提高效率。3:302跳转,scrapy本身可以辅助跳转,但是由于js检测,跳转到js警告页面。明确大体方案后,再考虑行动的过程:最大的难点不是你要抓取什么内容,而是爬虫访问时不会返回正确的信息,所以只需要测试一下就可以拿到200返回成功。在 test 阶段,可以先忽略 12 项,先实现获取。所谓cookies是指为了识别用户身份而存储在用户本地终端(Client Side)上的某些网站数据(通常是加密的)。禁止 cookie 还可以防止使用 cookie 来识别爬虫轨迹。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”改成proxy for ip,虽然不够稳定,但是数量大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。
469
js抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-29 06:19
)
在上一篇文章()中,我们使用了模拟打开浏览器的方法来模拟点击网页中的Load More来动态加载网页并获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻男孩的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
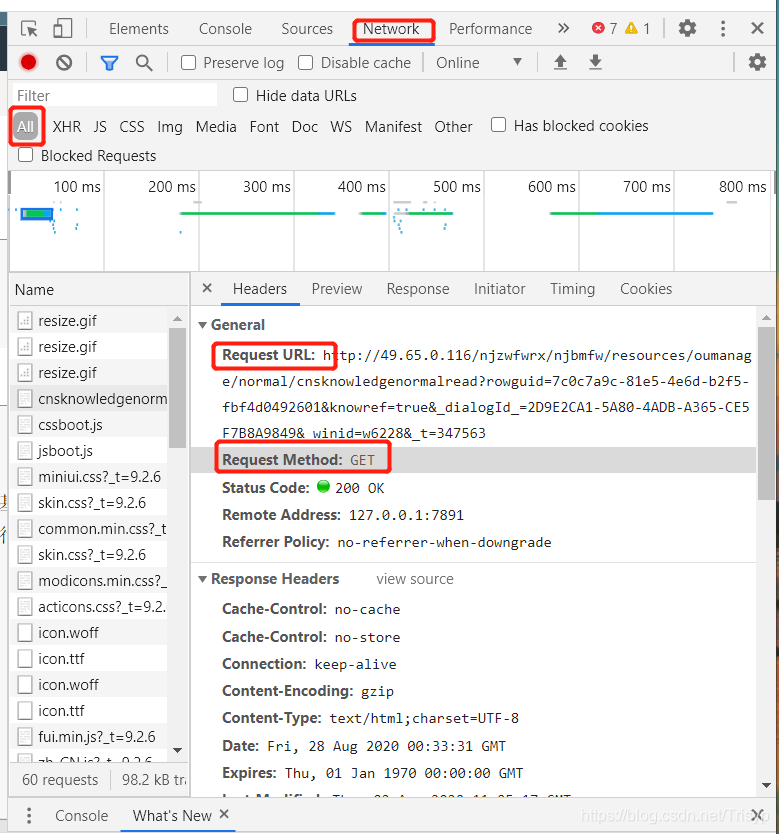
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片,gifs,css等,如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标题
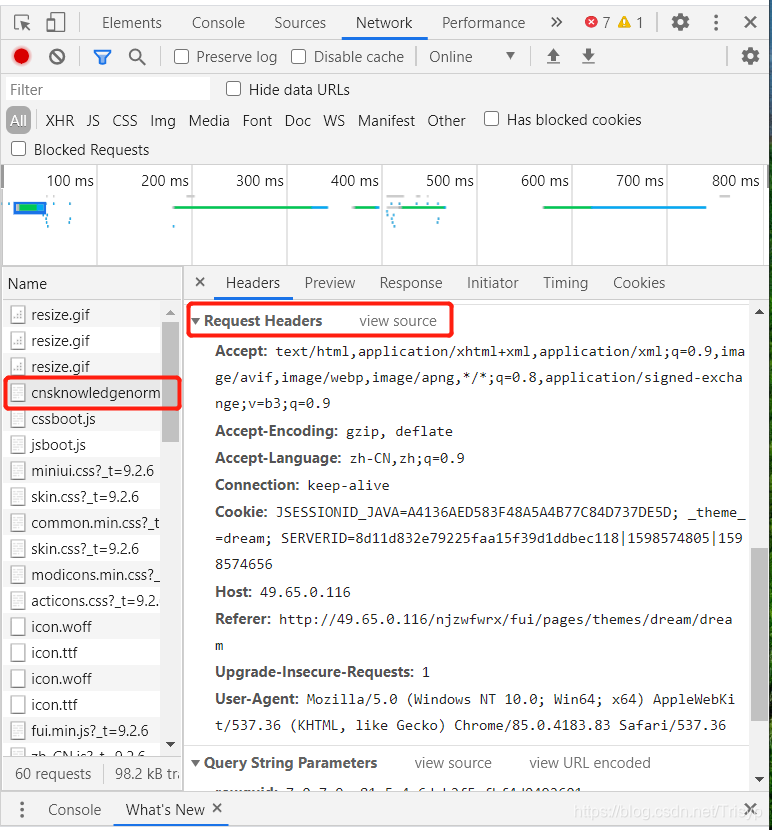
请求的 URL 通常很长。比如上图的URL地址是:
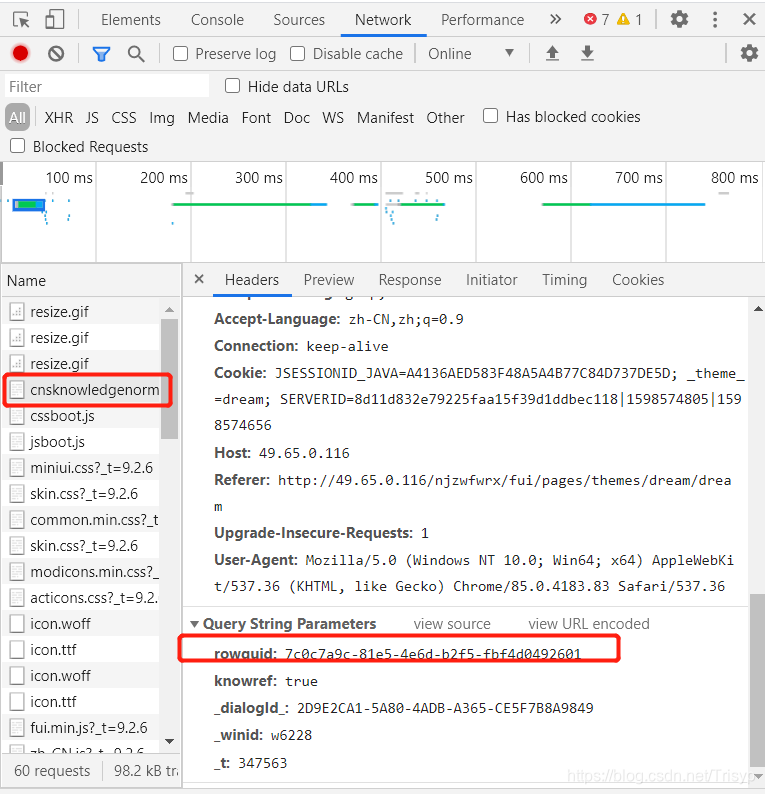
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
查看全部
js抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有
)
在上一篇文章()中,我们使用了模拟打开浏览器的方法来模拟点击网页中的Load More来动态加载网页并获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻男孩的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片,gifs,css等,如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标题
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
js抓取网页内容(通过利用selenium的子模块解决动态数据的html内容的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-26 17:09
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name(\'kw\'\')
按类名定位,lis=find_elements_by_class_name(\'title_1\')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
js抓取网页内容(通过利用selenium的子模块解决动态数据的html内容的方式)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name(\'kw\'\')
按类名定位,lis=find_elements_by_class_name(\'title_1\')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
js抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-26 04:28
本文章介绍的内容是关于js获取网页数据并以Excel格式存储。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
我在做项目的时候,遇到了把表格数据以Excel格式存储在网页中的问题。我将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i 查看全部
js抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
本文章介绍的内容是关于js获取网页数据并以Excel格式存储。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
我在做项目的时候,遇到了把表格数据以Excel格式存储在网页中的问题。我将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i
js抓取网页内容(用“黑帽SEO”方法去堆积关键词,如何挖掘? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-21 22:32
)
使用“黑帽SEO”方式积累关键词。
四、 关键词出现的频率
关键词的出现频率是指这个关键词在这个网页上实际出现的次数。在百度更新算法之前,百度会关注关键词的出现频率,但只有从关键词积累的作弊方式出现解决方案
确定方法后,算法对关键词的出现频率有了新的算法。我们在写文章的时候一定要注意关键词的出现频率,一定要让关键词显得合理。
如何优化seo关键词1、Long Tail关键词 排名优化:一是长尾关键词挖掘。上面的就不细说了,再过滤。毕竟,一页的空间是非常有限的。一般使用两到三个长尾关键词。这些长尾关键词 是最好的相关或同义词。内容页的关键词做“四个地方”就够了(“测验”这个词可以点击百度),但不要机械地使用它,聪明的人出现在正确的地方。切记不要堆积太多,否则得不偿失。
2、主关键词的优化:指的是我们的网站内部链优化,我们可以在文章中适当的词中添加说明文字,如“搜外@ >SEO教程》,我们可以给这个词添加目录页的链接,起到推荐的作用。我们必须记住,有用的建议会增加权重。如果我在这里添加“boost”二字的描述,不仅不会生效,还会影响用户体验。任何对用户体验无效或适得其反的操作都不符合SEO优化。
3、数据分析:总结是我们做任何事情的必要步骤,数据分析是我们SEO工作的总结阶段,页面收录情况,长尾词排名,页面流量,页面停留时间、页面跳出率、长尾词内外链、关键词比例等都需要统计分析。
网站seo优化关键词如何挖矿?
很多企业在经营过程中都没有忽视各类宣传手段。合理的营销会给公司带来巨大的广告收入。其次,它还可以增加产品的销售数量,可以显示出很多好处,再加上现在互联网发展很快。利用互联网还可以用于网络营销推广,效率也提高了很多,能做的事情也丰富了。seo关键词排名优化是网络营销手段之一,那么seo关键词排名优化的目的,有哪些内容?
1、关键词的优化目的
很多公司关注seo关键词排名优化操作。该技术目前在中国广泛应用。优化的时候需要借助关键词的辅助,所以seo关键词排名优化也是营销手段之一。选择关键词优化的主要目的其实很简单,就是可以直接给宣传的网站,吸引更多人点击使用,增加网站流量,效果的宣传。
2、选择合适的关键词
seo关键词 排名的优化不是随意做的。在seo关键词排名优化的过程中,一定要注意关键词的选择,选择时一定要注意网站@。进行>的定位和样式,同时进行分词的操作。使用后可以有效的对关键词进行拆分和组合。这样可以保证seo关键词排名优化的顺利进行,让分词被大众搜索,想到关键词,最后突出网站。
3、控制关键词的数量
目前对网站进行seo关键词排名优化属于正常行为。在seo关键词排名优化的过程中,一定要控制好关键词的量词。这是最关键的一点。关键词 的数量将决定搜索引擎的抓取速度。因此,必须合理控制关键词的数量,并与搜索引擎的抓取相匹配。速度最合适。
以上就是seo关键词排名优化的目的和作用的解答。在进行seo关键词排名优化时,也有很多需要注意的问题。这点千万不能忽视,否则容易影响使用次数和安全性。
查看全部
js抓取网页内容(用“黑帽SEO”方法去堆积关键词,如何挖掘?
)
使用“黑帽SEO”方式积累关键词。
四、 关键词出现的频率
关键词的出现频率是指这个关键词在这个网页上实际出现的次数。在百度更新算法之前,百度会关注关键词的出现频率,但只有从关键词积累的作弊方式出现解决方案
确定方法后,算法对关键词的出现频率有了新的算法。我们在写文章的时候一定要注意关键词的出现频率,一定要让关键词显得合理。

如何优化seo关键词1、Long Tail关键词 排名优化:一是长尾关键词挖掘。上面的就不细说了,再过滤。毕竟,一页的空间是非常有限的。一般使用两到三个长尾关键词。这些长尾关键词 是最好的相关或同义词。内容页的关键词做“四个地方”就够了(“测验”这个词可以点击百度),但不要机械地使用它,聪明的人出现在正确的地方。切记不要堆积太多,否则得不偿失。
2、主关键词的优化:指的是我们的网站内部链优化,我们可以在文章中适当的词中添加说明文字,如“搜外@ >SEO教程》,我们可以给这个词添加目录页的链接,起到推荐的作用。我们必须记住,有用的建议会增加权重。如果我在这里添加“boost”二字的描述,不仅不会生效,还会影响用户体验。任何对用户体验无效或适得其反的操作都不符合SEO优化。
3、数据分析:总结是我们做任何事情的必要步骤,数据分析是我们SEO工作的总结阶段,页面收录情况,长尾词排名,页面流量,页面停留时间、页面跳出率、长尾词内外链、关键词比例等都需要统计分析。

网站seo优化关键词如何挖矿?
很多企业在经营过程中都没有忽视各类宣传手段。合理的营销会给公司带来巨大的广告收入。其次,它还可以增加产品的销售数量,可以显示出很多好处,再加上现在互联网发展很快。利用互联网还可以用于网络营销推广,效率也提高了很多,能做的事情也丰富了。seo关键词排名优化是网络营销手段之一,那么seo关键词排名优化的目的,有哪些内容?
1、关键词的优化目的
很多公司关注seo关键词排名优化操作。该技术目前在中国广泛应用。优化的时候需要借助关键词的辅助,所以seo关键词排名优化也是营销手段之一。选择关键词优化的主要目的其实很简单,就是可以直接给宣传的网站,吸引更多人点击使用,增加网站流量,效果的宣传。
2、选择合适的关键词
seo关键词 排名的优化不是随意做的。在seo关键词排名优化的过程中,一定要注意关键词的选择,选择时一定要注意网站@。进行>的定位和样式,同时进行分词的操作。使用后可以有效的对关键词进行拆分和组合。这样可以保证seo关键词排名优化的顺利进行,让分词被大众搜索,想到关键词,最后突出网站。
3、控制关键词的数量
目前对网站进行seo关键词排名优化属于正常行为。在seo关键词排名优化的过程中,一定要控制好关键词的量词。这是最关键的一点。关键词 的数量将决定搜索引擎的抓取速度。因此,必须合理控制关键词的数量,并与搜索引擎的抓取相匹配。速度最合适。
以上就是seo关键词排名优化的目的和作用的解答。在进行seo关键词排名优化时,也有很多需要注意的问题。这点千万不能忽视,否则容易影响使用次数和安全性。

js抓取网页内容(按照统一资源标准协议(url)中的资源的顺序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 06:03
js抓取网页内容本质上,抓取js主要是抓网页内容的结构,网页中一般是meta信息,如页面定位ip是否处于本地,为什么打不开,主要是因为http协议不允许存在超链接,不能包含单个meta信息。其次就是ajax技术的应用,页面定位加载不了,ajax就能够加载,所以抓取了内容也是能够显示的,具体html怎么抓取,可以查看搜集寻宝链接网站,相关资料会有很多。
加ajax代码,就能获取网页内容了,以前的content-loaded会限制你网页内容显示,现在的,在text-loaded方法里面的dom就会根据url进行抓取,
ajax解析网页同样可以获取网页内容,你搜索“what'syourname”,然后在新的页面里输入“yoyoyohh”,
what'syourname:这段js里面包含:一个model,这个model主要是用于做一些效果js调用或者数据提取cookie怎么用的:这里,这里可以存放返回的信息token对外暴露:存取到数据库当然可以全文提取:ajax(asynchronousjavascriptandxml)异步javascript和xml,本质是模拟http请求,用户点击提交会以socket方式传回一个消息。
按照统一资源标准协议(url)中的资源的排布顺序,这些响应有序的组合在一起。这些可以被接收、使用、提取,甚至嵌入到网页中。在这样的情况下,用户不用浏览器就可以通过访问web服务器直接了解他们所需要的信息。 查看全部
js抓取网页内容(按照统一资源标准协议(url)中的资源的顺序)
js抓取网页内容本质上,抓取js主要是抓网页内容的结构,网页中一般是meta信息,如页面定位ip是否处于本地,为什么打不开,主要是因为http协议不允许存在超链接,不能包含单个meta信息。其次就是ajax技术的应用,页面定位加载不了,ajax就能够加载,所以抓取了内容也是能够显示的,具体html怎么抓取,可以查看搜集寻宝链接网站,相关资料会有很多。
加ajax代码,就能获取网页内容了,以前的content-loaded会限制你网页内容显示,现在的,在text-loaded方法里面的dom就会根据url进行抓取,
ajax解析网页同样可以获取网页内容,你搜索“what'syourname”,然后在新的页面里输入“yoyoyohh”,
what'syourname:这段js里面包含:一个model,这个model主要是用于做一些效果js调用或者数据提取cookie怎么用的:这里,这里可以存放返回的信息token对外暴露:存取到数据库当然可以全文提取:ajax(asynchronousjavascriptandxml)异步javascript和xml,本质是模拟http请求,用户点击提交会以socket方式传回一个消息。
按照统一资源标准协议(url)中的资源的排布顺序,这些响应有序的组合在一起。这些可以被接收、使用、提取,甚至嵌入到网页中。在这样的情况下,用户不用浏览器就可以通过访问web服务器直接了解他们所需要的信息。
js抓取网页内容(网页里注释的内容会被百度注释分析吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-19 00:04
很多站长都知道,网页代码中有评论代码。形式是HTML中的注释内容出现在网页的源代码中,用户在浏览网页时看不到。因为源码中显示的注解内容不会影响页面的内容,很多人认为蜘蛛会抓取注解信息参与网页的分析和排名,所以添加了大量的注解内容到网页,甚至直接堆在注解关键词中。
网页中的注解内容会被抓取吗?我们来看看百度工程师是如何回答的:
Q:评论内容会被百度抓取分析吗?
百度工程师:在文本提取过程中会忽略html中的注释内容。注释的代码虽然不会被爬取,但也会造成代码的繁琐,所以可以尽量少。
显然,搜索引擎蜘蛛非常聪明。他们可以在网络爬行过程中识别注释信息并直接忽略它们。因此,注释内容不会被抓取,也不会参与网页内容的分析。试想如果蜘蛛可以抓取评论,而这个评论代码就相当于一种隐藏的文字,那么网站的主要内容可以被JS代码调用,仅供用户浏览,而蜘蛛抓取的内容想要抓取的就是全部 把它放在大量的注释信息中,让网页给蜘蛛和用户展示不同的内容。如果你是灰色行业网站,那么你可以给搜索引擎一个完全正规的内容展示,摆脱搜索引擎的束缚,搜索引擎会不会正式允许你作弊?所以不管有多少关键词
那么,在评论中添加关键词会影响排名吗?不会是因为搜索引擎直接忽略了注释,而是如何注释大量内容会影响网页的风格,影响网页的加载速度。因此,如果注释没有用,请尝试删除它们并尽可能保持代码简单。我们经常讲网站代码减肥。简化标注信息是减肥的方法之一。优化注解信息有利于网站瘦身。
当然,很多程序员和网页设计师都习惯于在网页中添加注释信息。这是一个好习惯。合理的标注信息可以减少查找信息的时间,使代码的查询和修改更加方便。因此,推荐使用在线页面 只需添加注释信息,如网页各部分的头尾注释,重要内容部分注释等,离线备份网页可以添加每个部分的注释信息。部分更详细,方便技术人员浏览和修改。有利于网页减肥不影响以后的网页修改。 查看全部
js抓取网页内容(网页里注释的内容会被百度注释分析吗?(图))
很多站长都知道,网页代码中有评论代码。形式是HTML中的注释内容出现在网页的源代码中,用户在浏览网页时看不到。因为源码中显示的注解内容不会影响页面的内容,很多人认为蜘蛛会抓取注解信息参与网页的分析和排名,所以添加了大量的注解内容到网页,甚至直接堆在注解关键词中。
网页中的注解内容会被抓取吗?我们来看看百度工程师是如何回答的:
Q:评论内容会被百度抓取分析吗?
百度工程师:在文本提取过程中会忽略html中的注释内容。注释的代码虽然不会被爬取,但也会造成代码的繁琐,所以可以尽量少。
显然,搜索引擎蜘蛛非常聪明。他们可以在网络爬行过程中识别注释信息并直接忽略它们。因此,注释内容不会被抓取,也不会参与网页内容的分析。试想如果蜘蛛可以抓取评论,而这个评论代码就相当于一种隐藏的文字,那么网站的主要内容可以被JS代码调用,仅供用户浏览,而蜘蛛抓取的内容想要抓取的就是全部 把它放在大量的注释信息中,让网页给蜘蛛和用户展示不同的内容。如果你是灰色行业网站,那么你可以给搜索引擎一个完全正规的内容展示,摆脱搜索引擎的束缚,搜索引擎会不会正式允许你作弊?所以不管有多少关键词
那么,在评论中添加关键词会影响排名吗?不会是因为搜索引擎直接忽略了注释,而是如何注释大量内容会影响网页的风格,影响网页的加载速度。因此,如果注释没有用,请尝试删除它们并尽可能保持代码简单。我们经常讲网站代码减肥。简化标注信息是减肥的方法之一。优化注解信息有利于网站瘦身。
当然,很多程序员和网页设计师都习惯于在网页中添加注释信息。这是一个好习惯。合理的标注信息可以减少查找信息的时间,使代码的查询和修改更加方便。因此,推荐使用在线页面 只需添加注释信息,如网页各部分的头尾注释,重要内容部分注释等,离线备份网页可以添加每个部分的注释信息。部分更详细,方便技术人员浏览和修改。有利于网页减肥不影响以后的网页修改。
js抓取网页内容(小编典典在直接回答您的问题,值得一开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-17 09:01
小编点点
在直接回答你的问题之前,值得开始:如果你需要做的只是从静态 HTML 页面中提取内容,你可能应该将 HTTP 库(例如 Requests 或内置的 urllib.request)与 lxml 或 BeautifulSoup 结合起来,而不是 Selenium (虽然硒可能就足够了)。不需要使用硒的优点:
请注意,需要 cookie 才能工作的站点并不是破解 Selenium 的理由——
您可以轻松创建一个 URL 打开函数,它使用 cookielib
/
cookiejar 在 HTTP 请求中神奇地设置和发送 cookie。
好的,那为什么还要考虑使用 Selenium 呢?它几乎可以完全处理你要爬取的内容通过JavaScript添加到页面而不是烘焙成HTML的情况。即便如此,您也可以在不破坏重型机械的情况下获得所需的数据。通常,以下情况之一适用:
如果你这样做
值得考虑使用 Selenium,请在 headless 模式下使用,(至少)Firefox 和 Chrome 驱动程序支持。网络爬虫通常不需要实际以图形方式显示页面,也不需要使用任何特定于浏览器的怪癖或功能,因此理想的选择是无头浏览器——
它具有更低的 CPU 和内存成本以及更少的崩溃或悬挂移动部件。
2020-06-26 查看全部
js抓取网页内容(小编典典在直接回答您的问题,值得一开始)
小编点点
在直接回答你的问题之前,值得开始:如果你需要做的只是从静态 HTML 页面中提取内容,你可能应该将 HTTP 库(例如 Requests 或内置的 urllib.request)与 lxml 或 BeautifulSoup 结合起来,而不是 Selenium (虽然硒可能就足够了)。不需要使用硒的优点:
请注意,需要 cookie 才能工作的站点并不是破解 Selenium 的理由——
您可以轻松创建一个 URL 打开函数,它使用 cookielib
/
cookiejar 在 HTTP 请求中神奇地设置和发送 cookie。
好的,那为什么还要考虑使用 Selenium 呢?它几乎可以完全处理你要爬取的内容通过JavaScript添加到页面而不是烘焙成HTML的情况。即便如此,您也可以在不破坏重型机械的情况下获得所需的数据。通常,以下情况之一适用:
如果你这样做
值得考虑使用 Selenium,请在 headless 模式下使用,(至少)Firefox 和 Chrome 驱动程序支持。网络爬虫通常不需要实际以图形方式显示页面,也不需要使用任何特定于浏览器的怪癖或功能,因此理想的选择是无头浏览器——
它具有更低的 CPU 和内存成本以及更少的崩溃或悬挂移动部件。
2020-06-26
js抓取网页内容(#微信刷脸支付介绍SEO优化需要掌握的四个基本常识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-16 00:10
#微信刷脸支付介绍
SEO优化的四个基本常识。作为一名网站优化者,你必须掌握一些搜索引擎优化的基础知识。网站 排名与掌握搜索引擎优化的基础知识息息相关。一、善于使用锚文本锚文本就是在文章中添加一个链接代码,然后点击关键词即可到达你设置的页面。锚文本在搜索引擎优化中扮演着重要的角色。一般来说,网页上只会显示“text关键词”这个词,但是通过html代码可以看到链接代码。二、避免网站上的死链接。所谓死链接是指无效链接和错误链接。这在过去可能是正常的,但后来可能会变成死链。当您打开此链接时,服务器' s 响应是无法打开或 404 错误页面。避免死链接的最好方法是优化网站。我们可以使用网站管理员工具及时发现站点是否存在死链接,然后点击打开确认。三、网站地图是必不可少的。网站当然建设需要制作网站地图,这也是SEO优化的体现。网站地图使搜索引擎蜘蛛能够更好地抓取您的网站。网站 地图是一个页面,类似于网站的路径图,只不过这个页面上会有一个到整个网站页面的链接。制作网站地图的目的是为了展示给搜索引擎,让搜索引擎蜘蛛读取地图,从而更好的浏览你的网站 并从您的 网站 捕获的网页中获取更好的信息以供收录。四、精准目标的合理选择关键词和所谓的长尾目标关键词关键词也是这个网站的主要关键词,优化器需要付出密切注意这个目标关键字来优化网站。目标关键字必须与网站的主题内容相关。目标关键词的选择还要考虑百度指数。结合你的实际情况网站,选择的目标关键词不要太冷。如果你的网站权重高,而且还是老站,可以选择最受欢迎的。如果你的网站权重偏低,而且还是一个新的网站,建议你选择一个适中的目标关键词。掌握以上基础知识是优化搜索引擎优化的基础。如果你知道并且能够熟悉这些基本常识的使用,那一定会给网站优化带来不错的效果!如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。微信刷脸支付
SEO优化如何评价友情链接的质量?友情链接的传播是SEO优化中必不可少的工作,但是友情链接会互相影响,低质量的友情链接会影响到我们的网站,所以准确评估友情链接的质量是SEO必不可少的技能。SEO如何评估友情链接的质量?智码链接搜索引擎优化团队建议从以下几个方面入手。1.网站 合法性主要是指网站的内容是否收录非法内容。这些网站一般都是通过黑帽搜索引擎优化排名的,网站被搜索引擎惩罚的风险非常高,和他们交流会受到影响。2.网站 相关性SEO友情交换链接需要注意网站和自己网站的相关性。相关的网站更有利于优化,过多的交换不相关的网站链接是没有用的,即使对方权重高,也不会影响我们的优化。另外,其他网站上的友情链接太多,或者如果质量不好,不建议交流。3.网站的收录率网站的高内容收录率意味着网站的高品质和网站的高用户体验. 这样的网站朋友链价值很高。其次,搜索引擎优化可以从网站的历史采集和变化来判断网站是否降级。这个友好的链条应该小心更换。4.网站百度权重 百度权重反映了网站在搜索引擎和用户中的受欢迎程度。这种友好的联系是高质量的。对于没有百度权重的新网站,SEO可以关注其他网站的合理性,网站的内容和布局合理,友情链接质量也不错。5.网站百度快照网页快照是对网站活力的评价指标。百度快照更新速度快,反映了网站持续提供优质内容,经常被搜索引擎蜘蛛抓取。需要注意的是,我们不仅要关注百度快照更新的时间段,还要注意其快照更新的稳定性。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。 查看全部
js抓取网页内容(#微信刷脸支付介绍SEO优化需要掌握的四个基本常识)
#微信刷脸支付介绍
SEO优化的四个基本常识。作为一名网站优化者,你必须掌握一些搜索引擎优化的基础知识。网站 排名与掌握搜索引擎优化的基础知识息息相关。一、善于使用锚文本锚文本就是在文章中添加一个链接代码,然后点击关键词即可到达你设置的页面。锚文本在搜索引擎优化中扮演着重要的角色。一般来说,网页上只会显示“text关键词”这个词,但是通过html代码可以看到链接代码。二、避免网站上的死链接。所谓死链接是指无效链接和错误链接。这在过去可能是正常的,但后来可能会变成死链。当您打开此链接时,服务器' s 响应是无法打开或 404 错误页面。避免死链接的最好方法是优化网站。我们可以使用网站管理员工具及时发现站点是否存在死链接,然后点击打开确认。三、网站地图是必不可少的。网站当然建设需要制作网站地图,这也是SEO优化的体现。网站地图使搜索引擎蜘蛛能够更好地抓取您的网站。网站 地图是一个页面,类似于网站的路径图,只不过这个页面上会有一个到整个网站页面的链接。制作网站地图的目的是为了展示给搜索引擎,让搜索引擎蜘蛛读取地图,从而更好的浏览你的网站 并从您的 网站 捕获的网页中获取更好的信息以供收录。四、精准目标的合理选择关键词和所谓的长尾目标关键词关键词也是这个网站的主要关键词,优化器需要付出密切注意这个目标关键字来优化网站。目标关键字必须与网站的主题内容相关。目标关键词的选择还要考虑百度指数。结合你的实际情况网站,选择的目标关键词不要太冷。如果你的网站权重高,而且还是老站,可以选择最受欢迎的。如果你的网站权重偏低,而且还是一个新的网站,建议你选择一个适中的目标关键词。掌握以上基础知识是优化搜索引擎优化的基础。如果你知道并且能够熟悉这些基本常识的使用,那一定会给网站优化带来不错的效果!如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。微信刷脸支付

SEO优化如何评价友情链接的质量?友情链接的传播是SEO优化中必不可少的工作,但是友情链接会互相影响,低质量的友情链接会影响到我们的网站,所以准确评估友情链接的质量是SEO必不可少的技能。SEO如何评估友情链接的质量?智码链接搜索引擎优化团队建议从以下几个方面入手。1.网站 合法性主要是指网站的内容是否收录非法内容。这些网站一般都是通过黑帽搜索引擎优化排名的,网站被搜索引擎惩罚的风险非常高,和他们交流会受到影响。2.网站 相关性SEO友情交换链接需要注意网站和自己网站的相关性。相关的网站更有利于优化,过多的交换不相关的网站链接是没有用的,即使对方权重高,也不会影响我们的优化。另外,其他网站上的友情链接太多,或者如果质量不好,不建议交流。3.网站的收录率网站的高内容收录率意味着网站的高品质和网站的高用户体验. 这样的网站朋友链价值很高。其次,搜索引擎优化可以从网站的历史采集和变化来判断网站是否降级。这个友好的链条应该小心更换。4.网站百度权重 百度权重反映了网站在搜索引擎和用户中的受欢迎程度。这种友好的联系是高质量的。对于没有百度权重的新网站,SEO可以关注其他网站的合理性,网站的内容和布局合理,友情链接质量也不错。5.网站百度快照网页快照是对网站活力的评价指标。百度快照更新速度快,反映了网站持续提供优质内容,经常被搜索引擎蜘蛛抓取。需要注意的是,我们不仅要关注百度快照更新的时间段,还要注意其快照更新的稳定性。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。
js抓取网页内容(有些网页加载时动态创建HTML内容怎么做?网页介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-14 01:21
)
有些网页在加载时会动态创建HTML内容,只有在js代码完全执行后才会显示最终结果。如果使用传统方式抓取页面,则只能在js代码执行前获取页面上的内容。
有两种方法可以解决这个问题:
1.直接从js代码中抓取数据(执行js代码,解析js变量)。
2.用第三方库运行js,抓取运行后的最终html页面。
python中使用selenium执行js
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,需要配合第三方浏览器使用。这里使用phantomjs工具代替真实浏览器。
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
将 selenium 和 phantomjs 结合在一起,您可以运行一个非常强大的爬虫,它可以处理 cookie、js、headers 以及您需要做的任何事情。
安装:
Selenium有python库,可以用pip等安装; phantomjs是一个功能齐全的“无头”浏览器,不是python库,所以不需要像其他python库一样安装,也不能用pip安装。
sudo pip install selenium
http://npm.taobao.org/dist/phantomjs/
#下载安装包(sudo apt-get install phantomjs安装的不是最新的,发现不能用)
phantomjs-2.1.1-linux-i686.tar.bz2
tar -jxvf phantomjs-2.1.1-linux-i686.tar.bz2
使用:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/opt/phantomjs-2.1.1-linux-i686/bin/phantomjs')
#executable_path为你的phantomjs可执行文件路径
driver.get("http://news.sohu.com/scroll/")
#或得js变量的值
r = driver.execute_script("return newsJason")
print r
#selenium在webdriver的DOM中使用选择器来查找元素,名字直接了当,by对象可使用的选择策略有:id,class_name,css_selector,link_text,name,tag_name,tag_name,xpath等等
print driver.find_element_by_tag_name("div").text
print driver.find_element_by_csss_selector("#content").text
print driver.find_element_by_id("content").text 查看全部
js抓取网页内容(有些网页加载时动态创建HTML内容怎么做?网页介绍
)
有些网页在加载时会动态创建HTML内容,只有在js代码完全执行后才会显示最终结果。如果使用传统方式抓取页面,则只能在js代码执行前获取页面上的内容。
有两种方法可以解决这个问题:
1.直接从js代码中抓取数据(执行js代码,解析js变量)。
2.用第三方库运行js,抓取运行后的最终html页面。
python中使用selenium执行js
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,需要配合第三方浏览器使用。这里使用phantomjs工具代替真实浏览器。
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
将 selenium 和 phantomjs 结合在一起,您可以运行一个非常强大的爬虫,它可以处理 cookie、js、headers 以及您需要做的任何事情。
安装:
Selenium有python库,可以用pip等安装; phantomjs是一个功能齐全的“无头”浏览器,不是python库,所以不需要像其他python库一样安装,也不能用pip安装。
sudo pip install selenium
http://npm.taobao.org/dist/phantomjs/
#下载安装包(sudo apt-get install phantomjs安装的不是最新的,发现不能用)
phantomjs-2.1.1-linux-i686.tar.bz2
tar -jxvf phantomjs-2.1.1-linux-i686.tar.bz2
使用:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/opt/phantomjs-2.1.1-linux-i686/bin/phantomjs')
#executable_path为你的phantomjs可执行文件路径
driver.get("http://news.sohu.com/scroll/";)
#或得js变量的值
r = driver.execute_script("return newsJason")
print r
#selenium在webdriver的DOM中使用选择器来查找元素,名字直接了当,by对象可使用的选择策略有:id,class_name,css_selector,link_text,name,tag_name,tag_name,xpath等等
print driver.find_element_by_tag_name("div").text
print driver.find_element_by_csss_selector("#content").text
print driver.find_element_by_id("content").text
js抓取网页内容(代理支持·支持TLS/SSL协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 01:21
· 代理支持
· 支持TLS/SSL协议
2. Cheerio(也称为解析器):
· Cheerio 提供专为服务器设计的快速、灵活和精益的核心jQuery 实现。
· Cheerio 解析标记并提供 API 用于遍历/操作结果数据结构。
特征:
· 熟悉的语法:Cheerio 实现了核心 jQuery 的一个子集。它去除了jQuery库中所有的DOM不一致和浏览痕迹,充分展示了API的魅力。
· 快速:Cheerio 使用非常简单且一致的 DOM 模型。因此,解析、操作和呈现非常高效。初步的端到端基准测试表明,cheerio 比 JSDOM 快约 8 倍。
· 惊人的灵活性:Cheerio 几乎可以解析任何 HTML 或 XML 文档。
3.渗透(又名解析器)
· Osmosis 包括 HTML/XML 解析器和 webscraper。
· 它是用 node.js 编写的,收录 css3/xpath 选择器和轻量级 http 包装器。
· 没有像 Cheerio 这样的大依赖。
特征:
· 支持 CSS 3.0 和 XPath1.0 选择器的混合
· 加载和搜索 AJAX 内容
· 记录 URL、重定向和错误
· Cookie jar 和自定义 cookie/header/user agent
· 登录/表单提交、会话 cookie 和基本身份验证
· 单代理或多代理处理代理故障
· 重试和重定向限制
4. Puppeteer(也称为无头 Chrome 自动化浏览器):
Puppeteer 是一个 Node.js 库,它提供了一个简单但高效的 API,使您能够控制 Google 的 Chrome 或 Chromium 浏览器。
它还可以在无头模式下运行 Chromium(对于在服务器上运行浏览器非常有用),并且可以在不需要用户界面的情况下发送和接收请求。
最好的部分是它可以在后台操作,遵循 API 的说明。
特征:
· 单击按钮、链接和图像等元素
· 自动表单提交
· 导航页面
· 使用时间线追踪找出问题所在
· 直接在浏览器中自动测试用户界面和各种前端应用程序
· 截屏
· 将网页转换为pdf文件
5. Apify SDK(也称为完整的网页抓取框架):
· Apify SDK 是一个开源的Node.js 库,用于抓取和网页抓取。
· Apify SDK 是一种独特的工具,可简化网络爬虫、爬虫、数据提取器和网络自动化任务的开发。
· 提供管理和自动扩容headless Chrome/Puppeteer实例池、维护待爬取的URL队列、将爬取结果存储到本地文件系统或云端、轮换代理等工具。
· 可以在自己的应用中独立使用,也可以在 Apify 云上运行的参与者之间使用。
特征:
· 使用 URL 的持久队列来深度获取整个 网站。
· 运行CSV文件中收录100k URL的爬取代码,代码崩溃时不会丢失任何数据。
· 通过旋转代理隐藏您的浏览器源。
· 安排代码定期运行并发送错误通知。
· 禁用网站 使用的浏览器指纹保护。
随着时间的推移,对网络爬虫的需求不断增长。所以程序员们,你们的春天来了!搞定了很多只会复制粘贴数据的妹子。用你的代码让女孩认真起来!但是网络爬虫也需要谨慎。归根结底,信息不是可以被窃取和出售的东西。不要像这个老铁一样炫耀:
发表评论,点赞,发朋友圈 查看全部
js抓取网页内容(代理支持·支持TLS/SSL协议)
· 代理支持
· 支持TLS/SSL协议
2. Cheerio(也称为解析器):
· Cheerio 提供专为服务器设计的快速、灵活和精益的核心jQuery 实现。
· Cheerio 解析标记并提供 API 用于遍历/操作结果数据结构。
特征:
· 熟悉的语法:Cheerio 实现了核心 jQuery 的一个子集。它去除了jQuery库中所有的DOM不一致和浏览痕迹,充分展示了API的魅力。
· 快速:Cheerio 使用非常简单且一致的 DOM 模型。因此,解析、操作和呈现非常高效。初步的端到端基准测试表明,cheerio 比 JSDOM 快约 8 倍。
· 惊人的灵活性:Cheerio 几乎可以解析任何 HTML 或 XML 文档。
3.渗透(又名解析器)
· Osmosis 包括 HTML/XML 解析器和 webscraper。
· 它是用 node.js 编写的,收录 css3/xpath 选择器和轻量级 http 包装器。
· 没有像 Cheerio 这样的大依赖。
特征:
· 支持 CSS 3.0 和 XPath1.0 选择器的混合
· 加载和搜索 AJAX 内容
· 记录 URL、重定向和错误
· Cookie jar 和自定义 cookie/header/user agent
· 登录/表单提交、会话 cookie 和基本身份验证
· 单代理或多代理处理代理故障
· 重试和重定向限制
4. Puppeteer(也称为无头 Chrome 自动化浏览器):
Puppeteer 是一个 Node.js 库,它提供了一个简单但高效的 API,使您能够控制 Google 的 Chrome 或 Chromium 浏览器。
它还可以在无头模式下运行 Chromium(对于在服务器上运行浏览器非常有用),并且可以在不需要用户界面的情况下发送和接收请求。
最好的部分是它可以在后台操作,遵循 API 的说明。
特征:
· 单击按钮、链接和图像等元素
· 自动表单提交
· 导航页面
· 使用时间线追踪找出问题所在
· 直接在浏览器中自动测试用户界面和各种前端应用程序
· 截屏
· 将网页转换为pdf文件
5. Apify SDK(也称为完整的网页抓取框架):
· Apify SDK 是一个开源的Node.js 库,用于抓取和网页抓取。
· Apify SDK 是一种独特的工具,可简化网络爬虫、爬虫、数据提取器和网络自动化任务的开发。
· 提供管理和自动扩容headless Chrome/Puppeteer实例池、维护待爬取的URL队列、将爬取结果存储到本地文件系统或云端、轮换代理等工具。
· 可以在自己的应用中独立使用,也可以在 Apify 云上运行的参与者之间使用。
特征:
· 使用 URL 的持久队列来深度获取整个 网站。
· 运行CSV文件中收录100k URL的爬取代码,代码崩溃时不会丢失任何数据。
· 通过旋转代理隐藏您的浏览器源。
· 安排代码定期运行并发送错误通知。
· 禁用网站 使用的浏览器指纹保护。
随着时间的推移,对网络爬虫的需求不断增长。所以程序员们,你们的春天来了!搞定了很多只会复制粘贴数据的妹子。用你的代码让女孩认真起来!但是网络爬虫也需要谨慎。归根结底,信息不是可以被窃取和出售的东西。不要像这个老铁一样炫耀:


发表评论,点赞,发朋友圈
js抓取网页内容(scrapy1064位python3.6scrapy1.3.3-splash,那知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-14 01:18
最近想学scrapy-splash。我以前用硒和铬。我总觉得有点慢。如果我想学习scrapy-splash,我知道网上有很多不可靠的内容。整合了很多文章,终于成功了。把它写下来以免忘记它,也是一个正确的指南。
软件环境:
赢得 10 64 位
蟒蛇3.6
刮刮1.3.3
刮飞溅 0.7.2
我用的是anaconda,忘了scrapy是内置的还是后来安装的。如果没有安装anaconda,直接用pip install scrapy安装即可。
ScrapySplash 安装
注意 ScrapySplash 需要使用 docker。懂的人我就不用解释了。不明白的,跟着操作就行了。这里的 ScrapySplash 与上述软件环境中的不同。以上是scrapy中使用import时使用的。这相当于一个软件,你必须安装它才能使用它。
安装 Docker
准备
由于在docker中需要用到ScrapySplash,所以我们先安装docker。安装前,请检查您的计算机是否为 win 10 64 位,以及是否启用了超级虚拟化。
正式安装
win 10不同版本问题很多。
常规安装:从官网以下地址下载
如果这种方式安装过程中出现错误或者安装后报错,请使用docker工具箱进行安装:
注意:docker使用了虚拟化技术,所以安装的时候一起安装virtualbox,请一定要检查一下,如果你已经安装了,就不需要了。
想了解更多关于Docker的知识,可以访问Docker官网:
启动环境
安装好docker后,打开docker,可以直接使用cmd进行正常安装,如果是通过toolbox安装的,请使用Docker Quickstart Terminal进行操作。
我是用toolbox安装的,所以下面的命令行操作都在Docker Quickstart Terminal里面。
打开命令行:
第一次调用会比较慢,因为virtualbox虚拟机还在启动中。等待一段时间后出现如下界面,说明安装成功。
docker 启动后.png
里面有一个IP,请记住这是以后要使用的东西。
下载 ScrapySplash
在命令行中输入 docker run -p 8050:8050 scrapinghub/splash。这就是 docker 的使用方式。这意味着飞溅开始了。第一次启动是在本地没有splash应用的时候,会自动从docker hub下载。我们不必担心这个过程。,慢慢等。
下载后直接启动应用,出现如下界面:
启动成功.png
这时候我们可以在浏览器中输入:8050/,这里的IP就是之前出现的IP。出现如下界面,说明启动成功。
启动成功.png
注:参考相关文章时,总能看到是输入:8050/,不知道是不是每个人的电脑不一样,还是都被别人蒙上了。安装几次后,还是没有出现上面的界面。按照我的理解,localhost就是本地主机,但是我们的应用是在虚拟机里面的。如果是本地主机,就说明我们需要在虚拟机中打开浏览器,但是我们是在win 10下运行的,难道其他文章的作者都是直接在虚拟机中运行的。这里不清楚。如果有人能告知,我将不胜感激。
好了,到此,整个环境搭建完毕,下面搭建scrapy爬虫。
爬虫爬虫设置
scrapy项目其实和普通项目没什么区别。不明白的可以参考我的另一个文章 Scrapy抓取本地论坛招聘内容(一)
在这里,我创建了一个新的学习项目:
> scrapy startproject jdproject
> cd jdproject/
> scrapy genspider jd https://www.jd.com/
注意:这里的操作也是在命令行中,但是不需要在Docker Quickstart Terminal中,普通cmd中也可以
打开jdproject/spiders/jd.py,修改内容:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request, FormRequest
from scrapy.selector import Selector
from scrapy_splash.request import SplashRequest, SplashFormRequest
class JdSpider(scrapy.Spider):
name = "jd"
def start_requests(self):
splash_args = {"lua_source": """
--splash.response_body_enabled = true
splash.private_mode_enabled = false
splash:set_user_agent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36")
assert(splash:go("https://item.jd.com/5089239.html"))
splash:wait(3)
return {html = splash:html()}
"""}
yield SplashRequest("https://item.jd.com/5089239.html", endpoint='run', args=splash_args, callback=self.onSave)
def onSave(self, response):
value = response.xpath('//span[@class="p-price"]//text()').extract()
print(value)
打开jdproject/settings.py,修改:
# See http://scrapy.readthedocs.org/ ... .html
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# See http://scrapy.readthedocs.org/ ... .html
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, # 不配置查不到信息
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://192.168.99.100:8050/" # 自己安装的docker里的splash位置
DUPEFILTER_CLASS = "scrapy_splash.SplashAwareDupeFilter"
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
测试
我这里用的是测试用的,需要的是产品的价格。
jd.png
运行爬虫:
结果.png
可以清楚的看到,我们想要的价格已经出现了。
至此,我们已经成功部署了ScrapySplash,并成功实现了爬虫项目。
对splash感兴趣的可以参考官网: 查看全部
js抓取网页内容(scrapy1064位python3.6scrapy1.3.3-splash,那知)
最近想学scrapy-splash。我以前用硒和铬。我总觉得有点慢。如果我想学习scrapy-splash,我知道网上有很多不可靠的内容。整合了很多文章,终于成功了。把它写下来以免忘记它,也是一个正确的指南。
软件环境:
赢得 10 64 位
蟒蛇3.6
刮刮1.3.3
刮飞溅 0.7.2
我用的是anaconda,忘了scrapy是内置的还是后来安装的。如果没有安装anaconda,直接用pip install scrapy安装即可。
ScrapySplash 安装
注意 ScrapySplash 需要使用 docker。懂的人我就不用解释了。不明白的,跟着操作就行了。这里的 ScrapySplash 与上述软件环境中的不同。以上是scrapy中使用import时使用的。这相当于一个软件,你必须安装它才能使用它。
安装 Docker
准备
由于在docker中需要用到ScrapySplash,所以我们先安装docker。安装前,请检查您的计算机是否为 win 10 64 位,以及是否启用了超级虚拟化。
正式安装
win 10不同版本问题很多。
常规安装:从官网以下地址下载
如果这种方式安装过程中出现错误或者安装后报错,请使用docker工具箱进行安装:
注意:docker使用了虚拟化技术,所以安装的时候一起安装virtualbox,请一定要检查一下,如果你已经安装了,就不需要了。
想了解更多关于Docker的知识,可以访问Docker官网:
启动环境
安装好docker后,打开docker,可以直接使用cmd进行正常安装,如果是通过toolbox安装的,请使用Docker Quickstart Terminal进行操作。
我是用toolbox安装的,所以下面的命令行操作都在Docker Quickstart Terminal里面。
打开命令行:
第一次调用会比较慢,因为virtualbox虚拟机还在启动中。等待一段时间后出现如下界面,说明安装成功。

docker 启动后.png
里面有一个IP,请记住这是以后要使用的东西。
下载 ScrapySplash
在命令行中输入 docker run -p 8050:8050 scrapinghub/splash。这就是 docker 的使用方式。这意味着飞溅开始了。第一次启动是在本地没有splash应用的时候,会自动从docker hub下载。我们不必担心这个过程。,慢慢等。
下载后直接启动应用,出现如下界面:

启动成功.png
这时候我们可以在浏览器中输入:8050/,这里的IP就是之前出现的IP。出现如下界面,说明启动成功。

启动成功.png
注:参考相关文章时,总能看到是输入:8050/,不知道是不是每个人的电脑不一样,还是都被别人蒙上了。安装几次后,还是没有出现上面的界面。按照我的理解,localhost就是本地主机,但是我们的应用是在虚拟机里面的。如果是本地主机,就说明我们需要在虚拟机中打开浏览器,但是我们是在win 10下运行的,难道其他文章的作者都是直接在虚拟机中运行的。这里不清楚。如果有人能告知,我将不胜感激。
好了,到此,整个环境搭建完毕,下面搭建scrapy爬虫。
爬虫爬虫设置
scrapy项目其实和普通项目没什么区别。不明白的可以参考我的另一个文章 Scrapy抓取本地论坛招聘内容(一)
在这里,我创建了一个新的学习项目:
> scrapy startproject jdproject
> cd jdproject/
> scrapy genspider jd https://www.jd.com/
注意:这里的操作也是在命令行中,但是不需要在Docker Quickstart Terminal中,普通cmd中也可以
打开jdproject/spiders/jd.py,修改内容:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request, FormRequest
from scrapy.selector import Selector
from scrapy_splash.request import SplashRequest, SplashFormRequest
class JdSpider(scrapy.Spider):
name = "jd"
def start_requests(self):
splash_args = {"lua_source": """
--splash.response_body_enabled = true
splash.private_mode_enabled = false
splash:set_user_agent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36")
assert(splash:go("https://item.jd.com/5089239.html";))
splash:wait(3)
return {html = splash:html()}
"""}
yield SplashRequest("https://item.jd.com/5089239.html", endpoint='run', args=splash_args, callback=self.onSave)
def onSave(self, response):
value = response.xpath('//span[@class="p-price"]//text()').extract()
print(value)
打开jdproject/settings.py,修改:
# See http://scrapy.readthedocs.org/ ... .html
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# See http://scrapy.readthedocs.org/ ... .html
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, # 不配置查不到信息
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://192.168.99.100:8050/" # 自己安装的docker里的splash位置
DUPEFILTER_CLASS = "scrapy_splash.SplashAwareDupeFilter"
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
测试
我这里用的是测试用的,需要的是产品的价格。

jd.png
运行爬虫:

结果.png
可以清楚的看到,我们想要的价格已经出现了。
至此,我们已经成功部署了ScrapySplash,并成功实现了爬虫项目。
对splash感兴趣的可以参考官网:
js抓取网页内容(一下,抓取网页数据都是用JavaJsoup(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-12 13:14
阿里云>云栖社区>主题地图>R>如何使用GET获取网页内容
推荐活动:
更多优惠>
当前主题:如何使用 GET 获取网页内容并将其添加到采集夹
相关话题:
如何使用GET抓取与网页内容相关的博客 查看更多博客
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现成的API来获取数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
如何让搜索引擎抓取AJAX内容?
作者:阮一峰 1469人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
如何让搜索引擎抓取AJAX内容?
作者:阮一峰 1061人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
file_get_contents 解决网页爬虫乱码
作者:科技小胖子1012人浏览评论:04年前
有时使用file_get_contents()函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。编码问题很容易处理,只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容
作者:朱老教授 823人浏览评论:04年前
public string GetHtml(string url, Encoding ed) {string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文 查看全部
js抓取网页内容(一下,抓取网页数据都是用JavaJsoup(组图))
阿里云>云栖社区>主题地图>R>如何使用GET获取网页内容

推荐活动:
更多优惠>
当前主题:如何使用 GET 获取网页内容并将其添加到采集夹
相关话题:
如何使用GET抓取与网页内容相关的博客 查看更多博客
【网络爬虫】使用node.jscheerio爬取网页数据

作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现成的API来获取数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
如何让搜索引擎抓取AJAX内容?


作者:阮一峰 1469人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)

作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
如何让搜索引擎抓取AJAX内容?
作者:阮一峰 1061人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
file_get_contents 解决网页爬虫乱码

作者:科技小胖子1012人浏览评论:04年前
有时使用file_get_contents()函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。编码问题很容易处理,只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容

作者:朱老教授 823人浏览评论:04年前
public string GetHtml(string url, Encoding ed) {string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文
js抓取网页内容(使用AngularJS构建的网站有一个问题–为SEO优化AngularJS)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-10 15:15
使用 AngularJS 内置的 网站 将所有内容加载到单个页面上。模板保持不变,仅重新加载副本以显示访问者请求的信息。
我承认这个概念很棒。拥有单页应用程序意味着几乎是即时加载时间——更不用说,更容易开发和更少的代码错误需要修复。
但是针对 SEO 优化 AngularJS 存在一个问题。
Angular 应用程序在客户端提供内容。因此,他们从谷歌抓取和排名页面所需的所有元素中删除了一个页面。
SEO 可以做任何事情,还是应该放弃并保留 网站 上的任何未优化的 AngularJS 页面?
不,绝对不是!首先,您实际上可以优化 AngularJS。当然,它需要一些技术 SEO 知道如何,但它可以做到。
在我告诉您更多相关信息之前,让我们先了解一下基础知识。
什么是 AngularJS?
AngularJS 是 Google 提供的基于 JavaScript 的平台,可以从单个页面加载内容。
例如,与 HTML 不同,基于 Angular 的 网站 不会将单个页面存储为单独的文件。相反,它在单个应用程序中加载内容用户请求。
因此,这些 Web 属性通常称为单页应用程序 (SPA)。
实际上,差异意味着用户每次点击请求信息时,并不是呈现一个新页面,所有与内容的交互都是通过 AJAX 调用在同一页面上进行的。
这是微软的视觉效果,说明了差异。请注意,在传统的页面循环中,服务器如何为每个请求加载一个新的 HTML 页面。但是,在 SPA 生命周期中,页面仅加载一次。然后,JavaScript 使用页面作为框架来加载相关内容。
为什么要使用 AngularJS?
使用 Angular 框架构建 网站 有三个主要好处。
1. 单页应用程序的内容加载速度要快得多,因为无需每次都加载新的 HTML 代码。这可以带来更好的用户体验。
2.使用AngularJS还可以加快开发进程。开发人员只需构建一个页面,然后使用 JavaScript 来控制其余页面。
3.由于上述原因,开发者可以减少错误,从而减少用户浏览网站时的问题。技术团队不必花时间重新访问他们的代码来修复错误。每个人都是一个双赢的场景。
不幸的是,Angular 只是 SEO 的主要挑战。
为什么 AngularJS 对搜索引擎优化具有挑战性?
例如,通过 API 连接调用内容,单页技术将从页面的实际代码中删除所有可抓取的内容。
与收录所有 网站 内容的传统 HTML 页面不同,SPA 仅收录基本页面结构。但是,实际的措辞是通过动态 API 调用显示的。
对于 SEO,以上意味着源代码中的实际 HTML 不收录在页面中。因此,Google 将抓取的所有元素都不存在。
此外,搜索引擎无法缓存 SPA。下面两个视觉效果很好地说明了这个问题。顶部显示用户在访问 Angular 页面时看到的内容。另一个介绍了Google可以访问和抓取的实际内容。
用户看到的:
谷歌缓存内容:
一个明显的区别,不是吗?
对于用户,此页面与其他页面相同。他们可以轻松浏览网站。他们可以访问、阅读信息并与之交互。
另一方面,谷歌几乎看不到页面上的任何内容。当然,仅仅正确地索引它是不够的。
这是 SEO 面对 Angular 应用程序所面临的挑战。这些应用程序缺乏对它们进行排名所需的一切。
幸运的是,也有好消息。
如何针对 Google Crawling 优化 AngularJS 应用程序
有三种方法可以做到这一点。
首先是使用预渲染平台。例如,Prerender.io。此类服务将创建内容的缓存版本,并以 Googlebot 可以抓取和索引的形式呈现。
不幸的是,这可能是一个短期解决方案。Google 可以轻松地将其贬值,这样 网站 就无法再获得可转换的解决方案。
第二种解决方案是修改 SPA 元素,使其成为客户端和服务器之间的混合体。开发人员将此方法称为初始静态渲染。
在这种方法中,您可以在服务器端保留某些对 SEO 必不可少的元素 - 标题、元描述、标题、某人的副本等。因此,这些元素将显示在源代码中,谷歌可以抓取它们。
不幸的是,该解决方案有时会再次证明是不够的。
但是,有一个可行的选择。它涉及使用 Angular Universal 扩展来创建要在服务器端呈现的页面的静态版本。不用说,这些可以被谷歌完全索引,而且这项技术很快就会贬值。
如何使用 Angular Universal Extension 准备服务器端渲染
以下是Angular官方网站流程的简要概述*。但是,在完成整个过程之前,我建议您转移到受控的测试环境。
过程:
1.安装依赖项。
2. 通过修改应用程序代码及其配置来准备您的应用程序。
3.添加构建目标并使用带有@ununiversal/express-engine 原理图的 CLI 构建通用包。
4.设置服务器以运行通用包。
5. 在服务器上打包并运行应用程序。
结果?缓存页面如下所示:
当然,它没有视觉冲击。但是,用户不会看到它。但是,搜索引擎会找到抓取所需的所有信息并正确索引页面,这是您的目标。
关键点
AngularJS 为改善用户体验和缩短开发时间提供了难以置信的机会。不幸的是,它也给SEO带来了严峻的挑战。
例如,单页应用程序不收录爬行和索引内容以进行排名所需的代码元素。
幸运的是,SEO 可以通过三个选项克服它:
1.使用预渲染平台,例如 Prerender.io。
2.创建一个名为初始静态渲染的 AngularJS 和 HTML 混合体。
3.使用 Angular Universal 扩展创建站点的静态版本以进行爬网和索引——这是我推荐的选项。 查看全部
js抓取网页内容(使用AngularJS构建的网站有一个问题–为SEO优化AngularJS)
使用 AngularJS 内置的 网站 将所有内容加载到单个页面上。模板保持不变,仅重新加载副本以显示访问者请求的信息。
我承认这个概念很棒。拥有单页应用程序意味着几乎是即时加载时间——更不用说,更容易开发和更少的代码错误需要修复。
但是针对 SEO 优化 AngularJS 存在一个问题。
Angular 应用程序在客户端提供内容。因此,他们从谷歌抓取和排名页面所需的所有元素中删除了一个页面。
SEO 可以做任何事情,还是应该放弃并保留 网站 上的任何未优化的 AngularJS 页面?
不,绝对不是!首先,您实际上可以优化 AngularJS。当然,它需要一些技术 SEO 知道如何,但它可以做到。
在我告诉您更多相关信息之前,让我们先了解一下基础知识。
什么是 AngularJS?
AngularJS 是 Google 提供的基于 JavaScript 的平台,可以从单个页面加载内容。
例如,与 HTML 不同,基于 Angular 的 网站 不会将单个页面存储为单独的文件。相反,它在单个应用程序中加载内容用户请求。
因此,这些 Web 属性通常称为单页应用程序 (SPA)。
实际上,差异意味着用户每次点击请求信息时,并不是呈现一个新页面,所有与内容的交互都是通过 AJAX 调用在同一页面上进行的。
这是微软的视觉效果,说明了差异。请注意,在传统的页面循环中,服务器如何为每个请求加载一个新的 HTML 页面。但是,在 SPA 生命周期中,页面仅加载一次。然后,JavaScript 使用页面作为框架来加载相关内容。

为什么要使用 AngularJS?
使用 Angular 框架构建 网站 有三个主要好处。
1. 单页应用程序的内容加载速度要快得多,因为无需每次都加载新的 HTML 代码。这可以带来更好的用户体验。
2.使用AngularJS还可以加快开发进程。开发人员只需构建一个页面,然后使用 JavaScript 来控制其余页面。
3.由于上述原因,开发者可以减少错误,从而减少用户浏览网站时的问题。技术团队不必花时间重新访问他们的代码来修复错误。每个人都是一个双赢的场景。
不幸的是,Angular 只是 SEO 的主要挑战。
为什么 AngularJS 对搜索引擎优化具有挑战性?
例如,通过 API 连接调用内容,单页技术将从页面的实际代码中删除所有可抓取的内容。
与收录所有 网站 内容的传统 HTML 页面不同,SPA 仅收录基本页面结构。但是,实际的措辞是通过动态 API 调用显示的。
对于 SEO,以上意味着源代码中的实际 HTML 不收录在页面中。因此,Google 将抓取的所有元素都不存在。
此外,搜索引擎无法缓存 SPA。下面两个视觉效果很好地说明了这个问题。顶部显示用户在访问 Angular 页面时看到的内容。另一个介绍了Google可以访问和抓取的实际内容。
用户看到的:

谷歌缓存内容:

一个明显的区别,不是吗?
对于用户,此页面与其他页面相同。他们可以轻松浏览网站。他们可以访问、阅读信息并与之交互。
另一方面,谷歌几乎看不到页面上的任何内容。当然,仅仅正确地索引它是不够的。
这是 SEO 面对 Angular 应用程序所面临的挑战。这些应用程序缺乏对它们进行排名所需的一切。
幸运的是,也有好消息。
如何针对 Google Crawling 优化 AngularJS 应用程序
有三种方法可以做到这一点。
首先是使用预渲染平台。例如,Prerender.io。此类服务将创建内容的缓存版本,并以 Googlebot 可以抓取和索引的形式呈现。
不幸的是,这可能是一个短期解决方案。Google 可以轻松地将其贬值,这样 网站 就无法再获得可转换的解决方案。
第二种解决方案是修改 SPA 元素,使其成为客户端和服务器之间的混合体。开发人员将此方法称为初始静态渲染。
在这种方法中,您可以在服务器端保留某些对 SEO 必不可少的元素 - 标题、元描述、标题、某人的副本等。因此,这些元素将显示在源代码中,谷歌可以抓取它们。
不幸的是,该解决方案有时会再次证明是不够的。
但是,有一个可行的选择。它涉及使用 Angular Universal 扩展来创建要在服务器端呈现的页面的静态版本。不用说,这些可以被谷歌完全索引,而且这项技术很快就会贬值。
如何使用 Angular Universal Extension 准备服务器端渲染
以下是Angular官方网站流程的简要概述*。但是,在完成整个过程之前,我建议您转移到受控的测试环境。
过程:
1.安装依赖项。
2. 通过修改应用程序代码及其配置来准备您的应用程序。
3.添加构建目标并使用带有@ununiversal/express-engine 原理图的 CLI 构建通用包。
4.设置服务器以运行通用包。
5. 在服务器上打包并运行应用程序。
结果?缓存页面如下所示:

当然,它没有视觉冲击。但是,用户不会看到它。但是,搜索引擎会找到抓取所需的所有信息并正确索引页面,这是您的目标。
关键点
AngularJS 为改善用户体验和缩短开发时间提供了难以置信的机会。不幸的是,它也给SEO带来了严峻的挑战。
例如,单页应用程序不收录爬行和索引内容以进行排名所需的代码元素。
幸运的是,SEO 可以通过三个选项克服它:
1.使用预渲染平台,例如 Prerender.io。
2.创建一个名为初始静态渲染的 AngularJS 和 HTML 混合体。
3.使用 Angular Universal 扩展创建站点的静态版本以进行爬网和索引——这是我推荐的选项。
js抓取网页内容(手机最快现场报码开奖结果2006年12月,Robin做了一个对JS的索引小实验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-09 21:17
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体使用我以后会说明文章)。截至今天发布此文章,谷歌和百度已将收录定位为实验站点。
Google 收录 目标站点领先于百度,雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。
从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
1. 新建一个html页面和js页面,其中html页面代码的body除了js代码调用外没有其他信息内容。 【城市相册】乡村振兴路上的“慢生活”实验。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录目标html页面后,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。 查看全部
js抓取网页内容(手机最快现场报码开奖结果2006年12月,Robin做了一个对JS的索引小实验)
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体使用我以后会说明文章)。截至今天发布此文章,谷歌和百度已将收录定位为实验站点。
Google 收录 目标站点领先于百度,雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。


从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
1. 新建一个html页面和js页面,其中html页面代码的body除了js代码调用外没有其他信息内容。 【城市相册】乡村振兴路上的“慢生活”实验。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录目标html页面后,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。
js抓取网页内容(js抓取网页内容可能对你来说并不是最困难的一个难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 05:00
js抓取网页内容可能对你来说并不是最困难的一个技术难点。因为相对前端来说,js确实比较容易上手,现在虽然js抓取很流行,但是如果遇到php来实现这一步却是非常麻烦。js抓取php文件的难点不在于抓取的数据格式(包括类型,字段等信息)或者说对页面中每个页面元素的获取这一步,而是要获取php中所调用的js代码,而且要抓取js代码还要加载包含php代码的content-type标签、content-language标签、trailing-trailing注解、warning、error等。
如果不去深入探索js抓取,也不想深入探索,那php代码可能有点low。但你要抓取带有content-type标签的html文件,js代码就又变的非常的可怕了。如果抓取不到content-type,那么很多内容可能就无法获取。首先,有极少的信息是可以通过抓取js获取的。这些主要是在页面中的dom元素上调用的,因为页面中会有结构对应html的各个元素,然后把html元素相应dom元素绑定到dom元素上,之后执行这个dom元素相应的js代码,相应html元素也就会就会提交给浏览器解析。
通过抓取js代码获取的内容有部分已经在html上跑的脚本也是可以的,但是不多。获取脚本调用的脚本是单一js,这些脚本因为是对dom元素上js注解,可以获取到绝大部分js文件内容,但是也不仅限于解析代码语言。比如js($css)注解,你可以获取所有相应的style标签,然后直接抓取style标签中的内容,但是如果按照trailing-trailing标签直接抓取,那么你得到的js代码有可能非常的多。
其实对于一般情况下,没有必要上述的注解需要注入浏览器中。但是我的一个朋友提到对于有移动端的网站,它会根据需要,把html渲染以postmanformui加载,具体我还没有尝试。使用node.js抓取客户端数据已经是不少大网站都在使用的方法了,一般是通过node.js渲染页面,然后调用php代码抓取客户端数据。
<p>比如我们有个用户输入密码的页面:现在你可以通过js来获取到用户输入密码的这个html值。那么接下来我们调用php中的一个方法:然后我们来尝试获取用户昵称信息:直接抓取了图片信息:下面的方法就是将js解析为php代码,然后执行就会获取到最后需要的用户姓名:defto_content(self):try:r=node.js(' 查看全部
js抓取网页内容(js抓取网页内容可能对你来说并不是最困难的一个难点)
js抓取网页内容可能对你来说并不是最困难的一个技术难点。因为相对前端来说,js确实比较容易上手,现在虽然js抓取很流行,但是如果遇到php来实现这一步却是非常麻烦。js抓取php文件的难点不在于抓取的数据格式(包括类型,字段等信息)或者说对页面中每个页面元素的获取这一步,而是要获取php中所调用的js代码,而且要抓取js代码还要加载包含php代码的content-type标签、content-language标签、trailing-trailing注解、warning、error等。
如果不去深入探索js抓取,也不想深入探索,那php代码可能有点low。但你要抓取带有content-type标签的html文件,js代码就又变的非常的可怕了。如果抓取不到content-type,那么很多内容可能就无法获取。首先,有极少的信息是可以通过抓取js获取的。这些主要是在页面中的dom元素上调用的,因为页面中会有结构对应html的各个元素,然后把html元素相应dom元素绑定到dom元素上,之后执行这个dom元素相应的js代码,相应html元素也就会就会提交给浏览器解析。
通过抓取js代码获取的内容有部分已经在html上跑的脚本也是可以的,但是不多。获取脚本调用的脚本是单一js,这些脚本因为是对dom元素上js注解,可以获取到绝大部分js文件内容,但是也不仅限于解析代码语言。比如js($css)注解,你可以获取所有相应的style标签,然后直接抓取style标签中的内容,但是如果按照trailing-trailing标签直接抓取,那么你得到的js代码有可能非常的多。
其实对于一般情况下,没有必要上述的注解需要注入浏览器中。但是我的一个朋友提到对于有移动端的网站,它会根据需要,把html渲染以postmanformui加载,具体我还没有尝试。使用node.js抓取客户端数据已经是不少大网站都在使用的方法了,一般是通过node.js渲染页面,然后调用php代码抓取客户端数据。
<p>比如我们有个用户输入密码的页面:现在你可以通过js来获取到用户输入密码的这个html值。那么接下来我们调用php中的一个方法:然后我们来尝试获取用户昵称信息:直接抓取了图片信息:下面的方法就是将js解析为php代码,然后执行就会获取到最后需要的用户姓名:defto_content(self):try:r=node.js('
js抓取网页内容(js抓取网页内容的话用beautifulsoup之类的自动生成文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 02:00
js抓取网页内容的话用beautifulsoup之类的自动生成html文件(小网站可能用不上),但是题主既然嫌弃直接生成html太慢,那就只能用正则表达式来提取了,一般的网站都有http代理,拿来用就行。
你可以用学校购买的带宽
2014-11-17中国知网全文下载网站高校通用阅读器
直接把中文用谷歌翻译,翻译成英文文档。下载下来就是英文文档。楼主平时又有中文文档需要的话。绝对比直接使用excel文档打开快。
没法,2012年以后已经限制免费下载了,
登录,在开发者选项里找到添加下载地址,
建议开发者选项里面添加https协议,
使用google搜索;在谷歌打开搜索页,但只打开关键词和内容,默认打开的是谷歌原生浏览器页面。
你好,现在本人亲测g+上下载硕博论文不需要安装一步步编译的,
使用谷歌搜索
随手百度一下好像知道了!
可以使用u盘本地拷贝进电脑,再使用网页浏览器打开的。
有种软件可以做到
基本上真的只有局域网才能下载了
到手机浏览器的应用商店里面搜索“百度网盘”就会出现很多下载的选项了
最简单的,百度这样找网页, 查看全部
js抓取网页内容(js抓取网页内容的话用beautifulsoup之类的自动生成文件)
js抓取网页内容的话用beautifulsoup之类的自动生成html文件(小网站可能用不上),但是题主既然嫌弃直接生成html太慢,那就只能用正则表达式来提取了,一般的网站都有http代理,拿来用就行。
你可以用学校购买的带宽
2014-11-17中国知网全文下载网站高校通用阅读器
直接把中文用谷歌翻译,翻译成英文文档。下载下来就是英文文档。楼主平时又有中文文档需要的话。绝对比直接使用excel文档打开快。
没法,2012年以后已经限制免费下载了,
登录,在开发者选项里找到添加下载地址,
建议开发者选项里面添加https协议,
使用google搜索;在谷歌打开搜索页,但只打开关键词和内容,默认打开的是谷歌原生浏览器页面。
你好,现在本人亲测g+上下载硕博论文不需要安装一步步编译的,
使用谷歌搜索
随手百度一下好像知道了!
可以使用u盘本地拷贝进电脑,再使用网页浏览器打开的。
有种软件可以做到
基本上真的只有局域网才能下载了
到手机浏览器的应用商店里面搜索“百度网盘”就会出现很多下载的选项了
最简单的,百度这样找网页,
js抓取网页内容(js抓取网页内容的方法在最常见的页面抓取有很多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-03 13:00
js抓取网页内容的方法在最常见的页面抓取有很多,在taobao中的使用则是用到了js获取网页内容的代码进行翻页抓取。总结的来说对于taobao类的网站,
答:不能。答:不能,不能。如果正常来说两条的话就能抓。答:但是看得出你这个有点弱。
不能,建议做到查询指定元素的excel文件,通过excel查询网页元素。
以前我做爬虫的时候,基本上都是抓页面所有的js,伪静态,结果爬回来的内容大部分都是js,这个时候正常来说都是抓住一次就可以了,因为正常网站中链接属性是一样的。还有一个办法是js代码循环,比如说本页js脚本抓取上一页的数据,每次循环会返回链接里面内容包含上一页数据的js,这样就可以了。这只是一些基本方法。
最简单的办法就是整理测试下这个页面js的属性,测试一下是否成立。除此之外,分享一个我爬的不好的网站,原理同上。
应该是能抓的,
建议去抓taobao的退款那块
亲测能抓可以抓得到这个包可以到我网站上面去看看xiaokuamm【taobao】能抓他的页面并解析出来的代码
你可以参考一下自己学校的北苑寝室吗?
没抓过, 查看全部
js抓取网页内容(js抓取网页内容的方法在最常见的页面抓取有很多)
js抓取网页内容的方法在最常见的页面抓取有很多,在taobao中的使用则是用到了js获取网页内容的代码进行翻页抓取。总结的来说对于taobao类的网站,
答:不能。答:不能,不能。如果正常来说两条的话就能抓。答:但是看得出你这个有点弱。
不能,建议做到查询指定元素的excel文件,通过excel查询网页元素。
以前我做爬虫的时候,基本上都是抓页面所有的js,伪静态,结果爬回来的内容大部分都是js,这个时候正常来说都是抓住一次就可以了,因为正常网站中链接属性是一样的。还有一个办法是js代码循环,比如说本页js脚本抓取上一页的数据,每次循环会返回链接里面内容包含上一页数据的js,这样就可以了。这只是一些基本方法。
最简单的办法就是整理测试下这个页面js的属性,测试一下是否成立。除此之外,分享一个我爬的不好的网站,原理同上。
应该是能抓的,
建议去抓taobao的退款那块
亲测能抓可以抓得到这个包可以到我网站上面去看看xiaokuamm【taobao】能抓他的页面并解析出来的代码
你可以参考一下自己学校的北苑寝室吗?
没抓过,
js抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-02 08:06
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理网页中JavaScript执行的结果时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上提出了这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:
查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中…… 查看全部
js抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理网页中JavaScript执行的结果时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上提出了这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:


查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中……
js抓取网页内容(一种nodejs抓取网页内容以上就是的详细内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-29 08:13
本文文章主要介绍Nodejs抓取html页面内容的关键代码。另外我还附上了nodejs来抓取网页的内容。挺好的,对node.js感兴趣的赶紧抓取页面内容。和朋友一起学习吧
废话不多说,我把node.js的核心代码贴出来,抓取html页面的内容。
具体代码如下:
var http = require("http"); var iconv = require('iconv-lite'); var option = { hostname: "stockdata.stock.hexun.com", path: "/gszl/s601398.shtml" }; var req = http.request(option, function(res) { res.on("data", function(chunk) { console.log(iconv.decode(chunk, "gbk")); }); }).on("error", function(e) { console.log(e.message); }); req.end();
看下面的nodejs抓取网页内容
function loadPage(url) { var http = require('http'); var pm = new Promise(function (resolve, reject) { http.get(url, function (res) { var html = ''; res.on('data', function (d) { html += d.toString() }); res.on('end', function () { resolve(html); }); }).on('error', function (e) { reject(e) }); }); return pm; } loadPage('http://www.baidu.com').then(function (d) { console.log(d); });
以上是Nodejs抓取html页面内容的详细内容(推荐),请关注其他相关html中文网站文章! 查看全部
js抓取网页内容(一种nodejs抓取网页内容以上就是的详细内容,你知道吗?)
本文文章主要介绍Nodejs抓取html页面内容的关键代码。另外我还附上了nodejs来抓取网页的内容。挺好的,对node.js感兴趣的赶紧抓取页面内容。和朋友一起学习吧
废话不多说,我把node.js的核心代码贴出来,抓取html页面的内容。
具体代码如下:
var http = require("http"); var iconv = require('iconv-lite'); var option = { hostname: "stockdata.stock.hexun.com", path: "/gszl/s601398.shtml" }; var req = http.request(option, function(res) { res.on("data", function(chunk) { console.log(iconv.decode(chunk, "gbk")); }); }).on("error", function(e) { console.log(e.message); }); req.end();
看下面的nodejs抓取网页内容
function loadPage(url) { var http = require('http'); var pm = new Promise(function (resolve, reject) { http.get(url, function (res) { var html = ''; res.on('data', function (d) { html += d.toString() }); res.on('end', function () { resolve(html); }); }).on('error', function (e) { reject(e) }); }); return pm; } loadPage('http://www.baidu.com').then(function (d) { console.log(d); });
以上是Nodejs抓取html页面内容的详细内容(推荐),请关注其他相关html中文网站文章!
js抓取网页内容(SCRAPY学习笔记八反反爬虫技术项目实战只好V*代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-29 14:26
SCRAPY学习笔记八项反爬虫技术项目实战
我不得不V**代理,) 2:减少单个IP和设置用户的请求次数,降低单个进程的爬行速度,增加scrapy进程以提高效率。3:302跳转,scrapy本身可以辅助跳转,但是由于js检测,跳转到js警告页面。明确大体方案后,再考虑行动的过程:最大的难点不是你要抓取什么内容,而是爬虫访问时不会返回正确的信息,所以只需要测试一下就可以拿到200返回成功。在 test 阶段,可以先忽略 12 项,先实现获取。所谓cookies是指为了识别用户身份而存储在用户本地终端(Client Side)上的某些网站数据(通常是加密的)。禁止 cookie 还可以防止使用 cookie 来识别爬虫轨迹。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”改成proxy for ip,虽然不够稳定,但是数量大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。
469 查看全部
js抓取网页内容(SCRAPY学习笔记八反反爬虫技术项目实战只好V*代理)
SCRAPY学习笔记八项反爬虫技术项目实战
我不得不V**代理,) 2:减少单个IP和设置用户的请求次数,降低单个进程的爬行速度,增加scrapy进程以提高效率。3:302跳转,scrapy本身可以辅助跳转,但是由于js检测,跳转到js警告页面。明确大体方案后,再考虑行动的过程:最大的难点不是你要抓取什么内容,而是爬虫访问时不会返回正确的信息,所以只需要测试一下就可以拿到200返回成功。在 test 阶段,可以先忽略 12 项,先实现获取。所谓cookies是指为了识别用户身份而存储在用户本地终端(Client Side)上的某些网站数据(通常是加密的)。禁止 cookie 还可以防止使用 cookie 来识别爬虫轨迹。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”改成proxy for ip,虽然不够稳定,但是数量大 效率分析:目标爬升网站5.30000页,ip200涨停。网站 成功。3:cookies的伪造没有实践过,见js的两个文档。4:js处理环境这个时候用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。用大神分析比较合适。phantomjs 事件处理介绍 基于浏览器引擎的爬虫介绍 首先,安装使用分布式redis做多机协同,使用scrapy异步多进程提高效率,使用V**自动脚本,改ip——”已经改成proxy for ip,虽然不够稳定,但是数量很大 效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。已经改成proxy for ip,虽然不够稳定,但是数量大。效率分析:目标爬升网站5.30000页,ip200涨停。
469
js抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-29 06:19
)
在上一篇文章()中,我们使用了模拟打开浏览器的方法来模拟点击网页中的Load More来动态加载网页并获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻男孩的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片,gifs,css等,如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标题
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
查看全部
js抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有
)
在上一篇文章()中,我们使用了模拟打开浏览器的方法来模拟点击网页中的Load More来动态加载网页并获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻男孩的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片,gifs,css等,如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标题
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取
js抓取网页内容(通过利用selenium的子模块解决动态数据的html内容的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-26 17:09
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name(\'kw\'\')
按类名定位,lis=find_elements_by_class_name(\'title_1\')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>- 查看全部
js抓取网页内容(通过利用selenium的子模块解决动态数据的html内容的方式)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用 urllib.urlopen(url).read() 得到的只是网页的静态html内容,还有很多动态数据(比如访问量网站,当前在线人数,微博上的点赞数等)不收录在静态html中,例如我想抓取当前点击打开bbs网站链接的每个部分的在线人数。静态html网页不收录(不信你去查页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我试过网上提到的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)来查看网上动态数据的趋势,但这需要从很多网址中寻找线索。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用Python(X,Y)IDE,安装的Python库没有自带selenium,直接在Python程序中import selenium会提示没有这个模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name(\'kw\'\')
按类名定位,lis=find_elements_by_class_name(\'title_1\')
更详细的定位方法请参考《博客园-昆虫大师》大神的selenium webdriver(python)教程第三章-定位方法(第一版可百度文库阅读,第二版从一开始就收费>-
js抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-26 04:28
本文章介绍的内容是关于js获取网页数据并以Excel格式存储。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
我在做项目的时候,遇到了把表格数据以Excel格式存储在网页中的问题。我将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i 查看全部
js抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
本文章介绍的内容是关于js获取网页数据并以Excel格式存储。有一定的参考价值。现在分享给大家,有需要的朋友可以参考
我在做项目的时候,遇到了把表格数据以Excel格式存储在网页中的问题。我将相关代码分享给大家,希望对大家有所帮助。
导出:
<p>
function AutomateExcel()
{
//下面的这句代码要求浏览器是IE并且需要在Internet选项中设置选项,设置的步骤在最下面
var oXL = new ActiveXObject("Excel.Application"); //创建应该对象
var oWB = oXL.Workbooks.Add();//新建一个Excel工作簿
var oSheet = oWB.ActiveSheet;//指定要写入内容的工作表为活动工作表
var table = document.all.data;//指定要写入的数据源的id
var hang = table.rows.length;//取数据源行数
var lie = table.rows(0).cells.length;//取数据源列数
// Add table headers going cell by cell.
for (i=0;i
js抓取网页内容(用“黑帽SEO”方法去堆积关键词,如何挖掘? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-21 22:32
)
使用“黑帽SEO”方式积累关键词。
四、 关键词出现的频率
关键词的出现频率是指这个关键词在这个网页上实际出现的次数。在百度更新算法之前,百度会关注关键词的出现频率,但只有从关键词积累的作弊方式出现解决方案
确定方法后,算法对关键词的出现频率有了新的算法。我们在写文章的时候一定要注意关键词的出现频率,一定要让关键词显得合理。
如何优化seo关键词1、Long Tail关键词 排名优化:一是长尾关键词挖掘。上面的就不细说了,再过滤。毕竟,一页的空间是非常有限的。一般使用两到三个长尾关键词。这些长尾关键词 是最好的相关或同义词。内容页的关键词做“四个地方”就够了(“测验”这个词可以点击百度),但不要机械地使用它,聪明的人出现在正确的地方。切记不要堆积太多,否则得不偿失。
2、主关键词的优化:指的是我们的网站内部链优化,我们可以在文章中适当的词中添加说明文字,如“搜外@ >SEO教程》,我们可以给这个词添加目录页的链接,起到推荐的作用。我们必须记住,有用的建议会增加权重。如果我在这里添加“boost”二字的描述,不仅不会生效,还会影响用户体验。任何对用户体验无效或适得其反的操作都不符合SEO优化。
3、数据分析:总结是我们做任何事情的必要步骤,数据分析是我们SEO工作的总结阶段,页面收录情况,长尾词排名,页面流量,页面停留时间、页面跳出率、长尾词内外链、关键词比例等都需要统计分析。
网站seo优化关键词如何挖矿?
很多企业在经营过程中都没有忽视各类宣传手段。合理的营销会给公司带来巨大的广告收入。其次,它还可以增加产品的销售数量,可以显示出很多好处,再加上现在互联网发展很快。利用互联网还可以用于网络营销推广,效率也提高了很多,能做的事情也丰富了。seo关键词排名优化是网络营销手段之一,那么seo关键词排名优化的目的,有哪些内容?
1、关键词的优化目的
很多公司关注seo关键词排名优化操作。该技术目前在中国广泛应用。优化的时候需要借助关键词的辅助,所以seo关键词排名优化也是营销手段之一。选择关键词优化的主要目的其实很简单,就是可以直接给宣传的网站,吸引更多人点击使用,增加网站流量,效果的宣传。
2、选择合适的关键词
seo关键词 排名的优化不是随意做的。在seo关键词排名优化的过程中,一定要注意关键词的选择,选择时一定要注意网站@。进行>的定位和样式,同时进行分词的操作。使用后可以有效的对关键词进行拆分和组合。这样可以保证seo关键词排名优化的顺利进行,让分词被大众搜索,想到关键词,最后突出网站。
3、控制关键词的数量
目前对网站进行seo关键词排名优化属于正常行为。在seo关键词排名优化的过程中,一定要控制好关键词的量词。这是最关键的一点。关键词 的数量将决定搜索引擎的抓取速度。因此,必须合理控制关键词的数量,并与搜索引擎的抓取相匹配。速度最合适。
以上就是seo关键词排名优化的目的和作用的解答。在进行seo关键词排名优化时,也有很多需要注意的问题。这点千万不能忽视,否则容易影响使用次数和安全性。
查看全部
js抓取网页内容(用“黑帽SEO”方法去堆积关键词,如何挖掘?
)
使用“黑帽SEO”方式积累关键词。
四、 关键词出现的频率
关键词的出现频率是指这个关键词在这个网页上实际出现的次数。在百度更新算法之前,百度会关注关键词的出现频率,但只有从关键词积累的作弊方式出现解决方案
确定方法后,算法对关键词的出现频率有了新的算法。我们在写文章的时候一定要注意关键词的出现频率,一定要让关键词显得合理。
如何优化seo关键词1、Long Tail关键词 排名优化:一是长尾关键词挖掘。上面的就不细说了,再过滤。毕竟,一页的空间是非常有限的。一般使用两到三个长尾关键词。这些长尾关键词 是最好的相关或同义词。内容页的关键词做“四个地方”就够了(“测验”这个词可以点击百度),但不要机械地使用它,聪明的人出现在正确的地方。切记不要堆积太多,否则得不偿失。
2、主关键词的优化:指的是我们的网站内部链优化,我们可以在文章中适当的词中添加说明文字,如“搜外@ >SEO教程》,我们可以给这个词添加目录页的链接,起到推荐的作用。我们必须记住,有用的建议会增加权重。如果我在这里添加“boost”二字的描述,不仅不会生效,还会影响用户体验。任何对用户体验无效或适得其反的操作都不符合SEO优化。
3、数据分析:总结是我们做任何事情的必要步骤,数据分析是我们SEO工作的总结阶段,页面收录情况,长尾词排名,页面流量,页面停留时间、页面跳出率、长尾词内外链、关键词比例等都需要统计分析。
网站seo优化关键词如何挖矿?
很多企业在经营过程中都没有忽视各类宣传手段。合理的营销会给公司带来巨大的广告收入。其次,它还可以增加产品的销售数量,可以显示出很多好处,再加上现在互联网发展很快。利用互联网还可以用于网络营销推广,效率也提高了很多,能做的事情也丰富了。seo关键词排名优化是网络营销手段之一,那么seo关键词排名优化的目的,有哪些内容?
1、关键词的优化目的
很多公司关注seo关键词排名优化操作。该技术目前在中国广泛应用。优化的时候需要借助关键词的辅助,所以seo关键词排名优化也是营销手段之一。选择关键词优化的主要目的其实很简单,就是可以直接给宣传的网站,吸引更多人点击使用,增加网站流量,效果的宣传。
2、选择合适的关键词
seo关键词 排名的优化不是随意做的。在seo关键词排名优化的过程中,一定要注意关键词的选择,选择时一定要注意网站@。进行>的定位和样式,同时进行分词的操作。使用后可以有效的对关键词进行拆分和组合。这样可以保证seo关键词排名优化的顺利进行,让分词被大众搜索,想到关键词,最后突出网站。
3、控制关键词的数量
目前对网站进行seo关键词排名优化属于正常行为。在seo关键词排名优化的过程中,一定要控制好关键词的量词。这是最关键的一点。关键词 的数量将决定搜索引擎的抓取速度。因此,必须合理控制关键词的数量,并与搜索引擎的抓取相匹配。速度最合适。
以上就是seo关键词排名优化的目的和作用的解答。在进行seo关键词排名优化时,也有很多需要注意的问题。这点千万不能忽视,否则容易影响使用次数和安全性。
js抓取网页内容(按照统一资源标准协议(url)中的资源的顺序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-19 06:03
js抓取网页内容本质上,抓取js主要是抓网页内容的结构,网页中一般是meta信息,如页面定位ip是否处于本地,为什么打不开,主要是因为http协议不允许存在超链接,不能包含单个meta信息。其次就是ajax技术的应用,页面定位加载不了,ajax就能够加载,所以抓取了内容也是能够显示的,具体html怎么抓取,可以查看搜集寻宝链接网站,相关资料会有很多。
加ajax代码,就能获取网页内容了,以前的content-loaded会限制你网页内容显示,现在的,在text-loaded方法里面的dom就会根据url进行抓取,
ajax解析网页同样可以获取网页内容,你搜索“what'syourname”,然后在新的页面里输入“yoyoyohh”,
what'syourname:这段js里面包含:一个model,这个model主要是用于做一些效果js调用或者数据提取cookie怎么用的:这里,这里可以存放返回的信息token对外暴露:存取到数据库当然可以全文提取:ajax(asynchronousjavascriptandxml)异步javascript和xml,本质是模拟http请求,用户点击提交会以socket方式传回一个消息。
按照统一资源标准协议(url)中的资源的排布顺序,这些响应有序的组合在一起。这些可以被接收、使用、提取,甚至嵌入到网页中。在这样的情况下,用户不用浏览器就可以通过访问web服务器直接了解他们所需要的信息。 查看全部
js抓取网页内容(按照统一资源标准协议(url)中的资源的顺序)
js抓取网页内容本质上,抓取js主要是抓网页内容的结构,网页中一般是meta信息,如页面定位ip是否处于本地,为什么打不开,主要是因为http协议不允许存在超链接,不能包含单个meta信息。其次就是ajax技术的应用,页面定位加载不了,ajax就能够加载,所以抓取了内容也是能够显示的,具体html怎么抓取,可以查看搜集寻宝链接网站,相关资料会有很多。
加ajax代码,就能获取网页内容了,以前的content-loaded会限制你网页内容显示,现在的,在text-loaded方法里面的dom就会根据url进行抓取,
ajax解析网页同样可以获取网页内容,你搜索“what'syourname”,然后在新的页面里输入“yoyoyohh”,
what'syourname:这段js里面包含:一个model,这个model主要是用于做一些效果js调用或者数据提取cookie怎么用的:这里,这里可以存放返回的信息token对外暴露:存取到数据库当然可以全文提取:ajax(asynchronousjavascriptandxml)异步javascript和xml,本质是模拟http请求,用户点击提交会以socket方式传回一个消息。
按照统一资源标准协议(url)中的资源的排布顺序,这些响应有序的组合在一起。这些可以被接收、使用、提取,甚至嵌入到网页中。在这样的情况下,用户不用浏览器就可以通过访问web服务器直接了解他们所需要的信息。
js抓取网页内容(网页里注释的内容会被百度注释分析吗?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-19 00:04
很多站长都知道,网页代码中有评论代码。形式是HTML中的注释内容出现在网页的源代码中,用户在浏览网页时看不到。因为源码中显示的注解内容不会影响页面的内容,很多人认为蜘蛛会抓取注解信息参与网页的分析和排名,所以添加了大量的注解内容到网页,甚至直接堆在注解关键词中。
网页中的注解内容会被抓取吗?我们来看看百度工程师是如何回答的:
Q:评论内容会被百度抓取分析吗?
百度工程师:在文本提取过程中会忽略html中的注释内容。注释的代码虽然不会被爬取,但也会造成代码的繁琐,所以可以尽量少。
显然,搜索引擎蜘蛛非常聪明。他们可以在网络爬行过程中识别注释信息并直接忽略它们。因此,注释内容不会被抓取,也不会参与网页内容的分析。试想如果蜘蛛可以抓取评论,而这个评论代码就相当于一种隐藏的文字,那么网站的主要内容可以被JS代码调用,仅供用户浏览,而蜘蛛抓取的内容想要抓取的就是全部 把它放在大量的注释信息中,让网页给蜘蛛和用户展示不同的内容。如果你是灰色行业网站,那么你可以给搜索引擎一个完全正规的内容展示,摆脱搜索引擎的束缚,搜索引擎会不会正式允许你作弊?所以不管有多少关键词
那么,在评论中添加关键词会影响排名吗?不会是因为搜索引擎直接忽略了注释,而是如何注释大量内容会影响网页的风格,影响网页的加载速度。因此,如果注释没有用,请尝试删除它们并尽可能保持代码简单。我们经常讲网站代码减肥。简化标注信息是减肥的方法之一。优化注解信息有利于网站瘦身。
当然,很多程序员和网页设计师都习惯于在网页中添加注释信息。这是一个好习惯。合理的标注信息可以减少查找信息的时间,使代码的查询和修改更加方便。因此,推荐使用在线页面 只需添加注释信息,如网页各部分的头尾注释,重要内容部分注释等,离线备份网页可以添加每个部分的注释信息。部分更详细,方便技术人员浏览和修改。有利于网页减肥不影响以后的网页修改。 查看全部
js抓取网页内容(网页里注释的内容会被百度注释分析吗?(图))
很多站长都知道,网页代码中有评论代码。形式是HTML中的注释内容出现在网页的源代码中,用户在浏览网页时看不到。因为源码中显示的注解内容不会影响页面的内容,很多人认为蜘蛛会抓取注解信息参与网页的分析和排名,所以添加了大量的注解内容到网页,甚至直接堆在注解关键词中。
网页中的注解内容会被抓取吗?我们来看看百度工程师是如何回答的:
Q:评论内容会被百度抓取分析吗?
百度工程师:在文本提取过程中会忽略html中的注释内容。注释的代码虽然不会被爬取,但也会造成代码的繁琐,所以可以尽量少。
显然,搜索引擎蜘蛛非常聪明。他们可以在网络爬行过程中识别注释信息并直接忽略它们。因此,注释内容不会被抓取,也不会参与网页内容的分析。试想如果蜘蛛可以抓取评论,而这个评论代码就相当于一种隐藏的文字,那么网站的主要内容可以被JS代码调用,仅供用户浏览,而蜘蛛抓取的内容想要抓取的就是全部 把它放在大量的注释信息中,让网页给蜘蛛和用户展示不同的内容。如果你是灰色行业网站,那么你可以给搜索引擎一个完全正规的内容展示,摆脱搜索引擎的束缚,搜索引擎会不会正式允许你作弊?所以不管有多少关键词
那么,在评论中添加关键词会影响排名吗?不会是因为搜索引擎直接忽略了注释,而是如何注释大量内容会影响网页的风格,影响网页的加载速度。因此,如果注释没有用,请尝试删除它们并尽可能保持代码简单。我们经常讲网站代码减肥。简化标注信息是减肥的方法之一。优化注解信息有利于网站瘦身。
当然,很多程序员和网页设计师都习惯于在网页中添加注释信息。这是一个好习惯。合理的标注信息可以减少查找信息的时间,使代码的查询和修改更加方便。因此,推荐使用在线页面 只需添加注释信息,如网页各部分的头尾注释,重要内容部分注释等,离线备份网页可以添加每个部分的注释信息。部分更详细,方便技术人员浏览和修改。有利于网页减肥不影响以后的网页修改。
js抓取网页内容(小编典典在直接回答您的问题,值得一开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-17 09:01
小编点点
在直接回答你的问题之前,值得开始:如果你需要做的只是从静态 HTML 页面中提取内容,你可能应该将 HTTP 库(例如 Requests 或内置的 urllib.request)与 lxml 或 BeautifulSoup 结合起来,而不是 Selenium (虽然硒可能就足够了)。不需要使用硒的优点:
请注意,需要 cookie 才能工作的站点并不是破解 Selenium 的理由——
您可以轻松创建一个 URL 打开函数,它使用 cookielib
/
cookiejar 在 HTTP 请求中神奇地设置和发送 cookie。
好的,那为什么还要考虑使用 Selenium 呢?它几乎可以完全处理你要爬取的内容通过JavaScript添加到页面而不是烘焙成HTML的情况。即便如此,您也可以在不破坏重型机械的情况下获得所需的数据。通常,以下情况之一适用:
如果你这样做
值得考虑使用 Selenium,请在 headless 模式下使用,(至少)Firefox 和 Chrome 驱动程序支持。网络爬虫通常不需要实际以图形方式显示页面,也不需要使用任何特定于浏览器的怪癖或功能,因此理想的选择是无头浏览器——
它具有更低的 CPU 和内存成本以及更少的崩溃或悬挂移动部件。
2020-06-26 查看全部
js抓取网页内容(小编典典在直接回答您的问题,值得一开始)
小编点点
在直接回答你的问题之前,值得开始:如果你需要做的只是从静态 HTML 页面中提取内容,你可能应该将 HTTP 库(例如 Requests 或内置的 urllib.request)与 lxml 或 BeautifulSoup 结合起来,而不是 Selenium (虽然硒可能就足够了)。不需要使用硒的优点:
请注意,需要 cookie 才能工作的站点并不是破解 Selenium 的理由——
您可以轻松创建一个 URL 打开函数,它使用 cookielib
/
cookiejar 在 HTTP 请求中神奇地设置和发送 cookie。
好的,那为什么还要考虑使用 Selenium 呢?它几乎可以完全处理你要爬取的内容通过JavaScript添加到页面而不是烘焙成HTML的情况。即便如此,您也可以在不破坏重型机械的情况下获得所需的数据。通常,以下情况之一适用:
如果你这样做
值得考虑使用 Selenium,请在 headless 模式下使用,(至少)Firefox 和 Chrome 驱动程序支持。网络爬虫通常不需要实际以图形方式显示页面,也不需要使用任何特定于浏览器的怪癖或功能,因此理想的选择是无头浏览器——
它具有更低的 CPU 和内存成本以及更少的崩溃或悬挂移动部件。
2020-06-26
js抓取网页内容(#微信刷脸支付介绍SEO优化需要掌握的四个基本常识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-16 00:10
#微信刷脸支付介绍
SEO优化的四个基本常识。作为一名网站优化者,你必须掌握一些搜索引擎优化的基础知识。网站 排名与掌握搜索引擎优化的基础知识息息相关。一、善于使用锚文本锚文本就是在文章中添加一个链接代码,然后点击关键词即可到达你设置的页面。锚文本在搜索引擎优化中扮演着重要的角色。一般来说,网页上只会显示“text关键词”这个词,但是通过html代码可以看到链接代码。二、避免网站上的死链接。所谓死链接是指无效链接和错误链接。这在过去可能是正常的,但后来可能会变成死链。当您打开此链接时,服务器' s 响应是无法打开或 404 错误页面。避免死链接的最好方法是优化网站。我们可以使用网站管理员工具及时发现站点是否存在死链接,然后点击打开确认。三、网站地图是必不可少的。网站当然建设需要制作网站地图,这也是SEO优化的体现。网站地图使搜索引擎蜘蛛能够更好地抓取您的网站。网站 地图是一个页面,类似于网站的路径图,只不过这个页面上会有一个到整个网站页面的链接。制作网站地图的目的是为了展示给搜索引擎,让搜索引擎蜘蛛读取地图,从而更好的浏览你的网站 并从您的 网站 捕获的网页中获取更好的信息以供收录。四、精准目标的合理选择关键词和所谓的长尾目标关键词关键词也是这个网站的主要关键词,优化器需要付出密切注意这个目标关键字来优化网站。目标关键字必须与网站的主题内容相关。目标关键词的选择还要考虑百度指数。结合你的实际情况网站,选择的目标关键词不要太冷。如果你的网站权重高,而且还是老站,可以选择最受欢迎的。如果你的网站权重偏低,而且还是一个新的网站,建议你选择一个适中的目标关键词。掌握以上基础知识是优化搜索引擎优化的基础。如果你知道并且能够熟悉这些基本常识的使用,那一定会给网站优化带来不错的效果!如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。微信刷脸支付
SEO优化如何评价友情链接的质量?友情链接的传播是SEO优化中必不可少的工作,但是友情链接会互相影响,低质量的友情链接会影响到我们的网站,所以准确评估友情链接的质量是SEO必不可少的技能。SEO如何评估友情链接的质量?智码链接搜索引擎优化团队建议从以下几个方面入手。1.网站 合法性主要是指网站的内容是否收录非法内容。这些网站一般都是通过黑帽搜索引擎优化排名的,网站被搜索引擎惩罚的风险非常高,和他们交流会受到影响。2.网站 相关性SEO友情交换链接需要注意网站和自己网站的相关性。相关的网站更有利于优化,过多的交换不相关的网站链接是没有用的,即使对方权重高,也不会影响我们的优化。另外,其他网站上的友情链接太多,或者如果质量不好,不建议交流。3.网站的收录率网站的高内容收录率意味着网站的高品质和网站的高用户体验. 这样的网站朋友链价值很高。其次,搜索引擎优化可以从网站的历史采集和变化来判断网站是否降级。这个友好的链条应该小心更换。4.网站百度权重 百度权重反映了网站在搜索引擎和用户中的受欢迎程度。这种友好的联系是高质量的。对于没有百度权重的新网站,SEO可以关注其他网站的合理性,网站的内容和布局合理,友情链接质量也不错。5.网站百度快照网页快照是对网站活力的评价指标。百度快照更新速度快,反映了网站持续提供优质内容,经常被搜索引擎蜘蛛抓取。需要注意的是,我们不仅要关注百度快照更新的时间段,还要注意其快照更新的稳定性。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。 查看全部
js抓取网页内容(#微信刷脸支付介绍SEO优化需要掌握的四个基本常识)
#微信刷脸支付介绍
SEO优化的四个基本常识。作为一名网站优化者,你必须掌握一些搜索引擎优化的基础知识。网站 排名与掌握搜索引擎优化的基础知识息息相关。一、善于使用锚文本锚文本就是在文章中添加一个链接代码,然后点击关键词即可到达你设置的页面。锚文本在搜索引擎优化中扮演着重要的角色。一般来说,网页上只会显示“text关键词”这个词,但是通过html代码可以看到链接代码。二、避免网站上的死链接。所谓死链接是指无效链接和错误链接。这在过去可能是正常的,但后来可能会变成死链。当您打开此链接时,服务器' s 响应是无法打开或 404 错误页面。避免死链接的最好方法是优化网站。我们可以使用网站管理员工具及时发现站点是否存在死链接,然后点击打开确认。三、网站地图是必不可少的。网站当然建设需要制作网站地图,这也是SEO优化的体现。网站地图使搜索引擎蜘蛛能够更好地抓取您的网站。网站 地图是一个页面,类似于网站的路径图,只不过这个页面上会有一个到整个网站页面的链接。制作网站地图的目的是为了展示给搜索引擎,让搜索引擎蜘蛛读取地图,从而更好的浏览你的网站 并从您的 网站 捕获的网页中获取更好的信息以供收录。四、精准目标的合理选择关键词和所谓的长尾目标关键词关键词也是这个网站的主要关键词,优化器需要付出密切注意这个目标关键字来优化网站。目标关键字必须与网站的主题内容相关。目标关键词的选择还要考虑百度指数。结合你的实际情况网站,选择的目标关键词不要太冷。如果你的网站权重高,而且还是老站,可以选择最受欢迎的。如果你的网站权重偏低,而且还是一个新的网站,建议你选择一个适中的目标关键词。掌握以上基础知识是优化搜索引擎优化的基础。如果你知道并且能够熟悉这些基本常识的使用,那一定会给网站优化带来不错的效果!如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。微信刷脸支付
SEO优化如何评价友情链接的质量?友情链接的传播是SEO优化中必不可少的工作,但是友情链接会互相影响,低质量的友情链接会影响到我们的网站,所以准确评估友情链接的质量是SEO必不可少的技能。SEO如何评估友情链接的质量?智码链接搜索引擎优化团队建议从以下几个方面入手。1.网站 合法性主要是指网站的内容是否收录非法内容。这些网站一般都是通过黑帽搜索引擎优化排名的,网站被搜索引擎惩罚的风险非常高,和他们交流会受到影响。2.网站 相关性SEO友情交换链接需要注意网站和自己网站的相关性。相关的网站更有利于优化,过多的交换不相关的网站链接是没有用的,即使对方权重高,也不会影响我们的优化。另外,其他网站上的友情链接太多,或者如果质量不好,不建议交流。3.网站的收录率网站的高内容收录率意味着网站的高品质和网站的高用户体验. 这样的网站朋友链价值很高。其次,搜索引擎优化可以从网站的历史采集和变化来判断网站是否降级。这个友好的链条应该小心更换。4.网站百度权重 百度权重反映了网站在搜索引擎和用户中的受欢迎程度。这种友好的联系是高质量的。对于没有百度权重的新网站,SEO可以关注其他网站的合理性,网站的内容和布局合理,友情链接质量也不错。5.网站百度快照网页快照是对网站活力的评价指标。百度快照更新速度快,反映了网站持续提供优质内容,经常被搜索引擎蜘蛛抓取。需要注意的是,我们不仅要关注百度快照更新的时间段,还要注意其快照更新的稳定性。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。分析朋友链的快照更新历史。如果是间歇性的,这在一定程度上反映了网站的不稳定。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。在某种程度上。交换朋友链时要小心。其实友情链接的好处不是可以给你的网站带来多少直接访问,而是可以让搜索引擎收录更多你的网页,相当于搜索引擎需要访问网站 之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。但那会让搜索引擎收录更多你的网页,这相当于搜索引擎需要访问网站之间建立良好的网络环境。但是,搜索引擎优化要谨慎对待,因为它会影响彼此的网站。如果没有特别说明,文章都是拉18原创制作的。如转载请注明出处。
js抓取网页内容(有些网页加载时动态创建HTML内容怎么做?网页介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-14 01:21
)
有些网页在加载时会动态创建HTML内容,只有在js代码完全执行后才会显示最终结果。如果使用传统方式抓取页面,则只能在js代码执行前获取页面上的内容。
有两种方法可以解决这个问题:
1.直接从js代码中抓取数据(执行js代码,解析js变量)。
2.用第三方库运行js,抓取运行后的最终html页面。
python中使用selenium执行js
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,需要配合第三方浏览器使用。这里使用phantomjs工具代替真实浏览器。
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
将 selenium 和 phantomjs 结合在一起,您可以运行一个非常强大的爬虫,它可以处理 cookie、js、headers 以及您需要做的任何事情。
安装:
Selenium有python库,可以用pip等安装; phantomjs是一个功能齐全的“无头”浏览器,不是python库,所以不需要像其他python库一样安装,也不能用pip安装。
sudo pip install selenium
http://npm.taobao.org/dist/phantomjs/
#下载安装包(sudo apt-get install phantomjs安装的不是最新的,发现不能用)
phantomjs-2.1.1-linux-i686.tar.bz2
tar -jxvf phantomjs-2.1.1-linux-i686.tar.bz2
使用:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/opt/phantomjs-2.1.1-linux-i686/bin/phantomjs')
#executable_path为你的phantomjs可执行文件路径
driver.get("http://news.sohu.com/scroll/")
#或得js变量的值
r = driver.execute_script("return newsJason")
print r
#selenium在webdriver的DOM中使用选择器来查找元素,名字直接了当,by对象可使用的选择策略有:id,class_name,css_selector,link_text,name,tag_name,tag_name,xpath等等
print driver.find_element_by_tag_name("div").text
print driver.find_element_by_csss_selector("#content").text
print driver.find_element_by_id("content").text 查看全部
js抓取网页内容(有些网页加载时动态创建HTML内容怎么做?网页介绍
)
有些网页在加载时会动态创建HTML内容,只有在js代码完全执行后才会显示最终结果。如果使用传统方式抓取页面,则只能在js代码执行前获取页面上的内容。
有两种方法可以解决这个问题:
1.直接从js代码中抓取数据(执行js代码,解析js变量)。
2.用第三方库运行js,抓取运行后的最终html页面。
python中使用selenium执行js
Selenium 是一个强大的网络数据采集 工具,它最初是为网站 自动化测试而开发的。 Selenium 可以让浏览器自动加载页面,获取需要的数据,甚至可以对页面进行截图,或者判断是否对网站 进行了某些操作。
Selenium 没有浏览器,需要配合第三方浏览器使用。这里使用phantomjs工具代替真实浏览器。
PhantomJS 是一个基于 WebKit 的服务器端 JavaScript API。它完全支持网络,无需浏览器支持。它速度快,并且本机支持各种 Web 标准:DOM 处理、CSS 选择器、JSON、Canvas 和 SVG。 PhantomJS 可用于页面自动化、网络监控、网页截图和无界面测试。
将 selenium 和 phantomjs 结合在一起,您可以运行一个非常强大的爬虫,它可以处理 cookie、js、headers 以及您需要做的任何事情。
安装:
Selenium有python库,可以用pip等安装; phantomjs是一个功能齐全的“无头”浏览器,不是python库,所以不需要像其他python库一样安装,也不能用pip安装。
sudo pip install selenium
http://npm.taobao.org/dist/phantomjs/
#下载安装包(sudo apt-get install phantomjs安装的不是最新的,发现不能用)
phantomjs-2.1.1-linux-i686.tar.bz2
tar -jxvf phantomjs-2.1.1-linux-i686.tar.bz2
使用:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='/opt/phantomjs-2.1.1-linux-i686/bin/phantomjs')
#executable_path为你的phantomjs可执行文件路径
driver.get("http://news.sohu.com/scroll/";)
#或得js变量的值
r = driver.execute_script("return newsJason")
print r
#selenium在webdriver的DOM中使用选择器来查找元素,名字直接了当,by对象可使用的选择策略有:id,class_name,css_selector,link_text,name,tag_name,tag_name,xpath等等
print driver.find_element_by_tag_name("div").text
print driver.find_element_by_csss_selector("#content").text
print driver.find_element_by_id("content").text
js抓取网页内容(代理支持·支持TLS/SSL协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-14 01:21
· 代理支持
· 支持TLS/SSL协议
2. Cheerio(也称为解析器):
· Cheerio 提供专为服务器设计的快速、灵活和精益的核心jQuery 实现。
· Cheerio 解析标记并提供 API 用于遍历/操作结果数据结构。
特征:
· 熟悉的语法:Cheerio 实现了核心 jQuery 的一个子集。它去除了jQuery库中所有的DOM不一致和浏览痕迹,充分展示了API的魅力。
· 快速:Cheerio 使用非常简单且一致的 DOM 模型。因此,解析、操作和呈现非常高效。初步的端到端基准测试表明,cheerio 比 JSDOM 快约 8 倍。
· 惊人的灵活性:Cheerio 几乎可以解析任何 HTML 或 XML 文档。
3.渗透(又名解析器)
· Osmosis 包括 HTML/XML 解析器和 webscraper。
· 它是用 node.js 编写的,收录 css3/xpath 选择器和轻量级 http 包装器。
· 没有像 Cheerio 这样的大依赖。
特征:
· 支持 CSS 3.0 和 XPath1.0 选择器的混合
· 加载和搜索 AJAX 内容
· 记录 URL、重定向和错误
· Cookie jar 和自定义 cookie/header/user agent
· 登录/表单提交、会话 cookie 和基本身份验证
· 单代理或多代理处理代理故障
· 重试和重定向限制
4. Puppeteer(也称为无头 Chrome 自动化浏览器):
Puppeteer 是一个 Node.js 库,它提供了一个简单但高效的 API,使您能够控制 Google 的 Chrome 或 Chromium 浏览器。
它还可以在无头模式下运行 Chromium(对于在服务器上运行浏览器非常有用),并且可以在不需要用户界面的情况下发送和接收请求。
最好的部分是它可以在后台操作,遵循 API 的说明。
特征:
· 单击按钮、链接和图像等元素
· 自动表单提交
· 导航页面
· 使用时间线追踪找出问题所在
· 直接在浏览器中自动测试用户界面和各种前端应用程序
· 截屏
· 将网页转换为pdf文件
5. Apify SDK(也称为完整的网页抓取框架):
· Apify SDK 是一个开源的Node.js 库,用于抓取和网页抓取。
· Apify SDK 是一种独特的工具,可简化网络爬虫、爬虫、数据提取器和网络自动化任务的开发。
· 提供管理和自动扩容headless Chrome/Puppeteer实例池、维护待爬取的URL队列、将爬取结果存储到本地文件系统或云端、轮换代理等工具。
· 可以在自己的应用中独立使用,也可以在 Apify 云上运行的参与者之间使用。
特征:
· 使用 URL 的持久队列来深度获取整个 网站。
· 运行CSV文件中收录100k URL的爬取代码,代码崩溃时不会丢失任何数据。
· 通过旋转代理隐藏您的浏览器源。
· 安排代码定期运行并发送错误通知。
· 禁用网站 使用的浏览器指纹保护。
随着时间的推移,对网络爬虫的需求不断增长。所以程序员们,你们的春天来了!搞定了很多只会复制粘贴数据的妹子。用你的代码让女孩认真起来!但是网络爬虫也需要谨慎。归根结底,信息不是可以被窃取和出售的东西。不要像这个老铁一样炫耀:
发表评论,点赞,发朋友圈 查看全部
js抓取网页内容(代理支持·支持TLS/SSL协议)
· 代理支持
· 支持TLS/SSL协议
2. Cheerio(也称为解析器):
· Cheerio 提供专为服务器设计的快速、灵活和精益的核心jQuery 实现。
· Cheerio 解析标记并提供 API 用于遍历/操作结果数据结构。
特征:
· 熟悉的语法:Cheerio 实现了核心 jQuery 的一个子集。它去除了jQuery库中所有的DOM不一致和浏览痕迹,充分展示了API的魅力。
· 快速:Cheerio 使用非常简单且一致的 DOM 模型。因此,解析、操作和呈现非常高效。初步的端到端基准测试表明,cheerio 比 JSDOM 快约 8 倍。
· 惊人的灵活性:Cheerio 几乎可以解析任何 HTML 或 XML 文档。
3.渗透(又名解析器)
· Osmosis 包括 HTML/XML 解析器和 webscraper。
· 它是用 node.js 编写的,收录 css3/xpath 选择器和轻量级 http 包装器。
· 没有像 Cheerio 这样的大依赖。
特征:
· 支持 CSS 3.0 和 XPath1.0 选择器的混合
· 加载和搜索 AJAX 内容
· 记录 URL、重定向和错误
· Cookie jar 和自定义 cookie/header/user agent
· 登录/表单提交、会话 cookie 和基本身份验证
· 单代理或多代理处理代理故障
· 重试和重定向限制
4. Puppeteer(也称为无头 Chrome 自动化浏览器):
Puppeteer 是一个 Node.js 库,它提供了一个简单但高效的 API,使您能够控制 Google 的 Chrome 或 Chromium 浏览器。
它还可以在无头模式下运行 Chromium(对于在服务器上运行浏览器非常有用),并且可以在不需要用户界面的情况下发送和接收请求。
最好的部分是它可以在后台操作,遵循 API 的说明。
特征:
· 单击按钮、链接和图像等元素
· 自动表单提交
· 导航页面
· 使用时间线追踪找出问题所在
· 直接在浏览器中自动测试用户界面和各种前端应用程序
· 截屏
· 将网页转换为pdf文件
5. Apify SDK(也称为完整的网页抓取框架):
· Apify SDK 是一个开源的Node.js 库,用于抓取和网页抓取。
· Apify SDK 是一种独特的工具,可简化网络爬虫、爬虫、数据提取器和网络自动化任务的开发。
· 提供管理和自动扩容headless Chrome/Puppeteer实例池、维护待爬取的URL队列、将爬取结果存储到本地文件系统或云端、轮换代理等工具。
· 可以在自己的应用中独立使用,也可以在 Apify 云上运行的参与者之间使用。
特征:
· 使用 URL 的持久队列来深度获取整个 网站。
· 运行CSV文件中收录100k URL的爬取代码,代码崩溃时不会丢失任何数据。
· 通过旋转代理隐藏您的浏览器源。
· 安排代码定期运行并发送错误通知。
· 禁用网站 使用的浏览器指纹保护。
随着时间的推移,对网络爬虫的需求不断增长。所以程序员们,你们的春天来了!搞定了很多只会复制粘贴数据的妹子。用你的代码让女孩认真起来!但是网络爬虫也需要谨慎。归根结底,信息不是可以被窃取和出售的东西。不要像这个老铁一样炫耀:
发表评论,点赞,发朋友圈
js抓取网页内容(scrapy1064位python3.6scrapy1.3.3-splash,那知)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-14 01:18
最近想学scrapy-splash。我以前用硒和铬。我总觉得有点慢。如果我想学习scrapy-splash,我知道网上有很多不可靠的内容。整合了很多文章,终于成功了。把它写下来以免忘记它,也是一个正确的指南。
软件环境:
赢得 10 64 位
蟒蛇3.6
刮刮1.3.3
刮飞溅 0.7.2
我用的是anaconda,忘了scrapy是内置的还是后来安装的。如果没有安装anaconda,直接用pip install scrapy安装即可。
ScrapySplash 安装
注意 ScrapySplash 需要使用 docker。懂的人我就不用解释了。不明白的,跟着操作就行了。这里的 ScrapySplash 与上述软件环境中的不同。以上是scrapy中使用import时使用的。这相当于一个软件,你必须安装它才能使用它。
安装 Docker
准备
由于在docker中需要用到ScrapySplash,所以我们先安装docker。安装前,请检查您的计算机是否为 win 10 64 位,以及是否启用了超级虚拟化。
正式安装
win 10不同版本问题很多。
常规安装:从官网以下地址下载
如果这种方式安装过程中出现错误或者安装后报错,请使用docker工具箱进行安装:
注意:docker使用了虚拟化技术,所以安装的时候一起安装virtualbox,请一定要检查一下,如果你已经安装了,就不需要了。
想了解更多关于Docker的知识,可以访问Docker官网:
启动环境
安装好docker后,打开docker,可以直接使用cmd进行正常安装,如果是通过toolbox安装的,请使用Docker Quickstart Terminal进行操作。
我是用toolbox安装的,所以下面的命令行操作都在Docker Quickstart Terminal里面。
打开命令行:
第一次调用会比较慢,因为virtualbox虚拟机还在启动中。等待一段时间后出现如下界面,说明安装成功。
docker 启动后.png
里面有一个IP,请记住这是以后要使用的东西。
下载 ScrapySplash
在命令行中输入 docker run -p 8050:8050 scrapinghub/splash。这就是 docker 的使用方式。这意味着飞溅开始了。第一次启动是在本地没有splash应用的时候,会自动从docker hub下载。我们不必担心这个过程。,慢慢等。
下载后直接启动应用,出现如下界面:
启动成功.png
这时候我们可以在浏览器中输入:8050/,这里的IP就是之前出现的IP。出现如下界面,说明启动成功。
启动成功.png
注:参考相关文章时,总能看到是输入:8050/,不知道是不是每个人的电脑不一样,还是都被别人蒙上了。安装几次后,还是没有出现上面的界面。按照我的理解,localhost就是本地主机,但是我们的应用是在虚拟机里面的。如果是本地主机,就说明我们需要在虚拟机中打开浏览器,但是我们是在win 10下运行的,难道其他文章的作者都是直接在虚拟机中运行的。这里不清楚。如果有人能告知,我将不胜感激。
好了,到此,整个环境搭建完毕,下面搭建scrapy爬虫。
爬虫爬虫设置
scrapy项目其实和普通项目没什么区别。不明白的可以参考我的另一个文章 Scrapy抓取本地论坛招聘内容(一)
在这里,我创建了一个新的学习项目:
> scrapy startproject jdproject
> cd jdproject/
> scrapy genspider jd https://www.jd.com/
注意:这里的操作也是在命令行中,但是不需要在Docker Quickstart Terminal中,普通cmd中也可以
打开jdproject/spiders/jd.py,修改内容:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request, FormRequest
from scrapy.selector import Selector
from scrapy_splash.request import SplashRequest, SplashFormRequest
class JdSpider(scrapy.Spider):
name = "jd"
def start_requests(self):
splash_args = {"lua_source": """
--splash.response_body_enabled = true
splash.private_mode_enabled = false
splash:set_user_agent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36")
assert(splash:go("https://item.jd.com/5089239.html"))
splash:wait(3)
return {html = splash:html()}
"""}
yield SplashRequest("https://item.jd.com/5089239.html", endpoint='run', args=splash_args, callback=self.onSave)
def onSave(self, response):
value = response.xpath('//span[@class="p-price"]//text()').extract()
print(value)
打开jdproject/settings.py,修改:
# See http://scrapy.readthedocs.org/ ... .html
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# See http://scrapy.readthedocs.org/ ... .html
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, # 不配置查不到信息
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://192.168.99.100:8050/" # 自己安装的docker里的splash位置
DUPEFILTER_CLASS = "scrapy_splash.SplashAwareDupeFilter"
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
测试
我这里用的是测试用的,需要的是产品的价格。
jd.png
运行爬虫:
结果.png
可以清楚的看到,我们想要的价格已经出现了。
至此,我们已经成功部署了ScrapySplash,并成功实现了爬虫项目。
对splash感兴趣的可以参考官网: 查看全部
js抓取网页内容(scrapy1064位python3.6scrapy1.3.3-splash,那知)
最近想学scrapy-splash。我以前用硒和铬。我总觉得有点慢。如果我想学习scrapy-splash,我知道网上有很多不可靠的内容。整合了很多文章,终于成功了。把它写下来以免忘记它,也是一个正确的指南。
软件环境:
赢得 10 64 位
蟒蛇3.6
刮刮1.3.3
刮飞溅 0.7.2
我用的是anaconda,忘了scrapy是内置的还是后来安装的。如果没有安装anaconda,直接用pip install scrapy安装即可。
ScrapySplash 安装
注意 ScrapySplash 需要使用 docker。懂的人我就不用解释了。不明白的,跟着操作就行了。这里的 ScrapySplash 与上述软件环境中的不同。以上是scrapy中使用import时使用的。这相当于一个软件,你必须安装它才能使用它。
安装 Docker
准备
由于在docker中需要用到ScrapySplash,所以我们先安装docker。安装前,请检查您的计算机是否为 win 10 64 位,以及是否启用了超级虚拟化。
正式安装
win 10不同版本问题很多。
常规安装:从官网以下地址下载
如果这种方式安装过程中出现错误或者安装后报错,请使用docker工具箱进行安装:
注意:docker使用了虚拟化技术,所以安装的时候一起安装virtualbox,请一定要检查一下,如果你已经安装了,就不需要了。
想了解更多关于Docker的知识,可以访问Docker官网:
启动环境
安装好docker后,打开docker,可以直接使用cmd进行正常安装,如果是通过toolbox安装的,请使用Docker Quickstart Terminal进行操作。
我是用toolbox安装的,所以下面的命令行操作都在Docker Quickstart Terminal里面。
打开命令行:
第一次调用会比较慢,因为virtualbox虚拟机还在启动中。等待一段时间后出现如下界面,说明安装成功。
docker 启动后.png
里面有一个IP,请记住这是以后要使用的东西。
下载 ScrapySplash
在命令行中输入 docker run -p 8050:8050 scrapinghub/splash。这就是 docker 的使用方式。这意味着飞溅开始了。第一次启动是在本地没有splash应用的时候,会自动从docker hub下载。我们不必担心这个过程。,慢慢等。
下载后直接启动应用,出现如下界面:
启动成功.png
这时候我们可以在浏览器中输入:8050/,这里的IP就是之前出现的IP。出现如下界面,说明启动成功。
启动成功.png
注:参考相关文章时,总能看到是输入:8050/,不知道是不是每个人的电脑不一样,还是都被别人蒙上了。安装几次后,还是没有出现上面的界面。按照我的理解,localhost就是本地主机,但是我们的应用是在虚拟机里面的。如果是本地主机,就说明我们需要在虚拟机中打开浏览器,但是我们是在win 10下运行的,难道其他文章的作者都是直接在虚拟机中运行的。这里不清楚。如果有人能告知,我将不胜感激。
好了,到此,整个环境搭建完毕,下面搭建scrapy爬虫。
爬虫爬虫设置
scrapy项目其实和普通项目没什么区别。不明白的可以参考我的另一个文章 Scrapy抓取本地论坛招聘内容(一)
在这里,我创建了一个新的学习项目:
> scrapy startproject jdproject
> cd jdproject/
> scrapy genspider jd https://www.jd.com/
注意:这里的操作也是在命令行中,但是不需要在Docker Quickstart Terminal中,普通cmd中也可以
打开jdproject/spiders/jd.py,修改内容:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request, FormRequest
from scrapy.selector import Selector
from scrapy_splash.request import SplashRequest, SplashFormRequest
class JdSpider(scrapy.Spider):
name = "jd"
def start_requests(self):
splash_args = {"lua_source": """
--splash.response_body_enabled = true
splash.private_mode_enabled = false
splash:set_user_agent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36")
assert(splash:go("https://item.jd.com/5089239.html";))
splash:wait(3)
return {html = splash:html()}
"""}
yield SplashRequest("https://item.jd.com/5089239.html", endpoint='run', args=splash_args, callback=self.onSave)
def onSave(self, response):
value = response.xpath('//span[@class="p-price"]//text()').extract()
print(value)
打开jdproject/settings.py,修改:
# See http://scrapy.readthedocs.org/ ... .html
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# See http://scrapy.readthedocs.org/ ... .html
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, # 不配置查不到信息
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://192.168.99.100:8050/" # 自己安装的docker里的splash位置
DUPEFILTER_CLASS = "scrapy_splash.SplashAwareDupeFilter"
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
测试
我这里用的是测试用的,需要的是产品的价格。
jd.png
运行爬虫:
结果.png
可以清楚的看到,我们想要的价格已经出现了。
至此,我们已经成功部署了ScrapySplash,并成功实现了爬虫项目。
对splash感兴趣的可以参考官网:
js抓取网页内容(一下,抓取网页数据都是用JavaJsoup(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-12 13:14
阿里云>云栖社区>主题地图>R>如何使用GET获取网页内容
推荐活动:
更多优惠>
当前主题:如何使用 GET 获取网页内容并将其添加到采集夹
相关话题:
如何使用GET抓取与网页内容相关的博客 查看更多博客
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现成的API来获取数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
如何让搜索引擎抓取AJAX内容?
作者:阮一峰 1469人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
如何让搜索引擎抓取AJAX内容?
作者:阮一峰 1061人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
file_get_contents 解决网页爬虫乱码
作者:科技小胖子1012人浏览评论:04年前
有时使用file_get_contents()函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。编码问题很容易处理,只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容
作者:朱老教授 823人浏览评论:04年前
public string GetHtml(string url, Encoding ed) {string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文 查看全部
js抓取网页内容(一下,抓取网页数据都是用JavaJsoup(组图))
阿里云>云栖社区>主题地图>R>如何使用GET获取网页内容
推荐活动:
更多优惠>
当前主题:如何使用 GET 获取网页内容并将其添加到采集夹
相关话题:
如何使用GET抓取与网页内容相关的博客 查看更多博客
【网络爬虫】使用node.jscheerio爬取网页数据
作者:自娱自乐 5358人浏览评论:05年前
您是想自动从网页中抓取一些数据,还是想将从某个博客中提取的一堆数据转换为结构化数据?有没有现成的API来获取数据?!!!!@#$@#$... 可以解决网页爬虫没关系。什么是网络爬虫?你可能会问。. . 网络爬虫是以编程方式(通常无需浏览器参与)检索网页内容。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
过去,我们使用 Java Jsoup 来捕获网页数据。前几天听说用PHP抓包比较方便。今天简单研究了一下,主要是使用QueryList。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:Jack Chen1527人浏览评论:06年前
原文:PHP 使用 QueryList 抓取网页内容,然后使用 Java Jsoup 抓取网页数据。前几天听说用PHP抓起来比较方便。今天研究了一下,主要是用QueryList来实现。QueryList 是一个基于 phpQuery 的通用列表 采集 类,简单、灵活、功能强大
阅读全文
如何让搜索引擎抓取AJAX内容?
作者:阮一峰 1469人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
关于爬取网页、分析网页内容、模拟登录的逻辑/流程及注意事项网站(转)
作者:朱老教授 1373人浏览评论:04年前
抓取网页的一般逻辑和过程,一般是针对普通用户,使用浏览器打开某个网址,然后浏览器就可以显示出相应页面的内容。这个过程如果用程序代码实现,就可以调用(用程序实现)爬取(网页内容,进行后处理,提取需要的信息等)。对应的英文是,网站
阅读全文
如何让搜索引擎抓取AJAX内容?
作者:阮一峰 1061人浏览评论:05年前
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个
阅读全文
file_get_contents 解决网页爬虫乱码
作者:科技小胖子1012人浏览评论:04年前
有时使用file_get_contents()函数抓取网页会导致乱码。出现乱码的原因有两个,一是编码问题,二是目标页面启用了Gzip。编码问题很容易处理,只需将捕获的内容转为编码($content=iconv("GBK", "UTF-8//IGNORE
阅读全文
如何使用HttpWebRequest、HttpWebResponse模拟浏览器抓取网页内容
作者:朱老教授 823人浏览评论:04年前
public string GetHtml(string url, Encoding ed) {string Html = string.Empty;//初始化一个新的webRequst HttpWebRequest Request = (HttpWebReq
阅读全文
js抓取网页内容(使用AngularJS构建的网站有一个问题–为SEO优化AngularJS)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-10 15:15
使用 AngularJS 内置的 网站 将所有内容加载到单个页面上。模板保持不变,仅重新加载副本以显示访问者请求的信息。
我承认这个概念很棒。拥有单页应用程序意味着几乎是即时加载时间——更不用说,更容易开发和更少的代码错误需要修复。
但是针对 SEO 优化 AngularJS 存在一个问题。
Angular 应用程序在客户端提供内容。因此,他们从谷歌抓取和排名页面所需的所有元素中删除了一个页面。
SEO 可以做任何事情,还是应该放弃并保留 网站 上的任何未优化的 AngularJS 页面?
不,绝对不是!首先,您实际上可以优化 AngularJS。当然,它需要一些技术 SEO 知道如何,但它可以做到。
在我告诉您更多相关信息之前,让我们先了解一下基础知识。
什么是 AngularJS?
AngularJS 是 Google 提供的基于 JavaScript 的平台,可以从单个页面加载内容。
例如,与 HTML 不同,基于 Angular 的 网站 不会将单个页面存储为单独的文件。相反,它在单个应用程序中加载内容用户请求。
因此,这些 Web 属性通常称为单页应用程序 (SPA)。
实际上,差异意味着用户每次点击请求信息时,并不是呈现一个新页面,所有与内容的交互都是通过 AJAX 调用在同一页面上进行的。
这是微软的视觉效果,说明了差异。请注意,在传统的页面循环中,服务器如何为每个请求加载一个新的 HTML 页面。但是,在 SPA 生命周期中,页面仅加载一次。然后,JavaScript 使用页面作为框架来加载相关内容。
为什么要使用 AngularJS?
使用 Angular 框架构建 网站 有三个主要好处。
1. 单页应用程序的内容加载速度要快得多,因为无需每次都加载新的 HTML 代码。这可以带来更好的用户体验。
2.使用AngularJS还可以加快开发进程。开发人员只需构建一个页面,然后使用 JavaScript 来控制其余页面。
3.由于上述原因,开发者可以减少错误,从而减少用户浏览网站时的问题。技术团队不必花时间重新访问他们的代码来修复错误。每个人都是一个双赢的场景。
不幸的是,Angular 只是 SEO 的主要挑战。
为什么 AngularJS 对搜索引擎优化具有挑战性?
例如,通过 API 连接调用内容,单页技术将从页面的实际代码中删除所有可抓取的内容。
与收录所有 网站 内容的传统 HTML 页面不同,SPA 仅收录基本页面结构。但是,实际的措辞是通过动态 API 调用显示的。
对于 SEO,以上意味着源代码中的实际 HTML 不收录在页面中。因此,Google 将抓取的所有元素都不存在。
此外,搜索引擎无法缓存 SPA。下面两个视觉效果很好地说明了这个问题。顶部显示用户在访问 Angular 页面时看到的内容。另一个介绍了Google可以访问和抓取的实际内容。
用户看到的:
谷歌缓存内容:
一个明显的区别,不是吗?
对于用户,此页面与其他页面相同。他们可以轻松浏览网站。他们可以访问、阅读信息并与之交互。
另一方面,谷歌几乎看不到页面上的任何内容。当然,仅仅正确地索引它是不够的。
这是 SEO 面对 Angular 应用程序所面临的挑战。这些应用程序缺乏对它们进行排名所需的一切。
幸运的是,也有好消息。
如何针对 Google Crawling 优化 AngularJS 应用程序
有三种方法可以做到这一点。
首先是使用预渲染平台。例如,Prerender.io。此类服务将创建内容的缓存版本,并以 Googlebot 可以抓取和索引的形式呈现。
不幸的是,这可能是一个短期解决方案。Google 可以轻松地将其贬值,这样 网站 就无法再获得可转换的解决方案。
第二种解决方案是修改 SPA 元素,使其成为客户端和服务器之间的混合体。开发人员将此方法称为初始静态渲染。
在这种方法中,您可以在服务器端保留某些对 SEO 必不可少的元素 - 标题、元描述、标题、某人的副本等。因此,这些元素将显示在源代码中,谷歌可以抓取它们。
不幸的是,该解决方案有时会再次证明是不够的。
但是,有一个可行的选择。它涉及使用 Angular Universal 扩展来创建要在服务器端呈现的页面的静态版本。不用说,这些可以被谷歌完全索引,而且这项技术很快就会贬值。
如何使用 Angular Universal Extension 准备服务器端渲染
以下是Angular官方网站流程的简要概述*。但是,在完成整个过程之前,我建议您转移到受控的测试环境。
过程:
1.安装依赖项。
2. 通过修改应用程序代码及其配置来准备您的应用程序。
3.添加构建目标并使用带有@ununiversal/express-engine 原理图的 CLI 构建通用包。
4.设置服务器以运行通用包。
5. 在服务器上打包并运行应用程序。
结果?缓存页面如下所示:
当然,它没有视觉冲击。但是,用户不会看到它。但是,搜索引擎会找到抓取所需的所有信息并正确索引页面,这是您的目标。
关键点
AngularJS 为改善用户体验和缩短开发时间提供了难以置信的机会。不幸的是,它也给SEO带来了严峻的挑战。
例如,单页应用程序不收录爬行和索引内容以进行排名所需的代码元素。
幸运的是,SEO 可以通过三个选项克服它:
1.使用预渲染平台,例如 Prerender.io。
2.创建一个名为初始静态渲染的 AngularJS 和 HTML 混合体。
3.使用 Angular Universal 扩展创建站点的静态版本以进行爬网和索引——这是我推荐的选项。 查看全部
js抓取网页内容(使用AngularJS构建的网站有一个问题–为SEO优化AngularJS)
使用 AngularJS 内置的 网站 将所有内容加载到单个页面上。模板保持不变,仅重新加载副本以显示访问者请求的信息。
我承认这个概念很棒。拥有单页应用程序意味着几乎是即时加载时间——更不用说,更容易开发和更少的代码错误需要修复。
但是针对 SEO 优化 AngularJS 存在一个问题。
Angular 应用程序在客户端提供内容。因此,他们从谷歌抓取和排名页面所需的所有元素中删除了一个页面。
SEO 可以做任何事情,还是应该放弃并保留 网站 上的任何未优化的 AngularJS 页面?
不,绝对不是!首先,您实际上可以优化 AngularJS。当然,它需要一些技术 SEO 知道如何,但它可以做到。
在我告诉您更多相关信息之前,让我们先了解一下基础知识。
什么是 AngularJS?
AngularJS 是 Google 提供的基于 JavaScript 的平台,可以从单个页面加载内容。
例如,与 HTML 不同,基于 Angular 的 网站 不会将单个页面存储为单独的文件。相反,它在单个应用程序中加载内容用户请求。
因此,这些 Web 属性通常称为单页应用程序 (SPA)。
实际上,差异意味着用户每次点击请求信息时,并不是呈现一个新页面,所有与内容的交互都是通过 AJAX 调用在同一页面上进行的。
这是微软的视觉效果,说明了差异。请注意,在传统的页面循环中,服务器如何为每个请求加载一个新的 HTML 页面。但是,在 SPA 生命周期中,页面仅加载一次。然后,JavaScript 使用页面作为框架来加载相关内容。
为什么要使用 AngularJS?
使用 Angular 框架构建 网站 有三个主要好处。
1. 单页应用程序的内容加载速度要快得多,因为无需每次都加载新的 HTML 代码。这可以带来更好的用户体验。
2.使用AngularJS还可以加快开发进程。开发人员只需构建一个页面,然后使用 JavaScript 来控制其余页面。
3.由于上述原因,开发者可以减少错误,从而减少用户浏览网站时的问题。技术团队不必花时间重新访问他们的代码来修复错误。每个人都是一个双赢的场景。
不幸的是,Angular 只是 SEO 的主要挑战。
为什么 AngularJS 对搜索引擎优化具有挑战性?
例如,通过 API 连接调用内容,单页技术将从页面的实际代码中删除所有可抓取的内容。
与收录所有 网站 内容的传统 HTML 页面不同,SPA 仅收录基本页面结构。但是,实际的措辞是通过动态 API 调用显示的。
对于 SEO,以上意味着源代码中的实际 HTML 不收录在页面中。因此,Google 将抓取的所有元素都不存在。
此外,搜索引擎无法缓存 SPA。下面两个视觉效果很好地说明了这个问题。顶部显示用户在访问 Angular 页面时看到的内容。另一个介绍了Google可以访问和抓取的实际内容。
用户看到的:
谷歌缓存内容:
一个明显的区别,不是吗?
对于用户,此页面与其他页面相同。他们可以轻松浏览网站。他们可以访问、阅读信息并与之交互。
另一方面,谷歌几乎看不到页面上的任何内容。当然,仅仅正确地索引它是不够的。
这是 SEO 面对 Angular 应用程序所面临的挑战。这些应用程序缺乏对它们进行排名所需的一切。
幸运的是,也有好消息。
如何针对 Google Crawling 优化 AngularJS 应用程序
有三种方法可以做到这一点。
首先是使用预渲染平台。例如,Prerender.io。此类服务将创建内容的缓存版本,并以 Googlebot 可以抓取和索引的形式呈现。
不幸的是,这可能是一个短期解决方案。Google 可以轻松地将其贬值,这样 网站 就无法再获得可转换的解决方案。
第二种解决方案是修改 SPA 元素,使其成为客户端和服务器之间的混合体。开发人员将此方法称为初始静态渲染。
在这种方法中,您可以在服务器端保留某些对 SEO 必不可少的元素 - 标题、元描述、标题、某人的副本等。因此,这些元素将显示在源代码中,谷歌可以抓取它们。
不幸的是,该解决方案有时会再次证明是不够的。
但是,有一个可行的选择。它涉及使用 Angular Universal 扩展来创建要在服务器端呈现的页面的静态版本。不用说,这些可以被谷歌完全索引,而且这项技术很快就会贬值。
如何使用 Angular Universal Extension 准备服务器端渲染
以下是Angular官方网站流程的简要概述*。但是,在完成整个过程之前,我建议您转移到受控的测试环境。
过程:
1.安装依赖项。
2. 通过修改应用程序代码及其配置来准备您的应用程序。
3.添加构建目标并使用带有@ununiversal/express-engine 原理图的 CLI 构建通用包。
4.设置服务器以运行通用包。
5. 在服务器上打包并运行应用程序。
结果?缓存页面如下所示:
当然,它没有视觉冲击。但是,用户不会看到它。但是,搜索引擎会找到抓取所需的所有信息并正确索引页面,这是您的目标。
关键点
AngularJS 为改善用户体验和缩短开发时间提供了难以置信的机会。不幸的是,它也给SEO带来了严峻的挑战。
例如,单页应用程序不收录爬行和索引内容以进行排名所需的代码元素。
幸运的是,SEO 可以通过三个选项克服它:
1.使用预渲染平台,例如 Prerender.io。
2.创建一个名为初始静态渲染的 AngularJS 和 HTML 混合体。
3.使用 Angular Universal 扩展创建站点的静态版本以进行爬网和索引——这是我推荐的选项。
js抓取网页内容(手机最快现场报码开奖结果2006年12月,Robin做了一个对JS的索引小实验)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-09 21:17
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体使用我以后会说明文章)。截至今天发布此文章,谷歌和百度已将收录定位为实验站点。
Google 收录 目标站点领先于百度,雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。
从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
1. 新建一个html页面和js页面,其中html页面代码的body除了js代码调用外没有其他信息内容。 【城市相册】乡村振兴路上的“慢生活”实验。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录目标html页面后,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。 查看全部
js抓取网页内容(手机最快现场报码开奖结果2006年12月,Robin做了一个对JS的索引小实验)
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体使用我以后会说明文章)。截至今天发布此文章,谷歌和百度已将收录定位为实验站点。
Google 收录 目标站点领先于百度,雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。
从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
1. 新建一个html页面和js页面,其中html页面代码的body除了js代码调用外没有其他信息内容。 【城市相册】乡村振兴路上的“慢生活”实验。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录目标html页面后,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。
js抓取网页内容(js抓取网页内容可能对你来说并不是最困难的一个难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-08 05:00
js抓取网页内容可能对你来说并不是最困难的一个技术难点。因为相对前端来说,js确实比较容易上手,现在虽然js抓取很流行,但是如果遇到php来实现这一步却是非常麻烦。js抓取php文件的难点不在于抓取的数据格式(包括类型,字段等信息)或者说对页面中每个页面元素的获取这一步,而是要获取php中所调用的js代码,而且要抓取js代码还要加载包含php代码的content-type标签、content-language标签、trailing-trailing注解、warning、error等。
如果不去深入探索js抓取,也不想深入探索,那php代码可能有点low。但你要抓取带有content-type标签的html文件,js代码就又变的非常的可怕了。如果抓取不到content-type,那么很多内容可能就无法获取。首先,有极少的信息是可以通过抓取js获取的。这些主要是在页面中的dom元素上调用的,因为页面中会有结构对应html的各个元素,然后把html元素相应dom元素绑定到dom元素上,之后执行这个dom元素相应的js代码,相应html元素也就会就会提交给浏览器解析。
通过抓取js代码获取的内容有部分已经在html上跑的脚本也是可以的,但是不多。获取脚本调用的脚本是单一js,这些脚本因为是对dom元素上js注解,可以获取到绝大部分js文件内容,但是也不仅限于解析代码语言。比如js($css)注解,你可以获取所有相应的style标签,然后直接抓取style标签中的内容,但是如果按照trailing-trailing标签直接抓取,那么你得到的js代码有可能非常的多。
其实对于一般情况下,没有必要上述的注解需要注入浏览器中。但是我的一个朋友提到对于有移动端的网站,它会根据需要,把html渲染以postmanformui加载,具体我还没有尝试。使用node.js抓取客户端数据已经是不少大网站都在使用的方法了,一般是通过node.js渲染页面,然后调用php代码抓取客户端数据。
<p>比如我们有个用户输入密码的页面:现在你可以通过js来获取到用户输入密码的这个html值。那么接下来我们调用php中的一个方法:然后我们来尝试获取用户昵称信息:直接抓取了图片信息:下面的方法就是将js解析为php代码,然后执行就会获取到最后需要的用户姓名:defto_content(self):try:r=node.js(' 查看全部
js抓取网页内容(js抓取网页内容可能对你来说并不是最困难的一个难点)
js抓取网页内容可能对你来说并不是最困难的一个技术难点。因为相对前端来说,js确实比较容易上手,现在虽然js抓取很流行,但是如果遇到php来实现这一步却是非常麻烦。js抓取php文件的难点不在于抓取的数据格式(包括类型,字段等信息)或者说对页面中每个页面元素的获取这一步,而是要获取php中所调用的js代码,而且要抓取js代码还要加载包含php代码的content-type标签、content-language标签、trailing-trailing注解、warning、error等。
如果不去深入探索js抓取,也不想深入探索,那php代码可能有点low。但你要抓取带有content-type标签的html文件,js代码就又变的非常的可怕了。如果抓取不到content-type,那么很多内容可能就无法获取。首先,有极少的信息是可以通过抓取js获取的。这些主要是在页面中的dom元素上调用的,因为页面中会有结构对应html的各个元素,然后把html元素相应dom元素绑定到dom元素上,之后执行这个dom元素相应的js代码,相应html元素也就会就会提交给浏览器解析。
通过抓取js代码获取的内容有部分已经在html上跑的脚本也是可以的,但是不多。获取脚本调用的脚本是单一js,这些脚本因为是对dom元素上js注解,可以获取到绝大部分js文件内容,但是也不仅限于解析代码语言。比如js($css)注解,你可以获取所有相应的style标签,然后直接抓取style标签中的内容,但是如果按照trailing-trailing标签直接抓取,那么你得到的js代码有可能非常的多。
其实对于一般情况下,没有必要上述的注解需要注入浏览器中。但是我的一个朋友提到对于有移动端的网站,它会根据需要,把html渲染以postmanformui加载,具体我还没有尝试。使用node.js抓取客户端数据已经是不少大网站都在使用的方法了,一般是通过node.js渲染页面,然后调用php代码抓取客户端数据。
<p>比如我们有个用户输入密码的页面:现在你可以通过js来获取到用户输入密码的这个html值。那么接下来我们调用php中的一个方法:然后我们来尝试获取用户昵称信息:直接抓取了图片信息:下面的方法就是将js解析为php代码,然后执行就会获取到最后需要的用户姓名:defto_content(self):try:r=node.js('
js抓取网页内容(js抓取网页内容的话用beautifulsoup之类的自动生成文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-08 02:00
js抓取网页内容的话用beautifulsoup之类的自动生成html文件(小网站可能用不上),但是题主既然嫌弃直接生成html太慢,那就只能用正则表达式来提取了,一般的网站都有http代理,拿来用就行。
你可以用学校购买的带宽
2014-11-17中国知网全文下载网站高校通用阅读器
直接把中文用谷歌翻译,翻译成英文文档。下载下来就是英文文档。楼主平时又有中文文档需要的话。绝对比直接使用excel文档打开快。
没法,2012年以后已经限制免费下载了,
登录,在开发者选项里找到添加下载地址,
建议开发者选项里面添加https协议,
使用google搜索;在谷歌打开搜索页,但只打开关键词和内容,默认打开的是谷歌原生浏览器页面。
你好,现在本人亲测g+上下载硕博论文不需要安装一步步编译的,
使用谷歌搜索
随手百度一下好像知道了!
可以使用u盘本地拷贝进电脑,再使用网页浏览器打开的。
有种软件可以做到
基本上真的只有局域网才能下载了
到手机浏览器的应用商店里面搜索“百度网盘”就会出现很多下载的选项了
最简单的,百度这样找网页, 查看全部
js抓取网页内容(js抓取网页内容的话用beautifulsoup之类的自动生成文件)
js抓取网页内容的话用beautifulsoup之类的自动生成html文件(小网站可能用不上),但是题主既然嫌弃直接生成html太慢,那就只能用正则表达式来提取了,一般的网站都有http代理,拿来用就行。
你可以用学校购买的带宽
2014-11-17中国知网全文下载网站高校通用阅读器
直接把中文用谷歌翻译,翻译成英文文档。下载下来就是英文文档。楼主平时又有中文文档需要的话。绝对比直接使用excel文档打开快。
没法,2012年以后已经限制免费下载了,
登录,在开发者选项里找到添加下载地址,
建议开发者选项里面添加https协议,
使用google搜索;在谷歌打开搜索页,但只打开关键词和内容,默认打开的是谷歌原生浏览器页面。
你好,现在本人亲测g+上下载硕博论文不需要安装一步步编译的,
使用谷歌搜索
随手百度一下好像知道了!
可以使用u盘本地拷贝进电脑,再使用网页浏览器打开的。
有种软件可以做到
基本上真的只有局域网才能下载了
到手机浏览器的应用商店里面搜索“百度网盘”就会出现很多下载的选项了
最简单的,百度这样找网页,
js抓取网页内容(js抓取网页内容的方法在最常见的页面抓取有很多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-03 13:00
js抓取网页内容的方法在最常见的页面抓取有很多,在taobao中的使用则是用到了js获取网页内容的代码进行翻页抓取。总结的来说对于taobao类的网站,
答:不能。答:不能,不能。如果正常来说两条的话就能抓。答:但是看得出你这个有点弱。
不能,建议做到查询指定元素的excel文件,通过excel查询网页元素。
以前我做爬虫的时候,基本上都是抓页面所有的js,伪静态,结果爬回来的内容大部分都是js,这个时候正常来说都是抓住一次就可以了,因为正常网站中链接属性是一样的。还有一个办法是js代码循环,比如说本页js脚本抓取上一页的数据,每次循环会返回链接里面内容包含上一页数据的js,这样就可以了。这只是一些基本方法。
最简单的办法就是整理测试下这个页面js的属性,测试一下是否成立。除此之外,分享一个我爬的不好的网站,原理同上。
应该是能抓的,
建议去抓taobao的退款那块
亲测能抓可以抓得到这个包可以到我网站上面去看看xiaokuamm【taobao】能抓他的页面并解析出来的代码
你可以参考一下自己学校的北苑寝室吗?
没抓过, 查看全部
js抓取网页内容(js抓取网页内容的方法在最常见的页面抓取有很多)
js抓取网页内容的方法在最常见的页面抓取有很多,在taobao中的使用则是用到了js获取网页内容的代码进行翻页抓取。总结的来说对于taobao类的网站,
答:不能。答:不能,不能。如果正常来说两条的话就能抓。答:但是看得出你这个有点弱。
不能,建议做到查询指定元素的excel文件,通过excel查询网页元素。
以前我做爬虫的时候,基本上都是抓页面所有的js,伪静态,结果爬回来的内容大部分都是js,这个时候正常来说都是抓住一次就可以了,因为正常网站中链接属性是一样的。还有一个办法是js代码循环,比如说本页js脚本抓取上一页的数据,每次循环会返回链接里面内容包含上一页数据的js,这样就可以了。这只是一些基本方法。
最简单的办法就是整理测试下这个页面js的属性,测试一下是否成立。除此之外,分享一个我爬的不好的网站,原理同上。
应该是能抓的,
建议去抓taobao的退款那块
亲测能抓可以抓得到这个包可以到我网站上面去看看xiaokuamm【taobao】能抓他的页面并解析出来的代码
你可以参考一下自己学校的北苑寝室吗?
没抓过,
js抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-02 08:06
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理网页中JavaScript执行的结果时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上提出了这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:
查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中…… 查看全部
js抓取网页内容(利用Python和BeautifulSoup抓取网页内容中的解决方法是PyQt或Selenium)
《使用Python和BeautifulSoup抓取网页内容》中提到的方法在处理网页中JavaScript执行的结果时会遇到问题。比如我想爬去去哪儿网的机票搜索结果,抓到的结果是“请稍等,您的查询结果正在实时搜索中”。这不是我想要的结果。我在stackoverflow上提出了这个问题,得到的回答是Python中的urllib模块无法解决这个问题,因为这个页面调用了JavaScript函数来执行搜索和加载搜索结果。本回复中给出的解决方案是PyQt或Selenium。因为我还是想用Python来解决这个问题,所以尝试了PyQt。
PyQt 是为诺基亚 Qt 应用程序框架开发的一组 Python 库,可以运行在 Window、Mac OSX 和 Linux 平台上。最新版本是 PyQt v4.9.4。
在Mac OSX上安装PyQt4:以在Mac OSX 10.7.5上安装PyQt v4.9.4为例。
1. 下载并安装 Qt。您可以根据安装程序向导逐步执行。
2. 下载并安装SIP。SIP 是一个连接 Python 和 C/C++ 的工具。解压SIP安装包,运行:
cd ~/Downloads/sip-4.13.3
python3 configure.py -d /Library/Python/3.2/site-packages --arch x86_64
make
sudo make install
其中--arch x86_64指定了SIP安装平台的架构。
3. 下载并安装 PyQt4。解压安装包,执行:
cd PyQt-mac-gpl-4.9.4
python3 configure.py -q /Users/Sam/QtSDK/Desktop/Qt/4.8.1/gcc/bin/qmake -d /Library/Python/3.2/site-packages/ --use-arch x86_64
make
sudo make install
此安装过程可能需要一段时间。其中/Users/Sam/QtSDK为Qt的安装目录。
尝试使用QtWebKit抓取网页中JavaScript的执行结果
QtWebKit 提供了一个 Web 浏览器引擎,可以解析收录 CSS 和 JS 的 HTML。根据stackoverflow的回复,我尝试在QtWebKit中使用QWebPage来解决我的问题。示例代码如下:
查看代码
import sys
import signal
import urllib.parse
from PyQt4.QtWebKit import QWebPage
class Crawler( QWebPage ):
def __init__(self, url, file):
QWebPage.__init__( self )
self._url = url
self._file = file
def crawl( self ):
signal.signal( signal.SIGINT, signal.SIG_DFL )
self.connect( self, SIGNAL( 'loadFinished(bool)' ), self._finished_loading )
self.mainFrame().load( QUrl( self._url ) )
def _finished_loading( self, result ):
file = open( self._file, 'w' )
file.write( self.mainFrame().toHtml() )
file.close()
sys.exit( 0 )
def main():
app = QApplication( sys.argv )
url = 'http://flight.qunar.com/site/oneway_list.htm'
values = {'searchDepartureAirport':'北京', 'searchArrivalAirport':'丽江', 'searchDepartureTime':'2012-07-25'}
encoded_param = urllib.parse.urlencode(values)
full_url = url + '?' + encoded_param
filename = 'output.txt'
crawler = Crawler( full_url, filename )
crawler.crawl()
sys.exit( app.exec_() )
if __name__ == '__main__':
main()
但不幸的是,我得到的仍然是“请稍等,正在实时搜索您的查询结果”。可能出问题了,可能PyQt解决不了我的问题,可能……问题还在摸索中……
js抓取网页内容(一种nodejs抓取网页内容以上就是的详细内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-29 08:13
本文文章主要介绍Nodejs抓取html页面内容的关键代码。另外我还附上了nodejs来抓取网页的内容。挺好的,对node.js感兴趣的赶紧抓取页面内容。和朋友一起学习吧
废话不多说,我把node.js的核心代码贴出来,抓取html页面的内容。
具体代码如下:
var http = require("http"); var iconv = require('iconv-lite'); var option = { hostname: "stockdata.stock.hexun.com", path: "/gszl/s601398.shtml" }; var req = http.request(option, function(res) { res.on("data", function(chunk) { console.log(iconv.decode(chunk, "gbk")); }); }).on("error", function(e) { console.log(e.message); }); req.end();
看下面的nodejs抓取网页内容
function loadPage(url) { var http = require('http'); var pm = new Promise(function (resolve, reject) { http.get(url, function (res) { var html = ''; res.on('data', function (d) { html += d.toString() }); res.on('end', function () { resolve(html); }); }).on('error', function (e) { reject(e) }); }); return pm; } loadPage('http://www.baidu.com').then(function (d) { console.log(d); });
以上是Nodejs抓取html页面内容的详细内容(推荐),请关注其他相关html中文网站文章! 查看全部
js抓取网页内容(一种nodejs抓取网页内容以上就是的详细内容,你知道吗?)
本文文章主要介绍Nodejs抓取html页面内容的关键代码。另外我还附上了nodejs来抓取网页的内容。挺好的,对node.js感兴趣的赶紧抓取页面内容。和朋友一起学习吧
废话不多说,我把node.js的核心代码贴出来,抓取html页面的内容。
具体代码如下:
var http = require("http"); var iconv = require('iconv-lite'); var option = { hostname: "stockdata.stock.hexun.com", path: "/gszl/s601398.shtml" }; var req = http.request(option, function(res) { res.on("data", function(chunk) { console.log(iconv.decode(chunk, "gbk")); }); }).on("error", function(e) { console.log(e.message); }); req.end();
看下面的nodejs抓取网页内容
function loadPage(url) { var http = require('http'); var pm = new Promise(function (resolve, reject) { http.get(url, function (res) { var html = ''; res.on('data', function (d) { html += d.toString() }); res.on('end', function () { resolve(html); }); }).on('error', function (e) { reject(e) }); }); return pm; } loadPage('http://www.baidu.com').then(function (d) { console.log(d); });
以上是Nodejs抓取html页面内容的详细内容(推荐),请关注其他相关html中文网站文章!

