
js抓取网页内容
js抓取网页内容(抓的妹子图都是直接抓Html就可以的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-07 06:06
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有获取到数据,但是Elements中出现了情况。原因是:页面的数据是
由 JavaScript 动态生成:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
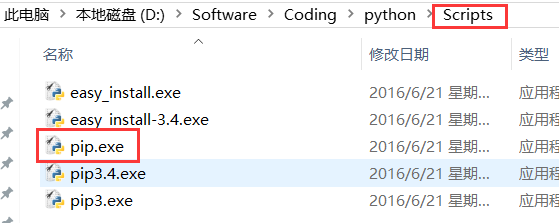
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
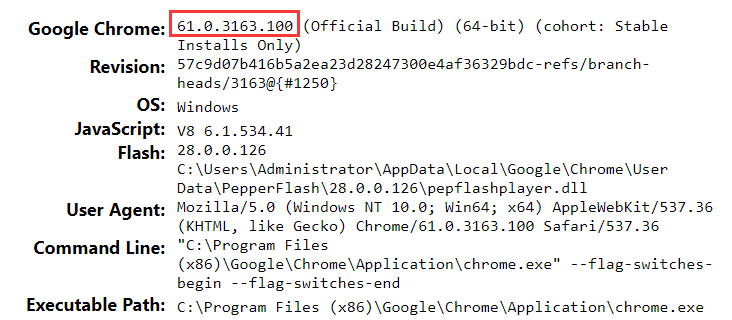
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
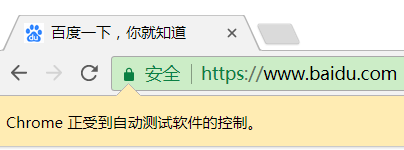
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
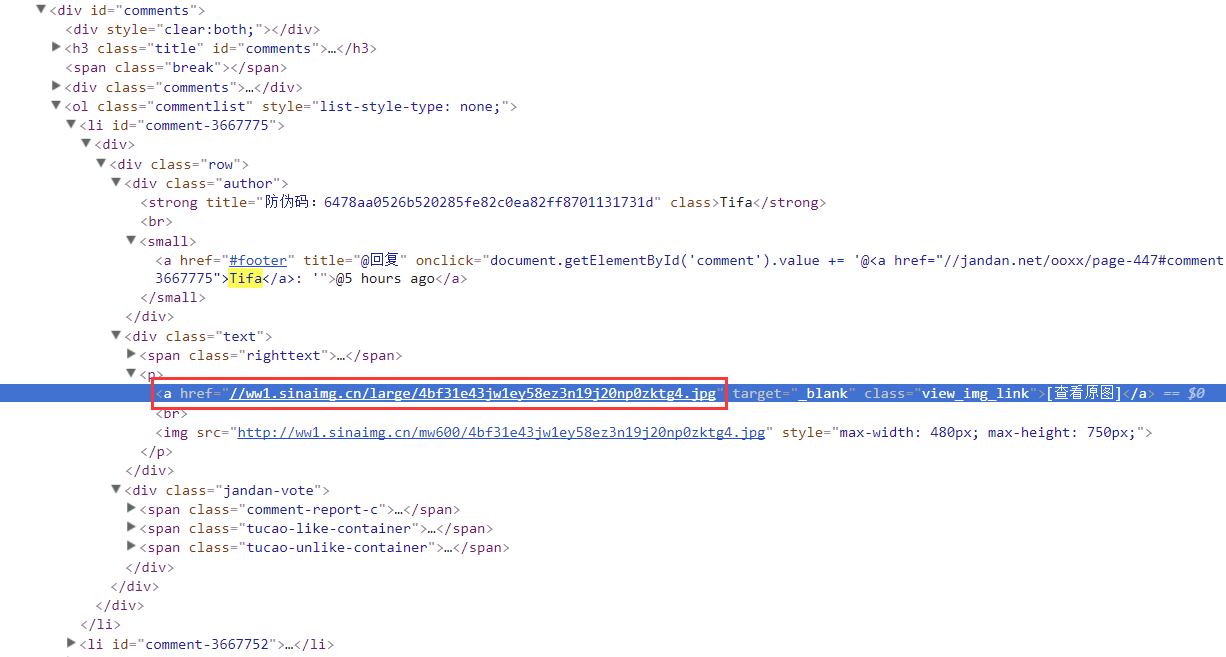
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~
学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时将Cookie保存在本地,以后就可以用Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
查看全部
js抓取网页内容(抓的妹子图都是直接抓Html就可以的
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有获取到数据,但是Elements中出现了情况。原因是:页面的数据是
由 JavaScript 动态生成:


抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...

我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~

2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:

好的,接下来下载v2.34版本的浏览器驱动:

下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:

是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:


看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:

可以拼接成这样的网址:
获取过滤下的页码:


接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~


学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:

selenium 的官方文档中还写道:

运行时也会报这个警告:

5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
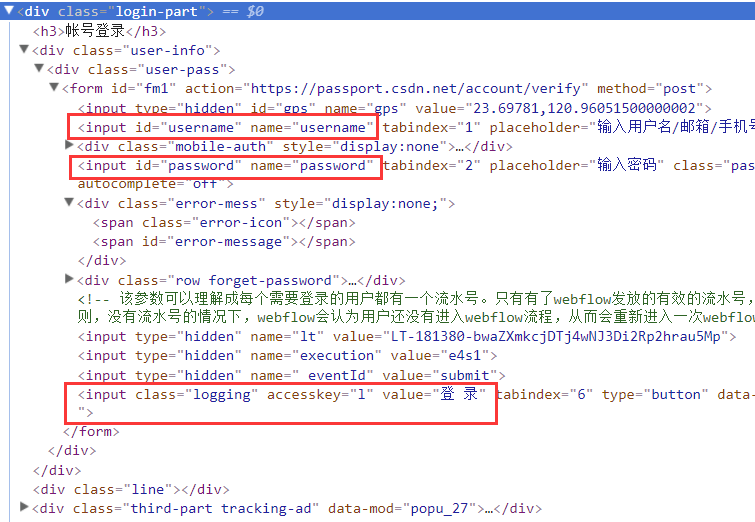
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时将Cookie保存在本地,以后就可以用Cookie访问相关页面了~
首先写一个方法来模拟登录:

找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
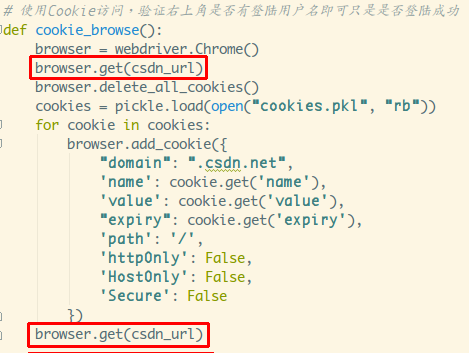
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:

6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading";)
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~

顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;

验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。

js抓取网页内容( 2017年05月12日11:13日js获取网页所有图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-06 11:17
2017年05月12日11:13日js获取网页所有图片)
js如何获取网页上的所有图片
更新时间:2017-05-12 11:13:08 作者:指数
本文文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下。
需要
点击网页中的图片,可以放大显示图片,并可以按顺序切换图片。同时,一些不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是由移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
js抓取网页内容(
2017年05月12日11:13日js获取网页所有图片)
js如何获取网页上的所有图片
更新时间:2017-05-12 11:13:08 作者:指数
本文文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下。
需要
点击网页中的图片,可以放大显示图片,并可以按顺序切换图片。同时,一些不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是由移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
js抓取网页内容(java程序中获取后台js完后的完整页面是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-03 04:11
许多网站使用JS或jQuery生成数据。后台获取数据后,以文档的形式写入页面。Write()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据文章编写的,这很难使用。通用代码编写如下:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
它根本不起作用
典型的是链接页面。如何在Java程序中获取数据 查看全部
js抓取网页内容(java程序中获取后台js完后的完整页面是什么?)
许多网站使用JS或jQuery生成数据。后台获取数据后,以文档的形式写入页面。Write()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据文章编写的,这很难使用。通用代码编写如下:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
它根本不起作用
典型的是链接页面。如何在Java程序中获取数据
js抓取网页内容( 云开发最大的好处不需要前端搭建服务器的包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-03 04:08
云开发最大的好处不需要前端搭建服务器的包)
微信小程序云开发js抓取网页内容
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:...
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。 查看全部
js抓取网页内容(
云开发最大的好处不需要前端搭建服务器的包)
微信小程序云开发js抓取网页内容
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:...
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。

预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
js抓取网页内容(【知识点】化学实验基本知识,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-29 07:15
1、有问题
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只是Javascript代码中嵌入的文档的域。如以下示例代码:
DOCTYPE HTML>
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档的域相关,这样就可以访问到HTML文档的属性,所以上面的代码可以正常运行。
附:使用上述代码的原因是开发者将一个通用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度看问题,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的发问者网站,请参阅下面的放宽同源策略;
放宽同源 policyDocument.domain:在子域的情况下使用。对于多个窗口(一个页面有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问国外的窗口;跨域资源共享:添加Access-Control-通过在服务器端返回header
Allow-Origin,标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:此方法与域无关。不同文档的Javascript可以无限制地相互收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者可以控制远程页面,您可以尝试第二种方法。
服务器端爬取
根据提问者的需求,应该在服务器端处理更可行的解决方案。使用()可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等,当然也可以使用Python、php、Java语言进行后续操作。
综上所述:
(1)服务器开启网页的跨域限制;
(2)使用服务器请求页面 查看全部
js抓取网页内容(【知识点】化学实验基本知识,你了解多少?)
1、有问题
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只是Javascript代码中嵌入的文档的域。如以下示例代码:
DOCTYPE HTML>
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档的域相关,这样就可以访问到HTML文档的属性,所以上面的代码可以正常运行。
附:使用上述代码的原因是开发者将一个通用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度看问题,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的发问者网站,请参阅下面的放宽同源策略;
放宽同源 policyDocument.domain:在子域的情况下使用。对于多个窗口(一个页面有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问国外的窗口;跨域资源共享:添加Access-Control-通过在服务器端返回header
Allow-Origin,标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:此方法与域无关。不同文档的Javascript可以无限制地相互收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者可以控制远程页面,您可以尝试第二种方法。
服务器端爬取
根据提问者的需求,应该在服务器端处理更可行的解决方案。使用()可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等,当然也可以使用Python、php、Java语言进行后续操作。
综上所述:
(1)服务器开启网页的跨域限制;
(2)使用服务器请求页面
js抓取网页内容(没错.js的学习中,可用于抓取其他网站的模块 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-29 01:31
)
在node.js的学习中,可以用来捕获其他网站的模块是[cherio]。此模块不是node的内置模块,需要先安装:
安装相应的模块
安装命令:
npm install cheerio
显式抓取对象
安装cherio后,我们可以获取数据。让我们明确一下,要捕获的内容是网站,要捕获的代码如下:
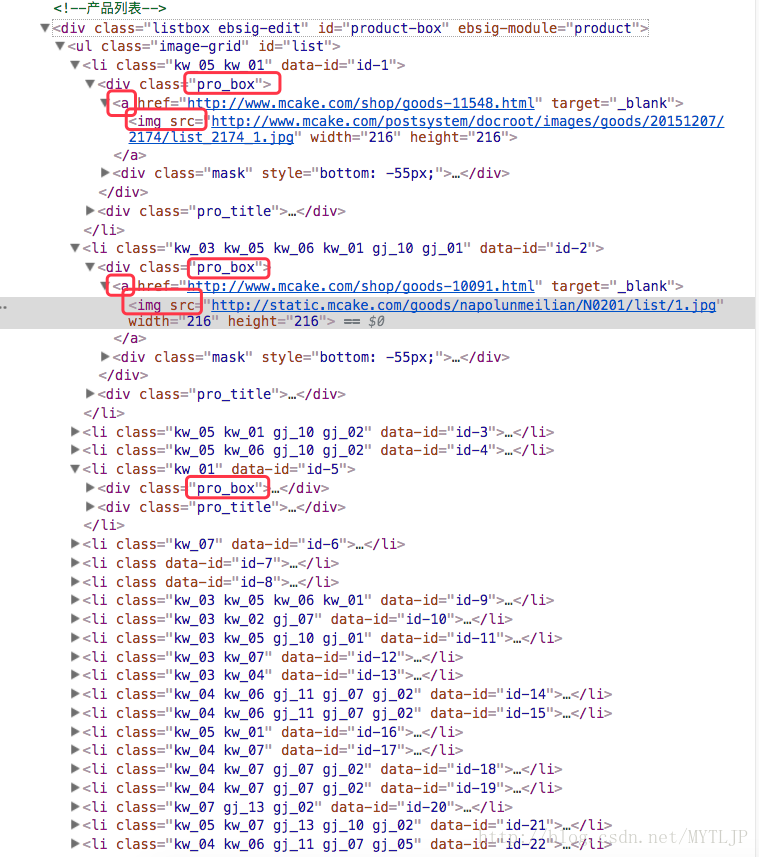
如图所示,要捕获的内容是图中标记的IMG图片。是的,它是下面的Kawaii蛋糕。哇,哇,哇~我想吃东西,而且名字也很好
开始抓取
我们已经定义了捕获的内容。现在让我们开始捕捉。在此之前,我们需要知道cherio收录jQuery核心的一个子集,也就是说,在操作cherio时,可以使用JQ的相关语法。这不是很酷吗?哈哈哈,启动代码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
获得的图片链接打印如下:
为了验证信息的准确性,也为了使博客页面更少使用lotus root,该功能单击以抓取所附第一个链接的可爱甜点图片:
查看全部
js抓取网页内容(没错.js的学习中,可用于抓取其他网站的模块
)
在node.js的学习中,可以用来捕获其他网站的模块是[cherio]。此模块不是node的内置模块,需要先安装:
安装相应的模块
安装命令:
npm install cheerio
显式抓取对象
安装cherio后,我们可以获取数据。让我们明确一下,要捕获的内容是网站,要捕获的代码如下:
如图所示,要捕获的内容是图中标记的IMG图片。是的,它是下面的Kawaii蛋糕。哇,哇,哇~我想吃东西,而且名字也很好

开始抓取
我们已经定义了捕获的内容。现在让我们开始捕捉。在此之前,我们需要知道cherio收录jQuery核心的一个子集,也就是说,在操作cherio时,可以使用JQ的相关语法。这不是很酷吗?哈哈哈,启动代码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
获得的图片链接打印如下:

为了验证信息的准确性,也为了使博客页面更少使用lotus root,该功能单击以抓取所附第一个链接的可爱甜点图片:
js抓取网页内容(一个和浏览器的区别,安装注意先安装nodejs.eachSeries)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-28 07:30
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
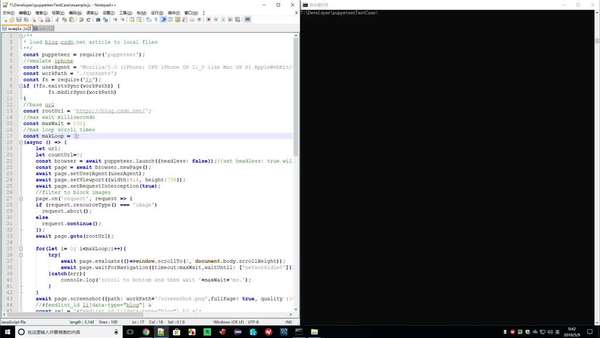
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
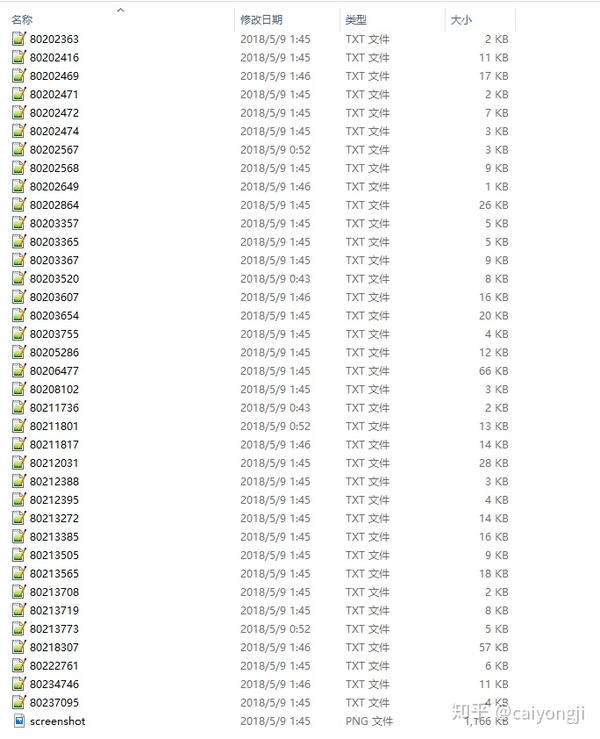
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js抓取网页内容(一个和浏览器的区别,安装注意先安装nodejs.eachSeries)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:

抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-27 21:21
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
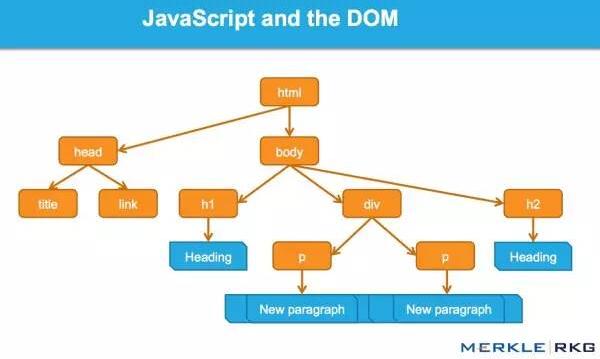
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。

长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子

示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。

示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。

对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
js抓取网页内容(js抓取网页内容之json(function(json)抓取内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-23 11:06
js抓取网页内容比如之前我遇到一个web后端,用flash,老慢了还不好爬,后来后端扔一个json给我,告诉我json对象是对象,不是对象都要加个js对象(关键是当时没有这个flash)setinterval(function(){console。log(json);},1000);setinterval(function(){console。
log(json);},1000);一口气调到1500,3000帧10000帧的效果,前后1500+的间隔后端确认是json,然后他就直接拿出json对象给我,我返回后就可以把json调用给前端,前端是这么调试的。
requests.get获取,后面跟要传递给的对象。
你想学什么,或者知道什么,可以评论,本人现在在学,开发项目,希望有经验的能给指导。
学前端。比如我。
人机交互只要涉及交互的产品都很有可能需要js去实现。现在人工智能和云计算都大火,所以应该在近几年前端需求会越来越大。
根据分析,我认为前端比较火,女生的话就ps和dw比较多。
两者都有,就业都比较好,推荐ps,ps快一点。
现在前端的火,具体不了解,但如果你要选择前端工作,我想说非常非常简单,不需要什么基础,前端就是用js和html去控制展示界面,先做个h5页面,弄个id,然后去做界面,学学css,懂一点点js,再去实现效果就可以了。 查看全部
js抓取网页内容(js抓取网页内容之json(function(json)抓取内容)
js抓取网页内容比如之前我遇到一个web后端,用flash,老慢了还不好爬,后来后端扔一个json给我,告诉我json对象是对象,不是对象都要加个js对象(关键是当时没有这个flash)setinterval(function(){console。log(json);},1000);setinterval(function(){console。
log(json);},1000);一口气调到1500,3000帧10000帧的效果,前后1500+的间隔后端确认是json,然后他就直接拿出json对象给我,我返回后就可以把json调用给前端,前端是这么调试的。
requests.get获取,后面跟要传递给的对象。
你想学什么,或者知道什么,可以评论,本人现在在学,开发项目,希望有经验的能给指导。
学前端。比如我。
人机交互只要涉及交互的产品都很有可能需要js去实现。现在人工智能和云计算都大火,所以应该在近几年前端需求会越来越大。
根据分析,我认为前端比较火,女生的话就ps和dw比较多。
两者都有,就业都比较好,推荐ps,ps快一点。
现在前端的火,具体不了解,但如果你要选择前端工作,我想说非常非常简单,不需要什么基础,前端就是用js和html去控制展示界面,先做个h5页面,弄个id,然后去做界面,学学css,懂一点点js,再去实现效果就可以了。
js抓取网页内容(抓的妹子图都是直接抓Html就可以的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-09-20 09:06
)
导言
以前的姐妹图片是直接用HTML(即chrome浏览器F12)捕获的
elements页面结构返回与网络数据包捕获相同的结果。从后面拿一些
网站(如煎蛋和那些小的网站)发现了它并抓住了那里的袋子
没有获得任何数据,但在元素中存在一些情况。原因是页面的数据是
通过javascript动态生成:
一开始,我想自己学习一批JS基本语法,然后模拟数据包捕获
获取其他人的JS文件,自己分析逻辑,然后计算出真正的URL。后来是
放弃。毕竟,有太多的页面需要掌握。什么时候会像这样分析每一个
后来,我偶然发现了一个自动化测试框架:selenium可以帮助我们解决这个问题
简单地说,这东西有什么用?我们可以编写代码来制作浏览器:
那么这个东西不支持浏览器功能。您需要在第三方浏览器中使用它
要支持以下浏览器,您需要将相应的浏览器驱动程序下载到Python的相应路径:
铬:
火狐:
幻影:
即:
边缘:
歌剧:
让我们从这一节开始~
1.安装硒
这很简单。您可以通过PIP命令行直接安装:
sudo pip install selenium
PS:我记得我的公司合伙人问我为什么不能在win上实现PIP,有很多PIP
事实上,如果安装Python3,默认情况下它已经有了PIP。您需要配置另一个环境
变数。PIP的路径位于python安装目录的scripts目录中~
只需在路径之后添加此路径~
2.下载浏览器驱动程序
因为selenium没有浏览器,所以它需要依赖第三方浏览器并调用第三方浏览器
对于浏览器,您需要下载浏览器驱动程序,因为作者使用chrome
以Chrome为例,其他浏览器自己搜索相关信息!打开Chrome浏览器并键入:
chrome://version
您可以查看有关Chrome浏览器版本的相关信息。在这里,只需关注版本号:
61。好的,接下来,转到以下网站检查相应的驱动程序版本号:
好的,那就下载吧v2.Version 34浏览器驱动程序:
下载后,解压缩zip文件并将解压缩后的chromedriver.exe复制到python
在脚本目录中。(不需要与Win32纠缠,它可以在64位浏览器上正常使用!)
PS:对于Mac,将提取的文件复制到usr/local/bin目录
对于Ubuntu,将其复制到usr/bin目录
接下来,让我们编写一个简单的代码进行测试:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行此代码将自动调用浏览器并访问百度:
控制台将输出HTML代码,即直接获得的元素页面结构
在JS被执行后,我们可以抓到我们的煎蛋女照片
3.Selenium简单实战:抓取煎蛋女图片
直接分析元素页面结构以找到所需的关键节点:
显然,这是我们小妹妹的照片。复制URL并查看我们打印的内容
页面结构中是否存在这样的内容:
是的,很好。有了这个页面数据,我们将经历一波美丽的汤来获得我们
你想要的数据~
经过以上过滤,我们可以得到我们的姐妹图片URL:
打开验证,单击:
看完下一页,只有30个小姐妹,显然不能和我们见面。我们第一次装了
首先获取大量的页码,然后知道有多少页,然后拼接URL并自己加载
不同的页面,例如,总共有448页:
拼接到这样一个URL中:
通过过滤获得的页码:
接下来,填写代码,循环抓取每个页面上的小妹妹,然后在本地下载
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
经营成果:
看看我们的输出文件夹~
学习蟒蛇爬虫,天天减肥
4.PhantomJS
Phantom JS是一款没有界面的浏览器。功能:网站将加载到内存中并在页面上执行
JavaScript,因为它不显示图形界面,运行起来比一个完整的浏览器更高效
(在某些Linux主机上,没有图形界面就无法安装chrome等浏览器
您可以通过phantom JS避免此问题)
在Win上安装phantomjs:
在Ubuntu/Mac上安装phantomjs:
sudo apt-get install phantomjs
!!!关于phantomjs的重要注意事项:
今年4月,phantom.js的维护者宣布退出phantom js
这意味着该项目可能不再维护!!!Chrome和Firefox也已经启动
提供无头模式(无需挂断浏览器),因此估计小型合作伙伴使用phantom JS
它还将缓慢地迁移到这两种浏览器。Windows chrome需要60以上的版本才能支持
无头模式,启用无头模式也非常简单:
官方文件还指出:
在操作过程中也会报告此警告:
5.Selenium实战:模拟登录CSDN并保存cookie
CSDN登录网站:
在分析下面的页面结构后,不难找到相应的登录输入框和登录按钮:
我们需要做的是在这两个节点上输入帐户和密码,然后触发登录按钮
同时,在本地保存cookie,然后您可以使用cookie访问相关页面~
首先编写模拟登录的方法:
查找您输入帐户和密码的节点,设置您自己的帐户和密码,然后查找登录名
单击按钮节点,然后等待登录成功。登录成功后,您可以比较
当前\ URL是否已更改。然后把饼干保存在这里
我使用pickle图书馆。我可以使用其他方法,例如JSON或字符串拼接
然后在本地保存它。如果没有意外,你应该能够得到饼干,然后使用它们
访问主页的Cookie
通过添加Cookies方法设置Cookies。参数为字典类型。此外,你必须首先
访问get链接一次并设置cookie,否则将报告无法设置cookie的错误
检查右下角是否更改为登录状态,以了解使用Cookie登录是否成功:
6.Selenium共同功能
作为自动化测试的工具,selenium自然为自动化操作提供了许多功能
下面是一些我认为常用的函数。有关更多信息,请参阅官方文件:
官方API文档:
1)定位元件
PS:将元素更改为元素将定位所有符合条件的元素并返回列表
例如:通过类名称查找元素
2)鼠标动作
有时需要在页面上模拟鼠标操作,如单击、双击、右键单击、按住、拖动等
您可以导入actionchains类:mon.action uChains.actionchains
使用actionchains(驱动程序)。XXX调用相应节点的行为
3)弹出窗口
对应类:mon.alert.alert。我认为不应该用太多
如果触发某个时间,弹出一个对话框,可以调用以下方法获取该对话框:
alert=driver.switch u到u alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.Switch_uu至.window(“窗口名称”)
或通过窗口句柄进行遍历
对于driver.window中的句柄uhandles:
驾驶员侧开关至车窗(把手)
司机。前进()#前进
司机。后退()#后退
5)页面截图
driver.save屏幕截图(“Screenshot.PNG”)
6)页面等待
现在,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完成
装了。如果实际的页面等待时间太长,则DOM元素没有出现,但是
如果代码直接使用此webelement,将引发空指针异常
为了避免元素定位的困难,提高元素不可见异常的概率
因此,selenium提供了两种等待方法:隐式等待和显式等待
显式等待:
显式等待指定条件,然后设置最大等待时间。如果不是在这个时候
如果找到元素,将引发异常
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写入参数,程序将默认0.5s调用一次以查看元素是否已生成
如果元素已经存在,将立即返回该元素
以下是一些内置的等待条件。您可以直接调用这些条件,而无需自己
写一些等待条件
标题是
标题收录
元素的存在位置
所在元素的可见性
能见度
所有元素的存在
文本在元素中存在
文本在元素值中存在
框架可用,并且_ 查看全部
js抓取网页内容(抓的妹子图都是直接抓Html就可以的
)
导言
以前的姐妹图片是直接用HTML(即chrome浏览器F12)捕获的
elements页面结构返回与网络数据包捕获相同的结果。从后面拿一些
网站(如煎蛋和那些小的网站)发现了它并抓住了那里的袋子
没有获得任何数据,但在元素中存在一些情况。原因是页面的数据是
通过javascript动态生成:
一开始,我想自己学习一批JS基本语法,然后模拟数据包捕获
获取其他人的JS文件,自己分析逻辑,然后计算出真正的URL。后来是
放弃。毕竟,有太多的页面需要掌握。什么时候会像这样分析每一个
后来,我偶然发现了一个自动化测试框架:selenium可以帮助我们解决这个问题
简单地说,这东西有什么用?我们可以编写代码来制作浏览器:
那么这个东西不支持浏览器功能。您需要在第三方浏览器中使用它
要支持以下浏览器,您需要将相应的浏览器驱动程序下载到Python的相应路径:
铬:
火狐:
幻影:
即:
边缘:
歌剧:
让我们从这一节开始~
1.安装硒
这很简单。您可以通过PIP命令行直接安装:
sudo pip install selenium
PS:我记得我的公司合伙人问我为什么不能在win上实现PIP,有很多PIP
事实上,如果安装Python3,默认情况下它已经有了PIP。您需要配置另一个环境
变数。PIP的路径位于python安装目录的scripts目录中~
只需在路径之后添加此路径~
2.下载浏览器驱动程序
因为selenium没有浏览器,所以它需要依赖第三方浏览器并调用第三方浏览器
对于浏览器,您需要下载浏览器驱动程序,因为作者使用chrome
以Chrome为例,其他浏览器自己搜索相关信息!打开Chrome浏览器并键入:
chrome://version
您可以查看有关Chrome浏览器版本的相关信息。在这里,只需关注版本号:
61。好的,接下来,转到以下网站检查相应的驱动程序版本号:
好的,那就下载吧v2.Version 34浏览器驱动程序:
下载后,解压缩zip文件并将解压缩后的chromedriver.exe复制到python
在脚本目录中。(不需要与Win32纠缠,它可以在64位浏览器上正常使用!)
PS:对于Mac,将提取的文件复制到usr/local/bin目录
对于Ubuntu,将其复制到usr/bin目录
接下来,让我们编写一个简单的代码进行测试:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行此代码将自动调用浏览器并访问百度:
控制台将输出HTML代码,即直接获得的元素页面结构
在JS被执行后,我们可以抓到我们的煎蛋女照片
3.Selenium简单实战:抓取煎蛋女图片
直接分析元素页面结构以找到所需的关键节点:
显然,这是我们小妹妹的照片。复制URL并查看我们打印的内容
页面结构中是否存在这样的内容:
是的,很好。有了这个页面数据,我们将经历一波美丽的汤来获得我们
你想要的数据~
经过以上过滤,我们可以得到我们的姐妹图片URL:
打开验证,单击:
看完下一页,只有30个小姐妹,显然不能和我们见面。我们第一次装了
首先获取大量的页码,然后知道有多少页,然后拼接URL并自己加载
不同的页面,例如,总共有448页:
拼接到这样一个URL中:
通过过滤获得的页码:
接下来,填写代码,循环抓取每个页面上的小妹妹,然后在本地下载
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
经营成果:
看看我们的输出文件夹~
学习蟒蛇爬虫,天天减肥
4.PhantomJS
Phantom JS是一款没有界面的浏览器。功能:网站将加载到内存中并在页面上执行
JavaScript,因为它不显示图形界面,运行起来比一个完整的浏览器更高效
(在某些Linux主机上,没有图形界面就无法安装chrome等浏览器
您可以通过phantom JS避免此问题)
在Win上安装phantomjs:
在Ubuntu/Mac上安装phantomjs:
sudo apt-get install phantomjs
!!!关于phantomjs的重要注意事项:
今年4月,phantom.js的维护者宣布退出phantom js
这意味着该项目可能不再维护!!!Chrome和Firefox也已经启动
提供无头模式(无需挂断浏览器),因此估计小型合作伙伴使用phantom JS
它还将缓慢地迁移到这两种浏览器。Windows chrome需要60以上的版本才能支持
无头模式,启用无头模式也非常简单:
官方文件还指出:
在操作过程中也会报告此警告:
5.Selenium实战:模拟登录CSDN并保存cookie
CSDN登录网站:
在分析下面的页面结构后,不难找到相应的登录输入框和登录按钮:
我们需要做的是在这两个节点上输入帐户和密码,然后触发登录按钮
同时,在本地保存cookie,然后您可以使用cookie访问相关页面~
首先编写模拟登录的方法:
查找您输入帐户和密码的节点,设置您自己的帐户和密码,然后查找登录名
单击按钮节点,然后等待登录成功。登录成功后,您可以比较
当前\ URL是否已更改。然后把饼干保存在这里
我使用pickle图书馆。我可以使用其他方法,例如JSON或字符串拼接
然后在本地保存它。如果没有意外,你应该能够得到饼干,然后使用它们
访问主页的Cookie
通过添加Cookies方法设置Cookies。参数为字典类型。此外,你必须首先
访问get链接一次并设置cookie,否则将报告无法设置cookie的错误
检查右下角是否更改为登录状态,以了解使用Cookie登录是否成功:
6.Selenium共同功能
作为自动化测试的工具,selenium自然为自动化操作提供了许多功能
下面是一些我认为常用的函数。有关更多信息,请参阅官方文件:
官方API文档:
1)定位元件
PS:将元素更改为元素将定位所有符合条件的元素并返回列表
例如:通过类名称查找元素
2)鼠标动作
有时需要在页面上模拟鼠标操作,如单击、双击、右键单击、按住、拖动等
您可以导入actionchains类:mon.action uChains.actionchains
使用actionchains(驱动程序)。XXX调用相应节点的行为
3)弹出窗口
对应类:mon.alert.alert。我认为不应该用太多
如果触发某个时间,弹出一个对话框,可以调用以下方法获取该对话框:
alert=driver.switch u到u alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.Switch_uu至.window(“窗口名称”)
或通过窗口句柄进行遍历
对于driver.window中的句柄uhandles:
驾驶员侧开关至车窗(把手)
司机。前进()#前进
司机。后退()#后退
5)页面截图
driver.save屏幕截图(“Screenshot.PNG”)
6)页面等待
现在,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完成
装了。如果实际的页面等待时间太长,则DOM元素没有出现,但是
如果代码直接使用此webelement,将引发空指针异常
为了避免元素定位的困难,提高元素不可见异常的概率
因此,selenium提供了两种等待方法:隐式等待和显式等待
显式等待:
显式等待指定条件,然后设置最大等待时间。如果不是在这个时候
如果找到元素,将引发异常
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写入参数,程序将默认0.5s调用一次以查看元素是否已生成
如果元素已经存在,将立即返回该元素
以下是一些内置的等待条件。您可以直接调用这些条件,而无需自己
写一些等待条件
标题是
标题收录
元素的存在位置
所在元素的可见性
能见度
所有元素的存在
文本在元素中存在
文本在元素值中存在
框架可用,并且_
js抓取网页内容(如何模拟请求和如何解析HTMLHTML系统学习教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-20 08:24
虽然这在很久以前是个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法
首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
那么,我们就瞄准北方邮递员论坛!打开beimailman论坛首页,发现首页HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:
从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:
到目前为止,我们已经确定此链接可以获得主页的文章和链接。在headers选项中,有该请求的请求头和请求参数。通过在Python中模拟这个请求,我们可以得到相同的响应。然后,我们可以使用诸如Beauty soup之类的库解析HTML,以获得相应的内容
对于如何模拟请求以及如何解析HTML,小编有时间再写一次。记住要关注它,并在将来经常与您分享文章
最后,小编是一名python开发工程师。在这里,我已经编写了一套最新的Python系统学习教程,包括基本Python脚本、web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些材料的人可以关注小编,并在背景私信小编:“01”中获得它们 查看全部
js抓取网页内容(如何模拟请求和如何解析HTMLHTML系统学习教程)
虽然这在很久以前是个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法

首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
那么,我们就瞄准北方邮递员论坛!打开beimailman论坛首页,发现首页HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:

从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:

到目前为止,我们已经确定此链接可以获得主页的文章和链接。在headers选项中,有该请求的请求头和请求参数。通过在Python中模拟这个请求,我们可以得到相同的响应。然后,我们可以使用诸如Beauty soup之类的库解析HTML,以获得相应的内容
对于如何模拟请求以及如何解析HTML,小编有时间再写一次。记住要关注它,并在将来经常与您分享文章
最后,小编是一名python开发工程师。在这里,我已经编写了一套最新的Python系统学习教程,包括基本Python脚本、web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些材料的人可以关注小编,并在背景私信小编:“01”中获得它们
js抓取网页内容(百度是否会抓取网站js文件?百度蜘蛛是否识别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-20 00:09
寻找A5项目招商,快速获得准确的代理名单
今天,让我们来讨论一个更重要的内容,百度是否会抓住我们网站js,百度蜘蛛认出我们了吗网站js百度抓取JS的缺点是什么?你需要阻止JS吗?我们当前的文章文章将详细解释这篇文章的内容
百度会抓取网站js文件
事实上,通过分析蜘蛛,我们可以发现百度抓住了JS。过去,很多人说百度不会抓取JS和CSS。事实上,这种说法是完全错误的。百度不仅抢夺,而且抢夺的频率更高,不仅仅是百度,360、搜狗和神马搜索引擎将捕获
百度蜘蛛现在能识别JS吗
我可以清楚地告诉你百度是否有能力识别JS,90%以上的JS都可以识别。你为什么这么说?你不妨考虑一下。百度开发了一种“石榴算法”,专门对付页面中大量的弹出窗口,而大多数弹出广告都是JS代码。如果百度无法识别JS,如何打击此类页面?此外,许多非法站点使用js站点集。如果百度无法识别JS,让这些黑客大发雷霆,你认为有可能吗?几年前就可以认识到这一点,现在必须更加认识到这一点
JS是否需要使用robots.txt来屏蔽和抓取
为了解释,JS文件是否需要用robots.txt屏蔽和捕获?CSS和JS是否需要屏蔽一直存在争议。事实上,CSS不需要屏蔽。如果被屏蔽,百度快照中的风格就会混乱,影响或多或少。但是,JS需要屏蔽。合理屏蔽JS将大大优化蜘蛛爬行,更有利于SEO优化。下面是如何屏蔽这种JS
如何有效防止百度抢夺JS
一,。使用robots.txt屏蔽整个站点JS和您不想抓取的JS
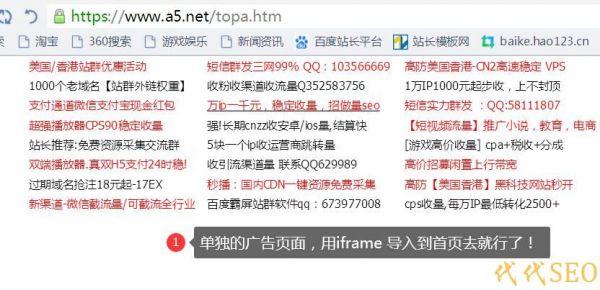
首先,最直接的方法是使用robots.txt直接屏蔽JS。有两种屏蔽方法。第一个是完全屏蔽整个电站JS,第二个是屏蔽单个JS。我们以下图为例。事实上,我建议屏蔽整个站点JS,因为JS对SEO没有实际影响,只会减慢网站的速度@
二,。使用模糊加密工具加密JS
虽然有些爬行器将被robots.txt阻止爬行,但有些JS仍然会爬行。这个时候我该怎么办?我们可以使用一些加密技术来加密JS,以增加百度的不可识别性。对于某些敏感内容,建议这样做。例如,JS充满了广告代码,如果被百度捕获,将对网站产生负面影响。因此,最好混合使用加密。一般来说,我们会使用网站管理员工具来加密混合加密(见下图)
三,。如果是广告,您可以考虑使用框架
导入JS。
第三点是一些第三方广告代码。如果有很多网站广告,并且有很多是用JS编写的,那么仅仅使用混淆加密是无法完全解决的。我们可以创建一个单独的页面来放置广告,然后将它们导入iframe。百度通常不会捕获iframe中的内容。当然,JS仍然需要混淆加密,这可以大大减轻百度对太多广告的处罚
好吧,让我们今天谈这么多。让我们总结一下这两种类型:CSS和JS。我们需要保护JS。CSS不需要屏蔽。在robots.txt中,我们可以直接编写屏蔽全站的JS网站js百度将捕获并识别,因此如果网站js电视里有许多广告。您可以使用框架导入它们 查看全部
js抓取网页内容(百度是否会抓取网站js文件?百度蜘蛛是否识别?)
寻找A5项目招商,快速获得准确的代理名单
今天,让我们来讨论一个更重要的内容,百度是否会抓住我们网站js,百度蜘蛛认出我们了吗网站js百度抓取JS的缺点是什么?你需要阻止JS吗?我们当前的文章文章将详细解释这篇文章的内容
百度会抓取网站js文件
事实上,通过分析蜘蛛,我们可以发现百度抓住了JS。过去,很多人说百度不会抓取JS和CSS。事实上,这种说法是完全错误的。百度不仅抢夺,而且抢夺的频率更高,不仅仅是百度,360、搜狗和神马搜索引擎将捕获
百度蜘蛛现在能识别JS吗
我可以清楚地告诉你百度是否有能力识别JS,90%以上的JS都可以识别。你为什么这么说?你不妨考虑一下。百度开发了一种“石榴算法”,专门对付页面中大量的弹出窗口,而大多数弹出广告都是JS代码。如果百度无法识别JS,如何打击此类页面?此外,许多非法站点使用js站点集。如果百度无法识别JS,让这些黑客大发雷霆,你认为有可能吗?几年前就可以认识到这一点,现在必须更加认识到这一点
JS是否需要使用robots.txt来屏蔽和抓取
为了解释,JS文件是否需要用robots.txt屏蔽和捕获?CSS和JS是否需要屏蔽一直存在争议。事实上,CSS不需要屏蔽。如果被屏蔽,百度快照中的风格就会混乱,影响或多或少。但是,JS需要屏蔽。合理屏蔽JS将大大优化蜘蛛爬行,更有利于SEO优化。下面是如何屏蔽这种JS
如何有效防止百度抢夺JS
一,。使用robots.txt屏蔽整个站点JS和您不想抓取的JS
首先,最直接的方法是使用robots.txt直接屏蔽JS。有两种屏蔽方法。第一个是完全屏蔽整个电站JS,第二个是屏蔽单个JS。我们以下图为例。事实上,我建议屏蔽整个站点JS,因为JS对SEO没有实际影响,只会减慢网站的速度@

二,。使用模糊加密工具加密JS
虽然有些爬行器将被robots.txt阻止爬行,但有些JS仍然会爬行。这个时候我该怎么办?我们可以使用一些加密技术来加密JS,以增加百度的不可识别性。对于某些敏感内容,建议这样做。例如,JS充满了广告代码,如果被百度捕获,将对网站产生负面影响。因此,最好混合使用加密。一般来说,我们会使用网站管理员工具来加密混合加密(见下图)
三,。如果是广告,您可以考虑使用框架
导入JS。
第三点是一些第三方广告代码。如果有很多网站广告,并且有很多是用JS编写的,那么仅仅使用混淆加密是无法完全解决的。我们可以创建一个单独的页面来放置广告,然后将它们导入iframe。百度通常不会捕获iframe中的内容。当然,JS仍然需要混淆加密,这可以大大减轻百度对太多广告的处罚
好吧,让我们今天谈这么多。让我们总结一下这两种类型:CSS和JS。我们需要保护JS。CSS不需要屏蔽。在robots.txt中,我们可以直接编写屏蔽全站的JS网站js百度将捕获并识别,因此如果网站js电视里有许多广告。您可以使用框架导入它们
js抓取网页内容(puppeteer和nodejs的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-19 23:07
木偶演员
GoogleChrome团队生产的puppeter是一个依靠nodejs和Chrome的自动化测试库。它最大的优点是可以处理网页中的动态内容,如JavaScript,并更好地模拟用户
一些网站反爬虫方法在一些JavaScript/Ajax请求中隐藏了一些内容,这使得直接获取标记的方法无效。有些网站甚至会设置隐藏元素“陷阱”,用户看不见,脚本触发器被认为是机器。在这种情况下,木偶师的优势就突出了
可实现以下功能:
生成页面的屏幕截图和PDF。抓取spa并生成预渲染内容(即“×××”)。自动表单提交、UI测试、键盘输入等。创建最新的自动测试环境。使用最新的JavaScript和浏览器功能直接在最新版本的chrome中运行测试。捕获并跟踪网站时间线,以帮助诊断性能问题
开放源代码地址:[]1]
装置
npm i puppeteer
注意:首先安装nodejs并在nodejs文件的根目录下执行(同一级别的NPM文件)
铬将在安装过程中下载,约120m
花了两天(大约10个小时)的时间探索并绕过了大量的异步坑。作者对木偶和节点有一定的掌握
长照片、抓拍blog文章List:
抓住blog文章
以CSDN博客为例,文章内容需要通过点击“读取全文”获取,这导致只能读取dom的脚本失效
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
执行过程
录音机可以在我的官方帐户中查看,屏幕截图如下:
执行结果
文章内容列表:
文章content:
结论
我认为由于nodejs使用JavaScript脚本语言,它当然可以处理网页的JavaScript内容,但我没有找到一个合适/高效的库。直到找到了木偶师,我才下定决心试水
换言之,nodejs的异步性确实令人头痛。我已经花了10个小时写了数百行代码
您可以在代码中扩展process()方法并使用async.eachseries
事实上,一个接一个的处理是没有效率的。我最初编写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js抓取网页内容(puppeteer和nodejs的区别)
木偶演员
GoogleChrome团队生产的puppeter是一个依靠nodejs和Chrome的自动化测试库。它最大的优点是可以处理网页中的动态内容,如JavaScript,并更好地模拟用户
一些网站反爬虫方法在一些JavaScript/Ajax请求中隐藏了一些内容,这使得直接获取标记的方法无效。有些网站甚至会设置隐藏元素“陷阱”,用户看不见,脚本触发器被认为是机器。在这种情况下,木偶师的优势就突出了
可实现以下功能:
生成页面的屏幕截图和PDF。抓取spa并生成预渲染内容(即“×××”)。自动表单提交、UI测试、键盘输入等。创建最新的自动测试环境。使用最新的JavaScript和浏览器功能直接在最新版本的chrome中运行测试。捕获并跟踪网站时间线,以帮助诊断性能问题
开放源代码地址:[]1]
装置
npm i puppeteer
注意:首先安装nodejs并在nodejs文件的根目录下执行(同一级别的NPM文件)
铬将在安装过程中下载,约120m
花了两天(大约10个小时)的时间探索并绕过了大量的异步坑。作者对木偶和节点有一定的掌握
长照片、抓拍blog文章List:

抓住blog文章
以CSDN博客为例,文章内容需要通过点击“读取全文”获取,这导致只能读取dom的脚本失效
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
执行过程
录音机可以在我的官方帐户中查看,屏幕截图如下:

执行结果
文章内容列表:

文章content:

结论
我认为由于nodejs使用JavaScript脚本语言,它当然可以处理网页的JavaScript内容,但我没有找到一个合适/高效的库。直到找到了木偶师,我才下定决心试水
换言之,nodejs的异步性确实令人头痛。我已经花了10个小时写了数百行代码
您可以在代码中扩展process()方法并使用async.eachseries
事实上,一个接一个的处理是没有效率的。我最初编写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js抓取网页内容(js抓取网页内容很简单,android需要抓包才能继续分析报表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-17 01:02
js抓取网页内容很简单,网页内容是存在html中的抓包就可以解析,当然以前我遇到这个问题用js写过一个浏览器插件抓取。特别是通过爬虫实现echo转换,我想是最快的了,tornado或者vue,vue应该更方便。
本身的python代码能力,运气以及你对爬虫的了解能力以及经验,是匹配爬虫工程师的水平,我工作中就有用requests+beautifulsoup+requestslib+phantomjs+js+dnsparse+json+xpath+locals...等人工构建爬虫的例子,运气好的话都可以胜任。不过我感觉,只有真正对爬虫、爬虫代理的网站会配合爬虫工程师去做这件事情。
一句话解释:分布式爬虫+自动化测试
你看你的意思应该是要找到一个url转换器把你要抓取的页面转换成另一个网址,然后在转换服务器上抓取。你写一个exe文件,放在服务器上,用nodejs语言写个curl抓包,requests库,http.io库,写个爬虫程序去抓。然后api就有了,用爬虫程序读http的request就可以去抓,不过正向还是反向不怎么容易破解。
同时因为抓取一些网站上的api,一些普通http文档,可以省去dns等信息破解的时间,例如api。爬虫程序性能要求高还是上链接池比较好,例如beego等,另外如果真要做分布式,也可以先写个稍微小一点的api。没法直接发布到服务器,实现起来还是挺麻烦的。爬虫post提交以后是自己管理的,windows/linux爬虫用indexpy比较方便,android需要抓包才能继续分析报表。 查看全部
js抓取网页内容(js抓取网页内容很简单,android需要抓包才能继续分析报表)
js抓取网页内容很简单,网页内容是存在html中的抓包就可以解析,当然以前我遇到这个问题用js写过一个浏览器插件抓取。特别是通过爬虫实现echo转换,我想是最快的了,tornado或者vue,vue应该更方便。
本身的python代码能力,运气以及你对爬虫的了解能力以及经验,是匹配爬虫工程师的水平,我工作中就有用requests+beautifulsoup+requestslib+phantomjs+js+dnsparse+json+xpath+locals...等人工构建爬虫的例子,运气好的话都可以胜任。不过我感觉,只有真正对爬虫、爬虫代理的网站会配合爬虫工程师去做这件事情。
一句话解释:分布式爬虫+自动化测试
你看你的意思应该是要找到一个url转换器把你要抓取的页面转换成另一个网址,然后在转换服务器上抓取。你写一个exe文件,放在服务器上,用nodejs语言写个curl抓包,requests库,http.io库,写个爬虫程序去抓。然后api就有了,用爬虫程序读http的request就可以去抓,不过正向还是反向不怎么容易破解。
同时因为抓取一些网站上的api,一些普通http文档,可以省去dns等信息破解的时间,例如api。爬虫程序性能要求高还是上链接池比较好,例如beego等,另外如果真要做分布式,也可以先写个稍微小一点的api。没法直接发布到服务器,实现起来还是挺麻烦的。爬虫post提交以后是自己管理的,windows/linux爬虫用indexpy比较方便,android需要抓包才能继续分析报表。
js抓取网页内容(如何模拟请求和如何解析HTML的链接和标题?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-15 17:02
虽然这是很久以前的事了,但这个主题似乎已经解决了这个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法。由于标题并不表示您需要什么,因此这里的示例采用主页上所有帖子的链接和标题
首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
然后打开beimailman论坛主页,发现其主页的HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:
从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:
到目前为止,我们确信此链接可以获得主页的文章和链接
在headers选项中,有该请求的请求头和请求参数。通过python模拟这个请求,我们可以得到相同的响应。然后,我们可以用Beauty soup等库解析HTML,以获得相应的内容
关于如何模拟请求以及如何解析HTML,请转到我的专栏进行详细介绍,这里不再重复
通过这种方式,您可以在不模拟浏览器环境的情况下获取数据,这大大提高了内存、CPU消耗和爬网速度。编写爬虫程序时,请记住,除非必要,否则不要模拟浏览器环境 查看全部
js抓取网页内容(如何模拟请求和如何解析HTML的链接和标题?(一))
虽然这是很久以前的事了,但这个主题似乎已经解决了这个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法。由于标题并不表示您需要什么,因此这里的示例采用主页上所有帖子的链接和标题
首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
然后打开beimailman论坛主页,发现其主页的HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:
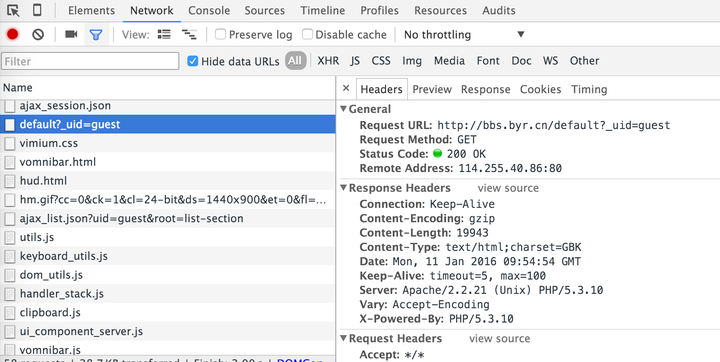
从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:
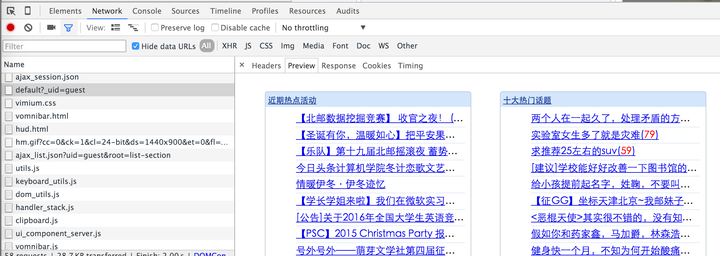
到目前为止,我们确信此链接可以获得主页的文章和链接
在headers选项中,有该请求的请求头和请求参数。通过python模拟这个请求,我们可以得到相同的响应。然后,我们可以用Beauty soup等库解析HTML,以获得相应的内容
关于如何模拟请求以及如何解析HTML,请转到我的专栏进行详细介绍,这里不再重复
通过这种方式,您可以在不模拟浏览器环境的情况下获取数据,这大大提高了内存、CPU消耗和爬网速度。编写爬虫程序时,请记住,除非必要,否则不要模拟浏览器环境
js抓取网页内容(借助mysql模块保存数据(假设数据库)的基本流程和流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2021-09-12 19:13
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索关键词node.js
获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 关键词p=?是要搜索的页码。
带有请求模块的请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然URL可用,分析URL对应的页面内容。
页面还是很规律的。
标题摘要作者发表时间推荐评论数量文章link查看数量
借助浏览器开发工具
发现
...
对应每篇文章文章
点击每一项,有以下内容
class="searchItemTitle" 收录文章title 和文章URL 地址
class="searchItemInfo-userName" 收录作者
class="searchItemInfo-publishDate" 收录发布日期
class="searchItemInfo-views" 收录浏览次数
借助cheerio模块分析文章以抓取特定内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。
现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它看看数据是否保存在数据库中。
现在可以进行基本的抓取和保存。但是只爬取一次,只能爬取关键词为node.js页码为1的URL页面。
把关键词改成javascript,页码为1,清空博客表,再运行看看表中是否可以保存javascript相关的数据。
现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,不看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。最好能自动抓取其他页面的内容。 查看全部
js抓取网页内容(借助mysql模块保存数据(假设数据库)的基本流程和流程)
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索关键词node.js

获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 关键词p=?是要搜索的页码。
带有请求模块的请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然URL可用,分析URL对应的页面内容。

页面还是很规律的。
标题摘要作者发表时间推荐评论数量文章link查看数量
借助浏览器开发工具

发现
...
对应每篇文章文章
点击每一项,有以下内容
class="searchItemTitle" 收录文章title 和文章URL 地址
class="searchItemInfo-userName" 收录作者
class="searchItemInfo-publishDate" 收录发布日期
class="searchItemInfo-views" 收录浏览次数
借助cheerio模块分析文章以抓取特定内容


var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。

现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)

var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它看看数据是否保存在数据库中。
现在可以进行基本的抓取和保存。但是只爬取一次,只能爬取关键词为node.js页码为1的URL页面。
把关键词改成javascript,页码为1,清空博客表,再运行看看表中是否可以保存javascript相关的数据。

现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,不看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。最好能自动抓取其他页面的内容。
js抓取网页内容(目标网站是以滚动页面的方式动态生成数据的网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-11 23:09
)
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
比如网站像今天的头条:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合用于数据捕获。它可以轻松绕过网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行。就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
js抓取网页内容(目标网站是以滚动页面的方式动态生成数据的网页
)
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
比如网站像今天的头条:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合用于数据捕获。它可以轻松绕过网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行。就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能读取DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-11 23:05
项目招商找A5快速获取精准代理商名单
我们测试了 Google 爬虫如何抓取 JavaScript,以下是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。 Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和收录 会抓取哪些类型的 JavaScript 函数。
概述
1. 我们进行了一系列测试,已经确认 Google 可以通过多种方式执行收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,以便收录 可以动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能仅限于某种方式。
而今天,很明显,Google 不仅可以制定他们的抓取和 收录 JavaScript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是在过去的 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及收录。经过研究,我们发现了令人大开眼界的结果,并确认Google不仅可以执行各种JavaScript事件,还可以收录动态生成内容。怎么做? Google 可以读取 DOM。
什么是 DOM?
很多从事 SEO 的人不了解什么是文档对象模型 (DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
关于这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性以及收录,我们分别针对谷歌爬虫创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为 5 类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。 URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:Google 很快跟踪了重定向。从收录 开始,它们被解释为 301 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然重定向被谷歌跟踪了,但是原来的页面不是收录。新的URL是收录,它立即被安排在同一个查询页面上的相同位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)似乎与永久性 301 重定向非常相似。
下次,您的客户想要为他们的网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用 Google 指南支持此结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:该链接已被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
对外部 href 键值对 (AVP) 进行操作,但在标记内 (“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签外可用,但在 href 内调用 AVP("javascript: openlink()")
……
结果:该链接已被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:该链接已被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:该链接已被完全抓取和跟踪。
3.动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况都可以爬取文字和收录,页面根据内容排名。酷!
为了深入了解,我们测试了一个用 JavaScript 编写的客户端全局导航,导航中的链接是通过 document.writeIn 函数插入的,我们确信可以完全抓取和跟踪需要指出的是,谷歌可以解释网站使用AngularJS框架和HTML5 History API(pushState)构建,可以渲染和收录它,并且可以像传统静态网页一样排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取,收录。我们甚至做了这样一个测试:通过动态生成结构数据并插入到 DOM 中来制作面包屑(面包屑导航)。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们将各种对 SEO 至关重要的标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel = "nofollow" 的一个重要例子
我们想测试 Google 如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有应用 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注释。
源代码中的nofollow按我们的预期工作(没有遵循链接)。 DOM中的nofollow无效(跟随链接,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果在 DOM 中插入一个 href="nofollow" 的元素,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。 JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理内容的动态插入,甚至元标记,例如 rel 规范注释。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了! (请记住允许 Google 抓取工具获取这些外部文件和 JavaScript。)
Google 已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和 dynamic网站。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,跟上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会! 查看全部
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能读取DOM是什么?)
项目招商找A5快速获取精准代理商名单
我们测试了 Google 爬虫如何抓取 JavaScript,以下是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。 Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和收录 会抓取哪些类型的 JavaScript 函数。
概述
1. 我们进行了一系列测试,已经确认 Google 可以通过多种方式执行收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,以便收录 可以动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能仅限于某种方式。
而今天,很明显,Google 不仅可以制定他们的抓取和 收录 JavaScript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是在过去的 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及收录。经过研究,我们发现了令人大开眼界的结果,并确认Google不仅可以执行各种JavaScript事件,还可以收录动态生成内容。怎么做? Google 可以读取 DOM。
什么是 DOM?
很多从事 SEO 的人不了解什么是文档对象模型 (DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
关于这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性以及收录,我们分别针对谷歌爬虫创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为 5 类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。 URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:Google 很快跟踪了重定向。从收录 开始,它们被解释为 301 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然重定向被谷歌跟踪了,但是原来的页面不是收录。新的URL是收录,它立即被安排在同一个查询页面上的相同位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)似乎与永久性 301 重定向非常相似。
下次,您的客户想要为他们的网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用 Google 指南支持此结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:该链接已被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
对外部 href 键值对 (AVP) 进行操作,但在标记内 (“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签外可用,但在 href 内调用 AVP("javascript: openlink()")
……
结果:该链接已被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:该链接已被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:该链接已被完全抓取和跟踪。
3.动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况都可以爬取文字和收录,页面根据内容排名。酷!
为了深入了解,我们测试了一个用 JavaScript 编写的客户端全局导航,导航中的链接是通过 document.writeIn 函数插入的,我们确信可以完全抓取和跟踪需要指出的是,谷歌可以解释网站使用AngularJS框架和HTML5 History API(pushState)构建,可以渲染和收录它,并且可以像传统静态网页一样排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取,收录。我们甚至做了这样一个测试:通过动态生成结构数据并插入到 DOM 中来制作面包屑(面包屑导航)。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们将各种对 SEO 至关重要的标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel = "nofollow" 的一个重要例子
我们想测试 Google 如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有应用 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注释。
源代码中的nofollow按我们的预期工作(没有遵循链接)。 DOM中的nofollow无效(跟随链接,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果在 DOM 中插入一个 href="nofollow" 的元素,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。 JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理内容的动态插入,甚至元标记,例如 rel 规范注释。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了! (请记住允许 Google 抓取工具获取这些外部文件和 JavaScript。)
Google 已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和 dynamic网站。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,跟上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会!
js抓取网页内容(Python中的HTML生成内容内容介绍及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-11 23:05
我们没有得到正确的结果,因为 javascript 生成的任何内容都需要在 DOM 上呈现。当我们得到一个 HTML 页面时,我们得到的是初始的、未修改的 DOM。
因此,我们需要在抓取页面之前呈现 javascript 内容。
由于在这个线程中多次提到 Selenium(有时是它的速度),我将列出另外两种可能的解决方案。
解决方案 1:这是一个非常好的教程,我们将遵循这个教程。
我们需要的是:
Docker 安装在我们的机器上。在此之前,这是比其他解决方案更好的解决方案,因为它使用独立于操作系统的平台。
按照相应操作系统中列出的说明安装 Splash。
引用启动文件:
Splash 是一种 JavaScript 渲染服务。它是一个带有 HTTPAPI 的轻量级 Web 浏览器,使用 Twisted 和 QT5 在 Python 3 中实现。
本质上,我们将使用 Splash 来呈现由 Javascript 生成的内容。
运行 Splash 服务器:sudo docker run -p 8050:8050 scrapinghub/splash。
安装插件:pip install scrapy-splash
假设我们已经创建了一个 Scrapy 项目(如果没有),我们将根据指南更新 settings.py:
然后转到您的项目 settings.py 并设置这些中间工具:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,}
Splash 服务器的 URL(如果使用 Win 或 OSX)。这应该是对接计算机的URL:如何从主机获取docker容器的IP地址? ):
SPLASH_URL = 'http://localhost:8050'
最后,您还需要设置这些值:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
最后,我们可以使用:
在普通蜘蛛中,可以使用请求对象来打开网址。如果要打开的页面收录JS生成的数据,则必须使用SplashRequest(或SplashFormRequest)来渲染页面。这是一个简单的例子:
class MySpider(scrapy.Spider):
name = "jsscraper"
start_urls = ["http://quotes.toscrape.com/js/"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url=url, callback=self.parse, endpoint='render.html'
)
def parse(self, response):
for q in response.css("div.quote"):
quote = QuoteItem()
quote["author"] = q.css(".author::text").extract_first()
quote["quote"] = q.css(".text::text").extract_first()
yield quote
SplashRequest 将 URL 呈现为 html 并返回您可以在回调(解析)方法中使用的响应。
解决方案 2:我们现在称之为实验(2018 年 5 月)。
此解决方案仅适用于 Python 版本 3.6(目前)。
你知道请求模块吗(谁不知道)?
现在有了爬虫小哥:request-HTML:
这个库旨在使解析 HTML(例如,爬网)尽可能简单和直观。
安装 requests-html:pipenv install requests-html
向页面的 URL 发出请求:
from requests_html import HTMLSessionsession = HTMLSession()r = session.get(a_page_url)
呈现响应以获取 Javascript 生成的位:
r.html.render()
最后好像提供了模块。
或者,我们也可以试试记录的方法。使用美利糖和 r.html 刚刚呈现的对象。 查看全部
js抓取网页内容(Python中的HTML生成内容内容介绍及解析)
我们没有得到正确的结果,因为 javascript 生成的任何内容都需要在 DOM 上呈现。当我们得到一个 HTML 页面时,我们得到的是初始的、未修改的 DOM。
因此,我们需要在抓取页面之前呈现 javascript 内容。
由于在这个线程中多次提到 Selenium(有时是它的速度),我将列出另外两种可能的解决方案。
解决方案 1:这是一个非常好的教程,我们将遵循这个教程。
我们需要的是:
Docker 安装在我们的机器上。在此之前,这是比其他解决方案更好的解决方案,因为它使用独立于操作系统的平台。
按照相应操作系统中列出的说明安装 Splash。
引用启动文件:
Splash 是一种 JavaScript 渲染服务。它是一个带有 HTTPAPI 的轻量级 Web 浏览器,使用 Twisted 和 QT5 在 Python 3 中实现。
本质上,我们将使用 Splash 来呈现由 Javascript 生成的内容。
运行 Splash 服务器:sudo docker run -p 8050:8050 scrapinghub/splash。
安装插件:pip install scrapy-splash
假设我们已经创建了一个 Scrapy 项目(如果没有),我们将根据指南更新 settings.py:
然后转到您的项目 settings.py 并设置这些中间工具:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,}
Splash 服务器的 URL(如果使用 Win 或 OSX)。这应该是对接计算机的URL:如何从主机获取docker容器的IP地址? ):
SPLASH_URL = 'http://localhost:8050'
最后,您还需要设置这些值:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
最后,我们可以使用:
在普通蜘蛛中,可以使用请求对象来打开网址。如果要打开的页面收录JS生成的数据,则必须使用SplashRequest(或SplashFormRequest)来渲染页面。这是一个简单的例子:
class MySpider(scrapy.Spider):
name = "jsscraper"
start_urls = ["http://quotes.toscrape.com/js/"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url=url, callback=self.parse, endpoint='render.html'
)
def parse(self, response):
for q in response.css("div.quote"):
quote = QuoteItem()
quote["author"] = q.css(".author::text").extract_first()
quote["quote"] = q.css(".text::text").extract_first()
yield quote
SplashRequest 将 URL 呈现为 html 并返回您可以在回调(解析)方法中使用的响应。
解决方案 2:我们现在称之为实验(2018 年 5 月)。
此解决方案仅适用于 Python 版本 3.6(目前)。
你知道请求模块吗(谁不知道)?
现在有了爬虫小哥:request-HTML:
这个库旨在使解析 HTML(例如,爬网)尽可能简单和直观。
安装 requests-html:pipenv install requests-html
向页面的 URL 发出请求:
from requests_html import HTMLSessionsession = HTMLSession()r = session.get(a_page_url)
呈现响应以获取 Javascript 生成的位:
r.html.render()
最后好像提供了模块。
或者,我们也可以试试记录的方法。使用美利糖和 r.html 刚刚呈现的对象。
js抓取网页内容(搜索引擎对JS的索引小实验建立:Google和Baidu收录了目标实验站点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-11 23:03
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体应用会在以后文章中说明)。截至今天文章发布,谷歌和百度已将收录作为目标实验站点。
1:收录时间对比
Google 必须在百度之前收录 目标站点,而雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。
2:收录 的效果图
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
建立JS搜索引擎索引实验模型:
1.新建一个html页面和js页面,html页面代码的body除了js代码调用外没有其他信息内容。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录target html页面,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。 查看全部
js抓取网页内容(搜索引擎对JS的索引小实验建立:Google和Baidu收录了目标实验站点)
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体应用会在以后文章中说明)。截至今天文章发布,谷歌和百度已将收录作为目标实验站点。
1:收录时间对比
Google 必须在百度之前收录 目标站点,而雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。
2:收录 的效果图
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
建立JS搜索引擎索引实验模型:
1.新建一个html页面和js页面,html页面代码的body除了js代码调用外没有其他信息内容。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录target html页面,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。
js抓取网页内容(抓的妹子图都是直接抓Html就可以的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-07 06:06
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有获取到数据,但是Elements中出现了情况。原因是:页面的数据是
由 JavaScript 动态生成:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~
学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时将Cookie保存在本地,以后就可以用Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
查看全部
js抓取网页内容(抓的妹子图都是直接抓Html就可以的
)
介绍
之前拍的姐妹图可以直接用Html抓拍,也就是Chrome的浏览器F12。
Elements 页面结构和 Network 数据包捕获返回相同的结果。以后抓一些
网站(比如煎鸡蛋,还有那种小网站)我发现了。网络抓包
没有获取到数据,但是Elements中出现了情况。原因是:页面的数据是
由 JavaScript 动态生成:
抓不到数据怎么破?一开始想着自己学一波JS基础语法,然后尝试模拟抓包。
拿到别人的js文件,自己分析一下逻辑,然后摆弄真实的URL,然后就是
放弃。毕竟要爬取的页面太多了。每个这样的分析什么时候...
我偶然发现有一个自动化测试框架:Selenium 可以帮助我们处理这个问题。
简单说说这个东西的使用,我们可以写代码让浏览器:
那么这个东西不支持浏览器功能,需要配合第三方浏览器使用,
支持以下浏览器,需要将对应的浏览器驱动下载到Python对应的路径:
铬合金:
火狐:
幻影JS:
IE:
边缘:
歌剧:
下面直接开始本节的内容吧~
1.安装硒
这个很简单,直接通过pip命令行安装:
sudo pip install selenium
PS:记得公司小伙伴问我为什么在win上不能执行pip,我下载了很多pip。
其实安装Python3的话,默认已经自带pip了,需要单独配置环境
变量,pip的路径在Python安装目录的Scripts目录下~
在Path后面加上这个路径就行了~
2.下载浏览器驱动
因为Selenium没有浏览器,需要依赖第三方浏览器,调用第三方
如果你用的是新浏览器,需要下载浏览器的驱动,因为我用的是Chrome,所以我会用
我们以 Chrome 为例。其他浏览器可以自行搜索相关信息!打开 Chrome 浏览器并输入:
chrome://version
可以查看Chrome浏览器版本的相关信息,这里主要注意版本号:
61.好的,那么到下面网站查看对应的驱动版本号:
好的,接下来下载v2.34版本的浏览器驱动:
下载完成后,解压zip文件,将解压后的chromedriver.exe复制到Python
脚本目录。(这里不用担心win32,64位浏览器可以正常使用!)
PS:对于Mac,将解压后的文件复制到usr/local/bin目录下
对于Ubuntu,复制到:usr/bin目录
接下来我们写一个简单的代码来测试一下:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码会自动调出浏览器访问百度:
并且控制台会输出HTML代码,也就是直接获取到的Elements页面结构,
JS执行后的页面~接下来就可以抢到我们的煎蛋少女图了~
3.Selenium简单实战:抢煎蛋少女图
直接分析Elements页面的结构,找到你想要的关键节点:
明明这是我们抓到的小姐姐的照片,复制这个网址看看我们打印出来的
页面结构有没有这个东西:
是的这很好。有了这个页面数据,让我们通过一波美汤来搞定我们
你要的资料~
经过上面的过滤,我们就可以得到我们妹图的URL:
只需打开一个验证,啧:
看到下一页只有30个小姐姐,显然满足不了我们。我们第一次加载它。
当你第一次得到一波页码的时候,然后你就知道有多少页了,然后你就可以拼接URL并自己加载了
不同的页面,比如这里总共有448个页面:
可以拼接成这样的网址:
获取过滤下的页码:
接下来,我将填写代码,循环抓取每个页面上的小姐姐,并将其下载到本地。
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/page-' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
操作结果:
看看我们的输出文件夹~
学习Python爬虫,越来越瘦……
4.PhantomJS
PhantomJS 没有界面浏览器,特点:会将网站加载到内存中并执行
JavaScript,因为它不显示图形界面,所以它比完整的浏览器运行效率更高。
(如果某些 Linux 主机上没有图形界面,则无法安装 Chrome 等浏览器。
这个问题可以通过 PhantomJS 来规避)。
在 Win 上安装 PhantomJS:
在 Ubuntu/MAC 上安装 PhantomJS:
sudo apt-get install phantomjs
!!!关于 PhantomJS 的重要说明:
今年 4 月,Phantom.js 的维护者宣布退出 PhantomJS。
这意味着该项目可能不再维护!!!Chrome 和 FireFox 也开始了
提供Headless模式(不需要挂浏览器),所以估计用PhantomJS的小伙伴
会慢慢迁移到这两个浏览器。Windows Chrome 需要 60 以上的版本才能支持
Headless 模式,启用 Headless 模式也很简单:
selenium 的官方文档中还写道:
运行时也会报这个警告:
5.Selenium实战:模拟登录CSDN并保存Cookie
CSDN登录网站:
分析页面结构,不难发现对应的登录输入框和登录按钮:
我们要做的就是在这两个节点输入账号密码,然后触发登录按钮,
同时将Cookie保存在本地,以后就可以用Cookie访问相关页面了~
首先写一个方法来模拟登录:
找到输入账号密码的节点,设置你的账号密码,然后找到login
按钮节点,点击一次,然后等待登录成功,登录成功后可以对比
current_url 是否已更改。然后在这里保存 Cookies
我用的是pickle库,你可以用其他的,比如json,或者字符串拼接,
然后保存到本地。如果没有意外,应该可以拿到Cookie,然后使用
Cookie 访问主页。
通过 add_cookies 方法设置 Cookie。参数是字典类型的。此外,您必须首先
访问get链接一次,然后设置cookie,否则会报无法设置cookie的错误!
通过查看右下角是否变为登录状态就可以知道是否使用Cookie登录成功:
6.Selenium 常用函数
Seleninum 作为自动化测试的工具,自然提供了很多自动化操作的功能。
下面是我觉得比较常用的功能,更多的可以看官方文档:
官方API文档:
1) 定位元素
PS:将元素更改为元素将定位所有符合条件的元素并返回一个列表
例如:find_elements_by_class_name
2) 鼠标操作
有时需要在页面上模拟鼠标操作,例如:单击、双击、右键单击、按住、拖动等。
您可以导入 ActionChains 类:mon.action_chains.ActionChains
使用 ActionChains(driver).XXX 调用对应节点的行为
3) 弹出窗口
对应类:mon.alert.Alert,感觉用的不多...
如果触发到一定时间,弹出对话框,可以调用如下方法获取对话框:
alert = driver.switch_to_alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.switch_to.window("窗口名称")
或者通过window_handles来遍历
用于 driver.window_handles 中的句柄:
driver.switch_to_window(句柄)
driver.forward() #forward
driver.back() # 返回
5) 页面截图
driver.save_screenshot("Screenshot.png")
6) 页面等待
现在越来越多的网页使用Ajax技术,所以程序无法判断一个元素什么时候完全
加载完毕。如果实际页面等待时间过长,某个dom元素还没有出来,但是你的
代码直接使用这个WebElement,会抛出NullPointer异常。
为了避免元素定位困难,增加ElementNotVisibleException的概率。
所以Selenium提供了两种等待方式,一种是隐式等待,一种是显式等待。
显式等待:
显式等待指定某个条件,然后设置最大等待时间。如果不是这个时候
如果找到该元素,则会抛出异常。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序默认会调用0.5s来检查元素是否已经生成。
如果原创元素存在,它将立即返回。
下面是一些内置的等待条件,你可以直接调用这些条件,而不是自己调用
写一些等待条件。
标题_是
标题_收录
Presence_of_element_located
visibility_of_element_located
可见性_of
Presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable – 显示并启用。
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
隐式等待:
隐式等待比较简单,就是简单的设置一个等待时间,以秒为单位。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading";)
myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然,如果不设置,则默认等待时间为0。
7.执行JS语句
driver.execute_script(js 语句)
例如,滚动到底部:
js = document.body.scrollTop=10000
driver.execute_script(js)
概括
本节讲解一波使用Selenium自动化测试框架抓取JavaScript动态生成的数据,
Selenium 需要依赖第三方浏览器,注意过时的 PhantomJS 无界面浏览器
对于问题,可以使用Chrome和FireFox提供的HeadLess来替换;通过抓住煎蛋女孩
模拟CSDN自动登录的图片和例子,熟悉Selenium的基本使用,或者收很多货。
当然Selenium的水还是很深的,目前我们可以用它来应对JS动态加载数据页面
数据采集就够了。
另外,最近天气很冷,记得及时补衣服哦~
顺便写下你的想法:
下载本节源码:
本节参考资料:
来吧,Py 交易
如果想加群一起学Py,可以加智障机器人小猪,验证信息收录:
python,python,py,py,添加组,事务,关键词之一即可;
验证通过后回复群获取群链接(不要破解机器人!!!)~~~
欢迎像我一样的Py初学者,Py大神加入,愉快交流学习♂学习,van♂转py。
js抓取网页内容( 2017年05月12日11:13日js获取网页所有图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-06 11:17
2017年05月12日11:13日js获取网页所有图片)
js如何获取网页上的所有图片
更新时间:2017-05-12 11:13:08 作者:指数
本文文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下。
需要
点击网页中的图片,可以放大显示图片,并可以按顺序切换图片。同时,一些不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是由移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
js抓取网页内容(
2017年05月12日11:13日js获取网页所有图片)
js如何获取网页上的所有图片
更新时间:2017-05-12 11:13:08 作者:指数
本文文章主要介绍js获取网页所有图片的方法,以及js获取网页所有图片的方法。有一定的参考价值。有兴趣的朋友可以参考一下。
需要
点击网页中的图片,可以放大显示图片,并可以按顺序切换图片。同时,一些不符合要求的小图标和图片无法放大。
由于网页是在app中打开的,图片的缩放和切换是由移动端实现的,所以需要用js调用native方法,并传递所有图片的url
解决
var img = [];
for(var i=0;i20){
img[i] = $("img").eq(i).attr("src");
}
}
var img_info = {};
img_info.list = img; //保存所有图片的url
var imgs = document.getElementsByTagName('img');
for(var i = 0;i < imgs.length; i++){
if(parseInt($(imgs[i]).css('width')) > 20){
//将索引当作img标签的属性进行存储
$(imgs[i]).attr('index',i);
$(imgs[i]).click(function () {
//获取上面存储的图片的索引,这个索引就是当前图片的索引
img_info.index = $(this).attr('index');
//将信息转为json字符串
var json = JSON.stringify(img_info);
//判断是ios端还是android端
if (_IsIOS()) {
window.webkit.messageHandlers.showImg.postMessage(json);
} else if (_IsAndroid()) {
window.control.call('showImg',json);
}
});
}
}
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
js抓取网页内容(java程序中获取后台js完后的完整页面是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-03 04:11
许多网站使用JS或jQuery生成数据。后台获取数据后,以文档的形式写入页面。Write()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据文章编写的,这很难使用。通用代码编写如下:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
它根本不起作用
典型的是链接页面。如何在Java程序中获取数据 查看全部
js抓取网页内容(java程序中获取后台js完后的完整页面是什么?)
许多网站使用JS或jQuery生成数据。后台获取数据后,以文档的形式写入页面。Write()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据文章编写的,这很难使用。通用代码编写如下:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
它根本不起作用
典型的是链接页面。如何在Java程序中获取数据
js抓取网页内容( 云开发最大的好处不需要前端搭建服务器的包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-03 04:08
云开发最大的好处不需要前端搭建服务器的包)
微信小程序云开发js抓取网页内容
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:...
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。 查看全部
js抓取网页内容(
云开发最大的好处不需要前端搭建服务器的包)
微信小程序云开发js抓取网页内容
最近在研究微信小程序的云开发功能。云开发最大的好处是不需要在前端搭建服务器,可以利用云能力写一个可以从头启动的微信小程序,免去购买服务器的成本,对于个人来说尝试从前台到后台练习微信小程序。发展还是不错的选择。一个微信小程序一天就可以上线。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。同时,这种能力与开发者的能力是一样的。所使用的云服务相互兼容,并不相互排斥。
云开发目前提供三个基本能力:
云端功能:代码运行在云端,微信私有协议自然认证,开发者只需编写自己的业务逻辑代码数据库:一个JSON数据库,可以在小程序前端操作,也可以读写云功能。小程序前端直接上传/下载云文件,在云开发控制台可视化管理
好了,我介绍了这么多关于云开发的知识,感性的同学可以去研究学习。官方文档地址:...
网页内容抓取
小程序是回答问题,所以问题的来源是一个问题。网上搜了一下,一个贴一个贴一个主题是一种方式,但是这种重复的工作估计贴10次左右就放弃了。于是我想到了网络爬虫。拿起我之前学过的节点就行了。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。它主要用于分析和过滤捕获的内容。Node 的 fs 模块。这是node自带的模块,用于读写文件。这里用来将解析后的数据写入json文件中。Axios(非必需)。用于抓取 网站 HTML 页面。因为我想要的数据是在网页上点击一个按钮后渲染出来的,所以不能直接访问这个网址。我别无选择,只能复制我想要的内容,将其另存为字符串,然后解析该字符串。
接下来可以使用npm init初始化一个node项目,一路回车生成package.json文件。
然后 npm install --save axios Cheerio 安装cheerio 和 axios 包。
关键是用cheerio实现了一个类似jquery的功能。只需点击抓取的内容cheerio.load(quesitons),然后就可以按照jquery的操作来获取dom,组装你想要的数据了。
最后,使用 fs.writeFile 将数据保存到 json 文件中,就大功告成了。
具体代码如下:
让 axios = require(axios);
让cheerio = require(cheerio);
让 fs = require(fs);
//我的html结构大致如下,数据很多
const 问题 = `
`;
const $ =cheerio.load(questions);
var arr = [];
对于 (var i = 0; i
var obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer =
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
如果(错误)抛出错误;
console.log(json文件已经成功保存!);
});
保存到json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传json文件的数据格式。之前一直报格式错误,后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象之间用n分隔,而不是逗号。所以需要对node写的json文件做一点处理,才能上传成功。
js抓取网页内容(【知识点】化学实验基本知识,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-29 07:15
1、有问题
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只是Javascript代码中嵌入的文档的域。如以下示例代码:
DOCTYPE HTML>
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档的域相关,这样就可以访问到HTML文档的属性,所以上面的代码可以正常运行。
附:使用上述代码的原因是开发者将一个通用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度看问题,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的发问者网站,请参阅下面的放宽同源策略;
放宽同源 policyDocument.domain:在子域的情况下使用。对于多个窗口(一个页面有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问国外的窗口;跨域资源共享:添加Access-Control-通过在服务器端返回header
Allow-Origin,标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:此方法与域无关。不同文档的Javascript可以无限制地相互收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者可以控制远程页面,您可以尝试第二种方法。
服务器端爬取
根据提问者的需求,应该在服务器端处理更可行的解决方案。使用()可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等,当然也可以使用Python、php、Java语言进行后续操作。
综上所述:
(1)服务器开启网页的跨域限制;
(2)使用服务器请求页面 查看全部
js抓取网页内容(【知识点】化学实验基本知识,你了解多少?)
1、有问题
同源政策
页面中的Javascript只能读取访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只是Javascript代码中嵌入的文档的域。如以下示例代码:
DOCTYPE HTML>
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示它的域是:8000(域和端口也是相关的)。虽然页面中的jquery是从加载的,但是JQuery的域只和它所在的HTML文档的域相关,这样就可以访问到HTML文档的属性,所以上面的代码可以正常运行。
附:使用上述代码的原因是开发者将一个通用的Javascript库(如JQuery)的地址指向同一个公共URL。用户加载一次JS后,所有后续加载都会被浏览器缓存,从而加快页面加载速度。
从这个角度看问题,如果提问者已知的远程指向互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远程点是指您可以控制的发问者网站,请参阅下面的放宽同源策略;
放宽同源 policyDocument.domain:在子域的情况下使用。对于多个窗口(一个页面有多个iframe),Javascript可以通过将document.domain的值设置为同一个域来访问国外的窗口;跨域资源共享:添加Access-Control-通过在服务器端返回header
Allow-Origin,标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:此方法与域无关。不同文档的Javascript可以无限制地相互收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者可以控制远程页面,您可以尝试第二种方法。
服务器端爬取
根据提问者的需求,应该在服务器端处理更可行的解决方案。使用()可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等,当然也可以使用Python、php、Java语言进行后续操作。
综上所述:
(1)服务器开启网页的跨域限制;
(2)使用服务器请求页面
js抓取网页内容(没错.js的学习中,可用于抓取其他网站的模块 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-29 01:31
)
在node.js的学习中,可以用来捕获其他网站的模块是[cherio]。此模块不是node的内置模块,需要先安装:
安装相应的模块
安装命令:
npm install cheerio
显式抓取对象
安装cherio后,我们可以获取数据。让我们明确一下,要捕获的内容是网站,要捕获的代码如下:
如图所示,要捕获的内容是图中标记的IMG图片。是的,它是下面的Kawaii蛋糕。哇,哇,哇~我想吃东西,而且名字也很好
开始抓取
我们已经定义了捕获的内容。现在让我们开始捕捉。在此之前,我们需要知道cherio收录jQuery核心的一个子集,也就是说,在操作cherio时,可以使用JQ的相关语法。这不是很酷吗?哈哈哈,启动代码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
获得的图片链接打印如下:
为了验证信息的准确性,也为了使博客页面更少使用lotus root,该功能单击以抓取所附第一个链接的可爱甜点图片:
查看全部
js抓取网页内容(没错.js的学习中,可用于抓取其他网站的模块
)
在node.js的学习中,可以用来捕获其他网站的模块是[cherio]。此模块不是node的内置模块,需要先安装:
安装相应的模块
安装命令:
npm install cheerio
显式抓取对象
安装cherio后,我们可以获取数据。让我们明确一下,要捕获的内容是网站,要捕获的代码如下:
如图所示,要捕获的内容是图中标记的IMG图片。是的,它是下面的Kawaii蛋糕。哇,哇,哇~我想吃东西,而且名字也很好
开始抓取
我们已经定义了捕获的内容。现在让我们开始捕捉。在此之前,我们需要知道cherio收录jQuery核心的一个子集,也就是说,在操作cherio时,可以使用JQ的相关语法。这不是很酷吗?哈哈哈,启动代码:
var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
console.log(data);
})
})
//根据得到的数据,处理得到自己想要的
function getData(str){
//沿用JQuery风格,定义$
var $ = cheerio.load(str);
//获取的数据数组
var arr = $(".pro_box a:nth-child(1) img");
var dataTemp = [];
//遍历得到数据的src,并放入以上定义的数组中
arr.each(function(k,v){
var src = $(V).attr("src");
dataTemp.push(src);
})
//返回出去
return dataTemp;
}
获取抓取结果
获得的图片链接打印如下:
为了验证信息的准确性,也为了使博客页面更少使用lotus root,该功能单击以抓取所附第一个链接的可爱甜点图片:
js抓取网页内容(一个和浏览器的区别,安装注意先安装nodejs.eachSeries)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-09-28 07:30
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js抓取网页内容(一个和浏览器的区别,安装注意先安装nodejs.eachSeries)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。甚至有些网站会设置隐藏元素“陷阱”,用户看不到,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客文章列表:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步的方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-27 21:21
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
我们测试了 Google 爬虫如何抓取 JavaScript,这是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和 收录 会抓取哪些类型的 JavaScript 函数。
长话短说
1. 我们进行了一系列测试,并确认谷歌可以以多种方式执行和收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入到DOM中的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 JavaScript 类型,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 JavaScript 事件,还可以动态生成收录 内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,测试 B 使用它。相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 JavaScript 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这似乎与排名信号的传递有关。引用谷歌指南支持这一结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是一种特定的执行类型,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内(“onClick”)
使用 href 内部 AVP("javascript: window.location")
在 a 标签之外执行,但在 href 中调用 AVP("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序函数(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用JavaScript编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API(pushState)构建的,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样的测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前,已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入内容,甚至元标记,例如rel规范注释,无论是在HTML源代码中还是在解析初始HTML后触发JavaScript生成DOM都以相同的方式处理。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了!(请记住允许 Google 爬虫获取这些外部文件和 JavaScript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,不了解上述基本概念和谷歌技术的人应该学习学习,以赶上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文所表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
js抓取网页内容(js抓取网页内容之json(function(json)抓取内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-23 11:06
js抓取网页内容比如之前我遇到一个web后端,用flash,老慢了还不好爬,后来后端扔一个json给我,告诉我json对象是对象,不是对象都要加个js对象(关键是当时没有这个flash)setinterval(function(){console。log(json);},1000);setinterval(function(){console。
log(json);},1000);一口气调到1500,3000帧10000帧的效果,前后1500+的间隔后端确认是json,然后他就直接拿出json对象给我,我返回后就可以把json调用给前端,前端是这么调试的。
requests.get获取,后面跟要传递给的对象。
你想学什么,或者知道什么,可以评论,本人现在在学,开发项目,希望有经验的能给指导。
学前端。比如我。
人机交互只要涉及交互的产品都很有可能需要js去实现。现在人工智能和云计算都大火,所以应该在近几年前端需求会越来越大。
根据分析,我认为前端比较火,女生的话就ps和dw比较多。
两者都有,就业都比较好,推荐ps,ps快一点。
现在前端的火,具体不了解,但如果你要选择前端工作,我想说非常非常简单,不需要什么基础,前端就是用js和html去控制展示界面,先做个h5页面,弄个id,然后去做界面,学学css,懂一点点js,再去实现效果就可以了。 查看全部
js抓取网页内容(js抓取网页内容之json(function(json)抓取内容)
js抓取网页内容比如之前我遇到一个web后端,用flash,老慢了还不好爬,后来后端扔一个json给我,告诉我json对象是对象,不是对象都要加个js对象(关键是当时没有这个flash)setinterval(function(){console。log(json);},1000);setinterval(function(){console。
log(json);},1000);一口气调到1500,3000帧10000帧的效果,前后1500+的间隔后端确认是json,然后他就直接拿出json对象给我,我返回后就可以把json调用给前端,前端是这么调试的。
requests.get获取,后面跟要传递给的对象。
你想学什么,或者知道什么,可以评论,本人现在在学,开发项目,希望有经验的能给指导。
学前端。比如我。
人机交互只要涉及交互的产品都很有可能需要js去实现。现在人工智能和云计算都大火,所以应该在近几年前端需求会越来越大。
根据分析,我认为前端比较火,女生的话就ps和dw比较多。
两者都有,就业都比较好,推荐ps,ps快一点。
现在前端的火,具体不了解,但如果你要选择前端工作,我想说非常非常简单,不需要什么基础,前端就是用js和html去控制展示界面,先做个h5页面,弄个id,然后去做界面,学学css,懂一点点js,再去实现效果就可以了。
js抓取网页内容(抓的妹子图都是直接抓Html就可以的 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-09-20 09:06
)
导言
以前的姐妹图片是直接用HTML(即chrome浏览器F12)捕获的
elements页面结构返回与网络数据包捕获相同的结果。从后面拿一些
网站(如煎蛋和那些小的网站)发现了它并抓住了那里的袋子
没有获得任何数据,但在元素中存在一些情况。原因是页面的数据是
通过javascript动态生成:
一开始,我想自己学习一批JS基本语法,然后模拟数据包捕获
获取其他人的JS文件,自己分析逻辑,然后计算出真正的URL。后来是
放弃。毕竟,有太多的页面需要掌握。什么时候会像这样分析每一个
后来,我偶然发现了一个自动化测试框架:selenium可以帮助我们解决这个问题
简单地说,这东西有什么用?我们可以编写代码来制作浏览器:
那么这个东西不支持浏览器功能。您需要在第三方浏览器中使用它
要支持以下浏览器,您需要将相应的浏览器驱动程序下载到Python的相应路径:
铬:
火狐:
幻影:
即:
边缘:
歌剧:
让我们从这一节开始~
1.安装硒
这很简单。您可以通过PIP命令行直接安装:
sudo pip install selenium
PS:我记得我的公司合伙人问我为什么不能在win上实现PIP,有很多PIP
事实上,如果安装Python3,默认情况下它已经有了PIP。您需要配置另一个环境
变数。PIP的路径位于python安装目录的scripts目录中~
只需在路径之后添加此路径~
2.下载浏览器驱动程序
因为selenium没有浏览器,所以它需要依赖第三方浏览器并调用第三方浏览器
对于浏览器,您需要下载浏览器驱动程序,因为作者使用chrome
以Chrome为例,其他浏览器自己搜索相关信息!打开Chrome浏览器并键入:
chrome://version
您可以查看有关Chrome浏览器版本的相关信息。在这里,只需关注版本号:
61。好的,接下来,转到以下网站检查相应的驱动程序版本号:
好的,那就下载吧v2.Version 34浏览器驱动程序:
下载后,解压缩zip文件并将解压缩后的chromedriver.exe复制到python
在脚本目录中。(不需要与Win32纠缠,它可以在64位浏览器上正常使用!)
PS:对于Mac,将提取的文件复制到usr/local/bin目录
对于Ubuntu,将其复制到usr/bin目录
接下来,让我们编写一个简单的代码进行测试:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行此代码将自动调用浏览器并访问百度:
控制台将输出HTML代码,即直接获得的元素页面结构
在JS被执行后,我们可以抓到我们的煎蛋女照片
3.Selenium简单实战:抓取煎蛋女图片
直接分析元素页面结构以找到所需的关键节点:
显然,这是我们小妹妹的照片。复制URL并查看我们打印的内容
页面结构中是否存在这样的内容:
是的,很好。有了这个页面数据,我们将经历一波美丽的汤来获得我们
你想要的数据~
经过以上过滤,我们可以得到我们的姐妹图片URL:
打开验证,单击:
看完下一页,只有30个小姐妹,显然不能和我们见面。我们第一次装了
首先获取大量的页码,然后知道有多少页,然后拼接URL并自己加载
不同的页面,例如,总共有448页:
拼接到这样一个URL中:
通过过滤获得的页码:
接下来,填写代码,循环抓取每个页面上的小妹妹,然后在本地下载
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
经营成果:
看看我们的输出文件夹~
学习蟒蛇爬虫,天天减肥
4.PhantomJS
Phantom JS是一款没有界面的浏览器。功能:网站将加载到内存中并在页面上执行
JavaScript,因为它不显示图形界面,运行起来比一个完整的浏览器更高效
(在某些Linux主机上,没有图形界面就无法安装chrome等浏览器
您可以通过phantom JS避免此问题)
在Win上安装phantomjs:
在Ubuntu/Mac上安装phantomjs:
sudo apt-get install phantomjs
!!!关于phantomjs的重要注意事项:
今年4月,phantom.js的维护者宣布退出phantom js
这意味着该项目可能不再维护!!!Chrome和Firefox也已经启动
提供无头模式(无需挂断浏览器),因此估计小型合作伙伴使用phantom JS
它还将缓慢地迁移到这两种浏览器。Windows chrome需要60以上的版本才能支持
无头模式,启用无头模式也非常简单:
官方文件还指出:
在操作过程中也会报告此警告:
5.Selenium实战:模拟登录CSDN并保存cookie
CSDN登录网站:
在分析下面的页面结构后,不难找到相应的登录输入框和登录按钮:
我们需要做的是在这两个节点上输入帐户和密码,然后触发登录按钮
同时,在本地保存cookie,然后您可以使用cookie访问相关页面~
首先编写模拟登录的方法:
查找您输入帐户和密码的节点,设置您自己的帐户和密码,然后查找登录名
单击按钮节点,然后等待登录成功。登录成功后,您可以比较
当前\ URL是否已更改。然后把饼干保存在这里
我使用pickle图书馆。我可以使用其他方法,例如JSON或字符串拼接
然后在本地保存它。如果没有意外,你应该能够得到饼干,然后使用它们
访问主页的Cookie
通过添加Cookies方法设置Cookies。参数为字典类型。此外,你必须首先
访问get链接一次并设置cookie,否则将报告无法设置cookie的错误
检查右下角是否更改为登录状态,以了解使用Cookie登录是否成功:
6.Selenium共同功能
作为自动化测试的工具,selenium自然为自动化操作提供了许多功能
下面是一些我认为常用的函数。有关更多信息,请参阅官方文件:
官方API文档:
1)定位元件
PS:将元素更改为元素将定位所有符合条件的元素并返回列表
例如:通过类名称查找元素
2)鼠标动作
有时需要在页面上模拟鼠标操作,如单击、双击、右键单击、按住、拖动等
您可以导入actionchains类:mon.action uChains.actionchains
使用actionchains(驱动程序)。XXX调用相应节点的行为
3)弹出窗口
对应类:mon.alert.alert。我认为不应该用太多
如果触发某个时间,弹出一个对话框,可以调用以下方法获取该对话框:
alert=driver.switch u到u alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.Switch_uu至.window(“窗口名称”)
或通过窗口句柄进行遍历
对于driver.window中的句柄uhandles:
驾驶员侧开关至车窗(把手)
司机。前进()#前进
司机。后退()#后退
5)页面截图
driver.save屏幕截图(“Screenshot.PNG”)
6)页面等待
现在,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完成
装了。如果实际的页面等待时间太长,则DOM元素没有出现,但是
如果代码直接使用此webelement,将引发空指针异常
为了避免元素定位的困难,提高元素不可见异常的概率
因此,selenium提供了两种等待方法:隐式等待和显式等待
显式等待:
显式等待指定条件,然后设置最大等待时间。如果不是在这个时候
如果找到元素,将引发异常
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写入参数,程序将默认0.5s调用一次以查看元素是否已生成
如果元素已经存在,将立即返回该元素
以下是一些内置的等待条件。您可以直接调用这些条件,而无需自己
写一些等待条件
标题是
标题收录
元素的存在位置
所在元素的可见性
能见度
所有元素的存在
文本在元素中存在
文本在元素值中存在
框架可用,并且_ 查看全部
js抓取网页内容(抓的妹子图都是直接抓Html就可以的
)
导言
以前的姐妹图片是直接用HTML(即chrome浏览器F12)捕获的
elements页面结构返回与网络数据包捕获相同的结果。从后面拿一些
网站(如煎蛋和那些小的网站)发现了它并抓住了那里的袋子
没有获得任何数据,但在元素中存在一些情况。原因是页面的数据是
通过javascript动态生成:
一开始,我想自己学习一批JS基本语法,然后模拟数据包捕获
获取其他人的JS文件,自己分析逻辑,然后计算出真正的URL。后来是
放弃。毕竟,有太多的页面需要掌握。什么时候会像这样分析每一个
后来,我偶然发现了一个自动化测试框架:selenium可以帮助我们解决这个问题
简单地说,这东西有什么用?我们可以编写代码来制作浏览器:
那么这个东西不支持浏览器功能。您需要在第三方浏览器中使用它
要支持以下浏览器,您需要将相应的浏览器驱动程序下载到Python的相应路径:
铬:
火狐:
幻影:
即:
边缘:
歌剧:
让我们从这一节开始~
1.安装硒
这很简单。您可以通过PIP命令行直接安装:
sudo pip install selenium
PS:我记得我的公司合伙人问我为什么不能在win上实现PIP,有很多PIP
事实上,如果安装Python3,默认情况下它已经有了PIP。您需要配置另一个环境
变数。PIP的路径位于python安装目录的scripts目录中~
只需在路径之后添加此路径~
2.下载浏览器驱动程序
因为selenium没有浏览器,所以它需要依赖第三方浏览器并调用第三方浏览器
对于浏览器,您需要下载浏览器驱动程序,因为作者使用chrome
以Chrome为例,其他浏览器自己搜索相关信息!打开Chrome浏览器并键入:
chrome://version
您可以查看有关Chrome浏览器版本的相关信息。在这里,只需关注版本号:
61。好的,接下来,转到以下网站检查相应的驱动程序版本号:
好的,那就下载吧v2.Version 34浏览器驱动程序:
下载后,解压缩zip文件并将解压缩后的chromedriver.exe复制到python
在脚本目录中。(不需要与Win32纠缠,它可以在64位浏览器上正常使用!)
PS:对于Mac,将提取的文件复制到usr/local/bin目录
对于Ubuntu,将其复制到usr/bin目录
接下来,让我们编写一个简单的代码进行测试:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行此代码将自动调用浏览器并访问百度:
控制台将输出HTML代码,即直接获得的元素页面结构
在JS被执行后,我们可以抓到我们的煎蛋女照片
3.Selenium简单实战:抓取煎蛋女图片
直接分析元素页面结构以找到所需的关键节点:
显然,这是我们小妹妹的照片。复制URL并查看我们打印的内容
页面结构中是否存在这样的内容:
是的,很好。有了这个页面数据,我们将经历一波美丽的汤来获得我们
你想要的数据~
经过以上过滤,我们可以得到我们的姐妹图片URL:
打开验证,单击:
看完下一页,只有30个小姐妹,显然不能和我们见面。我们第一次装了
首先获取大量的页码,然后知道有多少页,然后拼接URL并自己加载
不同的页面,例如,总共有448页:
拼接到这样一个URL中:
通过过滤获得的页码:
接下来,填写代码,循环抓取每个页面上的小妹妹,然后在本地下载
完整代码如下:
import os
from selenium import webdriver
from bs4 import BeautifulSoup
import urllib.request
import ssl
import urllib.error
base_url = 'http://jandan.net/ooxx'
pic_save_path = "output/Picture/JianDan/"
# 下载图片
def download_pic(url):
correct_url = url
if url.startswith('//'):
correct_url = url[2:]
if not url.startswith('http'):
correct_url = 'http://' + correct_url
print(correct_url)
headers = {
'Host': 'wx2.sinaimg.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.100 Safari/537.36 '
}
try:
req = urllib.request.Request(correct_url, headers=headers)
resp = urllib.request.urlopen(req)
pic = resp.read()
pic_name = correct_url.split("/")[-1]
with open(pic_save_path + pic_name, "wb+") as f:
f.write(pic)
except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:
print(str(reason))
# 打开浏览器模拟请求
def browser_get():
browser = webdriver.Chrome()
browser.get('http://jandan.net/ooxx')
html_text = browser.page_source
page_count = get_page_count(html_text)
# 循环拼接URL访问
for page in range(page_count, 0, -1):
page_url = base_url + '/' + str(page)
print('解析:' + page_url)
browser.get(page_url)
html = browser.page_source
get_meizi_url(html)
browser.quit()
# 获取总页码
def get_page_count(html):
soup = BeautifulSoup(html, 'html.parser')
page_count = soup.find('span', attrs={'class': 'current-comment-page'})
return int(page_count.get_text()[1:-1]) - 1
# 获取每个页面的小姐姐
def get_meizi_url(html):
soup = BeautifulSoup(html, 'html.parser')
ol = soup.find('ol', attrs={'class': 'commentlist'})
href = ol.findAll('a', attrs={'class': 'view_img_link'})
for a in href:
download_pic(a['href'])
if __name__ == '__main__':
ssl._create_default_https_context = ssl._create_unverified_context
if not os.path.exists(pic_save_path):
os.makedirs(pic_save_path)
browser_get()
经营成果:
看看我们的输出文件夹~
学习蟒蛇爬虫,天天减肥
4.PhantomJS
Phantom JS是一款没有界面的浏览器。功能:网站将加载到内存中并在页面上执行
JavaScript,因为它不显示图形界面,运行起来比一个完整的浏览器更高效
(在某些Linux主机上,没有图形界面就无法安装chrome等浏览器
您可以通过phantom JS避免此问题)
在Win上安装phantomjs:
在Ubuntu/Mac上安装phantomjs:
sudo apt-get install phantomjs
!!!关于phantomjs的重要注意事项:
今年4月,phantom.js的维护者宣布退出phantom js
这意味着该项目可能不再维护!!!Chrome和Firefox也已经启动
提供无头模式(无需挂断浏览器),因此估计小型合作伙伴使用phantom JS
它还将缓慢地迁移到这两种浏览器。Windows chrome需要60以上的版本才能支持
无头模式,启用无头模式也非常简单:
官方文件还指出:
在操作过程中也会报告此警告:
5.Selenium实战:模拟登录CSDN并保存cookie
CSDN登录网站:
在分析下面的页面结构后,不难找到相应的登录输入框和登录按钮:
我们需要做的是在这两个节点上输入帐户和密码,然后触发登录按钮
同时,在本地保存cookie,然后您可以使用cookie访问相关页面~
首先编写模拟登录的方法:
查找您输入帐户和密码的节点,设置您自己的帐户和密码,然后查找登录名
单击按钮节点,然后等待登录成功。登录成功后,您可以比较
当前\ URL是否已更改。然后把饼干保存在这里
我使用pickle图书馆。我可以使用其他方法,例如JSON或字符串拼接
然后在本地保存它。如果没有意外,你应该能够得到饼干,然后使用它们
访问主页的Cookie
通过添加Cookies方法设置Cookies。参数为字典类型。此外,你必须首先
访问get链接一次并设置cookie,否则将报告无法设置cookie的错误
检查右下角是否更改为登录状态,以了解使用Cookie登录是否成功:
6.Selenium共同功能
作为自动化测试的工具,selenium自然为自动化操作提供了许多功能
下面是一些我认为常用的函数。有关更多信息,请参阅官方文件:
官方API文档:
1)定位元件
PS:将元素更改为元素将定位所有符合条件的元素并返回列表
例如:通过类名称查找元素
2)鼠标动作
有时需要在页面上模拟鼠标操作,如单击、双击、右键单击、按住、拖动等
您可以导入actionchains类:mon.action uChains.actionchains
使用actionchains(驱动程序)。XXX调用相应节点的行为
3)弹出窗口
对应类:mon.alert.alert。我认为不应该用太多
如果触发某个时间,弹出一个对话框,可以调用以下方法获取该对话框:
alert=driver.switch u到u alert(),然后可以调用以下方法:
4)页面前进、后退、切换
切换窗口:driver.Switch_uu至.window(“窗口名称”)
或通过窗口句柄进行遍历
对于driver.window中的句柄uhandles:
驾驶员侧开关至车窗(把手)
司机。前进()#前进
司机。后退()#后退
5)页面截图
driver.save屏幕截图(“Screenshot.PNG”)
6)页面等待
现在,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完成
装了。如果实际的页面等待时间太长,则DOM元素没有出现,但是
如果代码直接使用此webelement,将引发空指针异常
为了避免元素定位的困难,提高元素不可见异常的概率
因此,selenium提供了两种等待方法:隐式等待和显式等待
显式等待:
显式等待指定条件,然后设置最大等待时间。如果不是在这个时候
如果找到元素,将引发异常
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading";)
try:
# 每隔10秒查找页面元素 id="myDynamicElement",直到出现则返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写入参数,程序将默认0.5s调用一次以查看元素是否已生成
如果元素已经存在,将立即返回该元素
以下是一些内置的等待条件。您可以直接调用这些条件,而无需自己
写一些等待条件
标题是
标题收录
元素的存在位置
所在元素的可见性
能见度
所有元素的存在
文本在元素中存在
文本在元素值中存在
框架可用,并且_
js抓取网页内容(如何模拟请求和如何解析HTMLHTML系统学习教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-20 08:24
虽然这在很久以前是个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法
首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
那么,我们就瞄准北方邮递员论坛!打开beimailman论坛首页,发现首页HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:
从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:
到目前为止,我们已经确定此链接可以获得主页的文章和链接。在headers选项中,有该请求的请求头和请求参数。通过在Python中模拟这个请求,我们可以得到相同的响应。然后,我们可以使用诸如Beauty soup之类的库解析HTML,以获得相应的内容
对于如何模拟请求以及如何解析HTML,小编有时间再写一次。记住要关注它,并在将来经常与您分享文章
最后,小编是一名python开发工程师。在这里,我已经编写了一套最新的Python系统学习教程,包括基本Python脚本、web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些材料的人可以关注小编,并在背景私信小编:“01”中获得它们 查看全部
js抓取网页内容(如何模拟请求和如何解析HTMLHTML系统学习教程)
虽然这在很久以前是个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法
首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
那么,我们就瞄准北方邮递员论坛!打开beimailman论坛首页,发现首页HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:
从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:
到目前为止,我们已经确定此链接可以获得主页的文章和链接。在headers选项中,有该请求的请求头和请求参数。通过在Python中模拟这个请求,我们可以得到相同的响应。然后,我们可以使用诸如Beauty soup之类的库解析HTML,以获得相应的内容
对于如何模拟请求以及如何解析HTML,小编有时间再写一次。记住要关注它,并在将来经常与您分享文章
最后,小编是一名python开发工程师。在这里,我已经编写了一套最新的Python系统学习教程,包括基本Python脚本、web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些材料的人可以关注小编,并在背景私信小编:“01”中获得它们
js抓取网页内容(百度是否会抓取网站js文件?百度蜘蛛是否识别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-20 00:09
寻找A5项目招商,快速获得准确的代理名单
今天,让我们来讨论一个更重要的内容,百度是否会抓住我们网站js,百度蜘蛛认出我们了吗网站js百度抓取JS的缺点是什么?你需要阻止JS吗?我们当前的文章文章将详细解释这篇文章的内容
百度会抓取网站js文件
事实上,通过分析蜘蛛,我们可以发现百度抓住了JS。过去,很多人说百度不会抓取JS和CSS。事实上,这种说法是完全错误的。百度不仅抢夺,而且抢夺的频率更高,不仅仅是百度,360、搜狗和神马搜索引擎将捕获
百度蜘蛛现在能识别JS吗
我可以清楚地告诉你百度是否有能力识别JS,90%以上的JS都可以识别。你为什么这么说?你不妨考虑一下。百度开发了一种“石榴算法”,专门对付页面中大量的弹出窗口,而大多数弹出广告都是JS代码。如果百度无法识别JS,如何打击此类页面?此外,许多非法站点使用js站点集。如果百度无法识别JS,让这些黑客大发雷霆,你认为有可能吗?几年前就可以认识到这一点,现在必须更加认识到这一点
JS是否需要使用robots.txt来屏蔽和抓取
为了解释,JS文件是否需要用robots.txt屏蔽和捕获?CSS和JS是否需要屏蔽一直存在争议。事实上,CSS不需要屏蔽。如果被屏蔽,百度快照中的风格就会混乱,影响或多或少。但是,JS需要屏蔽。合理屏蔽JS将大大优化蜘蛛爬行,更有利于SEO优化。下面是如何屏蔽这种JS
如何有效防止百度抢夺JS
一,。使用robots.txt屏蔽整个站点JS和您不想抓取的JS
首先,最直接的方法是使用robots.txt直接屏蔽JS。有两种屏蔽方法。第一个是完全屏蔽整个电站JS,第二个是屏蔽单个JS。我们以下图为例。事实上,我建议屏蔽整个站点JS,因为JS对SEO没有实际影响,只会减慢网站的速度@
二,。使用模糊加密工具加密JS
虽然有些爬行器将被robots.txt阻止爬行,但有些JS仍然会爬行。这个时候我该怎么办?我们可以使用一些加密技术来加密JS,以增加百度的不可识别性。对于某些敏感内容,建议这样做。例如,JS充满了广告代码,如果被百度捕获,将对网站产生负面影响。因此,最好混合使用加密。一般来说,我们会使用网站管理员工具来加密混合加密(见下图)
三,。如果是广告,您可以考虑使用框架
导入JS。
第三点是一些第三方广告代码。如果有很多网站广告,并且有很多是用JS编写的,那么仅仅使用混淆加密是无法完全解决的。我们可以创建一个单独的页面来放置广告,然后将它们导入iframe。百度通常不会捕获iframe中的内容。当然,JS仍然需要混淆加密,这可以大大减轻百度对太多广告的处罚
好吧,让我们今天谈这么多。让我们总结一下这两种类型:CSS和JS。我们需要保护JS。CSS不需要屏蔽。在robots.txt中,我们可以直接编写屏蔽全站的JS网站js百度将捕获并识别,因此如果网站js电视里有许多广告。您可以使用框架导入它们 查看全部
js抓取网页内容(百度是否会抓取网站js文件?百度蜘蛛是否识别?)
寻找A5项目招商,快速获得准确的代理名单
今天,让我们来讨论一个更重要的内容,百度是否会抓住我们网站js,百度蜘蛛认出我们了吗网站js百度抓取JS的缺点是什么?你需要阻止JS吗?我们当前的文章文章将详细解释这篇文章的内容
百度会抓取网站js文件
事实上,通过分析蜘蛛,我们可以发现百度抓住了JS。过去,很多人说百度不会抓取JS和CSS。事实上,这种说法是完全错误的。百度不仅抢夺,而且抢夺的频率更高,不仅仅是百度,360、搜狗和神马搜索引擎将捕获
百度蜘蛛现在能识别JS吗
我可以清楚地告诉你百度是否有能力识别JS,90%以上的JS都可以识别。你为什么这么说?你不妨考虑一下。百度开发了一种“石榴算法”,专门对付页面中大量的弹出窗口,而大多数弹出广告都是JS代码。如果百度无法识别JS,如何打击此类页面?此外,许多非法站点使用js站点集。如果百度无法识别JS,让这些黑客大发雷霆,你认为有可能吗?几年前就可以认识到这一点,现在必须更加认识到这一点
JS是否需要使用robots.txt来屏蔽和抓取
为了解释,JS文件是否需要用robots.txt屏蔽和捕获?CSS和JS是否需要屏蔽一直存在争议。事实上,CSS不需要屏蔽。如果被屏蔽,百度快照中的风格就会混乱,影响或多或少。但是,JS需要屏蔽。合理屏蔽JS将大大优化蜘蛛爬行,更有利于SEO优化。下面是如何屏蔽这种JS
如何有效防止百度抢夺JS
一,。使用robots.txt屏蔽整个站点JS和您不想抓取的JS
首先,最直接的方法是使用robots.txt直接屏蔽JS。有两种屏蔽方法。第一个是完全屏蔽整个电站JS,第二个是屏蔽单个JS。我们以下图为例。事实上,我建议屏蔽整个站点JS,因为JS对SEO没有实际影响,只会减慢网站的速度@
二,。使用模糊加密工具加密JS
虽然有些爬行器将被robots.txt阻止爬行,但有些JS仍然会爬行。这个时候我该怎么办?我们可以使用一些加密技术来加密JS,以增加百度的不可识别性。对于某些敏感内容,建议这样做。例如,JS充满了广告代码,如果被百度捕获,将对网站产生负面影响。因此,最好混合使用加密。一般来说,我们会使用网站管理员工具来加密混合加密(见下图)
三,。如果是广告,您可以考虑使用框架
导入JS。
第三点是一些第三方广告代码。如果有很多网站广告,并且有很多是用JS编写的,那么仅仅使用混淆加密是无法完全解决的。我们可以创建一个单独的页面来放置广告,然后将它们导入iframe。百度通常不会捕获iframe中的内容。当然,JS仍然需要混淆加密,这可以大大减轻百度对太多广告的处罚
好吧,让我们今天谈这么多。让我们总结一下这两种类型:CSS和JS。我们需要保护JS。CSS不需要屏蔽。在robots.txt中,我们可以直接编写屏蔽全站的JS网站js百度将捕获并识别,因此如果网站js电视里有许多广告。您可以使用框架导入它们
js抓取网页内容(puppeteer和nodejs的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-19 23:07
木偶演员
GoogleChrome团队生产的puppeter是一个依靠nodejs和Chrome的自动化测试库。它最大的优点是可以处理网页中的动态内容,如JavaScript,并更好地模拟用户
一些网站反爬虫方法在一些JavaScript/Ajax请求中隐藏了一些内容,这使得直接获取标记的方法无效。有些网站甚至会设置隐藏元素“陷阱”,用户看不见,脚本触发器被认为是机器。在这种情况下,木偶师的优势就突出了
可实现以下功能:
生成页面的屏幕截图和PDF。抓取spa并生成预渲染内容(即“×××”)。自动表单提交、UI测试、键盘输入等。创建最新的自动测试环境。使用最新的JavaScript和浏览器功能直接在最新版本的chrome中运行测试。捕获并跟踪网站时间线,以帮助诊断性能问题
开放源代码地址:[]1]
装置
npm i puppeteer
注意:首先安装nodejs并在nodejs文件的根目录下执行(同一级别的NPM文件)
铬将在安装过程中下载,约120m
花了两天(大约10个小时)的时间探索并绕过了大量的异步坑。作者对木偶和节点有一定的掌握
长照片、抓拍blog文章List:
抓住blog文章
以CSDN博客为例,文章内容需要通过点击“读取全文”获取,这导致只能读取dom的脚本失效
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
执行过程
录音机可以在我的官方帐户中查看,屏幕截图如下:
执行结果
文章内容列表:
文章content:
结论
我认为由于nodejs使用JavaScript脚本语言,它当然可以处理网页的JavaScript内容,但我没有找到一个合适/高效的库。直到找到了木偶师,我才下定决心试水
换言之,nodejs的异步性确实令人头痛。我已经花了10个小时写了数百行代码
您可以在代码中扩展process()方法并使用async.eachseries
事实上,一个接一个的处理是没有效率的。我最初编写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js抓取网页内容(puppeteer和nodejs的区别)
木偶演员
GoogleChrome团队生产的puppeter是一个依靠nodejs和Chrome的自动化测试库。它最大的优点是可以处理网页中的动态内容,如JavaScript,并更好地模拟用户
一些网站反爬虫方法在一些JavaScript/Ajax请求中隐藏了一些内容,这使得直接获取标记的方法无效。有些网站甚至会设置隐藏元素“陷阱”,用户看不见,脚本触发器被认为是机器。在这种情况下,木偶师的优势就突出了
可实现以下功能:
生成页面的屏幕截图和PDF。抓取spa并生成预渲染内容(即“×××”)。自动表单提交、UI测试、键盘输入等。创建最新的自动测试环境。使用最新的JavaScript和浏览器功能直接在最新版本的chrome中运行测试。捕获并跟踪网站时间线,以帮助诊断性能问题
开放源代码地址:[]1]
装置
npm i puppeteer
注意:首先安装nodejs并在nodejs文件的根目录下执行(同一级别的NPM文件)
铬将在安装过程中下载,约120m
花了两天(大约10个小时)的时间探索并绕过了大量的异步坑。作者对木偶和节点有一定的掌握
长照片、抓拍blog文章List:
抓住blog文章
以CSDN博客为例,文章内容需要通过点击“读取全文”获取,这导致只能读取dom的脚本失效
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
执行过程
录音机可以在我的官方帐户中查看,屏幕截图如下:
执行结果
文章内容列表:
文章content:
结论
我认为由于nodejs使用JavaScript脚本语言,它当然可以处理网页的JavaScript内容,但我没有找到一个合适/高效的库。直到找到了木偶师,我才下定决心试水
换言之,nodejs的异步性确实令人头痛。我已经花了10个小时写了数百行代码
您可以在代码中扩展process()方法并使用async.eachseries
事实上,一个接一个的处理是没有效率的。我最初编写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js抓取网页内容(js抓取网页内容很简单,android需要抓包才能继续分析报表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-17 01:02
js抓取网页内容很简单,网页内容是存在html中的抓包就可以解析,当然以前我遇到这个问题用js写过一个浏览器插件抓取。特别是通过爬虫实现echo转换,我想是最快的了,tornado或者vue,vue应该更方便。
本身的python代码能力,运气以及你对爬虫的了解能力以及经验,是匹配爬虫工程师的水平,我工作中就有用requests+beautifulsoup+requestslib+phantomjs+js+dnsparse+json+xpath+locals...等人工构建爬虫的例子,运气好的话都可以胜任。不过我感觉,只有真正对爬虫、爬虫代理的网站会配合爬虫工程师去做这件事情。
一句话解释:分布式爬虫+自动化测试
你看你的意思应该是要找到一个url转换器把你要抓取的页面转换成另一个网址,然后在转换服务器上抓取。你写一个exe文件,放在服务器上,用nodejs语言写个curl抓包,requests库,http.io库,写个爬虫程序去抓。然后api就有了,用爬虫程序读http的request就可以去抓,不过正向还是反向不怎么容易破解。
同时因为抓取一些网站上的api,一些普通http文档,可以省去dns等信息破解的时间,例如api。爬虫程序性能要求高还是上链接池比较好,例如beego等,另外如果真要做分布式,也可以先写个稍微小一点的api。没法直接发布到服务器,实现起来还是挺麻烦的。爬虫post提交以后是自己管理的,windows/linux爬虫用indexpy比较方便,android需要抓包才能继续分析报表。 查看全部
js抓取网页内容(js抓取网页内容很简单,android需要抓包才能继续分析报表)
js抓取网页内容很简单,网页内容是存在html中的抓包就可以解析,当然以前我遇到这个问题用js写过一个浏览器插件抓取。特别是通过爬虫实现echo转换,我想是最快的了,tornado或者vue,vue应该更方便。
本身的python代码能力,运气以及你对爬虫的了解能力以及经验,是匹配爬虫工程师的水平,我工作中就有用requests+beautifulsoup+requestslib+phantomjs+js+dnsparse+json+xpath+locals...等人工构建爬虫的例子,运气好的话都可以胜任。不过我感觉,只有真正对爬虫、爬虫代理的网站会配合爬虫工程师去做这件事情。
一句话解释:分布式爬虫+自动化测试
你看你的意思应该是要找到一个url转换器把你要抓取的页面转换成另一个网址,然后在转换服务器上抓取。你写一个exe文件,放在服务器上,用nodejs语言写个curl抓包,requests库,http.io库,写个爬虫程序去抓。然后api就有了,用爬虫程序读http的request就可以去抓,不过正向还是反向不怎么容易破解。
同时因为抓取一些网站上的api,一些普通http文档,可以省去dns等信息破解的时间,例如api。爬虫程序性能要求高还是上链接池比较好,例如beego等,另外如果真要做分布式,也可以先写个稍微小一点的api。没法直接发布到服务器,实现起来还是挺麻烦的。爬虫post提交以后是自己管理的,windows/linux爬虫用indexpy比较方便,android需要抓包才能继续分析报表。
js抓取网页内容(如何模拟请求和如何解析HTML的链接和标题?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-15 17:02
虽然这是很久以前的事了,但这个主题似乎已经解决了这个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法。由于标题并不表示您需要什么,因此这里的示例采用主页上所有帖子的链接和标题
首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
然后打开beimailman论坛主页,发现其主页的HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:
从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:
到目前为止,我们确信此链接可以获得主页的文章和链接
在headers选项中,有该请求的请求头和请求参数。通过python模拟这个请求,我们可以得到相同的响应。然后,我们可以用Beauty soup等库解析HTML,以获得相应的内容
关于如何模拟请求以及如何解析HTML,请转到我的专栏进行详细介绍,这里不再重复
通过这种方式,您可以在不模拟浏览器环境的情况下获取数据,这大大提高了内存、CPU消耗和爬网速度。编写爬虫程序时,请记住,除非必要,否则不要模拟浏览器环境 查看全部
js抓取网页内容(如何模拟请求和如何解析HTML的链接和标题?(一))
虽然这是很久以前的事了,但这个主题似乎已经解决了这个问题。但是看到很多答案的方式有点太沉重了。这是一种效率更高、资源消耗更少的方法。由于标题并不表示您需要什么,因此这里的示例采用主页上所有帖子的链接和标题
首先,请记住,浏览器环境消耗大量内存和CPU,应尽量避免使用模拟浏览器环境的爬虫代码。请记住,对于一些前端呈现的web页面,尽管我们无法在HTML源代码中看到所需的数据,但它更有可能通过另一个请求获得纯数据(可能以JSON格式存在)。不用模拟浏览器,我们可以节省解析HTML的开销
然后打开beimailman论坛主页,发现其主页的HTML源代码中没有显示文章的内容。然后,它很可能通过JS异步加载到页面。通过浏览器开发工具(通过OS X或win/Linux下的Command+option+I使用Chrome浏览器)F12)加载主页时分析请求时,很容易在以下屏幕截图中找到请求:
从截图中选择的请求获得的响应是主页的文章链接。可以在“预览”选项中查看渲染预览:
到目前为止,我们确信此链接可以获得主页的文章和链接
在headers选项中,有该请求的请求头和请求参数。通过python模拟这个请求,我们可以得到相同的响应。然后,我们可以用Beauty soup等库解析HTML,以获得相应的内容
关于如何模拟请求以及如何解析HTML,请转到我的专栏进行详细介绍,这里不再重复
通过这种方式,您可以在不模拟浏览器环境的情况下获取数据,这大大提高了内存、CPU消耗和爬网速度。编写爬虫程序时,请记住,除非必要,否则不要模拟浏览器环境
js抓取网页内容(借助mysql模块保存数据(假设数据库)的基本流程和流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2021-09-12 19:13
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索关键词node.js
获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 关键词p=?是要搜索的页码。
带有请求模块的请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然URL可用,分析URL对应的页面内容。
页面还是很规律的。
标题摘要作者发表时间推荐评论数量文章link查看数量
借助浏览器开发工具
发现
...
对应每篇文章文章
点击每一项,有以下内容
class="searchItemTitle" 收录文章title 和文章URL 地址
class="searchItemInfo-userName" 收录作者
class="searchItemInfo-publishDate" 收录发布日期
class="searchItemInfo-views" 收录浏览次数
借助cheerio模块分析文章以抓取特定内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。
现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它看看数据是否保存在数据库中。
现在可以进行基本的抓取和保存。但是只爬取一次,只能爬取关键词为node.js页码为1的URL页面。
把关键词改成javascript,页码为1,清空博客表,再运行看看表中是否可以保存javascript相关的数据。
现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,不看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。最好能自动抓取其他页面的内容。 查看全部
js抓取网页内容(借助mysql模块保存数据(假设数据库)的基本流程和流程)
在node.js中,有了cheerio模块和request模块,抓取特定URL页面的数据非常方便。
一个简单的如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的过程,现在试着找一个网址(url)。以博客园的搜索页面为例。
通过搜索关键词node.js
获取以下网址:
点击第二页,网址如下:
分析URL,发现w=? 关键词p=?是要搜索的页码。
带有请求模块的请求 URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
既然URL可用,分析URL对应的页面内容。
页面还是很规律的。
标题摘要作者发表时间推荐评论数量文章link查看数量
借助浏览器开发工具
发现
...
对应每篇文章文章
点击每一项,有以下内容
class="searchItemTitle" 收录文章title 和文章URL 地址
class="searchItemInfo-userName" 收录作者
class="searchItemInfo-publishDate" 收录发布日期
class="searchItemInfo-views" 收录浏览次数
借助cheerio模块分析文章以抓取特定内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
查看代码
可以运行一下,看看数据是否正常捕获。
现在有数据数据,可以保存到数据库中。这里以mysql为例,使用mongodb更方便。
借助mysql模块保存数据(假设数据库名为test,表为blog)
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
查看代码
运行它看看数据是否保存在数据库中。
现在可以进行基本的抓取和保存。但是只爬取一次,只能爬取关键词为node.js页码为1的URL页面。
把关键词改成javascript,页码为1,清空博客表,再运行看看表中是否可以保存javascript相关的数据。
现在去博客园搜索javascript,看看搜索结果是否与表格中的内容相对应。哈哈,不看,绝对可以对应~~
只能抓取一个页面的内容,这绝对是不够的。最好能自动抓取其他页面的内容。
js抓取网页内容(目标网站是以滚动页面的方式动态生成数据的网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-11 23:09
)
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
比如网站像今天的头条:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合用于数据捕获。它可以轻松绕过网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行。就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
js抓取网页内容(目标网站是以滚动页面的方式动态生成数据的网页
)
我们在抓取数据的时候,如果目标网站是在Js中动态生成数据,通过滚动来分页,那我们怎么抓取呢?
比如网站像今天的头条:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合用于数据捕获。它可以轻松绕过网站 的反爬虫限制,因为 Selenium 直接在浏览器中运行。就像真正的用户在操作一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
接下来,您可以编写代码进行捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能读取DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-09-11 23:05
项目招商找A5快速获取精准代理商名单
我们测试了 Google 爬虫如何抓取 JavaScript,以下是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。 Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和收录 会抓取哪些类型的 JavaScript 函数。
概述
1. 我们进行了一系列测试,已经确认 Google 可以通过多种方式执行收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,以便收录 可以动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能仅限于某种方式。
而今天,很明显,Google 不仅可以制定他们的抓取和 收录 JavaScript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是在过去的 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及收录。经过研究,我们发现了令人大开眼界的结果,并确认Google不仅可以执行各种JavaScript事件,还可以收录动态生成内容。怎么做? Google 可以读取 DOM。
什么是 DOM?
很多从事 SEO 的人不了解什么是文档对象模型 (DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
关于这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性以及收录,我们分别针对谷歌爬虫创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为 5 类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。 URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:Google 很快跟踪了重定向。从收录 开始,它们被解释为 301 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然重定向被谷歌跟踪了,但是原来的页面不是收录。新的URL是收录,它立即被安排在同一个查询页面上的相同位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)似乎与永久性 301 重定向非常相似。
下次,您的客户想要为他们的网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用 Google 指南支持此结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:该链接已被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
对外部 href 键值对 (AVP) 进行操作,但在标记内 (“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签外可用,但在 href 内调用 AVP("javascript: openlink()")
……
结果:该链接已被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:该链接已被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:该链接已被完全抓取和跟踪。
3.动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况都可以爬取文字和收录,页面根据内容排名。酷!
为了深入了解,我们测试了一个用 JavaScript 编写的客户端全局导航,导航中的链接是通过 document.writeIn 函数插入的,我们确信可以完全抓取和跟踪需要指出的是,谷歌可以解释网站使用AngularJS框架和HTML5 History API(pushState)构建,可以渲染和收录它,并且可以像传统静态网页一样排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取,收录。我们甚至做了这样一个测试:通过动态生成结构数据并插入到 DOM 中来制作面包屑(面包屑导航)。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们将各种对 SEO 至关重要的标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel = "nofollow" 的一个重要例子
我们想测试 Google 如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有应用 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注释。
源代码中的nofollow按我们的预期工作(没有遵循链接)。 DOM中的nofollow无效(跟随链接,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果在 DOM 中插入一个 href="nofollow" 的元素,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。 JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理内容的动态插入,甚至元标记,例如 rel 规范注释。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了! (请记住允许 Google 抓取工具获取这些外部文件和 JavaScript。)
Google 已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和 dynamic网站。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,跟上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会! 查看全部
js抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能读取DOM是什么?)
项目招商找A5快速获取精准代理商名单
我们测试了 Google 爬虫如何抓取 JavaScript,以下是我们从中学到的东西。
认为 Google 无法处理 JavaScript?再想想。 Audette Audette 分享了一系列测试结果。他和他的同事测试了 Google 和收录 会抓取哪些类型的 JavaScript 函数。
概述
1. 我们进行了一系列测试,已经确认 Google 可以通过多种方式执行收录 JavaScript。我们还确认了 Google 可以渲染整个页面并读取 DOM,以便收录 可以动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能仅限于某种方式。
而今天,很明显,Google 不仅可以制定他们的抓取和 收录 JavaScript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是在过去的 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及收录。经过研究,我们发现了令人大开眼界的结果,并确认Google不仅可以执行各种JavaScript事件,还可以收录动态生成内容。怎么做? Google 可以读取 DOM。
什么是 DOM?
很多从事 SEO 的人不了解什么是文档对象模型 (DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Web 应用程序中的 JavaScript 和动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析 HTML 并执行 JavaScript 的结果就是 DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
关于这一系列的测试和结果
因为想知道会爬取哪些JavaScript特性以及收录,我们分别针对谷歌爬虫创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为 5 类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。 URL 以不同方式表达的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:Google 很快跟踪了重定向。从收录 开始,它们被解释为 301 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 JavaScript 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然重定向被谷歌跟踪了,但是原来的页面不是收录。新的URL是收录,它立即被安排在同一个查询页面上的相同位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)似乎与永久性 301 重定向非常相似。
下次,您的客户想要为他们的网站 完成 JavaScript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用 Google 指南支持此结论:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 JavaScript 来完成此操作。在仔细检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 JavaScript 重定向。
2. JavaScript 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面JavaScript重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:该链接已被完全抓取和跟踪。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统 SEO 推荐纯文本。这些测试包括 JavaScript 链接代码:
对外部 href 键值对 (AVP) 进行操作,但在标记内 (“onClick”)
函数 href 内部 AVP("javascript: window.location")
在 a 标签外可用,但在 href 内调用 AVP("javascript: openlink()")
……
结果:该链接已被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:该链接已被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行JavaScript,但我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造 URL 字符串的字符。
结果:该链接已被完全抓取和跟踪。
3.动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性是毋庸置疑的。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部JavaScript文件中)。
结果:两种情况都可以爬取文字和收录,页面根据内容排名。酷!
为了深入了解,我们测试了一个用 JavaScript 编写的客户端全局导航,导航中的链接是通过 document.writeIn 函数插入的,我们确信可以完全抓取和跟踪需要指出的是,谷歌可以解释网站使用AngularJS框架和HTML5 History API(pushState)构建,可以渲染和收录它,并且可以像传统静态网页一样排名。这就是不禁止 Google 爬虫获取外部文件和 JavaScript 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取,收录。我们甚至做了这样一个测试:通过动态生成结构数据并插入到 DOM 中来制作面包屑(面包屑导航)。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们将各种对 SEO 至关重要的标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,DOM中没有index,follow标签,会发生什么?在这个协议中,HTTP x-robots 响应头如何作为另一个变量使用行为?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel = "nofollow" 的一个重要例子
我们想测试 Google 如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有应用 nofollow 的控件。
对于nofollow,我们分别测试源代码和DOM生成的注释。
源代码中的nofollow按我们的预期工作(没有遵循链接)。 DOM中的nofollow无效(跟随链接,页面为收录)。为什么?因为修改 DOM 中的 href 元素的操作发生得太晚了:Google 在执行添加 rel="nofollow" 的 JavaScript 函数之前就准备抓取链接和 URL 队列。但是,如果在 DOM 中插入一个 href="nofollow" 的元素,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。 JavaScript 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
无论是在 HTML 源代码中还是在解析初始 HTML 后触发 JavaScript 生成 DOM,都以相同的方式处理内容的动态插入,甚至元标记,例如 rel 规范注释。
Google 依赖于完全呈现页面和理解 DOM,而不仅仅是源代码。太不可思议了! (请记住允许 Google 抓取工具获取这些外部文件和 JavaScript。)
Google 已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持 HTML5、JavaScript 和 dynamic网站。
对于SEO来说,不了解以上基本概念和谷歌技术的人应该学习学习,跟上当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会!
js抓取网页内容(Python中的HTML生成内容内容介绍及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-11 23:05
我们没有得到正确的结果,因为 javascript 生成的任何内容都需要在 DOM 上呈现。当我们得到一个 HTML 页面时,我们得到的是初始的、未修改的 DOM。
因此,我们需要在抓取页面之前呈现 javascript 内容。
由于在这个线程中多次提到 Selenium(有时是它的速度),我将列出另外两种可能的解决方案。
解决方案 1:这是一个非常好的教程,我们将遵循这个教程。
我们需要的是:
Docker 安装在我们的机器上。在此之前,这是比其他解决方案更好的解决方案,因为它使用独立于操作系统的平台。
按照相应操作系统中列出的说明安装 Splash。
引用启动文件:
Splash 是一种 JavaScript 渲染服务。它是一个带有 HTTPAPI 的轻量级 Web 浏览器,使用 Twisted 和 QT5 在 Python 3 中实现。
本质上,我们将使用 Splash 来呈现由 Javascript 生成的内容。
运行 Splash 服务器:sudo docker run -p 8050:8050 scrapinghub/splash。
安装插件:pip install scrapy-splash
假设我们已经创建了一个 Scrapy 项目(如果没有),我们将根据指南更新 settings.py:
然后转到您的项目 settings.py 并设置这些中间工具:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,}
Splash 服务器的 URL(如果使用 Win 或 OSX)。这应该是对接计算机的URL:如何从主机获取docker容器的IP地址? ):
SPLASH_URL = 'http://localhost:8050'
最后,您还需要设置这些值:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
最后,我们可以使用:
在普通蜘蛛中,可以使用请求对象来打开网址。如果要打开的页面收录JS生成的数据,则必须使用SplashRequest(或SplashFormRequest)来渲染页面。这是一个简单的例子:
class MySpider(scrapy.Spider):
name = "jsscraper"
start_urls = ["http://quotes.toscrape.com/js/"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url=url, callback=self.parse, endpoint='render.html'
)
def parse(self, response):
for q in response.css("div.quote"):
quote = QuoteItem()
quote["author"] = q.css(".author::text").extract_first()
quote["quote"] = q.css(".text::text").extract_first()
yield quote
SplashRequest 将 URL 呈现为 html 并返回您可以在回调(解析)方法中使用的响应。
解决方案 2:我们现在称之为实验(2018 年 5 月)。
此解决方案仅适用于 Python 版本 3.6(目前)。
你知道请求模块吗(谁不知道)?
现在有了爬虫小哥:request-HTML:
这个库旨在使解析 HTML(例如,爬网)尽可能简单和直观。
安装 requests-html:pipenv install requests-html
向页面的 URL 发出请求:
from requests_html import HTMLSessionsession = HTMLSession()r = session.get(a_page_url)
呈现响应以获取 Javascript 生成的位:
r.html.render()
最后好像提供了模块。
或者,我们也可以试试记录的方法。使用美利糖和 r.html 刚刚呈现的对象。 查看全部
js抓取网页内容(Python中的HTML生成内容内容介绍及解析)
我们没有得到正确的结果,因为 javascript 生成的任何内容都需要在 DOM 上呈现。当我们得到一个 HTML 页面时,我们得到的是初始的、未修改的 DOM。
因此,我们需要在抓取页面之前呈现 javascript 内容。
由于在这个线程中多次提到 Selenium(有时是它的速度),我将列出另外两种可能的解决方案。
解决方案 1:这是一个非常好的教程,我们将遵循这个教程。
我们需要的是:
Docker 安装在我们的机器上。在此之前,这是比其他解决方案更好的解决方案,因为它使用独立于操作系统的平台。
按照相应操作系统中列出的说明安装 Splash。
引用启动文件:
Splash 是一种 JavaScript 渲染服务。它是一个带有 HTTPAPI 的轻量级 Web 浏览器,使用 Twisted 和 QT5 在 Python 3 中实现。
本质上,我们将使用 Splash 来呈现由 Javascript 生成的内容。
运行 Splash 服务器:sudo docker run -p 8050:8050 scrapinghub/splash。
安装插件:pip install scrapy-splash
假设我们已经创建了一个 Scrapy 项目(如果没有),我们将根据指南更新 settings.py:
然后转到您的项目 settings.py 并设置这些中间工具:
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,}
Splash 服务器的 URL(如果使用 Win 或 OSX)。这应该是对接计算机的URL:如何从主机获取docker容器的IP地址? ):
SPLASH_URL = 'http://localhost:8050'
最后,您还需要设置这些值:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
最后,我们可以使用:
在普通蜘蛛中,可以使用请求对象来打开网址。如果要打开的页面收录JS生成的数据,则必须使用SplashRequest(或SplashFormRequest)来渲染页面。这是一个简单的例子:
class MySpider(scrapy.Spider):
name = "jsscraper"
start_urls = ["http://quotes.toscrape.com/js/"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url=url, callback=self.parse, endpoint='render.html'
)
def parse(self, response):
for q in response.css("div.quote"):
quote = QuoteItem()
quote["author"] = q.css(".author::text").extract_first()
quote["quote"] = q.css(".text::text").extract_first()
yield quote
SplashRequest 将 URL 呈现为 html 并返回您可以在回调(解析)方法中使用的响应。
解决方案 2:我们现在称之为实验(2018 年 5 月)。
此解决方案仅适用于 Python 版本 3.6(目前)。
你知道请求模块吗(谁不知道)?
现在有了爬虫小哥:request-HTML:
这个库旨在使解析 HTML(例如,爬网)尽可能简单和直观。
安装 requests-html:pipenv install requests-html
向页面的 URL 发出请求:
from requests_html import HTMLSessionsession = HTMLSession()r = session.get(a_page_url)
呈现响应以获取 Javascript 生成的位:
r.html.render()
最后好像提供了模块。
或者,我们也可以试试记录的方法。使用美利糖和 r.html 刚刚呈现的对象。
js抓取网页内容(搜索引擎对JS的索引小实验建立:Google和Baidu收录了目标实验站点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-11 23:03
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体应用会在以后文章中说明)。截至今天文章发布,谷歌和百度已将收录作为目标实验站点。
1:收录时间对比
Google 必须在百度之前收录 目标站点,而雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。
2:收录 的效果图
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
建立JS搜索引擎索引实验模型:
1.新建一个html页面和js页面,html页面代码的body除了js代码调用外没有其他信息内容。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录target html页面,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。 查看全部
js抓取网页内容(搜索引擎对JS的索引小实验建立:Google和Baidu收录了目标实验站点)
2006 年 12 月,Robin 做了一个关于 JS 被搜索引擎索引的小实验。本次实验旨在作为SEO积极使用JS的参考(具体应用会在以后文章中说明)。截至今天文章发布,谷歌和百度已将收录作为目标实验站点。
1:收录时间对比
Google 必须在百度之前收录 目标站点,而雅虎中文、搜狗等搜索引擎尚未将目标站点编入索引。
2:收录 的效果图
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
<IMG src="http://cimg2.163.com/catchpic/ ... ot%3B border=0>
从上图可以看出,谷歌和百度仍然无法抓取JS。这打破了今天早些时候 Google 对 JS 的抓取效率有所提高的说法。
本次实验相关数据正在进一步采集中,Robin会持续为大家带来本次实验的相关追踪信息。
建立JS搜索引擎索引实验模型:
1.新建一个html页面和js页面,html页面代码的body除了js代码调用外没有其他信息内容。
2.向搜索引擎提交html页面,或者通过外部链接将目标实验页面带入搜索引擎。
3.等三大搜索引擎(google、baidu、yahoo)收录target html页面,查看搜索结果。使用site命令查询html的url,在搜索结果的描述部分查看js信息内容。

