js抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有 )
优采云 发布时间: 2021-11-29 06:19js抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有
)
在上一篇文章()中,我们使用了模拟打开浏览器的方法来模拟点击网页中的Load More来动态加载网页并获取网页内容。不幸的是,网站 的这部分部分是使用 js 动态加载的。当我们用普通的方法获取的时候,发现有些地方是空白的,所以无法获取到Xpath,所以第一部分文章的方法就会失败。
可能有的童鞋一开始会觉得代码不对,然后把网页的全部内容打印出来,发现确实缺少想要的部分内容,然后用浏览器访问网页,右键查看网页源代码,发现确实缺少这部分代码。我就是那个傻男孩的鞋子!!!
所以本文文章希望通过抓取js动态加载的网页来解决这个问题。首先想到的肯定是使用selenium调用浏览器进行爬取,但是第一句话说明无法获取Xpath,所以无法通过点击页面元素来实现。这个时候看到了这个文章(),使用selenium+phantomjs进行无界面爬取。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载完成后,直接解压就可以了,然后就可以使用pip安装selenium了。
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
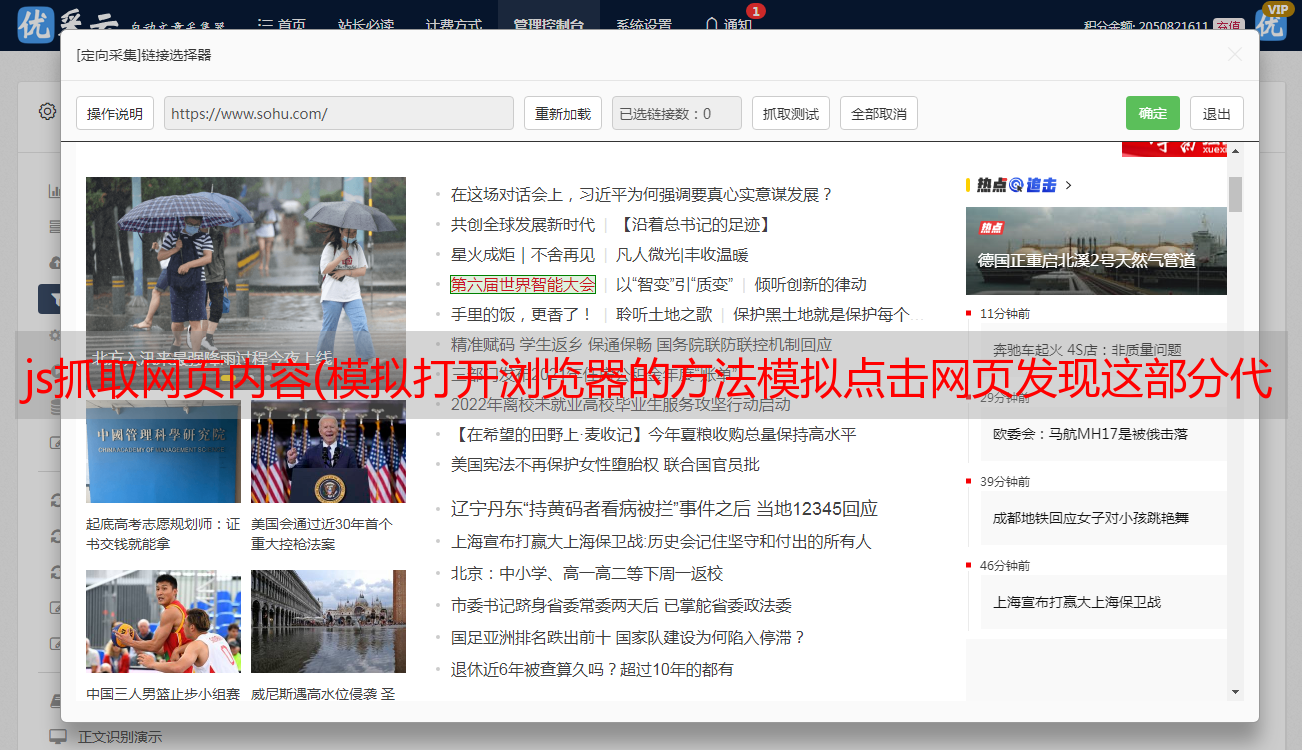
排除图片,gifs,css等,如果你想找到你想要的网页,你只需要尝试打开一个新的浏览器访问上面的url,然后你就可以看到页面信息,如果是你想要的信息想要,使用 request Get 方法,只需完全添加标题
请求的 URL 通常很长。比如上图的URL地址是:
其实只需要保留rowguid,即只需要访问:
那么rowguid只需要传入查询参数即可获取