
js抓取网页内容
js抓取网页内容(如何使用RPA工具进行自动化工具?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-28 15:25
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
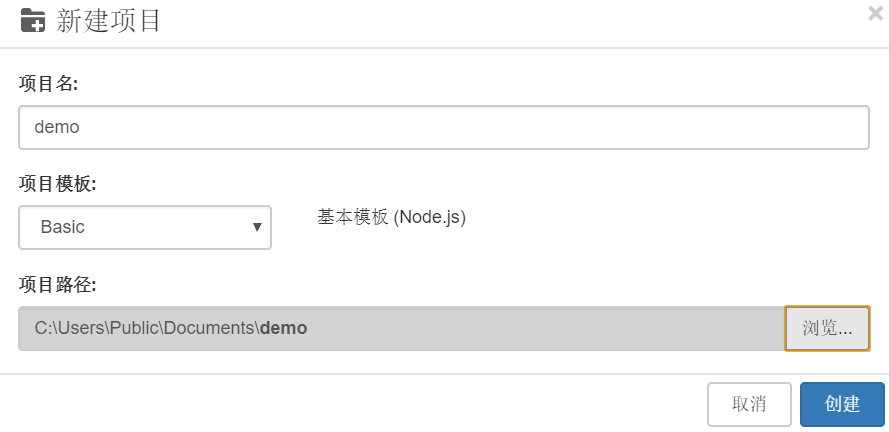
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击 LeanRunner 打开命令行工具按钮
,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm作为node.js的包管理机制,需要安装在node.js环境中才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
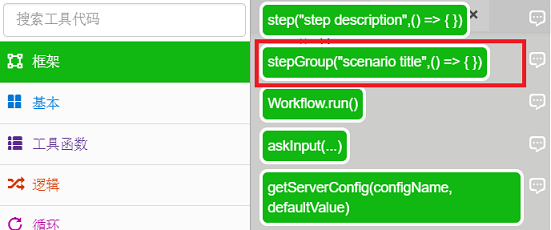
一种。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
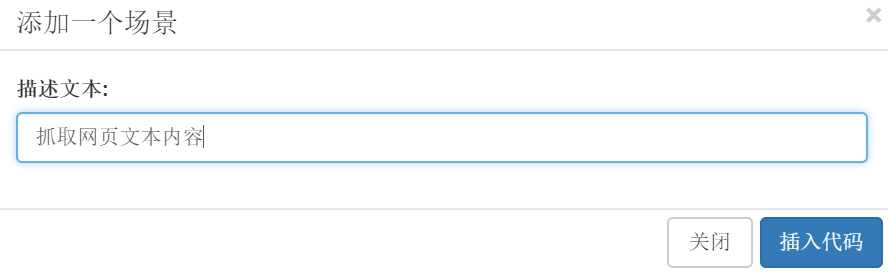
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
e. 按照上述步骤插入抓取文本并再次关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别实现以上操作步骤:
一种。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
, 或者点击“运行项目”按钮
可以看到浏览器打开网页,在 LeanRunner 设计器的输出面板中打印出文本内容。
如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们就完成了一个网页基本操作的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存储到Excel表格或者数据库中。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。 查看全部
js抓取网页内容(如何使用RPA工具进行自动化工具?工具)
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击 LeanRunner 打开命令行工具按钮

,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm作为node.js的包管理机制,需要安装在node.js环境中才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
一种。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
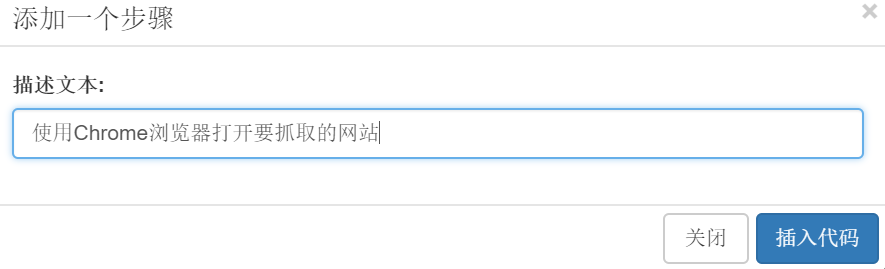
e. 按照上述步骤插入抓取文本并再次关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别实现以上操作步骤:
一种。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮

, 或者点击“运行项目”按钮

可以看到浏览器打开网页,在 LeanRunner 设计器的输出面板中打印出文本内容。

如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们就完成了一个网页基本操作的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存储到Excel表格或者数据库中。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。
js抓取网页内容(有什么办法能防止搜索引擎抓取网站?对内容使用JavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-27 22:19
1、有什么办法可以防止搜索引擎爬取网站?
第一种方法:robots.txt方法
网站根目录下有robots.txt。如果没有,您可以创建一个新的并上传。
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理: *
禁止:/css/
禁止:/管理员/
禁止所有搜索引擎访问css和admin目录,只需将css或admin目录修改为你指定的文件目录或文件即可。
第二种:网页编码方式
中间添加代码,该标签禁止搜索引擎抓取网站并显示网页快照。
注意:添加了禁止码,但是搜索引擎还是可以搜索到的,因为搜索引擎索引库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。
二、搜索引擎可以抓取JS吗?
1、 JS的内容是不爬取的,但是Google会抓到JS分析,但是有的已经能够在javecipt脚本上获取到链接,甚至执行脚本并跟踪链接。其实javascript因素还是flash 网站 ,这种做法给搜索引擎的收录和index.js带来了麻烦。所以,如果不是期望被拒绝,最直接的方法就是写robots文件。
2、部分超链接的导航能力完全由Javascript模拟。例如,在 HTML A 元素中添加一段 onclick 事件处理代码。当点击超链接时,会有页面导航的Javascript代码;
3、部分页面显示的多级菜单是用Javascript实现的,菜单的显示和消失由Javascript控制。如果这些菜单所激发的操作是导航到另一个页面,那么导航信息就很难被抓取 Grab
4、切勿使用 JavaScript 进行导航和其他链接。导航和链接是搜索引擎抓取网页的基础。如果搜索引擎无法抓取网页,则意味着该网页不会出现在索引结果中,也就无从谈起排名。尽量避免对内容使用 JavaScript。尤其是与关键词相关的内容,要尽量避免使用JavaScript来展示,否则无疑会减少。
5、 真正需要用到JavaScript的部分,把这部分JavaScript脚本放在一个或几个.js文件中,以免干扰搜索引擎的抓取和分析
.js 文件中确实放不下的一些 JavaScript 脚本,放在底部,</body> 之前,以便搜索引擎在分析网页时找到,减少对搜索引擎的干扰
6、由于普通搜索引擎很难处理Javascript代码,所以可以利用这个功能来屏蔽页面上一些不需要被搜索引擎索引的内容,从而对页面进行改进。这类信息可以称为“垃圾信息”,例如广告、版权声明、大量与内容无关的信息等,这些垃圾信息可以扔到一个或多个.js文件中,从而减少干扰到页面的实际内容,改进和展示页面内容的核心给搜索引擎。 查看全部
js抓取网页内容(有什么办法能防止搜索引擎抓取网站?对内容使用JavaScript)
1、有什么办法可以防止搜索引擎爬取网站?
第一种方法:robots.txt方法
网站根目录下有robots.txt。如果没有,您可以创建一个新的并上传。
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理: *
禁止:/css/
禁止:/管理员/
禁止所有搜索引擎访问css和admin目录,只需将css或admin目录修改为你指定的文件目录或文件即可。
第二种:网页编码方式
中间添加代码,该标签禁止搜索引擎抓取网站并显示网页快照。
注意:添加了禁止码,但是搜索引擎还是可以搜索到的,因为搜索引擎索引库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。
二、搜索引擎可以抓取JS吗?
1、 JS的内容是不爬取的,但是Google会抓到JS分析,但是有的已经能够在javecipt脚本上获取到链接,甚至执行脚本并跟踪链接。其实javascript因素还是flash 网站 ,这种做法给搜索引擎的收录和index.js带来了麻烦。所以,如果不是期望被拒绝,最直接的方法就是写robots文件。
2、部分超链接的导航能力完全由Javascript模拟。例如,在 HTML A 元素中添加一段 onclick 事件处理代码。当点击超链接时,会有页面导航的Javascript代码;
3、部分页面显示的多级菜单是用Javascript实现的,菜单的显示和消失由Javascript控制。如果这些菜单所激发的操作是导航到另一个页面,那么导航信息就很难被抓取 Grab
4、切勿使用 JavaScript 进行导航和其他链接。导航和链接是搜索引擎抓取网页的基础。如果搜索引擎无法抓取网页,则意味着该网页不会出现在索引结果中,也就无从谈起排名。尽量避免对内容使用 JavaScript。尤其是与关键词相关的内容,要尽量避免使用JavaScript来展示,否则无疑会减少。
5、 真正需要用到JavaScript的部分,把这部分JavaScript脚本放在一个或几个.js文件中,以免干扰搜索引擎的抓取和分析
.js 文件中确实放不下的一些 JavaScript 脚本,放在底部,</body> 之前,以便搜索引擎在分析网页时找到,减少对搜索引擎的干扰
6、由于普通搜索引擎很难处理Javascript代码,所以可以利用这个功能来屏蔽页面上一些不需要被搜索引擎索引的内容,从而对页面进行改进。这类信息可以称为“垃圾信息”,例如广告、版权声明、大量与内容无关的信息等,这些垃圾信息可以扔到一个或多个.js文件中,从而减少干扰到页面的实际内容,改进和展示页面内容的核心给搜索引擎。
js抓取网页内容(前端侧对于动态生成的内容进行下载的实时截图下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-27 02:08
)
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是页面内容的实时截图. 此时,图像是动态的。纯 HTML 显然不能满足我们的需求。借助JS和其他一些HTML5功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器中,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中不起作用。所以上面的funDownload()方法有一个appendChild和removeChild处理,是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的 File 对象。或者一个 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。比如在XMLHttpRequest中,如果responseType指定为blob,那么得到的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了保证良好的性能和内存使用,应该在保证不再使用时释放它。
2、URL.revokeObjectURL() 方法将释放由 URL.createObjectURL() 创建的对象 URL。当您使用了对象 URL 时,您必须让浏览器知道该 URL 不再需要指向相应的 URL。该方法需要在安装文件时调用。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL. 查看全部
js抓取网页内容(前端侧对于动态生成的内容进行下载的实时截图下载
)
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是页面内容的实时截图. 此时,图像是动态的。纯 HTML 显然不能满足我们的需求。借助JS和其他一些HTML5功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器中,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中不起作用。所以上面的funDownload()方法有一个appendChild和removeChild处理,是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的 File 对象。或者一个 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。比如在XMLHttpRequest中,如果responseType指定为blob,那么得到的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了保证良好的性能和内存使用,应该在保证不再使用时释放它。
2、URL.revokeObjectURL() 方法将释放由 URL.createObjectURL() 创建的对象 URL。当您使用了对象 URL 时,您必须让浏览器知道该 URL 不再需要指向相应的 URL。该方法需要在安装文件时调用。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL.
js抓取网页内容(PHP先说获取网页内容绑定data事件的能力分析与应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-26 04:19
nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
<p> //引入模块 var http = require("http"), fs = require('fs'), url = require('url'); //写入文件,把结果写入不同的文件 var writeRes = function(p, r) { fs.appendFile(p , r, function(err) { if(err) console.log(err); else console.log(r); }); }, //发请求,并验证内容,把结果写入文件 postHttp = function(arr, num) { console.log('第'+num+"条!") var a = arr[num].split(" - "); if(!a[0] || !a[1]) { return; } var address = url.parse(a[1]), options = { host : address.host, path: address.path, hostname : address.hostname, method: 'GET', headers: { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36' } } var req = http.request(options, function(res) { if (res.statusCode == 200) { res.setEncoding('UTF-8'); var data = ''; res.on('data', function (rd) { data += rd; }); res.on('end', function(q) { if(!~data.indexOf("www.baidu.com")) { return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n'); } else { return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n"); } }) } else { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n'); } }); req.on('error', function(e) { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n'); }) req.end(); }, //读取文件,获取需要抓取的页面 openFile = function(path, coding) { fs.readFile(path, coding, function(err, data) { var res = data.split("\n"); for (var i = 0, rl = res.length; i 查看全部
js抓取网页内容(PHP先说获取网页内容绑定data事件的能力分析与应用)
nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
<p> //引入模块 var http = require("http"), fs = require('fs'), url = require('url'); //写入文件,把结果写入不同的文件 var writeRes = function(p, r) { fs.appendFile(p , r, function(err) { if(err) console.log(err); else console.log(r); }); }, //发请求,并验证内容,把结果写入文件 postHttp = function(arr, num) { console.log('第'+num+"条!") var a = arr[num].split(" - "); if(!a[0] || !a[1]) { return; } var address = url.parse(a[1]), options = { host : address.host, path: address.path, hostname : address.hostname, method: 'GET', headers: { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36' } } var req = http.request(options, function(res) { if (res.statusCode == 200) { res.setEncoding('UTF-8'); var data = ''; res.on('data', function (rd) { data += rd; }); res.on('end', function(q) { if(!~data.indexOf("www.baidu.com")) { return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n'); } else { return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n"); } }) } else { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n'); } }); req.on('error', function(e) { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n'); }) req.end(); }, //读取文件,获取需要抓取的页面 openFile = function(path, coding) { fs.readFile(path, coding, function(err, data) { var res = data.split("\n"); for (var i = 0, rl = res.length; i
js抓取网页内容(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-24 04:03
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text 查看全部
js抓取网页内容(python爬取js执行后输出的信息1.11.1)
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text
js抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-23 12:18
主流热图的实现
热图展示的一般实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理过的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta x-frame-options为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,客户网站需要做一些工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有需要检测和分析的网站用户都可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先,我们绕过x-frame-options是sameorgin的问题,只需要解决js控制的问题。对于抓取到的页面,我们可以通过特殊对应的方式进行处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async gethtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newpage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里需要用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面,这可以通过以下伪代码来解释:
const puppeteer = require("puppeteer");
async autologin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.waitfornavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitfornavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autologinv2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 抓取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是网站不同,处理方法也会不同,不能复用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。 查看全部
js抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
主流热图的实现
热图展示的一般实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理过的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta x-frame-options为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,客户网站需要做一些工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有需要检测和分析的网站用户都可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先,我们绕过x-frame-options是sameorgin的问题,只需要解决js控制的问题。对于抓取到的页面,我们可以通过特殊对应的方式进行处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async gethtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newpage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里需要用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面,这可以通过以下伪代码来解释:
const puppeteer = require("puppeteer");
async autologin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.waitfornavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitfornavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autologinv2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 抓取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是网站不同,处理方法也会不同,不能复用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。
js抓取网页内容(谷歌爬虫是如何抓取javascript的?学习到的知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-20 18:09
我们测试了谷歌爬虫是如何抓取javascript的,以下是我们从中学到的知识。
认为谷歌无法处理 javascript?再想想。audette audette 分享了一系列的测试结果,他和他的同事测试了谷歌和收录 会抓取什么类型的javascript函数。
长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 javascript。我们也确认了谷歌可以渲染整个页面并读取dom,可以收录动态生成内容。
2. dom中的seo信号(页面标题、meta描述、canonical标签、meta robots标签等)都是关注的。动态插入dom的内容也可以爬取和收录。此外,在某些情况下,dom 甚至可能优先于 html 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:google 执行javascript & 读取dom
早在2008年,google就成功爬取了javascript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 javascript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在merkle,我们的seo 技术团队希望更好地了解Google 爬虫可以抓取哪些类型的javascript 事件和收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 javascript 事件,还可以动态生成 收录 内容。怎么做?谷歌可以读取dom。
什么是dom?
很多搞seo的人不明白什么是文档对象模型(dom)。
当浏览器请求一个页面时会发生什么,以及 dom 如何参与其中。
在 Web 浏览器中使用时,dom 本质上是一个应用程序接口或 api,用于标记和构建数据(例如 html 和 xml)。该界面允许 Web 浏览器将它们组合成一个文档。
dom 还定义了如何获取和操作结构。尽管 dom 是一种独立于语言的 API(不绑定到特定的编程语言或库),但它通常用于 javascript 和 Web 应用程序的动态内容。
dom 代表一个接口或“桥”,它将网页与编程语言连接起来。解析html并执行javascript的结果是dom。网页的内容不是(不仅)源代码,而是 dom。这使它变得非常重要。
javascript 如何通过 dom 接口工作。
我们很高兴地发现 Google 可以读取 dom,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些javascript函数和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 url 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、javascript 重定向
2、javascript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 javascript 能力的页面。
1. javascript 重定向
我们首先测试了常见的javascript重定向,不同方式表达的URL会有什么结果?我们为两个测试选择了 window.location 对象:test a 使用绝对路径 url 调用 window.location,而 test b 使用它的相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态的url,而不是google收录中的redirect url。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 javascript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的url为收录,立即被安排在同一个查询页面的同一个位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 javascript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌的指导方针支持这一结论:
使用 javascript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 javascript 来完成此操作。在仔细检查 javascript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您无权访问您的 网站 服务器,您可以为此使用 javascript 重定向。
2. javascript 链接
我们用多种编码方式测试了不同类型的js链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面javascript重定向的强制操作。
示例:google 工作页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 javascript 链接。以下是最常见的 javascript 链接类型,而传统的 seo 推荐纯文本。这些测试包括 javascript 链接代码:
作用于外部 href 键值对 (avp),但在标签内 ("onclick")
函数 href 内部 avp("javascript: window.location")
在 a 标签之外进行操作,但在 href 中调用 avp("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用事件处理程序进行鼠标移动,然后隐藏 url 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行javascript,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造url字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的html源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的html源代码之外(在外部javascript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用javascript编写的客户端全局导航,导航中的链接是通过document.writein函数插入的,确认可以完全爬取和跟踪。需要指出的是,谷歌可以解释网站使用angularjs框架和html5历史api(pushstate)构建,可以渲染和收录它,并且可以像传统的静态网页一样排名。这就是不禁止谷歌爬虫获取外部文件和javascript的重要性,这可能也是谷歌将其从“支持Ajax的Seo指南”中删除的原因。当您可以简单地呈现整个页面时,谁需要一个 html 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到dom后会被抓取和收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到dom中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 json-ld 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 seo 至关重要的标签插入到 dom 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 html 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,dom中没有index,follow标签,会发生什么?在这个协议中,http x-robots 响应头部如何将行为作为另一个变量使用?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 dom。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和dom的链接级别的nofollow属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源码vs dom生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是dom中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改dom中href元素的操作发生得太晚了:在执行添加rel=”nofollow”的javascript函数之前,谷歌已经准备好抓取链接并排队等待url。但是,如果将带有 href="nofollow" 的 a 元素插入到 dom 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 seo 建议都尽可能关注“纯文本”内容。而动态生成的内容,ajax和javascript链接都会损害主流搜索引擎的seo。显然,这对谷歌来说不再是问题。javascript 链接的操作方式类似于普通的html 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是meta标签,比如rel规范的注解,无论是在html源码中还是在解析初始html后触发JavaScript生成dom,都会被同样处理。
Google 依赖于能够完全呈现页面并理解 dom,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 javascript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持html5、javascript和dynamic网站。
对于seo,不了解上述基本概念和google技术的人应该学习学习,以追赶当前的技术。如果你不考虑dom,你可能会失去一半的份额。
本文所表达的观点并非全部由搜索引擎地(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js抓取网页内容(谷歌爬虫是如何抓取javascript的?学习到的知识)
我们测试了谷歌爬虫是如何抓取javascript的,以下是我们从中学到的知识。
认为谷歌无法处理 javascript?再想想。audette audette 分享了一系列的测试结果,他和他的同事测试了谷歌和收录 会抓取什么类型的javascript函数。

长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 javascript。我们也确认了谷歌可以渲染整个页面并读取dom,可以收录动态生成内容。
2. dom中的seo信号(页面标题、meta描述、canonical标签、meta robots标签等)都是关注的。动态插入dom的内容也可以爬取和收录。此外,在某些情况下,dom 甚至可能优先于 html 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:google 执行javascript & 读取dom
早在2008年,google就成功爬取了javascript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 javascript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在merkle,我们的seo 技术团队希望更好地了解Google 爬虫可以抓取哪些类型的javascript 事件和收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 javascript 事件,还可以动态生成 收录 内容。怎么做?谷歌可以读取dom。
什么是dom?
很多搞seo的人不明白什么是文档对象模型(dom)。

当浏览器请求一个页面时会发生什么,以及 dom 如何参与其中。
在 Web 浏览器中使用时,dom 本质上是一个应用程序接口或 api,用于标记和构建数据(例如 html 和 xml)。该界面允许 Web 浏览器将它们组合成一个文档。
dom 还定义了如何获取和操作结构。尽管 dom 是一种独立于语言的 API(不绑定到特定的编程语言或库),但它通常用于 javascript 和 Web 应用程序的动态内容。
dom 代表一个接口或“桥”,它将网页与编程语言连接起来。解析html并执行javascript的结果是dom。网页的内容不是(不仅)源代码,而是 dom。这使它变得非常重要。

javascript 如何通过 dom 接口工作。
我们很高兴地发现 Google 可以读取 dom,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些javascript函数和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 url 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、javascript 重定向
2、javascript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子

示例:用于测试 Google 抓取工具理解 javascript 能力的页面。
1. javascript 重定向
我们首先测试了常见的javascript重定向,不同方式表达的URL会有什么结果?我们为两个测试选择了 window.location 对象:test a 使用绝对路径 url 调用 window.location,而 test b 使用它的相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态的url,而不是google收录中的redirect url。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 javascript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的url为收录,立即被安排在同一个查询页面的同一个位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 javascript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌的指导方针支持这一结论:
使用 javascript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 javascript 来完成此操作。在仔细检查 javascript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您无权访问您的 网站 服务器,您可以为此使用 javascript 重定向。
2. javascript 链接
我们用多种编码方式测试了不同类型的js链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面javascript重定向的强制操作。

示例:google 工作页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 javascript 链接。以下是最常见的 javascript 链接类型,而传统的 seo 推荐纯文本。这些测试包括 javascript 链接代码:
作用于外部 href 键值对 (avp),但在标签内 ("onclick")
函数 href 内部 avp("javascript: window.location")
在 a 标签之外进行操作,但在 href 中调用 avp("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用事件处理程序进行鼠标移动,然后隐藏 url 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行javascript,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造url字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的html源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的html源代码之外(在外部javascript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用javascript编写的客户端全局导航,导航中的链接是通过document.writein函数插入的,确认可以完全爬取和跟踪。需要指出的是,谷歌可以解释网站使用angularjs框架和html5历史api(pushstate)构建,可以渲染和收录它,并且可以像传统的静态网页一样排名。这就是不禁止谷歌爬虫获取外部文件和javascript的重要性,这可能也是谷歌将其从“支持Ajax的Seo指南”中删除的原因。当您可以简单地呈现整个页面时,谁需要一个 html 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到dom后会被抓取和收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到dom中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 json-ld 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 seo 至关重要的标签插入到 dom 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 html 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,dom中没有index,follow标签,会发生什么?在这个协议中,http x-robots 响应头部如何将行为作为另一个变量使用?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 dom。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和dom的链接级别的nofollow属性。我们还创建了一个没有 nofollow 的控件。

对于nofollow,我们分别测试了源码vs dom生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是dom中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改dom中href元素的操作发生得太晚了:在执行添加rel=”nofollow”的javascript函数之前,谷歌已经准备好抓取链接并排队等待url。但是,如果将带有 href="nofollow" 的 a 元素插入到 dom 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 seo 建议都尽可能关注“纯文本”内容。而动态生成的内容,ajax和javascript链接都会损害主流搜索引擎的seo。显然,这对谷歌来说不再是问题。javascript 链接的操作方式类似于普通的html 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是meta标签,比如rel规范的注解,无论是在html源码中还是在解析初始html后触发JavaScript生成dom,都会被同样处理。
Google 依赖于能够完全呈现页面并理解 dom,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 javascript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持html5、javascript和dynamic网站。
对于seo,不了解上述基本概念和google技术的人应该学习学习,以追赶当前的技术。如果你不考虑dom,你可能会失去一半的份额。
本文所表达的观点并非全部由搜索引擎地(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
js抓取网页内容(安装LinuxWindows原理和运行结果测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-20 01:15
本文信息本文由Method SEO顾问发表于2015-11-2218:24:38,共1927字,请注明:【张亚楠】Selenium+PhantomJS+Xpath爬取网页JS内容_【Method SEO顾问】 】,如果我网站的文章对你有帮助的话,来百度的口碑给个好评吧!
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装
Linux
sudo pip install selenium
sudo apt-get install PhantomJS
视窗
原则
关于硒
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例
剑试-抢夺称号
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
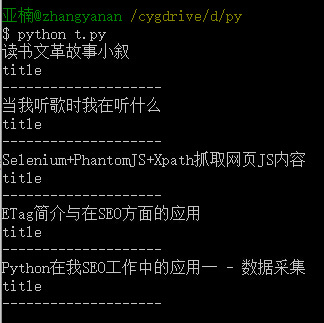
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534----
其他功能
参考
评论
图片来自库尔特·阿里戈。 查看全部
js抓取网页内容(安装LinuxWindows原理和运行结果测试)
本文信息本文由Method SEO顾问发表于2015-11-2218:24:38,共1927字,请注明:【张亚楠】Selenium+PhantomJS+Xpath爬取网页JS内容_【Method SEO顾问】 】,如果我网站的文章对你有帮助的话,来百度的口碑给个好评吧!

之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装
Linux
sudo pip install selenium
sudo apt-get install PhantomJS
视窗
原则
关于硒
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例
剑试-抢夺称号
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534----
其他功能
参考
评论
图片来自库尔特·阿里戈。
js抓取网页内容(安装LinuxWindows原理关于SeleniumSelenium的运行结果,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-20 01:14
文章内容
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测验-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534 – – – –
其他功能参考说明 查看全部
js抓取网页内容(安装LinuxWindows原理关于SeleniumSelenium的运行结果,你了解多少?)
文章内容
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测验-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:

捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534 – – – –
其他功能参考说明
js抓取网页内容(不时之需:我的理解不时之需:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-10-18 15:03
phantomjs:我的理解是它是一个非显示浏览器,也就是说除了不能显示页面的内容外,基本上可以做浏览器能做的所有任务。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学习了PHANTOMJS,由于网上没有找到太多的例子,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来详细实现一下:
下载并解压phantom到D盘,里面有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit,达到预期目的:比如生成网页快照。我想做什么就是爬上AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]查看原件
在 CODE 上查看代码片段
源自我的代码片段
system = require('system') //传递一些需要的参数给js文件 address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到 var page = require('webpage').create(); var url = address; page.open(url, function (status) { if (status !== 'success') { console.log('Unable to post!'); } else { var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。 for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦 phantom.outputEncoding = encodings[i]; console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容 } } phantom.exit(); });
接下来就是java类的准备工作:
[java]查看原件
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest; import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; public class GetAjaxHtml { public static String getAjaxContent(String url) throws Exception { Runtime rt = Runtime.getRuntime(); Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url); InputStream is = p.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is)); StringBuffer sbf = new StringBuffer(); String tmp = ""; while((tmp=br.readLine())!=null) { sbf.append(tmp + "\n"); } return sbf.toString(); } public static void main(String[] args) throws Exception { long start = System.currentTimeMillis(); String result = getAjaxContent("http://114.111.162.220:8093/404Web/"); System.out.println(result); long end = System.currentTimeMillis(); System.out.println("===============耗时:" + (end - start) + "==============="); } }
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案 查看全部
js抓取网页内容(不时之需:我的理解不时之需:)
phantomjs:我的理解是它是一个非显示浏览器,也就是说除了不能显示页面的内容外,基本上可以做浏览器能做的所有任务。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学习了PHANTOMJS,由于网上没有找到太多的例子,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来详细实现一下:
下载并解压phantom到D盘,里面有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit,达到预期目的:比如生成网页快照。我想做什么就是爬上AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]查看原件
在 CODE 上查看代码片段
源自我的代码片段
system = require('system') //传递一些需要的参数给js文件 address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到 var page = require('webpage').create(); var url = address; page.open(url, function (status) { if (status !== 'success') { console.log('Unable to post!'); } else { var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。 for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦 phantom.outputEncoding = encodings[i]; console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容 } } phantom.exit(); });
接下来就是java类的准备工作:
[java]查看原件
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest; import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; public class GetAjaxHtml { public static String getAjaxContent(String url) throws Exception { Runtime rt = Runtime.getRuntime(); Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url); InputStream is = p.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is)); StringBuffer sbf = new StringBuffer(); String tmp = ""; while((tmp=br.readLine())!=null) { sbf.append(tmp + "\n"); } return sbf.toString(); } public static void main(String[] args) throws Exception { long start = System.currentTimeMillis(); String result = getAjaxContent("http://114.111.162.220:8093/404Web/";); System.out.println(result); long end = System.currentTimeMillis(); System.out.println("===============耗时:" + (end - start) + "==============="); } }
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案
js抓取网页内容(什么是JS的元素,你知道吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-18 15:02
在编写JS或者JQuery的时候,在使用$("#btn1")或者Domcument.getElementById获取相关标签元素时,偶尔会出现获取不到对应元素的情况。报如下错误等:
无法读取空错误的属性“XXX”
无法读取未定义的属性“可见性”
其实这个问题只有一个原因,就是没有获取到对应的标签元素值,也就是$("#btn1")获取的值为null,所以当你获取到这个元素下的属性时,自然会报错,出现这种情况的原因可能如下。
1.Html页面还未加载,在元素加载前调用元素
根据html页面的特点,从上到下依次加载,即遇到什么就加载什么。因此,有可能在页面的 DOM 元素之前加载 JS 方法。
如果此时提前调用了JS方法,由于label元素还没有加载,所以找不到对应的元素,所以会报这个找不到元素的错误。
这种错误的解决方法也很简单,只需:
将对应的JS代码放在html页面的最后,在label元素加载完成后调用对应的JS方法。
或使用:
JS window.onload() 方法
onload 事件将在指令页面上的所有元素(包括图像和其他文件)加载完成后立即发生。
JQuery 的 ready() 方法
ready 事件将在文档结构加载后立即发生(不包括图片等非文本媒体文件)。
思路是让JS方法在页面完全加载后运行,这样就可以保证一定要加载相应的元素。
2.多层iframe嵌套,无法获取iframe不同层次的元素
当整个 HTML 页面使用多层 iframe 嵌套时,很容易找到对应内部 iframe 中的元素。
当我们获取元素时,我们会默认在外层 iframe 中找到该元素。如果是多层嵌套的iframe页面,那么当我们想要在内部iframe中查找元素时,需要切换到iframe ID指定的iframe层中,重新获取该元素。
var obj=document.getElementById("Iframe").contentWindow;
obj.document.getElementById("menu").style.visibility="hidden";//隐藏元素
还有一种情况是被调用的JS方法在内部iframe中,而外部窗口没有对应的ID。
可以使用window.parent方法获取当前窗口的父窗口,然后使用父窗口方法获取对应的元素。
window.parent.document.getElementById("null_box").getElementsByTagName("input")[0].style.visibility="visible";//恢复元素
当对应的label元素不可用时,记住一个前端的想法
当元素标签不可用时,可以尝试查找元素标签的父标签。
按照这个寻父的思路,一个一个的往上查找,当可以得到最外层的父级时,就可以按照这个层级关系依次往下查找这个元素。 查看全部
js抓取网页内容(什么是JS的元素,你知道吗?(一))
在编写JS或者JQuery的时候,在使用$("#btn1")或者Domcument.getElementById获取相关标签元素时,偶尔会出现获取不到对应元素的情况。报如下错误等:
无法读取空错误的属性“XXX”
无法读取未定义的属性“可见性”
其实这个问题只有一个原因,就是没有获取到对应的标签元素值,也就是$("#btn1")获取的值为null,所以当你获取到这个元素下的属性时,自然会报错,出现这种情况的原因可能如下。
1.Html页面还未加载,在元素加载前调用元素
根据html页面的特点,从上到下依次加载,即遇到什么就加载什么。因此,有可能在页面的 DOM 元素之前加载 JS 方法。
如果此时提前调用了JS方法,由于label元素还没有加载,所以找不到对应的元素,所以会报这个找不到元素的错误。
这种错误的解决方法也很简单,只需:
将对应的JS代码放在html页面的最后,在label元素加载完成后调用对应的JS方法。
或使用:
JS window.onload() 方法
onload 事件将在指令页面上的所有元素(包括图像和其他文件)加载完成后立即发生。
JQuery 的 ready() 方法
ready 事件将在文档结构加载后立即发生(不包括图片等非文本媒体文件)。
思路是让JS方法在页面完全加载后运行,这样就可以保证一定要加载相应的元素。
2.多层iframe嵌套,无法获取iframe不同层次的元素
当整个 HTML 页面使用多层 iframe 嵌套时,很容易找到对应内部 iframe 中的元素。
当我们获取元素时,我们会默认在外层 iframe 中找到该元素。如果是多层嵌套的iframe页面,那么当我们想要在内部iframe中查找元素时,需要切换到iframe ID指定的iframe层中,重新获取该元素。
var obj=document.getElementById("Iframe").contentWindow;
obj.document.getElementById("menu").style.visibility="hidden";//隐藏元素
还有一种情况是被调用的JS方法在内部iframe中,而外部窗口没有对应的ID。
可以使用window.parent方法获取当前窗口的父窗口,然后使用父窗口方法获取对应的元素。
window.parent.document.getElementById("null_box").getElementsByTagName("input")[0].style.visibility="visible";//恢复元素
当对应的label元素不可用时,记住一个前端的想法
当元素标签不可用时,可以尝试查找元素标签的父标签。
按照这个寻父的思路,一个一个的往上查找,当可以得到最外层的父级时,就可以按照这个层级关系依次往下查找这个元素。
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-18 15:01
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/");
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了 查看全部
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/";);
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
js抓取网页内容(即为如何通过selenium-java爬取异步加载的数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-17 22:18
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:
按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:
纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:
持仓市值通知系统,他每天会根据自己的持仓配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。 查看全部
js抓取网页内容(即为如何通过selenium-java爬取异步加载的数据的方法)
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:

按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:

纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:
持仓市值通知系统,他每天会根据自己的持仓配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-17 16:20
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/");
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了 查看全部
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/";);
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
js抓取网页内容(网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-16 17:22
这篇文章的内容主要讲解了《防止网站页面内容被抓取的技巧有哪些》,有兴趣的可以看看。本文介绍的方法简单、快捷、实用。现在就让小编带你一起学习《防止网站页面内容被爬取的技巧有哪些》!
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。能不能通过,就看网站工地主的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5. 使用robots文件在页面上使用iframe标签来显示需要搜索引擎的内容收录robots文件可以防止iframe标签外的内容被收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传输到浏览器中进行显示,所以这也无法阻止收录。
说到这里,相信大家对“防止网站页面内容被爬取的技巧有哪些”有了更深的了解,一起来看看吧!这里是易速云网站,更多相关内容可以进入相关频道,关注我们,持续学习! 查看全部
js抓取网页内容(网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么样)
这篇文章的内容主要讲解了《防止网站页面内容被抓取的技巧有哪些》,有兴趣的可以看看。本文介绍的方法简单、快捷、实用。现在就让小编带你一起学习《防止网站页面内容被爬取的技巧有哪些》!
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。能不能通过,就看网站工地主的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5. 使用robots文件在页面上使用iframe标签来显示需要搜索引擎的内容收录robots文件可以防止iframe标签外的内容被收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传输到浏览器中进行显示,所以这也无法阻止收录。
说到这里,相信大家对“防止网站页面内容被爬取的技巧有哪些”有了更深的了解,一起来看看吧!这里是易速云网站,更多相关内容可以进入相关频道,关注我们,持续学习!
js抓取网页内容(ROBOTS开发界两个办法:一个是robots.txt,另一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-11 04:02
有时会有一些你不想被 ROBOTS 抓取并公开的网站内容。为了解决这个问题,ROBOTS开发社区提供了两种方法:一种是robots.txt,一种是The Robots META标签。
1、默认为全部
属性如下:
设置为all:会检索文件,可以查询页面上的链接;
设置为none:不会检索文件,无法查询页面上的链接;
设置为索引:文件将被检索;
设置为follow:可以查询页面上的链接;
设置为noindex:不会检索文件,但可以查询页面上的链接;
设置为nofollow:不会检索文件,可以查询页面上的链接。
2、revisit-after(重访)
通知搜索引擎访问天数
其他:
-------------------------------------------------- -------------------------------------------------- --------
meta标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。
1、Content-Type 和 Content-Language(显示字符集设置)
说明:设置页面使用的字符集,表示首页使用的文字已经是该语言的,浏览器会根据这个调用对应的字符集来显示页面的内容。
注意:这个meta标签定义了HTML页面使用的字符集为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 Meta 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日文字符集是“iso-2022-jp”,韩文字符集是“ks_c_5601”。
字符集选项:ISO-8859-1(英文)、BIG5、UTF-8、SHIFT-Jis、Euc、Koi8-2、us-ascii、x-mac-roman、iso- 8859-2、x-mac-ce、iso-2022-jp、x-sjis、x-euc-jp、euc-kr、iso-2022-kr、gb2312、gb_2312-80、x-euc-tw、x- cns11643-1、x-cns11643-2等字符集;Content-Language 也可以是:EN、FR 等语言代码。
2、刷新(刷新)
3、过期(过期)
注意:指定缓存中网页的过期时间。一旦网页过期,必须在服务器上检索它。
注意:必须使用 GMT 的时间格式,或者直接设置为 0(数字表示会过期多少时间)。
4、编译指示(缓存模式)
注意:浏览器禁止从本机缓存中读取页面内容。
注意:网页不保存在缓存中,每次访问都会刷新页面。使用此设置,访问者将无法离线浏览。
5、Set-Cookie(cookie设置)
注意:当浏览器访问一个页面时,它会存储在缓存中,下次再次访问时可以从缓存中读取,以提高速度。如果您希望访问者每次都刷新您的广告图标,或每次都刷新您的计数器,请禁用缓存。通常,没有必要禁用 HTML 文件的缓存。对于ASP等页面,可以禁用缓存,因为每次看到服务器上动态生成的页面,缓存就没有意义了。如果网页过期,保存的 cookie 将被删除。
用法:
98 年 10 月 21 日 16:14:21 格林威治标准时间;路径=/">
注意:必须使用 GMT 的时间格式。
6、Window-target(显示窗口设置)
说明:强制页面在当前窗口中显示为单独的页面。
用法:
注意:此属性用于防止其他人在框架中调用您的页面。内容选项:_blank、_top、_self、_parent。
7、图片标签(网络 RSAC 评级)
注意:IE的Internet选项中有一个内容设置,可以防止浏览一些受限的网站,以及网站的受限级别
不要被这个参数设置。
用法:
“(图片-1.1”
我生成评论'RSACi North America Sever' by''
for '' on '1997.06.30T14:21-0500' r(n0 s0 v0 l0))">
注意:不要将级别设置得太高。RSAC 的评估系统提供了评估网站内容的标准。用户可以设置Microsoft Internet Explorer(IE3.0 及以上)排除收录色情和暴力内容的站点。上面例子中的 HTML 取自微软的主页。代码中的 (n 0 s 0 v 0 l 0) 表示该网站不收录不健康的内容。评级由美国娱乐委员会的评级机构 RSAC 评估。如果您想了解更多关于RSAC 评估系统 Grade 内容,或者需要自己评估的网站,可以访问 RSAC 的网站:。
8、Page-Enter, Page-Exit(进入和退出)
说明:这是页面加载和调用时的一些特殊效果。
用法:
注意:blendTrans 是一种动态滤镜,会产生淡入淡出的效果。另一个动态过滤器 RevealTrans 也可以用于页面进入和退出效果:
Duration 表示滤镜效果的持续时间(单位:秒)
过渡过滤器类型。表示使用哪种特效,取值为0-23。
0 矩形缩小
1 矩形展开
2 减圈
3 圆圈放大
4 从下往上刷新
5 从上到下刷新
6 从左到右刷新
7 从右向左刷新
8个垂直百叶窗
9 水平百叶窗
10个错位的水平百叶窗
11 错位的垂直百叶窗
12点差
13 从左到右刷新
14次从中间到左右刷新
15 中间到顶部和底部
16 上下到中心
17 右下至左上
18 右上至左下
19 左上至右下
20 左下至右上
21个单杠
22个竖条
23 以上 22种随机选择一种
9、MSThemeCompatible (XP 主题)
说明:是否关闭IE中的xp主题
用法:
注意:关闭xp的蓝色立体按钮系统显示风格,与win2k非常相似。
10、IE6(页面生成器)
描述:页面生成器生成器,ie6
用法:
注意:它的成分与产品的制造商相似。
11、Content-Script-Type(脚本相关)
注意:这是最近的 W3C 规范,用于指定页面中的脚本类型。
用法:
★NAME变量
名称描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。您还可以指定其他任意值,例如:creationdate(创建日期)、
证件号(document number)和级别(level)等。
名称的内容指定实际内容。例如,如果您将级别指定为值,则内容可能是初级、中级或高级。
1、关键字(关键字)
描述:为搜索引擎提供的关键字列表
用法:
注意:使用英文逗号“,”来分隔每个关键词。META的通常用途是指定搜索引擎以提高搜索质量关键词。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、说明(介绍)
描述:描述用于告诉搜索引擎你的网站的主要内容。
用法:
注意:
3、机器人(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。Content的参数为all、none、index、noindex、follow、nofollow。默认是全部。
用法:
注:很多搜索引擎使用robot/spider搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特性来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接;(与“noindex, no follow”功能相同)
index:文件将被检索;(让机器人/蜘蛛登录)
关注:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接;(不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。(不要让机器人/蜘蛛跟着本页链接往下看)
4、作者 (Author)
说明:注释页面的作者或制作团队
用法:">
注意:内容可以是:您或您的制作团队的姓名,或电子邮件 查看全部
js抓取网页内容(ROBOTS开发界两个办法:一个是robots.txt,另一个)
有时会有一些你不想被 ROBOTS 抓取并公开的网站内容。为了解决这个问题,ROBOTS开发社区提供了两种方法:一种是robots.txt,一种是The Robots META标签。
1、默认为全部
属性如下:
设置为all:会检索文件,可以查询页面上的链接;
设置为none:不会检索文件,无法查询页面上的链接;
设置为索引:文件将被检索;
设置为follow:可以查询页面上的链接;
设置为noindex:不会检索文件,但可以查询页面上的链接;
设置为nofollow:不会检索文件,可以查询页面上的链接。
2、revisit-after(重访)
通知搜索引擎访问天数
其他:
-------------------------------------------------- -------------------------------------------------- --------
meta标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。
1、Content-Type 和 Content-Language(显示字符集设置)
说明:设置页面使用的字符集,表示首页使用的文字已经是该语言的,浏览器会根据这个调用对应的字符集来显示页面的内容。
注意:这个meta标签定义了HTML页面使用的字符集为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 Meta 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日文字符集是“iso-2022-jp”,韩文字符集是“ks_c_5601”。
字符集选项:ISO-8859-1(英文)、BIG5、UTF-8、SHIFT-Jis、Euc、Koi8-2、us-ascii、x-mac-roman、iso- 8859-2、x-mac-ce、iso-2022-jp、x-sjis、x-euc-jp、euc-kr、iso-2022-kr、gb2312、gb_2312-80、x-euc-tw、x- cns11643-1、x-cns11643-2等字符集;Content-Language 也可以是:EN、FR 等语言代码。
2、刷新(刷新)
3、过期(过期)
注意:指定缓存中网页的过期时间。一旦网页过期,必须在服务器上检索它。
注意:必须使用 GMT 的时间格式,或者直接设置为 0(数字表示会过期多少时间)。
4、编译指示(缓存模式)
注意:浏览器禁止从本机缓存中读取页面内容。
注意:网页不保存在缓存中,每次访问都会刷新页面。使用此设置,访问者将无法离线浏览。
5、Set-Cookie(cookie设置)
注意:当浏览器访问一个页面时,它会存储在缓存中,下次再次访问时可以从缓存中读取,以提高速度。如果您希望访问者每次都刷新您的广告图标,或每次都刷新您的计数器,请禁用缓存。通常,没有必要禁用 HTML 文件的缓存。对于ASP等页面,可以禁用缓存,因为每次看到服务器上动态生成的页面,缓存就没有意义了。如果网页过期,保存的 cookie 将被删除。
用法:
98 年 10 月 21 日 16:14:21 格林威治标准时间;路径=/">
注意:必须使用 GMT 的时间格式。
6、Window-target(显示窗口设置)
说明:强制页面在当前窗口中显示为单独的页面。
用法:
注意:此属性用于防止其他人在框架中调用您的页面。内容选项:_blank、_top、_self、_parent。
7、图片标签(网络 RSAC 评级)
注意:IE的Internet选项中有一个内容设置,可以防止浏览一些受限的网站,以及网站的受限级别
不要被这个参数设置。
用法:
“(图片-1.1”
我生成评论'RSACi North America Sever' by''
for '' on '1997.06.30T14:21-0500' r(n0 s0 v0 l0))">
注意:不要将级别设置得太高。RSAC 的评估系统提供了评估网站内容的标准。用户可以设置Microsoft Internet Explorer(IE3.0 及以上)排除收录色情和暴力内容的站点。上面例子中的 HTML 取自微软的主页。代码中的 (n 0 s 0 v 0 l 0) 表示该网站不收录不健康的内容。评级由美国娱乐委员会的评级机构 RSAC 评估。如果您想了解更多关于RSAC 评估系统 Grade 内容,或者需要自己评估的网站,可以访问 RSAC 的网站:。
8、Page-Enter, Page-Exit(进入和退出)
说明:这是页面加载和调用时的一些特殊效果。
用法:
注意:blendTrans 是一种动态滤镜,会产生淡入淡出的效果。另一个动态过滤器 RevealTrans 也可以用于页面进入和退出效果:
Duration 表示滤镜效果的持续时间(单位:秒)
过渡过滤器类型。表示使用哪种特效,取值为0-23。
0 矩形缩小
1 矩形展开
2 减圈
3 圆圈放大
4 从下往上刷新
5 从上到下刷新
6 从左到右刷新
7 从右向左刷新
8个垂直百叶窗
9 水平百叶窗
10个错位的水平百叶窗
11 错位的垂直百叶窗
12点差
13 从左到右刷新
14次从中间到左右刷新
15 中间到顶部和底部
16 上下到中心
17 右下至左上
18 右上至左下
19 左上至右下
20 左下至右上
21个单杠
22个竖条
23 以上 22种随机选择一种
9、MSThemeCompatible (XP 主题)
说明:是否关闭IE中的xp主题
用法:
注意:关闭xp的蓝色立体按钮系统显示风格,与win2k非常相似。
10、IE6(页面生成器)
描述:页面生成器生成器,ie6
用法:
注意:它的成分与产品的制造商相似。
11、Content-Script-Type(脚本相关)
注意:这是最近的 W3C 规范,用于指定页面中的脚本类型。
用法:
★NAME变量
名称描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。您还可以指定其他任意值,例如:creationdate(创建日期)、
证件号(document number)和级别(level)等。
名称的内容指定实际内容。例如,如果您将级别指定为值,则内容可能是初级、中级或高级。
1、关键字(关键字)
描述:为搜索引擎提供的关键字列表
用法:
注意:使用英文逗号“,”来分隔每个关键词。META的通常用途是指定搜索引擎以提高搜索质量关键词。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、说明(介绍)
描述:描述用于告诉搜索引擎你的网站的主要内容。
用法:
注意:
3、机器人(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。Content的参数为all、none、index、noindex、follow、nofollow。默认是全部。
用法:
注:很多搜索引擎使用robot/spider搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特性来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接;(与“noindex, no follow”功能相同)
index:文件将被检索;(让机器人/蜘蛛登录)
关注:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接;(不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。(不要让机器人/蜘蛛跟着本页链接往下看)
4、作者 (Author)
说明:注释页面的作者或制作团队
用法:">
注意:内容可以是:您或您的制作团队的姓名,或电子邮件
js抓取网页内容(Nodejs对于网页抓取的能力首先要推荐用Python!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-09 12:18
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须要等上一页爬完才能拿到数据,下一页才能爬出来,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签: node.js 抓取 nodejs 抓取网页 查看全部
js抓取网页内容(Nodejs对于网页抓取的能力首先要推荐用Python!!)
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须要等上一页爬完才能拿到数据,下一页才能爬出来,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签: node.js 抓取 nodejs 抓取网页
js抓取网页内容( 如何模拟请求和如何解析HTML的链接和标题?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-08 20:12
如何模拟请求和如何解析HTML的链接和标题?(一))
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:
截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS 查看全部
js抓取网页内容(
如何模拟请求和如何解析HTML的链接和标题?(一))
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:

截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:

至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS
js抓取网页内容(Python爬虫入门,快速抓取大规模数据(第二部分)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-08 12:30
如果您还没有阅读前两部分,建议阅读前几部分:
Python爬虫入门,快速爬取大规模数据
Python爬虫入门,快速爬取大规模数据(二)
Python爬虫入门,快速爬取大规模数据(三)
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的网页渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver 介绍
Selenium webdriver是我们这里要使用的工具,用来控制浏览器执行JS生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供自动化API。因此,我们可以很方便的通过webdriver提供的API来操纵浏览器访问网页生成内容并返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,让我们简单的尝试一下webdriver驱动浏览器打开网页。
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/")
爬虫实例中的应用
现在让我们回到我们的爬虫示例。最初,我们使用 requests 库来获取内容。现在我们使用 webdriver 来驱动浏览器来获取 web 内容。这样就可以得到执行JS动态加载内容的网页了。
if __name__== "__main__":
...
# 抓取网页内容
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/")
content = driver.page_source
browser.quit()
# 提取页面包含的数据
soup = BeautifulSoup(content, "html.parser")
get_web_data(soup)
...
通常浏览器会打开一个窗口,但这对于爬虫来说不是必需的。幸运的是,我们可以使用phantomjs来代替浏览器。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器。几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码与我们之前使用的浏览器没有太大区别,唯一的区别在于我们初始化浏览器的代码。
browser = webdriver.PhantomJS()
总结
在这一部分,我们简要讨论了如何使用 webdriver 获取动态加载的网页内容。事实上,webdriver 有很多非常有趣的应用,有机会我们会再看一遍。
来源:/i65657671/ 查看全部
js抓取网页内容(Python爬虫入门,快速抓取大规模数据(第二部分)(组图))
如果您还没有阅读前两部分,建议阅读前几部分:
Python爬虫入门,快速爬取大规模数据
Python爬虫入门,快速爬取大规模数据(二)
Python爬虫入门,快速爬取大规模数据(三)
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的网页渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver 介绍
Selenium webdriver是我们这里要使用的工具,用来控制浏览器执行JS生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供自动化API。因此,我们可以很方便的通过webdriver提供的API来操纵浏览器访问网页生成内容并返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,让我们简单的尝试一下webdriver驱动浏览器打开网页。
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/";)
爬虫实例中的应用
现在让我们回到我们的爬虫示例。最初,我们使用 requests 库来获取内容。现在我们使用 webdriver 来驱动浏览器来获取 web 内容。这样就可以得到执行JS动态加载内容的网页了。
if __name__== "__main__":
...
# 抓取网页内容
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/";)
content = driver.page_source
browser.quit()
# 提取页面包含的数据
soup = BeautifulSoup(content, "html.parser")
get_web_data(soup)
...
通常浏览器会打开一个窗口,但这对于爬虫来说不是必需的。幸运的是,我们可以使用phantomjs来代替浏览器。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器。几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码与我们之前使用的浏览器没有太大区别,唯一的区别在于我们初始化浏览器的代码。
browser = webdriver.PhantomJS()
总结
在这一部分,我们简要讨论了如何使用 webdriver 获取动态加载的网页内容。事实上,webdriver 有很多非常有趣的应用,有机会我们会再看一遍。
来源:/i65657671/
js抓取网页内容(为了更好的让百度识别PC版对应的移动页面代码如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-07 21:21
对于大多数网站来说,为了让网页打开速度更快,用户体验更好,应该启用Webkit内核。代码如下。
2、 当网站没有对应的手机版页面或百度无法识别适配时,百度会自动将PC版转码为手机版,会损失部分广告收入,需要添加到页面以下代码禁止百度转码。
3、为了更好的让百度识别PC版对应的手机页面,需要添加如下Meta语句:
http://3g.sina.com.cn/">
http://sina.cn/">
更多说明参见:开放适配服务站长信息百度站长平台
4、如果你的页面有地理属性,可以添加如下代码:
5、360 搜索(好搜)设计了一套类似于 Facebook 的开放图谱协议的 Meta 标签,用于搜索格式的展示。详细内容参考:Smart summary_360搜索帮助
标准化标签模板支持短视频、电影、小说、新闻、商品、论坛帖子、博客等内容类型数据。
例如,对于我们的信息页面,我们计划添加以下 Meta:
注意:添加后,您需要在360站长平台主动注册才能提交您的页面。
关注
一个普通的链接是这样写的:
黄页88网
现在添加nofollow标签,如下:
黄页88网
这告诉搜索引擎蜘蛛不要点击这个链接。当你不想减肥到一个链接,但又必须在内容中显示该链接时,可以使用此方法来阻止它。
常见的例子有:“关于我们”、“联系我们”等。几乎所有网站底部都有这些链接,需要Nofollow标签。
这些页面带来的SEO价值不高,与当前页面的相关性一般不大。为了避免浪费搜索蜘蛛的爬行,需要通过Nofollow标签进行拦截。
知道原理后,我们也可以屏蔽所有其他的链接,比如天超中的唯一记录链接:
http://www.miitbeian.gov.cn" rel="nofollow" target="_blank">京ICP备XXX号
还有“登录”、“注册”,甚至“首页”都可以根据需要进行屏蔽,从而引导蜘蛛抓取收录更重要、更有希望的内容。
iframe 标签
搜索引擎的蜘蛛不会识别iframe中调用的图片、文本、网址等内容,因为这些内容不属于页面,而是在访问时临时调用。百度SEO建议也说:“frame/frameset/iframe”等标签会导致百度蜘蛛抓取困难。
使用这个,我们可以将网站中需要用户查看但不需要被搜索引擎抓取的内容展示出来。
比如网站顶部的一些topbar导航栏,常用于注册、登录等,可以写成一个iframe框架。
还有一些赞助广告,如果不需要SEO效果,可以放在单独的iframe中,在页面引用即可。
但是也不好用太多,可能会被认为是作弊,而且iframe明显不利于页面加载速度。
CSS 和 JS 最好将 CSS 和 JS 放在单独的外部文件中,这样可以减少代码量,使内容更加简洁,便于搜索引擎识别。
当然,有时为了减少 CSS 和 JS 请求的数量,一些大的 网站 会直接在内容页面中输出 CSS 和 JS。一般网站 不这样做。
虽然搜索引擎现在可以识别 JS 中的内容,但一般来说,JS 文件中的内容不会影响页面的 SEO。利用这一点,你可以将必须显示但与页面主题内容无关的内容放入JS并写回页面,从而避免降低页面的密度关键词或传递链接权重。document.write("XXX") CSS 样式命名
搜索引擎越来越智能,通过你的css样式很容易识别页面内容。
合理有序的CSS命名规则不仅可以提高代码质量,而且更符合搜索引擎规范。
例如:
标题:标题
顶部导航:顶部栏
登录:登录栏
标志:标志
侧边栏:侧边栏
广告:横幅
导航:导航
子导航:subNav
菜单:菜单
子菜单:子菜单
搜索:搜索
滚动:滚动
主页面:main
内容:内容
标签页:tab
文章列表:列表
提示:味精/提示
栏目标题:标题
加入:加入
指南:指南
服务:服务
热点:热
新闻:新闻
下载:下载
注册:注册
状态:状态
按钮:btn/按钮
投票:投票
广告:广告
合伙人:合伙人
友情链接:friendLink/links
页脚:页脚 查看全部
js抓取网页内容(为了更好的让百度识别PC版对应的移动页面代码如下)
对于大多数网站来说,为了让网页打开速度更快,用户体验更好,应该启用Webkit内核。代码如下。
2、 当网站没有对应的手机版页面或百度无法识别适配时,百度会自动将PC版转码为手机版,会损失部分广告收入,需要添加到页面以下代码禁止百度转码。
3、为了更好的让百度识别PC版对应的手机页面,需要添加如下Meta语句:
http://3g.sina.com.cn/">
http://sina.cn/">
更多说明参见:开放适配服务站长信息百度站长平台
4、如果你的页面有地理属性,可以添加如下代码:
5、360 搜索(好搜)设计了一套类似于 Facebook 的开放图谱协议的 Meta 标签,用于搜索格式的展示。详细内容参考:Smart summary_360搜索帮助
标准化标签模板支持短视频、电影、小说、新闻、商品、论坛帖子、博客等内容类型数据。
例如,对于我们的信息页面,我们计划添加以下 Meta:
注意:添加后,您需要在360站长平台主动注册才能提交您的页面。
关注
一个普通的链接是这样写的:
黄页88网
现在添加nofollow标签,如下:
黄页88网
这告诉搜索引擎蜘蛛不要点击这个链接。当你不想减肥到一个链接,但又必须在内容中显示该链接时,可以使用此方法来阻止它。
常见的例子有:“关于我们”、“联系我们”等。几乎所有网站底部都有这些链接,需要Nofollow标签。
这些页面带来的SEO价值不高,与当前页面的相关性一般不大。为了避免浪费搜索蜘蛛的爬行,需要通过Nofollow标签进行拦截。
知道原理后,我们也可以屏蔽所有其他的链接,比如天超中的唯一记录链接:
http://www.miitbeian.gov.cn" rel="nofollow" target="_blank">京ICP备XXX号
还有“登录”、“注册”,甚至“首页”都可以根据需要进行屏蔽,从而引导蜘蛛抓取收录更重要、更有希望的内容。
iframe 标签
搜索引擎的蜘蛛不会识别iframe中调用的图片、文本、网址等内容,因为这些内容不属于页面,而是在访问时临时调用。百度SEO建议也说:“frame/frameset/iframe”等标签会导致百度蜘蛛抓取困难。
使用这个,我们可以将网站中需要用户查看但不需要被搜索引擎抓取的内容展示出来。
比如网站顶部的一些topbar导航栏,常用于注册、登录等,可以写成一个iframe框架。
还有一些赞助广告,如果不需要SEO效果,可以放在单独的iframe中,在页面引用即可。
但是也不好用太多,可能会被认为是作弊,而且iframe明显不利于页面加载速度。
CSS 和 JS 最好将 CSS 和 JS 放在单独的外部文件中,这样可以减少代码量,使内容更加简洁,便于搜索引擎识别。
当然,有时为了减少 CSS 和 JS 请求的数量,一些大的 网站 会直接在内容页面中输出 CSS 和 JS。一般网站 不这样做。
虽然搜索引擎现在可以识别 JS 中的内容,但一般来说,JS 文件中的内容不会影响页面的 SEO。利用这一点,你可以将必须显示但与页面主题内容无关的内容放入JS并写回页面,从而避免降低页面的密度关键词或传递链接权重。document.write("XXX") CSS 样式命名
搜索引擎越来越智能,通过你的css样式很容易识别页面内容。
合理有序的CSS命名规则不仅可以提高代码质量,而且更符合搜索引擎规范。
例如:
标题:标题
顶部导航:顶部栏
登录:登录栏
标志:标志
侧边栏:侧边栏
广告:横幅
导航:导航
子导航:subNav
菜单:菜单
子菜单:子菜单
搜索:搜索
滚动:滚动
主页面:main
内容:内容
标签页:tab
文章列表:列表
提示:味精/提示
栏目标题:标题
加入:加入
指南:指南
服务:服务
热点:热
新闻:新闻
下载:下载
注册:注册
状态:状态
按钮:btn/按钮
投票:投票
广告:广告
合伙人:合伙人
友情链接:friendLink/links
页脚:页脚
js抓取网页内容(如何使用RPA工具进行自动化工具?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-10-28 15:25
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击 LeanRunner 打开命令行工具按钮
,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm作为node.js的包管理机制,需要安装在node.js环境中才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
一种。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
e. 按照上述步骤插入抓取文本并再次关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别实现以上操作步骤:
一种。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
, 或者点击“运行项目”按钮
可以看到浏览器打开网页,在 LeanRunner 设计器的输出面板中打印出文本内容。
如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们就完成了一个网页基本操作的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存储到Excel表格或者数据库中。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。 查看全部
js抓取网页内容(如何使用RPA工具进行自动化工具?工具)
背景
RPA工作流中最常见的场景是操作浏览器,对页面内容进行相关操作。本例以页面为例。带领大家初步探索如何使用RPA工具自动抓取页面文本内容。
本文将使用 JavaScript 开发 RPA 脚本。这里使用的RPA工具LeanRunner可以直接从Windows应用商店下载,支持使用node.js开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的 RPA 脚本。
脚步
新项目
打开LeanRunner,选择【项目】-【新建】-【选择基本项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的操作 Web 自动化库。使用 chromedriver 库可以驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
点击 LeanRunner 打开命令行工具按钮
,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
备注:npm作为node.js的包管理机制,需要安装在node.js环境中才能使用
(下载链接:)
定义流程步骤
流程步骤被定义为使自动化流程可读。
一种。打开main.js,在【Toolbox】-【Frame】中找到stepGroup方法,拖拽到js文件中。
湾 在弹出的对话框中输入描述文字:抓取网页文字内容,点击插入代码。
C。此时,main.js文件的内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d. 继续拖拽【Toolbox】-【Frame】中的step方法来描述文字输入:使用Chrome浏览器打开你要截取的网站:
e. 按照上述步骤插入抓取文本并再次关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【Toolbox】-【Framework】中选择Workrun.run()函数:
G。在运行函数中输入“main”:
最后的代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别实现以上操作步骤:
一种。使用Chrome浏览器打开你要截取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建了一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾 抓取文本:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用css选择器定位要访问的元素并打印出来。
C。关闭浏览器
await driver.close();
最终代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
, 或者点击“运行项目”按钮
可以看到浏览器打开网页,在 LeanRunner 设计器的输出面板中打印出文本内容。
如果是运行项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们就完成了一个网页基本操作的RPA。后续的操作可以在这个RPA的基础上进一步深化,比如将抓取到的文本内容存储到Excel表格或者数据库中。
本文使用的 selenium-webdriver 自动化库是一个非常流行的开源库,可以支持各种类型的浏览器,并且可以及时更新以支持最新版本的浏览器。同时,Node.js 也是一个非常流行的开源平台。基于这些技术,开发RPA自动化脚本来维护RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速构建自己的流程自动化。
js抓取网页内容(有什么办法能防止搜索引擎抓取网站?对内容使用JavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-27 22:19
1、有什么办法可以防止搜索引擎爬取网站?
第一种方法:robots.txt方法
网站根目录下有robots.txt。如果没有,您可以创建一个新的并上传。
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理: *
禁止:/css/
禁止:/管理员/
禁止所有搜索引擎访问css和admin目录,只需将css或admin目录修改为你指定的文件目录或文件即可。
第二种:网页编码方式
中间添加代码,该标签禁止搜索引擎抓取网站并显示网页快照。
注意:添加了禁止码,但是搜索引擎还是可以搜索到的,因为搜索引擎索引库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。
二、搜索引擎可以抓取JS吗?
1、 JS的内容是不爬取的,但是Google会抓到JS分析,但是有的已经能够在javecipt脚本上获取到链接,甚至执行脚本并跟踪链接。其实javascript因素还是flash 网站 ,这种做法给搜索引擎的收录和index.js带来了麻烦。所以,如果不是期望被拒绝,最直接的方法就是写robots文件。
2、部分超链接的导航能力完全由Javascript模拟。例如,在 HTML A 元素中添加一段 onclick 事件处理代码。当点击超链接时,会有页面导航的Javascript代码;
3、部分页面显示的多级菜单是用Javascript实现的,菜单的显示和消失由Javascript控制。如果这些菜单所激发的操作是导航到另一个页面,那么导航信息就很难被抓取 Grab
4、切勿使用 JavaScript 进行导航和其他链接。导航和链接是搜索引擎抓取网页的基础。如果搜索引擎无法抓取网页,则意味着该网页不会出现在索引结果中,也就无从谈起排名。尽量避免对内容使用 JavaScript。尤其是与关键词相关的内容,要尽量避免使用JavaScript来展示,否则无疑会减少。
5、 真正需要用到JavaScript的部分,把这部分JavaScript脚本放在一个或几个.js文件中,以免干扰搜索引擎的抓取和分析
.js 文件中确实放不下的一些 JavaScript 脚本,放在底部,</body> 之前,以便搜索引擎在分析网页时找到,减少对搜索引擎的干扰
6、由于普通搜索引擎很难处理Javascript代码,所以可以利用这个功能来屏蔽页面上一些不需要被搜索引擎索引的内容,从而对页面进行改进。这类信息可以称为“垃圾信息”,例如广告、版权声明、大量与内容无关的信息等,这些垃圾信息可以扔到一个或多个.js文件中,从而减少干扰到页面的实际内容,改进和展示页面内容的核心给搜索引擎。 查看全部
js抓取网页内容(有什么办法能防止搜索引擎抓取网站?对内容使用JavaScript)
1、有什么办法可以防止搜索引擎爬取网站?
第一种方法:robots.txt方法
网站根目录下有robots.txt。如果没有,您可以创建一个新的并上传。
用户代理: *
不允许: /
禁止所有搜索引擎访问网站的所有部分
用户代理: *
禁止:/css/
禁止:/管理员/
禁止所有搜索引擎访问css和admin目录,只需将css或admin目录修改为你指定的文件目录或文件即可。
第二种:网页编码方式
中间添加代码,该标签禁止搜索引擎抓取网站并显示网页快照。
注意:添加了禁止码,但是搜索引擎还是可以搜索到的,因为搜索引擎索引库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。
二、搜索引擎可以抓取JS吗?
1、 JS的内容是不爬取的,但是Google会抓到JS分析,但是有的已经能够在javecipt脚本上获取到链接,甚至执行脚本并跟踪链接。其实javascript因素还是flash 网站 ,这种做法给搜索引擎的收录和index.js带来了麻烦。所以,如果不是期望被拒绝,最直接的方法就是写robots文件。
2、部分超链接的导航能力完全由Javascript模拟。例如,在 HTML A 元素中添加一段 onclick 事件处理代码。当点击超链接时,会有页面导航的Javascript代码;
3、部分页面显示的多级菜单是用Javascript实现的,菜单的显示和消失由Javascript控制。如果这些菜单所激发的操作是导航到另一个页面,那么导航信息就很难被抓取 Grab
4、切勿使用 JavaScript 进行导航和其他链接。导航和链接是搜索引擎抓取网页的基础。如果搜索引擎无法抓取网页,则意味着该网页不会出现在索引结果中,也就无从谈起排名。尽量避免对内容使用 JavaScript。尤其是与关键词相关的内容,要尽量避免使用JavaScript来展示,否则无疑会减少。
5、 真正需要用到JavaScript的部分,把这部分JavaScript脚本放在一个或几个.js文件中,以免干扰搜索引擎的抓取和分析
.js 文件中确实放不下的一些 JavaScript 脚本,放在底部,</body> 之前,以便搜索引擎在分析网页时找到,减少对搜索引擎的干扰
6、由于普通搜索引擎很难处理Javascript代码,所以可以利用这个功能来屏蔽页面上一些不需要被搜索引擎索引的内容,从而对页面进行改进。这类信息可以称为“垃圾信息”,例如广告、版权声明、大量与内容无关的信息等,这些垃圾信息可以扔到一个或多个.js文件中,从而减少干扰到页面的实际内容,改进和展示页面内容的核心给搜索引擎。
js抓取网页内容(前端侧对于动态生成的内容进行下载的实时截图下载 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-27 02:08
)
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是页面内容的实时截图. 此时,图像是动态的。纯 HTML 显然不能满足我们的需求。借助JS和其他一些HTML5功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器中,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中不起作用。所以上面的funDownload()方法有一个appendChild和removeChild处理,是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的 File 对象。或者一个 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。比如在XMLHttpRequest中,如果responseType指定为blob,那么得到的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了保证良好的性能和内存使用,应该在保证不再使用时释放它。
2、URL.revokeObjectURL() 方法将释放由 URL.createObjectURL() 创建的对象 URL。当您使用了对象 URL 时,您必须让浏览器知道该 URL 不再需要指向相应的 URL。该方法需要在安装文件时调用。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL. 查看全部
js抓取网页内容(前端侧对于动态生成的内容进行下载的实时截图下载
)
有时需要在前端下载动态生成的内容,比如页面上的某条文字信息,或者分享页面的时候,希望分享的图片是页面内容的实时截图. 此时,图像是动态的。纯 HTML 显然不能满足我们的需求。借助JS和其他一些HTML5功能,例如将页面元素转换为画布,然后转换为图片以供下载。
原理其实很简单。我们可以借助Blob将文本或JS字符串信息转换成二进制,然后作为元素的href属性,配合download属性实现下载。
代码也比较简单,如下图(兼容Chrome和Firefox):
function funcDownload (content, filename) {
// 创建隐藏的可下载链接
var eleLink = document.createElement('a');
eleLink.download = filename;
eleLink.style.display = 'none';
// 字符内容转变成blob地址
var blob = new Blob([content]);
eleLink.href = URL.createObjectURL(blob);
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
}
function dn (){
var ss = document.querySelector('html').outerHTML;
funcDownload(ss, 'ceshi.html')
}
其中,content是指需要下载的文本或字符串内容,filename是指下载到系统的文件名。
以上代码可以将当前整个网页下载为html文件,但是网页内外的部分资源无法显示。
在Chrome浏览器中,模拟点击创建的元素即使没有追加到页面中也能触发下载,但在火狐浏览器中不起作用。所以上面的funDownload()方法有一个appendChild和removeChild处理,是为了兼容火狐浏览器。
1、URL.createObjectURL() 方法会根据传入的参数创建一个指向参数对象的URL。这个URL的生命周期只存在于创建它的文档中,新的对象URL指向执行的 File 对象。或者一个 Blob 对象。
objectURL = URL.createObjectURL(blob || file);
参数:文件对象或 Blob 对象。这里可能是 File 对象和 Blob 对象:
文件对象:它是一个文件。例如,如果我上传一个带有 input type="file" 标签的文件,那么其中的每个文件都是一个 File 对象。
Blob 对象:它是二进制数据。比如new Blob()创建的对象就是一个Blob对象。比如在XMLHttpRequest中,如果responseType指定为blob,那么得到的返回值也是一个blob对象。
注意:每次调用 createObjectURL 时,都会创建一个新的 URL 对象。即使您为同一个文件创建了 URL。如果你不再需要这个对象,要释放它,你需要使用 URL.revokeObjectURL() 方法。当页面关闭时,浏览器会自动释放它,但为了保证良好的性能和内存使用,应该在保证不再使用时释放它。
2、URL.revokeObjectURL() 方法将释放由 URL.createObjectURL() 创建的对象 URL。当您使用了对象 URL 时,您必须让浏览器知道该 URL 不再需要指向相应的 URL。该方法需要在安装文件时调用。具体含义是一个对象URL可以使用这个url访问指定的文件,但我可能只需要访问一次。一旦被访问,对象 URL 就不再需要,并且被释放和释放。将来,对象 URL 将不再指向指定的文件。例如,对于一张图片,我创建了一个对象 URL,然后通过这个对象 URL,我将图片加载到我的页面上。既然已经加载好了,就不用再加载这张图片了,那我就放出对象的URL。
window.URL.revokeObjectURL(objectURL);
//objectURL 是一个通过URL.createObjectURL()方法创建的对象URL.
js抓取网页内容(PHP先说获取网页内容绑定data事件的能力分析与应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-26 04:19
nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
<p> //引入模块 var http = require("http"), fs = require('fs'), url = require('url'); //写入文件,把结果写入不同的文件 var writeRes = function(p, r) { fs.appendFile(p , r, function(err) { if(err) console.log(err); else console.log(r); }); }, //发请求,并验证内容,把结果写入文件 postHttp = function(arr, num) { console.log('第'+num+"条!") var a = arr[num].split(" - "); if(!a[0] || !a[1]) { return; } var address = url.parse(a[1]), options = { host : address.host, path: address.path, hostname : address.hostname, method: 'GET', headers: { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36' } } var req = http.request(options, function(res) { if (res.statusCode == 200) { res.setEncoding('UTF-8'); var data = ''; res.on('data', function (rd) { data += rd; }); res.on('end', function(q) { if(!~data.indexOf("www.baidu.com")) { return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n'); } else { return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n"); } }) } else { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n'); } }); req.on('error', function(e) { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n'); }) req.end(); }, //读取文件,获取需要抓取的页面 openFile = function(path, coding) { fs.readFile(path, coding, function(err, data) { var res = data.split("\n"); for (var i = 0, rl = res.length; i 查看全部
js抓取网页内容(PHP先说获取网页内容绑定data事件的能力分析与应用)
nodejs 获取绑定到数据事件的网页内容,获取的数据会分几次。如果要匹配全局内容,则需要等待请求结束,在end结束事件中操作累积的全局数据。本文介绍节点。js抓取并分析网页内容,针对有特殊内容的js文件,有需要的朋友可以参考
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
<p> //引入模块 var http = require("http"), fs = require('fs'), url = require('url'); //写入文件,把结果写入不同的文件 var writeRes = function(p, r) { fs.appendFile(p , r, function(err) { if(err) console.log(err); else console.log(r); }); }, //发请求,并验证内容,把结果写入文件 postHttp = function(arr, num) { console.log('第'+num+"条!") var a = arr[num].split(" - "); if(!a[0] || !a[1]) { return; } var address = url.parse(a[1]), options = { host : address.host, path: address.path, hostname : address.hostname, method: 'GET', headers: { 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36' } } var req = http.request(options, function(res) { if (res.statusCode == 200) { res.setEncoding('UTF-8'); var data = ''; res.on('data', function (rd) { data += rd; }); res.on('end', function(q) { if(!~data.indexOf("www.baidu.com")) { return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n'); } else { return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n"); } }) } else { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n'); } }); req.on('error', function(e) { writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n'); }) req.end(); }, //读取文件,获取需要抓取的页面 openFile = function(path, coding) { fs.readFile(path, coding, function(err, data) { var res = data.split("\n"); for (var i = 0, rl = res.length; i
js抓取网页内容(python爬取js执行后输出的信息1.11.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-24 04:03
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text 查看全部
js抓取网页内容(python爬取js执行后输出的信息1.11.1)
Python有很多库,可以让我们轻松编写网络爬虫,爬取某些页面,获取有价值的信息!但很多情况下,爬虫抓取到的页面只是一个静态页面,即网页的源代码,就像在浏览器上“查看网页的源代码”一样。一些动态的东西,比如javascript脚本执行后产生的信息,是无法捕捉到的。下面是一些可以用于python抓取js执行后输出信息的解决方案。
1. 两种基本解决方案
1.1 使用dryscrape库动态抓取页面
js脚本通过浏览器执行并返回信息,因此,js执行后抓取页面最直接的方式之一就是用python模拟浏览器的行为。WebKit 是一个开源浏览器引擎。Python 提供了许多库来调用这个引擎。干刮就是其中之一。它调用webkit引擎来处理收录js等的网页!
1 importdryscrape2 #使用dryscrape库动态抓取页面
3 defget_url_dynamic(url): 4 session_req=dryscrape.Session() 5 session_req.visit(url) #请求页面
6 response=session_req.body() #网页文字
7 #打印(响应)
8 returnresponse9 get_text_line(get_url_dynamic(url)) #将输出一个文本
这也适用于其他收录js的网页!虽然可以满足抓取动态页面的要求,但是缺点还是很明显:慢!太慢了。其实想想也是有道理的。Python调用webkit来请求页面,页面加载完成后,加载js文件,让js执行,返回执行的页面。应该会更慢!另外,可以调用webkit的库还有很多:PythonWebkit、PyWebKitGit、Pygt(你可以用它来写浏览器)、pyjamas等,听说它们也可以实现同样的功能!
1.2 selenium web 测试框架
Selenium 是一个网页测试框架,它允许调用本地浏览器引擎发送网页请求,因此也可以实现抓取网页的要求。
# 使用selenium webdriver是可行的,但是会实时打开浏览器窗口
1 defget_url_dynamic2(url):2 driver=webdriver.Firefox() #调用本地火狐浏览器,Chrom甚至Ie也是可以的
3 driver.get(url) #请求页面,会打开一个浏览器窗口
4 html_text=driver.page_source5 driver.quit()6 #print html_text
7 returnhtml_text8 get_text_line(get_url_dynamic2(url)) #将输出一个文本
这也是临时解决办法!类似selenium的框架也有风车,感觉有点复杂,就不赘述了!
2. selenium 的安装和使用
2.1 selenium的安装
要在 Ubuntu 上安装,您可以直接使用 pip install selenium。出于以下原因:
1. selenium 3.x 启动,在 webdriver/firefox/webdriver.py 的 __init__ 中,executable_path="geckodriver"; 并且 2.x 是 executable_path="wires"
2. Firefox 47 及以上,需要下载第三方驱动,geckodriver
还需要一些特殊的操作:
1. 下载geckodriverckod地址:mozilla/geckodriver
2. 解压后,将geckodriverckod存放在/usr/local/bin/路径下: sudo mv ~/Downloads/geckodriver /usr/local/bin/
2.2 selenium的使用
1. 运行错误:
驱动程序 = webdriver.chrome()
类型错误:“模块”对象不可调用
解决方法:浏览器名称需要大写Chrome和Firefox,即
2. 通过
1 content = driver.find_element_by_class_name('content')
为了定位元素,该方法返回 FirefoxWebElement。当你想获取收录的值时,你可以通过
1 个值 = content.text
js抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-23 12:18
主流热图的实现
热图展示的一般实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理过的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta x-frame-options为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,客户网站需要做一些工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有需要检测和分析的网站用户都可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先,我们绕过x-frame-options是sameorgin的问题,只需要解决js控制的问题。对于抓取到的页面,我们可以通过特殊对应的方式进行处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async gethtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newpage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里需要用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面,这可以通过以下伪代码来解释:
const puppeteer = require("puppeteer");
async autologin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.waitfornavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitfornavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autologinv2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 抓取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是网站不同,处理方法也会不同,不能复用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。 查看全部
js抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
主流热图的实现
热图展示的一般实现需要经过以下几个阶段:
1.获取网站页面
2.获取处理过的用户数据
3.绘制热图
本文主要围绕stage 1详细介绍获取热图中网站页面的主流实现
4.使用iframe直接嵌入用户网站
5. 抓取用户页面并保存到本地,通过iframe嵌入本地资源(这里所谓的本地资源被认为是分析工具端)
两种方法各有优缺点
首先,第一种是直接嵌入用户网站。这有一定的限制。比如用户网站阻止了iframe劫持,就不允许嵌套iframe(设置meta x-frame-options为sameorgin或者直接设置http头,甚至控制if (!== window.self){ .location = window.location;}) 直接通过js。在这种情况下,客户网站需要做一些工作才能通过工具进行分析加载iframe使用起来不是那么方便,因为并不是所有需要检测和分析的网站用户都可以管理网站。
第二种方式是直接抓取网站页面到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经来了,我们可以为所欲为。首先,我们绕过x-frame-options是sameorgin的问题,只需要解决js控制的问题。对于抓取到的页面,我们可以通过特殊对应的方式进行处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多缺点:1、不能抓取spa页面,不能抓取需要用户登录授权的页面,不能抓取用户白白设置的页面等等。
这两种方法都有 https 和 http 资源。同源策略带来的另一个问题是https站无法加载http资源。因此,为了获得最佳的兼容性,热图分析工具需要与http协议一起应用。当然,可以根据详细信息进行访问。对客户网站及具体分站优化。
如何优化网站页面的抓取
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,增加爬取成功的概率,主要优化了以下两个页面:
1.水疗页面
spa页面在当前页面被认为是主流,但一直都知道对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,过程通常是向用户网站(应该是用户网站服务器)发起http get请求。这种爬取方式本身就会有问题。首先,直接请求用户服务器。用户服务器对非浏览器代理应该有很多限制,需要绕过处理;其次,请求返回原创内容,需要处理。浏览器中js渲染的部分无法获取(当然嵌入iframe后,js的执行还是会一定程度上弥补这个问题的)。最后,如果页面是spa页面,
针对这种情况,如果是基于puppeteer,流程就变成
puppeteer启动浏览器打开用户网站-->页面渲染-->并返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async gethtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newpage();
await page.goto(url);
return await page.content();
}
这样我们得到的内容就是渲染出来的内容,不管页面是怎么渲染的(客户端渲染还是服务端)
需要登录的页面
需要登录页面的情况其实有很多:
您需要登录才能查看该页面。未登录会跳转到登录页面(各种管理系统)
对于这种类型的页面,我们需要做的是模拟登录。所谓模拟登录就是让浏览器登录,这里需要用户提供网站对应的用户名和密码,然后我们按照以下流程进行:
访问用户网站-->用户网站检测未登录跳转登录-->puppeteer控制浏览器自动登录然后跳转到真正需要抓取的页面,这可以通过以下伪代码来解释:
const puppeteer = require("puppeteer");
async autologin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.waitfornavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitfornavigation();
return await page.content();
}
无论是否登录都可以查看页面,但登录后内容会有所不同(各种电子商务或门户页面)
这种情况会更容易处理,你可以简单地认为是以下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autologinv2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newpage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班了。
补充(偿还昨天的债务):puppeteer虽然可以友好地抓取页面内容,但也有很多限制
1. 抓取的内容是渲染后的原创html,即资源路径(css、image、javascript)等都是相对路径。保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染的结构已经完成)
2. puppeteer 抓取页面的性能会比直接http get 差,因为额外的渲染过程
3. 也不能保证页面的完整性,但是大大提高了完整性的概率。虽然页面对象提供的各种wait方法都可以解决这个问题,但是网站不同,处理方法也会不同,不能复用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持万千网。
js抓取网页内容(谷歌爬虫是如何抓取javascript的?学习到的知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-20 18:09
我们测试了谷歌爬虫是如何抓取javascript的,以下是我们从中学到的知识。
认为谷歌无法处理 javascript?再想想。audette audette 分享了一系列的测试结果,他和他的同事测试了谷歌和收录 会抓取什么类型的javascript函数。
长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 javascript。我们也确认了谷歌可以渲染整个页面并读取dom,可以收录动态生成内容。
2. dom中的seo信号(页面标题、meta描述、canonical标签、meta robots标签等)都是关注的。动态插入dom的内容也可以爬取和收录。此外,在某些情况下,dom 甚至可能优先于 html 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:google 执行javascript & 读取dom
早在2008年,google就成功爬取了javascript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 javascript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在merkle,我们的seo 技术团队希望更好地了解Google 爬虫可以抓取哪些类型的javascript 事件和收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 javascript 事件,还可以动态生成 收录 内容。怎么做?谷歌可以读取dom。
什么是dom?
很多搞seo的人不明白什么是文档对象模型(dom)。
当浏览器请求一个页面时会发生什么,以及 dom 如何参与其中。
在 Web 浏览器中使用时,dom 本质上是一个应用程序接口或 api,用于标记和构建数据(例如 html 和 xml)。该界面允许 Web 浏览器将它们组合成一个文档。
dom 还定义了如何获取和操作结构。尽管 dom 是一种独立于语言的 API(不绑定到特定的编程语言或库),但它通常用于 javascript 和 Web 应用程序的动态内容。
dom 代表一个接口或“桥”,它将网页与编程语言连接起来。解析html并执行javascript的结果是dom。网页的内容不是(不仅)源代码,而是 dom。这使它变得非常重要。
javascript 如何通过 dom 接口工作。
我们很高兴地发现 Google 可以读取 dom,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些javascript函数和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 url 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、javascript 重定向
2、javascript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 javascript 能力的页面。
1. javascript 重定向
我们首先测试了常见的javascript重定向,不同方式表达的URL会有什么结果?我们为两个测试选择了 window.location 对象:test a 使用绝对路径 url 调用 window.location,而 test b 使用它的相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态的url,而不是google收录中的redirect url。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 javascript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的url为收录,立即被安排在同一个查询页面的同一个位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 javascript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌的指导方针支持这一结论:
使用 javascript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 javascript 来完成此操作。在仔细检查 javascript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您无权访问您的 网站 服务器,您可以为此使用 javascript 重定向。
2. javascript 链接
我们用多种编码方式测试了不同类型的js链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面javascript重定向的强制操作。
示例:google 工作页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 javascript 链接。以下是最常见的 javascript 链接类型,而传统的 seo 推荐纯文本。这些测试包括 javascript 链接代码:
作用于外部 href 键值对 (avp),但在标签内 ("onclick")
函数 href 内部 avp("javascript: window.location")
在 a 标签之外进行操作,但在 href 中调用 avp("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用事件处理程序进行鼠标移动,然后隐藏 url 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行javascript,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造url字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的html源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的html源代码之外(在外部javascript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用javascript编写的客户端全局导航,导航中的链接是通过document.writein函数插入的,确认可以完全爬取和跟踪。需要指出的是,谷歌可以解释网站使用angularjs框架和html5历史api(pushstate)构建,可以渲染和收录它,并且可以像传统的静态网页一样排名。这就是不禁止谷歌爬虫获取外部文件和javascript的重要性,这可能也是谷歌将其从“支持Ajax的Seo指南”中删除的原因。当您可以简单地呈现整个页面时,谁需要一个 html 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到dom后会被抓取和收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到dom中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 json-ld 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 seo 至关重要的标签插入到 dom 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 html 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,dom中没有index,follow标签,会发生什么?在这个协议中,http x-robots 响应头部如何将行为作为另一个变量使用?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 dom。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和dom的链接级别的nofollow属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源码vs dom生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是dom中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改dom中href元素的操作发生得太晚了:在执行添加rel=”nofollow”的javascript函数之前,谷歌已经准备好抓取链接并排队等待url。但是,如果将带有 href="nofollow" 的 a 元素插入到 dom 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 seo 建议都尽可能关注“纯文本”内容。而动态生成的内容,ajax和javascript链接都会损害主流搜索引擎的seo。显然,这对谷歌来说不再是问题。javascript 链接的操作方式类似于普通的html 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是meta标签,比如rel规范的注解,无论是在html源码中还是在解析初始html后触发JavaScript生成dom,都会被同样处理。
Google 依赖于能够完全呈现页面并理解 dom,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 javascript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持html5、javascript和dynamic网站。
对于seo,不了解上述基本概念和google技术的人应该学习学习,以追赶当前的技术。如果你不考虑dom,你可能会失去一半的份额。
本文所表达的观点并非全部由搜索引擎地(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js抓取网页内容(谷歌爬虫是如何抓取javascript的?学习到的知识)
我们测试了谷歌爬虫是如何抓取javascript的,以下是我们从中学到的知识。
认为谷歌无法处理 javascript?再想想。audette audette 分享了一系列的测试结果,他和他的同事测试了谷歌和收录 会抓取什么类型的javascript函数。
长话短说
1. 我们进行了一系列的测试,并确认谷歌可以以多种方式执行和收录 javascript。我们也确认了谷歌可以渲染整个页面并读取dom,可以收录动态生成内容。
2. dom中的seo信号(页面标题、meta描述、canonical标签、meta robots标签等)都是关注的。动态插入dom的内容也可以爬取和收录。此外,在某些情况下,dom 甚至可能优先于 html 源代码语句。虽然这需要更多的工作,但这是我们的几个测试之一。
简介:google 执行javascript & 读取dom
早在2008年,google就成功爬取了javascript,但很可能仅限于某种方式。
今天,很明显,Google 不仅可以制定自己的抓取和 收录 javascript 类型,而且在呈现整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在merkle,我们的seo 技术团队希望更好地了解Google 爬虫可以抓取哪些类型的javascript 事件和收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 javascript 事件,还可以动态生成 收录 内容。怎么做?谷歌可以读取dom。
什么是dom?
很多搞seo的人不明白什么是文档对象模型(dom)。
当浏览器请求一个页面时会发生什么,以及 dom 如何参与其中。
在 Web 浏览器中使用时,dom 本质上是一个应用程序接口或 api,用于标记和构建数据(例如 html 和 xml)。该界面允许 Web 浏览器将它们组合成一个文档。
dom 还定义了如何获取和操作结构。尽管 dom 是一种独立于语言的 API(不绑定到特定的编程语言或库),但它通常用于 javascript 和 Web 应用程序的动态内容。
dom 代表一个接口或“桥”,它将网页与编程语言连接起来。解析html并执行javascript的结果是dom。网页的内容不是(不仅)源代码,而是 dom。这使它变得非常重要。
javascript 如何通过 dom 接口工作。
我们很高兴地发现 Google 可以读取 dom,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取哪些javascript函数和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 url 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
1、javascript 重定向
2、javascript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = "nofollow" 的一个重要例子
示例:用于测试 Google 抓取工具理解 javascript 能力的页面。
1. javascript 重定向
我们首先测试了常见的javascript重定向,不同方式表达的URL会有什么结果?我们为两个测试选择了 window.location 对象:test a 使用绝对路径 url 调用 window.location,而 test b 使用它的相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态的url,而不是google收录中的redirect url。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 javascript 重定向到同一站点的新页面。原创网址在 Google 热门查询的主页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的url为收录,立即被安排在同一个查询页面的同一个位置。这让我们感到惊讶。从排名的角度来看,JavaScript 重定向行为(有时)与永久性 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 javascript 重定向操作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。引用谷歌的指导方针支持这一结论:
使用 javascript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,则可以使用 javascript 来完成此操作。在仔细检查 javascript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但是如果您无权访问您的 网站 服务器,您可以为此使用 javascript 重定向。
2. javascript 链接
我们用多种编码方式测试了不同类型的js链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪这种类型的链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面javascript重定向的强制操作。
示例:google 工作页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 javascript 链接。以下是最常见的 javascript 链接类型,而传统的 seo 推荐纯文本。这些测试包括 javascript 链接代码:
作用于外部 href 键值对 (avp),但在标签内 ("onclick")
函数 href 内部 avp("javascript: window.location")
在 a 标签之外进行操作,但在 href 中调用 avp("javascript: openlink()")
还有很多
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用事件处理程序进行鼠标移动,然后隐藏 url 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行javascript,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接了可以构造url字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以统计动态插入的文本,文本来自页面的html源代码。
2)。测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的html源代码之外(在外部javascript文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用javascript编写的客户端全局导航,导航中的链接是通过document.writein函数插入的,确认可以完全爬取和跟踪。需要指出的是,谷歌可以解释网站使用angularjs框架和html5历史api(pushstate)构建,可以渲染和收录它,并且可以像传统的静态网页一样排名。这就是不禁止谷歌爬虫获取外部文件和javascript的重要性,这可能也是谷歌将其从“支持Ajax的Seo指南”中删除的原因。当您可以简单地呈现整个页面时,谁需要一个 html 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到dom后会被抓取和收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到dom中。结果?成功插入后的面包屑出现在搜索结果中(搜索引擎结果页面)。
值得注意的是,Google 现在推荐使用 json-ld 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 seo 至关重要的标签插入到 dom 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 html 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index,nofollow标签,dom中没有index,follow标签,会发生什么?在这个协议中,http x-robots 响应头部如何将行为作为另一个变量使用?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 dom。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和dom的链接级别的nofollow属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源码vs dom生成的注解。
源代码中的 nofollow 按我们预期的方式工作(未跟踪链接)。但是dom中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改dom中href元素的操作发生得太晚了:在执行添加rel=”nofollow”的javascript函数之前,谷歌已经准备好抓取链接并排队等待url。但是,如果将带有 href="nofollow" 的 a 元素插入到 dom 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 seo 建议都尽可能关注“纯文本”内容。而动态生成的内容,ajax和javascript链接都会损害主流搜索引擎的seo。显然,这对谷歌来说不再是问题。javascript 链接的操作方式类似于普通的html 链接(这只是表面,我们不知道程序在幕后做了什么)。
JavaScript 重定向的处理方式与 301 重定向类似。
动态插入的内容,即使是meta标签,比如rel规范的注解,无论是在html源码中还是在解析初始html后触发JavaScript生成dom,都会被同样处理。
Google 依赖于能够完全呈现页面并理解 dom,而不仅仅是源代码。不可思议!(请记住允许 Google 爬虫获取这些外部文件和 javascript。)
谷歌已经以惊人的速度在创新方面将其他搜索引擎甩在了后面。我们希望在其他搜索引擎中看到相同类型的创新。如果他们要在新的网络时代保持竞争力并取得实质性进展,就意味着他们必须更好地支持html5、javascript和dynamic网站。
对于seo,不了解上述基本概念和google技术的人应该学习学习,以追赶当前的技术。如果你不考虑dom,你可能会失去一半的份额。
本文所表达的观点并非全部由搜索引擎地(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
js抓取网页内容(安装LinuxWindows原理和运行结果测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-20 01:15
本文信息本文由Method SEO顾问发表于2015-11-2218:24:38,共1927字,请注明:【张亚楠】Selenium+PhantomJS+Xpath爬取网页JS内容_【Method SEO顾问】 】,如果我网站的文章对你有帮助的话,来百度的口碑给个好评吧!
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装
Linux
sudo pip install selenium
sudo apt-get install PhantomJS
视窗
原则
关于硒
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例
剑试-抢夺称号
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534----
其他功能
参考
评论
图片来自库尔特·阿里戈。 查看全部
js抓取网页内容(安装LinuxWindows原理和运行结果测试)
本文信息本文由Method SEO顾问发表于2015-11-2218:24:38,共1927字,请注明:【张亚楠】Selenium+PhantomJS+Xpath爬取网页JS内容_【Method SEO顾问】 】,如果我网站的文章对你有帮助的话,来百度的口碑给个好评吧!
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装
Linux
sudo pip install selenium
sudo apt-get install PhantomJS
视窗
原则
关于硒
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例
剑试-抢夺称号
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534----
其他功能
参考
评论
图片来自库尔特·阿里戈。
js抓取网页内容(安装LinuxWindows原理关于SeleniumSelenium的运行结果,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-20 01:14
文章内容
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测验-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534 – – – –
其他功能参考说明 查看全部
js抓取网页内容(安装LinuxWindows原理关于SeleniumSelenium的运行结果,你了解多少?)
文章内容
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖拽. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多种功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测验-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver browser = webdriver.PhantomJS('D:phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
rowser.quit()
操作结果:
2015-09-24 3534 – – – –
其他功能参考说明
js抓取网页内容(不时之需:我的理解不时之需:)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-10-18 15:03
phantomjs:我的理解是它是一个非显示浏览器,也就是说除了不能显示页面的内容外,基本上可以做浏览器能做的所有任务。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学习了PHANTOMJS,由于网上没有找到太多的例子,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来详细实现一下:
下载并解压phantom到D盘,里面有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit,达到预期目的:比如生成网页快照。我想做什么就是爬上AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]查看原件
在 CODE 上查看代码片段
源自我的代码片段
system = require('system') //传递一些需要的参数给js文件 address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到 var page = require('webpage').create(); var url = address; page.open(url, function (status) { if (status !== 'success') { console.log('Unable to post!'); } else { var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。 for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦 phantom.outputEncoding = encodings[i]; console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容 } } phantom.exit(); });
接下来就是java类的准备工作:
[java]查看原件
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest; import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; public class GetAjaxHtml { public static String getAjaxContent(String url) throws Exception { Runtime rt = Runtime.getRuntime(); Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url); InputStream is = p.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is)); StringBuffer sbf = new StringBuffer(); String tmp = ""; while((tmp=br.readLine())!=null) { sbf.append(tmp + "\n"); } return sbf.toString(); } public static void main(String[] args) throws Exception { long start = System.currentTimeMillis(); String result = getAjaxContent("http://114.111.162.220:8093/404Web/"); System.out.println(result); long end = System.currentTimeMillis(); System.out.println("===============耗时:" + (end - start) + "==============="); } }
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案 查看全部
js抓取网页内容(不时之需:我的理解不时之需:)
phantomjs:我的理解是它是一个非显示浏览器,也就是说除了不能显示页面的内容外,基本上可以做浏览器能做的所有任务。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学习了PHANTOMJS,由于网上没有找到太多的例子,只好自己总结一下,以备不时之需。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来详细实现一下:
下载并解压phantom到D盘,里面有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit,达到预期目的:比如生成网页快照。我想做什么就是爬上AJAX页面上的图片,先看js文件:将其命名为s.js
[javascript]查看原件
在 CODE 上查看代码片段
源自我的代码片段
system = require('system') //传递一些需要的参数给js文件 address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到 var page = require('webpage').create(); var url = address; page.open(url, function (status) { if (status !== 'success') { console.log('Unable to post!'); } else { var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。 for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦 phantom.outputEncoding = encodings[i]; console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容 } } phantom.exit(); });
接下来就是java类的准备工作:
[java]查看原件
在 CODE 上查看代码片段
源自我的代码片段
package com.mvc.rest; import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; public class GetAjaxHtml { public static String getAjaxContent(String url) throws Exception { Runtime rt = Runtime.getRuntime(); Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url); InputStream is = p.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is)); StringBuffer sbf = new StringBuffer(); String tmp = ""; while((tmp=br.readLine())!=null) { sbf.append(tmp + "\n"); } return sbf.toString(); } public static void main(String[] args) throws Exception { long start = System.currentTimeMillis(); String result = getAjaxContent("http://114.111.162.220:8093/404Web/";); System.out.println(result); long end = System.currentTimeMillis(); System.out.println("===============耗时:" + (end - start) + "==============="); } }
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
这是最终的解决方案
js抓取网页内容(什么是JS的元素,你知道吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-18 15:02
在编写JS或者JQuery的时候,在使用$("#btn1")或者Domcument.getElementById获取相关标签元素时,偶尔会出现获取不到对应元素的情况。报如下错误等:
无法读取空错误的属性“XXX”
无法读取未定义的属性“可见性”
其实这个问题只有一个原因,就是没有获取到对应的标签元素值,也就是$("#btn1")获取的值为null,所以当你获取到这个元素下的属性时,自然会报错,出现这种情况的原因可能如下。
1.Html页面还未加载,在元素加载前调用元素
根据html页面的特点,从上到下依次加载,即遇到什么就加载什么。因此,有可能在页面的 DOM 元素之前加载 JS 方法。
如果此时提前调用了JS方法,由于label元素还没有加载,所以找不到对应的元素,所以会报这个找不到元素的错误。
这种错误的解决方法也很简单,只需:
将对应的JS代码放在html页面的最后,在label元素加载完成后调用对应的JS方法。
或使用:
JS window.onload() 方法
onload 事件将在指令页面上的所有元素(包括图像和其他文件)加载完成后立即发生。
JQuery 的 ready() 方法
ready 事件将在文档结构加载后立即发生(不包括图片等非文本媒体文件)。
思路是让JS方法在页面完全加载后运行,这样就可以保证一定要加载相应的元素。
2.多层iframe嵌套,无法获取iframe不同层次的元素
当整个 HTML 页面使用多层 iframe 嵌套时,很容易找到对应内部 iframe 中的元素。
当我们获取元素时,我们会默认在外层 iframe 中找到该元素。如果是多层嵌套的iframe页面,那么当我们想要在内部iframe中查找元素时,需要切换到iframe ID指定的iframe层中,重新获取该元素。
var obj=document.getElementById("Iframe").contentWindow;
obj.document.getElementById("menu").style.visibility="hidden";//隐藏元素
还有一种情况是被调用的JS方法在内部iframe中,而外部窗口没有对应的ID。
可以使用window.parent方法获取当前窗口的父窗口,然后使用父窗口方法获取对应的元素。
window.parent.document.getElementById("null_box").getElementsByTagName("input")[0].style.visibility="visible";//恢复元素
当对应的label元素不可用时,记住一个前端的想法
当元素标签不可用时,可以尝试查找元素标签的父标签。
按照这个寻父的思路,一个一个的往上查找,当可以得到最外层的父级时,就可以按照这个层级关系依次往下查找这个元素。 查看全部
js抓取网页内容(什么是JS的元素,你知道吗?(一))
在编写JS或者JQuery的时候,在使用$("#btn1")或者Domcument.getElementById获取相关标签元素时,偶尔会出现获取不到对应元素的情况。报如下错误等:
无法读取空错误的属性“XXX”
无法读取未定义的属性“可见性”
其实这个问题只有一个原因,就是没有获取到对应的标签元素值,也就是$("#btn1")获取的值为null,所以当你获取到这个元素下的属性时,自然会报错,出现这种情况的原因可能如下。
1.Html页面还未加载,在元素加载前调用元素
根据html页面的特点,从上到下依次加载,即遇到什么就加载什么。因此,有可能在页面的 DOM 元素之前加载 JS 方法。
如果此时提前调用了JS方法,由于label元素还没有加载,所以找不到对应的元素,所以会报这个找不到元素的错误。
这种错误的解决方法也很简单,只需:
将对应的JS代码放在html页面的最后,在label元素加载完成后调用对应的JS方法。
或使用:
JS window.onload() 方法
onload 事件将在指令页面上的所有元素(包括图像和其他文件)加载完成后立即发生。
JQuery 的 ready() 方法
ready 事件将在文档结构加载后立即发生(不包括图片等非文本媒体文件)。
思路是让JS方法在页面完全加载后运行,这样就可以保证一定要加载相应的元素。
2.多层iframe嵌套,无法获取iframe不同层次的元素
当整个 HTML 页面使用多层 iframe 嵌套时,很容易找到对应内部 iframe 中的元素。
当我们获取元素时,我们会默认在外层 iframe 中找到该元素。如果是多层嵌套的iframe页面,那么当我们想要在内部iframe中查找元素时,需要切换到iframe ID指定的iframe层中,重新获取该元素。
var obj=document.getElementById("Iframe").contentWindow;
obj.document.getElementById("menu").style.visibility="hidden";//隐藏元素
还有一种情况是被调用的JS方法在内部iframe中,而外部窗口没有对应的ID。
可以使用window.parent方法获取当前窗口的父窗口,然后使用父窗口方法获取对应的元素。
window.parent.document.getElementById("null_box").getElementsByTagName("input")[0].style.visibility="visible";//恢复元素
当对应的label元素不可用时,记住一个前端的想法
当元素标签不可用时,可以尝试查找元素标签的父标签。
按照这个寻父的思路,一个一个的往上查找,当可以得到最外层的父级时,就可以按照这个层级关系依次往下查找这个元素。
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-18 15:01
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/");
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了 查看全部
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/";);
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
js抓取网页内容(即为如何通过selenium-java爬取异步加载的数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-17 22:18
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:
按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:
纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:
持仓市值通知系统,他每天会根据自己的持仓配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。 查看全部
js抓取网页内容(即为如何通过selenium-java爬取异步加载的数据的方法)
在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但是有时候我们无法捕获我们想要的数据通过这两种方法。必要的数据,例如看下面的例子。
1. 需求场景:
想抢股票的最新价格,页面F12信息如下:
按照前面的方法,爬取到的代码如下:
/**
* @description: 爬取股票的最新股价
* @author: JAVA开发老菜鸟
* @date: 2021-10-16 21:47
*/
public class StockPriceSpider {
Logger logger = LoggerFactory.getLogger(this.getClass());
public static void main(String[] args) {
StockPriceSpider stockPriceSpider = new StockPriceSpider();
String html = stockPriceSpider.httpClientProcess();
stockPriceSpider.jsoupProcess(html);
}
private String httpClientProcess() {
String html = "";
String uri = "http://quote.eastmoney.com/sh600036.html";
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet(uri);
try {
request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
// HttpHost proxy = new HttpHost("3.211.17.212", 80);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
html = EntityUtils.toString(httpEntity, "utf-8");
logger.info("访问{} 成功,返回页面数据{}", uri, html);
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
logger.info("访问{},返回状态不是200", uri);
logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
return html;
}
private void jsoupProcess(String html) {
Document document = Jsoup.parse(html);
Element price = document.getElementById("price9");
logger.info("股价为:>>> {}", price.text());
}
}
操作结果:
纳尼,股价是“-”?不可能的。
之所以爬不出来正确结果,是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.异步加载数据的Java爬取方法
如何抓取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以像静态页面一样得到js渲染出来的页面。常用的内核有
这里我选择了Selenium,它是一个模拟浏览器,也是一个自动化测试工具。它提供了一组 API 来与真正的浏览器内核进行交互。当然,爬虫也可以使用。
具体做法如下:
2.2逆向分析法
逆向分析的方法是通过F12找到Ajax异步数据获取链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
这个方法的关键是找到这个Ajax链接。我没有研究这个方法。有兴趣的可以百度下载。这里略。
3.结论
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:
持仓市值通知系统,他每天会根据自己的持仓配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以查看。
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-17 16:20
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/");
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了 查看全部
js抓取网页内容(phantomjs不时之需:我的理解不时之需)
phantomjs:我的理解是它是一个非显示浏览器,也就是说它基本上可以做浏览器能做的所有任务,除了不能显示页面的内容。所以,最近由于实验需要,不得不从某电商公司爬取一些图片,但是是AJAX生成的。简单的爬取HTML的方法行不通,o(╯□╰)o,于是求助后,;学了PHANTOMJS,因为网上没找到太多例子,所以只好自己总结一下,以防万一。另外,直接看官网的文档会很有收获的~顺便锻炼一下你的英文o(╯□╰)o。我们拿一个栗子来实现:
下载并解压phantom到D盘,目录下有一个phantomjs.exe文件(win7)通过js文件调用这个WebKit就可以达到想要的目的:比如生成网页快照我要做的是爬AJAX页面上的图片,先看js文件:将其命名为s.js
system = require('system') //传递一些需要的参数给js文件
address = system.args[1];//获得命令行第二个参数 ,也就是指定要加载的页面地址,接下来会用到
var page = require('webpage').create();
var url = address;
page.open(url, function (status) {
if (status !== 'success') {
console.log('Unable to post!');
} else {
var encodings = ["euc-jp", "sjis", "utf8", "System"];//这一步是用来测试输出的编码格式,选择合适的编码格式很重要,不然你抓取下来的页面会乱码o(╯□╰)o,给出的几个编码格式是官网上的例子,根据具体需要自己去调整。
for (var i = 3; i < encodings.length; i++) {//我这里只要一种编码就OK啦
phantom.outputEncoding = encodings[i];
console.log(phantom.outputEncoding+page.content);//最后返回webkit加载之后的页面内容
}
}
phantom.exit();
});
接下来就是java类的编写:
package com.mvc.rest;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
public class GetAjaxHtml {
public static String getAjaxContent(String url) throws Exception {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec("D:/tools/phantomjs/phantomjs.exe D:/tools/phantomjs/examples/s.js " + url);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp=br.readLine())!=null) {
sbf.append(tmp + "\n");
}
return sbf.toString();
}
public static void main(String[] args) throws Exception {
long start = System.currentTimeMillis();
String result = getAjaxContent("http://114.111.162.220:8093/404Web/";);
System.out.println(result);
long end = System.currentTimeMillis();
System.out.println("===============耗时:" + (end - start) + "===============");
}
}
至此,你已经有了你需要的完整AJAX页面的代码串,然后就可以为所欲为了
js抓取网页内容(网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么样)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-16 17:22
这篇文章的内容主要讲解了《防止网站页面内容被抓取的技巧有哪些》,有兴趣的可以看看。本文介绍的方法简单、快捷、实用。现在就让小编带你一起学习《防止网站页面内容被爬取的技巧有哪些》!
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。能不能通过,就看网站工地主的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5. 使用robots文件在页面上使用iframe标签来显示需要搜索引擎的内容收录robots文件可以防止iframe标签外的内容被收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传输到浏览器中进行显示,所以这也无法阻止收录。
说到这里,相信大家对“防止网站页面内容被爬取的技巧有哪些”有了更深的了解,一起来看看吧!这里是易速云网站,更多相关内容可以进入相关频道,关注我们,持续学习! 查看全部
js抓取网页内容(网站页面不是让搜索引擎抓的越多越好吗,怎么还会有怎么样)
这篇文章的内容主要讲解了《防止网站页面内容被抓取的技巧有哪些》,有兴趣的可以看看。本文介绍的方法简单、快捷、实用。现在就让小编带你一起学习《防止网站页面内容被爬取的技巧有哪些》!
有朋友可能会疑惑,网站的页面不就是让搜索引擎尽量抓取吗?怎么能有防止网站的内容被爬取的想法。
首先,一个网站可以分配的权重是有限的,即使是Pr10站,也不可能无限分配权重。此权重包括指向其他人 网站 的链接和自己的 网站 内部链接。
锁链之外,除非是想被锁链的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
内链,因为一些网站有很多重复或者冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外,网站管理着登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,有必要防止网页的某些内容,或某些页面被搜索引擎搜索收录。
笔者首先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为的内容收录
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为谷歌和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个主要用于网站管理页面、测试页面等。
3.使用nofollow标签来包装你不想成为的内容收录
这种方法并不能完全保证它不会是收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4. 使用Meta Noindex标签添加关注标签
这种方法既可以防止收录,也可以传递权重。能不能通过,就看网站工地主的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5. 使用robots文件在页面上使用iframe标签来显示需要搜索引擎的内容收录robots文件可以防止iframe标签外的内容被收录。因此,您可以将您不想要的内容 收录 放在普通页面标签下。想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经能够抓取表单内容,无法阻止收录。
2.使用Javascript和Ajax技术
以目前的技术,Ajax和javascript的最终计算结果还是以HTML的形式传输到浏览器中进行显示,所以这也无法阻止收录。
说到这里,相信大家对“防止网站页面内容被爬取的技巧有哪些”有了更深的了解,一起来看看吧!这里是易速云网站,更多相关内容可以进入相关频道,关注我们,持续学习!
js抓取网页内容(ROBOTS开发界两个办法:一个是robots.txt,另一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-11 04:02
有时会有一些你不想被 ROBOTS 抓取并公开的网站内容。为了解决这个问题,ROBOTS开发社区提供了两种方法:一种是robots.txt,一种是The Robots META标签。
1、默认为全部
属性如下:
设置为all:会检索文件,可以查询页面上的链接;
设置为none:不会检索文件,无法查询页面上的链接;
设置为索引:文件将被检索;
设置为follow:可以查询页面上的链接;
设置为noindex:不会检索文件,但可以查询页面上的链接;
设置为nofollow:不会检索文件,可以查询页面上的链接。
2、revisit-after(重访)
通知搜索引擎访问天数
其他:
-------------------------------------------------- -------------------------------------------------- --------
meta标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。
1、Content-Type 和 Content-Language(显示字符集设置)
说明:设置页面使用的字符集,表示首页使用的文字已经是该语言的,浏览器会根据这个调用对应的字符集来显示页面的内容。
注意:这个meta标签定义了HTML页面使用的字符集为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 Meta 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日文字符集是“iso-2022-jp”,韩文字符集是“ks_c_5601”。
字符集选项:ISO-8859-1(英文)、BIG5、UTF-8、SHIFT-Jis、Euc、Koi8-2、us-ascii、x-mac-roman、iso- 8859-2、x-mac-ce、iso-2022-jp、x-sjis、x-euc-jp、euc-kr、iso-2022-kr、gb2312、gb_2312-80、x-euc-tw、x- cns11643-1、x-cns11643-2等字符集;Content-Language 也可以是:EN、FR 等语言代码。
2、刷新(刷新)
3、过期(过期)
注意:指定缓存中网页的过期时间。一旦网页过期,必须在服务器上检索它。
注意:必须使用 GMT 的时间格式,或者直接设置为 0(数字表示会过期多少时间)。
4、编译指示(缓存模式)
注意:浏览器禁止从本机缓存中读取页面内容。
注意:网页不保存在缓存中,每次访问都会刷新页面。使用此设置,访问者将无法离线浏览。
5、Set-Cookie(cookie设置)
注意:当浏览器访问一个页面时,它会存储在缓存中,下次再次访问时可以从缓存中读取,以提高速度。如果您希望访问者每次都刷新您的广告图标,或每次都刷新您的计数器,请禁用缓存。通常,没有必要禁用 HTML 文件的缓存。对于ASP等页面,可以禁用缓存,因为每次看到服务器上动态生成的页面,缓存就没有意义了。如果网页过期,保存的 cookie 将被删除。
用法:
98 年 10 月 21 日 16:14:21 格林威治标准时间;路径=/">
注意:必须使用 GMT 的时间格式。
6、Window-target(显示窗口设置)
说明:强制页面在当前窗口中显示为单独的页面。
用法:
注意:此属性用于防止其他人在框架中调用您的页面。内容选项:_blank、_top、_self、_parent。
7、图片标签(网络 RSAC 评级)
注意:IE的Internet选项中有一个内容设置,可以防止浏览一些受限的网站,以及网站的受限级别
不要被这个参数设置。
用法:
“(图片-1.1”
我生成评论'RSACi North America Sever' by''
for '' on '1997.06.30T14:21-0500' r(n0 s0 v0 l0))">
注意:不要将级别设置得太高。RSAC 的评估系统提供了评估网站内容的标准。用户可以设置Microsoft Internet Explorer(IE3.0 及以上)排除收录色情和暴力内容的站点。上面例子中的 HTML 取自微软的主页。代码中的 (n 0 s 0 v 0 l 0) 表示该网站不收录不健康的内容。评级由美国娱乐委员会的评级机构 RSAC 评估。如果您想了解更多关于RSAC 评估系统 Grade 内容,或者需要自己评估的网站,可以访问 RSAC 的网站:。
8、Page-Enter, Page-Exit(进入和退出)
说明:这是页面加载和调用时的一些特殊效果。
用法:
注意:blendTrans 是一种动态滤镜,会产生淡入淡出的效果。另一个动态过滤器 RevealTrans 也可以用于页面进入和退出效果:
Duration 表示滤镜效果的持续时间(单位:秒)
过渡过滤器类型。表示使用哪种特效,取值为0-23。
0 矩形缩小
1 矩形展开
2 减圈
3 圆圈放大
4 从下往上刷新
5 从上到下刷新
6 从左到右刷新
7 从右向左刷新
8个垂直百叶窗
9 水平百叶窗
10个错位的水平百叶窗
11 错位的垂直百叶窗
12点差
13 从左到右刷新
14次从中间到左右刷新
15 中间到顶部和底部
16 上下到中心
17 右下至左上
18 右上至左下
19 左上至右下
20 左下至右上
21个单杠
22个竖条
23 以上 22种随机选择一种
9、MSThemeCompatible (XP 主题)
说明:是否关闭IE中的xp主题
用法:
注意:关闭xp的蓝色立体按钮系统显示风格,与win2k非常相似。
10、IE6(页面生成器)
描述:页面生成器生成器,ie6
用法:
注意:它的成分与产品的制造商相似。
11、Content-Script-Type(脚本相关)
注意:这是最近的 W3C 规范,用于指定页面中的脚本类型。
用法:
★NAME变量
名称描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。您还可以指定其他任意值,例如:creationdate(创建日期)、
证件号(document number)和级别(level)等。
名称的内容指定实际内容。例如,如果您将级别指定为值,则内容可能是初级、中级或高级。
1、关键字(关键字)
描述:为搜索引擎提供的关键字列表
用法:
注意:使用英文逗号“,”来分隔每个关键词。META的通常用途是指定搜索引擎以提高搜索质量关键词。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、说明(介绍)
描述:描述用于告诉搜索引擎你的网站的主要内容。
用法:
注意:
3、机器人(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。Content的参数为all、none、index、noindex、follow、nofollow。默认是全部。
用法:
注:很多搜索引擎使用robot/spider搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特性来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接;(与“noindex, no follow”功能相同)
index:文件将被检索;(让机器人/蜘蛛登录)
关注:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接;(不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。(不要让机器人/蜘蛛跟着本页链接往下看)
4、作者 (Author)
说明:注释页面的作者或制作团队
用法:">
注意:内容可以是:您或您的制作团队的姓名,或电子邮件 查看全部
js抓取网页内容(ROBOTS开发界两个办法:一个是robots.txt,另一个)
有时会有一些你不想被 ROBOTS 抓取并公开的网站内容。为了解决这个问题,ROBOTS开发社区提供了两种方法:一种是robots.txt,一种是The Robots META标签。
1、默认为全部
属性如下:
设置为all:会检索文件,可以查询页面上的链接;
设置为none:不会检索文件,无法查询页面上的链接;
设置为索引:文件将被检索;
设置为follow:可以查询页面上的链接;
设置为noindex:不会检索文件,但可以查询页面上的链接;
设置为nofollow:不会检索文件,可以查询页面上的链接。
2、revisit-after(重访)
通知搜索引擎访问天数
其他:
-------------------------------------------------- -------------------------------------------------- --------
meta标签分为两部分:HTTP头信息(HTTP-EQUIV)和页面描述信息(NAME)。
1、Content-Type 和 Content-Language(显示字符集设置)
说明:设置页面使用的字符集,表示首页使用的文字已经是该语言的,浏览器会根据这个调用对应的字符集来显示页面的内容。
注意:这个meta标签定义了HTML页面使用的字符集为GB2132,即国标汉字代码。如果将“charset=GB2312”替换为“BIG5”,则本页使用的字符集为繁体中文Big5代码。当您浏览一些国外网站时,IE浏览器会提示您下载xx语言支持以正确显示页面。该函数通过读取 HTML 页面的 Meta 标签的 Content-Type 属性,知道需要使用哪个字符集来显示页面。如果系统中没有安装相应的字符集,IE会提示下载。其他语言也对应不同的字符集。例如,日文字符集是“iso-2022-jp”,韩文字符集是“ks_c_5601”。
字符集选项:ISO-8859-1(英文)、BIG5、UTF-8、SHIFT-Jis、Euc、Koi8-2、us-ascii、x-mac-roman、iso- 8859-2、x-mac-ce、iso-2022-jp、x-sjis、x-euc-jp、euc-kr、iso-2022-kr、gb2312、gb_2312-80、x-euc-tw、x- cns11643-1、x-cns11643-2等字符集;Content-Language 也可以是:EN、FR 等语言代码。
2、刷新(刷新)
3、过期(过期)
注意:指定缓存中网页的过期时间。一旦网页过期,必须在服务器上检索它。
注意:必须使用 GMT 的时间格式,或者直接设置为 0(数字表示会过期多少时间)。
4、编译指示(缓存模式)
注意:浏览器禁止从本机缓存中读取页面内容。
注意:网页不保存在缓存中,每次访问都会刷新页面。使用此设置,访问者将无法离线浏览。
5、Set-Cookie(cookie设置)
注意:当浏览器访问一个页面时,它会存储在缓存中,下次再次访问时可以从缓存中读取,以提高速度。如果您希望访问者每次都刷新您的广告图标,或每次都刷新您的计数器,请禁用缓存。通常,没有必要禁用 HTML 文件的缓存。对于ASP等页面,可以禁用缓存,因为每次看到服务器上动态生成的页面,缓存就没有意义了。如果网页过期,保存的 cookie 将被删除。
用法:
98 年 10 月 21 日 16:14:21 格林威治标准时间;路径=/">
注意:必须使用 GMT 的时间格式。
6、Window-target(显示窗口设置)
说明:强制页面在当前窗口中显示为单独的页面。
用法:
注意:此属性用于防止其他人在框架中调用您的页面。内容选项:_blank、_top、_self、_parent。
7、图片标签(网络 RSAC 评级)
注意:IE的Internet选项中有一个内容设置,可以防止浏览一些受限的网站,以及网站的受限级别
不要被这个参数设置。
用法:
“(图片-1.1”
我生成评论'RSACi North America Sever' by''
for '' on '1997.06.30T14:21-0500' r(n0 s0 v0 l0))">
注意:不要将级别设置得太高。RSAC 的评估系统提供了评估网站内容的标准。用户可以设置Microsoft Internet Explorer(IE3.0 及以上)排除收录色情和暴力内容的站点。上面例子中的 HTML 取自微软的主页。代码中的 (n 0 s 0 v 0 l 0) 表示该网站不收录不健康的内容。评级由美国娱乐委员会的评级机构 RSAC 评估。如果您想了解更多关于RSAC 评估系统 Grade 内容,或者需要自己评估的网站,可以访问 RSAC 的网站:。
8、Page-Enter, Page-Exit(进入和退出)
说明:这是页面加载和调用时的一些特殊效果。
用法:
注意:blendTrans 是一种动态滤镜,会产生淡入淡出的效果。另一个动态过滤器 RevealTrans 也可以用于页面进入和退出效果:
Duration 表示滤镜效果的持续时间(单位:秒)
过渡过滤器类型。表示使用哪种特效,取值为0-23。
0 矩形缩小
1 矩形展开
2 减圈
3 圆圈放大
4 从下往上刷新
5 从上到下刷新
6 从左到右刷新
7 从右向左刷新
8个垂直百叶窗
9 水平百叶窗
10个错位的水平百叶窗
11 错位的垂直百叶窗
12点差
13 从左到右刷新
14次从中间到左右刷新
15 中间到顶部和底部
16 上下到中心
17 右下至左上
18 右上至左下
19 左上至右下
20 左下至右上
21个单杠
22个竖条
23 以上 22种随机选择一种
9、MSThemeCompatible (XP 主题)
说明:是否关闭IE中的xp主题
用法:
注意:关闭xp的蓝色立体按钮系统显示风格,与win2k非常相似。
10、IE6(页面生成器)
描述:页面生成器生成器,ie6
用法:
注意:它的成分与产品的制造商相似。
11、Content-Script-Type(脚本相关)
注意:这是最近的 W3C 规范,用于指定页面中的脚本类型。
用法:
★NAME变量
名称描述网页,对应Content(网页内容),方便搜索引擎机器人查找和分类(目前几乎所有搜索引擎都使用在线机器人自动查找元值对网页进行分类)。
name (name="") 的值指定所提供信息的类型。一些值已经定义。例如描述(description)、关键字(keyword)、刷新(refresh)等等。您还可以指定其他任意值,例如:creationdate(创建日期)、
证件号(document number)和级别(level)等。
名称的内容指定实际内容。例如,如果您将级别指定为值,则内容可能是初级、中级或高级。
1、关键字(关键字)
描述:为搜索引擎提供的关键字列表
用法:
注意:使用英文逗号“,”来分隔每个关键词。META的通常用途是指定搜索引擎以提高搜索质量关键词。当多个 META 元素提供文档语言依赖信息时,搜索引擎将使用 lang 特性通过用户的语言优先级引用来过滤和显示搜索结果。例如:
2、说明(介绍)
描述:描述用于告诉搜索引擎你的网站的主要内容。
用法:
注意:
3、机器人(机器人向导)
说明:Robots 用于告诉搜索机器人哪些页面需要编入索引,哪些页面不需要编入索引。Content的参数为all、none、index、noindex、follow、nofollow。默认是全部。
用法:
注:很多搜索引擎使用robot/spider搜索登录网站。这些机器人/蜘蛛会使用meta元素的一些特性来决定如何登录。
all:会检索文件,可以查询页面上的链接;
none:不会检索文件,无法查询页面上的链接;(与“noindex, no follow”功能相同)
index:文件将被检索;(让机器人/蜘蛛登录)
关注:页面上的链接可以查询;
noindex:不会检索文件,但可以查询页面上的链接;(不要让机器人/蜘蛛登录)
nofollow:不会检索文件,可以查询页面上的链接。(不要让机器人/蜘蛛跟着本页链接往下看)
4、作者 (Author)
说明:注释页面的作者或制作团队
用法:">
注意:内容可以是:您或您的制作团队的姓名,或电子邮件
js抓取网页内容(Nodejs对于网页抓取的能力首先要推荐用Python!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-09 12:18
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须要等上一页爬完才能拿到数据,下一页才能爬出来,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签: node.js 抓取 nodejs 抓取网页 查看全部
js抓取网页内容(Nodejs对于网页抓取的能力首先要推荐用Python!!)
Nodejs获取绑定到data事件的web内容,获取到的数据会分多次。如果要匹配全局内容,需要等待请求结束,在end结束事件中对累积的全局数据进行操作!
比如想在页面上查找,就不多说了,直接放上代码:
//引入模块
var http = require("http"),
fs = require('fs'),
url = require('url');
//写入文件,把结果写入不同的文件
var writeRes = function(p, r) {
fs.appendFile(p , r, function(err) {
if(err)
console.log(err);
else
console.log(r);
});
},
//发请求,并验证内容,把结果写入文件
postHttp = function(arr, num) {
console.log('第'+num+"条!")
var a = arr[num].split(" - ");
if(!a[0] || !a[1]) {
return;
}
var address = url.parse(a[1]),
options = {
host : address.host,
path: address.path,
hostname : address.hostname,
method: 'GET',
headers: {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36'
}
}
var req = http.request(options, function(res) {
if (res.statusCode == 200) {
res.setEncoding('UTF-8');
var data = '';
res.on('data', function (rd) {
data += rd;
});
res.on('end', function(q) {
if(!~data.indexOf("www.baidu.com")) {
return writeRes('./no2.txt', a[0] + '--' + a[1] + '\n');
} else {
return writeRes('./has2.txt', a[0] + '--' + a[1] + "\n");
}
})
} else {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + res.statusCode + '\n');
}
});
req.on('error', function(e) {
writeRes('./error2.txt', a[0] + '--' + a[1] + '--' + e + '\n');
})
req.end();
},
//读取文件,获取需要抓取的页面
openFile = function(path, coding) {
fs.readFile(path, coding, function(err, data) {
var res = data.split("\n");
for (var i = 0, rl = res.length; i < rl; i++) {
if(!res[i])
continue;
postHttp(res, i);
};
})
};
openFile('./sites.log', 'utf-8');
你可以理解上面的代码。如果您有任何问题,请给我留言。具体要看大家在实践中的应用。
下面给大家介绍一下Nodejs的网页抓取能力。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须要等上一页爬完才能拿到数据,下一页才能爬出来,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签: node.js 抓取 nodejs 抓取网页
js抓取网页内容( 如何模拟请求和如何解析HTML的链接和标题?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-08 20:12
如何模拟请求和如何解析HTML的链接和标题?(一))
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:
截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS 查看全部
js抓取网页内容(
如何模拟请求和如何解析HTML的链接和标题?(一))
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这已经是很久以前的事了,但题目似乎已经解决了这个问题。但是看到很多答案的方法有点太重了,这里提供一个效率更高,消耗资源更少的方法。由于主题没有指定需要什么,这里的示例采用主页上所有帖子的链接和标题。
首先请记住浏览器环境对内存和CPU的消耗非常严重,尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在HTML源代码中是看不到的,但更有可能是通过另一个请求(最有可能是JSON格式)得到纯数据。我们不仅不需要模拟浏览器,还可以节省解析HTML的消耗。
然后,我打开北京邮政论坛的首页,发现首页的HTML源代码并没有收录页面显示的文章的内容。那么,很有可能这是通过JS异步加载到页面的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载主页时的请求,很容易在下面的截图中找到请求:
截图中选择的请求的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以拿到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏。有详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗和爬行速度。编写爬虫时请记住,如果没有必要,不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了一个接口。但是这两种方法都要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方式模拟真实行为。谷歌幻影JS
js抓取网页内容(Python爬虫入门,快速抓取大规模数据(第二部分)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-08 12:30
如果您还没有阅读前两部分,建议阅读前几部分:
Python爬虫入门,快速爬取大规模数据
Python爬虫入门,快速爬取大规模数据(二)
Python爬虫入门,快速爬取大规模数据(三)
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的网页渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver 介绍
Selenium webdriver是我们这里要使用的工具,用来控制浏览器执行JS生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供自动化API。因此,我们可以很方便的通过webdriver提供的API来操纵浏览器访问网页生成内容并返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,让我们简单的尝试一下webdriver驱动浏览器打开网页。
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/")
爬虫实例中的应用
现在让我们回到我们的爬虫示例。最初,我们使用 requests 库来获取内容。现在我们使用 webdriver 来驱动浏览器来获取 web 内容。这样就可以得到执行JS动态加载内容的网页了。
if __name__== "__main__":
...
# 抓取网页内容
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/")
content = driver.page_source
browser.quit()
# 提取页面包含的数据
soup = BeautifulSoup(content, "html.parser")
get_web_data(soup)
...
通常浏览器会打开一个窗口,但这对于爬虫来说不是必需的。幸运的是,我们可以使用phantomjs来代替浏览器。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器。几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码与我们之前使用的浏览器没有太大区别,唯一的区别在于我们初始化浏览器的代码。
browser = webdriver.PhantomJS()
总结
在这一部分,我们简要讨论了如何使用 webdriver 获取动态加载的网页内容。事实上,webdriver 有很多非常有趣的应用,有机会我们会再看一遍。
来源:/i65657671/ 查看全部
js抓取网页内容(Python爬虫入门,快速抓取大规模数据(第二部分)(组图))
如果您还没有阅读前两部分,建议阅读前几部分:
Python爬虫入门,快速爬取大规模数据
Python爬虫入门,快速爬取大规模数据(二)
Python爬虫入门,快速爬取大规模数据(三)
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的网页渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver 介绍
Selenium webdriver是我们这里要使用的工具,用来控制浏览器执行JS生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供自动化API。因此,我们可以很方便的通过webdriver提供的API来操纵浏览器访问网页生成内容并返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,让我们简单的尝试一下webdriver驱动浏览器打开网页。
from selenium import webdriver
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/";)
爬虫实例中的应用
现在让我们回到我们的爬虫示例。最初,我们使用 requests 库来获取内容。现在我们使用 webdriver 来驱动浏览器来获取 web 内容。这样就可以得到执行JS动态加载内容的网页了。
if __name__== "__main__":
...
# 抓取网页内容
browser = webdriver.Firefox()
browser.get("https://blog.csdn.net/nj_kevin_peng/";)
content = driver.page_source
browser.quit()
# 提取页面包含的数据
soup = BeautifulSoup(content, "html.parser")
get_web_data(soup)
...
通常浏览器会打开一个窗口,但这对于爬虫来说不是必需的。幸运的是,我们可以使用phantomjs来代替浏览器。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器。几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码与我们之前使用的浏览器没有太大区别,唯一的区别在于我们初始化浏览器的代码。
browser = webdriver.PhantomJS()
总结
在这一部分,我们简要讨论了如何使用 webdriver 获取动态加载的网页内容。事实上,webdriver 有很多非常有趣的应用,有机会我们会再看一遍。
来源:/i65657671/
js抓取网页内容(为了更好的让百度识别PC版对应的移动页面代码如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-07 21:21
对于大多数网站来说,为了让网页打开速度更快,用户体验更好,应该启用Webkit内核。代码如下。
2、 当网站没有对应的手机版页面或百度无法识别适配时,百度会自动将PC版转码为手机版,会损失部分广告收入,需要添加到页面以下代码禁止百度转码。
3、为了更好的让百度识别PC版对应的手机页面,需要添加如下Meta语句:
http://3g.sina.com.cn/">
http://sina.cn/">
更多说明参见:开放适配服务站长信息百度站长平台
4、如果你的页面有地理属性,可以添加如下代码:
5、360 搜索(好搜)设计了一套类似于 Facebook 的开放图谱协议的 Meta 标签,用于搜索格式的展示。详细内容参考:Smart summary_360搜索帮助
标准化标签模板支持短视频、电影、小说、新闻、商品、论坛帖子、博客等内容类型数据。
例如,对于我们的信息页面,我们计划添加以下 Meta:
注意:添加后,您需要在360站长平台主动注册才能提交您的页面。
关注
一个普通的链接是这样写的:
黄页88网
现在添加nofollow标签,如下:
黄页88网
这告诉搜索引擎蜘蛛不要点击这个链接。当你不想减肥到一个链接,但又必须在内容中显示该链接时,可以使用此方法来阻止它。
常见的例子有:“关于我们”、“联系我们”等。几乎所有网站底部都有这些链接,需要Nofollow标签。
这些页面带来的SEO价值不高,与当前页面的相关性一般不大。为了避免浪费搜索蜘蛛的爬行,需要通过Nofollow标签进行拦截。
知道原理后,我们也可以屏蔽所有其他的链接,比如天超中的唯一记录链接:
http://www.miitbeian.gov.cn" rel="nofollow" target="_blank">京ICP备XXX号
还有“登录”、“注册”,甚至“首页”都可以根据需要进行屏蔽,从而引导蜘蛛抓取收录更重要、更有希望的内容。
iframe 标签
搜索引擎的蜘蛛不会识别iframe中调用的图片、文本、网址等内容,因为这些内容不属于页面,而是在访问时临时调用。百度SEO建议也说:“frame/frameset/iframe”等标签会导致百度蜘蛛抓取困难。
使用这个,我们可以将网站中需要用户查看但不需要被搜索引擎抓取的内容展示出来。
比如网站顶部的一些topbar导航栏,常用于注册、登录等,可以写成一个iframe框架。
还有一些赞助广告,如果不需要SEO效果,可以放在单独的iframe中,在页面引用即可。
但是也不好用太多,可能会被认为是作弊,而且iframe明显不利于页面加载速度。
CSS 和 JS 最好将 CSS 和 JS 放在单独的外部文件中,这样可以减少代码量,使内容更加简洁,便于搜索引擎识别。
当然,有时为了减少 CSS 和 JS 请求的数量,一些大的 网站 会直接在内容页面中输出 CSS 和 JS。一般网站 不这样做。
虽然搜索引擎现在可以识别 JS 中的内容,但一般来说,JS 文件中的内容不会影响页面的 SEO。利用这一点,你可以将必须显示但与页面主题内容无关的内容放入JS并写回页面,从而避免降低页面的密度关键词或传递链接权重。document.write("XXX") CSS 样式命名
搜索引擎越来越智能,通过你的css样式很容易识别页面内容。
合理有序的CSS命名规则不仅可以提高代码质量,而且更符合搜索引擎规范。
例如:
标题:标题
顶部导航:顶部栏
登录:登录栏
标志:标志
侧边栏:侧边栏
广告:横幅
导航:导航
子导航:subNav
菜单:菜单
子菜单:子菜单
搜索:搜索
滚动:滚动
主页面:main
内容:内容
标签页:tab
文章列表:列表
提示:味精/提示
栏目标题:标题
加入:加入
指南:指南
服务:服务
热点:热
新闻:新闻
下载:下载
注册:注册
状态:状态
按钮:btn/按钮
投票:投票
广告:广告
合伙人:合伙人
友情链接:friendLink/links
页脚:页脚 查看全部
js抓取网页内容(为了更好的让百度识别PC版对应的移动页面代码如下)
对于大多数网站来说,为了让网页打开速度更快,用户体验更好,应该启用Webkit内核。代码如下。
2、 当网站没有对应的手机版页面或百度无法识别适配时,百度会自动将PC版转码为手机版,会损失部分广告收入,需要添加到页面以下代码禁止百度转码。
3、为了更好的让百度识别PC版对应的手机页面,需要添加如下Meta语句:
http://3g.sina.com.cn/">
http://sina.cn/">
更多说明参见:开放适配服务站长信息百度站长平台
4、如果你的页面有地理属性,可以添加如下代码:
5、360 搜索(好搜)设计了一套类似于 Facebook 的开放图谱协议的 Meta 标签,用于搜索格式的展示。详细内容参考:Smart summary_360搜索帮助
标准化标签模板支持短视频、电影、小说、新闻、商品、论坛帖子、博客等内容类型数据。
例如,对于我们的信息页面,我们计划添加以下 Meta:
注意:添加后,您需要在360站长平台主动注册才能提交您的页面。
关注
一个普通的链接是这样写的:
黄页88网
现在添加nofollow标签,如下:
黄页88网
这告诉搜索引擎蜘蛛不要点击这个链接。当你不想减肥到一个链接,但又必须在内容中显示该链接时,可以使用此方法来阻止它。
常见的例子有:“关于我们”、“联系我们”等。几乎所有网站底部都有这些链接,需要Nofollow标签。
这些页面带来的SEO价值不高,与当前页面的相关性一般不大。为了避免浪费搜索蜘蛛的爬行,需要通过Nofollow标签进行拦截。
知道原理后,我们也可以屏蔽所有其他的链接,比如天超中的唯一记录链接:
http://www.miitbeian.gov.cn" rel="nofollow" target="_blank">京ICP备XXX号
还有“登录”、“注册”,甚至“首页”都可以根据需要进行屏蔽,从而引导蜘蛛抓取收录更重要、更有希望的内容。
iframe 标签
搜索引擎的蜘蛛不会识别iframe中调用的图片、文本、网址等内容,因为这些内容不属于页面,而是在访问时临时调用。百度SEO建议也说:“frame/frameset/iframe”等标签会导致百度蜘蛛抓取困难。
使用这个,我们可以将网站中需要用户查看但不需要被搜索引擎抓取的内容展示出来。
比如网站顶部的一些topbar导航栏,常用于注册、登录等,可以写成一个iframe框架。
还有一些赞助广告,如果不需要SEO效果,可以放在单独的iframe中,在页面引用即可。
但是也不好用太多,可能会被认为是作弊,而且iframe明显不利于页面加载速度。
CSS 和 JS 最好将 CSS 和 JS 放在单独的外部文件中,这样可以减少代码量,使内容更加简洁,便于搜索引擎识别。
当然,有时为了减少 CSS 和 JS 请求的数量,一些大的 网站 会直接在内容页面中输出 CSS 和 JS。一般网站 不这样做。
虽然搜索引擎现在可以识别 JS 中的内容,但一般来说,JS 文件中的内容不会影响页面的 SEO。利用这一点,你可以将必须显示但与页面主题内容无关的内容放入JS并写回页面,从而避免降低页面的密度关键词或传递链接权重。document.write("XXX") CSS 样式命名
搜索引擎越来越智能,通过你的css样式很容易识别页面内容。
合理有序的CSS命名规则不仅可以提高代码质量,而且更符合搜索引擎规范。
例如:
标题:标题
顶部导航:顶部栏
登录:登录栏
标志:标志
侧边栏:侧边栏
广告:横幅
导航:导航
子导航:subNav
菜单:菜单
子菜单:子菜单
搜索:搜索
滚动:滚动
主页面:main
内容:内容
标签页:tab
文章列表:列表
提示:味精/提示
栏目标题:标题
加入:加入
指南:指南
服务:服务
热点:热
新闻:新闻
下载:下载
注册:注册
状态:状态
按钮:btn/按钮
投票:投票
广告:广告
合伙人:合伙人
友情链接:friendLink/links
页脚:页脚

